⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-15 更新
SDI-Paste: Synthetic Dynamic Instance Copy-Paste for Video Instance Segmentation
Authors:Sahir Shrestha, Weihao Li, Gao Zhu, Nick Barnes
Data augmentation methods such as Copy-Paste have been studied as effective ways to expand training datasets while incurring minimal costs. While such methods have been extensively implemented for image level tasks, we found no scalable implementation of Copy-Paste built specifically for video tasks. In this paper, we leverage the recent growth in video fidelity of generative models to explore effective ways of incorporating synthetically generated objects into existing video datasets to artificially expand object instance pools. We first procure synthetic video sequences featuring objects that morph dynamically with time. Our carefully devised pipeline automatically segments then copy-pastes these dynamic instances across the frames of any target background video sequence. We name our video data augmentation pipeline Synthetic Dynamic Instance Copy-Paste, and test it on the complex task of Video Instance Segmentation which combines detection, segmentation and tracking of object instances across a video sequence. Extensive experiments on the popular Youtube-VIS 2021 dataset using two separate popular networks as baselines achieve strong gains of +2.9 AP (6.5%) and +2.1 AP (4.9%). We make our code and models publicly available.
数据增强方法,如Copy-Paste,已被研究证明是扩大训练数据集的有效方法,同时成本较低。虽然这些方法已被广泛应用于图像级任务,但我们发现没有针对视频任务的Copy-Paste的可扩展实现。在本文中,我们利用生成模型的视频保真度的最新增长,探索将合成生成的对象纳入现有视频数据集的有效方法,以人工扩大对象实例池。我们首先获取具有随时间动态变化的对象的合成视频序列。我们精心设计的管道会自动分割,然后在任何目标背景视频序列的帧上复制粘贴这些动态实例。我们将我们的视频数据增强管道命名为合成动态实例Copy-Paste,并在复杂的视频实例分割任务上对其进行测试,该任务结合了视频序列中对象实例的检测、分割和跟踪。在流行的Youtube-VIS 2021数据集上进行的大量实验,使用两个流行的网络作为基线取得了+2.9 AP(6.5%)和+2.1 AP(4.9%)的强劲增长。我们公开提供了代码和模型。
论文及项目相关链接
摘要
视频数据扩充技术有了新的突破。该研究创新性地使用合成动态实例复制粘贴方法,旨在增强视频数据集的物体实例池。研究团队引入了动态合成的视频序列,自动分割并复制粘贴这些动态实例至目标背景视频序列的各帧。这种新方法命名为合成动态实例复制粘贴技术,并成功应用于复杂的视频实例分割任务中。通过在YouTube VIS 2021数据集上的大量实验验证,采用两种不同的流行网络基线分别取得了显著的提升效果。该研究公开发布了代码和模型。
要点分析
- 数据扩充方法如复制粘贴被证明是扩展训练数据集的有效方式,且成本较低。
- 尽管这些方法在图像级别的任务中得到了广泛应用,但在视频任务中缺乏可扩展的复制粘贴实现。
- 研究团队利用生成模型的视频保真度的最新进展,探索将合成对象融入现有视频数据集的有效方式,以人工扩展物体实例池。
- 研究引入了动态合成的视频序列,这些序列中的物体随时间变化而动态变化。
- 团队开发了一个自动分割管道,将动态实例复制到目标背景视频序列的各帧中。
- 这种新的视频数据扩充管道在视频实例分割任务中表现出良好的效果,结合了检测、分割和跟踪技术。
- 在流行的YouTube VIS 2021数据集上进行的实验显示,使用两种流行的网络基线分别取得了显著的改进效果。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何通过有效的数据增强方法来扩展视频训练数据集,以便更好地训练网络以进行视频实例分割(Video Instance Segmentation, VIS)。具体来说,论文中提到了以下几个关键点:
数据多样性挑战:在现实世界中,通过记录的图像序列很难捕捉到场景的巨大多样性和细微差别。为了应对这一挑战,研究者依赖于越来越大的数据集来满足更大和更深网络的需求。
人工标注瓶颈:视频实例分割任务需要密集标注的图像序列,其中每个感兴趣的对象都被识别、标记,并用分割掩码追踪其形状。这种分割标注的成本和时间通常是其他视觉任务(如分类)的数倍。
数据增强方法的局限性:尽管数据增强方法如Copy-Paste已经在图像级别的任务中得到了广泛的实施,但论文发现没有可扩展的Copy-Paste实现是专门为视频任务构建的。
合成数据在视频领域的应用:尽管合成数据在图像领域的实例分割中已经显示出改进性能的潜力,但在视频领域的Copy-Paste应用尚未被探索。
为了解决这些问题,论文提出了一种名为Synthetic Dynamic Instance Copy-Paste (SDI-Paste)的新型数据增强方法,专门针对视频实例分割任务。该方法通过在现有视频数据集中引入模拟现实世界对象动态变化的合成对象实例来人工扩展对象实例池。这种方法不需要手动密集标注,并且可以无限扩展。
Q: 有哪些相关研究?
A: 论文中提到了多个与视频实例分割(VIS)和数据增强相关的研究工作,以下是一些主要的相关研究:
视频实例分割(VIS)方法:
- 论文主要将VIS方法分为离线(offline)和在线(online)两大类。离线方法如[2, 22, 29, 48],它们同时处理整个视频剪辑,允许在它们之间有更深层次的上下文理解。而在线方法如[17, 21, 50, 52–54],它们仅使用局部范围内的少量帧进行实例分割,旨在实现近实时处理。
视频生成:
- 论文提到了基于扩散模型(diffusion models)的文本到视频(Text-to-Video, T2V)生成网络,如[14, 16, 19],这些网络能够基于文本提示生成具有显著真实感的复杂视频场景。
基于图像的数据增强:
- 论文讨论了Copy-paste作为一种对象感知的数据增强框架,它通过从标记数据集中提取对象实例,并将它们粘贴到现有的背景图像上[8, 9, 12]。此外,还有使用3D渲染将对象插入图像场景的方法[23,34,44]。
视频任务的数据增强策略:
- 论文提到了一些扩展图像基础方法用于视频分类的数据增强策略,如DynaAugment[24]和Group RandAugment[1]。还有通过混合多个视频场景的方法,例如VideoMix[56]和SV-Mix[46]。
使用生成模型进行数据增强:
- 论文中提到了X-Paste[60],它将使用Stable Diffusion[40]生成的对象实例引入CopyPaste框架,用于实例分割。
其他相关研究:
- 论文还提到了一些使用生成对抗网络(GAN)或其他生成模型来生成“动态”图像或模拟视频道路场景的研究[11,28,49]。
这些相关研究为论文提出的SDI-Paste方法提供了理论基础和技术背景,同时也展示了在视频实例分割和数据增强领域中存在的研究空白,即缺乏专门针对视频任务的可扩展Copy-Paste实现。论文通过结合最新的生成模型和自监督对象分割技术,探索了一种新的视频数据增强方法,以期提高视频实例分割的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Synthetic Dynamic Instance Copy-Paste (SDI-Paste)的新型数据增强框架来解决视频实例分割(VIS)中的数据多样性和人工标注瓶颈问题。以下是该框架的主要步骤和方法:
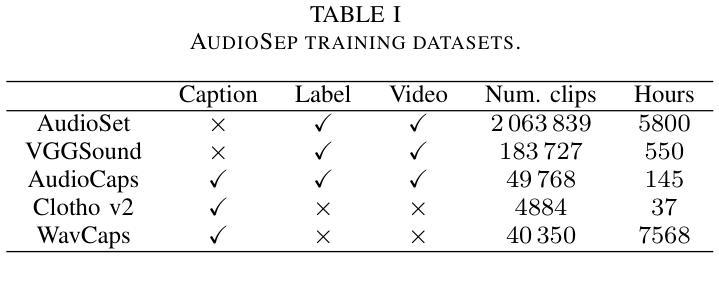
1. Synthetic Video Generation(合成视频生成)
- 使用基于文本的生成模型(例如AnimateDiff)来创建包含动态变化对象的视频场景。
- 通过向模型提供描述动态场景中对象的文本提示来生成特定类别的动画序列。
- 这些生成的视频序列能够捕捉到丰富的对象语义和多样的动作状态。
2. Video Instance Segmentation(视频实例分割)
- 利用现成的自监督显著对象分割器(例如TokenCut)来从生成的视频中提取对象的分割掩码。
- 使用零样本图像识别模型(例如CLIP)来过滤分割掩码,确保生成和分割过程的有效性。
- 移除面积过小或过大的分割掩码,以减少错误分割的情况。
3. Dynamic Instance Composition(动态实例合成)
- 采用类别平衡策略从分割掩码中采样实例,并随机地将它们粘贴到背景视频帧上。
- 引入一种动态实例复制粘贴策略,该策略可以在背景视频序列中的不同帧上移动位置粘贴对象实例。
- 使用线性随机轨迹系统来确定对象在连续帧中的位置,其中方向固定但位移在帧间随机变化。
4. 性能测试和验证
- 在YouTube-VIS 2021数据集上使用两种不同的在线VIS网络(CTVIS和IDOL)作为基线,通过集成SDI-Paste框架来测试其效果。
- 通过大量实验验证SDI-Paste在提高视频实例分割性能方面的有效性,并与其他数据增强方法进行比较。
5. 代码和模型的公开
- 为了促进未来的视频数据增强研究,作者公开了代码和模型。
SDI-Paste的核心优势在于其无需手动密集标注,可以无限扩展,并且能够适应新的生成模型和对象分割技术的发展。通过这种方式,论文旨在为视频实例分割任务提供一种有效的数据增强策略,以提高模型对复杂视频场景中多样对象特征的泛化能力。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证SDI-Paste数据增强框架的有效性。以下是实验的主要内容和结果:
1. 实施细节(Implementation)
- 数据集:使用YTVIS21数据集进行训练、测试和评估,这是一个包含40个常见对象类别的流行VIS数据集。
- 基线框架:在两个流行的在线VIS框架CTVIS和IDOL上测试SDI-Paste,这两个框架都基于预训练的ResNet-50模型。
- SDI-Paste设置:使用AnimateDiff作为文本到视频生成器,TokenCut作为图像前景分割器。对于AnimateDiff,为YTVIS21中的每个40个对象类别生成470个视频序列,每个序列包含16帧。
2. 主要结果(Main Results)
- 性能提升:与基线模型相比,使用SDI-Paste训练的模型在CTVIS上实现了6.5%的性能提升,在IDOL上实现了4.9%的性能提升。
- 与其他数据增强方法的比较:与Copy-Paste和X-Paste等其他数据增强方法相比,SDI-Paste在性能上取得了更好的提升。
3. 消融研究(Ablation Study)
- 轨迹系统:比较了三种不同的实例复制粘贴方法(线性、贝塞尔曲线和线性随机)对性能的影响。结果表明,线性随机轨迹系统提供了最佳结果。
- 分割方法:比较了X-Paste中使用的CLIP引导的分割策略和TokenCut分割器的性能。TokenCut分割器表现更好。
- 更多实例的影响:通过改变生成的动态实例数量(150个序列和470个序列),研究了更多实例对模型性能的影响。结果表明,增加实例数量可以提高模型性能。
4. 结论(Conclusion)
- 论文通过实验验证了SDI-Paste作为一种新的合成数据增强管道,可以有效地提高视频实例分割的性能。
- 论文还强调了SDI-Paste框架的可扩展性和适应性,随着文本到视频生成器和对象分割器技术的进步,SDI-Paste可以进一步改进。
这些实验结果表明,SDI-Paste作为一种数据增强策略,不仅提高了视频实例分割的性能,而且具有很好的适应性和扩展性,为未来的视频数据增强研究提供了新的方向。
Q: 有什么可以进一步探索的点?
A: 论文中提出了一些可能的研究方向和可以进一步探索的点,包括:
结合多种运动轨迹:
- 论文中提到了线性随机轨迹系统在实验中表现最好,但贝塞尔曲线轨迹表现不佳。未来的工作可以探索结合多种运动轨迹的方法,以提高数据增强的效果。
生成更多实例:
- 由于计算资源的限制,论文中生成的动态实例数量有限。更多的实例可能会进一步提高模型性能,因此生成更大数量的动态实例是一个值得探索的方向。
改进文本到视频生成模型:
- 论文使用了AnimateDiff作为文本到视频的生成模型。随着未来更先进的生成模型的出现,使用这些新模型可能会进一步提高生成视频的质量和多样性。
改进对象分割器:
- 尽管TokenCut在论文中的实验效果不错,但持续改进对象分割器的性能,尤其是在处理复杂背景和动态场景时,可以进一步提高数据增强的质量。
适应不同的视频任务:
- 论文提出的SDI-Paste框架主要是为视频实例分割任务设计的。该框架可以进一步适配和测试在其他视频任务,如视频分类、行为识别等任务中的有效性。
探索不同的数据增强策略:
- 论文中提到了动态实例能够提供更多样化的对象特征。未来的研究可以探索结合静态和动态实例的数据增强策略,以获得更好的性能。
跨领域数据增强:
- 考虑到不同领域数据之间的差异,未来的工作可以探索如何将SDI-Paste框架应用于跨领域视频数据增强,以提高模型的泛化能力。
实时视频数据增强:
- 论文中的数据增强方法主要针对离线训练。实时视频数据增强是一个挑战,未来的工作可以探索如何将SDI-Paste应用于实时视频流的数据增强。
更深入的消融研究:
- 论文进行了一些消融研究,但还有更多的方面可以探索,例如不同的轨迹参数设置、不同的实例数量对性能的影响等。
模型的可解释性和鲁棒性分析:
- 对于使用SDI-Paste训练的模型,进一步分析其可解释性和鲁棒性,了解模型在面对异常情况时的表现,也是未来工作的一个方向。
这些点提供了未来研究的潜在方向,可以帮助进一步提升视频数据增强技术的性能和应用范围。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出在视频实例分割(VIS)任务中,由于数据多样性和人工标注成本高,训练网络以泛化和扩展到大规模数据集是一个挑战。
现有方法的局限性:
- 尽管数据增强方法如Copy-Paste在图像任务中有效,但缺乏为视频任务设计的可扩展实现。
SDI-Paste框架:
- 论文提出了一个名为Synthetic Dynamic Instance Copy-Paste (SDI-Paste)的新型数据增强框架,专门针对视频实例分割任务。
- 该框架通过结合文本到视频的生成模型和自监督对象分割技术,自动生成、分割并合成动态对象实例到现有的视频数据集中。
方法细节:
- 合成视频生成:使用AnimateDiff模型根据文本提示生成包含动态变化对象的视频序列。
- 视频实例分割:利用TokenCut分割器提取对象的分割掩码,并通过CLIP模型过滤以确保分割质量。
- 动态实例合成:采用线性随机轨迹系统将动态对象实例粘贴到背景视频帧上,模拟真实世界中对象的动态变化。
实验验证:
- 在YTVIS21数据集上,使用CTVIS和IDOL两个在线VIS网络作为基线,展示了SDI-Paste在提高模型性能方面的有效性。
- 通过与Copy-Paste和X-Paste等其他数据增强方法的比较,证明了SDI-Paste在提升模型性能方面的优势。
消融研究:
- 论文还进行了消融研究,包括不同轨迹系统、分割方法和实例数量对模型性能的影响。
结论与未来工作:
- 论文总结了SDI-Paste作为一种有效的视频数据增强策略,并讨论了其可扩展性和适应性。
- 提出了未来可能的研究方向,包括改进生成模型、对象分割器,以及将SDI-Paste应用于其他视频任务等。
总体而言,这篇论文提出了一个创新的数据增强框架,通过合成动态实例来增强视频数据集,有效地提高了视频实例分割任务的性能,并为未来的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



Parameter-efficient Fine-tuning in Hyperspherical Space for Open-vocabulary Semantic Segmentation
Authors:Zelin Peng, Zhengqin Xu, Zhilin Zeng, Yaoming Wang, Wei Shen
Open-vocabulary semantic segmentation seeks to label each pixel in an image with arbitrary text descriptions. Vision-language foundation models, especially CLIP, have recently emerged as powerful tools for acquiring open-vocabulary capabilities. However, fine-tuning CLIP to equip it with pixel-level prediction ability often suffers three issues: 1) high computational cost, 2) misalignment between the two inherent modalities of CLIP, and 3) degraded generalization ability on unseen categories. To address these issues, we propose H-CLIP a symmetrical parameter-efficient fine-tuning (PEFT) strategy conducted in hyperspherical space for both of the two CLIP modalities. Specifically, the PEFT strategy is achieved by a series of efficient block-diagonal learnable transformation matrices and a dual cross-relation communication module among all learnable matrices. Since the PEFT strategy is conducted symmetrically to the two CLIP modalities, the misalignment between them is mitigated. Furthermore, we apply an additional constraint to PEFT on the CLIP text encoder according to the hyperspherical energy principle, i.e., minimizing hyperspherical energy during fine-tuning preserves the intrinsic structure of the original parameter space, to prevent the destruction of the generalization ability offered by the CLIP text encoder. Extensive evaluations across various benchmarks show that H-CLIP achieves new SOTA open-vocabulary semantic segmentation results while only requiring updating approximately 4% of the total parameters of CLIP.
