⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-14 更新
EmoDubber: Towards High Quality and Emotion Controllable Movie Dubbing
Authors:Gaoxiang Cong, Jiadong Pan, Liang Li, Yuankai Qi, Yuxin Peng, Anton van den Hengel, Jian Yang, Qingming Huang
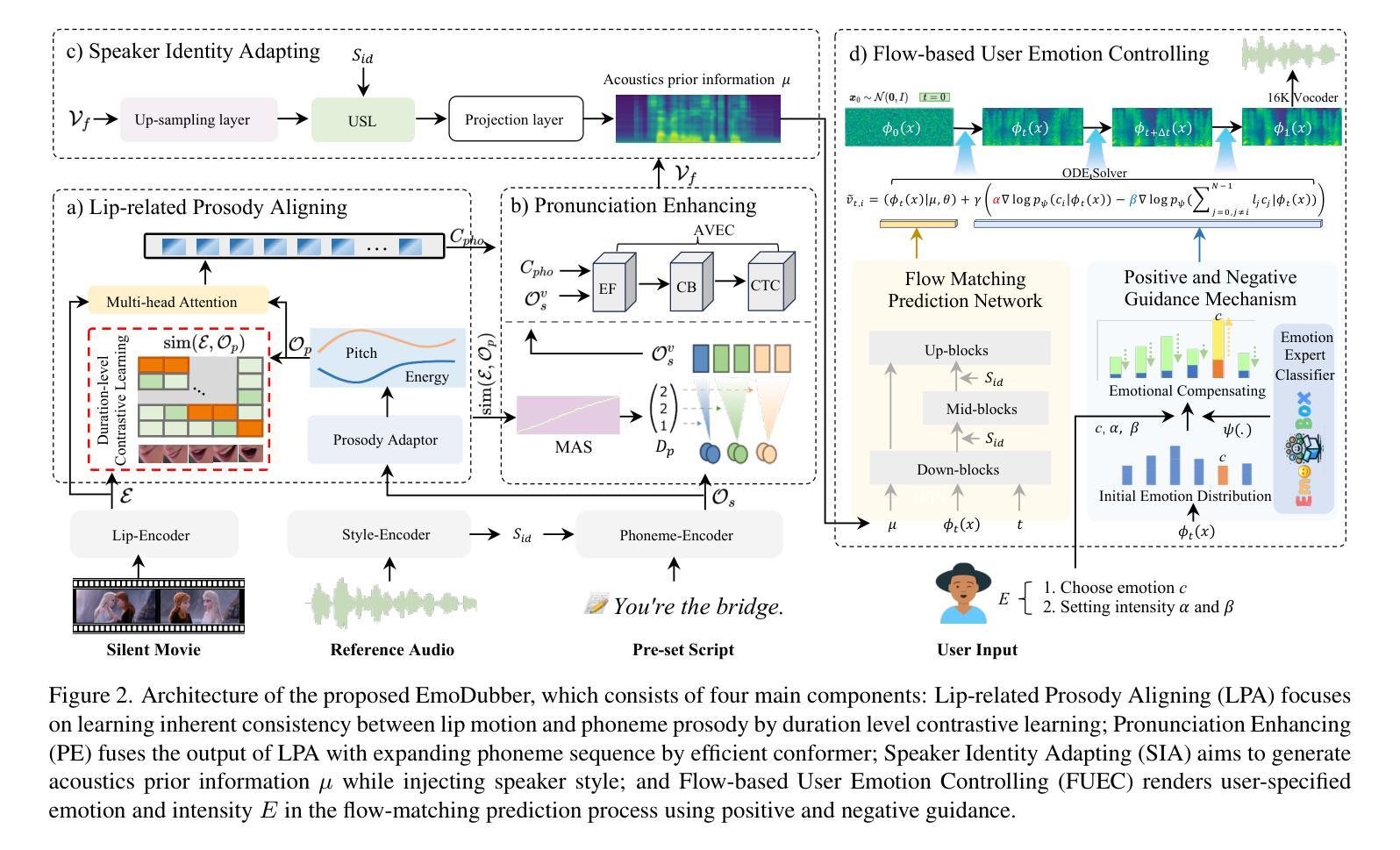
Given a piece of text, a video clip, and a reference audio, the movie dubbing task aims to generate speech that aligns with the video while cloning the desired voice. The existing methods have two primary deficiencies: (1) They struggle to simultaneously hold audio-visual sync and achieve clear pronunciation; (2) They lack the capacity to express user-defined emotions. To address these problems, we propose EmoDubber, an emotion-controllable dubbing architecture that allows users to specify emotion type and emotional intensity while satisfying high-quality lip sync and pronunciation. Specifically, we first design Lip-related Prosody Aligning (LPA), which focuses on learning the inherent consistency between lip motion and prosody variation by duration level contrastive learning to incorporate reasonable alignment. Then, we design Pronunciation Enhancing (PE) strategy to fuse the video-level phoneme sequences by efficient conformer to improve speech intelligibility. Next, the speaker identity adapting module aims to decode acoustics prior and inject the speaker style embedding. After that, the proposed Flow-based User Emotion Controlling (FUEC) is used to synthesize waveform by flow matching prediction network conditioned on acoustics prior. In this process, the FUEC determines the gradient direction and guidance scale based on the user’s emotion instructions by the positive and negative guidance mechanism, which focuses on amplifying the desired emotion while suppressing others. Extensive experimental results on three benchmark datasets demonstrate favorable performance compared to several state-of-the-art methods.
给定一段文本、一个视频片段和参考音频,电影配音任务旨在生成与视频对齐的语音,同时克隆所需的语音。现有方法存在两个主要缺陷:一是难以同时保持音视频同步和清晰的发音;二是缺乏表达用户定义情绪的能力。为了解决这些问题,我们提出了EmoDubber,一种情感可控的配音架构,允许用户指定情绪类型和情绪强度,同时满足高质量的唇部同步和发音。具体来说,我们首先设计了唇相关韵律对齐(LPA),它专注于通过学习唇动和韵律变化之间的内在一致性,通过时长级别对比学习来进行合理的对齐。然后,我们设计了发音增强(PE)策略,通过高效conformer融合视频级音素序列,以提高语音清晰度。接下来,说话人身份适应模块旨在解码声音先验并注入说话人风格嵌入。之后,所提出的基于流的用户情绪控制(FUEC)用于通过流匹配预测网络合成波形,该网络以声音先验为条件。在此过程中,FUEC通过正负引导机制,根据用户的情绪指令确定梯度方向和指导规模,侧重于放大所需情绪的同时抑制其他情绪。在三个基准数据集上的广泛实验结果证明,与几种最新方法相比,我们的方法表现出优越的性能。
论文及项目相关链接
PDF Under review
摘要
该文本介绍了一种电影配音任务的方法,旨在生成与视频对齐的语音,同时克隆所需的语音。现有方法存在两个主要缺陷:一是难以同时保持视听同步和清晰的发音;二是缺乏表达用户定义情绪的能力。为解决这些问题,提出了EmoDubber情感可控配音架构,允许用户指定情绪类型和情绪强度,同时满足高质量唇同步和发音。通过设计唇相关韵律对齐(LPA)和发音增强(PE)策略,以及基于流的用户情绪控制(FUEC),实现了合理的对齐、提高语音清晰度、解码声学先验并注入说话者风格嵌入,同时根据用户的情绪指令合成波形。实验结果在三个基准数据集上表现出优于几种最新方法的性能。
关键见解
- 电影配音任务旨在生成与视频对齐的语音,同时克隆所需语音。
- 现有方法存在视听同步和清晰发音的双重挑战,以及缺乏表达用户定义情绪的能力。
- EmoDubber情感可控配音架构允许用户指定情绪类型和强度,同时满足高质量唇同步和发音。
- 通过LPA和PE策略,实现了合理的对齐和提高语音清晰度。
- 提出了基于流的用户情绪控制(FUEC)方法,根据用户的情绪指令合成波形。
- FUEC通过正负指导机制确定梯度方向和指导规模,侧重于放大所需情绪并抑制其他情绪。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为EmoDubber的电影配音架构,旨在解决现有电影配音方法中的两个主要缺陷:
音视频同步与清晰发音的挑战:现有的方法在生成与视频同步的语音时,往往难以同时保持音视频同步和清晰的发音。
缺乏情绪表达能力:现有的方法通常缺乏表达用户定义情绪的能力,这限制了它们在电影后期制作中的应用,尤其是在情感表达方面。
为了解决这些问题,EmoDubber架构允许用户指定所需的情绪类型和情绪强度,同时确保高质量的唇部同步和清晰的发音。具体来说,EmoDubber通过以下几个关键模块来实现这一目标:
- **Lip-related Prosody Aligning (LPA)**:通过时序级别的对比学习,学习唇动和韵律变化之间的固有一致性,以实现合理的对齐。
- **Pronunciation Enhancing (PE)**:通过扩展视频级别的音素序列并使用高效Conformer模型融合,以提高语音的可理解性。
- **Speaker Identity Adapting (SIA)**:通过注入说话人风格嵌入来生成声学先验信息。
- **Flow-based User Emotion Controlling (FUEC)**:基于流匹配预测网络,根据用户的情绪指令合成波形,同时通过正负引导机制(PNGM)灵活调整情绪强度。
通过这些模块,EmoDubber能够在保持音视频同步和清晰发音的同时,实现情绪的可控合成,从而满足电影制作或爱好者对配音质量的需求。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究可以分为以下几个领域:
Visual Voice Cloning (V2C):
- 该领域专注于生成与角色口型同步,并且具有参考音频中展示的嗓音风格的文本语音。一些工作专注于改善多说话人场景中的说话人身份识别,例如:
- V2CNet [3] 和 VDTTS [15] 使用预训练的 GE2E [47] 来获得独特且归一化的言语嵌入。
- StyleDubber [6] 应用多尺度学习将风格线索应用于 GE2E 提取的嵌入。
- Speak2Dub [50] 采用预训练策略在 TTS 语料库上提高表达性。
- 该领域专注于生成与角色口型同步,并且具有参考音频中展示的嗓音风格的文本语音。一些工作专注于改善多说话人场景中的说话人身份识别,例如:
Flow Matching 和 Classifier Guidance:
- Flow Matching 是一种无需模拟的方法,用于训练连续归一化流(CNFs)模型,这些模型可以模拟任意概率路径,并捕获由扩散过程表示的概率轨迹。它在图像生成和几何领域表现出色,例如:
- Stable Diffusion 3 [10], Lumina-T2X [11], 和 EQUIFM [44]。
- Classifier Guidance (CG) 被广泛用于控制特定属性,例如文本到图像和情感 TTS [13, 26, 45]。
- Flow Matching 是一种无需模拟的方法,用于训练连续归一化流(CNFs)模型,这些模型可以模拟任意概率路径,并捕获由扩散过程表示的概率轨迹。它在图像生成和几何领域表现出色,例如:
情感表达和控制:
- 一些研究 [18] 表明,配音中的情感强度可以影响听众的情感和对电影的心理感知。因此,电影的后期制作可以通过控制情感表达来弥补先前录音的不足。
音频-视觉同步评估:
- 使用 Lip Sync Error Distance (LSE-D) 和 Lip Sync Error Confidence (LSE-C) 等指标来量化生成语音与视频之间的同步性,这些指标基于预训练的 SyncNet [5]。
语音质量评估:
- 使用 Word Error Rate (WER) [36] 来衡量发音准确性,并使用 Speaker Encoder Cosine Similarity (SECS) 来评估生成配音与参考音频之间的音色一致性。
情感评估:
- 使用 Intensity Score 来衡量生成音频中的情感强度,这比之前使用平均分类概率的方法更精细。
这些相关研究为 EmoDubber 架构的开发提供了理论基础和技术背景,使其能够在保持音视频同步和清晰发音的同时,实现情绪的可控合成。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为EmoDubber的架构来解决电影配音中存在的问题,具体解决方案如下:
1. Lip-related Prosody Aligning (LPA)
- 目标:学习唇动和韵律变化之间的固有一致性,以实现正确的音视频对齐。
- 方法:通过时序级别的对比学习(Duration level contrastive learning),控制语音速度,使得模型能够推理正确的音视频对齐。
2. Pronunciation Enhancing (PE)
- 目标:提高语音的清晰度和可理解性。
- 方法:通过单调对齐搜索(Monotonic alignment search, MAS)扩展视频级别的音素序列,并与LPA的输出通过高效的Conformer模型进行融合。
3. Speaker Identity Adapting (SIA)
- 目标:生成声学先验信息,并注入说话人的风格。
- 方法:从PE模块的输出中吸收融合序列,并注入来自参考说话人的样式嵌入,以生成目标声学先验信息。
4. Flow-based User Emotion Controlling (FUEC)
- 目标:根据用户指定的情绪指令合成波形,同时渲染用户指定的情绪。
- 方法:使用基于流匹配的预测网络,并结合正负引导机制(Positive and Negative Guidance Mechanism, PNGM),动态调整流匹配向量场预测过程,以实现情绪强度的灵活控制。
技术细节
- 多尺度风格学习:通过多尺度学习来应用风格线索,增强说话人特征。
- 上下文视频场景的融合:通过结合前后视频场景来增强生成语音的韵律表达。
- 情感控制:通过情感专家分类器和流匹配预测网络,根据用户的情绪指令动态调整情绪强度。
实验结果
- 数据集:在三个基准数据集(Chem, GRID, V2C-Animation)上进行了广泛的实验。
- 性能:与几种最先进的方法相比,EmoDubber在音视频同步、发音清晰度和情感控制方面均展现出优越性能。
通过上述方法,EmoDubber能够在保持音视频同步和清晰发音的同时,实现情绪的可控合成,满足用户对电影配音质量和情感表达的需求。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证EmoDubber架构的性能和效果。以下是实验的详细内容:
1. 实施细节
- 视频帧采样率为25 FPS,所有音频重新采样为16kHz。
- 唇部区域调整为96×96,并在ResNet-18上进行预训练。
- STFT(短时傅里叶变换)的窗口长度、帧大小和跳跃长度分别为640、1024和160。
- 流预测网络在LibriSpeech上进行预训练。
- 使用PyTorch在GeForce RTX 4090 GPU上进行训练和推理。
2. 数据集
- Chem:一个流行的配音数据集,记录了化学老师在课堂上的讲话。
- GRID:一个多说话人的配音基准数据集。
- V2C-Animation:一个用于动画电影配音的多说话人数据集,包含身份和情感注释。
3. 评估指标
- 音视频同步评估:使用Lip Sync Error Distance (LSE-D) 和 Lip Sync Error Confidence (LSE-C)。
- 语音质量评估:使用Word Error Rate (WER)、Speaker Encoder Cosine Similarity (SECS)、Mel Cepstral Distortion Dynamic Time Warping (MCD) 和MCD-SL。
- 情感评估:使用Intensity Score来衡量生成音频中的情感强度。
- 主观评估:使用MOS-naturalness (MOS-N) 和 MOS-similarity (MOS-S) 来评估生成语音的自然度和目标语音的识别度。
4. 与现有技术的比较
- 与没有情感控制功能的SOTA(State-of-the-Art)配音模型进行比较,包括Fastspeech2、StyleSpeech、Face-TTS、V2C-Net、HPMDubbing、Speaker2Dub和StyleDubber等。
5. 消融研究
- 通过移除EmoDubber架构中的不同模块(LPA、PE、SIA)来评估每个模块对整体性能的贡献。
6. 情感控制评估
- 强度控制结果:展示了EmoDubber在Chem基准上通过调整正负引导尺度(α和β)来控制情感强度的能力。
- 情感零样本转换:在没有情感标签的Chem数据集上重新合成具有五种不同情感的语音,与现有的情感TTS基线模型GenerSpeech进行比较。
- 情感语音质量结果:在Chem测试集上测试了七种情感的语音质量,验证情感控制对音频-视觉同步、发音清晰度和说话人相似性的影响。
7. 定性结果
- 邀请志愿者在三个视频上表达预期的情感和强度,并使用EmoDubber生成的音频样本进行可视化比较。
这些实验全面评估了EmoDubber在音视频同步、语音质量、情感控制和用户自定义情感强度方面的表现,并与现有技术进行了比较,证明了其优越性能。
Q: 有什么可以进一步探索的点?
