⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-16 更新
On-Device Emoji Classifier Trained with GPT-based Data Augmentation for a Mobile Keyboard
Authors:Hossam Amer, Joe Osborne, Michael Zaki, Mohamed Afify
Emojis improve communication quality among smart-phone users that use mobile keyboards to exchange text. To predict emojis for users based on input text, we should consider the on-device low memory and time constraints, ensure that the on-device emoji classifier covers a wide range of emoji classes even though the emoji dataset is typically imbalanced, and adapt the emoji classifier output to user favorites. This paper proposes an on-device emoji classifier based on MobileBert with reasonable memory and latency requirements for SwiftKey. To account for the data imbalance, we utilize the widely used GPT to generate one or more tags for each emoji class. For each emoji and corresponding tags, we merge the original set with GPT-generated sentences and label them with this emoji without human intervention to alleviate the data imbalance. At inference time, we interpolate the emoji output with the user history for emojis for better emoji classifications. Results show that the proposed on-device emoji classifier deployed for SwiftKey increases the accuracy performance of emoji prediction particularly on rare emojis and emoji engagement.
表情符号改善了使用移动键盘交换文本智能手机用户之间的沟通质量。为了根据输入文本为用户预测表情符号,我们应该考虑设备上的低内存和时间约束,确保设备上的表情符号分类器能够覆盖广泛的表情符号类别,尽管表情符号数据集通常是不平衡的,并且适应表情符号分类器的输出以符合用户的喜好。本文提出了一种基于MobileBert的设备和内存要求合理的SwiftKey表情符号分类器。为了解决数据不平衡问题,我们利用广泛使用的GPT为每个表情符号类别生成一个或多个标签。对于每个表情符号和相应的标签,我们将原始集合与GPT生成的句子合并,并不用人为干预的方式将它们标记为对应的表情符号,以减轻数据不平衡的问题。在推理时间方面,我们通过结合用户历史表情符号输出预测来改进表情符号分类。结果表明,为SwiftKey部署的提议的表情符号分类器提高了表情符号预测的准确性性能,特别是对稀有表情符号和表情符号参与度有明显提升。
论文及项目相关链接
PDF 8 pages
Summary
本文探讨了使用表情符号在智能手机用户中的沟通质量提升问题。针对基于文本输入预测用户表情符号的需求,提出了一种基于MobileBert的在线表情符号分类器。考虑到内存和时间限制,以及表情符号数据集的不平衡问题,通过GPT生成每个表情符号的标签来平衡数据集。结合用户历史表情符号数据,提高表情符号分类的准确性。实验结果表明,针对SwiftKey推出的在线表情符号分类器提高了表情符号预测的准确性,特别是在罕见表情符号和表情符号参与度方面。
Key Takeaways
- 表情符号提高了智能手机用户之间的文本沟通质量。
- 针对基于文本输入的emoji预测,提出了一种基于MobileBert的在线emoji分类器。
- 考虑到了内存和时间限制,确保分类器在移动设备上的高效运行。
- 通过GPT生成标签来平衡emoji数据集,解决了数据不平衡的问题。
- 结合用户历史emoji数据,提高emoji分类的准确性。
- 提出的分类器特别提高了罕见emoji和emoji参与度的预测准确性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决在智能手机用户使用移动键盘交换文本时,如何基于输入文本预测用户想要使用的emoji表情符号的问题。具体来说,论文关注以下几个挑战:
设备端的低内存和时间限制:需要在设备端部署一个emoji分类器,这个分类器需要满足低内存使用和低延迟的要求。
广泛的emoji类别覆盖:即使emoji数据集通常是不平衡的,分类器也需要能够覆盖广泛的emoji类别。
用户偏好的适应性:emoji分类器的输出需要能够适应用户的个人喜好,例如,如果用户经常插入笑脸emoji,那么在预测时应该优先显示这个emoji。
为了应对这些挑战,论文提出了一个基于MobileBert的设备端emoji分类器,并采用了基于GPT的数据增强方法来处理emoji数据集的不平衡分布问题,同时利用用户历史数据重新对分类器输出进行排序,以适应用户的选择。
Q: 有哪些相关研究?
A: 论文中提到了多个与emoji分类相关的研究工作,这些工作可以分为两大类:多标签emoji分类和单标签emoji分类。以下是一些具体的相关研究:
多标签emoji分类:
- Lin et al. (2019) 提出了一个基于检索策略的emoji组合预测方法。
- Peng and Zhao (2021) 提出了一个编码器-解码器模型来预测32种emoji的组合。
- Lee et al. (2022) 引入了一个LSTM架构来预测64种emoji的组合,并探索了emoji和情感之间的相关性。
- Peng et al. (2023) 展示了一个成功的将输入文本转换为emoji组合的方法,同时使用GPT生成的合成样本。
单标签emoji分类:
- Barbieri et al. (2017) 提出了一个双向长短期记忆网络(BLSTMs)模型,用于在20种最频繁的emoji中进行分类。
- Barbieri et al. (2018c; Felbo et al., 2017) 引入了一个带有标签注意力的LSTM架构,针对SemEVal 2018共享任务和最多200个emoji的数据集。
- Gandhi et al. (2022) 在Bert基础上训练了一个emoji分类器,用于预测700个emoji,并采用了传统采样和成本敏感训练技术来处理emoji数据集的不平衡分布。
- Choudhary et al. (2018) 提出了孪生网络,并关注了低资源语言的emoji分类性能。
- Ramaswamy et al. (2019) 成功实现了一个设备端emoji分类器,用于GBoard的emoji预测,使用了LSTM架构。
这些研究为本文提出的设备端emoji分类器提供了理论基础和技术参考。论文在这些研究的基础上,专注于单emoji分类,并提出了一个适用于不平衡emoji数据集分布的设备端emoji分类器,特别是在类别众多、需要考虑用户偏好以及必须满足延迟/内存要求的情况下。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决在移动设备上基于输入文本预测用户想要使用的emoji表情符号的问题:
1. 模型选择和量化(Model Selection and Quantization)
- 论文首先通过一系列实验比较了不同的模型架构,包括LSTM、DeepMoji和MobileBert,并选择了MobileBert作为基础架构,因为它在准确性和模型大小之间取得了良好的平衡。
- 进一步通过量化技术减小MobileBert模型的大小,同时保持性能。选择了具有2层的MobileBert模型,因为它在保持较小的运行时内存(11MB)的同时,性能几乎不受int8量化的影响,模型大小可进一步减小至3MB。
2. 数据集构建和增强(Dataset Construction and Augmentation)
- 针对emoji数据集的不平衡分布问题,论文利用GPT生成与每个emoji类别相关的一个或多个标签,并基于这些标签创建合成句子,然后将这些句子与对应的emoji标签合并,以增加数据集的大小并减少不平衡问题。
- 通过这种方式,不仅为罕见的emoji增加了数据集,还增加了对emoji的新文本意义的覆盖。
3. 训练过程(Training Procedure)
- 使用PyTorch对所选的MobileBert模型进行训练,使用GPU加速,并设置了合适的批量大小、学习率等参数。
- 训练数据集是人工编写的训练集和GPT生成的合成数据集的结合。
4. 基于用户偏好的emoji分类器重新排序(Emoji Classifier Reranking by User Favorites)
- 在推理时,根据用户的历史选择对emoji分类器的输出进行重新排序,以适应用户的个人喜好。
- 使用了一个公式来结合模型输出的概率分布和用户偏好的概率分布,通过调整参数α来平衡模型输出和用户偏好的影响。
5. 实验结果(Experimental Results)
- 论文提供了基于不同版本的MobileBert emoji分类器(90类、590类和1090类)的评估结果,并展示了数据增强和用户偏好重新排序对模型性能的提升。
- 还包括了在真实用户数据上的实验结果,验证了所提出的方法在实际应用中的有效性。
通过这些步骤,论文成功地提出了一个能够在设备端运行的emoji分类器,该分类器不仅能够处理emoji数据集的不平衡问题,还能够根据用户的个人喜好进行适应性调整,从而提高了emoji预测的准确性和用户参与度。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估提出的设备端emoji分类器的性能和效果。以下是实验的详细描述:
1. 模型性能比较实验
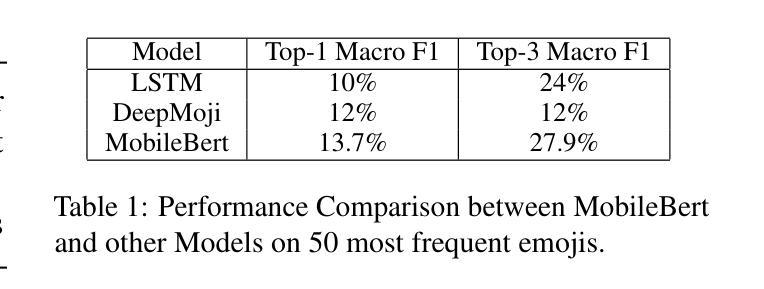
- 模型选择实验:比较了LSTM、DeepMoji和MobileBert在50个最频繁emoji类别上的性能,使用Top-1 Macro F1和Top-3 Macro F1作为评估指标。结果显示MobileBert在准确性和模型大小之间取得了良好的平衡。
2. 模型量化实验
- 模型大小与性能权衡实验:训练了不同层数的MobileBert模型(1层、2层和3层),并评估了它们的Top-3 Macro F1性能和模型大小。2层的MobileBert在保持较小的运行时内存(11MB)的同时,性能几乎不受int8量化的影响,模型大小可进一步减小至3MB。
3. 数据增强实验
- 数据增强效果实验:通过GPT生成的合成数据集与人工编写的训练集结合,评估了数据增强对模型性能的影响。结果显示,数据增强尤其在提高罕见emoji的预测准确性方面效果显著。
4. 用户偏好重新排序实验
- 用户偏好对模型输出重新排序的影响实验:评估了根据用户历史选择对emoji分类器输出进行重新排序的效果。结果显示,结合用户偏好可以提高模型的预测准确性。
5. 推理时间和模型大小分析
- 推理时间与模型大小实验:使用Android Jetpack Microbenchmark库在Samsung A23设备上测量了不同模型的推理时间,并比较了模型大小。结果显示所有模型的推理时间都在20毫秒以内,模型大小也保持在较小的范围内。
6. 真实用户实验(Live Experiments)
- 在线实验:在SwiftKey的Android用户群体中进行了在线实验,比较了基线模型(使用逻辑回归)和提出的1090C模型的性能。评估指标包括精确度、外部emoji率(ExRate)和点击通过率(CTR)。结果显示提出的模型在CTR、ExRate和精确度方面相对于基线模型都有显著提升。
7. 离线与在线实验结果对比
- 离线与在线实验结果对比:比较了离线实验结果和在线实验结果的一致性。结果显示两者之间存在较大的一致性,进一步验证了所提出方法的有效性。
这些实验全面评估了提出的设备端emoji分类器在不同方面的表现,包括模型性能、数据增强的效果、用户偏好的适应性、推理效率以及在真实用户环境中的应用效果。通过这些实验,论文证明了所提出方法的有效性和实用性。
Q: 有什么可以进一步探索的点?
A: 论文在最后提出了一些可以进一步探索的点,具体包括:
多语言支持:
- 论文中的实验主要针对英语(美国)用户,忽略了其他语言。未来的工作可以探索该设备端分类器和方法如何扩展到高资源语言和低资源语言,尤其是低资源语言,由于样本的有限性,这是一个特别有趣的探索领域。
预测多个emoji:
- 论文中提出的分类器目前仅预测单个emoji。未来的工作可以扩展这个分类器,使其能够预测多个emoji,这将更贴近用户在实际交流中同时使用多个emoji表达复杂情感的需求。
优化模型性能:
- 尽管论文中提出的模型在设备端表现良好,但仍有进一步优化的空间,包括提高预测准确性、减少模型大小和降低推理时间。
增强数据增强方法:
- 论文中使用GPT进行数据增强取得了一定的效果,但还可以探索更多先进的数据增强技术,以进一步提高模型对罕见emoji的识别能力。
改进用户偏好适应机制:
- 论文提出了一种基于用户历史选择的emoji分类器输出重新排序方法,未来的工作可以探索更复杂的用户偏好建模和适应机制,以进一步提升个性化预测的准确性。
跨领域和跨平台的模型泛化能力:
- 研究模型在不同领域(如社交媒体、即时通讯等)和不同平台(iOS、Android等)的泛化能力,以及如何调整模型以适应不同的使用场景。
用户隐私和数据安全:
- 在收集和使用用户数据进行模型训练和优化时,需要考虑用户隐私和数据安全的问题,探索如何在保护用户隐私的前提下有效利用数据。
实时性能和用户体验:
- 研究如何进一步提升模型的实时性能,减少用户在等待emoji预测结果时的延迟,从而改善用户体验。
这些探索点可以帮助研究者和开发者进一步提升设备端emoji分类器的性能和用户体验,同时拓展其在多语言和多场景下的应用。
Q: 总结一下论文的主要内容
A: 这篇论文主要研究了在移动设备上基于用户输入文本预测emoji的问题,并提出了一个解决方案。以下是论文的主要内容总结:
1. 问题背景和挑战
- Emojis在智能手机用户间的沟通中扮演着重要角色,尤其在移动键盘应用中。
- 设备端emoji分类器需要满足低内存和低延迟的要求。
- Emoji数据集通常是不平衡的,常见emoji出现的频率远高于罕见emoji。
- 分类器输出需要适应用户的个人喜好。
2. 提出的解决方案
- 提出了一个基于MobileBert的设备端emoji分类器,满足内存和延迟要求。
- 使用GPT生成与每个emoji相关的标签,并基于这些标签创建合成句子,以增强数据集并减少不平衡问题。
- 在推理时,根据用户历史选择对分类器输出进行重新排序,以适应用户偏好。
3. 实验和评估
- 进行了模型选择和量化实验,确定了MobileBert作为基础架构。
- 通过数据增强实验,验证了GPT生成的数据在提高模型性能,尤其是在预测罕见emoji上的有效性。
- 用户偏好重新排序实验表明,结合用户偏好可以提高预测准确性。
- 推理时间和模型大小分析显示,所有模型均满足设备端部署的要求。
- 在真实用户数据上的在线实验验证了模型的有效性,并与离线实验结果一致。
4. 结论和未来工作
- 提出的设备端emoji分类器通过GPT的数据增强和用户偏好适应,提高了用户在SwiftKey预测面板上的参与度,特别是在预测罕见emoji上表现良好。
- 论文还指出了未来工作的方向,包括扩展到多语言、预测多个emoji、优化模型性能和用户体验等。
总体而言,这篇论文针对设备端emoji分类问题提出了一个创新的解决方案,并通过一系列实验验证了其有效性,为未来在这一领域的研究提供了新的思路和方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



GPT-Guided Monte Carlo Tree Search for Symbolic Regression in Financial Fraud Detection
Authors:Prashank Kadam
With the increasing number of financial services available online, the rate of financial fraud has also been increasing. The traffic and transaction rates on the internet have increased considerably, leading to a need for fast decision-making. Financial institutions also have stringent regulations that often require transparency and explainability of the decision-making process. However, most state-of-the-art algorithms currently used in the industry are highly parameterized black-box models that rely on complex computations to generate a score. These algorithms are inherently slow and lack the explainability and speed of traditional rule-based learners. This work introduces SR-MCTS (Symbolic Regression MCTS), which utilizes a foundational GPT model to guide the MCTS, significantly enhancing its convergence speed and the quality of the generated expressions which are further extracted to rules. Our experiments show that SR-MCTS can detect fraud more efficiently than widely used methods in the industry while providing substantial insights into the decision-making process.
随着网上提供的金融服务数量不断增加,金融欺诈的速率也在上升。互联网的流量和交易速率显著增加,需要快速做出决策。金融机构也有严格的法规,通常要求决策过程的透明性和可解释性。然而,当前行业中使用的最先进的算法大多数是高度参数化的黑箱模型,这些模型依赖复杂计算来生成分数。这些算法本质上缓慢,且缺乏传统基于规则的学习者的可解释性和速度。这项工作介绍了SR-MCTS(符号回归MCTS),它利用基础的GPT模型来指导MCTS,显著提高了其收敛速度和生成的表达式的质量,这些表达式进一步被提取为规则。我们的实验表明,SR-MCTS比行业中广泛使用的方法更能有效地检测欺诈行为,同时为决策过程提供了实质性的见解。
论文及项目相关链接
PDF ACM International Conference on Information and Knowledge Management 2024 RAG - Enterprise
Summary:随着在线金融服务数量的增加,金融欺诈率也在上升。由于互联网上的流量和交易率大幅增加,需要快速决策。金融机构有严格的监管要求,需要决策过程的透明度和可解释性。然而,当前行业中使用的大多数最先进的算法都是高度参数化的黑箱模型,依靠复杂计算生成分数,这些算法本质上缓慢,缺乏传统基于规则的学习者的可解释性和速度。这项工作引入了SR-MCTS(符号回归MCTS),它利用基础GPT模型来指导MCTS,显著提高了其收敛速度和生成表达式的质量,这些表达式进一步提取为规则。实验表明,SR-MCTS比行业中广泛使用的方法更有效地检测欺诈,同时提供对决策过程的重大见解。
Key Takeaways:
- 在线金融服务数量的增加导致金融欺诈率上升。
- 金融机构需要快速决策,并满足严格的监管要求,需要决策过程的透明度和可解释性。
- 当前先进的算法大多为黑箱模型,虽然复杂但缺乏必要的可解释性和速度。
- SR-MCTS利用GPT模型指导MCTS,提高了收敛速度和生成规则的质量。
- SR-MCTS能更高效地检测欺诈。
- SR-MCTS提供的决策过程见解重大。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是在线金融服务中金融欺诈检测的效率和可解释性问题。随着在线金融服务的增多,金融欺诈的发生率也在上升,这导致了对快速决策的需求。金融机构通常需要遵守严格的规定,这些规定往往要求决策过程的透明度和可解释性。然而,目前行业中使用的最新算法大多是高度参数化的黑盒模型,它们依赖于复杂的计算来生成分数,这些算法本质上速度慢且缺乏传统基于规则的学习器的可解释性和速度。论文中介绍了SR-MCTS(符号回归蒙特卡洛树搜索)算法,该算法利用基础的GPT模型来指导MCTS,显著提高了其收敛速度和生成表达式的质量,这些表达式进一步被提取为规则。实验表明,SR-MCTS能够比行业广泛使用的方法更有效地检测欺诈,同时提供了对决策过程的深入洞察。
Q: 有哪些相关研究?
A: 论文中提到了以下相关研究:
传统金融欺诈检测方法:
- 依赖于专家构建的规则来批准或拒绝交易,这些方法快速且可解释,但难以适应不断演变的欺诈模式。
机器学习技术:
- 逻辑回归(Logistic Regression) [14]:提供了更好的适应性,但降低了决策的可解释性。
- 支持向量机(Support Vector Machines) [13]:同上。
- 随机森林(Random Forest) [12]:同上。
- XGBoost [11]:提高了适应性,但决策过程的可解释性降低。
基于树的算法:
- 使用SHAP [17] 提供洞察,但计算成本高且难以解释为规则。
图神经网络模型:
- 图注意力网络(Graph Attention Networks) [9]、Care-GNN [8] 和 Semi-GNN [10]:改善了决策制定,但仍然是黑盒且成本高昂。
生成预训练变换器(GPT):
- GPT [21] 在不同机器学习领域取得了突破性成功,但在关键决策中受到幻觉问题的限制。
蒙特卡洛树搜索(MCTS):
- MCTS [16] 在解决组合问题时非常有效,通过集成深度神经网络进行值估计来增强其效果。
神经网络与MCTS结合:
- 神经MCTS方法如专家迭代(Expert Iteration)[25] 和AlphaZero [26],使用神经网络来近似策略和价值函数。
符号回归和遗传编程:
- Koza [19] 提出了遗传编程,这是一种通过自然选择手段对计算机进行编程的方法。
这些研究为论文提出的SR-MCTS算法提供了理论基础和技术支持,展示了在金融欺诈检测领域中不同方法的优缺点,并为改进这些方法提供了新的方向。
Q: 论文如何解决这个问题?
A: 论文通过提出SR-MCTS(Symbolic Regression MCTS)算法来解决金融欺诈检测中的效率和可解释性问题。以下是该方法的关键步骤和解决方案:
1. 结合符号回归和蒙特卡洛树搜索(MCTS)
- 符号回归:利用基础的GPT模型生成数学表达式,这些表达式结合了数据集特征、操作符和常数来创建用于欺诈检测的规则集。
- 蒙特卡洛树搜索(MCTS):使用MCTS来搜索和优化这些表达式,提高搜索效率和表达式的质量。
2. 定义马尔可夫决策过程(MDP)
- 将符号回归问题建模为MDP,包括状态空间、操作符、动作空间、转移函数和奖励函数,以最大化累积奖励并最小化损失函数。
3. PUCT策略和符号GPT引导
- 使用PUCT(Predictor + Upper Confidence bounds for Trees)策略来搜索表达式空间,结合符号GPT预测的概率分布来平衡探索和利用。
4. 评估和损失计算
- 生成的表达式根据其相对于目标变量的预测性能进行评估,使用二元交叉熵损失函数来计算损失,并为表现最佳的表达式分配奖励。
5. 符号GPT模型和再训练
- 将符号GPT模型在金融交易数据上进行微调,以指导MCTS。使用MCTS生成的最佳表达式来进一步训练和优化符号GPT模型。
6. 规则提取
- 从生成的最佳表达式中提取规则集,通过解线性方程组来找到可解释的规则,用于评估交易是否为欺诈。
7. 实验验证
- 在专有的金融欺诈数据集上评估SR-MCTS,与行业标准算法进行比较,结果表明SR-MCTS在检测效率和准确性方面优于现有技术,同时提供了可解释的决策过程。
通过这种方法,论文成功地提高了金融欺诈检测的速度和可解释性,同时保持了与现有技术的兼容性和透明度。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
数据集:
- 使用了名为Proprietary Financial Fraud Dataset (PFFD)的专有数据集,该数据集包含了来自Vesta Corporation的电子商务客户的加密客户订单详情,如姓名、地址、电子邮件、电话、设备和支付信息,以确保隐私。数据集涵盖了约125万笔交易,其中包含13,454个欺诈案例,占数据的1.07%。
参数设置:
- 在实验中,参数 ( k ) 被设置为0.2,意味着从每次训练迭代中选择表现最佳的前20%的表达式用于微调符号GPT模型。最大表达式长度被设置为40,MDP在下一个操作数时终止。
基准算法:
- 将SR-MCTS与多个行业标准的算法进行比较,包括逻辑回归(Logistic Regression)、XGBoost、随机森林(Random Forest)、长短期记忆网络(LSTM)、图卷积网络(GCN)和图注意力网络(GAT)。
性能评估:
- 使用召回率(Recall)和接收者操作特征曲线下面积(AUC)作为评估指标,来衡量不同算法在金融欺诈检测任务上的性能。
结果对比:
- 通过对比实验结果,论文展示了SR-MCTS在检测效率和准确性方面优于其他技术,同时提供了可解释的决策过程。
以下是实验结果的表格:
| 算法 | 召回率 | AUC |
|---|---|---|
| SVM | 0.536 | 0.507 |
| 随机森林 | 0.629 | 0.574 |
| XGBoost | 0.678 | 0.634 |
| LSTM | 0.621 | 0.587 |
| GCN | 0.725 | 0.711 |
| GAT | 0.784 | 0.765 |
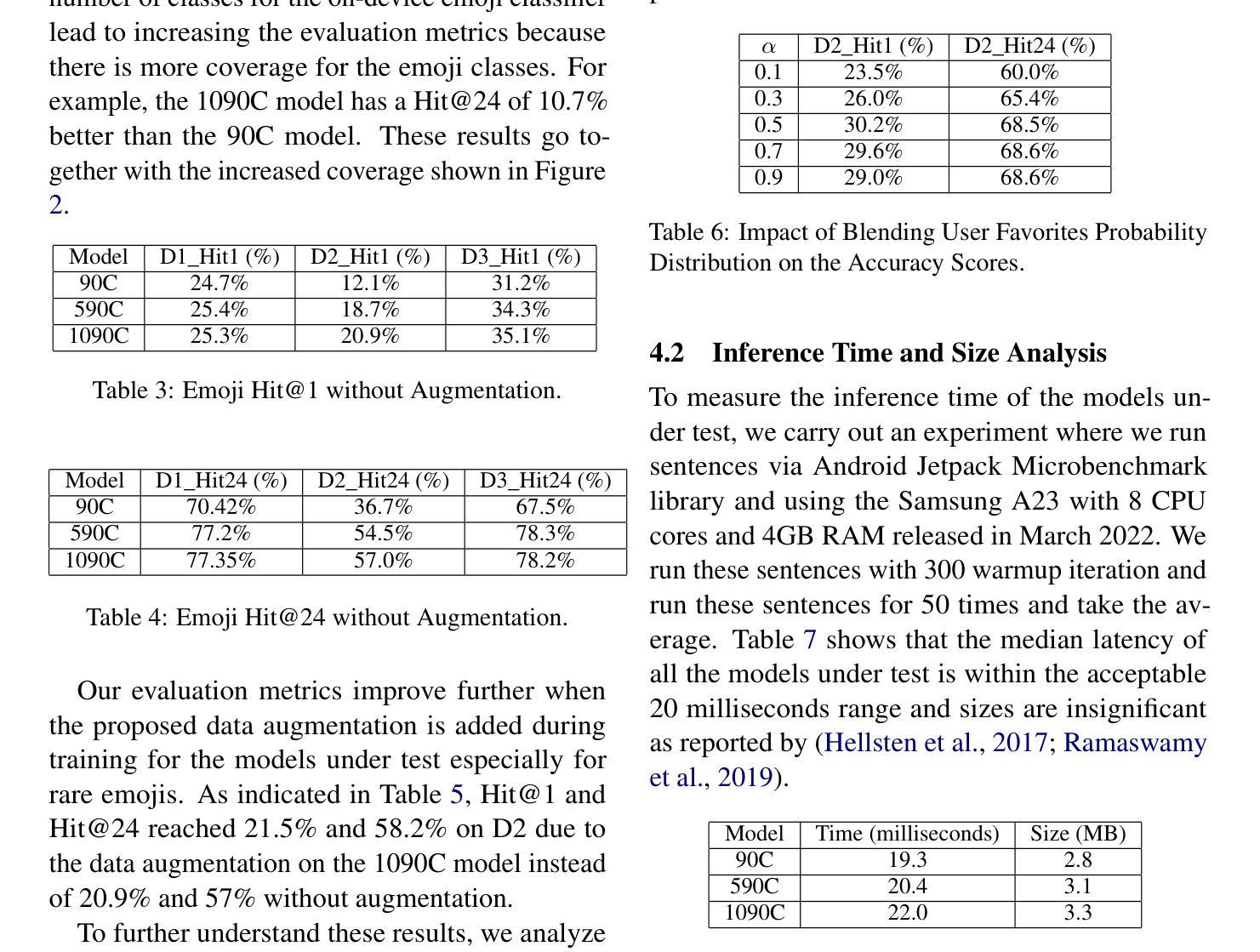
| SR-MCTS | 0.812 | 0.797 |
这些实验结果表明,SR-MCTS算法在金融欺诈检测任务上不仅提高了检测效率,还增强了模型的可解释性,相比其他方法有显著的性能提升。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些未来工作的方向,以下是可以进一步探索的点:
模型优化和改进:
- 进一步优化SR-MCTS算法,可能包括改进搜索策略、调整PUCT公式中的参数、或者改进状态和动作空间的定义。
探索其他领域:
- 将SR-MCTS算法应用于其他领域,如网络安全、保险欺诈检测等,以评估其在不同场景下的适用性和有效性。
处理更长的表达式和更复杂的操作符:
- 研究如何有效地处理更长的数学表达式,以及如何整合更复杂的数学操作符(如指数、对数等)到模型中。
动态检测参数 ( k ) 和终止状态:
- 开发动态调整参数 ( k ) 和确定MDP终止状态的策略,以提高模型的适应性和灵活性。
提高模型的泛化能力:
- 通过在更大的数据集上训练或使用迁移学习等技术,提高模型在未知数据上的泛化能力。
增强模型的解释性:
- 研究如何从生成的表达式中提取更有用和直观的规则,以增强模型的解释性。
减少幻觉问题:
- 探索新的方法来减少GPT模型在金融欺诈检测中的幻觉问题,提高模型的可靠性。
跨领域比较:
- 将SR-MCTS与其他先进的机器学习技术进行比较,如深度学习、集成学习等,以更全面地评估其性能。
实时应用和在线学习:
- 研究如何将SR-MCTS算法应用于实时欺诈检测场景,并探索在线学习的可能性,以便模型能够持续适应新的欺诈模式。
模型的可扩展性和计算效率:
- 研究如何提高SR-MCTS算法的可扩展性和计算效率,使其能够处理更大规模的数据集。
这些探索点可以帮助研究者更深入地理解SR-MCTS算法的潜力和局限性,并推动金融欺诈检测技术的发展。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
问题背景:
- 随着在线金融服务的增多,金融欺诈的发生率也在上升,需要快速、可解释且准确的欺诈检测方法。
现有技术的局限性:
- 传统方法虽然快速和可解释,但难以适应新的欺诈模式。
- 现代机器学习模型虽然适应性强,但缺乏可解释性。
- 黑盒模型如深度神经网络难以提供透明的决策过程。
提出的解决方案:
- 引入SR-MCTS(Symbolic Regression MCTS),一种结合了符号回归和蒙特卡洛树搜索的方法,利用预训练的GPT模型指导MCTS,以提高收敛速度和生成表达式的质量。
方法细节:
- MDP建模:将符号回归问题建模为马尔可夫决策过程(MDP),定义了状态空间、动作空间、转移函数和奖励函数。
- PUCT策略和符号GPT引导:使用PUCT策略结合符号GPT模型预测的概率分布来平衡探索和利用。
- 评估和损失计算:基于预测性能评估生成的表达式,并计算二元交叉熵损失。
- 符号GPT模型和再训练:微调符号GPT模型以指导MCTS,并使用生成的最佳表达式进一步训练模型。
- 规则提取:从生成的表达式中提取规则集,用于评估交易是否为欺诈。
实验验证:
- 在专有的金融欺诈数据集上评估SR-MCTS,并与多种行业标准算法进行比较,结果表明SR-MCTS在检测效率和准确性方面优于现有技术,同时提供了可解释的决策过程。
结论和未来工作:
- SR-MCTS显著提高了金融欺诈检测的速度和可解释性,未来工作将包括模型优化、探索其他领域、处理更长的表达式和更复杂的操作符、动态检测参数和终止状态、提高模型泛化能力、增强模型解释性、减少幻觉问题、跨领域比较、实时应用和在线学习、模型的可扩展性和计算效率等。
论文通过提出一种新的算法SR-MCTS,有效地解决了金融欺诈检测中的效率和可解释性问题,并展示了其在实际数据集上的应用潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Prompt Engineering Using GPT for Word-Level Code-Mixed Language Identification in Low-Resource Dravidian Languages
Authors:Aniket Deroy, Subhankar Maity
Language Identification (LI) is crucial for various natural language processing tasks, serving as a foundational step in applications such as sentiment analysis, machine translation, and information retrieval. In multilingual societies like India, particularly among the youth engaging on social media, text often exhibits code-mixing, blending local languages with English at different linguistic levels. This phenomenon presents formidable challenges for LI systems, especially when languages intermingle within single words. Dravidian languages, prevalent in southern India, possess rich morphological structures yet suffer from under-representation in digital platforms, leading to the adoption of Roman or hybrid scripts for communication. This paper introduces a prompt based method for a shared task aimed at addressing word-level LI challenges in Dravidian languages. In this work, we leveraged GPT-3.5 Turbo to understand whether the large language models is able to correctly classify words into correct categories. Our findings show that the Kannada model consistently outperformed the Tamil model across most metrics, indicating a higher accuracy and reliability in identifying and categorizing Kannada language instances. In contrast, the Tamil model showed moderate performance, particularly needing improvement in precision and recall.
语言识别(LI)对于各种自然语言处理任务至关重要,它是情感分析、机器翻译和信息检索等应用中的基础步骤。在印度等多语言社会中,特别是在社交媒体上参与的青年,文本通常会表现出代码混合现象,即在不同的语言层面上将当地语言与英语混合使用。这一现象给LI系统带来了巨大挑战,尤其是在单词内部的语言混合时。印度南部流行的德拉维语拥有丰富的形态结构,但在数字平台上的代表性不足,导致采用罗马或混合脚本进行交流。本文介绍了一种基于提示的方法,用于针对德拉维语单词级LI挑战的共同任务。在这项工作中,我们利用GPT-3.5 Turbo来了解大型语言模型是否能够正确地将单词分类到正确的类别中。我们的研究结果表明,坎纳达模型在大多数指标上表现优于泰米尔模型,显示出在识别和分类坎纳达语言实例方面的高准确性和可靠性。相反,泰米尔模型表现中等,特别是在精确度和召回率方面有待提高。
论文及项目相关链接
PDF Accepted at FIRE 2024 (Track: Word-level Language Identification in Dravidian Languages)
Summary
本文探讨了语言识别(LI)在自然语言处理任务中的重要性,特别是在印度等多元语言社会中的社交媒体使用场景下。文本中的代码混合现象给LI系统带来了挑战,特别是在单词级别的语言混合中。本文介绍了一种针对德拉维语系(印度南部常用语言)单词级LI挑战的共同任务提示方法,并尝试使用GPT-3.5 Turbo进行分类。研究结果显示,坎纳达模型在大多数指标上表现优于泰米尔模型,具有较高的准确性和可靠性;而泰米尔模型表现中等,特别是在精确率和召回率方面有待提升。
Key Takeaways
- 语言识别(LI)在自然语言处理任务中起关键作用,特别是在多元语言社会的社交媒体环境中。
- 文本中的代码混合现象给LI系统带来挑战,特别是在单词层面。
- 德拉维语系(印度南部常用语言)在数字平台上表示不足,导致使用罗马或混合脚本进行交流的现象。
- 论文提出了一种基于提示的方法来解决德拉维语系单词级别的LI挑战。
- GPT-3.5 Turbo被用来分类单词,验证大语言模型的性能。
- 坎纳达模型在大多数评估指标上优于泰米尔模型,表现出较高的准确性和可靠性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是低资源德拉维达语系(Dravidian languages)中的语言识别(LI)挑战,特别是在单词层面上的识别问题。具体来说,论文关注以下几个方面:
多语言社会中的代码混合(Code-mixing)现象:在印度等多语言社会中,尤其是在社交媒体上的年轻人群中,文本常常展现出代码混合,即将本地语言与英语在不同语言层面上混合使用。这种现象对语言识别系统提出了巨大挑战,尤其是在单词内部语言交织的情况下。
德拉维达语系的数字化挑战:德拉维达语系在南印度广泛使用,包括卡纳达语(Kannada)、泰米尔语(Tamil)、马拉雅拉姆语(Malayalam)等,这些语言具有丰富的形态结构和多样的语言特征。然而,由于这些语言在数字平台上的代表性不足,导致它们在技术处理任务(如语言识别)上面临挑战。
低资源语言的语言识别:这些语言因缺乏标注数据集和复杂的形态特征而在语言识别领域相对未被充分研究。此外,这些语言在社交媒体和非正式通信中常见的代码混合文本(使用罗马字母或混合脚本)对现有的语言识别模型提出了额外的挑战。
为了解决这些问题,论文提出了一种基于提示(prompt-based)的方法,利用GPT-3.5 Turbo模型来正确分类单词到正确的类别,旨在通过实验不同的温度值来提高对这些语言的处理能力,从而为低资源语言提供更准确和包容的语言处理技术。
Q: 有哪些相关研究?
A: 相关研究涵盖了以下几个领域:
语言识别(LI):这是自然语言处理(NLP)中的一个重要领域,因为它在情感分析、机器翻译和信息检索等应用中扮演基础角色。传统的方法主要关注单语言或双语环境,但在多语言和代码混合环境中面临挑战。
代码混合(Code-mixing):早期的研究集中在英语-西班牙语或印地语-英语这样的语言对上,这些代码混合文本主要使用罗马字母。研究探索了代码切换文本的语言学特征,并强调了在单词层面上分割和识别语言的困难。
德拉维达语系的语言识别:由于缺乏标注数据集和这些语言固有的复杂形态特征,德拉维达语系在语言识别方面的研究相对较少。先前的工作已经开发了初始数据集和模型,但这些模型在处理代码混合文本时常常不足。
大型语言模型(LLMs):像GPT-3这样的大型语言模型在各种NLP任务中显示出了希望,包括语言识别。以往的工作展示了GPT-3在零样本和少样本学习中的潜力,使其成为在资源受限环境中进行语言识别的有力工具。
多语言LI:最近的研究开始探索使用变换器和预训练模型进行多语言LI,但在代码混合的德拉维达语系中,特别是在单词层面上,这些模型的有效性需要进一步研究。
具体到论文中引用的相关文献,以下是一些重要的相关研究:
- [11] T. Jauhiainen, H. Jauhiainen, K. Linden, A survey on automatic language identification in written texts, in: Journal of Artificial Intelligence Research, volume 65, 2019, pp. 675–782.
- [31] M. Zampieri, S. Malmasi, Y. Scherrer, Predicting the language of informal code-switched text, in: Proceedings of the 6th Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2019), 2019, pp. 135–144.
- [37] A. Deroy, S. Maity, Code generation and algorithmic problem solving using llama 3.1 405b, arXiv preprint arXiv:2409.19027 (2024).
- [42] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, Language models are unsupervised multitask learners, in: OpenAI Blog, volume 1, 2019.
这些文献涵盖了从自动语言识别的综述、非正式代码切换文本的语言预测,到大型语言模型的应用等多个方面,为本文的研究提供了理论和实证基础。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决低资源德拉维达语系中单词层面的语言识别问题:
数据集准备:
- 论文介绍了四个不同的数据集,包括Tulu、Kannada、Tamil和Malayalam数据集,这些数据集包含了代码混合的句子,并被转换成罗马字母。这些数据集为语言识别任务提供了必要的训练和测试材料。
任务定义:
- 明确定义了任务目标,即将代码混合文本中的单词分类到预定义的类别中,包括英语、德拉维达语、混合语、专有名词、地点、符号以及其他类别。
方法论:
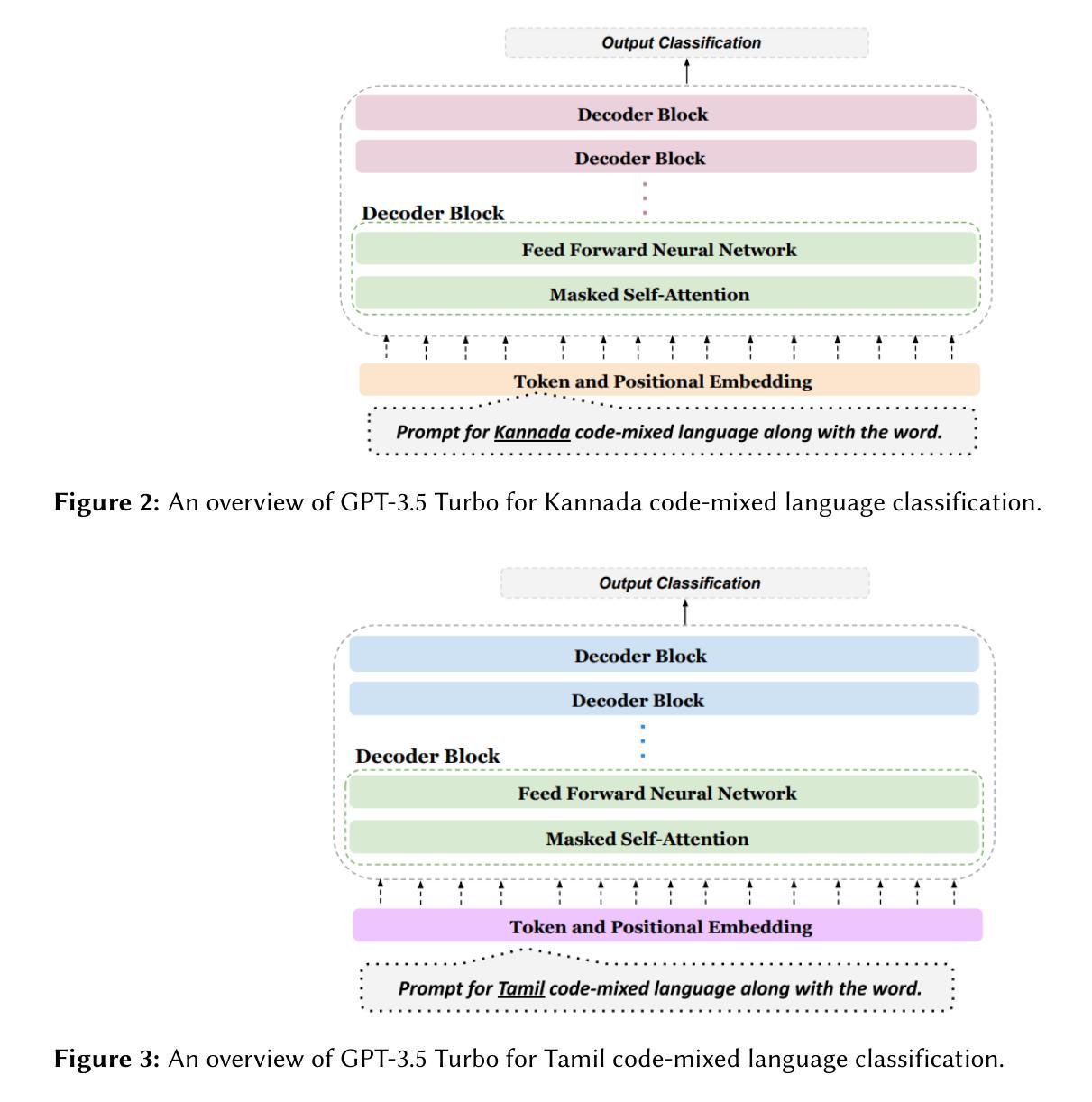
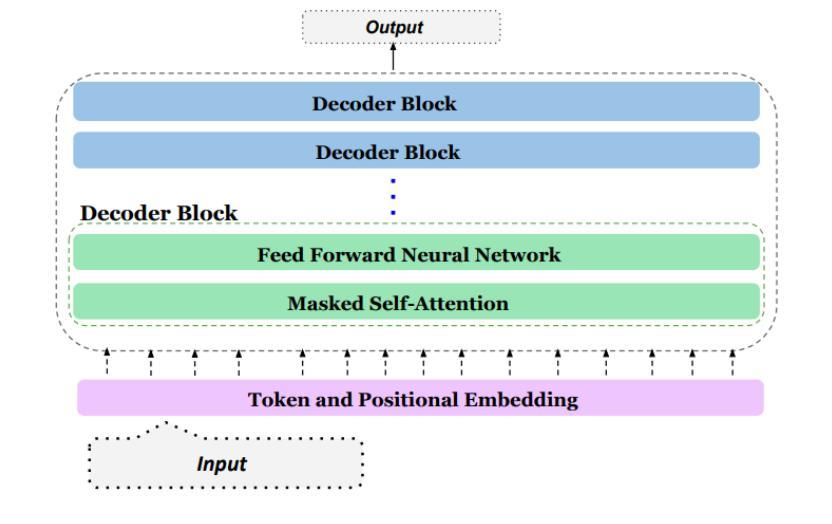
- 采用基于提示(Prompting)的方法,利用GPT-3.5 Turbo模型来处理单词级别的分类问题。提示方法包括向模型提供特定的输入格式,以便模型能够理解任务并生成正确的输出。
实验设计:
- 通过在不同的温度值(0.7、0.8和0.9)下实验GPT模型,来评估模型在不同设置下的表现。这些实验有助于理解模型在处理德拉维达语系语言时的效能。
模型架构和工作流程:
- 详细描述了GPT-3.5 Turbo模型的内部工作机制,包括分词(Tokenization)、嵌入(Embedding)、位置编码(Positional Encoding)、注意力机制(Attention Mechanism)、前馈神经网络(Feedforward Neural Networks)和输出生成(Output Generation)等步骤。
结果分析:
- 通过比较不同评估指标(如宏F1分数、宏精确度、宏召回率、加权F1、加权精确度、加权召回率和准确度)来分析和比较泰米尔语和卡纳达语的语言识别模型的性能。
结论和未来工作:
- 基于实验结果,论文得出了卡纳达语模型在大多数指标上一致优于泰米尔语模型的结论,并指出了泰米尔语模型在精确度和召回率方面需要改进的地方。同时,论文提出了未来可能的研究方向,包括模型训练的进一步优化、模型架构的调整和数据集的扩展。
通过这些步骤,论文不仅提出了一种基于GPT-3.5 Turbo的解决方案来处理低资源语言中的语言识别问题,还为未来的研究提供了方向,以进一步提高这些语言的语言处理技术。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行的实验包括以下几个方面:
模型选择与配置:
- 使用GPT-3.5 Turbo模型进行实验,并在不同的温度值(0.7、0.8和0.9)下进行测试,以了解这些设置如何影响模型对单词分类任务的性能。
数据集应用:
- 应用了四个不同的数据集,包括Tulu、Kannada、Tamil和Malayalam数据集,这些数据集包含了代码混合的句子,并被转换成罗马字母。这些数据集被用来训练和测试模型。
分类任务:
- 将代码混合文本中的单词分类到预定义的类别中,包括英语(English)、德拉维达语(Dravidian)、混合语(Mixed)、专有名词(Name)、地点(Location)、符号(Symbol)以及其他类别(Other)。
性能评估:
- 对比了两种语言(泰米尔语和卡纳达语)的语言识别模型的性能,使用多种评估指标,包括宏F1分数(Macro F1)、宏精确度(Macro Precision)、宏召回率(Macro Recall)、加权F1分数(Weighted F1)、加权精确度(Weighted Precision)、加权召回率(Weighted Recall)和准确度(Accuracy)。
提示工程:
- 利用提示工程技术,通过给定的特定格式的提示来引导GPT-3.5 Turbo模型进行分类任务,并对卡纳达语和泰米尔语分别设计了不同的提示。
模型内部工作机制分析:
- 描述了GPT-3.5 Turbo模型处理提示并生成输出的内部步骤,包括分词、嵌入、位置编码、注意力机制、前馈神经网络以及输出生成等。
这些实验的目的是为了评估和比较GPT-3.5 Turbo模型在处理低资源德拉维达语系语言的单词级别语言识别任务中的性能,并探索不同的实验设置对结果的影响。通过这些实验,论文旨在为低资源语言的语言识别提供深入的见解和可能的改进方向。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和结论,以下是一些可以进一步探索的点:
模型优化:
- 对GPT-3.5 Turbo模型进行微调(Fine-tuning),特别是在更大的德拉维达语系语言数据集上,以提高其对这些语言的识别能力。
数据集扩展和多样化:
- 扩充和多样化现有的数据集,包括更多的代码混合文本和上下文样本,以提高模型的泛化能力。
多模态学习:
- 探索结合文本和语音数据的多模态学习方法,以提高低资源语言的识别效果。
上下文感知模型:
- 开发能够更好地理解代码混合文本上下文的模型,以提高在复杂语言环境中的识别精度。
跨领域适应性:
- 研究模型在不同领域(如法律、医疗等专业领域)的适应性和有效性。
模型解释性:
- 提高模型的可解释性,以便更好地理解模型的决策过程,并识别模型可能的偏见或错误。
跨语言特征学习:
- 研究跨语言特征学习,以识别和利用德拉维达语系语言之间的共同特征,提高识别效率。
实时语言识别系统:
- 开发实时语言识别系统,用于社交媒体监控、客户服务自动化等应用。
多语言模型集成:
- 探索集成多个语言模型的方法,以提高对多种语言和代码混合文本的识别能力。
鲁棒性和错误分析:
- 对模型进行鲁棒性测试,并进行错误分析,以识别模型在特定类型文本或语言结构上的性能瓶颈。
算法创新:
- 开发新的算法或改进现有算法,以更好地处理低资源语言和代码混合文本。
跨领域和跨语言的评估框架:
- 建立一个综合的评估框架,用于评估不同模型在多种语言和领域中的表现。
这些探索点可以帮助研究者和开发者进一步提高低资源语言处理技术的性能,特别是在复杂和多变的语言环境中。
Q: 总结一下论文的主要内容
A: 这篇论文主要探讨了在低资源德拉维达语系中进行单词级别的语言识别(LI)问题,尤其是在多语言社会中常见的代码混合现象。以下是论文的主要内容总结:
问题背景:
- 语言识别对于自然语言处理(NLP)应用至关重要,但在多语言社会中,尤其是代码混合文本,使得LI任务变得复杂。
研究挑战:
- 德拉维达语系语言在数字化平台上代表性不足,面临技术挑战,如语言识别和脚本多样性。
方法论:
- 提出了一种基于提示的方法,使用GPT-3.5 Turbo模型来分类代码混合文本中的单词到正确的语言类别。
数据集:
- 介绍了四个数据集:Tulu、Kannada、Tamil和Malayalam,这些数据集包含了代码混合的句子,并被转换成罗马字母。
实验设计:
- 在不同的温度值下实验GPT模型,以评估其在单词级别LI任务中的性能。
结果分析:
- 通过比较宏F1分数、宏精确度、宏召回率等多个评估指标,发现Kannada模型在大多数指标上优于Tamil模型。
结论:
- 研究结果表明,GPT-3.5 Turbo能够有效地识别和分类Kannada语言实例,而Tamil模型则需要在精确度和召回率方面进行改进。
未来工作:
- 提出了未来可能的研究方向,包括模型训练的进一步优化、模型架构的调整和数据集的扩展。
总体而言,这篇论文通过实验验证了GPT-3.5 Turbo在低资源语言LI任务中的潜力,并指出了现有模型在处理德拉维达语系语言时的局限性和改进空间。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