开放词汇语义分割旨在使用任意文本描述来标记图像中的每个像素。视觉语言基础模型,尤其是CLIP,最近被强大的工具所采纳,以获得开放词汇能力。然而,微调CLIP以使其具备像素级预测能力通常面临三个问题:1)计算成本高,2)CLIP的两个固有模态之间的不对齐,以及3)未见类别的泛化能力下降。为了解决这些问题,我们提出了H-CLIP,这是一种在超球空间中对CLIP的两个模态进行的对称参数高效微调(PEFT)策略。具体来说,PEFT策略是通过一系列高效的块对角可学习转换矩阵和所有可学习矩阵之间的双向跨关系通信模块来实现的。由于PEFT策略对两个CLIP模态进行了对称处理,因此缓解了它们之间的不对齐问题。此外,根据超球能量原理,我们对CLIP文本编码器上的PEFT施加了额外的约束。也就是说,在微调过程中最小化超球能量可以保持原始参数空间的内在结构,防止破坏CLIP文本编码器所提供的泛化能力。在多个基准测试上的广泛评估表明,H-CLIP实现了新的最先进的开放词汇语义分割结果,而只需要更新CLIP大约4%的总参数。
论文及项目相关链接
Summary
基于CLIP模型的开放词汇语义分割方法存在计算成本高、两种模态间存在不匹配以及未见类别泛化能力下降等问题。为此,提出了H-CLIP方法,采用对称参数高效微调策略,在超球空间对CLIP两种模态进行优化。通过高效块对角可学习转换矩阵和双交叉关联通信模块实现。对称调整策略减轻了模态间的失配,并应用超球能量原理的额外约束,保护CLIP文本编码器的内在结构,防止泛化能力受损。仅在更新CLIP约4%的参数情况下,H-CLIP就实现了先进的开放词汇语义分割效果。
Key Takeaways
- 开放词汇语义分割旨在用任意文本描述对图像中的每个像素进行标注。
- CLIP模型在获取开放词汇能力方面具有潜力,但在像素级预测方面存在计算成本高、模态不匹配和泛化能力下降等问题。
- H-CLIP方法被提出以解决这些问题,采用对称参数高效微调策略,在超球空间中对CLIP的两种模态进行优化。
- PEFT策略通过高效块对角可学习转换矩阵和双交叉关联通信模块实现。
- H-CLIP方法对称调整两种模态,减轻模态间失配,并应用超球能量原理的约束保护CLIP文本编码器的内在结构。
- H-CLIP方法仅在更新约4%的CLIP参数情况下就实现了先进的开放词汇语义分割效果。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决在使用CLIP进行开放词汇语义分割时遇到的三个主要问题:
高计算成本:传统的微调方法在有限的类别上微调CLIP,这会影响其泛化能力,导致在未见过的类别上性能显著下降。
CLIP两种固有模态之间的不对齐:当前的微调策略通常是不对称的,这不可避免地导致CLIP的两种模态(即图像和文本)之间的不对齐,可能导致次优性能。
在未见类别上泛化能力的下降:尽管取得了显著的性能提升,但这些方法通常依赖于计算密集型的全微调,这引发了关于可扩展性和可负担性的担忧。
为了解决这些问题,论文提出了一种对称的参数高效微调(PEFT)策略,称为H-CLIP,该策略在超球空间中对CLIP的两种模态进行微调。通过一系列高效的块对角可学习变换矩阵和所有可学习矩阵之间的双重交叉关系通信模块来实现PEFT策略,以减轻不同模态之间的不对齐问题。此外,论文还根据超球能量原理对CLIP文本编码器上的PEFT应用了额外的约束,即在微调期间最小化超球能量以保持原始参数空间的内在结构,防止破坏CLIP文本编码器提供的泛化能力。
Q: 有哪些相关研究?
A: 论文中提到了与开放词汇语义分割和大规模模型微调相关的一些研究工作,以下是部分相关研究的概述:
开放词汇语义分割:
- 初始的工作直接在主流分割数据集上微调CLIP,例如COCO。
- 一些方法选择保持CLIP冻结,以维持其泛化能力,同时微调额外的掩码生成器来进行分割。
- 其他研究提出了一种更高级的解决方案,只微调CLIP的选定参数,例如某些层,以启用像素级预测,同时保持大部分参数固定,从而最小化泛化能力的损失。
大规模模型微调:
- 随着大规模基础模型的发展,例如segment anything model,许多微调工作被提出来适应不同的下游场景。
- 这些方法的核心在于只更新有限的参数以捕获不同场景的特定特征,同时保持大部分参数固定以维持泛化。
论文中还提到了一些具体的研究工作,例如:
- [41, 5, 32, 37, 11, 17, 25, 20, 26, 13, 18, 28, 10, 27, 43]:这些引用涉及视觉-语言基础模型。
- [50, 46, 7, 48]:这些引用涉及用于开放词汇语义分割的微调方法。
- [35, 34, 4, 55, 56, 14, 52, 45, 30, 59]:这些引用涉及大规模模型的微调工作。
这些研究工作为本文提出的H-CLIP框架提供了背景和对比,展示了在开放词汇语义分割和大规模模型微调领域中,如何通过不同的方法来平衡模型的泛化能力和特定任务的学习。
Q: 论文如何解决这个问题?
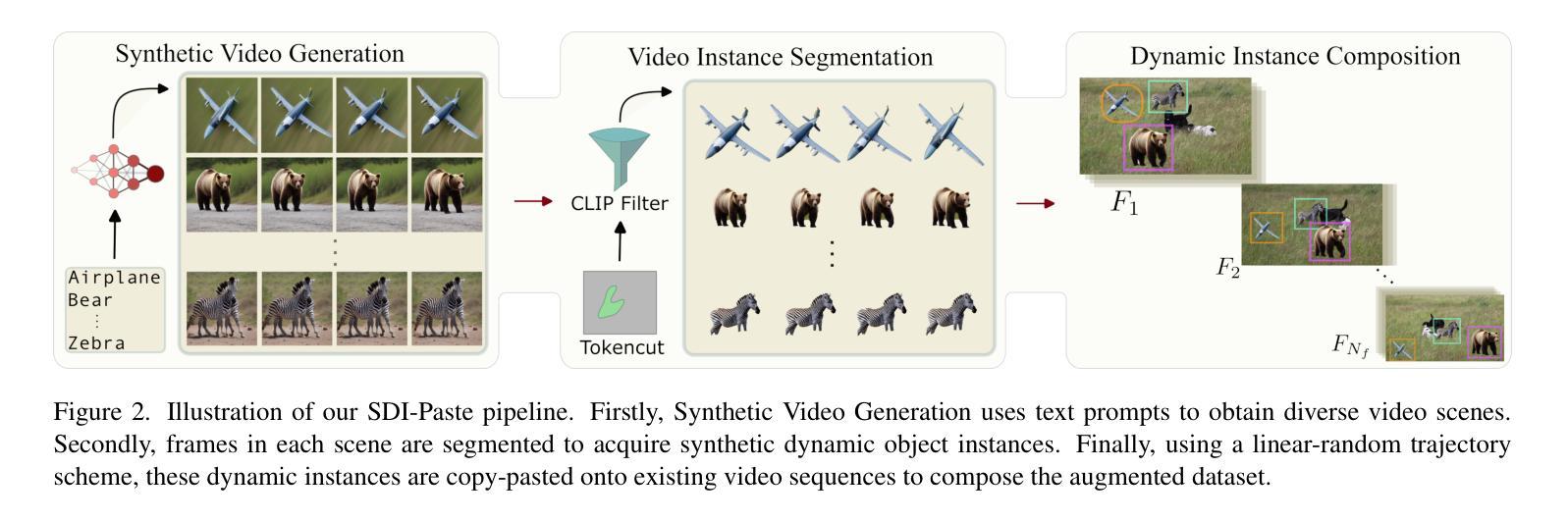
A: 论文提出了一个名为H-CLIP的框架,采用对称的参数高效微调(PEFT)策略来解决开放词汇语义分割中的三个问题。以下是解决这些问题的具体方法:
引入超球空间中的部分正交微调(Partial Orthogonal Fine-tuning, POF):
- 在超球空间中微调CLIP的文本编码器,通过正交变换保持超球能量,从而保持预训练参数空间的内在结构。
- 使用Cayley参数化确保可调整矩阵严格正交,以便于更新。
设计块对角结构:
- 为了提高效率,引入了块对角结构,通过参数化的方式将正交矩阵分解为多个小块。
双重交叉关系通信(Dual Cross-Relation Communication, DCRC)模块:
- 通过两个关系投影实现不同层和模态(文本和图像)之间的交叉通信。
- 使用张量积定义了3阶T积和更高阶T积,以增强不同块对角矩阵之间的交互。
应用超球能量原理:
- 在微调过程中,通过最小化超球能量来保持原始参数空间的结构,防止CLIP文本编码器的泛化能力被破坏。
实验验证:
- 在多个基准测试中进行广泛的评估,证明H-CLIP在只更新了CLIP总参数量的大约4%的情况下,达到了新的最先进水平。
通过这些方法,H-CLIP框架有效地减轻了不同模态之间的不对齐问题,同时保持了模型的泛化能力,并减少了计算成本。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证H-CLIP框架的有效性:
实验设置:
- 使用COCO-Stuff数据集作为训练集,包含约118,000张密集标注图像,涵盖171个不同的语义类别。
- 在ADE20K、PASCAL VOC和PASCAL Context数据集上进行推理,并与最先进的方法进行比较。
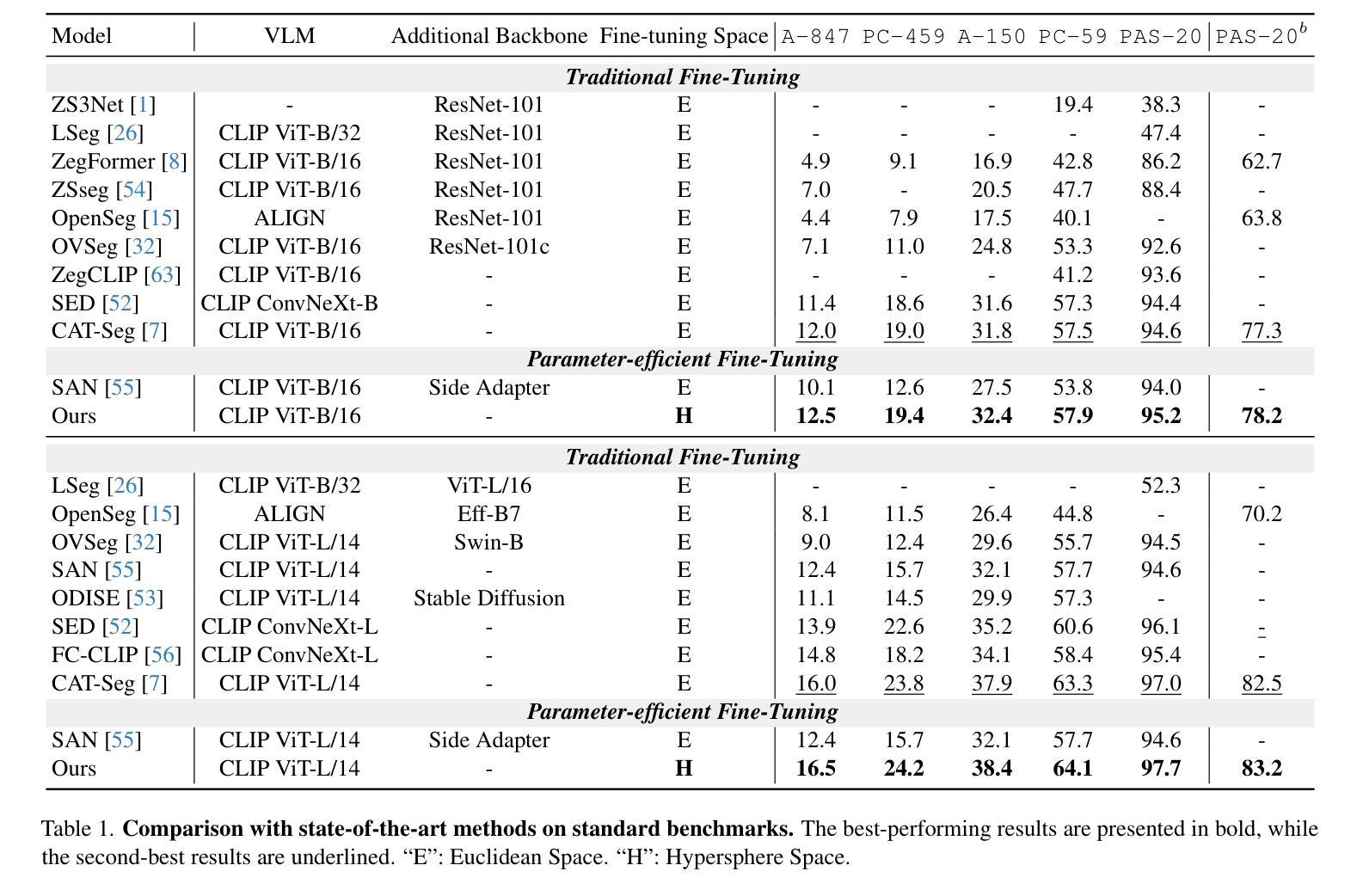
主要结果:
- 与现有的开放词汇语义分割方法相比,H-CLIP在多个测试集上取得了最佳性能。
- 展示了H-CLIP方法在不同数据集上的定量结果,包括A-847、PC-459、A-150、PC-59、PAS-20和PAS-20b。
定性结果:
- 可视化展示了H-CLIP方法在PC-459数据集上的代表性示例分割结果,并与CAT-Seg等现有方法进行了比较。
效率比较:
- 与其他使用CLIP ViT模型的方法(如OVSeg、CAT-Seg和SAN)进行了效率比较,展示了H-CLIP在保持预训练模型泛化性和学习新知识灵活性的同时,使用的可训练参数最少。
消融研究:
- 对H-CLIP的主要组件进行了消融研究,包括部分正交微调(POF)和双重交叉关系通信(DCRC)。
- 展示了不同设计选择对POF性能的影响,包括不同的块维度q和正交性约束的应用。
不同设计的POF:
- 对POF的不同设计进行了实验,包括块维度q和正交约束的不同应用方式。
这些实验结果表明,H-CLIP在保持CLIP模型泛化能力的同时,有效地学习了分割知识,并且在参数效率和性能之间取得了良好的平衡。
Q: 有什么可以进一步探索的点?
A: 尽管H-CLIP在开放词汇语义分割方面取得了显著的成果,但仍有一些潜在的研究方向可以进一步探索:
改进的超球空间微调策略:研究不同的超球空间变换方法,以更有效地保持模型的泛化能力。
增强的跨模态通信机制:开发更复杂的跨模态通信技术,以进一步提高图像和文本模态之间的一致性。
更广泛的数据集测试:在更多样化的数据集上测试H-CLIP,以评估其泛化能力,并探索在不同领域和复杂场景下的应用。
计算效率优化:研究如何进一步减少计算资源消耗,特别是在大规模数据集和高分辨率图像上的应用。
多任务学习:探索将H-CLIP扩展到多任务学习框架中,例如同时进行语义分割、目标检测和图像分类。
模型压缩和加速:研究模型压缩技术,以减少模型大小并加速推理过程,使其更适合边缘计算和移动设备。
鲁棒性改进:提高模型对于遮挡、光照变化和图像噪声等不利条件的鲁棒性。
可解释性和可视化:提高模型的可解释性,通过可视化技术帮助理解模型如何学习和进行像素级预测。
跨领域适应性:研究如何通过迁移学习等技术,使H-CLIP能够适应不同的领域和应用场景。
与现有技术的集成:探索将H-CLIP与其他先进的计算机视觉技术(如生成对抗网络、图神经网络等)结合的可能性。
长尾类别处理:研究如何改进模型对长尾分布中少数类别的识别和分割能力。
实时应用:优化模型以实现实时语义分割,这对于视频处理和增强现实等应用至关重要。
这些探索点可以帮助推动开放词汇语义分割技术的发展,并扩展其在各种实际应用中的潜力。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以概括为以下几个要点:
问题背景:开放词汇语义分割旨在让模型能够根据文本描述为图像中的每个像素分配任意类别标签。CLIP模型作为一种视觉-语言基础模型,被广泛用于赋予模型开放词汇识别能力。然而,直接微调CLIP以获得像素级预测能力时,存在高计算成本、模态不对齐和泛化能力下降等问题。
H-CLIP框架:为了解决上述问题,论文提出了H-CLIP框架,这是一个对称的参数高效微调(PEFT)策略,通过在超球空间中对CLIP的两种模态(图像和文本)进行微调。
核心策略:
- 部分正交微调(POF):通过引入一系列高效的块对角可学习变换矩阵,对CLIP的文本编码器进行正交变换,以保持超球能量,从而维持模型的泛化能力。
- 双重交叉关系通信(DCRC):引入一个通信模块,通过张量积定义的3阶T积和更高阶T积,增强不同层和模态之间的交互,以解决模态不对齐问题。
实验验证:通过在多个基准数据集上的实验,论文证明了H-CLIP在只更新了CLIP总参数量的大约4%的情况下,达到了新的最先进水平的开放词汇语义分割结果。
消融研究:论文还进行了消融实验,以展示H-CLIP各个组件(如POF和DCRC)的贡献,并探讨了不同设计选择对性能的影响。
结论:H-CLIP框架通过引入超球空间中的PEFT策略和DCRC模块,有效地解决了开放词汇语义分割中的高计算成本、模态不对齐和泛化能力下降问题,为该领域的未来研究提供了新的方向。
论文通过提出H-CLIP框架,不仅提高了开放词汇语义分割的性能,还保持了模型的泛化能力和计算效率,展示了在这一领域内的重要进展。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Semi-Supervised Semantic Segmentation Based on Pseudo-Labels: A Survey
Authors:Lingyan Ran, Yali Li, Guoqiang Liang, Yanning Zhang
Semantic segmentation is an important and popular research area in computer vision that focuses on classifying pixels in an image based on their semantics. However, supervised deep learning requires large amounts of data to train models and the process of labeling images pixel by pixel is time-consuming and laborious. This review aims to provide a first comprehensive and organized overview of the state-of-the-art research results on pseudo-label methods in the field of semi-supervised semantic segmentation, which we categorize from different perspectives and present specific methods for specific application areas. In addition, we explore the application of pseudo-label technology in medical and remote-sensing image segmentation. Finally, we also propose some feasible future research directions to address the existing challenges.
语义分割是计算机视觉中一个重要且热门的研究领域,它专注于根据图像的语义对像素进行分类。然而,有监督的深度学习需要大量的数据来训练模型,而逐像素标注图像的过程既耗时又费力。本文旨在提供伪标签方法在半监督语义分割领域中的最新研究成果的全面、系统概述,我们从不同的角度对这些成果进行分类,并针对特定的应用领域介绍具体的方法。此外,我们还探讨了伪标签技术在医疗和遥感图像分割中的应用。最后,我们还提出了一些可行的未来研究方向,以应对现有挑战。
论文及项目相关链接
PDF Accepted by IEEE Transactions on Circuits and Systems for Video Technology(TCSVT)
Summary
语义分割是计算机视觉中一个重要且热门的研究领域,主要对图像中的像素进行分类。然而,深度学习方法需要大量的数据进行训练,对图像进行像素级的标注是耗时的。这篇综述旨在提供伪标签方法在半监督语义分割领域最新的、全面的研究结果,从不同角度分类并介绍特定应用领域的方法。此外,还探讨了伪标签技术在医疗和遥感图像分割中的应用,并提出了解决现有挑战的未来研究方向。
Key Takeaways
- 语义分割是计算机视觉领域的一个重要研究方向,主要对图像中的像素进行分类。
- 深度学习方法需要大量的数据进行训练,标注过程耗时且繁琐。
- 伪标签方法在半监督语义分割领域得到了广泛应用。
- 伪标签方法在不同角度进行了分类,且有特定应用于医疗和遥感图像分割的方法。
- 当前研究中存在一些挑战,需要进一步的研究来解决。
- 文章提供了全面的综述,涵盖了伪标签方法的最新研究进展。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是语义分割任务中的半监督学习方法,特别是在像素级别上对图像进行分类时,如何有效地利用有限的标注数据来训练深度学习模型。在计算机视觉领域,语义分割是一个重要且受欢迎的研究领域,它涉及到对图像中的每个像素进行分类。然而,监督深度学习需要大量的数据来训练模型,而逐像素地标注图像的过程既耗时又费力。为了克服这些挑战,论文提供了一个关于伪标签方法在半监督语义分割领域的最新研究结果的全面和系统性的概述。这些方法从不同的角度进行分类,并针对特定应用领域提出了具体的方法。此外,论文还探讨了伪标签技术在医学图像分割和遥感图像分割中的应用,并提出了一些可行的未来研究方向来应对现有挑战。
Q: 有哪些相关研究?
