⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-15 更新
NestedMorph: Enhancing Deformable Medical Image Registration with Nested Attention Mechanisms
Authors:Gurucharan Marthi Krishna Kumar, Janine Mendola, Amir Shmuel
Deformable image registration is crucial for aligning medical images in a nonlinear fashion across different modalities, allowing for precise spatial correspondence between varying anatomical structures. This paper presents NestedMorph, a novel network utilizing a Nested Attention Fusion approach to improve intra-subject deformable registration between T1-weighted (T1w) MRI and diffusion MRI (dMRI) data. NestedMorph integrates high-resolution spatial details from an encoder with semantic information from a decoder using a multi-scale framework, enhancing both local and global feature extraction. Our model notably outperforms existing methods, including CNN-based approaches like VoxelMorph, MIDIR, and CycleMorph, as well as Transformer-based models such as TransMorph and ViT-V-Net, and traditional techniques like NiftyReg and SyN. Evaluations using the HCP dataset demonstrate that NestedMorph achieves superior performance across key metrics, including SSIM, HD95, and SDlogJ, with the highest SSIM of 0.89, the lowest HD95 of 2.5 and SDlogJ of 0.22. These results highlight NestedMorph’s ability to capture both local and global image features effectively, leading to superior registration performance. The promising outcomes of this study underscore NestedMorph’s potential to significantly advance deformable medical image registration, providing a robust framework for future research and clinical applications. The source code and our implementation are available at: https://github.com/AS-Lab/Marthi-et-al-2024-NestedMorph-Deformable-Medical-Image-Registration
可变形的图像配准对于跨不同模态以非线性方式对齐医学图像至关重要,它允许在不同解剖结构之间实现精确的空间对应关系。本文介绍了NestedMorph,这是一种新型网络,采用Nested Attention Fusion方法,旨在改进T1加权(T1w)MRI和扩散MRI(dMRI)数据之间的个体内可变形配准。NestedMorph通过多尺度框架将编码器的高分辨率空间细节与解码器的语义信息进行集成,提高了局部和全局特征提取能力。我们的模型显著优于现有方法,包括基于CNN的方法(如VoxelMorph、MIDIR和CycleMorph),基于Transformer的方法(如TransMorph和ViT-V-Net),以及传统技术(如NiftyReg和SyN)。使用HCP数据集进行的评估表明,NestedMorph在关键指标上表现出卓越的性能,包括SSIM、HD95和SDlogJ,其中SSIM最高达到0.89,HD95最低为2.5,SDlogJ为0.22。这些结果突显了NestedMorph在有效捕获局部和全局图像特征方面的能力,从而实现了出色的配准性能。这项研究的令人鼓舞的结果强调了NestedMorph在可变形医学图像配准方面的潜力,为未来的研究和临床应用提供了稳健的框架。源代码和我们的实现可在https://github.com/AS-Lab/Marthi-et-al-2024-NestedMorph-Deformable-Medical-Image-Registration上找到。
论文及项目相关链接
PDF Accepted to IEEE/CVF Winter Conference on Applications of Computer Vision 2025
摘要
本文介绍了一种名为NestedMorph的新型网络,该网络采用Nested Attention Fusion方法,改进了T1加权MRI和扩散MRI数据之间的个体内可变形图像配准。NestedMorph结合了编码器的高分辨率空间细节和解码器的语义信息,利用多尺度框架,增强了局部和全局特征提取。与现有的VoxelMorph、MIDIR、CycleMorph等CNN模型,以及TransMorph、ViT-V-Net等Transformer模型和NiftyReg、SyN等传统技术相比,我们的模型表现优异。在HCP数据集上的评估结果表明,NestedMorph在关键指标SSIM、HD95和SDlogJ上表现卓越,其中SSIM最高达到0.89,HD95最低为2.5,SDlogJ为0.22。这些结果证明了NestedMorph在捕捉图像局部和全局特征方面的有效性,实现了出色的配准性能。该研究的成果为NestedMorph在可变形医学图像配准方面的应用提供了潜力,为未来的研究和临床应用提供了稳健的框架。
要点
- NestedMorph网络采用Nested Attention Fusion方法,改进了跨不同模态的非线性医学图像配准。
- 该模型结合了高分辨率的空间细节和语义信息,使用多尺度框架进行特征提取。
- NestedMorph在关键指标SSIM、HD95和SDlogJ上表现优于其他现有方法。
- 研究结果证明了NestedMorph在捕捉图像局部和全局特征方面的有效性。
- NestedMorph具有潜在的临床应用价值,为未来的医学图像配准研究提供了稳健的框架。
- 公开了源代码和实现,便于进一步研究和应用。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是医学图像配准中的非刚性(可变形)图像配准问题,特别是在不同模态之间对齐医学图像,例如T1加权(T1w)MRI和扩散MRI(dMRI)数据。具体来说,论文旨在通过提出一个名为NestedMorph的新型网络,利用嵌套注意力融合方法来改善主体内(intra-subject)T1w MRI和dMRI数据之间的可变形配准。
论文强调了以下几点挑战和目标:
非刚性图像配准的重要性:在医学成像任务中,非刚性图像配准对于通过非线性映射对齐固定和移动图像至关重要,这有助于建立不同解剖结构之间的精确空间对应关系。
现有方法的局限性:尽管卷积神经网络(CNN)和视觉Transformer(ViT)已在非刚性图像配准中取得了进展,但它们在准确建模变形场方面仍面临挑战。
提出的方法:论文提出了一个基于CNN和Transformer混合模型的无监督深度学习方法,专门针对主体内T1w和dMRI模板之间的对齐,以实现准确的解剖和扩散数据对应。
性能提升:通过与现有最先进方法(包括基于CNN的方法如VoxelMorph、MIDiR、CycleMorph,基于Transformer的模型如TransMorph和ViT-V-Net,以及传统技术如NiftyReg和SyN)的比较,论文展示了NestedMorph在关键指标(如SSIM、HD95和SDlogJ)上取得了更好的性能。
方法的潜力:论文的结果强调了NestedMorph在捕获局部和全局图像特征方面的有效性,从而实现了更优越的配准性能,并指出了其在推进可变形医学图像配准方面的潜力,为未来的研究和临床应用提供了一个强大的框架。
Q: 有哪些相关研究?
A: 论文中提到了多个与可变形医学图像配准相关的研究工作,以下是一些关键的相关研究:
VoxelMorph [5]:这是一个基于CNN的编码器-解码器架构,类似于UNet,用于计算移动和固定图像对之间的变形场,并通过空间变换网络迭代地扭曲移动图像。
MIDiR [25]:该方法采用B样条参数化来生成微分同胚变形场,使用互信息损失和平稳速度场(SVF)以实现平滑变形。
CycleMorph [18]:该方法结合了两个配准网络来计算位移向量场,并引入了一个循环一致性学习模型,以在保持图像拓扑结构的同时进行无监督配准。
TransMorph [9]:这是一个新颖的混合模型,结合了Transformer和CNN,专门用于3D医学图像配准。该模型利用Transformer的自注意力机制和广泛的有效感受野来增强配准精度。
ViT-V-Net [10]:这是一个混合CNN-Transformer架构,用于自监督体积图像配准。它将视觉Transformer(ViT)应用于高级图像特征以捕获长距离依赖,而长跳跃连接保持编码器和解码器阶段之间的定位信息。
NiftyReg [24] 和 SyN [2]:这些是传统的配准方法,通过优化算法来实现图像之间的对齐。
其他监督学习方法:这些方法利用外部数据,如标签图,来指导训练过程。它们需要真实的变形场,这在计算上可能很昂贵。
其他无监督学习方法:这些方法不依赖于真实的变形场,而是通过探索数据的内在特征来执行配准。
这些相关研究展示了可变形医学图像配准领域的多样性,从传统的基于优化的方法到最新的基于深度学习的方法,每种方法都有其优势和局限性。论文提出的NestedMorph模型旨在结合这些方法的优点,通过嵌套注意力机制和多尺度框架来提高配准的准确性和鲁棒性。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为NestedMorph的新型网络来解决医学图像的非刚性配准问题,具体方法如下:
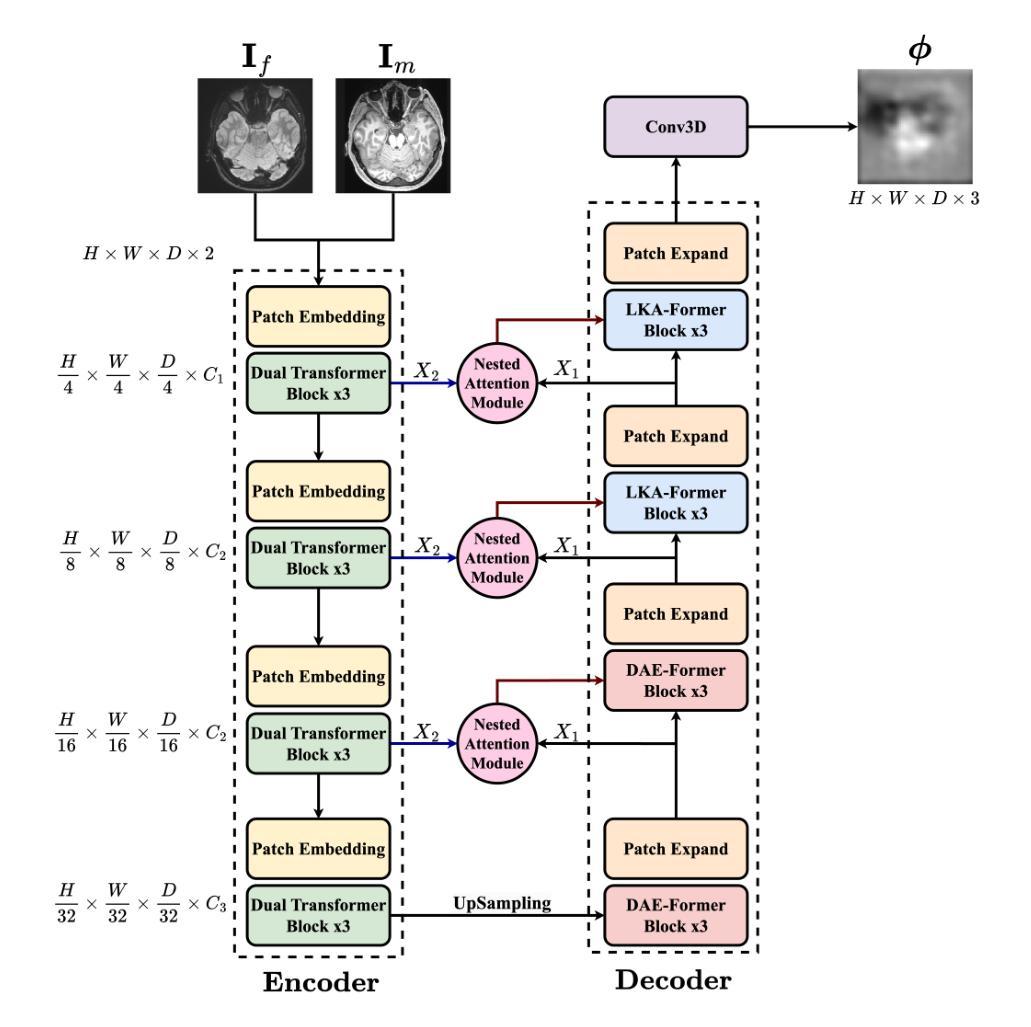
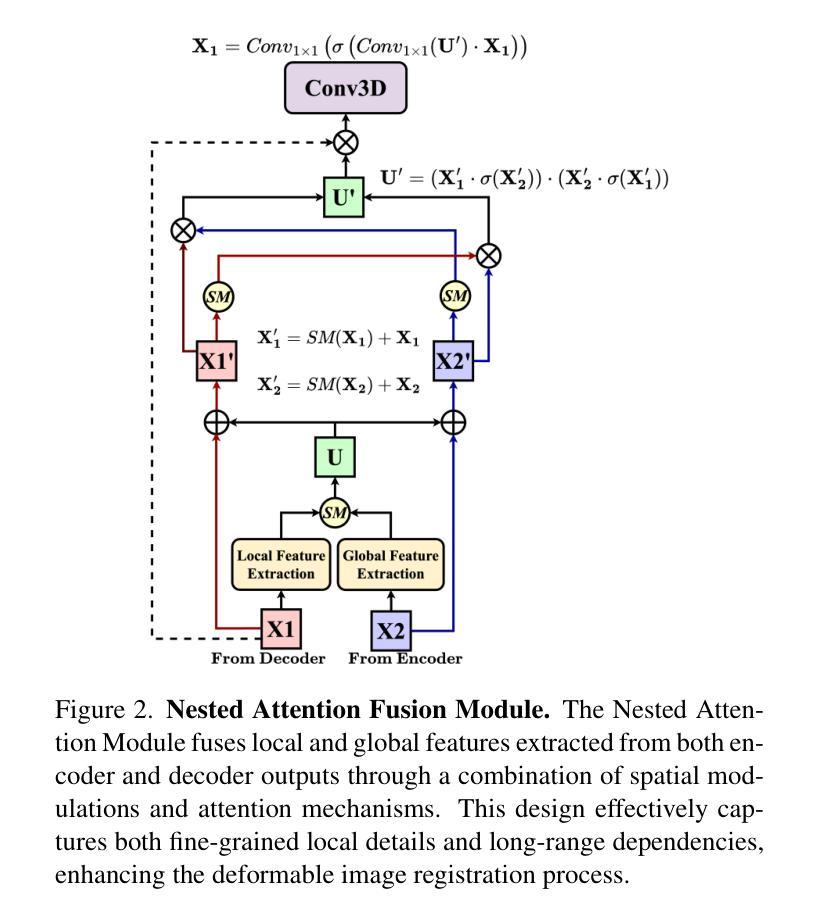
1. Nested Attention Fusion网络架构
- 编码器(Encoder):使用多级设计,结合重叠的patch嵌入和双注意力机制(Efficient Attention和Channel Attention),从3D医学图像中提取和处理特征。编码器通过不同阶段处理输入图像,逐步降低空间维度并增加特征丰富度,最终输出多尺度特征图。
2. 双注意力机制
- Efficient Attention:通过优化上下文矩阵的计算来增强传统自注意力,使用单通道特征图作为所有位置的权重,减少计算复杂度同时保持高表示能力。
- Channel Attention:通过转置注意力机制处理更大的输入尺寸,集中于整个通道维度,提高效率。
3. 双注意力Transformer块
- 结合Efficient Attention和Channel Attention,通过Add & Norm步骤和MLP(多层感知机)增强特征提取和表示。
4. 解码器(Decoder)
- DAE-Former块:在较低分辨率的图像中保持长距离依赖性,整合空间和通道注意力,保持图像结构完整性。
- LKA(Large Kernel Attention)模块:处理局部和全局特征,对高分辨率图像处理尤为重要。
5. 嵌套注意力融合模块(Nested Attention Fusion Module)
- 利用多尺度融合技术聚合编码器和解码器输出,通过空间选择和交叉调制增强特征映射,整合局部细节和全局上下文。
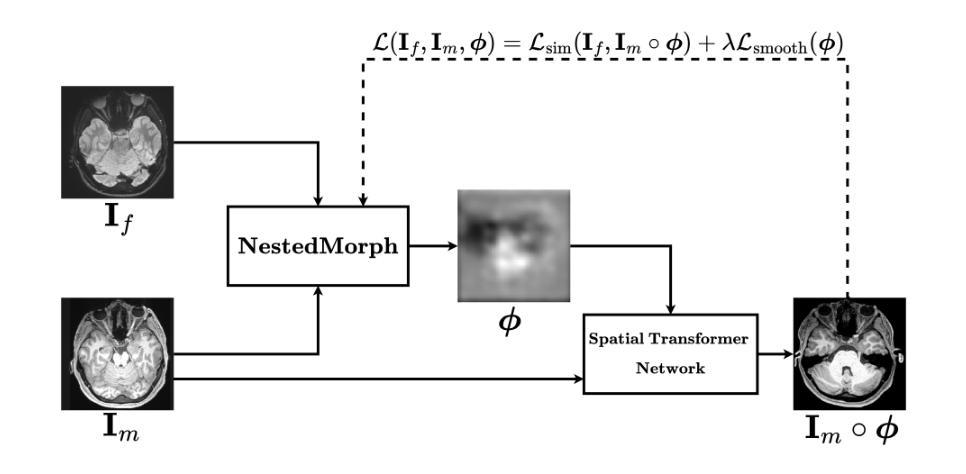
6. 空间变换网络(Spatial Transformer Network, STN)
- 应用预测的变形场对移动图像进行扭曲,通过迭代训练最小化移动图像和固定图像之间的差异。
7. 实验和评估
- 使用HCP(Human Connectome Project)数据集对模型进行评估,显示出NestedMorph在SSIM、HD95和SDlogJ等关键指标上优于现有方法。
8. 无监督学习方法
- 该方法为无监督的,不依赖于真实的变形场,而是通过探索数据的内在特征来执行配准。
通过上述方法,NestedMorph能够有效地捕捉局部和全局图像特征,提供精确的变形场估计,从而实现T1w MRI和dMRI数据之间的准确对齐。这种设计提高了配准的精度和可靠性,为医学图像配准领域提供了一个强大的新工具。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和验证NestedMorph模型的性能,具体实验包括:
1. 数据集和预处理
- 使用了来自HCP Aging Dataset的205名受试者的数据,包括T1w和dMRI扫描。
- 其中180名受试者的数据用于训练网络,剩余的25名受试者的数据用于测试。
- T1w扫描的体素大小为0.7 mm等向性,dMRI扫描的体素大小为1.25 mm等向性。
- 将T1w和平均dMRI扫描调整为128×128×128体素。
- 使用SimpleITK将T1w图像仿射配准到平均dMRI图像,形成移动的T1w和固定的平均dMRI图像对。
2. 训练参数
- NestedMorph模型使用PyTorch框架在NVIDIA A100 GPU上实现。
- 训练使用了一批大小为4的随机梯度下降,基础学习率为(1 \times 10^{-4}),权重衰减为(3 \times 10^{-5})。
- 模型训练了100个周期,使用复合损失函数计算变形移动图像和固定图像之间的相似性,并施加变形场的平滑性以正则化。
3. 基线和比较
- 将NestedMorph网络与现有的无监督可变形配准技术进行比较,包括CNN方法(VoxelMorph、MIDiR、CycleMorph)和基于Transformer的方法(TransMorph、ViT-V-Net)。
- 还包括了传统方法(NiftyReg和SyN)。
- 使用结构相似性指数(SSIM)、95百分位数Hausdorff距离(HD95)和Jacobian行列式对数的标准差(SDlogJ)等相似性指标来评估不同配准网络的性能。
4. 定量结果
- 使用25名受试者的数据进行测试,比较不同配准网络的性能。
- NestedMorph在SSIM、HD95和SDlogJ三个评估指标上均优于其他模型,显示出最高的SSIM值和最低的HD95和SDlogJ值。
5. 消融研究
- 对NestedMorph模型进行了消融研究,以评估不同网络模块对配准性能的影响。
- 研究了注意力头数、网络深度、patch大小和批量大小等参数对性能的影响。
- 还探讨了不同配置的注意力机制和DAE-Former及LKA块的数量对配准性能的影响。
这些实验全面评估了NestedMorph模型的性能,并与现有的先进方法进行了比较,证明了其在医学图像配准中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 论文提出了NestedMorph这一新型网络架构,并在T1w MRI和dMRI数据的非刚性配准任务中取得了优异的性能。尽管如此,仍有一些领域可以进一步探索和研究:
1. 跨模态和跨受试者配准
- 论文主要关注了主体内(intra-subject)配准,未来的研究可以探索NestedMorph在跨受试者(inter-subject)和跨模态(cross-modality)配准任务中的有效性。
2. 计算复杂度优化
- NestedMorph由于其双注意力机制和多尺度融合框架,计算复杂度较高。未来的研究可以探索优化策略,以减少计算资源的需求,使其更适合资源受限的环境。
3. 网络架构调整
- 论文中通过消融实验确定了最佳的网络配置,但可能还有其他的网络架构调整可以进一步提升性能,例如不同的注意力头数、层数或不同类型的注意力机制。
4. 损失函数和优化策略
- 研究不同的损失函数和优化策略对模型性能的影响,可能可以发现更适合特定配准任务的损失函数或优化算法。
5. 临床应用和验证
- 在临床环境中对NestedMorph进行验证,评估其在实际临床工作流程中的适用性和效果。
6. 大规模数据集的测试
- 在更大的、多样化的数据集上测试NestedMorph,以评估其泛化能力和鲁棒性。
7. 多任务学习
- 探索将配准任务与其他相关任务(如分割、分类)结合的多任务学习框架,以提高模型的效用和准确性。
8. 实时性能
- 研究NestedMorph在实时或近实时应用中的性能,这对于手术导航等应用场景非常重要。
9. 模型解释性
- 提高模型的可解释性,帮助医生和研究人员理解模型的决策过程,增加其在临床应用中的可信度。
10. 集成传统方法
- 探索将NestedMorph与传统的医学图像配准方法结合,以利用各自的优势,可能提高配准的准确性和鲁棒性。
这些方向不仅可以推动NestedMorph模型的发展,还可能为医学图像配准领域带来新的突破。
Q: 总结一下论文的主要内容
A: 本文提出了一个名为NestedMorph的新型网络,旨在提高医学图像非刚性配准的性能,特别是在T1加权(T1w)MRI和扩散MRI(dMRI)数据之间的配准。以下是论文的主要内容总结:
1. 问题背景
- 非刚性图像配准对于跨不同模态对齐医学图像至关重要,它通过连续变形场建立精确的空间对应关系。
2. 现有方法的局限性
- 尽管基于CNN和Transformer的方法在配准领域取得了进展,但仍存在挑战,特别是在准确建模变形场方面。
3. NestedMorph网络
- 提出了一个无监督的混合CNN-Transformer深度学习模型,专门用于主体内T1w和dMRI模板之间的对齐。
- NestedMorph利用嵌套注意力融合方法,整合编码器的高分辨率空间细节和解码器的语义信息,增强局部和全局特征提取。
4. 网络架构
- 编码器:采用多级设计,结合重叠patch嵌入和双注意力机制(Efficient Attention和Channel Attention)来提取特征。
- 解码器:使用Dual Attention Enhanced Transformer(DAE-Former)块和Large Kernel Attention(LKA)模块来维持长距离依赖和结构完整性。
- 嵌套注意力融合模块:整合编码器和解码器的特征,通过多尺度融合技术聚合局部和全局特征。
- 空间变换网络(STN):应用预测的变形场对移动图像进行扭曲,以实现精确的图像配准。
5. 实验和评估
- 使用HCP数据集对NestedMorph进行评估,与现有的CNN和Transformer方法以及传统技术进行比较。
- NestedMorph在SSIM、HD95和SDlogJ等关键指标上显示出优越的性能。
6. 消融研究
- 对NestedMorph模型的不同组件和参数进行了消融研究,以评估它们对配准性能的影响。
7. 讨论和结论
- NestedMorph通过其嵌套注意力机制有效地捕获局部和全局图像特征,提供了一种强大的框架,用于改进医学图像的非刚性配准。
- 尽管NestedMorph在精度上表现出色,但也存在计算复杂度高的挑战,未来研究可以探索优化和扩展其应用。
总体而言,NestedMorph为医学图像配准领域提供了一种新的深度学习方法,具有显著的性能提升潜力,并为未来的研究和临床应用铺平了道路。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Grading and Anomaly Detection for Automated Retinal Image Analysis using Deep Learning
Authors:Syed Mohd Faisal Malik, Md Tabrez Nafis, Mohd Abdul Ahad, Safdar Tanweer
The significant portion of diabetic patients was affected due to major blindness caused by Diabetic retinopathy (DR). For diabetic retinopathy, lesion segmentation, and detection the comprehensive examination is delved into the deep learning techniques application. The study conducted a systematic literature review using the PRISMA analysis and 62 articles has been investigated in the research. By including CNN-based models for DR grading, and feature fusion several deep-learning methodologies are explored during the study. For enhancing effectiveness in classification accuracy and robustness the data augmentation and ensemble learning strategies are scrutinized. By demonstrating the superior performance compared to individual models the efficacy of ensemble learning methods is investigated. The potential ensemble approaches in DR diagnosis are shown by the integration of multiple pre-trained networks with custom classifiers that yield high specificity. The diverse deep-learning techniques that are employed for detecting DR lesions are discussed within the diabetic retinopathy lesions segmentation and detection section. By emphasizing the requirement for continued research and integration into clinical practice deep learning shows promise for personalized healthcare and early detection of diabetics.
大量糖尿病患者受到糖尿病视网膜病变(DR)导致的主要失明影响。针对糖尿病视网膜病变、病变分割和检测,深入研究深度学习技术的应用。该研究采用PRISMA分析进行了系统文献综述,并调查了62篇文章。研究中探索了多种深度学习方法论,包括用于DR分级的CNN模型和特征融合。为了提高分类精度和稳健性,对数据增强和集成学习策略进行了严格审查。通过展示相较于单一模型的优越性能,对集成学习方法的功效进行了调查。通过集成多个预训练网络与自定义分类器,显示出集成方法在DR诊断中的潜在应用,取得了较高的特异性。在糖尿病视网膜病变病变分割和检测部分,讨论了用于检测DR病变的各种深度学习技术。深度学习强调继续研究和融入临床实践的需求,为个性化医疗和糖尿病的早期检测带来了希望。
论文及项目相关链接
PDF Diabetic retinopathy, segmentation, images on retinal fundus, convolutional neural network
Summary
糖尿病视网膜病变(DR)严重影响糖尿病患者,其病变检测与分割需深入研究深度学习技术。本研究通过PRISMA分析进行文献综述,探讨卷积神经网络(CNN)在DR分级中的应用及特征融合等深度学习手段。为提高分类精度和稳健性,研究数据增强和集成学习策略。集成学习方法通过对比单一模型展现优势,在DR诊断中展现出潜在价值。深度学习技术对于DR病变检测具有临床意义,并有望应用于个性化医疗和糖尿病早期检测。
Key Takeaways
- 糖尿病视网膜病变(DR)是糖尿病患者中的主要致盲原因。
- 深度学习技术在DR病变分割和检测方面进行了深入研究,包括CNN模型的应用。
- 研究通过PRISMA分析进行文献综述,共调查了62篇文章。
- 数据增强和集成学习策略被研究以提高分类精度和稳健性。
- 集成学习方法在DR诊断中展现出优势,通过集成多个预训练网络和自定义分类器获得高特异性。
- 深度学习技术对于DR病变检测具有临床意义,并有望应用于个性化医疗。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文主要探讨了利用深度学习技术进行糖尿病视网膜病变(Diabetic Retinopathy, DR)的自动分级和异常检测。论文试图解决的关键问题包括:
DR的早期检测和诊断:糖尿病视网膜病变是导致失明的主要原因之一,尤其在糖尿病患者中。论文强调了早期检测和治疗对于预防由DR引起的失明的重要性。
深度学习技术的应用:研究了深度学习技术,特别是卷积神经网络(CNN)在DR的病变分割和检测中的应用,以及如何通过这些技术提高DR的诊断准确性和鲁棒性。
数据增强和集成学习方法:探讨了数据增强和集成学习策略在提高分类准确性和模型鲁棒性方面的有效性,以及如何通过集成多个预训练网络与自定义分类器来提高DR诊断的特异性。
临床实践的整合:论文强调了将深度学习技术整合到临床实践中的必要性,以实现糖尿病的个性化医疗和早期检测。
系统性文献综述:通过系统性文献综述,研究者们调查了62篇文章,以提供一个关于深度学习模型开发、数据集分析、预处理流程和临床实际应用的综合视角。
技术挑战和未来发展:论文讨论了在模型可解释性、数据集异质性和跨不同人群的适用性等挑战,并展望了深度学习技术在DR诊断中的未来发展方向。
总的来说,这篇论文试图提供一个关于如何利用深度学习技术来提高DR检测和分级的准确性和效率的全面分析,并探讨了这些技术在实际临床环境中的应用潜力。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与糖尿病视网膜病变(DR)的深度学习技术相关的研究:
Nielsen KB, Lautrup ML, Andersen JKH, Savarimuthu TR, Grauslund J. 这项研究系统性地回顾了基于深度学习的糖尿病视网膜病变筛查算法的诊断性能。[Ophthalmology Retina, 2019]
Islam MM, Yang HC, Poly TN, Jian WS, (Jack) Li YC. 这项系统回顾和元分析研究了基于深度学习的算法在视网膜底片照片中检测糖尿病视网膜病变的能力。[Computer Methods and Programs in Biomedicine, 2020]
Asiri N, Hussain M, Al Adel F, Alzaidi N. 这项调查研究了基于深度学习的计算机辅助诊断系统在糖尿病视网膜病变中的应用。[Artificial Intelligence in Medicine, 2019]
Badar M, Haris M, Fatima A. 这篇综述文章探讨了深度学习在视网膜图像分析中的应用。[Computer Science Review, 2020]
Grzybowski A, Brona P, Lim G, Ruamviboonsuk P, Tan GSW, Abramoff M, et al. 这篇综述文章讨论了人工智能在糖尿病视网膜病变筛查中的应用。[Eye, 2020]
Li T, Gao Y, Wang K, Guo S, Liu H, Kang H. 这项研究对深度学习算法在糖尿病视网膜病变筛查中的诊断评估进行了探讨。[Information Sciences, 2019]
Esfahani MT, Ghaderi M, Kafiyeh R. 该研究使用新的深度学习方法对糖尿病和正常眼底图像进行分类。[Leonardo Electron J Pract Technol, 2018]
Lam C, Yi D, Guo M, Lindsey T. 这项研究探讨了使用深度学习自动检测糖尿病视网膜病变。[AMIA summits on translational science proceedings, 2018]
Das S, Kharbanda K, M S, Raman R, D ED. 这项研究基于分割的眼底图像特征构建深度学习架构,用于糖尿病视网膜病变的分类。[Biomedical Signal Processing and Control, 2021]
Melo T, Mendonça AM, Campilho A. 这项研究针对糖尿病视网膜病变筛查中的微动脉瘤检测。[Computers in Biology and Medicine, 2020]
这些研究涵盖了从深度学习算法的开发、性能评估到特定病变检测等多个方面,体现了深度学习技术在糖尿病视网膜病变检测和分级中的广泛应用和研究进展。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决糖尿病视网膜病变(DR)的自动分级和异常检测问题:
系统性文献综述:
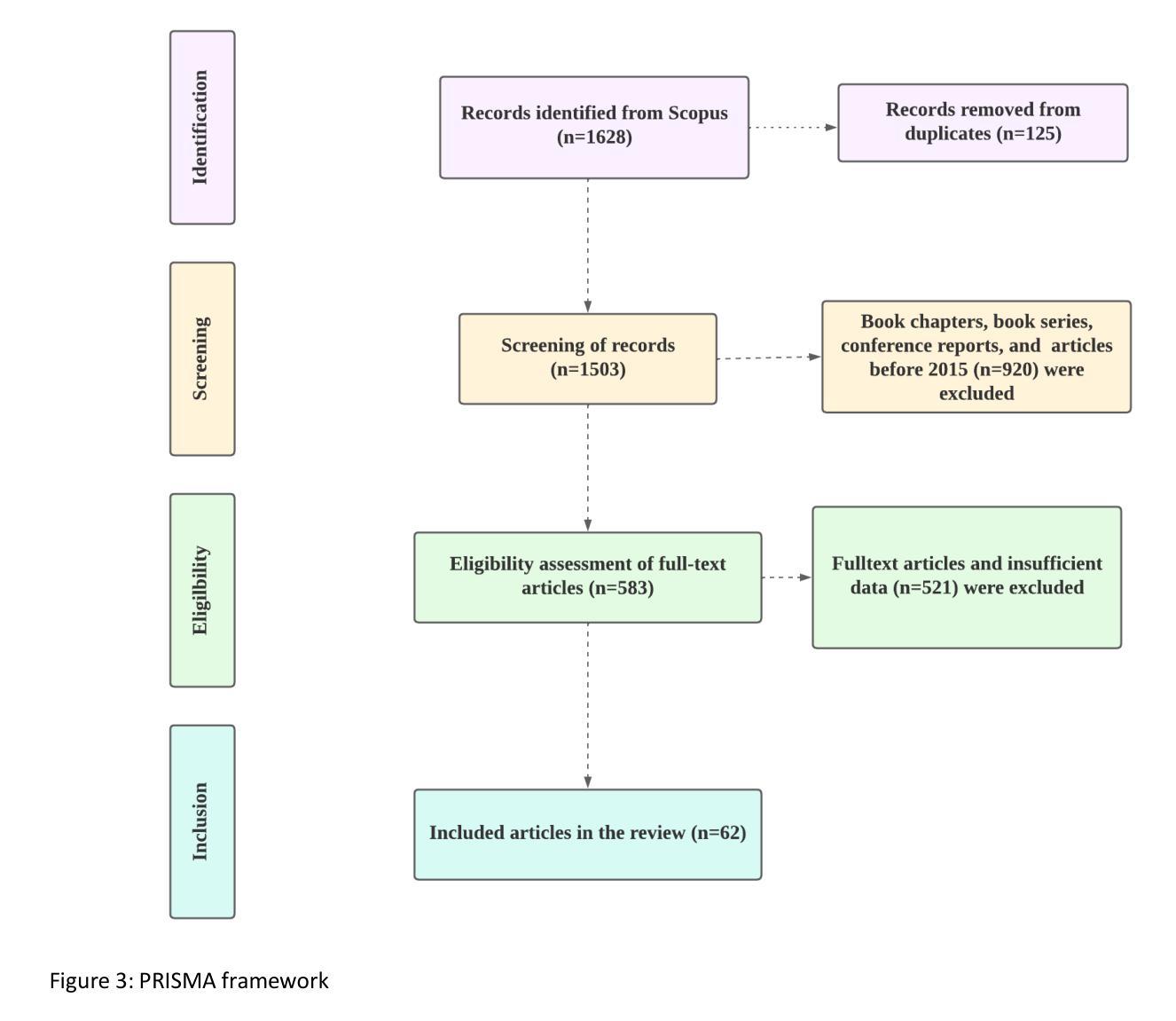
- 使用PRISMA分析方法对相关文献进行系统性回顾,筛选和分析了62篇相关研究文章。
深度学习技术的应用:
- 探索了基于卷积神经网络(CNN)的模型以及其他深度学习方法在DR的检测和分割中的应用。
- 研究了数据增强和集成学习策略以提高分类准确性和模型的鲁棒性。
模型性能评估:
- 利用混淆矩阵和不同的性能评估指标(如Cohen’s Kappa、Sensitivity、Accuracy、F1 Score和Specificity)来评估二元分类模型的性能。
- 使用ROC曲线和AUC值来量化分类器的整体性能。
深度学习模型的开发与比较:
- 开发和评估了不同的深度学习模型,包括CNN架构,以及它们的变体和集成模型,用于DR的自动诊断。
- 比较了单个模型与集成学习方法的性能,展示了集成方法如何通过结合多个预训练网络和自定义分类器来提高特异性。
数据集的分析与应用:
- 分析了多个公开的视网膜图像数据集,这些数据集用于训练、验证和测试深度学习系统,并比较不同系统的性能。
图像预处理技术:
- 讨论了图像预处理方法,包括尺寸调整、裁剪、归一化和去噪,以提高图像特征的一致性。
DR分类和分割方法:
- 详细讨论了用于DR分级的不同分类系统和用于DR病变分割和检测的深度学习技术。
集成学习方法的应用:
- 展示了如何通过集成多个预训练网络来构建集成模型,以提高疾病分级和识别的性能。
未来研究方向的讨论:
- 强调了将深度学习技术整合到临床实践中的必要性,并讨论了模型可解释性、数据集异质性和跨不同人群的适用性等挑战。
通过这些步骤,论文提供了一个全面的分析框架,以评估和改进深度学习技术在DR自动检测和分级中的应用,旨在推动这些技术向临床实践的转化,并提高DR的早期检测和管理。
Q: 论文做了哪些实验?
A: 根据论文内容,以下是一些关键的实验和研究活动:
系统性文献回顾:
- 遵循PRISMA指南进行系统性文献回顾,通过Scopus数据库检索相关文章,并按照特定的纳入和排除标准筛选出62篇相关研究文章进行深入分析。
深度学习模型的应用与评估:
- 实施了基于卷积神经网络(CNN)的模型来处理DR的分级和检测问题。
- 探索了数据增强和集成学习策略以提高模型的分类准确性和鲁棒性。
性能评估指标的计算:
- 使用混淆矩阵、Cohen’s Kappa、Sensitivity、Accuracy、F1 Score和Specificity等指标来评估模型性能。
- 利用ROC曲线和AUC值来量化分类器的整体性能。
二元筛查实验:
- 使用CNN对Kaggle数据集中的正常图像进行自动分类,并对数据进行增强和尺寸调整。
- 应用不同的CNN架构和SoftMax函数进行图像的分类。
多级DR分类实验:
- 利用CNN方法对Eyepacs-1数据集和Messidor-2数据集进行测试,以检测糖尿病视网膜病变和糖尿病黄斑水肿。
- 训练了多个CNN模型,并使用线性平均函数计算最终结果。
集成学习方法实验:
- 设计了集成模型,结合多个预训练网络进行特征提取,并与自定义的密集神经网络耦合作为分类器。
- 使用Adaboost分类器结合三个模型(基于Inception V3, Inception-Resnet-V2架构, ResNet152)进行训练。
DR病变分割和检测实验:
- 利用深度学习方法和领域知识来检测DR图像中的红病变。
- 应用随机森林方法对DIARETDB1、MESSIDOR和E-ophtha数据集中的图像进行分类。
这些实验覆盖了从数据预处理、模型训练、性能评估到结果验证等多个方面,旨在全面评估深度学习技术在糖尿病视网膜病变自动检测和分级中的有效性和准确性。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些挑战和未来的研究方向,以下是一些可以进一步探索的点:
模型可解释性:
- 增强深度学习模型在DR诊断中的可解释性,以便医生和临床工作者能够理解和信任AI系统的决策过程。
数据集的多样性和异质性:
- 扩展和多样化训练数据集,以包含不同种族、性别和地理位置的患者,以提高模型的泛化能力。
跨人群的适用性:
- 评估和改进深度学习模型在不同人群和不同医疗环境中的适用性,特别是资源受限的环境。
集成学习策略的优化:
- 进一步研究和优化集成学习策略,以提高模型的性能和鲁棒性。
实时诊断系统的开发:
- 开发实时或近实时的DR诊断系统,可以直接在临床设置中使用。
临床协议的整合:
- 将深度学习技术更紧密地整合到临床协议和工作流程中,以促进其在实际医疗实践中的应用。
标准化和验证:
- 在更大的、多样化的数据集上验证模型,并制定标准化流程,以便在不同研究和应用之间进行公平比较。
技术进步的利用:
- 利用最新的技术进步,如新的深度学习架构、注意力机制和多模态学习,以进一步提高DR检测和分级的准确性。
患者结果的改善:
- 研究如何通过深度学习技术改善糖尿病患者的结果,包括早期检测、个性化治疗和长期管理。
成本效益分析:
- 进行成本效益分析,以评估深度学习技术在DR筛查和诊断中的经济可行性。
跨学科合作:
- 促进眼科医生、计算机科学家、数据科学家和政策制定者之间的合作,以推动深度学习技术在DR管理中的应用。
这些探索点可以帮助研究人员、开发者和医疗专业人员更好地理解和应用深度学习技术,以提高糖尿病视网膜病变的检测和管理。
Q: 总结一下论文的主要内容
A: 这篇论文主要探讨了利用深度学习技术进行糖尿病视网膜病变(DR)的自动分级和异常检测。以下是其主要内容的总结:
背景与重要性:
- 论文强调了糖尿病视网膜病变(DR)作为导致失明的主要原因之一,尤其在全球糖尿病患病率上升的背景下,早期检测和治疗的重要性。
深度学习技术:
- 论文探讨了多种基于深度学习的方法,特别是卷积神经网络(CNN)在DR的病变分割和检测中的应用。
数据增强与集成学习:
- 研究了数据增强和集成学习策略在提高分类准确性和模型鲁棒性方面的有效性。
系统性文献综述:
- 遵循PRISMA指南,对62篇相关研究文章进行了系统性回顾,提供了一个关于深度学习模型开发、数据集分析、预处理流程和临床实际应用的综合视角。
性能评估:
- 使用混淆矩阵和多种性能评估指标(如Cohen’s Kappa、Sensitivity、Accuracy、F1 Score和Specificity)来评估模型性能。
DR分类与分割实验:
- 实施了多个实验,包括二元筛查、多级分类和DR病变的分割与检测,展示了深度学习模型在这些任务上的应用和性能。
集成学习方法的应用:
- 展示了如何通过集成多个预训练网络来构建集成模型,以提高疾病分级和识别的性能。
挑战与未来方向:
- 讨论了将深度学习技术整合到临床实践中的必要性,并强调了模型可解释性、数据集异质性和跨不同人群的适用性等挑战。
结论:
- 论文得出结论,深度学习技术在DR的自动检测和分级中显示出巨大潜力,但仍需进一步研究和标准化,以充分发挥其在临床诊断中的作用。
总体而言,这篇论文提供了一个全面的分析框架,以评估和改进深度学习技术在DR自动检测和分级中的应用,并探讨了这些技术在实际临床环境中的应用潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

