⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-17 更新
A Universal Degradation-based Bridging Technique for Domain Adaptive Semantic Segmentation
Authors:Wangkai Li, Rui Sun, Tianzhu Zhang
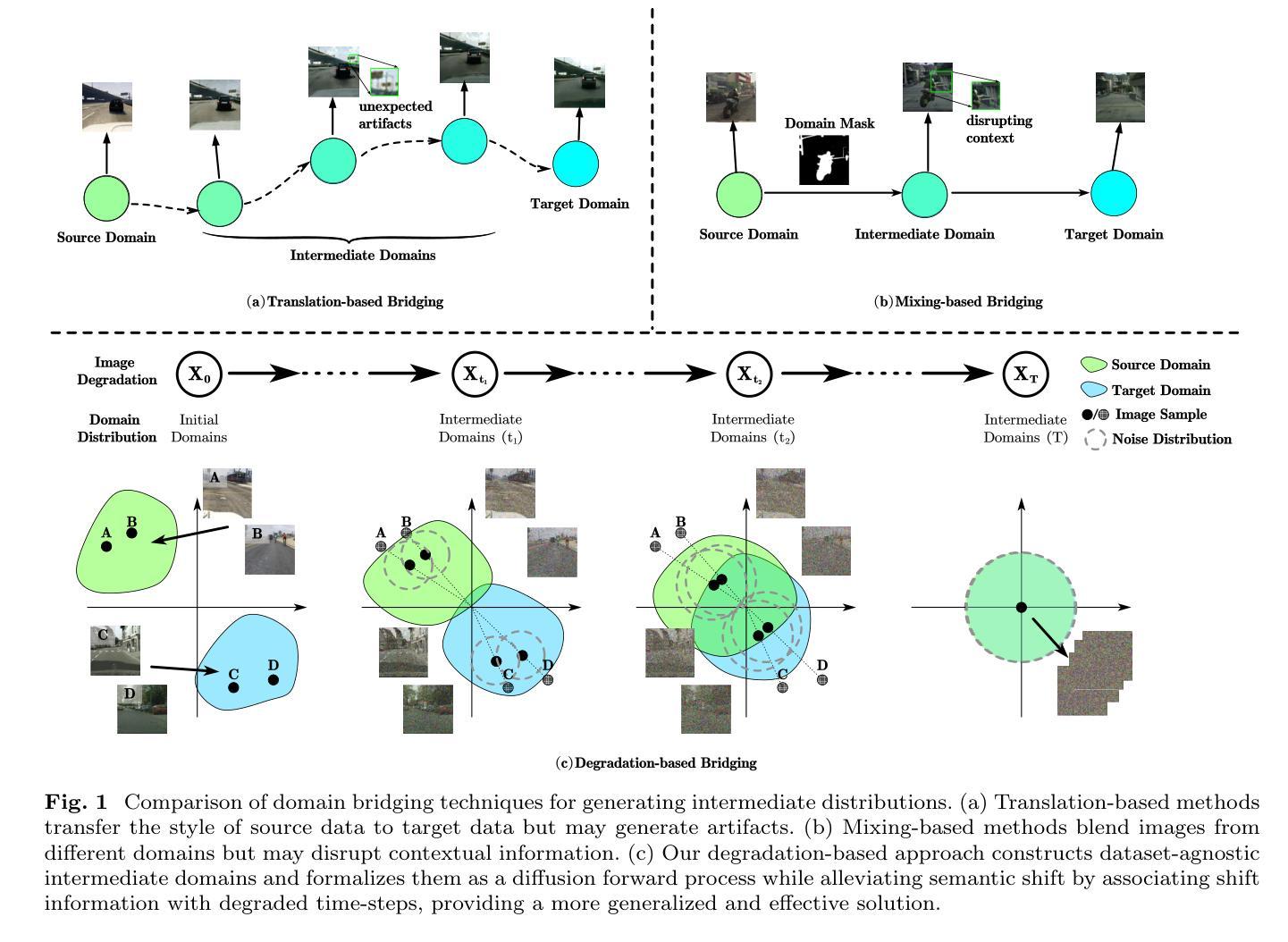
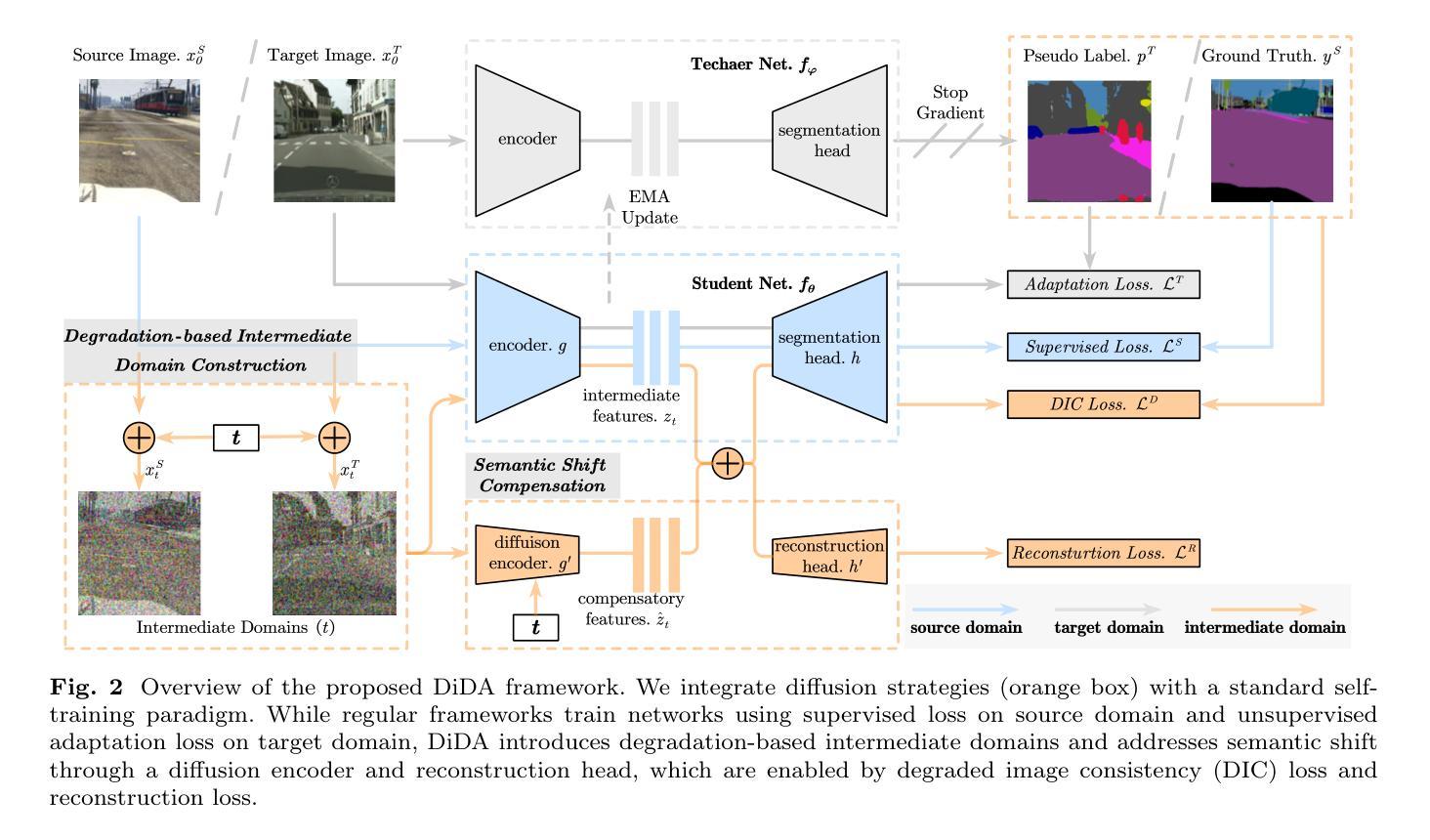
Semantic segmentation often suffers from significant performance degradation when the trained network is applied to a different domain. To address this issue, unsupervised domain adaptation (UDA) has been extensively studied. Existing methods introduce the domain bridging techniques to mitigate substantial domain gap, which construct intermediate domains to facilitate the gradual transfer of knowledge across different domains. However, these strategies often require dataset-specific designs and may generate unnatural intermediate distributions that lead to semantic shift. In this paper, we propose DiDA, a universal degradation-based bridging technique formalized as a diffusion forward process. DiDA consists of two key modules: (1) Degradation-based Intermediate Domain Construction, which creates continuous intermediate domains through simple image degradation operations to encourage learning domain-invariant features as domain differences gradually diminish; (2) Semantic Shift Compensation, which leverages a diffusion encoder to encode and compensate for semantic shift information with degraded time-steps, preserving discriminative representations in the intermediate domains. As a plug-and-play solution, DiDA supports various degradation operations and seamlessly integrates with existing UDA methods. Extensive experiments on prevalent synthetic-to-real semantic segmentation benchmarks demonstrate that DiDA consistently improves performance across different settings and achieves new state-of-the-art results when combined with existing methods.
