⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-16 更新
CSSinger: End-to-End Chunkwise Streaming Singing Voice Synthesis System Based on Conditional Variational Autoencoder
Authors:Jianwei Cui, Yu Gu, Shihao Chen, Jie Zhang, Liping Chen, Lirong Dai
Singing Voice Synthesis (SVS) aims to generate singing voices of high fidelity and expressiveness. Conventional SVS systems usually utilize an acoustic model to transform a music score into acoustic features, followed by a vocoder to reconstruct the singing voice. It was recently shown that end-to-end modeling is effective in the fields of SVS and Text to Speech (TTS). In this work, we thus present a fully end-to-end SVS method together with a chunkwise streaming inference to address the latency issue for practical usages. Note that this is the first attempt to fully implement end-to-end streaming audio synthesis using latent representations in VAE. We have made specific improvements to enhance the performance of streaming SVS using latent representations. Experimental results demonstrate that the proposed method achieves synthesized audio with high expressiveness and pitch accuracy in both streaming SVS and TTS tasks.
歌唱声音合成(SVS)旨在生成高保真和富有表现力的歌唱声音。传统的SVS系统通常使用声学模型将乐谱转换为声学特征,然后通过声码器重建歌唱声音。最近的研究表明,端到端建模在SVS和文本到语音(TTS)领域是有效的。因此,在这项工作中,我们提出了一种完全端到端的SVS方法,以及分块流式推理来解决实际使用中的延迟问题。值得注意的是,这是首次尝试使用变分自动编码器(VAE)的潜在表示来完全实现端到端流式音频合成。我们对使用潜在表示的流式SVS的性能进行了专项改进。实验结果表明,该方法在流式SVS和TTS任务中均实现了高表现力和音高准确度的合成音频。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
新一代歌唱声音合成(SVS)技术通过端到端建模实现了高质量与高表现力的声音生成。本系统采用全端至端SVS方法,结合分块流式推理解决实际应用中的延迟问题。这是首次尝试在VAE中使用潜在表示实现端到端流式音频合成。实验结果证明,该方法在流式SVS和TTS任务中均实现了高表现力和音高准确度的合成音频。
Key Takeaways
- SVS旨在生成高保真和表现力的歌唱声音。
- 传统的SVS系统通常使用声学模型将乐谱转换为声学特征,然后使用声码器重建歌声。
- 端到端建模在SVS和文本到语音(TTS)领域效果显著。
- 全端至端SVS方法结合分块流式推理解决实际应用中的延迟问题。
- 此为首次尝试在VAE中使用潜在表示实现端到端流式音频合成。
- 针对使用潜在表示的流式SVS性能进行了特定改进。
- 实验结果显示,该方法在流式SVS和TTS任务中合成的音频表现力和音高准确度较高。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个基于条件变分自编码器(Conditional Variational Autoencoder, VAE)的端到端分块流式(chunkwise streaming)歌唱语音合成系统(ChunkStreamSinger, CSSinger),旨在解决以下问题:
