⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-14 更新
Mogo: RQ Hierarchical Causal Transformer for High-Quality 3D Human Motion Generation
Authors:Dongjie Fu
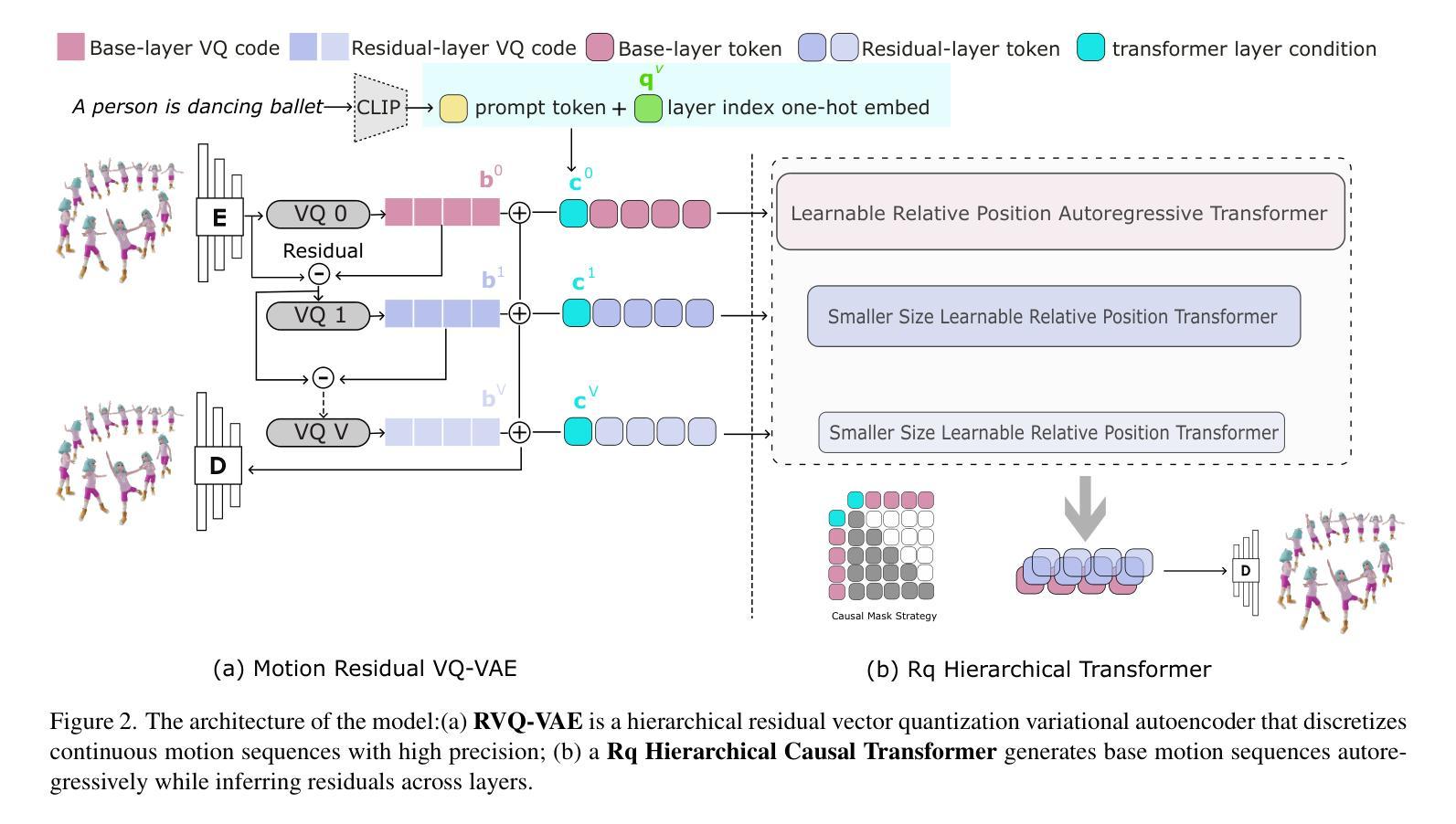
In the field of text-to-motion generation, Bert-type Masked Models (MoMask, MMM) currently produce higher-quality outputs compared to GPT-type autoregressive models (T2M-GPT). However, these Bert-type models often lack the streaming output capability required for applications in video game and multimedia environments, a feature inherent to GPT-type models. Additionally, they demonstrate weaker performance in out-of-distribution generation. To surpass the quality of BERT-type models while leveraging a GPT-type structure, without adding extra refinement models that complicate scaling data, we propose a novel architecture, Mogo (Motion Only Generate Once), which generates high-quality lifelike 3D human motions by training a single transformer model. Mogo consists of only two main components: 1) RVQ-VAE, a hierarchical residual vector quantization variational autoencoder, which discretizes continuous motion sequences with high precision; 2) Hierarchical Causal Transformer, responsible for generating the base motion sequences in an autoregressive manner while simultaneously inferring residuals across different layers. Experimental results demonstrate that Mogo can generate continuous and cyclic motion sequences up to 260 frames (13 seconds), surpassing the 196 frames (10 seconds) length limitation of existing datasets like HumanML3D. On the HumanML3D test set, Mogo achieves a FID score of 0.079, outperforming both the GPT-type model T2M-GPT (FID = 0.116), AttT2M (FID = 0.112) and the BERT-type model MMM (FID = 0.080). Furthermore, our model achieves the best quantitative performance in out-of-distribution generation.
在文本到动作生成领域,Bert类型的Masked模型(MoMask,MMM)目前相较于GPT类型的自回归模型(T2M-GPT)能产出更高质量的输出。然而,这些Bert类型的模型通常缺乏游戏和多媒体环境应用所需的流式输出能力,这是GPT类型模型所固有的一种特性。此外,它们在非分布生成方面的表现较弱。为了超越BERT类型模型的质量,同时利用GPT类型的结构,并且不增加额外的细化模型以简化数据规模,我们提出了一种新型架构Mogo(只生成一次动作)。Mogo通过训练单个变压器模型,就能生成高质量、逼真的3D人类动作。Mogo仅包含两个主要组件:1)RVQ-VAE,这是一种分层残差向量量化变分自编码器,能够高精度地离散连续动作序列;2)分层因果变压器,它以自回归的方式生成基础动作序列,同时在不同层推断残差。实验结果表明,Mogo能够生成长达260帧(13秒)的连续和循环动作序列,超越了现有数据集如HumanML3D的196帧(10秒)长度限制。在HumanML3D测试集上,Mogo的FID得分为0.079,优于GPT类型的T2M-GPT(FID=0.116)、AttT2M(FID=0.112)和BERT类型的MMM(FID=0.080)。此外,我们的模型在非分布生成方面取得了最佳定量性能。
论文及项目相关链接
Summary
本文介绍了在文本到动作生成领域的研究进展。当前,BERT类型的Masked模型如MoMask、MMM虽然输出质量较高,但缺乏GPT类型模型的流式输出能力,且在非分布生成方面表现较弱。为结合BERT模型的高质量与GPT模型的流式输出优势,同时避免复杂的数据缩放模型,提出了一种新型架构Mogo(仅生成一次动作)。Mogo由两个主要组件构成:RVQ-VAE(层次残差矢量量化变分自编码器)和分层因果变换器。实验结果显示,Mogo能够生成连续和循环的动作序列,长度达到260帧(13秒),超越了现有数据集如HumanML3D的限制。在HumanML3D测试集上,Mogo的FID分数为0.079,优于GPT类型的T2M-GPT和ATT2M以及BERT类型的MMM。同时,Mogo在非分布生成方面也取得了最佳定量表现。
Key Takeaways
- BERT类型的Masked模型在文本到动作生成领域具有较高的输出质量,但缺乏流式输出能力,且在非分布生成方面表现较弱。
- 为提高质量并具备GPT模型的流式输出能力,提出了一种新型架构Mogo。
- Mogo由两个主要组件构成:RVQ-VAE和分层因果变换器。
- Mogo能够生成连续和循环的动作序列,长度超过现有数据集的限制。
- 在HumanML3D测试集上,Mogo的FID分数优于其他模型。
- Mogo在非分布生成方面取得了最佳定量表现。
- Mogo架构具有潜力改善文本到动作生成领域的现有问题,并为未来的研究提供新的方向。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在文本到运动(text-to-motion)生成领域中,如何利用GPT(Generative Pre-trained Transformer)类型的模型来生成高质量、长序列的3D人体动作,同时处理开放词汇表(open-vocabulary)提示。具体来说,论文中提到以下几点挑战和目标:
BERT型模型与GPT型模型的比较:在文本到运动生成领域,基于BERT的掩码模型(例如MoMask, MMM)相较于GPT型的自回归模型(例如T2M-GPT)能产生更高质量的输出。然而,BERT型模型通常缺乏GPT型模型所固有的流式输出能力,这在视频游戏和多媒体环境中是必需的。
长序列生成和开放词汇表处理:GPT型模型在长序列生成和多风格适应方面具有优势,这对于运动生成是固有要求的。论文提出通过使用RVQ-VAE(残差向量量化变分自编码器)作为高质量的运动标记器,并利用单一的分层因果变换器模型进行推理,来实现这一点。
提高生成质量和泛化能力:论文提出了一个名为Mogo(Motion Only Generate Once)的新型架构,旨在超越BERT型模型的质量,同时利用GPT型结构,无需添加额外的精细化模型来复杂化数据扩展。
突破训练数据集的运动序列长度限制:Mogo能够生成比现有数据集(如HumanML3D)中的最大运动数据序列长度(10秒,196帧)更长的连续和循环运动序列,达到了13秒(260帧)。
优化输入提示:通过LLM(大型语言模型)模型优化推理过程中的输入提示,以增强Mogo在零样本和少样本场景下的生成性能。
综上所述,这篇论文的核心目标是开发一个能够生成高质量、长序列3D人体动作的GPT型模型,同时处理开放词汇表提示,并在生成质量和泛化能力上超越现有的BERT型模型。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
文本到运动生成(Text-to-Motion Generation):
- 早期的工作通常采用确定性模型进行运动生成,如[1]和[10]。
- 基于随机模型的方法,例如[4]和[39],使用GAN模型基于条件生成运动序列。
- [15]和[28]使用时序VAE和变换器架构来建模和推断运动。
- 在文本驱动的运动生成领域,[13]使用时序VAE建模文本和运动之间的映射。
- 随着变换器架构和扩散模型在文本和图像领域的广泛应用,它们在运动生成中的潜力也被探索,如[7]、[20]、[21]、[34]、[44]和[45]。
基于变换器的模型(Transformer-based Models):
- [16]、[29]和[43]等研究展示了变换器算法在生成质量和实时性能方面的优势。
- [18]、[43]和[46]使用GPT型自回归变换器模型进行文本到运动的生成。
GPT型模型(GPT-type Models):
- GPT型模型在语言建模方面表现出色,特别是在少样本学习、可扩展性和长序列生成方面,如[2]、[19]和[37]。
分层变换器模型(Hierarchical Transformer Models):
- 分层变换器模型在自然语言处理、图像生成和计算机视觉等领域被广泛应用,如[26]、[27]、[6]和[9]。
运动标记器(Motion Tokenizer):
- [14]首次将VQ-VAE引入运动生成领域,将连续的人类运动映射到离散的标记。
- [43]通过EMA和码本重置技术优化了VQ-VAE的性能。
- [16]不仅使用RVQ-VAE生成基础运动序列标记,还捕获表示残差信息的标记,显著提高了离散运动序列的重建精度。
这些相关研究为本文提出的Mogo模型提供了理论基础和技术背景,同时也展示了文本到运动生成领域的研究进展和挑战。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Mogo(Motion Only Generate Once)的新型架构来解决上述问题,该架构包含两个主要组件:
RVQ-VAE(Residual Vector Quantization Variational Autoencoder):
- 这是一个分层残差向量量化变分自编码器,用于将连续的运动序列以高精度离散化成多个层次的运动标记(tokens)。
- RVQ-VAE通过V+1个量化层将运动潜在序列表示为有序的代码序列,其中V表示量化层数。
- 该设计允许模型在不同层级捕捉到不同精细度的运动特征,从而更有效地处理高维和复杂的任务。
Hierarchical Causal Transformer:
- 这是一个分层的因果变换器模型,负责自回归地生成基础运动序列,同时跨不同层推断残差。
- 模型为每个变换器层构建输入,包括文本嵌入、量化层嵌入和之前各层运动嵌入的累积表示。
- 该设计使得当前层的特征建立在之前所有层的累积信息和层级顺序信息之上,从而提高了模型的生成质量。
此外,论文还采取了以下策略:
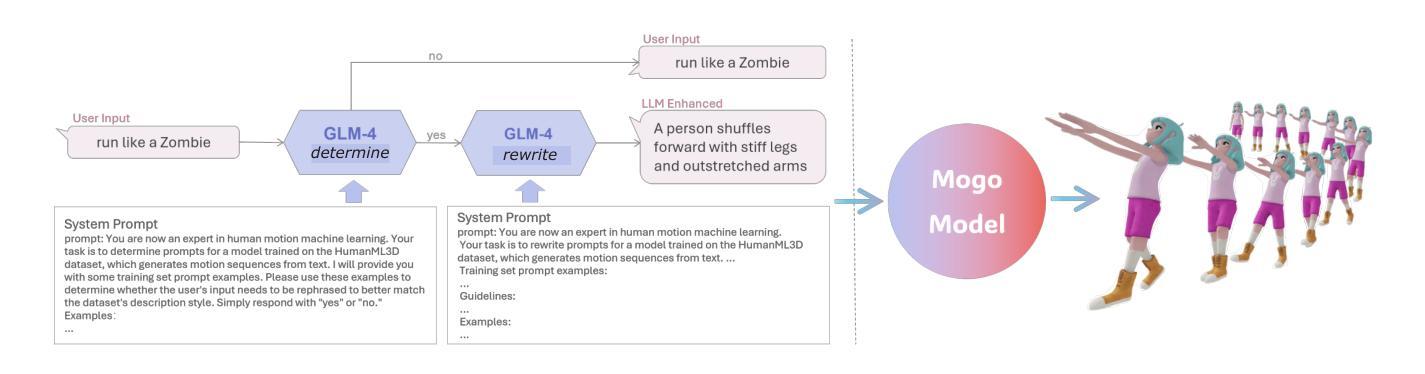
优化输入提示(Prompt Engineering):
- 通过LLM模型优化推理过程中的输入提示,以增强Mogo在零样本和少样本场景下的生成性能。
- 使用GLM-4模型评估和优化用户提示,使其更符合训练集的描述风格。
相对位置编码(Relative Positional Encodings):
- 为了处理更长的序列长度,论文采用了相对位置编码,增强了模型捕获长距离注意力依赖的能力,并提高了生成运动序列的连贯性和自然性。
数据增强策略:
- 在训练过程中,采用数据增强策略,通过替换一定比例的真实代码索引为随机值来提升模型的泛化能力。
通过这些方法,Mogo模型能够在保持GPT型模型流式输出和少样本学习优势的同时,生成高质量、长序列的3D人体动作,并且在开放词汇表提示的处理上表现出色。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估Mogo模型的性能,以下是实验的主要内容和结果:
数据集和评估指标:
- 使用了HumanML3D和KIT-ML数据集进行训练和测试。
- 采用Fréchet Inception Distance(FID)评估生成运动与真实运动之间的分布差异。
- 使用R-Precision和Multimodal Distance(MM-Dist)评估生成运动与输入文本的一致性。
- 通过MultiModality(MModality)评估从同一描述生成的多个运动之间的差异。
实现细节:
- 模型使用PyTorch实现。
- RVQ-VAE和Hierarchical Causal Transformer的具体参数设置和训练细节被详细描述。
推理能力优化:
- 使用GLM-4模型进行提示预处理,以优化零样本和少样本场景下的生成性能。
- 在NVIDIA RTX 4090上,每帧的平均推理和解码时间为0.002秒,满足多媒体环境中实时流式输出的要求。
与最新技术的比较:
- 通过定量评估和用户反馈,将Mogo模型的性能与最新的运动生成模型进行比较。
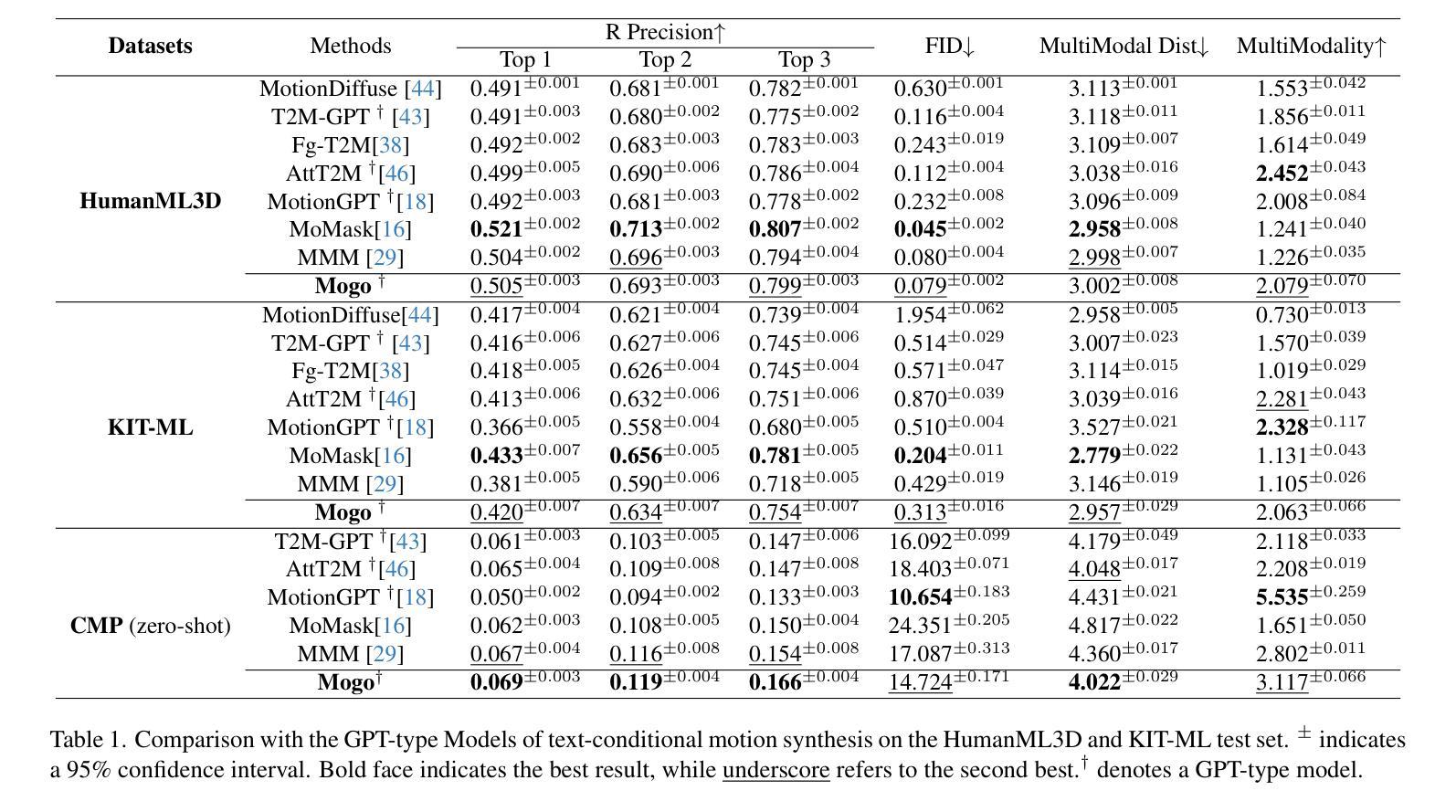
- 在HumanML3D和KIT-ML测试集上,Mogo在所有GPT型模型中实现了最佳性能,并在零样本评估中达到了最佳性能。
用户研究:
- 通过评分系统对Mogo、MoMask、T2M-GPT和MMM在HumanML3D上生成的样本进行评估。
- 评估指标包括提示对齐和生成质量。
- 用户研究结果显示,Mogo在双盲测试中得到了20个用户的青睐。
消融研究:
- 对Mogo架构的不同方面进行了消融研究,包括码本大小、RVQ-VAE层数、数据集大小、输入条件以及层数和注意力头对模型性能的影响。
- 这些实验提供了关于模型设计选择如何影响最终性能的洞察。
限制和讨论:
- 论文讨论了Mogo模型的局限性,包括对时间完成模型编辑的固有支持不足以及生成长度的限制。
结论:
- Mogo通过结合残差量化器和分层自回归变换器,实现了与BERT型模型相媲美或更好的生成质量,并在多项指标上达到了最新性能。
这些实验全面评估了Mogo模型在文本到3D人体运动生成任务中的性能,包括其生成质量、泛化能力、实时性能以及对不同输入条件的适应性。
Q: 有什么可以进一步探索的点?
A: 尽管Mogo模型在文本到3D人体运动生成领域取得了显著的进展,但仍有一些领域可以进一步探索和改进:
模型编辑能力:
- 论文提到GPT型模型缺乏BERT型模型中的时间完成模型编辑能力。研究如何将编辑能力整合到GPT型模型中,以便更好地控制生成的运动序列,是一个有价值的方向。
生成长度限制:
- 尽管Mogo能够生成长达260帧的连续、循环运动序列,但对于非连续运动,它仍然受限于196帧的限制。探索如何突破这一限制,允许模型生成更长、更复杂的运动序列。
多模态输入输出:
- Mogo主要关注文本到运动的生成。扩展模型以支持多模态输入(如图像或音频)和输出(如运动和文本的联合生成)可能会增加其应用范围。
优化和加速:
- 尽管Mogo满足了实时流式输出的要求,但在多媒体环境中进一步优化模型的推理速度和效率,特别是在资源受限的设备上,仍然是一个重要的研究方向。
提高泛化能力:
- 尽管Mogo在零样本和少样本学习方面表现出色,但进一步提高模型对未见过的文本描述的泛化能力,特别是在多样化和极端情况下,是一个挑战。
更复杂的运动类型:
- Mogo主要针对日常动作和一些特定的动作类型。探索如何使模型能够处理更复杂的运动类型,如涉及多个角色的交互或高度协调的任务。
细粒度控制:
- 提供对生成运动的细粒度控制,例如指定特定的身体部位或风格的具体控制,可以增强模型的灵活性和适用性。
模型解释性:
- 提高模型的可解释性,帮助研究人员和用户理解模型的决策过程,特别是在生成不符合预期的运动时。
数据集的多样性和质量:
- 扩展和多样化训练数据集,以包含更广泛的动作类型和风格,可以提高模型的鲁棒性和适应性。
跨领域应用:
- 探索Mogo模型在其他领域的应用,如虚拟现实(VR)、增强现实(AR)和机器人技术,这些领域可能对3D人体运动生成有特定的需求和挑战。
这些方向不仅可以推动文本到运动生成技术的发展,还可能为计算机图形学、人机交互和其他相关领域带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为Mogo(Motion Only Generate Once)的新型GPT型模型,旨在生成高质量、长序列的3D人体动作。以下是论文的主要内容总结:
问题背景:
- 文本到运动生成领域中,BERT型模型虽然质量较高,但缺乏流式输出能力,而GPT型模型具有此能力但质量稍逊。Mogo旨在结合GPT型模型的优势,同时达到或超过BERT型模型的生成质量。
Mogo架构:
- RVQ-VAE(Residual Vector Quantization Variational Autoencoder):用于将连续运动序列离散化为高精度的多层次运动标记。
- Hierarchical Causal Transformer:用于自回归地生成基础运动序列,并跨层推断残差,实现单次传递生成。
实验结果:
- Mogo在HumanML3D测试集上达到了0.079的Fréchet Inception Distance(FID)得分,优于其他GPT型和BERT型模型。
- 能够生成长达260帧(13秒)的连续循环运动序列,突破了现有数据集的极限。
优化输入提示:
- 利用大型语言模型(LLM)优化输入提示,提高零样本和少样本场景下的生成性能。
消融研究:
- 探究了码本大小、RVQ-VAE层数、数据集规模等因素对模型性能的影响。
用户研究:
- 通过用户反馈实验,验证了Mogo在生成质量和提示对齐方面的优势。
限制与讨论:
- Mogo存在无法进行时间完成模型编辑和生成长度限制的问题。
结论:
- Mogo利用残差量化器和分层自回归变换器,在文本到3D运动生成任务中实现了最新的性能,具有高质量、长序列生成和优越的泛化能力。
总体而言,Mogo通过创新的架构和优化策略,在保持GPT型模型优势的同时,显著提升了文本到3D人体运动生成的质量,为视频游戏、虚拟现实和动画制作等领域的应用提供了新的可能性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

SoPo: Text-to-Motion Generation Using Semi-Online Preference Optimization
Authors:Xiaofeng Tan, Hongsong Wang, Xin Geng, Pan Zhou
Text-to-motion generation is essential for advancing the creative industry but often presents challenges in producing consistent, realistic motions. To address this, we focus on fine-tuning text-to-motion models to consistently favor high-quality, human-preferred motions, a critical yet largely unexplored problem. In this work, we theoretically investigate the DPO under both online and offline settings, and reveal their respective limitation: overfitting in offline DPO, and biased sampling in online DPO. Building on our theoretical insights, we introduce Semi-online Preference Optimization (SoPo), a DPO-based method for training text-to-motion models using “semi-online” data pair, consisting of unpreferred motion from online distribution and preferred motion in offline datasets. This method leverages both online and offline DPO, allowing each to compensate for the other’s limitations. Extensive experiments demonstrate that SoPo outperforms other preference alignment methods, with an MM-Dist of 3.25% (vs e.g. 0.76% of MoDiPO) on the MLD model, 2.91% (vs e.g. 0.66% of MoDiPO) on MDM model, respectively. Additionally, the MLD model fine-tuned by our SoPo surpasses the SoTA model in terms of R-precision and MM Dist. Visualization results also show the efficacy of our SoPo in preference alignment. Our project page is https://sopo-motion.github.io.
