⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-16 更新
Radiology Report Generation via Multi-objective Preference Optimization
Authors:Ting Xiao, Lei Shi, Peng Liu, Zhe Wang, Chenjia Bai
Automatic Radiology Report Generation (RRG) is an important topic for alleviating the substantial workload of radiologists. Existing RRG approaches rely on supervised regression based on different architectures or additional knowledge injection,while the generated report may not align optimally with radiologists’ preferences. Especially, since the preferences of radiologists are inherently heterogeneous and multidimensional, e.g., some may prioritize report fluency, while others emphasize clinical accuracy. To address this problem,we propose a new RRG method via Multi-objective Preference Optimization (MPO) to align the pre-trained RRG model with multiple human preferences, which can be formulated by multi-dimensional reward functions and optimized by multi-objective reinforcement learning (RL). Specifically, we use a preference vector to represent the weight of preferences and use it as a condition for the RRG model. Then, a linearly weighed reward is obtained via a dot product between the preference vector and multi-dimensional reward. Next,the RRG model is optimized to align with the preference vector by optimizing such a reward via RL. In the training stage,we randomly sample diverse preference vectors from the preference space and align the model by optimizing the weighted multi-objective rewards, which leads to an optimal policy on the entire preference space. When inference,our model can generate reports aligned with specific preferences without further fine-tuning. Extensive experiments on two public datasets show the proposed method can generate reports that cater to different preferences in a single model and achieve state-of-the-art performance.
自动放射学报告生成(RRG)是缓解放射科医生巨大工作量的一个重要课题。现有的RRG方法依赖于基于不同架构的回归或附加知识的注入,而生成的报告可能无法最佳地与放射科医生的偏好对齐。特别是,由于放射科医生的偏好本质上是异质和多维的,例如,有些人可能优先考虑报告的流畅性,而另一些人则强调临床准确性。为了解决这个问题,我们提出了一种新的RRG方法,通过多目标偏好优化(MPO)使预训练的RRG模型与多种人类偏好对齐,这可以通过多维奖励函数来表示,并可以通过多目标强化学习(RL)进行优化。具体来说,我们使用偏好向量来表示偏好的权重,并将其用作RRG模型的条件。然后,通过偏好向量与多维奖励之间的点积来获得线性加权奖励。接下来,通过RL优化此类奖励,使RRG模型与偏好向量对齐。在训练阶段,我们从偏好空间中随机抽取不同的偏好向量,通过优化加权的多目标奖励来对齐模型,从而在整个偏好空间上形成最佳策略。在推理时,我们的模型可以在无需进一步微调的情况下,生成符合特定偏好的报告。在两个公共数据集上的大量实验表明,该方法能够在单一模型中适应不同的偏好,并达到最先进的性能。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
本文提出一种基于多目标偏好优化(MPO)的自动放射学报告生成(RRG)新方法,以解决放射学报告生成与放射科医生偏好不一致的问题。该方法可以通过多目标强化学习(RL)将预训练的RRG模型与多种人类偏好对齐。实验证明,该方法可以在单一模型内生成满足不同偏好的报告,达到业界最佳性能。
Key Takeaways
- 放射学报告生成(RRG)是缓解放射科医生工作负担的重要课题。
- 现有RRG方法主要基于监督回归和不同架构或额外知识注入,但生成的报告可能与放射科医生的偏好不一致。
- 放射科医生的偏好是多元多维的,例如,有些人注重报告流畅性,而另一些人强调临床准确性。
- 提出了一种新的RRG方法,即基于多目标偏好优化(MPO),通过多目标强化学习(RL)将预训练的RRG模型与多种人类偏好对齐。
- 使用偏好向量表示偏好权重,并将其作为RRG模型的条件。
- 通过线性加权获得奖励,并通过RL优化模型以与偏好向量对齐。
- 在训练阶段,从偏好空间随机采样不同的偏好向量,通过优化加权的多目标奖励来实现对整个偏好空间的最优策略。在推理阶段,模型可以生成与特定偏好对齐的报告,无需进一步微调。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是放射科医生在自动放射报告生成(Radiology Report Generation, RRG)中面临的偏好多样性和多维性问题。具体来说,论文中提到现有的RRG方法主要依赖于不同架构的监督回归或额外知识注入,但这些生成的报告可能无法最佳地符合放射科医生的偏好。由于放射科医生的偏好本质上是异质的和多维的,例如,一些医生可能优先考虑报告的流畅性,而其他医生可能更强调临床准确性。因此,RRG模型必须能够迎合不同放射科医生的多样化偏好,这是一个挑战,并且之前的研究中尚未探索。为了解决这个问题,论文提出了一种新的RRG方法,通过多目标偏好优化(Multi-objective Preference Optimization, MPO)来调整预训练的RRG模型以符合多种人类偏好。
Q: 有哪些相关研究?
A: 相关研究主要可以分为两大类:提高模型架构和注入额外知识。
提高模型架构:
- 早期的RRG研究基于CNN-RNN或CNN-LSTM架构。
- 最近的工作集中在基于CNN-Transformer架构的网络上进行改进。例如,CMN和MAN引入了跨模态记忆网络,XPRONET提出了跨模态原型驱动网络,METrans引入了多个可学习的“专家”标记。
- 为了捕捉放射图像的微妙差异,开发了多种注意力机制来增强报告生成中的特征鲁棒性,例如共同注意力机制、Ali-Transformer模型和跨模态对比注意力模型等。
注入额外知识:
- 这类工作探索注入额外知识,如疾病标签、检索报告和知识图,以协助报告生成。例如,PPKED结合异常发现、知识图和检索报告来模仿放射科医生的工作模式,KiUT通过注入知识蒸馏器整合视觉和上下文知识以及外部临床洞察来增强结果。
通过强化学习进行RRG:
- 将强化学习(RL)整合到RRG任务中,通过精心设计奖励的适当监督来增强报告生成能力。这些奖励通常基于自然语言生成(NLG)指标或语义相关性指标计算。
这些相关研究构成了自动放射报告生成领域的研究进展,并且本文提出的多目标偏好优化(MPO)方法在这些现有研究的基础上,尝试解决放射科医生偏好的多样性和多维性问题。
Q: 论文如何解决这个问题?
A: 论文通过提出一种新的自动放射报告生成(RRG)方法,即多目标偏好优化(Multi-objective Preference Optimization, MPO),来解决放射科医生偏好的多样性和多维性问题。具体解决方案包括以下几个关键步骤:
多目标偏好优化(MPO):
- 利用多维奖励函数和多目标强化学习(RL)来优化预训练的RRG模型,使其符合多种人类偏好。
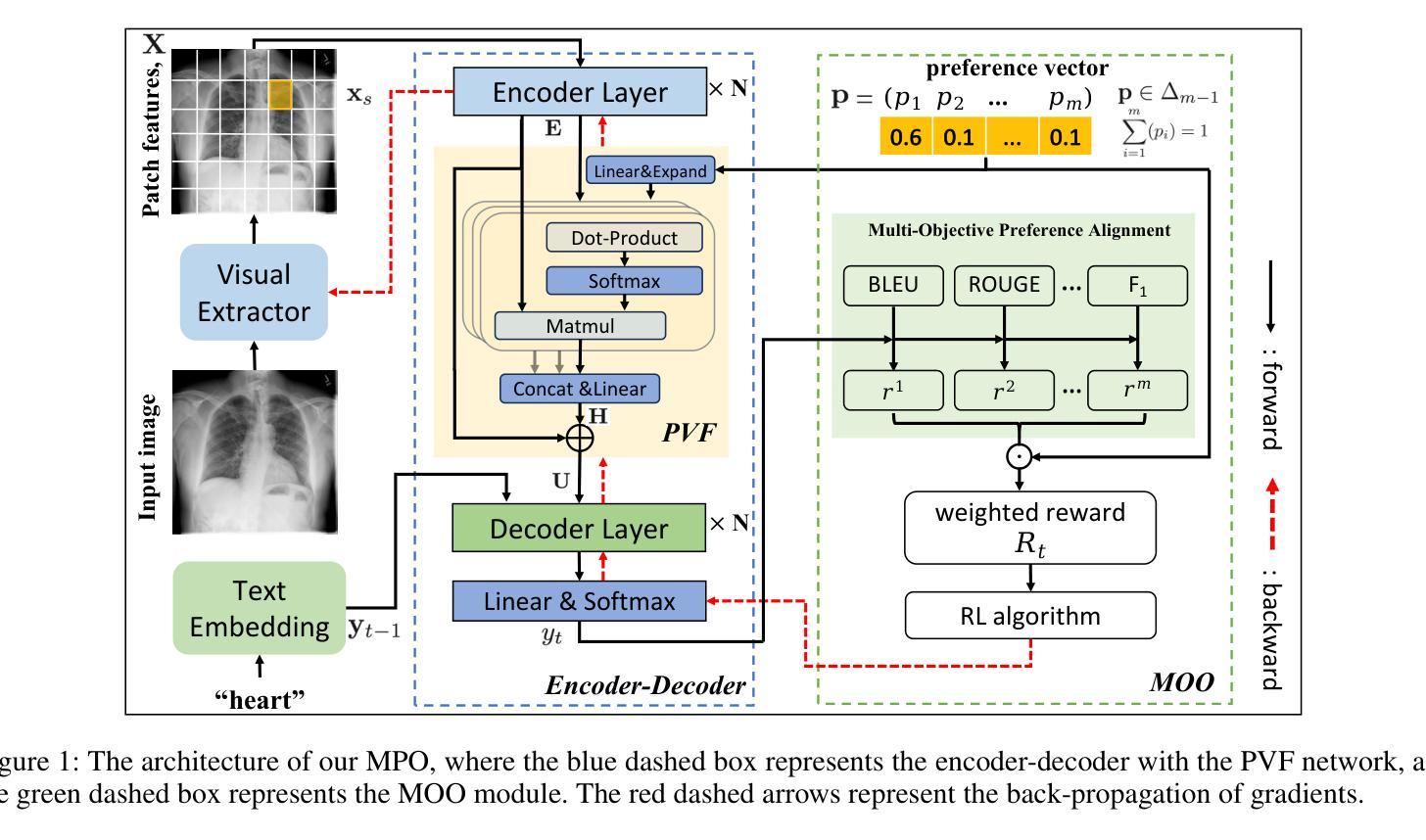
偏好向量融合(Preference Vector Fusion, PVF)网络:
- 在标准的Transformer模型的编码器和解码器之间引入PVF网络,使用多头注意力机制和残差连接将偏好向量与编码的图像特征融合,实现条件生成。
多目标优化(MOO)模块:
- 使用偏好向量表示偏好的权重,并通过点积将多维奖励与偏好向量线性加权结合。
- 然后,使用RL优化加权后的多目标奖励函数,促使RRG模型与偏好向量对齐。
训练阶段:
- 在训练阶段,从偏好空间中随机采样多样化的偏好向量,并通过优化加权的多目标奖励函数来对齐模型,从而在整体偏好空间上获得最优策略。
推理阶段:
- 在推理阶段,给定一个偏好向量,模型可以生成符合特定偏好的报告,无需进一步微调。
实验验证:
- 通过在两个公共数据集上的广泛实验,验证所提方法可以在单一模型内迎合不同偏好,并实现最先进的性能。
通过这些步骤,论文提出的MPO方法能够使RRG模型适应不同放射科医生的偏好,同时保持生成报告的高质量,解决了放射科医生偏好的异质性和多维性问题。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出的多目标偏好优化(MPO)方法的有效性:
数据集:
- IU-Xray:包含7,470张胸部X光图像和3,955份报告。
- MIMIC-CXR:包含337,110张胸部X光图像和227,835份相应的报告。
评估指标:
- 自然语言生成(NLG)指标:包括BLEU{1-4}、METOR和ROUGE-L,用于评估生成文本报告的质量。
- 临床效果(CE)指标:使用CheXbert标注14种医学报告中的观察结果,计算Precision(P)、Recall(R)和F1分数。
实现细节:
- 使用PyTorch实现,训练在NVIDIA 4090 GPU上进行。
- 使用预训练在ImageNet上的ResNet101作为视觉提取器,以及随机初始化的Transformer作为编码器-解码器模型。
- 使用Adam优化器进行训练,并包含宽度为3的beam search。
- 对于IU-Xray,最大报告长度设置为60个单词;对于MIMIC-CXR,最大长度设置为100个单词。
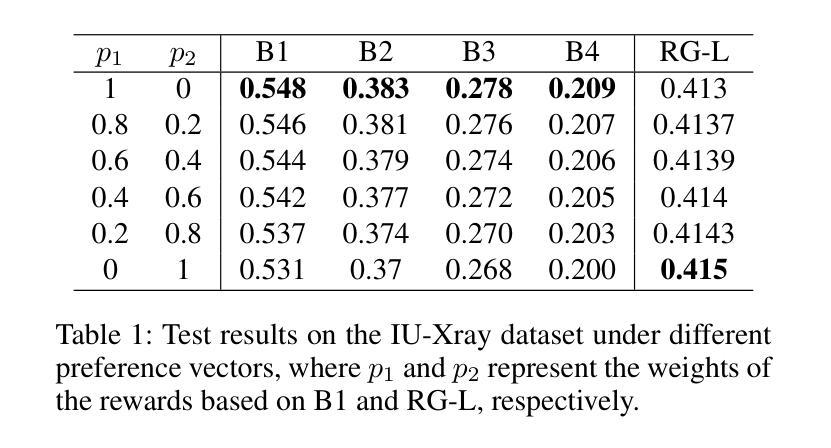
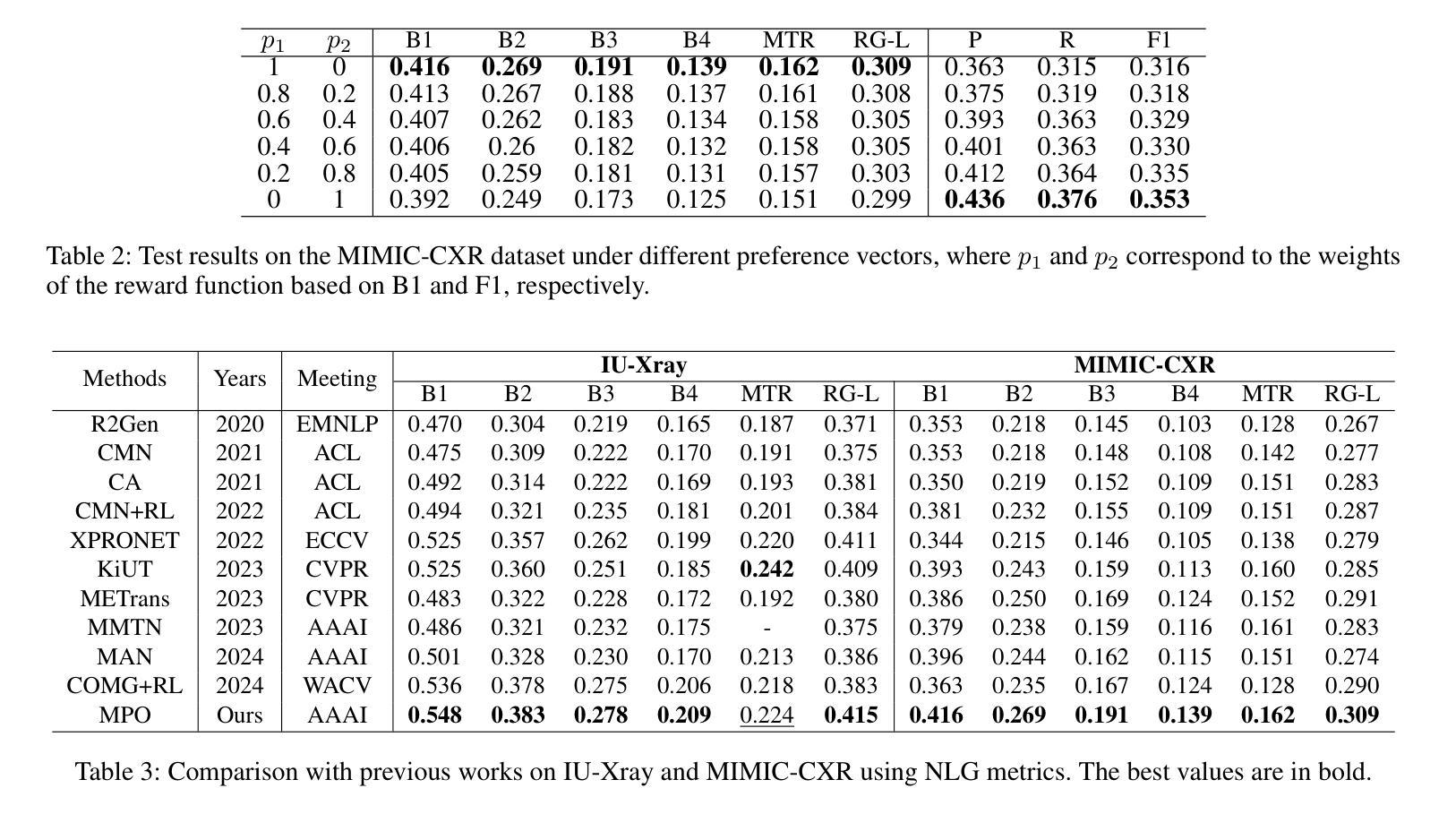
偏好指导的有效性:
- 在二维和三维偏好向量空间中测试模型,展示不同偏好向量配置下的测试结果,验证模型行为可以通过控制偏好向量来定制。
定性结果:
- 对MIMIC-CXR数据集进行定性分析,比较不同偏好配置下生成的报告与参考报告(GT)之间的差异。
与先前工作的比较:
- 将MPO方法与过去五年内的一系列最先进(SOTA)方法进行比较,包括R2Gen、CMN、CA、CMN+RL等,使用NLG和CE指标。
消融研究:
- 对MPO方法中的每个组件进行消融研究,包括基础模型(Base)、结合MOO模块的模型(Base+MOO)和完整模型(Base+MOO+PVF)。
融合方法:
- 探索不同的融合方法来融合偏好向量,包括连接(Concat)、加法(Add)和点乘(Mul)方法,并与PVF网络进行比较。
超参数分析:
- 对PVF网络中的超参数α进行分析,以确定其对模型性能的影响。
计算复杂性和效率分析:
- 对比不同方法在IU-Xray和MIMIC-CXR数据集上的参数数量、FLOPs、GPU内存使用情况以及训练/推理时间。
这些实验全面地评估了MPO方法在自动放射报告生成任务中的性能,并与现有技术进行了比较,证明了其在迎合不同放射科医生偏好的同时,能够生成更高质量的报告。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
新的评价指标作为奖励函数:
- 论文提到在未来的工作中,将探索设计新的评价指标作为偏好对齐的奖励函数。这可能包括更精细的临床准确性指标或考虑医生反馈的个性化指标。
偏好学习的自动化:
- 研究如何自动学习和调整偏好向量,以更好地适应不同放射科医生的偏好,而无需手动配置。
多模态学习:
- 进一步探索如何结合图像、文本和其他医疗数据(如患者历史数据)来生成更准确的报告。
模型的可解释性和透明度:
- 提高模型的可解释性,让医生能够理解模型生成报告的依据,增加其信任度和接受度。
跨领域适应性:
- 研究模型在不同类型的放射图像(如CT、MRI)和不同身体部位(如头部、腹部)的适应性和泛化能力。
实时性能优化:
- 探索如何优化模型以满足实时或近实时的临床需求,特别是在大规模应用中。
模型鲁棒性测试:
- 对模型进行压力测试和鲁棒性评估,确保在面对异常、模糊或不完整数据时仍能生成准确报告。
多语言和跨文化适应性:
- 研究模型在不同语言和文化背景下的适用性,为全球医疗环境提供支持。
集成更多临床知识:
- 通过集成更丰富的医学知识(如解剖学、病理学知识)来提升报告的深度和准确性。
模型压缩和优化:
- 研究如何压缩和优化模型,以便于在资源受限的医疗环境中部署。
用户研究和临床试验:
- 进行用户研究和临床试验,收集医生和患者的反馈,以改进模型的实际应用效果。
这些探索点可以帮助推动自动放射报告生成技术的发展,提高其在实际医疗场景中的应用价值。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 自动化放射报告生成(RRG)旨在减轻放射科医生的工作负担,但现有方法可能无法很好地符合放射科医生的个性化偏好,这些偏好是异质和多维的。
研究目标:
- 提出一种新的RRG方法,通过多目标偏好优化(MPO)来调整预训练的RRG模型,使其能够符合多个人类的偏好。
方法论:
- 提出了包含两个新模块的MPO方法:偏好向量融合(PVF)网络和多目标优化(MOO)模块。
- PVF网络使用多头注意力机制和残差连接将偏好向量与编码的图像特征融合,实现条件生成。
- MOO模块通过偏好向量加权多维奖励,并使用强化学习(RL)优化加权奖励函数,以对齐模型与偏好。
训练和推理:
- 在训练阶段,从偏好空间中随机采样多样化的偏好向量,并通过优化加权的多目标奖励函数来对齐模型。
- 在推理阶段,模型可以根据给定的偏好向量生成符合特定偏好的报告,无需进一步微调。
实验验证:
- 在两个公共数据集IU-Xray和MIMIC-CXR上进行了广泛的实验,验证了所提方法可以在单一模型内迎合不同偏好,并实现最先进的性能。
主要贡献:
- 提出了一种新的RRG方法,首次将人类偏好与RRG模型对齐作为一个多目标优化强化学习问题。
- 提出了PVF模块,使用注意力机制和残差连接融合编码图像特征与偏好向量。
- 证明了所提方法能够在不同偏好下生成报告,无需进一步微调,并且在两个公共数据集上实现了最佳性能。
未来工作:
- 探索设计新的评价指标作为偏好对齐的奖励函数。
综上所述,论文通过提出一种新的多目标偏好优化方法,有效地解决了放射科医生在自动放射报告生成中的个性化偏好问题,并在实验中验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


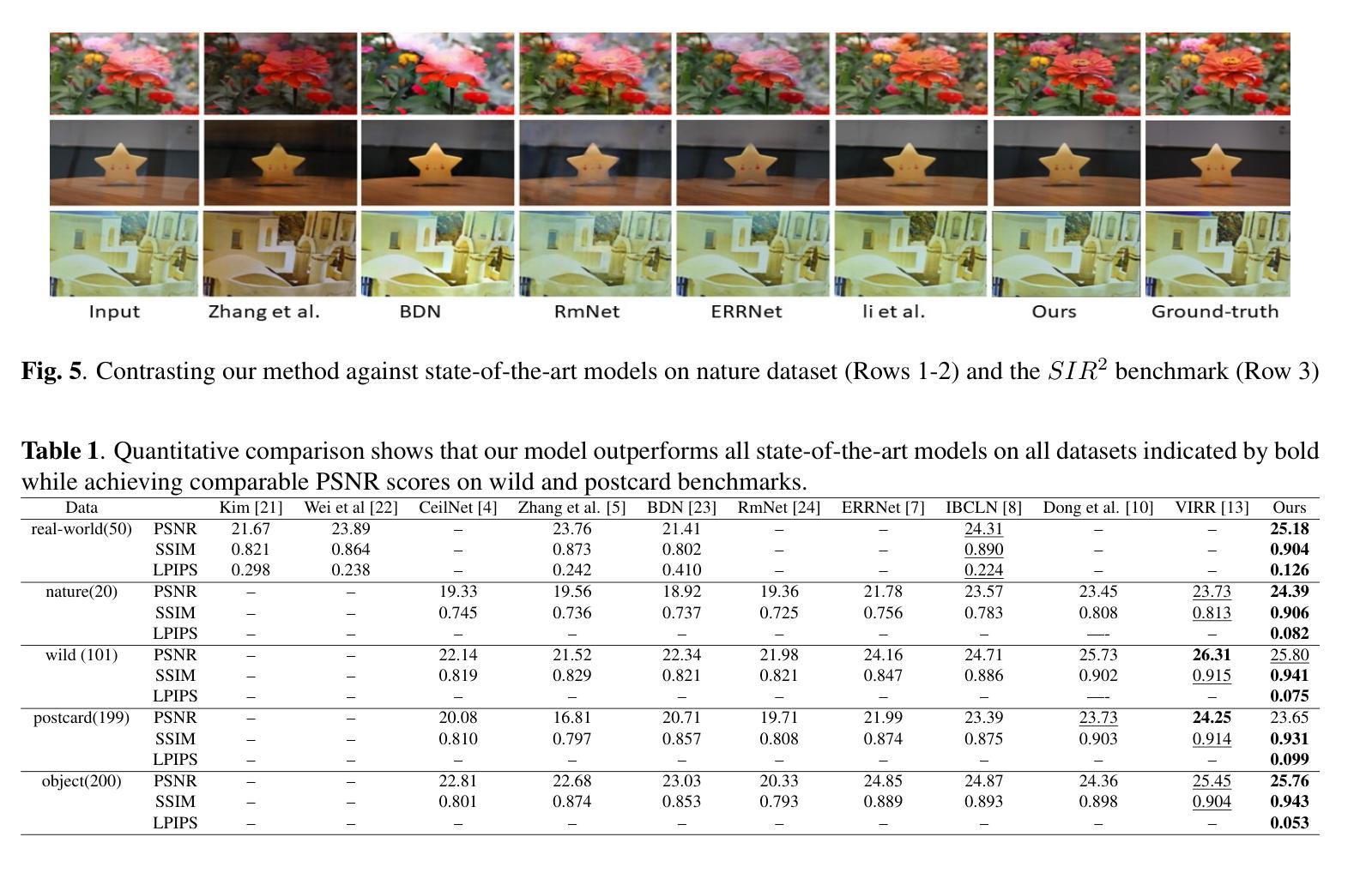
Utilizing Multi-step Loss for Single Image Reflection Removal
Authors:Abdelrahman Elnenaey, Marwan Torki
Image reflection removal is crucial for restoring image quality. Distorted images can negatively impact tasks like object detection and image segmentation. In this paper, we present a novel approach for image reflection removal using a single image. Instead of focusing on model architecture, we introduce a new training technique that can be generalized to image-to-image problems, with input and output being similar in nature. This technique is embodied in our multi-step loss mechanism, which has proven effective in the reflection removal task. Additionally, we address the scarcity of reflection removal training data by synthesizing a high-quality, non-linear synthetic dataset called RefGAN using Pix2Pix GAN. This dataset significantly enhances the model’s ability to learn better patterns for reflection removal. We also utilize a ranged depth map, extracted from the depth estimation of the ambient image, as an auxiliary feature, leveraging its property of lacking depth estimations for reflections. Our approach demonstrates superior performance on the SIR^2 benchmark and other real-world datasets, proving its effectiveness by outperforming other state-of-the-art models.
图像反射消除对于恢复图像质量至关重要。扭曲的图像会对目标检测和图像分割等任务产生负面影响。在本文中,我们提出了一种使用单幅图像进行图像反射消除的新方法。我们没有关注模型架构,而是引入了一种可以推广到图像到图像问题的新训练技术,输入和输出的性质相似。这种技术体现在我们的多步损失机制中,在反射去除任务中已被证明是有效的。此外,我们通过使用Pix2Pix GAN合成了一种高质量的非线性合成数据集RefGAN,解决了反射去除训练数据的稀缺问题。该数据集显著提高了模型学习更好反射去除模式的能力。我们还利用从环境图像的深度估计中提取的范围深度图作为辅助特征,利用其缺乏反射深度估计的属性。我们的方法在SIR^2基准和其他真实世界数据集上展示了卓越的性能,超越了其他最先进的模型,证明了其有效性。
简化说明
论文及项目相关链接
PDF 6 pages, 6 figures, IEEE AICCSA 2024
Summary
本文提出了一种新的图像反射去除方法,利用单张图像进行反射去除。研究重点不在于模型架构,而是引入了一种可推广至图像到图像问题的通用化训练技术。通过多步骤损失机制,有效应对反射去除任务。同时,为解决反射去除训练数据不足的问题,研究团队使用Pix2Pix GAN合成了一个高质量的非线性合成数据集RefGAN。此外,研究还利用从环境图像深度估计中提取的深度图作为辅助特征,发挥其缺乏反射深度估计的特性。该方法在SIR^2基准测试和其他真实世界数据集上表现出卓越性能,超越了其他最先进模型。
Key Takeaways
- 引入了一种新的图像反射去除方法,使用单张图像进行处理。
- 研究的重点不在于模型架构的改进,而是提出一种可推广至图像到图像问题的通用化训练技术。
- 通过多步骤损失机制有效应对反射去除任务。
- 使用Pix2Pix GAN合成了一个高质量的非线性合成数据集RefGAN,用于解决反射去除训练数据不足的问题。
- 借助从环境图像深度估计中提取的深度图作为辅助特征,以提高模型性能。
- 该方法在SIR^2基准测试和其他真实世界数据集上表现出卓越性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决单张图片中的反射去除问题,这对于恢复图像质量和提高诸如目标检测、图像分割等计算机视觉任务的性能至关重要。具体来说,论文关注以下几个问题:
图像反射的影响:图像中的反射会扭曲视觉内容,降低依赖清晰图像的算法的性能,例如,反射可能会遮挡目标检测中的关键特征,引起场景布局解释的歧义,以及导致增强现实叠加中的错位。
现有方法的局限性:传统的反射去除方法通常需要多张图片或复杂的硬件,这在只有单张图片可用的场景中是不切实际的。
训练数据的稀缺性:对于训练反射去除模型来说,存在高质量、多样化的训练数据集的缺乏问题。
模型性能和泛化能力的提升:如何设计有效的损失函数和训练技术,以提高模型在各种场景下的性能和泛化能力。
为了解决这些问题,论文提出了一种新颖的方法,包括一个多步损失机制、一个合成的高质量非线性数据集RefGAN,以及使用范围深度图作为辅助特征,以提高反射去除的效果。
Q: 有哪些相关研究?
A: 论文中提到的相关研究可以分为以下几个类别:
非机器学习基础的方法
- 区域感知技术:结合内容和梯度信息以增强精度的方法,例如 [1]。
- 使用非闪光环境图像去除反射和伪影:例如 [2]。
- 利用景深指导区分聚焦和反射区域:例如 [3]。
单图像反射去除方法
- CeilNet:利用深度学习预测无反射图像,无需手工特征,例如 [4]。
- 感知损失:用于提高反射去除质量,例如 [5]。
- 卷积编码器-解码器网络:例如 [6]。
- ERRNet:在不对齐的实际数据上提高性能,例如 [7]。
- 级联细化方法:例如 [8]。
- 语义引导预测:例如 [9]。
- 具有反射检测和循环模块的新型架构:例如 [10]。
- 自注意力机制和局部鉴别损失:用于更有效的反射分离,例如 [11]。
- 屏幕模糊组合技术:用于更好地模拟反射特性,例如 [12]。
- 深度变分推断反射去除(VIRR)方法:首次使用这种方法,专注于学习潜在分布以获得更好的可解释性,例如 [13]。
闪光/无闪光图像反射去除方法
- 利用闪光和环境图像对:提取仅闪光图像以估计无反射的传输图像,例如 [14]。
这些相关研究为单图像反射去除领域提供了多种技术和方法,而本文提出的新方法旨在通过引入多步损失机制、合成数据集和范围深度图来进一步改进这些技术。
Q: 论文如何解决这个问题?
A: 论文通过以下三个主要贡献来解决单张图片中的反射去除问题:
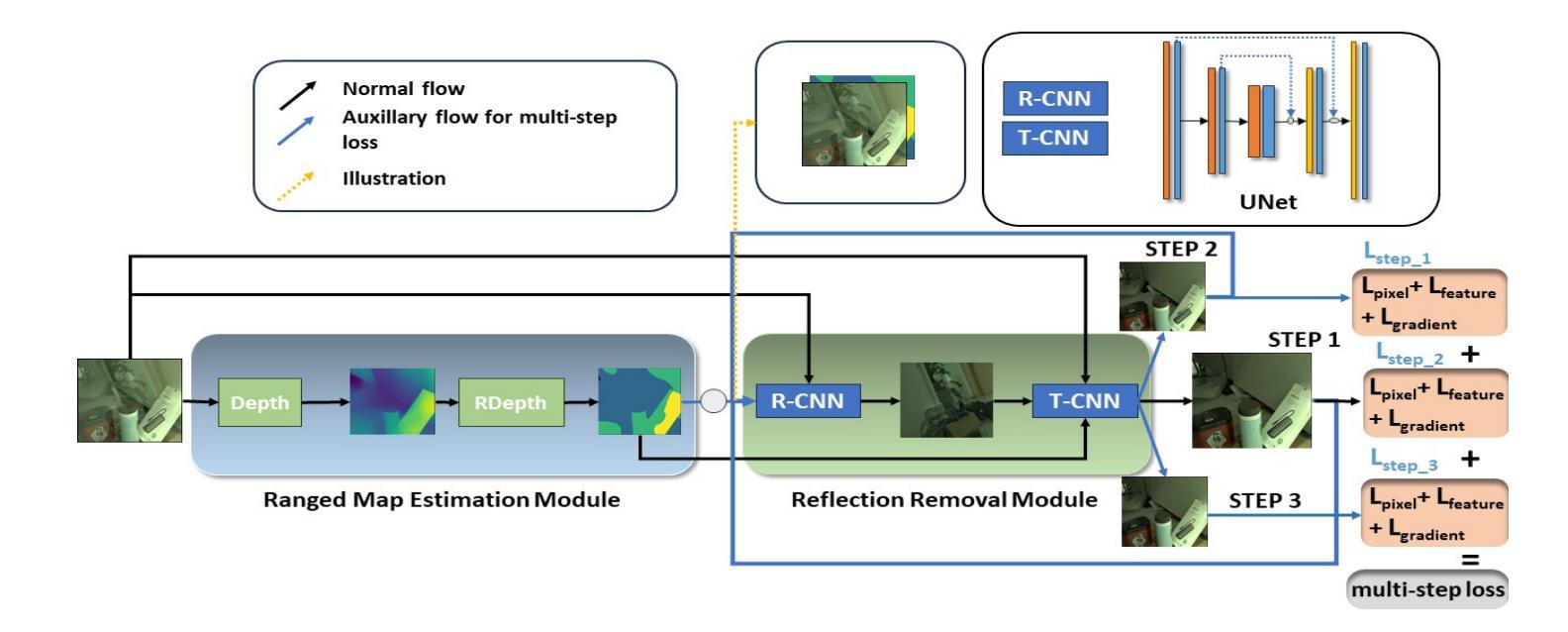
1. 多步损失机制(Multi-step Loss Mechanism)
- 多步损失函数:提出了一种新的多步损失函数,该函数迭代地将输出作为输入用于连续的步骤,并在每一步累积损失。这种机制放大了错误去除反射的损失,提供了模型性能在挑战性情况下的更具代表性的度量。
- 损失累积:与在多个步骤中平均或平滑损失不同,多步损失机制通过观察每个图像中每个步骤的不同反射比率来增强模型处理不同反射强度的能力,从而提高整体性能。
2. RefGAN数据集
- 合成数据集:为了解决训练数据不足的问题,论文通过Pix2Pix GAN合成了一个高质量的非线性合成数据集RefGAN。这个数据集提供了广泛的反射模式和强度,增强了模型学习反射去除更好模式的能力。
- 增强模型鲁棒性:RefGAN数据集显著增强了模型的鲁棒性和有效性,使其能够处理更多样化的反射情况。
3. 范围深度图(Ranged Depth Map)
- 辅助特征:使用从环境图像的深度估计中提取的范围深度图作为辅助特征,利用其缺乏反射的深度估计的特性。
- 排除反射:范围深度图帮助模型有效地从环境图像中提取目标场景,并且通过仅关注实际场景内容来排除反射。
- 增强反射去除过程:范围深度图还帮助模型建立原始图像中落在相同范围内的邻近像素之间的关系,进一步增强了反射去除过程。
方法结构
- 范围图估计模块:负责从环境图像中导出范围深度图。使用预训练的Midas Small模型计算初始深度图,并将每个像素分配到特定范围,形成范围深度图。
- 反射去除模块:利用范围深度图作为辅助特征进行反射估计。采用R-CNN架构,结合UNet预测反射图像。最终阶段使用T-CNN,将估计的反射、范围深度图和输入的环境图像一起作为输入,预测目标图像。
这些方法的结合在SIR2基准测试和其他实际数据集上展示了优越的性能,证明了其在单张图像反射去除中的有效性,并超越了其他最先进的模型。
Q: 论文做了哪些实验?
A: 论文中进行的实验包括以下几个方面:
1. 实验设置
- 硬件平台:使用Nvidia Tesla T4 GPU进行实验。
- 训练参数:模型以1的批量大小训练100个周期,初始学习率为(10^{-4}),采用余弦退火调度,从(10^{-4})开始,在第100个周期接近0。使用Adam优化器,并在模型性能稳定后从2步损失升级到3步损失。
2. 数据集
- 训练数据:包括来自[14]的真实世界数据,这些数据包含来自[17]和[18]的合成图像,以及来自[8]的Nature数据集。此外,还合成了RefGAN数据集,包含7115对环境-传输图像对。
- 验证数据:使用来自[14]验证集的30张真实世界图像。
- 评估数据:在来自[14]测试集的50张真实世界图像、来自[8]的Nature数据集的20张真实世界图像和SIR2基准测试[20](包括wild、solid object和postcard三个子测试数据集)上进行评估。
3. 定量结果
- 评估指标:使用峰值信噪比(PSNR)、结构相似性(SSIM)和Learned Perceptual Image Patch Similarity(LPIPS)等广泛接受的指标。
- 结果对比:与现有的最先进的单图像反射去除方法进行比较,结果表明所提出的方法在所有数据集上均优于其他方法。
4. 定性结果
- 结果展示:通过图5和图6展示了模型与现有最先进方法在Nature数据集和SIR2基准测试上的定性比较结果。
5. 消融研究
- 范围深度图与纯深度图的比较:评估使用纯深度图与范围深度图作为辅助特征的效果。
- RefGAN数据集的影响:评估在有无RefGAN数据集训练的情况下模型的性能差异。
- 不同范围深度图范围(K值)的性能:研究不同K值对模型性能的影响。
- 多步损失机制的影响:评估不同配置的多步损失对模型性能的影响。
这些实验全面评估了所提出方法的有效性,并深入分析了各个组成部分对性能的影响,从而证明了所提出方法在单图像反射去除任务中的优越性能。
Q: 有什么可以进一步探索的点?
