⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-15 更新
AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward
Authors:Haonan Han, Xiangzuo Wu, Huan Liao, Zunnan Xu, Zhongyuan Hu, Ronghui Li, Yachao Zhang, Xiu Li
Recently, text-to-motion models have opened new possibilities for creating realistic human motion with greater efficiency and flexibility. However, aligning motion generation with event-level textual descriptions presents unique challenges due to the complex relationship between textual prompts and desired motion outcomes. To address this, we introduce AToM, a framework that enhances the alignment between generated motion and text prompts by leveraging reward from GPT-4Vision. AToM comprises three main stages: Firstly, we construct a dataset MotionPrefer that pairs three types of event-level textual prompts with generated motions, which cover the integrity, temporal relationship and frequency of motion. Secondly, we design a paradigm that utilizes GPT-4Vision for detailed motion annotation, including visual data formatting, task-specific instructions and scoring rules for each sub-task. Finally, we fine-tune an existing text-to-motion model using reinforcement learning guided by this paradigm. Experimental results demonstrate that AToM significantly improves the event-level alignment quality of text-to-motion generation.
最近,文本到动作模型以其更高的效率和灵活性为创建逼真的人类动作提供了新的可能性。然而,由于文本提示和期望的动作结果之间的复杂关系,将动作生成与事件级别的文本描述对齐呈现出独特的挑战。为了解决这一问题,我们引入了AToM框架,该框架通过利用GPT-4Vision的奖励来增强生成动作与文本提示之间的对齐。AToM主要包括三个阶段:首先,我们构建了一个MotionPrefer数据集,该数据集将三种事件级别的文本提示与生成的动作配对,涵盖了动作的完整性、时间关系和频率。其次,我们设计了一种利用GPT-4Vision进行详细动作注释的方法,包括视觉数据格式化、针对特定任务的指令以及每个子任务的评分规则。最后,我们使用由此范式引导的强化学习对现有的文本到动作模型进行微调。实验结果表明,AToM显著提高了文本到动作生成的事件级对齐质量。
论文及项目相关链接
Summary
文本到动作模型为创建真实人类运动提供了新的可能性,但其对齐运动生成与事件级别文本描述带来了独特挑战。为解决这个问题,引入AToM框架,通过利用GPT-4Vision的奖励增强生成运动与文本提示的对齐。AToM包含三个阶段:构建MotionPrefer数据集,设计利用GPT-4Vision进行详细运动注释的模式,以及微调现有文本到动作模型。实验结果证明,AToM显著提高了文本到动作生成的事件级别对齐质量。
Key Takeaways
- 文本到动作模型能够高效灵活地创建真实人类运动。
- 事件级别文本描述与运动生成对齐存在独特挑战。
- AToM框架通过利用GPT-4Vision的奖励增强生成运动与文本提示的对齐。
- AToM包含构建MotionPrefer数据集、设计利用GPT-4Vision进行运动注释的模式以及微调现有文本到动作模型三个阶段。
- MotionPrefer数据集包含关于运动的完整性、时间关系和频率的三种类型的文本提示与生成运动的配对。
- GPT-4Vision用于详细运动注释,包括视觉数据格式化、任务特定指令和每个子任务的计分规则。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是文本到动作(text-to-motion)模型在根据文本提示生成人体动作时与事件级别的文本描述对齐的挑战。具体来说,挑战存在于以下几个方面:
复杂文本提示与期望动作结果之间的复杂关系:由于文本提示和期望动作结果之间存在复杂的映射关系,模型很难准确地将复杂的文本描述(例如,包含多个动作事件或具有时间关系和指定频率的动作)映射到相应的动作序列。
数据稀缺和粗糙的文本描述:现有的文本-动作对数据稀缺,且文本描述通常是粗糙的,覆盖的动作场景有限,这限制了模型对新颖描述的泛化能力。
模型泛化能力有限:由于上述限制,模型在零样本和多事件场景下的性能表现不佳,难以处理复杂的文本提示。
为了解决这些问题,论文提出了一个名为AToM的框架,该框架通过利用GPT-4Vision提供的奖励来增强生成动作和文本提示之间的对齐度。AToM框架包含三个主要阶段:构建与事件级别的文本提示配对的数据集、设计利用GPT-4Vision进行详细动作标注的范式,以及使用这种范式指导的强化学习来微调现有的文本到动作模型。实验结果表明,AToM显著提高了文本到动作生成的事件级别对齐质量。
Q: 有哪些相关研究?
A: 论文中提到了多个与文本到动作生成(Text-to-Motion, T2M)相关的研究工作,以下是一些主要的相关研究:
Text2Action [2]:利用基于SEQ2SEQ模型的GAN将简短描述映射到人体动作。
Language2Pose [3]:引入了一种课程学习方法,用于开发文本和姿态的关节级嵌入。
Lin et al. [18]:提出了一个端到端的SEQ2SEQ模型,用于生成更真实的动画。
Ghosh et al. [10]:开发了一个分层的双流序列模型,能够处理描述多个动作的长句子。
MotionCLIP [30]:将人类动作流形与CLIP空间对齐,赋予模型零样本能力。
TEACH [5]:基于Transformer的模型,能够生成遵循复杂、顺序动作指令的真实3D人体动作。
TEMOS [36]:使用基于Transformer的VAE和额外的文本编码器进行多对象3D场景生成和编辑。
T2M-GPT [33]:结合VQ-VAE和GPT获得高质量的离散表示,实现有竞争力的动作生成结果。
MotionDiffuse [34]:基于扩散模型,允许对身体部位进行细粒度控制。
MDM [27]:无分类器的扩散模型,预测动作样本而非噪声,便于几何损失的应用。
MLD [9]:使用潜在扩散模型进一步推进动作生成。
MotionGPT [15]:开发了统一的大型动作语言模型,通过离散向量量化表示人类动作。
除了这些,论文还讨论了与人类/AI反馈对齐模型相关的研究,包括:
Reinforcement Learning from Human Feedback (RLHF) [7, 22]:用于模型对齐的技术,特别是在目标复杂或不明确的情况下。
Direct Preference Optimization (DPO) [25] 和 Slic-hf [37]:直接基于人类偏好优化模型策略的方法。
InstructMotion [29]:第一个通过人类反馈的强化学习微调文本到动作模型的工作。
RLAIF [8]:展示了另一种有前景的替代方案,即使用AI反馈进行模型对齐。
这些研究构成了文本到动作生成领域的研究基础,并为本文提出的AToM框架提供了理论和技术背景。
Q: 论文如何解决这个问题?