文本到动作生成对于推动创意产业的发展至关重要,但在生成连贯、逼真的动作时常常面临挑战。为了解决这个问题,我们专注于微调文本到动作模型,使其始终偏向于高质量、人类偏好的动作,这是一个关键但尚未被充分探索的问题。在这项工作中,我们理论地研究了在线和离线环境下的DPO(动态偏好优化),并揭示了它们各自的局限性:离线DPO的过度拟合和在线DPO的偏向采样。基于我们的理论见解,我们引入了半在线偏好优化(SoPo),这是一种基于DPO的方法,用于使用“半在线”数据对训练文本到动作模型进行微调。该数据对由在线分布中的非首选动作和离线数据集中的首选动作组成。这种方法结合了在线和离线DPO,使它们能够相互弥补彼此的局限性。大量实验表明,SoPo优于其他偏好对齐方法,在MLD模型上的MM-Dist为3.25%(例如与MoDiPO的0.76%相比),在MDM模型上为2.91%(例如与MoDiPO的0.66%相比)。此外,经过我们的SoPo微调后的MLD模型在R-precision和MM Dist方面超过了当前最佳模型。可视化结果也显示了我们在偏好对齐方面的有效性。我们的项目页面是https://sopo-motion.github.io。
简化版
论文及项目相关链接
Summary
文本到动作生成对于创意产业的发展至关重要,但面临生成一致、真实动作的挑战。本研究关注于精细调整文本到动作模型,以持续偏向高质量、人类偏好的动作,这是一个关键但尚未被充分探索的问题。本研究在在线和离线设置下理论上研究DPO的局限性,并提出基于DPO的半在线偏好优化(SoPo)方法,使用“半在线”数据对训练文本到动作模型。该方法利用在线和离线DPO,使它们相互补偿。实验表明,SoPo优于其他偏好对齐方法。
Key Takeaways
- 文本到动作生成在创意产业中的重要性及其所面临的挑战。
- 对DPO在在线和离线设置下的局限性进行理论研究。
- 提出半在线偏好优化(SoPo)方法,结合在线和离线DPO的优势。
- SoPo在MLD和MDM模型上的表现优于其他偏好对齐方法。
- SoPo能提高MLD模型的R-precision并优化MM Dist。
- 视觉化结果证明了SoPo在偏好对齐方面的有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决文本到动作生成(Text-to-motion generation)中的一个重要问题:如何生成与文本描述一致、高质量且符合人类偏好的3D人体动作。具体来说,论文关注于以下几个挑战:
模型训练数据的多样性和不一致性:现有的文本到动作模型通常在风格、细节和目的上差异很大的文本-动作对上进行训练,这可能导致生成的动作不符合现实主义或准确性标准。
模型输出的多样性:由于模型是概率性的,对于每个文本描述可能产生多种输出,这虽然增加了多样性,但也增加了生成不理想变化的可能性。
人体关节协调的复杂性:协调多个灵活的人体关节产生可预测的结果非常困难,这增加了生成平滑和现实动作的难度。
论文的主要贡献在于提出了一种名为Semi-online Preference Optimization (SoPo) 的方法,用于微调文本到动作模型,使其能够一致地生成高质量且符合人类偏好的动作。SoPo通过结合在线和离线数据对(online and offline data pairs)来训练模型,其中在线数据对包括从在线分布中生成的不受欢迎的动作,以及离线数据集中的受欢迎动作。这种方法利用在线和离线DPO(Direct Preference Optimization)各自的优势,以弥补对方的局限性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要分为两个领域:文本到动作生成(Text-to-Motion Generation)和直接偏好优化(Direct Preference Optimization)。以下是一些具体的相关研究:
文本到动作生成(Text-to-Motion Generation)
扩散模型(Diffusion-based Models):
- MotionDiffuse [42]:一个开创性的文本驱动扩散模型,支持细粒度的身体控制和灵活的、任意长度的动作合成。
- Tevet et. al. [33]:基于变换器的扩散模型,利用几何损失提高训练效率和性能。
- Chen et. al. [3]:结合潜在空间和条件扩散技术,高效生成人体动作。
- Kong et. al. [14]:使用离散表示和自适应噪声计划,优先考虑重要动作,实现更丰富和多样化的动作生成。
- Dai et. al. [5]:实时可控的动作生成模型,使用潜在一致性蒸馏平衡效率和高质量输出。
其他文本到动作生成方法:
- 论文中还引用了其他一些文本到动作生成的研究,如 [6, 10, 15, 16, 18, 40, 41, 45, 46]。
直接偏好优化(Direct Preference Optimization)
离线DPO(Offline DPO):
- 这类方法在预先准备好的离线数据集上进行训练,其中偏好数据由人工标注或通过AI生成的反馈获得。例如 [22, 34]。
在线DPO(Online DPO):
- 这类方法动态地使用策略或参考模型生成数据,然后基于人类或AI的反馈构建配对偏好数据。例如 [17, 21, 37, 39]。
特定领域的DPO应用:
- MoDiPO [23]:将DPO方法应用于文本到动作领域,通过在每个描述配对中包含首选和非首选动作的数据集上微调模型,引导模型产生更理想的输出。
这些相关研究为文本到动作生成和偏好对齐提供了理论基础和技术方法,而本论文提出的SoPo方法在这些研究的基础上,进一步探索了如何改进文本到动作模型的偏好对齐问题。
Q: 论文如何解决这个问题?
A: 论文通过提出一种名为Semi-online Preference Optimization(SoPo)的方法来解决文本到动作生成中生成与文本描述一致、高质量且符合人类偏好的3D人体动作的问题。SoPo方法的核心思想是结合在线和离线数据对来训练文本到动作模型,其中离线数据对包括高质量的首选动作,而在线数据对包括动态生成的不受欢迎的动作。下面是具体的解决方案步骤:
1. 理论分析
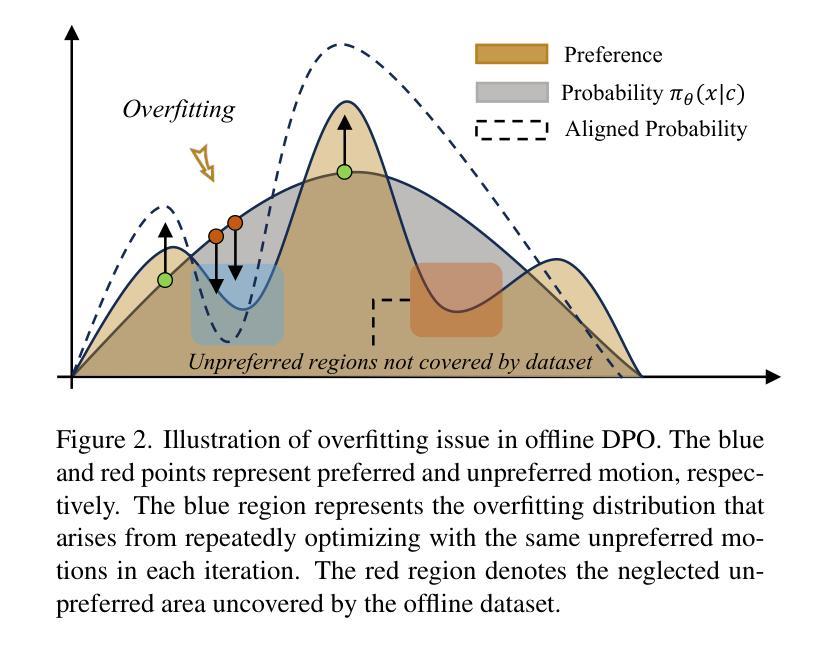
- 分析在线DPO和离线DPO的局限性:论文首先分析了在线和离线DPO在文本到动作生成中的局限性,包括在线DPO中的采样偏差和离线DPO中的过拟合问题。
2. SoPo方法
- 结合在线和离线数据对:SoPo通过利用在线分布中的不受欢迎动作和离线数据集中的受欢迎动作来训练模型。这种方法可以让每个数据对补偿对方的局限性。
3. 在线生成不受欢迎动作
- 动态生成多样化的不受欢迎动作:给定一个条件c,首先从策略模型πθ生成K个动作样本,并选择偏好值最低的动作作为不受欢迎动作。
4. 离线采样首选动作
- 利用离线数据集中的高质量首选动作:这些首选动作有助于增加与在线DPO生成的动作之间的偏好差距,从而提高训练效果。
5. 优化策略
- 设计损失函数:SoPo定义了一个损失函数,该函数结合了在线和离线的优化目标,使得模型能够同时学习如何生成高质量的首选动作和避免不受欢迎的动作。
6. 实验验证
- 在HumanML3D数据集上进行实验:通过在HumanML3D数据集上的实验,论文验证了SoPo方法在提高文本到动作生成的对齐质量方面的有效性。
7. 可视化结果
- 展示偏好对齐的效力:通过可视化结果,论文展示了SoPo在偏好对齐方面的有效性,说明了该方法能够帮助文本到动作模型避免常见的错误。
综上所述,SoPo方法通过结合在线和离线数据对的优势,提出了一种新的训练策略,有效地解决了文本到动作生成中的偏好对齐问题。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来验证Semi-online Preference Optimization (SoPo) 方法的有效性。以下是实验的具体内容:
数据集
- HumanML3D dataset:这是一个广泛使用的文本驱动动作生成的基准数据集,包含14,616个动作,每个动作由三个文本注释描述。
评估指标
- 对齐质量:使用动作检索精度(R-Precision)和多模态距离(MM Dist)来评估。
- 生成质量:使用多样性(Diversity)和Fréchet Inception Distance(FID)来评估。
实现细节
- 使用HumanML3D数据集的训练集作为离线首选动作数据集。
- 采用TRM(text-to-motion retrieval model)作为奖励模型来在线生成不受欢迎的动作。
- 设置截止阈值τ为0.45,超参数C和β分别为2和1,在线采样动作数量K分别为MDM模型的4个和MLD模型的2个。
- 每个模型在单个NVIDIA GeForce RTX 4090 GPU上训练最多100分钟。
主要结果
- 与SOTA(State-of-the-Art)方法进行比较,包括偏好对齐方法和文本到动作生成方法。
- 使用SoPo微调MLD和MDM模型,并与MoDiPO等偏好对齐方法进行比较。
- 将使用SoPo微调的MLD*模型与SOTA文本到动作方法进行比较。
消融研究
- 检验不同对齐方法、不同的截止阈值τ以及不同采样动作数量K对模型性能的影响。
可视化结果
- 展示SoPo在HumanML3D数据集上生成的动作的可视化结果,以展示模型如何避免常见错误并改善文本与动作之间的对齐。
这些实验结果表明,SoPo方法在提高文本到动作生成的对齐质量方面具有显著优势,并且在生成质量方面也表现出色。通过这些实验,作者证明了SoPo方法的有效性,并展示了其在实际应用中的潜力。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的Semi-online Preference Optimization (SoPo) 方法在文本到动作生成中取得了显著的效果,但仍有一些方面可以进一步探索和改进:
1. 奖励模型的改进
- 论文中提到,奖励模型可能成为SoPo方法的瓶颈。如果奖励模型存在偏差,可能会导致策略模型学习到错误的模式。因此,研究更准确或更鲁棒的奖励模型是一个重要的方向。
2. 多样化的在线和离线数据对
- 探索如何生成更多样化的在线和离线数据对,以进一步提高模型的泛化能力和减少过拟合的风险。
3. 超参数调整和优化
- 论文中使用了一些固定的超参数,如τ、C和β。研究如何自动调整这些超参数以适应不同的数据集和任务,可能会进一步提高模型性能。
4. 扩展到其他模态
- 将SoPo方法扩展到其他模态,如从文本到图像或视频的生成任务,探索其在这些领域的有效性和适用性。
5. 计算效率和可扩展性
- 研究如何提高SoPo方法的计算效率,使其能够处理更大规模的数据集和更复杂的任务。
6. 长期一致性和稳定性
- 在长期训练过程中,研究如何保持生成动作的一致性和稳定性,避免模型性能的波动。
7. 多任务学习
- 探索将SoPo方法应用于多任务学习框架,同时优化多个相关任务,如动作生成和动作分类。
8. 无监督和半监督学习
- 研究在无监督或半监督设置下应用SoPo方法,减少对大量标注数据的依赖。
9. 跨领域适应性
- 研究SoPo方法在不同领域(如体育、舞蹈、日常活动)的适应性和迁移学习能力。
10. 交互式应用
- 探索SoPo方法在交互式应用中的潜力,如虚拟现实和增强现实,提高用户与系统的交互质量。
这些方向不仅可以推动文本到动作生成技术的发展,还可能为其他生成任务提供新的视角和解决方案。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
1. 问题陈述
论文针对文本到动作生成领域中生成与文本描述一致、高质量且符合人类偏好的3D人体动作的问题。该问题由于训练数据的多样性、模型输出的不确定性和人体关节协调的复杂性而变得具有挑战性。
2. 相关工作
论文回顾了文本到动作生成和直接偏好优化(Direct Preference Optimization, DPO)的相关研究,指出现有方法的局限性,尤其是在偏好对齐方面。
3. 方法论
提出了一种名为Semi-online Preference Optimization(SoPo)的新方法,该方法结合在线和离线数据对来训练文本到动作模型,利用在线DPO的多样性和离线DPO的质量标签来补偿各自的不足。
4. SoPo核心思想
- 在线生成不受欢迎动作:动态生成多样化的不受欢迎动作,以增加模型训练的多样性。
- 离线采样首选动作:利用人工标注的高质量首选动作,以保持与不受欢迎动作之间的明显偏好差距。
- 优化策略:设计损失函数来同时优化在线和离线数据对,使模型能够学习生成高质量首选动作和避免不受欢迎动作。
5. 实验验证
在HumanML3D数据集上进行实验,使用R-Precision、MM Dist、Diversity和FID等指标评估SoPo方法,并与现有SOTA方法进行比较,验证了SoPo在提高文本到动作生成对齐质量方面的有效性。
6. 可视化结果
通过可视化结果展示SoPo在偏好对齐方面的有效性,说明了该方法能够帮助文本到动作模型避免常见的错误。
7. 结论与局限性
论文总结了SoPo方法的主要贡献,并讨论了其局限性,特别是奖励模型可能成为瓶颈的问题。
8. 未来工作
论文提出了未来可能的研究方向,包括改进奖励模型、扩展到其他模态、提高计算效率等。
总体而言,这篇论文提出了一种创新的方法来解决文本到动作生成中的偏好对齐问题,并通过实验验证了其有效性,为该领域的发展提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

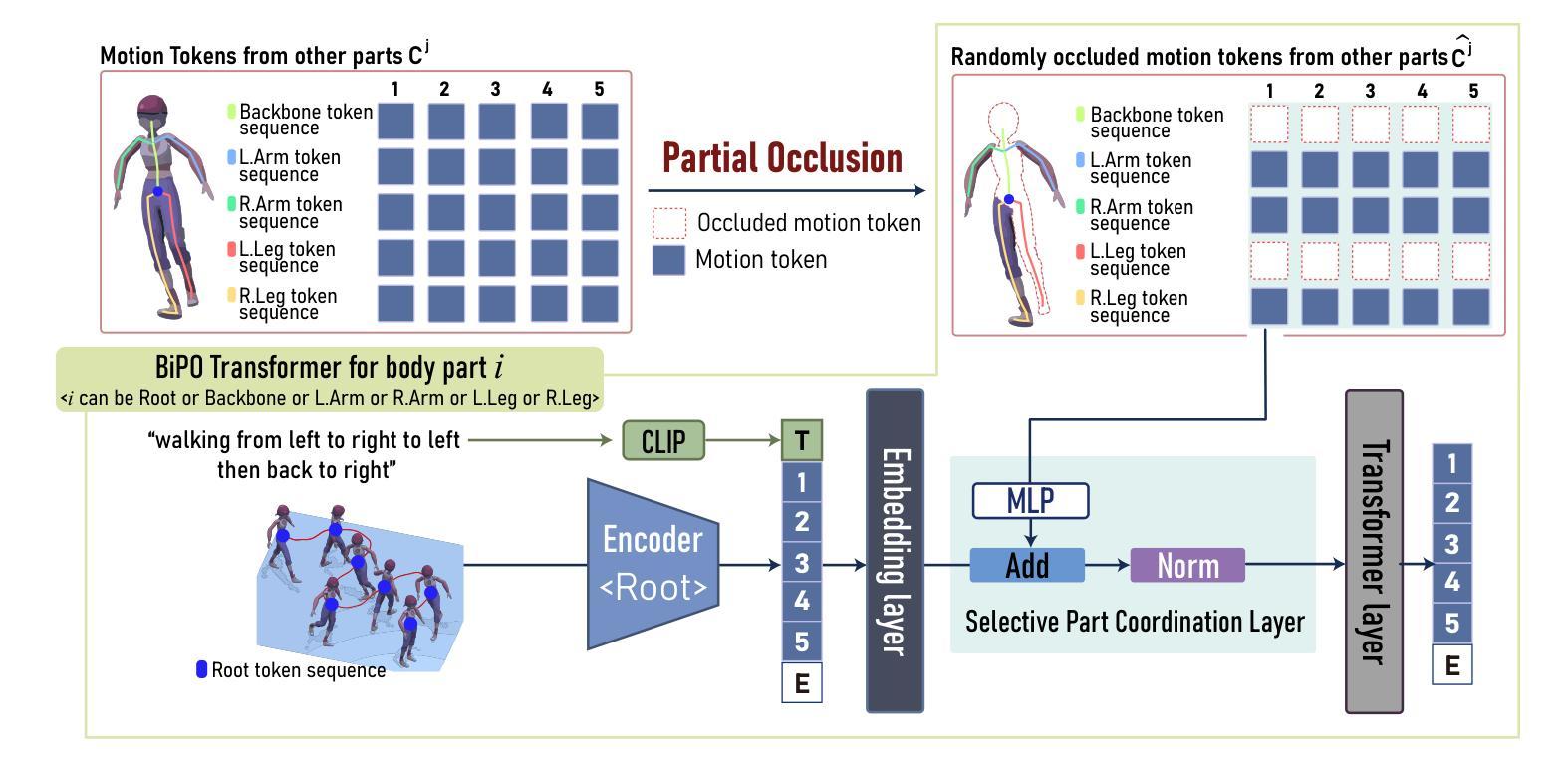
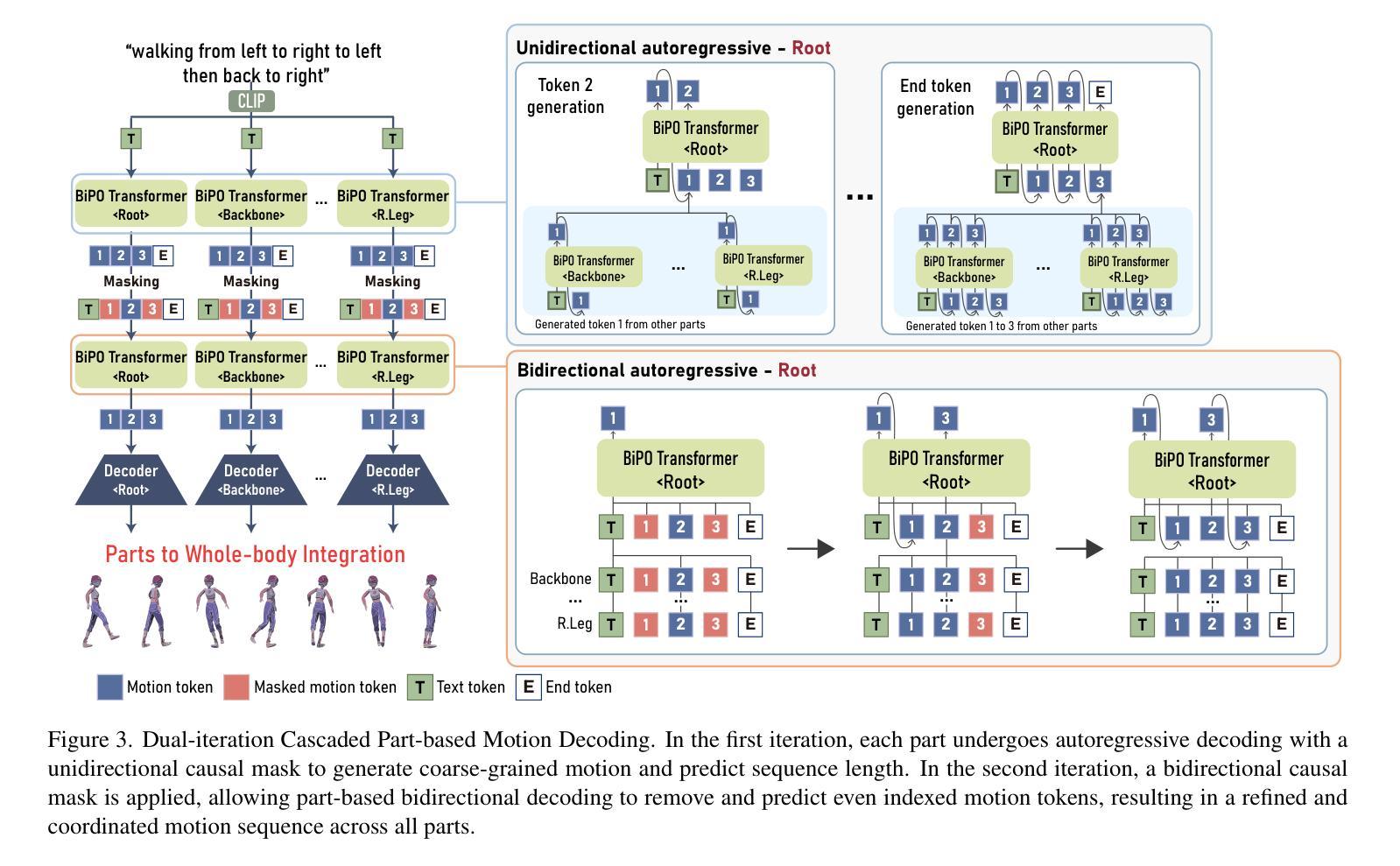
BiPO: Bidirectional Partial Occlusion Network for Text-to-Motion Synthesis
Authors:Seong-Eun Hong, Soobin Lim, Juyeong Hwang, Minwook Chang, Hyeongyeop Kang
Generating natural and expressive human motions from textual descriptions is challenging due to the complexity of coordinating full-body dynamics and capturing nuanced motion patterns over extended sequences that accurately reflect the given text. To address this, we introduce BiPO, Bidirectional Partial Occlusion Network for Text-to-Motion Synthesis, a novel model that enhances text-to-motion synthesis by integrating part-based generation with a bidirectional autoregressive architecture. This integration allows BiPO to consider both past and future contexts during generation while enhancing detailed control over individual body parts without requiring ground-truth motion length. To relax the interdependency among body parts caused by the integration, we devise the Partial Occlusion technique, which probabilistically occludes the certain motion part information during training. In our comprehensive experiments, BiPO achieves state-of-the-art performance on the HumanML3D dataset, outperforming recent methods such as ParCo, MoMask, and BAMM in terms of FID scores and overall motion quality. Notably, BiPO excels not only in the text-to-motion generation task but also in motion editing tasks that synthesize motion based on partially generated motion sequences and textual descriptions. These results reveal the BiPO’s effectiveness in advancing text-to-motion synthesis and its potential for practical applications.
从文本描述生成自然且富有表现力的人类动作是一个挑战,这主要是因为需要协调全身动力学并捕捉扩展序列中的细微动作模式,以准确反映给定的文本。为了解决这一问题,我们引入了BiPO,即用于文本到动作合成的双向局部遮挡网络。BiPO是一种新型模型,通过结合基于部分的生成与双向自回归架构,增强了文本到动作合成。这种结合使得BiPO在生成过程中能够考虑过去和未来的上下文,同时增强了对单个身体部位的精细控制,而无需使用真实动作的长度。为了缓解因集成而产生的身体部位之间的依赖关系,我们设计了局部遮挡技术,该技术会在训练过程中概率性地遮挡某些动作部位的信息。在我们的综合实验中,BiPO在人类ML3D数据集上达到了最新技术水平,在FID得分和整体动作质量方面优于最近的ParCo、MoMask和BAMM等方法。值得注意的是,BiPO不仅在文本到动作生成任务上表现出色,而且在基于部分生成的动作序列和文本描述进行动作编辑的任务上也表现出色。这些结果揭示了BiPO在推动文本到动作合成方面的有效性及其在实际应用中的潜力。
论文及项目相关链接
Summary
文本挑战在于从文本描述生成自然且富有表现力的动作,因为这涉及到协调全身动态、捕捉长期动作的微妙模式以及准确反映文本内容。为此,我们推出了BiPO模型,即用于文本到动作合成的双向局部遮挡网络。该模型通过集成部分生成和双向自回归架构,增强了文本到动作合成的功能。这种集成允许BiPO在生成过程中考虑过去和未来的上下文,同时对个别身体部位进行精细控制,无需真实动作的长度。为了减轻因集成而产生的身体部位间的相互依赖性,我们采用了局部遮挡技术,在训练过程中概率性地遮挡某些动作部分的信息。在全面的实验中,BiPO在HumanML3D数据集上取得了最先进的性能表现,超越了ParCo、MoMask和BAMM等方法,在FID分数和整体运动质量方面表现出色。BiPO不仅在文本到动作生成任务上表现出色,而且在基于部分生成的动作序列和文本描述的运动编辑任务上也表现出色。这些结果证明了BiPO在推动文本到动作合成的有效性及其在实际应用中的潜力。
Key Takeaways
- BiPO模型集成了部分生成和双向自回归架构,增强了文本到动作合成的功能。
- 该模型能够考虑过去和未来的上下文,同时精细控制个别身体部位。
- BiPO采用局部遮挡技术,以减轻身体部位间的相互依赖性。
- 在HumanML3D数据集上的实验表明,BiPO在FID分数和整体运动质量方面取得最先进的性能。
- BiPO不仅擅长文本到动作生成任务,而且在运动编辑任务上也有出色表现。
- BiPO模型具有推动文本到动作合成的潜力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为BiPO(Bidirectional Partial Occlusion Network)的模型,旨在解决从文本描述生成自然和富有表现力的人体动作的挑战。具体来说,论文试图解决的问题包括:
全身动态的复杂性:生成准确反映给定文本的全身动作序列在协调全身动态和捕捉细微动作模式方面存在复杂性。
部分独立性和全局连贯性之间的平衡:现有方法在建模复杂全身动态时常常导致过于简化的表示,缺乏身体各部分之间细腻的协调。
单向自回归架构的局限性:一些现有方法采用单向自回归架构,这限制了模型预测未来动作的能力,影响了长期动作协调。
缺乏对个体身体部位的详细控制:尽管部分方法独立处理每个身体部位以捕捉独特的运动模式,但它们通常缺乏部分之间的连贯性。
实际应用中的不灵活性:一些方法需要真实的动作长度作为输入,在实际应用中这是不切实际的。
BiPO模型通过整合基于部分的生成和双向自回归架构来增强文本到动作的合成,同时不需要真实的动作长度作为输入。此外,为了减轻模型在训练期间对身体部位之间相互依赖性的问题,论文提出了部分遮挡(Partial Occlusion, PO)技术。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
文本到动作生成(Text-to-motion generation):
- 早期模型通过在共享潜在空间中对齐文本和动作来生成动作,但这些模型在处理时间依赖性方面存在困难。
- 基于变分自编码器(VAE)和变换器(transformer)的模型可以更好地学习潜在表示,但可能因建模复杂数据分布的能力受限而产生细节不足的动作。
- 基于生成对抗网络(GAN)的模型能够提供更清晰、细节更丰富的动作,但训练不稳定和模式崩溃问题限制了其多样性。
- 基于扩散模型的方法在高质量动作生成方面取得了进展,但需要大量的计算资源,并且通常需要真实的动作长度。
基于向量量化变分自编码器(Vector Quantized Variational AutoEncoders, VQ-VAE):
- 这些方法通过将动作量化为离散的标记,实现对动作的离散表示学习。
基于部分的动作生成(Part-Based Motion Generation):
- 部分方法旨在对个体身体部位进行详细控制,例如SCA、AttT2M和ParCo等模型。
双向方法(Bidirectional methods):
- 这些方法考虑过去和未来的上下文,以产生更高质量的动作,但通常需要预定义的动作长度。
混合方法(Hybrid approaches):
- 如BAMM模型,结合了自回归和双向方法,先自回归地生成粗略动作,然后双向地细化它们。
特定领域的应用:
- 包括动画、虚拟现实、视频游戏和机器人技术等领域的应用研究。
具体到论文中提到的一些研究工作,例如:
- ParCo:利用所有部分的信息在训练期间增强全局运动连贯性。
- MoMask 和 BAMM:采用双向方法,利用过去和未来的上下文进行更全面的序列理解。
- SCA、AttT2M:基于部分的方法,旨在对个体身体部位进行详细控制。
这些相关研究构成了BiPO模型的理论基础,并在论文中被用来与BiPO模型的性能进行比较。
Q: 论文如何解决这个问题?
