⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-14 更新
LCFO: Long Context and Long Form Output Dataset and Benchmarking
Authors:Marta R. Costa-jussà, Pierre Andrews, Mariano Coria Meglioli, Joy Chen, Joe Chuang, David Dale, Christophe Ropers, Alexandre Mourachko, Eduardo Sánchez, Holger Schwenk, Tuan Tran, Arina Turkatenko, Carleigh Wood
This paper presents the Long Context and Form Output (LCFO) benchmark, a novel evaluation framework for assessing gradual summarization and summary expansion capabilities across diverse domains. LCFO consists of long input documents (5k words average length), each of which comes with three summaries of different lengths (20%, 10%, and 5% of the input text), as well as approximately 15 questions and answers (QA) related to the input content. Notably, LCFO also provides alignments between specific QA pairs and corresponding summaries in 7 domains. The primary motivation behind providing summaries of different lengths is to establish a controllable framework for generating long texts from shorter inputs, i.e. summary expansion. To establish an evaluation metric framework for summarization and summary expansion, we provide human evaluation scores for human-generated outputs, as well as results from various state-of-the-art large language models (LLMs). GPT-4o-mini achieves best human scores among automatic systems in both summarization and summary expansion tasks (~ +10% and +20%, respectively). It even surpasses human output quality in the case of short summaries (~ +7%). Overall automatic metrics achieve low correlations with human evaluation scores (~ 0.4) but moderate correlation on specific evaluation aspects such as fluency and attribution (~ 0.6). The LCFO benchmark offers a standardized platform for evaluating summarization and summary expansion performance, as well as corresponding automatic metrics, thereby providing an important evaluation framework to advance generative AI.
本文介绍了长语境与形式输出(LCFO)基准测试,这是一个新的评估框架,用于评估跨不同领域的渐进摘要和摘要扩展能力。LCFO包含长输入文档(平均长度5000字),每个文档都附带三个不同长度的摘要(输入文本的20%、10%和5%),以及与输入内容相关的约15个问题和答案(QA)。值得注意的是,LCFO还在7个领域提供了特定QA对和相应摘要之间的对齐。提供不同长度摘要的主要动机是建立一个可控的框架,从较短的输入生成长文本,即摘要扩展。为了为摘要和摘要扩展建立评估指标框架,我们提供了对人工生成输出的人类评估分数,以及来自各种最新大型语言模型(LLM)的结果。GPT-4o-mini在摘要和摘要扩展任务中均获得最佳人类评分(分别高出约10%和20%),甚至在短摘要的情况下超越了人类输出质量(高出约7%)。总体而言,自动度量与人类评估分数之间的相关性较低(约0.4),但在特定评估方面(如流畅度和归因度)的相关性适中(约0.6)。LCFO基准测试提供了一个标准化的平台来评估摘要和摘要扩展性能以及相应的自动度量,从而为推动生成式人工智能提供了一个重要的评估框架。
论文及项目相关链接
Summary:
本文介绍了Long Context and Form Output(LCFO)基准测试,这是一个新的评估框架,用于评估跨不同领域的渐进摘要和摘要扩展能力。LCFO包含平均长度为5000字的长期输入文档,每个文档都有三个不同长度的摘要(分别为输入文本的20%、10%和5%),以及大约与输入内容相关的15个问题和答案。LCFO还提供在7个领域内的特定问答对与相应摘要之间的对齐。提供不同长度的摘要的主要动机是建立一个可控的框架,用于从较短的输入生成长文本,即摘要扩展。为了建立摘要和摘要扩展的评价指标框架,我们提供了对人工生成输出的人类评价分数,以及各种先进的大型语言模型(LLM)的结果。GPT-4o-mini在摘要和摘要扩展任务中的自动系统中表现最佳,分别提高了约10%和20%,并且在短摘要的情况下甚至超越了人类输出质量约7%。总的来说,自动指标与人类评价分数的相关性较低(约0.4),但在特定评价方面如流畅性和归属度方面的相关性为中等(约0.6)。LCFO基准测试提供了一个标准化的平台来评估摘要和摘要扩展的性能以及相应的自动指标,从而为推动生成性人工智能提供了一个重要的评估框架。
Key Takeaways:
- LCFO基准测试是一个用于评估渐进摘要和摘要扩展能力的新型评价框架。
- 它包含长文档、不同长度的摘要、与文档内容相关的问题和答案。
- LCFO提供了在七个领域内的特定问答对与相应摘要之间的对齐。
- 不同长度的摘要旨在支持从短输入生成长文本,即摘要扩展。
- GPT-4o-mini在摘要和摘要扩展任务中表现最佳,超过人类表现。
- 自动评估指标与人类评价分数的总体相关性较低,但在某些特定方面如流畅性和归属度的相关性为中等。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为Long Context and Form Output (LCFO)的基准测试框架,旨在解决以下问题:
评估大型语言模型(LLMs)在长文本摘要和摘要扩展任务上的性能:特别是在处理非常长的输入文档和生成长摘要或长摘要扩展时的性能评估。
建立一个可控的框架来从较短的输入生成长文本:即摘要扩展(summary expansion)任务,通过提供不同长度的摘要来实现。
提供一个标准化平台来评估摘要和摘要扩展的性能:包括相应的自动评估指标,以推进生成性人工智能的发展。
提供一个人工标注的基准测试和挑战数据集:涵盖自然语言理解和生成的多个领域,并且完全由人类修订,不依赖于LLMs。
提供详细的语言学指导和抽象型的问答(QA)对:这些QA对可以用来评估模型输出的质量,类似于以往的提议。
评估多个LLMs在LCFO数据集上的性能:包括自动和手动评估,以及自动评估指标在摘要和摘要扩展任务上的表现。
提供人工评估分数:为人类生成的输出提供人工评估分数,并与各种最先进大型语言模型(LLMs)的结果进行比较。
综上所述,LCFO基准旨在提供一个评估框架和数据集,以更好地理解和改进LLMs在长文本处理和生成任务上的能力。
Q: 有哪些相关研究?
A: 相关研究涵盖了以下几个领域:
长文本上下文数据集:
- NIAH, RULER等无限长度数据集,处理分散信息。
- Longbench和Marathon等有限长度非分散数据集,包含5-25k上下文的任务。
- Loong多文档QA数据集,上下文高达200k,评估RAG能力。
- HelloBench,包括长输入文档(3k到6k词长)的摘要。
长文本输出数据集:
- 缺乏基于参考的长文本输出数据集。
- StoryGen,包括生成故事的提示。
- HelloBench,包括故事、剧本、关键词写作等多样化的长文本生成。
摘要评估指标:
- 基于字符串的流行指标,如ROUGE或BLEU或意义表示分数。
- 更复杂的意义表示分数(例如BERTScore)和/或有监督指标,已在多个基准上成功训练。
- 替代使用摘要作为黄金参考的方法,包括基于人类预先标注的QA的方法。
长文本度量:
- 基于流畅性、多样性和语义的多种标准。
- 更多关注连贯性和事实性的评估。
使用LLM作为评估者:
- 显示了作为评估者的乐观结果,但也显示出在验证和一致性方面需要改进的空间。
基于QA的方法和人类标注:
- 专注于信息丰富性和文本输出的覆盖范围。
人类评估:
- 包括StoryGen指南等,显示了任务的难度。
这些相关研究提供了对长文本处理和评估的深入理解,并为LCFO基准测试框架的发展提供了背景和对比。LCFO通过提供新的数据集和评估协议,为这一领域做出了贡献。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决评估大型语言模型(LLMs)在长文本摘要和摘要扩展任务上的性能问题:
建立LCFO基准测试框架:
- 提出一个名为Long Context and Form Output (LCFO)的评估框架,用于评估不同领域的渐进式摘要和摘要扩展能力。
创建数据集:
- 构建了一个人工标注的数据集,包含长输入文档(平均长度为5k词)以及与这些文档相关的三种不同长度的摘要(分别为输入文本的20%、10%和5%)。
- 提供了与输入内容相关的大约15个问题和答案(QA)对,以及在7个领域中的特定QA对和相应摘要之间的对齐。
定义任务和指标:
- 明确定义了长文本(超过5k词)和结构化/分层文档的概念。
- 定义了渐进式摘要(Gradual Summarization, GS)和摘要扩展(Summary Expansion, SE)的任务。
- 提供了人类生成输出的人类评估分数,并使用不同的LLMs进行了实验。
人工总结和QA对生成:
- 开发了详细的指导方针,要求母语为英语的写作者阅读长篇文档并写出三种不同长度的摘要。
- 要求写作者为每个长文档提供一组问题和答案,覆盖摘要中反映的要点。
自动输出和后处理:
- 对当前最先进的模型在新基准上的表现进行了自动摘要和摘要扩展的测试。
- 实现了自动段落对齐(APA)以减少人类评估者的认知负荷。
人类评估:
- 设计了人类评估指南,对自动和手动生成的摘要以及模型生成的摘要扩展进行了评估。
自动评估:
- 计算了多个参考自由的度量指标,每个指标针对特定的属性,如重复性、流畅性、连贯性和归属性。
提供标准化平台:
- LCFO提供了一个标准化平台,用于评估摘要和摘要扩展的性能以及相应的自动度量,为推进生成性AI提供了重要的评估框架。
通过这些步骤,论文不仅提出了一个评估长文本输入和输出的新框架,而且还提供了模型和人类输出的评估结果,展示了LLMs在短摘要生成方面超越人类结果的潜力,并质疑了为长文档短摘要手动生成人类参考的有用性。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了以下实验:
模型选择和设置:
- 实验中使用了封闭和开放的大型语言模型(LLMs)。选择了GPT-4o-mini-64k作为封闭模型,Llama-3.1-70B作为开放源模型。
- 对于摘要任务,模型运行了所有长度比(5%,10%,20%),而对于摘要扩展任务,仅将摘要扩展到完整文档的20%。
摘要任务的实验:
- 使用不同的模型在LCFO数据集上生成不同长度比的摘要,并进行了人类评估和自动评估。
- 摘要任务的实验结果被详细记录,并按领域分解,以展示不同模型在不同领域中的表现。
摘要扩展任务的实验:
- 仅选择了不包含事实信息的领域数据进行评估,包括SummScreen、BookSum、SQuality和FacetSum。
- 使用相同的模型生成长文本输出,并进行了人类评估和自动评估。
- 记录了模型在将20%的摘要扩展到完整文档时的性能。
人类和模型输出的评估:
- 对人类和模型生成的摘要以及模型生成的摘要扩展进行了人类评估。
- 展示了LLMs在生成短摘要时能够超越人类结果的能力。
自动评估指标的计算:
- 计算了多个参考自由的度量指标,包括重复性(REP-3)、流畅性(CoLA)、连贯性(COH-2)、归属性(SH-4)、覆盖度(SH-5)和整体质量(AVG和HE)。
- 分析了这些自动评估指标与人类评估分数之间的相关性。
评估统计数据:
- 提供了LCFO数据集的统计数据,包括不同子集和领域的分布,以及文档的平均词长。
相关性分析:
- 计算了Spearman相关系数,比较了自动度量和人类评估在摘要和摘要扩展任务中的相关性。
这些实验旨在全面评估和比较不同LLMs在处理长文本摘要和摘要扩展任务时的性能,并探索自动评估指标与人类评估之间的一致性。通过这些实验,作者旨在验证LCFO基准测试框架的有效性,并为未来的研究提供基础数据和见解。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
利用QA对作为自动评估的一部分:
- 论文提到了QA对可以用于评估模型生成的摘要的质量,即评分模型生成的摘要中正确回答了多少问题。这可以作为一个未来的工作方向,以进一步探索和完善自动评估方法。
数据集的扩展和多样化:
- 虽然LCFO数据集覆盖了多个领域,但可以进一步扩展,包括更多的文档和摘要对,尤其是那些涉及不同语言和文化背景的数据,以增强数据集的多样性和覆盖范围。
改进自动评估指标:
- 论文指出,目前没有单一的自动评估指标能够完全捕捉到摘要任务的所有质量方面。因此,开发和验证更好的自动评估指标是一个重要的研究方向。
探索不同的模型架构和训练策略:
- 论文主要关注了GPT-4o-mini和Llama-3.1模型。未来的工作可以探索其他类型的LLMs,以及不同的训练策略,如对抗训练、多任务学习等,以提高模型性能。
长文本生成的认知负荷研究:
- 论文提到长文本输入处理和长文本输出生成都涉及高认知负荷。可以进一步研究如何减轻人类评估者在评估长文本时的认知负荷,并探索评估长文本输出的更佳方法。
跨领域评估:
- 虽然LCFO数据集覆盖了多个领域,但不同领域之间的性能差异尚未深入探讨。未来的研究可以更详细地分析模型在不同领域中的表现,并探索领域适应性和迁移学习策略。
模型解释性和透明度:
- 论文没有深入探讨模型的解释性和透明度。未来的工作可以集中在提高模型决策过程的可解释性,以便更好地理解和信任模型生成的内容。
多模态和交互式摘要生成:
- 考虑到摘要任务的多样性,未来的研究可以探索多模态(如结合文本和图像)和交互式摘要生成方法,以提供更丰富的用户体验。
实时性能评估:
- 论文中的评估主要是离线进行的。未来的工作可以考虑实时性能评估,特别是在新闻报道和社交媒体等快速变化的领域。
这些探索点可以帮助研究社区更深入地理解长文本处理的挑战,并推动生成性AI技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了Long Context and Form Output (LCFO)基准测试框架,旨在评估大型语言模型(LLMs)在长文本摘要和摘要扩展任务上的性能。以下是论文的主要内容概述:
LCFO基准测试框架:提出了一个新的评估框架,用于评估长文本输入和长文本输出的生成能力。
数据集构建:构建了一个人工标注的数据集,包含长输入文档(平均长度为5k词)和三种不同长度的摘要(分别为输入文本的20%、10%和5%),以及与输入内容相关的15个问题和答案(QA)对。
任务定义:定义了渐进式摘要(GS)和摘要扩展(SE)任务,并提供了详细的操作步骤和评估指标。
人类评估和自动评估:提供了人类生成输出的评估分数,并使用不同的LLMs进行了实验,包括GPT-4o-mini和Llama-3.1-70B模型。
实验结果:发现GPT-4o-mini在自动系统中的表现最佳,甚至在短摘要任务中超过了人类输出的质量。
评估指标相关性分析:自动评估指标与人类评估分数之间的相关性较低(约0.4),但在特定评估方面如流畅性和归属性有中等相关性(约0.6)。
贡献和局限性:论文的主要贡献是提供了LCFO数据集和评估协议,但也指出了数据集的局限性,如数据污染和实验选择的局限性。
未来工作:提出了未来可能的研究方向,包括利用QA对作为自动评估的一部分,以及开发更好的自动评估指标。
总体而言,LCFO基准测试框架提供了一个标准化的平台,用于评估和推进生成性AI在长文本处理和生成任务上的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

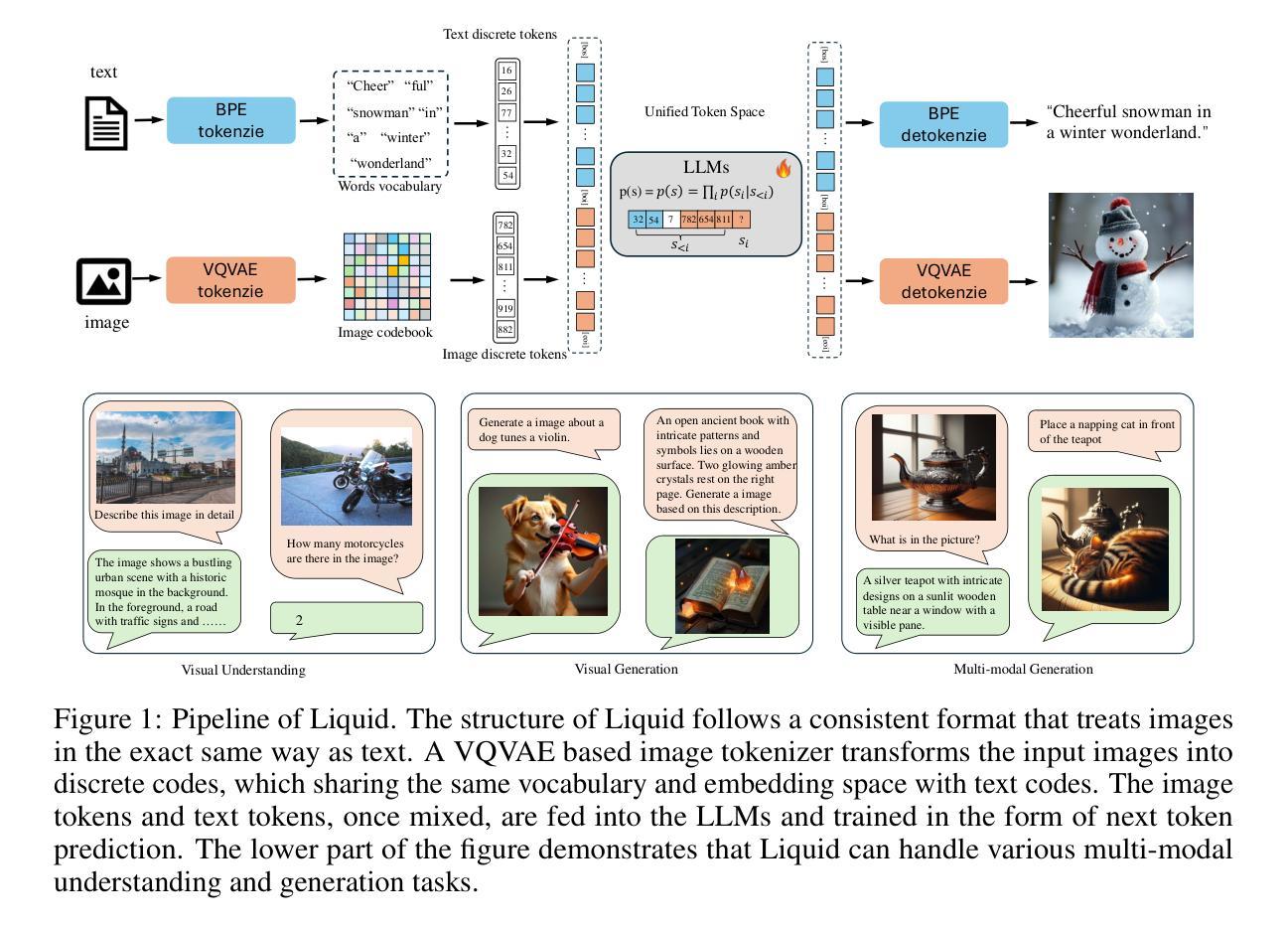
Liquid: Language Models are Scalable Multi-modal Generators
Authors:Junfeng Wu, Yi Jiang, Chuofan Ma, Yuliang Liu, Hengshuang Zhao, Zehuan Yuan, Song Bai, Xiang Bai
We present Liquid, an auto-regressive generation paradigm that seamlessly integrates visual comprehension and generation by tokenizing images into discrete codes and learning these code embeddings alongside text tokens within a shared feature space for both vision and language. Unlike previous multimodal large language model (MLLM), Liquid achieves this integration using a single large language model (LLM), eliminating the need for external pretrained visual embeddings such as CLIP. For the first time, Liquid uncovers a scaling law that performance drop unavoidably brought by the unified training of visual and language tasks diminishes as the model size increases. Furthermore, the unified token space enables visual generation and comprehension tasks to mutually enhance each other, effectively removing the typical interference seen in earlier models. We show that existing LLMs can serve as strong foundations for Liquid, saving 100x in training costs while outperforming Chameleon in multimodal capabilities and maintaining language performance comparable to mainstream LLMs like LLAMA2. Liquid also outperforms models like SD v2.1 and SD-XL (FID of 5.47 on MJHQ-30K), excelling in both vision-language and text-only tasks. This work demonstrates that LLMs such as LLAMA3.2 and GEMMA2 are powerful multimodal generators, offering a scalable solution for enhancing both vision-language understanding and generation. The code and models will be released at https://github.com/FoundationVision/Liquid.
