⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-17 更新
BrushEdit: All-In-One Image Inpainting and Editing
Authors:Yaowei Li, Yuxuan Bian, Xuan Ju, Zhaoyang Zhang, Ying Shan, Qiang Xu
Image editing has advanced significantly with the development of diffusion models using both inversion-based and instruction-based methods. However, current inversion-based approaches struggle with big modifications (e.g., adding or removing objects) due to the structured nature of inversion noise, which hinders substantial changes. Meanwhile, instruction-based methods often constrain users to black-box operations, limiting direct interaction for specifying editing regions and intensity. To address these limitations, we propose BrushEdit, a novel inpainting-based instruction-guided image editing paradigm, which leverages multimodal large language models (MLLMs) and image inpainting models to enable autonomous, user-friendly, and interactive free-form instruction editing. Specifically, we devise a system enabling free-form instruction editing by integrating MLLMs and a dual-branch image inpainting model in an agent-cooperative framework to perform editing category classification, main object identification, mask acquisition, and editing area inpainting. Extensive experiments show that our framework effectively combines MLLMs and inpainting models, achieving superior performance across seven metrics including mask region preservation and editing effect coherence.
随着基于反演法和指令法的方法的发展,图像编辑在扩散模型的推动下取得了显著的进步。然而,当前的基于反演的方法在大型修改(例如添加或删除对象)方面遇到了困难,这主要归因于反演噪声的结构性特征限制了大幅改动。同时,基于指令的方法通常将用户限制在黑箱操作中,限制了直接交互指定编辑区域和强度的能力。为了解决这些限制,我们提出了BrushEdit,这是一种基于图像修复指令引导的新型图像编辑范式,它利用多模态大型语言模型(MLLMs)和图像修复模型,实现自主、友好、交互式的自由形式指令编辑。具体来说,我们设计了一个系统,通过集成MLLMs和双重分支图像修复模型,在一个代理协作框架内进行编辑类别分类、主要对象识别、获取掩模和编辑区域修复,以实现自由形式的指令编辑。大量实验表明,我们的框架有效地结合了MLLMs和图像修复模型,在包括掩模区域保留和编辑效果连贯性在内的七个指标上表现出卓越的性能。
论文及项目相关链接
PDF WebPage available at https://liyaowei-stu.github.io/project/BrushEdit/
摘要
随着扩散模型的发展,图像编辑技术已经取得了重大进展,出现了基于反转和指令的方法。然而,当前的基于反转的方法在进行大型修改(例如添加或删除对象)时面临困难,因为反转噪声的结构性质阻碍了重大变化。而基于指令的方法通常将用户限制在黑箱操作中,限制了直接指定编辑区域和强度的交互性。为解决这些问题,我们提出了BrushEdit,一种基于图像补全指令引导的图像编辑新范式,它利用多模式大型语言模型(MLLMs)和图像补全模型,实现自主、友好、交互式的自由形式指令编辑。具体而言,我们设计了一个系统,通过集成MLLMs和双分支图像补全模型,在一个代理协作框架中进行编辑类别分类、主要对象识别、获取掩膜和编辑区域补全。大量实验表明,我们的框架有效地结合了MLLMs和补全模型,在包括掩膜区域保留和编辑效果连贯性在内的七个指标上取得了卓越的性能。
关键见解
- 当前图像编辑中的基于反转的方法在进行大型修改时存在困难。
- 基于指令的图像编辑方法限制了用户与编辑区域的直接交互。
- BrushEdit结合MLLMs和图像补全模型来解决上述限制。
- BrushEdit能够实现自主、友好、交互式的自由形式指令编辑。
- 该系统设计用于分类编辑类别、识别主要对象、获取掩膜以及执行编辑区域补全。
- 通过集成多个技术模块,BrushEdit框架在多个指标上实现了卓越性能。
- 该系统通过代理协作框架促进了有效的图像编辑流程。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为BrushEdit的新型图像编辑框架,旨在解决现有图像编辑方法面临的几个主要问题:
大修改的挑战:传统的基于反转的方法(inversion-based approaches)在进行大规模修改(如添加或删除对象)时存在困难,因为反转噪声的结构性限制了重大变化的实现。
用户交互性限制:基于指令的编辑方法(instruction-based methods)通常限制用户在黑盒操作中,缺乏直接交互以指定编辑区域和强度的能力。
数据收集难度:基于扩散模型的图像编辑方法需要大量的配对数据(源图像-指令-目标图像),而这些数据难以收集。
编辑质量和效率:现有方法在执行效率、保持背景真实性、遵循编辑指令以及整体内容一致性方面存在不足。
为了解决这些问题,论文提出了BrushEdit框架,它结合了多模态大型语言模型(MLLMs)和图像修复技术,以实现自主、用户友好和交互式的自由形式指令编辑。该框架通过四个主要步骤(编辑类别分类、主要编辑对象识别、编辑掩模和目标标题获取、图像修复)来实现基于指令的图像编辑,同时支持用户在编辑过程中进行多轮交互式调整,以达到满意的编辑结果。此外,BrushEdit通过统一处理随机掩模和分割掩模,避免了为每种掩模类型单独训练模型的需要,增强了对真实世界用户掩模的适应性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要分为以下几个领域:
A. 图像编辑(Image Editing)
- 扩散模型:近期在图像编辑中,扩散模型(diffusion models)取得了显著进展,如基于文本指令的图像编辑方法,这些方法利用模态如文本指令、遮罩、布局等来实现控制和引导编辑。
- 基于反转的编辑方法:这些方法通过操纵通过反转获得的潜在表示(latents)来实现编辑,主要分为注意力整合、目标嵌入和潜在整合三种范式。
- 端到端方法:这些方法通过训练端到端的扩散模型来进行图像编辑,支持更广泛的编辑类型,并避免了反转方法的速度劣势。
B. 图像修复(Image Inpainting)
- 传统方法和基于VAE/GAN的方法:早期的图像修复方法依赖手工特征,而VAE和GAN方法在图像修复中也有所应用。
- 基于扩散的模型:近期,基于扩散的模型因其优越的生成质量和精确控制而受到关注,这些方法通过修改采样策略或专门训练来增强模型的内容和形状感知能力。
C. 多模态大型语言模型(MLLM)的应用
- 图像编辑中的MLLM应用:MLLM被用于提升图像编辑中的视觉和语言理解能力,例如MGIE、SmartEdit、FlexEdit和GenArtist等方法,它们通过生成更详细和富有表现力的提示或增强复杂指令的理解和推理来改进基于指令的编辑。
这些相关研究展示了图像编辑和修复领域的最新进展,包括基于文本的图像生成、控制引导编辑、以及结合MLLM和图像生成模型的新方法。BrushEdit框架正是在这些研究的基础上,提出了一个新的图像编辑范式,旨在通过结合MLLM和图像修复技术来克服现有方法的局限性。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为BrushEdit的框架来解决上述问题,具体方法如下:
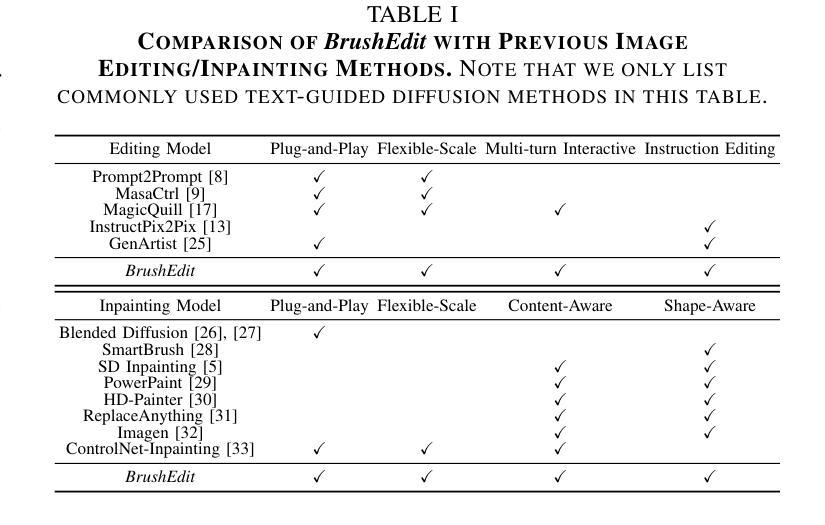
1. 编辑指导的解释和目标识别
- 使用预训练的多模态大型语言模型(MLLM)来解释用户的自由形式编辑指令。
- 对编辑类别进行分类,并识别出主要的编辑对象。
2. 编辑掩模和目标标题的获取
- 利用检测模型根据识别出的对象生成编辑掩模。
- 结合编辑类型、目标对象和源图像生成编辑后的图像标题。
3. 图像修复(Inpainting)模型
- 采用双分支图像修复模型BrushNet,该模型能够处理任意掩模形状,无需针对每种掩模类型单独训练模型。
- 利用混合微调策略,结合随机掩模和分割掩模进行训练,以提高模型处理多样化掩模任务的能力。
4. 代理协作框架
- 将MLLM和图像修复模型集成在一个代理协作框架中,实现自由形式、多轮交互式指令编辑。
- 用户可以在编辑过程中的任何阶段修改或优化中间控制输入,如编辑掩模或编辑后图像的标题,以实现灵活和交互式的编辑。
5. 灵活的控制和定制
- 提供灵活的控制能力,包括基础扩散模型选择和比例调整,以适应不同的编辑或修复需求。
- 允许用户调整未编辑区域保护的程度,提供精确和定制化的编辑结果。
6. 统一的模型处理
- 通过在BrushData-v2数据集上训练,该数据集整合了分割掩模和随机掩模,BrushEdit能够统一处理所有掩模类型的图像编辑和修复任务。
7. 定量和定性评估
- 在多个基准测试和数据集上进行广泛的实验,以定量和定性的方式评估BrushEdit的性能,验证其在保持背景真实性和遵循编辑指令方面的优越性能。
通过这些方法,BrushEdit能够有效地结合MLLM和图像修复模型,实现高质量的交互式指令编辑,同时保持背景区域的真实性和编辑区域的语义一致性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估BrushEdit框架的性能,具体实验包括:
A. 评估基准和指标
- 图像编辑:使用
PIE-Bench(Prompt-based Image Editing Benchmark)评估BrushEdit和其他基线方法在图像编辑任务上的性能。这个基准包含700张图像,涵盖10种编辑类型,分布在自然和人工场景中。 - 图像修复:使用
BrushBench(针对分割掩模)和EditBench(针对随机刷掩模)两个基准来评估图像修复性能。这些基准覆盖了真实和生成的图像,包括人体、动物和室内外场景。
B. 数据集
- BrushData-v2:在之前
BrushData的基础上,整合了分割掩模和随机掩模的子集,并从Laion-Aesthetic数据集中扩展数据,创建了BrushData-v2。这个数据集用于训练和测试BrushEdit模型。
C. 指标
- 背景真实性:使用PSNR、LPIPS、MSE和SSIM等标准指标评估生成图像与原始图像未编辑区域之间的一致性。
- 文本对齐:使用CLIP相似度(CLIP Sim)评估文本-图像一致性,通过将文本和图像投影到CLIP模型的共享嵌入空间并测量它们的表示相似度。
D. 实施细节
- 使用NVIDIA Tesla V100 GPU和Stable Diffusion v1.5作为基础模型进行评估,所有方法都使用推荐的超参数以确保公平性。
E. 定量比较(图像编辑)
- 对比了BrushEdit与其他几种反转方法和编辑方法在
PNPBench上的性能,包括DDIM反转、Null-Text反转、Negative-Prompt反转、StyleDiffusion等。
F. 定性比较(图像编辑)
- 展示了BrushEdit与先前图像编辑方法在自然和合成图像上的编辑操作(如删除对象、添加对象、修改属性和交换对象)的定性比较。
G. 定量比较(图像修复)
- 在
BrushBench和EditBench上对比了BrushEdit与其他扩散模型的结果,包括Blended Latent Diffusion、Stable Diffusion Inpainting、HD-Painter、PowerPaint和ControlNet-Inpainting等。
H. 定性比较(图像修复)
- 展示了BrushEdit与先前图像修复方法在随机掩模修复和分割掩模修复任务上的定性比较。
I. 灵活控制能力
- 展示了BrushEdit在基础扩散模型选择和比例调整方面的灵活控制能力。
J. 消融研究
- 对模型设计的不同方面进行了消融研究,包括双分支与单分支设计、额外分支架构的影响等。
这些实验全面评估了BrushEdit在图像编辑和修复任务中的性能,并与现有方法进行了比较,验证了其在保持背景真实性和遵循编辑指令方面的优越性能。
Q: 有什么可以进一步探索的点?
A: 根据论文的讨论部分,以下是一些可以进一步探索的点:
1. 模型依赖性
- 研究不同基础模型的影响:由于BrushEdit生成的质量和内容依赖于选定的基础模型,探索不同基础模型对编辑结果的影响是一个有价值的方向。
2. 编辑指令和掩模优化
- 优化编辑指令和掩模的处理:研究如何改进模型以更好地处理不规则形状的掩模和与掩模图像不完全对齐的文本指令。
3. 交互式编辑的增强
- 增强用户交互式编辑能力:开发更复杂的用户交互机制,允许用户在编辑过程中进行更细致的控制和调整。
4. 模型泛化能力
- 提高模型的泛化能力:研究如何提高模型处理各种编辑任务的泛化能力,特别是对于未见过的对象和场景。
5. 计算效率
- 提高模型的计算效率:探索模型优化策略,减少计算资源消耗,使得BrushEdit能够更快地执行编辑任务。
6. 多模态输入的融合
- 改进多模态输入的融合:研究如何更有效地融合文本、图像和其他模态输入,以实现更自然和准确的编辑结果。
7. 伦理和社会影响
- 考虑伦理和社会影响:研究如何负责任地使用图像编辑技术,避免放大社会偏见和生成误导性内容。
8. 数据集和训练策略
- 改进数据集和训练策略:研究如何构建更高质量的训练数据集和更有效的训练策略,以提高模型的性能和鲁棒性。
9. 实际应用测试
- 在实际应用中的测试:将BrushEdit应用于实际的图像编辑任务,评估其在现实世界中的有效性和可用性。
10. 模型解释性
- 提高模型的解释性:研究如何提高模型决策过程的透明度和可解释性,帮助用户理解和信任编辑结果。
这些探索点可以帮助研究者进一步提升BrushEdit的性能,扩展其应用范围,并确保技术的安全和负责任使用。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为BrushEdit的创新图像编辑框架,旨在解决现有图像编辑技术在处理大规模修改和用户交互方面的限制。以下是论文的主要内容总结:
1. 问题陈述
- 现有基于反转的方法在进行大规模图像修改时受限于结构噪声,难以实现如添加或删除对象等操作。
- 基于指令的方法通常限制用户在黑盒操作中,缺乏直接交互以指定编辑区域和强度的能力。
2. BrushEdit框架
- 交互式编辑:结合预训练的多模态大型语言模型(MLLMs)和图像修复模型,实现自由形式的指令编辑。
- 代理协作:通过MLLM识别编辑类型、目标对象,并生成编辑掩模和目标标题,然后由图像修复模型完成实际编辑。
- 双分支图像修复模型:BrushNet,能够处理任意掩模形状,无需为每种掩模类型单独训练模型。
3. 方法
- 编辑指导解释:利用MLLM解释用户指令,识别编辑类型和目标对象。
- 编辑掩模和标题获取:基于目标对象生成编辑掩模,并生成编辑后的图像标题。
- 图像修复:使用双分支模型BrushNet,基于目标标题和编辑掩模进行图像修复。
4. 实验
- 在图像编辑和修复基准测试中评估BrushEdit的性能,包括PIE-Bench、BrushBench和EditBench。
- 使用定量和定性指标评估模型性能,包括背景真实性、文本对齐和用户研究。
5. 结果
- BrushEdit在保持背景真实性和遵循编辑指令方面表现出色,与现有方法相比,在多个评估指标上取得了更好的性能。
6. 讨论和未来工作
- 论文讨论了模型的局限性,如对基础模型的依赖和处理不规则掩模的能力。
- 提出了未来的研究方向,包括提高模型泛化能力、优化用户交互和考虑伦理社会影响。
总体而言,BrushEdit通过结合MLLM和图像修复技术,提供了一个用户友好、交互式的图像编辑解决方案,能够在保持背景真实性的同时实现复杂的编辑操作。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Coherent 3D Scene Diffusion From a Single RGB Image
Authors:Manuel Dahnert, Angela Dai, Norman Müller, Matthias Nießner
We present a novel diffusion-based approach for coherent 3D scene reconstruction from a single RGB image. Our method utilizes an image-conditioned 3D scene diffusion model to simultaneously denoise the 3D poses and geometries of all objects within the scene. Motivated by the ill-posed nature of the task and to obtain consistent scene reconstruction results, we learn a generative scene prior by conditioning on all scene objects simultaneously to capture the scene context and by allowing the model to learn inter-object relationships throughout the diffusion process. We further propose an efficient surface alignment loss to facilitate training even in the absence of full ground-truth annotation, which is common in publicly available datasets. This loss leverages an expressive shape representation, which enables direct point sampling from intermediate shape predictions. By framing the task of single RGB image 3D scene reconstruction as a conditional diffusion process, our approach surpasses current state-of-the-art methods, achieving a 12.04% improvement in AP3D on SUN RGB-D and a 13.43% increase in F-Score on Pix3D.
我们提出了一种基于扩散的新方法,用于从单一RGB图像进行连贯的3D场景重建。我们的方法利用了一个受图像条件控制的3D场景扩散模型,同时去除场景中所有物体的3D姿态和几何形状的噪声。鉴于该任务的病态性质和为了获得一致的场景重建结果,我们通过同时以所有场景物体为条件来学习生成场景先验,以捕捉场景上下文,并允许模型在整个扩散过程中学习物体间的关系。我们还提出了一种高效的表面对齐损失,即使在缺少常见的公开数据集的全真实标注的情况下,也能促进训练。这种损失利用了一种表现丰富的形状表示,使得能够从中间形状预测中直接采样点。通过将单一RGB图像的3D场景重建任务构造成一个条件扩散过程,我们的方法超越了当前最先进的方法,在SUN RGB-D数据集上AP3D提高了12.04%,在Pix3D数据集上F-Score提高了13.43%。
论文及项目相关链接
PDF Project Page: https://www.manuel-dahnert.com/research/scene-diffusion - Accepted at NeurIPS 2024
Summary
本文提出了一种基于扩散的新方法,用于从单一RGB图像进行连贯的3D场景重建。该方法利用图像条件化的3D场景扩散模型,同时去噪场景内所有物体的3D姿态和几何结构。通过同时考虑所有场景物体并允许模型在扩散过程中学习物体间的关联,学习生成场景先验。此外,还提出了一种高效的表面对齐损失,即使在缺乏常见的公开数据集的全真标注情况下,也能促进训练。通过将有条件的扩散过程作为单一RGB图像的3D场景重建任务框架,该方法超越了当前的最佳实践,在SUN RGB-D上的AP3D提高了12.04%,在Pix3D上的F-Score提高了13.43%。
Key Takeaways
- 提出了一种基于扩散的新方法,用于从单一RGB图像进行3D场景重建。
- 利用图像条件化的3D场景扩散模型,同时去噪场景内物体的3D姿态和几何结构。
- 通过学习生成场景先验,同时考虑所有场景物体并学习它们之间的关系。
- 引入了一种高效的表面对齐损失,可在缺乏全真标注的情况下促进训练。
- 方法利用了条件扩散过程作为任务框架,实现了3D场景重建。
- 在SUN RGB-D和Pix3D数据集上,该方法显著超越了当前的最佳实践。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种基于扩散模型的新方法,用于从单个RGB图像中重建出连贯的三维场景。这项工作旨在解决以下几个挑战和问题:
单视图3D场景重建的不确定性:从单个RGB图像重建三维场景是一个不确定的问题,因为存在多种可能的3D结构可以对应于同一2D观察结果。这项工作通过引入条件扩散过程来解决这一问题,该过程能够同时预测场景中所有对象的姿态和几何形状。
场景上下文和对象间关系:先前的方法往往独立地恢复3D形状,未能利用场景上下文和对象间关系。这可能导致不切实际和相互交叉的对象排列。论文提出的方法通过学习一个生成性场景先验来捕捉对象间的关系,并在整个扩散过程中进行建模。
在部分标注数据集上的联合训练问题:公共可用的3D数据集通常只提供部分地面真实标注,这使得形状和姿态的联合训练变得复杂。为了克服这一点,论文提出了一种高效的表面对齐损失函数,即使在缺乏完整地面真实监督的情况下也能进行训练。
与现有技术的比较:论文的方法在SUN RGB-D和Pix3D等标准数据集上超越了当前最先进的方法,分别在AP3D和F-Score指标上取得了12.04%和13.43%的改进。
总的来说,这项工作的主要贡献在于提出了一种新的基于扩散的3D场景重建方法,该方法能够联合预测场景中所有可见对象的姿态和形状,并通过学习场景上下文和对象间关系来提高重建的准确性和连贯性。此外,论文还提出了一种有效的表面对齐损失函数,使得在标注不完整的公共数据集上进行训练成为可能。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要涉及以下几个领域:
单视图3D重建(Single-View 3D Reconstruction):
- 对象重建(Object Reconstruction):涉及从单个图像中学习3D对象结构的方法,包括使用图像编码器网络处理输入图像并提取特征,然后将这些特征与形状数据库相关联以检索合适的形状,或使用3D解码器重建特定3D表示(如体素网格、点云、网格或神经场)中的对象。
- 场景重建(Scene Reconstruction):早期工作将单视图场景重建表述为从给定或估计的深度信息中完成3D场景,使用体积网格表示。还有使用原始、体素网格或CAD模型表示对象的方法,同时考虑对象间的关系。
3D扩散模型(3D Diffusion Models):
- 去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPMs):作为一类通用的生成模型,已在图像和视频生成中展示出令人印象深刻的结果。这些方法通过迭代地逆转马尔可夫噪声过程来生成详细的输出。
- 条件扩散用于3D重建(Conditional Diffusion for 3D Reconstruction):利用扩散模型进行单视图对象重建的方法,例如通过去噪一组2D图像来学习单一类别的形状分布,或在扩散过程中将图像特征投影到噪声点云上以确保几何合理性。
与本文直接相关的工作:
- Total3D:直接从图像特征中回归3D对象姿态,并使用网格变形和边缘去除方法重建形状。
- Im3D:使用隐式形状表示和图神经网络来细化姿态预测。
- InstPIFu:专注于单对象重建,并提出从输入图像中查询实例对齐特征的方法,以处理遮挡问题。
这些相关研究为本文提出的从单个RGB图像进行3D场景重建的方法提供了理论和技术背景,同时也突显了现有方法的局限性,如对场景上下文和对象间关系的忽视,以及在重构过程中对精确姿态估计和形状细节的挑战。本文通过引入新的生成性场景先验和表面对齐损失函数,旨在克服这些挑战,并在多个标准数据集上取得了优于现有技术的性能。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键技术解决了单视图3D场景重建的问题:
基于扩散的3D场景重建方法:
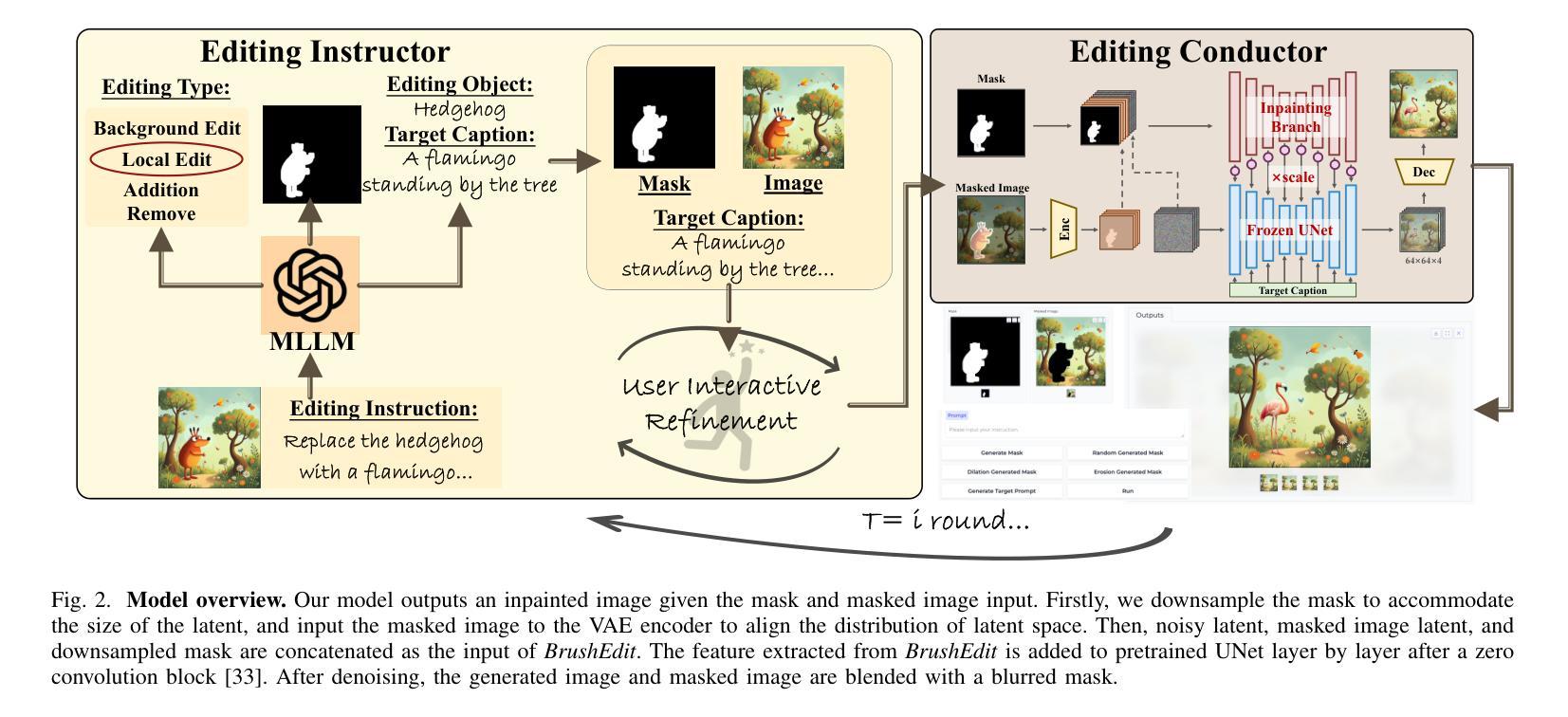
- 将3D场景重建任务框架为一个条件生成问题,使用一个条件扩散模型,该模型在输入视图的条件下同时预测场景中所有对象的姿态(poses)和3D几何形状(geometries)。
生成性场景先验:
- 通过在条件上同时对所有场景对象进行建模,来学习场景上下文和对象间的关系,这有助于捕获场景的全局结构和对象间的相互关系。
表面对齐损失(Surface Alignment Loss):
- 提出了一种高效的表面对齐损失公式(L_{align}),该公式利用表达性强的中间形状表示来进行额外的监督,即使在缺乏完整地面真实标注的情况下也能进行训练。
架构设计:
- 采用了一个预训练的图像背景模型,一个新颖的图像条件场景先验扩散模型,以及一个条件形状解码器扩散模块。
训练和实现细节:
- 使用AdamW优化器进行模型训练,并在Pix3D和SUN RGB-D数据集上进行训练和评估。
具体来说,论文中的方法通过以下步骤实现:
条件3D场景扩散(Conditional 3D Scene Diffusion):使用扩散模型来逐步从带噪声的数据点中恢复出原始的3D形状和姿态。
对象姿态参数化(Object Pose Parameterization):定义对象的姿态为3D中心、空间尺寸和方向。
形状编码(Shape Encoding):使用高斯混合模型来表示和编码对象的形状。
场景先验建模(Scene Prior Modeling):通过引入场景内注意力(Intra-Scene Attention, ISA)模块,使场景中的所有对象能够相互关注,有效地建模它们之间的关系。
表面对齐损失(Surface Alignment Loss):通过从中间形状表示中直接采样点云,并与部分深度信息对齐,提供了额外的监督信号。
架构(Architecture):结合了预训练的2D实例分割模型和时间条件的UNet架构,以及Transformer模型来去噪对象姿态和形状。
这些技术的结合使得论文提出的方法能够在各种标准数据集上超越当前最先进方法,并在单视图3D场景重建任务中实现更准确的对象姿态和更清晰的几何形状。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出方法的有效性:
与现有技术的比较:
- 与现有的最先进的方法进行比较,包括Total3D、Im3D和InstPIFu,使用标准的3D场景重建基准测试。
数据集:
- 在SUN RGB-D数据集上评估3D姿态估计性能,该数据集包含10,335张室内场景图像,每张图像都有2D和3D边界框标注。
- 在Pix3D数据集上评估3D形状重建性能,该数据集包含10,046张图像,涵盖9个类别的常见家具对象,具有像素对齐的3D形状。
评估协议:
- 对于姿态估计,使用IoU3D(3D边界框的交集比)和AP15 3D(平均精度,以15%的IoU3D阈值)进行评估。
- 对于3D形状重建,采样10,000个点在预测的形状表面和地面真实形状上,并计算Chamfer距离(CD)和F-score(在网格对齐后)。
与最新技术的定量比较:
- 在SUN RGB-D和Pix3D数据集上展示与基线方法的定量比较,包括IoU3D、AP15 3D、Lalign、CD和F-Score等指标。
消融研究:
- 对于去噪公式、场景先验建模和联合训练的影响进行了消融研究,以验证所提出的设计决策和贡献的有效性。
泛化能力测试:
- 在ScanNet数据集上评估模型的泛化能力,使用在SUN RGB-D上训练的模型进行推理,不进行额外的微调。
无条件合成结果:
- 展示了通过将空条件(∅)注入模型得到的无条件结果,以展示模型学习到的形状先验在多个语义类别中合成高质量和多样化结果的能力。
形状分解能力:
- 通过将重建网格的每个顶点分配给最近的3D高斯中心,并以不同颜色进行可视化,展示了模型的形状分解能力。
这些实验全面评估了论文提出方法的性能,并与现有技术进行了对比,验证了其在3D场景重建任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的方法在单视图3D场景重建方面取得了显著的进展,但仍有一些领域可以进一步探索和改进:
提高对未见类别的泛化能力:
- 目前的方法依赖于在已知类别上训练的形状先验。未来的工作可以探索如何将该模型与基于文本-图像预训练模型结合,以支持对未见类别的3D形状合成。
动态场景建模:
- 论文中的方法目前假设场景是静态的。未来的研究可以集成对象的可操作性和关节性,以支持更丰富的人-场景交互。
改进2D检测性能:
- 由于该方法依赖于2D对象检测,因此可以通过集成最新的2D检测模型来提高整体性能。
更丰富的数据集和标注:
- 尽管论文提出了一种在标注不完整的情况下进行训练的方法,但使用更丰富的数据集和更完整的标注可以进一步提高模型的性能和鲁棒性。
实时性能优化:
- 探索优化策略,使得模型能够满足实时应用的需求,例如在增强现实(AR)和虚拟现实(VR)中的场景重建。
多模态输入和融合:
- 考虑将其他类型的传感器数据(如深度信息、红外图像)与RGB图像结合,以提供更全面的3D信息。
更复杂的场景和对象关系建模:
- 进一步研究如何更精确地建模场景内对象间的复杂关系和交互,以实现更自然和真实的场景重建。
提高形状和姿态估计的准确性:
- 尽管论文提出的方法在这些领域取得了进展,但仍有空间通过改进模型架构或损失函数进一步提升准确性。
跨模态迁移学习:
- 探索如何将模型从一个领域(例如室内场景)迁移到另一个领域(如室外场景或不同的室内布局)。
可解释性和可视化:
- 提高模型决策过程的可解释性,并通过直观的可视化展示模型是如何逐步构建3D场景的。
鲁棒性测试:
- 在各种异常条件下测试模型的鲁棒性,包括极端光照、遮挡和背景杂乱等情况。
这些方向不仅可以推动单视图3D场景重建技术的发展,还可能对相关领域如计算机视觉、机器人导航和增强现实等产生积极影响。
Q: 总结一下论文的主要内容
A: 论文提出了一种基于扩散模型的新方法,用于从单个RGB图像中重建出连贯的三维场景。主要内容包括:
方法介绍:利用一个图像条件的3D场景扩散模型,同时去噪并预测场景内所有对象的姿态和几何形状。
生成性场景先验:通过在所有场景对象上同时进行条件化,学习场景上下文和对象间的关系,以获得一致的重建结果。
表面对齐损失:提出了一种有效的表面对齐损失公式,即使在只有部分地面真实标注的情况下,也能联合训练形状和姿态。
架构设计:结合了预训练的2D实例分割模型、图像条件场景先验扩散模型和条件形状解码器扩散模块。
实验验证:在SUN RGB-D和Pix3D数据集上进行实验,超越了当前最先进方法,在AP3D和F-Score指标上取得了显著的改进。
消融研究:验证了扩散公式、场景先验建模和联合训练对于性能提升的重要性。
泛化能力:展示了模型在未见过的室内数据集上的泛化能力,无需额外的微调。
无条件合成:展示了模型学习到的形状先验能够在没有条件输入的情况下合成多样化和详细的3D形状。
局限性:讨论了模型依赖于2D对象检测性能和对未见类别泛化能力有限等局限性。
结论:该方法通过结合简单的去噪公式和强大的生成性场景先验,在多个基准上显著提高了3D场景理解的性能,并为未来在混合现实、内容创建和机器人技术等领域的研究奠定了基础。
论文的主要贡献在于提出了一种新的3D场景重建方法,该方法能够有效地利用场景内对象间的关系和上下文信息,以实现更准确和一致的3D场景重建。此外,该方法还解决了公共3D数据集中标注不完整的问题,使其能够在有限的监督下进行训练。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion
Authors:Jiapeng Tang, Davide Davoli, Tobias Kirschstein, Liam Schoneveld, Matthias Niessner
We propose a novel approach for reconstructing animatable 3D Gaussian avatars from monocular videos captured by commodity devices like smartphones. Photorealistic 3D head avatar reconstruction from such recordings is challenging due to limited observations, which leaves unobserved regions under-constrained and can lead to artifacts in novel views. To address this problem, we introduce a multi-view head diffusion model, leveraging its priors to fill in missing regions and ensure view consistency in Gaussian splatting renderings. To enable precise viewpoint control, we use normal maps rendered from FLAME-based head reconstruction, which provides pixel-aligned inductive biases. We also condition the diffusion model on VAE features extracted from the input image to preserve details of facial identity and appearance. For Gaussian avatar reconstruction, we distill multi-view diffusion priors by using iteratively denoised images as pseudo-ground truths, effectively mitigating over-saturation issues. To further improve photorealism, we apply latent upsampling to refine the denoised latent before decoding it into an image. We evaluate our method on the NeRSemble dataset, showing that GAF outperforms the previous state-of-the-art methods in novel view synthesis by a 5.34% higher SSIM score. Furthermore, we demonstrate higher-fidelity avatar reconstructions from monocular videos captured on commodity devices.
