⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-17 更新
GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion
Authors:Jiapeng Tang, Davide Davoli, Tobias Kirschstein, Liam Schoneveld, Matthias Niessner
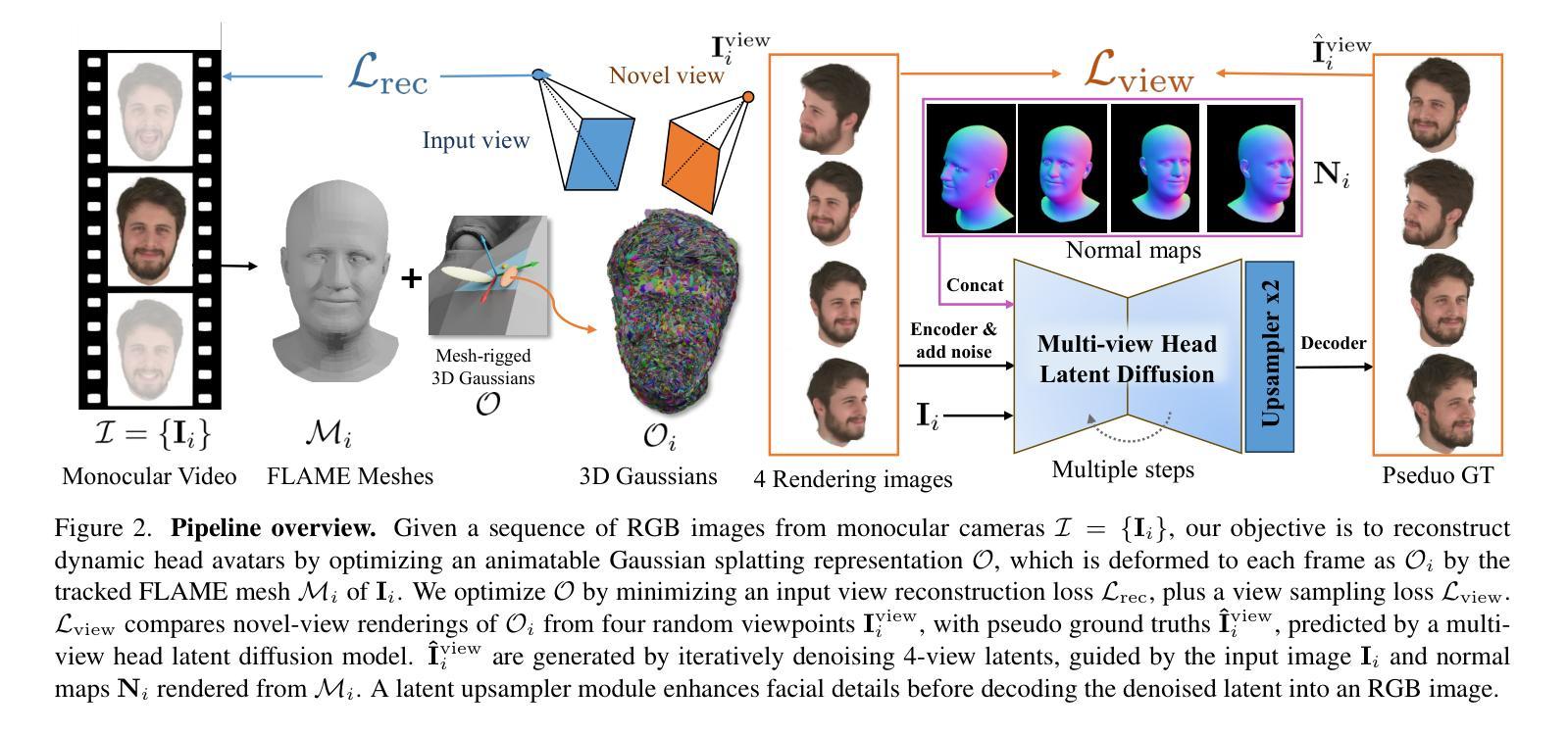
We propose a novel approach for reconstructing animatable 3D Gaussian avatars from monocular videos captured by commodity devices like smartphones. Photorealistic 3D head avatar reconstruction from such recordings is challenging due to limited observations, which leaves unobserved regions under-constrained and can lead to artifacts in novel views. To address this problem, we introduce a multi-view head diffusion model, leveraging its priors to fill in missing regions and ensure view consistency in Gaussian splatting renderings. To enable precise viewpoint control, we use normal maps rendered from FLAME-based head reconstruction, which provides pixel-aligned inductive biases. We also condition the diffusion model on VAE features extracted from the input image to preserve details of facial identity and appearance. For Gaussian avatar reconstruction, we distill multi-view diffusion priors by using iteratively denoised images as pseudo-ground truths, effectively mitigating over-saturation issues. To further improve photorealism, we apply latent upsampling to refine the denoised latent before decoding it into an image. We evaluate our method on the NeRSemble dataset, showing that GAF outperforms the previous state-of-the-art methods in novel view synthesis by a 5.34% higher SSIM score. Furthermore, we demonstrate higher-fidelity avatar reconstructions from monocular videos captured on commodity devices.