我们推出了Liquid,这是一种自动回归生成范式,它通过图像标记为离散代码并学习这些代码嵌入与文本标记在共享特征空间中的视觉和语言嵌入,无缝集成了视觉理解和生成。与之前的多模态大型语言模型(MLLM)不同,Liquid使用一个单一的大型语言模型(LLM)来实现这种集成,无需外部预训练的视觉嵌入(如CLIP)。Liquid首次揭示了一个规律:随着模型规模的增加,由视觉和语言任务统一训练带来的性能下降必然减少。此外,统一的标记空间使得视觉生成和理解任务能够相互增强,有效地消除了早期模型中常见的干扰。我们展示了现有的LLM可以作为Liquid的强大基础,在训练成本上节省了高达100倍的同时,其多模态能力超越了变色龙(Chameleon),并保持了与LLAMA等主流LLM相当的语言性能。Liquid还优于SD v2.1和SD-XL等模型(在MJHQ-30K上的FID为5.47),擅长处理视觉语言和纯文本任务。这项研究表明,LLMA3.2和GEMMA等LLM具有强大的多模态生成能力,为解决增强视觉语言理解和生成问题提供了可扩展的解决方案。代码和模型将在https://github.com/FoundationVision/Liquid发布。
论文及项目相关链接
PDF Technical report. Project page: https://github.com/FoundationVision/Liquid
Summary
本文介绍了Liquid模型,该模型实现了视觉理解和生成的自然融合。通过将图像划分为离散代码并学习这些代码嵌入与文本标记的共同特征空间,Liquid实现了视觉和语言任务的统一训练。相较于早期多模态大型语言模型,Liquid仅使用一个大型语言模型即可实现这一融合,无需依赖外部预训练的视觉嵌入。随着模型规模的增加,性能下降的现象逐渐减轻。此外,Liquid还能让视觉生成和理解任务相互增强,消除早期模型中的典型干扰。Liquid表现优异,超越了其他模型如SD v2.1和SD-XL等。
Key Takeaways
- Liquid实现了视觉和语言任务的统一训练,无需外部预训练的视觉嵌入。
- 通过将图像划分为离散代码和与文本标记的共同特征空间,Liquid实现了视觉理解和生成的自然融合。
- 随着模型规模的增加,性能下降的现象逐渐减轻。
- Liquid消除了早期模型中的典型干扰,让视觉生成和理解任务能够相互增强。
- Liquid超越了其他模型如SD v2.1和SD-XL等,在多项任务上表现优异。
- 现有大型语言模型(LLMs)可以作为Liquid的强大基础,节省大量训练成本。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为Liquid的框架,旨在解决以下几个问题:
多模态集成问题:传统的多模态大型语言模型(MLLMs)通常依赖于外部的视觉嵌入(如CLIP)来实现视觉和语言的集成,这增加了系统的复杂性,并可能成为扩展LLMs时的瓶颈。
视觉和语言任务的性能权衡:在统一空间中同时训练视觉和语言任务时,较小的模型可能会在原始语言任务上表现下降,并且在视觉生成任务上也表现不佳。
训练成本问题:以往的一些方法需要从头开始进行大量的训练,这使得在这种形式下的探索变得计算成本高昂。
视觉生成和理解的统一:以往的研究尝试将视觉生成和理解集成到基于LLMs的统一多模态大型模型中,但这些方法通常需要额外的架构复杂性,并且没有充分利用LLMs在视觉生成中的潜力。
模型扩展性问题:以往的模型在扩展时面临性能瓶颈,尤其是在视觉生成和语言任务的统一训练中。
Liquid框架通过以下几个方面来解决这些问题:
使用单一的大型语言模型(LLM):通过将图像标记化成离散代码,并在视觉和语言共享的特征空间内学习这些代码嵌入,消除了对外部预训练视觉嵌入(如CLIP)的需求。
扩展现有LLMs:利用现有的LLMs作为基础,通过扩展它们的词汇表来容纳来自VQVAE的图像标记索引,而不是从头开始训练,从而节省训练成本。
统一的多模态混合训练:通过在统一的框架下进行视觉理解和视觉生成任务的训练,使得这两个任务能够相互促进,提高了模型的多模态能力。
模型扩展性研究:通过研究不同规模的LLMs在Liquid框架下的性能,发现随着模型规模的增加,视觉和语言任务之间的性能权衡逐渐消失,证明了利用LLMs直接进行图像生成的扩展优势。
Q: 有哪些相关研究?
A: 论文中提到了多个与Liquid框架相关的研究工作,可以归纳为以下几个方面:
多模态大型语言模型(MLLMs)
- LLaVA系列:[38, 36, 41, 5, 7, 37, 32] 这些模型使用预训练的CLIP模型作为视觉标记器,通过两阶段训练过程对齐视觉和语言特征空间。
- MiniGPT4:[76] 提出了将预训练的视觉基础模型特征投影到LLMs的特征空间中。
- Blip系列:[30, 29] 提出了通过冻结图像编码器和使用大型语言模型来引导语言-图像预训练的方法。
视觉生成
- 扩散模型:[44, 50, 46, 34, 48] 这一类模型通过在连续潜在空间上的扩散过程生成高质量、高分辨率的图像。
- 自回归模型:[49, 12, 71, 56] 这些模型通过预测序列中的下一个标记来生成图像,例如DALL-E、CogView、Parti和LlamaGen。
统一多模态理解和生成
- 使用VQVAE的模型:[39, 59, 68] 这些工作使用VQVAE将图像编码成离散标记,并训练LLMs来预测它们。
- 结合ViT和VQVAE的模型:[40, 69, 67] 这些工作同时使用ViT和VQVAE作为标记器,以结合它们的优势。
- LWM和Chameleon:[39, 59] 这些模型探索了使用VQVAE作为通用视觉标记器的方法,但需要大量的预训练数据。
其他相关研究
- Flamingo:[1] 提出了一个视觉语言模型,用于少样本学习。
- Qwen-vl:[2] 提出了一个具有多种能力的前沿大型视觉语言模型。
- Piqa:[3] 专注于物理常识推理。
- Mistral:[8×7B] 一个大型语言模型。
- IDEFICS-9B:[26] 一个视觉语言模型的复现研究。
- DreamLLM:[13] 一个协同多模态理解和创造的模型。
这些相关工作为Liquid框架提供了理论基础和技术背景,同时也展示了在多模态学习和生成领域的研究进展。Liquid框架在这些研究的基础上,提出了一种新的、统一的多模态生成和理解方法,旨在提高效率并减少训练成本,同时保持或提升性能。
Q: 论文如何解决这个问题?
A: 论文通过提出Liquid框架来解决上述问题,具体方法如下:
1. 集成视觉和语言的统一表示
Liquid框架通过使用VQVAE模型作为视觉标记器,将图像编码成离散的代码(tokens),这些代码与文本tokens共享相同的词汇表和嵌入空间。这样,视觉和语言数据可以在一个统一的特征空间内被处理,消除了对外部预训练视觉嵌入(如CLIP)的需求。
2. 构建高效的多模态生成框架
Liquid框架是一个自回归的生成范式,它利用现有的大型语言模型(LLMs),通过扩展这些模型的词汇表来容纳图像tokens。这种方法允许Liquid框架在不改变原有LLMs结构的情况下,直接在这些模型上进行多模态混合训练,从而节省了大量的训练成本。
3. 多模态混合训练
Liquid框架使用文本数据和图像-文本对数据进行混合训练,使得模型能够同时处理文本任务、图像理解任务和文本引导的图像生成任务。这种混合训练方法使得模型在视觉和语言任务之间能够相互增强。
4. 探索模型规模对性能的影响
通过在不同规模的LLMs上进行实验,论文发现随着模型规模的增加,视觉和语言任务之间的性能权衡逐渐消失。这表明大型LLMs有足够的容量同时处理视觉生成和语言任务。
5. 验证视觉理解和生成任务的相互促进
通过数据消融实验,论文发现视觉理解和视觉生成任务在Liquid框架下可以相互促进。添加更多的视觉理解数据可以提高视觉生成任务的性能,反之亦然。这表明在统一的特征空间内,这两种任务可以共享优化目标并相互增强。
6. 实验验证
论文通过在多个基准测试上的实验验证了Liquid框架在文本引导的图像生成、视觉理解和一般文本任务上的性能。实验结果表明,Liquid框架不仅在视觉任务上取得了优异的性能,而且在文本任务上也保持了与主流LLMs相当的性能。
综上所述,Liquid框架通过统一的视觉和语言表示、高效的多模态生成框架、多模态混合训练以及模型规模的探索,解决了多模态集成问题,提高了训练效率,并保持了优异的性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证Liquid框架的性能,这些实验覆盖了以下几个方面:
1. 训练细节和评估设置
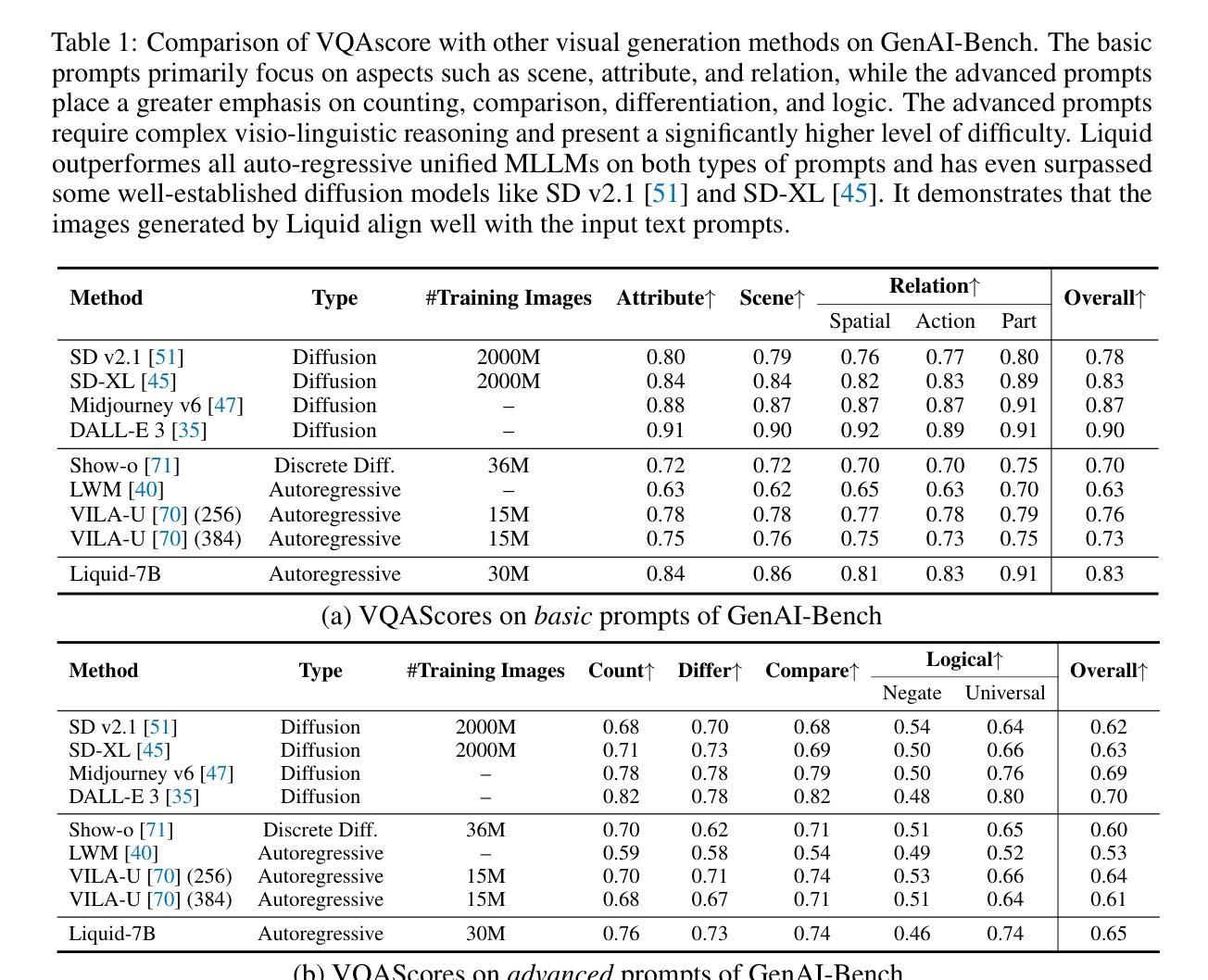
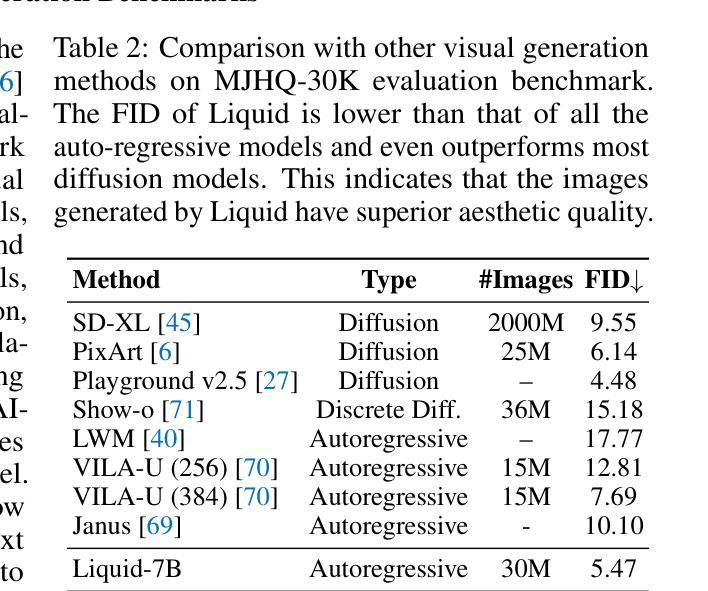
- 图像生成任务:在GenAI-Bench和MJHQ-30K两个基准上评估模型的图像生成能力。
- 视觉理解任务:在VQA-v2、GQA、TextVQA、MME等公共视觉语言基准上测试模型。
- 文本任务:在多个流行的基准上验证模型的原始语言能力,包括HellaSwag、WinoGrande、ARC-Easy、ARC-Challenge、OpenBookQA、PIQA、SIQA和BoolQ等。
2. 视觉生成结果
- MJHQ-30K评估基准:比较Liquid与其他视觉生成方法的FID(Frechet Inception Distance)得分。
- GenAI-Bench基准:比较Liquid在基本提示和高级提示下的VQAScore与其他视觉生成方法。
3. 视觉-语言理解
- 公共视觉语言基准测试:比较Liquid与其他使用离散视觉标记的方法在视觉理解任务上的性能。
4. 语言任务
- 标准文本基准测试:评估Liquid在预训练模型上的文本任务性能,并与其他最新的大型语言模型和多模态语言模型进行比较。
5. 扩展结果
- 不同规模模型的性能:构建不同规模(1B、2B、9B和27B)的Liquid模型,并观察它们在不同任务上的性能,以探索统一训练图像和文本生成任务是否会影响各自的性能。
6. 视觉生成和理解的相互促进
- 数据添加实验:通过在预训练阶段添加更多的视觉生成数据或视觉理解数据,观察不同数据添加对所有任务性能的影响。
这些实验全面评估了Liquid框架在多模态任务中的表现,包括图像生成、视觉理解以及语言任务,并探索了模型规模对性能的影响和不同任务之间的相互促进作用。通过这些实验,论文证明了Liquid框架的有效性和潜力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
1. 模型扩展性和性能上限
- 更大模型的探索:研究更大尺寸的Liquid模型是否会进一步消除视觉和语言任务之间的性能权衡,以及是否会在多模态任务上实现更高的性能。
2. 视觉理解能力的提升
- 图像-文本对齐:探索不同的图像-文本对齐方法,例如通过改进VQVAE训练过程来更好地桥接视觉和语言特征空间。
- 多模态预训练数据集:研究使用更大规模或更高质量的多模态预训练数据集对模型性能的影响。
3. 视觉生成任务的优化
- 生成控制和编辑能力:研究如何使Liquid模型能够更精确地控制图像生成过程,例如通过添加更多的条件或编辑现有图像。
- 样式和内容的解耦:探索在生成过程中解耦图像的样式和内容,以实现更多样化和可控的图像输出。
4. 跨模态任务的探索
- 多模态翻译:研究Liquid模型是否能够处理图像到文本或文本到图像的翻译任务,并探索其在跨模态检索中的应用。
- 视频生成和理解:将Liquid框架扩展到视频领域,研究视频内容的生成和理解。
5. 模型训练效率和可扩展性
- 训练策略的优化:研究不同的训练策略,如对比学习、增强学习等,以提高模型的训练效率和性能。
- 计算资源优化:探索如何优化模型训练过程中的计算资源分配,以实现更高效的训练。
6. 模型解释性和安全性
- 模型解释性:研究Liquid模型的决策过程,提供可视化工具和解释方法,以增加模型的透明度和可解释性。
- 防止偏见和滥用:研究如何减少模型在生成内容时可能出现的偏见,并确保模型的安全使用。
7. 跨领域应用
- 特定领域的适应性:研究Liquid模型在特定领域(如医疗、法律等)的应用,并探索如何对模型进行微调以适应这些领域的需求。
这些探索点可以帮助研究者更深入地理解Liquid模型的潜力和局限性,并推动多模态大型语言模型在更广泛领域的应用。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了Liquid,这是一个高效的多模态生成框架,它能够无缝地集成视觉理解和生成任务。以下是论文的主要内容总结:
核心贡献
- 统一的多模态框架:Liquid通过将图像标记化成离散代码,并与文本共享嵌入空间,实现了视觉和语言模态的统一表示。
- 扩展现有LLMs:利用现有的大型语言模型(LLMs)作为基础,通过扩展词汇表来包含图像tokens,避免了从头开始训练,节省了大量成本。
- 多模态混合训练:通过文本数据和图像-文本对数据的混合训练,Liquid能够在保持语言能力的同时,获得视觉理解和生成能力。
- 模型扩展性研究:发现随着模型规模的增加,视觉和语言任务之间的性能权衡逐渐消失,证明了LLMs在多模态生成中的潜力。
实验验证
- 视觉生成任务:在GenAI-Bench和MJHQ-30K基准上评估,Liquid在图像生成质量上超越了多个自回归模型和一些扩散模型。
- 视觉-语言理解任务:在VQA-v2、GQA、TextVQA、MME等基准上测试,Liquid超越了使用标准VQVAE的模型,并与使用CLIP的模型性能相当。
- 语言任务:在多个文本任务基准上评估,Liquid保持了与主流LLMs相当的性能,证明了其语言能力的保留。
扩展探索
- 视觉理解和生成的相互促进:发现在统一的特征空间内,视觉理解和生成任务可以相互增强,表明LLMs在多模态任务中具有潜力。
- 模型规模对性能的影响:随着模型规模的增加,视觉和语言任务之间的性能权衡减少,强调了利用LLMs进行图像生成的扩展优势。
结论
Liquid框架证明了LLMs可以有效地扩展到多模态任务,无需改变原有结构,同时保持了在视觉和语言任务上的优秀性能。这项工作展示了LLMs作为通用多模态生成器的潜力,并为未来的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


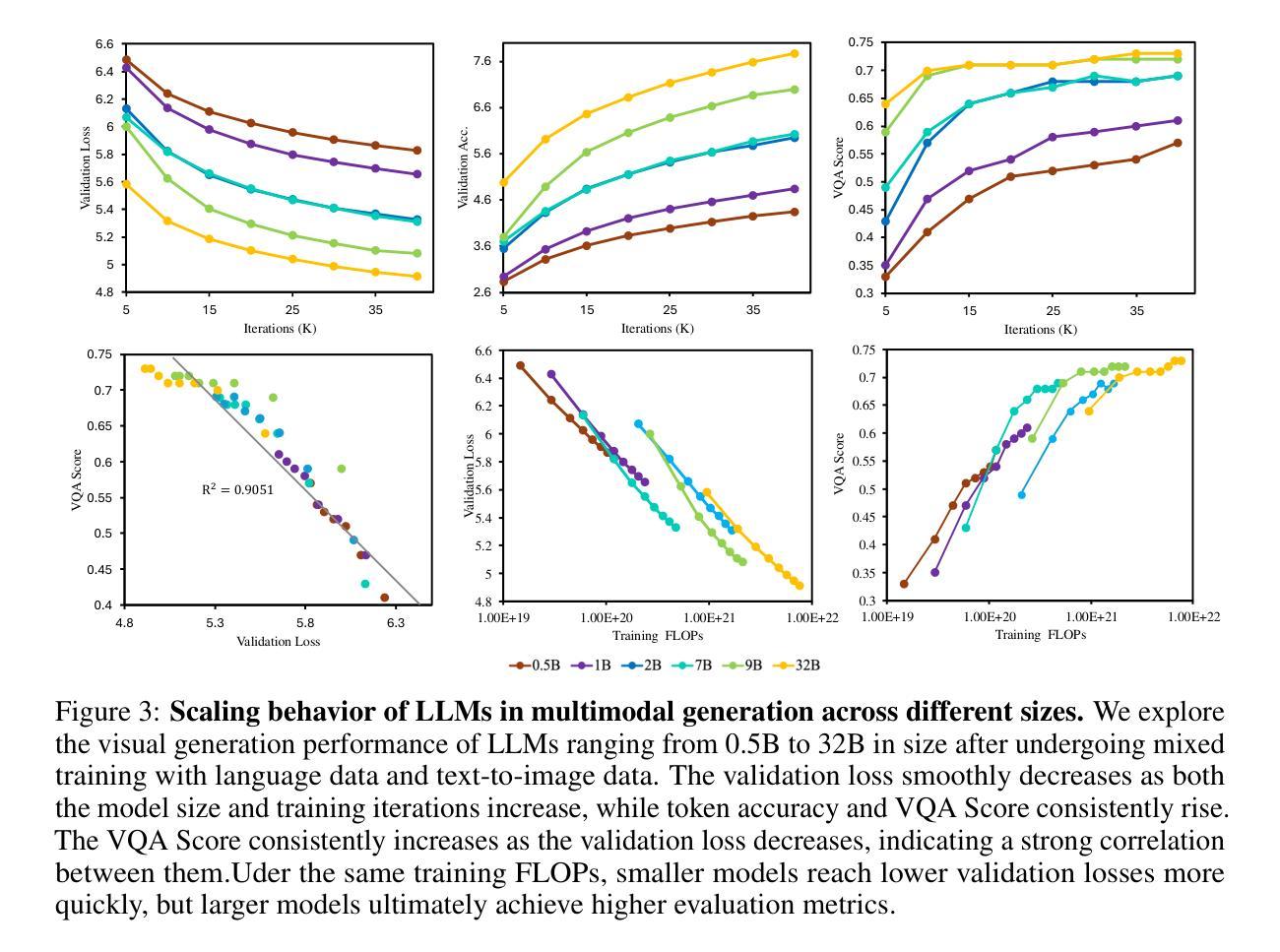
Monet: Mixture of Monosemantic Experts for Transformers
Authors:Jungwoo Park, Young Jin Ahn, Kee-Eung Kim, Jaewoo Kang
Understanding the internal computations of large language models (LLMs) is crucial for aligning them with human values and preventing undesirable behaviors like toxic content generation. However, mechanistic interpretability is hindered by polysemanticity – where individual neurons respond to multiple, unrelated concepts. While Sparse Autoencoders (SAEs) have attempted to disentangle these features through sparse dictionary learning, they have compromised LLM performance due to reliance on post-hoc reconstruction loss. To address this issue, we introduce Mixture of Monosemantic Experts for Transformers (Monet) architecture, which incorporates sparse dictionary learning directly into end-to-end Mixture-of-Experts pretraining. Our novel expert decomposition method enables scaling the expert count to 262,144 per layer while total parameters scale proportionally to the square root of the number of experts. Our analyses demonstrate mutual exclusivity of knowledge across experts and showcase the parametric knowledge encapsulated within individual experts. Moreover, Monet allows knowledge manipulation over domains, languages, and toxicity mitigation without degrading general performance. Our pursuit of transparent LLMs highlights the potential of scaling expert counts to enhance mechanistic interpretability and directly resect the internal knowledge to fundamentally adjust model behavior. The source code and pretrained checkpoints are available at https://github.com/dmis-lab/Monet.
