⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-17 更新
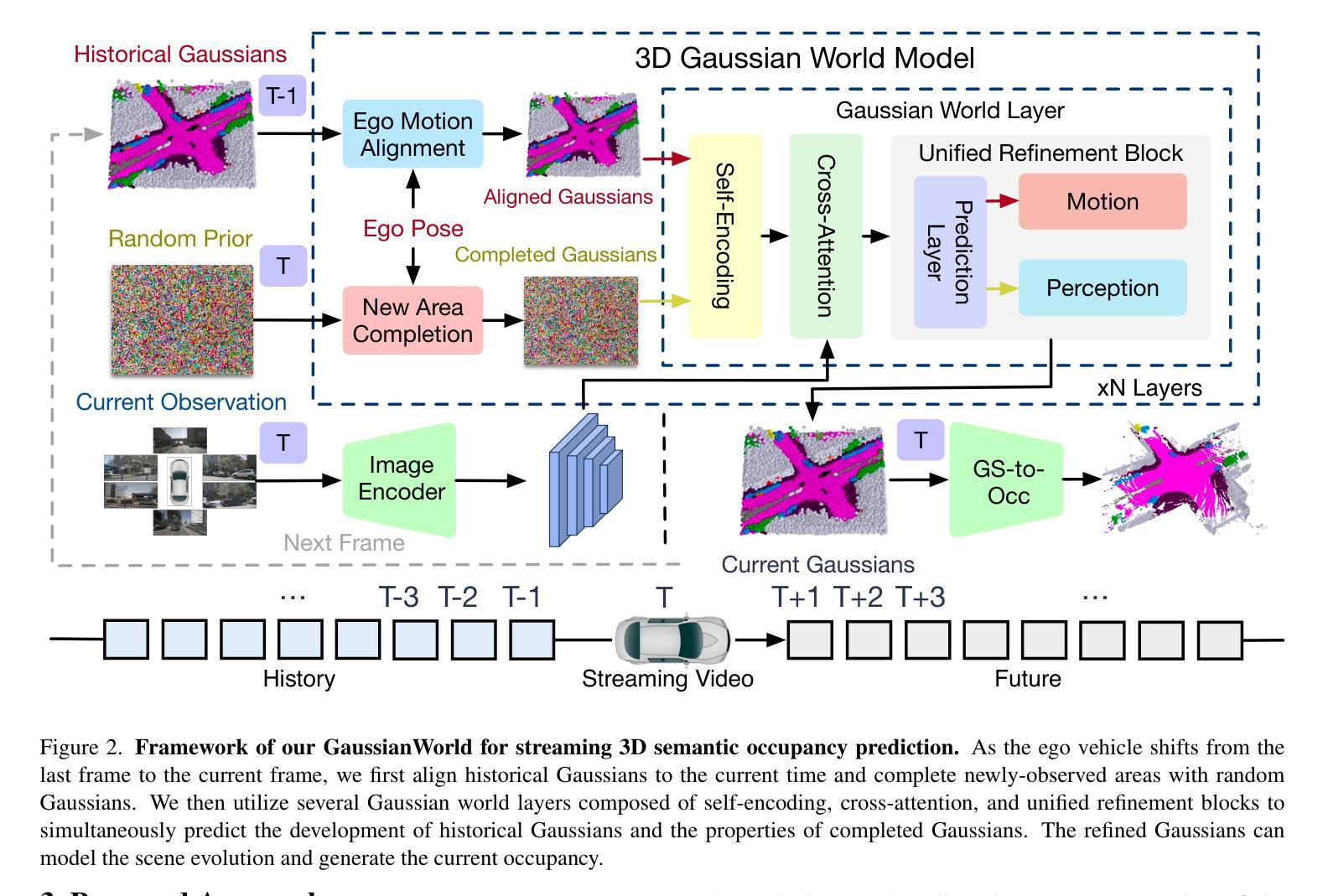
GaussianWorld: Gaussian World Model for Streaming 3D Occupancy Prediction
Authors:Sicheng Zuo, Wenzhao Zheng, Yuanhui Huang, Jie Zhou, Jiwen Lu
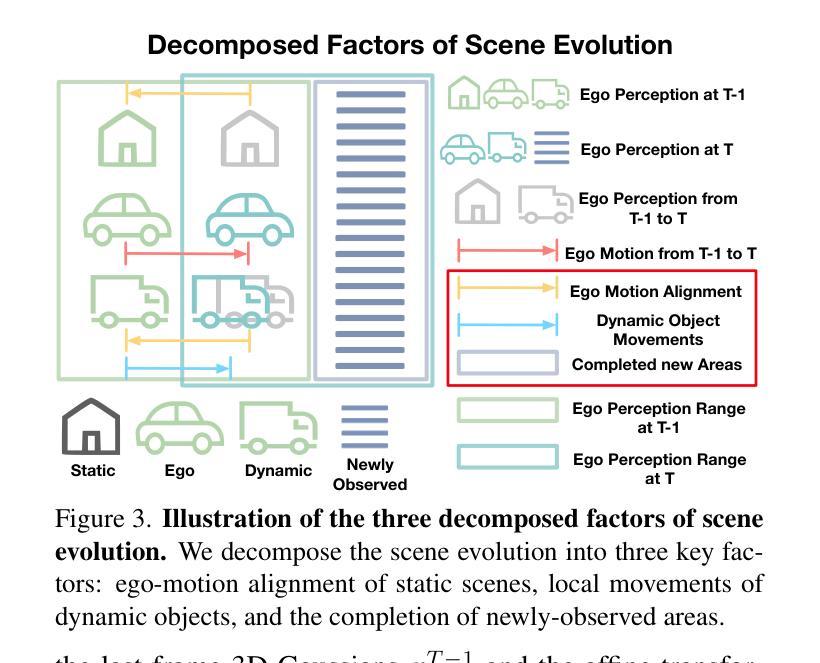
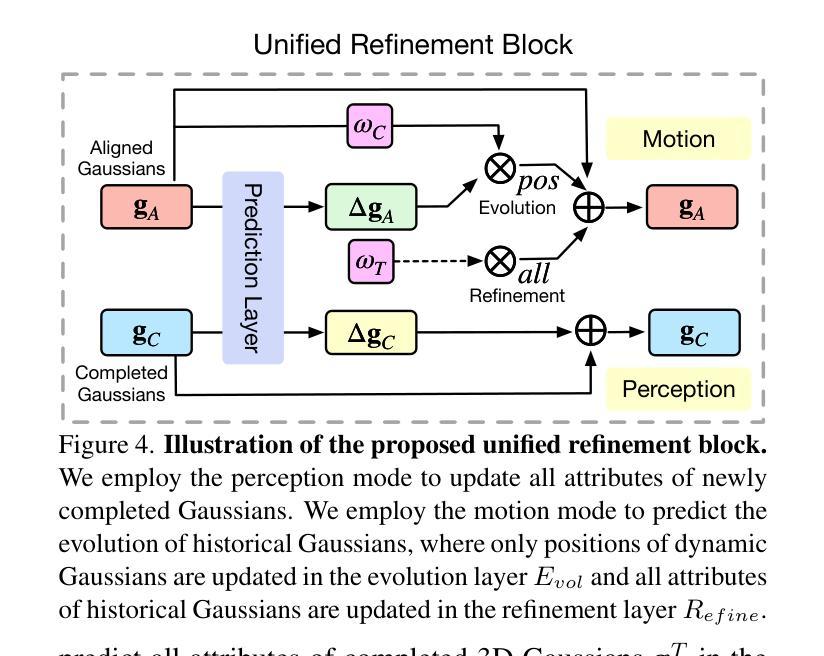
3D occupancy prediction is important for autonomous driving due to its comprehensive perception of the surroundings. To incorporate sequential inputs, most existing methods fuse representations from previous frames to infer the current 3D occupancy. However, they fail to consider the continuity of driving scenarios and ignore the strong prior provided by the evolution of 3D scenes (e.g., only dynamic objects move). In this paper, we propose a world-model-based framework to exploit the scene evolution for perception. We reformulate 3D occupancy prediction as a 4D occupancy forecasting problem conditioned on the current sensor input. We decompose the scene evolution into three factors: 1) ego motion alignment of static scenes; 2) local movements of dynamic objects; and 3) completion of newly-observed scenes. We then employ a Gaussian world model (GaussianWorld) to explicitly exploit these priors and infer the scene evolution in the 3D Gaussian space considering the current RGB observation. We evaluate the effectiveness of our framework on the widely used nuScenes dataset. Our GaussianWorld improves the performance of the single-frame counterpart by over 2% in mIoU without introducing additional computations. Code: https://github.com/zuosc19/GaussianWorld.
三维占用预测对于自动驾驶至关重要,因为它对周围环境的感知是全面的。为了融入序列输入,大多数现有方法融合来自前一帧的表示来推断当前的三维占用情况。然而,它们未能考虑驾驶场景的连续性,并忽略了三维场景演变所提供的强烈先验(例如,只有动态物体才会移动)。在本文中,我们提出了一个基于世界模型的框架来利用场景演变进行感知。我们将三维占用预测重新表述为一个以当前传感器输入为条件的四维占用预测问题。我们将场景演变分解为三个因素:1)静态场景的自我运动对齐;2)动态对象的局部运动;3)新观察场景的完成。然后,我们采用高斯世界模型(GaussianWorld)来明确利用这些先验知识,并结合当前的RGB观测值在三维高斯空间中推断场景演变。我们在广泛使用的nuscenes数据集上评估了我们的框架的有效性。我们的GaussianWorld在不引入额外计算的情况下,提高了单帧模型的平均交并比(mIoU)超过2%。代码:https://github.com/zuosc19/GaussianWorld。
论文及项目相关链接
PDF Code is available at: https://github.com/zuosc19/GaussianWorld
Summary
本文提出一种基于世界模型的框架,利用场景演变进行感知,将3D占用预测重新构建为基于当前传感器输入的4D占用预测问题。文章分解场景演变为三个因素:静态场景的自我运动对齐、动态对象的局部运动以及新观察场景的完成。然后采用高斯世界模型(GaussianWorld)明确利用这些先验知识,并结合当前RGB观测,在3D高斯空间中推断场景演变。在广泛使用的nuScenes数据集上验证了该框架的有效性,高斯世界模型在不影响计算量的情况下,提高了单帧模型的mIoU性能超过2%。
Key Takeaways
- 3D占用预测对自动驾驶至关重要,因为它提供了周围环境的全面感知。
- 现有方法通过融合先前帧的表示来推断当前3D占用,但忽略了驾驶场景的连续性以及3D场景演变提供的强烈先验信息。
- 本文提出一种基于世界模型的框架,利用场景演变进行感知,将3D占用预测重新构建为4D占用预测问题。
- 场景演变被分解为三个因素:静态场景的自我运动对齐、动态对象的局部运动以及新观察场景的完成。
- 采用高斯世界模型(GaussianWorld)利用场景演变先验知识,并在3D高斯空间中结合当前RGB观测进行推断。
- 在nuScenes数据集上,高斯世界模型提高了单帧模型的mIoU性能超过2%,验证了框架的有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在自动驾驶领域中有效地进行3D语义占用预测。具体来说,论文关注以下几个关键点:
整合序列输入:大多数现有的3D占用预测方法仅依赖单帧输入,而忽略了驾驶场景的时间连续性。论文提出利用序列输入(即时间信息)来提高预测性能。
考虑驾驶场景的连续性:现有的方法在融合来自先前帧的表示时,没有考虑到驾驶场景的连续性和简单性,这导致模型难以理解驾驶场景的发展。
减少计算开销:传统的多帧融合方法会增加额外的计算负担。论文提出的方法旨在不增加额外计算开销的情况下改善性能。
显式建模场景演变:论文提出了一个基于世界模型的框架,通过显式地建模场景演变(包括静态场景的自我运动对齐、动态对象的局部运动和新观测区域的完成)来改进3D占用预测。
总的来说,论文旨在通过提出一个新的基于世界模型的框架(GaussianWorld),在保持计算效率的同时,提高3D语义占用预测的性能,特别是在处理序列输入和场景演变方面。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
3D Occupancy Prediction:
- 早期的方法使用激光雷达(LiDAR)点作为输入来完成整个场景的语义理解。
- 近期的研究集中在更具挑战性的视觉基础3D占用预测。
- 一些方法从图像中获得密集体素表示以预测3D占用。
- 其他方法探索了更有效的表示,例如Tri-Perspective View (TPV)、3D Gaussians和点。
World Models for Autonomous Driving:
- 世界模型通常被定义为基于历史观察和动作对未来的预测模型。
- 应用于自动驾驶的世界模型主要包括驾驶场景生成、规划和表示学习。
- 基于先进生成模型的世界模型能够生成多样化的驾驶序列。
Temporal Modeling for 3D Perception:
- 利用时间信息对3D感知至关重要。
- 常见的方法包括将多帧场景表示融合以增强感知任务。
- 这些方法通过将多帧表示对齐到当前时间并聚合时间信息来实现。
具体到论文中提到的一些工作,包括但不限于:
- MonoScene [4]:单目3D场景补全。
- BEVFormer [22]:使用多相机图像通过时空变换器学习鸟瞰图表示。
- TPVFormer [14]:基于三视角的3D语义占用预测。
- GaussianFormer [15]:将场景表示为3D高斯,用于基于视觉的3D语义占用预测。
- CVT-Occ [48]:探索3D体积特征的时间融合以改善3D占用预测。
这些相关工作构成了论文提出方法的理论基础和对比基准。论文通过对比这些方法,展示了其提出方法在性能和效率上的优势。
Q: 论文如何解决这个问题?
A: 论文通过提出一个基于世界模型的框架,称为GaussianWorld,来解决3D语义占用预测问题。以下是该框架解决这个问题的关键步骤和方法:
将3D占用预测重新定义为4D占用预测问题:
- 论文将传统的3D占用预测问题扩展为一个4D问题,即在当前传感器输入的条件下预测场景的演变。
显式建模场景演变:
- 将场景演变分解为三个因素:静态场景的自我运动对齐、动态对象的局部运动和新观测区域的完成。
- 利用3D高斯(Gaussians)作为场景表示,显式和连续地建模对象运动。
GaussianWorld模型:
- 采用GaussianWorld来处理上述分解的场景演变因素,并在3D高斯空间中预测场景的演变。
- 包括对历史3D高斯的对齐、动态高斯的位置更新以及新观测区域的高斯完成。
处理静态场景和动态对象:
- 通过全局仿射变换对齐历史3D高斯,以补偿自我运动的影响。
- 区分动态和静态高斯,并分别对它们进行更新,以模拟动态对象的运动。
新观测区域的完成:
- 对于观测到的新区域,用随机初始化的高斯进行完成,以维持一致数量的3D高斯表示。
迭代细化:
- 通过多个进化层(evolution layers)和细化层(refinement layers)迭代地细化3D高斯表示,增强模型学习场景演变的能力。
流式训练策略:
- 采用流式训练策略,逐渐增加输入模型的图像序列长度,使模型适应于预测更长的序列。
效率和性能:
- GaussianWorld在不增加额外计算开销的情况下,相对于单帧模型提高了超过2%的mIoU性能。
通过这些方法,GaussianWorld能够有效地利用时间信息来改进3D语义占用预测,同时保持了计算效率。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估GaussianWorld模型的有效性:
数据集:
- 使用了广泛使用的nuScenes数据集进行实验,该数据集包含1000个不同的驾驶场景,分为700个训练序列、150个验证序列和150个测试序列。
评估指标:
- 使用了交集比并集(IoU)来评估模型的几何重建性能。
- 使用了平均交集比并集(mIoU)来评估模型的语义感知能力。
实现细节:
- 设定输入图像分辨率为900×1600。
- 使用ResNet101-DCN作为图像主干网络,并采用特征金字塔网络(FPN)提取多尺度图像特征。
- 使用总共25600个高斯来表示3D场景,并使用4个高斯世界层来细化高斯的属性。
结果和分析:
- 在nuScenes验证集上与其他最先进的方法进行了全面的比较。
- 展示了GaussianWorld在单帧设置下的变体(GaussianFormer-B)与当前最先进方法的比较性能。
- 展示了引入时间融合变体(GaussianFormer-T)后的性能,并与GaussianWorld的性能进行了比较。
不同时间建模方法的比较:
- 探索了在GaussianFormer基础上实现的两种时间融合方法:3D高斯空间中的时间融合和透视图空间中的时间融合。
- 比较了这些方法的性能和效率,并展示了GaussianWorld在保持低延迟和内存消耗的同时显著提升性能。
分解场景演变因素的消融研究:
- 对GaussianWorld显式建模的三个场景演变因素进行了消融研究,以验证它们的效果。
不同序列长度的流式预测性能:
- 展示了使用不同流式长度时GaussianWorld的mIoU和IoU性能,并分析了性能变化的原因。
流式训练策略的消融研究:
- 探索了不同的流式训练策略,包括序列长度的增加、梯度累积方法以及是否使用概率建模。
可视化结果:
- 提供了GaussianWorld与现有方法相比的定性分析,展示了跨帧一致性,特别是对于静态元素的预测效果。
这些实验全面评估了GaussianWorld模型的性能,并与现有方法进行了比较,证明了其在3D语义占用预测任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
跨帧一致性的改进:
- 尽管GaussianWorld在跨帧一致性方面取得了进展,但论文指出该模型还未能实现静态场景的完全跨帧一致性,这主要是由于动态和静态元素之间的不准确分离。未来的工作可以集中在改进这种分离,以进一步提高预测的一致性。
处理更复杂的动态场景:
- 论文提出的方法主要关注驾驶场景,未来的研究可以探索将该方法应用于更复杂的动态环境,如城市中心或高交通流量区域。
提高模型的泛化能力:
- 探索如何使模型更好地泛化到未见过的场景和不同的数据集,这可能涉及到使用更多样化的数据进行训练或开发更健壮的特征提取方法。
优化计算效率:
- 尽管GaussianWorld在不增加额外计算开销的情况下提高了性能,但进一步优化模型以实现实时或近实时的3D语义占用预测仍然是一个有价值的研究方向。
多模态输入的融合:
- 考虑将其他类型的传感器数据(如激光雷达、雷达)与视觉输入相结合,以提高预测的准确性和鲁棒性。
更细粒度的语义理解:
- 研究如何提高模型对场景中更细粒度语义信息的理解和预测能力,例如区分不同类型的车辆或行人。
长序列预测的性能和稳定性:
- 探索模型在处理更长序列时的性能和稳定性,以及如何通过改进训练策略和模型架构来进一步提升长序列预测的能力。
应用到其他感知任务:
- 论文最后提到将GaussianWorld模型应用于其他感知任务是一个有趣的未来方向。这可能包括对象检测、跟踪、场景重建等任务。
模型的可解释性和透明度:
- 提高模型的可解释性,让研究人员和最终用户更好地理解模型的决策过程,特别是在安全关键的应用中。
鲁棒性测试和不确定性量化:
- 在各种异常和挑战条件下测试模型的鲁棒性,并研究如何量化模型预测的不确定性,这对于自动驾驶系统的安全性至关重要。
这些探索点可以帮助推动3D语义占用预测技术的发展,并将其应用到更广泛的自动驾驶和机器人领域中。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个基于世界模型的框架,名为GaussianWorld,用于流式的3D语义占用预测,主要贡献和内容可以总结如下:
问题定义:
- 针对自动驾驶中3D占用预测问题,提出利用时间序列信息改善预测性能,同时避免额外的计算开销。
方法论:
- 将3D占用预测问题重新定义为基于当前传感器输入的4D占用预测问题。
- 将场景演变分解为三个因素:静态场景的自我运动对齐、动态对象的局部运动和新观测区域的完成。
- 提出使用3D高斯(Gaussians)作为场景表示,以显式和连续地建模对象运动。
GaussianWorld模型:
- 采用GaussianWorld模型来处理分解的场景演变因素,并在3D高斯空间中预测场景演变。
- 包括对历史3D高斯的对齐、动态高斯的位置更新以及新观测区域的高斯完成。
实验验证:
- 在nuScenes数据集上进行实验,验证了GaussianWorld模型的有效性。
- 与单帧模型和其他时间融合方法相比,GaussianWorld在不增加额外计算开销的情况下提高了超过2%的mIoU性能。
未来方向和局限性:
- 提出了未来可能的研究方向,包括改进跨帧一致性、处理更复杂的动态场景等。
- 指出了模型的局限性,包括无法完全实现静态场景的跨帧一致性。
总体而言,这篇论文通过引入世界模型的概念,并利用3D高斯作为场景表示,提出了一个新颖的框架来改进3D语义占用预测任务,特别是在整合时间信息和提高预测性能方面。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

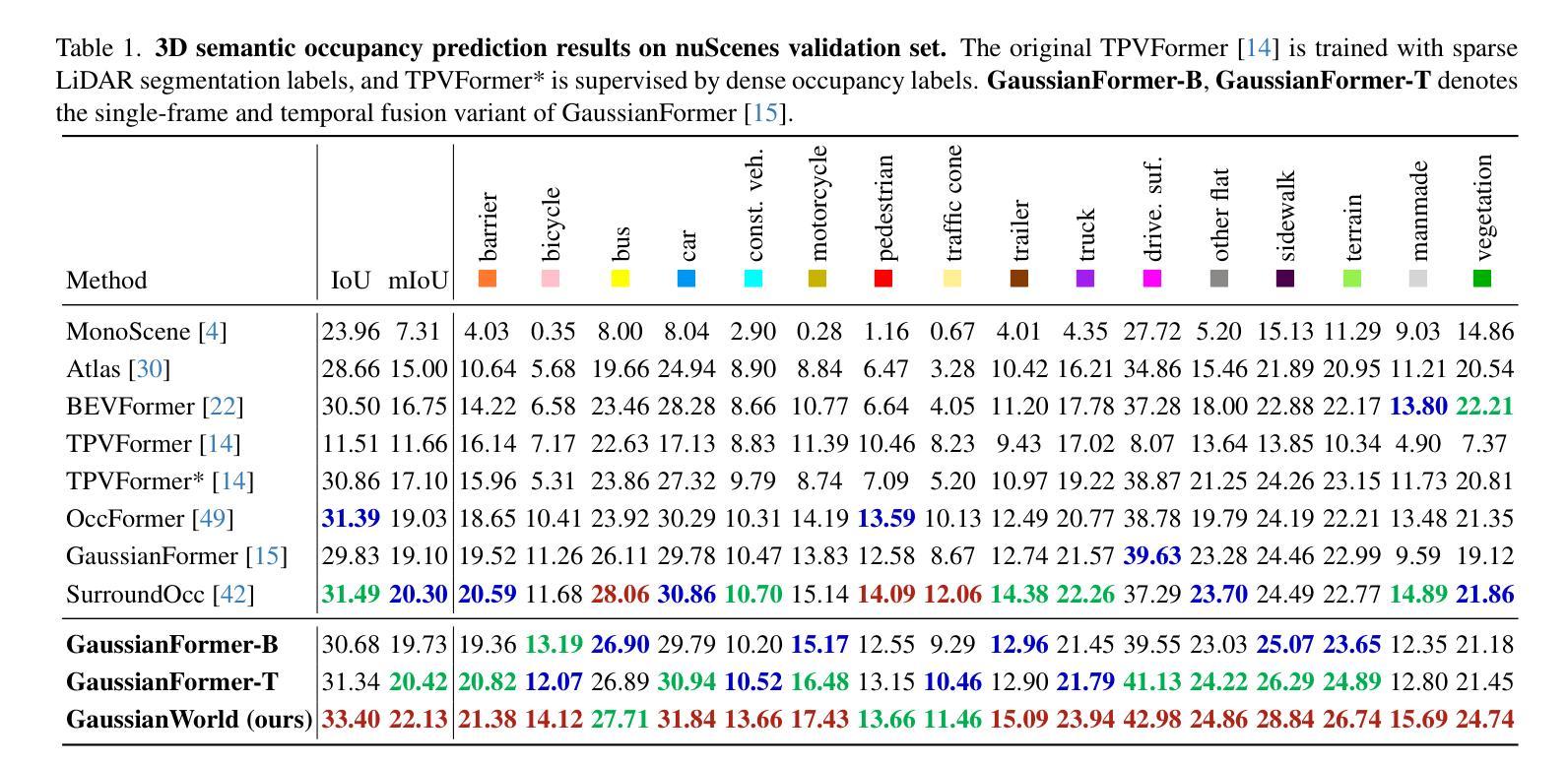
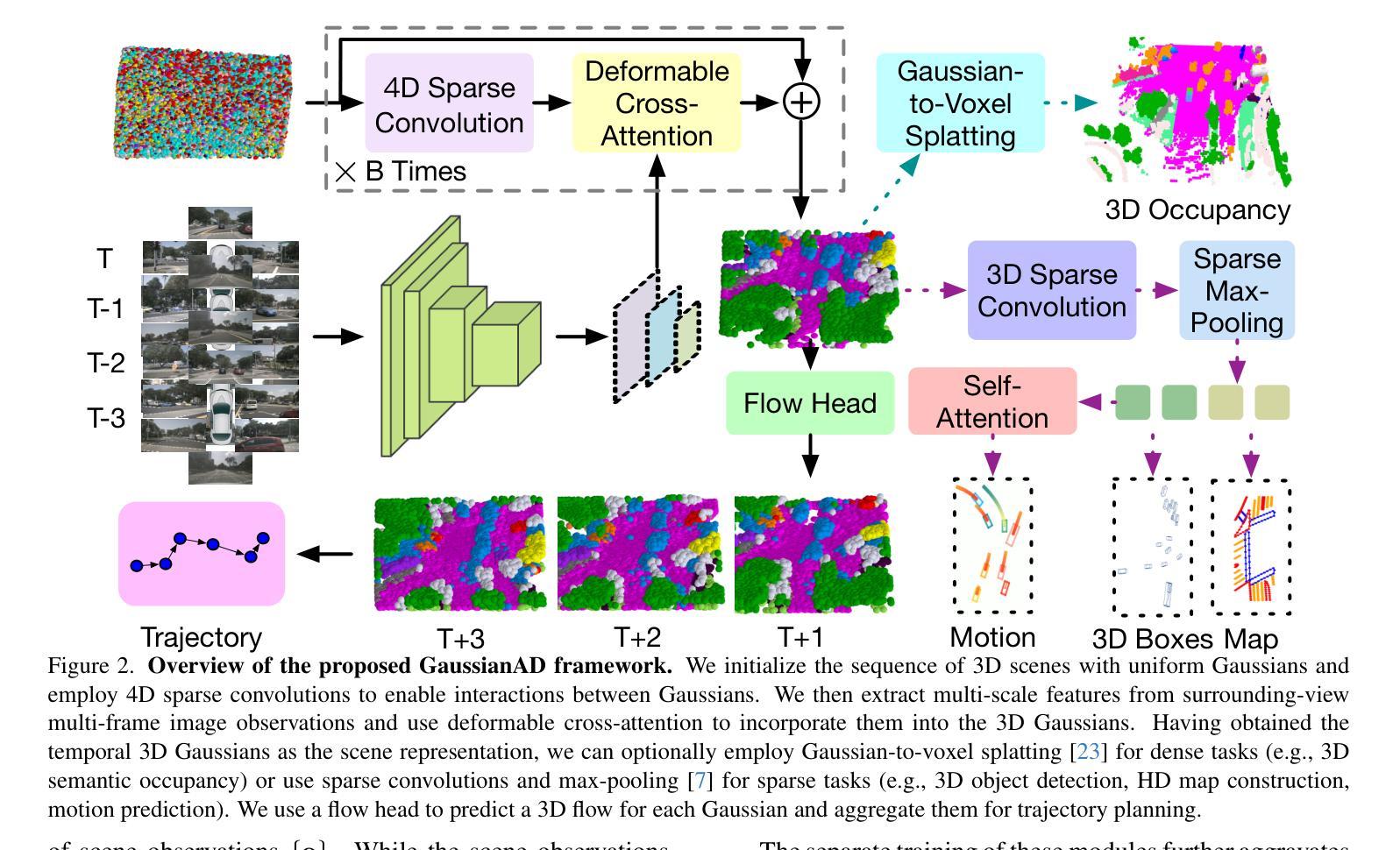
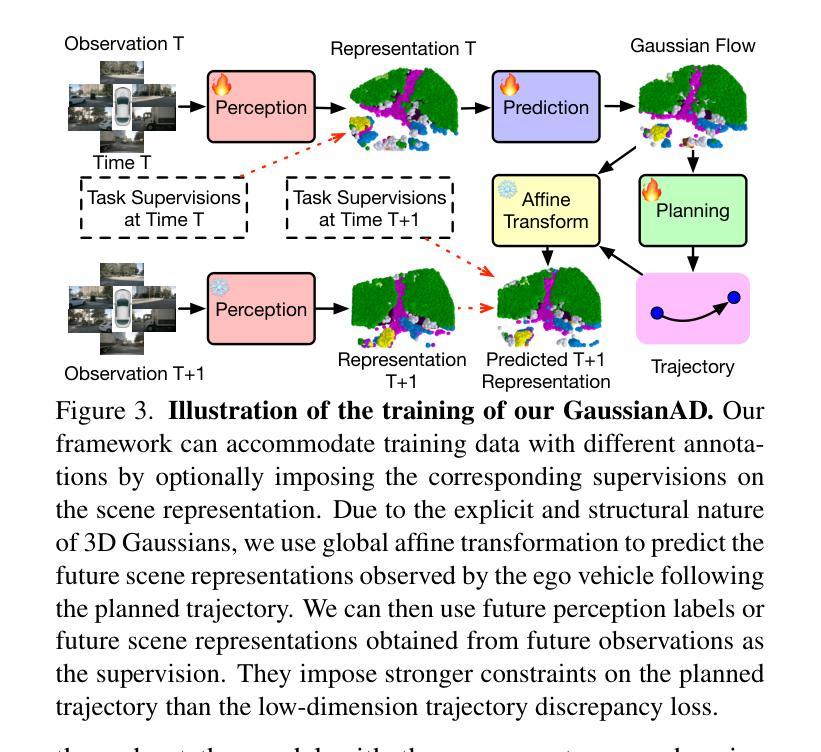
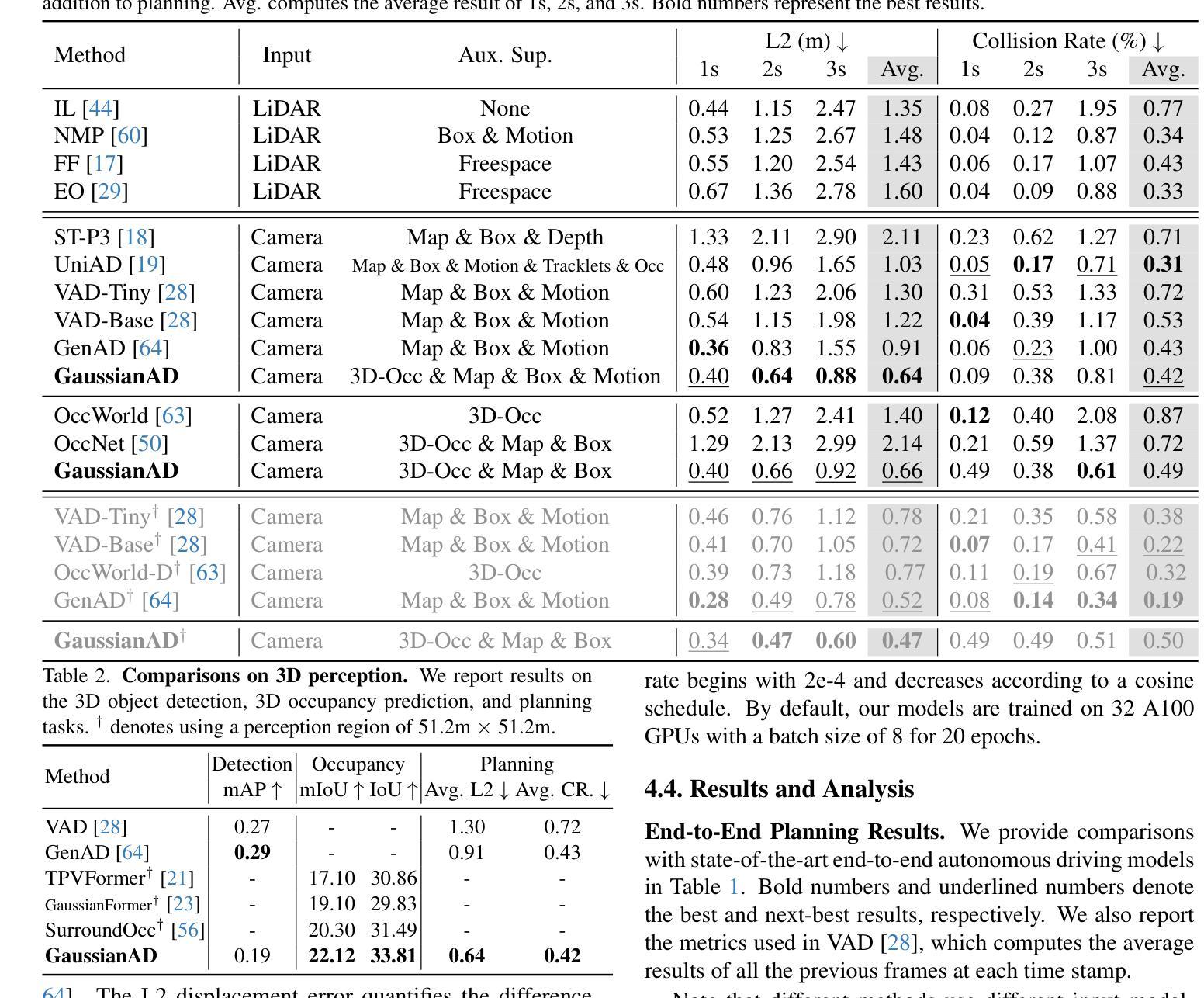
GaussianAD: Gaussian-Centric End-to-End Autonomous Driving
Authors:Wenzhao Zheng, Junjie Wu, Yao Zheng, Sicheng Zuo, Zixun Xie, Longchao Yang, Yong Pan, Zhihui Hao, Peng Jia, Xianpeng Lang, Shanghang Zhang
Vision-based autonomous driving shows great potential due to its satisfactory performance and low costs. Most existing methods adopt dense representations (e.g., bird’s eye view) or sparse representations (e.g., instance boxes) for decision-making, which suffer from the trade-off between comprehensiveness and efficiency. This paper explores a Gaussian-centric end-to-end autonomous driving (GaussianAD) framework and exploits 3D semantic Gaussians to extensively yet sparsely describe the scene. We initialize the scene with uniform 3D Gaussians and use surrounding-view images to progressively refine them to obtain the 3D Gaussian scene representation. We then use sparse convolutions to efficiently perform 3D perception (e.g., 3D detection, semantic map construction). We predict 3D flows for the Gaussians with dynamic semantics and plan the ego trajectory accordingly with an objective of future scene forecasting. Our GaussianAD can be trained in an end-to-end manner with optional perception labels when available. Extensive experiments on the widely used nuScenes dataset verify the effectiveness of our end-to-end GaussianAD on various tasks including motion planning, 3D occupancy prediction, and 4D occupancy forecasting. Code: https://github.com/wzzheng/GaussianAD.
基于视觉的自动驾驶技术因其出色的性能和较低的成本而展现出巨大的潜力。现有的大多数方法采用密集表示(例如鸟瞰图)或稀疏表示(例如实例框)进行决策,这需要在全面性和效率之间进行权衡。本文探索了以高斯为中心的端到端自动驾驶(GaussianAD)框架,并利用3D语义高斯值来广泛但稀疏地描述场景。我们使用统一的3D高斯值来初始化场景,并使用周围视图图像进行逐步细化,以获得3D高斯场景表示。然后,我们使用稀疏卷积有效地执行3D感知(例如3D检测、语义地图构建)。我们预测具有动态语义的高斯值的3D流,并根据未来场景预测的目标来规划自我轨迹。我们的GaussianAD可以在有可用感知标签的情况下以端到端的方式进行训练。在广泛使用的nuScenes数据集上的大量实验验证了我们的端到端GaussianAD在包括运动规划、3D占用预测和4D占用预测等各种任务上的有效性。代码地址:https://github.com/wzzheng/GaussianAD。