A: 论文在第5节“结论”中提到了未来的研究方向,以下是一些可以进一步探索的点:
先进的模型架构:尽管本研究展示了损失函数、训练数据质量和辅助输入特征的有效性,未来的工作可以探索将这些方法与更先进的模型架构结合,以实现更好的性能提升。
更准确的物理模型:研究可以进一步探索集成更准确的物理模型来描述反射形成过程,这可能会在图像到图像的任务中实现更进一步的性能和泛化能力的提升。
多模态数据融合:考虑将多模态数据(例如,结合RGB图像与深度图像、红外图像等)融合到模型中,以提供更丰富的信息辅助反射去除。
实时性能优化:研究如何优化模型以实现实时或近实时的反射去除,这对于增强现实和实时视频处理等应用尤为重要。
更广泛的数据集和场景:扩展和多样化训练数据集,包括更多类型的反射和不同环境下的场景,以提高模型的泛化能力。
模型的可解释性和透明度:研究模型的决策过程,提高模型的可解释性,这有助于理解模型的行为并进一步改进算法。
跨域适应性:研究模型在不同设备和不同光照条件下的适应性,以提高其在实际应用中的灵活性和鲁棒性。
端到端的解决方案:开发一个端到端的系统,该系统可以直接在移动设备或嵌入式设备上运行,而无需复杂的后处理步骤。
长尾分布问题:针对训练数据中可能存在的类别不平衡问题,研究有效的策略来处理长尾分布,提高模型对罕见反射类型的敏感性。
模型压缩和加速:研究模型压缩技术,以减少模型大小并加速推理过程,使其更适合资源受限的环境。
这些方向不仅可以推动单图像反射去除技术的发展,也可能对计算机视觉中的其他图像到图像翻译任务产生积极影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题陈述:
- 论文关注于单张图像中的反射去除问题,这对于恢复图像质量和提高计算机视觉任务的性能至关重要。
- 传统的反射去除方法需要多张图像或复杂硬件,不适用于仅有单张图像的场景。
主要贡献:
- 提出了一种新颖的多步损失机制,用于改善模型在训练过程中的性能和泛化能力。
- 合成了一个名为RefGAN的高质量非线性合成数据集,增强了模型的鲁棒性和有效性。
- 利用范围深度图作为辅助特征来排除反射,专注于实际场景内容,以提高反射去除的效果。
方法论:
- 介绍了一个包含范围图估计模块和反射去除模块的架构。
- 使用预训练的Midas Small模型来计算初始深度图,并生成范围深度图。
- 利用R-CNN和T-CNN网络结构来预测反射和目标图像。
实验:
- 在Nvidia Tesla T4 GPU上进行实验,使用不同的数据集进行训练、验证和评估。
- 通过定量和定性结果展示了所提方法相较于现有技术的优越性。
- 进行了消融研究,分析了不同组件对性能的影响。
结论与未来工作:
- 论文提出的多步损失机制、RefGAN数据集和范围深度图在单图像反射去除任务中表现出色,超越了其他最先进模型。
- 论文还提出了未来可能的研究方向,包括探索更先进的模型架构、更准确的物理模型、多模态数据融合等。
总体而言,这篇论文通过引入新的损失机制和数据集,以及利用范围深度图作为辅助特征,提供了一种有效的单图像反射去除方法,并在多个数据集上验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图





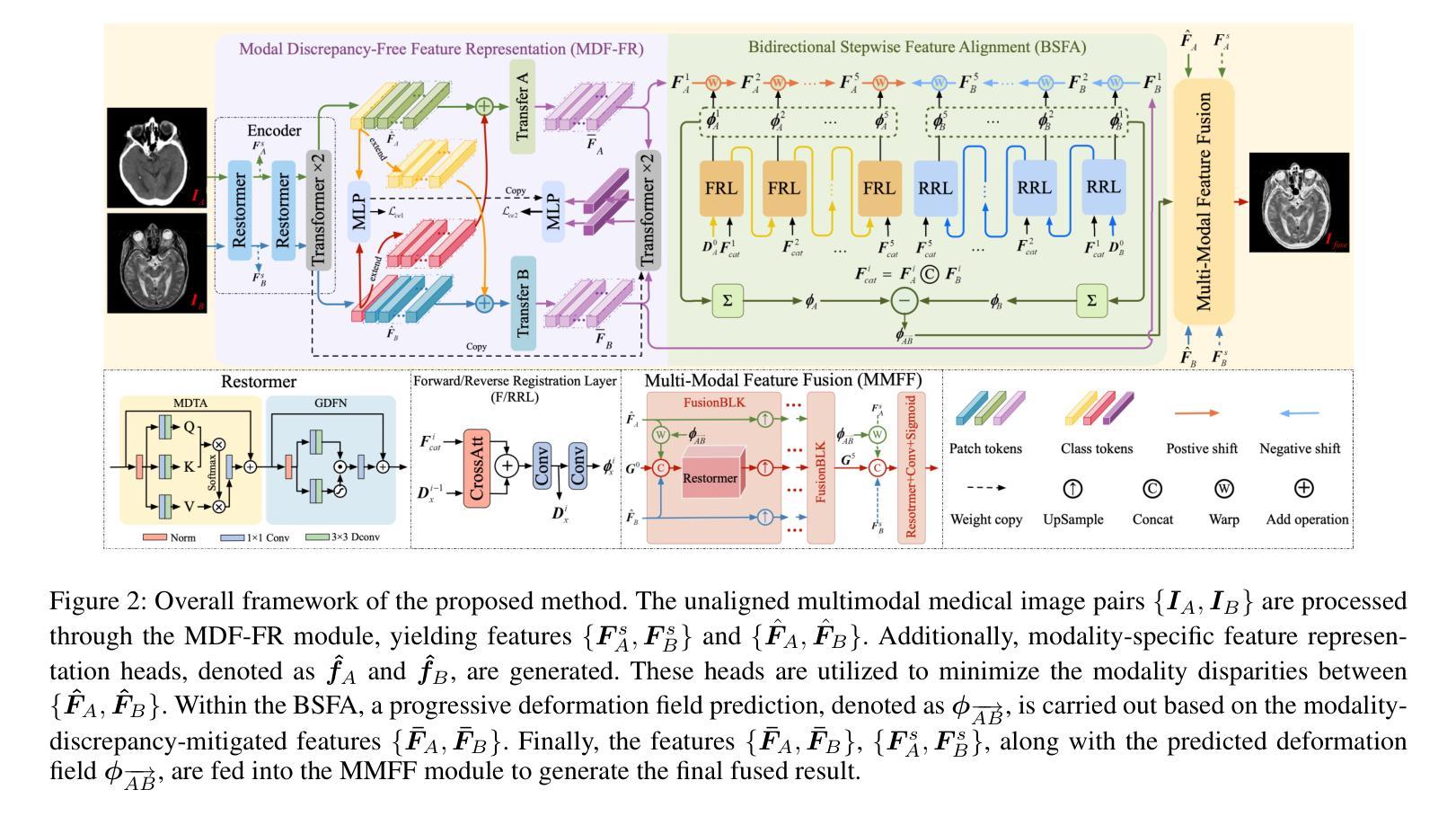
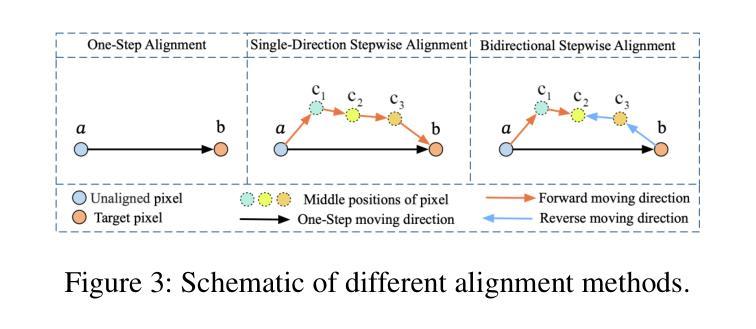
BSAFusion: A Bidirectional Stepwise Feature Alignment Network for Unaligned Medical Image Fusion
Authors:Huafeng Li, Dayong Su, Qing Cai, Yafei Zhang
If unaligned multimodal medical images can be simultaneously aligned and fused using a single-stage approach within a unified processing framework, it will not only achieve mutual promotion of dual tasks but also help reduce the complexity of the model. However, the design of this model faces the challenge of incompatible requirements for feature fusion and alignment; specifically, feature alignment requires consistency among corresponding features, whereas feature fusion requires the features to be complementary to each other. To address this challenge, this paper proposes an unaligned medical image fusion method called Bidirectional Stepwise Feature Alignment and Fusion (BSFA-F) strategy. To reduce the negative impact of modality differences on cross-modal feature matching, we incorporate the Modal Discrepancy-Free Feature Representation (MDF-FR) method into BSFA-F. MDF-FR utilizes a Modality Feature Representation Head (MFRH) to integrate the global information of the input image. By injecting the information contained in MFRH of the current image into other modality images, it effectively reduces the impact of modality differences on feature alignment while preserving the complementary information carried by different images. In terms of feature alignment, BSFA-F employs a bidirectional stepwise alignment deformation field prediction strategy based on the path independence of vector displacement between two points. This strategy solves the problem of large spans and inaccurate deformation field prediction in single-step alignment. Finally, Multi-Modal Feature Fusion block achieves the fusion of aligned features. The experimental results across multiple datasets demonstrate the effectiveness of our method. The source code is available at https://github.com/slrl123/BSAFusion.
如果能够在统一的处理框架内采用单阶段方法同时对多种不匹配的医学图像进行对齐和融合,不仅可以实现双重任务的相互促进,还有助于减少模型的复杂性。然而,该模型的设计面临着特征融合与对齐要求不兼容的挑战;具体而言,特征对齐要求对应特征之间的一致性,而特征融合则要求特征彼此互补。为了解决这一挑战,本文提出了一种称为双向逐步特征对齐与融合(BSFA-F)策略的未对齐医学图像融合方法。为了减少模态差异对跨模态特征匹配的负面影响,我们将模态差异无关特征表示(MDF-FR)方法纳入BSFA-F。MDF-FR利用模态特征表示头(MFRH)来整合输入图像的全局信息。通过将当前图像的MFRH中包含的信息注入到其他模态图像中,它在保持不同图像所携带的互补信息的同时,有效地减少了模态差异对特征对齐的影响。在特征对齐方面,BSFA-F采用了一种基于两点间矢量位移路径独立性的双向逐步对齐变形场预测策略。该策略解决了单步对齐中跨度大、变形场预测不准确的问题。最后,多模态特征融合模块实现了对齐特征的融合。在多个数据集上的实验结果证明了我们的方法的有效性。源代码可在https://github.com/slrl123/BSAFusion找到。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
医学图像多模态融合挑战在于特征融合与对齐的要求不兼容。为此,本文提出一种名为BSFA-F的未对齐医学图像融合方法,结合MDF-FR技术减少模态差异对特征对齐的负面影响,利用MFRH整合图像全局信息。BSFA-F采用基于两点间向量位移路径独立性的双向逐步对齐变形场预测策略,解决单步对齐中的大范围和不准确变形场预测问题。最终通过多模态特征融合模块实现特征融合。实验结果表明该方法的有效性。
Key Takeaways
- 未对齐的多模态医学图像融合面临特征融合与对齐要求不兼容的挑战。
- 本文提出一种名为BSFA-F的融合方法,旨在实现单一处理框架内的同时对齐和融合。
- 结合MDF-FR技术减少模态差异对特征对齐的负面影响,通过MFRH整合全局信息。
- 采用双向逐步对齐变形场预测策略,解决单步对齐中的大范围和不准确问题。
- 多模态特征融合模块实现特征融合。
- 实验结果证明该方法的有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为BSAFusion的单阶段多模态医学图像融合框架,旨在解决以下问题:
非对齐多模态医学图像融合:传统的医学图像融合方法通常假设待融合的源图像在像素级别上是严格对齐的。然而,在实际应用中,这种假设往往不成立,导致融合算法无法产生预期结果。为了解决这一问题,研究者们通常先使用配准算法对图像进行对齐,然后再进行融合。
多模态图像配准的挑战:跨模态图像配准面临诸多挑战,包括模态差异和图像间特征的不一致性。
融合与配准的联合处理:近年来,研究者开始探索将多源图像配准和融合集成到一个统一框架中,以解决上述问题。通过利用融合结果的监督,可以提高配准性能。
单阶段处理模式的挑战:在单阶段处理模式中实现多模态医学图像的配准和融合仍然面临挑战,主要涉及解决特征提取中配准和融合的冲突需求。
模型复杂性:传统的两阶段方法需要独立的、完整的配准过程,增加了模型复杂性,限制了在计算资源受限的环境中的部署,并可能导致融合失败。
综上所述,这篇论文旨在通过提出一个单阶段框架,同时实现非对齐多模态医学图像的配准和融合,以减少模型复杂性并提高融合效果。
Q: 有哪些相关研究?
A: 论文中提到了多个与多模态医学图像融合(MMIF)相关的研究工作,这些工作根据所使用的特征提取网络类型可以分为基于卷积神经网络(CNN)的方法、基于Transformer的方法以及混合方法。以下是一些具体的相关工作:
基于CNN的方法:
- 侧重于网络架构设计,包括残差连接、跳跃连接、密集连接和网络架构搜索等框架。
- 动态元学习方法和医学语义引导的双分支方法。
基于Transformer的方法:
- Transformer解决了CNN在建模长距离依赖方面的局限性,相关方法包括FATMusic和MATR。
混合方法:
- 结合了CNN和Transformer在特征提取方面的互补优势,提出的混合方法包括DesTrans、DFENet和MRSC-Fusion。
多模态图像融合方法:
- U2Fusion、Cddfuse、DDFM、EMMA、QuadzBayer和HFT等方法,这些方法虽然有效,但都假设源图像已经被注册。
联合配准和融合方法:
- ReCoNet、UMF-CMGR、SuperFusion、RFNet、MURF、IVFWSR和MERF等方法,这些方法不是专门针对多模态医学图像设计的,并且在该领域没有表现出预期的优势。
专门设计的多模态医学图像融合方法:
- PAMRFuse,专为未注册的多模态医学图像融合而设计,但其性能受限于生成图像的质量。
这些相关工作展示了多模态医学图像融合领域的研究进展,同时也突显了现有方法的局限性,特别是在处理未对齐的多模态医学图像时。BSAFusion框架正是为了解决这些挑战而提出的。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Bidirectional Stepwise Feature Alignment and Fusion (BSFA-F) 的方法来解决非对齐多模态医学图像融合的问题。BSFA-F策略包括以下几个关键技术:
**Modality Discrepancy-Free Feature Representation (MDF-FR)**:
- 利用Modality Feature Representation Head (MFRH) 整合输入图像的全局信息。
- 通过将当前图像的MFRH信息注入到其他模态图像中,减少模态差异对特征对齐的影响,同时保留不同图像携带的互补信息。
**Bidirectional Stepwise Feature Alignment (BSFA)**:
- 基于两点之间矢量位移的路径独立性,采用双向逐步对齐变形场预测策略,解决单步对齐中大跨度和变形场预测不准确的问题。
**Multi-Modal Feature Fusion (MMFF)**:
- 应用预测的变形场对多模态特征进行对齐,然后在特征级别上实现输入图像的精确对齐和有效融合。
具体来说,BSFA-F的工作流程如下:
MDF-FR模块:处理非对齐的多模态医学图像对,输出特征表示,同时生成模态特定的特征表示头,用于减少模态间差异。
BSFA模块:基于MDF-FR输出的特征,预测非对齐图像特征之间的变形场,采用双向逐步对齐策略实现特征空间对齐。
MMFF模块:接收对齐后的特征和原始特征,通过一系列融合块(FusionBLK)融合特征,最终生成融合图像。
此外,论文还提出了以下损失函数来优化模型:
- **交叉熵损失 (Lce1 和 Lce2)**:确保模态特征表示头包含输入图像的模态信息。
- 平滑损失 (Lsmooth) 和 **一致性损失 (Lconsis)**:确保变形场的质量。
- 结构损失 (Lstruct)、像素强度损失 (Linten) 和 **梯度损失 (Lgrad)**:确保融合图像与源图像在结构和对比度上的一致性。
通过这些技术和策略,BSFA-F能够在单阶段处理框架内同时实现特征对齐和图像融合,有效地解决了非对齐多模态医学图像融合的问题。
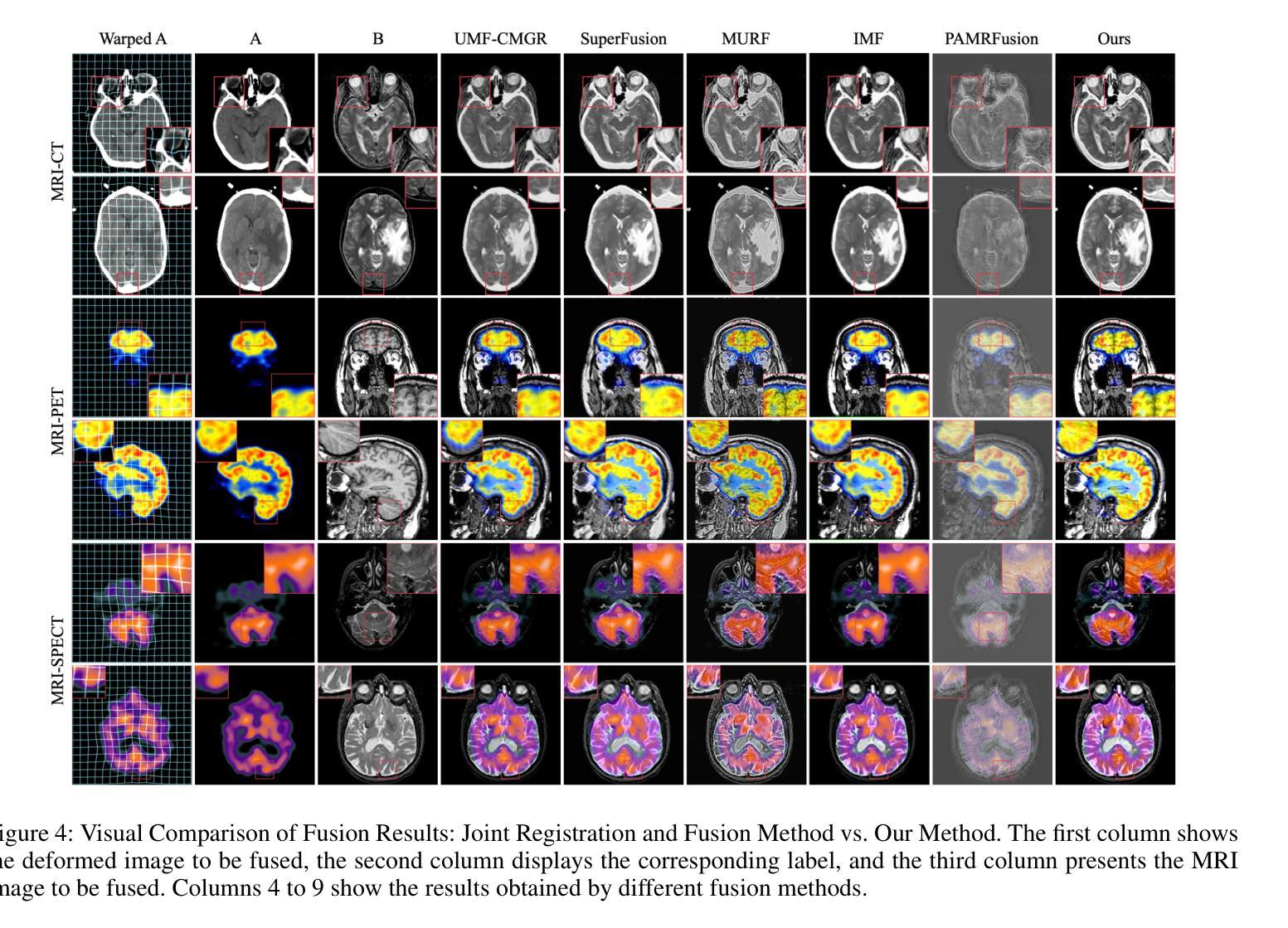
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出方法的有效性,具体实验包括:
实验设置:
- 使用了来自Harvard的CT-MRI、PET-MRI和SPECT-MRI数据集进行训练和测试,这些数据集包含了严格注册的图像对。
- 为了模拟实际场景中的非对齐图像对,研究者将MRI图像作为参考,并对非MRI图像应用了刚性和非刚性变形,创建了所需的训练集。
- 对于测试集,同样对严格注册的图像对应用了这些变形。
评估指标:
- 选择了五个常用的图像质量评估指标:Gradient-based Fusion Performance (QAB/F)、Chen-Varshney Metric (QCV)、Visual Information Fidelity (QVIF)、Structure-based Metric (QS)和Structural Similarity Index Measure (QSSIM)。
与现有方法的比较:
- 与“Registration+Fusion”方法和“Joint Registration and Fusion”方法进行了比较。
- 比较了与五种联合配准和融合方法的性能:UMFCMGR、SuperFusion、MURF、IMF和PAMRFuse。
视觉比较:
- 展示了不同方法生成的融合结果的直观比较。
客观评估结果:
- 通过箱形图展示了不同方法在各个评估指标上的性能差异。
消融研究:
- 对MDF-FR和BSFA组件进行了消融实验,以验证它们对特征对齐和融合性能的影响。
- 进一步评估了MDF-FR、BSFA和MMFF对融合性能的影响。
模型复杂性分析:
- 分析了所提方法与现有方法在计算复杂性(FLOPs)和参数数量方面的对比。
补充实验:
- 与“Registration+Fusion”方法进行了额外的视觉和客观数据比较。
- 提供了不同方法对齐效果的可视化比较。
- 对MDF-FR、BSFA和MMFF进行了更深入的消融研究。