理解大型语言模型(LLM)的内部计算对于将其与人类价值观对齐并防止生成有毒内容等不当行为至关重要。然而,多义性(即单个神经元对多个不相关概念的响应)阻碍了机械解释性。稀疏自动编码器(SAE)曾试图通过稀疏字典学习来解开这些特征,但由于依赖事后重建损失,它们损害了LLM的性能。为了解决这一问题,我们引入了为Transformer设计的单语义专家混合(Monet)架构,它将稀疏字典学习直接纳入端到端的专家混合预训练。我们新颖的专家分解方法能够实现每层专家数量增加到262,144个,同时总参数按专家数量的平方根比例进行扩展。我们的分析证明了专家之间知识的相互独立性,并展示了单个专家中封装的参数知识。此外,Monet允许对领域、语言和毒性进行知识操作,而不会降低整体性能。我们对透明LLM的追求突显了增加专家数量以提高机械解释性的潜力,并可直接调整内部知识以从根本上改变模型行为。源代码和预先训练的检查点可用于参考或扩展,地址为:https://github.com/dmis-lab/Monet。
论文及项目相关链接
Summary
大型语言模型(LLM)的内部计算理解对于与人类价值观对齐及防止生成有毒内容等不期望的行为至关重要。然而,由于神经元的多义性(即单个神经元对多个不相关概念的响应),机制解释性受到阻碍。为解决这一问题,我们提出了Mixture of Monosemantic Experts for Transformers(Monet)架构,该架构将稀疏字典学习直接纳入端到端的专家混合预训练。我们的新型专家分解方法使每层的专家数量能够扩展到262,144个,同时总参数数量与专家数量的平方根成比例增长。分析表明,各专家间的知识相互独立,展示了单个专家所包含的参数知识。此外,Monet能够在不降低总体性能的情况下,实现对领域、语言和毒性的知识操控。我们对透明LLM的追求突显了增加专家数量以提高机制解释性的潜力,并可直接调整内部知识以根本改变模型行为。
Key Takeaways
- 理解大型语言模型(LLM)的内部计算对于与人类价值观对齐至关重要。
- 神经元的多义性阻碍了机制解释性。
- Mixture of Monosemantic Experts for Transformers(Monet)架构通过直接纳入稀疏字典学习来解决这一问题。
- Monet的新型专家分解方法允许每层增加更多的专家,同时保持总参数数量的增长相对较慢。
- 各专家间的知识相互独立,单个专家可包含特定的参数知识。
- Monet能够在不降低模型总体性能的情况下,实现对领域、语言和毒性的知识操控。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决大型语言模型(LLMs)中的多义性(polysemanticity)问题,即单个神经元对多个不相关概念的响应。多义性问题使得理解这些模型的内部计算变得复杂,因为它违背了神经网络通过高维空间压缩编码更多特征的叠加假设(superposition hypothesis)。这不仅对将语言模型与人类价值观对齐至关重要,也是防止生成有毒内容等不期望行为的关键。
具体来说,论文中提到的问题包括:
机制解释性(Mechanistic interpretability):理解神经网络如何生成输出是提高模型透明度和可解释性的关键。然而,由于多义性的存在,单个神经元可能会响应多个概念,这使得对模型内部过程的解释变得困难。
后处理重建损失(Post-hoc reconstruction loss):先前尝试解决多义性问题的方法(如稀疏自编码器,SAEs)依赖于后处理重建损失,这可能会降低模型性能,因为它们在训练时与LLMs的语料库不匹配,导致分布外问题难以诊断。
可操纵性和性能权衡(Manipulability and performance trade-offs):尽管已有尝试根据学习到的字典特征来引导LLMs,但这些方法往往忽视了对模型在其他任务上通用性能的影响。
为了解决这些问题,论文提出了一种名为MONET(MIXTURE OF MONOSEMANTIC EXPERTS FOR TRANSFORMERS)的架构,它通过直接将稀疏字典学习整合到端到端的Mixture-of-Experts(MoE)预训练中,以实现专家的有效专业化,从而增强LLMs的机制解释性。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与MONET架构相关的研究:
Sparse Autoencoders (SAEs): 用于解决多义性问题,通过学习稀疏、过完备的基来解耦神经网络中的压缩特征。具体文献包括 [Sharkey et al., 2022; Bricken et al., 2023; Cunningham et al., 2024]。
Mixture-of-Experts (MoE) 架构: 与MONET结合的稀疏字典学习,被认为是实现专家专业化和单义性(monosemanticity)的有前景的方法。相关研究包括 [Gao et al., 2024; Fedus et al., 2022a;b]。
Parameter Efficient Expert Retrieval (PEER): 一种比其他SMoE架构处理更多专家的计算高效路由机制。PEER利用产品密钥算法来检索专家,减少了计算复杂度。参考自 [Lample et al., 2019]。
Sparse Mixture-of-Experts (SMoE): 通过仅激活专家子集来有效扩展模型容量,减少计算成本。参考自 [Fedus et al., 2022b; Du et al., 2022]。
神经网络的可解释性研究: 包括尝试通过解耦内部过程来提高神经网络的可解释性,如 [Bereska & Gavves, 2024]。
大型语言模型 (LLMs) 的行为和控制: 包括对LLMs的控制和行为调整的研究,如 [Ji et al., 2023; Hendrycks et al., 2023]。
神经网络特征的多义性: 研究了单个神经元如何响应多个不相关概念,如 [Aroora et al., 2018; Mu & Andreas, 2020; Olah et al., 2020]。
神经网络表示的特征: 探讨了神经网络通过高维空间编码更多特征的叠加假设,如 [Elhage et al., 2022]。
知识操控和模型行为调整: 包括对SAEs学习到的字典特征进行操控的研究,如 [Marks et al., 2024; Templeton, 2024]。
模型预训练中编码可解释权重的方法: 如 [Tamkin et al., 2023; Hewitt et al., 2023]。
这些相关研究为MONET架构提供了理论基础和技术背景,使其能够通过增加专家数量和整合稀疏字典学习来提高LLMs的机制解释性,并允许对知识进行操作,而不降低模型的一般性能。
Q: 论文如何解决这个问题?
A: 论文通过提出MONET(MIXTURE OF MONOSEMANTIC EXPERTS FOR TRANSFORMERS)架构来解决大型语言模型(LLMs)中的多义性问题。具体来说,MONET通过以下几个关键方法来解决这个问题:
专家分解方法(Expert Decomposition Method):
- 参数高效架构:MONET通过一种新颖的专家分解方法,使得每层的专家数量可以扩展到262,144个,同时确保总参数量与专家数量的平方根成比例。这通过水平分解(Horizontal Decomposition, HD)和垂直分解(Vertical Decomposition, VD)两种方法实现,有效解决了内存限制问题。
稀疏字典学习与MoE预训练集成:
- MONET将稀疏字典学习直接集成到端到端的Mixture-of-Experts(MoE)预训练中,从而避免了传统方法中后处理重建损失的问题。
单义性专家(Monosemantic Experts):
- MONET通过增加专家数量来促进专家的细粒度专业化,使得每个专家能够捕获互斥的知识方面,从而增强了模型的机制解释性。
知识操作能力:
- MONET允许在不降低模型一般性能的情况下,对知识领域、语言和毒性缓解进行操作。这通过透明观察专家路由模式和个体专家行为来实现。
计算和内存效率:
- 通过水平和垂直分解方法,MONET减少了计算复杂度和内存占用,使得模型可以有效地扩展专家数量,同时保持计算和内存效率。
自适应路由与批量归一化:
- 为了避免硬件效率低下的top-k排序,MONET使用批量归一化来估计专家路由分位数,而无需执行top-k操作,这减少了训练时间并保持了性能。
负载平衡损失和歧义损失:
- MONET引入了负载平衡损失和歧义损失,以促进模型在不同专家间的均匀路由,并鼓励模型为每个token分配特定专家,从而提高专家的专业化程度。
通过这些方法,MONET旨在实现透明的语言建模,通过增加专家数量和直接在预训练中整合稀疏字典学习,来提高LLMs的机制解释性,并允许对模型内部知识进行直接调整,以根本上改变模型行为。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了一系列实验来评估MONET(MIXTURE OF MONOSEMANTIC EXPERTS FOR TRANSFORMERS)模型的性能和特性。以下是实验的详细情况:
4.1 模型设置(Model Setups)
- 参数规模变化:作者训练了不同参数规模的MONET模型,从850M到4.1B,并与相同参数规模的LLAMA架构模型进行比较。
- 预训练数据集:所有模型都在大规模数据集上进行预训练,使用LLAMA架构进行公平比较。
- 微调:特别地,MONET-1.4B模型在指令遵循任务上进行了微调,以实现自动化解释框架。
4.2 开放式基准测试结果(Open-Ended Benchmark Results)
- 0-shot 和 5-shot 设置:作者在多个语言建模基准测试中评估了模型性能,包括WinoGrande(WG)、OpenBookQA(OBQA)、HellaSwag(HS)和CommonsenseQA(CSQA)。
- 与现有模型比较:将MONET模型的性能与现有的预训练模型(如OLMoE和Gemma 2)进行比较,这些模型使用Gemma Scope进行后处理训练。
4.3 定性结果(Qualitative Results)
- 专家路由得分可视化:在C4验证数据集和StarCoder数据集上,展示了MONET模型中专家的路由得分。
- 专家单义性:展示了专家如何在不同上下文和语言中专门化于特定概念。
- 自我解释专家:使用自动化解释框架,基于LLMs中的隐藏状态来解释各个专家。
5.1 领域掩蔽(Domain Masking)
- MMLU Pro基准测试:使用MMLU Pro将问题-答案集合分为14个不同类别,通过选择性删除特定领域的专家来评估模型在各个领域的表现。
5.2 多语言掩蔽(Multilingual Masking)
- MULTIPL-E基准测试:在CODEMONET 1.4B模型上进行编程语言掩蔽实验,通过选择性删除特定编程语言的专家来评估模型在不同编程语言上的表现。
5.3 有毒专家清除(Toxic Expert Purging)
- REALTOXICITYPROMPTS和ToxiGen基准测试:通过删除与毒性输出相关的专家来减少模型生成有害内容的能力,并在两个毒性基准测试上评估其影响。
这些实验旨在全面评估MONET模型的性能、可解释性和对特定知识的操控能力,从而证明其在提高大型语言模型透明度和控制能力方面的潜力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
高级专家选择方法:
- 论文中提到,专家的选择是基于路由分数的偏斜度,这是一个相对简单的方法。可以探索更复杂的专家选择方法,例如基于深度学习和模式识别的技术,以更精确地识别和选择特定领域的专家。
自动化解释技术:
- 尽管论文展示了自我解释专家的定性结果,但自动化解释性仍需量化评估。未来的研究可以集中在开发和验证这些技术的有效性,以提高模型的可解释性。
多义性与单义性专家的深入分析:
- 进一步研究专家的多义性和单义性,以及它们如何影响模型的性能和可解释性。这可能包括对专家行为的更深入分析,以及如何优化专家以提高单义性。
知识操控的扩展应用:
- 论文中提到了通过删除特定专家来实现知识“遗忘”。可以探索其他形式的知识操控,例如增强特定类型的知识或引入新的知识领域。
跨模态能力的扩展:
- 论文中提到了VISIONMONET模型,这是一个结合视觉和语言能力的模型。未来的研究可以探索如何将这种单义性专家的概念扩展到其他模态(如音频或触觉),以及如何实现更复杂的跨模态交互。
模型性能与可解释性的权衡:
- 研究模型性能和可解释性之间的权衡,以及如何优化模型以在保持高性能的同时提高可解释性。
长期学习与记忆:
- 探索MONET架构在长期学习场景中的应用,特别是在处理连续学习任务时如何保持和整合知识。
安全性和伦理考量:
- 考虑到模型可能生成有害内容,进一步研究如何通过设计和训练过程确保模型的安全性和伦理性。
跨领域和跨语言的应用:
- 探索MONET模型在不同领域和语言中的应用,以及如何调整模型以适应不同的数据分布和任务需求。
模型压缩和加速:
- 研究如何通过专家选择和知识操控来实现模型压缩和加速,同时保持模型性能。
这些探索点可以帮助推动大型语言模型的发展,使其更加透明、可控和适用于多种应用场景。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了MONET(MIXTURE OF MONOSEMANTIC EXPERTS FOR TRANSFORMERS)架构,旨在解决大型语言模型(LLMs)中的多义性问题,并提高模型的机制解释性。以下是论文的主要内容总结:
问题陈述:
- 大型语言模型(LLMs)的内部计算对于理解其行为和防止不良输出(如有毒内容生成)至关重要。
- 现有的方法,如稀疏自编码器(SAEs),在尝试解决多义性问题时,由于后处理重建损失和对模型性能的影响,存在局限性。
MONET架构:
- 提出了MONET架构,它通过在Mixture-of-Experts(MoE)预训练中直接整合稀疏字典学习来解决上述问题。
- MONET通过专家分解方法显著增加了每层的专家数量(达到262,144个),同时保持参数量与专家数量的平方根成比例,解决了内存限制问题。
主要贡献:
- 参数高效架构:通过专家分解方法,实现了专家数量的扩展,同时保持了参数量的可控性。
- 机制解释性:通过观察专家的路由模式和行为,MONET展示了专家之间的知识互斥性,并能够对单个专家的参数知识进行定性分析。
- 知识操作能力:MONET允许在不降低模型性能的情况下,对不同领域、语言和毒性缓解的知识进行操作。
实验:
- 在多个语言建模基准上评估了MONET模型的性能,结果表明MONET在保持竞争力的同时,能够进行有效的知识操作。
- 通过领域掩蔽、多语言掩蔽和有毒专家清除等实验,展示了MONET在知识编辑方面的能力。
结论与展望:
- MONET通过增加专家数量和促进专家的单义性专业化,为提高LLMs的解释性和可控性提供了新的途径。
- 论文还指出了未来研究的方向,包括开发更先进的专家选择方法、自动化解释技术和扩展模型的应用范围。
总体而言,这篇论文提出了一种新的架构,旨在通过增加专家数量和促进专家的专业化来提高大型语言模型的解释性和可控性,同时保持模型性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

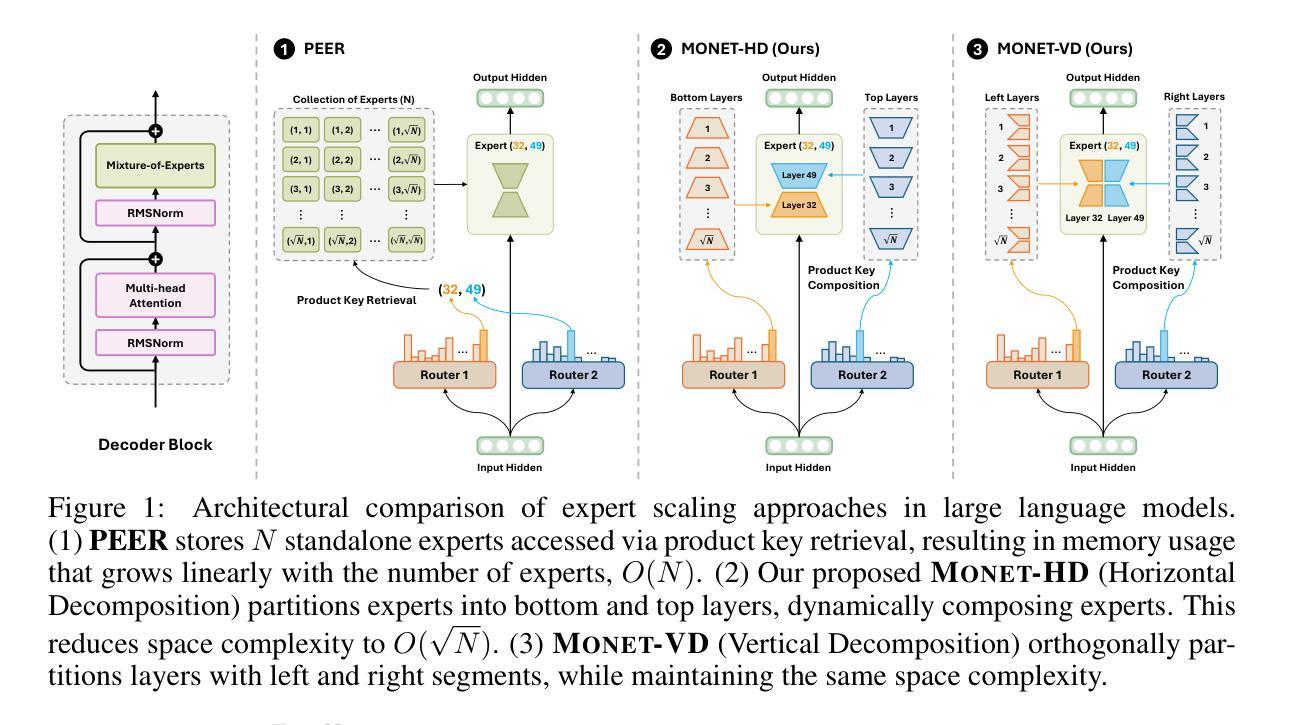
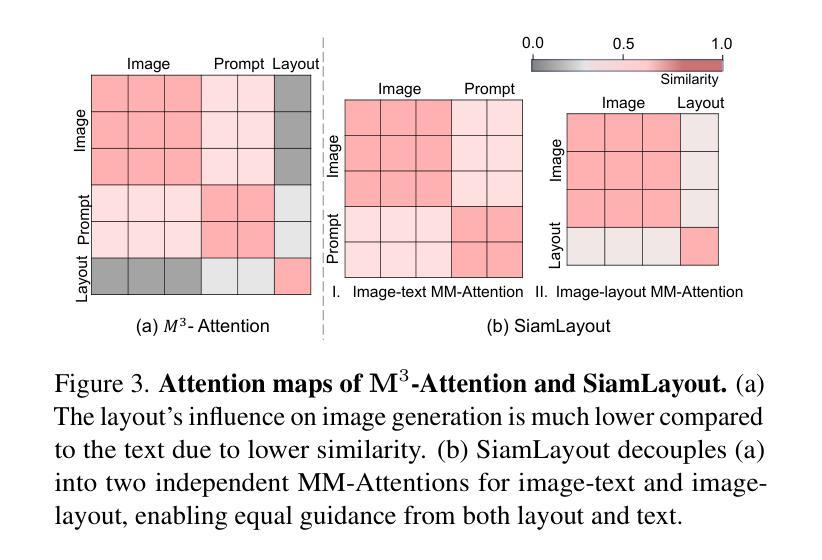
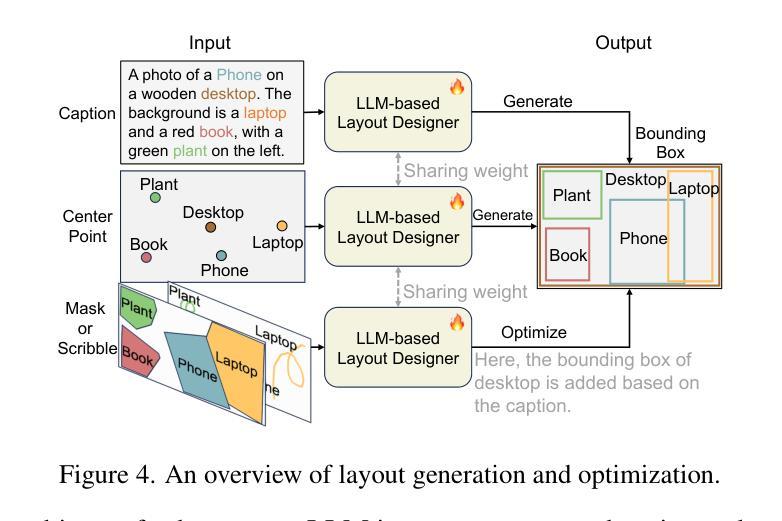
CreatiLayout: Siamese Multimodal Diffusion Transformer for Creative Layout-to-Image Generation
Authors:Hui Zhang, Dexiang Hong, Tingwei Gao, Yitong Wang, Jie Shao, Xinglong Wu, Zuxuan Wu, Yu-Gang Jiang
Diffusion models have been recognized for their ability to generate images that are not only visually appealing but also of high artistic quality. As a result, Layout-to-Image (L2I) generation has been proposed to leverage region-specific positions and descriptions to enable more precise and controllable generation. However, previous methods primarily focus on UNet-based models (e.g., SD1.5 and SDXL), and limited effort has explored Multimodal Diffusion Transformers (MM-DiTs), which have demonstrated powerful image generation capabilities. Enabling MM-DiT for layout-to-image generation seems straightforward but is challenging due to the complexity of how layout is introduced, integrated, and balanced among multiple modalities. To this end, we explore various network variants to efficiently incorporate layout guidance into MM-DiT, and ultimately present SiamLayout. To Inherit the advantages of MM-DiT, we use a separate set of network weights to process the layout, treating it as equally important as the image and text modalities. Meanwhile, to alleviate the competition among modalities, we decouple the image-layout interaction into a siamese branch alongside the image-text one and fuse them in the later stage. Moreover, we contribute a large-scale layout dataset, named LayoutSAM, which includes 2.7 million image-text pairs and 10.7 million entities. Each entity is annotated with a bounding box and a detailed description. We further construct the LayoutSAM-Eval benchmark as a comprehensive tool for evaluating the L2I generation quality. Finally, we introduce the Layout Designer, which taps into the potential of large language models in layout planning, transforming them into experts in layout generation and optimization. Our code, model, and dataset will be available at https://creatilayout.github.io.
