⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-15 更新
If Eleanor Rigby Had Met ChatGPT: A Study on Loneliness in a Post-LLM World
Authors:Adrian de Wynter
Loneliness, or the lack of fulfilling relationships, significantly impacts a person’s mental and physical well-being and is prevalent worldwide. Previous research suggests that large language models (LLMs) may help mitigate loneliness. However, we argue that the use of widespread LLMs like ChatGPT is more prevalent–and riskier, as they are not designed for this purpose. To explore this, we analysed user interactions with ChatGPT, particularly those outside of its marketed use as task-oriented assistant. In dialogues classified as lonely, users frequently (37%) sought advice or validation, and received good engagement. However, ChatGPT failed in sensitive scenarios, like responding appropriately to suicidal ideation or trauma. We also observed a 35% higher incidence of toxic content, with women being 22 times more likely to be targeted than men. Our findings underscore ethical and legal questions about this technology, and note risks like radicalisation or further isolation. We conclude with recommendations for research and industry to address loneliness.
孤独感或缺乏充实的人际关系会显著影响一个人的身心健康,这一现象在全球范围内普遍存在。之前的研究表明,大型语言模型(LLM)可能有助于缓解孤独感。然而,我们认为广泛使用如ChatGPT等大型语言模型的现象更加普遍,而且风险更高,因为它们并非为此目的而设计。为了探究这一点,我们分析了用户与ChatGPT的互动,尤其是那些超出其作为任务导向型助理的市场用途之外的对话。在被归类为孤独的对话中,用户经常(37%)寻求建议或认可,并获得了良好的互动。然而,ChatGPT在敏感场景(如适当回应自杀念头或创伤)下表现不佳。我们还观察到有毒内容的发病率高出35%,女性被攻击的可能性是男性的22倍。我们的研究结果强调了关于这项技术的伦理和法律问题,并指出了激进化或进一步孤立等风险。最后,我们为研究和产业解决孤独问题提出建议。
论文及项目相关链接
Summary
本研究探讨了孤独感对个人心理健康和身体健康的影响,并指出大型语言模型(LLM)如ChatGPT在缓解孤独感方面的作用。研究发现,ChatGPT在与孤独感相关的对话中被频繁用于寻求建议和验证,但也存在回应不敏感甚至有毒的回应,包括不恰当应对自杀想法和创伤场景等风险问题。因此存在伦理和法律责任的问题,以及加剧孤立化风险等问题。
Key Takeaways
- LLM技术可用来帮助缓解孤独感,特别是针对寻找建议和验证的情境。ChatGPT在其中常被用于这类交流对话。
- 频繁出现用户利用ChatGPT寻求建议和验证的孤独对话场景,但也存在不良回应的情况。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了在后大型语言模型(LLM)时代,孤独感对个人的心理和生理健康的影响,以及大型语言模型(如ChatGPT)在缓解孤独感方面的潜在作用和风险。具体来说,论文试图解决以下几个问题:
孤独感的普遍性和影响:论文首先介绍了孤独感作为一种全球性问题,它影响着许多人的心理和生理健康,并可能导致抑郁、痴呆和死亡率增加等一系列健康问题。
LLMs在缓解孤独感中的潜力和风险:研究指出,尽管LLMs(如ChatGPT)被设计为生产力工具,但它们也可能被用来提供陪伴,从而帮助缓解孤独感。然而,这些模型并非专为心理健康辅助设计,可能存在风险。
用户与ChatGPT的互动分析:论文通过分析用户与ChatGPT的互动,特别是那些超出其作为任务导向助手市场用途的互动,来探索LLMs作为服务在缓解孤独感方面的有效性和局限性。
伦理和法律问题:论文强调了LLMs在公开可访问的全球环境中安全使用和部署的挑战,尤其是在处理孤独感问题时,涉及伦理和法律问题,如知情同意和责任归属。
解决孤独感的建议:最后,论文总结了针对技术和研究社区的建议,以解决孤独感问题,包括透明度、安全标准和设计促进健康社交联系的技术。
总的来说,这篇论文试图解决的核心问题是理解LLMs在缓解孤独感方面的潜力和风险,并提出相应的研究和行业建议,以确保这些技术的负责任使用。
Q: 有哪些相关研究?
A: 论文中提到了多个与孤独感、大型语言模型(LLMs)以及聊天机器人相关的研究。以下是一些关键的相关研究:
**Valtolina和Hu (2021)**:研究了通过提示和部署定制化解决方案来使用LLMs处理孤独感的问题。
**Alessa和AlKhalifa (2023)**:探讨了为老年人设计ChatGPT对话伴侣的可能性。
**Ryu等人 (2020)**:研究了设计聊天机器人服务以改善老年人的心理健康。
**Jo等人 (2023)**:研究了利用大型语言模型进行公共卫生干预的益处和挑战。
**Perlman和Peplau (1981)**:讨论了孤独感的定义和影响,强调孤独感与个人关系的质量及数量有关。
**Hawkley和Cacioppo (2010)**:研究了孤独感与皮质醇水平升高和整体死亡率增加之间的关联。
**Holt-Lunstad等人 (2015)**:进行了孤独感和社交隔离作为死亡风险因素的元分析。
**Jung和Hahn (2023)**:研究了孤独个体对人类化机器人和人工伴侣的偏好。
**Eyssel和Reich (2013)**:研究了孤独感如何增加个体对机器人的心理拟人化。
**Jain等人 (2018)**:研究了人们偏好具有类似人类对话的聊天机器人。
Kim等人 (2024) 和 **Choudhury和Chaudhry (2024)**:探讨了对LLMs的过度依赖问题。
Deshpande等人 (2023) 和 **Chan等人 (2024)**:研究了LLMs如何改变用户的观点和选择。
Sharma等人 (2023) 和 **Pataranutaporn等人 (2023)**:探讨了用户如何通过影响模型输出与自己观点一致的内容来加强自己的信仰。
这些研究为理解孤独感的影响、LLMs在缓解孤独感中的潜在作用以及这些技术部署时可能遇到的挑战提供了理论基础和实证数据。论文通过综合这些研究的发现,提出了对LLMs在处理孤独感方面应用的更深入分析。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决孤独感问题以及相关联的语言模型使用问题:
数据收集与分析:
- 研究者分析了79,951个用户与ChatGPT之间的对话,这些对话被标记为非任务导向的互动。
- 使用GPT-4模型对这些对话进行分类,识别出孤独用户的对话。
孤独感评估:
- 采用Jiang等人 (2022)设计的分类体系来评估和标记孤独感。
- 通过定性分析(Reflexive Thematic Analysis)来深入理解孤独用户的对话。
对话内容分类:
- 将对话分为寻求建议、提供帮助、寻求验证和肯定、社交接触等类别,并分析这些对话的特征。
- 识别和分类对话中的有害内容,包括暴力、有害或性内容,并特别关注这些内容针对的群体(如女性、未成年人)。
伦理和法律问题的探讨:
- 讨论了LLMs在公开可访问的全球环境中安全使用和部署的挑战,尤其是在处理孤独感问题时涉及的伦理和法律问题。
风险识别:
- 识别了LLMs可能加剧社会隔离、无意中造成伤害或放大有害行为的风险。
建议与对策:
- 论文最后提出了针对研究和行业如何应对孤独感的建议,包括技术公司应如何透明地处理其技术对社会联系的影响、支持安全标准以及设计能够培养健康社交联系的技术。
推动社会变革:
- 强调需要社会转变,通过减少对孤独感的污名化和强调个人关系的价值来解决孤独感问题。
通过这些方法,论文不仅分析了LLMs在缓解孤独感方面的潜力和风险,还提出了具体的建议和措施,以促进这些技术的负责任使用,并推动更广泛的社会变革来解决孤独感问题。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
数据集构建和标注:
- 研究者使用了名为WildChat的数据集,该数据集包含了100万次用户与ChatGPT之间的互动记录。
- 从这个数据集中随机抽取了79,951个互动实例进行分析。
- 使用GPT-4模型对这些互动进行类型标注,包括意图、原因和目标等分类信息。
孤独感评估:
- 采用Jiang等人 (2022)提出的分类体系对用户对话进行孤独感评估。
- 对标注结果进行手动检查和统计分析,以确保标注的准确性。
对话内容分析:
- 对标注为孤独感相关的对话进行了定性分析,特别是前500条对话,以识别和理解孤独用户与ChatGPT互动的模式和特点。
- 对显示出有害行为的孤独用户对话进行了全面的定性分析。
可靠性分析:
- 对GPT-4模型的标注结果进行了学生t检验,以评估标注的可靠性,并计算了95%置信区间的准确率。
有毒内容分析:
- 对比了包含有害、暴力或性内容的对话在孤独和非孤独对话中的分布情况。
- 分析了这些有毒内容针对的不同目标群体(如性别和年龄)的分布差异。
这些实验的目的是为了评估ChatGPT在处理孤独感问题时的有效性,以及其在与用户互动中可能出现的风险和问题。通过这些实验,研究者能够深入理解ChatGPT作为陪伴工具的潜力和局限性,并提出了相应的建议和对策。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些重要的发现和问题,以下是一些可以进一步探索的点:
LLMs在心理健康支持中的作用:
- 进一步研究LLMs在提供心理健康支持方面的能力,特别是在处理孤独感和自杀意念等敏感问题时的有效性。
伦理和法律框架:
- 开发和评估针对LLMs在心理健康领域的应用的伦理和法律框架,包括知情同意和责任问题。
用户对LLMs的依赖性:
- 研究用户对LLMs的依赖性,以及这种依赖可能对个人心理健康和社会关系产生的影响。
LLMs的个性化和定制化:
- 探索如何更好地个性化和定制化LLMs,以满足不同用户群体的需求,特别是在缓解孤独感方面。
有害内容的检测和过滤:
- 开发更有效的机制来检测和过滤LLMs生成的有害内容,尤其是针对边缘化群体的内容。
用户交互的长期影响:
- 研究LLMs与用户交互的长期影响,包括是否能够真正缓解孤独感,以及可能产生的任何负面后果。
多语言和文化差异:
- 考虑多语言和文化差异对LLMs在不同地区和文化中缓解孤独感效果的影响。
社会和技术的协同作用:
- 研究如何通过社会政策和技术发展共同减少孤独感,包括促进健康的社交联系和社区参与。
LLMs的教育和培训:
- 探索如何使用LLMs作为教育工具,帮助人们更好地理解和处理孤独感。
跨学科研究:
- 促进计算机科学、心理学、社会学和法律等领域的跨学科合作,以全面理解和应对孤独感问题。
这些探索点可以帮助我们更深入地理解LLMs在缓解孤独感方面的潜力和挑战,并为未来的研究和技术发展提供指导。
Q: 总结一下论文的主要内容
A: 这篇论文《如果Eleanor Rigby遇到了ChatGPT:后LLM世界中孤独感的研究》主要探讨了以下几个核心内容:
问题背景:
- 论文首先介绍了孤独感作为一个全球性问题,它对人们的心理健康和生理健康产生重大影响。
- 论文指出,大型语言模型(LLMs)可能有助于缓解孤独感,但存在被滥用的风险,尤其是像ChatGPT这样的模型,它们并非为心理健康支持而设计。
研究目的:
- 论文旨在分析用户与ChatGPT的互动,特别是那些超出其作为任务导向助手市场用途的互动,以探索LLMs作为服务在缓解孤独感方面的有效性和风险。
研究发现:
- 通过对79,951次用户与ChatGPT之间的对话进行定性和定量分析,发现8%的对话可以被归类为孤独。
- 在这些孤独对话中,用户更倾向于寻求建议或验证,并且与ChatGPT的互动轮数多于平均水平。
- ChatGPT在处理需要专业干预的复杂问题(如自杀意念或创伤处理)时表现不佳。
- 孤独对话中有毒内容(暴力、有害或性内容)的比例更高,尤其是针对女性和未成年人。
风险和伦理问题:
- 论文强调了LLMs在公开可访问的环境中安全使用和部署的挑战,尤其是在处理孤独感问题时涉及的伦理和法律问题。
建议和对策:
- 论文最后提出了针对研究和行业如何应对孤独感的建议,包括技术公司应如何透明地处理其技术对社会联系的影响、支持安全标准以及设计能够培养健康社交联系的技术。
社会变革的呼吁:
- 论文强调需要社会转变,通过减少对孤独感的污名化和强调个人关系的价值来解决孤独感问题。
综上所述,论文通过对用户与ChatGPT互动的分析,揭示了LLMs在缓解孤独感方面的潜力和风险,并提出了相应的研究和行业建议,以确保这些技术的负责任使用,并推动更广泛的社会变革来解决孤独感问题。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


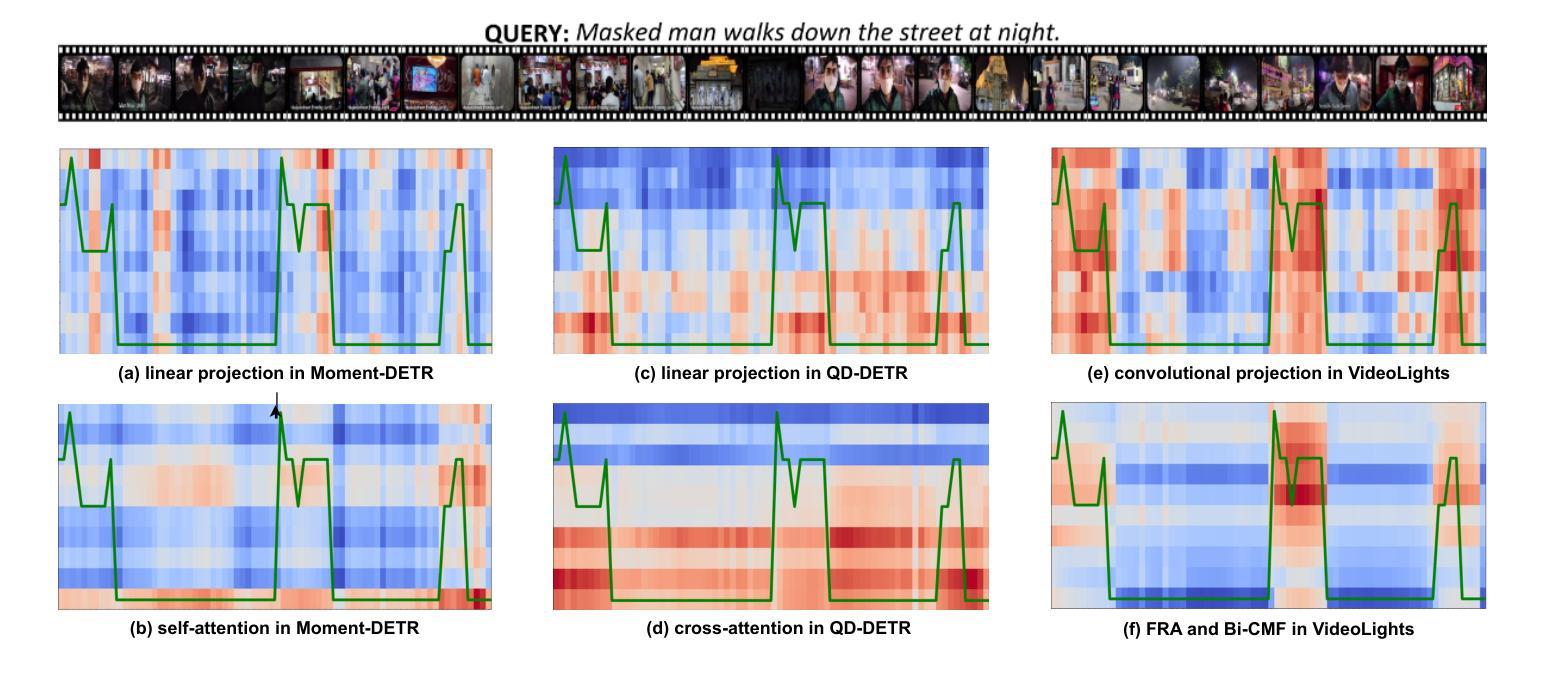
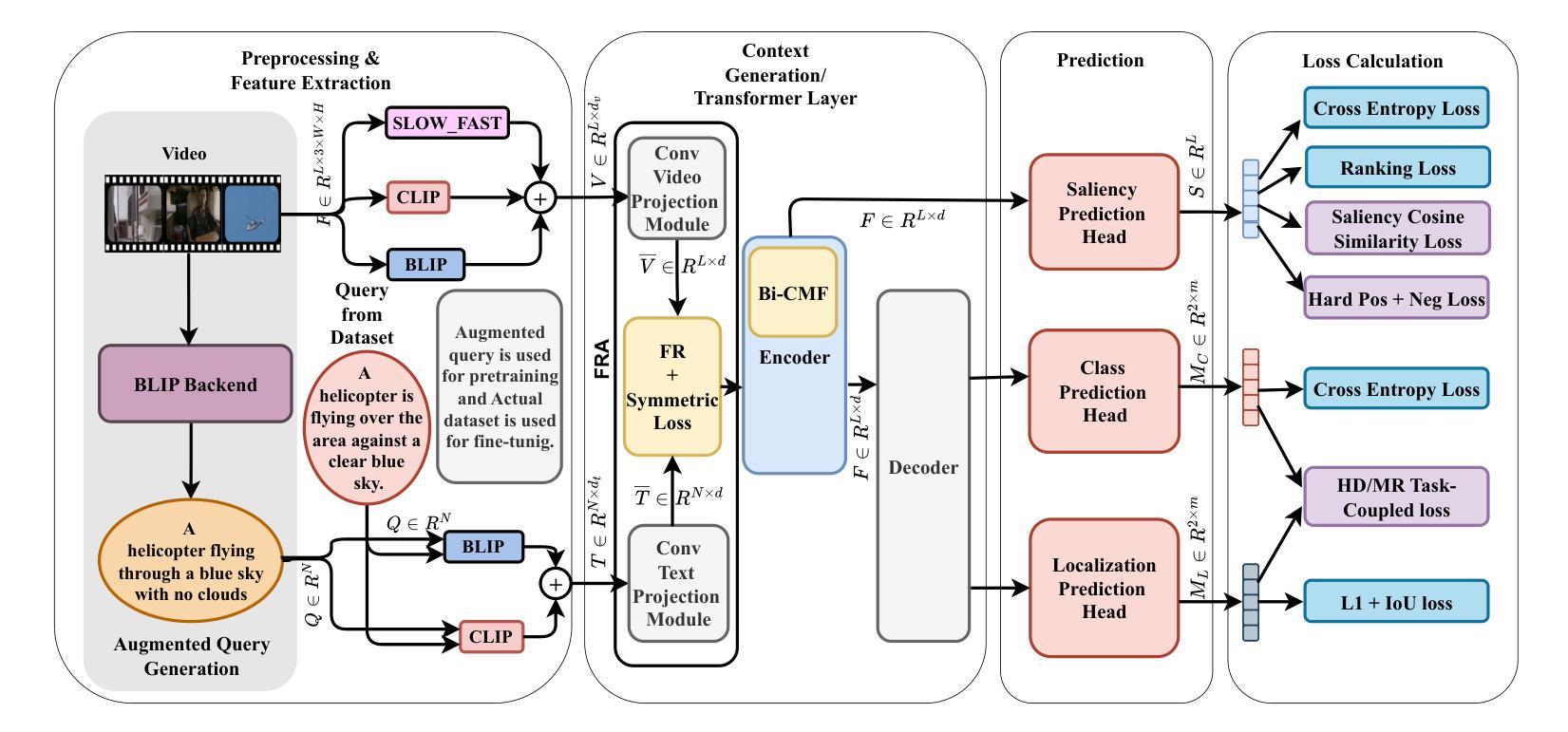
VideoLights: Feature Refinement and Cross-Task Alignment Transformer for Joint Video Highlight Detection and Moment Retrieval
Authors:Dhiman Paul, Md Rizwan Parvez, Nabeel Mohammed, Shafin Rahman
Video Highlight Detection and Moment Retrieval (HD/MR) are essential in video analysis. Recent joint prediction transformer models often overlook their cross-task dynamics and video-text alignment and refinement. Moreover, most models typically use limited, uni-directional attention mechanisms, resulting in weakly integrated representations and suboptimal performance in capturing the interdependence between video and text modalities. Although large-language and vision-language models (LLM/LVLMs) have gained prominence across various domains, their application in this field remains relatively underexplored. Here we propose VideoLights, a novel HD/MR framework addressing these limitations through (i) Convolutional Projection and Feature Refinement modules with an alignment loss for better video-text feature alignment, (ii) Bi-Directional Cross-Modal Fusion network for strongly coupled query-aware clip representations, and (iii) Uni-directional joint-task feedback mechanism enhancing both tasks through correlation. In addition, (iv) we introduce hard positive/negative losses for adaptive error penalization and improved learning, and (v) leverage LVLMs like BLIP-2 for enhanced multimodal feature integration and intelligent pretraining using synthetic data generated from LVLMs. Comprehensive experiments on QVHighlights, TVSum, and Charades-STA benchmarks demonstrate state-of-the-art performance. Codes and models are available at https://github.com/dpaul06/VideoLights .
视频高光检测和时刻检索(HD/MR)是视频分析中的关键。最近的联合预测transformer模型往往忽略了它们的跨任务动态和视频文本对齐和细化。此外,大多数模型通常使用有限的单向注意力机制,导致表示融合较弱,在捕捉视频和文本模态之间的互依赖性方面表现不佳。尽管大型语言模型和视觉语言模型(LLM/LVLMs)在各个领域都获得了突出地位,但它们在视频分析领域的应用仍然相对未被充分探索。在这里,我们提出了VideoLights,这是一个新的HD/MR框架,通过以下方面解决这些限制:(i)卷积投影和特征细化模块以及用于更好的视频文本特征对齐的对齐损失;(ii)双向跨模态融合网络用于强烈耦合的查询感知剪辑表示;(iii)通过相关性增强两个任务的单向联合任务反馈机制。此外,(iv)我们引入了硬正负损失用于自适应误差惩罚和改进学习,(v)利用LVLMs(如BLIP-2)进行增强的多模态特征融合和智能预训练,使用从LVLMs生成的合成数据进行训练。在QVHighlights、TVSum和Charades-STA基准测试上的综合实验证明了其卓越的性能。代码和模型可在https://github.com/dpaul06/VideoLights找到。
论文及项目相关链接
摘要
本文提出了VideoLights框架,解决了视频分析中视频高光检测与时刻检索(HD/MR)的关键问题。通过引入卷积投影和特征细化模块、双向跨模态融合网络、单向联合任务反馈机制等创新技术,实现了视频与文本特征的良好对齐和查询感知剪辑表示。此外,还引入了硬正负损失用于自适应误差惩罚和改进学习,并借助LVLMs如BLIP-2增强多模态特征融合和智能预训练。实验表明,VideoLights在QVHighlights、TVSum和Charades-STA等多个基准数据集上取得了最新技术性能。
关键见解
- VideoLights框架解决了视频高光检测与时刻检索中跨任务动力学和视频文本对齐的问题。
- 通过卷积投影和特征细化模块,实现了视频与文本特征的良好对齐。
- 双向跨模态融合网络提供了查询感知的剪辑表示,增强了视频与文本的相互依赖性。
- 单向联合任务反馈机制通过相关性增强了两个任务的表现。
- 引入硬正负损失用于自适应误差惩罚和改进学习。
- 利用LVLMs如BLIP-2进行智能预训练和多模态特征融合,增强了性能。
- 在多个基准数据集上的实验结果表明VideoLights取得了最新技术性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为VideoLights的框架,旨在解决视频分析中的两个关键任务:视频高光检测(Highlight Detection, HD)和时刻检索(Moment Retrieval, MR)。具体来说,论文试图解决的问题包括:
跨任务动态和视频-文本对齐与细化的忽略:现有的联合预测模型往往忽视了HD和MR任务之间的相互关系以及视频和文本模态之间的对齐和细化,这限制了模型捕捉视频和文本之间相互依赖性的潜力。
有限的、单向注意力机制:大多数模型通常使用有限的、单向(从文本到视频)的注意力机制,导致在视频和文本模态之间集成的表示较弱,无法最优地捕捉两者之间的相互依赖性。
大型语言和视觉-语言模型(LLM/LVLMs)在该领域的应用不足:尽管LLM/LVLMs在各个领域已显示出其重要性,但在视频高光检测和时刻检索领域的应用仍相对未被充分探索。
为了解决这些问题,VideoLights框架通过以下几个关键组件来增强跨模态和跨任务的交互:
特征细化和对齐模块(Feature Refinement and Alignment, FRA):通过CNN基础的内模态和跨模态特征交互细化,以及文本-视频对应关系的对齐损失,实现更好的视频-文本特征对齐。
双向跨模态融合网络(Bi-Directional Cross-Modal Fusion, Bi-CMF):采用多阶段层次化处理进行双向文本-视频注意力,生成与查询强相关的视频表示。
单向联合任务反馈机制(Uni-directional joint-task feedback mechanism, Uni-JFM):通过特定任务和跨任务损失增强任务之间的相关性。
自适应误差校正:引入硬正例/负例损失以适应性地惩罚模型在片段显著性预测中的错误,改善学习效果。
智能模型预训练:利用大型视觉-语言模型(如BLIP-2)生成的合成数据进行模型预训练,增强多模态特征集成和智能预训练。
通过这些方法,VideoLights旨在提高视频高光检测和时刻检索任务的性能,并在QVHighlights、TVSum和Charades-STA等基准数据集上展示了其优越性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要集中在视频理解领域,尤其是视频高光检测(Highlight Detection, HD)和时刻检索(Moment Retrieval, MR)。以下是一些与VideoLights框架相关的研究工作:
Moment-DETR [16]:这是一个基于编码器-解码器变换器模型的早期工作,它使用预训练的视觉-语言模型(如CLIP)的特征来表示视频和文本,并进行查询相关的视频时刻检索和高光检测。
UMT [17]:提出了一个统一的多模态架构,用于处理视频和音频数据进行MR和HD任务。该方法在编码器中增加了音频输入,在解码器中增加了文本输入。
QD-DETR [19]:开发了一个查询依赖的视频表示模块,以对齐文本和视频,改进了MR和HD任务的性能。
UniVTG [20]:提出了一个多任务学习方法,使用统一的微调和预训练方法,但在任务头之间没有直接的跨任务交互。
TaskWeave [18] 和 TR-DETR [22]:这两个模型通过首先独立计算HD和MR,然后让它们相互合作(HD到MR和反之亦然)来重新计算结果,从而解决了(双向)跨任务关系问题。
CLIP [24] 和 BLIP [25]:这些是预训练的视觉-语言模型,它们通过利用文本和视频特征嵌入来理解文本和视频模态,并已在多模态数据的语义对齐和多模态推理中显示出显著的有效性。
SlowFast [27]:这是一个结合了视觉和时间信息的模型,它提供了额外的视觉嵌入,以补充CLIP主要在静态图像和文本上训练的局限性。
GPT-4V [28]、LLaVA [29] 和 BLIP-2 [30]:这些是大型视觉-语言模型(LVLMs),它们在视觉和语言领域的各项任务中表现出了强大的推理能力和成功。
这些研究构成了VideoLights框架的理论基础和技术背景,VideoLights通过结合这些研究的成果,提出了一种新的联合预测HD/MR模型,专注于跨模态和跨任务的相互作用,并在多个基准数据集上取得了优异的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出VideoLights框架来解决视频高光检测(HD)和时刻检索(MR)的问题,具体方法如下:
1. 特征细化和对齐模块(Feature Refinement and Alignment, FRA)
- 实现基于CNN的内模态和跨模态特征交互细化,并通过跨模态对齐损失实现文本-视频对应关系。
- 通过两阶段过程,包括局部(剪辑或单词级别)和全局(视频或句子级别)对齐,增强视频和查询令牌之间的对应关系。
2. 双向跨模态融合网络(Bi-Directional Cross-Modal Fusion, Bi-CMF)
- 利用多阶段层次化处理进行双向文本-视频注意力,生成与查询强相关的视频表示。
- 通过三个多头注意力层实现,包括文本到视频、视频到文本、再次文本到视频的注意力,以提取与查询相关的视频上下文。
3. 单向联合任务反馈机制(Unidirection Joint-Task Feedback Module, Uni-JFM)
- 通过特定任务和跨任务损失增强任务之间的相关性。
- 利用余弦相似度在HD和MR任务的特征向量上计算相似性分数,以改善跨任务学习效率。
4. 自适应误差校正
- 设计了针对难分正例和难分负例的自适应损失函数,以识别和纠正模型中的持续错误。
- 通过动态调整损失权重,强化模型对难分样本的学习。
5. 智能模型预训练
- 利用大型视觉-语言模型(如BLIP-2)的图像到文本生成能力,从视频语料库生成高质量的配对文本查询进行模型预训练。
- 通过将视频分割成10秒间隔,为代表性帧生成描述性字幕,并创建合成数据对,用于模型训练。
6. 综合实验和消融研究
- 在QVHighlights、TVSum和Charades-STA等广泛认可的基准数据集上进行评估,验证VideoLights框架的有效性。
- 通过消融研究分析各个组件和损失函数对模型性能的影响。
通过这些方法,VideoLights框架能够有效地从跨模态和跨任务的交互中学习,提高了视频高光检测和时刻检索任务的性能,并在多个基准数据集上取得了新的最先进结果。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估VideoLights框架的性能,并与现有方法进行比较:
数据集
- QVHighlights:一个独特的数据集,结合了时刻检索和高光检测任务,提供了广泛的视频注释,并通过网络服务器维持评估的公正性。
- Charades-STA:用于时刻检索的数据集,包含了大量视频和查询文本。
- TVSum:用于高光检测的数据集,包含了多个类别的视频。
评估指标
- 对于时刻检索,计算了在预定阈值下的召回率(Recall@1)、平均精度均值(mean Average Precision, mAP)以及在多个交并比(Intersection over Union, IoU)阈值下的平均mAP。
- 对于高光检测,评估了平均精度(mAP)和最高得分片段的命中率(HIT@1)。
实施细节
- 训练了四个模型变体:VideoLights、VideoLights-pt(使用CLIP和SlowFast特征)、VideoLights-B(整合了CLIP、BLIP和SlowFast特征)和VideoLights-B-pt(预训练版本)。
- 对于TVSum数据集,使用了I3D模型提取视觉特征,以便与其他方法进行比较。
- 设置了特定的超参数,如隐藏单元大小、Bi-CMF层数、编码器和解码器层数等,并使用AdamW优化器进行训练。
主要结果
- QVHighlights:VideoLights在大多数评估指标上取得了最佳性能,显著超越了先前的方法。
- Charades-STA:VideoLights在没有预训练的情况下在三个评估指标上达到了最佳性能,并与预训练设置下的UniVTG(pt)竞争。
- TVSum:VideoLights在多个领域展现了竞争力的表现,并在整体平均值上接近先前的最佳方法。
消融研究
- FRA模块的影响:通过对比有无FRA模块的模型性能,展示了FRA在提升模型性能方面的效果。
- Bi-CMF模块的影响:通过对比双向和单向跨模态融合的效果,证明了Bi-CMF在提高模型性能方面的优势。
- 新损失函数的影响:通过引入自适应硬正例和负例损失、任务耦合损失、显著性余弦相似度损失和对齐损失,展示了这些损失函数在提升模型性能方面的贡献。
- BLIP-2特征和预训练的影响:通过对比使用不同特征和预训练方法的模型性能,展示了BLIP-2特征和预训练策略在提升模型性能方面的效果。
结论
这些实验和消融研究证明了VideoLights框架在视频高光检测和时刻检索任务中的有效性,并显示了其在多个评估指标上超越现有最先进方法的性能。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些可以进一步探索的点,主要包括:
多模态融合技术的改进:
- 研究更先进的多模态融合技术,以更好地整合视频和文本信息,提高跨模态交互的效果。
特征对齐和细化方法的优化:
- 开发更有效的特征对齐和细化方法,以提高视频和文本特征之间的对应关系和交互。
实际视频平台的更广泛应用:
- 将VideoLights框架应用于实际视频平台,探索其在现实世界视频内容管理、推荐和编辑等方面的潜力。
大型视觉-语言模型(LVLMs)在时刻检索任务中的有效性:
- 进一步探索和评估大型视觉-语言模型在视频时刻检索任务中的性能和应用潜力。
预训练模型的依赖和计算开销问题:
- 解决依赖预训练模型可能导致的计算开销和外部资源依赖问题,提高方法的可扩展性和实用性。
预训练数据的偏差和不准确性问题:
- 改进弱监督预训练方法,减少由视觉-语言预训练模型生成的字幕偏差或不准确性对训练过程的影响。
Bi-CMF模块对输入特征和注意力机制的依赖性问题:
- 提高Bi-CMF模块对输入特征和注意力机制的鲁棒性,以适应更复杂和多样化的视频内容。
模型的可解释性和透明度:
- 提高模型的可解释性,帮助理解模型的决策过程,增强用户对模型预测的信任。
模型在不同语言和文化背景下的适应性:
- 探索模型在处理不同语言和文化背景下的视频内容时的适应性和泛化能力。
模型的实时性能和资源效率:
- 优化模型以实现实时视频处理,并提高其在资源受限设备上的运行效率。
这些进一步探索的点有助于推动视频高光检测和时刻检索技术的发展,提高视频内容分析的准确性和效率,并扩展其在实际应用中的潜力。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为VideoLights的框架,旨在联合处理视频高光检测(Highlight Detection, HD)和时刻检索(Moment Retrieval, MR)任务。以下是论文的主要内容总结:
1. 问题定义
- 论文指出现有模型在处理视频高光检测和时刻检索时,常忽略跨任务动态和视频-文本对齐,导致性能受限。
- 引入大型视觉-语言模型(LVLMs)如BLIP-2,以增强模型在视频理解任务中的表现。
2. VideoLights框架
- 特征细化和对齐模块(FRA):通过CNN和对齐损失实现更好的视频-文本特征对齐。
- 双向跨模态融合网络(Bi-CMF):通过多阶段注意力机制加强文本-视频特征的融合。
- 单向联合任务反馈机制(Uni-JFM):通过任务特定和任务耦合损失提升跨任务学习效率。
- 自适应误差校正:引入硬正例/负例损失以适应性地惩罚模型错误。
- 智能模型预训练:利用LVLMs生成合成数据进行预训练,增强模型的多模态特征集成能力。
3. 实验
- 在QVHighlights、TVSum和Charades-STA数据集上进行了广泛的实验,验证了VideoLights在视频高光检测和时刻检索任务上的有效性。
- 与现有方法相比,VideoLights在多个评估指标上取得了新的最佳性能。
4. 消融研究
- 通过消融研究分析了各个组件和损失函数对模型性能的影响,证明了所提方法的有效性。
5. 限制和未来工作
- 论文讨论了当前方法的局限性,包括对预训练模型的依赖和计算开销问题,并提出了未来研究的方向,如改进多模态融合技术和特征对齐方法。
总体而言,VideoLights框架通过创新的跨模态和跨任务交互机制,有效地提高了视频高光检测和时刻检索的性能,并为未来视频理解系统的发展提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

