⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-17 更新
Prompt2Perturb (P2P): Text-Guided Diffusion-Based Adversarial Attacks on Breast Ultrasound Images
Authors:Yasamin Medghalchi, Moein Heidari, Clayton Allard, Leonid Sigal, Ilker Hacihaliloglu
Deep neural networks (DNNs) offer significant promise for improving breast cancer diagnosis in medical imaging. However, these models are highly susceptible to adversarial attacks–small, imperceptible changes that can mislead classifiers–raising critical concerns about their reliability and security. Traditional attacks rely on fixed-norm perturbations, misaligning with human perception. In contrast, diffusion-based attacks require pre-trained models, demanding substantial data when these models are unavailable, limiting practical use in data-scarce scenarios. In medical imaging, however, this is often unfeasible due to the limited availability of datasets. Building on recent advancements in learnable prompts, we propose Prompt2Perturb (P2P), a novel language-guided attack method capable of generating meaningful attack examples driven by text instructions. During the prompt learning phase, our approach leverages learnable prompts within the text encoder to create subtle, yet impactful, perturbations that remain imperceptible while guiding the model towards targeted outcomes. In contrast to current prompt learning-based approaches, our P2P stands out by directly updating text embeddings, avoiding the need for retraining diffusion models. Further, we leverage the finding that optimizing only the early reverse diffusion steps boosts efficiency while ensuring that the generated adversarial examples incorporate subtle noise, thus preserving ultrasound image quality without introducing noticeable artifacts. We show that our method outperforms state-of-the-art attack techniques across three breast ultrasound datasets in FID and LPIPS. Moreover, the generated images are both more natural in appearance and more effective compared to existing adversarial attacks. Our code will be publicly available https://github.com/yasamin-med/P2P.
深度神经网络(DNNs)在医学影像学中提高乳腺癌诊断方面具有巨大潜力。然而,这些模型容易受到对抗性攻击的影响——一些微小的、难以察觉的改变可能会误导分类器,这引发了人们对这些模型的可靠性和安全性的严重关注。传统攻击依赖于固定范数的扰动,这与人类感知不一致。相比之下,基于扩散的攻击需要预先训练的模型,当这些模型不可用时需要大量数据,这在数据稀缺的情况下限制了实际应用。然而,在医学影像学中,由于数据集的有限可用性,这往往并不可行。基于最近的可学习提示的进展,我们提出了Prompt2Perturb(P2P)这一新的语言引导攻击方法,它能够根据文本指令生成有意义的攻击示例。在提示学习阶段,我们的方法利用文本编码器中的可学习提示来创建微妙而有影响力的扰动,这些扰动虽然难以察觉,但可以引导模型达到预期的结果。与当前的基于提示学习的方法相比,我们的P2P通过直接更新文本嵌入而脱颖而出,避免了需要重新训练扩散模型。此外,我们利用这样一个发现:仅优化早期的逆向扩散步骤可以提高效率,同时确保生成的对抗性示例包含微妙的噪声,从而保持超声图像的质量而不会引入明显的伪影。我们的方法在三个乳腺超声数据集上的FID和LPIPS指标上超越了最新的攻击技术。此外,生成的图像在外观上更加自然,与现有的对抗性攻击相比更加有效。我们的代码将在https://github.com/yasamin-med/P2P上公开可用。
论文及项目相关链接
Summary
本文介绍了深度神经网络在乳腺癌诊断中的潜力及其面临的挑战。文章指出传统攻击方法不适用于医学成像领域,并提出了一种基于学习提示的新型攻击方法——Prompt2Perturb(P2P)。该方法通过文本指令生成有意义攻击实例,无需重新训练扩散模型,提高了效率。此外,它通过优化早期逆向扩散步骤生成对抗样本,生成的超声图像更自然、更实用。研究代码已公开。
Key Takeaways
- 深度神经网络在乳腺癌诊断中有潜力,但面临攻击可靠性挑战。
- 传统攻击方法不适应医学成像领域。
- 引入Prompt2Perturb(P2P)方法,基于学习提示生成有意义攻击实例。
- P2P无需重新训练扩散模型,可直接更新文本嵌入。
- 优化早期逆向扩散步骤,提高生成对抗样本的效率并保持图像质量。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决深度神经网络(DNNs)在医学成像领域,特别是在乳腺癌诊断中对对抗性攻击的脆弱性问题。对抗性攻击是指通过引入微小的、难以察觉的变化来误导分类器的行为,这引起了对DNNs可靠性和安全性的严重担忧。论文中提到,尽管DNNs在医学成像领域有很大的应用前景,但它们对对抗性攻击的高敏感性使得这些模型在实际应用中存在风险。
具体来说,论文试图解决以下几个问题:
传统对抗性攻击方法的局限性:传统的基于梯度的方法(如FGSM、PGD等)虽然可以生成对抗性样本,但这些样本往往与自然图像的真实数据分布有较大偏差,导致在对抗性样本的有效性和隐蔽性之间存在权衡。
医学图像数据的稀缺性:在医学成像领域,由于数据集的有限可用性,使得基于大规模预训练模型的对抗性攻击方法在实际应用中受到限制。
现有方法与医学术语的适应性问题:现有的基于文本指导的攻击方法可能不适应临床术语,因此在医学领域中的意义有限。
为了解决这些问题,论文提出了一种名为Prompt2Perturb(P2P)的新型语言引导攻击方法,该方法能够通过文本指令生成有意义的攻击样本,同时保持对医学图像数据的适应性和临床术语的相关性。
Q: 有哪些相关研究?