LLMs are Highly-Constrained Biophysical Sequence Optimizers
Authors:Angelica Chen, Samuel D. Stanton, Robert G. Alberstein, Andrew M. Watkins, Richard Bonneau, Vladimir Gligorijević, Kyunghyun Cho, Nathan C. Frey
Large language models (LLMs) have recently shown significant potential in various biological tasks such as protein engineering and molecule design. These tasks typically involve black-box discrete sequence optimization, where the challenge lies in generating sequences that are not only biologically feasible but also adhere to hard fine-grained constraints. However, LLMs often struggle with such constraints, especially in biological contexts where verifying candidate solutions is costly and time-consuming. In this study, we explore the possibility of employing LLMs as highly-constrained bilevel optimizers through a methodology we refer to as Language Model Optimization with Margin Expectation (LLOME). This approach combines both offline and online optimization, utilizing limited oracle evaluations to iteratively enhance the sequences generated by the LLM. We additionally propose a novel training objective – Margin-Aligned Expectation (MargE) – that trains the LLM to smoothly interpolate between the reward and reference distributions. Lastly, we introduce a synthetic test suite that bears strong geometric similarity to real biophysical problems and enables rapid evaluation of LLM optimizers without time-consuming lab validation. Our findings reveal that, in comparison to genetic algorithm baselines, LLMs achieve significantly lower regret solutions while requiring fewer test function evaluations. However, we also observe that LLMs exhibit moderate miscalibration, are susceptible to generator collapse, and have difficulty finding the optimal solution when no explicit ground truth rewards are available.
大型语言模型(LLM)在蛋白质工程和分子设计等生物任务中显示出巨大的潜力。这些任务通常涉及黑盒离散序列优化,挑战在于生成不仅生物上可行还符合精细粒度约束的序列。然而,LLM在处理这些约束时经常遇到困难,特别是在生物上下文中,验证候选解决方案既昂贵又耗时。本研究探索了通过我们称为带有余量期望的语言模型优化(LLOME)的方法,将LLM作为高度约束的两级优化器的可能性。这种方法结合了离线优化和在线优化,利用有限的oracle评估来迭代改进LLM生成的序列。我们还提出了一种新的训练目标——余量对齐期望(MargE),用于训练LLM在奖励和参考分布之间平滑插值。最后,我们引入了一套合成测试套件,它在几何上与真实的生物物理问题具有很强的相似性,并能够在不需要耗时实验室验证的情况下快速评估LLM优化器。我们的研究发现,与遗传算法基准相比,LLM实现了显著更低的遗憾解决方案,同时需要的测试函数评估次数更少。然而,我们还观察到LLM存在适度的校准误差,容易遭受生成器崩溃的问题,并且在没有明确的地面真实奖励时,很难找到最优解决方案。
论文及项目相关链接
PDF Supercedes arXiv:2407.00236v1
Summary
LLMs在蛋白质工程和分子设计等生物任务中展现出巨大潜力,但面临验证候选解决方案成本高、耗时长的问题。本研究提出一种名为语言模型优化与边际期望(LLOME)的方法,结合离线与在线优化,利用有限的oracle评估来迭代优化LLM生成的序列。同时引入新的训练目标——边际对齐期望(MargE),训练LLM在奖励和参考分布之间平滑插值。此外,本研究还引入了与真实生物物理问题具有强几何相似性的合成测试套件,可在不需要耗时耗力的实验室验证的情况下快速评估LLM优化器。研究结果表明,与遗传算法相比,LLM可以实现更低的后悔解决方案并减少测试功能评估的次数,但仍存在误校准等问题。
Key Takeaways
- LLMs在生物任务如蛋白质工程和分子设计中表现出巨大潜力。
- LLMs在面临验证候选解决方案时面临挑战,因为生物验证过程成本高且耗时长。
- 提出了一种新的方法——语言模型优化与边际期望(LLOME),结合了离线与在线优化。
- 引入新的训练目标——边际对齐期望(MargE),使LLM能在奖励和参考分布之间平滑插值。
- 提出了一种合成测试套件,可以快速评估LLM优化器,无需耗时的实验室验证。
- LLMs相比遗传算法可以实现更低的后悔解决方案并减少测试功能评估次数。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了如何有效地利用大型语言模型(LLMs)来解决高度受限的生物物理序列优化问题。这类问题通常涉及黑盒离散序列优化,挑战在于生成不仅在生物学上可行,同时也满足严格约束条件的序列。尽管LLMs在多个生物物理优化任务(如蛋白质工程和分子设计)上展现出潜力,但它们在处理这些复杂约束时常常遇到困难,特别是在生物学背景下,验证候选解的成本高昂且耗时。
论文中提到的问题和挑战主要包括:
LLMs与硬约束的适应性:LLMs在生成满足硬细粒度约束的输出时常常表现不佳,例如固定字数的文本、特定前缀或关键词等。
数据稀缺性:在生物学优化问题中,由于验证解候选需要昂贵且低通量的实验室实验,导致可用于训练LLMs的数据稀缺。
混合优化循环:现实实验室环境中,反馈周期慢且成本高,需要优化器能够在有限的“神谕”(oracle)标签下生成、排名和筛选候选解。
LLMs作为双层优化器:论文提出了将LLMs嵌入到双层优化循环中的方法,即在外循环中基于神谕标签训练模型,在内循环中生成并迭代改进候选解而不立即访问神谕。
LLMs的训练目标:论文提出了一个新的LLMs训练目标——边际对齐期望(MargE),旨在平滑地插值目标和参考分布之间的差异。
合成测试套件:为了快速评估LLM优化器而不需要耗时的实验室验证,论文引入了与真实生物物理问题具有强几何相似性的合成测试函数。
总的来说,论文试图通过提出一个新的方法论(LLOME)和训练目标(MargE),使LLMs能够更有效地解决具有严格约束的生物物理序列优化问题,并减少对实验室验证的依赖。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究可以被分为以下几个领域:
离散序列黑盒优化(Discrete Sequence Black-Box Optimization):
- 该领域的研究涉及启发式算法,如进化算法,以及它们在序列设计中的应用。这些算法通常结合随机变异和高通量筛选来优化序列。
- 相关文献包括对进化算法在理论及实践中的应用,如[7]和[89]。
LLMs在优化和科学发现中的应用(LLMs for Optimization and Scientific Discovery):
- 这部分研究探讨了如何利用LLMs来解决优化问题,包括将自然语言描述的问题转化为代码或建模语言,然后使用辅助求解器。
- 相关文献包括[83]、[2]、[61]和[1],这些文献讨论了如何将LLMs与优化问题结合。
可控文本生成(Controllable Text Generation, CTG):
- 可控文本生成是优化的一个特例,目标是生成具有特定属性值的序列,而非仅仅最大化目标函数。
- 相关文献包括[43]、[70]和[82],这些文献探讨了如何使用控制代码或上下文提示来引导LLMs生成符合特定要求的文本。
LLMs的适应性和约束问题(Adapting LLMs to Solve Black-Box Optimization Problems):
- 一些研究专注于如何使LLMs适应解决黑盒优化问题,包括使用辅助求解器或判别模型来引导生成过程。
- 相关文献包括[54]、[84]和[1]。
LLMs的训练和优化技术(Training and Optimization Techniques for LLMs):
- 这部分研究关注如何训练LLMs以提高其在优化任务中的表现,包括使用不同的训练目标和算法。
- 相关文献包括[79]、[94]和[116],这些文献讨论了直接偏好优化(DPO)和强化学习从人类反馈(RLHF)等技术。
LLMs的迭代优化(Iterative Optimization with LLMs):
- 有些研究展示了LLMs在迭代生成序列时能够单调地增加特定属性值,这对于优化问题尤为重要。
- 相关文献包括[14]、[70]。
LLMs的校准问题(Calibration of LLMs):
- 校准是评估LLMs输出与实际结果匹配程度的重要方面,特别是在优化和生成任务中。
- 相关文献包括[19]、[107],这些文献探讨了LLMs在控制生成任务中的表现。
这些相关研究为本文提出的LLOME框架提供了理论基础和技术背景,涉及LLMs在优化问题中的应用、训练技术以及可控文本生成等多个方面。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法来解决大型语言模型(LLMs)在高度受限的生物物理序列优化问题中的应用问题:
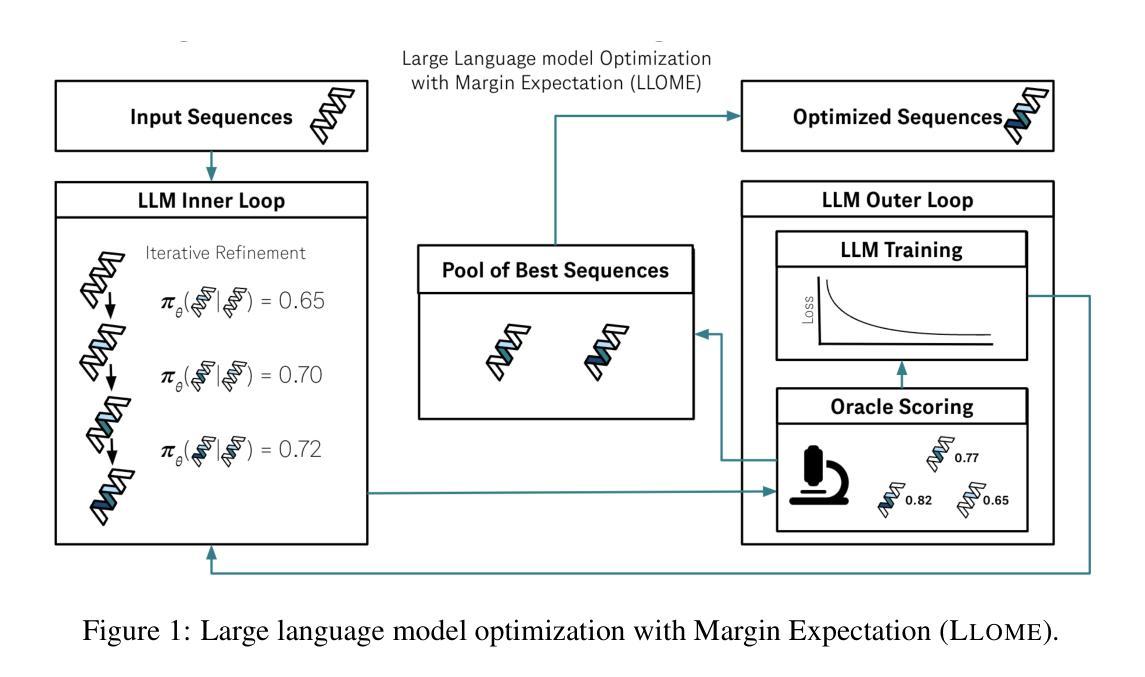
1. 提出LLOME方法
LLOME(Large Language model Optimization with Margin Expectation)是一种新的方法论,将LLMs嵌入到双层优化循环中。这种方法结合了离线和在线优化,利用有限的神谕(oracle)评估来迭代增强LLM生成的序列。
- 外循环(Outer Loop):使用神谕标签(如实验室验证或合成测试函数的评估)来训练优化器。
- 内循环(Inner Loop):优化器生成并迭代改进候选序列,而不立即访问神谕标签。
2. 引入Ehrlich函数作为合成测试套件
为了快速评估LLM优化器而不需要耗时的实验室验证,论文提出了Ehrlich函数,这是一类具有硬细粒度约束的闭式测试函数,具有与真实生物物理序列优化问题强几何相似性。
3. 提出新的LLM训练目标MargE
MargE(Margin-Aligned Expectation)是一种新的LLM训练目标,它平滑地插值目标和参考分布。这种目标利用输入和目标之间的奖励边际,与常见的LLM离线训练目标(如监督式微调SFT和直接偏好优化DPO)相比,MargE更有效地利用了奖励信息。
4. 实验验证
论文通过一系列实验验证了LLOME方法相对于遗传算法基线的性能,特别是在需要少量测试函数评估时找到低遗憾(regret)解决方案的能力。实验结果表明,LLOME在给定固定预算的函数评估下,比遗传算法基线找到更低遗憾的解决方案。
5. 分析LLMs的优化能力
论文探讨了LLMs在优化过程中的几个基本问题,包括它们是否能有效选择最佳生成、预测的校准程度、在没有神谕标签的情况下在推理时迭代外推的能力,以及在训练期间需要明确的奖励值。
通过这些方法,论文不仅提出了一种新的LLM训练目标和优化框架,而且还提供了一种合成测试方法来快速评估和迭代LLM优化器,这对于数据稀缺的实验室环境特别有用。
Q: 论文做了哪些实验?
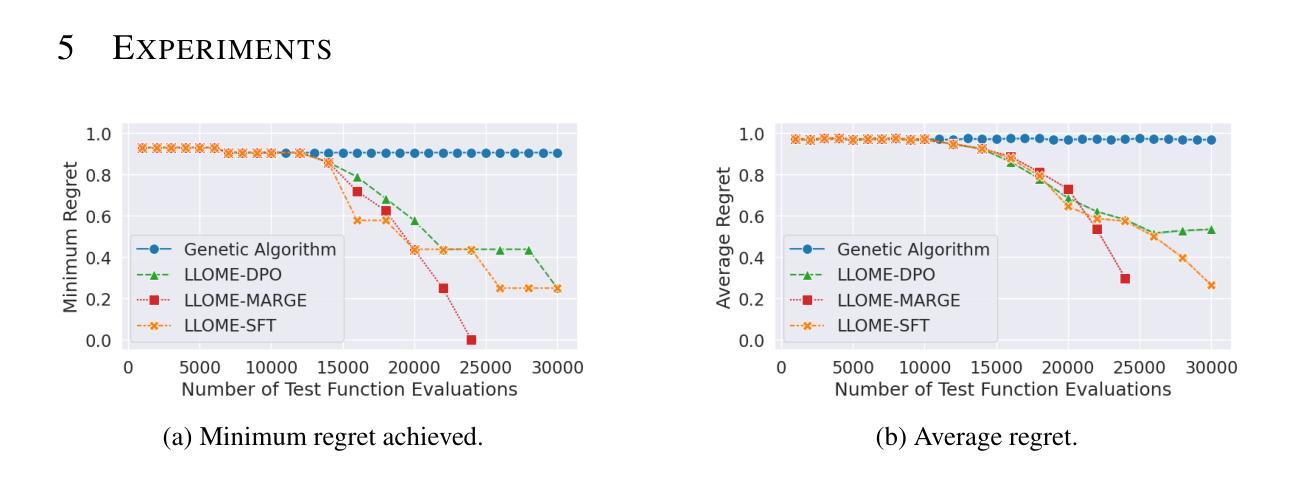
A: 论文中进行了一系列实验来评估LLOME(Large Language model Optimization with Margin Expectation)框架的性能,并与其他方法进行比较。以下是实验的主要内容和发现:
1. 性能比较实验
- 对比方法:LLOME的三种变体(LLOME-SFT、LLOME-DPO、LLOME-MARGE)与遗传算法(GA)进行比较。
- 性能指标:最小遗憾(minimum regret)和平均遗憾(average regret)。
- 结果:所有LLOME变体都实现了比遗传算法更低的最小遗憾值,其中LLOME-MARGE是唯一发现最优解(最小遗憾为0)的变体。
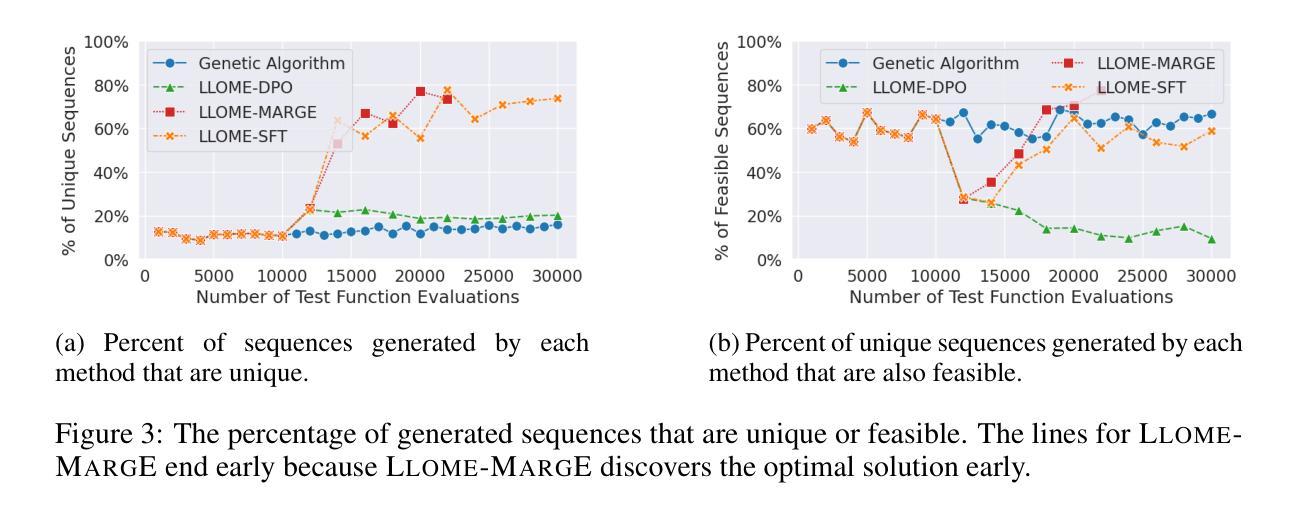
2. 独特性和可行性实验
- 独特性:比较每种方法生成的唯一序列的百分比。
- 可行性:比较每种方法生成的可行序列的百分比。
- 结果:LLOME-SFT和LLOME-MARGE在初始阶段可行性下降后,学会了如何生成更多可行序列。LLOME-DPO未能提高输出的多样性或可行性。
3. 迭代外推能力实验
- 目的:评估LLMs在没有明确指导的情况下,是否能够迭代地从训练分布中外推。
- 结果:LLMs能够通过迭代改进显著降低遗憾,但后期改进效果减弱,表明LLMs的外推能力有限。
4. 自身输出排名实验
- 目的:评估LLMs在自身输出中选择最佳候选的能力。
- 结果:LLMs通常能够选择高分候选,但并非总是选择最高分的候选。
5. 超参数、测试函数难度和种子数据集的鲁棒性实验
- 目的:评估LLOME对超参数设置、问题难度和种子数据集选择的敏感性。
- 结果:LLOME-MARGE在各种设置下展现出最好的样本效率。
6. 多阶段SFT+MargE训练实验
- 目的:测试在不同阶段结合SFT和MargE训练的效果。
- 结果:LLOME-SFT1-MARGE9是唯一找到最优解的流程,并获得了最好的校准曲线。
7. 强插值标准(SIC)的影响实验
- 目的:比较MargE和REINFORCE方法,测试是否满足SIC对LLM优化能力的影响。
- 结果:LLOME-REINFORCE虽然能够降低遗憾,但未能达到最优解,表明SIC可能对LLM的优化能力有重要影响。
这些实验全面评估了LLOME框架的性能,并探讨了LLMs在高度受限的生物物理序列优化问题中的潜力和局限性。通过这些实验,论文展示了LLOME相对于传统方法的优势,特别是在样本效率和找到低遗憾解决方案的能力上。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
1. 改进LLMs的校准问题:
- 论文中提到LLMs在生成序列时存在一定程度的校准问题,特别是在输出扩展到训练分布之外时。研究如何改进LLMs的校准,使其更好地反映真实性能是一个有价值的方向。
2. 增强LLMs的外推能力:
- LLMs在迭代外推时表现出一定的局限性。探索如何通过训练策略或模型架构的改进来增强LLMs在未见过的区域进行有效外推的能力。
3. 优化算法的混合使用:
- 论文中提到了LLMs与传统优化算法(如遗传算法)的结合使用。研究如何更有效地混合使用这些算法,以及如何利用各自的优势来提高整体优化性能。
4. 探索更多的训练目标:
- 除了提出的MargE训练目标外,是否可以开发出其他更有效的训练目标,以更好地利用奖励信息并提高LLMs的优化能力。
5. 多任务和迁移学习:
- 探索LLMs在多任务设置下的表现,以及如何通过迁移学习将一个领域的知识应用到另一个领域,特别是在生物物理序列优化问题上。
6. 计算和实验成本的进一步降低:
- 虽然论文提出了合成测试套件来减少实验成本,但进一步探索如何降低实际生物物理问题的计算和实验成本也是一个重要的研究方向。
7. 更复杂的约束和目标函数:
- 论文中的Ehrlich函数提供了一个基础的测试平台,研究更复杂的约束和目标函数,以及它们对LLMs优化能力的影响。
8. 模型的可解释性和透明度:
- 提高LLMs在优化过程中的可解释性,帮助研究人员和实践者更好地理解模型的决策过程。
9. 鲁棒性和泛化能力的测试:
- 对LLMs在不同参数设置、不同问题难度和不同种子数据集下的鲁棒性和泛化能力进行更深入的测试和分析。
10. 实时反馈和在线学习:
- 探索LLMs在实时反馈和在线学习环境中的表现,特别是在动态变化的生物物理序列优化问题中。
这些探索点可以帮助研究者更全面地理解LLMs在解决复杂优化问题中的潜力和挑战,并推动相关技术的发展。
Q: 总结一下论文的主要内容
A: 本文探讨了大型语言模型(LLMs)在解决高度受限的生物物理序列优化问题中的应用和性能。主要内容包括:
问题背景:LLMs在诸如蛋白质工程和分子设计等生物任务中显示出潜力,但它们在处理硬性细粒度约束时常常遇到困难,特别是在需要实验验证的生物领域。
LLOME方法:提出了一种名为LLOME的方法,该方法通过结合离线和在线优化,利用有限的神谕评估来迭代增强LLM生成的序列。
Ehrlich函数:引入了Ehrlich函数,一类具有硬细粒度约束的闭式测试函数,用于快速评估LLM优化器而无需耗时的实验室验证。
MargE训练目标:提出了一个新的LLM训练目标——边际对齐期望(MargE),它平滑地插值目标和参考分布,有效利用奖励信息。
实验验证:通过一系列实验,验证了LLOME框架相对于遗传算法等传统方法在发现低遗憾解决方案方面的优势,尤其是LLOME-MARGE变体展现出更高的样本效率。
LLMs的优化能力分析:分析了LLMs在优化过程中的表现,包括它们选择最佳生成的能力、预测校准程度、在没有神谕标签的情况下的推理外推能力,以及训练期间对明确奖励值的需求。
进一步探索点:论文还提出了未来研究的方向,包括改进LLMs的校准问题、增强外推能力、探索更多的训练目标和算法混合使用等。
总体而言,本文通过提出新的框架和训练目标,展示了LLMs在解决具有严格约束的复杂优化问题上的应用潜力,并提供了一种无需实验室验证的快速评估方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