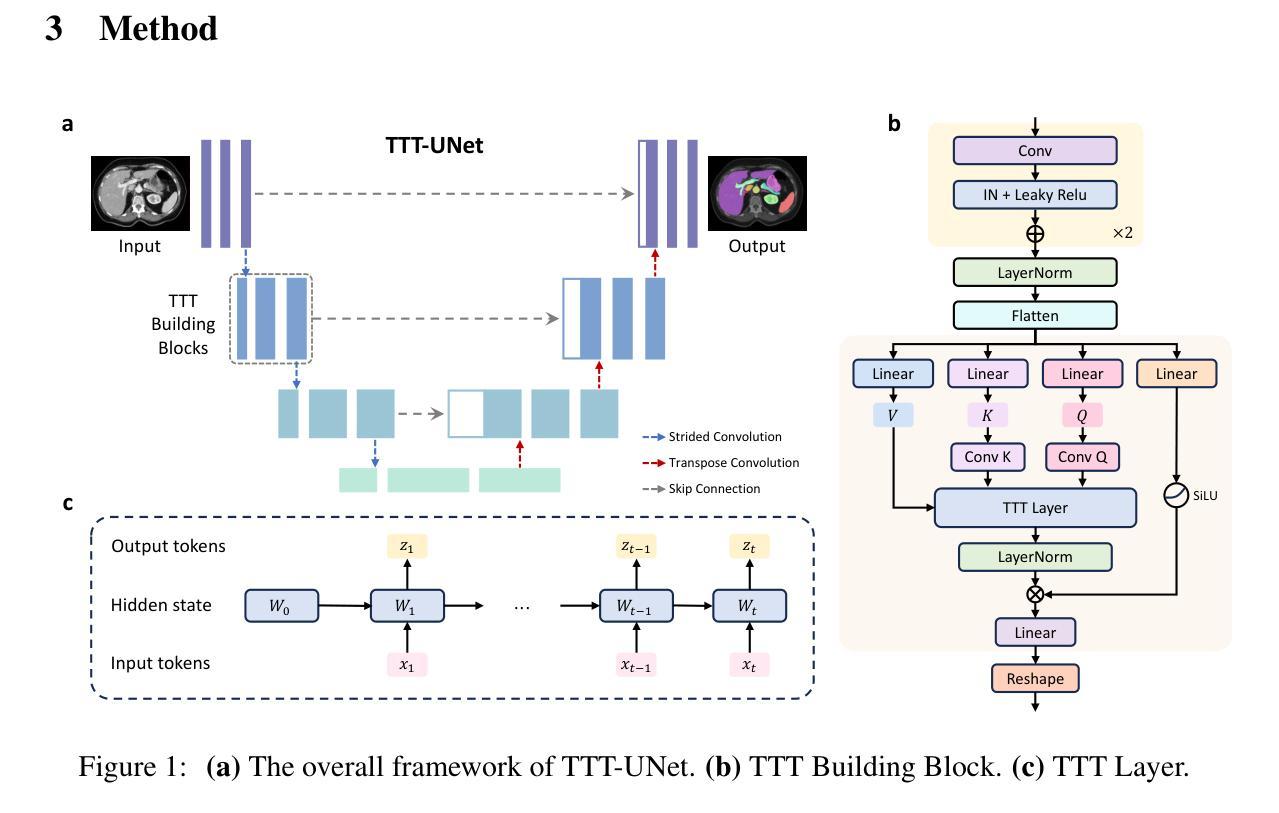
TTT-Unet: Enhancing U-Net with Test-Time Training Layers for Biomedical Image Segmentation
Authors:Rong Zhou, Zhengqing Yuan, Zhiling Yan, Weixiang Sun, Kai Zhang, Yiwei Li, Yanfang Ye, Xiang Li, Lifang He, Lichao Sun
Biomedical image segmentation is crucial for accurately diagnosing and analyzing various diseases. However, Convolutional Neural Networks (CNNs) and Transformers, the most commonly used architectures for this task, struggle to effectively capture long-range dependencies due to the inherent locality of CNNs and the computational complexity of Transformers. To address this limitation, we introduce TTT-Unet, a novel framework that integrates Test-Time Training (TTT) layers into the traditional U-Net architecture for biomedical image segmentation. TTT-Unet dynamically adjusts model parameters during the testing time, enhancing the model’s ability to capture both local and long-range features. We evaluate TTT-Unet on multiple medical imaging datasets, including 3D abdominal organ segmentation in CT and MR images, instrument segmentation in endoscopy images, and cell segmentation in microscopy images. The results demonstrate that TTT-Unet consistently outperforms state-of-the-art CNN-based and Transformer-based segmentation models across all tasks. The code is available at https://github.com/rongzhou7/TTT-Unet.
生物医学图像分割对于准确诊断和治疗各种疾病至关重要。然而,卷积神经网络(CNN)和Transformer是最常用于此任务的架构,由于CNN的固有局部性和Transformer的计算复杂性,它们难以有效地捕获长距离依赖关系。为了解决这一局限性,我们引入了TTT-Unet,这是一个将测试时间训练(TTT)层集成到传统U-Net架构中的新型框架,用于生物医学图像分割。TTT-Unet在测试时动态调整模型参数,提高了模型捕获局部和长距离特征的能力。我们在多个医学成像数据集上评估了TTT-Unet的性能,包括CT和MR图像的3D腹部器官分割、内窥镜图像的仪器分割以及显微镜图像的细胞分割。结果表明,TTT-Unet在所有任务上均优于最新的基于CNN和基于Transformer的分割模型。代码可通过以下链接获取:[链接](https://github.com/rongzhou7/TTT-Unet)。
论文及项目相关链接
Summary
生物医学图像分割对于疾病的准确诊断和治疗分析至关重要。针对卷积神经网络(CNNs)和Transformer在捕捉长距离依赖方面的局限性,我们提出了TTT-Unet框架。它将测试时训练(TTT)层融入传统U-Net架构中,可在测试时动态调整模型参数,提升模型捕捉局部和长距离特征的能力。在多个医学图像数据集上的评估显示,TTT-Unet在所有任务上均优于最新的CNN和Transformer分割模型。
Key Takeaways
- 生物医学图像分割对疾病诊断和治疗分析至关重要。
- 卷积神经网络(CNNs)和Transformer在捕捉长距离依赖方面存在局限性。
- TTT-Unet框架结合了测试时训练(TTT)层和传统U-Net架构。
- TTT-Unet能在测试时动态调整模型参数。
- TTT-Unet增强了模型捕捉局部和长距离特征的能力。
- 在多个医学图像数据集上,TTT-Unet的表现优于其他先进的CNN和Transformer分割模型。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决生物医学图像分割中准确捕捉长距离依赖性的问题。具体来说,它指出了现有的卷积神经网络(CNNs)和变换器(Transformers)在处理这项任务时面临的挑战:
CNNs的局限性:由于卷积核固有的局部性,CNNs在建模图像中的长距离依赖性方面存在固有的局限性。尽管U-Net架构中的跳跃连接有助于合并低级细节和高级特征,但它们主要用于直接合并局部特征,这并不能显著提升网络建模长距离依赖性的能力。
Transformers的计算复杂性:虽然Transformers能够自然理解全局上下文,从而捕捉全局依赖性,但它们在密集的生物医学图像分割任务中的计算成本较高。
为了克服这些限制,论文引入了一种名为TTT-Unet的新型框架,该框架通过在传统的U-Net架构中整合测试时训练(Test-Time Training, TTT)层,动态调整模型参数,以增强模型捕获局部和长距离特征的能力。
Q: 有哪些相关研究?
A: 相关研究涵盖了多个方面,主要聚焦在生物医学图像分割领域,特别是U-Net及其变体、基于Transformer的模型,以及混合模型(结合CNN和SSMs)。以下是论文中提及的一些具体相关研究:
U-Net及其变体:
- U-Net:一种对称的编码器-解码器架构,通过跳跃连接更好地保留细节,广泛应用于生物医学图像分割。
- nnU-Net:一种自配置的U-Net框架,能够在多种生物医学图像分割任务中表现出色。
- TransUNet:将Vision Transformer(ViT)用于编码阶段的特征提取,并与CNN结合用于解码,展示了处理全局信息的能力。
- Swin-UNETR 和 UNETR:将Transformer架构与传统U-Net结合,增强3D成像分析。
基于Transformer的模型:
- Transformer在生物医学图像分割中的应用:如TransUNet、UNETR和SwinUNETR,展示了Transformer在处理长距离依赖性方面的优势。
混合模型(结合CNN和SSMs):
- U-Mamba:首次将SSM(状态空间模型)应用于医学图像领域,结合了高分辨率空间细节和长距离依赖性建模。
- SegMamba 和 nnMamba:在编码器中结合SSM,在解码器中使用CNN,展示了SSM在增强医学成像分析中的有效性和多样性。
其他相关技术:
- 自配置的网络结构:如nnU-Net,能够根据数据集自动调整网络结构。
- 跳跃连接:在U-Net架构中用于合并不同层级的特征,以改善分割性能。
这些研究为TTT-Unet的发展提供了基础,特别是在处理长距离依赖性和提高分割精度方面。TTT-Unet通过整合测试时训练(TTT)层,进一步增强了模型在这些方面的性能。
Q: 论文如何解决这个问题?
A: 论文通过引入TTT-Unet框架解决了生物医学图像分割中长距离依赖性的问题。TTT-Unet是一种新颖的混合架构,它将测试时训练(Test-Time Training, TTT)层集成到传统的U-Net框架中。以下是解决这个问题的关键步骤:
集成TTT层:TTT-Unet在U-Net网络的Mamba块中整合了TTT层,这使得模型能够根据测试数据持续更新其参数,从而增强其特征提取能力,并使其能够自适应地学习长距离依赖性。
动态参数调整:TTT层将传统的固定大小的隐藏状态视为可以通过自监督学习动态更新的机器学习模型。这种动态调整允许模型根据测试数据来细化其参数,从而提供更大的灵活性和表现力,以捕捉复杂的长距离依赖性。
自监督任务:TTT层采用自监督任务来训练模型,这包括从输入数据生成多个视图,并通过学习这些视图之间的关系来提升模型对输入数据的深入理解。
TTT-Unet架构:该架构由编码器-解码器结构组成,其中编码器通过TTT构建块增强了适应性,而解码器遵循标准U-Net设计,专注于重建分割图。
实验验证:作者在多个医学成像数据集上广泛实验,包括3D腹部器官分割、内窥镜图像中的仪器分割和显微镜图像中的细胞分割等任务。实验结果表明,TTT-Unet在所有任务中一致性地超越了现有的最先进模型。
通过这些方法,TTT-Unet能够有效地处理复杂的解剖结构,并在多样化的临床场景中表现出鲁棒性。特别是,TTT-Unet在生物医学图像分割任务中展示了显著的改进,使其成为医学图像分析的多功能解决方案。
Q: 论文做了哪些实验?
A: 论文中进行了多个实验来评估TTT-Unet在生物医学图像分割任务中的性能和可扩展性。以下是实验的具体内容:
数据集:实验使用了四个不同的生物医学图像数据集,涵盖了多种分割任务和成像方式,包括:
- Abdomen CT dataset:用于腹部器官从CT扫描中的分割。
- Abdomen MRI dataset:用于腹部器官从MRI扫描中的分割。
- Endoscopy dataset:用于内窥镜图像中仪器的分割。
- Microscopy dataset:用于显微镜图像中细胞的分割。
实验设置:实验的设置与U-Mamba和nnU-Net保持一致,以确保公平比较。实验采用了Dice损失和交叉熵损失的无权重组合,使用SGD优化器进行训练。
基线比较:TTT-Unet与多个先进的CNN和Transformer模型进行比较,包括nnU-NET、SegResNet、UNETR和SwinUNETR等。
评估指标:使用了Dice相似系数(DSC)、归一化表面距离(NSD)和F1分数等指标来评估分割性能。
定量分割结果:在2D和3D分割任务中,TTT-Unet在所有数据集上均展现出优越的性能,超越了其他比较的模型。
定性分割结果:通过可视化分割结果,展示了TTT-Unet在处理复杂解剖结构和仪器分割任务中的有效性。
变体评估:论文还实现了TTT-Unet的两种变体:TTT-Unet_Bot和TTT-Unet_Enc,分别在瓶颈部分和整个编码器中应用TTT层,以评估不同集成方式的效果。
这些实验结果一致表明,TTT-Unet在多种生物医学图像分割任务中提供了显著的性能改进,证明了其在处理复杂和多样化的医学图像数据中的有效性和鲁棒性。
Q: 有什么可以进一步探索的点?
A: 尽管TTT-Unet在生物医学图像分割任务中表现出色,但仍有一些潜在的研究方向可以进一步探索:
优化测试时训练(TTT)层:虽然TTT层在动态调整模型参数方面表现出色,但是计算成本相对较高。未来的研究可以集中在优化TTT层,以减少计算开销,同时保持或提高性能。
扩展到更多数据集和任务:目前的实验主要在几个特定的数据集上进行。将TTT-Unet扩展到更广泛的数据集和不同类型的生物医学图像分割任务上,可以进一步验证其泛化能力和实用性。
实时应用:考虑TTT-Unet在实时或近实时临床应用中的可行性,探索如何平衡测试时训练带来的性能提升和实时处理的需求。
更复杂的网络架构:研究是否可以将TTT层与其他先进的网络架构(如更深的网络或注意力机制)结合,以进一步提升分割性能。
解释性和可视化:提高模型的可解释性,通过可视化技术揭示TTT层是如何在测试时动态调整参数以及这些调整如何影响最终的分割结果。
多模态数据融合:探索TTT-Unet在处理和融合来自不同成像模态(如CT、MRI、超声等)的数据时的表现,以及如何优化模型以处理多模态数据。
鲁棒性和泛化能力的进一步研究:尽管TTT-Unet在多个数据集上表现良好,但进一步研究其在面对更具挑战性的数据(如存在噪声、不完整或异常值的数据)时的鲁棒性和泛化能力仍然很重要。
临床验证和评估:与临床医生合作,进行更深入的临床验证和评估,以确定TTT-Unet在实际临床环境中的潜在价值和局限性。
软件和硬件的协同优化:研究如何结合软件和硬件的优化来提升TTT-Unet的运行效率,使其更适合在资源受限的环境中使用。
通过这些进一步的探索,可以不断提升TTT-Unet的性能,扩展其应用范围,并推动生物医学图像分析技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了TTT-Unet,这是一个创新的生物医学图像分割框架,它通过整合测试时训练(Test-Time Training, TTT)层到传统的U-Net架构中,有效提升了模型在捕获局部和长距离特征方面的能力。以下是论文的主要内容总结:
问题阐述:论文首先指出了现有的卷积神经网络(CNNs)和变换器(Transformers)在生物医学图像分割任务中面临的挑战,尤其是在捕捉图像中的长距离依赖性方面的局限性。
TTT-Unet框架:为了解决上述问题,论文提出了TTT-Unet,这是一个将TTT层集成到U-Net架构中的混合模型。TTT层允许模型在测试期间动态调整参数,从而更好地适应不同测试样本的特点。
TTT层的介绍:详细描述了TTT层的工作原理,包括其如何通过自监督学习动态更新模型权重,以及如何利用输入数据的多个视图来提升模型对长距离依赖性的捕捉能力。
TTT-Unet架构:论文阐述了TTT-Unet的整体架构,包括编码器和解码器的设计,以及如何通过TTT构建块增强编码器的适应性。
实验验证:通过在多个医学成像数据集上的广泛实验,论文展示了TTT-Unet在3D腹部器官分割、内窥镜图像中的仪器分割和显微镜图像中的细胞分割等任务中的优越性能。实验结果表明,TTT-Unet在各项任务中均超越了现有的最先进模型。
定性分析:论文还提供了定性分析,通过可视化分割结果,展示了TTT-Unet在处理复杂解剖结构和不同成像模态中的有效性。
讨论和结论:最后,论文讨论了TTT-Unet的主要优势,包括其在测试时动态调整参数的能力以及在多样化数据集上的鲁棒性能。同时,论文也指出了未来工作的方向,如进一步优化TTT层以减少计算开销。
总体而言,TTT-Unet通过其创新的测试时训练机制,为生物医学图像分割领域提供了一种新的、有效的解决方案,具有在多种临床场景中应用的潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


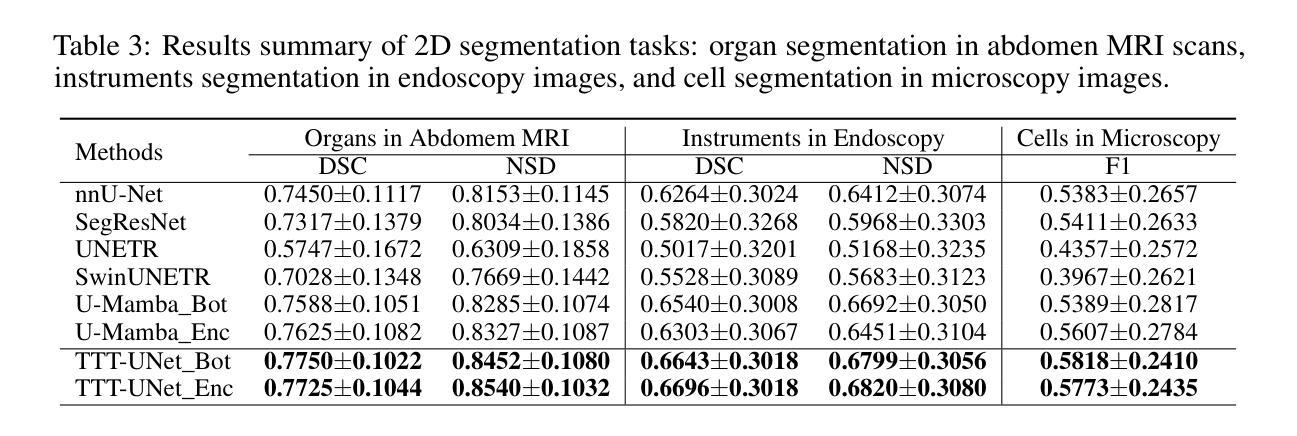
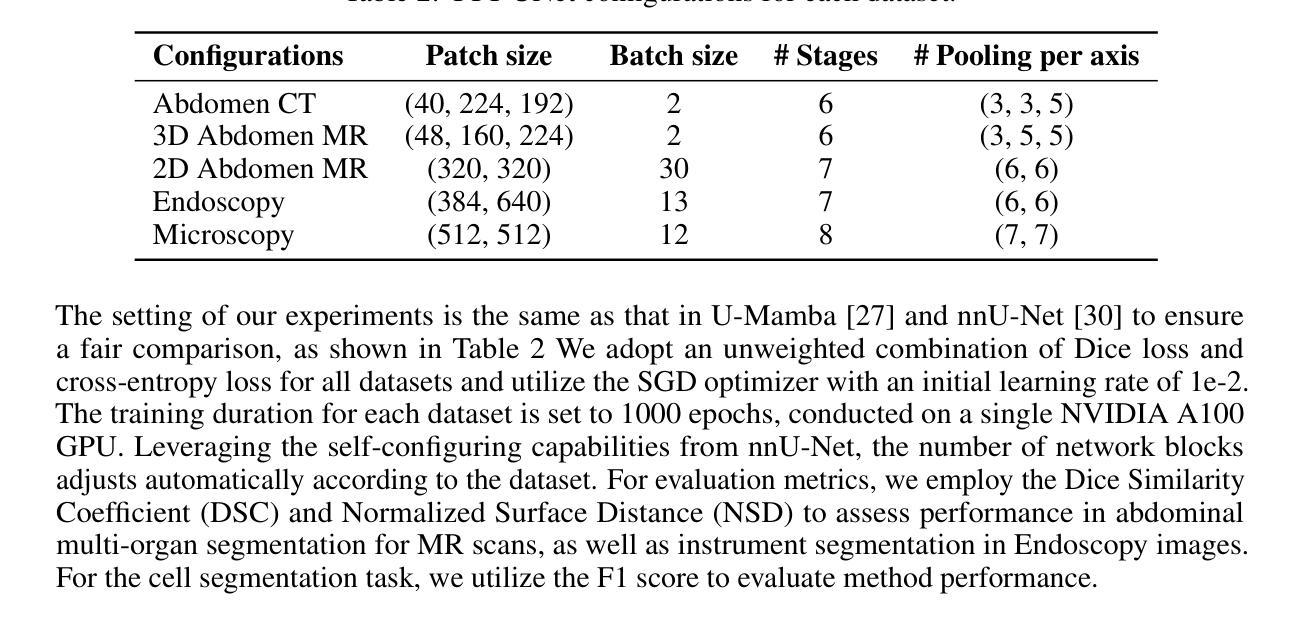
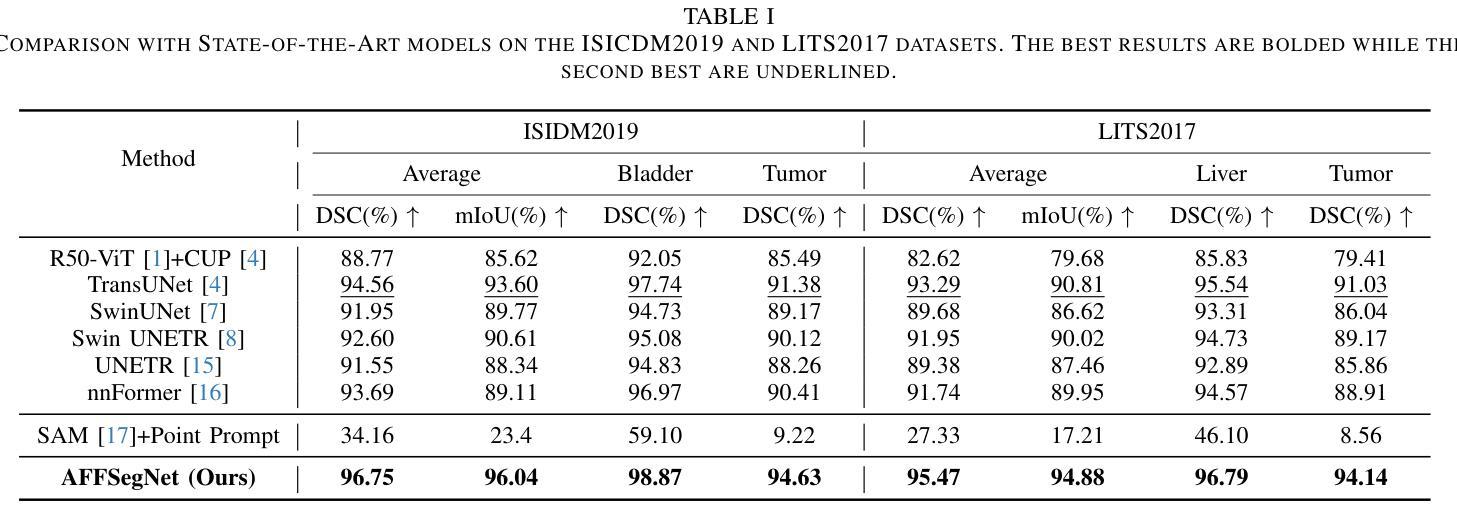
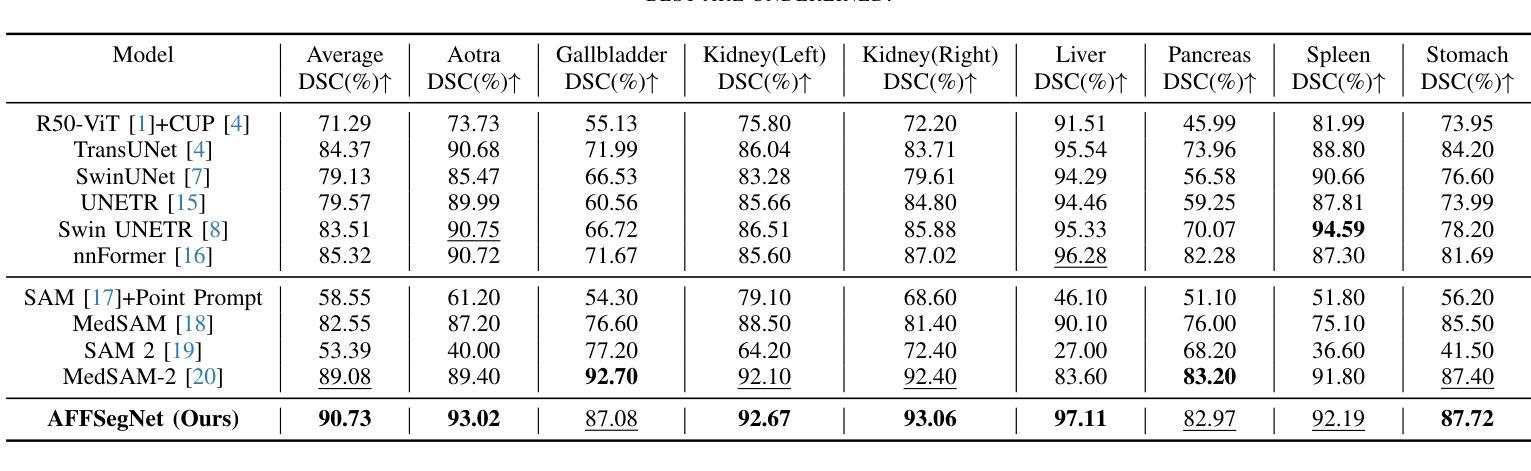
AFFSegNet: Adaptive Feature Fusion Segmentation Network for Microtumors and Multi-Organ Segmentation
Authors:Fuchen Zheng, Xinyi Chen, Xuhang Chen, Haolun Li, Xiaojiao Guo, Weihuang Liu, Chi-Man Pun, Shoujun Zhou
Medical image segmentation, a crucial task in computer vision, facilitates the automated delineation of anatomical structures and pathologies, supporting clinicians in diagnosis, treatment planning, and disease monitoring. Notably, transformers employing shifted window-based self-attention have demonstrated exceptional performance. However, their reliance on local window attention limits the fusion of local and global contextual information, crucial for segmenting microtumors and miniature organs. To address this limitation, we propose the Adaptive Semantic Segmentation Network (ASSNet), a transformer architecture that effectively integrates local and global features for precise medical image segmentation. ASSNet comprises a transformer-based U-shaped encoder-decoder network. The encoder utilizes shifted window self-attention across five resolutions to extract multi-scale features, which are then propagated to the decoder through skip connections. We introduce an augmented multi-layer perceptron within the encoder to explicitly model long-range dependencies during feature extraction. Recognizing the constraints of conventional symmetrical encoder-decoder designs, we propose an Adaptive Feature Fusion (AFF) decoder to complement our encoder. This decoder incorporates three key components: the Long Range Dependencies (LRD) block, the Multi-Scale Feature Fusion (MFF) block, and the Adaptive Semantic Center (ASC) block. These components synergistically facilitate the effective fusion of multi-scale features extracted by the decoder while capturing long-range dependencies and refining object boundaries. Comprehensive experiments on diverse medical image segmentation tasks, including multi-organ, liver tumor, and bladder tumor segmentation, demonstrate that ASSNet achieves state-of-the-art results. Code and models are available at: \url{https://github.com/lzeeorno/ASSNet}.
医学图像分割是计算机视觉中的一项重要任务,它有助于自动描绘解剖结构和病理,支持临床医生进行诊断、治疗规划和疾病监测。值得注意的是,采用基于移位窗口的自注意力的变压器表现出了卓越的性能。然而,它们对局部窗口注意力的依赖,限制了局部和全局上下文信息的融合,这对于分割微肿瘤和微小器官至关重要。为了解决这一局限性,我们提出了自适应语义分割网络(ASSNet),这是一种有效的结合局部和全局特征的变压器架构,用于精确医学图像分割。ASSNet由基于变压器的U形编码器-解码器网络组成。编码器在五个分辨率上利用移位窗口自注意力提取多尺度特征,然后通过跳跃连接传播到解码器。我们在编码器内引入增强型多层感知器,以在特征提取过程中显式建模长距离依赖关系。认识到传统对称编码器-解码器设计的局限性,我们提出了一种自适应特征融合(AFF)解码器来补充我们的编码器。该解码器包含三个关键组件:长距离依赖(LRD)块、多尺度特征融合(MFF)块和自适应语义中心(ASC)块。这些组件协同工作,促进解码器提取的多尺度特征的有效融合,同时捕捉长距离依赖关系并细化对象边界。在多种医学图像分割任务上的综合实验,包括多器官、肝脏肿瘤和膀胱肿瘤分割,证明了ASSNet达到了最新结果。代码和模型可在https://github.com/lzeeorno/ASSNet上找到。
论文及项目相关链接
PDF 8 pages, 4 figures, 3 tables
摘要
医学图像分割是计算机视觉中的关键任务,有助于自动描绘解剖结构和病理,支持临床医生进行诊断、治疗计划和疾病监测。采用基于移位窗口的自注意力的变压器展示了卓越的性能,但它们依赖于局部窗口注意力,限制了局部和全局上下文信息的融合,对于分割微肿瘤和微小器官尤为重要。为解决此局限性,我们提出了自适应语义分割网络(ASSNet),这是一种有效的结合局部和全局特征的变压器架构,用于精确医学图像分割。ASSNet由基于变压器的U形编码器-解码器网络组成。编码器利用五个分辨率的移位窗口自注意力提取多尺度特征,然后通过跳过连接传播到解码器。我们在编码器内引入增强型多层感知器,以在特征提取过程中显式建模长程依赖关系。考虑到传统对称编码器-解码器设计的局限性,我们提出了一种自适应特征融合(AFF)解码器来补充我们的编码器。该解码器包含三个关键组件:长程依赖(LRD)块、多尺度特征融合(MFF)块和自适应语义中心(ASC)块。这些组件协同工作,有助于解码器提取的多尺度特征的有效融合,同时捕捉长程依赖关系并细化对象边界。在多种医学图像分割任务上的综合实验,包括多器官、肝脏肿瘤和膀胱肿瘤分割,表明ASSNet达到了最新结果。代码和模型可用链接:\url{https://github.com/lzeeorno/ASSNet}。
关键见解
- 医学图像分割是计算机视觉中的核心任务,有助于临床诊断、治疗规划和疾病监测。
- 基于移位窗口自注意力的变压器在医学图像分割中展现出卓越性能。
- 局部窗口注意力限制了上下文信息的融合,特别是在分割微肿瘤和微小器官时。
- 提出了一种新的医学图像分割方法——自适应语义分割网络(ASSNet)。
- ASSNet结合局部和全局特征,采用基于变压器的U形编码器-解码器网络。
- 编码器利用多尺度特征和移位窗口自注意力,而解码器通过自适应特征融合进行补充。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为AFFSegNet(Adaptive Feature Fusion Segmentation Network)的新型网络架构,旨在解决医学图像分割领域中的关键问题,尤其是在微肿瘤和多器官分割方面。具体来说,论文试图解决以下几个问题:
局部和全局特征的捕捉:现有的方法在捕获局部和全局特征方面存在局限性,尤其是在对小物体的特征提取和图像边缘的准确描绘上。
长距离依赖关系的建模:许多模型在对长距离依赖关系的建模上存在挑战,这影响了它们对图像中远距离特征相关性的捕捉能力。
多尺度特征融合:有效整合多尺度局部和全局特征是一个持续的挑战,尤其是在医学图像分割中,这对于精确分割小结构和复杂边缘结构至关重要。
编码器-解码器设计的局限性:传统的对称编码器-解码器设计在特征融合和利用方面存在不足,特别是在解码器中整合多尺度局部和全局特征的能力。
为了解决这些问题,论文提出了AFFSegNet,这是一个基于Transformer的架构,通过在编码器中引入增强的多层感知机(MLP)和提出一个新颖的自适应特征融合(AFF)解码器,有效地整合了局部和全局特征,以实现精确的分割。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要涉及以下几个方面:
Vision Transformer和混合架构:
- Vision Transformer (ViT) 模型利用自注意力机制捕获图像中的长距离依赖关系,已在图像分类任务中取得了突破性的性能。
- Swin Transformer 展示了在各种医学图像应用中的卓越性能,采用分层方法计算局部窗口内的自注意力,然后通过移动窗口捕获不同图像区域间的关系,降低了计算复杂性同时保留了建模长距离依赖的能力。
医学图像分割网络:
- ResUnet 和 Swin-transformer 结合了窗口注意力机制和空间注意力机制,以及U形结构和残差连接,用于提高分割效率。
- TransUNet 和 SwinUNet 是基于Transformer的网络,它们通过使用U-Net类似的结构来改进医学图像分割。
编码器-解码器结构的局限性:
- 论文提到了现有编码器-解码器结构在特征融合和利用方面的局限性,特别是在解码器中整合多尺度局部和全局特征的能力。
自注意力和多头自注意力机制:
- 论文中提到了在标准Transformer中使用的多头自注意力(MSA)模块,并对其进行了改进以适应医学图像分割任务。
损失函数和优化:
- 论文中提到了BCE Dice损失,这是一种结合了二元交叉熵损失和Dice损失的组合,广泛应用于医学图像分割任务。
数据集和评估指标:
- 论文中使用了LiTS2017、ISICDM2019和Synapse等公共医学图像数据集,并采用Dice相似系数(DSC)和平均交并比(mIoU)作为性能评估指标。
这些相关研究为AFFSegNet的设计提供了理论基础和技术支持,同时也表明了医学图像分割领域的研究进展和挑战。AFFSegNet通过结合这些相关研究的优势,提出了一种新的网络架构来提高医学图像分割的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为AFFSegNet(Adaptive Feature Fusion Segmentation Network)的新型网络架构来解决上述问题。AFFSegNet的设计包含了以下几个关键组件和策略:
1. 增强的编码器和多层感知机(MLP)
- 编码器:引入了一个增强的多层感知机(MLP)来显式地建模特征提取过程中的长距离依赖关系。这是通过在编码器中加入额外的MLP层来实现的,以增强对全局特征的捕捉能力。
2. 改进的编码器-解码器结构
- EFFN(Enhanced Forward Feedback Network):为了补充编码器并克服传统对称编码器-解码器设计的局限性,提出了EFFN。EFFN通过前馈反馈机制来增强特征的传递和融合。
3. 自适应特征融合(AFF)解码器
- AFF解码器:包括三个关键组件:长距离依赖(LRD)块、多尺度特征融合(MFF)块和自适应语义中心(ASC)块。这些组件共同工作,有效地利用编码器派生的特征,实现小结构的精确分割,尤其是在边缘区域,并促进多尺度特征的融合。
4. 多尺度窗口注意力(MWA)Transformer块
- MWA Transformer块:作为AFFSegNet的核心编码器组件,通过替换标准Transformer中的多头自注意力(MSA)模块为基于窗口的MSA模块,并保留其他组件不变。每个MWA块包括一个基于窗口的MSA模块,后跟一个EFFN。
5. 损失函数
- BCE Dice损失:在训练过程中,AFFSegNet使用结合了二元交叉熵(BCE)损失和Dice损失的BCE Dice损失函数,这种损失函数在医学图像分割任务中广泛使用。
6. 实验验证
- 广泛的实验:在包括多器官、肝肿瘤和膀胱肿瘤在内的多种医学图像分割任务上进行了广泛的实验,验证了所提出网络的鲁棒性和适应性。
通过这些设计和策略,AFFSegNet能够有效地整合局部和全局特征,实现精确的医学图像分割,特别是在微肿瘤和多器官分割方面。这些创新的设计使得AFFSegNet在多个医学图像分割数据集上取得了优于现有最先进模型的性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证AFFSegNet的性能,并与现有的最先进方法进行比较。以下是实验的具体内容:
数据集和实现细节
数据集:实验使用了三个公共医学图像数据集,包括:
- LiTS2017:专注于肝脏肿瘤分割,包含131个对比增强的3D腹部CT扫描。
- ISICDM2019:专注于膀胱肿瘤分割,包括2200张膀胱癌图像。
- Synapse:针对多器官分割,由40个3D腹部CT扫描组成,涵盖多个器官。
实验设置:使用nnformer数据集划分(80%训练,15%验证,5%测试)以保证一致性和公平比较。输入图像被调整至512×512像素。AFFSegNet在PyTorch中实现,并在NVIDIA GeForce RTX 4090 GPU上训练。
性能比较
- 与最先进方法的比较:在上述三个数据集上,AFFSegNet与多种现有的最先进医学图像分割方法进行了性能比较。结果总结在论文的表I和表II中,包括对肝脏肿瘤、膀胱肿瘤和多器官分割的性能评估。
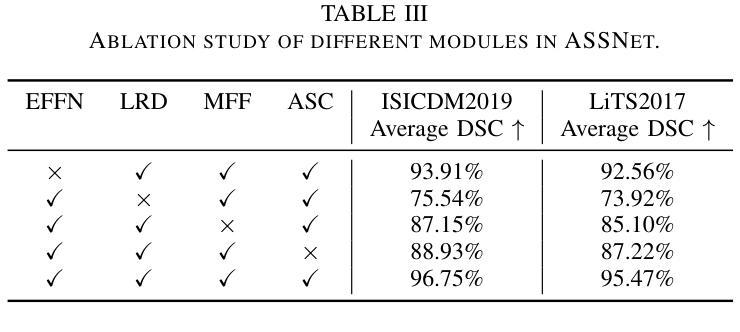
消融研究
- 消融研究:为了研究AFFSegNet中各个组件的贡献,进行了消融研究,逐个移除网络中的组件,并评估性能变化。结果表明所有组件都对AFFSegNet的整体性能有所贡献,特别是EFFN、LRD、MFF和ASC块。
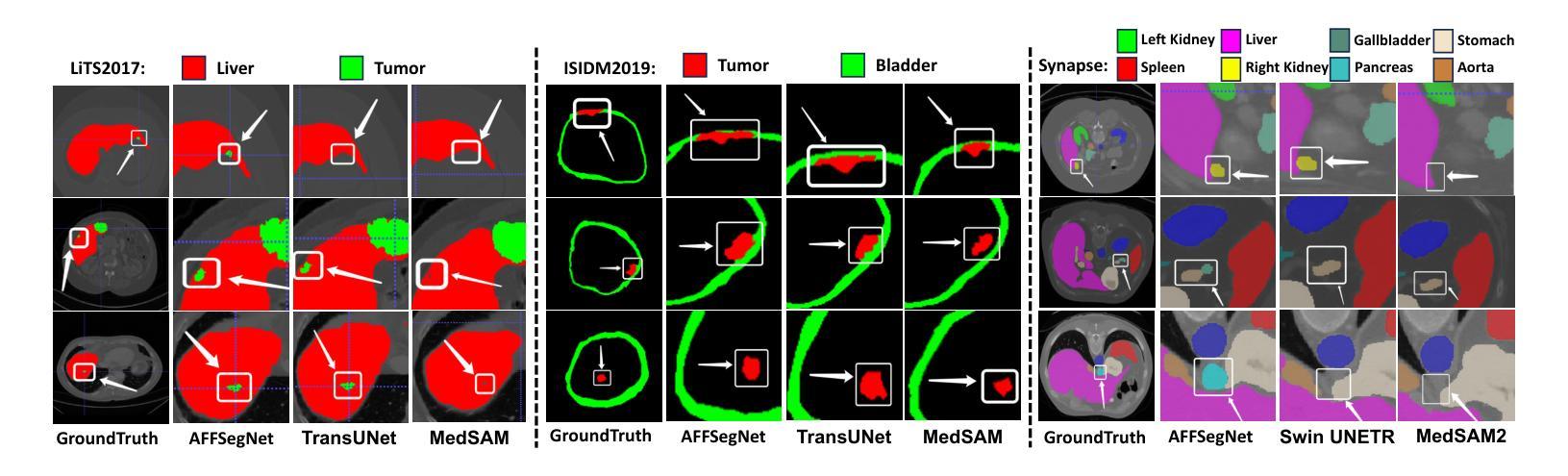
可视化分割结果
- 可视化评估:为了直观评估AFFSegNet的分割能力,论文中还展示了与其他最先进方法在LiTS2017、ISICDM2019和Synapse数据集中代表性切片的定性比较。AFFSegNet能够准确地分割肝脏周边的小肿瘤结节,并保留经常被其他方法遗漏或分割不准确的小型器官的完整性。
这些实验全面验证了AFFSegNet在医学图像分割任务中的有效性和优越性,并展示了其在不同肿瘤类型和成像方式中的鲁棒性和适应性。
Q: 有什么可以进一步探索的点?
A: 尽管AFFSegNet在医学图像分割领域取得了显著的性能提升,但仍有一些方向可以进一步探索和改进:
1. 数据集的多样性和泛化能力
- 多模态数据集:探索AFFSegNet在多模态医学图像数据集上的性能,例如MRI和CT图像的组合,以测试模型的泛化能力。
- 跨疾病类型的泛化:评估AFFSegNet在不同疾病类型和病理条件下的表现,例如在心脏病或神经系统疾病中的应用。
2. 模型的计算效率和实用性
- 计算资源优化:研究如何减少AFFSegNet的计算资源需求,使其更适合在资源受限的环境中使用,例如在移动设备或边缘计算设备上。
- 实时性能:探索模型在实时医学图像分割任务中的性能,这对于手术导航和介入治疗等应用至关重要。
3. 模型解释性和可视化
- 特征可视化:通过可视化技术来解释模型的决策过程,帮助理解模型是如何学习和识别不同特征的。
- 错误分析:对模型的失败案例进行深入分析,以识别模型的局限性和潜在的改进方向。
4. 模型的鲁棒性和安全性
- 对抗性攻击和防御:研究模型对对抗性攻击的鲁棒性,并开发有效的防御策略,以确保在实际应用中的安全性。
- 数据增强和正则化技术:探索不同的数据增强和正则化技术,以提高模型对异常值和噪声的鲁棒性。
5. 模型的集成和融合
- 多模型融合:研究如何将AFFSegNet与其他类型的网络(如基于CNN的模型)集成,以进一步提高分割的准确性和鲁棒性。
- 跨尺度特征融合:进一步探索不同尺度特征的融合策略,以更有效地捕捉图像中的局部和全局信息。
6. 临床验证和应用
- 临床数据的验证:与医疗机构合作,使用真实的临床数据来验证模型的性能,并根据临床需求调整模型。
- 实际应用开发:开发基于AFFSegNet的实际应用,如辅助诊断工具或个性化治疗规划系统。
这些方向不仅可以推动AFFSegNet技术的发展,还可能为医学图像分割领域带来新的突破和应用。
Q: 总结一下论文的主要内容
A: 本文提出了一个名为AFFSegNet(Adaptive Feature Fusion Segmentation Network)的新型Transformer架构,专门用于医学图像分割任务,特别是在微肿瘤和多器官分割方面。以下是论文的主要内容总结:
1. 问题背景
- 医学图像分割是计算机视觉中的一个重要任务,对于辅助临床医生进行诊断、治疗规划和疾病监测至关重要。
- 现有方法在捕获局部和全局特征方面存在局限性,尤其是在对小物体和图像边缘的精确分割上。
2. 方法论
- AFFSegNet架构:提出了一个基于Transformer的网络,通过在编码器中引入增强的多层感知机(MLP)和提出自适应特征融合(AFF)解码器,有效地整合了局部和全局特征。
- MWA Transformer块:作为核心编码器组件,通过替换标准Transformer中的多头自注意力(MSA)模块为基于窗口的MSA模块,并保留其他组件不变。
- AFF解码器:包括长距离依赖(LRD)块、多尺度特征融合(MFF)块和自适应语义中心(ASC)块,以增强对小结构和复杂边缘结构的分割能力。
3. 实验
- 在LiTS2017、ISICDM2019和Synapse等多个医学图像分割数据集上进行了广泛的实验,与现有的最先进方法进行了比较。
- 实验结果表明,AFFSegNet在各种数据集上均取得了优于现有最先进模型的性能,特别是在Dice相似系数(DSC)和平均交并比(mIoU)两个评估指标上。
- 进行了消融研究,验证了网络中各个组件的重要性和贡献。
4. 结论
- AFFSegNet作为一种新的Transformer架构,在微肿瘤和多器官分割方面表现出色,能够有效地捕捉局部和全局特征,提高医学图像分割的精度和效率。
- 该网络有望成为辅助临床医生进行关键诊断和治疗规划的有力工具。
总体而言,AFFSegNet通过其创新的网络架构和自适应特征融合策略,在医学图像分割领域提供了一种新的解决方案,具有显著的性能提升和广泛的应用前景。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Exploring Machine Learning Models for Lung Cancer Level Classification: A comparative ML Approach
Authors:Mohsen Asghari Ilani, Saba Moftakhar Tehran, Ashkan Kavei, Hamed Alizadegan
This paper explores machine learning (ML) models for classifying lung cancer levels to improve diagnostic accuracy and prognosis. Through parameter tuning and rigorous evaluation, we assess various ML algorithms. Techniques like minimum child weight and learning rate monitoring were used to reduce overfitting and optimize performance. Our findings highlight the robust performance of Deep Neural Network (DNN) models across all phases. Ensemble methods, including voting and bagging, also showed promise in enhancing predictive accuracy and robustness. However, Support Vector Machine (SVM) models with the Sigmoid kernel faced challenges, indicating a need for further refinement. Overall, our study provides insights into ML-based lung cancer classification, emphasizing the importance of parameter tuning to optimize model performance and improve diagnostic accuracy in oncological care.
本文探讨了利用机器学习(ML)模型对肺癌等级进行分类,以提高诊断准确性和预后预测的方法。通过参数调整和严格评估,我们评估了多种ML算法。采用最小子节点增长和学习速率监测等技术以减少过度拟合并优化性能。我们的研究结果突出了深度神经网络(DNN)模型在所有阶段的稳健性能。集成方法,包括投票和集成袋,也显示出在提高预测准确性和稳健性方面的潜力。然而,使用Sigmoid内核的支持向量机(SVM)模型面临挑战,表明需要进一步改进。总体而言,本研究为基于ML的肺癌分类提供了见解,强调参数调整在优化模型性能和提高肿瘤护理中的诊断准确性方面的重要性。
论文及项目相关链接
Summary
医学图像领域机器学习模型在肺癌分类中的应用。通过参数调整与严格评估,发现深度神经网络模型表现稳健,集成方法能提高预测精度和稳健性。支持向量机模型需进一步优化。研究为提高肺癌诊断准确性提供了见解。
Key Takeaways
- 机器学习模型被应用于医学图像领域以分类肺癌水平,旨在提高诊断准确性和预后。
- 通过参数调整和严格评估,发现深度神经网络模型在所有阶段都表现出稳健的性能。
- 集成方法(如投票和bagging)提高了预测精度和稳健性。
- 支持向量机模型使用Sigmoid核时面临挑战,需要进一步改进。
- 研究强调了参数调整在优化模型性能和提高肺癌诊断准确性方面的重要性。
- 研究结果可为医学图像领域的肺癌分类提供有价值的见解。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是利用机器学习(ML)模型对肺癌水平进行分类,以提高诊断的准确性和预后。具体来说,论文通过参数调整和严格评估各种ML算法,探讨了不同模型在肺癌水平分类任务中的性能,旨在通过优化模型性能来改善肿瘤学护理中的诊断准确性。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的研究:
肺癌风险预测与机器学习模型:
- Dritsas E, Trigka M. 在《Big Data and Cognitive Computing》上发表的论文《Lung Cancer Risk Prediction with Machine Learning Models》。[参考文献 1]
基于基因表达水平的肺癌分类机器学习算法评估:
- Podolsky MD 等人在《Asian Pacific Journal of Cancer Prevention》上发表的论文《Evaluation of Machine Learning Algorithm Utilization for Lung Cancer Classification Based on Gene Expression Levels》。[参考文献 2]
机器学习方法预测肺癌对肿瘤反应:
- El Naqa I 在《Wiley Interdiscip Rev Data Min Knowl Discov》上发表的论文《Machine learning methods for predicting tumor response in lung cancer》。[参考文献 6]
基于质谱的肺癌预测机器学习方法:
- Hilario M 等人在《Proteomics》上发表的论文《Machine learning approaches to lung cancer prediction from mass spectra》。[参考文献 7]
机器学习在肺癌检测中的应用:
- Singh GAP, Gupta PK 在《Neural Comput Appl》上发表的论文《Performance analysis of various machine learning-based approaches for detection and classification of lung cancer in humans》。[参考文献 9]
基于集成特征选择和机器学习方法的肺癌分类:
- Cai Z 等人在《Mol Biosyst》上发表的论文《Classification of lung cancer using ensemble-based feature selection and machine learning methods》。[参考文献 10]
使用机器学习算法的肺癌检测比较研究:
- Radhika PR 等人在《Proceedings of 2019 3rd IEEE International Conference on Electrical, Computer and Communication Technologies, ICECCT 2019》上发表的论文《A Comparative Study of Lung Cancer Detection using Machine Learning Algorithms》。[参考文献 11]
使用常规临床和实验室数据的机器学习进行早期肺癌识别:
- Gould MK 等人在《Am J Respir Crit Care Med》上发表的论文《Machine learning for early lung cancer identification using routine clinical and laboratory data》。[参考文献 12]
这些研究涵盖了机器学习在肺癌风险预测、分类、检测以及早期识别等多个方面的应用,为本研究提供了理论和实证基础。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决肺癌水平分类的问题:
数据收集与预处理:
- 从全球多样化的数据源(如世界卫生组织、Kaggle和Google数据集)中收集数据,确保数据集具有代表性,并能够覆盖不同的地理区域和临床情况。
- 对数据进行严格的清洗和预处理,以建立特征与目标变量之间的有意义关系。
特征选择:
- 通过相关性分析识别与肺癌水平有显著相关性的特征,创建新的数据框列以增强模型的预测效果。
- 移除相关性较低的特征,以避免模型过拟合。
数据分割:
- 使用MinMaxScaler进行数据标准化,确保特征尺度统一。
- 应用SMOTE技术处理类别不平衡问题,以促进训练数据中少数类别的均衡表示。
- 采用train_test_split方法进行数据划分,保持训练集和测试集类别分布的一致性。
模型训练与评估:
- 使用k折交叉验证(k=5)来评估模型性能,减少过拟合的风险,并提供模型性能的准确估计。
- 训练六种不同的机器学习模型,包括深度神经网络(DNN)、投票分类器、Bagging、以及采用不同核函数的支持向量机(SVM)。
模型优化与调整:
- 通过调整最小子权重和学习率等超参数来控制模型复杂性,防止过拟合。
- 监控训练和验证误差,确保模型在不同数据集上具有良好的泛化能力。
结果分析:
- 分析不同模型的性能,比较它们的准确性、精确度、召回率和F1分数。
- 通过混淆矩阵和学习曲线评估模型的稳定性和收敛行为。
结论与未来研究方向:
- 基于模型性能的比较分析,总结每种模型的优势和局限性。
- 提出未来研究的方向,包括进一步优化ML算法和技术,以提高肺癌分类的准确性和可靠性。
通过这些步骤,论文旨在提供一个基于机器学习的肺癌水平分类框架,以提高诊断的准确性和预后,并为未来的研究提供坚实的基础。
Q: 论文做了哪些实验?
A: 根据论文内容,以下是进行的实验和分析:
数据收集与预处理:
- 从多个公共数据源收集数据,并对数据进行清洗和预处理,以建立特征与目标变量之间的有意义关系。
特征选择与工程:
- 通过相关性分析识别与肺癌水平有显著相关性的特征,并据此创建新的数据框列,以增强模型的预测效果。
- 对特征进行组合以形成新的数据列,增强数据集的预测能力。
数据分割:
- 使用MinMaxScaler进行数据标准化处理。
- 应用SMOTE技术处理类别不平衡问题。
- 采用train_test_split方法进行数据划分,保持训练集和测试集类别分布的一致性。
模型训练与评估:
- 训练六种不同的机器学习模型,包括深度神经网络(DNN)、投票分类器、Bagging以及采用不同核函数的支持向量机(SVM)。
- 使用k折交叉验证(k=5)来评估模型性能,减少过拟合的风险,并提供模型性能的准确估计。
性能监测与优化:
- 监控训练和验证误差,调整最小子权重和学习率等超参数,以控制模型复杂性,防止过拟合。
结果分析:
- 分析不同模型的性能,比较它们的准确性、精确度、召回率和F1分数。
- 使用混淆矩阵和学习曲线评估模型的稳定性和收敛行为。
模型性能比较:
- 提供了详细的比较分析图表,展示了不同模型在各种评估指标上的性能。
这些实验和分析构成了论文的主要研究内容,旨在评估和比较不同机器学习模型在肺癌水平分类任务中的性能,并探索提高诊断准确性和预后的方法。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
改进和优化模型架构:
- 对于表现不佳的模型,如SVM与Sigmoid核,进一步调整和优化其超参数,以提高其性能。
- 探索不同的神经网络架构,例如卷积神经网络(CNN)或循环神经网络(RNN),以处理可能的图像或时间序列肺癌数据。
集成学习和模型融合:
- 研究不同的集成学习技术,如Stacking或Blending,以结合多个模型的预测,提高整体分类性能。
- 探索模型融合策略,比如通过加权平均或学习最优权重来组合不同模型的输出。
特征重要性分析:
- 进行更深入的特征选择和特征重要性分析,以识别对肺癌分类最有影响的特征。
- 使用先进的特征选择方法,如基于模型的特征选择或基于聚类的特征选择。
数据增强和合成数据生成:
- 应用数据增强技术,如图像旋转、缩放等,以增加数据多样性并提高模型的泛化能力。
- 使用生成模型,如生成对抗网络(GANs),生成合成的肺癌数据以解决数据不平衡问题。
多模态数据融合:
- 结合不同类型的数据(如基因组数据、影像数据和临床数据)进行多模态学习,以提高肺癌分类的准确性。
跨数据集验证:
- 在更多的数据集上验证模型性能,包括不同地区、不同人群的数据集,以测试模型的泛化能力。
实时数据和动态学习:
- 探索实时数据流的机器学习模型,以适应随时间变化的肺癌诊断模式。
- 开发动态学习系统,能够根据新数据不断更新和调整模型。
解释性和可视化:
- 提高模型的可解释性,使医生和研究人员能够理解模型的决策过程。
- 开发可视化工具,以直观展示模型发现的模式和关系。
临床试验和实际应用:
- 与医疗机构合作,进行临床试验,以评估模型在实际医疗环境中的表现和影响。
- 探索将机器学习模型集成到电子健康记录和临床决策支持系统中。
伦理和社会影响考量:
- 研究机器学习模型在医疗诊断中的伦理问题,如隐私保护、数据安全和算法偏见。
- 探讨机器学习技术在肺癌诊断中应用的社会和经济影响。
这些探索点可以帮助研究人员和开发者进一步提高肺癌分类的准确性,优化模型性能,并推动机器学习技术在医疗健康领域的应用。
Q: 总结一下论文的主要内容
A: 本文的主要内容概括如下:
研究目的:
- 探索机器学习(ML)模型在肺癌水平分类中的应用,旨在提高诊断的准确性和预后。
数据收集与预处理:
- 从全球多样化的数据源收集数据,并进行严格的清洗和预处理,以建立特征与目标变量之间的有意义关系。
特征工程:
- 通过相关性分析识别与肺癌水平显著相关的特征,并通过特征组合增强数据集的预测能力。
数据分割:
- 使用MinMaxScaler进行数据标准化,SMOTE技术处理类别不平衡问题,并采用train_test_split方法进行数据划分。
模型训练与评估:
- 训练六种不同的机器学习模型,包括深度神经网络(DNN)、投票分类器、Bagging以及采用不同核函数的支持向量机(SVM)。
- 使用k折交叉验证评估模型性能,减少过拟合的风险,并提供模型性能的准确估计。
性能监测与优化:
- 监控训练和验证误差,调整最小子权重和学习率等超参数,以控制模型复杂性,防止过拟合。
结果分析:
- 分析不同模型的性能,比较它们的准确性、精确度、召回率和F1分数。
- 使用混淆矩阵和学习曲线评估模型的稳定性和收敛行为。
结论与未来研究方向:
- 基于模型性能的比较分析,总结每种模型的优势和局限性,并提出未来研究的方向。
总的来说,论文通过综合评估多种机器学习模型在肺癌水平分类任务中的性能,并探索提高诊断准确性和预后的方法,为未来的研究提供了坚实的基础。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