我们提出了一种从单目视频重建可动画的三维高斯化身的新方法,这些视频是由智能手机等商品设备捕捉的。从这样的记录中进行逼真的三维头部化身重建是一个挑战,因为观察有限,这使得未观察到的区域约束不足,可能导致新视角出现伪影。为了解决这个问题,我们引入了一个多视角头部扩散模型,利用它的先验知识来填充缺失的区域,并确保在高斯平面渲染中的视角一致性。为了实现精确的观点控制,我们使用基于FLAME的头部重建渲染的法线图,这提供了像素对齐的归纳偏见。我们还根据从输入图像中提取的VAE特征对扩散模型进行条件处理,以保留面部身份和外观的细节。对于高斯化身重建,我们通过使用迭代去噪图像作为伪真实值来提炼多视角扩散先验知识,有效地减轻了过度饱和问题。为了进一步提高逼真度,我们应用潜在上采样来细化去噪的潜在因素,然后再将其解码为图像。我们在NeRSemble数据集上评估了我们的方法,结果表明GAF在新型视角合成方面优于以前的最先进方法,提高了5.34%的SSIM得分。此外,我们还展示了从单目视频捕捉的商品设备上进行的高保真化身重建。
论文及项目相关链接
PDF Paper Video: https://youtu.be/QuIYTljvhyg Project Page: https://tangjiapeng.github.io/projects/GAF
Summary
本文提出了一种利用单目视频构建可动画的三维高斯头像的新方法,该方法使用普通设备如智能手机进行视频捕捉。针对从此类视频进行逼真三维头像重建所面临的挑战,引入了一种多视角头部扩散模型,该模型通过利用其先验知识来填充缺失区域并保证在高斯绘制渲染中的视角一致性。为实现对精确视角的控制,本文采用基于FLAME的头部重建进行法线映射渲染,以提供像素对齐的诱导偏见。此外,还将扩散模型调节到输入图像的VAE特征上,以保留面部身份和外观的细节。通过迭代去噪图像作为伪真实值来提炼多视角扩散先验,有效缓解过度饱和问题。最后通过潜在上采样改善逼真性。在NeRSemble数据集上的评估显示,GAF在新型视角合成方面较之前的最优方法提高了5.34%的SSIM得分。
Key Takeaways
关于这项研究的见解主要有以下七点:
提出了一种新颖的方法利用普通设备拍摄的单目视频来构建可动画的三维高斯头像。
引入了多视角头部扩散模型来解决由于观察受限导致的未观测区域约束不足的问题,并减少新视角的伪影。
利用基于FLAME的头部重建进行法线映射渲染,实现精确视角控制。
将扩散模型调节到输入图像的VAE特征上,确保面部身份和外观的细节得以保留。
通过迭代去噪图像作为伪真实值来提炼多视角扩散先验,解决过度饱和问题。
采用潜在上采样技术改善重建头像的光泽和细节。
在NeRSemble数据集上的实验表明,该方法在新型视角合成方面表现优异,相较于先前技术提高了SSIM得分。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一种新的方法,旨在解决从由普通设备(如智能手机)拍摄的单目视频中重建可动画化的3D高斯头像的问题。具体来说,论文试图解决以下几个挑战:
有限观测导致的约束不足:单目视频由于观测角度有限,导致对头像的不可见区域(如侧面)的重建不足,这会在新视角渲染时产生伪影。
新视角一致性:如何确保从单目视频重建的头像在新视角下渲染时,能够保持外观和身份的一致性。
真实感渲染:从单目视频中重建的头像在新视角下渲染时,如何保持照片级真实感。
为了解决这些问题,论文提出了一种基于多视角头部扩散模型的方法,利用该模型的先验知识来填补缺失区域,并确保在高斯绘制渲染中的视角一致性。此外,论文还引入了从FLAME基础头部重建中渲染的正常图来提供精确的视点控制,并使用从输入图像中提取的VAE特征来保持面部身份和外观的细节。通过迭代去噪图像作为伪真实值,有效缓解了过饱和问题,并应用潜在上采样来提高头像重建的保真度。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与本研究相关的工作:
3D场景表示:
- **Neural Radiance Fields (NeRF)**及其变体:这些方法彻底改变了从多视图图像重建3D场景的方式,但通常在训练和推理阶段计算效率低下。
- **Gaussian Splatting (GS)**:与NeRF相比,GS通过将场景表示为离散的几何原语(3D高斯)并使用显式光栅化器进行渲染,在训练和推理阶段实现了显著的运行速度提升。
参数化面部/头部模型:
- 基于3D形态模型(3DMM)的工作学习从单RGB图像/视频中重建和跟踪3D面部/头部。
- 更近期的方法使用基于坐标的多层感知机(coordinate-MLPs)来实现更细粒度的几何重建,包括头发和胡须。
真实感头像重建:
- 将NeRF/GS与3D形态模型(3DMM)结合起来,以创建真实感和可动画化的头部头像。
- 一些工作探索了基于点的表示以实现高效的训练。
2D先验知识用于3D生成:
- 通过使用Score Distillation Sampling (SDS)损失,可以将大规模预训练的文本到图像先验用于3D资产生成。
多视角扩散模型:
- 一些工作学习图像条件的新视角扩散先验,利用输入图像的身份和外观细节来生成一致的新视角图像。
与Gaussian Splatting相关的工作:
- 将高斯绘制与FLAME网格结合起来,通过三角形变形控制高斯绘制的属性,以实现头像的动画化。
这些相关工作涵盖了3D场景重建、参数化模型、真实感头像生成、2D到3D的转换以及多视角图像生成等领域,为本研究提供了理论和技术基础。论文通过结合这些相关技术,提出了一种新的方法来从单目视频中重建3D高斯头像,并在新视角下进行真实感渲染。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤解决了从单目视频中重建3D高斯头像的问题:
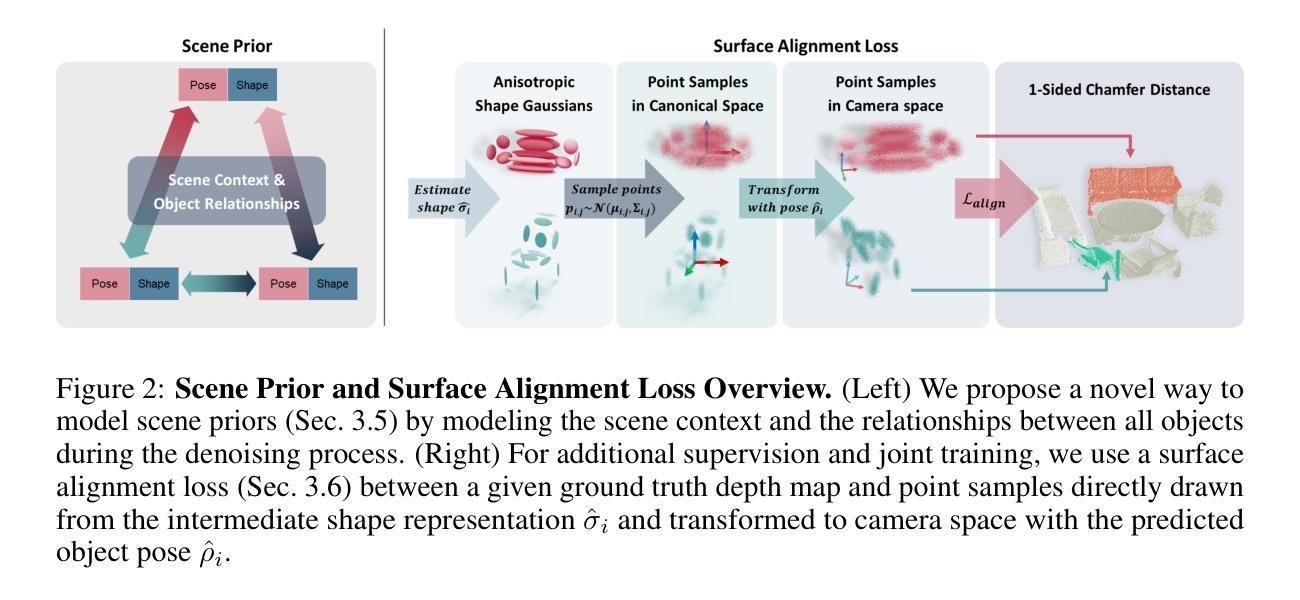
1. 多视角头部扩散模型
论文提出了一个多视角头部扩散模型,该模型能够从单一视图输入生成一致的多视角图像。这个模型利用了扩散先验来填补单目视频中缺失的区域,并确保在高斯绘制渲染中的视角一致性。
2. 正常图引导
为了实现精确的视点控制,论文使用从FLAME头部重建渲染的正常图作为扩散过程的引导。与相机姿态嵌入相比,正常图提供了更强的归纳偏置,从而实现更精确和可靠的新视角生成。
3. VAE特征融合
论文将从输入图像中提取的VAE特征直接整合到多视角扩散模型中。通过在多视角去噪潜在空间和VAE潜在空间之间进行交叉注意力操作,有效地传递了特定身份的细节。
4. 迭代去噪图像作为伪真实值
为了利用多视角扩散先验进行高斯头部重建,论文采用了迭代去噪图像作为伪真实值,而不是单步得分蒸馏采样损失。这种方法可以减少由于随机噪声水平和种子引入的噪声梯度,从而缓解合成3D资产中的过饱和问题。
5. 潜在上采样模型
为了提高高斯渲染的真实感,论文引入了一个潜在上采样模型,在将去噪潜在空间解码回图像空间之前增强面部细节。
6. 损失函数
论文通过组合损失函数来优化高斯绘制,包括像素级L1损失、SSIM损失和LPIPS损失,以及用于惩罚异常分布的高斯的位置和尺度正则化项。
7. 实现细节
论文详细描述了多视角头部扩散模型的训练过程,包括初始化、训练策略和训练数据集的构建。此外,还提供了高斯头像优化的具体实现细节,如FLAME网格的初始获取、可动画高斯的优化过程以及运行时性能。
通过这些方法,论文能够有效地从单目视频中重建出真实感和可动画化的3D高斯头像,并在新视角下进行高质量的渲染。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了以下实验:
数据集
- NeRSemble 数据集:用于头部头像重建实验的多视角视频数据集,包含16个视角的RGB视频序列,覆盖了正面和侧面的脸部。
- Monocular Video 数据集:包含从 INSTA 数据集和智能手机捕获的单目视频,用于评估在普通设备上捕获的视频的头像重建效果。
评估指标
- L1损失、LPIPS、PSNR 和 SSIM:用于量化评估重建头像与真实头像之间的相似度。
实验设置
- 新视角合成:评估重建的头像在训练期间看到的头部姿势和表情下,从15个保留的视点渲染的效果。
- 新表情合成:评估重建的头像在训练期间未见的头部姿势和表情下,从5个附近的保留视点渲染的效果。
基线比较
- INSTA、FlashAvatar 和 GaussianAvatars:与三种最先进的方法进行比较。
实验结果
- 定量比较:在 NeRSemble 数据集上,论文的方法在新视角合成任务中超过了所有基线方法,特别是在 PSNR 和 SSIM 指标上取得了显著提升。
- Monocular Video 数据集:由于缺乏单目捕获的真实视角渲染的地面真实数据,只进行了动画效果的定量评估,论文的方法在所有指标上均优于其他方法。
消融研究
- 对多视角头部扩散先验、正常图条件、迭代去噪图像作为伪真实值以及潜在上采样模块等设计选择进行了详细的消融研究,验证了每个组件的有效性。
鲁棒性分析
- 分析了输入单目视频帧数对重建性能的影响,证明了即使在输入帧数较少的情况下,论文的方法也能保持稳定的性能。
额外比较
- 提供了额外的定性比较,包括新视角合成、自我/交叉重演以及不同输入帧数下的鲁棒性分析。
这些实验全面评估了论文提出方法的有效性,并与现有技术进行了比较,同时也探讨了不同设计选择对性能的影响。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和当前的研究进展,以下是一些可以进一步探索的点:
1. 头发建模和动画
当前的参数化头部模型缺乏详细的头发几何形状和动画。未来的工作可以扩展高斯头部头像以包含细粒度的头发建模和动画。
2. 实时4D头像重建
论文提到优化头部高斯使用迭代更新的伪真实值从扩散模型是耗时的。探索实时4D头像重建与前馈大型重建模型可能是一个有价值的研究方向。
3. 材料和外观分离
论文没有明确区分头部的材料和外观,这可能限制了重新照明应用。研究如何分离材料和外观,以支持更多动态的光照和渲染效果。
4. 更广泛的数据集和场景
目前的实验主要基于特定的数据集和受控环境。将方法扩展到更多样化的数据集和更复杂、更自然的场景中,以提高泛化能力。
5. 交互式应用和VR/AR集成
研究如何将头像重建技术集成到交互式应用和虚拟现实(VR)/增强现实(AR)产品中,以提高用户体验。
6. 性能优化和硬件加速
探索新的方法来优化算法性能,减少内存使用和计算时间,使其更适合在资源受限的设备上运行。
7. 更多的先验知识融合
研究如何融合更多的先验知识(如形状先验、表情先验等)到模型中,以提高重建质量和鲁棒性。
8. 多模态输入
考虑将更多的模态(如深度信息、IR图像等)整合到重建流程中,以提供更丰富的输入信息。
9. 伦理和隐私问题
随着技术的发展,进一步探讨与真实感头像生成相关的伦理和隐私问题,确保技术的负责任使用。
10. 用户自定义和编辑能力
研究如何提供用户自定义和编辑头像的能力,以满足个性化需求和创意表达。
这些探索点可以帮助推动3D头像重建技术的发展,并在更广泛的应用中实现其潜力。
Q: 总结一下论文的主要内容
A: 本论文提出了一种从单目视频中重建可动画化的3D高斯头像的新方法,旨在解决由于观测限制导致的重建难题。以下是论文的主要内容总结:
1. 问题定义
- 从普通设备(如智能手机)捕获的单目视频中重建真实感和可动画化的3D头部头像存在挑战,因为有限的观测会导致未观测区域的重建不足,从而在新视角渲染时产生伪影。
2. 关键思想
- 利用多视角头部扩散模型的先验知识来填补单目视频中缺失的区域,并确保在高斯绘制渲染中的视角一致性。
3. 方法论
- 多视角头部扩散模型:通过迭代去噪图像作为伪真实值,生成与输入图像视角一致的多视角图像。
- 正常图引导:使用FLAME头部重建渲染的正常图进行视点控制,提供精确的新视角生成。
- VAE特征融合:将输入图像的VAE特征整合到扩散模型中,以保持面部身份和外观的细节。
- 潜在上采样模型:在将去噪潜在空间解码回图像空间之前增强面部细节,提高渲染的真实感。
4. 实验
- 在NeRSemble数据集和Monocular Video数据集上进行实验,与现有技术进行比较,证明了该方法在新视角合成和新表情合成方面的优越性。
- 进行了消融研究,验证了多视角扩散先验、正常图条件、迭代去噪图像和潜在上采样模块的有效性。
- 进行了鲁棒性分析,展示了该方法对输入视频帧数变化的鲁棒性。
5. 贡献
- 提出了一种新的方法,使用多视角头部扩散先验从单目视频中重建真实感和可动画化的头部头像。
- 提出了一种多视角头部扩散模型,从单一视图输入生成一致的多视角图像,改善了视点控制。
- 通过整合潜在上采样和多视角扩散先验,提高了高斯绘制的跨视角一致性和真实感。
6. 未来工作和局限性
- 论文讨论了当前方法的局限性,如缺乏头发建模和动画、优化过程耗时以及受限于参数化头部模型的表达能力。
- 提出了未来可能的研究方向,包括头发建模、实时4D头像重建和性能优化等。
总体而言,这项工作通过引入多视角扩散先验和潜在上采样,显著提高了从单目视频中重建3D高斯头像的质量,为虚拟现实和增强现实应用中的真实感头像创建提供了新的可能性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

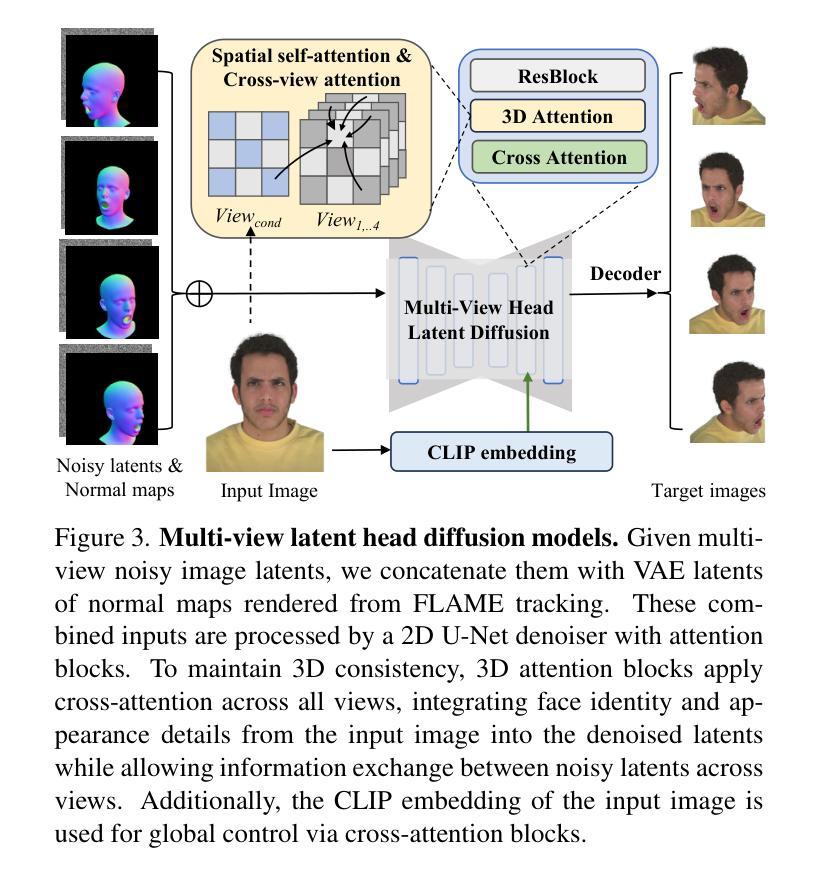
Efficient Generative Modeling with Residual Vector Quantization-Based Tokens
Authors:Jaehyeon Kim, Taehong Moon, Keon Lee, Jaewoong Cho
We explore the use of Residual Vector Quantization (RVQ) for high-fidelity generation in vector-quantized generative models. This quantization technique maintains higher data fidelity by employing more in-depth tokens. However, increasing the token number in generative models leads to slower inference speeds. To this end, we introduce ResGen, an efficient RVQ-based discrete diffusion model that generates high-fidelity samples without compromising sampling speed. Our key idea is a direct prediction of vector embedding of collective tokens rather than individual ones. Moreover, we demonstrate that our proposed token masking and multi-token prediction method can be formulated within a principled probabilistic framework using a discrete diffusion process and variational inference. We validate the efficacy and generalizability of the proposed method on two challenging tasks across different modalities: conditional image generation} on ImageNet 256x256 and zero-shot text-to-speech synthesis. Experimental results demonstrate that ResGen outperforms autoregressive counterparts in both tasks, delivering superior performance without compromising sampling speed. Furthermore, as we scale the depth of RVQ, our generative models exhibit enhanced generation fidelity or faster sampling speeds compared to similarly sized baseline models. The project page can be found at https://resgen-genai.github.io
我们探讨了残差向量量化(RVQ)在向量量化生成模型中的高保真生成应用。这种量化技术通过采用更深入的标记来保持更高的数据保真度。然而,在生成模型中增加标记数量会导致推理速度变慢。为此,我们引入了ResGen,这是一个基于RVQ的高效离散扩散模型,能够在不牺牲采样速度的情况下生成高保真样本。我们的关键想法是预测集体标记的向量嵌入而不是单个标记。此外,我们证明了所提出的标记遮挡和多标记预测方法可以在一个以离散扩散过程和变分推断为原则的概率框架内制定。我们在两个不同的模态中具有挑战性的任务上验证了所提出方法的有效性和通用性:在ImageNet 256x256上进行条件图像生成和零样本文本到语音合成。实验结果表明,ResGen在这两个任务中的表现都优于自回归模型,具有卓越的性能且不牺牲采样速度。此外,随着我们扩展RVQ的深度,我们的生成模型相较于相似规模的基准模型展现出更高的生成保真度或更快的采样速度。项目页面位于https://resgen-genai.github.io。
论文及项目相关链接
Summary
本文探讨了基于Residual Vector Quantization(RVQ)技术的离散扩散模型在生成高质量样本方面的应用。该模型能高效生成高质量样本,同时保持快速的采样速度。它通过预测集体向量的嵌入来实现这一点,而不是单独预测每个标记。此外,本文还展示了如何在离散扩散过程和变分推断的框架下,将提出的标记掩码和多标记预测方法公式化。在ImageNet 256x256的条件图像生成和零样本文本到语音合成等任务上的实验验证了该方法的有效性和泛化能力。与传统的自回归模型相比,ResGen在提高性能的同时不牺牲采样速度。随着RVQ深度的增加,我们的生成模型的生成保真度进一步提高或采样速度更快,相较于类似规模的基准模型表现出优势。
Key Takeaways
- 使用了Residual Vector Quantization(RVQ)技术以提高生成模型的保真度。
- 提出的ResGen模型能在保持快速采样速度的同时生成高质量样本。
- 通过预测集体向量的嵌入,而非单独预测每个标记,提高了效率。
- 将标记掩码和多标记预测方法整合到离散扩散过程和变分推断的框架中。
- 在条件图像生成和零样本文本到语音合成任务上验证了方法的有效性。
- ResGen相较于自回归模型在提高性能的同时不牺牲采样速度。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在向量量化生成模型中实现高保真度数据生成,同时保持较快的采样速度。具体来说,论文探讨了使用残差向量量化(Residual Vector Quantization, RVQ)技术来提高数据重建质量,同时提出了一个高效的RVQ基的离散扩散模型(ResGen),用于在不牺牲采样速度的情况下生成高保真度样本。论文的主要贡献包括:
直接预测集体标记的向量嵌入:ResGen通过直接预测集体标记的向量嵌入而不是逐个预测每个标记,从而解耦了采样复杂度与序列长度和深度的关系。
基于离散扩散过程和变分推断的概率框架:论文展示了所提出的标记掩蔽和多标记预测方法可以被纳入一个基于离散扩散过程和变分推断的原则化概率框架中。
在不同模态上验证方法的有效性和泛化能力:通过在ImageNet上的有条件图像生成任务和零样本文本到语音合成任务上的实验,论文证明了ResGen在这些任务上相较于自回归模型具有优越的性能,且没有牺牲采样速度。
分析模型特性和超参数的影响:通过消融研究,论文还分析了不同超参数(如采样步骤)对生成质量的影响,并考察了模型在不同RVQ深度下的特性。
总的来说,这篇论文旨在通过引入新的RVQ基生成模型ResGen,解决在生成高分辨率、高保真度数据时面临的质量和计算效率之间的平衡问题。
Q: 有哪些相关研究?
A: 根据论文内容,以下是与本研究相关的一些工作:
向量量化(VQ)标记基础的生成模型:
- VQ-GAN (Esser et al., 2021) 和 DALLE (Ramesh et al., 2021) 利用离散表示进行图像合成,使用变换器(transformers)来实现高质量的数据生成,同时保持计算资源的可管理性。
离散扩散模型:
- MaskGIT (Chang et al., 2022) 和 VQ-Diffusion (Gu et al., 2022) 专注于对平面标记序列进行掩蔽标记预测,与自回归模型相比提高了采样效率。
- GIVT (Tschannen et al., 2023) 引入了一种方法,用基于高斯混合的向量预测代替基于softmax的标记预测,逐步填充掩蔽位置。
基于RVQ的生成模型:
- RQ-Transformer (Lee et al., 2022) 是第一个展示在RVQ标记上使用自回归模型进行生成建模的研究,其计算复杂度随着序列长度和深度的乘积增加。
- Vall-E (Wang et al., 2023) 预测第一深度的标记,然后顺序地预测每个深度的剩余标记。
- SoundStorm (Borsos et al., 2023) 使用掩蔽标记预测给定语义标记生成标记,但其采样时间复杂度仍随残差量化深度线性增加。
- NaturalSpeech 2 (Shen et al., 2024) 在RVQ嵌入空间中使用基于扩散的生成建模而不是标记生成。
- CLaM-TTS (Kim et al., 2024) 使用向量预测进行多标记预测,但以自回归方式沿序列长度操作。
其他生成模型方法:
- VAR (Tian et al., 2024) 和 MAR (Li et al., 2024) 提出了替代基于标记的自回归建模的新范式。VAR引入了粗到细的下一尺度预测机制,有效地捕获了图像中的层次结构。MAR通过使用基于扩散的方法在连续值空间中对概率进行建模,消除了对离散标记的依赖,简化了流程同时保持了强大的性能。
这些相关工作提供了不同的视角和技术,用于处理基于标记的生成模型中的挑战,特别是在处理高分辨率、高保真度数据生成时的质量和计算效率之间的平衡问题。ResGen方法与这些工作相比,提供了一个更有效的解决方案,通过预测掩蔽标记的向量嵌入,从序列长度和标记深度中解耦采样时间复杂度。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为ResGen的高效RVQ(Residual Vector Quantization)基的离散扩散模型来解决高保真度数据生成与快速采样之间的平衡问题。以下是ResGen解决该问题的关键方法:
1. 直接预测集体标记的向量嵌入
ResGen的核心思想是直接预测集体标记的向量嵌入,而不是逐个预测每个标记。这种方法通过对累积嵌入的预测,允许模型在不同深度上估计相关联的标记,与残差量化过程自然对齐。这样,ResGen能够从序列长度和深度中解耦采样复杂度,生成高保真度样本而不影响采样速度。
2. 掩蔽标记策略和多标记预测
掩蔽标记策略:ResGen采用一种特别适合RVQ标记的掩蔽策略,从最高量化层开始逐步掩蔽标记,利用RVQ的层次性质,其中更深层次的标记捕获更精细的细节。
多标记预测:ResGen在训练和解码阶段通过聚焦于预测聚合向量嵌入z而不是直接预测目标标记,有效预测掩蔽标记。这种方法避免了沿深度的标记条件独立性,这对于模型性能可能是有害的。
3. 基于离散扩散过程和变分推断的概率框架
ResGen将掩蔽标记预测过程纳入一个基于离散扩散模型和变分推断的原则化概率框架中。这种观点允许将ResGen视为一个基于似然的生成过程,并为其设计提供了理论基础。
前向离散扩散过程:将标记掩蔽过程解释为离散扩散模型在标记序列上的前向扩散步骤,逐渐将完全未掩蔽的标记序列转化为完全掩蔽的序列。
反向离散扩散过程:旨在从部分掩蔽的序列中重建原始标记,定义了重建原始标记的概率,并计算数据对数似然的变分下界。
4. 实验验证
论文通过在ImageNet上的有条件图像生成任务和零样本文本到语音合成任务上的实验验证了ResGen的有效性和泛化能力。实验结果显示,ResGen在这些任务上的性能超过了自回归模型,并且在RVQ深度扩展时,与同样大小的基线生成模型相比,展现了更高的生成保真度或更快的采样速度。
5. 消融研究
论文还通过消融研究分析了不同超参数(例如采样步骤)对生成质量的影响,并考察了模型在不同RVQ深度下的特性。
通过这些方法,ResGen有效地解决了在向量量化生成模型中生成高保真度数据与保持快速采样速度之间的平衡问题。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证ResGen模型的有效性和泛化能力:
1. 实验设置
实验任务:
- 视觉领域:在ImageNet数据集上进行条件图像生成任务,分辨率为256×256。
- 音频领域:使用Voicebox启发的两个任务进行评估:(1) 继续任务(continuation),给定文本和3秒的真实语音段落,目标是生成与提供段落相同风格的无缝语音;(2) 跨句子任务(cross-sentence),给定文本、3秒语音段落及其与文本不同的转录,目标是生成用提供段落风格朗读文本的语音。
评估指标:
- 视觉任务:使用Fréchet Inception Distance (FID) 来比较与其他最先进图像生成模型。
- 音频任务:使用字符错误率(CER)、单词错误率(WER)和说话人相似度(SIM)等客观指标进行评估。
基线和训练配置:与包括自回归模型和非自回归模型在内的最新生成模型进行比较,并详细说明ResGen模型的训练配置。
2. 实验结果
视觉任务:
- 展示了ResGen在保持参数效率的同时,与基线模型相比在准确性和推理时间上的优势。
- 使用FID指标评估生成质量,比较不同模型在生成质量、内存效率和生成速度方面的表现。
音频任务:
- 与生成RVQ标记的自回归模型进行比较,展示了ResGen在WER、CER和SIM指标上的优势,以及需要更少的推理步骤。
- 与最新的TTS模型进行比较,展示了ResGen在计算效率和准确性方面的优势。
3. 消融研究
- 分析了不同采样超参数(如采样步骤数、top-p值和温度缩放)对模型行为和生成质量的影响。
- 展示了增加采样步骤数、调整top-p值和温度对生成质量的改善。
这些实验验证了ResGen在不同模态上的强大性能,包括图像生成和文本到语音合成任务,并与现有的自回归和非自回归方法进行了比较。实验结果显示,ResGen在保持高保真度的同时,提供了更快的采样速度和更好的内存效率。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
1. 利用键值(KV)缓存优化采样速度
论文提到,通过在变换器架构中使用键值(KV)缓存,可以重用已经完全填充的标记的预计算KV值,减少冗余计算。这种策略可以显著提高采样速度和降低整体计算开销,是一个值得未来研究的方向。
2. 探索新的量化方法
论文提到了残差向量量化(RVQ)标记,但也提到了有限标量量化(FSQ)可能带来额外的好处。将ResGen方法扩展到支持FSQ可能需要不同的标记化和嵌入过程,探索这一方向可能带来新的量化策略和改进的生成性能。
3. 提供理论解释
论文中提到,ResGen方法在相对较少的迭代次数下就实现了高质量的生成,相比传统的扩散模型更有效。论文假设这种效率来自于解掩过程而不是去噪过程,因为基于完全解掩的标记进行预测比基于噪声输入的预测更容易。尽管如此,论文缺乏对这一现象的理论证明,提供正式的理论分析解释是一个有前景的未来研究方向。
4. 扩展到其他模态和任务
论文中的实验主要集中在图像和语音合成任务上,但ResGen模型的框架是通用的。将其扩展到其他模态(如视频或更复杂的音频任务)和不同类型的生成任务(如无条件生成或交互式生成)是另一个值得探索的方向。
5. 提高模型的泛化能力
虽然ResGen在特定任务上表现出色,但提高模型对不同领域和分布的泛化能力始终是一个重要的研究方向。这可能包括在更多样化的数据集上训练模型,或者开发更先进的技术来适应不同的生成场景。
6. 优化模型的计算效率
尽管ResGen在内存效率和采样速度方面已经表现出色,但进一步优化模型的计算效率,特别是在资源受限的环境中,仍然是一个重要的研究方向。
7. 探索不同的训练策略
论文中提到了一些训练策略,如使用混合高斯分布来表示潜在嵌入的分布。探索不同的训练策略和正则化技术,以进一步提高模型的性能和稳定性,也是一个有价值的研究方向。
这些方向不仅可以推动ResGen模型的发展,也有助于推动整个生成模型领域的进步。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为ResGen的高效RVQ(Residual Vector Quantization)基的离散扩散模型,旨在解决在向量量化生成模型中生成高保真度数据与保持快速采样速度之间的平衡问题。以下是论文的主要内容总结:
1. 研究动机
- 向量量化生成模型在高保真度数据生成方面面临挑战,尤其是在平衡生成质量和计算效率方面。
2. ResGen模型
- 核心思想:直接预测集体标记的向量嵌入而不是逐个预测每个标记,以解耦采样复杂度与序列长度和深度的关系。
- 掩蔽标记策略:采用特别适合RVQ标记的掩蔽策略,从最高量化层开始逐步掩蔽标记。
- 多标记预测:通过聚焦于预测聚合向量嵌入而不是直接预测目标标记,有效预测掩蔽标记。
3. 概率框架
- 将掩蔽标记预测过程纳入基于离散扩散模型和变分推断的原则化概率框架中,提供了理论基础。
4. 实验验证
- 在ImageNet上的有条件图像生成任务和零样本文本到语音合成任务上的实验验证了ResGen的有效性和泛化能力。
- 实验结果显示,ResGen在这些任务上的性能超过了自回归模型,并且在RVQ深度扩展时,与同样大小的基线生成模型相比,展现了更高的生成保真度或更快的采样速度。
5. 消融研究
- 分析了不同采样超参数对模型行为和生成质量的影响,包括采样步骤数、top-p值和温度缩放。
6. 结论与未来方向
- ResGen通过直接预测集体标记的向量嵌入,有效地解决了生成高保真度数据与快速采样之间的平衡问题。
- 提出了进一步探索的方向,包括利用键值缓存优化采样速度、探索新的量化方法、提供理论解释、扩展到其他模态和任务等。
总的来说,这篇论文提出了一个创新的解决方案来提高向量量化生成模型的效率和保真度,并在多个任务上验证了其有效性,为未来的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

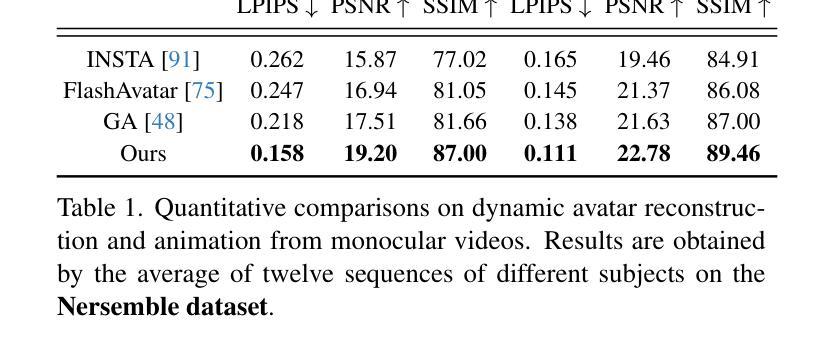
Simple Guidance Mechanisms for Discrete Diffusion Models
Authors:Yair Schiff, Subham Sekhar Sahoo, Hao Phung, Guanghan Wang, Sam Boshar, Hugo Dalla-torre, Bernardo P. de Almeida, Alexander Rush, Thomas Pierrot, Volodymyr Kuleshov
Diffusion models for continuous data gained widespread adoption owing to their high quality generation and control mechanisms. However, controllable diffusion on discrete data faces challenges given that continuous guidance methods do not directly apply to discrete diffusion. Here, we provide a straightforward derivation of classifier-free and classifier-based guidance for discrete diffusion, as well as a new class of diffusion models that leverage uniform noise and that are more guidable because they can continuously edit their outputs. We improve the quality of these models with a novel continuous-time variational lower bound that yields state-of-the-art performance, especially in settings involving guidance or fast generation. Empirically, we demonstrate that our guidance mechanisms combined with uniform noise diffusion improve controllable generation relative to autoregressive and diffusion baselines on several discrete data domains, including genomic sequences, small molecule design, and discretized image generation.