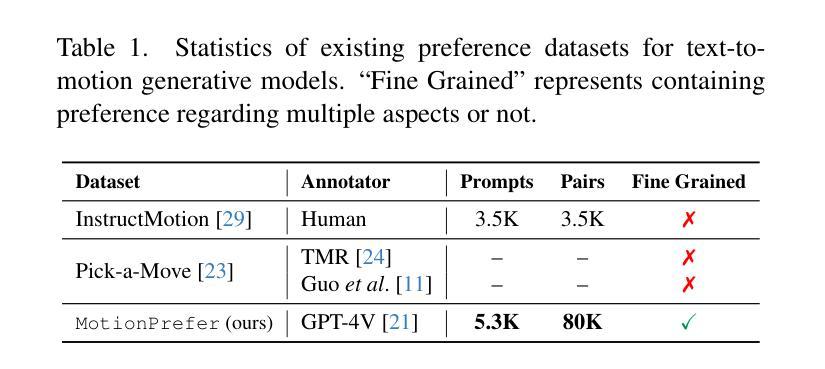
A: 论文通过提出一个名为AToM(Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward)的框架来解决文本到动作模型与事件级别文本描述对齐的问题。AToM框架主要包含以下三个阶段:
1. 数据集构建(Dataset Construction)
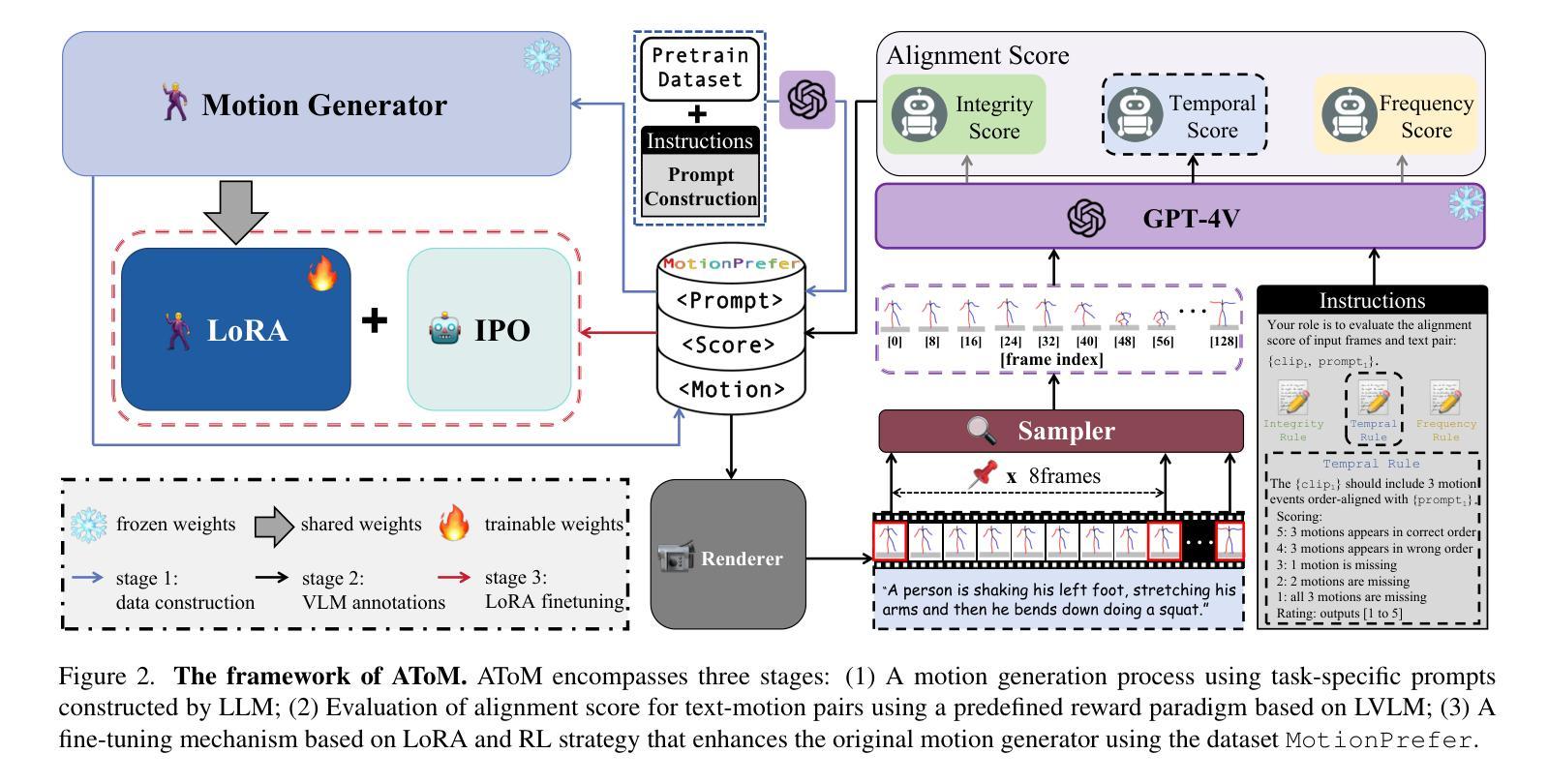
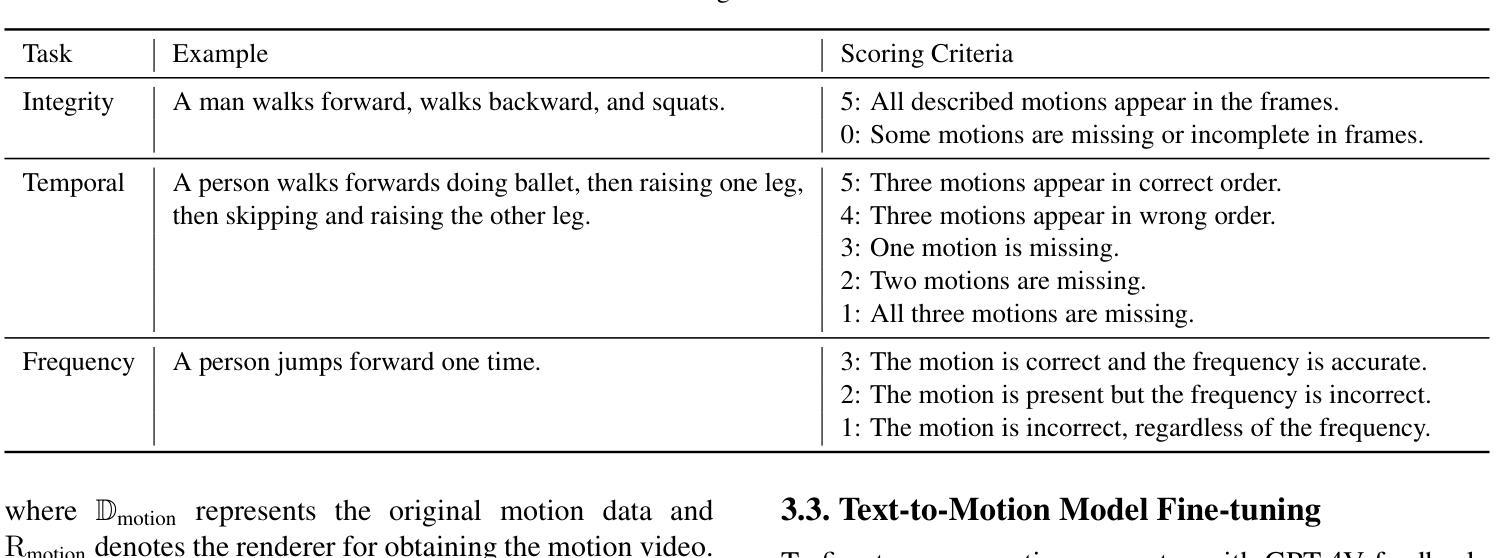
- 首先,研究者们构建了一个名为MotionPrefer的数据集,该数据集将三种类型的事件级别文本提示与生成的动作配对,涵盖了动作的完整性、时间关系和频率。
- 使用GPT-4生成初始文本提示,然后输入到动作生成模型(例如MotionGPT)中,为每个文本提示生成多个不同的动作。
- 总共包含5,276个提示和47.1k个动作样本。
2. 奖励范式设计(Reward Paradigm Design)
- 将MotionGPT生成的动作序列渲染成视频,并从中采样一系列帧。
- 将采样的动作帧和对应的文本提示输入到GPT-4Vision模型中,利用该模型评估文本和动作之间的对齐得分。
- 根据给定的评分规则为每个子任务(完整性、时间顺序和频率)计算对齐得分,生成带有对齐得分的文本-动作对,构成MotionPrefer数据集。
3. 文本到动作模型微调(Text-to-Motion Model Fine-tuning)
- 使用MotionPrefer数据集和GPT-4Vision的对齐得分作为反馈,微调现有的文本到动作模型(如MotionGPT)。
- 采用LoRA(Low-Rank Adaptation)和IPO(一种强化学习策略)算法进行微调,以提高模型在特定任务上的对齐性能。
- 实验结果表明,AToM显著提高了文本到动作生成的事件级别对齐质量。
通过这三个阶段,AToM框架能够有效地利用视觉语言大模型(如GPT-4Vision)的反馈,显著提高文本到动作模型在事件级别上的对齐质量,从而在文本提示和生成动作之间建立更加精确的对应关系。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估AToM框架的有效性,这些实验主要分为以下几个部分:
1. 实施细节(Implementation Details)
- 数据集:使用预训练的MotionGPT模型,并在MotionPrefer数据集的三个子集上进行微调,分别针对时间、完整性和频率任务。
- 实现具体内容:设置了学习率、批量大小和训练周期等超参数,并使用了AdamW优化器和余弦学习率调度器。
- 评估指标:包括多模态距离(MM-Dist)、R-Precision、FID、多样性和MModality等,用于评估动作质量和文本-动作对齐度。
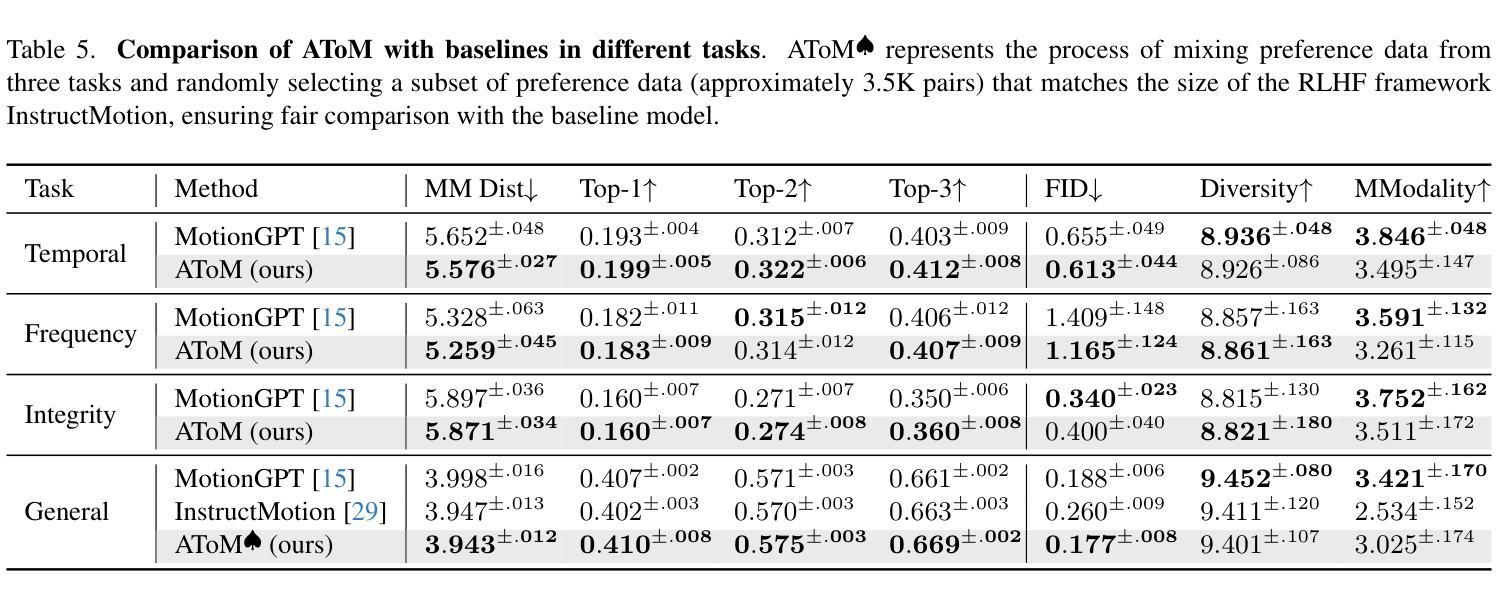
2. 主要结果(Main Results)
- 定量实验:在时间、频率和完整性任务中,AToM在多个评估指标上一致优于基线模型(MotionGPT和InstructMotion),显示出更好的文本-动作对齐度、动作质量和生成真实性。
- 定性实验:通过视觉样本比较,展示了预训练模型(MotionGPT)和微调后的模型(AToM)在生成忠实度上的差异,AToM在多样化动作事件、复杂时间顺序和特定频率方面表现更优。
- 用户研究:50名参与者对AToM和MotionGPT生成的动作在时间、频率和完整性方面进行了评估,AToM在所有子任务中的胜率均高于MotionGPT。
3. 消融研究(Ablation Study)
- 动作注入形式:比较了三种不同的动作注入策略(逐帧、全图像、轨迹图像)对GPT-4V提问的影响。
- 分数过滤:研究了在偏好对构建中使用分数过滤的效果,只有评分高于3的样本被视为正面样本。
- LoRA利用:探讨了LoRA在微调中的效果,与传统微调方法相比,LoRA能够更有效地调整模型参数。
- 强化学习策略:比较了不同的强化学习策略(IPO、DPO、KTO、PPO)在生成模型微调后的表现。
- 动作序列采样步长:研究了不同帧采样间隔对对齐和质量指标的影响。
4. 额外结果(Additional Results)
- 更多定性结果:提供了额外的AToM和基线模型生成的视觉样本比较。
- 微调迭代次数:探讨了微调迭代次数对模型性能的影响。
- IPO超参数β的影响:分析了IPO策略中超参数β对对齐和质量指标的影响。
- 偏好数据集体积对模型性能的影响:研究了偏好对数量对模型性能的影响。
这些实验全面评估了AToM框架在不同方面的表现,并与现有技术进行了比较,证明了其在提高文本到动作模型对齐质量方面的有效性。
Q: 有什么可以进一步探索的点?
A: 基于论文内容和实验结果,以下是一些可以进一步探索的点:
1. 扩展数据集的多样性和复杂性
- 跨领域数据集:探索将AToM框架应用于更广泛的动作类型和场景,例如体育活动、舞蹈和日常复杂交互。
- 多语言支持:研究模型对不同语言文本提示的泛化能力,并构建多语言数据集进行训练和测试。
2. 增强模型的解释性和可视化
- 注意力机制分析:通过引入注意力机制来分析模型在处理特定文本提示时关注的区域,增强模型的解释性。
- 生成过程可视化:研究生成过程中的关键帧和动作变化,以可视化的方式展示模型是如何根据文本提示生成动作的。
3. 探索不同的强化学习策略
- 混合策略:结合人类反馈和AI反馈的优势,开发混合强化学习策略以进一步提高模型性能。
- 自适应策略:研究自适应调整强化学习策略中的参数,以动态适应不同的训练阶段和任务需求。
4. 提升模型的鲁棒性和泛化能力
- 对抗训练:通过引入对抗样本来测试和增强模型的鲁棒性,特别是在面对异常或模糊的文本提示时。
- 零样本学习:探索模型在零样本或少样本情况下的泛化能力,尤其是在未见过的动作类型或描述上。
5. 跨模态应用和集成
