⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-17 更新
UniMed-CLIP: Towards a Unified Image-Text Pretraining Paradigm for Diverse Medical Imaging Modalities
Authors:Muhammad Uzair Khattak, Shahina Kunhimon, Muzammal Naseer, Salman Khan, Fahad Shahbaz Khan
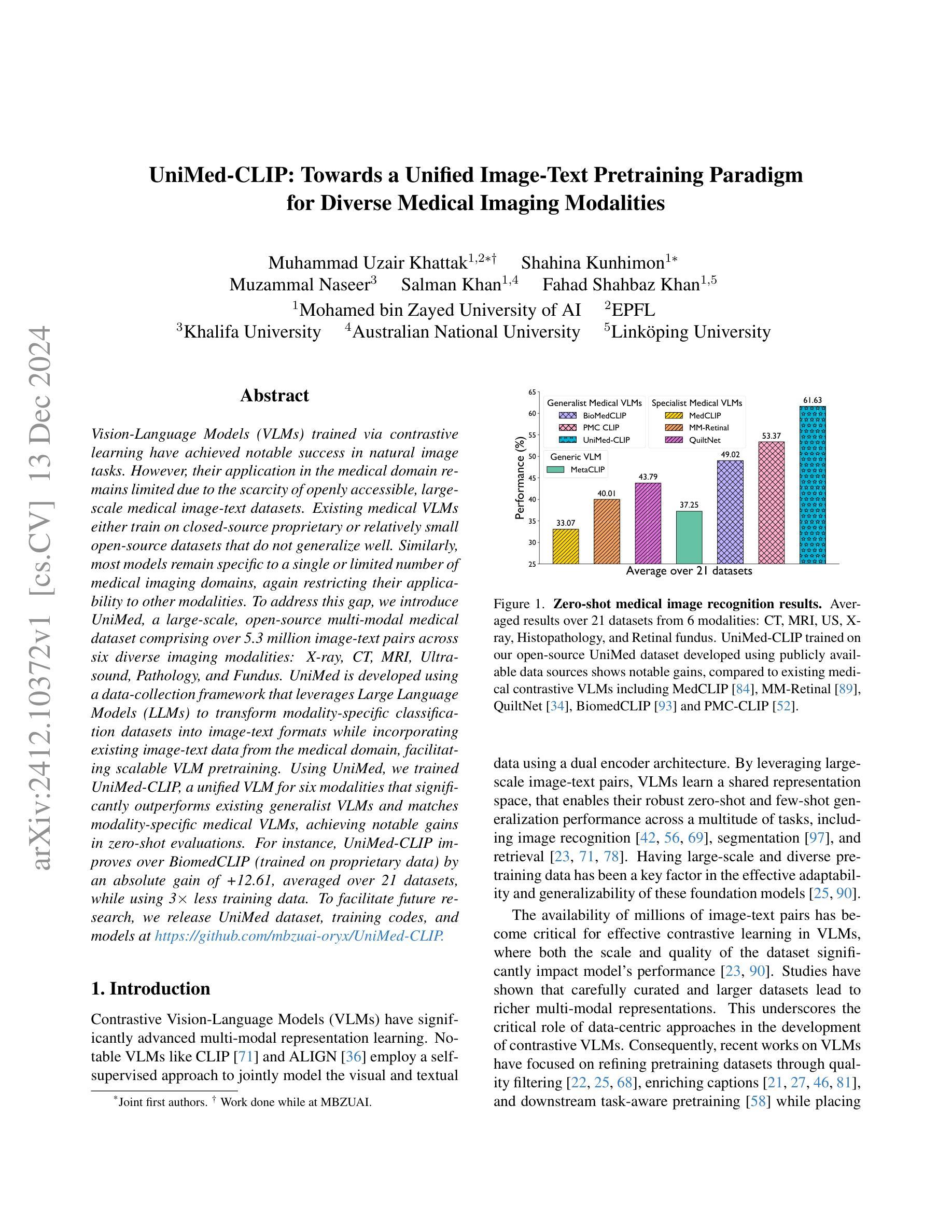
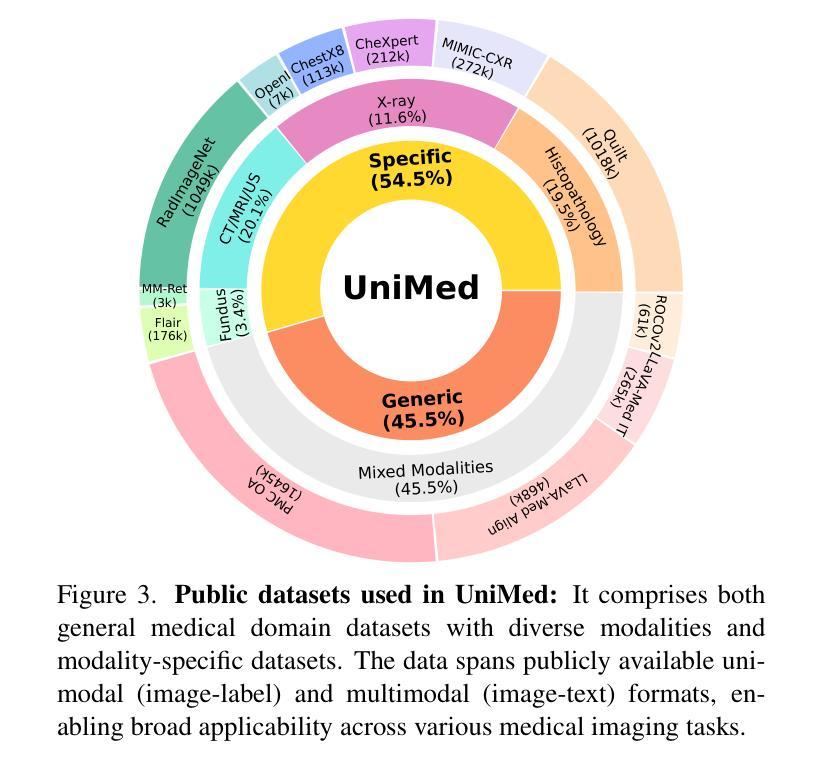
Vision-Language Models (VLMs) trained via contrastive learning have achieved notable success in natural image tasks. However, their application in the medical domain remains limited due to the scarcity of openly accessible, large-scale medical image-text datasets. Existing medical VLMs either train on closed-source proprietary or relatively small open-source datasets that do not generalize well. Similarly, most models remain specific to a single or limited number of medical imaging domains, again restricting their applicability to other modalities. To address this gap, we introduce UniMed, a large-scale, open-source multi-modal medical dataset comprising over 5.3 million image-text pairs across six diverse imaging modalities: X-ray, CT, MRI, Ultrasound, Pathology, and Fundus. UniMed is developed using a data-collection framework that leverages Large Language Models (LLMs) to transform modality-specific classification datasets into image-text formats while incorporating existing image-text data from the medical domain, facilitating scalable VLM pretraining. Using UniMed, we trained UniMed-CLIP, a unified VLM for six modalities that significantly outperforms existing generalist VLMs and matches modality-specific medical VLMs, achieving notable gains in zero-shot evaluations. For instance, UniMed-CLIP improves over BiomedCLIP (trained on proprietary data) by an absolute gain of +12.61, averaged over 21 datasets, while using 3x less training data. To facilitate future research, we release UniMed dataset, training codes, and models at https://github.com/mbzuai-oryx/UniMed-CLIP.
通过对比学习训练的视觉语言模型(VLMs)在自然图像任务中取得了显著的成功。然而,由于公开可访问的大规模医学图像文本数据集的稀缺,它们在医学领域的应用仍然有限。现有的医学VLM要么在封闭源代码专有数据上进行训练,要么在相对较小的开源数据集上进行训练,这些数据集并不具备良好的泛化能力。同样,大多数模型仅限于单个或数量有限的医学成像领域,再次限制了它们在其他模态中的应用。为了解决这一差距,我们推出了UniMed,这是一个大规模、开源的多模式医学数据集,包含超过530万张跨六种不同成像模式的图像文本对:X射线、CT、MRI、超声、病理学和眼底。UniMed是采用数据收集框架开发的,该框架利用大型语言模型(LLM)将特定模态分类数据集转换为图像文本格式,同时融入医学领域的现有图像文本数据,便于可扩展的VLM预训练。使用UniMed,我们训练了UniMed-CLIP,这是一个统一的六模态VLM,它显著优于现有的通用VLM,并与特定模态的医学VLM相匹配,在零样本评估中取得了显著的进步。例如,UniMed-CLIP在21个数据集上的平均表现优于使用专有数据训练的BiomedCLIP,绝对增益为+12.61%,同时使用的训练数据少了三倍。为了方便未来研究,我们在https://github.com/mbzuai-oryx/UniMed-CLIP发布了UniMed数据集、训练代码和模型。
论文及项目相关链接
PDF Code, models and demo available at https://github.com/mbzuai-oryx/UniMed-CLIP
Summary
本文介绍了UniMed这一大规模、开源的多模态医疗数据集,包含超过530万张图像和文本对,涵盖了六种不同的医学影像模态。通过利用大型语言模型,该数据集能将特定分类数据集转化为图像-文本格式,并融入现有的医学图像-文本数据,从而促进了通用视觉语言模型的预训练。基于UniMed数据集训练的UniMed-CLIP模型在六种模态上表现出显著性能,相比基于私有数据训练的BioMedCLIP模型平均提升了+12.61的准确率,同时使用更少的数据量。该数据集及相关资源已发布在GitHub上。
Key Takeaways
- UniMed是一个大规模、多模态的医疗数据集,包含超过530万张图像和文本对。
- 数据集涵盖了六种不同的医学影像模态,包括X光、CT、MRI、超声、病理学和眼底图像。
- UniMed利用大型语言模型将特定分类数据集转化为图像-文本格式,便于视觉语言模型的预训练。
- UniMed-CLIP模型在多种医疗影像数据集上表现出卓越性能,显著优于通用视觉语言模型,并接近或达到模态特定模型的性能。
- UniMed-CLIP相比BioMedCLIP模型在平均准确率上提升了+12.61,且在较少数据量下实现这一提升。
- UniMed数据集及相关资源已在GitHub上公开发布,便于未来研究使用。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是如何有效地将视觉-语言模型(Vision-Language Models, VLMs)应用于医学图像领域。具体来说,论文指出了以下几个关键问题:
数据稀缺性:在医学领域,公开可访问的、大规模的医学图像-文本数据集非常稀缺,这限制了VLMs在医学领域的应用和发展。
数据集封闭性:现有的一些高性能医学VLMs依赖于专有的封闭源数据集,这阻碍了数据为中心的研究,因为公众无法访问这些数据。
模型泛化能力有限:大多数现有的医学VLMs只能在单一或有限数量的医学成像领域中表现良好,限制了它们在其他模态中的适用性。
模型性能受限:由于训练数据规模小,一些VLMs的性能受到了限制。
为了解决这些问题,论文介绍了UniMed,这是一个大规模、开源的多模态医学数据集,包含超过530万张图像-文本对,覆盖了六种不同的成像模态:X光、CT、MRI、超声、病理和眼底图像。UniMed通过利用大型语言模型(LLMs)将模态特定的分类数据集转换为图像-文本格式,同时结合医学领域已有的图像-文本数据,促进了VLMs的可扩展预训练。此外,论文还训练了一个统一的VLM,称为UniMed-CLIP,它在多种基准测试中表现出色,特别是在零样本评估中,与特定模态的医学VLMs相匹配,同时显著优于现有的通用VLMs。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究主要涉及以下几个方面:
对比视觉-语言模型(Contrastive Vision-Language Models, VLMs):
- CLIP [71] 和 ALIGN [36] 是两个著名的VLMs,它们采用自监督方法联合建模视觉和文本数据,并在多个任务中表现出色,如图像识别、分割和检索。
医学视觉-语言模型(Medical VLMs):
- MedCLIP [84]:专注于X光图像表示学习的图像-文本数据集。
- BiomedCLIP [93]:使用封闭源PMC-15M数据集来提高零样本和少样本迁移性能。
- Quilt-1M [34] 和 MM-Retinal [89]:分别使用病理和视网膜数据训练的专业基础模型。
多模态训练使用单模态数据(Multi-modal training using uni-modal data):
- MedCLIP [84]:结合成对和非成对数据,通过解耦框架和语义匹配进行训练。
- FLAIR [98]、BioViL [8] 和 LLaVA-Med [47]:这些作品通过创新技术从胸部X光分类标签生成字幕,将数据转换为多模态格式。
公开可用的医学数据集:
- MIMIC-CXR [39]、PMC-OA [52]、ROCOv2 [72]、LLaVA-Med [47] 等数据集被用于VLMs的预训练。
大型语言模型(Large Language Models, LLMs):
- 使用LLMs将高质量的图像-标签数据转换为图像-文本对,以支持VLMs的预训练。
零样本学习(Zero-shot learning):
- 论文中提到了多个VLMs在零样本学习方面的研究,包括CLIP和其衍生模型,它们在没有显式训练的情况下对新类别进行识别。
下游任务迁移(Downstream task transfer):
- 论文中提到了通过线性探测(linear probing)实验评估学习到的表示的可迁移性。
这些相关研究构成了UniMed-CLIP研究的理论基础和技术背景,展示了在医学图像领域中VLMs的发展和挑战。通过这些相关工作,论文提出了一个新的数据集UniMed和相应的VLM UniMed-CLIP,旨在通过统一的预训练范式解决现有医学VLMs的局限性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决上述问题:
1. 创建UniMed数据集
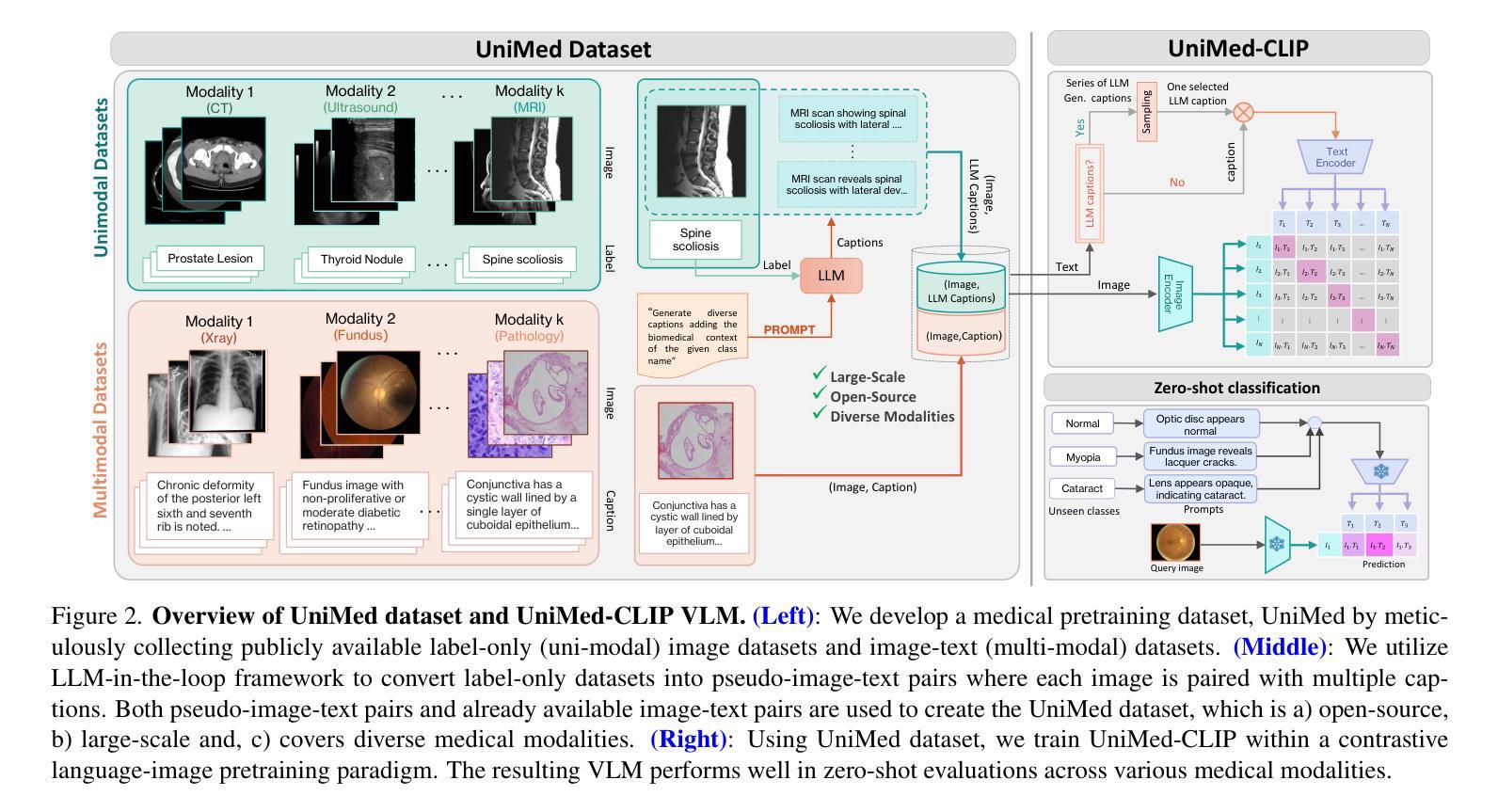
- 数据收集:作者收集了公开可用的医学图像数据,包括图像-文本对和仅含图像标签的数据集,以确保数据的多样性和覆盖多种医学成像模态。
- 利用LLMs生成描述:对于仅含图像标签的数据集,使用大型语言模型(LLMs)将标签信息转换成描述性的文本,从而创建伪图像-文本对。这一步骤增加了数据集的规模,并使得数据集适用于VLM预训练。
2. 训练UniMed-CLIP模型
- 双编码器架构:UniMed-CLIP采用双编码器架构,分别对图像和文本进行编码,并通过对比学习的方式进行预训练。
- 多标题策略:在预训练过程中,对于来自标签数据的图像,UniMed-CLIP使用多个由LLM生成的描述,每次随机选择一个描述作为文本输入,增加了数据集的多样性。
3. 实现显著的性能提升
- 零样本评估:UniMed-CLIP在多个医学图像识别数据集上进行了零样本评估,显示出相比于现有通用VLMs和特定模态VLMs的显著性能提升。
- 下游任务迁移:通过线性探测实验,评估了UniMed-CLIP在不同下游任务上的迁移能力,证明了其学习到的表示具有较好的泛化性。
4. 促进进一步研究
- 开源资源:作者计划开源UniMed数据集、训练代码和模型检查点,以鼓励和促进医学VLMs领域的进一步研究和应用。
通过上述步骤,论文不仅提出了一个大规模、多模态、开源的医学图像-文本数据集,还展示了一个在该数据集上训练的统一VLM,有效地解决了医学图像领域VLMs的应用和发展中的关键问题。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估UniMed-CLIP模型的性能,包括零样本分类任务和下游任务迁移实验。以下是实验的具体内容:
零样本医学图像分类(Zero-shot Medical Imaging Classification)
- 实验目的:评估UniMed-CLIP在未经见过的数据集上的表现,并与现有的视觉-语言模型(VLMs)进行比较。
- 数据集:使用了21个覆盖6种不同医学成像模态(X光、CT、MRI、超声、病理和视网膜眼底图像)的数据集。
- 任务:涉及多种诊断任务,包括疾病检测、器官分类、分级和肿瘤识别等。
- 性能指标:对于平衡数据集使用准确率(Accuracy),对于不平衡数据集使用曲线下面积(AUC)作为评估指标。
- 结果:UniMed-CLIP在多个数据集上显示出比现有通用VLMs更好的性能,并且与特定模态的VLMs性能相当。
下游任务迁移(Downstream Task Transfer)
- 实验目的:评估UniMed-CLIP学到的表示在新任务上的迁移能力。
- 方法:通过线性探测(linear probing)技术,冻结预训练的编码器,并在下游任务数据上微调一个线性层。
- 数据集:使用与零样本评估相同的数据集。
- 样本比例:在实验中,使用了从训练集中抽取的1%、10%和100%的数据点。
- 结果:UniMed-CLIP在不同模态的数据集上表现出一致的性能提升,特别是在数据量有限的情况下,UniMed-CLIP的性能接近或超过了在完整数据集上训练的其他模型。
消融研究(Ablative Analysis)
- 实验目的:分析不同设计选择对UniMed-CLIP性能的影响。
- 文本描述多样性:研究了为图像-标签数据集使用多个描述的影响,以及随机选择单个描述来增加数据集多样性的效果。
- 测试时提示集成(Test-time Prompt Ensembling):分析了在测试时使用多个提示模板对零样本性能的影响。
- 模态特定数据的重要性:通过逐步移除模态特定数据集,研究了这些数据对UniMed-CLIP性能的贡献。
这些实验全面评估了UniMed-CLIP的性能,并验证了其在医学图像领域的有效性和泛化能力。通过这些实验,论文展示了UniMed-CLIP作为一个统一的预训练范式在多样化医学成像模态中的潜力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
多模态融合方法:
- 探索不同的图像和文本融合方法,以改善模型性能。例如,可以尝试不同的注意力机制或者图神经网络来更好地整合多模态信息。
数据增强技术:
- 研究不同的数据增强技术,特别是针对医学图像,以提高模型的鲁棒性和泛化能力。
模型架构改进:
- 对现有的双编码器架构进行改进或尝试新的网络架构,以适应医学图像的特点,可能能够进一步提升模型性能。
细粒度的模态特定分析:
- 对不同医学成像模态进行更细粒度的分析,以了解模型在每种模态中的表现,并针对特定模态优化模型参数。
跨模态学习:
- 研究如何利用UniMed数据集中的不同模态信息进行跨模态学习,可能有助于提高模型在特定任务上的表现。
半监督和无监督学习:
- 探索半监督或无监督学习策略,以利用大量未标记的医学图像数据,这可能有助于提高模型的泛化能力。
模型解释性:
- 提高模型的可解释性,尤其是在医学领域,这可以帮助医生理解模型的决策过程,并增加模型在临床应用中的可信度。
临床验证和应用:
- 将UniMed-CLIP模型应用于实际的临床环境,并进行验证,以评估其在真实世界中的有效性和实用性。
数据集扩展和多样化:
- 进一步扩展UniMed数据集,增加更多模态和疾病类型,以提高模型的多样性和适用性。
长尾分布问题:
- 针对医学图像数据中常见的类别不平衡问题,研究有效的长尾学习策略,以改善模型在少数类上的性能。
跨领域适应性:
- 探索模型在不同医疗机构和设备间的适应性,解决设备差异和数据分布变化带来的挑战。
实时性能优化:
- 针对实际应用中的实时处理需求,优化模型的计算效率和速度。
这些探索点可以帮助研究者更深入地理解医学视觉-语言模型的潜力和局限性,并推动其在医疗健康领域的应用。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出在医学图像领域应用视觉-语言模型(VLMs)面临的挑战,包括公开可访问的大型医学图像-文本数据集的稀缺性、现有模型的泛化能力有限以及模型过于专一化于特定模态。
UniMed数据集的创建:
- 为了解决上述问题,作者提出了UniMed,一个大规模、多模态、开源的医学数据集,包含超过530万张图像-文本对,覆盖六种不同的成像模态:X光、CT、MRI、超声、病理和眼底图像。
- UniMed数据集是通过结合现有的图像-文本数据和利用大型语言模型(LLMs)将仅含图像标签的数据转换为图像-文本对来创建的。
UniMed-CLIP模型的训练:
- 基于UniMed数据集,作者训练了一个统一的VLM,称为UniMed-CLIP,它采用对比学习的方法,并在多模态数据上进行预训练。
- UniMed-CLIP模型在零样本评估中显示出显著的性能提升,并与特定模态的医学VLMs相匹配,同时在多个基准测试中优于现有的通用VLMs。
实验评估:
- 论文通过零样本分类任务和下游任务迁移实验来评估UniMed-CLIP的性能,并与现有的VLMs进行比较。
- 实验结果表明,UniMed-CLIP在多个医学图像识别数据集上展现出了优越的性能,并且在数据受限的情况下也能很好地泛化。
开源贡献:
- 为了促进医学VLMs领域的进一步研究,作者计划开源UniMed数据集、训练代码和模型检查点。
总结来说,这篇论文通过创建一个大规模的多模态医学数据集UniMed,并基于此数据集训练了一个统一的VLM UniMed-CLIP,有效地解决了医学图像领域VLMs的应用和发展中的关键问题,并推动了该领域的研究进展。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

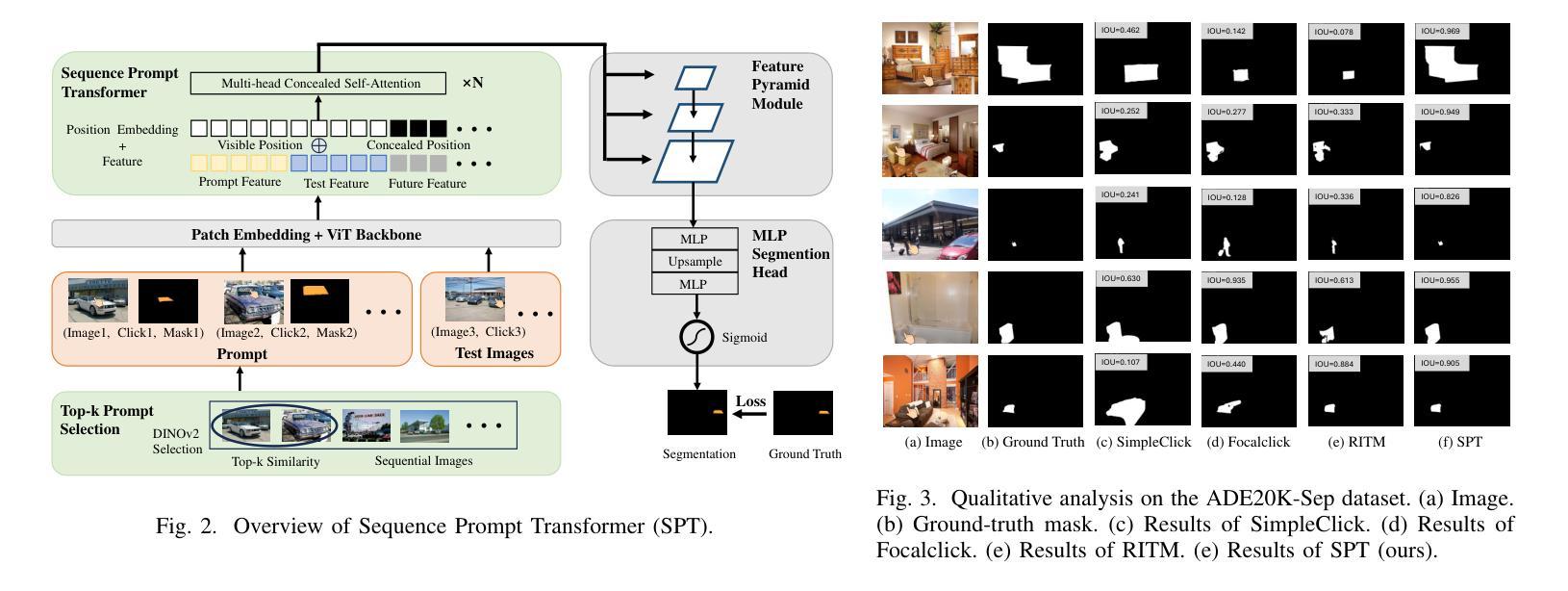
SPT: Sequence Prompt Transformer for Interactive Image Segmentation
Authors:Senlin Cheng, Haopeng Sun
Interactive segmentation aims to extract objects of interest from an image based on user-provided clicks. In real-world applications, there is often a need to segment a series of images featuring the same target object. However, existing methods typically process one image at a time, failing to consider the sequential nature of the images. To overcome this limitation, we propose a novel method called Sequence Prompt Transformer (SPT), the first to utilize sequential image information for interactive segmentation. Our model comprises two key components: (1) Sequence Prompt Transformer (SPT) for acquiring information from sequence of images, clicks and masks to improve accurate. (2) Top-k Prompt Selection (TPS) selects precise prompts for SPT to further enhance the segmentation effect. Additionally, we create the ADE20K-Seq benchmark to better evaluate model performance. We evaluate our approach on multiple benchmark datasets and show that our model surpasses state-of-the-art methods across all datasets.
交互式分割旨在根据用户提供的点击从图像中提取感兴趣的对象。在现实世界应用中,通常需要分割一系列具有同一目标对象的图像。然而,现有方法通常一次只处理一个图像,忽略了图像的序列性质。为了克服这一局限性,我们提出了一种名为序列提示转换器(SPT)的新方法,它是第一个利用序列图像信息进行交互式分割的方法。我们的模型包括两个关键组件:(1)序列提示转换器(SPT),用于从图像序列、点击和掩膜中获取信息,以提高准确性。(2)Top-k提示选择(TPS)为SPT选择精确提示,以进一步增强分割效果。此外,我们创建了ADE20K-Seq基准测试,以更好地评估模型性能。我们在多个基准数据集上评估了我们的方法,结果表明我们的模型在所有数据集上的表现均超过了最先进的方法。
论文及项目相关链接
Summary
序列提示Transformer(SPT)是一种采用序列图像信息来进行交互式分割的新方法。此方法结合了序列图像信息和用户提供的点击,以提高目标对象的准确性。还采用顶部K提示选择(TPS)进一步提高分割效果。此外,创建了ADE20K-Seq基准测试来更好地评估模型性能。在多基准数据集上的评估显示,该方法在分割性能上优于最先进的方法。
Key Takeaways
- 交互式分割是基于用户提供的点击从图像中提取感兴趣对象的技术。
- 现有方法通常一次处理一个图像,忽略了图像的序列性质。
- Sequence Prompt Transformer(SPT)用于从图像序列、点击和掩膜中获取信息进行交互式分割,提高准确性。
- Top-k Prompt Selection(TPS)用于选择精确的提示,进一步增强分割效果。
- 创建了ADE20K-Seq基准测试来评估模型性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种名为Sequence Prompt Transformer(SPT)的新方法,旨在解决交互式图像分割中的一个特定问题:现有方法通常一次处理一张图片,未能利用一系列图片中的顺序信息。在现实世界的应用中,经常需要从一个目标对象的多张图片中提取对象,例如汽车窗户、猫耳朵、人手等。现有方法在处理一系列图片时,需要对每张图片进行修正,这既耗时又耗费资源,并且不同图片中的时间、场景不一致,使得基于视频的交互式分割方法不适用。因此,论文提出了SPT方法,首次利用序列图像信息进行交互式分割,以提高分割的准确性和效率。
Q: 有哪些相关研究?
A: 相关研究包括以下几个方面:
基于图的交互式图像分割方法:
- 早期研究使用图来处理图像像素,关注低级图像特征,但在处理复杂对象时常常遇到困难。
深度学习和大型数据集的应用:
- 随着深度学习的发展和大型数据集的出现,现代方法显著提高了交互式图像分割的质量。
- CDNet利用自注意力机制更好地关注相关图像区域。
- RITM通过基于点击的交互策略改进分割。
- FocalClick开发迭代方法以增强掩码质量。
- PseudoClick通过预测未来的点击来减少用户输入。
- SimpleClick使用Vision Transformer (ViT) 作为骨干网络,利用预训练权重。
零样本模型:
- Segment Anything Model (SAM) 使用大型数据集处理多样化的对象和场景。
- HQSAM在此基础上通过高质量输出令牌和全局-局部特征融合改进复杂对象的准确性。
这些模型显著提高了交互式图像分割的效率、准确性和适用性。然而,现有方法忽略了序列图像中的顺序信息,导致在对象分割中出现错误。SPT方法据称是第一个将顺序信息纳入交互式图像分割的方法,有效提高了准确性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤解决了交互式图像分割中序列信息利用不足的问题:
1. Sequence Prompt Transformer (SPT)
- SPT是论文提出的核心方法,它利用序列图像、点击和预测掩码作为提示(prompts),以增强分割的准确性。
- SPT通过捕获序列内图像之间的关系来整合来自先前输入和先前预测的属性。
2. Top-k Prompt Selection (TPS)
- 为了选择最合适的提示,论文引入了TPS模块。
- TPS使用DINOv2进行特征提取,并选择与测试图像最相似的k个图像、点击和掩码作为提示。
3. 网络输入
- 网络输入包括属于同一类别的一系列图像,以及相应的点击和掩码。
- 利用点击模拟策略来模拟用户对图像进行迭代点击的真实体验。
4. 骨干网络
- 使用ViT作为骨干网络,将图像、点击和掩码的嵌入表示通过ViT网络进行特征提取。
5. 特征提取和处理
- 将编码后的信息通过Patch-Embedding和ViT网络传递,然后输入到SPT中。
- 特征随后通过Feature Pyramid Module (FPM)和MLP Segmentation Head (MSH)处理,以产生预测的分割结果。
6. 新的基准数据集 ADE20K-Seq
- 为了更好地评估提出的方法,论文引入了ADE20K-Seq数据集,这是第一个专门针对同一类别的序列图像进行交互式分割的数据集。
7. 实验验证
- 在多个交互式分割基准数据集上进行了广泛的实验,证明了SPT方法的优越性。
通过这些步骤,论文成功地将序列信息纳入交互式图像分割中,提高了分割任务的效率和准确性。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验:
A. 实验设置
数据集:
- 训练数据集:COCO 和 LIVIS。
- 评估基准:GrabCut、Berkeley、COCO-MVal 和 DAVIS。
- 新基准数据集:ADE20K-Seq,扩展自ADE20K数据集,包含7个类别特定基准,每个类别包含超过100张图像。
实现:
- 图像缩放和数据增强技术。
- 使用两个ViT模型(ViT-B 和 ViT-H)作为骨干网络,并进行预训练权重初始化。
- 使用Adam优化器进行训练,并在COCO和LVIS数据集上训练55个周期。
评估指标:
- 使用“NoC”(Number of Clicks)作为评估指标,包括NoC85和NoC90,分别表示达到85%和90% IoU所需的点击次数。
B. 实验结果
与基线模型的比较:
- 在五个基准数据集上与多个基线模型(包括RITM、EdgeFlow、CDNet、PseudoClick、Focalclick等)进行比较,SPT框架在所有数据集和评估指标上均优于基线模型。
不同点击输入数量的实验:
- 在ADE20K-Sep数据集上进行实验,结果表明,无论输入点击数量如何,SPT方法均能取得最佳结果。
C. 消融研究
Sequence Prompt Transformer (SPT) 的效果:
- 对比不同长度的提示序列对性能的影响,证明了SPT方法对交互式分割性能的有效提升。
Top-k Prompt Selection (TPS) 的效果:
- 对比有无TPS方法的性能差异,证明了TPS在提升模型性能中的重要作用。
D. 定性分析
- 在ADE20K-Seq数据集上的可视化分析:
- 展示了SPT与先前最先进方法相比,能产生更精确的结果,具有更好的语义和更精细的分割边界。
这些实验验证了SPT方法在交互式图像分割任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了SPT方法并在多个基准数据集上取得了优异的性能,但仍有一些点可以进一步探索:
更深层次的序列建模:
- 虽然SPT利用了序列信息,但可能还有进一步探索更复杂或不同类型的序列建模方法的空间,例如循环神经网络(RNN)或长短期记忆网络(LSTM)。
多模态输入:
- 考虑将文本描述或其他模态数据与图像序列结合,以提供额外的上下文信息,可能有助于进一步改善分割性能。
更广泛的数据集和场景:
- 在更多样化的数据集和更复杂的实际应用场景中测试SPT的性能,例如医学图像分割或卫星图像分割。
实时性能优化:
- 研究如何优化SPT以实现实时或近实时的交互式分割,这对于许多应用场景(如视频编辑或增强现实)至关重要。
鲁棒性和泛化能力:
- 探索SPT在面对不同光照条件、遮挡和背景复杂性时的鲁棒性,并研究如何提高模型的泛化能力。
更细粒度的控制:
- 提供更细粒度的用户控制选项,例如允许用户指定分割的特定区域或对象部分。
交互式分割的可解释性:
- 研究如何提高交互式分割模型的可解释性,帮助用户理解模型的决策过程。
跨域适应性:
- 研究SPT在不同领域(如从自然图像到医学图像)的适应性和迁移学习能力。
联合学习与协作分割:
- 探索如何利用多个用户的点击和分割结果来改进模型性能,实现联合学习和协作分割。
模型压缩和加速:
- 研究如何压缩SPT模型以减少计算资源需求,使其更适合在资源受限的设备上运行。
这些探索点可以帮助推动交互式图像分割技术的发展,提高其在实际应用中的有效性和可用性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文针对交互式图像分割领域中现有方法未能有效利用序列图像信息的问题,提出了一种新的方法。
方法论:
- 提出了一种名为Sequence Prompt Transformer (SPT) 的模型,该模型能够利用序列图像、用户点击和预测掩码信息来提高分割的准确性。
- 引入了Top-k Prompt Selection (TPS) 模块,使用DINOv2模型进行特征提取,选择与测试图像最相似的k个图像、点击和掩码作为提示,以进一步增强分割效果。
数据集:
- 为了更好地评估模型性能,论文创建了一个新的基准数据集ADE20K-Seq,它扩展自ADE20K数据集,包含来自同一类别的多张序列图像。
实验:
- 在多个交互式图像分割基准数据集上进行了广泛的实验,包括GrabCut、Berkeley、COCO-MVal、DAVIS和ADE20K-Seq。
- 实验结果表明,SPT模型在所有数据集上均超越了现有的最先进方法。
消融研究:
- 进行了消融实验来评估SPT和TPS模块的有效性,结果证明了这些组件对提高分割性能的重要性。
定性分析:
- 通过在ADE20K-Seq数据集上的可视化分析,展示了SPT相较于其他最先进方法能够产生更精确的分割结果。
结论:
- 论文提出的SPT方法有效地利用了序列图像信息,通过选择更适当的提示来提高交互式图像分割的准确性,并在多个基准数据集上验证了其优越性。
总体而言,这篇论文在交互式图像分割领域提出了一种创新的方法,通过结合序列信息和先进的提示选择策略,显著提高了分割任务的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