An Evolved Universal Transformer Memory
Authors:Edoardo Cetin, Qi Sun, Tianyu Zhao, Yujin Tang
Prior methods propose to offset the escalating costs of modern foundation models by dropping specific parts of their contexts with hand-designed rules, while attempting to preserve their original performance. We overcome this trade-off with Neural Attention Memory Models (NAMMs), introducing a learned network for memory management that improves both the performance and efficiency of transformers. We evolve NAMMs atop pre-trained transformers to provide different latent contexts focusing on the most relevant information for individual layers and attention heads. NAMMs are universally applicable to any model using self-attention as they condition exclusively on the values in the produced attention matrices. Learning NAMMs on a small set of problems, we achieve substantial performance improvements across multiple long-context benchmarks while cutting the model’s input contexts up to a fraction of the original sizes. We show the generality of our conditioning enables zero-shot transfer of NAMMs trained only on language to entirely new transformer architectures even across input modalities, with their benefits carrying over to vision and reinforcement learning.
先前的方法提议通过采用手工设计的规则来忽略现代基础模型上下文的特定部分,以抵消日益增加的成本,同时尝试保持其原始性能。我们通过引入神经网络注意力记忆模型(NAMMs)克服了这一权衡,该模型通过改进变压器的性能和效率来学习进行内存管理。我们在预训练的变压器上发展NAMMs,以提供不同的潜在上下文,专注于各层和注意力头最相关的信息。由于它们仅依赖于生成的注意力矩阵中的值,因此NAMMs可普遍适用于任何使用自注意力的模型。通过在少数问题上学习NAMMs,我们在多个长上下文基准测试中实现了显著的性能提升,同时能将模型的输入上下文缩减到原始大小的一小部分。我们证明了我们的条件通用性能够实现在语言上训练的NAMMs的零样本迁移到全新的变压器架构,甚至跨越输入模式,其优势同样适用于计算机视觉和强化学习。
论文及项目相关链接
PDF Preprint, under submission. Source code is available at https://github.com/SakanaAI/evo-memory
Summary
现代基础模型的成本不断上升,此前的解决方案尝试通过手动设计的规则来减少模型的上下文部分,同时试图保持其原始性能。我们采用神经注意力记忆模型(NAMMs)来解决这一权衡问题,通过引入用于内存管理的神经网络,改进了变压器性能和效率。我们将NAMMs在预训练的变压器上进化,提供不同的潜在上下文,专注于个别层和注意力头最相关的信息。NAMMs可广泛应用于任何使用自注意力的模型,因为它们仅根据产生的注意力矩阵中的值进行条件处理。通过在少数问题上学习NAMMs,我们在多个长上下文基准测试中实现了显著的性能提升,同时减少了模型输入上下文的长度至原始大小的几分之一。我们证明了我们的条件通用性允许仅通过语言训练的NAMMs零样本迁移到全新的变压器架构,甚至跨越输入模式,其在视觉和强化学习中的优势得以保留。
Key Takeaways
- NAMMs通过引入学习网络进行内存管理,提高了Transformer的性能和效率。
- NAMMs可以在预训练的Transformer上进行进化,提供专注于最相关信息的不同潜在上下文。
- NAMMs可广泛应用于使用自注意力的模型,仅基于注意力矩阵的值进行条件处理。
- 在多个长上下文基准测试中,NAMMs实现了显著的性能提升。
- NAMMs能够减少模型输入上下文的长度至原始大小的几分之一。
- NAMMs的条件通用性允许其零样本迁移到新的Transformer架构,甚至跨越输入模式。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种名为Neural Attention Memory Models (NAMMs) 的方法,旨在解决现代基础模型(如Transformer架构)在处理长文本时面临的性能与效率之间的权衡问题。具体来说,论文试图解决以下几个关键问题:
长文本处理的挑战:Transformer模型在处理长文本时需要较大的上下文窗口,这直接影响了训练和推理的成本,使得这些模型在资源消耗上变得越来越昂贵。
现有方法的局限性:以往的方法尝试通过手工设计的规则来量化模型潜在记忆中每个token的重要性,并以此决定哪些token可以被移除以减少内存大小,但这些方法往往需要在效率和性能之间做出妥协。
记忆管理的非微分性:传统的基于梯度的优化方法不适用于具有二元结果(选择保留/丢弃token)的记忆管理操作,这限制了通过直接优化来改进记忆管理的可能性。
跨领域和模态的通用性:现有的记忆管理方法往往针对特定类型的模型或任务设计,缺乏跨不同输入模态和任务领域的通用性。
为了克服这些问题,NAMMs通过学习网络来管理记忆,以一种可学习的方式来选择保留哪些信息,从而在不牺牲性能的同时提高Transformer模型的效率。此外,NAMMs还被设计为可以零样本转移到不同的Transformer架构和输入模态,包括视觉和强化学习任务,这进一步证明了其通用性和灵活性。
Q: 有哪些相关研究?
A: 与NAMMs(Neural Attention Memory Models)相关的研究涵盖了以下几个领域:
长文本处理:
- 研究者们探索了如何扩展Transformer模型的上下文窗口,以处理长文本任务。例如,通过修改模型架构或训练策略来提升模型对长距离依赖的处理能力。
记忆管理与压缩:
- 许多研究工作集中在如何减少Transformer模型中的Key-Value(KV)缓存大小,以降低模型的内存占用。这些方法通常涉及基于启发式策略的token重要性评估,以及选择性地移除最不重要的token。
基于注意力的模型优化:
- 一些研究提出了改进自注意力机制的方法,例如通过线性化注意力计算或引入新的持久化token和存储机制来提高效率和性能。
神经网络与记忆模型的结合:
- 先前的工作探索了如何将神经网络与记忆模型相结合,通过直接替换网络层或引入辅助组件来模拟记忆系统的读写操作。
进化策略在模型优化中的应用:
- 与NAMMs类似,一些研究使用进化算法来优化模型的不同方面,如神经架构搜索或模型合并策略,以提高模型性能。
跨模态和多任务学习:
- 研究者们还探索了如何使模型能够处理和学习跨不同输入模态(如语言、视觉等)的信息,这对于提升模型在多任务环境中的通用性和灵活性至关重要。
具体到文献中提及的一些工作,包括但不限于:
- L2 magnitude 和 entropy 用于评估token重要性的方法(Devoto et al., 2024; Yao et al., 2024)。
- 基于attention matrix统计分析的策略(Liu et al., 2024; Oren et al., 2024; Zhang et al., 2024c)。
- MQA 和 GQA 方法,用于在训练期间合并不同的注意力头以提高部署时的吞吐量(Shazeer, 2019; Ainslie et al., 2023)。
- 记忆网络,通过引入辅助组件来模拟记忆系统的读写操作(Weston et al., 2014; Sukhbaatar et al., 2015)。
- 进化策略用于优化Transformer模型的不同方面(So et al., 2019; Akiba et al., 2024)。
这些相关工作为NAMMs提供了理论基础和技术背景,同时也展示了在长文本处理和模型优化领域的研究进展。
Q: 论文如何解决这个问题?
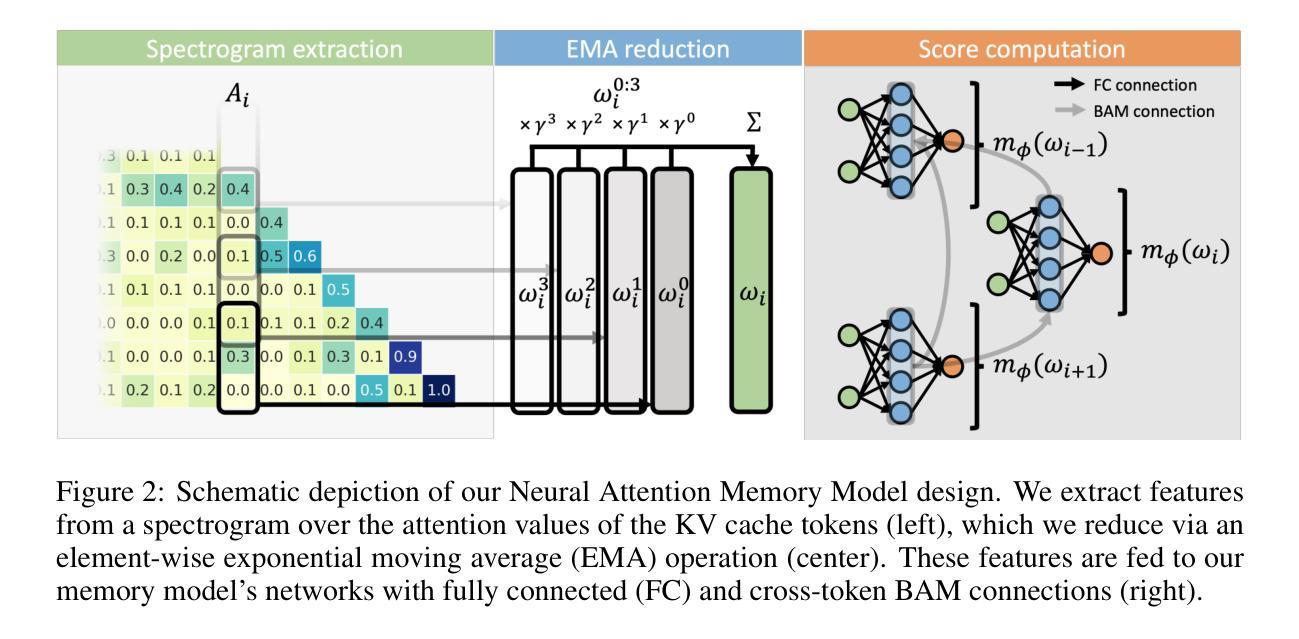
A: 论文通过提出Neural Attention Memory Models (NAMMs)来解决这个问题,具体方法如下:
特征提取:NAMMs首先使用Short-Time Fourier Transform (STFT)来处理注意力矩阵中的值,生成一个频谱图(spectrogram),这个频谱图可以捕捉到每个token在所有过去查询中的相对重要性,并将这些信息压缩成一个较小的形式。
记忆模型设计:NAMMs设计了一个小型神经网络( m_\phi ),该网络输出KV缓存中每个token的标量选择分数。通过将频谱图压缩成一个较小的特征向量,并将其与位置编码一起输入到网络中,最终通过一个线性层输出每个token的分数。
反向注意力记忆架构(Backward Attention Memory Architecture, BAM):为了在不同token之间共享信息,NAMMs使用了一种特殊的自注意力机制,称为反向注意力(BAM)。这种设计允许token仅与其在KV缓存中的后续亲戚进行交互,从而促进了跨token的竞争和多样性。
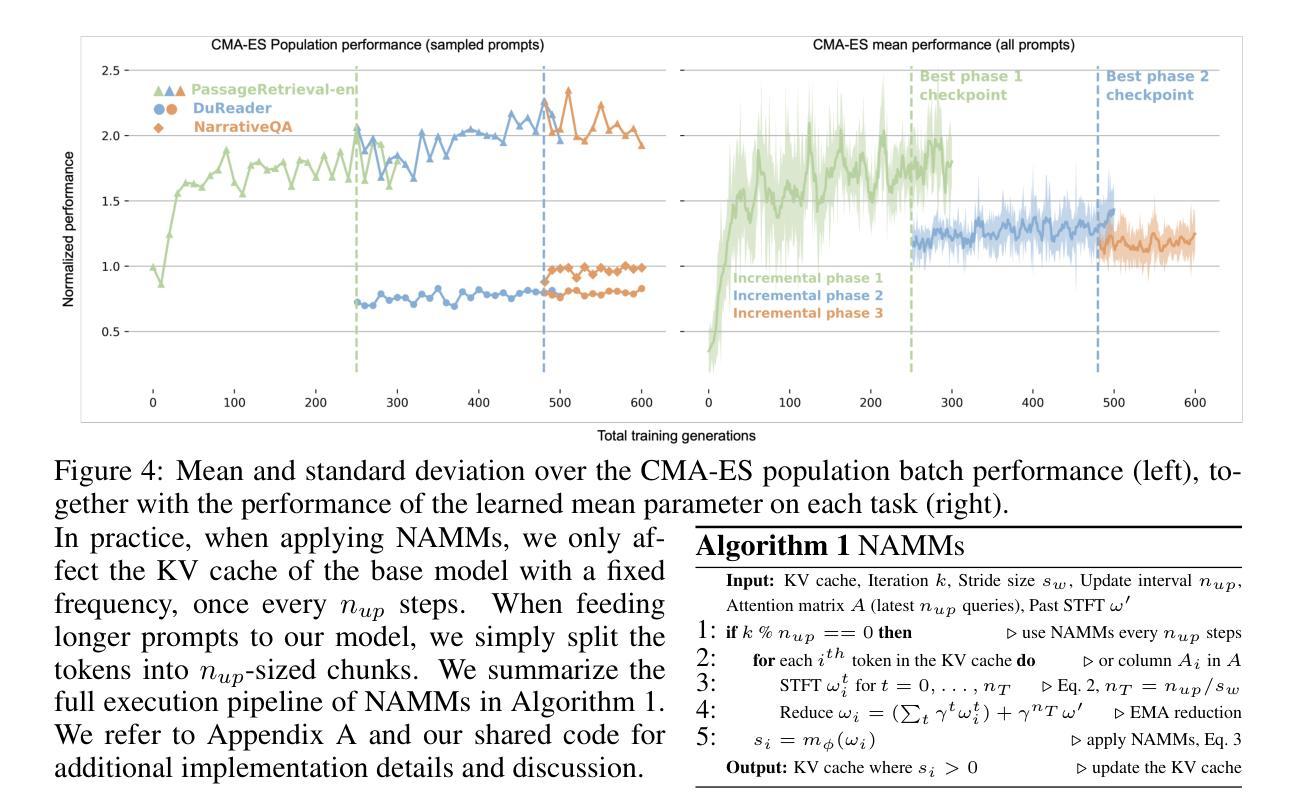
增量进化训练:NAMMs使用CMA-ES优化算法进行训练,通过增量进化的方式逐步提高模型在长文本任务上的性能。训练从单一任务开始,并在后续阶段添加更多任务,以此作为正则化手段提高模型的泛化能力。
零样本转移:由于NAMMs仅依赖于注意力矩阵中的值,因此可以零样本转移到不同的Transformer架构、输入模态和任务领域。这意味着在一种类型的任务上训练的NAMM可以直接应用到另一种完全不同的任务上,而无需额外的训练。
跨领域验证:论文验证了NAMMs在多种长文本基准测试中的性能,包括不同语言的理解和新的任务领域,如计算机视觉和强化学习。
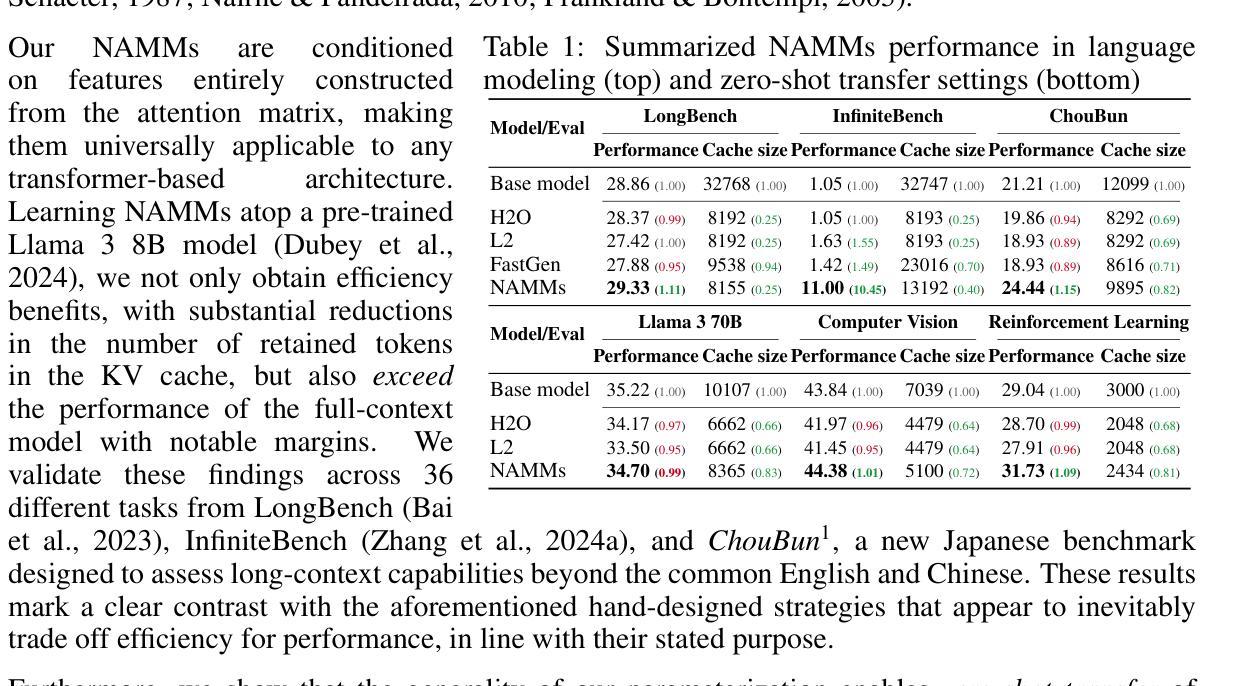
通过上述方法,NAMMs能够在减少模型输入上下文大小的同时提高模型性能,实现了在不同任务和领域中有效管理Transformer模型记忆的目标。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估Neural Attention Memory Models (NAMMs)的性能,包括以下几个方面:
长文本语言建模任务:
- 使用LongBench、InfiniteBench和ChouBun三个不同的长文本基准测试来评估NAMMs在多种任务上的性能。
- 这些任务覆盖了包括单文档问答、多文档问答、摘要生成等不同语言理解任务。
零样本转移能力测试:
- 将NAMMs从Llama 3 8B模型零样本转移到Llama 3 70B模型,并在LongBench上进行评估。
- 在计算机视觉领域,使用Llava Next Video 7B模型在LongVideoBench和MLVU基准测试上评估NAMMs。
- 在强化学习领域,使用决策变换器(Decision Transformer)在D4RL基准测试上评估NAMMs。
不同NAMMs架构的比较:
- 比较了使用不同架构(如MLP和BAM)的NAMMs在语言建模任务上的性能。
- 分析了在不同阶段增量训练后的NAMMs性能,以及与不使用增量训练的NAMMs性能比较。
训练和性能曲线分析:
- 提供了使用CMA-ES算法训练NAMMs时的种群批量性能和优化均值参数在每个任务上的性能曲线。
- 分析了NAMMs在训练过程中记忆大小的演变。
定性分析:
- 通过检查解码后保留在KV缓存中的文本,对NAMMs在不同层和不同任务上的行为进行了定性分析。
- 分析了NAMMs如何影响基础模型在特定任务(如InfiniteBench中的En.Sum任务)上的表现,并与GPT4模型生成的答案进行了比较。
梯度敏感性分析:
- 分析了NAMMs对注意力矩阵中不同频率维度的敏感性,以及位置编码的影响。
这些实验全面评估了NAMMs在不同任务、不同模型规模以及不同输入模态上的有效性和泛化能力,同时也探索了NAMMs设计空间和潜在的改进方向。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的Neural Attention Memory Models (NAMMs)在多个任务和领域中显示出了潜力,但仍有许多可以进一步探索的方向:
NAMMs的设计空间:
- 探索不同的特征提取方法,例如使用不同大小的窗口或不同类型的傅里叶变换。
- 尝试不同的神经网络架构,如深度网络或不同类型的注意力机制,以提高NAMMs的性能。
训练策略:
- 研究不同的进化算法,如遗传算法或强化学习,以优化NAMMs的权重。
- 探索是否可以通过梯度下降方法来辅助进化算法,以提高训练效率。
正则化技术:
- 开发新的正则化策略来防止NAMMs过拟合,并提高其在未知任务上的泛化能力。
跨领域适配:
- 研究如何通过微调或继续训练来进一步提高NAMMs在新领域的适应性。
资源效率:
- 探索NAMMs在不同硬件平台上的实现,以优化其计算和内存效率。
长文本稀疏检索:
- 改进NAMMs在处理长文本稀疏信息检索任务时的性能,例如通过调整EMA(指数移动平均)系数或学习这一参数。
理论分析:
- 对NAMMs的决策过程进行更深入的理论分析,以理解其在不同任务中的行为。
应用到更多领域:
- 将NAMMs应用到更多的NLP任务,如机器翻译、文本摘要等,以及非NLP领域,如推荐系统、图形处理等。
可解释性和可视化:
- 提高NAMMs的可解释性,通过可视化技术来展示其在处理信息时的内部机制。
与现有技术的结合:
- 研究如何将NAMMs与现有的Transformer优化技术(如量化、剪枝等)结合起来,以进一步提升性能。
长期记忆和短期记忆的平衡:
- 研究如何在NAMMs中模拟人类的记忆系统,平衡长期记忆和短期记忆的需求。
这些方向不仅可以推动NAMMs技术的发展,还可能为Transformer模型及其他深度学习架构的优化提供新的视角和方法。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为Neural Attention Memory Models (NAMMs) 的方法,旨在提高Transformer模型在处理长文本任务时的性能和效率。主要内容可以总结如下:
问题陈述:
- Transformer模型在处理长文本时面临性能与效率的权衡问题。
- 现有方法通过手工设计的规则来减少模型的上下文窗口大小,但这通常会损害模型性能。
NAMMs介绍:
- NAMMs是一种基于神经网络的注意力内存模型,通过学习来管理Transformer的Key-Value缓存,以保留最相关的信息。
- NAMMs使用特征提取技术(如Short-Time Fourier Transform)来处理注意力矩阵,并使用一个小型神经网络来评估每个token的重要性。
方法论:
- NAMMs通过反向注意力机制(Backward Attention Memory Architecture, BAM)来促进token间的竞争和多样性。
- 使用进化算法(如CMA-ES)来训练NAMMs,直接优化长文本任务的性能。
实验结果:
- NAMMs在多个长文本基准测试中取得了显著的性能提升,同时减少了模型的输入上下文大小。
- NAMMs展示了零样本转移的能力,能够将从语言任务学到的知识迁移到视觉和强化学习等新领域。
主要贡献:
- 提出了NAMMs这一新的内存进化框架,为优化Transformer模型提供了新的维度。
- 证明了NAMMs在多种长文本任务中的性能和效率优势。
- 展示了NAMMs的通用性,能够在不同模型架构和输入模态间进行迁移。
未来工作:
- 探索NAMMs的设计空间,包括特征提取方法和神经网络架构。
- 研究如何进一步提高NAMMs的泛化能力和资源效率。
- 将NAMMs应用于更多的任务和领域,以及与其他优化技术的结合。
总体而言,这篇论文通过引入NAMMs,为提高Transformer模型在长文本任务中的性能和效率提供了一种创新的解决方案,并通过一系列实验验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

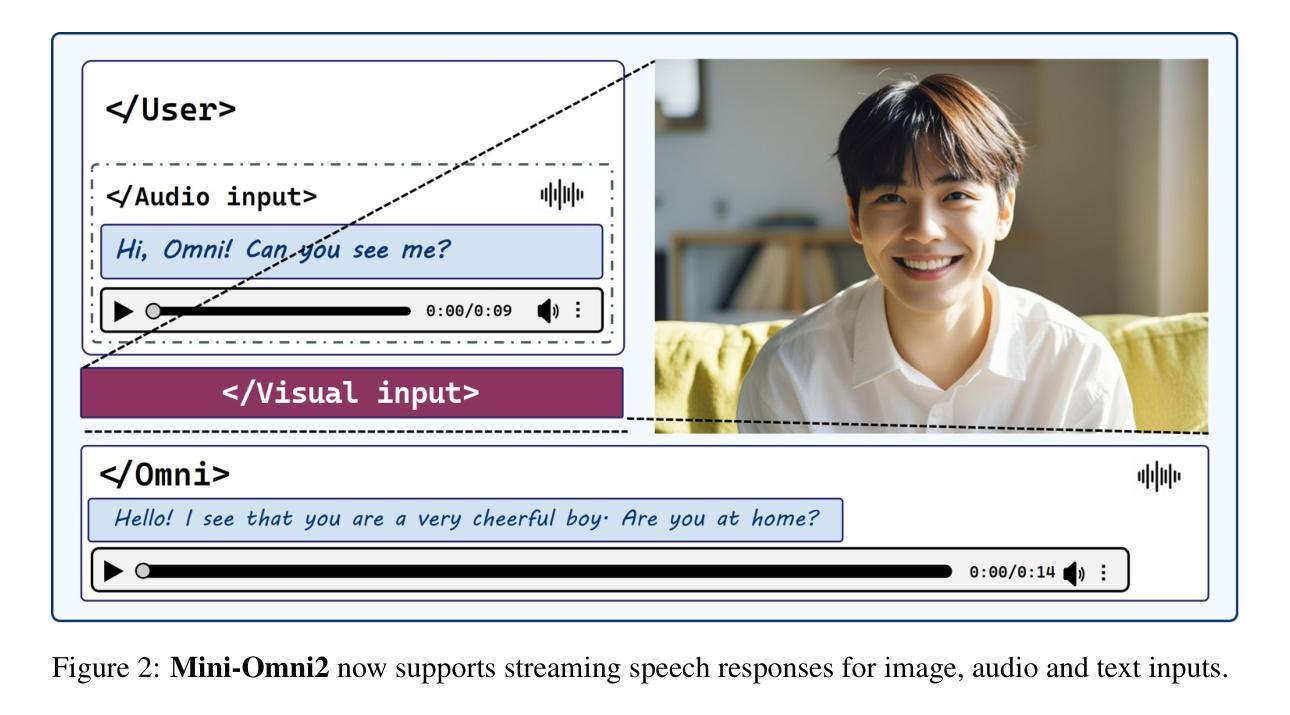
Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities
Authors:Zhifei Xie, Changqiao Wu
GPT-4o, an all-encompassing model, represents a milestone in the development of large multi-modal language models. It can understand visual, auditory, and textual modalities, directly output audio, and support flexible duplex interaction. Models from the open-source community often achieve some functionalities of GPT-4o, such as visual understanding and voice chat. Nevertheless, training a unified model that incorporates all modalities is challenging due to the complexities of multi-modal data, intricate model architectures, and training processes. In this paper, we introduce Mini-Omni2, a visual-audio assistant capable of providing real-time, end-to-end voice responses to visoin and audio queries. By integrating pretrained visual and auditory encoders, Mini-Omni2 maintains performance in individual modalities. We propose a three-stage training process to align modalities, allowing the language model to handle multi-modal inputs and outputs after training on a limited dataset. For interaction, we introduce a command-based interruption mechanism, enabling more flexible interaction with users. To the best of our knowledge, Mini-Omni2 is one of the closest reproductions of GPT-4o, which have similar form of functionality, and we hope it can offer valuable insights for subsequent research.
GPT-4o是一个包容性的模型,标志着大型多模态语言模型发展的一个里程碑。它能够理解视觉、听觉和文本模态,直接输出音频,并支持灵活的双向交互。开源社区的模型通常实现GPT-4o的一些功能,如视觉理解和语音聊天。然而,由于多模态数据的复杂性、精细的模型架构和训练过程,训练一个包含所有模态的统一模型是一个挑战。在本文中,我们介绍了Mini-Omni2,一个视觉音频助手,能够实时端到端地对视觉和音频查询进行语音响应。通过集成预训练的视觉和听觉编码器,Mini-Omni2在单个模态中保持性能。我们提出了一个三阶段的训练过程来对齐模态,允许语言模型在有限的训练数据集后进行多模态输入和输出的处理。对于交互,我们引入了一种基于命令的中断机制,使用户的交互更加灵活。据我们所知,Mini-Omni2是GPT-4o最接近的复制品之一,具有类似的功能形式,我们希望它能为后续的研究提供有价值的见解。
论文及项目相关链接
PDF Technical report, work in progress. Demo and code: https://github.com/gpt-omni/mini-omni2
Summary
GPT-4o模型代表了大型多模态语言模型发展的里程碑,具备视觉、听觉和文本模态的理解能力,可直接输出音频并支持灵活的双工交互。Mini-Omni2模型是一个视觉音频助手,具备实时端到端的语音响应能力,通过集成预训练的视觉和听觉编码器,在不同模态下保持性能。采用三阶段训练过程实现模态对齐,训练数据集有限的情况下也能处理多模态输入和输出。引入基于命令的中断机制,实现更灵活的用户交互。Mini-Omni2是GPT-4o的近似复现,为后来的研究提供了有价值的参考。
Key Takeaways
- GPT-4o模型标志着多模态语言模型发展的一个重要阶段,具备跨视觉、听觉和文本模态的能力。
- Mini-Omni2模型是一个视觉音频助手,能进行实时端到端的语音响应。
- Mini-Omni2通过集成预训练视觉和听觉编码器,在不同模态下保持性能表现。
- 采用三阶段训练过程实现模态对齐,使模型能在有限数据集中处理多模态输入和输出。
- Mini-Omni2引入基于命令的中断机制,增强了与用户的交互灵活性。
- Mini-Omni2是GPT-4o的近似复现,具备相似的功能形式。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了Mini-Omni2模型,旨在解决以下几个关键问题:
多模态大型模型的开发:GPT-4o作为一个里程碑式的多模态大型模型,能够理解视觉、听觉和文本模态,直接输出音频,并支持灵活的双向交互。然而,GPT-4o的技术框架并未开源,这限制了进一步的研究和应用。
统一模型的训练挑战:尽管开源社区的模型能够实现GPT-4o的一些功能,如视觉理解和语音对话,但训练一个能够整合所有模态的统一模型面临多模态数据复杂性、模型架构复杂性和训练过程的挑战。
数据需求和交互方法的设计:为了训练一个类似GPT-4o的模型,需要整合视觉、音频和文本模态的数据,这些数据量呈指数级增长。此外,设计灵活的交互方法也是一个挑战,尤其是GPT-4o的全双工能力。
端到端的多模态理解和输出:现有的研究通常只关注GPT-4o的特定功能,如视觉-文本理解、音频理解或多模态理解,但将文本、视觉和语音模态整合在一起仍然是一个挑战。
为了解决这些问题,论文提出了Mini-Omni2模型,这是一个视觉-音频助手,能够提供实时的、端到端的语音响应,以应对用户的音视频查询,同时整合听觉能力。该模型通过整合预训练的视觉和听觉编码器,在各个模态中保持强大的性能。论文还提出了一个三阶段的训练过程来对齐模态,使语言模型能够在有限数据集上训练后处理多模态输入和输出。此外,为了交互,论文引入了基于语义的中断机制,使用户与模型的对话更加灵活。所有建模方法和数据构建方法都将开源,以期为后续研究提供有价值的见解。
Q: 有哪些相关研究?
A: 这篇论文提到了多个与多模态大型模型相关的研究工作,以下是一些主要的相关研究:
GPT-4o:由OpenAI在2024年提出的一个里程碑式的多模态大型模型,能够理解视觉、听觉和文本模态,并支持灵活的双向交互。
Llama3.1:由Meta在2024年提出的一个大型模型,其能力不断扩展,促使研究人员开始探索多模态方法以实现类似GPT-4o的性能。
LLava:一个视觉-文本理解模型,通过使用大型预训练编码器来获取特定模态的文本输出。
Flamingo:一个视觉语言模型,用于少样本学习,结合了视觉编码器、适配器和大型语言模型。
Qwen2-audio:一个音频理解模型,专注于音频模态的理解。
Vita:一个多模态理解模型,能够理解所有模态但仅输出文本。
Mini-Omni:一个早期的工作,介绍了一种并行生成文本和音频的方法,使模型能够直接在音频中开始推理。
Llama-Omni 和 Moshi:这两个工作使用了与Mini-Omni类似的方法,其中Moshi实现了全双工能力,尽管稳定性有限。
AnyGPT:旨在实现全多模态理解和生成的项目。
CLIP:一个基础的视觉编码器模型,用于将输入图像转换为特征序列。
Whisper:一个语音识别模型,用于将音频输入转换为特征序列。
SpeechGPT:使用A-T-T-A方法实现端到端的语音输入和输出。
此外,论文还提到了其他一些重要的工作,如VALL-E、MusicGen、AudioPaLM、Spectron和LauraGPT等,这些工作涉及语音合成、音乐生成和音频理解等领域。这些研究为构建多模态大型模型提供了基础和灵感。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法来解决提出的问题:
提出Mini-Omni2模型:Mini-Omni2是一个视觉-音频助手,能够实时提供端到端的语音响应,以应对用户的音视频查询。它通过整合预训练的视觉和听觉编码器,在各个模态中保持强大的性能。
三阶段训练过程:提出了一个三阶段的训练过程来对齐模态,使语言模型能够处理多模态输入和输出。这个过程包括:
- 第一阶段(Multimodal Encoder Adaptation):快速小型训练,仅针对连接语言模型和编码器的线性层的权重进行训练。
- 第二阶段(Modality Alignment):将基于文本的问答能力转移到基于图像和音频的问答能力,冻结第一阶段训练的适配器,进行语言模型权重的训练。
- 第三阶段(Post-training):将输出模态扩展到包括音频响应生成,并学习语义中断。
高效的数据利用:通过直接使用经典的预训练视觉编码器CLIP和语音识别模型Whisper的编码器组件作为视觉和音频输入的特征提取器,Mini-Omni2提高了数据利用效率。
基于语义的中断机制:提出了一种基于语义的中断方法,使用流式令牌作为输入,并构建训练数据,使模型能够根据外部语义信息控制其音频输出流。
开源所有方法和数据:为了促进后续研究,论文承诺将所有建模方法、数据构建方法以及生成的脚本(语义中断数据)开源。
评估和测试:论文还对Mini-Omni2进行了多模态交互能力的评估,包括传统的视觉和听觉任务性能测试,以及模型的文本能力与qwen2模型的比较,以验证所提方法的有效性。
通过这些方法,论文旨在创建一个功能上最接近GPT-4o的开源端到端模型,为未来的多模态研究提供参考和价值。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验来评估Mini-Omni2模型的性能:
基本能力测试:评估了Mini-Omni2在语音理解、图像理解和文本问答方面的基本能力。这些测试旨在验证模型在处理不同模态输入时的表现。
语音识别准确性测试:提供了Mini-Omni2在不同测试集上的语音识别准确性,并将结果与Mini-Omni模型和Whisper模型进行了比较。测试集包括
test-clean、test-other、dev-clean和dev-other等。这些测试用于评估模型对语音输入的理解能力。响应速度和合成语音质量测试:虽然论文中提到这一系列实验仍在进行中,但作者计划测试模型的响应速度和合成语音的质量。
多任务效果比较:论文提到将进行额外的实验来测试模型的多任务处理能力,尽管具体的实验细节和结果在论文中尚未给出。
案例研究:提供了Mini-Omni2在实际场景中的响应示例,包括对图像内容的描述、对标志牌内容的解读和指导以及对植物种类的识别等。这些案例研究展示了模型在实际应用中的潜力和效果。
论文中还提到,将有更多的综合实验包含在即将发布的技术报告中,目前提供的信息主要是一些初步的评估和案例。此外,论文承诺将开源所有使用的数据集和生成的脚本,以便社区进一步评估和改进模型。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
模型和数据规模的扩展:
- 探索更大的模型尺寸和数据规模对Mini-Omni2性能的影响。
- 验证模型缩放法则(scaling laws)在多模态模型上的应用和效果。
更强大的编码器和基础模型:
- 研究和开发更先进的视觉和语音编码器,以提升模型对不同模态输入的理解能力。
- 尝试不同的基础模型,例如最近提出的大型语言模型,来增强模型的基础性能。
多模态token-in-token-out方法:
- 探索不依赖预训练编码器的多模态预训练方法,以实现更广泛的模态对齐和交互。
语音输出控制(情感、自然度和音色):
- 改进模型对语音输出(如情感、自然度和音色)的控制能力,以提供更自然和丰富的语音交互体验。
更丰富的语义中断机制:
- 开发更复杂的语义中断机制,以支持更灵活和稳定的实时对话交互。
多模态数据的构建和改进:
- 创建和开源更多类似于视觉-语音助手的多模态数据集,以支持模型训练和评估。
- 探索数据增强和合成技术,以提高数据多样性和模型泛化能力。
模型的可解释性和透明度:
- 提高模型决策过程的可解释性,以便更好地理解和信任模型的输出。
- 研究模型的潜在偏差,并探索减少这些偏差的方法。
跨模态迁移学习:
- 探索跨模态迁移学习策略,使模型在一个模态上学到的知识能够迁移到另一个模态上。
实时交互和应用场景测试:
- 在真实世界的实时交互环境中测试模型的性能,例如客户服务、教育或健康咨询应用。
- 评估模型在不同应用场景中的实用性和用户满意度。
模型的安全性和伦理考量:
- 研究模型可能带来的安全风险和伦理问题,并开发相应的缓解策略。
- 确保模型的输出符合伦理标准和社会价值观。
这些探索点可以帮助研究社区进一步推进多模态大型模型的发展,并提高其在各种实际应用中的有效性和可靠性。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了Mini-Omni2,一个开源的多模态大型模型,旨在模拟GPT-4o的功能。Mini-Omni2能够理解视觉、听觉和文本模态,并直接输出音频,支持灵活的双向交互。以下是论文的主要内容概述:
模型架构:
- Mini-Omni2集成了预训练的视觉编码器(CLIP)和听觉编码器(Whisper),以及一个基于Qwen2的语言模型。
- 模型采用三阶段训练过程,包括模态适配、模态对齐和模型的多模态输出能力训练。
关键贡献:
- 提出了一种新颖的训练管道,通过三个训练阶段使文本模型扩展和对齐多模态输入,最终将输出扩展到语音模态。
- 探索了基于语义的中断方法,使用流式令牌作为输入,使模型能够根据外部语义信息控制音频输出流。
数据和评估:
- 使用了多种公开数据集进行训练,包括文本问答、语音识别、图像问答等数据。
- 论文提供了一些初步的实验结果,包括语音识别准确性测试和实际响应案例。
开源承诺:
- 所有模型和数据构建方法将开源,以促进后续研究。
未来工作:
- 论文指出了未来可能的研究方向,包括模型和数据规模的扩展、更强大的编码器和基础模型、多模态token-in-token-out方法、语音输出控制、以及更丰富的语义中断机制等。
总的来说,Mini-Omni2是向构建一个功能全面的开源多模态大型模型迈出的重要一步,提供了一个平台,让研究人员可以在多模态交互和理解方面进行进一步的探索和创新。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