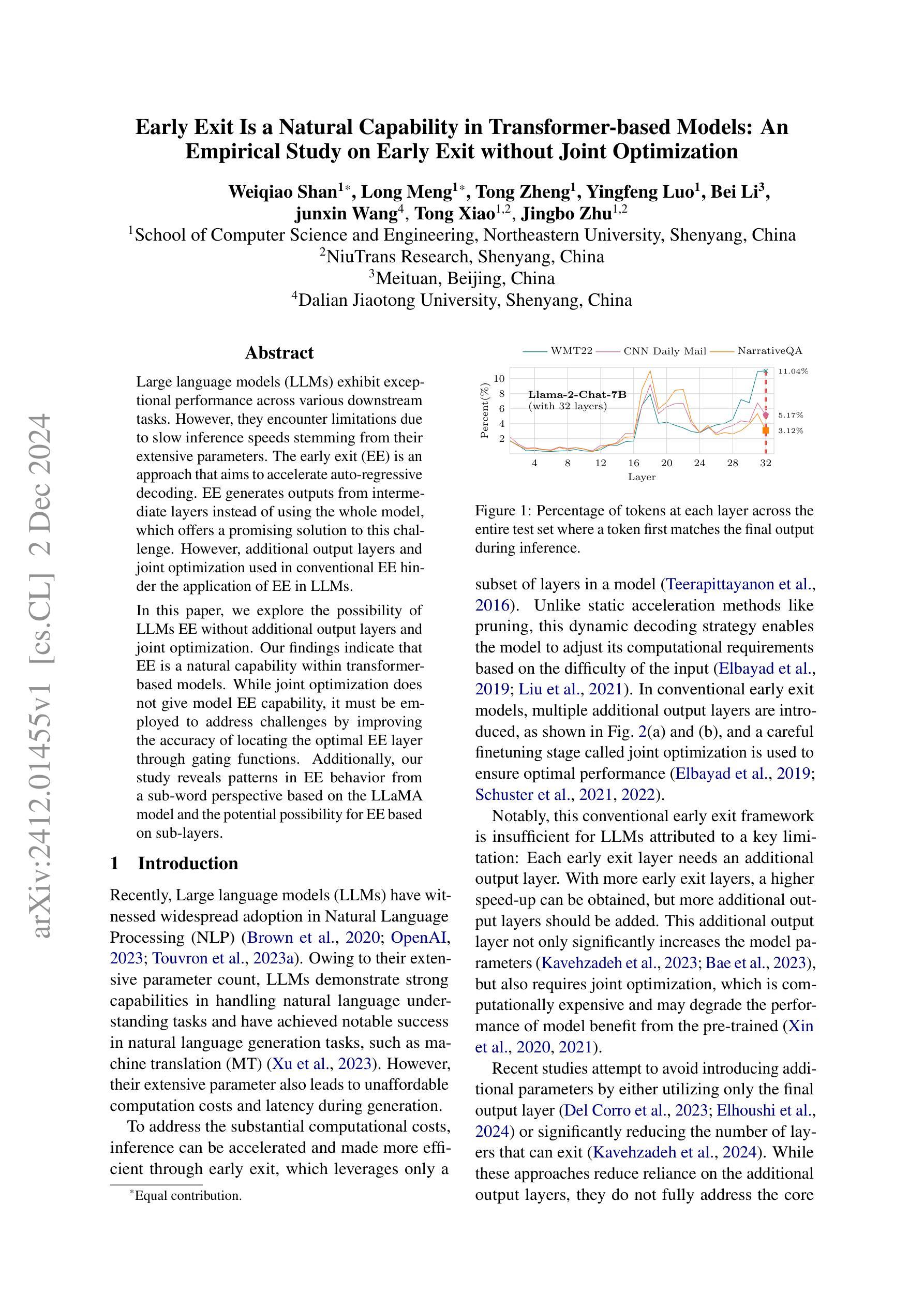
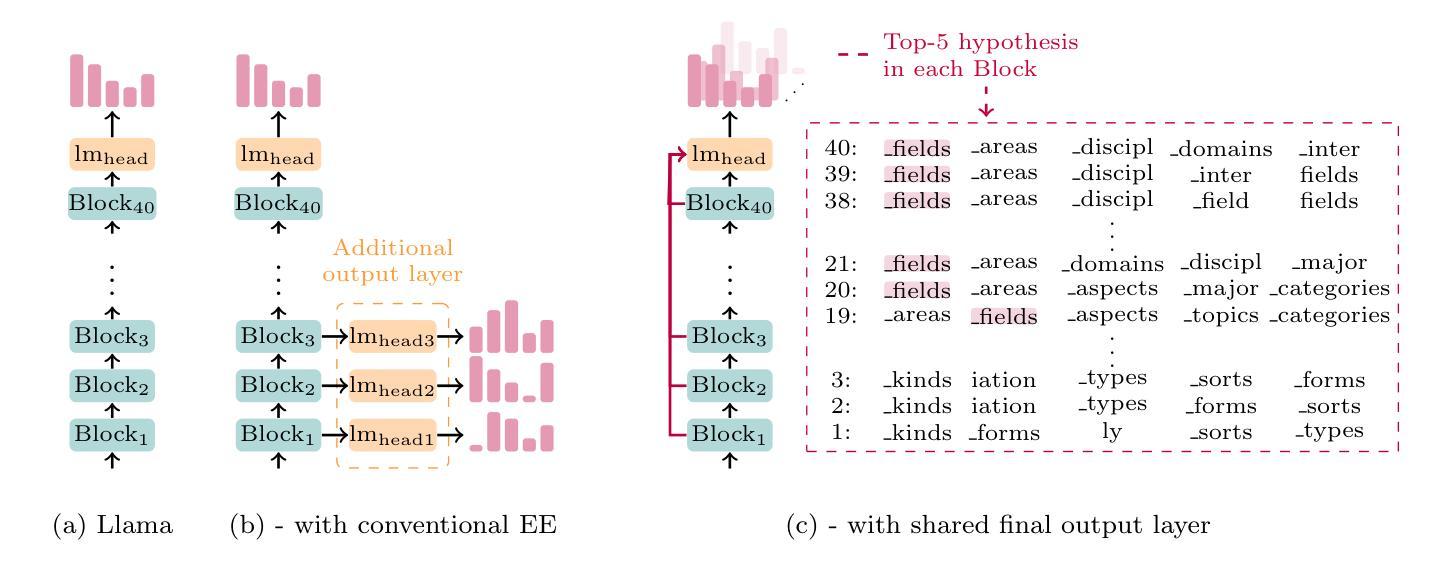
Early Exit Is a Natural Capability in Transformer-based Models: An Empirical Study on Early Exit without Joint Optimization
Authors:Weiqiao Shan, Long Meng, Tong Zheng, Yingfeng Luo, Bei Li, junxin Wang, Tong Xiao, Jingbo Zhu
Large language models (LLMs) exhibit exceptional performance across various downstream tasks. However, they encounter limitations due to slow inference speeds stemming from their extensive parameters. The early exit (EE) is an approach that aims to accelerate auto-regressive decoding. EE generates outputs from intermediate layers instead of using the whole model, which offers a promising solution to this challenge. However, additional output layers and joint optimization used in conventional EE hinder the application of EE in LLMs. In this paper, we explore the possibility of LLMs EE without additional output layers and joint optimization. Our findings indicate that EE is a natural capability within transformer-based models. While joint optimization does not give model EE capability, it must be employed to address challenges by improving the accuracy of locating the optimal EE layer through gating functions. Additionally, our study reveals patterns in EE behavior from a sub-word perspective based on the LLaMA model and the potential possibility for EE based on sub-layers.
大型语言模型(LLM)在各种下游任务中表现出卓越的性能。然而,由于庞大的参数导致的推理速度慢,它们遇到了限制。早期退出(EE)是一种旨在加速自回归解码的方法。EE从中间层生成输出,而不是使用整个模型,这为解决这一挑战提供了有前景的解决方案。然而,传统EE中使用额外的输出层和联合优化阻碍了EE在LLM中的应用。在本文中,我们探索了没有额外输出层和联合优化的LLM EE的可能性。我们的研究结果表明,EE是基于transformer模型的固有功能。虽然联合优化不会赋予模型EE功能,但必须通过改进通过门控函数定位最佳EE层的准确性来解决挑战。此外,我们的研究还基于LLaMA模型从子词视角揭示了EE行为的模式,以及基于子层的EE的潜在可能性。
论文及项目相关链接
Summary
基于大型语言模型(LLM)在多种下游任务中的出色表现,本文探讨了加速其自回归解码的问题。早期退出(EE)作为一种旨在加速LLM的方法被提出。它通过生成中间层的输出来减少模型计算的负担。研究发现在不使用附加输出层和联合优化的前提下,LLM具有潜在的早期退出能力。然而,为实现EE的高效性,仍需要采用联合优化来改进最佳退出层的定位精度。此外,本文还根据LLaMA模型揭示了EE行为的子词视角和基于子层的EE可能性。
Key Takeaways
- 大型语言模型(LLM)在各种下游任务中表现出卓越的性能,但存在推理速度慢的问题。
- 早期退出(EE)方法旨在加速LLM的自回归解码过程。
- EE通过生成中间层的输出来减少计算负担,是一种有前途的解决方案。
- 不需要额外的输出层和联合优化,LLM本身就具有潜在的早期退出能力。
- 联合优化虽不赋予模型EE能力,但能提高定位最佳退出层的准确性。
- 基于LLaMA模型的子词视角揭示了EE行为的模式。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了在大型语言模型(LLMs)中应用早期退出(Early Exit, EE)策略时遇到的问题。具体来说,论文试图解决以下几个关键问题:
大型语言模型的推理速度慢:大型语言模型因其庞大的参数量,在处理自然语言理解和生成任务时表现出色,但这也导致了它们在生成过程中的计算成本和延迟较高。
早期退出策略的局限性:传统的早期退出方法通过在模型的中间层生成输出来加速自回归解码,但这需要额外的输出层和联合优化过程。这些额外的输出层不仅增加了模型参数,而且联合优化过程计算成本高,可能会降低模型性能。
早期退出在大型语言模型中的应用:论文探索了在不增加额外输出层和联合优化的情况下,大型语言模型是否具有自然早期退出的能力,即模型能否在不经过全部层的情况下生成与最终层一致的输出。
早期退出的准确性和效率:论文研究了如何准确定位最优的早期退出层,以及如何提高早期退出策略的效率,特别是在不依赖联合优化的情况下。
早期退出在不同层级的应用:论文还探讨了基于子层(sub-layers)的早期退出的可能性,以及从子词(sub-word)和词性(part-of-speech)角度分析早期退出行为的模式。
总的来说,论文的核心目标是提高大型语言模型的推理效率,同时保持或提高模型性能,通过深入分析和实验验证早期退出策略在这些模型中的自然能力和应用潜力。
Q: 有哪些相关研究?
A: 论文中提到了以下相关研究:
早期退出(Early Exit):
- Panda et al. (2016) 提出了基于条件深度学习的能源效率和增强模式识别。
- Elbayad et al. (2019) 提出了深度自适应变换器(Depth-adaptive Transformer)。
- Liao et al. (2021) 提出了全局过去-未来早期退出方法,用于加速预训练语言模型的推理。
- Schwartz et al. (2020) 讨论了匹配模型和实例复杂度的工具。
- Zhou et al. (2020) 提出了基于耐心的早期退出方法,用于快速且鲁棒的BERT推理。
饱和事件(Saturation Events):
- Geva et al. (2020) 提出了变换器前馈层作为关键-值记忆的观点。
- Geva et al. (2022) 发现变换器前馈层通过在词汇空间中提升概念来构建预测。
大型语言模型(LLMs):
- Brown et al. (2020) 展示了语言模型是少数样本学习者。
- OpenAI (2023) 发布了GPT-4技术报告。
优化和推理加速:
- Xin et al. (2020, 2021) 提出了DeeBERT和Berxit,用于加速BERT推理。
- Kavehzadeh et al. (2023, 2024) 提出了Sorted LLaMa模型,用于动态推理。
其他相关工作:
- Cai et al. (2019) 提出了Once-for-All模型,用于训练一个网络并专门化它以实现高效部署。
- Huang et al. (2017) 提出了多尺度密集网络,用于资源高效的图像分类。
- Sun et al. (2021) 提出了早期退出与集成内部分类器的方法。
这些研究涵盖了早期退出策略的不同方面,包括理论基础、实现方法、以及在特定模型和任务中的应用。论文通过这些相关工作,构建了对早期退出策略的全面理解,并在此基础上探索了不依赖于额外输出层和联合优化的早期退出能力。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决大型语言模型(LLMs)中早期退出(Early Exit, EE)的问题:
探索早期退出的自然能力:
- 论文首先探索了LLMs在没有额外输出层和联合优化的情况下,是否具有自然早期退出的能力。通过实验发现,在不同的任务和模型中,中间层的输出开始与最终输出匹配,表明早期退出是变换器模型的内在特性。
分析早期退出行为:
- 论文通过分析LLaMA模型的子词和词性角度的早期退出行为模式,揭示了早期退出的潜在可能性,并分析了不同子层的早期退出能力。
评估联合优化的必要性:
- 论文评估了联合优化对于早期退出能力的影响,发现虽然联合优化不会赋予模型早期退出能力,但通过改善门控函数的准确性,它对于确定最佳的早期退出层是必需的。
实验验证:
- 论文在多种变换器模型上进行了广泛的实验,包括BERT、RoBERTa和LLaMA模型,验证了早期退出能力的普遍性和有效性。
开发独立的门控函数:
- 鉴于现有的门控网络受限于联合优化,论文探索了开发一个不依赖于联合优化的门控网络的可能性,以减少LLMs中的计算成本。
分析隐藏状态和输出分布的相似性:
- 论文分析了隐藏状态和输出分布的相似性,发现联合优化增强了每层输出分布的相似性,从而提高了门控函数的效果。
处理长序列中的早期退出问题:
- 论文探讨了在长序列生成场景中应用早期退出时,复制键值(KV)缓存会导致错误传播的问题,并提出了解决方案。
总结和展望:
- 论文总结了早期退出在变换器模型中的自然能力,并指出了未来研究的方向,包括在更广泛的模型和资源场景中进行实验,以确保发现可以被推广。
通过这些步骤,论文不仅揭示了早期退出在变换器模型中的自然能力,还探索了在不依赖于传统联合优化的情况下,如何有效地利用这种能力来提高LLMs的推理效率。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来探索早期退出(Early Exit, EE)在大型语言模型(LLMs)中的应用和效果。以下是实验的详细描述:
1. 自然早期退出能力的探索实验
- 目的:验证LLMs是否具有不依赖于额外输出层和联合优化的自然早期退出能力。
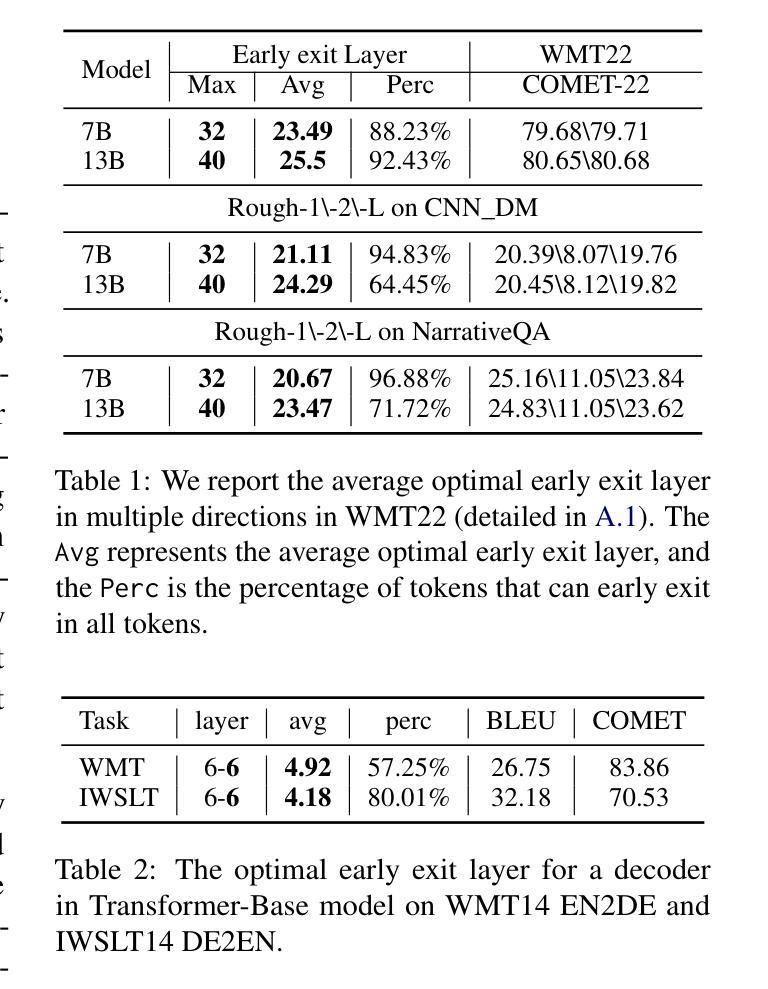
- 方法:使用Llama-2-7b-chat和Llama-2-13b-chat模型在WMT22机器翻译基准、NarrativeQA数据集和CNN/DailyMail数据集上进行实验。
- 结果:发现在各种任务中,中间层的输出开始与最终输出匹配,表明早期退出是变换器模型的内在特性。
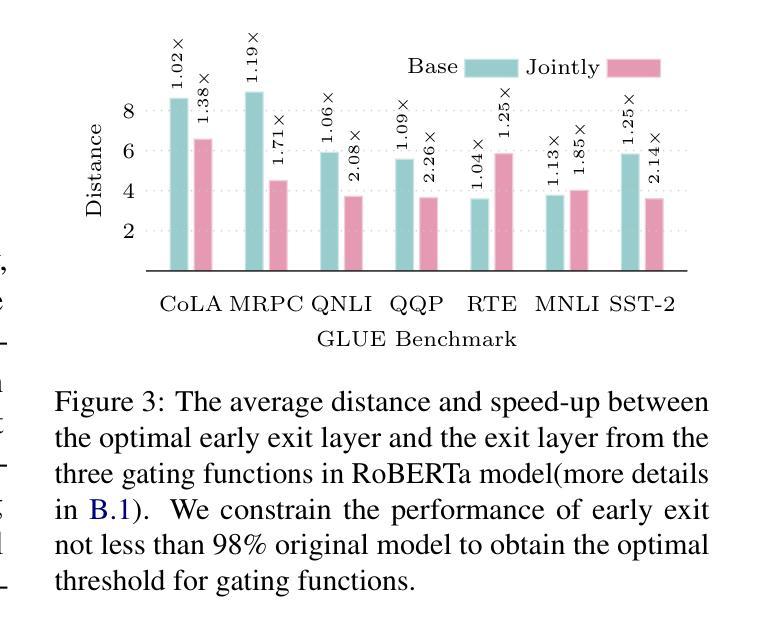
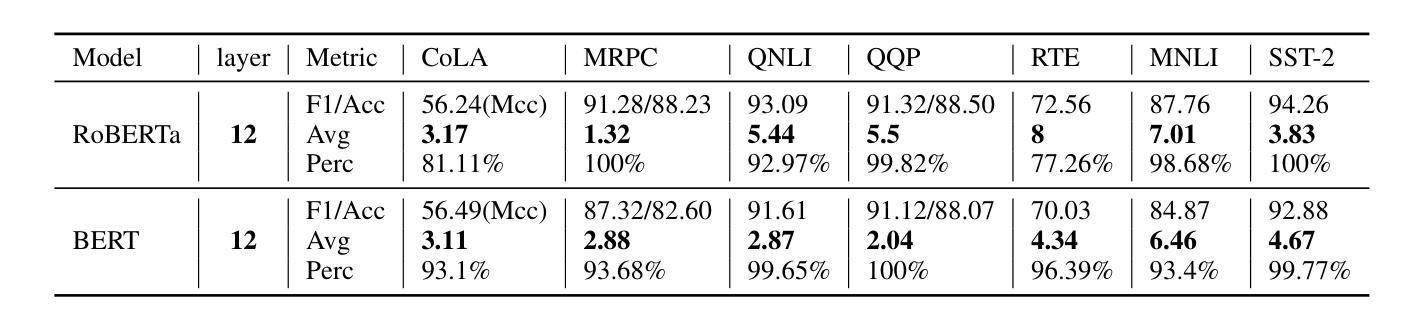
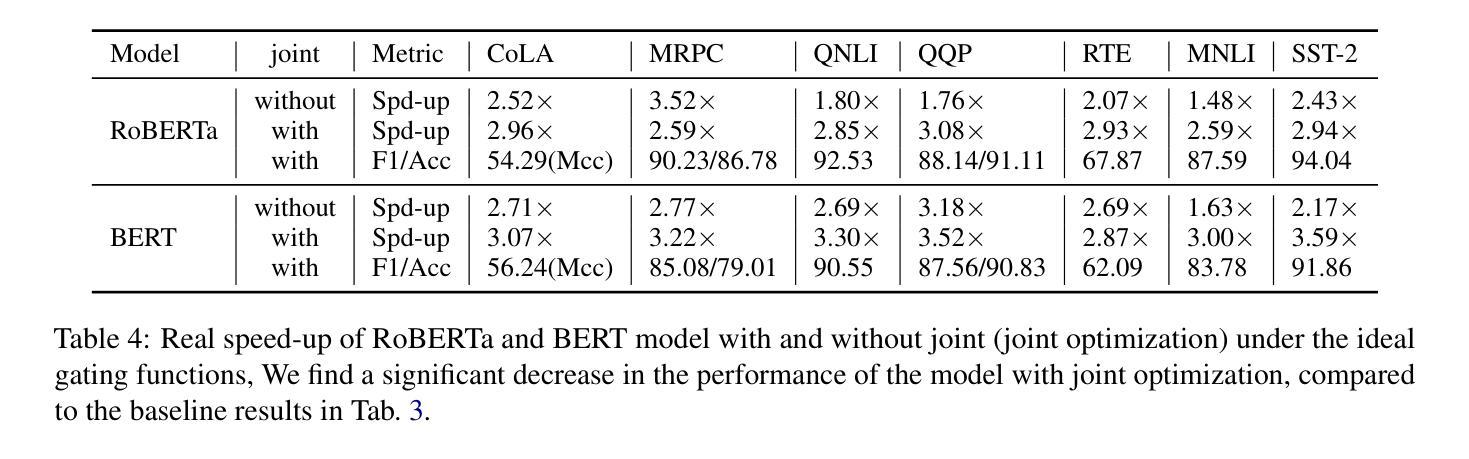
2. 早期退出能力的普遍性实验
- 目的:探索早期退出能力是否普遍存在于不同的变换器模型和任务中。
- 方法:在包括Transformer-base模型、BERT和RoBERTa模型在内的多种模型和任务上进行实验,使用WMT14-DE2EN数据集和GLUE基准。
- 结果:发现早期退出能力普遍存在于不同的模型和任务中。
3. 早期退出在序列级别和标记级别场景中的实验
- 目的:评估早期退出能力是否可以直接用于提高解码效率,并测试现有的门控函数是否能准确识别最早的退出层。
- 方法:在GLUE基准上使用BERT和RoBERTa模型进行序列级别早期退出实验;在LLaMA模型上进行标记级别早期退出实验。
- 结果:发现在没有联合优化的情况下,准确识别最优早期退出层是一个挑战,而联合优化有助于提高门控网络的准确性。
4. 联合优化对门控函数性能的影响实验
- 目的:分析联合优化如何通过提高输出分布的相似性来增强门控函数的性能。
- 方法:比较了有和没有联合优化的模型在每层输出分布的最大置信度分数。
- 结果:发现联合优化提高了浅层的置信度分数变化,使得门控函数倾向于更早的退出点。
5. 长序列中的早期退出实验
- 目的:探索早期退出是否能够在长序列生成场景中加速LLMs的解码。
- 方法:在LLaMA模型上进行标记级别早期退出实验,测试复制键值(KV)缓存的影响。
- 结果:发现在长序列中,基于最优早期退出层的早期退出会导致重复生成和无法终止序列的问题。
6. 基于子层的早期退出潜力探索实验
- 目的:探索基于子层的早期退出的可能性。
- 方法:分析了最优早期退出层与输出序列长度的关系,并从隐藏状态、子词和词性角度进行了详细分析。
- 结果:发现最优早期退出层随输出序列长度的增加而降低,表明长文本场景中早期退出的潜力更大。
这些实验全面地评估了早期退出在不同模型、任务和场景中的适用性和效果,为早期退出策略的进一步研究和应用提供了实证基础。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些可以进一步探索的点,包括:
更广泛的模型和数据集:
- 论文提到当前研究受限于可用设备,因此只能对有限的模型进行实验。未来的工作可以扩展到更广泛的模型和数据集,以确保发现可以被推广到更多环境。
独立的门控函数开发:
- 论文指出现有的门控网络受限于联合优化,因此探索开发一个不依赖于联合优化的门控网络可以减少LLMs中的计算成本。
长序列生成中的早期退出:
- 论文中提到在长序列生成中应用早期退出时,复制键值(KV)缓存会导致错误传播的问题。进一步探索如何在长序列中有效应用早期退出是一个重要的研究方向。
基于子层的早期退出:
- 论文发现最优早期退出层与输出序列长度有关,这表明长文本场景中早期退出的潜力更大。进一步研究基于子层的早期退出策略,以及如何利用这些信息来优化模型的推理过程。
隐藏状态和输出分布的相似性:
- 论文分析了隐藏状态和输出分布的相似性,并发现联合优化增强了每层输出分布的相似性。进一步探索这些相似性如何影响早期退出决策是一个有价值的研究方向。
词性和子词角度的早期退出行为:
- 论文从词性和子词角度分析了早期退出行为的模式。进一步研究这些模式如何影响早期退出策略的设计和优化。
早期退出与模型性能的权衡:
- 论文提到联合优化虽然提高了门控网络的准确性,但也降低了整体模型性能。研究如何在早期退出带来的加速和模型性能之间取得最佳权衡。
早期退出在实际应用中的部署:
- 考虑将早期退出策略部署到实际应用中,评估其在现实世界场景中的有效性和实用性。
早期退出的动态调整:
- 研究如何根据输入的难度动态调整早期退出策略,以实现更优的计算效率和模型性能。
这些探索点可以帮助研究者更深入地理解早期退出机制,并为设计更高效、更实用的LLMs推理策略提供指导。
Q: 总结一下论文的主要内容
A: 论文《Early Exit Is a Natural Capability in Transformer-based Models: An Empirical Study on Early Exit without Joint Optimization》主要探讨了在不依赖额外输出层和联合优化的情况下,大型语言模型(LLMs)是否具有自然早期退出(Early Exit, EE)的能力。以下是论文的主要内容总结:
问题背景:
- 大型语言模型(LLMs)在各种下游任务中表现出色,但由于参数众多导致推理速度慢。
- 早期退出(EE)是一种加速自回归解码的方法,它从模型的中间层生成输出,而不是使用整个模型。
研究目标:
- 探索LLMs在没有额外输出层和联合优化的情况下是否具有早期退出的能力。
- 分析早期退出行为的模式,并探索基于子层的早期退出可能性。
实验设计:
- 在多种变换器模型上进行实验,包括BERT、RoBERTa和LLaMA模型。
- 使用GLUE基准、WMT14 EN2DE翻译任务、WMT22、CNN Daily Mail和NarrativeQA数据集。
主要发现:
- 变换器模型具有自然早期退出能力,这种能力不依赖于联合优化。
- 联合优化通过提高相邻层输出分布的相似性来提高门控函数的准确性,但也可能会降低模型性能。
- 在序列级别场景中实施早期退出相对简单,而在标记级别场景中由于缺少先前标记的关键和值信息,实施早期退出面临挑战。
实验结果:
- 在多个任务和模型中观察到早期退出能力,表明这是一种普遍现象。
- 没有联合优化的情况下,准确识别最优早期退出层是一个挑战。
- 联合优化提高了模型在早期退出时的速度,但也降低了整体模型性能。
进一步探索的方向:
- 探索更广泛的模型和数据集。
- 开发独立的门控函数。
- 研究长序列生成中的早期退出策略。
- 分析基于子层的早期退出潜力。
结论:
- 早期退出是变换器模型的内在特性,不依赖于额外输出层和联合优化。
- 联合优化对于提高门控函数的准确性和扩大早期退出空间是必需的,但以降低模型性能为代价。
论文通过广泛的实验验证了早期退出的自然能力,并探讨了在实际应用中利用这种能力的可能性和挑战。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图
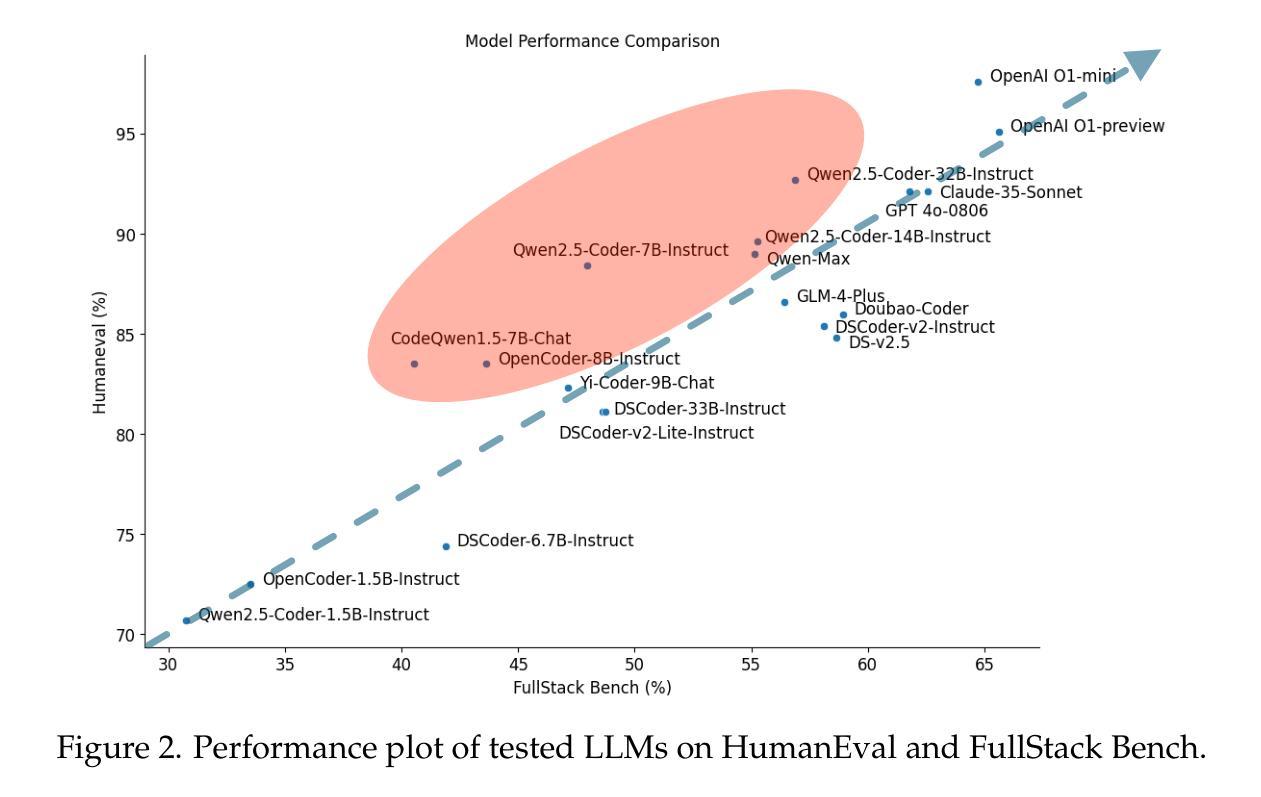
FullStack Bench: Evaluating LLMs as Full Stack Coders
Authors:Siyao Liu, He Zhu, Jerry Liu, Shulin Xin, Aoyan Li, Rui Long, Li Chen, Jack Yang, Jinxiang Xia, Z. Y. Peng, Shukai Liu, Zhaoxiang Zhang, Jing Mai, Ge Zhang, Wenhao Huang, Kai Shen, Liang Xiang
As the capabilities of code large language models (LLMs) continue to expand, their applications across diverse code intelligence domains are rapidly increasing. However, most existing datasets only evaluate limited application domains. To address this gap, we have developed a comprehensive code evaluation dataset FullStack Bench focusing on full-stack programming, which encompasses a wide range of application domains (e.g., basic programming, data analysis, software engineering, mathematics, and machine learning). Besides, to assess multilingual programming capabilities, in FullStack Bench, we design real-world instructions and corresponding unit test cases from 16 widely-used programming languages to reflect real-world usage scenarios rather than simple translations. Moreover, we also release an effective code sandbox execution tool (i.e., SandboxFusion) supporting various programming languages and packages to evaluate the performance of our FullStack Bench efficiently. Comprehensive experimental results on our FullStack Bench demonstrate the necessity and effectiveness of our FullStack Bench and SandboxFusion.
随着大型代码语言模型(LLM)的功能不断扩展,它们在各种代码智能领域的应用也在迅速增加。然而,大多数现有数据集只评估有限的应用领域。为了弥补这一空白,我们开发了一个全面的代码评估数据集FullStack Bench,专注于全栈编程,涵盖广泛的应用领域(如基本编程、数据分析、软件工程、数学和机器学习等)。此外,为了评估多语言编程能力,在FullStack Bench中,我们从1 6种广泛使用的编程语言中设计真实世界的指令和相应的单元测试案例,以反映真实世界的使用场景,而非简单的翻译。而且,我们还发布了一款有效的代码沙盒执行工具(即SandboxFusion),支持各种编程语言和软件包,以高效评估我们的FullStack Bench的性能。在我们FullStack Bench上的综合实验结果证明了FullStack Bench和SandboxFusion的必要性和有效性。
论文及项目相关链接
PDF 26 pages
Summary
全面评价大型代码语言模型(LLM)的应用能力,推出FullStack Bench数据集。该数据集涵盖全栈编程的多个应用领域,包括基本编程、数据分析、软件工程、数学和机器学习等。设计来自16种流行编程语言的真实指令和相应的单元测试案例,以反映真实使用场景而非简单翻译。同时发布支持多种编程语言和包的有效代码沙箱执行工具SandboxFusion,以高效评估FullStack Bench的性能。
Key Takeaways
- LLM的应用在代码智能领域迅速增加,但现有数据集评价领域有限。
- FullStack Bench数据集旨在全面评价编程能力,覆盖多个应用领域。
- 设计了来自16种编程语言的真实指令和单元测试案例,反映真实使用场景。
- 推出SandboxFusion工具,支持多种编程语言和包,高效评估FullStack Bench性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是现有代码大型语言模型(LLMs)评估数据集覆盖的应用领域有限,无法全面评估模型在真实世界代码开发场景中的代码相关能力。具体来说,论文中提到:
现有数据集局限性:大部分现有的代码评估数据集只涵盖了有限的应用领域,如基本编程、数据分析等,而没有覆盖更广泛的计算机科学领域和编程语言,这限制了对代码LLMs能力的全面评估。
真实世界应用场景需求:真实世界的软件开发涉及多个领域,包括但不限于基础编程、软件工程、数据分析、机器学习等。现有的评估数据集无法充分模拟这些多样化的应用场景。
多语言编程能力评估:随着代码LLMs在多语言编程领域的应用增加,需要有能够评估模型在多种编程语言下性能的数据集。
为了解决这些问题,论文提出了FullStack Bench数据集和SandboxFusion执行环境:
FullStack Bench:这是一个全面的代码评估数据集,包含了3374个问题,覆盖16种编程语言和多个计算机科学领域,旨在全面评估大型模型在各种真实世界代码开发场景中的能力。
SandboxFusion:这是一个有效的代码沙箱执行工具,支持多种编程语言和包,能够高效评估FullStack Bench中的问题,提供编译和执行反馈,帮助研究人员更好地理解和改进LLMs的性能。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与FullStack Bench和SandboxFusion相关的研究工作:
代码大型语言模型(LLMs):
- Chen et al. (2021a) 和 Chen et al. (2021b) 提出了评估在代码上训练的大型语言模型。
- Roziere et al. (2023), Zheng et al. (2023), 和 Guo et al. (2024a) 在代码生成、代码调试、代码翻译等任务中展示了代码LLMs的能力。
代码评估基准(Code Benchmark):
- Austin et al. (2021a) 和 Austin et al. (2021b) 提出了程序合成任务,要求LLMs阅读自然语言描述并生成相应的代码片段。
- Jiao et al. (2023), Yan et al. (2023), 和 Zhu et al. (2022) 专注于代码翻译的评估。
- Huang et al. (2021), Husain et al. (2019), 和 Li et al. (2024) 研究了代码检索任务。
- Huq et al. (2022), Prenner and Robbes (2023), 和 Richter and Wehrheim (2022) 专注于漏洞修复任务。
多语言编程代码生成和调试:
- Roziere et al. (2023), Guo et al. (2024a), 和 Hui et al. (2024) 提出了多语言编程代码生成和调试任务的最新代码LLMs。
代码沙箱执行环境:
- DifySandbox (LangGenius, 2024), MultiPLE (Cassano et al., 2023), 和 MPLSandbox (Dou et al., 2024) 是一些已经提出的沙箱执行环境,它们在支持的语言和功能方面存在局限性。
其他相关数据集和基准:
- HumanEval (Chen et al., 2021a), MBPP (Austin et al., 2021b), DS-1000 (Lai et al., 2022), 和 xCodeEval (Khan et al., 2023) 是一些流行的代码评估数据集,它们主要关注特定的编程任务和领域。
这些相关工作为FullStack Bench和SandboxFusion提供了背景和动机,展示了在代码LLMs评估领域的研究进展和挑战。FullStack Bench旨在通过覆盖更广泛的应用领域和编程语言,提供一个更全面的评估框架,而SandboxFusion则提供了一个有效的执行环境来支持这些评估。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决现有代码评估数据集覆盖范围有限和无法全面评估代码LLMs能力的问题:
开发FullStack Bench数据集:
- 论文提出了一个全面的代码评估数据集FullStack Bench,包含3374个问题,这些问题覆盖了16种广泛使用的编程语言和多个计算机科学领域,如基础编程、软件工程、数据分析、机器学习等。
- 每个问题都包括了实际场景中的指令和相应的单元测试用例,以模拟真实世界的编程任务。
设计多语言编程能力评估:
- FullStack Bench中的问题不仅包含英文指令,还有中文指令,以评估模型在不同语言下的性能。
发布SandboxFusion执行工具:
- 为了有效评估FullStack Bench中的问题,论文发布了一个名为SandboxFusion的代码沙箱执行工具,支持多种编程语言和包。
- SandboxFusion具备以下特点:
- 支持多种语言:能够处理23种常用的编程语言,满足不同的实际使用场景。
- 易于部署:仅需单个服务器即可部署,适用于大型模型评估场景。
- 统一的多数据集执行环境:除了FullStack Bench,还支持10多个广泛使用的代码评估基准。
实验验证:
- 论文通过在FullStack Bench上对多个流行的代码语言模型进行实验,验证了FullStack Bench和SandboxFusion的必要性和有效性。
- 实验结果表明,大多数模型在HumanEval上表现良好,但在FullStack Bench上的表现相对较低,这突出了FullStack Bench评估真实世界编程能力的重要性。
详细分析:
- 论文还对模型在不同编程语言、不同难度级别上的表现进行了详细分析,并探讨了SandboxFusion反馈对模型性能的影响。
通过这些步骤,论文不仅提供了一个更全面的评估框架来测试和改进代码LLMs的能力,还通过SandboxFusion提供了一个有效的执行环境来支持这些评估,从而推动了代码智能领域的发展。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验:
模型性能测试:
- 选择了27个流行的代码语言模型(包括开源和闭源模型),在FullStack Bench数据集上测试这些模型的性能。
- 根据模型大小将这些AI编码器分为五组:1B+、6B+、13B、20B+和70B+,并比较了它们的性能。
不同领域性能分析:
- 系统地评估了AI编码器在FullStack Bench覆盖的11个实际领域(如基础编程、软件工程、数据分析等)的性能,并在表格中呈现了结果。
不同编程语言性能分析:
- 展示了不同AI编码器在多种编程语言(如Bash、C++、C#、D、Go等)上的性能,并分析了模型在这些语言上的表现。
编译与测试通过率分析:
- 使用SandboxFusion提供的编译器反馈,评估了模型响应的编译通过率,并分析了编译通过率与测试通过率之间的关系。
中英文问题性能分析:
- 分析了模型对中文和英文问题的性能,探讨了问题语言对模型性能的影响。
模型规模定律分析:
- 根据模型大小,分析了不同模型系列的性能,探讨了模型规模与性能之间的关系。
不同难度级别性能分析:
- 根据问题的难易程度(易、中、难),分析了模型在不同难度级别上的性能。
SandboxFusion反馈效果分析:
- 比较了使用SandboxFusion反馈进行自我改进的策略(Reflection)和简单多次推断(BoN)策略的性能差异。
这些实验全面评估了不同代码语言模型在多样化的实际编程任务上的性能,并验证了FullStack Bench数据集和SandboxFusion执行工具的有效性。通过这些实验,论文展示了不同模型在各种编程语言和任务中的性能差异,并分析了影响模型性能的因素。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
模型泛化能力的提升:
- 研究和开发更有效的技术以提高模型在未见过的编程语言和应用领域上的泛化能力。
多语言和多领域融合学习:
- 探索如何通过融合学习不同语言和领域的数据来提升模型的多语言和多领域编程能力。
模型解释性:
- 提高模型的解释性,以便更好地理解模型在解决特定编程问题时的决策过程。
模型训练数据的影响:
- 分析不同训练数据集对模型性能的影响,并探索如何构建更有效的训练数据集。
模型大小与性能的进一步研究:
- 深入研究模型大小与性能之间的关系,特别是对于不同复杂度的任务。
强化学习在代码生成中的应用:
- 利用强化学习进一步优化代码生成任务,特别是在复杂编程问题上。
模型在实际开发环境中的应用:
- 探索模型在实际软件开发流程中的应用,例如在代码审查、自动化测试和维护中的作用。
安全性和隐私保护:
- 研究如何在保护用户数据隐私和代码安全的前提下,使用模型辅助编程。
模型的可扩展性和维护性:
- 研究如何构建易于扩展和维护的模型,以适应不断变化的编程语言和框架。
模型在教育领域的应用:
- 探索模型在编程教育中的应用,例如自动生成教学材料、辅助学生学习和编码。
跨领域知识融合:
- 研究如何将领域外知识融合到模型中,以提高模型解决复杂编程问题的能力。
模型的公平性和偏见问题:
- 研究模型可能存在的偏见问题,并探索减少这些偏见的方法。
这些探索点可以帮助研究人员和开发者更好地理解代码LLMs的能力,并推动其在实际软件开发中的应用。
Q: 总结一下论文的主要内容
A: 论文《FullStack Bench: Evaluating LLMs as Full Stack Coders》主要论文《FullStack Bench: Evaluating LLMs as Full Stack Coders》主要内容包括以下几个方面:
问题陈述:
- 论文指出现有的代码大型语言模型(LLMs)评估数据集覆盖的应用领域有限,无法全面评估模型在真实世界代码开发场景中的代码相关能力。
FullStack Bench数据集:
- 为了解决上述问题,论文提出了一个全面的代码评估数据集FullStack Bench,包含3374个问题,覆盖16种编程语言和多个计算机科学领域,如基础编程、软件工程、数据分析等。
- 每个问题都包括实际场景中的指令和相应的单元测试用例,以模拟真实世界的编程任务。
多语言编程能力评估:
- FullStack Bench中的问题设计为中英文两种语言,以评估模型在不同语言下的性能。
SandboxFusion执行工具:
- 为了有效评估FullStack Bench中的问题,论文发布了一个名为SandboxFusion的代码沙箱执行工具,支持多种编程语言和包。
- SandboxFusion具备支持多种语言、易于部署和统一的多数据集执行环境等特点。
实验验证:
- 论文通过在FullStack Bench上对多个流行的代码语言模型进行实验,验证了FullStack Bench和SandboxFusion的必要性和有效性。
- 实验结果表明,大多数模型在HumanEval上表现良好,但在FullStack Bench上的表现相对较低,突出了FullStack Bench评估真实世界编程能力的重要性。
详细分析:
- 论文还对模型在不同编程语言、不同难度级别上的表现进行了详细分析,并探讨了SandboxFusion反馈对模型性能的影响。
贡献总结:
- 提出了FullStack Bench数据集,覆盖更多主流应用领域,相比现有代码评估基准更全面。
- 发布了SandboxFusion执行工具,有效评估不同编程任务。
- 通过实验结果和分析,展示了FullStack Bench和SandboxFusion的必要性和有效性。
论文通过提出新的评估数据集和执行工具,旨在更全面地评估代码LLMs的能力,并推动代码智能领域的发展。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