实时性和计算资源限制:传统的歌唱语音合成(Singing Voice Synthesis, SVS)系统和文本到语音(Text to Speech, TTS)系统通常包含一个声学模型和一个声码器,这些系统在处理长序列时计算量大,实时性能不佳,尤其是在边缘设备和在线网络服务中部署时。
端到端流式音频合成:这是首次尝试完全实现使用VAE中的潜在表示进行端到端流式音频合成。流式合成对于减少延迟和提高实时性至关重要。
潜在表示用于声码器:使用VAE的潜在表示作为声码器的输入并不直观,尤其是对于歌唱语音,直接使用潜在表示进行音频生成会导致合成音频质量下降。
提高流式SVS性能:论文中提出了特定的改进措施,以增强使用潜在表示的流式SVS性能。
综上所述,论文的主要贡献在于提出了一种新的端到端流式歌唱语音合成方法,该方法不仅能够生成高表达性和音高准确性的合成音频,而且相较于传统的平行计算模型,能够显著降低延迟,提高实时性,更好地适应边缘设备和在线服务等实际应用场景。
Q: 有哪些相关研究?
A: 相关研究主要涉及以下几个领域:
Singing Voice Synthesis (SVS): 论文提到了多个基于深度学习的SVS系统,例如XiaoiceSing、ByteSing、VISinger和VISinger2。这些系统利用深度神经网络生成基于乐谱的高质量歌唱语音。
Text-to-Speech (TTS): 论文中提到了TTS系统中使用的端到端建模方法,如VITS (Kim, Kong, and Son 2021) 和SiFiSinger (Cui et al. 2024),它们基于条件VAE框架进行声学建模和音频合成。
Conditional Variational Autoencoder (VAE): VAE作为一种深度生成模型,在语音合成领域有广泛应用,如VITS、VISinger和SiFiSinger等系统,它们利用VAE学习潜在空间表示,以提高合成音频的自然度和真实感。
Streaming and Autoregressive Modeling: 论文中提到了一些研究工作,它们关注于流式自回归建模,例如Tacotron2和WaveNet。这些模型分别用于声学建模和波形生成,但存在推理效率低下和生成速度慢的问题。
Neural Audio Synthesis: 论文中提到了HiFi-GAN,这是一个用于高保真语音合成的生成对抗网络,它在CSSinger系统中被用于流式音频合成。
Efficient Neural Audio Synthesis: 论文中提到了WaveRNN,这是一个用于实时应用的神经音频合成模型,它通过减小模型大小和权重稀疏化来加速生成过程。
这些相关研究为CSSinger系统的提出提供了理论基础和技术背景,CSSinger系统在这些研究的基础上,通过引入流式处理和潜在表示的改进,旨在实现更高效、更自然的歌唱语音合成。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为ChunkStreamSinger(CSSinger)的系统来解决上述问题,具体解决方案包括以下几个关键点:
端到端条件VAE框架:
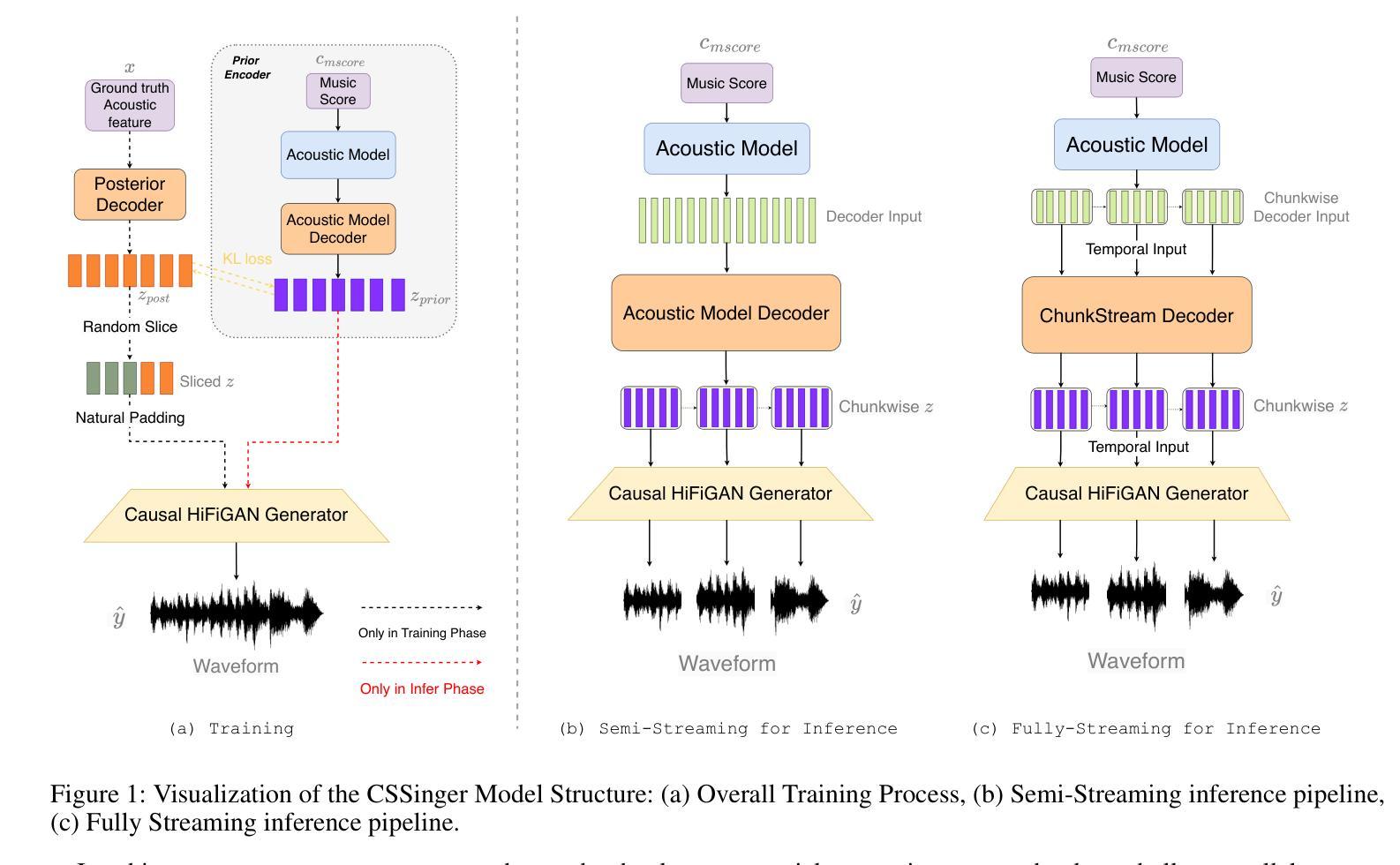
- 使用条件变分自编码器(VAE)来学习音乐评分(如歌词、音高、时长)的潜在表示,并直接生成合成音频。
- 该框架包括一个先验编码器(Prior Encoder)和一个后验编码器(Posterior Encoder),用于学习潜在空间的表示,并从这些表示中直接生成合成音频。
分块流式推理(Chunkwise Streaming Inference):
- 采用分块方式处理音频合成任务,降低实时处理的延迟,并减少计算资源消耗。
- 在声码器(vocoder)中使用因果转置卷积(causal transposed convolutions)来生成音频,避免了传统填充方法导致的音质下降问题。
自然填充(Natural Padding)策略:
- 为了避免在因果卷积中使用传统常数填充(如零填充或复制填充)导致的音质问题,论文提出了自然填充策略。
- 该策略通过在训练过程中动态地使用实际的潜在表示作为填充,而不是固定的常数值,以提高音频合成质量。
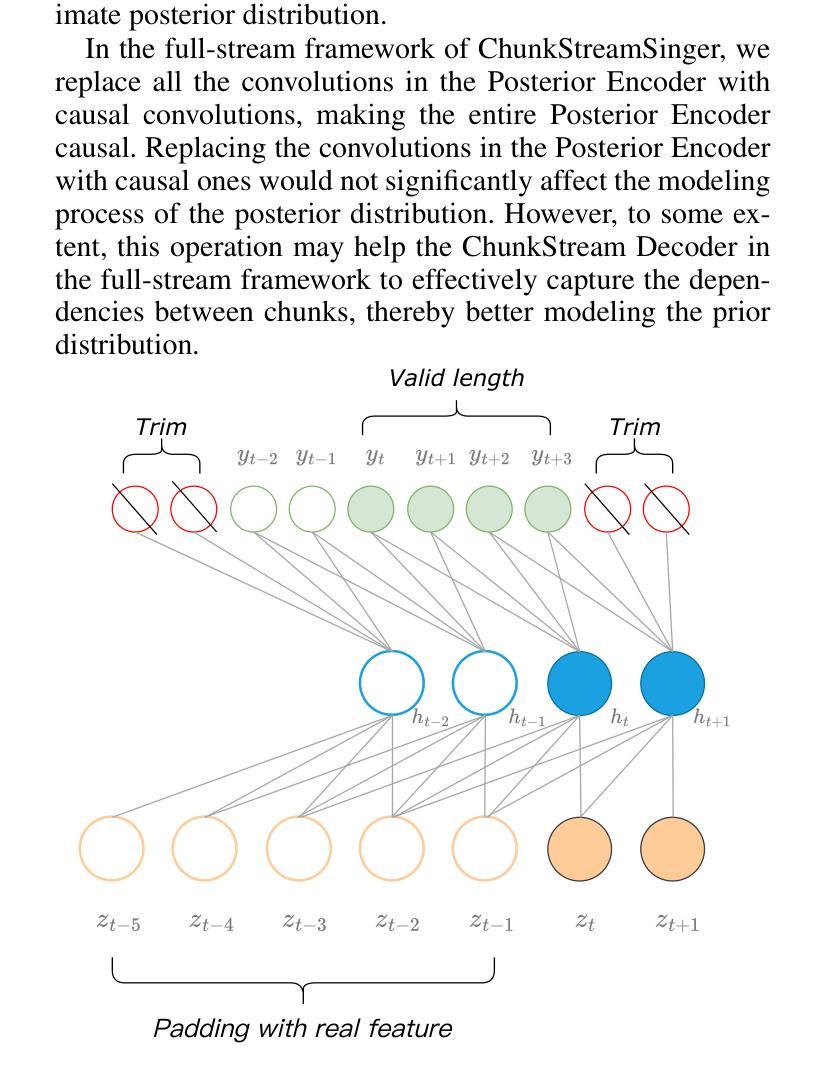
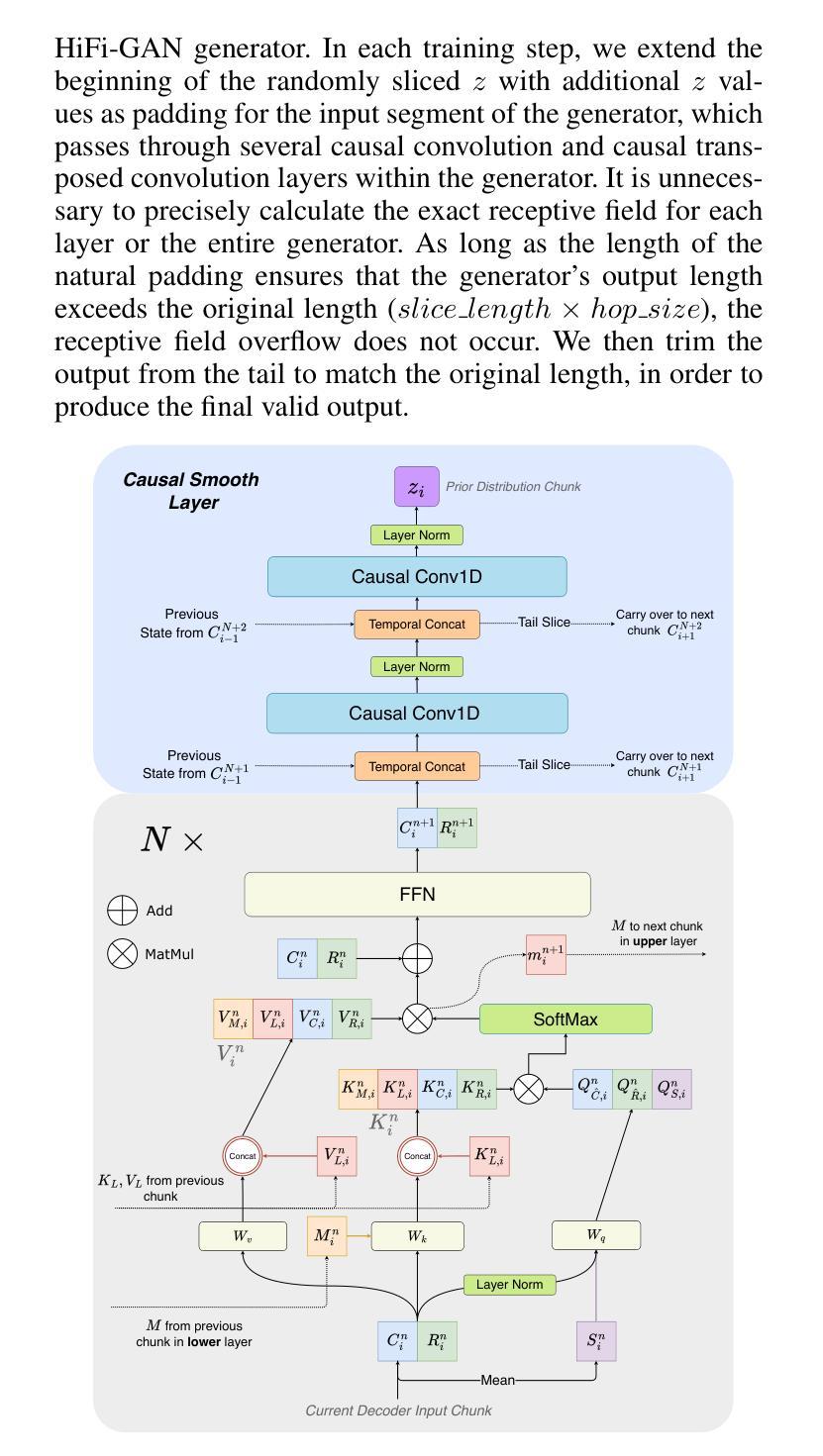
ChunkStream Decoder:
- 为了实现完全的流式推理,提出了ChunkStream Decoder,它将潜在表示的生成转换为基于块的流式处理。
- 该解码器借鉴了Emformer模型的机制,将完整的输入特征向量分解为多个固定长度的块,并在各个块之间提供上下文信息,确保注意力机制可以在每个块上并行计算。