扩散模型因其能够生成不仅在视觉上吸引人而且艺术质量高的图像而备受瞩目。因此,提出了Layout-to-Image(L2I)生成方法,利用特定区域的位置和描述来实现更精确和可控的生成。然而,以往的方法主要关注基于UNet的模型(如SD1.5和SDXL),对多模态扩散变压器(MM-DiT)的探索有限,而MM-DiT已显示出强大的图像生成能力。尽管使MM-DiT用于布局到图像生成似乎很简单,但由于引入、集成和平衡布局在多种模态中的复杂性,这仍然是一个挑战。为此,我们探索了各种网络变体,以有效地将布局指导融入MM-DiT,并最终推出SiamLayout。为了继承MM-DiT的优点,我们使用一组独立的网络权重来处理布局,将其视为与图像和文本模态同样重要。同时,为了减轻模态之间的竞争,我们将图像布局交互从图像文本交互中分离出来,作为一个孪生分支,并在后期进行融合。此外,我们还贡献了一个大规模布局数据集LayoutSAM,其中包括270万张图像文本对和1070万个实体。每个实体都带有边界框和详细描述。我们进一步构建了LayoutSAM-Eval基准测试,作为评估L2I生成质量的一个综合工具。最后,我们介绍了布局设计师,它利用大型语言模型在布局规划中的潜力,将其转化为布局生成和优化的专家。我们的代码、模型和数据集将在https://creatilayout.github.io上提供。
论文及项目相关链接
PDF 16 pages, 13 figures
Summary
本文探讨了Layout-to-Image(L2I)生成技术在图像生成领域的应用。文章指出,尽管Diffusion模型能够生成高质量图像,但现有的方法主要集中在基于UNet的模型上,对Multimodal Diffusion Transformers(MM-DiT)的探索有限。文章通过探索网络变体,将布局指导有效地融入MM-DiT,提出了SiamLayout模型。同时,文章还贡献了一个大规模布局数据集LayoutSAM,并建立了评估L2I生成质量的基准测试。最后,文章介绍了Layout Designer,展现了大型语言模型在布局规划方面的潜力。
Key Takeaways
- Diffusion模型在图像生成领域表现出强大的能力。
- Layout-to-Image(L2I)生成技术利用区域特定位置和描述来实现更精确和可控的生成。
- 现有方法主要集中在基于UNet的模型上,对Multimodal Diffusion Transformers(MM-DiT)的探索有限。
- SiamLayout模型通过融入布局指导到MM-DiT中,实现了布局到图像的生成。
- 文章贡献了一个大规模布局数据集LayoutSAM,用于支持研究。
- 建立了LayoutSAM-Eval基准测试,用于评估L2I生成质量。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何有效地将布局信息整合到多模态扩散变换器(Multimodal Diffusion Transformers,简称MM-DiTs)中,以实现高质量的、精确可控的布局到图像(Layout-to-Image,简称L2I)生成。具体来说,论文面临的挑战包括:
布局引入的复杂性:如何将布局信息引入到MM-DiTs中,并与其他模态(如图像和文本)进行有效的整合和平衡。
模态间的竞争:在多模态交互过程中,如何缓解不同模态(布局、图像、文本)之间的竞争,确保布局信息能够对图像生成过程产生足够的影响。
数据集限制:现有的布局数据集在规模和细节上的局限性,限制了模型生成具有复杂属性(如颜色、形状、纹理)的图像的能力。
布局规划的复杂性:如何将大型语言模型(LLMs)转化为专业的布局规划器,以支持不同粒度的用户输入,并优化布局生成。
为了解决这些问题,论文提出了一个名为Siamese Multimodal Diffusion Transformer(简称SiameLayout)的新方法,它将布局作为与图像和文本同等重要的独立模态进行处理,并通过特殊的网络结构设计来缓解模态间的竞争。此外,论文还贡献了一个大规模的布局数据集LayoutSAM,以及一个用于评估L2I生成质量的基准LayoutSAM-Eval。最后,论文提出了Layout Designer,这是一个基于大型语言模型的布局规划器,能够处理不同粒度的用户输入,并优化布局生成。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究主要涉及以下几个领域:
Text-to-Image Generation(文本到图像生成):
- 该领域研究了如何根据文本描述生成相应的图像。论文中提到了一些相关的研究,如SD3、SD3.5、FLUX.1和Playground-v3,这些研究通过多模态扩散变换器(MM-DiT)提升了文本到图像的生成质量。
Layout-to-Image Generation(布局到图像生成):
- 该领域旨在基于布局指导(包括空间位置和区域描述)生成图像,以实现更精确和可控的图像生成。论文中提到了GLIGEN、Ranni、MIGC等研究,这些方法主要基于UNet架构,通过引入额外的图像-布局融合模块来实现布局控制。
Layout Datasets(布局数据集):
- 论文中比较了不同的布局数据集,如COCO、Instance和Ranni,这些数据集包含图像-文本对和实体注释。这些数据集通常用于支持布局到图像的生成任务。
Large Language Model for Layout Generation(大型语言模型在布局生成中的应用):
- 该领域的研究探索了使用大型语言模型(LLMs)基于文本描述生成布局,然后引导图像生成。论文中提到了LayoutDesigner,这是一个基于LLM的布局规划器,能够将各种用户输入转换和优化为和谐且美观的布局。
Denoising Diffusion Probabilistic Models(去噪扩散概率模型):
- 这类研究关注于如何通过扩散过程生成高质量的图像,论文中提到了Denoising Diffusion Probabilistic Models作为生成模型的一个重要分支。
Multimodal Diffusion Transformers(多模态扩散变换器):
- 论文中提到了多模态扩散变换器在文本到图像生成中的应用,这些模型将文本视为与图像同等重要的模态,并使用MM-Attention代替传统的交叉注意力进行模态间的交互。
Vision-Language Models(视觉-语言模型):
- 论文中提到了使用视觉-语言模型来生成图像的详细描述或进行实体检测,这些模型在布局数据集的构建和布局到图像的生成中发挥了重要作用。
这些相关研究为论文提出的Siamese Multimodal Diffusion Transformer提供了理论基础和技术背景。通过结合这些领域的最新进展,论文旨在实现更高质量的布局到图像生成。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法解决了将布局信息整合到多模态扩散变换器(MM-DiTs)以实现高质量、精确可控的布局到图像(L2I)生成的问题:
1. Siamese Multimodal Diffusion Transformer (SiameLayout)
- 独立模态处理:将布局作为与图像和文本同等重要的独立模态进行处理,使用单独的变换器参数集来处理布局模态。
- 减少模态间竞争:通过将图像-布局和图像-文本的交互解耦为两个并行的“暹罗分支”(siamese branches),分别独立且同时地处理,减少了模态间的直接竞争。
- 精确控制生成:通过这种结构,布局和文本可以独立指导图像生成,然后后期融合,从而实现对图像生成的精确控制。
2. LayoutSAM 数据集和 LayoutSAM-Eval 基准
- 大规模布局数据集:贡献了一个大规模的布局数据集 LayoutSAM,包含 2.7M 图像-文本对和 10.7M 实体,每个实体都有边界框和详细描述。
- 评估基准:构建了 LayoutSAM-Eval 基准,用于全面评估 L2I 生成质量,包括区域质量和全局质量。
3. Layout Designer
- 布局规划和优化:提出了一个基于大型语言模型的布局规划器 LayoutDesigner,能够处理不同粒度的用户输入(如中心点、遮罩、涂鸦或粗略想法),并将其转换和优化为和谐且美观的布局。
4. 训练和推理策略
- 时间步偏差采样:由于布局涉及图像的结构内容,主要在较大的时间步生成,因此模型采用偏向于大时间步的采样策略。
- 区域感知损失:通过为布局指定区域的损失增加权重,增强模型对这些区域的关注,加速模型的收敛。
通过这些方法,论文成功地将布局信息整合到 MM-DiTs 中,并实现了高质量的、精确可控的布局到图像生成。这些方法不仅提高了生成图像的视觉质量和艺术性,还增强了对复杂属性(如颜色、形状、纹理和文本)的渲染能力。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了以下实验来验证他们提出的方法:
1. Layout-to-Image Generation (L2I) 实验
在 LayoutSAM 数据集上的实验:
- 使用 LayoutSAM 数据集(包含 2.7M 图像-文本对和 10.7M 实体)进行训练,并在 LayoutSAM-Eval(包含 5,000 个布局数据点)上进行评估。
- 使用区域质量和全局质量两个方面来评估 L2I 生成质量,包括空间准确性、属性准确性、视觉质量、全局标题遵循度等。
在 COCO 2017 数据集上的实验:
- 在 COCO 数据集上训练并验证 SiamLayout 在粗粒度封闭集布局到图像生成中的泛化能力。
- 使用 YOLO-v11x 检测生成图像中的对象,并计算 AP、AP50 和 AR 以评估模型的布局遵循度。
- 使用 FID、CLIP 分数和 IS 来衡量全局图像质量。
2. Text-to-Image Generation (T2I) 实验
- 在 T2I-CompBench 上进行实验,评估引入布局对文本到图像生成的影响。
- 使用 SD3 和 SiamLayout 生成图像,并比较在空间、颜色、形状、纹理和数量等方面对提示的遵循度。
3. Layout Generation 和 Optimization 实验
- 使用从 LayoutSAM 训练集派生的 180,000 个训练集来训练 LayoutDesigner,并在 LayoutSAM-Eval 上构建的 1,000 个验证集上进行评估。
- 评估 LayoutDesigner 在不同输入粒度(全局标题、中心点、子优布局)下的布局生成和优化能力。
4. Ablation Study
- 对不同网络变体进行消融研究,包括 Layout Adapter、M3-Attention 和 SiamLayout,以评估它们在布局遵循度方面的性能。
- 探索训练策略(如时间步偏差采样和区域感知损失)对 SiamLayout 性能的影响。
5. 定性结果分析
- 提供了额外的定性结果,展示 SiamLayout 在生成具有复杂属性(如颜色、纹理、形状)的实体方面的优势。
这些实验全面评估了 SiamLayout 在不同方面的性能,包括其在开放集和封闭集布局到图像生成任务上的表现,以及在文本到图像生成和布局规划任务中的有效性。通过这些实验,作者证明了他们提出的方法在实现高质量、精确可控的布局到图像生成方面的优势。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和研究结果,以下是一些可以进一步探索的点:
1. 端到端模型集成
- 论文中提出了一个大型语言模型用于布局规划,这增加了额外的计算成本。未来的研究可以探索将布局规划与布局到图像生成集成到一个端到端模型中,以减少计算开销并可能提高整体性能。
2. 自动注释管道的改进
- 自动注释管道可能会引入噪声数据,主要是由于对象检测模型的不准确性。进一步研究这些噪声数据对布局到图像模型性能的影响,并探索改进自动注释流程的方法是一个重要的方向。
3. 模态竞争的深入研究
- 尽管SiameLayout通过解耦图像-布局和图像-文本交互缓解了模态竞争问题,但进一步研究模态竞争的机制和影响,以及如何更有效地平衡不同模态的贡献,仍然是一个有价值的研究方向。
4. 多模态交互的增强
- 探索新的多模态交互技术,以进一步提升MM-DiTs在处理图像、文本和布局等多种模态数据时的性能和控制能力。
5. 跨域泛化能力
- 评估SiameLayout在不同领域和不同类型的布局数据集上的泛化能力,特别是在更多样化和复杂的现实世界布局生成任务中。
6. 用户交互和编辑能力
- 开发更直观的用户交互界面,允许用户对生成的布局和图像进行编辑和微调,以更好地满足用户的个性化需求。
7. 计算效率优化
- 研究如何优化SiameLayout的计算效率,包括减少训练和推理时间,使其更适合实际应用。
8. 评估指标的多样化
- 开发和测试更多的评估指标,以全面衡量布局到图像生成模型在各个方面的性能,如创造性、多样性和用户满意度。
9. 可解释性和可视化
- 提高模型的可解释性,通过可视化技术揭示模型是如何理解和处理布局、文本和图像模态的,这有助于理解和改进模型的决策过程。
10. 多语言和跨文化支持
- 探索模型对不同语言和文化背景的适应性,使其能够处理来自不同地区和文化的用户输入和布局风格。
这些方向不仅可以推动布局到图像生成技术的发展,还可能对多模态人工智能领域的其他应用产生积极影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题定义:论文针对的是如何将布局信息有效整合到多模态扩散变换器(MM-DiTs)中,以实现高质量和精确可控的布局到图像(L2I)生成。这一任务因布局引入、整合和多模态平衡的复杂性而充满挑战。
**Siamese Multimodal Diffusion Transformer (SiameLayout)**:提出了一个名为SiameLayout的新方法,它将布局作为与图像和文本同等重要的独立模态进行处理,并通过特殊的网络结构设计来减轻模态间的竞争,从而精确控制图像生成。
LayoutSAM 数据集和 LayoutSAM-Eval 基准:为了训练和评估L2I模型,作者贡献了一个大规模的布局数据集LayoutSAM,包含2.7M图像-文本对和10.7M实体,以及一个评估L2I生成质量的综合工具LayoutSAM-Eval。
Layout Designer:提出了一个基于大型语言模型的布局规划器LayoutDesigner,能够处理不同粒度的用户输入,并将其转换和优化为和谐且美观的布局。
实验:通过在LayoutSAM和COCO数据集上的实验,验证了SiameLayout在生成具有复杂属性(如颜色、形状、纹理)的实体方面的优势。此外,还进行了文本到图像生成和布局规划的实验,证明了引入布局信息可以显著提升图像生成的质量。
消融研究:通过对不同网络变体的消融研究,展示了SiameLayout在布局遵循度方面的优越性能,并探索了训练策略对模型性能的影响。
结论与未来工作:论文总结了SiameLayout如何通过将布局作为独立模态处理并减少模态间竞争,实现了高质量的L2I生成,并提出了未来可能的研究方向,如端到端模型集成和自动注释流程的改进。
总体而言,这篇论文提出了一个创新的方法来处理布局到图像的生成问题,并通过大规模实验验证了其方法的有效性,为未来在这一领域的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


How Good is ChatGPT in Giving Adaptive Guidance Using Knowledge Graphs in E-Learning Environments?
Authors:Patrick Ocheja, Brendan Flanagan, Yiling Dai, Hiroaki Ogata
E-learning environments are increasingly harnessing large language models (LLMs) like GPT-3.5 and GPT-4 for tailored educational support. This study introduces an approach that integrates dynamic knowledge graphs with LLMs to offer nuanced student assistance. By evaluating past and ongoing student interactions, the system identifies and appends the most salient learning context to prompts directed at the LLM. Central to this method is the knowledge graph’s role in assessing a student’s comprehension of topic prerequisites. Depending on the categorized understanding (good, average, or poor), the LLM adjusts its guidance, offering advanced assistance, foundational reviews, or in-depth prerequisite explanations, respectively. Preliminary findings suggest students could benefit from this tiered support, achieving enhanced comprehension and improved task outcomes. However, several issues related to potential errors arising from LLMs were identified, which can potentially mislead students. This highlights the need for human intervention to mitigate these risks. This research aims to advance AI-driven personalized learning while acknowledging the limitations and potential pitfalls, thus guiding future research in technology and data-driven education.
电子学习环境中越来越频繁地使用类似GPT-3.5和GPT-4等大型语言模型(LLM),以提供定制化的教育支持。本研究介绍了一种将动态知识图谱与LLM相结合的方法,以提供微妙的学生辅助。通过评估学生过去的和正在进行中的互动,该系统确定并将最突出的学习上下文添加到针对LLM的提示中。此方法的核心是知识图谱在评估学生对主题先决条件的理解中的作用。根据分类的理解程度(良好、一般或差),LLM会调整其指导,分别提供高级辅助、基础复习或深入的先决条件解释。初步结果表明,学生可能从这种分层的支持中受益,实现增强的理解和改进的任务结果。然而,也发现了与LLM可能产生的潜在错误相关的一些问题,可能会误导学生。这强调了需要人为干预来减轻这些风险。本研究旨在推动人工智能驱动的个性化学习,同时承认其局限性和潜在缺陷,从而为技术和数据驱动的教育未来的研究提供指导。
论文及项目相关链接
摘要
一项新研究将动态知识图谱与大型语言模型(LLM)相结合,应用于电子学习环境,以提供个性化的学生支持。系统通过评估学生的过去和当前互动来识别最重要的学习背景信息,并添加到针对LLM发出的提示中。根据学生对课题要求的理解程度进行评判(良好、一般或不佳),LLM会调整其指导方式,提供进阶辅导、基础复习或深入讲解前置知识。初步研究结果表明,这种分层支持有助于学生提高理解能力和任务效果。然而,研究也发现大型语言模型可能会产生的潜在错误和误导风险问题。这需要人工介入来缓解风险。本研究旨在推动AI驱动个性化学习的发展,同时认识到局限性和潜在问题,为未来科技与数据驱动的教育研究提供指导。
关键见解
- 大型语言模型(LLM)正在越来越多地被应用于电子学习环境,以提供个性化的教育支持。
- 动态知识图谱是评估学生对课题要求理解程度的关键工具。根据理解程度的不同,LLM会提供不同层次的指导。
- 通过整合动态知识图谱与LLM,电子学习环境可以提供分层支持,帮助学生提高理解能力和任务效果。
- 大型语言模型可能会产生潜在错误和误导风险问题,需要人工介入来缓解这些风险。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了如何将大型语言模型(LLMs)与动态知识图谱相结合,以提供适应性的学生指导,特别是在电子学习环境中。论文的主要目标是解决以下问题:
个性化指导的提供:如何根据学生当前的困境和知识状态提供个性化指导?
LLMs生成精确答案的能力:LLMs是否能够生成正确答案,精确地解决学生的学习困境?
论文通过评估学生过去和正在进行的互动,识别并附加最相关的学习背景到针对LLMs的提示中,从而根据学生对主题先决条件的理解(分为好、平均或差)调整其指导,提供高级协助、基础复习或深入的先决条件解释。这种方法旨在克服传统智能辅导系统(ITSs)的局限性,提供更细致和适应性的个性化支持,以满足个别学生的需求。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与本研究相关的研究:
AI在教育中的应用:
- [1] R. S. Baker, T. Martin, 和 L. M. Rossi 提出了教育数据挖掘和学习分析的概念。
- [2] P. Blikstein 和 M. Worsley 探讨了多模态学习分析和教育数据挖掘,使用计算技术来测量复杂的学习任务。
大型语言模型(LLMs):
- [4] A. Radford 等人展示了语言模型是无监督的多任务学习者。
- [12] H. Li 等人讨论了大型语言模型在医学和医学研究中的伦理问题。
智能辅导系统(ITSs):
- [6] G.-J. Hwang 提出了基于概念图的智能辅导系统模型。
- [7] P. Phobun 和 J. Vicheanpanya 讨论了适应性智能辅导系统在电子学习系统中的应用。
LLMs在教育中的潜力:
- [26] L. Yan 等人进行了关于LLMs在教育中的实用和伦理挑战的系统性综述。
- [27] T. Phung 等人使用大型语言模型为编程语法错误生成高精度反馈。
知识图谱在教育中的应用:
- [29] B. Xue 和 L. Zou 提供了知识图谱质量管理的综合调查。
- [30] G. Tamašauskaitė 和 P. Groth 通过系统回顾定义了知识图谱开发过程。
评估LLMs的效果和挑战:
- [28] J. Qadir 讨论了在ChatGPT时代工程教育的前景和LLMs在教育中的潜力与陷阱。
- [35] Q. Wu 等人提出了一个多代理对话框架,使下一代LLM应用成为可能。
这些相关研究涵盖了从AI在教育中的应用、LLMs的多任务学习能力、智能辅导系统的发展、LLMs在教育中的潜力和挑战,到知识图谱在教育中的应用等多个方面。这些研究为本论文提出的将动态知识图谱与LLMs相结合的方法提供了理论基础和实践参考。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决提出的问题:
1. 知识图谱的创建和节点识别
- 利用知识图谱确定学生需要学习的课题和子课题之间的关系及层级结构。
- 使用教科书《Math Algebra 2》构建简化的知识图谱,将每个章节的单元视为一个概念,并使用“GO for Help”指标建立概念间的关系,如先决条件。
2. 问题的检索和排名
- 根据知识图谱中的节点,使用树遍历算法检索所有直接连接的后代节点,确定学生的先决知识领域或概念问题。
- 将问题分为不同的难度等级(简单A、中等B和困难C),并根据概念的基础知识水平进行分类。
3. 学生困境的识别
- 假设学生通过输入提示描述他们在特定问题上的挑战或困境。
- 请专家基于标准解决方案审查每个问题,并为不同难度级别的问题估计不同类型学生可能遇到的困境。
4. 基于LLM的个性化解决方案生成
- 使用LLM(本研究中使用的是ChatGPT4)生成针对给定问题的个性化答案,重点放在困境和追溯的先决条件上。
- 通过将学生的当前知识状态作为提示的一部分输入LLM,期望LLM能够生成解决学生特定挑战的定制反馈。
5. 实验设计和评估
- 设计实验,选择不同难度水平的问题,并为每种学生类型生成个性化反馈。
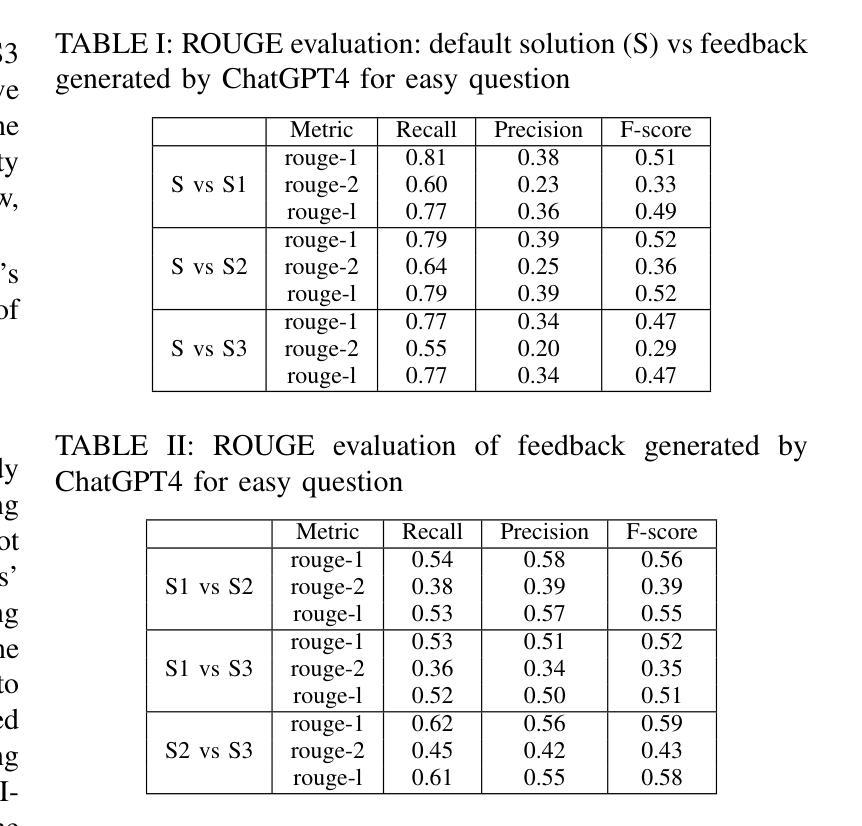
- 使用ROUGE方法评估文本摘要的质量,并请专家基于几个标准(正确性、精确性、幻觉和变化性)评估生成的反馈。
6. 结果分析和讨论
- 分析ROUGE评估结果和专家评估结果,以确定LLM生成的反馈的个性化程度和质量。
- 讨论结果的意义,包括LLM在教育中应用的潜力和局限性,并强调在教育环境中使用LLM时需要人类监督的必要性。
通过这些步骤,论文提出了一个综合的方法框架,用于在电子学习环境中利用LLMs提供个性化的学生反馈,并通过对该方法的实验评估来展示其有效性。
Q: 论文做了哪些实验?