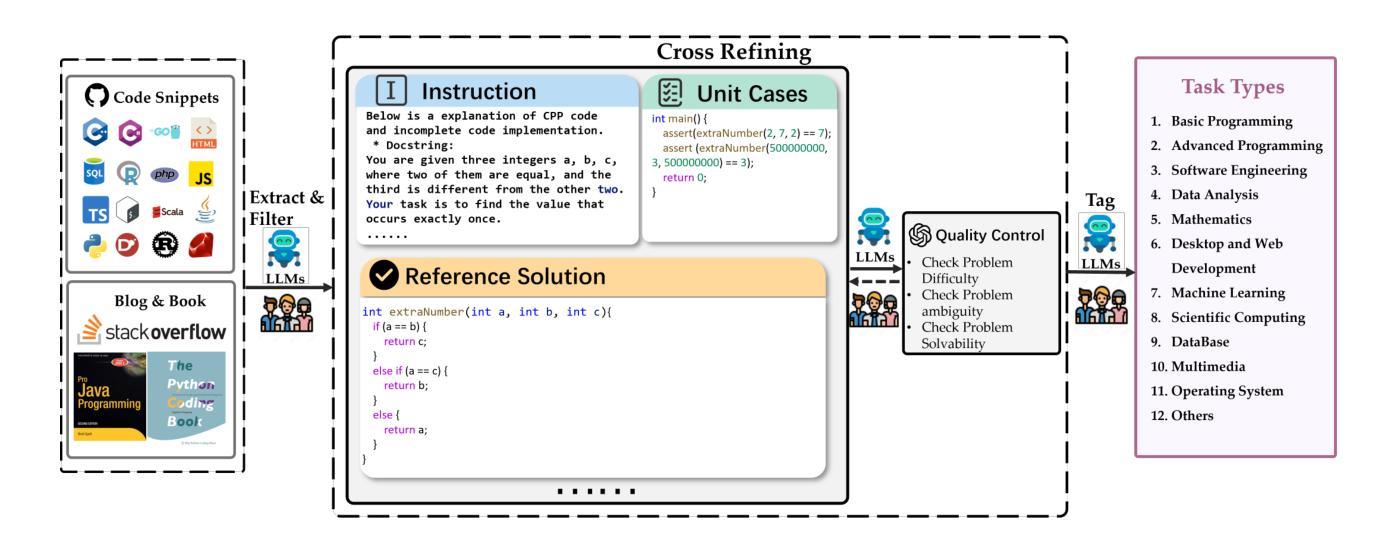

Forma mentis networks predict creativity ratings of short texts via interpretable artificial intelligence in human and GPT-simulated raters
Authors:Edith Haim, Natalie Fischer, Salvatore Citraro, Giulio Rossetti, Massimo Stella
Creativity is a fundamental skill of human cognition. We use textual forma mentis networks (TFMN) to extract network (semantic/syntactic associations) and emotional features from approximately one thousand human- and GPT3.5-generated stories. Using Explainable Artificial Intelligence (XAI), we test whether features relative to Mednick’s associative theory of creativity can explain creativity ratings assigned by humans and GPT-3.5. Using XGBoost, we examine three scenarios: (i) human ratings of human stories, (ii) GPT-3.5 ratings of human stories, and (iii) GPT-3.5 ratings of GPT-generated stories. Our findings reveal that GPT-3.5 ratings differ significantly from human ratings not only in terms of correlations but also because of feature patterns identified with XAI methods. GPT-3.5 favours ‘its own’ stories and rates human stories differently from humans. Feature importance analysis with SHAP scores shows that: (i) network features are more predictive for human creativity ratings but also for GPT-3.5’s ratings of human stories; (ii) emotional features played a greater role than semantic/syntactic network structure in GPT-3.5 rating its own stories. These quantitative results underscore key limitations in GPT-3.5’s ability to align with human assessments of creativity. We emphasise the need for caution when using GPT-3.5 to assess and generate creative content, as it does not yet capture the nuanced complexity that characterises human creativity.
创造力是人类认知的基本技能。我们使用文本形式心智网络(TFMN)来提取大约一千个人类和GPT3.5生成的故事中的网络(语义/句法关联)和情感特征。我们利用可解释人工智能(XAI)测试,基于Mednick的创造性联想理论的相关特征,来阐释人类和GPT-3.5给出的创造力评价。使用XGBoost,我们研究了三种情景:(i)人类对人类故事的评分,(ii)GPT-3.5对人类故事的评分,以及(iii)GPT-3.5对GPT生成的故事的评分。我们的研究发现,GPT-3.5的评分与人类评分存在显著差异,不仅体现在相关性上,还因为使用XAI方法识别出的特征模式。GPT-3.5偏爱“自己的”故事,对人类故事的评分与人类不同。通过SHAP分数进行的特征重要性分析表明:(i)网络特征对人类创造力和GPT-3.5对人类故事的评分预测更为准确;(ii)在GPT-3.5对自己故事的评分中,情感特征的作用大于语义/句法网络结构。这些定量结果强调了GPT-3.5与人类评估创造力对齐的关键局限性。我们强调在使用GPT-3.5评估和生成创造性内容时要谨慎,因为它还没有捕捉到人类创造力的微妙复杂性。
论文及项目相关链接
Summary
本研究利用文本形式心智网络(TFMN)提取语义、句法关联和情感特征,对比人类和GPT3.5对故事的创造力评价。通过可解释人工智能(XAI)和XGBoost分析,发现GPT3.5的评价与人类存在显著差异,不仅体现在相关性上,还体现在特征模式上。GPT3.5更偏向于评价其生成的故事,对人类故事的评价与人类不同。网络特征对预测人类和GPT3.5的创造力评价都很重要,而情感特征在GPT3.5自评故事时作用更大。这些结果突显了GPT3.5在评估创造力方面的关键局限性。
Key Takeaways
- 本研究使用TFMN提取故事中的语义、句法关联和情感特征。
- 对比了人类和GPT3.5对故事的创造力评价。
- 通过XAI和XGBoost分析,发现GPT3.5的评价与人类存在显著差异。
- GPT3.5更偏向于评价其生成的故事。
- 网络特征对预测人类和GPT3.5的创造力评价都很重要。
- 情感特征在GPT3.5自评故事时作用更大。
- GPT3.5在评估创造力方面存在局限性,需要谨慎使用。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何通过可解释的人工智能(XAI)来预测和理解人类和GPT模拟评分者对短文本创意评分。具体来说,论文通过以下几个方面来探讨这个问题:
创意的量化评估:研究如何利用文本形式心智网络(Textual forma mentis networks, TFMN)从大约一千个由人类和GPT3.5生成的故事中提取网络(语义/句法关联)和情感特征,并测试这些特征是否能够解释人类和GPT-3.5赋予的创意评分。
人类与AI评分的比较:通过对比人类和GPT-3.5对人类故事的评分,以及GPT-3.5对自己生成故事的评分,来揭示两者在创意评估上的差异。
创意评分的特征模式:使用XGBoost算法和SHAP值分析来检验不同场景下(人类评分人类故事、GPT-3.5评分人类故事、GPT-3.5评分GPT生成故事)哪些网络和情感特征对于预测创意评分更为重要。
情感在创意评分中的角色:研究情感特征如何影响创意评分,特别是在GPT-3.5评分自己生成的故事时情感特征与语义/句法网络结构的相对重要性。
AI在创意评估中的应用限制:强调在使用GPT-3.5评估和生成创意内容时需要谨慎,因为它尚未捕捉到人类创意的复杂性。
综上所述,论文的核心目标是利用可解释的人工智能方法来深入理解影响创意评分的关键因素,并评估GPT-3.5在模拟人类创意评估中的准确性和局限性。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的研究:
Mednick的联想理论:Mednick (1962) 提出的关联理论认为,创造力产生于在语义网络中形成遥远且看似无关概念之间的连接能力。这个理论为本研究中使用网络距离作为测试创意水平的代理提供了理论基础。
**Boden (1998)**:Boden 将创造力定义为人类认知的一个基本技能,并探讨了概念关联如何传达创造力。
**Runco & Chand (1995)**:他们对创造力的定义强调了生成新颖且有价值的想法或产品的能力。
Weinstein et al. (2022) 和 **Johnson et al. (2023)**:这些研究提出了评估文本创造力的度量标准,如单词的不频繁使用、独特的单词组合、句法独特性等,并探讨了如何利用网络科学和机器学习方法来评估创造力。
**Guo et al. (2019)、Heinen & Johnson (2018)、Semeraro et al. (2024)**:这些研究强调了个体中语义网络结构与创造力水平之间的显著相关性,并提出网络特征可以作为叙事创造力的可靠指标。
**Acar (2023)、Beaty & Johnson (2021)**:这些研究利用语义网络特征和机器学习算法减少创造力评分中的主观性,并自动赋予更客观的创造力分数。
**Vaswani et al. (2017)**:介绍了BERT模型,这是一个深度学习语言模型,通过分析单词的共现来理解文本中单词的上下文。
Siew et al. (2019) 和 **Stella et al. (2024)**:这些研究在认知网络科学领域提倡可解释模型,其中联想知识被表示为由一种或多种类型的关联链接的概念关系集。
**Plutchik (1980)**:Plutchik 的基本情绪理论认为有八种主要情绪,每种情绪都有一个对立情绪,这些情绪可以组合形成更复杂的情感,对人类如何体验和表达情感起着关键作用。
**Semeraro et al. (2024)**:对比了BERT和TFMNs在复现相同文本数据的创造力评分时显示的不同特征。
**D’Souza (2021)**:识别了短叙事中的创造性,如新词形、情节中的意外转折和原始生动的设定。
Amabile et al. (2005) 和 **Wang et al. (2017)**:研究了积极情绪状态对认知灵活性和创造性问题解决任务表现的影响。
这些相关研究为本论文提供了理论基础和方法论支持,帮助研究者探索和理解人类和人工智能评估创意的不同方式。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决预测和理解人类及GPT模拟评分者对短文本创意评分的问题:
数据收集:
- 收集了约一千个由人类和GPT-3.5生成的故事。
- 使用相同的三个单词提示,让人类参与者和GPT-3.5都创作故事,以保证实验条件的一致性。
特征提取:
- 利用文本形式心智网络(TFMN)从故事中提取语义、句法和情感特征。
- 这些特征包括网络结构特征(如网络距离、聚类系数、度中心性)和情感特征(基于Plutchik基本情绪理论的情绪得分)。
模型开发:
- 使用可解释人工智能(XAI)方法,特别是XGBoost算法,来预测不同评分者对故事的创意评分。
- 开发了三种不同的模型来分析数据集:人类对人类故事的评分、GPT-3.5对人类故事的评分,以及GPT-3.5对自己生成故事的评分。
模型评估:
- 采用4折交叉验证来评估模型性能,确保模型的稳健性和泛化能力。
- 使用混淆矩阵和ROC AUC分数来衡量模型在区分不同创意评分水平上的表现。
特征重要性分析:
- 应用SHAP值方法来解释XGBoost模型的预测,识别对创意评分影响最大的网络和情感特征。
- 通过SHAP值分析,比较人类评分者和GPT-3.5评分者在评估创意时依赖的特征差异。
结果解释和讨论:
- 对比人类和GPT-3.5评分者在创意评估上的不同特征模式,揭示GPT-3.5在评估和生成创意内容时的局限性。
- 讨论GPT-3.5在评估人类故事与自己生成故事时的内部评估标准的差异,以及这对使用GPT-3.5进行创意评估和内容生成的影响。
结论和建议:
- 基于研究发现,强调在使用GPT-3.5评估和生成创意内容时需要谨慎,并指出未来研究的方向。
通过这些步骤,论文不仅提供了对人类和GPT-3.5评分者评估创意的深入理解,还揭示了当前大型语言模型在理解和生成创意内容方面的局限性。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,实验设计和步骤如下:
数据收集:
- 实验收集了由人类参与者和GPT-3.5生成的故事数据集。人类数据集来源于Johnson等人的研究,包含153名参与者创作的1071个故事。GPT-3.5数据集则包含同样数量的故事,由GPT-3.5根据相同的提示创作。
故事创作:
- 人类参与者和GPT-3.5都根据给定的三个单词提示创作4-6句的短故事。这些故事后续用于分析和评分。
评分过程:
- 人类故事由四名人类评分者和四个GPT-3.5评分者进行评分,评分范围为1至5,代表从最不创意到最创意。
- GPT-3.5生成的故事仅由GPT-3.5评分者进行评分。
构建文本形式心智网络(TFMN):
- 对每个故事应用TFMN来提取语义、句法和情感特征。这包括使用spaCy库进行自然语言处理,以识别故事中的概念关系和情绪值。
特征提取:
- 从故事的TFMN中提取网络特征,如直径、平均最短路径长度、聚类系数、度中心性和PageRank中心性。
模型训练与评估:
- 使用XGBoost分类器,通过4折交叉验证对三个不同场景的数据集进行模型训练和评估:
- 人类对人类故事的评分(人类评分者)
- GPT-3.5对人类故事的评分(GPT评分者)
- GPT-3.5对自己生成故事的评分(GPT评分者)
- 使用XGBoost分类器,通过4折交叉验证对三个不同场景的数据集进行模型训练和评估:
特征重要性分析:
- 利用SHAP值方法分析不同特征对模型预测的贡献,以识别影响创意评分的关键因素。
统计测试:
- 对人类和GPT-3.5生成的故事进行Mann-Whitney U检验,以确定两者在网络和情感特征上的统计学差异。
描述性统计:
- 对故事的长度、网络特征和情感特征进行描述性统计分析。
这些实验步骤共同构成了论文的研究设计,旨在通过定量的方法比较人类和GPT-3.5在创意评估上的表现,并探索影响创意评分的关键因素。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
更先进的AI模型:
- 研究更先进的模型,如GPT-4或未来的版本,以了解它们在创意评估和生成方面是否比GPT-3.5表现得更好,以及它们是否能够更准确地捕捉人类对创意的评估标准。
跨语言研究:
- 测试不同语言背景下的故事,以确定影响创意评分的结构和情感特征是否具有普遍性,从而为开发跨语言有效的AI模型提供依据。
故意创作不具创意的故事:
- 指导GPT-3.5故意创作不具创意的故事,并由人类和GPT-3.5评分者进行评分,以探索GPT-3.5是否能够准确识别和产生低创意水平的故事。
个体评分者的行为差异:
- 使用线性混合模型等统计方法,考虑不同人类评分者的行为差异,以减少评分者特定倾向可能引入的偏差。
AI评估的偏差问题:
- 深入研究GPT-3.5在评估创意内容时的偏差问题,尤其是对GPT-3.5生成的故事的偏好,以及如何校正这些偏差。
情感和创造力的关系:
- 进一步研究情感在创造力评估中的作用,特别是在GPT-3.5生成的故事中情感特征与创意评分之间的关系。
叙事结构和复杂性:
- 探索AI生成的故事是否缺乏人类创造力中通常关联的结构复杂性,并尝试改进AI模型以更好地模拟人类创意过程。
教育和专业设置中的应用:
- 研究在教育和专业环境中使用GPT-3.5评估创意的潜在应用和局限性,以及如何结合人类评估和AI评估以获得更准确的结果。
AI创意生成的伦理和社会影响:
- 探讨AI在创意内容生成中的应用可能带来的伦理和社会问题,例如版权、原创性和创意作品的社会影响。
多模态创意评估:
- 结合文本、视觉和其他模态数据来评估创意,以提供更全面的创意评估方法。
这些探索点可以帮助研究者更深入地理解AI在创意评估和生成中的能力,以及如何改进AI模型以更好地与人类创意评估标准对齐。
Q: 总结一下论文的主要内容
A: 这篇论文主要探讨了如何利用可解释的人工智能(XAI)技术来预测和理解人类以及GPT-3.5模型对短文本创意评分。以下是论文的主要内容总结:
研究背景与目的:
- 论文强调了创造力是人类认知的一个基本技能,研究如何通过概念关联传达创造力成为了科学关注的焦点。
- 论文旨在使用文本形式心智网络(TFMN)和可解释的人工智能技术来测试与Mednick的关联理论相关的特征是否能解释人类和GPT-3.5赋予的创意评分。
数据集:
- 论文使用了两个数据集:人类创作的故事和GPT-3.5生成的故事,每个数据集包含约一千个短故事。
- 故事由人类参与者和GPT-3.5根据给定的三个单词提示创作。
方法论:
- 利用TFMN从故事中提取语义、句法和情感特征。
- 使用XGBoost算法来评估不同场景下(人类评分人类故事、GPT-3.5评分人类故事、GPT-3.5评分GPT生成故事)的创意评分。
- 应用SHAP值分析来解释模型预测,并识别影响创意评分的关键特征。
主要发现:
- GPT-3.5对人类故事的评分与人类评分者存在显著差异,表明GPT-3.5在评估创意时可能使用不同的标准。
- GPT-3.5倾向于给自己生成的故事较高的创意评分,显示了对“自己”故事的偏好。
- 网络特征对于人类评分者的创意评分预测更为重要,而对于GPT-3.5评分自己生成的故事,情感特征的重要性超过了语义/句法网络结构。
讨论与结论:
- 论文讨论了GPT-3.5在评估和生成创意内容时的局限性,并强调在使用GPT-3.5进行创意评估时应谨慎。
- 论文指出了未来研究方向,包括跨语言研究、探索AI评估的偏差问题,以及进一步研究情感和创造力的关系。
贡献与意义:
- 论文通过定量方法比较了人类和GPT-3.5在创意评估上的表现,并探索了影响创意评分的关键因素,为理解AI在创意评估和生成中的潜力和局限提供了见解。
总体而言,这篇论文通过结合认知科学、机器学习和网络科学的方法,提供了对人类和AI评估创意的新视角,并揭示了当前AI模型在理解和生成创意内容方面的限制。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

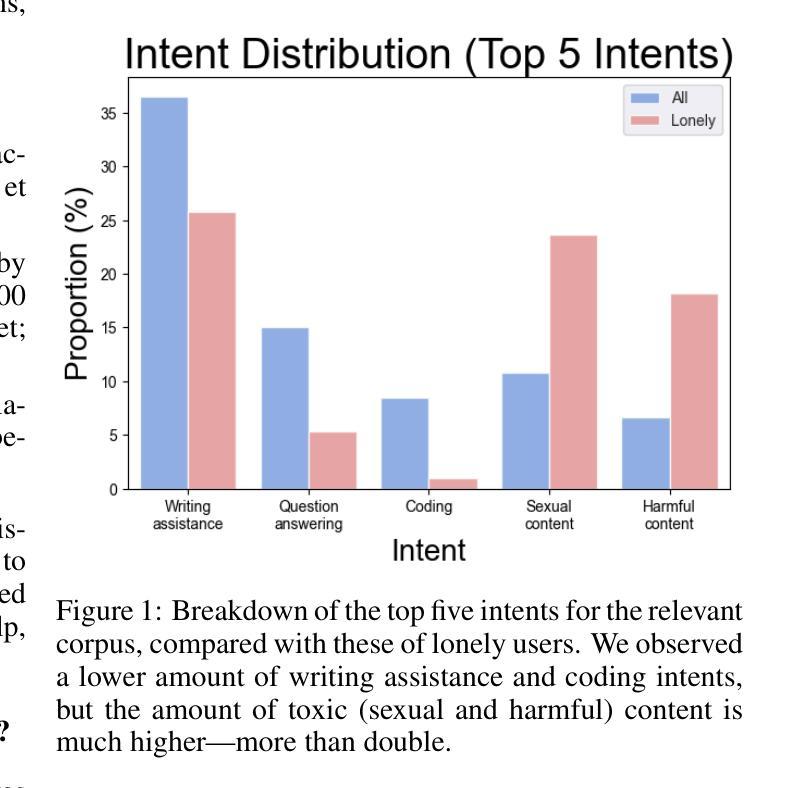
Non-native speakers of English or ChatGPT: Who thinks better?
Authors:Mohammed Q. Shormani
This study sets out to answer one major question: Who thinks better, non-native speakers of English or ChatGPT?, providing evidence from processing and interpreting center-embedding English constructions that human brain surpasses ChatGPT, and that ChatGPT cannot be regarded as a theory of language. Fifteen non-native speakers of English were recruited as participants of the study. A center-embedding English sentence was presented to both the study participants and ChatGPT. The study findings unveil that human brain is still far ahead of Large Language Models, specifically ChatGPT, even in the case of non-native speakers of an L2, here English. The study concludes that human brain’s ability to process and interpret natural language data is unique and that ChatGPT still lags behind this human unique ability.
本研究旨在回答一个主要问题:在处理和理解中心嵌入的英语结构时,是非英语母语者的大脑思考得更好,还是ChatGPT?本研究提供证据显示,在处理和理解中心嵌入的英语结构方面,人类大脑超越了ChatGPT,且ChatGPT不能被看作是语言理论。本研究招募了15名非英语母语者作为参与者。向这些参与者以及ChatGPT呈现了一个中心嵌入的英语句子。研究发现,即使对于非英语母语者,人类大脑仍然远远领先于大型语言模型,尤其是ChatGPT。研究得出结论,人类大脑处理和解释自然语言数据的能力是独一无二的,而ChatGPT在这方面仍然落后于人类。
论文及项目相关链接
PDF 16 pages, 2 figures
Summary:本研究旨在回答一个重要问题:在处理中心嵌入英语结构时,非英语母语者还是ChatGPT思考得更好?研究结果显示,人类大脑仍然远远超过ChatGPT,即使在非英语母语者的情况下也是如此。这表明人类大脑处理和解释自然语言数据的能力是独一无二的,而ChatGPT在这方面仍落后于人类。
Key Takeaways:
- 本研究关注非英语母语者和ChatGPT在处理中心嵌入英语结构时的思考能力对比。
- 研究结果表明,在处理此类任务时,人类大脑的能力仍然远超ChatGPT。
- 即使是非英语母语者,他们的大脑在处理自然语言数据时也表现出独特的优势。
- 本研究共招募了15名非英语母语者作为参与者。
- 实验结果揭示出人类大脑具有独特的语言处理能力,这一能力在目前的大型语言模型(如ChatGPT)中尚未达到。
- ChatGPT在处理自然语言数据方面仍然滞后于人类。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是:在处理和解释中心嵌入(center-embedding)英语结构方面,非母语英语使用者(non-native speakers of English)和ChatGPT(一种大型语言模型)哪个表现得更好。具体来说,研究旨在提供证据,证明人类大脑(即使是非母语英语使用者的大脑)在处理这类复杂语言结构时,仍然远远超过ChatGPT,并且ChatGPT不能被视为一种语言理论。
Q: 有哪些相关研究?
A: 相关研究包括以下几个方面:
中心嵌入结构的研究:
- Chomsky 和 Miller (1963) 提出了中心嵌入结构对人类工作记忆造成的压力,这是后续研究的基础。
- Frazier (1985) 发现处理这些结构时存在处理中断。
- Dickey (1995) 通过阅读时间实验揭示了不恰当的先行词插入导致的更快阅读时间。
- Thomas (1995) 研究了理解中心嵌入和自嵌入结构的句子所涉及的认知过程。
人工智能(AI)和语言模型的争议:
- Piantadosi (2023) 和 Ambridge & Blything (2024) 认为大型语言模型(LLMs)如ChatGPT是优秀的语言理论,甚至可以“反驳”乔姆斯基的生成语法方法。
- 相反,Katz (2012) 和 Shormani (2024a) 等学者认为尽管这些模型完成了伟大的任务,AI模型仍未达到人类大脑的水平。
AI的起源和定义:
- McCarthy et al. (1955) 提出AI的定义,即让机器表现出如果人类这么做则被称为智能的行为。
- Haenlein & Kaplan (2019) 讨论了AI的现代用途,特别是在处理、计算和解释自然语言数据方面。
LLMs和中心嵌入现象:
- Jiang et al. (2024) 开发了基于提示的方法(PromptEOL),用于嵌入句子并探索其效果。
- Harris et al. (2024) 探索了使用LLMs预处理输入文本以提高文本嵌入性能的方法。
- Kodner et al. (2024) 和 Dentella et al. (2024) 都强调了LLMs作为科学理论的局限性,并认为它们不能替代语言学理论。
- Katzir (2023) 批评了LLMs作为人类语言认知的有力理论的说法,并提出了对Piantadosi (2023) 论点的反驳。
LLMs的自然语言理解(NLU)能力:
- Zhong et al. (2023) 评估了ChatGPT与微调BERT模型的NLU能力,并发现ChatGPT在特定NLU任务中落后于高度专业化的微调模型。
这些研究提供了对LLMs在处理和解释自然语言,特别是复杂结构如中心嵌入句子时的能力和局限的深入理解。论文通过这些研究来构建其研究框架,并探讨非母语英语使用者与ChatGPT在处理这类结构时的表现差异。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决提出的问题:
1. 研究设计
- 参与者招募:招募了15名非母语英语使用者(NNSs)作为研究参与者,他们都是高级的英语学习者。
- 研究材料:使用一个涉及中心嵌入现象的句子作为研究工具,即 “The man that the soldier that the thief slapped deceived died.” 这句话被用作判断和解释的工具。
2. 过程
- 任务分配:通过WhatsApp向参与者发送上述英语句子,并询问他们每个人(男人、士兵和小偷)在句子中做了什么。
- 时间限制:给参与者24小时回答,答案提交时间不同,从立即回答到第二天都有。
- 数据收集:记录参与者的回答以及ChatGPT的回答。
3. 数据分析
- 结果统计:统计参与者和ChatGPT对于句子中各个角色行为的回答。
- 错误分析:分析参与者和ChatGPT在理解中心嵌入结构时的错误。
4. 结果讨论
- 性能对比:比较非母语英语使用者和ChatGPT在处理和解释中心嵌入句子时的表现。
- 错误对比:讨论ChatGPT在处理任务和语法判断任务中的错误,并与人类参与者的表现进行对比。
5. 结论
- 人类大脑的优势:得出结论,即使是非母语英语使用者,人类大脑在处理和解释自然语言数据方面仍然优于ChatGPT。
- LLMs的局限性:指出ChatGPT和其他大型语言模型(LLMs)在处理复杂语言结构时的局限性,并认为它们不能被视为语言的理论。
6. 研究局限和未来方向
- 研究局限:讨论了研究的局限性,如句子类型的限制和ChatGPT版本的限制。
- 未来研究方向:建议未来的研究可以涉及更广泛的复杂英语句子类型,并使用更先进的ChatGPT版本。
通过这些步骤,论文旨在揭示人类大脑(即使是非母语使用者)在处理自然语言时的独特能力,并指出ChatGPT等LLMs在模拟人类语言处理方面的不足。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包含以下两个部分:
1. 句子理解任务
- 实验目的:评估非母语英语使用者(NNSs)和ChatGPT处理和解释中心嵌入英语句子的能力。
- 实验材料:使用了一个特定的中心嵌入句子:“The man that the soldier that the thief slapped deceived died.”
- 参与者:15名非母语英语使用者,包括不同学习阶段的高级英语学习者(BA、MA和PhD学生)。
- 实验过程:通过WhatsApp向参与者发送上述句子,并询问每个人(男人、士兵和小偷)在句子中做了什么。要求参与者在24小时内回答。
- 数据收集:记录参与者的回答,并对比ChatGPT的回答。
2. 语法判断任务
- 实验目的:评估ChatGPT对同一中心嵌入句子的语法正确性判断能力。
- 实验过程:询问ChatGPT该句子是否语法正确,并记录其回答和判断理由。
这两个实验的设计旨在直接比较非母语英语使用者和ChatGPT在理解和处理复杂语言结构方面的能力,特别是在中心嵌入结构的理解和解释上。通过这些实验,研究者能够收集到有关人类和人工智能在语言处理上表现差异的实证数据。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些研究的局限性,并建议了未来研究可以进一步探索的方向。以下是一些可以进一步探索的点:
更广泛的句型研究:
- 进行包含更多类型复杂英语句子的研究,例如涉及DP-islands、多重wh-问题、照应和弱/强交叉现象的句子,以评估NNSs和ChatGPT在更广泛语境下的语言处理能力。
使用更新版本的ChatGPT:
- 使用ChatGPT-4或更新版本进行研究,因为这些版本在功能和特性上据说更加先进,可能提供更深入的见解。
跨语言比较:
- 将研究扩展到其他语言,以评估NNSs和LLMs在不同语言背景下处理复杂句型的能力。
个体差异的影响:
- 研究个体差异(如语言学习背景、年龄、认知能力等)如何影响NNSs处理复杂语言结构的能力。
学习过程的动态性:
- 探索NNSs在学习过程中对复杂语言结构理解能力的变化,以及这种变化如何与他们的语言能力发展相关联。
教育干预的效果:
- 研究特定的教育干预措施如何帮助NNSs提高处理和解释复杂语言结构的能力。
LLMs的解释能力和限制:
- 深入研究LLMs在解释语言结构时的能力和限制,以及它们与人类语言处理机制的差异。
LLMs在不同领域的应用:
- 探索LLMs在不同领域(如法律、医学、教育等)中的应用,并评估其在特定领域内的表现。
LLMs的伦理和社会影响:
- 研究LLMs的广泛应用可能带来的伦理和社会问题,例如偏见、隐私和就业影响。
LLMs与人类协作:
- 探索LLMs如何与人类协作,以提高语言处理任务的效率和准确性。
这些探索点可以帮助未来的研究者更全面地理解NNSs和LLMs在语言处理方面的表现,并为语言学、教育学和人工智能等领域提供新的见解。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
研究目的:
- 探讨非母语英语使用者(NNSs)和ChatGPT在处理和解释中心嵌入英语句子方面的能力,并比较两者谁表现得更好。
理论背景:
- 论文回顾了中心嵌入结构的语言学研究,以及人工智能(AI)和大型语言模型(LLMs)如ChatGPT在语言处理任务中的争议和辩论。
研究方法:
- 招募了15名非母语英语使用者作为研究对象,并通过WhatsApp向他们提出了一个中心嵌入句子的理解任务。
- 同时,也向ChatGPT提出了相同的任务,并询问了其对句子语法正确性的判断。
研究结果:
- 非母语英语使用者在理解和解释中心嵌入句子的任务中表现优于ChatGPT。
- ChatGPT在处理任务和语法判断任务中均出现错误,显示了其在处理复杂语言结构时的局限性。
讨论与结论:
- 论文得出结论,即使是非母语英语使用者,人类大脑在处理自然语言数据方面的能力也是独特的,并且优于ChatGPT。
- 论文认为ChatGPT和其他LLMs不能被视为语言的理论,因为它们在模拟人类语言处理方面存在不足。
研究局限和未来方向:
- 论文讨论了研究的局限性,包括句子类型的限制和ChatGPT版本的限制,并提出了未来研究可以进一步探索的方向。
总体而言,这篇论文提供了对人类(即使是非母语使用者)与LLMs在处理复杂语言结构方面能力的比较分析,并强调了人类大脑在语言处理方面的优越性和LLMs的局限性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

ScratchEval: Are GPT-4o Smarter than My Child? Evaluating Large Multimodal Models with Visual Programming Challenges
Authors:Rao Fu, Ziyang Luo, Hongzhan Lin, Zhen Ye, Jing Ma
Recent advancements in large multimodal models (LMMs) have showcased impressive code generation capabilities, primarily evaluated through image-to-code benchmarks. However, these benchmarks are limited to specific visual programming scenarios where the logic reasoning and the multimodal understanding capacities are split apart. To fill this gap, we propose ScratchEval, a novel benchmark designed to evaluate the visual programming reasoning ability of LMMs. ScratchEval is based on Scratch, a block-based visual programming language widely used in children’s programming education. By integrating visual elements and embedded programming logic, ScratchEval requires the model to process both visual information and code structure, thereby comprehensively evaluating its programming intent understanding ability. Our evaluation approach goes beyond the traditional image-to-code mapping and focuses on unified logical thinking and problem-solving abilities, providing a more comprehensive and challenging framework for evaluating the visual programming ability of LMMs. ScratchEval not only fills the gap in existing evaluation methods, but also provides new insights for the future development of LMMs in the field of visual programming. Our benchmark can be accessed at https://github.com/HKBUNLP/ScratchEval .
最近大型多模态模型(LMM)的进展展示了令人印象深刻的代码生成能力,主要通过图像到代码的基准测试进行评估。然而,这些基准测试仅限于特定的视觉编程场景,其中逻辑推理和多模态理解能力是分开评估的。为了填补这一空白,我们提出了ScratchEval,这是一个新型基准测试,旨在评估LMM的视觉编程推理能力。ScratchEval基于Scratch,一种广泛应用于儿童编程教育的基于图块的视觉编程语言。通过整合视觉元素和嵌入式编程逻辑,ScratchEval要求模型处理视觉信息和代码结构,从而全面评估其编程意图理解能力。我们的评估方法超越了传统的图像到代码的映射,侧重于统一的逻辑思维和问题解决能力,为评估LMM的视觉编程能力提供了更全面、更具挑战性的框架。ScratchEval不仅弥补了现有评估方法的空白,而且为视觉编程领域LMM的未来发展提供了新的见解。我们的基准测试可在https://github.com/HKBUNLP/ScratchEval访问。
论文及项目相关链接
Summary
大型多模态模型(LMMs)在代码生成能力上展现出显著进步,主要通过图像到代码的基准测试进行评估。然而,这些基准测试局限于特定的视觉编程场景,忽视了逻辑理解和多模态感知的综合能力。为此,我们提出ScratchEval基准测试,旨在评估LMMs在视觉编程推理方面的能力。ScratchEval基于Scratch编程语言构建,融合了视觉元素和嵌入式编程逻辑,要求模型处理视觉信息和代码结构,全面评估其编程意图理解能力。我们的评估方法超越了传统的图像到代码的映射,注重统一的逻辑思维和问题解决能力,为LMMs在视觉编程领域的评估提供了更全面、更具挑战性的框架。
Key Takeaways
- LMMs展现出强大的代码生成能力,主要通过图像到代码的基准测试进行评估。
- 现有基准测试局限于特定视觉编程场景,缺乏逻辑理解和多模态感知的综合评估。
- 提出ScratchEval基准测试,旨在全面评估LMMs在视觉编程推理方面的能力。
- ScratchEval基于Scratch编程语言构建,融合视觉元素和编程逻辑。
- ScratchEval要求模型处理视觉信息和代码结构,评估其编程意图理解能力。
- 评估方法超越图像到代码的映射,注重统一的逻辑思维和问题解决能力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为ScratchEval的新基准测试,旨在评估大型多模态模型(LMMs)在视觉编程任务中的表现。具体来说,论文试图解决以下几个问题:
现有评估方法的局限性:当前对LMMs的评估主要通过图像到代码的基准测试进行,这些基准测试仅限于特定的视觉编程场景,并且将逻辑推理和多模态理解能力分开评估。ScratchEval旨在通过一个更综合的框架来填补这一空白。
视觉编程能力的综合评估:ScratchEval基于Scratch(一种广泛用于儿童编程教育的基于块的视觉编程语言),要求模型同时处理视觉信息和代码结构,从而全面评估其编程意图理解能力。
逻辑思考和问题解决能力:论文强调需要评估LMMs的视觉编程能力,将视觉理解和逻辑推理统一起来,而不是仅仅关注传统的编程语言和语法错误。
现有模型的视觉代码推理能力不足:通过ScratchEval的测试,论文发现现有的最先进LMMs在视觉代码推理方面表现不佳,这表明需要进一步研究,以提升AI系统在视觉理解和逻辑推理之间的桥梁。
评估方法的发展:ScratchEval不仅填补了现有评估方法的空白,还为未来LMMs在视觉编程领域的发展提供了新的见解。
总的来说,这篇论文试图通过一个基于Scratch的新型评估方法,更全面和挑战性地评估LMMs的视觉编程能力,并指出了现有模型的不足和未来研究的方向。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与ScratchEval基准测试相关的研究工作:
多模态理解评估:
- MMMU (Yue et al., 2023):一个大规模多学科多模态理解和推理的基准测试,用于专家级通用人工智能。
- MME (Fu et al., 2023):一个全面评估多模态大型语言模型的基准测试。
- MathVista (Lu et al., 2024):评估基础模型在视觉环境中的数学推理能力。
视觉编程推理能力评估:
- MMCode (Li et al., 2024):评估多模态代码大型语言模型在视觉丰富的编程问题上的表现。
- Design2Code (Si et al., 2024):评估多模态大型语言模型在从设计图生成代码方面的能力。
- Plot2Code (Wu et al., 2024):一个全面评估多模态大型语言模型在从科学图表生成代码方面的能力。
- CharMimic (Shi et al., 2024):通过图表到代码生成评估LMM的跨模态推理能力。
多模态模型和基准测试:
- MMBench (Liu et al., 2023):评估多模态模型是否是全能型选手。
- InternVL2 (Chen et al., 2024b):扩展视觉基础模型并为通用视觉语言任务对齐。
视觉编码和推理:
- Pixtral (Agrawal et al., 2024):一个12B参数的多模态模型。
- LLaVA-v1.6 (Liu et al., 2024):一个34B参数的多模态模型。
链式思考(Chain of Thought)提示策略:
- COT (Wei et al., 2023):研究表明适当的提示可以增强大型语言模型的性能。
这些相关研究涵盖了多模态模型的评估、视觉编程推理、数学推理以及多模态任务的基准测试。ScratchEval在这些领域的研究基础上,提出了一个新的基准测试,专注于评估LMMs在视觉编程任务中的视觉代码推理能力。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决评估大型多模态模型(LMMs)在视觉编程任务中的表现的问题:
构建ScratchEval基准测试:
- 基于Scratch(一种广泛用于儿童编程教育的基于块的视觉编程语言),创建了一个包含305个多项选择题的新基准测试,每个问题都包含问题描述、选项和包含Scratch脚本及其他必要信息的图片。
数据组织和分类:
- 将问题分为四个领域:数学、逻辑思考、图形感知和空间感知,以全面评估模型的视觉代码推理能力。
评估方法论:
- 设计了一个三阶段的评估过程:生成答案、提取答案和计算分数。使用准确率作为评估指标,以确定性评估模型性能。
实验设置:
- 对10个现有的开源和闭源LMMs进行评估,并研究不同的提示策略对模型性能的影响。
分析和案例研究:
- 对测试结果进行详细分析,识别模型在不同任务中的性能差异,并进行案例研究以分析模型的性能瓶颈。
提示策略研究:
- 探索了适当的提示(如Chain of Thought prompting)如何增强模型的视觉代码推理能力。
结果讨论和未来研究方向:
- 论文讨论了现有模型在视觉代码推理能力上的不足,并指出了未来研究的方向,以提升AI系统在视觉理解和逻辑推理之间的桥梁。
通过这些步骤,论文不仅提出了一个全面的评估框架来测试LMMs的视觉编程能力,而且揭示了现有模型的局限性,并为未来的研究提供了新的方向。此外,论文还讨论了ScratchEval的局限性,并强调了需要进一步研究和开发更全面的评估方法。
Q: 论文做了哪些实验?
A: 论文中进行的实验包括以下几个方面:
实验设置:
- 评估了总共10个大型多模态模型(LMMs),包括闭源和开源模型,如Gemini-1.5-Pro、GPT-4o、Claude3.5-Sonnet等。使用准确率作为评估指标。
性能评估:
- 在ScratchEval基准测试上评估了这些模型,包括中文和英文数据。分析了模型在数学、逻辑思考、图形感知和空间感知四个不同领域的表现。
提示策略研究:
- 研究了不同的提示策略(如原始提示、零样本链式思考(CoT)和扩展链式思考(eCoT))对模型视觉代码推理能力的影响。
案例研究:
- 对表现最佳的模型Gemini-1.5-Pro的错误案例进行了分析,以解释为什么ScratchEval对大多数模型来说是一个挑战,并揭示模型在某些领域存在的不足。
跨语言评估:
- 通过比较中文和英文数据集的结果,评估了模型在不同语言背景下的跨语言鲁棒性和适应性。
数据分布和分析:
- 根据问题内容将问题分类,并分析了每个类别中问题的具体分布。
评估方法论验证:
- 验证了所提出的评估方法的有效性,包括答案生成、提取和分数计算的三个阶段。
这些实验旨在全面评估LMMs的视觉编程推理能力,并探索提升这些模型性能的可能途径。通过这些实验,论文揭示了现有模型在视觉代码推理方面的局限性,并为未来的研究提供了方向。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
模型的跨语言能力:
- 进一步研究和改进模型在处理不同语言视觉编程问题时的跨语言能力。
模型的多步推理能力:
- 针对数学和逻辑推理任务中模型表现不佳的问题,探索如何提升模型的多步推理能力。
视觉编码器的改进:
- 研究如何改进视觉编码器,以提高模型对图像的理解和视觉代码推理能力。
提示策略的优化:
- 探索更有效的提示策略,以进一步提升模型的性能,尤其是在视觉代码推理任务中。
数据集的扩展和多样化:
- 扩展和多样化ScratchEval数据集,包括更多的视觉编程场景和更复杂的任务,以全面评估模型的能力。
模型的可解释性:
- 提高模型的可解释性,以便更好地理解模型的决策过程和推理链。
模型的泛化能力:
- 研究如何提升模型的泛化能力,使其能够处理更广泛的实际视觉编程任务。
模型的鲁棒性测试:
- 对模型进行鲁棒性测试,包括对抗性攻击和异常情况的处理能力。
结合传统编程语言评估:
- 将视觉编程评估与基于传统编程语言的评估结合起来,以获得关于模型编程能力的更全面视图。
模型训练数据的影响研究:
- 研究不同训练数据(如视觉-语言配对数据)对模型性能的影响,并探索如何利用这些数据提升模型能力。
模型的实时性能:
- 评估模型在实时视觉编程环境中的性能,特别是在需要快速响应的场景中。
多模态融合技术:
- 探索新的多模态融合技术,以改善模型对视觉信息和编程逻辑的整合能力。
这些探索点可以帮助研究者们更好地理解现有模型的局限性,并指导未来模型的开发和优化,以提高其在视觉编程任务中的表现。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为ScratchEval的新型基准测试,旨在全面评估大型多模态模型(LMMs)在视觉编程任务中的表现。以下是论文的主要内容总结:
背景与动机:
- 论文指出现有的图像到代码基准测试无法全面评估LMMs的视觉编程能力,尤其是在逻辑推理和多模态理解方面。
- 为了填补这一空白,提出了ScratchEval,一个基于Scratch(一种儿童视觉编程语言)的基准测试,要求模型同时处理视觉信息和代码结构。
ScratchEval基准测试:
- 包含305个多项选择题,分为数学、逻辑思考、图形感知和空间感知四个领域,以全面评估模型的视觉代码推理能力。
- 数据集包含中文和英文两部分,以评估模型在不同语言背景下的表现。
评估方法论:
- 评估过程包括生成答案、提取答案和计算分数三个阶段,使用准确率作为评估指标。
实验设置与分析:
- 对10个现有的开源和闭源LMMs进行评估,包括Gemini-1.5-Pro、GPT-4o、Claude3.5-Sonnet等。
- 分析了模型在不同任务中的表现,发现大多数模型在视觉代码推理方面表现不佳,尤其是数学和逻辑推理任务。
提示策略研究:
- 研究了不同的提示策略(如原始提示、零样本链式思考(CoT)和扩展链式思考(eCoT))对模型性能的影响。
- 发现CoT和eCoT技术显著提升了模型的视觉代码推理能力,但没有任何模型的整体准确率超过70%。
案例研究:
- 对表现最佳的模型Gemini-1.5-Pro的错误案例进行分析,揭示了模型在某些领域(如细微图像区分)的不足。
结论与局限性:
- 论文得出结论,尽管现有的LMMs在视觉理解方面取得了一些进展,但在视觉代码推理方面仍面临挑战。
- 论文也承认ScratchEval的局限性,如模型无法直接操作图形编程语言,以及基准测试的领域狭窄。
未来研究方向:
- 论文指出了未来研究的方向,包括改进模型的视觉编码器、提升多步推理能力、优化提示策略等。
总的来说,这篇论文通过ScratchEval基准测试,揭示了现有LMMs在视觉编程任务中的不足,并为未来的研究提供了新的方向和见解。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