A: 论文中提到了多项与半监督语义分割和伪标签方法相关的研究,以下是一些关键的相关研究:
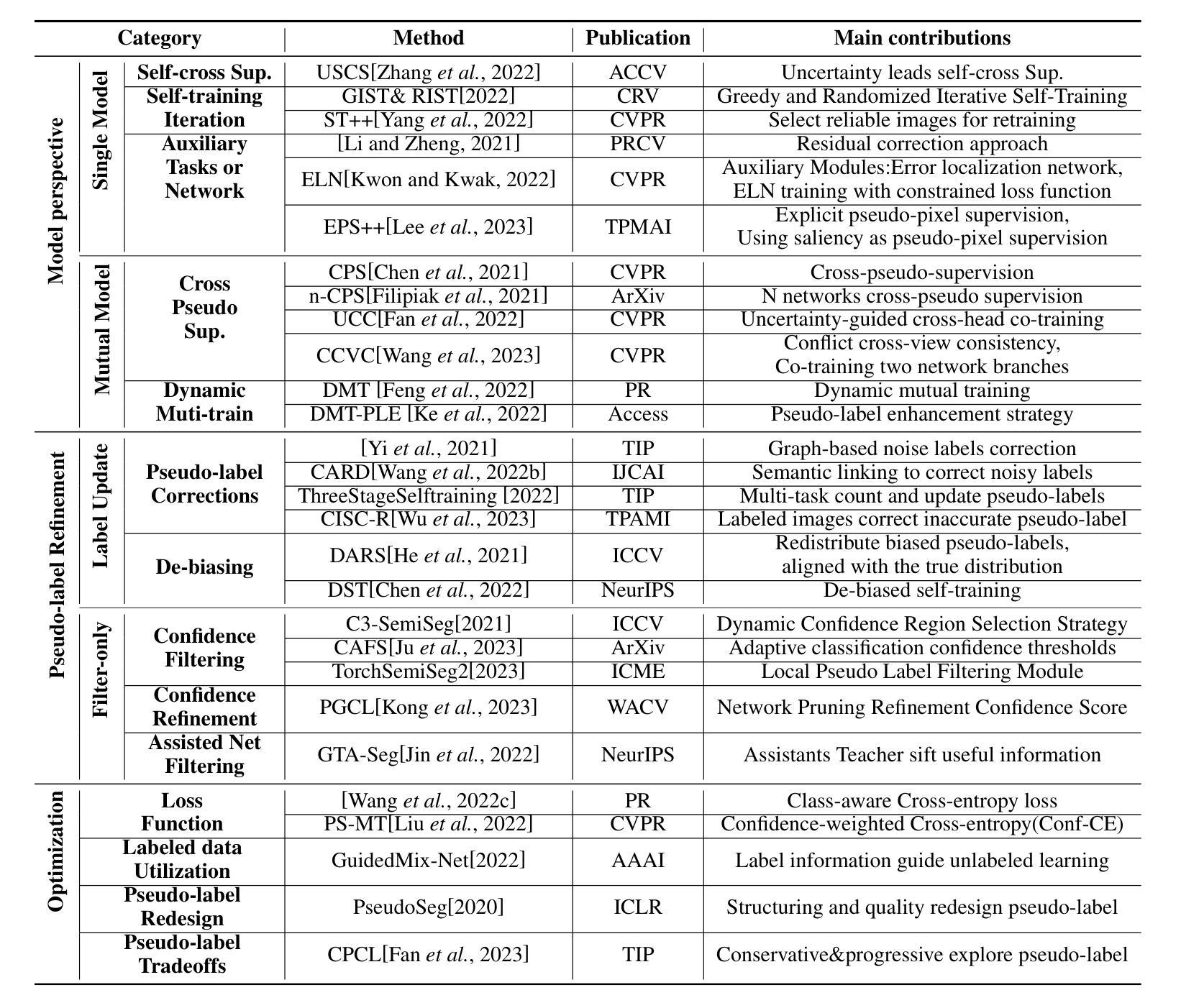
Mean Teacher (Tarvainen and Valpola, 2017): 提出了一种基于一致性正则化的半监督学习方法,通过在训练过程中使用教师模型的输出来指导学生模型。
Cross Pseudo Supervision (Chen et al., 2021): 提出了一种交叉伪监督方法,通过两个不同初始化的网络相互提供伪标签来提高模型性能。
Uncertainty-Guided Cross-Head Co-training (Fan et al., 2022): 利用不确定性引导的交叉头训练来提高模型的泛化能力。
Dynamic Mutual Training (Feng et al., 2022): 提出了一种动态互训练方法,通过比较两个不同模型的预测来识别标签错误,并动态调整训练过程中的权重损失。
Graph-based Noise Labels Correction (Yi et al., 2021): 引入了一种基于图的标签噪声检测和纠正框架,用于处理伪标签中的噪声问题。
Self-Cross Supervision (Zhang et al., 2022): 提出了一种不确定性引导的自交叉监督方法,用于半监督语义分割。
C3-SemiSeg (Zhou et al., 2021): 提出了一种动态置信度区域选择策略,用于在高置信度区域进行损失计算。
GuidedMix-Net (Tu et al., 2022): 提出了一种使用标签信息指导未标注样本学习的方法,以提高伪标签的质量。
PseudoSeg (Zou et al., 2020): 提出了一种结构化和质量设计的伪标签方法,通过结合来自分割模型输出和类激活图的伪标签来生成高质量的伪标签。
Conservative-Progressive Collaborative Learning (CPCL) (Fan et al., 2023): 从双模型互训练的角度出发,提出了一种保守分支和进步分支的方法,用于半监督语义分割。
这些研究涵盖了从模型结构设计、伪标签的生成和优化技术,到特定应用领域的具体方法,如医学图像分割和遥感图像分割。这些工作为半监督语义分割领域提供了丰富的理论和实践基础。
Q: 论文如何解决这个问题?
A: 论文通过以下几个主要方面来解决半监督语义分割中的伪标签问题:
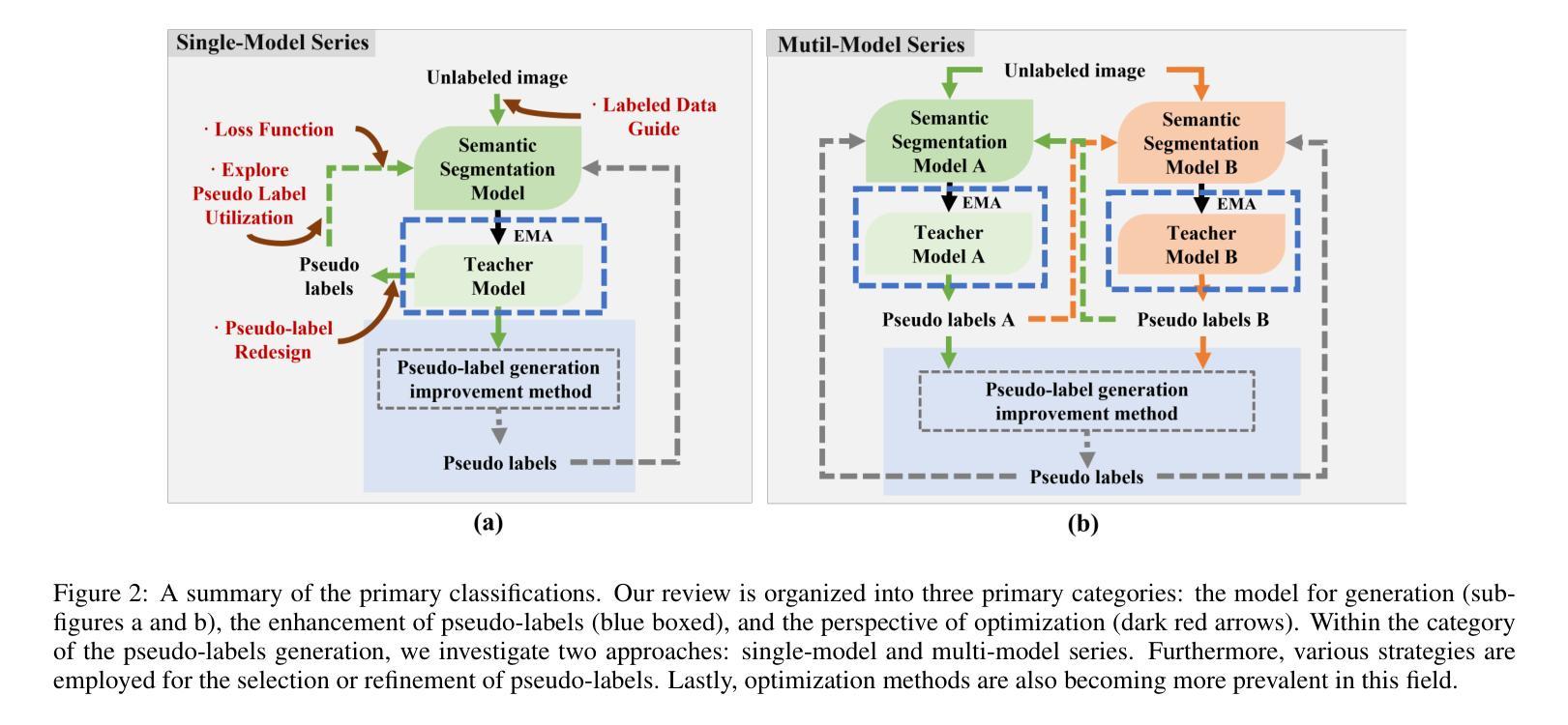
综述和分类:论文首先提供了一个全面的综述,将现有的伪标签方法从不同的角度进行分类,包括模型视角、伪标签的精炼以及优化措施。这有助于读者理解当前研究的多样性和各自的优势。
模型结构设计:论文探讨了单模型和多模型互训练方法。单模型方法依赖于单个模型生成伪标签,而多模型方法通过多个模型相互训练来提高性能。这些方法有助于提高模型的泛化能力和鲁棒性。
伪标签的精炼:为了提高伪标签的质量,论文讨论了标签更新和过滤方法。这些方法包括基于图的噪声标签纠正、置信度过滤以及辅助网络过滤等,旨在减少训练过程中的噪声和错误。
优化技术:论文还研究了一些新兴的优化技术,如损失函数的改进、伪标签的重新设计以及标签数据的有效利用。这些技术有助于提高模型在半监督学习环境下的性能。
特定应用领域的探讨:论文特别关注了伪标签技术在医学图像分割和遥感图像分割中的应用。这些领域通常面临标注数据稀缺的问题,伪标签方法在这些领域具有重要的应用价值。
挑战和未来研究方向:论文最后讨论了当前伪标签方法面临的挑战,并提出了未来研究的潜在方向,如基础模型的质量提升、额外信息的利用、主动选择和精细化过程的参与,以及在复杂分割场景中的应用探索。
通过这些方法,论文旨在提供一个结构化的框架,以促进半监督语义分割领域的研究,并为未来的研究提供指导。
Q: 论文做了哪些实验?
A: 论文本身是一个综述性质的工作,它并不包含原始的实验数据或实验结果。相反,它提供了对现有文献中关于半监督语义分割和伪标签方法的广泛研究的总结和分析。这些研究包括了各种实验设计、数据集、性能指标和模型架构的详细讨论。
论文中提到的实验通常涉及以下几个方面:
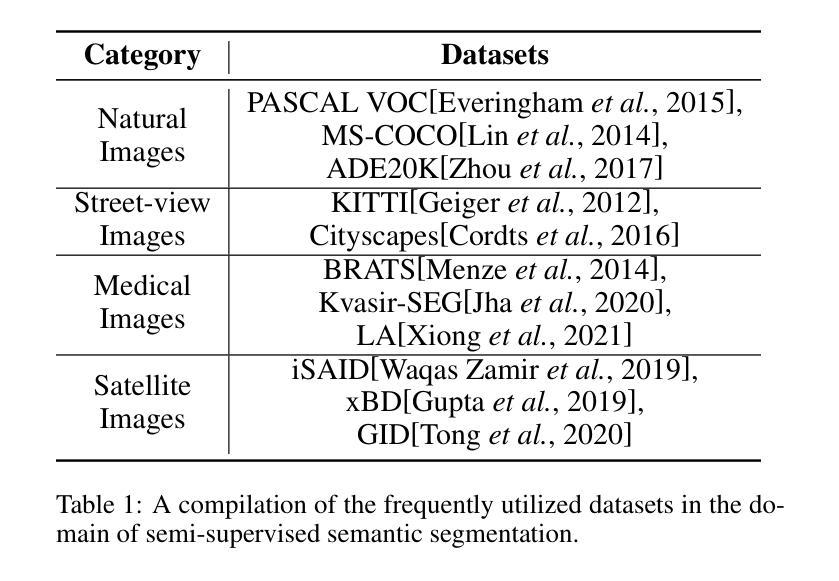
数据集:研究者们在不同的数据集上测试他们的方法,如PASCAL VOC、MS-COCO、ADE20K、KITTI、Cityscapes、BRATS、Kvasir-SEG、iSAID、xBD和GID等。
性能指标:使用像素准确率、平均准确率、平均交并比(mIoU)、加权交并比等指标来评估模型性能。
模型架构:研究者们提出了各种模型架构,包括单模型和多模型互训练方法,以及用于生成和优化伪标签的不同策略。
实验设置:包括模型训练的具体步骤、损失函数的选择、超参数的调整等。
结果分析:研究者们比较了他们的方法与其他现有方法的性能,讨论了伪标签方法的优势和局限性。
论文通过引用这些实验结果来支持对不同伪标签方法的讨论,并为读者提供了一个关于这些方法在实际应用中表现的全面视角。然而,具体的实验细节和结果需要查阅原始的研究论文。
Q: 有什么可以进一步探索的点?
A: 论文提出了几个可以进一步探索的研究方向,以应对当前伪标签方法在半监督语义分割中面临的挑战:
基础模型的质量提升:利用最新的基础模型,如Segment Anything Model (SAM),来提高伪标签的生成质量和模型的泛化能力。
额外信息的利用:探索如何将其他形式的监督信号整合到模型中,以便更有效地利用粗粒度和细粒度的标注数据。
主动选择和精细化过程:研究主动学习策略,选择最有信息量的样本进行标注,以提高模型训练的效率和效果。
复杂分割场景的探索:将伪标签方法应用于更广泛的现实世界场景,例如使用ADE20K等包含更多类别的数据集进行研究。
模型结构的创新:设计新的网络结构,以更好地适应半监督学习环境,提高模型对未标注数据的利用效率。
伪标签的改进:开发新的算法和技术来提高伪标签的准确性,减少噪声和错误标签的影响。
跨领域适应性:研究如何使伪标签方法在不同领域(如医学图像和遥感图像)之间具有更好的适应性和泛化能力。
不确定性建模:深入研究模型预测的不确定性,并探索如何利用这种不确定性来改进伪标签的生成和模型的训练。
多任务学习:考虑将伪标签方法与其他任务(如目标检测、实例分割等)结合起来,以实现更全面的视觉理解。
计算效率和资源优化:研究如何在保持模型性能的同时减少计算资源的需求,特别是在资源受限的环境中。
这些研究方向不仅有助于提高半监督语义分割的性能,还可能推动计算机视觉领域其他相关任务的发展。
Q: 总结一下论文的主要内容
A: 这篇论文提供了一个关于半监督语义分割中伪标签方法的全面综述。主要内容可以总结如下:
问题背景:介绍了语义分割的重要性以及在计算机视觉中的应用,同时指出了监督学习在数据需求和标注成本方面的挑战。
伪标签方法:详细讨论了伪标签技术作为一种有效的半监督学习方法,它通过生成伪标签来利用未标注数据,从而减少对大量标注数据的依赖。
研究分类:从模型结构、伪标签的精炼和优化技术三个角度对现有的伪标签方法进行了分类和综述。
模型结构:探讨了单模型和多模型互训练方法,以及它们在半监督语义分割中的应用。
伪标签精炼:分析了如何通过标签更新、过滤和去偏见等方法来提高伪标签的质量。
优化技术:讨论了损失函数、标签数据利用和伪标签设计的优化策略。
特定领域应用:探讨了伪标签技术在医学图像分割和遥感图像分割等特定领域的应用。
挑战与未来方向:指出了当前伪标签方法面临的挑战,并提出了未来研究的可能方向,如基础模型的质量提升、额外信息的利用、主动选择和精细化过程等。
结论:总结了伪标签方法在半监督语义分割中的研究进展,并强调了其在解决数据标注成本和提高模型泛化能力方面的潜力。
整体而言,这篇论文为读者提供了一个关于半监督语义分割中伪标签技术的深入理解,并为未来的研究方向提供了指导。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Multi-task Learning To Improve Semantic Segmentation Of CBCT Scans Using Image Reconstruction
Authors:Maximilian Ernst Tschuchnig, Julia Coste-Marin, Philipp Steininger, Michael Gadermayr
Semantic segmentation is a crucial task in medical image processing, essential for segmenting organs or lesions such as tumors. In this study we aim to improve automated segmentation in CBCTs through multi-task learning. To evaluate effects on different volume qualities, a CBCT dataset is synthesised from the CT Liver Tumor Segmentation Benchmark (LiTS) dataset. To improve segmentation, two approaches are investigated. First, we perform multi-task learning to add morphology based regularization through a volume reconstruction task. Second, we use this reconstruction task to reconstruct the best quality CBCT (most similar to the original CT), facilitating denoising effects. We explore both holistic and patch-based approaches. Our findings reveal that, especially using a patch-based approach, multi-task learning improves segmentation in most cases and that these results can further be improved by our denoising approach.