A: 论文中进行的实验包括以下几个关键步骤:
实验设置
选择问题:
- 从三个不同的难度级别(简单A、中等B和困难C)中各选取一个问题。
生成个性化反馈:
- 使用ChatGPT4为每个难度级别下的问题生成个性化反馈,针对三种不同类型的学生(S1、S2和S3)。
评估方法
ROUGE方法:
- 使用ROUGE方法比较标准解决方案和ChatGPT4为每种学生类型生成的个性化反馈之间的相似性。
- 分析不同学生类型间的反馈差异性,以评估反馈的个性化程度。
专家评估:
- 邀请专家根据正确性、精确性、幻觉和变化性等标准对ChatGPT4生成的反馈进行评分。
实验结果
简单(A)问题:
- 对于简单问题,所有学生类型(S1、S2和S3)的反馈与标准解决方案的一致性较高。
中等难度(B)问题:
- 对于中等难度问题,不同学生类型的反馈与标准解决方案的一致性有所不同,显示出个性化反馈的需求。
困难(C)问题:
- 对于困难问题,不同学生类型的反馈与标准解决方案的一致性差异更大,表明需要更个性化的指导。
专家评估的可靠性
- 使用Cohen’s Kappa统计量评估三位评估者之间的一致性,结果显示对简单和中等难度问题的评估具有适度一致性,而对困难问题的评估一致性较低。
用户研究
- 进行了一项涉及大学生的初步用户研究,以评估他们与所提出的AI感i系统(如图1所示)的互动和反馈。
- 在初步调查中,测量了学生对AI工具在教育中的感知和反馈寻求行为。
- 参与者被随机分配到三种学生档案之一(S1、S2或S3),并给出了一个数学问题来解决。
- 参与者还被要求对从AI感i收到的响应质量进行评分。
这些实验结果有助于评估所提出的基于知识图谱和LLM的个性化反馈方法的有效性,并展示了在不同难度级别和学生类型下反馈的个性化程度。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些可以进一步探索的点,包括:
多学科和多语言支持:
- 目前的研究仅限于数学科目,未来可以扩展到更多学科,并考虑不同语言环境下的学生。
更广泛的知识图谱应用:
- 研究可以扩展到更全面的知识图谱,覆盖更广泛的学术领域,以评估LLM反馈的普遍性和适用性。
真实学生互动数据的收集:
- 由于实验中缺少真实学生的数据,未来的研究可以收集真实学生的数据,以更准确地捕捉学生困境的多样性和不可预测性。
LLMs的解释能力和错误分析:
- 进一步研究LLMs在特定领域(如数学)中的解释能力和错误产生的原因,以及如何改进LLMs以减少错误。
教育实践中LLMs的集成和验证:
- 在真实教育环境中集成LLMs,并进行更大规模的验证研究,以评估其对学习成效的影响。
人类监督与LLMs的协同工作:
- 探索人类教育者与LLMs协同工作的最佳实践,以确保教育内容的准确性和适用性。
学习困境的自动检测和分类:
- 开发更先进的算法来自动检测和分类学生的学习困境,减少对专家评估的依赖。
个性化学习路径的动态调整:
- 研究如何根据学生的学习进度和困境动态调整个性化学习路径。
伦理和隐私问题:
- 随着LLMs在教育中的广泛应用,需要进一步探讨相关的伦理和隐私问题,确保学生数据的安全和合规使用。
跨文化研究:
- 考虑到不同文化背景下学生学习方式的差异,进行跨文化研究以评估LLMs在全球教育环境中的有效性。
这些探索点可以帮助研究者更深入地理解LLMs在教育中的应用,并为未来的教育技术发展提供指导。
Q: 总结一下论文的主要内容
A: 这篇论文探讨了如何将大型语言模型(LLMs)与动态知识图谱相结合,以提供适应性的学生指导,特别是在电子学习环境中。以下是论文的主要内容总结:
研究背景与目标
- 介绍了利用大型语言模型(如GPT-3.5和GPT-4)在电子学习环境中提供个性化教育支持的重要性。
- 强调了提供针对学生个体认知差距和学习风格的反馈的重要性。
- 提出了一个新方法,该方法通过评估学生互动来识别学生的学习背景,并据此调整LLMs的指导。
方法论
- 利用知识图谱评估学生对先决条件主题的理解,并根据理解程度(好、平均或差)调整LLMs的反馈。
- 提出了一个系统架构,称为AI-sensei,结合知识图谱、学习分析和基于LLM的反馈生成,以提供适应性指导。
实验设计
- 设计了一个实验,选择不同难度的问题,并为三类学生(S1、S2和S3)生成个性化反馈。
- 使用ROUGE方法和专家评估来衡量反馈的质量和个性化程度。
实验结果
- 对于简单问题,所有学生类型的反馈与标准解决方案的一致性较高,表明简单问题的反馈需求较为统一。
- 对于中等难度和困难问题,不同学生类型的反馈与标准解决方案的一致性降低,表明需要更个性化的指导。
- 专家评估显示,对于所测试的问题,ChatGPT4生成的反馈在正确性上表现良好,但在精确性和个性化方面存在差异。
讨论与局限性
- 讨论了LLMs在教育中应用的潜力和挑战,强调了人类监督的重要性。
- 指出了ROUGE方法的局限性,并讨论了专家评估的结果。
- 论文承认了研究的局限性,包括学科范围、语言限制和缺乏真实学生数据。
结论
- 提出的方法能够为不同难度的问题提供不同程度的个性化反馈,但需要谨慎使用LLMs,并进行持续验证和监督。
- LLMs展现出在教育中辅助教师和个性化反馈的潜力,但不能完全取代人类干预。
未来研究方向
- 建议未来的研究应考虑多学科、多语言环境,以及真实学生数据的收集和分析。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Benchmarking terminology building capabilities of ChatGPT on an English-Russian Fashion Corpus
Authors:Anastasiia Bezobrazova, Miriam Seghiri, Constantin Orasan
This paper compares the accuracy of the terms extracted using SketchEngine, TBXTools and ChatGPT. In addition, it evaluates the quality of the definitions produced by ChatGPT for these terms. The research is carried out on a comparable corpus of fashion magazines written in English and Russian collected from the web. A gold standard for the fashion terminology was also developed by identifying web pages that can be harvested automatically and contain definitions of terms from the fashion domain in English and Russian. This gold standard was used to evaluate the quality of the extracted terms and of the definitions produced. Our evaluation shows that TBXTools and SketchEngine, while capable of high recall, suffer from reduced precision as the number of terms increases, which affects their overall performance. Conversely, ChatGPT demonstrates superior performance, maintaining or improving precision as more terms are considered. Analysis of the definitions produced by ChatGPT for 60 commonly used terms in English and Russian shows that ChatGPT maintains a reasonable level of accuracy and fidelity across languages, but sometimes the definitions in both languages miss crucial specifics and include unnecessary deviations. Our research reveals that no single tool excels universally; each has strengths suited to particular aspects of terminology extraction and application.
本文比较了使用SketchEngine、TBXTools和ChatGPT提取术语的准确性。此外,它还评估了ChatGPT为这些术语生成的定义的品质。该研究是在网上收集的英语和俄语时尚杂志的可比语料库上进行的。通过识别可以自动收割的网页,这些网页包含英语和俄语时尚领域的术语定义,从而制定了时尚术语的金标准。这个金标准被用来评估提取的术语和产生的定义的品质。我们的评估显示,TBXTools和SketchEngine虽然召回率高,但随着术语数量的增加,精确率下降,这影响了它们的整体性能。相反,ChatGPT表现出卓越的性能,在考虑更多术语时,能保持或提高精确率。对ChatGPT为英语和俄语中60个常用术语所生成定义的分析表明,ChatGPT在跨语言时保持了合理的准确性和忠实度,但有时两种语言的定义都会遗漏关键细节,并包含不必要的偏差。我们的研究表明,没有单一的工具可以普遍胜任;每个工具都有适合特定方面的术语提取和应用的优势。
论文及项目相关链接
PDF To appear in the Proceedings of Translating and the Computer 2024 (TC46)
Summary
本文比较了SketchEngine、TBXTools和ChatGPT三种工具在提取时尚杂志术语方面的准确性,并评估了ChatGPT生成的术语定义的质量。研究基于从网络上收集的英语和俄语时尚杂志的可比语料库进行。通过开发一个包含英语和俄语时尚术语定义的金标准来评估提取的术语和定义的质量。评价结果显示,TBXTools和SketchEngine虽然召回率高,但随着术语数量的增加,精度下降,整体性能受影响。而ChatGPT则表现出卓越的性能,在考虑更多术语时,能保持或提高精度。对ChatGPT为60个常用英语和俄语术语生成的定义分析表明,ChatGPT在多语言环境下的准确度及忠实度保持合理水平,但部分定义缺乏关键细节,存在不必要的偏差。研究结果表明,没有单一的工具可以普遍胜任,每个工具在特定术语提取和应用方面都有其优势。
Key Takeaways
- SketchEngine、TBXTools和ChatGPT三种工具在提取时尚杂志术语的准确性上进行了比较。
- 研究是基于英语和俄语的时尚杂志语料库进行的。
- 金标准被用来评估提取的术语和定义的质量。
- TBXTools和SketchEngine在术语数量增加时,虽然召回率高,但精度下降。
- ChatGPT在保持或提高精度方面表现出卓越性能。
- ChatGPT生成的术语定义在多语言环境下具有合理的准确度和忠实度,但部分定义存在缺陷。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何准确提取和评估专业领域(特别是时尚领域)的术语,并比较不同工具在提取这些术语及其定义方面的性能。具体来说,论文的目标包括:
比较不同工具的术语提取准确性:研究比较了SketchEngine、TBXTools和ChatGPT这三个工具在提取英语和俄语时尚领域术语的准确性。
评估ChatGPT生成的定义质量:除了提取术语,论文还评估了ChatGPT为这些术语生成的定义的质量。
开发和验证金标准:为了评估提取的术语和定义的质量,研究者开发了一个包含英语和俄语时尚术语的金标准,并使用这个金标准来评估不同工具的性能。
构建可靠的双语语料库:研究旨在展示编译一个可靠和高质量的英语和俄语时尚文本语料库的可行性,该语料库可以作为创建双语词汇表的宝贵资源,帮助翻译工作者。
评估不同工具的优缺点:论文讨论了每个工具在术语提取和应用方面的特定优势和局限性,以指导在特定领域术语提取任务中选择合适的工具。
综上所述,论文试图提供一个系统性的评估,以了解不同工具在专业术语提取和定义生成方面的表现,并为未来的术语提取实践提供指导。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的研究:
**Chodkiewicz et al. (2002)**:这项研究讨论了如何从专业语料库中制作出可用的专业词汇表,这对于理解和处理专业术语的提取具有重要意义。
**Giguere et al. (2023)**:这项研究比较了GPT4使用统计模型提取的术语,是少数评估ChatGPT在术语提取性能方面的学术研究之一。
**Lew (2023)**:这项研究成功地利用了生成性人工智能(GenAI)来为字典词条生成定义,展示了大型语言模型(LLMs)在术语提取和定义生成方面的潜力。
**Massion (2024)**:这项研究探讨了人工智能时代术语学理论的转变,为理解术语学在现代技术环境下的发展提供了理论基础。
**Muegge (2023)**:这项研究提供了关于如何使用ChatGPT和其他低成本的基于网络的程序快速轻松地创建术语提取列表和词汇表的实用指南。
**Kilgarriff et al. (2014)**:这项研究介绍了SketchEngine工具,这是一个在学术界广泛用于术语提取的工具,因其高度可定制的特性和全面的语言学资源而受到青睐。
**Oliver and Vazquez (2015)**:这项研究介绍了TBXTools,这是一个用于自动术语提取的工具,它提供了多种功能,包括统计术语提取、语言术语提取等。
这些研究为本文提供了理论基础和技术支持,它们涉及专业术语的提取、大型语言模型在术语学中的应用、以及相关工具的开发和评估。通过这些研究,本文旨在进一步探索和评估不同工具在术语提取和定义生成方面的性能,并为专业领域的术语提取提供更深入的见解。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决准确提取和评估专业领域术语的问题:
语料库构建:
- 通过从互联网上收集和下载时尚杂志和网站的内容,创建了一个英俄双语的比较语料库。
- 确保语料库在内容和语言上的多样性和平衡性,以全面代表时尚领域的语言使用。
语料库清洗:
- 使用ChatGPT来清洗从PDF和HTML转换来的TXT文件中的噪声,如符号、数字、单词间的巨大空白和不必要的符号。
- 通过实验不同的提示(prompts),优化ChatGPT的文本清洗效果,并手动检查结果以确保信息的准确性和完整性。
金标准开发:
- 利用Google搜索引擎定位包含时尚相关术语的网页,并通过定制的Python脚本自动收集这些术语。
- 包括从单语英语网站自动翻译并校对的术语,确保术语在两种语言框架中的准确性和相关性。
术语提取工具评估:
- 使用SketchEngine、TBXTools和ChatGPT对预处理后的数据进行术语识别,并比较它们的性能。
- 通过计算精确度(precision)、召回率(recall)和F-measure等标准指标来评估这些工具提取术语的准确性。
术语提取性能比较:
- 分析每个工具提取的术语与金标准之间的匹配程度,并讨论它们在平衡精确度和召回率方面的优势和局限性。
ChatGPT定义生成评估:
- 对ChatGPT为60个常用术语生成的定义进行分析,使用Levenshtein距离来衡量模型生成的定义与参考定义之间的相似度。
- 详细分析ChatGPT生成的定义与金标准之间的差异,包括核心概念的处理、同义词替换、结构变化、详细阐述和具体细节的省略。
综合讨论和结论:
- 根据上述步骤的结果,论文讨论了不同工具在术语提取和定义生成方面的性能,并得出结论。
- 强调了选择适合特定需求和上下文的术语提取工具的重要性,并指出了ChatGPT在提供高质量术语列表和准确定义方面的潜力。
通过这些步骤,论文提供了一个系统性的评估框架,以理解和改进专业术语的提取和定义生成过程。
Q: 论文做了哪些实验?
A: 根据论文内容,以下是进行的实验:
语料库构建实验:
- 收集和下载了24本时尚杂志(12本英文和12本俄文)和52个时尚相关网站的内容(英文和俄文各半)。
- 将收集到的PDF和HTML文件转换成TXT格式,以便于后续的术语提取。
语料库清洗实验:
- 使用ChatGPT对转换后的TXT文件进行清洗,以去除噪声和不必要的符号。
- 对比了多个文本清洗工具的效果,并最终选择了ChatGPT作为清洗工具。
- 进行了多次实验,使用不同的提示(prompts)来优化清洗结果。
金标准开发实验:
- 利用Google搜索引擎和定制的Python脚本自动收集和提取时尚相关的术语。
- 从单语英语网站自动翻译术语,并由母语者校对,以创建包含354个术语(其中60个有定义)的金标准。
术语提取工具评估实验:
- 使用SketchEngine、TBXTools和ChatGPT对预处理后的语料库进行术语识别。
- 计算了每个工具提取术语的精确度、召回率和F-measure,并进行了比较分析。
术语提取性能比较实验:
- 分析了每个工具提取的前50个术语与金标准之间的匹配程度,以识别提取过程中的偏差和不准确之处。
ChatGPT定义生成评估实验:
- 使用ChatGPT为60个常用术语生成定义,并与从在线术语表中提取的参考定义进行比较。
- 使用Levenshtein距离来衡量ChatGPT生成的定义与参考定义之间的相似度。
- 对ChatGPT生成的定义进行了详细分析,包括核心概念的处理、同义词替换、结构变化、详细阐述和具体细节的省略。
这些实验旨在全面评估不同术语提取工具的性能,并探索ChatGPT在术语提取和定义生成方面的潜力和准确性。通过这些实验,论文提供了对这些工具在专业领域术语提取任务中的适用性和有效性的深入见解。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
多语言和跨领域应用:
- 将研究扩展到其他语言对和专业领域,以评估所提出方法的普适性和适应性。
改进术语提取算法:
- 针对特定领域或语言特点,开发更精细的算法以提高术语提取的精确度和召回率。
ChatGPT的深入分析:
- 对ChatGPT在不同领域和语言中的表现进行更深入的分析,以了解其在术语提取和定义生成方面的强项和弱点。
自动化和API集成:
- 利用ChatGPT的API进行自动化处理,通过级联提示(cascade of prompts)来优化文本清洗和术语提取流程。
术语定义的质量评估:
- 开发更全面的评价指标,以评估术语定义的准确性、完整性和适用性,超越Levenshtein距离等基本文本相似度度量。
上下文感知的术语提取:
- 探索如何利用上下文信息来提高术语提取的准确性,尤其是在处理多义词和领域特定用法时。
术语可扩展性和适应性:
- 研究如何使术语库能够适应新术语和概念的快速变化,特别是在快速发展的领域中。
用户界面和交互设计:
- 开发更友好的用户界面和交互设计,使非技术用户也能轻松地使用这些工具进行术语提取和定义生成。
结合传统工具和AI技术:
- 探索如何将传统术语提取工具与AI技术(如ChatGPT)结合,以利用各自的优势,提高整体性能。
术语提取的可解释性和透明度:
- 提高术语提取过程的可解释性,让用户能够理解模型的决策过程,并增加对结果的信任。
大规模数据集的测试:
- 在更大规模和多样化的数据集上测试这些工具,以评估它们在实际应用中的性能和稳定性。
跨学科合作:
- 与语言学家、计算机科学家和领域专家合作,以获得对术语提取和定义生成更深入的理解。
这些探索点可以帮助研究者和实践者更好地理解和改进专业术语的提取和定义生成过程,同时也为未来的研究提供了新的方向。
Q: 总结一下论文的主要内容
A: 论文的主要内容总结如下:
研究目标:
- 比较和评估不同工具(SketchEngine、TBXTools和ChatGPT)在提取英语和俄语时尚领域术语的准确性。
- 评估ChatGPT为这些术语生成的定义的质量。
- 开发一个英俄时尚领域的双语语料库,并基于此创建一个双语词汇表。
语料库构建和清洗:
- 收集了24本时尚杂志和52个时尚相关网站的内容,构建了一个英俄双语的比较语料库。
- 使用ChatGPT清洗从PDF和HTML转换来的TXT文件中的噪声,优化了文本质量。
金标准开发:
- 利用Google搜索引擎和Python脚本自动收集时尚相关的术语,创建了一个包含354个术语(其中60个附有定义)的金标准。
术语提取工具评估:
- 应用SketchEngine、TBXTools和ChatGPT对语料库进行术语识别,并计算它们的精确度、召回率和F-measure。
- 发现TBXTools和SketchEngine在召回率上表现良好,但精确度较低;而ChatGPT在精确度和F-measure上得分较高,但召回率较低。
术语提取性能比较:
- 分析了每个工具提取的前50个术语与金标准之间的匹配程度,发现ChatGPT提取的术语更为相关和准确。
ChatGPT定义生成评估:
- 使用Levenshtein距离评估ChatGPT生成的术语定义与参考定义之间的相似度。
- 发现ChatGPT在保持术语核心概念的同时,有时会省略关键细节或添加不必要的信息。
结论:
- 没有单一工具在所有方面都表现最佳;每个工具都有其特定的优势,适用于术语提取和应用的不同方面。
- ChatGPT在生成高质量术语列表和准确定义方面展现出潜力,但产生的候选术语列表较短,可能遗漏重要术语。
- 强调了根据术语提取任务的具体需求和上下文选择合适工具的重要性。
论文通过系统的实验和评估,提供了对不同术语提取工具性能的深入见解,并探讨了ChatGPT在术语提取和定义生成方面的潜力和准确性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Theoretical limitations of multi-layer Transformer
Authors:Lijie Chen, Binghui Peng, Hongxun Wu
Transformers, especially the decoder-only variants, are the backbone of most modern large language models; yet we do not have much understanding of their expressive power except for the simple $1$-layer case. Due to the difficulty of analyzing multi-layer models, all previous work relies on unproven complexity conjectures to show limitations for multi-layer Transformers. In this work, we prove the first $\textit{unconditional}$ lower bound against multi-layer decoder-only transformers. For any constant $L$, we prove that any $L$-layer decoder-only transformer needs a polynomial model dimension ($n^{\Omega(1)}$) to perform sequential composition of $L$ functions over an input of $n$ tokens. As a consequence, our results give: (1) the first depth-width trade-off for multi-layer transformers, exhibiting that the $L$-step composition task is exponentially harder for $L$-layer models compared to $(L+1)$-layer ones; (2) an unconditional separation between encoder and decoder, exhibiting a hard task for decoders that can be solved by an exponentially shallower and smaller encoder; (3) a provable advantage of chain-of-thought, exhibiting a task that becomes exponentially easier with chain-of-thought. On the technical side, we propose the multi-party $\textit{autoregressive}$ $\textit{communication}$ $\textit{model}$ that captures the computation of a decoder-only Transformer. We also introduce a new proof technique that finds a certain $\textit{indistinguishable}$ $\textit{decomposition}$ of all possible inputs iteratively for proving lower bounds in this model. We believe our new communication model and proof technique will be helpful to further understand the computational power of transformers.