A: 尽管EmoDubber在电影配音任务中取得了显著的性能,但仍有一些领域可以进一步探索和改进:
1. 模型泛化能力
- 多语言和方言支持:当前模型主要针对单一语言,探索多语言和方言的支持可以扩大模型的应用范围。
- 跨领域泛化:研究模型在不同类型的视频(如动画、纪录片、访谈等)和不同场景下的泛化能力。
2. 情感表达的精细度
- 更丰富的情感类别:目前EmoDubber主要处理几种基本情感,可以考虑引入更细致的情感类别,如“惊讶”、“轻蔑”等。
- 情感转换的平滑性:研究如何在不同情感之间平滑过渡,使配音听起来更自然。
3. 模型训练和优化
- 训练效率:探索更高效的训练策略,如迁移学习、半监督学习等,以减少训练时间和资源消耗。
- 模型压缩和加速:研究模型压缩技术,以便在资源受限的设备上部署EmoDubber。
4. 用户交互和控制
- 用户界面:开发直观的用户界面,让用户更容易地指定情感类型和强度,以及实时预览配音效果。
- 个性化定制:允许用户上传自己的语音样本,使模型能够学习并模仿用户的特定语音特征。
5. 音频和视频质量
- 更高分辨率的音频和视频:探索使用更高分辨率的音频和视频输入,以提高最终输出的质量。
- 噪声和复杂背景的处理:研究如何在嘈杂或复杂背景中保持高质量的唇音同步和清晰的发音。
6. 多模态融合
- 更多的视觉信息:除了唇动,还可以考虑融合面部表情、肢体语言等其他视觉信息,以增强情感表达。
- 音频-视觉不一致的处理:研究如何处理音频和视频不一致的情况,例如,当视频中的说话人快速移动或遮挡嘴唇时。
7. 伦理和隐私问题
- 数据隐私保护:确保在训练和使用过程中保护个人隐私,特别是在使用真实人物的视频时。
- 伦理使用指南:制定使用指南,防止EmoDubber被用于制造虚假信息或侵犯版权。
这些探索点不仅可以推动EmoDubber技术的发展,还有助于提高电影配音的自然度和表现力,同时也需要关注其在实际应用中的伦理和隐私问题。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为EmoDubber的情绪可控电影配音架构,旨在生成与视频同步的语音,同时复制所需的声音,并允许用户指定情绪类型和情绪强度。以下是论文的主要内容总结:
1. 问题定义
- 电影配音任务需要将文本转换成语音,与视频角色的口型同步,并表现出参考音频中的声音特征。
- 现有方法存在两个主要问题:音视频同步与清晰发音难以同时保证,以及缺乏表达用户定义情绪的能力。
2. EmoDubber架构
- **Lip-related Prosody Aligning (LPA)**:通过时序级别的对比学习,学习唇动和韵律变化之间的一致性,以实现音视频对齐。
- **Pronunciation Enhancing (PE)**:通过扩展视频级别的音素序列并使用高效Conformer模型融合,提高语音的可理解性。
- **Speaker Identity Adapting (SIA)**:生成声学先验信息,并注入说话人的风格。
- **Flow-based User Emotion Controlling (FUEC)**:基于流匹配预测网络,根据用户的情绪指令合成波形,并通过正负引导机制灵活调整情绪强度。
3. 实验
- 在三个基准数据集(Chem, GRID, V2C-Animation)上进行了广泛的实验。
- 使用了多种评估指标,包括音视频同步评估、语音质量评估、情感评估和主观评估。
- 实验结果表明,EmoDubber在保持音视频同步和清晰发音的同时,能够实现情绪的可控合成,并优于几种最先进的方法。
4. 贡献
- 提出了EmoDubber,一个可控情绪配音架构,允许用户指定所需情绪,同时满足高质量唇部同步和清晰发音。
- 设计了具有正负引导的FUEC,动态调整流匹配向量场预测过程,实现灵活的情绪强度控制。
- 通过时序级别的对比学习和音素增强策略,实现了高质量的唇部同步和清晰发音。
5. 未来工作
- 探索多语言和方言支持、情感表达的精细度、模型训练和优化、用户交互和控制、音频和视频质量、多模态融合以及伦理和隐私问题等方向。
EmoDubber的提出为电影配音领域带来了新的可能性,通过结合先进的语音合成技术和情感控制机制,提高了配音的自然度和表现力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

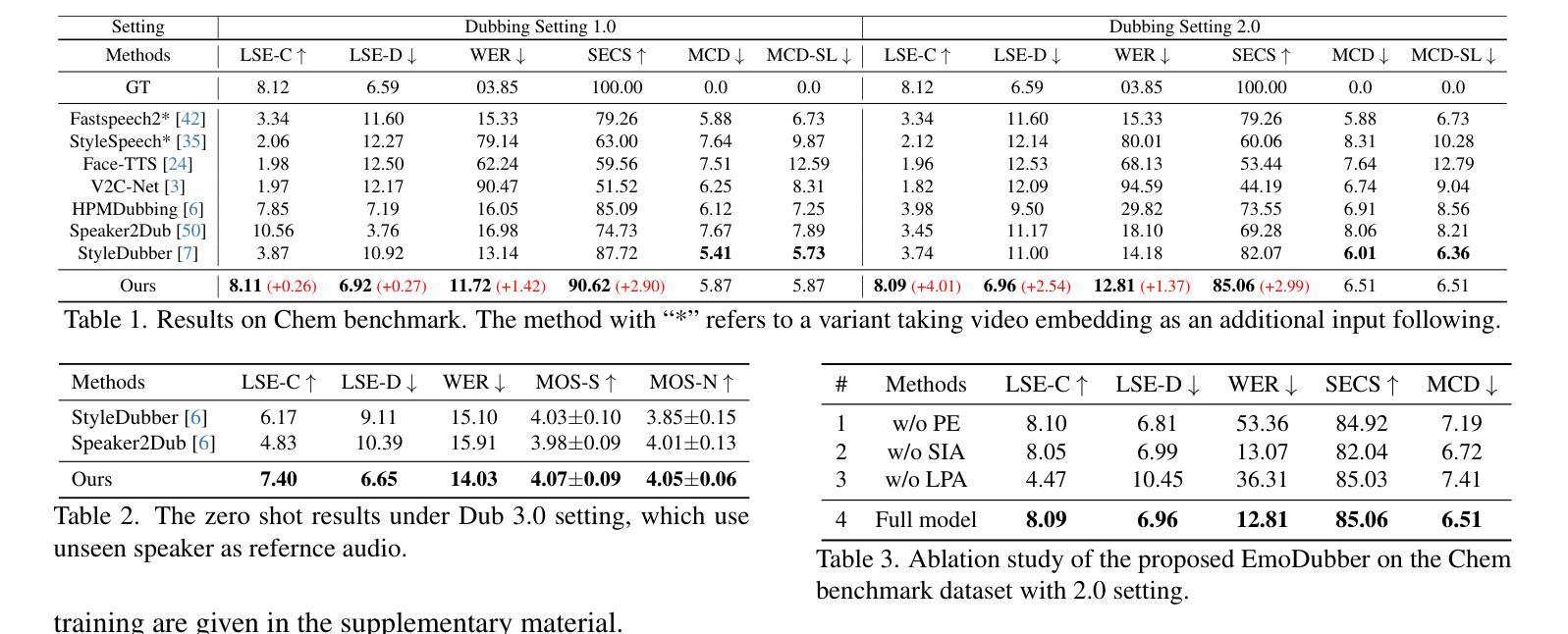
MCDubber: Multimodal Context-Aware Expressive Video Dubbing
Authors:Yuan Zhao, Zhenqi Jia, Rui Liu, De Hu, Feilong Bao, Guanglai Gao
Automatic Video Dubbing (AVD) aims to take the given script and generate speech that aligns with lip motion and prosody expressiveness. Current AVD models mainly utilize visual information of the current sentence to enhance the prosody of synthesized speech. However, it is crucial to consider whether the prosody of the generated dubbing aligns with the multimodal context, as the dubbing will be combined with the original context in the final video. This aspect has been overlooked in previous studies. To address this issue, we propose a Multimodal Context-aware video Dubbing model, termed \textbf{MCDubber}, to convert the modeling object from a single sentence to a longer sequence with context information to ensure the consistency of the global context prosody. MCDubber comprises three main components: (1) A context duration aligner aims to learn the context-aware alignment between the text and lip frames; (2) A context prosody predictor seeks to read the global context visual sequence and predict the context-aware global energy and pitch; (3) A context acoustic decoder ultimately predicts the global context mel-spectrogram with the assistance of adjacent ground-truth mel-spectrograms of the target sentence. Through this process, MCDubber fully considers the influence of multimodal context on the prosody expressiveness of the current sentence when dubbing. The extracted mel-spectrogram belonging to the target sentence from the output context mel-spectrograms is the final required dubbing audio. Extensive experiments on the Chem benchmark dataset demonstrate that our MCDubber significantly improves dubbing expressiveness compared to all advanced baselines. The code and demos are available at https://github.com/XiaoYuanJun-zy/MCDubber.
自动视频配音(AVD)旨在根据给定的脚本生成与唇部动作和语调表达相匹配的语音。当前的AVD模型主要利用当前句子的视觉信息来增强合成语音的语调。然而,在考虑生成的配音的语调是否与多模态上下文对齐时,关键在于配音将与最终视频中的原始上下文相结合。这一点在以前的研究中已被忽视。为了解决这一问题,我们提出了一种多模态上下文感知的视频配音模型,称为“MCDubber”,将建模对象从单个句子转换为具有上下文信息的更长的序列,以确保全局上下文语调的连贯性。MCDubber主要包括三个主要组件:(1)上下文持续时间对齐器旨在学习文本和唇部帧之间的上下文感知对齐;(2)上下文语调预测器旨在读取全局上下文视觉序列并预测上下文感知的全局能量和音调;(3)上下文声学解码器最终借助目标句子的相邻真实mel频谱图来预测全局上下文mel频谱图。通过这种方式,MCDubber在配音时充分考虑了多模态上下文对当前句子语调表达的影响。从输出的上下文mel频谱图中提取出属于目标句子的mel频谱图就是最终所需的配音音频。在Chem基准数据集上的大量实验表明,我们的MCDubber与所有先进的基线相比,显著提高了配音的表达性。代码和演示可在https://github.com/XiaoYuanJun-zy/MCDubber找到。
论文及项目相关链接
PDF Accepted by NCMMSC2024
Summary
自动视频配音(AVD)旨在根据给定的剧本生成与唇部动作和语调表达相匹配的语音。当前,AVD模型主要通过当前句子的视觉信息增强合成语音的语调。然而,关键问题在于生成的配音的语调是否与多模态上下文相符,因为配音最终会与原始视频上下文结合。针对这一问题,我们提出了一个名为MCDubber的多模态上下文感知视频配音模型。它将建模对象从单个句子转变为具有上下文信息的更长的序列,以确保全局上下文语调的连贯性。该模型包括三个主要组件:(1)上下文时长对齐器旨在学习文本和唇帧之间的上下文感知对齐;(2)上下文语调预测器旨在读取全局上下文视觉序列并预测上下文感知的全局能量和音调;(3)上下文声学解码器最终借助目标句子的相邻真实mel光谱图来预测全局上下文mel光谱图。通过这种方式,MCDubber在配音时充分考虑了多模态上下文对当前句子语调表达的影响。实验表明,与所有先进的基线相比,我们的MCDubber在配音表现力方面有了显著提高。代码和演示可在https://github.com/XiaoYuanJun-zy/MCDubber获取。
Key Takeaways
- AVD的目标是根据剧本生成与唇部动作和语调表达匹配的语音。
- 当前AVD模型主要利用当前句子的视觉信息增强语音语调。
- 在配音中,需要考虑生成的语调是否与多模态上下文相符。
- MCDubber模型旨在确保全局上下文语调的连贯性。
- MCDubber包括三个主要组件:上下文时长对齐器、上下文语调预测器和上下文声学解码器。
- MCDubber通过考虑多模态上下文的影响,提高了配音的表达力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是自动视频配音(Automatic Video Dubbing, AVD)中的多模态上下文信息整合问题。具体来说,作者指出在现有的自动视频配音模型中,大多数研究只关注当前句子的视觉信息来增强合成语音的韵律表达性,而忽略了生成的配音与原始视频中的多模态上下文(包括视觉和音频信息)的一致性。为了解决这个问题,论文提出了一个名为MCDubber的多模态上下文感知视频配音模型,该模型将建模对象从单一句子扩展到包含上下文信息的更长序列,以确保全局上下文韵律的一致性。通过这种方式,MCDubber能够在配音时充分考虑多模态上下文对当前句子韵律表达性的影响。
Q: 有哪些相关研究?
A: 在自动视频配音(AVD)和文本到语音(TTS)领域,有许多相关研究,这些研究为本文提出的MCDubber模型提供了理论和技术基础。以下是一些与本文相关的研究:
Tacotron 1/2 [3, 4]: 这些是早期的TTS模型,它们通过端到端的方式从文本合成语音。
FastSpeech 1/2 [5, 6]: 这些模型通过引入前馈变换器(Feed-Forward Transformer, FFT)来加速梅尔频谱图的生成。
Neural Dubber [1]: 这是一个AVD模型,使用跨模态注意力机制来学习文本和口型动作之间的对齐。
DSU-AVO [7]: 这个模型通过自监督的方式学习离散语音单元,以提高对齐的准确性。
VDTTS [8], HPMDubbing [9], 和 3D-VD [2]: 这些方法通过整合当前(目标)句子的面部视觉信息来提高配音的韵律表达性。
ContextSpeech [23]: 该研究使用记忆缓存递归机制将全局文本和声学上下文整合到句子编码中,以提高语音质量和韵律表达性。
MaskedSpeech [10]: 该方法通过整合上下文语义和声学特征来增强韵律生成。
HiFi-GAN [13]: 这是一个声码器,用于将梅尔频谱图转换为时域波形。
Montreal Forced Aligner [24]: 这是一个文本-语音对齐工具,用于获取与选定音素对应的梅尔频谱图。
S3FD [27]: 这是一个用于人脸检测和特征提取的网络,用于从视频中提取情感特征。
这些研究涵盖了从文本到语音的合成、音频-视觉同步、情感和上下文信息的整合等多个方面,为本文提出的MCDubber模型提供了丰富的技术资源和研究背景。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为MCDubber的多模态上下文感知视频配音模型来解决这个问题。MCDubber模型主要包含以下三个关键组件:
上下文时长对齐器(Context Duration Aligner, CDA):该组件通过将前后句子的音素和口型帧作为输入,学习文本和口型之间的上下文感知对齐。它使用Text-Video Aligner来处理时长控制和音视频同步的挑战。
上下文韵律预测器(Context Prosody Predictor, CPP):该组件分析全局上下文视觉序列,并预测上下文感知的全局能量和音高。它利用情感面部对齐网络从视频中提取情感特征,并结合口型-音素特征来预测全局能量和音高。
上下文声学解码器(Context Acoustic Decoder, CAD):该组件预测全局上下文梅尔频谱图,并借助相邻句子的真实梅尔频谱图来实现。它通过双注意力块(Double Attention Block, DAB)聚合和传播来自梅尔频谱图和上下文真实梅尔频谱图的特征,最终通过Postnet预测全局上下文梅尔频谱图。
通过这个过程,MCDubber充分考虑了多模态上下文对当前句子韵律表达性的影响,确保生成的配音音频与原始视频的多模态上下文保持一致。此外,MCDubber还采用了一种两阶段的训练策略,先在原始Chem数据集上进行训练,然后在包含上下文信息的Context Chem数据集上继续训练,以提高模型的性能。
论文通过在Chem基准数据集上的广泛实验验证了MCDubber模型在提高配音表达性和确保生成的配音与多模态上下文一致性方面的有效性。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估MCDubber模型的性能:
数据集介绍:首先介绍了Chem数据集,这是一个单说话者英语语音数据集,包含了从YouTube收集的6,319个短视频片段及其对应的文本转录。然后,作者重新收集了包含前后句子的连续样本,形成了Context Chem数据集,用于评估模型。
实现细节:详细描述了模型的实现,包括使用的FFT块数量、表示维度、视频处理的帧率和采样率、STFT参数等。
训练策略:由于Context Chem数据集的样本数量有限,作者采用了两阶段训练策略。第一阶段使用原始Chem数据集的所有样本进行训练,第二阶段使用Context Chem数据集的样本继续训练。
评估指标:使用了客观和主观两种评估指标。客观指标包括GPE(Gross Pitch Error)、FFE(F0 Frame Error)、STOI(Short-Time Objective Intelligibility)、LSEC(Lip Sync Error-Confidence)和LSE-D(Lip Sync Error-Distance)。主观指标通过Mean Opinion Score (MOS) 测试进行,包括AQ(Audio Quality)、AV Syn(Audio-Visual Synchronization)、MOSC(MOS-Context)、MOS-S(MOS-Similarity)和MOS-N(MOS-Naturalness)。
多模态上下文长度分析:通过统计Context Chem数据集中前后句子的音素序列长度,分析了超参数K(最大多模态上下文长度)对模型性能的影响。
视频配音结果:与三个基线模型(FastSpeech2、DSU-AVO和HPMDubbing)进行了比较,展示了MCDubber在客观和主观评估指标上的优势。
消融研究:为了评估MCDubber中各个组件(CDA、CPP、CAD)以及多模态上下文信息和训练策略的有效性,进行了消融研究。
未来工作:论文最后提出了未来工作的方向,即探索多模态上下文在AVD任务中建模情感表达性的影响。
这些实验全面评估了MCDubber模型在提高配音表达性和确保与多模态上下文一致性方面的能力,并与其他先进方法进行了比较。
Q: 有什么可以进一步探索的点?
A: 根据论文的结论部分,以下是一些可以进一步探索的点:
情感表达性建模:论文提到,未来的工作将探索多模态上下文对自动视频配音(AVD)任务中情感表达性建模的影响。这意味着可以研究如何将情感状态更准确地融入配音过程中,以提高合成语音的情感丰富度和表现力。
多模态上下文的深入分析:虽然论文已经考虑了视频的视觉信息和音频信息,但可能还有更多的上下文信息可以利用,例如场景信息、角色关系、对话内容等,这些都可能对配音的情感和韵律产生影响。
模型的可扩展性和泛化能力:研究MCDubber模型在不同类型的视频和不同语言上的泛化能力,以及如何调整模型以适应不同的配音场景和需求。
实时性能优化:探索如何优化模型以实现实时或近实时的配音生成,这对于实际应用中的用户体验至关重要。
用户交互和定制化:研究如何使MCDubber更加用户友好,允许用户根据自己的需求定制配音的风格、速度、音量等参数。
多任务学习:考虑将配音任务与其他相关任务(如情感识别、语音识别等)结合起来,通过多任务学习提高模型的整体性能。
模型鲁棒性:研究模型对于不同质量的输入数据(如噪声、不清晰的口型等)的鲁棒性,并探索提高鲁棒性的方法。
社会和伦理考量:随着技术的发展,研究自动视频配音技术可能带来的社会和伦理问题,例如版权、隐私和内容操纵等。
跨领域应用:探索MCDubber在其他领域的应用潜力,如电影制作、游戏开发、语言学习等。
这些探索点可以帮助研究者和开发者更好地理解和改进自动视频配音技术,同时也为未来的研究提供了新的方向。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题定义:论文针对的是自动视频配音(AVD)任务中如何生成与视频角色口型和情感表达性相匹配的语音的问题。作者指出,现有方法主要关注当前句子的视觉信息,而忽略了配音与视频多模态上下文的一致性。
MCDubber模型:为了解决上述问题,作者提出了一个名为MCDubber的多模态上下文感知视频配音模型。该模型包含三个主要组件:
- 上下文时长对齐器(CDA):学习文本和口型帧之间的上下文感知对齐。
- 上下文韵律预测器(CPP):读取全局上下文视觉序列并预测全局能量和音高。
- 上下文声学解码器(CAD):预测全局上下文梅尔频谱图,并确保配音与多模态上下文的韵律一致性。
方法细节:论文详细介绍了MCDubber模型的工作流程,包括音视频同步、多模态上下文选择、各个组件的实现细节以及训练和评估的指标。
实验验证:作者在Chem数据集上进行了广泛的实验,包括多模态上下文长度分析、与其他先进方法的比较、消融研究等,以验证MCDubber模型的有效性。
结果分析:实验结果表明,MCDubber在客观和主观评估指标上均优于现有方法,能够显著提高配音的表达性,并确保配音与多模态上下文的一致性。
未来工作:论文提出了未来可能的研究方向,包括探索多模态上下文对情感表达性建模的影响等。
代码和演示:作者提供了MCDubber的代码和演示,以便其他研究者和开发者进一步研究和应用。
总的来说,这篇论文在自动视频配音领域提出了一种新颖的方法,通过考虑多模态上下文信息来提高配音的质量和自然度,对于推动AVD技术的发展具有重要意义。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

MINT: a Multi-modal Image and Narrative Text Dubbing Dataset for Foley Audio Content Planning and Generation
Authors:Ruibo Fu, Shuchen Shi, Hongming Guo, Tao Wang, Chunyu Qiang, Zhengqi Wen, Jianhua Tao, Xin Qi, Yi Lu, Xiaopeng Wang, Zhiyong Wang, Yukun Liu, Xuefei Liu, Shuai Zhang, Guanjun Li
Foley audio, critical for enhancing the immersive experience in multimedia content, faces significant challenges in the AI-generated content (AIGC) landscape. Despite advancements in AIGC technologies for text and image generation, the foley audio dubbing remains rudimentary due to difficulties in cross-modal scene matching and content correlation. Current text-to-audio technology, which relies on detailed and acoustically relevant textual descriptions, falls short in practical video dubbing applications. Existing datasets like AudioSet, AudioCaps, Clotho, Sound-of-Story, and WavCaps do not fully meet the requirements for real-world foley audio dubbing task. To address this, we introduce the Multi-modal Image and Narrative Text Dubbing Dataset (MINT), designed to enhance mainstream dubbing tasks such as literary story audiobooks dubbing, image/silent video dubbing. Besides, to address the limitations of existing TTA technology in understanding and planning complex prompts, a Foley Audio Content Planning, Generation, and Alignment (CPGA) framework is proposed, which includes a content planning module leveraging large language models for complex multi-modal prompts comprehension. Additionally, the training process is optimized using Proximal Policy Optimization based reinforcement learning, significantly improving the alignment and auditory realism of generated foley audio. Experimental results demonstrate that our approach significantly advances the field of foley audio dubbing, providing robust solutions for the challenges of multi-modal dubbing. Even when utilizing the relatively lightweight GPT-2 model, our framework outperforms open-source multimodal large models such as LLaVA, DeepSeek-VL, and Moondream2. The dataset is available at https://github.com/borisfrb/MINT .