A: 论文通过提出BiPO(Bidirectional Partial Occlusion Network)模型来解决文本到动作合成中的挑战,具体解决方案包括以下几个关键点:
整合基于部分的生成与双向自回归架构:
- BiPO模型首次将基于部分的生成与双向自回归架构相结合,以实现对个体身体部位的详细控制和全局运动连贯性的增强。
部分遮挡(Partial Occlusion, PO)技术:
- 为了减轻模型对身体部位之间相互依赖性的问题,论文提出了PO技术。这种技术在训练期间通过随机遮挡某些身体部位的运动部分信息来放松身体部位之间的依赖关系。
双迭代级联部分运动解码(Dual-iteration Cascaded Part-based Motion Decoding):
- 模型首先进行单向自回归解码以生成粗略的运动序列并预测序列长度。然后,应用双向因果掩码,允许基于部分的双向解码来去除和预测先前生成序列中的偶数索引运动标记,从而产生一个经过细化和协调的运动序列。
优化的训练策略:
- 通过最小化不同掩码方案下的损失函数之和来训练模型,以实现在不同掩码方案下的运动标记的高可能性。
在HumanML3D数据集上的综合实验:
- 论文在HumanML3D数据集上进行了广泛的实验,验证了BiPO模型在文本到动作生成任务中的有效性,并在运动编辑任务中表现出色。
无需真实动作长度输入:
- BiPO模型不依赖于真实的动作长度作为输入,使其更适用于实际应用场景。
通过这些解决方案,BiPO模型在保持个体身体部位独立性的同时,能够生成与文本描述相匹配的自然、连贯的全身动作,从而在文本到动作合成领域取得了新的进步。
Q: 论文做了哪些实验?
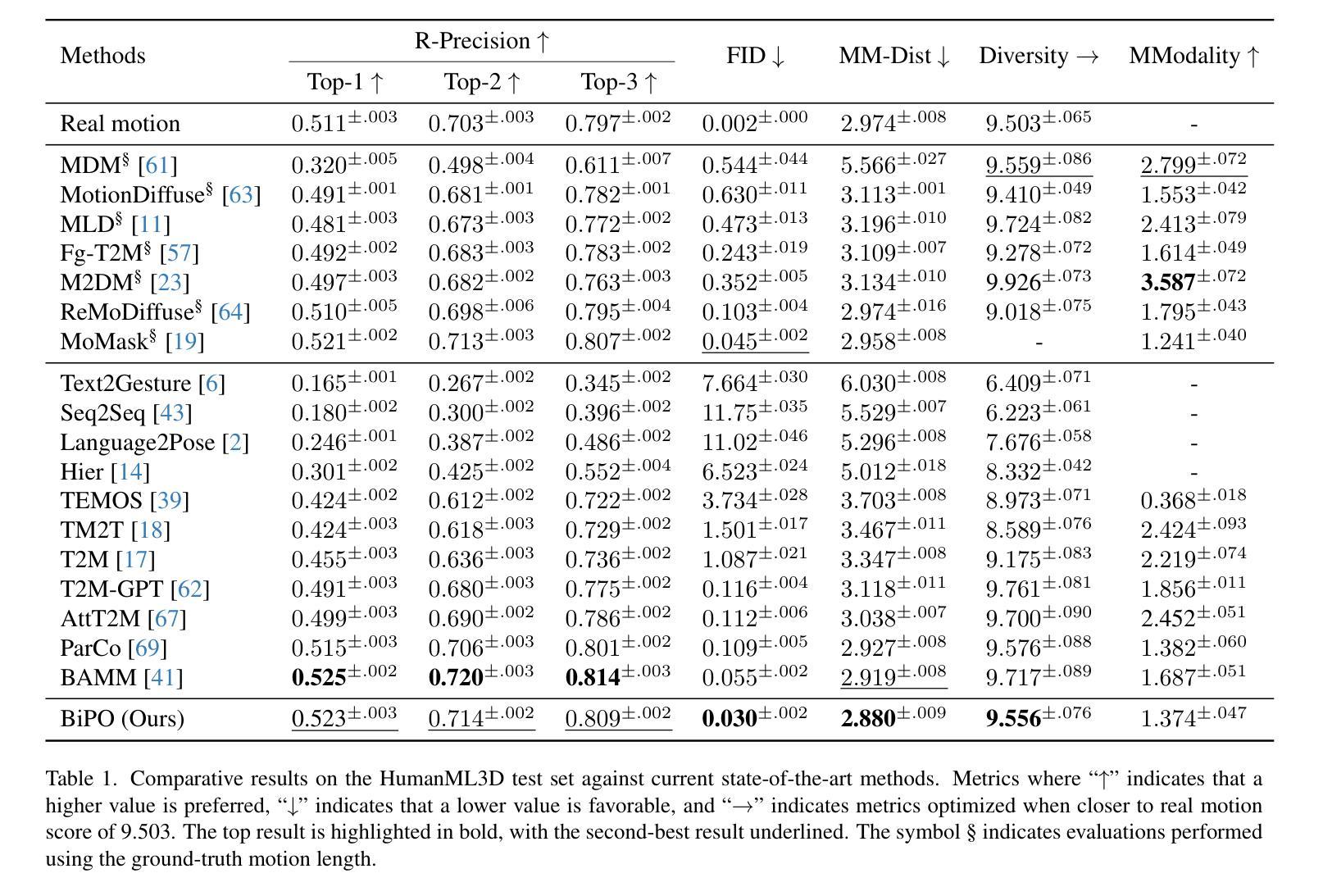
A: 论文中进行了一系列实验来评估BiPO模型的性能,具体实验包括:
实验设置:
- 使用HumanML3D基准数据集进行评估,该数据集包含来自AMASS和HumanAct12数据集的14616个动作序列,与44970个文本描述配对。
评估指标:
- 使用了多个标准指标,包括R-precision、FID、MM-Dist、Diversity和MModality,来评估生成动作的语义对齐、分布差异、特征距离、多样性和从同一文本描述生成不同动作的能力。
与现有方法的比较评估:
- 与现有的文本到动作生成方法进行了广泛的比较,包括MDM、MotionDiffuse、MLD、Fg-T2M、M2DM、ReMoDiffuse、MoMask、Text2Gesture、Seq2Seq、Language2Pose、Hier、TEMOS、TM2T、T2M、T2M-GPT、AttT2M、ParCo和BAMM等。
定性比较:
- 展示了BiPO与现有方法的定性比较,通过图表直观展示了不同模型生成的动作与文本描述的匹配程度。
运动编辑评估:
- 评估了BiPO在运动编辑任务中的性能,包括时间插值(Temporal Inpainting)、时间外插(Temporal Outpainting)、前缀(Prefix)和后缀(Suffix)四种场景。
消融研究:
- 进行了消融研究来分析双向自回归(BA)方法和部分遮挡(PO)技术的效果,与仅使用基于部分的单向自回归方法的基线模型进行比较。
用户研究:
- 通过用户研究评估BiPO与其他模型相比的偏好率,使用30名参与者对不同模型生成的动作进行评价。
这些实验全面评估了BiPO模型在文本到动作合成任务中的性能,并与现有技术进行了比较,证明了BiPO在生成自然、富有表现力的人体动作方面的优势。
Q: 有什么可以进一步探索的点?
A: 尽管BiPO模型在文本到动作合成领域取得了显著进展,但论文也提出了一些有前景的研究方向供未来探索:
自适应遮挡策略:
- 虽然PO技术减轻了身体部位之间的相互依赖性,但它目前依赖于固定的遮挡概率。研究基于上下文动态调整遮挡概率的自适应遮挡策略可能进一步提高模型的鲁棒性。
物理约束的整合:
- 将基于物理的约束整合到模型中,可能增强生成动作的物理合理性,使其更接近现实世界的适用性。
提高推理速度:
- 作为自回归模型,BiPO依赖于序列生成,这比非自回归方法慢。探索优化技术或替代架构以提高推理速度是一个有价值的研究方向。
更广泛的数据集和应用:
- 在更多种类的动作和更广泛的数据集上测试BiPO模型,以及探索其在动画、虚拟现实、游戏和机器人技术等领域的应用。
更复杂的文本描述:
- 研究模型如何处理更复杂的文本描述,例如包含多个动作指令或更详细动作属性的描述。
长期依赖性和高级运动模式:
- 进一步改进模型以更好地捕捉长期依赖性和更高级的运动模式,这对于生成复杂和现实的动作序列至关重要。
交互式应用:
- 考虑如何将BiPO模型集成到交互式应用中,例如动态响应用户输入的动作合成。
多模态学习:
- 探索结合视觉、音频和文本输入的多模态学习方法,以实现更丰富和更自然的动作合成。
模型泛化能力:
- 研究BiPO模型在未见过的动作类型和新颖文本描述上的泛化能力。
模型解释性:
- 提高模型的可解释性,帮助研究者和开发者更好地理解模型的决策过程和潜在的改进空间。
这些方向不仅可以推动文本到动作合成技术的发展,还可能对相关领域的研究和应用产生深远影响。
Q: 总结一下论文的主要内容
A: 论文介绍了一个名为BiPO(Bidirectional Partial Occlusion Network)的新型模型,旨在通过结合部分生成和双向自回归架构来增强从文本到动作合成的能力。以下是论文的主要内容总结:
问题陈述:
- 生成自然和富有表现力的人体动作从文本描述中是具有挑战性的,因为需要协调全身动态并准确捕捉细微的运动模式。
BiPO模型介绍:
- BiPO模型通过整合部分生成和双向自回归架构来解决现有方法的局限性,增强了对个体身体部位的详细控制和全局运动连贯性,同时不依赖于真实的动作长度输入。
部分遮挡(PO)技术:
- 为了减轻身体部位间的过度依赖,论文提出了PO技术,该技术在训练期间随机遮挡某些身体部位的运动信息,促使模型学习在信息不完整的情况下生成协调的动作。
双迭代级联部分运动解码:
- 模型首先进行单向自回归解码以生成粗略的运动序列,然后使用双向自回归方法细化运动序列,提高动作质量和部位间的协调性。
实验评估:
- 在HumanML3D数据集上进行的实验表明,BiPO在FID分数和整体运动质量方面优于现有的最先进方法,如ParCo、MoMask和BAMM。
运动编辑任务:
- BiPO在基于部分生成的运动序列和文本描述进行运动编辑任务方面也表现出色,证明了其适应性和鲁棒性。
消融研究:
- 消融研究显示,双向自回归方法和PO技术显著提高了模型在多个评估指标上的性能。
用户研究:
- 用户研究结果表明,与其它模型相比,用户更偏好BiPO生成的动作,这进一步证实了BiPO在生成自然和与文本描述对齐的动作方面的优势。
未来研究方向:
- 论文提出了未来可能的研究方向,包括开发自适应遮挡策略、整合物理约束、提高推理速度等。
总的来说,BiPO通过其创新的方法在文本到动作合成领域实现了突破,为未来更自然和直观的内容创作和人机交互提供了新的可能性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

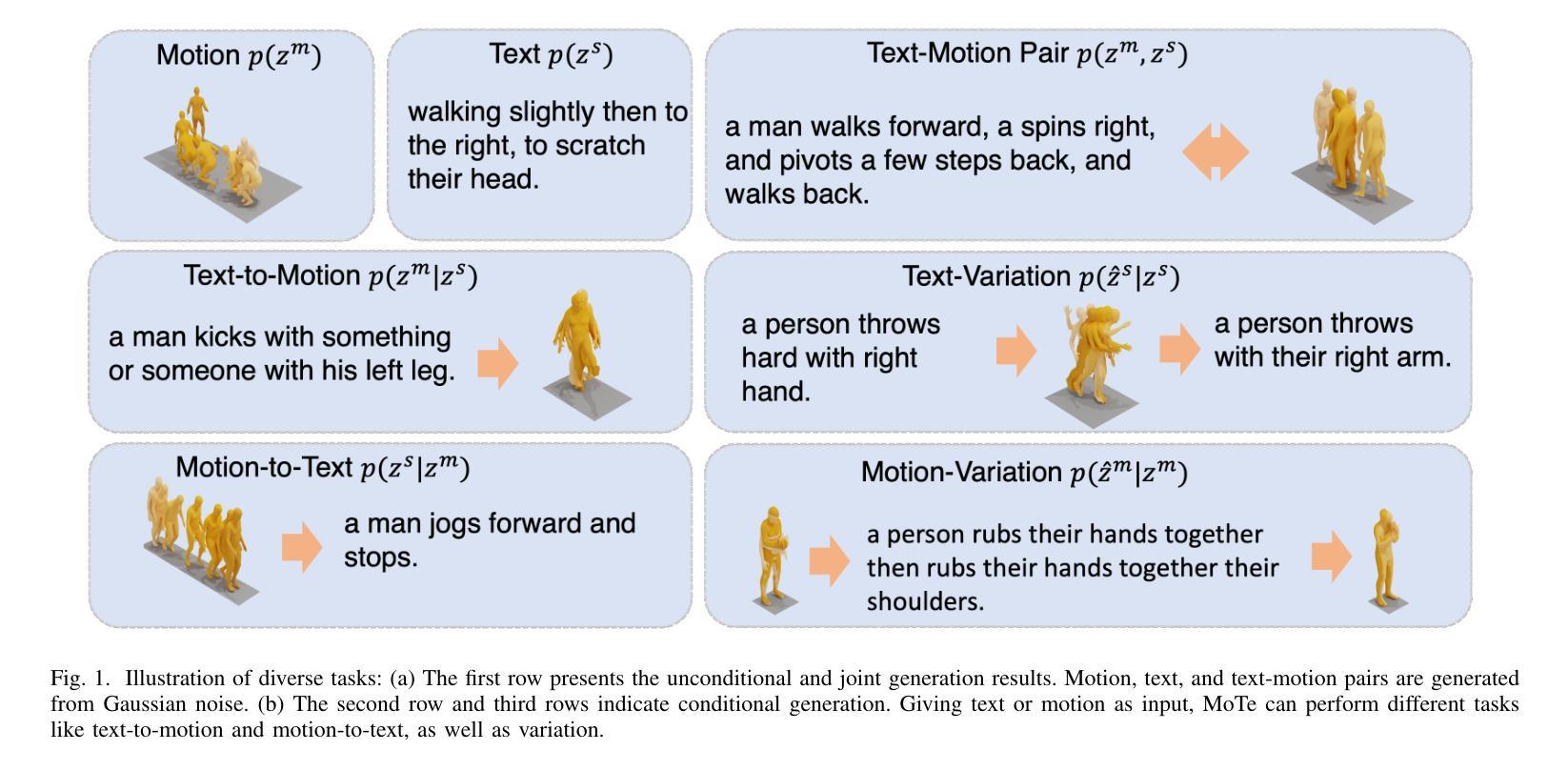
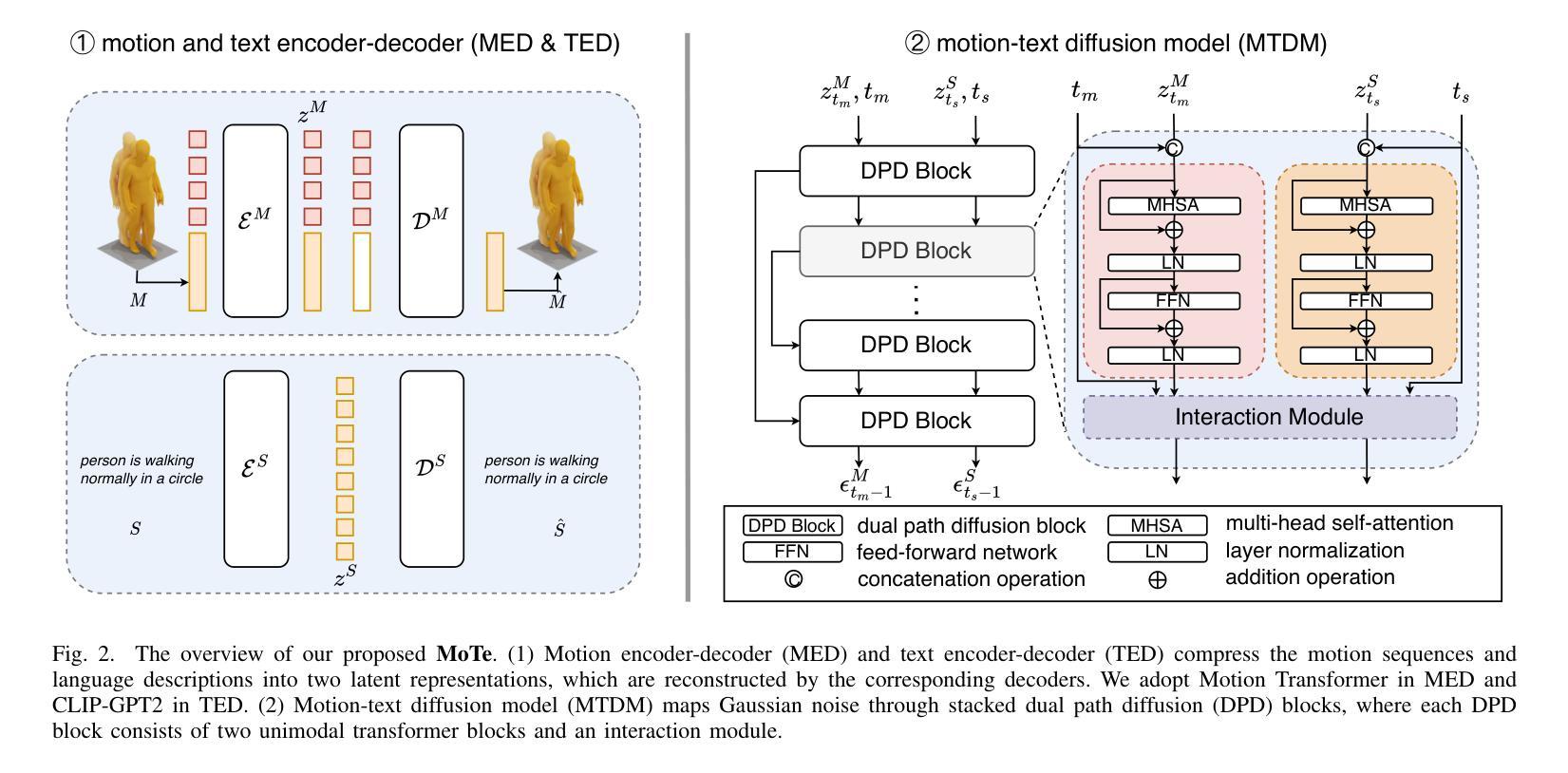
MoTe: Learning Motion-Text Diffusion Model for Multiple Generation Tasks
Authors:Yiming Wu, Wei Ji, Kecheng Zheng, Zicheng Wang, Dong Xu
Recently, human motion analysis has experienced great improvement due to inspiring generative models such as the denoising diffusion model and large language model. While the existing approaches mainly focus on generating motions with textual descriptions and overlook the reciprocal task. In this paper, we present~\textbf{MoTe}, a unified multi-modal model that could handle diverse tasks by learning the marginal, conditional, and joint distributions of motion and text simultaneously. MoTe enables us to handle the paired text-motion generation, motion captioning, and text-driven motion generation by simply modifying the input context. Specifically, MoTe is composed of three components: Motion Encoder-Decoder (MED), Text Encoder-Decoder (TED), and Moti-on-Text Diffusion Model (MTDM). In particular, MED and TED are trained for extracting latent embeddings, and subsequently reconstructing the motion sequences and textual descriptions from the extracted embeddings, respectively. MTDM, on the other hand, performs an iterative denoising process on the input context to handle diverse tasks. Experimental results on the benchmark datasets demonstrate the superior performance of our proposed method on text-to-motion generation and competitive performance on motion captioning.