Transformer,尤其是仅解码器变体,是大多数现代大型语言模型的骨干;然而,除了简单的1层情况外,我们对它们的表达能力知之甚少。由于分析多层模型的难度,所有之前的工作都依赖于未经证实的复杂性猜想来展示多层Transformer的局限性。在这项工作中,我们证明了针对多层仅解码器变压器的第一个无条件下界。对于任何常数L,我们证明了任何L层仅解码器变压器需要以多项式模型维度(n^Ω(1))来执行L个函数的顺序组合,输入为n个令牌。因此,我们的结果证明了:(1)多层变压器的深度宽度权衡,表明L步组合任务对于L层模型相比(L+1)层模型而言指数级更难;(2)编码器与解码器之间的无条件分离,表现出对于解码器来说的一项艰巨任务,而一个更浅且更小的编码器可以解决这个问题;(3)思维链的优势,表现出一项任务,通过思维链变得指数级更容易。在技术方面,我们提出了多方自回归通信模型,该模型捕获了仅解码器Transformer的计算。我们还介绍了一种新的证明技术,该技术通过迭代方式对模型中所有可能的输入进行某种不可区分的分解,以找到证明下界的依据。我们相信我们的新通信模型和证明技术将有助于进一步理解变压器的计算能力。
论文及项目相关链接
摘要
本文首次对多层解码器模型进行了无条件限制分析。针对任何常数L,证明了对于含有n个代币的输入序列进行L个函数的连续组合时,任何L层解码器模型都需要多项式模型维度(n^Ω(1))。本研究首次揭示了多层Transformer的深度与宽度之间的权衡关系,并展示了相比于(L+1)层模型,L层模型在处理此类任务时面临指数级困难。此外,本研究还展示了无条件编码器与解码器的分离现象,即存在某些任务仅通过解码器难以解决,但可以由较浅且较小的编码器轻松解决。本研究证明了使用链式思维的优势,展示了一种任务,通过链式思维可以使任务变得指数级简单。在技术上,我们提出了多方的自回归通信模型来捕捉解码器Transformer的计算过程,并引入了一种新的证明技术,通过迭代找到所有可能的输入信号的不可区分分解来证实该模型中的下界。我们相信我们的新通信模型和证明技术将有助于进一步理解Transformer的计算能力。
关键见解
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了多层Transformer模型的理论局限性,尤其是针对解码器仅(decoder-only)变体。尽管Transformer架构,特别是解码器仅变体,是现代大型语言模型(LLMs)的核心,但人们对其表达能力的理解主要限于单层情况。论文的主要目标是证明针对多层解码器仅Transformer的第一个无条件下界(lower bound),并探讨这些模型在执行特定任务时的深度-宽度权衡(depth-width trade-off)、编码器与解码器之间的性能差异,以及链式思考(chain-of-thought)的优势。
具体来说,论文试图解决以下问题:
多层Transformer的理论下界:证明对于任何常数L,任何L层解码器仅Transformer需要多项式模型维度(n^Ω(1))来执行L个函数在n个token输入上的序列组合。
深度-宽度权衡:展示Transformer在序列组合任务中的深度-宽度权衡,即L步组合任务对于L层模型相比(L+1)层模型是指数级更难的。
编码器与解码器的分离:展示编码器和解码器之间的无条件分离,即存在一个对解码器来说很难的任务,但可以被指数级更浅和更小的编码器解决。
链式思考的优势:展示链式思考在解决特定任务时的指数级优势,即一个任务通过链式思考可以变得指数级更容易。
新的通信模型和证明技术:提出了一种新的多方自回归通信模型来捕捉解码器仅Transformer的计算,并引入了一种新的证明技术,通过迭代地找到所有可能输入的某种不可区分分解来证明这一模型中的下界。
通过这些研究,论文旨在从计算(表示)的角度更深入地理解Transformer架构的潜在限制和弱点。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的工作:
Transformer架构的基础和应用:
- [VSP+17] Ashish Vaswani 等人的原始Transformer模型论文,提出了基于自注意力机制的Transformer架构。
- [AAA+23] 提供了GPT-4技术报告,展示了大型语言模型的最新进展。
Transformer的表达能力和局限性:
- [Hah20] Michael Hahn 讨论了自注意力机制在神经序列模型中的局限性。
- [PNP24] Binghui Peng 等人研究了Transformer架构的局限性。
- [SHT23] Clayton Sanford 等人探讨了Transformer在表示上的强项和局限性。
深度和宽度的权衡(Depth-Width Trade-offs):
- [MCPZ13] James Martens 等人研究了受限玻尔兹曼机的表示效率。
- [ES16] Ronen Eldan 和 Ohad Shamir 研究了前馈神经网络中深度的力量。
- [VS20] Gal Vardi 和 Ohad Shamir 探讨了具有小权重的神经网络和深度分离障碍。
编码器与解码器的比较:
- [ECZ+24] Ethan Ewer 等人比较了编码器和解码器架构。
- [FLY+23] Zihao Fu 等人解释了语言模型作为正则化编码器-解码器的解释。
链式思考(Chain-of-Thought):
- [WWS+22] Jason Wei 等人展示了链式思考提示如何引发大型语言模型中的推理。
- [LLZM24] Zhiyuan Li 等人研究了链式思考如何增强Transformer解决固有序列问题的能力。
Transformer与电路复杂性:
- [IPS97] Russell Impagliazzo 等人展示了阈值电路的大小深度权衡。
- [CSS18] Ruiwen Chen 等人提供了小阈值电路的平均情况下界和可满足性算法。
Transformer与计算模型:
- [SHT24b] Clayton Sanford 等人探讨了Transformer、并行计算和对数深度。
- [MS23b] William Merrill 和 Ashish Sabharwal 讨论了对数精度Transformer的局限性。
这些相关工作涵盖了Transformer模型的理论基础、表达能力、深度学习中的权衡问题、编码器与解码器架构的比较、链式思考的应用,以及Transformer与电路复杂性之间的关系。这些研究为理解Transformer模型提供了多角度的视野,并为本论文的研究提供了理论和实证基础。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决多层Transformer的理论局限性问题:
提出理论框架:
- 论文提出了一个多方自回归通信模型(autoregressive communication model),该模型能够捕捉仅解码器(decoder-only)Transformer的计算能力。
定义L-sequential function composition任务:
- 论文定义了一个L-sequential function composition任务,用于测试Transformer模型在执行函数序列组合方面的能力。这个任务要求模型能够处理嵌套函数调用,这对于理解模型的表达能力和复杂性至关重要。
证明无条件下界:
- 论文证明了对于任何常数L,任何L层仅解码器Transformer需要多项式模型维度(n^Ω(1))来执行L个函数在n个token输入上的序列组合。这是通过展示小模型(即参数规模较小的模型)无法有效解决这一任务来实现的。
深度-宽度权衡:
- 论文展示了L步组合任务对于L层模型相比(L+1)层模型是指数级更难的,从而揭示了Transformer在深度和宽度之间的权衡。
编码器与解码器的分离:
- 论文证明了存在一个任务,该任务对于解码器来说很难,但可以被指数级更浅和更小的编码器解决,从而揭示了编码器和解码器架构之间的性能差异。
链式思考的优势:
- 论文展示了链式思考(chain-of-thought)在解决特定任务时的指数级优势,即通过逐步推理可以使任务变得更容易。
新的证明技术:
- 论文引入了一种新的证明技术,该技术通过迭代地找到所有可能输入的某种不可区分分解来证明自回归通信模型中的下界。
技术细节和证明:
- 论文详细阐述了如何通过归纳法构造不可区分分解(indistinguishable decomposition),并利用这一概念来证明L-sequential function composition任务在自回归通信模型中的通信复杂性下界。
通过这些步骤,论文不仅提出了新的理论模型和证明技术,还为理解Transformer模型的计算能力提供了新的视角,并揭示了其在处理复杂任务时的潜在局限性。这些结果有助于进一步理解Transformer的工作原理,并为未来的模型设计和优化提供了理论指导。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,论文本身并没有提到进行实验的部分。论文主要集中在理论分析和证明上,旨在展示多层Transformer模型在表达能力上的理论限制。论文通过提出新的通信模型和证明技术,来证明对于任何常数层数L的解码器仅Transformer,需要多项式模型维度来执行特定任务,即L函数的序列组合。
论文的重点在于以下几个理论贡献:
无条件下界(Unconditional Lower Bound):证明了对于任何常数L,L层解码器仅Transformer需要多项式模型维度来执行L函数的序列组合。
深度-宽度权衡(Depth-Width Trade-off):展示了L步组合任务对于L层模型相比(L+1)层模型是指数级更难的。
编码器与解码器的分离(Separation between Encoder and Decoder):证明了存在一个任务,该任务对于解码器来说很难,但可以被指数级更浅和更小的编码器解决。
链式思考的优势(Provable Benefits of Chain of Thought):展示了链式思考在解决特定任务时的指数级优势。
这些理论结果并没有依赖于实验验证,而是通过数学证明和理论分析得出的。论文的技术贡献在于提出了新的通信模型和证明技术,这些技术有助于进一步理解Transformer的计算能力。因此,论文的研究方法主要是理论的,而非实验的。
Q: 有什么可以进一步探索的点?
A: 论文提出了多层Transformer模型的理论局限性,并围绕这一主题展开了一系列的理论分析和证明。以下是一些可以进一步探索的点:
实验验证:
- 尽管论文提供了理论分析,但实验验证这些理论结果的有效性也是非常重要的。可以通过构建不同层数和参数规模的Transformer模型,并在特定的序列组合任务上测试它们的表现,来验证理论结果的准确性。
改进模型结构:
- 探索新的Transformer结构或改进现有的结构,以克服论文中提到的理论限制。例如,研究是否可以设计出更高效的注意力机制,以减少模型在执行复杂任务时所需的层数和参数。
优化算法:
- 研究新的训练算法或优化策略,以提高多层Transformer模型在复杂任务上的表现,尤其是在资源有限的情况下。
理论分析的扩展:
- 将论文中的分析扩展到更广泛的任务和模型变体上,例如考虑带有不同类型注意力机制的Transformer模型,或者探索其他类型的神经网络结构。
计算复杂性理论:
- 进一步探索与Transformer相关的计算复杂性问题,例如证明更强的下界结果,或者研究Transformer与其他计算模型(如电路)之间的关系。
实际应用中的Transformer表现:
- 在实际应用中测试Transformer模型,特别是那些需要复杂推理和序列组合的任务,以了解模型在实际环境中的表现和局限性。
可解释性和透明度:
- 提高Transformer模型的可解释性,使研究人员和开发者能够更好地理解模型的决策过程,特别是在执行复杂任务时。
跨领域应用:
- 探索Transformer模型在其他领域的应用,如计算机视觉、语音识别等,以了解其在不同类型任务中的适用性和表现。
资源效率:
- 研究如何构建资源效率更高的Transformer模型,尤其是在计算资源受限的环境中,如移动设备或嵌入式系统。
对抗性攻击和鲁棒性:
- 研究Transformer模型对于对抗性攻击的鲁棒性,并开发防御机制以提高模型的安全性。
这些探索点可以帮助我们更全面地理解Transformer模型的潜力和局限性,并推动相关技术的发展。
Q: 总结一下论文的主要内容
A: 论文《Theoretical limitations of multi-layer Transformer》主要研究了多层Transformer模型的理论局限性,尤其是针对解码器仅(decoder-only)变体。以下是论文的主要内容总结:
研究背景:
- Transformer架构,尤其是解码器仅变体,是现代大型语言模型(LLMs)的核心。
- 尽管Transformer在多种自然语言处理任务上表现出色,但对其多层模型的表达能力理解有限。
主要贡献:
- 提出了第一个针对多层解码器仅Transformer的无条件下界(lower bound)。
- 证明了任何L层解码器仅Transformer需要多项式模型维度(n^Ω(1))来执行L个函数在n个token输入上的序列组合。
理论结果:
- 展示了Transformer在序列组合任务中的深度-宽度权衡,即L步组合任务对于L层模型相比(L+1)层模型是指数级更难的。
- 证明了编码器和解码器之间的无条件分离,即存在对解码器来说很难的任务,但可以被指数级更浅和更小的编码器解决。
- 展示了链式思考(chain-of-thought)在解决特定任务时的指数级优势。
技术贡献:
- 提出了多方自回归通信模型,该模型能够捕捉仅解码器Transformer的计算能力。
- 引入了一种新的证明技术,通过迭代地找到所有可能输入的某种不可区分分解来证明这一模型中的下界。
理论分析:
- 通过构造不可区分分解(indistinguishable decomposition)来证明L-sequential function composition任务在自回归通信模型中的通信复杂性下界,从而得出对Transformer模型的理论限制。
结论:
- 论文的研究结果揭示了Transformer模型在处理复杂任务时的潜在局限性,并为理解Transformer的工作原理提供了新的视角。
- 提出的新通信模型和证明技术有助于进一步理解Transformer的计算能力,并为未来的模型设计和优化提供了理论指导。
总的来说,论文通过理论分析和证明技术,深入探讨了多层Transformer模型的计算能力,揭示了其在执行复杂任务时可能面临的理论限制,并提出了一些可能的改进方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Can ChatGPT capture swearing nuances? Evidence from translating Arabic oaths
Authors:Mohammed Q. Shormani
This study sets out to answer one major question: Can ChatGPT capture swearing nuances? It presents an empirical study on the ability of ChatGPT to translate Arabic oath expressions into English. 30 Arabic oath expressions were collected from the literature. These 30 oaths were first translated via ChatGPT and then analyzed and compared to the human translation in terms of types of gaps left unfulfilled by ChatGPT. Specifically, the gaps involved are: religious gap, cultural gap, both religious and cultural gaps, no gap, using non-oath particles, redundancy and noncapturing of Arabic script diacritics. It concludes that ChatGPT translation of oaths is still much unsatisfactory, unveiling the need of further developments of ChatGPT, and the inclusion of Arabic data on which ChatGPT should be trained including oath expressions, oath nuances, rituals, and practices.