因果平滑层(Causal Smooth Layer):
- 为了减少块之间的边界效应,引入了因果平滑层,该层由一维因果卷积和LayerNorm层组成。
- 这层保留了前一个块的相同层级的特征,并为下一个块提供特征,以增强合成音频的自然度和流畅性。
实验验证:
- 在多个中文歌唱语音数据集和一个TTS数据集上进行了实验,验证了所提出方法在主观和客观评价指标上相较于现有系统的优越性。
- 展示了CSSinger-FS在MOS评分和客观评价指标上的优势,并在不同硬件配置下评估了模型的延迟和实时性。
通过这些技术方案,论文成功地实现了一个低延迟、高效率的端到端流式歌唱语音合成系统,该系统不仅提高了合成音频的质量,还降低了实时应用中的延迟,使其更适合于边缘设备和在线服务等资源受限环境。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估所提出的ChunkStreamSinger(CSSinger)系统的性能,包括主观和客观的评估。以下是实验的详细内容:
数据集
- Opencpop2:一个公开的高质量中文歌唱语音数据集,包含100首普通话歌曲,由专业女歌手演唱,包含3,756个话语,总时长5.2小时。
- PopCS:另一个中文普通话歌唱语音数据集,包含117首歌曲,总时长约5.89小时,由专业女歌手演唱。
- Baker3:一个中文女性语音数据集,包含约12小时的标准普通话女性语音,包含10,000个句子,平均每个句子16个字符。
比较方法
- Recording:使用真实的歌唱语音音频作为基准。
- SiFiSinger:一个完全并行推理的基线系统。
- CSSinger-SS:CSSinger的半流式方法,只有HiFiGAN声码器以分块流式方式运行。
- CSSinger-SS-NP:CSSinger-SS加上自然填充(Natural Padding)的半流式结构。
- CSSingerFS(提出的模型):CSSinger的全流式框架,使用ChunkStream Decoder实现潜在表示z的流式推理。
实施细节
- 使用44.1KHz采样的音频处理Opencpop和PopCS数据集,而Baker数据集的音频采样率为48KHz,被重新采样到16KHz。
- 模型隐藏层大小设置为192,FFN隐藏层的通道数为768。
- Acoustic Model Decoder和ChunkStream Decoder都有4个注意力层。
- 使用diffsptk4提取80维melcepstrum(mcep)作为声学特征。
- 所有实验中HiFi-GAN生成器的训练随机切片大小设置为20,CSSinger模型的块大小也为20。
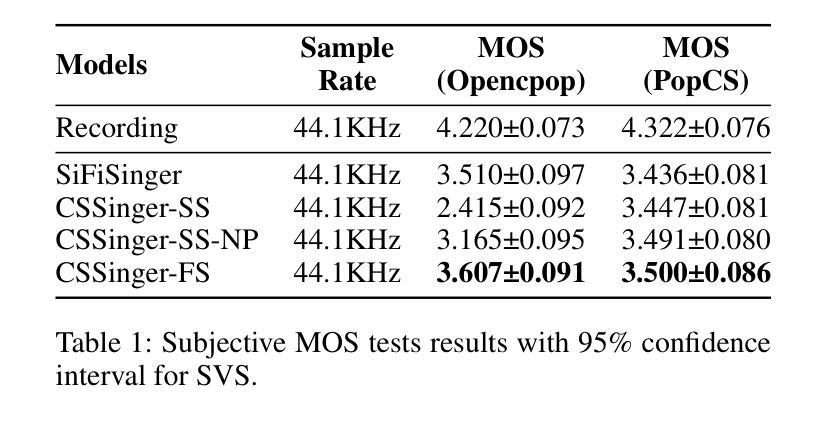
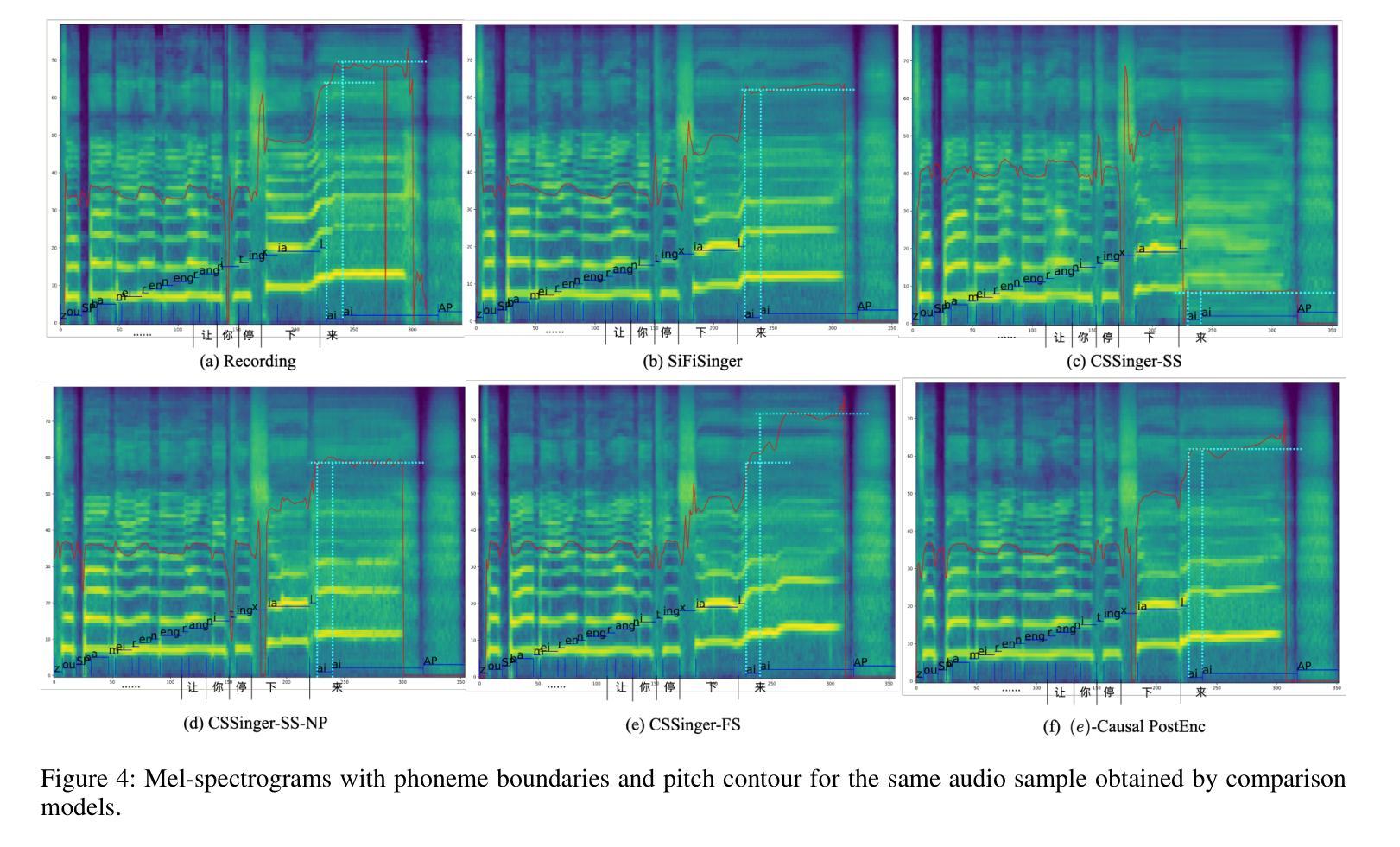
主要结果与分析
- 主观评估(MOS测试):在Opencpop和PopCS数据集上进行,随机选择20个样本,邀请20名母语人士进行主观评估。
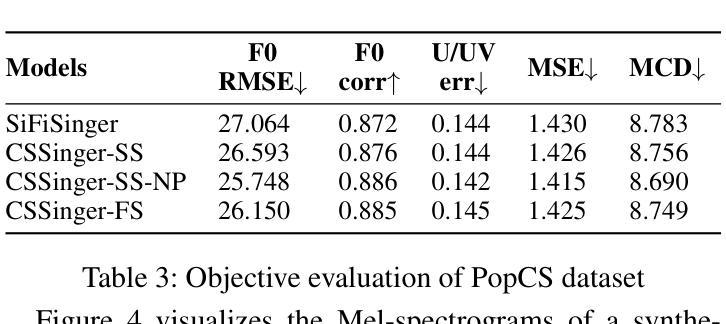
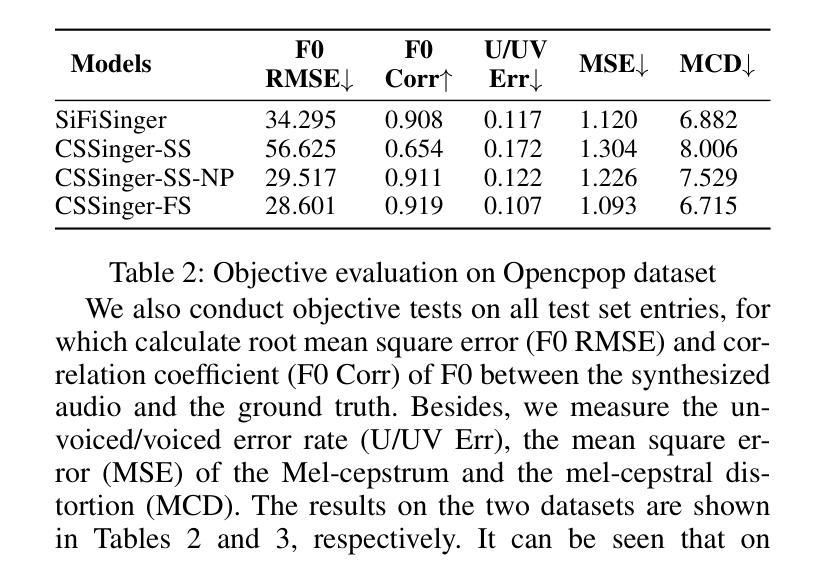
- 客观评估:计算合成音频与真实音频之间的基频均方根误差(F0 RMSE)、基频相关系数(F0 Corr)、无声/有声错误率(U/UV Err)、Mel-cepstrum均方误差(MSE)和Mel-cepstral失真(MCD)。
延迟评估
- 测量从输入特征到合成音频生成的延迟(秒)、从输入特征到音频处理完成的总处理时间(秒)和实时因子(RTF)作为系统效率的指标。
- 在GPU、CPU和单核单线程CPU限制(CPU-Limited)三种情况下测试延迟指标。
结论
- CSSinger-FS在多个客观和主观指标上表现出色,优于现有的并行和半流式系统。
- 在GPU和CPU硬件配置下,CSSinger-FS显示出较低的延迟和优越的实时推理效率,这对于高实时需求的应用和计算资源受限的场景非常重要。
这些实验全面评估了CSSinger系统的性能,证明了其在歌唱语音合成任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的ChunkStreamSinger(CSSinger)系统在歌唱语音合成方面取得了显著的性能提升,但仍有一些领域可以进一步探索和改进:
模型泛化能力:
- 在更多种类和风格的歌唱数据集上测试模型的泛化能力,包括不同语言、不同性别和不同演唱技巧的数据集。
更深入的客观评估:
- 开发更精细的客观评价指标,以更全面地评估合成音频的自然度、清晰度和音乐性等。
实时性能优化:
- 进一步优化模型以降低延迟和计算资源消耗,特别是在资源受限的设备上,如移动设备或嵌入式系统。
多风格和多歌手建模:
- 探索如何使模型能够处理多个歌手和不同演唱风格,提供更丰富的合成选项。
端到端训练的改进:
- 研究如何改进端到端训练过程,可能包括更好的损失函数、优化算法或正则化技术,以进一步提高合成质量。
声码器的改进:
- 研究新型声码器或改进现有声码器,以生成更高保真度和更自然的音频。
上下文感知建模:
- 提高模型对歌曲上下文的感知能力,例如,理解和模拟歌曲的情绪和节奏变化。
交互式应用:
- 探索CSSinger在交互式应用中的潜力,如卡拉OK系统或音乐教育软件,其中实时反馈和调整是必要的。
模型解释性:
- 提高模型的可解释性,帮助研究人员和开发者更好地理解模型的决策过程和潜在空间的结构。
多任务学习:
- 考虑将歌唱语音合成与其他任务(如音乐生成、节奏识别)结合起来,以创建更全面的音乐生成系统。
模型鲁棒性测试:
- 对模型进行鲁棒性测试,尤其是在面对不完整或噪声数据时的性能。
跨领域应用:
- 探索CSSinger在其他领域的应用,如语音编码、语音增强或语音转换。
这些探索方向不仅可以推动歌唱语音合成技术的发展,还可能为整个语音合成和音频处理领域带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个基于条件变分自编码器(Conditional Variational Autoencoder, VAE)的端到端分块流式(chunkwise streaming)歌唱语音合成系统ChunkStreamSinger(CSSinger)。以下是论文的主要内容总结:
问题陈述:
- 论文旨在解决传统歌唱语音合成(SVS)系统中存在的实时性和计算资源限制问题,特别是在边缘设备和在线网络服务中部署时的高延迟问题。
系统架构:
- CSSinger基于SiFiSinger构建,采用条件VAE框架,包含先验编码器和后验编码器,直接从音乐评分生成合成音频。
- 系统支持分块流式推理,以减少延迟并提高实时性。
关键技术:
- 自然填充(Natural Padding):解决VAE潜在表示用于声码器输入时的音质下降问题。
- ChunkStream Decoder:实现完全流式推理,将潜在表示的生成转换为基于块的流式处理。
- 因果平滑层(Causal Smooth Layer):减少块之间的边界效应,增强合成音频的自然度和流畅性。
实验验证:
- 在两个中文歌唱语音数据集和一个文本到语音(TTS)数据集上进行了实验,验证了CSSinger系统在主观和客观评价指标上相较于现有系统的优越性。
- 展示了CSSinger在不同硬件配置下(GPU和CPU)的低延迟和优越的实时推理效率。
结论:
- CSSinger-FS(全流式框架)在MOS评分和客观评价指标上优于现有的并行和半流式系统。
- 该系统不仅提高了合成音频的质量,还降低了实时应用中的延迟,使其更适合于边缘设备和在线服务等资源受限环境。
未来工作:
- 论文提出了一些可以进一步探索的方向,包括模型泛化能力的提升、实时性能的进一步优化、多风格和多歌手建模等。
总体而言,这篇论文提出了一个创新的端到端流式歌唱语音合成系统,通过引入先进的技术方案,有效地提高了合成音频的质量和实时性,为SVS领域的发展提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

CAS-GAN for Contrast-free Angiography Synthesis
Authors:De-Xing Huang, Xiao-Hu Zhou, Mei-Jiang Gui, Xiao-Liang Xie, Shi-Qi Liu, Shuang-Yi Wang, Hao Li, Tian-Yu Xiang, Zeng-Guang Hou
Iodinated contrast agents are widely utilized in numerous interventional procedures, yet posing substantial health risks to patients. This paper presents CAS-GAN, a novel GAN framework that serves as a “virtual contrast agent” to synthesize X-ray angiographies via disentanglement representation learning and vessel semantic guidance, thereby reducing the reliance on iodinated contrast agents during interventional procedures. Specifically, our approach disentangles X-ray angiographies into