我们提出了一种新的方法,可以从如智能手机等商品设备捕获的单目视频中重建可动画的3D高斯虚拟人。从这种记录中进行逼真的3D头部虚拟人重建是一个挑战,因为观察有限,导致未观察到的区域约束不足,并在新视角中产生伪影。为了解决这个问题,我们引入了一个多视角头部扩散模型,利用它的先验知识来填充缺失区域,并确保高斯光斑渲染中的视图一致性。为了实现精确的视点控制,我们使用基于FLAME的头部重建渲染的正态图,这提供了像素对齐的归纳偏见。我们还将在扩散模型的条件置于从输入图像中提取的VAE特征上,以保留面部身份和外观的细节。对于高斯虚拟人重建,我们通过使用迭代去噪图像作为伪真实值来提炼多视角扩散先验,有效地减轻了过度饱和问题。为了进一步改善逼真度,我们应用潜在上采样来精细化去噪潜在码,然后再将其解码为图像。我们在NeRSemble数据集上评估了我们的方法,结果表明GAF在新型视角合成方面比现有最佳方法高出5.34%的SSIM得分。此外,我们还展示了从单目视频捕获的商品设备上进行的高保真虚拟人重建。
论文及项目相关链接
PDF Paper Video: https://youtu.be/QuIYTljvhyg Project Page: https://tangjiapeng.github.io/projects/GAF
Summary
本文提出了一种利用单目视频重建可动画的3D高斯化身的新方法,该方法适用于智能手机等普通设备捕捉的视频。文章解决了从这类视频中进行逼真3D头像重建的挑战,通过引入多视角头部扩散模型,利用先验知识填充缺失区域,并确保高斯拼贴渲染中的视角一致性。结合从FLAME基础的头部重建渲染的正常地图,实现了精确的视角控制。此外,文章还将扩散模型的条件设置为输入图像的VAE特征,以保留面部身份和外观的细节。通过迭代去噪图像作为伪真实值,提取高斯化身重建的多视角扩散先验,有效减轻过度饱和问题。最后,通过潜在上采样提高去噪潜伏品的细腻度,进一步提高化身的光泽度。在NeRSemble数据集上的评估结果表明,GAF在新型视角合成方面较之前的最优方法提高了5.34%的SSIM得分。
Key Takeaways
- 提出了一种基于单目视频重建可动画的3D高斯化身的新方法。
- 通过引入多视角头部扩散模型解决了从智能手机等普通设备捕捉的视频中进行逼真3D头像重建的挑战。
- 利用先验知识填充缺失区域,确保高斯拼贴渲染中的视角一致性。
- 利用正常地图实现精确视角控制。
- 通过将扩散模型的条件设置为输入图像的VAE特征,保留了面部身份和外观的细节。
- 通过迭代去噪图像作为伪真实值,有效提取了高斯化身重建的多视角扩散先验,减轻了过度饱和问题。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种新的方法,旨在解决从由普通设备(如智能手机)拍摄的单目视频中重建可动画化的3D高斯头像的问题。具体来说,论文试图解决以下几个挑战:
有限观测导致的约束不足:单目视频由于观测角度有限,导致对头像的不可见区域(如侧面)的重建不足,这会在新视角渲染时产生伪影。
新视角一致性:如何确保从单目视频重建的头像在新视角下渲染时,能够保持外观和身份的一致性。
真实感渲染:从单目视频中重建的头像在新视角下渲染时,如何保持照片级真实感。
为了解决这些问题,论文提出了一种基于多视角头部扩散模型的方法,利用该模型的先验知识来填补缺失区域,并确保在高斯绘制渲染中的视角一致性。此外,论文还引入了从FLAME基础头部重建中渲染的正常图来提供精确的视点控制,并使用从输入图像中提取的VAE特征来保持面部身份和外观的细节。通过迭代去噪图像作为伪真实值,有效缓解了过饱和问题,并应用潜在上采样来提高头像重建的保真度。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的工作:
3D场景表示:
- **Neural Radiance Fields (NeRF)**及其变体:这些方法彻底改变了从多视图图像重建3D场景的方式,但通常在训练和推理阶段计算效率低下。
- **Gaussian Splatting (GS)**:与NeRF相比,GS通过将场景表示为离散的几何原语(3D高斯)并使用显式光栅化器进行渲染,在训练和推理阶段实现了显著的运行速度提升。
参数化面部/头部模型:
- 基于3D形态模型(3DMM)的工作学习从单RGB图像/视频中重建和跟踪3D面部/头部。
- 更近期的方法使用基于坐标的多层感知机(coordinate-MLPs)来实现更细粒度的几何重建,包括头发和胡须。
真实感头像重建:
- 将NeRF/GS与3D形态模型(3DMM)结合起来,以创建真实感和可动画化的头部头像。
- 一些工作探索了基于点的表示以实现高效的训练。
2D先验知识用于3D生成:
- 通过使用Score Distillation Sampling (SDS)损失,可以将大规模预训练的文本到图像先验用于3D资产生成。
多视角扩散模型:
- 一些工作学习图像条件的新视角扩散先验,利用输入图像的身份和外观细节来生成一致的新视角图像。
与Gaussian Splatting相关的工作:
- 将高斯绘制与FLAME网格结合起来,通过三角形变形控制高斯绘制的属性,以实现头像的动画化。
这些相关工作涵盖了3D场景重建、参数化模型、真实感头像生成、2D到3D的转换以及多视角图像生成等领域,为本研究提供了理论和技术基础。论文通过结合这些相关技术,提出了一种新的方法来从单目视频中重建3D高斯头像,并在新视角下进行真实感渲染。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤解决了从单目视频中重建3D高斯头像的问题:
1. 多视角头部扩散模型
论文提出了一个多视角头部扩散模型,该模型能够从单一视图输入生成一致的多视角图像。这个模型利用了扩散先验来填补单目视频中缺失的区域,并确保在高斯绘制渲染中的视角一致性。
2. 正常图引导
为了实现精确的视点控制,论文使用从FLAME头部重建渲染的正常图作为扩散过程的引导。与相机姿态嵌入相比,正常图提供了更强的归纳偏置,从而实现更精确和可靠的新视角生成。
3. VAE特征融合
论文将从输入图像中提取的VAE特征直接整合到多视角扩散模型中。通过在多视角去噪潜在空间和VAE潜在空间之间进行交叉注意力操作,有效地传递了特定身份的细节。
4. 迭代去噪图像作为伪真实值
为了利用多视角扩散先验进行高斯头部重建,论文采用了迭代去噪图像作为伪真实值,而不是单步得分蒸馏采样损失。这种方法可以减少由于随机噪声水平和种子引入的噪声梯度,从而缓解合成3D资产中的过饱和问题。
5. 潜在上采样模型
为了提高高斯渲染的真实感,论文引入了一个潜在上采样模型,在将去噪潜在空间解码回图像空间之前增强面部细节。
6. 损失函数
论文通过组合损失函数来优化高斯绘制,包括像素级L1损失、SSIM损失和LPIPS损失,以及用于惩罚异常分布的高斯的位置和尺度正则化项。
7. 实现细节
论文详细描述了多视角头部扩散模型的训练过程,包括初始化、训练策略和训练数据集的构建。此外,还提供了高斯头像优化的具体实现细节,如FLAME网格的初始获取、可动画高斯的优化过程以及运行时性能。
通过这些方法,论文能够有效地从单目视频中重建出真实感和可动画化的3D高斯头像,并在新视角下进行高质量的渲染。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了以下实验:
数据集
- NeRSemble 数据集:用于头部头像重建实验的多视角视频数据集,包含16个视角的RGB视频序列,覆盖了正面和侧面的脸部。
- Monocular Video 数据集:包含从 INSTA 数据集和智能手机捕获的单目视频,用于评估在普通设备上捕获的视频的头像重建效果。
评估指标
- L1损失、LPIPS、PSNR 和 SSIM:用于量化评估重建头像与真实头像之间的相似度。
实验设置
- 新视角合成:评估重建的头像在训练期间看到的头部姿势和表情下,从15个保留的视点渲染的效果。
- 新表情合成:评估重建的头像在训练期间未见的头部姿势和表情下,从5个附近的保留视点渲染的效果。
基线比较
- INSTA、FlashAvatar 和 GaussianAvatars:与三种最先进的方法进行比较。
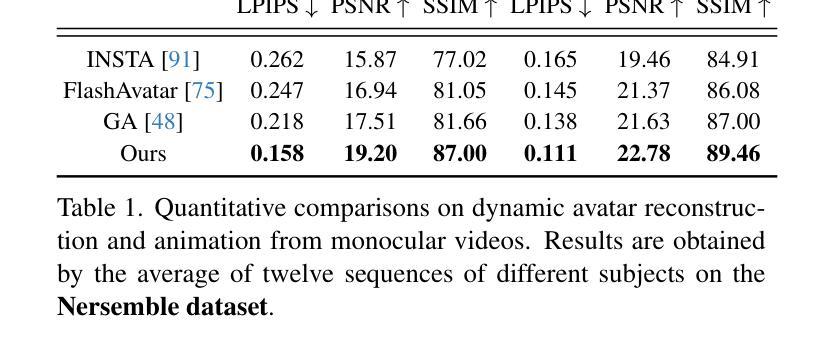
实验结果
- 定量比较:在 NeRSemble 数据集上,论文的方法在新视角合成任务中超过了所有基线方法,特别是在 PSNR 和 SSIM 指标上取得了显著提升。
- Monocular Video 数据集:由于缺乏单目捕获的真实视角渲染的地面真实数据,只进行了动画效果的定量评估,论文的方法在所有指标上均优于其他方法。
消融研究
- 对多视角头部扩散先验、正常图条件、迭代去噪图像作为伪真实值以及潜在上采样模块等设计选择进行了详细的消融研究,验证了每个组件的有效性。
鲁棒性分析
- 分析了输入单目视频帧数对重建性能的影响,证明了即使在输入帧数较少的情况下,论文的方法也能保持稳定的性能。
额外比较
- 提供了额外的定性比较,包括新视角合成、自我/交叉重演以及不同输入帧数下的鲁棒性分析。
这些实验全面评估了论文提出方法的有效性,并与现有技术进行了比较,同时也探讨了不同设计选择对性能的影响。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和当前的研究进展,以下是一些可以进一步探索的点:
1. 头发建模和动画
当前的参数化头部模型缺乏详细的头发几何形状和动画。未来的工作可以扩展高斯头部头像以包含细粒度的头发建模和动画。
2. 实时4D头像重建
论文提到优化头部高斯使用迭代更新的伪真实值从扩散模型是耗时的。探索实时4D头像重建与前馈大型重建模型可能是一个有价值的研究方向。
3. 材料和外观分离
论文没有明确区分头部的材料和外观,这可能限制了重新照明应用。研究如何分离材料和外观,以支持更多动态的光照和渲染效果。
4. 更广泛的数据集和场景
目前的实验主要基于特定的数据集和受控环境。将方法扩展到更多样化的数据集和更复杂、更自然的场景中,以提高泛化能力。
5. 交互式应用和VR/AR集成
研究如何将头像重建技术集成到交互式应用和虚拟现实(VR)/增强现实(AR)产品中,以提高用户体验。
6. 性能优化和硬件加速
探索新的方法来优化算法性能,减少内存使用和计算时间,使其更适合在资源受限的设备上运行。
7. 更多的先验知识融合
研究如何融合更多的先验知识(如形状先验、表情先验等)到模型中,以提高重建质量和鲁棒性。
8. 多模态输入
考虑将更多的模态(如深度信息、IR图像等)整合到重建流程中,以提供更丰富的输入信息。
9. 伦理和隐私问题
随着技术的发展,进一步探讨与真实感头像生成相关的伦理和隐私问题,确保技术的负责任使用。
10. 用户自定义和编辑能力
研究如何提供用户自定义和编辑头像的能力,以满足个性化需求和创意表达。
这些探索点可以帮助推动3D头像重建技术的发展,并在更广泛的应用中实现其潜力。
Q: 总结一下论文的主要内容
A: 本论文提出了一种从单目视频中重建可动画化的3D高斯头像的新方法,旨在解决由于观测限制导致的重建难题。以下是论文的主要内容总结:
1. 问题定义