A: 论文中提到了多个与对抗性攻击、医学成像以及文本引导的攻击相关的研究工作。以下是一些主要的相关研究:
对抗性攻击方法:
- FGSM (Fast Gradient Sign Method) [20]:一种基于梯度的白盒攻击方法,通过在输入图像上添加小的扰动来误导分类器。
- Carlini & Wagner (C-W) [8]:另一种白盒攻击方法,旨在生成对抗性样本,这些样本在视觉上与原始图像难以区分。
- PGD (Projected Gradient Descent) [40]:一种迭代的梯度下降方法,用于生成有效的对抗性攻击样本。
- DeepFool [42]:一种简单的方法,通过迭代地扰动输入图像来欺骗深度神经网络。
医学成像中的对抗性攻击:
- AdvDiffuser [11] 和 Diff-PGD [61]:这些方法结合了PGD方法和扩散模型,以增强生成图像的真实性。
- Instruct2Attack [37]:利用潜在扩散模型通过优化输入提示来欺骗目标模型。
扩散模型在对抗性攻击中的应用:
- 扩散模型被用于增强对抗性扰动的不可感知性、风格转换以及攻击扩散模型的净化方法。
提示学习(Prompt Learning):
- 提示学习最初是作为在自然语言处理(NLP)中利用预训练语言模型的一种方法,后来被适应于对抗性目的。
- BadCLIP [4] 和 BAPLe [21]:这些方法通过在提示学习阶段注入后门或引入可学习的噪声触发器来攻击模型。
医学成像中的深度学习模型:
- 论文提到了一些用于改进诊断结果的深度学习模型,如ResNet34、SqueezeNet1.1和DenseNet121。
其他相关研究:
- MIRST [50]:提出用于防御非定向对抗性攻击的方法。
- Adversarially Robust Feature Learning [22]:通过包含特征相关性度量来促进鲁棒特征的学习。
这些研究构成了论文提出的Prompt2Perturb (P2P)方法的理论基础和技术背景。论文通过结合这些相关技术,提出了一种新的针对医学图像的对抗性攻击方法,旨在提高攻击的隐蔽性和有效性,同时保持对医学术语的适应性。
Q: 论文如何解决这个问题?