近期,由于去噪扩散模型等生成模型的启发以及大型语言模型的推动,人类动作分析领域取得了巨大的进步。然而,现有的方法主要侧重于根据文本描述生成动作,而忽视了逆向任务。在本文中,我们提出了一个统一的跨模态模型MoTe,它能够同时学习动作和文本的边际分布、条件分布和联合分布,从而处理多样化的任务。MoTe通过简单地修改输入上下文,使我们能够处理配对文本动作生成、动作描述以及文本驱动的动作生成。具体来说,MoTe由三个组件构成:动作编码器-解码器(MED)、文本编码器-解码器(TED)以及动作文本扩散模型(MTDM)。其中,MED和TED被训练用于提取潜在嵌入,随后分别从提取的嵌入中重建动作序列和文本描述。另一方面,MTDM则对输入上下文进行迭代去噪处理,以处理各种任务。在基准数据集上的实验结果表明,我们提出的方法在文本到动作的生成任务上表现卓越,在动作描述任务上表现具有竞争力。
论文及项目相关链接
PDF Five figures, six tables
Summary
最近,人类动作分析因受到去噪扩散模型等大型语言模型的启发而取得了巨大的进步。现有方法主要关注通过文本描述生成动作,而忽视了逆向任务。本文提出了一个统一的跨模态模型MoTe,它能通过学习动作和文本的边际、条件和联合分布来处理各种任务。MoTe允许我们通过简单地修改输入上下文来处理配对文本动作生成、动作描述以及文本驱动的动作生成。具体来说,MoTe包括三个组件:动作编码器解码器(MED)、文本编码器解码器(TED)和动作文本扩散模型(MTDM)。特别是,MED和TED经过训练以提取潜在嵌入,然后重构动作序列和文本描述。相比之下,MTDM则通过对输入上下文进行迭代去噪过程来处理各种任务。在基准数据集上的实验结果表明,我们提出的方法在文本到动作的生成上具有卓越性能,并且在动作描述上具有竞争力。
Key Takeaways
- MoTe是一个统一的跨模态模型,可处理多种任务,如文本动作生成、动作描述和文本驱动的动作生成。
- MoTe通过学习动作和文本的边际、条件和联合分布来实现其功能。
- MoTe包括三个主要组件:MED、TED和MTDM,分别负责动作和文本的编码解码以及动作文本的扩散模型。
- MED和TED能够提取潜在嵌入并重构动作序列和文本描述。
- MTDM通过迭代去噪过程处理各种任务,增强模型的适应性。
- 基准数据集上的实验结果表明MoTe在文本到动作的生成上具有卓越性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为MoTe(Motion-Text Diffusion Model)的统一多模态模型,旨在解决以下问题:
多任务处理能力:现有的方法主要关注于根据文本描述生成动作,而忽略了相反的任务,即从动作生成文本描述。MoTe模型能够通过简单地修改输入上下文,处理包括文本-动作生成、动作描述(motion captioning)和文本驱动的动作生成等多种任务。
模态对齐:为了构建一个能够处理多样动作相关任务的多模态生成模型,正确对齐动作和语言模态是关键。尽管原始动作序列和语言描述中存在冗余和噪声,但它们在语义空间中有相似性。MoTe通过在潜在空间中对齐这两种模态来解决这一问题。
多模态内容生成:多模态和多任务生成模型在通用人工智能中扮演着重要角色。MoTe模型通过学习边缘、条件和联合分布,使得在单一模型内执行多任务生成成为可能。
总结来说,MoTe模型的目标是提供一个能够处理多种动作相关任务的统一框架,通过学习动作和文本之间的联合、条件和边缘分布,实现文本到动作、动作到文本以及它们之间的变体生成任务。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个方面:
人动作合成(Human Motion Synthesis):
- 利用各种输入(如动作标签、文本、音频)创造类似人类的动作。特别是文本输入,因其用户友好和灵活性而受到广泛探索。
- 早期工作使用RNN、VAE和GANs等方法处理这一任务。
- 近期基于扩散模型(如DM)和大型语言模型(如LLM)的方法因其出色的拟合能力而表现出色。
多模态和多任务生成模型:
- 多模态内容生成涉及通过视觉和语言预训练(VLP)学习多模态特征。
- 代表性工作包括CLIP、BEIT-3和ImageBind等,它们通过对比损失、掩码建模等方法在图像、文本和图像-文本对上进行训练。
- 扩散模型和LLM从单模态扩展到多模态,如MM-Diffusion、Versatile Diffusion和UniDiffuser等。
具体到人动作合成的相关研究:
- MDM:首次使用扩散模型处理多样的动作相关任务,包括动作到动作、文本到动作、动作插值和动作预测。
- MLD:推进了基于潜在扩散模型的人类动作生成。
- FgT2M:强调了细粒度语言描述的重要性,并在扩散模型框架内引入了多步渐进式推理策略。
- T2M-GPT:基于VQVAE和GPT提出了一个框架,实现了文本到动作的生成,并在该任务上达到了最先进的性能。
- MotionGPT:扩展了Flan-T5以处理多种动作相关任务,通过指令调优实现了多模态大型语言模型的多功能性。
这些相关研究为人动作合成领域提供了不同的方法和技术,从早期的RNN和VAE到最近的扩散模型和大型语言模型,不断推动着该领域的研究进展。MoTe模型正是在此基础上,尝试通过统一的多模态框架来处理多样的动作相关任务。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为MoTe(Motion-Text Diffusion Model)的统一多模态模型,通过以下步骤解决多任务处理能力和模态对齐的问题:
两阶段训练方法
第一阶段:
- 训练运动编码器-解码器(MED)和文本编码器-解码器(TED): 这两个模块分别用于将运动序列和文本描述映射到潜在空间。MED通过运动编码器将运动序列编码为潜在的运动嵌入,并通过运动解码器重构原始运动序列。TED使用CLIP和GPT2模型将文本编码为潜在的文本嵌入,并重构原始文本。
第二阶段:
- 优化扩散模型以生成潜在的运动和文本嵌入: 在这一阶段,通过迭代添加高斯噪声来获得扰动嵌入。通过最小化一个加权的目标函数来训练去噪网络,该目标函数结合了联合分布和条件分布的损失。
关键组件
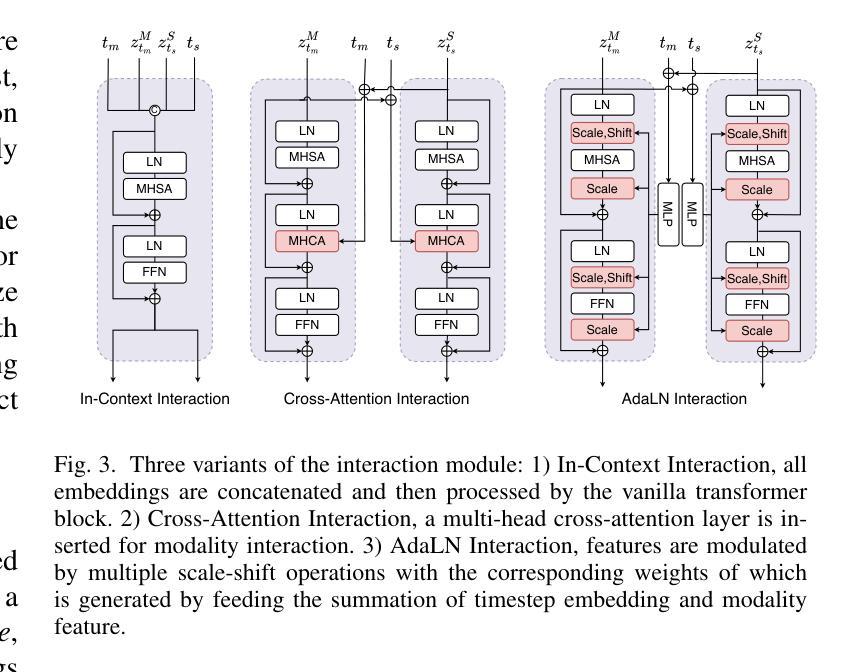
- 运动-文本扩散模型(MTDM): 该模型将高斯噪声通过堆叠的双路径扩散(DPD)块映射,每个DPD块由两个单模态变换器块和一个交互模块组成。交互模块对于学习分布至关重要,论文探索了三种变体:上下文内交互、交叉注意力交互和自适应归一化交互。
多任务处理
- 无条件生成: 通过在单模态上执行迭代推断来启动无条件生成。
- 条件生成: 给定条件和其对应的时间步在去噪过程中保持固定。
- 联合运动-文本生成: 对于这一任务,运动和文本都从T-th步开始去噪,运动和语言的时间步经验性地共享。
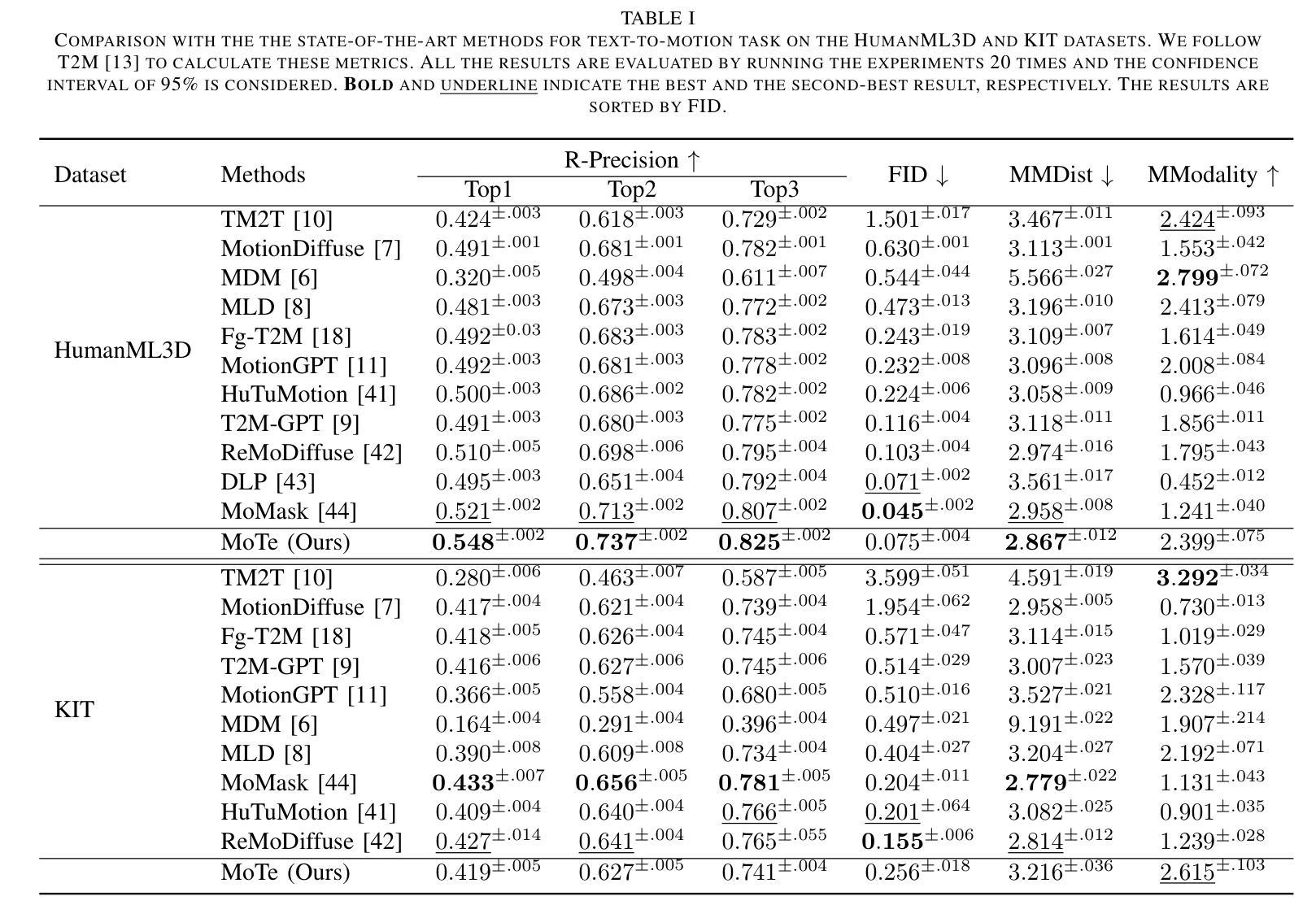
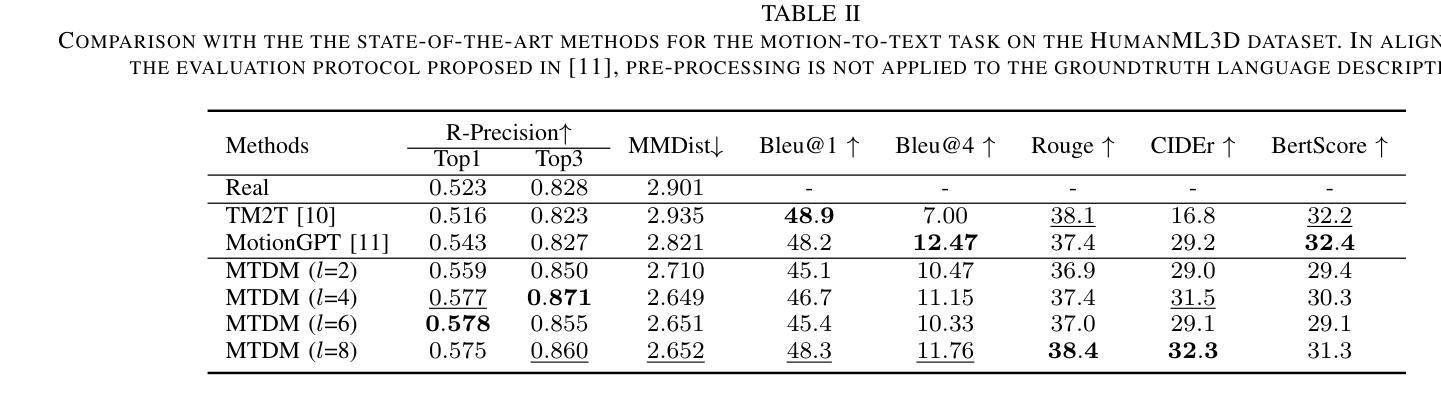
实验结果
论文通过在两个广泛使用的数据集HumanML3D和KIT上的实验,展示了MoTe在文本到运动生成和运动到文本任务上的优越性能。此外,论文还提供了对不同交互模块变体的详细分析,确定了上下文内交互模块在大多数情况下表现优于其他模块,并在MoTe中采用了这种交互模块。
总结来说,MoTe模型通过两阶段训练方法、关键组件的设计以及多任务处理策略,解决了多任务处理能力和模态对齐的问题,并在多个数据集上验证了其有效性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估MoTe模型的性能,具体实验包括:
数据集
- HumanML3D:一个大型的3D人类动作-语言数据集,包含14,616个动作和44,970个语言描述。
- KIT:包含3,911个动作和6,278个语言描述的数据集。
评估指标
对于文本到动作任务和动作到文本任务,使用了多种评估指标,包括:
- 检索精度(Retrieval-Precision, RPrecision)
- 匹配分数(Matching Score, MMDist)
- Fréchet Inception Distance (FID)
- 多模态性(Multi-Modality, MModality)
- Bleu@1, Bleu@4, Rouge, CIDEr, BertScore(用于评估文本质量)
实现细节
- 使用基于Transformer的运动VAE(用于MED)和CLIP-GPT2模型(用于TED)。
- 对MTDM使用AdamW优化器进行训练,初始学习率为1e-4,权重衰减为0.01,批大小为128,使用余弦学习率调度器在6000个训练周期内进行训练。
与最新技术的比较
- 对MoTe在文本到动作生成任务和动作到文本生成任务上的性能与多个最新技术方法进行了比较,包括T2M-GPT、MotionGPT等。
用户研究
- 对于文本到动作任务和动作到文本任务,进行了用户研究,收集了用户对生成动作和文本的评估。
定性比较
- 在HumanML3D数据集上,与MLD和MotionGPT等最新技术方法进行了视觉结果比较。
消融研究
- 对分类器自由引导(Classifier-free Guidance)进行了消融研究,以确定最佳的wm和ws值。
- 对MTDM中潜在运动大小l的影响进行了消融研究,以评估不同l值对性能的影响。
- 对DPD块中的交互模块的有效性进行了消融研究,比较了In-Context Interaction、Cross-Attention Interaction和AdaLN Interaction三种不同的交互模块。
这些实验全面评估了MoTe模型在多任务动作相关任务中的性能,并与现有技术进行了比较,同时也探索了模型的不同组件对最终性能的影响。通过这些实验,论文证明了MoTe模型在文本到动作和动作到文本任务上的优越性能,并分析了模型的有效性和局限性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和结论部分提到的限制及失败案例,以下是一些可以进一步探索的点:
提高精确控制能力:
- 论文中提到模型在精确捕捉细粒度描述以进行精确运动控制方面存在困难。可以探索更精细的文本特征提取方法,例如采用粗到细(coarse-to-fine)的文本特征提取策略,以改善模型对精确动作控制的能力。
增强对领域外描述的适应性:
- 模型在适应领域外文本描述时面临挑战。通过开发和利用更大且更多样化的训练数据集可能增强模型的适应性。
解决文本生成中的重复问题:
- 尽管尝试了各种采样方法,模型仍未完全克服文本生成中的重复问题。整合更先进的文本生成模型(例如T5)可能有效解决这一问题。
扩展到更复杂的场景:
- 论文主要关注单一角色的多模态生成问题,限制了其在复杂场景中的应用。未来的工作可以探索如何将方法扩展到人-物交互和人-人交互的场景。
改进交互模块:
- 尽管In-Context交互模块在大多数情况下表现最佳,但进一步的研究可以探索设计更高效、更强大的交互模块,以提升模型性能。
多模态数据融合:
- 研究如何更有效地融合来自不同模态(如视觉、语言、音频)的信息,以生成更加自然和逼真的动作和文本。
模型泛化能力:
- 探索提高模型泛化能力的方法,使其能够在未见过的新动作类型和文本描述上表现良好。
计算效率和可扩展性:
- 研究如何优化模型的计算效率和可扩展性,以便在资源受限的环境中部署和应用。
交互式应用和实时系统:
- 考虑将模型集成到交互式应用和实时系统中,如虚拟现实(VR)和增强现实(AR)应用。
伦理和隐私问题:
- 随着技术的发展,研究相关的伦理和隐私问题,确保技术的应用符合伦理标准并保护用户隐私。
这些探索点可以帮助研究者进一步提升MoTe模型的性能,扩展其应用范围,并解决当前面临的挑战。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为MoTe(Motion-Text Diffusion Model)的统一多模态模型,旨在通过学习运动和文本的边缘、条件和联合分布来处理多种动作相关任务。以下是论文的主要内容总结:
1. 问题背景
- 人类动作分析技术因生成模型(如去噪扩散模型和大型语言模型)而取得巨大进步。
- 现有方法主要关注基于文本描述生成动作,而忽略了相反任务(即基于动作生成文本描述)。
2. MoTe模型
- 组件:MoTe由运动编码器-解码器(MED)、文本编码器-解码器(TED)和运动-文本扩散模型(MTDM)三部分组成。
- 训练:通过两阶段训练方法,首先训练MED和TED将动作序列和文本描述映射到潜在空间,然后优化MTDM以从噪声中生成潜在的动作和文本嵌入。
- 交互模块:MTDM中的交互模块对于学习多模态分布至关重要,论文探索了三种交互模块变体。
3. 多任务处理
- MoTe能够通过简单修改输入上下文来处理多种任务,包括无条件生成、条件生成和联合动作-文本生成。
4. 实验
- 在HumanML3D和KIT数据集上评估了MoTe的性能。
- 与最新技术方法比较,MoTe在文本到动作生成任务上表现优越,在动作到文本生成任务上表现具有竞争力。
- 进行了用户研究和定性比较,进一步验证了MoTe的有效性。
5. 消融研究
- 分析了分类器自由引导、潜在运动大小和交互模块对模型性能的影响。
6. 限制和未来工作
- 论文讨论了MoTe的局限性,包括对精确控制、领域外描述的适应性以及文本生成中的重复问题。
- 提出了未来可能的研究方向,如扩展到更复杂的场景、改进交互模块等。
总的来说,MoTe模型通过统一的多模态框架有效地处理了多样的动作相关任务,并在实验中展示了其优越性能。论文还深入探讨了模型的局限性,并为未来的研究提供了方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

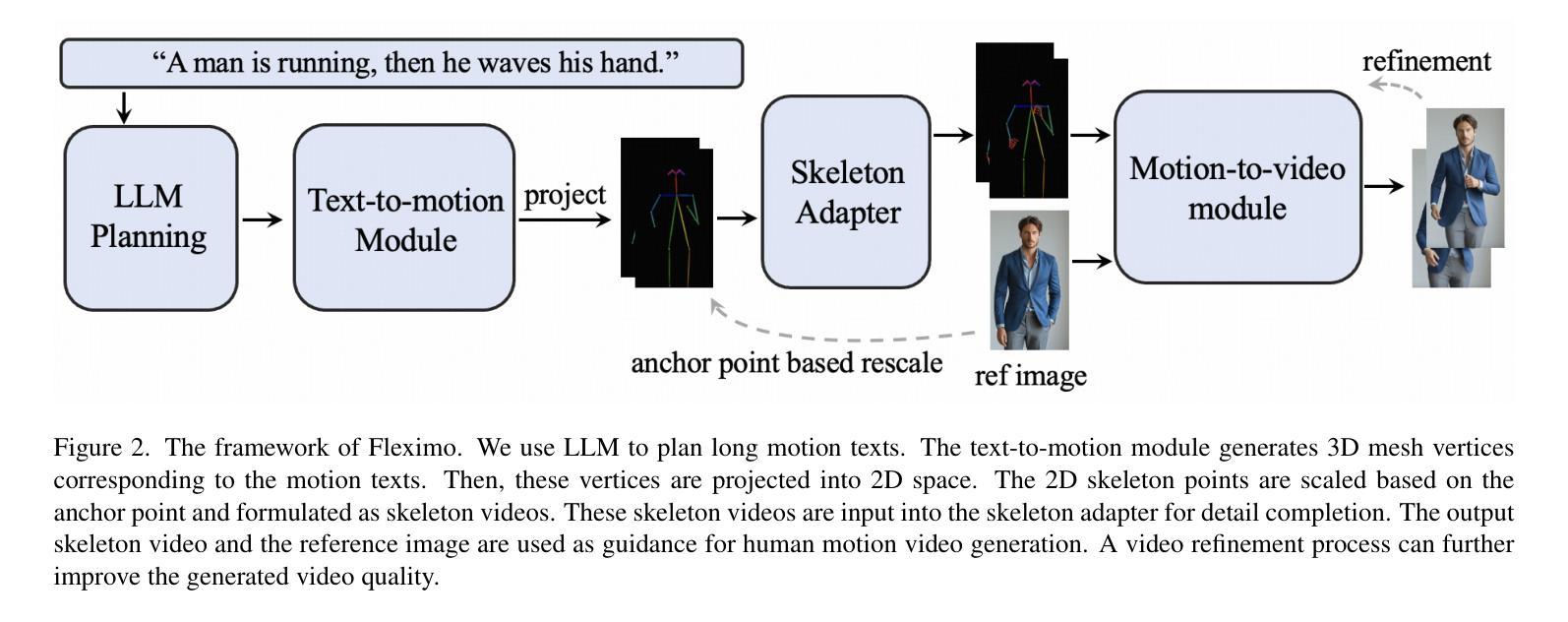
Fleximo: Towards Flexible Text-to-Human Motion Video Generation
Authors:Yuhang Zhang, Yuan Zhou, Zeyu Liu, Yuxuan Cai, Qiuyue Wang, Aidong Men, Huan Yang
Current methods for generating human motion videos rely on extracting pose sequences from reference videos, which restricts flexibility and control. Additionally, due to the limitations of pose detection techniques, the extracted pose sequences can sometimes be inaccurate, leading to low-quality video outputs. We introduce a novel task aimed at generating human motion videos solely from reference images and natural language. This approach offers greater flexibility and ease of use, as text is more accessible than the desired guidance videos. However, training an end-to-end model for this task requires millions of high-quality text and human motion video pairs, which are challenging to obtain. To address this, we propose a new framework called Fleximo, which leverages large-scale pre-trained text-to-3D motion models. This approach is not straightforward, as the text-generated skeletons may not consistently match the scale of the reference image and may lack detailed information. To overcome these challenges, we introduce an anchor point based rescale method and design a skeleton adapter to fill in missing details and bridge the gap between text-to-motion and motion-to-video generation. We also propose a video refinement process to further enhance video quality. A large language model (LLM) is employed to decompose natural language into discrete motion sequences, enabling the generation of motion videos of any desired length. To assess the performance of Fleximo, we introduce a new benchmark called MotionBench, which includes 400 videos across 20 identities and 20 motions. We also propose a new metric, MotionScore, to evaluate the accuracy of motion following. Both qualitative and quantitative results demonstrate that our method outperforms existing text-conditioned image-to-video generation methods. All code and model weights will be made publicly available.
当前生成人类运动视频的方法依赖于从参考视频中提取姿态序列,这限制了灵活性和控制性。此外,由于姿态检测技术的局限性,提取的姿态序列有时可能不准确,导致视频输出质量低下。我们引入了一项旨在仅从参考图像和自然语言生成人类运动视频的新任务。这种方法提供了更大的灵活性和易用性,因为文本比所需的指导视频更容易获取。然而,为这个任务训练端到端模型需要数百万高质量文本和人类运动视频对,这是难以获得的。
为了解决这个问题,我们提出了一个名为Fleximo的新框架,它利用大规模预训练的文本到3D运动模型。这种方法并不简单,因为文本生成的骨架可能无法与参考图像的比例一致,并且可能缺乏详细信息。为了克服这些挑战,我们提出了一种基于锚点的重新缩放方法,并设计了一个骨架适配器来填补缺失的细节,并弥合了文本到运动和运动到视频生成之间的差距。我们还提出了一个视频优化过程,以进一步提高视频质量。
论文及项目相关链接
摘要
本文介绍了基于参考图像和自然语言的全新人体运动视频生成任务。针对现有从参考视频提取姿态序列的方法的限制,如灵活性不足和准确度问题,本文提出了Fleximo框架。该框架利用大规模预训练的文本到3D运动模型,通过锚点重缩放方法和骨架适配器技术解决文本生成骨架与参考图像尺度不匹配及细节缺失的问题。此外,本文还引入了视频优化流程以提高视频质量。采用大型语言模型将自然语言分解为离散运动序列,实现任意长度的运动视频生成。本文建立了新的MotionBench基准测试集和MotionScore评估指标,以评估Fleximo的性能。结果证明,该方法优于现有的文本条件下图像到视频的生成方法。
关键见解
- 引入全新任务:基于参考图像和自然语言生成人体运动视频,提高灵活性和易用性。
- 现有方法依赖于参考视频,存在灵活性和准确度问题。
- Fleximo框架利用大规模预训练文本到3D运动模型解决这一问题。
- 引入锚点重缩放方法和骨架适配器技术,解决文本生成骨架与参考图像尺度不匹配及细节缺失的问题。
- 采用大型语言模型分解自然语言为离散运动序列,实现任意长度运动视频生成。
- 建立新的MotionBench基准测试集和MotionScore评估指标以评估性能。
- Fleximo方法优于现有文本条件下图像到视频的生成方法。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为Fleximo的新框架,旨在解决以下问题:
生成人类动作视频的灵活性和控制问题:现有的方法依赖于从参考视频中提取姿势序列,这限制了灵活性和精确度。由于姿势检测技术的局限性,提取的姿势序列可能不准确,导致生成的视频质量低下。
训练端到端模型的数据获取难题:为了训练一个能够仅基于参考图像和自然语言生成人类动作视频的模型,需要数百万高质量的文本和人类动作视频对,这些数据难以获得。
生成的2D骨架与参考图像的比例不匹配问题:文本生成的骨架可能与参考图像的比例不一致,导致生成的视频与参考图像中的人物身份不一致。
2D骨架细节信息缺失问题:尤其是手部和面部等区域的细节信息不足。
为了解决这些问题,论文提出了以下解决方案:
Fleximo框架:利用大规模预训练的文本到3D动作模型,通过将3D网格投影到2D骨架上指导视频生成。
锚点基于的重缩放方法:使用参考图像的关键点和帧间仿射变换进行比例调整,以匹配参考图像的比例。
骨架适配器:填补缺失的细节信息,生成包含准确手部动作的完整骨架视频。
视频细化过程:进一步提高视频质量。
大型语言模型(LLM):处理长文本输入,通过将它们分割成离散的动作部分,使得框架能够生成任何所需长度的动作序列和视频。
这些解决方案旨在提高生成人类动作视频的灵活性和易用性,同时提高视频输出的质量。
Q: 有哪些相关研究?
A: 论文中提到了多个与文本到动作生成(Text-to-Motion Generation)和动作到视频生成(Motion-to-Video Generation)相关的研究工作。以下是一些主要的相关研究:
文本到动作生成(Text-to-Motion Generation)
**MDM [28]**:引入了一个基于扩散的生成模型,分别在不同的动作任务上进行训练。
**MLD [5]**:扩展了潜在扩散模型到从不同的条件输入生成动作。
**T2M-GPT [39]**:探索了一个结合VQ-VAE和GPT的生成框架,用于从文本生成动作。
这些方法成功地从文本生成了3D动作网格,但它们不适合视频生成,因为它们在3D空间中操作,导致比例不一致和缺失面部及手部信息。
动作到视频生成(Motion-to-Video Generation)
**Disco [32]**:引入了一个姿势和背景控制网络,以控制角色动作并保持背景一致性。
**MagicPose [2]**:使用外观控制模型增强生成质量。
**MagicAnimate [36]**:用DensePose替换OpenPose,遵循类似的方法。
**AnimateAnyone [12]**:采用两阶段训练过程,分别训练ReferenceNet和动作层,确保更好的角色ID一致性。
**Champ [45]**:通过结合SMPL序列的深度图像、法线贴图和语义贴图以及基于骨架的动作指导,丰富视频生成。
**MimicMotion [43]**:提出信心感知的姿势指导和区域损失放大,以处理姿势检测器的噪声,实现高质量的人类舞蹈视频。
这些方法能够产生高质量的动作视频,但它们依赖于获取骨架或网格序列进行条件控制,这可能不够用户友好和可控。
其他相关研究
**RPG Diffusion [37]**:用于处理长文本输入,将长输入动作文本分割成较小的动作段。
**MotionLLM [4]**:用于评估生成视频与动作文本的对齐程度。
这些研究为文本到人类动作视频生成领域提供了理论基础和技术手段,Fleximo框架在这些研究的基础上,通过结合文本到3D动作模型和骨架适配器等技术,提出了一种新的解决方案来生成更高质量、更灵活的人类动作视频。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Fleximo的新框架来解决这个问题,具体解决方案包括以下几个关键步骤:
1. 利用预训练的文本到3D动作模型
Fleximo框架利用了大规模数据预训练的文本到3D动作模型,将文本转换成3D网格顶点,然后将这些顶点投影到2D空间中,形成2D骨架点序列。这一步骤将文本描述的动作转换成了可以用于视频生成的骨架序列。
2. 锚点基于的重缩放方法
为了解决生成的2D骨架与参考图像的比例不一致的问题,论文提出了一种基于锚点的重缩放方法。该方法首先使用仿射变换对齐生成的骨架关键点和参考图像中检测到的关键点,然后选择一个锚点(如颈部),并单独调整每个连接的关键点,以确保与参考图像中的身体部位长度完全一致。
3. 骨架适配器
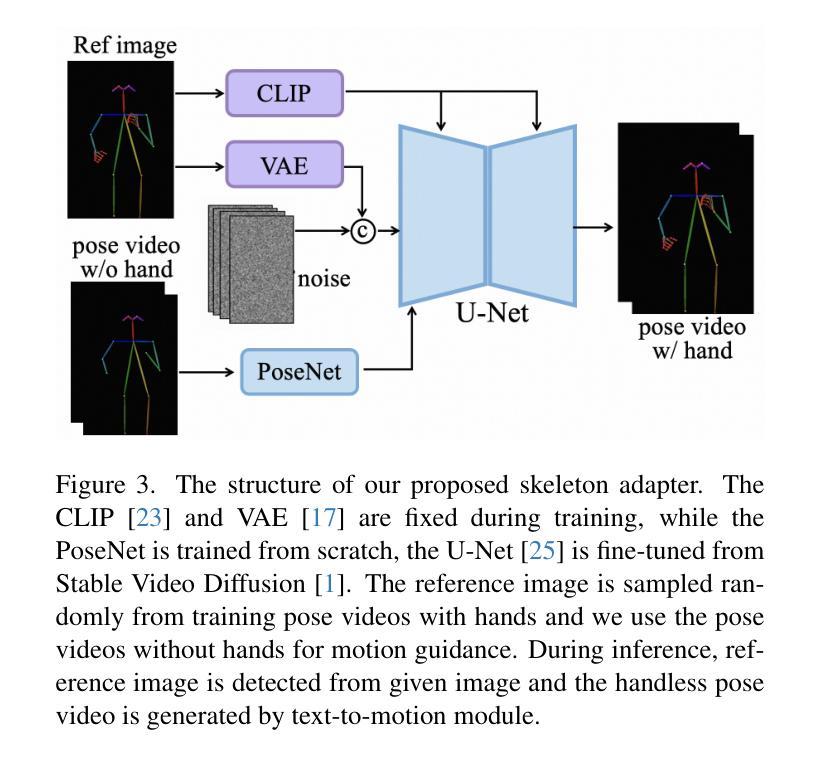
为了补偿文本生成的骨架视频中缺失的面部和手部细节信息,论文设计了一个骨架适配器。这个适配器通过训练一个视频扩散模型,使用无手部信息的骨架视频作为动作指导,同时使用带有手部信息的参考图像作为动作细节的补充,从而生成包含手部细节的完整骨架视频。
4. 视频细化过程
为了进一步提高生成视频的质量,论文提出了一个视频细化过程。首先,使用参考图像和文本生成的骨架视频生成一个初始锚视频,然后使用DWPose从锚视频中提取骨架视频,最后将这个提取的骨架视频和参考图像一起用于生成最终的细化运动视频。
5. 大型语言模型(LLM)规划
为了处理长文本输入并生成任意长度的动作序列,论文引入了一个大型语言模型(LLM),将长文本输入分割成离散的动作部分,使得框架能够生成任意长度的动作序列和视频。
6. 性能评估
为了评估Fleximo的性能,论文引入了一个新的基准测试集MotionBench和一个新的评估指标MotionScore。MotionBench包含400个视频,涵盖了20个不同身份和20种不同的动作。MotionScore用于评估生成视频与输入动作文本的对齐程度。
通过这些技术和方法的结合,Fleximo框架能够生成高质量、与文本描述一致的人类动作视频,同时保持参考图像中人物的身份特征。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估Fleximo框架的性能,包括以下几个方面:
1. 实施细节
- 模型在HumanVid数据集上进行训练,包含约8K个高质量的垂直人类动作视频。
- U-Net和PoseNet的权重从MimicMotion初始化。
- 学习率设置为(10^{-5}),没有线性预热。
- 使用8个NVIDIA H100 GPU(80G)进行训练,分辨率为1024(高度)×576(宽度),训练步数为50K,帧长为14,每个设备的批量大小为1。
2. 与其他SOTA方法的比较
- 与现有的最先进的文本条件图像到视频方法进行比较,包括I2VGen-XL、VideoCrafter和DynamiCrafter。
- 通过视觉结果和定量指标进行比较,包括PSNR、SSIM、LPIPS、DreamSim、FID、FVD和MotionScore。
3. 骨架适配器生成的骨架视频
- 展示了骨架适配器如何从无手部信息的骨架视频中生成包含详细和现实手部信息的骨架视频。
4. 用户研究
- 进行了一项盲用户研究,8名参与者对不同方法生成的800个视频进行评分,从视频质量、身份保持和动作-文本对齐三个方面进行评估。
5. 消融研究
- 对Fleximo中提出的各个模块进行了消融研究,以验证每个组件的有效性,包括锚点重缩放、骨架适配器、LLM规划和视频细化。
6. 失败案例和局限性
- 讨论了Fleximo在生成大规模动作时的挑战,例如在文本提示中包含显著位置变化的动作时,保持身份和身体一致性的困难。
7. MotionBench基准测试
- 介绍了新基准测试集MotionBench,包含400个视频,涵盖20个不同身份和20种不同的动作,并提出了新的评估指标MotionScore。
这些实验全面评估了Fleximo框架在生成与文本描述一致的高质量人类动作视频方面的性能,并与其他现有方法进行了比较。通过这些实验,论文证明了Fleximo在灵活性和用户友好性方面的优势,以及在生成细节丰富、与文本描述一致的视频方面的有效性。
Q: 有什么可以进一步探索的点?