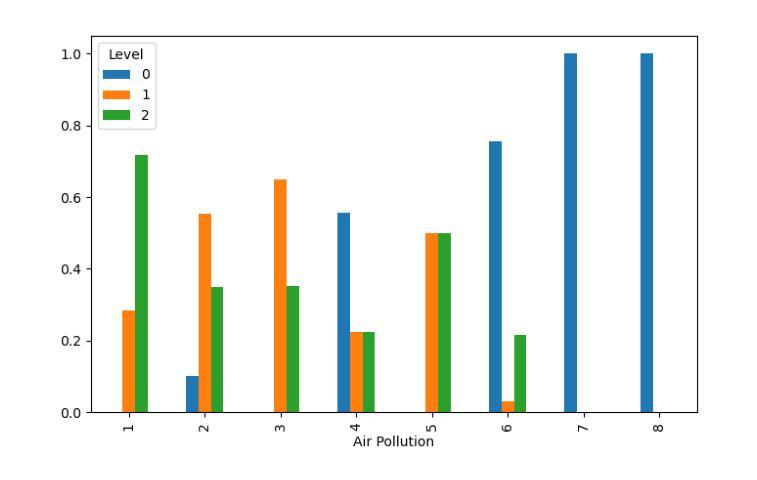
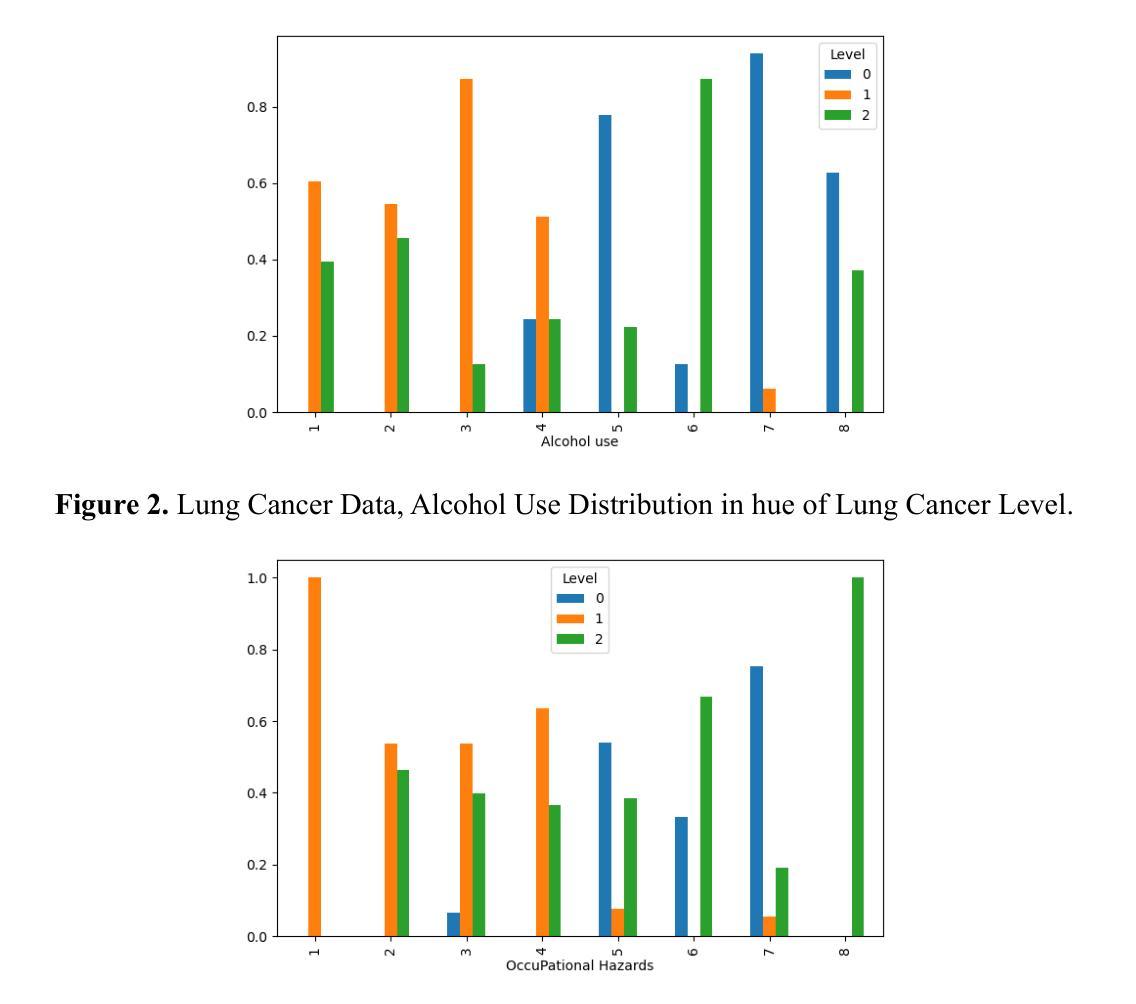
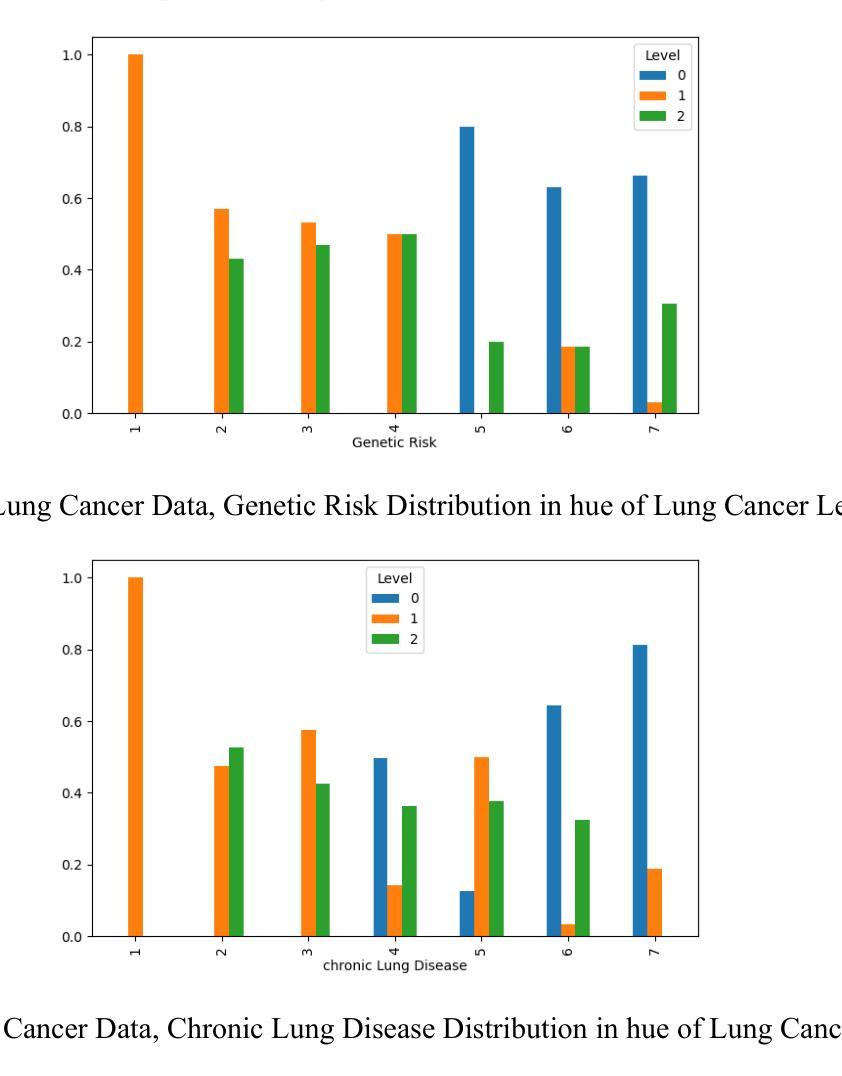
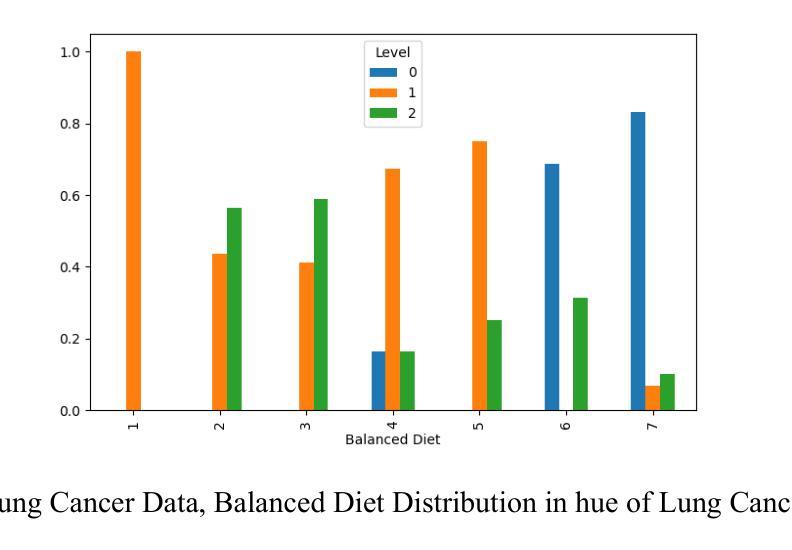
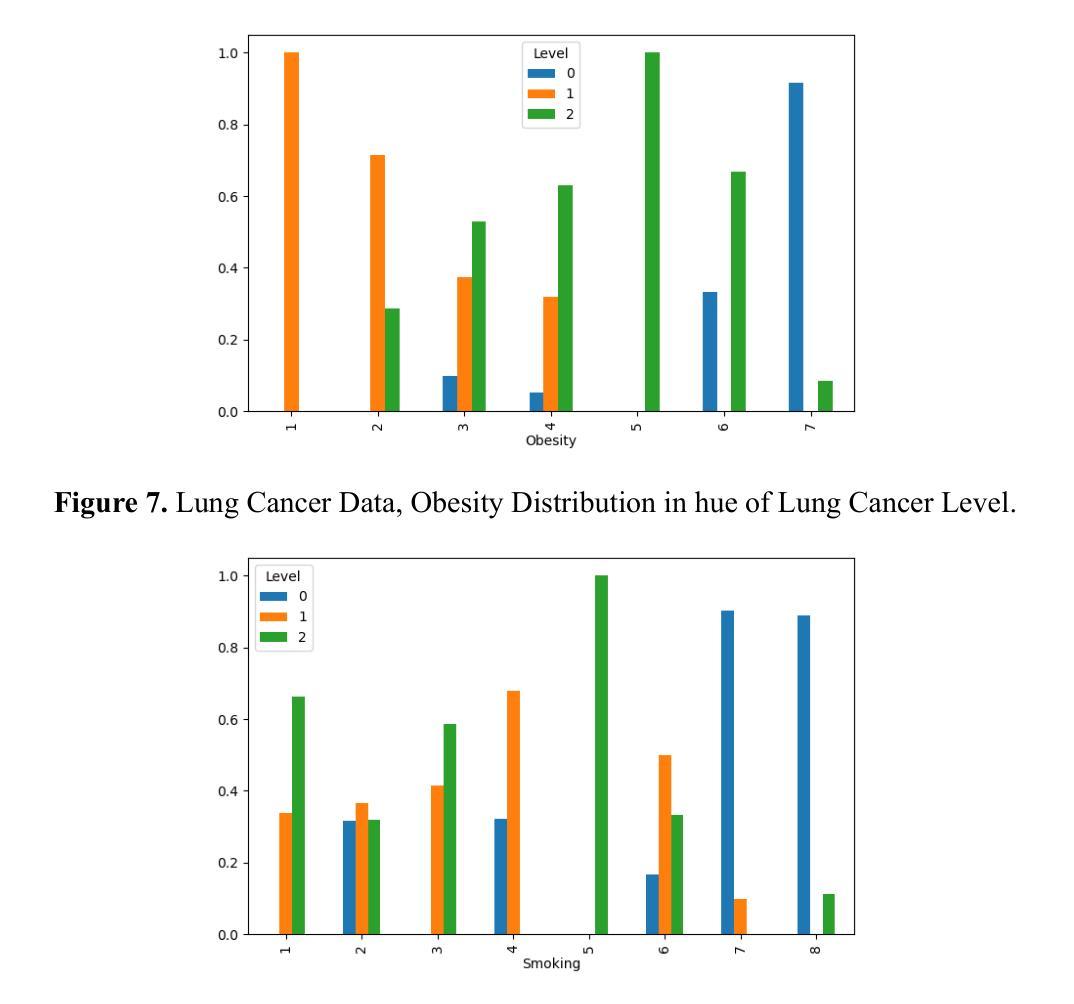
Fire Dynamic Vision: Image Segmentation and Tracking for Multi-Scale Fire and Plume Behavior
Authors:Daryn Sagel, Bryan Quaife
The increasing frequency and severity of wildfires highlight the need for accurate fire and plume spread models. We introduce an approach that effectively isolates and tracks fire and plume behavior across various spatial and temporal scales and image types, identifying physical phenomena in the system and providing insights useful for developing and validating models. Our method combines image segmentation and graph theory to delineate fire fronts and plume boundaries. We demonstrate that the method effectively distinguishes fires and plumes from visually similar objects. Results demonstrate the successful isolation and tracking of fire and plume dynamics across various image sources, ranging from synoptic-scale ($10^4$-$10^5$ m) satellite images to sub-microscale ($10^0$-$10^1$ m) images captured close to the fire environment. Furthermore, the methodology leverages image inpainting and spatio-temporal dataset generation for use in statistical and machine learning models.
野火的频率和严重程度不断增加,凸显了对准确火势和烟羽扩散模型的需求。我们介绍了一种方法,该方法可以有效地在不同空间和时间尺度以及不同类型的图像中隔离和追踪火势和烟羽行为,识别系统中的物理现象,并为开发和验证模型提供有用的见解。我们的方法结合了图像分割和图论来划分火线和烟羽边界。我们证明该方法可以有效地将火势和烟羽与视觉上相似的物体区分开来。结果展示了在各种图像源中火势和烟羽动态的成功隔离和追踪,从宏观尺度的卫星图像($10^4$-$10^5$米)到接近火环境的微观尺度图像($10^0$-$10^1$米)。此外,该方法还利用图像修复和时空数据集生成,用于统计和机器学习模型。
论文及项目相关链接
Summary
本文介绍了一种结合图像分割和图论的方法,用于在不同空间和时间尺度以及不同类型的图像中有效识别和追踪火灾和烟羽行为。该方法能够区分火灾和烟羽与视觉上相似的物体,并为开发和验证模型提供有用的见解。此外,该方法还利用图像修复和时空数据集生成技术,为统计和机器学习模型提供数据。
Key Takeaways
- 介绍了结合图像分割和图论的方法,有效识别和追踪火灾和烟羽行为。
- 方法可以在不同空间和时间尺度以及多种类型的图像中应用。
- 通过区分火灾和烟羽与视觉上相似的物体,为模型开发和验证提供有价值的信息。
- 利用图像修复技术提高模型的性能。
- 该方法可用于生成时空数据集,为统计和机器学习模型提供数据。
- 该方法对于应对日益频繁和严重的野火灾害具有重要意义。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一种名为Fire Dynamic Vision (FDV) 的方法,旨在解决以下问题:
野火和烟羽行为的准确模型需求:随着全球大型野火的频率和严重性的增加,需要更深入地理解和更精确的预测野火及烟羽行为的能力。这对于土地管理者、消防人员和政策制定者来说尤为关键,因为他们面临着日益增长的城市-野生界面、更强烈的火灾、空气质量法规和越来越窄的计划燃烧窗口等问题。
复杂火行为的多尺度、多物理和多视角建模挑战:火灾的驱动元素(大气、热量、燃料)之间存在复杂的相互作用,表现出跨物理和时间尺度的多变性。这导致了多方面、多物理和多尺度的系统特性,开发和验证统计上准确的模型和数值方法仍然是一个挑战。
现有火灾和烟羽动态测量方法的局限性:传统的测量仪器(如风速计、温度计等)通常昂贵,并且只能在一两个位置记录稀疏的测量数据。此外,设备需要防火保护,这常常使得在燃烧领域内测量小尺度特征变得困难或不可能。
图像和视频资料在火灾研究中的未充分利用:尽管摄像头是捕捉火灾和烟羽特征的优秀工具,但现有的计算机视觉工具和黑盒算法通常不适合研究火环境中的湍流运动。
为了解决这些问题,FDV方法结合了图像分割和图论来划分火前线和烟羽边界,能够有效地区分火灾和烟羽与视觉上相似的物体。该方法成功地在不同图像源(从大尺度的卫星图像到近距离捕捉的亚微观尺度图像)中隔离和跟踪火和烟羽动态,并利用图像修复和时空数据集生成,用于统计和机器学习模型。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究主要集中在以下几个领域:
火灾和烟羽动态模型:研究人员开发了多种模型来描述火灾和烟羽动力学,这些模型涵盖了从景观尺度到热解和燃烧尺度的范围。这些模型需要大量的计算工作,并且必须用实地收集的数据进行验证和校准。
图像分割和聚类分析:在计算机视觉应用中,仅依赖RGB分割通常被认为是不够的。HSV颜色空间因其在分割时的成功而被广泛记录,特别是在区分具有相似RGB颜色的对象时。此外,k-means、模糊c-均值和DBSCAN等聚类分析方法被广泛应用于卫星图像的分析。
基于视频的跟踪:跟踪火或烟羽的边界对于研究人员和从业者都很重要。粒子图像测速(PIV)或热图像测速(TIV)等光学流动方法被用来通过相关兴趣点和温度区域在连续帧之间跟踪演变结构。
基于视频的检测:近年来,机器学习领域在利用视觉视频进行火灾检测方面的兴趣显著增加。这在一定程度上归因于大型卫星图像数据集的可用性以及火焰区域和烟雾羽流的独特视觉外观。
图像修复:图像修复技术用于处理视频中的遮挡问题,如由于画面中的树木导致的分割结果中的间隙。这使得研究人员能够使用更广泛的视频源,而不受视频可用性特征的限制。
多尺度和多视图工具:FDV(Fire Dynamic Vision)是一个多尺度和多视图工具,它在视觉和红外视频以及统计解释火和烟羽动态中分割火和烟羽。
统计分析:使用马尔可夫链蒙特卡洛(MCMC)等方法对火和烟羽扩散的动态进行统计描述,以增强对潜在过程的理解。
这些研究为FDV方法的开发提供了理论基础和技术手段,使其能够有效地处理和分析火和烟羽行为的图像和视频数据。
Q: 论文如何解决这个问题?
A: 论文通过开发一个名为Fire Dynamic Vision (FDV) 的方法来解决上述问题。FDV是一个多尺度和多视图工具,它结合了图像分割和图论来隔离和跟踪火和烟羽行为。以下是FDV解决这些问题的关键步骤:
图像分割:FDV使用RGB和HSV颜色空间对视觉图像进行分割,同时对红外图像根据温度进行分割。这有助于区分火焰、燃烧区域和烟羽,即使它们在视觉上与周围环境相似。
边界计算和聚类分析:通过空间聚类分析方法(如DBSCAN)对分割后的图像进行清理和区域识别,然后使用α-shape算法计算每个感兴趣区域的边界。
跟踪和统计分析:FDV计算连续帧之间边界点的局部位移,并将这些位移转换为速度向量。然后,使用马尔可夫链蒙特卡洛(MCMC)方法对速度分布进行统计拟合,提供更准确的结果和误差范围。
数据集生成:FDV能够自动生成和格式化基于用户指定的区域和计算结果的时空数据集。这些数据集可以直接用于训练机器学习模型和进行统计分析。
图像修复:FDV可选地使用图像修复技术来处理视频中的遮挡问题,如树木导致的间隙,使得研究人员能够利用更广泛的视频源生成空间连续的数据集。
多尺度和多视角处理:FDV能够处理从微观尺度(如几米)到宏观尺度(如数十公里)的图像,并且可以处理从不同视角(如顶视图和侧视图)捕获的视频。
通过这些方法,FDV能够有效地从各种图像源中隔离和跟踪火和烟羽动态,为火灾行为建模和验证提供详细的观察数据。此外,FDV的自动化数据处理和分析功能提高了火灾行为分析的效率和准确性,使其成为该领域研究人员和从业者的宝贵工具。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来验证Fire Dynamic Vision (FDV) 方法的有效性。这些实验包括:
分布拟合实验:作者使用MCMC(马尔可夫链蒙特卡洛)和矩匹配方法对火线传播速度和燃烧时间的统计分布进行了拟合。实验结果表明,MCMC在拟合分布时比矩匹配方法更为准确,并且能够提供误差范围。
亚微观尺度火势扩散实验:作者使用FDV处理了在2米 x 2米松针燃料床上进行的火势扩散的红外和视觉图像数据。通过比较红外和视觉数据,作者分析了火势在水平(x-y)平面上的结构和运动。
视觉数据不同采样率的比较实验:作者探讨了视觉视频以不同采样率(1 Hz和2 Hz)记录时,FDV计算出的火势扩散速度分布的差异。实验结果表明,尽管最大和最小值有所不同,但两种采样率下的速度分布形状相似。
微观尺度烟羽演变实验:作者分析了在10米 x 10米松针燃料床上进行的烟羽扩散实验的视觉图像数据。这些数据以30 Hz的频率记录,并使用FDV计算了烟羽边界的演变和速度。
不同火势几何形态的分割和边界计算:作者展示了FDV在处理环状火势和两个接近的侧翼火势前线等更复杂的火势几何形态时的分割和边界计算能力。
卫星图像的分析:作者还简要展示了FDV在分析卫星图像上的潜力,尽管更深入的分析被留给了未来的工作。
这些实验覆盖了从微观到宏观的不同尺度,包括了不同的图像源和视角,验证了FDV方法在多种情况下的有效性和适用性。通过这些实验,作者展示了FDV在火势和烟羽行为分析中的实用性,并证明了其在自动生成用于机器学习和统计分析的数据集方面的潜力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
多方向火势扩散分析:论文中提到了FDV处理环状火和两个接近的侧翼火前线的能力,但对多方向火势扩散和多个火焰前线之间相互作用的详细分析被保留为未来的工作。可以进一步研究这些复杂火势场景中的火焰动态。
结合视觉和红外数据的烟羽分析:论文提出了将FDV应用于结合视觉和红外数据的烟羽分析的可能性,但尚未进行深入研究。可以探索这种结合方法如何提高对烟羽行为的理解。
扩展烟羽物理计算:论文提到了烟羽物理计算(如涡度、扫掠和喷射等)的初步分析,表明不同实验间的趋势具有相似性。未来的工作可以扩展这些计算,以包括更多样化的烟羽情景。
图像稳定化方法:使用无人机或其他非固定数据捕获框架时,需要讨论图像稳定化方法。论文提到,火环境由于画面中大部分元素的不断运动和火焰可见度的变化,为图像稳定化带来了独特的挑战。可以进一步研究针对火环境的最优算法选择和每种方法引入误差的量化。
卫星图像的详细分析:论文简要展示了FDV在分析卫星图像方面的潜力。未来的工作可以更详细地分析宏观尺度的烟羽动态,以及与火灾研究相关的其他卫星测量,如大气化学化合物浓度。
算法优化和计算效率:虽然FDV已经在多种资源条件下表现出良好的效率,但进一步优化算法和提高计算效率始终是一个值得探索的方向,特别是在处理大规模数据集或实现实时分析时。
数据集和模型的进一步验证:论文中提到了FDV生成的数据集可以用于训练机器学习模型。可以进一步探索这些数据集在不同模型和算法中的应用,以及它们在实际火灾预测和分析中的有效性。
用户界面和可用性改进:为了使FDV更容易被非专业用户使用,可以探索开发更友好的用户界面和提高软件的可用性,包括自动化参数选择、增强的可视化工具和更直观的操作流程。
这些探索点不仅可以增强FDV作为一个研究工具的能力,还可能为火灾科学和应急管理领域带来新的见解和应用。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一种名为Fire Dynamic Vision (FDV) 的方法,旨在提高对野火和烟羽行为的理解和预测能力。以下是论文的主要内容总结:
问题背景:论文指出了全球大型野火频率和严重性的增加,以及对更准确的火灾和烟羽行为预测模型的需求。强调了火灾的复杂性,以及现有模型和测量方法的局限性。
FDV方法介绍:FDV结合了图像分割、图论和统计分析技术,用于从各种图像源(包括卫星图像、无人机拍摄的图像和近距离拍摄的图像)中分割和跟踪火和烟羽行为。
图像分割:FDV使用RGB和HSV颜色空间对视觉图像进行分割,同时对红外图像进行基于温度的分割。这种方法有助于区分火焰、燃烧区域和烟羽,即使它们在视觉上与周围环境相似。
边界计算和聚类分析:通过空间聚类分析方法(如DBSCAN)对分割后的图像进行清理和区域识别,然后使用α-shape算法计算每个感兴趣区域的边界。
跟踪和统计分析:FDV计算连续帧之间边界点的位移,并将其转换为速度向量。使用马尔可夫链蒙特卡洛(MCMC)方法对速度分布进行统计拟合,提供更准确的结果和误差范围。
数据集生成:FDV能够自动生成和格式化基于用户指定的区域和计算结果的时空数据集,这些数据集可以直接用于训练机器学习模型和进行统计分析。
图像修复:FDV可选地使用图像修复技术来处理视频中的遮挡问题,如树木导致的间隙,使得研究人员能够利用更广泛的视频源生成空间连续的数据集。
实验验证:论文通过一系列实验验证了FDV方法的有效性,包括分布拟合、亚微观尺度火势扩散、视觉数据不同采样率的比较、微观尺度烟羽演变等。
应用和未来工作:论文讨论了FDV在处理不同火势几何形态、卫星图像分析等方面的应用潜力,并提出了未来研究的方向,包括多方向火势扩散分析、结合视觉和红外数据的烟羽分析等。
总体而言,FDV提供了一个强大的工具,用于分析和理解火灾和烟羽行为,有助于改进火灾模型的验证和预测能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


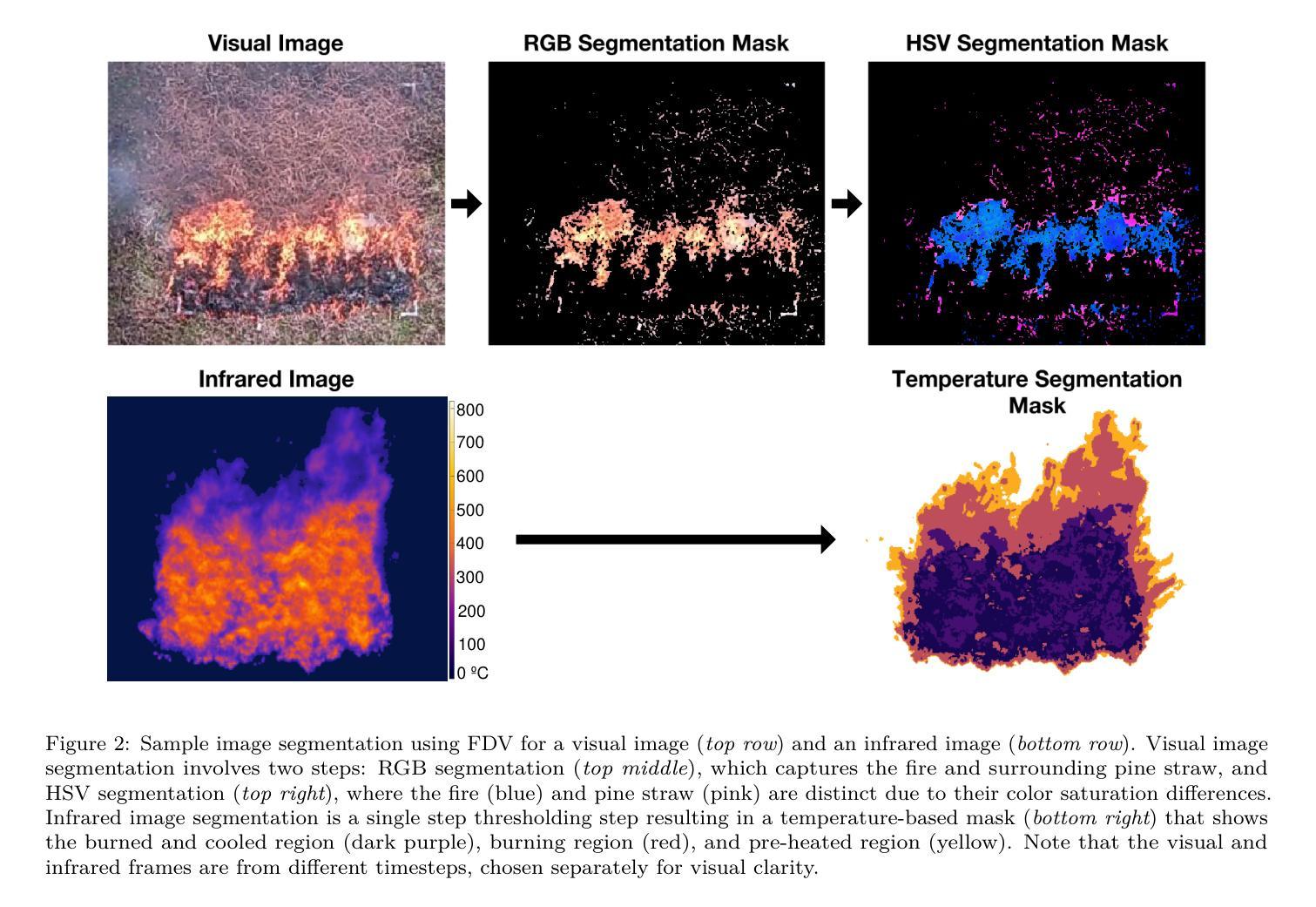
How to Segment in 3D Using 2D Models: Automated 3D Segmentation of Prostate Cancer Metastatic Lesions on PET Volumes Using Multi-angle Maximum Intensity Projections and Diffusion Models
Authors:Amirhosein Toosi, Sara Harsini, François Bénard, Carlos Uribe, Arman Rahmim
Prostate specific membrane antigen (PSMA) positron emission tomography/computed tomography (PET/CT) imaging provides a tremendously exciting frontier in visualization of prostate cancer (PCa) metastatic lesions. However, accurate segmentation of metastatic lesions is challenging due to low signal-to-noise ratios and variable sizes, shapes, and locations of the lesions. This study proposes a novel approach for automated segmentation of metastatic lesions in PSMA PET/CT 3D volumetric images using 2D denoising diffusion probabilistic models (DDPMs). Instead of 2D trans-axial slices or 3D volumes, the proposed approach segments the lesions on generated multi-angle maximum intensity projections (MA-MIPs) of the PSMA PET images, then obtains the final 3D segmentation masks from 3D ordered subset expectation maximization (OSEM) reconstruction of 2D MA-MIPs segmentations. Our proposed method achieved superior performance compared to state-of-the-art 3D segmentation approaches in terms of accuracy and robustness in detecting and segmenting small metastatic PCa lesions. The proposed method has significant potential as a tool for quantitative analysis of metastatic burden in PCa patients.
前列腺特异性膜抗原(PSMA)正电子发射断层扫描/计算机断层扫描(PET/CT)成像为可视化前列腺癌(PCa)转移病灶提供了一个非常激动人心的前沿领域。然而,由于信号与噪声比较低以及病灶大小、形状和位置的差异,准确分割转移病灶是一个挑战。本研究提出了一种新的方法,利用二维去噪扩散概率模型(DDPMs)自动分割PSMA PET/CT三维容积图像中的转移病灶。该方法不是在二维横断面切片或三维体积上进行分割,而是在生成的PSMA PET图像的多角度最大强度投影(MA-MIPs)上进行病灶分割,然后从二维MA-MIPs分割的3D有序子集期望最大化(OSEM)重建中获得最终的3D分割掩膜。与最先进的3D分割方法相比,我们所提出的方法在检测和分割小型转移性PCa病灶的准确性和稳健性方面表现出卓越的性能。该方法作为定量分析工具评估PCa患者的转移负担具有显著潜力。
论文及项目相关链接
PDF 11 pages, 2 figures, accepted in the DGM4MICCAI workshop, MICCAI, 2024
Summary
PSMA PET/CT成像在前列腺癌转移灶的可视化方面有着巨大的潜力,但准确分割转移灶是一个挑战。本研究提出了一种基于二维去噪扩散概率模型(DDPMs)的自动化分割方法,该方法在PSMA PET图像的多个角度最大强度投影(MA-MIPs)上进行分割,然后从二维MA-MIPs分割的3D有序子集期望最大化(OSEM)重建中获得最终的3D分割掩膜。该方法在检测和小型转移前列腺癌病灶的分割方面表现出卓越的性能和稳健性,有望作为定量评估前列腺癌患者转移负担的工具。
Key Takeaways
- PSMA PET/CT成像在可视化前列腺癌转移灶方面具有巨大潜力。
- 准确分割转移灶具有挑战性,原因在于信号噪声比低以及病灶大小、形状和位置的多样性。
- 本研究提出了一种新的自动化分割方法,该方法基于二维去噪扩散概率模型(DDPMs)。
- 该方法在MA-MIPs上进行分割,然后结合3D OSEM重建获得最终的3D分割掩膜。
- 该方法在检测和小型转移前列腺癌病灶的分割方面表现出卓越的性能。
- 该方法相较于现有的其他三维分割方法具有更高的准确性和稳健性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种新的方法,用于在前列腺特异性膜抗原(PSMA)正电子发射断层扫描/计算机断层扫描(PET/CT)的3D容积图像中自动分割前列腺癌(PCa)转移性病变。这项研究的主要挑战在于,由于转移性病变的信号-噪声比较低、大小、形状和位置的变异性,使得准确分割这些病变变得困难。论文中提出的解决方案是利用2D去噪扩散概率模型(DDPMs)在生成的多角度最大强度投影(MA-MIPs)上进行病变分割,然后从2D MA-MIPs分割的3D有序子集期望最大化(OSEM)重建中获得最终的3D分割掩模。这种方法在检测和分割小的转移性前列腺癌病变方面,与现有的最先进的3D分割方法相比,展现出了更高的准确性和鲁棒性。
Q: 有哪些相关研究?
A: 论文中提到了若干相关研究,主要集中在以下几个方面:
前列腺癌的诊断和治疗决策:前列腺癌的复发可能表现为区域淋巴结和骨骼结构的转移。随着疾病进展,可能还会涉及到肝脏和肺部等其他部位。因此,精确识别复发位置对于治疗决策至关重要。
PSMA-PET/CT成像:正电子发射断层扫描(PET)成像技术的最新进展提高了对许多类型原发和转移性病变的检测和定量能力。特别是针对PSMA的PET放射性药物,如[18F]DCFPyL,与传统成像方式相比具有更高的灵敏度和特异性。
深度学习算法在计算机辅助诊断中的应用:深度学习算法在医学图像分割和检测方面展现出巨大潜力,但它们必须应对成像方式带来的挑战,包括低对比度、患者间和患者内的高度异质性,以及图像中的模糊和噪声。
前列腺癌转移性病变的分割:论文中提到了使用深度学习算法进行前列腺癌肿瘤/转移性病变检测和分割的先前研究,但这些研究主要集中在局部原发性(前列腺内)肿瘤分割,这是一个相对容易的任务。
2D和3D分割方法:论文中提到了在前列腺癌复发患者的数据集上评估基于卷积神经网络(CNN)的分割模型的性能的研究。
扩散模型(Diffusion Models):论文中使用了一种去噪扩散概率模型(DDPM),这是一种用于图像分割的深度学习模型,它通过在2D图像上训练并在3D容积上应用来实现分割。
有序子集期望最大化(OSEM)算法:这是一种在医学成像中广泛使用的迭代重建技术,用于从不同角度获取的2D投影数据重建3D容积图像。
多角度最大强度投影(MA-MIPs):论文中提出了一种新颖的方法,使用MA-MIPs来增强2D分割模型的性能,并通过OSEM算法将2D分割结果重建为3D分割掩模。
这些研究为论文提出的新方法提供了理论和技术基础,并帮助作者构建了一个在前列腺癌转移性病变分割方面具有优越性能的自动化系统。
Q: 论文如何解决这个问题?
A: 论文提出了一种创新的方法来解决前列腺癌转移性病变在PSMA PET/CT 3D容积图像中的自动分割问题。具体解决方案包括以下几个关键步骤:
多角度最大强度投影(MA-MIPs)生成:首先,从PSMA PET图像数据中生成MA-MIPs。这些投影通过在多个角度(每5度一个)旋转原始3D体积数据来创建,以增强病变的可视化并减少背景噪声。
数据预处理:将PSMA-PET的活性浓度值转换为标准摄取值(SUV),并对SUV值进行裁剪,以降低高摄取正常器官与小病变之间的对比度。此外,对CT和PET图像进行重采样和裁剪,以统一图像尺寸。
2D去噪扩散概率模型(DDPM):使用DDPM进行2D图像分割。DDPM通过在正向过程中逐步添加高斯噪声,然后在反向过程中逐步去除噪声来训练模型。这种方法利用了U-Net架构的网络,通过L2损失进行训练。
3D分割的OSEM重建:使用有序子集期望最大化(OSEM)算法,将2D分割掩模重建为3D分割体积。OSEM算法通常用于从2D投影数据中重建3D图像,这里创新性地应用于从2D MA-MIPs分割结果中重建3D分割掩模。
模型训练与评估:使用U-Net作为DDPM模型的骨干网络进行训练。模型在NVIDIA V100 GPU上训练,并使用Adam优化器进行优化。训练完成后,使用测试集评估模型性能。
性能比较:将所提出的基于MIP-DDPM的方法与现有的最先进的3D分割方法进行比较,以验证新方法的有效性。
通过这种方法,论文成功地提高了小转移性前列腺癌病变的检测和分割的准确性和鲁棒性,为前列腺癌患者的量化分析提供了一个有潜力的工具。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估所提出的基于多角度最大强度投影(MA-MIPs)和2D去噪扩散概率模型(DDPM)的3D分割方法:
数据集准备:使用了510个全身体[18F]DCFPyL PSMA-PET/CT图像,这些图像来自经过初次治疗后生化复发的前列腺癌患者。
数据预处理:包括SUV值的转换和裁剪,以及CT和PET图像的重采样和裁剪。
MA-MIPs生成:对每个患者的PSMA-PET图像数据,生成72个不同角度的旋转体积,并计算这些体积的最大强度投影(MIPs)。
DDPM模型训练:使用U-Net作为DDPM模型的骨干网络,对MA-MIPs进行训练。训练使用了特定的噪声计划和优化器设置。
模型评估:在独立的测试集上评估DDPM模型的性能,包括生成多个分割掩模并进行集成,以提高分割精度。
3D重建:使用有序子集期望最大化(OSEM)算法,将2D分割掩模重建为3D分割体积。
性能比较:将所提出的MIP-DDPM方法与其他8种现有的最先进的3D分割方法进行比较,使用Dice分数、95百分位Hausdorff距离、Jaccard指数和体积误差百分比等指标。
视觉比较:在样本病例上,通过视觉比较展示了所提出方法与其他方法的分割结果。
临床意义讨论:讨论了所提出方法在早期检测转移性病变、改善管理决策方面的潜在临床应用。
这些实验结果表明,所提出的MIP-DDPM方法在分割精度、鲁棒性等方面优于现有的3D分割技术,为前列腺癌转移性病变的自动分割提供了一种有效的新工具。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一种有效的3D分割方法,但仍有一些潜在的研究方向可以进一步探索,以提高性能或扩展应用:
算法优化:进一步优化DDPM模型,可能通过改进网络结构、调整训练策略或引入新的损失函数来提高分割精度。
数据增强:研究不同的数据增强技术,以增加训练数据的多样性并提高模型的泛化能力。
多模态融合:探索将PET/CT图像与其他成像模态(如MRI)结合,以提供更丰富的解剖和功能信息,可能有助于提高分割的准确性。
自动化阈值选择:研究自动化阈值选择方法,以替代固定的阈值(如0.5),可能有助于提高分割掩模的质量。
模型泛化能力:在不同的患者群体、不同的疾病阶段或不同的成像设备上测试模型的泛化能力。
计算效率:研究如何提高模型的计算效率,减少训练和推理时间,使其更适合实时或大规模临床应用。
模型解释性:提高模型的解释性,帮助医生理解模型的决策过程,增加模型在临床环境中的可接受性。
多任务学习:探索多任务学习方法,同时进行病变分割和其他相关任务(如病变检测、疾病分期)。
跨病变类型泛化:研究模型在不同类型病变(如肺癌、乳腺癌等)上的泛化能力,探索其在其他癌症类型中的应用潜力。
临床验证:在更大的患者群体中进行前瞻性临床试验,以验证模型在实际临床环境中的有效性和安全性。
集成学习:研究如何将所提出的方法与其他先进的分割技术结合,通过集成学习提高整体性能。
模型鲁棒性:研究模型在面对不同噪声水平、不同病变大小和形状时的鲁棒性,并探索提高鲁棒性的方法。
这些研究方向可以帮助进一步推动医学图像分割技术的发展,提高其在临床诊断和治疗决策中的应用价值。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以概括为以下几个要点:
研究背景:前列腺癌(PCa)是男性中第二常见的癌症,PSMA-PET/CT成像技术在可视化前列腺癌转移性病变方面具有重要意义,但准确分割这些病变存在挑战。
研究目标:提出一种自动化方法,用于在PSMA PET/CT 3D容积图像中分割前列腺癌的转移性病变。
方法论:
- 使用多角度最大强度投影(MA-MIPs)增强病变的可视化。
- 应用2D去噪扩散概率模型(DDPM)在MA-MIPs上进行病变分割。
- 利用有序子集期望最大化(OSEM)算法将2D分割结果重建为3D分割掩模。
实验设计:
- 从510个全身体[18F]DCFPyL PSMA-PET/CT图像中选择数据集,包括经过初次治疗后生化复发的前列腺癌患者。
- 对图像数据进行预处理,包括SUV值的转换和裁剪,以及图像的重采样和裁剪。
- 生成MA-MIPs并使用DDPM模型进行训练和评估。
实验结果:所提出的MIP-DDPM方法在Dice分数、Hausdorff距离、Jaccard指数和体积误差百分比等指标上优于现有的最先进的3D分割方法。
临床意义:该方法有助于早期检测转移性病变,改善治疗决策,特别是在生化复发疾病的情况下。
结论:论文提出的基于2D模型的3D分割方法在分割小的转移性前列腺癌病变方面表现出色,具有重要的临床应用潜力。
致谢:研究得到了加拿大健康研究院(CIHR)项目资助和微软AI for Health提供的计算资源与服务支持。
利益披露:作者声明没有与本文内容相关的竞争利益。
参考文献:论文列出了相关领域的参考文献,涵盖了前列腺癌的转移模式、PSMA-PET/CT成像技术、深度学习在医学成像中的应用等主题。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