多媒体内容中的沉浸式体验,离不开音频背景配乐技术的加持,而在人工智能生成内容(AIGC)领域,音频背景配乐技术面临着重大挑战。尽管文本和图像生成方面的AIGC技术取得了进展,但由于跨模态场景匹配和内容关联方面的困难,音频背景配乐仍然停留在初级阶段。现有的文本到音频技术依赖于详细且声音相关的文本描述,在实际的视频配音应用中表现不佳。现有的数据集如AudioSet、AudioCaps、Clotho、Sound-of-Story和WavCaps等不能完全满足现实世界中音频背景配乐任务的需求。为解决这一问题,我们推出了多模态图像和叙事文本配音数据集(MINT),旨在提高主流配音任务,如文学故事有声读物配音、图像/无声视频配音的体验。此外,为了解决现有文本到音频技术在理解和规划复杂提示方面的局限性,我们提出了音频背景配乐内容规划、生成与对齐(CPGA)框架,其中包括一个内容规划模块,利用大型语言模型进行复杂的多模态提示理解。此外,使用基于近端策略优化的强化学习优化了训练过程,显著提高了生成音频背景的对齐性和听觉逼真性。实验结果表明,我们的方法显著推动了音频背景配乐的发展,为解决多模态配音的挑战提供了稳健的解决方案。即使使用相对轻量级的GPT-2模型,我们的框架也优于开源的多模态大型模型,如LLaVA、DeepSeek-VL和Moondream2。数据集可在https://github.com/borisfrb/MINT找到。
论文及项目相关链接
Summary
本文介绍了多媒体内容中用于增强沉浸式体验的重要技术——音频填充所面临的挑战。尽管人工智能生成内容(AIGC)领域的文本和图像生成技术取得了进展,但由于跨模态场景匹配和内容关联的难度,音频填充仍然很基础。现有数据集无法满足现实世界的音频填充任务需求。为解决这个问题,引入了多模态图像和叙事文本配音数据集(MINT),旨在改进主流配音任务。此外,针对现有文本转音频技术在理解和规划复杂提示方面的局限性,提出了音频内容规划、生成和对齐(CPGA)框架,该框架利用大型语言模型进行复杂的多模态提示理解。通过近端策略优化强化学习优化训练过程,显著提高了生成音频的对齐性和听觉逼真性。实验结果表明,该方法在音频填充领域取得了显著进展,即使使用相对轻量级的GPT-2模型,也能超越开源多模态大型模型。数据集可在XX网站下载。
Key Takeaways
- 多媒体内容的沉浸式体验中,音频填充技术至关重要,但在人工智能生成内容领域面临挑战。
- 当前数据集无法满足现实世界的音频填充任务需求。
- 引入多模态图像和叙事文本配音数据集(MINT),用于改进主流配音任务。
- 提出音频内容规划、生成和对齐(CPGA)框架,解决现有文本转音频技术的局限性。
- CPGA框架利用大型语言模型进行复杂的多模态提示理解。
- 使用近端策略优化强化学习优化训练过程,提高了生成音频的对齐性和听觉逼真性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在人工智能生成内容(AIGC)领域中,Foley音频(即用于增强多媒体内容沉浸感的日常音效)的生成面临的挑战。具体来说,论文关注以下几个关键问题:
跨模态场景匹配和内容关联的困难:在实际视频配音应用中,需要将音频描述与图像和文本模态对齐,这一过程存在挑战。
现有文本到音频(TTA)技术的局限性:目前的TTA技术依赖于详细且与声学相关的文字描述,这在实际视频配音应用中存在不足。
现有数据集的不足:现有的数据集如AudioSet、AudioCaps等,并不能充分满足现实世界中Foley音频配音任务的需求。
为了解决这些问题,论文提出了以下贡献:
MINT数据集:创建了一个多模态图像和叙事文本配音数据集(MINT),旨在提升主流配音任务,如文学故事有声书配音、图像/无声视频配音等。
CPGA框架:提出了一个Foley音频内容规划、生成和对齐(CPGA)框架,该框架包括利用大型语言模型来理解复杂多模态提示的内容规划模块,并通过基于近端策略优化(PPO)的强化学习来优化训练过程,显著提高了生成Foley音频的对齐度和听觉真实性。
实验结果:展示了该方法在Foley音频配音领域显著的进展,即使在使用相对较轻量级的GPT-2模型时,也超过了其他开源的多模态大型模型,如LLaVA、DeepSeek-VL和Moondream2。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与Foley音频生成、多模态数据集和文本到音频技术(TTA)相关的研究工作:
AudioSet:这是一个广泛使用的声音事件数据集,它涵盖了多种声音事件,用于声音识别和分类任务。[5]
AudioCaps:这个数据集通过为AudioSet中的声音事件生成文本描述,促进了从文本描述到音频的建模。[6]
Clotho:一个音频描述数据集,旨在通过各种方式处理和注释文本描述,以便于从文本到音频的转换。[7]
Sound-of-Story:一个多模态故事讲述数据集,结合了音频和文本信息。[8]
WavCaps:一个弱标签音频描述数据集,用于音频-语言多模态研究。[9]
AudioGen:一个自回归TTA模型,用于生成与文本输入紧密对齐的高质量音频。[10]
DiffSound 和 Make-An-Audio:这两个工作采用了离散扩散模型来进行文本到音频的生成。[11], [12]
AudioLDM2 和 TANGO:这两个工作结合了大型语言模型(LLMs)和音频编解码器来进行音频生成。[13], [14]
Sora:一个技术,能够从最小化的提示中产生连续的视觉内容,但在生成Foley音频方面仍然处于初级阶段。[2]
LLaVA, DeepSeek-VL, 和 Moondream2:这些是多模态大型模型,它们在处理多模态信息和理解方面具有一定的能力,但在专门的配音任务训练方面存在不足。[26], [25], [2]
这些研究工作构成了Foley音频生成领域的研究基础,并指出了现有技术的局限性,特别是在处理多模态提示和长叙事文本方面。论文提出的MINT数据集和CPGA框架旨在解决这些局限性,并推动Foley音频生成技术的发展。
Q: 论文如何解决这个问题?
A: 论文通过以下几个主要步骤来解决Foley音频生成中的问题:
1. 创建MINT数据集
- 多模态数据集构建:论文提出了一个多模态图像和叙事文本配音数据集(MINT),这个数据集包含了用于配音任务的关键应用场景,如叙事文本描述和图像的视觉表达。这个数据集旨在解决现有TTA数据集的局限性,即仅描述声学环境,而没有考虑复杂的多模态提示和长叙事文本。
2. 提出CPGA框架
- 内容规划模块:CPGA框架中的内容规划模块利用大型语言模型(LLMs)来增强对复杂文本和跨模态提示的理解。这个模块通过融合和分析多模态提示来生成准确的文本描述,解决了现有技术中手动设计和调整耗时的问题。
- 音频生成模块:使用修改过的TTA模型进行音频生成,确保生成的音频与内容的视觉和叙事方面保持一致。
- 对齐模块:通过强化学习机制,特别是近端策略优化(PPO),来优化音频生成过程。这个模块通过建立基于生成音频与真实音频样本声学相似性的奖励函数来微调语言模型,确保生成的文本提示与所需的声学属性对齐。
3. 实验验证
- 实验结果:论文通过实验验证了所提出的方法在多模态配音任务中的有效性。与现有的多模态大型模型相比,即使使用相对较轻量级的GPT-2模型,CPGA框架也能显著提高Foley音频配音的性能。
4. 优化训练过程
- 基于PPO的强化学习:通过PPO优化训练过程,显著提高了生成Foley音频的对齐度和听觉真实性。
通过这些步骤,论文不仅提出了一个新的数据集来支持Foley音频生成的研究,还提出了一个综合框架来处理复杂的多模态提示,并生成与这些提示相匹配的高质量音频。这种方法有效地解决了现有技术在内容规划和细节处理方面的局限性,为Foley音频生成领域提供了新的研究方向和解决方案。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的MINT数据集和CPGA框架的有效性。以下是实验的详细描述:
1. MINT数据集测试主流TTA模型
- 目的:测试现有的主流文本到音频(TTA)模型在处理MINT数据集时的表现。
- 结果:发现现有的TTA模型(包括AudioGen, AudioLDM, Tango)在处理叙事文本时表现不佳,与AudioCaps中的标注音频文本描述相比,性能显著下降。
2. MINT数据集测试主流多模态大型模型
- 目的:评估几个领先的多模态大型模型在MINT数据集上的表现。
- 结果:LLaVA在多模态Foley配音中表现优于Moondream2和DeepSeek-VL,但在专业配音任务上仍有明显不足。
3. 评估CPGA框架
- 目的:使用GPT-2模型评估所提出的CPGA框架,并使用FD(Frechet Distance)、KL(Kullback-Leibler divergence)、OVL(Overall audio quality)和REL(Relevance to the text caption)等指标进行评估。
- 结果:CPGA框架在SFT(Supervised Fine-Tuning)操作后,与未进行SFT操作相比,Foley音频配音的性能得到了显著提升。同时,使用多模态提示作为输入时,整体性能更好。
4. 客观和主观评估
- 客观评估:使用FD和KL散度作为客观评估的主要指标,基于最先进的音频分类器PANNs计算得出。
- 主观评估:邀请五位人类评估者对生成音频的总体音质(OVL)和与文本字幕的相关性(REL)进行评分,随机选择每种方法生成的20个音频样本,并要求参与者按照1到100的评分标准进行评分。
这些实验结果表明,所提出的MINT数据集和CPGA框架在多模态配音任务中具有显著的性能提升,尤其是在处理复杂的多模态提示和长叙事文本方面。通过这些实验,论文验证了其方法的有效性和实用性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
内容关键元素规划:尽管CPGA框架在处理多模态提示和长叙事文本方面取得了进展,但仍可以进一步研究如何更有效地规划和生成Foley音频中的关键内容元素。
多模态输入的深度融合:研究如何更深入地融合多模态输入(如图像、视频、文本等),以提高Foley音频生成的准确性和自然性。
强化学习优化:进一步探索强化学习在Foley音频生成中的应用,特别是如何优化奖励函数和策略,以提高音频生成的质量和对齐度。
多模态数据集的扩展:扩展MINT数据集,包括更多的场景、音频类型和叙事文本,以提高模型的泛化能力和鲁棒性。
跨模态转换研究:研究在非对齐场景下的跨模态转换,强调理解和创造,以提高Foley音频生成的多样性和适应性。
模型的可解释性和透明度:提高CPGA框架中内容规划和音频生成模块的可解释性,以便更好地理解和控制生成过程。
实时Foley音频生成:研究如何优化模型以实现实时Foley音频生成,这对于视频游戏和互动媒体等应用场景尤为重要。
多语言和跨文化研究:扩展研究范围,探索多语言和跨文化背景下的Foley音频生成,以适应全球化的内容制作需求。
音频质量的客观评价指标:开发和验证更多的客观评价指标,以更全面地评估生成音频的质量,包括声学相似性、情感表达和上下文相关性。
模型的轻量化和部署:研究如何将CPGA框架轻量化,以便在资源受限的设备上部署,如移动设备和嵌入式系统。
这些探索点可以帮助推动Foley音频生成技术的发展,提高其在多媒体内容制作中的应用价值和用户体验。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容概括如下:
问题陈述:
- Foley音频对于增强多媒体内容的沉浸感至关重要,但在AI生成内容(AIGC)领域中,Foley音频的生成面临跨模态场景匹配和内容关联的挑战。
- 现有的文本到音频(TTA)技术依赖于详细且声学相关的文字描述,在实际视频配音应用中存在不足。
- 现有的数据集无法完全满足现实世界中Foley音频配音任务的需求。
MINT数据集:
- 论文介绍了一个多模态图像和叙事文本配音数据集(MINT),旨在提高主流配音任务的效率,如文学故事有声书配音和图像/无声视频配音。
- MINT数据集包含关键应用场景,涵盖叙事文本描述和图像的视觉表达,以解决现有TTA数据集的局限性。
CPGA框架:
- 提出了一个Foley音频内容规划、生成和对齐(CPGA)框架,包括内容规划模块,利用大型语言模型(LLMs)增强复杂文本和跨模态提示的理解。
- 通过基于近端策略优化(PPO)的强化学习优化训练过程,显著提高生成Foley音频的对齐度和听觉真实性。
实验结果:
- 实验结果表明,MINT数据集和CPGA框架显著推进了Foley音频配音领域的发展。
- 即使使用相对较轻量级的GPT-2模型,CPGA框架也优于其他开源多模态大型模型,如LLaVA、DeepSeek-VL和Moondream2。
未来工作:
- 论文提出了未来研究的方向,包括进一步改进内容关键元素规划和探索更多模态下的配音情况。
贡献:
- 论文的主要贡献包括MINT数据集的构建、CPGA框架的提出,以及基于声学指导的PPO方法,这些都有效地提高了多模态配音任务的性能。
综上所述,论文通过构建新的数据集和提出新的框架,旨在解决Foley音频生成中的挑战,并在多模态配音任务中取得了显著的性能提升。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


DubWise: Video-Guided Speech Duration Control in Multimodal LLM-based Text-to-Speech for Dubbing
Authors:Neha Sahipjohn, Ashishkumar Gudmalwar, Nirmesh Shah, Pankaj Wasnik, Rajiv Ratn Shah
Audio-visual alignment after dubbing is a challenging research problem. To this end, we propose a novel method, DubWise Multi-modal Large Language Model (LLM)-based Text-to-Speech (TTS), which can control the speech duration of synthesized speech in such a way that it aligns well with the speakers lip movements given in the reference video even when the spoken text is different or in a different language. To accomplish this, we propose to utilize cross-modal attention techniques in a pre-trained GPT-based TTS. We combine linguistic tokens from text, speaker identity tokens via a voice cloning network, and video tokens via a proposed duration controller network. We demonstrate the effectiveness of our system on the Lip2Wav-Chemistry and LRS2 datasets. Also, the proposed method achieves improved lip sync and naturalness compared to the SOTAs for the same language but different text (i.e., non-parallel) and the different language, different text (i.e., cross-lingual) scenarios.
音频与视频对齐是配音后一个具有挑战性的研究问题。为此,我们提出了一种新的方法,基于DubWise多模态大型语言模型(LLM)的文本到语音(TTS),该方法可以控制合成语音的语音时长,以便与参考视频中的说话人的唇部动作对齐,即使在口语文本不同或语言不同的情况下也是如此。为了完成这项工作,我们提议在基于GPT的TTS中使用跨模态注意力技术。我们将文本的语言标记、通过语音克隆网络的说话人身份标记以及通过提出的时长控制器网络的视频标记结合起来。我们在Lip2Wav-Chemistry和LRS2数据集上展示了系统的有效性。此外,与相同语言但不同文本(即非平行)和不同语言不同文本(即跨语言)的场景相比,所提出的方法实现了更好的唇部同步和更自然的语音表现。
论文及项目相关链接
PDF Accepted at INTERSPEECH 2024
Summary
文本提出了一种新的方法,DubWise多媒体模态大型语言模型(LLM)基于文本到语音(TTS)技术,可控制合成语音的持续时间,以便与参考视频中的说话人唇部动作对齐,即使使用的文本不同或语言不同也是如此。通过结合文本的语言标记、通过语音克隆网络获得的说话人身份标记以及通过提出的持续时间控制器网络获得的视频标记来实现。在Lip2Wav-Chemistry和LRS2数据集上验证了系统的有效性。与当前最佳技术相比,该方法在相同语言但文本不同(即非平行)和不同语言、不同文本(即跨语言)的场景中实现了改进的唇部同步和自然度。
Key Takeaways
- 音频与视觉对齐在配音研究中是一个挑战性问题。
- 提出了一种新的方法DubWise多媒体模态大型语言模型(LLM)-基于文本到语音(TTS)。
- 此方法可以控制合成语音的持续时间,以便与视频中的说话人的唇部动作对齐。
- 该方法利用跨模态注意力技术在一个基于GPT的TTS上实现。
- 结合了文本的语言标记、说话人的身份标记和视频的标记来实现这一方法。
- 在Lip2Wav-Chemistry和LRS2数据集上验证了该系统的有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为DubWise的新型方法,旨在解决在视频配音中实现音视频同步的挑战性问题。具体来说,DubWise是一个基于多模态大型语言模型(LLM)的文本到语音(TTS)系统,能够控制合成语音的持续时间,使其与参考视频中说话者的口型动作相匹配,即使在所说的文本不同或使用不同的语言时也能实现。这项工作的核心贡献在于:
- 利用视频模态实现自回归(AR)大型语言模型(LLM)基础的多模态TTS中语音持续时间的可控性。
- 提出了一种新的持续时间损失函数,以实现对语音持续时间的进一步控制。
- 提出了一种跨模态注意力技术,将视频模态与传统的拼接策略相结合。
- 提出了一种轻量级、快速的训练策略,只训练模型中随机初始化的交叉注意力层和转置卷积层。
- 提出了利用VideoCLIP特征整合以理解全局场景上下文,以实现改进的零样本声音克隆能力。
总结来说,这篇论文试图解决的主要问题是在不同语言和不同文本的情况下,如何实现高质量的音视频同步,以提高配音的自然度和真实感。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与DubWise研究相关的工作:
基于LLM的高质量语音合成和声音克隆技术:
- GPT-2 [1-4] 和 XTTS [5,6] 等模型的出现使得基于LLM的高质量语音合成和声音克隆成为可能。
AI配音技术:
- 配音技术首先使用自动语音识别(ASR)服务生成源语言字幕,然后通过神经机器翻译(NMT)服务将这些字幕从源语言转换为目标语言,最后使用文本到语音(TTS)技术生成目标语言的语音信号 [8]。
时间尺度修改的信号处理算法:
- WSOLA等算法被用于改变合成语音的长度,以实现全局持续时间控制 [11-13]。
视频帧的上下采样方法:
- 通过插值方法对源视频帧进行下采样或上采样,以改变视频长度 [14]。
音素持续时间预测网络:
- 在TTS中使用音素持续时间预测网络,通过乘法因子调节合成语音的总持续时间 [15, 16]。
多模态TTS系统:
- 传统上,多模态TTS系统的目标是从视频模态控制情感或特定于说话者的信息 [17-21]。
自动视频配音(AVD):
- 从多个角度探讨了AVD问题,例如VideoDubber [9] 和 Chronopoulou 等人 [10] 提出的基于参考语音持续时间的翻译系统,以及SeamlessM4T [22] 在保持输入语音韵律的同时执行语音到语音翻译的模型。
多模态LLM:
- 提出了多种将图像和视频整合到基于文本的LLM中的方法,例如LLaVA [26] 和 Flamingo [27]。
图像和视频理解和讲故事:
- 其他方法专注于图像和视频理解以及讲故事,但DubWise通过利用视频输入引入了对GPT基础TTS系统的可控性。
这些相关工作涵盖了从语音合成、声音克隆到视频配音等多个方面,为DubWise的研究提供了理论和技术基础。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为DubWise的多模态大型语言模型(LLM)基础的文本到语音(TTS)系统来解决音视频同步的问题。以下是该系统的关键解决方案和步骤:
1. 利用跨模态注意力技术
DubWise在预训练的基于GPT的TTS中使用跨模态注意力技术,结合了以下三种类型的令牌:
- 文本的语言学令牌:从输入文本中提取。
- 说话者身份令牌:通过声音克隆网络获得。
- 视频令牌:通过提出的持续时间控制器网络学习获得。
2. 模型架构
DubWise的模型核心是一个预训练的、多语言的基于GPT2架构的TTS。该模型整合了以下组件:
- 语言学令牌:使用字节对编码器对输入文本进行编码。
- 说话者嵌入:使用说话者编码网络捕获说话者的独特特征,并由感知器网络处理以获得固定维度的表示。
- 视频CLIP特征:用于捕获整体场景和说话风格,同时训练感知器。
- 语言ID:使用基于one-hot向量的语言ID指定输入文本的语言。
3. 视频编码器
给定一个源语言视频,DubWise通过以下步骤提取唇部特征:
- 唇部区域提取:从源视频中裁剪唇部区域。
- 唇部特征提取:使用唇读模型提取唇部表示特征。
4. 视频特征整合
DubWise探索了两种将视频特征整合到TTS系统中的方法:
- 方法一:将视频特征与说话者嵌入和文本连接成一个单一的提示输入到GPT模型中。
- 方法二:在LLM架构内引入跨注意力层,直接关注视频特征。
5. 损失函数
模型的损失函数包括:
- 音频令牌的交叉熵损失(CEaudio)。
- 缩放的文本令牌损失(CEtext)。
- 缩放的持续时间损失(duration loss)。
6. HiFi-GAN声码器
使用基于HiFi-GAN的声码器从GPT输出的潜在表示中提取音频。
7. 实验和评估
论文通过在Lip2Wav-Chemistry和LRS2数据集上的实验来展示所提方法的有效性,并与现有技术(SOTA)方法进行比较,评估指标包括持续时间控制、语音清晰度和唇部同步误差等。
总结来说,DubWise通过结合先进的TTS技术和跨模态学习,实现了对合成语音持续时间的精确控制,使其能够与视频中的口型动作相匹配,即使在不同语言或不同文本的情况下也能达到良好的同步效果。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
数据集
- Lip2Wav-Chemistry 数据集:这是一个单说话者、时长为9.2小时的YouTube讲座视频数据集。
- LRS2 数据集:这是一个多说话者、时长为29小时的YouTube剪辑数据集。
基线方法
- 与以下SOTA(State-of-the-Art)方法进行比较:
- FastSpeech2:通过音素进行全局持续时间控制。
- YourTTS:利用随机持续时间预测器。
- XTTS:基于GPT2的TTS模型,没有明确的持续时间控制能力。
- XTTS+WSOLA:使用Wave Similarity Overlap and Add算法调整XTTS生成语音的长度。
- HPMDubbing:一个多模态配音管道,用于相同文本场景。
评估指标
客观评估:
- 持续时间建模能力:使用合成语音与参考视频持续时间的比率(DR,理想值为1)和差异(DD,理想值为0)。
- 语音清晰度和TTS性能:计算词错误率(WER)和字符错误率(CER)。
- 语音对口型动作的对齐(唇同步):使用唇同步误差-置信度(LSE-C)和唇同步误差-距离(LSE-D)进行评估。
- 音视频时间偏移(AV-Offset):使用预训练的SyncNet模型进行测量。
主观评估:
- 通过Mean Opinion Score(MOS)对不同方法生成的语音样本的整体质量和清晰度进行评分。
实验场景
- 相同文本条件:输入与参考视频中相同的文本,以合成音频样本。
- 不同文本条件:使用与视频中不同的文本合成音频样本,改变句子结构±50%的词数。
- 跨语言条件:使用印地语文本和英语参考视频控制生成音频的持续时间。
实验结果
- 在相同文本条件下,DubWise在DR和DD上接近真实值,并且在WER和CER上优于其他基线方法。
- 在不同文本条件下,DubWise同样显示出较低的WER和CER,并具有合理的持续时间比率。
- 在跨语言条件下,DubWise保持语音清晰度和质量,同时最小化持续时间的差异。
多说话者能力演示
- 在LRS2数据集上评估相同文本和翻译后的印地语文本场景,并与基线XTTS模型比较持续时间控制能力。
消融实验
- 通过消融分析研究了DubWise模型的不同架构,包括将视频特征与GPT-TTS集成的不同方法,以及视频CLIP特征和持续时间损失的引入对性能的影响。
这些实验全面评估了DubWise方法在不同条件下的性能,并与现有技术进行了比较,验证了其在音视频同步方面的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 论文在最后一部分提出了一些未来可能的研究方向,以下是一些可以进一步探索的点:
改进全局持续时间控制能力:虽然DubWise在视频引导的语音持续时间控制方面取得了进展,但论文指出需要进一步改善全局持续时间控制能力,以及单词级别和短语级别的持续时间控制。
跨语言和跨文本场景的性能提升:尽管DubWise在跨语言和非平行文本场景下表现良好,但仍有改进空间,特别是在不同语言和文本的配音任务中。
提高声音克隆的自然度和多样性:研究如何进一步提升通过声音克隆技术生成的语音的自然度和多样性。
优化模型训练策略:探索更高效的模型训练方法,可能包括利用更大规模的数据集、改进的优化算法或正则化技术。
增强模型的鲁棒性和泛化能力:研究如何提高模型在面对不同说话风格、口音和噪声条件下的鲁棒性和泛化能力。
实时配音应用:探索DubWise在实时视频配音中的应用,这可能需要进一步降低模型的延迟和提高处理速度。
多模态信息融合:研究如何更有效地融合来自视频的视觉信息和语音信号,以实现更精确的音视频同步。
情感和韵律的控制:除了持续时间控制之外,探索如何在TTS系统中控制情感和韵律,以生成更具表现力的语音。
模型压缩和优化:研究模型压缩技术,以使DubWise模型更适合在资源受限的设备上部署。
用户交互和定制化:研究如何使DubWise系统更加用户友好,允许用户根据个人喜好调整语音输出的特性。
这些方向不仅可以推动DubWise技术的发展,还可能对整个多模态TTS和配音领域产生深远影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为DubWise的多模态大型语言模型(LLM)基础的文本到语音(TTS)系统,旨在解决视频配音中的音视频同步问题。以下是论文的主要内容总结:
1. 问题背景
- 配音中,目标语言的语音长度与源语言不匹配,导致音视频不同步,影响观看体验。
2. DubWise系统
- 核心:基于预训练的GPT模型,结合了文本、声音克隆网络和视频特征。
- 目标:控制合成语音的持续时间,使其与参考视频中的说话者口型对齐,即使在不同语言或不同文本的情况下。
3. 方法论
- 视频特征提取:使用唇读模型从视频中提取唇部特征。
- 跨模态注意力技术:结合视频特征、说话者身份和文本信息。
- 损失函数:包括音频令牌的交叉熵损失、文本令牌损失和持续时间损失。
4. 实验
- 在Lip2Wav-Chemistry和LRS2数据集上验证了DubWise的有效性。
- 与现有技术(SOTA)方法比较,包括FastSpeech2、YourTTS、XTTS、XTTS+WSOLA和HPMDubbing。
- 评估指标包括持续时间控制、语音清晰度(WER和CER)和唇同步误差(LSE-D和LSE-C)。
5. 结果
- DubWise在保持语音质量和清晰度的同时,实现了更好的唇同步和自然度。
- 在不同文本和跨语言场景下均优于或接近SOTA方法。
6. 未来工作
- 改进全局和局部(单词和短语级别)的持续时间控制。
- 提高声音克隆的自然度和多样性。
- 优化模型训练和提高鲁棒性。
总的来说,DubWise通过创新地融合多模态信息和跨模态注意力机制,在视频配音中实现了高质量的音视频同步,为多模态TTS领域提供了一个新的研究方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

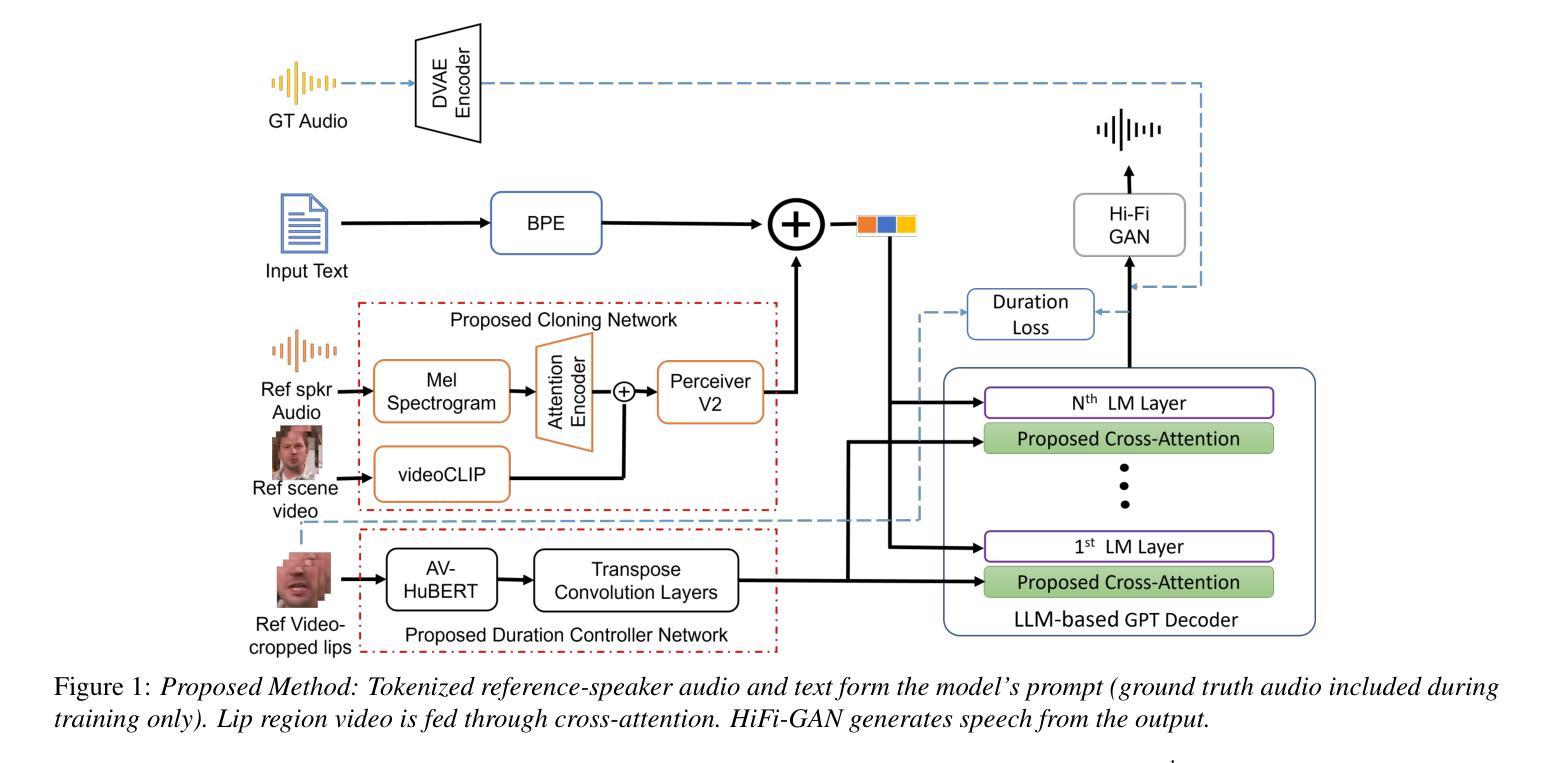

StyleDubber: Towards Multi-Scale Style Learning for Movie Dubbing
Authors:Gaoxiang Cong, Yuankai Qi, Liang Li, Amin Beheshti, Zhedong Zhang, Anton van den Hengel, Ming-Hsuan Yang, Chenggang Yan, Qingming Huang
Given a script, the challenge in Movie Dubbing (Visual Voice Cloning, V2C) is to generate speech that aligns well with the video in both time and emotion, based on the tone of a reference audio track. Existing state-of-the-art V2C models break the phonemes in the script according to the divisions between video frames, which solves the temporal alignment problem but leads to incomplete phoneme pronunciation and poor identity stability. To address this problem, we propose StyleDubber, which switches dubbing learning from the frame level to phoneme level. It contains three main components: (1) A multimodal style adaptor operating at the phoneme level to learn pronunciation style from the reference audio, and generate intermediate representations informed by the facial emotion presented in the video; (2) An utterance-level style learning module, which guides both the mel-spectrogram decoding and the refining processes from the intermediate embeddings to improve the overall style expression; And (3) a phoneme-guided lip aligner to maintain lip sync. Extensive experiments on two of the primary benchmarks, V2C and Grid, demonstrate the favorable performance of the proposed method as compared to the current stateof-the-art. The code will be made available at https://github.com/GalaxyCong/StyleDubber.
给定脚本,电影配音(视觉语音克隆,V2C)的挑战在于根据参考音频的语调生成与视频在时间、情感上对齐的语音。现有的最先进的V2C模型根据视频帧之间的划分来拆分脚本中的音素,这解决了时间对齐问题,但会导致音素发音不完整和身份稳定性差。为了解决这一问题,我们提出了StyleDubber,它将配音学习从帧级别切换到音素级别。它包含三个主要组件:(1)多模态风格适配器在音素级别操作,从参考音频中学习发音风格,并生成由视频中呈现的面部情感所启发的中间表示;(2)句子级别的风格学习模块,指导梅尔频谱图的解码和从中间嵌入到改进整体风格表达的精炼过程;(3)音素引导的唇部对齐器以维持唇部同步。在V2C和Grid两个主要基准测试上的大量实验表明,与当前最先进的水平相比,所提出的方法表现出优越的性能。代码将在https://github.com/GalaxyCong/StyleDubber上提供。
论文及项目相关链接
Summary
在视频配音任务中,同步语音和动作是一项挑战。当前的主流模型存在时间同步问题以及语音风格不一致的问题。本文提出StyleDubber模型,将学习配音的方式从帧级别转换为音素级别,包括三个主要部分:多模态风格适配器、话语级别的风格学习模块和音素引导唇同步器。实验证明StyleDubber在主要基准测试上表现优越。
Key Takeaways
- StyleDubber模型解决了现有视频配音模型中的时间同步问题和语音风格不一致问题。
- StyleDubber通过音素级别的学习来生成语音,提高了语音的完整性和身份稳定性。
- 多模态风格适配器能够从参考音频中学习发音风格,同时根据视频中的面部表情生成中间表示。
- 话语级别的风格学习模块指导了从中间嵌入到mel频谱图解码和精炼过程的风格表达。
- 音素引导的唇同步器保证了语音和动作的同步。
- StyleDubber在V2C和Grid等主要基准测试上的表现优于当前的主流模型。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是电影配音(Visual Voice Cloning, V2C)中的挑战,即如何根据参考音频的语调和情感,生成与视频在时间和情感上都匹配的语音。具体来说,论文针对以下几个关键问题提出了解决方案:
时间对齐问题:现有的V2C模型通过将脚本中的音素根据视频帧的划分进行对齐,虽然解决了时间对齐问题,但导致了音素发音不完整和身份稳定性差。
发音风格学习:为了更好地模仿参考音频中的发音风格,论文提出了在音素级别进行配音学习,而不是传统的帧级别。
情感表达与身份稳定性:论文提出了一种多模态风格适配器(MPA),在音素级别学习发音风格,并在生成中间表示时考虑视频中呈现的面部情感。
唇形同步:为了保持唇形与生成语音的同步,论文设计了一个音素引导的唇形对齐器(PLA)。
整体风格表达:在句子级别,论文引入了一个句子级别的风格学习模块(USL),以指导从中间嵌入到梅尔频谱图的解码和细化过程,以改善整体风格表达。
通过这些方法,论文提出的StyleDubber模型旨在提高语音生成的清晰度和与视频的时间对齐,同时在保持唇形同步的同时,模仿所需的个人风格。
Q: 有哪些相关研究?
A: 相关研究主要集中在以下几个领域:
文本到语音(TTS):这是一项长期存在的研究问题,近年来的模型在生成自然、流畅的语音方面取得了显著进步。例如,FastSpeech2通过显式建模变体信息来缓解文本到语音的多对一映射问题。Min等人通过基于情节的元学习和生成对抗网络来提高泛化能力。Le等人提出了一种非自回归流匹配模型,用于单语言或跨语言的零样本文本到语音合成。
视觉语音克隆(V2C):这是专门为解决电影配音问题而提出的方法。它要求将提供的文本转换为具有参考音频和无声视频中提取的声音和情感的语音。基于此,Cong等人提出了一种层次化的韵律配音模型,通过与唇部、面部和场景关联,专注于帧级别的韵律学习。Hassid等人通过将每个说话者归一化到单位范数并添加自回归解码器来匹配身份。Face-TTS直接从面部图像提取生物识别信息作为风格,使用基于分数的扩散模型来改进身份建模。
人类发音建模:这项研究旨在学习个体的发音变异,这对于生成可理解、自然和可接受的语音至关重要。与固定说话者表示相比,依赖于音素的方法可以更好地控制语音并描述更多的发音特征。Zhou等人通过参考注意力分析了局部发音内容与准音素级别的说话者嵌入之间的相关性。
这些研究为StyleDubber模型提供了理论基础和技术支持,特别是在情感建模、唇形同步和多模态风格学习方面。StyleDubber通过结合这些研究成果,提出了一种新的电影配音方法,旨在提高配音的自然度和风格适应性。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为StyleDubber的模型,通过以下几个关键组件来解决电影配音(Visual Voice Cloning, V2C)中的问题:
多模态风格适配器(Multimodal Phoneme-level Adaptor, MPA):
- 在音素级别学习发音风格,从参考音频中捕捉发音习惯。
- 结合文本音素和参考音频的交叉注意力机制,以及视觉情感,生成考虑所需情感的中间语音表示。
句子级别风格学习模块(Utterance-level Style Learning, USL):
- 在句子级别引导梅尔频谱图的解码和细化过程,以强化个人特征。
- 使用全局风格信息(如音色)来指导中间表示的解码和细化。
音素引导的唇形对齐器(Phoneme-guided Lip Aligner, PLA):
- 使用单调注意力学习唇动和文本音素嵌入之间的上下文对齐特征。
- 通过唇动-文本音素持续时间预测器,基于上下文对齐特征输出每个音素的持续时间。
训练策略:
- 通过优化所有损失的总和来进行端到端训练,包括风格一致性损失、情感分类损失、重建损失、单调对齐损失和持续时间损失。
实验验证:
- 在两个主要的V2C基准测试集(V2C-Animation和GRID)上进行广泛的实验,与当前最先进的方法进行比较,证明了所提出方法的有效性。
通过这些组件和策略,StyleDubber能够在保持唇形同步的同时,更好地模仿参考音频中的个人风格,包括发音细节和整体的情感表达。这使得生成的配音在清晰度和与视频的时间对齐方面都有显著提升。
Q: 论文做了哪些实验?