语义分割在将训练好的网络应用于不同领域时,常常会遇到性能显著下降的问题。为了解决这一问题,无监督域自适应(UDA)已经得到了广泛的研究。现有方法引入了域桥接技术来减轻域之间的差异,构建中间域,以促成不同域之间的知识逐步迁移。然而,这些策略通常需要针对特定数据集进行设计,并可能产生不自然的中间分布,从而导致语义漂移。在本文中,我们提出了DiDA,这是一种基于退化桥接技术的通用方法,形式化为扩散前向过程。DiDA由两个关键模块组成:(1)基于退化的中间域构建,通过简单的图像退化操作创建连续的中间域,随着域差异的逐渐减小,鼓励学习域不变特征;(2)语义漂移补偿,利用扩散编码器对退化时间步的语义漂移信息进行编码和补偿,保留中间域的判别表示。作为一个即插即用的解决方案,DiDA支持各种退化操作,并能无缝集成到现有的UDA方法中。在流行的合成到真实的语义分割基准测试上的大量实验表明,DiDA在不同设置下始终提高了性能,并与现有方法相结合实现了新的最新结果。
论文及项目相关链接
Summary
本文提出了一种基于退化的无监督域自适应(UDA)方法,称为DiDA,用于解决语义分割中的跨域性能下降问题。该方法通过构建基于退化的中间域和补偿语义漂移,实现了在各种不同设置下的一致性能提升,并达到了与现有方法相结合的新水平。
Key Takeaways
- 无监督域自适应(UDA)是解决语义分割中跨域性能下降的有效方法。
- 现有UDA方法常需针对特定数据集设计,且可能产生不自然的中间分布导致语义漂移。
- DiDA方法通过基于退化的中间域构建,创建连续中间域以鼓励学习域不变特征。
- DiDA利用扩散编码器补偿语义漂移信息,在中间域中保持判别性表示。
- DiDA作为一种即插即用解决方案,支持各种退化操作,并与现有UDA方法无缝集成。
- 在主流合成到真实语义分割基准测试上,DiDA在不同设置下均实现了性能提升。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是语义分割在不同领域间迁移时遇到的显著性能下降问题。具体来说,当在源领域训练的网络应用于目标领域数据时,由于领域间的差异,网络性能往往会受到严重影响。为了缓解这一问题,论文提出了一种名为DiDA(Degradation-based bridging technique for Domain Adaptive semantic segmentation)的方法,这是一种无监督领域适应(UDA)技术,通过构建中间领域来逐步减少源域和目标域之间的分布差异,从而增强网络的跨领域适应能力。此外,DiDA还设计了一种补偿机制来解决中间领域可能导致的语义偏移问题,即由于图像分布的剧烈扰动导致图像与其对应的语义标签之间的对齐问题。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要涉及以下几个领域:
无监督领域适应(UDA):
- UDA旨在将从标记的源域学到的知识转移到未标记的目标域。这项技术在计算机视觉的多个领域,包括图像分类、目标检测和语义分割中得到了广泛的研究。
领域桥接(Domain Bridging, DB):
- 为了减少源域和目标域之间的显著差异,一些研究工作提出了通过构建中间领域来逐步转移知识的方法。这些方法在图像级别、特征级别或输出级别上构建中间领域。
对抗训练方法:
- 对抗训练方法专注于通过最小-最大对抗优化游戏学习领域不变表示,通过训练一个特征提取器来迷惑领域鉴别器,从而实现跨域特征分布的对齐。
自训练方法:
- 自训练方法因Transformer的领域鲁棒性而受到关注,这些方法基于教师-学生优化框架生成目标图像的伪标签。
生成模型在分割中的应用:
- 生成模型如GANs和VAEs旨在将数据点映射到遵循简单元素(高斯)分布的潜在代码中,从而实现数据点的生成和操作。最近,Denoising Diffusion Probabilistic Models(DDPMs)因其将传输映射问题视为马尔可夫链并将其分解为多个步骤的能力而受到关注。
扩散模型:
- 扩散模型通过考虑传输映射问题作为一个马尔可夫链,并在真实数据和潜在代码之间构建一系列中间分布,从而在语义分割中得到应用。
这些相关研究构成了DiDA方法的理论基础,并为解决领域适应中的语义分割问题提供了不同的视角和技术路径。DiDA方法通过结合这些相关技术,提出了一个新的框架来提高跨领域语义分割的性能。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为DiDA(Degradation-based bridging technique for Domain Adaptive semantic segmentation)的方法来解决领域适应中的语义分割问题。DiDA主要通过以下两个关键模块来解决性能下降和语义偏移的问题:
1. 基于退化的中间域构建(Degradation-based Intermediate Domain Construction)
这一模块的核心思想是通过简单的图像退化操作来创建连续的中间域。这些操作被形式化为一个扩散前向过程,通过逐渐添加噪声来逐步减少源域和目标域之间的分布差异。这种方法的优势在于:
- 通用性:使用简单的图像退化操作,无需特定于数据集的设计,提高了方法的灵活性和通用性。
- 灵活性:可以直接构建中间分布,不需要额外的训练成本或复杂的混合策略。
2. 语义偏移补偿(Semantic Shift Compensation)
由于中间域可能导致语义偏移,即图像分布的剧烈扰动可能导致图像与其对应的语义标签之间的对齐问题,DiDA引入了一个补偿机制:
- 扩散编码器:使用一个可训练的扩散编码器来捕获与退化时间步相关的语义偏移信息。
- 特征融合:通过残差连接在层次特征之间进行特征融合,补偿中间域中丢失的区分性表示,确保特征与语义标签之间的更好对齐。
训练和推理
DiDA的训练过程保留了自训练框架的原始操作,并引入了额外的插件式组件。在每个训练迭代中,通过固定的噪声计划和随机采样的时间步对当前训练批次的图像进行前向扩散过程。然后,这些图像被输入到网络中,通过扩散编码器和重建头进行处理,并分别通过退化图像一致性(DIC)损失和重建损失进行监督。
扩展到任意退化
DiDA还展示了其对不同退化类型的支持,包括模糊和掩码操作,这进一步证明了DiDA的通用性和可扩展性。
通过这些设计,DiDA能够有效地构建中间域,减轻语义偏移问题,并在多种UDA方法和网络架构上提高性能。实验结果表明,DiDA在两个标准的UDA语义分割基准测试中验证了其有效性,并在与现有方法结合时实现了新的最先进性能。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验来验证DiDA方法的有效性:
实现细节:
- 使用了两个广泛使用的基准数据集:GTAv和SYNTHIA作为源域,Cityscapes作为目标域。
- 报告了不同类别的交并比(IoU)以及所有类别的平均IoU(mIoU)作为性能指标。
整体定量结果:
- 在不同的UDA方法、网络架构和源域组合上,展示了DiDA与基线方法相比的性能提升。
- DiDA在与各种UDA方法和网络架构结合时,均显示出一致的性能提升。
类别级比较:
- 对每个基准数据集上的性能进行了详细的类别级比较,展示了DiDA在大多数类别上都能实现更高的准确率。
与其他插件方法的比较:
- 将DiDA与其他插件方法(如FST、DiGA和DTS)进行了比较,DiDA在相同基线方法上实现了更优越的性能。
定性结果:
- 通过定性比较展示了DiDA与DAFormer和MIC等方法相比在目标域上的性能提升。
诊断实验:
- 组件消融分析:通过移除DiDA的不同组件来分析每个部分对性能的贡献。
- 参数设置影响:研究了DIC损失权重λD、重建损失权重λR和扩散步骤T等参数设置对性能的影响。
- 时间表选择的影响:比较了不同时间表(线性、余弦、sigmoid)对性能的影响。
- 扩展版本的更多结果:展示了DiDA在扩展到模糊和掩码操作时的性能。
- DiDA的工作机制:通过设计两种推理模式(隐式去噪推理和显式去噪推理)来进一步理解DiDA的工作机制。
- 固定扩散时间的推理:评估了在不同固定扩散时间下推理的性能。
- 基于退化的领域桥接:通过t-SNE可视化和最大均值差异(MMD)度量来比较不同扩散时间下源域和目标域之间的特征分布差异。
- 重建结果的可视化:展示了在不同退化水平和不同固定扩散时间下图像重建的结果。
这些实验全面地验证了DiDA方法的有效性,并展示了其在不同设置和条件下的性能和鲁棒性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