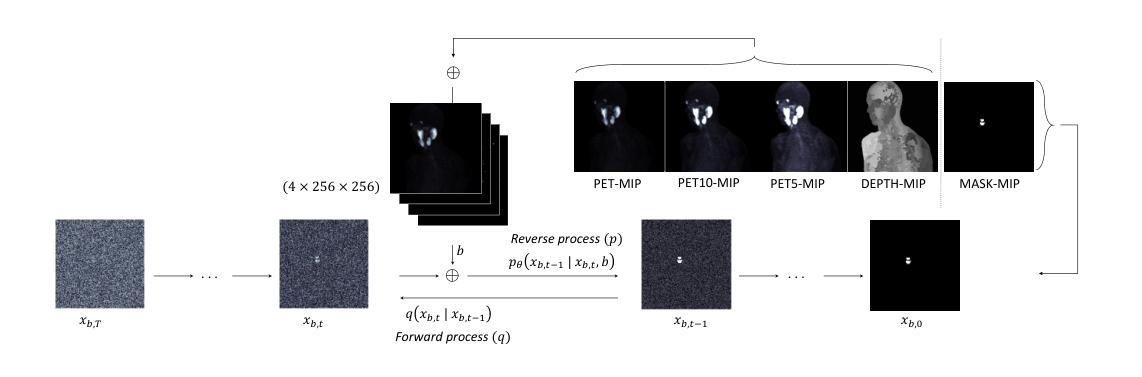
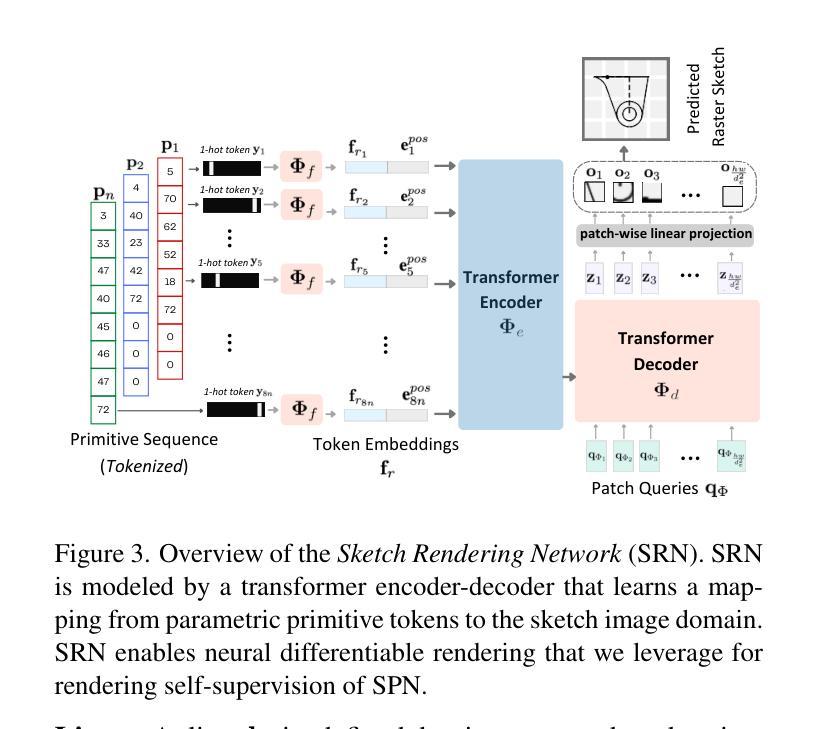
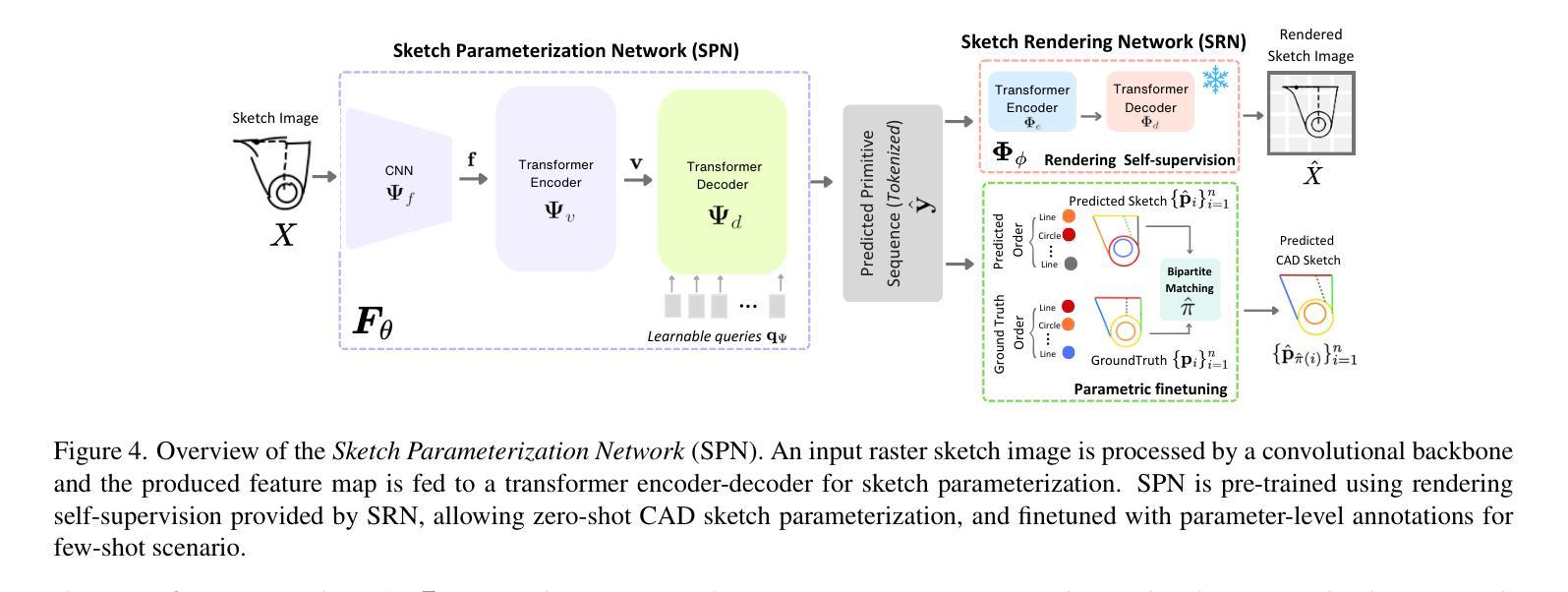
PICASSO: A Feed-Forward Framework for Parametric Inference of CAD Sketches via Rendering Self-Supervision
Authors:Ahmet Serdar Karadeniz, Dimitrios Mallis, Nesryne Mejri, Kseniya Cherenkova, Anis Kacem, Djamila Aouada
This work introduces PICASSO, a framework for the parameterization of 2D CAD sketches from hand-drawn and precise sketch images. PICASSO converts a given CAD sketch image into parametric primitives that can be seamlessly integrated into CAD software. Our framework leverages rendering self-supervision to enable the pre-training of a CAD sketch parameterization network using sketch renderings only, thereby eliminating the need for corresponding CAD parameterization. Thus, we significantly reduce reliance on parameter-level annotations, which are often unavailable, particularly for hand-drawn sketches. The two primary components of PICASSO are (1) a Sketch Parameterization Network (SPN) that predicts a series of parametric primitives from CAD sketch images, and (2) a Sketch Rendering Network (SRN) that renders parametric CAD sketches in a differentiable manner and facilitates the computation of a rendering (image-level) loss for self-supervision. We demonstrate that the proposed PICASSO can achieve reasonable performance even when finetuned with only a small number of parametric CAD sketches. Extensive evaluation on the widely used SketchGraphs and CAD as Language datasets validates the effectiveness of the proposed approach on zero- and few-shot learning scenarios.
本文介绍了PICASSO,这是一个将手绘和精确草图图像参数化为二维CAD草图框架。PICASSO将给定的CAD草图图像转换为可以无缝集成到CAD软件中的参数化基本元素。我们的框架利用渲染自监督功能,使用草图渲染进行CAD草图参数化网络的预训练,从而无需相应的CAD参数化。因此,我们极大地减少了对于参数级别注释的依赖,这些注释通常不可用,尤其是对手绘草图而言。PICASSO的两个主要组件包括:(1)草图参数化网络(SPN),可从CAD草图图像预测一系列参数化基本元素;(2)草图渲染网络(SRN),以可区分的方式呈现参数化CAD草图,并促进计算用于自监督的渲染(图像级别)损失。我们证明,即使仅使用少量的参数化CAD草图进行微调,所提出的PICASSO也可以实现合理的性能。在广泛使用的SketchGraphs和CAD作为语言数据集上进行评估,验证了该方法在零样本和少样本学习场景中的有效性。
论文及项目相关链接
PDF Accepted at WACV 2025
Summary
本文介绍了PICASSO框架,该框架可将手绘和精确草图图像转化为参数化原始形式,并无缝集成到CAD软件中。PICASSO利用渲染自监督技术,仅使用草图渲染进行CAD草图参数化网络的预训练,从而无需对应的参数化标注。这大大降低了对参数级别标注的依赖,尤其是手绘草图。PICASSO主要包括两个组件:Sketch Parameterization Network (SPN) 和 Sketch Rendering Network (SRN)。SPN可从CAD草图图像预测一系列参数化原始形式,而SRN则以可区分的方式渲染参数化CAD草图,并为自监督计算图像级损失。实验证明,PICASSO在仅使用少量参数化CAD草图进行微调时也能取得合理的效果。在广泛使用的SketchGraphs和CAD as Language数据集上的评估验证了该方法在零样本和少样本学习场景中的有效性。
Key Takeaways
- PICASSO是一个用于将手绘和精确草图图像转化为参数化原始形式的框架,可无缝集成到CAD软件中。
- 利用渲染自监督技术,仅使用草图渲染进行预训练,降低对参数级别标注的依赖。
- 主要包含两个组件:Sketch Parameterization Network (SPN) 和 Sketch Rendering Network (SRN)。
- SPN能从CAD草图图像预测参数化原始形式。
- SRN以可区分的方式渲染参数化CAD草图,计算图像级损失以实现自监督。
- PICASSO在仅使用少量参数化CAD草图进行微调时表现出合理的效果。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为PICASSO的框架,旨在解决从手绘和精确草图图像中参数化2D CAD草图的问题。具体来说,PICASSO的目标是将给定的CAD草图图像转换成可以无缝集成到CAD软件中的参数化基元。这个框架通过利用渲染自监督(rendering self-supervision)来实现这一点,从而在不需要对应的CAD参数化的情况下,使用仅草图渲染进行CAD草图参数化网络的预训练,显著减少了对参数级注释的依赖,这些注释通常难以获得,尤其是对于手绘草图。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要集中在以下几个领域:
CAD Sketch Parameterization:
- 研究工作集中在CAD草图的生成或合成上。最近的方法采用自回归变换器(autoregressive transformers)来处理CAD草图的参数化。
- 例如,[14]利用协议缓冲区规范(protocol buffer specification)为2D草图生成受约束的CAD草图。
- [41]探索了基于超图(hypergraphs)或海龟图形(turtle graphics)的两种不同的草图表示,并引入了相应的生成模型CurveGen和TurtleGen。
- [29]和[38]提出了两阶段架构,分别用于基元和约束的生成,并研究了这些模型用于手绘草图参数化的有效性。
Parametric Rendering:
- 渲染是指将矢量参数转换为光栅图像的过程。由于直接矢量监督并不总是可用的,渲染模块可以连接矢量和光栅域,并启用基于梯度的优化。
- 相关工作探索了可微分渲染器(differentiable renderers),这些渲染器可以自动计算相对于输入矢量参数的梯度。
- 更多相关工作调查了可学习的渲染方法,将参数转换为光栅图像,允许使用基于图像的损失进行优化。
Differentiable Rendering:
- [18]、[23]等研究了可微分渲染技术,这些技术可以将参数转换为光栅图像,允许通过图像损失进行优化。
- 这些工作通常处理矢量图形,与矢量图形相比,用于CAD草图自监督的渲染应该能够捕获多种类型的参数基元(例如线条、圆形)。
这些相关研究为PICASSO框架的开发提供了理论基础和技术背景。PICASSO框架通过结合这些领域的技术,提出了一种新的自监督学习方法,用于在参数注释有限或不可用的情况下进行CAD草图的参数化。
Q: 论文如何解决这个问题?
A: 论文通过提出PICASSO框架来解决从手绘和精确草图图像中参数化2D CAD草图的问题。PICASSO框架主要包含两个组成部分:
**Sketch Parameterization Network (SPN)**:这是一个预测网络,用于从CAD草图图像中预测一系列参数基元。SPN采用前馈(feed-forward)变换器编码器-解码器架构,将输入的草图图像编码成一组参数基元的标记(tokens)。
**Sketch Rendering Network (SRN)**:这是一个神经可微分渲染器,用于将参数CAD草图渲染成可微分的方式,从而计算自监督的渲染(图像级)损失。SRN使得仅使用草图渲染进行SPN的预训练成为可能,从而减少了对参数级注释的依赖。
解决方案的关键步骤如下:
渲染自监督:通过SRN,PICASSO能够仅使用草图渲染进行SPN的预训练,无需对应的CAD参数化。这通过计算预测基元和输入草图图像之间的图像到图像损失来实现。
零样本和少样本学习:利用预训练的SPN,PICASSO能够在参数注释有限或不可用的情况下,直接从精确或手绘图像中学习参数化CAD草图。在零样本设置中,预训练的SPN直接用于推断草图参数。在少样本场景中,预训练的SPN使用少量注释样本进行微调。
前馈网络设计:与最近的自回归网络设计不同,SPN是一个前馈网络,将草图视为无序的基元集合,并以非自回归方式预测CAD序列。
多尺度L2损失:为了在不同分辨率下提供信息梯度,PICASSO使用了多尺度L2损失来计算预测渲染和输入光栅图像之间的差异。
通过这些方法,PICASSO框架能够在参数注释稀缺或不存在的情况下,有效地从手绘或精确的CAD草图光栅图像中学习参数化CAD草图。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证PICASSO框架的有效性,具体包括:
Few-shot和Zero-shot CAD Sketch Parameterization:
- 在Few-shot设置中,首先使用渲染自监督对PICASSO进行预训练,然后在较小的、策划好的参数化草图数据集上进行微调。
- 在Zero-shot设置中,直接使用通过渲染自监督预训练的SPN模型来推断草图参数,完全不需要参数级注释。
Cross-dataset Evaluation:
- 为了评估模型的泛化能力,作者将在SketchGraphs数据集上训练的Few-shot模型测试在CAD as a Language数据集上。
Ablation Study:
- 比较了提出的SRN与不同的可微分渲染器DiffVG,在测试时优化设置下的性能。
- 评估了不同损失函数对SRN训练的影响。
- 评估了SPN在有参数监督的情况下对精确和手绘草图图像进行CAD草图参数化的性能。
- 对SPN的不同架构组件进行了消融研究,包括双分图匹配(Bipartite Matching)和基于U-Net的背景。
Impact of CAD Sketch Parameterization on CAD Constraint Inference:
- 评估了由PICASSO推断的参数化基元对现有约束预测模型性能的影响。
Semi-supervised CAD Sketch Parameterization via Rendering Supervision:
- 探索了通过渲染监督进行半监督学习的场景,其中SRN在未标记的草图图像上进行渲染监督训练,并在较小的参数化草图数据集上进行参数监督训练。
Sensitivity to Rendering Quality:
- 进行了消融研究,探讨了SRN渲染性能的变化如何影响自监督预训练的有效性。
Extension to Other Primitives:
- 作为未来工作的预实验,作者在包含随机生成的B-splines的合成数据集上训练和测试了SPN和SRN,并与DiffVG进行了比较。
Qualitative Results:
- 提供了Few-shot CAD草图参数化的额外视觉结果。
- 展示了Zero-shot CAD草图参数化的额外视觉结果。
- 展示了在精确草图上进行测试时优化的视觉结果。
这些实验全面评估了PICASSO框架在不同设置下的性能,并与现有方法进行了比较,证明了PICASSO在参数化2D CAD草图方面的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
扩展到更多类型的CAD基元:
- 论文中提到,由于现有数据集中自由曲线(如B样条、双曲线和NURBS)的表示不足,这些类型的基元没有被包括在内。未来的工作可以探索如何将PICASSO框架扩展到这些自由曲线。
提高零样本学习的性能:
- 论文指出,在零样本设置中,由于手绘草图和SRN渲染的精确草图之间的差异,渲染自监督可能会受到影响。开发对手绘图不变的损失函数,以提高零样本性能,是一个有趣的研究方向。
改进渲染网络(SRN):
- 进一步优化SRN的渲染质量,使其能够更准确地捕捉手绘草图的特性,这可能会提高自监督预训练的效果。
探索半监督学习:
- 论文中提到了通过渲染监督进行半监督学习的可能性。未来的工作可以更深入地研究这种设置,特别是如何更有效地结合渲染监督和参数监督。
优化网络架构:
- 对SPN和SRN的网络架构进行进一步的优化和调整,以提高参数化精度和渲染质量。
处理复杂和噪声数据:
- 研究如何提高PICASSO处理复杂或噪声数据的能力,特别是在实际应用中,手绘草图的质量可能变化很大。
减少对合成数据的依赖:
- 探索如何减少对合成数据的依赖,通过利用少量的真实世界数据来提高模型的泛化能力。
实际应用和集成:
- 将PICASSO集成到实际的CAD软件中,并在真实世界的机械设计任务中测试其性能和实用性。
提高计算效率:
- 尽管SPN比自回归模型快,但仍有进一步优化空间,特别是在处理大规模数据集时。
多模态学习:
- 探索如何结合视觉信息和其他模态信息(如触觉反馈或语音指令)来改进CAD草图的参数化。
这些探索点可以帮助推动CAD草图参数化技术的发展,提高其在实际应用中的有效性和可靠性。
Q: 总结一下论文的主要内容
A: 论文介绍了PICASSO框架,这是一个用于从手绘和精确草图图像中参数化2D CAD草图的前馈式(feed-forward)框架。主要内容包括:
问题背景:
- CAD软件在产品设计中广泛使用,而将手绘草图转换为参数化CAD草图是一个耗时的过程。
- 现有的基于学习的方法依赖大规模标注数据集,但在现实场景中,这些标注数据尤其是手绘草图的参数化信息难以获得。
PICASSO框架:
- 包含两个主要组件:Sketch Parameterization Network(SPN)和Sketch Rendering Network(SRN)。
- SPN用于从草图图像中预测参数基元,而SRN用于可微分地渲染这些参数基元,从而实现自监督学习。
渲染自监督:
- 利用SRN仅通过草图图像进行SPN的预训练,无需CAD参数化标注,减少了对参数级注释的依赖。
零样本和少样本学习:
- PICASSO能够在零样本和少样本的设置下进行CAD草图参数化,这对于参数化手绘草图尤其重要。
实验验证:
- 在SketchGraphs和CAD as Language数据集上进行了广泛的实验,验证了PICASSO在零样本和少样本学习场景下的有效性。
- 与现有方法相比,PICASSO在参数化精确和手绘CAD草图方面取得了更好的性能。
主要贡献:
- 提出了一种新的框架,允许在没有大规模标注数据的情况下进行CAD草图参数化。
- 首次探索了使用神经可微分渲染器进行CAD草图参数化的自监督学习。
- 提出的前馈式SPN在CAD草图参数化任务中达到了最先进的性能。
未来工作:
- 探索将PICASSO扩展到更多类型的CAD基元,包括自由曲线。
- 改进SRN的渲染质量,提高零样本学习的性能。
- 进一步优化网络架构,提高计算效率,并探索实际应用中的集成。
总体而言,PICASSO通过其创新的自监督学习方法,为在参数化标注稀缺的情况下从图像中直接参数化CAD草图提供了一个有效的解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

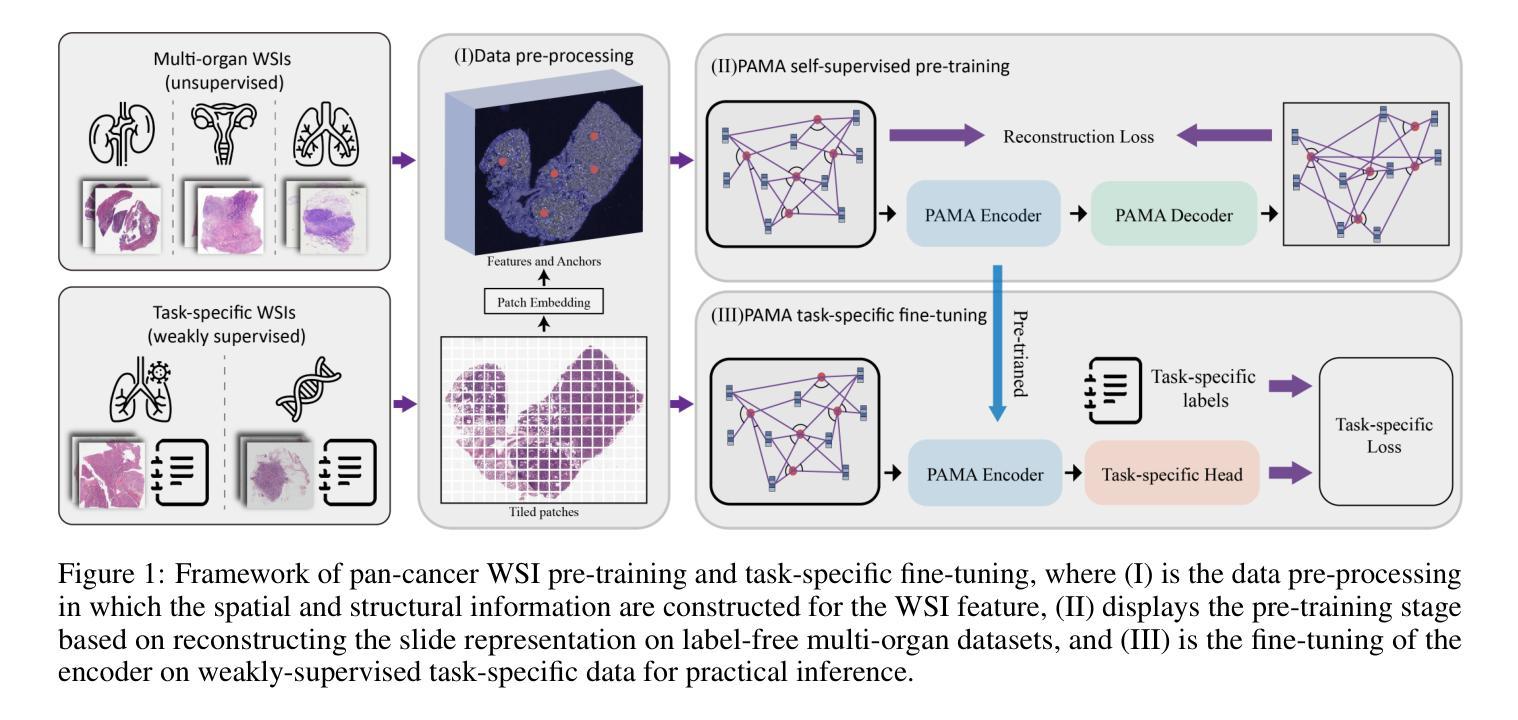
Pan-cancer Histopathology WSI Pre-training with Position-aware Masked Autoencoder
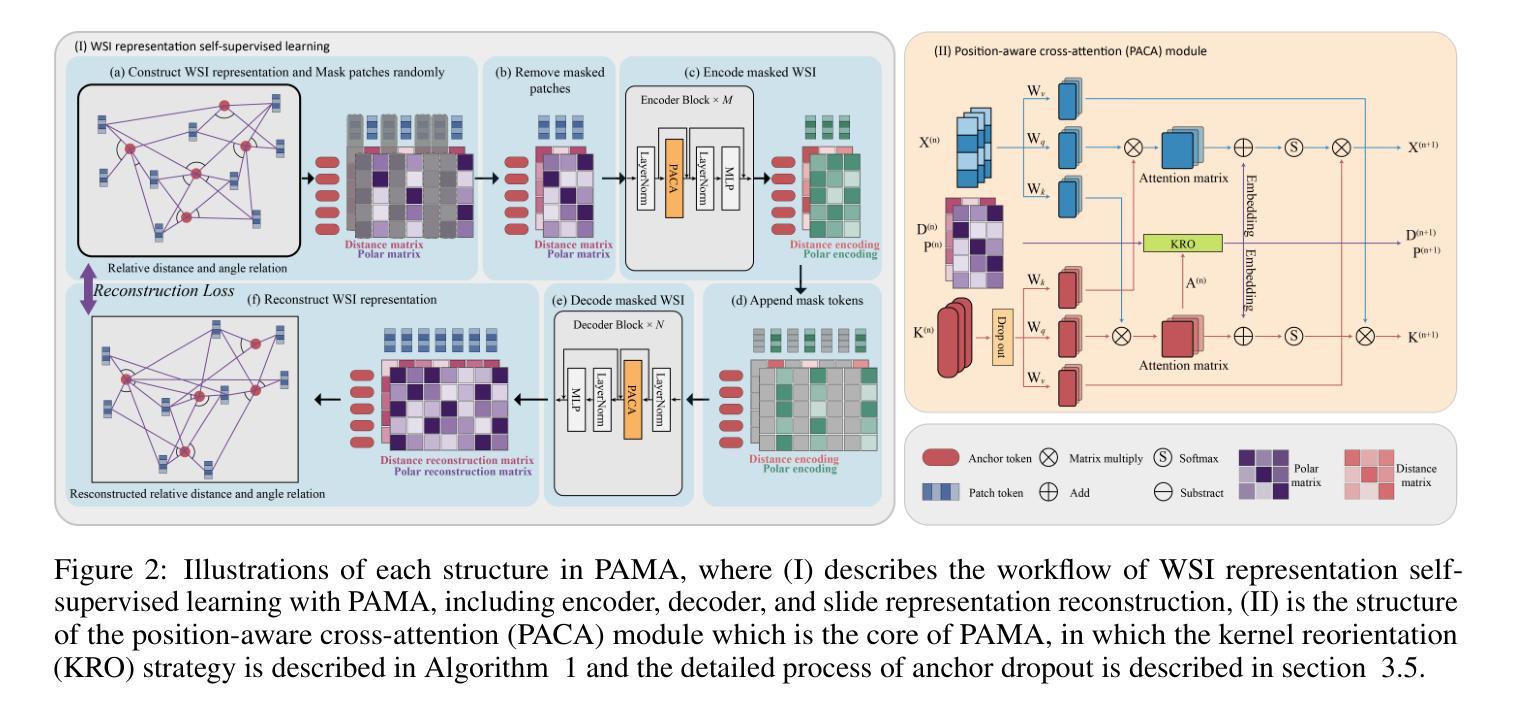
Authors:Kun Wu, Zhiguo Jiang, Kunming Tang, Jun Shi, Fengying Xie, Wei Wang, Haibo Wu, Yushan Zheng
Large-scale pre-training models have promoted the development of histopathology image analysis. However, existing self-supervised methods for histopathology images primarily focus on learning patch features, while there is a notable gap in the availability of pre-training models specifically designed for WSI-level feature learning. In this paper, we propose a novel self-supervised learning framework for pan-cancer WSI-level representation pre-training with the designed position-aware masked autoencoder (PAMA). Meanwhile, we propose the position-aware cross-attention (PACA) module with a kernel reorientation (KRO) strategy and an anchor dropout (AD) mechanism. The KRO strategy can capture the complete semantic structure and eliminate ambiguity in WSIs, and the AD contributes to enhancing the robustness and generalization of the model. We evaluated our method on 7 large-scale datasets from multiple organs for pan-cancer classification tasks. The results have demonstrated the effectiveness and generalization of PAMA in discriminative WSI representation learning and pan-cancer WSI pre-training. The proposed method was also compared with 8 WSI analysis methods. The experimental results have indicated that our proposed PAMA is superior to the state-of-the-art methods. The code and checkpoints are available at https://github.com/WkEEn/PAMA.
大规模预训练模型促进了病理图像分析的发展。然而,现有的针对病理图像的自我监督方法主要集中在学习补丁特征上,而在专为WSI级特征学习设计的预训练模型方面存在明显的差距。在本文中,我们提出了一种新型的自监督学习框架,用于具有位置感知掩码自动编码器(PAMA)的泛癌WSI级表示预训练。同时,我们提出了带有内核重新定位(KRO)策略和锚点丢弃(AD)机制的位置感知交叉注意力(PACA)模块。KRO策略可以捕获完整的语义结构并消除WSIs中的歧义,而AD有助于提高模型的鲁棒性和通用性。我们在来自多个器官的7个大型数据集上对我们的方法进行了泛癌分类任务的评估。结果证明了PAMA在判别WSI表示学习和泛癌WSI预训练中的有效性和通用性。将所提出的方法与8种WSI分析方法进行了比较。实验结果表明,我们提出的PAMA优于最先进的方法。代码和检查点位于https://github.com/WkEEn/PAMA。
论文及项目相关链接
Summary
一种针对大规模预训练模型的新颖自监督学习框架被提出,用于泛癌全视野显微镜图像(WSI)级别的特征学习。该框架引入了位置感知掩码自编码器(PAMA),并结合了位置感知交叉注意力(PACA)模块、内核重新定位(KRO)策略和锚点丢弃(AD)机制。在多个器官的七个大型数据集上进行泛癌分类任务评估,证明其在区分全视野显微镜图像表示学习和泛癌WSI预训练中的有效性和泛化能力。与现有方法相比,PAMA展现出优越性。
Key Takeaways
- 自监督学习方法在病理图像分析中得到发展,但针对全视野显微镜图像(WSI)级别的预训练模型存在缺口。
- 提出了一种新型自监督学习框架,用于泛癌WSI级别的特征学习。
- 引入了位置感知掩码自编码器(PAMA)以及位置感知交叉注意力(PACA)模块。
- 采用内核重新定位(KRO)策略捕捉完整的语义结构并消除WSIs中的歧义。
- 锚点丢弃(AD)机制增强了模型的稳健性和泛化能力。
- 在七个大型数据集上进行了泛癌分类任务评估,证明所提方法的有效性和泛化能力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为PAMA(Position-Aware Masked Autoencoder)的自监督学习框架,旨在解决以下问题:
全切片图像(WSI)级别的特征学习:现有的自监督学习方法主要关注于学习组织切片图像的局部特征(即图像块特征),而缺乏专门针对WSI级别特征学习的预训练模型。PAMA框架通过设计位置感知的掩码自编码器来填补这一空白,专注于从大规模未标记数据中挖掘WSI的语义特征。
多癌种(pan-cancer)WSI的预训练:尽管有多癌种分析模型和数据库的研究,但缺乏能够利用大量未标记WSI进行WSI级别特征学习的模型。PAMA框架通过在多器官数据集上进行预训练,展示了其在多癌种分析中的有效性和泛化能力。
位置感知和结构信息的整合:传统的Transformer模型可能无法有效处理病理图像的各向异性特征,导致位置编码产生歧义。PAMA框架通过提出位置感知交叉注意力(PACA)模块和核心重定向(KRO)策略,整合了局部和全局信息的双向通信,并动态更新锚点的主方向,以更好地获取完整的语义结构并消除歧义。
提高模型的鲁棒性和泛化能力:通过引入锚点dropout机制,增强模型对不同数据集的泛化能力,并减少WSI预训练过程中的过拟合问题。
总结来说,这篇论文主要关注于开发一个能够处理大规模病理图像数据、具有位置感知能力、并且能够进行多癌种预训练的自监督学习框架,以提高WSI级别的表示学习,并在多种病理学图像分析任务中实现更好的性能。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
基于MIL的方法(Multiple Instance Learning based methods):
- 这些方法通常用于WSI分析,涉及提取图像块特征和聚合WSI级别的表示。
- 例如,Li等人[25]提出了一个双流框架整合实例,并应用金字塔融合机制进行多尺度WSI特征提取。
- 其他研究如Graph Attention MIL[26]和LAGE-Net[27]构建了图像块的图结构以编码局部关系。
自监督学习(Self-supervised learning):
- 这类方法在计算机视觉中越来越受到关注,主要集中于不同的代理任务以进行无监督预训练。
- 一些工作关注基于上下文的方法,例如预测病理图像的交叉染色、预测WSI中的分辨率序列排序等[35-37]。
- 其他方法利用生成模型构建代理任务,通过最小化像素空间中的重构损失隐式学习特征,例如SD-MAE[31]和MAE-MIL[32]。
全切片图像(WSI)分析:
- 涉及使用深度学习框架促进癌症亚型、组织病理图像检索、基因突变预测和生存预测等方面的研究。
- 例如,Huang等人[20]将CLIP[14]应用于多模态病理语言-图像预训练(PLIP)。
基于Transformer的结构:
- Transformer结构在自然语言处理领域取得了令人印象深刻的进展,也被用于WSI分析以捕获和聚合长距离信息。
- 例如,TransMIL[28]和SETMIL[29]利用CNN块和空间编码模块聚合局部信息,并使用自注意力模型进行全局信息传递。
多癌种分析(Pan-cancer analysis):
- 涉及构建多癌种分析模型和相关数据库的计算病理学研究。
- 例如,Komura等人[47]构建了一个通用编码器,通过深度神经网络从多种癌症类型的组织学图像中预测基因组特征。
这些相关研究展示了在病理图像分析领域,特别是在WSI级别的特征学习和多癌种分析中,如何利用深度学习和自监督学习技术来处理和分析大规模数据集。PAMA框架正是基于这些相关研究,进一步提出了一个新颖的自监督学习框架来改进WSI级别的表示学习。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法解决了全切片图像(WSI)级别的特征学习问题:
提出PAMA(Position-Aware Masked Autoencoder)框架:
- PAMA是一个自监督学习框架,用于在WSI级别上进行表示预训练。通过设计slide-level的掩码图像建模(MIM)代理任务,PAMA能够从大量未标记数据中挖掘出病理幻灯片的语义特征。
引入PACA(Position-Aware Cross-Attention)模块:
- PACA模块嵌入了相对距离和方向信息到幻灯片表示中,使得模型能够保持空间语义的完整性。
- PACA模块通过动态更新策略和锚点dropout机制增强模型的鲁棒性和泛化能力。
设计KRO(Kernel Reorientation)策略:
- KRO策略动态更新锚点的主要方向,以更好地获取完整的语义结构并消除WSI表示中的歧义。
采用AD(Anchor Dropout)机制:
- 通过随机丢弃一些锚点来增强模型的泛化能力,类似于神经网络中的神经元dropout机制。
多器官数据集的预训练和评估:
- 作者收集了7个大规模数据集,包含13,685个WSI,涵盖了多个器官,用于评估PAMA框架的有效性和泛化能力。
- 通过与8种WSI分析方法的比较实验,展示了PAMA在组织学WSI预训练和下游任务(包括癌症亚型和生物标志物预测)中的优越性能。
实验验证:
- 论文中的实验部分验证了PAMA在多个数据集上的性能,并与现有的SOTA方法进行了比较,证明了PAMA在多癌种分类任务中的有效性和泛化能力。
通过这些方法,论文成功地提出了一个能够处理大规模病理图像数据、具有位置感知能力、并且能够进行多癌种预训练的自监督学习框架,以提高WSI级别的表示学习,并在多种病理学图像分析任务中实现更好的性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估PAMA框架的有效性和泛化能力,具体实验包括:
数据集收集与划分:
- 作者收集了四个公共大规模数据集和三个内部数据集,包含多个器官的8,892个WSI,用于多器官预训练和特定任务的微调。数据集被随机划分为训练、验证和测试子集。
预训练条件实验:
- 在WSI级别的表示预训练阶段,作者没有使用任何监督信息。预训练的编码器将被用作各种下游任务的幻灯片表示提取器。作者比较了不同预训练策略(无预训练、单器官预训练和多器官预训练)的性能。
多器官预训练的有效性:
- 作者展示了PAMA在多器官数据集上预训练后,在各个内部数据集测试集上的性能,以证明PAMA在利用大量未标记的组织病理学图像数据和增强表示能力方面的有效性。
跨域预训练的泛化能力:
- 作者使用来自TCGA的大规模多癌种数据集作为跨域数据,评估了PAMA预训练的泛化能力。将PAMA与SOTA方法Prov-GigaPath进行比较,展示了PAMA在未见数据上的特征表征和分析能力。
半监督WSI分类的有效性:
- 作者评估了在有限WSI标签条件下WSI级别自监督学习的有效性。比较了PAMA与MAE、HIPT和Prov-GigaPath等方法的性能。
与其他弱监督方法的比较:
- 作者将PAMA与BYOL、MAE、HIPT、Prov-GigaPath等自监督框架以及其他SOTA弱监督方法(包括DSMIL、TransMIL、SETMIL和KAT)在Endometrium-3k和TCGA-NSCLC数据集上进行了比较。
消融研究:
- 作者进行了消融研究,验证了相对空间嵌入和策略(包括极角嵌入、KRO模块、相对距离嵌入和AD机制)对性能的影响。
超参数分析:
- 作者对PAMA框架的不同超参数进行了调整和分析,包括掩码比率、dropout概率、每个锚点的补丁数和极角箱数,以找到最佳的参数设置。
可视化分析:
- 作者通过可视化评估了PAMA框架的可解释性,展示了预训练和微调过程中锚点注意力的分布情况。
这些实验全面地评估了PAMA框架在不同条件下的性能,并与其他方法进行了比较,证明了PAMA在组织病理学图像分析中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
多癌种分析的扩展:
- 论文中提到的多器官数据集尚未包含所有癌症类型,未来的工作可以扩展数据集以包含更多种类的癌症,以进行更全面的多癌种分析。
多模态数据融合:
- 目前PAMA框架仅依赖于病理图像数据。未来的研究可以探索将基因组学等多模态数据融入预训练过程中,以增强癌症诊断的准确性。
空间属性的显式设计:
- 尽管PAMA框架通过PACA模块和KRO策略处理了WSI的空间结构信息,但未来的工作可以进一步探索显式设计来挖掘多癌种数据中的语义信息,例如构建特定的损失函数。
泛癌种特征的深入研究:
- 论文中提到了跨癌种分析模型的构建,未来的研究可以更深入地探讨跨癌种特征,以及如何利用这些特征进行更有效的疾病建模。
模型泛化能力的进一步提升:
- 尽管PAMA显示出良好的跨域泛化能力,但进一步研究如何提升模型在面对更多样化、更复杂的病理图像数据时的泛化能力仍然是一个重要的研究方向。
计算效率的优化:
- 考虑到病理图像数据的大规模特性,优化PAMA框架的计算效率,减少资源消耗,使其更适合在实际临床环境中部署也是一个值得探索的方向。
模型解释性的增强:
- 提高模型的可解释性,使得病理学家能够更好地理解和信任模型的决策过程,这对于临床应用至关重要。
更广泛的下游任务探索:
- 除了论文中提到的肿瘤亚型分类和生物标志物预测任务外,探索PAMA预训练模型在更多病理学图像分析任务中的应用,如肿瘤边界检测、组织分割等。
跨平台数据的一致性和校准:
- 不同医疗中心可能使用不同的染色和扫描技术,研究如何校准跨平台数据以保持一致性,对于构建更稳健的预训练模型非常重要。
这些探索点可以帮助研究人员进一步提升PAMA框架的性能,并扩展其在病理学图像分析领域的应用范围。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为PAMA(Position-Aware Masked Autoencoder)的自监督学习框架,专门针对病理学全切片图像(WSI)的预训练和表示学习。以下是论文的主要内容总结:
问题陈述:
- 针对现有的自监督学习方法主要关注于局部图像块特征学习,缺乏专门针对WSI级别特征学习的预训练模型的问题。
PAMA框架:
- 提出了PAMA框架,通过slide-level的掩码图像建模(MIM)代理任务,从大量未标记数据中挖掘病理幻灯片的语义特征。
PACA模块:
- 引入了位置感知交叉注意力(PACA)模块,嵌入相对距离和方向信息,以保持WSI的空间语义完整性。
KRO策略:
- 提出了核心重定向(KRO)策略,动态更新锚点的主方向,以消除WSI表示中的歧义。
AD机制:
- 引入锚点dropout(AD)机制,增强模型的鲁棒性和泛化能力。
数据集和实验:
- 作者收集了7个大规模数据集,包含13,685个WSI,覆盖多个器官,用于评估PAMA框架的有效性和泛化能力。
- 与8种WSI分析方法比较,证明了PAMA在多癌种分类任务中的优越性能。
实验结果:
- 实验结果表明,PAMA在组织学WSI预训练和下游任务(包括癌症亚型和生物标志物预测)中表现出色,具有很好的泛化能力。
未来工作:
- 论文指出了两个主要的改进方向:扩展多器官数据集以包含更多癌症类型,以及引入多模态数据(如基因组数据)参与预训练过程。
总的来说,这篇论文通过提出PAMA框架,为病理学WSI的自监督学习提供了一个有效的解决方案,通过在多器官数据集上进行预训练,展示了其在多癌种分析中的有效性和泛化能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Transfer or Self-Supervised? Bridging the Performance Gap in Medical Imaging
Authors:Zehui Zhao, Laith Alzubaidi, Jinglan Zhang, Ye Duan, Usman Naseem, Yuantong Gu
Recently, transfer learning and self-supervised learning have gained significant attention within the medical field due to their ability to mitigate the challenges posed by limited data availability, improve model generalisation, and reduce computational expenses. Transfer learning and self-supervised learning hold immense potential for advancing medical research. However, it is crucial to recognise that transfer learning and self-supervised learning architectures exhibit distinct advantages and limitations, manifesting variations in accuracy, training speed, and robustness. This paper compares the performance and robustness of transfer learning and self-supervised learning in the medical field. Specifically, we pre-trained two models using the same source domain datasets with different pre-training methods and evaluated them on small-sized medical datasets to identify the factors influencing their final performance. We tested data with several common issues in medical domains, such as data imbalance, data scarcity, and domain mismatch, through comparison experiments to understand their impact on specific pre-trained models. Finally, we provide recommendations to help users apply transfer learning and self-supervised learning methods in medical areas, and build more convenient and efficient deployment strategies.
最近,迁移学习和自监督学习在医学领域受到了广泛关注,因为它们能够缓解因数据有限而带来的挑战,提高模型的通用性,并降低计算成本。迁移学习和自监督学习在推动医学研究方面拥有巨大潜力。然而,重要的是要认识到迁移学习和自监督学习架构具有各自独特的优势和局限性,在准确性、训练速度和稳健性方面存在差异。本文比较了迁移学习和自监督学习在医学领域的性能和稳健性。具体来说,我们使用相同的源域数据集和不同预训练方法对两个模型进行预训练,并在小型医学数据集上评估它们,以确定影响它们最终性能的因素。我们测试了医学领域中存在的几个常见问题数据,如数据不平衡、数据稀缺和领域不匹配等,通过对比实验来了解它们对特定预训练模型的影响。最后,我们提供建议,帮助用户了解在医学领域应用迁移学习和自监督学习方法,并建立更便捷高效的部署策略。
论文及项目相关链接
PDF 37 pages, 8 figures
Summary
这篇论文比较了迁移学习和自监督学习在医学领域的性能和稳健性。研究通过对使用相同源域数据集但采用不同预训练方法的两个模型进行预训练,并在小型医学数据集上进行评估,以识别影响最终性能的因素。此外,该研究还通过对比实验测试了数据不平衡、数据稀缺和域不匹配等医学领域常见问题的模型影响,并提供了针对迁移学习和自监督学习方法在医学领域应用的建议,以构建更便捷高效的部署策略。
Key Takeaways
- 迁移学习和自监督学习在医学领域具有显著潜力,能有效解决数据有限和计算成本高昂的问题,提高模型的通用性。
- 迁移学习和自监督学习在准确性、训练速度和稳健性方面展现出不同的优势和局限性。
- 论文通过预训练两个模型并对其进行评估,探讨了不同预训练方法对模型性能的影响。
- 研究通过对比实验,深入了解了数据不平衡、数据稀缺和域不匹配等医学领域常见问题对模型的影响。
- 论文提供了针对迁移学习和自监督学习方法在医学领域的实际应用建议。
- 通过研究,可以更好地理解如何构建更便捷高效的模型部署策略。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在医学领域中,如何选择和利用迁移学习(Transfer Learning, TL)和自监督学习(Self-supervised Learning, SSL)这两种预训练方法来提高模型性能、解决数据稀缺问题,并减少计算成本。具体来说,论文的主要目标包括:
比较迁移学习和自监督学习:通过实验对比这两种方法在不同类型(彩色和灰度)医学图像数据集上的表现,包括准确率、训练速度和鲁棒性。
解决数据不平衡问题:研究数据增强和下采样技术与预训练模型结合使用时,在处理不平衡数据方面的效率。
处理领域不匹配问题:探索双重微调技术(double fine-tuning)在减少源域和目标域之间的领域不匹配问题方面的有效性。
提高模型的可解释性:使用可解释人工智能(XAI)技术评估预训练模型的可靠性和鲁棒性。
提供选择指导:为研究人员提供在不同场景下选择最合适预训练设置的指导,以提高模型在医学研究中的性能和应用潜力。
论文通过广泛的实验和分析,提供了对这两种预训练方法在医学图像分析中性能的深入理解,并探讨了它们在实际应用中的潜在价值和局限性。
Q: 有哪些相关研究?
A: 论文中提及了多个与迁移学习(Transfer Learning, TL)和自监督学习(Self-supervised Learning, SSL)在医学图像处理领域应用相关的研究。以下是一些关键的相关研究:
Niu et al. (2020): 该研究探讨了迁移学习在医学图像分析中的广泛应用,包括不同疾病的研究。
Raghu et al. (2019): 这项研究提出了对医学领域使用ImageNet预训练模型的普遍性提出质疑,因为ImageNet数据集与医学图像在领域上存在差异。
Yang et al. (2020): 进行了迁移学习和自监督学习两种预训练方法的比较实验,分析了领域相似性对这两种预训练方法的影响。
Azizi et al. (2023): 阐明了SSL方法的好处,指出其在目标域数据少于10%的情况下,能够实现与TL模型相当的性能。
Hosseinzadeh Taher et al. (2021): 对迁移学习和自监督学习的性能进行了基准测试,为未来架构的改进提供了信息。
Ericsson et al. (2022b): 研究了预训练数据集的大小和模型容量对下游任务性能的影响。
Morid et al. (2021): 报道了使用预训练的ImageNet模型在彩色目标数据集上取得的积极结果。
Alzubaidi et al. (2020): 指出预训练的ImageNet特征与医学图像不匹配,尤其是在灰度医学数据集上。
Shurrab & Duwairi (2022): 讨论了自监督学习在医学领域的吸引力,提供了一种有效的解决方案来使用大量未标记的数据。
Truong et al. (2021): 研究了使用ImageNet和自监督预训练方法进行医学成像任务的积极结果。
Wu et al. (2023): 研究了自监督学习框架,并探讨了视觉注意力驱动的良性-恶性肺结节分类。
Zhang et al. (2023): 深入研究了自监督学习在医学图像分析中的细节。
Zhao et al. (2023): 提供了TL和SSL方法的比较综述,定义、应用、优势和局限性。
这些研究涵盖了迁移学习和自监督学习在医学图像分析中的多个方面,包括它们的适用性、性能、以及面临的挑战。论文通过这些相关研究,进一步探讨了在医学领域中如何选择和优化预训练方法。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决选择和利用迁移学习(Transfer Learning, TL)和自监督学习(Self-supervised Learning, SSL)在医学图像处理领域的问题:
实验设计:作者设计了一个比较实验,使用两种广泛采用的深度学习模型,Xception和ResNet,分别在迁移学习和自监督学习设置下提取特征。然后,这些预训练模型在彩色(Kvasirv2, EyePacs)和灰度(BusI, 胸部CT)医学数据集上进行了微调(fine-tuning)和测试。
数据集选择:研究涉及多个彩色和灰度医学图像数据集,这些数据集代表了不同的医学成像技术(如X射线、CT、MRI等)和不同的疾病类型。
数据增强和下采样:为了解决医学领域常见的数据不平衡问题,作者采用了数据增强和下采样技术,并与预训练模型结合使用,以比较它们在处理这些问题方面的效率。
双重微调技术:针对领域不匹配问题,作者采用了双重微调技术,结合提出的预训练TL和SSL模型,以减少源域和目标医学数据之间的差异。
可解释人工智能技术:使用可解释人工智能(XAI)技术评估预训练模型的可靠性,包括生成类激活映射(Class Activation Mapping, CAM),以可视化和解释模型的决策过程。
性能评估:通过比较两种预训练方法在不同数据集上的性能(包括准确率、训练速度和鲁棒性),作者探讨了它们在医学图像分析中的优势和局限性。
结果分析和建议:基于实验结果,作者提出了关于在医学研究中选择适当预训练设置的建议,并讨论了如何根据不同场景选择TL或SSL方法。
深入分析:作者探讨了颜色信息、数据集大小和领域差异对预训练方法性能的影响,并提供了详细的分析和讨论。
通过这些步骤,论文不仅提供了TL和SSL在医学图像分析中的比较分析,还提出了实用的指导建议,帮助研究人员在面对特定医学图像处理任务时,选择最合适的预训练策略。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来比较迁移学习(Transfer Learning, TL)和自监督学习(Self-supervised Learning, SSL)在医学图像处理中的性能。以下是实验的主要步骤和内容:
预训练模型的选择:选择了Xception和ResNet两种深度学习模型,分别用于迁移学习和自监督学习的预训练。
数据集:使用了多个彩色和灰度医学图像数据集进行实验,包括Kvasirv2、EyePacs、BusI和胸部CT扫描数据集。
预训练:
- 迁移学习:使用Xception模型和预训练的ImageNet权重进行迁移学习。
- 自监督学习:使用ResNet模型和SimCLR方法进行自监督学习。
微调和测试:在预训练完成后,对模型进行了微调,并在目标数据集上进行了测试。
数据增强和下采样:
- 数据增强:对训练数据应用了旋转、翻转、缩放和模糊等数据增强技术,以解决数据不平衡问题。
- 下采样:通过随机删除多数类样本,使各类样本数量一致,以处理数据不平衡。
双重微调:
- 对预训练的模型首先在一个相关领域数据集上进行微调,然后再在目标数据集上进行微调,以减少领域不匹配问题。
模型性能评估:使用准确率、损失、敏感性、精确度和F1分数等指标评估模型性能。
可解释性分析:使用Grad-CAM技术生成热图,以可视化模型在进行预测时关注图像的哪些区域,评估模型的可靠性和鲁棒性。
比较分析:
- 比较了TL和SSL方法在不同数据集上的性能。
- 分析了数据增强和下采样技术对模型性能的影响。
- 对比了双重微调前后的模型性能。
- 将提出的模型与当前最先进的模型进行了比较。
结果总结:基于实验结果,提供了在不同医学应用场景下选择合适预训练方法的指导。
这些实验提供了深入的见解,帮助理解迁移学习和自监督学习在医学图像分析中的适用性和效果,以及如何通过不同的技术和方法提高模型的性能和鲁棒性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提供了关于迁移学习(TL)和自监督学习(SSL)在医学图像处理中的深入比较和分析,但仍有一些领域和方向可以进一步探索:
更广泛的数据集和任务:研究可以在更广泛的医学图像数据集和不同类型的任务(如分割、检测)上进行,以验证和比较TL和SSL方法的普适性和有效性。
更先进的预训练模型:随着深度学习模型的快速发展,可以尝试使用更先进的模型(如Vision Transformers)进行TL和SSL,探索它们在医学图像分析中的潜力。
多模态学习:在医学领域中,多模态数据(如图像、文本、电子健康记录)的融合越来越受到关注。研究TL和SSL在多模态学习中的应用可能揭示新的见解。
半监督和无监督学习:除了完全监督的迁移学习和完全无监督的自监督学习,探索半监督学习或弱监督学习在医学图像处理中的应用,可能会在标注成本和模型性能之间取得更好的平衡。
领域适应和对抗训练:研究领域适应技术,如对抗训练,以进一步提高模型对新领域或分布外数据的泛化能力。
计算效率和资源优化:在资源有限的环境中,如移动设备或边缘设备,探索如何优化TL和SSL方法以实现高效的模型推理。
模型压缩和加速:研究如何对预训练的医学图像模型进行压缩和加速,使其在临床实践中更加实用。
长期跟踪和预测:在医学图像分析中,长期跟踪疾病进展的能力非常重要。研究如何利用TL和SSL方法进行时间序列分析和预测可能具有重要意义。
模型解释性和伦理:提高模型的可解释性,并考虑伦理问题,如隐私保护和公平性,特别是在处理敏感的医疗数据时。
跨领域应用:探索TL和SSL方法在其他领域的应用,如金融、安全和自动驾驶,以了解这些方法在不同行业中的适用性和挑战。
合作和多任务学习:研究TL和SSL在多任务学习设置中的性能,这可能有助于提高模型的效率和效果。
动态数据和实时分析:研究模型如何处理动态变化的数据集,以及如何实时更新和优化模型以适应新的数据。
这些方向不仅可以推动医学图像分析技术的发展,还可以为深度学习在更广泛领域的应用提供有价值的见解。
Q: 总结一下论文的主要内容
A: 这篇论文主要探讨了在医学图像处理领域,迁移学习(Transfer Learning, TL)和自监督学习(Self-supervised Learning, SSL)两种方法的性能比较。以下是论文的主要内容总结:
研究背景:论文首先介绍了迁移学习(TL)和自监督学习(SSL)在医学图像分析中的研究背景和重要性,强调了这两种方法在处理医学数据时面临的挑战,如数据隐私、数据收集成本和数据不平衡问题。
研究目的:论文旨在通过实验比较TL和SSL在不同类型(彩色和灰度)医学图像数据集上的性能,包括准确率、训练速度和鲁棒性,并探讨它们在医学领域的应用潜力。
实验设计:研究者选择了Xception和ResNet两种深度学习模型,分别在TL和SSL设置下进行预训练,然后在多个彩色和灰度医学图像数据集上进行微调和测试。
数据集:实验使用了多个公开的医学图像数据集,包括Kvasirv2、EyePacs、BusI和胸部CT扫描数据集。
实验方法:
- 迁移学习:使用预训练的ImageNet权重初始化Xception模型,然后在医学图像数据集上进行微调。
- 自监督学习:使用SimCLR方法和ResNet模型在医学图像数据集上进行预训练,然后进行微调。
数据增强和下采样:研究了数据增强和下采样技术在处理数据不平衡问题方面的有效性。
双重微调:探讨了双重微调技术在减少领域不匹配问题和提高模型性能方面的有效性。
性能评估:使用准确率、损失、敏感性、精确度和F1分数等指标评估模型性能。
可解释性分析:使用Grad-CAM技术生成热图,评估模型的可靠性和鲁棒性。
结果分析:
- TL在彩色数据集上表现更好,而SSL在灰度数据集上表现更优。
- 数据增强技术提高了预训练模型的鲁棒性,而下采样技术可能导致信息丢失。
- 双重微调技术有效提高了模型在目标数据集上的性能。
结论和建议:论文最后提出了在选择TL和SSL方法时应考虑的因素,并提供了在不同医学应用场景下选择合适预训练方法的指导。
研究贡献:论文的贡献在于提供了TL和SSL在医学图像分析中的比较评估,深入分析了它们的优势和局限性,并为未来的研究提供了有价值的见解和指导。
整体而言,这篇论文通过实验研究和分析,为医学图像分析领域中迁移学习和自监督学习的应用提供了深入的见解,并探讨了如何优化这些方法以提高模型性能和鲁棒性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