论文及项目相关链接
PDF Code is available at: https://github.com/wzzheng/GaussianAD
Summary
本文提出了一种基于高斯中心的端到端自动驾驶(GaussianAD)框架,利用3D语义高斯图来全面而简洁地描述场景。通过统一初始的3D高斯并利用周围视图图像进行逐步优化,实现了高效的3D感知和轨迹规划。GaussianAD具有潜力解决现有方法在表示场景时的全面性和效率之间的权衡问题。
Key Takeaways
- GaussianAD框架采用3D语义高斯来描述场景,旨在解决现有方法在决策过程中的全面性和效率之间的权衡问题。
- 该框架使用周围视图图像逐步优化初始的3D高斯图,形成场景的表示。
- 通过稀疏卷积实现高效的3D感知,如3D检测和语义地图构建。
- GaussianAD预测具有动态语义的3D流,并根据未来场景预测进行轨迹规划。
- 该框架可端到端地进行训练,当可用时,可以使用可选的感知标签。
- 在广泛使用的nuScenes数据集上进行的实验验证了GaussianAD在多种任务上的有效性,包括运动规划、3D占用预测和4D占用预测。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为GaussianAD的框架,旨在解决基于视觉的自动驾驶中的关键问题:如何设计一个既能全面描述场景又能保持计算效率的中间3D场景表示。具体来说,论文试图解决以下几个问题:
现有方法的局限性:大多数现有方法采用密集表示(例如,鸟瞰图)或稀疏表示(例如,实例框)进行决策,这些方法在全面性和效率之间存在权衡。密集表示能够捕获更多的细节,但计算成本高;而稀疏表示虽然计算效率高,但可能遗漏关键信息。
端到端自动驾驶的挑战:传统的自动驾驶研究通常将任务分解为感知、预测和规划模块,并分别训练它们。这种方法可能导致信息丢失,并且不同任务关注的信息不同,可能导致规划模块获得的信息不全面。
3D场景表示的设计:为了实现端到端自动驾驶,需要设计一个能够从2D图像中推断出3D结构信息的中间3D场景表示。这个表示需要能够在保持计算效率的同时,传递尽可能多的信息,以支持决策过程。
未来场景预测:为了提高自动驾驶的安全性,需要预测场景的未来发展,包括动态和静态元素的演变。现有的方法主要关注动态对象的运动预测,而GaussianAD提出了一种新的方法来预测包括动态和静态元素在内的整个场景的演变。
综上所述,GaussianAD框架通过使用3D语义高斯来稀疏但全面地描述场景,旨在提供一个既能有效保持细节又具有计算效率的3D场景表示,以提高端到端自动驾驶的性能。
Q: 有哪些相关研究?
A: 论文中提到了多个与自动驾驶相关的研究工作,涉及感知、预测和规划等多个方面。以下是一些主要的相关研究:
感知任务:
- 3D对象检测:[20, 31, 32, 42, 45, 62] 提出了多种基于视觉的3D对象检测方法。
- 语义地图重建:[30, 34, 38, 62] 研究了如何从视觉输入中恢复鸟瞰图(BEV)中的静态地图元素。
预测任务:
- 场景演变预测:[13, 16, 27, 37, 41, 58, 62] 专注于基于过去的位置和语义地图信息预测交通参与者的运动。
- 基于传感器输入的端到端运动预测:[13, 16, 27, 28, 62] 开始直接从传感器输入中探索运动预测。
规划任务:
- 基于规则的规划方法:[1, 12, 51] 提出了一些传统的基于规则的规划方法。
- 基于学习的规划方法:[8, 43, 46] 近年来,基于学习的方法因其在大规模训练数据上的潜力而受到越来越多的关注。
- 模仿学习规划器:[9, 14, 25, 26, 53, 65] 作为简单而有效的基于学习的解决方案,模仿学习规划器已成为端到端方法的首选。
3D表示和场景理解:
- 3D占用预测:[21, 49, 50, 55, 56, 66] 提出了多种3D占用预测方法,以更全面地描述包括动态和静态元素在内的周围场景。
- 3D语义高斯表示:[23] 提出了使用3D语义高斯来稀疏地表示场景,以便进行3D占用预测。
端到端自动驾驶方法:
- 直接从图像输入规划未来轨迹的方法:[18, 19, 28, 59, 64] 这些方法旨在减少从输入到输出的信息丢失。
这些相关研究构成了GaussianAD框架的研究背景,GaussianAD在此基础上进一步探索了如何使用3D语义高斯来实现端到端的自动驾驶,并在感知、预测和规划任务上进行了实验验证。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为GaussianAD的框架来解决上述问题,具体解决方案如下:
1. Gaussian-Centric Autonomous Driving Framework
- 3D Scene Representation:GaussianAD框架使用3D语义高斯(Gaussians)作为场景的中间表示方法。这些高斯分布在3D空间中,能够稀疏但全面地描述场景,既保持了信息的全面性,又维持了计算的高效性。
2. 初始化和优化3D Gaussians
- Uniform Initialization:初始场景用一组均匀分布的3D高斯来表示,然后通过周围视图图像逐步优化这些高斯,以获得3D高斯场景表示。
3. 利用稀疏卷积进行3D感知
- Sparse Convolution:利用稀疏卷积来高效执行3D感知任务,例如3D检测和语义地图构建。
4. 预测3D Flows
- Gaussian Flows:提出了3D高斯流的概念,用于全面和显式地建模场景演变,预测每个高斯的未来位移。
5. 规划自我轨迹
- Trajectory Planning:根据动态语义的3D流预测结果,相应地规划自我(ego)轨迹。
6. 端到端训练
- End-to-End Training:GaussianAD可以端到端地进行训练,并且在可用时可以选择性地使用感知标签进行训练。
7. 灵活性和适应性
- Flexibility:框架能够适应不同的数据,并且可以根据不同的可用注释来施加密集或稀疏的监督,以指导场景表示的学习过程。
8. 实验验证
- Experiments:通过在nuScenes数据集上进行广泛的实验,验证了GaussianAD框架在各种任务(包括运动规划、3D占用预测和4D占用预测)上的有效性。
总结
GaussianAD框架通过利用3D语义高斯作为中间表示,有效地平衡了信息的全面性和计算的效率。通过端到端的训练方式,该框架能够直接从图像输入预测未来的轨迹,减少了信息的丢失,并提高了自动驾驶系统的性能。此外,该框架的灵活性使其能够适应不同的训练数据和注释,进一步增强了其实用性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列的实验来评估GaussianAD框架的性能,实验主要围绕以下几个方面:
1. 数据集
- nuScenes 数据集:这是一个广泛使用的自动驾驶数据集,包含1000个驾驶序列,每个序列提供20秒的视频,由RGB和LiDAR传感器捕获。该数据集提供了2Hz的关键帧标注,包括用于语义地图构建和3D对象检测任务的标签。此外,SurroundOcc为nuScenes补充了3D语义占用的标注。
2. 评估指标
- L2位移误差:用于量化规划轨迹与真实轨迹之间的差异。
- 碰撞率:指示自动驾驶车辆按照规划路径行驶时与其他代理发生碰撞的频率。
3. 实施细节
- 模型架构:使用ResNet101-DCN作为骨干网络,并采用特征金字塔网络生成多尺度图像特征。
- 输入分辨率:输入图像分辨率为1600×900。
- 高斯数量:默认使用25600个高斯。
- 优化器和学习率:使用AdamW优化器,初始学习率为2e-4,按照余弦衰减策略调整。
4. 结果和分析
- 端到端规划结果:与现有的端到端自动驾驶模型进行比较,展示了GaussianAD在L2误差和碰撞率上的性能。
- 3D占用预测:评估了GaussianAD在3D对象检测和3D占用预测任务上的性能,使用了平均精度(mAP)和平均交并比(mIoU)作为指标。
- 4D占用预测:评估了GaussianAD在预测未来3D占用上的能力,测量了未来1s、2s和3s时刻的3D占用质量(mIoU和IoU)。
- 不同监督信号的效果:分析了使用不同辅助监督信号(如3D占用、3D检测、地图构建、运动预测和场景预测标签)对规划性能的影响。
- 高斯修剪:分析了进一步修剪高斯以减少冗余对性能的影响。
5. 可视化
- 结果展示:提供了GaussianAD在3D对象检测和规划任务中的可视化结果,展示了模型在多种场景下的有效性。
这些实验全面地评估了GaussianAD框架在不同任务上的性能,并与现有技术进行了比较,证明了其在端到端自动驾驶领域的有效性和竞争力。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些可以进一步探索的点,主要包括:
更大规模的端到端模型:
- 探索基于3D高斯场景表示的更大规模端到端模型,这些模型可以利用更多样化的数据进行训练。
提高场景演变预测的准确性:
- 目前GaussianAD无法准确预测新观察到的区域的演变,因此,改进场景演变预测是一个重要的研究方向。
多模态数据融合:
- 考虑融合更多类型的传感器数据(例如,雷达、激光雷达、摄像头等),以提高自动驾驶系统的整体性能和鲁棒性。
更复杂的场景和环境:
- 在更复杂、更具挑战性的场景中测试和改进GaussianAD框架,例如城市环境、高速公路等。
提高计算效率:
- 进一步优化算法和计算过程,以提高GaussianAD的计算效率,使其更适合实时应用。
增强模型的泛化能力:
- 通过在多样化的数据集上训练,增强模型对于不同地区、不同天气条件和不同交通状况的泛化能力。
更丰富的辅助监督信号:
- 探索使用更丰富的辅助监督信号,如交通规则、驾驶员行为数据等,以提高模型的预测和规划能力。
模型的可解释性和安全性:
- 提高模型的可解释性,确保自动驾驶决策过程的透明度和安全性。
模仿学习和强化学习的结合:
- 结合模仿学习和强化学习,利用专家演示和环境反馈来提高规划性能。
实时性能优化:
- 针对实时应用场景,优化模型的推理速度和资源消耗。
这些方向不仅可以推动GaussianAD框架的发展,也有助于自动驾驶技术的整体进步。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为GaussianAD的框架,旨在解决基于视觉的自动驾驶中如何设计一个全面且高效的3D场景表示问题。以下是论文的主要内容总结:
1. 问题背景
- 自动驾驶系统需要从视觉输入中推断出3D结构信息,并在决策过程中保持信息的全面性和计算的效率。
2. GaussianAD框架
- 采用3D语义高斯来稀疏但全面地描述场景,平衡了信息的全面性和计算效率。
- 利用稀疏卷积进行3D感知任务,如3D检测和语义地图构建。
- 提出3D高斯流以全面显式地建模场景演变,预测每个高斯的未来位移。
- 根据动态语义的3D流预测结果规划自我轨迹。
3. 端到端训练
- GaussianAD可以端到端地进行训练,并且在可用时可以选择性地使用感知标签进行训练。
4. 实验验证
- 在nuScenes数据集上进行了广泛的实验,验证了GaussianAD框架在运动规划、3D占用预测和4D占用预测等任务上的有效性。
- 与现有技术相比,GaussianAD在端到端规划任务上展现了竞争性能。
5. 灵活性和适应性
- 框架能够适应不同的数据,并且可以根据不同的可用注释来施加密集或稀疏的监督。
6. 进一步探索的点
- 探索基于3D高斯场景表示的更大规模端到端模型。
- 提高场景演变预测的准确性。
- 考虑多模态数据融合和更复杂的场景环境。
- 提高模型的泛化能力、可解释性和安全性。
总体而言,GaussianAD通过其创新的3D高斯表示和端到端训练方法,为自动驾驶领域提供了一个新的视角,展示了在多个自动驾驶关键任务上的应用潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

SuperGSeg: Open-Vocabulary 3D Segmentation with Structured Super-Gaussians
Authors:Siyun Liang, Sen Wang, Kunyi Li, Michael Niemeyer, Stefano Gasperini, Nassir Navab, Federico Tombari
3D Gaussian Splatting has recently gained traction for its efficient training and real-time rendering. While the vanilla Gaussian Splatting representation is mainly designed for view synthesis, more recent works investigated how to extend it with scene understanding and language features. However, existing methods lack a detailed comprehension of scenes, limiting their ability to segment and interpret complex structures. To this end, We introduce SuperGSeg, a novel approach that fosters cohesive, context-aware scene representation by disentangling segmentation and language field distillation. SuperGSeg first employs neural Gaussians to learn instance and hierarchical segmentation features from multi-view images with the aid of off-the-shelf 2D masks. These features are then leveraged to create a sparse set of what we call Super-Gaussians. Super-Gaussians facilitate the distillation of 2D language features into 3D space. Through Super-Gaussians, our method enables high-dimensional language feature rendering without extreme increases in GPU memory. Extensive experiments demonstrate that SuperGSeg outperforms prior works on both open-vocabulary object localization and semantic segmentation tasks.
3D高斯贴图技术因其高效的训练和实时渲染功能而近期受到广泛关注。虽然基本的高斯贴图表示主要用于视图合成,但近期的研究调查了如何将其与场景理解和语言特征相结合。然而,现有方法缺乏对场景的详细理解,限制了它们在复杂结构分割和解释方面的能力。为此,我们引入了SuperGSeg,这是一种通过分离分割和语言场蒸馏来形成连贯、上下文感知的场景表示的新方法。SuperGSeg首先使用神经高斯从多视角图像中学习实例和层次分割特征,借助现成的2D掩膜。然后,利用这些特征创建我们所谓的超级高斯稀疏集。超级高斯有助于将2D语言特征蒸馏到3D空间。通过超级高斯,我们的方法能够在不增加GPU内存的情况下实现高维语言特征的渲染。大量实验表明,SuperGSeg在开放词汇对象定位和语义分割任务上的性能优于以前的工作。
论文及项目相关链接
PDF 13 pages, 8 figures
Summary
本文介绍了SuperGSeg,一种基于3D高斯喷绘技术的新型场景表示方法。SuperGSeg通过神经高斯学习实例和层次分割特征,结合多视角图像和现成的二维掩膜,实现场景内各物体的分割与理解。在此基础上,SuperGSeg利用所谓的超级高斯将二维语言特征蒸馏到三维空间,实现了高效的语言特征渲染,而不会过度增加GPU内存负担。实验表明,SuperGSeg在开放词汇对象定位和语义分割任务上均优于先前的方法。
Key Takeaways
- SuperGSeg是一种基于3D高斯喷绘技术的场景表示方法。
- 它通过神经高斯学习实例和层次分割特征,结合多视角图像进行场景理解。
- SuperGSeg利用二维掩膜创建所谓的超级高斯,实现语言特征从二维到三维的蒸馏。
- 该方法能够在不增加过多GPU内存负担的情况下,实现高效的语言特征渲染。
- SuperGSeg在开放词汇对象定位和语义分割任务上表现出优异性能。
- 该方法提高了场景理解的详细程度,增强了分割和解释复杂结构的能力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为SuperGSeg的新方法,旨在解决3D场景理解中的几个关键问题:
开放词汇的3D分割(Open-Vocabulary 3D Segmentation):传统的3D Gaussian Splatting(3DGS)主要用于视图合成,而SuperGSeg旨在扩展3DGS框架以实现开放词汇理解,允许通过基于语言的查询与渲染场景进行交互。
复杂结构的详细理解(Detailed Comprehension of Complex Structures):现有方法在理解和解释复杂场景时存在局限性,SuperGSeg通过将分割和语言领域蒸馏分离,促进了具有凝聚力和上下文感知的场景表示。
高维语言特征的有效渲染(Efficient Rendering of High-Dimensional Language Features):SuperGSeg通过引入Super-Gaussians(结构化超高斯)来支持高维语言特征的渲染,而不显著增加GPU内存需求。
多特征场的集成(Integration of Diverse Feature Fields):SuperGSeg整合了多种特征场,包括实例分割特征和层次分割特征,以实现对3D场景的全面理解。
实时渲染和高效训练(Efficient Training and Real-time Rendering):3DGS因其在实时渲染和高效训练方面的优势而受到关注,SuperGSeg在此基础上进一步增强了这些属性,使其更适合广泛的应用,如3D重建、内容生成和场景理解。
总的来说,SuperGSeg通过引入Super-Gaussians这一新概念,有效地整合了多种特征场,并支持开放词汇的语义分割、实例分割和层次分割等多种功能,提高了对复杂3D场景的分割和理解能力。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与SuperGSeg相关的研究工作:
3D Gaussian Splatting (3DGS) [1]:
- 引入了一种新的3D场景显式表示方法,通过一组3D高斯来优化位置和外观,实现高质量的实时渲染。
Neural Radiance Fields (NeRF) [2]:
- 结合了神经隐式表示和可微分体积渲染,对3D场景进行建模。
ScaffoldGS [20]:
- 引入了一种层次化、区域感知的3D场景表示方法,使用锚点和神经高斯来改进渲染质量和重建性能。
LERF [21] 和相关方法 [22]-[24]:
- 将语言特征嵌入到3D空间中,以实现交互式开放词汇分割。
SPInNeRF [25] 和 SA3D [26]:
- 通过视频分割初始化2D掩码,并将它们提升到3D,然后进行多视图细化以实现一致的3D分割。
OmniSeg3D [27]:
- 一种通用的3D分割方法,将不一致的2D分割转换为全局一致的3D特征场。
LangSplat [7]:
- 利用场景特定的语言自编码器学习场景特定的语言特征,提供清晰的对象边界区分。
Feature3DGS [9]:
- 引入了一个并行的N维高斯光栅器,用于为场景编辑和分割等任务提取高维特征。
Gaussian Grouping [10]:
- 执行联合3D重建和分割开放世界对象,由基于SAM的2D掩码预测和3D空间约束引导。
OpenGaussian [11]:
- 增强了3DGS在3D点级别的开放词汇理解,将高维、无损的CLIP特征与3D高斯关联,实现一致的学习和独特特征。
这些相关工作涵盖了3D场景表示、语义分割、实例分割和开放词汇理解等领域,为SuperGSeg提供了理论和技术基础。SuperGSeg在此基础上进一步发展,通过引入Super-Gaussians概念,实现了更细粒度的场景理解和更高效的特征场整合。
Q: 论文如何解决这个问题?