The Impact of Example Selection in Few-Shot Prompting on Automated Essay Scoring Using GPT Models
Authors:Lui Yoshida
This study investigates the impact of example selection on the performance of au-tomated essay scoring (AES) using few-shot prompting with GPT models. We evaluate the effects of the choice and order of examples in few-shot prompting on several versions of GPT-3.5 and GPT-4 models. Our experiments involve 119 prompts with different examples, and we calculate the quadratic weighted kappa (QWK) to measure the agreement between GPT and human rater scores. Regres-sion analysis is used to quantitatively assess biases introduced by example selec-tion. The results show that the impact of example selection on QWK varies across models, with GPT-3.5 being more influenced by examples than GPT-4. We also find evidence of majority label bias, which is a tendency to favor the majority la-bel among the examples, and recency bias, which is a tendency to favor the label of the most recent example, in GPT-generated essay scores and QWK, with these biases being more pronounced in GPT-3.5. Notably, careful example selection enables GPT-3.5 models to outperform some GPT-4 models. However, among the GPT models, the June 2023 version of GPT-4, which is not the latest model, exhibits the highest stability and performance. Our findings provide insights into the importance of example selection in few-shot prompting for AES, especially in GPT-3.5 models, and highlight the need for individual performance evaluations of each model, even for minor versions.
本研究旨在探讨示例选择对使用GPT模型的少样本提示技术在自动化作文评分(AES)性能上的影响。我们评估了少样本提示中示例的选择和顺序对几个版本的GPT-3.5和GPT-4模型的影响。我们的实验涉及119个带有不同示例的提示,并使用二次加权kappa(QWK)来计算GPT和人类评分者分数之间的协议。回归分析被用来定量评估示例选择所带来的偏见。结果表明,示例选择对QWK的影响在不同模型中是变化的,GPT-3.5受示例的影响比GPT-4更大。我们还发现了多数标签偏见和最近偏见的证据,即倾向于支持示例中的多数标签和最新标签的偏见,这些偏见在GPT生成的作文分数和QWK中更为突出,尤其是在GPT-3.5中。值得注意的是,通过仔细选择示例,GPT-3.5模型能够超越一些GPT-4模型的表现。然而,在GPT模型中,并非最新版本的2023年6月的GPT-4版本表现出了最高的稳定性和性能。我们的研究为AES的少样本提示中示例选择的重要性提供了见解,特别是在GPT-3.5模型中,并强调了需要对每个模型,甚至是较小版本进行个别性能评估的必要性。
论文及项目相关链接
PDF Accepted in AIED2024. This preprint has not undergone any post-submission improvements or corrections. The Version of Record of this contribution is published in Communications in Com-puter and Information Science, vol 2150, and is available online at https://doi.org/
Summary
本研究探讨了使用GPT模型进行少量提示时的示例选择对自动作文评分(AES)性能的影响。实验评估了不同GPT-3.5和GPT-4模型在少量提示中的示例选择和顺序的影响,通过二次加权卡帕(QWK)来衡量GPT和人类评分者之间的评分一致性。回归分析用于定量评估示例选择引入的偏见。研究结果表明,示例选择对QWK的影响在不同模型中有所不同,GPT-3.5受到示例的影响较大。此外,还发现存在多数标签偏见和最近偏见,这些偏见在GPT生成的作文评分和QWK中更为突出,且在GPT-3.5中更为显著。研究指出,通过谨慎的示例选择,GPT-3.5模型能够超越某些GPT-4模型的表现。然而,在GPT模型中,并非最新版本的2023年6月的GPT-4模型展现出最高的稳定性和性能。本研究强调了示例选择在GPT模型少量提示中的AES中的重要性,特别是在GPT-3.5模型中,并指出需要对每个模型进行个别性能评估。
Key Takeaways
- 研究探究了示例选择在自动化作文评分中的影响,特别是在使用GPT模型进行少量提示时的效果。
- 通过实验评估了GPT-3.5和GPT-4模型在不同示例选择和顺序下的性能差异。
- 研究发现示例选择对QWK的影响在不同模型中有所不同,GPT-3.5更易受示例影响。
- 存在多数标签偏见和最近偏见,这些偏见在GPT-3.5中的表现尤为突出。
- 谨慎的示例选择能够提升GPT-3.5模型的表现,有时甚至能超越GPT-4模型。
- GPT模型中并非最新版本表现最佳,本研究中发现2023年6月的GPT-4模型表现最为稳定与高效。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是:在使用GPT模型进行自动作文评分(Automated Essay Scoring, AES)时,通过少量样本提示(few-shot prompting)中的示例选择对评分性能的影响。具体来说,论文探讨了以下问题:
示例选择和顺序的影响:研究在少量样本提示中选择和排列示例对不同版本的GPT-3.5和GPT-4模型性能的影响。
性能提升的可能性:探讨通过仔细选择示例是否能够进一步提高AES的性能,尤其是在成本效益较高的GPT-3.5模型上。
模型间影响的一致性:评估示例选择对不同GPT模型(包括小版本)的影响是否一致,以确定是否可以将从一个模型获得的见解应用到其他模型上。
偏见的识别和量化:通过回归分析定量评估示例选择引入的偏见,如多数标签偏见(majority label bias)和最近性偏见(recency bias)。
模型性能的个体评估:强调即使对于小版本,也需要对每个模型进行单独的性能评估,因为最新模型并不总是保证最高性能。
论文通过实验和分析,旨在提供对示例选择在少量样本提示中对AES性能影响的深入理解,并为实际应用提供指导。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的研究:
**Yancey et al. (2023)**:验证了GPT-3.5和GPT-4在AES上的性能,确认了在提示中包含评分示例可以提高性能。GPT-4的表现几乎达到了专家水平。
[ \text{Yancey et al. [7]} ]
**Zhao et al. (2021)**:指出了在情感分析中,少量样本提示的准确性不稳定,并且具体示例的顺序和类型可以引起偏见,显著改变结果。这表明了在AES中可能存在类似的偏见。
[ \text{Zhao et al. [11]} ]
Wei et al. (2022) 和 **Zhang et al. (2022)**:研究了链式思考(Chain of Thought, CoT)提示,即描述解决任务的过程,可以增强性能。
[ \text{Wei et al. [12]} ]
[ \text{Zhang et al. [13]} ]Kojima et al. (2023) 和 **Sanh et al. (2022)**:探讨了零样本提示(zero-shot prompts)也可以改善LLMs的性能,例如通过添加“Let’s think step by step”可以实现CoT并显著提高任务执行性能。
[ \text{Kojima et al. [14]} ]
[ \text{Sanh et al. [15]} ]**Page (1966)**:开始了自动作文评分(AES)的研究,Project Essay Grade是最早的研究之一。
[ \text{Page [18]} ]
Landauer (2003) 和 **Attali and Burstein (2006)**:进一步发展了AES的研究,包括手动设计特征和创建标记数据,以及使用多回归分析、潜在语义分析和机器学习技术。
[ \text{Landauer [19]} ]
[ \text{Attali and Burstein [20]} ]**Uto (2021)**:回顾了基于深度神经网络的AES模型。
[ \text{Uto [26]} ]
Yang et al. (2020) 和 **Wang et al. (2022)**:研究了使用BERT等预训练语言模型进行AES的方法。
[ \text{Yang et al. [27]} ]
[ \text{Wang et al. [28]} ]
这些研究为理解LLMs在AES中的应用和性能提供了背景,并指出了在设计提示和选择示例时需要考虑的关键因素。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决研究问题:
实验设计:
- 使用TOEFL11数据集,包含八个作文提示和相应的考生作文,每个提示大约有1000到1600篇作文,总共12100篇作文,以及专家对作文的评分。
- 从每个提示中选取三篇高分、中分和低分的作文,共72篇作文进行GPT模型评分。
GPT模型选择:
- 选择了OpenAI的GPT-3.5和GPT-4模型的三个不同版本进行实验,以评估跨模型的影响。
示例和提示开发:
- 基于Yancey等人的研究,开发包含指令、作文提示、响应、评分标准、评分示例和输出格式的提示。
- 准备四类提示:零样本提示(N)、一样本提示(1-shot)、两样本提示(2-shot)和三样本提示(3-shot),并为每个类别准备了不同评分等级的变体。
评分和一致性评估:
- 使用API从六个GPT模型获取50976个评分,并将GPT评分转换为与人类评分相同的三个等级(高、中、低),计算二次加权kappa(QWK)以评估GPT评分与人类评分之间的一致性。
回归分析:
- 对GPT生成的作文评分和QWK进行回归分析,以定量评估示例选择引入的偏见,包括多数标签偏见和最近性偏见。
结果分析:
- 分析不同GPT模型在不同提示条件下的QWK平均值和标准差,以确定模型对示例选择的敏感性。
- 通过回归分析结果,识别和比较不同模型中的偏见,并讨论这些偏见对评分和QWK的影响。
讨论和结论:
- 讨论了示例选择对AES性能的影响,不同GPT模型之间的性能差异,以及偏见的存在和影响。
- 强调了对每个模型进行单独性能评估的必要性,包括小版本,并指出最新模型并不总是保证最高性能。
通过这些步骤,论文提供了关于示例选择在少量样本提示中对AES性能影响的深入见解,并为实际应用提供了指导。
Q: 论文做了哪些实验?
A: 论文中进行的实验包括以下几个方面:
数据集选择:
- 使用TOEFL11作为作文数据集,包含八个作文提示和相应的考生作文,总共12,100篇作文,以及专家的评分。
样本选择:
- 从每个提示中选取三篇高分、中分和低分的作文,共72篇作文进行GPT模型评分。
GPT模型应用:
- 应用了三个版本的GPT-3.5和GPT-4模型,以评估跨模型的影响。
提示开发:
- 基于Yancey等人的研究,开发了包含不同评分示例的提示,分为零样本提示(N)、一样本提示(1-shot)、两样本提示(2-shot)和三样本提示(3-shot)。
评分获取:
- 使用API从六个GPT模型获取50,976个评分。
一致性评估:
- 计算二次加权kappa(QWK),以评估GPT评分与人类评分之间的一致性。
回归分析:
- 对GPT生成的作文评分和QWK进行回归分析,以定量评估示例选择引入的偏见,包括多数标签偏见和最近性偏见。
结果分析:
- 分析不同GPT模型在不同提示条件下的QWK平均值和标准差,以确定模型对示例选择的敏感性。
- 识别和比较不同模型中的偏见,并讨论这些偏见对评分和QWK的影响。
这些实验步骤综合起来,旨在评估和理解在使用GPT模型进行自动作文评分时,示例选择和顺序对评分性能的影响,以及不同版本的GPT模型对这些示例选择的敏感性。通过这些实验,论文旨在提供对示例选择在少量样本提示中对AES性能影响的深入见解,并为实际应用提供指导。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和研究结果,以下是一些可以进一步探索的点:
跨模型比较:
- 探索更多不同的大型语言模型(LLMs),如Gemini、Claude、LLaMA和Vicuna,以获得跨模型的见解,并比较它们在AES任务上的表现和对示例选择的敏感性。
更大规模的数据集:
- 增加评估作文的数据集规模,以获得更详细的发现,并验证结果的一致性和普遍性。
不同特征的分析:
- 分析示例中除了评分之外的其他特征,如语言特征和文体特征,以更深入地了解这些特征如何影响评分结果。
偏见的深入研究:
- 对多数标签偏见和最近性偏见进行更深入的研究,探索这些偏见的来源和潜在的缓解策略。
模型训练和微调:
- 研究是否可以通过训练或微调模型来减少示例选择对评分性能的影响,以及提高模型对偏见的鲁棒性。
多语言和跨文化研究:
- 将研究扩展到其他语言和文化背景,以了解模型在不同语言环境中的表现和适用性。
实际应用和教育实践:
- 在实际的教育环境中部署和测试AES系统,以评估其在现实世界中的有效性和可行性。
模型解释性和透明度:
- 提高模型的解释性,使教育工作者和学生能够更好地理解评分背后的逻辑和依据。
评分标准的优化:
- 研究不同的评分标准和方法,以找到最适合自动评分任务的标准,并提高评分的准确性和一致性。
交互式评分系统:
- 开发交互式评分系统,允许用户与模型进行交互,提供反馈,并根据反馈调整评分结果。
这些进一步探索的点可以帮助研究者更全面地理解自动作文评分系统的潜力和局限性,并推动该领域的研究和应用发展。
Q: 总结一下论文的主要内容
A: 这篇论文主要研究了在使用GPT模型进行自动作文评分(AES)时,少量样本提示(few-shot prompting)中示例选择对评分性能的影响。以下是论文的主要内容总结:
研究背景:
- 大型语言模型(LLMs)在教育领域,尤其是自动作文评分(AES)中显示出巨大潜力。
- 少量样本学习是一种提高LLMs性能的强大方法,但示例的选择和顺序可能会引入偏见。
研究目的:
- 评估在少量样本提示中选择和顺序的示例对不同版本的GPT-3.5和GPT-4模型性能的影响。
- 使用二次加权kappa(QWK)衡量GPT评分与人类评分员之间的一致性,并进行回归分析以定量评估示例选择引入的偏见。
实验设计:
- 使用TOEFL11数据集,包含12100篇作文和专家评分。
- 从每个提示中选取三篇不同评分等级的作文,共72篇作文进行评分。
- 应用六个GPT模型(三个版本的GPT-3.5和GPT-4)进行评分。
提示开发:
- 设计了包括零样本提示和一至三样本提示的不同类别的提示。
- 为每个类别准备了不同评分等级的变体。
结果分析:
- GPT-4 (Jun23)模型在所有类别中显示出最高的平均QWK,而GPT-3.5 (Jun23)的QWK最低。
- GPT-3.5模型比GPT-4模型更受示例选择的影响。
- 通过回归分析,发现GPT-3.5模型中存在显著的多数标签偏见和最近性偏见,而GPT-4模型主要表现出多数标签偏见。
结论与建议:
- 仔细选择示例可以提高GPT-3.5模型的性能,使其在某些情况下超过一些GPT-4模型。
- 强调了对每个模型,包括小版本,进行单独性能评估的必要性,因为最新模型并不总是表现最佳。
- 发现的偏见表明,示例选择对AES性能有显著影响,尤其是在GPT-3.5模型中。
未来研究方向:
- 探索更多LLMs,增加样本量,分析示例的其他特征,以及研究减少偏见的策略等。
论文的发现为理解和改进自动作文评分系统提供了重要见解,并强调了在实际应用中考虑示例选择的重要性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward
Authors:Haonan Han, Xiangzuo Wu, Huan Liao, Zunnan Xu, Zhongyuan Hu, Ronghui Li, Yachao Zhang, Xiu Li
Recently, text-to-motion models have opened new possibilities for creating realistic human motion with greater efficiency and flexibility. However, aligning motion generation with event-level textual descriptions presents unique challenges due to the complex relationship between textual prompts and desired motion outcomes. To address this, we introduce AToM, a framework that enhances the alignment between generated motion and text prompts by leveraging reward from GPT-4Vision. AToM comprises three main stages: Firstly, we construct a dataset MotionPrefer that pairs three types of event-level textual prompts with generated motions, which cover the integrity, temporal relationship and frequency of motion. Secondly, we design a paradigm that utilizes GPT-4Vision for detailed motion annotation, including visual data formatting, task-specific instructions and scoring rules for each sub-task. Finally, we fine-tune an existing text-to-motion model using reinforcement learning guided by this paradigm. Experimental results demonstrate that AToM significantly improves the event-level alignment quality of text-to-motion generation.
最近,文本到动作模型为创建更高效、更灵活的真实人类动作开辟了新的可能性。然而,由于文本提示和期望的动作结果之间的复杂关系,使动作生成与事件级别的文本描述对齐呈现出独特的挑战。为了解决这一问题,我们引入了AToM框架,该框架通过利用GPT-4Vision的奖励来增强生成动作与文本提示之间的对齐。AToM主要包括三个阶段:首先,我们构建了一个MotionPrefer数据集,它将三种类型的事件级文本提示与生成的动作配对,涵盖了动作的完整性、时间关系和频率。其次,我们设计了一种利用GPT-4Vision进行详细动作注释的方法,包括视觉数据格式化、针对特定任务的指令以及每个子任务的评分规则。最后,我们使用由此范式引导的强化学习对现有的文本到动作模型进行微调。实验结果表明,AToM显著提高了文本到动作生成的事件级对齐质量。
论文及项目相关链接
Summary
文本至动作模型为创建更真实、更高效和更灵活的人类动作提供了新的可能性。然而,由于文本提示和期望的动作结果之间的复杂关系,使动作生成与事件级别的文本描述对齐带来了独特的挑战。为解决此问题,我们推出了AToM框架,它通过利用GPT-4Vision的奖励值增强了生成动作与文本提示之间的对齐度。AToM主要包括三个阶段:首先,我们构建了一个MotionPrefer数据集,该数据集将三种事件级别的文本提示与生成的动作配对,涵盖了动作的完整性、时间关系和频率。其次,我们设计了一种利用GPT-4Vision进行详细动作注释的方法论,包括视觉数据格式化、针对特定任务的指令和每项子任务的计分规则。最后,我们利用强化学习微调现有的文本至动作模型,由该方法论引导。实验结果表明,AToM显著提高了文本至动作生成的与事件级别的对齐质量。
Key Takeaways
- 文本至动作模型可创建更真实、高效和灵活的人类动作。
- 对齐文本提示和生成动作是一个挑战,因为存在文本与动作的复杂关系。
- AToM框架通过利用GPT-4Vision的奖励值提高了文本与动作的对齐度。
- AToM包含三个主要阶段:构建MotionPrefer数据集、设计利用GPT-4Vision进行动作详细注释的方法论以及微调现有的文本至动作模型。
- MotionPrefer数据集涵盖了动作的完整性、时间关系和频率的文本提示与动作的配对。
- GPT-4Vision用于详细动作注释,包括视觉数据格式化、任务特定指令和子任务计分规则。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是文本到动作(text-to-motion)模型在根据文本提示生成人体动作时与事件级别的文本描述对齐的挑战。具体来说,挑战存在于以下几个方面:
复杂文本提示与期望动作结果之间的复杂关系:由于文本提示和期望动作结果之间存在复杂的映射关系,模型很难准确地将复杂的文本描述(例如,包含多个动作事件或具有时间关系和指定频率的动作)映射到相应的动作序列。
数据稀缺和粗糙的文本描述:现有的文本-动作对数据稀缺,且文本描述通常是粗糙的,覆盖的动作场景有限,这限制了模型对新颖描述的泛化能力。
模型泛化能力有限:由于上述限制,模型在零样本和多事件场景下的性能表现不佳,难以处理复杂的文本提示。
为了解决这些问题,论文提出了一个名为AToM的框架,该框架通过利用GPT-4Vision提供的奖励来增强生成动作和文本提示之间的对齐度。AToM框架包含三个主要阶段:构建与事件级别的文本提示配对的数据集、设计利用GPT-4Vision进行详细动作标注的范式,以及使用这种范式指导的强化学习来微调现有的文本到动作模型。实验结果表明,AToM显著提高了文本到动作生成的事件级别对齐质量。
Q: 有哪些相关研究?
A: 论文中提到了多个与文本到动作生成(Text-to-Motion, T2M)相关的研究工作,以下是一些主要的相关研究:
Text2Action [2]:利用基于SEQ2SEQ模型的GAN将简短描述映射到人体动作。
Language2Pose [3]:引入了一种课程学习方法,用于开发文本和姿态的关节级嵌入。
Lin et al. [18]:提出了一个端到端的SEQ2SEQ模型,用于生成更真实的动画。
Ghosh et al. [10]:开发了一个分层的双流序列模型,能够处理描述多个动作的长句子。
MotionCLIP [30]:将人类动作流形与CLIP空间对齐,赋予模型零样本能力。
TEACH [5]:基于Transformer的模型,能够生成遵循复杂、顺序动作指令的真实3D人体动作。
TEMOS [36]:使用基于Transformer的VAE和额外的文本编码器进行多对象3D场景生成和编辑。
T2M-GPT [33]:结合VQ-VAE和GPT获得高质量的离散表示,实现有竞争力的动作生成结果。
MotionDiffuse [34]:基于扩散模型,允许对身体部位进行细粒度控制。
MDM [27]:无分类器的扩散模型,预测动作样本而非噪声,便于几何损失的应用。
MLD [9]:使用潜在扩散模型进一步推进动作生成。
MotionGPT [15]:开发了统一的大型动作语言模型,通过离散向量量化表示人类动作。
除了这些,论文还讨论了与人类/AI反馈对齐模型相关的研究,包括:
Reinforcement Learning from Human Feedback (RLHF) [7, 22]:用于模型对齐的技术,特别是在目标复杂或不明确的情况下。
Direct Preference Optimization (DPO) [25] 和 Slic-hf [37]:直接基于人类偏好优化模型策略的方法。
InstructMotion [29]:第一个通过人类反馈的强化学习微调文本到动作模型的工作。
RLAIF [8]:展示了另一种有前景的替代方案,即使用AI反馈进行模型对齐。
这些研究构成了文本到动作生成领域的研究基础,并为本文提出的AToM框架提供了理论和技术背景。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为AToM(Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward)的框架来解决文本到动作模型与事件级别文本描述对齐的问题。AToM框架主要包含以下三个阶段:
1. 数据集构建(Dataset Construction)
- 首先,研究者们构建了一个名为MotionPrefer的数据集,该数据集将三种类型的事件级别文本提示与生成的动作配对,涵盖了动作的完整性、时间关系和频率。
- 使用GPT-4生成初始文本提示,然后输入到动作生成模型(例如MotionGPT)中,为每个文本提示生成多个不同的动作。
- 总共包含5,276个提示和47.1k个动作样本。
2. 奖励范式设计(Reward Paradigm Design)
- 将MotionGPT生成的动作序列渲染成视频,并从中采样一系列帧。
- 将采样的动作帧和对应的文本提示输入到GPT-4Vision模型中,利用该模型评估文本和动作之间的对齐得分。
- 根据给定的评分规则为每个子任务(完整性、时间顺序和频率)计算对齐得分,生成带有对齐得分的文本-动作对,构成MotionPrefer数据集。
3. 文本到动作模型微调(Text-to-Motion Model Fine-tuning)
- 使用MotionPrefer数据集和GPT-4Vision的对齐得分作为反馈,微调现有的文本到动作模型(如MotionGPT)。
- 采用LoRA(Low-Rank Adaptation)和IPO(一种强化学习策略)算法进行微调,以提高模型在特定任务上的对齐性能。
- 实验结果表明,AToM显著提高了文本到动作生成的事件级别对齐质量。
通过这三个阶段,AToM框架能够有效地利用视觉语言大模型(如GPT-4Vision)的反馈,显著提高文本到动作模型在事件级别上的对齐质量,从而在文本提示和生成动作之间建立更加精确的对应关系。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估AToM框架的有效性,这些实验主要分为以下几个部分:
1. 实施细节(Implementation Details)
- 数据集:使用预训练的MotionGPT模型,并在MotionPrefer数据集的三个子集上进行微调,分别针对时间、完整性和频率任务。
- 实现具体内容:设置了学习率、批量大小和训练周期等超参数,并使用了AdamW优化器和余弦学习率调度器。
- 评估指标:包括多模态距离(MM-Dist)、R-Precision、FID、多样性和MModality等,用于评估动作质量和文本-动作对齐度。
2. 主要结果(Main Results)
- 定量实验:在时间、频率和完整性任务中,AToM在多个评估指标上一致优于基线模型(MotionGPT和InstructMotion),显示出更好的文本-动作对齐度、动作质量和生成真实性。
- 定性实验:通过视觉样本比较,展示了预训练模型(MotionGPT)和微调后的模型(AToM)在生成忠实度上的差异,AToM在多样化动作事件、复杂时间顺序和特定频率方面表现更优。
- 用户研究:50名参与者对AToM和MotionGPT生成的动作在时间、频率和完整性方面进行了评估,AToM在所有子任务中的胜率均高于MotionGPT。
3. 消融研究(Ablation Study)
- 动作注入形式:比较了三种不同的动作注入策略(逐帧、全图像、轨迹图像)对GPT-4V提问的影响。
- 分数过滤:研究了在偏好对构建中使用分数过滤的效果,只有评分高于3的样本被视为正面样本。
- LoRA利用:探讨了LoRA在微调中的效果,与传统微调方法相比,LoRA能够更有效地调整模型参数。
- 强化学习策略:比较了不同的强化学习策略(IPO、DPO、KTO、PPO)在生成模型微调后的表现。
- 动作序列采样步长:研究了不同帧采样间隔对对齐和质量指标的影响。
4. 额外结果(Additional Results)
- 更多定性结果:提供了额外的AToM和基线模型生成的视觉样本比较。
- 微调迭代次数:探讨了微调迭代次数对模型性能的影响。
- IPO超参数β的影响:分析了IPO策略中超参数β对对齐和质量指标的影响。
- 偏好数据集体积对模型性能的影响:研究了偏好对数量对模型性能的影响。
这些实验全面评估了AToM框架在不同方面的表现,并与现有技术进行了比较,证明了其在提高文本到动作模型对齐质量方面的有效性。
Q: 有什么可以进一步探索的点?
A: 基于论文内容和实验结果,以下是一些可以进一步探索的点:
1. 扩展数据集的多样性和复杂性
- 跨领域数据集:探索将AToM框架应用于更广泛的动作类型和场景,例如体育活动、舞蹈和日常复杂交互。
- 多语言支持:研究模型对不同语言文本提示的泛化能力,并构建多语言数据集进行训练和测试。
2. 增强模型的解释性和可视化
- 注意力机制分析:通过引入注意力机制来分析模型在处理特定文本提示时关注的区域,增强模型的解释性。
- 生成过程可视化:研究生成过程中的关键帧和动作变化,以可视化的方式展示模型是如何根据文本提示生成动作的。
3. 探索不同的强化学习策略
- 混合策略:结合人类反馈和AI反馈的优势,开发混合强化学习策略以进一步提高模型性能。
- 自适应策略:研究自适应调整强化学习策略中的参数,以动态适应不同的训练阶段和任务需求。
4. 提升模型的鲁棒性和泛化能力
- 对抗训练:通过引入对抗样本来测试和增强模型的鲁棒性,特别是在面对异常或模糊的文本提示时。
- 零样本学习:探索模型在零样本或少样本情况下的泛化能力,尤其是在未见过的动作类型或描述上。
5. 跨模态应用和集成
- 动作识别和预测:将AToM框架应用于动作识别和预测任务,评估模型在视频理解和未来动作预测方面的表现。
- 虚拟现实和游戏:将模型集成到虚拟现实和游戏引擎中,实现基于自然语言指令的实时动作生成和控制。
6. 优化和加速训练过程
- 分布式训练:研究如何利用分布式计算资源来加速模型的训练过程。
- 模型压缩和加速:探索模型压缩技术,减少模型大小和计算需求,使其更适合在资源受限的设备上运行。
7. 社会和伦理考量
- 偏见和公平性:评估和解决模型可能存在的偏见问题,确保生成的动作多样性和包容性。
- 用户隐私和数据安全:在使用真实世界数据进行训练和测试时,确保遵守数据保护法规和用户隐私。
这些探索点可以帮助研究者们更深入地理解AToM框架的潜力和局限性,并推动文本到动作生成技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一个名为AToM(Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward)的框架,旨在提高文本到动作(Text-to-Motion, T2M)模型在事件级别上与文本提示对齐的质量。以下是论文的主要内容总结:
1. 问题背景
- 文本到动作模型能够根据文本提示生成人体动作,但在处理复杂的、多动作事件的文本描述时面临挑战。
- 现有模型在泛化到未见过的文本描述和多事件场景时受限,需要更精细的对齐评估。
2. AToM框架
- 数据集构建:创建了一个名为MotionPrefer的数据集,包含5.3K个文本提示和80K个动作偏好对,涵盖动作的完整性、时间关系和频率。
- 奖励范式设计:利用GPT-4Vision对生成的动作序列和文本描述之间的对齐进行评分,基于给定的评分规则计算对齐得分。
- 模型微调:使用MotionPrefer数据集和GPT-4Vision的对齐得分作为反馈,通过LoRA和IPO强化学习策略微调现有的文本到动作模型。
3. 实验结果
- 定量实验:AToM在多个评估指标上优于基线模型,显示出更好的文本-动作对齐度、动作质量和生成真实性。
- 定性实验:通过视觉样本比较,展示了AToM在生成忠实度上的优势。
- 用户研究:AToM在所有子任务中的用户评估胜率均高于基线模型。
4. 消融研究
- 探讨了不同的动作注入策略、分数过滤、LoRA利用和强化学习策略对模型性能的影响。
5. 结论
- AToM框架有效地利用视觉语言大模型的反馈,显著提高了文本到动作生成的事件级别对齐质量,为文本提示和生成动作之间建立了更精确的对应关系。
这篇论文通过提出一个新的框架,解决了文本到动作模型在复杂文本描述下对齐质量不足的问题,并展示了通过利用先进的视觉语言模型进行微调可以显著提升模型性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Dspy-based Neural-Symbolic Pipeline to Enhance Spatial Reasoning in LLMs
Authors:Rong Wang, Kun Sun, Jonas Kuhn
Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, yet they often struggle with spatial reasoning. This paper presents a novel neural-symbolic framework that enhances LLMs’ spatial reasoning abilities through iterative feedback between LLMs and Answer Set Programming (ASP). We evaluate our approach on two benchmark datasets: StepGame and SparQA, implementing three distinct strategies: (1) direct prompting baseline, (2) Facts+Rules prompting, and (3) DSPy-based LLM+ASP pipeline with iterative refinement. Our experimental results demonstrate that the LLM+ASP pipeline significantly outperforms baseline methods, achieving an average 82% accuracy on StepGame and 69% on SparQA, marking improvements of 40-50% and 8-15% respectively over direct prompting. The success stems from three key innovations: (1) effective separation of semantic parsing and logical reasoning through a modular pipeline, (2) iterative feedback mechanism between LLMs and ASP solvers that improves program rate, and (3) robust error handling that addresses parsing, grounding, and solving failures. Additionally, we propose Facts+Rules as a lightweight alternative that achieves comparable performance on complex SparQA dataset, while reducing computational overhead.Our analysis across different LLM architectures (Deepseek, Llama3-70B, GPT-4.0 mini) demonstrates the framework’s generalizability and provides insights into the trade-offs between implementation complexity and reasoning capability, contributing to the development of more interpretable and reliable AI systems.
大型语言模型(LLM)在各种任务中表现出了显著的能力,但在空间推理方面常常遇到困难。本文提出了一种新颖的神经符号框架,它通过迭代反馈增强LLM的空间推理能力,这种反馈存在于LLM和答案集编程(ASP)之间。我们在两个基准数据集上评估了我们的方法:StepGame和SparQA,实施了三种不同的策略:(1)直接提示基线,(2)Facts+Rules提示,以及(3)基于DSPy的LLM+ASP管道,具有迭代细化功能。我们的实验结果表明,LLM+ASP管道显著优于基线方法,在StepGame上平均准确率为82%,在SparQA上为69%,相对于直接提示分别提高了40-50%和8-15%。成功源于三个关键创新点:(1)通过模块化管道有效地分离语义解析和逻辑推理,(2)LLM和ASP求解器之间的迭代反馈机制,提高了程序执行率,(3)稳健的错误处理,解决了解析、接地和求解失败的问题。此外,我们提出了Facts+Rules作为轻量级替代方案,在复杂的SparQA数据集上实现了相当的性能,同时降低了计算开销。我们对不同的LLM架构(Deepseek、Llama3-70B、GPT-4.0 mini)的分析表明了该框架的通用性,并深入探讨了实现复杂性和推理能力之间的权衡,为开发更具可解释性和可靠性的AI系统做出了贡献。
论文及项目相关链接
Summary:
本文介绍了一种新型的神经符号框架,它通过迭代反馈机制增强了大型语言模型在空间推理方面的能力。实验表明,该框架在StepGame和SparQA两个基准数据集上的表现显著优于基线方法,平均准确率分别达到82%和69%。其成功源于模块化管道的有效分离语义解析和逻辑推理、LLMs和ASP求解器之间的迭代反馈机制,以及解决解析、接地和求解失败的稳健错误处理。此外,还提出了一种轻量级的Facts+Rules方法,在复杂的SparQA数据集上实现了良好的性能,并降低了计算开销。该框架可应用于不同的LLM架构,为开发更具解释性和可靠性的AI系统提供了见解。
Key Takeaways:
- 神经符号框架通过迭代反馈机制增强了大型语言模型的空间推理能力。
- 在StepGame和SparQA基准数据集上的实验表明,该框架显著提高了空间推理任务的准确率。
- 框架成功源于模块化管道的有效分离语义解析和逻辑推理、LLMs和ASP求解器之间的迭代反馈,以及稳健的错误处理机制。
- 提出了轻量级的Facts+Rules方法,在复杂的SparQA数据集上实现了良好的性能,并降低了计算开销。
- 该框架适用于不同的LLM架构,为AI系统的开发提供了更广泛的选择。
- 框架的贡献包括提高空间推理能力、增强模型可解释性和可靠性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是大型语言模型(Large Language Models,简称LLMs)在空间推理方面的能力不足。具体来说,论文指出LLMs虽然在多种任务上表现出色,但在处理涉及空间、物理和具身推理的任务时,由于缺乏足够的基础,往往难以表现出色。空间推理是人类认知功能的一个重要部分,它使得人们能够在二维或三维空间中概念化和预测对象的运动和相互作用。为了使LLMs接近通用人工智能(Artificial General Intelligence,简称AGI),它们必须具备与人类相当的空间推理能力,这不仅对LLMs自身的发展至关重要,也对基于LLMs的机器人技术、任务规划、路径规划和导航等应用至关重要。
论文中提到,空间推理包括定量和定性推理两个主要类别,LLMs在处理这些空间关系时面临重大挑战,因为它们不仅要理解场景的语义描述,还要进行复杂的多跳推理,以了解对象在空间中如何相互关联。因此,论文提出了一个新颖的神经符号框架(neural-symbolic framework),以增强LLMs的空间推理能力,并在两个基准数据集StepGame和SparQA上评估了这种方法。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与LLMs空间推理能力提升相关的研究:
Bang et al. (2023): 这项研究强调了像ChatGPT这样的模型在演绎逻辑推理、空间推理和非文本语义推理方面的局限性。
Cohn (2023): 这项工作突出了LLMs在演绎逻辑推理、空间推理和非文本语义推理方面的限制,并强调了进一步改进空间推理的必要性。
Sharma (2023) 和 Chen et al. (2024): 这些研究强调了空间推理能力在机器人技术、任务规划、路径规划和导航等LLMs应用中的重要性。
Li et al. (2024a) 和 Yang et al. (2024): 这些研究讨论了LLMs在处理空间关系时面临的挑战,尤其是在需要多跳推理的场景中。
Mirzaee and Kordjamshidi (2022): 这项工作介绍了SparQA数据集,这是一个针对空间推理的文本问答基准,强调了模型需要理解自然语言描述的复杂空间关系,并执行多跳推理以准确回答问题。
Fang et al. (2024): 这项研究展示了通过增加外部工具来增强LLMs在需要算术、导航和知识库查找的任务上的表现。
Yang et al. (2023): 提出了一种将语言转换为逻辑的神经符号策略,以增强LLMs的空间推理能力。
Li et al. (2024a): 这项工作关注于简单的数据集(例如StepGame),并应用了一些非神经符号的方法。
Mirzaee and Kordjamshidi (2023): 这项研究尝试通过多个LLMs来探索LLMs的空间推理能力,并通过多个LLMs实施完整的反馈循环。
这些研究提供了对LLMs在空间推理方面局限性的理解,并探索了不同的方法来提升LLMs的空间推理能力。论文中提出的神经符号框架正是在这些研究的基础上,旨在通过结合神经网络和符号系统的优势来解决LLMs在空间推理方面的挑战。
Q: 论文如何解决这个问题?
A: 论文提出了一个新颖的神经符号框架(neural-symbolic framework),通过以下三种策略来增强大型语言模型(LLMs)的空间推理能力:
ASP(Answer Set Programming)基于符号推理:
- 使用ASP作为一种强大的声明式编程范式,适合于复杂推理任务,尤其是涉及知识表示和组合搜索问题的场景。
- 通过逻辑关系定义问题域中的基本事实、规则、约束和查询,利用ASP求解器自动确定满足给定条件的解决方案。
LLM + ASP 管道使用DSPy:
- 提出了一个新颖的神经符号管道,使用DSPy(Declarative Self-improving Language Programs)将LLMs与ASP结合起来。
- 该管道包括四个主要阶段:事实生成阶段、ASP精炼阶段、符号推理阶段和结果解释与评估阶段。
- 利用LLM将自然语言描述转换为符号公式和正式查询,然后迭代地精炼ASP表示,添加规则、检查一致性,并从错误消息中获取反馈。
- 使用Clingo求解器进行推理,确保通过结合LLM的能力和逻辑推理来准确和可解释的推理。
事实 + 逻辑规则:
- 提出了一种替代的神经符号方法,该方法在保持结构化知识表示的优势的同时,减少了形式逻辑编程的复杂性。
- 通过自然语言提示直接嵌入逻辑规则,使LLM能够在结构化知识表示中执行推理,而不是依赖外部逻辑求解器进行推理。
- 通过使用具有精确参数结构的谓词,指导LLM创建一致的知识表示,作为问题回答的中间基础。
这三种策略的实施,使得LLMs在空间推理任务中的表现得到了显著提升。通过实验,论文展示了这些方法在StepGame和SparQA两个基准数据集上的有效性,证明了神经符号方法在增强LLMs空间推理能力方面的潜力。此外,论文还提出了一个集成的、简单而有效的策略集,使用神经符号管道来提升LLMs的空间推理能力,这些策略展示了强大的泛化性和更广泛的适用性。
Q: 论文做了哪些实验?
A: 论文中进行了两个主要的实验来评估提出的神经符号框架在增强LLMs空间推理能力方面的效果:
实验 1: 提出的LLM + ASP方法
实验在StepGame数据集上进行了详细的实施和结果分析。StepGame是一个合成的空间问答数据集,包含需要1到10个推理步骤的问题。实验中,研究者将StepGame数据集分为两个不同的集合:清洁集和噪声集。研究者专注于清洁数据集,并且考虑到StepGame数据集的推理跳跃范围从1到10,分布在10个子集中。实验中,对于每个推理跳跃k ∈ {1, …, 10},收集了前100个数据实例,并使用准确率指标来评估结果。
实验 2: Fact + Logical rules方法
实验扩展到了SparQA数据集,这是一个比StepGame更复杂的基准测试,包含更长的句子、更多样的问题类型和复杂的推理要求。SparQA数据集基于NLVR(自然语言视觉推理)图像构建,展示各种空间排列的合成场景。实验中,研究者构建了SparQA的一个子集,包含220个示例(每种问题类型55个)用于模型推理。实验采用了与StepGame相同的管道方法:(1) 将自然语言上下文和问题转换为ASP事实;(2) 添加规则并完善ASP程序;(3) 符号推理;(4) 结果映射和评估。
实验结果表明,提出的神经符号管道在不同模型和问题类型上显示出了混合的结果。在“寻找关系”(Finding Relation, FR)问题上表现出显著的改进,准确率提高了约20%。在“寻找块”(Finding Block, FB)问题上也取得了显著的提升,尤其是在GPT 4.0模型上。然而,对于“是/否”(Yes/No, YN)问题,直接提示的表现更好,表明更简单的问题类型可能不会从神经符号方法的额外复杂性中受益。
这些实验不仅验证了神经符号方法在增强LLMs空间推理能力方面的有效性,还展示了这些方法在不同复杂度的空间推理挑战中的适应性和泛化能力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
增强神经符号系统的鲁棒性和适应性:
- 研究如何提高系统处理不一致信息和不确定性的能力,特别是在空间关系推理中。
上下文感知知识图谱嵌入:
- 探索上下文感知知识图谱嵌入的方法,以更有效地捕获隐含的关系,如Zhu和Sun (2024)所建议的。
概率推理能力的整合:
- 将概率推理能力整合到神经符号系统中,以增强系统处理空间关系中的不确定性,如De Raedt等人 (2020)所示范的。
错误检测和自动调试机制:
- 开发错误检测和自动调试机制,以提高系统的可靠性并减少手动干预的需求,如Gu等人 (2023)所建议的。
优化模型间交互:
- 探索优化多个模型和推理组件之间的交互,涉及更复杂的协同技术,改进概率推理与符号求解器的集成,并在神经符号系统的各个阶段利用不同LLMs的优势。
提高模型的解释性和透明度:
- 研究如何增强神经符号系统的解释性和透明度,特别是在复杂的空间推理任务中。
跨领域应用:
- 将神经符号方法应用于其他复杂推理任务,如时间推理和演绎推理,以测试其在不同问题领域的适用性。
改进自然语言到逻辑程序的转换:
- 研究如何减少自然语言到逻辑程序转换过程中的错误,并提高这一转换过程的准确性和可靠性。
计算效率的优化:
- 探索如何优化神经符号系统的计算效率,特别是在需要大量迭代和复杂逻辑推理的场景中。
多模态输入的处理:
- 研究如何将神经符号系统扩展到处理多模态输入(如结合视觉和语言信息)的场景中,以增强模型对复杂情境的理解。
这些探索点可以帮助推动神经符号AI领域的发展,提高LLMs在复杂任务中的性能,并为实现更智能、可解释和高效的AI系统提供新的思路。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个神经符号框架,旨在增强大型语言模型(LLMs)在空间推理方面的能力。主要内容可以总结如下:
问题陈述:
- LLMs在空间推理任务上表现不佳,这限制了它们在需要空间、物理和具身推理的应用中的性能。
研究目标:
- 提出一个神经符号框架,通过结合LLMs和符号推理来提升空间推理能力。
方法论:
- 提出了三种策略:ASP(Answer Set Programming)符号推理、LLM + ASP管道以及事实 + 逻辑规则方法。
实验设计:
- 在两个基准数据集StepGame和SparQA上评估提出的方法。
实验结果:
- 提出的方法在StepGame数据集上实现了40-50%的准确率提升,在更复杂的SparQA数据集上实现了3-13%的准确率提升。
主要发现:
- 神经符号方法能有效提升LLMs的空间推理能力,尤其是在处理复杂空间关系和多跳推理任务时。
- “LLM + ASP”管道在寻找关系(FR)和寻找块(FB)问题上表现尤为出色。
讨论与局限性:
- 尽管神经符号方法提高了性能,但在不同问题类型上的效果并不一致,特别是在简单问题类型上可能不会受益。
- 领域敏感性和自然语言到逻辑程序转换中的错误是需要进一步解决的挑战。
未来方向:
- 增强系统的鲁棒性和适应性,优化模型间交互,提高解释性和透明度,以及探索跨领域应用。
结论:
- 该研究提出的神经符号管道显著提升了LLMs的空间推理能力,并为未来在更广泛的推理领域中的应用奠定了基础。
整体而言,这篇论文展示了通过神经符号集成方法增强LLMs空间推理能力的潜力,并指出了这一领域的未来研究方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Politicians vs ChatGPT. A study of presuppositions in French and Italian political communication
Authors:Davide Garassino, Vivana Masia, Nicola Brocca, Alice Delorme Benites
This paper aims to provide a comparison between texts produced by French and Italian politicians on polarizing issues, such as immigration and the European Union, and their chatbot counterparts created with ChatGPT 3.5. In this study, we focus on implicit communication, in particular on presuppositions and their functions in discourse, which have been considered in the literature as a potential linguistic feature of manipulation. This study also aims to contribute to the emerging literature on the pragmatic competences of Large Language Models.
本文旨在比较法国和意大利政治家在移民和欧盟等极化问题上产生的文本与他们使用ChatGPT 3.5创建的聊天机器人之间的对话。在这项研究中,我们重点关注隐性沟通,尤其是预设及其在对话中的功能。文献中认为预设可能具有操纵性语言特征的作用。此外,本研究旨在为关于大型语言模型语用能力的新兴文献做出贡献。
论文及项目相关链接
PDF Published: 2024-07-04
Summary:
本文旨在比较法国和意大利政治家在移民和欧盟等极化问题上以及用ChatGPT 3.5创建的聊天机器人对这些问题的文本输出。研究重点为隐性沟通,特别是预设及其在话语中的功能,被视为潜在的操纵性语言特征。同时,该研究旨在为新兴的大型语言模型语用能力文献做出贡献。
Key Takeaways:
- 本研究对比了法国和意大利政治家在敏感议题上的文本输出与聊天机器人(使用ChatGPT 3.5技术)的生成文本。
- 隐性沟通,特别是预设是研究的重点,这些预设可能在话语中具有操纵性语言特征。
- 该研究关注大型语言模型(LLM)的语用能力。
- 文章强调了预设在语境中的重要性以及其与隐性沟通的其他要素之间的联系。
- 通过比较政治家与聊天机器人的文本输出,探讨了大型语言模型在模拟人类语言表达方面的能力差异。
- 此研究期望对LLM的语言理解能力和语言生成策略的改进提供有价值的信息。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文主要试图解决以下几个问题:
比较政治沟通中的预设(presuppositions)使用:论文旨在比较法国和意大利政治家在关于移民和欧盟等分裂性议题上的演讲文本与使用ChatGPT 3.5生成的聊天机器人文本之间的差异。特别关注隐性沟通中的预设及其在话语中的功能,这些在文献中被认为是潜在的语言操纵特征。
评估大型语言模型的语用能力:研究结果还旨在为有关大型语言模型(LLMs)的语用能力新兴文献做出贡献。
分析AI生成文本中的可疑预设:论文的主要贡献之一是展示平均而言,ChatGPT生成的文本比政治家的原始演讲包含更多的可疑预设(questionable presuppositions)。
探讨AI生成文本的文本和语用属性:鉴于生成文本的广泛传播,论文认为现在是评估它们的文本和语用属性以及它们传播假新闻和可疑内容的潜力的时候了。
研究问题细化:论文进一步将主要研究问题细化为三个子问题:
- Q1. 频率:与政治家生成的真实文本相比,ChatGPT生成的文本中是否平均含有更多或更少的PMPs(潜在操纵性预设)?
- Q2. 形式:ChatGPT文本中的PMPs形式(即激活它们的触发器)是否与政治家文本中的相似?
- Q3. 功能:ChatGPT文本中PMPs的话语功能是否与政治家文本中的相似?
总结来说,这篇论文试图通过对比分析政治家和AI聊天机器人在特定议题上的沟通策略,来探索和理解隐性沟通中的预设如何被用作可能的操纵手段,并评估大型语言模型在这些方面的性能和潜力。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的研究:
**Sbisà (2007) 和 Lombardi Vallauri (2016, 2021)**:这些文献将预设视为潜在的说服性隐性内容,其研究有助于探索和理解政治沟通中的操纵策略。
**Reboul (2011, 2017)**:在语言和沟通演化领域,Reboul 提出了基于说话者和听者双方成本和利益的说服和操纵的区别。
**Mercier 和 Sperber (2017)**:他们认为人类沟通自然倾向于论证和说服,即改变他人的心理状态和信仰。
**Bender, Gebru, McMillan-Major 和 Shmitchell (2021)**:这项研究涉及了与性别和社会政治框架相关的偏见,以及假新闻和错误信息的传播。
**Bai, Voelkel, Eichstaedt 和 Willer (2023)**:研究表明,当前的大型语言模型(LLMs)生成的文本能够说服人们,即使是在涉及极化问题时。
**Goldstein, Sastry, Musser 等人 (2023)**:他们报告了一个感知实验的结果,参与者对由人类宣传者或ChatGPT 3.0生成的文章中的争议性或明显虚假的论点表示同意或不同意,结果表明参与者对两种文本的同意程度相似。
**Zou, Wang, Carlini 等人 (2023)**:这项研究显示,尽管OpenAI和Google努力防止聊天机器人产生虚假和攻击性内容,但可以(且容易)绕过这些内容过滤器来产生攻击性内容。
**Brocca, Garassino 和 Masia (2016);Lombardi Vallauri (2019)**:这些研究探讨了隐性沟通与语言操纵之间的强联系,特别是在广告和政治话语领域。
**Stalnaker (1973, 2002)**:Stalnaker对预设进行了表征,将其视为被视为理所当然的信息,即说话者假定已经在对话的共同背景中的知识点。
**Kiparsky 和 Kiparsky (1971);Sbisà (2007);Lombardi Vallauri (2009)**:这些文献提供了预设触发器的详尽列表,预设触发器是专门用于激活预设的语言类别或结构。
**Loftus (1975);Langford 和 Holmes (1979);Schwarz (2015)**:这些早期实验文献表明预设很可能以肤浅的方式被解码,即接收者不会彻底关注其所有细节。
**Garassino, Masia 和 Brocca (2019);Garassino, Brocca 和 Masia (2022)**:这些研究基于语料库分析了政治语言中的预设策略,包括传统演讲和政治家在Twitter或其他社交网络上发布的信息。
这些相关研究为理解预设在隐性沟通和潜在操纵中的作用提供了理论基础和实证支持,并且为本研究提供了对比分析的背景。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决提出的问题:
构建研究语料库:
- 收集法国和意大利政治家的演讲文本以及使用ChatGPT 3.5生成的对应文本。
- 选择的政治家包括Emmanuel Macron、Marine Le Pen、Nicola Zingaretti和Giorgia Meloni,他们分别代表不同的政治立场,并在国家选举期间就欧盟和移民等议题发表演讲。
设计生成ChatGPT文本的提示(prompts):
- 根据特定的模板创建提示,让ChatGPT模拟每位政治家的身份,并提供实际演讲的摘录。
- 调整ChatGPT的内部参数(如温度和多样性惩罚)以影响输出的创造性和重复性。
文本标注与一致性检验:
- 两位研究者独立识别和标注文本中的潜在操纵性预设(PMPs)及其触发器和话语功能。
- 使用Cohen’s k和Gwet’s AC1两个指标计算标注者之间的一致性,并在必要时通过讨论解决分歧。
定量分析:
- 对比分析政治家和ChatGPT生成文本中PMPs的频率、形式和功能。
- 使用卡方检验、Fisher精确检验和对数线性分析等统计方法来确定不同文本类型间PMPs分布的显著性差异。
结果讨论:
- 分析ChatGPT生成文本与政治家演讲在PMPs使用上的差异,并探讨这些差异的可能原因。
- 讨论ChatGPT的架构特性,如重复性和泛化倾向,以及这些特性如何影响PMPs的生成。
研究局限与未来方向:
- 讨论研究的局限性,包括语料库的代表性和LLMs生成文本的随机性。
- 提出未来研究方向,比如探索更先进的AI技术如何处理这些隐性沟通策略,并扩展分析到其他隐性沟通策略。
通过上述步骤,论文提供了对AI生成文本在模仿人类语言特别是在政治沟通中的隐性策略方面的深入分析,揭示了AI在生成潜在操纵性内容方面的能力,并讨论了这些发现对政治沟通和AI技术未来发展的意义。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,本研究进行的主要实验包括:
语料库构建:
- 收集法国和意大利政治家的演讲文本以及相应的由ChatGPT 3.5生成的文本。
文本生成:
- 使用特定的提示(prompts)让ChatGPT模拟政治家的身份,并生成演讲文本。
文本标注:
- 两位研究者独立识别和标注文本中的潜在操纵性预设(PMPs)及其触发器和话语功能。
一致性检验:
- 使用Cohen’s k和Gwet’s AC1两个指标计算标注者之间的一致性,并在必要时通过讨论解决分歧。
定量分析:
- 对比分析政治家和ChatGPT生成文本中PMPs的频率、形式和功能。
- 使用卡方检验、Fisher精确检验和对数线性分析等统计方法来确定不同文本类型间PMPs分布的显著性差异。
统计分析:
- 对于频率(Q1)、形式(Q2)和功能(Q3)的比较,使用描述性统计和推断性统计来分析PMPs在政治家和ChatGPT文本中的分布差异。
对数线性分析:
- 进行对数线性分析来测试三个或更多分类变量之间的关联性,包括话语功能、组别(ChatGPT和政治家)、语言(法语和意大利语)。
可视化表示:
- 使用镶嵌图(mosaic plots)来可视化不同变量之间的交互作用和标准化残差。
这些实验步骤构成了论文的研究设计,旨在探索和比较由人类政治家和AI聊天机器人生成的文本中预设的使用情况,并评估大型语言模型在生成具有潜在操纵性内容方面的能力和倾向。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
更先进的AI技术:
- 探索ChatGPT 4.0或其他更新版本的AI技术在检测和应用隐性沟通策略方面的潜在改进。
其他隐性沟通策略:
- 将分析扩展到其他隐性沟通策略,例如模糊性(vagueness)等,以更全面地理解AI生成文本中隐性沟通的使用情况。
预设触发器的具体指称目标:
- 对预设触发器的选择及其具体的指称目标进行更详细的分析,以丰富对ChatGPT生成文本中PMPs分布的理解。
多语言和跨文化研究:
- 考虑不同语言和文化背景下的政治沟通,分析AI生成文本在跨语言和跨文化环境中的表现和差异。
预设的神经机制:
- 研究不同预设触发器类型背后的神经机制,以及这些机制如何影响人类的信息处理和AI模型的生成策略。
AI生成文本的可检测性:
- 开发和测试更有效的工具和技术来检测AI生成的文本,这对于识别和防范潜在的虚假信息传播至关重要。
训练数据的影响:
- 研究训练数据的不平衡(如ChatGPT训练数据中英语的高比例)如何影响其他语言文本的生成和质量。
AI伦理和偏见问题:
- 深入探讨AI模型生成文本时可能出现的伦理问题和偏见,以及如何通过设计和训练过程来减少这些问题。
用户交互和参数调整:
- 研究用户如何通过调整参数(如温度和多样性惩罚)来控制ChatGPT的输出,以及这些调整如何影响生成文本的质量和适用性。
AI在政治沟通中的角色:
- 进一步分析AI在政治沟通中的角色,包括其在塑造公众舆论、传播信息和影响选举结果方面的潜力和影响。
这些探索点可以帮助研究者更深入地理解AI在政治沟通中的应用,以及如何优化AI技术以提高其在这一领域的有效性和伦理性。
Q: 总结一下论文的主要内容
A: 本论文的主要内容概括如下:
研究目的:论文旨在比较法国和意大利政治家在关于分裂性议题(如移民和欧盟)上的演讲文本与使用ChatGPT 3.5生成的聊天机器人文本,特别关注隐性沟通中的预设及其在话语中的功能,这些预设被视为潜在的语言操纵特征。
研究重要性:研究结果有助于了解大型语言模型(LLMs)在生成文本时的语用能力,以及它们在公共话语中传播假新闻和可疑内容的潜力。
研究方法:通过构建包含真实政治家演讲和ChatGPT生成文本的语料库,研究者进行了详细的文本标注和一致性检验,以识别和分类潜在操纵性预设(PMPs)及其触发器和话语功能。
实验设计:实验包括文本生成、标注、一致性检验和定量分析,使用了描述性统计和推断性统计方法来分析PMPs在政治家和ChatGPT文本中的分布差异。
主要发现:
- ChatGPT生成的文本平均含有比政治家演讲更多的可疑预设。
- ChatGPT文本中预设的形式和话语功能与政治家演讲存在显著差异。
- ChatGPT倾向于使用和重复某些由变化状态动词构成的政治口号作为预设触发器。
讨论与解释:这些差异可能与ChatGPT的架构特性有关,如倾向于在长文本中变得啰嗦和重复,选择和重复(或多或少)空洞的政治口号。
研究局限与未来方向:论文讨论了研究的局限性,包括语料库的代表性和LLMs生成文本的随机性,并提出了未来研究方向,例如探索更先进的AI技术如何处理隐性沟通策略。
结论:研究强调了AI在模仿复杂人类沟通模式方面日益增长的复杂性,这为AI驱动的说服性语言的未来带来了机遇和挑战。
总的来说,这篇论文提供了对AI生成文本在模仿人类语言特别是在政治沟通中的隐性策略方面的深入分析,并探讨了这些发现对政治沟通和AI技术未来发展的意义。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