这些实验全面评估了所提出方法在多模态医学图像融合任务中的性能,并与现有技术进行了比较,展示了所提方法在特征对齐、对比度保持和细节保留方面的优势。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和补充材料,以下是一些可以进一步探索的点:
模型轻量化:
- 论文提到当前模型由于包含多个FRL&RRL和FusionBLK模块而不够轻量。未来的工作可以探索如何优化和精简模型结构,以降低模型复杂度并提高计算效率。
多模态图像配准和融合的联合学习:
- 进一步研究如何更有效地结合配准和融合任务,可能通过深入学习它们之间的相互关系和依赖性。
不同模态图像的融合:
- 扩展模型以适应更多的医学成像模态和应用场景,例如结合CT、MRI、PET和SPECT等。
提高变形场预测的准确性:
- 研究更高级的变形场预测技术,以应对更复杂的非刚性变形。
损失函数的改进:
- 设计新的损失函数或优化现有损失函数,以更好地保持源图像的结构信息和对比度。
网络架构的创新:
- 探索新型的神经网络架构,可能通过引入注意力机制、图卷积网络或其他先进的深度学习技术来增强特征提取能力。
数据增强技术:
- 研究更有效的数据增强技术,以提高模型对不同类型变形的泛化能力。
多尺度和多级别的特征融合:
- 进一步探索多尺度和多级别的特征融合策略,以更有效地整合来自不同模态的互补信息。
临床验证:
- 将所提出的方法应用于临床数据,并与临床专家合作评估其在实际诊断和治疗规划中的有效性。
跨模态特征表示学习:
- 研究如何学习更具辨别力的跨模态特征表示,以改善不同成像模态之间的特征匹配和融合。
实时性能优化:
- 针对实时应用场景,优化算法以满足低延迟要求。
开源代码和社区反馈:
- 论文提供了源代码,可以通过开源社区收集反馈,进一步改进模型并增加新的功能。
这些探索点可以帮助推动多模态医学图像融合技术的发展,提高其在临床和科研中的应用价值。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为BSAFusion的单阶段多模态医学图像融合框架,旨在同时解决非对齐多模态医学图像的配准和融合问题。以下是论文的主要内容总结:
问题陈述:
- 论文指出,现有的多模态医学图像融合方法通常假设源图像在像素级别上是严格对齐的,但在实际应用中这种假设往往不成立,导致融合结果不理想。此外,传统的两阶段方法(先配准后融合)存在模型复杂度高和可能的融合失败问题。
BSAFusion框架:
- 提出了一个单阶段框架BSAFusion,该框架通过共享单个特征编码器将特征跨模态对齐和融合集成在一起,避免了引入额外编码器导致的模型复杂度增加。
关键技术:
- **Modality Discrepancy-Free Feature Representation (MDF-FR)**:通过为每个输入图像添加模态特征表示头(MFRH)来整合全局信息,减少模态差异对特征对齐的影响。
- **Bidirectional Stepwise Feature Alignment (BSFA)**:基于两点之间矢量位移的路径独立性,采用双向逐步对齐变形场预测策略,提高特征对齐的准确性和效率。
- **Multi-Modal Feature Fusion (MMFF)**:应用预测的变形场对多模态特征进行对齐,并基于对齐的特征构建融合图像。
实验验证:
- 论文通过多个数据集的实验,验证了所提方法在特征对齐、对比度保持和细节保留方面的优势。与现有的“Registration+Fusion”和“Joint Registration and Fusion”方法相比,BSAFusion在视觉和客观评估指标上均展现出更好的性能。
消融研究:
- 通过消融研究验证了MDF-FR、BSFA和MMFF模块对融合性能的贡献,结果表明这些组件对于实现高质量的融合结果至关重要。
模型复杂性分析:
- 论文还分析了所提方法与现有方法在计算复杂性(FLOPs)和参数数量方面的对比,表明BSAFusion在保持高性能的同时具有较低的模型复杂度。
结论与未来工作:
- 论文总结了BSAFusion框架的主要贡献,并指出了未来的研究方向,包括模型轻量化和扩展到更多医学成像模态。
总体而言,这篇论文提出了一个创新的单阶段多模态医学图像融合框架,通过有效地处理非对齐图像的配准和融合问题,提高了融合质量,并展示了在实际应用中的潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Magnetic Resonance Imaging Feature-Based Subtyping and Model Ensemble for Enhanced Brain Tumor Segmentation
Authors:Zhifan Jiang, Daniel Capellán-Martín, Abhijeet Parida, Austin Tapp, Xinyang Liu, María J. Ledesma-Carbayo, Syed Muhammad Anwar, Marius George Linguraru
Accurate and automatic segmentation of brain tumors in multi-parametric magnetic resonance imaging (mpMRI) is essential for quantitative measurements, which play an increasingly important role in clinical diagnosis and prognosis. The International Brain Tumor Segmentation (BraTS) Challenge 2024 offers a unique benchmarking opportunity, including various types of brain tumors in both adult and pediatric populations, such as pediatric brain tumors (PED), meningiomas (MEN-RT) and brain metastases (MET), among others. Compared to previous editions, BraTS 2024 has implemented changes to substantially increase clinical relevance, such as refined tumor regions for evaluation. We propose a deep learning-based ensemble approach that integrates state-of-the-art segmentation models. Additionally, we introduce innovative, adaptive pre- and post-processing techniques that employ MRI-based radiomic analyses to differentiate tumor subtypes. Given the heterogeneous nature of the tumors present in the BraTS datasets, this approach enhances the precision and generalizability of segmentation models. On the final testing sets, our method achieved mean lesion-wise Dice similarity coefficients of 0.926, 0.801, and 0.688 for the whole tumor in PED, MEN-RT, and MET, respectively. These results demonstrate the effectiveness of our approach in improving segmentation performance and generalizability for various brain tumor types. The source code of our implementation is available at https://github.com/Precision-MedicalImaging-Group/HOPE-Segmenter-Kids. Additionally, an open-source web-application is accessible at https://segmenter.hope4kids.io/ which uses the docker container aparida12/brats-peds-2024:v20240913 .
在多变参磁共振成像(mpMRI)中,脑肿瘤的精准自动分割对于定量测量至关重要,这在临床诊断和预后中发挥着越来越重要的作用。国际脑肿瘤分割挑战赛(BraTS Challenge 2024)提供了一个独特的基准测试机会,包括成人和儿童人口中的多种类型的脑肿瘤,如儿童脑肿瘤(PED)、脑膜瘤(MEN-RT)和脑转移瘤(MET)等。相较于之前的版本,BraTS 2024进行了更改,以显著提高临床相关性,例如增加了用于评估的精细肿瘤区域。我们提出了一种基于深度学习的集成方法,该方法结合了最先进的分割模型。此外,我们引入了创新的自适应预处理和后置处理技巧,采用基于MRI的放射组学分析来区分肿瘤亚型。考虑到BraTS数据集中存在的肿瘤的异质性特征,此方法提高了分割模型的精确性和通用性。在最终测试集上,我们的方法达到了针对PED、MEN-RT和MET的全肿瘤的病变级Dice相似系数分别为0.926、0.801和0.688。这些结果证明了我们方法在改进各种脑肿瘤类型的分割性能和通用性方面的有效性。我们实现的源代码可在[https://github.com/Precision-MedicalImaging-Group/HOPE-Segmenter-Kids上获取。此外,一个开源的web应用程序可在[https://segmenter.hope4kids.io/上使用,该应用程序使用docker容器aparida12/brats-peds-2024:v20240913。](https://github.com/Precision-MedicalImaging-Group/HOPE-Segmenter-Kids%E4%B8%8A%E8%8E%B7%E5%8F%96%E3%80%82%E5%A6%82%E5%A4%96%EF%BC%8C%E4%B8%80%E4%B8%AA%E5%BC%BA%E5%A4%9F%E7%9A%84web-%E5%BA%94%E7%9B%AE%E7%AD%BE%E5%AE%BEapp可在https://segmenter.hope4kids.io/%E4%BD%BF%E7%94%A8%EF%BC%8C%E8%AF%A5%E5%BA%94%E7%9B%BEappdock)
论文及项目相关链接
PDF 11 pages, 4 figures, 3 tables. This paper was accepted at MICCAI-BraTS 2024
Summary
本文介绍了在多种参数磁共振成像(mpMRI)中准确自动分割脑肿瘤的重要性,这对于在临床诊断和治疗中发挥越来越重要作用的定量测量至关重要。文章聚焦于BraTS 2024挑战赛,该挑战赛为各种脑肿瘤的分割提供了一个独特的基准测试机会,包括成人和儿童群体的肿瘤类型,如儿童脑肿瘤(PED)、脑膜瘤(MEN-RT)和脑转移瘤(MET)等。相较于之前的版本,BraTS 2024在评价方面进行了更为精细的肿瘤区域划分,从而增加了临床相关性。研究提出了一种基于深度学习的集成方法,融合了最先进的分割模型,并引入了MRI的放射组学分析,用于区分肿瘤亚型。该方法针对BraTS数据集中肿瘤的异质性特征,提高了分割模型的精确性和泛化能力。在最终测试集上,该方法在PED、MEN-RT和MET的全肿瘤分割上分别取得了平均病灶水平的Dice相似系数0.926、0.801和0.688。相关源代码可通过链接访问。
Key Takeaways
- BraTS 2024挑战赛为脑肿瘤的分割提供了独特的基准测试机会,涵盖多种肿瘤类型。
- 与之前的版本相比,BraTS 2024在评价方面更加注重临床相关性。
- 研究提出了一种基于深度学习的集成方法用于分割脑肿瘤,并结合了先进的预处理和后处理技术。
- 利用MRI的放射组学分析来区分肿瘤亚型,增强了模型的精确性和泛化能力。
- 该方法在BraTS 2024的最终测试集上取得了良好的分割效果,特别是对于不同类型的脑肿瘤。
- 该研究的源代码已经公开可用。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是准确和自动地在多参数磁共振成像(mpMRI)中分割脑肿瘤。这对于临床诊断和预后的定量测量至关重要。具体来说,论文针对的是国际脑肿瘤分割(BraTS)挑战2024,该挑战包括成人和儿童人群中的各种脑肿瘤类型,如儿童脑肿瘤(PED)、脑膜瘤(MEN-RT)和脑转移瘤(MET)等。与以往的版本相比,BraTS 2024进行了改进,以增加临床相关性,例如细化了评估的肿瘤区域。论文提出了一种基于深度学习的集成方法,整合了最先进的分割模型,并引入了创新的自适应预处理和后处理技术,这些技术利用基于MRI的放射组学分析来区分肿瘤亚型。这种方法旨在提高分割模型的精确度和泛化能力,以应对BraTS数据集中肿瘤的异质性。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与该研究相关的研究:
Bakas, S. et al.: 该研究团队在多个场合提供了TCGA-GBM和TCGA-LGG数据集的分割标签和放射组特征,这些数据集被广泛用于脑肿瘤分割和放射组学特征分析。
Bakas, S., Akbari, H., Sotiras, A., et al.: 他们对脑肿瘤的分割和放射组学特征进行了表征,提供了重要的背景信息和方法论基础。
Capellan-Martin, D., Jiang, Z., Parida, A., Liu, X., Lam, V., Nisar, H., Tapp, A., Elsharkawi, S., Ledesma-Carbayo, M., Anwar, S.M., Linguraru, M.G.: 提出了一种用于磁共振成像中脑肿瘤分割的模型集成方法,与本文提出的集成方法相关。
Isensee, F., Jaeger, P.F., Kohl, S.A., et al.: 发表了nnU-Net,这是一种自配置的深度学习方法,用于生物医学图像分割,本文中使用了这一方法。
Kamnitsas, K., Ledig, C., Newcombe, V.F.J., et al.: 提出了一种用于脑损伤分割的高效多尺度3D CNN方法,与本文中的分割方法有相似之处。
Menze, B.H., Jakab, A., Bauer, S., et al.: 提出了多模态脑肿瘤图像分割基准(BRATS),为脑肿瘤分割领域的研究提供了重要的参考。
Ronneberger, O., Fischer, P., Brox, T.: 提出了U-Net,这是一种用于生物医学图像分割的卷积网络,本文中的方法基于此网络结构。
Roy, S., Koehler, G., Ulrich, C., Baumgartner, M., Petersen, J., Isensee, F., Jaeger, P.F., Maier-Hein, K.H.: 提出了MedNeXt,这是一种结合了卷积神经网络和注意力机制的混合方法,本文中也使用了这一方法。
Tang, Y., Yang, D., Li, W., Roth, H.R., et al.: 提出了Swin Transformers用于3D医学图像分析的自监督预训练方法,本文中的SwinUNETR模型基于此方法。
这些研究为本文提出的脑肿瘤分割方法提供了理论基础和技术背景。论文中可能还引用了其他相关研究,但以上是直接从提供的文本中识别出的关键相关研究。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决了准确和自动地在多参数磁共振成像(mpMRI)中分割脑肿瘤的问题:
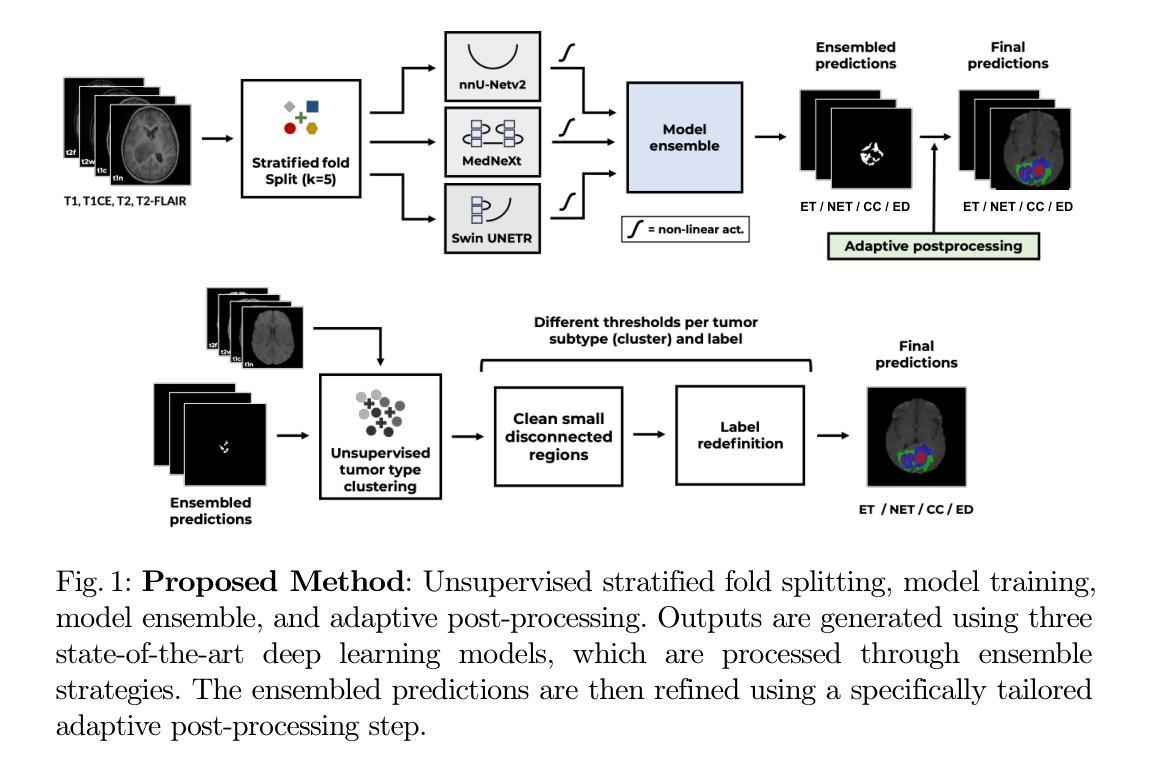
1. 提出深度学习集成方法
论文提出了一个基于深度学习的集成方法,该方法整合了多个最先进的分割模型,包括nnU-Net、MedNeXt和SwinUNETR。这些模型各自具有不同的优势,通过集成它们的预测结果,可以提高分割的准确性和鲁棒性。
2. 引入自适应预处理和后处理技术
论文引入了创新的自适应预处理和后处理技术,这些技术利用基于MRI的放射组学分析来区分肿瘤亚型。具体步骤如下:
2.1 MRI放射组学特征用于肿瘤亚型定义
- 使用PyRadiomics包提取MRI放射组学特征。
- 对每个任务的输入MRI序列中的最大病变区域计算这些特征。
- 应用主成分分析(PCA)选择最相关特征,并使用k-means聚类算法根据这些特征将肿瘤分为不同的亚型。