不同的退化操作:
- 论文中提到了DiDA可以扩展到不同的图像退化操作,如模糊和掩码操作。可以探索更多类型的退化操作,例如压缩伪影、光照变化等,以增强模型的泛化能力。
优化扩散过程:
- 研究不同的扩散过程参数设置,如噪声添加策略、扩散步数等,以优化模型性能和训练效率。
损失函数和权重调整:
- 进一步研究不同的损失函数组合和权重调整策略,以提高模型在特定类别或特定情况下的性能。
网络架构的改进:
- 探索不同的网络架构,如最新的Transformer变体,以提高特征提取能力,并进一步改善跨领域适应性能。
多任务学习:
- 将DiDA应用于多任务学习框架,结合语义分割和其他视觉任务(如目标检测、实例分割等),以提高模型的多模态学习能力。
半监督学习:
- 研究如何将DiDA与半监督学习策略结合,利用少量标注数据和大量未标注数据进行训练,以提高模型在目标领域的性能。
跨领域泛化能力:
- 探索DiDA在更多源域和目标域组合上的性能,以及其在不同领域间迁移时的泛化能力。
实时性能优化:
- 研究如何优化DiDA以满足实时或近实时应用的需求,例如在自动驾驶和机器人导航等领域。
理论分析:
- 进行更深入的理论分析,以理解DiDA在减少领域差异和缓解语义偏移方面的工作原理。
鲁棒性和不确定性估计:
- 研究模型在面对源领域和目标领域数据分布变化时的鲁棒性,并探索不确定性估计在领域适应中的作用。
这些探索点可以帮助研究者更全面地理解和改进DiDA方法,并将其应用于更广泛的实际问题和应用场景中。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为DiDA(Degradation-based bridging technique for Domain Adaptive semantic segmentation)的方法,旨在解决语义分割在不同领域迁移时的性能下降问题。以下是论文的主要内容总结:
问题陈述:
- 语义分割网络在源领域训练后,直接应用于目标领域时会遭遇性能显著下降的问题,这是由于领域间差异导致的。
DiDA方法:
- 提出了DiDA,一个基于退化的中间域构建和语义偏移补偿的无监督领域适应技术。
- DiDA通过简单的图像退化操作创建连续的中间域,通过形式化的扩散前向过程逐渐减少源域和目标域之间的分布差异。
关键模块:
- Degradation-based Intermediate Domain Construction:利用图像退化操作构建中间域,鼓励网络学习领域不变特征。
- Semantic Shift Compensation:使用扩散编码器捕获和补偿语义偏移信息,保持中间域中的区分性表示。
实验验证:
- 在标准的UDA语义分割基准测试中评估DiDA,包括GTAv到Cityscapes和SYNTHIA到Cityscapes的数据集迁移任务。
- DiDA在多个基线方法和网络架构上显示出一致的性能提升,并在某些情况下达到了新的最佳性能。
扩展性:
- 展示了DiDA可以扩展到不同类型的图像退化操作,如模糊和掩码操作,证明了其通用性和灵活性。
贡献:
- 提出了一个插件式、数据集不可知的领域桥接机制,克服了以往方法依赖于特定数据集先验知识的限制。
- 将扩散策略与UDA训练流程结合起来,通过显式的时间建模有效缓解中间域中的语义偏移问题。
结论:
- DiDA通过构建中间域和补偿语义偏移,提供了一种有效且通用的领域适应方法,能够提升现有UDA方法的性能,并在多个基准测试中取得了优异的结果。
论文的主要贡献在于提出了一种新的领域适应框架,通过创新的退化操作和语义偏移补偿机制,有效地桥接了源域和目标域之间的差异,提高了语义分割模型在不同领域间的迁移能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

RemDet: Rethinking Efficient Model Design for UAV Object Detection
Authors:Chen Li, Rui Zhao, Zeyu Wang, Huiying Xu, Xinzhong Zhu
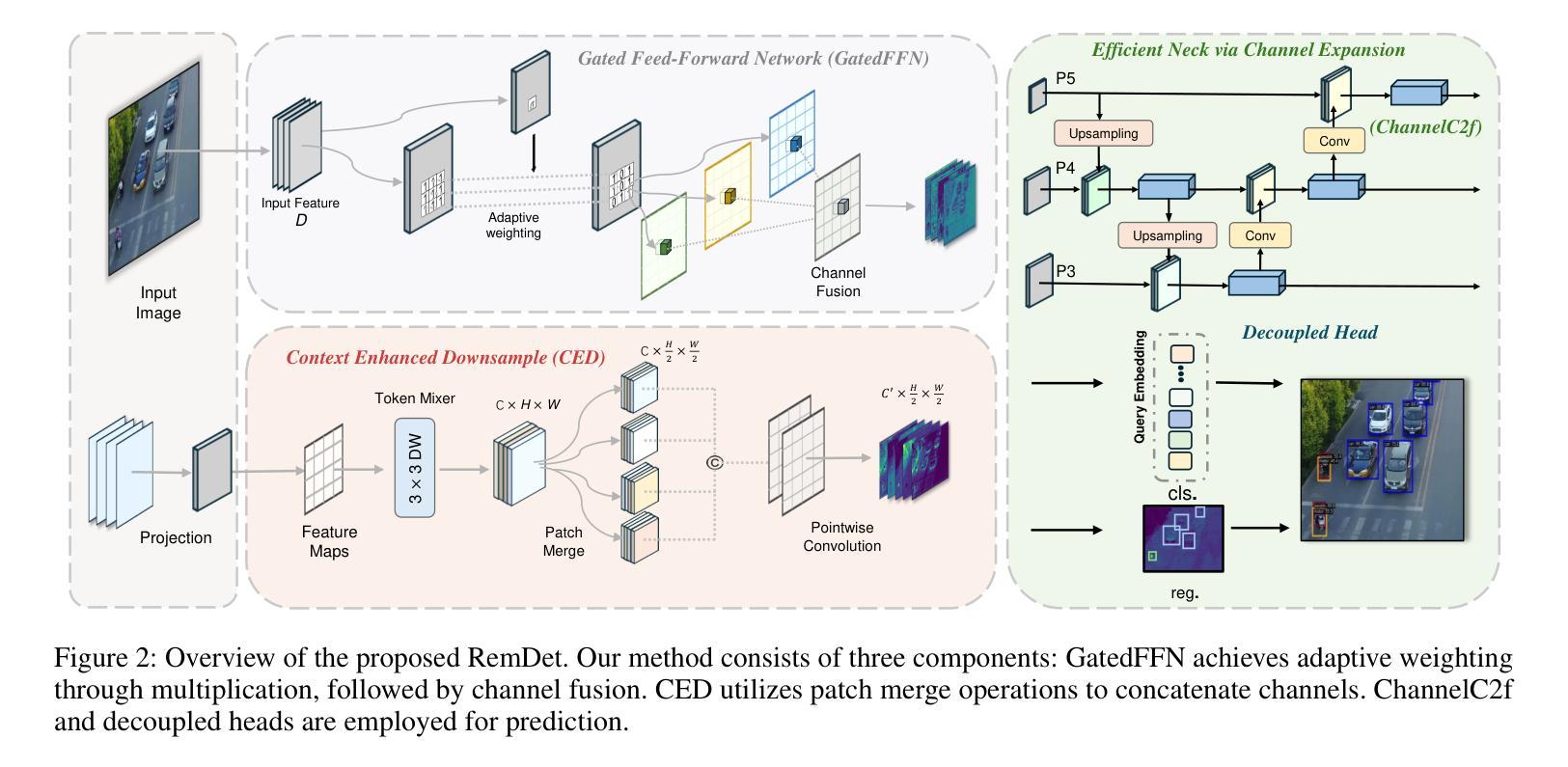
Object detection in Unmanned Aerial Vehicle (UAV) images has emerged as a focal area of research, which presents two significant challenges: i) objects are typically small and dense within vast images; ii) computational resource constraints render most models unsuitable for real-time deployment. Current real-time object detectors are not optimized for UAV images, and complex methods designed for small object detection often lack real-time capabilities. To address these challenges, we propose a novel detector, RemDet (Reparameter efficient multiplication Detector). Our contributions are as follows: 1) Rethinking the challenges of existing detectors for small and dense UAV images, and proposing information loss as a design guideline for efficient models. 2) We introduce the ChannelC2f module to enhance small object detection performance, demonstrating that high-dimensional representations can effectively mitigate information loss. 3) We design the GatedFFN module to provide not only strong performance but also low latency, effectively addressing the challenges of real-time detection. Our research reveals that GatedFFN, through the use of multiplication, is more cost-effective than feed-forward networks for high-dimensional representation. 4) We propose the CED module, which combines the advantages of ViT and CNN downsampling to effectively reduce information loss. It specifically enhances context information for small and dense objects. Extensive experiments on large UAV datasets, Visdrone and UAVDT, validate the real-time efficiency and superior performance of our methods. On the challenging UAV dataset VisDrone, our methods not only provided state-of-the-art results, improving detection by more than 3.4%, but also achieve 110 FPS on a single 4090.Codes are available at (this URL)(https://github.com/HZAI-ZJNU/RemDet).