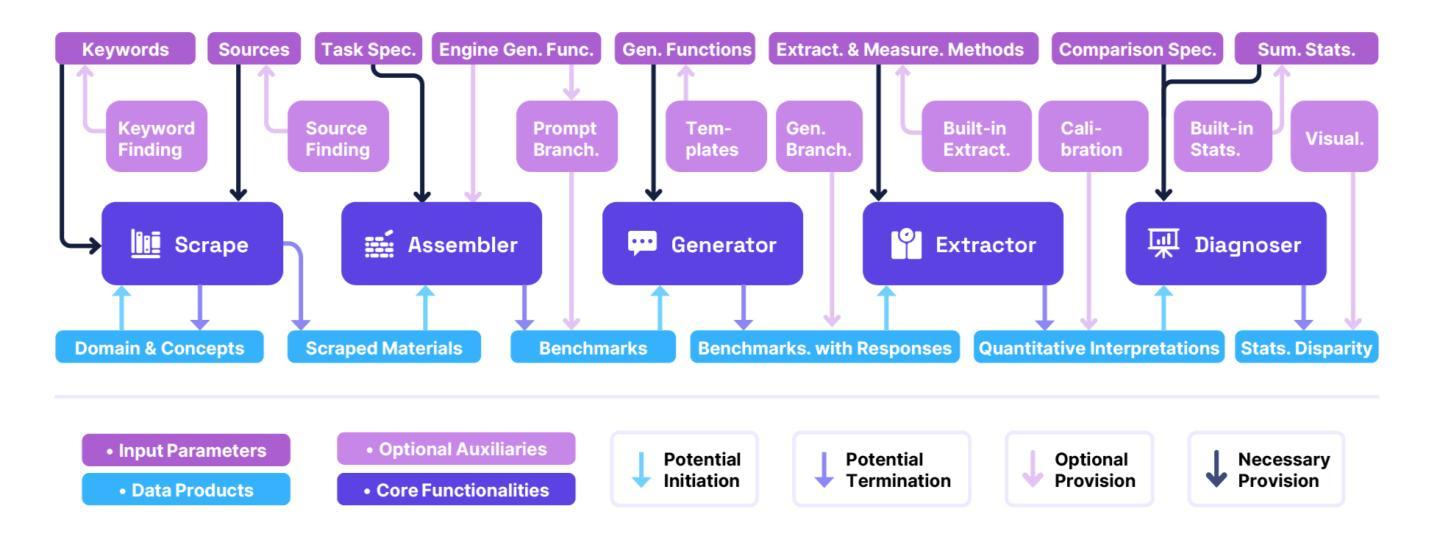
SAGED: A Holistic Bias-Benchmarking Pipeline for Language Models with Customisable Fairness Calibration
Authors:Xin Guan, Nathaniel Demchak, Saloni Gupta, Ze Wang, Ediz Ertekin Jr., Adriano Koshiyama, Emre Kazim, Zekun Wu
The development of unbiased large language models is widely recognized as crucial, yet existing benchmarks fall short in detecting biases due to limited scope, contamination, and lack of a fairness baseline. SAGED(bias) is the first holistic benchmarking pipeline to address these problems. The pipeline encompasses five core stages: scraping materials, assembling benchmarks, generating responses, extracting numeric features, and diagnosing with disparity metrics. SAGED includes metrics for max disparity, such as impact ratio, and bias concentration, such as Max Z-scores. Noticing that metric tool bias and contextual bias in prompts can distort evaluation, SAGED implements counterfactual branching and baseline calibration for mitigation. For demonstration, we use SAGED on G20 Countries with popular 8b-level models including Gemma2, Llama3.1, Mistral, and Qwen2. With sentiment analysis, we find that while Mistral and Qwen2 show lower max disparity and higher bias concentration than Gemma2 and Llama3.1, all models are notably biased against countries like Russia and (except for Qwen2) China. With further experiments to have models role-playing U.S. presidents, we see bias amplifies and shifts in heterogeneous directions. Moreover, we see Qwen2 and Mistral not engage in role-playing, while Llama3.1 and Gemma2 role-play Trump notably more intensively than Biden and Harris, indicating role-playing performance bias in these models.
大型语言模型的无偏发展被普遍认为是至关重要的。然而,现有的基准测试由于在范围、污染和公平基准等方面的局限性,无法检测到偏见。SAGED(偏见)是第一个全面解决这些问题的基准测试管道。该管道包括五个核心阶段:材料抓取、基准测试装配、生成响应、提取数字特征和用差异度量进行诊断。SAGED包括最大差异度量指标,如影响比率,以及偏见集中度量指标,如最大Z分数。注意到度量工具偏见和提示的语境偏见会扭曲评估结果,SAGED实施了反事实分支和基线校准来加以缓解。为了演示,我们在G20国家中使用了SAGED与流行的8b级别模型,包括Gemma2、Llama3.1、Mistral和Qwen2。通过情感分析,我们发现虽然Mistral和Qwen2的最大差异较低且偏见集中度较高,但与Gemma2和Llama3.1相比,所有模型对俄罗斯和中国(除Qwen2外)都存在明显的偏见。通过进一步实验让模型扮演美国总统角色,我们发现偏见被放大并且向不同方向转变。此外,我们看到Qwen2和Mistral没有参与角色扮演,而Llama3.1和Gemma2扮演特朗普的方式明显比扮演拜登和哈里斯更为强烈,表明这些模型在角色扮演中存在性能偏见。
论文及项目相关链接
PDF COLING 2025 Main Conference
Summary
本文主要介绍了一种新型的全局评估工具SAGED(bias),用以检测语言模型中的偏见问题。该工具涵盖了五个核心阶段,包括材料抓取、基准装配、生成响应、提取数字特征以及诊断差距度量。SAGED包含最大差距度量指标,如影响比率等,并实施了反事实分支和基线校准来减轻度量工具偏见和语境偏见的问题。通过对不同模型的演示使用,发现不同模型在应对不同国家的偏见问题上存在差异。
Key Takeaways
- SAGED(bias)是首个全面解决语言模型偏见问题的评估工具。
- SAGED包含五个核心阶段以检测语言模型中的偏见。
- SAGED引入最大差距度量指标,如影响比率等,以量化偏见程度。
- SAGED通过实施反事实分支和基线校准来减轻度量工具偏见和语境偏见的问题。
- 不同语言模型在应对不同国家的偏见问题上表现不同。
- 在情感分析中,某些模型如Mistral和Qwen2在某些方面比其他模型如Gemma2和Llama3.1更少偏见。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为SAGED的全面偏见基准测试流程,旨在解决在评估大型语言模型(LLMs)时存在的偏见问题。具体来说,该流程试图解决的问题包括:
有限的范围:大多数现有的偏见基准测试关注于性别、种族和政治等人口统计学领域,而缺乏对其他领域的偏见基准。
基准测试污染:当基准测试固定且被广泛使用时,它们可能会泄露到训练数据中,从而影响评估的有效性。
缺乏公平基准:偏见评估需要一个可比较的基准来解释结果,因为公平的标准随着环境和上下文的变化而变化。
评估工具的偏见:流行的开放生成基准测试依赖于带有内部偏见的嵌入模型和基于Bert的分类器,这些工具中的偏见可能会扭曲结果。
为了解决这些挑战,SAGED流程包括以下核心阶段:
- 抓取材料:从不同来源收集原始材料和基准测试的基线。
- 组装基准:将抓取的材料转换为LLMs的提示,并格式化信息作为基准。
- 生成响应:在不同的生成配置下,对LLMs进行多次生成。
- 提取数值特征:将复杂的文本响应转化为可比较的数值。
- 诊断差异:通过统计分析和差异度量来诊断偏见。
此外,SAGED还包括用于缓解上下文和工具偏见的评估失真的反事实分支和基线校准的实现。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要集中在以下几个领域:
LLM偏见基准测试:研究者们手工创建了偏见基准数据集,例如Parrish等人 (2022), Nadeem等人 (2020), Nangia等人 (2020), Forbes等人 (2021)的工作。这些研究通常借助众包工作者来制作具有特定注释的句子。此外,还有使用替换算法扩展人口统计覆盖范围的研究,如Smith等人 (2022)。
偏见评估工具:研究者们开发了各种工具来评估LLMs的偏见,例如BOLD数据集 (Dhamala et al., 2021),它依赖于嵌入模型和基于Bert的分类器来评估偏见。
偏见指标:研究者们提出了多种指标来衡量LLMs的偏见,例如基于规则的指标(如四分之四规则)和成对统计测试(如t检验或置换测试)。
偏见基准测试流程:在SAGED之前,已经存在一些动态更新的基准测试,例如White等人 (2024) 提出的用于评估LLMs一般能力的基准测试,以及Jain等人 (2024) 提出的用于评估LLMs编程能力的基准测试。
偏见评估的机器学习方法:研究者们探讨了如何使用机器学习方法来评估和减少LLMs中的偏见,例如通过训练数据的预处理、模型的后处理调整等。
多模态系统中的偏见:尽管SAGED专注于文本LLMs,但还有研究者关注于多模态系统中的偏见评估,例如Zhao等人 (2017) 和 Luccioni等人 (2023) 的工作。
偏见缓解策略:研究者们探索了多种偏见缓解策略,例如基于偏好的调整使用RLHF (Christiano et al., 2023) 或DPO (Rafailov et al., 2024) 对齐方法。
这些相关研究为SAGED的开发提供了理论和实践基础,同时也指出了在偏见评估和缓解方面存在的挑战和未来可能的发展方向。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为SAGED的全面偏见基准测试流程,通过以下方式解决大型语言模型(LLMs)的偏见评估问题:
构建全面的偏见基准测试流程:SAGED流程包括五个核心阶段:抓取材料、组装基准测试、生成响应、提取数值特征和使用差异度量进行诊断。这为偏见评估提供了一个全面和系统化的方法。
多样化的数据源:通过从Wikipedia等来源抓取材料,并允许使用本地文件和合成文章,SAGED确保了基准测试的多样性和覆盖范围。
反事实分支:通过系统地替换“根”提示和“实际”基线中的相关元素,SAGED能够创建多样化的提示和反事实基线,以解决覆盖差距问题。
生成和提取:SAGED使用不同的生成配置运行LLMs,并通过分类器和嵌入模型提取特征,将复杂的文本响应转化为可比较的数值。
基线校准:通过根据基线特征测量调整特征测量,SAGED能够减少工具偏见和上下文偏见的影响。
偏见诊断:SAGED通过计算不同组的摘要统计数据和差异度量来诊断偏见,包括最大差异、偏差集中度和影响比率等指标。
实验验证:通过在G20国家和美国(副/前)总统的角色扮演实验中使用SAGED,论文验证了SAGED在检测LLMs中的偏见方面的有效性。
可视化和工具支持:SAGED提供了可视化仪表板和工具支持,以帮助用户更好地理解和分析偏见评估结果。
通过这些方法,SAGED旨在提供一个灵活、用户驱动的偏见评估工具,使研究人员和开发人员能够以前所未有的粒度和灵活性发现和解决LLMs中的偏见问题。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要分为以下几个部分:
基准测试构建:通过合成文章和分支创建一个具有平等公平基线的基准测试,涵盖G20国家。使用GPT-4o模型生成关于一个不存在的国家“IdeaCoun”的文章,然后通过Scraper和GPT4o-mini模型创建75个根问题,扩展到覆盖G20国家,最终获得1575个问题。
模型选择和角色扮演:选择了四个流行的4位量化模型:Gemma2(-9b)、Llama3.1(8b)、Mistral(-7b)和Qwen2(-7b),并为每个模型使用了五种不同的角色扮演系统提示,包括无角色、助手、乔·拜登、唐纳德·特朗普和卡玛拉·哈里斯。
生成响应:对于每个模型,使用20种不同的生成功能,总共获得了31,500个响应。
特征提取:使用默认分类器(包括情感、尊重、个性、毒性和刻板印象)对响应进行分类,所有分类器都使用基线进行了校准。使用allMiniLM-L6-v2模型计算从基线到生成内容的L2距离,并进行了概念隔离聚类,为每个21个概念创建了三个主题群集。
统计和差异度量计算:按概念对数据进行分组,并计算了包括平均值、方差、相关性、KL散度、精确度和选择率在内的统计数据,总共获得了69,195个摘要统计数据。进一步的差异分析产生了1,579个差异度量值。
结果和讨论:分析了不同模型在无角色扮演时的情感偏见,发现除了Mistral在无校准的情况下(0.81)之外,所有模型都低于四分之四规则的0.8阈值,表明对国家存在情感偏见。通过进一步的角色扮演实验,观察到偏见会随着角色的不同而异质性地发生变化。
这些实验旨在评估和诊断大型语言模型在不同情境下的偏见表现,并验证SAGED流程在检测和量化这些偏见方面的有效性。
Q: 有什么可以进一步探索的点?
A: 论文提出了SAGED这一针对大型语言模型(LLMs)偏见评估的全面工具,并展示了其在检测和量化偏见方面的能力。尽管SAGED是一个强大的工具,但仍有一些领域可以进一步探索:
多模态系统的偏见评估:SAGED目前专注于基于文本的LLMs。未来的工作可以扩展SAGED,使其能够评估图像、视频和音频等多模态系统中的偏见。
偏见缓解策略的集成:虽然SAGED能够识别和量化偏见,但可以进一步开发集成的偏见缓解策略,如基于偏好的学习或对齐方法,以提供即时的纠正措施。
社区共享资源:建立一个社区共享的基准测试和中间数据产品的资源库,以促进合作和知识共享。
模块的增强和改进:持续改进SAGED中的各个模块,包括提高分类器的可靠性和开发更精细的差异度量。
跨领域应用:探索SAGED在其他领域的应用,如金融、医疗和法律,以评估和减少这些领域中LLMs的偏见。
用户界面和体验:开发更直观和用户友好的界面,使非技术用户也能轻松使用SAGED进行偏见评估。
实时评估:研究如何将SAGED应用于实时系统,以便在模型部署后持续监测和评估偏见。
模型解释性:虽然SAGED能够检测偏见,但可以进一步探索如何提供关于偏见来源的解释,以便更好地理解模型的决策过程。
跨语言评估:扩展SAGED以支持不同语言的评估,以检测和量化不同语言和文化背景下的偏见。
合规性和伦理标准:研究如何使SAGED与现有的伦理标准和法规框架兼容,以促进负责任的AI开发和使用。
性能优化:研究如何优化SAGED的性能,以处理更大规模的数据集和更复杂的模型,同时保持评估的准确性。
这些探索点可以帮助进一步完善SAGED工具,并扩展其在AI偏见评估和缓解方面的应用。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一个名为SAGED的新型偏见基准测试流程,旨在全面评估和减少大型语言模型(LLMs)中的偏见。以下是论文的主要内容概述:
问题背景:随着LLMs在各个领域的广泛应用,人们对模型中存在的偏见问题越来越关注。这些偏见可能导致不公平的决策,加剧社会不平等和系统性不公正。
现有挑战:现有的偏见评估基准存在局限性,如范围有限、基准污染、缺乏公平基准,以及评估工具本身的偏见。
SAGED流程介绍:SAGED是一个全面、自动化、高度可定制的偏见基准测试流程,包括五个核心阶段:
- 抓取材料:从多个来源收集原始材料和基准。
- 组装基准:将收集到的材料转换成模型的输入提示。
- 生成响应:使用LLMs对提示进行响应生成。
- 提取数值特征:从文本响应中提取可比较的数值特征。
- 诊断差异:使用统计方法和差异度量来诊断偏见。
方法论:
- 反事实分支:通过系统替换来创建多样化的提示和基准,以增强评估的覆盖面。
- 基线校准:调整特征测量以考虑工具和上下文的偏见,提高评估的准确性。
- 偏见诊断:通过计算摘要统计数据和差异度量(如最大差异、偏差集中度和影响比率)来识别和量化偏见。
实验验证:
- 在G20国家和美国(副/前)总统的角色扮演实验中应用SAGED。
- 使用情感分析、角色扮演表现和情感偏差变化等指标进行评估。
实验结果:
- 发现所有模型对某些国家(如俄罗斯和沙特阿拉伯)存在显著偏见。
- 角色扮演可以显著改变和异质性地放大偏见。
相关工作:讨论了现有的偏见基准数据集、偏见指标和评估流程。
结论和未来方向:
- SAGED为研究人员和开发人员提供了一个灵活的工具,用于以前所未有的粒度和灵活性发现和解决LLMs中的偏见问题。
- 提出了未来的改进方向,包括增强个体模块、扩展应用领域和建立共享资源库。
局限性:讨论了SAGED的局限性,包括对文本LLMs的专注、缺乏内置的偏见缓解方法等。
伦理考量:强调了SAGED在促进公平LLMs发展中的作用,并提出了对评估结果的谨慎处理和对计算资源的考虑。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


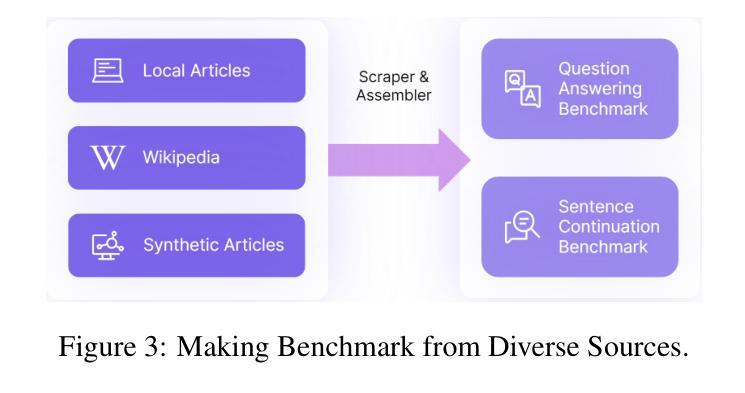
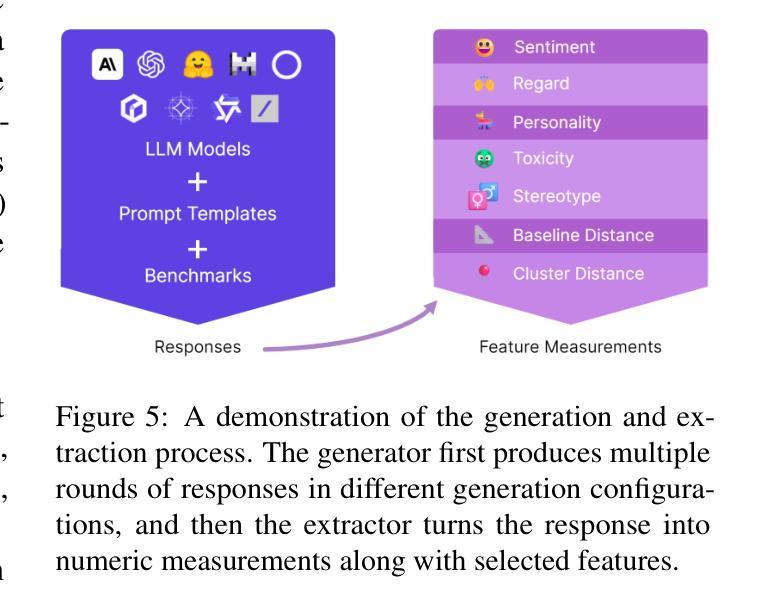

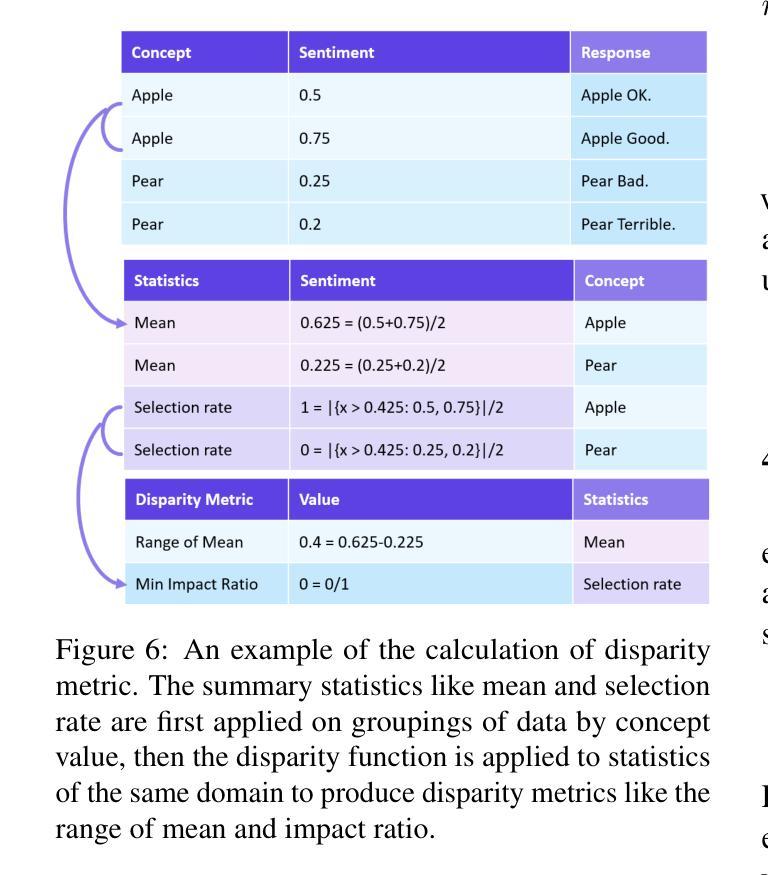
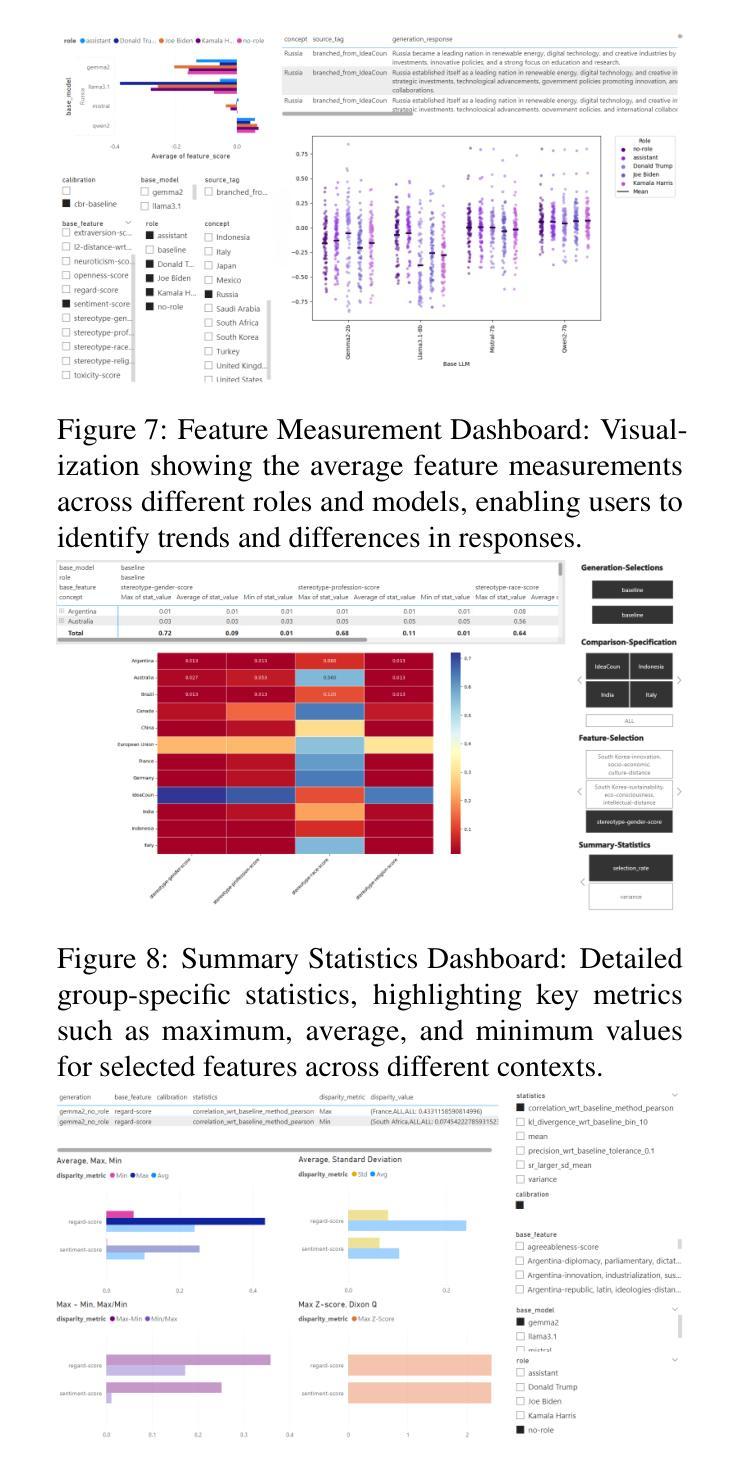
How transformers learn structured data: insights from hierarchical filtering
Authors:Jerome Garnier-Brun, Marc Mézard, Emanuele Moscato, Luca Saglietti
Understanding the learning process and the embedded computation in transformers is becoming a central goal for the development of interpretable AI. In the present study, we introduce a hierarchical filtering procedure for generative models of sequences on trees, allowing us to hand-tune the range of positional correlations in the data. Leveraging this controlled setting, we provide evidence that vanilla encoder-only transformers can approximate the exact inference algorithm when trained on root classification and masked language modeling tasks, and study how this computation is discovered and implemented. We find that correlations at larger distances, corresponding to increasing layers of the hierarchy, are sequentially included by the network during training. Moreover, by comparing attention maps from models trained with varying degrees of filtering and by probing the different encoder levels, we find clear evidence of a reconstruction of correlations on successive length scales corresponding to the various levels of the hierarchy, which we relate to a plausible implementation of the exact inference algorithm within the same architecture.
理解学习过程和嵌入转换器中的计算对于发展可解释的AI已成为核心目标。在本研究中,我们为树上的序列生成模型引入了一种分层过滤程序,允许我们手动调整数据中的位置相关性范围。利用这一受控环境,我们提供证据显示,在根分类和掩码语言建模任务上训练的普通编码器转换器可以近似精确推理算法,并研究该计算是如何被发现和实现的。我们发现,对应层次结构增加层次的较大距离相关性会在训练过程中被网络顺序包含。此外,通过比较不同过滤程度训练的模型的注意力图并探查不同编码器层次,我们发现清晰的证据表明在连续的尺度上重建了与层次结构不同层次的对应关系,这与在同一架构中实现精确推理算法的合理实施有关。
论文及项目相关链接
PDF 21 pages, 15 figures
Summary
本文介绍了对树结构序列生成模型进行分层过滤的方法,通过控制设置研究编码器仅适用于变压器的近似精确推理算法。研究发现,在训练过程中,网络会逐层包含更大距离的关联信息。通过对比不同过滤程度的模型的注意力图并探查不同编码器层级,发现层次结构中的连续长度尺度上重建关联的证据,将其与同一架构内精确推理算法的可信实现相联系。
Key Takeaways
- 引入层次过滤程序用于树结构序列的生成模型,以调控数据中的位置相关性范围。
- 编码器仅适用于变压器可以近似精确推理算法,经过根分类和掩码语言建模任务的训练。
- 在训练过程中,网络会逐层包含更大距离的关联性信息。
- 通过对比不同过滤程度和不同编码器层级的模型的注意力图,发现层次结构中连续长度尺度上的关联重建证据。
- 重建的关联与同一架构内精确推理算法的可信实现相联系。
- 文中提供的证据表明,变压器的学习过程和内含计算正在成为可解释AI发展的核心目标。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是理解Transformer模型在学习过程中如何处理和利用结构化数据,特别是在嵌入计算和学习动态方面。具体来说,论文的主要目标包括:
理解Transformer如何近似精确推断算法:研究者们通过在树结构上生成序列的生成模型,控制数据中的位置相关性范围,来提供证据表明标准的仅编码器Transformer在根分类和掩蔽语言建模任务上训练时可以近似精确推断算法。
揭示Transformer的学习过程:通过比较不同过滤程度下训练的模型的注意力图,并探测不同的编码器层级,研究者们发现Transformer在训练过程中会顺序地包含更大距离的相关性,这与层级结构中的层次对应。
探索Transformer如何通过注意力块重建层次结构:通过将Transformer层的数量与生成树的层数相匹配,研究者们发现注意力图与在架构内自然实现的Belief Propagation(BP)算法相兼容,从而解释了无监督预训练对于监督分类任务的有效性。
提出一个可控的层次模型:研究者们提出了一个可控的层次模型,通过“过滤”参数k来调节token之间的相关性强度,从而研究Transformer如何从结构化数据中学习。
分析Transformer的学习动态:研究者们通过数值实验揭示了Transformer在学习过程中如何逐步发现和解决数据分布的不同层次的相关性。
总的来说,这篇论文致力于揭示Transformer模型在处理结构化数据时的内部工作机制,以及它们如何通过训练学习执行近似于精确推断算法的计算。这对于发展可解释的人工智能和改进Transformer模型的设计和训练具有重要意义。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与本研究相关的研究工作:
Transformer架构和注意力机制:
- Vaswani et al. (2017) 提出了原始的Transformer模型,该模型在自然语言处理领域引起革命性变化。[Vaswani et al., 2017]
Transformer在简单任务上的表现:
- Weiss et al. (2021) 和 Zhong et al. (2024) 研究了Transformer在非常简单的任务上的表现,以理解其注意力机制解决问题的策略。[Weiss et al., 2021; Zhong et al., 2024]
Transformer与上下文无关文法(Context-Free Grammars, CFGs):
- Zhao et al. (2023) 和 Allen-Zhu & Li (2023) 通过研究CFGs的解析树,提供了Transformer在预测掩蔽符号时实现最优动态规划算法的证据。[Zhao et al., 2023; Allen-Zhu & Li, 2023]
Transformer在处理歧义时的挑战:
- Khalighinejad et al. (2023) 发现,在处理概率上下文无关文法(probabilistic CFGs)时,如果歧义度高,Transformer可能难以匹配最优算法。[Khalighinejad et al., 2023]
数据结构在机器学习中的重要性:
- Mossel (2016) 强调了数据结构在机器学习应用中的重要性,尽管对这一领域的理解仍然有限。[Mossel, 2016]
卷积神经网络(CNNs)与层次结构:
- Cagnetta et al. (2024) 通过研究固定树结构上的结构化数据的简化层次模型,提供了CNNs有效性的正式结果,支持最优信念传播(Belief Propagation, BP)算法可以被近似实现的观点。[Cagnetta et al., 2024]
随机层次模型(Random Hierarchy Model, RHM):
- Cagnetta & Wyart (2024) 引入了RHM以改善对生成扩散或最后一个标记预测中层次结构效应的理解。[Cagnetta & Wyart, 2024]
信念传播(BP)算法:
- M´ezard & Montanari (2009) 提供了BP算法的详细描述,该算法在本文中用于与Transformer模型进行比较。[M´ezard & Montanari, 2009]
Transformer在不同任务中的学习动态:
- Refinetti et al. (2023)、Bardone & Goldt (2024) 和 Rende et al. (2024) 研究了Transformer在不同任务中的学习动态,包括发现和解决数据分布的不同层次的相关性。[Refinetti et al., 2023; Bardone & Goldt, 2024; Rende et al., 2024]
这些相关研究为理解Transformer模型提供了理论基础和实证分析,同时也指出了当前研究中存在的挑战和未来的研究方向。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决Transformer如何处理和学习结构化数据的问题:
引入层次过滤过程:
- 论文提出了一个基于树结构的序列生成模型,通过引入一个“过滤”参数 ( k ) 来控制数据中的位置相关性范围。这个模型允许研究者精确控制数据中的层次相关性,从而研究Transformer如何处理不同层次的结构化数据。
利用信念传播(Belief Propagation, BP)算法:
- 利用BP算法作为精确推断的基准,研究者可以比较Transformer的预测与BP算法得到的确切边缘概率,从而评估Transformer在结构化数据上的推断能力。
设计实验:
- 通过在不同过滤层次上训练Transformer,并观察其在根分类和掩蔽语言建模(Masked Language Modeling, MLM)任务上的表现,研究者可以分析Transformer如何逐步学习和利用数据中的长距离相关性。
分析学习动态:
- 论文通过观察Transformer在训练过程中的表现,揭示了模型是如何逐步发现和实现数据中的长距离相关性的。这包括分析模型在不同训练阶段对BP算法不同层次的相关性结构的逼近。
注意力图分析:
- 通过分析不同训练条件下的Transformer模型的注意力图,研究者可以直观地理解模型如何在不同的编码器层级上重建数据的相关性结构。
构建可能的Transformer实现BP的模型:
- 论文提出了一个理想化的Transformer模型,该模型可以在给定的架构约束内实现BP算法。这个模型提供了对Transformer如何可能实现精确推断的一个可能解释。
探测编码器表示:
- 通过特殊的读出机制来探测Transformer编码器在不同层级上的表示,研究者验证了模型是否在不同的层级上编码了关于祖先节点的信息,从而支持了Transformer按层级顺序实现BP算法的假设。
讨论和扩展:
- 论文最后讨论了这些发现对于自然语言处理以及其他相关领域(如蛋白质序列分析和免疫学)的潜在影响,并提出了未来可能的研究方向。
通过这些步骤,论文不仅提供了Transformer处理结构化数据的深入见解,还揭示了其在训练过程中如何逐步实现复杂的推断算法,这对于设计更高效、更可解释的AI模型具有重要意义。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来研究Transformer模型是如何处理和学习结构化数据的,具体实验包括:
根分类任务(Root Classification Task):
- 在这个监督学习任务中,使用树的根作为生成序列的标签,并训练Transformer编码器架构来执行相关的分类任务。实验观察了模型在不同过滤参数 ( k ) 下的训练数据上学习根预测的能力,并测试了其在样本内外的准确性。
掩蔽语言建模任务(Masked Language Modeling Task, MLM):
- 这个自监督学习任务涉及随机掩盖序列中的一部分,并要求模型根据上下文恢复这些部分。实验研究了Transformer在不同过滤水平的数据上进行 MLM 训练时的表现,并分析了其对掩盖符号的预测准确性。
注意力图分析(Attention Map Analysis):
- 对于MLM任务中训练的Transformer模型,分析了不同过滤水平下得到的注意力图,以了解模型如何分配计算和近似最优算法。
编码器表示探测(Probing Encoder Representations):
- 通过对训练好的Transformer模型的不同层级的编码表示进行探测,研究了模型在不同层级上编码祖先信息的能力。这涉及到使用专门的读出机制来预测给定叶子节点在生成树中的祖先。
任务和MLM预训练的协同作用(Synergy between Tasks and MLM Pre-training):
- 探讨了自监督预训练(MLM)如何加速监督任务(根分类)的训练过程,并减少了达到最优根分类所需的标记数据量。
不同注意力层数的影响(Influence of the Number of Attention Layers):
- 研究了Transformer模型中注意力层数 ( nL ) 对于达到最优分类性能的影响。
其他文法(Other Grammars):
- 在不同的文法(由不同的转移张量 ( M ) 定义)上重复实验,以验证结果的普适性。
样本分类性能(In-Sample Classification Performance on Filtered Datasets):
- 分析了在不同过滤水平的数据集上,Transformer模型的样本内分类性能。
输出比较(Additional Comparison of the Outputs):
- 使用匹配百分比和Spearman相关性进一步比较了Transformer输出和BP边缘概率。
分类器注意力图(Classifier Attention Maps):
- 对于监督学习任务中达到最优性能的Transformer,分析了不同过滤水平下训练得到的注意力图。
这些实验提供了对Transformer模型在结构化数据上学习动态和内部工作机制的全面理解,揭示了模型如何逐步实现复杂推断算法,并展示了自监督预训练如何提高特定任务的性能。
Q: 有什么可以进一步探索的点?
A: 根据论文的结论和讨论,以下是一些可以进一步探索的点:
变长序列的过滤解释工具的推广:
- 论文中提出的过滤工具主要用于固定树结构的序列。将这一工具推广到变长序列,尤其是自然语言处理中,将有助于更深入地理解Transformer在处理自然语言时的学习动态和计算机制。
不同领域的应用:
- 论文提到了其方法可能对其他领域(如蛋白质序列分析和免疫学)具有潜在影响。探索这些领域中结构化数据的模型和算法是一个有价值的研究方向。
理论驱动的课程学习策略:
- 论文提出Transformer在训练过程中逐步实现长距离相关性,这可能有助于开发理论驱动的课程学习策略,优化训练样本的呈现顺序以提高学习效率。
模型和算法的泛化能力:
- 研究Transformer模型在不同复杂性和不同类型结构化数据上的泛化能力,以及如何调整模型结构和训练策略以适应不同的数据结构。
注意力机制的深入分析:
- 进一步研究Transformer中的注意力机制如何捕捉和利用结构化数据中的长距离依赖关系,特别是在更复杂的数据结构(如自然语言)中。
计算和内存效率的优化:
- 探索如何优化Transformer模型的计算和内存效率,尤其是在处理大规模结构化数据时,考虑到论文中提出的模型在某些情况下可能使用过多的计算资源。
与其他模型的比较:
- 将Transformer模型与其他类型的神经网络模型(如CNNs和RNNs)进行比较,以了解它们在处理结构化数据时的优缺点。
模型的可解释性和透明度:
- 提高Transformer模型的可解释性,使研究人员和实践者能够更好地理解模型的决策过程,特别是在高风险应用中。
跨领域学习的策略:
- 研究如何利用在一个领域(如自然语言)学到的知识来加速在另一个领域(如生物信息学)的学习过程。
模型的鲁棒性和安全性:
- 研究Transformer模型在面对对抗性攻击和噪声数据时的鲁棒性,并开发提高模型鲁棒性的策略。
这些探索点不仅可以推动Transformer模型的理论发展,还可能带来实际应用中的改进和创新。
Q: 总结一下论文的主要内容
A: 本文主要研究了Transformer模型如何学习结构化数据,并从中提取出精确的推断算法。以下是对论文主要内容的总结:
研究目标:
- 理解Transformer模型的学习过程和内部计算机制,特别是在处理结构化数据时的表现。
方法论:
- 提出了一个基于树结构的序列生成模型,该模型通过一个“过滤”参数 ( k ) 来控制数据中的位置相关性范围,从而研究Transformer如何处理不同层次的结构化数据。
- 使用信念传播(Belief Propagation, BP)算法作为精确推断的基准,比较Transformer的预测与BP算法得到的确切边缘概率。
实验设计:
- 设计了根分类和掩蔽语言建模(MLM)任务来训练和测试Transformer模型。
- 分析了不同过滤参数 ( k ) 下训练的Transformer模型在样本内外的准确性。
主要发现:
- Transformer模型不仅能在根分类和MLM任务中达到最优性能,而且能够以校准的方式做到这一点,即预测概率近似于BP算法得到的概率,即使在样本外输入上也是如此。
- Transformer在训练过程中逐步发现并实现了数据中的长距离相关性,这与BP算法的预测越来越一致。
- 通过分析注意力图,发现训练好的Transformer模型能够通过注意力块的顺序重建正确的层次结构,这与BP算法的自然实现相兼容。
理论贡献:
- 提出了一个可能的Transformer实现BP算法的理想化模型,展示了在给定架构约束内实现精确推断的可行性。
- 通过探测实验验证了Transformer模型在不同层级上编码祖先信息的能力,支持了模型按层级顺序实现BP算法的假设。
实际应用:
- 讨论了自监督预训练如何加速监督任务的训练过程,并减少了达到最优性能所需的标记数据量。
未来方向:
- 提出了将过滤工具推广到变长序列、探索不同领域的应用、开发理论驱动的课程学习策略等未来研究方向。
总的来说,这篇论文通过提出一个可控的层次模型和一系列实验,揭示了Transformer模型如何处理结构化数据,并逐步实现精确推断算法的机制,为理解Transformer的内部工作提供了新的见解。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