2.2 模型训练
- 对每个BraTS挑战(PED、MEN-RT和MET)训练了nnU-Net、MedNeXt和SwinUNETR模型。
- 使用了类权重损失函数,结合Dice损失和交叉熵损失进行优化。
- 在训练过程中,采用了随机梯度下降(SGD)优化器,并使用了NVIDIA的高性能GPU进行训练。
2.3 模型集成
- 使用模型集成策略来增强分割结果的准确性和鲁棒性。
- 根据各个模型在训练集上的表现,为每个模型分配不同的权重,然后结合这些加权预测来获得最终的分割结果。
2.4 后处理
- 在交叉验证的全肿瘤(WT)预测上应用自适应后处理技术。
- 通过k-means算法训练并确定最优阈值,以消除小的、不连续的组件,减少假阳性。
- 对这些细化的分割图进行第二次阈值搜索,以重新定义标签。
3. 实现和评估
- 实现了一个开源的web应用程序,允许用户上传MRI序列以获得分割和体积测量结果。
- 在BraTS挑战的验证和测试数据集上评估了模型的性能,使用了病变-wise Dice分数和95th百分位病变-wise Hausdorff距离作为评估指标。
通过上述方法,论文成功提高了脑肿瘤分割的精确度和泛化能力,特别是在处理临床数据集中肿瘤的异质性方面。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,以下是论文中进行的实验:
1. 数据集和挑战任务
- BraTS 2024挑战:包括儿童脑肿瘤(PED)、脑膜瘤放疗(MEN-RT)和脑转移瘤(MET)三个子挑战,每个挑战都有其特定的数据集和任务。
2. 模型训练和验证
- nnU-Net、MedNeXt和SwinUNETR模型训练:针对每个挑战任务,使用相应的数据集训练了这三个深度学习模型。
- 五折交叉验证:对每个挑战任务的数据集进行了五折交叉验证,以评估和优化模型性能。
3. 模型集成
- 加权模型集成:根据各个模型在训练集上的表现,计算出各自的权重,并使用这些权重将不同模型的预测结果结合起来,以提高分割的准确性和鲁棒性。
4. 后处理
- 自适应后处理技术:在交叉验证的全肿瘤(WT)预测上应用自适应后处理技术,包括基于k-means聚类的最优阈值搜索和标签重新定义。
5. 性能评估
- 验证集评估:使用BraTS挑战的验证集评估模型预测的性能,使用病变-wise Dice分数和95th百分位病变-wise Hausdorff距离作为评估指标。
- 测试集评估:在最终测试集上评估模型的性能,这些测试集包括未见过的数据,以验证模型的泛化能力。
6. 可视化和定性分析
- 定性结果展示:通过图表和图像展示了模型在验证集上的定性分割结果,包括不同肿瘤区域的分割效果。
7. 开源实现和演示
- 开源代码和演示应用:提供了模型实现的开源代码,并开发了一个开源的web应用程序,允许用户上传MRI序列以获得分割和体积测量结果。
这些实验旨在全面评估所提出方法的有效性,包括模型的准确性、鲁棒性和泛化能力,以及在实际临床数据上的应用潜力。通过这些实验,论文展示了其方法在提高脑肿瘤分割性能方面的潜力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和结果,以下是一些可以进一步探索的点:
1. 模型集成策略的优化
- 探索不同的模型集成策略,例如基于投票、堆叠(stacking)或深度集成的方法,以进一步提高分割性能。
2. 放射组学特征的深入分析
- 对放射组学特征进行更深入的分析,以识别最具鉴别力的特征,并探索这些特征与肿瘤生物学特性之间的关系。
3. 肿瘤异质性的进一步研究
- 针对肿瘤异质性进行更细致的研究,探索不同肿瘤亚型之间的差异,并研究这些差异如何影响分割性能。
4. 跨模态数据的融合
- 探索将MRI数据与其他成像模态(如CT、PET)结合的方法,以利用不同模态的互补信息提高分割准确性。
5. 模型的泛化能力
- 在更多的临床数据集上测试模型,以评估其在不同人群和不同成像设备上的泛化能力。
6. 模型解释性
- 提高模型的解释性,通过可视化技术揭示模型如何做出分割决策,以及哪些特征对这些决策最为重要。
7. 计算效率的优化
- 探索模型压缩和加速技术,以减少模型的计算资源需求,使其更适合在临床环境中实时应用。
8. 多中心数据的一致性
- 研究不同医疗机构和不同成像设备采集的数据之间的一致性问题,并开发校正技术以提高跨中心数据的分割性能。
9. 长期追踪和临床结果的相关性
- 研究分割结果与患者长期追踪数据和临床结果之间的相关性,以评估分割模型在临床决策中的实际价值。
10. 交互式和实时分割工具的开发
- 开发交互式和实时的脑肿瘤分割工具,以辅助临床医生在手术规划和治疗监测中的实际应用。
这些探索点可以帮助研究者进一步提高脑肿瘤分割技术的准确性、鲁棒性和临床适用性,最终为患者提供更好的诊断和治疗支持。
Q: 总结一下论文的主要内容
A: 论文的主要内容概括如下:
问题阐述:
- 论文针对的主要问题是在多参数磁共振成像(mpMRI)中准确和自动地分割脑肿瘤,这对于临床诊断和预后具有重要意义。
研究背景:
- 论文参与了国际脑肿瘤分割(BraTS)挑战2024,该挑战包括多种脑肿瘤类型,如儿童脑肿瘤(PED)、脑膜瘤(MEN-RT)和脑转移瘤(MET)。
方法论:
- 提出了一种基于深度学习的集成方法,整合了nnU-Net、MedNeXt和SwinUNETR三个先进的分割模型。
- 引入了自适应预处理和后处理技术,利用MRI放射组学特征来区分肿瘤亚型,并优化分割结果。
实验设计:
- 对每个挑战任务的数据集进行了五折交叉验证,训练并验证了所提出的模型。
- 使用病变-wise Dice分数和95th百分位病变-wise Hausdorff距离作为评估指标。
实验结果:
- 在BraTS 2024的测试集上,所提方法取得了较高的平均Dice相似系数,显示出良好的分割性能和泛化能力。
讨论和结论:
- 论文讨论了模型集成技术如何提高分割模型的精确度和泛化能力,以及如何通过聚类相似肿瘤亚型来定制后处理步骤,以减少假阳性并提高分割准确性。
- 论文得出结论,所提出的基于深度学习的集成方法,配合创新的自适应预处理和后处理技术,能有效提高脑肿瘤分割的精确度和泛化能力,对临床数据集中肿瘤的异质性具有较好的处理能力。
未来工作:
- 论文提出了未来可能的研究方向,包括优化模型集成策略、深入分析放射组学特征、探索肿瘤异质性、跨模态数据融合等。
总体而言,论文提出了一种有效的脑肿瘤分割方法,并通过一系列实验验证了其有效性,为未来的研究和临床应用提供了新的思路和工具。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

CAS-GAN for Contrast-free Angiography Synthesis
Authors:De-Xing Huang, Xiao-Hu Zhou, Mei-Jiang Gui, Xiao-Liang Xie, Shi-Qi Liu, Shuang-Yi Wang, Hao Li, Tian-Yu Xiang, Zeng-Guang Hou
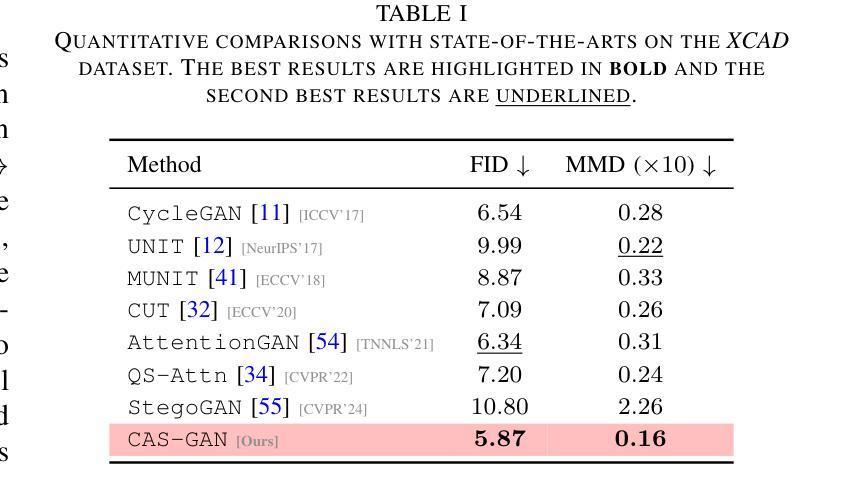
Iodinated contrast agents are widely utilized in numerous interventional procedures, yet posing substantial health risks to patients. This paper presents CAS-GAN, a novel GAN framework that serves as a “virtual contrast agent” to synthesize X-ray angiographies via disentanglement representation learning and vessel semantic guidance, thereby reducing the reliance on iodinated contrast agents during interventional procedures. Specifically, our approach disentangles X-ray angiographies into background and vessel components, leveraging medical prior knowledge. A specialized predictor then learns to map the interrelationships between these components. Additionally, a vessel semantic-guided generator and a corresponding loss function are introduced to enhance the visual fidelity of generated images. Experimental results on the XCAD dataset demonstrate the state-of-the-art performance of our CAS-GAN, achieving a FID of 5.87 and a MMD of 0.016. These promising results highlight CAS-GAN’s potential for clinical applications.
碘化造影剂在众多介入手术中得到了广泛应用,但为患者带来了较大的健康风险。本文提出了CAS-GAN,这是一种新型的GAN框架,可作为“虚拟造影剂”通过解耦表示学习和血管语义指导来合成X射线血管造影术,从而减少介入手术中对碘化造影剂的依赖。具体来说,我们的方法将X射线血管造影术分解为背景和血管成分,并利用医学先验知识。然后,一个专门的预测器学习这些成分之间的相互作用关系。此外,还引入了血管语义引导生成器和相应的损失函数,以提高生成图像的可视保真度。在XCAD数据集上的实验结果证明了CAS-GAN的卓越性能,达到FID 5.87和MMD 0.016。这些令人鼓舞的结果突显了CAS-GAN在临床应用中的潜力。
论文及项目相关链接
PDF IEEE Symposium Series on Computational Intelligence (SSCI 2025)
摘要
本文介绍了一种新型的GAN框架——CAS-GAN,作为“虚拟对比剂”在介入手术中合成X光血管造影图像。通过解耦表示学习和血管语义指导,CAS-GAN减少了对比碘造影剂的使用风险。该方法将X光血管造影图像分解为背景和血管成分,并利用医学先验知识进行处理。特殊的预测器学习这些成分之间的关系映射。此外,引入了血管语义引导的生成器和相应的损失函数,以提高生成图像的可视逼真度。在XCAD数据集上的实验结果表明,CAS-GAN的性能达到了最新的水平,实现了FID为5.87和MMD为0.016的优异结果。这些成果突显了CAS-GAN在临床应用中的潜力。
关键见解
- CAS-GAN作为一种新型的GAN框架,被用作介入手术中的“虚拟对比剂”,合成X光血管造影图像。
- CAS-GAN通过解耦表示学习来分解X光血管造影图像,分为背景和血管成分。
- 引入医学先验知识进行处理,并使用特殊的预测器学习背景与血管成分之间的关系映射。
- 引入血管语义引导的生成器和相应的损失函数,增强生成图像的视觉逼真度。
- 在XCAD数据集上的实验结果表明CAS-GAN具有优异的性能。
- CAS-GAN达到了先进的性能指标,如FID为5.87和MMD为0.016。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。通过使用CAS-GAN,研究者们希望能够合成出无需使用碘造影剂的X射线血管造影图像,从而减少对这些可能对患者造成潜在健康风险的造影剂的依赖。
具体来说,论文中提到了以下几个关键问题:
心血管疾病(CVDs)的治疗需求:心血管疾病是全球死亡的主要原因,而图像引导的血管介入手术是治疗心血管疾病的主流方法之一。
碘造影剂的健康风险:在X射线血管造影中,为了使血管显影,需要使用碘基的造影剂。然而,这些造影剂存在副作用,包括可能危及生命的过敏反应,以及对肾脏的潜在损害,尤其是在已有肾脏疾病或糖尿病患者中。
减少造影剂使用的需求:为了满足临床需求,同时显著减少造影剂剂量甚至不使用造影剂,同时保持成像质量,这是X射线血管造影系统必须解决的关键挑战。
生成对抗网络(GANs)的应用:论文提出了利用GANs作为“虚拟造影剂”来生成逼真的X射线血管造影图像的可能性,这可能会减少对碘造影剂的依赖,并提高介入手术的安全性和效率。
图像到图像的翻译挑战:将非对比X射线图像转换为X射线血管造影图像是一个具有挑战性的问题,因为它不仅需要在两个图像域之间进行风格转换,还需要精确的一对一图像映射。
论文提出的CAS-GAN框架通过解耦X射线血管造影图像的背景和血管成分,并利用医学先验知识,使用神经网络学习这些成分之间的相互关系,从而解决了上述挑战。此外,还引入了血管语义引导生成器和相应的损失函数,以增强生成图像的视觉保真度。
Q: 有哪些相关研究?
A: 论文中提到了多个与CAS-GAN相关的研究工作,可以归纳为以下几个方面:
1. 生成对抗网络(GANs)
- GANs由Goodfellow等人在2014年引入,通过建立一个最小最大优化游戏,其中生成器G旨在模仿真实数据样本的分布,而判别器D评估它们的真伪。
- 论文中提到了一些GAN的变种,它们通过更稳定的训练目标来解决训练GANs时的挑战,比如梯度消失和模式崩溃问题。
2. 图像到图像的翻译(Image-to-image translation)
- 这项工作涉及将图像从一个域转换到另一个域,同时保持其底层结构或内容。
- Isola等人提出了一个条件GAN框架,使用对抗损失和L1重建损失在成对数据上进行训练。
- 近期的研究集中在无成对数据的翻译上,引入了循环一致性等额外约束以保持域转换期间的语义一致性。
3. 解耦表示学习(Disentanglement representation learning)
- 解耦表示学习通过将图像分解为具有物理意义的成分来提高生成图像的可控性和可解释性。
- 一些工作尝试将图像分解为内容和风格表示,以实现通过交换风格表示进行图像翻译。
4. 医学图像生成和翻译
- 论文中提到了几项与医学图像生成和翻译相关的研究,包括使用GANs从非对比X射线图像生成X射线血管造影图像的研究。
5. 相关技术方法
- 论文还提到了一些技术方法,如注意力机制(attention mechanisms)、自监督对比损失(self-supervised contrast loss)等,这些方法被用于增强不同域之间语义关系的翻译。
具体论文和方法
- CycleGAN:用于无成对图像到图像的翻译。
- UNIT、MUNIT:用于无监督的图像到图像的翻译网络。
- AttentionGAN:使用注意力引导的生成对抗网络进行无成对图像到图像的翻译。
- QS-Attn:使用查询选择注意力进行对比学习。
- StegoGAN:用于非双射图像到图像的翻译,利用隐写术。
这些相关研究为CAS-GAN提供了理论基础和技术背景,同时也展示了在医学图像翻译领域中,如何利用深度学习技术来解决实际的临床问题。
Q: 论文如何解决这个问题?
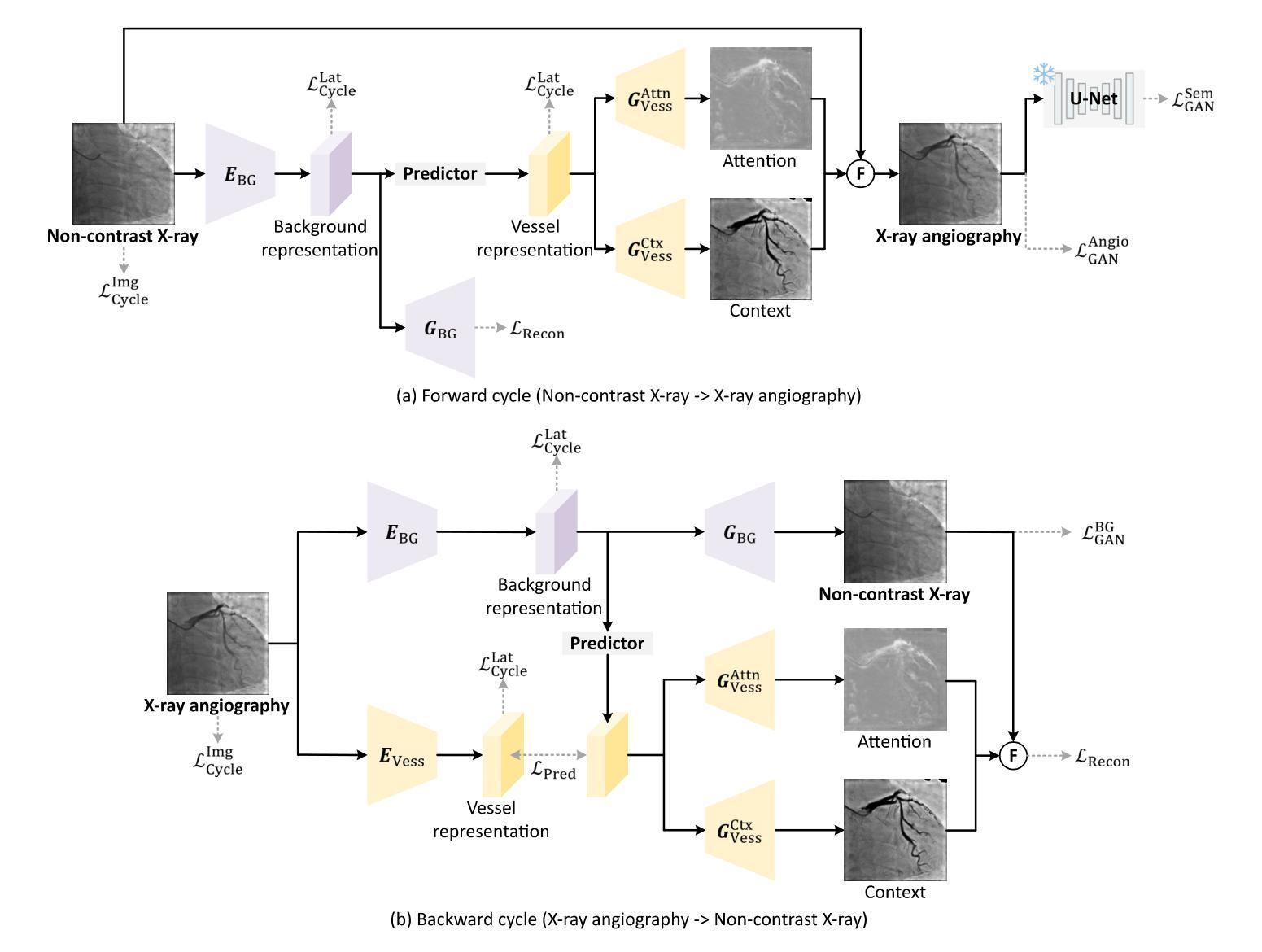
A: 论文通过提出一个名为CAS-GAN的新型生成对抗网络(GAN)框架来解决这个问题。CAS-GAN框架的核心思想是将X射线血管造影图像解耦为背景和血管成分,然后通过神经网络学习这两部分之间的相互关系,以此来生成逼真的血管造影图像。以下是该方法解决该问题的关键步骤:
解耦表示学习(Disentanglement Representation Learning):
- 使用两个专门的编码器(一个背景编码器和一个血管编码器)将X射线血管造影图像分解为背景和血管成分。
- 通过一个称为“预测器”的神经网络,从背景表示中推断出血管表示。
血管语义引导生成器(Vessel Semantic-Guided Generator):
- 为了提高生成图像中血管的真实性,引入了两个专门的生成器:一个用于注意力掩模,一个用于上下文掩模。
- 这些生成器利用预测器提供的血管表示来生成逼真的血管结构。
血管语义引导的对抗损失(Vessel Semantic-Guided Adversarial Loss):
- 为了提高GAN对真实和生成血管图像之间差异的识别能力,引入了一种新的对抗损失,专注于血管的语义差异。
- 使用预训练的U-Net网络提取原始和生成血管造影图像中的血管语义图像,然后定义基于这些语义图像的对抗损失。
训练目标(Training Objective):
- 由于两个图像域之间的映射高度不确定,因此结合了多种有效的损失函数来训练CAS-GAN,包括预测损失、对抗损失、循环一致性损失和重建损失。
- 这些损失函数的加权和构成了CAS-GAN的训练目标,以优化图像翻译过程的各个方面。
通过这些方法,CAS-GAN能够有效地从非对比X射线图像中生成逼真的X射线血管造影图像,从而减少对碘造影剂的依赖,并提高介入手术的安全性和效率。论文中的实验结果表明,CAS-GAN在XCAD数据集上实现了最先进的性能,证明了其在临床应用中的潜力。
Q: 论文做了哪些实验?