FairMedFM: Fairness Benchmarking for Medical Imaging Foundation Models
Authors:Ruinan Jin, Zikang Xu, Yuan Zhong, Qiongsong Yao, Qi Dou, S. Kevin Zhou, Xiaoxiao Li
The advent of foundation models (FMs) in healthcare offers unprecedented opportunities to enhance medical diagnostics through automated classification and segmentation tasks. However, these models also raise significant concerns about their fairness, especially when applied to diverse and underrepresented populations in healthcare applications. Currently, there is a lack of comprehensive benchmarks, standardized pipelines, and easily adaptable libraries to evaluate and understand the fairness performance of FMs in medical imaging, leading to considerable challenges in formulating and implementing solutions that ensure equitable outcomes across diverse patient populations. To fill this gap, we introduce FairMedFM, a fairness benchmark for FM research in medical imaging.FairMedFM integrates with 17 popular medical imaging datasets, encompassing different modalities, dimensionalities, and sensitive attributes. It explores 20 widely used FMs, with various usages such as zero-shot learning, linear probing, parameter-efficient fine-tuning, and prompting in various downstream tasks – classification and segmentation. Our exhaustive analysis evaluates the fairness performance over different evaluation metrics from multiple perspectives, revealing the existence of bias, varied utility-fairness trade-offs on different FMs, consistent disparities on the same datasets regardless FMs, and limited effectiveness of existing unfairness mitigation methods. Checkout FairMedFM’s project page and open-sourced codebase, which supports extendible functionalities and applications as well as inclusive for studies on FMs in medical imaging over the long term.
医疗保健领域基础模型(FMs)的出现,通过自动化分类和分割任务,为增强医学诊断提供了前所未有的机会。然而,这些模型也引发了关于其公平性的重大担忧,特别是在医疗保健应用中应用于多样化和代表性不足的群体时。目前,在医学成像中评估和理解FMs的公平性能还存在一些挑战,缺乏全面的基准测试、标准化的流程和易于适应的库,这导致在制定和实施解决方案时面临巨大挑战,以确保在不同患者群体中实现公平的结果。为了填补这一空白,我们引入了FairMedFM,这是医学成像中FM研究的公平性基准测试。FairMedFM集成了17个流行的医学成像数据集,涵盖了不同的模态、维度和敏感属性。它探讨了20种广泛使用的FMs,在各种下游任务(如零样本学习、线性探测、参数高效微调以及提示和分类和分割)中的用法。我们的详尽分析从不同角度评估了多种评估指标下的公平性表现,揭示了偏见的存在、不同FMs上的效用-公平性权衡的差异、同一数据集上无论使用何种FMs都存在持续的差异,以及现有不公平缓解方法的有限有效性。请查看FairMedFM的项目页面和开源代码库,该库支持可扩展的功能和应用,并长期包容医学成像领域中关于FMs的研究。
论文及项目相关链接
PDF 29 pages, 17 figures
Summary
基础模型(FMs)在医疗领域的应用为提升医学诊断提供了前所未有的机会,但其在多样化和代表性不足的群体中的公平性引发关注。当前,医疗影像中评估和理解FMs公平性能的基准、标准化流程和适配库尚缺乏,给确保不同患者群体间公平结果的解决方案制定和实施带来挑战。为填补这一空白,我们推出FairMedFM——医疗影像FMs的公平性基准。FairMedFM整合了17个流行医疗影像数据集,涵盖不同模态、维度和敏感属性。它探讨了20种广泛使用的FMs,在分类和分割等下游任务中探索零样本学习、线性探测、参数有效微调、提示等用法。我们的详尽分析从不同角度评估了公平性能,揭示了偏见的存在、不同FMs的效用-公平权衡差异、同一数据集上的持续差异以及现有不公平缓解方法的有效性有限。
Key Takeaways
- 基础模型(FMs)在医疗诊断中的应用带来了新的机会和挑战。
- 医疗影像中评估和理解FMs的公平性能面临缺乏基准、标准化流程和适配库的挑战。
- FairMedFM是医疗影像FMs的公平性基准,整合多个数据集并探讨多种FMs的用法。
- FairMedFM的分析揭示了偏见的存在以及不同FMs的效用与公平之间的权衡差异。
- 同一数据集上应用不同FMs存在持续差异。
- 现有不公平缓解方法在医疗影像中的有效性有限。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为FairMedFM的公平性基准测试,旨在解决医疗影像基础模型(Foundation Models,FMs)在应用中的公平性问题。具体来说,论文试图解决以下几个问题:
缺乏全面基准:目前缺乏一个综合的基准来评估和理解FMs在医疗影像中的公平性表现,这导致了在制定和实施确保不同患者群体公平结果的解决方案时面临重大挑战。
标准化流程的缺失:没有现有的文献或框架提供标准化的流程来研究FMs在医疗影像中的公平性,包括不同领域和类型的FMs、全面的功能(任务、应用和去偏见算法)、全面的数据(维度、器官、模态和敏感属性)以及全面的评估方面。
对公平性问题和效用权衡的理解不足:由于缺乏基于广泛实验的全面分析,对于FMs在医疗影像中的发展和部署过程中与公平性问题和效用权衡相关的理解仍然不足。
缺乏易于扩展的公平性评估代码库:现有的库虽然被公平机器学习社区认可,但并不完全满足医疗影像中FMs的多样化使用需求。
为了填补这些空白,FairMedFM提供了一个全面的评估流程,涵盖了17个不同的医疗影像数据集、20个FMs及其用法,并进行了深入的分析,揭示了FMs在使用中普遍存在的偏见问题、不同FMs和其用法对公平性-效用权衡的影响、不同数据集上相同敏感属性的一致性差异,以及现有不公平性缓解方法的有限效果。此外,FairMedFM的代码库是可扩展的,支持医疗影像FMs的长期研究和公平性评估。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与FairMedFM相关的研究:
Khan et al. [28]: 研究了医学影像基础模型在性别和种族方面的公平性。
MedFAIR [77]: 一个致力于评估医学影像中算法公平性的基准测试,主要关注非基础模型的传统机器学习。
Iurada et al. [23]: 探讨了跨域学习的公平性,提出了一个模型和度量的基准测试。
RadFusion et al. [76]: 研究了多模态肺栓塞检测的公平性和性能。
CXRFairness [72]: 专注于胸部X射线分类器的公平性改进。
FairTune [13]: 提出了一种优化参数高效微调以提高医学影像分析中公平性的方法。
Seyyed-Kalantari et al. [52]: 发现胸部X射线分类器对西班牙裔女性患者的漏诊率较高。
Jin et al. [24]: 提出了一种通用的去偏见编辑方法,用于公平的医学图像分类。
Xu et al. [67]: 提出了一种在潜在嵌入空间中添加对抗性训练扰动的方法,以减少分割任务中的偏见。
Zong et al. [77]: 提出了一个评估医学影像中公平性的基准测试,MedFair。
Afshar et al. [1]: 提供了一个适用于机器学习和深度学习的COVID-19 CT扫描数据集。
Azad et al. [2]: 提供了关于医学影像基础模型的全面调查和未来展望。
Bellamy et al. [4]: 提供了一个用于检测、理解和减轻算法偏见的可扩展工具包,AI Fairness 360。
Bird et al. [5]: 提供了一个用于评估和改进AI中公平性的微软工具包,Fairlearn。
Bommasani et al. [6]: 讨论了基础模型在医疗影像中的应用和风险。
这些研究涵盖了医学影像基础模型的公平性评估、偏见缓解策略、以及相关的基准测试和工具。论文通过与这些相关工作的比较,强调了FairMedFM在提供全面评估流程和深入分析方面的独特贡献。
Q: 论文如何解决这个问题?
A: 论文通过提出FairMedFM这一公平性基准测试框架来解决医疗影像基础模型(FMs)的公平性问题。以下是FairMedFM解决这一问题的主要方法和步骤:
综合评估流程:FairMedFM提供了一个全面的评估流程,覆盖了17个不同的医疗影像数据集、20个FMs及其用法。这一流程确保了对FMs公平性的一致性和标准化评估。
数据集集成:FairMedFM整合了多个具有不同模态、维度和敏感属性的流行医学影像数据集,以确保评估的多样性和代表性。
模型探索:论文探索了20种广泛使用的FMs,包括零样本学习、线性探测、参数高效微调和提示等不同的用法,以评估它们在不同下游任务(分类和分割)中的公平性。
多角度评估:FairMedFM从多个角度评估了FMs的公平性,包括但不限于效用、结果一致性公平性、预测对齐公平性、公平性-效用权衡等。
不公平性缓解方法:FairMedFM集成了多种不公平性缓解算法,如群体再平衡、对抗性训练、公平性约束、子群定制建模和领域泛化,以评估这些方法在FMs中的应用效果。
开源代码库:FairMedFM提供了一个可扩展的开源代码库,支持对FMs进行医学影像分析和公平性评估,促进了社区对FMs在医疗影像中的研究。
深入分析:通过FairMedFM,作者进行了深入的分析,发现了以下关键发现:
- FMs在医疗影像任务中普遍存在偏见。
- 不同的FMs及其用法呈现不同的公平性-效用权衡,因此需要仔细选择和适当使用FMs。
- 不同FMs在同一数据集上表现出一致的数据集特定偏见。
- 现有的不公平性缓解策略在FMs中并不总是有效。
未来工作计划:论文提出了未来的工作计划,包括继续改进基准测试的全面性,整合新的医学影像数据集和新兴的FM架构,以及探索更广泛的公平性定义和偏见缓解算法。
通过这些方法,FairMedFM旨在为医疗影像FMs的公平性评估提供一个全面、标准化和可扩展的框架,以促进公平算法的开发和医疗影像技术的公平性改进。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和分析医疗影像基础模型(FMs)的公平性。以下是主要的实验内容和步骤:
数据集集成与分析:
- 集成了17个公开可用的医学影像数据集,这些数据集涵盖了不同的任务类型(分类和分割)、维度(2D和3D)、模态(如X射线、CT、MRI等)、身体部位、类别数量、样本数量和敏感属性(如性别、年龄、种族等)。
模型评估:
- 评估了20个FMs,包括11个用于分类的FMs和9个用于分割的FMs。这些模型包括通用和医疗特定的视觉模型(VMs)和视觉-语言模型(VLMs)。
不公平性缓解方法的集成与测试:
- 集成并测试了6种不公平性缓解算法,包括群体再平衡、对抗性训练、公平性约束、子群定制建模、领域泛化等。
评估指标分类:
- 根据效用、结果一致性公平性、预测对齐公平性和公平性-效用权衡等不同方面,评估了9个公平性指标。
实验设计:
- 对分类任务,使用了线性探测(LP)、参数高效微调(PEFT)、CLIP-零样本(CLIP-ZS)和CLIP-适应(CLIP-Adapt)等方法。
- 对分割任务,使用了不同的提示类型,包括中心点、随机点、随机点集和边界框。
统计测试:
- 进行了统计显著性测试,以确保观察到的性能不是由于特定数据集的偶然性。
深入分析:
- 分析了FMs在不同数据集和不同敏感属性上的偏见和效用权衡。
- 探讨了不同FMs和用法对公平性-效用权衡的影响。
结果呈现:
- 展示了分类和分割任务中的偏见,如AUC差异(AUC∆)和Dice相似系数差异(DSC∆)。
- 展示了不同FMs和用法在公平性-效用权衡方面的表现,如公平性-效用权衡分数(AUCES和DSCES)。
代码库开源:
- 提供了一个可扩展的开源代码库,支持对FMs进行医学影像分析和公平性评估。
这些实验的目的是为了全面评估FMs在医疗影像任务中的公平性表现,并揭示不同模型、不同用法以及不同数据集上的偏见和效用权衡。通过这些实验,作者能够提出对FMs在医疗影像中应用的见解和建议。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和未来的工作计划,以下是一些可以进一步探索的点:
更广泛的数据集集成:尽管FairMedFM已经整合了多个数据集,但可以继续扩展,包括更多的医学影像数据集,特别是那些具有不同疾病、不同人群和不同地理区域的数据集。
新兴FM架构的评估:随着基础模型技术的快速发展,可以持续集成和评估新兴的FM架构,以确保基准测试的时效性和全面性。
更广泛的公平性定义:目前FairMedFM主要关注了结果一致性公平性、预测对齐公平性和公平性-效用权衡等方面。可以探索更多的公平性定义,如过程公平性、个体公平性等。
更多样化的不公平性缓解算法:虽然FairMedFM已经集成了一些不公平性缓解算法,但可以进一步研究和集成更多的算法,特别是那些针对特定任务或数据集的定制化算法。
跨任务和跨模态的公平性评估:除了分类和分割任务,还可以评估FMs在其他任务(如预测建模、目标检测、基于视觉的问答等)中的公平性表现。
长期和动态的公平性评估:目前的评估主要集中在静态数据集上。可以探索如何在动态变化的数据集上进行长期和持续的公平性评估。
公平性与模型性能的权衡:研究如何在提高模型性能的同时,不牺牲公平性。这可能涉及到模型设计、训练策略和评估方法的创新。
公平性评估的可解释性:提高公平性评估结果的可解释性,帮助用户理解模型的公平性表现以及不公平性产生的原因。
公平性评估的自动化和工具化:开发更自动化和用户友好的工具,使研究人员和开发者能够更容易地评估和改进FMs的公平性。
跨领域公平性问题的比较研究:将医疗影像FMs的公平性问题与其他领域(如自然语言处理、计算机视觉等)的公平性问题进行比较,以发现共性和差异。
实际临床环境中的应用研究:研究FMs在实际临床环境中的公平性表现,以及如何将公平性评估结果转化为实际的临床实践改进。
伦理和法律问题的考量:在评估和改进FMs的公平性时,考虑相关的伦理和法律问题,确保技术的应用符合社会价值观和法律法规。
通过这些进一步的探索,可以更全面地理解和解决医疗影像FMs的公平性问题,推动公平、有效和可信赖的医疗影像技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了FairMedFM,这是一个针对医疗影像基础模型(FMs)的公平性基准测试框架。以下是论文的主要内容总结:
背景与挑战:
- 论文指出,随着基础模型在医疗影像分析中的应用增加,评估和确保这些模型的公平性变得至关重要。然而,目前缺乏全面的基准测试、标准化流程和易于适应的库来评估FMs在医疗影像中的公平性。
FairMedFM框架:
- 为了填补这一空白,作者提出了FairMedFM,这是一个集成了17个流行医学影像数据集、20个FMs和多种不公平性缓解算法的公平性基准测试。该框架支持对FMs在分类和分割任务中的公平性进行全面评估。
数据集:
- FairMedFM包含了不同模态、维度、敏感属性的17个公开数据集,如CheXpert、MIMIC-CXR、HAM10000等,覆盖了分类和分割任务。
模型与用法:
- 论文探讨了20个FMs,包括视觉模型(VMs)和视觉-语言模型(VLMs),并评估了它们的不同用法,如零样本学习、线性探测、参数高效微调和提示。
不公平性缓解方法:
- FairMedFM集成了多种不公平性缓解算法,如群体再平衡、对抗性训练、公平性约束等,并评估了这些方法在FMs中的应用效果。
评估指标:
- 论文提出了一个全面的评估指标体系,包括效用、结果一致性公平性、预测对齐公平性、公平性-效用权衡等。
实验与分析:
- 通过FairMedFM,作者进行了深入的分析,发现FMs在医疗影像任务中普遍存在偏见,且不同FMs和用法对公平性-效用权衡有不同的影响。此外,还发现不同数据集上相同敏感属性的一致性差异,以及现有不公平性缓解策略的有限效果。
开源代码库:
- 为了促进社区的进一步研究,作者开源了FairMedFM的代码库,支持对FMs进行医学影像分析和公平性评估。
未来工作:
- 论文提出了未来的工作计划,包括扩展数据集和FMs的范围,探索更广泛的公平性定义和偏见缓解算法,以及维护和更新开源代码库。
结论:
- 论文强调了FairMedFM在评估医疗影像FMs公平性方面的重要性,并指出了FMs在实际应用中需要考虑的公平性和效用权衡问题。通过FairMedFM,作者希望能够提高医疗影像社区对公平性问题的认识,并促进公平算法的开发。
FairMedFM为医疗影像FMs的公平性评估提供了一个全面、标准化和可扩展的框架,有助于推动公平、有效和可信赖的医疗影像技术的发展。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

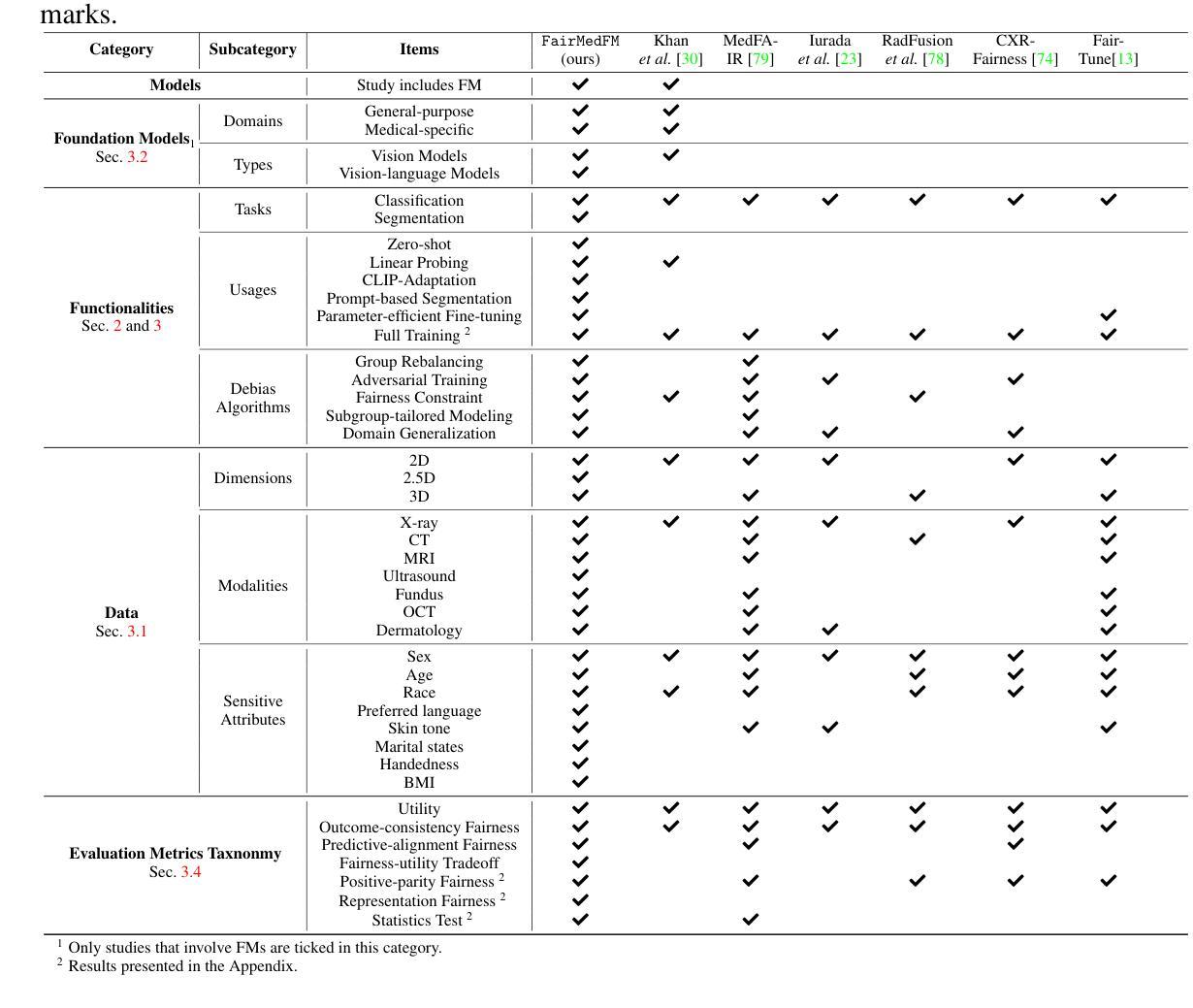
Segmentation-Free Outcome Prediction from Head and Neck Cancer PET/CT Images: Deep Learning-Based Feature Extraction from Multi-Angle Maximum Intensity Projections (MA-MIPs)
Authors:Amirhosein Toosi, Isaac Shiri, Habib Zaidi, Arman Rahmim
We introduce an innovative, simple, effective segmentation-free approach for outcome prediction in head & neck cancer (HNC) patients. By harnessing deep learning-based feature extraction techniques and multi-angle maximum intensity projections (MA-MIPs) applied to Fluorodeoxyglucose Positron Emission Tomography (FDG-PET) volumes, our proposed method eliminates the need for manual segmentations of regions-of-interest (ROIs) such as primary tumors and involved lymph nodes. Instead, a state-of-the-art object detection model is trained to perform automatic cropping of the head and neck region on the PET volumes. A pre-trained deep convolutional neural network backbone is then utilized to extract deep features from MA-MIPs obtained from 72 multi-angel axial rotations of the cropped PET volumes. These deep features extracted from multiple projection views of the PET volumes are then aggregated and fused, and employed to perform recurrence-free survival analysis on a cohort of 489 HNC patients. The proposed approach outperforms the best performing method on the target dataset for the task of recurrence-free survival analysis. By circumventing the manual delineation of the malignancies on the FDG PET-CT images, our approach eliminates the dependency on subjective interpretations and highly enhances the reproducibility of the proposed survival analysis method.
我们为头颈癌患者预后预测引入了一种创新、简单、有效的无分割方法。通过利用深度学习特征提取技术,并结合应用于氟脱氧葡萄糖正电子发射断层扫描(FDG-PET)体积的多角度最大强度投影(MA-MIPs),所提出的方法消除了对感兴趣区域(如原发肿瘤和受累淋巴结)进行手动分割的需要。相反,训练了一种最新物体检测模型,在PET体积上自动裁剪头部和颈部区域。然后,利用预训练的深度卷积神经网络骨干从裁剪PET体积的72个多角度轴向旋转所获得的MA-MIPs中提取深度特征。从这些PET体积的多个投影视图提取的深度特征被聚集和融合,并用于对489例头颈癌患者进行无复发生存分析。所提出的方法在目标数据集上针对无复发生存分析任务优于最佳方法。通过避免在FDG PET-CT图像上手动描绘恶性肿瘤,我们的方法消除了对主观解读的依赖,并大大提高了所提出生存分析方法的可重复性。
论文及项目相关链接
PDF 15 pages, 4 tables, 4 figures. Published in Cancers 2024, Volume 16, Issue 14, page 2538
Summary
本文介绍了一种用于预测头颈癌患者治疗效果的创新性、简单有效的无分割方法。该方法结合了深度学习特征提取技术和多角度最大强度投影,应用于氟脱氧葡萄糖正电子发射断层扫描体积数据,无需手动分割感兴趣区域,如原发肿瘤和受累淋巴结。通过训练先进的目标检测模型自动裁剪PET体积中的头颈部区域,再利用预训练的深度卷积神经网络提取多角度轴向旋转获得的MA-MIPs的深层特征。这些特征被聚合和融合,用于对489例头颈癌患者进行无复发生存分析。该方法在目标数据集上超越了最佳性能的方法,在无复发生存分析任务中表现出色。通过避免在FDG PET-CT图像上手动描绘恶性肿瘤,该方法消除了对主观解读的依赖,大大提高了生存分析方法的可重复性。
Key Takeaways
- 引入了一种无需分割的方法,用于头颈癌患者的治疗效果预测。
- 采用了深度学习特征提取技术,结合多角度最大强度投影(MA-MIPs)处理氟脱氧葡萄糖正电子发射断层扫描(FDG-PET)数据。
- 通过自动裁剪PET图像中的头颈部区域,避免了手动分割感兴趣区域的繁琐。
- 利用预训练的深度卷积神经网络提取深层特征,这些特征来自多个投影视角的PET图像。
- 聚合和融合这些特征,用于无复发生存分析。
- 该方法在目标数据集上的性能超越了现有最佳方法,尤其在无复发生存分析任务中表现优异。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一种创新的、无需分割的方法,用于预测头颈癌(Head and Neck Cancer, HNC)患者的治疗结果。这种方法利用基于深度学习的特征提取技术,结合多角度最大强度投影(Multi-Angle Maximum Intensity Projections, MA-MIPs)应用于氟脱氧葡萄糖正电子发射断层扫描(Fluorodeoxyglucose Positron Emission Tomography, FDG-PET)图像。该方法的主要目标是消除手动分割感兴趣区域(如原发肿瘤和受累淋巴结)的需要,从而提高生存分析方法的可重复性,并减少对主观解释的依赖。
具体来说,论文试图解决的问题包括:
手动分割的主观性和观察者间变异性:手动分割依赖于操作者的专业知识和判断,不同个体可能对图像数据有不同的解释,导致分割结果的不一致性。
时间和劳动强度:手动分割是一个耗时且需要大量人力的任务,需要专业知识和精确操作,这可能导致分析流程的延迟。
可扩展性和普适性的限制:手动分割不易扩展到大型数据集或多个中心,因为它是一个劳动密集型的过程。
肿瘤特征的变异性:头颈癌的肿瘤可能表现出多样的特征,如不规则形状、异质性强度模式和可变的对比度吸收,这使得仅基于视觉线索准确划分肿瘤变得具有挑战性。
肿瘤异质性的有限表示:手动分割通常关注整个肿瘤或感兴趣区域的划分,忽略了肿瘤内部可能具有不同特征的亚区域。
通过提出的方法,研究者们希望能够提高头颈癌患者治疗结果预测的准确性,同时减少对手动分割的依赖,提高分析的效率和可重复性。
Q: 有哪些相关研究?
A: 论文中提到了与头颈癌(HNC)成像、预后分析、以及深度学习在医学成像中的应用相关的多项研究。以下是一些关键点和相关研究的概述:
头颈癌的流行病学:论文引用了关于头颈癌全球发病率和死亡率的研究,以及与人类乳头瘤病毒(HPV)相关的口咽癌增加的趋势。
预后和分期:强调了准确的预后和分期对于改善患者护理、治疗规划和疾病管理的重要性。特别是无复发生存(Recurrence-Free Survival, RFS)分析,这是一种常用的结果预测方法,用于评估HNC治疗的有效性。
生物医学成像:讨论了计算机断层扫描(CT)、磁共振成像(MRI)和正电子发射断层扫描(PET)在HNC管理中的不同应用,特别是PET成像在分期、治疗规划、监测反应、复发检测和监测中的作用。
成像生物标志物和放射组学特征:提到了从FDG-PET和CT图像中提取的定量参数,如标准摄取值(SUV)、代谢肿瘤体积(Metabolic Tumor Volume, MTV)和总病变糖酵解(Total Lesion Glycolysis, TLG)等。
手动分割的挑战:讨论了手动分割ROIs的挑战,包括主观性、观察者间变异性、时间和劳动强度、可扩展性和普适性的限制,以及肿瘤特征的变异性和肿瘤异质性的有限表示。
深度学习和转移学习:论文提出了使用深度学习模型来自动裁剪FDG PET图像中的头颈区域,并使用预训练的深度卷积神经网络(CNN)来从MA-MIPs提取深度特征。
EfficientNet架构:论文中提到了EfficientNet作为一种高效的CNN架构,它通过均匀地缩放网络的深度、宽度和分辨率来实现高准确率,同时保持参数数量较低。
特征融合和生存分析:研究了不同的特征融合方法,包括统计总结方法、线性变换方法和非线性变换方法,以及使用Cox比例风险生存方法进行无复发生存预测。
相关研究和挑战:论文还提到了MICCAI HEADTOR挑战,这是一个关于头颈肿瘤分割和结果预测的国际比赛,以及在该挑战中表现良好的方法。
其他预训练CNN架构:论文比较了EfficientNet和其他几种预训练CNN架构(如InceptionResNetV2、InceptionV3、Resnet-152、VGG16、VGG19、Xception、DenseNet-201、NASNet-Large和ConvNeXt-Base)在特征提取任务中的表现。
这些研究为论文提出的无分割结果预测方法提供了理论和技术背景。论文通过结合这些研究成果,旨在提高头颈癌患者治疗结果预测的准确性和可重复性。
Q: 论文如何解决这个问题?
A: 论文提出了一种无需分割的方法来预测头颈癌(HNC)患者的无复发生存(Recurrence-Free Survival, RFS)结果。这个方法主要包含以下几个步骤:
自动裁剪头颈区域:使用深度学习基础的对象检测模型(TridentNet)自动定位并裁剪FDG PET图像中的头颈区域。这是通过在CT图像的冠状面和矢状面最大强度投影(MIP)上训练网络来完成的,从而避免了手动分割所需的时间和资源。
生成多角度最大强度投影(MA-MIP):对裁剪后的PET图像进行多角度旋转,并在每个旋转角度上生成MIP图像。这样,可以从不同角度捕获肿瘤的代谢活动。
深度特征提取:利用预训练的深度卷积神经网络(EfficientNet)从72个MA-MIP图像中提取深度特征。这些特征捕获了图像中的复杂模式、纹理和结构关系。
特征融合:将从不同视角提取的特征向量进行聚合和融合,以形成一个全面的、包含多视角信息的特征表示。
生存分析:使用机器学习管道对融合后的特征进行处理,以预测每个患者的生存风险。这包括使用Cox比例风险模型进行RFS分析。
通过这种方法,研究者能够避免手动分割肿瘤和淋巴结的需要,这不仅提高了分析的效率和可重复性,而且还减少了对主观解释的依赖。此外,使用预训练的CNN模型进行特征提取,使得该方法具有很好的泛化能力,能够适应不同的数据集和临床环境。
论文还对不同的特征提取网络、池化方法和特征融合技术进行了评估,以确定最佳的组合来提高预测准确性。通过这些技术,论文成功地展示了一种无需分割的方法,可以有效地从FDG PET图像中预测头颈癌患者的治疗结果。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的无分割方法在预测头颈癌(HNC)患者无复发生存(RFS)方面的有效性。以下是实验的主要步骤和内容:
数据集准备:使用第三届MICCAI头颈肿瘤分割和结果预测(HECKTOR2022)挑战的训练数据集,包含489名经组织学证实的头颈癌患者的FDG PET/CT图像以及临床和生存数据。
对象检测模型训练:在CT图像的冠状面和矢状面最大强度投影(MIP)上手动标注头颈区域的边界框,并使用TridentNet架构训练对象检测模型,以便自动裁剪PET图像中的相应区域。
多角度最大强度投影(MA-MIP)生成:对裁剪后的PET图像进行72个5度步长的轴向旋转,并在每个旋转角度生成MIP图像。
深度特征提取:使用预训练的EfficientNet深度卷积神经网络(CNN)从72个MA-MIP图像中提取深度特征。
特征融合:对从不同视角提取的特征向量应用不同的融合方法,包括统计总结方法、线性变换方法和非线性变换方法。
生存分析模型训练:使用融合后的特征向量,通过Cox比例风险生存方法训练机器学习模型,以预测每个患者的生存风险。
模型评估:采用嵌套5折交叉验证和20次重复来评估结果预测管道的性能。使用网格搜索进行参数调优,并在外部未见过的测试折叠上测试训练模型。
性能比较:将所提出方法的性能与其他预训练CNN架构和先前研究中的方法进行比较,以评估所提出方法的有效性。
结果分析:报告了不同特征提取器、池化方法和特征融合技术组合的实验结果,以确定最佳的方法组合。
通过这些实验,论文展示了所提出方法在目标数据集上的性能,并与当前最佳方法进行了比较。实验结果表明,该方法在预测头颈癌患者的RFS方面具有优越的性能,并且能够克服手动分割所带来的挑战。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一种创新的无分割方法来预测头颈癌患者的治疗结果,但仍有一些领域可以进一步探索和改进:
模型泛化能力:在更大的、多样化的患者群体上测试模型,以验证其泛化能力和在不同临床环境中的适用性。
特征提取网络的深度学习:探索是否可以通过对预训练的CNN网络进行微调(fine-tuning)来提高特征提取的性能,从而更好地适应目标数据集。
特征融合技术的改进:研究和开发更先进的特征融合技术,以更有效地结合从不同视角提取的信息。
计算效率:优化模型的计算效率,使其更适合于资源受限的环境,例如临床设置或移动设备。
解释性分析:提高模型的可解释性,帮助医生理解哪些特征对预测结果影响最大。
多模态数据融合:将PET图像与其他成像模式(如CT、MRI)结合,以提供更全面的疾病表征。
实时应用:开发能够实时处理和预测的模型,以便在临床环境中快速做出决策。
跨疾病应用:探索该方法在其他类型癌症的预后分析中的潜在应用。
自动化和半自动化工具:开发工具来辅助医生进行更精确的手动分割,或者用于生成训练自动分割模型所需的标注数据。
临床集成:研究如何将这些深度学习模型集成到现有的临床工作流程中,以及它们如何影响患者的治疗计划。
成本效益分析:评估所提方法的成本效益,包括时间节省、准确性提高和潜在的医疗成本降低。
患者隐私和数据安全:在开发和部署这些模型时,考虑患者数据的隐私和安全性。
长期随访研究:进行长期随访研究,以评估模型预测的长期准确性和患者的生存结果。
通过进一步探索这些点,研究者可以提高模型的性能,增强其在临床实践中的应用,并最终改善头颈癌患者的治疗结果。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种创新的无分割方法,用于预测头颈癌(HNC)患者的无复发生存(RFS)结果。以下是论文的主要内容概述:
问题背景:头颈癌是一种常见的癌症,准确的预后和分期对于治疗规划和疾病管理至关重要。传统的RFS分析依赖于临床和病理特征,可能无法完全捕捉肿瘤的异质性和微环境的动态变化。
方法介绍:研究者提出了一种基于深度学习的特征提取方法,该方法使用多角度最大强度投影(MA-MIPs)从FDG-PET图像中提取特征,无需手动分割感兴趣区域(ROIs)。
数据集:使用第三届MICCAI HEADTOR挑战的训练数据集,包含489名头颈癌患者的FDG PET/CT图像和相关临床生存数据。
技术流程:
- 使用TridentNet对象检测模型自动裁剪PET图像中的头颈区域。
- 从裁剪的PET体积中生成72个MA-MIP图像。
- 使用预训练的EfficientNet CNN从MA-MIPs中提取深度特征。
- 通过统计总结、线性变换和非线性变换方法融合多视角特征。
生存分析:利用融合后的特征向量,通过Cox比例风险模型进行RFS预测。
实验结果:所提出的方法在目标数据集上的表现优于现有最佳方法,证明了无分割方法的有效性。
优势讨论:该方法减少了对手动分割的依赖,提高了分析的可重复性和效率,并且通过使用预训练的CNN模型,增强了模型的泛化能力。
未来方向:论文讨论了进一步探索的点,包括模型泛化能力、特征提取网络的深度学习、特征融合技术的改进、计算效率优化、模型解释性分析等。
总的来说,这篇论文提出了一种新的无分割方法,通过深度学习和多角度投影分析,提高了头颈癌患者RFS预测的准确性和可操作性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