ChatGPT as speechwriter for the French presidents
Authors:Dominique Labbé, Cyril Labbé, Jacques Savoy
Generative AI proposes several large language models (LLMs) to automatically generate a message in response to users’ requests. Such scientific breakthroughs promote new writing assistants but with some fears. The main focus of this study is to analyze the written style of one LLM called ChatGPT by comparing its generated messages with those of the recent French presidents. To achieve this, we compare end-of-the-year addresses written by Chirac, Sarkozy, Hollande, and Macron with those automatically produced by ChatGPT. We found that ChatGPT tends to overuse nouns, possessive determiners, and numbers. On the other hand, the generated speeches employ less verbs, pronouns, and adverbs and include, in mean, too standardized sentences. Considering some words, one can observe that ChatGPT tends to overuse “to must” (devoir), “to continue” or the lemma “we” (nous). Moreover, GPT underuses the auxiliary verb “to be” (^etre), or the modal verbs “to will” (vouloir) or “to have to” (falloir). In addition, when a short text is provided as example to ChatGPT, the machine can generate a short message with a style closed to the original wording. Finally, we reveal that ChatGPT style exposes distinct features compared to real presidential speeches.
生成式人工智能提出几种大型语言模型(LLM),以自动根据用户需求生成响应消息。这样的科学突破促进了新型写作助手的出现,但也带来了一些担忧。本研究的主要焦点是通过将名为ChatGPT的LLM生成的文字与近期法国总统的演讲进行比较,分析其自然语言风格。为此,我们将齐拉克、萨科齐、奥朗德和马克龙年终演讲的文字与ChatGPT自动生成的文字进行比较。我们发现ChatGPT倾向于过度使用名词、限定词和数字。另一方面,生成的演讲则使用较少的动词、代词和副词,且平均下来句子过于标准化。考虑到某些词汇,可以观察到ChatGPT过度使用“必须”(devoir)、“继续”或代词“我们”(nous)。此外,GPT使用辅助动词“是”(être)或情态动词“将”(vouloir)、“必须”(falloir)的频率较低。另外,当为ChatGPT提供一段简短文本作为示例时,这台机器可以生成一条风格接近原文的简短消息。最后,我们揭示ChatGPT的风格与真实的总统演讲相比具有鲜明的特征。
论文及项目相关链接
Summary:该研究对比了ChatGPT生成的文字与法国历任总统年终演讲的风格,发现ChatGPT使用过于标准化的句子,过度使用某些词汇如“必须”、“继续”等,而少用某些助动词和动词。当提供简短文本作为示例时,ChatGPT能够生成风格相近的简短信息,但总体风格仍与真实的总统演讲存在明显区别。
Key Takeaways:
- Generative AI通过大型语言模型(LLMs)自动根据用户请求生成信息。
- ChatGPT作为LLM的一种,其生成的文字风格被研究并和法国总统的演讲进行了对比。
- ChatGPT倾向于过度使用名词、限定词和数字,而动词、代词和副词的使用较少。
- ChatGPT生成的句子较为标准化。
- ChatGPT在某些词汇上表现出过度使用的倾向,例如“必须”、“继续”以及“我们”等。
- 与真实的总统演讲相比,ChatGPT的风格存在明显区别。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文主要试图解决以下问题:
分析ChatGPT的写作风格: 论文通过比较ChatGPT生成的消息与法国近期总统的写作风格,来分析这种大型语言模型(LLM)在写作上的特点和差异。
比较ChatGPT与人类写作的差异: 研究试图通过实证测试ChatGPT是否能够模仿给定作者的风格,并分析ChatGPT生成的文本与人类写作的文本之间的文体差异。
检测ChatGPT生成文本的可能性: 论文探讨是否可以使用计算机化的工具来检测由ChatGPT生成的文本,尤其是在它模仿真实作者风格时。
揭示ChatGPT的文体特征: 研究试图识别和描述与ChatGPT相比真实作者所特有的一些文体特征。
探讨ChatGPT在特定文本类型中的性能: 论文专注于ChatGPT在生成相对短小的政治信息类文本时的表现,并与真实总统演讲的文体特征进行对比。
评估ChatGPT对语言细节的处理能力: 通过分析ChatGPT在词汇、句子长度等方面的处理,评估其在模仿人类写作时对语言细节的把握程度。
综上所述,论文的核心目标是深入理解ChatGPT在模仿人类写作风格时的表现,并探索检测其生成文本的可行性。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与本研究相关的研究:
Bubeck et al. (2023): 提出了GPT“产生与人类几乎无法区分(甚至更好)的输出”的观点。
Guo et al. (2023): 研究了能够区分GPT-3生成的文本和人类写作的文本的学习策略的有效性,基于训练有素的黑盒分类器(例如RoBERTa)。
Antoun et al. (2023): 探讨了在非英语(例如法语)情况下,区分机器生成文本和人类写作的能力。
Gao et al. (2023): 指出人类在检测机器生成的文本方面效率较低。
Labbé & Labbé (2013): 讨论了在科学论文中使用写作助手的问题,包括生成复杂句子的应用。
Picazo-Sanchez & Ortiz-Martin (2024): 分析了GPT在约10%的45,000篇来自3009个期刊的论文中使用的影响。
Soto et al. (2024): 发现大型语言模型(LLM)显示出相似和一致的结果。
Goodfellow et al. (2016): 讨论了深度学习架构的发展,以及不同的神经网络模型在解决复杂分类和预测任务中的应用。
Vaswami et al. (2017): 提出了变换器模型(例如BERT, LaMDA, GPT)来有效地解决序列到序列的任务。
这些相关研究涵盖了从深度学习模型的发展、文本生成的质量评估、以及机器生成文本检测方法等多个方面,为本研究提供了理论和实证基础。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决提出的问题:
数据收集与准备:
- 收集了法国四位总统(Chirac、Sarkozy、Hollande和Macron)的年终讲话作为自然文本(NTs)。
- 使用ChatGPT基于这些自然文本生成对应的年终讲话作为生成文本(GPTs)。
- 对NTs和GPTs进行标准化和标记处理,以确保比较的一致性。
文体特征分析:
- 分析了ChatGPT生成文本与真实总统演讲在词性分布(POS)上的差异。
- 比较了两组文本中最常用的词汇(动词、名词、形容词、副词等)的频率和排名。
- 研究了ChatGPT生成的文本与真实文本在句子长度和分布上的差异。
统计和比较分析:
- 使用统计方法比较了ChatGPT生成的文本和真实文本在词频、词性分布、句子长度等方面的差异。
- 计算了不同总统演讲之间的文体距离,以评估ChatGPT生成文本与真实文本之间的相似度。
检测方法的评估:
- 探讨了传统的文本检测方法(如互文距离和自动分类)在检测ChatGPT生成文本时的有效性。
- 合并了所有生成的文本和自然文本,以进行足够的统计分析,并评估了这些方法在区分真实文本和生成文本上的能力。
结果讨论与结论:
- 根据分析结果,讨论了ChatGPT在模仿人类写作风格时的表现和局限性。
- 提出了ChatGPT生成文本的独特特征,并讨论了这些特征对于文本检测的影响。
- 得出了关于ChatGPT生成文本检测难度的结论,并对未来的研究方向提出了建议。
通过这些步骤,论文不仅分析了ChatGPT的写作风格和生成文本的特点,还探讨了检测这些文本的方法和挑战,为理解和评估大型语言模型生成的文本提供了深入的见解。
Q: 论文做了哪些实验?
A: 根据论文内容,以下是进行的实验:
比较词性分布(Part-Of-Speech, POS):
- 将ChatGPT生成的文本与法国总统的真实演讲进行比较,分析了词性分布的差异。
词汇分析:
- 对比了总统演讲和ChatGPT生成文本中最常用的动词、名词、形容词和副词的频率和排名。
句子长度分析:
- 分析了ChatGPT生成文本与总统演讲在句子长度上的分布差异,并计算了主要的描述性统计值(如众数、中位数、平均值、标准差等)。
聚类分析:
- 使用互文距离方法对合并后的文本进行聚类分析,以评估ChatGPT生成的文本与真实文本之间的相似性,并尝试进行作者归属。
检测方法的有效性评估:
- 探讨了传统的文本检测方法(如互文距离和自动分类)在检测ChatGPT生成文本时的有效性。
统计显著性检验:
- 对于词频差异和句子长度差异,计算了统计显著性指数(S值),以确定ChatGPT的使用习惯与总统演讲的差异是否显著。
这些实验综合了定量分析和统计方法,旨在全面评估ChatGPT生成文本的风格、特征以及检测难度,并与真实作者的写作风格进行比较。通过这些实验,研究者们能够揭示ChatGPT在模仿人类写作时的能力和局限。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和结果,以下是一些可以进一步探索的点:
其他语言的实验:
- 论文主要关注法语材料。进一步的实验可以在其他语言,尤其是资源较少的语言中进行,以评估大型语言模型(LLM)在不同语言环境下的性能和局限性。
更广泛的文本类型:
- 研究可以扩展到更多种类的文本,例如政治演讲之外的文本,以了解ChatGPT在模仿不同文体和领域专业文本的能力。
改进检测方法:
- 开发和测试新的计算机化工具和技术,用于检测ChatGPT生成的文本,特别是在它能够较好地模仿给定风格时。
跨领域应用:
- 探索ChatGPT在学术写作、新闻报道、创意写作等不同领域的应用,并评估其对各个领域带来的影响。
模型训练和优化:
- 研究不同的训练方法和数据集对ChatGPT性能的影响,以及如何优化模型以更好地处理复杂的语言结构和风格变化。
伦理和社会影响:
- 探讨ChatGPT等LLMs在社会中的广泛应用可能带来的伦理问题,包括但不限于信息真实性、版权、学术诚信等。
用户交互和反馈:
- 研究用户如何与ChatGPT交互,以及用户的反馈如何被用来进一步训练和改进模型。
多模态应用:
- 考虑将ChatGPT与其他类型的AI模型(如视觉识别模型)结合,探索多模态应用的可能性。
模型透明度和可解释性:
- 提高模型的透明度和可解释性,帮助用户理解ChatGPT生成文本的原理和过程。
对抗性攻击和模型鲁棒性:
- 研究对抗性攻击对ChatGPT的影响,并探索提高模型鲁棒性的方法。
这些探索点可以帮助研究人员和开发者更好地理解ChatGPT的能力与局限,并指导未来的研究方向。
Q: 总结一下论文的主要内容
A: 论文的主要内容概括如下:
研究背景:
- 论文探讨了基于大型语言模型(LLMs)的生成性人工智能(AI),特别是ChatGPT,在自动生成消息响应用户请求方面的应用。这种技术进步带来了新的写作助手,但也伴随着一些担忧。
研究目的:
- 主要目的是分析ChatGPT的写作风格,通过将其生成的消息与法国近期总统的写作风格进行比较。
方法论:
- 通过比较ChatGPT生成的年终讲话与法国总统Chirac、Sarkozy、Hollande和Macron的实际讲话,研究者们分析了ChatGPT在词性分布、词汇使用和句子长度等方面的特征。
主要发现:
- ChatGPT倾向于过度使用名词、所有格限定词和数字,同时较少使用动词、代词和副词,导致生成的演讲过于标准化。
- ChatGPT在模仿特定作者风格时存在困难,尤其是在处理复杂的语法结构和词汇选择时。
- ChatGPT生成的文本与真实总统演讲在文体特征上有明显差异,例如在句子长度分布上。
技术挑战:
- 论文还探讨了检测ChatGPT生成文本的可能性,并发现传统的文本检测方法(如互文距离)在检测ChatGPT生成文本时可能不再有效。
结论:
- 尽管ChatGPT在模仿人类写作时存在局限性,但在最佳条件下,它能够较好地复制给定模型文本的主要形式特征。然而,目前缺乏有效的计算机化工具来检测这些生成的文本。
未来方向:
- 论文提出了进一步研究的方向,包括探索其他语言、改进检测方法、以及评估ChatGPT在不同文本类型和领域中的应用。
总体而言,论文提供了对ChatGPT写作风格的深入分析,并探讨了检测其生成文本的挑战,为理解和评估大型语言模型生成的文本提供了有价值的见解。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

GPT as ghostwriter at the White House
Authors:Jacques Savoy
Recently several large language models (LLMs) have demonstrated their capability to generate a message in response to a user request. Such scientific breakthroughs promote new perspectives but also some fears. The main focus of this study is to analyze the written style of one LLM called ChatGPT 3.5 by comparing its generated messages with those of the recent US presidents. To achieve this objective, we compare the State of the Union addresses written by Reagan to Obama with those automatically produced by ChatGPT. We found that ChatGPT tends to overuse the lemma “we” as well as nouns and commas. On the other hand, the generated speeches employ less verbs and include, in mean, longer sentences. Even when imposing a given style to ChatGPT, the resulting speech remains distinct from messages written by the target author. Moreover, ChatGPT opts for a neutral tone with mainly positive emotional expressions and symbolic terms (e.g., freedom, nation). Finally, we show that the GPT’s style exposes distinct features compared to real presidential addresses.
最近,几种大型语言模型(LLM)展示了它们根据用户需求生成消息的能力。这样的科学突破促进了新的观点,但也引发了一些担忧。本研究的主要焦点是通过将ChatGPT 3.5这种LLM生成的消息与最近的美国总统的演讲进行比较,来分析其书面风格。为了实现这一目标,我们将里根到奥巴马发表的国情咨文与ChatGPT自动生成的文本进行了比较。我们发现ChatGPT倾向于过度使用“我们”这个词以及名词和逗号。另一方面,生成的演讲使用的动词较少,平均句子较长。即使给ChatGPT设定特定的风格,其生成的演讲仍然与目标作者所写的消息有所不同。此外,ChatGPT选择了一种中立的语气,主要使用积极的情感表达和象征性术语(例如自由、国家)。最后,我们证明了GPT的风格与真实的总统演讲相比具有显著不同的特征。
论文及项目相关链接
Summary:
本研究主要分析了名为ChatGPT 3.5的大型语言模型(LLM)的书面风格,通过将其生成的对话与美国历任总统的国情咨文进行对比发现,ChatGPT倾向于过度使用“我们”、“名词”和逗号,同时生成的语句动词使用较少、句子更长。即使给定特定风格,ChatGPT的输出仍与目标作者的文章存在显著差异。此外,ChatGPT的语调中性,主要表达正面情感和象征性术语(如自由、国家)。总的来说,GPT的风格展现了其独特的特点,与真实的总统演讲存在明显差异。
Key Takeaways:
- ChatGPT 3.5大型语言模型的书体风格被分析。
- 与历任美国总统的国情咨文相比,发现ChatGPT的语言模式存在差异。
- ChatGPT过度使用某些词汇和语法结构,如“我们”、“名词”和逗号。
- ChatGPT生成的语句动词使用较少,句子更长。
- 即使给定特定风格,ChatGPT的输出仍具有独特性。
- ChatGPT的语调中性,主要表达正面情感和象征性术语。
- GPT的风格与真实的总统演讲存在显著差异。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文的主要目标是分析和比较一个名为ChatGPT 3.5的大型语言模型(LLM)生成的消息与最近几任美国总统所写的State of the Union(国情咨文)演说之间的写作风格差异。具体来说,论文试图回答以下几个问题:
ChatGPT能否生成与美国总统风格相符的政治演讲?
- 论文通过让ChatGPT根据里根(Reagan)的风格写一篇State of the Union演讲,并探讨我们是否能够区分生成的演讲和真实的演讲。
ChatGPT生成的演讲与真实演讲在风格上有何不同?
- 通过分析ChatGPT生成的演讲与真实演讲的文体特征,论文试图找出两者之间的差异。
ChatGPT是否能根据不同的美国总统生成不同风格的演讲?
- 论文探讨ChatGPT是否能够根据生成消息的不同美国总统展现出独特的风格,或者是否保持一种单一的风格。
ChatGPT的风格与真实总统演讲的风格相比有何独特之处?
- 论文通过比较ChatGPT的风格特征与真实总统演讲的风格特征,揭示了ChatGPT的独特风格。
总的来说,这篇论文试图通过比较ChatGPT生成的演讲和真实美国总统的演讲,来评估ChatGPT在模仿特定作者风格方面的能力,并识别出两者在写作风格上的主要差异。
Q: 有哪些相关研究?
A: 论文中提到的相关研究包括以下几个方面:
大型语言模型(LLMs)的应用:
- 论文提到了基于大型语言模型(如OpenAI的GPT、Meta的Llama、Google的Bard等)的应用,这些模型能够进行对话、自动翻译、解决数学问题、生成音乐、编写简单应用程序和生成图像等。
文体学(Stylometry)的应用:
- 文体学领域覆盖了作者归属、作者画像、抄袭检测和伪造文件检测等多个方面。论文特别提到了Savoy (2020)的研究,关于作者归属和文体学分析。
深度学习和变换器(Transformers)架构:
- 论文引用了Goodfellow et al. (2016)关于深度学习架构的工作,特别是基于变换器和注意力机制的序列模型(Vaswami et al. 2017)。
检测GPT-3生成文本的研究:
- 论文提到了Guo et al. (2023)的研究,该研究探讨了如何区分GPT-3生成的答案和人类写的答案,以及Antoun et al. (2023)关于非英语目标语言的研究。
自动检测机器人生成推文的研究:
- 论文引用了CLEF-PAN 2019国际评估活动,该活动评估了不同系统自动检测推文是由机器人还是人类生成的有效性。
个人代词使用与作者风格和心理特征的研究:
- 论文提到了Pennebaker (2011)的研究,该研究分析了个人代词的相对频率,揭示了作者的风格和心理特征。
基于LIWC(Linguistic Inquiry & Word Count)系统的文本分析:
- 论文引用了Tausczik & Pennebaker (2010)的研究,该研究使用LIWC系统将表达式组织在句法、情感或心理类别下。
这些相关研究为论文提供了理论基础和方法论支持,帮助作者分析和比较ChatGPT生成的政治演讲与真实美国总统演讲之间的风格差异。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决分析ChatGPT生成的政治演讲与真实美国总统演讲风格差异的问题:
数据收集:
- 作者要求ChatGPT为四位美国总统(里根、克林顿、布什和奥巴马)生成国情咨文演讲,并收集了这六位总统实际的国情咨文演讲作为比较数据集。
统计分析:
- 利用统计方法(例如比例检验和t检验)来比较ChatGPT生成的演讲和真实演讲中词汇、句子长度、词性分布等方面的差异。
文体测量:
- 计算平均词长、大词比例(BW)、型-符比(TTR)和平均句长(MSL)等文体学特征,以评估语言复杂性和词汇丰富度。
词性分布分析:
- 分析不同总统演讲和ChatGPT生成演讲中词性标签的分布差异,以揭示作者风格上的特点。
特征词汇分析:
- 使用Muller (1992)的方法确定每位总统特有的高频词汇,并比较ChatGPT生成的演讲与真实演讲中的特征词汇差异。
修辞和主题分析:
- 通过将语义相关的词汇归类到特定的标签下(例如“象征性”、“坚定性”、“指责”、“人类”和“成就”等),分析不同总统和ChatGPT生成演讲中的修辞和主题差异。
互文距离计算:
- 使用Labbé (2007)提出的互文距离方法,基于整个词汇表计算文本间的相似度,以评估ChatGPT生成的演讲与真实演讲之间的整体差异。
结果解释和讨论:
- 根据上述分析结果,讨论ChatGPT生成的演讲与真实演讲之间的相似之处和不同之处,并对未来的发展方向提出建议。
通过这些步骤,论文全面地分析了ChatGPT生成的政治演讲与真实美国总统演讲之间的风格差异,并得出了有价值的结论。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
比较最频繁使用的词汇(Lemmas):
- 通过比较ChatGPT生成的演讲和真实总统演讲中最常使用的词汇(lemmas),来识别两者在常用词汇上的相似性和差异。
个人代词使用频率分析:
- 分析ChatGPT和美国总统在演讲中个人代词的使用频率,以揭示作者风格和心理特征。
文体学测量:
- 计算平均词长、大词比例(BW)、型-符比(TTR)和平均句长(MSL)等文体学指标,比较ChatGPT生成文本和真实演讲的文体特征。
词性(Part-of-Speech, POS)分布分析:
- 比较ChatGPT生成的演讲和真实总统演讲中不同词性标签的分布,以揭示作者风格上的特点。
特征词汇分析:
- 确定每位总统特有的高频词汇,并比较ChatGPT生成的演讲与真实演讲中的特征词汇差异。
修辞和主题分析:
- 使用特定的词表来分析不同总统和ChatGPT生成演讲中的修辞和主题差异,包括情感内容、政治实体引用、坚定性、傲慢或人类关系等。
互文距离计算:
- 计算ChatGPT生成的演讲与真实总统演讲之间的互文距离,以评估两者之间的整体相似度和差异。
基于词汇的文本相似性分析:
- 使用基于词汇的相似性度量,评估ChatGPT生成的演讲与特定总统风格之间的接近程度。
这些实验通过定量分析方法,提供了对ChatGPT生成文本与真实总统演讲之间风格差异的深入理解。通过这些实验,论文旨在揭示ChatGPT在模仿特定作者风格方面的能力,并识别出两者在写作风格上的主要差异。
Q: 有什么可以进一步探索的点?
A: 尽管论文提供了对ChatGPT生成的政治演讲与真实美国总统演讲风格差异的深入分析,但仍有一些领域可以进一步探索:
更广泛的数据集:
- 扩展数据集以包括更多总统的演讲,甚至其他国家领导人的演讲,以更全面地评估ChatGPT在不同风格和文化背景下的表现。
上下文和领域适应性:
- 研究ChatGPT在特定政治事件或危机时期生成演讲的能力,以及它如何适应不同的政治和社会背景。
交互式和迭代生成:
- 开发方法使ChatGPT能够根据用户的反馈进行迭代,以生成更符合特定风格或内容要求的文本。
细粒度的文体特征分析:
- 对比分析更细粒度的文体特征,如语调、情感色彩、隐喻使用等,以更深入地理解ChatGPT生成文本与真实演讲之间的差异。
模型透明度和可解释性:
- 提高ChatGPT生成过程的透明度和可解释性,以便更好地理解其决策过程和生成策略。
错误分析和事实核查:
- 系统地分析ChatGPT生成的演讲中的错误和不准确信息,以及如何集成事实核查机制来提高生成内容的准确性。
多模态和跨媒体分析:
- 探索ChatGPT在生成包含文本、图像和其他媒体类型(如视频)的综合内容方面的能力。
伦理和社会影响:
- 研究ChatGPT生成的政治演讲可能对社会、政治和伦理方面产生的影响,特别是在信息传播和公众舆论形成方面。
对抗性攻击和防御机制:
- 研究对抗性攻击对ChatGPT生成文本的影响,并开发防御机制以提高其鲁棒性。
跨语言和文化适应性:
- 评估ChatGPT在不同语言和文化背景下生成文本的能力,以及如何调整模型以更好地适应不同语言和文化环境。
这些进一步探索的点可以帮助我们更全面地理解ChatGPT的能力和局限性,并指导未来研究和应用的发展。
Q: 总结一下论文的主要内容
A: 论文《GPT as ghostwriter at the White House: Compared with four US presidents, what are the differences between State of the Union addresses written by GPT and the true presidents》主要研究了大型语言模型(LLM)ChatGPT 3.5生成的政治演讲与真实美国总统的国情咨文(State of the Union addresses)之间的差异。以下是论文的主要内容总结:
研究目的:
- 分析ChatGPT生成的消息与美国总统的写作风格差异。
- 比较ChatGPT生成的国情咨文与里根至奥巴马四位总统的真实演讲。
方法论:
- 使用统计和文体学方法比较两组文本。
- 计算了词频、词性分布、文体特征(如平均词长、大词比例、型-符比、平均句长)。
- 分析了个人代词使用频率、特征词汇、修辞和主题。
主要发现:
- ChatGPT倾向于过度使用“我们”这一词元,以及名词和逗号。
- 生成的演讲使用较少的动词,并且包含更长的句子。
- 即使在给定特定风格的情况下,ChatGPT生成的演讲与目标作者的消息仍有明显区别。
- ChatGPT偏好中性语气,主要使用积极的情绵表达和象征性词汇(如自由、国家)。
实验:
- 对比了ChatGPT和真实总统演讲中最常使用的词汇。
- 分析了个人代词的使用,发现ChatGPT避免使用个人代词,除了过度使用的“我们”。
- 评估了语言复杂性,发现ChatGPT生成的文本复杂度更高。
- 通过互文距离评估了ChatGPT生成的演讲与真实演讲之间的相似度。
结论:
- ChatGPT能够生成与真实国情咨文有一定相似性的政治演讲。
- 然而,ChatGPT的风格与真实总统演讲存在明显区别,特别是在句子长度、词汇复杂性和个人代词的使用上。
- ChatGPT的风格被描述为说教性和中性,缺乏特定时间和空间的锚定,避免了可能引起分歧的论点。
未来方向:
- 论文提出了对ChatGPT进行进一步研究的建议,包括改进模型以包含更多的人称代词、名称和地理锚点,使其生成的演讲更接近真实的总统演讲。
论文通过这些分析,提供了对ChatGPT在模仿特定作者风格方面能力的新见解,并揭示了其在生成政治演讲方面的潜力和局限性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