A: 论文在两个主要的V2C基准测试集上进行了实验,以验证StyleDubber模型的性能。这些实验包括:
V2C-Animation数据集:
- 这是目前唯一公开可用的电影配音多说话者数据集,包含了来自26部迪士尼卡通电影的153个不同角色,每个角色都有说话者身份和情感注释。
- 数据集包含10,217个视频片段,音频样本采样率为22,050Hz,16位。
GRID数据集:
- 这是一个基本的多说话者配音基准测试集,包含33个说话者,每人有1000个短英语样本。
- 所有参与者在无噪音的录音室中录制,背景屏幕统一。
- 训练集包含32,670个样本,测试集包含每个说话者的100个样本。
实验设置了三种不同的测试场景(Dub 1.0, Dub 2.0, Dub 3.0),以评估模型在不同条件下的性能:
- Dub 1.0(原始设置):使用测试集中的真实说话者作为参考音频。
- Dub 2.0(参考说话者设置):使用同一说话者来自其他电影片段的非真实音频作为参考音频。
- Dub 3.0(未见说话者设置):使用另一个数据集中未见过的说话者的音频作为参考音频。
实验使用了以下评估指标:
- 客观指标:包括说话者身份相似度(SPK-SIM)、情感准确度(EMO-ACC)、梅尔倒谱动态时间扭曲(MCD-DTW)、MCD-DTW-SL(考虑持续时间一致性的MCD-DTW)、词错误率(WER)。
- 主观指标:通过人类研究进行5分制的平均意见得分(MOS),评估自然度和相似度。
实验结果表明,StyleDubber在几乎所有指标上都优于当前最先进的方法,特别是在身份准确度(SPK-SIM)和发音准确性(WER)方面。此外,模型在情感表达和唇形同步方面也表现出色,生成的配音在自然度和相似度方面更接近真实人类语音。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的StyleDubber模型在电影配音任务上取得了显著的成果,但仍有一些潜在的研究方向可以进一步探索:
多语言支持:当前的研究主要集中在单一语言的配音任务上。未来的工作可以探索如何使模型能够处理多种语言,实现跨语言的配音。
视频内容的动态调整:目前,StyleDubber专注于生成音频,而不改变视频内容。研究可以扩展到如何根据生成的音频动态调整视频内容,例如,改变角色的口型和表情以更好地匹配配音。
情感和风格的细粒度控制:虽然StyleDubber在情感和风格表达方面取得了进步,但还可以进一步研究如何实现更精细的情感和风格控制,例如,模拟特定情感状态或模仿特定文化背景下的发音风格。
数据集的多样性和规模:为了提高模型的泛化能力,可以构建更多样化和大规模的数据集,包括不同年龄、性别、口音和情感表达的说话者。
实时配音系统:研究可以探索如何将StyleDubber集成到实时配音系统中,以便在直播、视频会议或实时翻译等场景中应用。
模型的可解释性和透明度:为了提高用户对生成配音的信任度,可以研究如何提高模型的可解释性,让用户理解模型是如何做出决策的。
伦理和法律问题:随着技术的发展,需要关注配音技术可能带来的伦理和法律问题,例如,如何防止滥用技术制作虚假视频,以及如何确保技术的使用符合道德和法律规定。
硬件优化:为了在资源受限的设备上部署StyleDubber,可以研究如何优化模型以减少计算资源需求,提高运行效率。
交互式配音工具:开发交互式工具,允许用户通过简单的界面调整配音的各个方面,如语速、音量和情感,以满足个性化需求。
跨模态学习:探索如何结合视觉、听觉和文本信息,以更全面地理解和生成配音,例如,利用场景分析来增强情感表达。
这些研究方向不仅有助于提高电影配音技术的性能,还可以推动语音合成和多模态学习领域的整体发展。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为StyleDubber的模型,旨在解决电影配音(Visual Voice Cloning, V2C)中的挑战。主要内容包括:
问题定义:电影配音任务要求生成与视频在时间和情感上都匹配的语音,同时保持与参考音频的音色和情感一致性。现有模型在帧级别进行对齐,导致发音不完整和身份稳定性差。
方法提出:StyleDubber通过以下三个主要组件来解决上述问题:
- 多模态风格适配器(MPA):在音素级别学习发音风格,并考虑视频中的面部情感。
- 句子级别风格学习模块(USL):在句子级别强化个人特征,指导梅尔频谱图的解码和细化。
- 音素引导的唇形对齐器(PLA):同步唇动和音素嵌入,保持唇形同步。
实验验证:在V2C-Animation和GRID两个主要基准测试集上进行了广泛的实验,与当前最先进的方法进行了比较。实验结果表明,StyleDubber在多个评价指标上表现优于现有方法,特别是在身份相似度(SPK-SIM)和发音准确性(WER)方面。
贡献总结:
- 提出了StyleDubber,一个在音素和句子级别模仿个人风格的配音模型,提高了语音生成的清晰度和与视频的时间对齐。
- 设计了多模态风格适配器,学习文本音素的发音风格,并在生成中间语音表示时考虑面部表情。
- 在句子级别学习整体风格,并将这种风格应用于梅尔频谱图的解码和细化过程。
- 实验结果证明了模型的有效性,并在相关领域设定了新的性能标准。
代码开源:论文承诺将StyleDubber的代码开源,以便研究社区可以进一步研究和改进。
局限性:尽管StyleDubber在电影配音任务上取得了显著成果,但论文也指出了其局限性,例如,目前仅专注于音频生成,未来工作可以探索如何使视频内容与更新后的音频相匹配。
伦理声明:论文讨论了V2C技术可能带来的伦理问题,如就业影响和生成假视频的风险,并提出了相应的应对措施。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Dubbing for Everyone: Data-Efficient Visual Dubbing using Neural Rendering Priors
Authors:Jack Saunders, Vinay Namboodiri
Visual dubbing is the process of generating lip motions of an actor in a video to synchronise with given audio. Recent advances have made progress towards this goal but have not been able to produce an approach suitable for mass adoption. Existing methods are split into either person-generic or person-specific models. Person-specific models produce results almost indistinguishable from reality but rely on long training times using large single-person datasets. Person-generic works have allowed for the visual dubbing of any video to any audio without further training, but these fail to capture the person-specific nuances and often suffer from visual artefacts. Our method, based on data-efficient neural rendering priors, overcomes the limitations of existing approaches. Our pipeline consists of learning a deferred neural rendering prior network and actor-specific adaptation using neural textures. This method allows for $\textbf{high-quality visual dubbing with just a few seconds of data}$, that enables video dubbing for any actor - from A-list celebrities to background actors. We show that we achieve state-of-the-art in terms of $\textbf{visual quality}$ and $\textbf{recognisability}$ both quantitatively, and qualitatively through two user studies. Our prior learning and adaptation method $\textbf{generalises to limited data}$ better and is more $\textbf{scalable}$ than existing person-specific models. Our experiments on real-world, limited data scenarios find that our model is preferred over all others. The project page may be found at https://dubbingforeveryone.github.io/
视频配音是对视频中演员的唇部动作进行生成,以与给定的音频同步的过程。最近的进步已经朝着这个目标取得了一些进展,但尚未能够开发出适合大规模采用的方法。现有方法分为人物通用型或个人特定模型。个人特定模型产生的结果几乎与真实情况无法区分,但它们依赖于使用大型单人数据集的长时间训练。人物通用方法已经实现了任何视频到任何音频的视觉配音,无需进一步训练,但这些方法无法捕捉人物特定的细微差别,并且经常受到视觉伪影的困扰。我们的方法基于高效神经网络渲染先验,克服了现有方法的局限性。我们的管道包括学习延迟神经网络渲染先验网络和使用神经网络纹理进行演员特定适配。这种方法只需几秒钟的数据即可实现高质量的视觉配音,使得任何演员的视频配音成为可能——无论是顶级名人还是背景演员。我们通过两项用户研究在视觉质量和可识别性方面实现了最先进的水平,并且从数量和质量上均表现出色。我们的先验学习和适配方法更适用于有限数据并更具可扩展性,优于现有的个人特定模型。我们在真实世界有限数据场景的实验发现,我们的模型比其他模型更受欢迎。项目页面可在https://dubbingforeveryone.github.io/找到。
论文及项目相关链接
Summary
本文介绍了视觉配音技术的新进展。传统的视觉配音方法分为针对特定人的模型和通用的模型,分别存在训练时间长和缺乏个性化等缺点。本研究提出了一种基于数据高效神经网络渲染先验的方法,通过学习和适应演员特定的神经网络纹理,实现了高质量的视频配音。该方法只需几秒钟的数据就能为任何演员进行高质量视觉配音,无论是知名明星还是背景角色。本研究在视觉质量和可识别性方面达到领先水平,并通过两项用户研究进行了定量和定性的验证。此外,该方法在有限数据的场景下具有良好的泛化能力和可扩展性。
Key Takeaways
- 视觉配音技术旨在生成与给定音频同步的演员唇部动作。
- 现有方法分为针对特定人的模型和通用的模型,但都存在局限性。
- 本研究提出了一种基于数据高效神经网络渲染先验的方法,实现了高质量的视频配音。
- 该方法只需几秒钟的数据就能为任何演员进行视觉配音。
- 研究在视觉质量和可识别性方面达到领先水平,并通过用户研究进行了验证。
- 该方法在有限数据的场景下具有良好的泛化能力和可扩展性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是视频内容的高质量视觉配音(Visual Dubbing),即将视频中演员的嘴唇动作与新的音频同步,以适应不同语言的观众。现有的视觉配音方法存在一些局限性:
人特异模型(Person-specific models):这些模型针对特定个体进行训练,能够产生几乎与现实无法区分的结果,但需要使用大量单个个体的数据集进行长时间训练。
人通用模型(Person-generic models):这些模型可以在不需要额外训练的情况下对任何视频和音频进行视觉配音,但它们无法捕捉到个体特有的细节,并且常常出现视觉伪影。
为了克服这些限制,论文提出了一种基于数据高效神经渲染先验(Data-Efficient Neural Rendering Priors)的方法,该方法结合了人通用和人特异模型的优点,允许仅使用几秒钟的数据就能为任何演员(从A-list明星到背景演员)进行高质量、可识别和可扩展的视频配音。
Q: 有哪些相关研究?
A: 相关研究主要分为两类:人通用模型(Person-generic Models)和人特异模型(Person-specific Models)。
人通用模型
人通用模型能够在零次拍摄的情况下对任何新人和任何音频进行视觉配音。这些方法通常是2D基础的,并且可以分为以下几类:
基于专家判别器的方法:使用编码器-解码器模型从音频预测帧,并使用同一人的随机参考帧。这些方法结合对抗训练和专家Syncnet,预测视频和音频是否同步。
基于流的方法:这些模型通过估计运动(使用关键点或像素级流)来变形参考图像。这些模型仅使用单个参考帧来编码身份,这在捕捉身份的外观或说话风格方面存在显著问题。
人特异模型
人特异模型针对每个人进行训练,通常在控制条件下进行。这些模型通常比人通用模型质量更高,但不能为除训练对象之外的任何人产生结果。人特异模型通常使用某种形式的3D监督来改善结果。这些方法包括:
基于3D可变形模型(3D Morphable Model, 3DMM)的方法:3DMM允许姿势、光照、形状和纹理保持不变,仅改变面部表情。
基于隐式3D几何的方法:使用神经辐射场(Neural Radiance Fields, NeRFs)进行头部生成。音频驱动的模型将NeRFs与音频条件化,以产生自由视点渲染。
这些研究在方法论上有所不同,但都具有一些共同特点:它们都能产生非常高质量的结果,但需要大量的数据要求,从大约15秒到超过10分钟不等。相比之下,本文提出的方法能够使用仅4秒的训练数据达到类似的质量,这得益于人通用先验网络的训练和人特异适应。
Q: 论文如何解决这个问题?
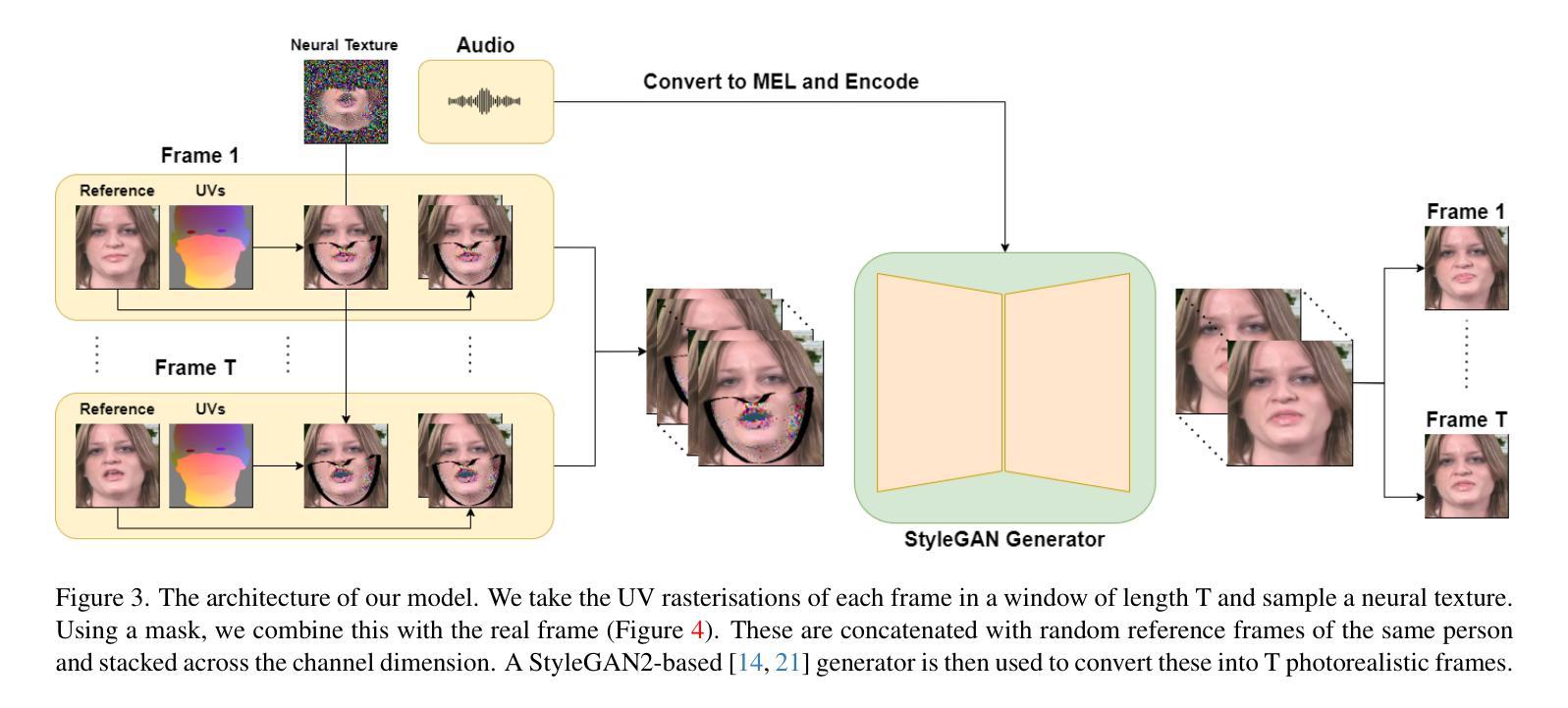
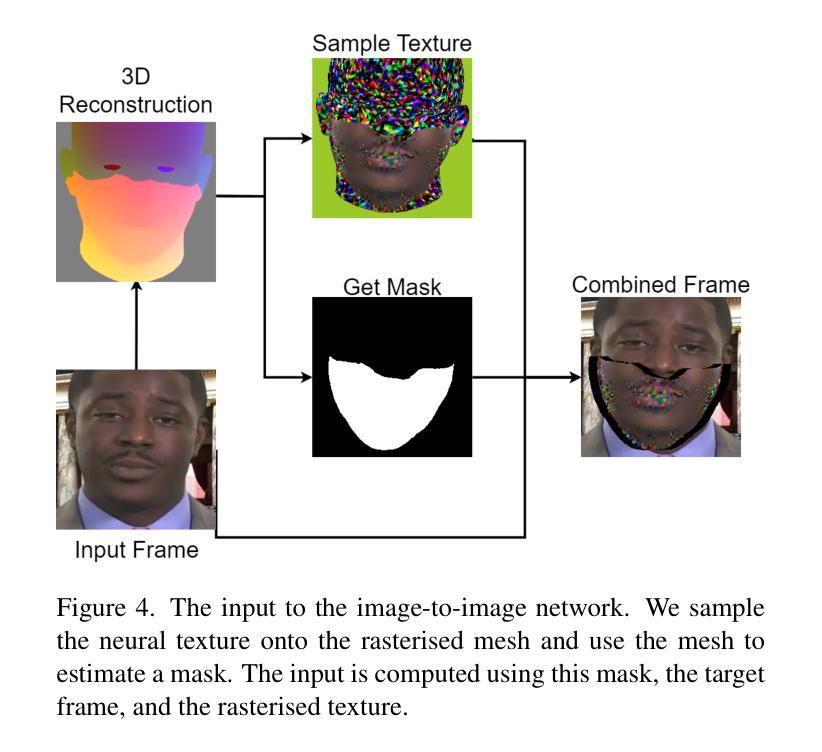
A: 论文提出了一种名为“Dubbing for Everyone”的方法,该方法结合了人通用(Person-generic)和人特异(Person-specific)模型的优点,以实现高质量、可识别、可扩展的视频配音。以下是该方法的关键组成部分:
人通用先验网络(Person-generic Prior Network):通过在多个身份上训练一个先验网络,使得模型能够泛化到新的个体。这个网络学习到的先验知识允许在有限的数据下进行有效的配音。
人特异适应(Actor-specific Adaptation):通过神经纹理(Neural Textures)对新个体进行适应,使得模型能够捕捉到个体特有的细节,从而产生高质量的配音。
多阶段方法(Multi-stage Approach):将视觉配音任务分为音频到唇部动作(Audio-to-lip-motion)和视频生成(Video Generation)两个阶段。这允许模型在每个个体的基础上明确地捕捉到独特的动作和外观。
预处理(Preprocessing):包括对视频帧进行裁剪以聚焦于脸部区域,并进行单目重建以获取参数化的3D脸部表示。
语音驱动动画模型(Audio-driven Animation Model):使用现有的语音驱动动画模型(如Imitator)来控制3D模型并改变视频中的唇部动作。
后处理(Post-processing):为了提高生成视频的质量,提出了一种后处理算法来移除生成视频中围绕边界的伪影。
通过这种方法,论文展示了在视觉质量、可识别性和训练速度方面达到或超过现有技术的状态。此外,该方法在少量数据情况下表现良好,并且能够适应新的个体,这使得它在实际应用中更具吸引力。
Q: 论文做了哪些实验?
A: 论文进行了一系列的实验来验证所提出的方法在视觉质量、可识别性、训练速度和对少量数据的鲁棒性方面的表现。以下是主要的实验内容:
与现有技术的比较:在两种数据量设置下(100帧和1000帧)与现有的人通用和人特异模型进行比较。使用定量指标(如FID、PSNR、SSIM)和用户评分来评估视觉质量、唇同步和个性化特征。
用户研究:设计了一个用户研究来模拟真实场景,即在有限数据下改变唇部动作以匹配配音音频。使用15-20秒的政客演讲视频,并与最高质量的人通用和人特异模型进行比较。通过强制选择实验来评估用户偏好。
消融研究(Ablation Study):进行了消融研究来验证后处理步骤和混合训练策略对模型性能的影响。在100帧的数据设置下评估这些组件对多个指标的影响。
训练速度:比较了所提出的方法与从头开始训练的基线模型在训练速度上的差异。记录了达到特定PSNR值所需的训练迭代次数。
数据集大小的影响:研究了训练数据集大小对模型性能的影响。比较了使用先验网络的方法与从头开始训练的基线模型在10秒视频剪辑上的表现。
伦理讨论:论文还包含了对所提出技术可能带来的伦理问题的讨论,特别是关于潜在的误用,如制造虚假信息和诽谤。
这些实验旨在全面评估所提出方法的有效性和实用性,并与现有的视觉配音技术进行比较。
Q: 有什么可以进一步探索的点?
A: 论文中提到了一些可以进一步探索的点,包括:
改进边界伪影:论文中提到,虽然后处理步骤可以减轻面部与背景之间的边界伪影,但并未完全消除。未来的工作可以探索首先将背景从人物中分割出来,仅在前景上训练模型,然后将结果合成,以解决这个问题。
加速单目重建:论文指出,单目重建阶段依赖于通过可微渲染器进行优化,速度较慢。未来的研究可以探索实时运行的时序回归模型,以提高重建速度。
更多样化的数据集:论文使用的HDTF数据集存在一定的偏见,特别是对白人美国人的偏见,以及只包含英语。未来的工作可以利用更多样化的数据集来训练模型,以提高模型的泛化能力。
深度伪造检测和水印技术:鉴于深度伪造技术的潜在滥用风险,未来的研究可以探索如何将隐形水印技术集成到模型中,以及如何提高深度伪造检测方法的准确性。
经济和文化价值:论文讨论了视觉配音技术在促进文化多样性和经济价值方面的潜在好处。未来的研究可以进一步量化这些好处,并探索如何最大化这些优势。
伦理和法律框架:随着技术的发展,可能需要建立新的伦理和法律框架来指导深度伪造技术的使用。未来的研究可以探讨如何制定这些框架,以确保技术的负责任使用。
模型的可解释性和透明度:为了提高用户对生成内容的信任,未来的研究可以探索如何提高模型的可解释性和透明度,让用户更好地理解模型是如何工作的。
模型的泛化能力:尽管论文中的方法在有限数据下表现良好,但仍然可以进一步研究如何提高模型在更广泛和多样化的数据分布上的泛化能力。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为“Dubbing for Everyone”的新方法,用于实现数据高效的视觉配音。这种方法结合了人通用和人特异模型的优点,能够在有限数据下为任何演员生成高质量的视觉配音。以下是论文的主要内容总结:
目标:
- 提供一种高质量、可识别、可扩展且通用的视频配音方法。
方法概述:
- 使用一个在多个身份上训练的先验网络(Deferred Neural Rendering Prior Network),以实现泛化。
- 通过神经纹理对新演员进行适应,以产生高质量的配音。
- 将视觉配音任务分为音频到唇部动作和视频生成两个阶段,以捕捉个体特有的动作和外观。
关键技术:
- 使用FLAME模型进行单目重建,以获得3D脸部表示。
- 采用StyleGAN2架构的图像到图像网络进行视频生成。
- 使用Imitator模型进行语音驱动的动画,以改变视频中的唇部动作。
实验结果:
- 在视觉质量、唇同步和个性化特征方面,与现有技术相比,该方法在定量和定性评估中均表现出色。
- 在少量数据(如100帧)的训练情况下,该方法比现有人特异模型快一个数量级。
- 用户研究显示,用户更喜欢该方法,尤其是在有限数据的情况下。
局限性与未来工作:
- 存在面部与背景边界的伪影问题,未来可能通过背景分割和前景训练来解决。
- 单目重建阶段速度较慢,未来可以探索实时时序回归模型。
- 需要更多样化的数据集来训练模型,以提高泛化能力。
伦理考虑:
- 论文强调了管理与深度伪造技术相关潜在危害的重要性,并在补充材料中包含了完整的伦理讨论。
结论:
- 提出的方法在多个评估指标上达到了最先进的水平,并且训练速度更快,数据需求更少,适用于少量数据场景。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

ANIM-400K: A Large-Scale Dataset for Automated End-To-End Dubbing of Video
Authors:Kevin Cai, Chonghua Liu, David M. Chan
The Internet’s wealth of content, with up to 60% published in English, starkly contrasts the global population, where only 18.8% are English speakers, and just 5.1% consider it their native language, leading to disparities in online information access. Unfortunately, automated processes for dubbing of video - replacing the audio track of a video with a translated alternative - remains a complex and challenging task due to pipelines, necessitating precise timing, facial movement synchronization, and prosody matching. While end-to-end dubbing offers a solution, data scarcity continues to impede the progress of both end-to-end and pipeline-based methods. In this work, we introduce Anim-400K, a comprehensive dataset of over 425K aligned animated video segments in Japanese and English supporting various video-related tasks, including automated dubbing, simultaneous translation, guided video summarization, and genre/theme/style classification. Our dataset is made publicly available for research purposes at https://github.com/davidmchan/Anim400K.