A: 论文通过提出SuperGSeg方法解决了上述问题,具体解决方案如下:
1. 引入Super-Gaussians
SuperGSeg首先使用神经高斯(neural Gaussians)来学习从多视图图像中的实例和层次分割特征。然后,利用这些特征创建一组稀疏的Super-Gaussians,这些Super-Gaussians基于空间和实例特征对高斯进行聚类,从而允许对场景进行鲁棒表示。
2. 多特征场的整合
SuperGSeg整合了多种特征场,包括从2D基础模型中学习到的实例分割特征和层次分割特征。这些特征被用来创建Super-Gaussians,进而使得高维语言特征得以嵌入到3D空间中,实现了复杂场景的丰富语义细节表示。
3. 高维语言特征的有效渲染
通过Super-Gaussians,SuperGSeg支持将高维语言特征渲染到3D空间中,而不会极端增加GPU内存需求。这使得SuperGSeg能够在保持语言信息的同时,增强复杂场景的结构完整性。
4. 分阶段训练
SuperGSeg的训练分为三个阶段:
- 第一阶段:使用RGB图像和由SAM生成的分割掩码来训练外观和分割特征。
- 第二阶段:利用分割特征和它们的空间位置生成Super-Gaussians,并进行训练。
- 第三阶段:训练Super-Gaussians中的高维语言特征,使用CLIP的2D特征图进行训练。
5. 对比学习
SuperGSeg使用对比学习来维持多视图一致性,并优化实例和层次特征场。这有助于在不同视图间保持特征的一致性,同时区分不同实例和部分。
6. 实验验证
通过在LERF-OVS和ScanNet数据集上进行广泛的实验,论文证明了SuperGSeg在开放词汇的3D对象级别和场景级别语义分割任务上相较于先前工作的优越性,特别是在捕获细粒度场景细节和密集像素语义分割任务上。
总结来说,SuperGSeg通过结合神经高斯、Super-Gaussians和高维语言特征渲染,提出了一种新的3D分割方法,有效地解决了开放词汇3D分割和复杂场景理解的问题。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证SuperGSeg方法的有效性,具体实验包括:
数据集
- ScanNet v2:包含了室内场景的RGBD图像和2D语义标签。论文从中随机选择了8个场景,用于训练和测试。
- LERF-OVS:是LERF数据集的扩展,包含了复杂户外场景的图像,并且标注了用于开放词汇3D语义分割和对象定位的文本查询的ground truth掩码。
基线和指标
- 基线方法:与三种基于高斯光栅的最近方法进行比较:LangSplat [7]、LEGaussian [8] 和 OpenGaussian [11]。
- 评估指标:对于开放词汇对象选择任务,使用与[11]中类似的策略进行评估。对于开放词汇语义分割任务,计算了20个类别的mIoU(平均交并比)和mAcc(平均准确度)。
实验设置
- SAM ViT-H模型:用于从输入图像中生成2D掩码,并提取每个实例掩码的语言特征。
- 训练过程:分为三个阶段,分别训练Scaffold-GS、SuperGaussian聚类网络和优化SuperGaussian的语言特征。
ScanNet数据集上的实验
- 定量结果:SuperGSeg在多个对象类别上取得了显著的平均mIoU和mAcc,显示出在捕获开放词汇语义信息方面的优越性能。
- 定性结果:SuperGSeg生成的分割掩码比先前的方法更精确,尤其是在处理遮挡时。
LERF-OVS数据集上的实验
- 定量结果:尽管OpenGaussian在某些类别上表现更好,但SuperGSeg在整体场景理解上保持了竞争优势,特别是在复杂环境中。
- 定性结果:SuperGSeg在3D空间中实现了更精确的3D定位,并产生了更清晰的边界。
多粒度分割
- 跨级别和跨帧分割:展示了SuperGSeg如何使用基于点击的视觉提示进行3D场景的多粒度分割。
消融研究
- SuperGaussian的必要性:通过消融研究验证了SuperGaussian在3D空间中理解的优势。
- 不同特征的影响:评估了仅使用坐标和几何特征与结合实例和层次特征对SuperGaussian学习的影响。
- 参数选择:研究了SuperGaussian属性更新器中涉及的参数,如SuperGaussian的总数和每个锚点考虑的邻近SuperGaussian的数量。
这些实验全面评估了SuperGSeg在开放词汇3D分割任务中的性能,并与现有方法进行了比较,证明了其在3D场景理解和分割方面的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和补充材料,以下是一些可以进一步探索的点:
1. 减少对原始视觉基础模型的依赖
- 论文提到SuperGSeg继承了原始视觉基础模型的偏差,这可能限制了其在多样化或未见过场景中的泛化能力。未来的工作可以探索减少这种依赖,提高模型泛化能力的方法。
2. 提高模型的可扩展性和适应性
- SuperGSeg目前针对特定场景的语言表示进行了优化,这限制了其在野外场景理解等需要快速适应或广泛泛化的任务中的应用。未来的研究可以集中在优化训练流程,提高模型的可扩展性和适应性。
3. 改进Super-Gaussians的生成和更新方法
- 论文中提到了使用不同的方法(如KMeans和VCCS)来生成Super-Gaussians,并发现这些方法存在局限性。未来的工作可以探索更有效的Super-Gaussians生成和更新方法,以提高模型性能。
4. 增强模型对遮挡的处理能力
- 在处理复杂场景时,遮挡是一个挑战。未来的研究可以集中在改进模型对遮挡的处理能力,以提高分割的准确性。
5. 多模态输入的融合
- 考虑将更多的模态(如深度信息、红外图像等)融入模型,以提高对3D场景的理解和分割能力。
6. 实时性能的优化
- 尽管SuperGSeg在实时渲染方面取得了进展,但在实际应用中,进一步提高模型的实时性能仍然是一个重要的研究方向。
7. 跨领域应用的探索
- 探索SuperGSeg在其他领域的应用,如自动驾驶、机器人导航、增强现实等,这些领域对3D场景理解有很高的要求。
8. 模型解释性的增强
- 提高模型的可解释性,使得用户能够更好地理解模型的决策过程,这对于提高用户对模型的信任和接受度至关重要。
9. 模型的鲁棒性和泛化能力的测试
- 在更多样化的数据集上测试模型的鲁棒性和泛化能力,包括不同光照条件、不同场景复杂度等。
10. 与现有技术的集成
- 探索将SuperGSeg与现有的3D建模和渲染技术(如NeRF)集成,以实现更高质量的3D场景重建和渲染。
这些方向不仅可以推动SuperGSeg技术的发展,还可能为3D场景理解和分割领域带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了SuperGSeg,一种用于3D场景分割的新方法,主要贡献和内容可以总结如下:
1. 问题定义
- 开放词汇的3D分割:SuperGSeg旨在扩展3D Gaussian Splatting(3DGS)框架,以实现开放词汇的3D场景理解,允许通过语言查询与渲染场景进行交互。
- 复杂结构理解:现有方法在理解和解释复杂3D结构方面存在局限性,SuperGSeg通过分离分割和语言特征蒸馏来提升场景表示能力。
2. 方法介绍
- Super-Gaussians:提出了Super-Gaussians概念,通过聚类相似的高斯来创建结构化、稀疏的3D表示,支持高维语言特征的渲染。
- 多特征场整合:整合了从2D基础模型学习到的实例和层次分割特征,创建Super-Gaussians,实现复杂场景的丰富语义细节表示。
- 分阶段训练:训练分为三个阶段,分别训练外观和分割特征、Super-Gaussian聚类和高维语言特征。
3. 实验验证
- 数据集:在ScanNet v2和LERF-OVS数据集上进行实验。
- 定量结果:在多个类别上取得了优于现有方法的平均mIoU和mAcc,显示出在捕获开放词汇语义信息方面的优越性能。
- 定性结果:生成的分割掩码比先前方法更精确,尤其是在处理遮挡时。
4. 多粒度分割
- 跨级别和跨帧分割:展示了SuperGSeg如何使用基于点击的视觉提示进行3D场景的多粒度分割。
5. 消融研究
- SuperGaussian的必要性:通过消融研究验证了SuperGaussian在3D空间中理解的优势。
- 不同特征的影响:评估了仅使用坐标和几何特征与结合实例和层次特征对SuperGaussian学习的影响。
6. 结论
- SuperGSeg通过利用神经高斯和Super-Gaussians,有效地整合了多种特征场,并支持开放词汇的语义分割、实例分割和层次分割等多种功能,提高了对复杂3D场景的分割和理解能力。
7. 未来工作
- 论文讨论了SuperGSeg的局限性,并提出了未来可能的研究方向,包括减少对原始视觉基础模型的依赖、提高模型的可扩展性和适应性等。
总的来说,SuperGSeg通过引入Super-Gaussians这一新概念,有效地整合了多种特征场,并支持开放词汇的语义分割、实例分割和层次分割等多种功能,提高了对复杂3D场景的分割和理解能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

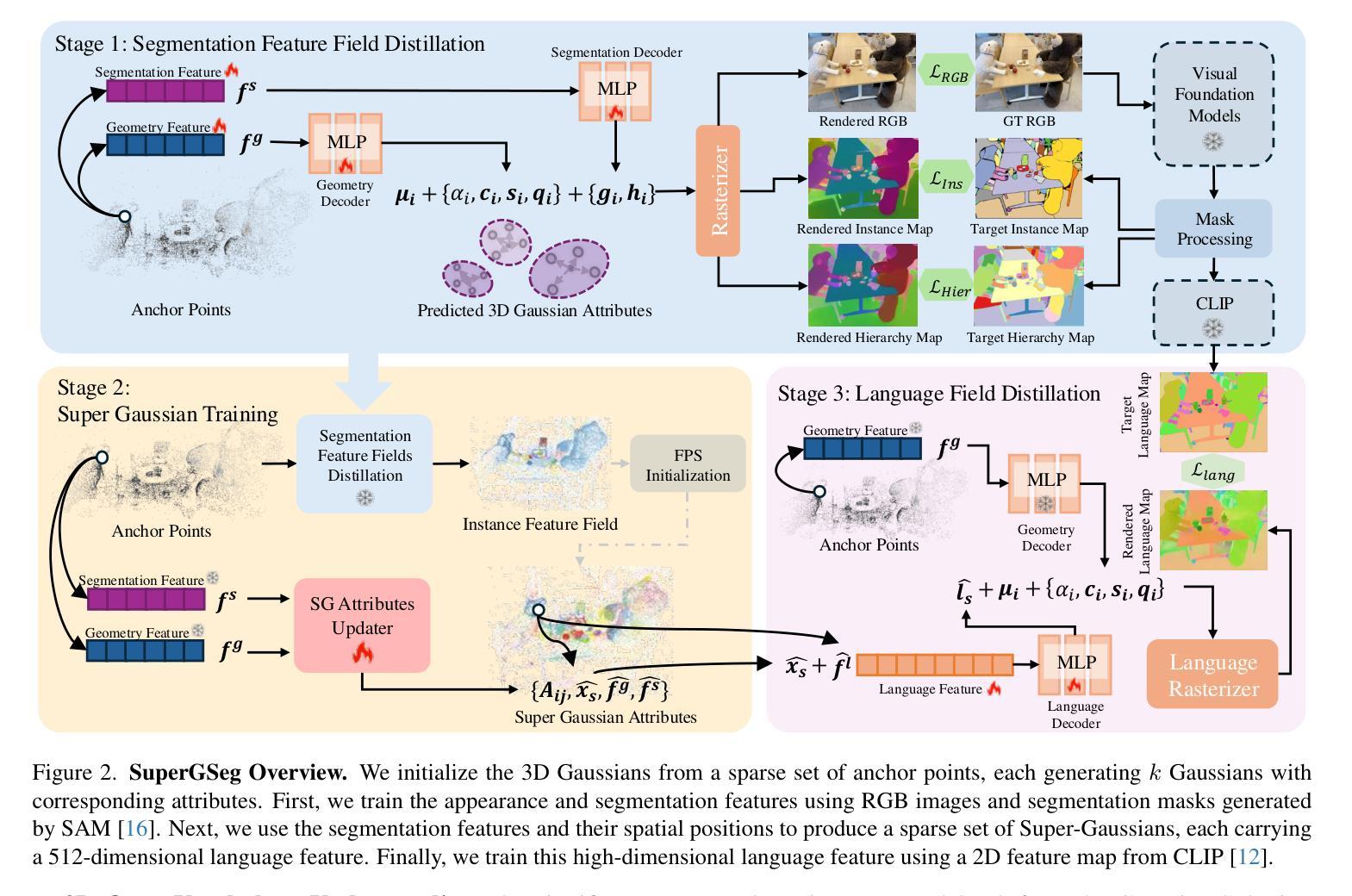

GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion
Authors:Jiapeng Tang, Davide Davoli, Tobias Kirschstein, Liam Schoneveld, Matthias Niessner
We propose a novel approach for reconstructing animatable 3D Gaussian avatars from monocular videos captured by commodity devices like smartphones. Photorealistic 3D head avatar reconstruction from such recordings is challenging due to limited observations, which leaves unobserved regions under-constrained and can lead to artifacts in novel views. To address this problem, we introduce a multi-view head diffusion model, leveraging its priors to fill in missing regions and ensure view consistency in Gaussian splatting renderings. To enable precise viewpoint control, we use normal maps rendered from FLAME-based head reconstruction, which provides pixel-aligned inductive biases. We also condition the diffusion model on VAE features extracted from the input image to preserve details of facial identity and appearance. For Gaussian avatar reconstruction, we distill multi-view diffusion priors by using iteratively denoised images as pseudo-ground truths, effectively mitigating over-saturation issues. To further improve photorealism, we apply latent upsampling to refine the denoised latent before decoding it into an image. We evaluate our method on the NeRSemble dataset, showing that GAF outperforms the previous state-of-the-art methods in novel view synthesis by a 5.34% higher SSIM score. Furthermore, we demonstrate higher-fidelity avatar reconstructions from monocular videos captured on commodity devices.
我们提出了一种从智能手机等普通设备捕获的单目视频中重建可动画的3D高斯半身像的新方法。由于观测有限,从这样的记录中重建逼真的三维头像半身像是一项挑战,有限的观测会导致未观测区域约束不足,并在新视角中产生伪影。为了解决这个问题,我们引入了一种多视角头部扩散模型,利用先验知识来填充缺失区域并确保高斯贴片渲染中的视图一致性。为了实现精确的视点控制,我们使用基于FLAME的头部重建渲染的正态图,这提供了像素对齐的归纳偏置。我们还根据从输入图像中提取的VAE特征对扩散模型进行条件处理,以保留面部身份和外观的细节。对于高斯半身像重建,我们通过使用迭代去噪图像作为伪真实值来提炼多视角扩散先验,有效地缓解了过饱和问题。为了进一步改善逼真度,我们应用潜在上采样来细化去噪的潜在代码,然后将其解码为图像。我们在NeRSemble数据集上评估了我们的方法,结果表明GAF在新型视角合成方面的表现优于先前最先进的方法,提高了5.34%的SSIM得分。此外,我们还展示了从普通设备的单目视频中重建的高保真半身像。
论文及项目相关链接
PDF Paper Video: https://youtu.be/QuIYTljvhyg Project Page: https://tangjiapeng.github.io/projects/GAF
Summary
一种全新的方法被提出,该方法可以从普通设备如智能手机拍摄的单目视频中重建出动态的3D高斯头像。该方法面临从这种视频重建出逼真的3D头像的挑战,由于观测受限,一些未观测到的区域缺乏约束,导致新的视角出现伪影。为解决这个问题,研究引入了一个多视角头部扩散模型,利用其先验知识填充缺失区域并确保高斯平铺渲染中的视角一致性。为了提供更精确的视角控制,该研究使用基于FLAME的头部重建所渲染的法线图,为像素对齐提供归纳偏置。此外,该研究将扩散模型调节至从输入图像中提取的VAE特征上,以保留面部身份和外观的细节。对于高斯头像重建,研究通过利用去噪图像作为伪真实值来提炼多视角扩散先验知识,有效地减轻了过度饱和问题。为进一步提高逼真度,研究应用潜在上采样来精细化去噪潜在代码,然后将其解码成图像。
Key Takeaways
- 提出了一种从单目视频重建动态3D高斯头像的新方法。
- 面临从普通设备拍摄的视频中重建逼真3D头像的挑战。
- 采用多视角头部扩散模型,利用先验知识填充缺失区域并确保视角一致性。
- 利用基于FLAME的头部重建的法线图提供精确视角控制。
- 将扩散模型调节至输入图像的VAE特征,以保留面部细节。
- 通过去噪图像作为伪真实值提炼多视角扩散先验知识。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种新的方法,旨在解决从由普通设备(如智能手机)拍摄的单目视频中重建可动画化的3D高斯头像的问题。具体来说,论文试图解决以下几个挑战:
有限观测导致的约束不足:单目视频由于观测角度有限,导致对头像的不可见区域(如侧面)的重建不足,这会在新视角渲染时产生伪影。
新视角一致性:如何确保从单目视频重建的头像在新视角下渲染时,能够保持外观和身份的一致性。
真实感渲染:从单目视频中重建的头像在新视角下渲染时,如何保持照片级真实感。
为了解决这些问题,论文提出了一种基于多视角头部扩散模型的方法,利用该模型的先验知识来填补缺失区域,并确保在高斯绘制渲染中的视角一致性。此外,论文还引入了从FLAME基础头部重建中渲染的正常图来提供精确的视点控制,并使用从输入图像中提取的VAE特征来保持面部身份和外观的细节。通过迭代去噪图像作为伪真实值,有效缓解了过饱和问题,并应用潜在上采样来提高头像重建的保真度。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的工作:
3D场景表示:
- **Neural Radiance Fields (NeRF)**及其变体:这些方法彻底改变了从多视图图像重建3D场景的方式,但通常在训练和推理阶段计算效率低下。
- **Gaussian Splatting (GS)**:与NeRF相比,GS通过将场景表示为离散的几何原语(3D高斯)并使用显式光栅化器进行渲染,在训练和推理阶段实现了显著的运行速度提升。
参数化面部/头部模型:
- 基于3D形态模型(3DMM)的工作学习从单RGB图像/视频中重建和跟踪3D面部/头部。
- 更近期的方法使用基于坐标的多层感知机(coordinate-MLPs)来实现更细粒度的几何重建,包括头发和胡须。
真实感头像重建:
- 将NeRF/GS与3D形态模型(3DMM)结合起来,以创建真实感和可动画化的头部头像。
- 一些工作探索了基于点的表示以实现高效的训练。
2D先验知识用于3D生成:
- 通过使用Score Distillation Sampling (SDS)损失,可以将大规模预训练的文本到图像先验用于3D资产生成。
多视角扩散模型:
- 一些工作学习图像条件的新视角扩散先验,利用输入图像的身份和外观细节来生成一致的新视角图像。
与Gaussian Splatting相关的工作:
- 将高斯绘制与FLAME网格结合起来,通过三角形变形控制高斯绘制的属性,以实现头像的动画化。
这些相关工作涵盖了3D场景重建、参数化模型、真实感头像生成、2D到3D的转换以及多视角图像生成等领域,为本研究提供了理论和技术基础。论文通过结合这些相关技术,提出了一种新的方法来从单目视频中重建3D高斯头像,并在新视角下进行真实感渲染。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤解决了从单目视频中重建3D高斯头像的问题:
1. 多视角头部扩散模型
论文提出了一个多视角头部扩散模型,该模型能够从单一视图输入生成一致的多视角图像。这个模型利用了扩散先验来填补单目视频中缺失的区域,并确保在高斯绘制渲染中的视角一致性。
2. 正常图引导
为了实现精确的视点控制,论文使用从FLAME头部重建渲染的正常图作为扩散过程的引导。与相机姿态嵌入相比,正常图提供了更强的归纳偏置,从而实现更精确和可靠的新视角生成。
3. VAE特征融合
论文将从输入图像中提取的VAE特征直接整合到多视角扩散模型中。通过在多视角去噪潜在空间和VAE潜在空间之间进行交叉注意力操作,有效地传递了特定身份的细节。
4. 迭代去噪图像作为伪真实值
为了利用多视角扩散先验进行高斯头部重建,论文采用了迭代去噪图像作为伪真实值,而不是单步得分蒸馏采样损失。这种方法可以减少由于随机噪声水平和种子引入的噪声梯度,从而缓解合成3D资产中的过饱和问题。
5. 潜在上采样模型
为了提高高斯渲染的真实感,论文引入了一个潜在上采样模型,在将去噪潜在空间解码回图像空间之前增强面部细节。
6. 损失函数
论文通过组合损失函数来优化高斯绘制,包括像素级L1损失、SSIM损失和LPIPS损失,以及用于惩罚异常分布的高斯的位置和尺度正则化项。
7. 实现细节
论文详细描述了多视角头部扩散模型的训练过程,包括初始化、训练策略和训练数据集的构建。此外,还提供了高斯头像优化的具体实现细节,如FLAME网格的初始获取、可动画高斯的优化过程以及运行时性能。
通过这些方法,论文能够有效地从单目视频中重建出真实感和可动画化的3D高斯头像,并在新视角下进行高质量的渲染。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了以下实验:
数据集
- NeRSemble 数据集:用于头部头像重建实验的多视角视频数据集,包含16个视角的RGB视频序列,覆盖了正面和侧面的脸部。
- Monocular Video 数据集:包含从 INSTA 数据集和智能手机捕获的单目视频,用于评估在普通设备上捕获的视频的头像重建效果。
评估指标
- L1损失、LPIPS、PSNR 和 SSIM:用于量化评估重建头像与真实头像之间的相似度。
实验设置
- 新视角合成:评估重建的头像在训练期间看到的头部姿势和表情下,从15个保留的视点渲染的效果。
- 新表情合成:评估重建的头像在训练期间未见的头部姿势和表情下,从5个附近的保留视点渲染的效果。
基线比较
- INSTA、FlashAvatar 和 GaussianAvatars:与三种最先进的方法进行比较。
实验结果
- 定量比较:在 NeRSemble 数据集上,论文的方法在新视角合成任务中超过了所有基线方法,特别是在 PSNR 和 SSIM 指标上取得了显著提升。
- Monocular Video 数据集:由于缺乏单目捕获的真实视角渲染的地面真实数据,只进行了动画效果的定量评估,论文的方法在所有指标上均优于其他方法。
消融研究
- 对多视角头部扩散先验、正常图条件、迭代去噪图像作为伪真实值以及潜在上采样模块等设计选择进行了详细的消融研究,验证了每个组件的有效性。
鲁棒性分析
- 分析了输入单目视频帧数对重建性能的影响,证明了即使在输入帧数较少的情况下,论文的方法也能保持稳定的性能。
额外比较
- 提供了额外的定性比较,包括新视角合成、自我/交叉重演以及不同输入帧数下的鲁棒性分析。
这些实验全面评估了论文提出方法的有效性,并与现有技术进行了比较,同时也探讨了不同设计选择对性能的影响。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和当前的研究进展,以下是一些可以进一步探索的点:
1. 头发建模和动画
当前的参数化头部模型缺乏详细的头发几何形状和动画。未来的工作可以扩展高斯头部头像以包含细粒度的头发建模和动画。
2. 实时4D头像重建
论文提到优化头部高斯使用迭代更新的伪真实值从扩散模型是耗时的。探索实时4D头像重建与前馈大型重建模型可能是一个有价值的研究方向。
3. 材料和外观分离
论文没有明确区分头部的材料和外观,这可能限制了重新照明应用。研究如何分离材料和外观,以支持更多动态的光照和渲染效果。
4. 更广泛的数据集和场景
目前的实验主要基于特定的数据集和受控环境。将方法扩展到更多样化的数据集和更复杂、更自然的场景中,以提高泛化能力。
5. 交互式应用和VR/AR集成
研究如何将头像重建技术集成到交互式应用和虚拟现实(VR)/增强现实(AR)产品中,以提高用户体验。
6. 性能优化和硬件加速
探索新的方法来优化算法性能,减少内存使用和计算时间,使其更适合在资源受限的设备上运行。
7. 更多的先验知识融合
研究如何融合更多的先验知识(如形状先验、表情先验等)到模型中,以提高重建质量和鲁棒性。
8. 多模态输入
考虑将更多的模态(如深度信息、IR图像等)整合到重建流程中,以提供更丰富的输入信息。
9. 伦理和隐私问题
随着技术的发展,进一步探讨与真实感头像生成相关的伦理和隐私问题,确保技术的负责任使用。
10. 用户自定义和编辑能力
研究如何提供用户自定义和编辑头像的能力,以满足个性化需求和创意表达。
这些探索点可以帮助推动3D头像重建技术的发展,并在更广泛的应用中实现其潜力。
Q: 总结一下论文的主要内容
A: 本论文提出了一种从单目视频中重建可动画化的3D高斯头像的新方法,旨在解决由于观测限制导致的重建难题。以下是论文的主要内容总结:
1. 问题定义
- 从普通设备(如智能手机)捕获的单目视频中重建真实感和可动画化的3D头部头像存在挑战,因为有限的观测会导致未观测区域的重建不足,从而在新视角渲染时产生伪影。
2. 关键思想
- 利用多视角头部扩散模型的先验知识来填补单目视频中缺失的区域,并确保在高斯绘制渲染中的视角一致性。
3. 方法论
- 多视角头部扩散模型:通过迭代去噪图像作为伪真实值,生成与输入图像视角一致的多视角图像。
- 正常图引导:使用FLAME头部重建渲染的正常图进行视点控制,提供精确的新视角生成。
- VAE特征融合:将输入图像的VAE特征整合到扩散模型中,以保持面部身份和外观的细节。
- 潜在上采样模型:在将去噪潜在空间解码回图像空间之前增强面部细节,提高渲染的真实感。
4. 实验
- 在NeRSemble数据集和Monocular Video数据集上进行实验,与现有技术进行比较,证明了该方法在新视角合成和新表情合成方面的优越性。
- 进行了消融研究,验证了多视角扩散先验、正常图条件、迭代去噪图像和潜在上采样模块的有效性。
- 进行了鲁棒性分析,展示了该方法对输入视频帧数变化的鲁棒性。
5. 贡献
- 提出了一种新的方法,使用多视角头部扩散先验从单目视频中重建真实感和可动画化的头部头像。
- 提出了一种多视角头部扩散模型,从单一视图输入生成一致的多视角图像,改善了视点控制。
- 通过整合潜在上采样和多视角扩散先验,提高了高斯绘制的跨视角一致性和真实感。
6. 未来工作和局限性
- 论文讨论了当前方法的局限性,如缺乏头发建模和动画、优化过程耗时以及受限于参数化头部模型的表达能力。
- 提出了未来可能的研究方向,包括头发建模、实时4D头像重建和性能优化等。
总体而言,这项工作通过引入多视角扩散先验和潜在上采样,显著提高了从单目视频中重建3D高斯头像的质量,为虚拟现实和增强现实应用中的真实感头像创建提供了新的可能性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

TSGaussian: Semantic and Depth-Guided Target-Specific Gaussian Splatting from Sparse Views
Authors:Liang Zhao, Zehan Bao, Yi Xie, Hong Chen, Yaohui Chen, Weifu Li
Recent advances in Gaussian Splatting have significantly advanced the field, achieving both panoptic and interactive segmentation of 3D scenes. However, existing methodologies often overlook the critical need for reconstructing specified targets with complex structures from sparse views. To address this issue, we introduce TSGaussian, a novel framework that combines semantic constraints with depth priors to avoid geometry degradation in challenging novel view synthesis tasks. Our approach prioritizes computational resources on designated targets while minimizing background allocation. Bounding boxes from YOLOv9 serve as prompts for Segment Anything Model to generate 2D mask predictions, ensuring semantic accuracy and cost efficiency. TSGaussian effectively clusters 3D gaussians by introducing a compact identity encoding for each Gaussian ellipsoid and incorporating 3D spatial consistency regularization. Leveraging these modules, we propose a pruning strategy to effectively reduce redundancy in 3D gaussians. Extensive experiments demonstrate that TSGaussian outperforms state-of-the-art methods on three standard datasets and a new challenging dataset we collected, achieving superior results in novel view synthesis of specific objects. Code is available at: https://github.com/leon2000-ai/TSGaussian.