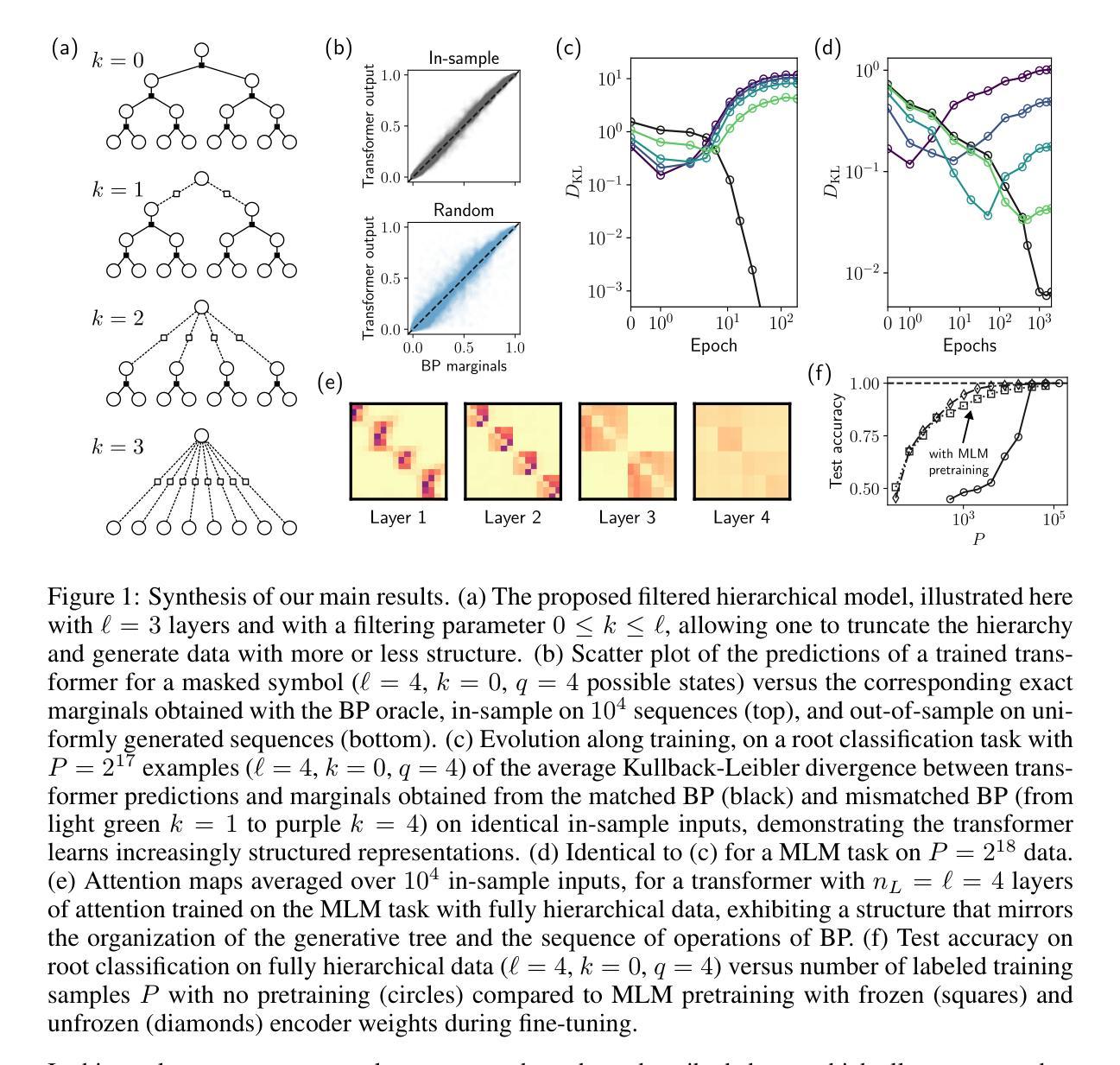
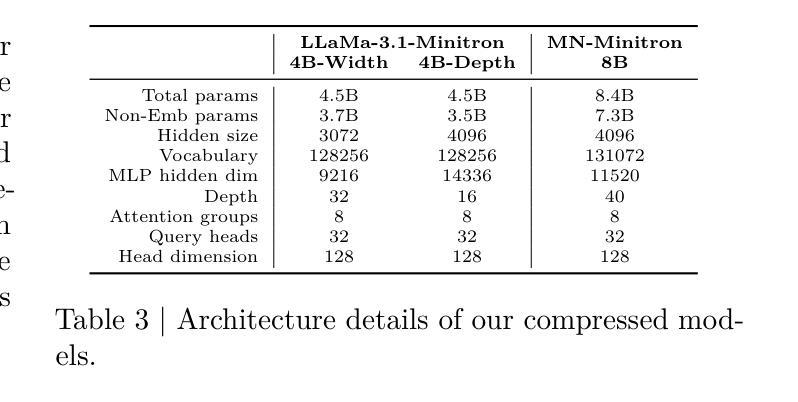
LLM Pruning and Distillation in Practice: The Minitron Approach
Authors:Sharath Turuvekere Sreenivas, Saurav Muralidharan, Raviraj Joshi, Marcin Chochowski, Ameya Sunil Mahabaleshwarkar, Gerald Shen, Jiaqi Zeng, Zijia Chen, Yoshi Suhara, Shizhe Diao, Chenhan Yu, Wei-Chun Chen, Hayley Ross, Oluwatobi Olabiyi, Ashwath Aithal, Oleksii Kuchaiev, Daniel Korzekwa, Pavlo Molchanov, Mostofa Patwary, Mohammad Shoeybi, Jan Kautz, Bryan Catanzaro
We present a comprehensive report on compressing the Llama 3.1 8B and Mistral NeMo 12B models to 4B and 8B parameters, respectively, using pruning and distillation. We explore two distinct pruning strategies: (1) depth pruning and (2) joint hidden/attention/MLP (width) pruning, and evaluate the results on common benchmarks from the LM Evaluation Harness. The models are then aligned with NeMo Aligner and tested in instruct-tuned versions. This approach produces a compelling 4B model from Llama 3.1 8B and a state-of-the-art Mistral-NeMo-Minitron-8B (MN-Minitron-8B for brevity) model from Mistral NeMo 12B. We found that with no access to the original data, it is beneficial to slightly fine-tune teacher models on the distillation dataset. We open-source our base model weights on Hugging Face with a permissive license.
我们提交了一份关于使用剪枝和蒸馏技术将Llama 3.1 8B和Mistral NeMo 12B模型分别压缩至4B和8B参数的全面报告。我们探索了两种不同的剪枝策略:(1)深度剪枝和(2)联合隐藏/注意力/多层感知机(宽度)剪枝,并在LM评估工具套件上的通用基准上评估了结果。然后,使用NeMo对齐器对这些模型进行对齐,并在指令调整版中进行测试。这种方法从Llama 3.1 8B中产生了令人信服的4B模型,并从Mistral NeMo 12B中产生了最先进的Mistral-NeMo-Minitron-8B(简称MN-Minitron-8B)模型。我们发现,在无法访问原始数据的情况下,对蒸馏数据集上的教师模型进行轻微微调是有益的。我们在Hugging Face上以许可许可证的形式开源了我们的基础模型权重。
论文及项目相关链接
PDF v4: Update author order
Summary
本文介绍了对Llama 3.1 8B和Mistral NeMo 12B模型进行压缩至4B和8B参数的研究,采用了剪枝和蒸馏技术。文章探索了两种独特的剪枝策略:深度剪枝和联合隐藏/注意力/MLP(宽度)剪枝,并在通用的LM Evaluation Harness基准测试上评估了结果。模型使用NeMo对齐器进行对齐,并进行了指令微调版本测试。该研究成功创建了具有竞争力的4B模型(源于Llama 3.1 8B)和先进的Mistral-NeMo-Minitron-8B模型(简称MN-Minitron-8B,源于Mistral NeMo 12B)。研究发现,在不访问原始数据的情况下,对蒸馏数据集进行微调教师模型是有益的。模型权重已在Hugging Face上以许可协议开源。
Key Takeaways
- 采用剪枝和蒸馏技术成功压缩了Llama 3.1 8B和Mistral NeMo 12B模型,分别至4B和8B参数。
- 探索了两种剪枝策略:深度剪枝和联合隐藏/注意力/MLP(宽度)剪枝。
- 在LM Evaluation Harness基准测试上评估了压缩模型的性能。
- 使用NeMo对齐器进行模型对齐,并进行了指令微调版本测试。
- 成功创建了具有竞争力的4B模型和先进的MN-Minitron-8B模型。
- 发现对蒸馏数据集进行微调教师模型有助于提高模型性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了如何有效地压缩大型语言模型(LLMs),以减少训练成本并提高部署效率。具体来说,它试图解决以下问题:
- 训练成本高昂:从头开始训练一系列不同规模的多亿参数模型(例如Llama 3.1 8B, 70B, 405B)非常耗时、耗数据和资源密集。
- 资源和数据限制:在没有访问原始训练数据的情况下,如何有效地进行模型压缩。
- 模型压缩和精度恢复:如何通过剪枝和知识蒸馏技术减少模型参数,同时尽量保持或恢复模型的准确性。
论文通过应用Minitron压缩策略,成功地将Llama 3.1 8B和Mistral NeMo 12B模型分别压缩到4B和8B参数,并探讨了两种不同的剪枝策略:深度剪枝和联合隐藏/注意力/MLP(宽度)剪枝。此外,论文还提出了一种“教师校正”的方法,即在剪枝和蒸馏之前,先对教师模型进行微调,以适应新的数据集。这种方法在没有原始数据的情况下特别有益。
Q: 有哪些相关研究?
A: 论文中提到了以下相关研究:
[1] Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, and Pavlo Molchanov. Compact language models via pruning and knowledge distillation. arXiv preprint arXiv:2407.14679, 2024. 这篇预印本论文讨论了通过剪枝和知识蒸馏来压缩语言模型的方法。
[2] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation, 12 2023. 这篇论文提出了一个用于少量样本语言模型评估的框架。
[3] Abhimanyu Dubey and Abhinav Jauhri et al. The llama 3 herd of models, 2024. 这篇论文讨论了Llama 3模型系列。
[4] Mistral AI team. Mistral nemo. https://mistral.ai/news/mistral-nemo, 2024. Accessed: 2024. 这是Mistral AI团队发布的Mistral NeMo模型的在线资源。
[5] Xin Men, Mingyu Xu, Qingyu Zhang, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen. ShortGPT: Layers in Large Language Models are More Redundant Than You Expect, 2024. 这篇论文研究了大型语言模型中层的冗余性。
[6] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An adversarial winograd schema challenge at scale. Commun. ACM, 64(9), 2021. 这篇论文介绍了WinoGrande基准,一个大规模的对抗性Winograd模式挑战。
[7] Solomon Kullback and Richard A. Leibler. On information and sufficiency. Annals of Mathematical Statistics, 22(1):79–86, 1951. 这篇经典论文介绍了KL散度,它在知识蒸馏中被用来衡量两个概率分布之间的差异。
[10] Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Daniel A. Roberts. The unreasonable ineffectiveness of the deeper layers. 2024. 这篇论文探讨了在某些情况下,模型的深层可能没有预期的那么有效。
[11] Gerald Shen, Zhilin Wang, Olivier Delalleau, Jiaqi Zeng, Yi Dong, Daniel Egert, Shengyang Sun, Jimmy Zhang, Sahil Jain, Ali Taghibakhshi, Markel Sanz Ausin, Ashwath Aithal, and Oleksii Kuchaiev. Nemoaligner: Scalable toolkit for efficient model alignment, 2024. 这篇论文介绍了Nemoaligner,一个用于高效模型对齐的工具包。
[12] Nvidia, and others. Nemotron-4 340b technical report, 2024. 这是Nvidia发布的关于Nemotron-4 340B模型的技术报告。
[13] Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911, 2023. 这篇预印本论文讨论了对大型语言模型进行指令跟随评估的方法。
这些相关研究为论文中提出的模型压缩和蒸馏方法提供了理论基础和实践指导。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决大型语言模型(LLM)压缩的问题:
教师模型的微调(Teacher Correction):由于没有访问原始训练数据,论文提出首先对教师模型进行微调(称为教师校正),以适应用于蒸馏的数据集。这有助于减少数据分布不匹配的问题,从而提高蒸馏的效果。
剪枝(Pruning):论文探索了两种剪枝策略——深度剪枝和联合隐藏/注意力/MLP(宽度)剪枝。通过计算模型中不同层、神经元、头和嵌入维度的重要性,然后根据重要性进行排序和剪枝,从而减少模型的大小。
蒸馏(Distillation):在剪枝之后,使用知识蒸馏来恢复模型的准确性。这一步骤涉及使用未剪枝的模型(教师模型)来指导剪枝后的模型(学生模型)的学习,通过最小化教师和学生模型之间的KL散度来实现。
模型架构的选择:论文没有使用神经架构搜索(NAS),而是根据原始论文中的网络架构相关知识,手动配置了Llama-3.1-Minitron-4B和MN-Minitron-8B的架构。
指令调优(Instruction Tuning):为了评估蒸馏模型的指令跟随能力,论文还对Llama-3.1-Minitron 4B模型进行了监督式微调,并在多个基准上进行了评估。
实验和评估:论文在多个常见的语言建模基准上评估了压缩模型的性能,包括MMLU、HumanEval、Arc-C、HellaSwag、TruthfulQA、WinoGrande和XL-Sum English等。
通过这些步骤,论文成功地将Llama 3.1 8B和Mistral NeMo 12B模型分别压缩到4B和8B参数,同时保持或提高了模型在多个基准上的性能。这表明了论文提出的方法在减少模型大小和训练成本方面是有效的,同时还能保持或提高模型的准确性和效率。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估所提出的模型压缩策略,包括剪枝和蒸馏方法的有效性。以下是论文中提到的主要实验:
基准测试:作者在多个常见的语言建模基准上评估了压缩后的模型,包括但不限于Winogrande、Arc_challenge、MMLU、Hellaswag、GSM8k、Truthfulqa、XLSum en和MBPP。这些测试覆盖了各种不同的任务,如文本理解、推理、摘要和代码生成。
剪枝策略比较:作者探索了两种剪枝策略——深度剪枝和宽度剪枝,并比较了它们的效果。深度剪枝关注于减少模型的深度,而宽度剪枝则关注于减少模型的宽度(例如隐藏层的维度和注意力头的数量)。
教师模型校正:作者对教师模型进行了校正,以适应用于蒸馏的数据集。他们比较了校正前后的教师模型在蒸馏过程中的表现。
蒸馏策略评估:作者评估了使用知识蒸馏来恢复剪枝后模型精度的效果。他们使用了前向KL散度损失作为蒸馏的损失函数。
指令调优评估:为了评估蒸馏模型的指令跟随能力,作者对Llama-3.1-Minitron 4B模型进行了指令调优,并在IFEval和MT-Bench等基准上进行了评估。
推理性能测试:作者使用TensorRT-LLM测量了MN-Minitron-8B模型和Llama-3.1-Minitron-4B模型的推理性能,并与教师模型进行了比较。
消融研究:作者进行了一系列消融研究,以更好地理解压缩特性,包括宽度与深度剪枝的比较、剪枝与蒸馏的正交效益、教师校正的影响、以及不同剪枝和蒸馏策略的效果。
这些实验的结果表明,作者提出的压缩策略能够在保持或提高模型性能的同时,显著减少模型的参数数量和训练成本。
Q: 有什么可以进一步探索的点?
A: 尽管论文已经展示了通过剪枝和蒸馏压缩大型语言模型(LLM)的有效性,但仍有一些领域可以进一步探索和改进:
更精细的剪枝策略:虽然论文中提到了深度剪枝和宽度剪枝,但可以探索更细粒度的剪枝方法,如针对特定层或神经元的剪枝,以进一步优化模型大小与性能之间的权衡。
更高效的蒸馏技术:研究更高效的蒸馏技术,例如,利用中间层特征蒸馏或对抗性蒸馏,以提高学生模型的性能并减少训练时间。
跨领域和跨语言的压缩:探索模型压缩策略在不同领域和不同语言上的效果,以及如何调整压缩方法以适应特定的应用场景。
长期维护和适应性:研究如何使压缩后的模型适应新的数据和任务,以及如何进行长期维护以保持其性能。
计算效率与硬件优化:进一步研究如何优化压缩模型以提高在特定硬件(如GPU、TPU或边缘设备)上运行时的计算效率。
模型鲁棒性和安全性:评估压缩后模型在面对对抗性攻击和数据偏移时的鲁棒性,并探索提高模型安全性的方法。
更广泛的任务和数据集测试:在更广泛的任务和数据集上测试压缩模型的性能,以更全面地评估其泛化能力。
模型解释性和可视化:研究剪枝和蒸馏过程中哪些部分对模型性能影响最大,以及如何通过可视化技术来解释模型的决策过程。
自动化压缩框架:开发自动化的模型压缩框架,该框架可以智能地确定最佳的剪枝和蒸馏策略,以实现用户定义的性能和大小目标。
社会影响和伦理考量:评估压缩模型在实际应用中可能带来的社会影响,以及如何在设计和部署过程中考虑伦理问题。
通过这些进一步的探索,可以提高模型压缩技术的实用性和有效性,同时确保压缩后的模型在各种应用中都能保持高性能和可靠性。
Q: 总结一下论文的主要内容
A: 这篇论文主要介绍了一种名为Minitron的模型压缩方法,该方法通过剪枝和蒸馏技术将大型语言模型(LLM)压缩到更小的规模,同时尽量保持模型性能。以下是论文的主要内容总结:
研究动机:训练大型语言模型成本高昂,资源和数据消耗大。为了帮助不同规模和计算预算的用户,研究者探索了模型压缩技术。
Minitron压缩策略:应用Minitron方法压缩Llama 3.1 8B和Mistral NeMo 12B模型到4B和8B参数。该策略包括教师模型的微调(教师校正)、剪枝和蒸馏。
剪枝策略:探索了两种剪枝策略——深度剪枝和宽度剪枝。深度剪枝关注减少模型层数,宽度剪枝关注减少模型宽度,如隐藏层维度和注意力头数。
教师校正:在没有原始训练数据的情况下,通过在目标数据集上微调教师模型来适应数据分布,称为教师校正。
蒸馏过程:使用知识蒸馏从教师模型向学生模型转移知识,通过最小化教师和学生模型之间的KL散度来实现。
实验结果:压缩后的模型在多个语言建模基准测试中表现出色,与同类规模模型相比具有更高的准确性和更快的推理速度。
消融研究:通过一系列消融实验,研究了剪枝和蒸馏方法的不同方面,如教师校正的必要性、剪枝策略的比较等。
指令调优:对压缩后的模型进行了指令调优,以评估其在遵循指令方面的能力。
开源贡献:研究者将基础模型权重开源,并在Hugging Face上以宽松许可提供。
结论:Minitron压缩策略成功地将大型模型压缩到更小规模,同时保持了良好的性能,证明了该方法在实际应用中的有效性和可行性。
论文通过这些研究,展示了在资源有限的情况下,如何有效地压缩大型语言模型,使其更易于部署和应用。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


GARLIC: GPT-Augmented Reinforcement Learning with Intelligent Control for Vehicle Dispatching
Authors:Xiao Han, Zijian Zhang, Xiangyu Zhao, Guojiang Shen, Xiangjie Kong, Xuetao Wei, Liqiang Nie, Jieping Ye, Yuanshao Zhu
As urban residents demand higher travel quality, vehicle dispatch has become a critical component of online ride-hailing services. However, current vehicle dispatch systems struggle to navigate the complexities of urban traffic dynamics, including unpredictable traffic conditions, diverse driver behaviors, and fluctuating supply and demand patterns. These challenges have resulted in travel difficulties for passengers in certain areas, while many drivers in other areas are unable to secure orders, leading to a decline in the overall quality of urban transportation services. To address these issues, this paper introduces GARLIC: a framework of GPT-Augmented Reinforcement Learning with Intelligent Control for vehicle dispatching. GARLIC utilizes multiview graphs to capture hierarchical traffic states, and learns a dynamic reward function that accounts for individual driving behaviors. The framework further integrates a GPT model trained with a custom loss function to enable high-precision predictions and optimize dispatching policies in real-world scenarios. Experiments conducted on two real-world datasets demonstrate that GARLIC effectively aligns with driver behaviors while reducing the empty load rate of vehicles.
随着城市居民对旅行品质的要求越来越高,车辆调度已成为在线叫车服务的重要组成部分。然而,当前车辆调度系统在应对城市交通动态的复杂性方面存在困难,包括不可预测的交通状况、驾驶员行为的多样性以及供需模式的波动。这些挑战导致某些地区的乘客出行困难,而其他地区的许多司机无法接到订单,从而导致城市运输服务整体质量下降。为了解决这些问题,本文介绍了GARLIC:一种用于车辆调度的GPT增强型强化学习智能控制框架。GARLIC利用多视图图来捕捉分层交通状态,并学习一个考虑个体驾驶行为的动态奖励函数。该框架进一步集成了一个使用自定义损失函数训练的GPT模型,以实现高精度预测,并在实际场景中优化调度策略。在两个真实数据集上进行的实验表明,GARLIC与驾驶员行为相一致,同时降低了车辆的空驶率。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
城市出行需求升级,车辆调度成在线约车服务关键环节。当前系统面临城市交通动态复杂性问题,如交通状况不可预测、司机行为多样及供需模式波动等。为解决这些问题,本文提出采用GPT增强型强化学习智能控制框架GARLIC进行车辆调度。该框架利用多视图图捕捉分层交通状态,学习动态奖励功能以考虑个体驾驶行为,并集成GPT模型进行高精度预测和优化实际场景中的调度策略。实验证明,GARLIC能有效符合司机行为并降低车辆空驶率。
Key Takeaways
- 城市居民对出行质量的需求提高,车辆调度成为在线约车服务的核心部分。
- 当前车辆调度系统面临诸多挑战,如处理复杂的城市交通动态。
- GARLIC框架被提出以解决这些问题,它结合了GPT增强型强化学习智能控制。
- GARLIC利用多视图图来捕捉分层交通状态,并学习考虑个体驾驶行为的动态奖励功能。
- GPT模型在框架中被集成,用于进行高精度预测和优化实际场景中的调度策略。
- 实验证明,GARLIC能有效适应司机行为,提高服务质量。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是在线打车服务中车辆调度的问题。具体来说,论文中提到,随着城市居民对出行质量的要求提高,车辆调度成为了在线打车服务的一个关键组成部分。然而,当前的车辆调度系统在应对城市交通动态的复杂性方面存在挑战,包括不可预测的交通状况、多样化的司机行为以及供需模式的波动。这些问题导致了某些区域乘客出行困难,而其他区域的司机却无法获得订单,进而导致城市交通服务整体质量的下降。为了解决这些问题,论文提出了一个名为GARLIC的框架,即GPT增强的强化学习与智能控制用于车辆调度。该框架利用多视图图来捕获分层的交通状态,并学习动态奖励函数以考虑个体驾驶行为,进一步整合了经过自定义损失函数训练的GPT模型,以实现在真实世界场景中优化调度策略的高精度预测。
Q: 有哪些相关研究?
A: 相关研究主要涉及以下几个方面:
车辆调度和重新定位任务:
- 许多先前研究将车辆调度建模为马尔可夫决策过程(Markov decision process),并利用强化学习(RL)来优化车辆重新定位任务。这些方法使用全局交通状态和奖励函数来提高重新定位的精度。
交通状态感知和通信延迟:
- 现有方法中全局交通状态感知存在高通信延迟,阻碍了实时调度。为了解决这个问题,论文设计了一个多视图图学习模块,限制了车辆间的通信跳数。
驾驶行为建模:
- 驾驶行为在交通分析中起着重要作用。近期研究开始将驾驶行为整合到驾驶应用中,例如使用逆强化学习(IL)方法复制人类驾驶行为,并将这些策略转移到自动驾驶场景中。
强化学习在车辆调度中的应用:
- 许多研究利用强化学习方法来增强车辆调度,将其视为一个多智能体顺序决策任务。
多智能体强化学习(MARL):
- 论文采用了一种新颖的MARL方法来优化在线车辆调度策略,每个车辆在路网中作为一个独立的智能体,具有不同的驾驶行为,并能够生成连续的轨迹和监控局部交通状况。
图表示学习:
- 为了准确表示和整合具有层次特性的城市时空数据,论文提出了将路网表示为多视图蜂巢图的方法,并使用图卷积网络(GCN)来提取交通嵌入。
动态奖励函数:
- 论文提出了一种动态奖励生成方法,结合驾驶行为和预期收入,通过分析实时车辆轨迹来量化驾驶员遵循其驾驶习惯的可能性。
这些相关研究为论文提出的GARLIC框架提供了理论基础和技术背景,使其能够有效地解决在线打车服务中车辆调度的复杂问题。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为GARLIC的框架来解决车辆调度问题,该框架包含三个主要模块:
分层交通状态表示(Hierarchical Traffic State Representation):
- 利用多视图图卷积网络(GCN)来整合不同粒度的交通信息,提供实时交通状态的全面表示。
- 通过GeoHash算法对车辆位置进行编码,并结合交通状态信息,准确计算每个车辆所在特定区域的实时交通状态。
动态奖励生成(Dynamic Reward Generation):
- 通过门控循环单元(GRU)模型来模拟驾驶行为,并生成动态奖励,这些奖励根据区域中位数车费进行加权,以反映驾驶行为的时间和空间细微差别。
GPT增强的调度策略学习(GPT-Augmented Dispatching Policy Learning):
- 将基于多智能体强化学习(MARL)的车辆调度任务框架训练为监督学习过程。
- 使用GPT增强模型来处理复杂的交通状态和驾驶行为,并输出高精度的车辆调度动作。
具体来说,GARLIC框架的工作流程如下:
多视图图表示学习:将路网划分为不同粒度的网格,并构建多视图图,每个网格作为一个节点,交通信息作为节点特征,边缘连接相邻网格。利用GCN模型提取交通嵌入。
动态奖励计算:使用基于GRU的RNN模型来分析车辆轨迹与驾驶行为之间的关系,并计算概率,结合区域中位数车费生成动态奖励。
GPT模型增强:将车辆调度问题转化为监督学习任务,利用GPT模型处理时序数据,并使用自定义的损失函数进行训练,以提高模型的表达能力。
自定义损失函数:为了更好地训练GARLIC框架,论文提出了一种新的损失函数,称为地理空间损失(GeoLoss),以最小化预测动作与真实动作之间的地理空间差异。
通过这些模块的协同工作,GARLIC能够有效地整合交通状态信息、考虑驾驶行为,并在真实世界场景中优化调度策略,从而减少车辆空驶率并提高司机收入。
Q: 论文做了哪些实验?
A: 论文中进行了广泛的实验,以评估GARLIC框架的有效性。以下是实验的具体内容:
实验设置:
- 数据集:使用了两个不同规模的真实世界数据集,一个位于美国纽约市曼哈顿下城和中城,另一个更大的数据集来自中国浙江省杭州市的出租车轨迹数据。
- 评估指标:使用了欧几里得距离误差(Error)来评估预测动作与驾驶员实际驾驶意图之间的差异,以及空驶率(empty-loaded rate)来衡量叫车服务的效率。
- 基线比较:将GARLIC与多个代表性基线方法进行比较,包括在线RL方法、离线RL方法和传统车辆调度系统。
实现细节:
- 考虑车辆间相关性随距离指数级减少,只允许相邻区域车辆间的V2V通信。
- 限制车辆广播和接收V2V多跳消息的等待时间为1秒,忽略超时传输。
- 实验在开源软件SUMO上模拟,并部署在具有高性能硬件配置的Linux服务器上。
整体性能:
- 展示了所有基线方法在两个数据集上的性能,以Error和空驶率两个指标衡量。
- GARLIC在减少误差方面显著优于其他基线,主要归功于采用了更有效的损失函数。
- 在空驶率指标上,GARLIC排名靠前,但由于模型需要权衡司机的个人驾驶行为习惯,因此在某些情况下空驶率略高于SS-DT方法。
消融研究:
- 探讨了多视图图学习在GARLIC中的作用,通过使用不同粒度的图进行实验,并比较了不同组合的图对模型性能的影响。
- 分析了驾驶行为对模型性能的影响,通过设置不同的超参数α来调整驾驶行为在动态奖励函数中的权重。
效率比较:
- 比较了GARLIC与基于模仿学习(IL)的方法,展示了GARLIC在训练迭代次数增加时的鲁棒性和较低的轨迹误差。
- 验证了动态奖励函数的效率,GARLIC能够有效地探索更高收入的轨迹,而IL方法仅从提供的数据中学习交通特征。
案例研究:
- 随机选择了杭州的一辆在线叫车车辆作为实验对象,模拟了不同方法的车辆调度路线,并与实际车辆轨迹进行比较。
这些实验全面评估了GARLIC框架的性能,并与现有方法进行了比较,证明了GARLIC在车辆调度任务中的有效性和效率。
Q: 有什么可以进一步探索的点?
A: 论文提出了GARLIC框架来解决车辆调度问题,并在实验中取得了良好的效果。以下是一些可以进一步探索的点:
算法优化:
- 研究更高效的图表示学习算法,以减少模型训练和推理的时间。
- 探索更先进的强化学习算法,以进一步提高调度策略的性能。
更复杂的交通场景:
- 将GARLIC框架应用于更复杂的交通网络和场景中,例如多模式交通系统,包括公共交通、自行车共享和步行等。
- 考虑不同天气条件和特殊事件(如节假日、大型活动)对交通状况的影响。
实时数据集成:
- 研究如何更好地集成实时交通数据,例如通过社交媒体、车载传感器等渠道获取的数据,以提高调度精度。
司机行为模型的完善:
- 收集更多关于司机行为的数据,以构建更精确的司机行为模型。
- 考虑司机的疲劳、情绪等非理性因素对驾驶行为的影响。
多目标优化:
- 除了最小化空驶率和最大化司机收入外,还可以考虑其他目标,如减少碳排放、提高乘客满意度等。
云边协同:
- 探索如何结合云计算和边缘计算,以实现更快的响应时间和更高的计算效率。
- 研究如何利用5G和6G等新一代通信技术来提高V2V通信的效率和可靠性。
算法的可扩展性和泛化能力:
- 研究GARLIC框架在不同城市和地区的可扩展性和泛化能力,以及如何调整算法以适应不同地区的交通特点。
安全性和隐私保护:
- 在收集和使用司机和乘客数据时,研究如何保护个人隐私和数据安全。
- 考虑如何设计安全机制,以防止恶意攻击和数据泄露。
用户界面和体验:
- 研究如何设计更直观、更友好的用户界面,以提高司机和乘客的使用体验。
- 探索如何通过用户反馈来优化调度算法和提高服务质量。
政策和法规遵从性:
- 考虑不同国家和地区的交通政策和法规,研究如何调整算法以确保合规性。
这些探索点可以帮助研究人员和实践者进一步改进车辆调度系统,提高城市交通的效率和可持续性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出城市交通服务中车辆调度的重要性以及现有系统面临的挑战,如不可预测的交通状况、多样化的司机行为和供需波动。
GARLIC框架介绍:
- 论文提出了GARLIC(GPT-Augmented Reinforcement Learning with Intelligent Control for vehicle dispatching),一个利用多视图图和强化学习的框架,以优化车辆调度。
分层交通状态表示:
- 利用多视图图卷积网络(GCN)整合不同粒度的交通信息,提供实时交通状态的全面表示。
动态奖励生成:
- 采用基于GRU的RNN模型模拟驾驶行为,并生成动态奖励,这些奖励根据区域中位数车费进行加权。
GPT增强的调度策略学习:
- 将MARL任务转化为监督学习问题,使用GPT模型处理时序数据,并自定义损失函数以提高模型表达能力。
实验评估:
- 在两个真实世界的数据集上进行实验,与多个基线方法比较,验证GARLIC框架的有效性和效率。
消融研究和案例研究:
- 进一步分析了多视图图学习的作用、驾驶行为对模型性能的影响,并提供了一个具体的车辆调度案例分析。
结论与未来工作:
- 论文总结了GARLIC框架的贡献,并提出了未来可能的研究方向,如结合Kafka引擎和云边协同技术进一步优化信息传输。
总体而言,这篇论文通过提出一个新颖的框架来解决在线打车服务中车辆调度的复杂问题,并通过实验验证了其有效性,为城市交通服务的优化提供了有价值的见解和工具。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