互联网的丰富内容,高达60%的内容以英语发布,这与全球人口形成鲜明对比,其中只有18.8%的人会说英语,仅有5.1%的人将其视为母语,导致在线信息访问存在差距。不幸的是,由于管道需求精确的时间、面部动作同步和语调匹配,视频自动配音(即用翻译后的音频替换视频的音频轨道)仍然是一个复杂且具有挑战性的任务。虽然端到端配音提供了一种解决方案,但数据稀缺继续阻碍端到端和基于管道的方法的进步。在这项工作中,我们介绍了Anim-400K,这是一个包含超过42.5万日语和英语对齐动画视频片段的综合数据集,支持各种视频相关任务,包括自动配音、即时翻译、指导性视频摘要和流派/主题/风格分类。我们的数据集已公开发布供研究使用,网址为:https://github.com/davidmchan/Anim400K。
论文及项目相关链接
PDF To appear in ICASSP 2024
Summary:
互联网内容丰富,但英语内容占比高达60%,与全球只有18.8%的人说英语、仅5.1%的人将其作为母语的情况形成鲜明对比,导致在线信息访问存在差距。自动视频配音(即将视频的音频轨道替换为翻译后的内容)仍然是一个复杂的任务,需要精确的时间控制、面部动作同步和语调匹配。尽管端到端的配音方法提供了一种解决方案,但数据稀缺仍然阻碍了端到端和基于管道的方法的进展。本研究介绍了Anim-400K数据集,包含超过42.5万个对齐的日语和英语动画视频片段,支持包括自动配音在内的多种视频任务。数据集已公开供研究使用。
Key Takeaways:
- 互联网内容以英语为主,但全球英语母语者比例较低,造成在线信息访问差距。
- 自动视频配音是一个复杂的任务,需要精确的时间控制、面部动作同步和语调匹配。
- 数据稀缺阻碍了自动配音方法的进展。
- Anim-400K数据集包含对齐的日语和英语动画视频片段,可用于多种视频任务,包括自动配音。
- 数据集已公开供研究使用,有助于推动相关领域的研究进展。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是自动化视频配音(dubbing)的挑战,特别是在缺乏大规模数据集支持的情况下,如何提高自动配音系统的性能。具体来说,论文提出了以下几个方面的问题和挑战:
全球互联网内容的英语主导性与全球英语使用者比例的不匹配:互联网上有高达60%的内容是英文的,但全球只有18.8%的人口使用英语,且仅有5.1%的人将英语作为母语。这种语言差异导致了信息获取的不平等。
自动化配音技术的复杂性:尽管字幕翻译可以通过自动语音识别(ASR)和机器翻译(MT)技术实现,但自动化配音仍然是一个复杂且具有挑战性的任务。它需要精确的时间同步、面部动作同步和韵律匹配。
数据稀缺性:自动化配音领域缺乏大规模的数据集来支持研究和开发,这限制了端到端(end-to-end)和基于流水线(pipeline-based)方法的进步。
为了解决这些问题,论文提出了一个新的大规模数据集Anim-400K,它包含超过425K个对齐的动画视频片段,支持多种与视频相关的任务,包括自动化配音、同声传译、引导视频摘要生成以及类型/主题/风格分类。这个数据集的发布旨在推动自动化配音技术的发展,并支持相关视频处理任务的研究。
Q: 有哪些相关研究?
A: 论文中提到了多项相关研究,这些研究主要集中在自动化配音(dubbing)技术的不同方面,包括但不限于:
自动化配音的复杂性:研究指出,自动化配音是一个复杂且具有挑战性的任务,因为它需要精确的时间同步、面部动作同步和韵律匹配。这些研究强调了在自动化配音过程中需要解决的关键技术问题。
端到端配音:一些研究提出了端到端配音的概念,即直接从原始源音频生成翻译后的音频,这种方法有潜力简化配音过程并提高质量。
自动化配音的数据处理:论文中提到了现有的一些数据集,如Heroes语料库,它们被用作自动化配音任务的训练和测试数据。然而,这些数据集通常规模较小,不足以支持深度神经网络的训练。
同声传译(Simultaneous Translation, ST)数据集:论文提到了如MuST-C和MuST-Cinema等数据集,它们通常包含大量的源语言音频,但缺少目标语言的音频,并且只包含文本翻译。
视频字幕和配音的质量评估:论文讨论了如何使用MUSHRA(MUlti Stimulus test with Hidden Reference and Anchor)方法来评估自动化配音的质量,这与传统的Mean Opinion Scoring(MOS)评分方法不同。
视频内容分析:论文还提到了与视频内容分析相关的研究,如视频总结、角色识别和描述、类型/主题/风格识别以及视频质量分析。
文化敏感性和伦理问题:论文最后讨论了使用自动化配音数据集时需要考虑的伦理问题,包括文化敏感性、版权合规性和用户隐私。
这些研究为自动化配音技术的发展提供了理论基础和实践指导,同时也指出了当前研究中存在的局限性和未来可能的研究方向。
Q: 论文如何解决这个问题?
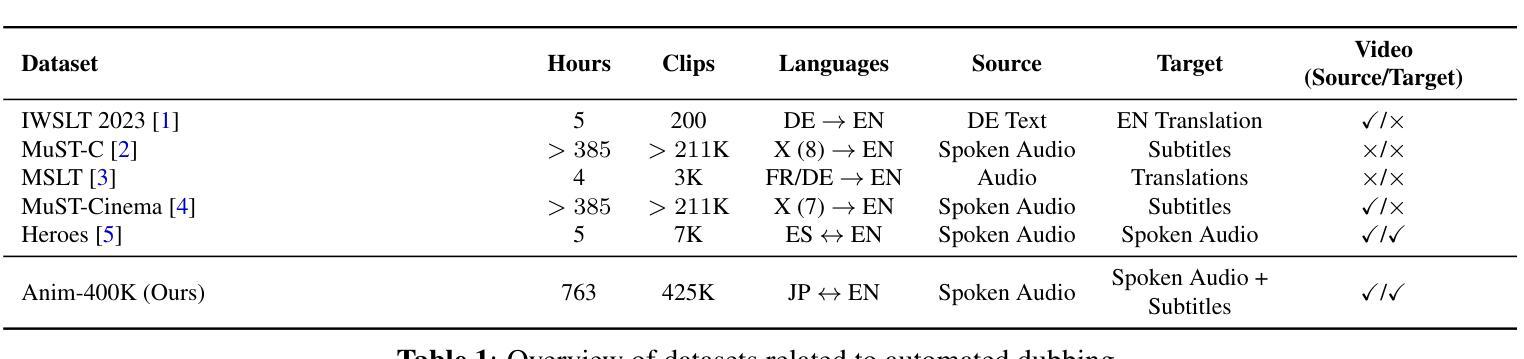
A: 论文通过引入一个新的大规模数据集Anim-400K来解决自动化视频配音领域中数据稀缺的问题。以下是论文提出的解决方案的关键步骤:
数据收集:从流行的动漫观看网站收集了大量公开可用的(广告支持)配音动画视频。这些视频包含原始的日语和英语音频轨道,以及日语音频轨道的英语字幕。
数据对齐:利用AWS Transcribe创建日语和英语版本的音频自动语音识别(ASR)转录本。由于视频对于每个音频轨道都是相同的,因此视频在全局时间上是同步的。通过递归合并ASR片段来生成本地片段对齐,确保所有片段总是对齐的,但可能存在噪声(包括ASR噪声和说话者噪声)。
元数据丰富:除了收集视觉信息外,还从流行来源收集了动漫视频元数据,并将其与收集的视频数据合并。这丰富了收集的数据,并为多个额外任务提供了支持。
标注:使用现成的说话人分割方法PyAnnote对每个片段进行说话人标注。这有助于理解每个片段的内容,并为配音方法提供了一个挑战,即正确隔离和复制多个并发说话者。
混合和清理:为了开发端到端配音库,生成的文本到语音音频需要与清晰的音频轨道混合以生成最终音频。除了日语和英语音频轨道外,还提供了一个“背景”音频轨道,该轨道是通过运行源分离工具从日语音频生成的。
基线创建:为了在数据集的测试部分上对自动化配音方法进行可重复和稳健的评估,论文提供了两个锚点轨道:一个是从EN配音收集的金标准音频,另一个是从简单流水线生成的基线自动配音。
支持的次要任务:Anim-400K数据集不仅支持自动化配音,还支持其他视频相关任务,如视频总结/预告片生成、角色识别和描述、类型/主题/风格识别、视频质量分析以及同声传译。
通过这些步骤,论文提供了一个大规模、全面对齐的数据集,旨在支持自动化配音研究,并促进相关视频处理任务的发展。
Q: 论文做了哪些实验?
A: 论文中并没有详细描述具体的实验步骤,但是提到了Anim-400K数据集支持多种视频相关任务,并且提供了一些实验性的基线(baselines)。以下是论文中提到的一些实验和评估方法:
MUSHRA评估:为了评估自动化配音方法,论文建议使用MUSHRA(MUlti Stimulus test with Hidden Reference and Anchor)方法。这种方法涉及向听众呈现一定数量的测试样本、一个参考的隐藏变化以及一个或多个锚点。为了实现一致的MUSHRA评估,论文提供了两个锚点轨道:一个是从EN配音收集的金标准音频,另一个是从简单流水线生成的基线自动配音。
基线自动配音:为了生成基线配音轨道,论文首先使用Spleeter将音频分割成歌声和伴奏。然后进行说话人分割,将所有多说话者日语片段分割成单说话者片段,以便在TTS过程中获得更好的性能。之后,对每个单独的日语说话者片段进行转录和翻译,以获取TTS的英文文本。最后,使用YourTTS进行TTS,并将这些歌声片段与伴奏音频重新组合。
数据集的局限性和伦理考虑:论文讨论了Anim-400K数据集可能存在的局限性,如数据偏见、代表性不足、文化敏感性、翻译质量和语音合成技术的限制。这些讨论虽然没有具体的实验步骤,但为使用数据集时的伦理和责任提供了指导。
支持的次要任务:论文概述了Anim-400K数据集支持的其他任务,如视频总结/预告片生成、角色识别和描述、类型/主题/风格识别、视频质量分析以及同声传译。这些任务可以通过数据集的丰富元数据来支持,尽管论文没有详细描述如何进行这些任务的实验。
总的来说,论文的重点在于介绍和描述Anim-400K数据集,以及它如何支持自动化配音和其他视频相关任务。具体的实验设计和结果分析在论文中没有详细说明。
Q: 有什么可以进一步探索的点?
A: 基于这篇论文的内容,有几个可以进一步探索的研究方向:
数据集的多样性和代表性:尽管Anim-400K是一个大规模的数据集,但它主要集中在动画内容上。未来的研究可以探索如何扩展数据集,以包含更广泛的视频类型,如电影、电视剧、纪录片等,以及不同的语言和文化背景。
端到端配音模型的改进:研究可以集中在开发新的机器学习模型,特别是深度学习模型,以提高自动化配音的质量。这可能包括改进时间同步、面部动作同步和韵律匹配的算法。
多模态学习:考虑到视频内容通常包含视觉和音频信息,研究可以探索如何利用多模态学习来提高配音的准确性和自然性。
用户反馈和评估:为了更好地理解自动化配音的效果,可以进行用户研究,收集用户对自动化配音视频的反馈。这可以帮助评估配音的质量,并指导未来的研究和开发。
文化敏感性和伦理问题:随着自动化配音技术的发展,需要进一步研究如何在尊重源材料的文化背景的同时进行配音。这可能涉及到开发新的工具和框架来确保配音的敏感性和伦理性。
版权和法律问题:随着自动化配音技术的应用,需要进一步探讨其可能引发的版权和法律问题,以及如何确保在遵守相关法律的前提下进行配音。
自动化配音的商业应用:研究可以探索自动化配音技术在不同行业中的潜在应用,如电影、电视、在线视频平台等,以及如何将这些技术商业化。
自动化配音的实时性:研究可以探索如何实现实时或近实时的自动化配音,这对于新闻报道、直播活动等场景尤其重要。
这些研究方向不仅有助于推动自动化配音技术的发展,还可以促进相关领域的研究,如多模态学习、用户研究、文化研究和法律研究。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了Anim-400K,这是一个大规模的、为自动化视频配音(dubbing)任务设计的对齐动画视频数据集。以下是论文的主要内容总结:
背景:
- 互联网上大部分内容是英文的,但全球只有一小部分人口以英语为母语,这导致了信息获取的不平等。
- 自动化视频配音是一个复杂任务,需要精确的时间同步、面部动作同步和韵律匹配。
- 现有的自动化配音方法依赖于复杂的流水线,缺乏大规模数据集支持。
Anim-400K数据集:
- 包含超过425K个对齐的日语和英语动画视频片段。
- 数据集规模是现有对齐配音视频数据集的40倍以上。
- 提供丰富的元数据,支持多种视频相关任务,如自动化配音、同声传译、引导视频摘要生成、类型/主题/风格分类等。
数据收集和处理:
- 从流行的动漫观看网站收集了公开可用的配音动画视频。
- 使用AWS Transcribe进行自动语音识别(ASR)转录,确保片段对齐。
- 提供了额外的“背景”音频轨道和混合比率,以便在生成最终音频时使用。
支持的次要任务:
- 视频总结/预告片生成:包含3.5K个人类生成的简短视频预告片描述。
- 角色识别和描述:收集了1828个角色的描述和7516张静态图像。
- 类型/主题/风格识别:为每个动画系列标记了至少一种类型和多达44个主题。
- 视频质量分析:收集了节目和剧集级别的质量指标。
- 同声传译:包含与音频片段重叠的英语字幕。
局限性和伦理问题:
- 数据集中可能存在偏见,可能无法完全捕捉动画行业的多样性。
- 自动化配音依赖于机器翻译和语音合成技术,可能无法达到人类翻译和配音团队的标准。
- 使用数据集时需考虑文化敏感性、版权合规性和用户隐私。
结论:
- Anim-400K为自动化配音提供了一个重要的资源,同时也支持其他视频相关任务。
- 在探索自动化配音的潜力时,应负责任地开发和考虑伦理问题,确保文化敏感性和翻译质量。
论文通过提供Anim-400K数据集,为自动化配音技术的研究和开发提供了新的机遇,同时也强调了在使用此类大规模数据集时需要考虑的伦理和实践限制。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

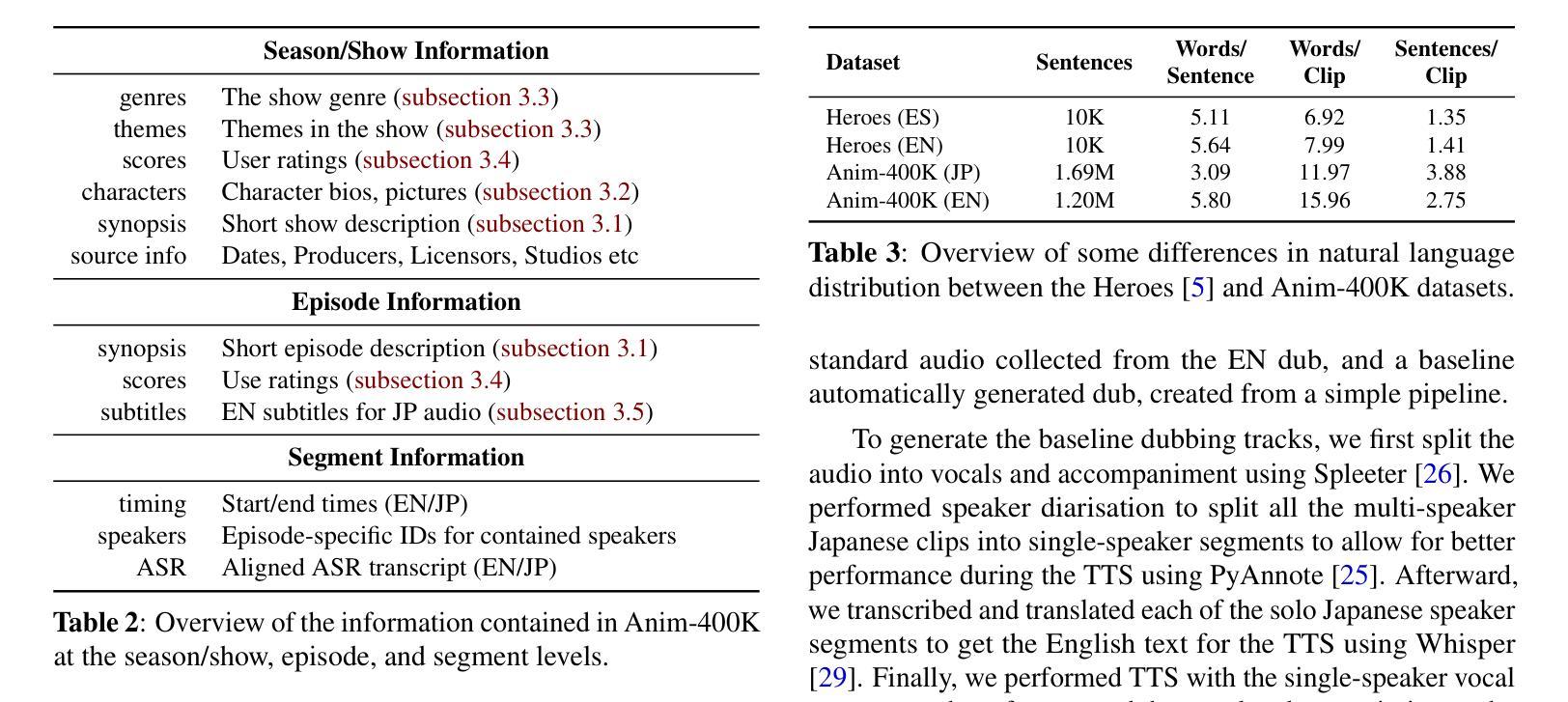
DiffDub: Person-generic Visual Dubbing Using Inpainting Renderer with Diffusion Auto-encoder
Authors:Tao Liu, Chenpeng Du, Shuai Fan, Feilong Chen, Kai Yu
Generating high-quality and person-generic visual dubbing remains a challenge. Recent innovation has seen the advent of a two-stage paradigm, decoupling the rendering and lip synchronization process facilitated by intermediate representation as a conduit. Still, previous methodologies rely on rough landmarks or are confined to a single speaker, thus limiting their performance. In this paper, we propose DiffDub: Diffusion-based dubbing. We first craft the Diffusion auto-encoder by an inpainting renderer incorporating a mask to delineate editable zones and unaltered regions. This allows for seamless filling of the lower-face region while preserving the remaining parts. Throughout our experiments, we encountered several challenges. Primarily, the semantic encoder lacks robustness, constricting its ability to capture high-level features. Besides, the modeling ignored facial positioning, causing mouth or nose jitters across frames. To tackle these issues, we employ versatile strategies, including data augmentation and supplementary eye guidance. Moreover, we encapsulated a conformer-based reference encoder and motion generator fortified by a cross-attention mechanism. This enables our model to learn person-specific textures with varying references and reduces reliance on paired audio-visual data. Our rigorous experiments comprehensively highlight that our ground-breaking approach outpaces existing methods with considerable margins and delivers seamless, intelligible videos in person-generic and multilingual scenarios.