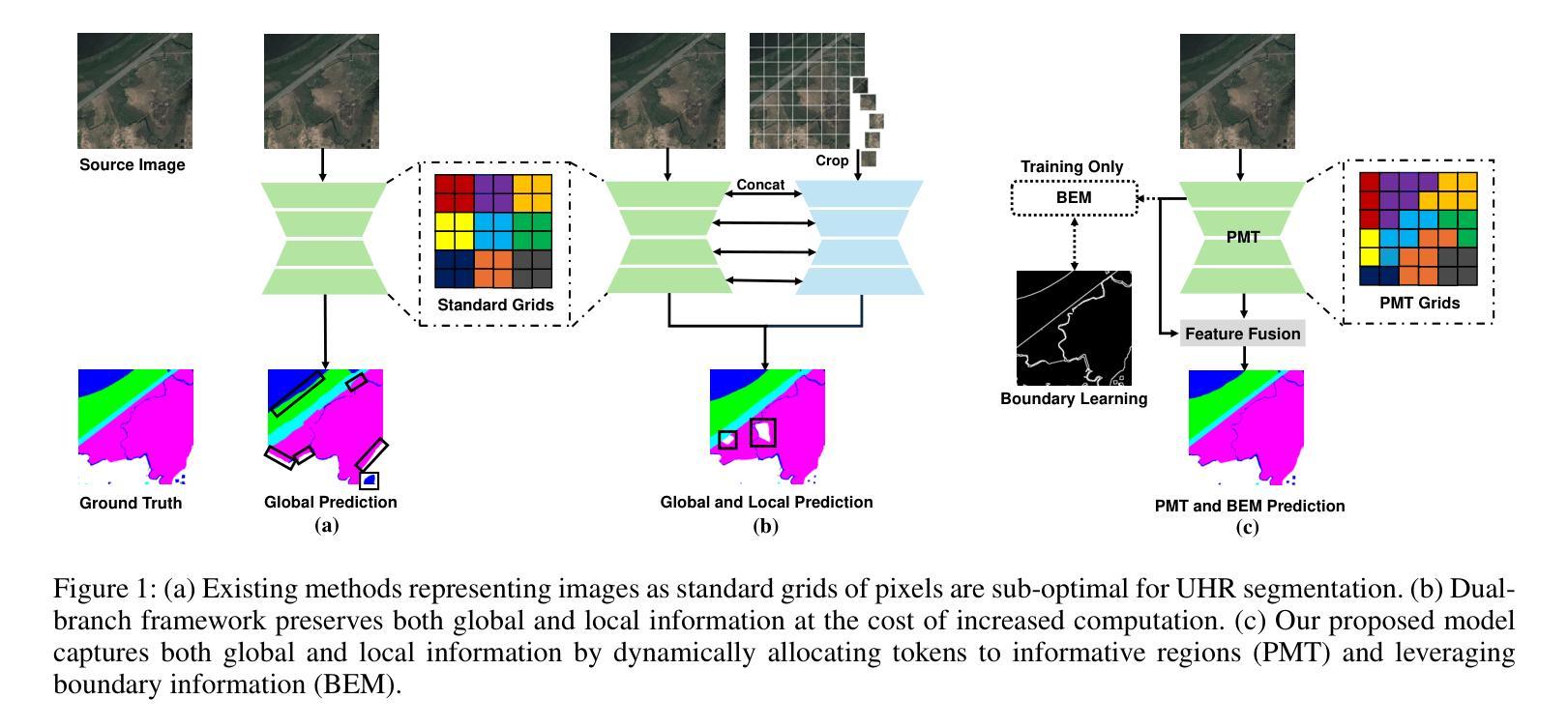
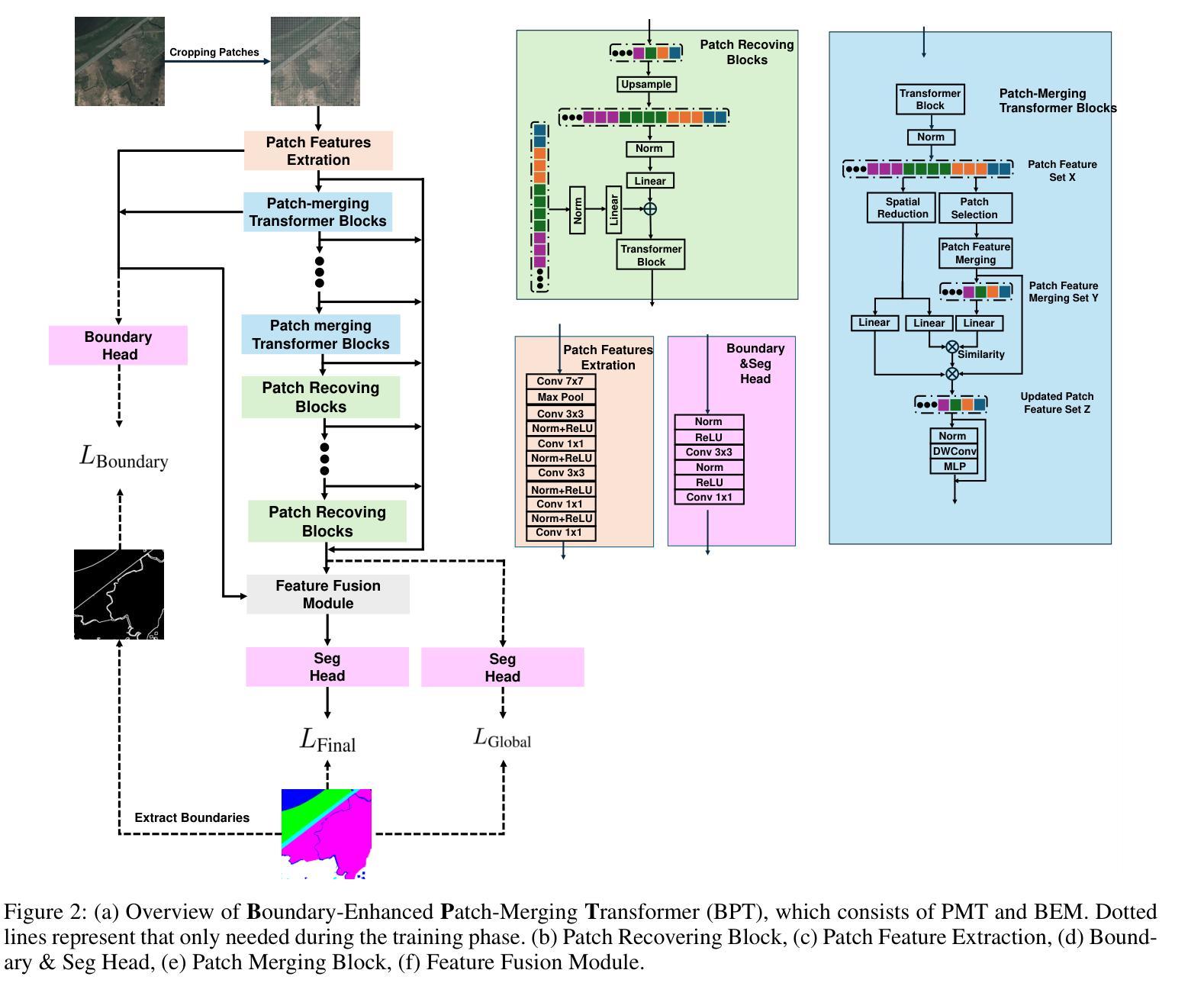
Ultra-High Resolution Segmentation via Boundary-Enhanced Patch-Merging Transformer
Authors:Haopeng Sun
Segmentation of ultra-high resolution (UHR) images is a critical task with numerous applications, yet it poses significant challenges due to high spatial resolution and rich fine details. Recent approaches adopt a dual-branch architecture, where a global branch learns long-range contextual information and a local branch captures fine details. However, they struggle to handle the conflict between global and local information while adding significant extra computational cost. Inspired by the human visual system’s ability to rapidly orient attention to important areas with fine details and filter out irrelevant information, we propose a novel UHR segmentation method called Boundary-enhanced Patch-merging Transformer (BPT). BPT consists of two key components: (1) Patch-Merging Transformer (PMT) for dynamically allocating tokens to informative regions to acquire global and local representations, and (2) Boundary-Enhanced Module (BEM) that leverages boundary information to enrich fine details. Extensive experiments on multiple UHR image segmentation benchmarks demonstrate that our BPT outperforms previous state-of-the-art methods without introducing extra computational overhead. Codes will be released to facilitate research.
超高分辨率(UHR)图像分割是一个具有许多应用的关键任务,但由于其高空间分辨率和丰富的细节,它带来了很大的挑战。最近的方法采用双分支架构,其中全局分支学习长程上下文信息,而局部分支捕获细节。然而,它们在处理全局和局部信息之间的冲突时遇到困难,同时增加了额外的计算成本。受人类视觉系统能够快速将注意力集中在具有细节的重要区域并过滤掉无关信息的能力的启发,我们提出了一种新的UHR分割方法,称为边界增强补丁合并转换器(BPT)。BPT由两个关键组件组成:(1)补丁合并转换器(PMT),用于动态分配令牌以获取全局和局部表示信息的有意义区域;(2)边界增强模块(BEM),利用边界信息丰富细节。在多个超高分辨率图像分割基准测试上的广泛实验表明,我们的BPT在不引入额外计算开销的情况下优于以前的最先进方法。我们将发布代码以促进研究。
论文及项目相关链接
总结
超高分辨率图像分割是一项具有许多应用的关键任务,但它在处理丰富的细节和高空间分辨率方面存在挑战。最近的方法采用双分支架构,全局分支学习长距离上下文信息,局部分支捕捉细节。然而,它们在处理全局和局部信息之间的冲突时面临困难,并增加了额外的计算成本。受人类视觉系统迅速关注细节重要区域并过滤掉无关信息的能力的启发,我们提出了一种新型的超高分辨率分割方法——边界增强补丁合并转换器(BPT)。BPT由两个关键组件组成:(1)补丁合并转换器(PMT),用于动态分配标记到信息区域以获取全局和局部表示;(2)边界增强模块(BEM),利用边界信息丰富细节。在多个超高分辨率图像分割基准测试上的广泛实验表明,我们的BPT在不需要引入额外计算开销的情况下优于之前的最先进方法。我们将发布代码以促进研究。
关键见解
- 超高分辨率(UHR)图像分割具有许多应用,但在处理高空间分辨率和丰富细节方面存在挑战。
- 现有方法采用双分支架构处理全局和局部信息,但面临处理冲突和计算成本增加的问题。
- 提出的Boundary-enhanced Patch-merging Transformer(BPT)受人类视觉系统的启发,能迅速关注细节的重要区域并过滤无关信息。
- BPT包括两个关键组件:Patch-Merging Transformer(PMT)和Boundary-Enhanced Module(BEM)。
- PMT能动态分配标记到信息区域,以获取全局和局部表示。
- BEM利用边界信息来丰富细节。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是超高清分辨率(UHR)图像的语义分割任务。具体来说,论文面临的挑战包括:
高空间分辨率和丰富细节的处理:由于UHR图像具有高空间分辨率和丰富的细节,这使得在保持细节的同时进行有效的语义分割变得困难。
全局与局部信息的冲突:现有的方法采用双分支架构来学习长范围的上下文信息和捕获细节信息,但它们在处理全局与局部信息的冲突时存在困难,并增加了额外的计算成本。
计算成本与分割精度的权衡:如何在不牺牲计算成本的情况下提高分割精度是一个挑战。
为了解决这些问题,论文提出了一种新颖的UHR图像分割方法,称为边界增强的Patch-Merging Transformer(BPT),它包含两个关键组件:Patch-Merging Transformer(PMT)和边界增强模块(BEM)。PMT动态地为信息丰富的区域分配tokens以获取全局和局部表示,而BEM利用边界信息来丰富细节。这种方法旨在在不增加额外计算开销的情况下提高分割性能。
Q: 有哪些相关研究?
A: 相关研究主要涉及以下几个方面:
通用图像分割:
- 早期基于全卷积网络(FCNs)的语义分割模型,如FCN、Deeplabv3、PSPNet和UNet等,这些模型通常使用编码器-解码器结构来提取高级语义特征并恢复空间分辨率。
- Transformer在图像分割中的应用,如SegFormer和MaskFormer等,它们利用Transformer结构捕获长距离依赖信息。
超高清分辨率(UHR)图像分割:
- 采用多分支网络来学习全局和局部信息的方法,例如GLNet、CascadePSP、FCtL、ISDNet、WSDNet和GPWFormer等。
- 利用多尺度特征融合和多编码器-解码器流的方法,以逐步融合全局和局部信息。
特定技术与方法:
- 动态补丁合并方法,如Patch-Merging Transformer(PMT),动态地表示不同区域的图像块。
- 边界增强模块(BEM),用于整合详细的边界空间信息,而不引入额外的耗时分支。
这些相关研究为处理UHR图像的分割问题提供了不同的视角和方法,而本文提出的BPT方法则是在这些现有研究的基础上,通过结合动态补丁合并和边界信息增强来提高分割性能和计算效率。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为边界增强的Patch-Merging Transformer(BPT)的新方法来解决超高清分辨率(UHR)图像分割的问题。BPT方法主要包括两个关键组件:
**Patch-Merging Transformer (PMT)**:
- 动态补丁合并:PMT采用动态补丁合并方法,其中视觉tokens代表不同区域,具有动态的形状和大小。这种方法通过动态地为包含关键细节的区域采用高分辨率,同时保留全局上下文信息,有效地捕获全局和局部信息。
- **Patch Feature Extraction (PFE)**:输入的UHR图像被均匀分割成小块,并通过PFE提取块特征。使用较小的块有助于更精细的分割。
- **Patch Merging Block (PMB)**:通过PMB自动合并块以减少块的数量,从而降低内存消耗。使用基于密度峰值的聚类算法(DPC-KNN)来选择块中心,并将其他块分配给最近的块中心。
- **Patch Recovering Block (PRB)**:PRB聚合不同尺度的块(常规和动态合并的块特征),并重建用于上采样的输出特征。
**边界增强模块 (Boundary-Enhanced Module, BEM)**:
- 边界预测任务:为了保留边界细节,引入了一个辅助任务,指导低层学习边界预测。这个任务以二元分割任务的形式进行,使用Canny算子和膨胀操作来获得边界掩码。
- 特征融合模块:PMT路径在语义上是准确的,但在边界上丢失了空间和几何细节。BEM路径保留了边界细节,但缺乏全局语义信息。特征融合模块通过解决信息冲突来实现更好的分割精度。
此外,论文还提出了损失函数的组合,包括语义损失、边界损失和最终损失,以优化模型的性能。通过这种方式,BPT方法能够在不增加额外计算开销的情况下,有效地处理UHR图像的分割任务,并在多个基准数据集上取得了优于现有方法的性能。
Q: 论文做了哪些实验?
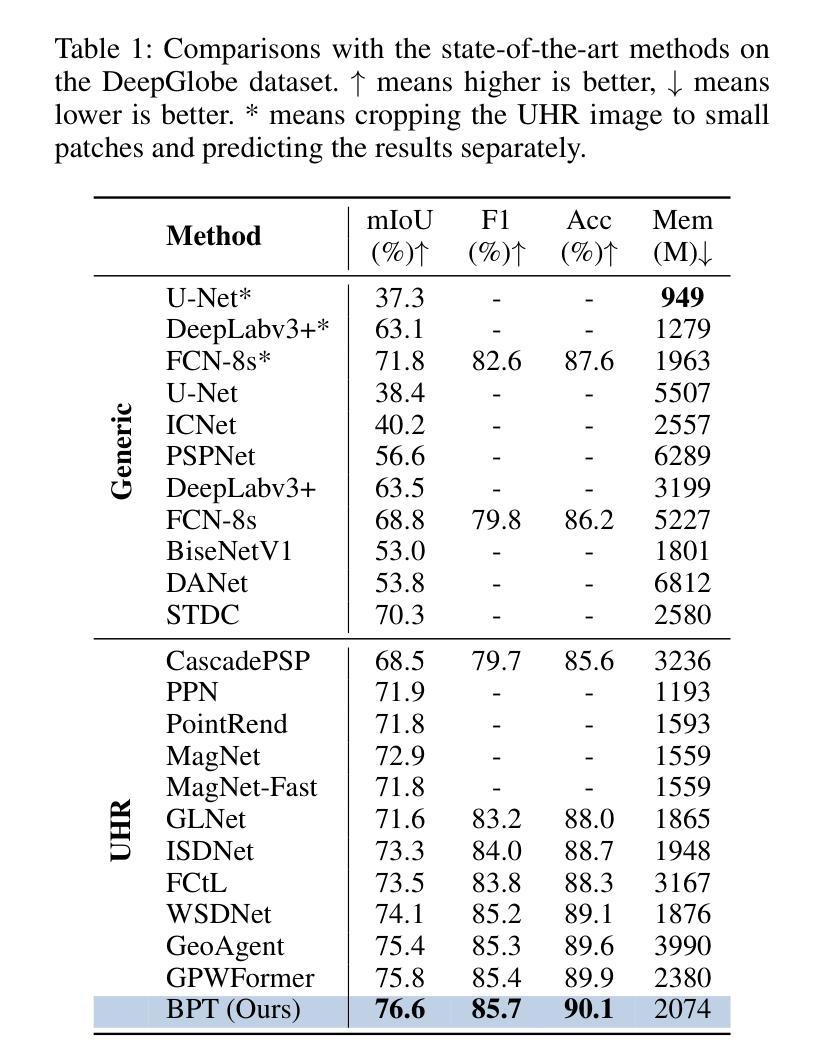
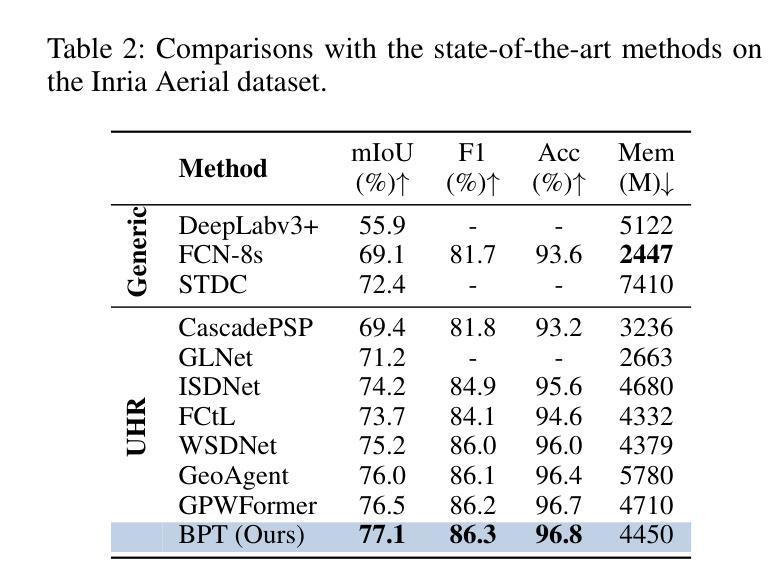
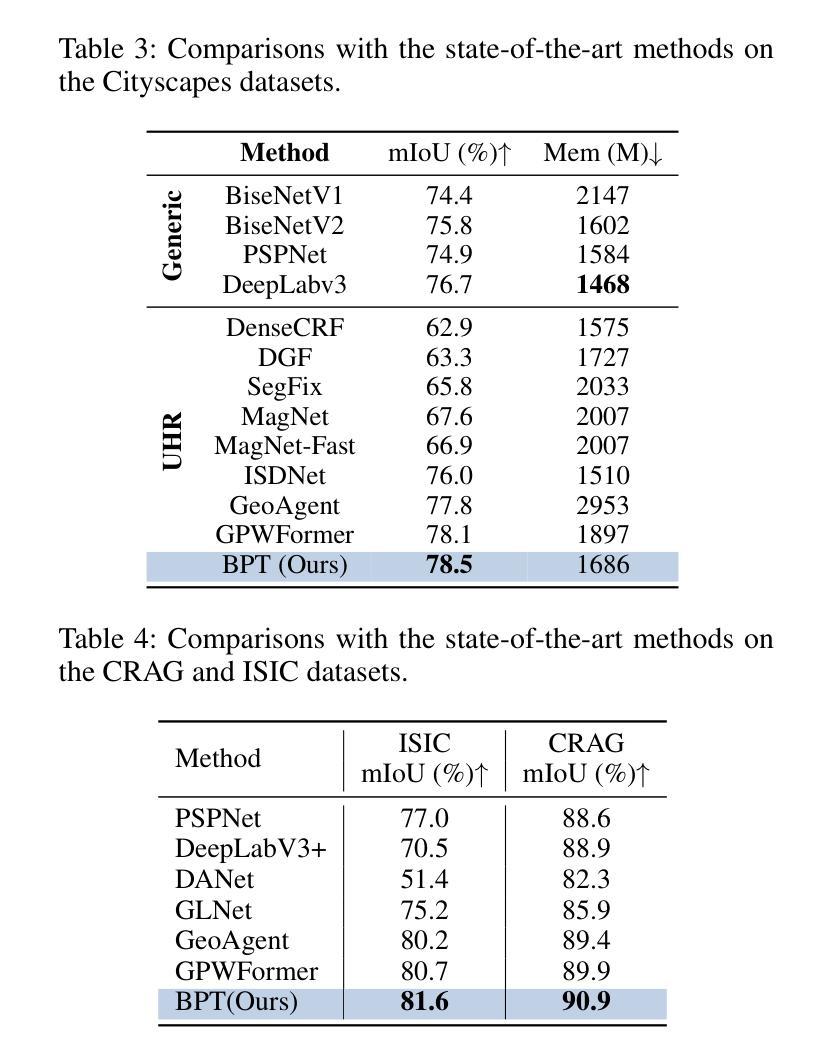
A: 论文中进行了一系列实验来验证所提出的Boundary-Enhanced Patch-Merging Transformer (BPT)方法的有效性。具体的实验包括:
数据集:
- DeepGlobe:包含803张UHR图像,分为455/207/142用于训练、验证和测试,每个图像大小为2448×2448像素,包含七个景观类别的标注。
- Inria Aerial:包含180张5000×5000像素的UHR图像,有建筑/非建筑区域的二进制掩码,分为126/27/27用于训练、验证和测试。
- Cityscapes:包含5000张图像,涵盖19个语义类别,分为2979/500/1525用于训练、验证和测试。
- ISIC:包含2596张UHR图像,分为2077/260/259用于训练、验证和测试。
- CRAG:包含213张图像,有腺体形态学标注,分为173用于训练和40用于测试,平均大小为1512×1516。
评估指标:
- 主要使用平均交并比(mIoU)、F1分数和像素准确率(Acc)来评估分割性能,其中mIoU是主要指标。
- 同时评估效率,通过GPU内存消耗来衡量,使用”gpustat”工具,以1的mini-batch大小进行测量。
基线比较:
- 与多个代表性基线模型进行比较,包括为UHR图像设计的模型(标记为”UHR”)和其他通用模型(”Generic”)。
实现细节:
- 对于PMT,设置补丁大小为32×32,Patch-Merging Transformer Blocks和Patch Recovering Blocks的数量为四个。
- 使用AdamW优化器进行训练,初始学习率为1×10−4,并使用多项式衰减策略。
实验结果:
- 在DeepGlobe、Inria Aerial、Cityscapes、ISIC和CRAG数据集上展示了BPT与基线方法的性能比较,包括mIoU、F1分数、Acc和内存消耗。
- 展示了BPT在各个数据集上的性能均优于现有方法。
消融研究:
- 对Patch-Merging Transformer (PMT)和Boundary-Enhanced Module (BEM)的有效性进行了消融研究,以评估这些组件对整体性能的贡献。
定性分析:
- 在DeepGlobe数据集上进行了定性分析,通过可视化比较了源图像、PMT生成的补丁tokens、真实掩码、以前SOTA方法(GPWFormer)的结果以及BPT的结果,以展示BPT在保持全局和局部信息方面的优越性能。
这些实验全面地验证了BPT方法在UHR图像分割任务中的有效性和优越性能。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的Boundary-Enhanced Patch-Merging Transformer (BPT)在多个数据集上取得了优异的性能,但仍有一些可以进一步探索的点:
算法优化:
- 计算效率:虽然BPT在设计时考虑了计算效率,但进一步优化算法以减少计算资源消耗和提高处理速度仍然是有价值的。
- 参数调整:研究不同参数设置对模型性能的影响,包括学习率、损失函数权重等,以找到最优配置。
模型泛化能力:
- 跨数据集泛化:测试BPT在未见过的数据集或不同来源(如不同传感器或不同分辨率)的数据上的表现。
- 多任务学习:探索BPT在其他任务(如目标检测、实例分割)上的应用,以及是否能够通过多任务学习进一步提升模型性能。
边界增强模块的改进:
- 更复杂的边界信息:研究是否可以通过引入更复杂的边界信息(如形状信息、纹理信息)来进一步提升边界分割的精度。
- 自适应边界学习:探索自适应机制来动态调整边界学习的重要性,以适应不同的分割任务。
Patch-Merging Transformer (PMT)的改进:
- 动态合并策略:研究不同的动态合并策略,以更好地平衡全局和局部信息。
- 多尺度融合:探索在PMT中引入多尺度信息融合的可能性,以捕捉不同尺度的特征。
损失函数的设计:
- 损失函数的改进:研究设计新的损失函数或优化现有损失函数,以更好地处理类别不平衡问题和提高分割质量。
模型解释性:
- 特征可视化:通过可视化技术研究模型学习到的特征,以理解模型是如何捕捉全局和局部信息的。
- 错误分析:进行错误分析,以识别模型在哪些类型的图像或场景中表现不佳,并探索改进方法。
实际应用:
- 实时处理:将BPT应用于需要实时处理的场景,如自动驾驶、机器人导航等,并针对性能和延迟进行优化。
- 跨领域应用:探索BPT在医学图像分割、卫星图像分析等其他领域的应用潜力。
这些探索点可以帮助研究者更深入地理解BPT的工作机制,提高其性能,并扩展其在各种实际应用中的有效性。
Q: 总结一下论文的主要内容
A: 论文提出了一种新颖的超高清分辨率(UHR)图像分割方法,名为边界增强的Patch-Merging Transformer(BPT)。BPT方法旨在解决UHR图像分割中的挑战,特别是在处理高空间分辨率和丰富细节时平衡全局和局部信息的冲突,同时控制计算成本。主要内容包括:
方法介绍:
- BPT包含两个关键组件:Patch-Merging Transformer(PMT)和边界增强模块(BEM)。
- PMT通过动态地为信息丰富的区域分配不同形状和大小的tokens来获取全局和局部表示。
- BEM利用边界信息来丰富细节,增强分割精度,且在推理时不增加额外计算开销。
**Patch-Merging Transformer (PMT)**:
- 由Patch Feature Extraction(PFE)、Patch Merging Block(PMB)和Patch Recovering Block(PRB)组成。
- PFE将输入图像分割成小块以提取特征。
- PMB通过聚类算法动态合并相似的patch特征,减少tokens数量。
- PRB恢复原始数量的patches并获取特征图。
**边界增强模块 (BEM)**:
- 引入辅助边界学习任务,使用Canny算子和膨胀操作生成边界掩码。
- 特征融合模块(FFM)解决信息冲突,提高分割精度。
损失函数:
- 总损失函数是语义损失、边界损失和最终损失的加权组合。
实验:
- 在五个公共UHR图像分割基准数据集上进行了广泛的实验。
- 实验结果表明BPT在各项指标上均优于现有的最先进方法。
贡献:
- 提出了一种新的高效的UHR图像分割方法BPT,平衡了计算精度。
- 提出了PMT,动态表示不同区域的tokens,捕获全局上下文信息和丰富的局部细节。
- 提出了BEM,整合详细的边界空间信息,无需额外的耗时分支。
- 证明了BPT方法的有效性,超越了现有方法。
论文的代码将被公开,以促进进一步的研究。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Scalable magnetic resonance fingerprinting: Incremental inference of high dimensional elliptical mixtures from large data volumes
Authors:Geoffroy Oudoumanessah, Thomas Coudert, Carole Lartizien, Michel Dojat, Thomas Christen, Florence Forbes
Magnetic Resonance Fingerprinting (MRF) is an emerging technology with the potential to revolutionize radiology and medical diagnostics. In comparison to traditional magnetic resonance imaging (MRI), MRF enables the rapid, simultaneous, non-invasive acquisition and reconstruction of multiple tissue parameters, paving the way for novel diagnostic techniques. In the original matching approach, reconstruction is based on the search for the best matches between in vivo acquired signals and a dictionary of high-dimensional simulated signals (fingerprints) with known tissue properties. A critical and limiting challenge is that the size of the simulated dictionary increases exponentially with the number of parameters, leading to an extremely costly subsequent matching. In this work, we propose to address this scalability issue by considering probabilistic mixtures of high-dimensional elliptical distributions, to learn more efficient dictionary representations. Mixture components are modelled as flexible ellipitic shapes in low dimensional subspaces. They are exploited to cluster similar signals and reduce their dimension locally cluster-wise to limit information loss. To estimate such a mixture model, we provide a new incremental algorithm capable of handling large numbers of signals, allowing us to go far beyond the hardware limitations encountered by standard implementations. We demonstrate, on simulated and real data, that our method effectively manages large volumes of MRF data with maintained accuracy. It offers a more efficient solution for accurate tissue characterization and significantly reduces the computational burden, making the clinical application of MRF more practical and accessible.
磁共振指纹技术(MRF)是一种新兴技术,有潜力彻底改变放射学和医学诊断。与传统磁共振成像(MRI)相比,MRF能够实现快速、同时、非侵入性地获取和重建多种组织参数,为新型诊断技术铺平道路。在原始匹配方法中,重建是基于体内获取的信号与具有已知组织特性的高维模拟信号(指纹)字典之间最佳匹配的搜索。一个关键且具限制性的挑战是,模拟字典的大小会随着参数数量的增加而呈指数增长,导致后续匹配极其昂贵。在这项工作中,我们提出通过考虑高维椭圆分布的概率混合来解决这一可扩展性问题,以学习更有效的字典表示。混合成分被建模为低维子空间中的灵活椭圆形形状。它们被用来聚类相似信号,并在局部聚类中降低其维度,以限制信息丢失。为了估计这种混合模型,我们提供了一种能够处理大量信号的新增量算法,使我们能够远远超出标准实施中所遇到的硬件限制。我们在模拟和真实数据上证明,我们的方法有效地管理了大量MRF数据,并保持了准确性。它为准确的组织特征化提供了更有效的解决方案,并大大降低了计算负担,使MRF的临床应用更加实用和可及。
论文及项目相关链接
Summary
磁共振指纹技术(MRF)是一种新兴技术,可快速、同时、无创地获取和重建多种组织参数,为诊断技术带来革新。工作提出了基于高维椭圆分布概率混合的模型来解决模拟字典随参数数量增长而带来的匹配成本问题。模型利用椭圆形状在低维子空间中的灵活性,聚类相似信号并局部集群降低其维度以减少信息损失。新的增量算法能够处理大量信号,有效管理MRF大数据量并保持准确性,为组织特征提供更高效的解决方案,并显著降低计算负担,使MRF的临床应用更加实用和可访问。
Key Takeaways
- 磁共振指纹技术(MRF)是一种新兴技术,可快速、同时、无创地获取和重建多种组织参数,有助于革新医疗诊断和放射学。
- MRF使用模拟字典进行匹配,但模拟字典的大小随参数数量呈指数增长,导致匹配成本高昂。
- 工作提出使用基于高维椭圆分布概率混合的模型来解决这个问题,通过聚类相似信号并降低维度来减少信息损失。
- 模型利用椭圆形状在低维子空间中的灵活性,可以更有效地处理大量信号。
- 新的增量算法能够处理大量信号,有效管理MRF大数据量并保持准确性。
- 该方法提高了组织特征的准确性,并显著降低了计算负担。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是磁共振指纹(Magnetic Resonance Fingerprinting, MRF)技术在处理大规模数据集时的可扩展性和计算效率问题。MRF技术是一种新兴的医学成像技术,它能够快速、非侵入性地同时获取和重建多个组织参数。然而,随着需要估计的参数数量增加,MRF技术面临的挑战是模拟字典(dictionary)的大小会随着参数数量指数级增长,导致匹配过程变得极其耗时和计算成本高昂。
具体来说,论文中提到的关键问题包括:
字典大小的指数增长:在原始的匹配方法中,需要在体内获取的信号与已知组织属性的高维模拟信号(指纹)之间寻找最佳匹配。随着参数数量的增加,模拟字典的大小迅速增加,导致匹配过程的成本极高。
计算和内存限制:传统的MRF重建方法在处理大规模数据集时受到硬件限制,如内存容量,这限制了它们能够处理的数据量。
重建时间:随着参数数量的增加,MRF重建所需的时间显著增加,从小时到天,限制了其在临床应用中的实用性。
为了解决这些问题,论文提出了一种新的方法,即通过考虑高维椭圆分布的混合模型来学习更高效的字典表示。这种方法能够将相似的信号聚类,并在局部降维以减少信息丢失,同时提出了一个新的增量算法来处理大量信号,从而克服了标准实现中遇到的硬件限制。论文展示了该方法在模拟和真实数据上的有效性,证明了其在处理大量MRF数据时能够保持准确性,同时显著降低了计算负担,使得MRF的临床应用更加实用和可访问。
Q: 有哪些相关研究?
A: 论文中提到了多项与MRF(Magnetic Resonance Fingerprinting)重建相关的研究,以下是一些关键的相关研究和方法:
传统MRI与qMRI方法:
- 论文提到了传统的磁共振成像(MRI)和定量磁共振成像(qMRI)方法,这些方法通常基于单一序列,一次只能测量一个参数。
MRF技术:
- Ma et al. (2013) 提出了MRF技术,允许快速、同时、非侵入性地获取多个组织参数。
- Poorman et al. (2020) 和 McGivney et al. (2020) 讨论了MRF数据的获取和重建技术。
字典匹配方法:
- 最常用的MRF方法是字典匹配,包括网格搜索、查找表或k-最近邻方法。这些方法通过最小化观测信号与模拟信号之间的相似性度量来寻找最佳匹配。
基于学习的方法:
- Cohen, Zhu and Rosen (2018) 使用了一个四层全连接网络(DRONE)来学习字典信号,用于重建T1和T2参数。
- Cabini et al. (2024) 提出了一个带有长短期记忆(LSTM)块的递归神经网络(RNN),用于T1和T2的重建,并提高了对噪声采集的鲁棒性。
基于CNN和注意力机制的方法:
- Soyak et al. (2021) 和 Gu et al. (2024) 使用UNet架构直接从整个MRF图像中推断T1和T2。
- Li and Hu (2024) 提出了使用局部-全局视觉Transformer来全局捕获空间信息。
贝叶斯逆问题方法:
- Boux et al. (2021) 提出了使用GLLiM模型,该模型将MRF重建转化为贝叶斯逆问题,并使用学习方法解决。
字典的高效表示:
- McGivney et al. (2014) 应用奇异值分解(SVD)来降低字典的维度。
- Yang et al. (2018) 提出了使用随机SVD。
- Golbabaee et al. (2019) 在训练神经网络之前对字典应用SVD。
增量学习方法:
- Bellas et al. (2013) 提出了一种基于启发式近似的增量MPPCA方法。
这些研究为MRF技术的发展提供了理论基础和技术方法,同时也指出了现有方法的局限性,特别是在处理大规模数据集时的计算和内存限制。论文提出的HD-MED(High Dimensional Mixtures of Elliptical Distributions)框架旨在通过更高效的字典表示和增量学习算法来解决这些问题。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤解决MRF(Magnetic Resonance Fingerprinting)技术在处理大规模数据集时的可扩展性和计算效率问题:
1. 高维椭圆分布混合模型(HD-MED)
- 论文提出了一种基于高维椭圆分布混合(HD-MED)的方法来学习更有效的字典表示。这种方法将概率混合模型中的每个组分建模为低维子空间中的灵活椭圆形状,这些形状被用来聚类相似的信号,并在局部(即在每个聚类级别)降低它们的维度,以限制信息丢失。
2. 降维和聚类
- 利用HD-MED模型,作者实现了一种“全局聚类,局部降维”的策略。这种方法首先将数据聚类到不同的组(clusters)中,然后在每个组内执行特定的降维操作。这样做的好处是,相比于单一子空间的全局降维,这种分而治之的方法可以更有效地表示数据。
3. 增量算法
- 为了估计HD-MED模型,论文提供了一个新的增量(增量学习或在线学习)算法,该算法能够处理大量的信号数据。这种增量算法允许逐个或以小批量处理数据,从而克服了标准实现中遇到的硬件限制,尤其是在内存大小受限的情况下。
4. 模拟和真实数据上的验证
- 论文通过在模拟和真实数据上的实验,展示了所提出方法在处理大量MRF数据时的有效性。实验结果表明,该方法能够在保持准确性的同时,显著减少计算负担,使得MRF技术的临床应用更加实用和可访问。
5. 算法实现和优化
- 论文还详细描述了算法的实现细节,包括如何初始化模型参数,如何使用贝叶斯信息准则(BIC)选择模型中的聚类数量和每个聚类的降维维度,以及如何通过在线EM算法迭代更新模型参数。
通过这些方法,论文成功地解决了MRF技术在处理大规模数据集时面临的挑战,提高了MRF技术的可扩展性和计算效率,为MRF技术的临床应用提供了新的解决方案。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出方法的有效性:
1. 在模拟和真实数据上的验证
- 论文首先在模拟数据上验证了所提出方法的有效性,以展示该方法能够处理大量MRF数据并保持准确性。
- 之后,论文在真实数据上进行了实验,这些数据来自6名健康志愿者的MRF成像数据。
2. 模型选择和初始化
- 使用贝叶斯信息准则(BIC)来选择模型中的聚类数量 (K) 和每个聚类的降维维度 (d)。
- 通过随机选择一个能够适应内存的字典子集,并运行批量全协方差EM算法来确定初始的 (\Sigma_k) 估计值。
- 使用这些估计值来确定 (D_k) 和 (A_k),并应用kneedle算法来确定每个聚类的降维维度 (d_k)。
3. 组织和敏感性参数重建
- 对于六名受试者,比较了使用HD-GMM和HD-STM得到的参数图与使用传统全匹配方法得到的参数图。
- 计算了每种参数图与全匹配参数估计之间的平均绝对误差(MAE)。
- 使用结构相似性指数(SSIM)来评估重建质量,并与全匹配进行比较。
4. 计算时间比较
- 在Nvidia V100-32gb GPU上,使用HD-GMM和HD-STM重建一个受试者的切片只需要7分钟,而全匹配需要45分钟,实现了6倍的时间减少。
- 在Apple M2 Pro CPU上,全匹配需要几天时间,而HD-GMM和HD-STM只需要4小时30分钟。
5. 参数图质量评估
- 通过比较全匹配和HD-STM得到的参数图,评估了参数图的质量。
- 展示了T1、T2、CBV和R参数图,并与文献中报告的健康受试者范围进行比较,以验证HD-STM方法的准确性。
这些实验验证了所提出方法在减少计算时间、提高处理大规模数据集的能力以及保持参数图质量方面的优势。通过这些实验,论文展示了HD-MED模型在MRF重建中的潜力和有效性。
Q: 有什么可以进一步探索的点?
A: 论文提出了一种新的方法来处理MRF(Magnetic Resonance Fingerprinting)数据,以提高其在临床应用中的可扩展性和计算效率。尽管取得了一定的成果,但仍有一些领域可以进一步探索和改进:
1. 结合回归模型或神经网络
- 论文提到了将HD-MED与回归模型或神经网络结合的可能性,以替代简单的匹配过程。这可能进一步提高MRF重建的准确性和效率。
2. 利用空间信息
- 目前的方法没有利用体素级别的空间信息来进行参数预测。可以考虑引入空间信息,例如通过考虑体素邻近性来改进或加速参数预测。
3. 优化算法性能
- 虽然论文提出的增量算法已经显著减少了计算时间,但仍有进一步优化算法性能的空间,例如通过改进初始化方法、调整学习率策略或利用并行计算技术。
4. 扩展到更广泛的临床应用
- 论文中的方法主要针对特定的MRF参数进行优化。可以考虑将这种方法扩展到更广泛的临床应用,例如不同的成像序列或不同的疾病标志物。
5. 提高模型的鲁棒性
- 虽然HD-STM在实验中表现优于HD-GMM,但在某些参数(如CBV和R)的重建上仍有改进空间。可以考虑进一步研究如何提高模型对噪声和异常值的鲁棒性。
6. 跨平台验证
- 论文中的实验主要在特定的硬件上进行。为了提高方法的通用性,可以在不同的硬件平台和软件环境中验证算法的性能。
7. 探索更多的高维混合模型
- 论文提出了基于高维椭圆分布混合的方法。可以探索其他类型的高维混合模型,例如混合高斯模型或其他类型的椭圆分布,以找到更适合特定数据特征的模型。
8. 临床数据的大规模验证
- 尽管论文在小规模的健康志愿者数据上展示了方法的有效性,但在更大规模的临床数据集上进行验证是必要的,以确保方法的临床适用性。
9. 算法的实时性能
- 考虑到临床应用中对实时或近实时处理的需求,可以进一步研究如何优化算法以满足实时处理的要求。
这些探索点不仅可以推动MRF技术的发展,还可能对其他需要处理大规模高维数据的领域产生影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文针对磁共振指纹(MRF)技术在处理大规模数据集时面临的可扩展性和计算效率问题。MRF技术允许快速、非侵入性地获取多个组织参数,但随着参数数量的增加,模拟字典的大小指数级增长,导致匹配过程成本极高。
方法论:
- 提出了一种基于高维椭圆分布混合(HD-MED)的方法来学习更有效的字典表示,通过聚类相似信号并在局部降维以限制信息丢失。
- 开发了一个新的增量算法,能够处理大量信号,克服了标准实现中的硬件限制。
实验验证:
- 在模拟和真实数据上验证了所提方法的有效性,包括在6名健康志愿者的MRF成像数据上的实验。
- 比较了使用HD-GMM和HD-STM与传统全匹配方法得到的参数图,展示了所提方法在保持准确性的同时显著减少了计算负担。
计算效率:
- 在Nvidia V100-32gb GPU上,使用HD-GMM和HD-STM重建一个受试者的切片只需要7分钟,而全匹配需要45分钟,实现了6倍的时间减少。
参数图质量评估:
- 通过比较全匹配和HD-STM得到的参数图,评估了参数图的质量,并与文献中报告的健康受试者范围进行比较,以验证HD-STM方法的准确性。
进一步探索的点:
- 论文提出了一些可以进一步探索的方向,包括结合回归模型或神经网络、利用空间信息、优化算法性能、扩展到更广泛的临床应用等。
结论:
- 论文结合了鲁棒的潜在变量表示、聚类和增量学习,提出了一种新的处理和表示大量潜在异构高维数据的可行和准确的方法。这种方法不仅减少了计算时间,还有助于减少患者数据采集时间,使高级MRF技术更易于在临床实践中应用。
总的来说,这篇论文提出了一种创新的方法来提高MRF技术的可扩展性和计算效率,使其更适用于临床环境,并为未来的研究和应用提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