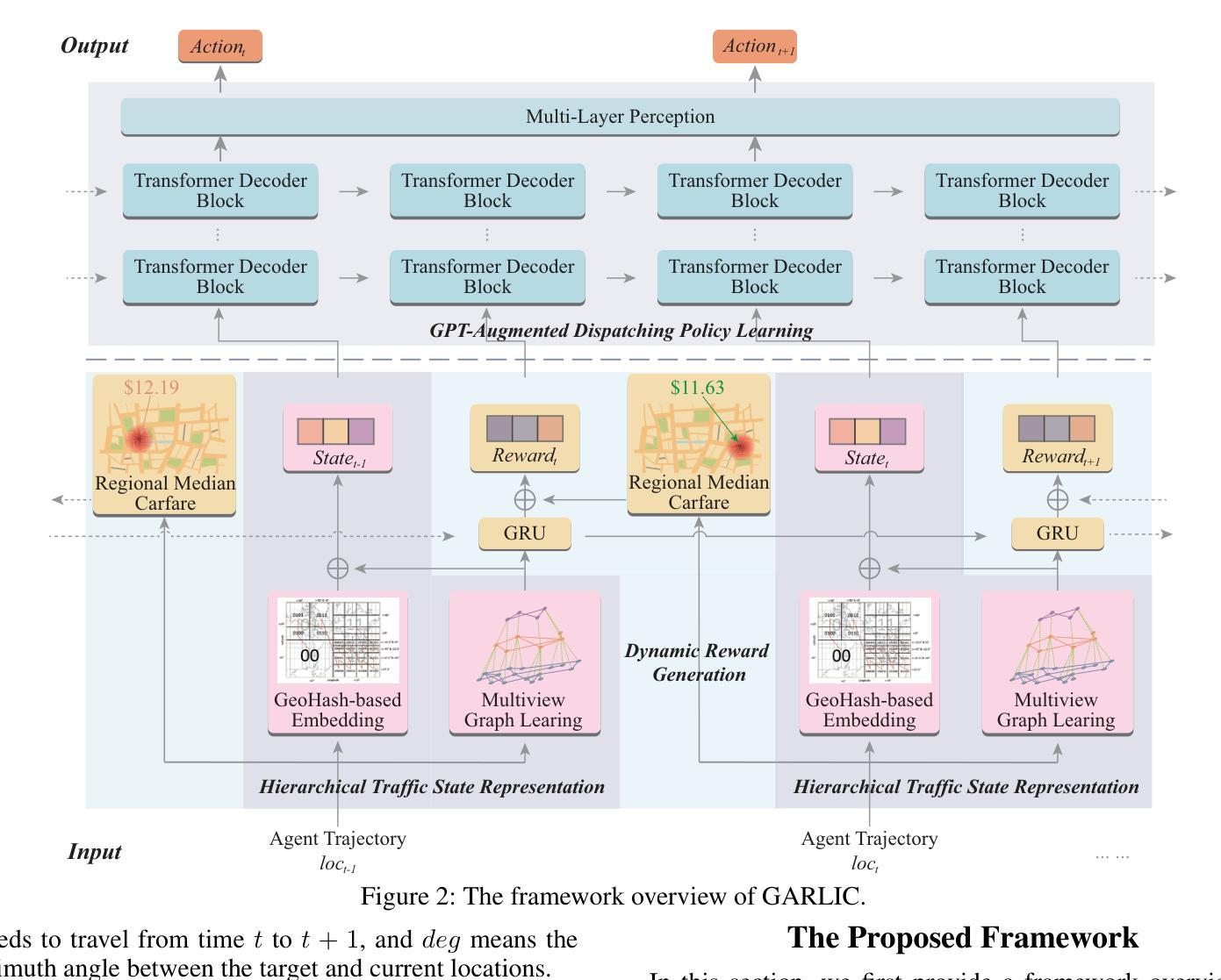
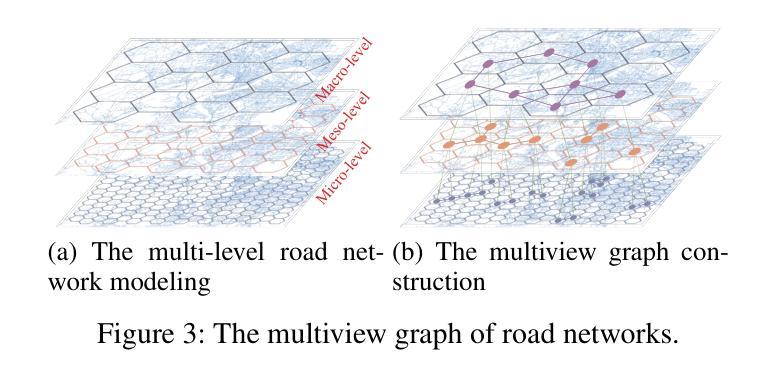
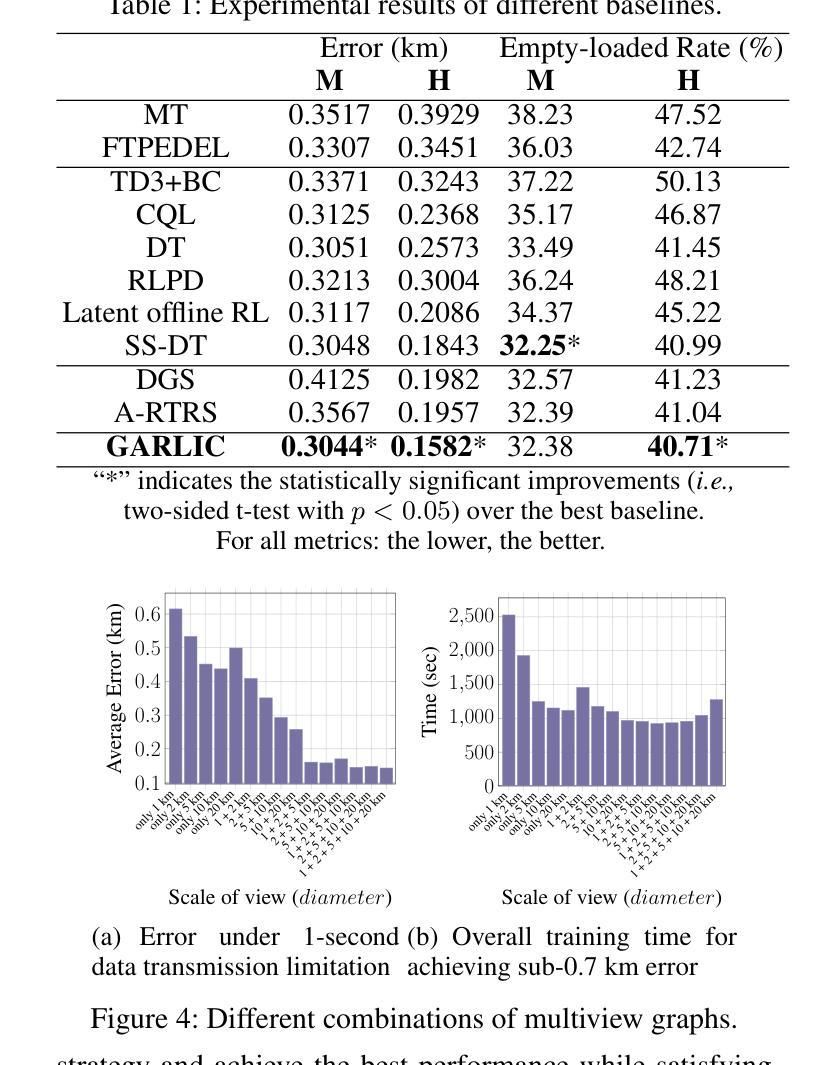
Can Large Language Models Understand Symbolic Graphics Programs?
Authors:Zeju Qiu, Weiyang Liu, Haiwen Feng, Zhen Liu, Tim Z. Xiao, Katherine M. Collins, Joshua B. Tenenbaum, Adrian Weller, Michael J. Black, Bernhard Schölkopf
Against the backdrop of enthusiasm for large language models (LLMs), there is an urgent need to scientifically assess their capabilities and shortcomings. This is nontrivial in part because it is difficult to find tasks which the models have not encountered during training. Utilizing symbolic graphics programs, we propose a domain well-suited to test multiple spatial-semantic reasoning skills of LLMs. Popular in computer graphics, these programs procedurally generate visual data. While LLMs exhibit impressive skills in general program synthesis and analysis, symbolic graphics programs offer a new layer of evaluation: they allow us to test an LLM’s ability to answer different-grained semantic-level questions of the images or 3D geometries without a vision encoder. To semantically understand the symbolic programs, LLMs would need to possess the ability to “imagine” and reason how the corresponding graphics content would look with only the symbolic description. We use this task to evaluate LLMs by creating a large benchmark for the semantic visual understanding of symbolic graphics programs, built procedurally with minimal human effort. Particular emphasis is placed on transformations of images that leave the image level semantics invariant while introducing significant changes to the underlying program. We evaluate commercial and open-source LLMs on our benchmark to assess their ability to reason about visual output of programs, finding that LLMs considered stronger at reasoning generally perform better. Lastly, we introduce a novel method to improve this ability – Symbolic Instruction Tuning (SIT), in which the LLM is finetuned with pre-collected instruction data on symbolic graphics programs. Interestingly, we find that SIT not only improves LLM’s understanding on symbolic programs, but it also improves general reasoning ability on various other benchmarks.
在大型语言模型(LLM)备受关注的大背景下,科学评估其能力和短板显得尤为重要。这是非常重要的任务部分原因是难以找到模型在训练过程中没有遇到过的任务来进行评估。我们利用符号图形程序提出了一个非常适合测试LLM多重空间语义推理能力的领域。这些程序在计算机图形学中很受欢迎,可以程序化生成视觉数据。虽然LLM在一般的程序合成和分析方面表现出令人印象深刻的技能,但符号图形程序为我们提供了一个新的评估层次:它们允许我们测试LLM回答图像或3D几何的不同粒度语义层面问题而无需使用视觉编码器的能力。为了语义理解这些符号程序,LLM需要具备仅凭符号描述就能“想象”并推理出相应图形内容外观的能力。我们通过创建大型基准测试来评估LLM对符号图形程序的语义视觉理解能力,这些基准测试是通过程序生成,所需的人力投入极小。我们特别重视图像转换任务,这种转换不会改变图像级别的语义,但同时会对底层程序引入显著变化。我们在基准测试上评估了商用和开源的LLM,以评估它们对程序视觉输出的推理能力,我们发现推理能力较强的LLM通常表现更好。最后,我们引入了一种改进这种能力的新方法——符号指令微调(SIT),其中对LLM进行微调,使其适应预先收集的符号图形程序的指令数据。有趣的是,我们发现SIT不仅提高了LLM对符号程序的理解能力,还提高了其在其他基准测试上的通用推理能力。
论文及项目相关链接
PDF Technical Report v3 (47 pages, 26 figures, project page: https://sgp-bench.github.io/, added visual illusion examples)
摘要
在大型语言模型(LLM)热潮的背景下,对其能力和局限性进行科学评估具有紧迫性。本文提出利用符号图形程序领域来测试LLM的多重空间语义推理能力。符号图形程序能够程序性地生成视觉数据,为计算机图形学领域广泛使用。尽管LLM在一般程序合成和分析方面表现出令人印象深刻的能力,但符号图形程序提供了一个新的评估层面:它们允许我们测试LLM在没有视觉编码器的情况下回答图像或3D几何的不同粒度语义级问题的能力。为了语义地理解符号程序,LLM需要具备仅通过符号描述来“想象”并推理相应图形内容外观的能力。我们通过创建符号图形程序的语义视觉理解大型基准测试来评估LLM,这些测试通过程序生成,所需人力极少。我们特别强调图像转换任务,这类任务使图像级别的语义保持不变,同时引入对底层程序的重大变化。我们对商业和开源LLM在我们的基准测试上进行了评估,以评估它们对程序视觉输出的推理能力,发现被认为具有更强推理能力的LLM通常表现更好。最后,我们提出了一种改进这一能力的新方法——符号指令微调(SIT),其中对LLM进行微调,使其适应符号图形程序的预收集指令数据。有趣的是,我们发现SIT不仅提高了LLM对符号程序的理解能力,而且还提高了其在其他基准测试中的一般推理能力。
关键见解
- LLM在符号图形程序领域的表现可用于评估其空间-语义推理能力。
- 符号图形程序提供了一个新的评估层面,允许测试LLM回答图像或3D几何的语义级问题的能力,无需视觉编码器。
- LLM需要理解符号描述以“想象”和推理图形内容的外观,体现其语义理解能力。
- 创建了针对符号图形程序的语义视觉理解大型基准测试,以评估LLM的能力。
- 在图像转换任务中,LLM需保持图像级别的语义不变,同时理解底层程序的变化。
- 评估显示,被认为具有更强推理能力的LLM在基准测试上表现更好。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了大型语言模型(Large Language Models,简称LLMs)是否能够理解符号图形程序(symbolic graphics programs)。符号图形程序是一种流行的图形内容表示方式,它通过程序化的方式生成视觉数据,例如2D图像或3D几何图形。尽管大型语言模型在程序合成方面展现出了潜力,但它们是否能够“理解”这些符号图形程序仍是一个开放性问题。
论文的主要贡献包括:
提出了一个新的任务:评估LLMs对符号图形程序的“理解”,特别是它们是否能够回答与图形内容相关的语义问题。
构建了一个名为SGP-Bench的大规模基准测试,用于评估LLMs在符号图形程序的语义理解和一致性方面的能力。
提出了一种新的方法,称为符号指令调整(Symbolic Instruction Tuning,简称SIT),通过查询强大的视觉-语言模型来生成问题和图像,然后使用这些数据对LLMs进行微调,以提高它们对符号图形程序的理解。
通过实验发现,即使是最强大的LLM(例如GPT-4o)在理解某些符号图形程序时也只能达到接近随机水平的性能,这表明LLMs对符号图形程序的理解与人类视觉识别存在显著差异。
展示了SIT方法不仅可以提高LLMs在特定任务上的性能,还可以提升它们在通用指令调整方面的能力。
总的来说,这篇论文试图通过创建新的基准测试和微调方法,来评估和提高LLMs对符号图形程序的理解能力,这对于推动LLMs在视觉推理领域的应用具有重要意义。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要集中在以下几个领域:
符号图形程序:研究使用符号程序通过过程建模生成视觉数据的方法,这在计算机图形学中非常重要。常见的程序类型包括构造性实体几何(CSG)、计算机辅助设计(CAD)、矢量图形(如SVG)、L-系统和定制领域。
图形程序理解和生成:探索如何从2D图像、3D对象和3D场景中发现图形程序,这些研究通常涉及到从视觉数据中合成图形程序。
大型语言模型(LLMs):研究LLMs在多种应用中的潜力,包括数学问题求解、定理证明辅助、生物发现等。特别是在编程任务中的应用,如代码检索、自动化测试、修复、文档生成等。
相关基准和数据集:评估LLMs在不同方面的性能,例如AI安全性/伦理、分布外性能、API/工具使用、代码生成等。此外,还有研究视觉-语言模型在视觉理解方面的能力,这些研究通常涉及到多模态数据集,如图像描述、视觉问答等。
视觉问题回答(VQA):研究如何利用图形程序进行视觉问题回答,这涉及到对图像的理解以及相关问题的回答。
程序合成:研究如何使用LLMs合成图形程序以重建视觉输入,这与本文的研究目标相似,即评估LLMs在语义级别上对图形程序的理解。
认知视角:从认知科学的角度研究LLMs在符号图形程序理解方面的能力,探讨它们在处理这类结构化表示时的潜力。
这些研究为本文提出的符号图形程序理解任务提供了背景和基础,同时也表明了这一领域的研究正在不断扩展和深化。论文通过构建新的基准测试和提出改进方法,为这一领域的研究贡献了新的视角和工具。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决大型语言模型(LLMs)是否能理解符号图形程序的问题:
定义理解的内涵:首先,论文定义了对于符号图形程序的“理解”是指模型能够基于程序文本提示回答与图形内容相关的语义问题。
创建基准测试(SGP-Bench):为了评估LLMs对符号图形程序的理解能力,作者构建了一个大规模基准测试,包括两个类型的评估:
- 语义理解:基于一组图像构建多个语义问题(如多项选择题),这些问题对人类来说容易回答,但对仅基于程序文本的模型来说具有挑战性。
- 语义一致性:通过对原始符号程序进行随机平移和旋转来评估模型对程序的语义理解是否具有鲁棒性。
数据集构建流程:使用强大的视觉-语言模型(如GPT-4o)基于渲染图像生成语义问题,然后手动检查这些问题的合理性和正确性。
评估LLMs:在SGP-Bench上评估商业和开源的LLMs,以揭示它们在理解视觉场景方面的能力。
提出改进方法(SIT):为了提高LLMs对符号图形程序的理解能力,作者提出了一种新的方法——符号指令调整(Symbolic Instruction Tuning)。这种方法通过查询强大的视觉-语言模型来收集指令遵循数据集,然后对开源LLMs进行微调。
实验验证:通过实验,作者发现SIT可以显著提高模型对符号程序的语义理解能力。此外,作者还发现SIT可以提高模型在通用指令遵循方面的表现。
挑战和未来工作:作者提出了一个挑战性的SVG程序理解任务(SGP-MNIST),展示了即使对于人类来说易于识别的图像,LLMs在理解对应的符号程序时也可能面临困难。这表明LLMs在符号图形程序理解方面与人类存在显著差异,并为未来的研究提供了新的方向。
通过这些步骤,论文不仅评估了LLMs在符号图形程序理解方面的能力,还提出了一种有效的方法来提高这种能力,为未来的研究和应用提供了有价值的见解。
Q: 论文做了哪些实验?
A: 论文中进行了多种实验来评估和提高大型语言模型(LLMs)对符号图形程序的理解能力。以下是论文中提到的主要实验:
基准测试(SGP-Bench):创建了一个大规模基准测试,用于评估LLMs对SVG和CAD(计算机辅助设计)程序的语义理解能力。这包括两种类型的评估:
- 语义理解:基于图像构建语义问题,并将这些问题用于评估LLMs。
- 语义一致性:通过对原始符号程序进行随机平移和旋转,测试LLMs在程序变化后是否能保持一致的答案。
数据集构建:使用强大的视觉-语言模型(如GPT-4o)基于渲染图像生成语义问题,然后手动检查这些问题的合理性和正确性。
模型评估:在SGP-Bench上评估了商业和开源的LLMs,以确定它们在理解视觉场景方面的能力。
符号指令调整(SIT):提出了一种新的方法来提高LLMs对符号程序的语义理解能力。这包括:
- 生成符号指令数据:使用渲染图像查询GPT-4o以获得详细的语义描述。
- 监督微调:使用收集到的指令数据对开源LLMs进行微调。
性能提升实验:展示了SIT方法如何提高LLMs在SGP-Bench上的性能,包括在SVG和CAD数据集上的理解能力。
挑战性任务(SGP-MNIST):构建了一个挑战性的SVG程序理解任务,其中LLMs需要识别由SVG程序生成的MNIST图像。尽管这些图像对人类来说很容易识别,但LLMs在理解对应的符号程序时表现不佳。
通用指令调整性能测试:在多种流行的LLM评估基准上测试了使用SIT数据进行指令调整的模型,包括语言理解、推理和数学问题解决等任务。
人类研究:进行了人类研究以验证GPT-4o为基准测试生成的标签,通过让参与者回答基于图像的问题,并与GPT-4o的答案进行比较。
预测熵比较:计算了LLMs和人类在回答基于符号程序的问题时的预测熵,以评估它们的共识程度。
这些实验不仅评估了LLMs在特定任务上的性能,还探索了提高它们对符号图形程序理解能力的方法,并揭示了LLMs在这一领域的潜力和挑战。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
模型内部工作机制:深入研究LLMs在理解符号图形程序时的内部工作机制,特别是在语义理解方面。
提高理解能力:探索新的方法和技术来提高LLMs对符号图形程序的理解能力,特别是在当前方法无法完全解决的领域。
跨模态学习:研究如何将符号图形程序与其他类型的数据(如自然语言、图像等)结合起来,以提高模型的多模态学习能力。
数据集扩展:扩充现有的基准测试数据集,包括更多的符号图形程序类型和更复杂的视觉场景。
鲁棒性测试:设计新的测试来评估模型在面对更复杂或更多样化的符号图形程序时的鲁棒性。
人类与机器的比较研究:更深入地比较人类和机器在理解符号图形程序方面的差异,以指导模型的改进。
应用开发:探索LLMs在符号图形程序理解方面的实际应用,例如在计算机辅助设计、游戏开发或虚拟现实等领域。
教育工具:研究如何将LLMs用于教育领域,帮助学生更好地理解程序设计和图形学概念。
交互式系统:开发交互式系统,允许用户通过自然语言与符号图形程序进行交互,以提高用户体验。
安全性和伦理考量:研究在应用LLMs进行符号图形程序理解时可能涉及的安全性和伦理问题,并探索相应的解决方案。
模型优化:研究如何优化模型以减少计算资源消耗,同时保持或提高性能。
多任务学习:探索LLMs在同时处理多个任务(如程序理解、代码生成、视觉问答等)时的表现和潜力。
这些探索点可以帮助研究者更全面地理解LLMs在符号图形程序理解方面的能力,并推动该领域的进一步发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题提出:论文探讨了大型语言模型(LLMs)是否能理解符号图形程序,这是一种流行的图形内容表示,可以程序化地生成视觉数据。
任务定义:作者定义了LLMs对符号图形程序的“理解”为能够回答与图形内容相关的语义问题。
基准测试创建:为了评估LLMs的这种能力,作者创建了一个名为SGP-Bench的大规模基准测试,包括SVG(可缩放矢量图形)和CAD(计算机辅助设计)程序。
评估方法:基准测试包括两个部分:
- 语义理解:基于图像构建问题,评估LLMs能否正确回答。
- 语义一致性:通过对程序进行随机平移和旋转,测试LLMs的答案是否保持一致。
数据集构建:使用强大的视觉-语言模型(如GPT-4o)基于渲染图像生成语义问题,然后手动检查这些问题的合理性和正确性。
实验结果:实验表明,现有的LLMs在理解符号图形程序方面存在挑战,但通过特定的微调方法可以提高它们的性能。
符号指令调整(SIT):提出了一种新的微调方法SIT,通过查询视觉-语言模型来收集指令数据,然后对LLMs进行微调以提高其对符号图形程序的理解。
性能提升:实验结果显示,SIT可以显著提高LLMs在SGP-Bench上的性能,尤其是在SVG数据集上。
挑战性任务:作者还提出了一个挑战性的任务SGP-MNIST,展示了即使是最强大的LLM(如GPT-4o)在理解某些SVG程序时也只能达到接近随机水平的性能。
未来工作:论文指出,尽管取得了一些进展,但LLMs在符号图形程序理解方面仍有很大的提升空间,并鼓励未来的研究探索这一领域。
贡献总结:论文的主要贡献包括提出了新的评估任务、构建了大规模基准测试、提出了SIT微调方法,并展示了LLMs在这一领域的潜力和挑战。
论文通过这些研究,为理解和改进LLMs在视觉推理方面的能力提供了新的视角和工具。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图




Evaluating Research Quality with Large Language Models: An Analysis of ChatGPT’s Effectiveness with Different Settings and Inputs
Authors:Mike Thelwall
Evaluating the quality of academic journal articles is a time consuming but critical task for national research evaluation exercises, appointments and promotion. It is therefore important to investigate whether Large Language Models (LLMs) can play a role in this process. This article assesses which ChatGPT inputs (full text without tables, figures and references; title and abstract; title only) produce better quality score estimates, and the extent to which scores are affected by ChatGPT models and system prompts. The results show that the optimal input is the article title and abstract, with average ChatGPT scores based on these (30 iterations on a dataset of 51 papers) correlating at 0.67 with human scores, the highest ever reported. ChatGPT 4o is slightly better than 3.5-turbo (0.66), and 4o-mini (0.66). The results suggest that article full texts might confuse LLM research quality evaluations, even though complex system instructions for the task are more effective than simple ones. Thus, whilst abstracts contain insufficient information for a thorough assessment of rigour, they may contain strong pointers about originality and significance. Finally, linear regression can be used to convert the model scores into the human scale scores, which is 31% more accurate than guessing.
评估学术期刊文章的质量是一个既耗时又关键的国家级研究评估任务,关乎职位的委任与晋升。因此,探索大型语言模型(LLM)能否在此过程中发挥作用具有重要意义。本文评估了哪种ChatGPT输入(全文不含表格、图表和参考文献;标题和摘要;仅标题)能产生更好的质量评分估算,以及ChatGPT模型和系统提示对评分的影响程度。结果显示,最佳输入为文章标题和摘要,基于这些内容的ChatGPT平均分数(对51篇文章的数据集进行30次迭代)与人类分数之间的相关性达到0.67,为迄今为止报告的最高值。ChatGPT 4o略优于3.5-turbo(0.66),且优于4o-mini(0.66)。结果还表明,文章全文可能会干扰LLM对研究质量的评估,尽管对此任务的复杂系统指令比简单指令更有效。因此,尽管摘要中包含的信息不足以进行全面严格的评估,但它们可能包含有关原创性和重要性的强烈暗示。最后,可以使用线性回归将模型分数转换为人类尺度分数,这比猜测更准确,准确度高31%。
论文及项目相关链接
Summary
本文探讨了使用大型语言模型(LLM)评估学术期刊文章质量的可能性,重点研究了不同ChatGPT输入(全文、仅标题和摘要、仅标题)对评估结果的影响,以及ChatGPT模型和系统提示对评分的影响程度。结果表明,最佳的输入方式是文章标题和摘要的结合,基于这些内容的ChatGPT评分与人类评分的平均相关性达到了0.67,为迄今为止的最高值。此外,更复杂的系统指令比简单的指令更有效。
Key Takeaways
- 大型语言模型(LLM)可用于评估学术期刊文章的质量。
- 最佳的输入方式是结合文章的标题和摘要进行ChatGPT评分。
- ChatGPT评分与人类评分的平均相关性达到0.67,为相关性的最高值。
- ChatGPT 4o模型在评估中略优于3.5-turbo和4o-mini。
- 文章全文可能会混淆LLM对研究质量的评估。
- 复杂的系统指令在LLM评估中比简单的指令更有效。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了使用大型语言模型(Large Language Models,LLMs)来评估学术期刊文章质量的可能性和有效性。具体来说,论文试图解决以下几个问题:
确定最佳的ChatGPT输入:研究者想要知道哪种输入(全文但不包括表格、图表和参考文献;仅标题和摘要;或者只有标题)能够产生更高质量的分数估计。
评估ChatGPT迭代次数与预测准确性的关系:研究者探索了进行多少次ChatGPT迭代可以得到与人类评价最相关的预测结果。
不同ChatGPT模型对研究质量评估的影响:研究者比较了不同版本的ChatGPT模型(如3.5-turbo、4o和4o-mini)在评估研究质量时的差异。
系统提示的复杂性对评估结果的影响:研究者评估了简单与复杂的系统提示对ChatGPT进行研究质量评估时的效果。
评估大型语言模型在研究质量评估中的潜力:研究者通过实验结果来评估LLMs是否能够作为自动化工具或辅助工具来评估学术研究的质量,尤其是在传统的基于引用计数的科学计量学方法在直接评分研究质量方面表现参差不齐的情况下。
总的来说,这篇论文试图通过一系列实验来探索和优化使用ChatGPT评估学术文章质量的方法,并为未来的研究和实践提供指导。
Q: 有哪些相关研究?
A: 论文中提到了与大型语言模型(LLMs)在学术研究质量评估领域相关的一些研究,以下是部分相关研究的概述:
ChatGPT在学术作品反馈方面的研究:
- 先前的研究评估了LLMs在为会议或期刊提交的论文提供反馈方面的潜力,通常这些反馈用于帮助审稿人或编辑分析提交的论文,或支持作者进行文本修订。
LLMs在同行评审过程中的潜在问题:
- 由于LLMs生成的审稿意见可能足够合理,以至于忙碌的审稿人可能会使用它们来作弊,这威胁到了同行评审过程的完整性。
使用LLMs进行研究质量评估的先前研究:
- 有研究使用ChatGPT来评估论文的某些特征(如新颖性和参与度)与引用次数的相关性。
ChatGPT在预测研究质量分数方面的研究:
- 一项研究分析了未审阅的会议论文,并使用ChatGPT来预测审稿分数。
ChatGPT在评估研究质量方面的其他研究:
- 有研究使用ChatGPT来评估信息科学论文的研究质量,并与作者的自我评估进行比较。
使用机器学习预测研究质量分数的研究:
- 有研究尝试使用传统的机器学习技术来预测研究质量分数,但结果参差不齐。
关于LLMs在科学计量学中应用的研究:
- 一些研究提出了将LLMs用于科学计量学目的的想法。
关于LLMs在语言处理任务中的准确性的研究:
- 有研究评估了LLMs在多种语言处理任务中的相对准确性。
这些研究为本文的研究提供了背景和基础,同时也展示了LLMs在学术研究质量评估领域的应用潜力和挑战。论文通过这些相关研究来支持其研究问题,并在现有研究的基础上进一步探索和验证LLMs在评估学术文章质量方面的有效性。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤和方法来解决使用大型语言模型(LLMs)评估学术期刊文章质量的问题:
实验设计:研究者设计了一系列实验,以回答关于ChatGPT输入、迭代次数、模型选择和系统提示的特定研究问题(RQ1-RQ4)。
数据集准备:使用了51篇信息科学期刊文章的数据集,这些文章由同一作者撰写,并根据英国研究卓越框架(REF)的质量标准进行了评分。
不同输入的比较:研究者创建了不同的数据集,包括仅标题、标题和摘要、以及去除表格、图表和参考文献的全文(截断数据集)。
迭代次数分析:对每篇文章进行了30次ChatGPT迭代,以评估不同迭代次数对预测准确性的影响。
模型比较:比较了不同版本的ChatGPT模型(3.5-turbo、4o和4o-mini)在研究质量评估方面的表现。
系统提示的测试:测试了六种不同的系统提示变体,以确定哪种提示能够得到更准确的预测结果。
分数提取:开发了一个程序来从ChatGPT生成的报告中提取分数,处理了多种不同的报告格式。
相关性分析:使用Spearman相关性分析来评估ChatGPT分数与人类评分之间的一致性。
预测准确性评估:使用平均绝对偏差(MAD)来评估预测的准确性,并通过线性回归模型将模型分数转换为与人类评分相同的尺度。
结果分析与讨论:分析了不同输入、迭代次数、模型和提示对预测准确性的影响,并讨论了结果的意义和局限性。
策略优化:基于实验结果,提出了一种优化的策略,即使用ChatGPT 4o模型,基于文章标题和摘要进行30次迭代,然后应用回归公式来转换分数。
局限性和未来工作:论文讨论了研究的局限性,并提出了未来可能的研究方向和改进方法。
通过这些步骤,论文旨在评估和优化使用LLMs进行学术研究质量评估的方法,并为未来的研究和实践提供指导。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估大型语言模型(LLMs)在评估学术期刊文章质量方面的有效性。以下是实验的主要内容:
输入类型实验:
- 比较了三种不同的输入类型:文章的全文(不包括表格、图表和参考文献),仅标题和摘要,以及仅标题。
迭代次数实验:
- 评估了不同数量的迭代(从1次到30次)对ChatGPT预测准确性的影响。
模型版本比较实验:
- 比较了ChatGPT 3.5-turbo、ChatGPT 4o和ChatGPT 4o-mini三个不同版本的模型在评估研究质量方面的表现。
系统提示变体实验:
- 测试了六种不同的系统提示变体,包括基本的REF提示的简化版本,以及一个不请求在ChatGPT报告中提供反馈的提示(Strategy 0)。
分数提取和处理:
- 开发了一个程序来自动从ChatGPT生成的报告中提取分数,并处理了多种不同的报告格式。
相关性分析:
- 使用Spearman相关性分析来评估ChatGPT分数与人类评分之间的一致性。
预测准确性评估:
- 使用平均绝对偏差(MAD)来评估预测的准确性,并通过线性回归模型将模型分数转换为与人类评分相同的尺度。
不同输入和迭代策略的组合实验:
- 结合不同的输入类型和迭代次数,评估了它们的组合对预测准确性的影响。
模型性能和成本效益分析:
- 考虑了不同模型的性能和成本效益,以确定在需要最高准确性时的最佳选择。
这些实验的目的是为了深入理解如何从ChatGPT获得最准确的研究质量评估结果,并探索在实际应用中使用LLMs进行学术研究质量评估的潜力。
Q: 有什么可以进一步探索的点?
A: 根据论文的讨论和结论部分,以下是一些可以进一步探索的点:
更大规模的样本研究:
- 论文使用了单一作者的51篇文章作为样本,未来的研究可以在更大规模、更多样化的样本上进行,以验证模型的泛化能力。
跨学科的评估:
- 探索LLMs在不同学科领域的研究质量评估中的有效性,因为不同领域的研究可能需要不同的评估标准和方法。
系统提示的优化:
- 研究不同的系统提示对LLMs预测准确性的影响,以找到更有效的提示策略。
模型参数调整:
- 尝试不同的模型参数(如温度和top_p参数),以探索它们对评估结果的影响。
与其他LLMs的比较:
- 将ChatGPT与其他大型语言模型进行比较,以确定哪个模型在研究质量评估方面表现更好。
版权和数据使用问题:
- 研究如何在遵守版权法规的前提下,使用LLMs进行学术文章的评估。
理解预测背后的逻辑:
- 分析LLMs进行预测时所依赖的逻辑和标准,以识别可能存在的偏见。
评估模型的可靠性和稳定性:
- 对模型进行长期跟踪,以评估其在不同时间点的稳定性和可靠性。
探索自动化评估的伦理和社会影响:
- 研究使用LLMs进行研究质量评估可能带来的伦理问题和社会影响。
集成方法:
- 探索将LLMs与其他自动化工具或指标结合使用,以提高研究质量评估的综合准确性。
用户界面和体验:
- 研究如何改进用户界面和体验,使非技术用户也能有效地使用LLMs进行研究质量评估。
实时评估和反馈:
- 开发实时评估系统,为研究者提供即时反馈,帮助他们改进研究质量。
这些探索点可以帮助研究者更深入地理解LLMs在学术研究质量评估中的应用,并推动该领域的进一步发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
研究背景:论文讨论了评估学术研究质量的重要性,以及自动化评估工具在减轻学术研究者负担、提高效率方面的潜力。
研究目的:旨在探索大型语言模型(LLMs),特别是ChatGPT,在评估学术期刊文章质量方面的有效性。
研究问题:论文提出了四个研究问题(RQ1-RQ4),涉及最佳的ChatGPT输入类型、迭代次数、模型选择和系统提示的有效性。
实验设计:使用51篇信息科学期刊文章作为数据集,通过ChatGPT API进行了一系列实验,包括不同的输入类型、迭代次数和系统提示。
实验结果:
- 文章标题和摘要作为输入时,ChatGPT的评分与人类评分的相关性最高(0.67)。
- 模型ChatGPT 4o略优于3.5-turbo和4o-mini。
- 简单的系统提示不如复杂的提示有效。
数据分析方法:使用Spearman相关性分析和平均绝对偏差(MAD)来评估ChatGPT评分与人类评分之间的一致性和预测准确性。
线性回归:利用线性回归将ChatGPT的模型分数转换为与人类评分相同的尺度,提高了预测的准确性。
研究局限:论文指出了研究的局限性,包括样本规模较小、单一作者的样本可能影响结果的泛化性。
结论:尽管ChatGPT在研究质量评估方面显示出潜力,但在个体文章层面的预测准确性仍有待提高,不适合用于重要的学术评审或晋升决策。
未来工作:论文提出了未来研究的方向,包括跨学科评估、系统提示优化、模型参数调整等。
总的来说,论文通过一系列实验,评估了ChatGPT在评估学术研究质量方面的潜力,并探讨了提高其预测准确性的方法和策略。同时,论文也指出了当前方法的局限性,并对未来的研究方向提出了建议。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