最近高斯摊铺技术的进展极大地推动了该领域的发展,实现了对三维场景的全景和交互式分割。然而,现有方法往往忽视了从稀疏视角重建具有复杂结构指定目标的关键需求。为了解决这一问题,我们引入了TSGaussian,这是一个结合语义约束和深度先验的新型框架,以避免在具有挑战性的新型视图合成任务中出现几何退化。我们的方法在计算资源上优先考虑指定目标,同时最小化背景分配。YOLOv9的边界框作为提示信号,提示分割任何事情模型生成二维蒙版预测,确保语义准确性和成本效益。TSGaussian通过为每个高斯椭球引入紧凑的身份编码并融入三维空间一致性正则化,有效地聚集了三维高斯。利用这些模块,我们提出了一种有效的剪枝策略,以减少三维高斯中的冗余。大量实验表明,TSGaussian在三个标准数据集和我们收集的新挑战数据集上的表现优于最先进的方法,在特定对象的新型视图合成方面取得了优越的结果。代码可在以下网址找到:https://github.com/leon2000-ai/TSGaussian。
论文及项目相关链接
Summary
近期高斯融合技术的进展推动了全景及交互式三维场景分割的发展。为解决现有方法在稀疏视角对复杂结构目标重建中的不足,提出TSGaussian框架,结合语义约束和深度先验,优化指定目标的重建,避免几何退化问题。该框架采用YOLOv9的边界框为分割任务模型生成语义精确的二维掩模预测,同时利用紧凑的身份编码及三维空间一致性正则化实现高斯聚类。基于此框架设计冗余缩减策略,有效提高三维高斯数据的处理效率。TSGaussian在多个数据集上的表现优于现有技术,特别是在特定对象的新视角合成方面表现卓越。更多信息可访问:github链接。
Key Takeaways
- TSGaussian框架解决了现有方法在稀疏视角对复杂结构目标重建中的不足。
- 结合语义约束和深度先验,避免在新型视角合成任务中的几何退化问题。
- 采用YOLOv9的边界框为分割任务模型生成精确的二维掩模预测。
- 通过紧凑的身份编码实现高斯聚类,提高数据处理效率。
- 引入三维空间一致性正则化,优化指定目标的重建质量。
- 提出冗余缩减策略,减少三维高斯数据中的冗余信息。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在稀疏视图条件下,如何有效地重建具有复杂结构的特定目标的三维(3D)场景。具体来说,论文中提到现有方法在以下几个方面存在挑战:
特定目标的重建:现有的方法通常难以在复杂环境中隔离特定目标并保持语义一致性,避免几何退化。
计算资源优化:在保持重建场景质量的同时优化计算资源是一个重大挑战。
稀疏视图下的重建:对于特定对象的3D重建,输入图像序列可能因天气依赖性、高捕获成本和时间限制而相对稀疏,导致在全方位重建中难以保持几何完整性。
语义约束的缺乏:很少有算法引入语义约束来从稀疏视图中重建目标对象。
为了解决这些问题,论文提出了一个名为TSGaussian的新框架,该框架结合了语义约束和深度先验,以避免在具有挑战性的新视角合成任务中出现几何退化。TSGaussian通过优先考虑计算资源分配给指定目标的同时,最小化背景分配,有效地通过引入每个高斯椭球的紧凑身份编码和3D空间一致性正则化来聚类3D高斯,从而减少3D高斯的冗余。
Q: 有哪些相关研究?
A: 根据论文内容,以下是与TSGaussian框架相关的一些研究工作:
3D Gaussian Models for Novel View Synthesis:
- Mip-splatting:通过控制最大采样频率来调节高斯原素的大小,以减少重建过程中的伪影。
- VDGS(可能指基于神经网络的高斯模型):使用神经网络代替原始3DGS中的球谐函数,改善颜色和不透明度属性,实现更真实的渲染效果。
- LightGaussian:通过识别对场景重建贡献最小的高斯原素来加速渲染速度,同时减少高斯数量的冗余。
3D Scene Understanding:
- 主流方法通常将SAM的2D掩码预测与3D空间一致性约束结合起来,将语义特征嵌入到3D场景表示中。
- GP-NeRF(Geometry-Preserving Neural Radiance Fields):结合Transformer架构,同时聚合辐射和语义嵌入信息,提高语义场的区分度和质量,同时保持几何一致性。
Sparse Shot Novel View Synthesis:
- DNGaussian:通过结合软和硬深度正则化以及全局-局部深度归一化,提高对细微深度变化的敏感性,改善重建结果。
- SparseNeRF:利用预训练的深度估计模型预测深度图,并引入局部和全局深度损失,实现视觉上平滑的渲染效果。
这些研究工作展示了在全景重建和交互式语义方面的进步,但在复杂几何和复杂场景中的特定目标重建方面仍面临挑战。TSGaussian框架旨在通过结合语义约束和深度正则化,解决这些限制,实现从2D语义标签到3D语义理解的高效转换,特别关注快速重建目标对象。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为TSGaussian的新框架来解决上述问题,该框架主要通过以下几个技术亮点实现目标:
YOLOv9和SAM的集成:
- 使用YOLOv9进行场景理解,生成目标的边界框,作为提示(prompts)传递给Segment Anything Model(SAM)以实现成本效益的2D语义分割。
- 这种2D语义分割引导3D语义编码的训练,确保了语义准确性和成本效率。
语义操作符和剪枝策略:
- 设计了一个语义操作符来识别目标重建过程中不必要的高斯(Gaussians),并实施剪枝策略以最小化冗余计算。
单目深度估计作为先验:
- 将单目深度估计作为先验,并使用深度估计损失来增强3DGS在稀疏视图中的鲁棒性。
一致的目标语义分割:
- 通过集成YOLOv9和SAM生成更准确的2D语义掩码,并使用零样本跟踪器(zero-shot tracker)来对不同视图中的语义身份进行对齐。
身份编码和语义渲染:
- 引入身份编码机制为每个高斯函数分配语义属性,并通过语义渲染模块将高斯投影回2D语义掩码以计算2D身份损失。
- 引入3D语义正则化损失以增强一致性。
基于语义驱动的高斯控制和剪枝:
- 在高斯密度的动态调整过程中,基于高斯的语义属性实施控制机制,仅在感兴趣区域(ROI)内计算视图空间位置梯度。
- 根据需要克隆、分割和剪枝高斯,以减少错误的积累。
多尺度深度正则化:
- 结合全局和局部深度正则化来减少稀疏视图条件下的伪影,提高模型对深度误差的敏感性。
颜色重建:
- 结合L1重建损失和D-SSIM度量来确保渲染图像与实际图像之间的结构相似性。
通过这些方法,TSGaussian框架能够有效地从稀疏视图中重建特定目标,同时保持细节和结构的准确性,减少背景噪声的影响,并优化计算资源的使用。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证TSGaussian框架的性能:
数据集和实验设置:
- 使用了包括“garden”、“bouquet”和“bear”等场景的公共数据集,以及作者自己收集的针对特定目标(如柑橘)的360°全景图像数据集。
- 为了确保场景的完整性,从原始视图中均匀提取了三分之一的视图,并将其平均分配到训练集和测试集中。
与基线方法的比较:
- 与原始的3DGS及其变体进行比较,包括Gaussian Grouping、DNGaussian和SparseGS。
- 所有比较的算法都使用相同的特定对象的语义掩码以确保公平比较。
公共数据集上的定量和定性分析:
- 在公共数据集上,TSGaussian在SSIM、LPIPS和PSNR等指标上超越了所有基线方法。
- 例如,在“bear”场景中,TSGaussian的PSNR比3DGS高出6.28,在“bouquet”场景中,TSGaussian的SSIM比3DGS高出0.12。
自己数据集上的实验:
- 收集的数据集主要关注不同形状的柑橘,这些植物幼苗非常纤细,对稀疏视图3D重建构成重大挑战。
- TSGaussian在该数据集上表现出色,维持了稳健的几何结构,并在各种语义对象(如植物和花盆)上提供了精细的细节建模结果。
消融研究:
- 深度正则化消融:展示了没有深度正则化时,背景中会出现伪影,影响特定目标的高斯表示。
- 语义约束消融:展示了没有语义约束时,背景信息冗余,显著降低性能。
结论:
- TSGaussian通过结合深度正则化和语义约束来增强3D高斯绘制的性能。
- 该方法减少了数据采集成本,减少了冗余信息,并有效减少了重建过程中的伪影。
这些实验结果突出了将语义和深度信息整合到3D重建任务中的重要性,并展示了TSGaussian框架在稀疏视图条件下对特定目标进行3D重建的有效性。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些潜在的改进方向和未来的工作,以下是一些可以进一步探索的点:
改进语义与深度数据的结合:
- 研究如何更有效地结合语义和深度数据,以提高高斯重建方法的效率和效果。
提高算法的泛化能力:
- 尽管TSGaussian能够在复杂环境中实现稳健的识别,但进一步研究如何提高算法对未知环境或新类别目标的泛化能力仍然是一个重要的研究方向。
优化计算资源分配:
- 研究如何进一步优化计算资源分配,特别是在处理大规模数据集或实时应用时,如何平衡计算效率和重建质量。
提高稀疏视图下的性能:
- 探索新的技术或方法来提高在极稀疏视图条件下的3D重建性能,这可能包括改进的深度估计技术或更高级的正则化策略。
跨模态学习:
- 研究如何利用跨模态学习技术来提高从2D图像到3D表示的转换效率和准确性,尤其是在标注数据有限的情况下。
增强模型的可解释性:
- 研究如何提高模型的可解释性,特别是在语义分割和3D重建过程中,理解模型是如何做出决策的。
多任务学习:
- 探索多任务学习框架,将3D重建、语义分割和深度估计等任务结合起来,以实现更高效的联合学习。
模型压缩和加速:
- 研究模型压缩技术,减少模型大小并加速推理过程,使其更适合在资源受限的设备上部署。
鲁棒性的提升:
- 研究如何提高模型对于各种异常情况(如遮挡、光照变化、动态场景等)的鲁棒性。
应用到更广泛的领域:
- 将TSGaussian框架应用到更广泛的领域,如增强现实、机器人视觉、自动驾驶等,并针对这些领域的特定需求进行优化。
这些探索点可以帮助研究社区进一步推动3D重建技术的发展,并扩展其在实际应用中的有效性和可用性。
Q: 总结一下论文的主要内容
A: 本文提出了TSGaussian,一个新颖的框架,用于从稀疏视图中重建具有复杂结构的特定目标的三维场景。主要贡献和内容可以总结如下:
问题定义:
- 针对现有方法在稀疏视图条件下重建特定目标时面临的挑战,如保持语义一致性和避免几何退化。
TSGaussian框架:
- 结合语义约束和深度先验,优化计算资源分配,减少背景计算,专注于目标对象的重建。
技术亮点:
- 使用YOLOv9和Segment Anything Model(SAM)进行语义分割,提高分割的准确性和成本效率。
- 设计语义操作符和剪枝策略,减少冗余计算。
- 引入单目深度估计作为先验,增强3D高斯绘制(3DGS)在稀疏视图中的鲁棒性。
方法细节:
- 通过一致的目标语义分割和身份编码实现2D到3D的语义转换。
- 利用多尺度深度正则化减少稀疏视图条件下的伪影。
实验验证:
- 在公共数据集和自收集的数据集上进行广泛的实验,验证了TSGaussian在新视角合成方面的优越性能。
- 通过消融研究展示了深度正则化和语义约束对性能的重要性。
结论与未来工作:
- 提出了一种有效的方法来整合深度和语义信息,减少数据采集成本,并减少重建过程中的伪影。
- 强调了进一步改进语义与深度数据结合、提高算法泛化能力和计算效率的必要性。
总体而言,TSGaussian通过结合先进的2D场景理解技术与3D场景重建,为从稀疏视图中快速重建特定目标提供了一种有效的解决方案,并展示了在多个标准数据集上的优越性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

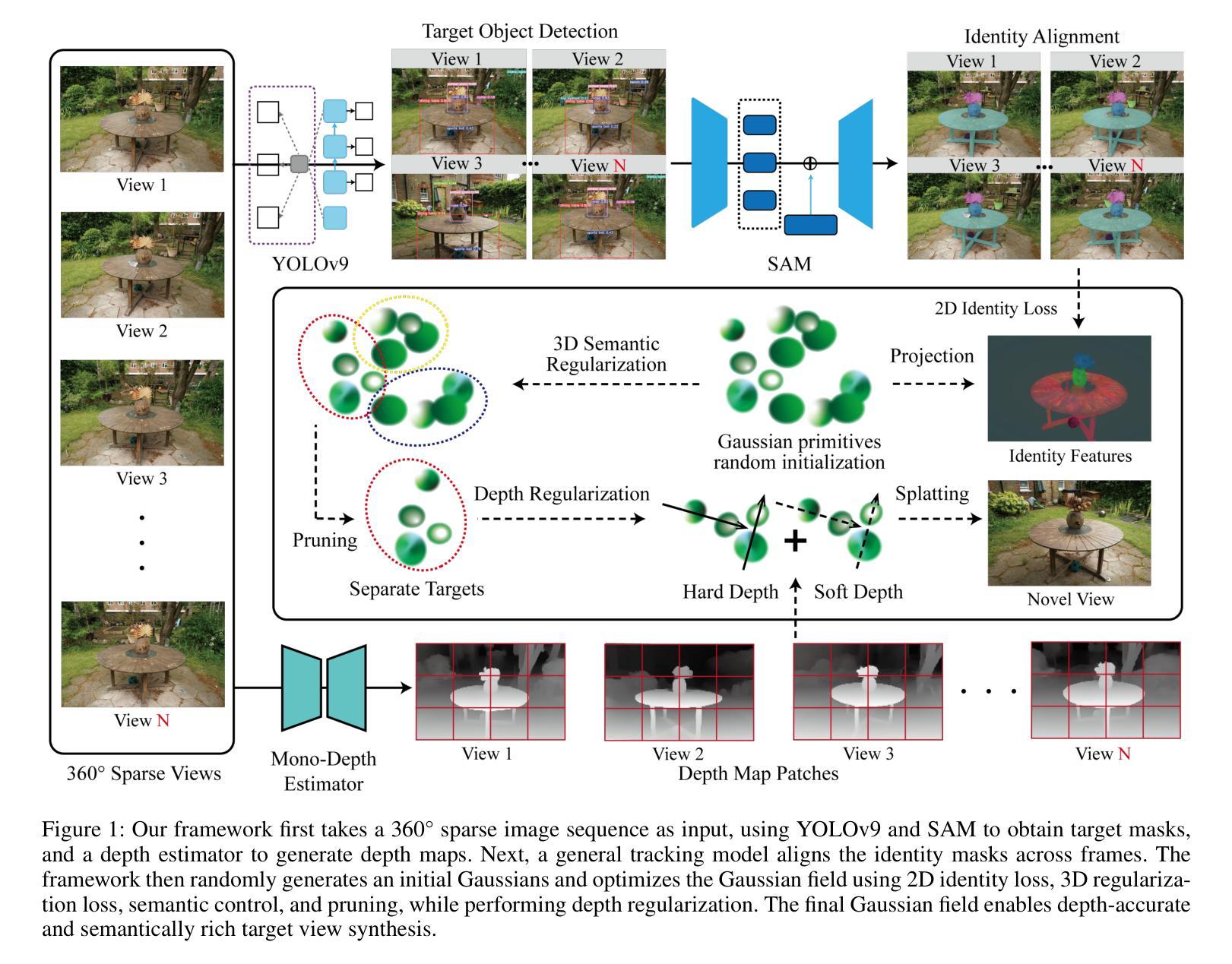



SplineGS: Robust Motion-Adaptive Spline for Real-Time Dynamic 3D Gaussians from Monocular Video
Authors:Jongmin Park, Minh-Quan Viet Bui, Juan Luis Gonzalez Bello, Jaeho Moon, Jihyong Oh, Munchurl Kim
Synthesizing novel views from in-the-wild monocular videos is challenging due to scene dynamics and the lack of multi-view cues. To address this, we propose SplineGS, a COLMAP-free dynamic 3D Gaussian Splatting (3DGS) framework for high-quality reconstruction and fast rendering from monocular videos. At its core is a novel Motion-Adaptive Spline (MAS) method, which represents continuous dynamic 3D Gaussian trajectories using cubic Hermite splines with a small number of control points. For MAS, we introduce a Motion-Adaptive Control points Pruning (MACP) method to model the deformation of each dynamic 3D Gaussian across varying motions, progressively pruning control points while maintaining dynamic modeling integrity. Additionally, we present a joint optimization strategy for camera parameter estimation and 3D Gaussian attributes, leveraging photometric and geometric consistency. This eliminates the need for Structure-from-Motion preprocessing and enhances SplineGS’s robustness in real-world conditions. Experiments show that SplineGS significantly outperforms state-of-the-art methods in novel view synthesis quality for dynamic scenes from monocular videos, achieving thousands times faster rendering speed.
从野外单目视频中合成新型视角是一项具有挑战性的任务,这主要是由于场景动态变化和缺乏多视角线索。为解决这一问题,我们提出了SplineGS,这是一个无需COLMAP的动态3D高斯模糊(3DGS)框架,用于从单目视频中实现高质量重建和快速渲染。其核心是一种新型的运动自适应曲线(MAS)方法,该方法使用少量控制点,通过三次Hermite曲线来表示连续的动态3D高斯轨迹。对于MAS,我们引入了一种运动自适应控制点修剪(MACP)方法,以模拟不同运动下每个动态3D高斯的变化,在保持动态建模完整性的同时逐步修剪控制点。此外,我们还提出了一种用于相机参数估计和3D高斯属性联合优化的策略,利用光度和几何一致性。这消除了对从运动结构中提取信息的预处理需求,提高了SplineGS在现实条件下的稳健性。实验表明,对于从单目视频中的动态场景合成新型视角,SplineGS在质量上显著优于最先进的方法,并且实现了数千倍的渲染速度提升。
论文及项目相关链接
PDF The first two authors contributed equally to this work (equal contribution). The last two authors advised equally to this work. Please visit our project page at this https://kaist-viclab.github.io/splinegs-site/
Summary
本文提出一种基于动态3D高斯映射(Dynamic 3D Gaussian Splatting,简称SplineGS)的方法,用于从单目视频中高质量重建和快速渲染场景。核心方法包括Motion-Adaptive Spline(MAS)和Motion-Adaptive Control points Pruning(MACP),以及用于相机参数估计和3D高斯属性联合优化的策略。SplineGS显著提高了动态场景的单目视频合成新视角的质量,并实现了数千倍的渲染速度提升。
Key Takeaways
- SplineGS是一种动态3D高斯映射(Dynamic 3D Gaussian Splatting)方法,适用于从单目视频中高质量重建和快速渲染场景。
- 核心方法包括Motion-Adaptive Spline(MAS),使用少量控制点表示连续动态3D高斯轨迹。
- 引入Motion-Adaptive Control points Pruning(MACP)方法,用于模拟不同运动下的动态3D高斯变形,同时保持动态建模的完整性。
- 提出联合优化策略,用于相机参数估计和3D高斯属性估计,利用光度和几何一致性。
- SplineGS不需要结构从运动(Structure-from-Motion)的预处理,增强了在现实条件下的稳健性。
- 实验表明,SplineGS在单目视频合成动态场景的新视角质量上显著优于现有技术。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是从野外单目视频中合成新视角视图的挑战,特别是在动态场景中。具体来说,论文中提到了以下几个关键问题:
场景动态性和缺乏多视角线索:在野外捕获的单目视频中,场景动态变化,且缺少多视角信息,这使得从单一视角合成新视图变得困难。
现有方法的局限性:现有的方法在处理动态场景时面临多个挑战,包括隐式表示增加计算开销、网格模型难以准确捕捉动态场景细节、多项式轨迹的固定次数限制了表示复杂运动的灵活性等。
依赖外部相机参数估计:大多数现有的动态新视角合成(NVS)方法依赖于外部的相机参数估计方法,如COLMAP,这些方法在处理野外单目视频时常常产生不精确的结果。
为了解决这些问题,论文提出了一个名为SplineGS的新框架,它是一个不依赖于COLMAP的动态3D高斯绘制(3DGS)框架,用于从单目视频中高质量重建动态场景并快速渲染新视图。SplineGS的核心是一个新的运动自适应样条(Motion-Adaptive Spline, MAS)方法,它使用少量控制点的三次Hermite样条来表示连续的动态3D高斯轨迹。此外,论文还提出了一种运动自适应控制点修剪(Motion-Adaptive Control points Pruning, MACP)方法,用于根据运动的复杂性调整每个动态3D高斯的控制点数量,以及一种联合优化策略,用于相机参数估计和3D高斯属性,利用光度和几何一致性,从而消除了对结构从运动(SfM)预处理的需求。
Q: 有哪些相关研究?