RTFAST-Spectra: Emulation of X-ray reverberation mapping for active galactic nuclei
Authors:Benjamin Ricketts, Daniela Huppenkothen, Matteo Lucchini, Adam Ingram, Guglielmo Mastroserio, Matthew Ho, Benjamin Wandelt
Bayesian analysis has begun to be more widely adopted in X-ray spectroscopy, but it has largely been constrained to relatively simple physical models due to limitations in X-ray modelling software and computation time. As a result, Bayesian analysis of numerical models with high physics complexity have remained out of reach. This is a challenge, for example when modelling the X-ray emission of accreting black hole X-ray binaries, where the slow model computations severely limit explorations of parameter space and may bias the inference of astrophysical parameters. Here, we present RTFAST-Spectra: a neural network emulator that acts as a drop in replacement for the spectral portion of the black hole X-ray reverberation model RTDIST. This is the first emulator for the reltrans model suite and the first emulator for a state-of-the-art x-ray reflection model incorporating relativistic effects with 17 physically meaningful model parameters. We use Principal Component Analysis to create a light-weight neural network that is able to preserve correlations between complex atomic lines and simple continuum, enabling consistent modelling of key parameters of scientific interest. We achieve a $\mathcal{O}(10^2)$ times speed up over the original model in the most conservative conditions with $\mathcal{O}(1%)$ precision over all 17 free parameters in the original numerical model, taking full posterior fits from months to hours. We employ Markov Chain Monte Carlo sampling to show how we can better explore the posteriors of model parameters in simulated data and discuss the complexities in interpreting the model when fitting real data.
贝叶斯分析在X射线光谱学中的应用逐渐广泛,但由于X射线建模软件和计算时间的限制,其应用主要集中在相对简单的物理模型上。因此,具有复杂物理特性的数值模型的贝叶斯分析仍然难以实现。当对吸积黑洞X射线双星进行X射线发射建模时,缓慢的计算模型严重限制了参数空间的探索,并可能误导天文物理参数的推断。在这里,我们推出了RTFAST-Spectra:这是一个神经网络模拟器,可以替代黑洞X射线回波模型RTDIST中的光谱部分。这是reltrans模型套件的首个模拟器,也是首款采用先进X射线反射模型、结合相对论效应、包含17个物理意义明确的模型参数的模拟器。我们使用主成分分析来创建轻量级神经网络,该网络能够保留复杂原子线与简单连续体之间的相关性,从而实现关键科学参数的连贯建模。在最保守的条件下,我们实现了相对于原始模型的$\mathcal{O}(10^2)$倍加速,并且在所有17个自由参数上保持了$\mathcal{O}(1%)$的精确度,从而将全后验拟合从数月缩短至数小时。我们采用马尔可夫链蒙特卡罗采样法,展示如何在模拟数据中更好地探索模型参数的后验分布,并讨论在拟合真实数据时解释模型的复杂性。
论文及项目相关链接
PDF 22 pages, 35 figures. Submitted to MNRAS
摘要
本文介绍了RTFAST-Spectra神经网络模拟器在X射线光谱分析中的应用。该模拟器可作为黑洞X射线回波模型RTDIST光谱部分的替代方案。它是首个为reltrans模型套件和首个为一流的考虑相对论效应的X射线反射模型创建的模拟器,该模型包含17个具有物理意义的模型参数。使用主成分分析创建轻量级神经网络,能够保留复杂原子线和简单连续谱之间的相关性,实现对关键科学参数的一致建模。在最保守的条件下,相对于原始模型实现了$\mathcal{O}(10^2)$倍的速度提升,在原始模型的17个自由参数上实现了$\mathcal{O}(1%)$的精度。通过Markov Chain Monte Carlo采样,可以更好地探索模拟数据的模型参数后验分布,并讨论了拟合真实数据时模型解释的复杂性。
关键见解
- Bayesian分析在X射线光谱中的应用已逐渐普及,但仍受限于X射线建模软件和计算时间的限制,难以应用于高物理复杂度的数值模型。
- 神经网络模拟器RTFAST-Spectra可作为黑洞X射线回波模型RTDIST的光谱替代方案,是首个为reltrans模型套件和一流的X射线反射模型创建的模拟器。
- 使用主成分分析创建的轻量级神经网络能够保留复杂原子线和简单连续谱之间的相关性,实现对关键科学参数的一致建模,包含17个具有物理意义的模型参数。
- RTFAST-Spectra实现了对原始模型的高速度提升和低精度损失。
- 通过Markov Chain Monte Carlo采样,可以更好地探索模拟数据的模型参数后验分布。
- 在拟合真实数据时,模型解释的复杂性被讨论。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在X射线光谱学中,尤其是对于活动星系核(AGN)和X射线双星系统中的吸积黑洞,进行贝叶斯分析时面临的计算限制。具体来说,这些限制来自于复杂的物理模型,如X射线反射和 reverberation 模型 RTDIST,这些模型在计算上非常昂贵,严重限制了参数空间的探索和天体物理参数的推断。
论文中提到的关键挑战包括:
模型计算复杂度高:对于黑洞X射线双星的X射线发射进行建模时,模型计算速度慢,极大地限制了参数空间的探索,可能会对天体物理参数的推断造成偏差。
贝叶斯分析的计算负担:尽管贝叶斯分析在X射线光谱学中开始被更广泛地采用,但由于X射线建模软件和计算时间的限制,它主要被限制在相对简单的物理模型中。
参数空间的探索:在复杂的参数空间中,不同的参数组合可能同样适合数据集,导致参数推断存在多解性(multimodal probability distributions),需要更广泛的参数空间探索来获得稳健的统计推断。
为了解决这些问题,论文提出了一个名为RTFAST-Spectra的神经网络仿真器,作为RTDIST模型光谱部分的替代品,以显著提高模型评估的速度,使得对复杂物理模型的全面贝叶斯分析成为可能。
Q: 有哪些相关研究?
A: 论文中提到了多个与研究相关的工作,涉及X射线光谱学、贝叶斯分析、机器学习在天文学中的应用等领域。以下是一些具体的相关研究:
X射线光谱学和黑洞物理相关研究:
- McClintock et al. (2011):测量黑洞的基本物理属性,如质量和自旋。
- Özel & Freire (2016):研究中子星的状态方程。
- Nemmen et al. (2012):研究相对论性喷流的形成条件。
X射线反射和 reverberation 模型:
- Fabian et al. (1989):提出了反射光谱的概念。
- García et al. (2013):研究了反射光谱的软过剩、铁线复合体和康普顿峰。
- Dauser et al. (2013):考虑了相对论性效应对反射光谱的影响。
贝叶斯分析和参数推断:
- Buchner et al. (2014):在X射线光谱建模中采用贝叶斯推断。
- Dias et al. (2024):进行了贝叶斯分析的相关研究。
机器学习和仿真技术在天文学中的应用:
- Heitmann et al. (2009, 2013):在宇宙学模拟中使用仿真技术。
- Alsing et al. (2020):在星系和Ia型超新星的光学和紫外线能谱研究中使用仿真。
- Matzeu et al. (2022):在活动星系核的吸积盘风的X射线光谱研究中使用仿真。
神经网络和机器学习技术:
- Bastos & O’hagan (2009):使用高斯过程进行仿真。
- Himes et al. (2022):使用人工神经网络进行仿真。
- Vicent et al. (2018):使用核岭回归进行仿真。
RTDIST模型:
- Ingram et al. (2019, 2022):开发了RTDIST模型,并在论文中详细描述了其特性和假设。
这些相关研究为本文提出的RTFAST-Spectra仿真器提供了理论基础和技术背景,同时也表明了在X射线光谱学和天体物理参数推断中,对高效计算方法的需求日益增长。通过引用这些研究,本文展示了其工作与现有研究的连续性,并强调了其对提高参数空间探索效率的贡献。
Q: 论文如何解决这个问题?
A: 论文通过开发一个名为RTFAST-Spectra的神经网络仿真器解决了在X射线光谱学中进行复杂物理模型分析的计算限制问题。以下是解决这个问题的关键步骤和方法:
1. 神经网络仿真器的开发
- 替代原有模型:RTFAST-Spectra被设计为RTDIST模型的替代品,RTDIST是一个用于模拟活动星系核和X射线双星系统中黑洞X射线反射和reverberation的复杂物理模型。
- 保持物理意义:RTFAST-Spectra是首个结合了相对论效应的先进X射线反射模型的仿真器,涵盖了17个物理意义明确的模型参数。
2. 主成分分析(PCA)
- 降维:使用PCA来创建一个轻量级的神经网络,该网络能够保持复杂原子线和简单连续体之间的相关性,从而实现关键科学参数的一致建模。
- 减少输出维度:通过PCA分解,将X射线光谱从2017个能量箱减少到200个主成分,显著降低了网络的复杂度和训练时间。
3. 神经网络架构和训练
- 网络设计:选择了一个简单的前馈神经网络架构,包含8个全连接层,每层有256个节点,使用GELU激活函数。
- 定制损失函数:开发了一个考虑每个PCA成分相对重要性的定制损失函数,通过加权因子推动网络优先学习对最终复现光谱影响最大的成分。
4. 集成方法
- 集成多个网络:训练了7个最佳性能的神经网络实例,并采用集成方法(averaging the outputs)来提高预测的准确性和稳健性。
5. 计算速度的提升
- 加速模型评估:RTFAST在最保守的条件下比原始模型快(O(10^2))倍,在模拟数据的后验分析中,使用MCMC采样可以显著减少从数周到数月的计算时间。
6. 贝叶斯分析的应用
- 探索后验分布:利用RTFAST加速的模型评估,可以更全面地探索模型参数的后验分布,这对于理解参数空间的复杂性和多重解性至关重要。
7. 测试和验证
- 直接比较:将RTFAST与RTDIST的输出进行直接比较,验证了仿真器在预定精度内的可靠性。
- 模拟观测的拟合:展示了RTFAST能够从模拟观测中恢复参数后验分布的能力,尽管存在小的系统偏差。
通过这些方法,论文成功地展示了如何利用机器学习技术来克服传统物理模型在计算上的限制,从而使得对复杂天体物理系统的贝叶斯分析变得更加可行和高效。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来测试和验证RTFAST-Spectra(简称RTFAST)神经网络仿真器的性能和可靠性。以下是主要的实验内容:
1. 直接比较实验
- 目的:直接比较RTFAST和RTDIST模型输出的光谱,以验证RTFAST能否在预定精度内复现RTDIST的结果。
- 方法:选择了测试集中的一个参数集,对比RTFAST和RTDIST生成的光谱,检查两者在不同能量下的一致性。
- 结果:在大多数能量范围内,RTFAST和RTDIST的光谱非常接近,差异在3%以内,满足论文设定的精度要求。
2. 预期模型行为测试
- 目的:检验RTFAST是否能够正确反映单一参数变化对光谱的影响。
- 方法:固定除Γ以外的所有参数,变化Γ参数,并观察RTFAST生成的光谱如何变化。
- 结果:RTFAST能够正确反映Γ参数变化导致的光谱变化,包括连续谱的陡峭化和Fe K线复杂的出现。
3. 参数空间和能量依赖性误差分析
- 目的:分析RTFAST在不同参数空间和能量范围内的误差分布。
- 方法:计算整个测试集上RTFAST和RTDIST之间的分数残差差异,并以热图形式展示。
- 结果:RTFAST在大多数能量箱和参数空间内表现良好,误差在3%以下,但在某些特定参数区域存在小的系统偏差。
4. 参数恢复实验
- 目的:验证RTFAST是否能够从模拟观测中恢复出真实的参数后验分布。
- 方法:使用RTDIST模拟观测数据,然后使用RTFAST进行贝叶斯参数估计,比较恢复的参数与真实参数。
- 结果:RTFAST能够较好地恢复大部分参数的后验分布,尽管在某些参数上存在小的偏差。
5. 外推能力测试
- 目的:检验RTFAST在训练数据范围之外的外推能力。
- 方法:在超出训练参数范围的情况下使用RTFAST,并与RTDIST的结果进行比较。
- 结果:RTFAST在训练范围之外的参数上表现不佳,产生不合理的结果,强调了不要在训练范围之外使用RTFAST的重要性。
这些实验全面评估了RTFAST的性能,包括其准确性、可靠性和局限性,并为未来的使用和改进提供了指导。通过这些实验,论文证明了RTFAST是一个有效的工具,可以在保持高物理精度的同时显著提高X射线光谱分析的计算效率。
Q: 有什么可以进一步探索的点?
A: 论文提出了RTFAST-Spectra这一神经网络仿真器,并展示了其在X射线光谱学中的应用。尽管取得了显著的成果,但仍有一些领域可以进一步探索和改进:
1. 提高精度和减少偏差
- 论文中提到RTFAST存在一定的系统误差,未来可以通过改进训练策略、增加训练数据或调整网络架构来减少这些误差,提高仿真器的精度。
2. 扩展到更多物理过程和模型
- RTFAST目前专注于模拟RTDIST模型的光谱部分。未来可以开发更复杂的仿真器,模拟包括时间产品在内的更多物理过程,提供更全面的模型仿真。
3. 探索不同的神经网络架构和训练技术
- 虽然前馈神经网络在这项工作中表现良好,但探索其他类型的神经网络(如卷积神经网络或递归神经网络)可能揭示新的建模技术和改进的性能。
4. 实际观测数据的应用
- 论文中主要使用了模拟数据来测试RTFAST的性能。将RTFAST应用于实际的天文观测数据,评估其在现实世界数据中的表现和准确性。
5. 多波段和多信使天体物理研究
- 考虑将RTFAST与其他波段(如光学、红外)的数据结合,进行多波段分析,或与引力波数据结合,进行多信使天体物理研究。
6. 软件和算法的优化
- 进一步优化RTFAST的软件实现,包括并行计算和GPU加速,以实现更快的仿真速度和更高效的资源利用。
7. 贝叶斯分析方法的扩展
- 探索使用RTFAST进行更复杂的贝叶斯分析,如汉密尔顿蒙特卡洛(Hamiltonian Monte Carlo)或基于模拟的推断(Simulation-Based Inference),以充分利用RTFAST提供的计算效率。
8. 跨领域应用
- 考虑将RTFAST或类似技术应用于其他领域,如医学成像、材料科学或环境科学,其中复杂的物理模型和高维数据分析也是挑战。
9. 模型和数据的开放共享
- 推动相关模型和训练数据的开放共享,促进更广泛的社区合作和进一步的研究。
通过这些进一步的探索,可以扩展RTFAST-Spectra的应用范围,提高其性能,并推动X射线光谱学及其他相关领域的发展。
Q: 总结一下论文的主要内容
A: 论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出在X射线光谱学中,尤其是对活动星系核(AGN)和X射线双星系统中的吸积黑洞进行贝叶斯分析时,由于计算限制,难以处理复杂的物理模型,如X射线反射和reverberation模型RTDIST。
RTFAST-Spectra介绍:
- 为了解决上述问题,作者提出了RTFAST-Spectra,一个神经网络仿真器,作为RTDIST模型的替代品,以显著提高模型评估的速度,并使得对复杂物理模型的全面贝叶斯分析成为可能。
方法论:
- 利用主成分分析(PCA)降低模型输出的复杂性,并通过前馈神经网络学习输入参数与PCA成分之间的关系。
- 设计了一个定制的损失函数,以加权方式训练网络,重点关注对最终光谱影响较大的PCA成分。
- 通过集成多个神经网络(ensemble method)来提高预测的准确性和稳健性。
实验与测试:
- 直接比较RTFAST和RTDIST生成的光谱,验证仿真器的准确性。
- 测试RTFAST对单一参数变化的响应,以确保其能够正确反映这些变化对光谱的影响。
- 分析RTFAST在整个参数空间和能量范围内的误差分布。
- 通过模拟观测数据,检验RTFAST恢复参数后验分布的能力。
- 测试RTFAST在训练数据范围之外的外推能力。
结果:
- RTFAST能够在保守条件下比原始模型快(O(10^2))倍,在某些情况下甚至快(O(10^4))倍。
- RTFAST能够在大多数情况下以3%的精度复现RTDIST的结果,尽管存在一些小的系统偏差。
讨论与未来工作:
- 论文讨论了RTFAST的潜在应用,包括更复杂的物理模型和多波段分析。
- 提出了未来工作的方向,如提高仿真器的精度、扩展到更多物理过程、优化软件和算法等。
结论:
- RTFAST-Spectra作为一种有效的工具,显著提高了X射线光谱分析的计算效率,使得对复杂天体物理系统的贝叶斯分析变得更加可行和高效。
总的来说,这篇论文展示了如何利用机器学习技术,特别是神经网络,来解决天体物理领域中的计算难题,并为未来的研究和应用提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

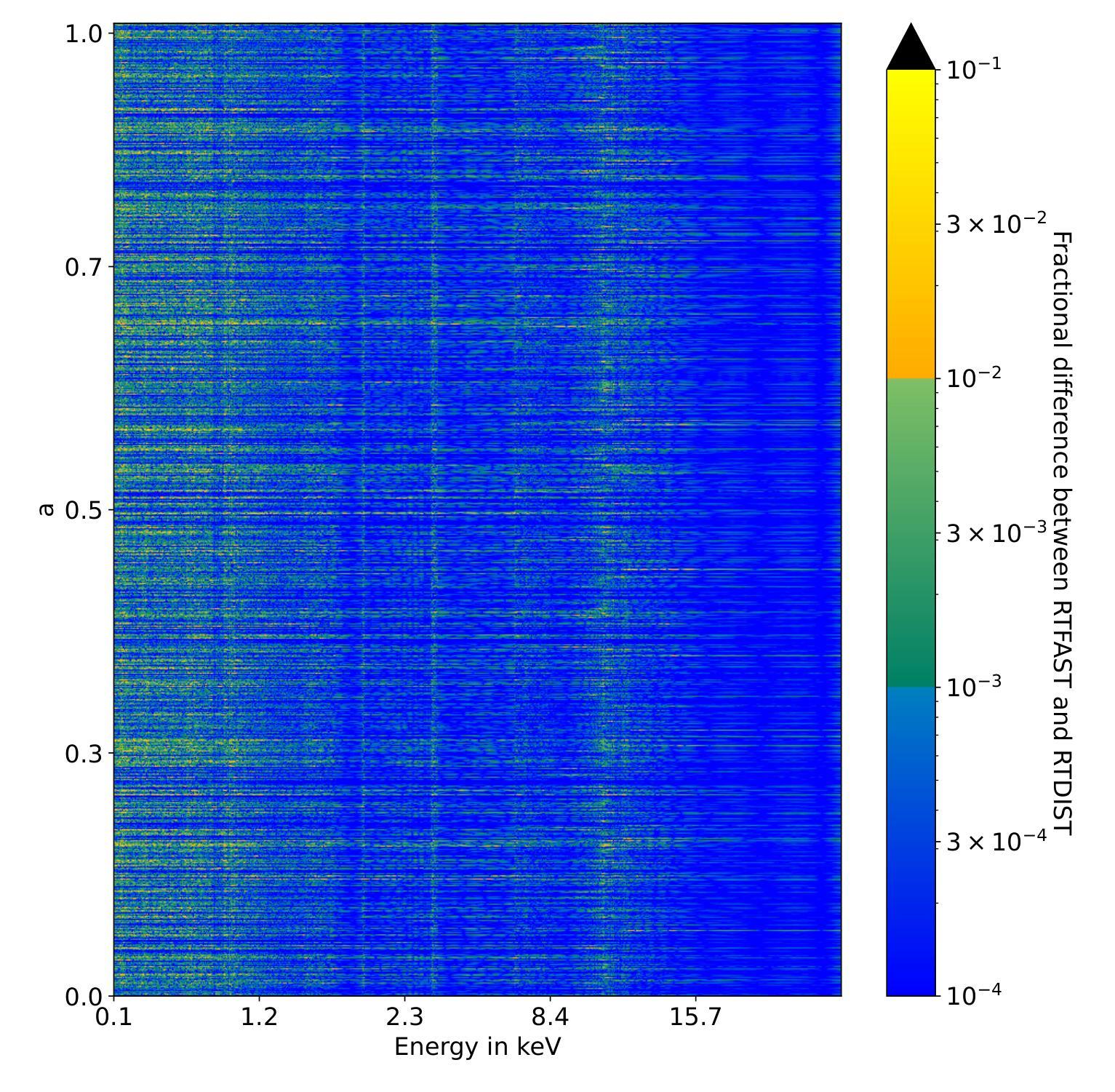
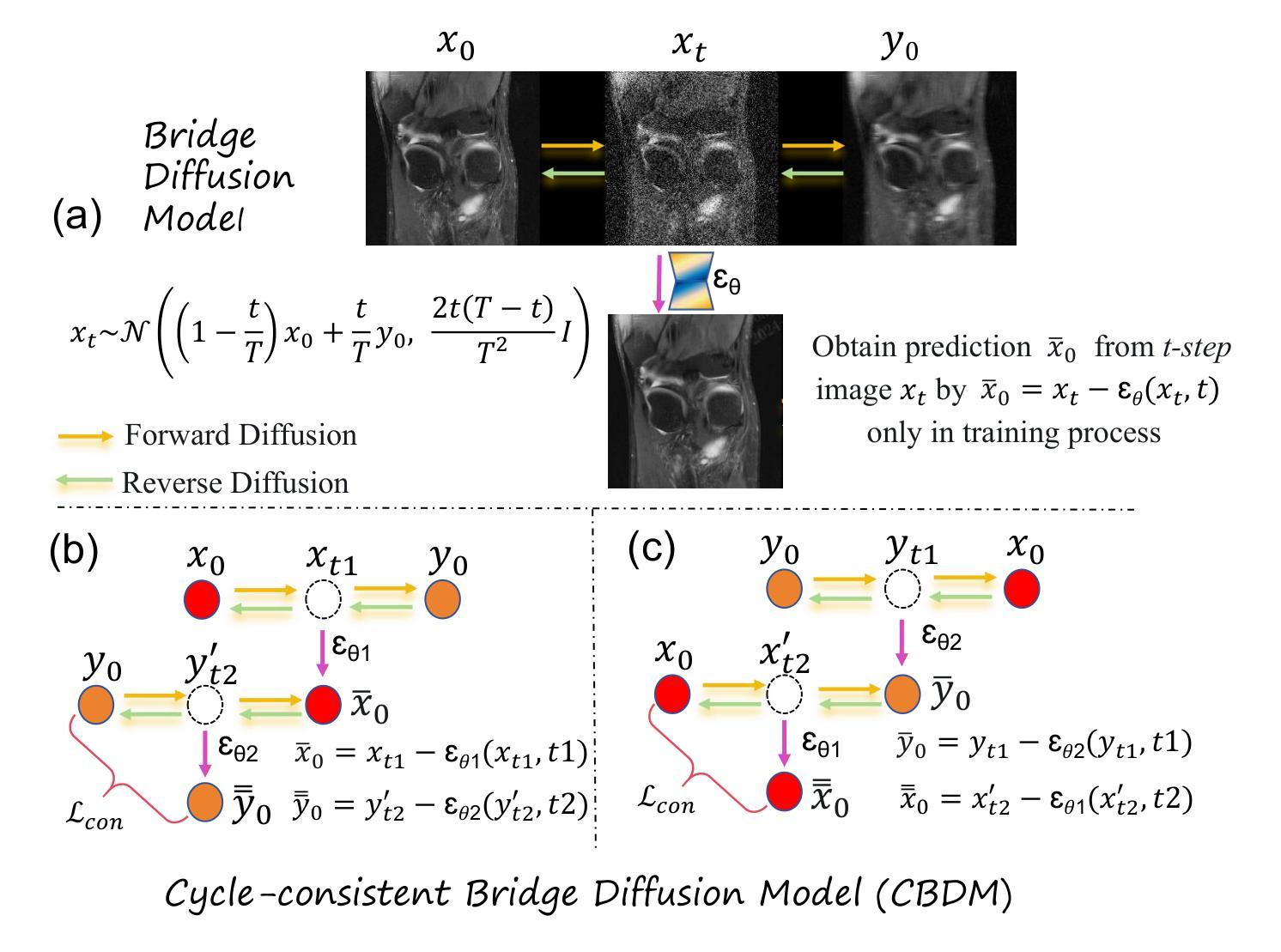
Cycle-Consistent Bridge Diffusion Model for Accelerated MRI Reconstruction
Authors:Tao Song, Yicheng Wu, Minhao Hu, Xiangde Luo, Guoting Luo, Guotai Wang, Yi Guo, Feng Xu, Shaoting Zhang
Accelerated MRI reconstruction techniques aim to reduce examination time while maintaining high image fidelity, which is highly desirable in clinical settings for improving patient comfort and hospital efficiency. Existing deep learning methods typically reconstruct images from under-sampled data with traditional reconstruction approaches, but they still struggle to provide high-fidelity results. Diffusion models show great potential to improve fidelity of generated images in recent years. However, their inference process starting with a random Gaussian noise introduces instability into the results and usually requires thousands of sampling steps, resulting in sub-optimal reconstruction quality and low efficiency. To address these challenges, we propose Cycle-Consistent Bridge Diffusion Model (CBDM). CBDM employs two bridge diffusion models to construct a cycle-consistent diffusion process with a consistency loss, enhancing the fine-grained details of reconstructed images and reducing the number of diffusion steps. Moreover, CBDM incorporates a Contourlet Decomposition Embedding Module (CDEM) which captures multi-scale structural texture knowledge in images through frequency domain decomposition pyramids and directional filter banks to improve structural fidelity. Extensive experiments demonstrate the superiority of our model by higher reconstruction quality and fewer training iterations, achieving a new state of the art for accelerated MRI reconstruction in both fastMRI and IXI datasets.
加速MRI重建技术旨在减少检查时间,同时保持高图像保真度,这在临床环境中对提高患者舒适度和医院效率都非常理想。现有的深度学习方法通常使用传统重建方法对欠采样数据进行图像重建,但它们仍难以提供高保真度的结果。近年来,扩散模型在提高生成图像的保真度方面显示出巨大潜力。然而,其从随机高斯噪声开始的推理过程会导致结果不稳定,通常需要数千个采样步骤,导致重建质量不佳和效率低下。为了解决这些挑战,我们提出了循环一致桥扩散模型(CBDM)。CBDM采用两个桥扩散模型来构建一个循环一致的扩散过程,并引入一致性损失,以增强重建图像的细节并减少扩散步骤的数量。此外,CBDM结合了轮廓分解嵌入模块(CDEM),通过频率域分解金字塔和方向滤波器库捕获图像的多尺度结构纹理知识,以提高结构保真度。大量实验表明,我们的模型在重建质量和训练迭代次数方面表现出卓越性能,在fastMRI和IXI数据集上的加速MRI重建方面达到了最新技术的前沿。
论文及项目相关链接
Summary
本文介绍了加速MRI重建技术,旨在减少检查时间同时保持高图像保真度。现有深度学习方法存在局限性,而扩散模型具有提高图像生成保真度的潜力。针对扩散模型的不足,提出了循环一致桥扩散模型(CBDM),通过两个桥扩散模型构建循环一致的扩散过程,增强重建图像的细节并减少扩散步骤数量。此外,CBDM结合Contourlet分解嵌入模块(CDEM)提高结构保真度。实验证明,该模型在快速MRI和IXI数据集上的重建质量达到新的先进水平。
Key Takeaways
- 加速MRI重建技术旨在减少检查时间并保持高图像保真度。
- 现有深度学习方法在MRI重建中面临挑战,而扩散模型显示出改善图像生成质量的潜力。
- 循环一致桥扩散模型(CBDM)通过构建循环一致的扩散过程来提高重建图像的细节和保真度。
- CBDM采用两个桥扩散模型,通过一致性损失减少扩散步骤数量。
- Contourlet分解嵌入模块(CDEM)用于提高图像的结构保真度。
- 实验证明CBDM在多个数据集上的MRI重建效果达到新的先进水平。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是加速磁共振成像(MRI)重建。具体来说,论文旨在减少MRI检查时间的同时保持高图像保真度,这在临床设置中非常有用,因为它可以提高病人的舒适度和医院的效率。论文指出,尽管现有的深度学习方法通常可以从欠采样数据中重建图像,并与传统重建方法结合使用,但它们仍然难以提供高保真度的结果。此外,扩散模型近年来显示出在提高生成图像保真度方面的巨大潜力,但其推理过程从随机高斯噪声开始,导致结果不稳定,并且通常需要数千个采样步骤,导致重建质量次优和效率低下。因此,论文提出了一种循环一致的桥扩散模型(Cycle-Consistent Bridge Diffusion Model, CBDM),旨在解决这些挑战。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个方面:
加速MRI重建的传统方法:
- **Sensitivity Encoding (SENSE)**:利用多个接收线圈的空间敏感性,通过减少采集时间来实现快速成像。
- **Generalized Autocalibrating Partially Parallel Acquisitions (GRAPPA)**:通过基于核的插值估计缺失的k空间数据,从而重建欠采样数据,提高图像质量并减少与并行成像技术相关的伪影。
深度学习在加速MRI重建中的应用:
- 结合深度学习和并行成像算法的方法,例如将深度学习与GRAPPA重建算法结合。
- 将迭代收缩阈值算法(ISTA)转化为深度神经网络,优化压缩感知(CS)以加速MRI重建。
- 使用对抗神经网络生成缺失的k空间数据。
生成对抗网络(GANs)在MRI重建中的应用:
- 提出了多种基于GAN的方法,以提高MRI重建的生成性能。
扩散模型在加速MRI重建中的应用:
- 近年来,扩散模型因其在图像生成方面的高性能而被广泛应用于加速MRI重建。
- 从无条件到条件扩散模型,再到基于先验的条件扩散模型的发展。
桥扩散模型:
- 桥扩散模型被提出用于图像翻译任务,扩散过程在成对图像之间构建,从确定性图像(无噪声)开始的逆向扩散使得采样过程更加稳定。
这些相关研究构成了论文提出的循环一致桥扩散模型(CBDM)的理论基础和技术支持。论文通过结合这些相关技术,旨在提高MRI重建的速度和质量。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为循环一致桥扩散模型(Cycle-Consistent Bridge Diffusion Model, CBDM)的方法来解决加速MRI重建的问题。具体解决方案包括以下几个关键点:
循环一致桥扩散模型(CBDM):
- 利用两个桥扩散模型构建循环一致的扩散过程,并引入一致性损失(consistency loss),以增强重建图像的细节,并减少扩散步骤的数量。
桥扩散模型:
- 该模型在两个确定性图像之间进行扩散过程,并且有明确的保证能够产生所需的条件分布,而不是仅依赖于条件图像。
轮廓分解嵌入模块(Contourlet Decomposition Embedding Module, CDEM):
- 通过频域分解金字塔和方向滤波器组捕捉图像中的多尺度结构纹理知识,以提高结构保真度。
- 利用迭代拉普拉斯金字塔和方向滤波器组从每个时间步的图像中提取结构纹理知识,并将其整合到去噪网络中,从而增强网络捕获结构纹理的能力。
实验验证:
- 在fastMRI和IXI数据集上进行了广泛的实验,证明了所提出模型的有效性,特别是在保持高重建质量和减少训练迭代次数方面达到了新的最佳水平。
具体技术实现:
- 论文详细描述了CBDM的框架,包括两个桥扩散模型用于x ← y和y ← x的转换,以及如何通过循环一致性损失来训练模型。
- 提出了一种基于轮廓分解的方法来显式考虑MRI图像的结构纹理知识,以解决欠采样和全采样MR图像之间由于高频成分缺失而引起的结构模糊和伪影问题。
通过这些方法,论文成功地提高了加速MRI重建的效率和图像质量,同时减少了模型训练和推理过程中的时间步骤,提高了临床部署的可行性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的循环一致桥扩散模型(CBDM)的有效性。具体的实验包括:
数据和实现细节:
- 实验在公共基准数据集fastMRI和IXI上进行。
- 从fastMRI数据集中选择了360名个体的多线圈膝盖数据集用于训练,8名用于验证,20名用于测试。
- 从IXI数据集中选择了577名患者的T1图像,随机分为训练(500名患者,44,935个2D图像)、验证(37名患者,3,330个图像)和测试(40名患者,3,600个图像)集。
- 所有图像被裁剪到特定尺寸并归一化到[0, 1]范围内。
- 应用等间距的笛卡尔欠采样,并设置了加速因子为4和8。
训练细节:
- 总迭代次数设置为200k,使用AdamW优化器,学习率为1e-4,批量大小为28。
- 对于CBDM,训练和采样步骤都设置为20,损失权重λ设置为1。
比较方法:
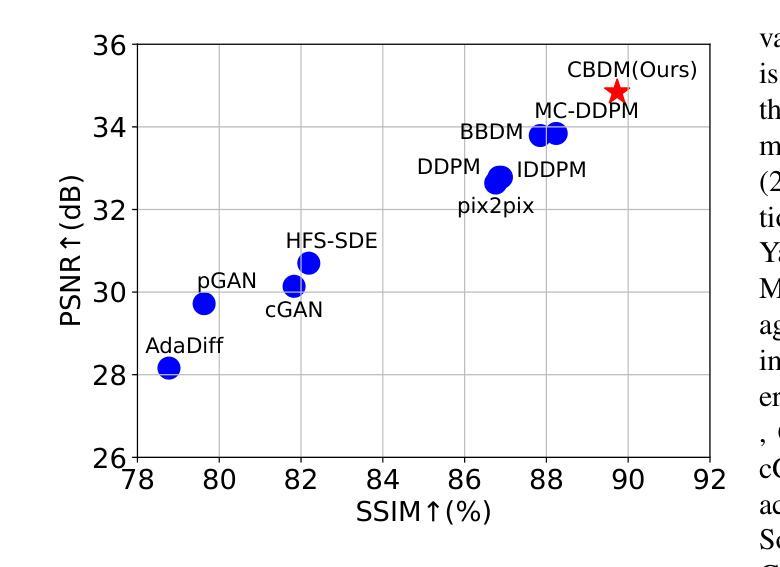
- 将CBDM与多种现有的方法进行比较,包括pGAN、cGAN、pix2pix、DDPM、IDDPM、AdaDiff、MC-DDPM、HFS-SDE和BBDM。
评价指标:
- 使用峰值信噪比(PSNR)、结构相似性指数(SSIM)和归一化均方误差(NMSE)来衡量重建质量。
分布内结果:
- 在fastMRI膝盖数据集和IXI数据集上,CBDM在所有评价指标上均优于其他方法。
分布外结果:
- 进行了分布外实验以验证模型的泛化能力。所有模型在fastMRI膝盖数据上训练,并在fastMRI脑部MRI扫描上进行测试。
- CBDM在脑部数据重建上实现了最佳性能。
推理效率:
- 比较了CBDM和其他扩散方法的推理效率,CBDM由于较少的采样步骤,具有更高的推理效率。
消融研究:
- 对CBDM的不同组件进行了消融研究,包括循环一致性和CDEM的有效性。
- 探讨了在训练过程中t1和t2的不同设置,以及不同噪声方差设置对模型性能的影响。
限制:
- 论文讨论了CBDM的局限性,包括训练过程中需要两个桥扩散模型同时训练可能带来的更高的训练成本,以及分布外实验中性能的下降。
这些实验全面地评估了CBDM在加速MRI重建任务中的表现,并与现有技术进行了比较,证明了其优越性和潜在的临床应用价值。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
降低训练成本:
- 论文提到,虽然循环一致的设计增强了图像表示,但训练过程需要同时训练两个桥扩散模型,这可能带来更高的训练成本。未来的工作可以探索如何减少模型训练的成本,例如通过设计更高效的网络架构或优化训练策略。
提高模型泛化能力:
- 论文中的分布外实验显示,模型的性能在新的分布上有所下降。未来的研究可以集中在提高模型的泛化能力上,使其能够更好地适应不同的数据分布和MRI扫描类型。
改进噪声方差设置:
- 论文中的消融实验表明,不同的噪声方差设置对模型性能有影响。可以进一步研究如何动态调整噪声方差,以提高模型的灵活性和适应性。
优化采样步骤:
- 尽管CBDM通过减少采样步骤提高了推理效率,但进一步优化采样过程,使其在更少的步骤下达到更好的重建效果,仍然是一个有价值的研究方向。
多模态和多对比度MRI重建:
- 扩展CBDM模型以处理多模态和多对比度MRI数据,这可能需要模型能够捕捉不同成像模式之间的复杂关系。
临床验证和评估:
- 在临床环境中对模型进行验证和评估,以确定其实际应用的可行性和效果,这可能包括与临床医生合作,以及在更大的、多样化的患者群体上进行测试。
模型解释性:
- 提高模型的可解释性,帮助临床医生理解模型的决策过程,增加模型在临床应用中的可信度。
跨中心和跨设备的数据融合:
- 探索如何将CBDM模型应用于跨中心和跨设备的数据融合问题,以提高MRI重建的鲁棒性。
结合其他成像技术:
- 研究如何将CBDM与CT、PET等其他成像技术结合,以提供更全面的诊断信息。
这些探索点可以帮助推动加速MRI重建技术的发展,并最终实现更好的临床应用。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
问题陈述:
- 论文针对加速磁共振成像(MRI)重建的问题,旨在减少MRI扫描时间同时保持图像质量,以提高临床舒适度和医院效率。
现有挑战:
- 现有深度学习方法在欠采样数据重建上存在局限性,扩散模型虽有潜力但存在推理不稳定和效率低下的问题。
方法提出:
- 提出循环一致桥扩散模型(CBDM),通过两个桥扩散模型建立循环一致的扩散过程,并引入一致性损失,以增强图像细节并减少扩散步骤。
技术创新:
- 引入轮廓分解嵌入模块(CDEM),通过频域分解捕捉图像的多尺度结构纹理知识,提高结构保真度。
实验验证:
- 在fastMRI和IXI数据集上进行广泛实验,证明了CBDM在重建质量和训练迭代次数上的优势。
结果展示:
- CBDM在多个评价指标上优于现有方法,包括PSNR、SSIM和NMSE,并在分布内外测试中展现了良好的泛化能力。
效率比较:
- CBDM展示了更高的推理效率,相比其他方法大大减少了采样步骤,同时保持了高性能。
消融研究:
- 通过消融研究验证了循环一致性和CDEM设计的有效性,并探讨了不同训练设置对模型性能的影响。
局限性与未来工作:
- 论文讨论了CBDM的局限性,包括训练成本和泛化能力,并提出了未来探索的方向,如降低训练成本和提高模型泛化能力。
结论:
- CBDM通过循环一致性和轮廓分解嵌入模块有效地恢复了MR图像的正常人体结构和纹理细节,并在基准数据集上实现了最先进的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
- CBDM通过循环一致性和轮廓分解嵌入模块有效地恢复了MR图像的正常人体结构和纹理细节,并在基准数据集上实现了最先进的性能。
点此查看论文截图