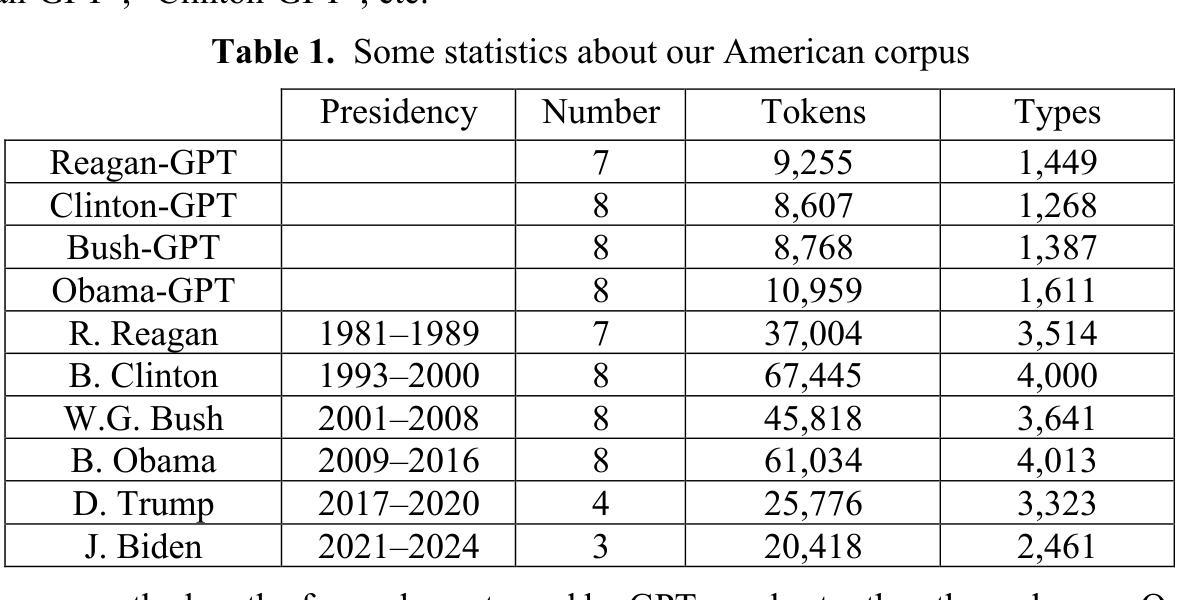
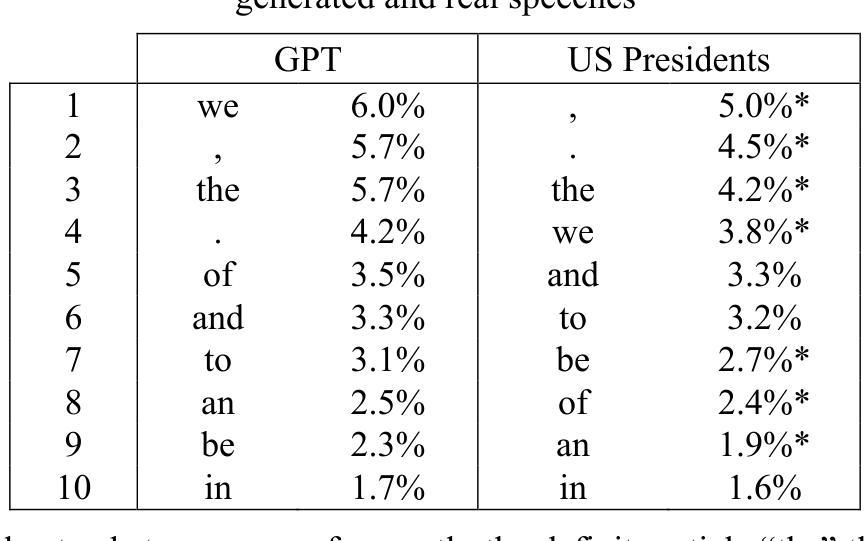
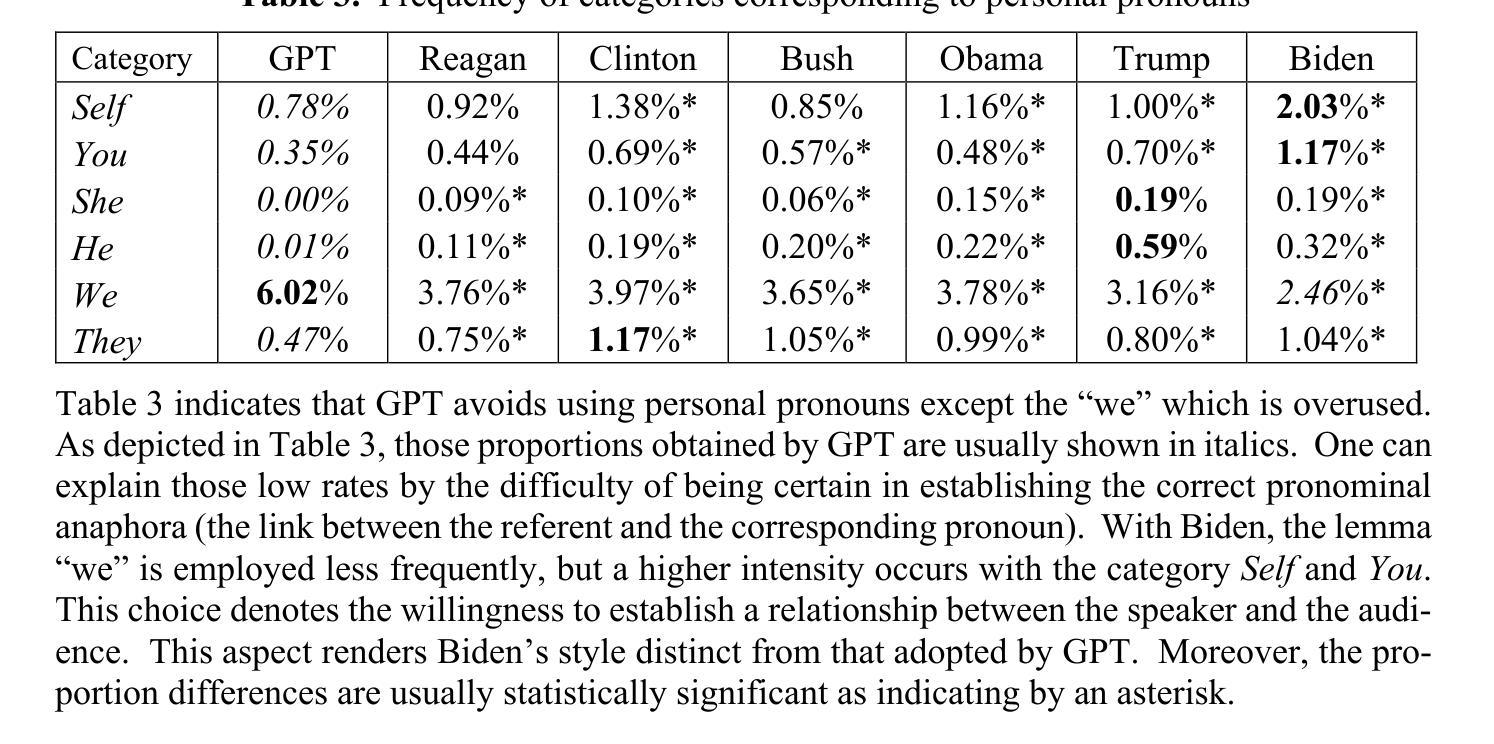
“Give me the code” – Log Analysis of First-Year CS Students’ Interactions With GPT
Authors:Pedro Alves, Bruno Pereira Cipriano
The impact of Large Language Models (LLMs) like GPT-3, GPT-4, and Bard in computer science (CS) education is expected to be profound. Students now have the power to generate code solutions for a wide array of programming assignments. For first-year students, this may be particularly problematic since the foundational skills are still in development and an over-reliance on generative AI tools can hinder their ability to grasp essential programming concepts. This paper analyzes the prompts used by 69 freshmen undergraduate students to solve a certain programming problem within a project assignment, without giving them prior prompt training. We also present the rules of the exercise that motivated the prompts, designed to foster critical thinking skills during the interaction. Despite using unsophisticated prompting techniques, our findings suggest that the majority of students successfully leveraged GPT, incorporating the suggested solutions into their projects. Additionally, half of the students demonstrated the ability to exercise judgment in selecting from multiple GPT-generated solutions, showcasing the development of their critical thinking skills in evaluating AI-generated code.
大型语言模型(如GPT-3、GPT-4和Bard)在计算机科学(CS)教育中的影响预计将是深远的。学生现在有能力生成各种编程作业的代码解决方案。对于一年级学生来说,这可能会特别成问题,因为基础技能仍在发展中,过度依赖生成式人工智能工具可能会阻碍他们掌握基本编程概念的能力。本文分析了69名大一本科生在解决一个特定编程问题时的提示,这个问题是作为项目作业提出的,并没有对他们进行事先的提示训练。我们还介绍了促进提示的练习规则,旨在在互动中培养批判性思维能力。尽管使用了不成熟的提示技术,但我们的研究结果表明,大多数学生成功地利用了GPT,并将建议的解决方案融入他们的项目中。此外,一半的学生展现出在多个GPT生成的解决方案中进行选择的能力,这证明了他们在评估AI生成的代码方面批判性思维技能的发展。
论文及项目相关链接
PDF This is the author’s version of the work. It is posted here for your personal use. Not for redistribution
Summary
大型语言模型(LLM)如GPT-3、GPT-4和Bard对计算机科学(CS)教育产生了深远影响。学生现在可以利用这些模型生成各种编程作业的代码解决方案。对于一年级学生而言,过度依赖这些工具可能会阻碍他们掌握基础编程概念。本文分析了69名大一学生在未接受提示训练的情况下,如何利用GPT解决一个特定编程问题。研究发现,大多数学生成功利用了GPT,并能够在项目中融入解决方案。一半的学生在多个GPT生成的选择中展现出判断力,说明他们在评估AI生成的代码时,批判性思维能力得到了发展。
Key Takeaways
- 大型语言模型(LLM)对计算机科学教育有深远影响。
- 学生能够利用LLM生成编程作业的代码解决方案。
- 对于一年级学生,过度依赖这些工具可能阻碍掌握基础编程概念。
- 大多数大一学生在未接受提示训练的情况下成功利用GPT解决问题。
- 学生能够将GPT生成的解决方案融入项目。
- 一半的学生展现出在多个GPT生成的选择中的判断力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了大型语言模型(LLMs),如GPT-3、GPT-4和Bard,在计算机科学(CS)教育中的影响,尤其是对大一学生的影响。论文主要关注以下几个问题:
学生对LLMs的依赖性:鉴于LLMs能够为广泛的编程任务生成代码解决方案,大一学生由于基础技能仍在发展中,过度依赖这些生成性AI工具可能会妨碍他们掌握基本的编程概念。
学生与LLMs的互动:论文分析了69名大一本科生在没有事先提示训练的情况下,使用LLMs解决特定编程问题时所使用的提示(prompts)。
学生评估AI生成代码的能力:研究学生是否能够将ChatGPT提供的解决方案整合到他们的项目中,并评估他们批判性思维技能的发展,特别是在评估AI生成的代码方面。
教学方法的适应:探讨了计算机科学教师如何应对LLMs的挑战,包括适应教学方法、评估方式等。
LLMs在教育中的整合:提出了一个练习模板,教师可以用来培养学生在与基于LLMs的工具互动时的批判性思维技能。
学生对LLMs工具的看法:通过后续调查,了解学生对于使用LLMs工具的看法及其在项目中的实用性。
总结来说,这篇论文试图理解在没有直接教师监督的情况下,学生如何与LLMs互动,他们是否能够在项目中成功利用LLMs,以及教师如何帮助学生在这个过程中发展必要的技能。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与本研究相关的研究:
Denny et al., 2023b:分析了学生与ChatGPT之间的互动,包括提示长度和尝试次数等多个维度。该研究要求学生编写生成代码的提示,而不是自己编写代码。
Prather et al., 2023:研究了大一学生如何使用Copilot(基于GPT的代码生成工具,训练于GitHub上的公开代码)来解决初级编程课程中的典型作业,并发现这些新手学生难以理解和使用Copilot,并对工具的影响持谨慎态度,但对将来将其整合到他们的开发工作流程中持乐观态度。
Prasad et al., 2023:分析了学生在应用逻辑和形式方法的高阶课程中使用IDE插件与GPT互动的情况。
Babe et al., 2023a:要求80名仅学过一个学期编程的学生为48个问题编写提示,并发现学生的提示对LLMs来说可能是模糊的。
Kazemitabaar et al., 2023:分析了从编程训练营招募的10至17岁学习者的互动日志,并验证了Codex(基于GPT的LLM)对他们独立学习Python能力的影响。他们发现一些学习者自我调节的证据,有的学习者积极添加代码以测试AI生成的代码,也有的学习者过度依赖,有的学习者仅用一个提示提交作业指导。
这些研究与本论文的研究不同之处在于,它们都以初级编程练习为基础来分析学生与LLMs的互动,而本研究中的学生需要为一个大型项目(在大约3个月的时间内开发)的特定部分生成代码,这意味着GPT生成的代码需要与学生的其余代码集成,因此具有额外的复杂性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决提出的问题:
设计练习模板:提出了一个练习模板,旨在培养学生在使用基于LLMs的工具时的批判性思维技能。这个模板要求学生与LLMs互动以获得解决方案,并要求他们记录所有互动,以便进一步分析。
实验设计:在数据结构和算法(DSA)课程的范围内进行了这项研究,要求学生在项目中使用ChatGPT来辅助读取和解析包含艺术家信息的大型CSV文件。项目分为两部分,第一部分主要涉及输入文件的读取和解析,第二部分则关注不同查询的实现。
日志文件分析:分析了69名大一计算机科学学生与ChatGPT互动产生的日志文件,这些日志文件记录了他们尝试解决特定练习的尝试。分析基于学生遵循的练习模板步骤:提出问题、请求替代解决方案,并得出结论。
调查问卷:在任务完成后对52名学生进行了简短的调查,以了解他们对任务的看法,特别是关于ChatGPT任务的实用性。
结果分析:对日志文件的定量和定性分析结果进行了评估,以回答研究问题。分析了学生提出的问题的抽象水平、性质(通用或特定于项目的)、初始提示的语言、类型、提供的上下文、限制、示例和函数签名等。
发现和建议:基于实验结果,论文提出了一些建议,包括将提示培训整合到课程中,鼓励学生在项目中使用LLMs作为解决复杂问题的工具,并使用练习模板来指导学生以批判性思维的方式接近LLMs。
讨论局限性:论文讨论了由于GPT行为的非确定性和动态变化导致的局限性,这使得很难泛化结论。
结论:论文得出结论,所提出的练习模板在促进学生与LLMs互动时的批判性思维方面取得了一定的成功,大多数学生能够有效地使用GPT,尽管他们的提示技巧有限。调查还表明,大多数学生认为这项任务是有用的,这表明在没有直接教师监督的情况下,学生能够成功地利用LLMs。
通过这些步骤,论文旨在评估和理解学生如何与LLMs互动,以及他们是否能够在没有正式培训的情况下成功地利用这些工具来解决编程问题。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要集中在分析大一计算机科学学生与ChatGPT互动的情况,以解决特定的编程问题。以下是实验的具体步骤和内容:
实验环境设置:
- 实验在数据结构和算法(DSA)课程中进行,该课程是计算机工程学位的一部分。
- 学生需要开发一个项目,通常是命令行应用程序,用于处理大型数据集(以多个CSV文件形式提供)的查询。
ChatGPT任务分配:
- 作为项目第一部分,学生被指示使用ChatGPT辅助读取和解析包含艺术家信息的大型CSV文件。
- 学生需要处理不同的挑战,例如处理单艺术家歌曲和多艺术家歌曲的不同格式、处理同一歌曲关联的不同行的多个艺术家、处理无效行等。
- 学生使用自动化评估工具(AAT)验证代码,可以多次提交,并获得多个单元测试的执行结果。
日志文件记录:
- 学生遵循提供的练习模板,与ChatGPT的所有互动都被记录在日志文件中。
- 日志文件包括学生提出的问题、请求的替代解决方案,以及最终选择的解决方案和选择的理由。
日志文件分析:
- 研究人员手动分析了37组学生提交的日志文件,这些文件详细记录了他们与ChatGPT的互动。
- 分析包括对问题、初始提示、第二次提示和结论的分类。
学生调查:
- 在任务完成后,对52名学生进行了问卷调查,以了解他们对ChatGPT任务的看法,特别是任务的实用性。
结果评估:
- 通过日志文件分析和调查结果,评估学生与ChatGPT互动的有效性,以及他们是否能够将ChatGPT提供的解决方案整合到他们的项目中。
这些实验步骤旨在评估学生在没有正式培训的情况下使用LLMs进行代码生成的能力,并探索他们如何评估和选择AI生成的代码解决方案。通过这些实验,研究人员能够收集有关学生使用LLMs的实际情况的数据,并对他们的批判性思维技能进行评估。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和研究结果,以下是一些可以进一步探索的点:
提高学生与LLMs互动的技能:
- 开发和评估专门针对提升学生与LLMs互动技能的培训课程,包括如何构建有效的提示(prompts)和评估AI生成的代码。
教学方法的改进:
- 研究和开发更多整合LLMs到计算机科学课程中的创新教学方法,以及这些方法对学生学习成效的影响。
评估LLMs在不同教育阶段的效果:
- 将研究扩展到不同教育阶段(如中级和高级课程),以了解LLMs在不同学习阶段的影响和效果。
LLMs在伦理和学术诚信中的角色:
- 探讨LLMs在学术环境中的伦理问题,特别是关于学术诚信和知识产权的问题。
LLMs对编程思维和问题解决能力的影响:
- 研究LLMs是否改变了学生对编程思维和问题解决能力的发展,以及如何平衡使用LLMs和培养独立编程能力。
LLMs的可访问性和公平性问题:
- 探讨LLMs工具的可访问性问题,以及它们可能对不同背景学生的影响,确保技术资源的公平分配。
LLMs的长期学习效果:
- 进行纵向研究,以评估学生长期使用LLMs对其编程技能和知识掌握的长期影响。
跨学科研究:
- 与其他学科(如教育学、心理学)合作,从多学科角度研究LLMs在教育中的应用和效果。
技术发展对LLMs性能的影响:
- 随着LLMs技术的快速发展,持续评估新版本模型的性能变化,以及这些变化对教育实践的影响。
LLMs在专业软件开发中的应用:
- 研究LLMs在专业软件开发中的使用情况,以及它们如何影响软件开发实践和职业发展。
这些探索点可以帮助教育工作者和研究人员更深入地理解LLMs在教育中的作用,并为未来的教学实践提供指导。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容集中在分析大一计算机科学学生如何与大型语言模型(LLMs)如ChatGPT互动来解决编程问题。以下是主要内容的总结:
背景与动机:
- LLMs如GPT-3、GPT-4和Bard对计算机科学教育的影响深远,特别是在学生能够利用这些工具生成编程作业的代码解决方案的情况下。
- 对于基础技能仍在发展的大一学生来说,过度依赖这些工具可能会妨碍他们掌握基本的编程概念。
研究问题:
- 研究大一学生是否能够在没有特定或正式训练的情况下利用LLMs进行代码生成。
- 探究学生是否能够将ChatGPT提供的解决方案整合到他们的项目中。
方法论:
- 设计了一个练习模板,要求学生与LLMs互动以获得解决方案,记录所有互动,并要求他们选择最佳解决方案。
- 在数据结构和算法课程中,学生被要求使用ChatGPT辅助读取和解析CSV文件,并将互动记录在日志文件中。
实验与分析:
- 分析了69名大一学生的日志文件,这些文件记录了他们如何使用ChatGPT解决特定编程问题。
- 通过日志文件分析和后续调查,评估学生对ChatGPT任务的看法和实用性。
结果:
- 发现大多数学生能够成功利用ChatGPT,即使他们使用的提示技术不够成熟。
- 一半的学生展示了从多个ChatGPT生成的解决方案中选择的能力,表现出批判性思维技能的发展。
- 72.2%的学生将ChatGPT的解决方案整合到了他们的项目中。
结论与建议:
- 提出的练习模板在促进学生批判性思维方面取得了一定的成功。
- 需要进一步培训学生以提高他们与LLMs互动的技能,并意识到这些工具的局限性。
- 强调了在专业生活中准备学生以更好地利用这些工具的重要性。
局限性:
- GPT的行为是非确定性的,并且会随时间变化,这使得很难泛化结论。
未来研究方向:
- 提出了进一步探索的点,包括提高学生与LLMs互动的技能、教学方法的改进、LLMs在不同教育阶段的效果等。
这篇论文提供了对LLMs在计算机科学教育中应用的初步理解,并为未来的教学实践和研究提供了见解。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



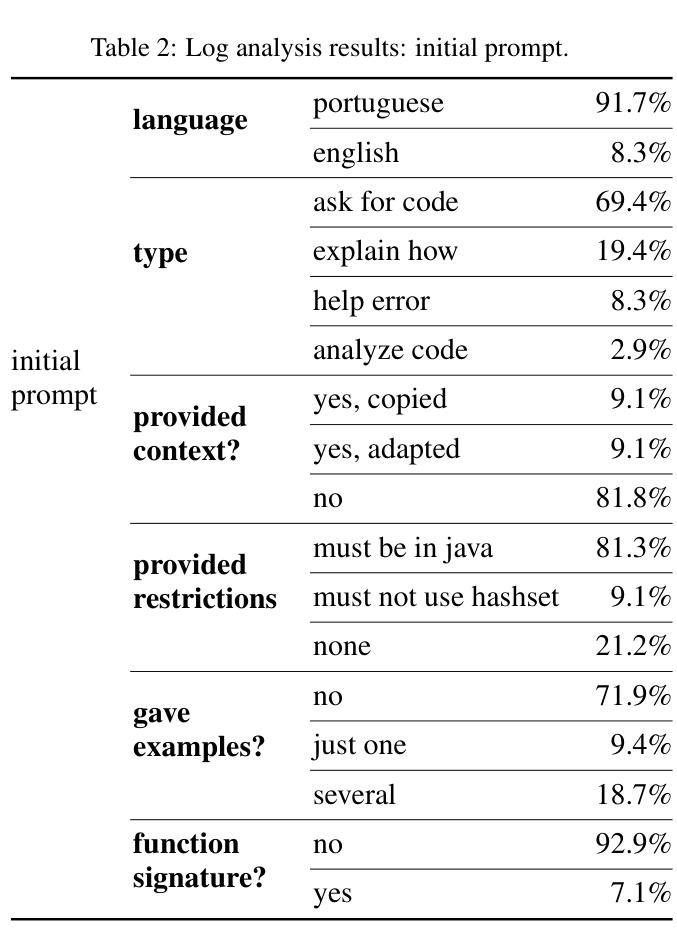

MarketGPT: Developing a Pre-trained transformer (GPT) for Modeling Financial Time Series
Authors:Aaron Wheeler, Jeffrey D. Varner
This work presents a generative pre-trained transformer (GPT) designed for modeling financial time series. The GPT functions as an order generation engine within a discrete event simulator, enabling realistic replication of limit order book dynamics. Our model leverages recent advancements in large language models to produce long sequences of order messages in a steaming manner. Our results demonstrate that the model successfully reproduces key features of order flow data, even when the initial order flow prompt is no longer present within the model’s context window. Moreover, evaluations reveal that the model captures several statistical properties, or ‘stylized facts’, characteristic of real financial markets and broader macro-scale data distributions. Collectively, this work marks a significant step toward creating high-fidelity, interactive market simulations.
本文介绍了一种针对金融时间序列建模的生成式预训练转换器(GPT)。GPT在离散事件模拟器内作为订单生成引擎运行,能够真实地复制限价订单簿的动力学。我们的模型利用大型语言模型的最新进展,以流式方式生成长序列的订单消息。结果表明,即使在模型的上下文窗口中没有最初的订单流提示时,该模型仍能成功再现订单流数据的关键特征。此外,评估表明,该模型捕捉到了许多与真实市场和宏观数据分布特征相一致的统计特征或“典型事实”。总之,这项工作在创建高保真、交互式市场模拟方面迈出了重要的一步。
论文及项目相关链接
PDF 13 pages, 8 figures
Summary
金融时间序列建模的生成预训练变压器(GPT)介绍。GPT作为离散事件模拟器内的订单生成引擎,能真实复制限价订单簿动态。模型利用大型语言模型的最新进展,以流式方式生成长订单消息序列。即使模型上下文窗口中没有初始订单流提示,模型仍能成功重现订单流数据的关键特征。评估显示,该模型能够捕捉真实市场特性和宏观数据分布的统计属性。本研究标志着创建高保真、交互式市场模拟的重要一步。
Key Takeaways
- GPT模型用于金融时间序列建模,可模拟限价订单簿动态。
- 模型基于大型语言模型的最新进展,能生成流式订单消息。
- 模型成功重现订单流数据的关键特征,即使在没有初始订单流提示的情况下。
- 评估表明,该模型能捕捉真实市场的统计特性和宏观数据分布。
- 模型在创建高保真市场模拟方面迈出重要一步。
- 该模型具有广泛的应用前景,可用于金融分析和风险管理等领域。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何利用深度学习和大型语言模型(LLMs)来生成和模拟金融市场中的订单流(order flow)。具体来说,论文提出了一个基于预训练的变换器(GPT)模型,用于模拟金融时间序列,特别是限价订单簿(Limit Order Book, LOB)的动态。这个模型旨在通过生成一系列订单消息来复制真实市场中的关键特征,即使在模型的上下文窗口中不再存在初始订单流提示时也能成功地再现这些特征。此外,该模型还旨在捕捉金融市场统计特性,即所谓的“风格化事实”(stylized facts),并为金融市场研究和应用(如压力测试交易策略和预先评估市场立法)提供高保真度、交互式的市场模拟。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与该研究相关的工作:
传统金融时间序列建模方法:
- 论文提到了传统的金融时间序列数据建模方法,如ARIMA模型、GARCH模型和向量自回归模型(VAR),这些方法通常采用自上而下的方法直接拟合时间序列数据(如价格和交易量数据)。
- 相关文献包括:
- Harvey AC (1990) ARIMA models.
- Engle R (2001) GARCH 101: The use of ARCH/GARCH models in applied econometrics.
- Stock JH, Watson MW (2001) Vector autoregressions.
基于机器学习的时间序列生成方法:
- 论文提到了使用生成对抗网络(GANs)来直接生成时间序列数据的方法。
- 相关文献包括:
- Goodfellow IJ, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, et al. (2014) Generative adversarial nets.
基于代理的模型(Agent-based models):
- 论文提到了一些包含市场微观结构特征(如限价订单簿)和不同复杂度代理行为的代理模型,这些模型成功地再现了金融市场的某些统计特性。
- 相关文献包括:
- Byrd D, Hybinette M, Balch TH (2020) Abides: Towards high-fidelity multi-agent market simulation.
自回归生成模型用于金融市场微观结构模拟:
- 论文提到了最近使用自回归生成模型进行金融市场微观结构模拟的工作。
- 相关文献包括:
- Hultin H, Hult H, Proutiere A, Samama S, Tarighati A (2023) A generative model of a limit order book using recurrent neural networks.
基于Transformer的模型:
- 论文中提到了基于Transformer架构的模型,这是现代大型语言模型(LLMs)的基础。
- 相关文献包括:
- Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, et al. (2017) Attention is all you need.
其他相关技术:
- 论文还提到了一些技术,如Byte Pair Encoding (BPE)算法用于减少表示消息所需的标记数量,以及不同的采样技术,如截断、温度缩放和核采样。
这些相关研究为本文提出的模型提供了理论基础和技术背景,同时也展示了该领域的研究进展和挑战。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决模拟金融时间序列的问题:
数据准备:
- 使用历史纳斯达克TotalView-ITCH 5.0消息数据训练模型,这些数据提供了在纳斯达克交易的证券的每个报价和订单的详细信息。
- 数据被分割为训练、验证和测试集,并排除了所有非交易时段的消息。
消息重构和预处理:
- 根据ITCH 5.0协议重构消息,并进行预处理,包括将价格字段从美元价值转换为相对于前一个中间价格的tick数,并添加消息之间的到达时间作为特征。
标记化(Tokenization):
- 将预处理后的消息转换为模型可以理解的实数值,建立一个有限的工作词汇表,以便模型可以从中预测下一个可能的标记。
基于Transformer的世界代理模型:
- 使用Transformer架构,这是现代大型语言模型(LLMs)的基石,来建模世界代理。
- 训练模型自回归地预测序列中的下一个标记,通过最小化训练数据批次上的交叉熵损失来优化模型参数。
处理长序列输入:
- 为了处理超出预训练上下文长度的输入,论文采用了注意力汇(attention sinks)和滚动KV缓存(rolling KV cache)技术,以有效处理消息流。
离散事件模拟器(DES):
- 构建了一个基于ABIDES模拟器框架的DES,该框架可以动态生成消息并构建LOB状态。
- 模拟器至少包括两个代理:基于Transformer的世界代理和接收订单消息并更新订单簿的交易所代理。
结果评估:
- 通过比较生成的消息和目标分布(未见过的测试数据—真实的历史消息),评估模型的输出。
- 评估模型是否能够再现消息级别的几个众所周知的统计规律,并评估结果价格和交易量轨迹的预测潜力。
模型限制和未来工作:
- 论文讨论了模型的局限性,包括推理时间较长、采样参数难以调整等问题,并提出了未来可能的研究方向,如探索多资产消息生成、增加数据源等。
通过这些步骤,论文成功地展示了一个能够生成真实订单流数据的模型,该数据捕获了金融市场的复杂和非线性特性,并且能够在没有明确包含这些属性的情况下再现许多风格化事实。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估模型的性能和准确性,具体实验包括:
模拟订单流(Simulated Order Flow):
- 对比模型生成的订单类型频率与实际数据,检查模型是否能够准确预测不同类型的订单消息。
- 分析模型生成的订单间隔时间与实际数据的一致性,包括对不同订单类型的间隔时间进行比较。
- 评估模型生成的订单大小分布与实际数据的相似性,并比较不同订单类型。
限价订单簿(LOB)模拟器性能:
- 检查模型在模拟最佳买卖价位层面的成交量和价差(spread)的表现。
- 分析模型在复制LOB流动性方面的能力,包括成交量和价差。
模拟回报特性(Simulated Properties of Returns):
- 检验模型生成的价格回报分布是否具有实际市场中的重尾特性。
- 分析模型生成的回报序列是否展现出波动率聚集和长程依赖性。
- 使用去趋势波动分析(DFA)和重缩放范围(R/S)分析来量化波动率聚集和长程依赖性。
模型预测能力(Predictive Properties of the Model):
- 评估模型生成的即时和未来消息的回报分布,检查模型是否能够生成与实际数据相似的回报轨迹。
- 比较模型生成的价格和交易量轨迹与实际数据,验证模型的预测能力。
模型限制(Model Limitations):
- 讨论了模型的局限性,包括推理时间较长、采样参数难以调整等问题,并提出了未来可能的研究方向。
这些实验旨在全面评估模型在模拟金融市场订单流方面的能力,包括其对市场微观结构的捕捉能力、统计特性的再现能力,以及潜在的预测能力。通过这些实验,研究者能够验证模型的有效性,并识别模型在实际应用中可能面临的挑战。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
多资产消息生成:
- 探索模型是否能够扩展到同时处理多种资产的消息生成,并研究这会对模型性能和计算成本产生何种影响。
增加数据源:
- 考虑将新闻事件、宏观经济数据等其他信息作为输入,以提高模型对价格动态的预测能力。
改进参数选择程序:
- 开发更稳健的参数选择程序,以优化模型的采样参数,并减少对试错方法的依赖。
模型和数据集扩展:
- 通过增加模型大小和数据集规模来提高模型的性能,尤其是在处理更长的时间序列时。
探索不同的模型架构:
- 研究其他模型架构,如循环架构或混合循环架构,以提高模型在长程任务上的表现。
市场影响研究:
- 进行市场影响研究,以确定模型是否可用于最优执行等金融应用。
更多统计规律的测试:
- 测试模型是否能够再现订单寿命的幂律行为、日内季节性等更多的统计规律。
硬件和计算效率的优化:
- 探索更先进的硬件或模型压缩技术,以降低模型的推理时间和计算成本。
模型解释性和透明度:
- 提高模型的解释性,以便更好地理解其决策过程,并增强用户对模拟结果的信任。
跨市场和跨资产的适用性:
- 测试模型在不同市场和资产类型中的适用性,以评估其泛化能力。
实时模拟和交易策略测试:
- 将模型应用于实时市场模拟,以及用于测试和评估交易策略。
模型鲁棒性的测试:
- 在各种市场条件下测试模型的鲁棒性,包括极端市场事件。
这些探索点可以帮助研究者进一步提升模型的性能,扩展其应用范围,并更好地理解金融市场的复杂性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
研究目标:
- 开发一个基于预训练变换器(GPT)的模型,用于模拟金融时间序列,特别是限价订单簿(LOB)的动态。
方法论:
- 利用历史纳斯达克ITCH 5.0消息数据训练模型,重构并预处理数据以适应深度学习任务。
- 采用标记化(Tokenization)方案将消息特征编码为模型可理解的实数值。
- 基于Transformer架构设计世界代理模型,通过自回归方式预测序列中的下一个标记。
实验设计:
- 评估模型生成的订单流数据与实际数据的一致性,包括订单类型、订单间隔、订单大小等统计特性。
- 分析模型在模拟LOB流动性和价格回报分布方面的表现。
- 测试模型是否能够再现金融市场的重尾特性、波动率聚集和长程依赖性等统计规律。
实验结果:
- 模型成功复制了订单流数据的多个关键特征,包括订单类型的分布、订单大小和到达时间间隔。
- 模型能够生成具有重尾特性和波动率聚集特性的价格回报序列。
- 尽管模型主要基于消息数据训练,它仍然能够产生逼真的价格和交易量轨迹。
模型限制与未来工作:
- 论文讨论了模型的局限性,包括高推理时间、采样参数调整困难等问题。
- 提出了未来可能的研究方向,如多资产消息生成、增加数据源、改进模型架构等。
结论:
- 论文开发的模型能够产生逼真的订单流数据,并在没有明确包含这些属性的情况下再现金融市场的多个风格化事实。
- 该研究为开发更现实和数据驱动的市场模拟器迈出了一步,这些模拟器可以用于金融及其他领域的多种应用。
总体而言,这篇论文展示了利用深度学习和大型语言模型来模拟金融市场订单流的潜力,并指出了这一领域未来研究的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

BeeManc at the PLABA Track of TAC-2024: RoBERTa for task 1 – LLaMA3.1 and GPT-4o for task 2
Authors:Zhidong Ling, Zihao Li, Pablo Romero, Lifeng Han, Goran Nenadic
This report is the system description of the BeeManc team for shared task Plain Language Adaptation of Biomedical Abstracts (PLABA) 2024. This report contains two sections corresponding to the two sub-tasks in PLABA 2024. In task one, we applied fine-tuned ReBERTa-Base models to identify and classify the difficult terms, jargon and acronyms in the biomedical abstracts and reported the F1 score. Due to time constraints, we didn’t finish the replacement task. In task two, we leveraged Llamma3.1-70B-Instruct and GPT-4o with the one-shot prompts to complete the abstract adaptation and reported the scores in BLEU, SARI, BERTScore, LENS, and SALSA. From the official Evaluation from PLABA-2024 on Task 1A and 1B, our \textbf{much smaller fine-tuned RoBERTa-Base} model ranked 3rd and 2nd respectively on the two sub-task, and the \textbf{1st on averaged F1 scores across the two tasks} from 9 evaluated systems. Our LLaMA-3.1-70B-instructed model achieved the \textbf{highest Completeness} score for Task-2. We share our fine-tuned models and related resources at \url{https://github.com/HECTA-UoM/PLABA2024}
本报告是BeeManc团队针对共享任务“生物医学摘要的平适应改编(PLABA 2024)”的系统描述。本报告包含两个部分,对应于PLABA 2024的两个子任务。在任务一中,我们应用了经过微调的ReBERTa-Base模型来识别和分类生物医学摘要中的难词、术语和缩写词,并报告了F1分数。由于时间限制,我们未完成替换任务。在任务二中,我们利用Llamma3.1-70B-Instruct和GPT-4o及一次性提示完成摘要的适应,并以BLEU、SARI、BERTScore、LENS和SALSA等指标报告了分数。根据PLABA-2024官方对任务1A和1B的评价,我们较小的经过微调的RoBERTa-Base模型在两个子任务中分别排名第三和第二名,并且在两个任务的平均F1分数上排名第一,在9个评估系统中表现突出。我们的LLaMA-3.1-70B-instructed模型在任务2中获得了最高的完整性得分。我们在https://github.com/HECTA-UoM/PLABA2024分享了我们的微调模型和相关资源。
论文及项目相关链接
PDF ongoing work - system report
摘要
本文介绍了BeeManc团队在Plain Language Adaptation of Biomedical Abstracts (PLABA) 2024共享任务中的系统描述。报告分为两部分,分别对应PLABA 2024的两个子任务。任务一中,我们采用微调后的ReBERTa-Base模型识别并分类生物医学摘要中的难词、术语和缩写词,并报告了F1分数。任务二中,我们利用Llamma3.1-70B-Instruct和GPT-4o结合一次提示完成摘要的适应,并报告了BLEU、SARI、BERTScore、LENS和SALSA等评分。在PLABA-2024的官方评估中,我们的较小的微调RoBERTa-Base模型在任务1A和1B中分别排名第三和第二名,两项任务的平均F1分数排名第一。我们的LLAMA-3.1-70B-instructed模型在任务2中获得了最高的完整性得分。我们在https://github.com/HECTA-UoM/PLABA2024共享我们的微调模型和相关资源。
关键见解
- BeeManc团队参与了PLABA 2024共享任务,并提供了系统描述。
- 任务一:应用微调ReBERTa-Base模型识别并分类生物医学摘要中的难词、术语和缩写词。
- 任务二中:使用Llamma3.1-70B-Instruct和GPT-4o结合一次提示完成摘要的适应。
- 在PLABA-2024的官方评估中,微调RoBERTa-Base模型在两项子任务中排名靠前。
- LLaMA-3.1-70B-instructed模型在任务2中获得最高完整性得分。
- 团队共享了他们的微调模型和相关资源。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文描述了BeeManc团队参加2024年的Plain Language Adaptation of Biomedical Abstracts (PLABA)共享任务的系统。PLABA任务旨在利用深度学习技术的进步,将复杂的科学文本自动简化为更易于患者和护理人员理解的语言。具体来说,这项工作试图解决以下问题:
生物医学摘要的简化:将生物医学摘要翻译成通俗易懂的语言,以提高公众的健康素养。
特定子任务的挑战:
- 任务1:识别和分类生物医学摘要中的难懂术语、行话和缩写词,并提供适当的替换词。
- 任务2:完成生物医学摘要的全文简化,生成适合普通大众的简化版本。
提高健康素养:通过将生物医学摘要转换成通俗易懂的语言,使其对公众更加易于访问和理解。
语言障碍问题:尽管生物医学信息在线高度可访问,但患者和护理人员常常因为语言障碍而难以理解这些信息,即使内容是用他们的母语呈现的。
论文中提出的解决方案包括使用RoBERTa模型进行术语替换任务(任务1),以及利用LLaMa-3.1-70B和GPT-4o模型通过一次性提示完成摘要适应任务(任务2)。这些方法旨在提高生物医学摘要的可读性,使其对非专业人群更加友好。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与PLABA任务和论文中描述的研究方法相关的研究工作:
大型语言模型(LLMs)的应用:
- 论文提到了之前在PLABA-2023任务中使用的LLMs,如ChatGPT、BioGPT和Flan-T5,以及控制机制(Li et al., 2024)。这些模型在自然语言处理(NLP)任务中表现出色,特别是在文本简化和生成任务中。
RoBERTa模型:
- Liu et al. (2019) 提出了RoBERTa模型,这是一个基于BERT的Transformer语言模型,通过改进预训练方法来提高性能。RoBERTa在多项NLP任务中超越了BERT。
文本简化评估指标:
- BLEU (Papineni et al., 2002):用于机器翻译和文本简化任务的评估指标,衡量生成文本与参考文本之间的n-gram相似度。
- SARI (Xu et al., 2016):专门设计用于评估文本简化任务的指标,考虑了添加、删除和保留单词的操作。
- BERTScore (Zhang* et al., 2020):基于BERT的深度上下文嵌入,衡量输出和参考之间的语义相似度。
- LENS (Maddela et al., 2023):使用机器学习模型评估生成文本的语义和上下文相似度。
- SALSA (Heineman et al., 2023):基于编辑的人类注释框架,用于无参考的文本简化评估。
健康素养和生物医学信息可访问性:
- Attal et al. (2023) 提供了一个用于生物医学摘要简化的数据集,该数据集包含了生物医学查询和PubMed上对应查询的前十大论文摘要,这些摘要由专家手动对齐和简化,并标记了难懂的短语及其替换方法。
人类评估和错误分类:
- Gladkoff and Han (2022) 提出了HOPE框架,这是一个以任务为导向、以人为中心的评估框架,使用专业后编辑来实现更有效的机器翻译评估。
这些研究为PLABA任务提供了理论基础和技术背景,帮助研究者开发出能够自动简化生物医学摘要的系统,以提高公众的健康素养。
Q: 论文如何解决这个问题?
A: 论文通过以下方法解决生物医学摘要简化的问题:
任务1:术语替换
数据集和预处理:
- 使用PLABA语料库,包含生物医学查询和PubMed上相关论文的摘要,这些摘要由专家手动对齐和简化,并标记了难懂的短语及其替换方法。
- 将这些标记转换为适合命名实体识别(NER)任务的格式,将短语级别的注释转换为子词级别的标签。
模型选择:
- 选择RoBERTa模型,这是一个基于BERT的Transformer语言模型,通过改进预训练方法来提高性能。
模型微调:
- 在RoBERTa模型的最后隐藏层后添加线性层,使用sigmoid函数将每个token的输出转换为11个类别的概率集合。
- 使用二元交叉熵作为损失函数,通过应用0.5的阈值来确定token是否属于特定标签。
后处理:
- 将子词标签合并为词级标签,并形成短语级别的输出,包含识别出的难懂短语及其对应的替换标签。
任务2:完整摘要适应
模型选择:
- 使用LLaMa 3.1-70B和GPT-4o这两个大型语言模型,通过一次性提示(one-shot prompts)来完成摘要的简化。
提示调整:
- 从简单的一次性提示开始,根据测试案例的输出结果,不断调整提示,直到模型几乎生成预期的结果。
后处理:
- 删除模型输出中的一些前缀词,如”Here’s a simplified version:”,并使用正则表达式尽可能提取简化后的句子。
评估和排名
- 使用官方PLABA-2024评估标准,包括BLEU、SARI、BERTScore、LENS和SALSA等自动评估指标,对模型的性能进行评估和排名。
结论和未来工作
- 论文展示了开源模型在医学领域文本简化任务中的潜力,并计划对LLaMa-3.1-70B-instructed模型的输出进行进一步的定性分析,以确定系统输出是否包含误导性或虚构的信息。
通过这些方法,论文提出了一个基于深度学习和大型语言模型的系统,以自动化简化复杂的生物医学摘要,使其更易于患者和护理人员理解。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要分为两个任务的实验,具体如下:
任务1:术语替换
数据预处理实验:
- 实验包括将原始训练数据转换为适合模型训练的格式,将短语级别的注释转换为子词级别的标签,并遵循特定的标记策略。
模型微调实验:
- 在RoBERTa模型上添加线性层,并使用二元交叉熵损失函数进行微调,将输出转换为多类别的概率分布。
后处理实验:
- 将子词标签合并为词级标签,并形成短语级别的输出。
自动评估实验:
- 在任务1B上,使用精确度(Precision)、召回率(Recall)和F1分数进行自动评估,并展示了包含和不包含’O’标签的微平均(micro)和宏平均(macro)F1分数。
任务2:完整摘要适应
模型选择和调整实验:
- 使用LLaMa 3.1-70B和GPT-4o模型,并通过一次性提示(one-shot prompts)生成简化版本的摘要句子。
提示调整实验:
- 基于测试案例的输出结果,不断调整提示,直到模型生成预期的输出。
后处理实验:
- 对模型输出进行后处理,删除前缀词,并使用正则表达式提取简化后的句子。
自动评估实验:
- 使用SALSA、LENS、SARI和BERTScore等指标对模型性能进行评估,并在训练集和测试集上比较两个模型的性能。
官方评估和排名
- 论文还报告了PLABA-2024官方组织者对任务1A和1B使用F1分数进行的系统排名,以及任务2的人类评估结果。
这些实验展示了BeeManc团队提交的系统在两个不同任务中的表现,并提供了对模型性能的深入分析。通过这些实验,研究者能够评估和比较不同模型和方法在生物医学摘要简化任务中的有效性。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些可以进一步探索的点,主要包括:
改进少数类别标签的处理:
- 论文中提到模型在处理训练数据中低频标签(如EXEMPLIFY, OMIT, 和 GENERALIZE)时表现不佳。未来的工作可以探索更有效的策略来处理类别不平衡问题,例如通过过采样少数类别或欠采样多数类别,或者设计新的损失函数来提高模型对少数类别的识别能力。
定性分析LLaMa-3.1-70B-instructed模型的输出:
- 论文计划对LLaMa-3.1-70B-instructed模型的输出进行进一步的定性分析,以确定系统输出是否包含误导性或虚构的信息。这可以通过人工评估或开发新的评估指标来实现。
人类评估与自动评估的关联研究:
- 论文中提到了LLaMa-3.1-70B-instructed模型在官方人类评估中获得了最高的完整性得分,但准确度得分最低。这表明可能需要进一步研究人类评估和自动评估之间的关联,并探索如何改进自动评估指标以更好地反映人类的评价。
模型的可解释性和透明度:
- 研究如何提高模型的可解释性,以便更好地理解模型的决策过程,特别是在生成文本简化时的替换和改写选择。
多模态和跨领域适应性:
- 探索模型在不同领域(如法律、金融等其他专业领域)的适应性和有效性,以及如何将这些技术应用于多模态数据(结合文本和图像)的简化。
增强模型的语言和风格多样性:
- 研究如何使模型生成的简化文本在语言和风格上更加多样化和自然,以更好地满足不同用户的需求。
实时反馈和迭代学习:
- 探索如何将用户的实时反馈整合到模型训练和优化中,以实现更精准和个性化的文本简化。
模型的鲁棒性和错误分析:
- 对模型在特定情况下可能失败的原因进行深入分析,并研究如何提高模型的鲁棒性,减少错误和偏差。
这些探索点可以帮助研究者进一步提升文本简化技术的性能和应用范围,同时也为未来的研究提供了新的方向和挑战。
Q: 总结一下论文的主要内容
A: 这篇论文主要介绍了BeeManc团队在2024年PLABA(Plain Language Adaptation of Biomedical Abstracts)共享任务中的两个子任务的系统设计和实验结果。以下是主要内容的总结:
背景与目标
- 健康素养:强调了提高公众健康素养的重要性,尤其是在理解生物医学信息方面。
- PLABA任务:旨在通过深度学习技术将复杂的生物医学摘要自动简化为普通公众更易理解的语言。
任务1:术语替换
- 子任务1A:识别非消费者术语(命名实体识别任务)。
- 子任务1B:对识别出的术语进行分类替换(多类多标签标记任务)。
- 方法:
- 使用RoBERTa模型进行微调,以识别和分类术语。
- 对训练数据进行预处理,将短语级注释转换为子词级标签。
- 采用二元交叉熵损失函数和sigmoid激活函数进行多标签分类。
- 后处理步骤将子词标签合并为词级标签,并形成短语。
任务2:完整摘要适应
- 方法:
- 使用LLaMa 3.1-70B和GPT-4o模型,通过一次性提示完成摘要的简化。
- 调整提示以优化模型输出。
- 后处理步骤包括删除前缀词和提取简化后的句子。
实验与评估
- 自动评估:使用BLEU、SARI、BERTScore、LENS和SALSA等指标对模型性能进行评估。
- 官方排名:在任务1A和1B中,BeeManc团队的RoBERTa模型在9个评估系统中平均F1得分最高。
- 人类评估:LLaMa 3.1-70B模型在任务2中获得了最高的完整性得分,但准确度得分最低。
结论与未来工作
- 结论:展示了开源模型在医学领域文本简化任务中的潜力,并指出了当前方法的局限性。
- 未来工作:计划对LLaMa-3.1-70B-instructed模型的输出进行定性分析,以探索输出中可能的误导性信息,并考虑使用人类评估指标如HOPE来分类错误类型。
总体而言,这篇论文提供了一个关于如何使用深度学习模型自动简化生物医学摘要的综合研究,并对未来的研究方向提出了一些有价值的建议。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