无人机图像中的目标检测已成为研究的一个重点领域,这带来了两大挑战:一是目标在巨大的图像中通常小而密集;二是计算资源限制使得大多数模型不适合实时部署。当前的实时目标检测器并不适用于无人机图像,而针对小目标检测设计的复杂方法往往缺乏实时性能。为了应对这些挑战,我们提出了一种新型检测器RemDet(重参数化高效乘法检测器)。我们的贡献如下:1)重新思考现有检测器在小型密集无人机图像面临的挑战,并提出信息损失作为高效模型设计指南。2)我们引入了ChannelC2f模块,以提高小目标检测性能,证明高维表示可以有效地减轻信息损失。3)我们设计了GatedFFN模块,不仅提供强大的性能,而且具有低延迟,有效地解决了实时检测的挑战。我们的研究表明,通过乘法使用GatedFFN比前馈网络更经济实惠,适用于高维表示。4)我们提出了CED模块,结合了ViT和CNN下采样的优点,有效地减少了信息损失。它特别增强了小且密集目标的上下文信息。在大规模无人机数据集Visdrone和UAVDT上的广泛实验验证了我们方法的实时效率和卓越性能。在具有挑战性的VisDrone无人机数据集上,我们的方法不仅提供了最先进的检测结果,提高了超过3.4%的检测性能,而且在单个4090上实现了110FPS。代码可从(此URL)(https://github.com/HZAI-ZJNU/RemDet)获得。
论文及项目相关链接
PDF Accepted to AAAI25
Summary
在无人机图像的目标检测中,存在两个主要挑战:目标小且密集,计算资源受限。针对这些挑战,本文提出了一种新型检测器RemDet,通过引入ChannelC2f模块提升小目标检测性能,设计GatedFFN模块实现强性能与低延迟的实时检测。本文研究揭示了GatedFFN使用乘法比前馈网络更经济高效。同时,提出CED模块结合ViT和CNN下采样的优点,减少信息损失并增强上下文信息。在大型无人机数据集上的实验验证了所提方法的高效性和优越性。
Key Takeaways
- 无人机图像目标检测面临两大挑战:目标小且密集,以及计算资源受限。
- 提出了一种新型检测器RemDet,针对无人机图像的特性进行设计。
- 引入了ChannelC2f模块以提升小目标检测性能。
- 设计了GatedFFN模块以实现实时检测,兼具高性能和低延迟。
- 研究表明,GatedFFN使用乘法比传统前馈网络更经济高效。
- 提出了CED模块,结合ViT和CNN下采样的优点,减少信息损失并增强上下文信息。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决无人机(UAV)图像中的目标检测问题,尤其关注于小目标和密集目标的检测。具体来说,论文面临的挑战包括:
- 小目标和密集目标的检测难度:无人机图像中的对象通常较小且分布密集,这使得检测任务变得更加困难。
- 计算资源限制:大多数现有的目标检测模型由于计算资源的限制,不适合实时部署在无人机上。
论文指出,尽管已有一些实时目标检测器,但它们并未针对无人机图像进行优化。同时,为小目标检测设计的复杂方法往往缺乏实时处理能力。因此,论文提出了一种新的检测器RemDet(Reparameter efficient multiplication Detector),旨在通过减少信息丢失来提高小目标和密集目标检测的效率和准确性。
Q: 有哪些相关研究?
A: 论文中提到了以下几类与无人机(UAV)图像目标检测相关的研究工作:
通用目标检测技术:
- Faster R-CNN (Girshick 2015)
- YOLO (Redmon et al. 2016; Redmon and Farhadi 2017)
- DETR (Carion et al. 2020)
轻量级和高效的架构:
- 针对目标检测设计的轻量级网络,利用深度可分离卷积、重参数化和剪枝技术,在目标检测任务中表现出色。
UAV图像的目标检测:
- ClusDet (Yang et al. 2019):使用基于聚类的尺度估计方法增强小目标检测。
- UFPMP-Det (Huang, Chen, and Huang 2022):通过聚类合并粗略检测器提供的子区域来抑制背景。
- AMRNET (Wei et al. 2020):通过两个特别设计的模块显著扩展了从粗到细的框架。
- CZDet (Meethal, Granger, and Pedersoli 2023):基于密度裁剪方法,首先检测密度裁剪区域和基本类别对象,然后输入到第二阶段推理。
- YOLC (Liu et al. 2024):基于CenterNet,自适应搜索聚类区域并调整到适当尺度,改进损失函数以增强性能。
实时UAV图像检测:
- YOLO系列:YOLOv8 (Jocher, Chaurasia, and Qiu 2023) 通过简单有效的C2f和解耦头提高实时性能。
- QueryDet (Yang, Huang, and Wang 2022) 和 CEASC (Du et al. 2023):在检测头中使用稀疏卷积来减少模型权重,降低计算需求。
这些研究提供了不同的方法和技术来提高无人机图像中目标检测的性能,特别是在小目标和密集目标检测方面。论文提出的RemDet模型在这些现有工作的基础上,进一步探索了如何通过减少信息丢失来优化无人机图像目标检测的效率和准确性。
Q: 论文如何解决这个问题?
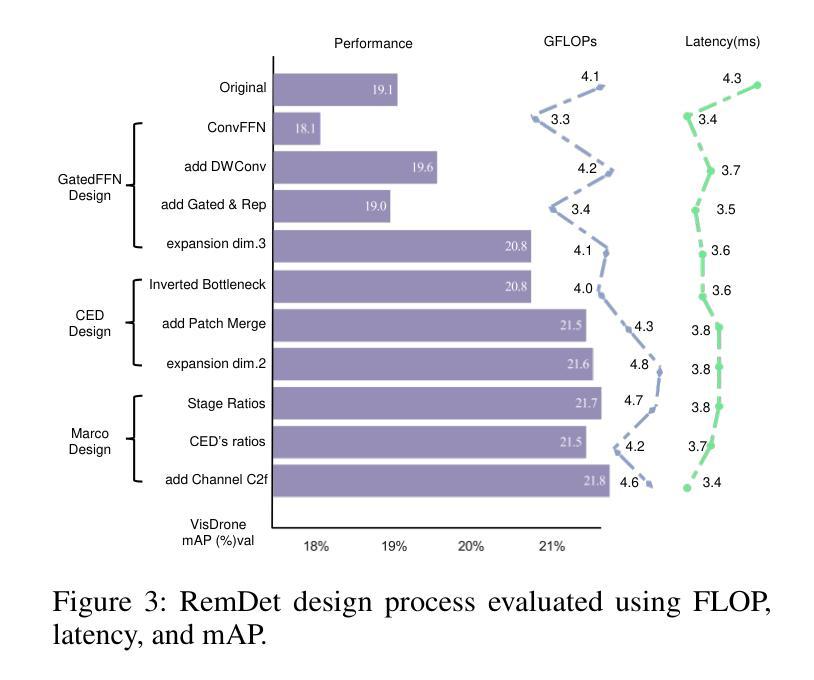
A: 论文通过提出一个名为RemDet(Reparameter efficient multiplication Detector)的新型检测器来解决无人机(UAV)图像中小目标和密集目标的检测问题。RemDet的设计重点在于减少信息丢失,同时满足实时部署的计算资源约束。具体的解决方案包括以下几个关键组件:
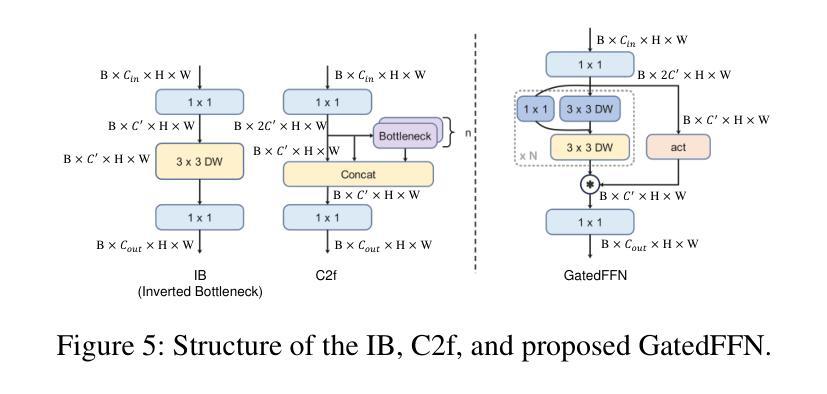
ChannelC2f模块:
- 该模块通过扩展C2f(Channel Concatenation and Fusion)结构,增加了额外的通道,以增强小目标检测性能。这种高维表示可以有效减少信息丢失。
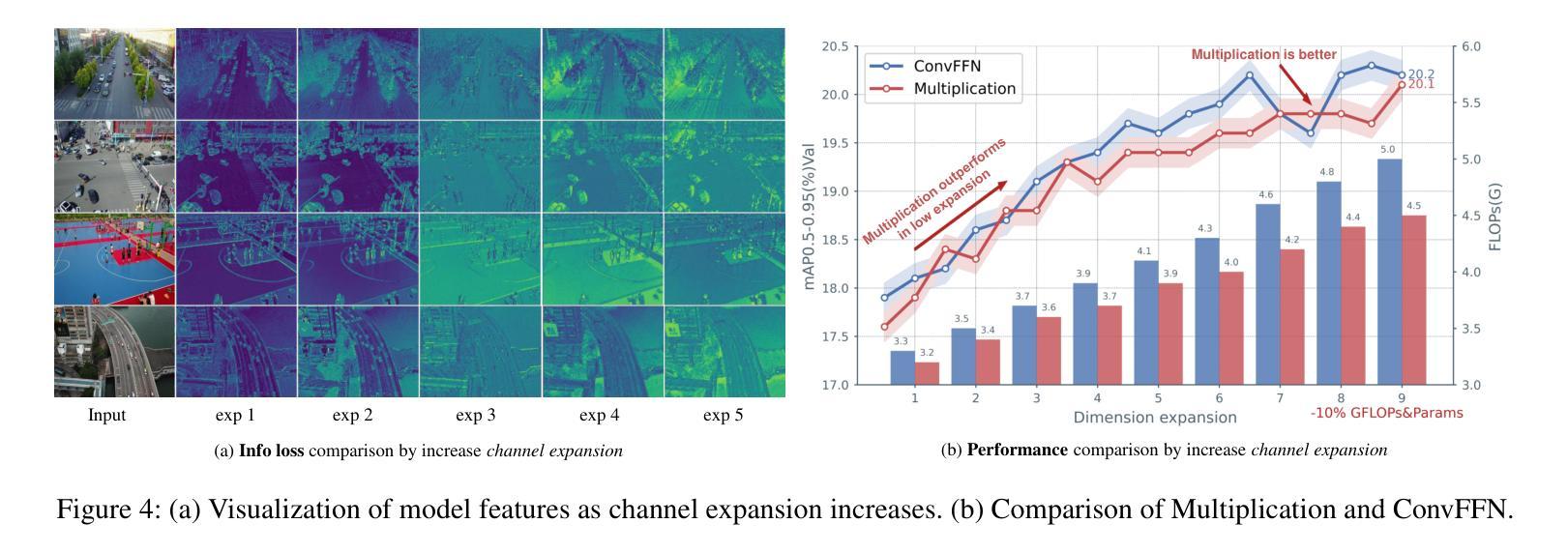
GatedFFN(Gated Feed-Forward Network)模块:
- 设计了GatedFFN模块来实现不仅性能强大而且延迟低的检测,通过使用乘法操作实现高维表示,比前馈网络更具成本效益,有效平衡性能和速度。
CED(Context Enhanced Downsample)模块:
- 结合了ViT和CNN下采样的优势,通过Patch Merge操作连接通道,减少信息丢失,特别增强了小目标和密集目标的上下文信息。
简化和优化结构:
- 论文反思了UAV检测器的设计,摒弃了复杂的手工设计,通过探索信息丢失,使用最简单的结构有效增强了小目标检测。
- 研究还表明,仅高维表示就可以减少信息丢失并增强小目标性能,通过实验结果、理论探索和可视化表示进行了验证。
实验验证:
- 在大型UAV数据集VisDrone和UAVDT上进行了广泛的实验,验证了所提方法的实时效率和优越性能。特别是,在挑战性的数据集VisDrone上,所提方法不仅提供了最先进的结果,提高了超过3.4%的检测性能,而且在一个单独的4090 GPU上实现了110 FPS的高帧率。
总的来说,RemDet通过精心设计的模块和结构优化,在不牺牲准确性的前提下,显著提高了无人机图像中小目标和密集目标的检测效率和实时性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的RemDet模型的性能和效率,具体实验包括:
数据集:
- 使用了VisDrone和UAVDT数据集进行UAV检测实验,并包括MSCOCO数据集作为额外的基准。
评估指标:
- 使用COCO风格的平均精度(AP)作为主要的性能评估指标,并报告了小、中、大目标的平均精度,以评估模型在检测小目标方面的性能。
- 使用GFLOPs(每秒浮点运算次数)和延迟(ms)来表示模型的效率。
与现有方法的比较:
- 在VisDrone数据集上,将RemDet与现有的模型进行了比较,包括YOLO系列、QueryDet、CEASC等,重点比较了模型的mAP、延迟和计算复杂度。
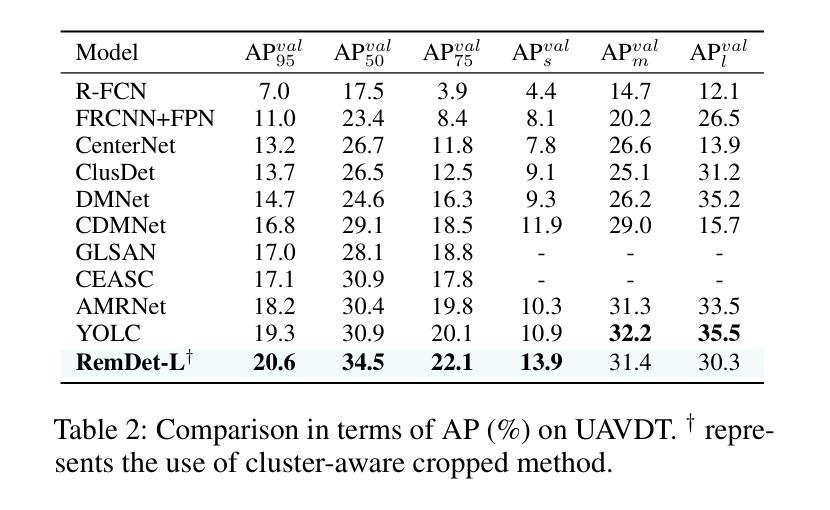
- 在UAVDT数据集上,与当前最先进的模型YOLC进行了比较,并展示了RemDet在小目标检测精度上的提升。
消融研究:
- 对RemDet的整体设计进行了消融研究,分析了不同模块(如GatedFFN、CED和ChannelC2f)对检测精度和计算复杂度的影响。
- 调整了模型中不同阶段的块比例,以找到最优的设计。
不同规模的模型比较:
- 在MSCOCO数据集上,将RemDet与不同规模的通用目标检测器进行了比较,展示了RemDet在小目标检测方面的性能提升。
实时目标检测器的比较:
- 在VisDrone数据集上,将RemDet与多个实时通用目标检测器进行了比较,评估了不同规模模型的性能和效率。
可视化结果:
- 对RetinaNet、CEASC、GFLv1和RemDet在VisDrone和UAVDT数据集上的结果进行了可视化比较,展示了RemDet在不同场景下的性能。
这些实验全面评估了RemDet在UAV图像目标检测任务中的性能,特别是在小目标和密集目标检测方面,同时也展示了其在实时性方面的优势。通过与现有技术的比较和消融研究,论文验证了所提出方法的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的RemDet模型在无人机(UAV)图像目标检测任务中取得了显著的性能提升,但仍有一些方向可以进一步探索和改进:
大目标检测性能提升:
- 论文中提到RemDet在大目标检测方面稍显不足。未来的工作可以专注于优化模型结构或引入新的技术来提升大目标的检测性能。
模型泛化能力:
- 进一步研究和改进模型的泛化能力,使其能够在更多的数据集和不同的场景下表现良好。
计算效率优化:
- 尽管RemDet已经具有较高的计算效率,但仍可以探索新的网络结构或算法来进一步减少计算资源消耗,使其更适合边缘设备。
实时视频流处理:
- 将RemDet应用于实时视频流检测任务,并优化以满足视频处理的低延迟要求。
模型压缩与加速:
- 研究模型压缩和加速技术,如网络剪枝、量化和知识蒸馏,以减少模型大小并加速推理过程。
多任务学习:
- 探索将目标检测与其他任务(如分割、识别)结合的多任务学习框架,以提高模型的实用性。
鲁棒性增强:
- 提高模型对于不同天气条件、光照变化和遮挡情况的鲁棒性。
融合不同传感器数据:
- 研究如何将来自不同传感器(如红外、多光谱)的数据融合到检测框架中,以提高检测的准确性和鲁棒性。
更深层次的特征融合:
- 探索更高级的特征融合技术,以更有效地结合不同层次的信息。
无监督和自监督学习:
- 研究无监督或自监督学习技术,以减少对大量标注数据的依赖。
模型解释性:
- 提高模型的可解释性,以便更好地理解检测决策过程。
跨域适应性:
- 研究如何使模型更好地适应不同的域,例如从仿真环境到真实世界的迁移。
这些方向不仅可以推动无人机目标检测技术的发展,还可能对计算机视觉领域的其他任务产生积极影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为RemDet(Reparameter efficient multiplication Detector)的新型无人机(UAV)图像目标检测器,旨在解决现有模型在处理UAV图像中的小目标和密集目标时存在的挑战。以下是论文的主要内容总结:
问题定义:
- 论文指出UAV图像目标检测面临两大挑战:小目标和密集目标的识别困难,以及计算资源限制导致的实时部署难题。
RemDet框架:
- 提出了RemDet,一个一阶段无锚点(anchor-free)检测器,专注于减少信息丢失,并优化小目标和密集目标的检测性能。
主要贡献:
- 重新思考UAV图像检测器的设计,提出了基于信息丢失的高效模型设计原则。
- 引入ChannelC2f模块和Context Enhanced Downsample(CED)模块,增强小目标检测性能。
- 设计了Gated Feed-Forward Network(GatedFFN)模块,通过乘法操作实现高维表示,有效平衡性能和速度。
实验验证:
- 在VisDrone和UAVDT数据集上进行了广泛的实验,验证了RemDet在实时效率和性能上的优越性。
- 与现有方法相比,RemDet在关键指标上取得了显著提升,特别是在小目标检测方面。
方法细节:
- 论文详细介绍了RemDet的各个组件,包括GatedFFN、CED和ChannelC2f的设计和实现。
- 探讨了信息瓶颈理论在模型设计中的应用,以及如何通过减少信息丢失来优化检测性能。
实验结果:
- RemDet在VisDrone数据集上取得了超过3.4%的性能提升,同时在单个4090 GPU上实现了110 FPS的高帧率。
- 在UAVDT数据集上,RemDet也显示出比现有最先进模型更好的性能。
未来工作:
- 尽管RemDet在小目标检测上表现出色,但在大目标检测方面仍有改进空间。
- 提出了未来可能的研究方向,包括模型泛化能力、计算效率优化、实时视频流处理等。
总体而言,这篇论文通过创新的模型设计和实验验证,为UAV图像目标检测领域提供了一个高效且性能强大的解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


ADA-Track++: End-to-End Multi-Camera 3D Multi-Object Tracking with Alternating Detection and Association
Authors:Shuxiao Ding, Lukas Schneider, Marius Cordts, Juergen Gall
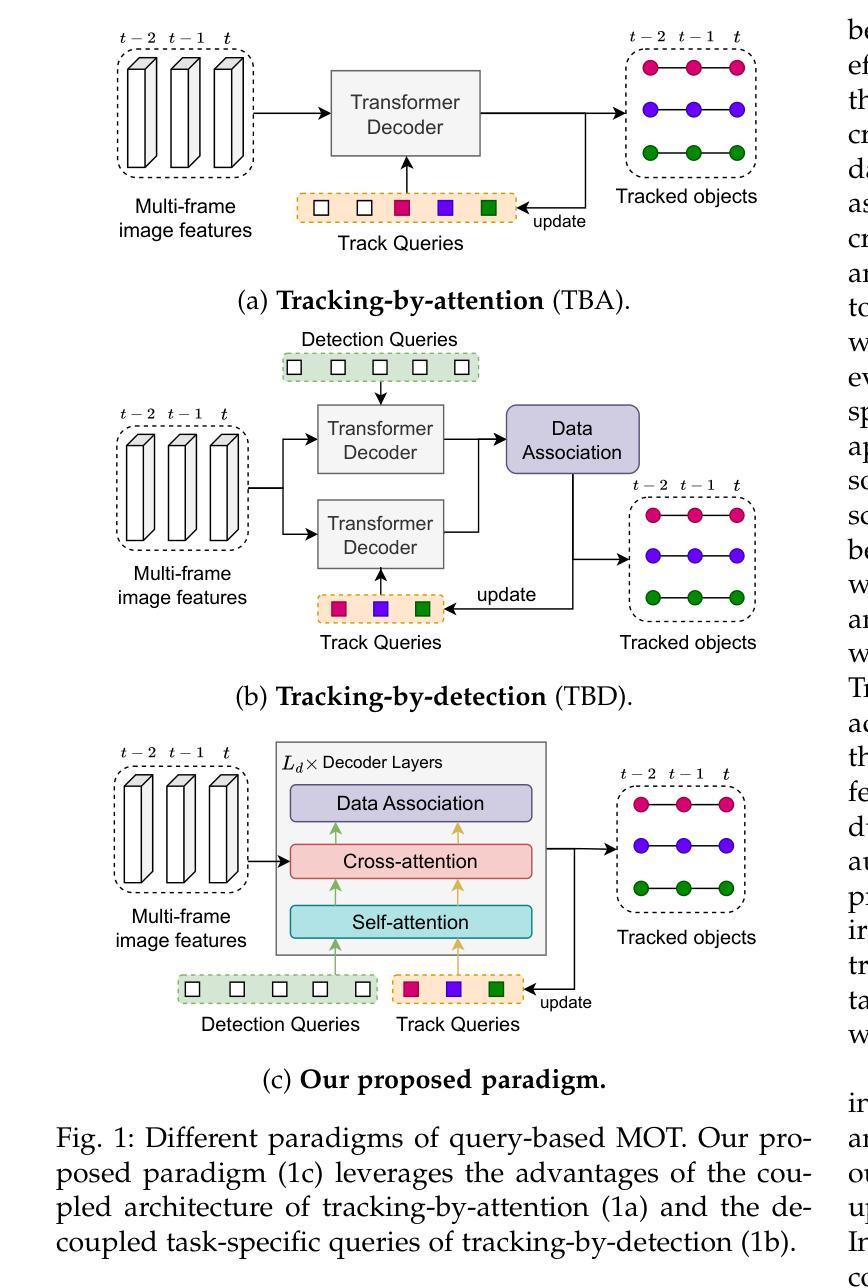
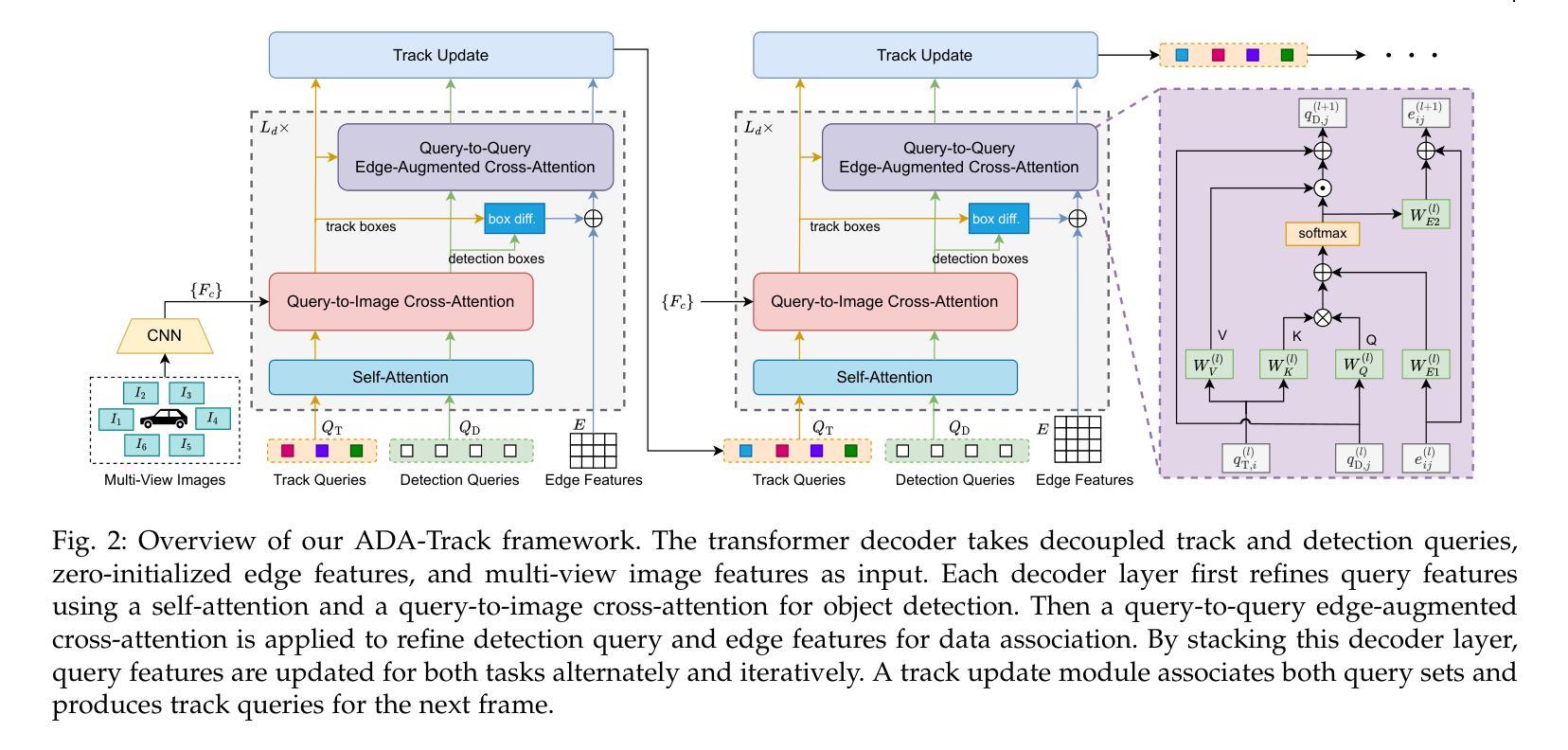
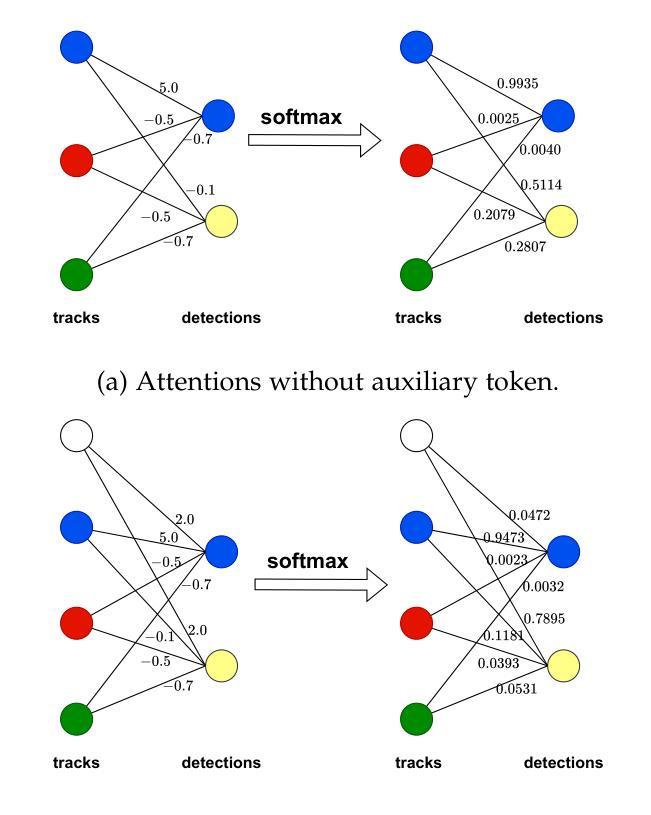
Many query-based approaches for 3D Multi-Object Tracking (MOT) adopt the tracking-by-attention paradigm, utilizing track queries for identity-consistent detection and object queries for identity-agnostic track spawning. Tracking-by-attention, however, entangles detection and tracking queries in one embedding for both the detection and tracking task, which is sub-optimal. Other approaches resemble the tracking-by-detection paradigm and detect objects using decoupled track and detection queries followed by a subsequent association. These methods, however, do not leverage synergies between the detection and association task. Combining the strengths of both paradigms, we introduce ADA-Track++, a novel end-to-end framework for 3D MOT from multi-view cameras. We introduce a learnable data association module based on edge-augmented cross-attention, leveraging appearance and geometric features. We also propose an auxiliary token in this attention-based association module, which helps mitigate disproportionately high attention to incorrect association targets caused by attention normalization. Furthermore, we integrate this association module into the decoder layer of a DETR-based 3D detector, enabling simultaneous DETR-like query-to-image cross-attention for detection and query-to-query cross-attention for data association. By stacking these decoder layers, queries are refined for the detection and association task alternately, effectively harnessing the task dependencies. We evaluate our method on the nuScenes dataset and demonstrate the advantage of our approach compared to the two previous paradigms.