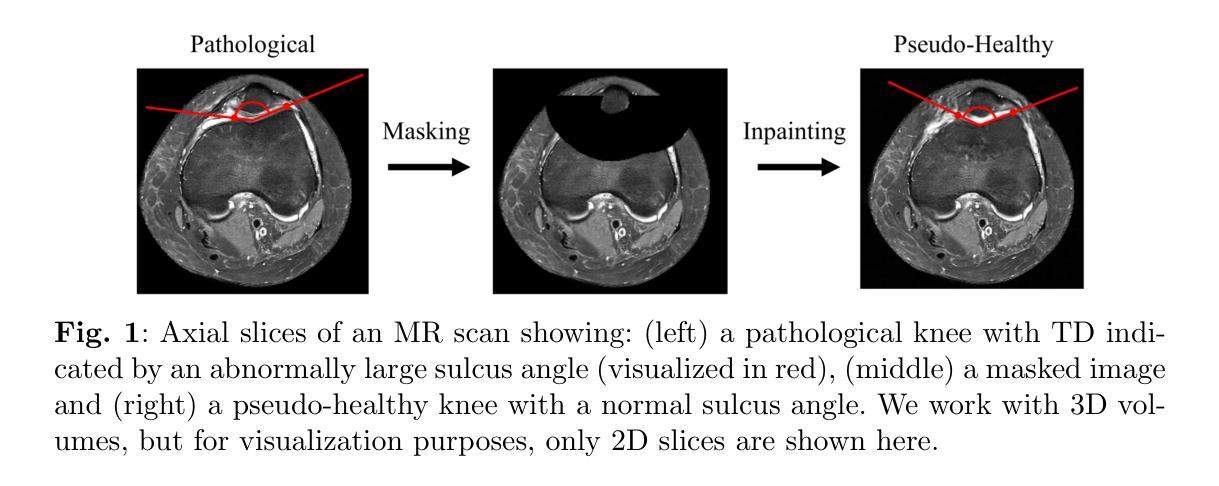
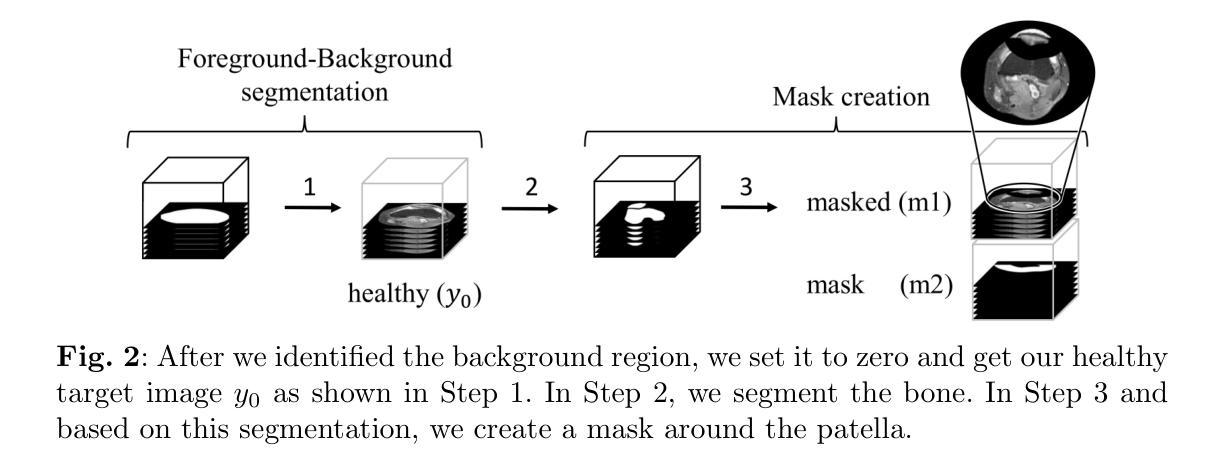
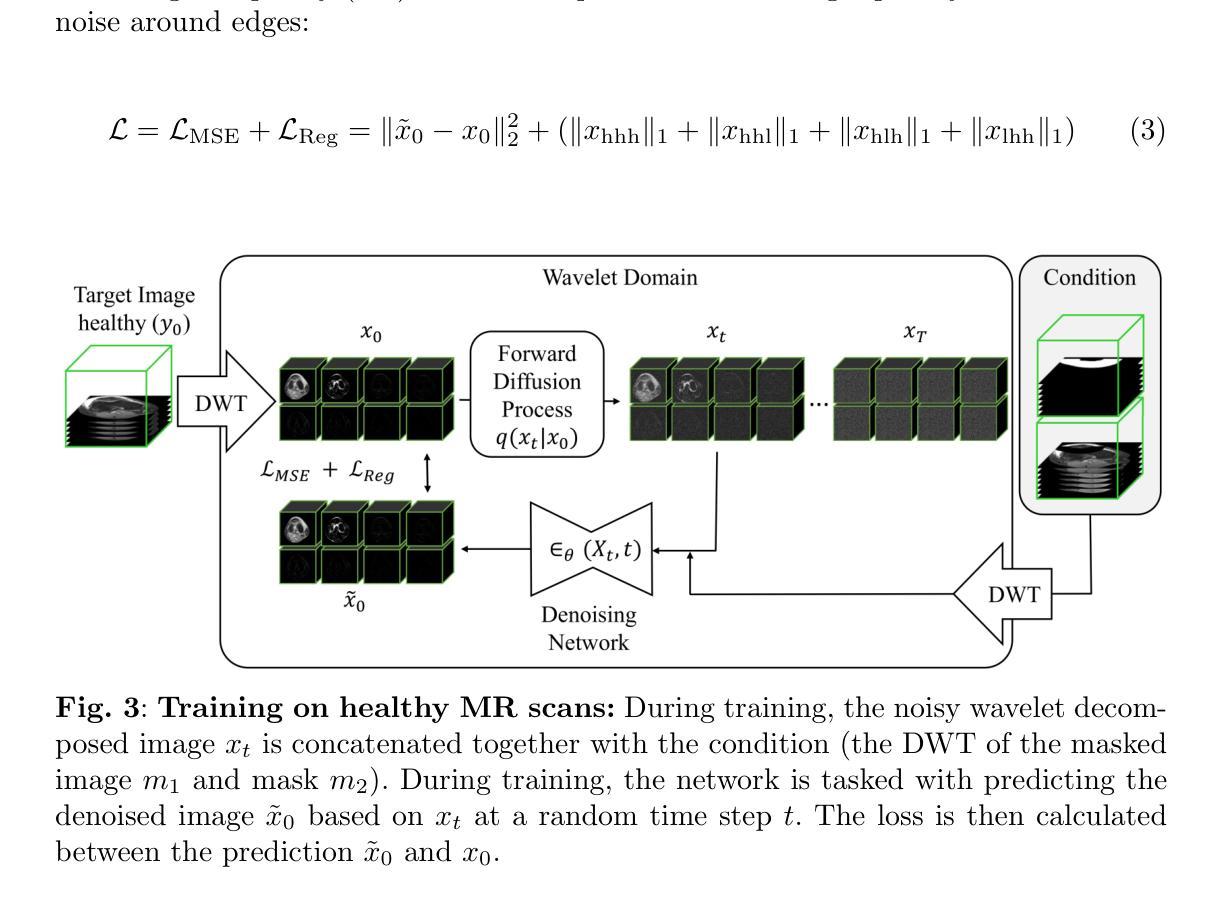
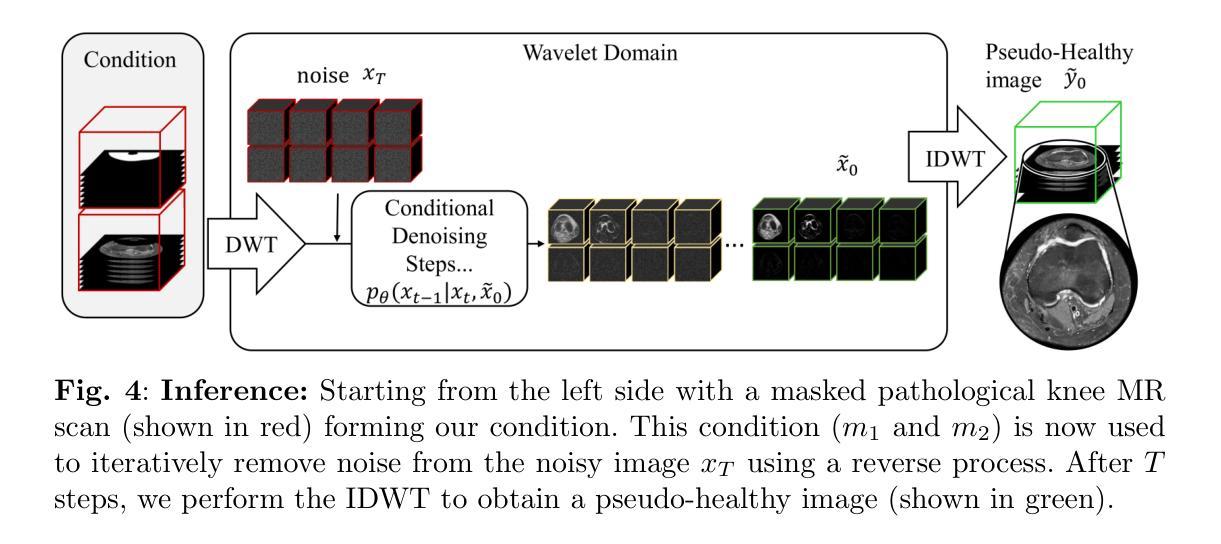
Generating 3D Pseudo-Healthy Knee MR Images to Support Trochleoplasty Planning
Authors:Michael Wehrli, Alicia Durrer, Paul Friedrich, Volodimir Buchakchiyskiy, Marcus Mumme, Edwin Li, Gyozo Lehoczky, Carol C. Hasler, Philippe C. Cattin
Purpose: Trochlear Dysplasia (TD) is a common malformation in adolescents, leading to anterior knee pain and instability. Surgical interventions such as trochleoplasty require precise planning to correct the trochlear groove. However, no standardized preoperative plan exists to guide surgeons in reshaping the femur. This study aims to generate patient-specific, pseudo-healthy MR images of the trochlear region that should theoretically align with the respective patient’s patella, potentially supporting the pre-operative planning of trochleoplasty. Methods: We employ a Wavelet Diffusion Model (WDM) to generate personalized pseudo-healthy, anatomically plausible MR scans of the trochlear region. We train our model using knee MR scans of healthy subjects. During inference, we mask out pathological regions around the patella in scans of patients affected by TD, and replace them with their pseudo-healthy counterpart. An orthopedic surgeon measured the sulcus angle (SA), trochlear groove depth (TGD) and D'ejour classification in MR scans before and after inpainting. The code is available at https://github.com/wehrlimi/Generate-Pseudo-Healthy-Knee-MRI . Results: The inpainting by our model significantly improves the SA, TGD and D'ejour classification in a study with 49 knee MR scans. Conclusion: This study demonstrates the potential of WDMs in providing surgeons with patient-specific guidance. By offering anatomically plausible MR scans, the method could potentially enhance the precision and preoperative planning of trochleoplasty, and pave the way to more minimally invasive surgeries.
目的:股骨槽形发育不良(Trochlear Dysplasia,简称TD)是青少年常见的畸形,会导致膝盖前部疼痛和不稳定。像槽形成形术(trochleoplasty)这样的手术干预需要精确的计划来纠正槽形沟。然而,目前还没有一个标准化的术前计划来指导外科医生重塑股骨。本研究旨在生成特定于患者的、伪健康的槽形区域的MRI图像,这些图像理论上应与患者的膝盖骨相匹配,从而支持槽形成形术的术前规划。
方法:我们采用小波扩散模型(Wavelet Diffusion Model,简称WDM)来生成个性化的、解剖上合理的槽形区域伪健康MRI扫描图像。我们使用健康受试者的膝关节MRI扫描来训练我们的模型。在推理过程中,我们掩盖了受TD影响的患者的膝盖骨周围病理区域,并用其伪健康对应物进行替换。骨科医生测量了MRI扫描中刺绣前后的凹沟角度(Sulcus Angle,简称SA)、槽沟深度(Trochlear Groove Depth,简称TGD)和D’ejour分类。代码可在https://github.com/wehrlimi/Generate-Pseudo-Healthy-Knee-MRI上找到。
结果:我们的模型的刺绣技术显著改善了49份膝关节MRI扫描研究中的SA、TGD和D’ejour分类。
论文及项目相关链接
PDF Early accepted at IPCAI 2025. Code: https://github.com/wehrlimi/Generate-Pseudo-Healthy-Knee-MRI
Summary
本文旨在通过应用Wavelet Diffusion Model(WDM)生成个性化的模拟健康膝关节MR图像,为Trochlear Dysplasia(股骨发育不良)患者提供术前的模拟参考。模型采用健康人群的膝关节MR图像进行训练,并在患者图像中填补病变区域,生成模拟健康的图像。研究结果显示,该方法能显著改善患者的股骨沟角度、深度及D’ejour分类等指标。此技术有助于提升手术精度和术前规划,为微创手术开辟新的道路。
Key Takeaways
- 研究目的:针对Trochlear Dysplasia(股骨发育不良)患者,生成个性化的模拟健康膝关节MR图像,辅助医生进行精确的手术规划。
- 技术方法:应用Wavelet Diffusion Model生成模拟健康的膝关节MR图像,填补患者病变区域,生成解剖上合理的图像。
- 数据来源:使用健康人群的膝关节MR图像进行模型训练。
- 研究结果:通过模拟健康的图像生成技术,显著改善患者的股骨沟角度、深度及D’ejour分类等指标。
- 代码公开:研究相关的代码已公开在GitHub上,便于其他研究者使用和改进。
- 潜在价值:该技术能提高手术精度和术前规划,为微创手术提供新的可能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是青少年中常见的骨骼畸形——股骨滑车发育不良(Trochlear Dysplasia, TD),它会导致前膝疼痛和不稳定。手术治疗,如滑车成形术(trochleoplasty),需要精确的规划来纠正滑车沟的形状。然而,目前不存在标准化的术前规划来指导外科医生重塑股骨。因此,这项研究的目标是生成患者特定的、伪健康的磁共振(MR)图像,这些图像理论上应与相应患者的髌骨对齐,可能支持滑车成形术的术前规划。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与研究相关的工作:
Barbosa et al. [15]: 提出了一种深度学习方法来检测TD的膝部标志点。
Fang et al. [16]: 提出了一个详细的术前患者特定计划,例如在正颌外科手术中的应用。
Van Haver et al. [17]: 使用统计形状建模来可视化滑车的异常,但尚未提供明确的矫正计划。
Durrer et al. [19]: 利用去噪扩散模型进行3D健康脑组织修复。
Friedrich et al. [20]: 提出了3D小波扩散模型(WDM),用于高分辨率医学图像合成。
Gu et al. [21]: 提出了一个通用模型SegmentAnyBone,用于在MRI上分割任何位置的任何骨骼。
这些研究为本文提出的使用Wavelet Diffusion Model (WDM)生成伪健康MR图像以支持滑车成形术规划的方法提供了理论基础和技术背景。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决股骨滑车发育不良(TD)的术前规划问题:
方法概述:
- 提出一种方法,生成伪健康MR图像,恢复滑车形状,同时根据患者独特的髌骨情况进行调整。
前景-背景分割和遮罩:
- 使用Otsu阈值分割、形态学开闭操作和最大连通组件提取来分割背景。
- 使用SegmentAnyBone工具进行骨骼分割,并基于此分割结果定位髌骨。
- 创建一个围绕髌骨的“碗”形遮罩,用于后续的图像修复。
去噪扩散概率模型(DDPMs):
- 利用DDPMs的迭代前向过程添加噪声,将输入图像转换为标准正态分布。
- 学习逆过程以尝试去除添加的噪声,该过程由神经网络参数化。
小波变换:
- 使用离散小波变换(DWT)分解图像到多个频率带,有效处理低频和高频成分。
- 利用逆离散小波变换(IDWT)重建原始图像。
DDPMs的修改用于图像修复训练过程:
- 修改逆过程,将遮罩图像的DWT和小波变换的遮罩作为条件输入。
- 网络学习在小波域内重建图像,然后通过IDWT回到原始表示域以获得修复后的图像。
实验:
- 使用fastMRI数据集进行训练,使用来自Basel大学儿童医院的TD患者MR图像进行评估。
- 对比修复前后的MR图像,使用已知的TD评估指标,包括滑车角(SA)、滑车沟深度(TGD)和D´ejour分类。
结果:
- 修复后的图像在TD的严重程度上表现出减少,允许更精确的术前规划。
- 通过图像质量评估指标(MSE、PSNR和SSIM)验证了生成图像的质量。
结论:
- 提出的方法能够生成适合个体患者的伪健康3D MR图像,有助于外科医生在滑车成形术的术前规划中做出更明智的决策。
该方法通过结合先进的图像处理技术和机器学习模型,提供了一种新的术前规划辅助工具,旨在提高手术的精确性和患者治疗效果。
Q: 论文做了哪些实验?
A: 论文中进行的实验包括:
数据集准备:
- 使用公开可用的fastMRI数据集进行模型训练,包含10,012个膝盖图像。
- 从这些数据中筛选出1,579个符合特定条件(PD AXIAL F/S或PD AXIAL FAT SAT)的序列。
- 将这些数据分为训练集(80%,1,181个独立患者,1,216个体积)和测试集(20%,296个独立患者,302个体积)。
伦理批准声明:
- 来自Basel大学儿童医院的数据集被匿名化,并获得了Ethikkommission Nordwest- und Zentralschweiz的豁免。
预处理:
- 将PD脂肪饱和序列的体素大小标准化为(0.6mm, 0.6mm, 4.5mm)。
- 将所有图像调整为固定大小(256, 256, 32)体素。
- 裁剪、填充和强度归一化。
诊断评估标准:
- 使用49个TD患者的膝盖MR扫描图像,在修复前后基于已知指标(滑车角SA、滑车沟深度TGD和D´ejour分类)进行比较。
- 由一名骨科副主治医师使用3D Slicer软件进行测量。
图像质量评估指标:
- 在fastMRI测试集图像上评估生成的修复图像,使用均方误差(MSE)、峰值信噪比(PSNR)和结构相似性指数(SSIM)。
- 所有评分仅计算图像的遮罩区域。
实现细节:
- 描述了使用的超参数设置,并指出实验在单个NVIDIA A100 (40 GB) GPU上进行,平均推理时间为45秒,内存占用为3.81 GB。
结果分析:
- 对49个病理性MR扫描图像进行分析,其中41个在D´ejour分类中显示出TD严重程度的降低。
- 在修复后,33个原本无法测量SA和TGD的扫描图像中,有46个能够测量SA和TGD。
- 使用Wilcoxon符号秩检验,发现SA和TGD在修复后都有显著改善。
这些实验验证了所提出方法的有效性,并展示了其在改善TD诊断和术前规划中的潜力。
Q: 有什么可以进一步探索的点?
A: 论文提出的方法虽然显示出潜力,但仍有一些可以进一步探索和改进的地方:
扩大和多样化训练数据库:
- 目前的模型可能受到fastMRI数据集的偏差影响。通过纳入更广泛和多样化的患者群体,特别是年轻患者,可以提高模型的泛化能力。
数据增强技术:
- 利用数据增强技术,如图像旋转、缩放、剪切等,可以增加模型训练的样本多样性,提高模型对不同患者解剖结构的适应性。
模型的可解释性和透明度:
- 研究模型的决策过程,提供更多关于模型如何学习和重建健康组织的信息,增加模型的可解释性。
交互式图像编辑工具:
- 开发允许外科医生在术前手动调整生成图像的工具,例如在虚拟现实中重新定位脱位的髌骨,以适应更复杂的病例。
多模态数据融合:
- 探索结合其他成像模式(如CT、X光)的数据,以提供更全面的解剖信息,尽管这可能涉及额外的辐射暴露。
长期跟踪和评估:
- 对接受手术的患者进行长期跟踪,评估使用伪健康MR图像辅助规划的手术效果,与常规手术结果进行比较。
临床试验和验证:
- 在实际临床环境中测试该方法,通过与外科医生合作,验证其在实际手术规划中的效果和可行性。
算法优化和计算效率:
- 进一步优化算法以减少计算资源需求,提高推理速度,使其更适合在临床环境中实时使用。
适应性学习:
- 研究模型是否能够根据手术结果反馈进行自我优化,以不断提高规划的准确性。
伦理和隐私问题:
- 在使用真实患者数据进行训练和测试时,确保遵守伦理准则和隐私保护法规。
这些探索点可以帮助研究者进一步提高方法的准确性、适用性和临床应用价值。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
研究目的:
- 针对青少年中常见的股骨滑车发育不良(Trochlear Dysplasia, TD),提出一种生成患者特定的伪健康MR图像的方法,以支持滑车成形术(trochleoplasty)的术前规划。
方法:
- 使用Wavelet Diffusion Model(WDM)生成个性化的伪健康、解剖学上可信的MR扫描图像。
- 训练模型时使用健康受试者的膝盖MR扫描。
- 在推理阶段,遮罩掉TD患者扫描中病理区域,并用伪健康对应部分替换。
实验:
- 使用fastMRI数据集训练模型,并用Basel大学儿童医院的TD患者MR图像评估模型。
- 对比修复前后的MR图像,使用已知的TD评估指标(滑车角SA、滑车沟深度TGD和D´ejour分类)进行测量。
结果:
- 修复后的图像在TD的严重程度上表现出减少,允许更精确的术前规划。
- 通过图像质量评估指标(MSE、PSNR和SSIM)验证了生成图像的质量。
结论:
- 提出的方法能够生成适合个体患者的伪健康3D MR图像,有助于外科医生在滑车成形术的术前规划中做出更明智的决策。
- 该方法有潜力提高手术的精确性和患者治疗效果,为未来更准确和患者定制的手术程序铺平道路。
未来工作:
- 通过扩大数据库、数据增强、交互式图像编辑工具等方法来改进和扩展该方法的应用范围。
论文展示了使用深度学习技术在医学图像处理和手术规划中的潜力,特别是在改善TD患者手术结果方面。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

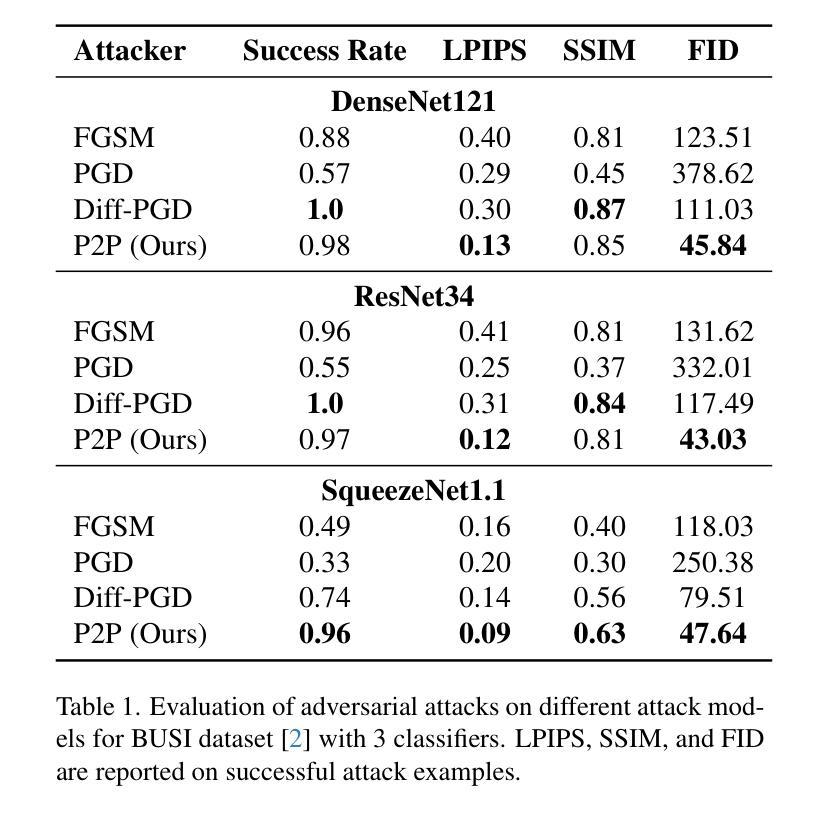
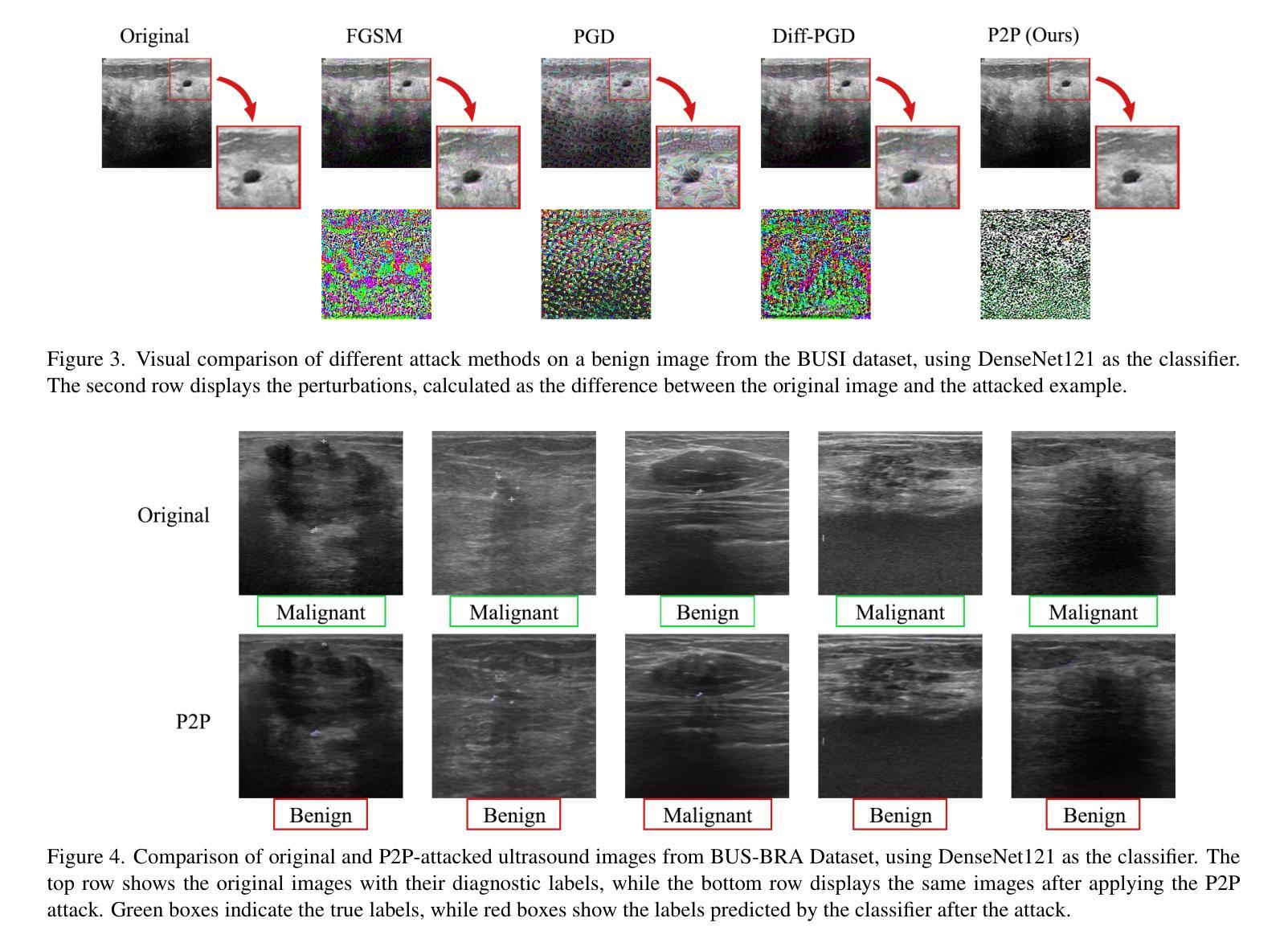
Prompt2Perturb (P2P): Text-Guided Diffusion-Based Adversarial Attacks on Breast Ultrasound Images
Authors:Yasamin Medghalchi, Moein Heidari, Clayton Allard, Leonid Sigal, Ilker Hacihaliloglu
Deep neural networks (DNNs) offer significant promise for improving breast cancer diagnosis in medical imaging. However, these models are highly susceptible to adversarial attacks–small, imperceptible changes that can mislead classifiers–raising critical concerns about their reliability and security. Traditional attacks rely on fixed-norm perturbations, misaligning with human perception. In contrast, diffusion-based attacks require pre-trained models, demanding substantial data when these models are unavailable, limiting practical use in data-scarce scenarios. In medical imaging, however, this is often unfeasible due to the limited availability of datasets. Building on recent advancements in learnable prompts, we propose Prompt2Perturb (P2P), a novel language-guided attack method capable of generating meaningful attack examples driven by text instructions. During the prompt learning phase, our approach leverages learnable prompts within the text encoder to create subtle, yet impactful, perturbations that remain imperceptible while guiding the model towards targeted outcomes. In contrast to current prompt learning-based approaches, our P2P stands out by directly updating text embeddings, avoiding the need for retraining diffusion models. Further, we leverage the finding that optimizing only the early reverse diffusion steps boosts efficiency while ensuring that the generated adversarial examples incorporate subtle noise, thus preserving ultrasound image quality without introducing noticeable artifacts. We show that our method outperforms state-of-the-art attack techniques across three breast ultrasound datasets in FID and LPIPS. Moreover, the generated images are both more natural in appearance and more effective compared to existing adversarial attacks. Our code will be publicly available https://github.com/yasamin-med/P2P.
深度神经网络(DNNs)在医学图像乳腺癌诊断方面具有巨大潜力。然而,这些模型极易受到对抗性攻击的影响——这些攻击能通过微小且难以察觉的改变误导分类器,从而对模型的可靠性和安全性提出严重质疑。传统攻击依赖于固定范数的扰动,这与人类感知不符。相比之下,基于扩散的攻击需要预先训练的模型,当这些模型不可用时会需要大量数据,这在数据稀缺的场景中限制了其实用性。然而,在医学成像中,由于数据集的有限可用性,这往往不可行。基于最近的可学习提示的进展,我们提出了Prompt2Perturb(P2P)这种新型的语言引导攻击方法,能够根据文本指令生成有意义的攻击示例。在提示学习阶段,我们的方法利用文本编码器中的可学习提示来创建微妙而有影响力的扰动,这些扰动在引导模型达到目标结果的同时保持难以察觉。与当前的基于提示学习的方法相比,我们的P2P通过直接更新文本嵌入而脱颖而出,避免了需要重新训练扩散模型的需要。此外,我们还发现优化早期反向扩散步骤既可以提高效率又能确保生成的对抗性示例融入微妙的噪声,从而在不引入明显伪影的情况下保持超声波图像质量。我们在三个乳房超声数据集上展示了我们的方法在FID和LPIPS指标上超越了最新的攻击技术。而且,生成的图像在外观上更加自然,与现有的对抗性攻击相比更加有效。我们的代码将在https://github.com/yasamin-med/P2P公开可用。
论文及项目相关链接
Summary
深度学习神经网络在医学图像乳腺癌诊断上具有巨大潜力,但易受对抗性攻击影响。提出一种新的语言引导攻击方法Prompt2Perturb(P2P),通过文本指令生成有意义的攻击样本。该方法通过更新文本嵌入避免重训扩散模型,优化早期反向扩散步骤提高效率,生成的对抗样本具有微妙噪声,不影响超声图像质量。P2P在三个乳房超声数据集上的表现优于最新攻击技术。
Key Takeaways
- 深度神经网络在医学图像乳腺癌诊断中有显著潜力,但存在被对抗性攻击误导的风险。
- 对抗攻击可能影响深度神经网络的可靠性,引发对模型安全性的关注。
- 传统的攻击方法基于固定范数扰动,与人类感知不符。
- 提出一种新的攻击方法Prompt2Perturb(P2P),基于语言引导生成攻击样本。
- P2P通过更新文本嵌入避免重训扩散模型,优化早期反向扩散步骤提高效率。
- P2P生成的对抗样本具有微妙的噪声,可以保持超声图像的质量,不会引入明显的伪影。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决深度神经网络(DNNs)在医学成像领域,特别是在乳腺癌诊断中对对抗性攻击的脆弱性问题。对抗性攻击是指通过引入微小的、难以察觉的变化来误导分类器的行为,这引起了对DNNs可靠性和安全性的严重担忧。论文中提到,尽管DNNs在医学成像领域有很大的应用前景,但它们对对抗性攻击的高敏感性使得这些模型在实际应用中存在风险。
具体来说,论文试图解决以下几个问题:
传统对抗性攻击方法的局限性:传统的基于梯度的方法(如FGSM、PGD等)虽然可以生成对抗性样本,但这些样本往往与自然图像的真实数据分布有较大偏差,导致在对抗性样本的有效性和隐蔽性之间存在权衡。
医学图像数据的稀缺性:在医学成像领域,由于数据集的有限可用性,使得基于大规模预训练模型的对抗性攻击方法在实际应用中受到限制。
现有方法与医学术语的适应性问题:现有的基于文本指导的攻击方法可能不适应临床术语,因此在医学领域中的意义有限。
为了解决这些问题,论文提出了一种名为Prompt2Perturb(P2P)的新型语言引导攻击方法,该方法能够通过文本指令生成有意义的攻击样本,同时保持对医学图像数据的适应性和临床术语的相关性。
Q: 有哪些相关研究?
A: 论文中提到了多个与对抗性攻击、医学成像以及文本引导的攻击相关的研究工作。以下是一些主要的相关研究:
对抗性攻击方法:
- FGSM (Fast Gradient Sign Method) [20]:一种基于梯度的白盒攻击方法,通过在输入图像上添加小的扰动来误导分类器。
- Carlini & Wagner (C-W) [8]:另一种白盒攻击方法,旨在生成对抗性样本,这些样本在视觉上与原始图像难以区分。
- PGD (Projected Gradient Descent) [40]:一种迭代的梯度下降方法,用于生成有效的对抗性攻击样本。
- DeepFool [42]:一种简单的方法,通过迭代地扰动输入图像来欺骗深度神经网络。
医学成像中的对抗性攻击:
- AdvDiffuser [11] 和 Diff-PGD [61]:这些方法结合了PGD方法和扩散模型,以增强生成图像的真实性。
- Instruct2Attack [37]:利用潜在扩散模型通过优化输入提示来欺骗目标模型。
扩散模型在对抗性攻击中的应用:
- 扩散模型被用于增强对抗性扰动的不可感知性、风格转换以及攻击扩散模型的净化方法。
提示学习(Prompt Learning):
- 提示学习最初是作为在自然语言处理(NLP)中利用预训练语言模型的一种方法,后来被适应于对抗性目的。
- BadCLIP [4] 和 BAPLe [21]:这些方法通过在提示学习阶段注入后门或引入可学习的噪声触发器来攻击模型。
医学成像中的深度学习模型:
- 论文提到了一些用于改进诊断结果的深度学习模型,如ResNet34、SqueezeNet1.1和DenseNet121。
其他相关研究:
- MIRST [50]:提出用于防御非定向对抗性攻击的方法。
- Adversarially Robust Feature Learning [22]:通过包含特征相关性度量来促进鲁棒特征的学习。
这些研究构成了论文提出的Prompt2Perturb (P2P)方法的理论基础和技术背景。论文通过结合这些相关技术,提出了一种新的针对医学图像的对抗性攻击方法,旨在提高攻击的隐蔽性和有效性,同时保持对医学术语的适应性。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Prompt2Perturb(P2P)的新方法来解决深度神经网络(DNNs)在医学成像领域对对抗性攻击的脆弱性问题。P2P方法的核心思想是利用文本指令引导生成对抗性样本,同时保持对医学图像数据的适应性和临床术语的相关性。以下是P2P方法解决这个问题的几个关键步骤:
利用可学习的提示(Prompts):
- P2P方法在文本编码器中使用可学习的提示来创建微小但有影响力的扰动,这些扰动在保持不可感知的同时引导模型朝向目标输出。
直接更新文本嵌入:
- 与当前基于提示学习方法不同,P2P通过直接更新文本嵌入来生成对抗性样本,避免了重新训练扩散模型的需要。
优化早期反向扩散步骤:
- 论文发现,仅优化早期的反向扩散步骤(相当于扩散过程的后期步骤)不仅提高了效率,还确保了生成的对抗性样本包含微妙的噪声,从而在不引入明显伪影的情况下保持了超声图像的质量。
针对临床术语的对抗性样本优化:
- P2P方法通过将临床术语纳入Stable Diffusion的文本嵌入中,确保生成的图像在医学背景下保持临床准确性和现实性,从而提高了攻击的有效性。
实验验证:
- 论文通过在三个不同的乳房超声数据集上与现有技术进行比较,使用FID(Fréchet Inception Distance)和LPIPS(Learned Perceptual Image Patch Similarity)等指标来验证P2P方法的有效性。实验结果表明,P2P方法在保持图像自然外观和有效性方面优于现有的对抗性攻击方法。
代码公开:
- 为了促进研究和进一步的开发,论文承诺将P2P方法的代码在GitHub上公开。
通过这些方法,P2P能够有效地对医学图像中的DNNs进行对抗性攻击,同时保持对医学术语的适应性和图像质量,解决了传统方法在医学成像领域中的局限性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和比较所提出的Prompt2Perturb(P2P)方法与其他现有技术。以下是实验的关键方面:
实验设置:
- 数据集:使用了三个公开的乳房超声数据集,包括BUSI、BUS-BRA和UDIAT。
- 模型:实验涉及三种广泛认可的分类器架构,ResNet34、SqueezeNet1.1和DenseNet121。
- 评估指标:使用成功率(Success Rate)、Learned Perceptual Image Patch Similarity(LPIPS)、Structural Similarity Index Measure(SSIM)和Fréchet Inception Distance(FID)来评估对抗性样本的质量。
与现有技术的比较:
- 将P2P方法与Diffusion-Based Projected Gradient Descent(DiffPGD)攻击和传统技术如FGSM和PGD进行了比较。
定量评估:
- 在不同数据集和分类器架构上评估了P2P方法的成功率、LPIPS、SSIM和FID,以全面分析对抗性样本的有效性和感知完整性。
定性结果:
- 通过视觉比较展示了不同攻击方法生成的图像和对抗性扰动。
- 展示了P2P攻击成功改变超声图像的诊断标签,同时保持图像语义外观的最小变化。
t-SNE可视化:
- 使用t-SNE可视化比较了四种攻击方法(FGSM、PGD、DiffPGD和P2P)在集成攻击样本与干净数据集方面的效果。
案例研究:
- 分析了训练集中高置信度分类器识别的图像的攻击样本,特别关注BUSI训练集中的恶性病例及其被DiffPGD和P2P方法攻击后的版本。
消融研究:
- 对P2P方法的不同组件进行了消融研究,以评估各个设计选择对方法有效性的贡献,包括损失函数和时间步的选择。
这些实验结果不仅证明了P2P方法在生成有效对抗样本方面的优越性,还展示了其在保持图像质量和结构相似性方面的高表现,从而证实了P2P方法在医学成像领域的实用性和有效性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一种有效的对抗性攻击方法,Prompt2Perturb(P2P),但仍有一些领域可以进一步探索和研究:
防御机制:
- 研究和开发针对P2P攻击的防御机制,以增强医学成像DNNs的鲁棒性。
模型泛化能力:
- 探索P2P方法在不同类型的医学成像数据(如CT、MRI)和其他疾病领域的泛化能力。
攻击检测技术:
- 开发有效的攻击检测技术,以识别和减轻P2P方法生成的对抗性样本的影响。
模型鲁棒性和准确性的权衡:
- 研究在提高模型鲁棒性的同时保持或提高其准确性的方法。
更深层次的临床术语集成:
- 探索将更深层次的临床术语和知识集成到文本嵌入中,以进一步提高攻击样本的质量和相关性。
计算效率优化:
- 进一步优化P2P方法的计算效率,尤其是在处理大规模数据集时。
跨模态攻击:
- 研究P2P方法在跨模态攻击(例如,从超声图像攻击到MRI图像)中的有效性。
对抗性训练:
- 通过将P2P生成的对抗性样本纳入训练过程,研究对抗性训练对模型鲁棒性的影响。
模型解释性:
- 提高模型的解释性,以更好地理解对抗性样本是如何影响模型决策的。
法律和伦理考量:
- 探讨对抗性攻击在医学成像中的法律和伦理问题,特别是在临床应用中。
多模态融合:
- 研究如何将P2P方法与其他模态(如病理报告、患者历史)融合,以生成更复杂的对抗性样本。
实时攻击和防御:
- 探索在实时医学成像系统中实施P2P攻击和防御的可行性和挑战。
这些探索方向不仅可以推动对抗性攻击技术的发展,还有助于提高深度学习模型在医学成像领域的安全性和可靠性。
Q: 总结一下论文的主要内容
A: 论文提出了一种名为Prompt2Perturb(P2P)的新方法,旨在生成针对医学成像中深度神经网络(DNNs)的对抗性攻击样本,特别是在乳腺癌超声图像分析中。以下是论文的主要内容总结:
问题背景:
- 医学成像中的DNNs对对抗性攻击非常敏感,这些攻击通过微小的、难以察觉的图像变化误导分类器,引发对模型可靠性和安全性的担忧。
现有方法的局限性:
- 传统对抗性攻击方法依赖固定范数扰动,与人类感知不匹配。
- 基于扩散的攻击需要预训练模型,这在数据稀缺的医学成像领域不切实际。
P2P方法:
- P2P利用文本指令引导生成对抗性样本,通过优化文本嵌入直接更新,避免了重新训练扩散模型。
- 该方法仅优化早期反向扩散步骤以提高效率,并保持超声图像质量。
实验评估:
- 在三个乳房超声数据集上评估P2P方法,并与FGSM、PGD和DiffPGD等现有技术进行比较。
- 使用成功率、LPIPS、SSIM和FID等指标评估对抗性样本的质量。
结果:
- P2P方法在成功率上与DiffPGD相当,但在保持图像自然性和有效性方面表现更优。
- 生成的对抗性样本在外观上更自然、更有效,且在医学背景下更具临床准确性和现实性。
代码公开:
- 论文承诺将P2P方法的代码在GitHub上公开,以促进研究和进一步开发。
结论:
- P2P方法为医学成像中的DNNs提供了一种有效的对抗性攻击手段,无需特定领域的预训练模型,同时保持了对医学术语的适应性。
论文的贡献在于提出了一种新的对抗性攻击方法,该方法特别适用于数据有限的医学成像领域,并且能够生成在视觉上难以察觉且临床相关的对抗性样本。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