由于连续数据扩散模型的高质量生成和控制机制,它们得到了广泛的应用。然而,对于离散数据的可控扩散面临挑战,因为连续指导方法并不直接适用于离散扩散。在这里,我们提供了无分类器指导和基于分类器的指导的直观推导,以及利用均匀噪声的新型扩散模型,这些模型具有更强的可引导性,因为它们可以连续编辑输出。我们利用一种新的连续时间变分下限提高了这些模型的质量,实现了最先进的性能,特别是在涉及指导或快速生成的环境中。从实证上看,我们证明了我们的指导机制与均匀噪声扩散相结合,相对于几个离散数据域的自回归和扩散基线,可控生成能力有所提高,包括基因组序列、小分子设计和离散图像生成。
论文及项目相关链接
PDF Code to reproduce our experiments is available here: https://github.com/kuleshov-group/discrete-diffusion-guidance
Summary
扩散模型因高质量生成和控制机制而广泛应用于连续数据领域。然而,在离散数据上的可控扩散面临挑战,因为连续指导方法并不直接适用于离散扩散。本文提供了无分类器指导和基于分类器的指导的直观推导,以及利用均匀噪声的新一类扩散模型,这些模型由于可以连续编辑输出而更具指导性。通过引入新型连续时间变分下限,提高了这些模型的质量,尤其在指导或快速生成设置中表现卓越。经验表明,我们的指导机制与均匀噪声扩散相结合,相对于多个离散数据域的自回归和扩散基线,可控生成能力有所提升,包括基因组序列、小分子设计和离散图像生成等领域。
Key Takeaways
- 扩散模型在连续数据领域广泛应用,但离散数据上的可控扩散面临挑战。
- 本文提供了无分类器和基于分类器的指导方法以及利用均匀噪声的扩散模型。
- 新型扩散模型因能连续编辑输出而更具指导性。
- 通过引入连续时间变分下限提高了模型质量。
- 在指导或快速生成设置中表现卓越。
- 实证表明,指导机制与均匀噪声扩散相结合提升了可控生成能力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了在离散数据上应用可控扩散模型的挑战,并提出了解决这些问题的方法。具体来说,论文试图解决以下几个问题:
离散数据的可控扩散生成挑战:传统的扩散模型和它们的引导机制通常不适用于离散数据,因为它们需要对数据进行梯度操作,而这在离散设置中并未定义。
现有离散扩散模型的局限性:流行的离散扩散模型扩展(例如D3PM)无法对生成的标记进行多次编辑,因此不适合可控生成。
离散扩散模型性能落后:在涉及引导或快速生成的类别中,离散扩散模型的性能(以困惑度衡量)落后于自回归(AR)模型。
为了解决这些问题,论文提出了以下贡献:
- 提供了简单且易于实现的离散分类器基础和无分类器基础引导的适应方法。
- 引入了一类新的离散扩散模型,称为均匀噪声扩散语言模型(UDLM),这些模型特别适用于引导,因为它们可以连续编辑离散数据。
- 通过导出一个连续时间版本的证据下界(ELBO),显著提高了这些模型的性能,特别是在引导或快速生成的设置中。
- 在多个领域(包括基因组序列、小分子设计和离散图像生成)展示了离散引导机制相对于自回归和扩散基线的可控生成优势。
Q: 有哪些相关研究?
A: 论文中提到了多个与离散扩散模型和引导机制相关的研究工作,具体如下:
扩散模型(Diffusion Models):
- Sohl-Dickstein et al. (2015) 提出了扩散模型的概念。
- Ho et al. (2020) 进一步发展了扩散模型,并应用于图像生成和信号处理。
引导机制(Guidance Mechanisms):
- Dhariwal & Nichol (2021a) 提出了基于分类器的引导方法。
- Nichol et al. (2021) 和 Ho & Salimans (2022) 提出了无分类器基础的引导方法。
离散扩散模型(Discrete Diffusion Models):
- Austin et al. (2021) 提出了结构化去噪扩散模型(D3PM)。
- Lou et al. (2023) 和 Sahoo et al. (2024a) 提出了离散扩散模型的扩展。
特定领域的应用:
- Song & Ermon (2019) 将扩散模型应用于MRI去噪。
- Poole et al. (2022) 和 Gao et al. (2024) 将扩散模型应用于3D重建。
- Saharia et al. (2022) 和 Gokaslan et al. (2024) 将扩散模型应用于条件生成。
其他相关工作:
- 论文还提到了一些与离散数据生成和引导相关的其他工作,例如Diffusion-LM (Li et al., 2022),SSD-LM (Han et al., 2022),LD4LG (Lovelace et al., 2024) 等。
这些相关工作为论文提出的离散扩散模型和引导机制提供了理论基础和技术背景。论文通过结合这些已有的研究成果,提出了新的离散扩散模型和引导算法,旨在提高离散数据生成的质量和可控性。
Q: 论文如何解决这个问题?
A: 论文针对离散数据的可控扩散模型面临的挑战,提出了以下解决方案:
1. 离散扩散模型和引导机制
- 离散分类器基础引导(Discrete Classifier-Based Guidance, D-CBG) 和 离散无分类器基础引导(Discrete Classifier-Free Guidance, D-CFG):论文提出了直接适应于离散域的分类器基础和无分类器基础引导方法。这些方法通过调整离散分布的概率,根据一个引导模型来控制生成过程。
2. 均匀噪声扩散语言模型(Uniform Diffusion Language Models, UDLM)
- 均匀噪声扩散:论文重新审视了均匀噪声扩散语言模型(UDLM),这类模型能够连续编辑离散数据,因此更适合引导。通过导出连续时间版本的证据下界(ELBO),论文提高了这些模型的性能。
3. 连续时间变分下界(Continuous-Time Variational Lower Bound)
- 改进的ELBO:论文提出了一个连续时间版本的变分下界,通过分析每个项(Lrecons, Ldiffusion, Lprior)来改进均匀噪声离散扩散模型。这导致了三个改进:简化的ELBO表达式、将Lrecons和Lprior的损失减少到零,以及通过连续时间扩展进一步收紧Ldiffusion。
4. 实验验证
- 跨领域实验:论文在多个领域(基因组学、分子生成和离散图像)进行了实验,证明了所提出的离散引导机制相对于自回归和扩散基线在可控生成方面的优势。
具体技术细节
对于D-CFG和D-CBG:论文详细描述了如何通过训练条件和无条件的去噪扩散网络,并在测试时通过特定的方式调整这些网络的输出概率来实现引导。
UDLM的连续时间ELBO:通过将T → ∞,并分析NELBO中的每个项,论文得到了一个更紧密的变分界限,从而提高了模型性能。
通过这些方法,论文旨在提高离散数据的可控生成质量,并在多个领域展示出相比于现有技术的优势。
Q: 论文做了哪些实验?
A: 论文中进行了多个实验来验证所提出的离散扩散模型和引导机制的有效性。以下是具体的实验内容:
1. 语言模型实验
数据集:使用了多个不同的离散数据领域,包括参考基因组(Species10)、小分子数据集(QM9)、离散化图像数据集(CIFAR10)以及三个自然语言处理数据集(text8、Amazon Review Polarity和LM1B)。
实验内容:
- UDLM性能测试:比较了UDLM(Uniform Diffusion Language Models)与其他离散扩散模型在小词汇表数据集上的性能,发现UDLM在小词汇表数据集上可以达到或超过吸收态扩散模型的性能。
- 连续时间ELBO的影响:通过增加T值(从有限步骤到无限步骤)来观察UDLM在Amazon Polarity数据集上的性能变化,发现增加T可以改善语言模型的性能。
2. 引导离散扩散实验
物种特定基因组生成:在Species10数据集上评估D-CFG(离散无分类器基础引导)与自回归模型(AR)的性能,使用Jensen-Shannon距离、AUROC和F1分数来衡量生成序列的质量和控制能力。
分子属性最大化:在QM9数据集上,研究了不同引导方法在最大化药物相似性(QED)和分子中环的数量这两个属性时的表现。
类条件图像生成:在CIFAR10数据集上,比较了MDLM和UDLM在条件图像生成任务中的性能,使用了Fréchet inception distance(FID)和Inception Score(IS)作为评价指标。
3. 快速采样的鲁棒性测试
- 不同T值的影响:在CIFAR10数据集上,探索了使用更小的T值(即更快的推理设置)对MDLM和UDLM性能的影响,发现UDLM对于更快的采样设置更加鲁棒。
这些实验覆盖了不同的数据类型和应用场景,旨在全面评估所提出方法的有效性和适用性。通过这些实验,论文展示了离散扩散模型和引导机制在多个领域的应用潜力和优越性能。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一些创新的方法来处理离散数据的扩散模型和引导机制,但仍有一些领域可以进一步探索和研究:
更广泛的数据集和应用领域:
- 论文中主要关注了基因组序列、小分子设计和图像生成等几个领域。将这些方法应用到更广泛的数据类型和应用场景,如文本生成、语音合成等,可能会揭示新的问题和改进方向。
改进引导机制:
- 虽然论文提出了离散分类器基础和无分类器基础引导方法,但仍可以探索更复杂的引导策略,如多任务学习或强化学习,以进一步提高生成的可控性和质量。
优化算法和计算效率:
- 论文中提到的一些方法在计算上可能非常昂贵,尤其是在大型数据集上。研究更高效的优化算法和计算策略,以减少训练和推理的时间和资源消耗。
理论分析和解释性:
- 对于提出的均匀噪声扩散模型和引导机制,可以进行更深入的理论分析,以更好地理解其工作原理和潜在的局限性。
模型鲁棒性和泛化能力:
- 研究模型在面对不同的噪声水平、数据分布偏移或对抗性攻击时的鲁棒性,以及如何提高模型的泛化能力。
结合其他生成模型:
- 考虑将扩散模型与其他类型的生成模型(如GANs、VAEs等)结合,以利用各自的优势,可能会产生新的模型架构和应用。
多模态和跨模态生成:
- 探索扩散模型在多模态数据(例如,结合图像和文本)上的生成能力,以及如何实现有效的跨模态转换和生成。
长序列生成和处理:
- 研究扩散模型在处理非常长的序列数据时的表现,以及如何有效地生成和控制这些长序列。
可解释性和可视化:
- 开发可解释性和可视化工具,以帮助研究人员和用户理解扩散模型的内部工作机制,以及它们是如何响应不同的引导信号的。
这些方向不仅可以推动扩散模型在离散数据上的研究进展,也可能为其他类型的生成模型和应用提供新的见解和方法。
Q: 总结一下论文的主要内容
A: 这篇论文主要研究了离散数据的可控扩散模型,并提出了一些改进方法来提高生成质量和控制能力。以下是论文的主要内容总结:
1. 问题背景
- 扩散模型在连续数据上取得了成功,但在离散数据上面临挑战,因为连续数据的引导方法不适用于离散数据。
2. 主要挑战
- 离散数据的扩散模型不能直接应用标准扩散模型和引导机制,因为它们需要对数据取梯度,而这在离散设置中未定义。
- 现有的离散扩散模型无法对生成的标记进行多次编辑,不适合可控生成。
- 离散扩散模型的性能落后于自回归模型,特别是在需要控制的类别中。
3. 贡献和方法
- 离散引导机制:提出了简单的离散分类器基础和无分类器基础引导方法。
- 均匀噪声扩散模型(UDLM):引入了一类新的离散扩散模型,特别适用于引导,因为它们可以连续编辑离散数据。
- 连续时间变分下界(ELBO):导出了一个连续时间版本的证据下界,显著提高了模型性能。
4. 实验验证
- 在基因组序列、小分子设计和离散图像生成等多个领域验证了所提出的离散引导机制的有效性。
- 证明了离散引导机制相对于自回归和扩散基线在可控生成方面的优势。
5. 实验结果
- 离散扩散模型在小词汇表数据集上可以达到或超过吸收态扩散模型的性能。
- 提出的UDLM在均匀噪声扩散模型中达到了最佳性能。
- 离散引导机制在多个任务中显示出比自回归模型更好的可控性。
6. 结论
- 论文提出了一种改进的离散扩散模型和引导机制,有效提高了离散数据的可控生成质量。
- 通过导出连续时间ELBO,显著提高了均匀噪声离散扩散模型的性能。
- 所提出的离散引导机制在多个领域展示了优越的可控生成能力。
总的来说,这篇论文为离散数据的可控扩散模型提供了新的视角和方法,通过改进引导机制和提出新的均匀噪声扩散模型,提高了离散数据生成的质量和可控性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

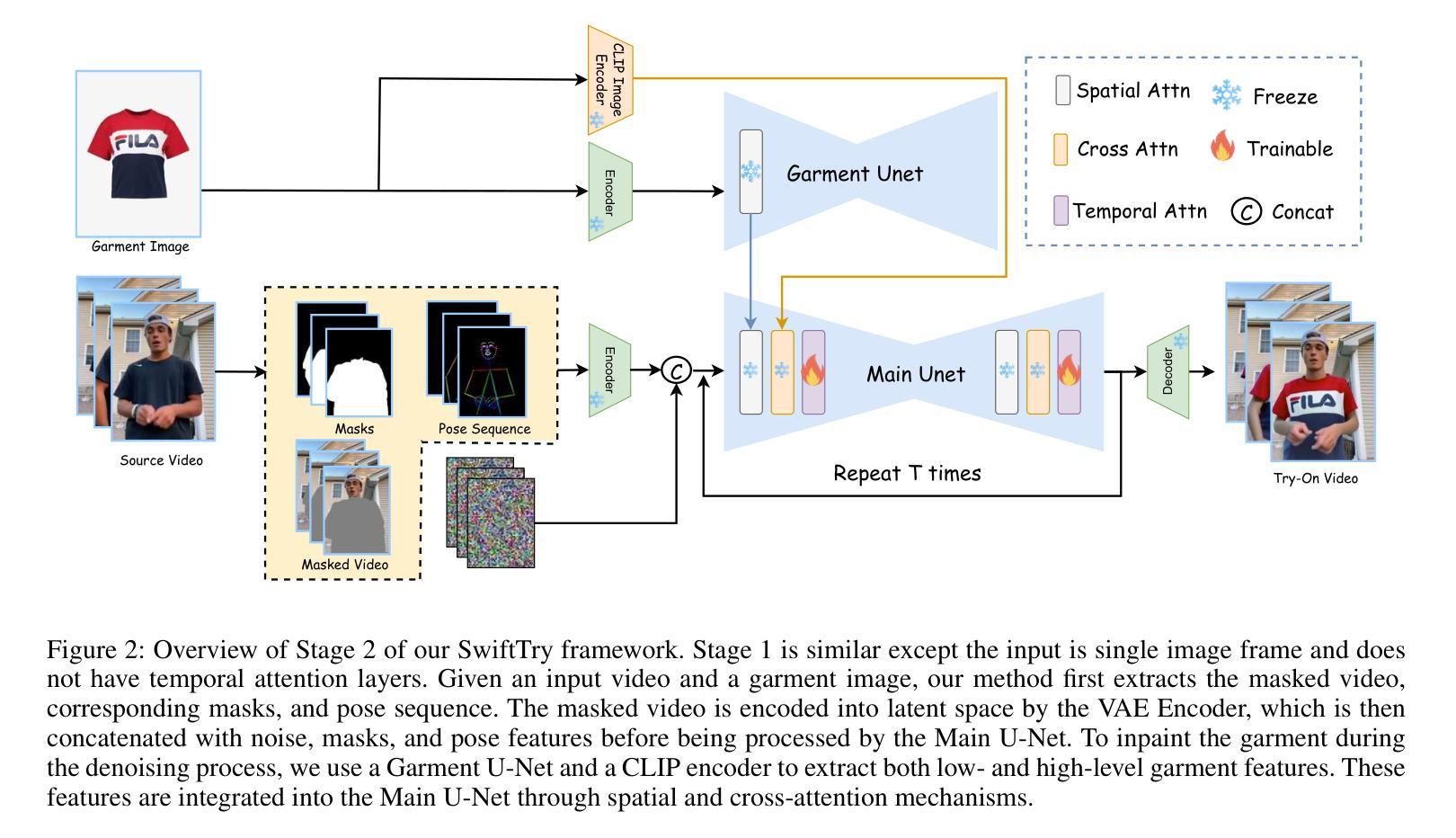
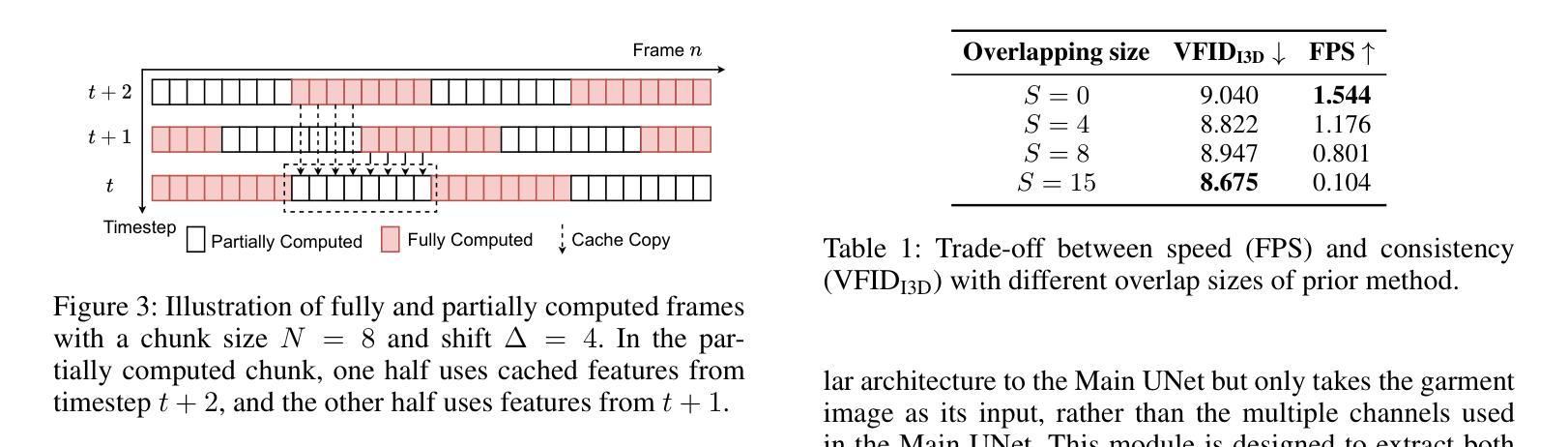
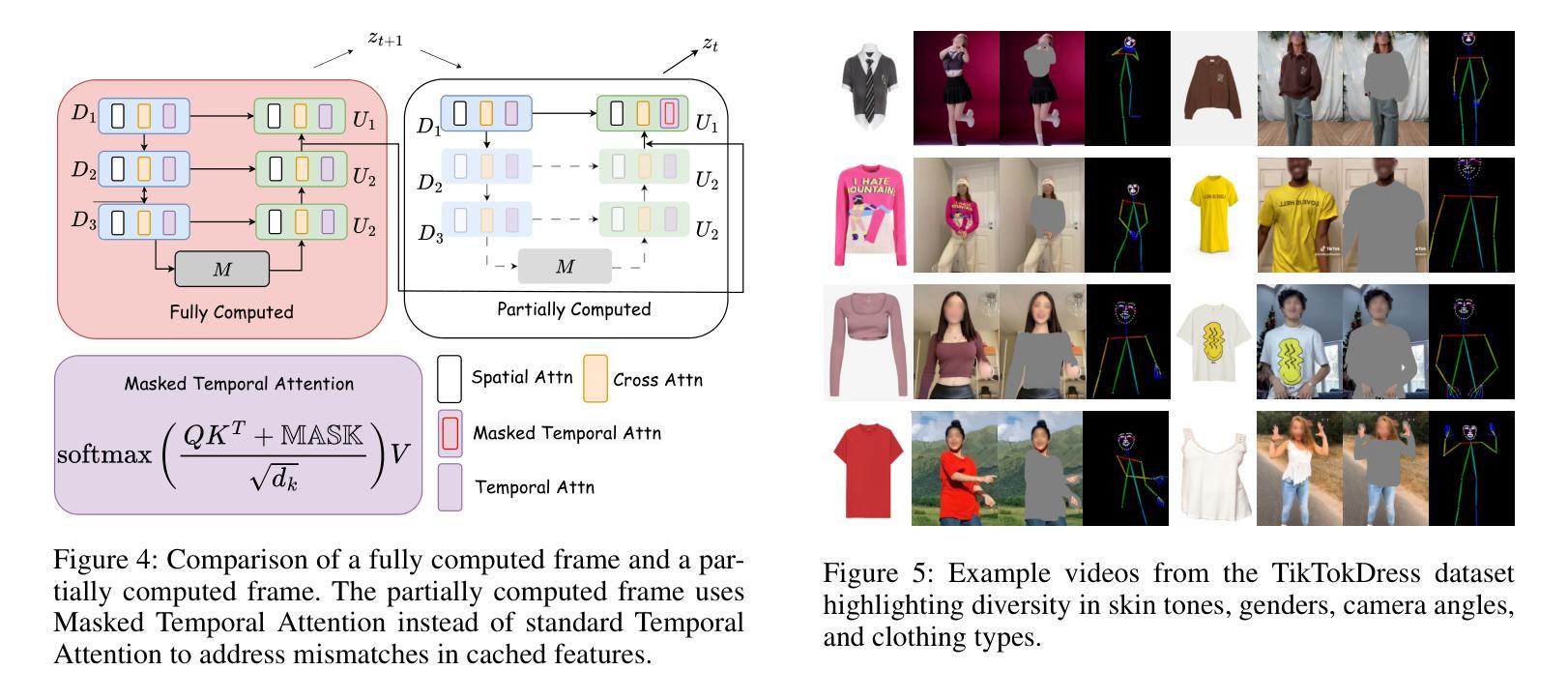
SwiftTry: Fast and Consistent Video Virtual Try-On with Diffusion Models
Authors:Hung Nguyen, Quang Qui-Vinh Nguyen, Khoi Nguyen, Rang Nguyen
Given an input video of a person and a new garment, the objective of this paper is to synthesize a new video where the person is wearing the specified garment while maintaining spatiotemporal consistency. While significant advances have been made in image-based virtual try-ons, extending these successes to video often results in frame-to-frame inconsistencies. Some approaches have attempted to address this by increasing the overlap of frames across multiple video chunks, but this comes at a steep computational cost due to the repeated processing of the same frames, especially for long video sequence. To address these challenges, we reconceptualize video virtual try-on as a conditional video inpainting task, with garments serving as input conditions. Specifically, our approach enhances image diffusion models by incorporating temporal attention layers to improve temporal coherence. To reduce computational overhead, we introduce ShiftCaching, a novel technique that maintains temporal consistency while minimizing redundant computations. Furthermore, we introduce the \dataname~dataset, a new video try-on dataset featuring more complex backgrounds, challenging movements, and higher resolution compared to existing public datasets. Extensive experiments show that our approach outperforms current baselines, particularly in terms of video consistency and inference speed. Data and code are available at https://github.com/VinAIResearch/swift-try
给定一个人穿着新衣物的输入视频,本文的目标是为合成一个新视频,其中人物穿着指定的衣物,同时保持时空一致性。虽然基于图像的虚拟试衣已经取得了重大进展,但这些成功扩展应用到视频上时,往往会导致帧间的不一致性。一些方法试图通过增加多个视频片段之间的帧重叠来解决这一问题,但这带来了高昂的计算成本,因为需要重复处理相同的帧,特别是对于长视频序列。为了应对这些挑战,我们将视频虚拟试衣重新构想为条件视频修复任务,衣物作为输入条件。具体来说,我们的方法通过融入时间注意力层来增强图像扩散模型,以提高时间连贯性。为了减少计算开销,我们引入了ShiftCaching这一新技术,它在保持时间一致性的同时最小化冗余计算。此外,我们推出了新的视频试穿数据集——dataname数据集,该数据集具有更复杂的背景、更具挑战性的动作和更高的分辨率,与现有公共数据集相比有所超越。大量实验表明,我们的方法在视频连贯性和推理速度方面超越了现有基线模型。数据和代码可通过https://github.com/VinAIResearch/swift-try获取。
论文及项目相关链接
Summary
本文旨在合成一个新视频,展示人物穿上指定服装并保持时空一致性。文章提出将视频虚拟试衣重新构想为条件性视频填充任务,以衣物作为输入条件。采用增强图像扩散模型结合时间注意力层来提高时空连贯性,并引入ShiftCaching技术减少计算冗余。此外,还介绍了新的视频试穿数据集,具有更复杂的背景、挑战性的动作和更高的分辨率。实验表明,该方法在视频一致性和推理速度方面优于当前基线。
Key Takeaways
- 本文目标是合成一个新视频,展示人物穿上特定服装,同时保持时空一致性。
- 提出将视频虚拟试衣视为条件性视频填充任务,其中衣物作为输入条件。
- 采用增强图像扩散模型,结合时间注意力层提高时空连贯性。
- 引入ShiftCaching技术,减少计算冗余,提高视频处理的效率。
- 介绍了新的视频试穿数据集,具有更复杂的背景、挑战性的动作和更高的分辨率。
- 实验结果表明,该方法在视频一致性和推理速度方面优于现有方法。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是视频虚拟试穿中的时空一致性和计算效率问题。具体来说,论文的目标是在给定一个人的视频和一件新服装的情况下,合成一个新的视频,显示这个人穿着指定的服装,同时保持时空一致性。以下是论文中提到的一些关键挑战和解决方案:
时空一致性:在视频虚拟试穿中,保持帧与帧之间的一致性是一个重大挑战,因为图像基础的虚拟试穿技术扩展到视频时往往会在帧间产生不一致性,导致视觉伪影和闪烁,影响虚拟试穿体验的真实感。
计算成本:处理长视频序列的高计算成本限制了这些方法在实际应用中的可行性。论文中提到,先前的方法通过增加多个视频块之间帧的重叠来解决这个问题,但这会导致重复处理相同帧的计算成本急剧增加,尤其是对于长视频序列。
数据集缺乏:现有的公共视频试穿数据集(如VVT)覆盖的基本图案服装、紧身T恤、统一背景、静态相机角度和重复的人体运动,限制了这些数据集在实际应用中的需求,特别是在处理复杂运动和多样化背景时。
为了解决这些问题,论文提出了以下两个主要贡献:
SwiftTry框架:这是一个新颖的视频虚拟试穿框架,它通过在UNet架构中引入时间注意力层来提高时间一致性,并在推理时引入了一种称为ShiftCaching的新技术,以确保视频剪辑之间的时间连贯性和平滑过渡,同时减少与先前方法相比的冗余计算。
TikTokDress数据集:这是一个新的视频试穿数据集,包含了更复杂的背景、挑战性的运动和更高分辨率,与现有的公共数据集相比,提供了一个更坚实的基础,以推进该领域的研究。
Q: 有哪些相关研究?
A: 论文中提到了多个与视频虚拟试穿相关的研究工作,这些工作可以大致分为图像虚拟试穿和视频虚拟试穿两个领域。以下是一些关键的相关研究:
图像虚拟试穿(Image Virtual Try-On)
基于GANs的方法:
- Han et al. (2018) 提出了一种使用薄板样条(TPS)变形的方法。
- Wang et al. (2018a) 提出了一种保持特征的图像基虚拟试穿网络。
- Ge et al. (2021) 提出了一种无需解析器的虚拟试穿方法,通过提取外观流来实现。
基于流估计的方法:
- Xie et al. (2023) 提出了一种基于流估计的方法,用于服装变形。
基于扩散模型的方法:
- Zhu et al. (2023) 提出了TryOnDiffusion,一种使用两个U-Net的虚拟试穿方法。
- Kim et al. (2023) 提出了StableVITON,一种使用ControlNet风格的零交叉注意力块来调节服装的方法。
- Choi et al. (2024) 提出了IDM-VTON,一种结合低级特征和通过IP-Adapter提取的高级语义特征的方法。
视频虚拟试穿(Video Virtual Try-On)
基于光流的方法:
- Dong et al. (2019b) 提出了FW-GAN,集成了Video2Video的光流预测模块,用于变形前一帧到当前帧。
基于记忆细化的方法:
- Zhong et al. (2021) 提出了MV-TON,引入了记忆细化模块,保留并细化前一帧的特征。
基于视觉变换器的方法:
- Jiang et al. (2022) 提出了ClothFormer,使用视觉变换器在其试穿生成器中,以最小化模糊和时间伪影。
基于扩散模型的方法:
- Xu et al. (2024b) 提出了Tunnel Try-On,是第一个将扩散模型应用于视频虚拟试穿的方法,有效处理摄像机运动并保持一致性。
基于大规模数据集的方法:
- Fang et al. (2024) 提出了ViViD,发布了第一个实用的视频虚拟试穿数据集,但受限于简单背景和运动。
这些研究工作为视频虚拟试穿领域提供了多种技术和方法,但大多数方法在处理长视频序列时面临帧间不一致性和计算成本高的问题。论文提出的SwiftTry框架和TikTokDress数据集旨在解决这些问题,提高视频虚拟试穿的质量和实用性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键技术和方法解决了视频虚拟试穿中的时空一致性和计算效率问题:
1. SwiftTry框架
时间注意力层:SwiftTry框架在UNet架构中引入了时间注意力层,以增强模型对视频帧之间时间相关性的理解。这种设计通过将2D层转换为伪3D层,并在空间和交叉注意力层之后添加时间注意力层,使得同一视频块内不同帧的特征能够相互交互。
ShiftCaching技术:为了减少冗余计算并保持视频剪辑之间的时间连贯性,论文提出了ShiftCaching技术。这种技术通过在推理时将长视频分成非重叠的视频块,并在每个DDIM采样时间步长中通过预定义的值∆来移动这些块,避免了重复计算重叠区域。
2. TikTokDress数据集
- 多样化和复杂性:为了提供更接近实际应用的数据支持,论文引入了TikTokDress数据集。该数据集包含了复杂背景、多样化动作和不同分辨率的视频,提供了一个更加全面的测试和训练环境。
3. 训练和推理优化
两阶段训练:SwiftTry的训练分为两个阶段。第一阶段是使用VITON-HD数据集训练扩散模型,第二阶段是将时间注意力层整合到模型中,并使用视频数据集进行训练。
部分计算和缓存:在ShiftCaching中,为了进一步加速推理过程,论文采用了部分计算和缓存机制。这种方法通过缓存先前计算的特征,并在当前时间步中使用这些特征来部分计算当前潜在表示,从而减少了UNet深层块的计算量。
4. 掩码和注意力机制
- 掩码精细控制:为了处理视频帧中的特征不匹配问题,论文提出了掩码时间注意力机制。这种机制在softmax注意力计算期间使用特殊掩码,以防止不太准确的特征影响更准确的特征,同时允许从好的特徵向坏的特征传递信息。
通过这些技术和方法的结合,论文成功地提高了视频虚拟试穿的时空一致性,并显著降低了处理长视频序列的计算成本,使得视频虚拟试穿技术更适用于实际应用场景。
Q: 论文做了哪些实验?