background and vessel components, leveraging medical prior knowledge. A specialized predictor then learns to map the interrelationships between these components. Additionally, a vessel semantic-guided generator and a corresponding loss function are introduced to enhance the visual fidelity of generated images. Experimental results on the XCAD dataset demonstrate the state-of-the-art performance of our CAS-GAN, achieving a FID of 5.87 and a MMD of 0.016. These promising results highlight CAS-GAN’s potential for clinical applications.
碘化造影剂在众多介入手术中被广泛应用,但会给患者带来重大健康风险。本文提出了CAS-GAN,这是一种新型的GAN框架,可作为“虚拟造影剂”通过解纠缠表示学习和血管语义指导来合成X射线血管造影术,从而减少介入手术中对碘化造影剂的依赖。具体来说,我们的方法将X射线血管造影术分解成背景和血管成分,利用医学先验知识。然后,一个专门的预测器学习这些成分之间的相互作用关系。此外,还引入了血管语义导向生成器和相应的损失函数,以提高生成图像的可视保真度。在XCAD数据集上的实验结果表明,我们的CAS-GAN达到了最新技术水平,FID为5.87,MMD为0.016。这些令人鼓舞的结果突出了CAS-GAN在临床应用中的潜力。
论文及项目相关链接
PDF IEEE Symposium Series on Computational Intelligence (SSCI 2025)
摘要
本研究提出一种新型GAN框架CAS-GAN,作为“虚拟造影剂”用于合成X光血管造影术图像。CAS-GAN通过解耦表示学习和血管语义指导,减少了介入手术中对碘造影剂的需求。它通过分解X光血管造影术图像为背景和血管成分,利用医学先验知识。一个专门的预测器学习这些成分之间的关系映射。此外,引入了血管语义引导的生成器和相应的损失函数,以提高生成图像的可视逼真度。在XCAD数据集上的实验结果表明,CAS-GAN达到了最先进的性能,FID为5.87,MMD为0.016。这些令人鼓舞的结果表明CAS-GAN在临床应用中的潜力。
要点
- CAS-GAN作为一种“虚拟造影剂”,在介入手术中减少对碘造影剂的需求。
- CAS-GAN通过解耦表示学习合成X光血管造影术图像。
- CAS-GAN将X光血管造影术图像分解为背景与血管成分。
- 利用医学先验知识,专门的预测器学习血管成分之间的关系映射。
- 引入血管语义引导的生成器和损失函数,提高生成图像的可视逼真度。
- 在XCAD数据集上的实验结果表明CAS-GAN性能先进。
- CAS-GAN在临床应用中具有潜在价值。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。通过使用CAS-GAN,研究者们希望能够合成出无需使用碘造影剂的X射线血管造影图像,从而减少对这些可能对患者造成潜在健康风险的造影剂的依赖。
具体来说,论文中提到了以下几个关键问题:
心血管疾病(CVDs)的治疗需求:心血管疾病是全球死亡的主要原因,而图像引导的血管介入手术是治疗心血管疾病的主流方法之一。
碘造影剂的健康风险:在X射线血管造影中,为了使血管显影,需要使用碘基的造影剂。然而,这些造影剂存在副作用,包括可能危及生命的过敏反应,以及对肾脏的潜在损害,尤其是在已有肾脏疾病或糖尿病患者中。
减少造影剂使用的需求:为了满足临床需求,同时显著减少造影剂剂量甚至不使用造影剂,同时保持成像质量,这是X射线血管造影系统必须解决的关键挑战。
生成对抗网络(GANs)的应用:论文提出了利用GANs作为“虚拟造影剂”来生成逼真的X射线血管造影图像的可能性,这可能会减少对碘造影剂的依赖,并提高介入手术的安全性和效率。
图像到图像的翻译挑战:将非对比X射线图像转换为X射线血管造影图像是一个具有挑战性的问题,因为它不仅需要在两个图像域之间进行风格转换,还需要精确的一对一图像映射。
论文提出的CAS-GAN框架通过解耦X射线血管造影图像的背景和血管成分,并利用医学先验知识,使用神经网络学习这些成分之间的相互关系,从而解决了上述挑战。此外,还引入了血管语义引导生成器和相应的损失函数,以增强生成图像的视觉保真度。
Q: 有哪些相关研究?