生成高质量、通用的人物视频配音仍然是一个挑战。最近的创新出现了一个两阶段范式,通过中间表示作为媒介,实现了渲染和唇部同步过程的分离。然而,之前的方法依赖于粗略的标记点,或者仅限于单一说话人,从而限制了其性能。在本文中,我们提出了基于扩散的配音方法:DiffDub。我们首先通过结合掩膜技术构建扩散自编码器,创建了一种填充渲染器,这允许无缝填充下半脸区域,同时保持其余部分不变。在我们的实验中,我们遇到了几个挑战。首先,语义编码器缺乏稳健性,限制了其捕捉高级特征的能力。此外,建模过程忽略了面部定位,导致嘴巴或鼻子在不同帧之间的抖动。为了解决这些问题,我们采用了多种策略,包括数据增强和额外的眼睛引导。此外,我们采用基于conformer的参考编码器和运动生成器,并辅以跨注意力机制。这使得我们的模型能够学习不同参考下的个人特定纹理,并减少对配对音视频数据的依赖。我们的严格实验全面证明,我们的突破性方法以显著的优势超越了现有方法,并在人物通用和多语言场景中生成了无缝、可理解的视频。
论文及项目相关链接
PDF 5 pages, Accepted to ICASSP 2024
Summary:
该文提出了一种基于扩散模型的自动配音方法DiffDub,通过构建扩散自编码器,结合掩码技术实现面部下半部分区域的流畅填充,同时保留其他部分。针对语义编码器缺乏鲁棒性和面部定位问题,采用数据增强和额外的眼动引导策略。此外,还引入了基于转换器的参考编码器和动作生成器,通过交叉注意力机制减少了对配对音视频数据的依赖,并在多语种场景下实现了流畅、可理解的视频生成。
Key Takeaways:
- 提出了基于扩散模型的自动配音方法DiffDub,解决了高质量、通用性视觉配音的挑战。
- 通过构建扩散自编码器,结合掩码技术实现面部下半部分区域的编辑。
- 针对语义编码器缺乏鲁棒性和面部定位问题,采取了数据增强和额外的眼动引导策略。
- 引入了基于转换器的参考编码器和动作生成器,减少了对配对音视频数据的依赖。
- 该方法支持多语种场景下的流畅、可理解的视频生成。
- 实验结果证明,该方法在性能上大幅度超越了现有方法。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是生成高质量且人物通用(person-generic)的视觉配音(visual dubbing)。具体来说,这项任务需要将源视频中的下面部运动与相应的驱动音频进行细致对齐,同时保留源视频中的原始身份、头部姿态和背景。这项任务在需要修改或替换音频内容(例如翻译目的)时变得尤为重要。面临的挑战包括保持高视觉质量、确保时间一致性(temporal consistency)和完善唇部同步(lip synchronization)。
Q: 有哪些相关研究?
A: 论文中提到了以下与视觉配音相关的研究工作:
**Wav2Lip [1]**:这是一个通过对抗方法训练的自动编码器,用于语音到唇部生成的研究。
**PCAVS [16]**:介绍了一种可控姿态的音频-视觉人脸生成方法。
IP-LAP [23] 和 **DAE-Talker [13]**:代表两阶段方法。IP-LAP 使用地标(landmark),而 DAE-Talker 使用潜在代码(latent code)。
**Deep Learning for Visual Speech Analysis: A Survey [5]**:提供了深度学习在视觉语音分析领域的综述。
**Diffusion Models in Talking Head Synthesis [7, 8, 9, 10, 11, 12, 13]**:展示了扩散模型(Diffusion Denoising Probabilistic Model, DDPM)在人头合成领域的应用。
**Image Inpainting [14, 15]**:与视觉配音任务相似,图像修复(inpainting)研究关注于修复图像中的特定区域,同时保持其他部分不变。
**Transformer [17] 和 Conformer [18]**:这些模型在处理短音频剪辑方面表现出色,并且能够捕获全局和局部的面部运动交互。
**Faceformer [21], Improving Few-Shot Learning for Talking Face System with TTS Data Augmentation [22], Identity-Preserving Talking Face Generation with Landmark and Appearance Priors [23]**:这些研究分别提出了不同的方法来改进基于语音的面部动画生成。
这些研究构成了视觉配音领域的技术背景,并为本文提出的DiffDub方法提供了对比和参考。DiffDub通过结合扩散自编码器和Conformer模型,旨在提高视觉配音任务的性能,特别是在多语言和人物通用的场景中。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为DiffDub的方法来解决高质量和人物通用视觉配音的问题。DiffDub方法包括以下几个关键步骤:
1. 两阶段范式(Two-Stage Paradigm)
DiffDub采用了一个两阶段范式,将渲染和唇部同步过程解耦,通过中间表示作为桥梁。这种范式包括:
- 第一阶段:使用扩散自编码器的修复渲染器(Inpainting Renderer with Diffusion Auto-encoder)
- 第二阶段:视频序列生成(Video Sequence Generation)
2. 扩散自编码器(Diffusion Auto-encoder)
- 掩码条件(Masked Conditions):使用一个掩码来划分图像为两个部分,一部分是需要保留的信息(如身份、姿态和背景),另一部分是需要编辑的区域(主要是面部运动区域)。
- 语义编码器(Semantic Encoder):仅对面部区域进行编码,以确保仅传递面部运动信息。
- 图像增强(Image Augmentation):在训练阶段使用图像增强,以确保语义编码器学习到高级特征而非简单的模式。
3. 视频序列生成(Video Sequence Generation)
- 参考编码器(Reference Encoder)和运动生成器(Motion Generator):基于Conformer模型,允许输入长度变化,并能够捕获全局和局部的面部运动交互。
- 潜在代码(Latent Codes):使用语义潜在代码和音频潜在代码,而不是预定义的结构表示。
- 交叉注意力机制(Cross-Attention Mechanism):引入交叉注意力机制,以生成个性化的面部运动潜在代码。
4. 策略和优化
- 数据增强(Data Augmentation):增强模型对不同条件下面部特征的鲁棒性。
- 补充眼部指导(Supplementary Eye Guidance):通过包含眼部区域来提高鼻和嘴位置的稳定性。
- 减少对配对音视频数据的依赖(Reducing Dependence on Paired Audio-Visual Data):通过Conformer模型和交叉注意力机制,减少对大量配对音视频数据的需求。
5. 实验和评估
- 在HDTF数据集上进行了定量和定性评估,包括在少量样本和单样本设置下的性能测试。
- 使用峰值信噪比(PSNR)、结构相似性(SSIM)和学习感知图像补丁相似性(LPIPS)等指标来评估视觉质量。
- 使用唇同步误差距离(LSE-D)、唇同步误差置信度(LSE-C)和地标距离(LMD)等指标来评估同步性能。
通过这些方法,DiffDub旨在生成无缝、清晰且可理解的视频,同时在人物通用和多语言场景中表现出色。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估DiffDub方法的性能:
1. 实验设置(Experimental Setups)
- 数据集(Dataset):使用HDTF数据集,包含从YouTube收集的高分辨率真实世界人头视频。数据集总时长约为16小时,分为245个剪辑用于训练和68个剪辑用于测试。
- 模型细节(Model Details):扩散模型基于U-Net,语义潜在代码的维度为512。采用多种数据增强技术,包括水平翻转、颜色抖动、高斯模糊、位移、缩放和旋转。DDIM的时间步长T设置为20。使用预训练的Hubert-large模型作为现成的音频编码器。
- 评估指标(Evaluation Metric):使用峰值信噪比(PSNR)、结构相似性(SSIM)和学习感知图像补丁相似性(LPIPS)来量化生成图像与真实图像之间的相似度。对于同步性(SYNC),使用唇同步误差距离(LSE-D)、唇同步误差置信度(LSE-C)和地标距离(LMD)。
2. 方法比较(Method Comparison)
- 三种典型场景:重建(使用真实音频)、配音(使用替代对白或其他说话者的音频)和单样本(仅使用单个肖像照片合成结果)。
- 定量比较(Quantitative Comparison):记录在HDTF数据集上重建任务的定量结果,包括视觉质量(VQ)和同步性(SYNC)的指标。
- 定性比较(Qualitative Comparison):展示重建和配音任务的定性结果,突出显示生成的下面部和牙齿区域的清晰度,并展示与更长发音单元(如音节)的一致性。
3. 消融研究(Ablation Study)
- 四种消融实验:移除语义编码器输入中的眼部区域、停用第一阶段的数据增强、使用Mel特征代替加权和(weighted sum)、减少第二阶段使用的配对音视频数据量至原始数据的十分之一。
- 结果:这些消融实验的结果有助于评估提出的模型组件的有效性。
4. 用户研究(Subjective Evaluation)
- 用户研究:通过12名参与者对DiffDub方法在嘴部保真度(MF)、阅读可理解度(RI)、自然度(N)和跨语言性能(CL)方面的评分。
- 结果:用户研究结果表明DiffDub在各个方面均优于基线方法。
这些实验全面评估了DiffDub方法在视觉质量和唇部同步方面的表现,并与现有的最先进方法进行了比较。通过定量和定性的结果,论文证明了DiffDub方法的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文中提出的DiffDub方法在视觉配音任务中取得了显著的成果,但仍有一些可以进一步探索的点:
1. 模型泛化能力
- 跨数据集测试:在不同的数据集上测试DiffDub模型,以评估其在多样化数据上的表现和泛化能力。
- 多语言和方言支持:探索模型在处理不同语言和方言时的效果,特别是对于那些唇部运动模式差异较大的语言。
2. 模型鲁棒性
- 极端条件下的性能:测试模型在极端条件下(如低光照、高噪声、表情变化等)的性能。
- 对抗性攻击的鲁棒性:研究模型对于对抗性攻击的鲁棒性,并探索相应的防御机制。
3. 计算效率和实时性
- 模型压缩和加速:探索模型压缩和加速技术,以使DiffDub能够部署在资源受限的设备上,如移动设备或嵌入式系统。
- 并行化和硬件加速:研究如何利用GPU或其他专用硬件来加速模型的推理过程,实现实时或近实时的配音生成。
4. 交互式应用
- 交互式视频编辑:开发基于DiffDub的交互式视频编辑工具,允许用户实时调整音频和视频内容。
- 虚拟现实和增强现实集成:探索将DiffDub技术集成到虚拟现实(VR)或增强现实(AR)应用中,以创建更加逼真和互动的体验。
5. 生成内容的多样性和控制
- 风格迁移和个性化:研究如何控制生成视频的风格和表情,以适应不同的应用场景和用户需求。
- 细粒度控制:开发细粒度控制机制,允许用户对生成视频中的特定面部区域(如嘴唇、眼睛、眉毛)进行精确控制。
6. 伦理和社会影响
- 深度伪造检测:研究如何检测和防范使用DiffDub技术生成的深度伪造视频,以减少其潜在的负面影响。
- 用户隐私和数据安全:探讨在使用DiffDub技术时如何保护用户的隐私和数据安全,特别是在处理敏感信息时。
这些探索点不仅可以推动视觉配音技术的发展,还可以帮助解决实际应用中遇到的挑战,并确保技术的可持续发展。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为DiffDub的创新方法,旨在解决高质量且人物通用的视觉配音问题。以下是论文的主要内容总结:
1. 问题背景
- 生成与驱动音频精确对齐的下面部运动,同时保留源视频中的身份、头部姿态和背景,是一个挑战。这在需要修改或替换音频内容(如翻译)的场景中尤为重要。
2. 相关工作
- 论文回顾了使用生成对抗网络(GANs)和扩散模型(DDPM)的视觉配音方法,指出了现有方法在训练稳定性、模式崩溃和唇部同步方面的局限性。
3. DiffDub方法
- 两阶段范式:DiffDub采用了一个两阶段范式,包括使用扩散自编码器的修复渲染器和视频序列生成。
- 扩散自编码器:通过掩码条件生成可编辑区域的语义潜在代码,同时保留不变的部分。
- 视频序列生成:利用基于Conformer的参考编码器和运动生成器,从参考图像和驱动音频生成人物特定的合成视频。
4. 挑战与策略
- 语义编码器的鲁棒性:采用数据增强和补充眼部指导来增强语义编码器的鲁棒性。
- 面部定位问题:通过交叉注意力机制减少对配对音视频数据的依赖,并学习人物特定的纹理。
5. 实验
- 在HDTF数据集上进行了定量和定性评估,包括视觉质量(VQ)和同步性(SYNC)指标。
- 与现有方法(如Wav2Lip、PC-AVS、IP-LAP和DAE-Talker)进行了比较。
- 进行了消融研究和用户研究,证明了DiffDub方法的有效性和优越性。
6. 结论
- DiffDub方法无需针对特定人物进行微调,即可生成无缝、清晰且可理解的视频,适用于人物通用和多语言场景。
7. 未来工作
- 论文提出了一些未来研究方向,包括模型泛化能力、鲁棒性、计算效率、交互式应用、生成内容的多样性和控制,以及伦理和社会影响。
总体而言,DiffDub通过结合扩散模型和Conformer模型,在视觉配音任务中取得了显著的性能提升,为未来在该领域的研究提供了新的思路和方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


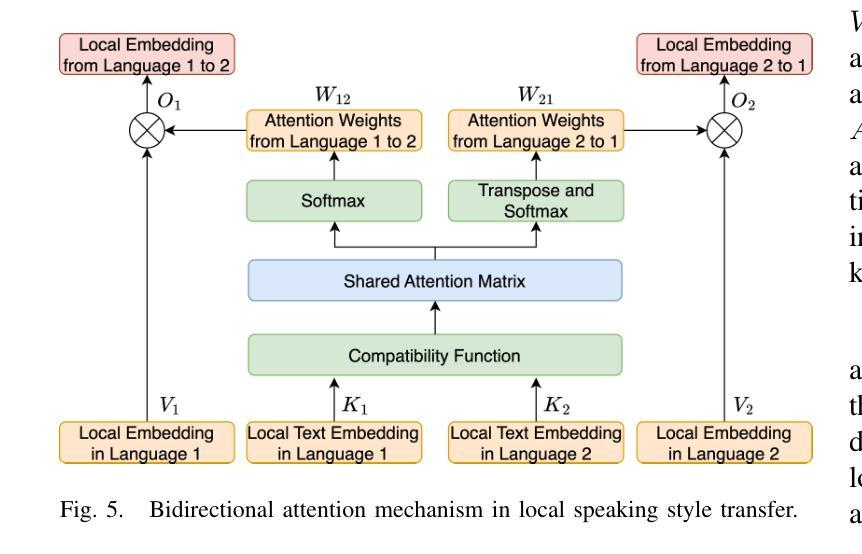
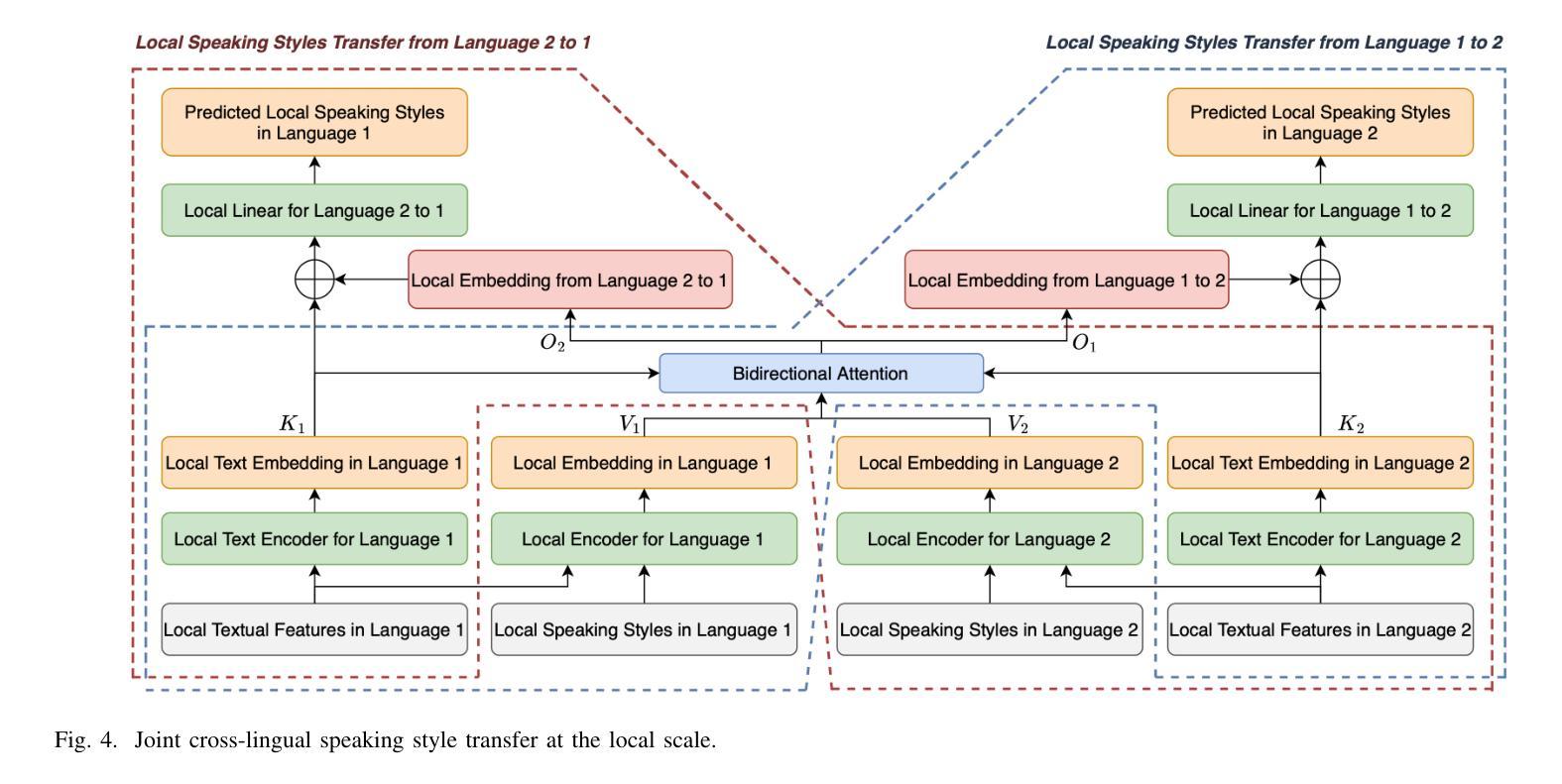
Joint Multi-scale Cross-lingual Speaking Style Transfer with Bidirectional Attention Mechanism for Automatic Dubbing
Authors:Jingbei Li, Sipan Li, Ping Chen, Luwen Zhang, Yi Meng, Zhiyong Wu, Helen Meng, Qiao Tian, Yuping Wang, Yuxuan Wang
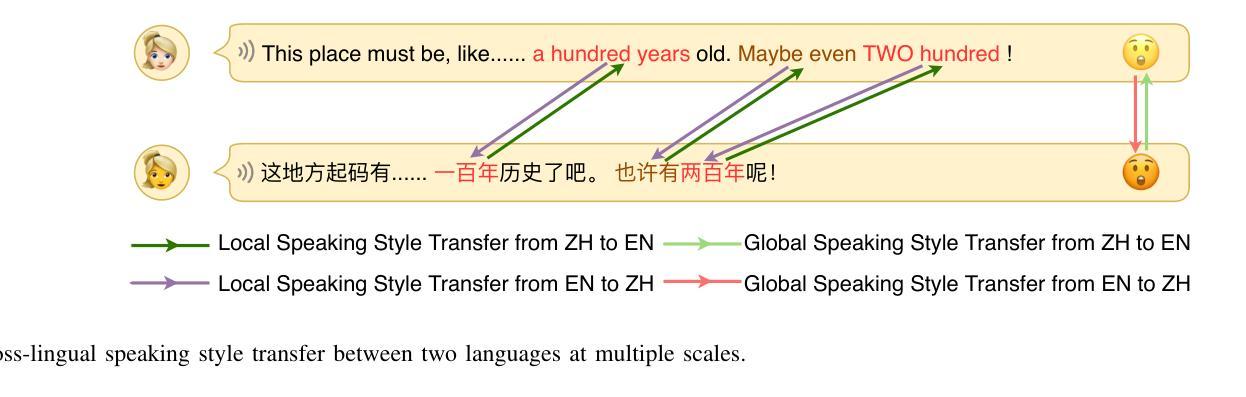
Automatic dubbing, which generates a corresponding version of the input speech in another language, could be widely utilized in many real-world scenarios such as video and game localization. In addition to synthesizing the translated scripts, automatic dubbing needs to further transfer the speaking style in the original language to the dubbed speeches to give audiences the impression that the characters are speaking in their native tongue. However, state-of-the-art automatic dubbing systems only model the transfer on duration and speaking rate, neglecting the other aspects in speaking style such as emotion, intonation and emphasis which are also crucial to fully perform the characters and speech understanding. In this paper, we propose a joint multi-scale cross-lingual speaking style transfer framework to simultaneously model the bidirectional speaking style transfer between languages at both global (i.e. utterance level) and local (i.e. word level) scales. The global and local speaking styles in each language are extracted and utilized to predicted the global and local speaking styles in the other language with an encoder-decoder framework for each direction and a shared bidirectional attention mechanism for both directions. A multi-scale speaking style enhanced FastSpeech 2 is then utilized to synthesize the predicted the global and local speaking styles to speech for each language. Experiment results demonstrate the effectiveness of our proposed framework, which outperforms a baseline with only duration transfer in both objective and subjective evaluations.