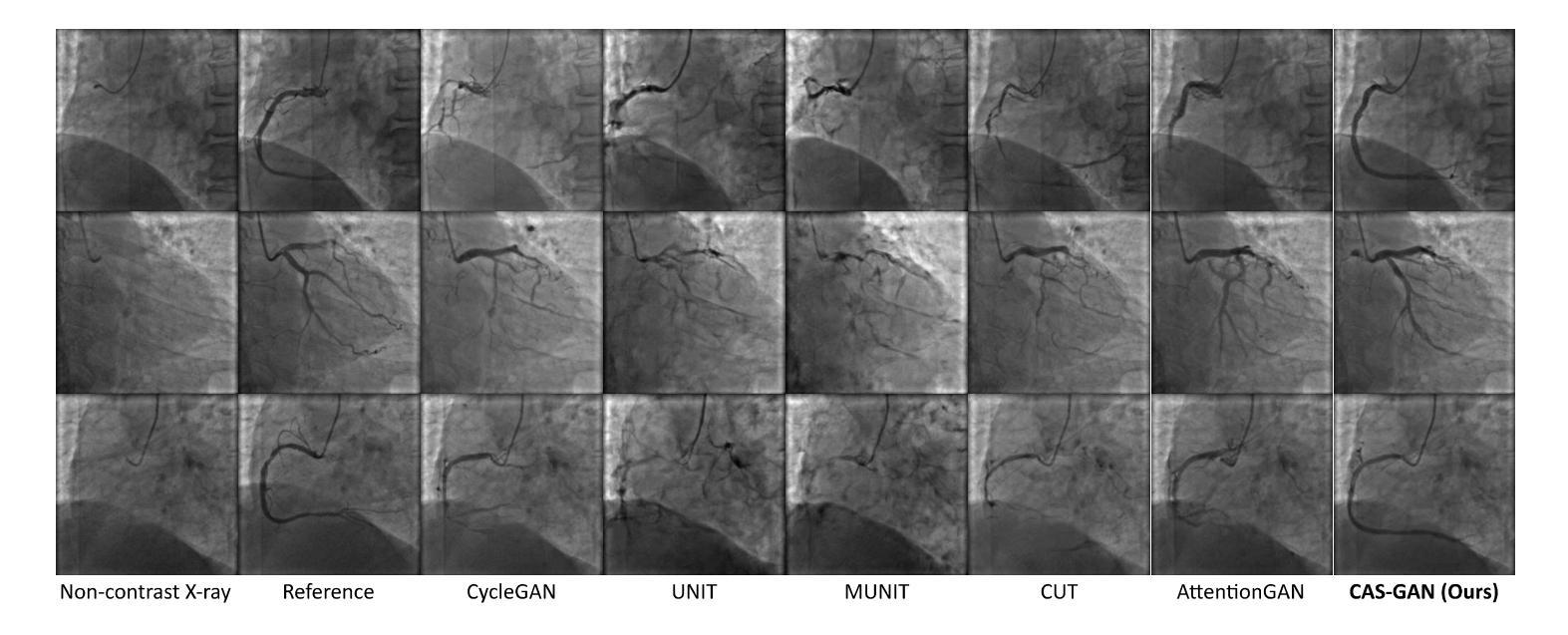
A: 论文中进行了多项实验来验证CAS-GAN模型的性能,包括与其他最先进方法的比较、消融研究以及外部验证。以下是实验的具体内容:
A. 数据集(Dataset)
- 使用了X射线血管造影冠状血管分割数据集(XCAD),该数据集包含非对比X射线图像和X射线血管造影图像。
- 数据集分为两个子集:一个用于图像翻译任务,另一个用于训练U-Net提取血管语义信息。
- 随机选择了621张非对比X射线图像和621张X射线血管造影图像作为测试集,其余作为训练集。
B. 实现细节(Implementation details)
- 采用了与CycleGAN相同的生成器和判别器架构,以进行公平比较。
- 预测器使用多层感知机(MLP)实现。
- 使用PyTorch、Python和Ubuntu环境,搭载NVIDIA GeForce RTX 4090 GPU进行实验。
- 使用Adam优化器进行1000个周期的训练,初始学习率设置为2e-4,并在700个周期后线性降低至零。
C. 评估指标(Evaluation metrics)
- 使用了Fréchet Inception Distance(FID)和Maximum Mean Discrepancy(MMD)两个指标来评估生成图像的性能。
D. 实验结果(Results)
1. 与最先进方法的比较(Comparisons with state-of-the-arts)
- 将CAS-GAN与其他几种领先的无成对图像到图像翻译方法进行了比较,包括CycleGAN、UNIT、MUNIT、CUT、AttentionGAN、QS-Attn和StegoGAN。
- 在XCAD数据集上的定量结果表明,CAS-GAN在FID和MMD两个指标上均优于其他基线方法。
2. 消融研究(Ablation studies)
- 进行了广泛的消融实验来验证CAS-GAN中几个设计的有效性,包括解耦表示学习(DRL)、血管语义引导生成器(VSGG)和血管语义引导损失(VSGL)。
- 实验结果显示,这些设计显著提高了模型的性能。
3. 外部验证(External validation)
- 为了验证模型的泛化能力,还在来自合作医院的外部数据集上进行了实验。
- 尽管所有方法在处理XCAD和外部数据集之间的显著差异时都遇到了困难,但CAS-GAN展示了相对较好的性能。
这些实验结果证明了CAS-GAN在无需对比剂的X射线血管造影合成任务中的有效性和优越性能。论文还指出,未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的能力。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些未来工作的方向,以下是一些可以进一步探索的关键点:
扩展训练数据集:通过增加数据集的大小和多样性来提高模型在外部数据集上的性能。这可能包括收集更多的X射线血管造影图像以及对应的非对比X射线图像,以提高模型的泛化能力。
纳入更先进的模型:探索使用更先进的生成模型,如StyleGAN等,以进一步提高生成图像的质量和真实感。
改进损失函数:研究和设计新的损失函数,以更好地捕捉血管造影图像的特定特征,从而提高生成图像的质量。
多模态数据融合:考虑将CAS-GAN与其他成像模态(如CT、MRI)结合,以实现多模态图像融合和翻译。
实时性能优化:优化模型的计算效率,使其能够在临床环境中实时生成高质量的血管造影图像。
临床验证:与医疗专家合作,进行临床试验以验证CAS-GAN生成的图像在实际诊断和治疗规划中的有效性和安全性。
交互式系统开发:开发交互式系统,使医生能够根据需要调整生成的血管造影图像,以更好地满足特定的临床需求。
模型解释性:提高模型的可解释性,使医生能够理解模型的决策过程,从而增加对生成图像的信任。
跨领域应用:探索CAS-GAN在其他医疗图像翻译任务中的应用,如不同模态之间的图像转换或病理图像的合成。
鲁棒性和安全性测试:对模型进行广泛的鲁棒性和安全性测试,以确保其在各种临床条件下都能稳定地工作。
这些方向不仅可以推动CAS-GAN技术的发展,还可能对医疗图像处理和计算机视觉领域产生更广泛的影响。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一种名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。CAS-GAN通过解耦表示学习和血管语义引导生成血管造影图像,以减少对碘造影剂的依赖。
以下是论文的主要内容概述:
问题背景:心血管疾病是全球主要死因之一,而X射线血管造影是诊断和治疗这些疾病的关键技术。然而,传统的X射线血管造影需要使用碘基造影剂,这些造影剂可能引起严重的副作用,包括过敏反应和肾脏损害。
CAS-GAN框架:提出了一种新颖的GAN框架,通过解耦背景和血管成分,利用医学先验知识,使用神经网络学习这两部分之间的相互关系,从而合成逼真的血管造影图像。
方法论:
- 解耦表示学习:使用专门的编码器将血管造影图像分解为背景和血管成分,并用一个神经网络(预测器)来推断血管表示。
- 血管语义引导生成器:引入两个专门的生成器来生成注意力掩模和上下文掩模,以增强生成图像中血管的真实性。
- 血管语义引导的对抗损失:提出了一种新的对抗损失,专注于血管的语义差异,以提高GAN对真实和生成血管图像之间差异的识别能力。
实验:
- 使用XCAD数据集进行实验,该数据集包含非对比X射线图像和X射线血管造影图像。
- 在定量和定性上与其他最先进方法进行比较,CAS-GAN在FID和MMD指标上均优于其他方法。
- 进行消融研究验证了解耦表示学习、血管语义引导生成器和血管语义引导损失的有效性。
- 在外部数据集上进行验证,展示了CAS-GAN的泛化能力。
结论与未来工作:CAS-GAN为减少介入手术中碘造影剂的使用提供了一种有前景的方法。未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的性能。
总的来说,这篇论文提出了一个创新的解决方案来应对医疗成像中的一个关键挑战,并展示了有希望的初步结果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

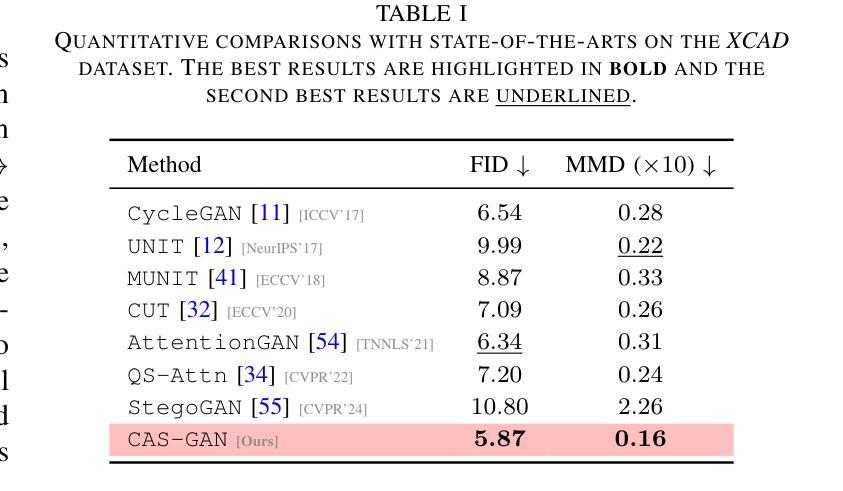
Enhanced Low-Dose CT Image Reconstruction by Domain and Task Shifting Gaussian Denoisers
Authors:Tim Selig, Thomas März, Martin Storath, Andreas Weinmann
Computed tomography from a low radiation dose (LDCT) is challenging due to high noise in the projection data. Popular approaches for LDCT image reconstruction are two-stage methods, typically consisting of the filtered backprojection (FBP) algorithm followed by a neural network for LDCT image enhancement. Two-stage methods are attractive for their simplicity and potential for computational efficiency, typically requiring only a single FBP and a neural network forward pass for inference. However, the best reconstruction quality is currently achieved by unrolled iterative methods (Learned Primal-Dual and ItNet), which are more complex and thus have a higher computational cost for training and inference. We propose a method combining the simplicity and efficiency of two-stage methods with state-of-the-art reconstruction quality. Our strategy utilizes a neural network pretrained for Gaussian noise removal from natural grayscale images, fine-tuned for LDCT image enhancement. We call this method FBP-DTSGD (Domain and Task Shifted Gaussian Denoisers) as the fine-tuning is a task shift from Gaussian denoising to enhancing LDCT images and a domain shift from natural grayscale to LDCT images. An ablation study with three different pretrained Gaussian denoisers indicates that the performance of FBP-DTSGD does not depend on a specific denoising architecture, suggesting future advancements in Gaussian denoising could benefit the method. The study also shows that pretraining on natural images enhances LDCT reconstruction quality, especially with limited training data. Notably, pretraining involves no additional cost, as existing pretrained models are used. The proposed method currently holds the top mean position in the LoDoPaB-CT challenge.
低剂量计算机断层扫描(LDCT)由于投影数据中的高噪声而具有挑战性。目前流行的LDCT图像重建方法主要采用两阶段方法,通常包括滤波反投影(FBP)算法和神经网络进行LDCT图像增强。两阶段方法因其简单性和计算效率而具有吸引力,通常仅需进行单次FBP和神经网络前向传递即可完成推理。然而,目前最佳重建质量是由展开迭代方法(Learned Primal-Dual和ItNet)实现的,尽管它们更复杂并且具有更高的训练和推理计算成本。我们提出了一种结合两阶段方法的简单性和高效性,同时拥有最新重建质量的方法。我们的策略是利用预训练的神经网络去除自然灰度图像中的高斯噪声,并针对LDCT图像增强进行微调。我们将此方法称为FBP-DTSGD(域和任务转移高斯去噪器),因为微调是从高斯去噪转移到增强LDCT图像的任务转移,以及从自然灰度到LDCT图像的域转移。使用三种不同的预训练高斯去噪器的消融研究表明,FBP-DTSGD的性能并不依赖于特定的去噪架构,这表明未来高斯去噪技术的进展可能对该方法产生积极影响。研究还表明,在自然图像上的预训练提高了LDCT的重建质量,特别是在有限的训练数据下。值得注意的是,预训练不涉及任何额外成本,因为使用的是现有的预训练模型。该方法目前在LoDoPaB-CT挑战中占据榜首的平均位置。
论文及项目相关链接
PDF 13 pages, 4 figures
摘要
基于低剂量计算机断层扫描(LDCT)的投影数据存在高噪声问题,因此带来诸多挑战。当前流行的LDCT图像重建方法主要采用两阶段法,即先使用滤波反投影(FBP)算法,再辅以神经网络进行LDCT图像增强。两阶段法因其简单性和计算效率而具有吸引力,通常仅需进行一次FBP和神经网络前向传递即可完成推理。然而,目前最佳重建质量由展开迭代方法(如Learned Primal-Dual和ItNet)实现,但它们更复杂,因此训练和推理的计算成本更高。本研究提出了一种结合两阶段法的简单性和高效性,同时拥有最新重建质量的方法。我们的策略是利用预训练的用于自然灰度图像高斯噪声去除的神经网络,并进行微调以用于LDCT图像增强。我们称这种方法为FBP-DTSGD(域和任务转移高斯去噪器),因为微调是从高斯去噪转移到增强LDCT图像的任务,并且是从自然灰度域转移到LDCT图像域。使用三种不同预训练高斯去噪器的消融研究表明,FBP-DTSGD的性能并不依赖于特定的去噪架构,这表明未来高斯去噪技术的进步可能对本方法有益。研究还表明,在自然图像上的预训练提高了LDCT的重建质量,特别是在训练数据有限的情况下。值得注意的是,预训练不涉及任何额外成本,因为可以使用现有的预训练模型。目前,该方法在LoDoPaB-CT挑战中占据首位。
关键见解
- LDCT面临高噪声问题,影响图像质量。
- 当前流行的LDCT图像重建方法包括两阶段法,即FBP与神经网络结合。
- 展开迭代方法(如Learned Primal-Dual和ItNet)虽然能提供最佳重建质量,但计算成本较高。
- 提出了一种新的方法FBP-DTSGD,结合了两阶段法的效率和最新重建技术。
- FBP-DTSGD利用预训练的高斯去噪器进行微调,以提高LDCT图像增强效果。
- 消融研究表明,FBP-DTSGD的性能不依赖于特定的去噪架构,预训练有助于提升质量。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是低剂量计算机断层扫描(Low-Dose CT, LDCT)图像的重建问题。由于低剂量CT扫描使用较低的辐射剂量,其图像质量相对较差,存在更多的噪声和伪影。提高LDCT图像的重建质量是一个具有挑战性的研究课题。
论文提出了一种两阶段的LDCT图像重建方法,主要包括:
预处理阶段:使用传统的滤波反投影(Filtered BackProjection, FBP)方法进行初步重建。
图像增强阶段:使用一个预训练的神经网络对FBP重建的图像进行增强。这个神经网络最初是在一个不同的任务上进行预训练的,即从自然灰度图像中去除高斯噪声。然后,作者对这个网络进行微调(fine-tune),以适应CT图像增强的下游任务。
论文的创新点在于,预训练使用的是非CT数据(自然图像),并且预训练任务是去除高斯噪声,这与LDCT图像的噪声特性显著不同。这种方法在LoDoPaB-CT基准测试中取得了竞争性的结果,证明了其有效性。
Q: 有哪些相关研究?
A: 论文中提到了多个与低剂量计算机断层扫描(LDCT)图像重建相关的研究,以下是一些主要的相关研究:
迭代变分正则化方法:这些方法曾是CT图像重建的前沿技术,基于总变分(total variation)、总广义变分(total generalized variation)或Hessian Schatten范数等正则化技术。
深度学习方法:近年来,深度学习方法在医学图像重建中引起了范式转变,特别是卷积神经网络(CNNs)在减少伪影和重建噪声方面展示了令人信服的能力。
全学习方法:这些方法通过深度学习架构直接重建图像,使用原始投影数据或正弦图作为输入。
迭代方法:如统计迭代重建或基于模型的迭代重建(MBIR),通过在重建和去噪之间交替来提高图像质量。
多阶段方法:在这些方法中,神经网络作为流程中的一步或多个步骤,用于提高初始重建的结果。例如,UNet++、ISTA UNet、Multiscale UNet-like Sparse Coding (MUSC) 和 ItNet。
UNet架构:原始的UNet架构被广泛应用于医学图像处理,并在非医学领域也显示出了效果。
GANs和其他架构:结合编码器-解码器架构和生成对抗网络(GANs)的方法也受到了关注,用于提高LDCT图像质量。
其他创新方法:如使用方向波let、边缘增强、感知损失函数和条件正态化流等技术。
这些研究展示了LDCT图像重建领域的多样性和活跃性,以及深度学习技术在其中扮演的重要角色。论文提出的两阶段方法与这些现有方法相比,具有结构上的简单性和计算效率上的优势。
Q: 论文如何解决这个问题?