- 从普通设备(如智能手机)捕获的单目视频中重建真实感和可动画化的3D头部头像存在挑战,因为有限的观测会导致未观测区域的重建不足,从而在新视角渲染时产生伪影。
2. 关键思想
- 利用多视角头部扩散模型的先验知识来填补单目视频中缺失的区域,并确保在高斯绘制渲染中的视角一致性。
3. 方法论
- 多视角头部扩散模型:通过迭代去噪图像作为伪真实值,生成与输入图像视角一致的多视角图像。
- 正常图引导:使用FLAME头部重建渲染的正常图进行视点控制,提供精确的新视角生成。
- VAE特征融合:将输入图像的VAE特征整合到扩散模型中,以保持面部身份和外观的细节。
- 潜在上采样模型:在将去噪潜在空间解码回图像空间之前增强面部细节,提高渲染的真实感。
4. 实验
- 在NeRSemble数据集和Monocular Video数据集上进行实验,与现有技术进行比较,证明了该方法在新视角合成和新表情合成方面的优越性。
- 进行了消融研究,验证了多视角扩散先验、正常图条件、迭代去噪图像和潜在上采样模块的有效性。
- 进行了鲁棒性分析,展示了该方法对输入视频帧数变化的鲁棒性。
5. 贡献
- 提出了一种新的方法,使用多视角头部扩散先验从单目视频中重建真实感和可动画化的头部头像。
- 提出了一种多视角头部扩散模型,从单一视图输入生成一致的多视角图像,改善了视点控制。
- 通过整合潜在上采样和多视角扩散先验,提高了高斯绘制的跨视角一致性和真实感。
6. 未来工作和局限性
- 论文讨论了当前方法的局限性,如缺乏头发建模和动画、优化过程耗时以及受限于参数化头部模型的表达能力。
- 提出了未来可能的研究方向,包括头发建模、实时4D头像重建和性能优化等。
总体而言,这项工作通过引入多视角扩散先验和潜在上采样,显著提高了从单目视频中重建3D高斯头像的质量,为虚拟现实和增强现实应用中的真实感头像创建提供了新的可能性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


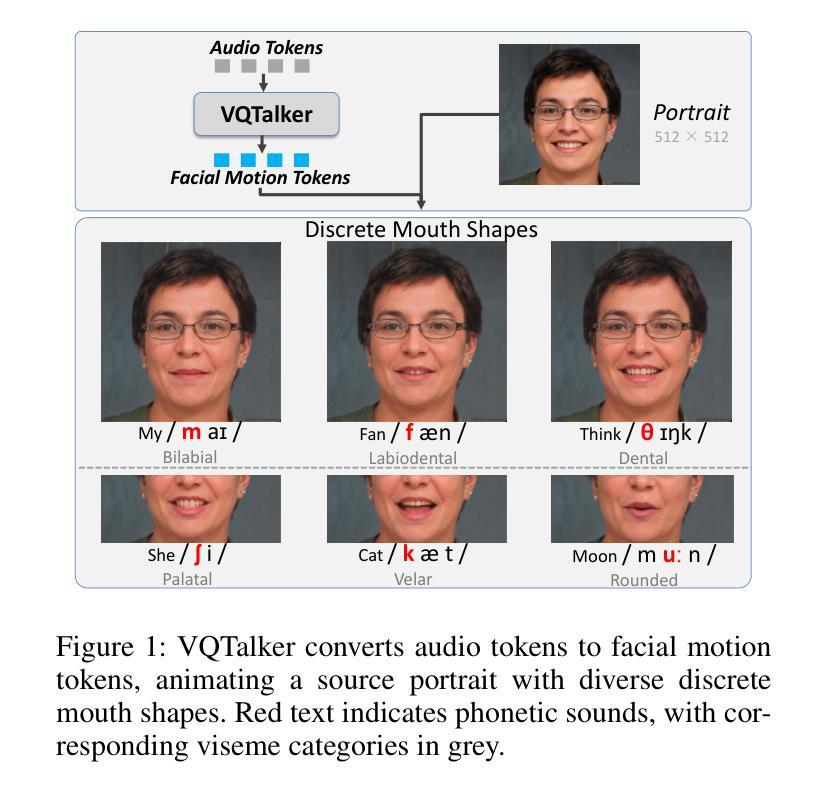
VQTalker: Towards Multilingual Talking Avatars through Facial Motion Tokenization
Authors:Tao Liu, Ziyang Ma, Qi Chen, Feilong Chen, Shuai Fan, Xie Chen, Kai Yu
We present VQTalker, a Vector Quantization-based framework for multilingual talking head generation that addresses the challenges of lip synchronization and natural motion across diverse languages. Our approach is grounded in the phonetic principle that human speech comprises a finite set of distinct sound units (phonemes) and corresponding visual articulations (visemes), which often share commonalities across languages. We introduce a facial motion tokenizer based on Group Residual Finite Scalar Quantization (GRFSQ), which creates a discretized representation of facial features. This method enables comprehensive capture of facial movements while improving generalization to multiple languages, even with limited training data. Building on this quantized representation, we implement a coarse-to-fine motion generation process that progressively refines facial animations. Extensive experiments demonstrate that VQTalker achieves state-of-the-art performance in both video-driven and speech-driven scenarios, particularly in multilingual settings. Notably, our method achieves high-quality results at a resolution of 512*512 pixels while maintaining a lower bitrate of approximately 11 kbps. Our work opens new possibilities for cross-lingual talking face generation. Synthetic results can be viewed at https://x-lance.github.io/VQTalker.