语义分割是医疗图像处理中的一项重要任务,对于分割器官或肿瘤等病变至关重要。本研究旨在通过多任务学习提高CBCTs的自动分割效果。为了评估不同体积质量的影响,我们从CT肝脏肿瘤分割基准测试集中合成了一个CBCT数据集。为了提高分割效果,我们调查了两种方法。首先,我们通过体积重建任务添加基于形态的正规化,以执行多任务学习。其次,我们使用此重建任务重建质量最佳的CBCT(最接近于原始CT),从而促进去噪效果。我们探索了整体和基于补丁的方法。我们的研究结果表明,特别是在使用基于补丁的方法时,多任务学习在大多数情况下都能提高分割效果,并且这些结果可以通过我们的去噪方法进一步改进。
论文及项目相关链接
PDF Accepted and presented at German Conference on Medical Image Computing (BVM) 2024 edit: During work on this publication Maximilian Ernst Tschuchnig was affiliated with Salzburg University of Applied Sciences and University of Salzburg
Summary
本摘要研究医学图像处理中的语义分割任务,针对CBCT(锥形束计算机断层扫描)图像的自动分割进行改进。该研究采用多任务学习技术,通过合成CBCT数据集评估不同体积质量的影响,并采用两种方法进行改进:一是通过体积重建任务添加基于形态的规则化;二是利用重建任务重建最接近原始CT的CBCT图像,以实现去噪效果。研究结果显示,采用基于补丁的方法的多任务学习在大多数情况下都能提高分割效果,而去噪方法能进一步提高结果。
Key Takeaways
以下是摘要中的关键要点:
- 研究集中于医学图像处理中的语义分割任务,特别是针对CBCT图像的自动分割改进。
- 采用多任务学习技术以提高分割效果。
- 通过合成CBCT数据集评估不同体积质量对分割的影响。
- 第一种方法是通过体积重建任务添加基于形态的规则化。
- 第二种方法利用重建任务实现去噪效果,以重建最接近原始CT的CBCT图像。
- 研究发现多任务学习在大多数情况下都能提高分割效果,特别是采用基于补丁的方法。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在医学图像处理中,特别是在锥形束计算机断层扫描(CBCT)图像的语义分割中提高自动化分割的准确性。具体来说,研究的目标是通过多任务学习来改善CBCT扫描的器官或病变(如肿瘤)的分割效果。研究中考虑了不同体积质量的影响,并探索了两种方法:一是利用体积重建任务通过多任务学习添加基于形态学的正则化;二是使用重建任务来重建最高质量的CBCT(与原始CT最相似),以实现去噪效果。
Q: 有哪些相关研究?
A: 论文中提到了以下相关研究:
nn-unet: Isensee等人提出的nn-unet是一个基于U-Net框架的自适应医学图像分割框架,它在多个CT分割任务中展现出了最先进的性能。[1]
UnetR 和 SegFormer: 这两个模型通过引入transformer块(如多头注意力)来扩展nn-unet的架构。[2] 和 [3]
多任务学习方法: Weninger等人和Mlynarski等人的研究探讨了通过添加重建任务或2D肿瘤检测评分任务来减少所需的标记训练数据量。[6] 和 [7]
这些研究为本文提出的多任务学习方法提供了理论基础和先前的技术路径。本文通过结合这些相关研究,提出了一个新的模型优化方法,即通过多任务学习进行分割和图像重建,以实现基于形态学的正则化,并在不同数据质量的CBCT数据集上进行实验验证。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决提高CBCT图像语义分割准确性的问题:
多任务学习框架:
- 引入多任务学习(MTL)框架,通过结合语义分割和图像重建任务来增强模型的正则化能力。
- 利用多任务学习共享不同任务之间的知识,以实现知识转移、正则化和数据效率。
模型优化:
- 将模型优化问题表述为通过多任务学习同时进行分割和图像重建。
- 通过添加一个额外的图像重建任务作为正则化项,来改善语义分割。
损失函数设计:
- 设计了一个综合损失函数,包括二元交叉熵(BCE)用于分割和L2损失用于重建。
- 损失函数公式为:[ \text{Loss} = \text{BCE}(\hat{s}, s) + l2(\hat{v}, v) ]
- 其中 ( s ) 是真实分割,( \hat{s} ) 是预测分割,( v ) 是当前图像,( \hat{v} ) 是重建图像。
数据集合成:
- 使用CT肝脏肿瘤分割基准(LiTS)数据集,并将其合成为不同质量的CBCT数据集,通过改变用于CT重建的投影数量。
去噪效果:
- 通过将重建目标设置为最高质量体积(( v_o )),进一步训练模型以去噪低视觉质量体积。
实验验证:
- 在LiTS数据集上进行实验,评估不同质量的CBCT数据集上的方法效果。
- 比较整体(holistic)和基于补丁(patch-based)的方法在肝脏和肝脏肿瘤分割上的表现。
结果分析:
- 分析多任务学习对于不同质量水平的CBCT图像分割的影响,并探讨多任务学习在整体和补丁方法中的效果差异。
通过这些步骤,论文展示了多任务学习可以改善3D语义分割的性能,尤其是在高分辨率、基于补丁的设置中。这种方法不仅提高了分割的准确性,还通过去噪效果进一步提升了模型性能。
Q: 论文做了哪些实验?
A: 论文中进行的实验包括以下几个方面:
数据集合成:
- 利用LiTS(Liver Tumor Segmentation Benchmark)数据集,将其转换为合成的CBCT(Cone-beam CT)扫描。通过模拟每个CT体积对应的投影,生成不同质量的CBCT体积,改变用于CT重建的投影数量 ( n_p ) 来控制质量。
多任务学习模型训练:
- 在3D nn-unet模型的基础上,添加多任务学习,训练模型同时进行语义分割和图像重建。
- 使用二元交叉熵(BCE)作为分割损失和L2作为重建损失,结合Dice损失,形成综合损失函数。
分割质量评估:
- 使用Dice分数评估模型的分割质量。
- 对模型输出应用0.5的阈值,将输出转换为二进制标签,然后计算Dice分数。
整体(Holistic)和基于补丁(Patch-based)的分割方法:
- 对肝脏和肝脏肿瘤分割进行整体和基于补丁的评估。
- 对于整体分割,将体积缩小2倍以适应NVIDIA RTX A6000显卡。
- 对于基于补丁的分割,从全尺寸CBCT数据中提取192×192×192大小的补丁,并在推理后重新聚合补丁分割结果。
不同质量水平的评估:
- 使用不同质量水平的CBCT数据集(基于投影数量)来评估模型和设置。
- 分析了两种重建目标设置:mt-c(使用当前质量的输入体积作为重建目标)和mt-b(始终使用最佳可能质量的输入体积作为重建目标)。
重复实验:
- 所有设置均训练和评估4次,以确保结果的稳定性,并使用相同的随机分割以便于结果比较。
训练-验证-测试数据集分离:
- 由于LiTS测试数据集没有标注,研究中忽略了测试数据集,并将原始训练数据集分离为训练-验证-测试数据,比例为0.7:0.2:0.1。
这些实验旨在验证多任务学习在不同数据质量水平和不同分割方法下对CBCT图像分割性能的影响。通过这些实验,论文展示了多任务学习可以提高分割性能,尤其是在高分辨率、基于补丁的设置中。
Q: 有什么可以进一步探索的点?
A: 论文在讨论部分提出了一些可以进一步探索的点,包括:
全分辨率整体方法:
- 论文建议未来的研究可以探索全分辨率的整体方法,以消除体积分辨率可能带来的混杂因素。这可以帮助更准确地评估多任务学习在不同设置下的效果。
不同质量水平的CBCT图像:
- 可以进一步研究不同质量水平的CBCT图像对分割性能的影响,以及多任务学习如何适应这些变化。
多任务学习在其他医学图像分割任务中的应用:
- 本研究的多任务学习方法可以应用于其他医学图像分割任务,以评估其普适性和有效性。
不同架构的比较:
- 可以探索不同的神经网络架构在多任务学习框架下的表现,以找到最适合特定任务的模型。
正则化技术:
- 研究不同的正则化技术如何影响多任务学习的性能,特别是在医学图像分割的背景下。
数据增强和合成技术:
- 进一步探索数据增强和合成技术在提高模型泛化能力和减少数据需求方面的作用。
计算效率和实际应用:
- 评估多任务学习模型在实际临床环境中的计算效率和实用性,特别是在资源受限的环境中。
不同疾病和病变类型的分割:
- 将多任务学习方法应用于不同类型的疾病和病变的分割任务,以验证其在不同医学领域的适用性。
模型解释性和可视化:
- 研究多任务学习模型的解释性,通过可视化技术理解模型是如何学习和整合不同任务的信息。
这些探索点可以帮助研究者更深入地理解多任务学习在医学图像分割中的应用,并推动该领域的进一步发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
研究背景:
- 论文强调了在医学图像处理中,语义分割对于识别和分割器官或病变(如肿瘤)的重要性。
- 传统的分割方法在处理复杂的病理和解剖结构时存在局限性,而深度学习方法,尤其是基于编码器-解码器模型的U-Net结构,已成为语义分割的先进方法。
多任务学习的应用:
- 论文提出了通过多任务学习(MTL)来提高CBCT图像的自动化分割质量,通过添加基于形态学的正则化和去噪效果。
- 多任务学习旨在通过共享多个任务的知识来提高模型的泛化能力和数据效率。
方法论:
- 论文介绍了一种模型不可知的方法,通过结合语义分割和图像重建任务来优化模型。
- 使用了3D nn-unet作为基线模型,并在此基础上添加了多任务学习,通过结合二元交叉熵(BCE)和L2损失来训练模型。
数据集和实验设置:
- 使用LiTS数据集,并将其转换为不同质量的CBCT扫描,以评估不同数据质量对分割效果的影响。
- 实验包括整体和基于补丁的分割方法,并使用Dice分数来评估分割质量。
实验结果:
- 实验结果显示,多任务学习在大多数情况下可以改善分割效果,尤其是基于补丁的方法。
- 使用最高质量的CBCT作为重建目标可以进一步改善分割效果,表明去噪效果是有益的。
讨论和未来工作:
- 论文讨论了多任务学习在整体和基于补丁的方法中的效果差异,并提出了未来研究的方向,包括探索全分辨率整体方法和多任务学习在其他医学图像分割任务中的应用。
结论:
- 论文得出结论,多任务学习可以通过添加图像重建任务来改善3D语义分割,尤其是在高分辨率、基于补丁的设置中。
致谢:
- 论文最后感谢了奥地利研究促进署(FFG)和萨尔茨堡州对项目的资金支持。
这篇论文通过实验验证了多任务学习在提高CBCT图像分割准确性方面的潜力,并为未来的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

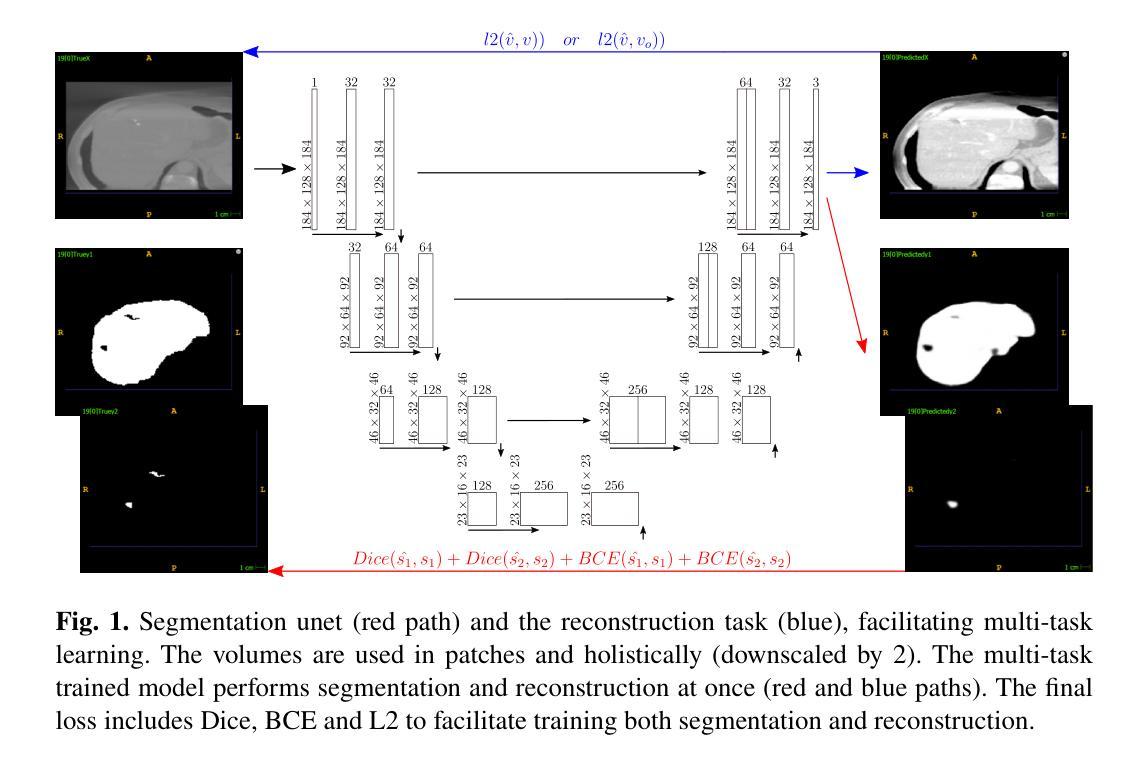
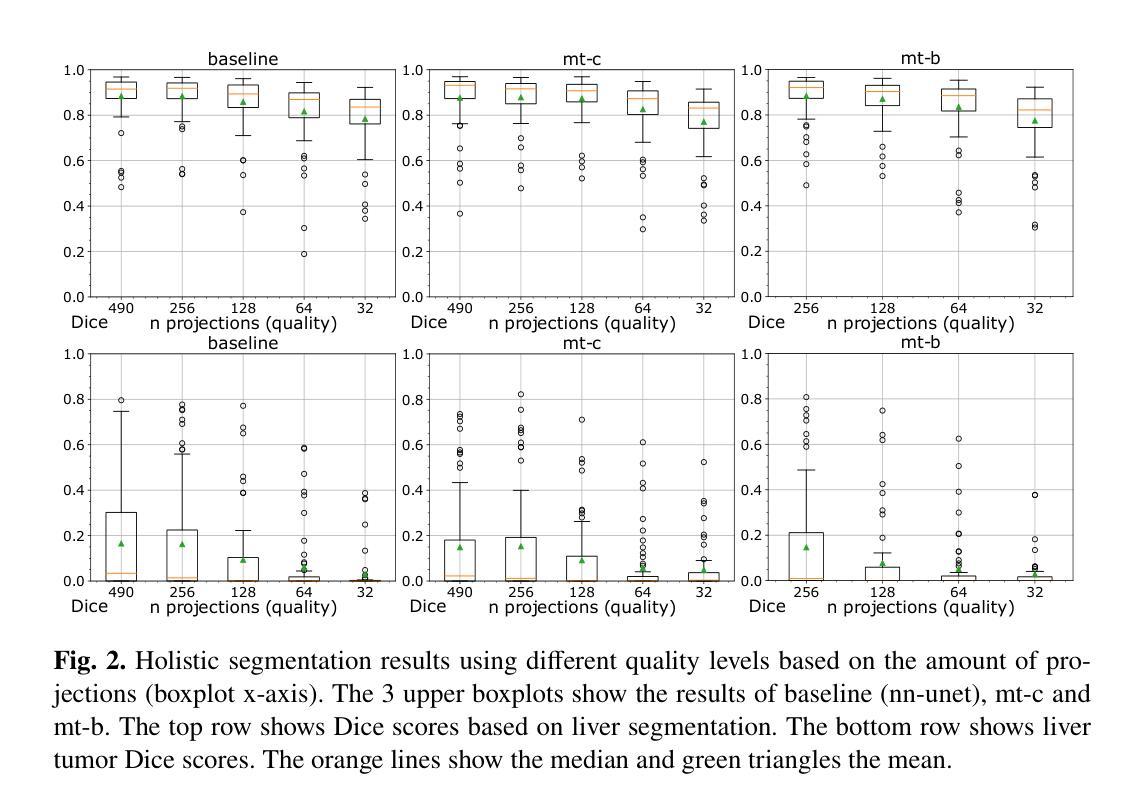
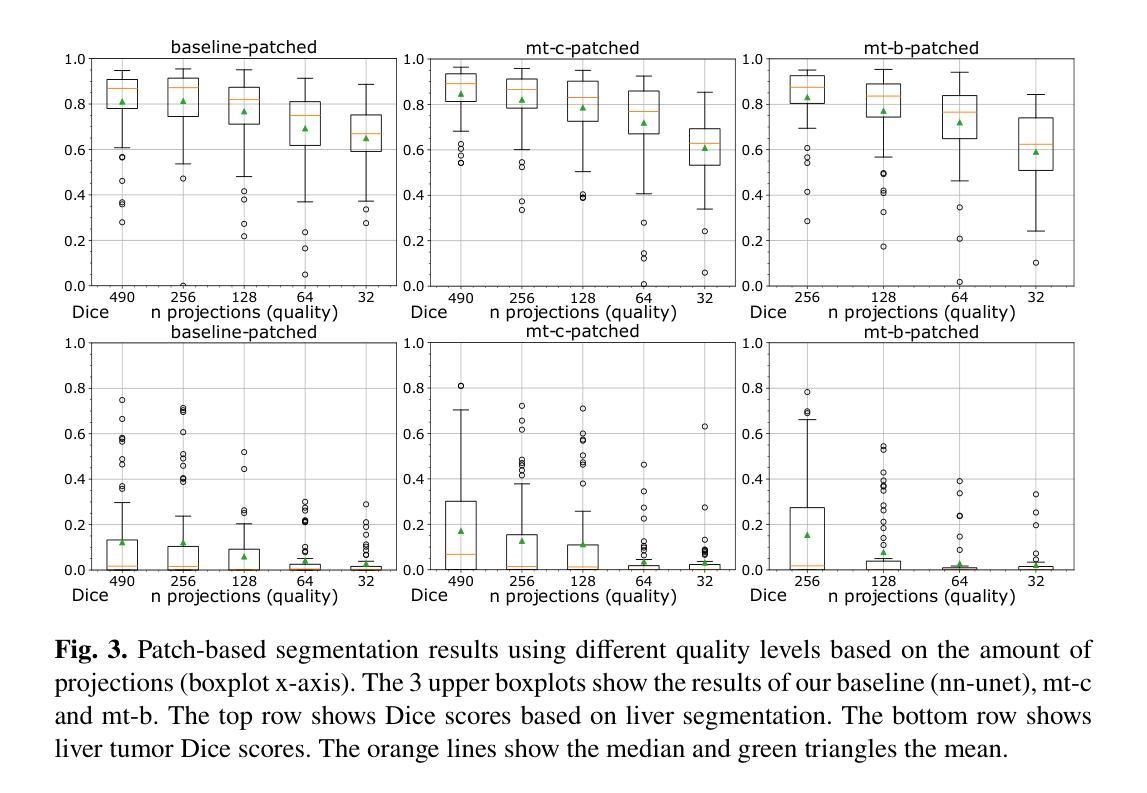
Image Augmentation with Controlled Diffusion for Weakly-Supervised Semantic Segmentation
Authors:Wangyu Wu, Tianhong Dai, Xiaowei Huang, Fei Ma, Jimin Xiao
Weakly-supervised semantic segmentation (WSSS), which aims to train segmentation models solely using image-level labels, has achieved significant attention. Existing methods primarily focus on generating high-quality pseudo labels using available images and their image-level labels. However, the quality of pseudo labels degrades significantly when the size of available dataset is limited. Thus, in this paper, we tackle this problem from a different view by introducing a novel approach called Image Augmentation with Controlled Diffusion (IACD). This framework effectively augments existing labeled datasets by generating diverse images through controlled diffusion, where the available images and image-level labels are served as the controlling information. Moreover, we also propose a high-quality image selection strategy to mitigate the potential noise introduced by the randomness of diffusion models. In the experiments, our proposed IACD approach clearly surpasses existing state-of-the-art methods. This effect is more obvious when the amount of available data is small, demonstrating the effectiveness of our method.