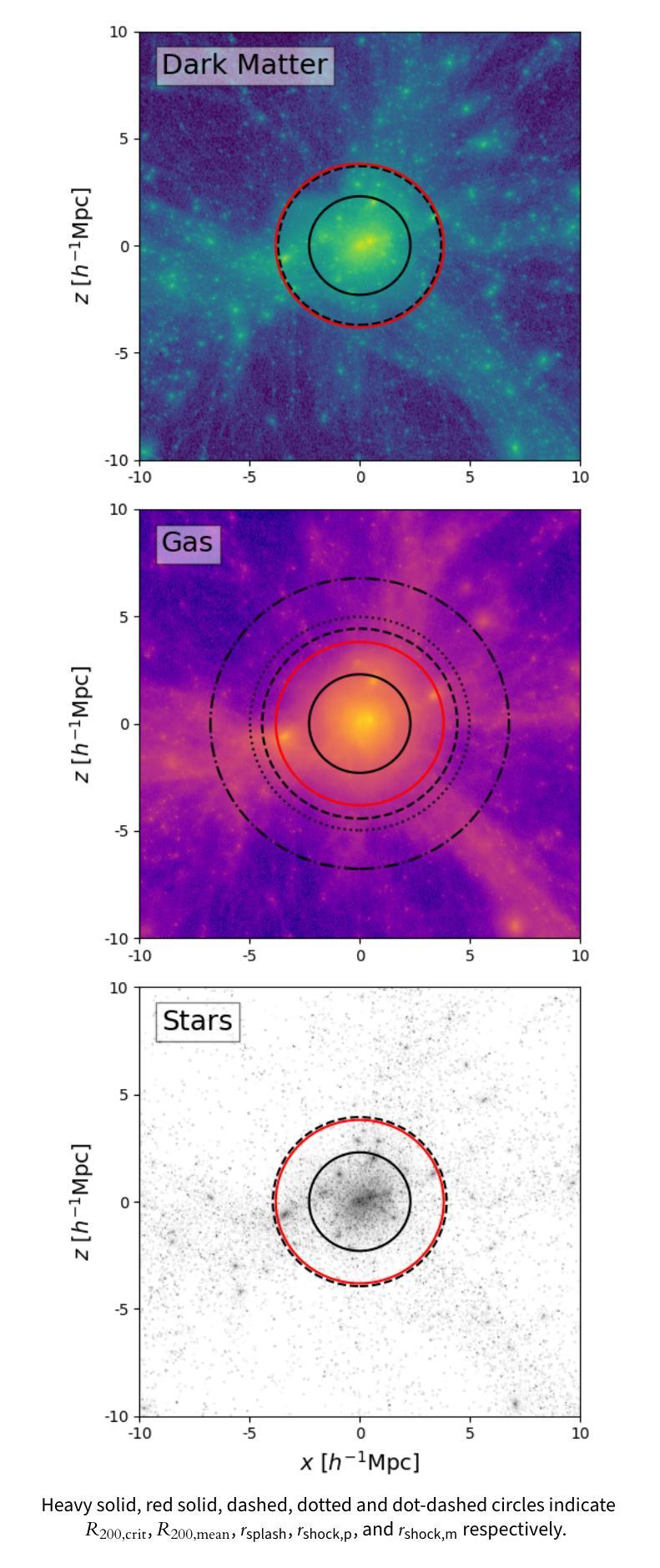
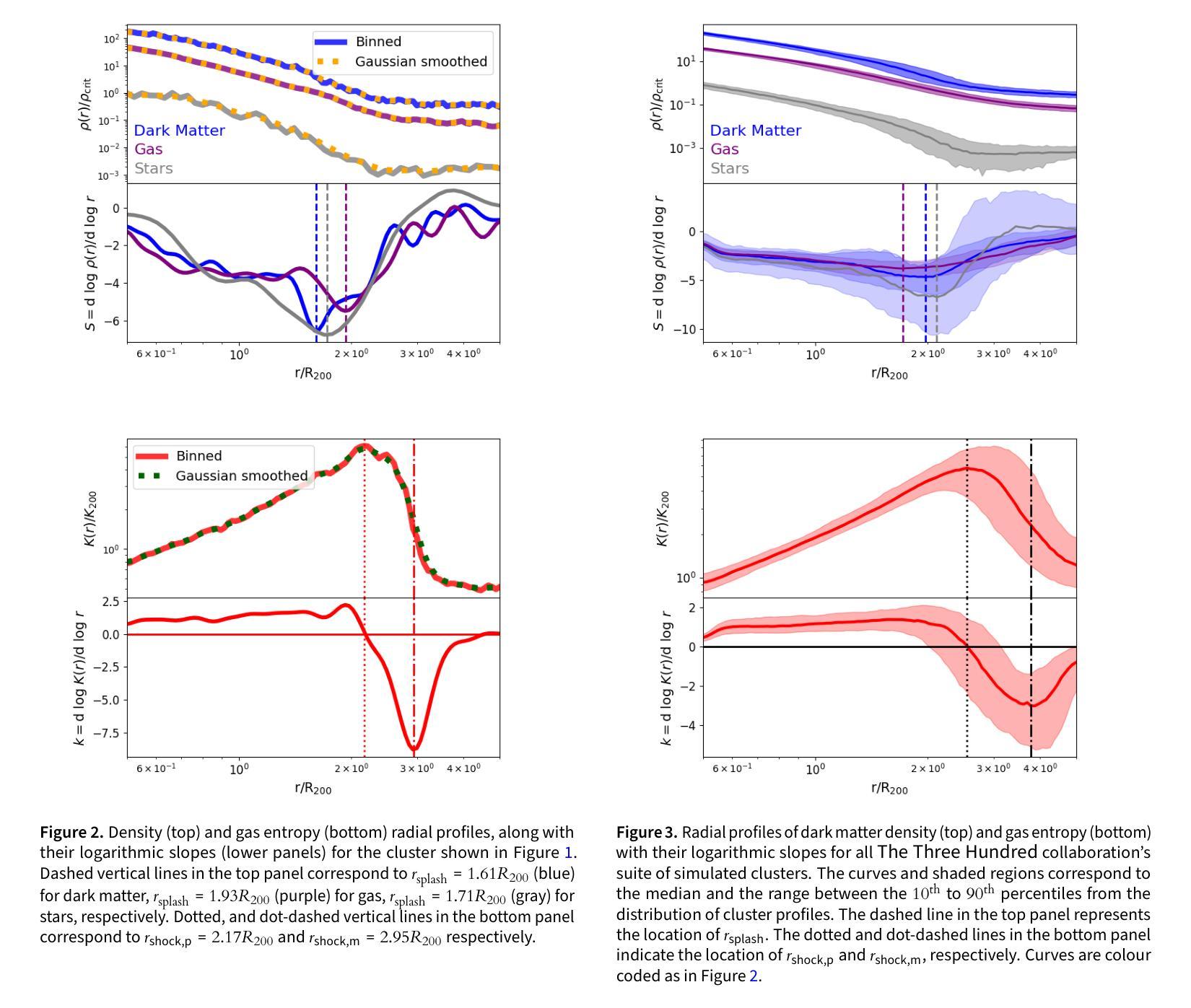
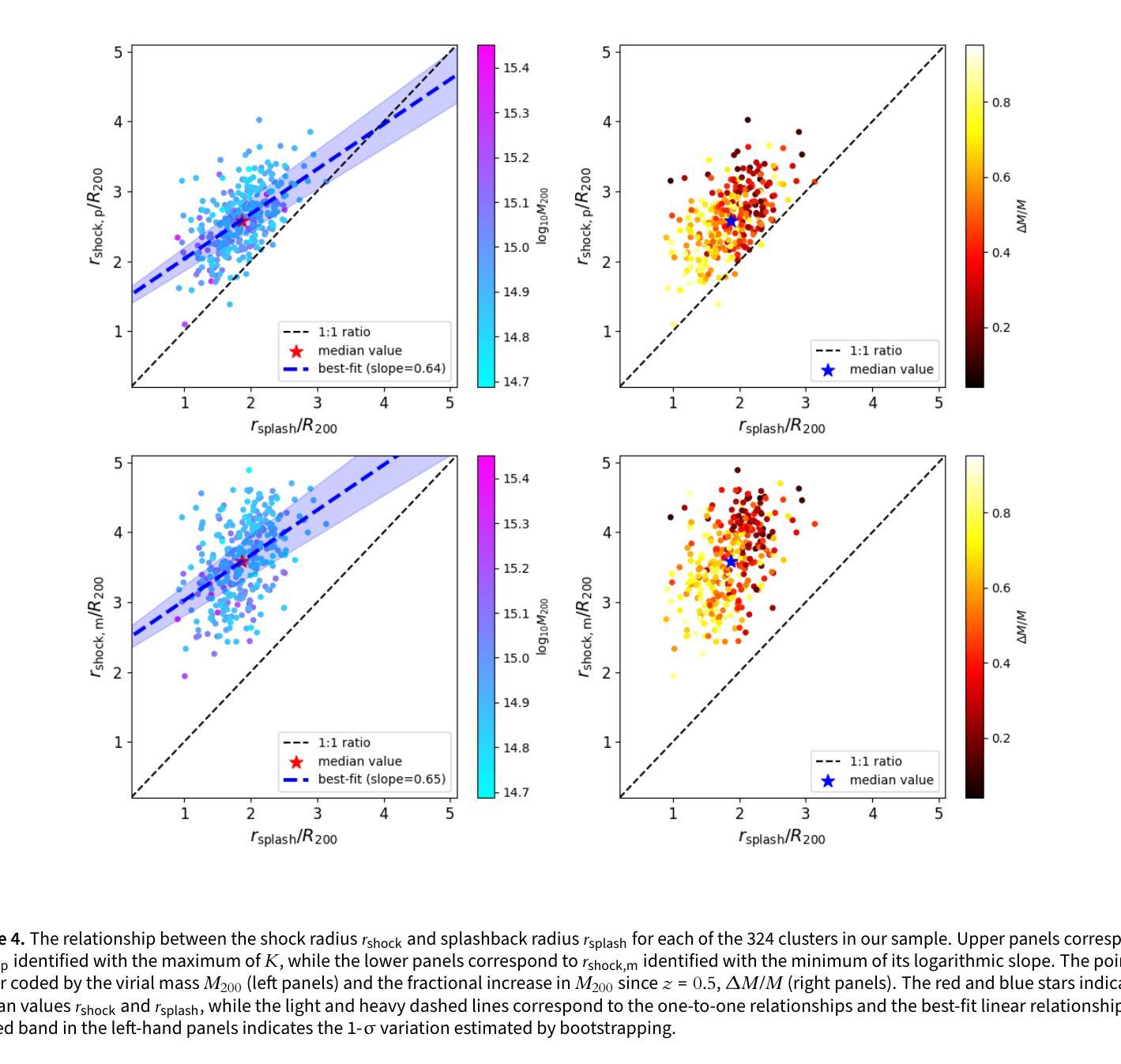
The Three Hundred Project: The relationship between the shock and splashback radii of simulated galaxy clusters
Authors:M. Zhang, K. Walker, A. Sullivan, C. Power, W. Cui, Y. Li, X. Zhang
Observations of the intracluster medium (ICM) in the outskirts of galaxy clusters reveal shocks associated with gas accretion from the cosmic web. Previous work based on non-radiative cosmological hydrodynamical simulations have defined the shock radius, $r_\text{shock}$, using the ICM entropy, $K \propto T/{n_\mathrm{e}}^{2/3}$, where $T$ and $n_\text{e}$ are the ICM temperature and electron density respectively; the $r_\text{shock}$ is identified with either the radius at which $K$ is a maximum or at which its logarithmic slope is a minimum. We investigate the relationship between $r_\text{shock}$, which is driven by gravitational hydrodynamics and shocks, and the splashback radius, $r_\text{splash}$, which is driven by the gravitational dynamics of cluster stars and dark matter and is measured from their mass profile. Using 324 clusters from {\small The Three Hundred} project of cosmological galaxy formation simulations, we quantify statistically how $r_\text{shock}$ relates to $r_\text{splash}$. Depending on our definition, we find that the median $r_\text{shock} \simeq 1.38 r_\text{splash} (2.58 R_{200})$ when $K$ reaches its maximum and $r_\text{shock} \simeq 1.91 r_\text{splash} (3.54 R_{200})$ when its logarithmic slope is a minimum; the best-fit linear relation increases as $r_\text{shock} \propto 0.65 r_\text{splash}$. We find that $r_\text{shock}/R_{200}$ and $r_\text{splash}/R_{200}$ anti-correlate with virial mass, $M_{200}$, and recent mass accretion history, and $r_\text{shock}/r_\text{splash}$ tends to be larger for clusters with higher recent accretion rates. We discuss prospects for measuring $r_\text{shock}$ observationally and how the relationship between $r_\text{shock}$ and $r_\text{splash}$ can be used to improve constraints from radio, X-ray, and thermal Sunyaev-Zeldovich surveys that target the interface between the cosmic web and clusters.
对星系团外围的团内介质(ICM)的观察揭示了与宇宙网气体增吸相关的冲击波。之前的工作基于非辐射宇宙流体动力学模拟,使用ICM熵$K \propto T/{n_\mathrm{e}}^{2/3}$定义了冲击半径$r_\text{shock}$,其中$T$和$n_\text{e}$分别是ICM的温度和电子密度;$r_\text{shock}$被识别为熵$K$最大的半径处或其对数斜率最小的半径处。我们调查了由重力流体动力学和冲击波驱动的$r_\text{shock}$与由星系团恒星和暗物质的引力动力学驱动的溅射半径$r_\text{splash}$之间的关系,并通过宇宙星系形成模拟的《三百个项目》中的324个星系团进行统计测量。根据我们的定义,我们发现当中熵$K$达到其最大值时,中位冲击半径$r_\text{shock} \approx 1.38 r_\text{splash} (2.58 R_{200})$;而当熵的对数斜率达到最小值时,$r_\text{shock} \approx 1.91 r_\text{splash} (3.54 R_{200})$。最佳拟合的线性关系随着$r_\text{shock} \propto 0.65 r_\text{splash}$而增加。我们发现$r_\text{shock}/R_{200}$和$r_\text{splash}/R_{200}$与维里尔质量$M_{200}$和近期的质量增吸历史呈负相关,并且冲击半径与溅射半径之比对于近期增吸率较高的星系团而言往往更大。我们讨论了观测测量冲击半径的前景,以及如何利用冲击半径与溅射半径之间的关系来改善针对宇宙网与星系团之间界面的无线电、X射线和热Sunyaev-Zeldovich调查的限制。
论文及项目相关链接
PDF 11 pages, 6 figures; accepted for publication in the Publications of the Astronomical Society of Australia (PASA)
Summary
宇宙网气体吸积与星系团外围的簇内介质(ICM)冲击相关,本文通过宇宙学流体动力学模拟观测到冲击半径(r_shock)与溅落半径(r_splash)之间的关系。利用来自宇宙星系形成模拟的The Three Hundred项目中的324个星系团数据,我们统计了r_shock与r_splash的关系。发现当熵达到最大值时,中值r_shock约为r_splash的1.38倍(或R_{200}的2.58倍),而当熵的对数斜率达到最小值时,r_shock约为r_splash的1.91倍(或R_{200}的3.54倍)。我们的研究也表明r_shock与M_{200}和反近期质量增长历史存在负相关关系。我们还探讨了观测上测量r_shock的可能性,以及如何利用其与r_splash的关系来改善针对宇宙网与星系团之间界面的无线电、X射线和热Sunyaev-Zeldovich调查约束。
Key Takeaways
- 观察到星系团外围的ICM冲击与宇宙网气体吸积相关。
- 通过模拟研究确定了冲击半径(r_shock)与溅落半径(r_splash)之间的统计关系。
- r_shock与熵最大值及熵对数斜率最小值有关。
- r_shock与星系团的质量及近期质量增长历史存在关联。
- r_shock相对于r_splash的比例在具有更高近期增长率的星系团中更大。
- 观测测量r_shock具有可能性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是量化和理解星系团中冲击半径(rshock)和溅回半径(rsplash)之间的关系。具体来说,论文探讨了以下问题:
冲击半径和溅回半径的定义差异:冲击半径(rshock)是基于星系团内介质(ICM)熵值来定义的,而溅回半径(rsplash)是基于星系团中恒星和暗物质的引力动力学来定义的。这两个半径都与星系团通过周围环境吸积物质的过程有关,但它们分别代表了不同的物理过程。
rshock和rsplash之间的统计关系:论文使用“Three Hundred”项目的324个星系团的宇宙学星系形成模拟,来量化rshock和rsplash之间的统计关系,并探讨这种关系如何随着星系团质量和近期吸积历史的变化而变化。
rshock和rsplash的观测测量前景:论文讨论了观测上测量rshock的可能性,并探讨了rshock和rsplash之间的关系如何被用来改进针对星系团与宇宙网界面的射电、X射线和热Sunyaev-Zeldovich(tSZ)效应调查的约束。
对分析模型的影响:论文指出,之前有分析模型假设rshock和rsplash是重合的,但实际模拟结果表明这种假设需要修正,并需要考虑质量吸积历史和大尺度环境的影响。
总的来说,这篇论文试图通过模拟数据来更好地理解星系团的这两个重要边界,并探讨它们之间的关系对于星系团形成和演化理论的意义。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与研究主题相关的研究:
星系团内介质(ICM)的熵研究:
- Babyk et al. (2018) 提供了星系团热大气在 $R_{2500}$ 内的普适熵模型。
- Lau et al. (2015) 研究了星系团外边缘的质量吸积及其对气体轮廓自相似性的影响。
星系团的溅回半径(rsplash):
- More et al. (2015) 首次提出了溅回半径作为物理晕边界的概念,并研究了晕质量增长。
- Diemer et al. (2017) 进一步研究了溅回半径与质量、吸积率、红移和宇宙学的关系。
- O’Neil et al. (2021) 在 Illustris TNG 模拟中研究了晕的溅回边界。
星系团的冲击半径(rshock):
- Shi (2016) 通过自相似球对称崩溃模型研究了星系团周围的吸积冲击的位置和ICM属性。
- Baxter et al. (2021) 使用“Three Hundred”模拟分析了星系团堆叠的Sunyaev-Zel’dovich(SZ)轮廓中的冲击。
星系团的观测研究:
- Anbajagane et al. (2022, 2024) 通过堆叠Compton-y图研究了星系团外围的宇宙学冲击,并尝试定位吸积冲击。
- Simionescu et al. (2021) 探讨了通过X射线观测来探测星系团外围的物理过程。
星系团形成和演化的模拟研究:
- Cui et al. (2018, 2022) 提供了“Three Hundred”项目的模拟数据,这些数据被用来进行本研究。
- Davé et al. (2019) 提供了SIMBA星系形成模型,该模型被用于GIZMO-Simba模拟。
星系团的热Sunyaev-Zeldovich(tSZ)效应:
- Baxter et al. (2021) 和 Anbajagane et al. (2022, 2024) 研究了tSZ效应在探测星系团吸积冲击方面的应用。
这些研究提供了对星系团的物理状态、形成和演化的深入理解,并为本文提供了理论和观测上的背景。通过引用这些相关研究,本文能够在现有知识的基础上进一步探索星系团的冲击半径和溅回半径之间的关系。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决冲击半径(rshock)和溅回半径(rsplash)之间关系的问题:
使用模拟数据:
- 论文利用了“Three Hundred”项目的324个星系团的宇宙学星系形成模拟数据。这些模拟覆盖了不同的质量范围和吸积历史,提供了一个统计上有意义的样本来研究rshock和rsplash之间的关系。
定义rshock和rsplash:
- 论文根据ICM的熵值定义了两个不同的rshock:一个是熵值达到最大时的半径(rshock,p),另一个是熵值对数斜率最小值时的半径(rshock,m)。
- rsplash定义为球对称密度轮廓对数斜率最小值处的半径。
统计分析:
- 论文通过统计分析,量化了rshock和rsplash之间的关系,并探讨了这种关系如何随着星系团的质量和近期吸积历史的变化而变化。
- 使用了最佳拟合线性关系来描述rshock和rsplash之间的关系,并计算了相关的统计不确定性。
考虑不同的物理过程:
- 论文考虑了星系团中不同的物理过程,如辐射冷却、星形成、黑洞增长、外流和喷流等,这些都被包含在模拟中,以提供对星系团形成的更现实处理。
对比观测和模拟结果:
- 论文将模拟结果与观测数据进行对比,以验证模拟的准确性,并探讨观测上测量rshock的可能性。
讨论结果的影响:
- 论文讨论了这些发现对于理解星系团形成和演化的理论意义,以及对于观测研究的潜在影响,特别是在射电、X射线和热Sunyaev-Zeldovich效应调查中。
敏感性分析:
- 论文还进行了敏感性分析,以检查结果对于质量分辨率和星系形成模型的依赖性,确保结果的稳健性。
通过这些步骤,论文提供了rshock和rsplash之间关系的定量描述,并探讨了这种关系如何受到星系团质量和吸积历史的影响,从而为理解星系团的物理状态和演化提供了新的见解。
Q: 论文做了哪些实验?
A: 这篇论文并没有进行传统意义上的“实验”,而是使用了数值模拟和统计分析的方法来研究星系团中的冲击半径(rshock)和溅回半径(rsplash)。具体来说,论文中的“实验”包括以下几个方面:
宇宙学模拟:
- 论文使用了“Three Hundred”项目的模拟数据,这是一个由GIZMO-Simba提供的高分辨率星系团模拟套件。这些模拟包括了复杂的物理过程,如辐射冷却、星形成、黑洞增长、外流和喷流等。
数据处理和分析:
- 对模拟数据进行了处理,包括计算星系团的质量和气体密度的径向轮廓,以及气体的熵值。
- 使用了AHF(Amiga’s Halo Finder)暗晕查找器来构建星系团的主暗晕及其子结构的星表。
统计关系量化:
- 对324个星系团样本中的rshock和rsplash之间的关系进行了量化分析。
- 分析了rshock和rsplash随星系团质量和近期吸积历史的变化。
敏感性测试:
- 对模拟结果进行了敏感性测试,比较了不同质量分辨率和星系形成模型对结果的影响。
结果对比:
- 将模拟结果与观测数据进行了对比,以评估模拟的准确性和对观测研究的潜在影响。
这些“实验”实际上是数值模拟和数据分析的过程,它们提供了对星系团物理特性的深入理解,并允许研究者探索和验证星系团形成和演化的理论模型。通过这种方式,论文能够探索rshock和rsplash之间的关系,并评估这种关系如何受到星系团质量和吸积历史的影响。
Q: 有什么可以进一步探索的点?
A: 根据论文的内容和结论,以下是一些可以进一步探索的点:
提高模拟精度:
- 进一步细化模拟的分辨率,以探索更小尺度上的rshock和rsplash之间的关系。
- 考虑更多的物理过程,如磁流体动力学效应、非热压力支持等,来提高模拟的准确性。
观测验证:
- 使用射电、X射线和热Sunyaev-Zeldovich效应等观测手段来验证模拟结果,尤其是rshock和rsplash之间的关系。
- 通过观测数据来约束和校准模拟模型,提高模拟结果与实际观测的一致性。
不同宇宙学模型的影响:
- 探索在不同的宇宙学模型(例如,不同的暗能量模型或中微子质量)下,rshock和rsplash之间的关系是否有显著变化。
星系团样本的多样性:
- 扩大星系团样本的范围,包括不同红移、不同质量、不同环境的星系团,以研究这些因素对rshock和rsplash关系的影响。
星系团内部结构的影响:
- 研究星系团内部结构(如子结构、偏心率等)对rshock和rsplash关系的影响。
星系团形成和演化的历史:
- 深入研究星系团的形成和演化历史如何影响rshock和rsplash的位置和形态。
改进分析方法:
- 开发新的分析方法来更准确地从模拟和观测数据中识别rshock和rsplash。
环境和大尺度结构的影响:
- 研究星系团所处的大尺度结构环境如何影响其rshock和rsplash。
与其他观测项目的协同:
- 与其他大型观测项目(如eROSITA、LSST、SKA等)合作,利用这些项目的丰富数据来探索rshock和rsplash的关系。
理论模型的发展:
- 基于模拟和观测结果,发展和完善描述星系团rshock和rsplash的理论模型。
这些进一步探索的点可以帮助我们更全面地理解星系团的结构、形成和演化,以及它们与宇宙大尺度结构之间的关系。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
研究目的:
- 论文旨在量化星系团中的冲击半径(rshock)和溅回半径(rsplash)之间的关系,并探讨这种关系如何随星系团质量和近期吸积历史变化。
数据和方法:
- 研究使用了“Three Hundred”项目的324个星系团模拟数据,这些数据来自GIZMO-Simba模拟套件。
- 论文定义了rshock的两种不同方式:基于ICM熵值最大处的rshock,p和基于熵值对数斜率最小值处的rshock,m。
- 使用统计方法来量化rshock和rsplash之间的关系,并分析这种关系如何随星系团的质量和近期吸积历史变化。
主要发现:
- 论文发现,根据不同的定义,rshock通常大于rsplash。
- 基于熵值最大处的rshock,p与rsplash的比值中位数约为1.38,而基于熵值对数斜率最小值处的rshock,m与rsplash的比值中位数约为1.91。
- rshock和rsplash都与星系团的维里质量(M200)和近期质量吸积历史呈反相关。
- 论文还发现rshock/rsplash比值在近期吸积率较高的星系团中倾向于更大。
讨论和意义:
- 论文讨论了测量rshock的观测前景,并探讨了rshock和rsplash之间的关系如何帮助改进来自射电、X射线和热Sunyaev-Zeldovich效应调查的约束。
- 论文指出,假设rshock和rsplash重合的分析模型需要修正,并应考虑质量吸积历史和大尺度环境的影响。
结论:
- 论文得出结论,rshock和rsplash之间的关系在统计上是一致的,并且这种关系受到星系团质量和近期吸积历史的影响。
- 论文强调了这种关系对于观测研究的潜在意义,并建议未来的工作应关注使用模拟观测数据来验证恢复rsplash和rshock的最可靠方法。
总体而言,这篇论文通过大规模模拟提供了rshock和rsplash之间关系的定量描述,并探讨了这种关系对于理解星系团物理状态和演化的重要性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Quantum Imaging with X-rays
Authors:Justin C. Goodrich, Ryan Mahon, Joseph Hanrahan, Dennis Bollweg, Monika Dziubelski, Raphael A. Abrahao, Sanjit Karmakar, Kazimierz J. Gofron, Thomas A. Caswell, Daniel Allan, Lonny Berman, Andrei Nomerotski, Andrei Fluerasu, Cinzia DaVia, Sean McSweeney
Quantum imaging encompasses a broad range of methods that exploit the quantum properties of light to capture information about an object. One such approach involves using a two-photon quantum state, where only one photon interacts with the object being imaged while its entangled partner carries spatial or temporal information. To implement this technique, it is necessary to generate specific quantum states of light and detect photons at the single-photon level. While this method has been successfully demonstrated in the visible electromagnetic spectrum, extending it to X-rays has faced significant challenges due to the difficulties in producing a sufficient rate of X-ray photon pairs and detecting them with adequate resolution. Here, we demonstrate record high rates of correlated X-ray photon pairs produced via a spontaneous parametric down-conversion process and we employ these photons to perform quantum correlation imaging of several objects, including a biological sample (E. cardamomum seedpod). Notably, we report an unprecedented detection rate of about 6,300 pairs per hour and the observation of energy anti-correlation for the X-ray photon pairs. We also present a detailed analysis of the properties of the down-converted X-ray photons, as well as a comprehensive study of the correlation imaging formation, including a study of distortions and corrections. These results mark a substantial advancement in X-ray quantum imaging, expanding the possibilities of X-ray quantum optical technologies, and illustrating the pathway towards enhancing biological imaging with reduced radiation doses.
量子成像利用光的量子特性捕捉物体信息,涵盖了广泛的方法。其中一种方法使用两光子量子态,其中只有一个光子与成像物体相互作用,而其纠缠的伙伴携带空间或时间信息。为了实现这一技术,必须生成特定的量子光态并在单光子层面检测光子。虽然这种方法在可见电磁谱中已经得到了成功验证,但将其扩展到X射线领域却面临着重大挑战,主要是由于生产足够速率的X射线光子对并以足够的分辨率检测它们存在困难。在这里,我们展示了通过自发参数下转换过程产生的高速率相关X射线光子对,并利用这些光子对多个物体进行量子关联成像,包括生物样本(香荚兰种子)。值得注意的是,我们报告了一个前所未有的检测速率,大约每小时6300对光子,并观察到X射线光子对的能量反关联。我们还对下转换的X射线光子的特性进行了详细分析,以及对关联成像的形成进行了综合研究,包括畸变和校正的研究。这些结果在X射线量子成像领域取得了重大进展,扩大了X射线量子光学技术的可能性,并说明了以较低的辐射剂量提高生物成像的路径。
论文及项目相关链接
PDF 12 pages, 6 figures, publication preprint
Summary
量子成像利用光的量子特性捕获物体的信息,涵盖一系列广泛的方法。近期,通过自发参量下转换过程生成了高相关性的X射线光子对,并利用这些光子进行量子关联成像,包括生物样本(如E. cardamomum种子荚)。该研究报道了前所未有的检测速率(每小时约6,300对光子),并详细分析了下转换的X射线光子的特性以及关联成像的形成过程。这些结果标志着X射线量子成像的重大进展,扩大了X射线量子光学技术的可能性,并展示了降低辐射剂量提高生物成像质量的途径。
Key Takeaways
- 量子成像利用光的量子特性进行信息捕捉,涵盖多种方法。
- 通过自发参量下转换过程生成高相关性的X射线光子对。
- 利用这些光子进行量子关联成像,包括生物样本成像。
- 报道了每小时约6,300对光子的高检测速率。
- 详细分析了下转换的X射线光子的特性。
- 深入研究了关联成像的形成过程,包括失真和校正。
- 该研究标志着X射线量子成像的重大进展,扩大了X射线量子光学技术的潜力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何将量子成像技术扩展到X射线领域,特别是在生物医学成像中减少辐射剂量的同时提高成像精度。具体来说,论文中提到了以下几个关键问题:
高精准度成像需求与辐射损伤之间的矛盾:在生物样本成像中,高精准度的测量需要高信噪比的图像,这通常通过高输入通量实现,但高剂量的X射线会诱导辐射损伤,造成样本的不可逆损害。
X射线量子成像的挑战:将量子成像技术应用于X射线领域面临着重大挑战,包括难以产生足够数量的X射线光子对以及难以用足够的分辨率检测这些光子。
量子成像技术的发展:量子成像技术在可见光和红外光谱范围内已经取得了进展,但在X射线范围内由于生成和检测相关X射线对的困难而进展缓慢。
提高X射线量子成像的效率和分辨率:论文中提出了通过改进理论理解和实验技术,提高X射线量子成像的效率和分辨率,以实现对辐射敏感的生物材料进行成像,同时减少辐射剂量。
综上所述,论文的目标是通过实现高效率的X射线光子对产生和高分辨率的检测,推动X射线量子成像技术的发展,并探索其在生物医学成像中的应用,以减少对样本的辐射损伤。
Q: 有哪些相关研究?
A: 论文中提到了若干与X射线量子成像相关的研究,以下是一些重要的相关研究:
X射线的参量下转换(SPDC):
- B. Levine和I. Freund进行了早期的X射线参量下转换实验 [15]。
- P. Eisenberger和S. L. McCall也进行了X射线的参量转换实验 [16]。
- Y. Yoda等人使用钻石晶体进行了X射线的参量散射实验 [18]。
量子成像技术的发展:
- A. Christ等人综述了参量下转换技术 [1]。
- P. J. Mosley等人实现了 heralded generation of ultrafast single photons in pure quantum states [2]。
- T. B. Pittman等人利用两光子量子纠缠进行光学成像 [13]。
X射线量子成像的实验研究:
- S. Shwartz等人观察到X射线在Langevin 极限下的参量下转换 [26]。
- A. Schori等人使用X射线光子对进行了鬼成像实验 [25]。
- D. Borodin等人实现了X射线光子对的高抑制背景 [28]。
量子成像的应用:
- S. Lloyd提出了通过量子照明增强光感度的概念 [32]。
- G. Brida等人实验实现了sub-shot-noise量子成像 [37]。
量子成像技术在生物医学领域的应用:
- E. F. Garman和M. Weik讨论了X射线辐射对生物样本的损伤 [31]。
- Q. Shen等人探讨了使用未来的相干X射线源进行非周期材料的衍射成像 [30]。
量子成像技术在提高成像分辨率和灵敏度方面的应用:
- C. A. Casacio等人实现了量子增强的非线性显微镜 [38]。
- G. B. Lemos等人利用未检测到的光子进行量子成像 [39]。
这些相关研究为X射线量子成像技术的发展提供了理论基础和实验方法,同时也展示了量子成像技术在提高成像质量和减少辐射剂量方面的潜力。论文中所提出的实验和理论分析建立在这些先前研究的基础上,并进一步推动了X射线量子成像技术的发展。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决X射线量子成像中的问题:
1. 实现高效率的X射线光子对产生
- 利用非线性光学过程,特别是自发参量下转换(SPDC),在钻石晶体中产生X射线光子对。
- 通过精确调整晶体的布拉格角和泵浦光束的参数,优化SPDC过程,实现了创纪录的高相关X射线光子对产生率,约6300对每小时。
2. 提高光子对检测效率和分辨率
- 使用高速、二维像素化区域探测器(Lynx T3探测器)来检测单个光子。
- 通过校准探测器的时间到达(ToA)和时间超阈值(ToT)功能,精确测量光子的能量和到达时间,从而区分SPDC光子和背景噪声。
3. 量子关联成像实验
- 对包括生物样本(如E. cardamomum种子荚)在内的多个物体进行量子关联成像。
- 通过相关检测器臂中的符合光子事件生成两个不同的量子图像,分别对应于信号和闲置参考系。
4. 分析和校正成像过程中的失真
- 研究了晶体质量、光束发散角对双光子属性的影响,并讨论了如何通过所谓的次射击噪声成像技术实现量子增强的样品透射测量。
- 提出了一种校正方法,通过调整闲置探测器上的事件径向距离来校正由于发射角分布引起的成像模糊。
5. 探索次射击噪声传输成像的可能性
- 讨论了通过改进探测器技术和背景抑制来实现次射击噪声成像的路径,这将允许在低光子计数区域进行精确测量,同时减少对样品的辐射剂量。
6. 理论分析与实验结果的对比
- 通过模拟和实验数据的对比,验证了理论预测与实验结果的一致性,加深了对SPDC X射线属性的理解。
7. 推动量子成像技术的发展
- 论文的研究成果不仅加深了对SPDC属性的理解,而且为优化量子成像系统提供了基础,为在高强度X射线源(如同步辐射和自由电子激光)上进行材料和生物科学的新方法铺平了道路。
通过这些步骤,论文展示了X射线量子成像技术的进步,并为未来在减少辐射剂量的同时提高成像质量的应用提供了可能。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验:
X射线量子关联成像实验:
- 实验利用非线性X射线衍射(SPDC)设置,通过同步辐射光源产生的15 keV泵浦X射线与钻石晶体相互作用,产生SPDC双光子。
- 使用高速二维像素化区域探测器(Lynx T3)来检测这些光子,生成量子关联放射图像。
探测器性能测试:
- 对Lynx T3探测器的时间到达(ToA)和时间超阈值(ToT)功能进行校准,以准确测量X射线光子的能量和到达时间。
- 测量探测器的分辨率,包括时间分辨率和能量分辨率,并进行像素到像素的校准。
SPDC光子对的产生和识别:
- 通过调整钻石晶体相对于泵浦光束的角度,实现了SPDC光子对的产生,并测量了光子对的发射角度和能量。
- 应用Timepix技术记录事件的ToA和ToT,以筛选出高相关性的SPDC光子对。
成像样品的量子关联成像:
- 对包括钨制的猫形状、字母‘F’和E. cardamomum种子荚在内的样品进行了量子关联成像。
- 分别在信号和闲置探测器上生成了量子直接(信号)关联图像和量子鬼(闲置)关联图像。
SPDC光子能量和空间属性分析:
- 分析了SPDC过程中生成的相关单光子的能量分布,并确定了光子的能量与其在探测器上的位置之间的关系。
空间关联性和解调校正:
- 研究了量子信号和闲置关联图像之间的镜像和翻转关系,并提出了校正成像过程中失真的方法。
次射击噪声传输成像的探索:
- 探讨了通过改进探测器技术和背景抑制实现次射击噪声成像的可能性,并使用贝叶斯概率模型来评估检测系统识别单个SPDC光子的能力。
这些实验不仅展示了X射线量子成像的可行性,还为量子成像技术的发展提供了宝贵的实验数据和理论分析。通过这些实验,研究人员能够深入理解SPDC属性,并探索量子成像在减少辐射剂量和提高成像质量方面的潜力。
Q: 有什么可以进一步探索的点?
A: 论文提出并实现了X射线量子成像技术的重要进展,但仍有一些领域可以进一步探索和研究:
提高探测器性能:
- 改进探测器的能量分辨率和时间分辨率,以更精确地识别和区分SPDC光子和背景噪声。
- 开发新的探测器技术,比如Timepix4,以实现更高的能量分辨率和更快的时间响应。
优化SPDC光源:
- 探索不同的非线性介质和泵浦光源,以提高SPDC效率和光子对产生率。
- 研究如何减少SPDC过程中的背景噪声,例如通过改进晶体质量和使用高阶布拉格反射。
量子成像技术的应用:
- 将量子成像技术应用于更多的生物医学成像案例,以评估其在实际应用中的潜力和效果。
- 研究量子成像技术在材料科学中的应用,如实现更高分辨率的显微技术和衍射方法。
次射击噪声成像技术:
- 实现次射击噪声成像技术的定量演示,这需要进一步改进探测器技术和背景抑制。
- 研究如何利用量子关联成像提高成像信噪比,特别是在低光子通量条件下。
量子成像的物理原理和理论模型:
- 深入研究SPDC过程中的物理机制,包括光子对产生和演化的量子动力学。
- 发展更精确的理论模型来描述X射线SPDC的属性,以及如何利用这些属性进行量子成像。
量子成像系统的集成和自动化:
- 研究如何将量子成像系统集成到现有的成像设施中,例如同步辐射和自由电子激光设施。
- 开发自动化的量子成像流程,以提高实验的效率和可重复性。
量子成像的数据处理和分析工具:
- 开发先进的数据处理算法,以充分利用量子成像数据中的信息,并提高成像结果的准确性。
- 探索机器学习和人工智能技术在量子成像数据分析中的应用。
量子成像技术的跨学科合作:
- 促进物理学家、生物学家、工程师和临床医生之间的合作,以推动量子成像技术的发展和应用。
这些探索点不仅可以推动量子成像技术的发展,还可能为医学诊断、生物研究和材料分析等领域带来革命性的进展。
Q: 总结一下论文的主要内容
A: 论文《Quantum Imaging with X-rays》主要探讨了如何利用量子成像技术在X射线领域取得进展,特别是在生物成像中减少辐射剂量的同时提高成像精度。以下是论文的主要内容总结:
研究背景与动机
- 高精度成像对于分析和理解系统至关重要,但高精度测量需要高信噪比的图像,这通常需要高输入通量,对于生物细胞而言,高剂量X射线会诱导辐射损伤。
- 量子成像技术利用光的量子属性来捕获信息,包括使用纠缠光子对进行成像,其中只有一个光子与被成像的物体相互作用,而其纠缠伙伴携带空间或时间信息。
实验方法与结果
- 利用自发参量下转换(SPDC)过程在钻石晶体中产生X射线光子对,并使用高速二维像素化探测器(Lynx T3)进行探测。
- 实现了创纪录的高相关X射线光子对产生率,约6300对每小时,并观察到X射线光子对的能量反相关性。
- 对包括生物样本(E. cardamomum种子荚)在内的多个物体进行了量子关联成像实验,并展示了量子关联成像的结果。
理论分析与实验验证
- 分析了下转换X射线光子的属性,并研究了晶体质量和光束发散角对双光子属性的影响。
- 提出了校正成像过程中失真的方法,并探讨了实现量子增强样本透射测量的途径。
- 通过模拟和实验数据的对比,验证了理论预测与实验结果的一致性。
技术进步与应用前景
- 论文的成果标志着X射线量子成像的重大进步,扩展了X射线量子光学技术的可能性,并为减少辐射剂量的生物成像提供了新路径。
- 论文还讨论了如何通过改进探测器技术和背景抑制实现次射击噪声成像,这将进一步推动量子成像技术的发展。
结论
- 论文展示了在高强度X射线源下,利用量子成像技术进行材料和生物科学探索的潜力,并为未来的量子成像系统优化和革新奠定了基础。
总体而言,论文通过实验和理论分析,展示了X射线量子成像技术的进步,并为未来在减少辐射剂量的同时提高成像质量的应用提供了可能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