我们提出VQTalker,这是一个基于矢量量化的多语言谈话头生成框架,解决了跨不同语言的嘴唇同步和自然动作挑战。我们的方法基于语音学原理,即人类语音由一组有限的不同声音单元(音素)和相应的视觉发音(面动单元)组成,这些单元往往在语言之间具有共性。我们引入了一种基于组残差有限标量量化(GRFSQ)的面部运动标记器,用于创建面部特征的离散表示。这种方法能够全面捕捉面部运动,同时提高对多种语言的泛化能力,即使在有限的训练数据下也是如此。基于这种量化表示,我们实现了一种从粗糙到精细的运动生成过程,逐步优化面部动画。大量实验表明,VQTalker在视频驱动和语音驱动场景中均达到了最新技术水平,特别是在多语言环境中。值得注意的是,我们的方法在512*512像素的分辨率下达到了高质量的结果,同时保持了大约11kbps的较低比特率。我们的工作开辟了跨语言对话面部生成的全新可能性。合成结果可查看:https://x-lance.github.io/VQTalker。
论文及项目相关链接
PDF 14 pages
Summary
基于向量量化的多语言说话人头部生成框架VQTalker。它解决了不同语言间的嘴唇同步和自然动作挑战。该框架建立在音素原则之上,人类语音由一组有限的不同声音单元(音素)和相应的视觉发音(维斯普)组成,这些在不同语言中往往具有共性。通过引入基于组残差有限标量量化(GRFSQ)的面部运动标记器,创建面部特征的离散表示,提高面部动作的捕捉能力,并改善对多种语言的泛化能力,即使训练数据有限。在此基础上,实现了一种从粗到细的运动生成过程,逐步优化面部动画。实验表明,VQTalker在视频驱动和语音驱动场景中均达到领先水平,特别是在多语言环境中。该方法在512*512像素的分辨率下实现高质量结果,同时保持约11kbps的较低比特率。
Key Takeaways
- VQTalker是一个基于向量量化的多语言说话头部生成框架。
- 它解决了嘴唇同步和自然动作的问题,适用于多种语言。
- 该方法基于音素原则,利用面部运动标记器捕捉面部特征。
- 通过量化表示实现粗到细的运动生成过程。
- 实验证明VQTalker在视频和语音驱动场景中表现优秀,尤其适用于多语言环境。
- 该方法在高分辨率下实现高质量结果,同时保持较低的比特率。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为VQTalker的框架,旨在解决多语言说话头像生成中的两个主要挑战:唇部同步和跨不同语言的自然运动。具体来说,论文试图解决的问题包括:
唇部同步问题:精确的唇部同步对于创造真实的面部动画至关重要,由于McGurk效应,人类的语音感知受到听觉和视觉线索之间复杂交互的影响。现有的音频驱动的说话头像生成方法在唇部同步方面仍然存在问题,例如音频和视觉线索之间的错位或缺少特定的唇形。
跨语言的泛化问题:大多数现有的训练数据集主要由印欧语系语言(如英语、德语和法语)主导,这导致在这些语言家族内训练的模型表现良好,但往往无法准确捕捉其他语言群体的唇部运动和面部表情。此外,现有方法依赖于连续表示,这可能导致训练难度增加,并导致模型过度拟合特定语言。
数据量和泛化能力问题:虽然有些方法通过增加其他语言的训练数据量来改善模型性能,但这种策略资源密集,对于少数语言尤其具有挑战性。简单地增加数据量可能无法完全解决模型需要跨不同语言系统泛化的根本需求。
VQTalker框架通过基于向量量化的方法来解决这些问题,通过将离散的语音单元映射到离散的面部运动标记,捕捉跨不同语言的语音驱动面部动画的基本元素,从而提高在多语言设置中的性能。
Q: 有哪些相关研究?