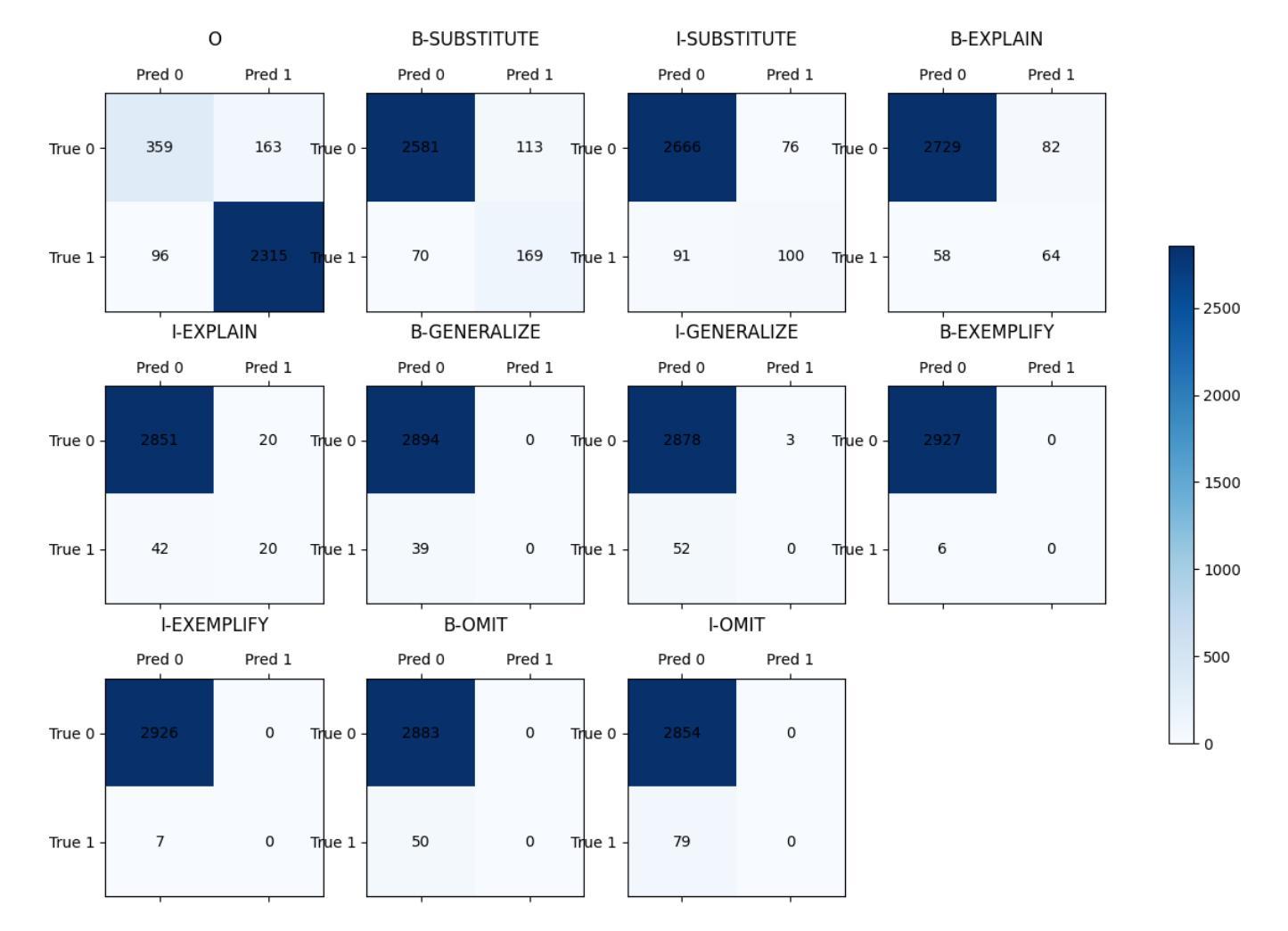
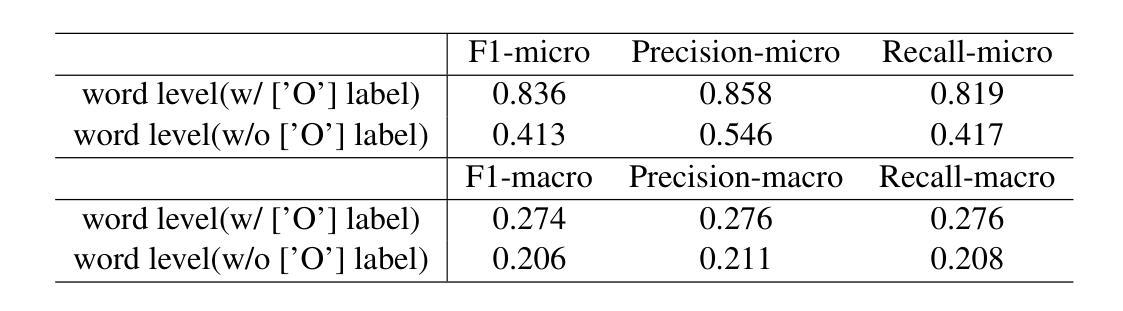
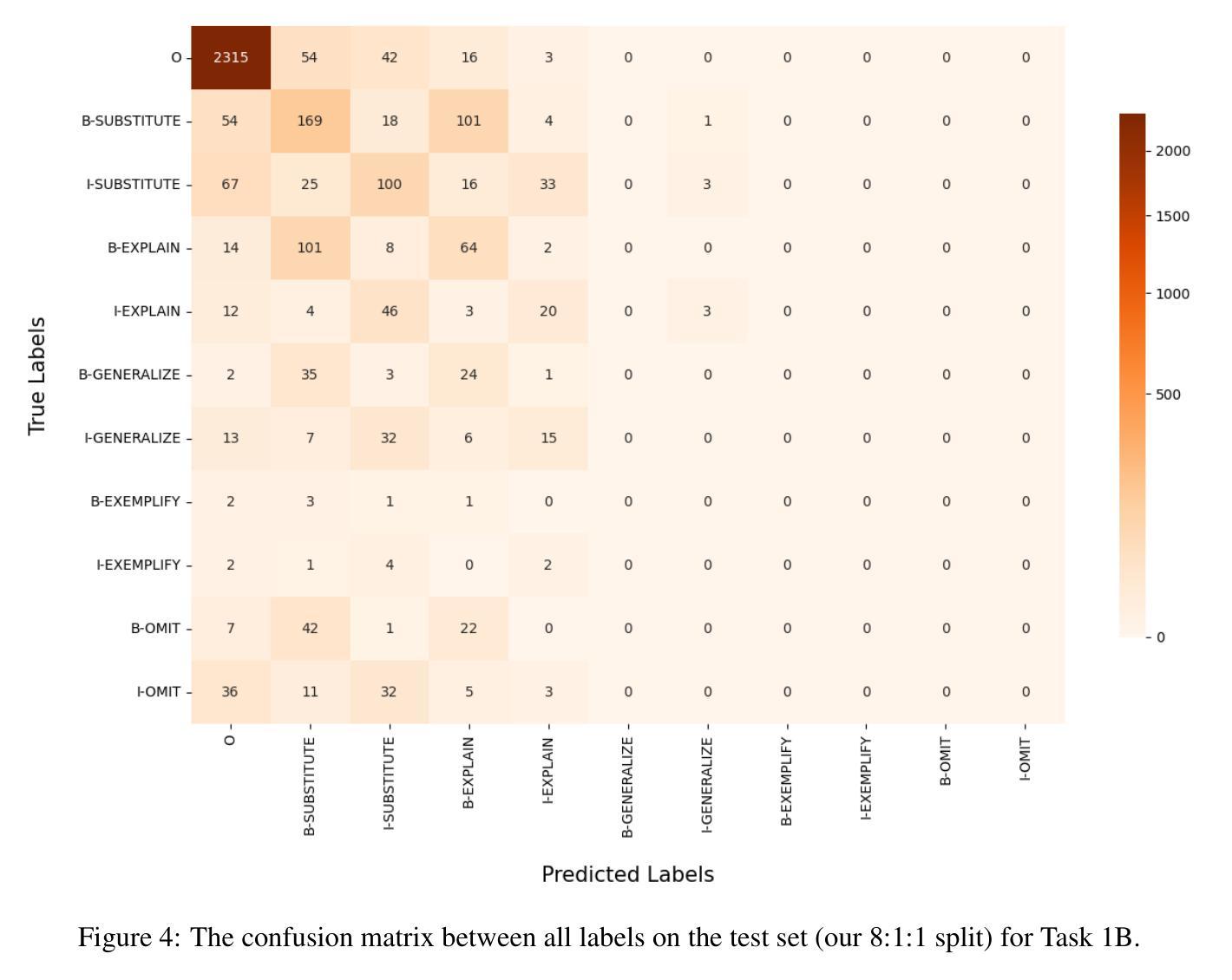
ConvMixFormer- A Resource-efficient Convolution Mixer for Transformer-based Dynamic Hand Gesture Recognition
Authors:Mallika Garg, Debashis Ghosh, Pyari Mohan Pradhan
Transformer models have demonstrated remarkable success in many domains such as natural language processing (NLP) and computer vision. With the growing interest in transformer-based architectures, they are now utilized for gesture recognition. So, we also explore and devise a novel ConvMixFormer architecture for dynamic hand gestures. The transformers use quadratic scaling of the attention features with the sequential data, due to which these models are computationally complex and heavy. We have considered this drawback of the transformer and designed a resource-efficient model that replaces the self-attention in the transformer with the simple convolutional layer-based token mixer. The computational cost and the parameters used for the convolution-based mixer are comparatively less than the quadratic self-attention. Convolution-mixer helps the model capture the local spatial features that self-attention struggles to capture due to their sequential processing nature. Further, an efficient gate mechanism is employed instead of a conventional feed-forward network in the transformer to help the model control the flow of features within different stages of the proposed model. This design uses fewer learnable parameters which is nearly half the vanilla transformer that helps in fast and efficient training. The proposed method is evaluated on NVidia Dynamic Hand Gesture and Briareo datasets and our model has achieved state-of-the-art results on single and multimodal inputs. We have also shown the parameter efficiency of the proposed ConvMixFormer model compared to other methods. The source code is available at https://github.com/mallikagarg/ConvMixFormer.
Transformer模型在自然语言处理(NLP)和计算机视觉等多个领域取得了显著的成果。随着对基于Transformer架构的兴趣不断增长,它们现在也被用于手势识别。因此,我们也探索并提出了一种新型的ConvMixFormer架构,用于动态手势识别。Transformer使用注意力特征的二次缩放与序列数据,这导致这些模型计算复杂且体积庞大。我们考虑到了Transformer的这一缺点,并设计了一个资源高效的模型,该模型用基于简单卷积层的令牌混合器替换了Transformer中的自注意力。与二次自注意力相比,基于卷积的混合器的计算成本和参数使用量相对较少。卷积混合器有助于模型捕捉局部空间特征,而自注意力由于其序列处理性质,很难捕捉到这些特征。此外,该设计还采用了一种有效的门控机制,取代了Transformer中的传统前馈网络,帮助模型控制所提出模型不同阶段内的特征流。这种设计使用的可学习参数较少,几乎是普通Transformer的一半,有助于实现快速和高效的训练。所提出的方法在Nvidia动态手势和Briareo数据集上进行了评估,我们的模型在单模态和多模态输入上均达到了最新技术水平。我们还展示了所提出的ConvMixFormer模型与其他方法的参数效率。源代码可在https://github.com/mallikagarg/ConvMixFormer找到。
论文及项目相关链接
Summary
卷积混合变压器(ConvMixFormer)模型用于动态手势识别,通过替换自我注意力机制为基于卷积层的令牌混合器,实现了资源高效利用。该模型能够捕捉局部空间特征,并使用有效的门控机制控制特征流。在NVidia动态手势和Briareo数据集上取得了先进的结果。
Key Takeaways
- ConvMixFormer是一个用于动态手势识别的模型。
- 它通过替换变压器的自我注意力机制,采用基于卷积层的令牌混合器,实现了资源的高效利用。
- 卷积混合器有助于模型捕捉局部空间特征,这是自我注意力机制由于其顺序处理性质而难以捕捉的。
- 该模型采用有效的门控机制,控制不同阶段的特征流。
- ConvMixFormer在NVidia动态手势和Briareo数据集上取得了先进的结果。
- 与其他方法相比,ConvMixFormer模型具有参数效率高的优点。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在动态手势识别领域中,基于Transformer模型的计算复杂性和模型复杂性问题。具体来说,论文中提到Transformer模型在处理图像数据时,由于其自注意力(self-attention)机制的二次方计算复杂度,导致模型在处理长序列数据时计算成本和参数数量显著增加。因此,论文提出了一种新颖的ConvMixFormer架构,旨在通过以下方式来解决这些问题:
设计一种资源高效的模型:通过将Transformer中的自注意力机制替换为基于卷积的token mixer,降低模型的计算成本和参数数量。
捕捉局部空间特征:由于自注意力在处理序列数据时难以捕捉局部特征,ConvMixFormer利用卷积层帮助模型捕捉局部空间特征,这对于手势识别任务来说是必要的,因为手势涉及手和手指的不同大小和运动。
引入有效的门控机制:在Transformer的前馈网络中引入门控机制(Gated Depthwise Feed Forward Network, GDFN),帮助模型控制不同阶段之间的特征流,提高模型对相关特征的关注,抑制无关信息,从而可能提高模型的鲁棒性和泛化能力。
在单模态和多模态输入上实现state-of-the-art性能:论文提出的ConvMixFormer模型在NVidia Dynamic Hand Gesture和Briareo数据集上进行了评估,并在单模态和多模态输入上取得了state-of-the-art的结果,同时展示了与其它方法相比的参数效率。
综上所述,论文的主要贡献在于提出了一种新的基于卷积的Transformer模型,旨在提高动态手势识别任务的效率和性能,同时减少模型的计算和参数复杂性。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与ConvMixFormer模型相关的研究工作:
Token Mixer相关研究:
- MetaFormer [48]:提出了一个通用的token mixer结构,用于高效替换Transformer中的自注意力机制。
- PoolFormer:使用非参数池化操作进行token混合,以非常简单的网络结构实现了高性能。
- ConvMixer [40]:仅使用标准卷积(深度卷积后跟逐点卷积)来实现Transformer模型中的混合步骤。
- MLP-Mixer [38]:探索了多层感知机(MLP)用于token混合。
- S2-MLP [47]:设计了一个新颖的空间位移MLP(S2-MLP),仅包含通道混合MLP。
- SepViT [29]:使用深度自注意力和逐点自注意力两个模块进行token混合。
- FNet [27] 和 Wavemix [22]:在频域中使用线性变换(如傅里叶变换和离散小波变换)来混合token。
Transformer在手势识别中的应用:
- Video Transformers [35]:用于处理多模态输入序列的动态手势识别。
- 动态手势识别中的Transformer模型 [6]:成功应用于手势识别任务,包括视频和多模态输入的处理。
将卷积神经网络(CNNs)与Transformer结合的研究:
- POTTER [55]、Convolutional Vision Transformer (CvT) [43]、Swin Transformer [30]、CSwin [10]、CeiT [50]、Unifying CNNs [28]、CoFormer [8] 等方法将CNNs与Transformer模型结合,以解决计算复杂性问题,并利用两种架构的优势。
这些相关研究为ConvMixFormer模型的设计提供了理论基础和技术背景,特别是在探索如何有效地替换Transformer中的自注意力机制以及如何将卷积神经网络与Transformer结合以提高计算效率和性能方面。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为ConvMixFormer的新型架构来解决Transformer模型在动态手势识别中的计算复杂性和模型复杂性问题。具体解决方案如下:
1. 设计ConvMixFormer模型
ConvMixFormer模型是一种资源高效的Transformer模型,它通过以下方式来减少计算复杂性和参数数量:
- 使用卷积层替换自注意力机制:传统的Transformer模型中,自注意力机制的计算复杂度随着输入序列长度的增加而呈二次方增长。ConvMixFormer通过使用卷积层代替自注意力机制来降低这种复杂度,因为卷积操作的复杂度通常低于自注意力。
2. 卷积Token Mixer
- 局部特征提取:卷积层有助于模型捕捉输入数据中的局部空间特征,这对于手势识别任务至关重要,因为手势涉及手和手指的不同大小和运动。
- 捕获空间依赖性:通过在序列上应用卷积,模型能够捕捉相邻token之间的交互,从而捕获空间依赖性和模式。
3. Gated Depthwise Feed Forward Network (GDFN)
- 信息流控制:在Transformer的前馈网络中引入门控机制(GDFN),帮助模型控制不同阶段之间的特征流。这种机制使模型能够专注于相关特征,同时抑制无关信息,可能提高模型的鲁棒性和泛化能力。
4. 多模态晚融合策略
- 增强准确性和可靠性:通过处理不同模态(如RGB、深度和IR图像)的图像来增强模型的准确性和可靠性。晚融合策略通过结合每种模态的概率分数来提高整体性能。
5. 实验验证
- 在NVGesture和Briareo数据集上评估:ConvMixFormer模型在NVGesture和Briareo数据集上进行了评估,并在单模态和多模态输入上取得了state-of-the-art的结果,证明了其参数效率和性能。
6. 参数效率
- 减少参数和计算量:与其它方法相比,ConvMixFormer显著减少了参数数量和MACs(乘累加操作),这进一步强调了其在计算资源方面的效率。
通过这些解决方案,论文成功地展示了ConvMixFormer模型在保持性能的同时,如何有效地减少Transformer模型的计算和参数复杂性,使其更适合于动态手势识别任务。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,以下是论文中进行的实验:
1. 数据集
论文使用了两个数据集进行实验评估:
- NVGesture:用于非接触式驾驶员控制和人机交互的动态手势识别数据集。包含深度、彩色和红外图像,共收集了25种不同类型的手势,由20名受试者进行表演。
- Briareo:在汽车环境中收集的用于建立人机交互的数据集。包含深度、RGB和运动图像,包含12种不同手势类别,由40名受试者表演。
2. 实施细节
- 模型实现:使用PyTorch 1.7.1和Nvidia GeForce GTX 1080 Ti GPU进行模型实现。
- 训练参数:使用Adam优化器,学习率为(1 \times 10^{-4}),并在50和75个epoch时进行权重衰减。
- 输入处理:输入图像被裁剪至224×224大小。
- 特征提取:遵循[12]的方法,从原始RGB、红外和深度图像中计算出法线和光流。
- 模型结构:模型包含6个ConvMixFormer阶段。
3. 结果和讨论
- NVGesture数据集:在NVGesture数据集上评估了ConvMixFormer模型,并与常规Transformer[12]进行了比较。实验结果显示ConvMixFormer在单模态和多模态输入上都取得了state-of-the-art的结果,并且参数数量更少。
- Briareo数据集:在Briareo数据集上,ConvMixFormer同样在单模态和多模态输入上展示了优异的性能,并与常规Transformer[12]进行了比较。
4. 消融研究
- 基线模型:论文还进行了消融研究,比较了三种基线模型(BL1、BL2和BL3)的性能和参数数量。BL1是带有前馈网络(FFN)的卷积混合器基线模型。BL2引入了门控机制。BL3与BL2类似,但在门控网络中使用了更少的参数。
5. 参数效率
- 参数和MACs比较:论文还比较了ConvMixFormer与其他最先进方法在参数数量和MACs(乘累加操作)方面的表现,证明了ConvMixFormer在减少参数和计算复杂性方面的优势。
这些实验验证了ConvMixFormer模型在动态手势识别任务中的有效性,并展示了其在参数效率和计算效率方面的优势。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
1. 更多数据集的验证
- 论文中主要在NVGesture和Briareo数据集上进行了实验验证。可以考虑在更多的手势识别数据集上进行测试,以进一步验证模型的泛化能力和鲁棒性。
2. 不同模型变体的比较
- 论文提出了ConvMixFormer模型,并与其他几种方法进行了比较。可以探索更多不同的模型变体,例如不同的卷积核大小、深度和结构,以找到最优的模型配置。
3. 多模态融合策略的改进
- 论文采用了简单的晚融合策略来处理多模态输入。可以探索更复杂的融合策略,如中间层融合或注意力机制引导的融合,以进一步提高模型性能。
4. 长序列处理能力
- 由于Transformer模型在处理长序列时的计算复杂度问题,可以探索ConvMixFormer在处理更长序列数据时的表现,并尝试优化以适应更长的输入序列。
5. 实时性能优化
- 考虑到动态手势识别在实时应用中的潜力,可以进一步优化ConvMixFormer模型以减少推理时间,使其更适合实时应用。
6. 更广泛的应用场景
- 除了动态手势识别,ConvMixFormer模型也可以应用于其他领域,如动作识别、视频理解等。探索模型在这些领域的应用潜力和性能表现。
7. 模型解释性
- 虽然ConvMixFormer模型在实验中取得了良好的性能,但其决策过程的解释性仍然是一个挑战。可以探索模型解释性的方法,以更好地理解模型的内部工作机制。
8. 模型压缩和加速
- 进一步研究模型压缩技术,如量化、剪枝和知识蒸馏,以减少模型大小并加速推理过程,使其更适合部署在资源受限的设备上。
9. 跨域性能
- 探索ConvMixFormer模型在不同域(如不同的光照条件、背景和手势风格)的性能表现,并研究域适应技术以提高模型的适应性。
这些探索点可以帮助研究者更深入地理解ConvMixFormer模型的潜力和局限性,并推动动态手势识别技术的发展。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
1. 研究背景与动机
- 论文探讨了基于Transformer的架构在动态手势识别领域的应用,并指出了传统Transformer模型在处理视觉任务时存在的性能和模型复杂性问题,特别是由于自注意力机制的二次方计算复杂度导致的。
2. ConvMixFormer架构
- 提出了一种新颖的资源高效模型ConvMixFormer,用于动态手势识别任务。该模型通过使用卷积层替换传统的自注意力机制,以降低计算复杂度和参数数量。
- 引入了卷积token mixer以捕捉局部空间特征,并采用门控机制(Gated Depthwise Feed Forward Network, GDFN)来控制特征流,增强模型对重要特征的关注。
3. 实验验证
- 在NVGesture和Briareo数据集上评估了ConvMixFormer模型,并与现有的Transformer模型和其他方法进行了比较。
- 实验结果显示ConvMixFormer在单模态和多模态输入上均取得了state-of-the-art的性能,并且参数数量显著减少。
4. 消融研究
- 通过对比不同基线模型,验证了所提出的ConvMixFormer模型设计的有效性,特别是在参数效率和性能之间的平衡。
5. 参数效率分析
- 论文还比较了ConvMixFormer与其他方法在参数数量和MACs(乘累加操作)方面的表现,进一步证明了其在计算资源效率方面的优势。
6. 结论
- 论文得出结论,基于卷积的token mixers非常适合于手势识别任务,ConvMixFormer通过减少参数和计算复杂度,同时保持或提高性能,为动态手势识别提供了一种有效的解决方案。
总体而言,论文的主要贡献在于提出了一种新的基于Transformer的模型ConvMixFormer,该模型通过创新的卷积token mixer和门控机制,在减少计算和参数复杂性的同时,实现了动态手势识别任务中的高效性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

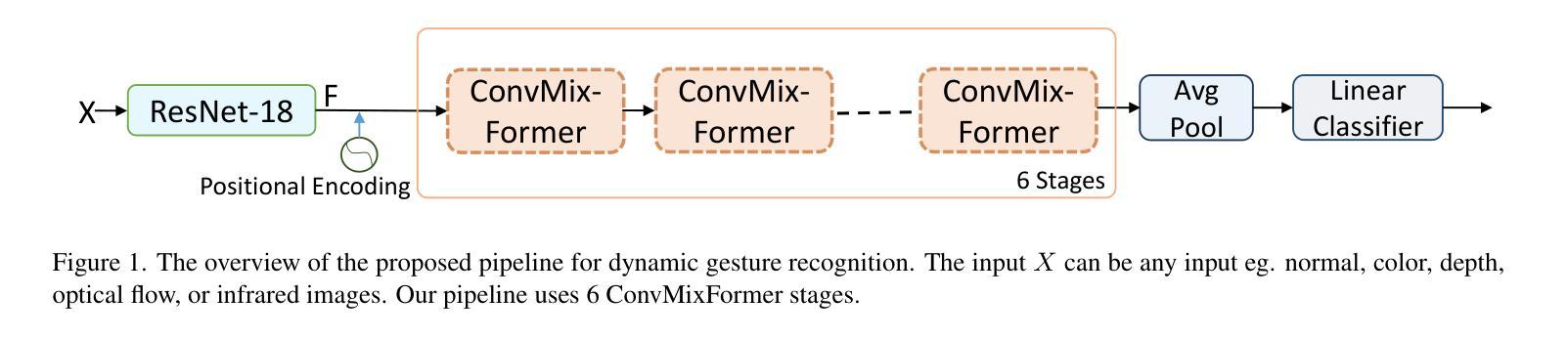
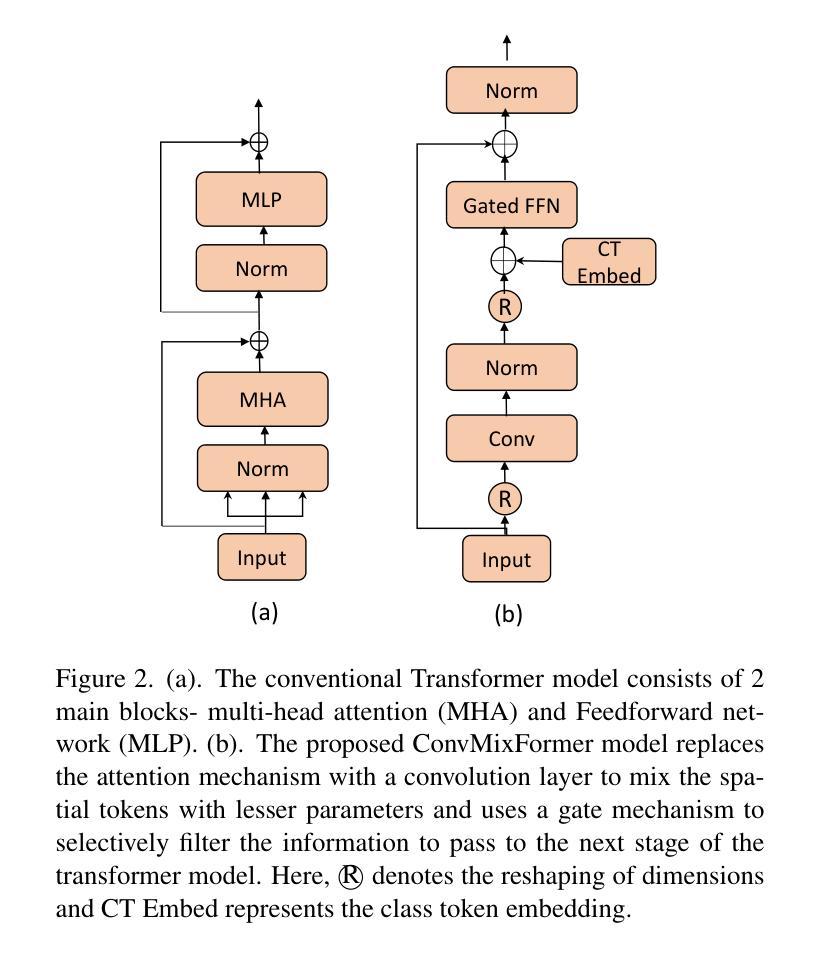
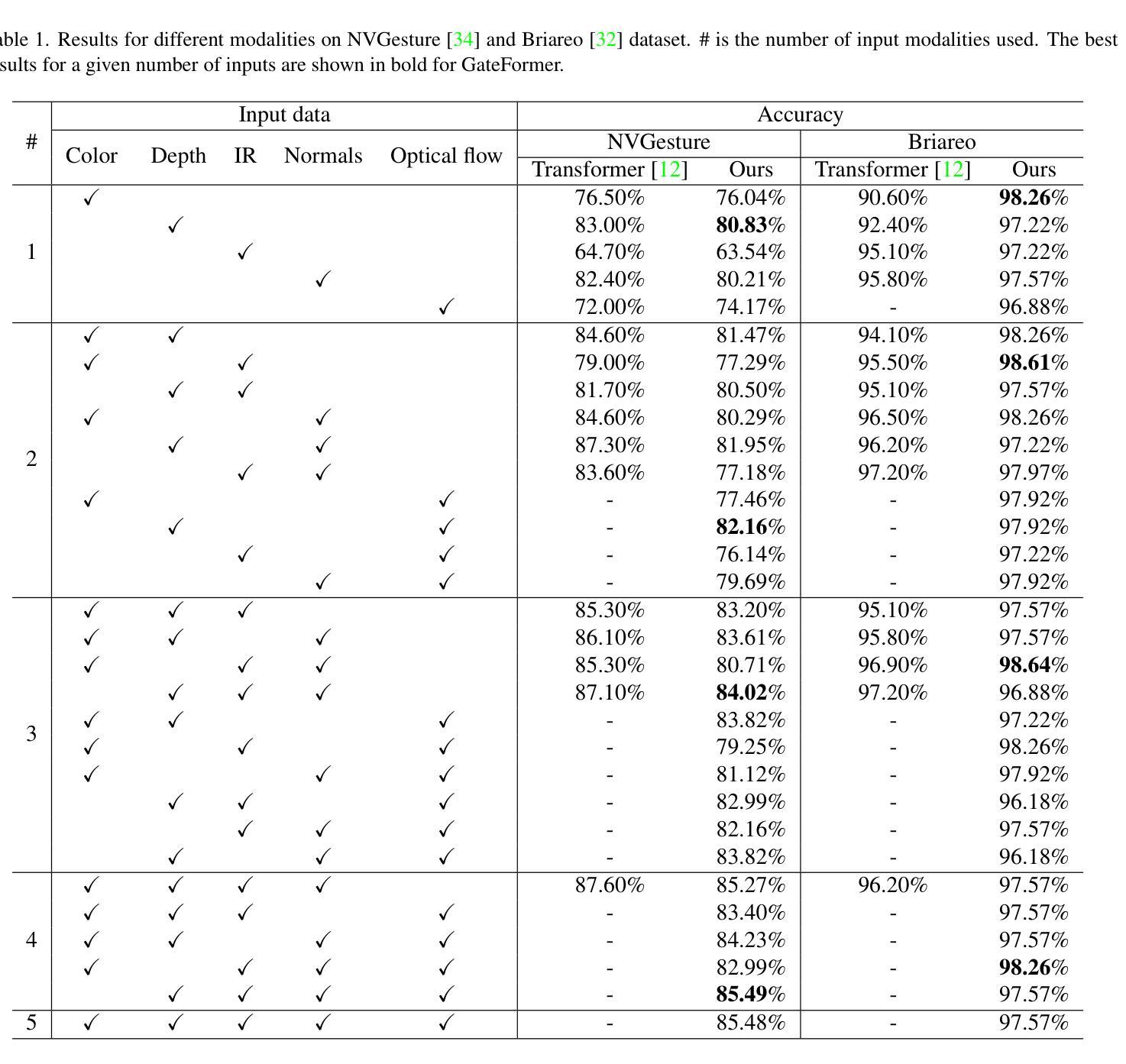
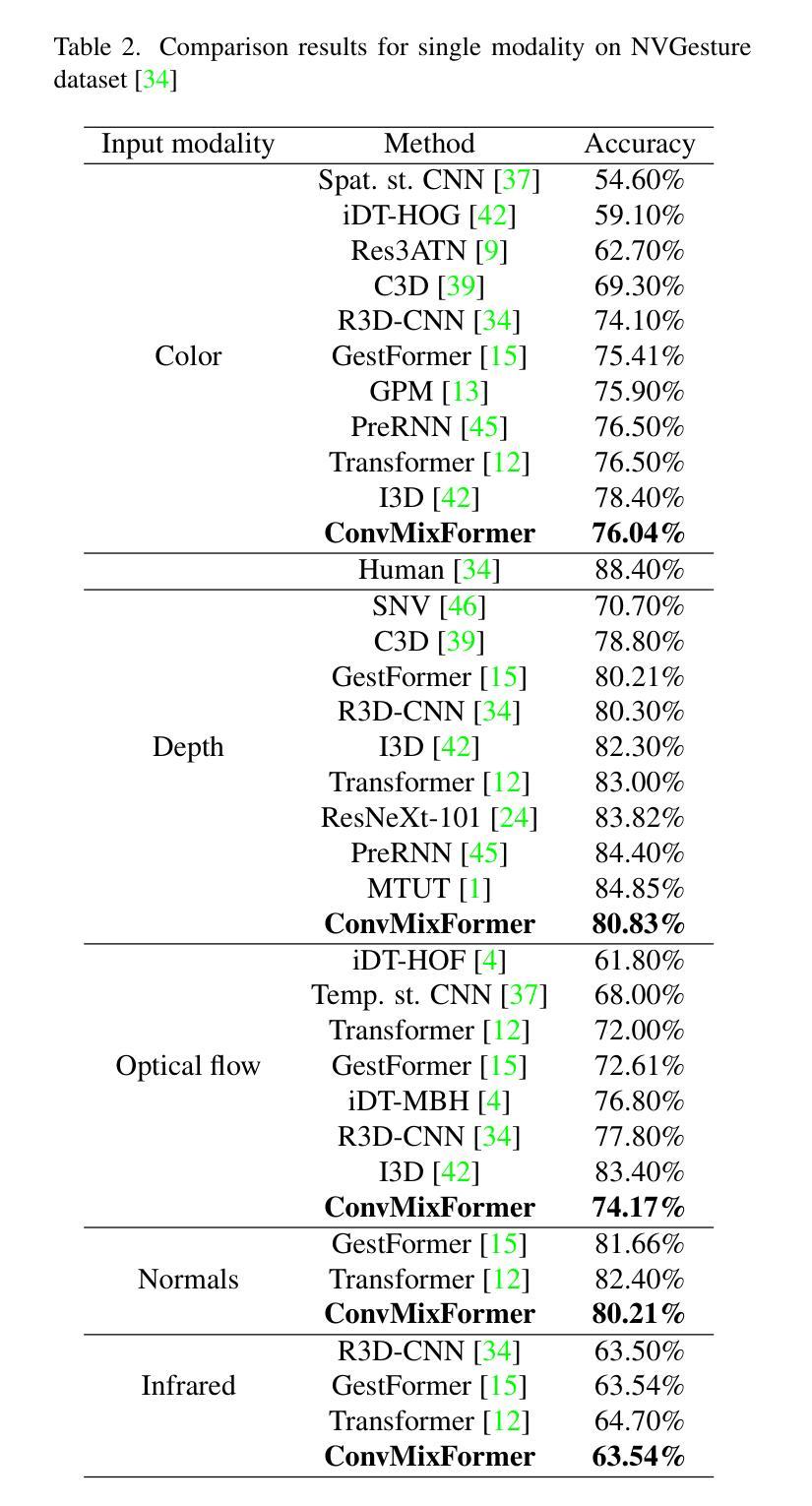
EVQAScore: Efficient Video Question Answering Data Evaluation
Authors:Hao Liang, Zirong Chen, Wentao Zhang
Video question-answering (QA) is a core task in video understanding. Evaluating the quality of video QA and video caption data quality for training video large language models (VideoLLMs) is an essential challenge. Although various methods have been proposed for assessing video caption quality, there remains a lack of dedicated evaluation methods for Video QA. To address this gap, we introduce EVQAScore, a reference-free method that leverages keyword extraction to assess both video caption and video QA data quality. Additionally, we incorporate frame sampling and rescaling techniques to enhance the efficiency and robustness of our evaluation, this enables our score to evaluate the quality of extremely long videos. Our approach achieves state-of-the-art (SOTA) performance (32.8 for Kendall correlation and 42.3 for Spearman correlation, 4.7 and 5.9 higher than the previous method PAC-S++) on the VATEX-EVAL benchmark for video caption evaluation. Furthermore, by using EVQAScore for data selection, we achieved SOTA results with only 12.5% of the original data volume, outperforming the previous SOTA method PAC-S and 100% of data.
视频问答(QA)是视频理解的核心任务之一。对于训练视频大型语言模型(VideoLLM)而言,评估视频QA和视频字幕数据质量是一个重大挑战。尽管已经提出了各种评估视频字幕质量的方法,但仍然缺乏针对视频QA的专用评估方法。为解决这一空白,我们引入了EVQAScore,这是一种无参考方法,利用关键词提取来评估视频字幕和视频QA数据的质量。此外,我们结合了帧采样和缩放技术,以提高评估的效率和稳健性,这使我们能够评估极长视频的质量。我们的方法在视频字幕评估的VATEX-EVAL基准测试上达到了最新技术水平(Kendall相关性为32.8,Spearman相关性为42.3,高于前一种方法PAC-S++的4.7和5.9)。此外,通过使用EVQAScore进行数据选择,我们只使用了原始数据量的12.5%,就取得了超越之前最佳方法PAC-S和100%数据的成绩。
论文及项目相关链接
Summary
视频问答是视频理解的核心任务之一。评估视频问答和视频字幕数据质量对于训练视频大型语言模型至关重要。当前,尽管有许多评估视频字幕质量的方法,但针对视频问答的专门评估方法仍然缺乏。为了填补这一空白,我们提出了EVQAScore这一无参考的评估方法,通过关键词提取来评估视频字幕和视频问答数据的质量。我们还结合了帧采样和缩放技术,以提高评估的效率与稳健性,使EVQAScore能够评估极长视频的质量。在视频字幕评估的VATEX-EVAL基准测试中,我们的方法达到了最先进的性能表现。此外,通过使用EVQAScore进行数据选择,我们只使用了原始数据的12.5%,便达到了超越先前最先进的PAC-S方法的效果。
Key Takeaways
- 视频问答和视频字幕数据质量的评估是训练视频大型语言模型的关键挑战。
- 当前缺乏专门针对视频问答的评估方法。
- EVQAScore是一种无参考的评估方法,通过关键词提取来评估视频问答和视频字幕数据质量。
- EVQAScore结合了帧采样和缩放技术,提高了评估效率和稳健性。
- EVQAScore在VATEX-EVAL基准测试中表现先进,达到了较高的评估性能。
- 使用EVQAScore进行数据选择,能够大幅度减少所需数据量,同时保持甚至超越先前的性能表现。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决视频问答(Video QA)数据评估的质量问题。具体来说,论文指出了在评估视频问答和视频字幕数据质量方面存在以下挑战:
无法准确理解字幕和问答语义(C1):以往的方法,如EMScore和PAC-S,依赖于TF-IDF来评估视频字幕数据,但这种方法仅计算词频,无法捕捉语义信息。因此,这些方法在评估视频字幕和视频问答数据时往往不够精确。
评估效率低下(C2):鉴于视频数据的庞大体量和长度,大规模训练数据集经常占用大量的存储空间,从几百GB到数TB不等。评估视频字幕和问答数据既耗时又耗费计算资源。先前的方法,如EMScore和PAC-S,处理每一帧视频,导致了大量的计算浪费。
缺乏针对VideoLLMs的视频问答数据评估实验(C3):虽然提出了多种评估视频字幕数据质量的方法,但它们没有结合VideoLLMs实验来评估其方法在训练VideoLLMs中的有效性。因此,需要更多的VideoLLMs实验来验证数据评估方法的有效性。
为了应对这些挑战,论文提出了EVQAScore,这是一个无需参考的评估方法,它利用关键词提取来评估视频字幕和视频问答数据的质量,并通过帧采样和重缩放技术提高评估的效率和鲁棒性,使得该方法能够评估极长视频的质量。
Q: 有哪些相关研究?
A: 论文中提到了多个与视频数据评估、数据质量与选择以及视频大型语言模型(VideoLLMs)相关的研究工作。以下是一些关键的相关研究:
视频数据评估:
- 基于n-gram匹配的指标:如BLEU、METEOR、ROUGE、CIDEr和SPICE,这些指标主要用于评估机器翻译等文本任务中生成和参考文本之间的词汇相似性。
- CLIP-Score:利用预训练的视觉-语言模型来衡量视频帧和字幕之间的粗粒度对齐。
- EMScore:引入了细粒度匹配,通过比较视频帧和字幕中特定单词之间的匹配来显著提高语义对齐。
- PAC-Score:在EMScore的基础上进一步增强了视频-文本对齐的精度,通过结合正增强的CLIP模型来更全面地评估视频内容。
数据质量与选择:
- 数据质量:研究强调了高质量数据对模型性能的重要性,并讨论了数据量增加时确保数据质量的挑战。
- 数据选择:讨论了基于大型语言模型(LLMs)的方法在数据选择中的应用,例如使用DeBERTa、ChatGPT和GPT-4等模型进行数据评分和选择。
视频大型语言模型(VideoLLMs):
- VideoLLaMA:作为VideoLLMs的先驱研究之一,使用视觉编码器和视频Q-Former投影器来理解视频。
- LLaVA:后续工作采用LLaVA的MLP结构,显著降低计算成本,同时保持SOTA性能。
- MiniGPT4Video:使用MLP适配器进行高效训练。
- VideoChat系列:包括VideoChat、VideoChat2、InternVideo和InternVideo2等模型,这些模型利用大量数据训练一个基于transformer结构的适配器,实现了SOTA性能。
这些研究为EVQAScore的提出提供了理论基础和技术背景,同时也表明了视频理解和评估领域的研究进展和挑战。EVQAScore通过结合这些相关研究的优势,提出了一种新的、高效的视频问答数据评估方法。
Q: 论文如何解决这个问题?
A: 论文通过提出EVQAScore方法来解决视频问答数据评估中的问题,具体解决方案如下:
1. 新视角和方法(New Perspective and Method):
- EVQAScore:提出了一个新颖的方法EVQAScore,它是第一个系统性地评估视频问答数据质量的方法。该方法利用大型语言模型(LLMs)提取关键词,以增强视频字幕和视频问答数据的评估。
2. 效率提升(Efficiency Improvement):
- 均匀帧采样(Uniform Frame Sampling):为了高效处理长视频,通过均匀采样关键帧减少处理帧数,降低计算成本30倍,同时不影响结果。
- 关键词提取(Keywords Extraction):使用LLMs提取文本输入中的关键短语,以提高视频-文本对齐的效率,关注最相关的关键词。
3. 视频字幕评估(Video Caption Evaluation):
- 粗粒度和细粒度EVQAScore:结合粗粒度分数和细粒度分数(包括基于关键帧匹配和基于关键词匹配),提高处理长视频和复杂文本描述的效率。
4. 视频问答评估(Video QA Evaluation):
- EVQAScore应用于视频问答数据:使用EVQAScore评估视频问答数据,通过计算问题和答案的合并表示与视频特征之间的匹配程度来评分。
5. 实验验证(Experimental Validation):
- 在VATEX-EVAL基准测试上评估方法性能,EVQAScore在视频字幕评估中取得了32.8的Kendall相关性和42.3的Spearman相关性,分别比之前的方法PAC-S++高出4.7和5.9个百分点。
- 使用EVQAScore进行数据选择,仅使用原始数据量的12.5%就取得了比之前SOTA方法PAC-S和100%数据更好的结果。
6. 代码开源:
- 提供了EVQAScore的代码,以便社区进一步研究和应用。
通过上述方法,论文成功地提出了一个有效的视频问答数据评估框架,不仅提高了评估效率,还提升了评估质量,并在多个基准测试中验证了其优越性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证EVQAScore方法的有效性,具体实验包括:
计算效率的EVQAScore实验:
- 目的:验证EVQAScore在不牺牲评估性能的前提下,能否高效地计算。
- 方法:采用均匀帧采样策略,选择不同的采样间隔(10、20和30帧),并记录处理1000个视频所需的时间。
- 结果:如表1所示,使用均匀关键帧提取显著减少了处理视频数据所需的时间,且对Kendall和Spearman相关性的影响微乎其微。
视频字幕评估实验:
- 目的:验证EVQAScore在视频字幕数据评估中的性能。
- 方法:使用VATEX-EVAL数据集,评估EVQAScore与人类判断的相关性。
- 结果:如表2所示,EVQAScore在无参考设置下,与人类判断的相关性超过了EMScore和PAC-S,取得了更好的Kendall和Spearman相关性分数。
视频问答数据过滤实验:
- 目的:验证EVQAScore在过滤视频问答数据中的效果。
- 方法:将EVQAScore与PAC-S进行比较,过滤出高质量和低质量的数据样本。
- 结果:如表4所示,EVQAScore在选择更少噪声数据的同时保留了更多的高质量数据,表明其在选择视频问答对时更为有效。
视频问答评估性能实验:
- 目的:验证EVQAScore在训练VideoLLMs时的性能。
- 方法:使用EVQAScore过滤的数据训练VideoLLaVA和VideoLLaMA2模型,并在多个基准测试(ActivityNet, MSVD, MSRVTT, TGIF, MVBench, VCGBench和VCGBench Diverse)上评估性能。
- 结果:如表3、5、6和7所示,EVQAScore在所有基准测试中均取得了SOTA性能,证明了其在不同模型和基准测试中的有效性和鲁棒性。
案例研究:评估视频字幕:
- 目的:通过案例研究展示EVQAScore相对于先前视频字幕评估方法的优势。
- 方法:提供了两个案例,一个展示EVQAScore能正确评估全面的答案,另一个展示EVQAScore能评估更长的问答对。
- 结果:如图1和图3所示,EVQAScore能有效地评估长视频和复杂字幕,而CLIPScore、EMScore和PAC-S由于CLIP的令牌限制而难以处理。
这些实验全面地验证了EVQAScore在视频问答数据评估中的效率、准确性和鲁棒性,并展示了其在实际应用中的潜力。
Q: 有什么可以进一步探索的点?
A: 尽管EVQAScore在视频问答数据评估方面取得了显著的成果,但仍有一些领域可以进一步探索和研究:
算法改进:
- 上下文感知的关键词提取:研究更高级的上下文感知关键词提取技术,以更准确地捕捉视频内容的语义信息。
- 多模态融合技术:探索更先进的多模态融合技术,以整合视频的视觉和文本信息,提高评估的准确性。
模型泛化能力:
- 跨领域评估:在不同的领域和类型的视频数据集上测试EVQAScore,以评估其泛化能力。
- 跨语言评估:将EVQAScore应用于非英语视频数据,探索其在跨语言视频问答评估中的有效性。
计算效率优化:
- 并行化和分布式计算:研究如何通过并行化和分布式计算进一步提高EVQAScore的评估效率。
- 轻量级模型:开发轻量级的模型变体,以在资源受限的环境中部署EVQAScore。
数据集和标注研究:
- 构建更大规模的数据集:构建更大规模、更多样化的视频问答数据集,以全面评估EVQAScore的性能。
- 细粒度标注:研究细粒度的视频内容标注方法,以提供更精确的训练和评估数据。
应用研究:
- 实际应用场景:探索EVQAScore在实际视频理解和分析任务中的应用,如视频内容监控、视频推荐系统等。
- 交互式视频问答系统:将EVQAScore集成到交互式视频问答系统中,以提供更准确的问答服务。
模型解释性和透明度:
- 模型解释性:研究如何提高EVQAScore的解释性,以便更好地理解其决策过程。
- 透明度和可追溯性:提高模型的透明度和可追溯性,以便在关键应用中建立用户信任。
鲁棒性和安全性:
- 对抗性攻击防御:研究如何提高EVQAScore对对抗性攻击的鲁棒性。
- 隐私保护:探索在保护用户隐私的同时进行有效的视频问答评估的方法。
这些方向不仅可以推动视频问答评估技术的发展,还可能为视频理解和分析领域带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出了视频问答(Video QA)数据评估的重要性,以及现有方法在评估视频字幕和问答数据质量方面的不足,特别是在理解字幕和问答对的语义、评估效率以及缺乏针对视频大型语言模型(VideoLLMs)的数据评估实验方面的挑战。
EVQAScore方法:
- 论文提出了EVQAScore,这是一种无需参考的评估方法,它利用大型语言模型(LLMs)提取关键词来评估视频字幕和视频问答数据的质量。
- EVQAScore通过均匀帧采样和关键词提取技术提高了评估的效率和鲁棒性,使其能够处理极长视频的评估。
主要贡献:
- 提出了一种新颖的评估方法EVQAScore,用于评估视频问答和字幕数据的质量。
- 利用均匀帧采样和关键词提取技术提高了评估的效率,减少了计算成本。
- 在VATEX-EVAL基准测试中取得了SOTA性能,通过使用EVQAScore进行数据选择,仅使用12.5%的数据量就超过了之前SOTA方法和100%数据的性能。
实验验证:
- 论文通过一系列实验验证了EVQAScore的有效性,包括评估效率、视频字幕评估、视频问答数据过滤和视频问答评估性能等方面的实验。
- 实验结果表明,EVQAScore在多个基准测试中均取得了SOTA性能,并在案例研究中展示了其相对于先前方法的优势。
结论:
- 论文总结了EVQAScore在评估视频问答数据质量方面的优势,并强调了其在提高数据效率和整体视频理解方面的潜力。
总体而言,这篇论文提出了一个创新的视频问答数据评估框架,通过结合先进的语言模型技术和高效的计算策略,显著提高了视频问答数据评估的效率和准确性,并在多个基准测试中验证了其优越性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