A: 论文中进行了一系列的实验来验证SwiftTry框架的性能和效率,具体实验包括:
数据集评估
VVT数据集:这是一个标准的视频虚拟试穿基准数据集,包含791对个体和服装图像的视频,用于训练和测试。论文在该数据集上评估了SwiftTry的性能。
TikTokDress数据集:这是论文新引入的数据集,包含更复杂的背景、动态动作和不同身体姿势的视频。该数据集提供了232,843帧用于训练和39,705帧用于测试。
性能指标
- 图像基础和视频基础指标:在成对和不成对的设置中,使用SSIM(结构相似性指数)和LPIPS(Learned Perceptual Image Patch Similarity)评估重建质量。使用Video Fréchet Inception Distance (VFID) 评估视觉质量和时间一致性,并测量推理速度(FPS)。
与其他方法的比较
- 与先前方法的比较:论文将SwiftTry与多种视频虚拟试穿方法进行了比较,包括基于GAN的方法(如FW-GAN、MV-TON和ClothFormer)和基于扩散模型的方法(如Tunnel Try-On、ViViD和WildVidFit)。
定量结果
VVT数据集上的比较:在VVT数据集上的比较显示,SwiftTry在VFID指标上表现优异,显示出更好的视觉质量和一致性,并且在FPS上也有显著提升。
TikTokDress数据集上的比较:在TikTokDress数据集上的评估表明,SwiftTry在处理复杂背景和动态动作时,相比其他方法能更好地保持服装纹理的一致性。
定性结果
- 与ViViD的比较:论文提供了与ViViD方法的定性比较,展示了SwiftTry在保持服装纹理和减少帧间闪烁方面的优越性。
消融研究
ShiftCaching技术的消融研究:论文探究了不同的掩码注意力机制对性能的影响,并发现Half Attention机制提供了最佳性能。
视频块长度对推理的影响:论文还研究了训练和推理视频块长度对结果的影响,发现将训练和推理视频块长度都设置为16帧时效果最佳。
这些实验全面评估了SwiftTry框架的性能,验证了其在视频虚拟试穿任务中的有效性和实用性。通过定量和定性的结果,论文展示了SwiftTry在保持时空一致性和提高推理速度方面的优势。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了SwiftTry框架和TikTokDress数据集来解决视频虚拟试穿中的挑战,但仍有一些领域可以进一步探索和改进:
1. 算法优化和模型泛化
- 模型泛化能力:探索如何提高模型对于不同种族、体型和年龄人群的泛化能力。
- 轻量化模型:研究如何优化模型结构和计算流程,以适应资源受限的环境,例如移动设备。
2. 数据集扩展和多样性
- 多语言和文化服装:扩展数据集以包含更多不同语言和文化背景下的服装,提高模型的全球适用性。
- 更复杂的背景和光照条件:增加背景和光照条件的复杂性,以更好地模拟现实世界的挑战。
3. 用户交互和体验
- 实时视频虚拟试穿:研究如何实现实时或近实时的视频虚拟试穿技术,以提升在线购物体验。
- 用户指导的试穿调整:开发允许用户在试穿过程中进行微调的工具,如调整服装大小、颜色等。
4. 计算效率和硬件加速
- 分布式计算和优化:探索使用分布式计算和专用硬件(如GPU、TPU)来加速虚拟试穿过程。
- 模型压缩和加速:研究模型压缩技术,减少模型大小和计算需求,同时保持性能。
5. 交互式应用和集成
- 增强现实(AR)集成:将视频虚拟试穿技术与AR技术结合,提供沉浸式的试穿体验。
- 电子商务平台集成:与电子商务平台合作,将虚拟试穿技术直接集成到购物流程中。
6. 伦理和隐私问题
- 数据隐私和安全性:确保在收集和使用用户数据时遵守隐私法规和伦理标准。
- 模型透明度和可解释性:提高模型的透明度和可解释性,让用户理解模型的工作原理和潜在偏差。
7. 多模态学习和跨领域应用
- 多模态数据融合:探索如何结合视觉、语音和文本等多种模态的数据来提升试穿体验。
- 跨领域技术迁移:研究如何将视频虚拟试穿技术迁移应用到其他领域,如影视制作、游戏开发等。
这些方向不仅可以推动视频虚拟试穿技术的发展,还能扩展其在更广泛领域的应用,为用户带来更加丰富和便捷的体验。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
1. 问题定义
论文的目标是解决视频虚拟试穿中的时空一致性和计算效率问题。具体来说,就是给定一个人的视频和一件服装,合成一个新的视频,显示这个人穿着指定的服装,同时保持时空一致性。
2. SwiftTry框架
- 时间注意力层:提出了一个基于扩散模型的视频虚拟试穿框架,通过在UNet架构中引入时间注意力层来增强模型对视频帧之间时间相关性的理解。
- ShiftCaching技术:为了减少冗余计算并保持视频剪辑之间的时间连贯性,提出了ShiftCaching技术,该技术通过在推理时将长视频分成非重叠的视频块,并在每个DDIM采样时间步长中通过预定义的值∆来移动这些块。
3. TikTokDress数据集
- 提出了一个新的视频虚拟试穿数据集TikTokDress,该数据集包含了更复杂的背景、挑战性的运动和更高分辨率的视频,提供了一个更全面的测试和训练环境。
4. 实验评估
- 在VVT和TikTokDress数据集上评估了SwiftTry的性能,并与其他视频虚拟试穿方法进行了比较。
- 使用了包括SSIM、LPIPS和VFID在内的多种定量和定性指标来评估重建质量和时间一致性。
- 进行了消融研究,探究了不同的掩码注意力机制和视频块长度对性能的影响。
5. 贡献总结
- 提出了ShiftCaching技术,以确保视频剪辑之间的时间连贯性,并减少冗余计算。
- 引入了TikTokDress数据集,提供了一个更接近实际应用场景的数据集,推动了视频虚拟试穿技术的发展。
6. 未来工作
- 论文还提出了一些未来可能的研究方向,包括算法优化、数据集扩展、用户交互体验改进、计算效率提升、跨领域应用等。
总的来说,这篇论文通过提出一个新的框架和数据集,有效地解决了视频虚拟试穿中的一些关键挑战,并展示了良好的性能和应用潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

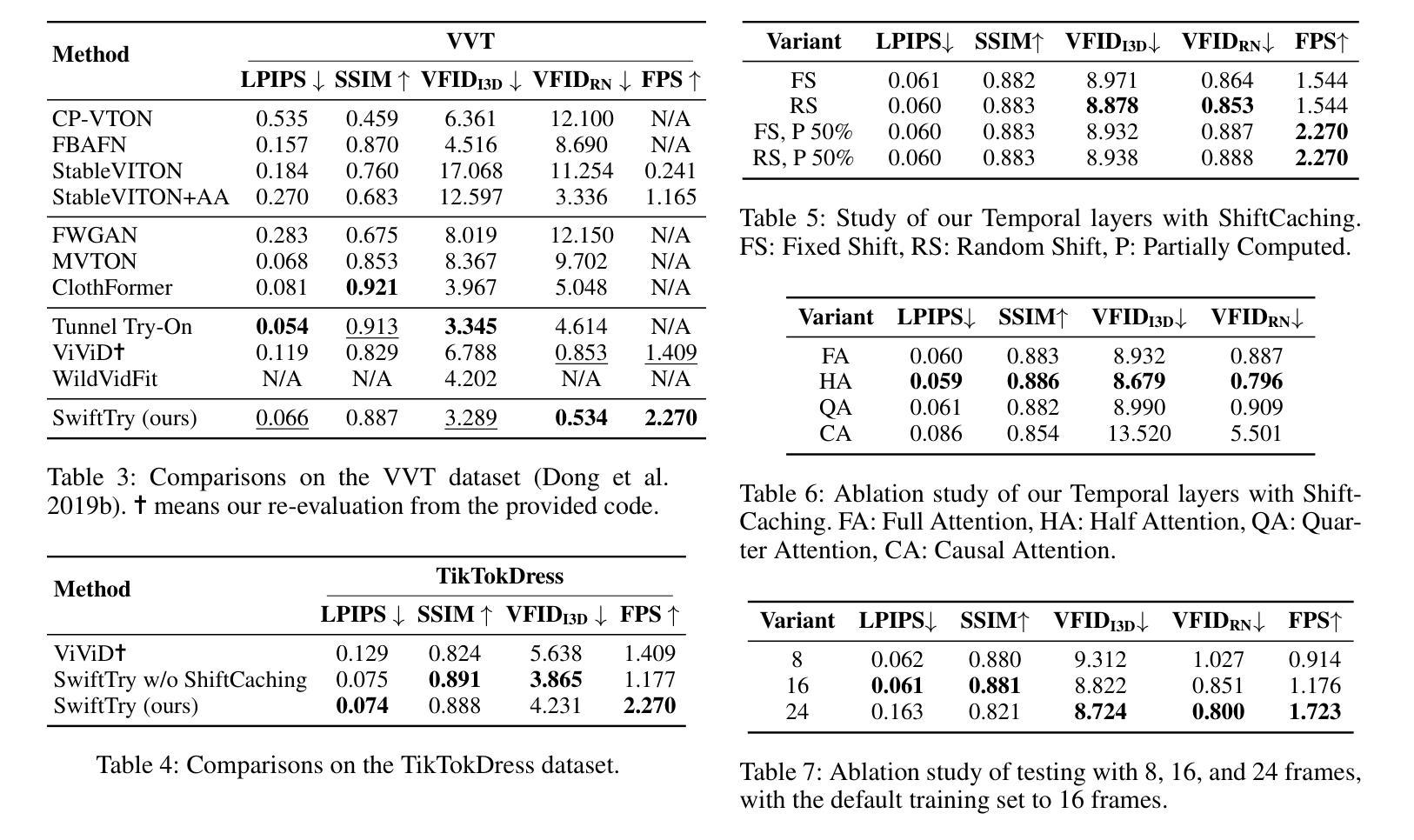
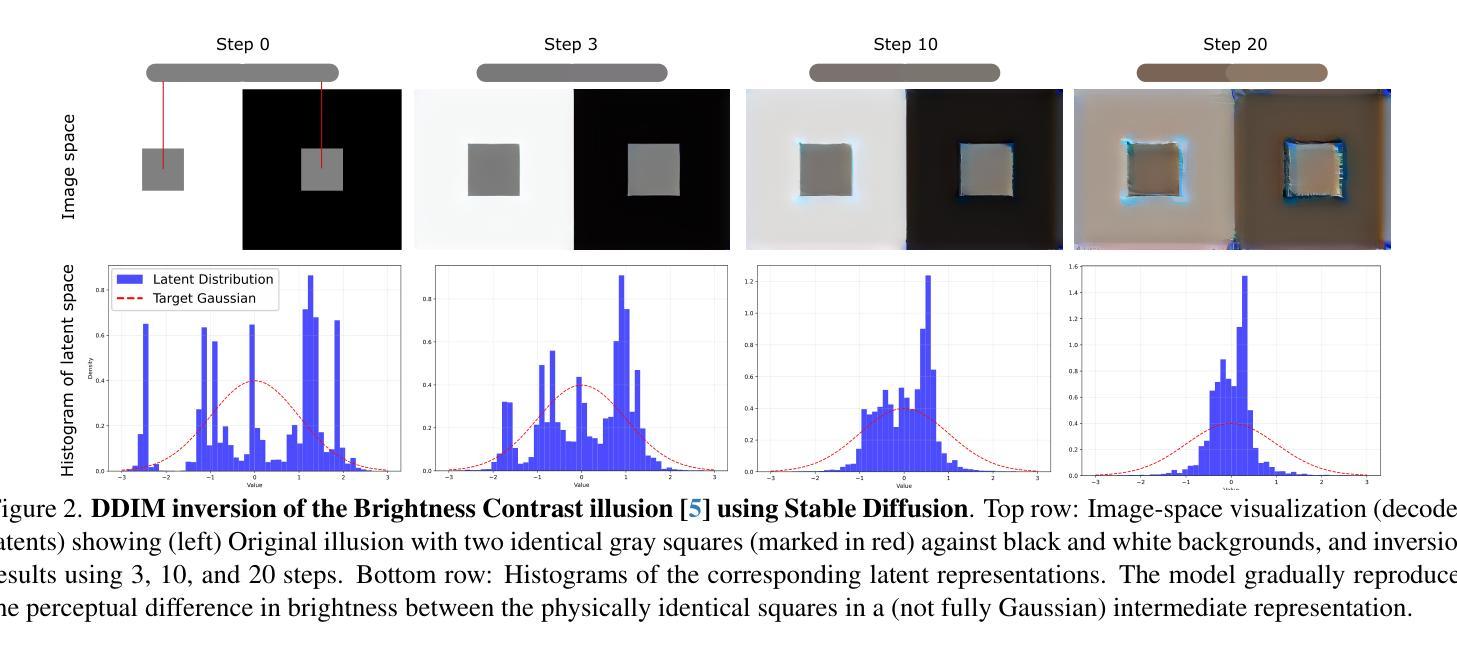
The Art of Deception: Color Visual Illusions and Diffusion Models
Authors:Alex Gomez-Villa, Kai Wang, Alejandro C. Parraga, Bartlomiej Twardowski, Jesus Malo, Javier Vazquez-Corral, Joost van de Weijer
Visual illusions in humans arise when interpreting out-of-distribution stimuli: if the observer is adapted to certain statistics, perception of outliers deviates from reality. Recent studies have shown that artificial neural networks (ANNs) can also be deceived by visual illusions. This revelation raises profound questions about the nature of visual information. Why are two independent systems, both human brains and ANNs, susceptible to the same illusions? Should any ANN be capable of perceiving visual illusions? Are these perceptions a feature or a flaw? In this work, we study how visual illusions are encoded in diffusion models. Remarkably, we show that they present human-like brightness/color shifts in their latent space. We use this fact to demonstrate that diffusion models can predict visual illusions. Furthermore, we also show how to generate new unseen visual illusions in realistic images using text-to-image diffusion models. We validate this ability through psychophysical experiments that show how our model-generated illusions also fool humans.
在人类中,视觉错觉的产生源于对异常分布刺激的解释:当观察者适应于某些统计数据时,对异常值的感知会偏离现实。最近的研究表明,人工神经网络(ANNs)也会受到视觉错觉的欺骗。这一发现引发了关于视觉信息本质的深刻问题。为什么人类大脑和人工神经网络这两个独立系统都会受到同样的错觉影响?任何人工神经网络都能感知视觉错觉吗?这些感知是特征还是缺陷?在这项工作中,我们研究了视觉错觉如何在扩散模型中编码。值得注意的是,我们展示它们在潜在空间中呈现出类似人类的亮度/色彩变化。我们利用这一事实来证明扩散模型可以预测视觉错觉。此外,我们还展示了如何使用文本到图像的扩散模型在真实图像中生成新的未见过的视觉错觉。我们通过心理物理实验验证了模型生成的错觉也能欺骗人类的能力。
论文及项目相关链接
Summary
人类和人工神经网络(ANNs)都会受到视觉错觉的影响,这引发了关于视觉信息本质的深刻问题。本研究探讨了扩散模型中如何编码视觉错觉,发现它们在人脑的亮度和颜色变化上具有类似性。利用这一点,我们证明了扩散模型可以预测视觉错觉,并通过心理物理实验验证了使用文本到图像扩散模型生成新的未见过视觉错觉在现实图像中的能力,这些生成的错觉同样可以欺骗人类。
Key Takeaways
- 人类和人工神经网络(ANNs)都会受到视觉错觉的影响。
- 扩散模型能够编码视觉错觉。
- 扩散模型在亮度和颜色变化上呈现出与人脑类似的特性。
- 扩散模型能够预测视觉错觉。
- 通过心理物理实验验证了使用文本到图像扩散模型生成新的未见过视觉错觉的能力。
- 生成的视觉错觉能够欺骗人类。
- 这种现象揭示了视觉信息处理的共同机制在人工智能和人类之间的相似性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了视觉错觉(Visual Illusions, VIs)在人类视觉感知和人工神经网络(Artificial Neural Networks, ANNs)中的出现,并研究了这些错觉如何在扩散模型(Diffusion Models, DMs)中被编码。具体来说,论文试图解决以下问题:
人类和ANNs对视觉错觉的相似性:论文试图解答为什么两个独立的系统——人脑和ANNs——会对相同的视觉错觉敏感。
ANNs感知视觉错觉的必要性:探讨是否所有的ANNs都应该能够感知视觉错觉。
视觉错觉的特征与缺陷:分析这些错觉的感知是ANNs的一个特征还是缺陷。
扩散模型中视觉错觉的编码:研究扩散模型如何在其潜在空间中编码视觉错觉,并展示这些模型展现出类人亮度/颜色偏移的现象。
利用扩散模型预测视觉错觉:基于扩散模型中的人类感知现象,提出使用扩散模型预测视觉错觉的方法。
生成新的未见视觉错觉:展示如何使用文本到图像的扩散模型在真实图像中生成新的、未见的视觉错觉,并通过心理物理实验验证这些模型生成的错觉也能欺骗人类观察者。
综上所述,这篇论文试图深入理解视觉错觉在人类和机器视觉系统中的作用,并探索扩散模型在模拟和生成视觉错觉方面的潜力。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个类别:
1. 视觉错觉在人工神经网络中的研究
- 早期工作:展示了多层感知器可以复制亮度错觉[8]。
- 后续研究:Gomez-Villa等人[12]表明卷积神经网络(CNNs)可以镜像人类在亮度和颜色错觉中的感知。
- 其他相关研究:包括在图像补全[19, 47]、亮度/颜色感知[13, 17, 24, 31, 32, 48]、对比度敏感性[1, 30]、形状感知[35, 54]和视觉-语言模型[6, 36, 44, 55]等领域的研究。
2. 视觉错觉的复制方法
- 图像恢复方法:使用预训练的图像恢复模型处理视觉错觉,并测量输出图像以测量感知[12, 13, 24, 30, 32]。
- 效应偏差方法:受神经科学刺激测量的启发,使用预训练的架构处理视觉错觉,然后使用ANN的内部激活来定义是否存在视觉错觉[1]。
- 似然方法:使用可逆流在自然图像上训练,估计图像中每个像素最可能的感知强度[17]。
- 语言引导方法:使用语言作为测量感知的工具,这些工作使用视觉-语言模型作为测试对象,并询问有关图像感知的问题[36, 55]。
3. 视觉错觉的生成方法
- 使用生成模型合成视觉错觉:尽管已有研究使用生成模型合成视觉错觉[14],但扩散模型最近才被提出作为生成引擎。
- 相关工作:包括通过混合图像和变换生成高级幻觉效应[6],以及创建更一般的幻觉,如旋转、颜色反转和混合图像[10, 11]。
- 与本文工作最相似的研究:Roy等人[43]使用稳定扩散(SD)通过关键词提示生成亮度视觉错觉,但他们的方法没有明确优化感知效果,也没有指定用于感知复制的区域。
这些相关研究为本文提供了理论和技术背景,同时也展示了在视觉错觉领域内的不同研究方向和方法。论文通过这些相关工作,进一步探索了扩散模型在模拟和生成视觉错觉方面的潜力,并提出了新的方法和见解。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决上述问题:
1. 分析扩散模型中的人类感知现象
- 论文首先报告了一个关键发现:在扩散模型的编码过程中,中间步骤显示出与人类感知显著一致的趋势。具体来说,当分析图像通过扩散过程反转时的轨迹,发现亮度和颜色属性的逐步变化与人类感知反应非常相似。
2. 提出基于扩散模型的视觉模型方法
- 论文提出了一种新方法,使用深度自编码器作为视觉模型,通过执行扩散反转过程,并在中间噪声空间测量感知。
3. 验证扩散模型在多种情况下复制人类感知的能力
- 通过在多个视觉错觉数据集、流行的已发布视觉错觉作品和自然图像上进行实验,展示了扩散模型在许多情况下复制人类感知的能力。
4. 提出使用文本到图像模型生成视觉错觉的新方法
- 利用扩散模型的感知能力,论文提出了一种使用文本到图像模型生成亮度/颜色视觉错觉的新方法。
5. 实施视觉错觉生成流程
- 论文概述了一个视觉错觉生成流程,该流程通过修改噪声潜在表示,使用自定义损失函数引导生成过程朝向感知上模糊的输出。
6. 进行心理物理实验验证
- 通过心理物理实验验证模型生成的错觉也能欺骗人类观察者,从而支持论文提出的方法。
7. 提供定量和定性评估
- 使用定量指标(如感知准确度得分)和定性结果(如图像示例和视觉比较)来评估模型在复制和生成视觉错觉方面的表现。
通过这些步骤,论文不仅展示了扩散模型在复制人类对视觉错觉的感知方面的潜力,而且还提出了一种新的方法来生成能够欺骗人类感知的新的视觉错觉,这为理解和模拟人类视觉感知提供了新的视角。
Q: 论文做了哪些实验?
A: 论文中进行了两组主要的实验来评估所提出方法的能力:
1. 复制视觉错觉的实验
- 目的:测试模型复制亮度和颜色视觉错觉的能力。
- 数据集:使用了BRI3L数据集(包含22366张灰度图像,涵盖五种亮度错觉类型)和视觉错觉VQA数据集(IllusionVQA、GVIL和HallusionBench)。
- 方法:通过比较输入和输出图像在标注的分割掩模内的强度差异来评估模型的性能。
- 评估指标:
- 对于BRI3L数据集,计算模型输出与输入图像在每个分割区域内的平均强度差异($\Delta I$)。
- 对于VQA数据集,创建分割掩模并考虑模型的答案是否与人类感知的预期强度相匹配,计算感知准确度得分(PAS)。
2. 生成视觉错觉的实验
- 目的:检查是否能够在T2I模型分布内的图像中生成视觉错觉。
- 方法:
- 使用DeepFloyd模型的S1阶段生成视觉错觉,然后在S2阶段将其扩展以生成更高分辨率的版本。
- 定义了特定的目标区域,并在这些区域内施加感知效果,同时满足文本提示和感知条件。
- 心理物理确认:
- 创建了40张强制模型产生特定颜色目标的错觉图像和40张对照图像(没有强制产生错觉)。
- 15名观察者参与实验,判断两个目标是否相同或不同。
- 分析结果表明,在模型强制产生错觉的图像中,观察者在64%(平均)和67%(中位数)的情况下认为目标不同,而在对照图像中这一比例为13%(平均)和7%(中位数)。
这些实验不仅展示了模型在复制和生成视觉错觉方面的能力,而且通过心理物理实验验证了生成的错觉能够欺骗人类观察者的感知,从而支持了论文提出的方法的有效性。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些有趣的发现和方法,但仍有一些领域可以进一步探索和研究:
1. 扩散模型的感知机制
- 研究扩散模型如何处理不同类型的视觉错觉:虽然论文主要关注亮度和颜色视觉错觉,但扩散模型可能对其他类型的错觉(如几何、运动错觉)也有反应,值得进一步研究。
2. 模型的泛化能力
- 提高模型对小区域效应的复制能力:由于扩散模型的图像反转过程中空间信息的丢失,模型难以复制基于小区域的视觉效应。改进模型以更好地保留这些细节可能提高复制效果。
3. 生成更自然的错觉
- 基于注意力图的感知区域定义:目前的T2I视觉错觉生成方法在推理时基于预定义区域。利用输入提示产生的注意力图来指导感知区域的定义,可能产生更自然的错觉。
4. 心理物理学实验的扩展
- 增加参与者和错觉类型:扩展心理物理学实验,包括更多的参与者和更多的错觉类型,以进一步验证模型生成的错觉对人类观察者的影响。
5. 模型的解释性和可视化
- 扩散过程的可视化和解释:虽然论文展示了扩散模型能够复制人类感知,但进一步研究和可视化扩散过程中的每一步,可能揭示模型内部的工作原理和感知机制。
6. 模型优化和调整
- 优化感知损失权重(γ):通过实验确定感知损失权重(γ)的最佳值,以更有效地生成视觉错觉。
7. 跨领域应用
- 将视觉错觉研究应用于其他领域:视觉错觉的研究可能对虚拟现实、增强现实、艺术创作等领域产生影响,探索这些跨领域应用是一个有趣的方向。
8. 模型的鲁棒性和可靠性
- 评估模型在不同条件下的鲁棒性:在不同的光照、背景和噪声条件下测试模型的鲁棒性,以确保其在各种环境条件下都能可靠地复制和生成视觉错觉。
这些进一步探索的点可以帮助我们更深入地理解扩散模型如何处理视觉信息,以及如何利用这些模型来模拟和操纵人类视觉感知。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容集中在探讨视觉错觉在人类视觉感知和人工神经网络(ANNs)中的表现,并特别研究了扩散模型(DMs)如何编码这些视觉错觉。以下是论文的核心内容总结:
1. 引言和背景
- 论文首先介绍了视觉错觉(VIs)对理解人类视觉感知的重要性,并讨论了扩散模型(DMs)在图像合成和处理中的最新进展。作者提出了关于人类大脑和ANNs对视觉错觉的相似反应的深刻问题。
2. 相关工作
- 论文回顾了先前在ANNs中复制视觉错觉的研究,并分类讨论了不同的复制方法,包括图像恢复方法、效应偏差方法、似然方法和语言引导方法。
3. 方法
- 扩散模型:介绍了扩散模型(DMs)的基本框架,特别是Denoising Diffusion Implicit Models(DDIM)及其在图像反转过程中的应用。
- DDIM反转可能复制人类视觉:提出了一个假设,即扩散模型在处理自然图像分布之外的刺激时,可能会展现出与人类感知类似的偏差。
- 使用DMs生成视觉错觉:基于上述发现,开发了一种自动生成亮度/颜色视觉错觉的方法,通过评估和推动扩散过程中的感知效果。
4. 实验设置
- 数据集:使用了多个视觉错觉数据集,包括BRI3L、IllusionVQA、GVIL和HallusionBench。
- 基准测试:与经典视觉科学模型和基于神经网络的模型进行比较。
- 评估指标:提出了定量评估模型复制和生成视觉错觉能力的方法。
5. 实验结果
- 复制视觉错觉:展示了模型在复制多种视觉错觉方面的能力,并与基线方法进行了比较。
- 生成视觉错觉:通过心理物理实验验证了模型生成的视觉错觉能够欺骗人类观察者。
6. 限制
- 论文讨论了在复制和生成视觉错觉方面的局限性,包括对小区域效应的处理困难和对预定义区域的依赖。
7. 结论
- 论文总结了两个关键贡献:扩散模型通过图像反转过程自然复制人类对亮度和颜色视觉错觉的响应,以及开发了一种使用文本到图像扩散模型生成视觉错觉的新方法。作者认为这些发现可能有助于开发更符合人类视觉认知的感知意识基础模型。
这篇论文通过实证研究展示了扩散模型在模拟人类视觉感知方面的潜力,并提出了一种新的生成视觉错觉的方法,这可能对未来视觉-语言模型的发展和图像编辑工作流程产生重要影响。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

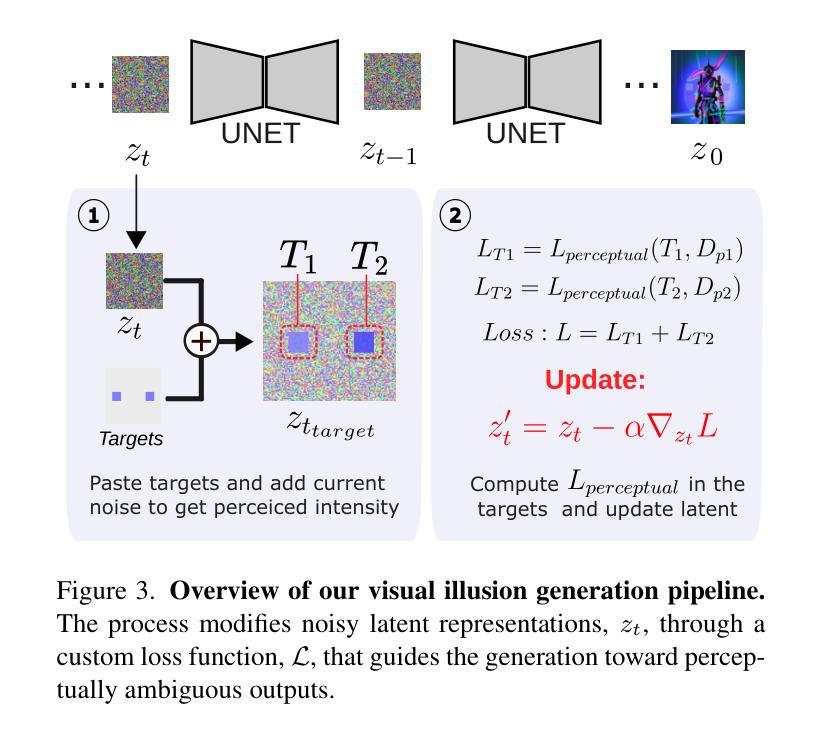
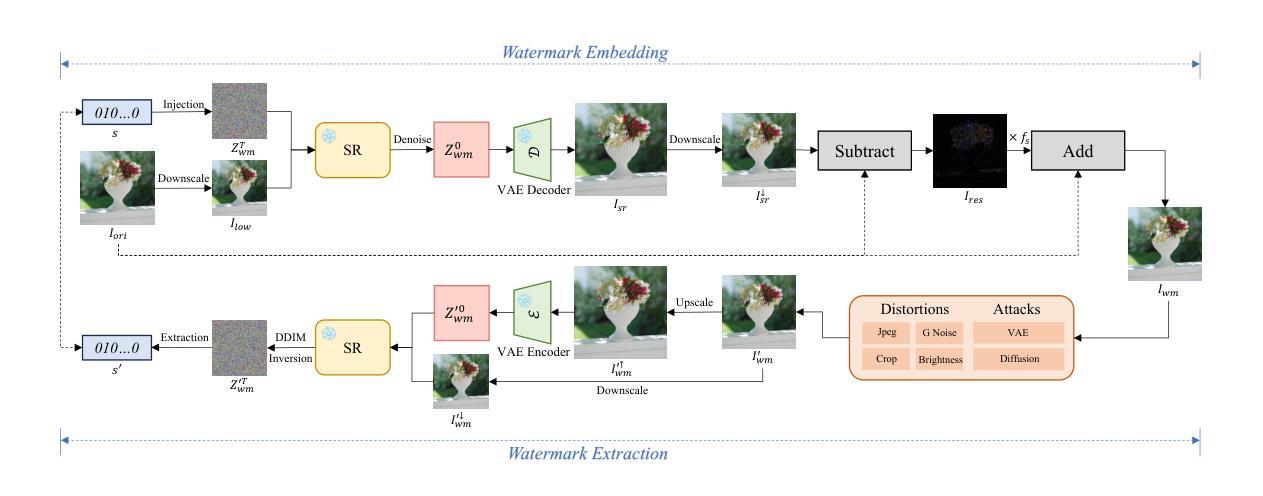
SuperMark: Robust and Training-free Image Watermarking via Diffusion-based Super-Resolution
Authors:Runyi Hu, Jie Zhang, Yiming Li, Jiwei Li, Qing Guo, Han Qiu, Tianwei Zhang
In today’s digital landscape, the blending of AI-generated and authentic content has underscored the need for copyright protection and content authentication. Watermarking has become a vital tool to address these challenges, safeguarding both generated and real content. Effective watermarking methods must withstand various distortions and attacks. Current deep watermarking techniques often use an encoder-noise layer-decoder architecture and include distortions to enhance robustness. However, they struggle to balance robustness and fidelity and remain vulnerable to adaptive attacks, despite extensive training. To overcome these limitations, we propose SuperMark, a robust, training-free watermarking framework. Inspired by the parallels between watermark embedding/extraction in watermarking and the denoising/noising processes in diffusion models, SuperMark embeds the watermark into initial Gaussian noise using existing techniques. It then applies pre-trained Super-Resolution (SR) models to denoise the watermarked noise, producing the final watermarked image. For extraction, the process is reversed: the watermarked image is inverted back to the initial watermarked noise via DDIM Inversion, from which the embedded watermark is extracted. This flexible framework supports various noise injection methods and diffusion-based SR models, enabling enhanced customization. The robustness of the DDIM Inversion process against perturbations allows SuperMark to achieve strong resilience to distortions while maintaining high fidelity. Experiments demonstrate that SuperMark achieves fidelity comparable to existing methods while significantly improving robustness. Under standard distortions, it achieves an average watermark extraction accuracy of 99.46%, and 89.29% under adaptive attacks. Moreover, SuperMark shows strong transferability across datasets, SR models, embedding methods, and resolutions.