A: 论文中提到了多个与VQTalker框架相关的研究工作,涉及的领域包括语音驱动的头像生成、面部表示学习、面部标记化以及向量量化技术等。以下是一些具体的相关研究:
语音驱动的头像生成方法:
- Zhang et al. (2023a)
- Ma et al. (2023)
- Liu et al. (2024)
面部表示学习:
- He et al. (2024)
- Xu et al. (2024)
- Drobyshev et al. (2024)
面部标记化(Facial Tokenization):
- Xing et al. (2023a)
- Tan, Ji, and Pan (2024)
- Yu et al. (2024)
向量量化(Vector Quantization, VQ)技术:
- Group VQ (GVQ):Baevski, Schneider, and Auli (2020); Chen, Watanabe, and Rudnicky (2023)
- Residual VQ (RVQ):Zeghidour et al. (2021); Copet et al. (2024)
- Finite Scalar Quantization (FSQ):Fabian et al. (2024)
其他相关技术:
- VQ-VAE (Esser, Rombach, and Ommer 2021):用于面部标记化的方法。
- BERT模型 (Devlin et al. 2019):用于粗到细的运动生成过程。
这些研究为VQTalker框架提供了理论基础和技术背景,特别是在处理多语言说话头像生成中的唇部同步和自然运动方面。通过结合这些技术,VQTalker旨在提高跨语言的泛化能力,并在有限的训练数据下实现更高效的面部动画生成。
Q: 论文如何解决这个问题?
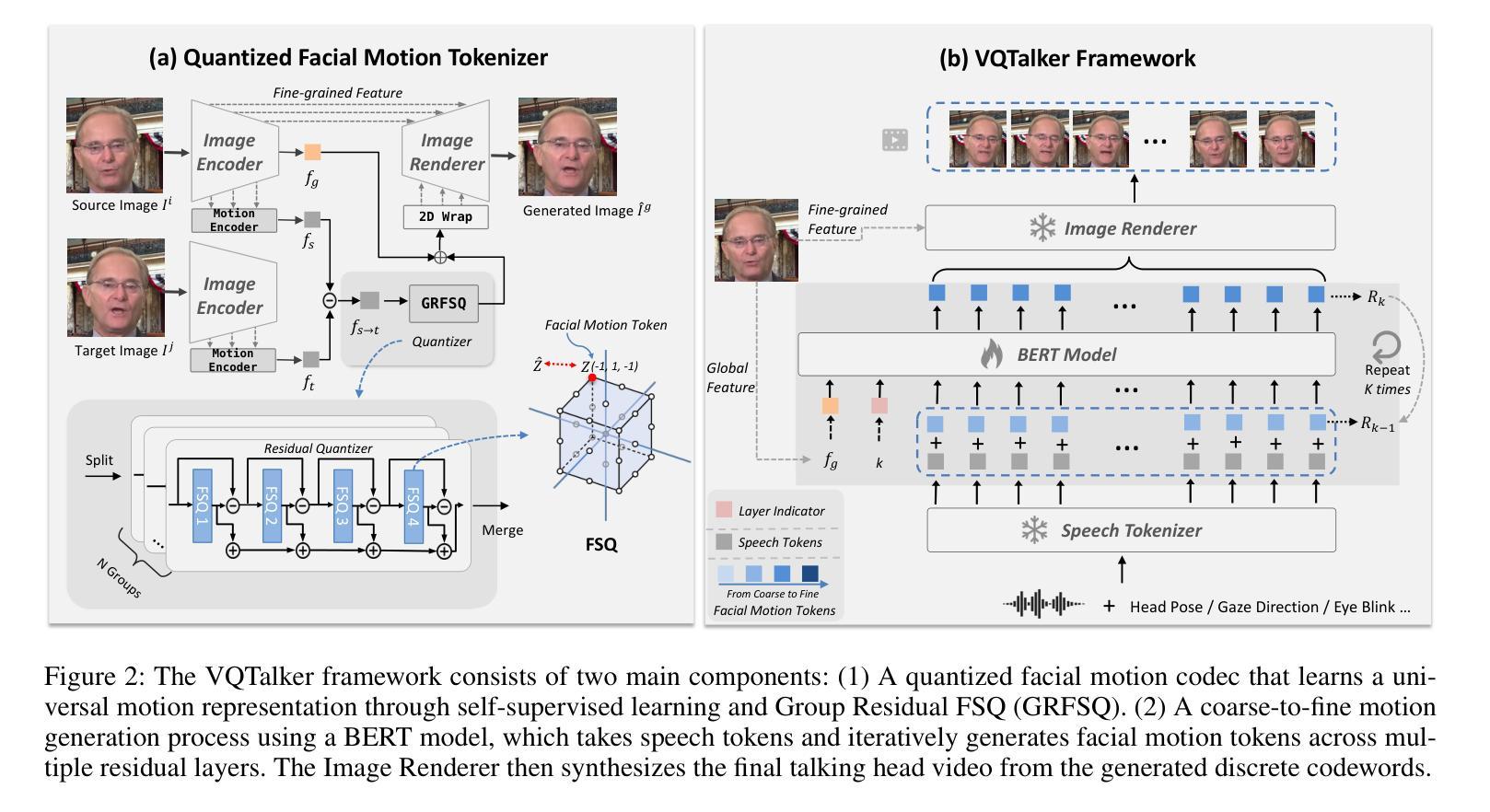
A: 论文通过提出VQTalker框架来解决多语言说话头像生成中的挑战,具体方法如下:
基于向量量化的框架(Vector Quantization-based framework):
- VQTalker利用基于向量量化的方法来捕捉面部运动,这种方法基于人类语音由有限的音素(phonemes)和相应的可视发音动作(visemes)组成的原理,这些在不同语言间通常有共通性。
面部运动标记化(Facial Motion Tokenization):
- 引入了基于Group Residual Finite Scalar Quantization(GRFSQ)的面部运动标记化方法,创建面部特征的离散表示。这种方法能够在有限的训练数据下改善对细微唇部运动的捕捉,并提高跨语言的泛化能力。
多策略量化方法(Multi-strategy Quantization Method):
- 采用GRFSQ方法,结合组量化、残差量化和有限标量量化策略,以实现高效的高分辨率面部运动建模,同时保持低比特率。
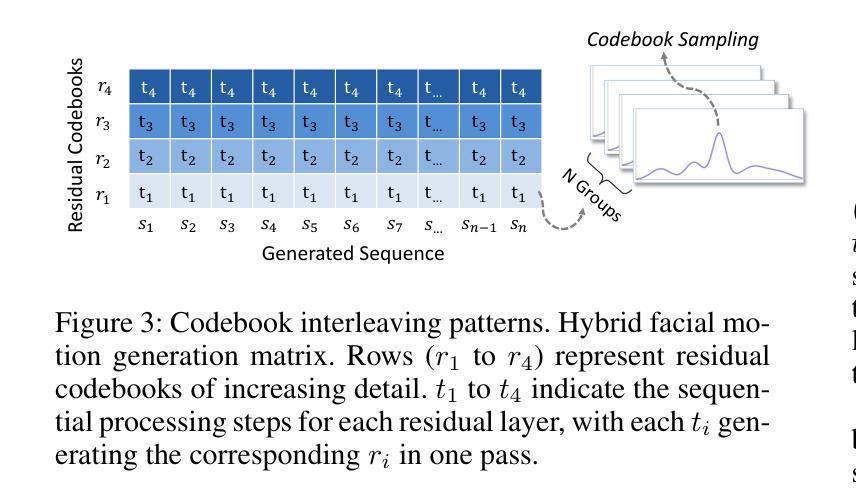
粗到细的运动生成过程(Coarse-to-fine Motion Generation Process):