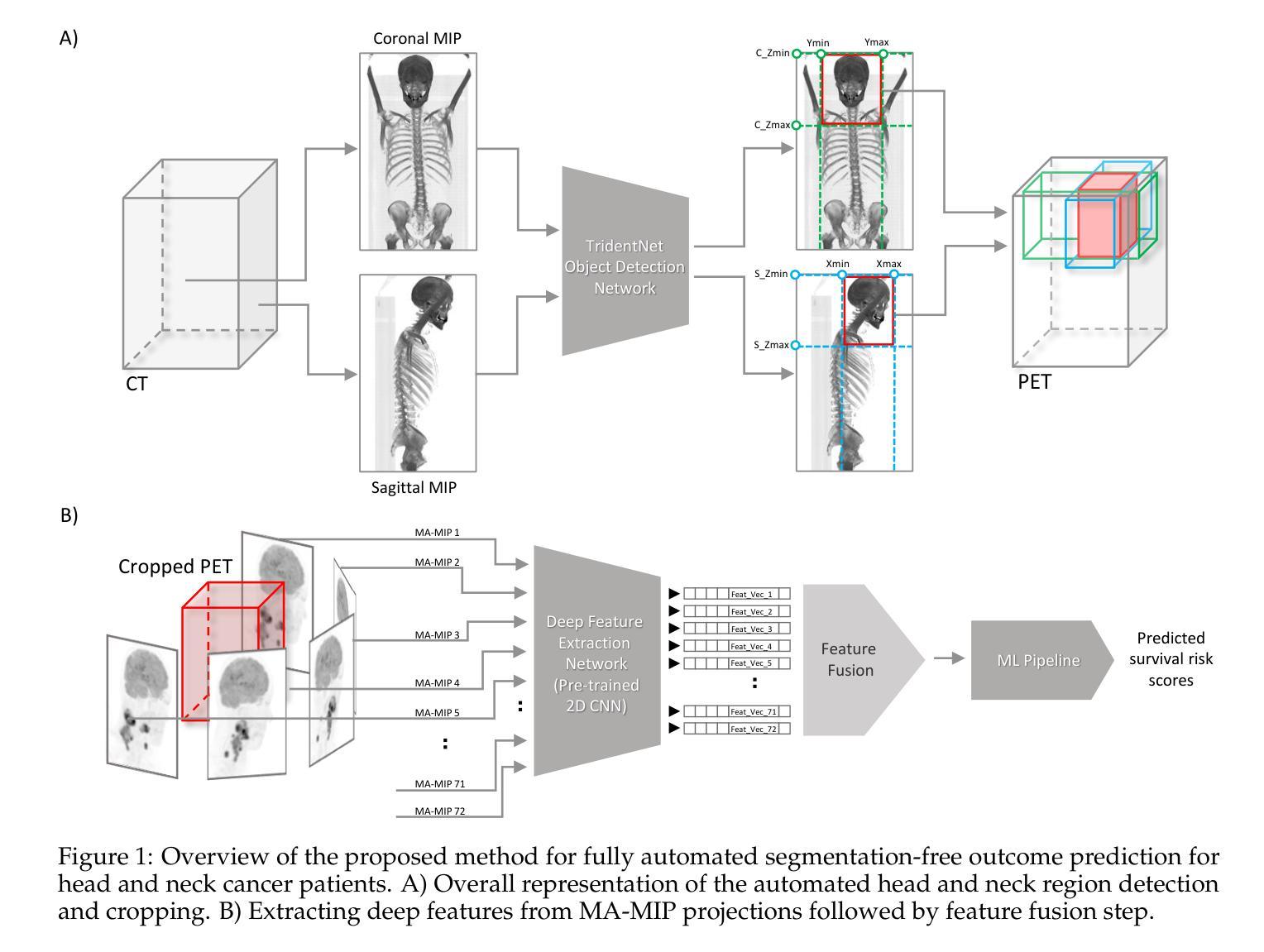
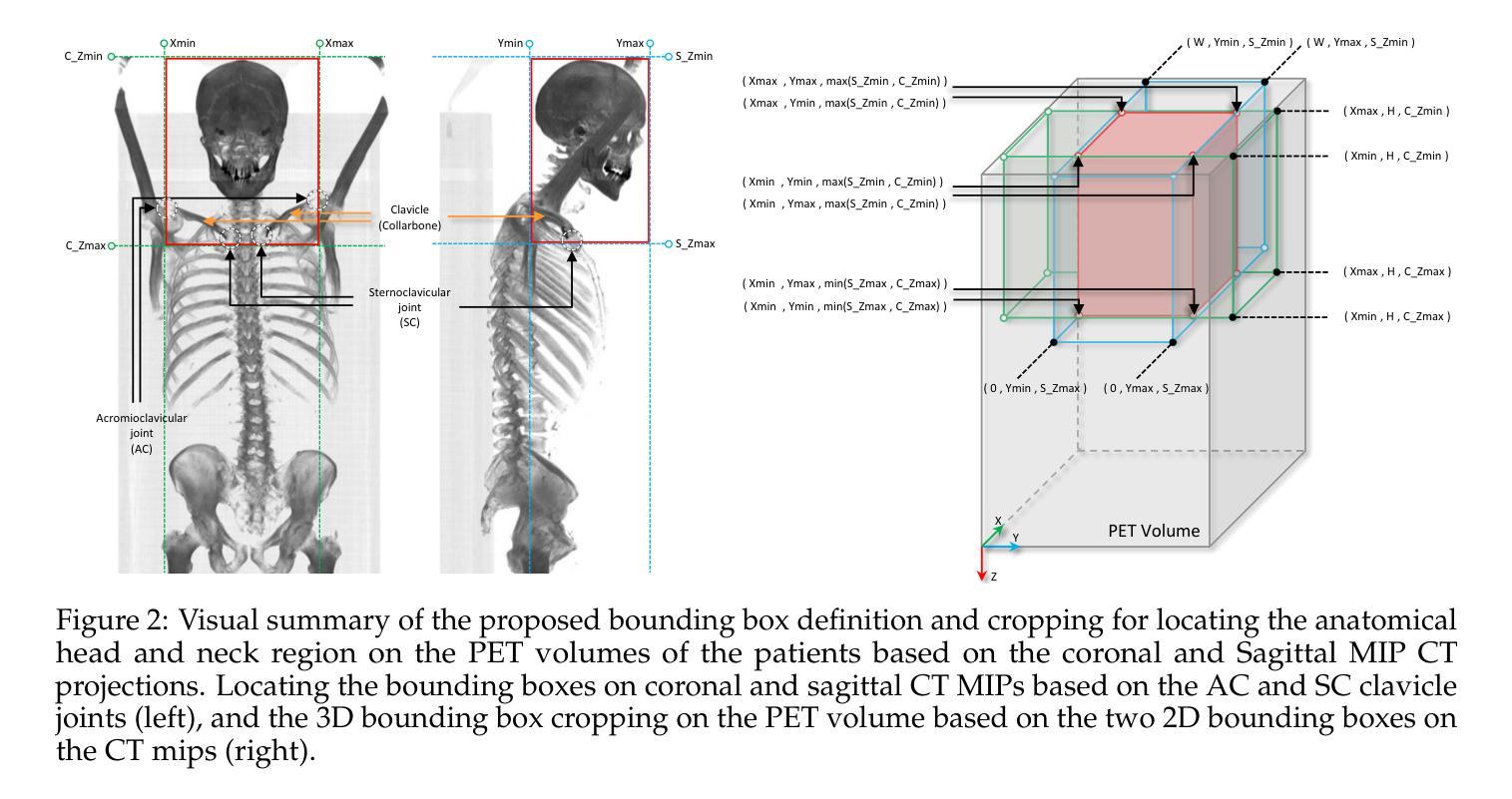
VHM: Versatile and Honest Vision Language Model for Remote Sensing Image Analysis
Authors:Chao Pang, Xingxing Weng, Jiang Wu, Jiayu Li, Yi Liu, Jiaxing Sun, Weijia Li, Shuai Wang, Litong Feng, Gui-Song Xia, Conghui He
This paper develops a Versatile and Honest vision language Model (VHM) for remote sensing image analysis. VHM is built on a large-scale remote sensing image-text dataset with rich-content captions (VersaD), and an honest instruction dataset comprising both factual and deceptive questions (HnstD). Unlike prevailing remote sensing image-text datasets, in which image captions focus on a few prominent objects and their relationships, VersaD captions provide detailed information about image properties, object attributes, and the overall scene. This comprehensive captioning enables VHM to thoroughly understand remote sensing images and perform diverse remote sensing tasks. Moreover, different from existing remote sensing instruction datasets that only include factual questions, HnstD contains additional deceptive questions stemming from the non-existence of objects. This feature prevents VHM from producing affirmative answers to nonsense queries, thereby ensuring its honesty. In our experiments, VHM significantly outperforms various vision language models on common tasks of scene classification, visual question answering, and visual grounding. Additionally, VHM achieves competent performance on several unexplored tasks, such as building vectorizing, multi-label classification and honest question answering. We will release the code, data and model weights at https://github.com/opendatalab/VHM .
本文开发了一种通用诚实视觉语言模型(VHM),用于遥感图像分析。VHM建立在一个大规模的遥感图像文本数据集(VersaD)和包含事实和欺骗性问题的诚实指令数据集(HnstD)之上。与现有的遥感图像文本数据集不同,VersaD的标题不仅关注少数突出对象及其关系,而且提供关于图像属性、对象特征和整体场景详细信息。这种全面的标题描述使VHM能够彻底理解遥感图像并执行多种遥感任务。此外,与仅包含事实问题的现有遥感指令数据集不同,HnstD包含源自对象不存在的欺骗性问题。这一特性使VHM不会对有悖常理的查询给出肯定的答案,从而确保其诚实性。在我们的实验中,VHM在场景分类、视觉问答和视觉定位等常见任务上的表现显著优于各种视觉语言模型。此外,VHM在几个未探索的任务上也表现出良好的性能,如建筑矢量化、多标签分类和诚实问答等。我们将在https://github.com/opendatalab/VHM上发布代码、数据和模型权重。
论文及项目相关链接
PDF Equal contribution: Chao Pang, Xingxing Weng, Jiang Wu; Corresponding author: Gui-Song Xia, Conghui He
Summary
该论文开发了一种用于遥感图像分析的通用诚实视觉语言模型(VHM)。VHM建立在一个大规模遥感图像文本数据集(VersaD)和包含事实和欺骗性问题的诚实指令数据集(HnstD)之上。VersaD的详细图像描述使VHM能全面理解遥感图像并执行多样的遥感任务。HnstD包含源自对象不存在的欺骗性问题,确保VHM不会对愚蠢的查询给出肯定的答案,从而确保其诚实。实验表明,VHM在场景分类、视觉问答和视觉定位等常见任务上显著优于各种视觉语言模型,并在建筑矢量化、多标签分类和诚实问答等未探索的任务上表现出良好的性能。
Key Takeaways
- VHM模型用于遥感图像分析,建立在大规模遥感图像文本数据集VersaD和诚实指令数据集HnstD之上。
- VersaD数据集提供详细的图像描述,包括图像属性、对象特征和整体场景,使VHM模型能全面理解遥感图像。
- HnstD数据集包含事实和欺骗性问题,增强了VHM模型的诚实度,避免对无意义问题给出肯定回答。
- VHM模型在场景分类、视觉问答和视觉定位等任务上表现优异。
- VHM模型还能处理建筑矢量化、多标签分类和诚实问答等未探索的任务,并表现出良好性能。
- 论文将公开VHM模型的代码、数据和权重。
- 该研究为遥感图像分析提供了一种新的通用诚实视觉语言模型。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是提高遥感(Remote Sensing, RS)图像领域中大型视觉语言模型(Vision-Language Models, VLMs)的性能。具体来说,它关注以下几个方面:
遥感图像的特殊性:遥感图像具有独特的特征,与常规图像有显著差异,需要专门的知识来理解。现有的通用大型视觉语言模型(如CLIP和ViT)在处理遥感图像时性能不佳,主要是因为它们对空间感知的能力有限。
数据集的不足:现有的遥感特定视觉语言模型(RSVLMs)由于缺乏大规模、高质量的遥感图像-文本数据集,其性能仍有待提高。这些数据集通常存在描述过于简单、非遥感图像过多、缺乏多样性等问题。
模型的“幻觉”问题:与大型语言模型(LLMs)类似,VLMs在实际应用中也面临“幻觉”问题,即模型可能会生成与实际图像内容不符的输出。为了提高模型的诚实性(honesty),需要教会模型识别无法回答的问题并拒绝回答。
为了解决这些问题,论文提出了以下解决方案:
构建新的数据集:创建了HqDC-1.4M数据集,这是一个包含140万个高质量、详细描述的遥感图像-文本对的数据集,旨在增强RSVLM对遥感图像的理解和空间感知能力。此外,还构建了RSSA数据集,旨在提高RSVLM的自我意识能力,通过包含可回答和不可回答的问题集来训练模型识别并拒绝不可回答问题。
提出新的模型:基于上述数据集,提出了H2RSVLM(Helpful and Honest Remote Sensing Vision Language Model),这是一个既具有帮助性(helpfulness)又具有诚实性(honesty)的遥感视觉语言模型。H2RSVLM在多个遥感公共数据集上取得了卓越的性能,并且能够识别并拒绝回答不可回答问题,有效减少了错误生成。
总结来说,这篇论文的目标是通过构建新的数据集和提出新的模型架构,显著提升遥感图像领域中视觉语言模型的性能,特别是在理解遥感图像内容、空间细节感知以及在面对不可回答问题时的诚实性方面。
Q: 有哪些相关研究?
A: 这篇论文中提到的相关研究主要集中在以下几个方面:
**遥感视觉语言模型 (RSVLMs)**:
- 受到大型语言模型 (LLMs) 和通用视觉语言模型 (VLMs) 技术的启发,许多研究开始探索VLMs在遥感领域的应用问题。例如,GeoChat [23] 采用了LLaVA [29] 的方法构建了一个微调指令数据集,引入了基于区域的问题回答和定位功能到RSVLM中。EarthGPT [69] 扩展了输入图像到SAR图像和红外图像。
大规模遥感视觉语言数据集:
- 近年来,出现了一些大规模视觉语言数据集,如RS5M [70]、SkyScripts [52]、LHRS-Align* [34] 和 ChatEarthNet* [62]。这些数据集主要关注于训练CLIP模型用于遥感应用,如零样本场景分类、图像检索等任务。
自我意识语言模型和视觉语言模型:
- 一些研究集中在LLMs [8, 15, 60, 67]和VLMs [51, 56]的自我意识能力上,即在面对未知或无法回答的问题时能够意识到自己的无知,并选择不回答。例如,SelfAware [60] 构建了一个包含无法回答或未知问题的数据集来评估LLM的识别未知知识的能力。
遥感图像的其他应用:
- 论文还提到了遥感图像在环境监测 [61, 68]、气候变化 [20, 35]、粮食安全 [22, 54] 和灾害预警 [1] 等领域的关键作用。
这些相关研究表明,遥感图像理解是一个多学科、多技术融合的领域,涉及到图像处理、机器学习、深度学习、自然语言处理等多个研究方向。而这篇论文的贡献在于,它通过构建新的数据集和模型架构,进一步提升了遥感图像领域的自动化分析能力。
Q: 论文如何解决这个问题?
A: 为了解决遥感图像领域中视觉语言模型(VLM)的性能问题,论文提出了以下解决方案:
构建新的数据集:
- HqDC-1.4M数据集:这是一个大规模的遥感图像和高质量详细描述的数据集,包含140万个图像-文本对。该数据集通过使用强大的VLM Gemini-Vision生成详细描述,这些描述包括图像的类型、场景、对象细节等,从而显著提高了VLM对遥感图像的理解和空间细节感知能力。
- RSSA数据集:这是第一个旨在提高RSVLM自我意识能力的数据集,包含一系列可回答和不可回答的任务,有效提高了RSVLM的诚实性并减少了幻觉。
提出新的模型:
- H2RSVLM:这是一个既具有帮助性又具有诚实性的遥感视觉语言模型。它基于上述数据集进行训练,不仅在遥感任务上表现出色,而且能够识别并拒绝回答无法回答的问题,从而避免了错误的生成。
模型训练策略:
- 预训练和微调:论文采用了两阶段训练策略。在预训练阶段,使用HqDC-1.4M数据集对模型进行全面的预训练,包括视觉编码器、语言模型和投影层。在监督微调阶段,使用包括HqDC-Instruct、RSSA和其他专业遥感指令数据集进行微调,进一步提高模型的性能。
评估和验证:
- 论文通过在多个遥感公共数据集上的实验来评估H2RSVLM的性能,包括场景分类、视觉问答、视觉定位等任务,并展示了模型在处理不可回答问题时的能力。
通过这些方法,论文成功地提出了一个能够更好地理解和处理遥感图像的模型,并通过实际应用案例展示了其有效性。这不仅提高了遥感图像分析的准确性,也为未来在该领域的研究和应用奠定了基础。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和验证H2RSVLM模型的性能。以下是主要的实验内容:
场景分类:
- 在包括NWPU、METER-ML、SIRI-WHU、AID和WHU-RS19在内的五个场景分类数据集上评估H2RSVLM和其他VLMs的性能。
- 通过平均准确率来衡量模型在监督学习和零样本学习任务上的表现。
视觉问答:
- 在RSVQA-LR和RSVQA-HR数据集上评估模型的视觉问答性能。
- 对比了H2RSVLM与其他VLMs在监督学习和零样本学习环境下的准确率。
视觉定位:
- 使用DIOR-RSVG测试集评估H2RSVLM和其他VLMs在视觉定位任务上的性能。
- 使用accuracy@0.5作为评估指标,即预测框与真实框的交并比(IoU)超过0.5的比例。
诚实性评估:
- 在RSSA测试集上评估H2RSVLM和其他VLMs对可回答和不可回答问题的处理能力。
- 对比了模型在不同类型问题上的表现,包括存在性、颜色、绝对位置和相对位置任务。
定性结果:
- 展示了H2RSVLM与用户之间的对话示例,证明了模型在多轮对话中回答问题的能力,以及在面对无法回答的问题时拒绝回答的能力。
消融研究:
- 进行了不同预训练策略的比较实验,包括去除预训练阶段和使用其他遥感视觉语言数据集代替HqDC-1.4M数据集。
- 评估了在不同预训练数据集下,模型在视觉定位、存在性、颜色、绝对位置、相对位置和计数任务上的性能。
这些实验不仅证明了H2RSVLM在遥感图像理解任务上的优越性能,还展示了其在处理无法回答的问题时的诚实性和自我意识能力。通过定量和定性的评估,论文全面地验证了H2RSVLM的有效性和实用性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的H2RSVLM在遥感图像理解方面取得了显著进展,但仍有一些方向可以进一步探索:
多模态数据集的扩展:
- 目前的数据集主要包含光学遥感图像。未来的研究可以探索包含合成孔径雷达(SAR)图像、红外图像、多光谱图像等更多类型的遥感数据,以提高模型的适用范围和鲁棒性。
更复杂的遥感任务:
- 研究可以探索更多专业的遥感应用任务,如土地覆盖变化检测、作物分类、城市规划分析等,进一步提升模型在实际遥感问题中的应用价值。
模型的可解释性:
- 提高模型的可解释性,帮助用户理解模型的决策过程,特别是在拒绝回答某些问题时提供清晰的解释。
模型的泛化能力:
- 研究如何提高模型在不同来源和分辨率的遥感图像上的泛化能力,使其能够更好地适应多样化的遥感数据。
实时处理能力:
- 探索如何优化模型以支持实时遥感图像分析,这对于灾害监测和响应等应用场景尤为重要。
交互式数据集的构建:
- 开发交互式数据集,允许用户与模型进行更自然的对话,以收集更丰富和多样化的遥感图像描述。
模型的自我监督学习:
- 研究自我监督学习方法来减少对大规模标注数据集的依赖,通过自学习来提高模型的性能。
跨领域知识融合:
- 探索如何将遥感专业知识与其他领域知识(如地理信息系统、气象学、环境科学等)结合起来,以提高模型对复杂遥感场景的理解。
模型的能耗和效率:
- 研究如何优化模型的计算效率和能耗,使其更适合部署在资源受限的环境中,如移动设备或边缘计算设备。
伦理和社会影响:
- 考虑模型在遥感图像分析中的伦理和社会影响,确保技术的发展符合社会价值观和法律法规。
通过这些进一步的探索,研究者可以不断提升遥感视觉语言模型的性能和实用性,推动遥感技术在更广泛领域的应用。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题陈述:论文指出,现有的通用大型视觉语言模型(VLMs)在遥感(RS)图像领域表现不佳,主要原因是这些模型对RS图像的特殊性质和空间感知能力理解不足。
数据集构建:为了解决这一问题,论文构建了两个新的数据集:HqDC-1.4M和RSSA。HqDC-1.4M包含140万个RS图像和高质量详细描述对,旨在提高模型对RS图像的理解和空间感知能力。RSSA数据集旨在提高模型的自我意识能力,使其能够识别并拒绝回答无法回答的问题。
模型提出:基于上述数据集,论文提出了H2RSVLM(Helpful and Honest Remote Sensing Vision Language Model),这是一个既具有帮助性又具有诚实性的RS视觉语言模型。
实验评估:论文通过在多个RS公共数据集上的实验来评估H2RSVLM的性能,包括场景分类、视觉问答、视觉定位等任务,并展示了模型在处理无法回答的问题时的能力。
结果:实验结果表明,H2RSVLM在多个RS视觉任务上取得了优异的性能,并能够有效地识别并拒绝回答无法回答的问题,从而减少了错误生成。
未来工作:论文讨论了未来的研究方向,包括扩展数据集以包含更多类型的遥感数据、探索更复杂的RS任务、提高模型的可解释性和泛化能力等。
总的来说,这篇论文通过构建新的数据集和提出新的模型架构,显著提升了RS图像领域中视觉语言模型的性能,并为未来在该领域的研究和应用奠定了基础。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

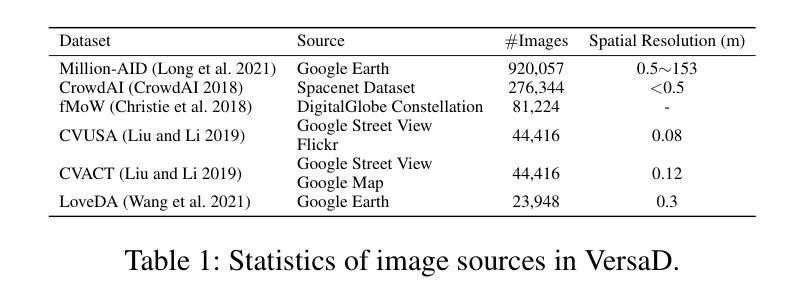

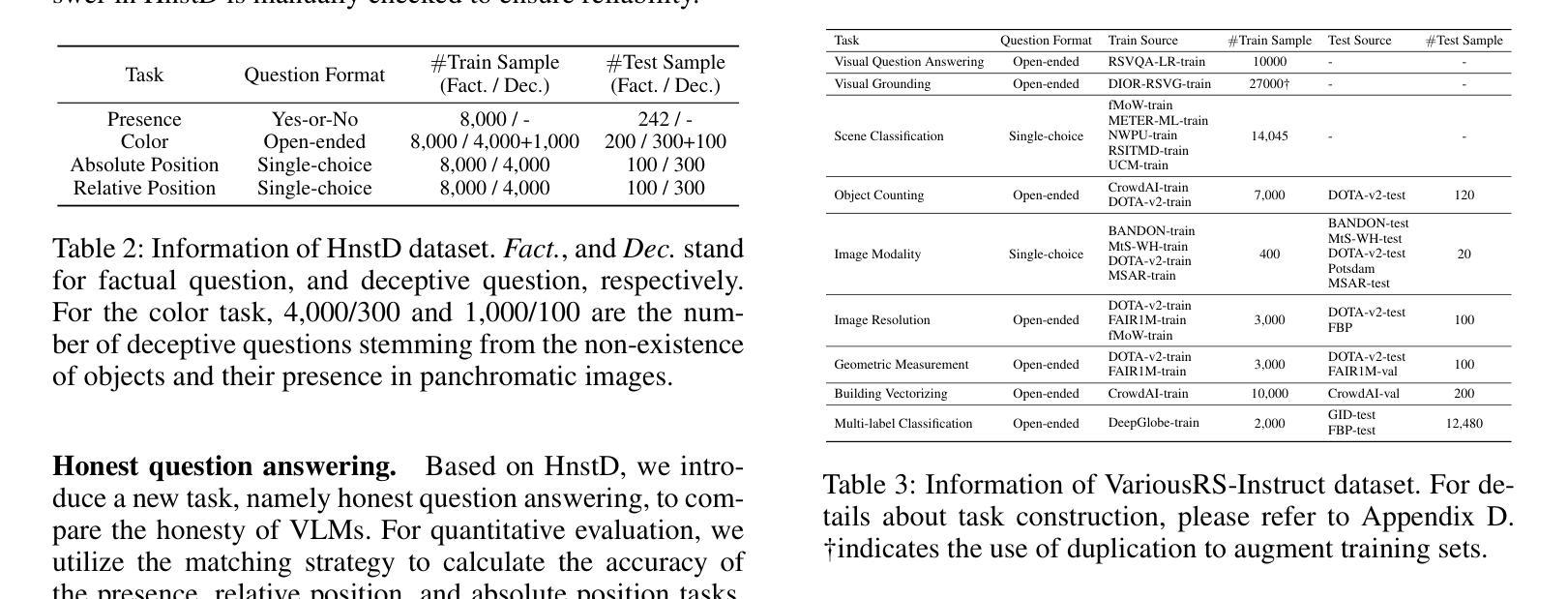

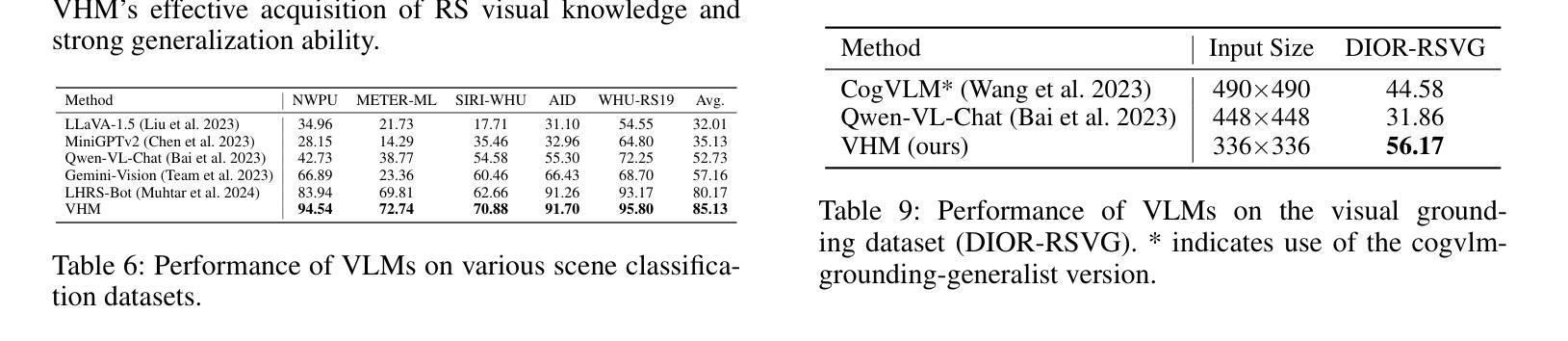
A Multi-Stage Framework for Joint Chest X-Ray Diagnosis and Visual Attention Prediction Using Deep Learning
Authors:Zirui Qiu, Hassan Rivaz, Yiming Xiao
Purpose: As visual inspection is an inherent process during radiological screening, the associated eye gaze data can provide valuable insights into relevant clinical decisions. As deep learning has become the state-of-the-art for computer-assisted diagnosis, integrating human behavior, such as eye gaze data, into these systems is instrumental to help align machine predictions with clinical diagnostic criteria, thus enhancing the quality of automatic radiological diagnosis. Methods: We propose a novel deep learning framework for joint disease diagnosis and prediction of corresponding clinical visual attention maps for chest X-ray scans. Specifically, we introduce a new dual-encoder multi-task UNet, which leverages both a DenseNet201 backbone and a Residual and Squeeze-and-Excitation block-based encoder to extract diverse features for visual attention map prediction, and a multi-scale feature-fusion classifier to perform disease classification. To tackle the issue of asynchronous training schedules of individual tasks in multi-task learning, we proposed a multi-stage cooperative learning strategy, with contrastive learning for feature encoder pretraining to boost performance. Results: Our proposed method is shown to significantly outperform existing techniques for chest X-ray diagnosis (AUC=0.93) and the quality of visual attention map prediction (Correlation coefficient=0.58). Conclusion: Benefiting from the proposed multi-task multi-stage cooperative learning, our technique demonstrates the benefit of integrating clinicians’ eye gaze into clinical AI systems to boost performance and potentially explainability.
目的:视觉检查是放射学筛查过程中的固有过程,相关的眼动数据可以为相关的临床决策提供有价值的见解。随着深度学习在计算机辅助诊断中成为最新技术,将人类行为(如眼动数据)融入这些系统有助于使机器预测与临床诊断标准相一致,从而提高自动放射学诊断的质量。方法:我们提出了一种新型的深度学习框架,用于联合疾病诊断和胸部X射线扫描对应的临床视觉注意力图预测。具体来说,我们引入了一种新的双编码器多任务UNet,它利用DenseNet201主干和基于残差和挤压兴奋块编码器来提取多样化的特征以进行视觉注意力图预测,以及多尺度特征融合分类器进行疾病分类。为了解决多任务学习中单个任务异步训练时间表的问题,我们提出了一种多阶段协作学习策略,使用对比学习对特征编码器进行预训练以提高性能。结果:所提出的方法在胸部X射线诊断(AUC=0.93)和视觉注意力图预测质量(相关系数=0.58)方面表现出显著优于现有技术的效果。结论:得益于所提出的多任务多阶段协作学习,我们的技术证明了将临床医生的眼动数据融入临床人工智能系统的好处,可以提高性能和潜在的解释性。
论文及项目相关链接
Summary
本文提出一种新型深度学习框架,用于联合诊断关节疾病并预测对应的临床视觉注意力地图。采用多任务UNet模型,结合DenseNet201骨干网和基于残差与挤压激励块的编码器,预测视觉注意力地图并进行疾病分类。通过采用分阶段合作学习策略及对比学习预训练方法,解决多任务学习中单独任务训练安排不同步的问题。实验结果显示,该方法在胸部X光诊断上的表现优于现有技术,且预测的视觉注意力地图质量良好。整合医生视线有助于提升人工智能系统的性能和解释性。
Key Takeaways
- 视觉检查是放射学筛查过程中的固有环节,相关的视线数据为临床决策提供有价值的信息。
- 深度学习已成为计算机辅助诊断的先进技术,整合人类行为(如视线数据)有助于使机器预测与临床诊断标准对齐。
- 提出一种新型深度学习框架,用于联合疾病诊断和预测临床视觉注意力地图。
- 采用多任务UNet模型,结合DenseNet201和基于残差与挤压激励块的编码器,以提高性能。
- 采用分阶段合作学习策略解决多任务学习中的任务同步问题。
- 对比学习预训练方法用于提升特征编码器的性能。
- 方法在胸部X光诊断上表现优异,视觉注意力地图预测质量良好。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在计算机辅助诊断(Computer-Assisted Diagnosis, CAD)中,特别是在胸部X射线(Chest X-ray, CXR)分析领域,如何提高深度学习(Deep Learning, DL)模型的解释性,以便更好地在临床环境中部署。尽管深度学习模型在胸部X射线分析中显示出了显著的潜力和效率,但它们的“黑箱”特性使得医疗专业人员难以理解和信任这些自动化临床决策过程。为了解决这个问题,论文提出了一种新的深度学习框架,该框架能够联合进行胸部X射线的疾病诊断和对应的视觉注意力(visual attention)预测。
具体来说,论文的贡献包括:
提出了一种多阶段合作学习策略,以解决多任务学习中各个任务的训练进度不同步的问题。
设计了一种新颖的双编码器多任务UNet,利用DenseNet201作为特征提取器,并通过残差和Squeeze-and-Excitation(SE)块增强编码器,以提取用于视觉注意力图预测的多样化特征。
实验表明,所提出的方法在胸部X射线诊断和视觉注意力图预测的质量方面优于现有技术。
此外,论文还探讨了如何利用临床医生在放射学筛查期间的视觉注意力图来提供重要的洞察,并可能提高计算机辅助诊断的质量。通过这种方式,论文旨在提高深度学习模型在医学图像分析中的透明度和可信度。
Q: 有哪些相关研究?
A: 论文中提到的相关研究主要集中在以下几个方面:
胸部X射线图像分析的深度学习模型:研究者们利用ResNet、DenseNet和EfficientNet等网络进行基于胸部X射线的疾病分类。
视觉注意力和解释性AI(XAI):为了提高深度学习模型的解释性,研究者们采用了Class Activation Map(CAM)和各种注意力机制(如自注意力和注意力门)来提供类似人类视觉注意力的解释。
利用注视数据的深度学习模型:一些研究尝试将记录的注视数据作为输入或辅助任务,以增强诊断准确性。例如,GazeRadar模型结合了放射组学和视觉注意力特征进行肺部疾病分类。
多任务学习:多任务学习框架被提出以同时提高个体任务的性能。例如,Zhu等人提出的多任务UNet通过采用基于不确定性的损失平衡方案来联合进行胸部X射线的疾病诊断和临床注意力图预测。
对比学习:对比学习被用于特征编码器的预训练,以提高模型性能。
视觉注意力图的预测:研究者们尝试使用深度学习模型来预测视觉注意力图,这些图反映了医生在诊断过程中的视觉焦点和注意力模式。
深度学习模型的预训练:使用对比三元组损失对DenseNet-201进行预训练,以增强特征表示的鲁棒性。
双编码器UNet和多尺度特征融合:提出了一种新的双编码器UNet结构,通过多尺度特征融合来增强多任务协作。
这些研究为本文提出的多任务深度学习模型提供了理论和技术基础,同时也展示了在胸部X射线分析领域中,如何通过结合视觉注意力和疾病分类任务来提高深度学习模型的解释性和准确性。
Q: 论文如何解决这个问题?
A: 论文通过提出一种新颖的深度学习框架来解决胸部X射线诊断中的解释性问题。这个框架包括以下几个关键组成部分:
多阶段合作学习策略:为了解决多任务学习中不同任务可能以不同速率过拟合的问题,作者提出了一种分阶段的训练方法。这种方法首先单独训练特征编码器,然后是视觉注意力图预测网络,最后是疾病分类器,以逐步引入任务间的合作。
双编码器多任务UNet:设计了一种新型的UNet,它结合了DenseNet201作为特征提取器,并使用基于残差和Squeeze-and-Excitation(SE)块的编码器来提取用于视觉注意力图预测的多样化特征。
多尺度特征融合分类器:在最后阶段,将DenseNet-201编码器的特征和UNet的上采样层特征结合起来,输入到一个简单的卷积神经网络(CNN)分类器中,以进行胸部X射线的疾病分类。
对比学习预训练:使用对比三元组损失对DenseNet-201特征编码器进行预训练,以增强其特征表示的鲁棒性。
视觉注意力图预测:利用从训练好的DenseNet201编码器中提取的特征,以及UNet编码分支的压缩特征,来生成反映医学专业人员诊断时注意力模式的视觉注意力图。
定量和定性评估:通过使用不同的评估指标(如AUC、准确率、KL散度、皮尔逊相关系数和直方图相似度)来定量评估模型在胸部X射线疾病分类和视觉注意力图预测方面的性能。同时,通过视觉比较来定性评估预测的视觉注意力图与真实注视数据的相似度。
通过这些方法,论文提出的框架能够在保持疾病分类准确性的同时,生成与医学专业人员视觉注意力模式相匹配的注意力图,从而提高了深度学习模型在胸部X射线分析中的解释性。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出方法的有效性:
定量性能评估:使用提出的双编码器特征融合UNet和比较技术(包括MT-UNet、GazeGNN、Inception ResNet v2和标准UNet)对胸部X射线图像进行分类和视觉注意力图预测。评估指标包括多类分类的曲线下面积(AUC)、分类准确率(ACC)以及每个类别的AUC。
视觉注意力图预测质量评估:采用KL散度、皮尔逊相关系数(PCC)和直方图相似度(HS)来衡量预测的视觉注意力图与真实注视热图之间的分布相似度。
统计显著性测试:使用双尾配对样本t检验来确认所提出技术在视觉注意力图生成质量上相对于比较方法的优越性。
消融研究:为了进一步了解所提出架构的各个组成部分的影响,进行了以下消融研究:
- 比较使用Residual和SE块的UNet(Res SE-UNet)与标准UNet在视觉注意力图生成质量上的差异。
- 确认预训练的DenseNet201编码器对视觉注意力图预测准确性的贡献。
- 比较全网络与仅使用DenseNet-201进行对比学习预训练的网络在胸部X射线分类准确率上的差异。
- 揭示对比学习预训练DenseNet-201对网络在胸部X射线分类性能上的优势。
定性评估:通过视觉比较,展示了所提出方法生成的视觉注意力图与MT-UNet、DenseNet-201的gradCAM输出以及真实注视数据的对比。
这些实验的目的是为了全面评估所提出方法在胸部X射线疾病分类和视觉注意力图预测任务上的性能,并与现有技术进行比较。通过这些实验,作者展示了所提出方法在提高模型解释性和诊断准确性方面的潜力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
模型泛化能力:在更广泛的数据集上测试模型,以评估其泛化能力和在不同患者群体中的适用性。
实时性能:优化模型以提高其在实际临床环境中的实时性能,这对于快速诊断至关重要。
更复杂的注意力模式:探索使用更复杂的视觉注意力模式,如扫描路径(scanpaths),以更深入地理解诊断过程。
不同疾病类型的分类:扩展模型以识别和分类更多类型的肺部疾病,如肺癌、肺结核等。
临床医生的参与:与临床医生合作,以更好地理解他们的需求,并确保模型的解释性与临床实践相匹配。
模型解释性的改进:进一步研究如何提高模型的解释性,例如通过可视化技术或生成更具信息量的视觉注意力图。
模型的临床验证:在临床试验中验证模型的性能,以评估其在实际临床工作流程中的可行性和效果。
对比学习和其他自监督学习方法:探索对比学习和其他自监督学习方法在特征预训练中的应用,以进一步提高模型性能。
模型的鲁棒性:研究模型对于不同图像质量、设备和技术变异的鲁棒性。
多模态学习:结合胸部X射线以外的其他成像数据(如CT扫描或MRI)来提高诊断的准确性。
模型的可解释性与准确性的权衡:研究在提高模型准确性的同时保持或提高其可解释性的方法。
模型的公平性和偏见:评估模型是否存在潜在的偏见,并探索减少这些偏见的方法。
深度学习模型的临床集成:研究如何将深度学习模型有效地集成到现有的临床工作流程中。
用户界面和体验:开发用户友好的界面,使医疗专业人员能够轻松地使用和理解模型的输出。
长期跟踪研究:进行长期跟踪研究,以评估模型在实际临床环境中的长期效果和影响。
这些探索点可以帮助研究者们进一步提高深度学习模型在医疗影像分析中的性能和实用性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题背景:随着深度学习在医学影像分析中的广泛应用,尤其是在胸部X射线(CXR)分析中,模型的解释性对于临床部署至关重要。
研究目标:提出一种新的深度学习框架,该框架能够联合进行胸部X射线的疾病诊断和对应的视觉注意力图预测,以增强模型的解释性。
方法论:
- 提出了一种多阶段合作学习策略,以解决多任务学习中不同任务训练进度不同步的问题。
- 设计了一种双编码器多任务UNet,利用DenseNet201作为特征提取器,并结合残差和Squeeze-and-Excitation(SE)块来提取特征。
- 使用对比学习对特征编码器进行预训练,以增强特征表示的鲁棒性。
实验设计:
- 使用“chest X-ray dataset with eye-tracking and report dictation”数据集进行模型训练和验证。
- 评估了模型在胸部X射线疾病分类和视觉注意力图预测任务上的性能。
实验结果:
- 提出的方法在胸部X射线诊断和视觉注意力图预测的质量方面优于现有技术。
- 通过消融研究验证了所提方法中各个组件的贡献和重要性。
讨论:
- 论文讨论了多阶段合作学习策略的优势,以及如何通过双编码器和多尺度特征融合提升性能。
- 强调了对比学习预训练对特征编码器性能的提升作用。
结论:
- 提出的多任务深度学习模型通过多阶段合作学习策略优化了个体任务的训练,并在提高模型解释性方面取得了显著成果。
未来工作:
- 提出了未来可能的研究方向,包括模型泛化能力的提升、实时性能的优化、更复杂的注意力模式的探索等。
论文通过提出一种新的深度学习框架,不仅提高了胸部X射线分析的准确性,而且通过生成与医学专业人员视觉注意力模式相匹配的注意力图,增强了模型的解释性,这对于临床部署具有重要意义。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

PePR: Performance Per Resource Unit as a Metric to Promote Small-Scale Deep Learning in Medical Image Analysis
Authors:Raghavendra Selvan, Bob Pepin, Christian Igel, Gabrielle Samuel, Erik B Dam
The recent advances in deep learning (DL) have been accelerated by access to large-scale data and compute. These large-scale resources have been used to train progressively larger models which are resource intensive in terms of compute, data, energy, and carbon emissions. These costs are becoming a new type of entry barrier to researchers and practitioners with limited access to resources at such scale, particularly in the Global South. In this work, we take a comprehensive look at the landscape of existing DL models for medical image analysis tasks and demonstrate their usefulness in settings where resources are limited. To account for the resource consumption of DL models, we introduce a novel measure to estimate the performance per resource unit, which we call the PePR score. Using a diverse family of 131 unique DL architectures (spanning 1M to 130M trainable parameters) and three medical image datasets, we capture trends about the performance-resource trade-offs. In applications like medical image analysis, we argue that small-scale, specialized models are better than striving for large-scale models. Furthermore, we show that using existing pretrained models that are fine-tuned on new data can significantly reduce the computational resources and data required compared to training models from scratch. We hope this work will encourage the community to focus on improving AI equity by developing methods and models with smaller resource footprints.
最近深度学习(DL)的进展得益于大规模数据和计算资源的支持而得到加速。这些大规模资源被用来训练逐渐更大的模型,这些模型在计算、数据、能源和碳排放方面资源密集。这些成本正成为研究者和实践者面临的一种新型准入壁垒,特别是在全球南方地区,获得如此大规模资源的机会有限。在这项工作中,我们全面研究了现有用于医学图像分析任务的DL模型景观,并展示了它们在资源有限的环境中尤其有用。为了考虑DL模型对资源的消耗,我们引入了一种新的度量标准来衡量每个资源单位的性能表现,我们称之为PePR得分。我们使用了多样化的架构系列,涵盖了包括拥有千万参数及以上的特定参数模型和包含千万个至数十亿级别独特网络结构类型的分布训练模式来建模统计医疗影像的数据集的特性;并使用这三个医学图像数据集展示了性能和资源之间的权衡趋势。在医疗图像分析等应用中,我们认为小规模的专业模型比追求大规模模型更好。此外,我们还表明,与使用新数据进行微调后的现有预训练模型相比,从头开始训练模型所需的计算资源和数据可以大大减少。我们希望这项工作能鼓励社区通过开发具有较小资源占用空间的方法和模型来改善人工智能的公平性发展环境。
论文及项目相关链接
PDF Accepted to be published at the Northern Lights Deep Learning Conference (NLDL), 2025. Source code available at https://github.com/saintslab/PePR
Summary
深度学习在医学图像分析领域的发展受限于大规模资源和计算能力的限制,特别是在全球南部地区。本文旨在研究现有的深度学习模型,探索其在实际应用中的性能和资源消耗关系,并提出了性能资源单位评估方法(PePR评分)。研究显示小规模专用模型性能优于大规模模型,并建议使用预训练模型微调以提高资源利用效率,鼓励发展资源占用更小的方法和模型以促进人工智能公平发展。
Key Takeaways
- 深度学习在医学图像分析领域的发展受限于大规模资源和计算能力的限制。
- 在资源受限的环境下,现有的深度学习模型对于医学图像分析任务具有实用价值。
- 提出了性能资源单位评估方法(PePR评分)来衡量模型性能与资源消耗的平衡。
- 研究发现小规模专用模型在医学图像分析应用中性能更佳。
- 使用预训练模型进行微调可显著减少计算资源和数据需求。
- 研究结果鼓励开发具有更小资源占用方法和模型的社区,以促进人工智能公平发展。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在资源受限的环境中提高深度学习(Deep Learning, DL)的可访问性和公平性。具体来说,论文关注以下几个方面:
资源消耗与性能的权衡:论文通过分析现有的深度学习模型在视觉任务上的表现,引入了一个新的度量标准PePR(Performance per Resource Unit),用于评估模型在单位资源消耗下的性能,从而揭示在资源受限情况下模型的性能-资源消耗权衡。
全球南部地区的研究差距:论文指出,全球南部地区在深度学习领域的研究出版物数量与全球北部地区存在显著差距,这可能部分是由于深度学习研究所需的资源成本日益增加所导致的。通过提倡小型深度学习模型,论文旨在降低进入壁垒,促进全球南部地区的研究发展。
预训练模型的有效性:论文展示了在资源受限的环境下,使用预训练模型可以显著减少计算资源和数据的需求,从而提高模型的效率。
促进AI公平性:论文强调,通过开发资源消耗更小的AI方法和模型,可以提高AI技术的公平性,特别是在医疗保健领域。
总的来说,论文的目标是鼓励研究社区关注和改进深度学习模型的资源效率,以便在资源受限的环境中,如全球南部地区,也能有效地应用深度学习技术。
Q: 有哪些相关研究?
A: 这篇论文提到了以下几个相关的研究领域和具体工作:
神经架构搜索(Neural Architecture Search, NAS):这是一个研究领域,致力于自动化地发现高效的神经网络架构。相关工作主要探讨了在性能和资源约束之间的帕累托优化问题。
资源约束下的模型剪枝:提出了一些方法来探索在特定资源约束(如碳足迹或能耗)下对模型进行剪枝的可能性。
医疗图像分析(Medical Image Analysis, MIA):在这一领域内,对于提高深度学习模型的资源效率以及报告能源和碳成本的呼吁日益增长,但对性能和能耗的联合优化关注较少。
公平的AI在医疗保健中的应用:一些工作从公平性的角度探讨了医疗保健中的AI问题,但主要关注的是结果的公平性,而不是从资源/访问角度。
环境可持续性:论文引用了一些关于深度学习技术的环境成本的研究,包括其能源消耗和相应的碳排放。
资源效率:论文提到了一些关于深度学习模型资源效率的研究,特别是在医疗图像分析社区中。
深度学习模型选择:论文提到了关于如何根据碳足迹选择和训练深度学习模型的研究。
资源受限的机器学习模型运行:论文讨论了在资源受限的环境中运行关键机器学习模型的问题。
这些相关研究为论文提出的PePR分数和对小规模深度学习模型的倡导提供了背景和动机。论文通过这些相关工作,强调了在资源受限环境中提高深度学习模型的效率和公平性的重要性。
Q: 论文如何解决这个问题?
A: 论文通过以下方法来解决在资源受限环境中提高深度学习可访问性和公平性的问题:
性能-资源单位表现(PePR)分数:论文引入了一个新的度量标准,称为PePR分数,用于评估深度学习模型在单位资源消耗下的性能。这个分数考虑了模型的性能和资源消耗(如数据、能源、时间和CO2排放),从而提供了一个综合性的评估指标。
广泛的模型分析:论文对131个不同的深度学习架构进行了分析,这些架构的可训练参数数量从1M到130M不等。通过在三个医疗图像分类数据集上评估这些模型,论文捕捉了性能与资源消耗之间的趋势。
预训练模型的使用:论文展示了预训练模型在资源受限的环境中的有效性。通过在预训练模型上进行微调,可以显著减少所需的计算资源和数据量,从而提高模型的效率。
小规模模型的倡导:论文主张在医疗图像分析等应用中,使用小规模、专门的模型可能比追求大规模模型更有益。特别是在资源受限的环境中,小规模模型提供了更好的性能与资源消耗之间的权衡。
实验和结果:论文通过一系列实验来支持其观点,包括研究预训练对测试性能的影响、训练数据规模的作用,以及计算PePR-E分数来比较测试性能和能源消耗之间的权衡。
讨论和结论:论文讨论了实验结果,并得出结论,即使用预训练模型可以在性能上获得显著提升,而且当考虑到资源消耗时,小规模模型提供了更好的性能与资源消耗之间的权衡。论文提出的PePR分数有助于在资源消耗和性能之间找到一个内置的平衡。
通过这些方法,论文旨在鼓励研究社区专注于开发资源消耗更小的AI方法和模型,以提高深度学习技术的公平性和可访问性,特别是在资源受限的环境中。
Q: 论文做了哪些实验?
A: 论文进行了以下三个主要实验来支持其观点和方法:
预训练对测试性能的影响:实验研究了使用预训练模型与从头开始训练模型的效果对比。所有131个模型都进行了10个周期的微调或从头开始训练。结果显示,使用预训练模型在相同的周期数内显著提高了性能。
训练数据规模的作用:为了研究训练数据量对模型性能的影响,实验只使用了每个数据集10%的训练数据,并报告了每个模型的平均测试性能。尽管使用较少数据的训练性能显著低于使用全部数据,但这表明在资源受限的情况下,即使是少量数据也可能有助于做出初步决策。
计算PePR-E分数:实验计算了PePR-E分数,以比较测试性能和能源消耗之间的权衡。PePR-E分数使用微调10个周期的能源消耗作为资源成本,并在每个实验(数据集)中进行归一化。实验结果显示,小规模模型的PePR-E分数中位数显著高于大规模模型,表明在资源受限的环境中,小规模模型提供了更好的性能与资源消耗之间的权衡。
这些实验的结果总结在论文的图5中,其中包括了各种模型在不同实验条件下的性能比较,以及PePR-E分数与模型参数数量之间的关系。通过这些实验,论文展示了在资源受限的环境中,小规模深度学习模型相对于大规模模型的优势,并强调了考虑资源消耗对于提高深度学习公平性和可访问性的重要性。
Q: 有什么可以进一步探索的点?
A: 论文提出的PePR分数和对小规模深度学习模型的倡导为未来的研究提供了多个可以进一步探索的点:
多目标优化:探索如何将PePR分数与其他性能指标(如准确率、召回率等)结合,进行多目标优化,以找到在性能和资源消耗之间达到最佳平衡的模型。
不同资源的PePR分数变体:除了能源消耗(PePR-E),还可以研究以其他资源类型(如数据量PePR-D、内存使用PePR-M、训练时间PePR-T等)为基础的PePR分数变体。
跨领域的应用:将PePR分数应用于除医疗图像分析之外的其他领域,如自然语言处理、语音识别等,以评估其在不同类型任务中的有效性和适用性。
模型压缩和量化:研究模型压缩和量化技术在减少资源消耗方面的潜力,以及这些技术与PePR分数的关系。
环境和社会影响:深入研究小规模模型对减少碳足迹和促进环境可持续性的影响,以及这些技术在社会公平性方面的作用。
资源受限环境下的模型部署:研究在资源受限的设备(如移动设备、边缘计算节点)上部署小规模模型的效果,以及如何优化这些模型以适应特定的硬件限制。
模型泛化能力:评估小规模模型在不同数据集和任务上的泛化能力,以及如何通过技术如数据增强、正则化等来提高其泛化性。
跨地域合作:鼓励全球北部和南部地区之间的合作,共享资源高效的模型和技术,以减少全球研究差距。
用户和社区参与:研究如何让最终用户和社区参与到模型的选择和开发过程中,确保技术解决方案能够满足他们的需求并得到有效应用。
这些探索点可以帮助研究者更全面地理解和改进深度学习模型在资源受限环境中的表现,同时促进技术的公平性和可持续性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题陈述:论文指出深度学习(DL)的最新进展依赖于大规模数据和计算资源,这导致了资源密集型的模型开发,增加了研究和实践的进入门槛,尤其是在全球南部地区。这种资源不平等可能加剧研究差距,并阻碍了深度学习技术的环境和社会可持续性。
PePR分数:为了解决这个问题,论文提出了一个新的度量标准——性能每资源单位(PePR)分数,用于评估模型在单位资源消耗下的性能。PePR分数旨在提供一个综合性的指标,考虑到模型的性能和资源消耗(如数据、能源、时间和碳排放)。
模型分析:论文对131个不同的深度学习架构进行了全面分析,这些架构的可训练参数数量从1M到130M不等。使用三个医疗图像数据集,论文研究了这些模型在资源受限环境中的性能和资源消耗趋势。
实验结果:通过一系列实验,论文发现使用预训练模型可以显著提高性能,并且在资源受限的环境下,小规模模型相对于大规模模型提供了更好的性能与资源消耗之间的权衡。
倡导小规模模型:论文主张在医疗图像分析等领域,应优先考虑小规模、专门的模型,而不是追求大规模模型。这有助于降低资源消耗,提高技术的公平性和可访问性。
结论:论文得出结论,通过专注于减少深度学习的资源成本,可以提高技术的公平性,特别是在资源受限的环境中。论文提出的PePR分数是一个有助于实现这一目标的有用工具。
未来方向:论文鼓励社区继续探索资源效率高的AI方法和模型,以进一步改善深度学习技术的公平性和可持续性。同时,论文提出了一些未来研究可以探索的潜在方向,如多目标优化、跨领域的应用、模型压缩和量化等。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