A: 尽管Fleximo框架在文本到人类动作视频生成方面取得了显著成果,但仍有一些领域可以进一步探索和改进:
1. 提高动作和文本对齐的准确性
尽管引入了MotionScore来评估动作和文本之间的对齐程度,但仍可以探索更复杂的自然语言处理技术,以更准确地理解和生成与文本描述完全一致的动作。
2. 改善大规模动作的生成质量
如论文中提到的,Fleximo在处理涉及大幅度位置变化的动作时存在挑战。研究如何更好地维持身份和身体一致性,尤其是在复杂和动态的场景中,是一个重要的研究方向。
3. 增强交互动作的生成
目前的框架主要关注单人动作的生成,而交互动作(如人与人之间的互动)的生成则更具挑战性。探索如何生成自然且真实的交互动作视频是一个值得研究的问题。
4. 多样化和泛化能力的提升
虽然MotionBench提供了多样化的数据集,但进一步增加数据集的多样性和复杂性,以及提升模型在未见动作和身份上的泛化能力,将使模型更加健壮和实用。
5. 减少对高质量数据集的依赖
预训练模型需要大量的高质量数据。研究如何减少对大规模数据集的依赖,例如通过迁移学习或自监督学习,可以使模型更加灵活和易于训练。
6. 提升计算效率
当前模型需要大量的计算资源进行训练和推理。探索更高效的模型架构和训练策略,以减少计算需求,对于实际应用尤为重要。
7. 探索更多的条件输入
除了文本之外,还可以考虑将音频、图像或其他传感器数据作为额外的输入条件,以生成更加丰富和动态的视频内容。
8. 改善模型的解释性和控制性
提高模型的可解释性,让用户能够更好地理解和控制生成过程,可以提升用户体验,并在特定应用中实现更精确的生成效果。
9. 伦理和隐私问题
随着生成技术的发展,伦理和隐私问题也日益重要。研究如何在保护个人隐私的同时,合理使用生成技术,是一个重要的研究方向。
这些探索方向不仅可以推动文本到视频生成技术的发展,还可能对计算机视觉、自然语言处理和机器学习等领域产生深远影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出了现有方法在生成人类动作视频时存在的局限性,包括依赖于提取的姿势序列限制了灵活性和控制能力,以及提取的姿势序列可能不准确导致视频质量下降。
新任务提出:
- 论文提出了一个新的任务:仅使用参考图像和自然语言文本生成人类动作视频,这提供了更大的灵活性和易用性。
Fleximo框架:
- 论文介绍了一个名为Fleximo的新框架,该框架利用大规模预训练的文本到3D动作模型,通过将3D网格投影到2D骨架上指导视频生成,并提出了锚点基于的重缩放方法和骨架适配器来解决比例不匹配和细节信息缺失的问题。
视频细化和LLM规划:
- 引入了视频细化过程来进一步提高视频质量,并使用大型语言模型(LLM)处理长文本输入,将它们分割成离散的动作部分,以生成任意长度的动作序列和视频。
性能评估:
- 论文提出了一个新的基准测试集MotionBench和一个新的评估指标MotionScore,用于评估生成视频与输入动作文本的对齐程度。
实验结果:
- 通过与其他现有方法的比较、用户研究和消融研究,论文证明了Fleximo在生成高质量、与文本描述一致的人类动作视频方面的优越性能。
讨论和局限性:
- 论文讨论了Fleximo的局限性,例如在生成大规模动作时的挑战,并提出了未来可能的研究方向。
总体而言,这篇论文提出了一个新的任务和框架,用于从文本和参考图像生成人类动作视频,通过一系列创新技术和评估方法,展示了在该领域的最新进展和潜在应用。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


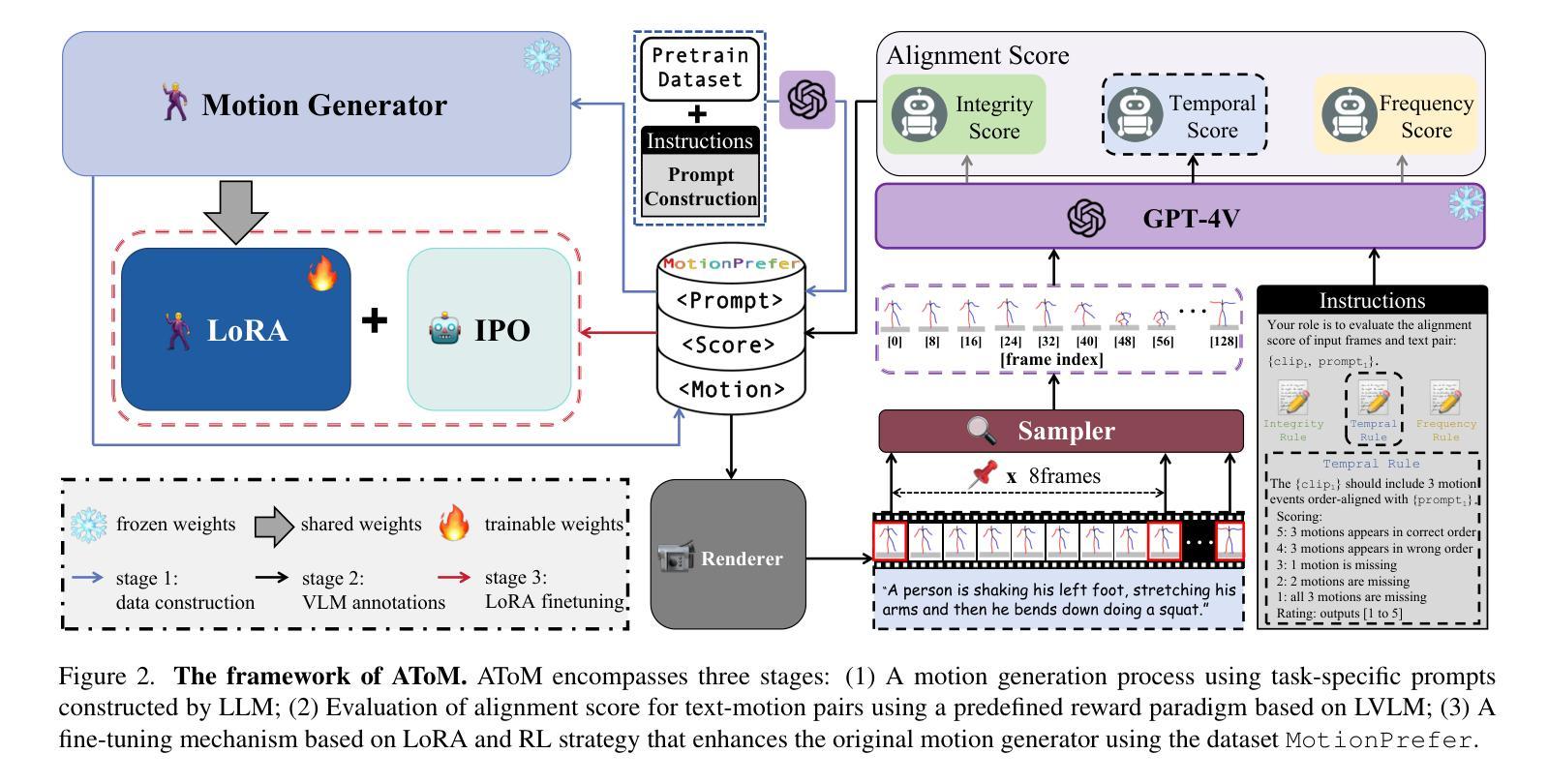
AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward
Authors:Haonan Han, Xiangzuo Wu, Huan Liao, Zunnan Xu, Zhongyuan Hu, Ronghui Li, Yachao Zhang, Xiu Li
Recently, text-to-motion models have opened new possibilities for creating realistic human motion with greater efficiency and flexibility. However, aligning motion generation with event-level textual descriptions presents unique challenges due to the complex relationship between textual prompts and desired motion outcomes. To address this, we introduce AToM, a framework that enhances the alignment between generated motion and text prompts by leveraging reward from GPT-4Vision. AToM comprises three main stages: Firstly, we construct a dataset MotionPrefer that pairs three types of event-level textual prompts with generated motions, which cover the integrity, temporal relationship and frequency of motion. Secondly, we design a paradigm that utilizes GPT-4Vision for detailed motion annotation, including visual data formatting, task-specific instructions and scoring rules for each sub-task. Finally, we fine-tune an existing text-to-motion model using reinforcement learning guided by this paradigm. Experimental results demonstrate that AToM significantly improves the event-level alignment quality of text-to-motion generation.
最近,文本到动作模型以更高的效率和灵活性为创建逼真的人类动作开启了新的可能性。然而,由于文本提示和期望的动作结果之间的复杂关系,使动作生成与事件级别文本描述对齐带来了独特的挑战。为了解决这一问题,我们引入了AToM框架,该框架通过利用GPT-4Vision的奖励来增强生成动作与文本提示之间的对齐。AToM主要包括三个阶段:首先,我们构建了一个MotionPrefer数据集,将三种事件级别的文本提示与生成的动作配对,涵盖了动作的完整性、时间关系和频率。其次,我们设计了一种利用GPT-4Vision进行详细动作注释的方法,包括视觉数据格式化、针对特定任务的指令以及每个子任务的评分规则。最后,我们使用由此范式引导的强化学习对现有的文本到动作模型进行微调。实验结果表明,AToM显著提高了文本到动作生成的事件级别对齐质量。
论文及项目相关链接
摘要
文本到动作模型为创建更真实、更高效和更灵活的人类动作提供了新的可能性。然而,由于文本提示和期望的动作结果之间的复杂关系,将动作生成与事件级别的文本描述对齐带来了独特的挑战。为应对这一挑战,我们引入了AToM框架,它通过利用GPT-4Vision的奖励来增强生成动作与文本提示之间的对齐。AToM包括三个阶段:首先,我们构建了一个MotionPrefer数据集,该数据集将三种事件级别的文本提示与生成的动作配对,涵盖了动作的完整性、时间关系和频率。其次,我们设计了一种利用GPT-4Vision进行详细动作注释的方法,包括视觉数据格式化、针对任务的特定指令以及每项子任务的计分规则。最后,我们使用此范式通过强化学习微调现有的文本到动作模型。实验结果表明,AToM显著提高了文本到动作生成的的事件级别对齐质量。
关键见解
- 文本到动作模型能够更有效率且灵活地创建真实人类动作。
- 对齐文本提示和期望动作结果存在挑战,因两者间存在复杂关系。
- AToM框架通过利用GPT-4Vision的奖励增强了生成动作与文本提示的对齐。
- AToM包括构建MotionPrefer数据集、设计GPT-4Vision利用方法和强化学习微调现有文本到动作模型三个主要阶段。
- MotionPrefer数据集涵盖动作的完整性、时间关系和频率。
- 利用GPT-4Vision进行详细的动作注释包括视觉数据格式化、特定任务指令和子任务计分规则的设计。
- AToM显著提高了文本到动作生成的的事件级别对齐质量。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是文本到动作(text-to-motion)模型在根据文本提示生成人体动作时与事件级别的文本描述对齐的挑战。具体来说,挑战存在于以下几个方面:
复杂文本提示与期望动作结果之间的复杂关系:由于文本提示和期望动作结果之间存在复杂的映射关系,模型很难准确地将复杂的文本描述(例如,包含多个动作事件或具有时间关系和指定频率的动作)映射到相应的动作序列。
数据稀缺和粗糙的文本描述:现有的文本-动作对数据稀缺,且文本描述通常是粗糙的,覆盖的动作场景有限,这限制了模型对新颖描述的泛化能力。
模型泛化能力有限:由于上述限制,模型在零样本和多事件场景下的性能表现不佳,难以处理复杂的文本提示。
为了解决这些问题,论文提出了一个名为AToM的框架,该框架通过利用GPT-4Vision提供的奖励来增强生成动作和文本提示之间的对齐度。AToM框架包含三个主要阶段:构建与事件级别的文本提示配对的数据集、设计利用GPT-4Vision进行详细动作标注的范式,以及使用这种范式指导的强化学习来微调现有的文本到动作模型。实验结果表明,AToM显著提高了文本到动作生成的事件级别对齐质量。
Q: 有哪些相关研究?
A: 论文中提到了多个与文本到动作生成(Text-to-Motion, T2M)相关的研究工作,以下是一些主要的相关研究:
Text2Action [2]:利用基于SEQ2SEQ模型的GAN将简短描述映射到人体动作。
Language2Pose [3]:引入了一种课程学习方法,用于开发文本和姿态的关节级嵌入。
Lin et al. [18]:提出了一个端到端的SEQ2SEQ模型,用于生成更真实的动画。
Ghosh et al. [10]:开发了一个分层的双流序列模型,能够处理描述多个动作的长句子。
MotionCLIP [30]:将人类动作流形与CLIP空间对齐,赋予模型零样本能力。
TEACH [5]:基于Transformer的模型,能够生成遵循复杂、顺序动作指令的真实3D人体动作。
TEMOS [36]:使用基于Transformer的VAE和额外的文本编码器进行多对象3D场景生成和编辑。
T2M-GPT [33]:结合VQ-VAE和GPT获得高质量的离散表示,实现有竞争力的动作生成结果。
MotionDiffuse [34]:基于扩散模型,允许对身体部位进行细粒度控制。
MDM [27]:无分类器的扩散模型,预测动作样本而非噪声,便于几何损失的应用。
MLD [9]:使用潜在扩散模型进一步推进动作生成。
MotionGPT [15]:开发了统一的大型动作语言模型,通过离散向量量化表示人类动作。
除了这些,论文还讨论了与人类/AI反馈对齐模型相关的研究,包括:
Reinforcement Learning from Human Feedback (RLHF) [7, 22]:用于模型对齐的技术,特别是在目标复杂或不明确的情况下。
Direct Preference Optimization (DPO) [25] 和 Slic-hf [37]:直接基于人类偏好优化模型策略的方法。
InstructMotion [29]:第一个通过人类反馈的强化学习微调文本到动作模型的工作。
RLAIF [8]:展示了另一种有前景的替代方案,即使用AI反馈进行模型对齐。
这些研究构成了文本到动作生成领域的研究基础,并为本文提出的AToM框架提供了理论和技术背景。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为AToM(Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward)的框架来解决文本到动作模型与事件级别文本描述对齐的问题。AToM框架主要包含以下三个阶段:
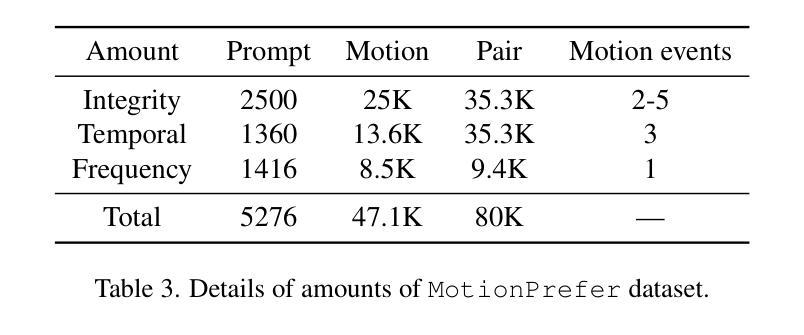
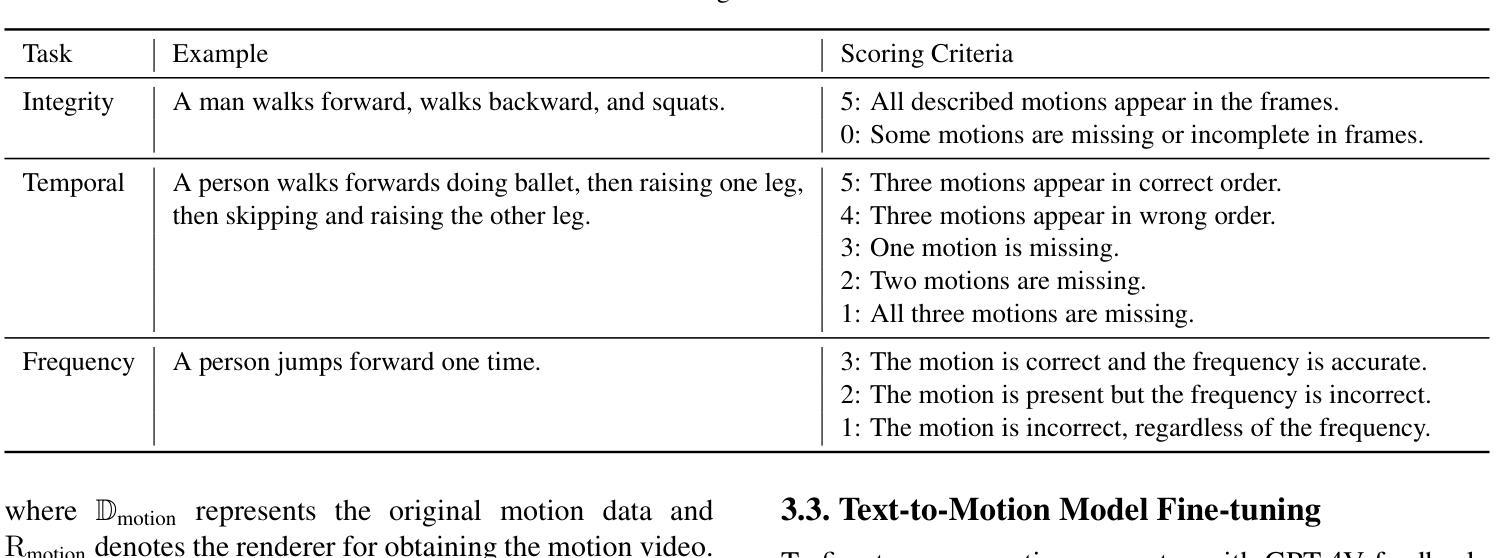
1. 数据集构建(Dataset Construction)
- 首先,研究者们构建了一个名为MotionPrefer的数据集,该数据集将三种类型的事件级别文本提示与生成的动作配对,涵盖了动作的完整性、时间关系和频率。
- 使用GPT-4生成初始文本提示,然后输入到动作生成模型(例如MotionGPT)中,为每个文本提示生成多个不同的动作。
- 总共包含5,276个提示和47.1k个动作样本。
2. 奖励范式设计(Reward Paradigm Design)
- 将MotionGPT生成的动作序列渲染成视频,并从中采样一系列帧。
- 将采样的动作帧和对应的文本提示输入到GPT-4Vision模型中,利用该模型评估文本和动作之间的对齐得分。
- 根据给定的评分规则为每个子任务(完整性、时间顺序和频率)计算对齐得分,生成带有对齐得分的文本-动作对,构成MotionPrefer数据集。
3. 文本到动作模型微调(Text-to-Motion Model Fine-tuning)
- 使用MotionPrefer数据集和GPT-4Vision的对齐得分作为反馈,微调现有的文本到动作模型(如MotionGPT)。
- 采用LoRA(Low-Rank Adaptation)和IPO(一种强化学习策略)算法进行微调,以提高模型在特定任务上的对齐性能。
- 实验结果表明,AToM显著提高了文本到动作生成的事件级别对齐质量。
通过这三个阶段,AToM框架能够有效地利用视觉语言大模型(如GPT-4Vision)的反馈,显著提高文本到动作模型在事件级别上的对齐质量,从而在文本提示和生成动作之间建立更加精确的对应关系。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估AToM框架的有效性,这些实验主要分为以下几个部分:
1. 实施细节(Implementation Details)
- 数据集:使用预训练的MotionGPT模型,并在MotionPrefer数据集的三个子集上进行微调,分别针对时间、完整性和频率任务。
- 实现具体内容:设置了学习率、批量大小和训练周期等超参数,并使用了AdamW优化器和余弦学习率调度器。
- 评估指标:包括多模态距离(MM-Dist)、R-Precision、FID、多样性和MModality等,用于评估动作质量和文本-动作对齐度。
2. 主要结果(Main Results)
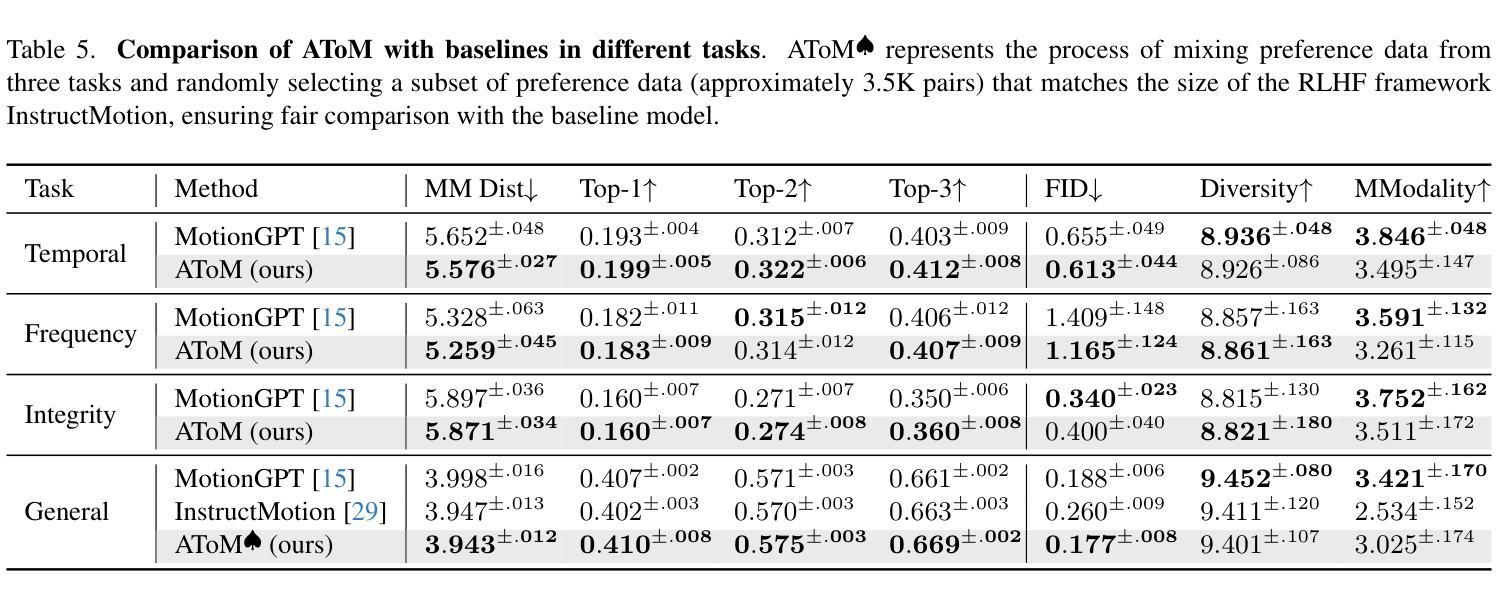
- 定量实验:在时间、频率和完整性任务中,AToM在多个评估指标上一致优于基线模型(MotionGPT和InstructMotion),显示出更好的文本-动作对齐度、动作质量和生成真实性。
- 定性实验:通过视觉样本比较,展示了预训练模型(MotionGPT)和微调后的模型(AToM)在生成忠实度上的差异,AToM在多样化动作事件、复杂时间顺序和特定频率方面表现更优。
- 用户研究:50名参与者对AToM和MotionGPT生成的动作在时间、频率和完整性方面进行了评估,AToM在所有子任务中的胜率均高于MotionGPT。
3. 消融研究(Ablation Study)
- 动作注入形式:比较了三种不同的动作注入策略(逐帧、全图像、轨迹图像)对GPT-4V提问的影响。
- 分数过滤:研究了在偏好对构建中使用分数过滤的效果,只有评分高于3的样本被视为正面样本。
- LoRA利用:探讨了LoRA在微调中的效果,与传统微调方法相比,LoRA能够更有效地调整模型参数。
- 强化学习策略:比较了不同的强化学习策略(IPO、DPO、KTO、PPO)在生成模型微调后的表现。
- 动作序列采样步长:研究了不同帧采样间隔对对齐和质量指标的影响。
4. 额外结果(Additional Results)
- 更多定性结果:提供了额外的AToM和基线模型生成的视觉样本比较。
- 微调迭代次数:探讨了微调迭代次数对模型性能的影响。
- IPO超参数β的影响:分析了IPO策略中超参数β对对齐和质量指标的影响。
- 偏好数据集体积对模型性能的影响:研究了偏好对数量对模型性能的影响。
这些实验全面评估了AToM框架在不同方面的表现,并与现有技术进行了比较,证明了其在提高文本到动作模型对齐质量方面的有效性。
Q: 有什么可以进一步探索的点?