- 动作识别和预测:将AToM框架应用于动作识别和预测任务,评估模型在视频理解和未来动作预测方面的表现。
- 虚拟现实和游戏:将模型集成到虚拟现实和游戏引擎中,实现基于自然语言指令的实时动作生成和控制。
6. 优化和加速训练过程
- 分布式训练:研究如何利用分布式计算资源来加速模型的训练过程。
- 模型压缩和加速:探索模型压缩技术,减少模型大小和计算需求,使其更适合在资源受限的设备上运行。
7. 社会和伦理考量
- 偏见和公平性:评估和解决模型可能存在的偏见问题,确保生成的动作多样性和包容性。
- 用户隐私和数据安全:在使用真实世界数据进行训练和测试时,确保遵守数据保护法规和用户隐私。
这些探索点可以帮助研究者们更深入地理解AToM框架的潜力和局限性,并推动文本到动作生成技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一个名为AToM(Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward)的框架,旨在提高文本到动作(Text-to-Motion, T2M)模型在事件级别上与文本提示对齐的质量。以下是论文的主要内容总结:
1. 问题背景
- 文本到动作模型能够根据文本提示生成人体动作,但在处理复杂的、多动作事件的文本描述时面临挑战。
- 现有模型在泛化到未见过的文本描述和多事件场景时受限,需要更精细的对齐评估。
2. AToM框架
- 数据集构建:创建了一个名为MotionPrefer的数据集,包含5.3K个文本提示和80K个动作偏好对,涵盖动作的完整性、时间关系和频率。
- 奖励范式设计:利用GPT-4Vision对生成的动作序列和文本描述之间的对齐进行评分,基于给定的评分规则计算对齐得分。
- 模型微调:使用MotionPrefer数据集和GPT-4Vision的对齐得分作为反馈,通过LoRA和IPO强化学习策略微调现有的文本到动作模型。
3. 实验结果
- 定量实验:AToM在多个评估指标上优于基线模型,显示出更好的文本-动作对齐度、动作质量和生成真实性。
- 定性实验:通过视觉样本比较,展示了AToM在生成忠实度上的优势。
- 用户研究:AToM在所有子任务中的用户评估胜率均高于基线模型。
4. 消融研究
- 探讨了不同的动作注入策略、分数过滤、LoRA利用和强化学习策略对模型性能的影响。
5. 结论
- AToM框架有效地利用视觉语言大模型的反馈,显著提高了文本到动作生成的事件级别对齐质量,为文本提示和生成动作之间建立了更精确的对应关系。
这篇论文通过提出一个新的框架,解决了文本到动作模型在复杂文本描述下对齐质量不足的问题,并展示了通过利用先进的视觉语言模型进行微调可以显著提升模型性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


LEAD: Latent Realignment for Human Motion Diffusion
Authors:Nefeli Andreou, Xi Wang, Victoria Fernández Abrevaya, Marie-Paule Cani, Yiorgos Chrysanthou, Vicky Kalogeiton
Our goal is to generate realistic human motion from natural language. Modern methods often face a trade-off between model expressiveness and text-to-motion alignment. Some align text and motion latent spaces but sacrifice expressiveness; others rely on diffusion models producing impressive motions, but lacking semantic meaning in their latent space. This may compromise realism, diversity, and applicability. Here, we address this by combining latent diffusion with a realignment mechanism, producing a novel, semantically structured space that encodes the semantics of language. Leveraging this capability, we introduce the task of textual motion inversion to capture novel motion concepts from a few examples. For motion synthesis, we evaluate LEAD on HumanML3D and KIT-ML and show comparable performance to the state-of-the-art in terms of realism, diversity, and text-motion consistency. Our qualitative analysis and user study reveal that our synthesized motions are sharper, more human-like and comply better with the text compared to modern methods. For motion textual inversion, our method demonstrates improved capacity in capturing out-of-distribution characteristics in comparison to traditional VAEs.