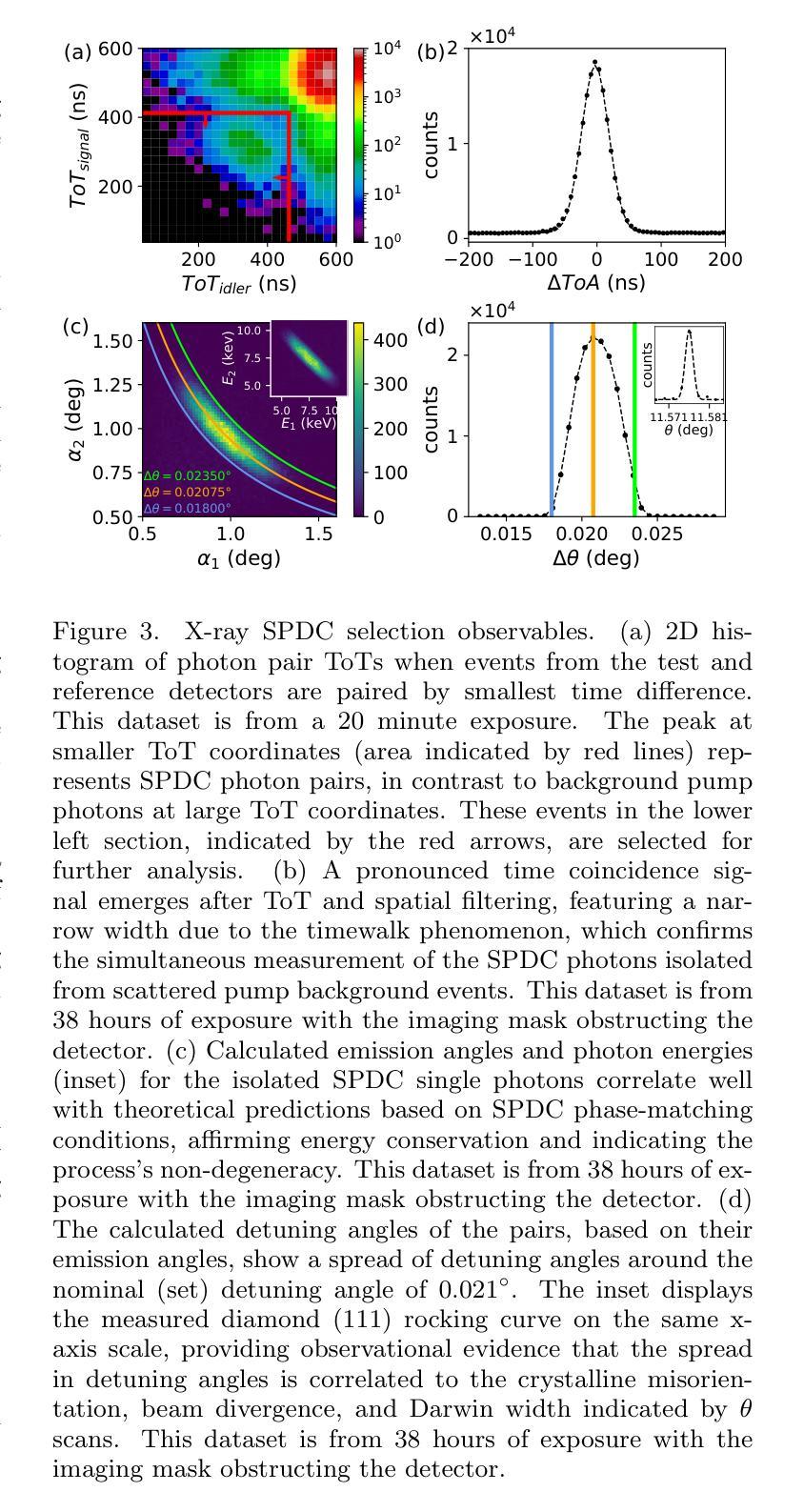
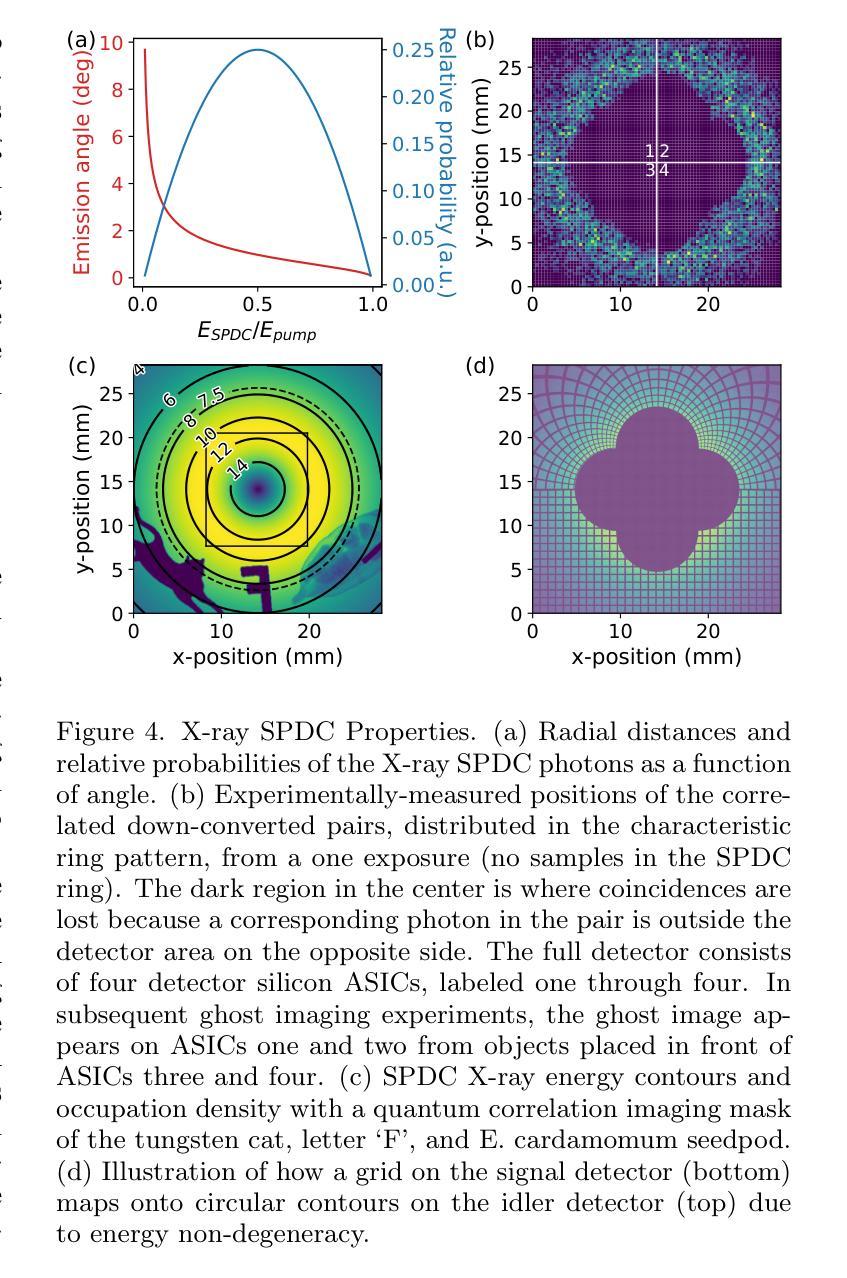
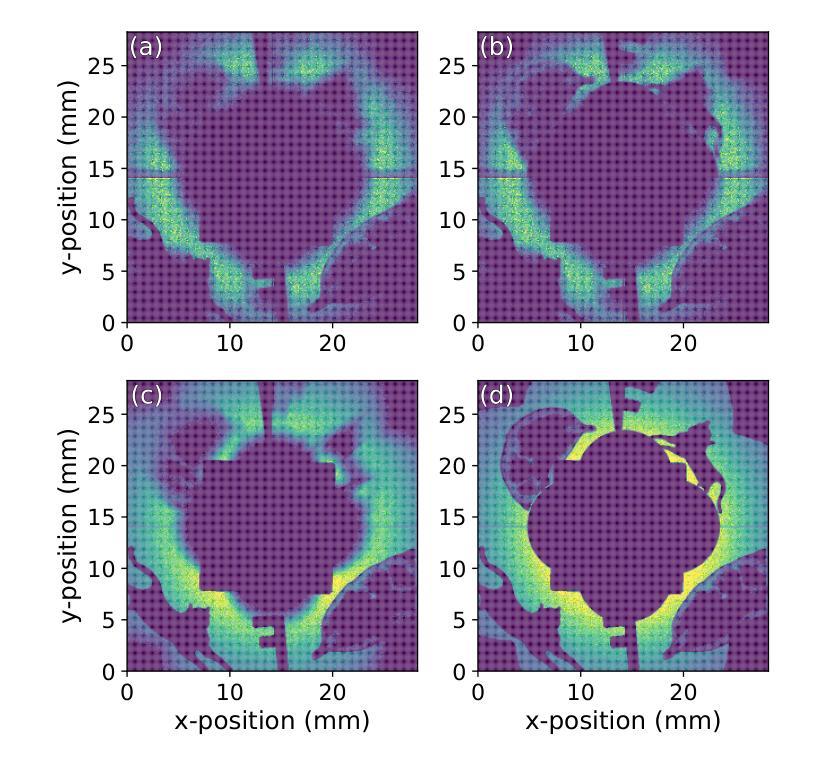
On Round-Off Errors and Gaussian Blur in Superresolution and in Image Registration
Authors:Serap A. Savari
Superresolution theory and techniques seek to recover signals from samples in the presence of blur and noise. Discrete image registration can be an approach to fuse information from different sets of samples of the same signal. Quantization errors in the spatial domain are inherent to digital images. We consider superresolution and discrete image registration for one-dimensional spatially-limited piecewise constant functions which are subject to blur which is Gaussian or a mixture of Gaussians as well as to round-off errors. We describe a signal-dependent measurement matrix which captures both types of effects. For this setting we show that the difficulties in determining the discontinuity points from two sets of samples even in the absence of other types of noise. If the samples are also subject to statistical noise, then it is necessary to align and segment the data sequences to make the most effective inferences about the amplitudes and discontinuity points. Under some conditions on the blur, the noise, and the distance between discontinuity points, we prove that we can correctly align and determine the first samples following each discontinuity point in two data sequences with an approach based on dynamic programming.
超分辨率理论和技术旨在从存在模糊和噪声的样本中恢复信号。离散图像配准可以作为融合来自同一信号的不同样本集信息的一种方法。空间域中的量化误差是数字化图像的固有特性。我们考虑超分辨率和离散图像配准,针对一维空间受限的分段常数函数,这些函数受到高斯模糊或高斯混合以及舍入误差的影响。我们描述了一个与信号相关的测量矩阵,该矩阵可以捕捉这两种效果。对于这个设置,我们展示了即使在没有其他类型的噪声的情况下,从两组样本中确定断点也是困难的。如果样本还受到统计噪声的影响,那么为了对振幅和断点进行最有效的推断,有必要对齐和分段数据序列。在关于模糊、噪声和断点之间距离的一些条件下,我们证明可以通过基于动态规划的方法正确地对齐并确定每个断点后的第一个样本。
论文及项目相关链接
Summary
超分辨率理论与技术旨在从存在模糊和噪声的样本中恢复信号。离散图像配准可作为融合来自同一信号的不同样本集信息的方法。我们考虑超分辨率和离散图像配准针对一维空间有限分段常函数,这些函数受到高斯或混合高斯模糊以及舍入误差的影响。我们描述了一个与信号相关的测量矩阵,该矩阵可以捕捉这两种影响。在此设置中,即使没有其他类型的噪声,从两组样本中确定断点也是困难的。如果样本还受到统计噪声的影响,那么需要对数据序列进行对齐和分段,以便对振幅和断点进行最有效的推断。在模糊、噪声和断点之间的距离满足某些条件的情况下,我们证明可以通过基于动态规划的方法正确地对齐并确定两个数据序列中每个断点后的第一个样本。
Key Takeaways
- 超分辨率理论与技术旨在从模糊和噪声样本中恢复信号。
- 离散图像配准可用于融合来自同一信号的不同样本集的信息。
- 一维空间有限分段常函数受高斯或混合高斯模糊以及舍入误差影响。
- 存在一个与信号相关的测量矩阵,用以捕捉模糊和舍入误差的两种影响。
- 确定断点是一个挑战,即使在没有其他噪声的情况下也是如此。
- 在存在统计噪声的情况下,需要对数据序列进行对齐和分段以进行有效推断。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了在超分辨率和图像配准领域中,如何处理和解决由于高斯模糊和量化误差(round-off errors)引起的问题。具体来说,论文试图解决以下问题:
超分辨率中的困难:在存在模糊和噪声的情况下,如何从样本中恢复信号。论文特别关注了一维空间受限的分段常数函数,这些函数受到高斯模糊或高斯混合模糊以及四舍五入误差的影响。
图像配准的挑战:在处理同一信号的多个低质量图像时,如何融合信息。这通常需要图像配准技术,而论文中提出了一种基于动态规划的方法来处理配准问题。
量化误差的影响:数字图像固有的量化误差如何影响超分辨率的性能。论文分析了量化误差对信号幅度的影响,并探讨了在不同噪声条件下,如何有效地从数据序列中推断出幅度和不连续点。
统计噪声下的数据分析:当样本也受到统计噪声的影响时,如何对数据序列进行对齐和分割,以做出关于幅度和不连续点的最有效推断。
测量矩阵的结构变化:随着模糊的增加,测量矩阵的结构如何变化,以及这些变化如何受到不连续点之间的最小距离、不连续性的幅度和采样网格位置的影响。
动态规划在图像配准中的应用:在满足一定条件的情况下,如何使用动态规划方法正确地对齐并确定两个数据序列中每个不连续点后的第一个样本的位置。
总的来说,这篇论文试图提供一个关于如何在存在模糊和量化误差的情况下进行有效的超分辨率重建和图像配准的理论框架和方法。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与研究相关的文献:
[1] X. Tong, Z. Ye, Y. Xu, S. Gao, H. Xie, Q. Du, S. Liu, X. Xu, S. Liu, K. Luan, and U. Stilla, “Image registration with Fourier-based image correlation: a comprehensive review of developments and applications,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 12(10), 4062-4081, Oct. 2019.
这篇文献提供了基于傅里叶的图像相关性的图像配准技术的综合评述,涵盖了发展和应用。
[2] E. J. Candès and C. Fernandez-Granda, “Towards a mathematical theory of super-resolution,” Communications on Pure and Applied Mathematics, 67, 906-956, 2014.
该文献为超分辨率的数学理论奠定了基础,提出了超分辨率的一些基本方法和理论。
[3] M. Jacob, M. P, Mani, and J. C. Ye, “Structured low-rank algorithms,” IEEE Signal Processing Magazine 37(1), 54-68, 2020.
这篇文献讨论了结构化低秩算法,这些算法在超分辨率中用于处理信号和图像。
[4] Q. Denoyelle, V. Duval, G. Peyr´e, and E. Soubies, “The sliding Frank-Wolfe algorithm and its application to super-resolution microscopy,” Inverse Problems 36 014001, 2020.
该文献介绍了滑动Frank-Wolfe算法及其在超分辨率显微镜中的应用。
[5] R. C. Gonzalez and R. E. Woods, Digital Image Processing, Fourth Edition, Pearson, New York, NY, 2018.
这是一本数字图像处理领域的经典教科书,详细介绍了图像处理的基本概念和技术,包括图像配准和超分辨率。
[6] M. T. Postek, A. E. Vl´adar and P. Cizmar, “Nanomanufacturing concerns about measurements made in the SEM Part III: Vibration and drift,” Proc. SPIE, 9173, 917306, 2014.
这篇文献讨论了扫描电子显微镜中测量的纳米制造问题,包括振动和漂移,这些问题与图像配准和超分辨率相关。
[7] M. H. Cheng, K. Flores De Jesus, S. D. Cronin, K. A, Sierros, and E. Bakhoum, “A versatile spatial resolution enhancement method for data acquisition,” Meas. Sci. Technol. 26, 045901, 2015.
该文献提出了一种用于数据采集的空间分辨率增强方法,与超分辨率技术相关。
[8] S. A. Savari, “On image registration and subpixel estimation,” arXiv.org preprint, arXiv:2405.12927, May 2024.
这篇预印本论文讨论了图像配准和亚像素估计的问题。
[9] S. A. Savari, “A counterexample in image registration,” arXiv.org preprint, arXiv:2410.10725, October 2024.
这篇预印本论文提供了图像配准中的一个反例。
[10] S. A. Savari, “A counterexample in cross-correlation template matching,” arXiv.org preprint, arXiv:2410.19085, October 2024.
这篇预印本论文提供了交叉相关模板匹配中的一个反例。
这些文献涵盖了超分辨率和图像配准的理论基础、算法发展、实际应用以及相关技术挑战,与本论文的研究主题密切相关。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决超分辨率和图像配准中的问题:
定义测量和差分矩阵:
- 论文首先定义了一个测量矩阵(Measurement Matrix)和一个差分矩阵(Difference Matrix),这两个矩阵用于描述信号在受到高斯模糊和量化误差影响后的观测数据。测量矩阵捕捉了信号、模糊和量化误差的联合效应。
分析不同模糊条件下的矩阵结构:
- 论文分析了在不同高斯模糊水平下测量矩阵的结构变化,特别是当模糊效应相对于量化误差可以忽略时,以及当模糊效应可辨时的情况。
提出动态规划方案:
- 论文提出了一个基于动态规划的算法,用于在满足一定条件下(如噪声水平、模糊大小和不连续点之间的距离),正确地对齐并确定两个数据序列中每个不连续点后的第一个样本的位置。
处理统计噪声:
- 论文讨论了当样本受到统计噪声影响时,如何通过将数据序列分割成段来提高推断的准确性,并且提出了一种方法来处理这些噪声。
证明算法的有效性:
- 论文通过理论证明,展示了在特定的噪声和模糊条件下,所提出的动态规划算法能够正确地对齐数据序列并确定不连续点的位置。
提供实验示例:
- 论文通过一个具体的例子说明了量化误差如何限制不连续点的确定,以及在存在模糊和噪声的情况下,传统的交叉相关模板匹配技术可能面临的困难。
对比传统方法:
- 论文对比了传统的交叉相关模板匹配方法和提出的动态规划方法,展示了在不同条件下后者的性能优势。
通过上述步骤,论文不仅分析了高斯模糊和量化误差对超分辨率和图像配准的影响,而且提出了一种新的算法框架来处理这些问题,并通过理论分析和实验验证了其有效性。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,论文中进行了以下实验:
理论分析与数学推导:
- 论文通过数学推导和理论分析来描述测量矩阵和差分矩阵的特性,以及它们在不同条件下的行为。这包括对纯高斯模糊和高斯混合模糊的处理,以及在不同模糊水平下测量矩阵的结构变化。
小规模示例分析:
- 论文提供了一个具体的一维空间受限分段常数函数的例子,并生成了两个数据序列,每个序列包含十三个样本。这个例子用于说明在没有统计噪声且已知幅度的情况下,确定所有不连续点的困难。同时,也展示了在统计噪声存在的情况下,选择交叉相关模板匹配最大值作为对齐技术可能表现不佳的问题。
噪声模型实验:
- 论文考虑了一种噪声模型,其中噪声取值为某个在[0, 0.5]范围内的整数倍的1/256,且等概率为正或负。通过这个模型,论文分析了两个受噪声影响的数据序列,并展示了在不同噪声水平下,交叉相关模板匹配的效果。
动态规划方案验证:
- 论文提出了一个基于动态规划的方案,并证明了在满足一定条件(如高斯模糊的大小、不连续点之间的最小距离和噪声水平)的情况下,该方案能够正确地对齐并确定两个数据序列中每个不连续点后的第一个样本的位置。论文通过理论证明支持了这一结论。
对比交叉相关模板匹配:
- 论文对比了所提出的动态规划方案与传统的交叉相关模板匹配方法,展示了在不同条件下,动态规划方案的性能优势,尤其是在噪声水平变化时,其性能下降不如交叉相关模板匹配方法那么突兀。
这些实验主要是理论分析和数学推导,辅以一些计算实验来验证理论结果。论文的重点在于通过理论分析和数学建模来解决超分辨率和图像配准中的问题,而不是通过大规模的实验数据来验证算法。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些有趣的点,以下是一些可以进一步探索的方向:
算法优化和改进:
- 研究如何优化动态规划算法,以处理更复杂的图像数据和实际应用中的噪声条件。
多维数据的超分辨率和图像配准:
- 将研究扩展到多维(如二维或三维)数据,探索在更高维度中处理模糊和量化误差的方法。
混合模糊模型的深入分析:
- 对混合高斯模糊模型进行更深入的分析,特别是在不同混合比例和不同标准差条件下的性能。
实际图像数据的实验验证:
- 在实际的图像数据集上测试所提出的方法,验证其在真实世界条件下的有效性和鲁棒性。
不同量化级别的影响:
- 研究不同量化级别(例如,不同的位深度)对超分辨率和图像配准的影响,并探索最佳量化策略。
算法的并行化和硬件加速:
- 探索如何将动态规划算法并行化,以及如何利用现代硬件(如GPU)来加速计算。
结合深度学习方法:
- 将传统的信号处理方法与深度学习技术结合,以提高超分辨率和图像配准的性能。
跨模态图像配准:
- 探索跨模态(如MRI和CT图像)的图像配准问题,这可能需要处理不同的模糊和噪声特性。
实时系统的集成:
- 研究如何将超分辨率和图像配准算法集成到实时系统中,例如在医疗成像或视频监控中。
算法的泛化能力:
- 研究算法对于不同类型的图像内容(如自然图像、人造结构图像等)的泛化能力,并探索提高泛化性的方法。
误差分析和不确定性量化:
- 对算法的误差进行更详细的分析,并研究如何量化不确定性,这对于许多实际应用(如医学诊断)至关重要。
算法的可解释性:
- 提高算法的可解释性,特别是在动态规划方案中,理解算法做出特定决策的原因。
这些方向不仅可以推动超分辨率和图像配准技术的发展,还可能对相关领域的研究产生影响。
Q: 总结一下论文的主要内容
A: 这篇论文主要探讨了在超分辨率和图像配准领域中,如何处理和解决由于高斯模糊和量化误差引起的问题,尤其是在处理一维空间受限的分段常数函数时。以下是论文的主要内容总结:
问题背景:
- 超分辨率旨在从有限分辨率的样本中恢复信号,而图像配准则用于融合不同样本集的信息。
- 数字图像的量化误差是固有的,论文考虑了高斯模糊和量化误差对超分辨率和图像配准的影响。
理论模型:
- 论文定义了测量矩阵和差分矩阵来描述信号在受到高斯模糊和量化误差后的观测数据。
- 分析了在不同模糊条件下测量矩阵的结构变化。
动态规划方案:
- 提出了一个基于动态规划的算法,用于在满足一定条件下正确地对齐并确定两个数据序列中每个不连续点后的第一个样本的位置。
统计噪声的处理:
- 讨论了当样本受到统计噪声影响时,如何通过分割数据序列来提高推断的准确性。
实验验证:
- 通过理论分析和具体示例,展示了量化误差和统计噪声对超分辨率和图像配准的影响。
- 对比了传统的交叉相关模板匹配方法和提出的动态规划方法,展示了在不同条件下的性能差异。
主要结论:
- 证明了在特定的噪声和模糊条件下,所提出的动态规划算法能够有效地对齐数据序列并确定不连续点的位置。
- 强调了在处理来自具有有限精度的仪器或传感器的数据时,理解机会和局限性的重要性。
总体而言,这篇论文提供了一个理论框架和方法,用于在存在模糊和量化误差的情况下进行有效的超分辨率重建和图像配准,并通过理论分析和实验验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

DQA: An Efficient Method for Deep Quantization of Deep Neural Network Activations
Authors:Wenhao Hu, Paul Henderson, José Cano
Quantization of Deep Neural Network (DNN) activations is a commonly used technique to reduce compute and memory demands during DNN inference, which can be particularly beneficial on resource-constrained devices. To achieve high accuracy, existing methods for quantizing activations rely on complex mathematical computations or perform extensive searches for the best hyper-parameters. However, these expensive operations are impractical on devices with limited computation capabilities, memory capacities, and energy budgets. Furthermore, many existing methods do not focus on sub-6-bit (or deep) quantization. To fill these gaps, in this paper we propose DQA (Deep Quantization of DNN Activations), a new method that focuses on sub-6-bit quantization of activations and leverages simple shifting-based operations and Huffman coding to be efficient and achieve high accuracy. We evaluate DQA with 3, 4, and 5-bit quantization levels and three different DNN models for two different tasks, image classification and image segmentation, on two different datasets. DQA shows significantly better accuracy (up to 29.28%) compared to the direct quantization method and the state-of-the-art NoisyQuant for sub-6-bit quantization.
深度神经网络(DNN)激活值的量化是一种常用于减少DNN推理过程中的计算和内存需求的技术,这在资源受限的设备上特别有益。为了提高精度,现有的激活值量化方法依赖于复杂的数学计算或进行广泛的超参数搜索。然而,这些昂贵的操作对于计算能力强、内存容量和能源预算有限的设备来说并不实用。此外,许多现有方法并不专注于低于6位(或深度)的量化。为了填补这些空白,本文提出了DQA(DNN激活值的深度量化)新方法,它专注于激活值的低于6位量化,并利用基于简单移位操作和霍夫曼编码来提高效率和实现高精度。我们在两个不同的数据集上,使用3位、4位和5位的量化级别以及三个不同的DNN模型进行图像分类和图像分割两项任务来评估DQA。与直接量化方法和最新的低于6位量化的NoisyQuant相比,DQA显示出更高的精度(高达29.28%)。
论文及项目相关链接
PDF Accepted to Second Workshop on Machine Learning with New Compute Paradigms at NeurIPS 2024 (MLNCP 2024)
Summary
本文提出一种针对深度神经网络(DNN)激活值的深度量化方法(DQA),旨在实现子6位量化,并借助简单的移位操作和霍夫曼编码来提高效率和准确性。通过在不同数据集上的三个不同DNN模型进行图像分类和图像分割任务评估,DQA在子6位量化方面表现出显著更高的准确性,相较于直接量化方法和现有的先进噪声量化技术,其准确性提高了高达29.28%。
Key Takeaways
- 深度神经网络(DNN)激活值的量化是减少计算与内存需求的有效方法,特别是在资源受限的设备上。
- 当前激活值量化方法常依赖复杂的数学计算或大量超参数搜索来追求高准确性,这不适用于计算能力和内存有限、能源预算紧张的设备。
- 针对子6位(或深度)量化,现有方法存在不足。
- 本文提出的DQA方法专注于激活值的子6位量化。
- DQA利用简单的移位操作和霍夫曼编码来提高效率和准确性。
- 在图像分类和图像分割任务上,使用三个不同数据集和模型进行的评估显示,DQA相较于其他方法表现出更高的准确性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在资源受限的设备上高效地对深度神经网络(DNN)的激活值进行量化,以减少推理过程中的计算和内存需求。具体来说,论文提出了一种名为DQA(Deep Quantization of DNN Activations)的新方法,专注于对激活值进行6位以下的深度量化,并利用简单的位移操作和霍夫曼编码来实现高效率和高精度。这种方法旨在解决现有量化方法在资源受限设备上的两个主要问题:
计算成本高昂:现有的一些量化方法依赖于复杂的数学运算或进行广泛的搜索以寻找最佳的超参数,这些操作在计算能力、内存容量和能源预算有限的设备上是不切实际的。
缺乏对深度量化的关注:许多现有方法没有专注于深度量化(例如,量化到少于6位),这对于内存受限的设备来说是更受偏好的。
DQA方法通过在量化过程中区分处理重要和不重要的激活通道,并利用霍夫曼编码优化内存使用,旨在克服这些限制,实现在资源受限设备上的高效和准确的DNN激活量化。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与DQA方法相关的研究工作:
NoisyQuant [13]:这是一种在激活值量化之前注入噪声,并在去量化后移除噪声的方法。尽管NoisyQuant并非专为资源受限设备设计,但它在论文的实验中显示出对其他类型的DNN也有效。
AWQ(Activation-Aware Weight Quantization) [11]:AWQ检查每层权重通道的重要性,并在量化前对重要通道进行放大,以减少舍入误差。这与DQA处理重要激活通道的方式相似。
混合精度量化(Mixed-precision quantization) [1]、[15]:这种方法为DNN模型的不同部分(如层或通道)分配不同的位长度,以满足它们不同的精度敏感性。DQA方法也采用了混合精度量化,以有效的方式适应不同重要性的激活通道。
深度量化(Deep quantization):一些现有方法没有专注于深度量化(例如,量化到少于6位),而DQA方法专注于这一点,使其更适合资源受限的设备。
量化方法的分类 [5]:论文中提到了量化方法通常分为均匀量化和非均匀量化,以及对称量化和非对称量化。DQA方法使用了均匀对称量化,因为它的计算成本相对较低且受欢迎。
DNN量化的相关工作:论文还提到了其他一些关于DNN量化的研究,这些研究主要关注模型权重和/或激活的量化。
这些相关研究为DQA方法提供了理论基础和技术背景,同时也突显了DQA在现有量化技术中的创新点,尤其是在资源受限设备上的深度量化和内存优化方面。
Q: 论文如何解决这个问题?
A: 论文提出了DQA(Deep Quantization of DNN Activations)方法来解决资源受限设备上深度神经网络(DNN)激活值量化的问题。DQA方法通过以下几个关键步骤实现高效和高精度的量化:
1. 离线确定激活通道的重要性
DQA首先使用训练或校准数据集来确定每个激活通道的重要性。这一步骤在离线状态下完成,利用贪婪搜索算法对激活通道进行排序,以确定哪些通道在量化时应该被特别对待。这种方法避免了在推理过程中进行耗时的动态排序。
2. 重要激活通道的量化
对于被识别为重要的激活通道,DQA首先使用( m )额外的位进行量化(其中( m )小于目标位数( n )),然后通过向右移动( m )位来达到目标位数。这种操作允许所有量化值最终以相同的位长度存储,从而避免存储浪费。
3. 位移错误的编码
由于向右移动操作会导致信息丢失,DQA会保存位移错误,并在去量化阶段将其加回去以补偿信息丢失。为了减少额外的内存开销,DQA使用霍夫曼编码来压缩这些位移错误,因为位移错误的分布不是均匀的,霍夫曼编码可以有效地压缩这些错误。
4. 不重要激活通道的直接量化
对于不重要的激活通道,DQA使用直接量化方法,即直接应用数学上的量化/去量化定义。
5. 详细的评估和比较
论文还对DQA进行了详细的评估,并与直接量化方法和NoisyQuant等现有方法进行了比较。实验结果表明,DQA在3、4和5位量化水平上,对于不同的DNN模型和任务(图像分类和图像分割),都能显著提高准确性。
6. 未来工作
论文提出了未来工作的方向,包括与硬件加速器的共同设计,以及在资源受限设备上评估系统性能(如推理延迟),以进一步利用DQA的优势。
通过这些步骤,DQA方法旨在为资源受限设备提供一种既高效又准确的DNN激活量化解决方案。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估DQA方法的性能,并与直接量化方法和NoisyQuant这两种现有方法进行了比较。实验设置如下:
实验环境和数据集
- 图像分类任务:使用了ResNet-32和MobileNetV2模型在CIFAR-10数据集上进行实验。
- 图像分割任务:使用了U-Net模型在CityScapes数据集上进行实验。
实验设置
- 量化位水平:实验中设置了3、4和5位的量化水平。
- 实验工具:使用PyTorch框架在Nvidia RTX 3090 GPU上运行实验。
- 实验重复:每个实验重复5次,并取平均值。
- 重要通道选择:使用训练数据的随机子集创建每个实验运行的排名表,并选择重要通道的比例分别为图像分类40%和图像分割50%。
实验结果
实验结果如表1所示,展示了三种DNN模型在不同量化方法和量化位水平下的准确率(Acc)结果。DQA在图像分类任务上相比于直接量化方法和NoisyQuant显示出高达29.28%的准确率提升,而在图像分割任务上,DQA在4位量化时提供了比直接量化和NoisyQuant更高的准确率(高达0.9%),在5位量化时准确率相似,而在3位量化时,DQA超过了直接量化但NoisyQuant提供了最佳的准确率值。
结论
实验结果表明,DQA在资源受限设备上对DNN激活进行深度量化时,相比于直接量化和NoisyQuant这两种现有方法,能够显著提高模型的准确率。论文还提出了未来的工作方向,包括与硬件加速器的共同设计和在资源受限设备上评估系统性能,以进一步利用DQA的优势。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
不同m值的探索:
- 论文中提到所有实验设置中( m = 3 )以简化评估。探索不同的( m )值对于不同量化水平的影响,可能会发现更优的配置。
硬件加速器的共同设计:
- 论文提出了未来工作的方向之一是与硬件加速器的共同设计。这可能涉及到为DQA方法定制硬件,以进一步减少推理延迟和提高效率。
系统性能评估:
- 在资源受限设备上评估DQA的系统性能,如推理延迟和能耗,这有助于全面理解DQA在实际应用中的性能。
不同DNN架构和任务的泛化能力:
- 论文主要关注了图像分类和图像分割任务。将DQA方法应用于其他类型的DNN架构和任务(如自然语言处理、语音识别等)上,以评估其泛化能力。
优化算法的集成:
- 考虑将DQA与其他神经网络优化技术(如剪枝、知识蒸馏等)结合使用,以进一步压缩模型并提高效率。
更广泛的数据集和模型评估:
- 在更多的数据集和不同类型的DNN模型上评估DQA的性能,以验证其在不同场景下的适用性和有效性。
不同硬件平台的移植和优化:
- 将DQA移植到不同的硬件平台(如ARM处理器、FPGA等)并进行优化,以适应不同的应用场景。
算法的鲁棒性测试:
- 对DQA进行鲁棒性测试,特别是在面对不同的输入数据分布和噪声条件时的性能表现。
理论分析和误差界限:
- 对DQA方法的理论分析,包括量化误差的界限和模型性能的理论保证。
自动化超参数调整:
- 开发自动化的超参数调整策略,以找到最佳的量化位和( m )值,而无需手动调整。
这些探索点可以帮助研究者更深入地理解DQA方法,并将其应用于更广泛的实际问题中。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为DQA(Deep Quantization of DNN Activations)的新方法,旨在为资源受限的设备提供一种高效的深度神经网络(DNN)激活量化技术。以下是论文的主要内容总结:
问题背景
- 量化是减少DNN在推理期间计算和内存需求的常用技术。
- 现有方法依赖复杂数学运算或广泛搜索最佳超参数,不适合资源受限设备。
- 许多方法未专注于6位以下的深度量化,这对于内存受限设备更有利。
DQA方法
- 离线重要性评估:使用训练或校准数据集通过贪婪搜索算法确定激活通道的重要性。
- 重要通道量化:对重要激活通道使用额外位数(( m ))进行量化,然后右移以实现目标位数,同时保存位移误差。
- 霍夫曼编码:对位移误差使用霍夫曼编码减少内存开销。
- 去量化:在去量化阶段,对重要通道解码霍夫曼编码的位移误差并加回,对非重要通道使用直接量化方法。
实验评估
- 在CIFAR-10和CityScapes数据集上,使用ResNet-32、MobileNetV2和U-Net模型进行图像分类和分割任务的评估。
- 与直接量化和NoisyQuant方法比较,DQA在3、4和5位量化水平上显示出显著更高的准确率。
主要贡献
- 提出了DQA,一种特别适合资源受限设备的深度(小于6位)量化方法。
- 探索了DQA中位移误差的模式,为使用霍夫曼编码提供了理由。
- 详细评估了DQA,并与现有方法比较,显示出在准确性上的优越性。
未来工作
- 与硬件加速器的共同设计,以评估资源受限设备上的系统性能,进一步利用DQA的优势。
总体而言,DQA通过简单高效的量化操作和霍夫曼编码优化,为资源受限设备上的DNN激活量化提供了一种新的方法,实现了高准确率和低资源消耗。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

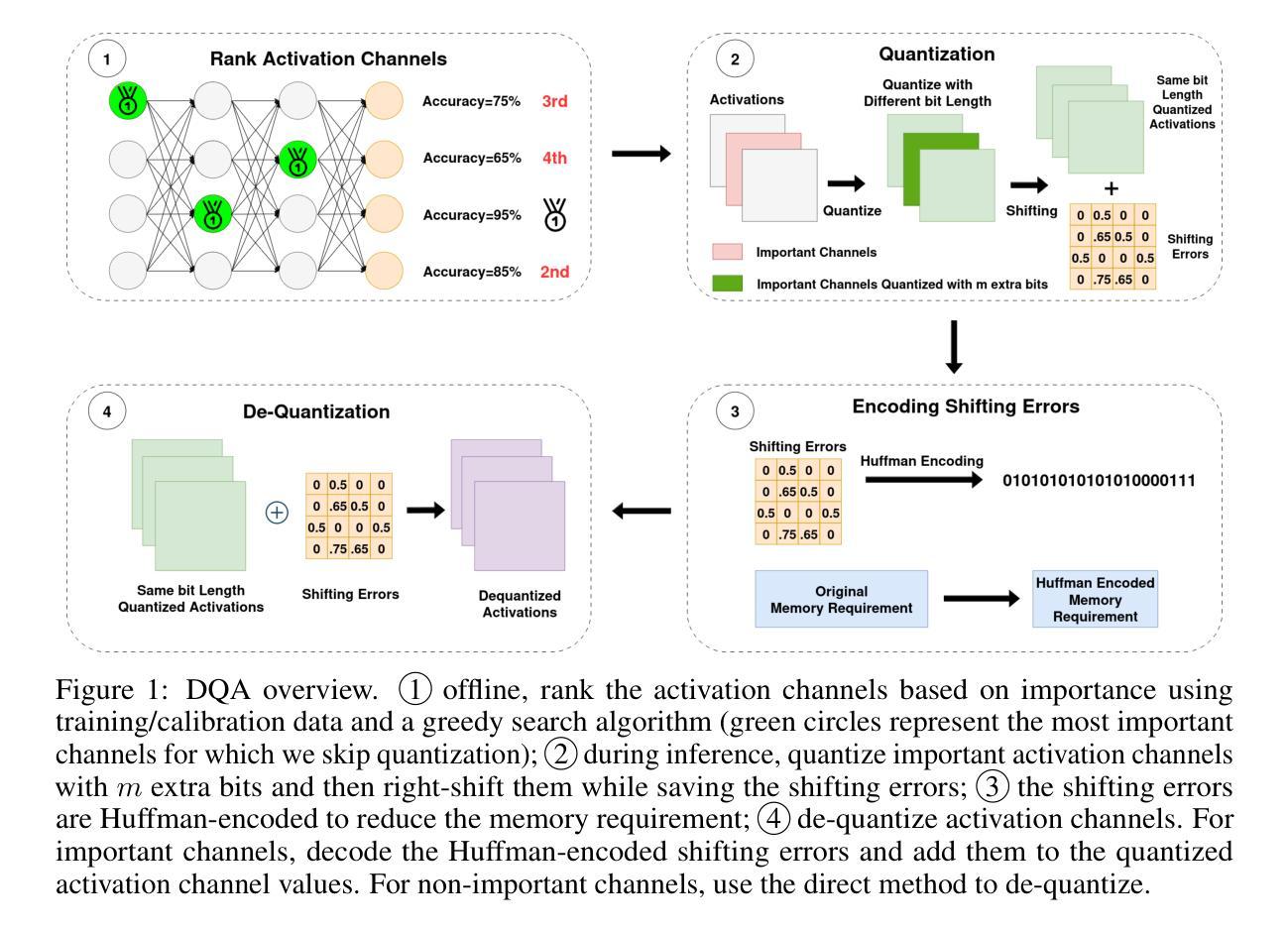

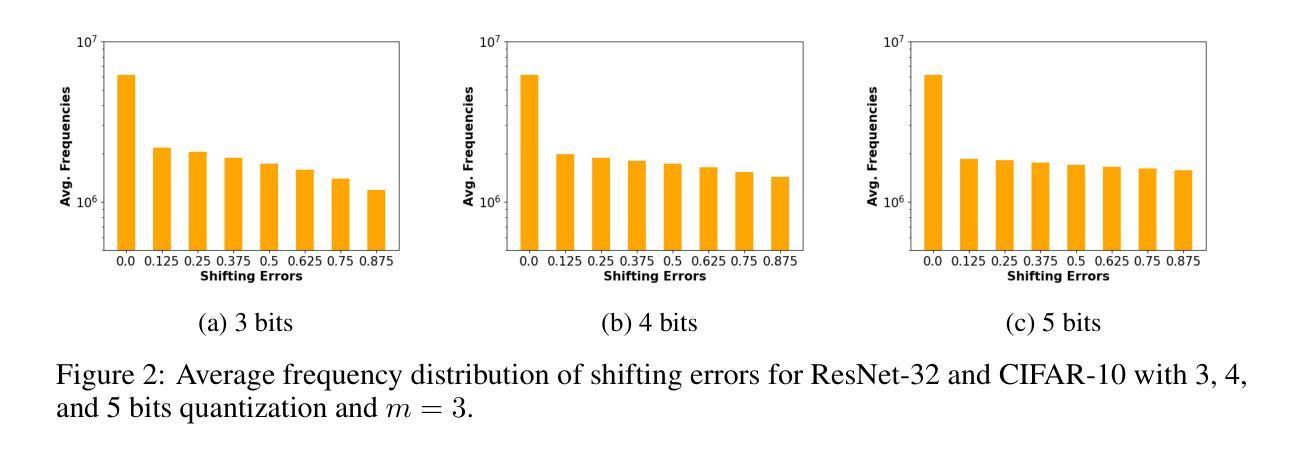
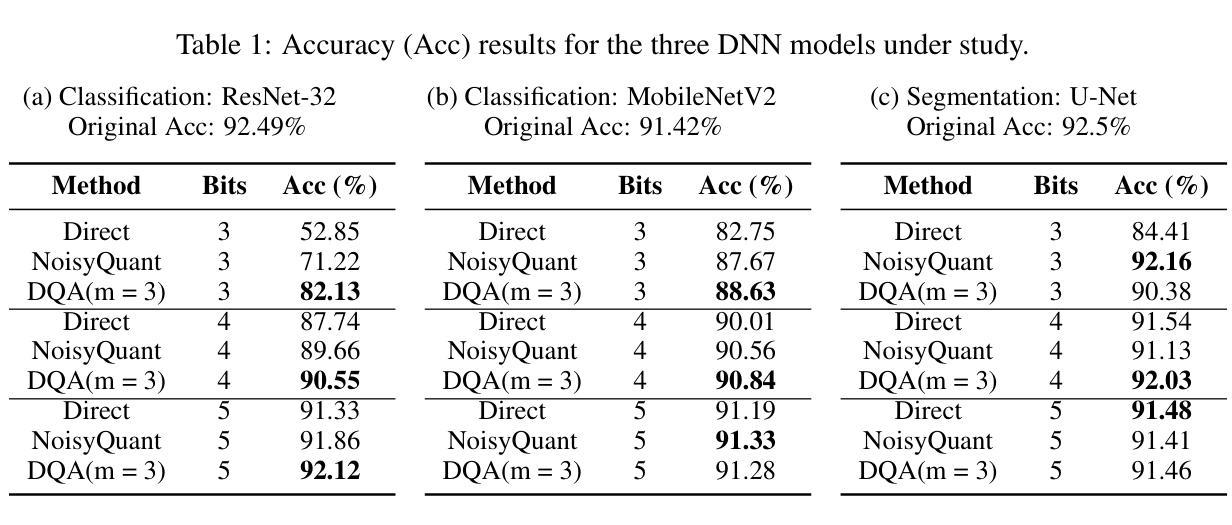
Utilizing Multi-step Loss for Single Image Reflection Removal
Authors:Abdelrahman Elnenaey, Marwan Torki
Image reflection removal is crucial for restoring image quality. Distorted images can negatively impact tasks like object detection and image segmentation. In this paper, we present a novel approach for image reflection removal using a single image. Instead of focusing on model architecture, we introduce a new training technique that can be generalized to image-to-image problems, with input and output being similar in nature. This technique is embodied in our multi-step loss mechanism, which has proven effective in the reflection removal task. Additionally, we address the scarcity of reflection removal training data by synthesizing a high-quality, non-linear synthetic dataset called RefGAN using Pix2Pix GAN. This dataset significantly enhances the model’s ability to learn better patterns for reflection removal. We also utilize a ranged depth map, extracted from the depth estimation of the ambient image, as an auxiliary feature, leveraging its property of lacking depth estimations for reflections. Our approach demonstrates superior performance on the SIR^2 benchmark and other real-world datasets, proving its effectiveness by outperforming other state-of-the-art models.
图像反射消除对于恢复图像质量至关重要。扭曲的图像会对目标检测、图像分割等任务产生负面影响。在本文中,我们提出了一种使用单幅图像进行图像反射消除的新方法。我们没有关注模型架构,而是引入了一种可推广至图像到图像问题的新训练技术,其输入和输出在本质上是相似的。这种技术体现在我们的多步骤损失机制中,该机制在反射消除任务中已被证明是有效的。此外,我们通过使用Pix2Pix GAN合成了一种名为RefGAN的高质量非线性合成数据集,解决了反射消除训练数据不足的问题。该数据集显著提高了模型学习反射消除模式的能力。我们还利用从环境图像的深度估计中提取的范围深度图作为辅助特征,利用其缺乏反射深度估计的属性。我们的方法在SIR^2基准测试和其他真实世界数据集上表现出卓越的性能,超越了其他最先进模型,证明了其有效性。
论文及项目相关链接
PDF 6 pages, 6 figures, IEEE AICCSA 2024
Summary
本文提出了一种基于单图像去除图像反射的新方法。该方法未关注模型架构,而是引入了一种可泛化到类似图像到图像问题的新训练技术。该技术体现在我们的多步骤损失机制中,该机制在去除反射的任务中证明了其有效性。此外,我们通过Pix2Pix GAN合成了一个高质量的非线性合成数据集RefGAN,以解决反射去除训练数据不足的问题。我们还利用从环境图像的深度估计中提取的范围深度图作为辅助特征,利用其缺乏反射深度估计的属性。该方法在SIR^2基准测试和其他真实世界数据集上表现出卓越的性能,超越了其他最先进模型。
Key Takeaways
- 提出了基于单图像的反射去除新方法。
- 引入了一种新的训练技术,适用于图像到图像的类似问题。
- 通过多步骤损失机制提高模型性能。
- 利用Pix2Pix GAN合成了一个高质量的非线性数据集RefGAN,解决了训练数据不足的问题。
- 使用范围深度图作为辅助特征,提高模型性能。
- 在SIR^2基准测试和其他真实世界数据集上表现优越。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决单张图片中的反射去除问题,这对于恢复图像质量和提高诸如目标检测、图像分割等计算机视觉任务的性能至关重要。具体来说,论文关注以下几个问题:
图像反射的影响:图像中的反射会扭曲视觉内容,降低依赖清晰图像的算法的性能,例如,反射可能会遮挡目标检测中的关键特征,引起场景布局解释的歧义,以及导致增强现实叠加中的错位。
现有方法的局限性:传统的反射去除方法通常需要多张图片或复杂的硬件,这在只有单张图片可用的场景中是不切实际的。
训练数据的稀缺性:对于训练反射去除模型来说,存在高质量、多样化的训练数据集的缺乏问题。
模型性能和泛化能力的提升:如何设计有效的损失函数和训练技术,以提高模型在各种场景下的性能和泛化能力。
为了解决这些问题,论文提出了一种新颖的方法,包括一个多步损失机制、一个合成的高质量非线性数据集RefGAN,以及使用范围深度图作为辅助特征,以提高反射去除的效果。
Q: 有哪些相关研究?
A: 论文中提到的相关研究可以分为以下几个类别:
非机器学习基础的方法
- 区域感知技术:结合内容和梯度信息以增强精度的方法,例如 [1]。
- 使用非闪光环境图像去除反射和伪影:例如 [2]。
- 利用景深指导区分聚焦和反射区域:例如 [3]。
单图像反射去除方法
- CeilNet:利用深度学习预测无反射图像,无需手工特征,例如 [4]。
- 感知损失:用于提高反射去除质量,例如 [5]。
- 卷积编码器-解码器网络:例如 [6]。
- ERRNet:在不对齐的实际数据上提高性能,例如 [7]。
- 级联细化方法:例如 [8]。
- 语义引导预测:例如 [9]。
- 具有反射检测和循环模块的新型架构:例如 [10]。
- 自注意力机制和局部鉴别损失:用于更有效的反射分离,例如 [11]。
- 屏幕模糊组合技术:用于更好地模拟反射特性,例如 [12]。
- 深度变分推断反射去除(VIRR)方法:首次使用这种方法,专注于学习潜在分布以获得更好的可解释性,例如 [13]。
闪光/无闪光图像反射去除方法
- 利用闪光和环境图像对:提取仅闪光图像以估计无反射的传输图像,例如 [14]。
这些相关研究为单图像反射去除领域提供了多种技术和方法,而本文提出的新方法旨在通过引入多步损失机制、合成数据集和范围深度图来进一步改进这些技术。
Q: 论文如何解决这个问题?
A: 论文通过以下三个主要贡献来解决单张图片中的反射去除问题:
1. 多步损失机制(Multi-step Loss Mechanism)
- 多步损失函数:提出了一种新的多步损失函数,该函数迭代地将输出作为输入用于连续的步骤,并在每一步累积损失。这种机制放大了错误去除反射的损失,提供了模型性能在挑战性情况下的更具代表性的度量。
- 损失累积:与在多个步骤中平均或平滑损失不同,多步损失机制通过观察每个图像中每个步骤的不同反射比率来增强模型处理不同反射强度的能力,从而提高整体性能。
2. RefGAN数据集
- 合成数据集:为了解决训练数据不足的问题,论文通过Pix2Pix GAN合成了一个高质量的非线性合成数据集RefGAN。这个数据集提供了广泛的反射模式和强度,增强了模型学习反射去除更好模式的能力。
- 增强模型鲁棒性:RefGAN数据集显著增强了模型的鲁棒性和有效性,使其能够处理更多样化的反射情况。
3. 范围深度图(Ranged Depth Map)
- 辅助特征:使用从环境图像的深度估计中提取的范围深度图作为辅助特征,利用其缺乏反射的深度估计的特性。
- 排除反射:范围深度图帮助模型有效地从环境图像中提取目标场景,并且通过仅关注实际场景内容来排除反射。
- 增强反射去除过程:范围深度图还帮助模型建立原始图像中落在相同范围内的邻近像素之间的关系,进一步增强了反射去除过程。
方法结构
- 范围图估计模块:负责从环境图像中导出范围深度图。使用预训练的Midas Small模型计算初始深度图,并将每个像素分配到特定范围,形成范围深度图。
- 反射去除模块:利用范围深度图作为辅助特征进行反射估计。采用R-CNN架构,结合UNet预测反射图像。最终阶段使用T-CNN,将估计的反射、范围深度图和输入的环境图像一起作为输入,预测目标图像。
这些方法的结合在SIR2基准测试和其他实际数据集上展示了优越的性能,证明了其在单张图像反射去除中的有效性,并超越了其他最先进的模型。
Q: 论文做了哪些实验?
A: 论文中进行的实验包括以下几个方面:
1. 实验设置
- 硬件平台:使用Nvidia Tesla T4 GPU进行实验。
- 训练参数:模型以1的批量大小训练100个周期,初始学习率为(10^{-4}),采用余弦退火调度,从(10^{-4})开始,在第100个周期接近0。使用Adam优化器,并在模型性能稳定后从2步损失升级到3步损失。
2. 数据集
- 训练数据:包括来自[14]的真实世界数据,这些数据包含来自[17]和[18]的合成图像,以及来自[8]的Nature数据集。此外,还合成了RefGAN数据集,包含7115对环境-传输图像对。
- 验证数据:使用来自[14]验证集的30张真实世界图像。
- 评估数据:在来自[14]测试集的50张真实世界图像、来自[8]的Nature数据集的20张真实世界图像和SIR2基准测试[20](包括wild、solid object和postcard三个子测试数据集)上进行评估。
3. 定量结果
- 评估指标:使用峰值信噪比(PSNR)、结构相似性(SSIM)和Learned Perceptual Image Patch Similarity(LPIPS)等广泛接受的指标。
- 结果对比:与现有的最先进的单图像反射去除方法进行比较,结果表明所提出的方法在所有数据集上均优于其他方法。
4. 定性结果
- 结果展示:通过图5和图6展示了模型与现有最先进方法在Nature数据集和SIR2基准测试上的定性比较结果。
5. 消融研究
- 范围深度图与纯深度图的比较:评估使用纯深度图与范围深度图作为辅助特征的效果。
- RefGAN数据集的影响:评估在有无RefGAN数据集训练的情况下模型的性能差异。
- 不同范围深度图范围(K值)的性能:研究不同K值对模型性能的影响。
- 多步损失机制的影响:评估不同配置的多步损失对模型性能的影响。
这些实验全面评估了所提出方法的有效性,并深入分析了各个组成部分对性能的影响,从而证明了所提出方法在单图像反射去除任务中的优越性能。
Q: 有什么可以进一步探索的点?
A: 论文在第5节“结论”中提到了未来的研究方向,以下是一些可以进一步探索的点:
先进的模型架构:尽管本研究展示了损失函数、训练数据质量和辅助输入特征的有效性,未来的工作可以探索将这些方法与更先进的模型架构结合,以实现更好的性能提升。
更准确的物理模型:研究可以进一步探索集成更准确的物理模型来描述反射形成过程,这可能会在图像到图像的任务中实现更进一步的性能和泛化能力的提升。
多模态数据融合:考虑将多模态数据(例如,结合RGB图像与深度图像、红外图像等)融合到模型中,以提供更丰富的信息辅助反射去除。
实时性能优化:研究如何优化模型以实现实时或近实时的反射去除,这对于增强现实和实时视频处理等应用尤为重要。
更广泛的数据集和场景:扩展和多样化训练数据集,包括更多类型的反射和不同环境下的场景,以提高模型的泛化能力。
模型的可解释性和透明度:研究模型的决策过程,提高模型的可解释性,这有助于理解模型的行为并进一步改进算法。
跨域适应性:研究模型在不同设备和不同光照条件下的适应性,以提高其在实际应用中的灵活性和鲁棒性。
端到端的解决方案:开发一个端到端的系统,该系统可以直接在移动设备或嵌入式设备上运行,而无需复杂的后处理步骤。
长尾分布问题:针对训练数据中可能存在的类别不平衡问题,研究有效的策略来处理长尾分布,提高模型对罕见反射类型的敏感性。
模型压缩和加速:研究模型压缩技术,以减少模型大小并加速推理过程,使其更适合资源受限的环境。
这些方向不仅可以推动单图像反射去除技术的发展,也可能对计算机视觉中的其他图像到图像翻译任务产生积极影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题陈述:
- 论文关注于单张图像中的反射去除问题,这对于恢复图像质量和提高计算机视觉任务的性能至关重要。
- 传统的反射去除方法需要多张图像或复杂硬件,不适用于仅有单张图像的场景。
主要贡献:
- 提出了一种新颖的多步损失机制,用于改善模型在训练过程中的性能和泛化能力。
- 合成了一个名为RefGAN的高质量非线性合成数据集,增强了模型的鲁棒性和有效性。
- 利用范围深度图作为辅助特征来排除反射,专注于实际场景内容,以提高反射去除的效果。
方法论:
- 介绍了一个包含范围图估计模块和反射去除模块的架构。
- 使用预训练的Midas Small模型来计算初始深度图,并生成范围深度图。
- 利用R-CNN和T-CNN网络结构来预测反射和目标图像。
实验:
- 在Nvidia Tesla T4 GPU上进行实验,使用不同的数据集进行训练、验证和评估。
- 通过定量和定性结果展示了所提方法相较于现有技术的优越性。
- 进行了消融研究,分析了不同组件对性能的影响。
结论与未来工作:
- 论文提出的多步损失机制、RefGAN数据集和范围深度图在单图像反射去除任务中表现出色,超越了其他最先进模型。
- 论文还提出了未来可能的研究方向,包括探索更先进的模型架构、更准确的物理模型、多模态数据融合等。
总体而言,这篇论文通过引入新的损失机制和数据集,以及利用范围深度图作为辅助特征,提供了一种有效的单图像反射去除方法,并在多个数据集上验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