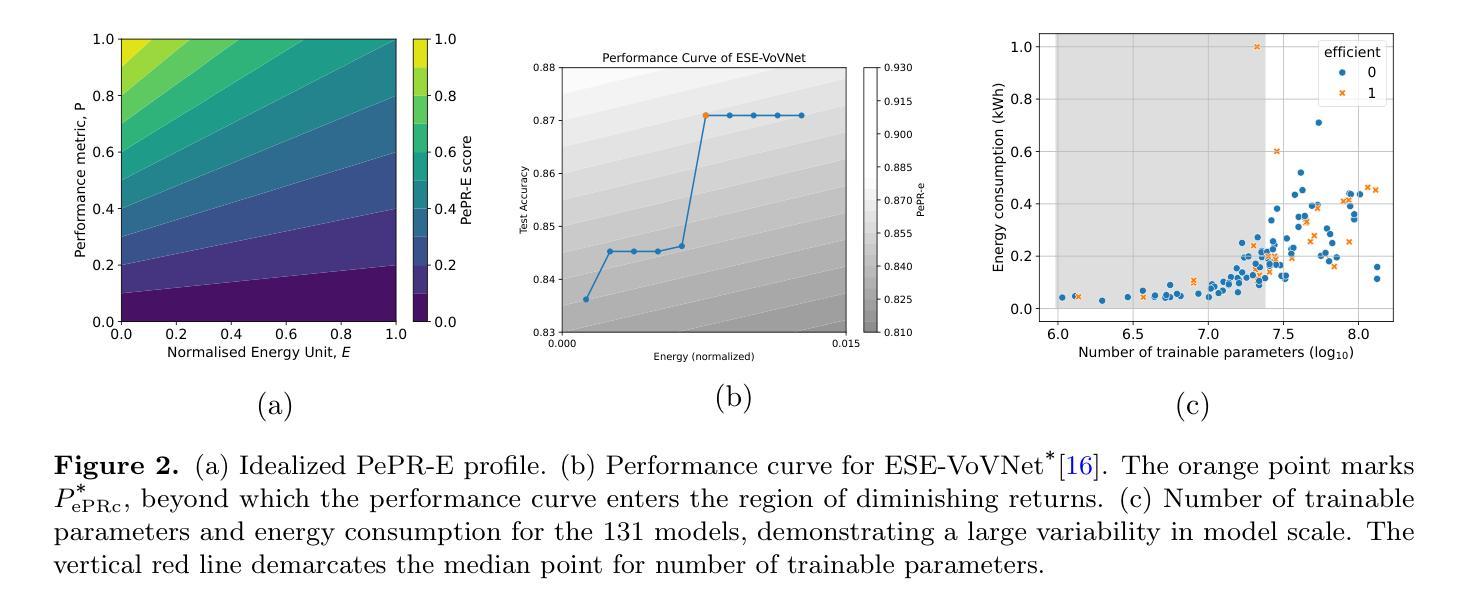
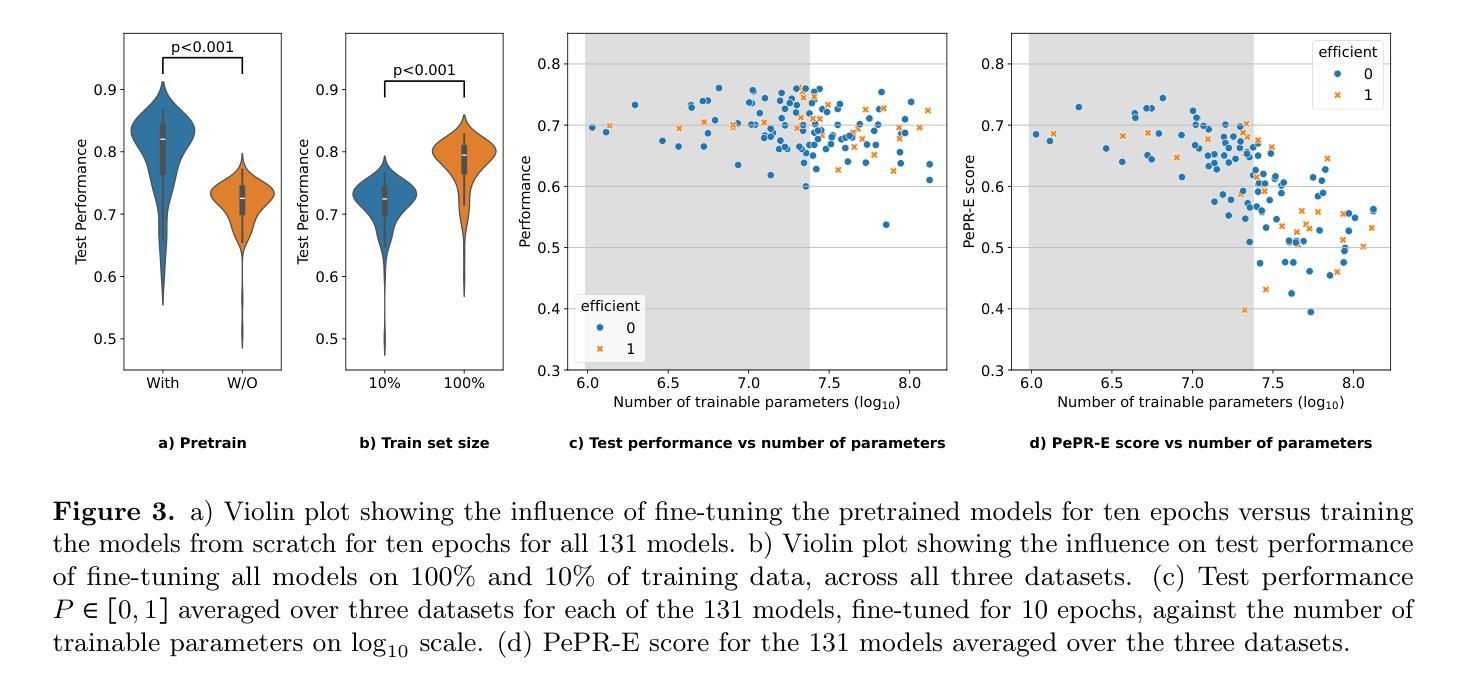
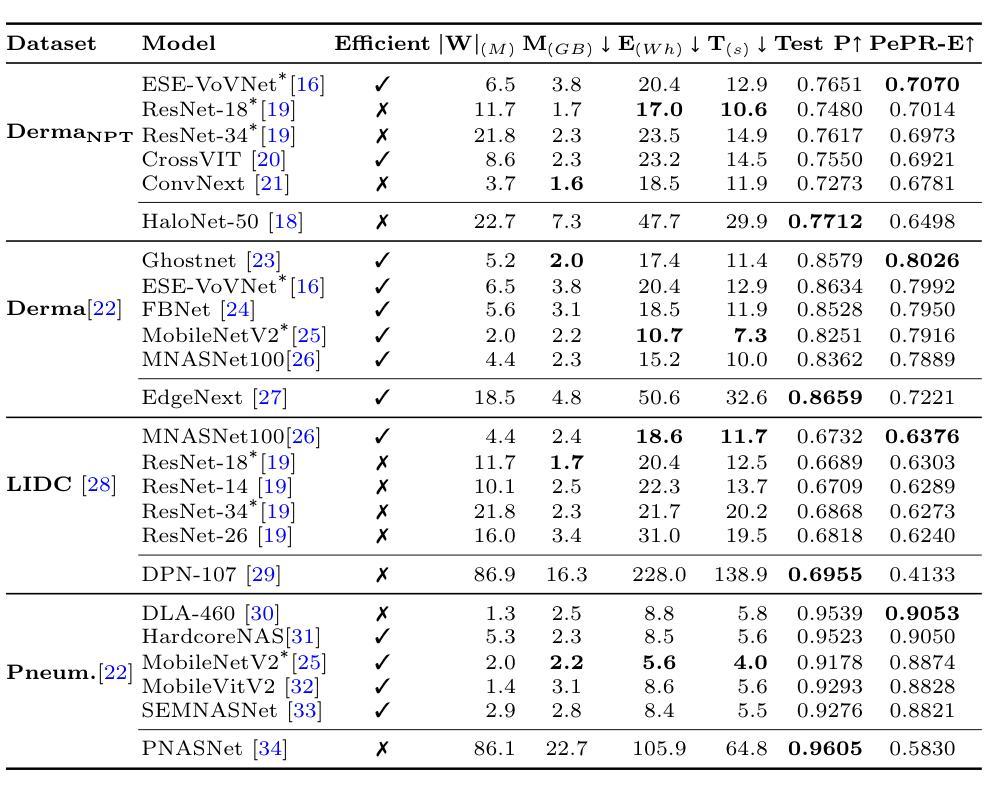
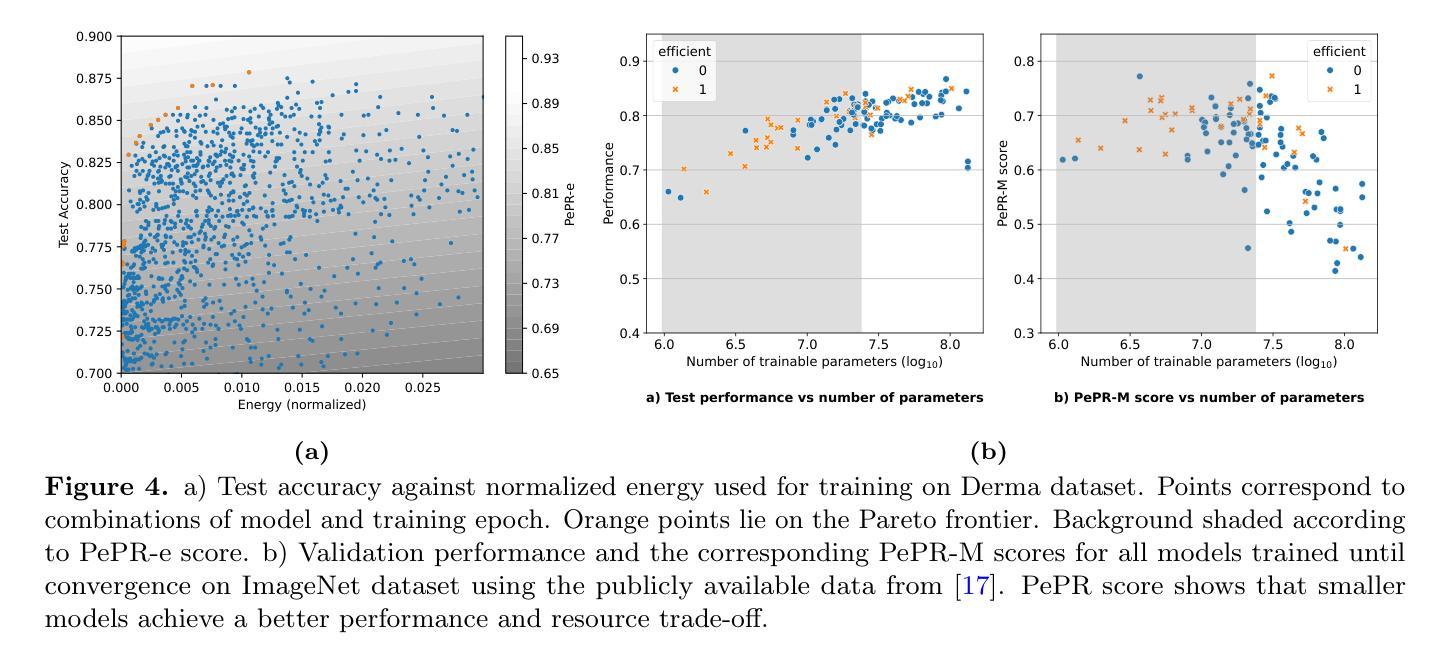
Breast Cancer Classification Using Gradient Boosting Algorithms Focusing on Reducing the False Negative and SHAP for Explainability
Authors:João Manoel Herrera Pinheiro, Marcelo Becker
Cancer is one of the diseases that kill the most women in the world, with breast cancer being responsible for the highest number of cancer cases and consequently deaths. However, it can be prevented by early detection and, consequently, early treatment. Any development for detection or perdition this kind of cancer is important for a better healthy life. Many studies focus on a model with high accuracy in cancer prediction, but sometimes accuracy alone may not always be a reliable metric. This study implies an investigative approach to studying the performance of different machine learning algorithms based on boosting to predict breast cancer focusing on the recall metric. Boosting machine learning algorithms has been proven to be an effective tool for detecting medical diseases. The dataset of the University of California, Irvine (UCI) repository has been utilized to train and test the model classifier that contains their attributes. The main objective of this study is to use state-of-the-art boosting algorithms such as AdaBoost, XGBoost, CatBoost and LightGBM to predict and diagnose breast cancer and to find the most effective metric regarding recall, ROC-AUC, and confusion matrix. Furthermore, our study is the first to use these four boosting algorithms with Optuna, a library for hyperparameter optimization, and the SHAP method to improve the interpretability of our model, which can be used as a support to identify and predict breast cancer. We were able to improve AUC or recall for all the models and reduce the False Negative for AdaBoost and LigthGBM the final AUC were more than 99.41% for all models.
癌症是世界上导致女性死亡最多的疾病之一,其中乳腺癌导致的癌症病例数和死亡人数最多。然而,通过早期发现和及时治疗,可以预防这种情况。对于乳腺癌的检测和预防的任何发展都对于更好的健康生活至关重要。许多研究集中在具有高准确性的癌症预测模型上,但有时仅准确性可能并非总是可靠的指标。这项研究采用一种调查方法来研究基于boosting的不同机器学习算法在预测乳腺癌方面的性能,重点关注召回率指标。已经证明,boosting机器学习算法是检测医学疾病的有效工具。使用了加利福尼亚大学欧文分校(UCI)存储库的数据集来训练和测试分类模型,其中包含其属性。这项研究的主要目的是使用最先进的boosting算法(如AdaBoost、XGBoost、CatBoost和LightGBM)来预测和诊断乳腺癌,并找到关于召回率、ROC-AUC和混淆矩阵的最有效指标。此外,我们的研究是首次使用这四个boosting算法与Optuna(一个超参数优化库)和SHAP方法相结合,以提高我们模型的解释性,可以用作识别和预测乳腺癌的支持。我们成功地提高了所有模型的AUC或召回率,并降低了AdaBoost和LigthGBM的误报率。所有模型的最终AUC均超过99.41%。
论文及项目相关链接
PDF 9 pages, 16 figures
Summary
本文研究了使用机器学习算法预测乳腺癌的问题。研究采用提升算法(boosting)的方法,如AdaBoost、XGBoost、CatBoost和LightGBM等,旨在提高乳腺癌预测和诊断的效能。研究使用加州大学欧文分校(UCI)的数据集进行模型训练和测试,并引入Optuna库进行超参数优化和SHAP方法提高模型的可解释性。最终,所有模型的AUC或召回率均有所提高,AdaBoost和LightGBM的假阴性也有所降低,所有模型的最终AUC均超过99.41%。
Key Takeaways
- 乳腺癌是世界上导致女性死亡最多的疾病之一,早期检测和治疗效果较好。
- 本研究采用提升算法(boosting)来预测乳腺癌,旨在提高预测和诊断的效能。
- 研究使用UCI数据集进行模型训练和测试。
- 研究引入了Optuna库进行超参数优化和SHAP方法提高模型的可解释性。
- 所有模型的AUC或召回率均有所提高。
- AdaBoost和LightGBM在减少假阴性方面表现出较好的效果。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何通过使用基于梯度提升的机器学习算法来提高乳腺癌分类的预测性能,特别关注于降低假阴性率(False Negative)并利用SHAP方法提高模型的可解释性。研究的主要目标是利用最新的梯度提升算法(如AdaBoost、XGBoost、CatBoost和LightGBM)来预测和诊断乳腺癌,并找到最有效的评估指标,如召回率(recall)、ROC-AUC和混淆矩阵。此外,研究还首次结合了这四种梯度提升算法与Optuna库进行超参数优化,以及SHAP方法来增强模型的解释能力,以便更好地支持识别和预测乳腺癌。
Q: 有哪些相关研究?
A: 这篇论文提到了以下相关研究:
深度学习方法在乳腺癌检测中的应用:一些研究利用深度学习技术在计算机辅助诊断中显示出潜力,例如在[18]中提供了检测和定位钙化和乳腺肿块的综合概述。
特征选择和集成方法:在[19]中,研究者结合了监督(Relief算法)和非监督(Autoencoder, PCA算法)技术进行特征选择,并集成到支持向量机(SVM)分类器中,实现了乳腺癌的准确及时检测。
不同机器学习算法的比较:在[22]中,研究者探索了多种算法,包括SVM、朴素贝叶斯(NB)、随机森林(RF)、决策树(DT)、K最近邻(KNN)、逻辑回归(LR)、多层感知器(MLP)、线性判别分析(LDA)、XGBoost(XGB)、Ada-Boost和梯度提升(GBC)。GBC算法在准确率上表现最佳。
不同性能指标的应用:在[24]中,比较了SVM、随机森林、逻辑回归、决策树(C4.5)和K最近邻(KNN)算法,基于包括AUC、精确度、敏感性、准确率和F-Measure等指标。SVM在AUC指标上表现更高效。
其他算法的应用:在[26]中,评估了包括支持向量机、K最近邻、朴素贝叶斯、决策树、K均值和人工神经网络在内的多种算法,人工神经网络取得了最高的准确率。
混合方法:在[36]中,提出了一种结合遗传算法和K最近邻(KNN)的混合方法,该方法达到了99%的准确率。
SHAP方法的应用:在[10]中,研究者探讨了如何通过SHAP方法解释任何分类器的预测,这对于决策支持尤为重要。
这些相关研究为当前论文提供了背景和对比,展示了在乳腺癌检测和预测领域中,不同机器学习方法和性能指标的应用情况。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决乳腺癌分类的问题:
数据集选择:使用加州大学欧文分校(UCI)存储库中的乳腺癌数据集进行模型训练和测试。
算法选择:选用了四种最新的基于梯度提升的算法,包括AdaBoost、XGBoost、CatBoost和LightGBM,这些算法在医学疾病检测中被证明是有效的工具。
性能指标:重点关注召回率(recall)这一性能指标,因为它惩罚了模型中的假阴性(即错误地将实际为恶性的病例判断为良性),在医疗诊断中这是非常重要的。
超参数优化:使用Optuna库进行超参数优化,以改善模型性能,特别是针对召回率的优化。
模型解释性:采用SHAP(SHapley Additive exPlanations)方法来提高模型的可解释性,这有助于识别和预测乳腺癌的关键特征,并支持最终的诊断决策。
实验设计:首先创建基线模型,然后在Optuna中对每个模型进行调优,以最大化Fβ度量,同时评估其他指标,如AUC和准确率。
结果分析:通过对比基线模型和Optuna优化后的模型,分析不同算法的性能,并使用SHAP对最终模型的预测结果进行解释。
通过这些步骤,论文旨在开发出一个性能提升且不过拟合的机器学习模型,同时确保模型的透明度和解释性,以便在实际的医疗诊断中得到应用。
Q: 论文做了哪些实验?
A: 论文中进行的实验包括以下几个方面:
数据预处理:对UCI数据集中的乳腺癌数据进行预处理,包括加载数据、分析数据分布、计算Spearman相关性等。
基线模型创建:使用AdaBoost、XGBoost、CatBoost和LightGBM算法创建未经超参数优化的基线模型,并在训练集上训练这些模型,在测试集上评估它们的性能,包括AUC、召回率、准确率和F1分数。
混淆矩阵和ROC曲线:为基线模型生成混淆矩阵和ROC曲线,以可视化模型的分类性能。
超参数优化:使用Optuna库对每个模型进行超参数优化,目标是最大化Fβ度量,以减少假阴性并提高召回率。优化过程中,对不同的超参数组合进行了大量试验。
最终模型评估:评估经过Optuna优化后的模型性能,包括AUC、召回率、准确率、F1分数和Fβ度量。同时,比较优化前后模型的性能提升。
SHAP解释性分析:对XGBoost、CatBoost和LightGBM模型应用SHAP方法,以解释模型预测中各个特征的贡献,提高模型的可解释性。
结果对比:将优化后的模型结果与基线模型进行对比,分析在召回率和AUC等指标上的性能改进。
这些实验旨在展示不同梯度提升算法在乳腺癌分类任务上的性能,并通过超参数优化和解释性分析来提高模型的预测准确性和实用性。
Q: 有什么可以进一步探索的点?
A: 尽管论文中提出的研究取得了一定的成果,但仍有一些方面可以进一步探索:
不同数据集的验证:在其他乳腺癌数据集上验证所提出模型的性能,以测试其泛化能力和适用性。
多模态数据融合:探索将临床数据、影像数据和其他生物标志物数据结合使用,以提高乳腺癌检测的准确性和可靠性。
模型解释性的深入研究:进一步研究和改进模型解释性方法,如SHAP,以便更好地理解模型决策过程和潜在的数据偏差。
特征工程:研究其他特征选择和特征提取技术,以识别更具预测价值的特征,并可能提高模型性能。
模型集成:探索不同模型的集成方法,例如将梯度提升算法与其他机器学习算法结合,以提高预测性能。
实时预测系统:开发实时乳腺癌检测和预测系统,以便在临床环境中快速部署和使用。
模型的临床评估:与医疗专业人员合作,对模型进行临床评估,以确定其在实际医疗诊断中的有效性和可行性。
算法的计算效率:研究算法的计算效率和内存使用情况,以便在资源受限的环境中使用。
模型的鲁棒性:评估模型在面对数据噪声、缺失值和异常值时的鲁棒性。
跨人群和地理区域的模型性能:研究模型在不同人群和地理区域中的表现,以解决可能的种族和地区差异问题。
通过这些进一步的探索,研究者可以提高乳腺癌预测模型的性能、可解释性和实用性,从而在全球范围内更有效地支持乳腺癌的早期检测和治疗。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
研究背景:乳腺癌是全球女性最常见的癌症之一,早期发现和治疗对提高患者生存率至关重要。机器学习在乳腺癌的检测和预测中发挥着重要作用。
研究目标:利用最新的梯度提升算法(AdaBoost、XGBoost、CatBoost和LightGBM)来提高乳腺癌分类的预测性能,特别关注降低假阴性率,并使用SHAP方法增强模型的可解释性。
方法论:
- 数据集来源于UCI存储库的乳腺癌数据集。
- 使用召回率作为主要性能指标,因为它在医疗诊断中避免假阴性方面更为重要。
- 通过Optuna库进行超参数优化,以改善模型性能。
- 应用SHAP方法来解释模型的预测结果。
实验设计:
- 首先建立基线模型,并在训练集上训练,在测试集上评估性能。
- 使用Optuna进行超参数优化,目标是最大化Fβ度量。
- 对优化后的模型进行评估,并使用SHAP进行解释性分析。
结果:
- 所有最终模型的AUC均超过99.41%,召回率超过96.9%。
- AdaBoost模型在召回率上有所提高,减少了假阴性。
- XGBoost、CatBoost和LightGBM模型在AUC和召回率上都有所提升。
结论:
- 论文成功地提高了模型的预测性能,特别是在降低假阴性方面。
- SHAP方法有效地增强了模型的可解释性,有助于医疗决策支持。
未来工作:
- 建议对不同算法进行单独的β值优化。
- 探索模型在其他数据集和多模态数据上的性能。
- 进一步研究模型的临床应用和实际部署。
这篇论文通过结合先进的机器学习技术和解释性方法,为乳腺癌的早期检测和诊断提供了新的视角和工具。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

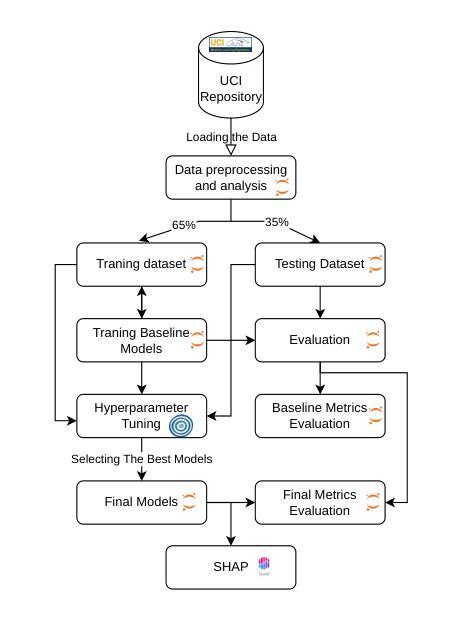
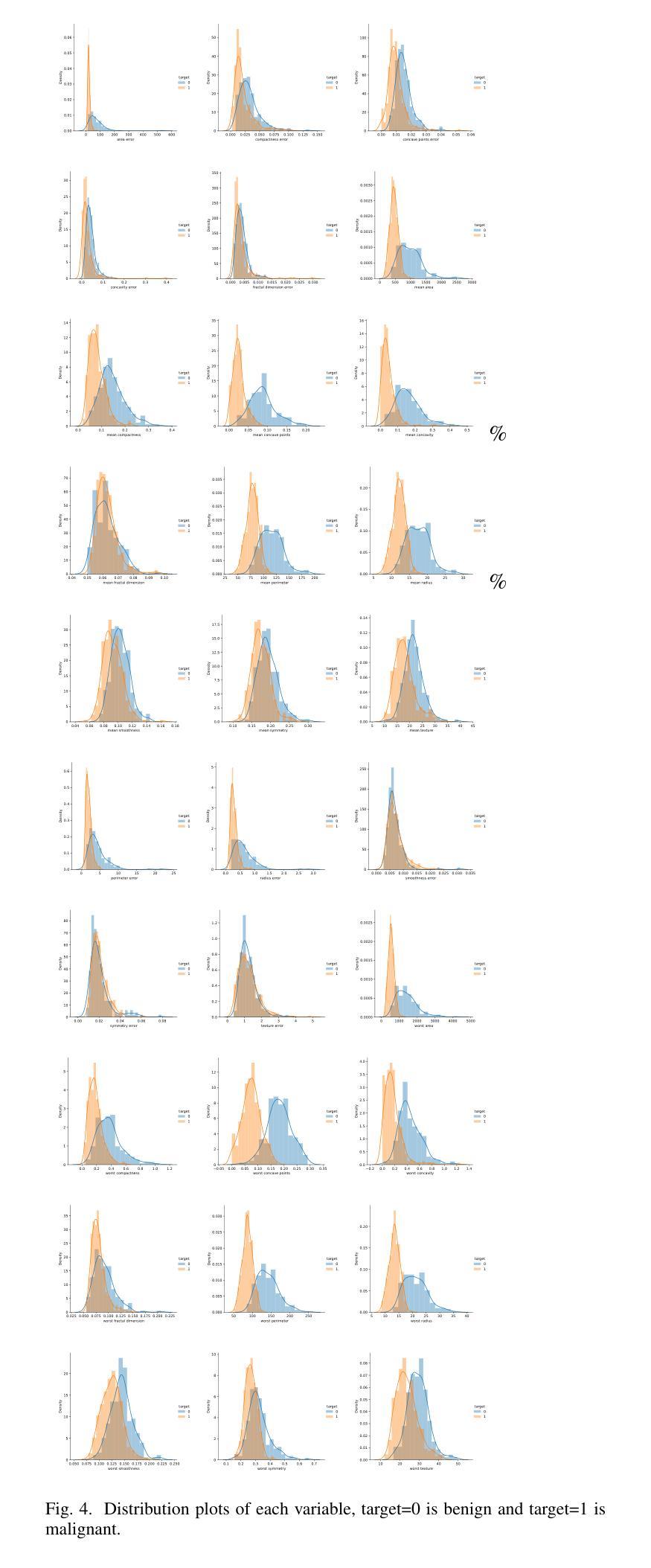
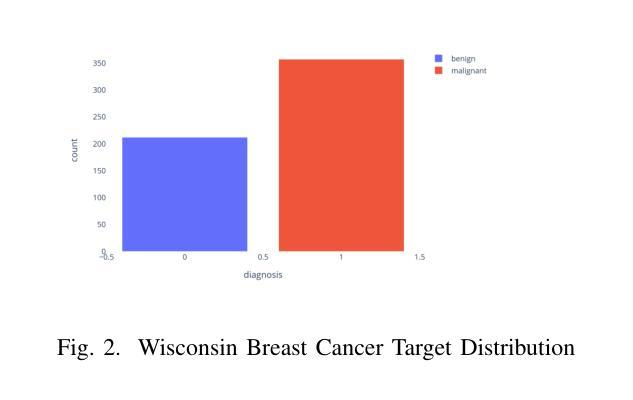
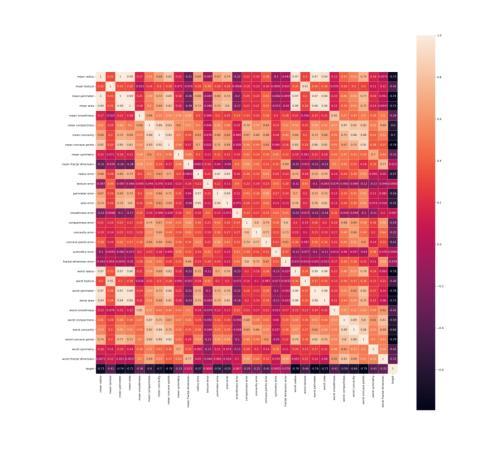

Enhanced Low-Dose CT Image Reconstruction by Domain and Task Shifting Gaussian Denoisers
Authors:Tim Selig, Thomas März, Martin Storath, Andreas Weinmann
Computed tomography from a low radiation dose (LDCT) is challenging due to high noise in the projection data. Popular approaches for LDCT image reconstruction are two-stage methods, typically consisting of the filtered backprojection (FBP) algorithm followed by a neural network for LDCT image enhancement. Two-stage methods are attractive for their simplicity and potential for computational efficiency, typically requiring only a single FBP and a neural network forward pass for inference. However, the best reconstruction quality is currently achieved by unrolled iterative methods (Learned Primal-Dual and ItNet), which are more complex and thus have a higher computational cost for training and inference. We propose a method combining the simplicity and efficiency of two-stage methods with state-of-the-art reconstruction quality. Our strategy utilizes a neural network pretrained for Gaussian noise removal from natural grayscale images, fine-tuned for LDCT image enhancement. We call this method FBP-DTSGD (Domain and Task Shifted Gaussian Denoisers) as the fine-tuning is a task shift from Gaussian denoising to enhancing LDCT images and a domain shift from natural grayscale to LDCT images. An ablation study with three different pretrained Gaussian denoisers indicates that the performance of FBP-DTSGD does not depend on a specific denoising architecture, suggesting future advancements in Gaussian denoising could benefit the method. The study also shows that pretraining on natural images enhances LDCT reconstruction quality, especially with limited training data. Notably, pretraining involves no additional cost, as existing pretrained models are used. The proposed method currently holds the top mean position in the LoDoPaB-CT challenge.
低剂量计算机断层扫描(LDCT)由于投影数据中的高噪声而具有挑战性。LDCT图像重建的流行方法包括两阶段方法,通常包括滤波反投影(FBP)算法和用于LDCT图像增强的神经网络。两阶段方法因其简单性和计算效率而具有吸引力,通常只需要一个FBP和一个神经网络前向传递来进行推断。然而,目前最好的重建质量是由展开的迭代方法(Learned Primal-Dual和ItNet)实现的,尽管它们更复杂并且具有更高的训练和推断计算成本。我们提出了一种结合两阶段方法的简单性和高效性以及最新重建质量的方法。我们的策略是利用针对自然灰度图像的Gaussian去噪预训练的神经网络,针对LDCT图像增强进行微调。我们将此方法称为FBP-DTSGD(域和任务转移的高斯去噪器),因为微调是从Gaussian去噪转移到增强LDCT图像的任务转移,以及从自然灰度到LDCT图像的域转移。使用三种不同的预训练Gaussian去噪器的消融研究表明,FBP-DTSGD的性能并不依赖于特定的去噪架构,这表明未来Gaussian去噪技术的进步可能对该方法有益。研究还表明,在自然图像上的预训练提高了LDCT的重建质量,特别是在有限的训练数据下。值得注意的是,预训练不涉及任何额外成本,因为使用的是现有的预训练模型。该方法目前在LoDoPaB-CT挑战中占据首位均值排名。
论文及项目相关链接
PDF 13 pages, 4 figures
摘要
低剂量计算机断层扫描(LDCT)由于投影数据的高噪声而具有挑战性。流行的LDCT图像重建方法包括两阶段法,通常先使用滤波反投影(FBP)算法,然后通过神经网络进行LDCT图像增强。两阶段法因其简单性和计算效率而具有吸引力,通常只需要一个FBP和一个神经网络前向传递来进行推断。然而,目前最好的重建质量是由展开迭代方法(如Learned Primal-Dual和ItNet)实现的,但它们更复杂,因此具有更高的训练和推断计算成本。我们提出了一种结合两阶段法的简单性和高效性与最新重建质量的方法。我们的策略是利用针对自然灰度图像的Gaussian噪声去除预训练的神经网络,微调用于LDCT图像增强。我们称这种方法为FBP-DTSGD(域和任务转移Gaussian去噪器),因为微调是从Gaussian去噪转移到增强LDCT图像的任务转移,以及从自然灰度到LDCT图像的域转移。使用三种不同的预训练Gaussian去噪器的消融研究表明,FBP-DTSGD的性能并不依赖于特定的去噪架构,这表明未来Gaussian去噪技术的进步可能对本方法有益。研究还表明,在自然图像上的预训练提高了LDCT的重建质量,特别是在训练数据有限的情况下。值得注意的是,预训练不涉及任何额外成本,因为可以使用现有的预训练模型。所提出的方法目前在LoDoPaB-CT挑战中占据最高平均位置。
关键见解
- LDCT面临高噪声导致的挑战。
- 当前流行的LDCT图像重建方法包括两阶段法,但其最佳重建质量由复杂的迭代方法实现。
- 提出了一种结合两阶段法的简单性和最新重建质量的方法——FBP-DTSGD。
- FBP-DTSGD利用预训练的神经网络进行Gaussian噪声去除,并微调用于LDCT图像增强。
- 消融研究表明,FBP-DTSGD的性能不依赖于特定的去噪架构,预训练有助于提升LDCT重建质量。
- 预训练可以在不使用额外成本的情况下进行,因为可以使用现有的预训练模型。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是低剂量计算机断层扫描(Low-Dose CT, LDCT)图像的重建问题。由于低剂量CT扫描使用较低的辐射剂量,其图像质量相对较差,存在更多的噪声和伪影。提高LDCT图像的重建质量是一个具有挑战性的研究课题。
论文提出了一种两阶段的LDCT图像重建方法,主要包括:
预处理阶段:使用传统的滤波反投影(Filtered BackProjection, FBP)方法进行初步重建。
图像增强阶段:使用一个预训练的神经网络对FBP重建的图像进行增强。这个神经网络最初是在一个不同的任务上进行预训练的,即从自然灰度图像中去除高斯噪声。然后,作者对这个网络进行微调(fine-tune),以适应CT图像增强的下游任务。
论文的创新点在于,预训练使用的是非CT数据(自然图像),并且预训练任务是去除高斯噪声,这与LDCT图像的噪声特性显著不同。这种方法在LoDoPaB-CT基准测试中取得了竞争性的结果,证明了其有效性。
Q: 有哪些相关研究?
A: 论文中提到了多个与低剂量计算机断层扫描(LDCT)图像重建相关的研究,以下是一些主要的相关研究:
迭代变分正则化方法:这些方法曾是CT图像重建的前沿技术,基于总变分(total variation)、总广义变分(total generalized variation)或Hessian Schatten范数等正则化技术。
深度学习方法:近年来,深度学习方法在医学图像重建中引起了范式转变,特别是卷积神经网络(CNNs)在减少伪影和重建噪声方面展示了令人信服的能力。
全学习方法:这些方法通过深度学习架构直接重建图像,使用原始投影数据或正弦图作为输入。
迭代方法:如统计迭代重建或基于模型的迭代重建(MBIR),通过在重建和去噪之间交替来提高图像质量。
多阶段方法:在这些方法中,神经网络作为流程中的一步或多个步骤,用于提高初始重建的结果。例如,UNet++、ISTA UNet、Multiscale UNet-like Sparse Coding (MUSC) 和 ItNet。
UNet架构:原始的UNet架构被广泛应用于医学图像处理,并在非医学领域也显示出了效果。
GANs和其他架构:结合编码器-解码器架构和生成对抗网络(GANs)的方法也受到了关注,用于提高LDCT图像质量。
其他创新方法:如使用方向波let、边缘增强、感知损失函数和条件正态化流等技术。
这些研究展示了LDCT图像重建领域的多样性和活跃性,以及深度学习技术在其中扮演的重要角色。论文提出的两阶段方法与这些现有方法相比,具有结构上的简单性和计算效率上的优势。
Q: 论文如何解决这个问题?
A: 论文提出了一种两阶段的低剂量计算机断层扫描(LDCT)图像重建方法,具体步骤如下:
第一阶段:滤波反投影(FBP):
- 使用传统的FBP方法进行初步的CT图像重建。
- FBP是一种分析技术,用于从X射线测量的各种角度获取的原始投影数据中重建CT图像。
- 由于FBP方法会放大测量噪声,特别是在低剂量CT扫描中,因此需要后续的图像增强步骤。
第二阶段:CT图像增强:
- 利用一个预训练的深度神经网络(DRUNet)对FBP重建的图像进行增强。
- DRUNet最初是在一个不同的任务上进行预训练的,即从自然灰度图像中去除高斯噪声。
- 预训练完成后,作者对这个网络进行微调(fine-tune),以适应CT图像增强的下游任务。
- 微调使用的是LoDoPaB-CT数据集,该数据集包含LDCT图像和相应的正常剂量CT(NDCT)图像对。
预训练和微调策略:
- 论文的关键创新点在于,预训练使用的是非CT数据(自然图像),并且预训练任务是去除高斯噪声,这与LDCT图像的噪声特性显著不同。
- 微调过程中,作者使用了结构相似性(SSIM)损失函数和均方误差(MSE)损失函数的组合,并加入了L2正则化项。
数据增强技术:
- 为了提高模型的鲁棒性,作者使用了两种数据增强技术:旋转增强和高斯噪声增强。
- 旋转增强使模型对输入图像的旋转方向不变,而高斯噪声增强使网络能够学习到更广泛的噪声模式。
实验和评估:
- 作者在LoDoPaB-CT挑战中评估了所提出的方法,并与现有的顶尖方法进行了比较。
- 提出的方法在SSIM指标上取得了最高的排名,并与ItNet方法共享第一名的位置。
简化的结构和计算效率:
- 与ItNet等其他方法相比,提出的两阶段方法结构更简单,因为它不需要迭代细化步骤。
- 从计算效率的角度来看,所提出的方法只需要执行FBP加上一次网络的前向传播。
通过这种两阶段方法,论文成功地提高了LDCT图像的重建质量,同时保持了计算效率。
Q: 论文做了哪些实验?
A: 论文中进行了多个实验来验证所提出方法的有效性和优化不同的参数设置。以下是论文中提到的一些关键实验:
旋转增强的有效性:
- 通过训练有无旋转增强的网络,并比较它们对不同方向输入图像的响应,来评估旋转增强的有效性。
高斯噪声增强的有效性:
- 通过比较不同高斯噪声增强策略(无增强、1%噪声增强、0.5%和1%噪声增强)对网络性能的影响。
FBP预处理中滤波器类型的影响:
- 比较了在FBP重建过程中使用Hann滤波器和Ram-Lak滤波器的效果。
SSIM基于损失函数的超参数调整:
- 对SSIM损失函数中的参数α进行了调整,以找到最佳的平衡点。
预训练/微调的有效性:
- 比较了使用预训练网络和从头开始训练的网络的性能差异。
LoDoPaB-CT挑战结果:
- 在LoDoPaB-CT挑战中评估了所提出的方法,并与当前领先的方法进行了比较。
不同设计选择和超参数设置的调查:
- 研究了使用正则化的SSIM损失函数与仅使用MAE损失的模型的性能差异。
- 研究了FBP输出的填充策略与裁剪策略对视觉伪影的影响。
- 评估了旋转增强在不同图像方向上的一致性。
- 考察了高斯噪声增强对性能的提升。
- 分析了不同滤波器在FBP预处理中的表现。
这些实验帮助作者优化了所提出方法的性能,并展示了其在LDCT图像重建任务中的有效性。通过这些实验,作者证明了预训练/微调策略、数据增强技术以及特定超参数选择对于提高重建质量的重要性。
Q: 有什么可以进一步探索的点?
A: 论文中提出了一些可能的研究方向,可以进一步探索以提高LDCT图像重建的质量或扩展所提出方法的应用范围:
其他成像模式的应用:
- 将所提出的方法应用于除CT之外的其他成像模式,如MRI或PET,这可能需要修改重建方法和微调数据集。
扩大预训练和网络架构的数据集大小:
- 利用更大的数据集进行预训练,并扩大网络架构的规模,这可能基于计算机视觉领域的观察,即大型网络在大型数据集上训练可以为下游任务提供更好的基础。
改进的网络架构:
- 开发更先进的神经网络架构,以更好地捕捉图像特征和减少重建伪影。
损失函数的优化:
- 研究和测试不同的损失函数,以找到更适合LDCT图像重建任务的损失函数。
正则化技术的进一步研究:
- 探索不同的正则化技术,以提高模型的泛化能力和鲁棒性。
计算效率的优化:
- 研究算法优化和硬件加速策略,以提高重建过程的计算效率。
临床验证:
- 在临床环境中验证所提出方法的有效性,包括与现有临床工作流程的集成。
多任务学习:
- 探索多任务学习框架,同时优化图像重建和其他相关任务,如图像分割或检测。
不确定性量化:
- 开发方法来量化重建过程中的不确定性,这对于临床决策可能很重要。
跨模态学习:
- 研究跨模态学习技术,以利用来自不同成像模态的信息来改进LDCT图像重建。
这些方向可以帮助研究者进一步提高LDCT图像重建的质量,或者将所提出的方法应用于新的领域和任务。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题背景:论文针对的是低剂量计算机断层扫描(LDCT)图像的重建问题。LDCT由于使用较低的辐射剂量,其图像质量相对较差,存在噪声和伪影问题。
研究目标:提出了一种两阶段的LDCT图像重建方法,旨在提高图像质量,减少噪声和伪影,同时保持计算效率。
方法介绍:
- 第一阶段使用传统的滤波反投影(FBP)方法进行初步重建。
- 第二阶段利用一个预训练的深度神经网络(DRUNet)对FBP重建的图像进行增强。
预训练和微调策略:
- DRUNet最初在自然灰度图像的高斯噪声去除任务上进行预训练。
- 然后,针对LDCT图像增强的下游任务进行微调。
技术创新点:
- 预训练使用的是非CT数据,且任务是去除高斯噪声,与LDCT图像的噪声特性不同。
- 提出的方法在结构上更简单,不需要迭代细化步骤。
实验验证:
- 在LoDoPaB-CT挑战中评估了所提出的方法,并与现有的顶尖方法进行了比较。
- 提出的方法在SSIM指标上取得了最高的排名,并与ItNet方法共享第一名的位置。
实验探索:
- 论文还探讨了不同的设计选择和超参数设置,如数据增强技术、损失函数的选择、滤波器类型等。
未来研究方向:
- 提出了一些可能的研究方向,包括将方法应用于其他成像模式、扩大预训练数据集和网络架构规模等。
结论:
- 论文提出的两阶段LDCT图像重建方法在保持计算效率的同时,取得了竞争性的结果,证明了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
- 论文提出的两阶段LDCT图像重建方法在保持计算效率的同时,取得了竞争性的结果,证明了其有效性。
点此查看论文截图