A: 基于论文内容和实验结果,以下是一些可以进一步探索的点:
1. 扩展数据集的多样性和复杂性
- 跨领域数据集:探索将AToM框架应用于更广泛的动作类型和场景,例如体育活动、舞蹈和日常复杂交互。
- 多语言支持:研究模型对不同语言文本提示的泛化能力,并构建多语言数据集进行训练和测试。
2. 增强模型的解释性和可视化
- 注意力机制分析:通过引入注意力机制来分析模型在处理特定文本提示时关注的区域,增强模型的解释性。
- 生成过程可视化:研究生成过程中的关键帧和动作变化,以可视化的方式展示模型是如何根据文本提示生成动作的。
3. 探索不同的强化学习策略
- 混合策略:结合人类反馈和AI反馈的优势,开发混合强化学习策略以进一步提高模型性能。
- 自适应策略:研究自适应调整强化学习策略中的参数,以动态适应不同的训练阶段和任务需求。
4. 提升模型的鲁棒性和泛化能力
- 对抗训练:通过引入对抗样本来测试和增强模型的鲁棒性,特别是在面对异常或模糊的文本提示时。
- 零样本学习:探索模型在零样本或少样本情况下的泛化能力,尤其是在未见过的动作类型或描述上。
5. 跨模态应用和集成
- 动作识别和预测:将AToM框架应用于动作识别和预测任务,评估模型在视频理解和未来动作预测方面的表现。
- 虚拟现实和游戏:将模型集成到虚拟现实和游戏引擎中,实现基于自然语言指令的实时动作生成和控制。
6. 优化和加速训练过程
- 分布式训练:研究如何利用分布式计算资源来加速模型的训练过程。
- 模型压缩和加速:探索模型压缩技术,减少模型大小和计算需求,使其更适合在资源受限的设备上运行。
7. 社会和伦理考量
- 偏见和公平性:评估和解决模型可能存在的偏见问题,确保生成的动作多样性和包容性。
- 用户隐私和数据安全:在使用真实世界数据进行训练和测试时,确保遵守数据保护法规和用户隐私。
这些探索点可以帮助研究者们更深入地理解AToM框架的潜力和局限性,并推动文本到动作生成技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一个名为AToM(Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward)的框架,旨在提高文本到动作(Text-to-Motion, T2M)模型在事件级别上与文本提示对齐的质量。以下是论文的主要内容总结:
1. 问题背景
- 文本到动作模型能够根据文本提示生成人体动作,但在处理复杂的、多动作事件的文本描述时面临挑战。
- 现有模型在泛化到未见过的文本描述和多事件场景时受限,需要更精细的对齐评估。
2. AToM框架
- 数据集构建:创建了一个名为MotionPrefer的数据集,包含5.3K个文本提示和80K个动作偏好对,涵盖动作的完整性、时间关系和频率。
- 奖励范式设计:利用GPT-4Vision对生成的动作序列和文本描述之间的对齐进行评分,基于给定的评分规则计算对齐得分。
- 模型微调:使用MotionPrefer数据集和GPT-4Vision的对齐得分作为反馈,通过LoRA和IPO强化学习策略微调现有的文本到动作模型。
3. 实验结果
- 定量实验:AToM在多个评估指标上优于基线模型,显示出更好的文本-动作对齐度、动作质量和生成真实性。
- 定性实验:通过视觉样本比较,展示了AToM在生成忠实度上的优势。
- 用户研究:AToM在所有子任务中的用户评估胜率均高于基线模型。
4. 消融研究
- 探讨了不同的动作注入策略、分数过滤、LoRA利用和强化学习策略对模型性能的影响。
5. 结论
- AToM框架有效地利用视觉语言大模型的反馈,显著提高了文本到动作生成的事件级别对齐质量,为文本提示和生成动作之间建立了更精确的对应关系。
这篇论文通过提出一个新的框架,解决了文本到动作模型在复杂文本描述下对齐质量不足的问题,并展示了通过利用先进的视觉语言模型进行微调可以显著提升模型性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


FTMoMamba: Motion Generation with Frequency and Text State Space Models
Authors:Chengjian Li, Xiangbo Shu, Qiongjie Cui, Yazhou Yao, Jinhui Tang
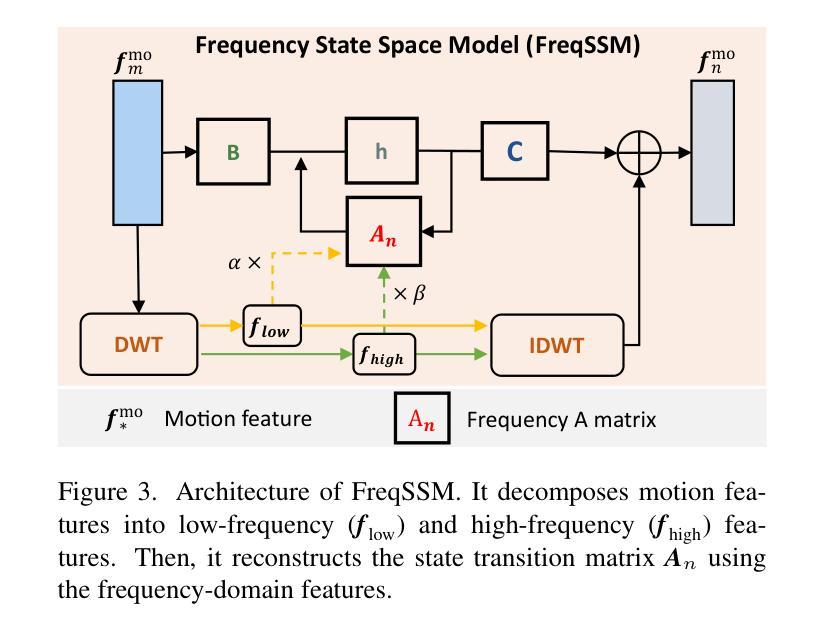
Diffusion models achieve impressive performance in human motion generation. However, current approaches typically ignore the significance of frequency-domain information in capturing fine-grained motions within the latent space (e.g., low frequencies correlate with static poses, and high frequencies align with fine-grained motions). Additionally, there is a semantic discrepancy between text and motion, leading to inconsistency between the generated motions and the text descriptions. In this work, we propose a novel diffusion-based FTMoMamba framework equipped with a Frequency State Space Model (FreqSSM) and a Text State Space Model (TextSSM). Specifically, to learn fine-grained representation, FreqSSM decomposes sequences into low-frequency and high-frequency components, guiding the generation of static pose (e.g., sits, lay) and fine-grained motions (e.g., transition, stumble), respectively. To ensure the consistency between text and motion, TextSSM encodes text features at the sentence level, aligning textual semantics with sequential features. Extensive experiments show that FTMoMamba achieves superior performance on the text-to-motion generation task, especially gaining the lowest FID of 0.181 (rather lower than 0.421 of MLD) on the HumanML3D dataset.
扩散模型在人类运动生成方面取得了令人印象深刻的性能表现。然而,当前的方法通常忽略了潜在空间中捕获精细运动频率域信息的重要性(例如,低频与静态姿势相关,高频与精细运动对齐)。此外,文本与运动之间存在语义差异,导致生成的运动与文本描述之间存在不一致。在这项工作中,我们提出了一种配备频率状态空间模型(FreqSSM)和文本状态空间模型(TextSSM)的新型基于扩散的FTMoMamba框架。具体来说,为了学习精细表示,FreqSSM将序列分解为低频和高频组件,分别指导静态姿势(例如坐、躺)和精细运动(例如过渡、跌倒)的生成。为了确保文本与运动之间的一致性,TextSSM在句子级别对文本特征进行编码,将文本语义与序列特征对齐。大量实验表明,FTMoMamba在文本到运动生成任务上表现卓越,特别是在HumanML3D数据集上实现了最低的门级度失真指数(FID)为0.181(远低于MLD的0.421)。
论文及项目相关链接
PDF 8 pages, 6 figures
Summary
本文介绍了扩散模型在人类运动生成方面的出色表现,但现有方法忽略了频率域信息在捕捉精细运动中的重要性。为此,本文提出了一种基于扩散的FTMoMamba框架,结合了频率状态空间模型(FreqSSM)和文本状态空间模型(TextSSM)。FreqSSM将序列分解为低频和高频成分以进行精细表示,分别引导静态姿势和精细运动的生成。TextSSM则通过句子级别的文本特征编码,确保文本与运动的一致性。实验表明,FTMoMamba在文本到运动生成任务上具有卓越性能,特别是在HumanML3D数据集上获得了较低的FID得分。
Key Takeaways
- 扩散模型在人类运动生成方面表现出色。
- 当前方法忽略了频率域信息在捕捉精细运动中的重要性。
- 提出的FTMoMamba框架结合了FreqSSM和TextSSM。
- FreqSSM通过分解序列为低频和高频成分来捕捉精细运动。
- TextSSM通过句子级别的文本特征编码确保文本与运动的一致性。
- FTMoMamba在文本到运动生成任务上具有卓越性能。
- 在HumanML3D数据集上,FTMoMamba的FID得分较低。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题主要集中在人类动作生成领域,特别是基于文本描述生成人类动作的任务。具体来说,论文旨在解决以下两个主要问题:
细粒度动作捕捉:现有基于扩散模型的方法通常忽略了频率域信息在潜在空间中捕捉细粒度动作的重要性。例如,低频信息与静态姿势相关,而高频信息与细粒度动作对齐。论文提出通过引入频率域信息来分别捕捉静态姿势和细粒度动作。
文本与动作的语义一致性:大多数基于扩散模型的方法不能很好地确保文本-动作语义信息在时空空间中的一致性,这是由于文本描述和动作序列之间固有的差异导致的。论文提出通过优化文本条件指导的设计来准确对齐文本和动作,以解决这个问题。
为了解决这些问题,论文提出了一个新颖的基于扩散的框架FTMoMamba,该框架配备了频率状态空间模型(FreqSSM)和文本状态空间模型(TextSSM)。FreqSSM用于学习细粒度表示,通过分解序列来指导静态姿势和细粒度动作的生成。TextSSM用于确保文本和动作之间的一致性,通过在句子级别对齐文本特征和序列特征。通过这种方式,FTMoMamba框架能够在文本到动作的生成任务中实现更优的性能,特别是在降低Fréchet Inception Distance (FID)指标上,相比于现有方法有显著提升。
Q: 有哪些相关研究?
A: 论文中提到了多个与人类动作生成相关的研究工作,具体如下:
基于自编码器的方法:
- [12, 23, 27]:这些工作通过将高维信息压缩到潜在空间来鲁棒地表示数据。
基于自回归模型的方法:
- [9, 17, 37]:这些模型通过基于之前生成的动作来预测下一个动作,逐步生成动作序列。
基于扩散模型的方法:
- [5, 25, 28, 33, 35]:这些方法通过渐进的去噪过程生成高质量的动作。
频率域状态空间模型:
- [15, 20, 32]:这些方法通过将图像分解为低频和高频信息,并利用信息注入和扫描策略来增强模型的图像处理能力。
跨模态状态空间模型:
- [7, 21]:这些方法通过Mamba的多个分支提取不同模态特征,并使用交叉注意力、连接或加法进行模态特征融合。
其他相关技术:
- [1, 2]:使用生成对抗网络(GANs)来生成人类动作。
- [8]:合成由文本描述组成的组合动画。
- [11]:基于条件生成的3D人类动作。
- [13]:通过音乐-文本整合来驱动的3D舞蹈生成。
- [14]:去噪扩散概率模型,用于增强动作生成。
- [16]:基于扩散模型的鲁棒和高效动作生成框架。
- [18]:基于频率的可微分解耦用于航拍视频动作识别。
- [19]:基于时间频率信息融合的CNN-Transformer模型,用于基于单导联ECG的OSA检测。
- [24]:从自然语言监督中学习可转移的视觉模型。
- [26]:语义感知的细粒度运动风格迁移。
- [28]:人类动作扩散模型。
- [30]:用于多模态语义分割的暹罗Mamba网络。
这些相关工作涵盖了人类动作生成的不同方面,包括数据表示、生成方法、模态融合等,为本文提出的FTMoMamba框架提供了理论和技术基础。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为FTMoMamba的框架来解决细粒度动作捕捉和文本与动作的语义一致性问题,具体方法如下:
1. 频率状态空间模型(FreqSSM)
FreqSSM专注于细粒度动作的生成,通过以下步骤利用低频和高频信息:
- 特征分解:使用离散小波变换(DWT)将动作序列分解为低频和高频成分。
- 动态调整:基于原始状态转移矩阵A,动态调整低频和高频信息的比例,形成频域状态转移矩阵An。
- 状态更新:利用An作为核心,结合矩阵B更新隐藏状态矩阵h。
- 残差结合:通过逆离散小波变换(IDWT)结合f low和f high,引入频域增强信息以实现细粒度动作生成。
2. 文本状态空间模型(TextSSM)
TextSSM确保文本和动作之间的一致性,通过以下步骤实现:
- 特征投影:将特征fmo u通过线性层投影到fLinear u。
- 特征提取:使用级联深度卷积(CDWConv)提取fLinear u的潜在时序特征。
- 文本对齐:TextSSM将CLIP提取的句子级特征与状态空间模型的输出矩阵C结合,实现文本到动作的对齐。
- 特征获得:通过观察矩阵获得对齐特征,确保文本和动作之间的一致性。
3. FTMamba模块
FTMamba模块结合了FreqMamba和TextMamba,利用频域信息指导动作生成,并确保文本-动作一致性:
- 噪声特征提取:从噪声特征zt和时间步t中提取特征fmo m。
- 频域特征增强:通过FreqSSM和TextSSM增强特征,分别获取ffreq m和ftext u。
- 信息选择:使用基于乘法的方法选择由频域信息和文本信息指导的特征fmo n和fmo v。
4. 扩散模型
FTMoMamba基于扩散模型,在潜在空间中压缩和解压原始动作序列,减少数据压缩引入的冗余信息,通过迭代去噪过程生成高质量的动作序列。
5. 实验验证
通过在HumanML3D数据集上的实验,论文验证了FTMoMamba在文本到动作生成任务中的优越性能,特别是在降低Fréchet Inception Distance (FID)指标上,相比于现有方法有显著提升,证明了所提方法的有效性。
综上所述,论文通过结合频率域信息和文本语义信息,提出了一种新颖的FTMoMamba框架,有效地解决了细粒度动作捕捉和文本与动作的语义一致性问题。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估所提出的FTMoMamba框架的性能。以下是实验的具体内容:
1. 数据集
- 使用了广泛使用的动觉-语言基准数据集HumanML3D进行评估。该数据集从AMASS和HumanAct12数据集中收集了14616个动作,每个动作由3个文本脚本来描述,总共有44970个描述。它包含了多种动作,如锻炼、跳舞和杂技等。
2. 评估指标
- 采用了以下标准评估指标:
- **Fréchet Inception Distance (FID)**:衡量生成动作的整体质量,通过量化生成动作的高级特征与真实动作之间的分布差异。
- R-Precision和**Multimodal Distance (MM-Dist)**:评估输入文本和生成动作之间的语义对齐。
- Diversity:衡量动作多样性。
- **Multimodality (MModality)**:评估从同一输入文本生成的动作的多样性。
3. 实现细节
- 对比实验中,编码器和解码器使用与MLD相同的配置和权重。
- 文本嵌入( f_t )和潜在( z )的维度设置。
- 在去噪UNet架构中,FTMamba设置为在编码器、中间和解码器阶段都有2层,每层有256个通道。
- 使用CLIP-ViT-L-14模型作为文本编码器,权重固定。
- 训练时使用AdamW优化器,固定学习率为( 10^{-4} ),批量大小设置为64,模型训练2000个epoch。
4. 定量和定性比较
- 定量比较:与基线方法(如MLD)和其他SOTA方法(如MotionGPT)在各个指标上进行比较,FTMoMamba在FID、R-Precision、MM-Dist、Diversity和MModality等指标上取得了显著的改进。
- 定性比较:与MotionDiffuse、MDM和MLD等方法进行视觉比较,展示了FTMoMamba在捕捉细粒度动作和文本对齐方面的优势。
5. 消融研究
- FreqMamba和TextMamba模块的有效性:单独使用FreqMamba或TextMamba时,与基线相比在FID、Diversity和MModality上都有显著提升,表明频域信息和句子级文本特征可以有效提升动作生成质量。
- 不同频域信息提取方法的有效性:比较了FFT和DWT在提取频域信息上的效果,DWT在多个指标上表现更优。
- 低频和高频信息的影响:展示了同时使用低频和高频信息可以提升R-Precision、MM-Dist和MModality,并降低FID。
这些实验验证了FTMoMamba框架在文本驱动的人类动作生成任务中的有效性和优越性能。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的FTMoMamba框架在文本驱动的人类动作生成任务中取得了显著的性能提升,但仍有一些方面可以进一步探索和改进:
1. 物理先验和损失函数
- 论文提到,缺乏足部接触损失、姿态损失等物理相关的损失函数,这限制了在其他评估指标上的优势。未来的工作可以考虑引入这些物理先验,以进一步提升动作生成的自然性和真实性。
2. 长序列动作生成
- 尽管FTMoMamba能够有效处理长序列动作生成,但在更长序列上的性能如何,以及如何进一步提升长序列生成的稳定性和连贯性,是值得进一步研究的问题。
3. 跨模态学习
- 论文中提到了跨模态状态空间模型,但如何更有效地融合不同模态信息,以及如何利用这些信息提升动作生成的质量和多样性,是一个值得探索的方向。
4. 细粒度控制
- 论文通过FreqSSM实现了对静态姿势和细粒度动作的控制,但对于更复杂动作的细粒度控制(如手指动作、面部表情等)仍需进一步研究。
5. 模型泛化能力
- 探索FTMoMamba在不同类型的动作数据集上的表现,以及如何提升模型对新场景和新动作类型的泛化能力。
6. 实时动作生成
- 研究如何优化FTMoMamba以实现实时或近实时的动作生成,这对于VR/AR应用尤为重要。
7. 交互式应用
- 探索FTMoMamba在交互式应用中的潜力,如虚拟角色控制、游戏开发等,以及如何根据用户的实时输入调整动作生成。
8. 模型解释性
- 提高模型的可解释性,让用户更好地理解模型是如何根据文本描述生成特定动作的,这对于提高用户信任和模型的可用性至关重要。
9. 多任务学习
- 考虑将动作生成任务与其他相关任务(如动作识别、预测等)结合起来,通过多任务学习提升模型的性能和鲁棒性。
这些方向不仅可以推动文本驱动的动作生成技术的发展,还可能为计算机视觉、机器学习以及人机交互等领域带来新的突破。
Q: 总结一下论文的主要内容
A: 论文提出了一个名为FTMoMamba的新颖框架,旨在通过文本指令生成人类动作。该框架通过结合频率状态空间模型(FreqSSM)和文本状态空间模型(TextSSM)来解决两个主要问题:细粒度动作的捕捉和文本与动作之间的语义一致性。以下是论文的主要内容总结:
1. 问题陈述
- 现有基于扩散模型的方法在捕捉静态姿势和细粒度动作方面存在不足,同时在文本和动作的语义对齐上也存在挑战。
2. FTMoMamba框架
- FreqSSM:通过分解动作序列为低频和高频成分来引导生成静态姿势和细粒度动作。
- TextSSM:在句子级别对齐文本特征和序列特征,确保文本和动作的一致性。
3. 方法细节
- 使用离散小波变换(DWT)提取频率信息,并动态调整状态转移矩阵中低频和高频信息的比例。
- 利用CLIP模型提取文本特征,并与状态空间模型的输出矩阵结合,实现文本到动作的对齐。
4. 实验
- 在HumanML3D数据集上进行实验,采用FID、R-Precision、MM-Dist、Diversity和MModality等指标评估生成动作的质量、语义对齐和多样性。
- 与现有方法(如MLD和MotionGPT)相比,FTMoMamba在降低FID和提高R-Precision方面展现出显著优势。
5. 消融研究
- 验证了FreqSSM和TextSSM模块的有效性,以及不同频域信息提取方法和低频与高频信息的影响。
6. 结论与未来工作
- FTMoMamba通过频域信息和文本语义信息的结合,在文本驱动的动作生成任务中实现了优异的性能。
- 论文提出了未来可能的研究方向,包括引入物理先验、提升模型泛化能力等。
总体而言,论文通过创新性地融合频率域和文本语义信息,提出了一个有效的框架来生成高质量且与文本描述一致的人类动作。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


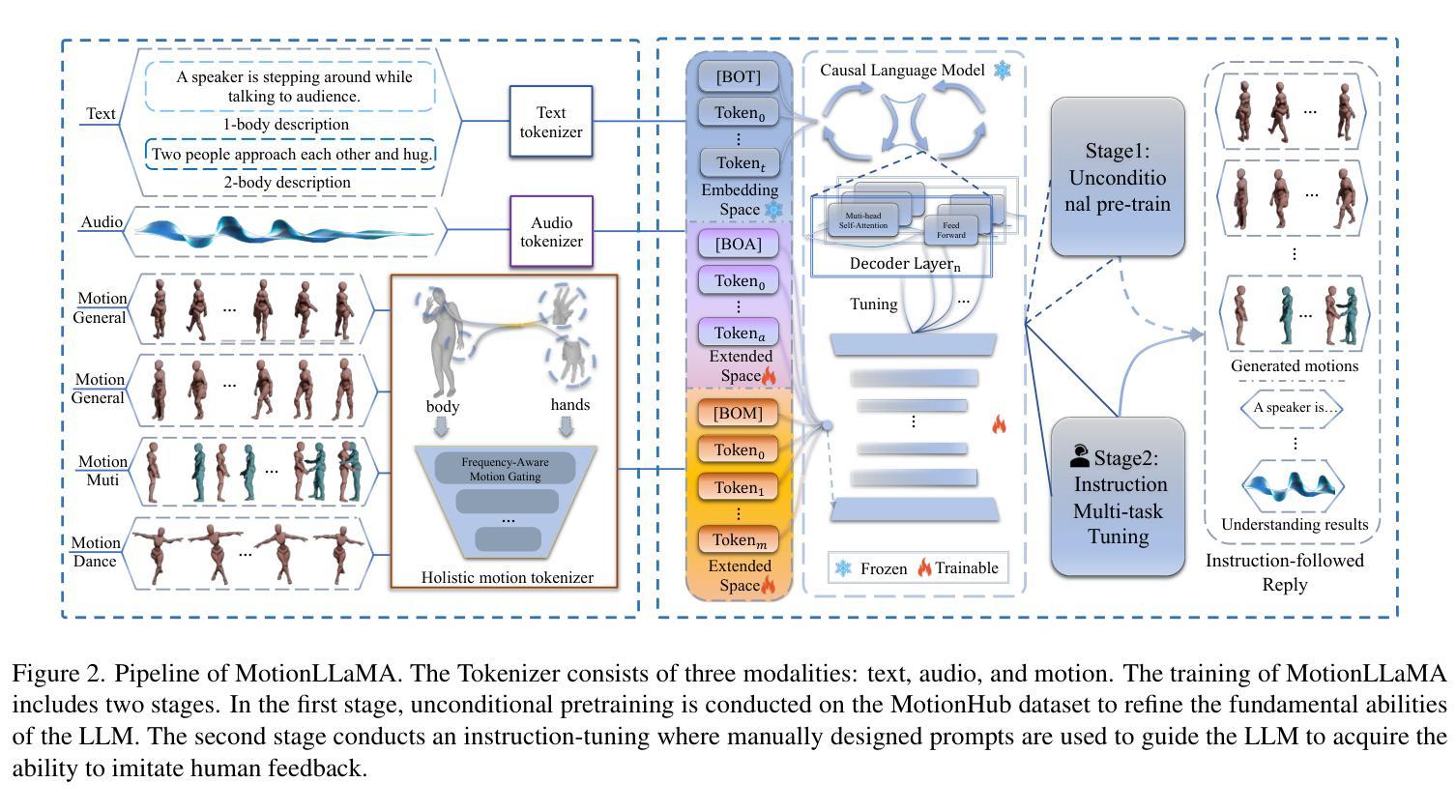
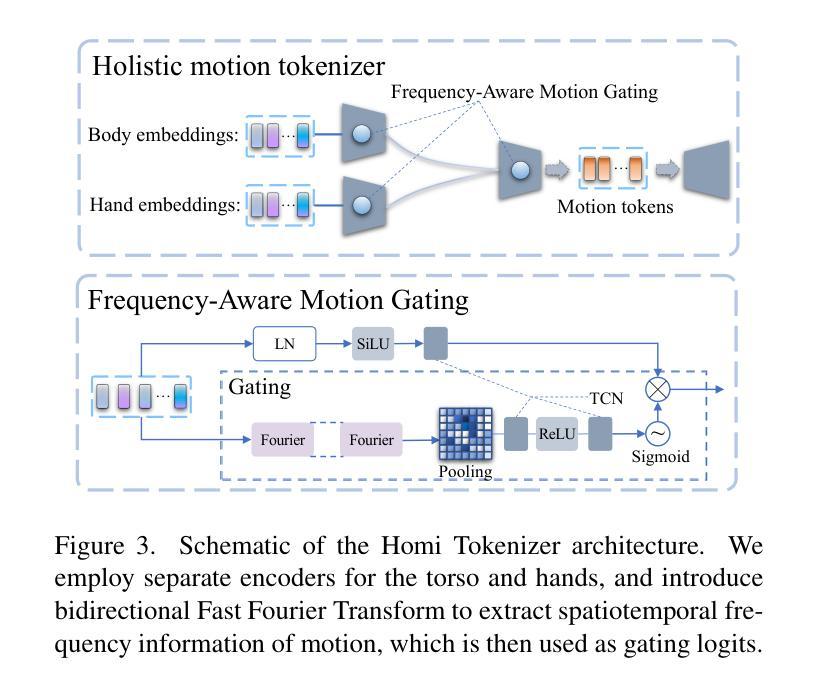
MotionLLaMA: A Unified Framework for Motion Synthesis and Comprehension
Authors:Zeyu Ling, Bo Han, Shiyang Li, Hongdeng Shen, Jikang Cheng, Changqing Zou
This paper introduces MotionLLaMA, a unified framework for motion synthesis and comprehension, along with a novel full-body motion tokenizer called the HoMi Tokenizer. MotionLLaMA is developed based on three core principles. First, it establishes a powerful unified representation space through the HoMi Tokenizer. Using a single codebook, the HoMi Tokenizer in MotionLLaMA achieves reconstruction accuracy comparable to residual vector quantization tokenizers utilizing six codebooks, outperforming all existing single-codebook tokenizers. Second, MotionLLaMA integrates a large language model to tackle various motion-related tasks. This integration bridges various modalities, facilitating both comprehensive and intricate motion synthesis and comprehension. Third, MotionLLaMA introduces the MotionHub dataset, currently the most extensive multimodal, multitask motion dataset, which enables fine-tuning of large language models. Extensive experimental results demonstrate that MotionLLaMA not only covers the widest range of motion-related tasks but also achieves state-of-the-art (SOTA) performance in motion completion, interaction dual-person text-to-motion, and all comprehension tasks while reaching performance comparable to SOTA in the remaining tasks. The code and MotionHub dataset are publicly available.