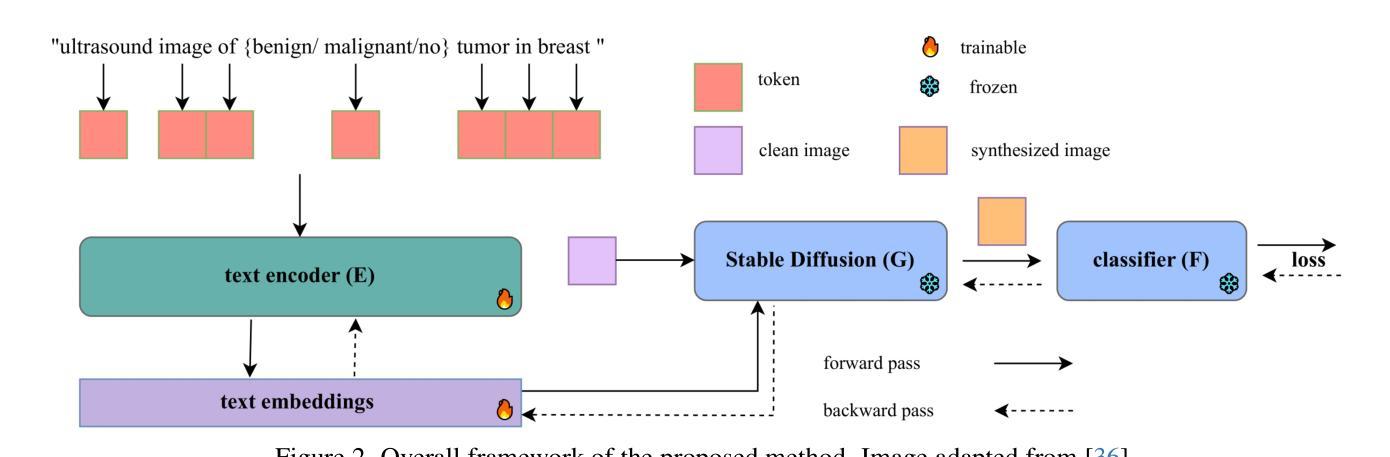
A: 论文通过提出一个名为Prompt2Perturb(P2P)的新方法来解决深度神经网络(DNNs)在医学成像领域对对抗性攻击的脆弱性问题。P2P方法的核心思想是利用文本指令引导生成对抗性样本,同时保持对医学图像数据的适应性和临床术语的相关性。以下是P2P方法解决这个问题的几个关键步骤:
利用可学习的提示(Prompts):
- P2P方法在文本编码器中使用可学习的提示来创建微小但有影响力的扰动,这些扰动在保持不可感知的同时引导模型朝向目标输出。
直接更新文本嵌入:
- 与当前基于提示学习方法不同,P2P通过直接更新文本嵌入来生成对抗性样本,避免了重新训练扩散模型的需要。
优化早期反向扩散步骤:
- 论文发现,仅优化早期的反向扩散步骤(相当于扩散过程的后期步骤)不仅提高了效率,还确保了生成的对抗性样本包含微妙的噪声,从而在不引入明显伪影的情况下保持了超声图像的质量。
针对临床术语的对抗性样本优化:
- P2P方法通过将临床术语纳入Stable Diffusion的文本嵌入中,确保生成的图像在医学背景下保持临床准确性和现实性,从而提高了攻击的有效性。
实验验证:
- 论文通过在三个不同的乳房超声数据集上与现有技术进行比较,使用FID(Fréchet Inception Distance)和LPIPS(Learned Perceptual Image Patch Similarity)等指标来验证P2P方法的有效性。实验结果表明,P2P方法在保持图像自然外观和有效性方面优于现有的对抗性攻击方法。
代码公开:
- 为了促进研究和进一步的开发,论文承诺将P2P方法的代码在GitHub上公开。