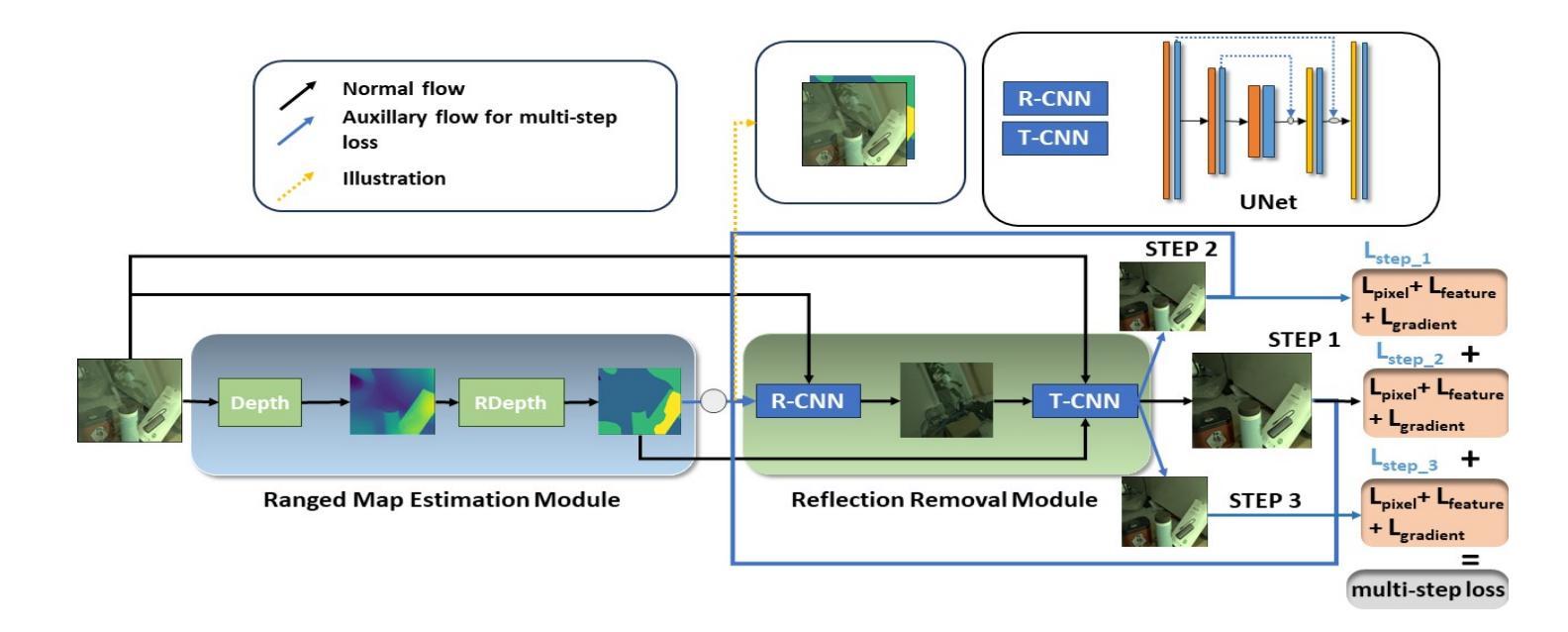


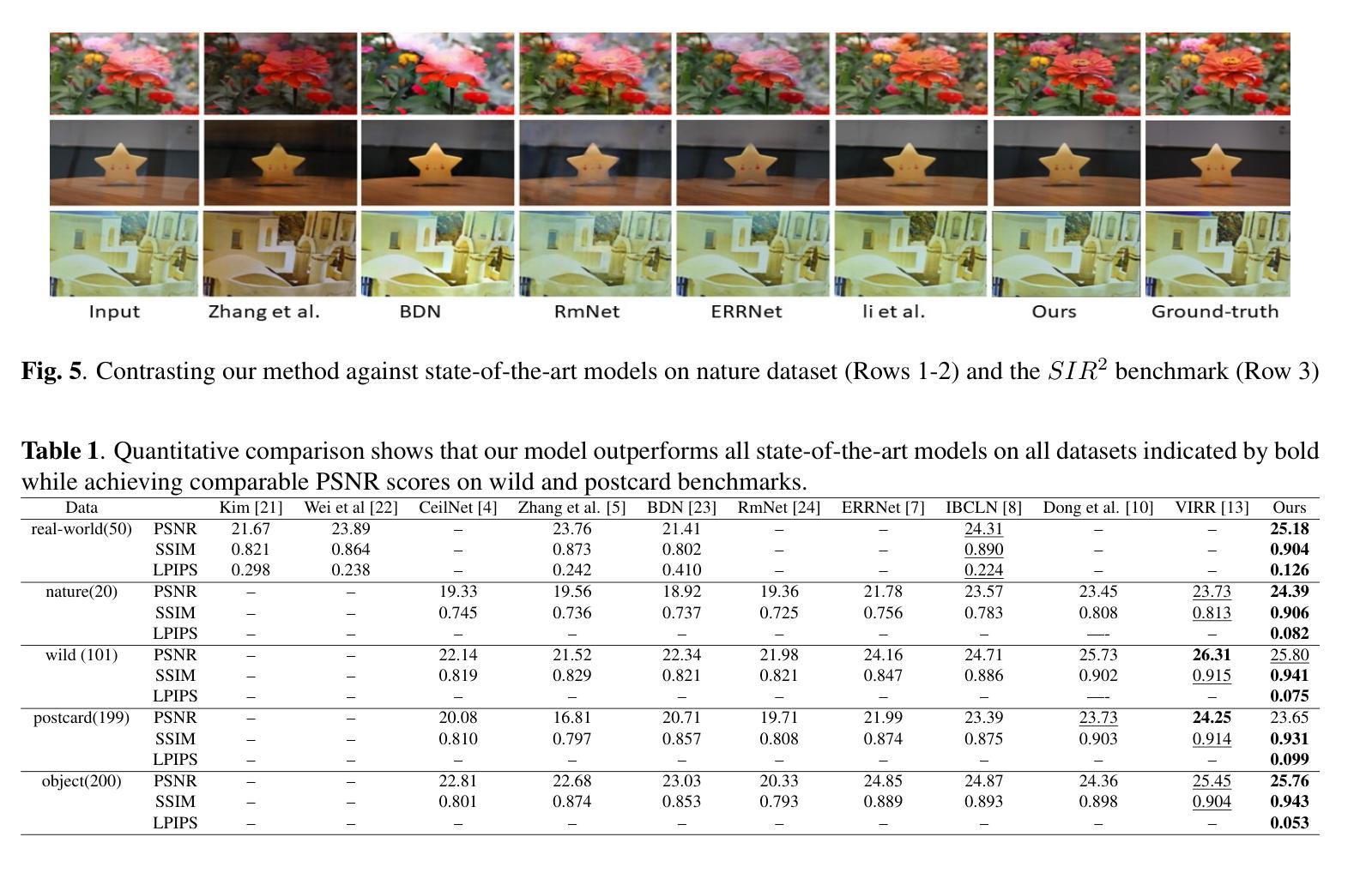
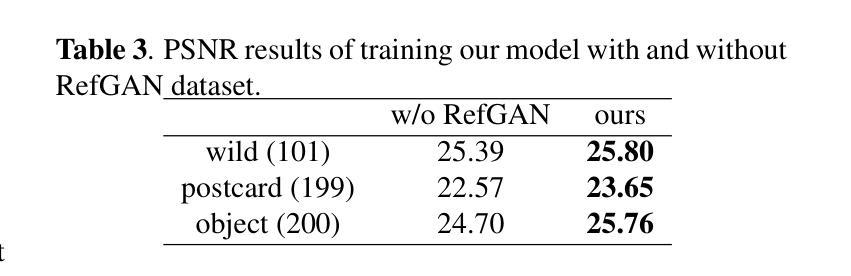


SVGDreamer++: Advancing Editability and Diversity in Text-Guided SVG Generation
Authors:Ximing Xing, Qian Yu, Chuang Wang, Haitao Zhou, Jing Zhang, Dong Xu
Recently, text-guided scalable vector graphics (SVG) synthesis has demonstrated significant potential in domains such as iconography and sketching. However, SVGs generated from existing Text-to-SVG methods often lack editability and exhibit deficiencies in visual quality and diversity. In this paper, we propose a novel text-guided vector graphics synthesis method to address these limitations. To enhance the editability of output SVGs, we introduce a Hierarchical Image VEctorization (HIVE) framework that operates at the semantic object level and supervises the optimization of components within the vector object. This approach facilitates the decoupling of vector graphics into distinct objects and component levels. Our proposed HIVE algorithm, informed by image segmentation priors, not only ensures a more precise representation of vector graphics but also enables fine-grained editing capabilities within vector objects. To improve the diversity of output SVGs, we present a Vectorized Particle-based Score Distillation (VPSD) approach. VPSD addresses over-saturation issues in existing methods and enhances sample diversity. A pre-trained reward model is incorporated to re-weight vector particles, improving aesthetic appeal and enabling faster convergence. Additionally, we design a novel adaptive vector primitives control strategy, which allows for the dynamic adjustment of the number of primitives, thereby enhancing the presentation of graphic details. Extensive experiments validate the effectiveness of the proposed method, demonstrating its superiority over baseline methods in terms of editability, visual quality, and diversity. We also show that our new method supports up to six distinct vector styles, capable of generating high-quality vector assets suitable for stylized vector design and poster design. Code and demo will be released at: http://ximinng.github.io/SVGDreamerV2Project/
最近,文本引导的可伸缩矢量图形(SVG)合成在图标和草图等领域表现出了巨大的潜力。然而,由现有文本到SVG方法生成的SVG通常缺乏可编辑性,并且在视觉质量和多样性方面存在缺陷。在本文中,我们提出了一种新型的文本引导矢量图形合成方法来解决这些限制。为了增强输出SVG的可编辑性,我们引入了分层图像矢量化(HIVE)框架,该框架在语义对象级别运行,并监督向量对象内组件的优化。这种方法促进了矢量图形分解为不同的对象和组件级别。我们提出的HIVE算法,结合图像分割先验知识,不仅确保了矢量图形的更精确表示,还实现了矢量对象内的精细编辑功能。为了提高输出SVG的多样性,我们提出了一种基于粒子得分的矢量化蒸馏(VPSD)方法。VPSD解决了现有方法中的过饱和问题,并提高了样本多样性。我们加入了一个预训练的奖励模型来重新权重向量粒子,提高了美观度并实现了更快的收敛。此外,我们设计了一种新型自适应矢量基本体控制策略,允许动态调整基本体的数量,从而增强了图形细节的呈现。大量实验验证了所提出方法的有效性,在可编辑性、视觉质量和多样性方面均优于基准方法。我们还表明,我们的新方法支持多达六种不同的矢量风格,能够生成适合风格化矢量和海报设计的高质量矢量资产。代码和演示将在http://ximinng.github.io/SVGDreamerV2Project/发布。
论文及项目相关链接
PDF 17 pages, 17 figures. Project Page: http://ximinng.github.io/SVGDreamerV2Project/. arXiv admin note: text overlap with arXiv:2312.16476
Summary
文本引导的可伸缩矢量图形(SVG)合成在图标和草图等领域展现出巨大潜力,但现有方法生成的SVG缺乏可编辑性,在视觉质量和多样性方面存在不足。本文提出了一种新的文本引导矢量图形合成方法,引入分层图像向量化(HIVE)框架,提高输出SVG的可编辑性。同时,采用基于粒子得分的矢量化蒸馏(VPSD)方法,提高SVG的多样性。此外,还设计了一种自适应的矢量基本形态控制策略。该方法在编辑能力、视觉质量和多样性方面均优于基准方法,支持多达六种不同的矢量风格,可生成适合风格化矢量设计和海报设计的高质量矢量资产。
Key Takeaways
- 文本引导的可伸缩矢量图形(SVG)合成在图标和草图等领域有广泛应用前景。
- 现有SVG生成方法缺乏可编辑性,视觉质量和多样性不足。
- 引入分层图像向量化(HIVE)框架,提高SVG的可编辑性,实现矢量图形的精细编辑。
- 采用基于粒子得分的矢量化蒸馏(VPSD)方法,解决现有方法的过饱和问题,提高SVG的多样性。
- 融入预训练奖励模型,改善矢量粒子的权重分配,提升美学效果和加快收敛速度。
- 设计自适应矢量基本形态控制策略,实现矢量形态的动态调整,增强图形细节表现。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决文本引导的可缩放矢量图形(SVG)生成中存在的几个关键问题:
编辑性(Editability):现有从文本到SVG的方法生成的SVG图像通常缺乏编辑性。与逐个添加独立元素的传统矢量图形创建方式不同,基于文本到图像(T2I)的方法在合成过程中无法区分不同的组件,导致生成的对象难以独立编辑或修改。
视觉质量和多样性(Visual Quality and Diversity):现有方法在生成SVG的视觉质量和多样性方面还有很大的提升空间。例如,使用得分蒸馏采样(SDS)的方法可能会导致颜色过饱和、过度平滑等问题,从而缺乏生成矢量图像中的细节。
为了解决这些问题,论文提出了一种新的文本引导的矢量图形合成方法,称为SVGDreamer++。这种方法通过引入以下几个关键技术来改进SVG的生成:
分层图像矢量化(Hierarchical Image Vectorization, HIVE)框架:通过在语义对象级别操作并监督矢量对象内组件的优化,增强输出SVG的编辑性。
基于矢量的粒子得分蒸馏(Vectorized Particle-based Score Distillation, VPSD)方法:解决现有方法中过度饱和问题,并增强样本多样性。
自适应矢量原语控制策略(Adaptive Vector Primitives Control):动态调整优化阶段的原语数量,以增强图形细节的表现。
这些技术的引入旨在提高SVG的编辑性、视觉质量和多样性,从而生成更高质量、风格多样且易于编辑的矢量图形。
Q: 有哪些相关研究?
A: 论文中提到了多个与文本引导的SVG生成相关的研究工作,具体如下:
基于优化的方法:
- CLIPDraw [1]:结合CLIP模型与DiffVG,使用CLIP作为监督源来进行矢量图形的生成。
- VectorFusion [7]:利用文本到图像扩散模型来优化矢量图形的参数。
- DiffSketcher [8]:尝试使用文本到图像扩散模型来进行矢量图形的生成。
基于神经网络的方法:
- 利用RNNs [25, 28]、VAEs [26] 和 Transformers [27, 29, 30, 31] 等网络架构学习SVG表示。
- 这些方法受限于大规模矢量数据集的可用性,通常只能合成特定类型的矢量图形,如单色图标、表情符号和字体。
扩散模型(Diffusion Models):
- 用于文本到图像合成的去噪扩散概率模型(DDPMs)[40, 41, 42, 43, 44, 45, 46]。
- 特定的文本条件扩散模型框架,如GLIDE [15]、Stable Diffusion [16]、DALL·E 2 [17]、Imagen [18] 和 DeepFloyd IF [19]。
文本到3D和文本到视频的生成:
- 利用2D预训练模型恢复3D结构的研究,例如DreamFusion [20]、Magic3D [55] 和 Fantasia3D [57]。
- 文本到视频生成的研究,如Video Diffusion Models [50, 51]。
矢量图形优化和矢量表示学习:
- 方法如NIVE [37],通过递归学习视觉概念来矢量化图像。
- 方法如LIVE [37],尝试通过优化闭合的Bézier路径来矢量化图像。
这些相关工作构成了文本引导的矢量图形合成领域的研究基础,并为本文提出的SVGDreamer++方法提供了对比和参考。论文中提出的新方法旨在通过引入新的技术来解决现有方法中存在的编辑性、视觉质量和多样性不足的问题。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为SVGDreamer++的新方法来解决文本引导的SVG生成中存在的问题,具体解决方案包括以下几个关键技术:
1. 分层图像矢量化(HIVE)框架
语义驱动的图像矢量化(SIVE):该过程包括两个阶段,即原语初始化和语义感知优化。通过使用文本提示中的交叉注意力图来初始化控制点,并将它们分配给不同的视觉对象,从而实现前景对象与背景的分离。这有助于在生成的SVG中保持对象级别的编辑性。
HIVE算法:在SIVE的基础上,HIVE算法利用图像分割先验来控制对象级和部件级的元素,以产生更精确的边界,并增强SVG的编辑性。HIVE结合了扩散模型和分割模型SAM,利用扩散模型的注意力先验来精确地控制SAM生成掩码。
2. 基于矢量的粒子得分蒸馏(VPSD)方法
- VPSD:为了提高输出SVG的多样性,论文提出了VPSD方法。与现有方法中的得分蒸馏采样(SDS)不同,VPSD将SVG建模为控制点和颜色的分布,并使用LoRA网络来估计这些分布,从而获得更多样化的SVG结果。此外,VPSD还集成了预训练的奖励模型来优化估计网络的训练过程,提高生成SVG的美观性。
3. 自适应矢量原语控制策略
- 动态调整原语数量:为了提高生成SVG的视觉质量,论文提出了一种自适应矢量原语控制策略,该策略可以在优化阶段动态调整矢量原语的数量。通过识别几何特征退化的区域,并在这些区域中增加路径,或者在路径过于简单时分裂路径,从而提高SVG合成的质量。
4. 实验验证
- 实验:通过广泛的实验,论文验证了SVGDreamer++在编辑性、视觉质量和多样性方面相较于基线方法的优越性。实验结果表明,SVGDreamer++能够支持多达六种不同的矢量风格,并能生成适用于风格化矢量设计和海报设计的高质量矢量资产。
综上所述,SVGDreamer++通过结合先进的图像矢量化技术和矢量原语控制策略,有效地提高了文本引导的SVG生成任务的编辑性和结果质量,并增强了输出的多样性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证SVGDreamer++方法的有效性,并与现有的文本到SVG方法进行了比较。以下是实验的主要内容:
数据集和评估指标
- 数据集:设计了三组提示集(Single object, Single object with surroundings, Multiple objects),以评估不同方法在处理简单对象、带有环境的对象和多个对象时的性能。
- 评估指标:使用了六个量化指标,包括FID、PSNR、CLIP分数、BLIP分数、美学分数和人类偏好分数,从视觉质量、颜色保真度、输入文本提示的对齐度和生成SVG的美学吸引力四个维度进行评估。
实验结果
1. 定性结果
- 通过图8展示了SVGDreamer++与现有方法(CLIPDraw、Evolution、DiffSketcher、VectorFusion)的定性比较,展示了SVGDreamer++在生成与文本提示匹配的SVG方面的优势。
2. 定量结果
- 表1提供了SVGDreamer++与其他基线方法在六个量化指标上的比较结果,显示SVGDreamer++在所有评估指标上均优于其他方法。
3. 编辑性
- 通过图9展示了SVGDreamer++生成的SVG在对象级别和局部级别的编辑能力,说明了SVGDreamer++生成的SVG可以有效地重用和组合。
4. 消融研究
- 对比了HIVE与SIVE和LIVE在图像矢量化过程中的效果(图10和图11),展示了HIVE在精确控制矢量路径和动态调整路径数量方面的优势。
- 展示了自适应矢量原语控制算法的行为(图12),说明了该算法在优化矢量化质量方面的有效性。
- 分析了VPSD与LSDS和ASDS的效果(表2),以及奖励反馈学习(ReFL)对VPSD的影响(图14),说明了VPSD在提高SVG多样性和美学质量方面的优势。
- 展示了不同数量的矢量粒子对生成结果的影响(图13),以及SVGDreamer++生成不同风格SVG的能力(图15)。
5. SVGDreamer++的实际应用
- 海报设计:通过图16比较了SVGDreamer++与现有基于T2I模型的海报合成方法,展示了SVGDreamer++在文本控制和编辑灵活性方面的优势。
- 创意矢量资产:通过图17展示了SVGDreamer++在生成不同风格矢量资产方面的应用,说明了SVGDreamer++生成的矢量图形在设计行业的潜在应用价值。
这些实验全面地验证了SVGDreamer++在文本引导的SVG生成任务中的性能,并展示了其在实际设计应用中的潜力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
提高编辑性:
- 虽然SVGDreamer++在编辑性方面取得了进展,但其编辑性仍然受限于所使用的文本到图像(T2I)模型。未来的研究可以探索如何进一步提升模型在对象级别和局部级别的编辑能力。
自动确定控制点数量:
- 在SIVE对象级别自动确定控制点的最优数量是一个有价值的研究方向。这可以使得模型在不同的输入图像和风格要求下更加灵活和适应性强。
优化算法效率和性能:
- 探索新的优化算法或改进现有算法,以减少SVGDreamer++在生成SVG时所需的迭代次数和计算资源。
扩展矢量风格和表示:
- 研究如何扩展和精确控制更多的矢量风格,以满足不同设计需求,例如增加更多种类的矢量艺术风格。
提高模型泛化能力:
- 探索如何提高模型对于更长、更复杂的文本提示的理解和生成能力,以及对于更多样化场景的泛化能力。
结合条件生成对抗网络(CGANs):
- 研究如何将条件生成对抗网络与SVGDreamer++结合,以进一步提高生成图像的质量和多样性。
多模态输入和输出:
- 探索模型如何处理和生成多模态输出,例如结合文本、图像和声音等多种输入,生成更为丰富的矢量图形。
交互式设计工具集成:
- 开发基于SVGDreamer++的交互式设计工具,允许用户实时编辑和调整生成的矢量图形,以提升用户体验和创意表达。
大规模数据集构建:
- 构建大规模、高质量的矢量图形数据集,以支持更深入的模型训练和评估。
实际应用中的性能测试:
- 在实际的设计工作流程中测试SVGDreamer++的性能,包括与现有设计软件的集成和用户反馈收集。
这些探索方向不仅可以推动文本到SVG生成技术的发展,还可能为设计自动化和创意产业带来新的机遇。
Q: 总结一下论文的主要内容
A: 论文提出了一个名为SVGDreamer++的新方法,用于文本引导的可缩放矢量图形(SVG)生成。该方法旨在解决现有技术中存在的编辑性差、视觉质量不足和结果多样性有限的问题。以下是论文的主要内容总结:
问题陈述:
- 现有文本到SVG的方法生成的SVG图像缺乏编辑性,视觉质量和多样性有待提高。
SVGDreamer++方法:
- HIVE(分层图像矢量化)框架:通过在语义对象级别操作并监督矢量对象内组件的优化,增强输出SVG的编辑性。
- VPSD(矢量化粒子基于得分的蒸馏)方法:提高输出SVG的多样性,解决过饱和问题,并增强样本多样性。
- 自适应矢量原语控制策略:动态调整优化阶段的矢量原语数量,以增强图形细节的表现。
实验验证:
- 通过定量和定性实验,验证了SVGDreamer++在编辑性、视觉质量和多样性方面相较于基线方法的优越性。
- SVGDreamer++能够支持多达六种不同的矢量风格,并生成适用于风格化矢量设计和海报设计的高质量矢量资产。
应用案例:
- 展示了SVGDreamer++在海报设计和生成创意矢量资产方面的应用,突出了其在实际设计任务中的潜力。
结论与讨论:
- SVGDreamer++通过引入先进的图像矢量化技术和矢量原语控制策略,有效地提高了文本引导的SVG生成任务的编辑性和结果质量,并增强了输出的多样性。
论文的贡献在于提出了一种创新的方法来生成高质量、高编辑性和多样化的SVG图像,这在设计领域具有重要的应用价值。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



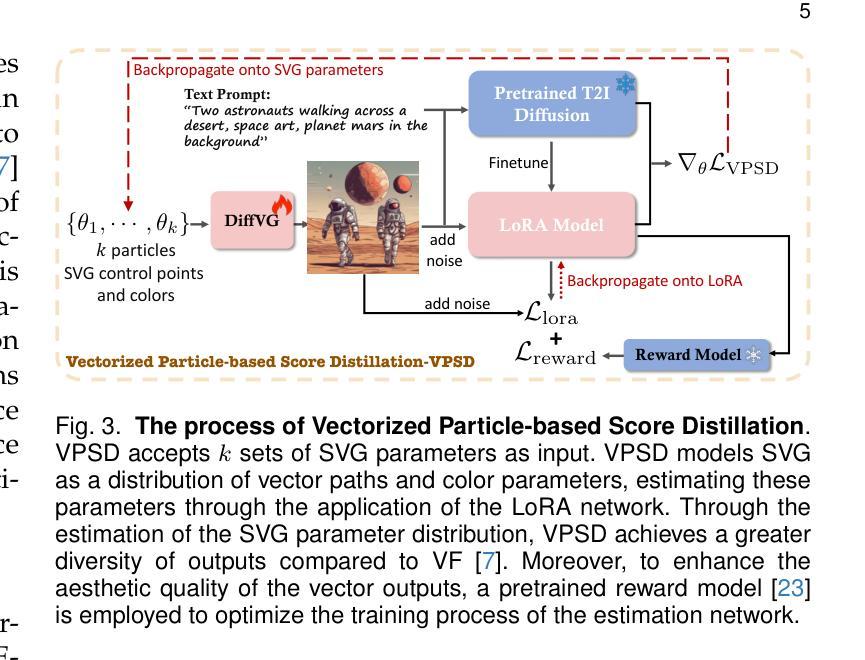
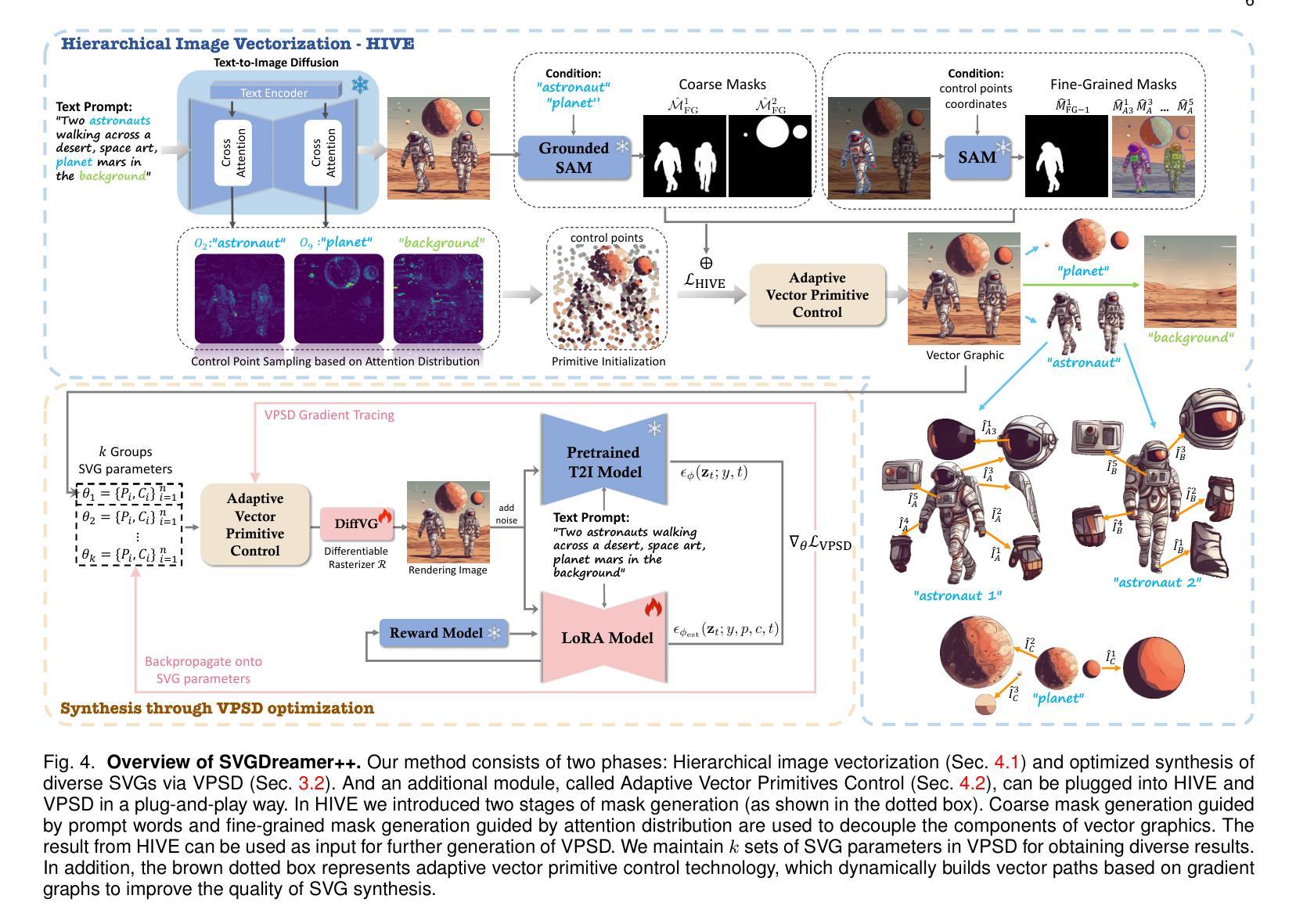
CAS-GAN for Contrast-free Angiography Synthesis
Authors:De-Xing Huang, Xiao-Hu Zhou, Mei-Jiang Gui, Xiao-Liang Xie, Shi-Qi Liu, Shuang-Yi Wang, Hao Li, Tian-Yu Xiang, Zeng-Guang Hou
Iodinated contrast agents are widely utilized in numerous interventional procedures, yet posing substantial health risks to patients. This paper presents CAS-GAN, a novel GAN framework that serves as a “virtual contrast agent” to synthesize X-ray angiographies via disentanglement representation learning and vessel semantic guidance, thereby reducing the reliance on iodinated contrast agents during interventional procedures. Specifically, our approach disentangles X-ray angiographies into background and vessel components, leveraging medical prior knowledge. A specialized predictor then learns to map the interrelationships between these components. Additionally, a vessel semantic-guided generator and a corresponding loss function are introduced to enhance the visual fidelity of generated images. Experimental results on the XCAD dataset demonstrate the state-of-the-art performance of our CAS-GAN, achieving a FID of 5.87 and a MMD of 0.016. These promising results highlight CAS-GAN’s potential for clinical applications.
碘化造影剂在众多介入手术中得到了广泛应用,但为患者带来了较大的健康风险。本文提出了CAS-GAN,这是一种新型的GAN框架,可作为“虚拟造影剂”通过解耦表示学习和血管语义指导来合成X射线血管造影术,从而减少介入手术中对碘化造影剂的依赖。具体来说,我们的方法将X射线血管造影术分解为背景和血管成分,并利用医学先验知识。然后,一个专门的预测器学习这些成分之间的相互关系。此外,还引入了血管语义引导生成器和相应的损失函数,以提高生成图像的可视保真度。在XCAD数据集上的实验结果表明,我们的CAS-GAN达到了最先进的性能,FID为5.87,MMD为0.016。这些令人鼓舞的结果突出了CAS-GAN在临床应用中的潜力。
论文及项目相关链接
PDF IEEE Symposium Series on Computational Intelligence (SSCI 2025)
摘要
这篇论文提出了一种新型的GAN框架,名为CAS-GAN,可作为“虚拟对比剂”合成X光血管造影术,通过解耦表示学习和血管语义指导,减少介入过程中对碘对比剂的需求。CAS-GAN将X光血管造影术分解为背景和血管成分,利用医学先验知识,通过专门的预测器学习这些成分之间的关系。同时,引入血管语义引导生成器和相应的损失函数,以提高生成图像的可视逼真度。在XCAD数据集上的实验结果表明,CAS-GAN的性能达到领先水平,FID为5.87,MMD为0.016。这些有前景的结果突出了CAS-GAN在临床应用中的潜力。
要点
- CAS-GAN作为一种“虚拟对比剂”,旨在减少介入过程中对碘对比剂的需求。
- CAS-GAN通过解耦表示学习,将X光血管造影术分解为背景和血管成分。
- 引入医学先验知识,通过专门的预测器学习血管成分之间的关系。
- 采用血管语义引导生成器和相应的损失函数,提高生成图像的视觉逼真度。
- CAS-GAN在XCAD数据集上的实验表现出领先水平,FID和MMD指标均表现优异。
- CAS-GAN有潜力应用于临床实践,减少碘对比剂的健康风险。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。通过使用CAS-GAN,研究者们希望能够合成出无需使用碘造影剂的X射线血管造影图像,从而减少对这些可能对患者造成潜在健康风险的造影剂的依赖。
具体来说,论文中提到了以下几个关键问题:
心血管疾病(CVDs)的治疗需求:心血管疾病是全球死亡的主要原因,而图像引导的血管介入手术是治疗心血管疾病的主流方法之一。
碘造影剂的健康风险:在X射线血管造影中,为了使血管显影,需要使用碘基的造影剂。然而,这些造影剂存在副作用,包括可能危及生命的过敏反应,以及对肾脏的潜在损害,尤其是在已有肾脏疾病或糖尿病患者中。
减少造影剂使用的需求:为了满足临床需求,同时显著减少造影剂剂量甚至不使用造影剂,同时保持成像质量,这是X射线血管造影系统必须解决的关键挑战。
生成对抗网络(GANs)的应用:论文提出了利用GANs作为“虚拟造影剂”来生成逼真的X射线血管造影图像的可能性,这可能会减少对碘造影剂的依赖,并提高介入手术的安全性和效率。
图像到图像的翻译挑战:将非对比X射线图像转换为X射线血管造影图像是一个具有挑战性的问题,因为它不仅需要在两个图像域之间进行风格转换,还需要精确的一对一图像映射。
论文提出的CAS-GAN框架通过解耦X射线血管造影图像的背景和血管成分,并利用医学先验知识,使用神经网络学习这些成分之间的相互关系,从而解决了上述挑战。此外,还引入了血管语义引导生成器和相应的损失函数,以增强生成图像的视觉保真度。
Q: 有哪些相关研究?
A: 论文中提到了多个与CAS-GAN相关的研究工作,可以归纳为以下几个方面:
1. 生成对抗网络(GANs)
- GANs由Goodfellow等人在2014年引入,通过建立一个最小最大优化游戏,其中生成器G旨在模仿真实数据样本的分布,而判别器D评估它们的真伪。
- 论文中提到了一些GAN的变种,它们通过更稳定的训练目标来解决训练GANs时的挑战,比如梯度消失和模式崩溃问题。
2. 图像到图像的翻译(Image-to-image translation)
- 这项工作涉及将图像从一个域转换到另一个域,同时保持其底层结构或内容。
- Isola等人提出了一个条件GAN框架,使用对抗损失和L1重建损失在成对数据上进行训练。
- 近期的研究集中在无成对数据的翻译上,引入了循环一致性等额外约束以保持域转换期间的语义一致性。
3. 解耦表示学习(Disentanglement representation learning)
- 解耦表示学习通过将图像分解为具有物理意义的成分来提高生成图像的可控性和可解释性。
- 一些工作尝试将图像分解为内容和风格表示,以实现通过交换风格表示进行图像翻译。
4. 医学图像生成和翻译
- 论文中提到了几项与医学图像生成和翻译相关的研究,包括使用GANs从非对比X射线图像生成X射线血管造影图像的研究。
5. 相关技术方法
- 论文还提到了一些技术方法,如注意力机制(attention mechanisms)、自监督对比损失(self-supervised contrast loss)等,这些方法被用于增强不同域之间语义关系的翻译。
具体论文和方法
- CycleGAN:用于无成对图像到图像的翻译。
- UNIT、MUNIT:用于无监督的图像到图像的翻译网络。
- AttentionGAN:使用注意力引导的生成对抗网络进行无成对图像到图像的翻译。
- QS-Attn:使用查询选择注意力进行对比学习。
- StegoGAN:用于非双射图像到图像的翻译,利用隐写术。
这些相关研究为CAS-GAN提供了理论基础和技术背景,同时也展示了在医学图像翻译领域中,如何利用深度学习技术来解决实际的临床问题。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为CAS-GAN的新型生成对抗网络(GAN)框架来解决这个问题。CAS-GAN框架的核心思想是将X射线血管造影图像解耦为背景和血管成分,然后通过神经网络学习这两部分之间的相互关系,以此来生成逼真的血管造影图像。以下是该方法解决该问题的关键步骤:
解耦表示学习(Disentanglement Representation Learning):
- 使用两个专门的编码器(一个背景编码器和一个血管编码器)将X射线血管造影图像分解为背景和血管成分。
- 通过一个称为“预测器”的神经网络,从背景表示中推断出血管表示。
血管语义引导生成器(Vessel Semantic-Guided Generator):
- 为了提高生成图像中血管的真实性,引入了两个专门的生成器:一个用于注意力掩模,一个用于上下文掩模。
- 这些生成器利用预测器提供的血管表示来生成逼真的血管结构。
血管语义引导的对抗损失(Vessel Semantic-Guided Adversarial Loss):
- 为了提高GAN对真实和生成血管图像之间差异的识别能力,引入了一种新的对抗损失,专注于血管的语义差异。
- 使用预训练的U-Net网络提取原始和生成血管造影图像中的血管语义图像,然后定义基于这些语义图像的对抗损失。
训练目标(Training Objective):
- 由于两个图像域之间的映射高度不确定,因此结合了多种有效的损失函数来训练CAS-GAN,包括预测损失、对抗损失、循环一致性损失和重建损失。
- 这些损失函数的加权和构成了CAS-GAN的训练目标,以优化图像翻译过程的各个方面。
通过这些方法,CAS-GAN能够有效地从非对比X射线图像中生成逼真的X射线血管造影图像,从而减少对碘造影剂的依赖,并提高介入手术的安全性和效率。论文中的实验结果表明,CAS-GAN在XCAD数据集上实现了最先进的性能,证明了其在临床应用中的潜力。
Q: 论文做了哪些实验?
A: 论文中进行了多项实验来验证CAS-GAN模型的性能,包括与其他最先进方法的比较、消融研究以及外部验证。以下是实验的具体内容:
A. 数据集(Dataset)
- 使用了X射线血管造影冠状血管分割数据集(XCAD),该数据集包含非对比X射线图像和X射线血管造影图像。
- 数据集分为两个子集:一个用于图像翻译任务,另一个用于训练U-Net提取血管语义信息。
- 随机选择了621张非对比X射线图像和621张X射线血管造影图像作为测试集,其余作为训练集。
B. 实现细节(Implementation details)
- 采用了与CycleGAN相同的生成器和判别器架构,以进行公平比较。
- 预测器使用多层感知机(MLP)实现。
- 使用PyTorch、Python和Ubuntu环境,搭载NVIDIA GeForce RTX 4090 GPU进行实验。
- 使用Adam优化器进行1000个周期的训练,初始学习率设置为2e-4,并在700个周期后线性降低至零。
C. 评估指标(Evaluation metrics)
- 使用了Fréchet Inception Distance(FID)和Maximum Mean Discrepancy(MMD)两个指标来评估生成图像的性能。
D. 实验结果(Results)
1. 与最先进方法的比较(Comparisons with state-of-the-arts)
- 将CAS-GAN与其他几种领先的无成对图像到图像翻译方法进行了比较,包括CycleGAN、UNIT、MUNIT、CUT、AttentionGAN、QS-Attn和StegoGAN。
- 在XCAD数据集上的定量结果表明,CAS-GAN在FID和MMD两个指标上均优于其他基线方法。
2. 消融研究(Ablation studies)
- 进行了广泛的消融实验来验证CAS-GAN中几个设计的有效性,包括解耦表示学习(DRL)、血管语义引导生成器(VSGG)和血管语义引导损失(VSGL)。
- 实验结果显示,这些设计显著提高了模型的性能。
3. 外部验证(External validation)
- 为了验证模型的泛化能力,还在来自合作医院的外部数据集上进行了实验。
- 尽管所有方法在处理XCAD和外部数据集之间的显著差异时都遇到了困难,但CAS-GAN展示了相对较好的性能。
这些实验结果证明了CAS-GAN在无需对比剂的X射线血管造影合成任务中的有效性和优越性能。论文还指出,未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的能力。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些未来工作的方向,以下是一些可以进一步探索的关键点:
扩展训练数据集:通过增加数据集的大小和多样性来提高模型在外部数据集上的性能。这可能包括收集更多的X射线血管造影图像以及对应的非对比X射线图像,以提高模型的泛化能力。
纳入更先进的模型:探索使用更先进的生成模型,如StyleGAN等,以进一步提高生成图像的质量和真实感。
改进损失函数:研究和设计新的损失函数,以更好地捕捉血管造影图像的特定特征,从而提高生成图像的质量。
多模态数据融合:考虑将CAS-GAN与其他成像模态(如CT、MRI)结合,以实现多模态图像融合和翻译。
实时性能优化:优化模型的计算效率,使其能够在临床环境中实时生成高质量的血管造影图像。
临床验证:与医疗专家合作,进行临床试验以验证CAS-GAN生成的图像在实际诊断和治疗规划中的有效性和安全性。
交互式系统开发:开发交互式系统,使医生能够根据需要调整生成的血管造影图像,以更好地满足特定的临床需求。
模型解释性:提高模型的可解释性,使医生能够理解模型的决策过程,从而增加对生成图像的信任。
跨领域应用:探索CAS-GAN在其他医疗图像翻译任务中的应用,如不同模态之间的图像转换或病理图像的合成。
鲁棒性和安全性测试:对模型进行广泛的鲁棒性和安全性测试,以确保其在各种临床条件下都能稳定地工作。
这些方向不仅可以推动CAS-GAN技术的发展,还可能对医疗图像处理和计算机视觉领域产生更广泛的影响。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一种名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。CAS-GAN通过解耦表示学习和血管语义引导生成血管造影图像,以减少对碘造影剂的依赖。
以下是论文的主要内容概述:
问题背景:心血管疾病是全球主要死因之一,而X射线血管造影是诊断和治疗这些疾病的关键技术。然而,传统的X射线血管造影需要使用碘基造影剂,这些造影剂可能引起严重的副作用,包括过敏反应和肾脏损害。
CAS-GAN框架:提出了一种新颖的GAN框架,通过解耦背景和血管成分,利用医学先验知识,使用神经网络学习这两部分之间的相互关系,从而合成逼真的血管造影图像。
方法论:
- 解耦表示学习:使用专门的编码器将血管造影图像分解为背景和血管成分,并用一个神经网络(预测器)来推断血管表示。
- 血管语义引导生成器:引入两个专门的生成器来生成注意力掩模和上下文掩模,以增强生成图像中血管的真实性。
- 血管语义引导的对抗损失:提出了一种新的对抗损失,专注于血管的语义差异,以提高GAN对真实和生成血管图像之间差异的识别能力。
实验:
- 使用XCAD数据集进行实验,该数据集包含非对比X射线图像和X射线血管造影图像。
- 在定量和定性上与其他最先进方法进行比较,CAS-GAN在FID和MMD指标上均优于其他方法。
- 进行消融研究验证了解耦表示学习、血管语义引导生成器和血管语义引导损失的有效性。
- 在外部数据集上进行验证,展示了CAS-GAN的泛化能力。
结论与未来工作:CAS-GAN为减少介入手术中碘造影剂的使用提供了一种有前景的方法。未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的性能。
总的来说,这篇论文提出了一个创新的解决方案来应对医疗成像中的一个关键挑战,并展示了有希望的初步结果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