我们的目标是从自然语言生成逼真的人类运动。现代方法经常在模型表达力和文本到运动的对齐之间面临权衡。一些方法对齐文本和运动潜在空间,但牺牲了表达力;另一些方法依赖扩散模型产生令人印象深刻的运动,但其潜在空间中缺乏语义含义。这可能会损害真实性、多样性和适用性。在这里,我们通过结合潜在扩散和重新对齐机制来解决这个问题,产生了一个新颖、语义结构化的空间,该空间编码了语言的语义。利用这一能力,我们引入了文本运动反转任务,从少数几个例子中捕捉新的运动概念。对于运动合成,我们在HumanML3D和KIT-ML上评估了LEAD,并在真实性、多样性和文本运动一致性方面显示出与最新技术相当的性能。我们的定性分析和用户研究结果表明,与我们合成的运动相比,我们的运动更加清晰、更像人类,并且更符合文本描述。对于运动文本反转,我们的方法在捕捉超出分布特性的方面表现出了比传统VAEs更强的能力。
论文及项目相关链接
Summary
文本的目标是从自然语言生成逼真的人类运动。现代方法常常面临模型表达力和文本到运动对齐之间的权衡。本研究通过结合潜在扩散和重新对齐机制,创建了一个新颖、语义结构化的空间,编码语言语义。此外,本研究引入了文本运动反转任务来从少量样本中捕获新的运动概念。在HumanML3D和KIT-ML上的运动合成评估显示,其在逼真性、多样性和文本运动一致性方面表现出与最新技术相当的性能。我们的定性分析和用户研究表明,合成的运动更加清晰、更像人类,并且更符合文本描述。对于运动文本反转,该方法在捕获非标准特征方面表现出优于传统VAE的能力。
Key Takeaways
- 目标是从自然语言生成逼真的人类运动。
- 现代方法在模型表达力和文本到运动对齐之间存在权衡。
- 结合潜在扩散和重新对齐机制,创建语义结构化空间,编码语言语义。
- 引入文本运动反转任务,从少量样本中捕获新的运动概念。
- 在HumanML3D和KIT-ML上的运动合成评估表现与最新技术相当。
- 定性分析和用户研究表明合成的运动更加清晰、更像人类,更符合文本描述。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何从自然语言描述中生成逼真的人类运动(Text-to-Motion, T2M)。具体来说,论文面临的挑战包括:
模型表达性与文本到运动对齐之间的权衡:一些方法通过将文本和运动的潜在空间对齐来实现,但牺牲了模型的表达性;而其他方法依赖于扩散模型生成令人印象深刻的运动,但这些运动缺乏潜在空间中的语义含义。这可能会影响生成运动的真实性、多样性和适用性。
潜在空间中的语义结构缺失:现有的扩散模型虽然能够生成令人印象深刻的运动,但观察到合成的动画可能不会一致地遵循输入文本,并且可能仍然生成不真实的运动。论文提出假设,一个语义结构化的运动潜在空间(即继承语言空间的一些丰富属性的空间)可以促进和改进文本到运动生成的任务。
运动领域的个性化生成:在图像领域,扩散模型已经超越了通用文本到图像生成,向着基于几个示例合成难以描述的概念的个性化生成发展。然而,据作者所知,没有运动扩散工作展示出执行反演或个性化的能力。
为了解决这些问题,论文提出了LEAD(Latent rEAlignment for human motion Diffusion),这是一个基于潜在扩散的新文本到运动模型,通过引入一个投影模块来解决潜在空间中缺乏语义结构的问题。此外,论文还引入了运动文本反演(Motion Textual Inversion, MTI)的任务,并展示了提出的投影器如何改善这一任务。
Q: 有哪些相关研究?
A: 相关研究主要围绕以下几个领域:
文本到运动(Text-to-Motion, T2M)生成:这是创建反映给定语言指令的类人运动的过程。此任务由于其在3D内容创建中的潜在应用以及在机器人技术、娱乐和虚拟现实等领域的众多应用而受到显著关注。相关工作包括TEMOS、L2JP、MotionCLIP等,这些方法构建了一个共同的潜在空间,同时编码自然语言和运动。
多模态运动合成:研究工作探索了使用文本、图像、音频、音乐和场景等作为条件来控制运动生成的方法。例如,一些工作通过将自然语言转换为潜在空间,作为条件信号来生成运动。
运动扩散模型(Motion Diffusion Models):扩散模型已经在文本到图像生成中展示了前所未有的能力,最近其在文本到运动任务中的潜力也被探索。例如,基于 transformer 的运动扩散模型(MDM)和使用跨模态线性变换器作为主干来增加生成运动多样性的 MotionDiffuse。
文本反演在扩散模型中的应用(Textual Inversion in Diffusion Models):文本反演的目标是将其他模态的数据反演到语言潜在空间,以便在预训练模型中引入新概念。例如,Gal 等人的工作通过优化方法来解决图像反演问题,通过视觉重建作为指导来找到对应新概念的标记嵌入。
运动表示学习:包括使用VAEs和Transformer架构来学习运动数据的有效表示,例如在HumanML3D和KIT-ML数据集上进行评估。
运动数据集:如HumanML3D和KIT-ML,这些数据集提供了大量的人类运动序列和相应的文本描述,用于训练和评估T2M模型。
评估指标:用于评估生成运动的真实性、文本运动一致性、生成多样性和多模态匹配的指标,如Fréchet Inception Distance (FID)、多模态距离 (MMdist) 和 R-precision。