对于基于查询的3D多目标跟踪(MOT)方法,许多都采用基于注意力的跟踪范式,利用跟踪查询进行身份一致的检测,并利用对象查询进行身份无关的跟踪生成。然而,基于注意力的跟踪将检测和跟踪查询纠缠在一个嵌入中,这对于检测和跟踪任务都是次优的。其他方法类似于基于检测的跟踪范式,使用解耦的跟踪和检测查询进行对象检测,然后进行后续关联。然而,这些方法并没有利用检测和关联任务之间的协同作用。结合两种范式的优点,我们引入了ADA-Track++,这是一种新的端到端3D MOT框架,适用于多视角相机。我们基于边缘增强交叉注意力,利用外观和几何特征,引入了一个可学习的数据关联模块。我们还在此基于注意力的关联模块中提出了一个辅助令牌,有助于减轻由于注意力归一化导致的不成比例地关注不正确的关联目标。此外,我们将此关联模块集成到DETR基础的3D检测器的解码层中,使检测与查询到查询的交叉注意力数据关联能够同时进行DETR式的查询到图像的交叉注意力。通过堆叠这些解码层,查询被交替地用于检测和关联任务,有效地利用任务依赖性。我们在nuScenes数据集上评估了我们的方法,并展示了与两种先前范式相比的优势。
论文及项目相关链接
PDF This work has been submitted to the IEEE for possible publication
Summary
基于注意力机制的3D多目标跟踪(MOT)方法存在不足,本文提出ADA-Track++框架,结合跟踪与检测的优势,实现多视角摄像头下的3D MOT。引入可学习的数据关联模块,基于边缘增强交叉注意力机制,利用外观和几何特征进行关联判断。提出辅助标记辅助模块以解决不当关注的问题。将其集成到DETR-based的3D检测器解码器层中,实现检测与关联的交叉注意力。实验验证方法有效性。
Key Takeaways
- 方法结合了跟踪与检测的优势实现新的3D MOT框架ADA-Track++。
- 引入数据关联模块,利用边缘增强交叉注意力机制实现对象关联。
- 创新性地引入辅助标记以解决不当关注问题。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为 ADA-Track 的新型端到端多相机 3D 多目标跟踪(MOT)框架,旨在解决以下问题:
跟踪查询的耦合问题:现有的基于查询的 3D MOT 方法中,很多采用了“tracking-by-attention”(TBA)范式,其中使用跟踪查询来一致性地检测同一身份的目标,并使用对象查询来初始化每帧中新出现对象的轨迹。然而,这种方法将检测和跟踪查询纠缠在一个嵌入中,既用于检测也用于跟踪任务,这是次优的。
检测与跟踪任务的分离:其他方法采用了“tracking-by-detection”(TBD)范式,先使用解耦的跟踪和检测查询进行目标检测,然后进行后续的关联。但这些方法没有充分利用检测和关联任务之间的协同作用。
数据关联的优化:TBA 方法使用自注意力机制隐式处理数据关联,但在推理过程中,网络只输出每个对象的一个置信度分数,不清楚它代表检测置信度还是关联置信度,这需要复杂的手动调整的后处理。
为了解决这些问题,ADA-Track 结合了 TBA 和 TBD 的优势,通过引入一个可学习的基于边增强交叉注意力的数据关联模块,并将其集成到基于 DETR 的 3D 检测器的解码器层中。该框架允许同时进行 DETR 类的查询到图像的交叉注意力用于检测和查询到查询的交叉注意力用于数据关联。通过堆叠这些解码器层,查询交替地为检测和关联任务进行细化,有效地利用了任务依赖性。
ADA-Track 在 nuScenes 数据集上进行了评估,并证明了其方法相比之前两种范式的优势。论文的代码已在 GitHub 上提供。
Q: 有哪些相关研究?
A: 论文中提到的相关研究可以分为以下几个类别:
多相机 3D 检测:研究工作主要分为两类,一类是将多视图图像特征转换为密集的 Bird’s-Eye View (BEV) 表示,另一类是利用稀疏的目标查询与多视图图像直接交互,构建以对象为中心的表示。
基于查询的 MOT:许多工作扩展了基于对象查询的方法到基于查询的 MOT,这些方法通常采用“tracking-by-attention” (TBA) 范式,利用自注意力机制进行隐式关联,并使用二分图匹配强制进行身份一致的目标分配。
**Tracking-by-attention (TBA)**:TBA 方法将多帧集合预测问题视为依赖于自注意力的隐式关联,例如 TrackFormer 和 MOTR。MUTR3D 将 TBA 范式扩展到多相机 3D MOT,STARTrack 通过提出 Latent Motion Model (LMM) 来更新查询的外观特征。
**Tracking-by-detection (TBD)**:TBD 方法使用独立的算法进行数据关联,可以与任意目标检测器结合。例如,SORT 使用卡尔曼滤波器作为运动模型,并使用匈牙利匹配进行对象关联。TBD 方法在联合检测和跟踪框架中也很受欢迎,通常与基于查询的检测器结合使用。
基于图结构的关联问题:学习型方法通常使用图结构表述关联问题,并使用图神经网络 (GNNs) 或变换器解决它。
端到端检测和跟踪方法:基于查询的检测器上的端到端检测和跟踪方法已成为流行的选择。
论文中提到的一些具体工作包括但不限于:
- TrackFormer [42]
- MOTR [61]
- MUTR3D [62]
- STARTrack [18]
- PF-Track [46]
- DETR [8]
- PETR [40]
- 3DMOTFormer [16]
这些工作为 ADA-Track 提供了理论基础和技术背景。ADA-Track 通过结合这些研究的优势,提出了一个新的框架来改进 3D 多目标跟踪的性能。
Q: 论文如何解决这个问题?