How ChatGPT Changed the Media’s Narratives on AI: A Semi-Automated Narrative Analysis Through Frame Semantics
Authors:Igor Ryazanov, Carl Öhman, Johanna Björklund
We perform a mixed-method frame semantics-based analysis on a dataset of more than 49,000 sentences collected from 5846 news articles that mention AI. The dataset covers the twelve-month period centred around the launch of OpenAI’s chatbot ChatGPT and is collected from the most visited open-access English-language news publishers. Our findings indicate that during the six months succeeding the launch, media attention rose tenfold$\unicode{x2014}$from already historically high levels. During this period, discourse has become increasingly centred around experts and political leaders, and AI has become more closely associated with dangers and risks. A deeper review of the data also suggests a qualitative shift in the types of threat AI is thought to represent, as well as the anthropomorphic qualities ascribed to it.
我们对一组来自5846篇提到人工智能的新闻文章的数据集进行了基于混合方法的框架语义分析。该数据集覆盖了以OpenAI聊天机器人ChatGPT发布为中心的前后共十二个月的时间段,并且数据来自访问量最大的英文开放新闻出版社。我们的研究结果表明,在发布后的六个月内,媒体关注度增长了十倍——这已经是一个创纪录的高水平。在此期间,讨论越来越集中于专家和政治人物之间,人工智能与危险和风险之间的联系也越来越紧密。对数据的深入审查还表明,人们对人工智能威胁的类型存在一种定性转变,以及赋予人工智能拟人特质的现象。
论文及项目相关链接
PDF 19 pages, 6 figures and 2 appendices (5 pages) Minds & Machines, published in November 2024
Summary:基于语义框架的混合方法分析显示,在围绕OpenAI聊天机器人ChatGPT发布的前后十二个月期间,媒体关注度上升了十倍,AI与危险和风险的联系日益紧密。此外,人们认为AI所代表的威胁类型以及对其赋予的人格化特质发生了显著变化。分析来自于五千多篇新闻文章的语料库,覆盖多种媒体来源和时间段。分析结果显示专家和政治领袖的讨论在逐渐增多。同时媒体视角的转变以及人们对AI的认识的深入也被关注。
Key Takeaways:
- 媒体对AI的关注在ChatGPT发布后的六个月内上升了十倍。
- 在这段时期中,专家和政治领袖的讨论变得更为集中。
- AI逐渐被关联上危险和风险的话题标签。
- 人们关于AI代表的威胁类型的看法发生了变化。
- AI的人格化特质发生了转变和深入讨论。
- 媒体视角的转变反映了人们对AI认识的深入。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是探讨和分析媒体对人工智能(AI)的叙述在OpenAI的聊天机器人ChatGPT发布之后发生了怎样的变化。具体来说,论文试图回答以下几个问题:
媒体对AI的关注度变化:论文试图量化ChatGPT发布后媒体对AI的关注度是否有所增加,以及这种增加的程度。
叙述焦点的转移:研究在ChatGPT发布后,媒体对AI的叙述是否更加集中在专家和政治领袖上,以及AI是否更多地与危险和风险联系在一起。
AI威胁类型的质的变化:分析ChatGPT发布后,媒体认为AI代表的威胁类型是否发生了质的变化。
AI的人格化特征:探讨ChatGPT发布后,媒体是否更多地赋予AI以人格化特征。
AI叙述的长期趋势和事件驱动的变化:论文试图通过比较ChatGPT发布前后的媒体叙述,来理解这一事件对AI媒体报道的长期趋势和短期事件驱动变化的影响。
方法论的改进:论文提出了一种基于框架语义学的新方法,通过自动化地标注提及AI的句子中的语义框架,来识别和分析媒体叙述,旨在克服以往研究中样本大小和分析深度之间的权衡问题。
总的来说,论文试图通过混合方法和新的方法论,提供一个更细致和大规模的分析,以了解ChatGPT发布对媒体AI叙述的影响,并探讨这些变化如何塑造公众对AI的看法。
Q: 有哪些相关研究?
A: 根据这篇论文,以下是一些与媒体对人工智能(AI)叙述相关的研究:
Cave et al., 2018:研究了媒体如何塑造公众对AI的看法,并可能影响研究、技术采纳和随后的监管的方向和范围。
Nader et al., 2022:探讨了通过娱乐媒体了解公众对人工智能的理解。
Brantner and Saurwein, 2021:研究了媒体对AI的报道,特别是在风险和技术责任方面的叙述。
Chuan et al., 2019:分析了美国报纸中AI的框架。
Sun et al., 2020:从新兴技术的角度考察了报纸对AI的报道。
Zhai et al., 2020:追溯了大众媒体话语中AI的概念化。
Brennan et al., 2018:研究了英国媒体如何报道AI,特别是关注行业主导的辩论。
Brennan et al., 2019:分析了30年来美国和英国媒体中AI专家如何塑造叙述,并指出了对女性专家和学术界专家的偏见。
Lupton, 2021:研究了澳大利亚媒体中对自动化决策技术的框架。
Nguyen and Hekman, 2022:通过批判性探索媒体对自动化的话语,研究了新闻框架中的人工智能。
Ouchchy et al., 2018:分析了媒体对AI的报道,特别是伦理问题的呈现。
Köstler and Ossewaarde, 2022:研究了德国政治和媒体话语中的AI未来框架。
Fast and Horvitz, 2017:观察了自2010年以来讨论变得更加乐观的趋势。
Garvey and Maskal, 2020:对新闻媒体对AI的报道进行了情感分析,没有发现对AI的负面偏见。
这些研究提供了对媒体如何报道AI的深入理解,包括报道的情感倾向、风险和利益的框架、专家和行业的影响,以及公众对AI的看法。论文通过这些相关研究,建立了其研究的背景,并在此基础上进一步探讨了ChatGPT发布对媒体AI叙述的影响。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决提出的问题:
1. 数据收集
- 从全球访问量最高的18个英语新闻网站收集5846篇提及AI的新闻文章,覆盖ChatGPT发布前后各六个月的时间。
- 使用关键词“AI”、“ChatGPT”和“Machine Learning”进行搜索,确保涵盖相关主题的文章。
2. 数据处理
- 对收集的文章进行清洗,移除非英语文章、重复文章以及未明确提及AI的文章。
- 最终得到6055篇文章作为工作数据集,并从中识别出49,120个明确提及AI的句子进行分析。
3. 分析方法
- 一般统计分析:计算和分析数据集中文章的一般统计数据,包括提及AI的频率、不同出版物的覆盖情况等。
- 框架语义分析:利用基于框架语义学的方法,自动标注提及AI或ChatGPT的句子中的语义框架,以识别相关段落进行定性分析。
- LOME模型:应用LOME(Large Ontology Multilingual Extraction)模型自动标注句子,识别与AI相关的语义框架和框架元素。
4. 探索性分析
- 采用探索性方法而非正式的假设检验,以发现数据中出现的有趣模式。
- 分析ChatGPT发布前后框架出现的频率变化,并调查这些变化背后可能的原因。
5. 特定主题分析
- 对于AI作为危险源和AI的拟人化这两个特定主题,手动策划相关的框架和框架元素列表,并分析ChatGPT发布后这些框架的显著变化。
- 从提及这些框架的句子中抽取样本,并进行两级主题分析,以探讨AI在话语中呈现的形式和变化。
6. 方法论局限
- 论文也讨论了其方法的局限性,如只关注明确提及AI的句子,忽略了可能通过上下文推断的隐含提及。
- 强调虽然观察到语言变化,但并不建立ChatGPT发布与语言变化之间的正式因果关系。
7. 结果分享
- 论文提出愿意与其他学者共享数据,以促进对AI媒体报道的进一步研究。
通过以上步骤,论文旨在提供一个结合大规模量化分析和定性主题分析的新方法,以理解ChatGPT发布对媒体AI叙述的影响。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,实验主要涉及以下几个方面:
1. 数据收集与处理
- 数据收集:从18个最受欢迎的英语新闻网站收集5846篇提及AI的文章,使用关键词”AI”、”ChatGPT”和”Machine Learning”进行搜索,覆盖ChatGPT发布前后各六个月。
- 数据清洗:移除非英语文章、重复文章以及未明确提及AI的文章,最终得到6055篇文章作为工作数据集。
2. 语义框架标注
- 使用LOME(Large Ontology Multilingual Extraction)模型自动标注提及AI的句子中的语义框架和框架元素,共产生420,155个语义框架标注。
3. 统计分析
- 一般统计:分析数据集中文章的分布、提及AI的频率等。
- 框架分布分析:比较ChatGPT发布前后最常见框架的出现频率变化。
4. 特定主题分析
- AI作为危险源:手动策划与风险和危险相关的框架列表,分析这些框架在发布前后的出现频率变化,并手动编码400个随机选取的句子以分类AI作为危险源的程度。
- AI拟人化:手动策划可能表示AI拟人化的框架和框架元素对列表,分析这些组合在发布前后的出现频率变化,并手动编码390个句子以分类AI拟人化的程度。
5. 定性分析
- 对于上述两个特定主题,进行了两级主题分析,以探讨AI在话语中呈现的形式和变化。
这些实验步骤结合了定量的统计分析和定性的语义框架分析,旨在揭示ChatGPT发布对媒体AI叙述的影响。通过这种方法,研究者能够识别和分析媒体叙述中的关键变化,特别是在AI的风险和拟人化方面。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和研究结果,以下是一些可以进一步探索的点:
长期趋势分析:
- 研究ChatGPT发布后媒体对AI的叙述是否持续变化,并探索这些变化是否具有长期趋势。
跨文化和地区比较:
- 将研究扩展到非英语媒体,以了解不同文化和地区对AI叙述的差异。
特定领域的影响:
- 分析特定领域(如医疗、教育、军事)内AI叙述的变化,以及这些变化如何影响公众对AI在这些领域应用的看法。
专家和公众的声音:
- 研究媒体叙述中专家和公众声音的代表性,以及这些声音如何塑造对AI的公众理解。
情感分析:
- 对媒体文章进行情感分析,以量化报道的正面、负面或中性倾向,并了解情感倾向如何随时间变化。
AI技术发展的对应关系:
- 将AI技术的发展与媒体报道进行对应分析,以了解技术进步如何影响媒体叙述。
政策和法规的影响:
- 研究政策和法规变化对媒体AI叙述的影响,以及这些叙述如何反过来影响政策制定。
AI拟人化的深入分析:
- 对AI拟人化的语言和叙述进行更深入的语言学和心理学分析,以了解其对人类行为和决策的影响。
新闻报道的来源和可靠性:
- 分析新闻报道中信息来源的多样性和可靠性,以及这对公众信任和理解AI的影响。
跨时间的比较研究:
- 将当前的研究结果与过去的研究进行比较,以了解AI叙述随时间的演变。
媒体叙述对实际应用的影响:
- 研究媒体叙述如何影响AI技术的实际应用和采纳,特别是在商业和工业领域。
数据集和方法论的扩展:
- 使用更广泛的数据集和更复杂的方法论来增强研究结果的普遍性和可靠性。
这些探索点可以帮助学术界和实践界更全面地理解媒体如何塑造公众对AI的看法,并为未来的研究方向提供指导。
Q: 总结一下论文的主要内容
A: 这篇论文主要探讨了OpenAI的聊天机器人ChatGPT发布后,媒体对人工智能(AI)的叙述如何变化。以下是论文的主要内容总结:
研究背景与目的
- 分析媒体对AI的叙述对塑造公众对AI的看法至关重要,可能影响AI研究和技术采纳的方向。
- 先前研究在方法论上存在局限性,且大多数在ChatGPT发布前完成,未能反映这一重大事件对媒体叙述的影响。
数据与方法
- 收集了来自18个最受欢迎英语新闻网站的5846篇文章,涵盖ChatGPT发布前后各六个月。
- 使用基于框架语义学的方法,自动标注提及AI的句子中的语义框架,以识别相关段落进行定性分析。
- 采用LOME模型进行自动标注。
主要发现
媒体关注度增加:
- ChatGPT发布后,媒体对AI的关注度增加了十倍,达到历史高水平。
叙述焦点转移:
- 叙述更加集中在专家和政治领袖上,AI与危险和风险的联系更紧密。
AI威胁类型的质的变化:
- 数据显示AI被认为代表的威胁类型发生了质的变化。
AI的拟人化特征:
- 论文还发现AI被赋予更多拟人化特征。
方法论局限
- 研究仅限于英语媒体,可能存在地域和文化偏差。
- 未建立ChatGPT发布与语言变化之间的正式因果关系。
结论与讨论
- 论文提出的方法成功结合了大规模量化分析和定性分析,揭示了ChatGPT发布对媒体AI叙述的显著影响。
- 讨论了AI叙述的变化趋势,包括对AI风险的关注增加和AI拟人化语言的使用。
- 论文邀请其他学者利用其数据进行进一步研究。
总的来说,这篇论文提供了对ChatGPT发布后媒体如何改变对AI叙述的深入分析,揭示了AI在公众话语中的形象和关注点的变化,并对学术界和实践界提出了进一步研究的建议。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

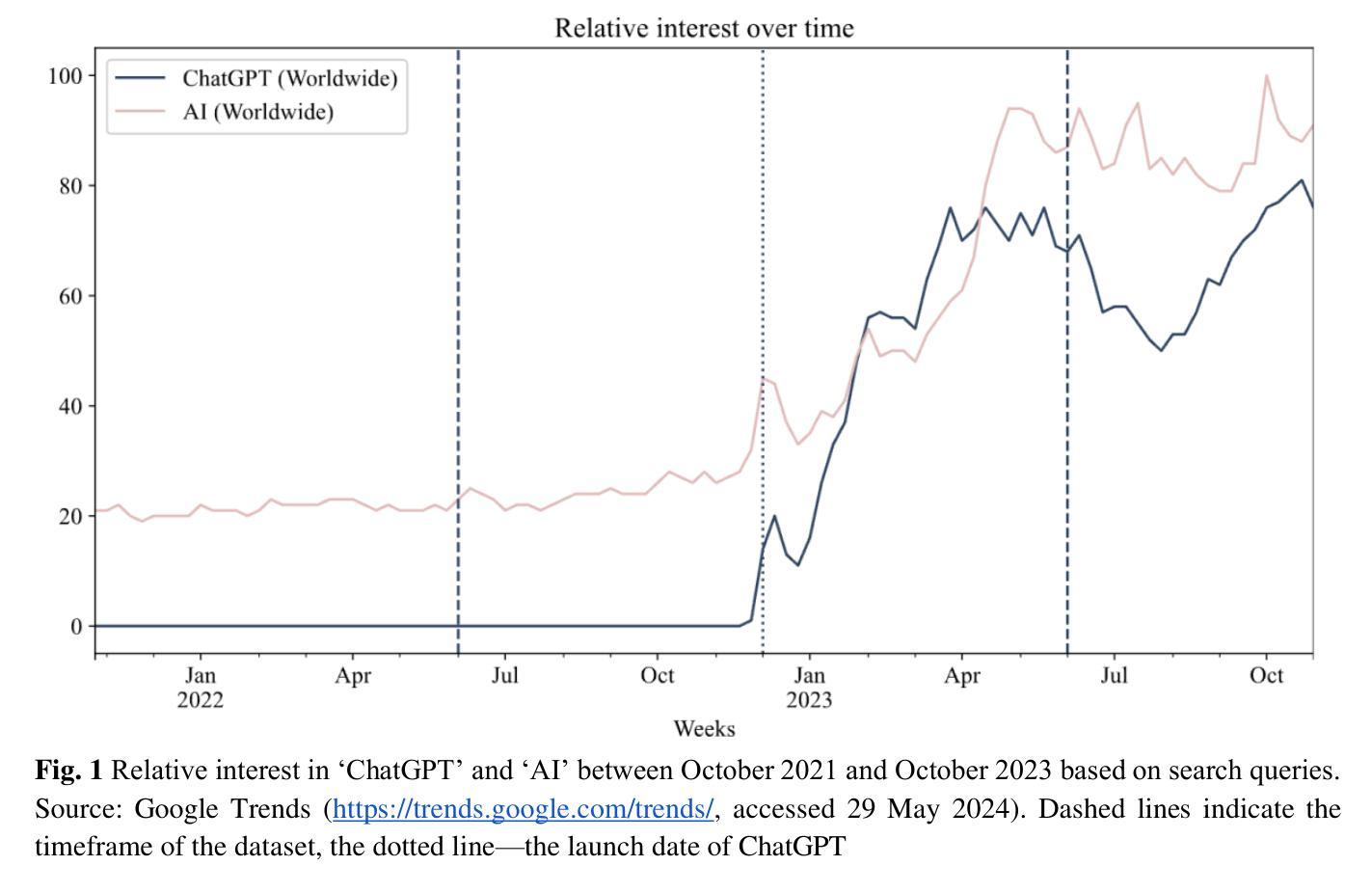

Dynamic Universal Approximation Theory: The Basic Theory for Transformer-based Large Language Models
Authors:Wei Wang, Qing Li
Language models have emerged as a critical area of focus in artificial intelligence, particularly with the introduction of groundbreaking innovations like ChatGPT. Large-scale Transformer networks have quickly become the leading approach for advancing natural language processing algorithms. Built on the Transformer architecture, these models enable interactions that closely mimic human communication and, equipped with extensive knowledge, can even assist in guiding human tasks. Despite their impressive capabilities and growing complexity, a key question remains-the theoretical foundations of large language models (LLMs). What makes Transformer so effective for powering intelligent language applications, such as translation and coding? What underlies LLMs’ ability for In-Context Learning (ICL)? How does the LoRA scheme enhance the fine-tuning of LLMs? And what supports the practicality of pruning LLMs? To address these critical questions and explore the technological strategies within LLMs, we leverage the Universal Approximation Theory (UAT) to offer a theoretical backdrop, shedding light on the mechanisms that underpin these advancements.
语言模型已成为人工智能领域的关注焦点,尤其是随着ChatGPT等突破性创新的引入。大规模的Transformer网络已迅速成为推进自然语言处理算法的主要方法。这些模型基于Transformer架构,使互动能够紧密模仿人类沟通,并凭借丰富的知识,甚至可以帮助指导人类任务。尽管它们的功能令人印象深刻,且复杂性不断增长,但关于大型语言模型(LLM)的理论基础的关键问题依然存在。什么使Transformer在驱动智能语言应用程序(如翻译和编码)方面如此有效?LLM的上下文学习能力(ICL)的基础是什么?LoRA方案如何增强LLM的微调?什么支持LLM修剪的实用性?为了解决这些关键问题并探索LLM内的技术策略,我们利用通用逼近理论(UAT)提供理论背景,阐明支持这些进展的机制。
论文及项目相关链接
Summary
大型语言模型(LLM)已成为人工智能领域的核心焦点,特别是随着ChatGPT等突破性创新的引入。基于Transformer架构的大型语言模型,能够模拟人类沟通互动,辅助人类完成任务。本文探讨了LLM的理论基础,包括Transformer为何能有效驱动智能语言应用、In-Context Learning(ICL)的底层原理、LoRA方案如何增强LLM的微调,以及为何可以实际实现LLM的修剪。通过利用Universal Approximation Theory(UAT)提供理论背景,本文揭示了支撑这些技术进步的机制。
Key Takeaways
- 大型语言模型(LLM)已成为人工智能领域的核心焦点。
- Transformer架构是驱动智能语言应用如翻译和编码的关键。
- In-Context Learning(ICL)是LLM的重要特性,使其能够理解上下文并据此作出响应。
- LoRA方案增强了LLM的微调能力,使其更适应特定任务。
- Universal Approximation Theory(UAT)为LLM的理论基础提供了支持,揭示了其技术进步的机制。
- LLMs的修剪技术使得大型模型更为实用,降低了计算和存储需求。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的关键问题包括:
- 大型语言模型(LLMs)的理论基础:探讨Transformer架构为何在支持智能语言应用(如翻译和编程)方面如此有效。
- In-Context Learning(ICL)的底层机制:分析LLMs如何实现ICL,即在给定上下文中学习并执行任务。
- LoRA方案如何增强LLMs的微调:研究LoRA(Low-rank Adaptation)技术如何提高在资源受限的情况下对大型模型进行微调的效率。
- 模型剪枝的实用性:探讨模型剪枝技术如何帮助在资源受限的环境中部署大型模型,以及为什么LLMs适合进行剪枝。
论文通过利用通用近似理论(Universal Approximation Theory, UAT)为这些关键问题提供理论背景,阐明支撑这些先进技术的机制。具体来说,论文的主要贡献包括:
- 证明Transformer是UAT的具体体现。
- 通过UAT为基于Transformer的LLMs提供严格的科学解释。
- 解释LLMs的特性,如ICL、指令跟随、多步推理,以及应用在LLMs中的技术,如LoRA、剪枝和LLMs的强大泛化能力。
- 对LLMs未来发展的见解。
Q: 有哪些相关研究?
A: 论文中提到了多个与大型语言模型(LLMs)相关的研究和技术创新,以下是一些主要的相关工作:
ChatGPT:由Radford和Narasimhan(2018)以及Brown等人(2020)提出的预训练语言模型,能够执行多种语言任务。
Llama:由Touvron等人(2023)提出的语言模型,旨在提供开放和高效的基础语言模型。
PaLM:Chowdhery等人(2023)提出的模型,专注于通过路径扩展语言建模。
GPT-3:Brown等人(2020)提出的具有1750亿参数的大型语言模型,展示了大规模模型的能力和潜力。
LongLoRA:Chen等人(2023)提出的一种技术,用于高效微调长上下文的大型语言模型。
LoRA:Hu等人(2021)提出的低秩适应方法,用于在资源受限的情况下微调大型语言模型。
模型剪枝:Sun等人(2023)和Ma等人(2023)提出的技术,用于减少模型大小以在较小设备上运行。
多任务提示训练:Sanh等人(2021)和Wei等人(2021, 2022)的工作,研究了如何通过提示训练提高模型的零样本学习能力。
**In-Context Learning (ICL)**:Xie等人(2021)和Min等人(2022)的研究,分析了ICL机制,即模型如何利用上下文信息进行学习。
Transformer网络的数学理论:Cybenko(2007)和Hornik等人(1989)提出的通用近似理论(UAT),为深度学习模型提供了数学基础。
这些研究为理解大型语言模型的工作原理、优化其性能以及探索其在不同领域的应用提供了理论基础和技术方法。论文通过将这些技术放在UAT的框架下进行分析,进一步加深了我们对LLMs的理解。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决上述问题:
理论框架建立:首先,论文提出了将大型语言模型(LLMs)的理论基础建立在通用近似理论(UAT)之上的观点。UAT是一个在深度学习中广泛认可的理论,它表明多层感知器(MLP)能够逼近任意连续函数。
Transformer与UAT的统一:论文的主要目标之一是将Transformer网络统一到UAT的框架下。这涉及到将Transformer中的线性(Linear)和多头注意力(MHA)操作转换为矩阵-向量乘法的形式。
矩阵-向量方法:提出了矩阵-向量方法(Matrix-Vector Method),这是一种重新排列输入数据和参数的方法,使得不同的变换操作能够在网络中统一地表示为矩阵-向量乘法。
钻石矩阵乘法:引入了一种新的计算方法——钻石矩阵乘法(Diamond Matrix Multiplication),用于清晰地描述线性和MHA模块转换为矩阵-向量格式的过程。
证明过程:论文详细阐述了如何将Linear和MHA操作转换为矩阵-向量形式,并通过数学证明展示了这些操作符合UAT。
解释LLMs的特性和技术创新:利用UAT的理论框架,论文解释了LLMs的关键特性,如ICL、指令跟随和多步推理,以及LoRA和剪枝等技术的应用。
未来发展的见解:基于UAT的视角,论文提供了对LLMs未来发展的见解,包括模型优化、技术进步和潜在的应用领域。
讨论和反思:论文还讨论了Transformer架构为何在LLMs中如此强大,以及如何通过UAT来理解和改进LLMs的训练和微调过程。
通过这些步骤,论文不仅为LLMs提供了坚实的理论基础,还为未来的研究和技术发展指明了方向。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,这篇论文主要聚焦于理论分析和数学证明,而不是实验性研究。论文的核心贡献在于:
- 提供了对大型语言模型(LLMs)的理论基础的深入分析,特别是基于通用近似理论(UAT)的视角。
- 证明了Transformer模型是UAT的具体实现,并通过数学方法展示了如何将Transformer中的Linear和MultiHead Attention(MHA)操作转换为矩阵-向量乘法形式。
- 讨论了Transformer架构为何在LLMs中表现出色,以及In-Context Learning(ICL)、LoRA微调和模型剪枝等技术的原理和效果。
论文中并没有提到具体的实验设置或实验结果。相反,作者通过数学推导和理论阐释来支持其观点和结论。这种方法侧重于建立和解释LLMs的数学模型,以及它们如何实现强大的语言处理能力。
Q: 有什么可以进一步探索的点?
A: 根据论文的内容和结论,以下是一些可以进一步探索的点:
模型泛化能力的深入研究:尽管论文讨论了Transformer模型的泛化能力,但可以进一步研究不同架构和训练策略对模型泛化能力的影响。
LoRA和剪枝技术的优化:论文提到了LoRA和剪枝技术,未来的工作可以探索更高效的微调和压缩方法,以适应不同的应用场景和资源限制。
长上下文处理的改进:LongLoRA技术为处理长上下文提供了一种解决方案,但可以进一步研究如何优化模型以更有效地处理长文本数据。
多模态学习:论文提到了人类多模态感知与LLMs的单模态表示之间的差异。未来的研究可以探索如何将多模态信息融合到LLMs中,以丰富模型的理解和生成能力。
自主学习和知识验证:论文指出了人类自主学习和知识验证与LLMs的差异。研究如何使LLMs能够进行自主学习和知识验证,可能是一个值得探索的领域。
模型解释性:提高LLMs的解释性,使人们能够更好地理解模型的决策过程,这有助于建立对模型的信任并提高其在关键应用中的可用性。
跨领域应用:探索LLMs在不同领域的应用,如医疗、法律、教育等,以及如何针对这些领域定制和优化模型。
模型鲁棒性和安全性:研究如何提高LLMs的鲁棒性,防止对抗性攻击,并确保模型输出的安全性和公正性。
模型训练和推理效率:进一步研究如何提高模型训练和推理的效率,包括算法优化、硬件加速等方面。
跨语言和跨文化能力:研究LLMs在处理不同语言和文化背景的文本时的表现,以及如何提高模型对跨语言和跨文化差异的适应性。
这些探索点可以帮助研究者和开发者更好地理解和改进LLMs,推动人工智能领域的发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以概括为以下几个要点:
理论基础探讨:论文深入探讨了大型语言模型(LLMs)的理论基础,尤其是基于通用近似理论(UAT)的视角。
Transformer与UAT的关联:证明了Transformer模型是UAT的具体实现,并展示了如何将Transformer中的Linear和MultiHead Attention(MHA)操作转换为矩阵-向量乘法形式。
矩阵-向量方法:提出了一种新的矩阵-向量方法来重新排列输入数据和参数,使得不同的变换操作能够在网络中统一地表示为矩阵-向量乘法。
钻石矩阵乘法:引入了钻石矩阵乘法,这是一种新的计算方法,用于清晰地描述线性和MHA模块转换为矩阵-向量格式的过程。
LLMs特性与技术解释:利用UAT的理论框架,论文解释了LLMs的关键特性,如In-Context Learning(ICL)、指令跟随和多步推理,以及LoRA和剪枝等技术的应用。
未来发展的见解:基于UAT的视角,论文提供了对LLMs未来发展的见解,包括模型优化、技术进步和潜在的应用领域。
讨论与反思:论文讨论了Transformer架构为何在LLMs中表现出色,并反思了人类与LLMs在语言处理上的差异,以及如何通过UAT来理解和改进LLMs的训练和微调过程。
局限性说明:论文指出其研究范围虽然专注于LLMs的一些关键特性和技术,但并不是穷尽所有可能的研究方向,承认了研究的局限性,并鼓励未来的研究工作。
总的来说,这篇论文为理解LLMs的工作原理提供了理论支持,并对如何进一步发展和优化这些模型提供了有价值的见解。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

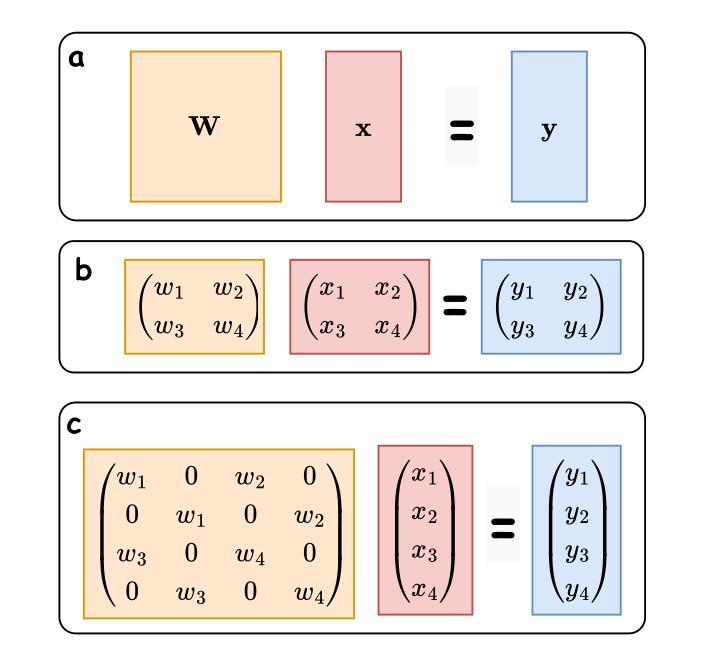

Finding Transformer Circuits with Edge Pruning
Authors:Adithya Bhaskar, Alexander Wettig, Dan Friedman, Danqi Chen
The path to interpreting a language model often proceeds via analysis of circuits – sparse computational subgraphs of the model that capture specific aspects of its behavior. Recent work has automated the task of discovering circuits. Yet, these methods have practical limitations, as they rely either on inefficient search algorithms or inaccurate approximations. In this paper, we frame automated circuit discovery as an optimization problem and propose Edge Pruning as an effective and scalable solution. Edge Pruning leverages gradient-based pruning techniques, but instead of removing neurons or components, it prunes the \emph{edges} between components. Our method finds circuits in GPT-2 that use less than half the number of edges compared to circuits found by previous methods while being equally faithful to the full model predictions on standard circuit-finding tasks. Edge Pruning is efficient even with as many as 100K examples, outperforming previous methods in speed and producing substantially better circuits. It also perfectly recovers the ground-truth circuits in two models compiled with Tracr. Thanks to its efficiency, we scale Edge Pruning to CodeLlama-13B, a model over 100x the scale that prior methods operate on. We use this setting for a case study comparing the mechanisms behind instruction prompting and in-context learning. We find two circuits with more than 99.96% sparsity that match the performance of the full model and reveal that the mechanisms in the two settings overlap substantially. Our case study shows that Edge Pruning is a practical and scalable tool for interpretability and sheds light on behaviors that only emerge in large models.
分析语言模型的路径通常是通过分析电路来完成的,这些电路是模型中的稀疏计算子图,能够捕捉其行为的特定方面。最近的工作已经实现了电路的自动发现。然而,这些方法存在实际局限性,因为它们依赖于低效的搜索算法或不准确的近似值。在本文中,我们将自动化电路发现表述为优化问题,并提出“边缘剪枝”作为一种有效且可扩展的解决方案。边缘剪枝利用基于梯度的剪枝技术,但不是移除神经元或组件,而是剪除组件之间的“边缘”。我们的方法在GPT-2中发现电路,使用不到之前方法发现电路的一半边缘数量,同时在标准电路发现任务上忠实于全模型的预测。即使在多达10万个示例的情况下,边缘剪枝也非常高效,在速度和产生的电路质量方面均优于之前的方法。它还完美地恢复了使用Tracr编译的两个模型的基准电路。凭借其高效率,我们将边缘剪枝扩展到CodeLlama-13B模型,这是一个比之前方法处理规模大100倍的模型。我们以此设置进行案例研究,比较指令提示和上下文学习背后的机制。我们发现两个电路的稀疏度超过99.96%,匹配全模型的性能,并显示两种设置中的机制有大量重叠。我们的案例研究表明,边缘剪枝是一种实用且可扩展的解读工具,可以揭示仅在大型模型中出现的行为。
论文及项目相关链接
PDF NeurIPS 2024 (Spotlight)
Summary
本文提出一种基于优化问题的自动化电路发现方法——边缘裁剪。该方法利用基于梯度的裁剪技术,但不同于移除神经元或组件,而是裁剪组件间的边。此方法在GPT-2中发现电路,所使用的边数量不到先前方法发现电路的一半,同时忠实于全模型的预测结果。边缘裁剪效率高,即使在10万样本量下也是如此,且在速度和电路质量上均优于先前方法。此外,该方法还能完全恢复Tracr编译的两个模型的基准电路。通过大型模型CodeLlama-13B的案例研究,展示边缘裁剪在实践中的实用性,并揭示了指令提示和上下文学习背后的机制重叠性。总体而言,边缘裁剪是一种实用且可伸缩的工具,有助于理解和解释大型模型的行为。
Key Takeaways
- 边缘裁剪是一种有效的自动化电路发现方法,通过裁剪模型中的边来发现特定行为的计算子图。
- 边缘裁剪在GPT-2模型中发现电路所使用的边数量少于先前方法。
- 边缘裁剪方法在速度和电路质量上表现优异,能高效处理大量样本。
- 边缘裁剪能够完全恢复Tracr编译模型的基准电路。
- 通过CodeLlama-13B模型的案例研究,展示了边缘裁剪在大型模型中的实用性。
- 边缘裁剪揭示了指令提示和上下文学习背后的机制具有一定的重叠性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何高效地发现和分析大型语言模型中的"电路"(circuits),即模型中的稀疏计算子图,这些子图能够捕捉模型行为的特定方面。具体来说,论文中提到了现有方法存在的一些实际限制:
- 效率问题:现有的自动化电路发现方法依赖于低效的搜索算法,无法扩展到大型数据集或大型参数模型。
- 准确性问题:一些方法使用基于梯度的线性近似来评估激活的重要性,但这些近似可能牺牲了对完整模型的忠实度。
- 忽视交互影响:现有方法可能没有考虑到不同边缘之间的相对重要性及其交互作用。
为了解决这些问题,论文提出了一种名为”边缘修剪”(Edge Pruning)的新方法,该方法将电路发现问题框架为一个优化问题,并通过基于梯度的修剪技术来解决。这种方法不是移除神经元或组件,而是修剪组件之间的边缘,从而在保持对完整模型预测的忠实度的同时,找到更稀疏的电路。
Q: 有哪些相关研究?
A: 论文中提到了与电路发现和模型解释性相关的一些研究工作,具体包括:
ACDC [Conmy et al., 2023]: 一种自动化电路发现工具,使用昂贵的贪婪搜索算法,逐个移除每条边以估计其重要性。
EAP (Edge Attribution Patching) [Syed et al., 2023]: 一种使用基于梯度的线性近似来同时评估所有边缘重要性的方法。
Tracr [Lindner et al., 2023]: 一个编译器,可以将用特定编程语言编写的程序编译成Transformer模型。
CodeLlama-13B [Rozière et al., 2024]: 一个大型的代码生成模型,用于案例研究中比较指令提示和上下文学习背后的机制。
相关工作:论文还提到了其他一些与电路发现和模型修剪相关的研究,例如使用注意力头的重要性估计进行修剪的方法 [Michel et al., 2019],以及结构化修剪节点以识别最重要节点的方法 [Cao et al., 2021]。
解释性工具:论文中还提到了一些用于帮助解释Transformer模型的可视化工具,例如基于稀疏自编码器发现的特征电路 [Marks et al., 2024],以及与符号算法对齐的计算 [Wu et al., 2023]。
其他方法:包括使用归因打补丁来识别特定领域模型组件的方法 [Ferrando and Voita, 2024],以及提出减少错误的变体的方法 [Krámar et al., 2024]。
这些研究为理解大型语言模型的内部工作机制提供了不同的视角和工具,而本文提出的边缘修剪方法则是在这些现有工作的基础上,提供了一种新的、有效的电路发现方法。
Q: 论文如何解决这个问题?
A: 论文通过提出一种名为“边缘修剪”(Edge Pruning)的方法来解决自动化电路发现的问题。这种方法主要基于以下几个关键步骤:
优化问题框架:将电路发现问题框架为一个优化问题,而不是使用传统的贪婪搜索或第一阶近似方法。
梯度基于修剪:利用基于梯度的修剪技术,不是修剪神经元或组件,而是修剪组件之间的边缘。这允许在更细粒度上进行优化。
反事实激活:对于修剪掉的边缘,使用来自扰动样本的反事实激活来替换缺失的边缘激活,确保模型的输出保持在分布内。
离散优化技术:使用L0正则化等离散优化技术来优化边缘掩码,并产生稀疏电路。
Transformer架构修改:引入所谓的“解耦残差流”(disentangled residual stream),保留所有先前激活的列表,并动态聚合这些激活。
目标稀疏性:通过Lagrangian项和硬混凝土参数化来强制执行目标稀疏性,使得优化过程中可以处理L0项的不可微性。
随机梯度下降:直接针对边缘权重进行随机梯度下降优化,最终将边缘权重转换为二进制掩码,确定最终的电路。
扩展性:证明了边缘修剪可以扩展到大规模数据集和大型模型,如CodeLlama-13B,这是一个超过100B参数的模型。
案例研究:通过在CodeLlama-13B上进行案例研究,比较了指令提示和上下文学习背后的机制,展示了边缘修剪在大型模型中的实用性和可扩展性。
通过这些方法,论文中的边缘修剪能够有效地发现稀疏且忠实于完整模型预测的电路,同时解决了现有方法的效率和准确性问题。
Q: 论文做了哪些实验?
A: 论文中进行了一系列的实验来评估和展示Edge Pruning方法的有效性。以下是主要的实验内容和结果:
基础实验设置:在GPT-2 Small模型上,使用不同的任务来比较Edge Pruning与现有方法(ACDC和EAP)的性能。实验包括间接宾语识别(IOI-t1和IOI)、比较大小(GT)、性别代词(GP)以及Tracr编译的程序。
忠实度和性能比较:通过KL散度和特定任务的性能指标(如Logit Difference和Probability Difference)来衡量发现的电路与完整模型的忠实度和性能。Edge Pruning在多个任务上显示出更好的忠实度和性能。
扩展性测试:创建了一个包含100K示例的IOI数据集的扩展版本,以测试Edge Pruning在处理更大规模数据集时的扩展性。结果表明Edge Pruning能够有效地利用更多示例,并在运行时间和忠实度上优于其他方法。
Tracr程序的电路发现:使用Tracr编译的两个程序(xproportion和reverse)来测试Edge Pruning是否能够准确地恢复已知的电路。实验结果显示Edge Pruning完美地重建了这两个电路。
大规模模型案例研究:在CodeLlama-13B模型上进行了案例研究,比较了指令提示和上下文学习背后的机制。Edge Pruning在该大型模型上找到了非常稀疏的电路,并且这些电路在不同的设置下表现良好,表明这两种设置下模型的机制有显著的重叠。
次要指标评估:除了主要的忠实度和性能指标外,还使用了Exact Match百分比和Kendall’s Tau分数作为次要指标来评估不同方法的忠实度。
边缘重要性分析:通过分析模型和电路中单个边缘的重要性,验证了Edge Pruning发现的电路在边缘层面上与模型的一致性。
计算资源评估:提供了不同实验的计算资源使用情况,包括GPU小时数,以展示Edge Pruning方法的可扩展性。
这些实验结果表明,Edge Pruning是一个有效、可扩展且实用的工具,适用于大型语言模型的电路发现和解释性分析。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的Edge Pruning方法在自动化电路发现方面取得了显著进展,但仍有一些潜在的领域可以进一步探索和改进:
效率与性能的平衡:虽然Edge Pruning在大型数据集和模型上表现出色,但在小数据集上,基于近似的方法如EAP可能更快。研究如何结合Edge Pruning和其他方法以实现效率和性能的最佳平衡是一个有趣的方向。
内存使用优化:Edge Pruning在大规模应用时可能需要较多的GPU内存。探索优化内存使用的技术,例如更高效的数据结构或算法调整,可以帮助减少资源消耗。
自动化解释性:尽管Edge Pruning能够发现稀疏电路,但完全自动化地解释这些电路仍然具有挑战性。开发更高级的自动化工具和技术来解释电路的功能和重要性将非常有价值。
评估指标:论文中提到了需要更好的评估指标来揭示电路可能带来的解释幻觉。研究和开发更准确的评估方法来衡量电路的忠实度和解释性。
跨任务泛化能力:研究Edge Pruning发现的电路在不同任务之间的泛化能力,以及如何通过迁移学习等技术提高电路的泛化性。
多模态模型的电路发现:当前的研究主要集中在文本模型上。将Edge Pruning扩展到多模态模型(如结合图像和文本的模型)的电路发现可能是一个值得探索的领域。
社会和伦理影响:论文提到了其工作对于安全开发和部署大型基础模型的重要性。进一步研究如何确保这些技术在社会和伦理方面的正面影响也很重要。
模型压缩与加速:虽然Edge Pruning的目标是发现电路,但其过程中产生的稀疏模型可能对模型压缩和加速有潜在的应用价值。探索这些稀疏模型在实际部署中的性能和效率将是有意义的。
模型鲁棒性:研究Edge Pruning发现的稀疏电路是否提高了模型对输入扰动的鲁棒性,以及如何进一步增强模型的鲁棒性。
用户交互和可视化工具:开发用户交互式工具和可视化技术,帮助研究人员更直观地理解电路结构和功能,促进电路发现和解释过程。
这些探索点不仅可以推动电路发现技术的发展,还可能对提高深度学习模型的可解释性和信任度产生重要影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题定义:论文首先定义了自动化电路发现的问题,即在大型语言模型中识别出能够捕捉模型行为特定方面的稀疏计算子图。
现有方法的局限性:分析了现有方法,如ACDC和EAP,它们在效率、准确性和考虑边缘交互方面存在的限制。
Edge Pruning方法:提出了一种新的优化方法,称为边缘修剪(Edge Pruning),它使用基于梯度的修剪技术来发现稀疏电路。
方法细节:
- 使用离散优化技术和L0正则化来优化边缘掩码。
- 引入了解耦残差流以处理动态聚合的激活。
- 通过修改Transformer架构来适应边缘修剪。
实验评估:
- 在GPT-2 Small模型上进行了实验,使用不同的任务(如IOI、GT、GP)来评估Edge Pruning与其他方法的比较。
- 测试了Edge Pruning在大规模数据集(100K示例)上的扩展性。
- 在CodeLlama-13B模型上进行了案例研究,比较了指令提示和上下文学习背后的机制。
结果:Edge Pruning在多个任务上显示出更好的忠实度和性能,能够高效地处理大规模数据集和大型模型。
讨论与局限性:论文讨论了Edge Pruning的局限性,包括在小数据集上的效率问题、内存使用以及解释性挑战,并提出了未来工作的方向。
社会和伦理影响:强调了该工作对于安全开发和部署大型基础模型的重要性,并未预见到Edge Pruning被用于不良社会或伦理目的。
贡献总结:论文总结了其贡献,包括提出Edge Pruning方法、证明其在不同任务上的有效性、以及在大型模型上的可扩展性。
致谢:最后,论文感谢了为实验和写作提供帮助的个人和资助机构。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