弱监督语义分割(WSSS)旨在仅使用图像级标签来训练分割模型,已引起广泛关注。现有方法主要关注利用可用图像及其图像级标签生成高质量伪标签。然而,当可用数据集大小有限时,伪标签的质量会显著下降。因此,本文从一个不同的角度解决这个问题,引入了一种称为受控扩散图像增强(IACD)的新方法。该框架通过受控扩散生成各种图像,有效地扩充了现有标记数据集,其中可用图像和图像级标签作为控制信息。此外,我们还提出了一种高质量图像选择策略,以减轻扩散模型随机性引入的潜在噪声。在实验中,我们提出的IACD方法明显超越了现有的最先进方法。当可用数据量较小时,这种效果更为明显,证明了我们方法的有效性。
论文及项目相关链接
PDF Accepted by ICASSP 2024
Summary
本文提出了一种新的图像增强方法——受控扩散图像增强(IACD),用于扩充有限的标注数据集。该方法利用已有的图像和图像级别的标签作为控制信息,通过受控扩散生成多样化的图像。同时,还提出了一种高质量图像选择策略,以减少扩散模型随机性引入的潜在噪声。实验表明,在数据量有限的情况下,IACD方法明显优于现有最先进的方法,验证了其有效性。
Key Takeaways
- 提出了一种新的图像增强方法——受控扩散图像增强(IACD),旨在扩充有限的标注数据集。
- 利用已有的图像和图像级别的标签作为控制信息,通过扩散过程生成多样化图像。
- 引入了高质量图像选择策略,以减少扩散模型的随机性可能带来的噪声。
- IACD方法在数据量有限的情况下表现更优秀。
- 该方法在弱监督语义分割(WSSS)领域具有潜在应用价值。
- 通过实验验证了IACD方法的有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决弱监督语义分割(Weakly-supervised Semantic Segmentation, WSSS)中的问题,即如何仅使用图像级别的标签来训练分割模型。具体来说,论文中提到现有方法主要集中于使用可用图像及其图像级标签生成高质量的伪标签,但当可用数据集的大小受限时,伪标签的质量会显著下降。因此,这篇论文提出了一种名为“Image Augmentation with Controlled Diffusion (IACD)”的新方法,通过控制扩散生成多样化的图像来有效地扩充现有的标记数据集,其中可用的图像和图像级标签作为控制信息。此外,论文还提出了一种高质量的图像选择策略,以减少扩散模型随机性引入的潜在噪声。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与本研究相关的研究工作:
注入类别信息到网络中:
- Zhaozhi Xie 和 Hongtao Lu 提出了一种探索类别一致性的方法,用于弱监督语义分割 [1]。
- Yu-Ting Chang 等人通过子类别探索来进行弱监督语义分割 [2]。
在现有训练数据上进行额外信息学习:
- 一些工作致力于优化网络结构以更好地适应弱监督场景下的学习,例如 Simone Rossetti 等人使用最大池化和视觉变换器(Vision Transformers)进行弱监督语义分割 [3]。
- Lian Xu 等人提出的多类别令牌变换器(Multi-class Token Transformer)用于弱监督语义分割 [4]。
- Lixiang Ru 等人提出的从注意力中学习亲和性(Learning Affinity from Attention)的方法,用于端到端的弱监督语义分割 [5]。
优化网络结构:
- 除了信息注入和信息学习之外,一些研究致力于优化网络结构以适应弱监督学习场景,如 Wangyu Wu 等人提出的 Top-k 池化与补丁对比学习的方法 [6]。
深度生成模型:
- 论文中提到了扩散概率模型(Diffusion Probabilistic Model, DPM)作为解决上述问题的一个有吸引力的选择,这类模型在计算机视觉领域最近变得突出 [7, 8, 9, 10]。
- 特别地,提到了 Stable Diffusion 与 ControlNet 结合使用来生成高质量的合成图像 [11, 12]。
这些相关研究为本文提出的 IACD 方法提供了理论基础和技术支持,特别是在生成高质量伪标签和优化弱监督语义分割模型性能方面。
Q: 论文如何解决这个问题?
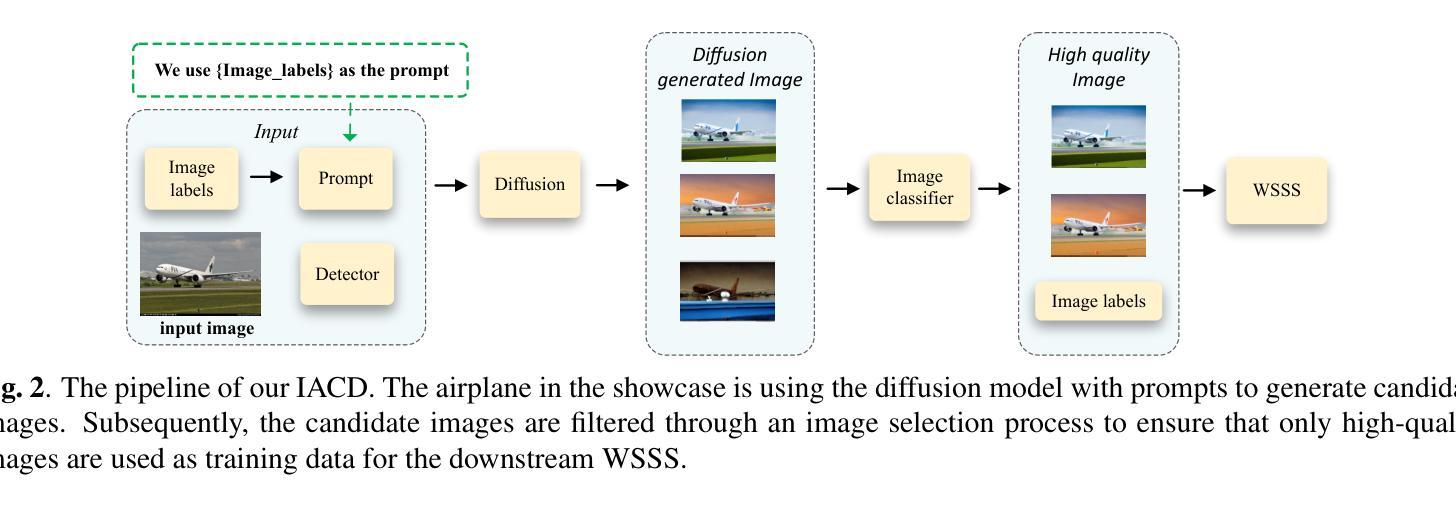
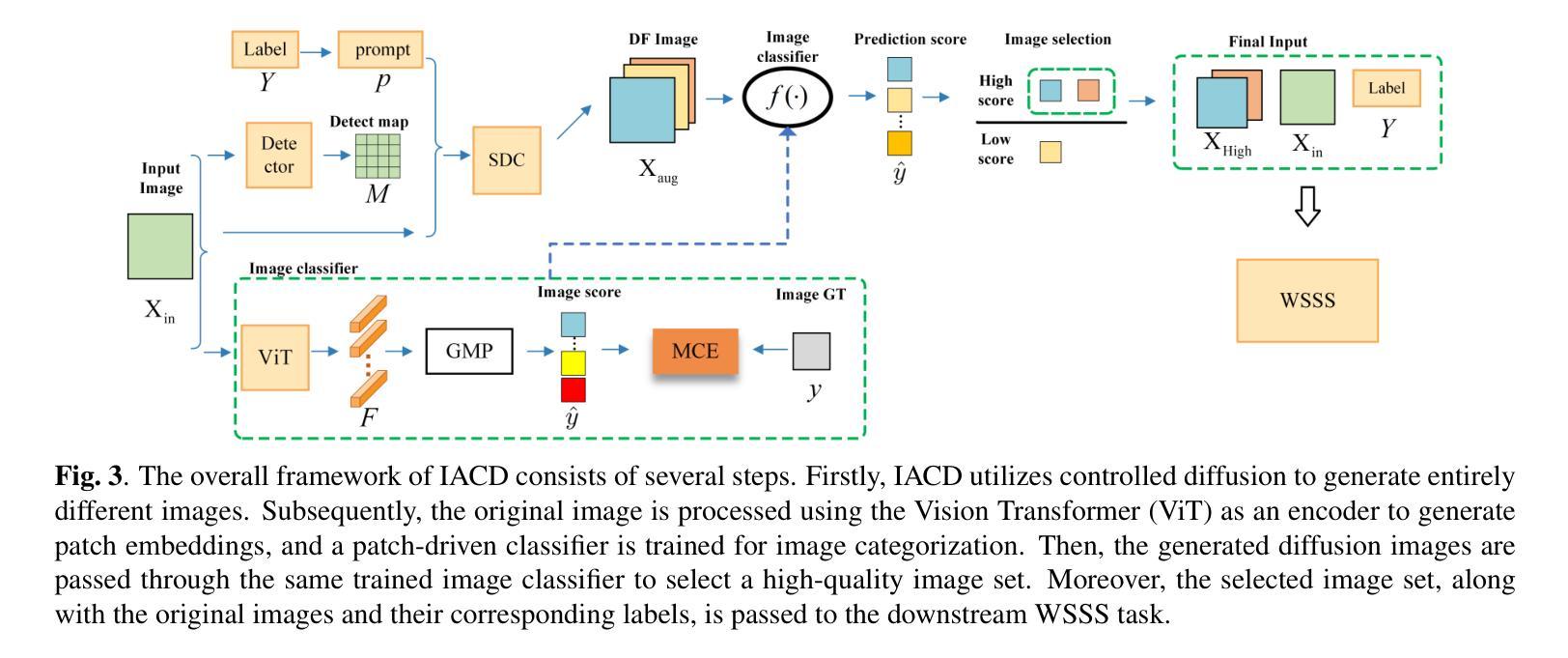
A: 论文通过以下步骤解决弱监督语义分割(WSSS)中数据量受限导致伪标签质量下降的问题:
1. 提出IACD框架
论文提出了一种名为Image Augmentation with Controlled Diffusion (IACD)的新方法。该框架利用扩散模型基于现有图像和图像级标签生成多样化的合成图像,以此扩充训练数据集。
2. 控制扩散模型
- 使用Stable Diffusion与ControlNet(SDC)作为生成模型,基于输入图像、文本提示和检测图生成新的训练数据。
- 文本提示由相应的图像级标签Y构成,检测图作为额外条件控制生成结果。
3. 高质量图像选择策略
- 为了确保用于训练的合成数据的质量,提出了一种选择策略,通过训练一个基于Vision Transformer(ViT)的图像分类器来选择高质量的生成样本。
- 通过全局最大池化(GMP)选择每个类别中所有块的最高预测分数,并使用这些分数来评估图像级别的分类。
- 只有当生成的图像的预测标签是输入图像标签的子集时,该生成样本才会被添加到合成数据集中。
4. 最终训练数据集的构建
- 将选定的高质量生成训练样本与原始数据集合并,形成扩展的数据集用于WSSS的训练。
5. 实验验证
- 在PASCAL VOC 2012数据集上进行实验,通过比较不同训练数据规模下的性能,验证了IACD方法在数据量较小时尤其有效。
- 与现有最先进方法的性能比较,展示了IACD方法在不同训练数据规模下的性能提升。
通过这些步骤,论文成功地展示了如何通过引入基于条件扩散的数据增强模块和高质量的图像选择模块来提升WSSS的性能,尤其是在训练数据受限的情况下。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来验证所提出的IACD方法的有效性。以下是实验的详细情况:
1. 实验设置
- 数据集:使用PASCAL VOC 2012数据集,包含21个类别,包括额外的背景类别。该数据集通常与SBD数据集一起使用进行训练,总共使用了10,582张图像进行训练和1,449张图像进行验证。
- 评估指标:使用平均交并比(mean Intersection-Over-Union, mIoU)作为评估标准。
- 训练数据量变化:评估了在原始训练数据量从100%逐渐减少到5%时IACD方法的性能。
2. 实现细节
- 使用ViT-B/16作为ViT模型,使用稳定扩散模型与ControlNet作为扩散模型。
- 图像在训练过程中被调整为384×384像素。
- 模型以16的批量大小训练,最多80个epoch。
- 图像选择阈值ϵ设置为0.9。
- 使用Canny Edge和Openpose作为ControlNet的检测器,总共20个扩散步骤。
- 由于计算资源限制,在实验中额外生成了10,582张图像。
3. 与现有技术的比较
- 不同训练数据百分比的比较:展示了IACD方法在不同训练数据规模下的性能提升。
- 使用伪掩码训练的性能比较:将IACD方法应用于当前最先进的ViT-PCM框架,并与现有技术进行比较。
4. 定性分割结果的比较
- 展示了使用IACD方法与ViT-PCM框架结合后的定性分割结果,并与原始ViT-PCM框架的结果进行比较。
5. 消融研究
- 对数据增强模块和高质量图像选择模块进行了消融研究,以验证这两个关键贡献对性能的影响。
通过这些实验,论文证明了IACD方法在弱监督语义分割任务中的有效性,特别是在训练数据量受限的情况下。实验结果表明,IACD方法能够显著提高分割性能,并在数据量较小时效果更加明显。
Q: 有什么可以进一步探索的点?
A: 基于论文内容,以下是一些可以进一步探索的点:
1. 扩散模型的改进和优化
- 探索不同类型的扩散模型或其变体,以提高生成图像的质量和多样性。
- 研究如何进一步控制扩散过程,以生成更符合特定任务需求的图像。
2. 图像选择策略的优化
- 研究更先进的图像选择或过滤策略,以进一步提高合成数据集的质量。
- 探索结合其他类型的图像特征或深度学习模型来提升图像选择的准确性。
3. 多模态融合技术
- 考虑将文本、图像以及其他模态数据(如音频或视频)融合,以增强模型的理解和泛化能力。
4. 跨领域应用
- 将IACD方法应用于其他领域,如医学图像分割、遥感图像分析等,验证其跨领域的有效性和适用性。
5. 更大规模数据集的测试
- 在更大规模和更复杂的数据集上测试IACD方法,以评估其在处理大规模数据时的性能和可扩展性。
6. 计算效率和资源优化
- 研究如何优化IACD框架以减少计算资源消耗,使其更适合在资源受限的环境中部署。
7. 模型鲁棒性和安全性
- 探索对抗性攻击对IACD方法的影响,并研究如何提升模型的鲁棒性。
- 考虑模型在实际应用中的安全性和隐私保护问题。
8. 半监督和无监督学习
- 研究如何将IACD方法扩展到半监督或无监督学习场景,减少对标注数据的依赖。
9. 模型解释性和可视化
- 提供模型内部工作机制的解释,通过可视化技术展示模型如何学习和生成图像。
10. 实时应用和系统集成
- 探索将IACD方法集成到实时应用中的可能性,如自动驾驶、机器人导航等。
这些探索点可以帮助研究者更深入地理解IACD方法的潜力和局限性,并推动弱监督语义分割技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为Image Augmentation with Controlled Diffusion (IACD)的新方法,用于弱监督语义分割(WSSS)。以下是论文的主要内容总结:
1. 问题背景
- 弱监督语义分割(WSSS)旨在仅使用图像级标签来训练分割模型。
- 现有方法主要集中于生成高质量的伪标签,但当可用数据集规模有限时,伪标签质量会显著下降。
2. IACD方法
- 框架:IACD利用扩散模型基于现有图像和图像级标签生成多样化的合成图像,扩充训练数据集。
- 控制扩散:使用Stable Diffusion与ControlNet生成新的训练数据,输入包括图像、文本提示和检测图。
- 图像选择:引入基于Vision Transformer的图像分类器来选择高质量的生成样本,过滤低质量图像,保证数据质量。
3. 实验验证
- 在PASCAL VOC 2012数据集上进行实验,评估不同训练数据规模下的性能。
- 与现有最先进方法的性能比较,展示了IACD方法在数据量较小时尤其有效。
- 进行消融研究,验证了数据增强和高质量图像选择两个关键贡献的有效性。
4. 主要贡献
- 提出了一种新的基于条件扩散的数据增强方法来提升WSSS性能。
- 提出了一种高质量的图像选择策略,有效过滤低质量生成图像,防止对模型训练的负面影响。
- 实验结果表明,IACD方法在不同训练数据规模下均优于现有最先进方法,尤其是在数据量较小时性能提升更明显。
5. 结论
- IACD方法通过引入扩散模型和高质量图像选择模块,有效地增强了WSSS任务中的训练数据,提高了分割性能。
这篇论文为弱监督语义分割领域提供了一种新的数据增强策略,通过生成高质量的合成图像来扩充有限的训练数据集,从而提高了模型的性能和泛化能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图




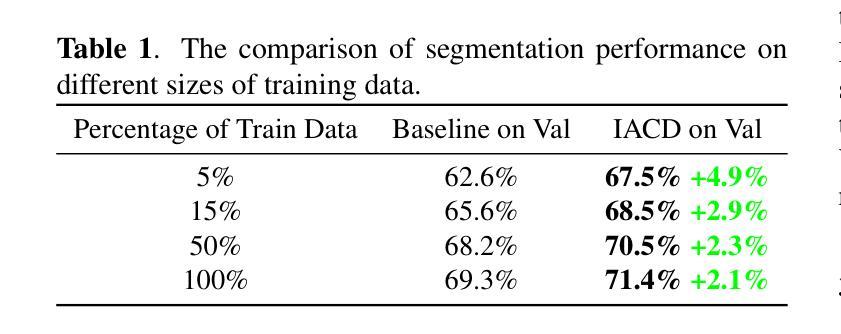


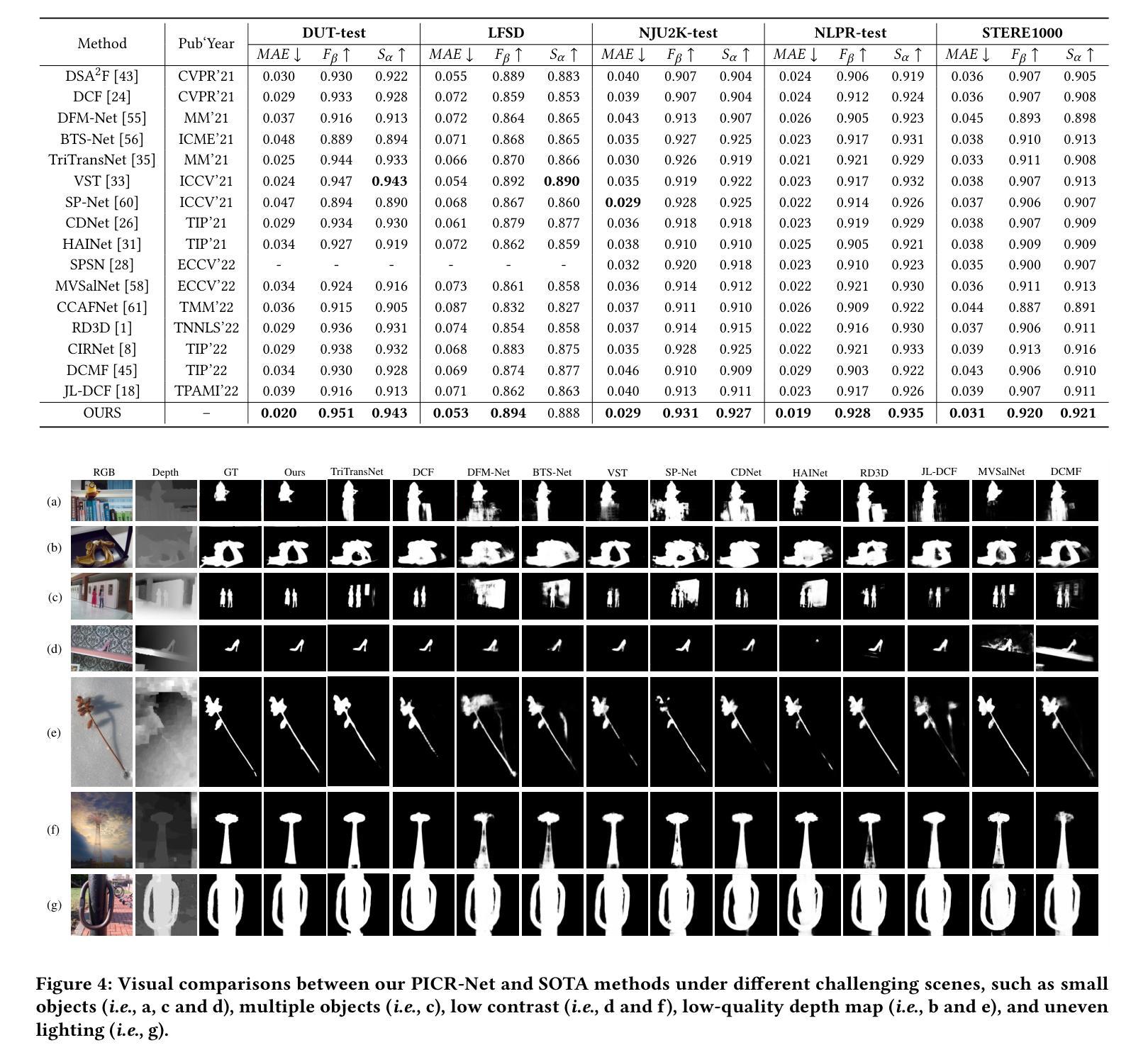
Point-aware Interaction and CNN-induced Refinement Network for RGB-D Salient Object Detection
Authors:Runmin Cong, Hongyu Liu, Chen Zhang, Wei Zhang, Feng Zheng, Ran Song, Sam Kwong
By integrating complementary information from RGB image and depth map, the ability of salient object detection (SOD) for complex and challenging scenes can be improved. In recent years, the important role of Convolutional Neural Networks (CNNs) in feature extraction and cross-modality interaction has been fully explored, but it is still insufficient in modeling global long-range dependencies of self-modality and cross-modality. To this end, we introduce CNNs-assisted Transformer architecture and propose a novel RGB-D SOD network with Point-aware Interaction and CNN-induced Refinement (PICR-Net). On the one hand, considering the prior correlation between RGB modality and depth modality, an attention-triggered cross-modality point-aware interaction (CmPI) module is designed to explore the feature interaction of different modalities with positional constraints. On the other hand, in order to alleviate the block effect and detail destruction problems brought by the Transformer naturally, we design a CNN-induced refinement (CNNR) unit for content refinement and supplementation. Extensive experiments on five RGB-D SOD datasets show that the proposed network achieves competitive results in both quantitative and qualitative comparisons.