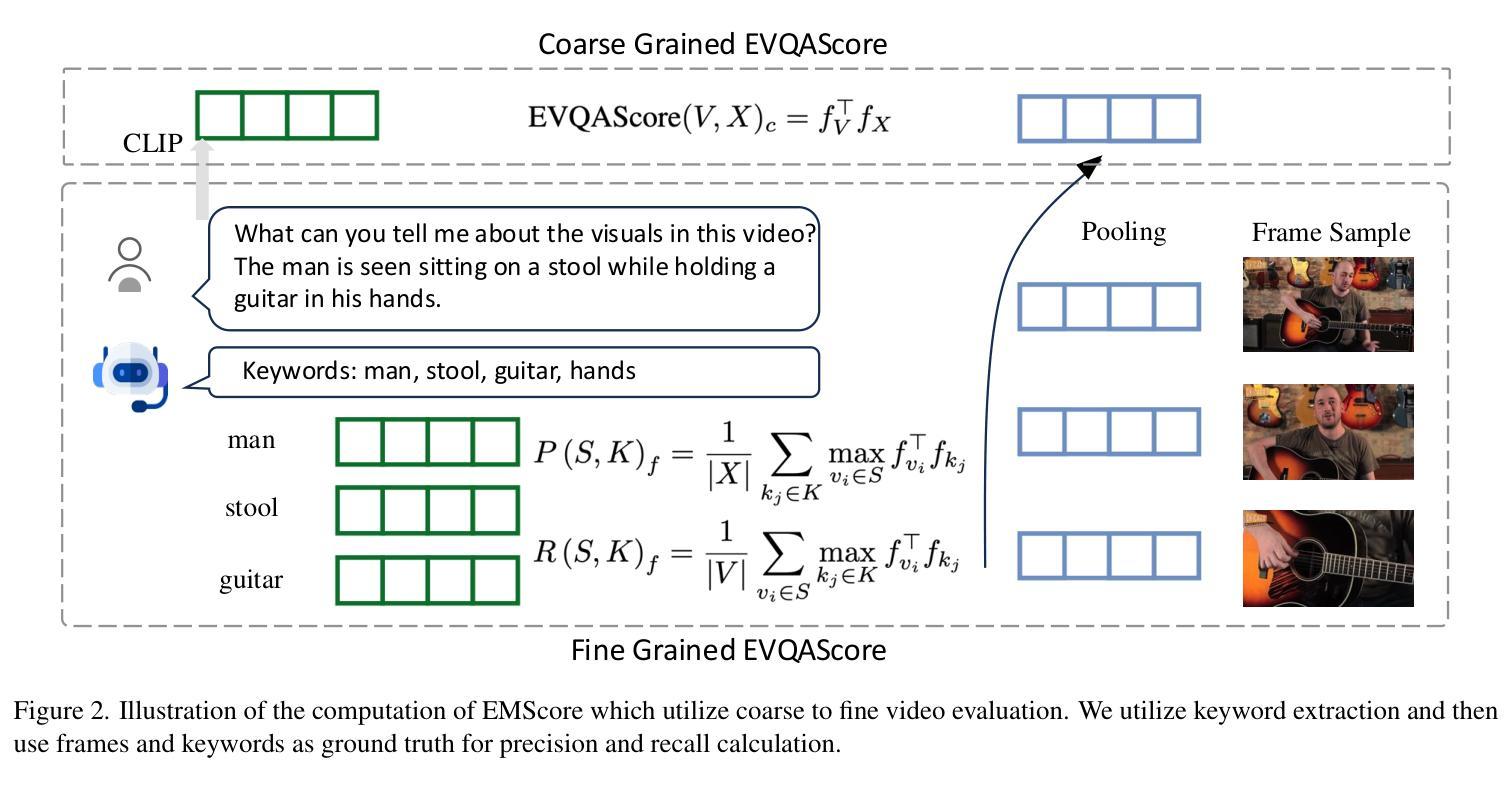

Prompt-Efficient Fine-Tuning for GPT-like Deep Models to Reduce Hallucination and to Improve Reproducibility in Scientific Text Generation Using Stochastic Optimisation Techniques
Authors:Daniil Sulimov
Large Language Models (LLMs) are increasingly adopted for complex scientific text generation tasks, yet they often suffer from limitations in accuracy, consistency, and hallucination control. This thesis introduces a Parameter-Efficient Fine-Tuning (PEFT) approach tailored for GPT-like models, aiming to mitigate hallucinations and enhance reproducibility, particularly in the computational domain of mass spectrometry. We implemented Low-Rank Adaptation (LoRA) adapters to refine GPT-2, termed MS-GPT, using a specialized corpus of mass spectrometry literature. Through novel evaluation methods applied to LLMs, including BLEU, ROUGE, and Perplexity scores, the fine-tuned MS-GPT model demonstrated superior text coherence and reproducibility compared to the baseline GPT-2, confirmed through statistical analysis with the Wilcoxon rank-sum test. Further, we propose a reproducibility metric based on cosine similarity of model outputs under controlled prompts, showcasing MS-GPT’s enhanced stability. This research highlights PEFT’s potential to optimize LLMs for scientific contexts, reducing computational costs while improving model reliability.
大型语言模型(LLM)越来越多地被用于复杂的科学文本生成任务,但它们在准确性、一致性和幻觉控制方面往往存在局限性。本论文针对GPT类模型提出了一种参数高效的微调(PEFT)方法,旨在减轻幻觉并增强可重复性,特别是在质谱计算领域。我们使用质谱文献专门语料库实现了低秩适配(LoRA)适配器来优化GPT-2,称为MS-GPT。通过应用于LLM的新型评估方法,包括BLEU、ROUGE和困惑度评分,经过微调的MS-GPT模型在文本连贯性和可重复性方面表现出优于基线GPT-2的性能,通过威尔科克森秩和检验进行统计分析后得到了证实。此外,我们提出了一种基于受控提示下模型输出余弦相似度的可重复性度量标准,展示了MS-GPT增强的稳定性。本研究突出了PEFT在优化科学背景下的LLM方面的潜力,降低了计算成本,提高了模型可靠性。
论文及项目相关链接
PDF 73 pages, 6 figures
Summary
大型语言模型(LLMs)在科学文本生成任务中广泛应用,但在准确性、一致性和幻觉控制方面存在局限。本论文针对GPT类模型提出一种参数有效微调(PEFT)方法,旨在减少幻觉并增强可重复性,特别是在质谱计算领域。通过采用低秩适配器(LoRA)对GPT-2进行微调,形成MS-GPT模型,使用质谱文献专用语料库进行训练。通过应用于LLM的新型评估方法,包括BLEU、ROUGE和困惑度评分,统计分析和Wilcoxon秩和检验证实,微调后的MS-GPT模型在文本连贯性和可重复性方面优于基线GPT-2。此外,提出基于受控提示下模型输出余弦相似性的可重复性度量,展示MS-GPT增强的稳定性。本研究突显PEFT在优化科学语境下的LLM方面的潜力,降低计算成本,提高模型可靠性。
Key Takeaways
- LLMs在科学文本生成中广泛应用,但存在准确性、一致性和幻觉控制方面的局限。
- 论文提出了一种参数有效微调(PEFT)方法,针对GPT类模型进行优化。
- 使用低秩适配器(LoRA)对GPT-2进行微调,形成专门针对质谱领域的MS-GPT模型。
- 通过多种评估方法,证明微调后的MS-GPT模型在文本连贯性和可重复性方面优于原始GPT-2。
- 论文提出了一个基于模型输出余弦相似性的可重复性度量标准,展示MS-GPT的稳定性增强。
- PEFT方法在优化科学语境下的LLM方面具有潜力,可降低计算成本,提高模型可靠性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何提高大型语言模型(LLMs),特别是GPT-2模型,在科学文本生成中的准确性和可复现性,以减少模型的“幻觉”现象(hallucination)并增强其在质谱学领域中的输出结果的准确性和可靠性。具体来说,论文的目标是通过以下方式来改善现有的LLMs:
减少模型幻觉:幻觉是指模型生成的错误信息,却假称其为真实信息的问题。这在需要高准确性的领域,如医疗或科学研究中,尤为关键。
提高答案的可复现性:通过微调(fine-tuning)GPT-2模型,使其在质谱学领域生成的文本更加可靠和一致。
改进模型的准确性:通过优化技术,如参数选择、优化器选择和学习率调整,提高模型在特定任务上的表现。
应用先进的微调方法:使用Low-Rank Adaptation (LoRA)适配器,这是一种参数效率的微调方法,可以在不显著增加模型大小的情况下,增加模型的可训练参数,提高其性能。
通过这些方法,论文旨在开发一个名为MassSpecGPT (MS-GPT)的新型文本生成模型,专门针对质谱学领域,以提高科学文本生成的质量。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与研究相关的工作和文献:
大型语言模型(LLMs)的发展:
- 论文中提到了几种不同的方法,包括递归神经网络(RNNs)[21, 22]、长短期记忆网络(LSTMs)[26, 8]和生成预训练变换器(GPT)[31]。这些研究展示了LLMs在理解和生成类人文本方面的进步。
文本生成基准测试:
- 论文提到了WikiText-103[7]、WikiText2、Text8等数据集,这些是评估语言模型性能的标准数据集。
模型大小和数据需求:
- 论文中提到了模型大小的增长,这反映了对大量数据的需求,无论是训练还是微调LLMs。
LLMs的挑战:
- 论文讨论了LLMs面临的挑战,包括偏见和幻觉问题,这些问题在医疗等领域尤为关键。
优化技术:
- 论文中提到了几种优化技术,包括SGD(随机梯度下降)[23]、Adagrad(自适应梯度)[6]、RMSProp和Adam(Adagrad+RMSProp)[12]。
微调技术:
- 论文讨论了微调的不同方法,包括P-Tuning、Prefix-Tuning和Parameter-Efficient Fine-Tuning (PEFT)。
LoRA(Low-Rank Adaptation)适配器:
- 论文中提到了LoRA适配器,这是一种在不改变预训练权重的情况下增加模型可训练参数的方法。
计算生物学中的LLMs应用:
- 论文提到了DNABERT[10]和DNAGPT[32],这些模型基于BERT或GPT架构,用于解码DNA语言。
统计测试:
- 论文中使用了Wilcoxon秩和检验[20]来评估微调模型的性能。
模型架构和自注意力机制:
- 论文详细描述了GPT-2模型的架构和自注意力机制,这是理解模型如何工作的关键。
这些相关研究为论文提供了理论基础和技术背景,帮助作者开发和评估针对质谱学领域的微调LLM。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决提高大型语言模型(LLMs)在科学文本生成中的准确性和可复现性的问题:
1. 数据收集与预处理
- 从Semantic Scholar研究数据库下载与计算质谱学相关的开放获取研究文章。
- 使用GROBID工具将PDF格式的文章转换为结构化的XML/TEI编码文档,然后提取出纯文本数据。
- 清洗数据,移除页眉、页脚和参考文献等非相关内容,确保用于训练的数据集质量和适用性。
2. 微调大型语言模型(LLM)
- 选择基模型:选择OpenAI开发的GPT-2模型作为基础模型进行微调。
- 应用LoRA适配器:使用Low-Rank Adaptation(LoRA)适配器,这是一种参数效率的微调方法,允许在不显著增加模型大小的情况下增加可训练参数。
- 选择优化器和学习率:通过网格搜索方法在样本数据上测试不同的优化器(SGD、Adam、RMSProp、Adagrad)和学习率,以确定最佳的训练参数。
- 全面模型微调:使用选定的最优参数在全部文本语料库上进行微调,生成最终的微调模型MassSpecGPT(MS-GPT)。
3. 模型评估
- 使用常见的自然语言生成(NLG)评估指标比较微调前后模型的准确性,包括BLEU、ROUGE和Perplexity。
- 进行统计测试(Wilcoxon秩和检验),以确定微调模型在各项指标上与原始GPT-2模型相比是否有显著改进。
4. 计算模型的可复现性
- 引入可复现性评分的计算方法,基于BERT模型计算生成文本的嵌入,然后通过余弦相似度衡量不同提示下生成文本的相似性。
- 对比微调模型和原始模型在带有“in mass spectrometry”短语的提示下的生成文本,评估其在质谱学领域的可复现性。
5. 结果分析与未来研究方向
- 论文总结了微调模型MS-GPT在Perplexity得分上相较于GPT-2的改进,并在可复现性上达到了统计学意义上的显著提升。
- 提出了未来可能的研究方向,包括开发结合编码器和解码器的对话型模型MS-Chat-GPT,以及将MS-GPT应用于质谱学实验室以辅助科学文本的完成和学生实验。
通过这些方法,论文不仅提高了LLMs在特定科学领域的准确性和可复现性,还为未来在更广泛领域的应用奠定了基础。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来验证微调后的模型(MassSpecGPT,简称MS-GPT)的性能,并与原始的GPT-2模型进行比较。以下是实验的详细步骤:
1. 数据收集和预处理
- 下载文章:使用Semantic Scholar提供的API密钥,下载与计算质谱学相关的研究文章。
- 文本提取:将下载的PDF文章转换为纯文本格式,使用GROBID工具进行转换,并去除非内容部分如页眉、页脚和参考文献。
2. 微调GPT-2模型
- 选择模型和适配器:选择GPT-2模型,并应用LoRA适配器进行参数效率的微调。
- 优化器和学习率选择:通过网格搜索在样本数据上测试不同的优化器(SGD、Adam、RMSProp、Adagrad)和学习率,以确定最佳的训练参数。
- 全模型微调:使用确定的最佳参数在全部文本语料库上进行微调,生成MS-GPT模型。
3. 模型评估
- 使用NLG评估指标:使用BLEU、ROUGE和Perplexity等指标比较MS-GPT和GPT-2模型的准确性。
- 统计测试:进行Wilcoxon秩和检验来评估两个模型在各项指标上的差异是否具有统计学意义。
4. 计算模型的可复现性
- 嵌入和余弦相似度:使用BERT模型计算生成文本的嵌入,然后通过余弦相似度衡量不同提示下生成文本的相似性。
- 可复现性评分:对MS-GPT和GPT-2模型在带有“in mass spectrometry”短语的提示下的生成文本进行可复现性评分。
- 统计学显著性检验:对可复现性评分进行Wilcoxon秩和检验,以确定MS-GPT在可复现性方面的改进是否具有统计学意义。
5. 结果记录和分析
- 记录和存储结果:将所有实验结果记录在表格和图表中,以便进行详细的分析和比较。
- 讨论改进方向:基于实验结果,讨论未来可能的改进方向和研究领域。
这些实验全面评估了MS-GPT模型在质谱学领域的性能,并与原始GPT-2模型进行了比较,验证了微调方法的有效性。
Q: 有什么可以进一步探索的点?
A: 根据论文的总结和结论部分,以下是一些可以进一步探索的点:
1. 人类监督训练文本语料库
- 进行详细的文本语料库审查,以提高训练数据的质量和自然性。这可能包括进一步清理数据,消除错误信息,以及确保数据的多样性和平衡性。
2. 选择不同的基模型
- 评估和比较不同的GPT类模型,以确定哪一个最适合作为质谱学领域微调的基础模型。这可能涉及比较不同模型的初始性能指标,并选择表现最好的模型进行进一步的微调。
3. 添加额外的网络层
- 在现有模型架构的基础上添加额外的层,以提高模型的性能。这将取决于训练数据的量和可用的计算资源。
4. 开发MS-Chat-GPT模型
- 开发一个包含编码器和解码器部分的对话型模型,以支持与用户的互动对话。这将需要大量的问答(QA)对数据集来训练模型。
5. 应用MS-GPT模型于实际场景
- 将MS-GPT模型应用于质谱学实验室,以辅助科研人员完成科学文本的编写和实验设计,提供更准确的信息。
6. 扩展到其他科学领域
- 将MS-GPT模型扩展到其他科学领域,如生物信息学、化学信息学等,以评估模型在不同科学领域的适用性和有效性。
7. 改进模型的泛化能力
- 研究如何提高模型的泛化能力,使其能够在处理未见过的新数据时保持高性能。
8. 探索更高效的微调技术
- 开发和测试新的参数效率微调技术,以减少模型微调所需的计算资源和时间。
9. 增强模型的解释性
- 提高模型的可解释性,使研究人员能够更好地理解模型的决策过程和生成的文本内容。
10. 多语言和跨领域适应性
- 探索模型在多语言和跨领域情境下的表现,以及如何调整模型以适应不同的语言和领域。
这些探索点可以帮助进一步优化和扩展MS-GPT模型的应用范围,提高其在科学研究中的实用性和有效性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容集中在如何通过微调大型语言模型(LLMs),特别是GPT-2模型,来提高其在科学文本生成中的准确性和可复现性,以减少模型的“幻觉”现象,并增强其在质谱学领域中的输出结果的准确性和可靠性。以下是论文的主要点:
1. 研究背景与目标
- 论文介绍了大型语言模型(LLMs)在文本生成和其他语言相关任务中的进展,以及它们面临的挑战,如数据偏见和幻觉问题。
- 论文的目标是改善LLMs的准确性和可复现性,特别是在计算质谱学领域。
2. 方法论
- 数据收集与预处理:从Semantic Scholar数据库下载相关论文,并使用GROBID工具将PDF转换为文本数据。
- 微调LLM:选择GPT-2模型,应用LoRA适配器进行参数效率的微调,并在样本数据上进行网格搜索以确定最优的优化器和学习率。
- 模型架构:介绍了GPT-2模型的架构和自注意力机制,以及如何通过LoRA适配器进行微调。
3. 实验与结果
- 模型评估:使用BLEU、ROUGE和Perplexity等指标比较微调后的MS-GPT模型和原始GPT-2模型的性能。
- 统计测试:通过Wilcoxon秩和检验评估两个模型在各项指标上的差异是否具有统计学意义。
- 可复现性评分:引入基于BERT模型的余弦相似度计算方法,评估模型在特定提示下的生成文本的可复现性,并进行统计测试。
4. 结论与贡献
- 微调后的MS-GPT模型在Perplexity得分上相较于GPT-2有所提高,并且在可复现性上达到了统计学意义上的显著提升。
- 论文提出了未来可能的研究方向,包括开发对话型模型和将MS-GPT应用于实际的质谱学实验室。
5. 代码与附录
- 论文提供了用于下载论文、文本提取、参数优化、模型微调和统计计算的代码附录。
总体而言,这篇论文展示了如何通过微调LLMs来提高其在特定科学领域的应用效果,并提供了一种新的方法来评估和提高模型的可复现性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Selecting Between BERT and GPT for Text Classification in Political Science Research
Authors:Yu Wang, Wen Qu, Xin Ye
Political scientists often grapple with data scarcity in text classification. Recently, fine-tuned BERT models and their variants have gained traction as effective solutions to address this issue. In this study, we investigate the potential of GPT-based models combined with prompt engineering as a viable alternative. We conduct a series of experiments across various classification tasks, differing in the number of classes and complexity, to evaluate the effectiveness of BERT-based versus GPT-based models in low-data scenarios. Our findings indicate that while zero-shot and few-shot learning with GPT models provide reasonable performance and are well-suited for early-stage research exploration, they generally fall short - or, at best, match - the performance of BERT fine-tuning, particularly as the training set reaches a substantial size (e.g., 1,000 samples). We conclude by comparing these approaches in terms of performance, ease of use, and cost, providing practical guidance for researchers facing data limitations. Our results are particularly relevant for those engaged in quantitative text analysis in low-resource settings or with limited labeled data.
政治科学家在文本分类中经常面临数据稀缺的问题。最近,经过微调后的BERT模型及其变体已经获得了牵引,成为解决这一问题的有效解决方案。在这项研究中,我们探讨了基于GPT的模型与提示工程相结合作为一种可行的替代方案的潜力。我们在各种分类任务中进行了一系列实验,这些任务在类别数量和复杂性方面有所不同,以评估在低数据场景下基于BERT的模型与基于GPT的模型的有效性。我们的研究结果表明,尽管GPT模型的零样本学习和少样本学习提供了合理的性能并且非常适合早期研究探索,但它们通常性能较差或表现平平,特别是在训练集达到相当大的规模时(例如,有1000个样本)无法超越经过微调后的BERT模型。最后我们通过比较这些方法的性能、易用性和成本,为面临数据限制的研究人员提供了实际指导。我们的研究结果对于在资源有限的环境中或从有限的标签数据中从事定量文本分析的研究人员尤其重要。
论文及项目相关链接
PDF 28 pages, 5 figures, 7 tables
Summary
BERT模型及其变种在文本分类中对于数据稀缺问题表现出优异效果。本研究探索了GPT模型结合提示工程技术的潜力,并与BERT模型进行了对比。实验结果显示,GPT模型在零样本和少样本学习场景下表现合理,适合初期研究探索,但在训练集达到一定规模时,其性能往往不如BERT微调。综合来看,研究者应充分考虑性能、易用性和成本因素。这些结果对于在低资源环境或有限标注数据下从事定量文本分析的研究人员尤为重要。
Key Takeaways
- BERT模型在处理文本分类中的数据稀缺问题上表现优异。
- GPT模型结合提示工程技术成为一种可行的替代方案。
- GPT模型在零样本和少样本学习场景下表现合理,适合初期研究探索。
- 在训练集达到一定规模时,GPT模型的性能往往不如BERT微调。
- 对比BERT和GPT模型,需要考虑性能、易用性和成本因素。
- 研究结果对于在低资源环境或有限标注数据下从事定量文本分析的研究人员尤为重要。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了政治科学研究中常见的文本分类问题,特别是在数据稀缺的情况下,如何选择合适的模型来处理这一问题。具体来说,论文试图解决的问题是如何在有限的标记数据条件下,有效地比较和选择BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer)这两种基于Transformer架构的语言模型,以进行有效的文本分类。
论文的主要目标是:
评估GPT模型结合提示工程(prompt engineering)作为BERT模型微调(fine-tuning)的替代方案的潜力:考虑到数据稀缺性,作者研究了GPT模型在少量样本情况下的表现,并与BERT模型进行了比较。
在不同分类任务中比较BERT和GPT模型的效果:通过在不同类别数量和复杂度的分类任务中进行实验,评估在低数据场景下基于BERT的模型与基于GPT的模型的有效性。
为面临数据限制的研究人员提供实际指导:论文最后根据性能、易用性和成本比较了这些方法,并为定量文本分析中资源有限的研究人员提供了实际指导。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的研究:
跨领域数据训练模型:
- Osnabrück et al. (2021) 研究了使用丰富的跨领域标记数据训练模型,然后将训练好的模型应用于特定领域的分类任务。
自动标注加速标记过程:
- Gilardi et al. (2023) 探讨了使用ChatGPT作为自动标注器来替代人工标注,以加快标记过程。
样本选择以减少标记样本数量:
- Kaufman (2024) 考虑了如何选择更具信息量的样本进行标记,以减少所需的标记样本数量。
BERT模型微调:
- Devlin et al. (2019) 提出了BERT模型,并通过结合预训练语言模型和特定任务样本证明了其在文本分类中的优越性能。
- Laurer et al. (2024) 和 Y. Wang (2023a) 等研究展示了BERT模型在政治科学文本分类中的应用。
词嵌入和循环神经网络:
- Mikolov et al. (2013), Pennington et al. (2014), 和 Y. Wang (2019b) 探讨了词嵌入技术,并将这些嵌入用作循环神经网络进行文本分类的输入。
传统模型:
- Hastie et al. (2009) 和 Y. Wang et al. (2022) 提到了使用词频作为输入的朴素贝叶斯、支持向量机和逻辑回归等传统模型。
GPT模型的应用:
- Radford et al. (2019) 和 Brown et al. (2020) 研究了GPT模型在文本生成任务中的表现,以及它们在零样本和少样本学习中的潜力。
政治科学中的文本分析:
- Nielbo et al. (2024), O. N. Kjell et al. (2024), 和 Y. Wang et al. (2022) 等研究在政治科学中应用文本分析技术。
这些相关研究涵盖了从传统模型到基于深度学习的现代方法,以及从词嵌入到基于Transformer的模型在政治科学文本分析中的应用。论文通过比较BERT和GPT模型在低数据情况下的表现,为政治科学中的文本分类问题提供了新的见解和方法。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决文本分类中的数据稀缺问题,并比较BERT和GPT模型的效果:
实验设计:
- 作者设计了一系列实验,覆盖了不同类别数量和复杂度的分类任务,包括二分类、8类分类、20类分类和22类分类任务。
- 对于每个实验,评估了使用200、500和1000个样本微调BERT模型的性能。
- 同时,计算了在没有样本、每类1个样本和每类2个样本的情况下GPT模型的性能。
模型选择:
- 选择了RoBERTa-large作为BERT模型的变体进行微调,因为它在BERT家族中性能较好。
- 选择了GPT-4作为GPT模型的版本,因为它提供了最佳性能。
超参数调整:
- 对BERT模型,优化了学习率等超参数。
- 对GPT模型,使用了两种不同的温度设置(0.2和0.8)来控制输出的变化。
实验执行:
- 对每个设置进行了三次实验,使用不同的随机种子以确保可重复性,并报告了平均值、最小值和最大值。
结果分析:
- 分析了增加训练样本数量对BERT模型微调和GPT模型提示的影响。
- 比较了在不同样本数量下,BERT微调和GPT提示的性能差异。
性能、易用性和成本比较:
- 论文不仅比较了模型的性能,还从易用性和成本的角度提供了实际指导。
- 讨论了BERT微调相对于GPT提示在不同情况下的优势和局限。
实际指导和建议:
- 根据实验结果,论文为政治科学和其他领域的研究人员提供了在数据受限情况下选择BERT或GPT模型的指导和建议。
通过这些步骤,论文提供了一个系统的方法来评估和选择在数据稀缺情况下适合的文本分类模型,并通过实验验证了GPT模型在某些情况下可以作为BERT模型微调的替代方案。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个:
经济情绪分类(二分类):
- 使用Sentiment Economy News数据集,目标是根据新闻标题和第一段内容判断经济表现的好与坏。
- 报告了训练集、验证集和测试集的分布情况。
- 对比了微调BERT模型(使用200、500、1000个样本)和GPT模型的零样本、单样本每类、双样本每类提示的性能。
政党宣言分类(8类):
- 使用来自WZB柏林社会科学中心的宣言数据集,进行8类话题分类。
- 报告了数据分布,并指出其中某些类别的样本量极少,实际上可视为7类分类问题。
- 对比了微调BERT模型和GPT模型提示的性能。
新西兰议会演讲分类(8类):
- 使用1987至2002年间新西兰议会的演讲稿,进行8类分类。
- 报告了训练集、验证集和测试集的分布情况。
- 对比了微调BERT模型和GPT模型提示的性能。
COVID-19政策措施分类(20类):
- 使用来自Cheng et al. (2020)的COVID-19政策措施数据集,包含20个类别。
- 报告了数据分布,并指出了数据集中的大类别和小类别。
- 对比了微调BERT模型和GPT模型提示的性能。
国情咨文演讲分类(22类):
- 使用国情咨文演讲数据集,进行22类分类。
- 报告了数据分布,并指出了数据集中的大类别和小类别。
- 对比了微调BERT模型和GPT模型提示的性能。
每个实验都评估了微调BERT模型和GPT模型在不同样本数量下的性能,并进行了多次实验以确保结果的可重复性。这些实验覆盖了从简单的二分类到复杂的多分类任务,提供了在不同分类任务中BERT和GPT模型性能的全面比较。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
混合精度训练:
- 研究混合精度训练在减少BERT模型微调的初始成本方面的潜力,特别是在处理大型数据集时。
先进的提示技术:
- 探索链式思考(chain-of-thought)和自我一致性(self-consistency)等先进的提示技术,以提高GPT模型的性能。
基于语义相似性的样本选择方法:
- 研究基于语义相似性等标准的更有效的样本选择方法,以增强GPT模型的提示效果。
成本效益分析:
- 对比不同模型在不同数据量和分类任务下的成本效益,考虑GPU使用时间、API调用费用等因素。
模型的可解释性:
- 提高模型的可解释性,以便更好地理解模型决策过程,并增强模型在政治科学领域的应用。
多模态数据融合:
- 考虑将文本数据与其他类型的数据(例如图像、视频)结合起来,进行更丰富的多模态分析。
跨语言和跨文化的应用:
- 探索模型在不同语言和文化背景下的应用,以及如何调整模型以适应不同的语言环境。
模型的鲁棒性和偏差检测:
- 研究模型的鲁棒性,并检测可能的偏差,以确保模型的公正性和可靠性。
模型在实时应用中的性能:
- 评估模型在实时或近实时应用场景中的表现,例如在社交媒体数据流上进行情绪分析。
模型微调和提示的结合:
- 研究将模型微调和提示结合起来的方法,以利用两者的优势,可能通过混合方法提高性能和效率。
这些探索点可以帮助研究人员更深入地理解BERT和GPT模型在政治科学和其他领域的应用,并推动相关技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容集中在探讨和比较BERT和GPT模型在政治科学研究中的文本分类任务上的应用,特别是在数据稀缺的情况下。以下是主要内容的总结:
问题陈述:
- 论文指出政治科学研究经常面临文本分类的数据稀缺问题,而BERT模型的微调是解决这一问题的有效方法。
研究目标:
- 论文旨在评估GPT模型结合提示工程作为BERT模型微调的替代方案的潜力,并比较两者在低数据场景下的效果。
实验设计:
- 作者设计了一系列实验,包括不同类别数量和复杂度的分类任务,如二分类、8类分类、20类分类和22类分类任务。
- 实验中评估了不同样本数量下微调BERT模型和GPT模型的性能。
模型和版本选择:
- 使用了RoBERTa-large作为BERT模型的变体,GPT-4作为GPT模型的版本。
超参数调整:
- 对BERT模型进行了学习率等超参数的优化,对GPT模型则调整了温度参数以控制输出变化。
实验结果:
- 发现微调BERT模型在大多数情况下性能优于GPT模型的提示方法,尤其是在样本数量较多时。
- 零样本和少样本的GPT提示在某些简单任务中可以与BERT微调相媲美。
性能、易用性和成本比较:
- 论文比较了微调BERT模型和GPT提示在性能、易用性和成本方面的差异。
- 指出GPT提示在易用性上优于BERT微调,但在成本上可能更高。
实际指导和建议:
- 论文为政治科学和其他领域的研究人员提供了在数据受限情况下选择BERT或GPT模型的指导和建议。
未来研究方向:
- 提出了一些未来研究方向,包括混合精度训练、先进的提示技术、基于语义相似性的样本选择方法等。
结论:
- 论文得出结论,尽管GPT模型在某些情况下可以作为BERT模型微调的替代方案,但微调BERT模型仍然是文本分类的首选方法,尤其是在样本数量较多时。同时,论文强调了在实际应用中考虑性能、易用性和成本的重要性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
- 论文得出结论,尽管GPT模型在某些情况下可以作为BERT模型微调的替代方案,但微调BERT模型仍然是文本分类的首选方法,尤其是在样本数量较多时。同时,论文强调了在实际应用中考虑性能、易用性和成本的重要性。
点此查看论文截图