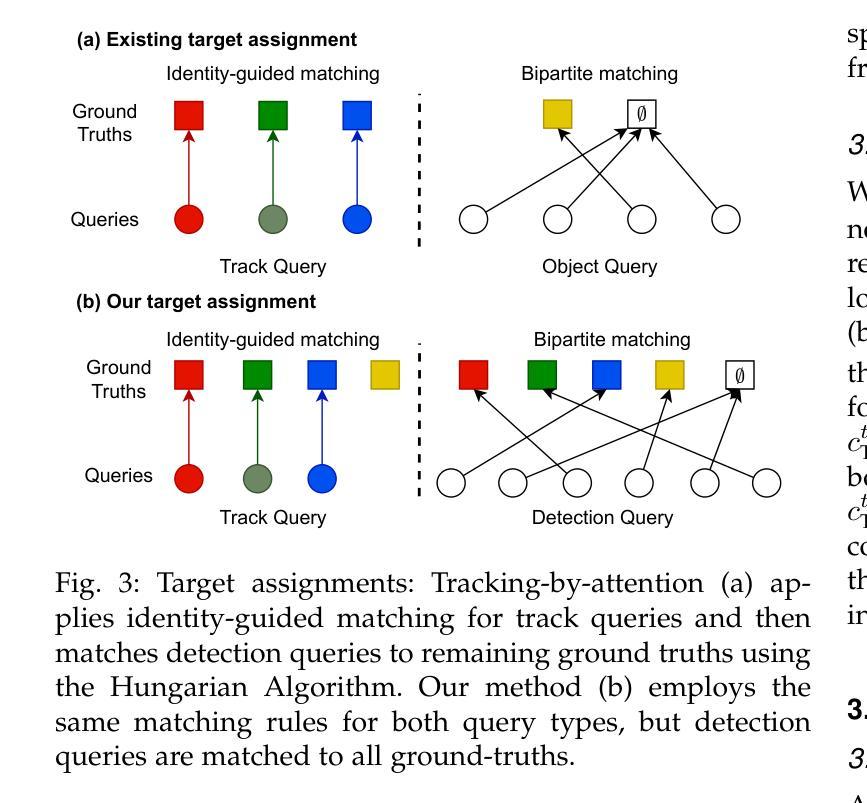
A: 论文提出了 ADA-Track,一个端到端的多相机 3D 多目标跟踪(MOT)框架,来解决现有方法中的一些问题。ADA-Track 的解决方案主要包括以下几个关键点:
交替检测和关联(Alternating Detection and Association):ADA-Track 采用了一种新的范式,通过交替进行对象检测和数据关联任务,利用这两个任务之间的协同作用。这种交替优化允许检测结果来初始化和简化关联,同时使用已建立的轨迹来纠正潜在的检测错误。
可学习的关联模块(Learned Association Module):提出了一个基于边增强交叉注意力(edge-augmented cross-attention)的学习型数据关联模块。该模块利用外观和几何特征来表示关联信息,并将这些特征融入到注意力计算中,从而实现端到端的训练。
集成到变换器解码器层(Integration into Transformer Decoder Layer):将关联模块集成到基于 DETR 的 3D 检测器的变换器解码器层中。这样,解码器层可以顺序进行查询到图像的交叉注意力来细化查询表示进行对象检测,以及查询到查询的交叉注意力来细化查询和边表示进行数据关联。
堆叠解码器层(Stacking Decoder Layers):通过堆叠解码器层,可以迭代地细化查询和边特征,为检测和关联任务提供有用的信息,实现任务之间的协调优化。
训练策略(Training Strategy):ADA-Track 在训练时采用了独立匹配的策略,即使用匈牙利算法(Hungarian Algorithm)独立匹配检测查询和跟踪查询到地面真实身份。此外,还引入了显式的关联损失函数,将关联模块视为一个二分类问题。
跟踪更新模块(Track Update Module):在所有解码器层之后,使用跟踪更新模块将跟踪查询和检测查询进行关联,生成下一帧的跟踪查询。
通过这些方法,ADA-Track 能够有效地解决现有 MOT 方法中的一些问题,如耦合的查询表示、次优的数据关联和缺乏任务协同作用等。论文中的实验结果表明,ADA-Track 在 nuScenes 数据集上相比其他范式的方法具有优势,并实现了最先进的性能。
Q: 论文做了哪些实验?
A: 论文中进行了多项实验来验证 ADA-Track 框架的有效性,主要包括以下几个方面:
范式比较:作者首先与两种主流的 3D MOT 方法进行了比较,即基于注意力的跟踪(TBA)和基于检测的跟踪(TBD)。作者创建了两种基线方法(TBA-Baseline 和 TBD-Baseline),并与提出的 ADA-Track 方法进行了比较。
与现有工作比较:ADA-Track 与当前最先进的基于 TBA 和 TBD 的方法进行了比较,包括但不限于 DQTrack、STAR-Track 和 PF-Track。
消融研究:作者进行了一系列消融实验来评估 ADA-Track 中不同组件的影响,包括:
- 训练样本长度 T 的影响。
- 结合不同解码器层的边界框和关联输出的效果。
- 特征更新权重 wt 的影响。
- 边界框更新策略。
- 使用不同数量的训练帧。
类别特定的 IDF1 分析:为了验证 ADA-Track 在不同类别上的关联一致性,作者展示了一个额外的 IDF1 分析。
复杂性和运行时间分析:作者比较了 ADA-Track 与 TBA-Baseline 和 TBD-Baseline 在参数数量、浮点运算次数(FLOPs)和推理时间上的复杂性。
不同关联模块的比较:作者比较了基于边增强交叉注意力的关联模块与其他替代关联模块的性能。
对自我运动的鲁棒性:作者评估了 ADA-Track 对于由于自我运动导致的目标外观变化的鲁棒性。
检测查询数量:作者研究了不同数量的检测查询 ND 对 ADA-Track 性能的影响。
关联损失权重:作者评估了关联损失权重 λasso 对模型性能的影响。
推理时的超参数:作者研究了在推理期间使用的两个超参数:未匹配轨迹保持的帧数 Td 和用于生成新轨迹的得分阈值 τnew。
这些实验在 nuScenes 数据集上进行,使用了 AMOTA(平均多目标跟踪精度)、AMOTP(平均多目标跟踪精度)、召回率、MOTA、IDS(身份切换)、FP(误报)、FN(漏报)等指标来评估性能。实验结果表明,ADA-Track 在多相机 3D 多目标跟踪任务上取得了优异的性能,并且相比于其他方法有显著的改进。
Q: 有什么可以进一步探索的点?
A: 尽管 ADA-Track 在多相机 3D 多目标跟踪方面取得了显著的成果,但仍有一些可以进一步探索和改进的点:
更复杂的场景:在更加复杂和动态的环境中测试 ADA-Track,例如城市交通、拥挤的街道或不同的天气条件,以验证其泛化能力和鲁棒性。
实时性能:研究如何优化 ADA-Track 以实现实时或近实时的性能,这对于许多实际应用场景(如自动驾驶)至关重要。
传感器融合:ADA-Track 目前主要依赖视觉信息,未来的工作可以探索如何有效地融合雷达、激光雷达(LiDAR)等其他传感器数据,以提高跟踪的准确性和鲁棒性。
长时跟踪:探索如何改进 ADA-Track 以更好地处理长时间跟踪问题,例如,通过更好地预测和处理遮挡、快速运动和消失的目标。
更细粒度的分析:进行更细粒度的性能分析,例如,针对不同类型的目标(如大小、形状、速度)或不同的跟踪挑战(如距离、视角变化)。
模型压缩和优化:研究模型压缩和优化技术,以减少 ADA-Track 的计算资源需求,使其更适合在资源受限的设备上运行。
端到端训练:探索是否可以通过端到端训练来进一步改进数据关联模块,而不是依赖于单独的损失函数。
可解释性和透明度:提高 ADA-Track 的可解释性,帮助用户理解模型的行为,特别是在做出错误预测时。
多任务学习:将 MOT 与其他相关任务(如行为预测、意图识别)结合起来,通过多任务学习共享表示学习的好处。
开放世界跟踪:在开放世界设置中测试 ADA-Track,其中目标类别是未知的或不断变化的。
模型泛化能力:研究 ADA-Track 在不同数据集和不同来源的数据(例如,不同制造商的相机、不同地理位置)上的泛化能力。
鲁棒性测试:对 ADA-Track 进行更严格的鲁棒性测试,包括对抗性攻击、模型健壮性等。
交互式跟踪:开发交互式跟踪系统,允许用户在跟踪过程中提供反馈,以纠正错误并提高整体性能。
资源受限环境的部署:探索在边缘计算设备或移动设备上部署 ADA-Track 的可能性,这可能需要进一步的模型压缩和优化。
这些探索点可以帮助研究者进一步提升多目标跟踪系统的性能,使其更加实用和可靠。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题定义:论文针对的是多相机3D多目标跟踪(MOT)问题,特别是在自动驾驶领域中的应用。作者指出了现有方法中的一些局限性,包括跟踪查询的耦合问题、检测与跟踪任务的分离问题,以及数据关联的次优处理。
ADA-Track框架:提出了一个名为ADA-Track的新型端到端多相机3D MOT框架。该框架结合了“tracking-by-attention”(TBA)和“tracking-by-detection”(TBD)两种范式的优点,通过交替进行检测和关联任务,充分利用了任务之间的协同作用。
关键技术:
- 提出了一个基于边增强交叉注意力的学习型数据关联模块,该模块利用外观和几何特征来表示关联信息。
- 将关联模块集成到变换器解码器层中,允许同时进行查询到图像的交叉注意力用于检测和查询到查询的交叉注意力用于数据关联。
- 通过堆叠解码器层,实现了查询和边特征的迭代细化,优化了检测和跟踪任务。
实验验证:在nuScenes数据集上对ADA-Track进行了评估,并与其他方法进行了比较。实验结果表明,ADA-Track在AMOTA(平均多目标跟踪精度)等指标上取得了优异的性能。
消融研究:通过一系列消融实验,作者分析了不同组件对整体性能的影响,包括训练样本长度、联合优化策略、特征更新权重、边界框更新策略等。
复杂性和性能分析:对ADA-Track的计算复杂性、参数数量、浮点运算次数(FLOPs)和推理时间进行了分析,并与其他基线方法进行了比较。
代码开源:作者提供了ADA-Track的实现代码,以便其他研究者可以复现和进一步研究。
研究支持:论文最后感谢了支持该研究项目的相关机构和资助信息。
总体来说,这篇论文提出了一个新的3D MOT框架,通过创新的交替检测和关联策略,有效地提高了跟踪性能,并在nuScenes数据集上取得了优异的结果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图