这些研究构成了LEAD方法的理论和实证基础,并帮助展示了该方法在文本到运动生成和运动文本反演任务中的潜力和优势。
Q: 论文如何解决这个问题?
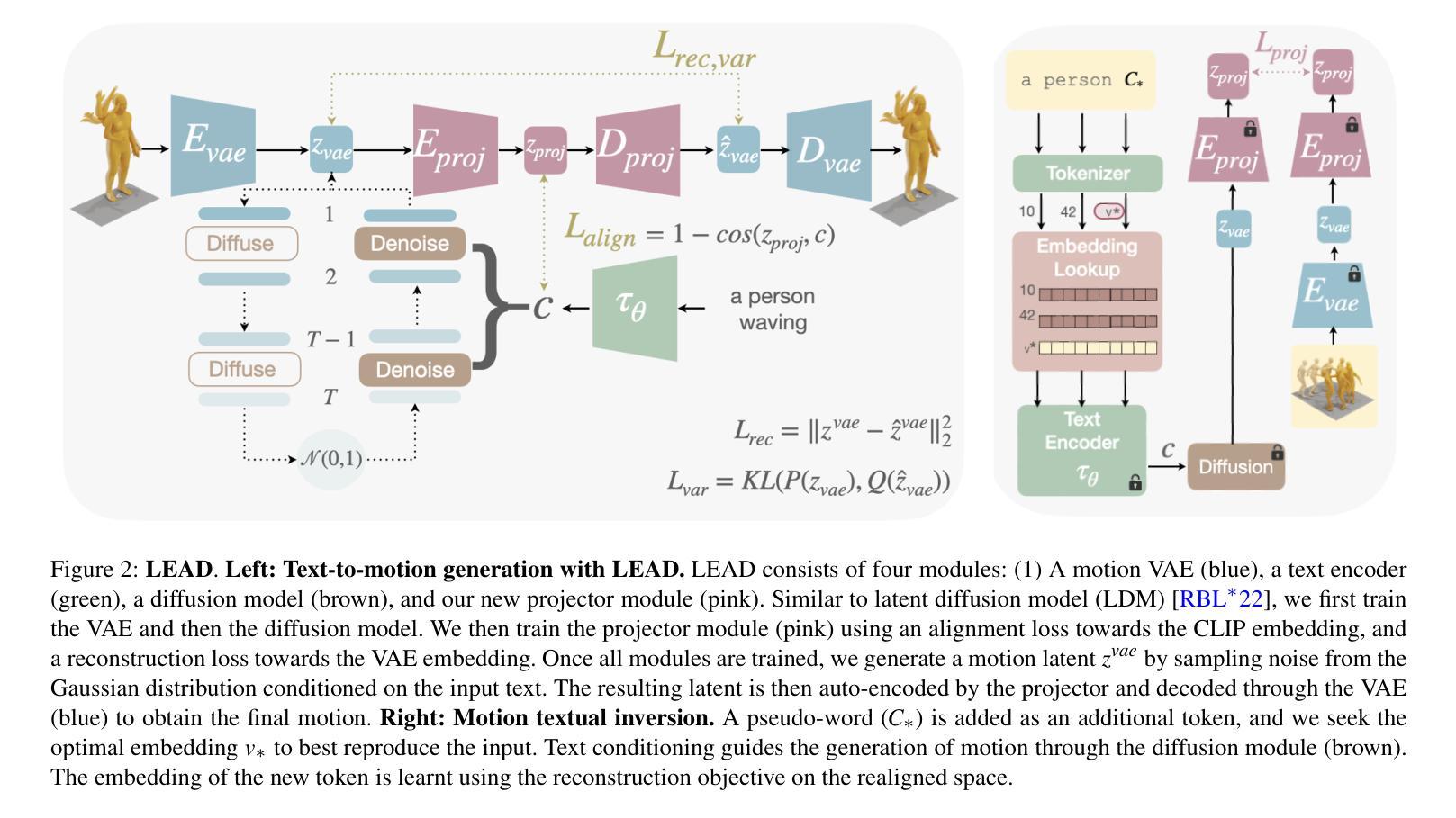
A: 论文通过提出一个名为LEAD(Latent rEAlignment for human motion Diffusion)的新文本到运动模型来解决这个问题。LEAD模型的核心思想是结合潜在扩散模型和一个重新对齐机制,以创建一个新颖的、语义结构化的空间,该空间编码语言的语义。以下是该方法的关键组成部分和解决步骤:
1. 架构组成
LEAD模型由四个主要模块组成:
- 一个运动VAE(variational autoencoder),
- 一个文本编码器,
- 一个条件扩散模型,
- 一个新颖的投影模块(projector module)。
2. 运动VAE和文本编码器
- 使用一个基于transformer的运动VAE来学习和表示运动序列的潜在空间。
- 使用CLIP模型的文本编码器将输入文本转换为潜在的嵌入空间。
3. 条件扩散模型
- 采用基于transformer的扩散模型,该模型能够根据当前的噪声版本、时间步和条件向量(文本嵌入)来预测噪声。
4. 投影模块
- 这是LEAD的核心创新点,包括一个编码器(Eproj)和一个解码器(Dproj)。编码器将VAE的潜在表示转换为与CLIP对齐的新嵌入空间,解码器再将其转换回VAE空间。
- 通过训练这个模块,使得转换后的潜在表示与CLIP的文本嵌入空间更加一致,从而改善语义结构。
5. 训练和损失函数
- 首先训练运动VAE。
- 然后冻结VAE和文本编码器,训练扩散模型。
- 最后,训练投影模块,使用对齐损失(alignment loss)和重构损失(reconstruction loss)。
6. 推断过程
- 通过标准的逆扩散过程生成潜在噪声向量,并使用条件CLIP嵌入逐步去噪。
- 将清洁的潜在表示通过投影模块,并最终通过VAE解码得到运动序列。
7. 运动文本反演(Motion Textual Inversion, MTI)
- 引入MTI任务,通过优化给定示例运动的文本嵌入,以生成具有特定特征的运动序列。
- 使用重构损失在重新对齐的空间中学习新嵌入,以更好地捕捉输入运动的特征。
通过以上步骤,LEAD模型能够生成与文本描述更加一致且逼真的人类运动序列,同时在生成过程中保持多样性。此外,通过MTI任务,LEAD能够从少量示例中捕捉新运动概念,为个性化运动生成铺平了道路。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估LEAD模型在文本到运动生成(Text-to-Motion, T2M)和运动文本反演(Motion Textual Inversion, MTI)任务上的性能。以下是主要的实验内容和结果:
1. 数据集和评估指标
- 数据集:使用了两个标准数据集HumanML3D和KIT-ML进行T2M任务的评估。HumanML3D包含14,616个人体姿态序列和44,970个描述,而KIT-ML包含6,353个文本描述对应3,911个动作。
- 评估指标:包括Fréchet Inception Distance (FID)、多模态距离(MMdist)、R-precision、生成多样性(Div)和多模态性(MModality)等,用于评估生成动作的真实性、文本与动作的一致性、生成多样性和多模态匹配。
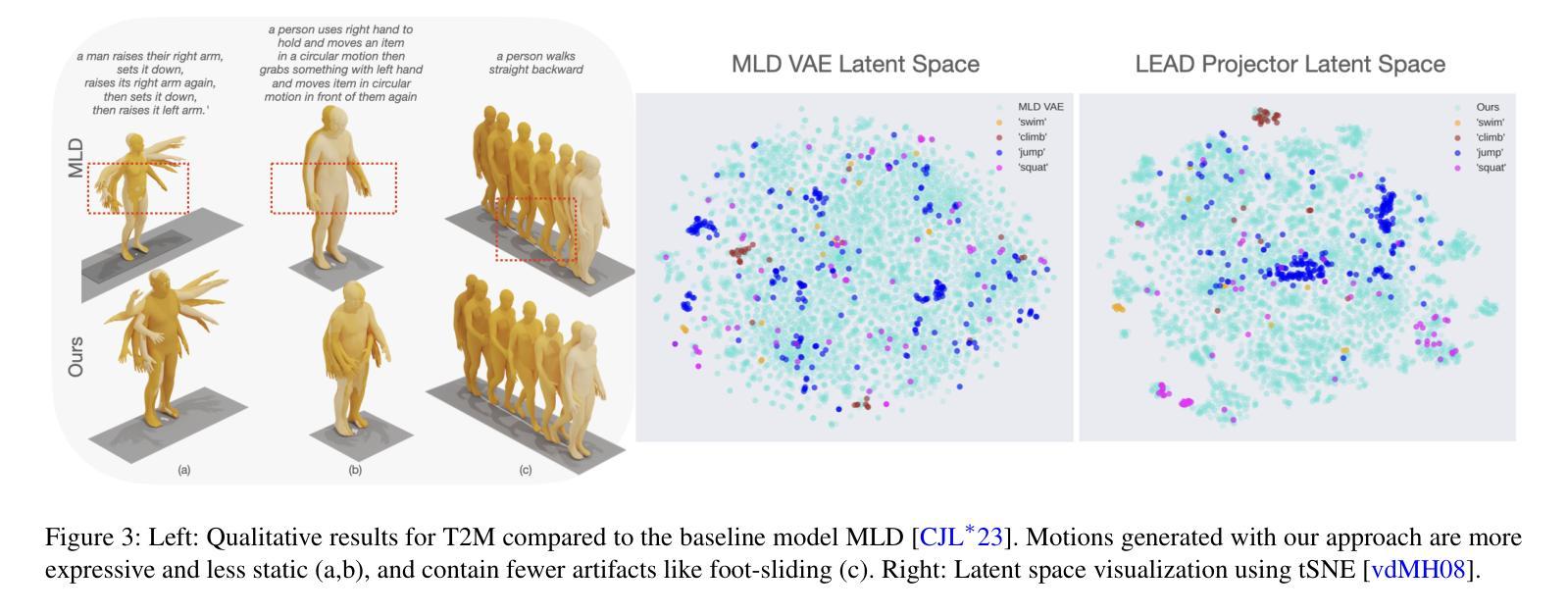
2. 文本到运动生成(T2M)
- 与现有的SOTA模型(如MLD、MotionLCM等)在HumanML3D和KIT-ML数据集上进行了比较。
- LEAD在运动真实性(FID)上取得了显著的改进,与其他方法相比,在保持多样性的同时,实现了更好的真实性和文本动作一致性。
3. 运动文本反演(MTI)
- 在HumanML3D的子集上进行了定量比较,评估了在不同空间(VAE空间、运动特征空间和重新对齐的空间)上进行MTI的效果。
- 结果表明,在重新对齐的空间上进行MTI可以改善生成动作的真实性和多模态对齐,证明了重新对齐机制在优化过程中的有效性。
4. 用户研究
- 进行了用户研究,比较了LEAD与MLD和MotionCLIP在运动真实性和文本动作相关性上的表现。
- 用户研究结果显示,LEAD生成的动作在真实性和与文本的匹配度上都优于其他方法。
5. LEAD潜在空间的可重用性
- 研究了LEAD潜在投影器在不同运动潜在扩散模型(如MotionLCM)上的泛化能力。
- 结果表明,即使在不同的文本编码方式下,LEAD的潜在空间也能改善文本动作对齐和动作质量,显示了潜在空间的鲁棒性和可转移性。
6. 消融研究
- 对LEAD模型的架构设计和训练损失进行了消融研究,以评估不同组件对最终性能的影响。
- 结果表明,使用基于transformer的架构和所有提出的损失函数能够实现最佳性能。
这些实验全面评估了LEAD模型在文本到运动生成和个性化运动生成任务中的有效性,并与现有方法进行了比较,证明了LEAD在生成逼真、多样化且与文本描述一致的人类运动方面的优势。
Q: 有什么可以进一步探索的点?