自动配音生成输入语音的另一种语言版本,可广泛应用于视频和游戏本地化等许多真实场景。除了合成翻译脚本外,自动配音还需要进一步将原始语言的发音风格转移到配音语音上,给观众留下角色在说他们母语的感觉。然而,最先进的自动配音系统只对持续时间和说话速度进行建模,忽视了说话风格的其他方面,如情感、音调和强调等也对完全呈现角色和语音理解至关重要。在本文中,我们提出了一个联合多尺度跨语言说话风格转移框架,以同时建模语言之间在全局(即句子水平)和局部(即单词水平)的双向说话风格转移。提取每种语言的全球和局部说话风格,并使用编码器-解码器框架和双向共享注意力机制来预测另一种语言的全球和局部说话风格。然后,利用多尺度说话风格增强的FastSpeech 2合成每种语言的预测全局和局部说话风格的语音。实验结果证明了我们提出的框架的有效性,该框架在客观和主观评估中都优于仅进行持续时间转移的基线方法。
论文及项目相关链接
PDF TASLP
Summary
自动配音技术在视频和游戏的本地化等领域有广泛应用。除了翻译文本外,自动配音还需将原说话风格转移到配音语言中,使用户产生身临其境的感觉。当前主流系统只关注语音持续时间和语速的风格转移,忽视了情感、语调等关键方面。本文提出一种联合多尺度跨语言说话风格转移框架,同时建模语言间的全局(如句子水平)和局部(如单词水平)说话风格转移。通过提取并利用每种语言的全球和局部说话风格,预测另一种语言的全球和局部说话风格,并利用多尺度说话风格增强的FastSpeech 2合成语音。实验结果表明,该框架在客观和主观评估中都优于仅基于持续时间转移的基线系统。
Key Takeaways
- 自动配音技术在视频和游戏的本地化领域有广泛应用。
- 除了翻译文本,自动配音还需考虑语音风格转移。
- 当前自动配音系统在风格转移上主要关注持续时间和语速,忽视了情感、语调等重要方面。
- 本文提出一种联合多尺度跨语言说话风格转移框架,包括全局和局部风格转移。
- 该框架利用编码器-解码器框架和双向注意机制来预测另一种语言的说话风格。
- 实验结果表明,该框架在客观和主观评估上表现优异。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决自动配音(Automatic dubbing)中的问题,即如何将输入语音中的说话风格(speaking style)转移到另一种语言的对应版本中。具体来说,这项工作关注以下几个关键问题:
多尺度跨语言说话风格转移(Multiscale Cross-lingual Speaking Style Transfer):除了考虑语音的持续时间和语速转移,论文还提出了一个框架,同时在全局尺度(即句子级别)和局部尺度(即单词级别)上对两种语言之间的双向说话风格进行建模和转移。
情感、语调和强调的传递:现有的自动配音系统通常只对语音的某些方面(如持续时间、语速)进行建模,而忽略了情感、语调和强调等其他同样重要的说话风格方面。这些风格对于全面理解角色和语言至关重要。
提高自动配音的自然度和表现力:通过更全面地模拟和优化两种语言之间的说话风格转移,论文旨在提高自动配音的自然度和表现力,使观众感觉到角色仿佛在使用他们的母语进行交流。
多任务学习:论文提出了一个多任务学习框架,联合优化两种语言之间的跨语言说话风格转移,以改善自动配音中的说话风格传递。
数据集的挑战:收集不同语言中意义和说话风格都平行的语音数据是一个挑战,论文通过从视频游戏中收集平行语音来解决这一问题,并基于这些数据来学习跨语言的说话风格转移模式。
综上所述,这篇论文的核心贡献在于提出了一个多尺度跨语言说话风格转移框架,以改善自动配音中的情感和语调传递,从而提高配音的自然度和表现力。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
A. Text-to-Speech Synthesis(文本到语音合成)
- 端到端TTS技术:传统的TTS系统通常包含复杂的流水线,而端到端TTS技术通过将传统TTS系统的各个组件集成到一个可训练的框架中,以减少错误累积并提供更稳健的合成语音。例如,Tacotron和FastSpeech等端到端TTS系统就是基于编码器-解码器结构,并利用注意力机制来生成原始语谱图。
B. Automatic Dubbing(自动配音)
- 基于韵律短语对齐的自动配音系统:这类系统通过提取两种语言之间韵律短语的映射关系,调整韵律短语的持续时间以匹配原始语言的持续时间。
- 基于隐马尔可夫模型(HMM)的韵律对齐算法:用于将配音语言的韵律短语与原始语音中的停顿相匹配,以提高配音的自然度。
C. 跨语言说话风格转移
- 全局风格标记(Global Style Token):用于表示整个话语中的说话风格属性,如情感和意图。
- 局部风格标记(Local Style Token):用于表示每个单词的说话风格属性,如强调、节奏和语调。
D. 其他相关技术
- 神经网络基础的对齐方法:例如,NeuFA(Neural Network-based Forced Aligner)用于学习文本和语音之间的双向信息映射。
- 多任务学习:用于联合优化跨语言说话风格转移的建模。
这些相关研究为自动配音领域提供了技术基础和理论支持,使得研究者能够开发出更自然、更具表现力的自动配音系统。论文提出的多尺度跨语言说话风格转移框架正是基于这些相关研究,进一步探索和改进自动配音技术。
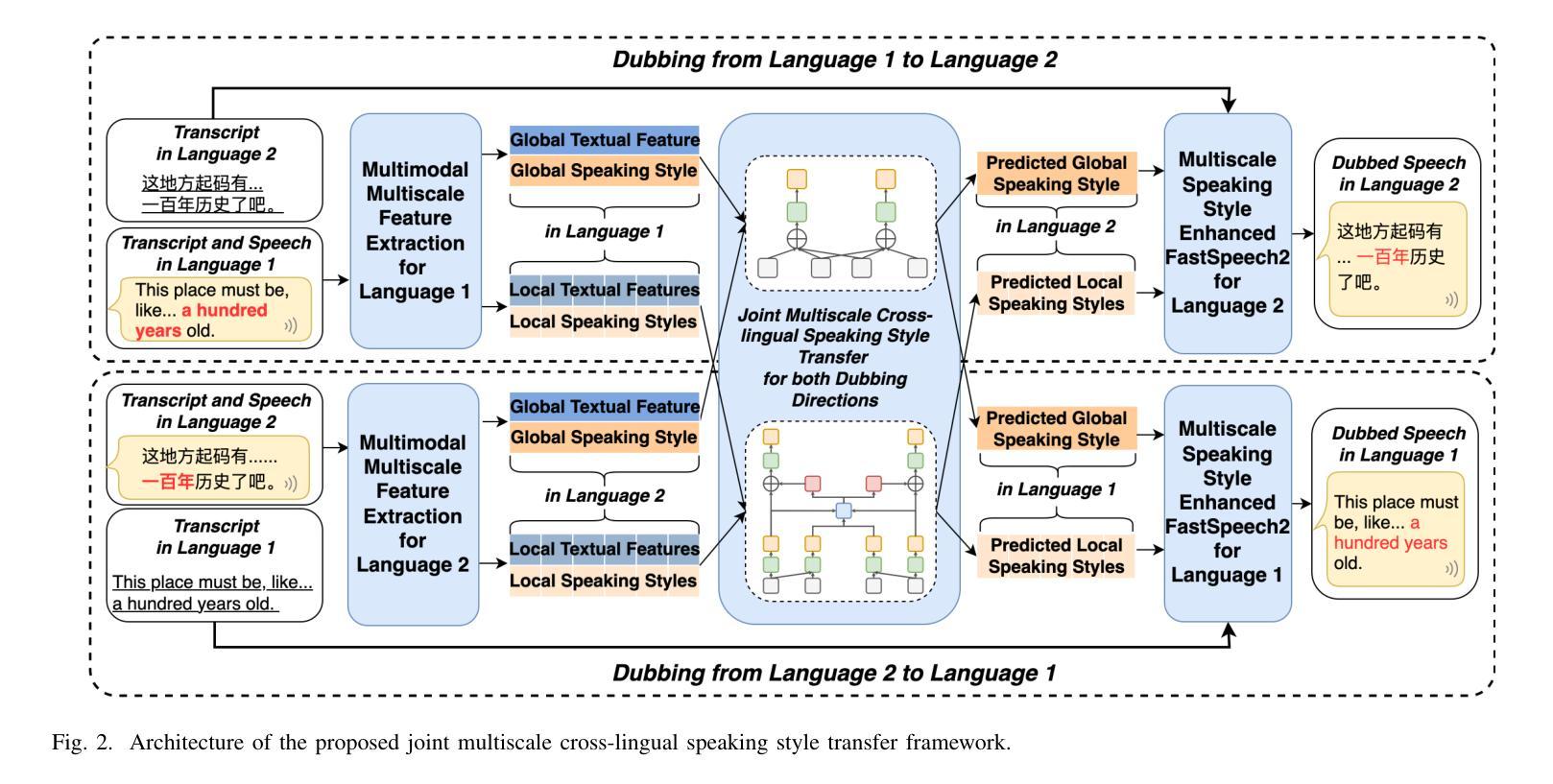
Q: 论文如何解决这个问题?
A: 论文通过提出一个联合多尺度跨语言说话风格转移框架(joint multiscale cross-lingual speaking style transfer framework)来解决自动配音中的问题。这个框架主要包含以下几个关键部分:
A. 多模态多尺度特征提取(Multimodal Multiscale Feature Extraction)
- 文本特征提取:使用预训练的BERT模型提取句子级和单词级的BERT嵌入,作为两种语言的文本特征。
- 说话风格提取:使用全局和局部说话风格编码器从输入语音中提取全局和局部的说话风格特征。
- 多模态特征融合:将提取的文本特征和说话风格特征进行融合,形成全局和局部的多模态特征。
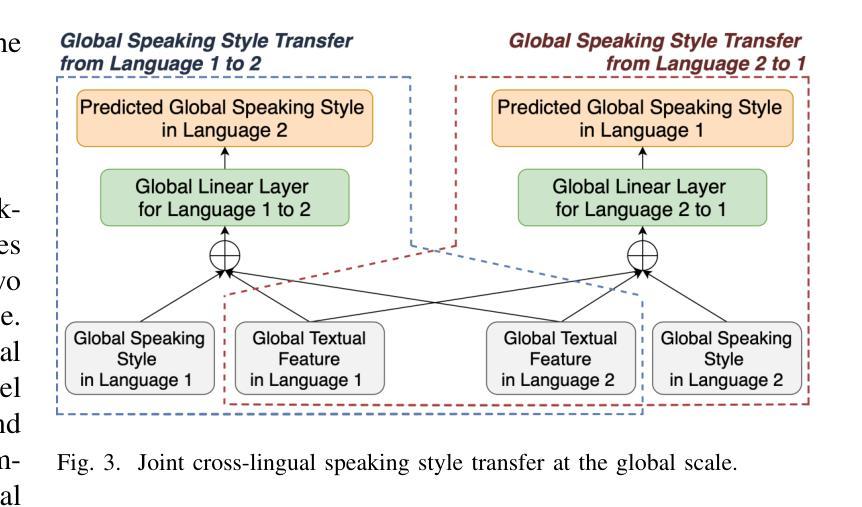
B. 联合多尺度跨语言说话风格转移(Joint Multiscale Cross-lingual Speaking Style Transfer)
- 全局尺度的说话风格转移:利用全局多模态特征和目标语言的文本特征来预测目标语言的全局说话风格。
- 局部尺度的说话风格转移:使用编码器-解码器框架和共享的双向注意力机制,根据源语言和目标语言之间的语义关系,学习局部尺度的说话风格转移。
C. 预测多尺度说话风格语音合成(Speech Synthesis with Predicted Multiscale Speaking Styles)
- MST-FastSpeech 2:使用多尺度说话风格增强的FastSpeech 2模型,将预测的全局和局部说话风格合成为目标语言的语音。
D. 训练策略(Training Strategy)
- 预训练:先分别预训练每种语言的全局和局部说话风格编码器以及对应的MST-FastSpeech 2,确保提取的说话风格与TTS主干兼容。
- 对抗性学习:使用梯度反转层(GRL)和领域对抗学习来提高说话风格的鲁棒性,并在预训练阶段将文本和说话人信息与说话风格解耦。
- 联合训练:将提出的跨语言多尺度说话风格转移框架进行训练和反向传播,最小化预测的全局和局部说话风格与真实值之间的均方误差(MSE)。
通过以上方法,论文提出的框架能够有效地从源语言中提取全局和局部的说话风格,并将其转移到目标语言的配音语音中,从而提高了自动配音的表现力和自然度。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估所提出的多尺度跨语言说话风格转移框架的有效性。以下是实验的主要内容:
A. 基线比较(Baselines)
论文使用了两种基线方法来与提出的框架进行比较:
无说话风格转移(No speaking style transfer):这是标准的FastSpeech 2模型,没有进行说话风格转移,代表现有的一些TTS和语音到语音翻译系统。
仅持续时间转移(Duration transfer):基于提出的框架,只转移每个单词的持续时间到另一种语言的语音中。这种方法受到现有自动配音系统的启发,应当具有相似或更好的性能。
B. 训练设置(Training Setup)
- 论文从游戏《Borderlands 3》的英语和中文配音中收集了4,914对平行话语作为研究语料库。
- 使用预训练的BERT模型提取句子和单词级别的BERT嵌入。
- 使用整个语料库来预训练MST-FastSpeech 2和两种语言的全局及局部说话风格编码器。
- 使用4,414对平行话语作为训练集来训练提出的多尺度说话风格转移框架。
C. 评估(Evaluation)
- 使用剩余的500对话语作为测试集进行评估。
- 采用客观和主观两种评价方法:
- 客观评价:计算预测的mel频谱图与真实mel频谱图之间的均方误差(MSE)。
- 主观评价:选择20个对话片段,由25名听众对合成语音的自然度和说话风格转移进行评分,计算平均意见得分(MOS)和偏好率。
D. 实验结果(Experimental Results)
- 客观评价结果显示,提出的多尺度说话风格转移框架在mel频谱图的MSE上显著优于基线方法。
- 主观评价结果表明,与仅持续时间转移的基线方法相比,提出的框架在说话风格转移的MOS上有所提高,并且听众更倾向于选择使用提出的框架生成的配音语音。
E. 消融研究(Ablation Study)
- 论文还进行了消融研究,以评估全局尺度和局部尺度说话风格转移以及双向多任务学习对性能的影响。
- 结果显示,提出的框架在考虑全局和局部尺度说话风格转移时表现最佳,且双向多任务学习有助于提高性能。
这些实验结果证明了所提出框架在自动配音任务中的有效性,尤其是在跨语言说话风格转移方面。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
1. 扩大和多样化数据集
- 论文中使用的数据集来源于单一游戏《Borderlands 3》,可能限制了模型的泛化能力。未来的工作可以扩大数据集,包含更多来源和类型的语料,如电影、电视剧、新闻广播等,以提高模型的泛化性和鲁棒性。
2. 改进说话风格编码器
- 探索更先进的说话风格编码器,以更精确地捕捉和表示说话风格特征,包括情感、语调、节奏等。
3. 跨语言和跨文化的适配
- 研究不同语言和文化背景下的说话风格差异,以及如何更好地适配和转换这些风格。
4. 实时自动配音系统
- 开发能够实时处理和生成配音的系统,这对于电影、游戏和直播等应用场景非常有价值。
5. 面部表情和肢体语言的同步
- 在自动配音的同时,考虑与视频中角色的面部表情和肢体语言同步,以提高整体的自然度和真实感。
6. 交互式配音系统
- 开发交互式配音系统,允许用户根据需要调整和控制配音的说话风格,以适应不同的应用需求。
7. 多模态学习
- 结合语音、文本、视觉等多种模态信息,以更全面地理解和生成说话风格。
8. 模型压缩和优化
- 对模型进行压缩和优化,以减少计算资源需求,使其更适合在资源受限的设备上运行。
9. 无监督和半监督学习
- 探索无监督和半监督学习方法,以减少对大量标注数据的依赖,降低数据准备的成本。
10. 多语言和跨领域应用
- 将模型扩展到更多的语言和领域,如医疗、教育、客服等,以验证模型的适用性和效果。
这些探索点可以帮助研究者和开发者进一步提升自动配音技术的性能和应用范围,满足更多实际应用需求。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个联合多尺度跨语言说话风格转移框架,旨在改善自动配音系统中的说话风格传递问题。以下是论文的主要内容总结:
1. 问题陈述
- 自动配音需要将源语言的说话风格(包括情感、语调、强调等)转移到目标语言的配音中,以提升观众的沉浸感和配音的自然度。现有系统主要关注持续时间和语速的转移,忽略了其他重要的说话风格方面。
2. 提出框架
- 论文提出了一个多尺度(全局和局部)跨语言说话风格转移框架,通过编码器-解码器结构和共享的双向注意力机制,同时建模两种语言之间的全局和局部说话风格转移。
3. 方法论
- 特征提取:使用BERT模型提取文本特征,并结合全局和局部说话风格编码器提取说话风格特征。
- 跨语言风格转移:通过线性投影层和共享的双向注意力机制,实现全局和局部尺度的跨语言风格预测。
- 语音合成:利用预测的风格特征,通过MST-FastSpeech 2模型合成具有所需说话风格的语音。
4. 实验
- 使用来自游戏《Borderlands 3》的英语和中文配音数据集进行训练和测试。
- 与基线方法(无风格转移和仅持续时间转移)相比,所提框架在客观和主观评价中均展现出更好的性能。
5. 贡献
- 首次提出在自动配音中同时考虑全局和局部尺度的说话风格转移。
- 首次采用多任务学习联合优化两种语言之间的跨语言说话风格转移。
- 提出了一种有效的方法来推断自动配音中的全局和局部说话风格。
6. 讨论与结论
- 所提出的框架能够有效地从源语言中提取全局和局部的说话风格,并将其转移到目标语言的配音语音中,从而提高了自动配音的表现力和自然度。
该研究不仅推动了自动配音技术的发展,也为未来在多语言和跨文化环境中的语音合成应用提供了新的思路和方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图