A: 论文提出了一种两阶段的低剂量计算机断层扫描(LDCT)图像重建方法,具体步骤如下:
第一阶段:滤波反投影(FBP):
- 使用传统的FBP方法进行初步的CT图像重建。
- FBP是一种分析技术,用于从X射线测量的各种角度获取的原始投影数据中重建CT图像。
- 由于FBP方法会放大测量噪声,特别是在低剂量CT扫描中,因此需要后续的图像增强步骤。
第二阶段:CT图像增强:
- 利用一个预训练的深度神经网络(DRUNet)对FBP重建的图像进行增强。
- DRUNet最初是在一个不同的任务上进行预训练的,即从自然灰度图像中去除高斯噪声。
- 预训练完成后,作者对这个网络进行微调(fine-tune),以适应CT图像增强的下游任务。
- 微调使用的是LoDoPaB-CT数据集,该数据集包含LDCT图像和相应的正常剂量CT(NDCT)图像对。
预训练和微调策略:
- 论文的关键创新点在于,预训练使用的是非CT数据(自然图像),并且预训练任务是去除高斯噪声,这与LDCT图像的噪声特性显著不同。
- 微调过程中,作者使用了结构相似性(SSIM)损失函数和均方误差(MSE)损失函数的组合,并加入了L2正则化项。
数据增强技术:
- 为了提高模型的鲁棒性,作者使用了两种数据增强技术:旋转增强和高斯噪声增强。
- 旋转增强使模型对输入图像的旋转方向不变,而高斯噪声增强使网络能够学习到更广泛的噪声模式。
实验和评估:
- 作者在LoDoPaB-CT挑战中评估了所提出的方法,并与现有的顶尖方法进行了比较。
- 提出的方法在SSIM指标上取得了最高的排名,并与ItNet方法共享第一名的位置。
简化的结构和计算效率:
- 与ItNet等其他方法相比,提出的两阶段方法结构更简单,因为它不需要迭代细化步骤。
- 从计算效率的角度来看,所提出的方法只需要执行FBP加上一次网络的前向传播。
通过这种两阶段方法,论文成功地提高了LDCT图像的重建质量,同时保持了计算效率。
Q: 论文做了哪些实验?
A: 论文中进行了多个实验来验证所提出方法的有效性和优化不同的参数设置。以下是论文中提到的一些关键实验:
旋转增强的有效性:
- 通过训练有无旋转增强的网络,并比较它们对不同方向输入图像的响应,来评估旋转增强的有效性。
高斯噪声增强的有效性:
- 通过比较不同高斯噪声增强策略(无增强、1%噪声增强、0.5%和1%噪声增强)对网络性能的影响。
FBP预处理中滤波器类型的影响:
- 比较了在FBP重建过程中使用Hann滤波器和Ram-Lak滤波器的效果。
SSIM基于损失函数的超参数调整:
- 对SSIM损失函数中的参数α进行了调整,以找到最佳的平衡点。
预训练/微调的有效性:
- 比较了使用预训练网络和从头开始训练的网络的性能差异。
LoDoPaB-CT挑战结果:
- 在LoDoPaB-CT挑战中评估了所提出的方法,并与当前领先的方法进行了比较。
不同设计选择和超参数设置的调查:
- 研究了使用正则化的SSIM损失函数与仅使用MAE损失的模型的性能差异。
- 研究了FBP输出的填充策略与裁剪策略对视觉伪影的影响。
- 评估了旋转增强在不同图像方向上的一致性。
- 考察了高斯噪声增强对性能的提升。
- 分析了不同滤波器在FBP预处理中的表现。
这些实验帮助作者优化了所提出方法的性能,并展示了其在LDCT图像重建任务中的有效性。通过这些实验,作者证明了预训练/微调策略、数据增强技术以及特定超参数选择对于提高重建质量的重要性。
Q: 有什么可以进一步探索的点?
A: 论文中提出了一些可能的研究方向,可以进一步探索以提高LDCT图像重建的质量或扩展所提出方法的应用范围:
其他成像模式的应用:
- 将所提出的方法应用于除CT之外的其他成像模式,如MRI或PET,这可能需要修改重建方法和微调数据集。
扩大预训练和网络架构的数据集大小:
- 利用更大的数据集进行预训练,并扩大网络架构的规模,这可能基于计算机视觉领域的观察,即大型网络在大型数据集上训练可以为下游任务提供更好的基础。
改进的网络架构:
- 开发更先进的神经网络架构,以更好地捕捉图像特征和减少重建伪影。
损失函数的优化:
- 研究和测试不同的损失函数,以找到更适合LDCT图像重建任务的损失函数。
正则化技术的进一步研究:
- 探索不同的正则化技术,以提高模型的泛化能力和鲁棒性。
计算效率的优化:
- 研究算法优化和硬件加速策略,以提高重建过程的计算效率。
临床验证:
- 在临床环境中验证所提出方法的有效性,包括与现有临床工作流程的集成。
多任务学习:
- 探索多任务学习框架,同时优化图像重建和其他相关任务,如图像分割或检测。
不确定性量化:
- 开发方法来量化重建过程中的不确定性,这对于临床决策可能很重要。
跨模态学习:
- 研究跨模态学习技术,以利用来自不同成像模态的信息来改进LDCT图像重建。
这些方向可以帮助研究者进一步提高LDCT图像重建的质量,或者将所提出的方法应用于新的领域和任务。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题背景:论文针对的是低剂量计算机断层扫描(LDCT)图像的重建问题。LDCT由于使用较低的辐射剂量,其图像质量相对较差,存在噪声和伪影问题。
研究目标:提出了一种两阶段的LDCT图像重建方法,旨在提高图像质量,减少噪声和伪影,同时保持计算效率。
方法介绍:
- 第一阶段使用传统的滤波反投影(FBP)方法进行初步重建。
- 第二阶段利用一个预训练的深度神经网络(DRUNet)对FBP重建的图像进行增强。
预训练和微调策略:
- DRUNet最初在自然灰度图像的高斯噪声去除任务上进行预训练。
- 然后,针对LDCT图像增强的下游任务进行微调。
技术创新点:
- 预训练使用的是非CT数据,且任务是去除高斯噪声,与LDCT图像的噪声特性不同。
- 提出的方法在结构上更简单,不需要迭代细化步骤。
实验验证:
- 在LoDoPaB-CT挑战中评估了所提出的方法,并与现有的顶尖方法进行了比较。
- 提出的方法在SSIM指标上取得了最高的排名,并与ItNet方法共享第一名的位置。
实验探索:
- 论文还探讨了不同的设计选择和超参数设置,如数据增强技术、损失函数的选择、滤波器类型等。
未来研究方向:
- 提出了一些可能的研究方向,包括将方法应用于其他成像模式、扩大预训练数据集和网络架构规模等。
结论:
- 论文提出的两阶段LDCT图像重建方法在保持计算效率的同时,取得了竞争性的结果,证明了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
- 论文提出的两阶段LDCT图像重建方法在保持计算效率的同时,取得了竞争性的结果,证明了其有效性。
点此查看论文截图

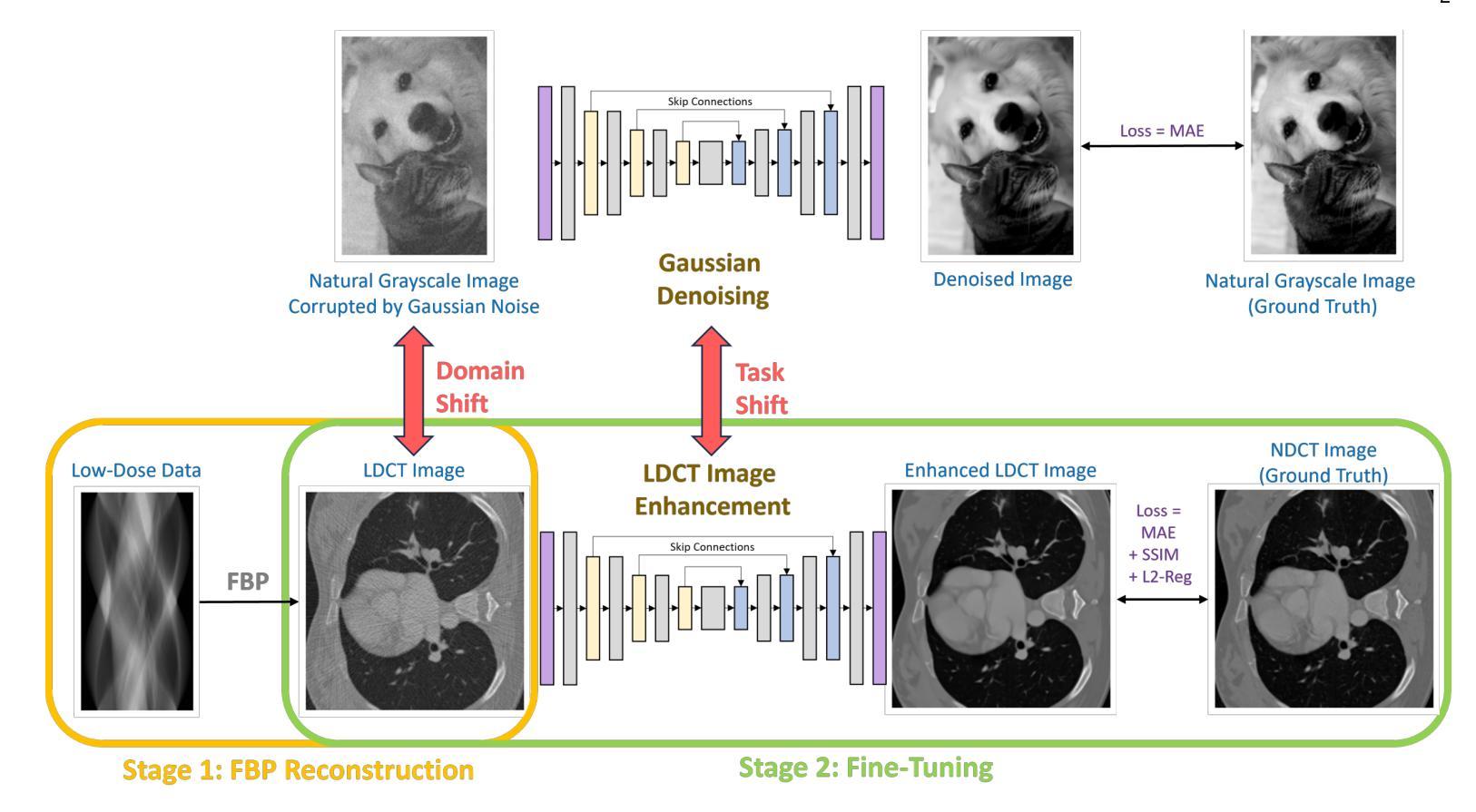

MoMA: Momentum Contrastive Learning with Multi-head Attention-based Knowledge Distillation for Histopathology Image Analysis
Authors:Trinh Thi Le Vuong, Jin Tae Kwak
There is no doubt that advanced artificial intelligence models and high quality data are the keys to success in developing computational pathology tools. Although the overall volume of pathology data keeps increasing, a lack of quality data is a common issue when it comes to a specific task due to several reasons including privacy and ethical issues with patient data. In this work, we propose to exploit knowledge distillation, i.e., utilize the existing model to learn a new, target model, to overcome such issues in computational pathology. Specifically, we employ a student-teacher framework to learn a target model from a pre-trained, teacher model without direct access to source data and distill relevant knowledge via momentum contrastive learning with multi-head attention mechanism, which provides consistent and context-aware feature representations. This enables the target model to assimilate informative representations of the teacher model while seamlessly adapting to the unique nuances of the target data. The proposed method is rigorously evaluated across different scenarios where the teacher model was trained on the same, relevant, and irrelevant classification tasks with the target model. Experimental results demonstrate the accuracy and robustness of our approach in transferring knowledge to different domains and tasks, outperforming other related methods. Moreover, the results provide a guideline on the learning strategy for different types of tasks and scenarios in computational pathology. Code is available at: \url{https://github.com/trinhvg/MoMA}.
毫无疑问,先进的人工智能模型和高质量的数据是开发计算病理学工具成功的关键。虽然病理学数据的总体数量不断增加,但由于包括患者隐私和伦理问题在内的几个原因,在特定任务中缺乏高质量数据是一个普遍存在的问题。在这项工作中,我们提出利用知识蒸馏技术,即利用现有模型学习新目标模型,以克服计算病理学中的这些问题。具体来说,我们采用学生-教师框架,从预训练的教师模型中学习目标模型,无需直接访问源数据,并通过带有多头注意力机制的动量对比学习进行知识蒸馏,这提供了一致的和上下文感知的特征表示。这使得目标模型能够吸收教师模型的信息化表示,同时无缝适应目标数据的独特细微差别。所提出的方法在不同的场景下进行了严格评估,其中教师模型在相同、相关和不相关的分类任务上与目标模型进行了训练。实验结果表明,我们的方法在转移到不同领域和任务时的准确性和稳健性,优于其他相关方法。此外,结果还为计算病理学中的不同类型任务和场景的学习策略提供了指导。代码可访问:https://github.com/trinhvg/MoMA。
论文及项目相关链接
Summary
本文提出利用知识蒸馏和动量对比学习来解决计算病理学中的数据质量问题。通过学生-教师框架和预训练教师模型,无需直接访问源数据即可学习目标模型,并通过多头注意力机制蒸馏相关知识。该方法在不同场景下进行了严格评估,实验结果表明该方法在跨域和任务转移知识方面的准确性和稳健性,优于其他相关方法,为计算病理学中的不同类型任务和场景提供了学习策略的指南。
Key Takeaways
- 先进的人工智能模型和高质量数据是开发计算病理学工具成功的关键。
- 病理学数据总体不断增加,但由于隐私和伦理问题等原因,特定任务时缺乏高质量数据是一个常见问题。
- 知识蒸馏被提出来解决计算病理学中的数据问题。
- 学生-教师框架被用于从预训练的教师模型中学习目标模型,无需直接访问源数据。
- 通过动量对比学习和多头注意力机制蒸馏相关知识。
- 实验结果表明该方法在跨域和任务转移知识方面的准确性和稳健性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是在计算病理学领域中,由于隐私和伦理问题以及数据共享的困难,导致特定任务缺乏高质量数据集的问题。具体来说,论文中提到了以下几个关键点:
数据量和质量问题:尽管病理数据的总量在不断增加,但是针对特定任务,由于各种原因(包括患者数据的隐私和伦理问题),往往难以获得足够的高质量数据。
数据多样性问题:公开可用的数据集数量有限,且数据集的多样性不足,这限制了人工智能模型在计算病理学中的泛化能力。
模型泛化性问题:如何构建准确且鲁棒的计算病理工具,使其能够适用于未见过的数据,是当前尚未完全解决的挑战。
为了解决这些问题,论文提出了一种名为MoMA(Momentum Contrastive Learning with Multi-head Attention-based Knowledge Distillation)的方法,该方法利用知识蒸馏技术,通过学生-教师框架从预训练的教师模型中学习目标模型,而无需直接访问源数据。这种方法通过动量对比学习和多头注意力机制来提取一致的、上下文感知的特征表示,使得目标模型能够吸收教师模型的信息表示,同时无缝适应目标数据的独特特点。实验结果表明,MoMA在不同领域和任务中传递知识方面的准确性和鲁棒性优于其他相关方法,为计算病理学中不同类型任务和场景的学习策略提供了指导。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究可以分为以下几个领域:
A. 计算病理学中的组织表型分析
- 机器学习在病理图像分析中的应用:早期的研究使用手工特征(如颜色直方图、灰度共生矩阵GLCM、局部二值模式等)结合随机森林和支持向量机等机器学习方法进行组织类型或癌症等级分类。
- 深度学习方法:随着GPU并行计算的发展,深度卷积神经网络(CNN)被用于病理图像的组织表型分析,例如用于前列腺癌检测和乳腺癌组织中的有丝分裂细胞检测。
- 性能改进方法:提出了多任务学习、多尺度学习和半监督学习方法等来提高深度学习模型的性能。
B. 知识蒸馏(Knowledge Distillation)
- 深度学习中的知识蒸馏:通过最小化两个模型之间的KL散度,将知识从一个大型模型转移到一个参数更少的模型。
- 特征图/嵌入蒸馏:利用中间特征图或嵌入进行知识蒸馏的方法,例如FitNet、Attention Transfer等。
- 跨模态知识转移:将知识从一个模态转移到另一个模态的方法,例如从RGB到深度模态的知识转移。
- 计算病理学中的知识蒸馏:提出了多层特征蒸馏、半监督学生-教师链等方法用于病理图像分类。
C. 自监督动量对比学习
- 自监督学习:通过预训练任务(如旋转、颜色化、拼图解决)来学习输入的特征表示。
- 对比学习:利用相似和/或不相似(对比)样本增强模型的表示能力,通常作为预训练机制。
- 动量对比(MoCo):通过平滑演变的编码器来保持记忆库中负样本的一致性。
D. 注意力机制
- 注意力在深度学习中的应用:注意力机制被用于聚焦于图像、区域或序列中最相关的部分。
- 自注意力和多头自注意力:自注意力机制允许估计一个图像、区域或序列与给定上下文中其他部分的相关性,是Transformer模型的主要成分。
这些相关研究为本文提出的MoMA框架提供了理论基础和技术背景,特别是在知识蒸馏、自监督学习和注意力机制方面。通过结合这些技术,MoMA旨在提高计算病理工具的准确性和鲁棒性,特别是在数据受限的情况下。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为MoMA(Momentum Contrastive Learning with Multi-head Attention-based Knowledge Distillation)的方法来解决计算病理学中因数据缺乏而导致的挑战。MoMA方法的核心思想是利用知识蒸馏(Knowledge Distillation, KD)框架,结合动量对比学习和多头自注意力机制,来实现从预训练的教师模型到目标学生模型的知识转移。以下是该方法的关键步骤和组件:
1. 学生-教师框架
- 教师模型(Teacher Model):一个已经在大型、高质量的数据集上预训练好的模型,能够提供丰富的特征表示和知识。
- 学生模型(Student Model):目标是在有限的目标数据集上训练的模型,旨在从教师模型中学习并适应目标数据集的特点。
2. 动量对比学习(Momentum Contrastive Learning)
- 利用动量更新策略来维护一个一致的负样本队列(Zqueue),增加负样本数量而不需要高GPU内存需求。
- 通过学生和教师模型分别生成正样本表示,这些表示的差异归因于两个在不同数据集上训练的模型。
3. 多头自注意力机制(Multi-head Attention)
- 采用自注意力机制来重新加权输入图像的特征表示,使其能够根据同一批次中其他图像的上下文进行调整。
- 通过多头自注意力(MSA)增强网络的特征表示能力,使模型能够关注重要的正样本,并在将负样本加入记忆库之前适当地加权。
4. 目标函数
- 结合交叉熵损失(LCE)、信息噪声对比损失(LNCE)和Hinton知识蒸馏损失(LKL),以优化模型性能。
5. 实验验证
- 在多组织病理数据集上评估MoMA,并在不同设置下与其他方法进行比较,包括相同任务、相关任务和不相关任务的知识转移。
6. 代码和资源
- 提供了代码的链接,以便其他研究者可以访问和使用MoMA方法。
通过这种方法,MoMA能够有效地从教师模型中提取知识,并将其传递给学生模型,使其能够在目标数据集上实现准确的分类,即使目标数据集相对较小。这种方法不仅提高了模型的泛化能力,还为计算病理学中不同任务和场景提供了一个有效的学习策略。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估MoMA(Momentum Contrastive Learning with Multi-head Attention-based Knowledge Distillation)方法在不同场景下的性能和有效性。以下是实验的详细描述:
A. 数据集
实验使用了多个数据集,包括前列腺癌(Prostate cANcer graDe Assessment, PANDA)数据集、前列腺USZ数据集、前列腺UBC数据集、前列腺AGGC数据集、结肠组织类型分类数据集(Colon K19和Colon K16)以及乳腺癌亚型分类数据集(BRACS)。
B. 实验设计
实验设计包括三种类型的蒸馏任务:
- 相同任务蒸馏:在前列腺癌分类模型之间进行蒸馏。
- 相关任务蒸馏:从4类前列腺癌分类蒸馏到5类前列腺癌分类。
- 不相关任务蒸馏:从前列腺癌分类蒸馏到结肠组织类型分类和乳腺癌亚型分类。
C. 实施细节
- 数据增强:使用RandAugment对所有学生模型进行训练。
- 训练细节:教师模型在ImageNet上预训练后在PANDA数据集上进行微调。学生模型在各自的目标数据集上进行微调,使用Adam优化器,批量大小分别为前列腺数据集64和结肠、乳腺和胃数据集256。
D. 定量评估
使用准确率(ACC)、宏平均F1分数(F1)和二次加权kappa统计量(κw)来评估MoMA和其他竞争模型在三种蒸馏任务上的性能。
E. 实验结果
- 相同任务蒸馏:MoMA在前列腺USZ和前列腺UBC数据集上的性能优于其他方法。
- 相关任务蒸馏:MoMA在前列腺AGGC数据集上的性能优于其他方法。
- 不相关任务蒸馏:MoMA在结肠组织类型分类和乳腺癌亚型分类数据集上的性能优于其他方法。
F. 学生和教师模型之间的类内和类间相关性
分析了学生和教师模型编码的特征嵌入之间的类内和类间相关性,以了解模型性能的差异。
G. 特征表示的可视化
使用t-SNE可视化和轮廓分数量化MoMA和其他竞争模型的特征表示。
H. 消融研究
进行了消融研究,比较了有无多头自注意力(MSA)的MoMA在三个蒸馏任务上的性能。
I. 自监督学习的效果
使用基于Transformer的模型(CTransPath和LunitDINO),这些模型通过自监督学习在大型病理图像数据上进行训练,并使用MoMA进行了三个蒸馏任务的实验。
这些实验全面评估了MoMA在不同任务和数据集上的性能,证明了其在知识蒸馏和特征表示学习方面的有效性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