本文介绍了MotionLLaMA,这是一个用于动作合成和理解的统一框架,以及一个全新的全身动作分词器——HoMi分词器。MotionLLaMA是基于三个核心原则开发的。首先,它通过HoMi分词器建立了一个强大的统一表示空间。在MotionLLaMA中,HoMi分词器使用一个代码本实现了与利用六个代码本的剩余向量量化分词器相当的重建精度,超越了所有现有的单代码本分词器。其次,MotionLLaMA集成了一个大型语言模型来解决各种与动作相关的任务。这种集成连接了不同的模态,促进了全面而复杂的动作合成和理解。第三,MotionLLaMA引入了MotionHub数据集,这是目前最大的多模态多任务动作数据集,能够实现对大型语言模型的微调。大量的实验结果表明,MotionLLaMA不仅涵盖了最广泛的动作相关任务,而且在动作完成、交互双人文本到动作以及所有理解任务上达到了最先进的性能,其余任务上的性能也与之相当。代码和MotionHub数据集可公开获取。
论文及项目相关链接
Summary
MotionLLaMA是一个统一运动合成与理解框架,引入全新全运动分词器HoMi Tokenizer。其核心优势在于建立强大的统一表示空间,通过单一代码本实现高精度重建;集成大型语言模型处理多种运动任务,实现跨模态桥梁;引入MotionHub数据集,为大型语言模型提供微调功能。MotionLLaMA覆盖广泛运动任务,并在多个任务上实现卓越性能。
Key Takeaways
- MotionLLaMA是一个统一框架,用于运动合成与理解。
- 引入全新的全运动分词器HoMi Tokenizer,使用单一代码本实现高精度重建。
- MotionLLaMA建立强大的统一表示空间,性能优于其他单一代码本的分词器。
- 集成大型语言模型,处理多种运动任务,实现跨模态交互。
- 引入MotionHub数据集,是目前最大的多模态多任务运动数据集。
- MotionLLaMA在多种运动任务上实现卓越性能,包括运动补全、交互双人文本到运动等任务。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为 MotionLLaMA 的统一框架,旨在解决以下问题:
运动合成与理解的统一表示空间:传统方法通常将运动合成和理解视为两个独立的任务。运动合成依赖于如 VAEs、GANs 和 DDPMs 等框架来生成人体动作,而运动理解则采用序列到序列的范式来解析和解释运动信号。这篇论文提出了一个基于 HoMi Tokenizer 的统一框架,通过单一代码本实现与使用六个代码本的残差向量量化 Tokenizers 相当的重建精度,从而在运动合成和理解之间建立强大的统一表示空间。
多模态任务的整合:通过整合大型语言模型(LLMs),MotionLLaMA 能够处理各种与运动相关的任务,包括文本到运动(T2M)、音乐到舞蹈(M2D)、语音到手势(S2G)等,实现了不同模态之间的桥梁,促进了全面和复杂的运动合成和理解。
大规模多模态多任务运动数据集的缺乏:为了微调大型语言模型,需要大量的训练数据。以往的基于 LLM 的运动生成模型受限于较小的数据集,限制了模型规模。为了解决数据不足的问题,作者构建了 MotionHub 数据集,这是迄今为止最全面的多模态、多任务人体运动数据集,包含了单人和双人运动数据。
细粒度运动合成的挑战:以往的运动合成方法在生成手指和手部等细节部分时存在不足。MotionLLaMA 通过 HoMi Tokenizer 编码全身运动和空间位置信息,形成了一个运动词汇表,作为 LLaMA-3 模型的扩展词汇,从而更有效地处理细粒度运动合成。
综上所述,这篇论文试图通过 MotionLLaMA 框架和 HoMi Tokenizer,提供一个能够统一处理运动合成和理解任务的解决方案,并在多个与运动相关的任务上实现了最先进的性能。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
运动中心的跨模态生成(Motion-Centric Cross-Modal Generation):
- 文本到运动(Text-to-Motion):旨在根据语义描述生成动作。
- 音乐到舞蹈(Music-to-Dance):专注于生成与音乐节奏一致的舞蹈动作。
- 语音到手势(Speech-to-Gesture):强调生成与语音相对应的面部和手部动作。
多模态大型语言模型(Multimodal Large Language Models, MLLMs):
- 这些模型通过集成和处理多种模态的信息来扩展传统大型语言模型(LLMs)的能力。
- 例如,NExT-GPT 利用多模态适配器和扩散解码器来执行涉及任意组合的文本、图像、视频和音频的任务。
运动大型语言模型(Motion LLMs):
- 应用于人体运动领域的 MLLMs,旨在解决各种以运动为中心的生成任务。
- 例如,MotionGPT、LMM、UDE-2、M3GPT 和 UniMuMo 等模型,它们通过整合不同的运动合成和理解任务,但模型规模通常在百万级别。
具体相关研究和方法包括:
- MotionGPT [23]:首次将 T5 模型整合到运动领域,使用运动 Tokenizer 实现运动和文本之间的互转。
- LMM [63]:基于 FineMoGen,引入 MoE 架构进行运动生成。
- UDE-2 [68]:构建类似 T5 的架构进行条件到运动的转换。
- M3GPT [33]:采用 T5 作为语言模型主干,搭配条件模态 Tokenizer 建立以运动为中心的 LLM。
- UniMuMo [55]:主要关注舞蹈动作,支持音乐和文本之间的转换。
- MotionAgent [50]:达到十亿级别的模型规模,但在细粒度运动合成方面存在挑战。
这些研究构成了 MotionLLaMA 框架的理论和实践基础,并在不同程度上影响了该框架的设计和实现。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键组件来解决提出的问题:
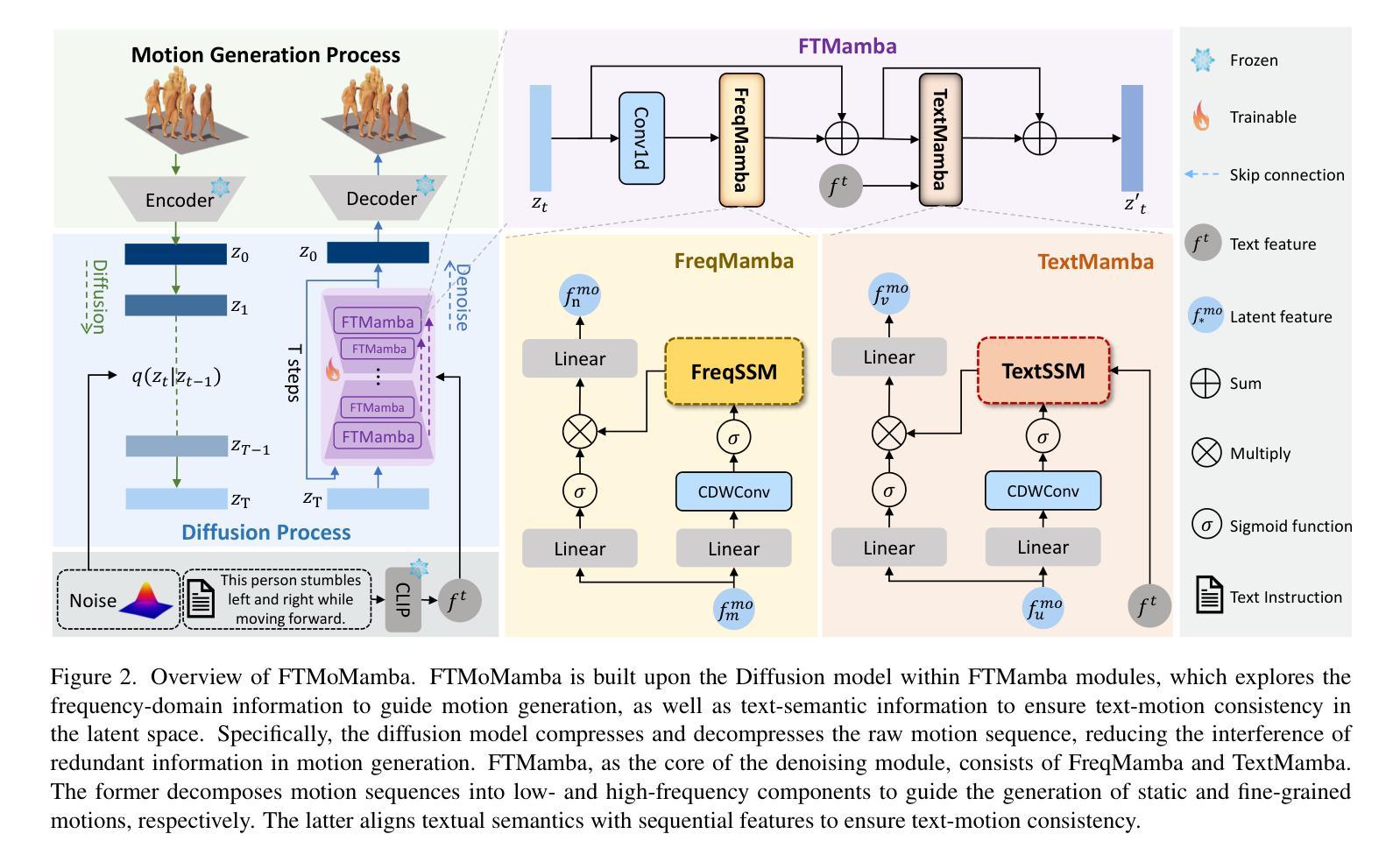
1. MotionLLaMA 框架
MotionLLaMA 是一个统一框架,它整合了运动合成和理解任务,支持多种与运动相关的任务。该框架基于三个核心原则:
- 统一表示空间:通过 HoMi Tokenizer 实现。
- 大型语言模型集成:整合大型语言模型以处理多模态任务。
- MotionHub 数据集:提供大规模多模态、多任务运动数据集以支持模型微调。
2. HoMi Tokenizer
HoMi Tokenizer 是一个新颖的全身运动 Tokenizer,它将完整的身体运动和空间位置信息编码成离散的运动 Token,形成运动词汇表,作为大型语言模型的扩展词汇表。HoMi Tokenizer 的特点包括:
- 频率感知运动门控(Frequency-Aware Motion Gating):使用双向快速傅里叶变换(FFT)提取运动的时空频率信息,并用作门控逻辑,以选择性地强调重要的频率成分。
- 身体和手部的分离编码:考虑到手部和身体运动之间的独立性以及幅度和频率的差异,使用独立的编码器对它们进行编码,然后通过小的 MLP 融合表示以获得全身运动 Token。
3. MotionHub 数据集
为了支持大型语言模型的微调,作者构建了 MotionHub 数据集,这是一个全面的多模态、多任务人体运动数据集。该数据集包括单人和双人运动数据,以及相应的文本描述和音频信息。
4. 训练策略
MotionLLaMA 的训练分为两个阶段:
- 无条件预训练(Unconditional Pre-training):在 MotionHub 数据集上进行自回归学习,以优化新引入的 Token 嵌入层参数,并使模型熟悉多模态 Token 的基本结构。
- 指令多任务调整(Instruction Multi-task Tuning):使用设计好的提示模板进行多任务联合学习,不针对单一任务进行微调,以优化解码器层并处理新引入的多模态任务。
通过这些组件和技术,MotionLLaMA 能够在多个与运动相关的任务上实现最先进的性能,并为计算机视觉和图形学中的多模态运动合成和理解提供了一个可扩展的解决方案。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证 MotionLLaMA 框架的性能,具体实验包括:
实现细节(Implementation Details):
- 介绍了多模态 Tokenizers 的配置,包括文本、音频和运动 Tokenizers 的参数设置。
- 描述了模型初始化和微调方法,包括使用 LLaMA 3.2 Instruct 版本,并采用 LoRA 方法进行微调。
评估设置(Evaluation Setup):
- 论文在 MotionHub 数据集上进行联合训练,并在多个任务上评估模型性能,包括 T2M(Text-to-Motion)、M2T(Motion-to-Text)、M2D(Music-to-Dance)、D2M(Dance-to-Music)、S2G(Speech-to-Gesture)、IT2M(Interaction Text-to-Motion)、IM2T(Interaction Motion-to-Text)、Motion Inbetween 和 Motion Completion。
文本-运动双向关联(Text-Motion Bidirectional Association):
- 对 M2T(Motion-to-Text)和 T2M(Text-to-Motion)任务进行了评估,比较了 MotionLLaMA 与先前 SOTA 方法的性能。
运动-运动任务(Motion-to-Motion Tasks):
- 评估了 MotionLLaMA 在 Motion Inbetween 和 Motion Completion 任务上的性能,使用 FID 和 Diversity 等指标。
音乐-舞蹈双向关联(Music-Dance Bidirectional Association):
- 分别在 AIST++ 和 FineDance 数据集上测试了 M2D(Music-to-Dance)和 D2M(Dance-to-Music)任务的性能。
语音-手势(Speech-to-Gesture):
- 使用 FGD(Frechet Gesture Distance)等指标评估了生成的手势动作与语音的节奏一致性和多样性。
重建质量评估(Reconstruction Quality Evaluation):
- 评估了 HoMi Tokenizer 在不同变体下重建运动的准确性,包括 MPJPE、N-MPJPE、ADE 和 FDE 等指标。
消融研究(Ablation Study):
- 分析了 HoMi Tokenizer 中各个组件(如 STH 和 FAMG)对重建质量的影响。
以上实验覆盖了广泛的任务和评估指标,旨在全面验证 MotionLLaMA 框架在运动合成和理解任务上的有效性和优越性。通过这些实验,论文展示了 MotionLLaMA 在多个任务上达到了 SOTA(State-of-the-Art)性能,证明了其作为多模态运动建模新基准的潜力。
Q: 有什么可以进一步探索的点?
A: 尽管 MotionLLaMA 框架在多模态运动合成和理解方面取得了显著的成果,但仍有一些领域可以进一步探索和改进:
算法优化:
- 精细控制和编辑能力:研究如何更精细地控制生成的运动,例如在特定关节或身体部位上实现更精确的编辑。
- 计算效率:探索减少模型计算复杂度的方法,以便在资源受限的环境中部署。
数据集扩展和多样化:
- 多语言支持:当前模型主要针对英文数据,扩展到多语言数据集可以增强模型的国际化应用。
- 更广泛的动作覆盖:增加数据集中动作类型的多样性,如特殊运动、文化特定动作等。
模型泛化能力:
- 跨领域泛化:研究模型在未见过的领域或与训练数据不同的分布上的泛化能力。
- 长尾数据问题:改善模型对数据集中较少见动作的识别和生成能力。
交互式应用:
- 实时运动捕捉和合成:将模型应用于实时系统,如虚拟现实(VR)或增强现实(AR)中的人体运动捕捉和合成。
- 用户交互式编辑:开发允许用户交互式编辑输入文本或音频,以生成定制化运动的应用。
伦理和隐私问题:
- 数据隐私:确保在收集和使用运动数据时符合隐私保护法规。
- 避免偏见:防止模型学习并复制训练数据中可能存在的偏见。
模型解释性:
- 内部工作机制:研究模型的决策过程,提供更多关于模型如何理解和生成运动的洞察。
- 结果解释:开发工具和方法来解释模型生成的特定运动,增强用户对结果的理解。
跨模态融合技术:
- 模态融合策略:研究不同的模态融合策略,以改善模型对多模态输入的处理能力。
- 模态注意力机制:探索注意力机制在多模态数据中的作用,以更好地对齐不同模态的信息。
细粒度动作捕捉和合成:
- 手部和面部动作:改进手部和面部动作的捕捉和合成,这些部位的动作在许多应用中至关重要。
- 情感和意图的表达:研究如何通过运动传达更细微的情感和意图。
这些探索点可以帮助研究者进一步提升 MotionLLaMA 框架的能力,扩展其应用范围,并解决实际应用中可能遇到的问题。
Q: 总结一下论文的主要内容
A: 论文介绍了 MotionLLaMA,这是一个统一的框架,用于运动合成和理解。主要内容包括:
框架介绍:
- MotionLLaMA 结合了一个新颖的全身运动 Tokenizer(HoMi Tokenizer)和一个大型语言模型(LLaMA-3),以实现运动的合成和理解。
- 该框架基于三个核心原则:强大的统一表示空间、大型语言模型的集成、以及最广泛的多模态多任务运动数据集(MotionHub)。
HoMi Tokenizer:
- 提出了一种新的基于单代码本的全身运动 VQ-VAE 模型,通过分离编码身体和手部以及使用频率感知门控机制,实现了与多代码本方法相当的重建性能。
数据集:
- 构建了 MotionHub 数据集,这是一个包含单人和双人运动数据的多模态、多任务运动数据集,旨在支持大型语言模型的微调。
实验结果:
- 通过广泛的实验,证明了 MotionLLaMA 在多个运动相关任务上达到了最先进的性能,包括运动完成、交互双人文本到运动、以及所有理解任务。
贡献总结:
- 提出了一个能够生成和理解单人和双人运动的统一自回归框架,支持9种不同的运动相关任务。
- 引入了一个在 MotionHub 数据集上表现最佳的全新运动 Tokenizer。
- 提供了一个包含大量单人和双人运动数据的多模态多任务运动数据集。
代码和数据集:
- 论文提供了 MotionLLaMA 的代码和 MotionHub 数据集的公开访问链接。
总体而言,MotionLLaMA 通过其统一的框架和强大的表示空间,在运动合成和理解领域提供了一个全面的解决方案,并在多个任务上实现了突破性的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


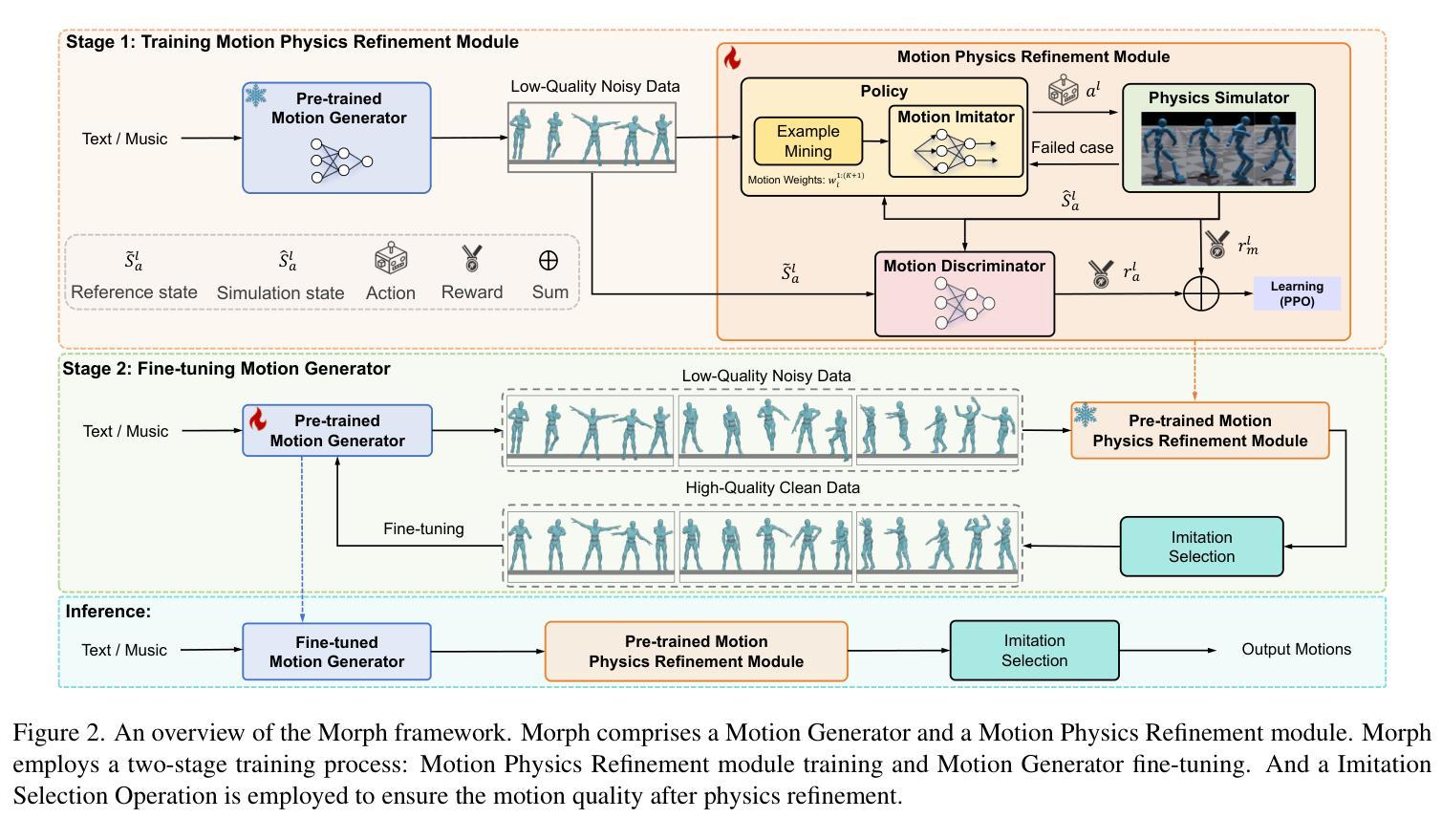
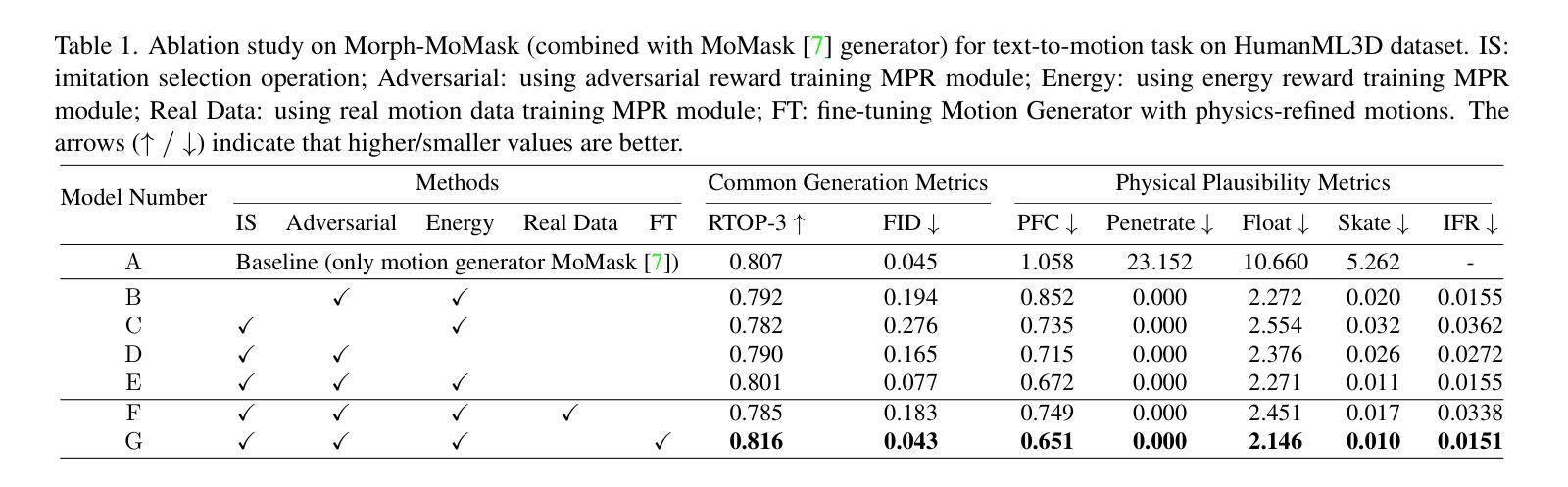
Morph: A Motion-free Physics Optimization Framework for Human Motion Generation
Authors:Zhuo Li, Mingshuang Luo, Ruibing Hou, Xin Zhao, Hao Liu, Hong Chang, Zimo Liu, Chen Li
Human motion generation plays a vital role in applications such as digital humans and humanoid robot control. However, most existing approaches disregard physics constraints, leading to the frequent production of physically implausible motions with pronounced artifacts such as floating and foot sliding. In this paper, we propose \textbf{Morph}, a \textbf{Mo}tion-f\textbf{r}ee \textbf{ph}ysics optimization framework, comprising a Motion Generator and a Motion Physics Refinement module, for enhancing physical plausibility without relying on costly real-world motion data. Specifically, the Motion Generator is responsible for providing large-scale synthetic motion data, while the Motion Physics Refinement Module utilizes these synthetic data to train a motion imitator within a physics simulator, enforcing physical constraints to project the noisy motions into a physically-plausible space. These physically refined motions, in turn, are used to fine-tune the Motion Generator, further enhancing its capability. Experiments on both text-to-motion and music-to-dance generation tasks demonstrate that our framework achieves state-of-the-art motion generation quality while improving physical plausibility drastically.