A: 论文中提到了多个与SplineGS相关的研究领域和具体工作,主要包括:
Dynamic NeRF:
- 扩展了静态NeRF模型以表示场景动态,包括使用场景流框架、规范场中的变形估计,以及4D网格基时空辐射场的方法。
- 代表性工作包括NSFF、DynNeRF和DynIBaR等,它们结合了时间独立和时间依赖的辐射场,从单目视频中合成新的时空视角。
Dynamic 3DGS:
- 在3DGS的基础上,通过使3D高斯属性变形来扩展到动态场景的研究,包括时间依赖的偏移、MLP网络、退火平滑训练机制等方法。
- 代表性工作包括D3DGS、4DGS和SC-GS等,它们通过不同的方法改进了渲染质量和效率。
Neural Rendering without SfM Preprocessing:
- 准确相机参数对于神经渲染方法捕捉细节至关重要。一些NeRF方法联合优化NeRF架构和相机参数,以减少对结构从运动(SfM)算法(如COLMAP)的依赖。
- 代表性工作包括RoDynRF和MoSca等,它们使用运动掩码从静态区域收集多视图线索,实现无需预计算相机参数的稳健渲染。
**3D Gaussian Splatting (3DGS)**:
- 3DGS通过使用各向异性3D高斯表示场景的辐射场,替代了隐式体积渲染,实现了实时渲染和更明确的场表示。
- 论文中提到了3DGS的基本原理和如何将其扩展到动态场景。
其他相关技术:
- 包括用于动态场景表示的隐式函数、网格模型、多项式轨迹等技术。
- 这些技术在动态NeRF和Dynamic 3DGS的研究中有所应用。
这些相关研究为SplineGS提供了理论基础和技术背景,同时也展示了该领域内的研究进展和挑战。SplineGS通过引入基于样条的运动自适应模型和控制点修剪方法,以及无需外部相机估计的联合优化策略,旨在提高动态场景重建和渲染的质量与效率。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为SplineGS的框架,通过以下几个关键技术解决了从单目视频中合成新视角视图的问题:
1. Motion-Adaptive Spline (MAS)
- 核心思想:使用三次Hermite样条(cubic Hermite splines)来表示连续的动态3D高斯轨迹,通过少量可学习的控制点来有效建模动态3D高斯的变形。
- 控制点优化:每个控制点都是一个可学习的参数,允许快速且精确地建模复杂运动轨迹。
2. Motion-Adaptive Control Points Pruning (MACP)
- 自适应调整:根据运动的复杂性,动态调整每个动态3D高斯的控制点数量,以优化渲染质量和效率。
- 实现方法:通过计算新的样条函数,并使用最小二乘近似来找到减少的控制点集,如果误差小于阈值,则更新控制点集。
3. 联合优化策略
- 相机参数估计:提出了一种联合优化策略,同时优化相机参数和3D高斯属性,利用光度和几何一致性,无需依赖外部的相机参数估计方法(如COLMAP)。
- 光度一致性:通过比较参考帧和目标帧的颜色对齐来鼓励视觉对齐。
- 几何一致性:计算3D空间中反投影像素的几何一致性,以增加优化的稳定性。
4. 两阶段优化过程
- 热身阶段:仅优化相机参数,使用光度和几何一致性。
- 主训练阶段:基于热身阶段预测的相机内参和外参,初始化动态3D高斯的控制点集,并联合优化静态和动态3D高斯以及相机参数估计。
5. 处理动态和静态背景
- 动态与静态3D高斯的分离:使用动态3D高斯表示移动对象,静态3D高斯表示静态背景,通过二元Dice损失函数来鼓励动态和静态3D高斯之间的更好分离。
通过这些技术,SplineGS能够从单目视频中高质量地重建动态场景并快速渲染新视图,同时避免了对外部相机参数估计方法的依赖,显著提高了动态场景新视角合成的质量和效率。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证SplineGS框架的性能和有效性。以下是实验的主要内容:
1. 实现细节
- 训练迭代:在热身阶段进行1K次迭代,在主训练阶段进行20K次迭代。
- 控制点优化:每100次迭代优化控制点的数量。
- 预训练模型:使用UniDepth和CoTracker的预训练模型分别进行深度和2D跟踪估计。
2. 数据集
- NVIDIA数据集:用于评估新视角和时间合成的定量和定性性能,包含具有挑战性的单目视频。
- DAVIS数据集:用于额外评估新视角合成性能,包含平均70帧的视频序列。
3. 与现有方法的比较
- 新视角合成:在NVIDIA数据集上,与基于COLMAP和不依赖COLMAP的方法进行定量比较,包括PSNR和LPIPS指标。
- 新视角和时间合成:在NVIDIA数据集上,比较SplineGS与基于NeRF和3DGS的方法,通过采样24个时间戳来评估。
4. 定性比较
- NVIDIA数据集:展示了SplineGS与现有方法在新视角合成上的视觉效果比较。
- DAVIS数据集:展示了SplineGS与现有方法在野外单目视频上新视角合成的视觉效果比较。
5. 消融研究
- 运动自适应样条(MAS):通过替换MAS模型与其他变形模型(如MLP、网格模型、多项式函数和Bézier曲线)来验证MAS的有效性。
- 运动自适应控制点修剪(MACP):比较完整模型与固定控制点数的模型,以评估MACP技术的有效性。
- 损失函数:评估不同损失函数对整体SplineGS架构的影响。
6. 内存占用比较
- 比较SplineGS与其他基于3DGS的方法在模型存储要求上的效率。
7. 动态3D高斯轨迹可视化
- 展示了SplineGS在DAVIS数据集上动态3D高斯轨迹的2D可视化结果,并与D3DGS和STGS进行了比较。
8. 方法论补充细节
- 提供了相机内参的预测方法、时间依赖的旋转和尺度的建模方法等额外信息。
9. 限制
- 讨论了SplineGS在处理模糊输入帧时的限制,并提出了可能的解决方案。
10. 额外的定性结果
- 提供了在NVIDIA和DAVIS数据集上的新视角合成、新视角和时间合成的额外视觉比较结果。
这些实验全面评估了SplineGS在动态场景重建和新视角合成任务中的性能,并与现有技术进行了比较,证明了其优越性和效率。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和补充材料,以下是一些可以进一步探索的点:
1. 集成去模糊技术
- 问题:野外视频常常包含模糊帧,这影响了渲染新视角视图的质量。
- 探索点:将先进的2D去模糊方法集成到重建流程中,或者开发一个联合去模糊和渲染优化框架,以改善渲染输出的质量。
2. 提高运动捕捉精度
- 问题:尽管SplineGS在捕捉动态3D高斯轨迹方面表现出色,但在快速和复杂运动中可能还有改进空间。
- 探索点:研究更高级的运动捕捉技术,如基于物理的模型或深度学习框架,以提高动态场景中运动捕捉的精度和鲁棒性。
3. 优化内存和计算效率
- 问题:尽管SplineGS在内存使用上已经比一些现有方法更高效,但仍有进一步优化的空间。
- 探索点:探索新的数据结构和算法,以减少模型的内存占用和提高计算效率,特别是在大规模动态场景中的应用。
4. 增强对复杂动态场景的处理能力
- 问题:复杂动态场景中的多物体交互和遮挡问题仍然是一个挑战。
- 探索点:开发更复杂的场景理解模型,能够更好地处理物体间的交互和遮挡,以及在复杂光照条件下的场景。
5. 扩展到多模态输入
- 问题:SplineGS主要处理单目视频输入,多模态输入(如结合RGB-D数据或事件相机数据)可能提供额外信息,改善重建质量。
- 探索点:研究如何融合多模态数据以增强场景的深度理解和动态捕捉能力。
6. 提升实时渲染性能
- 问题:虽然SplineGS实现了快速渲染,但在需要实时渲染的应用中(如AR/VR),对速度的要求更高。
- 探索点:优化算法和硬件加速,以实现接近实时或实时的渲染性能。
7. 增强泛化能力
- 问题:SplineGS在特定类型的视频上进行了测试,可能需要在更广泛的数据集上验证其泛化能力。
- 探索点:在多样化的数据集上进行测试,包括不同类型的动态场景和视频来源,以评估和提升模型的泛化能力。
8. 用户交互和编辑能力
- 问题:SplineGS提供了动态场景的重建和渲染,但用户交互和编辑能力有限。
- 探索点:开发用户友好的界面和工具,允许用户对动态场景进行交互式编辑和操作,增强应用的灵活性和创造性。
这些探索点可以帮助推动动态场景重建和新视角合成技术的发展,扩展其在虚拟现实、增强现实、电影制作等领域的应用。
Q: 总结一下论文的主要内容
A: 论文提出了一个名为SplineGS的新框架,旨在从单目视频中高质量且快速地重建和渲染动态场景的新视角。以下是论文的主要内容总结:
1. 问题背景
- 野外单目视频的新视角合成面临场景动态性和缺乏多视角线索的挑战。
- 现有方法在计算效率、细节捕捉和对复杂运动的表示上存在限制。
- 许多方法依赖于外部相机参数估计,如COLMAP,这些在单目视频中效果不佳。
2. SplineGS框架
- 提出了SplineGS,一个不依赖COLMAP的动态3D高斯绘制(3DGS)框架。
- 利用运动自适应样条(MAS)表示动态3D高斯的连续轨迹。
- 通过运动自适应控制点修剪(MACP)方法动态调整控制点数量以优化效率和质量。
- 采用联合优化策略估计相机参数和3D高斯属性,增强鲁棒性。
3. 核心技术
- MAS:使用三次Hermite样条建模动态3D高斯轨迹。
- MACP:基于运动复杂度自适应调整控制点数量。
- 相机参数估计:通过光度和几何一致性优化相机参数。
- 两阶段优化:先优化相机参数,再联合优化3D高斯属性和相机参数。
4. 实验结果
- 在NVIDIA和DAVIS数据集上进行了广泛的定量和定性实验。
- SplineGS在新视角合成质量上显著优于现有方法,并实现了数千倍的渲染速度提升。
- 消融研究验证了MAS和MACP方法的有效性。
- 内存占用比较显示SplineGS的效率更高。
5. 贡献
- 提出了一种新的基于样条的动态3D高斯绘制框架,无需依赖外部相机估计。
- 引入了MAS和MACP方法,提高了动态场景建模的效率和质量。
- 实现了快速且高质量的动态场景重建和新视角合成。
6. 未来工作
- 将去模糊技术集成到重建流程中。
- 提高对复杂动态场景的处理能力。
- 扩展到多模态输入和增强实时渲染性能。
SplineGS通过其创新的样条模型和优化策略,为从单目视频中合成动态场景的新视角提供了一个高效且高质量的解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

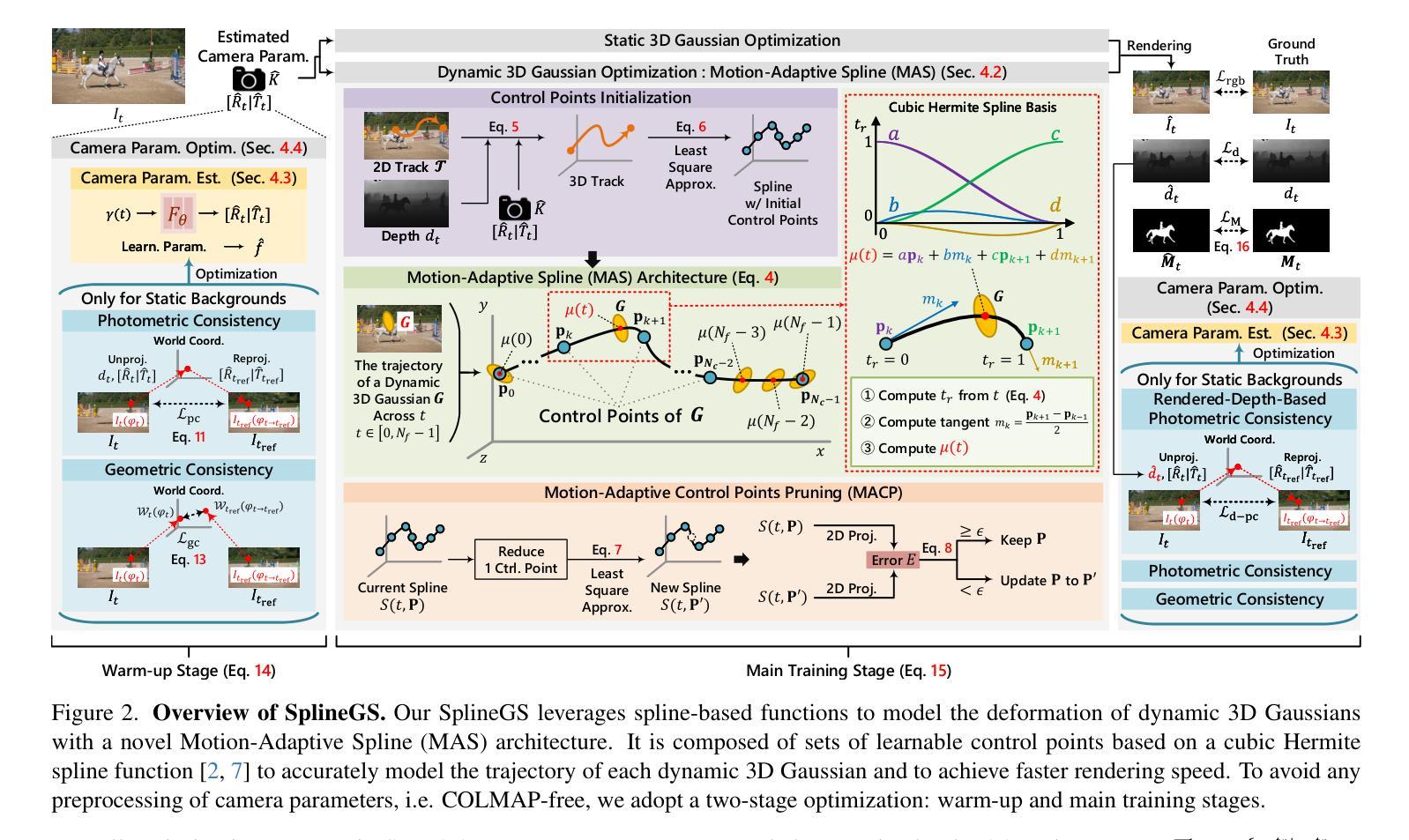

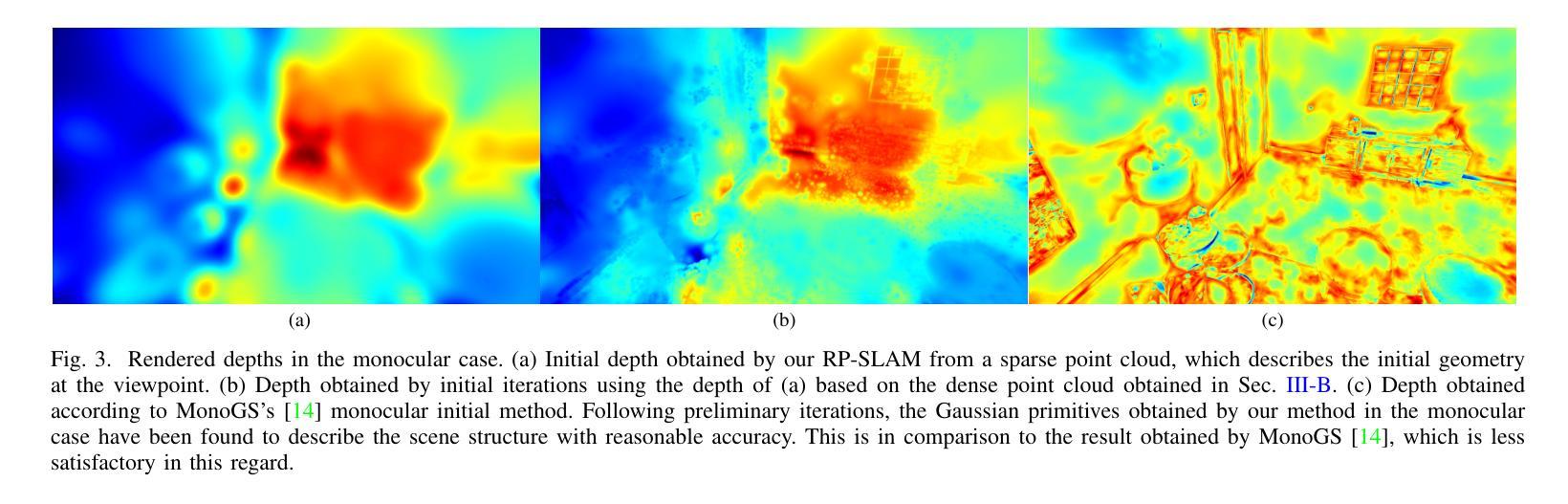
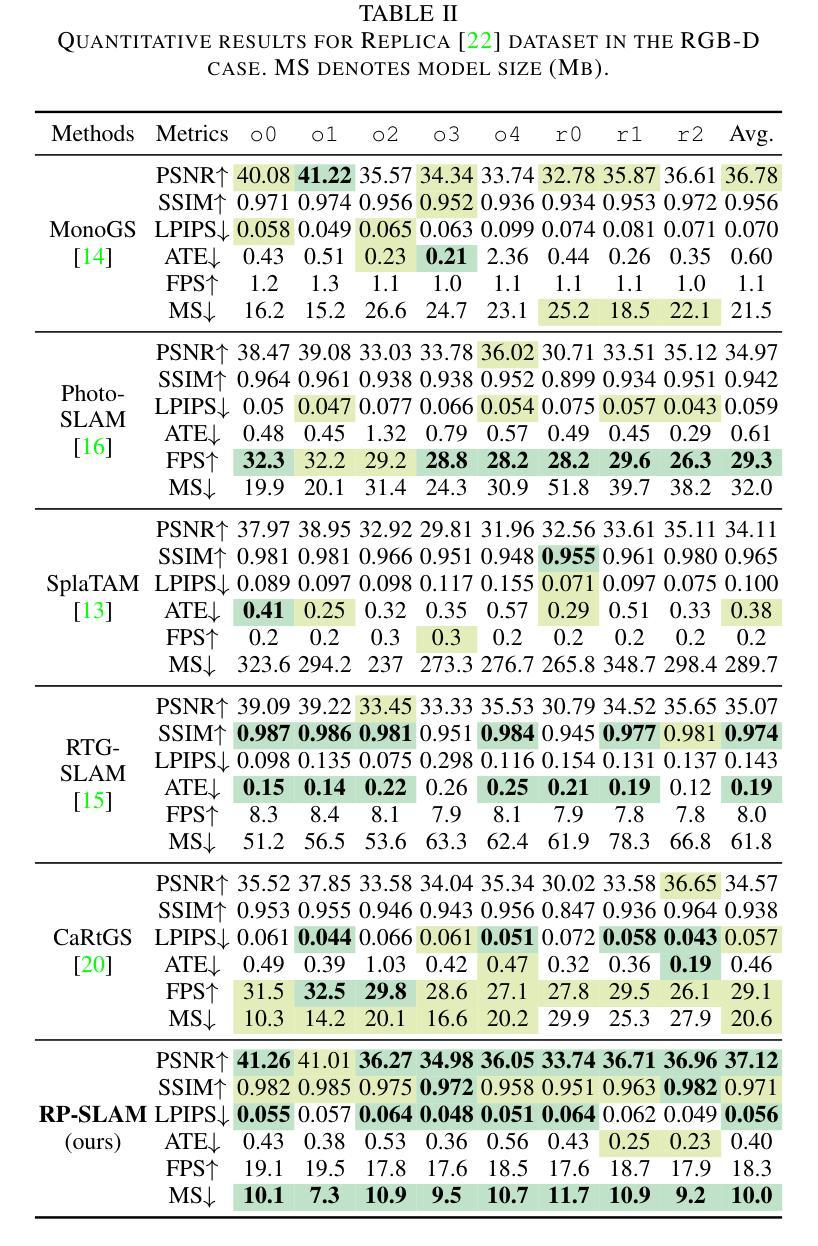
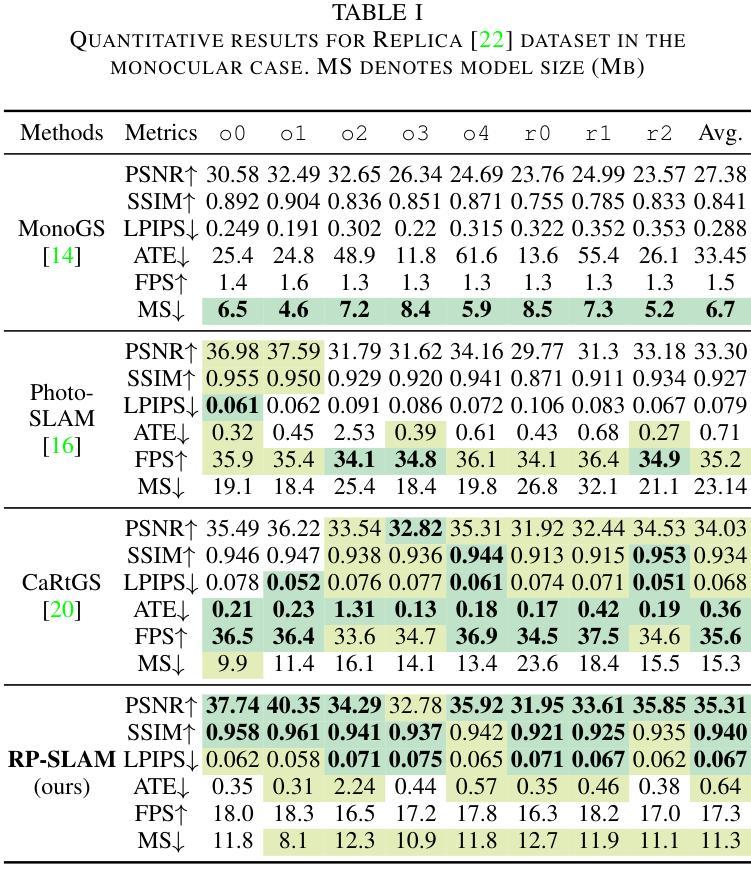
RP-SLAM: Real-time Photorealistic SLAM with Efficient 3D Gaussian Splatting
Authors:Lizhi Bai, Chunqi Tian, Jun Yang, Siyu Zhang, Masanori Suganuma, Takayuki Okatani
3D Gaussian Splatting has emerged as a promising technique for high-quality 3D rendering, leading to increasing interest in integrating 3DGS into realism SLAM systems. However, existing methods face challenges such as Gaussian primitives redundancy, forgetting problem during continuous optimization, and difficulty in initializing primitives in monocular case due to lack of depth information. In order to achieve efficient and photorealistic mapping, we propose RP-SLAM, a 3D Gaussian splatting-based vision SLAM method for monocular and RGB-D cameras. RP-SLAM decouples camera poses estimation from Gaussian primitives optimization and consists of three key components. Firstly, we propose an efficient incremental mapping approach to achieve a compact and accurate representation of the scene through adaptive sampling and Gaussian primitives filtering. Secondly, a dynamic window optimization method is proposed to mitigate the forgetting problem and improve map consistency. Finally, for the monocular case, a monocular keyframe initialization method based on sparse point cloud is proposed to improve the initialization accuracy of Gaussian primitives, which provides a geometric basis for subsequent optimization. The results of numerous experiments demonstrate that RP-SLAM achieves state-of-the-art map rendering accuracy while ensuring real-time performance and model compactness.
3D高斯插值作为一种前景技术,已经被广泛用于高质量3D渲染,这也引起了将3DGS集成到现实感SLAM系统中的兴趣增长。然而,现有方法面临诸如高斯基元冗余、连续优化过程中的遗忘问题以及由于缺少深度信息导致在单目情况下初始化基元困难等挑战。为了实现高效和逼真的映射,我们提出了RP-SLAM,这是一种基于3D高斯插值的视觉SLAM方法,适用于单目和RGB-D相机。RP-SLAM将相机姿态估计与高斯基元优化解耦,并包含三个关键组件。首先,我们提出了一种高效的增量映射方法,通过自适应采样和高斯基元滤波来实现场景的紧凑和准确表示。其次,提出了一种动态窗口优化方法,以减轻遗忘问题并提高地图的一致性。最后,对于单目相机,我们提出了一种基于稀疏点云的单目关键帧初始化方法,以提高高斯基元的初始化精度,为后续优化提供几何基础。大量实验结果表明,RP-SLAM在达到最先进的地图渲染精度的同时,确保了实时性能和模型紧凑性。
论文及项目相关链接
Summary
本文介绍了RP-SLAM方法,这是一种基于3D高斯贴图技术的视觉SLAM方法,适用于单目和RGB-D相机。该方法解决了现有技术面临的挑战,如高斯基本体的冗余问题、连续优化过程中的遗忘问题以及单目情况下由于缺乏深度信息而导致的原始基本体初始化困难。RP-SLAM通过高效增量映射方法实现紧凑准确的场景表示,采用动态窗口优化方法解决遗忘问题并提高地图一致性。针对单目情况,提出了一种基于稀疏点云的单目关键帧初始化方法,提高高斯基本体的初始化精度,为后续优化提供了几何基础。实验结果证明了RP-SLAM方法的实时性能和模型紧凑性同时实现了先进的地图渲染精度。
Key Takeaways
- RP-SLAM是一种结合3D高斯贴图技术的视觉SLAM方法,适用于单目和RGB-D相机。
- 解决现有技术中的高斯基本体冗余问题、连续优化中的遗忘问题以及单目情况下的原始基本体初始化难题。
- 采用高效增量映射方法实现场景紧凑准确表示。
- 使用动态窗口优化方法提高地图一致性和解决遗忘问题。
- 针对单目相机提出基于稀疏点云的初始化方法,提高高斯基本体的初始化精度。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了RP-SLAM,一个基于3D高斯绘制(3D Gaussian Splatting,简称3DGS)的视觉SLAM系统,旨在解决以下问题:
高斯原语冗余(Gaussian primitives redundancy):现有方法在进行场景表示时,常因均匀密集采样导致不必要的计算和存储开销,尤其在简单区域。
连续优化过程中的遗忘问题(forgetting problem):在进行连续优化时,固定关键帧窗口的方法可能会导致地图表示的质量下降,出现严重遗忘和过拟合问题。
单目情况下的初始化困难:在单目相机缺乏深度信息的情况下,准确添加新的高斯原语变得困难,导致初始化的不准确。
为了解决这些问题,论文提出了以下主要贡献:
- 高效的增量映射(Efficient Incremental Mapping):通过自适应采样和高斯原语过滤减少冗余的高斯原语,同时保持高渲染质量。
- 动态关键帧窗口优化(Dynamic Keyframe Window):动态调整关键帧窗口以优化地图表示,减轻遗忘问题的影响,增强映射一致性。
- 改进的单目关键帧初始化(Improved Monocular Keyframe Initialization):为单目相机提供相对准确的高斯原语放置,改善渲染质量和减少冗余。
这些贡献使得RP-SLAM在保持实时性能和模型紧凑性的同时,实现了高质量的3D场景渲染。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以概括为以下几个方向:
1. 经典视觉SLAM (Classical Visual SLAM)
- ORB-SLAM系列:基于提取和跟踪轻量级几何特征的方法,通过局部而不是全局的捆绑调整来实现实时操作。
- 直接SLAM方法:例如LSD-SLAM和DSO,直接使用原始图像强度进行操作,避免了几何特征提取的需要。
- DTAM和KinectFusion:早期的密集SLAM系统,使用光度一致性和多视图立体约束来更新密集场景模型。
2. 神经隐式视觉SLAM (Neural Implicit Visual SLAM)
- iNeRF:展示了在特定场景中,通过训练好的NeRF模型进行相机姿态回归的可行性。
- BARF:提出一种方法,即使初始估计粗糙,也能通过建立经典图像对齐和神经辐射场中联合对齐与重建之间的理论桥梁,同时拟合NeRF和优化相机姿态。
- iMAP:使用单个多层感知器(MLP)表示全局场景,联合优化场景地图和相机姿态。
- NICE-SLAM:通过将世界坐标框架划分为均匀网格,提高了推理速度和准确性。
3. 3D高斯绘制视觉SLAM (3D Gaussian Splatting Visual SLAM)
- MonoGS和SplaTAM:作为耦合GS-SLAM算法的基础工作,通过梯度反向传播联合优化高斯原语和相机姿态。
- GaussianSLAM和LoopSplat:引入子图的概念来减轻灾难性遗忘问题,并通过使用基于高斯绘制的闭环策略来增强通过改进的注册技术实现的姿态精度。
- Splat-SLAM和IG-SLAM:采用预训练的密集捆绑调整进行相机姿态跟踪,同时使用代理深度图优化地图表示。
这些相关研究为RP-SLAM提供了理论基础和技术背景。论文中提出的RP-SLAM结合了这些研究的优点,通过解耦相机姿态估计和高斯原语优化,实现了高效的实时照片级真实感SLAM系统。
Q: 论文如何解决这个问题?