通过这些方法,P2P能够有效地对医学图像中的DNNs进行对抗性攻击,同时保持对医学术语的适应性和图像质量,解决了传统方法在医学成像领域中的局限性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和比较所提出的Prompt2Perturb(P2P)方法与其他现有技术。以下是实验的关键方面:
实验设置:
- 数据集:使用了三个公开的乳房超声数据集,包括BUSI、BUS-BRA和UDIAT。
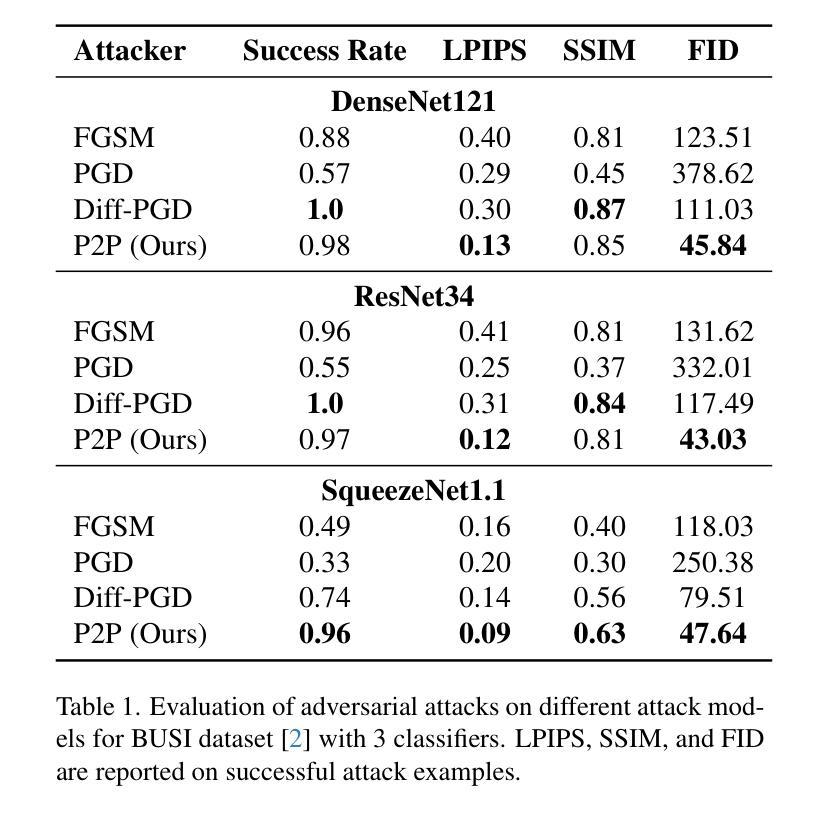
- 模型:实验涉及三种广泛认可的分类器架构,ResNet34、SqueezeNet1.1和DenseNet121。
- 评估指标:使用成功率(Success Rate)、Learned Perceptual Image Patch Similarity(LPIPS)、Structural Similarity Index Measure(SSIM)和Fréchet Inception Distance(FID)来评估对抗性样本的质量。
与现有技术的比较:
- 将P2P方法与Diffusion-Based Projected Gradient Descent(DiffPGD)攻击和传统技术如FGSM和PGD进行了比较。
定量评估:
- 在不同数据集和分类器架构上评估了P2P方法的成功率、LPIPS、SSIM和FID,以全面分析对抗性样本的有效性和感知完整性。
定性结果:
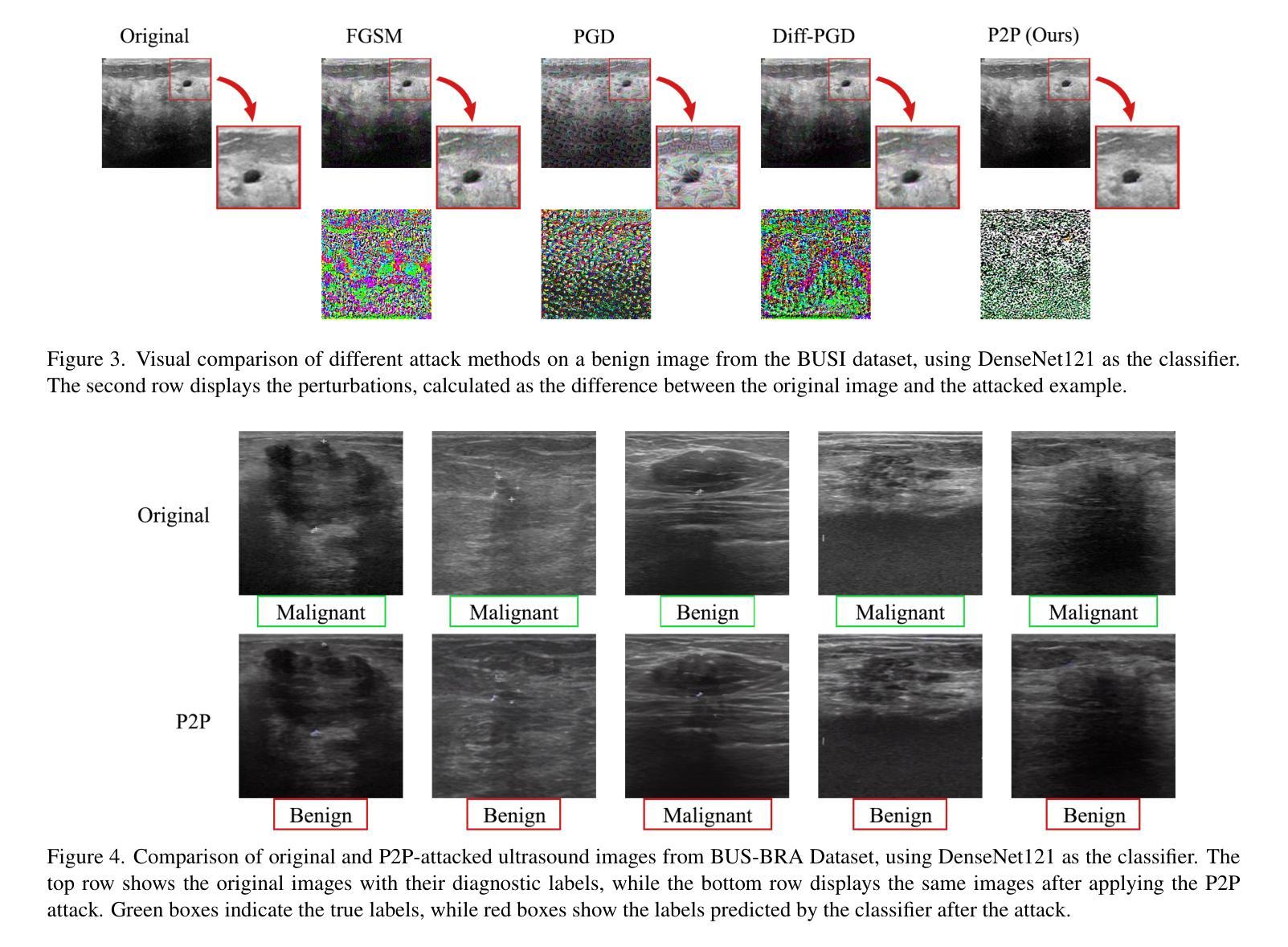
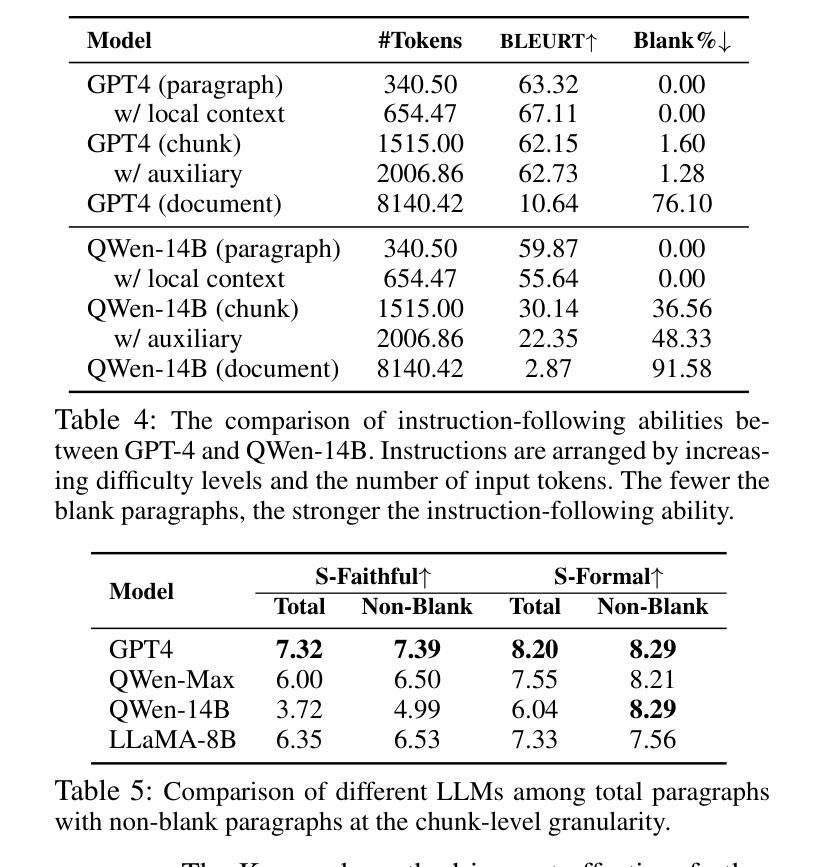
- 通过视觉比较展示了不同攻击方法生成的图像和对抗性扰动。
- 展示了P2P攻击成功改变超声图像的诊断标签,同时保持图像语义外观的最小变化。
t-SNE可视化:
- 使用t-SNE可视化比较了四种攻击方法(FGSM、PGD、DiffPGD和P2P)在集成攻击样本与干净数据集方面的效果。
案例研究:
- 分析了训练集中高置信度分类器识别的图像的攻击样本,特别关注BUSI训练集中的恶性病例及其被DiffPGD和P2P方法攻击后的版本。
消融研究:
- 对P2P方法的不同组件进行了消融研究,以评估各个设计选择对方法有效性的贡献,包括损失函数和时间步的选择。
这些实验结果不仅证明了P2P方法在生成有效对抗样本方面的优越性,还展示了其在保持图像质量和结构相似性方面的高表现,从而证实了P2P方法在医学成像领域的实用性和有效性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一种有效的对抗性攻击方法,Prompt2Perturb(P2P),但仍有一些领域可以进一步探索和研究:
防御机制:
- 研究和开发针对P2P攻击的防御机制,以增强医学成像DNNs的鲁棒性。
模型泛化能力:
- 探索P2P方法在不同类型的医学成像数据(如CT、MRI)和其他疾病领域的泛化能力。
攻击检测技术:
- 开发有效的攻击检测技术,以识别和减轻P2P方法生成的对抗性样本的影响。
模型鲁棒性和准确性的权衡:
- 研究在提高模型鲁棒性的同时保持或提高其准确性的方法。
更深层次的临床术语集成:
- 探索将更深层次的临床术语和知识集成到文本嵌入中,以进一步提高攻击样本的质量和相关性。
计算效率优化:
- 进一步优化P2P方法的计算效率,尤其是在处理大规模数据集时。
跨模态攻击:
- 研究P2P方法在跨模态攻击(例如,从超声图像攻击到MRI图像)中的有效性。
对抗性训练:
- 通过将P2P生成的对抗性样本纳入训练过程,研究对抗性训练对模型鲁棒性的影响。
模型解释性:
- 提高模型的解释性,以更好地理解对抗性样本是如何影响模型决策的。
法律和伦理考量:
- 探讨对抗性攻击在医学成像中的法律和伦理问题,特别是在临床应用中。
多模态融合:
- 研究如何将P2P方法与其他模态(如病理报告、患者历史)融合,以生成更复杂的对抗性样本。
实时攻击和防御:
- 探索在实时医学成像系统中实施P2P攻击和防御的可行性和挑战。