- 实现了一个从粗到细的运动生成过程,使用BERT模型将离散的音频特征转换为面部运动标记,并逐步优化面部动画。这种方法结合了非自回归时序和自回归粒度方法,提高了动画的一致性和效率。
离散表示的优势:
- 通过将连续的语音单元映射到离散的面部运动标记,VQTalker能够高效地模拟语音到面部运动的相关性,并且离散表示允许模型学习更紧凑的表示,减少信息泄露,而无需额外的模块或损失。
实验验证:
- 通过广泛的实验,论文展示了VQTalker在视频驱动和语音驱动场景下都达到了最先进的性能,特别是在多语言设置中。此外,该方法在512×512像素的高分辨率下实现了高质量的结果,同时保持了大约11 kbps的低比特率。
总结来说,VQTalker框架通过结合面部运动的离散表示和粗到细的生成过程,有效地解决了多语言说话头像生成中的唇部同步和自然运动问题,并在保持低比特率的同时实现了高分辨率的动画生成。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估VQTalker框架的性能,这些实验包括:
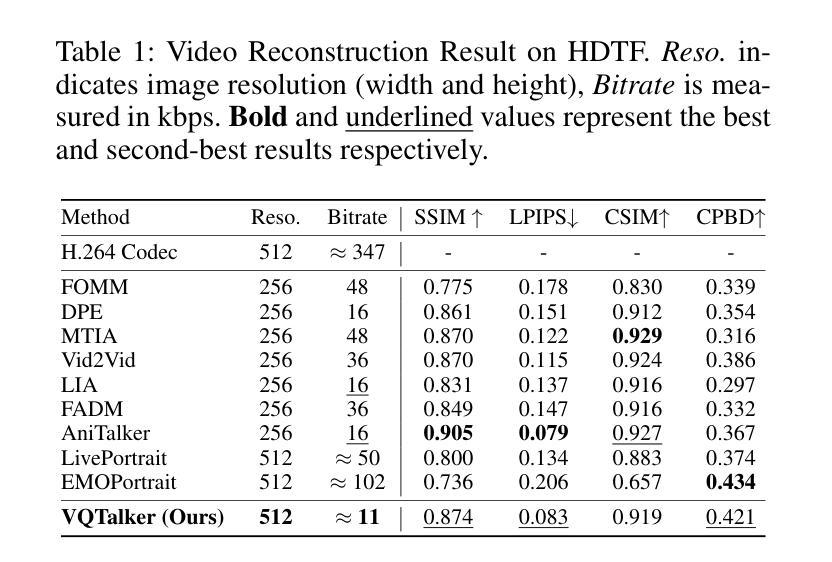
视频重建结果(Video Reconstruction Result):
- 在HDTF数据集上评估了VQTalker与其他几种最先进的面部重演方法的性能,包括FOMM、DPE、MTIA、Vid2Vid、LIA、FADM、AniTalker、LivePortrait和EMOPortrait。评估指标包括结构相似性指数(SSIM)、学习感知图像补丁相似性(LPIPS)、余弦相似性(CSIM)、累积概率模糊检测(CPBD)等。
粗到细实验(Coarse-to-fine Experiment):
- 评估了VQTalker与其他几种语音驱动方法(SadTalker、EAT、PD-FGC、AniTalker、EDTalker、EchoMimic)的性能,包括在印欧语系(HDTF数据集)和非印欧语系(MNTE数据集)上的性能。评估指标与视频重建结果相同。
消融研究(Ablation Study):
- 码本设计(Codebook Design):比较了不同的码本设计在跨身份驱动场景下的性能,包括VQ、GVQ、RVQ和GRVQ等方法。
- 离散与连续表示(Discrete vs. Continuous Representation):比较了离散和连续表示在音频和运动特征中的性能,包括Whisper Large v2、VQ-Wav2vec、CosyVoice和GRFSQ等方法。
特定损失权重的影响(Effects of Loss Weight):
- 进行了消融实验来展示在眼动和口型建模中区域特定加权方法的有效性。通过比较有无眼动和口型损失的重建结果,展示了加权损失对于改善特定面部特征建模的作用。
VQ作为瓶颈结构(VQ as a Bottleneck Structure):
- 通过可视化消融实验来展示离散表示相比于连续表示在跨身份驱动场景下更不容易出现信息泄露的问题。
这些实验全面评估了VQTalker在不同方面的性能,包括视频重建、语音驱动的面部动画生成、不同码本设计的影响、离散与连续表示的比较,以及特定损失权重对模型性能的影响。通过这些实验,论文展示了VQTalker在多语言设置中生成高质量、高分辨率面部动画的能力。
Q: 有什么可以进一步探索的点?