A: 论文通过提出RP-SLAM系统来解决上述问题,具体方法如下:
1. 高效的增量映射(Efficient Incremental Mapping)
- 自适应采样:使用基于图像梯度的四叉树递归细分方法,动态调整采样密度,集中对纹理复杂区域进行采样,减少对简单区域的冗余采样。
- 高斯原语过滤:通过KNN搜索评估新生成的高斯原语与现有原语的空间邻近度,消除冗余原语,保持地图表示的高效性。
2. 动态关键帧窗口优化(Dynamic Keyframe Window)
- 基于共视性的关键帧分类:将所有关键帧分为共视关键帧和其他关键帧,基于它们与当前关键帧的可见性关系。
- 动态窗口优化:在每次迭代中,根据共视性动态调整用于优化的关键帧集合,包括当前关键帧、随机选择的共视关键帧和非共视关键帧,以保持局部和全局一致性,减轻遗忘问题。
3. 改进的单目关键帧初始化(Improved Monocular Keyframe Initialization)
- 稀疏点云初始化:利用ORB-SLAM3提供的稀疏点云为单目相机模式下的新关键帧初始化高斯原语,提供几何基础。
- 深度图生成与优化:通过优化新关键帧的高斯原语生成初始深度图,为高效图像采样和高斯原语生成提供基础,创建与新关键帧对应的密集场景表示。
4. 3D高斯绘制(3D Gaussian Splatting)
- 显式场景表示:使用一组高斯原语映射场景,并通过基于平铺的光栅化渲染真实感图像。
- 优化场景表示:考虑光度损失和几何损失(仅用于RGB-D情况),以及各向同性正则化,以减少由尺度参数引起的伪影。
通过这些方法,RP-SLAM能够在保持实时性能和模型紧凑性的同时,实现高质量的3D场景渲染,解决了现有方法中存在的高斯原语冗余、遗忘问题以及单目初始化困难等问题。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证RP-SLAM系统的性能,包括:
1. 实验设置
- 数据集:使用了TUM-RGBD数据集、Replic数据集和ScanNet++数据集进行量化分析。
- 实现细节:实验在配备有Intel Core i9-14900KF CPU和NVIDIA RTX 4090 GPU的桌面PC上执行。使用ORB-SLAM3进行相机跟踪,并使用MonoGS中的3DGS模块。
- 评估指标:包括绝对轨迹误差(ATE)的均方根误差(RMSE)来评估相机跟踪精度,以及PSNR、SSIM和LPIPS等常用指标来评估地图渲染质量。此外,还通过系统帧率和映射后的模型大小来评估计算和存储效率。
- 基线方法:与MonoGS、SplaTAM、Photo-SLAM、RTG-SLAM和CaRtGS等几种最先进的高斯SLAM方法进行比较。
2. 相机跟踪精度
- 在单目和RGB-D模式下,评估RP-SLAM在不同数据集上的相机跟踪精度。
3. 渲染质量结果
- 在Replic、TUM和ScanNet++数据集上评估RP-SLAM在RGB-D模式下的渲染质量。
4. 计算和存储效率
- 通过评估Replic、TUM和ScanNet++数据集,展示了RP-SLAM在保持照片级真实感重建的同时,如何实现高帧率和紧凑模型大小。
5. 消融研究
- 分别对单目关键帧初始化(MKI)、高效增量映射(EIM)和动态关键帧窗口(DKW)模块进行了消融研究,以评估它们对渲染质量和模型大小的影响。
- 探究了不同最小单元尺寸对RGB-D情况下RP-SLAM性能的影响。
6. 定性结果
- 提供了与MonoGS、Photo-SLAM、RTG-SLAM、SplaTAM和CaRtGS等方法的定性比较,展示了RP-SLAM在单目和RGB-D情况下的渲染质量。
这些实验全面评估了RP-SLAM系统在不同方面的性能,包括跟踪精度、渲染质量、计算和存储效率,以及不同模块对系统性能的具体影响,从而验证了RP-SLAM的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管RP-SLAM在实现实时照片级真实感SLAM方面取得了显著的成果,但仍有一些可以进一步探索和改进的点:
1. 动态场景处理
- 论文中提到RP-SLAM目前还无法处理动态场景。未来的研究可以探索如何将RP-SLAM扩展以适应包含移动物体或变化环境的动态场景。
2. 优化算法
- 研究更高效的优化算法来进一步减少计算延迟,尤其是在处理高分辨率图像或大规模场景时。
3. 增强现实集成
- 探索如何将RP-SLAM集成到增强现实(AR)应用中,以利用其高质量的3D场景重建能力为用户提供更加真实和互动的AR体验。
4. 多传感器融合
- 考虑将RP-SLAM与其他类型的传感器数据(如IMU或LiDAR)结合起来,以提高系统的鲁棒性和准确性,特别是在GNSS信号不佳的室内环境中。
5. 实时性能优化
- 尽管RP-SLAM已经实现了实时性能,但在资源受限的设备上(如移动设备或嵌入式系统)进一步优化其性能仍然是一个挑战。
6. 算法泛化能力
- 提高RP-SLAM算法的泛化能力,使其能够适应各种不同的环境和光照条件。
7. 深度学习集成
- 考虑将深度学习技术融入RP-SLAM中,以进一步提高场景表示的质量和优化过程的效率。
8. 更多数据集的测试
- 在更多种类的数据集上测试RP-SLAM,包括不同类型的环境和传感器配置,以评估其泛化能力和鲁棒性。
9. 用户交互功能
- 开发用户交互功能,允许用户与重建的3D场景进行交互,这可以用于室内设计、游戏开发等领域。
10. 开源实现
- 考虑将RP-SLAM的代码开源,以便社区可以进一步开发、改进和定制该系统。
这些方向不仅可以推动RP-SLAM技术的发展,还可能为计算机视觉和机器人领域的其他应用带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文提出了RP-SLAM,一个基于3D高斯绘制的视觉SLAM系统,旨在实现单目和RGB-D相机的实时照片级真实感场景重建。下面是论文的主要内容总结:
1. 问题定义
- 针对现有方法在高斯原语冗余、遗忘问题和单目初始化困难等方面的挑战,提出了RP-SLAM系统。
2. 主要贡献
- 高效的增量映射方法:通过自适应采样和高斯原语过滤减少冗余,提高场景表示的效率和准确性。
- 动态关键帧窗口优化:基于共视性动态调整关键帧窗口,减轻遗忘问题,增强地图一致性。
- 改进的单目关键帧初始化:利用稀疏点云为单目相机提供准确的高斯原语初始化,改善渲染质量和减少冗余。
3. 方法细节
- 3D高斯绘制:使用一组高斯原语映射场景并通过基于平铺的光栅化渲染图像。
- 优化策略:考虑光度损失和几何损失(仅RGB-D情况)以及各向同性正则化,优化场景表示。
4. 实验验证
- 在多个数据集(TUM-RGBD、Replic、ScanNet++)上评估RP-SLAM的性能。
- 与现有方法比较,展示RP-SLAM在相机跟踪精度、渲染质量、计算和存储效率方面的优势。
- 进行消融研究和定性分析,验证所提方法的有效性。
5. 结论与未来工作
- RP-SLAM实现了实时照片级真实感SLAM,平衡了重建质量和模型大小。
- 未来工作将探索动态场景处理和算法优化。
总体而言,RP-SLAM通过其创新的方法在实时性和照片级真实感之间取得了平衡,为视觉SLAM领域提供了一个有效的解决方案,并指出了未来研究的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


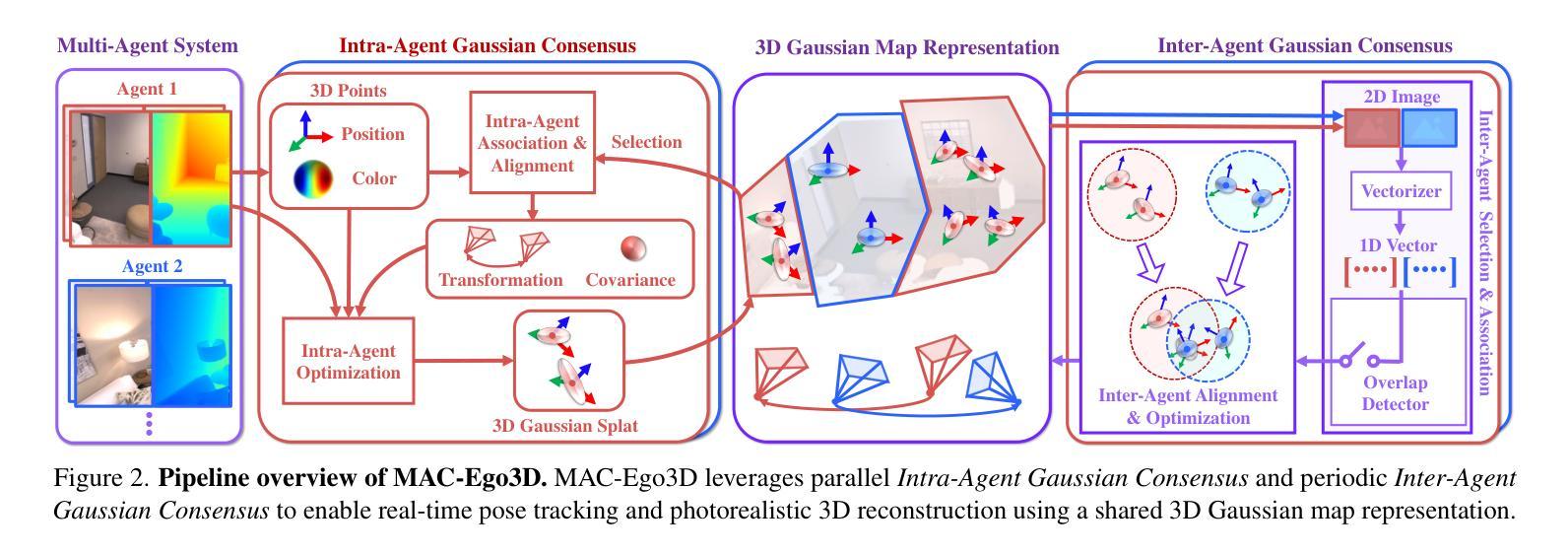
MAC-Ego3D: Multi-Agent Gaussian Consensus for Real-Time Collaborative Ego-Motion and Photorealistic 3D Reconstruction
Authors:Xiaohao Xu, Feng Xue, Shibo Zhao, Yike Pan, Sebastian Scherer, Xiaonan Huang
Real-time multi-agent collaboration for ego-motion estimation and high-fidelity 3D reconstruction is vital for scalable spatial intelligence. However, traditional methods produce sparse, low-detail maps, while recent dense mapping approaches struggle with high latency. To overcome these challenges, we present MAC-Ego3D, a novel framework for real-time collaborative photorealistic 3D reconstruction via Multi-Agent Gaussian Consensus. MAC-Ego3D enables agents to independently construct, align, and iteratively refine local maps using a unified Gaussian splat representation. Through Intra-Agent Gaussian Consensus, it enforces spatial coherence among neighboring Gaussian splats within an agent. For global alignment, parallelized Inter-Agent Gaussian Consensus, which asynchronously aligns and optimizes local maps by regularizing multi-agent Gaussian splats, seamlessly integrates them into a high-fidelity 3D model. Leveraging Gaussian primitives, MAC-Ego3D supports efficient RGB-D rendering, enabling rapid inter-agent Gaussian association and alignment. MAC-Ego3D bridges local precision and global coherence, delivering higher efficiency, largely reducing localization error, and improving mapping fidelity. It establishes a new SOTA on synthetic and real-world benchmarks, achieving a 15x increase in inference speed, order-of-magnitude reductions in ego-motion estimation error for partial cases, and RGB PSNR gains of 4 to 10 dB. Our code will be made publicly available at https://github.com/Xiaohao-Xu/MAC-Ego3D .
实时多智能体协同进行自主运动估计和高保真3D重建对于可扩展的空间智能至关重要。然而,传统方法生成的是稀疏、低细节地图,而最近的密集地图构建方法存在高延迟问题。为了克服这些挑战,我们提出了MAC-Ego3D,这是一个通过多智能体高斯共识进行实时协同光影真实3D重建的新型框架。MAC-Ego3D使智能体能独立构建、对齐并迭代优化本地地图,采用统一的高斯斑块表示法。通过智能体内高斯共识,它在智能体内的相邻高斯斑块之间强制执行空间一致性。对于全局对齐,并行化的智能体间高斯共识能异步对齐和优化本地地图,通过正规化多智能体高斯斑块无缝集成到高保真3D模型中。利用高斯基本元素,MAC-Ego3D支持高效的RGB-D渲染,可实现快速智能体间高斯关联和对齐。MAC-Ego3D结合了局部精度和全局一致性,提高了效率,大大减少了定位误差,提高了地图精度。它在合成和真实世界的基准测试上建立了新的最佳表现,实现了推理速度提高15倍,部分情况下自主运动估计误差大幅度降低,RGB峰值信噪比增益在4到10分贝之间。我们的代码将在https://github.com/Xiaohao-Xu/MAC-Ego3D上公开提供。
论文及项目相关链接
PDF 27 pages, 25 figures
Summary
实时多智能体协同合作对于自我运动估计和高保真3D重建的空间智能至关重要。针对传统方法地图稀疏、细节不足的问题,以及最近密集映射方法的高延迟挑战,提出MAC-Ego3D框架,通过多智能体高斯共识实现实时协同光影逼真3D重建。MAC-Ego3D使智能体能够独立构建、对齐并迭代优化本地地图,通过智能体内高斯共识强化邻近高斯splat的空间一致性。全局对齐则采用并行智能间高斯共识,异步对齐和优化本地地图,通过正则化多智能体高斯splat,无缝集成高保真3D模型。利用高斯原始数据,MAC-Ego3D支持高效RGB-D渲染,实现快速智能间高斯关联和对齐。MAC-Ego3D兼顾局部精度和全局一致性,提高效率,大幅降低定位误差,提升映射精度。在合成和真实世界基准测试上表现优异,实现推理速度提升15倍,部分情况下自我运动估计误差大幅度降低,RGB峰值信噪比增益4至10分贝。
Key Takeaways
- MAC-Ego3D是一个用于实时协同光影逼真3D重建的框架。
- 该框架采用多智能体高斯共识技术实现独立构建、对齐和优化本地地图的功能。
- 智能体内和智能体间的高斯共识保证了地图的空间一致性和全局对齐。
- MAC-Ego3D支持高效RGB-D渲染,提高重建效率和精度。
- 与传统方法相比,MAC-Ego3D具有更高的效率和精度,在多个基准测试中表现优异。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
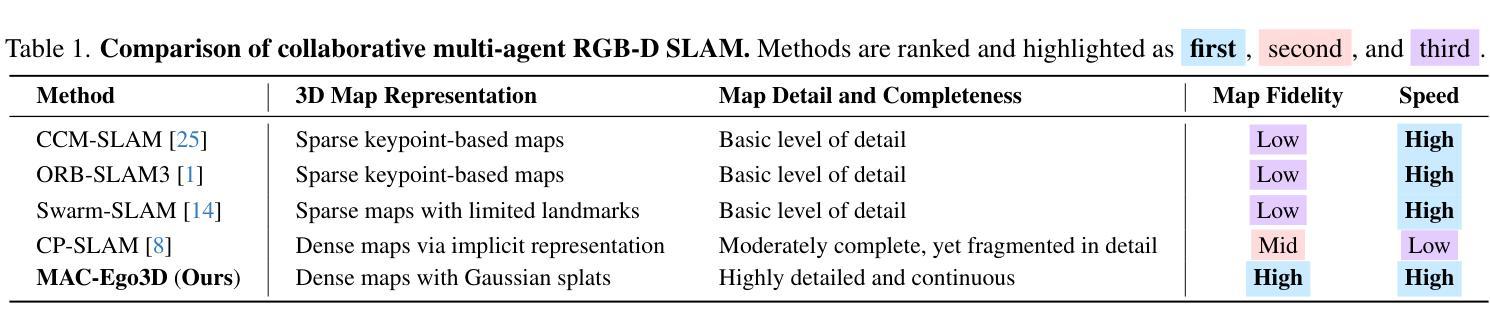
A: 这篇论文提出了一个名为MAC-Ego3D的框架,旨在解决以下问题:
实时多智能体协作的自我运动估计和高保真度3D重建:这是可扩展空间智能应用(如机器人群和增强现实)中的基本需求。现有的方法要么产生稀疏、细节低的地图,要么在处理密集映射时面临高延迟问题。
多智能体SLAM(Simultaneous Localization and Mapping)的局限性:尽管已有研究推动了多智能体SLAM的发展,现有系统仍然受限,主要集中在定位上,并产生缺乏高保真场景重建所需的细节的稀疏、低精度地图。集中式架构在智能体数量增加时,面临更高的延迟和通信需求,限制了可扩展性。分布式方法虽然更可扩展,但最近的多智能体密集映射方法仍然面临延迟和不一致性的问题。
高保真度和全局一致性的3D表示的实时交付:为了克服这些挑战,论文提出了MAC-Ego3D,这是一个通过多智能体高斯共识机制实现在线高保真度3D重建的协作实时多智能体SLAM框架。
总结来说,MAC-Ego3D框架通过使用高斯splat表示来捕捉空间结构和外观属性,使每个智能体能够独立构建和精细化局部地图,并定期共享姿态和高斯地图以协作优化地图和自我运动估计,从而解决了实时性、精度和一致性的问题。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
多智能体协作RGB-D SLAM系统:
- 集中式框架,例如CVI-SLAM [11],使用中央服务器管理数据共享和计算任务。
- 分布式SLAM系统,例如Swarm-SLAM [14],依赖于对等通信,实现去中心化方法。
- 基于神经表示的高保真度3D渲染,例如CP-SLAM [8],使用NeRF [18]启发式表示进行协作映射。
密集RGB-D SLAM模型:
- 传统的SLAM模型,如ORB-SLAM [19, 20],在自我运动估计方面表现出色,但因基于特征描述符而产生稀疏地图。
- 非神经SLAM模型提供详细的几何结构,但缺乏精细的外观细节。
- 密集神经SLAM模型结合几何和外观,实现高保真度、逼真的3D重建。
隐式神经技术在SLAM中的应用:
- NeRF [23]被纳入SLAM中,用于高质量的纹理重建。
- 持续的研究改进表现技术,例如[10, 24, 35, 39, 40]。
3D高斯Splatting:
- 3D高斯Splatting [13]显示出对高效RGBD渲染的承诺。
- 进一步的研究提高了SLAM渲染效率和保真度 [5, 6, 12, 17]。
这些相关研究构成了MAC-Ego3D框架的研究背景,其中涉及到多智能体协作、高保真度3D重建、隐式神经表示以及高斯splatting技术。这些技术的发展为实现实时、协作的高保真度3D重建提供了理论和实践基础。
Q: 论文如何解决这个问题?
A: 论文通过提出MAC-Ego3D框架解决了实时多智能体协作自我运动估计和高保真度3D重建的问题。下面是该框架的主要解决方案和步骤:
1. 多智能体高斯共识机制(Multi-Agent Gaussian Consensus)
- MAC-Ego3D 利用高斯splat表示环境,使每个智能体能够独立构建和精细化局部地图,并定期共享姿态和高斯地图以协作优化地图和自我运动估计。
2. 局部和全局高斯共识
- 局部智能体高斯共识(Intra-Agent Gaussian Consensus):每个智能体基于自己的观测构建局部高斯基础的3D地图,通过时间连贯性跨高斯splat进行优化。
- 全局智能体高斯共识(Inter-Agent Gaussian Consensus):多个智能体通过高效关联和协作精细化共视的高斯splat来对齐重叠地图。
3. 高斯共识的四个高级步骤
- 选择(Selection):识别重叠区域中相关的高斯splat以集中对齐工作。
- 关联(Association):基于空间和外观相似性建立对应关系。
- 对齐(Alignment):最小化重叠高斯之间的空间差异。
- 优化(Optimization):智能体微调其对齐的高斯和姿态,以确保局部地图之间的一致转换。
4. 高效的RGB-D渲染
- 利用高斯原语,MAC-Ego3D 支持高效的RGB-D渲染,实现快速智能体间高斯关联和对齐。
5. 平行化高斯共识设计
- MAC-Ego3D 的共识机制允许智能体内部过程和异步智能体间关联的独立执行,确保实时性能。
6. 实验验证
- 在合成和真实世界的基准测试中,MAC-Ego3D 在轨迹估计精度、3D重建保真度和运行时效率方面均优于现有方法。
通过这些解决方案,MAC-Ego3D 在多智能体系统中实现了局部精度和全局连贯性的桥梁,提供了更高的效率,显著降低了定位误差,并提高了映射保真度。
Q: 论文做了哪些实验?