在今天的数字时代,人工智能生成的内容和真实内容的融合强调了版权保护和内容认证的需求。水印已成为应对这些挑战的重要工具,保护生成的内容和真实内容。有效的水印方法必须能够承受各种失真和攻击。目前深度水印技术通常采用编码器-噪声层-解码器架构,并通过引入失真来提高稳健性。然而,它们难以在稳健性和保真度之间取得平衡,尽管经过大量训练,但仍容易受到适应性攻击的影响。为了克服这些限制,我们提出了SuperMark,一个稳健、无需训练的水印框架。SuperMark受到水印中水印嵌入/提取与扩散模型中的去噪/噪声处理过程之间的平行的启发,使用现有技术将水印嵌入初始高斯噪声中。然后,它应用预训练的超级分辨率(SR)模型对带水印的噪声进行去噪,生成最终的带水印图像。对于提取过程,则反之:带水印的图像通过DDIM反演返回初始带水印的噪声,从中提取嵌入的水印。这个灵活框架支持各种噪声注入方法和基于扩散的SR模型,实现了增强的自定义性。DDIM反演过程的鲁棒性允许SuperMark在保持高保真度的同时,实现对失真的强韧性。实验表明,SuperMark在保持与现有方法相当的保真度的同时,显著提高了稳健性。在标准失真下,它实现了平均99.46%的水印提取精度,在自适应攻击下为89.29%。此外,SuperMark在数据集、SR模型、嵌入方法和分辨率之间表现出强大的可转移性。
论文及项目相关链接
PDF robust image watermarking
Summary
在水印技术中,超级水印(SuperMark)作为一种无需训练的稳健框架,能够在数字时代的AI生成和真实内容融合中提供版权保护和内容认证。它利用扩散模型中的去噪/噪声处理与水印嵌入/提取的相似性,通过将水印嵌入初始高斯噪声并利用现有技术结合预训练的超级分辨率(SR)模型实现水印的最终输出和提取过程。这一方法具有高鲁棒性和灵活性,支持多种噪声注入方法和基于扩散的SR模型,实验证明其能够在保持高保真度的同时实现强大的抗失真效果,并具有在各种数据集上的优秀转移性能。同时抵御传统与自适应攻击的鲁棒性验证准确率相当优秀。简言之,这一创新框架提升了水印技术的稳健性和效率。
Key Takeaways
- AI生成内容和真实内容的融合加剧了版权保护和内容认证的需求。水印技术已成为应对此挑战的关键工具。
- 当前深度水印技术面临的挑战包括如何在维持稳健性的同时确保高保真度以及对抗自适应攻击的能力不足。
- SuperMark作为一种无需训练的稳健水印框架被提出,它通过结合扩散模型和预训练的超级分辨率模型来嵌入和提取水印。它通过在噪声中加入水印并结合去噪技术产生最终的带有水印的图像,过程灵活多变且支持多种方法。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在数字时代背景下,对由人工智能生成(AI-generated)和真实内容进行有效的版权保护和内容认证。具体来说,论文关注于图像水印技术,这是一种能够保护生成和真实图像内容的关键技术。论文指出,现有的基于深度学习的水印技术通常采用编码器-噪声层-解码器架构,并在训练过程中引入各种失真以增强鲁棒性,但这些方法往往难以平衡鲁棒性和保真度,并且在适应性攻击面前仍然脆弱,尽管进行了广泛的训练。
为了克服这些限制,论文提出了一个名为SuperMark的新颖鲁棒且无需训练的水印框架。SuperMark从水印模型中的水印嵌入/提取过程与扩散模型中的去噪/加噪过程之间的相似性中获得灵感,利用预训练的超分辨率(SR)模型来去噪加水印的噪声,生成最终的水印图像。对于提取过程,通过DDIM反演将加水印的图像转换回初始加水印的噪声,然后从中提取嵌入的水印。这种方法具有固有的对各种扰动的鲁棒性,同时保持高保真度。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个方面:
AI生成内容(AIGC)的水印技术:
- Tree-Ring(Wen et al., 2024)和Gaussian Shading(Yang et al., 2024)是两种针对基于扩散的文本到图像(T2I)模型的水印技术,它们通过在高斯噪声中嵌入水印并通过DDIM反演提取水印。
后处理水印方法:
- 传统的后处理方法如DwtDct(Rahman, 2013)和DwtDctSvd(Rahman, 2013)在变换域中嵌入水印信息,提供有限的鲁棒性。
- 基于深度学习的后处理水印方法,如MBRS(Jia et al., 2021)、StegaStamp(Tancik et al., 2020)、PIMoG(Fang et al., 2022)、SepMark(Wu et al., 2023)和Robust-Wide(Hu et al., 2024),它们采用编码器-噪声层-解码器框架,并引入定制的噪声层以增强特定类型的鲁棒性。
扩散模型(Diffusion Models, DMs):
- Denoising Diffusion Probabilistic Models(DDPMs, Ho et al., 2020)是扩散模型的一种广泛使用的实现,需要数千次去噪步骤来生成高质量的样本。
- Denoising Diffusion Implicit Models(DDIMs, Song et al., 2021)通过引入确定性采样过程来加速采样过程,同时保持生成数据的质量。
基于潜在扩散的图像超分辨率(SR)模型:
- Latent Diffusion Models(LDMs, Rombach et al., 2022)设计用于在压缩的、低维的潜在空间中操作,通过变分自编码器(VAE)显著降低计算成本。
对抗性攻击:
- 论文还提到了基于VAE和扩散模型的适应性攻击,如Bmshj18(Ballé et al., 2018)、Cheng20(Cheng et al., 2020)、Zhao23(Zhao et al., 2023)和InstructPix2Pix(Brooks et al., 2023)。
这些相关研究构成了SuperMark方法的理论和技术支持,同时也突显了现有技术的局限性,SuperMark旨在通过其新颖的框架来克服这些挑战。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为SuperMark的新颖鲁棒且无需训练的图像水印框架来解决现有深度水印技术中存在的问题。SuperMark框架的核心思想和解决方案如下:
利用扩散模型的鲁棒性:
- 论文发现扩散模型(特别是DDIM反演过程)具有固有的对各种扰动的鲁棒性。SuperMark利用这一特性,通过DDIM反演来实现水印的鲁棒提取。
无需训练的框架:
- 与传统的基于深度学习的水印方法不同,SuperMark不需要训练编码器和解码器。相反,它使用预训练的扩散模型(特别是超分辨率模型)来执行水印的嵌入和提取,从而避免了训练过程中鲁棒性和保真度之间的权衡问题。
水印嵌入和提取的可逆性:
- SuperMark将水印信息嵌入到初始高斯噪声中,然后使用预训练的超分辨率模型对加水印的噪声进行去噪,生成最终的水印图像。对于提取过程,SuperMark通过DDIM反演将加水印的图像转换回初始加水印的噪声,并从中提取水印。
灵活性和可定制性:
- SuperMark支持各种噪声注入方法和基于扩散的超分辨率模型,允许根据需要定制性能。这种灵活性使得SuperMark可以根据不同的应用场景和需求进行调整。
高保真度:
- 通过将加水印的噪声和原始图像输入到预训练的扩散模型中,SuperMark能够生成与原始图像视觉一致的水印图像,从而保持高保真度。
跨数据集、模型和分辨率的强迁移性:
- 论文通过广泛的实验验证了SuperMark在不同数据集、超分辨率模型、水印嵌入方法和图像分辨率下的有效性,展示了其出色的迁移能力。
综上所述,SuperMark通过创新地结合扩散模型的鲁棒性和预训练的超分辨率模型,提出了一种无需训练、鲁棒且保真的图像水印框架,有效地解决了现有深度水印技术中鲁棒性和保真度之间的权衡问题。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来评估SuperMark框架的性能,包括:
数据集测试:
- 使用MS-COCO数据集作为默认数据集,并从InstructPix2Pix官方数据集中提取配对指令-图像数据进行鲁棒性测试。
- 还在DiffusionDB、WikiArt、CLIC和MetFACE等其他数据集上进行了测试,以进一步验证SuperMark的有效性。
实现细节:
- 使用SD-Upscaler作为默认的超分辨率(SR)模型,并为采样和反演应用了特定的配置。
- 对于水印注入,配置了高斯遮蔽(Gaussian Shading)方法,并设置了特定的参数以嵌入32位水印。
正常失真和适应性攻击的鲁棒性测试:
- 考虑了包括JPEG压缩、随机裁剪、高斯模糊、高斯噪声和亮度调整在内的正常失真。
- 检查了包括基于VAE的方法(如Bmshj18和Cheng20)和基于扩散的攻击(如Zhao23和InstructPix2Pix)在内的适应性攻击。
评估指标:
- 使用峰值信噪比(PSNR)和结构相似性指数(SSIM)来评估水印图像的保真度。
- 使用比特准确度(Bit Accuracy)来衡量水印提取的鲁棒性和准确性。
与基线方法的比较:
- 将SuperMark与九种开源基线方法进行了比较,包括DwtDct、DwtDctSvd、RivaGAN、StegaStamp、MBRS、CIN、PIMoG、SepMark和RoSteALS。
迁移性测试:
- 在不同的数据集上测试SuperMark的通用性。
- 使用不同的超分辨率模型(如LDM-SR)来展示SuperMark的多样性。
- 采用Tree-Ring的水印注入方法进一步评估SuperMark的迁移性。
不同分辨率的测试:
- 在不同分辨率的图像上嵌入和提取水印,以评估SuperMark在不同分辨率下的性能。
消融研究:
- 研究了低分辨率图像大小(Slow)和强度因子(fs)对水印图像保真度和提取比特准确度的影响。
- 评估了推理和反演步骤对SuperMark性能的影响。
- 探讨了嵌入不同长度的水印比特对保真度和鲁棒性的影响。
这些实验全面评估了SuperMark在各种条件下的性能,包括其对正常失真和适应性攻击的鲁棒性、不同数据集和超分辨率模型的迁移性、以及不同参数设置下的性能变化。通过这些实验,作者证明了SuperMark在保持高保真度的同时,相比现有方法具有更强的鲁棒性。
Q: 有什么可以进一步探索的点?
A: 论文提出了SuperMark这一新颖的水印框架,并展示了其在多个方面的有效性和灵活性。以下是一些可以进一步探索的点:
改进水印注入技术:
- 研究和开发新的或改进的水印注入技术,以提高SuperMark的鲁棒性,尤其是对抗更复杂的攻击和失真。
优化超分辨率模型:
- 利用更先进的超分辨率模型来提高SuperMark的保真度和鲁棒性,尤其是对于复杂和详细的图像内容。
减少推理开销:
- 探索更高效的采样方法、模型压缩和加速技术,以减少SuperMark在实际应用中的推理开销。
提高反演精度:
- 研究更精确的反演技术,以减少重构误差并提高水印提取的准确性。
跨模态水印应用:
- 探索SuperMark在视频、音频或其他类型的多媒体内容上的应用,以及如何适应这些不同模态的特点。
安全性增强:
- 研究如何增强SuperMark的安全性,例如通过加密技术保护水印信息,防止潜在的攻击者篡改或移除水印。
实时性能优化:
- 针对实时应用场景,优化SuperMark的算法和计算流程,使其能够在保持高鲁棒性的同时实现实时处理。
更广泛的攻击和失真测试:
- 对SuperMark进行更广泛的攻击和失真测试,包括物理攻击和更复杂的数字攻击,以全面评估其鲁棒性。
用户自定义和交互:
- 开发用户友好的接口和工具,允许用户根据具体需求自定义水印参数和行为,如透明度、鲁棒性级别等。
跨平台和设备兼容性:
- 研究如何使SuperMark兼容不同的操作系统和硬件平台,包括移动设备和嵌入式系统。
水印的可逆性和撤销性:
- 探索水印的可逆性,即在需要时能够完全撤销水印,同时不损害原始内容。
水印的法律和伦理问题:
- 研究与水印技术相关的法律和伦理问题,确保SuperMark的应用符合相关法律法规和道德标准。
这些探索点不仅可以推动SuperMark技术的发展,还可能为数字版权保护和内容认证领域带来新的研究方向和解决方案。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为SuperMark的鲁棒且无需训练的图像水印框架,旨在解决数字时代背景下版权保护和内容认证的挑战。以下是论文的主要内容总结:
问题背景:
- 随着AI生成内容的增加,区分真实与生成内容变得困难,需要有效的水印技术来保护和验证这些内容。
现有技术的局限性:
- 当前深度水印技术难以平衡鲁棒性和保真度,并且容易受到适应性攻击的影响。
SuperMark框架:
- 提出了SuperMark,一个新颖的水印框架,利用扩散模型的鲁棒性和预训练的超分辨率(SR)模型来实现水印的嵌入和提取。
方法论:
- SuperMark框架包括水印嵌入和提取两个阶段,无需额外训练,利用DDIM反演实现鲁棒的水印提取。
实验结果:
- 通过广泛的实验,SuperMark在不同数据集和攻击下展示了优越的鲁棒性和高保真度。
贡献:
- 论文指出了现有深度水印技术的局限性,并提出了一个简单有效的基于扩散模型的水印框架。
- SuperMark展示了对正常失真和适应性攻击的强鲁棒性,同时保持高保真度。
迁移性:
- SuperMark展示了在不同数据集、SR模型、水印注入方法和图像分辨率下的强迁移性。
未来工作:
- 提出了未来可能的研究方向,包括改进水印注入技术、优化超分辨率模型、减少推理开销等。
总体而言,SuperMark通过其创新的框架和方法,在图像水印领域提供了一个有效的解决方案,以应对AI生成内容带来的挑战。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

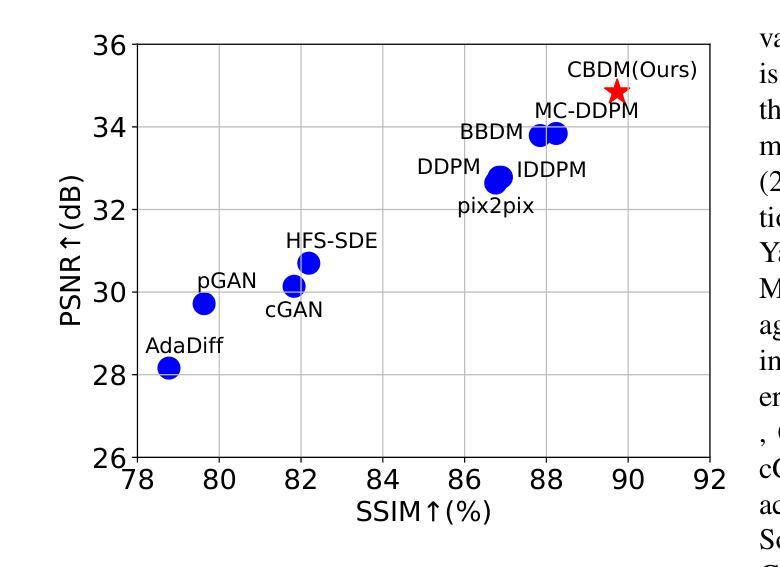
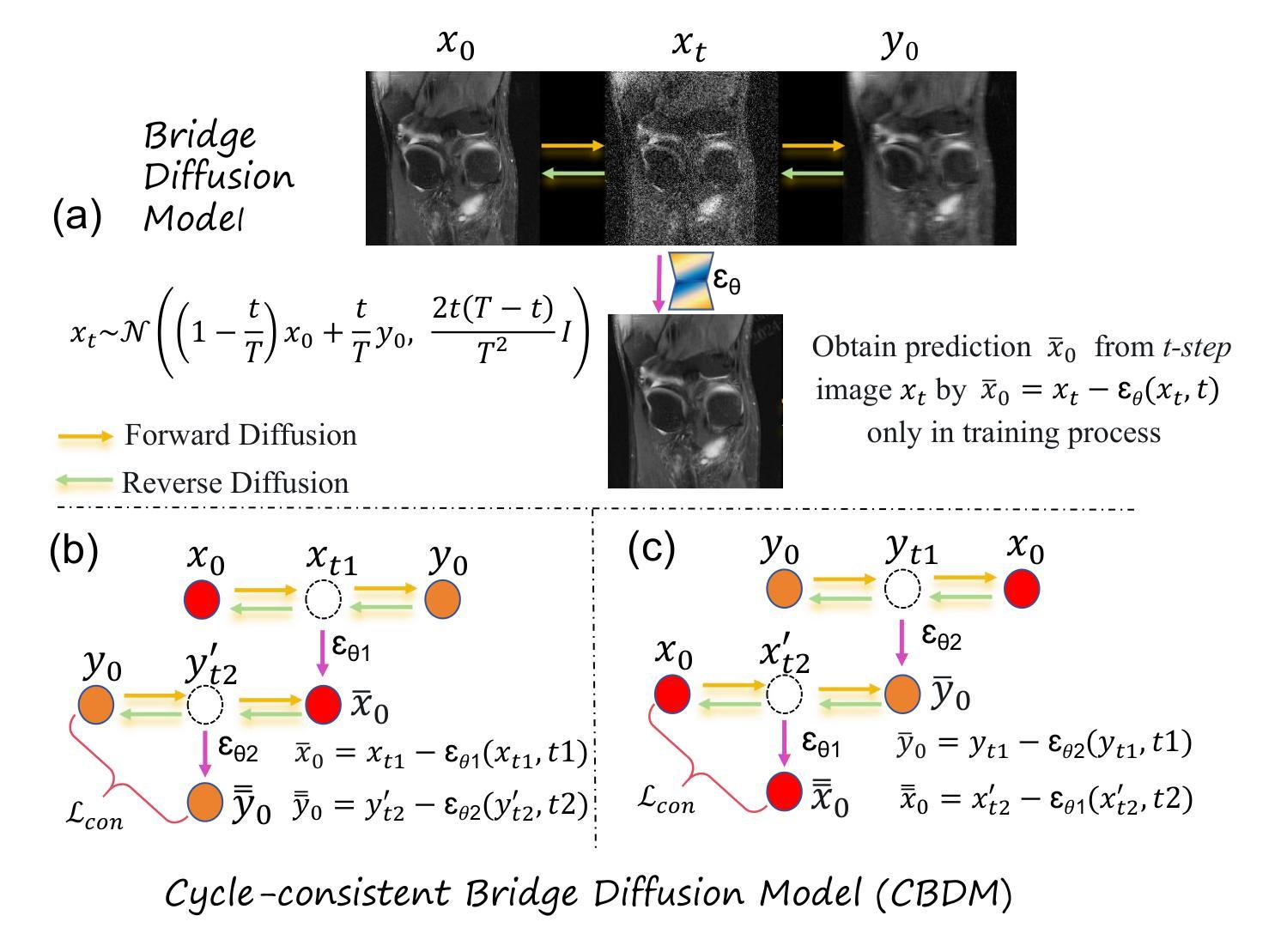
Cycle-Consistent Bridge Diffusion Model for Accelerated MRI Reconstruction
Authors:Tao Song, Yicheng Wu, Minhao Hu, Xiangde Luo, Guoting Luo, Guotai Wang, Yi Guo, Feng Xu, Shaoting Zhang
Accelerated MRI reconstruction techniques aim to reduce examination time while maintaining high image fidelity, which is highly desirable in clinical settings for improving patient comfort and hospital efficiency. Existing deep learning methods typically reconstruct images from under-sampled data with traditional reconstruction approaches, but they still struggle to provide high-fidelity results. Diffusion models show great potential to improve fidelity of generated images in recent years. However, their inference process starting with a random Gaussian noise introduces instability into the results and usually requires thousands of sampling steps, resulting in sub-optimal reconstruction quality and low efficiency. To address these challenges, we propose Cycle-Consistent Bridge Diffusion Model (CBDM). CBDM employs two bridge diffusion models to construct a cycle-consistent diffusion process with a consistency loss, enhancing the fine-grained details of reconstructed images and reducing the number of diffusion steps. Moreover, CBDM incorporates a Contourlet Decomposition Embedding Module (CDEM) which captures multi-scale structural texture knowledge in images through frequency domain decomposition pyramids and directional filter banks to improve structural fidelity. Extensive experiments demonstrate the superiority of our model by higher reconstruction quality and fewer training iterations, achieving a new state of the art for accelerated MRI reconstruction in both fastMRI and IXI datasets.
加速MRI重建技术旨在减少检查时间,同时保持高图像保真度,这在临床环境中对于改善患者舒适度和医院效率都非常理想。现有的深度学习方法通常使用传统重建方法对欠采样数据进行图像重建,但它们仍难以提供高保真结果。近年来,扩散模型在提高生成图像的保真度方面显示出巨大潜力。然而,它们的推理过程从随机高斯噪声开始,会导致结果不稳定,通常需要数千个采样步骤,从而导致重建质量不佳和效率低下。为了解决这些挑战,我们提出了循环一致桥梁扩散模型(CBDM)。CBDM采用两个桥梁扩散模型来构建一个循环一致的扩散过程,并使用一致性损失来增强重建图像的细节并减少扩散步骤的数量。此外,CBDM结合了轮廓分解嵌入模块(CDEM),通过频率域分解金字塔和方向滤波器库捕获图像的多尺度结构纹理知识,以提高结构保真度。大量实验表明,我们的模型在更高的重建质量和更少的训练迭代次数方面具有优越性,在fastMRI和IXI数据集上的加速MRI重建方面达到了最新的技术水平。
论文及项目相关链接
Summary
本文介绍了加速MRI重建技术及其面临的挑战。现有的深度学习方法在重建图像时通常使用传统的重建方法,但仍难以提供高保真结果。本文提出了一个名为Cycle-Consistent Bridge Diffusion Model(CBDM)的新模型,它通过两个桥扩散模型构建一个循环一致的扩散过程,并引入一致性损失来提高重建图像的细节和减少扩散步骤数量。此外,CBDM结合了Contourlet Decomposition Embedding Module(CDEM),通过频率域分解金字塔和方向滤波器库捕捉图像的多尺度结构纹理知识,以提高结构保真度。实验证明,该模型在fastMRI和IXI数据集上的重建质量更高,训练迭代次数更少,实现了加速MRI重建的最新技术。
Key Takeaways
以下是本文的主要见解:
- 加速MRI重建技术旨在减少检查时间并保持高图像保真度,对于改善患者舒适度和医院效率具有重要意义。
- 现有的深度学习方法在重建图像时仍面临高保真结果的挑战。
- Cycle-Consistent Bridge Diffusion Model(CBDM)通过引入一致性损失和两个桥扩散模型,提高了重建图像的细节和减少了扩散步骤数量。
- CBDM结合了Contourlet Decomposition Embedding Module(CDEM),以提高结构保真度。
- CBDM模型在MRI重建中表现出优异的性能,实现了更高的重建质量和更少的训练迭代次数。
- 该模型在fastMRI和IXI数据集上达到了最新的加速MRI重建技术。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是加速磁共振成像(MRI)重建。具体来说,论文旨在减少MRI检查时间的同时保持高图像保真度,这在临床设置中非常有用,因为它可以提高病人的舒适度和医院的效率。论文指出,尽管现有的深度学习方法通常可以从欠采样数据中重建图像,并与传统重建方法结合使用,但它们仍然难以提供高保真度的结果。此外,扩散模型近年来显示出在提高生成图像保真度方面的巨大潜力,但其推理过程从随机高斯噪声开始,导致结果不稳定,并且通常需要数千个采样步骤,导致重建质量次优和效率低下。因此,论文提出了一种循环一致的桥扩散模型(Cycle-Consistent Bridge Diffusion Model, CBDM),旨在解决这些挑战。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个方面:
加速MRI重建的传统方法:
- **Sensitivity Encoding (SENSE)**:利用多个接收线圈的空间敏感性,通过减少采集时间来实现快速成像。
- **Generalized Autocalibrating Partially Parallel Acquisitions (GRAPPA)**:通过基于核的插值估计缺失的k空间数据,从而重建欠采样数据,提高图像质量并减少与并行成像技术相关的伪影。
深度学习在加速MRI重建中的应用:
- 结合深度学习和并行成像算法的方法,例如将深度学习与GRAPPA重建算法结合。
- 将迭代收缩阈值算法(ISTA)转化为深度神经网络,优化压缩感知(CS)以加速MRI重建。
- 使用对抗神经网络生成缺失的k空间数据。
生成对抗网络(GANs)在MRI重建中的应用:
- 提出了多种基于GAN的方法,以提高MRI重建的生成性能。
扩散模型在加速MRI重建中的应用:
- 近年来,扩散模型因其在图像生成方面的高性能而被广泛应用于加速MRI重建。
- 从无条件到条件扩散模型,再到基于先验的条件扩散模型的发展。
桥扩散模型:
- 桥扩散模型被提出用于图像翻译任务,扩散过程在成对图像之间构建,从确定性图像(无噪声)开始的逆向扩散使得采样过程更加稳定。
这些相关研究构成了论文提出的循环一致桥扩散模型(CBDM)的理论基础和技术支持。论文通过结合这些相关技术,旨在提高MRI重建的速度和质量。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为循环一致桥扩散模型(Cycle-Consistent Bridge Diffusion Model, CBDM)的方法来解决加速MRI重建的问题。具体解决方案包括以下几个关键点:
循环一致桥扩散模型(CBDM):
- 利用两个桥扩散模型构建循环一致的扩散过程,并引入一致性损失(consistency loss),以增强重建图像的细节,并减少扩散步骤的数量。
桥扩散模型:
- 该模型在两个确定性图像之间进行扩散过程,并且有明确的保证能够产生所需的条件分布,而不是仅依赖于条件图像。
轮廓分解嵌入模块(Contourlet Decomposition Embedding Module, CDEM):
- 通过频域分解金字塔和方向滤波器组捕捉图像中的多尺度结构纹理知识,以提高结构保真度。
- 利用迭代拉普拉斯金字塔和方向滤波器组从每个时间步的图像中提取结构纹理知识,并将其整合到去噪网络中,从而增强网络捕获结构纹理的能力。
实验验证:
- 在fastMRI和IXI数据集上进行了广泛的实验,证明了所提出模型的有效性,特别是在保持高重建质量和减少训练迭代次数方面达到了新的最佳水平。
具体技术实现:
- 论文详细描述了CBDM的框架,包括两个桥扩散模型用于x ← y和y ← x的转换,以及如何通过循环一致性损失来训练模型。
- 提出了一种基于轮廓分解的方法来显式考虑MRI图像的结构纹理知识,以解决欠采样和全采样MR图像之间由于高频成分缺失而引起的结构模糊和伪影问题。
通过这些方法,论文成功地提高了加速MRI重建的效率和图像质量,同时减少了模型训练和推理过程中的时间步骤,提高了临床部署的可行性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的循环一致桥扩散模型(CBDM)的有效性。具体的实验包括:
数据和实现细节:
- 实验在公共基准数据集fastMRI和IXI上进行。
- 从fastMRI数据集中选择了360名个体的多线圈膝盖数据集用于训练,8名用于验证,20名用于测试。
- 从IXI数据集中选择了577名患者的T1图像,随机分为训练(500名患者,44,935个2D图像)、验证(37名患者,3,330个图像)和测试(40名患者,3,600个图像)集。
- 所有图像被裁剪到特定尺寸并归一化到[0, 1]范围内。
- 应用等间距的笛卡尔欠采样,并设置了加速因子为4和8。
训练细节:
- 总迭代次数设置为200k,使用AdamW优化器,学习率为1e-4,批量大小为28。
- 对于CBDM,训练和采样步骤都设置为20,损失权重λ设置为1。
比较方法:
- 将CBDM与多种现有的方法进行比较,包括pGAN、cGAN、pix2pix、DDPM、IDDPM、AdaDiff、MC-DDPM、HFS-SDE和BBDM。
评价指标:
- 使用峰值信噪比(PSNR)、结构相似性指数(SSIM)和归一化均方误差(NMSE)来衡量重建质量。
分布内结果:
- 在fastMRI膝盖数据集和IXI数据集上,CBDM在所有评价指标上均优于其他方法。
分布外结果:
- 进行了分布外实验以验证模型的泛化能力。所有模型在fastMRI膝盖数据上训练,并在fastMRI脑部MRI扫描上进行测试。
- CBDM在脑部数据重建上实现了最佳性能。
推理效率:
- 比较了CBDM和其他扩散方法的推理效率,CBDM由于较少的采样步骤,具有更高的推理效率。
消融研究:
- 对CBDM的不同组件进行了消融研究,包括循环一致性和CDEM的有效性。
- 探讨了在训练过程中t1和t2的不同设置,以及不同噪声方差设置对模型性能的影响。
限制:
- 论文讨论了CBDM的局限性,包括训练过程中需要两个桥扩散模型同时训练可能带来的更高的训练成本,以及分布外实验中性能的下降。
这些实验全面地评估了CBDM在加速MRI重建任务中的表现,并与现有技术进行了比较,证明了其优越性和潜在的临床应用价值。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
降低训练成本:
- 论文提到,虽然循环一致的设计增强了图像表示,但训练过程需要同时训练两个桥扩散模型,这可能带来更高的训练成本。未来的工作可以探索如何减少模型训练的成本,例如通过设计更高效的网络架构或优化训练策略。
提高模型泛化能力:
- 论文中的分布外实验显示,模型的性能在新的分布上有所下降。未来的研究可以集中在提高模型的泛化能力上,使其能够更好地适应不同的数据分布和MRI扫描类型。
改进噪声方差设置:
- 论文中的消融实验表明,不同的噪声方差设置对模型性能有影响。可以进一步研究如何动态调整噪声方差,以提高模型的灵活性和适应性。
优化采样步骤:
- 尽管CBDM通过减少采样步骤提高了推理效率,但进一步优化采样过程,使其在更少的步骤下达到更好的重建效果,仍然是一个有价值的研究方向。
多模态和多对比度MRI重建:
- 扩展CBDM模型以处理多模态和多对比度MRI数据,这可能需要模型能够捕捉不同成像模式之间的复杂关系。
临床验证和评估:
- 在临床环境中对模型进行验证和评估,以确定其实际应用的可行性和效果,这可能包括与临床医生合作,以及在更大的、多样化的患者群体上进行测试。
模型解释性:
- 提高模型的可解释性,帮助临床医生理解模型的决策过程,增加模型在临床应用中的可信度。
跨中心和跨设备的数据融合:
- 探索如何将CBDM模型应用于跨中心和跨设备的数据融合问题,以提高MRI重建的鲁棒性。
结合其他成像技术:
- 研究如何将CBDM与CT、PET等其他成像技术结合,以提供更全面的诊断信息。
这些探索点可以帮助推动加速MRI重建技术的发展,并最终实现更好的临床应用。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
问题陈述:
- 论文针对加速磁共振成像(MRI)重建的问题,旨在减少MRI扫描时间同时保持图像质量,以提高临床舒适度和医院效率。
现有挑战:
- 现有深度学习方法在欠采样数据重建上存在局限性,扩散模型虽有潜力但存在推理不稳定和效率低下的问题。
方法提出:
- 提出循环一致桥扩散模型(CBDM),通过两个桥扩散模型建立循环一致的扩散过程,并引入一致性损失,以增强图像细节并减少扩散步骤。
技术创新:
- 引入轮廓分解嵌入模块(CDEM),通过频域分解捕捉图像的多尺度结构纹理知识,提高结构保真度。
实验验证:
- 在fastMRI和IXI数据集上进行广泛实验,证明了CBDM在重建质量和训练迭代次数上的优势。
结果展示:
- CBDM在多个评价指标上优于现有方法,包括PSNR、SSIM和NMSE,并在分布内外测试中展现了良好的泛化能力。
效率比较:
- CBDM展示了更高的推理效率,相比其他方法大大减少了采样步骤,同时保持了高性能。
消融研究:
- 通过消融研究验证了循环一致性和CDEM设计的有效性,并探讨了不同训练设置对模型性能的影响。
局限性与未来工作:
- 论文讨论了CBDM的局限性,包括训练成本和泛化能力,并提出了未来探索的方向,如降低训练成本和提高模型泛化能力。
结论:
- CBDM通过循环一致性和轮廓分解嵌入模块有效地恢复了MR图像的正常人体结构和纹理细节,并在基准数据集上实现了最先进的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
- CBDM通过循环一致性和轮廓分解嵌入模块有效地恢复了MR图像的正常人体结构和纹理细节,并在基准数据集上实现了最先进的性能。
点此查看论文截图


EP-CFG: Energy-Preserving Classifier-Free Guidance
Authors:Kai Zhang, Fujun Luan, Sai Bi, Jianming Zhang
Classifier-free guidance (CFG) is widely used in diffusion models but often introduces over-contrast and over-saturation artifacts at higher guidance strengths. We present EP-CFG (Energy-Preserving Classifier-Free Guidance), which addresses these issues by preserving the energy distribution of the conditional prediction during the guidance process. Our method simply rescales the energy of the guided output to match that of the conditional prediction at each denoising step, with an optional robust variant for improved artifact suppression. Through experiments, we show that EP-CFG maintains natural image quality and preserves details across guidance strengths while retaining CFG’s semantic alignment benefits, all with minimal computational overhead.
无分类器引导(CFG)在扩散模型中广泛应用,但在较高的引导强度下通常会引入过度对比和过度饱和的伪影。我们提出了能量保持无分类器引导(EP-CFG),通过保留指导过程中的条件预测的能量的分布来解决这些问题。我们的方法简单地将引导输出的能量重新缩放,以匹配每个降噪步骤中的条件预测能量,并且还有一个可选的稳健变体,用于改善伪影抑制。通过实验,我们证明了EP-CFG在保持自然图像质量的同时,能够在不同的引导强度下保留细节,同时保留CFG的语义对齐优势,且计算开销最小。
论文及项目相关链接
Summary:
扩散模型中广泛应用Classifier-free guidance(CFG),但在较高指导强度下常出现过度对比度和过度饱和的伪影问题。本研究提出EP-CFG(Energy-Preserving Classifier-Free Guidance),在指导过程中保留条件预测的能量分布以解决这些问题。该方法通过重新调整引导输出的能量,使其在每个去噪步骤中与条件预测的能量相匹配,并有一个可选的稳健变种以提高伪影抑制效果。实验表明,EP-CFG在保持自然图像质量的同时,能够在不同的指导强度下保留细节,并保留CFG的语义对齐优势,且计算开销较小。
Key Takeaways:
- 扩散模型中广泛应用Classifier-free guidance(CFG),但在高指导强度下存在伪影问题。
- EP-CFG旨在解决CFG在较高指导强度下的过度对比度和过度饱和伪影问题。
- EP-CFG通过保留条件预测的能理分布来优化指导过程。
- 方法重新调整引导输出的能量,使其在每个去噪步骤中与条件预测相匹配。
- EP-CFG提供了一个可选的稳健变种以提高伪影抑制效果。
- 实验表明,EP-CFG在保持图像自然质量的同时,能够在不同指导强度下保留细节。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是,在扩散模型中使用分类器无关引导(Classifier-free guidance, CFG)进行文本引导生成时,常出现的过度对比度和过饱和现象。具体来说,CFG方法虽然能够增强语义对齐和结构一致性,但当CFG强度较高时,会导致生成的图像出现过度对比度和过饱和的伪影。论文提出了一种名为EP-CFG(Energy-Preserving Classifier-Free Guidance)的方法,旨在在保持CFG引导的强语义对齐的同时,通过调整能量分布来避免这些问题。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是与EP-CFG相关的研究:
分类器无关引导(CFG):
- Ho & Salimans (2022) 提出了分类器无关引导(CFG)的概念,这是一种在扩散模型中用于文本引导生成的技术。[Ho & Salimans, 2022]
扩散模型:
- Ho et al. (2020) 和 Song et al. (2020) 进行了扩散模型的研究,这些模型是CFG方法的基础。[Ho et al., 2020; Song et al., 2020]
高CFG强度问题:
- 论文中提到,现代文本到图像模型中CFG强度通常设置在7-10之间以生成高质量的视觉内容,但这样的高强度会导致过度对比度和过饱和伪影。[Rombach et al., 2022]
解决过饱和问题的方法:
- Sadat et al. (2024) 提出了APG(可能是另一种方法)来通过更新项分解解决过饱和问题。[Sadat et al., 2024]
扩散噪声计划和样本步数的研究:
- Lin et al. (2024) 对扩散噪声计划和样本步数进行了研究,并指出常见的扩散噪声计划和样本步数存在问题。[Lin et al., 2024]
高分辨率图像合成:
- Rombach et al. (2022) 研究了使用潜在扩散模型进行高分辨率图像合成的方法。[Rombach et al., 2022]
这些研究构成了EP-CFG方法的理论和实践基础,并与EP-CFG试图解决的问题直接相关。论文通过引用这些相关研究,展示了其在现有研究基础上的创新和改进。
Q: 论文如何解决这个问题?