A: 尽管LEAD模型在文本到运动生成和运动文本反演任务上取得了显著的成果,但仍有一些方面可以进一步探索和改进:
1. 处理更长的文本描述
论文提到LEAD在处理长和连续的文本描述时可能会遇到挑战,生成的运动可能无法完全符合文本描述。因此,研究如何改进模型以更好地理解和处理更长的文本序列是一个重要的研究方向。
2. 提高动作的复杂性和自然性
尽管LEAD生成的动作更加逼真,但仍然可能存在一些动作不自然或不符合物理规律的情况,如脚部滑动等。研究如何进一步优化模型以生成更加复杂和自然的动作是一个有价值的探索方向。
3. 扩展数据集和多样性
LEAD模型主要在HumanML3D和KIT-ML数据集上进行训练和评估。将模型扩展到更多样化的数据集,并探索如何生成更多样化的动作,特别是在不同场景和风格下的动作,可以进一步提高模型的泛化能力。
4. 提升个性化生成的能力
虽然LEAD引入了运动文本反演任务来实现一定程度的个性化生成,但如何进一步提升模型的个性化生成能力,使其能够根据更少的示例或更抽象的描述生成具有特定特征的动作,仍然是一个值得探索的问题。
5. 交互式应用和实时生成
将LEAD模型应用于交互式环境,如虚拟现实或游戏,需要模型能够实时生成动作。研究如何优化模型以满足实时生成的需求,同时保持动作的质量和多样性,具有重要的实际应用价值。
6. 多模态输入的融合
考虑将更多的模态信息,如音频或视觉信息,与文本描述一起作为输入,以实现更丰富和动态的动作生成。研究如何有效地融合多模态输入以提高动作生成的准确性和自然性是一个有趣的研究方向。
7. 可解释性和控制性
提高模型的可解释性,让研究人员和用户更好地理解模型的决策过程,以及如何通过特定的输入控制生成的动作,可以增加模型的透明度和可用性。
8. 伦理和隐私问题
随着个性化运动生成技术的发展,需要考虑其潜在的伦理和隐私问题,如如何防止滥用技术生成虚假内容,以及如何确保在生成动作时尊重个人隐私和授权。
通过在这些方向上进行进一步的研究和探索,可以不断提升基于文本的动作生成技术的性能和应用范围,推动相关领域的技术进步。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为LEAD(Latent rEAlignment for human motion Diffusion)的新型文本到运动(Text-to-Motion, T2M)生成模型。LEAD模型的核心贡献在于引入了一个潜在对齐机制,通过这一机制,模型能够生成与输入文本描述在语义上更一致、更逼真的人类运动序列。下面是该论文的主要内容总结:
1. 问题陈述
- 生成与文本描述相符的逼真人类运动是一个挑战,因为自然语言与人类运动之间存在较大的差异。
- 现有方法在模型表达性和文本到运动对齐之间存在权衡,导致生成的运动可能缺乏语义一致性或多样性。
2. LEAD模型
- LEAD基于潜在扩散模型,通过一个新颖的投影模块将运动VAE的潜在空间与语言模型(如CLIP)对齐,以获得更好的语义结构。
- 该模型由四个主要模块组成:运动VAE、文本编码器、扩散模型和投影模块。
3. 方法
- 训练:分三个阶段训练LEAD,首先训练运动VAE,然后是扩散模型,最后训练投影模块。
- 推断:在推断时,通过逆扩散过程生成潜在噪声向量,使用文本嵌入作为条件,并通过投影模块生成最终的运动序列。
- 运动文本反演(MTI):提出了一个新的任务,通过优化给定示例运动的文本嵌入,以生成具有特定特征的运动序列。
4. 实验
- 在HumanML3D和KIT-ML数据集上评估LEAD,与现有方法比较,显示了在运动真实性、文本运动一致性等方面的改进。
- 用户研究结果表明,与现有方法相比,LEAD生成的运动在真实性和文本相关性方面得到了更高的评价。
- 对于MTI任务,LEAD在生成具有特定特征的运动方面表现出更好的性能。
5. 贡献
- 提出了LEAD模型,通过潜在对齐机制在文本到运动生成任务中取得了新的状态。
- 引入了运动文本反演任务,并展示了重新对齐的潜在空间在生成特定特征运动方面的优势。
6. 社会影响和局限性
- 论文讨论了个性化运动生成技术的潜在风险,包括滥用技术生成虚假内容和隐私问题。
- 指出了LEAD的局限性,包括在处理长文本描述和生成复杂动作时的挑战。
总体而言,LEAD通过其创新的潜在对齐机制,在文本到运动生成领域提供了一种新的解决方案,能够生成更逼真、更符合文本描述的人类运动序列,并为个性化运动生成开辟了新的可能性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

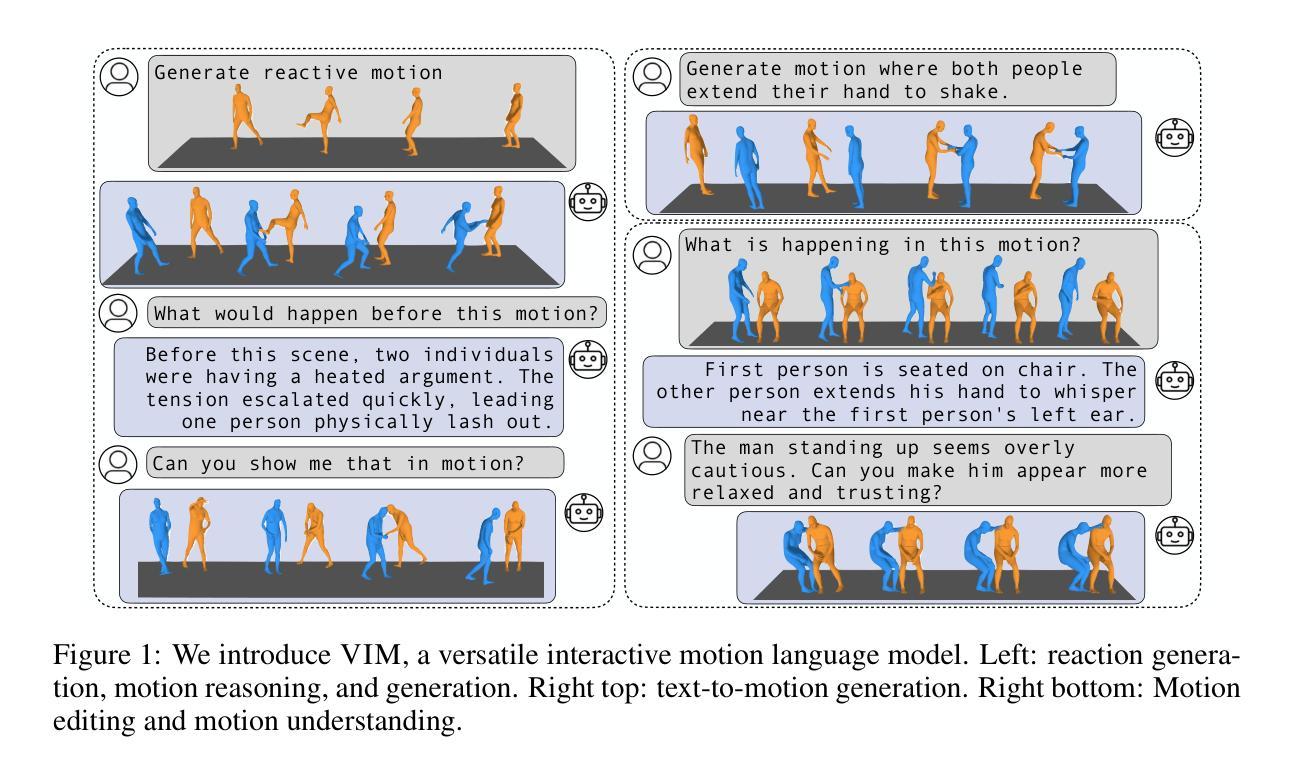
Versatile Motion Language Models for Multi-Turn Interactive Agents
Authors:Jeongeun Park, Sungjoon Choi, Sangdoo Yun
Recent advancements in large language models (LLMs) have greatly enhanced their ability to generate natural and contextually relevant text, making AI interactions more human-like. However, generating and understanding interactive human-like motion, where two individuals engage in coordinated movements, remains a challenge due to the complexity of modeling these coordinated interactions. Furthermore, a versatile model is required to handle diverse interactive scenarios, such as chat systems that follow user instructions or adapt to their assigned role while adjusting interaction dynamics. To tackle this problem, we introduce VIM, short for the Versatile Interactive Motion language model, which integrates both language and motion modalities to effectively understand, generate, and control interactive motions in multi-turn conversational contexts. To address the scarcity of multi-turn interactive motion data, we introduce a synthetic dataset, INERT-MT2, where we utilize pre-trained models to create diverse instructional datasets with interactive motion. Our approach first trains a motion tokenizer that encodes interactive motions into residual discrete tokens. In the pretraining stage, the model learns to align motion and text representations with these discrete tokens. During the instruction fine-tuning stage, VIM adapts to multi-turn conversations using the INTER-MT2 dataset. We evaluate the versatility of our method across motion-related tasks, motion to text, text to motion, reaction generation, motion editing, and reasoning about motion sequences. The results highlight the versatility and effectiveness of proposed method in handling complex interactive motion synthesis.