本研究旨在回答一个主要问题:ChatGPT能否捕捉到咒骂语的细微差别?它对ChatGPT将阿拉伯誓词语录翻译成英文的能力进行了实证研究。从文献中收集了30个阿拉伯誓词语录。这些誓词首先通过ChatGPT进行翻译,然后分析并比较ChatGPT未能实现的差距类型与人类翻译之间的差距。具体来说,涉及的差距包括:宗教差距、文化差距、宗教和文化双重差距、无差距、使用非誓词粒子、冗余以及不捕捉阿拉伯字母表发音符号。结论认为,ChatGPT对誓词的翻译仍然不尽人意,这揭示了进一步发展ChatGPT的必要性,以及需要在ChatGPT的训练数据中包含誓词语录、誓词的细微差别、仪式和习俗。
论文及项目相关链接
PDF 18 pages, 3 figures
Summary
ChatGPT在翻译阿拉伯语誓词表达时存在诸多不足,包括宗教、文化等方面的差距,以及非誓词粒子、冗余和非捕获阿拉伯语脚本变音符号等问题。现有研究建议进一步完善ChatGPT,并在训练过程中纳入阿拉伯语数据,包括誓词表达、誓词细微差别、仪式和实践等内容。
Key Takeaways
- 此研究旨在探究ChatGPT是否能捕捉阿拉伯誓词表达的细微差别。
- 收集了30个阿拉伯语誓词表达,并通过ChatGPT进行翻译。
- ChatGPT在翻译过程中存在多种不足,包括宗教、文化差距等。
- 非誓词粒子、冗余和阿拉伯语脚本变音符号的无法捕捉也是问题所在。
- ChatGPT在翻译誓词方面仍需进一步完善。
- 建议在训练ChatGPT时纳入阿拉伯语数据,包括誓词表达、细微差别、仪式和实践等。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是探究ChatGPT是否能够准确捕捉和翻译阿拉伯语誓言(oath expressions)中的细微差别,特别是那些涉及宗教和文化层面的内涵。具体来说,研究旨在通过实证研究检验ChatGPT将阿拉伯语誓言表达翻译成英语的能力,并分析与人类翻译相比,ChatGPT在翻译过程中未能充分满足的类型,包括宗教差异、文化差异、宗教和文化双重差异、冗余、未能捕捉阿拉伯语书写的音调和使用非誓言词汇等问题。研究得出的结论是ChatGPT在翻译这些誓言时的表现并不令人满意,揭示了进一步发展ChatGPT的必要性,以及需要包含阿拉伯语数据(包括誓言表达、细微差别、仪式和实践)在内的ChatGPT训练数据的重要性。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的研究:
**Nida和Charles (1969)**:他们提出了动态等价(Dynamic Equivalence)和形式等价(Formal Equivalence)两种翻译宗教文本的方法。动态等价强调在目标语言中复现源文本的整体效果和意义,而形式等价则强调尽可能忠实地再现原文的结构、句法和词汇。
**Sirriyya (2009)**:这项研究探讨了宗教文本的翻译难度,指出这些文本包括宗教仪式、信仰、祈祷等,并且由于其特殊性质和文化内嵌性,即使是人类翻译者也难以翻译。
**Newmark (1981, 1988)**:Newmark从文化的角度定义了翻译,并提出了翻译应考虑作者的意图和文本的意义。
**Catford (1965)**:Catford从语言学的角度定义了翻译,并强调了翻译在现代世界中的重要性。
**Bassnett (2014)**:Bassnett认为翻译不仅仅是桥接文化差异,而是文本和文化之间的协商过程。
**Conway (2012)**:讨论了翻译中应考虑的文化细微差别,并提出了适合翻译文化文本的方法。
**Qarabesh等人 (2023)**:这项研究探讨了誓言作为宗教和文化文本的性质,以及它们在人类行为中的作用。
**Brown (1999)**:讨论了誓言的普遍性和作为语言的一部分的可翻译性。
**Dergaa等人 (2023)**:研究了ChatGPT在学术写作中的潜力和潜在威胁。
**van Dis等人 (2023)**:提出了ChatGPT研究的五个优先领域。
**Cascella等人 (2023)**:评估了ChatGPT在医疗领域的可行性。
**Jiao等人 (2023)**:探讨了ChatGPT作为翻译工具的能力。
这些研究为理解翻译的复杂性、ChatGPT在翻译中的应用以及宗教和文化文本的特殊性提供了理论基础和实证数据。论文通过引用这些研究,构建了对ChatGPT翻译阿拉伯语誓言能力评估的理论框架。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决提出的问题:
数据收集:
- 选择了30个来自文献中的阿拉伯语誓言表达式(Islamic Arabic oath expressions)。
翻译过程:
- 使用ChatGPT将这些表达式翻译成英语。
分析与比较:
- 将ChatGPT的翻译结果与人类翻译者Qarabesh等人(2023)提供的翻译进行比较和对比。
分析方法:
- 采用了分析和比较的方法来评估ChatGPT的翻译质量,具体包括以下几个方面:
- 未留下任何差距(No gap)
- 宗教差距(Religious gap)
- 文化差距(Cultural gap)
- 宗教和文化双重差距(Cultural and religious gaps)
- 冗余(Redundancy)
- 未能捕捉阿拉伯语书写的音调(Noncapturing of Arabic diacritics)
- 使用非誓言词汇(Using non-oath particles)
- 采用了分析和比较的方法来评估ChatGPT的翻译质量,具体包括以下几个方面:
结果讨论:
- 根据分析结果讨论了ChatGPT在翻译过程中的表现,特别是在处理宗教和文化细微差别方面的能力。
结论与建议:
- 得出结论,即ChatGPT在翻译涉及宗教和文化细微差别的文本时仍有不足,需要进一步的开发和改进。
- 推荐人类翻译者在ChatGPT翻译后进行校对(postediting)以弥补翻译中的差距。
- 建议ChatGPT开发者将更多涉及宗教、仪式实践、特定术语和文化细微差别的数据纳入训练数据中,以提高翻译质量。
通过这些步骤,论文不仅评估了ChatGPT在特定翻译任务中的表现,还为如何改进其性能提供了具体的建议,以期在未来能够更好地处理涉及复杂文化和宗教背景的文本。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,本研究进行了以下实验:
数据收集:
- 从Qarabesh等人(2023)的研究中选取了30个阿拉伯语的誓言表达式。这些表达式已经被人类翻译者翻译成英语,因此可以作为对照标准。
翻译实验:
- 使用ChatGPT对这30个阿拉伯语誓言表达式进行英语翻译。
分析和比较实验:
- 对ChatGPT的翻译结果进行分析,并与人类翻译的结果进行比较和对比。具体分析的方面包括:
- 未留下任何差距(No gap)
- 宗教差距(Religious gap)
- 文化差距(Cultural gap)
- 宗教和文化双重差距(Cultural and religious gaps)
- 冗余(Redundancy)
- 未能捕捉阿拉伯语书写的音调(Noncapturing of Arabic diacritics)
- 使用非誓言词汇(Using non-oath particles)
- 对ChatGPT的翻译结果进行分析,并与人类翻译的结果进行比较和对比。具体分析的方面包括:
结果整理:
- 将ChatGPT的翻译结果和人类翻译的结果进行详细的列表对比,如论文中的表1所示。
讨论和结论:
- 基于上述实验结果,讨论ChatGPT在翻译阿拉伯语誓言表达式时的表现,并得出结论。
这个实验设计主要是为了评估ChatGPT在翻译特定类型的文本(即涉及宗教和文化的阿拉伯语誓言表达式)时的能力,并与人类翻译者的表现进行对比。通过这种方法,研究揭示了ChatGPT在处理这类文本时的局限性,并提出了改进建议。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和研究结果,以下是一些可以进一步探索的点:
训练数据的扩充:
- 研究建议将更多的宗教和文化数据纳入ChatGPT的训练集中,特别是伊斯兰教的宗教文本、仪式、实践和誓言表达。未来的研究可以探索这种数据扩充对ChatGPT翻译性能的具体影响。
算法优化:
- 研究ChatGPT使用的神经网络算法(NNA)的优化,以更好地处理宗教和文化相关的文本。这可能包括改进的语言模型架构或算法调整。
人类翻译者的校对(Postediting):
- 论文建议人类翻译者在ChatGPT翻译后进行校对。未来的研究可以探索有效的校对策略和工具,以提高翻译质量和效率。
多语言和跨文化研究:
- 扩展研究范围,探索ChatGPT在翻译其他语言和文化中的誓言表达式时的表现,特别是那些与英语和阿拉伯语截然不同的语言。
用户界面和交互设计:
- 研究如何改进ChatGPT的用户界面和交互设计,使其更适合翻译任务,特别是对于那些需要深入了解文化和宗教背景的用户。
伦理和偏见问题:
- 考虑到ChatGPT在处理敏感的宗教和文化文本时可能会引入偏见,未来的研究可以探讨如何减少这种偏见,并确保翻译的公正性和伦理性。
实时翻译和反馈机制:
- 开发实时翻译系统,允许用户在翻译过程中提供反馈,以动态调整和改进翻译结果。
跨领域应用:
- 探索ChatGPT在其他领域的应用,如法律、医疗和教育,特别是在这些领域中涉及敏感和专业术语的翻译。
教育和培训:
- 研究如何将ChatGPT和其他AI翻译工具集成到翻译和语言学的教育和培训中,以提高学生对现代翻译技术的理解。
长期跟踪研究:
- 进行长期跟踪研究,以评估ChatGPT和其他AI翻译工具随着时间和技术进步的演变,以及它们对翻译行业和实践的影响。
这些探索点可以帮助我们更深入地理解ChatGPT在翻译领域的潜力和局限性,并为未来的研究和技术发展提供方向。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容概括如下:
研究问题:
- 论文旨在探究ChatGPT是否能够准确捕捉和翻译阿拉伯语誓言中的细微差别,特别是涉及宗教和文化层面的内涵。
研究方法:
- 通过实证研究,选取了30个阿拉伯语誓言表达式,使用ChatGPT进行翻译,并将结果与人类翻译进行比较分析。
分析维度:
- 分析了ChatGPT翻译中存在的不同类型的差距,包括宗教差距、文化差距、宗教和文化双重差距、冗余、未能捕捉阿拉伯语书写的音调以及使用非誓言词汇。
研究结果:
- ChatGPT在翻译阿拉伯语誓言表达式时存在多方面的不足,特别是在捕捉宗教和文化细微差别方面。
结论与建议:
- 论文得出结论,ChatGPT翻译在涉及宗教和文化文本方面仍需进一步的开发和改进。
- 推荐人类翻译者在ChatGPT翻译后进行校对,以弥补翻译中的差距。
- 建议ChatGPT开发者将更多宗教和文化数据纳入训练数据中,以提高翻译质量。
未来研究方向:
- 提出了未来研究可以进一步探索的多个方向,包括训练数据扩充、算法优化、人类翻译者校对、多语言跨文化研究等。
论文强调了尽管ChatGPT在多个领域取得了进展,但在翻译具有深厚宗教和文化背景的文本方面仍面临挑战,需要结合人类翻译者的专业知识和技能来提高翻译的准确性和适当性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

WSI-LLaVA: A Multimodal Large Language Model for Whole Slide Image
Authors:Yuci Liang, Xinheng Lyu, Meidan Ding, Wenting Chen, Jipeng Zhang, Yuexiang Ren, Xiangjian He, Song Wu, Sen Yang, Xiyue Wang, Xiaohan Xing, Linlin Shen
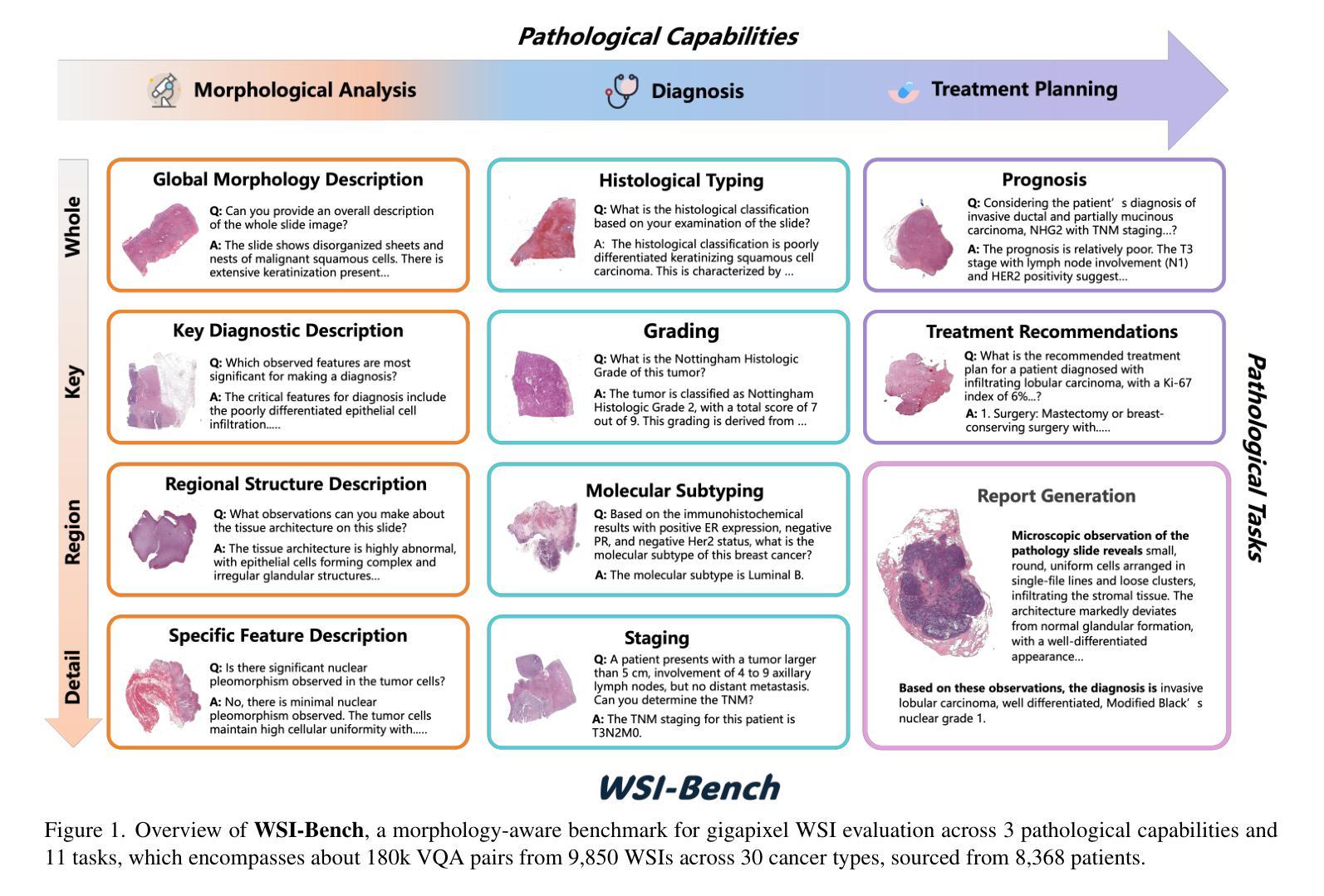
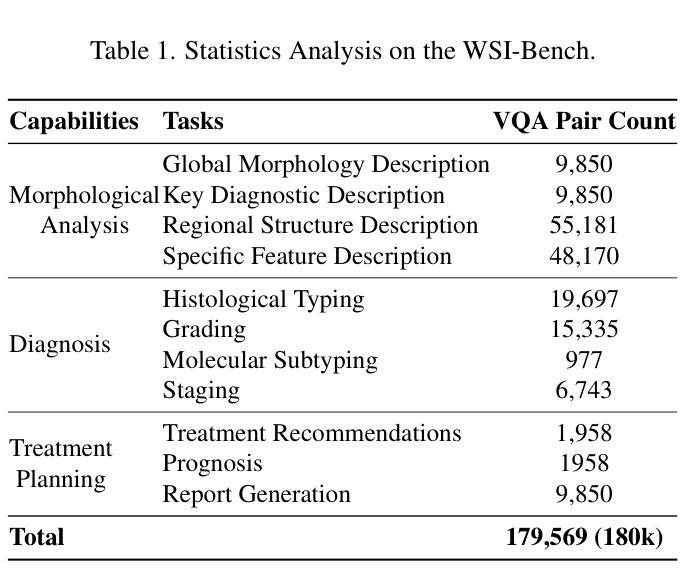
Recent advancements in computational pathology have produced patch-level Multi-modal Large Language Models (MLLMs), but these models are limited by their inability to analyze whole slide images (WSIs) comprehensively and their tendency to bypass crucial morphological features that pathologists rely on for diagnosis. To address these challenges, we first introduce WSI-Bench, a large-scale morphology-aware benchmark containing 180k VQA pairs from 9,850 WSIs across 30 cancer types, designed to evaluate MLLMs’ understanding of morphological characteristics crucial for accurate diagnosis. Building upon this benchmark, we present WSI-LLaVA, a novel framework for gigapixel WSI understanding that employs a three-stage training approach: WSI-text alignment, feature space alignment, and task-specific instruction tuning. To better assess model performance in pathological contexts, we develop two specialized WSI metrics: WSI-Precision and WSI-Relevance. Experimental results demonstrate that WSI-LLaVA outperforms existing models across all capability dimensions, with a significant improvement in morphological analysis, establishing a clear correlation between morphological understanding and diagnostic accuracy.
计算病理学领域的最新进展已经产生了补丁级别的多模态大型语言模型(MLLMs),但这些模型受到无法全面分析全幻灯片图像(WSIs)以及倾向于忽略病理医师诊断所依赖的关键形态特征的限制。为了解决这些挑战,我们首先推出了WSI-Bench,这是一个大规模的形态感知基准测试,包含来自9850张幻灯片图像的18万组问答对,涵盖30种癌症类型,旨在评估MLLMs对形态特征的认知,这对于准确诊断至关重要。在此基础上,我们提出了WSI-LLaVA,这是一个用于千兆像素WSI理解的全新框架,采用三阶段训练方法:WSI文本对齐、特征空间对齐和任务特定指令调整。为了更好地评估模型在病理背景下的性能,我们开发了两个专门的WSI指标:WSI精确度和WSI相关性。实验结果表明,WSI-LLaVA在所有能力维度上都优于现有模型,在形态分析方面取得了显著改进,建立了形态理解与诊断准确性之间的明确相关性。
论文及项目相关链接
PDF 38 pages, 22 figures, 35 tables
Summary
计算病理学领域的最新进展已经出现了基于patch的多模态大语言模型(MLLMs),但这些模型在分析全切片图像(WSIs)时存在局限性,无法全面分析并忽略了病理医生依赖的关键形态特征用于诊断。为解决这些问题,本文引入了WSI-Bench这一大规模形态感知基准测试,该测试包含来自9850个WSI的18万问答对,跨越了多种癌症类型,旨在评估MLLMs对诊断关键形态特征的理解能力。基于这一基准测试,本文提出了WSI-LLaVA框架,用于对全切片图像进行巨像素级别的理解。该框架采用三阶段训练方式:WSI文本对齐、特征空间对齐和任务特定指令调整。为更好地评估模型在病理学环境中的性能,本文开发了两种专门的WSI指标:WSI精度和WSI相关性。实验结果表明,WSI-LLaVA在各方面性能均优于现有模型,形态分析显著改善,形态理解与诊断准确性之间存在明确的相关性。
Key Takeaways
- 计算病理学领域出现了基于patch的多模态大语言模型(MLLMs)。
- MLLMs在分析全切片图像(WSIs)时存在局限性,无法全面分析和理解关键形态特征。
- 为评估MLLMs对形态特征的理解能力,引入了大规模形态感知基准测试WSI-Bench。
- WSI-LLaVA框架被提出用于对全切片图像进行巨像素级别的理解,采用三阶段训练方式。
- WSI-LLaVA框架在形态分析方面表现出显著改进,建立了形态理解与诊断准确性之间的明确关系。
- 为评估模型在病理学环境中的性能,开发了WSI精度和WSI相关性两种专门指标。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是如何提高计算病理学中的多模态大型语言模型(MLLMs)在分析整个玻片图像(Whole Slide Images, WSIs)时的全面性和准确性。具体来说,论文中提到了以下几个挑战:
现有模型的局限性:目前的MLLMs大多局限于对组织样本的局部区域进行分析,而病理诊断需要对整个WSIs进行整体分析。现有模型在捕获WSIs的全面上下文信息方面的能力有限,这限制了它们在临床实践中的应用。
忽略关键形态学特征:许多现有的MLLMs倾向于直接将病理图像映射到诊断结果,忽略了对准确诊断至关重要的形态学特征。病理学家在诊断时依赖于对这些形态学特征的详细观察。
跨模态差异:在MLLMs的训练中,需要解决WSI和文本描述之间的显著跨模态差异,这影响了MLLMs对WSIs的深入理解。
为了应对这些挑战,论文提出了以下解决方案:
WSI-Bench:这是一个大规模的形态学感知基准测试,包含180k个视觉问答(VQA)对,覆盖30种癌症类型的9,850个WSIs,旨在评估MLLMs对形态学特征的理解。
WSI-LLaVA框架:这是一个新颖的框架,用于理解和分析千兆像素级别的WSIs。该框架采用三阶段训练方法:WSI-文本对齐、特征空间对齐和任务特定指令调整,以弥合WSIs和文本描述之间的跨模态差异。
WSI特定评估指标:开发了两个专门的WSI指标(WSI-Precision和WSI-Relevance),以更准确地评估模型在病理学背景下的性能,这些指标解决了传统NLU指标的局限性,通过验证声明的准确性和响应的相关性来评估模型性能。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
Patch-Level WSI MLLMs(局部级别的WSI多模态大型语言模型):
- PathChat [17]:使用UNI视觉编码器,结合大型语言模型,针对视觉语言指令进行微调,以实现显著的诊断准确性。
- Quilt-LLaVA [22]:引入QuiltNet视觉编码器,并利用教育性质的组织病理学视频进行空间定位叙述。
WSI-Level WSI MLLMs(整个WSI级别的多模态大型语言模型):
- WSI-Caption [3]、HistGen [12]、WSI-VQA [4]、PRISM [23]:这些基于Transformer模型旨在生成详细的病理报告或回答特定问题,但在处理多变的临床查询或复杂对话方面缺乏灵活性。
- SlideChat [6]:结合局部级别和整体级别的编码器与大型语言模型,以实现多模态理解,但存在显著的跨模态差异问题。
WSI分析和评估:
- 论文中提到了WSI-Bench基准测试框架,这是首次提出针对千兆像素级别WSI评估的大规模形态学感知基准,包含180k个视觉问答对。
病理报告生成和视觉问答任务:
- MI-Gen [3] 和 Hist-Gen [12]:这些模型专门用于病理报告生成。
- WSI-VQA [4]:用于解释整个WSI的生成视觉问答任务。
大型语言模型(LLMs):
- GPT-4o [15]:作为一个通用目的的大型语言模型,用于评估其在病理学任务中的性能。
这些相关研究展示了在计算病理学和多模态学习领域中,如何利用大型语言模型来理解和分析病理图像,并生成病理报告。WSI-LLaVA框架和WSI-Bench基准测试框架的提出,旨在进一步推动这一领域的发展,通过更全面地理解和评估模型性能,提高临床相关性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法解决了上述问题:
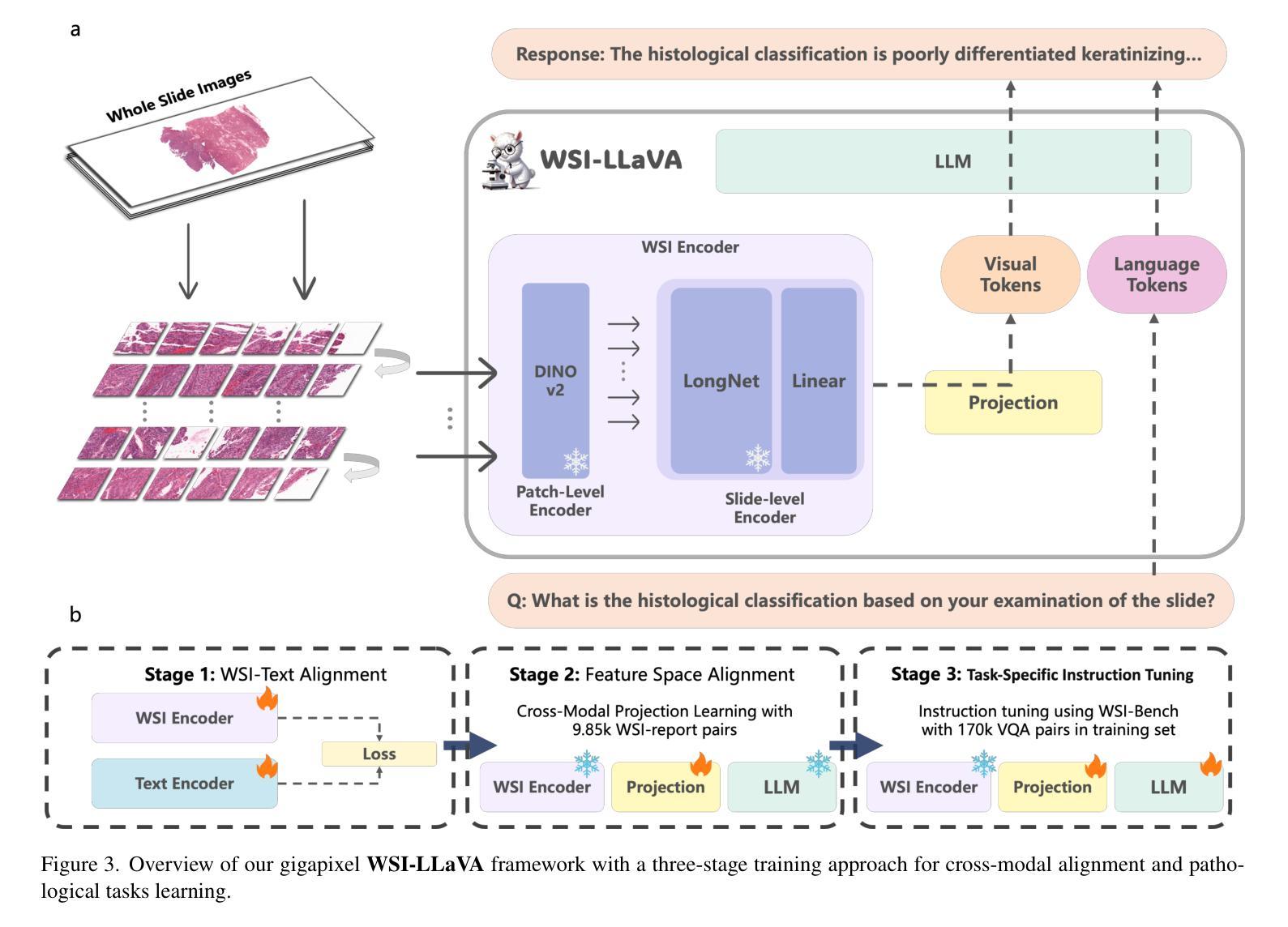
1. 引入WSI-Bench基准测试
- WSI-Bench是一个大规模的形态学感知基准测试,包含180k个视觉问答(VQA)对,覆盖30种癌症类型的9,850个WSIs。这个基准测试框架旨在全面评估MLLMs对形态学特征的理解,强调在评估WSI级MLLMs时考虑形态学观察的重要性。
2. 提出WSI-LLaVA框架
- WSI-LLaVA是一个新颖的框架,用于理解和分析千兆像素级别的WSIs。该框架采用三阶段训练方法:
- WSI-文本对齐:通过对比学习对齐WSI编码器和文本编码器,使WSI编码器能够提取与文本描述相对应的更丰富的语义特征。
- 特征空间对齐:通过一个投影层整合WSI编码器和大型语言模型(LLM),在保持预训练参数不变的情况下训练投影层,以对齐WSI编码器和LLM之间的特征空间。