A: 尽管VQTalker框架在多语言说话头像生成方面取得了令人瞩目的成果,但仍有一些领域可以进一步探索和改进:
极端面部运动的处理:
- 在涉及极端面部运动的场景中,可能会偶尔出现轻微的抖动。可以通过探索更高分辨率的量化空间或更先进的量化技术来减轻这一问题。
复杂背景和配饰的处理:
- 由于使用包裹方法,复杂的背景或配饰有时会导致背景或配饰边缘出现模糊。未来的研究可以集中于改进背景处理和配饰集成方法。
提高跨语言泛化能力:
- 尽管VQTalker在多语言设置中表现出色,但可以进一步研究如何提高模型对罕见或低资源语言的泛化能力。
计算效率优化:
- 研究如何优化VQTalker的计算效率,使其能够在资源受限的设备上实时运行。
更精细的面部特征控制:
- 进一步改进眼部、嘴部等关键面部特征的控制精度,以实现更加真实和准确的面部动画。
数据集和训练策略的改进:
- 开发更多样化和平衡的数据集,包含更多非印欧语系语言,以提高模型的泛化能力。
- 探索更有效的训练策略,例如对抗训练或元学习,以提高模型的鲁棒性和适应性。
伦理和隐私问题:
- 随着技术的发展,需要深入探讨与深度伪造、身份盗窃和错误信息传播相关的伦理和隐私问题,并制定相应的指导原则和验证系统。
多模态融合:
- 研究如何将VQTalker与其他模态信息(如情感、手势)更有效地融合,以创造更丰富和自然的交流体验。
模型解释性和透明度:
- 提高模型的可解释性,让研究人员和用户更好地理解模型的决策过程。
跨领域应用:
- 探索VQTalker在其他领域的应用,如虚拟助手、游戏角色、教育和培训模拟等。
这些探索点不仅可以推动VQTalker技术的进步,还可能为计算机视觉、计算机图形学和人工智能领域的其他研究提供新的思路和方法。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了VQTalker,一个基于向量量化的框架,用于生成多语言的说话头像。以下是论文的主要内容总结:
问题陈述:
- 针对音频驱动的头像生成中唇部同步和跨语言自然运动的挑战,尤其是在非印欧语系中。
核心理念:
- 基于音素(phonemes)和可视发音动作(visemes)共享的普遍性,提出了一种将离散语音单元映射到离散面部运动标记的方法。
VQTalker框架:
- 包含面部运动标记化和粗到细的运动生成过程。
- 利用Group Residual Finite Scalar Quantization(GRFSQ)进行面部运动的量化,以实现信息压缩和提高泛化能力。
技术贡献:
- 提出了一种面部运动标记化方法,通过离散表示改善唇部运动捕捉和跨语言泛化。
- GRFSQ方法结合了组量化、残差量化和有限标量量化策略,以实现高分辨率面部运动建模和低比特率。
- 实现了一个粗到细的运动生成过程,结合非自回归时序和自回归粒度方法,提高动画的一致性和效率。
实验结果:
- 在视频驱动和语音驱动场景下均达到了最先进的性能,特别是在多语言设置中。
- 在512×512像素分辨率下实现了高质量的结果,同时保持了约11 kbps的低比特率。
消融研究和对比实验:
- 对码本设计、离散与连续表示的影响进行了消融研究。
- 展示了VQTalker在不同语言上的性能,并与其他方法进行了对比。
潜在的改进和未来工作:
- 提出了可能的改进方向,包括处理极端面部运动、优化背景和配饰处理、提高跨语言泛化能力等。
伦理考量:
- 讨论了数字人类技术发展带来的伦理挑战,并强调了制定伦理指南和验证系统的重要性。
VQTalker通过其创新的离散表示和粗到细的生成方法,在多语言说话头像生成领域提供了一种有效的解决方案,同时为未来的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图