通过将RGB图像和深度图的互补信息整合,能够提升复杂且具有挑战性的场景中显著目标检测(SOD)的能力。近年来,卷积神经网络(CNNs)在特征提取和跨模态交互中的重要作用已被充分探索,但在建模自模态和跨模态的全局长距离依赖方面仍显不足。为此,我们引入了CNN辅助的Transformer架构,并提出了一种新型的RGB-D SOD网络,名为带有点感知交互和CNN引导精修的PICR-Net。一方面,考虑到RGB模态和深度模态之间的先验相关性,我们设计了注意力触发的跨模态点感知交互(CmPI)模块,以探索具有位置约束的不同模态的特征交互。另一方面,为了缓解Transformer自然带来的块效应和细节破坏问题,我们设计了一个CNN引导的精修(CNNR)单元,用于内容精修和补充。在五个RGB-D SOD数据集上的广泛实验表明,所提出网络在定量和定性比较中都取得了具有竞争力的结果。
论文及项目相关链接
PDF Accepted by ACM MM 2023
Summary
融合RGB图像和深度图的信息,提升显著目标检测(SOD)在复杂和具有挑战性的场景下的能力。虽然卷积神经网络(CNN)在特征提取和跨模态交互中的作用已被充分探索,但在建模自模态和跨模态的全局长距离依赖方面仍显不足。为此,我们引入了CNN辅助的Transformer架构,并提出了一种新型RGB-D SOD网络,具有点感知交互和CNN诱导细化(PICR-Net)。一方面,考虑到RGB模态和深度模态之间的先验相关性,设计了注意力触发的跨模态点感知交互(CmPI)模块,以探索不同模态的特征交互及位置约束。另一方面,为了缓解Transformer带来的块效应和细节破坏问题,我们设计了CNN诱导的细化(CNNR)单元进行内容细化和补充。在五个RGB-D SOD数据集上的广泛实验表明,该网络在定量和定性比较中均取得了有竞争力的结果。
Key Takeaways
- 通过融合RGB图像和深度图的信息,增强了显著目标检测在复杂场景中的性能。
- 虽然CNN在特征提取和跨模态交互中的作用被充分探索,但在处理全局长距离依赖方面仍有不足。
- 引入CNN辅助的Transformer架构,提出了一种新的RGB-D SOD网络PICR-Net。
- 设计的CmPI模块考虑到了RGB模态和深度模态之间的先验相关性,并探索了不同模态的特征交互及位置约束。
- 为了解决Transformer带来的块效应和细节破坏问题,引入了CNNR单元进行内容细化和补充。
- 在多个数据集上的实验表明,该网络在显著目标检测方面取得了有竞争力的结果。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决RGB-D(红绿蓝-深度)图像中的显著目标检测(Salient Object Detection, SOD)问题。具体来说,论文旨在通过整合RGB图像和深度图的互补信息来提高复杂和具有挑战性场景下显著目标检测的能力。论文指出,尽管卷积神经网络(CNNs)在特征提取和跨模态交互方面发挥了重要作用,但在建模自模态和跨模态的全局长距离依赖关系方面仍然存在不足。因此,论文提出了一种新的基于CNNs辅助的Transformer架构的网络,称为PICR-Net(Point-aware Interaction and CNN-induced Refinement Network),以改进RGB-D SOD任务的性能。
Q: 有哪些相关研究?
A: 论文中提到了多个与RGB-D显著目标检测(SOD)相关的研究工作,这些研究可以大致分为以下几个类别:
基于深度学习的RGB-D SOD模型:
- 在Vision Transformer出现之前,RGB-D SOD任务主要使用CNN作为主流架构,提出了多种模型,涉及跨模态交互、深度质量感知和轻量级设计等方面。
纯CNN架构:
- 例如,Zhang等人[51]设计了一个跨模态不一致交互策略,以实现RGB-D SOD任务中的高效融合。
- Cong等人[2]考虑了RGB-D SOD任务中深度图的质量,并提出了一个深度潜力感知的门控注意力网络来解决低质量深度图的负面影响。
- Chen等人[1]使用3-D卷积层堆叠作为编码器来实现RGB-D SOD,可以有效地融合跨模态特征,无需专门的或复杂的模块。
纯Transformer架构:
- Liu等人[33]从序列到序列建模的新视角为RGB-D SOD任务设计了一个纯Transformer架构,其中使用交叉注意力进行跨模态交互。
Transformer辅助的CNN架构:
- Song等人[42]充分利用自注意力和交叉注意力进行RGB-D SOD任务中的外观特征和几何特征之间的交互。
- Liu等人[35]在CNN之后嵌入Transformer以模拟卷积特征之间的长距离依赖关系,并同时实现融合。
其他相关研究:
- 包括一些早期的基于手工特征的方法,以及一些探索不同架构和方法的研究,如跨模态特征融合策略、深度图质量感知等。
这些相关研究为本文提出的PICR-Net提供了背景和对比,展示了RGB-D SOD领域的研究进展和挑战。论文通过对比这些方法,展示了其提出方法在性能和效率方面的优势。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为PICR-Net(Point-aware Interaction and CNN-induced Refinement Network)的新型网络架构来解决RGB-D显著目标检测(SOD)问题。这个网络架构综合利用了Transformer和CNN的特点,具体解决方案包括以下几个关键点:
1. CNNs-assisted Transformer架构
- 整体结构:PICR-Net遵循编码器-解码器结构,主要基于Transformer构建,同时在网络末尾加入了一个可插拔的CNN诱导细化(CNNR)单元,用于细节内容的精细化和补充。
2. 跨模态点感知交互模块(CmPI)
- 点感知交互:考虑到RGB图像和深度图之间的先行关联性,设计了一个基于注意力触发的跨模态点感知交互(CmPI)模块,通过位置约束探索不同模态特征之间的交互。
- 全局引导向量:引入全局显著性引导向量以强调全局约束,使得交互更加全面。
3. CNN诱导细化单元(CNNR)
- 细节补充:为了减轻Transformer结构带来的块效应和细节破坏问题,设计了CNNR单元用于内容细化和补充。
- 特征融合:利用预训练的VGG16模型提供更高分辨率和更丰富的细节特征,以生成最终的高质量显著性图。
4. 损失函数
- 混合损失:网络通过结合二元交叉熵损失、SSIM损失和交并比损失的混合损失进行监督,以获得高质量且边界清晰的显著性图。
5. 实验验证
- 数据集和评估指标:使用五个广泛使用的RGB-D SOD基准数据集进行性能评估,并采用F-measure、MAE和S-measure等常用指标进行定量评估。
- 与现有技术的比较:与16种最先进的方法进行比较,展示了PICR-Net在定量和定性方面的性能优势。
通过上述方法,论文提出的PICR-Net能够有效地结合RGB和深度信息,提高复杂场景下显著目标检测的准确性和鲁棒性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出PICR-Net网络的性能和有效性。具体实验包括:
数据集和评估指标:
- 使用了五个广泛使用的RGB-D SOD基准数据集进行评估,包括NLPR、NJU2K、LFSD、STERE1000和DUT。
- 采用的评估指标包括S-measure(结构相似性度量)、F-measure(包括精确度和召回率的加权调和平均)和MAE(平均绝对误差)。
与现有技术的比较:
- 将PICR-Net与16种最先进的方法进行了比较,包括纯CNN架构、纯Transformer架构和Transformer辅助CNN架构的方法。
- 在五个数据集上进行了定量评估,并在表1中展示了S-measure、F-measure和MAE分数的比较结果。
定性比较:
- 在图4中展示了PICR-Net与其他一些最先进方法在不同挑战性场景下的可视化比较结果,包括小目标、多目标、低对比度、低质量深度图和不均匀光照等情况。
消融研究:
- 对PICR-Net的不同组件和设计细节进行了消融研究,以验证每个模块和设计选择的有效性。
- 在表3和表4中展示了不同消融实验的定量结果,并在图5和图6中提供了一些可视化的消融研究结果。
推理速度评估:
- 在表2中评估了PICR-Net和其他一些典型最先进方法的推理速度,以证明PICR-Net在保持高性能的同时也能保持较快的推理速度。
超参数设置和不同融合阶段的评估:
- 在附录A中,论文还探讨了注意力掩码中-100这一超参数的效果,并通过表5展示了不同设置下的性能比较。
- 论文还评估了在编码器阶段与解码器阶段进行跨模态融合的效果,并通过表6展示了不同融合阶段的性能比较。
通过这些实验,论文全面地验证了PICR-Net在RGB-D显著目标检测任务上的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的PICR-Net在RGB-D显著目标检测方面取得了较好的性能,但仍有一些可以进一步探索的点:
实时性能优化:
- 尽管PICR-Net在推理速度上已经优于一些现有的SOTA模型,但仍未达到实时效率。未来的工作可以探索更高效的网络架构或压缩技术以提高模型的推理速度。
更深层次的特征融合:
- 论文中主要在解码阶段进行了跨模态特征的交互。未来的研究可以探索在编码阶段引入更深层次的特征融合策略,以更有效地结合RGB和深度信息。
注意力机制的改进:
- 虽然CmPI模块通过引入位置约束和全局引导向量提高了交互效率,但注意力机制本身仍有改进空间,如引入动态权重或自适应调整策略以更好地捕捉跨模态关系。
多模态数据的联合训练:
- 论文中提到了利用预训练的VGG16模型来提供细节信息,未来的工作可以探索如何更有效地结合多模态数据进行联合训练,以提高模型对不同模态信息的融合和理解能力。
模型的泛化能力:
- 进一步研究模型在不同场景、不同质量的深度图和复杂背景下的泛化能力,以及如何提高模型在这些情况下的鲁棒性。
损失函数的改进:
- 虽然论文采用了混合损失函数来优化模型性能,但可以进一步探索更有效的损失函数,以更好地指导模型学习显著目标的准确表示。
网络结构的简化和优化:
- 研究如何简化网络结构,减少参数数量,同时保持或提高模型性能,这对于实际应用中的模型部署具有重要意义。
多任务学习:
- 探索将显著目标检测与其他视觉任务(如目标识别、场景分割)结合的多任务学习框架,以提高模型的整体性能和应用范围。
无监督或弱监督学习:
- 研究无监督或弱监督学习策略,以减少对大量标注数据的依赖,降低数据准备的成本。
这些方向不仅可以推动RGB-D显著目标检测技术的发展,也可能为其他计算机视觉任务提供有价值的见解和技术。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文针对RGB-D图像中的显著目标检测(SOD)问题,提出通过结合RGB图像和深度图的互补信息来提高复杂场景下检测性能。
现有挑战:
- 指出现有方法在全局长距离依赖建模方面的不足,尤其是在自模态和跨模态特征交互上。
方法论:
- 提出一种新的网络架构PICR-Net,该架构基于CNNs辅助的Transformer,旨在充分利用Transformer进行全局上下文建模和CNNs进行细节捕捉。
- 引入跨模态点感知交互(CmPI)模块,通过位置约束和全局显著性引导向量,实现更有效的跨模态特征交互。
- 设计CNN诱导细化(CNNR)单元,以解决Transformer架构带来的块效应和细节破坏问题。
实验验证:
- 在五个RGB-D SOD数据集上进行了广泛的实验,包括定量和定性比较。
- 与16种现有先进方法进行比较,展示了PICR-Net在性能上的优势。
- 进行消融研究,验证了所提方法中各个组件和设计细节的有效性。
主要贡献:
- 提出了一种新的CNNs辅助Transformer架构,用于RGB-D SOD任务。
- 提出了跨模态点感知交互模块,以增强不同模态之间的特征交互。
- 设计了CNNR单元以改善细节和边界质量。
- 实验结果证明了所提出网络在多个数据集上的有效性和竞争力。
未来工作:
- 论文也指出了未来可能的研究方向,包括模型的实时性能优化、更深层次的特征融合、注意力机制的改进等。
总体而言,这篇论文通过创新的网络架构和跨模态交互机制,有效地提高了RGB-D图像中显著目标检测的性能,并在多个标准数据集上取得了优异的结果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