A: 论文提出了一种名为EP-CFG(Energy-Preserving Classifier-Free Guidance)的方法来解决扩散模型中使用CFG时出现的过度对比度和过饱和问题。具体解决方案如下:
能量重缩放机制:
- 论文提出了一个能量重缩放机制,用于调整CFG预测的能量分布,使其与条件预测的能量分布相匹配。具体地,对于给定的无条件预测(x_u)和条件预测(x_c),CFG预测(x_{cfg})由下式给出:
[
x_{cfg} = x_c + (λ - 1)(x_c - x_u)
]
其中,(λ \geq 1)是CFG强度。EP-CFG通过以下方式调整(x_{cfg})的能量:
[
x’{cfg} = x{cfg} \cdot \frac{E_c}{E_{cfg}}
]
其中,(E_c = |x_c|^2)和(E_{cfg} = |x_{cfg}|^2)分别表示条件预测和CFG预测的能量。
- 论文提出了一个能量重缩放机制,用于调整CFG预测的能量分布,使其与条件预测的能量分布相匹配。具体地,对于给定的无条件预测(x_u)和条件预测(x_c),CFG预测(x_{cfg})由下式给出:
鲁棒能量估计:
- 为了增强算法的鲁棒性,论文提出了一种鲁棒能量估计方法,通过忽略能量直方图的两个尾部,只考虑中间区域来估计能量项(E_c)和(E_{cfg})。具体地,设(P_l)和(P_h)为潜在(x)的第(l)和第(h)百分位数,则鲁棒能量为:
[
E_{robust} = \sum_i x_i^2 \cdot 1[P_l \leq x_i^2 \leq P_h]
]
论文推荐使用(l = 45)和(h = 55)作为百分位数,因为这种设置在实验中表现最佳。
- 为了增强算法的鲁棒性,论文提出了一种鲁棒能量估计方法,通过忽略能量直方图的两个尾部,只考虑中间区域来估计能量项(E_c)和(E_{cfg})。具体地,设(P_l)和(P_h)为潜在(x)的第(l)和第(h)百分位数,则鲁棒能量为:
简化的公式和信息保留:
- EP-CFG与先前解决方案的主要区别在于:它基于能量而不是标准差来缩放CFG预测,并且不在使用CFG和条件预测之间进行插值。因此,其公式更简单,更好地保留了CFG预测的信息。
通过这些方法,EP-CFG能够在保持CFG引导的强语义对齐的同时,避免过度对比度和过饱和伪影,从而生成更自然、质量更高的图像。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了一系列的实验来展示EP-CFG(Energy-Preserving Classifier-Free Guidance)方法在不同CFG(Classifier-free guidance)强度下的效果。以下是实验的具体内容:
不同CFG强度下的图像生成对比:
- 作者展示了在不同CFG强度(5, 7, 9, 12)下,有无EP-CFG时生成的图像对比。这些图像展示了EP-CFG在保持图像自然质量的同时,如何有效地避免了过饱和和对比度过高的问题。
具体场景的图像生成:
- 作者提供了多个具体的场景描述(prompts),并展示了在这些场景下,有无EP-CFG时生成的图像。这些场景包括:
- 宇航员在里约热内卢的小巷中奔跑
- 摩托车在魔法森林中高速行驶并进入一个洞穴,洞穴内部是纽约市
- 中国农历新年庆祝活动,有中国龙
- 花朵从郊区房屋的窗台上生长出来
- 马在梵高的《星夜》中奔腾
- 东方快车在幻想风景中行驶,画布上的油画
- 装饰华丽的宴会厅,内有金色和银色餐具、水晶吊灯、丝绸窗帘
- 中等侧脸肖像照片,扮演部落豹妆的武田信宏
- 有“Adobe”字样底座的大理石历史女神克利奥雕像
- 一个IT人员被电脑电缆缠绕,类似于拉奥孔雕像
- 从地面视角看,一条通往涂鸦覆盖的城市隧道的道路,背景中有摩天大楼
- 作者提供了多个具体的场景描述(prompts),并展示了在这些场景下,有无EP-CFG时生成的图像。这些场景包括:
图像质量评估:
- 通过视觉比较有无EP-CFG的生成结果,作者展示了EP-CFG如何在不同CFG强度下保持图像质量,特别是在背景、细节和整体自然度方面。
这些实验结果表明,EP-CFG能够有效地在保持CFG引导的强语义对齐的同时,减少过度对比度和过饱和伪影,从而在各种场景下生成更自然和高质量的图像。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了EP-CFG方法来解决扩散模型中CFG的过度对比度和过饱和问题,但仍有一些方向可以进一步探索和研究:
不同场景和数据集的验证:
- 论文中的实验主要基于特定的场景描述和图像生成任务。进一步的研究可以在更广泛的数据集和不同类型的图像生成任务上验证EP-CFG的效果,以评估其泛化能力和适用性。
定量评估指标:
- 论文主要通过视觉对比来展示EP-CFG的效果。未来工作可以引入更多的定量评估指标,如峰值信噪比(PSNR)、结构相似性指数(SSIM)和多尺度结构相似性(MS-SSIM)等,来更客观地评估图像质量。
不同CFG强度的优化:
- 论文中提到CFG强度通常设置在7-10之间以生成高质量的视觉内容。研究可以进一步探索不同CFG强度对图像质量的具体影响,并尝试自动调整CFG强度以获得最优的图像质量。
与其他技术的结合:
- 考虑将EP-CFG与其他图像生成技术(如GANs、VAEs等)结合,探索其在混合模型中的表现和潜在的改进。
计算效率和实时性:
- 研究EP-CFG方法的计算效率和实时性,特别是在资源受限的设备上,这对于实际应用非常重要。
更深入的理论研究:
- 对EP-CFG中的能量重缩放机制进行更深入的理论分析,探讨其对图像生成过程的影响,以及是否存在更优的能量调整策略。
用户研究和反馈:
- 进行用户研究,收集用户对使用EP-CFG生成的图像的反馈,以了解用户偏好并进一步优化算法。
多模态应用:
- 探索EP-CFG在多模态任务(如图像到图像翻译、文本到视频生成等)中的应用,评估其在这些任务中的有效性和挑战。
模型泛化性和鲁棒性:
- 研究EP-CFG在面对对抗性攻击、数据分布偏移等情况下的鲁棒性,以及如何提高模型的泛化能力。
这些方向不仅可以推动图像生成技术的发展,还可能为其他领域的研究提供新的视角和方法。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
论文指出,在扩散模型中使用分类器无关引导(CFG)进行文本引导生成时,高CFG强度会导致过度对比度和过饱和的伪影问题。EP-CFG方法提出:
为了解决上述问题,论文提出了一种名为EP-CFG(Energy-Preserving Classifier-Free Guidance)的方法。该方法通过调整CFG预测的能量分布来匹配条件预测的能量,从而在保持CFG引导的强语义对齐的同时,避免了过度对比度和过饱和伪影。能量重缩放机制:
EP-CFG的核心是能量重缩放机制,通过以下公式调整CFG预测的能量:
[
x’{cfg} = x{cfg} \cdot \frac{E_c}{E_{cfg}}
]
其中,(E_c)和(E_{cfg})分别表示条件预测和CFG预测的能量。鲁棒能量估计:
为了增强算法的鲁棒性,论文提出了一种鲁棒能量估计方法,通过忽略能量直方图的两个尾部,只考虑中间区域来估计能量项。实验验证:
论文通过一系列实验,展示了在不同CFG强度下,有无EP-CFG时生成的图像对比。实验结果表明,EP-CFG能够在保持CFG引导的强语义对齐的同时,减少过度对比度和过饱和伪影,从而生成更自然和高质量的图像。进一步探索的方向:
论文还提出了一些可以进一步探索的方向,如在不同场景和数据集上验证EP-CFG的效果、引入定量评估指标、探索不同CFG强度的优化、与其他技术的结合等。
总的来说,这篇论文针对扩散模型中CFG引导的过度对比度和过饱和问题,提出了一种有效的解决方案EP-CFG,并通过对比其他CFG强度下的图像生成结果,验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图






Generating 3D Pseudo-Healthy Knee MR Images to Support Trochleoplasty Planning
Authors:Michael Wehrli, Alicia Durrer, Paul Friedrich, Volodimir Buchakchiyskiy, Marcus Mumme, Edwin Li, Gyozo Lehoczky, Carol C. Hasler, Philippe C. Cattin
Purpose: Trochlear Dysplasia (TD) is a common malformation in adolescents, leading to anterior knee pain and instability. Surgical interventions such as trochleoplasty require precise planning to correct the trochlear groove. However, no standardized preoperative plan exists to guide surgeons in reshaping the femur. This study aims to generate patient-specific, pseudo-healthy MR images of the trochlear region that should theoretically align with the respective patient’s patella, potentially supporting the pre-operative planning of trochleoplasty. Methods: We employ a Wavelet Diffusion Model (WDM) to generate personalized pseudo-healthy, anatomically plausible MR scans of the trochlear region. We train our model using knee MR scans of healthy subjects. During inference, we mask out pathological regions around the patella in scans of patients affected by TD, and replace them with their pseudo-healthy counterpart. An orthopedic surgeon measured the sulcus angle (SA), trochlear groove depth (TGD) and D'ejour classification in MR scans before and after inpainting. The code is available at https://github.com/wehrlimi/Generate-Pseudo-Healthy-Knee-MRI . Results: The inpainting by our model significantly improves the SA, TGD and D'ejour classification in a study with 49 knee MR scans. Conclusion: This study demonstrates the potential of WDMs in providing surgeons with patient-specific guidance. By offering anatomically plausible MR scans, the method could potentially enhance the precision and preoperative planning of trochleoplasty, and pave the way to more minimally invasive surgeries.
目的:股骨髁发育不良(TD)是青少年常见的畸形,会导致膝关节前方疼痛和不稳定。像槽状成形术这样的手术干预需要精确的计划来纠正髁间凹。然而,目前尚无标准化的术前计划来指导外科医生重塑股骨。本研究旨在生成患者特定的假健康MR图像,理论上应与患者相应的膝盖髌骨相对应,这可能支持槽状成形术的术前规划。方法:我们使用小波扩散模型(WDM)来生成个性化的假健康、解剖上合理的髁部MR扫描图像。我们使用健康受试者的膝关节MR扫描图像来训练我们的模型。在推理过程中,我们掩盖了受TD影响的患者的膝盖髌骨周围的病理区域,并用他们的假健康对应物进行替换。骨科医生测量了MR扫描中的髁间角(SA)、髁间凹深度(TGD)和D’ejour分类,分别在修复前和修复后进行。代码可在https://github.com/wehrlimi/Generate-Pseudo-Healthy-Knee-MRI找到。结果:我们的模型的修复技术显著改善了49例膝关节MR扫描中的SA、TGD和D'ejour分类。结论:本研究展示了WDM在为外科医生提供患者特定指导方面的潜力。通过提供解剖上合理的MR扫描图像,该方法可能会提高槽状成形术的精度和术前规划,并为更微创的手术铺平道路。
论文及项目相关链接
PDF Early accepted at IPCAI 2025. Code: https://github.com/wehrlimi/Generate-Pseudo-Healthy-Knee-MRI
Summary:
本文旨在解决股骨发育异常(Trochlear Dysplasia,简称TD)的问题,利用Wavelet Diffusion Model(WDM)生成个性化的虚拟健康MRI扫描图像,帮助医生进行术前规划。通过对患者膝关节MRI扫描中的病变区域进行修复,改善患者的股骨沟形态,从而提高手术精度和术前规划。
Key Takeaways:
- 目的:研究旨在利用Wavelet Diffusion Model生成个性化的虚拟健康MRI图像,为患者特定股骨手术提供术前指导。
- 方法:使用健康主体的膝盖MRI扫描数据训练模型,对受影响患者的病变区域进行修复,生成虚拟健康的MRI图像。
- 结果:通过模型修复,明显改善了患者的股骨沟角度、深度和D’ejour分类。
- 应用:该方法为医生提供了个性化的指导,增强了手术精度和术前规划。
- 代码公开:研究代码已公开在GitHub上供查阅和使用。
- 模型潜力:WDM模型在提供个性化患者指导方面具有潜力,可推动更微创手术的发展。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是青少年中常见的骨骼畸形——股骨滑车发育不良(Trochlear Dysplasia, TD),它会导致前膝疼痛和不稳定。手术治疗,如滑车成形术(trochleoplasty),需要精确的规划来纠正滑车沟的形状。然而,目前不存在标准化的术前规划来指导外科医生重塑股骨。因此,这项研究的目标是生成患者特定的、伪健康的磁共振(MR)图像,这些图像理论上应与相应患者的髌骨对齐,可能支持滑车成形术的术前规划。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与研究相关的工作:
Barbosa et al. [15]: 提出了一种深度学习方法来检测TD的膝部标志点。
Fang et al. [16]: 提出了一个详细的术前患者特定计划,例如在正颌外科手术中的应用。
Van Haver et al. [17]: 使用统计形状建模来可视化滑车的异常,但尚未提供明确的矫正计划。
Durrer et al. [19]: 利用去噪扩散模型进行3D健康脑组织修复。
Friedrich et al. [20]: 提出了3D小波扩散模型(WDM),用于高分辨率医学图像合成。
Gu et al. [21]: 提出了一个通用模型SegmentAnyBone,用于在MRI上分割任何位置的任何骨骼。
这些研究为本文提出的使用Wavelet Diffusion Model (WDM)生成伪健康MR图像以支持滑车成形术规划的方法提供了理论基础和技术背景。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决股骨滑车发育不良(TD)的术前规划问题:
方法概述:
- 提出一种方法,生成伪健康MR图像,恢复滑车形状,同时根据患者独特的髌骨情况进行调整。
前景-背景分割和遮罩:
- 使用Otsu阈值分割、形态学开闭操作和最大连通组件提取来分割背景。
- 使用SegmentAnyBone工具进行骨骼分割,并基于此分割结果定位髌骨。
- 创建一个围绕髌骨的“碗”形遮罩,用于后续的图像修复。
去噪扩散概率模型(DDPMs):
- 利用DDPMs的迭代前向过程添加噪声,将输入图像转换为标准正态分布。
- 学习逆过程以尝试去除添加的噪声,该过程由神经网络参数化。
小波变换:
- 使用离散小波变换(DWT)分解图像到多个频率带,有效处理低频和高频成分。
- 利用逆离散小波变换(IDWT)重建原始图像。
DDPMs的修改用于图像修复训练过程:
- 修改逆过程,将遮罩图像的DWT和小波变换的遮罩作为条件输入。
- 网络学习在小波域内重建图像,然后通过IDWT回到原始表示域以获得修复后的图像。
实验:
- 使用fastMRI数据集进行训练,使用来自Basel大学儿童医院的TD患者MR图像进行评估。
- 对比修复前后的MR图像,使用已知的TD评估指标,包括滑车角(SA)、滑车沟深度(TGD)和D´ejour分类。
结果:
- 修复后的图像在TD的严重程度上表现出减少,允许更精确的术前规划。
- 通过图像质量评估指标(MSE、PSNR和SSIM)验证了生成图像的质量。
结论:
- 提出的方法能够生成适合个体患者的伪健康3D MR图像,有助于外科医生在滑车成形术的术前规划中做出更明智的决策。
该方法通过结合先进的图像处理技术和机器学习模型,提供了一种新的术前规划辅助工具,旨在提高手术的精确性和患者治疗效果。
Q: 论文做了哪些实验?
A: 论文中进行的实验包括:
数据集准备:
- 使用公开可用的fastMRI数据集进行模型训练,包含10,012个膝盖图像。
- 从这些数据中筛选出1,579个符合特定条件(PD AXIAL F/S或PD AXIAL FAT SAT)的序列。
- 将这些数据分为训练集(80%,1,181个独立患者,1,216个体积)和测试集(20%,296个独立患者,302个体积)。
伦理批准声明:
- 来自Basel大学儿童医院的数据集被匿名化,并获得了Ethikkommission Nordwest- und Zentralschweiz的豁免。
预处理:
- 将PD脂肪饱和序列的体素大小标准化为(0.6mm, 0.6mm, 4.5mm)。
- 将所有图像调整为固定大小(256, 256, 32)体素。
- 裁剪、填充和强度归一化。
诊断评估标准:
- 使用49个TD患者的膝盖MR扫描图像,在修复前后基于已知指标(滑车角SA、滑车沟深度TGD和D´ejour分类)进行比较。
- 由一名骨科副主治医师使用3D Slicer软件进行测量。
图像质量评估指标:
- 在fastMRI测试集图像上评估生成的修复图像,使用均方误差(MSE)、峰值信噪比(PSNR)和结构相似性指数(SSIM)。
- 所有评分仅计算图像的遮罩区域。
实现细节:
- 描述了使用的超参数设置,并指出实验在单个NVIDIA A100 (40 GB) GPU上进行,平均推理时间为45秒,内存占用为3.81 GB。
结果分析:
- 对49个病理性MR扫描图像进行分析,其中41个在D´ejour分类中显示出TD严重程度的降低。
- 在修复后,33个原本无法测量SA和TGD的扫描图像中,有46个能够测量SA和TGD。
- 使用Wilcoxon符号秩检验,发现SA和TGD在修复后都有显著改善。
这些实验验证了所提出方法的有效性,并展示了其在改善TD诊断和术前规划中的潜力。
Q: 有什么可以进一步探索的点?
A: 论文提出的方法虽然显示出潜力,但仍有一些可以进一步探索和改进的地方:
扩大和多样化训练数据库:
- 目前的模型可能受到fastMRI数据集的偏差影响。通过纳入更广泛和多样化的患者群体,特别是年轻患者,可以提高模型的泛化能力。
数据增强技术:
- 利用数据增强技术,如图像旋转、缩放、剪切等,可以增加模型训练的样本多样性,提高模型对不同患者解剖结构的适应性。
模型的可解释性和透明度:
- 研究模型的决策过程,提供更多关于模型如何学习和重建健康组织的信息,增加模型的可解释性。
交互式图像编辑工具:
- 开发允许外科医生在术前手动调整生成图像的工具,例如在虚拟现实中重新定位脱位的髌骨,以适应更复杂的病例。
多模态数据融合:
- 探索结合其他成像模式(如CT、X光)的数据,以提供更全面的解剖信息,尽管这可能涉及额外的辐射暴露。
长期跟踪和评估:
- 对接受手术的患者进行长期跟踪,评估使用伪健康MR图像辅助规划的手术效果,与常规手术结果进行比较。
临床试验和验证:
- 在实际临床环境中测试该方法,通过与外科医生合作,验证其在实际手术规划中的效果和可行性。
算法优化和计算效率:
- 进一步优化算法以减少计算资源需求,提高推理速度,使其更适合在临床环境中实时使用。
适应性学习:
- 研究模型是否能够根据手术结果反馈进行自我优化,以不断提高规划的准确性。
伦理和隐私问题:
- 在使用真实患者数据进行训练和测试时,确保遵守伦理准则和隐私保护法规。
这些探索点可以帮助研究者进一步提高方法的准确性、适用性和临床应用价值。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
研究目的:
- 针对青少年中常见的股骨滑车发育不良(Trochlear Dysplasia, TD),提出一种生成患者特定的伪健康MR图像的方法,以支持滑车成形术(trochleoplasty)的术前规划。
方法:
- 使用Wavelet Diffusion Model(WDM)生成个性化的伪健康、解剖学上可信的MR扫描图像。
- 训练模型时使用健康受试者的膝盖MR扫描。
- 在推理阶段,遮罩掉TD患者扫描中病理区域,并用伪健康对应部分替换。
实验:
- 使用fastMRI数据集训练模型,并用Basel大学儿童医院的TD患者MR图像评估模型。
- 对比修复前后的MR图像,使用已知的TD评估指标(滑车角SA、滑车沟深度TGD和D´ejour分类)进行测量。
结果:
- 修复后的图像在TD的严重程度上表现出减少,允许更精确的术前规划。
- 通过图像质量评估指标(MSE、PSNR和SSIM)验证了生成图像的质量。
结论:
- 提出的方法能够生成适合个体患者的伪健康3D MR图像,有助于外科医生在滑车成形术的术前规划中做出更明智的决策。
- 该方法有潜力提高手术的精确性和患者治疗效果,为未来更准确和患者定制的手术程序铺平道路。
未来工作:
- 通过扩大数据库、数据增强、交互式图像编辑工具等方法来改进和扩展该方法的应用范围。
论文展示了使用深度学习技术在医学图像处理和手术规划中的潜力,特别是在改善TD患者手术结果方面。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

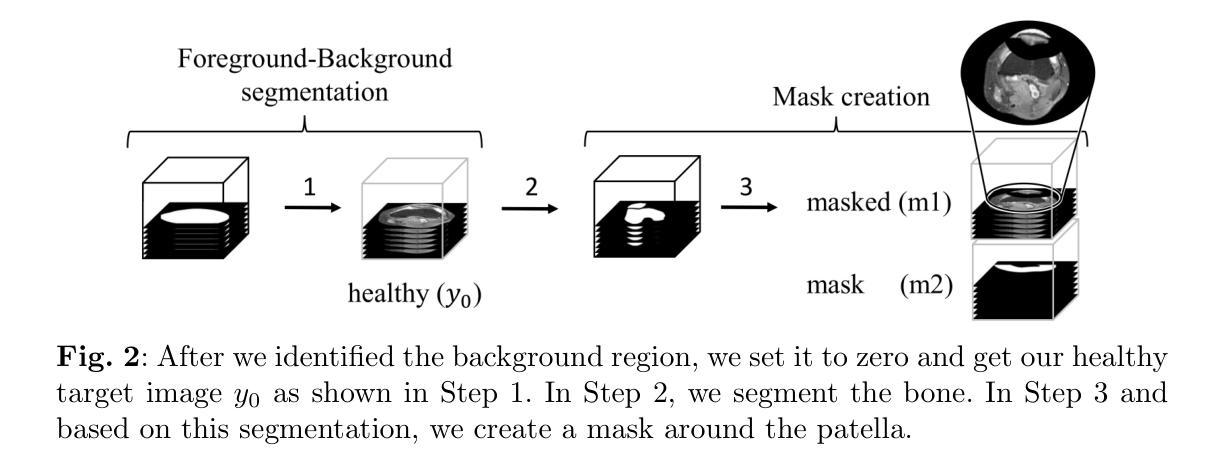
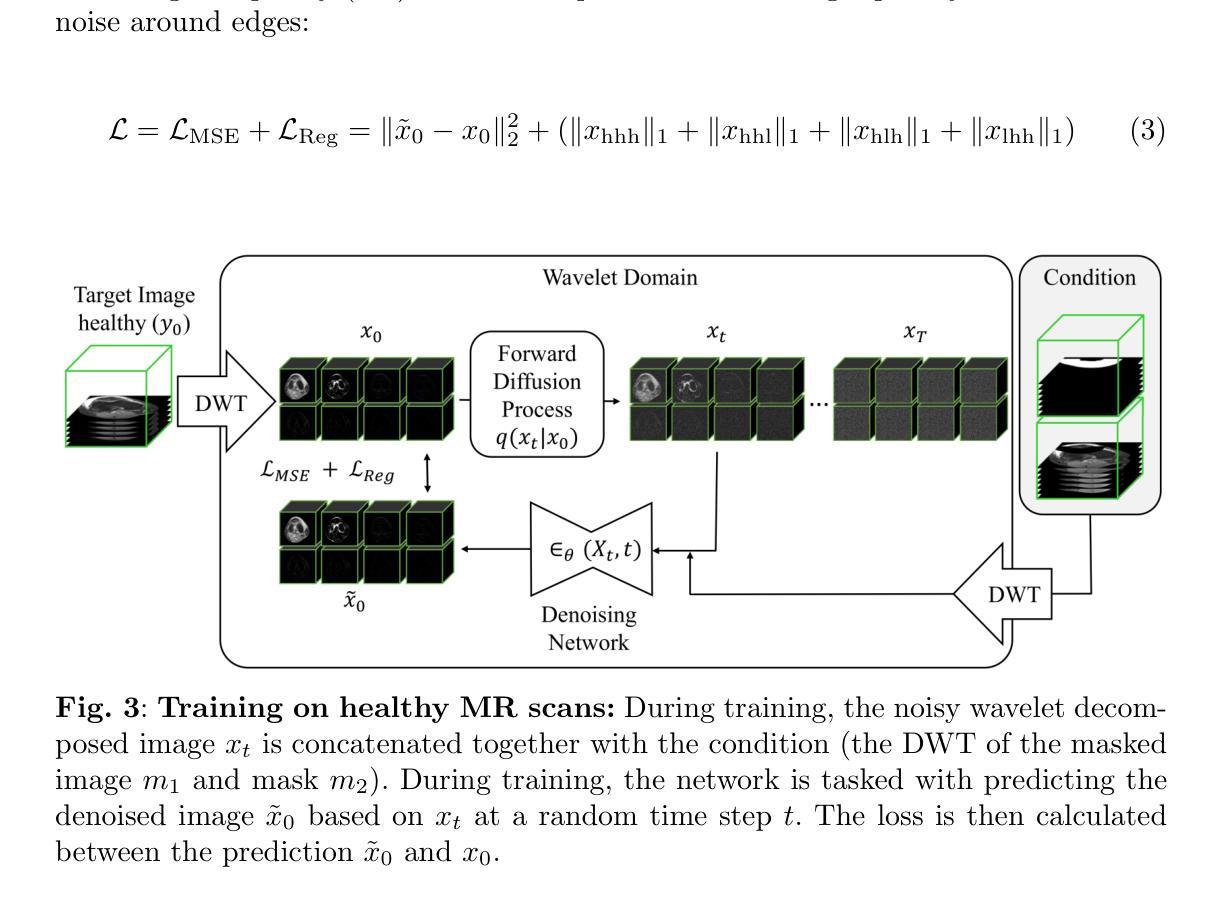
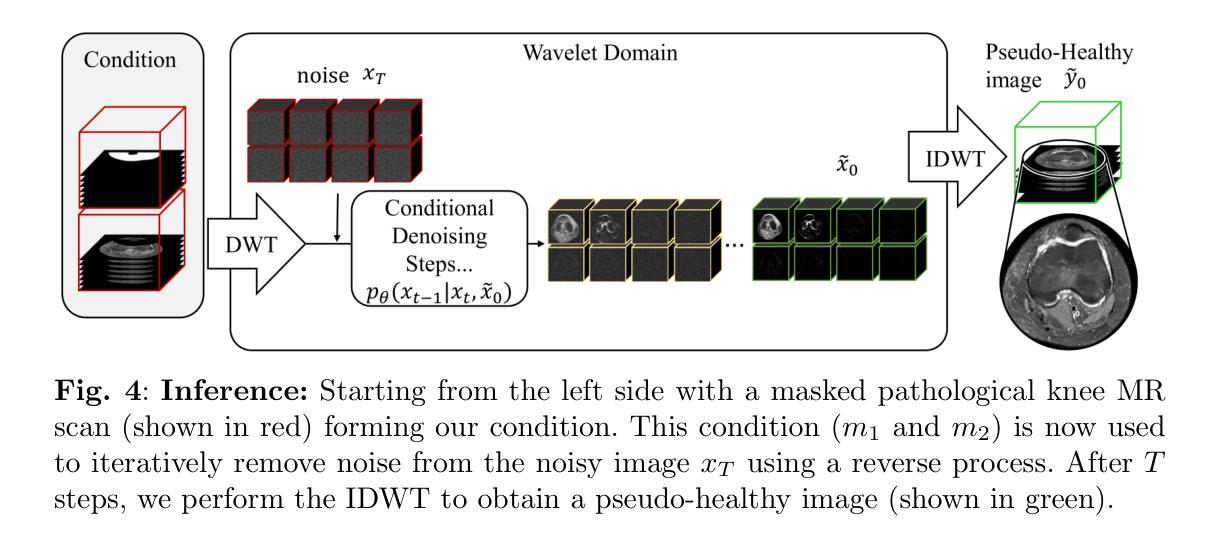
Efficient Dataset Distillation via Diffusion-Driven Patch Selection for Improved Generalization
Authors:Xinhao Zhong, Shuoyang Sun, Xulin Gu, Zhaoyang Xu, Yaowei Wang, Jianlong Wu, Bin Chen
Dataset distillation offers an efficient way to reduce memory and computational costs by optimizing a smaller dataset with performance comparable to the full-scale original. However, for large datasets and complex deep networks (e.g., ImageNet-1K with ResNet-101), the extensive optimization space limits performance, reducing its practicality. Recent approaches employ pre-trained diffusion models to generate informative images directly, avoiding pixel-level optimization and achieving notable results. However, these methods often face challenges due to distribution shifts between pre-trained models and target datasets, along with the need for multiple distillation steps across varying settings. To address these issues, we propose a novel framework orthogonal to existing diffusion-based distillation methods, leveraging diffusion models for selection rather than generation. Our method starts by predicting noise generated by the diffusion model based on input images and text prompts (with or without label text), then calculates the corresponding loss for each pair. With the loss differences, we identify distinctive regions of the original images. Additionally, we perform intra-class clustering and ranking on selected patches to maintain diversity constraints. This streamlined framework enables a single-step distillation process, and extensive experiments demonstrate that our approach outperforms state-of-the-art methods across various metrics.
数据集蒸馏提供了一种通过优化小型数据集来减少内存和计算成本的有效方法,其性能可与全尺寸原始数据集相当。然而,对于大型数据集和复杂的深度网络(例如,带有ResNet-101的ImageNet-1K),广泛的优化空间限制了性能,降低了其实用性。最近的方法采用预训练的扩散模型直接生成信息图像,避免了像素级的优化,并取得了显著的结果。然而,这些方法常常面临预训练模型和目标数据集之间分布转移的挑战,以及在不同设置下需要多次蒸馏步骤的问题。为了解决这些问题,我们提出了一种与现有基于扩散的蒸馏方法正交的新型框架,利用扩散模型进行选择而不是生成。我们的方法首先基于输入图像和文本提示(带有或不带标签文本)预测由扩散模型产生的噪声,然后计算每对对应的损失。通过损失差异,我们识别出原始图像的独特区域。此外,我们对所选补丁进行类内聚类和排名,以保持多样性约束。这种简化的框架使得单步蒸馏过程成为可能,大量实验表明,我们的方法在各种指标上优于最先进的方法。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2408.02752 by other authors
Summary
本文提出一种利用扩散模型进行选择的全新框架,该框架避免了基于生成的蒸馏方法面临的挑战。通过预测扩散模型生成的噪声和计算损失差异,该框架能够识别原始图像中的独特区域,并进行类内聚类和排名以维持多样性约束。此方法能够实现单步蒸馏过程,并在各种指标上超越现有方法。
Key Takeaways
- 扩散模型可用于减少数据集蒸馏中的内存和计算成本,提高模型性能。
- 在大型数据集和复杂深度网络(如ImageNet-1K与ResNet-101)中,传统优化空间限制了性能。
- 现有基于扩散的蒸馏方法面临预训练模型与目标数据集分布偏移以及需要多次蒸馏步骤的问题。
- 提出一种新型框架,利用扩散模型进行选择而非生成,基于输入图像和文本提示预测由扩散模型产生的噪声。
- 通过计算损失差异,能够识别原始图像中的独特区域。
- 框架包括类内聚类和排名步骤,以维持多样性约束。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是数据集蒸馏(Dataset Distillation)中的效率和泛化问题。具体来说,论文关注以下几个方面:
内存和计算成本:随着深度学习模型和训练数据集规模的增加,训练这些模型需要大量的内存和计算资源。数据集蒸馏通过优化一个较小的数据集来达到与大规模原始数据集相当的性能,从而减少资源消耗。
优化空间限制:对于大规模数据集和复杂的深度网络(例如ImageNet-1K与ResNet-101),现有的数据集蒸馏方法由于广泛的像素级优化空间而限制了性能,降低了实用性。
分布偏移问题:最近的方法使用预训练的扩散模型直接生成信息图像,避免了像素级优化并取得了显著结果。然而,这些方法常常因为预训练模型和目标数据集之间的分布偏移而面临挑战。
多次蒸馏步骤的需求:现有方法在处理不同的数据集子集时,通常需要在不同设置下进行多次蒸馏,导致计算成本高。
为了解决这些问题,论文提出了一个新的框架,该框架与现有的基于扩散的数据集蒸馏方法正交,利用扩散模型进行选择而不是生成。通过预测输入图像和文本提示(有或无标签文本)由扩散模型生成的噪声,然后计算每对噪声对应的损失,来识别原始图像中的独特区域。此外,还通过类内聚类和对选定的补丁进行排名来保持多样性约束。这个简化的框架实现了单步蒸馏过程,并在各种指标上超越了现有的最先进方法。
Q: 有哪些相关研究?
A: 根据这篇论文,相关研究主要涉及以下几个领域:
数据集蒸馏(Dataset Distillation):
- 最初将数据集蒸馏视为一个元学习问题,通过模型训练在合成数据集上最小化损失函数。
- 一些方法使用岭回归模型来近似内部循环优化。
- 另一类方法选择信息空间并计算代理信息以对齐合成数据集和原始数据集。
- 最近的方法提出解耦蒸馏策略,并成功将数据集蒸馏应用扩展到大规模数据集。
扩散模型(Diffusion Models):
- 扩散模型是生成模型,被训练用来将随机噪声转换为目标分布。
- 扩散过程是迭代的,涉及逐步减少噪声的影响。
- 变分自编码器(VAE)的引入显著减少了扩散模型的参数数量和训练样本的需求。
基于梯度匹配和特征匹配的数据集蒸馏方法:
- DC和DSA通过匹配在真实和合成数据集上训练的模型的权重梯度。
- DM、CAFE和DataDAM关注使用两个数据集之间的特征距离作为匹配目标。
- MTT和TESLA匹配在真实数据集和合成数据集上训练得到的模型参数轨迹。
基于GAN的数据集蒸馏方法:
- 引入GAN作为一种参数化技术。
基于扩散模型的数据集蒸馏方法:
- Minimax和D4M引入扩散模型直接生成合成数据集。
具体到论文中提到的一些方法,包括但不限于:
- SRe2L:通过使用预训练分类器计算合成数据集的交叉熵损失来进行更新。
- RDED:通过评估从原始图像随机裁剪的补丁,并使用预训练分类器将它们连接起来生成图像。
- Minimax:通过在ImageNet-1K上预训练的DiT模型进行微调,以目标数据集的分布作为正则化直接生成图像。
- D4M:应用预训练的文本到图像的潜在扩散模型(LDM)通过在潜在空间中聚类原始图像来生成合成数据集。
这些方法提供了数据集蒸馏领域的研究背景,并展示了该领域内的研究进展和技术挑战。论文提出的新方法旨在解决这些现有方法中存在的问题,如分布偏移和多次蒸馏步骤的需求。
Q: 论文如何解决这个问题?