- 任务特定指令调整:在WSI-Bench的训练集上微调WSI-LLaVA,以增强模型处理多样化指令查询的能力。
3. 开发WSI特定评估指标
- WSI-Precision和WSI-Relevance是两个新开发的WSI指标,用于更准确地评估模型在病理学背景下的性能。这些指标通过验证声明的准确性和响应的相关性来评估模型性能,解决了传统NLU指标在病理学复杂和相似术语方面的局限性。
4. 实验验证
- 通过在WSI-Bench上进行广泛的实验,论文展示了WSI-LLaVA相较于现有模型的优越性能,特别是在形态学分析方面,并建立了形态学能力和诊断准确性之间的明确相关性。
这些方法的结合不仅提高了模型对WSIs的全面理解,还增强了其在临床应用中的实用性和准确性,为开发更具临床相关性的计算病理工具提供了重要进展。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来验证WSI-LLaVA框架的性能和有效性。这些实验包括:
1. 基线模型评估
作者收集了多种WSI MLLMs在WSI-Bench数据集上进行评估,包括专门用于WSI报告生成的模型(如MI-Gen和Hist-Gen)以及设计用于病理VQA任务的模型(如Quilt-LLaVA和WSI-VQA)。此外,还包括了评估通用目的MLLM(如GPT-4o)的性能。
2. 定量评估
- 跨病理能力评估:比较WSI MLLMs和通用MLLM在WSI-Bench的三个病理能力(形态学分析、诊断和治疗计划)上的性能。
- 报告生成任务评估:比较WSI-LLaVA与WSI报告生成模型(MI-GEN和Hist-Gen)、WSI MLLMs(Quilt-LLaVA)和通用MLLMs(GPT-4o)在NLU指标和新提出的WSI特定指标上的性能。
3. 定性评估
- 病理VQA任务评估:展示WSI-LLaVA在病理VQA任务中的优越性能,通过正确识别Nottingham Grade 1分类并准确描述所有三个评分组件(管状形成、核异型性和有丝分裂计数)。
- 报告生成任务评估:比较WSI-LLaVA与MI-Gen在报告生成任务中的表现,通过识别未分化鳞状细胞癌和关键特征如坏死来展示WSI-LLaVA更高的准确性。
4. 消融研究
- WSI编码器的有效性:通过在WSI-LLaVA框架中消融WSI编码器,来证明其在提取WSI特征方面的有效性。
- 三阶段训练方案的有效性:通过消融WSI-LLaVA框架的第一阶段或第二阶段,来展示三阶段训练方案对提升性能的必要性。
5. NLU指标与WSI指标的比较
- 模型生成病理报告的评估:使用WSI-Precision和WSI-Relevance与传统NLU指标(如BLEU、ROUGE-L和METEOR)比较不同模型在生成病理报告方面的表现。
这些实验全面评估了WSI-LLaVA框架的性能,并与现有方法进行了比较,证明了其在形态学分析和诊断准确性方面的优越性。通过定量和定性的结果,论文展示了WSI-LLaVA在理解和分析WSIs方面的先进性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了WSI-LLaVA框架并在WSI-Bench基准测试上取得了显著的性能提升,但仍有一些领域可以进一步探索和改进:
1. 模型泛化能力
- 跨数据集验证:在其他公开的病理数据集上验证WSI-LLaVA的泛化能力,以确保模型不仅在特定数据集上表现良好,也能在不同的病理图像和任务上保持稳定性和准确性。
2. 实际临床应用
- 临床集成测试:将WSI-LLaVA集成到实际的临床工作流程中,评估其在现实世界病理诊断中的表现和影响。
- 用户研究:与病理学家合作,收集他们对模型输出的反馈,了解模型在实际诊断中可能的用途和局限性。
3. 模型解释性
- 特征可视化:研究WSI-LLaVA在做出诊断时所依赖的图像区域,提供模型决策的可视化解释。
- 错误分析:深入分析模型预测错误的案例,以识别模型的弱点并进行针对性改进。
4. 模型训练和优化
- 计算效率:探索更高效的训练策略,减少WSI-LLaVA训练和推理时的计算资源消耗。
- 半监督或无监督学习:研究如何利用少量标注数据或无标注数据来训练模型,以减少对大量标注数据的依赖。
5. 多模态融合策略
- 新的融合技术:尝试不同的特征融合技术,以改善WSI特征和文本描述之间的对齐和交互。
6. 模型鲁棒性
- 对抗性攻击和防御:测试模型对对抗性攻击的鲁棒性,并开发防御机制来提高模型在面对恶意输入时的稳定性。
7. 扩展病理任务
- 新的病理任务:探索WSI-LLaVA在其他病理任务上的应用,如肿瘤分级、预后预测等。
8. 跨模态学习
- 跨模态一致性:研究如何进一步提高WSI特征和文本描述之间的一致性,减少跨模态差异。
这些探索方向不仅可以推动WSI-LLaVA框架的发展,还可能为计算病理学领域带来新的见解和技术进步。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出了现有计算病理学中多模态大型语言模型(MLLMs)的局限性,尤其是在分析全切片图像(WSIs)时,这些模型无法全面分析,且往往忽略了病理学家诊断所依赖的关键形态学特征。
WSI-Bench基准测试:
- 为解决上述挑战,论文首次介绍了一个大规模的形态学感知基准测试WSI-Bench,包含180k个视觉问答(VQA)对,覆盖30种癌症类型的9,850个WSIs,旨在全面评估MLLMs对形态学特征的理解。
WSI-LLaVA框架:
- 论文提出了一个新颖的框架WSI-LLaVA,用于理解和分析千兆像素级别的WSIs。该框架采用三阶段训练方法:WSI-文本对齐、特征空间对齐和任务特定指令调整,以弥合WSIs和文本描述之间的跨模态差异。
WSI特定评估指标:
- 论文开发了两个专门的WSI指标:WSI-Precision和WSI-Relevance,以更准确地评估模型在病理学背景下的性能,解决了传统NLU指标的局限性。
实验验证:
- 通过在WSI-Bench上进行广泛的实验,论文展示了WSI-LLaVA相较于现有模型的优越性能,特别是在形态学分析方面,并建立了形态学能力和诊断准确性之间的明确相关性。
结论:
- 论文得出结论,WSI-LLaVA框架和WSI-Bench基准测试在推动计算病理工具向临床相关性发展方面取得了重要进展,能够有效地桥接WSIs和文本之间的跨模态差异,并提供更准确的模型性能评估。
总体而言,这篇论文通过引入新的基准测试、提出创新的模型框架和专门的评估指标,在提高病理学中MLLMs的性能和适用性方面做出了重要贡献。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Command-line Risk Classification using Transformer-based Neural Architectures
Authors:Paolo Notaro, Soroush Haeri, Jorge Cardoso, Michael Gerndt
To protect large-scale computing environments necessary to meet increasing computing demand, cloud providers have implemented security measures to monitor Operations and Maintenance (O&M) activities and therefore prevent data loss and service interruption. Command interception systems are used to intercept, assess, and block dangerous Command-line Interface (CLI) commands before they can cause damage. Traditional solutions for command risk assessment include rule-based systems, which require expert knowledge and constant human revision to account for unseen commands. To overcome these limitations, several end-to-end learning systems have been proposed to classify CLI commands. These systems, however, have several other limitations, including the adoption of general-purpose text classifiers, which may not adapt to the language characteristics of scripting languages such as Bash or PowerShell, and may not recognize dangerous commands in the presence of an unbalanced class distribution. In this paper, we propose a transformer-based command risk classification system, which leverages the generalization power of Large Language Models (LLM) to provide accurate classification and the ability to identify rare dangerous commands effectively, by exploiting the power of transfer learning. We verify the effectiveness of our approach on a realistic dataset of production commands and show how to apply our model for other security-related tasks, such as dangerous command interception and auditing of existing rule-based systems.
为了保护日益增长的计算机需求所必需的大规模计算环境,云服务提供商已经实施了安全措施来监控运维(O&M)活动,从而防止数据丢失和服务中断。命令拦截系统被用来拦截、评估和阻止危险的命令行界面(CLI)命令,以避免它们造成损害。传统的命令风险评估解决方案包括基于规则的系统,这些系统需要专业知识并需要人类不断审查以处理未见过的命令。为了克服这些局限性,已经提出了多种端到端学习系统来对CLI命令进行分类。然而,这些系统还有其他一些局限性,包括采用通用文本分类器,可能不适应Bash或PowerShell等脚本语言的特性,并且在类别分布不平衡的情况下无法识别危险命令。在本文中,我们提出了一种基于变压器的命令风险分类系统,该系统利用大型语言模型(LLM)的通用化能力提供准确的分类,并能够通过迁移学习的力量有效地识别罕见的危险命令。我们在生产命令的实际数据集上验证了我们的方法的有效性,并展示了如何将其应用于其他安全相关任务,如危险命令拦截和基于现有规则的系统的审计。
论文及项目相关链接
Summary
云提供商为应对日益增长的计算需求,采取安全措施保护大规模计算环境。本文提出一种基于大型语言模型的命令风险分类系统,利用转移学习,有效识别危险的命令行界面命令,并在实际生产命令数据集上验证了其有效性。该系统能克服传统解决方案的局限性,如基于规则的系统的缺陷,并适应脚本语言特性,有效识别危险命令。
Key Takeaways
- 云提供商采取措施保护大规模计算环境,实施安全和监控操作维护活动以防止数据丢失和服务中断。
- 传统命令风险评估解决方案采用基于规则的系统,需要专业知识和持续人工审查。
- 端到端学习系统已被提出用于分类CLI命令,但存在适应脚本语言特性和处理不平衡数据集的问题。
- 本研究提出了一种基于大型语言模型的命令风险分类系统,利用转移学习,具有准确分类和有效识别罕见危险命令的能力。
- 该系统在实际生产命令数据集上进行了验证,并展示了如何应用于其他安全相关任务,如危险命令拦截和现有基于规则的系统审计。
- 该系统能克服传统解决方案的局限性,并适应脚本语言的特性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在大规模计算环境中保护云计算资源,以满足日益增长的计算需求,并防止数据丢失和服务中断。具体来说,论文关注于如何有效地对命令行界面(CLI)命令进行风险评估,以拦截、评估和阻止可能造成损害的危险命令。传统的解决方案包括基于规则的系统,这些系统需要专家知识并且需要不断地人工修订以适应未见过的命令。为了克服这些限制,论文提出了一种基于Transformer的命令风险分类系统,利用大型语言模型(LLM)的泛化能力来提供准确的分类,并有效地识别罕见的危险命令,通过转移学习的能力来实现这一目标。
Q: 有哪些相关研究?
A: 论文中提到了以下相关研究:
**Hendler et al. [2]**:评估了多种机器学习模型用于恶意PowerShell命令检测,包括传统的NLP模型(如n-gram、BoW)和深度神经网络模型(如CNN、LSTM),以及一个结合3-gram和CNN模型的集成模型,该集成模型取得了最佳性能。
**Yamin et al. [10]**:使用Naive Bayes和CNN模型对命令行参数进行分类,以将PowerShell命令分类为恶意命令。他们的方法专注于PowerShell和混淆命令检测,并在包含14个命令类别的数据集上评估了分类准确性。
**PyComm [11]**:这是一个针对Python脚本的恶意命令检测模型,基于随机森林算法应用于一组静态特征和Python源代码字符串的混合。在评估中,他们获得了0.955的准确率和0.943的召回率。
这些研究提供了不同的方法来处理命令行数据的安全分类任务,包括使用传统的机器学习模型和深度学习模型。论文中提出的基于Transformer的方法旨在通过利用大型语言模型(LLM)的预训练和微调能力,提高对命令风险分类的准确性,尤其是在处理罕见且危险的命令时。
Q: 论文如何解决这个问题?
A: 论文通过提出一个基于Transformer的命令风险分类系统来解决这个问题,具体方法如下:
系统架构
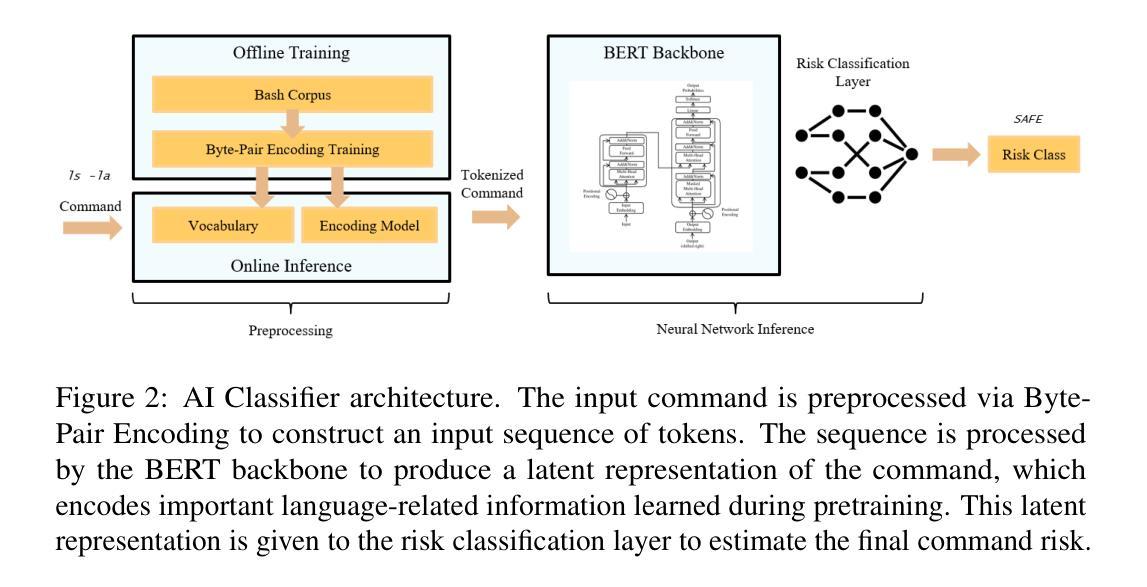
预处理算法:使用Byte-Pair Encoding (BPE)算法将原始命令字符串分割成一系列标记(tokens)。BPE是一种无监督的标记化方法,能够识别出语言中更频繁出现的字符对,并将它们替换为一个新字符,从而形成更优的标记集合。
神经网络架构:采用BERT(Bidirectional Encoder Representations from Transformers),这是一个基于转移学习的深度语言表示模型。BERT通过在上下文任务上预训练一个Transformer网络来学习语言的语法和上下文关系。
训练过程
数据集收集:从GitHub等公共数据源收集了大量的Bash脚本文件,以构建预训练所需的命令语料库。
BPE训练:使用收集到的Bash命令语料库,通过BPE算法学习脚本语言的标记和模式,生成一个大小为V的词汇表和编码算法。
BERT训练:
- 预训练:在自监督的上下文任务上训练Transformer网络,如掩蔽标记语言模型和下一句预测。
- 微调:在预训练的基础上,添加一个额外的分类层块,使用有监督的数据集进行微调,以适应具体的命令风险分类任务。
实验设置
模型实现:使用Python实现了BERT迷你模型,并选择了适当的超参数配置。
数据集划分:将收集到的标注有风险类别的命令数据集分为训练集、开发集和测试集,保持类别分布。
评估指标:使用准确率、精确率、召回率和F1分数等指标来评估模型性能,特别是在类别分布不均衡的情况下。
结果
论文中提出的模型在多个评估指标上优于现有的算法,特别是在检测罕见且危险的命令类别方面表现出色。此外,论文还展示了该模型在有限训练数据下对危险命令的识别能力,证明了其在转移学习方面的有效性。
应用案例
论文还讨论了如何将训练好的BERT模型应用于其他与命令行相关的工业应用,如在线风险分类、系统审计、命令分类和命名实体识别等任务,进一步扩展了模型的实用性。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验:
数据集收集和预处理:
- 从GitHub上收集了大约500MB的Bash脚本文件,共计71164个脚本。
- 使用Byte-Pair Encoding (BPE)算法对Bash命令语料库进行标记化,生成了词汇表和编码算法。
BERT预训练和微调:
- 在预训练阶段,BERT模型在自监督的上下文任务上进行训练,包括掩蔽标记语言模型和下一句预测任务。
- 在微调阶段,使用标注有风险类别的命令数据集对预训练的BERT模型进行微调,以适应命令风险分类任务。
模型性能评估:
- 使用精确率、召回率和F1分数等指标来评估模型性能,特别是在处理不平衡类别分布时。
- 将BERT模型与其他几种算法进行比较,包括Word2Vec+随机森林、3-gram模型、BoW模型、4-cnn和9-cnn模型、LSTM网络和集成模型。
不同训练数据量下的模型性能:
- 为了展示模型的转移学习能力,作者评估了在不同大小的训练数据集上训练的模型性能,从100到20000个命令样本不等。
应用案例:
- 论文还讨论了BERT模型在在线风险分类、系统审计、命令分类和命名实体识别等任务中的应用。
这些实验旨在验证所提出方法的有效性,并展示BERT模型在命令风险分类任务中的优越性能,特别是在处理罕见且危险的命令时。通过这些实验,论文证明了BERT模型能够提高对危险命令的检测能力,并在有限的训练数据下仍能保持高准确率。
Q: 有什么可以进一步探索的点?
A: 论文提出了基于BERT的命令风险分类系统,并在实验中展示了其有效性。以下是一些可以进一步探索的点:
模型泛化能力:
- 探索模型在不同类型的操作系统和脚本语言(如PowerShell、Python等)上的泛化能力。
- 研究模型对于未见过的命令和新型攻击手法的识别能力。
模型解释性:
- 提高模型的可解释性,以便安全专家可以理解模型的决策过程。
- 分析模型预测错误的原因,以改进模型和规则。
模型鲁棒性:
- 测试模型对于故意构造的、旨在绕过检测的混淆命令的鲁棒性。
- 研究对抗性攻击对模型性能的影响,并开发防御策略。
实时性能:
- 评估模型在实时命令拦截系统中的性能,包括推理时间和资源消耗。
- 优化模型以满足实时应用的需求。
多任务学习:
- 探索模型在多任务学习设置中的性能,例如同时进行命令风险分类和命令分类。
- 研究如何有效地共享和专门化模型的不同部分以处理多个相关任务。
跨领域适应性:
- 研究模型在不同行业和领域的适应性,以及如何快速适应新环境。
- 开发有效的领域适应技术,以减少在新领域上的重新训练需求。
模型压缩和加速:
- 探索模型压缩技术,以减少模型大小并加速推理过程。
- 研究如何平衡模型的准确性和效率,以适应资源受限的环境。
交互式工具开发:
- 开发交互式工具,帮助安全专家与模型协作,以提高审计和规则更新的效率。
- 结合自然语言处理技术,提供命令推荐和自动化修复建议。
长期监控和更新:
- 研究如何长期监控模型性能,并自动更新模型以适应环境变化。
- 探索在线学习策略,使模型能够在持续运行中学习新的命令和攻击模式。
法规和伦理考量:
- 考虑模型在处理命令数据时的隐私和合规性问题。
- 确保模型的开发和部署遵循相关的法律法规和伦理标准。
这些探索点可以帮助进一步改进模型的性能,提高其在实际应用中的有效性和可靠性,并扩展其在更多场景中的应用。
Q: 总结一下论文的主要内容
A: 论文的主要内容概括如下:
问题背景:
- 论文针对云计算环境中如何保护大规模计算资源,防止数据丢失和服务中断的问题。
- 特别关注于如何评估命令行界面(CLI)命令的风险,以拦截和阻止可能造成损害的危险命令。
现有解决方案的局限性:
- 传统基于规则的系统需要专家知识,并且需要不断人工修订以适应新出现的命令。
- 现有端到端学习系统采用通用文本分类器,可能不适应脚本语言的特性,且在类别不平衡时效果不佳。
提出的解决方案:
- 提出一种基于Transformer的命令风险分类系统,利用大型语言模型(LLM)的泛化能力,通过转移学习来准确分类命令并有效识别罕见的危险命令。
系统架构:
- 使用BERT(Bidirectional Encoder Representations from Transformers)作为模型基础,通过预训练和微调来适应具体的命令风险分类任务。
- 采用Byte-Pair Encoding(BPE)进行命令字符串的预处理和标记化。
训练和实验:
- 从GitHub收集大量Bash脚本文件进行预训练,使用BPE算法学习命令语言的标记和模式。
- 使用标注有风险类别的命令数据集对BERT模型进行微调。
- 在多个评估指标下比较BERT模型与其他算法的性能,显示出BERT模型在检测危险命令上的优势。
应用案例:
- 讨论了BERT模型在在线风险分类、系统审计、命令分类和命名实体识别等任务中的应用。
结论:
- 论文提出的基于BERT的命令风险分类模型能够有效提高对危险命令的检测能力,尤其是在处理罕见命令时。
- 论文还展示了如何根据实际生产命令的分布来训练模型,并评估了模型的准确性。
论文通过实验验证了所提出方法的有效性,并探讨了模型在不同安全相关任务中的应用潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图