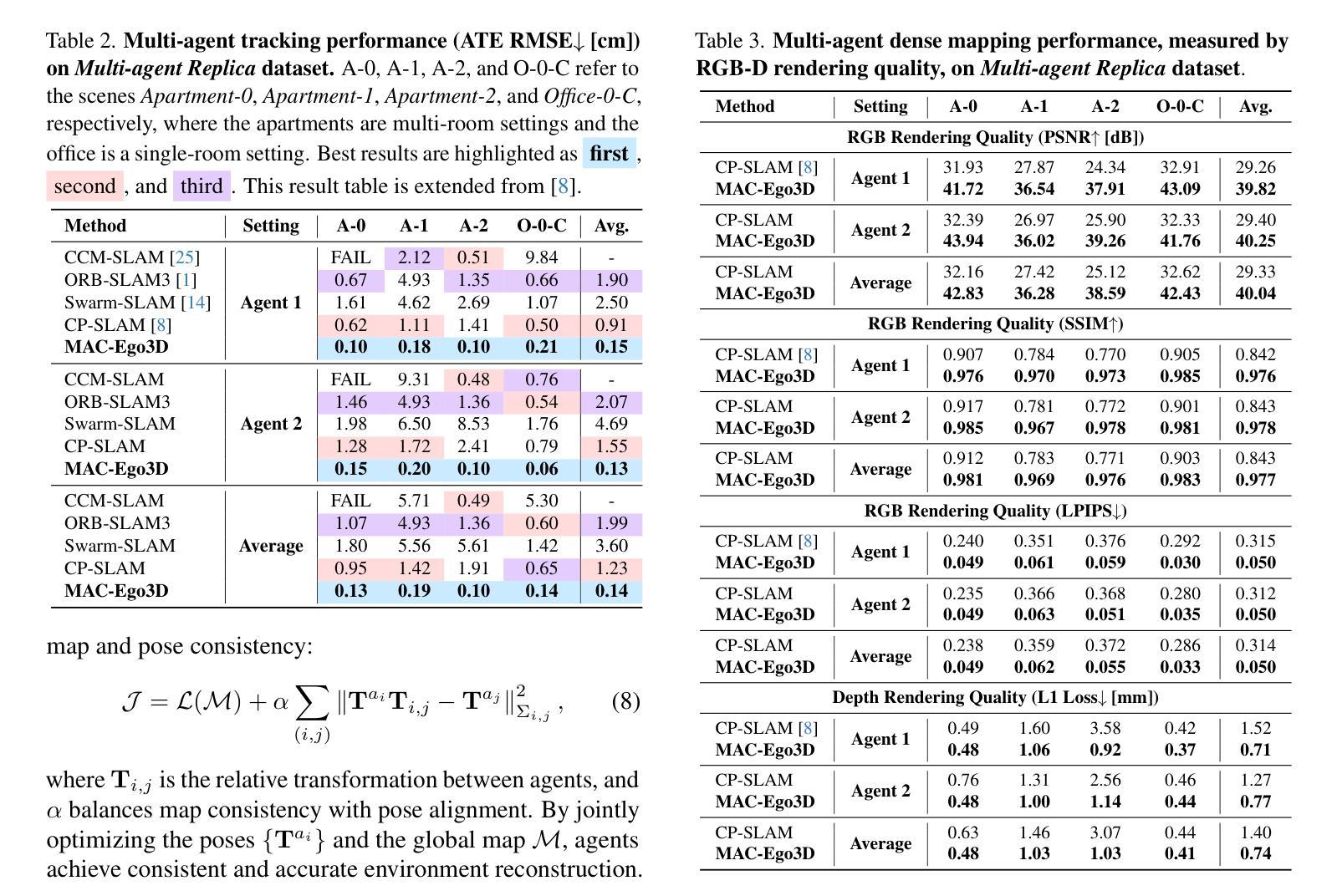
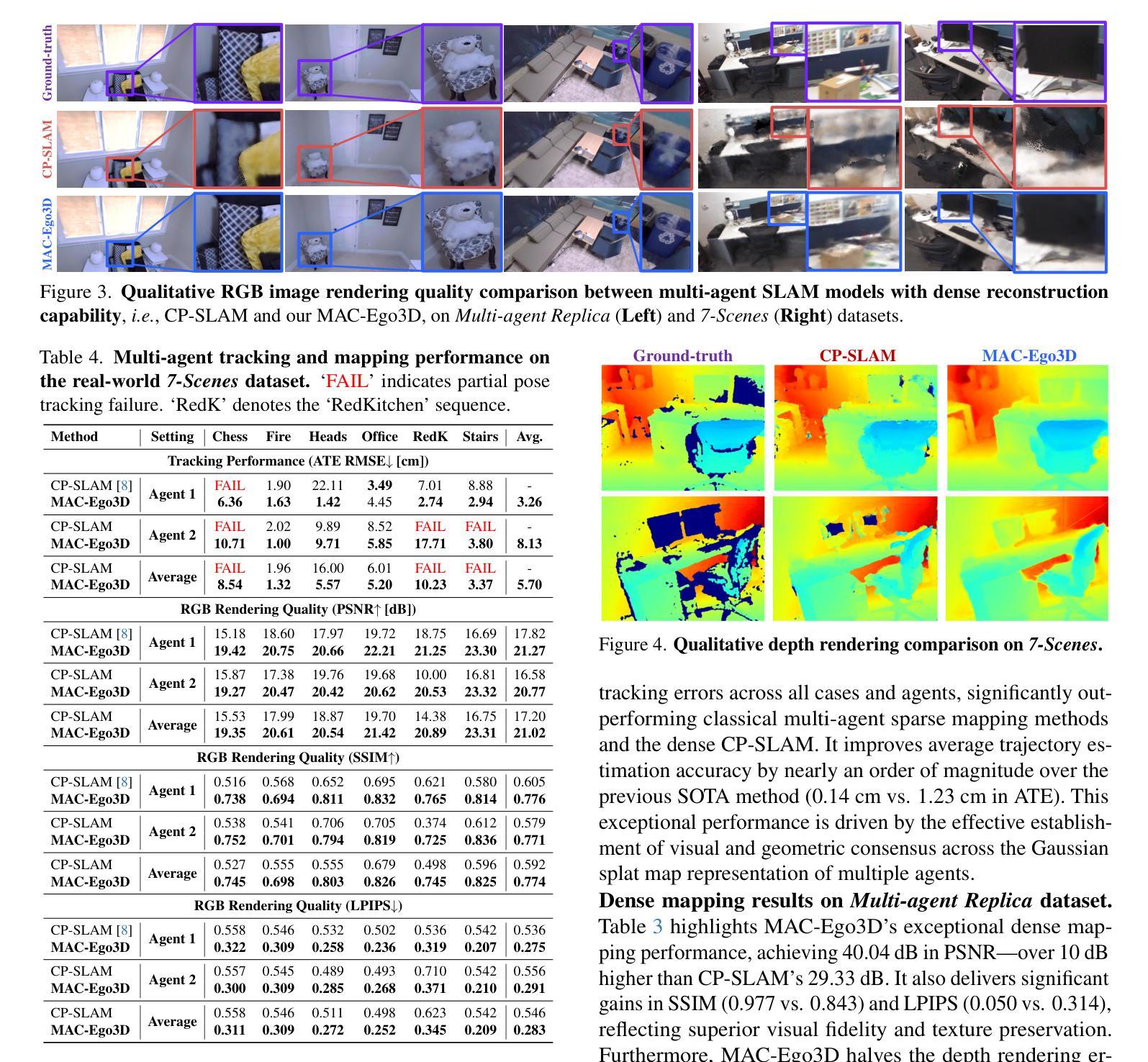
A: 论文中进行了一系列实验来评估MAC-Ego3D框架的性能,具体实验包括:
实验设置:
- 使用了两个多智能体数据集进行评估:合成的Multi-agent Replica数据集和真实世界的7-Scenes数据集。
主要定量结果:
- 在Multi-agent Replica数据集上,MAC-Ego3D在所有情况下都实现了最低的轨迹估计误差,显著优于传统的多智能体稀疏映射方法和密集的CP-SLAM方法。
- 在Multi-agent Replica数据集上,MAC-Ego3D在PSNR、SSIM和LPIPS等指标上显示出卓越的密集映射性能,与CP-SLAM相比,实现了超过10dB的PSNR提升。
- 在真实世界的7-Scenes数据集上,MAC-Ego3D在大多数序列中实现了更低的轨迹估计误差,并且在RGB渲染质量上一致优于CP-SLAM。
定性结果:
- 展示了MAC-Ego3D与CP-SLAM在RGB图像渲染质量、深度渲染和轨迹估计方面的比较,证明了MAC-Ego3D在细节捕捉、颜色准确性和几何完整性方面的优势。
效率和鲁棒性分析:
- 展示了MAC-Ego3D在具有重复环路的Multi-agent Replica序列中的运行时效率,与CP-SLAM相比,实现了更低的误差和更快的处理速度。
- 在存在观察噪声的情况下,MAC-Ego3D显示出比CP-SLAM更好的鲁棒性,无论是在RGB噪声、深度噪声还是复合RGB-D噪声下。
消融研究:
- 展示了通过多智能体协作进行高保真度3D重建的有效性,说明了合作对于提高映射一致性和质量的重要性。
- 分析了通过Inter-Agent Gaussian Consensus进行协作3D地图优化和姿态优化的效果,证明了这些步骤在提高性能方面的重要性。
这些实验全面评估了MAC-Ego3D框架在多智能体场景下的性能,包括轨迹跟踪的准确性、3D重建的保真度、运行时效率以及对噪声和复杂环境的鲁棒性。通过与现有技术的比较,论文证明了MAC-Ego3D在这些方面的优越性能。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
多房间和大规模环境的SLAM:
- 论文提到将多智能体协作SLAM扩展到多房间环境时,会面临关联不同空间中相似模式的挑战。未来的工作可以探索如何在大规模、无界室外环境中实现有效的多智能体SLAM。
高斯压缩技术:
- 由于3D高斯splat表示可能会随着场景规模的增长而增长,因此集成有效的高斯压缩技术对于管理内存效率至关重要。未来的研究可以探索如何优化这一表示以提高存储和计算效率。
增强鲁棒性:
- 尽管MAC-Ego3D在噪声条件下表现出鲁棒性,但在极端情况下或更复杂的动态环境中,其鲁棒性可以进一步增强。研究可以集中在提高系统在面对更极端噪声和快速动态变化时的性能。
提高实时性能:
- 虽然MAC-Ego3D实现了实时性能,但在更强大的硬件或优化算法的帮助下,可以进一步减少跟踪和映射的时间延迟。
跨模态融合:
- 考虑将其他传感器模态(如激光雷达、IMU等)融入框架,以实现更全面的环境感知和更精确的自我运动估计。
更复杂的场景和对象交互:
- 测试和改进MAC-Ego3D在包含更多复杂交互和动态对象的场景中的性能,例如拥挤的公共场所或交通场景。
优化和算法改进:
- 进一步研究和开发更高效的优化算法,以处理更大的数据集和更复杂的环境,同时保持实时性。
开源和社区贡献:
- 论文提到代码将公开提供,这为社区贡献和进一步开发提供了基础。可以通过社区合作进一步改进算法,并在各种应用中测试其有效性。
长期一致性和回环检测:
- 研究如何在长时间运行的SLAM系统中保持一致性,并改进回环检测机制,以处理长时间跨度和大范围环境中的挑战。
这些探索点可以帮助推动多智能体SLAM技术的发展,提高其在更广泛场景和应用中的适用性和有效性。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为MAC-Ego3D的框架,旨在通过多智能体高斯共识机制实现实时自我运动估计和高保真度的3D重建。以下是论文的主要内容总结:
问题定义:
- 论文针对实时多智能体协作在自我运动估计和高保真度3D重建方面的需求,指出现有方法在实时性和细节捕捉上的不足。
MAC-Ego3D框架:
- 提出了MAC-Ego3D框架,一个实时协作的多智能体SLAM系统,使用高斯splat作为连续的、逼真的地图表示,支持局部地图的独立构建、对齐和迭代细化。
多智能体高斯共识:
- 介绍了Intra-Agent和Inter-Agent高斯共识机制,分别用于智能体内部的空间连贯性和全局地图对齐。
- 详细描述了选择、关联、对齐和优化四个步骤,以实现有效的跟踪、快速的闭环检测和高保真度映射。
实验结果:
- 在合成和真实世界的基准测试中,MAC-Ego3D在轨迹估计精度、3D重建质量和运行时效率方面均优于现有方法。
- 实现了15倍的推理速度提升,位置估计误差的数量级降低,以及RGB峰值信噪比(PSNR)提高4到10分贝。
贡献:
- 首次提出了实时全周期多智能体密集SLAM系统,利用高斯splat进行连续、逼真的地图表示,实现高保真度3D重建和精确的姿态跟踪。
- 提出了一个统一框架,用于内部和外部智能体高斯共识优化,有效约束高斯splat,实现鲁棒的闭环检测和一致的地图对齐。
- 通过实验验证了MAC-Ego3D在多个多智能体基准测试中的性能,与先前的方法相比,在轨迹估计精度、3D重建保真度和运行时效率方面都有显著提升。
未来工作:
- 论文提出了未来可能的研究方向,包括扩展到大规模环境、集成高斯压缩技术以提高内存效率,以及提高系统的鲁棒性和实时性能。
总体而言,MAC-Ego3D通过其创新的多智能体高斯共识机制,为实时多智能体协作的自我运动估计和3D重建领域提供了一个高效和高保真的解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

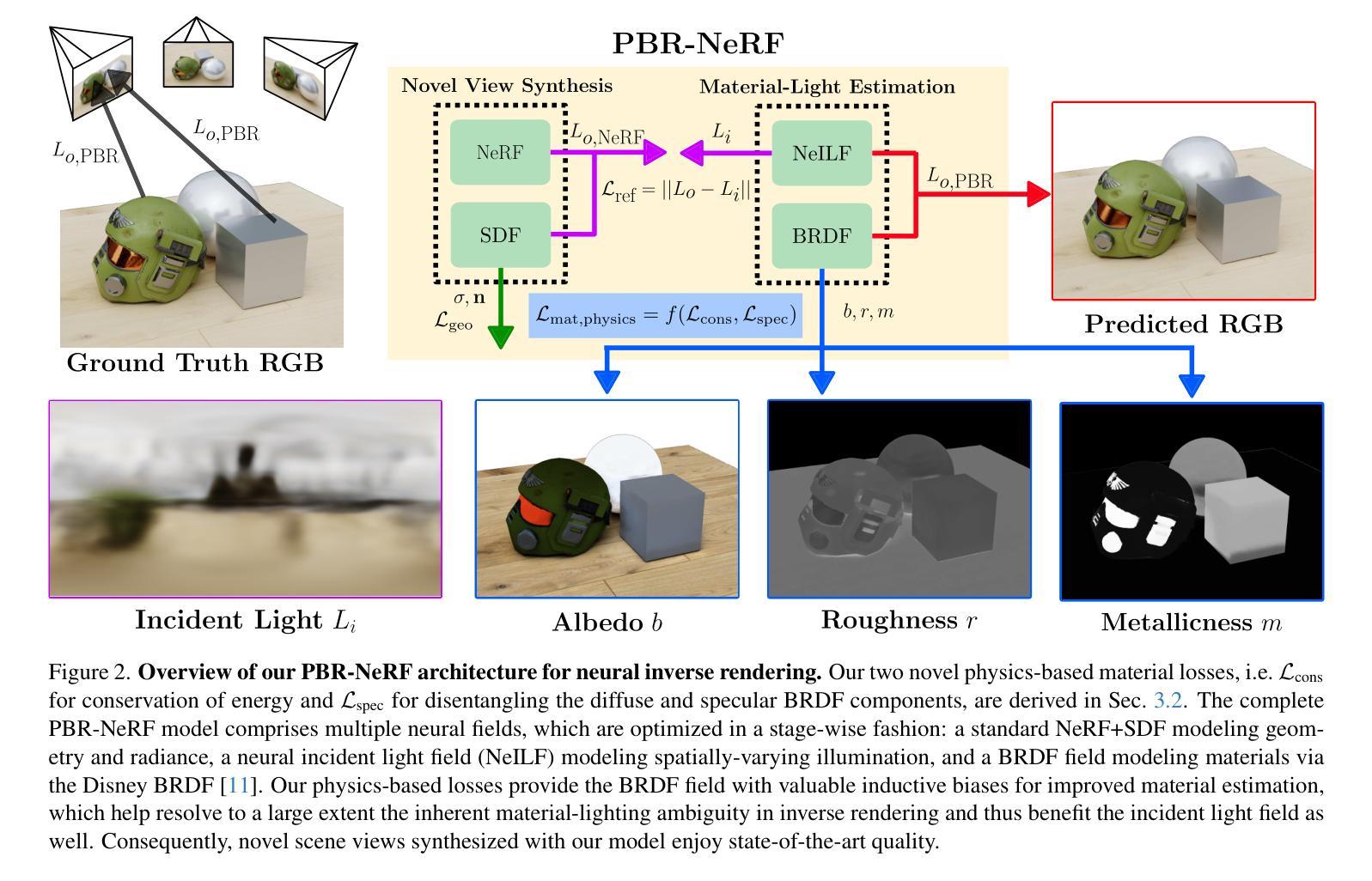
PBR-NeRF: Inverse Rendering with Physics-Based Neural Fields
Authors:Sean Wu, Shamik Basu, Tim Broedermann, Luc Van Gool, Christos Sakaridis
We tackle the ill-posed inverse rendering problem in 3D reconstruction with a Neural Radiance Field (NeRF) approach informed by Physics-Based Rendering (PBR) theory, named PBR-NeRF. Our method addresses a key limitation in most NeRF and 3D Gaussian Splatting approaches: they estimate view-dependent appearance without modeling scene materials and illumination. To address this limitation, we present an inverse rendering (IR) model capable of jointly estimating scene geometry, materials, and illumination. Our model builds upon recent NeRF-based IR approaches, but crucially introduces two novel physics-based priors that better constrain the IR estimation. Our priors are rigorously formulated as intuitive loss terms and achieve state-of-the-art material estimation without compromising novel view synthesis quality. Our method is easily adaptable to other inverse rendering and 3D reconstruction frameworks that require material estimation. We demonstrate the importance of extending current neural rendering approaches to fully model scene properties beyond geometry and view-dependent appearance. Code is publicly available at https://github.com/s3anwu/pbrnerf
我们采用基于物理渲染(PBR)理论指导的神经辐射场(NeRF)方法,解决了3D重建中的不适定逆渲染问题,称之为PBR-NeRF。我们的方法解决了大多数NeRF和3D高斯拼贴方法的关键局限性:它们在估计视图相关外观时没有对场景材质和照明进行建模。为了解决这一局限性,我们提出了一种能够联合估计场景几何、材质和照明的逆渲染(IR)模型。我们的模型建立在最近的NeRF基IR方法之上,但关键地引入了两种新型基于物理的先验知识,更好地约束了IR估计。我们的先验知识被严谨地制定为直观的损失项,实现了材料估计的最优状态,且不会损害新视图合成的质量。我们的方法很容易适应其他需要材料估计的逆渲染和3D重建框架。我们证明了将当前的神经网络渲染方法扩展到完全建模场景属性(而不仅仅是几何和视图相关外观)的重要性。代码公开在https://github.com/s3anwu/pbrnerf。
论文及项目相关链接
PDF 16 pages, 7 figures. Code is publicly available at https://github.com/s3anwu/pbrnerf
Summary
基于物理渲染理论的新型神经网络辐射场(NeRF)方法,名为PBR-NeRF,解决了三维重建中的逆向渲染问题。该方法能联合估计场景几何、材质和照明,克服了大多数NeRF和三维高斯拼贴方法的局限,即它们仅估计视觉相关的外观而未建模场景材质和照明。PBR-NeRF引入两个新的基于物理的先验知识,以更好地约束逆向渲染估计,且在材料估计方面达到了最佳效果,同时不影响新型视图合成的质量。该方法易于适应其他需要材料估计的逆向渲染和三维重建框架。
Key Takeaways
- PBR-NeRF解决了三维重建中的逆向渲染问题,结合了神经网络辐射场(NeRF)和基于物理渲染(PBR)理论的方法。
- 该方法能够联合估计场景的几何、材质和照明,克服了现有方法的局限。
- PBR-NeRF通过引入两个新的基于物理的先验知识来改进逆向渲染估计。
- 该方法在材料估计方面达到了最佳效果,同时保持了新型视图合成的质量。
- PBR-NeRF易于适应其他需要材料估计的逆向渲染和三维重建框架。
- 公开可用的代码可以在指定的GitHub仓库找到。
- 文章强调了完全建模场景属性(包括几何和视觉相关外观以外的属性)的重要性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决3D重建中的一个关键问题:逆渲染(inverse rendering)问题。逆渲染问题是指从一组多视角图像中准确重建场景的属性,包括几何形状、材料和照明。这个问题本质上是不适定的(ill-posed),因为存在材料-光照歧义,即同一图像可以由无限多的材质、光照和几何形状的组合来解释。为了克服这一挑战,论文提出了一种基于物理的神经场(Neural Radiance Fields,简称NeRF)方法,称为PBR-NeRF,该方法利用基于物理的渲染(Physics-Based Rendering,简称PBR)理论来提供强大的先验,以缩小可能的解空间。
具体来说,论文解决的问题包括:
视依赖外观的估计:大多数NeRF和3D高斯绘制方法没有模拟场景材料和照明,而是将场景视为“黑箱”,忽略了光传输的底层物理。这限制了这些方法在3D重建中的性能,因为它们无法准确和一致地模拟多样的光交互。
材料-光照-几何歧义:逆渲染问题由于材料、光照和几何的不确定性而变得复杂。为了解决这一问题,需要强有力的先验来约束可能的解决方案。
物理准确性:现有的NeRF和3DGS方法在模拟场景几何和视依赖外观方面取得了最先进的性能,但它们不能保证物理上准确的结果。例如,反射表面可能被错误地建模,导致“烘焙入”的高光等伪影。
论文通过引入两个基于物理的先验(损失项),即能量守恒损失和NDF加权的镜面损失,来改进逆渲染估计,并在不牺牲新视角合成质量的同时,实现了最先进的材质估计。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要涉及以下几个领域:
Neural Fields for Novel View Synthesis:
- 利用连续体积场表示3D场景的方法,通过可微分体积渲染实现从未见视角的照片级真实感合成。代表性的工作包括NeRF及其衍生方法,它们通过alpha合成沿每个相机射线采样点的颜色来估计外出辐射度。
Neural Inverse Rendering:
- 早于神经场的方法,学习从2D图像预测3D几何、材料和照明。这些方法通过逆渲染或内在分解来估计物理场景属性,如材料和照明,从而支持如重新照明、材质编辑和外观操作等复杂下游任务。
Decomposed Neural Fields:
- 将传统神经场扩展到估计物理场景属性(如材料和照明)的方法,通过逆渲染或内在分解实现。
Physics-Based Rendering (PBR) Theory:
- 计算机图形学中用于生成给定场景材料、照明和几何的物理准确图像的框架。通过逆转这一过程,可以从PBR理论中导出用于更好约束神经前向和逆向渲染的物理先验。
Material Priors for Inverse Rendering:
- 用于约束材料估计并减少材料-光照歧义的材料先验至关重要。先前工作中使用了基本的BRDF平滑先验,以阻止材料属性的空间变化。
NeRF and 3D Gaussians for Scene Geometry Representation:
- 使用密度场、3D高斯或签名距离场(SDFs)来表示场景几何。SDFs明确定义表面,提供准确的表面和法线估计,使其与依赖PBR的逆渲染任务天然兼容。
具体到论文引用的文献,以下是一些相关研究的示例:
- NeRF:Mildenhall et al. (2020) 提出了NeRF,用于从一组图像中合成新视角的场景。
- **3D Gaussian Splatting (3DGS)**:Kerbl et al. (2023) 提出了3DGS,用于实时辐射场渲染。
- **NeILF/NeILF++**:Yao et al. (2022, 2023) 提出了NeILF和NeILF++,用于基于物理的材料估计。
- PBR理论:Pharr et al. (2016) 的著作详细介绍了基于物理的渲染理论。
这些相关研究构成了PBR-NeRF方法的理论和实践基础,并为进一步的研究提供了参考和对比。
Q: 论文如何解决这个问题?