A: 论文提出了一种新颖的数据集蒸馏框架,通过以下步骤解决上述问题:
1. 利用扩散模型进行图像补丁选择
- 与现有基于扩散模型的蒸馏方法不同,该框架利用预训练的潜在扩散模型(LDM)来选择信息量最大的图像补丁,而不是直接生成图像。
- 对于原始数据集中的每张输入图像,首先使用LDM预测加入和不加入标签文本提示时的噪声图,计算每种情况下的损失。
- 通过损失差异来识别图像中最具有代表性和与标签相关的区域。
2. 类内聚类和排名
- 为了保持多样性约束,论文提出对选定的补丁执行类内聚类和排名。
- 使用扩散特征(DIFT)进行聚类,以捕获每个类别最具代表性的视觉特征。
- 根据补丁到类中心的距离和每个聚类中心的中位数R(p|c)对聚类进行排名,优先选择排名最高的补丁。
3. 细粒度图像重建
- 针对大规模数据集(例如ImageNet-1K),论文提出了根据图像数量和IPC(Images Per Class)设置调整图像重建策略。
- 当IPC较小时,将多个补丁拼接成单个图像,以便模型专注于代表性类别特征。
- 当IPC较大时,每个补丁被视为单独的图像,以提供与统计模式更接近的完整特征表示。
4. 有效的标签校准
- 论文指出,使用硬标签训练大规模合成数据集可能会阻碍模型准确学习有用信息。
- 因此,采用预训练教师模型提供的软标签来训练合成数据集,显著提高了学生模型的准确性和泛化能力。
5. 实现高效的单步蒸馏过程
- 与需要多次蒸馏步骤的现有方法不同,论文提出的方法实现了完全不受限制的单步蒸馏过程,消除了在不同设置下重复蒸馏的需要。
总结
通过上述方法,论文提出一种新的数据集蒸馏框架,该框架有效地解决了现有方法中的分布不匹配问题,实现了高效的单步蒸馏过程,并在大规模数据集和复杂模型架构上展示了优越的性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估提出方法的性能,并与现有方法进行比较。以下是实验的主要方面:
1. 实验设置
数据集和架构:
- 低分辨率数据集:CIFAR-10/100和TinyImageNet,使用ConvNet作为骨干网络。
- 高分辨率数据集:ImageNet-1K及其子集,包括ImageNet-100、ImageNette和ImageWoof,使用ResNet-18作为骨干网络。
基线比较:
- 包括数据匹配方法(DSA、CAFE、DATM)和最近适用于大规模数据集的方法(SRe2L、RDED、Minimax、D4M)。
评估:
- 设置IPC(Images Per Class)为10和50,对低分辨率数据集进行评估;对于高分辨率数据集,IPC设置为10、50和100。
- 使用固定的预训练分类器提供软标签,并在蒸馏数据集上训练五个随机初始化的网络,评估这些网络的平均性能。
2. 性能改进
- 对高分辨率和低分辨率数据集的性能进行了比较,展示了提出方法在不同设置下相对于基线方法的性能提升。
3. 单步蒸馏效率
- 展示了提出方法能够实现完全不受限制的单步蒸馏过程,并在不同设置下展示了优越的性能。
4. 跨架构泛化
- 评估了使用不同教师-学生网络组合时合成数据集的性能,包括CNN和ViT架构。
5. 消融研究
- 聚类策略:研究了聚类操作对合成数据集代表性的影响,以及CLIP特征和DIFT在聚类过程中的差异。
- 真实图像数量:探索了用于关键补丁提取的原始图像数量对性能的影响。
- 时间步长:研究了不同时间步长范围对计算DIFT特征和合成数据集性能的影响。
- 聚类中心数量:研究了不同数量的聚类中心对合成数据集性能的影响。
- 调整大小的影响:探索了不同输入图像大小和补丁大小对合成数据集性能的影响。
6. 定性分析
- 使用t-SNE可视化分析了不同方法生成的数据集,以更好地理解提出方法的优越性。
7. 可视化
- 提供了在不同IPC设置下,ImageWoof和ImageNette的完整合成数据集的可视化,以及“Golden Retriever”类别在IPC=100下的图像可视化。
这些实验全面评估了提出方法的有效性、效率和泛化能力,并与现有技术进行了比较。通过这些实验,论文证明了其方法在大规模数据集和复杂模型架构上的优势。
Q: 有什么可以进一步探索的点?
A: 尽管这篇论文提出了一个有效的数据集蒸馏框架,并在多个数据集上取得了优异的性能,但仍有一些方向可以进一步探索和研究:
1. 扩散模型的改进和优化
- 研究不同的扩散模型架构和训练策略,以提高模型的生成质量和多样性。
- 探索自适应扩散过程,根据不同的输入图像动态调整扩散步骤和噪声水平。
2. 多模态数据集蒸馏
- 将该框架扩展到多模态数据集(例如图像和文本),研究如何有效地融合不同模态的信息以提高数据集蒸馏的性能。
3. 跨领域泛化能力
- 测试该框架在不同领域(如医疗图像、卫星图像等)的数据集上的泛化能力,并针对特定领域进行优化。
4. 增强模型的鲁棒性
- 研究如何通过数据增强、对抗训练等技术提高蒸馏数据集的鲁棒性,特别是在面对噪声和异常值时。
5. 计算效率和可扩展性
- 进一步优化算法和代码,以减少计算资源消耗,提高数据集蒸馏过程的效率。
- 探索分布式计算和并行处理策略,以扩展该框架处理更大规模数据集的能力。
6. 混合数据集生成
- 结合原始数据和生成数据,研究如何平衡两者以生成更高质量的混合数据集。
7. 细粒度控制和编辑能力
- 研究如何提供细粒度的控制,允许用户指定特定类别或属性,以生成具有特定特征的数据集。
8. 模型解释性和可视化
- 开发更先进的可视化工具和技术,以直观展示数据集蒸馏过程中的关键步骤和决策。
- 研究模型的解释性,以更好地理解模型是如何从原始数据中学习并生成代表性样本的。
9. 实际应用和案例研究
- 将该框架应用于实际问题和项目中,评估其在现实世界数据和任务中的有效性和实用性。
- 通过案例研究,展示该框架如何解决特定行业或领域的具体挑战。
这些方向不仅可以推动数据集蒸馏技术的发展,还可能为深度学习和人工智能领域的其他问题提供新的见解和解决方案。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
1. 问题陈述
论文针对数据集蒸馏领域中存在的挑战,特别是大规模数据集和复杂深度网络下的内存与计算成本问题,以及现有方法在实际应用中的局限性,提出了一个新的框架。
2. 相关工作回顾
论文回顾了数据集蒸馏和扩散模型的相关研究,包括基于梯度匹配、特征匹配的方法,以及最近引入的GAN和扩散模型技术。
3. 方法论
提出了一个新颖的数据集蒸馏框架,该框架利用预训练的扩散模型来选择信息量最大的图像补丁,而不是直接生成图像。具体步骤包括:
- 使用扩散模型预测噪声图并计算损失差异,识别图像中的关键区域。
- 执行类内聚类和排名,以保持多样性并选择代表性补丁。
- 根据IPC设置调整图像重建策略,优化模型学习。
- 使用软标签进行训练,提高学生模型的准确性和泛化能力。
4. 实验验证
论文通过一系列实验验证了提出方法的有效性,包括:
- 在不同数据集和网络架构下的性能评估。
- 与现有方法的性能比较,展示提出方法在各种设置下的优势。
- 消融研究,分析了聚类策略、时间步长选择等对性能的影响。
- 定性分析和可视化,进一步展示了提出方法生成的数据集的质量和特性。
5. 结论与展望
论文总结了提出方法的主要贡献,并指出了未来可能的研究方向,包括扩散模型的改进、跨领域泛化能力测试、计算效率优化等。
总体而言,这篇论文提出了一个创新的数据集蒸馏框架,通过利用扩散模型进行图像补丁选择和类内聚类,实现了高效的单步蒸馏过程,并在多个数据集上取得了优异的性能,为数据集蒸馏领域提供了新的思路和解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

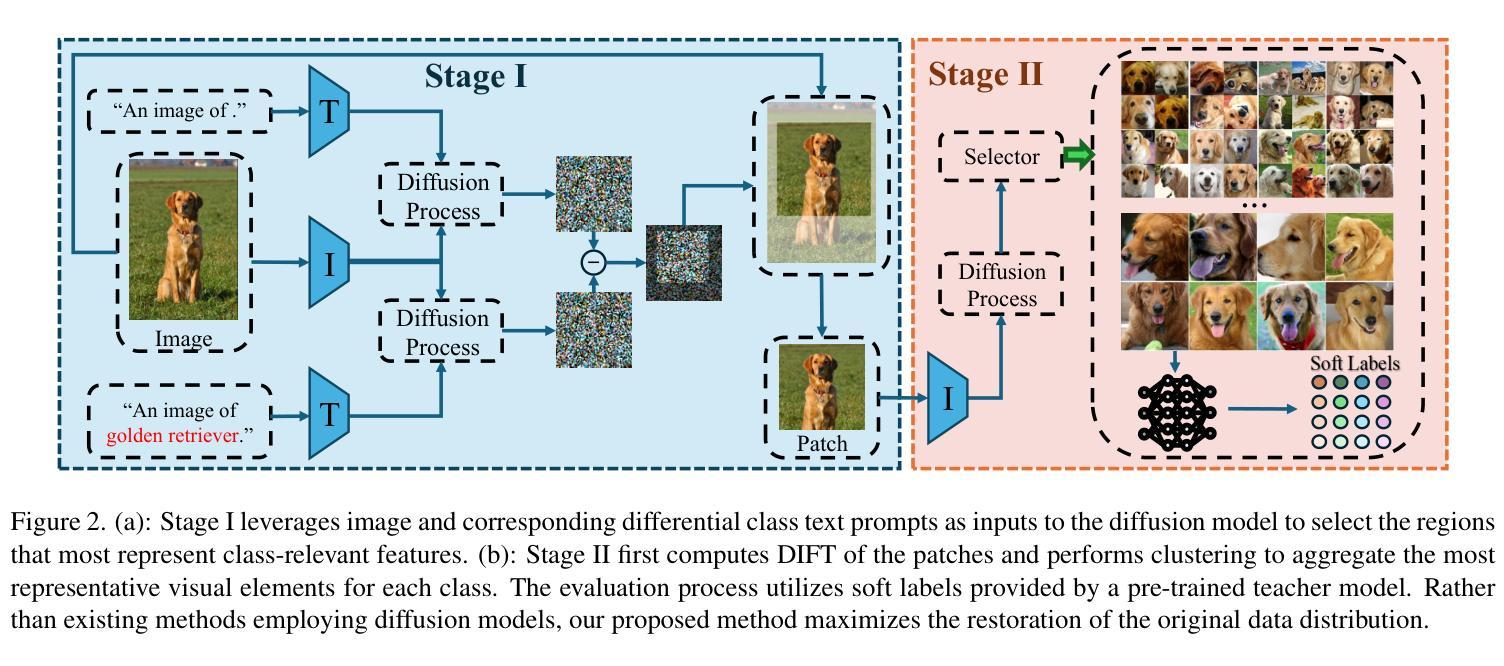


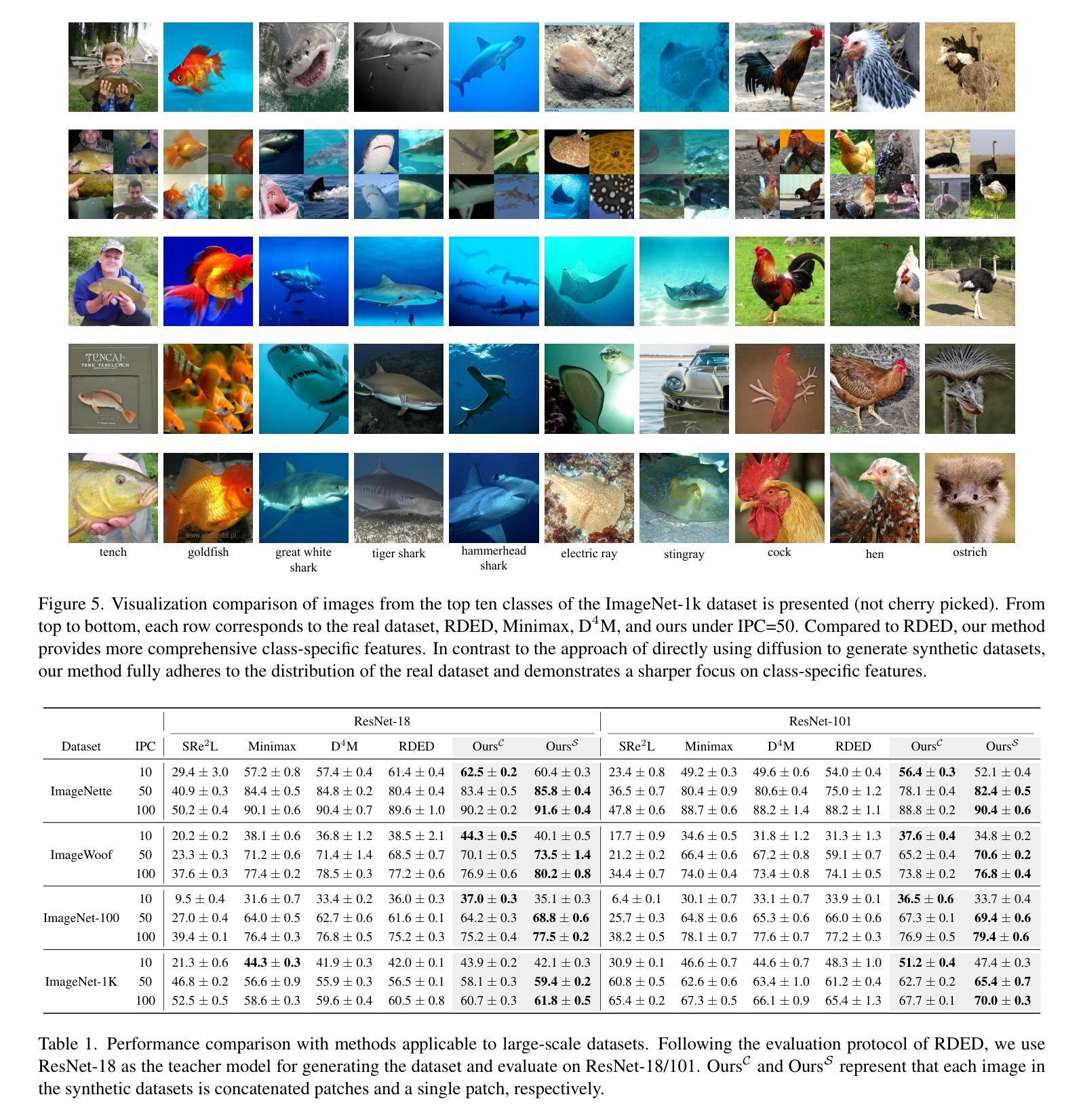
Prompt2Perturb (P2P): Text-Guided Diffusion-Based Adversarial Attacks on Breast Ultrasound Images
Authors:Yasamin Medghalchi, Moein Heidari, Clayton Allard, Leonid Sigal, Ilker Hacihaliloglu
Deep neural networks (DNNs) offer significant promise for improving breast cancer diagnosis in medical imaging. However, these models are highly susceptible to adversarial attacks–small, imperceptible changes that can mislead classifiers–raising critical concerns about their reliability and security. Traditional attacks rely on fixed-norm perturbations, misaligning with human perception. In contrast, diffusion-based attacks require pre-trained models, demanding substantial data when these models are unavailable, limiting practical use in data-scarce scenarios. In medical imaging, however, this is often unfeasible due to the limited availability of datasets. Building on recent advancements in learnable prompts, we propose Prompt2Perturb (P2P), a novel language-guided attack method capable of generating meaningful attack examples driven by text instructions. During the prompt learning phase, our approach leverages learnable prompts within the text encoder to create subtle, yet impactful, perturbations that remain imperceptible while guiding the model towards targeted outcomes. In contrast to current prompt learning-based approaches, our P2P stands out by directly updating text embeddings, avoiding the need for retraining diffusion models. Further, we leverage the finding that optimizing only the early reverse diffusion steps boosts efficiency while ensuring that the generated adversarial examples incorporate subtle noise, thus preserving ultrasound image quality without introducing noticeable artifacts. We show that our method outperforms state-of-the-art attack techniques across three breast ultrasound datasets in FID and LPIPS. Moreover, the generated images are both more natural in appearance and more effective compared to existing adversarial attacks. Our code will be publicly available https://github.com/yasamin-med/P2P.
深度神经网络(DNNs)在医学成像的乳腺癌诊断方面显示出巨大的潜力。然而,这些模型非常容易受到对抗性攻击的影响——这些攻击通过微小且难以察觉的改变来误导分类器,因此对模型的可靠性和安全性提出了严重的担忧。传统攻击依赖于固定范数的扰动,与人类感知不符。相比之下,基于扩散的攻击需要预先训练的模型,当这些模型不可用时需要大量数据,这在数据稀缺的场景中限制了实际应用。然而,在医学成像中,由于数据集的有限可用性,这通常并不可行。基于最近的可学习提示的进展,我们提出了Prompt2Perturb(P2P)这种新型的语言引导攻击方法,能够生成由文本指令驱动的具有意义的攻击示例。在提示学习阶段,我们的方法利用文本编码器中的可学习提示来创建细微但影响深远的扰动,这些扰动不会被人察觉,同时引导模型朝着目标结果发展。与当前的基于提示学习的方法相比,我们的P2P通过直接更新文本嵌入而脱颖而出,避免了重新训练扩散模型的必要。此外,我们利用了一个发现,即优化早期的反向扩散步骤可以提高效率,同时确保生成的对抗性示例包含细微的噪声,从而保持超声图像质量而不会引入明显的伪影。我们的方法在三个乳腺超声数据集上的FID和LPIPS上超过了最先进的攻击技术。此外,生成的图像在外观上更自然且相较于现有的对抗性攻击更有效。我们的代码将公开可用:https://github.com/yasamin-med/P2P。
论文及项目相关链接
Summary
深度学习神经网络在医学图像乳腺癌诊断上具有巨大潜力,但其易受对抗性攻击影响。传统攻击方法存在与人类感知不一致的问题,而扩散攻击需预先训练模型,在数据稀缺场景中使用受限。本文提出基于学习提示的攻击方法Prompt2Perturb(P2P),能根据文本指令生成有意义的攻击实例。该方法通过文本编码器的可学习提示创建微小但影响显著的不易察觉扰动,指导模型达到目标结果。与当前基于提示的学习方法相比,P2P直接更新文本嵌入,无需重新训练扩散模型。优化早期反向扩散步骤可提高效率,确保生成的对抗样本融入细微噪声,提高超声图像质量。实验表明,该方法在三个乳房超声数据集上的FID和LPIPS上优于最新攻击技术,生成的图像更自然、更有效。
Key Takeaways
- 深度学习神经网络在医学图像乳腺癌诊断中有广泛应用前景。
- 对抗性攻击对深度学习模型的可靠性和安全性构成重大威胁。
- 传统攻击方法存在与人类感知不一致的问题。
- 扩散攻击需要预先训练模型,在数据稀缺场景中受限。
- 提出了一种基于学习提示的攻击方法Prompt2Perturb(P2P)。
- P2P能够创建微小的、但影响显著的不易察觉的扰动,以引导模型达到特定结果。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决深度神经网络(DNNs)在医学成像领域,特别是在乳腺癌诊断中对对抗性攻击的脆弱性问题。对抗性攻击是指通过引入微小的、难以察觉的变化来误导分类器的行为,这引起了对DNNs可靠性和安全性的严重担忧。论文中提到,尽管DNNs在医学成像领域有很大的应用前景,但它们对对抗性攻击的高敏感性使得这些模型在实际应用中存在风险。
具体来说,论文试图解决以下几个问题:
传统对抗性攻击方法的局限性:传统的基于梯度的方法(如FGSM、PGD等)虽然可以生成对抗性样本,但这些样本往往与自然图像的真实数据分布有较大偏差,导致在对抗性样本的有效性和隐蔽性之间存在权衡。
医学图像数据的稀缺性:在医学成像领域,由于数据集的有限可用性,使得基于大规模预训练模型的对抗性攻击方法在实际应用中受到限制。
现有方法与医学术语的适应性问题:现有的基于文本指导的攻击方法可能不适应临床术语,因此在医学领域中的意义有限。
为了解决这些问题,论文提出了一种名为Prompt2Perturb(P2P)的新型语言引导攻击方法,该方法能够通过文本指令生成有意义的攻击样本,同时保持对医学图像数据的适应性和临床术语的相关性。
Q: 有哪些相关研究?
A: 论文中提到了多个与对抗性攻击、医学成像以及文本引导的攻击相关的研究工作。以下是一些主要的相关研究:
对抗性攻击方法:
- FGSM (Fast Gradient Sign Method) [20]:一种基于梯度的白盒攻击方法,通过在输入图像上添加小的扰动来误导分类器。
- Carlini & Wagner (C-W) [8]:另一种白盒攻击方法,旨在生成对抗性样本,这些样本在视觉上与原始图像难以区分。
- PGD (Projected Gradient Descent) [40]:一种迭代的梯度下降方法,用于生成有效的对抗性攻击样本。
- DeepFool [42]:一种简单的方法,通过迭代地扰动输入图像来欺骗深度神经网络。
医学成像中的对抗性攻击:
- AdvDiffuser [11] 和 Diff-PGD [61]:这些方法结合了PGD方法和扩散模型,以增强生成图像的真实性。
- Instruct2Attack [37]:利用潜在扩散模型通过优化输入提示来欺骗目标模型。
扩散模型在对抗性攻击中的应用:
- 扩散模型被用于增强对抗性扰动的不可感知性、风格转换以及攻击扩散模型的净化方法。
提示学习(Prompt Learning):
- 提示学习最初是作为在自然语言处理(NLP)中利用预训练语言模型的一种方法,后来被适应于对抗性目的。
- BadCLIP [4] 和 BAPLe [21]:这些方法通过在提示学习阶段注入后门或引入可学习的噪声触发器来攻击模型。
医学成像中的深度学习模型:
- 论文提到了一些用于改进诊断结果的深度学习模型,如ResNet34、SqueezeNet1.1和DenseNet121。
其他相关研究:
- MIRST [50]:提出用于防御非定向对抗性攻击的方法。
- Adversarially Robust Feature Learning [22]:通过包含特征相关性度量来促进鲁棒特征的学习。
这些研究构成了论文提出的Prompt2Perturb (P2P)方法的理论基础和技术背景。论文通过结合这些相关技术,提出了一种新的针对医学图像的对抗性攻击方法,旨在提高攻击的隐蔽性和有效性,同时保持对医学术语的适应性。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Prompt2Perturb(P2P)的新方法来解决深度神经网络(DNNs)在医学成像领域对对抗性攻击的脆弱性问题。P2P方法的核心思想是利用文本指令引导生成对抗性样本,同时保持对医学图像数据的适应性和临床术语的相关性。以下是P2P方法解决这个问题的几个关键步骤:
利用可学习的提示(Prompts):
- P2P方法在文本编码器中使用可学习的提示来创建微小但有影响力的扰动,这些扰动在保持不可感知的同时引导模型朝向目标输出。
直接更新文本嵌入:
- 与当前基于提示学习方法不同,P2P通过直接更新文本嵌入来生成对抗性样本,避免了重新训练扩散模型的需要。
优化早期反向扩散步骤:
- 论文发现,仅优化早期的反向扩散步骤(相当于扩散过程的后期步骤)不仅提高了效率,还确保了生成的对抗性样本包含微妙的噪声,从而在不引入明显伪影的情况下保持了超声图像的质量。
针对临床术语的对抗性样本优化:
- P2P方法通过将临床术语纳入Stable Diffusion的文本嵌入中,确保生成的图像在医学背景下保持临床准确性和现实性,从而提高了攻击的有效性。
实验验证:
- 论文通过在三个不同的乳房超声数据集上与现有技术进行比较,使用FID(Fréchet Inception Distance)和LPIPS(Learned Perceptual Image Patch Similarity)等指标来验证P2P方法的有效性。实验结果表明,P2P方法在保持图像自然外观和有效性方面优于现有的对抗性攻击方法。
代码公开:
- 为了促进研究和进一步的开发,论文承诺将P2P方法的代码在GitHub上公开。
通过这些方法,P2P能够有效地对医学图像中的DNNs进行对抗性攻击,同时保持对医学术语的适应性和图像质量,解决了传统方法在医学成像领域中的局限性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和比较所提出的Prompt2Perturb(P2P)方法与其他现有技术。以下是实验的关键方面:
实验设置:
- 数据集:使用了三个公开的乳房超声数据集,包括BUSI、BUS-BRA和UDIAT。
- 模型:实验涉及三种广泛认可的分类器架构,ResNet34、SqueezeNet1.1和DenseNet121。
- 评估指标:使用成功率(Success Rate)、Learned Perceptual Image Patch Similarity(LPIPS)、Structural Similarity Index Measure(SSIM)和Fréchet Inception Distance(FID)来评估对抗性样本的质量。
与现有技术的比较:
- 将P2P方法与Diffusion-Based Projected Gradient Descent(DiffPGD)攻击和传统技术如FGSM和PGD进行了比较。
定量评估:
- 在不同数据集和分类器架构上评估了P2P方法的成功率、LPIPS、SSIM和FID,以全面分析对抗性样本的有效性和感知完整性。
定性结果:
- 通过视觉比较展示了不同攻击方法生成的图像和对抗性扰动。
- 展示了P2P攻击成功改变超声图像的诊断标签,同时保持图像语义外观的最小变化。
t-SNE可视化:
- 使用t-SNE可视化比较了四种攻击方法(FGSM、PGD、DiffPGD和P2P)在集成攻击样本与干净数据集方面的效果。
案例研究:
- 分析了训练集中高置信度分类器识别的图像的攻击样本,特别关注BUSI训练集中的恶性病例及其被DiffPGD和P2P方法攻击后的版本。
消融研究:
- 对P2P方法的不同组件进行了消融研究,以评估各个设计选择对方法有效性的贡献,包括损失函数和时间步的选择。
这些实验结果不仅证明了P2P方法在生成有效对抗样本方面的优越性,还展示了其在保持图像质量和结构相似性方面的高表现,从而证实了P2P方法在医学成像领域的实用性和有效性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一种有效的对抗性攻击方法,Prompt2Perturb(P2P),但仍有一些领域可以进一步探索和研究:
防御机制:
- 研究和开发针对P2P攻击的防御机制,以增强医学成像DNNs的鲁棒性。
模型泛化能力:
- 探索P2P方法在不同类型的医学成像数据(如CT、MRI)和其他疾病领域的泛化能力。
攻击检测技术:
- 开发有效的攻击检测技术,以识别和减轻P2P方法生成的对抗性样本的影响。
模型鲁棒性和准确性的权衡:
- 研究在提高模型鲁棒性的同时保持或提高其准确性的方法。
更深层次的临床术语集成:
- 探索将更深层次的临床术语和知识集成到文本嵌入中,以进一步提高攻击样本的质量和相关性。
计算效率优化:
- 进一步优化P2P方法的计算效率,尤其是在处理大规模数据集时。
跨模态攻击:
- 研究P2P方法在跨模态攻击(例如,从超声图像攻击到MRI图像)中的有效性。
对抗性训练:
- 通过将P2P生成的对抗性样本纳入训练过程,研究对抗性训练对模型鲁棒性的影响。
模型解释性:
- 提高模型的解释性,以更好地理解对抗性样本是如何影响模型决策的。
法律和伦理考量:
- 探讨对抗性攻击在医学成像中的法律和伦理问题,特别是在临床应用中。
多模态融合:
- 研究如何将P2P方法与其他模态(如病理报告、患者历史)融合,以生成更复杂的对抗性样本。
实时攻击和防御:
- 探索在实时医学成像系统中实施P2P攻击和防御的可行性和挑战。
这些探索方向不仅可以推动对抗性攻击技术的发展,还有助于提高深度学习模型在医学成像领域的安全性和可靠性。
Q: 总结一下论文的主要内容
A: 论文提出了一种名为Prompt2Perturb(P2P)的新方法,旨在生成针对医学成像中深度神经网络(DNNs)的对抗性攻击样本,特别是在乳腺癌超声图像分析中。以下是论文的主要内容总结:
问题背景:
- 医学成像中的DNNs对对抗性攻击非常敏感,这些攻击通过微小的、难以察觉的图像变化误导分类器,引发对模型可靠性和安全性的担忧。
现有方法的局限性:
- 传统对抗性攻击方法依赖固定范数扰动,与人类感知不匹配。
- 基于扩散的攻击需要预训练模型,这在数据稀缺的医学成像领域不切实际。
P2P方法:
- P2P利用文本指令引导生成对抗性样本,通过优化文本嵌入直接更新,避免了重新训练扩散模型。
- 该方法仅优化早期反向扩散步骤以提高效率,并保持超声图像质量。
实验评估:
- 在三个乳房超声数据集上评估P2P方法,并与FGSM、PGD和DiffPGD等现有技术进行比较。
- 使用成功率、LPIPS、SSIM和FID等指标评估对抗性样本的质量。
结果:
- P2P方法在成功率上与DiffPGD相当,但在保持图像自然性和有效性方面表现更优。
- 生成的对抗性样本在外观上更自然、更有效,且在医学背景下更具临床准确性和现实性。
代码公开:
- 论文承诺将P2P方法的代码在GitHub上公开,以促进研究和进一步开发。
结论:
- P2P方法为医学成像中的DNNs提供了一种有效的对抗性攻击手段,无需特定领域的预训练模型,同时保持了对医学术语的适应性。
论文的贡献在于提出了一种新的对抗性攻击方法,该方法特别适用于数据有限的医学成像领域,并且能够生成在视觉上难以察觉且临床相关的对抗性样本。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Real-time Identity Defenses against Malicious Personalization of Diffusion Models
Authors:Hanzhong Guo, Shen Nie, Chao Du, Tianyu Pang, Hao Sun, Chongxuan Li
Personalized diffusion models, capable of synthesizing highly realistic images based on a few reference portraits, pose substantial social, ethical, and legal risks by enabling identity replication. Existing defense mechanisms rely on computationally intensive adversarial perturbations tailored to individual images, rendering them impractical for real-world deployment. This study introduces Real-time Identity Defender (RID), a neural network designed to generate adversarial perturbations through a single forward pass, bypassing the need for image-specific optimization. RID achieves unprecedented efficiency, with defense times as low as 0.12 seconds on a single GPU (4,400 times faster than leading methods) and 1.1 seconds per image on a standard Intel i9 CPU, making it suitable for edge devices such as smartphones. Despite its efficiency, RID matches state-of-the-art performance across visual and quantitative benchmarks, effectively mitigating identity replication risks. Our analysis reveals that RID’s perturbations mimic the efficacy of traditional defenses while exhibiting properties distinct from natural noise, such as Gaussian perturbations. To enhance robustness, we extend RID into an ensemble framework that integrates multiple pre-trained text-to-image diffusion models, ensuring resilience against black-box attacks and post-processing techniques, including JPEG compression and diffusion-based purification.
个性化扩散模型能够根据少量参考肖像合成高度逼真的图像,这带来了重大的社会、伦理和法律风险,因为身份复制成为可能。现有的防御机制依赖于针对个别图像的计算密集型对抗性扰动,使得它们在现实世界部署中不切实际。本研究引入了实时身份防御系统(RID),这是一种神经网络,旨在通过单次前向传递生成对抗性扰动,从而绕过对特定图像优化的需求。RID实现了前所未有的效率,在单个GPU上的防御时间低至0.12秒(比领先方法快4400倍),在标准Intel i9 CPU上每张图像的处理时间为1.1秒,非常适合智能手机等边缘设备。尽管效率很高,但RID在视觉和定量基准测试中达到了最先进的技术性能,有效地减轻了身份复制的风险。我们的分析表明,RID的扰动模仿了传统防御的有效性,同时表现出与自然噪声不同的特性,如高斯扰动。为了提高稳健性,我们将RID扩展为一个集成框架,该框架整合了多个预训练的文本到图像扩散模型,确保对黑盒攻击和后期处理技术的抵御能力,包括JPEG压缩和基于扩散的净化技术。
论文及项目相关链接
PDF 21 pages, 7 figures
Summary
基于个性化扩散模型能够根据少量肖像合成高度逼真的图像,带来身份复制的社会、伦理和法律风险问题。现有的防御机制依赖于针对个别图像的计算密集型对抗性扰动,使得它们在现实世界的部署不切实际。本研究提出了实时身份防御(RID)神经网络,通过单次前向传递生成对抗性扰动,无需针对特定图像进行优化。RID实现了前所未有的效率,在单个GPU上的防御时间低至0.12秒(比领先方法快4400倍),在标准Intel i9 CPU上每张图像的处理时间为1.1秒,适合边缘设备如智能手机使用。尽管效率出众,RID在视觉和定量基准测试中表现优异,能有效减轻身份复制风险。我们的分析表明,RID的扰动模仿了传统防御的有效性,同时表现出与自然噪声不同的特性,如高斯扰动。为提高稳健性,我们将RID扩展为一个集成框架,整合多个预训练的文本到图像扩散模型,确保对黑箱攻击和后期处理技术(包括JPEG压缩和基于扩散的净化技术)具有抗韧性。
Key Takeaways
- 个人化扩散模型能基于少量肖像合成高度逼真的图像,引发身份复制的社会、伦理和法律风险。
- 现有防御机制因计算密集和对特定图像优化而不适用于现实应用。
- 实时身份防御(RID)神经网络通过单次前向传递生成对抗性扰动,显著提高效率。
- RID在GPU和CPU上的处理速度极快,适合在智能手机等边缘设备上使用。
- RID在视觉和定量测试中表现优异,能有效减轻身份复制风险。
- RID的扰动模仿传统防御的有效性,具有与自然噪声不同的特性,如高斯扰动。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决由个性化扩散模型(personalized diffusion models)带来的社会、伦理和法律风险问题。这些模型能够基于少量参考肖像合成高度逼真的图像,从而使得身份复制成为可能。这种能力引发了关于个人隐私和公共信任的重大担忧。具体来说,论文中提到:
身份复制风险:通过微调开源模型(如Stable Diffusion),恶意行为者可以生成高度逼真但有害的内容,包括虚假信息或伪造媒体,威胁个人隐私和公共信任。
现有防御机制的局限性:现有的防御机制依赖于为单个图像量身定制的计算密集型对抗性扰动,这使得它们在大规模或实时应用中不切实际,因为它们需要超过500秒的时间来执行单个图像的优化。
为了应对这些挑战,论文提出了一种名为Real-time Identity Defender(RID)的神经网络,旨在通过单次前向传递生成对抗性扰动,绕过对图像特定优化的需求,以实现前所未有的效率,并在保持与现有方法相当的防御性能的同时,显著提高可扩展性。
Q: 有哪些相关研究?