A: 论文中提到了多个与CAS-GAN相关的研究工作,可以归纳为以下几个方面:
1. 生成对抗网络(GANs)
- GANs由Goodfellow等人在2014年引入,通过建立一个最小最大优化游戏,其中生成器G旨在模仿真实数据样本的分布,而判别器D评估它们的真伪。
- 论文中提到了一些GAN的变种,它们通过更稳定的训练目标来解决训练GANs时的挑战,比如梯度消失和模式崩溃问题。
2. 图像到图像的翻译(Image-to-image translation)
- 这项工作涉及将图像从一个域转换到另一个域,同时保持其底层结构或内容。
- Isola等人提出了一个条件GAN框架,使用对抗损失和L1重建损失在成对数据上进行训练。
- 近期的研究集中在无成对数据的翻译上,引入了循环一致性等额外约束以保持域转换期间的语义一致性。
3. 解耦表示学习(Disentanglement representation learning)
- 解耦表示学习通过将图像分解为具有物理意义的成分来提高生成图像的可控性和可解释性。
- 一些工作尝试将图像分解为内容和风格表示,以实现通过交换风格表示进行图像翻译。
4. 医学图像生成和翻译
- 论文中提到了几项与医学图像生成和翻译相关的研究,包括使用GANs从非对比X射线图像生成X射线血管造影图像的研究。
5. 相关技术方法
- 论文还提到了一些技术方法,如注意力机制(attention mechanisms)、自监督对比损失(self-supervised contrast loss)等,这些方法被用于增强不同域之间语义关系的翻译。
具体论文和方法
- CycleGAN:用于无成对图像到图像的翻译。
- UNIT、MUNIT:用于无监督的图像到图像的翻译网络。
- AttentionGAN:使用注意力引导的生成对抗网络进行无成对图像到图像的翻译。
- QS-Attn:使用查询选择注意力进行对比学习。
- StegoGAN:用于非双射图像到图像的翻译,利用隐写术。
这些相关研究为CAS-GAN提供了理论基础和技术背景,同时也展示了在医学图像翻译领域中,如何利用深度学习技术来解决实际的临床问题。
Q: 论文如何解决这个问题?
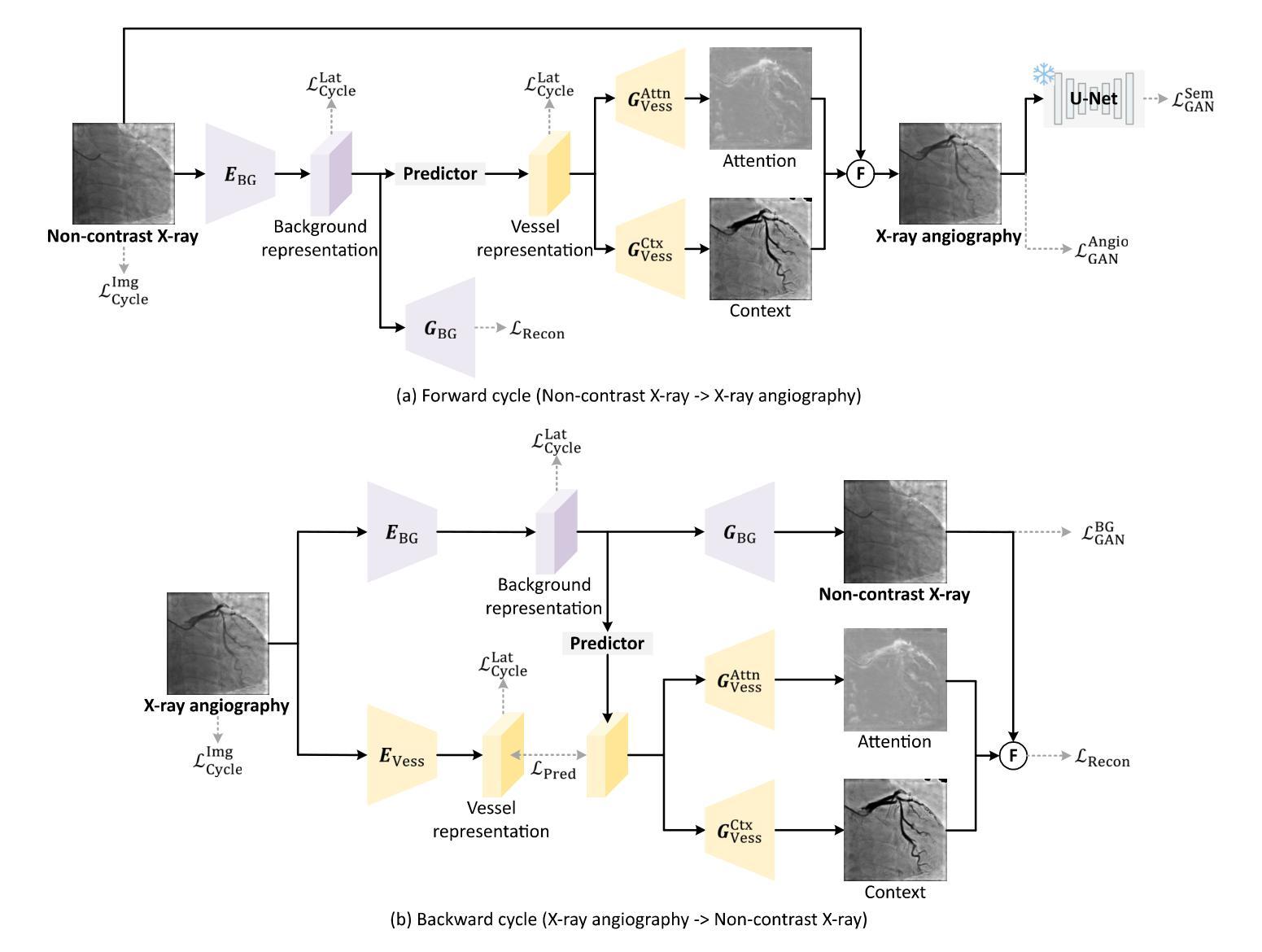
A: 论文通过提出一个名为CAS-GAN的新型生成对抗网络(GAN)框架来解决这个问题。CAS-GAN框架的核心思想是将X射线血管造影图像解耦为背景和血管成分,然后通过神经网络学习这两部分之间的相互关系,以此来生成逼真的血管造影图像。以下是该方法解决该问题的关键步骤:
解耦表示学习(Disentanglement Representation Learning):
- 使用两个专门的编码器(一个背景编码器和一个血管编码器)将X射线血管造影图像分解为背景和血管成分。
- 通过一个称为“预测器”的神经网络,从背景表示中推断出血管表示。
血管语义引导生成器(Vessel Semantic-Guided Generator):
- 为了提高生成图像中血管的真实性,引入了两个专门的生成器:一个用于注意力掩模,一个用于上下文掩模。
- 这些生成器利用预测器提供的血管表示来生成逼真的血管结构。
血管语义引导的对抗损失(Vessel Semantic-Guided Adversarial Loss):
- 为了提高GAN对真实和生成血管图像之间差异的识别能力,引入了一种新的对抗损失,专注于血管的语义差异。
- 使用预训练的U-Net网络提取原始和生成血管造影图像中的血管语义图像,然后定义基于这些语义图像的对抗损失。
训练目标(Training Objective):
- 由于两个图像域之间的映射高度不确定,因此结合了多种有效的损失函数来训练CAS-GAN,包括预测损失、对抗损失、循环一致性损失和重建损失。
- 这些损失函数的加权和构成了CAS-GAN的训练目标,以优化图像翻译过程的各个方面。
通过这些方法,CAS-GAN能够有效地从非对比X射线图像中生成逼真的X射线血管造影图像,从而减少对碘造影剂的依赖,并提高介入手术的安全性和效率。论文中的实验结果表明,CAS-GAN在XCAD数据集上实现了最先进的性能,证明了其在临床应用中的潜力。
Q: 论文做了哪些实验?