A: 论文通过提出PBR-NeRF方法解决了逆渲染问题,具体解决方案如下:
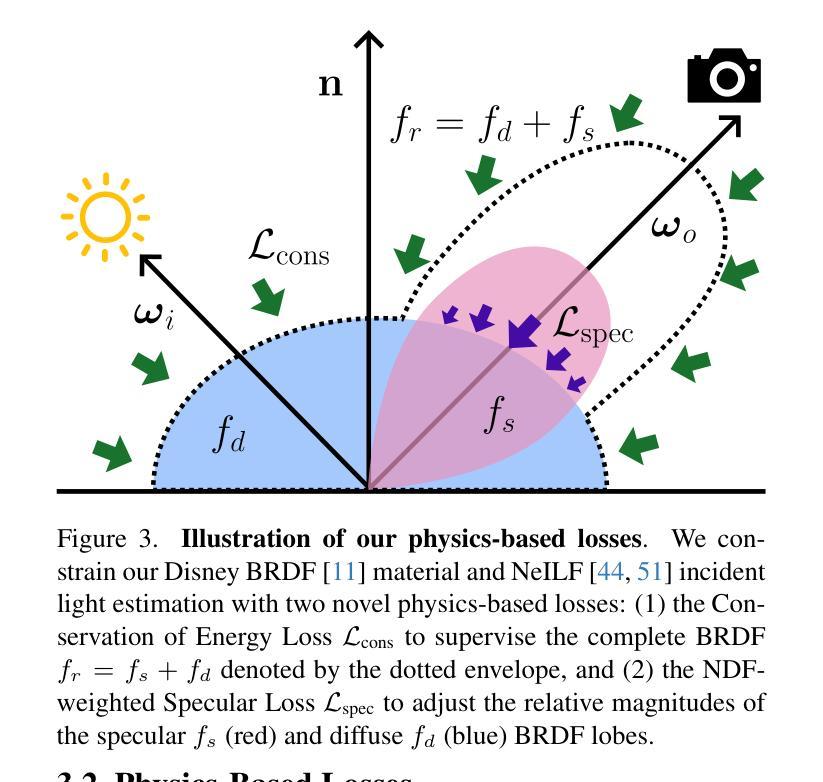
结合NeRF和PBR理论:
- 论文基于NeILF/NeILF++神经场框架,结合深度神经网络的表达能力和PBR理论的理论保证,扩展了NeILF/NeILF++的反射模型,通过利用其基础的迪士尼双向反射分布函数(Disney BRDF)模型。
引入两个物理先验损失:
- 能量守恒损失(Conservation of Energy Loss):此损失通过惩罚物理上无效的BRDF来强制执行能量守恒,确保材料不会创造或破坏能量。
- NDF加权的镜面损失(NDF-weighted Specular Loss):此损失通过在镜面区域惩罚过度的漫反射来促进BRDF的漫反射和镜面反射部分的分离,这对于准确模拟高镜面材料至关重要。
多阶段优化:
- 论文提出了一个三阶段优化流程:
- 几何阶段:仅训练NeRF SDF以初始化估计的几何形状。
- 材料阶段:在冻结NeRF SDF的情况下训练NeILF和BRDF MLP,以初始化估计的照明和材料。
- 联合优化阶段:同时训练所有场(NeRF SDF、NeILF、BRDF),使用所有损失进行优化。
- 论文提出了一个三阶段优化流程:
理论模型和实践验证:
- 论文不仅提出了理论模型,还通过在NeILF++和DTU数据集上的实验验证了PBR-NeRF的有效性。实验结果表明,PBR-NeRF在材料估计方面达到了新的最佳水平,同时保持或超过了基线的新视角合成性能。
通过这些方法,PBR-NeRF能够有效地解决逆渲染问题,准确地估计场景的几何形状、材料和照明,从而实现高质量的3D重建和新视角合成。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证PBR-NeRF方法的有效性,具体实验包括:
实验设置:
- 实现细节:PBR-NeRF基于NeILF++使用PyTorch实现,并保留了NeILF++的所有超参数,除了|SL|=256。训练迭代30K次,初始学习率为0.002,每10K迭代降低5倍。训练在单个NVIDIA RTX 4090上运行,运行时间从1到3小时不等。
数据集:
- NeILF++数据集:用于评估材料照明估计,假设已知几何形状。该数据集提供场景的地面真实几何形状、RGB、Albedo、Metallicness和Roughness,场景在6种静态照明模式下渲染,包括3种环境映射和3种混合照明场景。
- DTU数据集:捕获15个真实世界对象在受控实验室环境中的49个RGB LDR 1600×1200图像,分为44个训练图像和5个验证图像。仅定性评估DTU上的材料估计,因为它包含LDR图像且不提供地面真实材料。
与最新技术的比较:
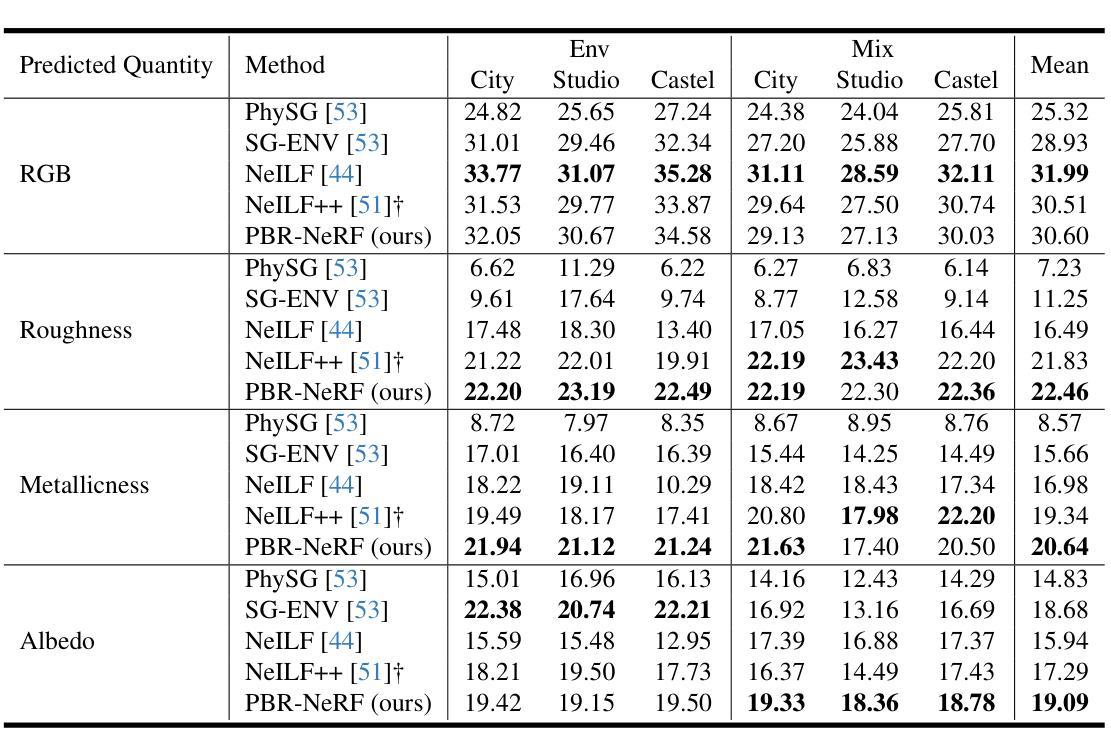
- 定量结果:使用PSNR指标比较NeILF++数据集上不同场景(City、Studio和Castel)和照明类型(Env和Mix)下的材料估计和新视角合成性能。
- PBR-NeRF在NeILF++数据集上实现了最先进的材料估计,平均PSNR在Albedo、Metallicness和Roughness上超过先前方法1-2dB。
- 在DTU数据集上,PBR-NeRF在新视角合成方面达到了最先进的结果,平均PSNR超过NeILF++ 0.37dB,并在10个场景中表现最佳。
定性结果:
- 与NeILF++在NeILF++数据集上的材料估计性能进行定性比较,PBR-NeRF在所有三种混合照明条件下都改善了照明和材料估计。
- 在DTU数据集上,PBR-NeRF在金属和粗糙度估计方面表现更好,准确预测金属物体,而NeILF++在金属部分和粗糙度方面产生了伪影。
消融研究:
- 对提出的物理先验损失进行消融研究,单独评估每个损失项的贡献。
- 结果表明,加入能量守恒损失(Lcons)改善了材料估计,加入镜面损失(Lspec)进一步提升了Albedo和Metallicness的估计。
这些实验全面验证了PBR-NeRF方法在逆渲染和新视角合成方面的有效性,并展示了其在材料估计方面的显著改进。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
高频镜面效应和反射表面处理:
- 论文中提到在处理高频镜面效应和反射表面时存在局限性,这表明需要进一步研究以改进对这类表面材质的估计和渲染。
更精细的材质和照明模型:
- 虽然PBR-NeRF利用了简化版的Disney BRDF模型,但可以考虑集成更复杂和详细的材质模型,以更准确地捕捉现实世界中的各种光照和材质交互。
优化算法和损失函数:
- 探索新的优化算法和损失函数,以进一步提高模型的性能和泛化能力,尤其是在处理复杂光照和材质时。
大规模场景和实时应用:
- 研究如何将PBR-NeRF扩展到大规模场景,并优化算法以实现实时渲染和交互。
数据集和标注:
- 开发和利用更多样化和大规模的数据集,包括更多的材质类型和光照条件,以及对应的详细标注,以训练和评估更先进的模型。
多模态数据融合:
- 考虑将多种传感器数据(如RGB-D、LiDAR、深度图等)融合到模型中,以提供更全面的物理场景信息。
可解释性和编辑性:
- 提高模型的可解释性,允许用户更好地理解和编辑重建的3D场景,这对于设计和创意应用尤其重要。
跨模态迁移和泛化能力:
- 研究模型在不同场景和条件下的迁移能力,以及如何提高模型对未知场景的泛化能力。
计算效率和资源优化:
- 探索更高效的计算方法,减少模型训练和推理所需的计算资源,使其更适合资源受限的环境。
鲁棒性和异常处理:
- 提高模型对异常数据和噪声的鲁棒性,确保在不理想的输入条件下也能产生合理的输出。
这些探索点可以帮助推动逆渲染和3D重建技术的发展,提高其在各种应用中的实用性和效果。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为PBR-NeRF的方法,旨在通过结合物理基础的渲染(PBR)理论与神经辐射场(NeRF)来解决3D重建中的逆渲染问题。以下是论文的主要内容总结:
问题阐述:
- 论文指出,现有的NeRF和3D高斯绘制方法在估计场景外观时没有考虑材料和照明,导致无法准确模拟复杂的光交互。逆渲染问题由于材料-光照-几何的不确定性而变得不适定。
PBR-NeRF方法:
- 基于NeILF/NeILF++框架,PBR-NeRF通过引入两个物理先验损失项来改进逆渲染估计:能量守恒损失和NDF加权的镜面损失。
- 这些损失项增强了物理有效性,改善了材料估计,同时不牺牲新视角合成的质量。
多阶段优化:
- 采用三阶段优化流程:几何初始化、材料估计和联合优化,每个阶段使用不同的损失函数来编码特定的先验或约束。
实验验证:
- 在NeILF++和DTU数据集上进行了实验,结果表明PBR-NeRF在材料估计方面达到了新的最佳水平,同时在新视角合成性能上保持或超过了基线。
定性和定量结果:
- 论文提供了与现有技术的定量比较和定性分析,展示了PBR-NeRF在处理复杂光照和材质时的优势。
消融研究:
- 通过消融研究验证了所提出的物理先验损失项对模型性能的贡献。
结论与展望:
- 论文认为PBR-NeRF在材料估计和逆渲染方面表现出色,并且其物理驱动的方法将激发更多基于PBR的分解神经场的研究。
总体而言,这篇论文通过结合先进的神经网络技术和物理基础的渲染理论,提出了一种新的逆渲染方法,有效地解决了3D场景重建中的一些关键挑战,并在多个数据集上展示了其优越的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

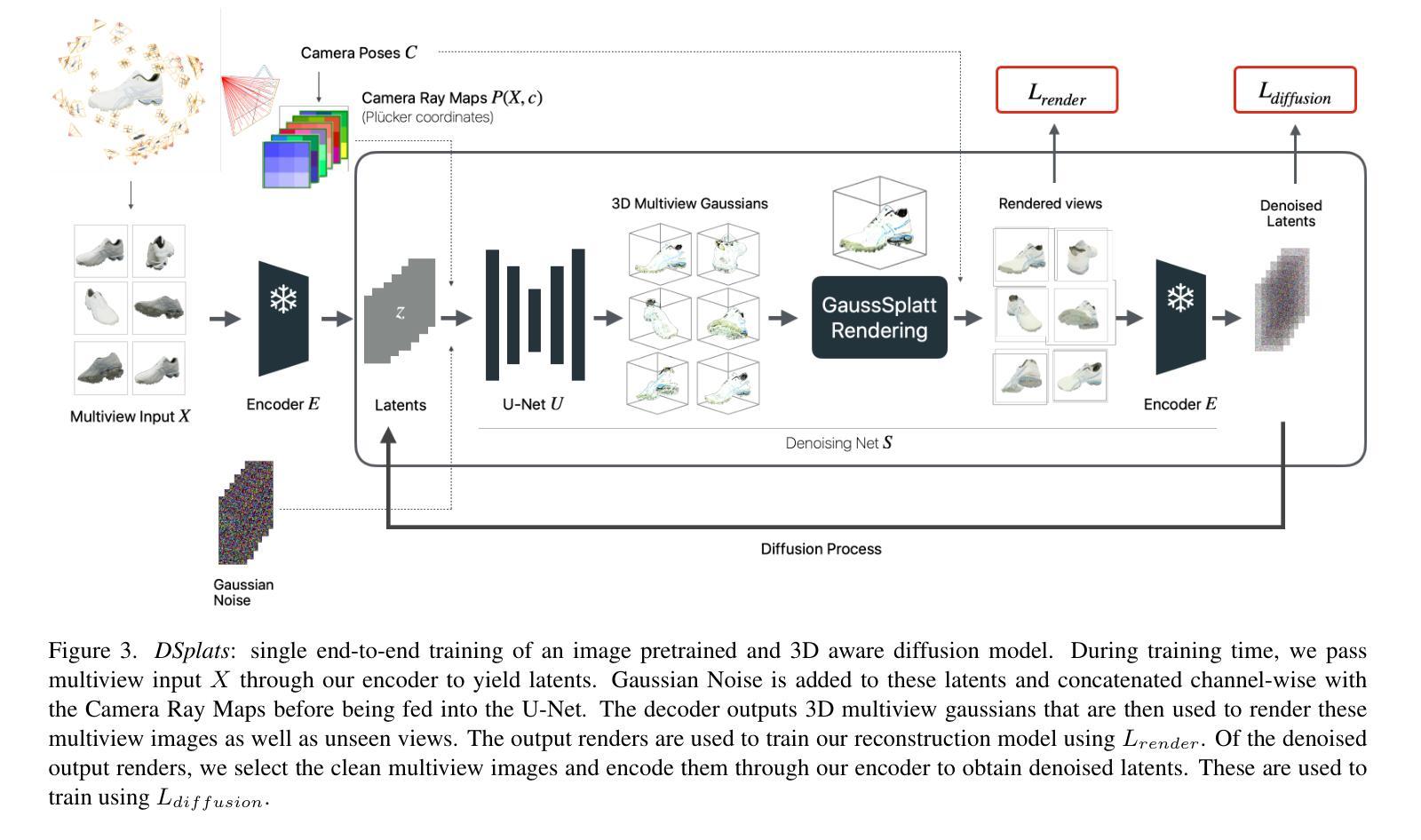
DSplats: 3D Generation by Denoising Splats-Based Multiview Diffusion Models
Authors:Kevin Miao, Harsh Agrawal, Qihang Zhang, Federico Semeraro, Marco Cavallo, Jiatao Gu, Alexander Toshev
Generating high-quality 3D content requires models capable of learning robust distributions of complex scenes and the real-world objects within them. Recent Gaussian-based 3D reconstruction techniques have achieved impressive results in recovering high-fidelity 3D assets from sparse input images by predicting 3D Gaussians in a feed-forward manner. However, these techniques often lack the extensive priors and expressiveness offered by Diffusion Models. On the other hand, 2D Diffusion Models, which have been successfully applied to denoise multiview images, show potential for generating a wide range of photorealistic 3D outputs but still fall short on explicit 3D priors and consistency. In this work, we aim to bridge these two approaches by introducing DSplats, a novel method that directly denoises multiview images using Gaussian Splat-based Reconstructors to produce a diverse array of realistic 3D assets. To harness the extensive priors of 2D Diffusion Models, we incorporate a pretrained Latent Diffusion Model into the reconstructor backbone to predict a set of 3D Gaussians. Additionally, the explicit 3D representation embedded in the denoising network provides a strong inductive bias, ensuring geometrically consistent novel view generation. Our qualitative and quantitative experiments demonstrate that DSplats not only produces high-quality, spatially consistent outputs, but also sets a new standard in single-image to 3D reconstruction. When evaluated on the Google Scanned Objects dataset, DSplats achieves a PSNR of 20.38, an SSIM of 0.842, and an LPIPS of 0.109.
生成高质量的三维内容需要能够学习复杂场景及其内部真实世界物体的稳健分布的模型。基于高斯函数的最近3D重建技术通过前馈方式预测3D高斯,已经从稀疏输入图像中恢复了高保真3D资产,取得了令人印象深刻的结果。然而,这些技术通常缺乏扩散模型提供的广泛先验知识和表现力。另一方面,二维扩散模型已成功应用于多视角图像的降噪,有潜力生成广泛的光照真实三维输出,但仍在明确的3D先验和一致性方面有所不足。在这项工作中,我们旨在通过引入DSplats来弥合这两种方法的差距,这是一种使用基于高斯Splat的重建器直接降噪多视角图像的新方法,以产生各种逼真的3D资产。为了利用二维扩散模型的广泛先验知识,我们将预训练的潜在扩散模型纳入重建器主干,以预测一组3D高斯。此外,去噪网络中嵌入的明确3D表示提供了一种强大的归纳偏见,确保几何一致的全新视角生成。我们的定性和定量实验表明,DSplats不仅产生高质量且空间上一致的输出,而且为单图像到3D重建设定了新的标准。在Google扫描对象数据集上进行评估时,DSplats的PSNR达到20.38,SSIM达到0.842,LPIPS达到0.109。
论文及项目相关链接
摘要
本研究旨在结合高斯扩散模型和二维扩散模型的优势,提出一种新型的三维重建方法。通过引入DSplats,该方法能够直接对多视角图像进行去噪,产生多样化的真实三维资产。利用二维扩散模型的先验信息,结合预训练的潜在扩散模型,预测三维高斯集,实现高质量的三维重建。实验证明,DSplats不仅能产生高质量、空间一致性的输出,还在单图像三维重建领域树立了新的标准。
关键见解
- 本研究结合了高斯扩散模型和二维扩散模型的优势,旨在生成高质量的三维内容。
- DSplats方法能够直接对多视角图像进行去噪,产生多样化的真实三维资产。
- 利用预训练的潜在扩散模型,预测三维高斯集,实现高质量的三维重建。
- DSplats方法保证了几何上的一致性,能够生成新颖且一致的视图。
- 在Google Scanned Objects数据集上进行的实验表明,DSplats达到了较高的性能指标,包括PSNR为20.38,SSIM为0.842和LPIPS为0.109。
- DSplats方法为单图像三维重建领域树立了新的标准。
- 该方法对于未来三维内容生成和虚拟现实应用具有潜在的重要意义。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是如何从单张图像生成高质量3D内容的问题。具体来说,它探讨了如何利用2D扩散模型的先验知识和显式的3D高斯表示来生成逼真的3D对象,并且能够从新的视角渲染这些对象。这项工作旨在弥合以下两种方法之间的差距:
基于高斯的3D重建技术:这些技术通过前馈方式预测3D高斯来从稀疏输入图像中恢复高保真度的3D资产,但它们通常缺乏扩散模型提供的广泛先验和表达能力。
2D扩散模型:这些模型已成功应用于多视图图像去噪,并显示出生成各种逼真3D输出的潜力,但在显式的3D先验和一致性方面仍有不足。
论文通过引入一种名为DSplats的新方法来解决这个问题,该方法直接使用基于高斯Splat的重建器对多视图图像进行去噪,以产生多样化的逼真3D资产。DSplats结合了2D扩散模型的丰富先验和基于高斯的重建器的显式3D建模能力,在单次训练中实现这一目标。通过这种方式,DSplats不仅能够生成高质量、空间一致的输出,而且在单图像到3D重建方面树立了新的标准。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要涉及以下几个领域:
3D重建和稀疏视图重建:
- NeRF(Neural Radiance Fields)[24]:用于高质量3D场景的视图插值。
- 3DGS(3D Gaussian Splatting)[17]:一种显式的3D高斯表示方法,能够快速优化并捕获细节。
- NGP(Neural Graphics Primitives)[25]:用于3D场景的高质量渲染。
- SDS(Score Distillation Sampling)[27]:将2D先验提升到3D的方法,如Point-E[26]、DreamFusion[27]和ImageDream[43]。
多视图扩散模型:
- Zero123++[31]、One-2-3-45++[22]、MVDream[32]和MVDiffusion[39]:应用于生成空间一致图像的方法,通过条件相机姿态生成新视图。
视频生成和时间一致性扩散:
- SV3D[41]和SV4D[48]:探索将扩散应用于顺序3D视图,保持多视图合成中的时间一致性。
姿态条件扩散模型:
- CAT3D[10]、ReconFusion[46]和ZeroNVS[30]:将姿态感知引入2D扩散模型,通过学习相机条件图像分布增强视图一致性。
基于重建器的去噪器:
- DMV3D[49]、Viewset Diffusion[34]和RenderDiffusion[1]:在多视图图像去噪方面表现出成功的方法,使用3D重建器背景进行潜在空间去噪。
这些相关研究为DSplats方法提供了理论基础和技术背景,特别是在3D表示、扩散模型和重建器基础的去噪器方面。通过结合这些领域的技术,DSplats旨在实现从单张图像到3D内容的高质量生成。
Q: 论文如何解决这个问题?
A: 论文通过提出DSplats方法解决了从单张图像生成高质量3D内容的问题。DSplats方法的核心在于结合了2D扩散模型的先验知识和显式的3D高斯表示。以下是具体的解决方案:
1. 模型架构
DSplats模型包括以下几个关键组件:
- 2D LDM-based Denoising Net:使用预训练的潜在扩散模型(例如Stable Diffusion),为多视图图像提供去噪能力。
- 3D Gaussian Representation:通过显式的3D高斯表示来捕获3D结构信息。
- Gaussian Splats:用于从3D高斯表示渲染出2D视图。
2. 训练框架
DSplats的训练框架整合了以下两个方面:
- 多视图扩散(Multiview Diffusion):通过在潜在空间中添加噪声并学习逆向去噪过程,实现多视图图像的一致性。
- 3D感知去噪网络(3D-Aware Denoising Net):网络不仅去噪潜在表示,还输出显式的3D模型和相关视图。
3. 端到端训练
DSplats通过以下步骤实现端到端训练:
- 编码(Encoding):使用编码器将多视图图像编码到潜在空间。
- 去噪(Denoising):通过3D感知去噪网络在潜在空间中重复去噪。
- 渲染(Rendering):将去噪后的潜在表示渲染回多视图图像。
4. 损失函数
DSplats使用两种损失函数来训练模型:
- 扩散损失(Diffusion Loss):推动去噪网络输出接近原始潜在表示。
- 渲染损失(Rendering Loss):确保中间3D模型的渲染视图接近输入图像视图。
5. 实验验证
通过在Google Scanned Objects数据集上的实验,DSplats在多个指标上取得了最先进的结果,包括PSNR、SSIM和LPIPS。生成的新视图展现出高视觉真实性和强几何一致性,这归功于2D扩散模型先验和显式3D表示的结合。
总结来说,DSplats通过结合2D扩散模型的丰富先验和3D高斯表示的显式3D建模能力,在单次训练中实现了从单张图像到高质量3D内容的生成。这种方法不仅提高了生成质量,还保持了新视图之间的空间一致性。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来评估DSplats模型的性能。以下是实验的详细描述:
1. 设置(Setup)
- 训练数据:使用了两个数据集,Objaverse和MVImgNet。Objaverse包含约800K个3D对象,从中筛选出约44K个高质量的模型。MVImgNet是一个包含约200K资产的多视图图像数据集,从中使用了约120个经过清洗和提取分割掩码的资产。
- 测试数据:使用了Google Scanned Objects(GSO)数据集,包含1000个真实世界扫描的对象。选择了250个对象进行评估。
- 数据增强:应用了网格扭曲和轨道相机抖动两种数据增强策略,以提高3D重建器的稳定性。
- 实现细节:模型在24个NVIDIA A100 GPU上训练,每个GPU有80GB的RAM,训练100k次迭代,使用bfloat16精度。
2. 评估和分析(Evaluation and Analysis)
- 3D对象的新视图:使用GSO数据集评估基于单视图生成的模型。使用20°仰角的视图作为输入,其余63个渲染用于评估。使用多种指标进行定量性能评估,包括PSNR、LPIPS、CLIP和SSIM。
- 场景的新视图:除了在单对象图像上应用DSplats并仅重建对象外,还展示了DSplats在真实世界图像中生成对象新视图的能力。这个任务的挑战在于视频轨迹的长度以及场景的复杂性,即背景的存在。
3. 定量结果(Quantitative Results)
- 表1:展示了单图像到多视图重建结果。DSplats在所有传统指标(如PSNR)和感知指标(如LPIPS)上均优于其他方法。
4. 定性结果(Qualitative Results)
- 图4:展示了DSplats与One-2-3-45和GRM在GSO数据集上的结果比较,显示DSplats在光照、纹理和几何先验方面的优势。
- 图5:展示了DSplats在真实世界图像中生成对象新视图的能力,包括对象和背景的逼真几何形状。
5. 消融研究(Ablations)
- 表2:通过改变训练数据、训练期间的条件视图数量以及有无姿态条件,进行了消融研究。结果表明,使用更多真实世界数据和更多视图可以提高性能,而姿态条件对性能的影响较小。
这些实验全面评估了DSplats模型在从单张图像生成高质量3D内容方面的性能,并与现有技术进行了比较,证明了其有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
模型泛化能力:
- 论文中提到DSplats在处理非对象中心数据(例如场景数据)时的泛化能力尚不明确。探索DSplats在更广泛的3D内容(如复杂场景和动态环境)上的应用和性能是一个重要的研究方向。
高频细节捕捉:
- 论文中提到模型在捕捉高频的纹理和几何细节方面存在挑战。研究如何提高模型对这些细节的捕捉能力,例如通过增加高斯的分辨率或改进网络架构。
光度效应问题:
- 论文指出Gaussian Splatting导致的“光度效应”问题,即生成的图像可能会比原图更亮、更不饱和。研究如何减少这种效应,以生成更真实的3D内容。
训练数据和条件优化:
- 论文通过消融实验表明,使用更多的真实世界数据和更多的视图可以提高模型性能。进一步探索不同训练数据组合和条件对模型性能的影响。
计算效率和推理速度:
- 研究如何优化模型以减少训练和推理时的计算资源消耗,使其更适合在资源受限的环境中使用。
多模态输入:
- 探索将文本、语音或其他模态的数据与图像结合作为输入,以实现更丰富的3D内容生成。
交互式应用:
- 将DSplats应用于需要实时3D内容生成的交互式应用,例如虚拟现实(VR)和增强现实(AR)。
模型解释性和可视化:
- 提高对模型内部工作机制的理解,并通过可视化技术直观展示模型是如何学习和生成3D内容的。
跨领域应用:
- 探索DSplats在其他领域的应用,如建筑、医疗成像或文化遗产保护,这些领域对高质量3D建模有特定需求。
鲁棒性和错误分析:
- 对模型的鲁棒性进行更深入的研究,并分析模型在特定类型输入上可能失败的原因,以指导未来的改进。
这些探索点可以帮助研究社区进一步推动3D生成技术的发展,并扩展DSplats模型的应用范围。
Q: 总结一下论文的主要内容
A: 本文介绍了DSplats,一种新颖的3D生成方法,通过去噪基于高斯Splat的多视图扩散模型来实现。DSplats结合了2D扩散模型的丰富先验和显式的3D高斯表示,能够从单张图像输入生成高质量、逼真的3D对象,并且可以从新的视角渲染这些对象。以下是论文的主要内容总结:
动机与挑战:
- 生成高质量的3D内容需要模型能够学习复杂场景和现实世界对象的稳健分布。
- 现有的基于高斯的3D重建技术和2D扩散模型各有优势,但都存在局限性。
DSplats方法:
- DSplats通过结合2D扩散模型的先验知识和3D高斯表示,提出了一种新的3D扩散模型。
- 该模型使用预训练的潜在扩散模型来预测一组3D高斯,并利用显式的3D表示确保几何一致性。
模型架构:
- DSplats模型包括一个编码器、一个3D感知去噪网络和一个基于高斯Splat的重建器。
- 模型通过两个主要步骤进行3D生成:将潜在表示映射到3D高斯表示,然后渲染这些高斯。
训练与损失函数:
- 模型通过扩散损失和渲染损失进行训练,以学习去噪潜在表示并生成与输入视图一致的渲染视图。
- 扩散损失推动模型逆转噪声过程,而渲染损失确保渲染的视图接近输入图像。
实验与评估:
- 在Google Scanned Objects数据集上的实验表明,DSplats在多个指标上达到了最先进的性能,包括PSNR、SSIM和LPIPS。
- 定性结果展示了DSplats生成的逼真3D对象和新视图的高质量。
消融研究:
- 通过改变训练数据、条件视图数量和姿态条件,消融研究揭示了这些因素对模型性能的影响。
结论与未来工作:
- DSplats展示了将2D扩散模型的先验与3D高斯表示相结合的潜力,并在单图像到3D重建方面树立了新的标准。
- 论文还指出了未来可能的研究方向,包括模型泛化能力的提升和高频细节捕捉的改进。
总体而言,DSplats通过创新地融合2D和3D技术,为从单张图像生成高质量3D内容提供了一个有效的解决方案,并在实验中验证了其优越性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图