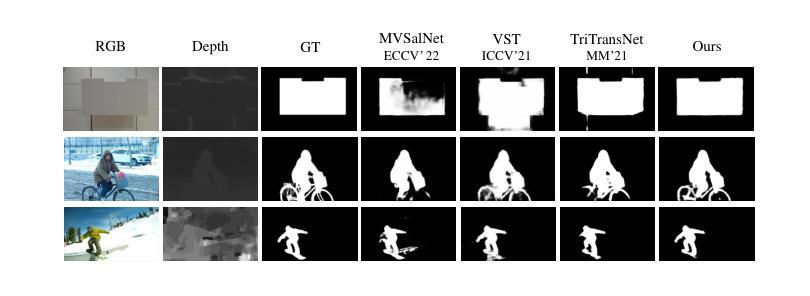
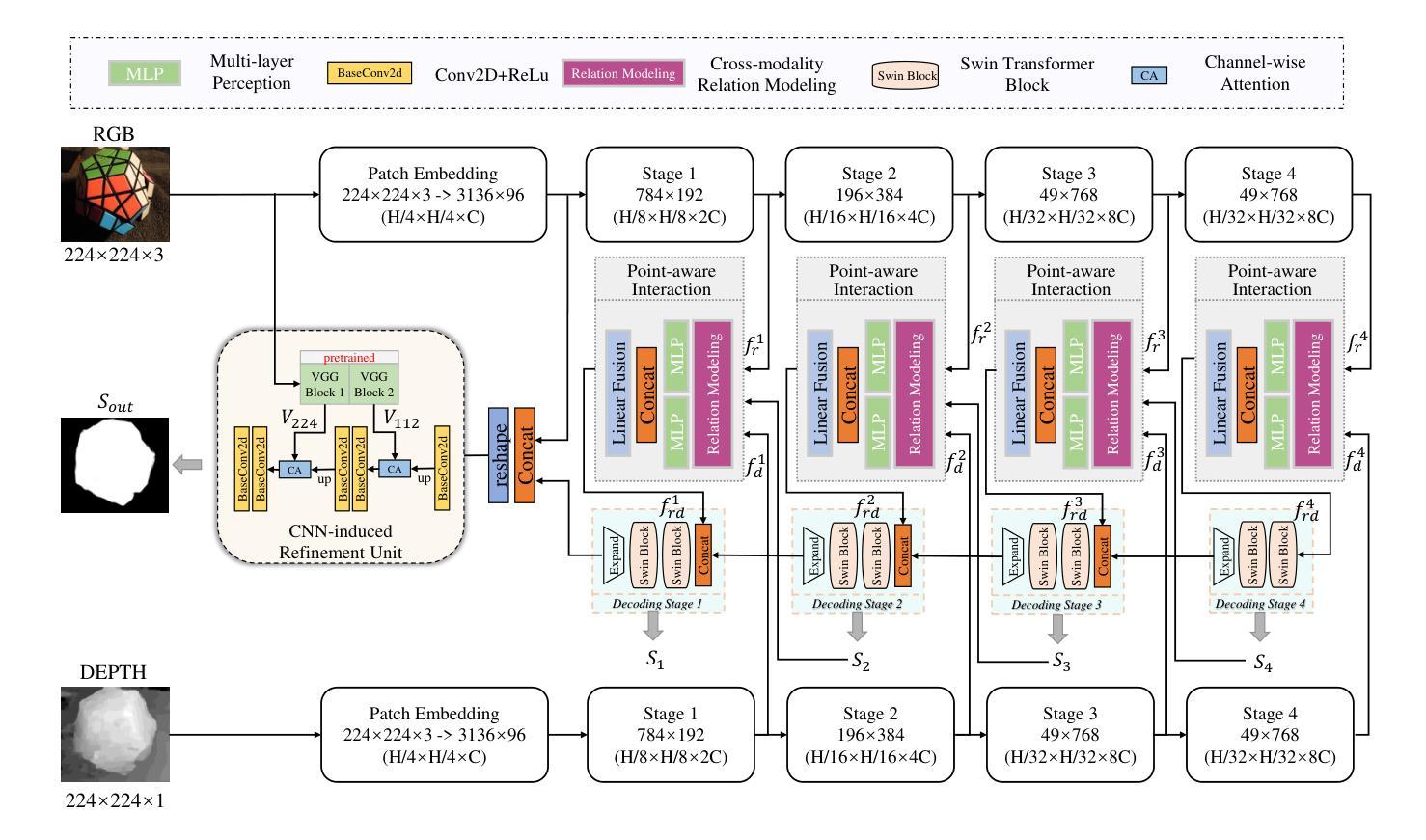
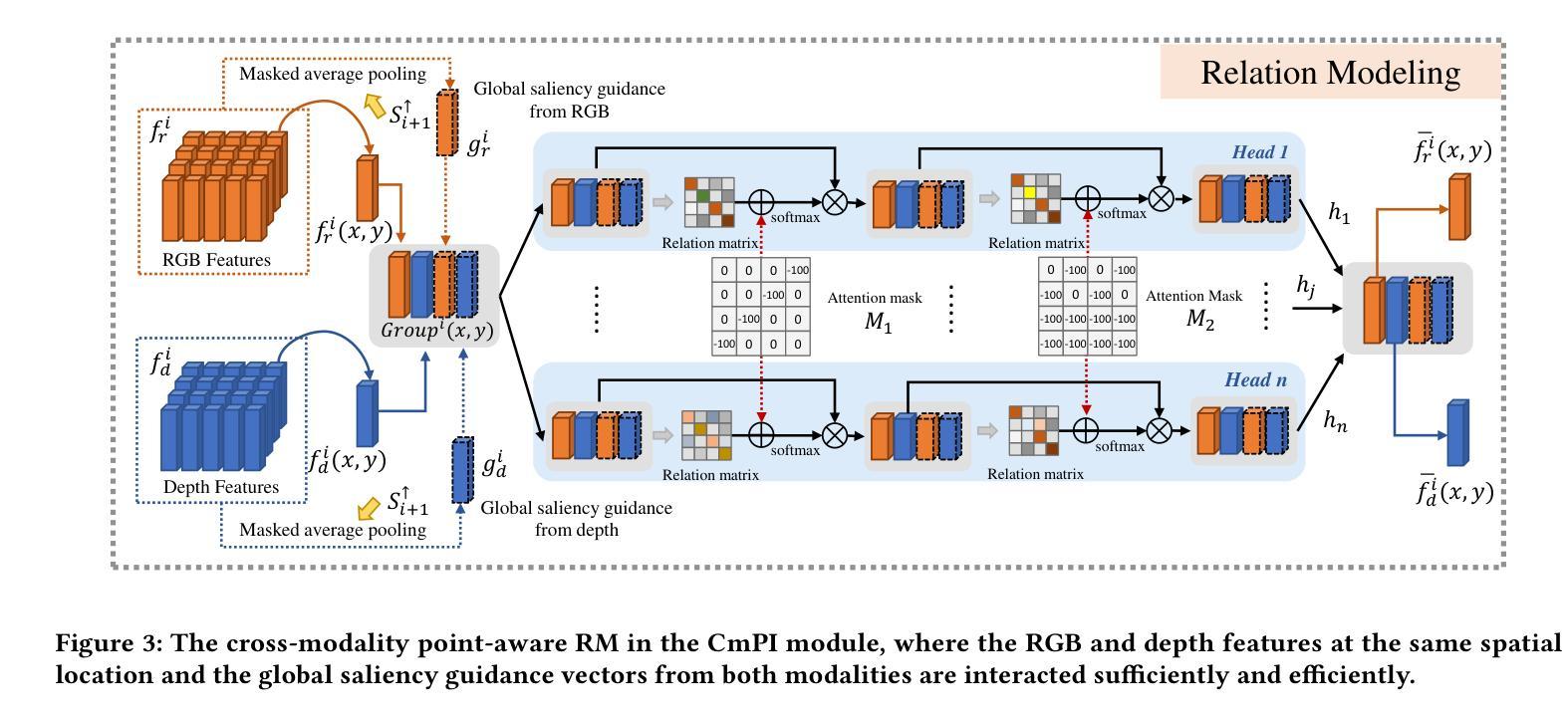
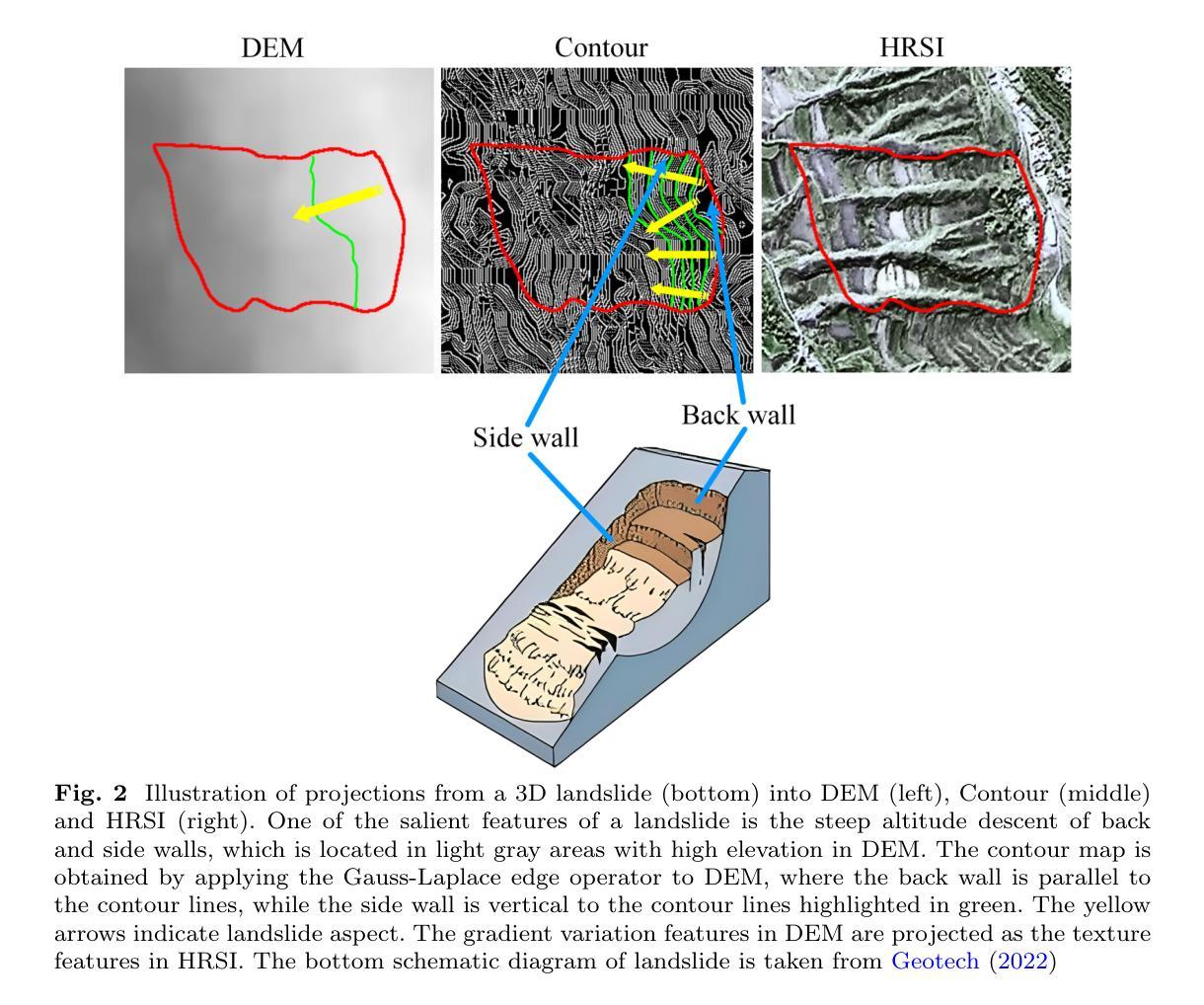
A Multi-Source Data Fusion-based Semantic Segmentation Model for Relic Landslide Detection
Authors:Yiming Zhou, Yuexing Peng, Junchuan Yu, Daqing Ge, Wei Xiang
As a natural disaster, landslide often brings tremendous losses to human lives, so it urgently demands reliable detection of landslide risks. When detecting relic landslides that present important information for landslide risk warning, problems such as visual blur and small-sized dataset cause great challenges when using remote sensing images. To extract accurate semantic features, a hyper-pixel-wise contrastive learning augmented segmentation network (HPCL-Net) is proposed, which augments the local salient feature extraction from boundaries of landslides through HPCL and fuses heterogeneous information in the semantic space from high-resolution remote sensing images and digital elevation model data. For full utilization of precious samples, a global hyper-pixel-wise sample pair queues-based contrastive learning method is developed, which includes the construction of global queues that store hyper-pixel-wise samples and the updating scheme of a momentum encoder, reliably enhancing the extraction ability of semantic features. The proposed HPCL-Net is evaluated on the Loess Plateau relic landslide dataset and experimental results verify that the proposed HPCL-Net greatly outperforms existing models, where the mIoU is increased from 0.620 to 0.651, the Landslide IoU is improved from 0.334 to 0.394 and the F1score is enhanced from 0.501 to 0.565.
作为自然灾害的一种,山体滑坡经常给人类生命带来巨大损失,因此迫切需要进行可靠的山体滑坡风险检测。在使用遥感图像检测遗留山体滑坡(这些滑坡为滑坡风险预警提供重要信息)时,视觉模糊和小型数据集等问题带来了很大的挑战。为了准确提取语义特征,提出了一种超像素级对比学习增强分割网络(HPCL-Net)。它通过HPCL增强了从山体滑坡边界提取局部显著特征的能力,并融合了来自高分辨率遥感图像和数字高程模型数据的语义空间中的异质信息。为了充分利用珍贵样本,开发了一种基于全局超像素级样本对队列对比学习方法,包括构建存储超像素级样本的全局队列和动量编码器的更新方案,可靠地提高了语义特征的提取能力。在黄土高原遗留山体滑坡数据集上对提出的HPCL-Net进行了评估,实验结果验证了HPCL-Net相较于现有模型具有显著优势,其中mIoU从0.620提高到0.651,滑坡IoU从0.334提高到0.394,F1分数从0.501提高到0.565。
论文及项目相关链接
Summary
本文介绍了一种基于超像素级对比学习的滑坡遥感图像分割网络(HPCL-Net)。针对滑坡遗迹检测中的视觉模糊和小样本集问题,HPCL-Net通过超像素级对比学习增强局部特征提取能力,并结合高分辨率遥感图像和数字高程模型数据的异质信息融合。采用全局超像素级样本对队列对比学习方法,建立全局队列存储超像素级样本,并开发动量编码器更新方案,提高语义特征提取能力。在黄土高原滑坡遗迹数据集上的实验结果表明,HPCL-Net较现有模型有显著提高,mIoU从0.620提高到0.651,滑坡IoU从0.334提高到0.394,F1分数从0.501提高到0.565。
Key Takeaways
- 滑坡灾害给人类生命带来巨大损失,急需可靠的滑坡风险检测方法。
- 在使用遥感图像进行滑坡遗迹检测时,视觉模糊和小样本集是面临的挑战。
- 提出的HPCL-Net通过超像素级对比学习增强局部特征提取能力。
- HPCL-Net结合了高分辨率遥感图像和数字高程模型数据的异质信息。
- 全局超像素级样本对队列对比学习方法用于提高语义特征提取能力。
- HPCL-Net在黄土高原滑坡遗迹数据集上的表现优于现有模型。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何利用遥感图像可靠地检测古老滑坡(relic landslides),这些滑坡对于滑坡风险预警具有重要意义。具体来说,论文中提到在利用遥感图像检测古老滑坡时面临的问题包括视觉模糊和小型数据集,这些因素给准确提取语义特征带来了巨大挑战。为了解决这些问题,论文提出了一个基于多源数据融合的语义分割模型,称为HPCL-Net,该模型通过增强超像素级对比学习和在语义空间中融合异构信息来提高检测古老滑坡的准确性。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与研究相关的工作:
传统滑坡检测方法:
- 依赖于现场调查和遥感数据,虽然可靠,但是耗时、效率低,且高度依赖专家经验,难以广泛应用。
遥感技术发展:
- Interferometric Synthetic Aperture Radar (InSAR) 数据提供形变特征。
- High-Resolution Satellite Image (HRSI) 数据提供光学特征。
- Digital Elevation Model (DEM) 和 Digital Surface Model (DSM) 数据提供地形信息。
基于像素的分类和对象导向分析 (OBA) 方法:
- 像素级方法基于光谱特征进行分类,但易受椒盐噪声影响,缺乏识别空间连续区域的能力。
- OBA 方法通过将相邻像素组合成具有同质性因子的段或对象,利用空间、纹理、上下文、几何和光谱特征,提高了空间连续性。
机器学习方法:
- 包括支持向量机、随机森林、逻辑回归和卷积神经网络 (CNNs) 在滑坡检测任务中展示了改进的准确性和效率。
CNNs 在滑坡检测中的应用:
- 用于滑坡检测的CNNs模型,例如基于双时相滑坡HRSI数据的暹罗CNN,用于滑坡的像素级变化检测。
- 设计了3D空间和通道注意力模块以增强滑坡特征提取。
- 提出了双路径注意力网络以利用遥感图像中的纹理和空间信息。
多模态数据融合方法:
- 早期融合(early fusion)和晚期融合(late fusion)策略,用于集成来自不同模态的数据。
对比学习方法:
- 用于增强特征提取,通过区分特征空间中的正样本和负样本。
具体研究案例:
- 论文中引用了多个具体研究案例,如Fang et al (2020), Ji et al (2020), Wang et al (2023b) 等,这些研究提供了不同的方法和模型来改进滑坡检测。
这些相关研究提供了背景信息和技术基础,使得本论文提出的HPCL-Net模型能够在前人工作的基础上进一步改进古老滑坡的检测性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个基于多源数据融合的语义分割模型HPCL-Net来解决古老滑坡检测的问题。以下是该模型解决该问题的关键步骤和方法:
1. 多模态数据融合
- HPCL-Net模型:该模型利用高分辨率遥感图像(HRSI)和数字高程模型(DEM)数据,在语义空间中融合异构信息。DEM数据提供高程特征和梯度模式,有效补充了HRSI的光学信息。
2. 异构特征提取
- 双分支异构特征提取器(HFE):通过设计一个双分支网络,独立提取HRSI和DEM数据的特征,并通过通道连接和坐标注意力(CA)机制进行融合。这种方法允许模型从两种不同类型的数据中提取和整合特征。
3. 对比学习增强特征提取
- 超像素级对比学习:提出了一种全局超像素级样本对队列基于对比学习方法,包括构建全局队列存储超像素级样本和动量编码器的更新方案。这种方法增强了模型提取语义特征的能力,尤其是在样本数量有限的情况下。
4. 特征提取增强模块(FEE)
- 对比样本对构造器(CSPC):从滑坡的背墙和侧墙区域构造超像素级锚点和键,以增强模型对局部显著特征的提取能力。
- 全局类别队列构造器(GCQC):通过构建全局类别队列实现跨图像对比学习,并使用动量编码器更新键,以避免异步更新问题。
5. 编码器-解码器架构
- 编码器:首先从HRSI和DEM数据中提取特征,然后在语义空间中进行融合。
- 解码器:将高级别特征映射恢复到输入大小,并输出类别分数图以获得分割结果。
6. 实验验证
- 在黄土高原古老滑坡数据集上评估HPCL-Net模型,并通过实验结果验证了模型的有效性。与现有模型相比,HPCL-Net在mIoU、滑坡IoU和F1分数上都有显著提高。
通过这些方法,HPCL-Net模型能够有效地从遥感图像中提取滑坡的语义特征,并提高了古老滑坡检测的准确性和可靠性。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验来评估和验证HPCL-Net模型的性能:
1. 总体比较实验
- 目的:比较HPCL-Net与基线模型FFS-Net的性能差异。
- 结果:HPCL-Net在mIoU、滑坡IoU和F1分数上均优于FFS-Net,显示出更好的滑坡检测性能。
2. 消融实验
- 目的:评估模型中不同组件(如异构特征提取器、对比样本对构造器和全局类别队列构造器)对整体性能的贡献。
- 结果:通过逐步添加各个组件,实验结果表明每个组件都对提高模型性能有积极影响,其中全局类别队列构造器对性能提升最为显著。
3. 交叉验证实验
- 目的:优化模型设计,比较不同的特征融合方法和注意力机制。
- 结果:通道连接方法比像素级相加更适合融合HRSI和DEM数据的特征;坐标注意力机制比其他注意力机制(如SENet和CBAM)表现更好。
4. DEM数据处理方案比较实验
- 目的:评估不同DEM数据处理方法对模型性能的影响。
- 结果:使用Kriging插值算法将DEM数据的分辨率与HRSI数据相匹配的方案在大多数性能指标上优于直接从原始DEM数据中提取语义特征的方案。
5. 复杂性分析
- 目的:比较HPCL-Net和FFS-Net在参数数量、计算复杂度(GFLOPs)和执行时间上的差异。
- 结果:尽管HPCL-Net的GFLOPs和执行时间有所增加,但其性能提升是显著的,表明增加的计算成本是可接受的。
6. 可视化分析
- 工具:使用梯度加权类激活映射(Grad-CAM)技术来可视化模型学习到的特征。
- 结果:通过比较不同实验设置下的热图,可以观察到HPCL-Net能够更有效地学习到滑坡的关键特征,特别是在滑坡的背墙和侧墙区域。
这些实验全面评估了HPCL-Net模型的性能,并验证了其在古老滑坡检测任务中的有效性和可靠性。
Q: 有什么可以进一步探索的点?