人类动作生成在数字人类和仿人形机器人控制等应用中扮演着至关重要的角色。然而,大多数现有方法忽略了物理约束,导致经常产生物理上不可行的动作,并出现明显的伪影,如漂浮和脚滑。在本文中,我们提出了一个名为Morph的运动自由物理优化框架,它由一个动作生成器和一个动作物理细化模块组成,旨在在不依赖昂贵的现实世界动作数据的情况下提高物理可行性。具体来说,动作生成器负责提供大规模合成动作数据,而动作物理细化模块利用这些合成数据在物理模拟器内训练运动模仿者,通过实施物理约束将嘈杂的动作投影到物理可行空间内。这些经过物理精炼的动作反过来又用于微调动作生成器,进一步提升其性能。在文本到动作和音乐到舞蹈生成任务上的实验表明,我们的框架在达到最新运动生成质量的同时,大大提高了物理可行性。
论文及项目相关链接
PDF 15 pages, 6 figures
Summary
文本主要介绍了人类动作生成在数字人类和机器人控制等领域的重要性,以及现有方法忽略物理约束导致的问题。为此,本文提出了一种名为Morph的运动优化框架,包括运动生成器和运动物理细化模块,旨在提高物理可信度,而无需依赖昂贵的真实世界动作数据。该框架通过合成大规模动作数据并进行物理细化处理,提高了动作生成的质量。
Key Takeaways
- 人类动作生成在数字人类和机器人控制等领域具有广泛应用。
- 现有方法忽略物理约束,导致生成的动作用存在浮动和脚部滑动等明显问题。
- 本文提出了一种名为Morph的运动优化框架,包括运动生成器和运动物理细化模块。
- 运动生成器负责提供大规模合成动作数据。
- 运动物理细化模块利用合成数据在物理模拟器中训练运动模仿者,并强制实施物理约束以将噪声运动投影到物理合理的空间中。
- 物理细化后的动作用于微调运动生成器,进一步提高其能力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为Morph的运动生成优化框架,旨在解决以下问题:
物理合理性问题:许多现有的运动生成方法忽略了物理约束,导致生成的运动经常展现出不切实际的物理行为,例如地面穿透、倾斜后仰、穿插、脚滑动、悬浮和不自然的旋转等。
数据依赖问题:一些尝试增强运动物理合理性的研究需要大量的、高质量的真实运动数据来训练物理优化机制,但收集这类数据是具有挑战性的。
模型泛化问题:现有的一些方法将物理优化操作定制为特定类型的生成模型,限制了它们向更广泛的生成模型和运动生成任务(如音乐到舞蹈)的迁移能力。
计算成本问题:一些方法在扩散过程中多次执行物理优化,这在推理过程中显著增加了计算成本。
为了解决这些问题,Morph框架提出了一个无需运动数据的物理优化框架,通过以下两个主要模块来提高运动的物理合理性:
- 运动生成器(Motion Generator, MG):负责提供大规模合成运动数据。
- 运动物理细化模块(Motion Physics Refinement, MPR):利用合成数据训练一个运动模仿器,在物理模拟器中强制执行物理约束,将噪声运动投影到物理合理空间中。
通过这种两阶段优化过程,Morph有效地将物理优化从生成模型中解耦出来,仅需要单步物理细化,且不依赖真实运动数据,从而实现经济、高效且模型不可知的物理优化器。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要集中在以下几个方面:
Human Motion Generation(人体运动生成):
- 该领域研究了基于不同信号(如文本描述、音乐和动作)的运动生成。具体到文本到运动(text-to-motion)和音乐到舞蹈(music-to-dance)生成的研究,主要方法包括扩散模型(diffusion-based methods)、自回归模型(autoregressive models)和生成掩码模型(generative masked modeling)。
Physically Plausible Motion Generation(物理上合理的运动生成):
- 一些研究尝试解决生成运动的物理合理性问题,例如通过将物理约束整合到扩散过程中(如PhysDiff和Reindiffuse),或者引入辅助损失以对齐特定方面的物理现实性(如EDGE)。
Conditional Diffusion Models(条件扩散模型):
- 这些模型用于文本到运动的生成,例如MDM使用基于Transformer的扩散模型和从CLIP提取的条件文本表示。
Conditional Autoregressive Models(条件自回归模型):
- 例如T2M-GPT设计了基于VQVAE和GPT的有条件的自回归Transformer模型。
Generative Masked Modeling(生成掩码建模):
- 如MoMask使用残差向量量化和生成掩码Transformers迭代生成运动。
Physics-Guided Motion Generation(物理引导的运动生成):
- 一些研究工作尝试通过物理引导的方式增强运动生成的物理合理性,例如PhysDiff和Reindiffuse。
Reinforcement Learning for Motion Imitation(强化学习用于运动模仿):
- 强化学习被用于训练运动模仿器,使其能够在物理模拟器中控制角色模拟给定的运动。
这些相关研究构成了Morph框架的理论基础和技术支持,Morph通过结合这些研究中的技术和方法,提出了一种新的无需运动数据的物理优化框架,以增强运动生成的物理合理性。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Morph的框架来解决上述问题,该框架包含两个主要模块:运动生成器(Motion Generator, MG)和运动物理细化模块(Motion Physics Refinement, MPR)。具体的解决方案分为以下几个步骤:
1. 运动生成器(MG)
- 利用一个预训练的运动生成模型来产生大规模的、带噪声的运动数据。这个运动生成器可以是任何现有的预训练模型,Morph框架对此是不可知的。
2. 运动物理细化模块(MPR)
- 运动模仿器(Motion Imitator):控制一个模拟角色在物理模拟器中模仿输入的带噪声运动。
- 物理模拟器(Physics Simulator):确保运动遵循物理定律,减少如悬浮和脚滑动等不真实的物理现象。
- 运动鉴别器(Motion Discriminator):确保经过物理细化后的运动在分布上与输入运动保持一致,以提高运动自然性。
3. 两阶段训练过程
- 第一阶段:使用MG产生的大规模带噪声运动数据来训练MPR模块,使其能够将输入的运动映射到物理上合理的空间。
- 第二阶段:利用经过物理细化的、高质量的运动数据来进一步微调MG,提高其生成真实运动的能力。
4. 模仿选择操作(Imitation Selection Operation)
- 在推理阶段,为了减少非地面运动(如坐在椅子上或游泳)的模拟误差,使用模仿选择操作作为后处理步骤,以确保物理细化后的运动质量。
5. 实验验证
- 在文本到运动和音乐到舞蹈的生成任务上评估Morph框架,与不同的运动生成模型结合使用,并在物理误差指标和生成指标上展示出显著的改进。
通过上述方法,Morph框架有效地将物理优化从生成模型中解耦出来,仅需要单步物理细化,且不依赖真实运动数据,实现了一个经济、高效且模型不可知的物理优化器。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估Morph框架的性能,具体实验包括:
数据集和评估指标:
- 使用了两个数据集:HumanML3D用于文本到运动(text-to-motion)任务,AIST++用于音乐到舞蹈(music-to-dance)任务。
- 评估指标包括常见的生成指标(如Frechet Inception Distance (FID)、R-Precision、Diversity等)和物理合理性指标(如Penetrate、Float、Skate、Physical Foot Contact (PFC)等)。
实现细节:
- 描述了基于PyTorch的Morph实现,使用NVIDIA的Isaac Gym作为物理模拟器,并详细说明了训练设置和数据预处理步骤。
消融研究(Ablation Studies):
- 验证了使用生成数据训练MPR模块的有效性,以及对抗性奖励和能量奖励在训练MPR模块中的作用。
- 探讨了模仿选择策略的有效性,以及使用模拟运动数据微动运动生成器的效果。
不同运动生成器的适应性评估:
- 将Morph与不同类型的运动生成器(如MDM、MotionDiffuse、T2M-GPT和MoMask)结合使用,并在物理合理性指标和生成指标上进行了评估。
与最新技术的比较:
- 在文本到运动和音乐到舞蹈的数据集上,将Morph与其他最新技术的方法进行了比较,展示了Morph在物理合理性方面的显著提升,同时在生成质量上也具有竞争力。
附加实验结果:
- 分析了模仿选择操作中阈值τ的影响,不同数量的噪声运动数据对MPR训练的影响,以及MPR模块和运动生成器多轮优化的效果。
- 提供了额外的定性结果,展示了Morph在文本到运动和音乐到舞蹈任务中的性能。
这些实验全面评估了Morph框架的性能,证明了其在提高运动生成物理合理性方面的有效性,并展示了其与不同运动生成模型的兼容性和灵活性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的Morph框架在提高运动生成的物理合理性方面取得了显著成果,但仍有一些可以进一步探索的点:
更广泛的运动类型和场景:
- 目前Morph主要针对非交互性和地面接触的运动。可以探索将Morph应用于更广泛的运动类型,如游泳、坐下、爬楼梯等交互性运动。
更复杂的物理约束:
- 考虑引入更复杂的物理约束,如不同地面材质对脚步的影响、衣物动力学等,以进一步提高运动的真实感。
提高模拟效率:
- 探索更高效的物理模拟方法,以减少推理过程中的计算成本,特别是对于需要实时反馈的应用场景。
模型泛化能力:
- 进一步测试Morph框架在不同类型的运动数据集和不同的运动生成任务上的泛化能力。
无监督或自监督学习:
- 研究无监督或自监督学习的方法来训练MPR模块,减少对大规模标注数据的依赖。
多模态输入的融合:
- 探索如何更有效地融合多模态输入(如文本、音乐、视觉信号)来生成更自然和一致的运动。
更精细的动作控制:
- 研究如何实现对生成动作的细节控制,例如动作的速度、力度和风格等。
交互式应用:
- 将Morph框架应用于虚拟现实或增强现实等交互式应用中,研究用户交互对运动生成的影响。
鲁棒性和错误处理:
- 提高Morph框架在面对异常输入或模拟错误时的鲁棒性,以及对错误的自动检测和处理能力。
跨领域应用:
- 探索Morph框架在其他领域的应用,如机器人控制、动画制作、游戏开发等。
模型解释性:
- 提高模型的可解释性,让用户理解模型的决策过程,以及如何影响最终生成的运动。
这些探索点可以帮助研究者进一步提升Morph框架的性能,并扩展其在不同领域的应用。
Q: 总结一下论文的主要内容
A: 论文提出了一个名为Morph的运动生成优化框架,旨在提高人体运动生成任务中的物理合理性,同时不依赖于成本高昂的真实世界运动数据。以下是论文的主要内容总结:
问题陈述:
- 现有运动生成方法忽略了物理约束,导致生成的运动经常包含不真实的物理行为,如地面穿透、倾斜后仰、脚滑动等。
- 这些不真实的运动阻碍了动画和虚拟现实等实际应用。
Morph框架:
- Morph包含两个主要模块:运动生成器(MG)和运动物理细化模块(MPR)。
- MG负责生成大规模合成运动数据,而MPR利用这些数据训练一个运动模仿器,在物理模拟器中强制执行物理约束,将噪声运动投影到物理合理空间。
两阶段训练过程:
- 第一阶段:使用MG产生的合成噪声运动数据训练MPR模块。
- 第二阶段:利用MPR模块生成的物理合理的运动数据进一步微调MG,提高其生成能力。
实验:
- 在文本到运动和音乐到舞蹈的任务上评估Morph框架,与不同类型的运动生成模型结合使用。
- 实验结果表明,Morph在提高物理合理性的同时,也保持了有竞争力的生成质量。
主要贡献:
- Morph是一个经济、高效且模型不可知的物理优化器,它解耦了物理优化和生成模型,仅需要单步物理细化,不依赖真实运动数据。
未来工作:
- 论文提出了一些可能的研究方向,包括扩展到更复杂的运动类型和场景、提高模拟效率、增强模型泛化能力等。
总体而言,Morph框架通过创新的两阶段训练方法,在不依赖真实运动数据的情况下,有效地提高了人体运动生成的物理合理性,为数字人和仿人机器人控制等领域的应用提供了新的可能性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Textual Decomposition Then Sub-motion-space Scattering for Open-Vocabulary Motion Generation
Authors:Ke Fan, Jiangning Zhang, Ran Yi, Jingyu Gong, Yabiao Wang, Yating Wang, Xin Tan, Chengjie Wang, Lizhuang Ma
Text-to-motion generation is a crucial task in computer vision, which generates the target 3D motion by the given text. The existing annotated datasets are limited in scale, resulting in most existing methods overfitting to the small datasets and unable to generalize to the motions of the open domain. Some methods attempt to solve the open-vocabulary motion generation problem by aligning to the CLIP space or using the Pretrain-then-Finetuning paradigm. However, the current annotated dataset’s limited scale only allows them to achieve mapping from sub-text-space to sub-motion-space, instead of mapping between full-text-space and full-motion-space (full mapping), which is the key to attaining open-vocabulary motion generation. To this end, this paper proposes to leverage the atomic motion (simple body part motions over a short time period) as an intermediate representation, and leverage two orderly coupled steps, i.e., Textual Decomposition and Sub-motion-space Scattering, to address the full mapping problem. For Textual Decomposition, we design a fine-grained description conversion algorithm, and combine it with the generalization ability of a large language model to convert any given motion text into atomic texts. Sub-motion-space Scattering learns the compositional process from atomic motions to the target motions, to make the learned sub-motion-space scattered to form the full-motion-space. For a given motion of the open domain, it transforms the extrapolation into interpolation and thereby significantly improves generalization. Our network, $DSO$-Net, combines textual $d$ecomposition and sub-motion-space $s$cattering to solve the $o$pen-vocabulary motion generation. Extensive experiments demonstrate that our DSO-Net achieves significant improvements over the state-of-the-art methods on open-vocabulary motion generation. Code is available at https://vankouf.github.io/DSONet/.
文本到动作生成是计算机视觉中的一项重要任务,它通过给定的文本生成目标3D动作。现有标注数据集规模有限,导致大多数现有方法过度拟合于小规模数据集,无法推广到开放领域的动作。一些方法试图通过对齐CLIP空间或使用预训练后微调范式来解决开放词汇动作生成问题。然而,当前标注数据集的规模仅允许它们实现从子文本空间到子运动空间的映射,而不是实现全文本空间和全运动空间之间的完全映射(全映射),这是实现开放词汇动作生成的关键。为此,本文提出利用原子动作(短时间内简单身体部分的运动)作为中间表示,并通过两个有序耦合的步骤,即文本分解和子运动空间散射,来解决全映射问题。在文本分解方面,我们设计了一种精细描述转换算法,并将其与大型语言模型的泛化能力相结合,将任何给定的运动文本转换为原子文本。子运动空间散射学习从原子动作到目标动作的组成过程,使学习到的子运动空间散射形成全运动空间。对于给定开放领域的动作,它将外推转化为内插,从而显著提高泛化能力。我们的网络DSO-Net结合了文本分解和子运动空间散射,解决了开放词汇动作生成问题。大量实验表明,我们的DSO-Net在开放词汇动作生成方面实现了显著的改进,超越了最先进的方法。代码可用在https://vankouf.github.io/DSONet/。
论文及项目相关链接
PDF project page: https://vankouf.github.io/DSONet/
Summary
文本转动作生成是计算机视觉中的关键任务,它通过给定的文本生成目标的三维动作。现有标注数据集规模有限,导致现有方法容易过拟合,无法泛化到开放域的动作。本文提出利用原子动作作为中间表示,通过文本分解和子动作空间散射两个有序耦合的步骤来解决全映射问题,实现开放词汇动作生成。设计精细描述转换算法,结合大型语言模型的泛化能力,将给定运动文本转换为原子文本。子动作空间散射学习从原子动作到目标动作的组合过程,使学习的子动作空间散布形成全动作空间。对于给定开放域的动作,它将外推转化为内插,从而显著提高泛化能力。本文提出的DSO-Net网络结合文本分解和子动作空间散射,解决了开放词汇动作生成问题,并在实验中取得了显著成果。
Key Takeaways
- 文本转动作生成是计算机视觉的重要任务,旨在通过文本指令生成相应的三维动作。
- 当前标注数据集规模有限,限制了方法的泛化能力,使得模型难以处理开放域的动作。
- 现有方法尝试通过映射子文本空间到子动作空间来解决开放词汇动作生成问题,但无法实现全映射。
- 本文提出利用原子动作作为中间表示,通过两个有序耦合的步骤——文本分解和子动作空间散射,来解决全映射问题。
- 文本分解通过精细描述转换算法结合大型语言模型的泛化能力,将运动文本转换为原子文本。
- 子动作空间散射学习从原子动作到目标动作的组合过程,使学习的子动作空间能够形成全动作空间。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决文本到动作(Text-to-motion, T2M)生成中的开放词汇表(open-vocabulary)动作生成问题。具体来说,它旨在通过给定的文本生成目标3D动作,并且能够处理在训练数据中未出现的词汇和动作,从而提高模型对新动作的泛化能力。现有方法由于标注数据集规模有限,导致模型过拟合,无法泛化到开放领域的动作。论文提出了一种新的框架,通过文本分解(Textual Decomposition)和子动作空间散射(Sub-motion-space Scattering)两个有序耦合的步骤来解决从全文本空间到全动作空间的映射问题,从而实现开放词汇表动作生成。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究可以分为以下几个领域:
文本到动作生成(Text-to-Motion Generation):
- 早期的工作通常基于给定的动作类别生成动作,例如 Action2Motion (Guo et al., 2020) 和 ACTOR (Petrovich et al., 2021)。
- 一些工作开始探索在自然语言文本下生成动作,例如 TEMOS (Petrovich et al., 2022) 和 T2M (Guo et al., 2022)。
- 引入 VQ-VAE 技术和自回归范式的动作生成,如 T2M-GPT (Zhang et al., 2023a) 和 MotionGPT (Jiang et al., 2023; Zhang et al., 2024b)。
- 使用扩散模型解决动作合成任务的工作,如 MDM (Tevet et al., 2022b) 和 MotionDiffuse (Zhang et al., 2022)。
开放词汇表生成(Open-Vocabulary Generation):
- CLIP (Radford et al., 2021) 通过对比学习方法预训练在大规模图像-文本对上,展现出强大的零样本泛化能力。
- 基于 CLIP 提取特征以增强模型泛化能力的方法,如 MotionCLIP (Tevet et al., 2022a) 和 AvatarCLIP (Hong et al., 2022)。
- 预训练-微调范式在大型语言模型中的应用,如 OMG (Liang et al., 2024a)。
生成掩码建模(Generative Mask Modeling):
- BERT (Devlin, 2018) 作为自然语言处理领域的代表性工作,通过随机掩码词并预测这些掩码词来预训练文本编码器。
- 在动作生成领域,MoMask (Guo et al., 2024) 首次引入生成掩码建模。
这些研究构成了本文提出的 DSO-Net 框架的理论基础和技术支持,旨在通过结合这些领域的最新进展来解决开放词汇表动作生成问题。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为DSO-Net(Textual Decomposition then Sub-motion-space Scattering)的框架来解决开放词汇表动作生成问题。这个框架主要包含两个有序耦合的步骤:
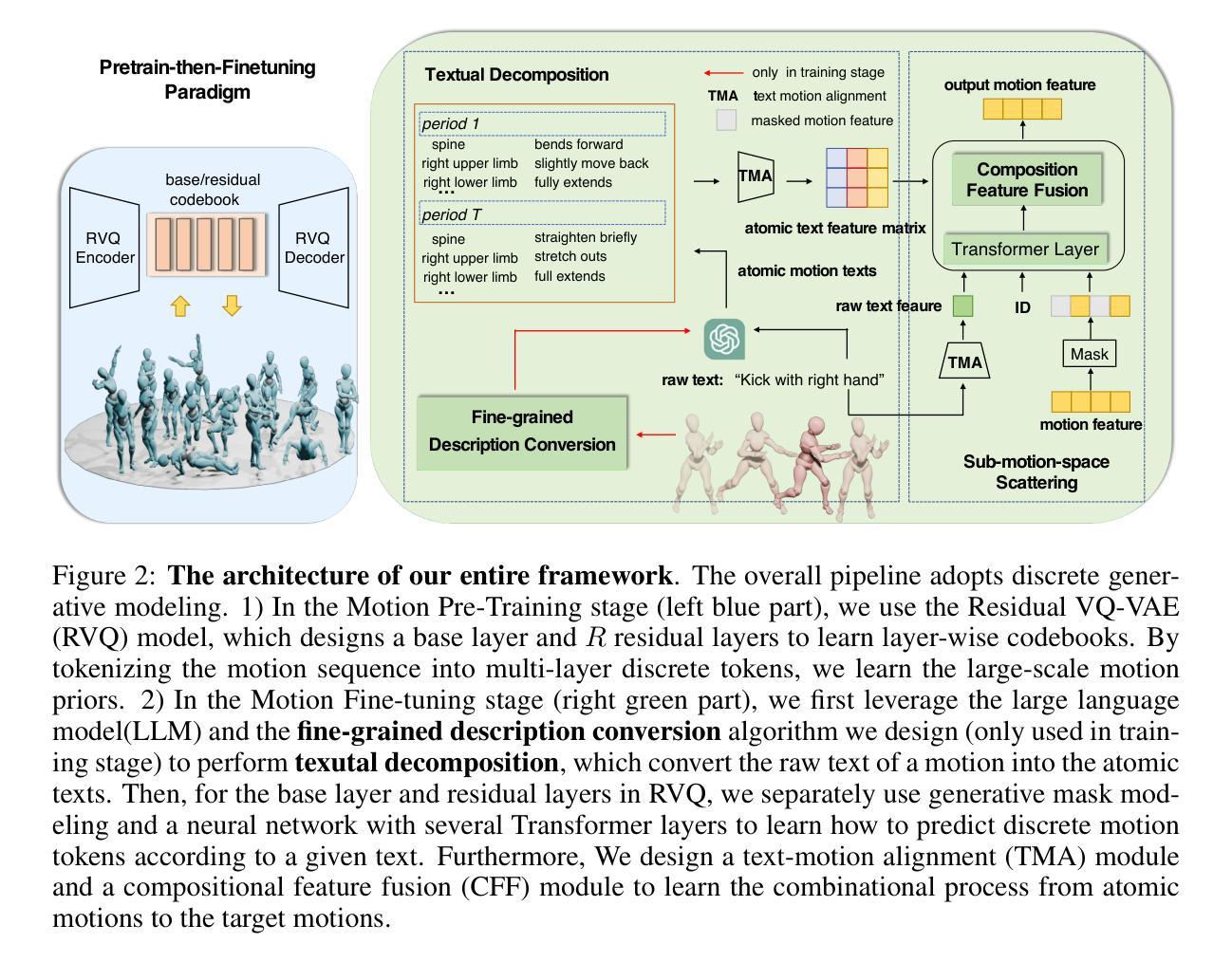
文本分解(Textual Decomposition):
- 将给定的原始动作文本转换成多个原子动作文本。原子动作文本描述的是简单身体部位在短时间内的动作,这有助于模型更好地理解和泛化开放词汇表中的动作文本。
- 通过设计一个细粒度描述转换算法,将输入动作分成若干时间段,并描述每个时间段内各个关节的运动和空间关系。
- 使用大型语言模型(LLM)将这些细粒度描述和原始文本一起输入,以生成原子动作文本。
子动作空间散射(Sub-motion-space Scattering):
- 学习从原子动作到目标动作的组合过程,将从有限配对数据中学到的子动作空间重新排列成更加分散的形式,从而形成全动作空间。
- 通过这种散射过程,将外推(extrapolation)生成过程转换为内插(interpolation)生成过程,显著提高模型的泛化能力。
- 包含文本-动作对齐(Text-Motion Alignment, TMA)模块和组合特征融合(Compositional Feature Fusion, CFF)模块,用于提取原子动作文本的特征,并学习从原子动作到目标动作的组合过程。
整体架构采用离散生成建模,并遵循预训练-微调流程。首先在大规模未标注的动作数据集上预训练一个残差VQ-VAE网络,然后在小规模文本-动作配对数据集上进行微调。通过这种方式,DSO-Net能够在有限的标注数据条件下学习从全文本空间到全动作空间的映射,实现开放词汇表动作生成。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了以下实验来验证他们提出的方法:
实验设置(Experiment Setup):
- 在预训练阶段,作者使用了多个公开的人类动作数据集,包括 MotionX、MoYo、InterHuman 和 KIT-ML,总共超过 22M 帧。
- 在微调阶段,使用 HumanML3D 数据集进行训练,该数据集包含文本-动作配对。
- 在推理阶段,作者在三个数据集上进行了实验,其中一个是领域内数据集(HumanML3D),另外两个是领域外数据集(Idea400 和 Mixamo)。
与现有方法的比较(Comparison):
- 作者定量比较了他们的方法与其他多种最新的方法在 Idea400 和 Mixamo 这两个领域外数据集上的性能,并在 HumanML3D 这个领域内数据集上进行了比较。
- 使用了 Frechet Inception Distance(FID)、Motion-retrieval precision(R-Precision)和 Diversity 这三个常用的评估指标。
消融研究(Ablation Study):
- 作者进行了一系列的消融实验来检验模型中每个组件的具体作用,包括大规模动作数据预训练的效果、文本分解的效果、文本-动作对齐(TMA)的效果以及组合特征融合(CFF)的效果。
定性比较(Qualitative Comparisons):
- 作者展示了他们的方法与其他代表性方法在开放词汇表文本生成上的定性比较结果。
这些实验旨在全面评估 DSO-Net 在开放词汇表动作生成任务上的性能,并与现有的最先进方法进行比较。通过这些实验,作者证明了他们的方法在定量和定性上都能显著提高开放词汇表动作生成的性能。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一个有效的框架来解决开放词汇表动作生成问题,但仍有一些方向可以进一步探索和改进:
更大规模的数据集:
- 探索使用更大规模的标注数据集进行训练,以进一步提升模型的泛化能力和对更多样化动作的覆盖。
更复杂的动作描述:
- 研究如何处理更复杂的动作描述,例如包含多个动作、更精细的动作细节或者情感色彩的文本。
跨领域泛化能力:
- 进一步研究模型在不同领域(如体育、舞蹈、日常活动等)之间的泛化能力,并探索提高跨领域泛化能力的方法。
实时动作生成:
- 优化模型以实现实时或近实时的动作生成,这对于许多应用场景(如虚拟现实、游戏等)非常重要。
交互式动作编辑:
- 开发交互式工具,允许用户通过自然语言指令对生成的动作进行微调和编辑。
多模态输入:
- 探索结合视觉、语音等多种模态输入来指导动作生成,以实现更自然和逼真的动作合成。
动作质量评估:
- 研究自动化的动作质量评估方法,以在训练和推理过程中提供反馈,进一步优化动作生成模型。
模型解释性:
- 提高模型的可解释性,让用户理解模型是如何将文本转换为动作的,以及模型做出特定动作决策的原因。
鲁棒性和错误分析:
- 对模型的鲁棒性进行测试,特别是在面对错误或模糊的文本输入时,分析模型的弱点并提出改进方案。
应用开发:
- 将模型集成到实际应用中,如动画制作、机器人控制等,以验证其实用性并根据实际需求进行调整。
这些方向不仅可以推动开放词汇表动作生成技术的发展,还可能带来新的研究问题和应用场景。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为DSO-Net的框架,旨在解决文本到动作(Text-to-Motion, T2M)生成中的开放词汇表问题。以下是论文的主要内容总结:
问题陈述:
- 现有的T2M方法受限于标注数据集规模,导致模型过拟合,无法泛化到开放领域的动作。
方法论:
- 提出了一个两步框架:文本分解(Textual Decomposition)和子动作空间散射(Sub-motion-space Scattering)。
- 文本分解:将原始动作文本转换为描述简单身体部位动作的原子文本。
- 子动作空间散射:学习从原子动作到目标动作的组合过程,将有限数据中学到的子动作空间扩展到全动作空间。
技术贡献:
- 设计了一个细粒度描述转换算法,将动作文本转换为原子动作文本。
- 提出了文本-动作对齐(TMA)模块和组合特征融合(CFF)模块,以改善模型的泛化能力。
实验:
- 在多个数据集上进行了广泛的实验,包括领域内和领域外数据集。
- 使用了Frechet Inception Distance(FID)、Motion-retrieval precision(R-Precision)和 Diversity 作为评估指标。
- 与现有最先进方法进行了定量和定性比较,展示了DSO-Net在开放词汇表动作生成上的优势。
结论:
- DSO-Net通过文本分解和子动作空间散射显著提高了模型对开放词汇表文本的泛化能力。
- 通过实验验证了该方法在不同数据集上的有效性。
总体而言,这篇论文针对开放词汇表动作生成问题提出了一种创新的解决方案,并通过一系列实验展示了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图