A: 论文中进行了多项实验来验证CAS-GAN模型的性能,包括与其他最先进方法的比较、消融研究以及外部验证。以下是实验的具体内容:
A. 数据集(Dataset)
- 使用了X射线血管造影冠状血管分割数据集(XCAD),该数据集包含非对比X射线图像和X射线血管造影图像。
- 数据集分为两个子集:一个用于图像翻译任务,另一个用于训练U-Net提取血管语义信息。
- 随机选择了621张非对比X射线图像和621张X射线血管造影图像作为测试集,其余作为训练集。
B. 实现细节(Implementation details)
- 采用了与CycleGAN相同的生成器和判别器架构,以进行公平比较。
- 预测器使用多层感知机(MLP)实现。
- 使用PyTorch、Python和Ubuntu环境,搭载NVIDIA GeForce RTX 4090 GPU进行实验。
- 使用Adam优化器进行1000个周期的训练,初始学习率设置为2e-4,并在700个周期后线性降低至零。
C. 评估指标(Evaluation metrics)
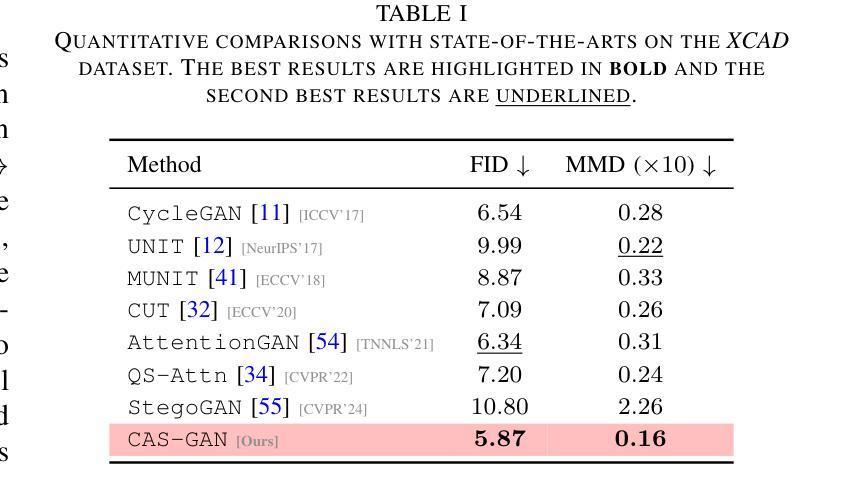
- 使用了Fréchet Inception Distance(FID)和Maximum Mean Discrepancy(MMD)两个指标来评估生成图像的性能。
D. 实验结果(Results)
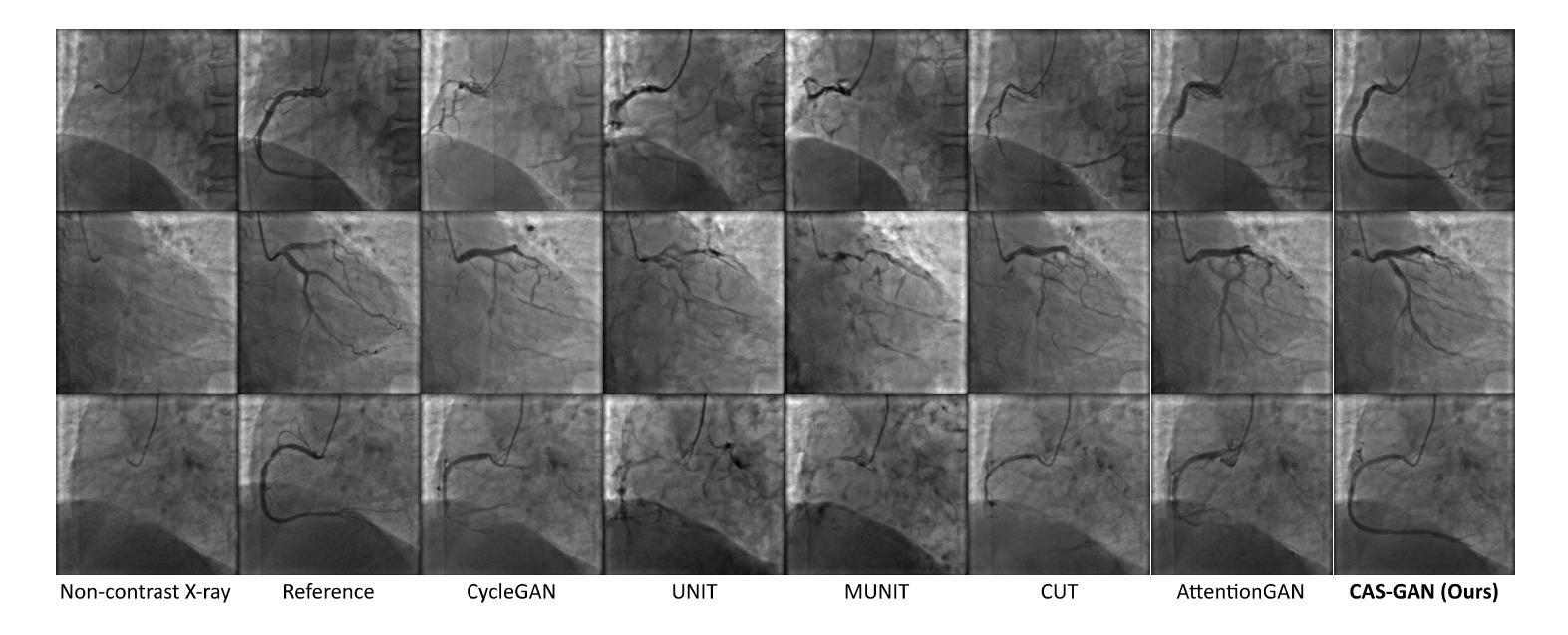
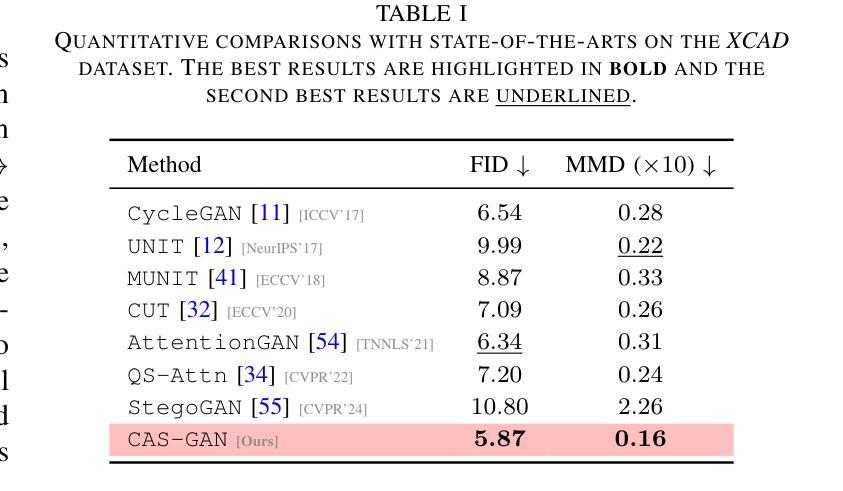
1. 与最先进方法的比较(Comparisons with state-of-the-arts)
- 将CAS-GAN与其他几种领先的无成对图像到图像翻译方法进行了比较,包括CycleGAN、UNIT、MUNIT、CUT、AttentionGAN、QS-Attn和StegoGAN。
- 在XCAD数据集上的定量结果表明,CAS-GAN在FID和MMD两个指标上均优于其他基线方法。
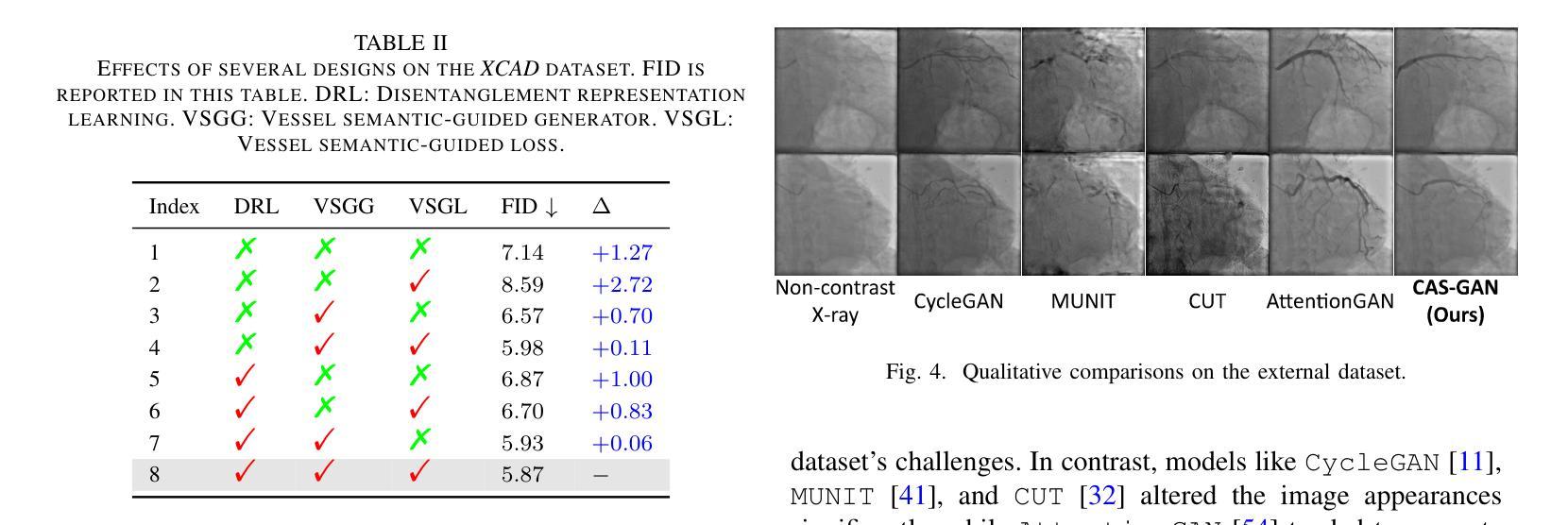
2. 消融研究(Ablation studies)
- 进行了广泛的消融实验来验证CAS-GAN中几个设计的有效性,包括解耦表示学习(DRL)、血管语义引导生成器(VSGG)和血管语义引导损失(VSGL)。
- 实验结果显示,这些设计显著提高了模型的性能。
3. 外部验证(External validation)
- 为了验证模型的泛化能力,还在来自合作医院的外部数据集上进行了实验。
- 尽管所有方法在处理XCAD和外部数据集之间的显著差异时都遇到了困难,但CAS-GAN展示了相对较好的性能。
这些实验结果证明了CAS-GAN在无需对比剂的X射线血管造影合成任务中的有效性和优越性能。论文还指出,未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的能力。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些未来工作的方向,以下是一些可以进一步探索的关键点:
扩展训练数据集:通过增加数据集的大小和多样性来提高模型在外部数据集上的性能。这可能包括收集更多的X射线血管造影图像以及对应的非对比X射线图像,以提高模型的泛化能力。