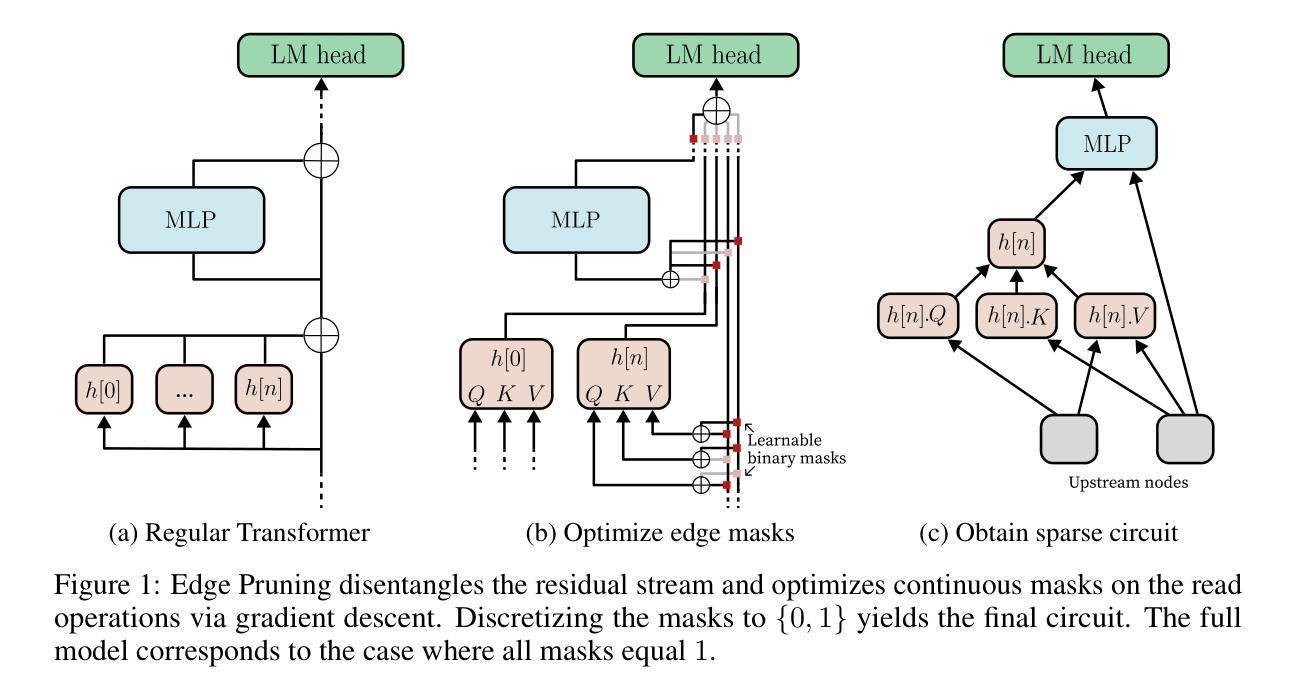
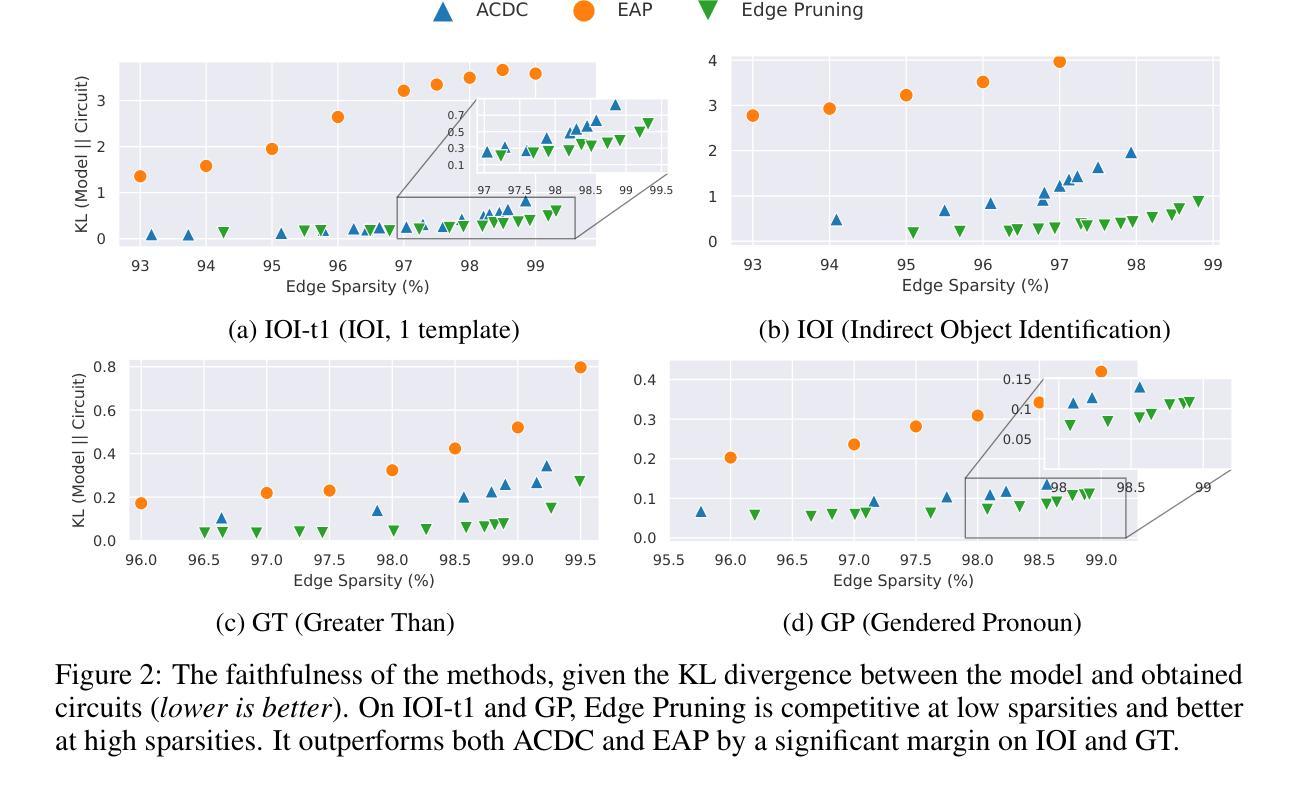
The GPT-WritingPrompts Dataset: A Comparative Analysis of Character Portrayal in Short Stories
Authors:Xi Yu Huang, Krishnapriya Vishnubhotla, Frank Rudzicz
The improved generative capabilities of large language models have made them a powerful tool for creative writing and storytelling. It is therefore important to quantitatively understand the nature of generated stories, and how they differ from human storytelling. We augment the Reddit WritingPrompts dataset with short stories generated by GPT-3.5, given the same prompts. We quantify and compare the emotional and descriptive features of storytelling from both generative processes, human and machine, along a set of six dimensions. We find that generated stories differ significantly from human stories along all six dimensions, and that human and machine generations display similar biases when grouped according to the narrative point-of-view and gender of the main protagonist. We release our dataset and code at https://github.com/KristinHuangg/gpt-writing-prompts.
大型语言模型的生成能力得到了提升,使其成为创意写作和讲故事的强大工具。因此,定量了解生成故事的本质以及它们与人类讲故事方式的差异至关重要。我们使用与GPT-3.5相同的提示,扩展了Reddit WritingPrompts数据集,其中包括由GPT-3.5生成的故事。我们量化并比较了人类和机器生成的故事在情感描述特征方面的六个维度的故事叙述特征。我们发现生成的故事在所有六个维度上都与人类故事存在显著差异,并且根据叙事视角和主人公的性别进行分组时,人类和机器的生成表现出相似的偏见。我们在https://github.com/KristinHuangg/gpt-writing-prompts上发布了我们的数据集和代码。
论文及项目相关链接
PDF 9 pages plus appendices; published at the 6th Workshop on Narrative Understanding, EMNLP 2024
Summary:大型语言模型的生成能力增强,使其成为创意写作和故事叙述的有力工具。为了定量了解生成故事的性质以及它们与人类叙事之间的差异,我们使用与GPT-3.5相同的提示生成Reddit WritingPrompts数据集的故事。我们量化并比较了人类和机器在六个维度上的叙述情感与描述性特征。我们发现生成的故事与人类故事在所有六个维度上都有显著差异,并且根据叙事观点的主角性别,人类和机器生成的叙述显示出相似的偏见。我们在https://github.com/KristinHuangg/gpt-writing-prompts发布我们的数据集和代码。
Key Takeaways:
- 大型语言模型在创意写作和故事叙述方面展现出强大的能力。
- 生成的故事与人类故事在多个维度上存在显著差异。
- GPT-3.5生成的故事与人类故事在情感与描述性特征上有所不同。
- 人类和机器叙事在叙事观点和主角性别方面存在相似的偏见。
- 定量了解生成故事的性质对于评估语言模型的创意写作潜力很重要。
- 公开的数据集和代码为深入研究语言模型的故事生成能力提供了资源。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是量化和比较人类和机器(特别是大型语言模型)在创造性写作和讲故事方面的差异。具体来说,它关注以下几个方面:
- 生成故事的性质理解:研究大型语言模型(如GPT-3.5)生成的故事与人类创作的故事在性质上的差异。
- 情感和描述性特征的比较:沿着六个维度(情感价值、唤醒度、支配度、智力、外貌和力量)量化和比较人类和机器生成的故事。
- 偏见的识别和分析:探讨当根据叙述视角和主要角色的性别进行分组时,人类和机器生成的故事是否显示出类似的偏见。
- 不同评价方法的一致性:使用不同的方法来识别主角属性和评估特定维度上的词汇属性,比较这些方法在测量偏见时的敏感性和一致性。
论文通过扩展Reddit WritingPrompts数据集,包括由OpenAI的GPT-3.5模型生成的短故事,来实现这些目标,并分析了人类和机器在相同提示下创作的叙事特征。这项研究有助于更好地理解大型语言模型在创造性文本生成方面与人类的差异,并识别可能存在的偏见。
Q: 有哪些相关研究?
A: 论文中提到了多个与本研究相关的领域和具体研究工作,主要包括以下几个方面:
自然语言生成模型(Generative Models of Natural Language):研究了几十年的NLP领域,特别是神经变换器模型(neural transformer models)的发展,如GPT系列、Llama模型和Claude模型等。
故事中的偏见(Biases in Stories):研究了人类和人工故事中角色描绘的偏见,特别是性别偏见。例如,Fast等人(2016b)创建了与行为刻板印象相关的词汇表,Sap等人(2017)研究了电影剧本中角色的权力和代理分配。
情感维度(Affective Dimensions):研究了故事中的情感维度,如Osgood等人(1958)提出的价情感(valence)、唤醒度(arousal)和支配度(dominance)。
角色描绘(Character Portrayal):研究了故事中角色的智力、外貌和力量等特征,这些特征在性别刻板印象研究中经常被提及。
Reddit WritingPrompts数据集:Fan等人(2018)收集了Reddit r/WritingPrompts论坛上的30万篇故事,这些故事是对97,223个写作提示的回应。
GPT-WritingPrompts数据集:通过使用OpenAI的GPT-3.5模型为每个提示生成故事,扩展了Reddit WritingPrompts数据集。
评估方法(Evaluation Methods):研究了评估机器生成文本的方法,包括基于参考的评估(reference-based evaluation)和无参考评估(reference-free evaluation)。
语言模型的一致性和偏差(Consistency and Bias in Language Models):研究了语言模型在文本生成中的一致性和可能的偏差,例如Lucy和Bamman(2021)以及Huang等人(2021)的研究。
常识推理(Commonsense Reasoning):使用COMET等模型进行常识推理,以识别故事中的隐含偏见。
这些相关研究为本文的研究提供了理论基础和方法论支持,帮助作者在量化和比较人类与机器生成故事的差异方面进行了深入的分析。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决量化和比较人类与机器生成故事的问题:
数据集扩展:将Reddit WritingPrompts数据集扩展,加入由GPT-3.5生成的短故事,创建了GPT-WritingPrompts数据集。
分析维度定义:确定了六个分析维度:情感价值(valence)、唤醒度(arousal)、支配度(dominance)、智力(intellect)、外貌(appearance)和力量(power)。
角色和视角识别:使用SpanBERT模型进行共指消解,识别故事中的主角,并根据使用的代词将故事分为第一人称、第二人称和第三人称视角,以及第三人称故事中主角的性别。
属性提取:通过两种方法提取描述主角的属性:
- 使用spaCy的依存关系识别与主角相关的动词和形容词。
- 使用COMET模型进行常识推理,推断故事文本中隐含的属性。
维度量化:使用NRC-VAD情感词典和其他相关词汇资源,将提取的属性转换为沿各维度的数值分数。
分数计算方法:采用三种方法将属性转换为分数:
- 平均词汇分数(lex-avg):使用词汇表中属性词的平均分数。
- 平均嵌入相似度(emb-sim):对于不在词汇表中的属性词,基于与词汇表中词的余弦相似度分配分数。
- 轴投影(axis-emb):构建一个编码维度属性的向量轴,并使用属性词的嵌入向量投影到这个轴上计算分数。
实例分析:比较了人类和GPT-3.5生成的故事在各个维度上的平均分数,并分析了不同视角和主角性别分组的差异。
结果比较:在聚合层面和实例层面上比较人类和机器生成的故事,发现两者在所有六个维度上都有显著差异。
偏差一致性分析:比较了不同分析方法在测量偏见时的一致性,发现GPT生成的故事与人类故事在性别偏见方面表现出相似的模式。
数据和代码共享:论文提供了数据集和代码的访问链接,以便其他研究者可以复现和扩展这些分析。
通过这些步骤,论文不仅量化了人类和机器生成故事的差异,还提供了对这些差异背后潜在偏见的深入理解。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来分析和比较人类编写的故事与GPT-3.5生成的故事在不同维度上的特征。以下是论文中提到的主要实验步骤和发现:
数据集构建:通过使用GPT-3.5模型对Reddit WritingPrompts数据集中的提示进行回应,生成了相应的机器故事,创建了GPT-WritingPrompts数据集。
视角和性别分类:通过识别故事中的代词使用,将故事分为第一人称、第二人称和第三人称视角,并进一步对第三人称故事中的主人公性别进行分类(男性、女性或其他)。
属性提取方法:使用两种方法提取描述主人公的属性:
- Linguistic Dependencies with spaCy:利用spaCy库分析句子中的依存关系,识别与主人公相关的动词和形容词。
- Implicit Attributes with COMeT:使用COMET模型进行常识推理,推断出故事文本中隐含的属性。
维度量化:使用NRC-VAD情感词典和其他相关词汇资源,将提取的属性转换为沿各维度(情感价值、唤醒度、支配度、智力、外貌和力量)的数值分数。
分数计算方法比较:对比了三种不同的分数计算方法(lex-avg、emb-sim和axis-emb),发现axis-emb方法在估计非词汇表项的强度分数方面表现更好。
故事分布分析:分析了人类编写和GPT-3.5生成的故事在不同视角类别下的分布情况。
故事特征比较:比较了人类编写和GPT-3.5生成的故事在不同视角和性别分组下的特征分数,发现GPT生成的故事倾向于使用更多与积极情感相关的词汇,但与智力和外貌相关的词汇较少。
实例级别差异分析:计算了每个提示下人类编写和GPT-3.5生成的故事之间的实例级别分数差异,并与人类控制组进行了比较。
偏差一致性分析:分析了不同分析方法在测量性别偏见时的一致性,发现女性主人公在积极情感、被动性、外貌相关词汇上的分数更高,而在智力相关词汇上的分数较低。
结果总结:总结了GPT生成的故事与人类编写的故事在情感和描述性特征上的显著差异,并讨论了这些差异对于理解大型语言模型在创造性写作中的应用和局限性的意义。
这些实验提供了对人类和机器生成故事差异的深入理解,并揭示了在创造性写作任务中可能存在的偏见和一致性问题。
Q: 有什么可以进一步探索的点?
A: 论文在研究人类和机器生成故事的比较分析中提出了一些局限性,并指出了可以进一步探索的点,以下是一些可能的研究方向:
更大规模的数据集:当前的数据集虽然包含大量的提示-故事对,但每个提示下的故事数量有限,这限制了对人类和机器生成过程差异的更深入研究。未来的工作可以扩展数据集,以包含更多的故事,以便进行更严格的统计分析。
更多样化的模型:研究限于GPT-3.5模型,但随着时间的推移,更多的模型(如GPT-4、Llama、Mistral和OLMo)已经出现。未来的研究可以探索这些新模型在故事生成方面的表现和潜在偏见。
更精细的性别分析:论文中的性别分析仅限于二元的男性/女性分类,未来的研究可以考虑更广泛的性别身份,包括非二元性别,并探索更细致的性别表达和偏见。
改进的共指消解模型:论文提到使用的共指消解模型可能在特定领域的表现未经验证。研究者可以开发或改进共指消解模型,以更好地适应故事文本的分析。
词汇资源的改进:使用的静态词汇资源可能无法完全覆盖所有语境下的语言使用,未来的工作可以开发更动态、上下文敏感的词汇资源。
更全面的评价方法:论文中提到了不同的分数计算方法,未来的研究可以探索更多的评价指标,以更全面地评估故事的质量和偏差。
跨领域和跨文化的分析:当前的研究可能受限于特定的文化和语言环境。未来的工作可以扩展到不同的语言和文化背景,以了解故事生成中的跨文化差异和偏见。
故事内容的深度分析:除了情感和描述性特征之外,还可以进一步分析故事的结构、情节发展、角色互动等更深层次的叙事元素。
交互式故事生成:研究机器生成故事的交互性,例如,如何根据读者的反馈或选择来调整故事的发展方向。
伦理和社会责任:随着大型语言模型在创意写作中的应用越来越广泛,需要进一步探讨这些模型可能带来的伦理问题和社会责任。
这些探索点不仅可以推动自然语言处理领域的研究,还有助于更好地理解人类和机器在创造性任务中的相互作用和影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以概括为以下几个要点:
研究背景与动机:探讨了大型语言模型(LLMs)在创意写作和故事叙述方面的应用,并指出了理解这些模型生成的故事性质及其与人类故事叙述的差异的重要性。
数据集构建:作者扩展了Reddit WritingPrompts数据集,加入了由GPT-3.5生成的短故事,创建了GPT-WritingPrompts数据集,用于比较人类和机器对相同提示的响应。
分析维度:确定了六个分析维度:情感价值(valence)、唤醒度(arousal)、支配度(dominance)、智力(intellect)、外貌(appearance)和力量(power)。
方法论:
- 使用SpanBERT进行共指消解,识别故事中的主角和视角。
- 利用spaCy和COMET提取描述主角的属性。
- 采用不同的分数计算方法(lex-avg、emb-sim、axis-emb)将属性转换为数值分数。
实验结果:
- GPT生成的故事在情感价值、支配度上得分较高,但在唤醒度、智力和外貌上得分较低。
- 无论人类还是机器生成的故事,都显示出对女性主角的相似偏见模式。
实例级别分析:比较了每个提示下人类和GPT生成的故事之间的差异,发现人类故事在回应相同提示时彼此之间的差异小于与机器生成故事的差异。
结论:指出了LLMs在模仿人类语言生成方面的差异,并强调了进一步研究的必要性。
局限性:讨论了数据集规模、模型泛化能力、性别分析的精细度、共指消解模型的准确性、词汇资源的覆盖度和评价方法的全面性等方面的局限性。
未来工作:提出了包括扩展数据集、探索新模型、改进性别分析、改进共指消解模型、开发更全面的词汇资源和评价方法等在内的未来研究方向。
资源共享:提供了数据集和代码的访问链接,以便其他研究者使用。
论文通过定量分析和比较,提供了对人类和机器生成故事差异的深入理解,并为未来的研究提供了方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

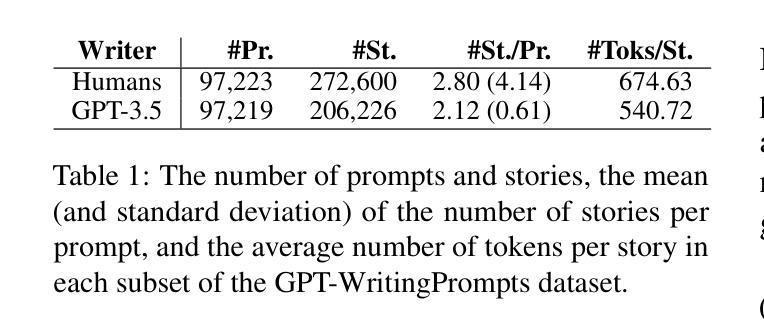
LLAVIDAL: A Large LAnguage VIsion Model for Daily Activities of Living
Authors:Dominick Reilly, Rajatsubhra Chakraborty, Arkaprava Sinha, Manish Kumar Govind, Pu Wang, Francois Bremond, Le Xue, Srijan Das
Current Large Language Vision Models (LLVMs) trained on web videos perform well in general video understanding but struggle with fine-grained details, complex human-object interactions (HOI), and view-invariant representation learning essential for Activities of Daily Living (ADL). This limitation stems from a lack of specialized ADL video instruction-tuning datasets and insufficient modality integration to capture discriminative action representations. To address this, we propose a semi-automated framework for curating ADL datasets, creating ADL-X, a multiview, multimodal RGBS instruction-tuning dataset. Additionally, we introduce LLAVIDAL, an LLVM integrating videos, 3D skeletons, and HOIs to model ADL’s complex spatiotemporal relationships. For training LLAVIDAL a simple joint alignment of all modalities yields suboptimal results; thus, we propose a Multimodal Progressive (MMPro) training strategy, incorporating modalities in stages following a curriculum. We also establish ADL MCQ and video description benchmarks to assess LLVM performance in ADL tasks. Trained on ADL-X, LLAVIDAL achieves state-of-the-art performance across ADL benchmarks. Code and data will be made publicly available at: https://adl-x.github.io/.
当前的大型语言视觉模型(LLVMs)在一般视频理解方面表现良好,但在精细粒度细节、复杂的人与物体交互(HOI)以及日常活动(ADL)所必需的视角不变表示学习方面存在困难。这一局限性源于缺乏专门的ADL视频指令调整数据集以及捕获区分性动作表示的模态融合不足。为了解决这一问题,我们提出了一个半自动的ADL数据集整理框架,创建了ADL-X,一个多视角、多模态RGBS指令调整数据集。此外,我们引入了LLAVIDAL,一个整合视频、3D骨骼和HOI的LLVM,以模拟ADL的复杂时空关系。对于LLAVIDAL的训练,所有模态的简单联合对齐会产生次优结果;因此,我们提出了一种多模态渐进(MMPro)训练策略,按照课程进度分阶段融入各种模态。我们还建立了ADL选择题和视频描述基准测试,以评估LLVM在ADL任务中的性能。在ADL-X数据集上训练的LLAVIDAL在ADL基准测试中达到了最先进的性能。代码和数据将在https://adl-x.github.io/公开提供。
论文及项目相关链接
Summary
当前的大型语言视觉模型(LLVMs)在一般视频理解方面表现良好,但在精细粒度、复杂的人与物体交互(HOI)以及日常活动(ADL)的视图不变表示学习方面存在困难。为解决此问题,提出了半自动化的ADL数据集构建框架,创建了ADL-X多视角、多模态RGBS指令调整数据集。此外,还介绍了LLAVIDAL,一个集成视频、3D骨骼和HOI的LLVM,以模拟ADL的复杂时空关系。由于简单联合对齐所有模态会导致效果不佳,因此提出了分阶段引入模态的多模态渐进(MMPro)训练策略。还建立了ADL选择题和视频描述基准测试来评估LLVM在ADL任务中的性能。在ADL-X上训练的LLAVIDAL在ADL基准测试中实现了最先进的性能。
Key Takeaways
- 当前大型语言视觉模型(LLVMs)在一般视频理解上表现良好,但在精细粒度、复杂交互和日常活动视图不变表示学习方面存在挑战。
- 缺乏专门的ADL视频指令调整数据集和模态集成不足是限制性能的主要原因。
- 提出了一个半自动化的框架来构建ADL数据集,创建了ADL-X多视角、多模态RGBS指令调整数据集以应对上述问题。
- 介绍了LLAVIDAL,一个集成视频、3D骨骼和人与物体交互(HOI)的大型语言视觉模型(LLVM)。
- 简单联合对齐所有模态效果不佳,因此提出了多模态渐进(MMPro)训练策略,分阶段引入不同模态。
- 建立了ADL选择题和视频描述基准测试来评估LLVM在模拟日常活动任务中的性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为LLAVIDAL的框架,旨在解决大型语言视觉模型(LLVMs)在理解和处理日常活动(Activities of Daily Living,简称ADL)视频时面临的挑战。具体来说,论文指出现有的LLVMs在处理互联网视频方面表现出色,但在理解ADL时存在困难,原因包括:
- 数据集限制:缺少针对ADL特定场景的大型、多样化的数据集。
- 模型设计:现有的LLVMs缺乏针对ADL中复杂的时空关系和细微动作的处理能力。
- 多模态信息融合:需要更好地整合视频、3D姿态和物体轨迹等多模态信息,以提高对ADL的理解。
为了解决这些问题,论文提出了以下主要贡献:
- ADL-X数据集:创建了一个包含100K RGB视频-指令对、3D骨架、语言描述和动作条件化的对象轨迹的多视角ADL数据集。
- LLAVIDAL模型:提出了一个能够整合3D姿态和相关对象轨迹来理解ADL中复杂时空关系的LLVM。
- ADLMCQ基准测试:设计了一个新的基准测试,用于量化LLVM在ADL场景中的有效性,包括动作识别和预测的多项选择问题。
- 实验验证:通过广泛的实验确定了将姿态或对象信息整合到LLAVIDAL中的最优策略,并证明了在ADL-X数据集上训练的LLAVIDAL在ADL基准测试上显著优于基线LLVMs。
总的来说,论文的目标是通过一个新的数据集和模型设计,提高LLVMs在理解和生成与ADL相关的语言描述方面的性能。
Q: 有哪些相关研究?
A: 论文中提到了多项相关研究,主要集中在以下几个方面:
多模态学习与大型语言模型(LLMs):研究了如何将视觉和语言模态整合到LLMs中,例如GPT、PALM和BLOOM等模型。
视频基的LLVMs:探讨了将视频整合到LLMs中的研究,以便捕获时空特征,例如VideoChatGPT、VideoLLaVA等。
ADL理解:研究了如何使用LLVMs来理解ADL视频,这包括处理多视角、细粒度活动、复杂的人-物交互和长期时序关系。
数据集:提到了多个视频指令数据集,如TimeIT、VideoChat、Valley、VideoChatGPT和TimeChat,这些数据集在提升一般视频理解方面取得了进展,但对ADL的理解仍有限制。
图像描述器+LLM:介绍了使用基础模型从图像生成视觉特征并将其投影到与语言模型兼容的空间的多模态对话模型,例如Flamingo、BLIP2、MiniGPT4、mPLUG-OWL、IntructBLIP、LLaVA、PaLI和Qwen-VL。
特定于任务的数据集:例如ActivityNet,这是一个大规模的视频基准测试,包含203个活动类别,但可能不足以覆盖ADL领域的特定挑战。
人-物交互:研究了如何通过识别和跟踪视频中的对象来理解ADL,这涉及到动作条件化的对象检测和对象定位与跟踪。
评估基准:提出了新的评估基准ADLMCQ,用于评估LLVMs在ADL任务上的性能,包括动作识别(ADLMCQ-AR)和动作预测(ADLMCQ-AF)。
模型架构:讨论了不同的模型架构,如Socratic Models、VideoChat、VideoChatCaptioner、ChatVideo、VideoLLaMA、TimeChat、VideoLLaVA和VideoChatGPT等,这些模型在视频理解和对话生成方面进行了探索。
这些研究为LLAVIDAL模型的开发提供了理论和技术基础,并帮助确定了在ADL理解方面存在的挑战和需求。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤解决大型语言视觉模型(LLVMs)在理解和处理日常活动(ADL)视频的问题:
创建ADL-X数据集:提出了一个包含100K RGB视频-指令对、3D骨架、语言描述和动作条件化的对象轨迹的多视角ADL数据集。这个数据集是通过一个新颖的半自动化框架从NTU RGB+D 120数据集中筛选和构建的,以增强LLVMs的训练。
开发LLAVIDAL模型:提出了一个名为LLAVIDAL的LLVM,它能够整合视频、3D姿态和对象线索到大型语言模型(LLM)的嵌入空间中。这种整合是通过特定的语言模型(LM)投影层实现的,以确保不同模态的有效对齐。
多模态训练:LLAVIDAL模型不仅使用视频数据,还结合了3D姿态和对象轨迹信息,以提高对ADL视频中复杂时空关系的理解和推理能力。
引入ADLMCQ基准测试:为了客观评估LLVMs在ADL任务上的性能,论文提出了一个新的基准测试ADLMCQ,它包括动作识别(ADLMCQ-AR)和动作预测(ADLMCQ-AF)的多项选择问题。
实验验证:通过广泛的实验,论文确定了将姿态或对象信息整合到LLAVIDAL中的最优策略,并通过与其他LLVMs的比较,证明了LLAVIDAL在ADL-X数据集上训练后在ADL基准测试上的性能优势。
策略探索:论文探索了不同的策略来整合3D姿态信息和人-物交互到LLAVIDAL中,包括将姿态和对象作为QA对、上下文或特征输入到模型中。
提供资源:为了推动该领域的研究,论文提供了数据集的链接,包括ADL-X数据集、LLAVIDAL模型的代码和预训练权重,以及其他相关特征和QA对。
通过这些步骤,论文成功地提出了一个能够更好地理解和生成关于人类日常活动的描述的LLVM框架,并在多个评估指标上展示了其优越的性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和展示LLAVIDAL模型的性能。以下是主要的实验内容和结果:
ADLMCQ-AR(Action Recognition)评估:
- 使用Charades和Toyota Smarthome数据集对模型进行动作识别的多项选择问题回答任务的评估。
- LLAVIDAL在这些任务上的表现超过了其他基线模型,包括VideoChatGPT。
ADLMCQ-AF(Action Forecasting)评估:
- 使用LEMMA和Toyota Smarthome Untrimmed (TSU)数据集对模型进行动作预测的评估。
- LLAVIDAL在预测下一个动作的任务上同样展现出了优越的性能。
视频描述生成:
- 在Charades和TSU数据集上评估模型生成视频描述的能力。
- LLAVIDAL在视频描述任务上超越了现有的最先进方法。
姿态和对象线索的整合:
- 探讨了将姿态和对象线索作为QA对、上下文或特征整合到LLAVIDAL中的不同策略。
- 实验结果表明,直接将姿态和对象特征作为输入令牌投影到LLM空间中可以获得最佳性能。
多模态特征的比较分析:
- 分析了姿态特征和对象特征对模型性能的影响,发现它们在不同的动作类别上提供了互补的信息。
定性评估:
- 提供了LLAVIDAL与其他最先进模型在ADLMCQ动作识别和预测任务上的定性比较。
- 展示了LLAVIDAL在视频描述生成任务上的样本输出,并与其它模型的输出进行了对比。
模型的局限性测试:
- 论文还讨论了LLAVIDAL在处理长视频时的局限性,并提出了未来工作的方向。
这些实验不仅验证了LLAVIDAL模型的有效性,还展示了其在理解ADL视频方面的多模态推理能力。通过与现有技术的比较,论文证明了其方法在多个评估指标上的优势。
Q: 有什么可以进一步探索的点?
A: 论文提出了LLAVIDAL模型和ADL-X数据集,为理解日常活动(ADL)视频提供了新的视角和工具。尽管取得了显著的成果,但仍有一些潜在的研究方向可以进一步探索:
多模态融合策略:尽管LLAVIDAL已经整合了视频、姿态和对象信息,但如何更有效地融合这些不同的模态仍然是一个值得探索的问题。研究者可以尝试开发新的融合方法或改进现有的架构来提高模型性能。
长视频理解:论文指出LLAVIDAL在处理长视频时存在局限性。未来的工作可以探索更有效的采样策略或模型设计,以更好地理解和描述长视频中的事件。
模型泛化能力:研究LLAVIDAL在不同类型的ADL视频和新的、未见过的活动场景中的泛化能力,以及如何通过改进模型结构或训练策略来提高泛化性。
实时性能优化:对于实际应用来说,模型的实时性能至关重要。研究如何优化LLAVIDAL以实现更快的推理速度,同时保持或提高准确性。
交互式应用:探索LLAVIDAL在交互式环境中的应用,例如智能助手或机器人,这些系统可以根据用户的需求提供定制化的信息和帮助。
多语言和跨文化研究:扩展LLAVIDAL以支持多语言和跨文化的场景,使其能够理解和描述不同语言和文化背景下的ADL视频。
鲁棒性研究:提高模型对于噪声、遮挡和不清晰视觉信息的鲁棒性,特别是在实际应用中可能遇到的各种复杂环境。
隐私和安全性:在收集和使用视频数据时,确保隐私保护和数据安全性,避免潜在的滥用风险。
可解释性和透明度:提高模型的可解释性,让用户理解模型的决策过程,这对于建立用户信任和确保模型的公正性至关重要。
跨领域应用:探索LLAVIDAL在医疗、教育、安全监控等其他领域的应用潜力,以及如何针对这些领域进行定制和优化。
模型压缩和加速:研究模型压缩和加速技术,以便将LLAVIDAL部署在资源受限的设备上,如移动设备或嵌入式系统。
持续学习和增量学习:研究LLAVIDAL如何通过持续学习和增量学习来适应新的数据和场景,而无需从头开始重新训练。
这些方向不仅可以推动LLAVIDAL模型本身的发展,也有助于推动整个ADL理解和多模态学习领域的进步。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以概括为以下几个要点:
问题识别:论文指出现有的大型语言视觉模型(LLVMs)在处理日常活动(ADL)视频时存在挑战,包括对复杂时空关系的有限理解、缺乏针对ADL优化的数据集和模型设计。
ADL-X数据集:为了解决上述问题,论文提出了一个新的多视角ADL数据集,名为ADL-X,包含100K RGB视频-指令对、3D骨架、语言描述和动作条件化的对象轨迹。
LLAVIDAL模型:论文介绍了一个名为LLAVIDAL的新型LLVM,它专门针对ADL进行了优化,能够整合3D姿态和对象轨迹信息,以提高对ADL视频中复杂时空关系的理解和推理能力。
多模态训练:LLAVIDAL通过多模态训练方法,结合视频、3D姿态和对象轨迹信息,来提升模型对ADL视频内容的深入理解。
ADLMCQ基准测试:为了评估LLVMs在ADL任务上的性能,论文提出了一个新的基准测试ADLMCQ,包括动作识别(ADLMCQ-AR)和动作预测(ADLMCQ-AF)的多项选择问题。
实验结果:通过广泛的实验,论文证明了LLAVIDAL在ADL-X数据集上训练后,在ADL基准测试上的性能优于其他基线LLVMs。
策略探索:论文探索了不同的策略来整合3D姿态信息和人-物交互到LLAVIDAL中,展示了语言上下文化的特征如何有效地整合到模型中。
资源提供:为了推动该领域的研究,论文提供了数据集链接、模型代码、预训练权重以及其他相关特征和QA对。
未来工作:论文讨论了可能的未来研究方向,包括改进模型的泛化能力、提高实时性能、优化长视频理解等。
伦理考量:论文强调了在研究和应用ADL-X数据集时遵循伦理标准的重要性,鼓励负责任地使用数据集,以促进对需要日常活动辅助的个体的生活质量的改善。
总的来说,这篇论文通过提出一个新的数据集、模型和基准测试,为理解和分析日常活动视频提供了新的工具和方法,展示了LLAVIDAL在多个评估指标上的优势,并为未来的研究提供了方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图