Efficient 3D affinely equivariant CNNs with adaptive fusion of augmented spherical Fourier-Bessel bases
Authors:Wenzhao Zhao, Steffen Albert, Barbara D. Wichtmann, Angelika Maurer, Ulrike Attenberger, Frank G. Zöllner, Jürgen Hesser
Filter-decomposition-based group equivariant convolutional neural networks (CNNs) have shown promising stability and data efficiency for 3D image feature extraction. However, these networks, which rely on parameter sharing and discrete transformation groups, often underperform in modern deep neural network architectures for processing volumetric images, such as the common 3D medical images. To address these limitations, this paper presents an efficient non-parameter-sharing continuous 3D affine group equivariant neural network for volumetric images. This network uses an adaptive aggregation of Monte Carlo augmented spherical Fourier-Bessel filter bases to improve the efficiency and flexibility of 3D group equivariant CNNs for volumetric data. Unlike existing methods that focus only on angular orthogonality in filter bases, the introduced spherical Bessel Fourier filter base incorporates both angular and radial orthogonality to improve feature extraction. Experiments on four medical image segmentation datasets show that the proposed methods achieve better affine group equivariance and superior segmentation accuracy than existing 3D group equivariant convolutional neural network layers, significantly improving the training stability and data efficiency of conventional CNN layers (at 0.05 significance level). The code is available at https://github.com/ZhaoWenzhao/WMCSFB.
基于滤波器分解的群等变卷积神经网络(CNNs)在3D图像特征提取方面显示出有希望的稳定性和数据效率。然而,这些网络依赖于参数共享和离散变换群,在处理体积图像(如常见的3D医学图像)的现代深度神经网络架构中往往表现不佳。为了解决这些局限性,本文提出了一种高效的非参数共享连续3D仿射群等变神经网络,用于体积图像。该网络使用Monte Carlo增强球形傅里叶-贝塞尔滤波器基的自适应聚合,提高了3D群等变CNN对体积数据的效率和灵活性。与现有仅关注滤波器基角正交性的方法不同,所引入的球形贝塞尔傅里叶滤波器基结合了角正交性和径向正交性,以改进特征提取。在四个医学图像分割数据集上的实验表明,所提出的方法实现了更好的仿射群等变性和更高的分割精度,优于现有的3D群等变卷积神经网络层,显著提高了传统CNN层的训练稳定性和数据效率(在0.05显著性水平下)。代码可在https://github.com/ZhaoWenzhao/WMCSFB找到。
论文及项目相关链接
Summary
这篇论文介绍了一种针对三维医学图像处理的非参数共享连续三维仿射群等价神经网络。通过采用蒙特卡洛增强型球面傅里叶贝塞尔滤波器基的自适应聚合,提高了三维群等价卷积神经网络对体积数据的效率和灵活性。与现有方法相比,该方法在角度和径向正交性方面都进行了改进,实现了更好的特征提取效果。实验结果显示,该方法在四个医学图像分割数据集上的表现优于现有三维群等价卷积神经网络层,显著提高了训练稳定性和数据效率。
Key Takeaways
- 该论文提出了一种针对三维医学图像处理的非参数共享连续三维仿射群等价神经网络,以解决现有网络在处理医学图像时的局限性。
- 该网络使用自适应聚合的蒙特卡洛增强型球面傅里叶贝塞尔滤波器基,提高了现有三维群等价卷积神经网络的效率和灵活性。
- 与其他方法相比,该论文提出的模型在角度和径向正交性方面都进行了改进,优化了特征提取过程。
- 实验结果表明,该网络在四个医学图像分割数据集上的表现优于现有网络,具有更好的仿射群等变性以及更高的分割精度。
- 该网络实现了训练稳定性和数据效率的显著提升,达到了一定的显著性水平(0.05)。
- 代码已经公开在相关网站上供公众查阅和使用。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何提高三维(3D)医学图像分割的效率和稳定性。具体来说,它针对以下几个关键问题:
现有3D群等变卷积神经网络(G-CNN)的局限性:现有的基于滤波器分解的3D G-CNN主要依赖于参数共享设计,并且大多限于旋转变换群。这些限制阻碍了其在深度神经网络架构中应用于医学图像分割。
提高训练稳定性和数据效率:为了克服现有方法在训练过程中的不稳定性,以及在有限医学数据上的性能饱和问题,论文提出了一种非参数共享的仿射群等变神经网络,以实现更高效的3D仿射群等变卷积神经网络的实现。
改进特征提取:通过引入结合角度和径向正交性的球面贝塞尔滤波器基,提高了特征提取的性能。
适应不同变换群:论文提出的网络能够适应不同的变换群,如旋转、平移、缩放等,这对于医学图像中的局部结构变换尤为重要。
实现深度网络架构的集成:通过非参数共享的群等变性,使得提出的网络能够与深度CNN架构集成,从而在实际应用中具有更高的灵活性。
总结来说,论文的目标是开发一种高效的3D群等变卷积单元,用于医学图像分割任务,同时提高训练稳定性、数据效率,并保持对局部结构变换的等变性。
Q: 有哪些相关研究?
A: 论文中提到了与3D群等变卷积神经网络(G-CNN)相关的几项研究,这些研究为本文的工作提供了背景和基础。以下是一些关键的相关研究:
**Cohen and Welling (2016a, 2016b)**:提出了基于滤波器分解的方法,称为可转向CNN,用于旋转-反射群等变性。此外,他们还设计了基于相同可学习卷积核变换的2D旋转等变CNN。
**Kondor and Trivedi (2018)**:在他们的工作中,提出了将群等变性先验集成到卷积单元设计中的概念,这是G-CNN的早期工作之一。
**Qiu et al. (2018)**:他们的研究展示了如何通过滤波器分解来稳定卷积核,并解耦可训练参数的数量和核大小。
**Sangalli et al. (2021), Sosnovik et al. (2019, 2021), Zhu et al. (2022), Gao et al. (2021)**:这些研究逐步将群等变性从2D旋转等变性扩展到2D尺度等变性、尺度-旋转等变性。
**Thomas et al. (2018), Zhu et al. (2023), Zhdanov et al. (2023), Shen et al. (2024)**:这些研究专注于为3D点云数据设计旋转等变网络,这些方法可能不适用于体积医学图像。
**Weiler et al. (2018)**:提出了第一个针对体积数据的3D群等变CNN,用于3D旋转群等变性。
**Zhao et al. (2023)**:提出了一种2D非参数共享的仿射群等变CNN,展示了数据和计算效率以及高灵活性。
**Isensee et al. (2021)**:提出了nnUNet,这是一种自配置的深度学习方法,用于基于深度学习的医学图像分割。
**Hatamizadeh et al. (2022)**:提出了Unetr,这是一种基于Transformer的网络架构,用于3D医学图像分割。
**Roy et al. (2023)**:提出了MedNeXt,这是一种基于Transformer的网络架构,用于医学图像分割。
**Azad et al. (2024)**:提出了D-LKA Net,这是一种用于医学图像分割的网络架构。
**Hatamizadeh et al. (2022), Shaker et al. (2022)**:这些研究探讨了结合CNN和Transformer方法以提高性能的可能性。
这些相关研究为本文提出的非参数共享的3D仿射群等变CNN提供了理论基础和技术背景。本文的工作在这些研究的基础上,通过引入新的滤波器基和权重蒙特卡洛方法,进一步提高了3D医学图像分割的性能。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤解决了提高3D医学图像分割效率和稳定性的问题:
非参数共享的仿射群等变神经网络:提出了一种新的非参数共享的3D仿射群等变卷积神经网络(CNN),这种网络能够适应不同的仿射变换,如旋转、平移、缩放等,而不需要共享参数。这有助于构建更深的神经网络架构,并提高了模型的灵活性。
蒙特卡洛增强的球面傅里叶-贝塞尔滤波器基:引入了一种新的滤波器基,结合了角度和径向正交性,称为球面傅里叶-贝塞尔基。这种基能够更好地提取特征,因为它不仅考虑了角度坐标,还考虑了径向坐标。
权重蒙特卡洛群卷积网络(WMCG-CNN):采用权重蒙特卡洛策略,通过随机权重和滤波器基的组合,实现了良好的群等变性。这种方法在训练初期就为神经网络提供了良好的群等变性,从而提高了训练的稳定性。
3D图像分割实验:在两个腹部图像集(BTCV和NIH Pancreas数据集)上进行了3D图像分割实验。实验结果表明,所提出的方法在训练稳定性和数据效率方面优于现有的3D神经网络,并且在性能上达到了最先进的水平。
代码开源:为了促进研究和进一步的开发,作者承诺将代码开源,这有助于其他研究者复现和扩展这些方法。
总结来说,论文通过提出一种新的非参数共享的仿射群等变CNN架构,结合蒙特卡洛增强的球面傅里叶-贝塞尔滤波器基,以及在实验中展示其在3D医学图像分割任务中的有效性,从而解决了提高3D医学图像分割效率和稳定性的问题。
Q: 论文做了哪些实验?
A: 论文中进行了以下几类实验来验证所提出方法的有效性:
数据集验证:
- BTCV数据集:这个数据集包含了30个受试者的腹部CT扫描图像,每个扫描有13个器官的标注。实验中,作者使用了这个数据集来训练和评估提出的网络。
- NIH Pancreas数据集:这个公开数据集包含了82个增强腹部CT体积,其中胰腺被手动标注。作者在这个数据集上进行了训练和测试。
消融实验(Ablation Experiments):
- 在BTCV数据集上,作者进行了消融实验,以评估不同网络设置对性能的影响。这包括不使用基底位移、使用不同范围的剪切角度、仅使用球面谐波基底,以及使用核重参数化方法。
不同神经网络架构的性能比较:
- 作者测试了提出的方法在改进现有最先进的网络架构(如nnUNet、MedNeXt、D-LKA Net、UNETR、UNETR++、UXNet和RepUXNet)上的性能。这些实验在两个数据集上进行,以展示提出方法在不同网络架构中的效果。
性能指标:
- 实验中使用了Dice相似系数(DSC)作为主要的性能评价指标,以及平均误差(MAE)和可训练参数数量(Params)和乘累加操作数(MACs)作为补充指标。
训练稳定性和数据效率:
- 通过比较不同网络在训练过程中的稳定性和数据效率,作者展示了提出方法在这些方面的优势。这包括在训练初期的群等变误差(mGE)的比较。
讨论:
- 在实验结果的基础上,作者讨论了训练稳定性、数据效率和灵活性等方面的影响因素,并与其他方法进行了比较。
这些实验旨在全面评估所提出方法在3D医学图像分割任务中的性能,并通过与现有技术的比较来证明其优越性。
Q: 有什么可以进一步探索的点?
A: 论文中提出了一些可以进一步探索的点,主要包括:
处理非常大的卷积核:论文指出,所提出的方法在处理非常大的卷积核(如21×21×21)时可能不是最优的,因为这需要大量的滤波器基,可能会给GPU带来巨大的内存负担。未来的工作可以探索如何有效地处理这种大尺寸的卷积核。
改进的滤波器基:虽然球面傅里叶-贝塞尔基已经显示出了优越的性能,但仍有可能开发出更高效的滤波器基,以进一步提高特征提取的能力。
更深层次的网络架构:论文中提出的方法是在现有的深度网络架构上进行改进的。未来的研究可以探索如何将这些方法应用到更深层次的网络中,以及如何设计新的网络架构来充分利用群等变性。
数据增强和正则化策略:虽然论文中提到了使用数据增强来提高网络的群等变性,但可以进一步探索更先进的数据增强和正则化技术,以提高模型的泛化能力和鲁棒性。
多模态和多尺度数据:在实际应用中,医学图像可能来自不同的成像模态,并且可能需要处理不同尺度的数据。未来的工作可以探索如何将群等变网络扩展到多模态和多尺度的数据上。
实时性能:对于临床应用,实时性能是一个重要的考虑因素。未来的研究可以探索如何优化群等变网络,以满足实时处理的要求。
理论分析:虽然论文中进行了实验验证,但对群等变网络的理论分析,特别是在不同变换群下的网络行为,仍然是一个值得深入研究的领域。
跨领域应用:群等变网络的概念和方法是否可以应用于其他领域,例如计算机视觉、自然语言处理等,也是一个值得探索的方向。
这些潜在的研究方向不仅可以推动医学图像分割技术的发展,也可能为深度学习和计算机视觉的其他领域带来新的见解和突破。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题背景:论文针对3D医学图像分割领域中现有的群等变卷积神经网络(G-CNN)的局限性,特别是参数共享设计和对旋转变换群的依赖,提出了改进方案。
方法提出:作者提出了一种非参数共享的3D仿射群等变神经网络,该网络基于蒙特卡洛增强的球面傅里叶-贝塞尔滤波器基,以提高特征提取的效率和灵活性。
关键贡献:
- 提出了一种新的3D仿射群等变神经网络架构,该架构能够有效地处理3D医学图像数据。
- 引入了球面傅里叶-贝塞尔基,这种基结合了角度和径向正交性,以改善特征提取。
- 在两个腹部图像数据集(BTCV和NIH Pancreas)上进行了实验,证明了所提出方法在训练稳定性和数据效率方面优于现有技术。
实验验证:通过一系列的实验,包括消融实验和与现有最佳网络架构的比较,论文展示了所提出方法的有效性。实验结果表明,新方法在3D图像分割任务中取得了优越的性能。
未来工作:论文指出了未来研究的方向,包括处理大尺寸卷积核的问题、探索更高效的滤波器基、优化网络架构以适应多模态和多尺度数据,以及提高网络的实时性能。
代码开源:为了促进研究和进一步的开发,作者承诺将代码开源,这有助于其他研究者复现和扩展这些方法。
总的来说,这篇论文在3D医学图像分割领域提出了一种新的高效且灵活的神经网络架构,并通过实验验证了其优越性,为未来的研究和应用奠定了基础。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

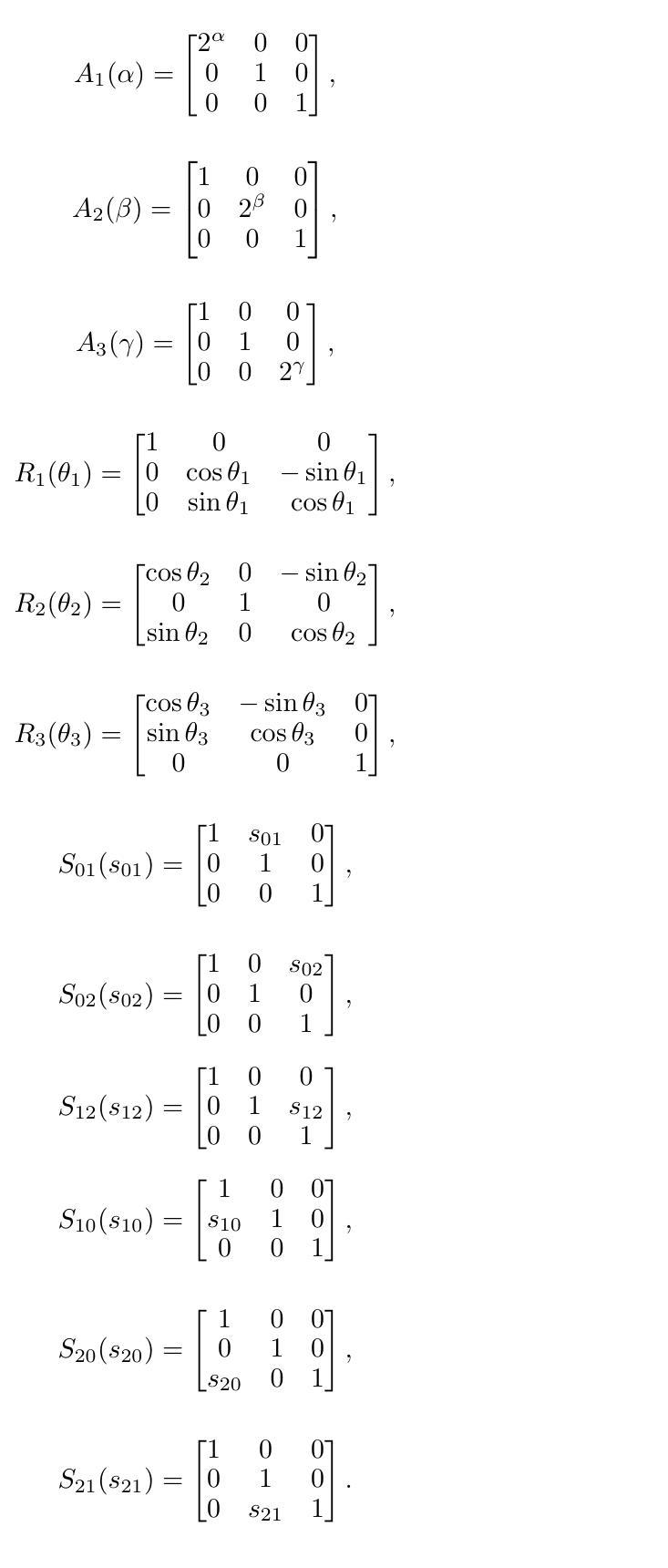
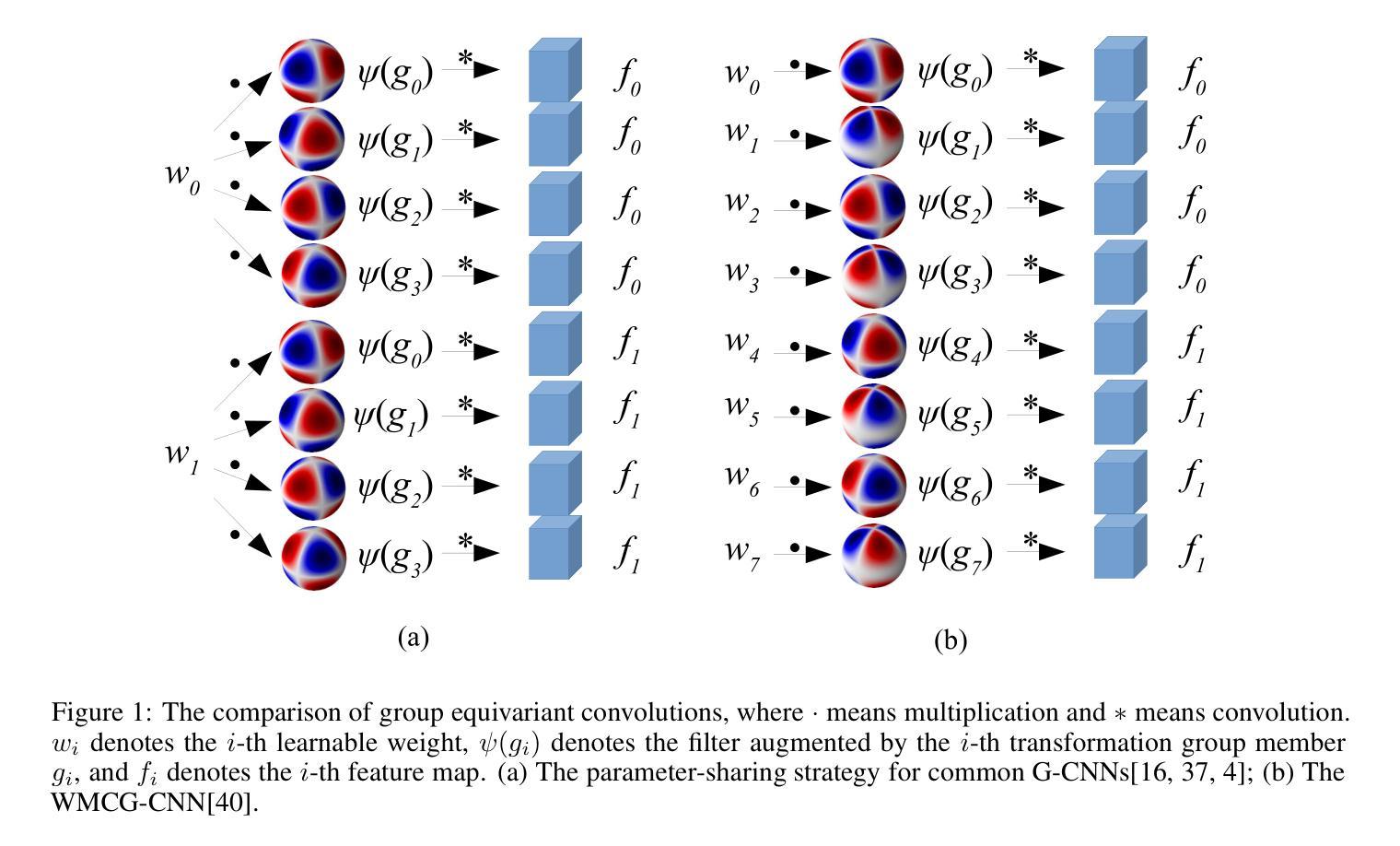
Understanding Neural Network Systems for Image Analysis using Vector Spaces and Inverse Maps
Authors:Rebecca Pattichis, Marios S. Pattichis
There is strong interest in developing mathematical methods that can be used to understand complex neural networks used in image analysis. In this paper, we introduce techniques from Linear Algebra to model neural network layers as maps between signal spaces. First, we demonstrate how signal spaces can be used to visualize weight spaces and convolutional layer kernels. We also demonstrate how residual vector spaces can be used to further visualize information lost at each layer. Second, we study invertible networks using vector spaces for computing input images that yield specific outputs. We demonstrate our approach on two invertible networks and ResNet18.
在开发可用于理解用于图像分析的复杂神经网络数学方法方面存在浓厚兴趣。在本文中,我们引入线性代数技术来建模神经网络层作为信号空间之间的映射。首先,我们展示了如何使用信号空间来可视化权重空间和卷积层内核。我们还演示了如何使用剩余向量空间来进一步可视化每一层丢失的信息。其次,我们使用向量空间研究可逆网络,以计算产生特定输出的输入图像。我们在两个可逆网络和ResNet18上展示了我们的方法。
论文及项目相关链接
PDF Accepted to IEEE’s Southwest Symposium on Image Analysis and Interpretation 2024
Summary
医学图像领域的研究人员正在积极开发用于理解复杂神经网络的数学方法。本文介绍利用线性代数技术将神经网络层建模为信号空间之间的映射。通过信号空间可视化权重空间和卷积层内核,以及利用残差向量空间可视化每层丢失的信息。此外,研究还涉及使用向量空间计算产生特定输出的输入图像的可逆网络,并在两种可逆网络和ResNet18上进行了演示。
Key Takeaways
- 医学图像分析领域对开发用于理解复杂神经网络的数学方法表现出浓厚兴趣。
- 线性代数技术被用于将神经网络层建模为信号空间之间的映射。
- 信号空间可用于可视化权重空间和卷积层内核。
- 残差向量空间用于可视化每层丢失的信息。
- 研究涉及使用向量空间计算的可逆网络,可以产生特定输出的输入图像。
- 在两种可逆网络和ResNet18上的演示展示了该方法的有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何更好地理解和解释在图像分析中使用的复杂神经网络系统。具体来说,它关注以下几个方面:
图像表示的捕捉:尽管神经网络在图像分析任务中表现出色,但对于不同层最好捕捉哪些图像表示仍然缺乏理解。
模型的可解释性:随着神经网络规模的增长以及它们在重要应用(如生物医学领域)的集成,使得模型具有可解释性变得至关重要。
基于向量空间和线性代数的方法:论文提出了使用向量空间和线性代数的方法来理解神经网络,特别是通过将神经网络层建模为信号空间之间的映射。
权重空间和卷积层核的可视化:论文展示了如何使用信号空间来可视化权重空间和卷积层核。
信息丢失的可视化:通过残差向量空间进一步可视化每一层丢失的信息。
可逆网络的概念和算法:引入了可逆网络(INNs)的概念,并提出了一种算法来计算产生特定输出的输入图像。
输入图像的生成:论文还探讨了如何基于理想的输出来计算输入图像,这涉及到使用各种方法来估计输入图像,以便它们能够生成特定的网络输出。
通过这些方法,论文旨在提高对神经网络如何在不同层之间转换输入图像到输出图像的理解,并识别在每一层中被移除的图像组件。
Q: 有哪些相关研究?
A: 论文中提到了与理解神经网络相关的一些研究,具体包括:
特征可视化:早期的研究工作集中在通过确定最大化给定输入图像激活函数的输入来可视化神经网络层,如 [2] 中所述。
显著性图:在 [3] 中,作者引入了显著性图(saliency maps)的使用,这允许验证图像的特定区域是否对其分类得分有所贡献。
解释深度神经网络:最近的一项调查 [4] 总结了多种解释深度神经网络的努力,包括可视化卷积过滤器的标准做法。
线性代数的应用:论文提出了一种不同于以往方法的焦点,即基于与权重矩阵相关联的四个基本向量空间来发展层次解释。
可逆网络:论文还讨论了可逆网络(INNs)的概念,这是指由可逆层组成的网络,其中信号向量空间可以直接从输出空间恢复。
输入图像的计算:论文中提到了基于理想输出计算输入图像向量的方法,这与 [3] 中的方法类似。
医学领域的可解释AI应用:在 [1] 中,作者进行了系统性的回顾,探讨了在医学领域中可解释AI应用的情况。
这些研究为理解神经网络提供了不同的视角和方法,包括特征可视化、显著性分析、网络解释性、以及在特定领域(如医学)中的应用。论文通过结合这些研究成果,提出了一种新的方法来理解和解释神经网络在图像分析中的应用。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决理解和解释神经网络系统的问题:
使用线性代数建模:论文首先介绍了如何使用线性代数的技术来将神经网络层建模为信号空间之间的映射。这是通过将输入图像视为列向量,并使用权重矩阵和激活函数来模拟输出向量来实现的。
定义四个基本信号空间:论文定义了四个基本信号空间,包括信号空间(Signal(W))、信号输出空间(SignalOut(W))、拒绝信号空间(RejSignal(W))和拒绝输出信号空间(RejSignalOut(W))。这些空间有助于理解输入图像如何被转换为输出图像,以及每层中哪些图像组件被移除。
权重向量和矩阵的理解:通过使用投影,论文解释了如何理解单个神经元的权重向量,并扩展到权重矩阵,使用奇异值分解(SVD)来计算信号空间。
简化卷积层的解释:论文提出了一种简化的方法来解释卷积层,通过将权重矩阵的行替换为卷积核的展平形式,从而将信号空间映射到输出像素。
可逆网络和输入图像生成:论文引入了可逆网络(INNs)的概念,并提出了一种算法来计算产生特定输出的输入图像。这涉及到使用可逆激活函数,如SELU、tanh或sigmoid,并迭代地反转每层以恢复信号分量。
实验验证:论文在标准的MNIST 10类分类问题上展示了三种神经网络架构(一个单层全连接神经网络、一个五层全连接神经网络和ResNet18)的方法。通过训练这些网络并解释不同层的信号空间,论文验证了其方法的有效性。
结果分析:论文通过可视化信号空间和残差向量空间,以及生成理想输入图像,来展示其方法如何帮助理解神经网络的内部工作机制。
结论和未来工作:最后,论文总结了使用四个基本向量空间来理解权重空间和残差空间如何将输入图像映射到输出图像的方法,并讨论了可逆网络和估计产生特定输出的输入图像的方法。论文还提出了未来研究的方向,包括探索可逆网络是否能够匹配非可逆网络的性能。
通过这些步骤,论文提供了一种系统的方法来理解和解释神经网络在图像分析中的工作原理。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出方法的有效性:
单层全连接神经网络(1-layer FCNN):作者构建了一个单层的全连接神经网络,并使用SELU激活函数来确保网络的可逆性。这个网络用于MNIST数据集上的10类分类问题。
五层全连接神经网络(5-layer FCNN):作者构建了一个更复杂的五层全连接神经网络,同样使用SELU激活函数,并在MNIST数据集上进行训练和测试。
ResNet18:作为更复杂的神经网络架构的例子,作者选择了ResNet18,并对其进行了训练和测试。
对于这些网络,作者进行了以下实验:
训练网络:所有网络都使用学习率为0.001、动量为0.9,并训练了20个周期。
分类准确率:作者报告了每个网络在MNIST数据集上的分类准确率,分别为1层FCNN的92%,5层FCNN的97%,以及ResNet18的99%。
信号空间的可视化:作者展示了1层FCNN的三个向量空间,并分析了信号向量的重要性。对于ResNet18,作者展示了第一个卷积层的信号空间,并讨论了信号核的方向选择性。
生成理想输入图像:作者使用不同的算法生成了每个类别的输入图像,包括平均图像(avg-img)、最小距离图像(min-img)、以及在最低25百分位距离内的平均图像(avg-min-img)。这些图像用于展示网络如何从输入图像生成特定的输出。
残差图像的分析:作者分析了当网络应用于每个类别的平均数字图像时的残差图像,以展示网络在处理输入图像时忽略了哪些信息。
这些实验结果帮助作者展示了他们的方法如何用于理解和解释神经网络的内部工作机制,以及如何生成特定的输入图像以产生期望的输出。
Q: 有什么可以进一步探索的点?
A: 论文在最后提出了一些未来研究的方向,可以进一步探索的点包括:
可逆网络的性能:研究可逆网络(INNs)是否能够达到与非可逆网络相同的性能水平。这可能涉及到设计更复杂的可逆层或者改进现有的可逆网络架构。
非可逆激活函数的向量空间重定义:对于非可逆激活函数,需要重新定义向量空间,可能涉及到使用凸多边形来描述信号空间。
输入图像生成的改进:探索更高效的算法来生成更接近理想输出的输入图像,这可能包括改进的优化技术或者更高级的网络训练策略。
残差空间的深入分析:进一步研究残差空间(rejected signal space)以更好地理解在神经网络的每一层中丢失的信息。
网络解释性的增强:开发新的方法来提高神经网络的解释性,这可能包括可视化技术、显著性分析或者网络决策过程的解释。
跨领域的应用:将这些方法应用于其他领域,如医学图像分析、自然语言处理或者时间序列分析,以验证其通用性和有效性。
网络架构的改进:设计新的网络架构,特别是那些能够更好地映射输入图像到输出图像的架构,同时保持网络的可解释性。
计算效率的优化:研究如何提高计算效率,特别是在处理大规模数据集或者深层网络时。
理论和实证研究的结合:结合理论和实证研究来更全面地理解神经网络的行为,包括网络的稳定性、泛化能力和鲁棒性。
跨学科合作:与认知科学、心理学和神经科学等领域的专家合作,以获得对神经网络工作原理更深入的理解。
这些探索点不仅可以推动神经网络理论的发展,还可能对实际应用产生重要影响,特别是在需要高度可解释性的领域。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
研究目的:旨在发展数学方法,以理解用于图像分析的复杂神经网络。
方法论:介绍了线性代数技术,将神经网络层建模为信号空间之间的映射。
信号空间:使用信号空间和残差(拒绝信号)空间来理解输入图像如何被转换为输出图像,以及每层中哪些图像组件被移除。
可逆网络:引入了可逆神经网络(INNs)的概念,并提出了一种算法来计算产生特定输出的输入图像。
实验:在MNIST数据集上,对单层和多层全连接神经网络(FCNN)以及ResNet18进行了实验,以验证所提方法的有效性。
结果:通过可视化信号空间和残差向量空间,以及生成理想输入图像,展示了方法如何帮助理解神经网络的内部工作机制。
结论:论文提出了使用四个基本向量空间来理解权重空间和残差空间如何将输入图像映射到输出图像的方法,并讨论了可逆网络和估计产生特定输出的输入图像的方法。
未来工作:提出了未来研究的方向,包括探索可逆网络的性能,以及将这些方法应用于其他领域和网络架构的改进。
论文通过结合理论和实证研究,为理解和解释神经网络在图像分析中的应用提供了新的视角。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



A simple thinking about the application of the attention mechanism in medical ultrasound image segmentation task
Authors:Gongping Chen, Rui Wang, Xiaotao Yin, Liang Cui, Yu Dai
The AI-based assisted diagnosis programs have been widely investigated on medical ultrasound images. Complex scenario of ultrasound image, in which the coupled interference of internal and external factors is severe, brings a unique challenge for localize the object region automatically and precisely in ultrasound images. In this study, we seek to propose a more general and robust Benchmark Attention Adaptive Framework (BAAF) to assist doctors segment or diagnose lesions and tissues in ultrasound images more quickly and accurately. Different from existing attention schemes, the BAAF consists of a parallel hybrid attention module (PHAM) and an adaptive calibration mechanism (ACM). Specifically, BAAF first coarsely calibrates the input features from the channel and spatial dimensions, and then adaptively selects more robust lesion or tissue characterizations from the coarse-calibrated feature maps. The design of BAAF further optimizes the “what” and “where” focus and selection problems in CNNs and seeks to improve the segmentation accuracy of lesions or tissues in medical ultrasound images. The method is evaluated on four medical ultrasound segmentation tasks, and the adequate experimental results demonstrate the remarkable performance improvement over existing state-of-the-art methods. In addition, the comparison with existing attention mechanisms also demonstrates the superiority of BAAF. This work provides the possibility for automated medical ultrasound assisted diagnosis and reduces reliance on human accuracy and precision.
基于人工智能的辅助诊断程序在医学超声图像上得到了广泛的应用。超声图像的复杂场景,其中内外部因素的耦合干扰严重,给超声图像中目标区域的自动和精确定位带来了独特的挑战。本研究旨在提出一种更通用、更稳健的基准注意力自适应框架(BAAF),以协助医生更快、更准确地分割或诊断超声图像中的病变和组织。不同于现有的注意力方案,BAAF包括一个并行混合注意力模块(PHAM)和一个自适应校准机制(ACM)。具体来说,BAAF首先校准输入特征通道和空间维度的特征,然后自适应地从粗略校准的特征图中选择更稳健的病变或组织表征。BAAF的设计进一步优化了CNN中的“什么”和“哪里”的焦点和选择问题,旨在提高医学超声图像中病变或组织的分割精度。该方法在四个医学超声分割任务上进行了评估,足够的实验结果表明其在现有最新技术方法上实现了显著的性能提升。此外,与现有注意力机制的对比也证明了BAAF的优越性。这项工作为自动化医学超声辅助诊断提供了可能性,并降低了对人类准确性和精确度的依赖。
论文及项目相关链接
PDF 10 pages, 11 figures
摘要
本研究提出了一种基于人工智能的辅助诊断程序,采用通用的稳健性更强的基准注意力自适应框架(BAAF),辅助医生更快速准确地识别超声图像中的病变组织。该框架包含并行混合注意力模块(PHAM)和自适应校准机制(ACM),通过初步校准输入特征并从粗校准的特征图中自适应选择更稳健的病变或组织表征,解决了超声图像中目标区域自动定位和精确识别难题。在四个医学超声分割任务上的实验结果表明,该方法在现有先进技术的基础上取得了显著的性能提升。这为自动超声辅助诊断提供了可能性,并降低了对人类精准度的依赖。
要点掌握
- AI辅助诊断程序在医学超声图像上被广泛研究。
- 超声图像复杂场景给自动定位目标区域带来独特挑战。
- 提出一种通用的稳健性更强的基准注意力自适应框架(BAAF)。
- BAAF包含并行混合注意力模块(PHAM)和自适应校准机制(ACM)。
- BAAF初步校准输入特征并自适应选择更稳健的病变或组织表征。
- 在医学超声分割任务上的实验表明,该方法优于现有技术。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是医学超声图像分割任务中由于内部和外部因素的复杂干扰导致的自动化和精确定位目标区域的挑战。具体来说,论文中提到:
自动化和精确定位的挑战:超声图像的复杂性,包括类似强度分布、可变主体形态和其他因素,给放射科医生快速准确地识别和分割超声图像中的病变和组织带来了独特的挑战。
提高分割准确性:为了提高卷积神经网络(CNNs)在超声图像分割任务中的性能,论文提出了一个更通用和鲁棒的基础注意力自适应框架(BAAF),以帮助网络更快更准确地定位和选择应该关注的“什么”和“哪里”。
现有方法的局限性:尽管基于Unet和FCNN的深度学习算法已经被开发用于自动分割医学超声图像,但它们仍然受到低级或非相关特征的影响,限制了这些AI模型在临床实践中的应用。
注意力机制的集成:为了进一步改善CNNs在超声分割任务中的性能,论文提出了将注意力机制集成到CNNs中,以帮助网络更好地聚焦于图像中的目标对象。
综上所述,论文的核心目标是通过提出一个新的注意力自适应框架(BAAF),来提高医学超声图像中病变或组织分割的自动化程度和准确性,从而辅助医生进行更快速和准确的诊断。
Q: 有哪些相关研究?
A: 论文中提到了多个与医学超声图像分割相关的研究工作,以下是一些主要的相关研究:
基于深度学习的医学图像分割算法:
- Unet和FCNN框架被广泛用于医学图像分割任务。例如,Wu等人使用级联FCNN框架逐步优化产前超声图像的分割结果[8]。
- Kim等人通过引入多尺度输入和混合损失函数在U-net中实现冠状动脉在超声图像中的自动分割[9]。
注意力机制在医学图像分割中的应用:
- Zhuang等人基于空间注意力模型设计了RDAUNet以实现乳腺肿瘤超声分割[14]。
- Lee等人通过引入具有多尺度平均池化操作的通道注意力模块在U-Net中尝试分割乳腺超声图像[15]。
- Xian等人构建了AENet,使用显著图来提高乳腺病变分割的准确性[16]。
- Yan等人提出了一种注意力增强U-net模型,用于分割乳腺超声图像[17]。
- Chen等人开发了一种混合注意力模型,用于肾脏超声图像分割[18]。
- Meng等人提出了一种新型的双全局注意力神经网络DGANet,通过整合双侧空间注意力模块和全局通道注意力模块来提高乳腺病变的检测准确性[19]。
多尺度特征信息与注意力机制的结合:
- Lyu等人设计了一个结合注意力机制和多尺度特征的金字塔注意力网络(AMS-PAN),以改善超声图像中乳腺肿瘤的特征描述[20]。
- Byra等人构建了一个新型CNN(SKNet),通过整合选择性核(SK)卷积,帮助网络在不同的感受野下选择更好地表征乳腺肿瘤的特征[21]。
- Chen等人提出了AAU-net和ESKNet,通过引入空间维度校准在SK卷积中,用于医学超声图像分割任务[3]和[22]。
这些研究工作展示了深度学习、特别是注意力机制在医学超声图像分割领域的应用和发展,为本研究提供了理论和技术基础。通过对比这些相关工作,论文提出的BAAF框架旨在通过更有效地结合通道和空间注意力以及自适应校准机制,以提高分割的鲁棒性和准确性。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为**基础注意力自适应框架(Basic Attention Adaptive Framework, BAAF)**的方法来解决医学超声图像分割中的问题。BAAF框架包含两个主要组件:**并行混合注意力机制(Parallel Hybrid Attention Mechanism, PHAM)**和**自适应校准机制(Adaptive Calibration Mechanism, ACM)**。以下是它们如何工作的详细说明:
并行混合注意力机制(PHAM)
PHAM负责从通道和空间两个维度对输入特征进行粗校准。具体来说:
空间注意力模块:
- 输入特征图 ( F \in \mathbb{R}^{C \times H \times W} ) 通过 ( 1 \times 1 ) 卷积和ReLU激活操作。
- 应用sigmoid函数获得空间维度的激活图 ( \alpha ),强调特征图 ( F ) 中对应空间信息的重要性。
- 将 ( \alpha ) 扩展到与特征图 ( F ) 相同的维度,并在 ( F ) 上执行校准活动,得到空间注意力校准后的特征 ( F_S )。
通道注意力模块:
- 输入特征图 ( F ) 通过全局平均池化(GAP)操作压缩特征尺度。
- 压缩后的特征图经过两个全连接层、ReLU激活和sigmoid激活,获得通道注意力图 ( \beta )。
- 将 ( \beta ) 重塑到与特征图 ( F ) 相同的尺度,并在 ( F ) 上执行校准活动,得到通道注意力校准后的特征 ( F_C )。
自适应校准机制(ACM)
ACM负责从不同注意力机制校准的特征图中自适应地选择更鲁棒的表示。具体步骤如下:
聚合不同注意力校准特征的全局信息:
- 使用全局平均池化(GAP)生成通道统计量 ( S_C )。
- 对特征向量 ( S_C ) 执行全连接操作、ReLU激活和全连接操作,产生新的特征向量 ( Z )。
生成通道激活图:
- 对 ( Z ) 执行重塑操作和softmax激活,生成 ( F_C ) 和 ( F_S ) 的通道激活图 ( \phi ) 和 ( \gamma )。
- 将 ( \phi ) 和 ( \gamma ) 应用于 ( F_C ) 和 ( F_S ),并通过连接操作合并特征图,得到最终的输出特征图 ( F_A )。
整体U形框架
论文中还构建了一个使用BAAF模块的U形网络框架,该框架包含七个下采样和七个上采样操作。在编码过程中,每个卷积模块由两个 ( 3 \times 3 ) 卷积层、两个批量归一化层和两个LeakyReLU层组成。在解码阶段,BAAF组件被引入到每个卷积模块中。
通过这种方式,BAAF框架能够优化CNNs中的“什么”和“哪里”的关注和选择问题,并提高医学超声图像中病变或组织分割的准确性。论文通过在四个医学超声分割任务上的实验结果证明了该方法相对于现有最先进方法的性能改进。
Q: 论文做了哪些实验?
A: 论文中进行了广泛的实验来评估所提出的**基础注意力自适应框架(BAAF)**在医学超声图像分割任务中的性能。以下是实验的具体内容:
数据集
实验使用了四个医学超声数据集进行评估:
- Dataset 1:由AlDhabyani等人构建,包含780张图像,这些图像由LOGIQ E9和LOGIQ E9 Agile超声设备在Baheya医院捕获。
- Dataset 2:由Yap等人收集,包含163张图像,由Siemens ACUSON Sequoia C512系统收集。
- Dataset 3(肾脏超声数据集,KUS):包含300张肾脏超声图像,由Esaote MyLab和Philips EPIQ7超声设备收集。
- Dataset 4(肾脏囊肿超声数据集,KCUS):包含300张超声图像,由Esaote MyLab、Hitachi和Philips EPIQ7超声设备收集。
实验设置
- 实验采用了K折交叉验证方法,其中Dataset 1和Dataset 2采用四折交叉验证,Dataset 3和Dataset 4采用三折交叉验证。
- 训练过程中使用二元交叉熵(BCE)作为损失函数,Adam优化器(初始学习率设为1e-3)。
- 开发环境为Ubuntu 20.04,Python 3.6,TensorFlow 2.6.0,使用NVIDIA RTX 3090 GPU。
- 在每个折叠的训练数据中随机选择20%作为验证数据,以确定网络终止的条件。
评估指标
使用了八个定量评估指标来评估预测结果与真实掩模之间的差异,包括:
- 基于区域的评估指标:Jaccard、Precision、Recall、Specificity、Dice。
- 基于边界的评估指标:Hausdorff距离(HD)、平均对称表面距离(ASSD)和平均边界距离(ABD)。
实验结果与讨论
- 论文将所提出的方法与多个经典的医学图像分割网络(如U-net、SegNet、Att U-net、U-net++、UNETR)以及特定于医学的分割方法(如AE U-net、STAN、RDAUNet、MADU-net、SKU-net)进行了比较。
- 提供了定量评估结果(包括Jaccard、Precision、Recall、Specificity、Dice等指标)和可视化预测掩模的比较。
- 进行了统计分析(t-test)来证明所提方法在定量指标上的显著改进。
- 展示了P-R曲线和ROC曲线来评估不同方法的AUC指标,以显示方法的置信水平。
- 与七个经典的注意力模块(如scSE、CBAM、SK、HAAM、AGM、SAM、ECA)进行了比较实验,以进一步讨论BAAF模块的能力。
架构消融实验
- 对比了不同网络组件(原始U-net、更深的U-net、加入PHAM模块的深U-net、加入BAAF模块的深U-net)在四个超声数据集上的分割性能。
- 提供了不同网络组件的定量结果和可视化预测掩模,以展示引入不同组件对预测结果的影响。
这些实验全面评估了BAAF在医学超声图像分割任务中的性能,并证明了其相对于现有最先进方法的优势。
Q: 有什么可以进一步探索的点?
A: 根据论文的讨论和实验结果,以下是一些可以进一步探索的点:
方法的可解释性和数学证明:
- 论文中提到,自适应校准机制(ACM)能够提升网络的分割性能,但缺乏对其工作原理的数学证据。未来的研究可以深入探讨ACM的数学模型,并提供更多的理论支持。
特征自适应选择机制的优化:
- 论文中提出的BAAF框架是一个对现有注意力机制的改进。未来的工作可以进一步优化特征自适应选择机制,例如通过引入类别内自适应和类别间自适应的方法来提高性能。
网络复杂度和计算开销的降低:
- 引入自适应注意力模块会增加网络参数和计算开销。未来的研究可以考虑如何在保持网络性能的同时减少这些开销。
减少漏检和误检:
- 根据论文中的实验结果,所提出的方法在减少漏检和误检方面仍有改进空间。未来的研究可以探索更先进的技术来进一步降低这些错误的发生。
跨模态和多任务学习:
- 考虑将BAAF框架应用于跨模态(例如,结合超声和MRI图像)和多任务学习(例如,同时进行分割和分类)的场景。
临床验证和实用性评估:
- 论文提供了在公共数据集上的实验结果,未来的研究可以探索在真实临床环境中的验证,以及评估方法的实用性和可行性。
更广泛的数据集和病变类型:
- 尽管论文使用了多个数据集,但扩展到更多类型的病变和更广泛的数据集可以进一步验证方法的泛化能力。
实时性能和系统集成:
- 考虑到临床应用的需求,未来的研究可以关注模型的实时性能,并探索如何将这些模型集成到现有的医疗设备和工作流程中。
对抗性攻击和模型鲁棒性:
- 研究模型对于对抗性攻击的鲁棒性,并探索提高模型在面对恶意输入时的稳定性和鲁棒性的方法。
注意力机制与其他技术的融合:
- 探索将注意力机制与其他先进的技术(如生成对抗网络、强化学习等)结合的可能性,以进一步提升模型性能。
这些探索点可以帮助推动医学超声图像分割技术的发展,并最终实现更准确的自动化诊断辅助工具。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题阐述:
- 论文针对医学超声图像分割任务中由于内部和外部因素的复杂干扰导致的自动化和精确定位目标区域的挑战,提出了一个新方法。
方法论:
- 提出了一个名为基础注意力自适应框架(BAAF)的方法,包含并行混合注意力机制(PHAM)和自适应校准机制(ACM),旨在优化CNNs中的“什么”和“哪里”的关注和选择问题,并提高医学超声图像中病变或组织分割的准确性。
实验设计:
- 使用四个医学超声数据集(两个乳腺数据集和两个肾脏数据集)进行实验验证。
- 实施了K折交叉验证、二元交叉熵损失函数、Adam优化器等实验设置。
- 应用了Jaccard、Precision、Recall、Specificity、Dice等定量评估指标。
实验结果:
- 论文方法在所有数据集上均显示出比现有最先进方法更好的性能。
- 通过P-R曲线和ROC曲线展示了方法的高置信水平。
- 进行了与多个经典注意力模块的比较实验,进一步证明了BAAF模块的优势。
架构消融实验:
- 对比了不同网络组件对分割性能的影响,验证了引入PHAM模块和BAAF模块可以显著提升分割准确性。
局限性和未来工作:
- 论文讨论了BAAF框架的局限性,包括对ACM工作机制缺乏数学证据、预测结果中仍然存在的漏检和误检问题,以及网络复杂度和计算开销的增加。
- 提出了未来研究的方向,如增强方法的可解释性、优化特征自适应选择机制、降低网络复杂度等。
结论:
- BAAF在医学超声图像分割任务中取得了令人满意的结果,为未来临床辅助诊断提供了可能性。
总体而言,这篇论文通过提出一个新的注意力自适应框架BAAF,有效地提高了医学超声图像分割的自动化程度和准确性,并在多个数据集上验证了其优越性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图