多教师模型的知识蒸馏
论文中提出的MoMA框架目前仅考虑了从单一教师模型蒸馏知识。未来的研究可以探索如何从多个教师模型中蒸馏知识,以训练单个目标/学生模型。这可能涉及到集成学习或投票机制,以从多个知识源中提取和整合信息。
不同类型的任务和器官
论文主要关注了四个器官的病理图像分类任务。不同的任务(如生存/预后预测)和器官类型可能会对知识蒸馏的效果产生不同的影响。未来的研究可以探索这些因素如何影响模型性能,并调整MoMA框架以适应这些变化。
跨架构的知识蒸馏
论文中使用了相同架构的教师和学生模型。探索不同架构之间的知识蒸馏(例如,从ViT教师模型到ViT学生模型,或从CNN教师模型到ViT学生模型)可能揭示跨架构知识转移的有效性。
病理学中其他类型的图像分类任务
除了分类任务,病理学中还有其他类型的图像分类任务,例如生存/预后预测,这些任务的数据集通常比癌症和组织分类的数据集更小。知识蒸馏在这些任务中可能发挥关键作用,值得进一步研究。
病理学特定模型的影响
论文中使用了EfficientNet-B0作为基线模型。尽管提出了几种病理学特定模型,但研究的主要焦点是调查知识蒸馏框架的效果。未来的研究可以探索MoMA框架在其他病理学特定模型上的效果。
跨域泛化能力
论文中提到了模型的泛化能力,特别是在未见过的数据上的表现。未来的研究可以进一步探索如何提高模型在跨域任务上的泛化能力,例如通过引入额外的正则化技术或改进数据增强策略。
实际临床应用
将MoMA框架应用于实际的临床环境,评估其在真实世界病理图像上的表现和实用性,这可能涉及到与病理学家的合作以及对模型解释性的研究。
算法优化和计算效率
研究如何优化MoMA框架以提高其计算效率和训练速度,使其更适合资源受限的环境。
这些探索点可以帮助进一步发展和完善知识蒸馏技术在计算病理学中的应用,提高模型的性能和适用性。
Q: 总结一下论文的主要内容
A: 本文提出了一种名为MoMA(Momentum Contrastive Learning with Multi-head Attention-based Knowledge Distillation)的学习方法,旨在解决计算病理学中由于数据隐私、伦理问题以及数据多样性不足而导致的数据缺乏问题。MoMA利用知识蒸馏技术,通过学生-教师框架从预训练的教师模型中学习,无需直接访问源数据。具体来说,MoMA结合了动量对比学习和多头自注意力机制来提取一致的、上下文感知的特征表示,使得目标模型能够吸收教师模型的知识,同时适应目标数据的独特性。论文中的实验表明,MoMA在不同领域和任务中传递知识方面表现出色,超越了其他相关方法。
主要贡献包括:
- 提出了MoMA框架,利用现有模型训练新的目标模型,以提高计算病理工具的准确性和鲁棒性。
- 采用了基于注意力的动量对比学习进行知识蒸馏,以一致可靠的方式从现有模型转移知识。
- 在多组织病理数据集上评估MoMA,并在不同设置下展示了其优越的性能。
- 提供了在计算病理学中不同任务和场景下学习的策略指导。
此外,论文还探讨了学生和教师模型之间的类内和类间相关性,并通过可视化和量化特征表示来展示MoMA在改善特征表示方面的优势。通过消融研究和不同预训练权重的比较,论文进一步验证了MoMA的有效性,并讨论了其在不同蒸馏任务中的潜在应用和限制。最后,论文指出了未来可能的研究方向,包括多教师模型的知识蒸馏、不同任务和器官类型的研究、跨架构的知识蒸馏等。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Artificial General Intelligence for Medical Imaging Analysis
Authors:Xiang Li, Lin Zhao, Lu Zhang, Zihao Wu, Zhengliang Liu, Hanqi Jiang, Chao Cao, Shaochen Xu, Yiwei Li, Haixing Dai, Yixuan Yuan, Jun Liu, Gang Li, Dajiang Zhu, Pingkun Yan, Quanzheng Li, Wei Liu, Tianming Liu, Dinggang Shen
Large-scale Artificial General Intelligence (AGI) models, including Large Language Models (LLMs) such as ChatGPT/GPT-4, have achieved unprecedented success in a variety of general domain tasks. Yet, when applied directly to specialized domains like medical imaging, which require in-depth expertise, these models face notable challenges arising from the medical field’s inherent complexities and unique characteristics. In this review, we delve into the potential applications of AGI models in medical imaging and healthcare, with a primary focus on LLMs, Large Vision Models, and Large Multimodal Models. We provide a thorough overview of the key features and enabling techniques of LLMs and AGI, and further examine the roadmaps guiding the evolution and implementation of AGI models in the medical sector, summarizing their present applications, potentialities, and associated challenges. In addition, we highlight potential future research directions, offering a holistic view on upcoming ventures. This comprehensive review aims to offer insights into the future implications of AGI in medical imaging, healthcare, and beyond.
大规模人工智能通用模型(AGI模型),包括大型语言模型(如ChatGPT/GPT-4)等,在各种通用领域任务中取得了前所未有的成功。然而,当这些模型直接应用于需要深度专业知识特化领域如医学影像时,面临着由于医学领域的固有复杂性和独特特性所带来的显著挑战。本文深入探讨了人工智能通用模型在医学影像和医疗保健中的潜在应用,重点关注大型语言模型、大型视觉模型和大型多模态模型。本文全面概述了大型语言模型和人工智能通用模型的关键特性和促进技术,并进一步探讨了人工智能通用模型在医疗领域的演进和实施路线图,总结了其当前应用、潜力和相关挑战。此外,本文还强调了未来可能的研究方向,为未来的探索提供了全面的视角。本文旨在提供关于人工智能在未来医学影像、医疗保健等领域的深刻见解。
论文及项目相关链接
Summary
大规模人工智能通用智能(AGI)模型,如ChatGPT/GPT-4等大型语言模型(LLM),在多种通用领域任务中取得了前所未有的成功。然而,当这些模型直接应用于医学成像等需要深度专业知识的专业领域时,面临着医学领域固有的复杂性和特殊性的挑战。本文重点介绍了AGI模型在医学成像和医疗保健中的潜在应用,主要关注LLM、大型视觉模型和大型多模态模型。本文概述了AGI和LLM的关键特性和使能技术,并探讨了AGI模型在医疗领域的演进和实施路线图,总结了其当前应用、潜力和相关挑战。
Key Takeaways
- 大规模人工智能通用智能(AGI)模型在通用领域任务中取得巨大成功。
- 在医学成像等专业领域,AGI模型面临医学领域复杂性和特殊性的挑战。
- LLM、大型视觉模型和大型多模态模型在医学领域的潜在应用受到关注。
- AGI和LLM的关键特性和使能技术被详细介绍。
- AGI模型在医疗领域的演进和实施路线图被概述。
- AGI模型在医学成像和医疗保健中的当前应用、潜力和相关挑战被总结。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了大规模人工通用智能(Artificial General Intelligence, AGI)模型,包括大型语言模型(Large Language Models, LLMs)在内,在医学影像分析领域的潜在应用和挑战。具体来说,论文试图解决的问题包括:
AGI模型在医学影像分析中的应用潜力:论文详细探讨了AGI模型在医学影像和医疗保健中的潜在应用,重点关注LLMs、大型视觉模型和大型多模态模型。
医学领域的独特挑战:论文分析了将AGI模型直接应用于医学影像分析时面临的挑战,这些挑战源于医学领域的固有复杂性和独特特征,例如临床文本和医学影像的专业性质、准确解释所需的专业知识、以及数据中缺乏标注/真实情况。
AGI模型在医学领域的适应性:论文讨论了如何使AGI模型适应医学影像分析,包括数据、知识和模型三个主要方向上的挑战和应对策略。
未来研究方向:论文提出了未来可能的研究方向,提供了对AGI在医学影像、医疗保健以及更广泛领域未来影响的全面视角。
技术基础和创新:论文还涵盖了AGI模型发展所依赖的技术基础和创新,如Transformer架构、上下文学习、提示支持和与人类反馈的对齐等。
伦理、隐私和合规性问题:论文讨论了在医学影像分析中应用AGI模型时需要考虑的伦理、隐私和合规性问题,包括数据隐私、监管合规性和跨机构使用AGI模型的挑战。
综上所述,这篇论文试图提供一个全面的调查研究,深入探讨AGI在医学影像分析中的应用前景、技术基础、实施路线图、当前和潜在的应用、挑战以及未来研究方向。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与AGI在医学影像分析领域相关的研究:
大型语言模型(LLMs):
- Radford et al. (2019) 提出了“Language models are unsupervised multitask learners”的观点,强调了LLMs在无监督多任务学习中的潜力。
- Brown et al. (2020) 在“Language models are few-shot learners”中讨论了LLMs在少量样本学习中的能力。
大型视觉模型(LVMs)和多模态模型:
- Dosovitskiy et al. (2020) 介绍了“An image is worth 16x16 words: Transformers for image recognition at scale”,展示了Vision Transformer (ViT) 在图像识别中的应用。
- Kirillov et al. (2023) 在“Segment anything”中提出了Segment Anything Model (SAM),这是一个能够进行多种分割任务的大型视觉模型。
医学影像分析:
- Rajpurkar et al. (2022) 在“AI in health and medicine”中讨论了AI在健康和医学中的应用,包括医学影像分析。
- Cascella et al. (2023) 在“Evaluating the feasibility of chatgpt in healthcare”中评估了ChatGPT在医疗保健中的可行性,包括多个临床和研究场景。
数据增强、迁移学习和提示调优:
- Su et al. (2023) 在“Rethinking data augmentation for single-source domain generalization in medical image segmentation”中重新思考了医学图像分割中的数据增强问题。
- Subramanian et al. (2024) 在“Towards foundation models for scientific machine learning: Characterizing scaling and transfer behavior”中探讨了科学机器学习中基础模型的迁移能力。
模型设计和隐私保护:
- Kuang et al. (2024) 在“Federatedscope-llm: A comprehensive package for fine-tuning large language models in federated learning”中提供了一个在联邦学习中微调大型语言模型的综合工具包。
- Brate et al. (2022) 在“Improving language model predictions via prompts enriched with knowledge graphs”中探讨了如何通过富含知识图谱的提示来提高语言模型的预测能力。
伦理和合规性问题:
- Char et al. (2020) 在“Identifying ethical considerations for machine learning healthcare applications”中识别了机器学习在医疗应用中的伦理考虑。
这些研究涵盖了AGI在医学影像分析中的多个方面,包括模型的发展、应用、伦理和合规性问题。这些研究为理解AGI在医学影像领域的应用提供了理论基础和实践指导。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决AGI在医学影像分析中的应用问题:
1. 技术综述与关键特征分析
- 论文首先对AGI模型,尤其是LLMs、大型视觉模型和大型多模态模型的关键特征和使能技术进行了全面的综述。
- 详细讨论了Transformer架构、上下文学习、提示支持和与人类反馈对齐等技术基础,为理解AGI模型的工作原理和在医学影像中的应用提供了基础。
2. 应用路线图规划
- 针对医学影像分析,论文提出了AGI模型的发展和实施路线图,包括数据、知识和模型三个主要方向。
- 讨论了如何通过数据增强、迁移学习、提示调优等方法解决数据稀缺和敏感性问题。
- 探索了如何将专家知识整合到AGI模型的学习和专家-机器对齐过程中,以及如何设计参数高效和隐私保护的模型。
3. 挑战与机遇并存
- 论文总结了AGI模型在医学影像分析中的当前应用、潜力和相关挑战。
- 强调了数据隐私、监管合规性和跨机构使用AGI模型的挑战,并提出了可能的解决方案。
4. 未来研究方向
- 提供了对未来研究方向的见解,包括潜在的偏见和信任度问题、跨机构合作、专家-机器对齐、真正的多模态AGI和AGI的安全保障等。
- 强调了在临床实践中部署AGI时需要考虑的资源和速度问题,并提出了结合大规模和本地小规模模型的解决方案。
5. 综合视角
- 论文旨在提供对未来AGI在医学影像、医疗保健和更广泛领域未来影响的全面视角。
- 强调了负责任地开发和应用AI技术的重要性,并指出了AGI在医疗保健中的机遇和挑战。
通过这些步骤,论文不仅提供了对当前AGI在医学影像分析中应用的全面理解,而且为未来的研究和实践提供了指导和启发。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,这篇综述文章并没有提到进行特定的实验研究。综述文章的目的是提供对现有研究和文献的全面分析和讨论,而不是报告新的实验结果。论文通过以下方式构建其研究框架:
文献搜索与筛选:作者通过在Google Scholar等数据库中搜索特定关键词,识别出与大型语言模型(LLMs)、大型视觉模型和大型多模态模型在医学影像分析领域相关的出版物。
研究工作综合调查:文章提供了对相关研究工作的全面调查,包括对AGI模型的关键特征和实现技术的基本解释,以及它们与医学影像分析的关系讨论。
发展和应用路线图分析:文章分析了AGI模型在医学领域的应用路线图,包括数据、知识和模型三个方向,并讨论了目前的进展和潜在的应用前景。
挑战与解决方案讨论:文章总结了AGI模型在医学影像分析中面临的挑战,并提供了可能的解决方案和未来的研究方向。
未来方向探讨:文章讨论了AGI在医学影像分析中的未来方向,包括潜在的偏见和信任度问题、跨机构合作、专家-机器对齐、真正的多模态AGI和AGI的安全保障等。
综述文章通过综合和分析现有的研究成果,提供了对AGI在医学影像分析领域应用的深入见解,并指出了未来研究的方向。它并不涉及原始数据的收集或实验验证,而是依赖于对已发表研究的分析和综合。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
A. 潜在偏见和信任度问题
- 减少AGI模型中的偏见:研究如何识别和减少训练数据和模型决策中的偏见。
- 建立信任度:探索如何建立医疗领域对AGI系统的信任,包括透明度、可解释性和可靠性。
B. 跨机构合作
- 数据共享和隐私保护:研究如何在保护患者隐私的同时促进数据共享,例如通过联邦学习。
- 跨机构治理框架:开发治理框架、数据使用协议和伦理指南,以促进不同医疗机构之间的信任和合作。
C. 专家-机器对齐
- 增强专家参与:研究如何通过强化学习或模型偏好优化进一步整合医疗专家的知识。
- 多维度评分系统:开发评估模型性能的多维度、综合评分方法,以适应医疗领域的需求。
D. 真正的多模态AGI
- 多模态数据融合:研究如何整合文本、图像和表格数据(例如电子健康记录)以增强医疗理解和推理。
- 跨模态数据生成:探索多模态AGI建立放射图像和文本报告之间反馈循环的能力。
E. 安全保障AGI
- 监督和验证框架:实施跨学科团队的鲁棒监督和验证框架,并建立风险检测和缓解的定期审计机制。
- 符合医疗数据保护法规:确保AGI应用符合HIPAA等医疗数据保护法律。
F. AGI在临床实践中的应用
- 计算资源和速度限制:研究如何在资源受限的环境中部署AGI,以及如何优化模型以满足实时处理的需求。
- 大规模与小规模模型的整合:探索如何通过知识蒸馏、迁移学习和模型剪枝等方法整合大规模和本地小规模模型。
这些探索点涉及AGI在医学影像分析中的伦理、技术、合作和实施等多个方面,旨在推动AGI技术的负责任发展和应用,以最大化其在医疗保健中的潜在益处。
Q: 总结一下论文的主要内容
A: 这篇论文主要探讨了人工通用智能(AGI)模型,特别是大型语言模型(LLMs)、大型视觉模型和大型多模态模型在医学影像分析中的应用、潜力、挑战和未来研究方向。以下是论文的主要内容总结:
1. 引言
- 论文介绍了AGI模型在医学影像分析中的快速增长和发展,并指出直接应用这些模型于医学领域面临的挑战,包括医学数据的专业性质、数据注释的缺乏和隐私问题。
2. AGI模型的使能技术
- Transformer架构:介绍了Transformer模型及其多头注意力机制,强调其在处理长距离依赖和上下文信息中的优势。
- 上下文学习:讨论了上下文学习技术,使模型能够根据提供的示例进行学习和推断。
- 提示支持:探讨了提示工程如何使模型适应特定任务。
- 与人类反馈对齐:强调了通过人类反馈训练模型以确保其行为符合伦理和责任。
3. 大型语言模型(LLMs)在医学影像中的应用
- 医疗领域路线图:讨论了专家知识整合、领域适应、医学信息集成和知识图构建等方向。
- 当前和潜在应用:探索了LLMs在医疗报告理解、疾病诊断、医疗教育和临床工作流程中的应用。
- 挑战和陷阱:分析了提示构建、数据隐私、数据可访问性和部署等方面的挑战。
4. 大型视觉模型在医学影像中的应用
- 部署和适应路线图:探讨了大规模数据集、模型适应、多模态成像、可解释性和少/零样本学习的重要性。
- 当前和潜在应用:讨论了大型视觉模型在医学图像分割、AI生成内容等方面的应用。
- 挑战和陷阱:分析了数据注释质量、准确性标准和长尾问题等挑战。
5. 大型多模态模型在医学影像中的应用
- 部署和适应路线图:讨论了数据规模和质量、预训练多模态基础模型和参数高效微调策略。
- 当前和潜在应用:探索了图像到文本和文本到图像模型的应用,如视觉问答和计算机辅助诊断。
- 挑战和陷阱:分析了缺乏配对数据和后门攻击等挑战。
6. 讨论
- 论文提出了未来工作的方向,包括AGI在医疗保健中的潜在偏见和信任度问题、跨机构合作、专家-机器对齐、真正的多模态AGI和AGI的安全保障。
7. 结论
- 论文总结了AGI在医学影像分析中的潜力和挑战,并强调了负责任地开发和应用AI技术的重要性。
这篇论文提供了一个全面的视角,以理解AGI在医学影像分析中的应用前景,并指出了未来研究的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图