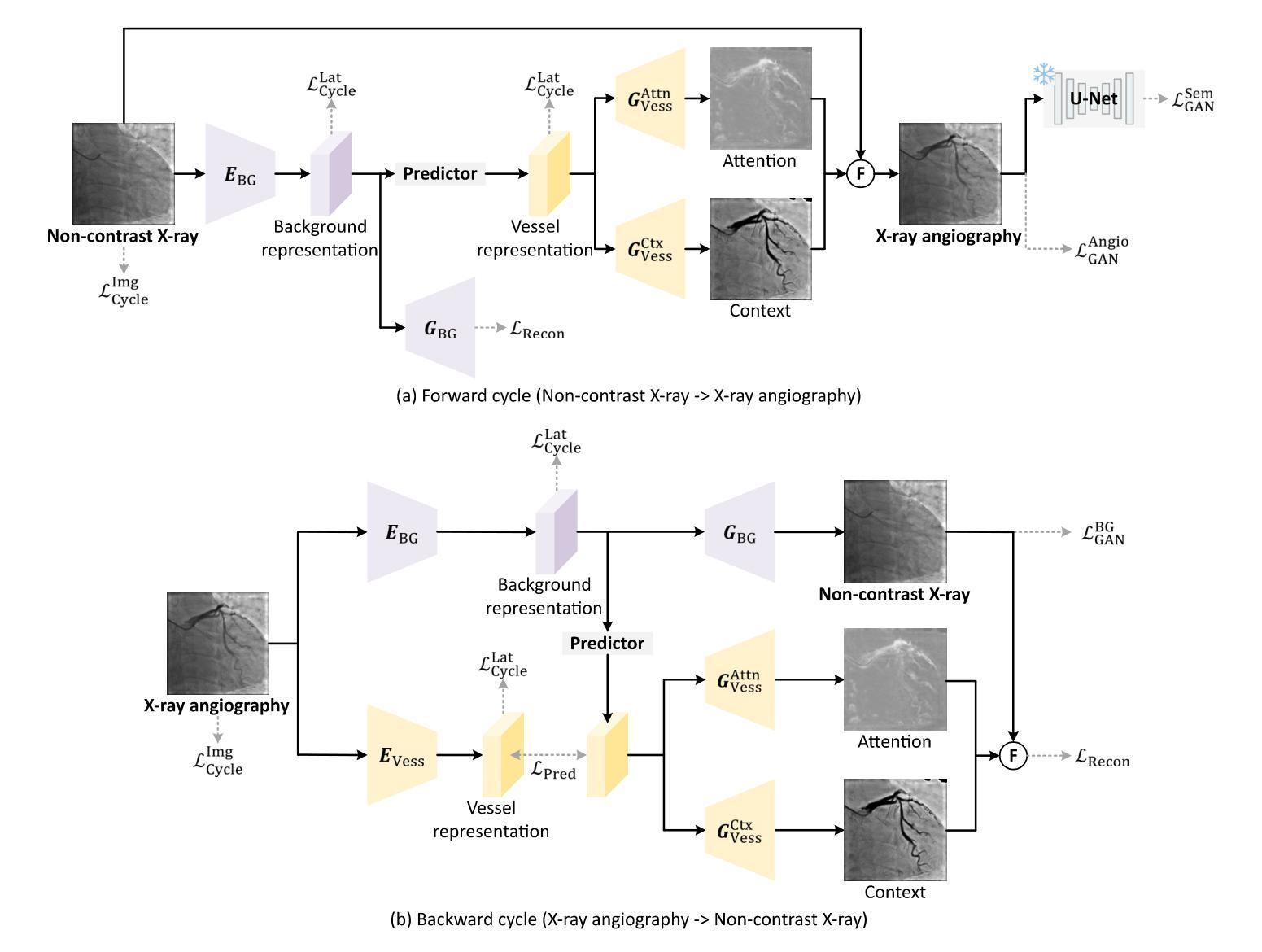
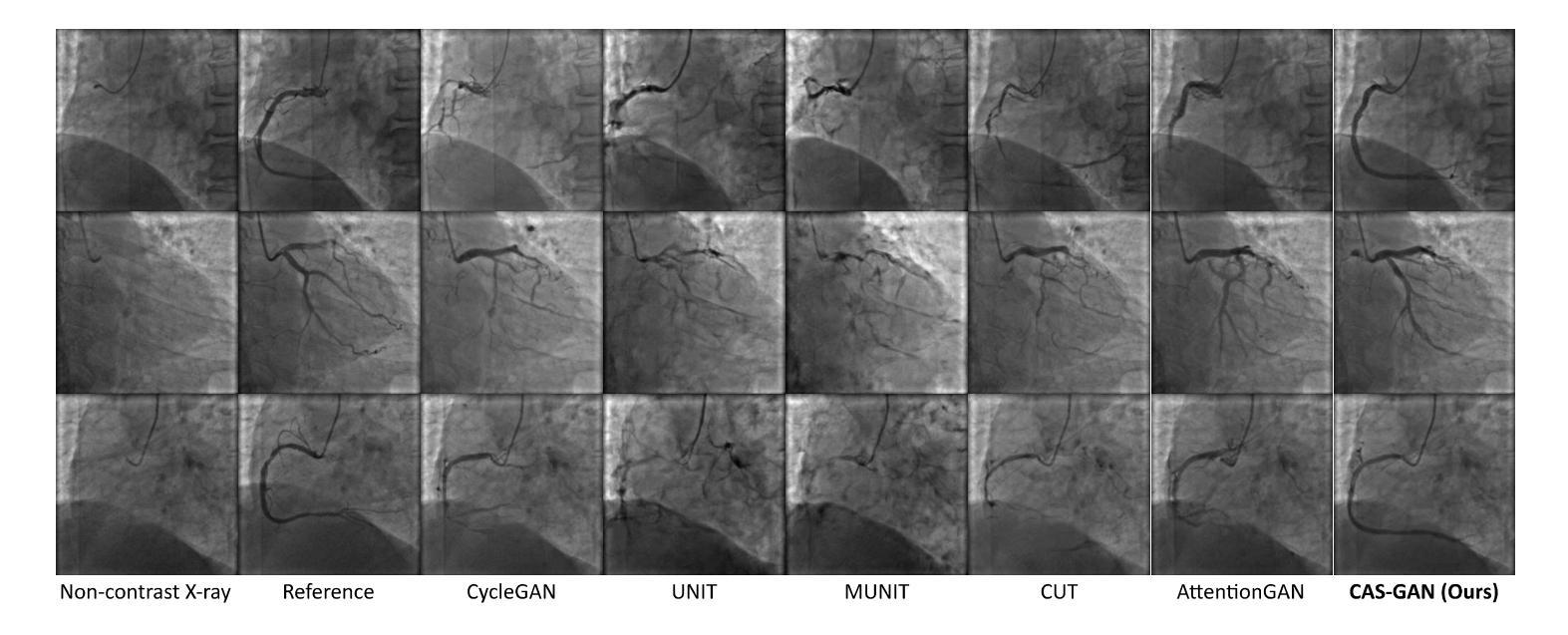
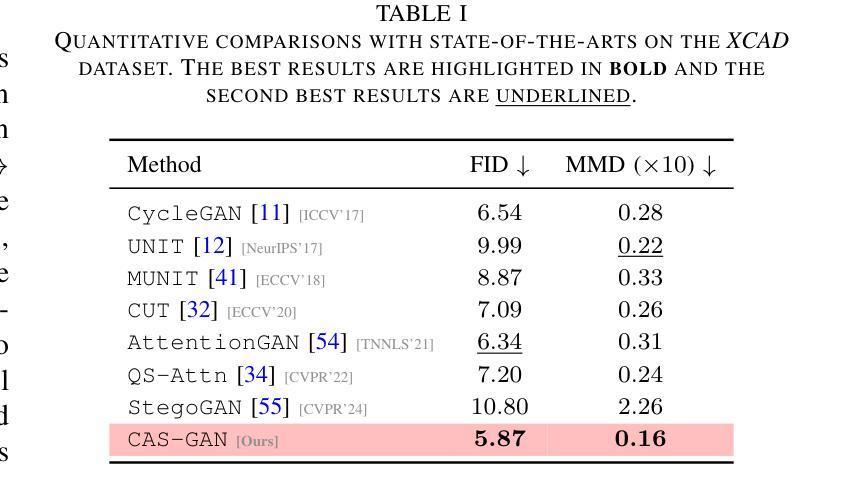
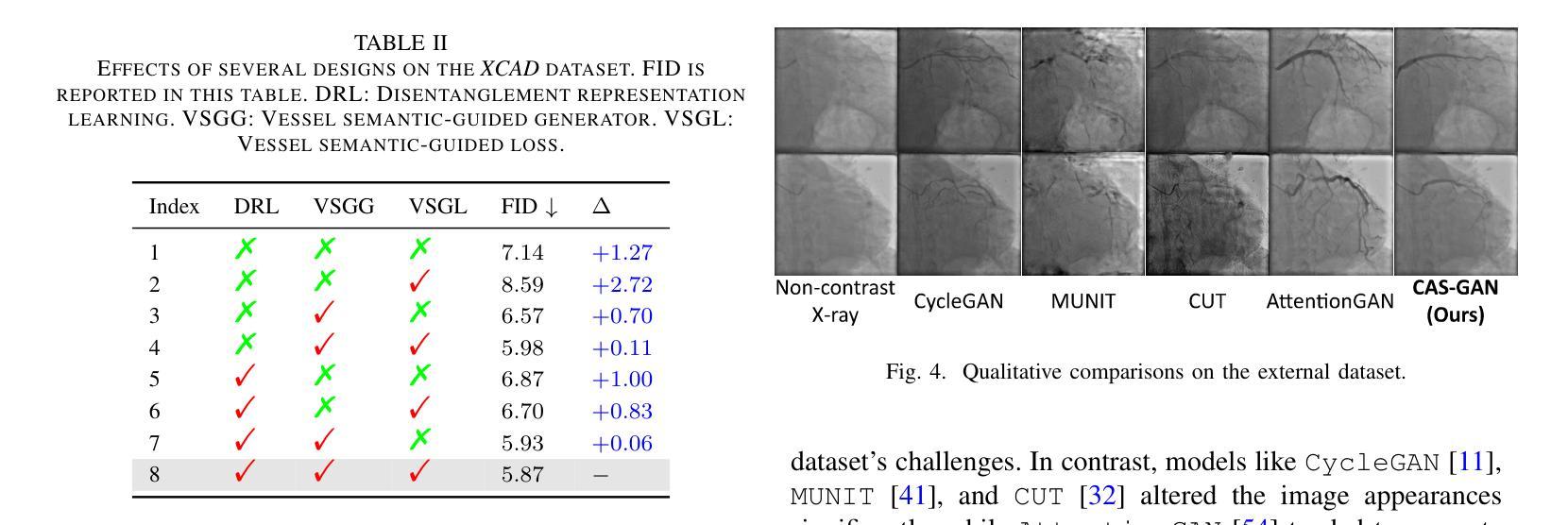
Evidence for Two-dimensional Weyl Fermions in Air-Stable Monolayer PtTe$_{1.75}$
Authors:Zhihao Cai, Haijun Cao, Haohao Sheng, Xuegao Hu, Zhenyu Sun, Qiaoxiao Zhao, Jisong Gao, Shin-ichiro Ideta, Kenya Shimada, Jiawei Huang, Peng Cheng, Lan Chen, Yugui Yao, Sheng Meng, Kehui Wu, Zhijun Wang, Baojie Feng
The Weyl semimetals represent a distinct category of topological materials wherein the low-energy excitations appear as the long-sought Weyl fermions. Exotic transport and optical properties are expected because of the chiral anomaly and linear energy-momentum dispersion. While three-dimensional Weyl semimetals have been successfully realized, the quest for their two-dimensional (2D) counterparts is ongoing. Here, we report the realization of 2D Weyl fermions in monolayer PtTe${1.75}$, which has strong spin-orbit coupling and lacks inversion symmetry, by combined angle-resolved photoemission spectroscopy, scanning tunneling microscopy, second harmonic generation, X-ray photoelectron spectroscopy measurements, and first-principles calculations. The giant Rashba splitting and band inversion lead to the emergence of three pairs of critical Weyl cones. Moreover, monolayer PtTe${1.75}$ exhibits excellent chemical stability in ambient conditions, which is critical for future device applications. The discovery of 2D Weyl fermions in monolayer PtTe$_{1.75}$ opens up new possibilities for designing and fabricating novel spintronic devices.
Weyl半金属是一类独特的拓扑材料,其中的低能激发表现为长期寻找的Weyl费米子。由于手性异常和线性能量-动量分散,预计会出现奇异的传输和光学特性。虽然三维Weyl半金属已经成功实现,但对其二维对应物的追求仍在继续。在这里,我们通过角度分辨光电子谱、扫描隧道显微镜、二次谐波产生、X射线光电子光谱测量和第一性原理计算相结合的方法,报告了在单层PtTe_{1.75}中实现二维Weyl费米子的结果,它具有强烈的自旋轨道耦合,并且没有反演对称性。巨大的Rashba分裂和能带反转导致三对临界Weyl锥的出现。此外,单层PtTe_{1.75}在环境条件下表现出优异的化学稳定性,这对于未来的设备应用至关重要。在单层PtTe_{1.75}中发现二维Weyl费米子为设计和制造新型自旋电子器件开辟了新的可能性。
论文及项目相关链接
Summary
单层PtTe_{1.75}中发现二维Weyl费米子,具有强自旋轨道耦合和反演对称性缺失的特性,通过多项实验和第一性原理计算证实。巨大Rashba分裂和能带反转导致三个对临界Weyl锥的出现。单层PtTe_{1.75}在环境条件下表现出优异的化学稳定性,为未来器件应用提供关键。这一发现有助于设计新型自旋电子器件。
Key Takeaways
- 单层PtTe_{1.75}是一种二维Weyl半金属,具有强自旋轨道耦合和反演对称性缺失的特性。
- 通过多项实验(如角度解析光发射光谱学、扫描隧道显微镜、二次谐波生成、X射线光电子光谱测量)和第一性原理计算,证实了二维Weyl费米子的存在。
- 巨大Rashba分裂和能带反转导致三个对临界Weyl锥的出现,这是Weyl半金属的重要特征。
- 单层PtTe_{1.75}在环境条件下表现出优异的化学稳定性,这对于其未来在器件应用中的使用至关重要。
- 二维Weyl费米子的发现为设计新型自旋电子器件提供了新的可能性。
- 该研究对于理解拓扑材料中的低能激发和自旋轨道耦合等物理现象有重要意义。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何实现并证实二维(2D)Weyl费米子的存在。Weyl半金属代表了一类特殊的拓扑材料,其中低能激发表现为Weyl费米子。尽管三维(3D)Weyl半金属已经被成功实现,但在二维(2D)领域寻找它们的对应物仍然是一个正在进行的研究课题。论文中提到,与三维Weyl半金属相比,二维Weyl半金属需要额外的对称性来稳定Weyl点。因此,实现2D Weyl半金属对于器件应用具有重要意义,因为它们可以提供额外的对称性要求,使得通过破坏特定对称性来驱动不同的拓扑相变,这在三维Weyl半金属中难以实现。
具体来说,论文中通过结合角分辨光电子能谱(ARPES)、扫描隧道显微镜(STM)、二次谐波生成(SHG)、X射线光电子能谱(XPS)测量和从头算计算,提供了在非中心对称的二维材料单层PtTe1.75中实现2D Weyl费米子状态的实验证据。这些实验结果不仅证实了单层PtTe1.75中存在Weyl锥,而且还表明了这种材料在各种化学环境中具有出色的稳定性,这对于未来量子器件的设计和制造具有重要意义。
Q: 有哪些相关研究?
A: 论文中提到了多个与二维Weyl费米子和拓扑材料相关的研究工作,以下是一些关键的参考文献和它们的贡献:
三维Weyl半金属的发现与性质:
- Xu, S.-Y.; Belopolski, I.; Alidoust, N.; et al. 发现了Weyl费米子半金属和拓扑费米弧。[Science 2015, 349, 613-617]
- Lv, B. Q.; Weng, H. M.; Fu, B. B.; et al. 实验发现了TaAs中的Weyl节点。[Nat. Phys 2015, 11, 724-727]
- Soluyanov, A. A.; Gresch, D.; Wang, Z.; et al. 提出了II型Weyl半金属的概念。[Nature 2015, 527, 495-498]
二维材料的研究:
- Neto, A. H. Castro; Guinea, F.; Peres, N. M. R.; et al. 综述了石墨烯的电子性质。[Rev. Mod. Phys. 2009, 81, 109-162]
- Manzeli, S.; Ovchinnikov, D.; Pasquier, D.; et al. 综述了二维过渡金属二硫化物。[Nat. Rev. Mater. 2017, 2, 17033]
二维Weyl半金属的理论预测:
- You, J.-Y.; Chen, C.; Zhang, Z.; et al. 提出了二维Weyl半金属和可调的量子反常霍尔效应。[Phys. Rev. B 2019, 100, 064408]
- Mella, J. D.; Torres, L. E. F. F. 研究了在非中心对称的二维拓扑半金属中自旋极化边缘态的鲁棒性。[Phys. Rev. B 2022, 105, 075403]
实验上诱导的二维Weyl费米子态:
- Lu, Q.; Reddy, P. V. S.; Jeon, H.; et al. 在外延铋烯中观察到2D Weyl费米子态。[arXiv:2303.02971]
- Guo, B.; Miao, W.; Huang, V.; et al. 在镉砷化物中通过塞曼场诱导的二维Weyl半金属相。[Phys. Rev. Lett. 2023, 131, 046601]
这些研究为理解Weyl费米子在三维和二维系统中的行为提供了理论基础和实验证据,并且为本文中关于单层PtTe1.75的研究提供了背景和对比。这些相关工作展示了Weyl半金属领域内的研究进展,以及如何通过不同的材料和实验手段探索和利用Weyl费米子的独特性质。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决实现并证实二维Weyl费米子存在的问题:
材料选择与设计:
- 选择了单层PtTe1.75作为研究对象,这是一个具有强自旋轨道耦合(SOC)且缺乏反演对称性的非中心对称二维材料。
实验表征:
- 角分辨光电子能谱(ARPES):用于直接观察PtTe1.75的能带结构和Weyl锥的线性色散。
- 扫描隧道显微镜(STM):用于观察PtTe1.75的表面结构。
- 二次谐波生成(SHG):用于证实材料的非中心对称性,这是Weyl费米子存在的关键条件。
- X射线光电子能谱(XPS):用于分析PtTe1.75的化学稳定性。
理论计算与模拟:
- 利用第一性原理计算,包括密度泛函理论(DFT),来计算PtTe1.75的能带结构、自旋纹理和Berry曲率,以预测和解释实验观察到的现象。
- 计算了PtTe1.75在Pt(111)基底上的结构优化和能带结构,以考虑基底对Weyl费米子状态的影响。
样品制备:
- 通过在Pt(111)基底上沉积Te原子并进行退火处理来合成PtTe1.75,以形成所需的二维结构。
化学稳定性测试:
- 将PtTe1.75暴露在空气和酒精丙酮混合物中,然后通过LEED和XPS测量其化学稳定性,结果显示PtTe1.75具有出色的稳定性。
结果分析与讨论:
- 分析ARPES测量结果,确认了Weyl节点的存在,并展示了Weyl锥的线性色散。
- 讨论了PtTe1.75的稳定性对于实际器件应用的重要性,并提出了从Pt(111)基底上分离出自由站立的PtTe1.75的可能性。
通过这些步骤,论文不仅证实了单层PtTe1.75中存在二维Weyl费米子,而且还展示了这种材料在各种化学环境中的优异稳定性,为未来基于Weyl费米子的量子器件的设计和制造提供了一个有前景的平台。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来研究单层PtTe1.75中的二维Weyl费米子:
角分辨光电子能谱(ARPES):
- 用于直接观察PtTe1.75的能带结构和Weyl锥的线性色散。
- 在Hiroshima Synchrotron Radiation Center的Beamline BL-1进行同步辐射基ARPES测量。
- 在实验室基的ARPES系统使用SPECS PHOIBUS 150电子能量分析器和氦放电灯(He Iα光)进行测量。
扫描隧道显微镜(STM):
- 用于观察PtTe1.75的表面结构。
- 在自制STM系统下77 K和基压优于2×10^-8 Pa条件下进行。
二次谐波生成(SHG):
- 用于证实PtTe1.75的非中心对称性,这对于Weyl费米子的存在至关重要。
- 使用自制SHG系统在室温下进行,使用可调谐激光器和光谱仪进行测量。
X射线光电子能谱(XPS):
- 用于分析PtTe1.75的化学稳定性。
- 在超高真空中生长后,将样品暴露在空气和酒精丙酮混合物中,然后进行LEED和XPS测量。
样品制备:
- 通过在Pt(111)基底上蒸发Te原子并进行600 K的退火处理来合成单层PtTe1.75。
化学稳定性测试:
- 将PtTe1.75暴露在空气和酒精丙酮混合物中,然后通过LEED和XPS测量其化学稳定性。
这些实验综合提供了单层PtTe1.75中存在二维Weyl费米子的直接证据,并证实了其在各种化学环境中的稳定性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提供了单层PtTe1.75中存在二维Weyl费米子的实验证据,并展示了其优异的化学稳定性,但仍有许多可以进一步探索的点:
物理性质的深入研究:
- 对单层PtTe1.75的输运性质进行更详细的测量,例如其电子迁移率、磁阻等,以全面理解其电子行为。
- 研究其在不同条件下(如低温、高压等)的物理性质变化。
理论模型的完善:
- 通过更精确的理论模型来预测和解释实验中观察到的物理现象,如能带结构、自旋纹理等。
- 探索通过外部条件(如应变、电场、磁场)调控Weyl点和费米弧的可能性。
器件应用的探索:
- 基于单层PtTe1.75的Weyl费米子特性,设计和制造新型量子器件,如低功耗电子器件、自旋电子学器件等。
- 研究其在实际器件中的集成和应用,以及与其他二维材料的异质结构。
合成方法的优化:
- 探索更高效的合成方法来获得高质量的单层PtTe1.75,以便于实验研究和工业应用。
- 研究通过机械剥离等方法从Pt(111)基底上分离出自由站立的PtTe1.75的可行性。
稳定性和环境适应性研究:
- 在更广泛的环境条件下测试单层PtTe1.75的稳定性,包括湿度、温度变化等。
- 研究其在实际应用环境中的耐久性和可靠性。
拓扑相变和对称性破缺:
- 探索通过破坏特定对称性来驱动不同的拓扑相变,这可能揭示新的物理现象和材料状态。
- 研究在不同对称性条件下PtTe1.75的拓扑相变和边缘态行为。
与其他拓扑材料的比较研究:
- 将PtTe1.75与其他拓扑材料(如拓扑绝缘体、其他Weyl半金属等)进行比较,以揭示其独特的物理特性和潜在的应用优势。
这些进一步的探索点不仅可以加深我们对二维Weyl费米子的理解,还可能推动新型量子器件的发展和拓扑量子计算等领域的进展。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
研究背景:
- Weyl半金属是一类特殊的拓扑材料,其中的低能激发表现为Weyl费米子。虽然三维Weyl半金属已经被成功实现,但二维(2D) Weyl费米子的实现仍然是一个挑战。
研究目标:
- 实现并证实单层PtTe1.75中的二维Weyl费米子状态,并探索其在器件应用中的潜力。
实验方法:
- 结合角分辨光电子能谱(ARPES)、扫描隧道显微镜(STM)、二次谐波生成(SHG)、X射线光电子能谱(XPS)测量和第一性原理计算。
实验结果:
- 单层PtTe1.75具有强自旋轨道耦合和缺乏反演对称性,导致在第一布里渊区出现三对Weyl节点。
- ARPES测量直接观察到具有线性色散的Weyl锥,与第一性原理计算结果一致。
- 单层PtTe1.75在各种环境中(包括空气、酒精和丙酮)展现出优异的化学稳定性。
理论计算:
- 计算确认了PtTe1.75的非中心对称结构、能带结构和Berry曲率分布,预测了Weyl点的存在。
- 计算还表明,即使在Pt(111)基底上,PtTe1.75的Weyl锥也得以保持,表明基底与PtTe1.75之间的杂化不足以破坏Weyl费米子。
结论:
- 论文提供了单层PtTe1.75中存在二维Weyl费米子的实验证据,并展示了其在各种化学环境中的稳定性,为设计和制造新型量子器件提供了一个有前景的平台。
未来展望:
- 提出了进一步探索单层PtTe1.75物理性质、器件应用、合成方法优化以及环境适应性的可能性。
总的来说,这项研究不仅在实验上证实了单层PtTe1.75中二维Weyl费米子的存在,而且展示了这种材料在实际应用中的巨大潜力,特别是在未来量子器件的设计和制造方面。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Pretraining Vision-Language Model for Difference Visual Question Answering in Longitudinal Chest X-rays
Authors:Yeongjae Cho, Taehee Kim, Heejun Shin, Sungzoon Cho, Dongmyung Shin
Difference visual question answering (diff-VQA) is a challenging task that requires answering complex questions based on differences between a pair of images. This task is particularly important in reading chest X-ray images because radiologists often compare multiple images of the same patient taken at different times to track disease progression and changes in its severity in their clinical practice. However, previous works focused on designing specific network architectures for the diff-VQA task, missing opportunities to enhance the model’s performance using a pretrained vision-language model (VLM). Here, we introduce a novel VLM called PLURAL, which is pretrained on natural and longitudinal chest X-ray data for the diff-VQA task. The model is developed using a step-by-step approach, starting with being pretrained on natural images and texts, followed by being trained using longitudinal chest X-ray data. The longitudinal data consist of pairs of X-ray images, along with question-answer sets and radiologist’s reports that describe the changes in lung abnormalities and diseases over time. Our experimental results show that the PLURAL model outperforms state-of-the-art methods not only in diff-VQA for longitudinal X-rays but also in conventional VQA for a single X-ray image. Through extensive experiments, we demonstrate the effectiveness of the proposed VLM architecture and pretraining method in improving the model’s performance.
差异视觉问答(diff-VQA)是一项具有挑战性的任务,它要求根据两幅图像之间的差异来回答复杂的问题。在阅读胸部X射线图像时,这项任务尤其重要,因为放射科医生在临床实践中经常比较同一病人在不同时间拍摄的多次图像,以追踪疾病的进展及其严重性的变化。然而,以前的研究工作主要集中在为diff-VQA任务设计特定的网络架构上,错过了利用预训练的视觉语言模型(VLM)提高模型性能的机会。在这里,我们引入了一种新型的VLM模型——PLURAL模型。它被预训练在自然和纵向的胸部X射线数据上进行diff-VQA任务。模型的开发采用了一种分步的方法,首先被预训练在自然图像和文本上,然后利用纵向的胸部X射线数据进行训练。纵向数据包括X射线图像对以及与描述肺部异常和疾病随时间变化的问题答案集和放射科医生报告组成。我们的实验结果表明,PLURAL模型不仅在纵向X射线的diff-VQA任务上优于最先进的方法,而且在针对单一X射线图像的常规VQA任务上也表现优异。通过大量的实验,我们证明了所提出的VLM架构和预训练方法在提高模型性能方面的有效性。
论文及项目相关链接
Summary
本文介绍了差异视觉问答(diff-VQA)任务的重要性及其在胸部X光图像分析中的应用。针对这一任务,提出了一种新型的预训练视觉语言模型(VLM)——PLURAL模型。该模型在天然和纵向胸部X光数据上进行预训练,能够应对差异视觉问答任务。实验结果表明,PLURAL模型不仅在纵向X光的diff-VQA任务上表现优异,而且在单X光图像的常规VQA任务上也有出色的表现。
Key Takeaways
- diff-VQA任务需要回答基于两幅图像差异的问题,对于胸部X光图像的阅读尤为重要。
- 此前的研究主要关注于设计特定的网络架构来解决diff-VQA任务,忽略了使用预训练的视觉语言模型来提升模型性能的机会。
- PLURAL模型是一种新型的VLM,首次被用于diff-VQA任务,并在天然和纵向胸部X光数据上进行预训练。
- PLURAL模型的预训练过程是分步进行的,首先是在天然图像和文本上进行预训练,然后是在纵向胸部X光数据上进行训练。
- 纵向数据包括X光图像对、问题答案集和描述肺部异常和疾病随时间变化的放射科报告。
- 实验结果表明,PLURAL模型在diff-VQA任务和常规VQA任务上均表现出卓越的性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是“差异视觉问答(Difference Visual Question Answering, diff-VQA)”任务在胸部X光图像中的应用。这个任务要求基于一对图像之间的差异来回答复杂问题,这在放射科医生的临床实践中尤为重要,因为他们需要比较同一患者在不同时间拍摄的多张图像,以追踪疾病的进展和严重程度的变化。然而,以往的研究主要集中在为diff-VQA任务设计特定的网络架构,而没有充分利用预训练的视觉-语言模型(Vision-Language Model, VLM)来提升模型性能。因此,论文提出了一种新的预训练视觉-语言模型(PLURAL),旨在通过在自然图像和文本以及纵向胸部X光数据上进行预训练,来提高diff-VQA任务的性能。
Q: 有哪些相关研究?
A: 相关研究主要集中在以下几个方面:
视觉问答(Visual Question Answering, VQA):这是一项挑战性任务,涉及回答关于图像的复杂问题。随着视觉-语言模型(VLMs)的兴起,VQA在医学图像解释等领域受到了关注。
差异视觉问答(Difference Visual Question Answering, diff-VQA):这是VQA的一个变体,专注于基于两幅图像之间的差异来回答问题。例如,放射科医生在比较不同时间点的CT图像时,可能会寻找恶性结节大小的变化,这在肺癌诊断中是一个常见指标。
预训练视觉-语言模型(Pretrained Vision-Language Models):这些模型通过在大量文本和图像数据上进行预训练,然后针对特定任务进行微调,以提高模型在各种视觉和语言任务上的性能。
医学图像分析:研究如何利用深度学习和计算机视觉技术来分析医学图像,如X光、CT扫描和MRI,以辅助诊断和治疗。
纵向医学图像分析:这项研究专注于分析同一患者在不同时间点拍摄的医学图像,以追踪疾病进展和治疗效果。
放射学报告生成:研究如何自动生成描述医学图像(如X光片)的报告,这些报告通常包含对图像中发现的详细描述和总结。
医学图像的自然语言处理(NLP):研究如何将自然语言处理技术应用于医学图像的描述和分析,以提高诊断的准确性和效率。
医学图像的多模态学习:探索如何结合图像数据和相关文本信息(如放射学报告)来提高医学图像分析的性能。
这些研究为开发新的预训练视觉-语言模型(如PLURAL)提供了理论和实践基础,特别是在处理纵向胸部X光图像的diff-VQA任务时。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决差异视觉问答(diff-VQA)在胸部X光图像中的应用问题:
预训练视觉-语言模型(PLURAL):提出了一个名为PLURAL的新型视觉-语言模型,该模型在自然图像和文本以及纵向胸部X光数据上进行预训练,以增强模型在diff-VQA任务上的性能。
分阶段训练:PLURAL模型的训练过程分为三个阶段:
- 第一阶段:使用自然图像和文本进行预训练,采用基于Transformer的网络架构。
- 第二阶段:在第一阶段的基础上,添加过去图像的输入分支,利用纵向胸部X光数据进行预训练,包括X光图像对、问答对和放射科医生的报告。
- 第三阶段:使用diff-VQA数据对模型进行微调,不改变网络架构。
模型架构:在第二和第三阶段,PLURAL模型采用了基于Transformer的编码器-解码器架构,通过添加新的输入分支来处理过去的图像,同时利用时间编码来区分两个输入图像的时间点。
数据集:使用了MIMIC-CXR和MIMIC-Diff-VQA两个数据集,前者包含胸部X光图像和放射科医生的报告,后者包含纵向胸部X光图像的问答对。
实验验证:通过与现有最先进方法的比较,展示了PLURAL模型在diff-VQA任务上的性能提升。同时,通过消融实验(ablation study)来验证预训练各阶段对模型性能的影响。
应用扩展:除了在diff-VQA任务上的应用,PLURAL模型还在非差异性视觉问答(non-difference VQA)任务上进行了评估,证明了其在多种类型的问答任务中的有效性。
通过这些方法,论文展示了PLURAL模型在理解和回答基于胸部X光图像差异的问题上的有效性,这对于放射科医生在临床实践中解读纵向胸部X光图像具有重要意义。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证PLURAL模型的有效性:
差异视觉问答(diff-VQA)性能评估:
- 使用MIMIC-Diff-VQA数据集,对比PLURAL模型与现有最先进方法(如MCCFormers、IDCPCL和EKAID)的性能。
- 通过自然语言生成(NLG)指标(如BLEU、METEOR、ROUGE-L和CIDEr)来衡量模型生成答案的质量。
消融研究(Ablation Study):
- 分别移除PLURAL模型预训练过程中的各个阶段,以评估每个阶段对最终性能的贡献。
- 研究输入结构(如过去的图像、放射科报告的不同部分)对模型性能的影响。
非差异视觉问答(Non-difference VQA)性能评估:
- 在非差异性VQA任务上评估PLURAL模型,与MMQ和EKAID等现有方法进行比较。
- 对于开放性和封闭性问题,计算模型输出与真实答案之间的精确匹配准确率。
模型架构和训练细节:
- 提供了PLURAL模型在不同训练阶段的详细架构和训练参数。
- 描述了模型在预训练和微调阶段所使用的硬件配置和训练策略。
这些实验旨在全面评估PLURAL模型在处理纵向胸部X光图像的diff-VQA任务上的性能,并探究预训练方法对模型性能的影响。通过这些实验,论文展示了PLURAL模型在diff-VQA任务上的优越性能,以及其在其他类型的VQA任务上的泛化能力。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了PLURAL模型并在diff-VQA任务上取得了显著的性能提升,但仍有一些潜在的研究方向可以进一步探索:
模型泛化能力:研究PLURAL模型在其他类型的医学图像(如CT、MRI)上的表现,以及其在其他医疗领域(如病理学、眼科)的应用。
模型解释性:提高模型的可解释性,以便医生能够理解模型是如何得出答案的,这对于临床应用至关重要。
多模态数据融合:探索更复杂的多模态数据融合方法,结合图像、文本、视频等多种数据类型,以提高模型对复杂医疗场景的理解。
实时性能优化:研究如何优化模型的推理速度,使其能够在实时或近实时的环境中应用,这对于临床决策支持系统尤为重要。
模型鲁棒性:研究如何提高模型对图像质量变化(如模糊、噪声)和标注不一致性的鲁棒性。
数据增强和迁移学习:开发新的数据增强技术,以及迁移学习策略,以提高模型在有限标注数据情况下的性能。
交互式问答系统:构建交互式的问答系统,允许医生与模型进行更自然的对话,以获取更详细的信息。
模型的临床验证:在真实的临床环境中对模型进行验证,收集医生的反馈,以进一步改进模型。
隐私保护和数据安全:在处理敏感的医疗数据时,研究如何确保数据的隐私和安全。
跨文化和多语言支持:研究如何使模型支持多种语言和文化背景,以满足全球不同地区的需求。
这些研究方向不仅有助于进一步提升PLURAL模型的性能和应用范围,还可能推动整个医疗图像分析领域的技术进步。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一个名为PLURAL的预训练视觉-语言模型,旨在解决基于胸部X光图像的差异视觉问答(diff-VQA)任务。以下是论文的主要内容总结:
问题背景:放射科医生在临床实践中需要比较同一患者在不同时间拍摄的胸部X光图像,以追踪疾病进展。然而,现有的diff-VQA研究主要集中在设计特定网络架构,而未充分利用预训练视觉-语言模型。
PLURAL模型:提出了一个基于Transformer的PLURAL模型,该模型首先在自然图像和文本上进行预训练,然后在纵向胸部X光数据上进一步预训练,最后使用diff-VQA数据进行微调。
训练过程:PLURAL模型的训练分为三个阶段,包括使用自然图像和文本的预训练、使用纵向胸部X光数据的预训练,以及使用diff-VQA数据的微调。
模型架构:PLURAL模型采用了编码器-解码器架构,通过添加新的输入分支来处理过去的图像,并利用时间编码来区分两个输入图像的时间点。
数据集:使用了MIMIC-CXR和MIMIC-Diff-VQA数据集,前者包含胸部X光图像和放射科医生的报告,后者包含纵向胸部X光图像的问答对。
实验结果:PLURAL模型在diff-VQA任务上的性能超过了现有最先进方法。通过消融实验,验证了预训练各阶段对模型性能的重要性。
应用扩展:PLURAL模型不仅在diff-VQA任务上表现优异,还在非差异性视觉问答任务上展示了其有效性。
结论:PLURAL模型通过结合预训练视觉-语言模型知识和纵向胸部X光数据中的时序信息,有效地解决了diff-VQA任务。这一新模型和训练流程有望促进diff-VQA任务在辅助放射科医生解读纵向胸部X光图像中的应用。
论文通过这些研究,展示了PLURAL模型在医学图像分析领域的潜力,特别是在辅助放射科医生解读和比较胸部X光图像方面。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图