这些探索方向不仅可以推动对抗性攻击技术的发展,还有助于提高深度学习模型在医学成像领域的安全性和可靠性。
Q: 总结一下论文的主要内容
A: 论文提出了一种名为Prompt2Perturb(P2P)的新方法,旨在生成针对医学成像中深度神经网络(DNNs)的对抗性攻击样本,特别是在乳腺癌超声图像分析中。以下是论文的主要内容总结:
问题背景:
- 医学成像中的DNNs对对抗性攻击非常敏感,这些攻击通过微小的、难以察觉的图像变化误导分类器,引发对模型可靠性和安全性的担忧。
现有方法的局限性:
- 传统对抗性攻击方法依赖固定范数扰动,与人类感知不匹配。
- 基于扩散的攻击需要预训练模型,这在数据稀缺的医学成像领域不切实际。
P2P方法:
- P2P利用文本指令引导生成对抗性样本,通过优化文本嵌入直接更新,避免了重新训练扩散模型。
- 该方法仅优化早期反向扩散步骤以提高效率,并保持超声图像质量。
实验评估:
- 在三个乳房超声数据集上评估P2P方法,并与FGSM、PGD和DiffPGD等现有技术进行比较。
- 使用成功率、LPIPS、SSIM和FID等指标评估对抗性样本的质量。
结果:
- P2P方法在成功率上与DiffPGD相当,但在保持图像自然性和有效性方面表现更优。
- 生成的对抗性样本在外观上更自然、更有效,且在医学背景下更具临床准确性和现实性。
代码公开:
- 论文承诺将P2P方法的代码在GitHub上公开,以促进研究和进一步开发。
结论:
- P2P方法为医学成像中的DNNs提供了一种有效的对抗性攻击手段,无需特定领域的预训练模型,同时保持了对医学术语的适应性。
论文的贡献在于提出了一种新的对抗性攻击方法,该方法特别适用于数据有限的医学成像领域,并且能够生成在视觉上难以察觉且临床相关的对抗性样本。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图