纳入更先进的模型:探索使用更先进的生成模型,如StyleGAN等,以进一步提高生成图像的质量和真实感。
改进损失函数:研究和设计新的损失函数,以更好地捕捉血管造影图像的特定特征,从而提高生成图像的质量。
多模态数据融合:考虑将CAS-GAN与其他成像模态(如CT、MRI)结合,以实现多模态图像融合和翻译。
实时性能优化:优化模型的计算效率,使其能够在临床环境中实时生成高质量的血管造影图像。
临床验证:与医疗专家合作,进行临床试验以验证CAS-GAN生成的图像在实际诊断和治疗规划中的有效性和安全性。
交互式系统开发:开发交互式系统,使医生能够根据需要调整生成的血管造影图像,以更好地满足特定的临床需求。
模型解释性:提高模型的可解释性,使医生能够理解模型的决策过程,从而增加对生成图像的信任。
跨领域应用:探索CAS-GAN在其他医疗图像翻译任务中的应用,如不同模态之间的图像转换或病理图像的合成。
鲁棒性和安全性测试:对模型进行广泛的鲁棒性和安全性测试,以确保其在各种临床条件下都能稳定地工作。
这些方向不仅可以推动CAS-GAN技术的发展,还可能对医疗图像处理和计算机视觉领域产生更广泛的影响。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一种名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。CAS-GAN通过解耦表示学习和血管语义引导生成血管造影图像,以减少对碘造影剂的依赖。
以下是论文的主要内容概述:
问题背景:心血管疾病是全球主要死因之一,而X射线血管造影是诊断和治疗这些疾病的关键技术。然而,传统的X射线血管造影需要使用碘基造影剂,这些造影剂可能引起严重的副作用,包括过敏反应和肾脏损害。
CAS-GAN框架:提出了一种新颖的GAN框架,通过解耦背景和血管成分,利用医学先验知识,使用神经网络学习这两部分之间的相互关系,从而合成逼真的血管造影图像。
方法论:
- 解耦表示学习:使用专门的编码器将血管造影图像分解为背景和血管成分,并用一个神经网络(预测器)来推断血管表示。
- 血管语义引导生成器:引入两个专门的生成器来生成注意力掩模和上下文掩模,以增强生成图像中血管的真实性。
- 血管语义引导的对抗损失:提出了一种新的对抗损失,专注于血管的语义差异,以提高GAN对真实和生成血管图像之间差异的识别能力。
实验:
- 使用XCAD数据集进行实验,该数据集包含非对比X射线图像和X射线血管造影图像。
- 在定量和定性上与其他最先进方法进行比较,CAS-GAN在FID和MMD指标上均优于其他方法。
- 进行消融研究验证了解耦表示学习、血管语义引导生成器和血管语义引导损失的有效性。
- 在外部数据集上进行验证,展示了CAS-GAN的泛化能力。
结论与未来工作:CAS-GAN为减少介入手术中碘造影剂的使用提供了一种有前景的方法。未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的性能。
总的来说,这篇论文提出了一个创新的解决方案来应对医疗成像中的一个关键挑战,并展示了有希望的初步结果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图