A: 基于论文内容和实验结果,以下是一些可以进一步探索的点:
1. 数据集的扩展和多样化
- 探索使用更大规模或多样化的数据集来训练和验证模型,以测试模型的泛化能力和鲁棒性。
2. 模型泛化能力的测试
- 在不同类型的滑坡(如新滑坡与古老滑坡)和不同地理环境下测试模型性能,以评估其泛化能力。
3. 更多模态数据的融合
- 考虑引入更多类型的遥感数据(如多光谱图像、InSAR数据等)来进一步丰富模型的输入信息。
4. 注意力机制的改进
- 研究和开发新的注意力机制,以更有效地聚焦于滑坡的关键特征,提高模型的检测精度。
5. 对比学习策略的优化
- 探索不同的对比学习策略和样本对构造方法,以进一步提升模型在小样本情况下的学习效率。
6. 模型压缩和加速
- 研究模型压缩和加速技术,以使HPCL-Net模型更适合在资源受限的设备上部署。
7. 实时监测系统的集成
- 将HPCL-Net模型集成到实时滑坡监测系统中,评估其在实际滑坡预警中的应用潜力。
8. 模型解释性的增强
- 利用可视化技术(如Grad-CAM)进一步分析和解释模型的决策过程,提高模型的可解释性。
9. 多任务学习框架
- 考虑将滑坡检测任务与其他相关任务(如滑坡易发性评估)结合,构建多任务学习框架。
10. 模型鲁棒性的测试与提升
- 研究模型在面对异常值、噪声干扰和数据不完整性时的鲁棒性,并探索提升模型鲁棒性的方法。
这些探索点可以帮助研究者更深入地理解和改进HPCL-Net模型,同时也为滑坡检测领域的研究提供新的方向。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文针对的主要问题是利用遥感图像检测古老滑坡(relic landslides),这些滑坡对于滑坡风险预警具有重要意义,但在检测时面临视觉模糊和小尺寸数据集的挑战。
HPCL-Net模型:
- 提出了一个基于多源数据融合的语义分割模型HPCL-Net,该模型通过增强超像素级对比学习和在语义空间中融合异构信息来提高检测古老滑坡的准确性。
异构特征提取:
- 设计了一个双分支的异构特征提取器(HFE),用于从高分辨率遥感图像(HRSI)和数字高程模型(DEM)数据中独立提取特征,并通过通道连接和坐标注意力(CA)机制进行融合。
对比学习增强:
- 提出了一种全局超像素级样本对队列基于对比学习方法,包括构建全局队列存储超像素级样本和动量编码器的更新方案,以增强模型提取语义特征的能力。
实验验证:
- 在黄土高原古老滑坡数据集上评估HPCL-Net模型,并与现有模型FFS-Net进行比较,实验结果表明HPCL-Net在mIoU、滑坡IoU和F1分数上都有显著提高。
消融实验和交叉验证:
- 通过消融实验和交叉验证实验,验证了模型中不同组件的有效性,并优化了模型设计。
复杂性分析:
- 对比了HPCL-Net和FFS-Net在参数数量、计算复杂度和执行时间上的差异,证明了HPCL-Net在性能提升上的合理性。
可视化分析:
- 使用Grad-CAM技术可视化了模型学习到的特征,进一步证明了HPCL-Net能够有效学习到滑坡的关键特征。
总的来说,这篇论文提出了一个有效的模型HPCL-Net,通过多源数据融合和对比学习技术,显著提高了古老滑坡检测的准确性和可靠性,并通过对比其他方法和消融实验验证了模型的有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Detection, Instance Segmentation, and Classification for Astronomical Surveys with Deep Learning (DeepDISC): Detectron2 Implementation and Demonstration with Hyper Suprime-Cam Data
Authors:G. M. Merz, Y. Liu, C. J. Burke, P. D. Aleo, X. Liu, M. C. Kind, V. Kindratenko, Y. Liu
The next generation of wide-field deep astronomical surveys will deliver unprecedented amounts of images through the 2020s and beyond. As both the sensitivity and depth of observations increase, more blended sources will be detected. This reality can lead to measurement biases that contaminate key astronomical inferences. We implement new deep learning models available through Facebook AI Research’s Detectron2 repository to perform the simultaneous tasks of object identification, deblending, and classification on large multi-band coadds from the Hyper Suprime-Cam (HSC). We use existing detection/deblending codes and classification methods to train a suite of deep neural networks, including state-of-the-art transformers. Once trained, we find that transformers outperform traditional convolutional neural networks and are more robust to different contrast scalings. Transformers are able to detect and deblend objects closely matching the ground truth, achieving a median bounding box Intersection over Union of 0.99. Using high quality class labels from the Hubble Space Telescope, we find that the best-performing networks can classify galaxies with near 100% completeness and purity across the whole test sample and classify stars above 60% completeness and 80% purity out to HSC i-band magnitudes of 25 mag. This framework can be extended to other upcoming deep surveys such as the Legacy Survey of Space and Time and those with the Roman Space Telescope to enable fast source detection and measurement. Our code, DeepDISC is publicly available at https://github.com/grantmerz/deepdisc.
下一代宽视场深度天文学调查将在未来几年内通过多段观测产生前所未有的大量图像。随着观测灵敏度和深度的提高,将检测到更多混合源。这种现实情况可能导致测量偏见,从而污染关键的天文学推论。我们通过利用Facebook AI Research的Detectron2存储库可用的新型深度学习模型来执行Hyper Suprime-Cam(HSC)大型多波段组合的目标识别、去混合和分类等任务。我们使用现有的检测/去混合代码和分类方法来训练一系列深度神经网络,包括最先进的转换器。训练完成后,我们发现变压器在性能上优于传统的卷积神经网络,并且对不同对比度缩放具有更强的适应性。变压器能够检测和混合与目标极为匹配的物体,其包围盒交集的平均值为高达 99%。我们使用哈勃太空望远镜的高质量类别标签进行展示发现性能最好的网络在整个测试样本中几乎可以完全和准确地分类星系,并且恒星分类的完整性超过 60%,纯度达到 80%,延伸至HSC i波段达25星等的幅度。这一框架可扩展到其他即将进行的深度调查任务中,如太空和时间的遗产调查和罗马太空望远镜的项目,从而实现快速的目标检测和测量。我们的代码DeepDISC已在 https://github.com/grantmerz/deepdisc上公开可用。
论文及项目相关链接
PDF 16 pages, 12 figures
Summary:下一代广域深度天文调查将在未来几十年内产生前所未有的大量图像。随着观测灵敏度和深度的提高,将检测到更多混合源。这可能导致测量偏差,从而污染关键的天文学推断。研究团队利用Facebook AI Research的Detectron2存储库中的深度学习模型,对Hyper Suprime-Cam(HSC)的大型多波段coadds进行目标识别、去混合和分类的同步任务。研究训练了一系列深度神经网络,包括最先进的转换器,发现转换器在目标检测和去混合方面表现优异,且对不同对比度具有鲁棒性。最佳性能的神经网络对星系进行分类的完整性和纯度接近百分之百,并对亮度达到HSC i波段星等25等的恒星进行分类,其完整性和纯度分别为60%和80%。该框架可扩展到其他即将进行的深度调查任务,如时空遗产调查和罗马太空望远镜的调查任务,以实现快速的目标检测和测量。相关代码DeepDISC可在https://github.com/grantmerz/deepdisc公开访问。
Key Takeaways:
- 下一代天文调查将产生大量图像数据。
- 随着观测灵敏度和深度的提升,混合源检测将变得更加重要。
- 深度学习模型用于目标识别、去混合和分类任务。
- 转换器在目标检测和去混合方面表现优于传统卷积神经网络。
- 转换器模型对不同的对比度具有鲁棒性。
- 最佳性能的神经网络可对星系进行高完整性和纯度的分类。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在天文观测中,特别是在处理大量图像数据时,有效地进行对象的检测、去重叠(deblending)和分类。具体来说,论文中提到以下几个关键问题:
宽场深空天文调查的挑战:新一代的天文调查,如LSST、Roman空间望远镜和Euclid等,将产生前所未有的大量成像数据。随着观测的灵敏度和深度增加,将检测到更多的重叠源,这可能导致测量偏差,影响关键的天文推断。
去重叠(Deblanding)问题:随着观测深度的增加,视线方向上的投影和物理合并导致重叠源的总数增加。如果无法识别这些重叠源,将对那些假设对象隔离的流程产生偏差。
机器学习在天文数据处理中的应用:论文探讨了如何利用深度学习模型,特别是Detectron2库中的模型,来同时执行对象识别、去重叠和分类任务。这些任务对于处理拥挤的星场和提高天文调查数据的质量至关重要。
模型性能和对比度缩放的鲁棒性:论文还研究了不同深度学习模型在不同对比度缩放下的性能,这对于将模型应用于不同数据集非常重要,因为不同的天文数据集可能具有不同的动态范围。
模型在真实天文数据上的表现:论文提出了一种使用实例分割模型处理真实天文数据的方法,并展示了当这些框架应用于深度图像时的潜力和挑战。
总的来说,这篇论文的目标是展示如何利用最新的深度学习技术来提高天文调查中源检测和测量的速度和准确性,特别是在处理大量重叠对象时。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与该研究相关的领域和具体研究:
天文图像处理和计算机视觉:
- 使用深度学习进行天文图像处理,包括对象检测、去重叠和分类。
- 应用机器学习方法于天文数据,特别是处理大规模图像数据集。
深度学习在天文中的应用:
- 利用深度神经网络(DNNs)进行天文图像的去重叠(deblending)和分类。
- 应用生成对抗网络(GANs)和变分自编码器(VAEs)于天文图像处理。
特定天文调查和项目:
- Legacy Survey of Space and Time (LSST):使用深度学习处理大量成像数据。
- Hyper Suprime-Cam Subaru Strategic Program (HSC SSP):用于测试深度学习框架的数据集。
- Dark Energy Survey (DES):同样产生大量天文数据,用于训练和测试深度学习模型。
深度学习模型和框架:
- Detectron2:Facebook AI Research 提供的下一代目标检测和分割模型库。
- Mask R-CNN:用于实例分割的深度学习模型,被应用于天文数据。
相关技术研究:
- Reiman & Göhre (2019) 使用 GAN 进行 SDSS 星系的去重叠。
- Arcelin et al. (2021) 使用变分自编码器去重叠模拟的 LSST 星系。
- Hemmati et al. (2022) 使用 GANs 恢复 Hubble 空间望远镜分辨率的图像。
星系和恒星分类:
- Tachibana & Miller (2018) 和 Miller & Hall (2021) 使用机器学习方法进行星系和恒星分类。
- Muyskens et al. (2022) 使用高斯过程分类器在 HSC 图像上进行星系/恒星分类。
天文数据模拟:
- 使用 Photon Simulator 代码(Peterson et al. 2015)生成模拟的拥挤星场。
这些研究提供了深度学习在天文数据处理中的背景和应用案例,展示了如何利用这些技术来提高数据处理的效率和准确性。论文中提到的这些研究和项目为作者们的工作提供了理论和实践基础。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决天文观测中对象检测、去重叠和分类的问题:
深度学习模型的实现:
- 使用Facebook AI Research的Detectron2库,实现了多种深度学习模型,包括传统卷积神经网络(CNNs)和最新的基于变换器(transformers)的架构。
数据集的准备:
- 利用Hyper Suprime-Cam(HSC)的多波段图像进行训练和测试。
- 通过现有的检测/去重叠代码(如scarlet)和星系目录匹配生成地面真实标签(ground truth labels)。
模型训练:
- 使用转移学习(transfer learning),即利用在其他领域(如自然图像)预训练的模型权重作为起点,进一步在HSC数据上进行微调。
- 设计了详细的训练过程,包括冻结特征提取网络的初始阶段,仅训练ROI和RPN网络的头部层,然后解冻整个网络进行训练。
性能评估:
- 使用精确度(precision)和召回率(recall)评估分类性能,并计算AP(平均精度)分数。
- 对比不同模型在不同对比度缩放下的性能,以评估模型对不同数据集的适应性。
模型比较和选择:
- 比较了基于ResNet和基于变换器的不同模型的性能,发现变换器模型在去重叠和分类任务中表现更优,且对不同对比度缩放更鲁棒。
结果分析和讨论:
- 分析了模型在不同条件下的表现,包括对不同大小和亮度的对象的分类能力。
- 讨论了模型可能的改进方向,如使用更多的训练数据、调整超参数、增加更多的光度信息等。
代码和数据共享:
- 提供了公开的代码(DeepDISC),以便其他研究者可以复现和扩展他们的工作。
通过这些步骤,论文展示了如何利用深度学习技术,特别是Detectron2库中的模型,来提高天文数据中对象检测、去重叠和分类的效率和准确性。此外,论文还强调了变换器模型在处理天文数据时的优势,为未来的天文调查提供了一种新的工具。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和比较不同深度学习模型在天文图像数据上的表现,具体实验包括:
模型训练与测试:
- 使用Detectron2库中的多种深度学习模型对Hyper Suprime-Cam(HSC)的多波段图像进行对象检测、去重叠和分类任务的训练和测试。
数据预处理:
- 对HSC数据应用了三种不同的对比度缩放方法:z-scale、Lupton scale和高对比度Lupton scale,以测试模型对不同数据动态范围的适应性。
性能度量:
- 使用精确度(precision)、召回率(recall)和平均精度(AP)分数来评估分类性能。
- 计算了不同模型配置在不同对比度缩放下的AP分数,包括对星系和恒星的分类评估。
错误标签偏差的缓解:
- 利用Hubble Space Telescope(HST)的COSMOS目录数据来生成更准确的测试集标签,以减少由于HSC目录标签不准确带来的偏差。
- 在HST COSMOS测试集上评估模型性能,以更公正地比较模型的分类能力。
缺失和额外标签偏差的缓解:
- 引入F1分数作为主要性能指标,以减少由于标签生成过程中的缺失和额外标签带来的影响。
- 分析了模型在不同i波段星等下的精确度和召回率,以评估模型对暗弱天体的分类能力。
去重叠能力评估:
- 计算了模型预测的边界框和分割掩模与真实标签之间的交并比(IOU),以量化模型的去重叠性能。
- 展示了模型在处理紧密重叠天体时的能力,并分析了不同对比度缩放对去重叠效果的影响。
模型架构比较:
- 对比了基于ResNet和基于变换器(如MViTv2和Swin Transformer)的模型架构,评估了它们在分类和去重叠任务中的表现。
模拟数据集测试(附录A中提到):
- 在模拟的Dark Energy Camera(DECam)数据集上测试了R101fpn和MViTv2两种模型架构,以比较卷积神经网络和基于变换器模型的性能。
这些实验全面评估了不同深度学习模型在处理真实天文数据时的性能,并探索了提高模型泛化能力和减少标签偏差的方法。通过这些实验,论文展示了变换器模型在天文图像分析中的潜力,并指出了未来改进的方向。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些可以进一步探索的点,包括但不限于:
更大的训练集和更准确的标签:
- 构建一个更大规模的训练集,并使用更精确的标签,可能会提高模型的分类和去重叠性能。
不同模型架构的超参数调整:
- 在训练之前对不同的模型架构进行更多的超参数调整,可能会进一步提升模型的性能。
多波段数据的使用:
- 目前的研究使用了HSC的i, r和g波段数据。将z和y波段数据也纳入分析可能会提供更多的光度信息,从而改善性能。
模型训练时长:
- 延长模型的训练时间或进行更细致的学习率调整,可能会帮助模型更好地学习天文图像的特征。
新的模型架构:
- 尝试在Detectron2库中实现和测试更多新的模型架构,特别是那些需要大量计算资源的大型模型,如Vision Transformer (ViT)。
红移估计网络的集成:
- 计划将红移估计网络集成到Mask R-CNN/变换器网络中,并与LSST软件RAIL接口。
使用模拟数据集进行训练:
- 利用LSST Dark Energy Science Collaboration (LSST DESC) 提供的真实LSST模拟数据集进行训练,以避免由于标签生成偏差。
多任务学习:
- 探索模型同时执行多个任务(例如,同时进行对象检测、去重叠、分类和红移估计)的能力。
模型的实时性能:
- 考虑到LSST等项目将产生大量数据,研究模型在实时或近实时条件下的性能。
模型的可解释性:
- 提高模型的可解释性,以更好地理解模型做出特定预测的原因。
模型的泛化能力:
- 测试模型在不同类型的天文数据集(例如,来自不同望远镜或不同条件下的数据)上的泛化能力。
模型对不同天文对象类型的适应性:
- 探索模型对不同天文对象类型(例如,不同类型星系、恒星和其他天体)的适应性和性能。
这些探索点可以帮助未来的研究者进一步提升天文图像分析的深度学习模型的性能,并扩展其应用范围。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容概述如下:
研究背景:
- 论文讨论了新一代宽视场深空天文调查所带来的挑战,尤其是随着观测灵敏度和深度的增加,越来越多的混合源(blended sources)被探测到,这可能导致测量偏差,影响关键天文推断。
研究目标:
- 论文的目标是利用深度学习模型,特别是Detectron2库中的模型,来同时执行天体的识别、去重叠(deblending)和分类任务。
数据和方法:
- 论文使用了Hyper Suprime-Cam(HSC)的多波段图像数据,并结合现有的检测/去重叠代码和分类方法来训练一系列深度神经网络,包括最新的变换器(transformers)模型。
- 论文详细描述了数据预处理、训练过程和评估指标,包括精确度、召回率和平均精度(AP)分数。
实验结果:
- 实验结果显示,变换器模型在去重叠和分类任务中表现优于传统的卷积神经网络,并且对不同的对比度缩放更加鲁棒。
- 使用Hubble Space Telescope(HST)的高质量类别标签,论文发现最佳性能网络能够以接近100%的完整性和纯度对整个测试样本中的星系进行分类,并且能够以超过60%的完整性和80%的纯度对HSC i波段星等达到25 mag的恒星进行分类。
讨论和结论:
- 论文讨论了模型性能的差异,与现有结果的比较,以及方法的优势和局限性。
- 论文强调了变换器模型在天文图像分析中的潜力,并指出了未来改进的方向,包括使用更多的训练数据、调整超参数和增加更多的光度信息。
代码和数据共享:
- 论文提供了公开的代码(DeepDISC),以便其他研究者可以复现和扩展他们的工作。
总的来说,这篇论文展示了深度学习技术在天文图像分析中的应用,并特别强调了变换器模型在处理天文数据时的优势,为未来的天文调查提供了一种新的工具。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图