近期大型语言模型(LLM)的进展极大地提升了生成自然和语境相关文本的能力,使得人工智能交互更加人性化。然而,生成和理解交互式人类运动——两个人进行协调运动——仍然是一个挑战,原因在于对协调交互进行建模的复杂性。此外,需要一种通用模型来处理各种交互场景,例如在遵循用户指令或适应分配的角色时调整交互动力的聊天系统。为了解决这个问题,我们引入了VIM,即通用交互式运动语言模型的简称,它结合了语言和运动模式,以有效地理解、生成和控制多轮对话语境中的交互式运动。为了解决多轮交互式运动数据的稀缺问题,我们引入了一个合成数据集INERT-MT2,我们利用预训练模型创建具有交互式运动的各种指令数据集。我们的方法首先训练一个运动令牌化器,该令牌化器将交互式运动编码为残余离散令牌。在预训练阶段,模型学习使用这些离散令牌对齐运动和文本表示。在指令微调阶段,VIM适应多轮对话,使用INTER-MT2数据集。我们评估了我们的方法在动作相关任务、动作到文本、文本到动作、反应生成、动作编辑和运动序列推理方面的通用性。结果突出了该方法在处理复杂交互式运动合成中的通用性和有效性。
论文及项目相关链接
PDF https://vim-motion-language.github.io/
Summary
大型语言模型(LLM)的进展提升了生成自然、语境相关文本的能力,使得人工智能交互更加人性化。然而,生成和理解交互式的类人动作(如两人协同动作)仍存在挑战。为应对这一问题,我们推出了VIM(通用交互式动作语言模型),它结合了语言和动作模态,能在多轮对话语境中有效地理解、生成和控制交互式动作。我们利用预训练模型创建了INERT-MT2合成数据集,以应对多轮交互式动作数据的稀缺问题。VIM首先训练动作标记器,将交互式动作编码为剩余离散标记。在预训练阶段,模型学习用这些离散标记对齐动作和文本表示。在指令微调阶段,VIM使用INTER-MT2数据集适应多轮对话。我们在多个动作相关任务上评估了该方法的多功能性,包括动作转文本、文本转动作、反应生成、动作编辑和推理动作序列。结果突显了该方法在处理复杂交互式动作合成方面的多功能性和有效性。
Key Takeaways
- 大型语言模型的进步使得AI文本生成更加自然和语境化,提升了人机交互的人性化程度。
- 交互式类人动作生成和理解仍是人工智能领域的一大挑战,需要复杂建模。
- VIM模型结合了语言和动作模态,能有效处理多种交互式场景,如遵循用户指令的聊天系统。
- INERT-MT2合成数据集解决了多轮交互式动作数据的稀缺问题。
- VIM通过训练动作标记器,将交互式动作编码为离散标记,促进动作和文本的相互理解。
- 模型的预训练阶段使其学习动作和文本的表示对齐,而在指令微调阶段则适应多轮对话。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何生成和理解交互式的人类运动,尤其是在多轮对话中的协调运动。尽管大型语言模型(LLMs)在生成类人文本和理解复杂语言交互方面取得了进展,但现有的方法通常只关注单一任务,如文本到运动或运动到文本的翻译,并且只考虑单一动作,没有交互。这限制了代理处理涉及多个代理、复杂交互和多轮对话场景的能力。
论文中提到的挑战包括:
多轮交互运动数据的稀缺性:缺乏包含两个个体之间交互运动以及多轮对话指令的数据集,这使得模型难以学习交互运动的细节和多轮动态。
交互运动的复杂性:交互运动涉及两个人之间的协调动作,这要求模型能够理解和控制交互,允许用户提供指令、分配角色或修改行为。
模型的多样性和灵活性:需要一个多功能的模型来处理多种交互场景,例如遵循用户指令的聊天系统,或在调整交互动态时适应分配的角色。
为了解决这些问题,论文介绍了VIM(Versatile Interactive Motion language model),这是一个集成了语言和运动模式的模型,可以有效理解、生成和控制多轮对话背景下的交互运动。此外,论文还介绍了一个合成数据集INTER-MT2,旨在通过使用预训练模型创建多样化的指令数据集和交互运动,来解决多轮交互运动数据不足的问题。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究包括以下几个方面:
人类运动建模与控制:
- 基于扩散的方法,例如MDM (Tevet et al., 2023),FG-T2M (Wang et al., 2023),和MotionDiffuse (Zhang et al., 2024a),擅长从文本合成逼真的人类运动。
- 基于Transformer模型与向量量化,例如TM2T (Guo et al., 2022) 和 T2M-GPT (Zhang et al., 2023),有效捕捉复杂的运动模式。
- MoMASK (Guo et al., 2024a) 通过残差tokenizers提高运动粒度。
- FineMoGEN (Zhang et al., 2024c) 基于用户指令提供细粒度的运动合成。
- MEOs (Goel et al., 2024) 使用字幕和大型语言模型来识别帧和身体部位进行编辑,而MotionFix (Athanasiou et al., 2024) 则在源运动和编辑文本的条件下对扩散模型进行条件化,以实现无缝的运动编辑。
运动语言模型:
- MotionGPT (Jiang et al., 2023) 在统一框架上展示了运动理解和生成的多功能性。
- MotionChain (Jiang et al., 2024) 引入了一个多轮对话系统,用于在对话上下文中解释和生成运动,包括图像输入。
- AvatarGPT (Zhou et al., 2024) 集成了运动生成和规划能力。
- M3-GPT (Luo et al., 2024) 模型了语音、音乐、文本和运动的互换性。
人与人之间交互运动建模:
- 多人交互数据集例如Inter-X (Xu et al., 2024a) 和 InterHuman (Liang et al., 2024) 已被开发。
- InterGEN (Xu et al., 2024a) 引入了扩散模型,具有空间约束损失。
- PriorMDM (Shafir et al., 2024) 利用预训练的运动扩散模型和瘦通信块。
- ReMoS (Ghosh et al., 2023) 合成反应运动,使用时空交叉注意力,而ReGenNet (Xu et al., 2024b) 则采用基于距离的交互损失的transformer模型来预测人类反应。
这些相关研究展示了在运动生成、控制、理解和交互式运动建模方面的最新进展,同时也指出了现有方法在处理多轮交互和复杂推理能力方面的局限性。论文提出的VIM模型和INTER-MT2数据集旨在通过结合这些领域的最新技术来解决这些挑战。
Q: 论文如何解决这个问题?
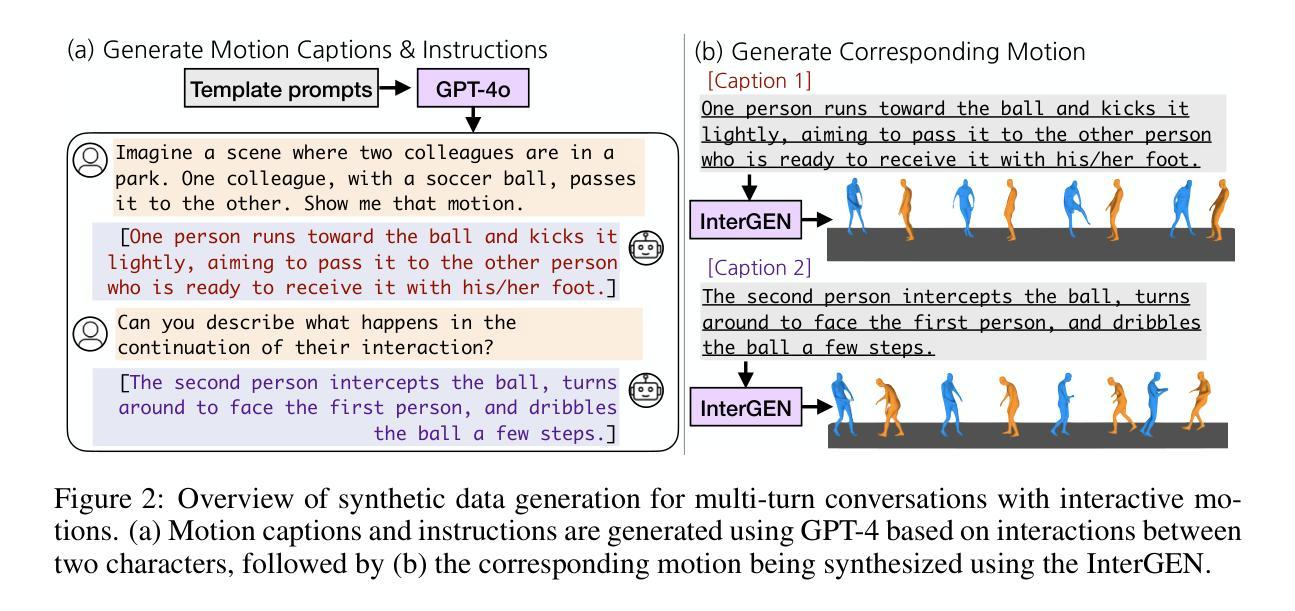
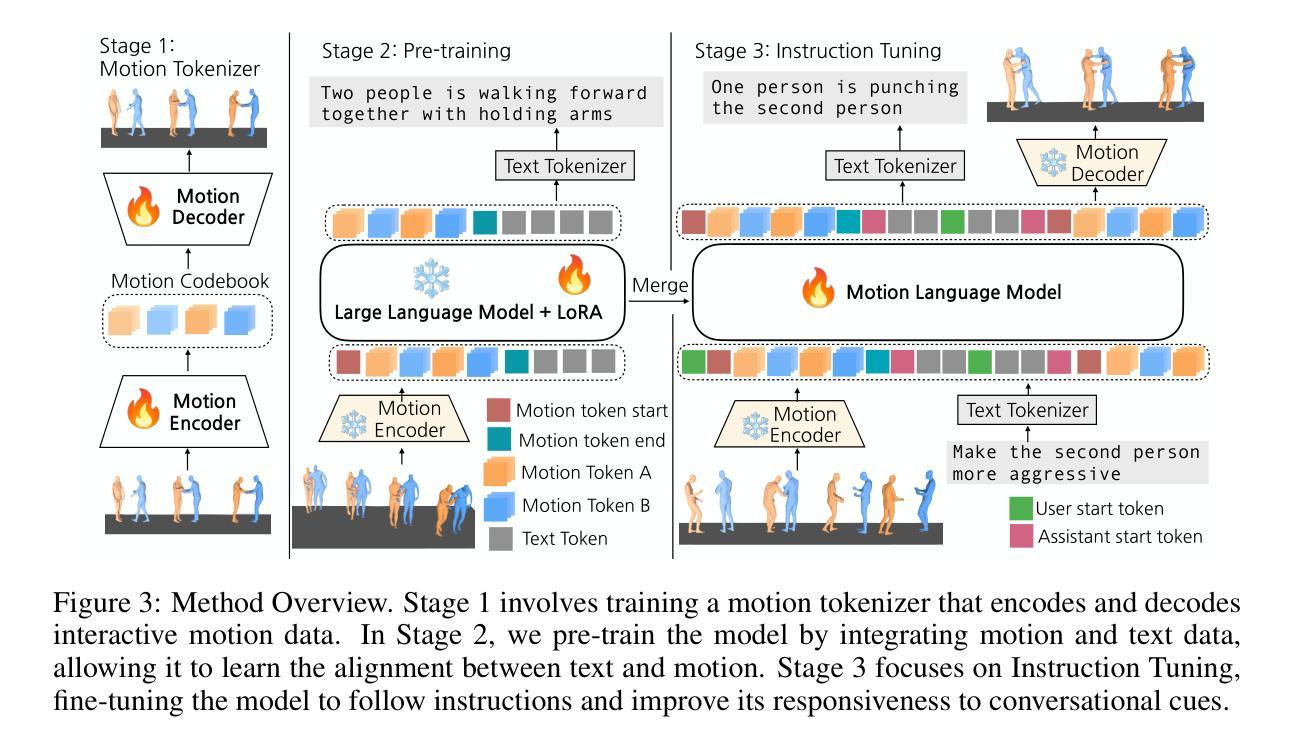
A: 论文通过以下几个关键步骤解决多轮交互式运动建模和理解的问题:
提出VIM模型:VIM(Versatile Interactive Motion language model)是一个多模态语言模型,集成了语言和运动模式,有效理解、生成和控制多轮对话背景下的交互运动。
创建INTER-MT2数据集:为了解决多轮交互运动数据的稀缺性,论文提出了一个新的合成数据集INTER-MT2,它包含了多轮对话中的多样化指令和交互运动。
设计训练流程:VIM模型的训练过程包括三个阶段:
- 运动标记器训练:训练一个运动标记器,将交互运动编码为残差离散标记。
- 预训练:在预训练阶段,模型学习将运动和文本表示与这些离散标记对齐。
- 指令微调:使用INTER-MT2数据集进行指令微调,以处理更复杂和多轮的指令。
多模态序列处理:VIM能够同时处理输入和输出两种模态(运动和文本),使用统一的词汇表来整合运动标记和文本标记。
评估方法:论文提出了新的评估协议,通过运动相关任务(如运动到文本、文本到运动、反应生成、运动编辑和运动序列推理)来评估VIM的性能。
交互式任务设计:论文设计了高级交互式运动任务,如运动推理和编辑,要求模型基于对话上下文预测过去或未来的事件,或对当前运动进行推理。
实验验证:通过实验,论文评估了VIM在生成详细的基于运动的聊天回应、进行复杂推理以及在传统运动相关任务中的表现。
消融研究:论文还进行了消融研究,比较了不同的运动标记器(如VQ-VAE与RQ-VAE)对模型性能的影响。
通过这些方法,论文旨在提高模型在复杂交互式运动合成任务中的性能,并使其能够更好地理解和生成与多轮对话相关的交互式运动。
Q: 论文做了哪些实验?
A: 论文中进行的实验旨在评估VIM模型在处理多轮交互式运动任务方面的能力。具体实验包括:
运动推理(Motion Reasoning):
- 通过预测交互式运动的过去或未来事件,或解释当前运动,评估模型的推理能力。
- 使用大型语言模型(LLMs)评估生成文本内容的一致性、准确性和自然性。
- 应用了诸如ROUGE-L、METEOR和MAUVE等计算语言指标来定量评估生成文本与INTER-MT2测试集中标记文本的相关性、准确性和自然性。
运动编辑(Motion Editing):
- 目标是基于用户指令修改参考运动,通过用户研究比较编辑后的运动样本。
- 使用5点Likert量表评估内容相似性、指令一致性和运动质量。
- 使用Frechet Inception Distance(FID)和平均每个关节位置误差(MPJPE)等数据驱动指标来评估生成编辑运动的质量。
传统运动相关任务:
- 在InterHuman和Inter-X数据集的测试集上评估了运动到文本(M2T)、文本到运动(T2M)和反应生成任务。
- 报告了检索精度、FID、MPJPE等指标来评估模型性能。
消融研究(Ablation Studies):
- 对比了使用VQ-VAE和RQ-VAE作为运动标记器的模型变体。
- 评估了这些变体在运动推理、编辑、M2T、T2M和反应生成任务上的性能。
基线比较:
- 将VIM与一些基线方法进行了比较,包括两阶段方法和修改过的MotionGPT模型。
定性结果:
- 展示了VIM在运动编辑、运动推理、M2T、T2M和反应生成任务上的定性结果。
这些实验全面评估了VIM模型在多轮交互式运动理解、生成和编辑任务中的有效性和灵活性。通过与传统基线方法的比较,论文证明了VIM在处理复杂交互式运动合成中的优越性能。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的VIM模型在多轮交互式运动建模方面取得了显著进展,但仍有一些潜在的研究方向和改进空间可以进一步探索:
数据集的多样性和规模:尽管INTER-MT2数据集为模型提供了多轮交互式运动的示例,但扩大数据集的规模和多样性可以进一步提高模型的泛化能力和鲁棒性。
更复杂的交互场景:当前的研究主要关注两个个体之间的交互。未来的工作可以探索涉及更多参与者的复杂交互场景。
个性化和适应性:模型可以进一步开发以更好地适应不同用户的具体需求和偏好。这可能涉及用户个性化和上下文感知的运动生成。
实时性能和资源效率:研究如何优化模型以实现实时应用和更高效的计算资源使用,这对于实际应用尤为重要。
细粒度的运动控制:虽然VIM能够处理交互运动,但进一步提高运动细节的控制能力,如精确的手势和面部表情,可以增加交互的真实感和自然性。
多模态输入和输出:扩展模型以处理和生成除了文本和运动之外的其他模态,如音频或图像,可能会进一步增强交互体验。
可解释性和透明度:提高模型决策过程的可解释性,帮助用户理解模型生成特定运动的原因,这对于建立用户信任和接受度至关重要。
交互式应用的实验:在实际的交互式环境中测试VIM模型,例如虚拟现实、游戏或机器人,以评估其在现实世界条件下的性能。
伦理和隐私问题:在处理涉及人类运动和交互的数据时,确保遵守伦理准则和隐私法规是至关重要的。
错误处理和异常管理:研究模型在遇到错误或异常输入时的鲁棒性和恢复能力,提高系统的稳定性和可靠性。
跨领域应用:探索VIM模型在其他领域的应用潜力,如健康监测、体育训练分析或社交互动研究。
通过这些进一步的探索和研究,可以不断提升交互式运动语言模型的性能和应用范围。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题定义:论文针对的是在多轮对话中生成和理解两个人之间交互式运动的问题。现有的大型语言模型虽然在文本生成和理解方面取得了进展,但在处理涉及多个代理、复杂交互和多轮对话的交互式运动方面存在挑战。
VIM模型介绍:为了解决这个问题,论文提出了一个名为VIM(Versatile Interactive Motion language model)的模型。VIM模型集成了语言和运动两种模态,可以有效地理解、生成和控制多轮对话中的交互运动。
INTER-MT2数据集:为了克服多轮交互运动数据的稀缺性,论文创建了一个合成数据集INTER-MT2,它包含了多轮对话中的多样化指令和交互运动。
训练流程:VIM模型的训练分为三个阶段:
- 运动标记器训练:训练一个运动标记器,将交互运动编码为残差离散标记。
- 预训练:在预训练阶段,模型学习将运动和文本表示与这些离散标记对齐。
- 指令微调:使用INTER-MT2数据集进行指令微调,以处理更复杂和多轮的指令。
评估方法:论文提出了新的评估协议,通过运动相关任务(如运动到文本、文本到运动、反应生成、运动编辑和运动序列推理)来评估VIM的性能。
实验结果:通过一系列实验,论文证明了VIM在生成详细的基于运动的聊天回应、进行复杂推理以及在传统运动相关任务中的表现优于现有方法。
消融研究:论文还进行了消融研究,比较了不同的运动标记器(如VQ-VAE与RQ-VAE)对模型性能的影响。
结论:VIM模型在多轮交互式运动建模方面展现了强大的性能,能够理解和生成与多轮对话相关的交互式运动。
局限性和未来工作:论文讨论了模型的局限性,如处理复杂或未见过动作的能力有限,序列长度过长可能导致效率问题,以及个性化和可解释性方面的挑战。论文还提出了一些未来可能的研究方向。
整体而言,这篇论文提出了一个创新的模型来处理多轮交互式运动的建模和理解问题,并通过实验验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图