A: 论文中提到了多个与个性化扩散模型和对抗性防御相关的研究工作。以下是一些关键的相关研究:
个性化扩散模型和概念复制:
- Nupur Kumari et al. [7] 提出了一种多概念定制的文本到图像扩散方法。
- Ziyi Dong et al. [8] 提出了DreamArtist,一种通过对比提示调整实现可控的一次性文本到图像生成的方法。
- Ligong Han et al. [9] 提出了SVDiff,一种用于扩散微调的紧凑参数空间方法。
- Guangxuan Xiao et al. [11] 提出了FastComposer,一种无需调整的多主题图像生成方法,使用局部注意力。
对抗性防御和安全性:
- Shawn Shan et al. [16] 提出了GLAZE,一种通过对抗性扰动保护艺术家免受风格模仿的方法。
- Chumeng Liang et al. [17] 提出了一种通过对抗性示例防止扩散模型绘画模仿的方法。
- Aleksander Madry et al. [18] 提出了深度学习模型对抗对抗性攻击的研究。
- Thanh Van Le et al. [19] 提出了Anti-Dreambooth,一种防止个性化文本到图像合成的方法。
扩散模型和图像生成:
- Aditya Ramesh et al. [1] 提出了零样本文本到图像生成的研究。
- Robin Rombach et al. [2] 提出了高分辨率图像合成的潜在扩散模型。
- Chitwan Saharia et al. [3] 提出了具有深度语言理解的逼真文本到图像扩散模型。
这些研究为理解个性化扩散模型的能力和潜在风险提供了基础,并探索了不同的防御策略来保护个人身份和版权。论文提出的Real-time Identity Defender (RID) 旨在通过实时生成对抗性扰动来解决现有防御机制的计算效率问题,并提高防御的实用性。
Q: 论文如何解决这个问题?
A: 论文通过提出Real-time Identity Defender (RID)来解决个性化扩散模型带来的问题。RID是一个神经网络,能够为图像生成对抗性扰动,而不需要对每张图像进行特定的优化。以下是RID解决该问题的关键步骤和方法:
1. 对抗性扰动生成:
- RID通过单次前向传递生成对抗性扰动,避免了对每张图像进行耗时的优化过程。
2. **Adversarial Score Distillation Sampling (Adv-SDS)**:
- RID采用Adv-SDS损失函数,该函数通过最大化扩散损失来优化网络生成的扰动,从而保护图像身份不被复制。
3. 正则化项:
- 为了提高防御图像的视觉质量,RID引入了一个正则化项,该项通过与预先计算的图像特定扰动对齐来减少由Adv-SDS引起的视觉伪影。
4. 训练数据集:
- RID使用VGGFace2数据集的筛选子集进行训练,确保模型能够泛化到不同的面部特征、姿态和光照条件。
5. 模型架构:
- RID使用Diffusion Transformer (DiT)的变体作为其骨干网络,该网络能够输出与输入匹配维度的扰动。
6. RID-Ensemble框架:
- 为了增强模型在未知模型和对抗后处理技术中的鲁棒性,论文提出了RID-Ensemble框架。这个框架通过集成多个预训练的扩散模型来训练RID,以提高在黑盒攻击和后处理技术(如JPEG压缩和基于扩散的净化)中的防御能力。
7. 实时防御性能:
- RID在单个GPU上处理图像的时间低至0.12秒,比现有方法快4400倍,使其适合在边缘设备如智能手机上部署。
8. 量化和视觉评估:
- 论文通过Frechet Inception Distance (FID)、Identity Score Matching (ISM)和BRISQUE等量化指标评估RID的防御效果,并与现有方法进行比较。
通过上述方法,RID在保持高效率的同时实现了与现有最先进方法相当的防御性能,有效减少了身份复制的风险,并提高了在实际应用中的可行性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估Real-time Identity Defender (RID) 的性能和鲁棒性。以下是主要的实验内容:
1. RID框架的评估:
- 训练和推理:展示了RID如何在单个前向传递中生成保护性扰动,以及其在不同硬件上的推理效率(GPU和CPU)。
2. 视觉特性评估:
- 通过视觉对比展示了RID保护的图像与原始图像的相似性,以及在RID保护下,个性化扩散模型无法准确复制身份的能力。
3. 计算效率比较:
- 比较了RID与基于优化的方法(如Anti-DB和AdvDM)的处理速度,显示RID在GPU和CPU上的速度提升。
4. 定量防御性能评估:
- 使用FID、ISM和BRISQUE三个指标,定量评估RID的防御效果,并与优化方法和无保护基线进行比较。
5. 视觉模式比较:
- 对比了RID保护图像与现有方法保护图像的视觉模式,展示了RID即使在不同的扰动模式下也能提供有效的保护。
6. 跨扰动水平、个性化技术和预训练模型的鲁棒性评估:
- 评估了RID在不同扰动水平、个性化技术和预训练扩散模型下的性能,验证了RID的适应性和鲁棒性。
7. RID生成扰动的特性分析:
- 分析了RID生成的扰动与高斯噪声和现有优化方法生成扰动的统计分布和语义结构的差异。
8. 扩散损失比较:
- 比较了不同扰动方法对预训练和个性化模型扩散损失的影响,验证了RID扰动的有效性。
9. RID-Ensemble的黑盒防御和后处理鲁棒性评估:
- 展示了RID-Ensemble在未知模型和常见后处理技术(如JPEG压缩和Diffpure)下的防御性能。
- 通过定量指标评估了RID-Ensemble在黑盒防御和后处理条件下的效果。
这些实验全面评估了RID在不同条件下的性能和鲁棒性,证明了RID作为一种实用、高效的身份保护解决方案的潜力。
Q: 有什么可以进一步探索的点?
A: 论文在讨论部分提出了一些可以进一步探索的研究方向,这些方向旨在提高身份防御技术的实用性、效果和伦理责任。以下是一些具体的探索点:
预训练扩散模型的多样性:
- 研究者可以探索如何使防御机制更好地泛化到未见过的预训练模型架构上。随着预训练模型的不断增加和演化,这是一个重要的研究方向。
对抗性方法的改进:
- 针对新兴的无需微调的个性化方法(如IP-Adapter和InstantID),需要开发新的防御策略。这些方法利用编码器而不是微调模型参数,因此需要不同的防御机制。
降低扰动可见性:
- 尽管RID在较小的噪声约束下实现了较强的保护,但在更严格的不可见性要求下进一步减少扰动的可见性是必要的,以促进这些技术在敏感场景中的实际部署。
优化扰动搜索空间:
- 研究者可以探索在频率域而非像素域中操作的防御方法,这可能在较小的噪声约束下实现更强的防御。
将防御扰动转化为有意义的信号:
- 将防御扰动转换为有意义的信号(例如化妆模式)可能是一种既实现身份保护又增加美观效果的方法。
扩展到其他创意产出的保护:
- 除了保护人像外,研究如何防止个性化技术未经艺术家同意复制其独特风格,以保护知识产权并促进生成AI系统的伦理使用。
平衡技术进步与个人及创作权利的保护:
- 未来的研究需要在技术创新和保护个人及创作权利之间找到平衡点,确保生成AI系统的安全和负责任的使用。
这些探索点不仅有助于提高身份防御技术的性能和实用性,还涉及对生成AI系统伦理使用的深入思考,是一个多维度、跨学科的研究领域。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一种名为Real-time Identity Defender(RID)的新型神经网络,旨在防御恶意行为者利用个性化扩散模型进行身份复制的风险。以下是论文的主要内容总结:
问题背景:
- 个性化扩散模型能够基于少量参考图像合成高度逼真的图像,引发隐私和法律风险。
- 现有防御方法计算成本高,不适合实时或大规模应用。
RID框架:
- RID通过单次前向传递生成对抗性扰动,无需对每张图像进行特定优化。
- 利用Adversarial Score Distillation Sampling(Adv-SDS)损失函数,高效地针对预训练的扩散模型生成扰动。
- 引入正则化项提升防御图像的视觉质量。
实验评估:
- RID在视觉和定量基准测试中与最先进方法表现相当,有效降低身份复制风险。
- RID在GPU上处理时间仅为0.12秒,比现有方法快4400倍,适合边缘设备部署。
鲁棒性和泛化能力:
- RID在不同扰动水平、个性化技术和预训练模型中展现出良好的适应性和鲁棒性。
- RID生成的扰动与优化方法相似,但与高斯噪声等自然噪声有明显区别。
RID-Ensemble扩展:
- 通过集成多个预训练的扩散模型,RID-Ensemble增强了对未知模型和后处理技术的防御能力。
- RID-Ensemble在黑盒防御和对抗JPEG压缩、Diffpure等后处理技术中表现出色。
未来研究方向:
- 提出了进一步探索优化扰动搜索空间、降低扰动可见性、扩展到其他创意产出保护等研究方向。
总体而言,这篇论文提出了一个高效且实用的身份防御解决方案,能够在保护个人隐私的同时,适应实时和大规模的应用场景。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

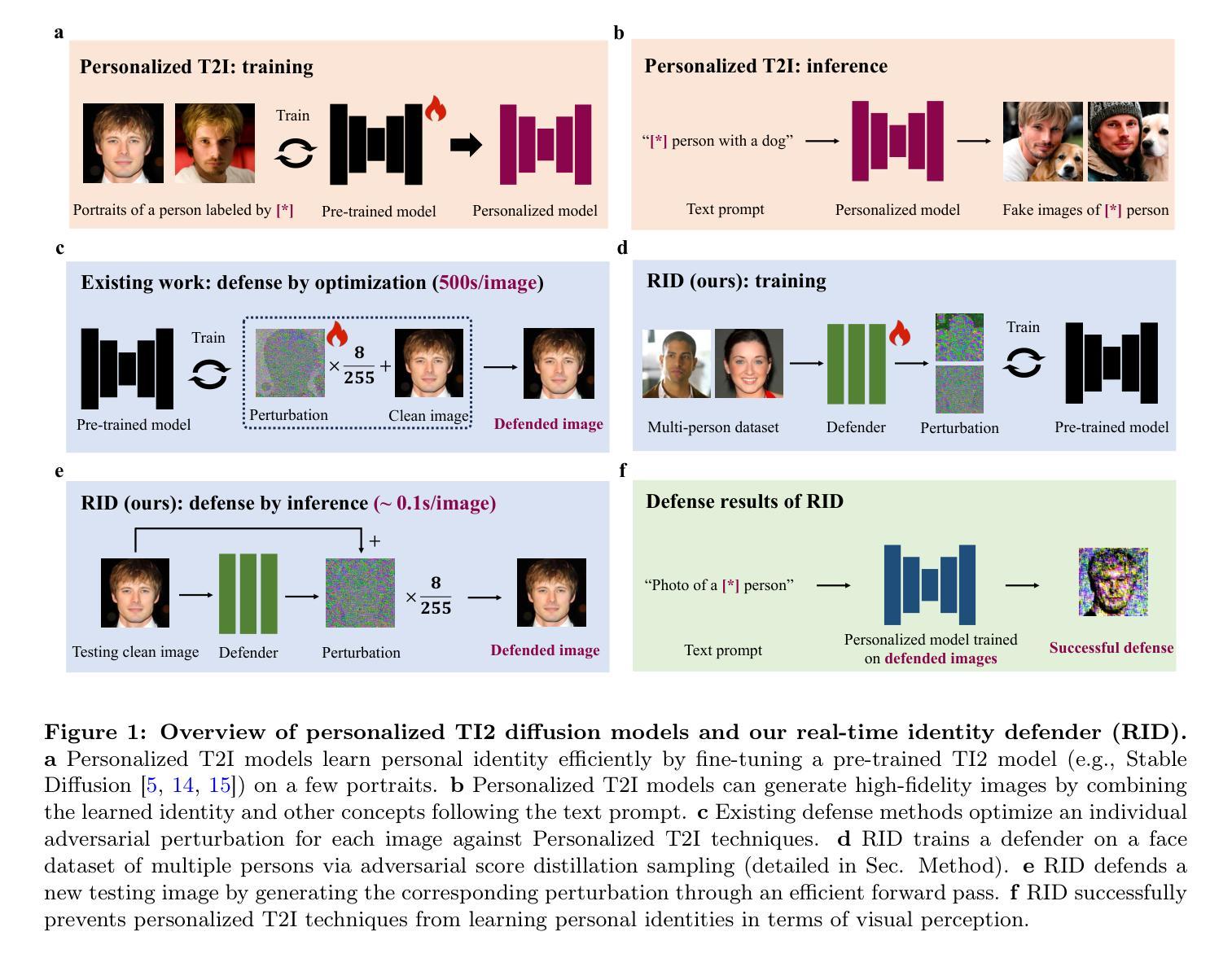
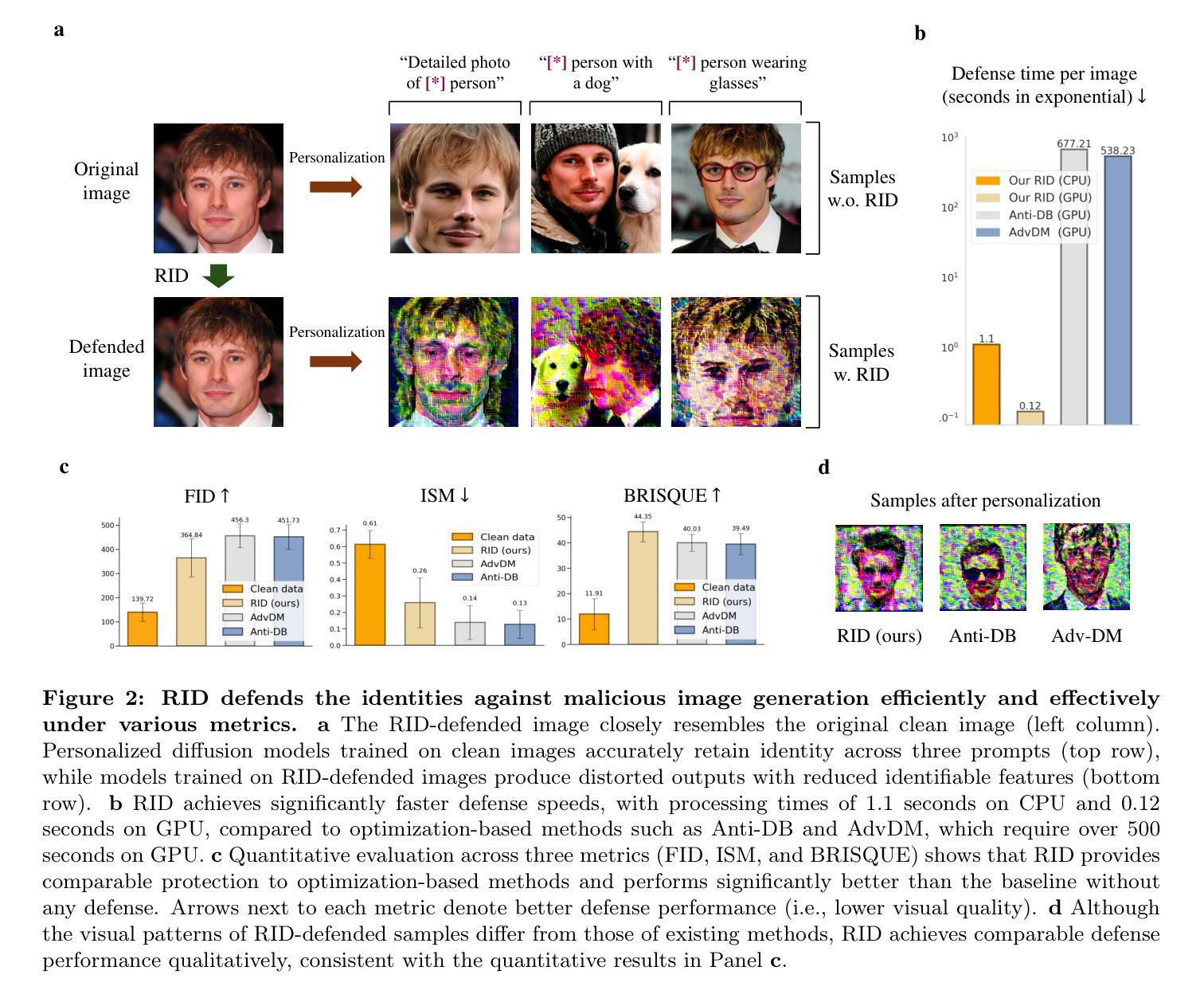
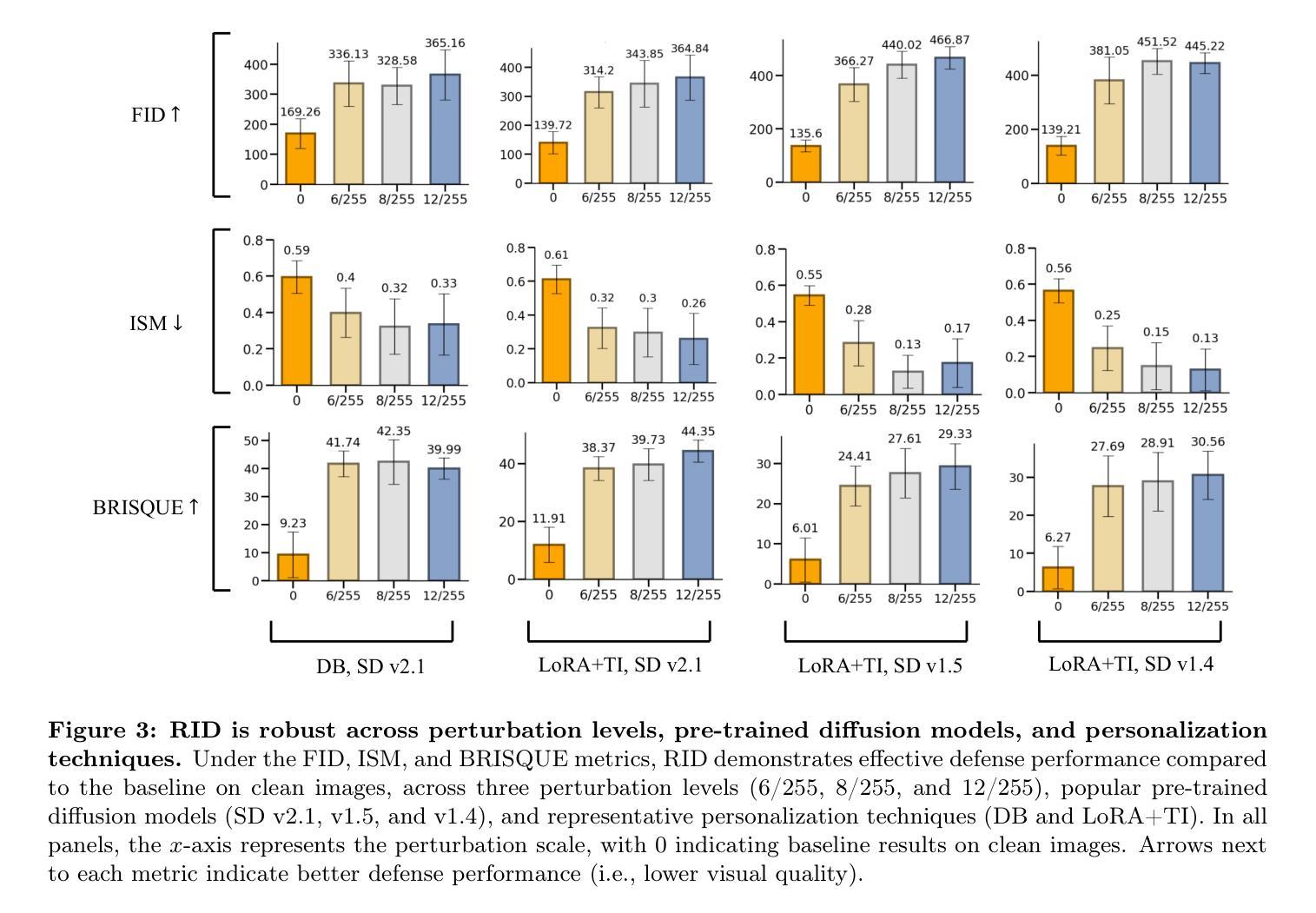
Leveraging Programmatically Generated Synthetic Data for Differentially Private Diffusion Training
Authors:Yujin Choi, Jinseong Park, Junyoung Byun, Jaewook Lee
Programmatically generated synthetic data has been used in differential private training for classification to enhance performance without privacy leakage. However, as the synthetic data is generated from a random process, the distribution of real data and the synthetic data are distinguishable and difficult to transfer. Therefore, the model trained with the synthetic data generates unrealistic random images, raising challenges to adapt the synthetic data for generative models. In this work, we propose DP-SynGen, which leverages programmatically generated synthetic data in diffusion models to address this challenge. By exploiting the three stages of diffusion models(coarse, context, and cleaning) we identify stages where synthetic data can be effectively utilized. We theoretically and empirically verified that cleaning and coarse stages can be trained without private data, replacing them with synthetic data to reduce the privacy budget. The experimental results show that DP-SynGen improves the quality of generative data by mitigating the negative impact of privacy-induced noise on the generation process.
程序化生成的合成数据在差分隐私训练的分类中已用于提高性能而不泄露隐私。然而,由于合成数据是由随机过程生成的,真实数据与合成数据的分布是可区分的,且难以转移。因此,使用合成数据训练的模型会产生不现实的随机图像,这给适应生成模型的合成数据带来了挑战。在这项工作中,我们提出了DP-SynGen,它利用扩散模型中的程序化生成合成数据来解决这一挑战。通过利用扩散模型的三个阶段(粗糙、上下文和清理),我们确定了可以有效利用合成数据的阶段。我们从理论和实证上验证了清理和粗糙阶段可以无需私人数据进行训练,用合成数据替换它们,以减少隐私预算。实验结果表明,DP-SynGen通过减轻隐私引起的噪声对生成过程的负面影响,提高了生成数据的质量。
论文及项目相关链接
Summary
本文介绍了在差分隐私训练分类时,使用程序生成合成数据以提高性能而不泄露隐私的挑战。由于合成数据由随机过程生成,与真实数据的分布有所区别,难以迁移。因此,使用合成数据训练的模型会产生不现实的随机图像。本文提出了DP-SynGen方法,利用扩散模型中的程序生成合成数据来解决此挑战。通过探索扩散模型的三个阶段(粗略、上下文和清理),我们确定了可以有效利用合成数据的阶段。理论上和实验上验证,清理和粗略阶段可以用合成数据替代真实数据进行训练,从而减少隐私预算。实验结果表明,DP-SynGen通过减轻隐私引起的噪声对生成过程的负面影响,提高了生成数据的质量。
Key Takeaways
- 程序生成的合成数据在差分隐私训练分类中用于提高性能,但存在与真实数据分布差异的问题。
- 合成数据在扩散模型的三个阶段(粗略、上下文和清理)中的应用具有潜力。
- 清理和粗略阶段可以用合成数据替代真实数据进行训练,降低隐私预算。
- DP-SynGen方法能有效提高生成数据的质量。
- DP-SynGen通过减轻隐私引起的噪声对生成过程的负面影响来实现这一提高。
- 实验结果证明了DP-SynGen方法的实际效果。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在差分隐私保护下的生成模型训练中,如何有效地利用程序生成的合成数据(programmatically generated synthetic data)来提高模型性能并减少隐私泄露的风险。具体来说,论文关注以下几个挑战:
差分隐私(Differential Privacy, DP)训练中的模型欠拟合问题:应用差分隐私保护时,通常会在模型训练中引入噪声,这可能导致模型性能下降,即模型欠拟合。
合成数据与真实数据分布差异问题:由于合成数据是通过随机过程生成的,其分布与真实数据存在显著差异,这使得直接使用合成数据进行模型预训练效果不佳,尤其是在生成模型中。
生成模型(特别是扩散模型)的训练挑战:扩散模型因其迭代去噪步骤简单且平滑而成为生成模型的主流选择,但在差分隐私训练中存在不稳定训练和训练步骤大的问题。
为了应对这些挑战,论文提出了一个名为DP-SynGen的框架,该框架通过在扩散模型的不同阶段有效利用合成数据来减少对隐私数据的依赖,从而在保护隐私的同时提高模型性能。
Q: 有哪些相关研究?
A: 论文中提到了以下相关研究:
差分隐私(Differential Privacy, DP):[1] C. Dwork, “Differential privacy,” 提出了差分隐私的基本概念和框架。
扩散模型(Diffusion Models):[11] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” 提出了去噪扩散概率模型(DDPM)。
差分隐私训练中的预训练方法:[2] J. Park, Y. Choi, and J. Lee, “In-distribution public data synthesis with diffusion models for differentially private image classification,” 研究了如何使用公共数据进行差分隐私图像分类。
大规模公共预训练数据的隐私问题:[4] F. Tramèr, G. Kamath, and N. Carlini, “Position: Considerations for differentially private learning with large-scale public pretraining,” 讨论了大规模公共预训练数据的隐私问题。
差分隐私扩散模型(DP Diffusion Models):[5] T. Dockhorn, T. Cao, A. Vahdat, and K. Kreis, “Differentially Private Diffusion Models,” 提出了差分隐私扩散模型(DPDM)。
合成数据在分类器训练中的应用:[6] M. Baradad Jurjo et al., “Learning to see by looking at noise,” 验证了合成数据在分类器训练中的有效性。
合成数据在差分隐私分类中的应用:[7] X. Tang, A. Panda, V. Sehwag, and P. Mittal, “Differentially private image classification by learning priors from random processes,” 利用合成数据进行差分隐私图像分类。
合成数据在差分隐私基础模型中的应用:[8] Y. Yu, M. Sanjabi, Y. Ma, K. Chaudhuri, and C. Guo, “Vip: A differentially private foundation model for computer vision,” 探讨了合成数据在差分隐私基础模型中的应用。
扩散过程的三个阶段:[9] J. Choi et al., “Perception prioritized training of diffusion models,” 识别了扩散过程的三个阶段:粗略(coarse)、上下文(context)和清洁(cleaning)。
公平图像生成:[10] Y. Choi, J. Park, H. Kim, J. Lee, and S. Park, “Fair sampling in diffusion models through switching mechanism,” 利用扩散模型的不同阶段进行公平图像生成。
这些研究为本文提出的DP-SynGen框架提供了理论基础和技术支持,特别是在差分隐私保护、扩散模型训练、以及合成数据的有效利用等方面。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为DP-SynGen的框架,通过以下步骤解决在差分隐私保护下利用合成数据训练生成模型的问题:
1. 识别扩散模型的三个阶段
论文基于之前的研究发现扩散过程可以被分为三个阶段:粗略(coarse)、上下文(context)和清洁(cleaning)。每个阶段对生成数据的影响不同,这为在不同阶段使用合成数据提供了理论依据。
2. 利用合成数据在特定阶段训练
- 粗略阶段(Coarse Stage):论文提出在粗略阶段使用合成数据进行训练不会显著影响生成数据的质量,因为这个阶段主要涉及学习数据的高层特征。
- 清洁阶段(Cleaning Stage):在清洁阶段,论文发现使用合成数据也能保持生成数据的质量,尽管这个阶段对细节特征的恢复很重要。
3. 提出DP-SynGen框架
DP-SynGen框架包括两种方法:DP-SynGen Coarse和DP-SynGen Cleaning,以及一个预训练方法DP-SynGen FineTune。这些方法通过在适当的阶段使用合成数据来减少对隐私数据的需求,从而减少隐私预算的消耗。
4. 减少隐私预算消耗
通过在粗略和清洁阶段使用合成数据,DP-SynGen减少了需要访问隐私数据的训练迭代次数,从而降低了每步训练中引入的隐私噪声,有助于提高模型性能。
5. 理论验证和实验结果
- 理论验证:论文通过理论分析和定理证明了在特定阶段使用合成数据的可行性和有效性。
- 实验结果:通过在MNIST、Fashion MNIST和CelebA数据集上的实验,论文展示了DP-SynGen在保持隐私的同时提高了生成数据的质量。
6. 寻找最优阈值
论文提出了一种基于信噪比(SNR)和βt-scheduling的方法来确定使用合成数据的阶段阈值τ,这有助于在不牺牲隐私的前提下优化模型训练。
总的来说,DP-SynGen框架通过在扩散模型的适当阶段引入合成数据,减少了对隐私数据的依赖,从而在保护隐私的同时提高了生成模型的性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证DP-SynGen框架的有效性,具体实验包括:
数据集
- MNIST:用于黑白图像数据集的实验。
- Fashion MNIST:用于时尚产品图像的数据集。
- CelebA:用于彩色图像的数据集。
合成数据类型
- 使用了不同类型的程序生成合成图像,例如“Dead-leaves”图像,以验证合成数据在训练中的效果。
性能指标
- **Fréchet Inception Distance (FID)**:用于衡量生成数据的质量。
- **Classification Accuracy Score (CAS)**:用于衡量生成数据的质量,特别是针对下游分类任务的性能。
实验设置
- DP-ϵ值:测试了不同的隐私预算ϵ值(例如0.2, 0.5, 1, 10)。
- 噪声多重性:测试了不同的噪声多重性(例如1, 4, 8, 16)。
比较方法
- 论文将DP-SynGen与DPDM等其他差分隐私保护方法进行了比较。
实验结果
- 表I:展示了在MNIST和Fashion MNIST数据集上,使用FID和CAS评估的生成性能结果。
- 表II、III、IV:展示了在不同DP-ϵ值和噪声多重性下,分类准确度分数(CAS)和FID分数的变化。
附加实验
- 阈值τ的选择:通过实验确定了在DP-SynGen Cleaning和DP-SynGen Coarse中使用合成数据的最佳阈值τ。
- 不同合成数据的影响:通过对比使用不同合成数据(如“Dead-leaves”和“salt-and-pepper”噪声)的实验结果,验证了合成数据类型对生成质量的影响。
生成样本
- 提供了在不同隐私预算和方法下,MNIST、Fashion MNIST和CelebA数据集的生成样本图像。
这些实验全面评估了DP-SynGen框架在不同设置下的性能,并与现有技术进行了比较,以证明其在保护隐私的同时提高生成模型性能的潜力。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了DP-SynGen框架并在实验中展示了其有效性,但仍有一些可以进一步探索的点:
1. 合成数据生成方法
- 多样化合成数据:探索更多种类的程序生成合成数据,以评估它们在不同类型和复杂度的数据集上的表现。
- 合成数据质量提升:研究如何提高合成数据的质量,使其更接近真实数据分布,从而可能提高预训练效果。
2. 扩散模型的阶段划分
- 自动化阶段划分:研究自动化方法来确定扩散模型的阶段划分,而不是依赖于预先设定的阈值。
- 阶段内的训练策略:探索不同阶段内更精细的训练策略,以充分利用合成数据和隐私数据。
3. 差分隐私算法的优化
- 隐私预算分配:研究如何更有效地分配隐私预算,以达到更好的隐私保护效果和模型性能。
- 噪声多重性的进一步研究:探讨噪声多重性对模型性能的影响,并寻找最优配置。
4. 跨模态和多任务学习
- 跨模态生成模型:将DP-SynGen应用于跨模态生成任务,例如文本到图像的生成,评估合成数据在这些任务中的有效性。
- 多任务学习:研究在多任务学习框架下使用DP-SynGen,以提高模型在多个相关任务上的性能。
5. 实际应用和案例研究
- 特定领域的应用:在医疗、金融等对隐私要求严格的领域中应用DP-SynGen,评估其在实际问题中的有效性和实用性。
- 长期隐私保护:研究DP-SynGen在长期训练和迭代过程中保护隐私的能力。
6. 算法的可扩展性和效率
- 大规模数据集:在大规模数据集上测试DP-SynGen的可扩展性和效率,优化算法以处理更大的数据集。
- 并行和分布式训练:研究如何利用并行和分布式计算资源来加速DP-SynGen的训练过程。
7. 理论分析和证明
- 泛化能力的理论研究:深入研究合成数据对模型泛化能力的影响,并提供理论证明。
- 隐私保护的严格性分析:提供更严格的隐私保护分析,证明DP-SynGen满足更高标准的隐私保护要求。
这些方向不仅可以推动差分隐私和生成模型的研究进展,还可能为实际应用提供新的解决方案。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
问题陈述:
- 论文探讨了在差分隐私保护下训练生成模型时面临的挑战,尤其是在分类模型中使用合成数据提升性能的同时,如何减少隐私泄露并提高生成模型的适应性。
研究动机:
- 由于合成数据的分布与真实数据存在差异,直接使用合成数据进行预训练效果不佳,尤其是在扩散模型中。因此,需要探索在保持隐私的同时提高模型性能的方法。
DP-SynGen框架:
- 提出了DP-SynGen框架,该框架利用程序生成的合成数据在扩散模型的不同阶段进行训练,以减少对隐私数据的依赖并降低隐私预算消耗。
- 框架包括DP-SynGen Coarse和DP-SynGen Cleaning两种方法,以及DP-SynGen FineTune预训练方法。
理论验证:
- 通过理论分析和定理证明,在扩散模型的特定阶段(粗略和清洁阶段)使用合成数据的可行性和有效性。
实验结果:
- 在MNIST、Fashion MNIST和CelebA数据集上的实验结果表明,DP-SynGen能够在保持隐私的同时提高生成数据的质量。
- 论文还探讨了不同隐私预算、噪声多重性对模型性能的影响。
最优阈值τ的确定:
- 提出了基于信噪比(SNR)和βt-scheduling的方法来确定使用合成数据的阶段阈值τ。
贡献总结:
- 论文的主要贡献在于提出了一种新的方法,通过在扩散模型的适当阶段引入合成数据,减少了对隐私数据的需求,从而在保护隐私的同时提高了生成模型的性能。
未来工作:
- 论文还提出了一些可以进一步探索的方向,如合成数据生成方法的改进、跨模态学习应用、算法的可扩展性和效率优化等。
总的来说,论文通过引入DP-SynGen框架,为在差分隐私保护下训练生成模型提供了一种新的思路和方法,并通过实验验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



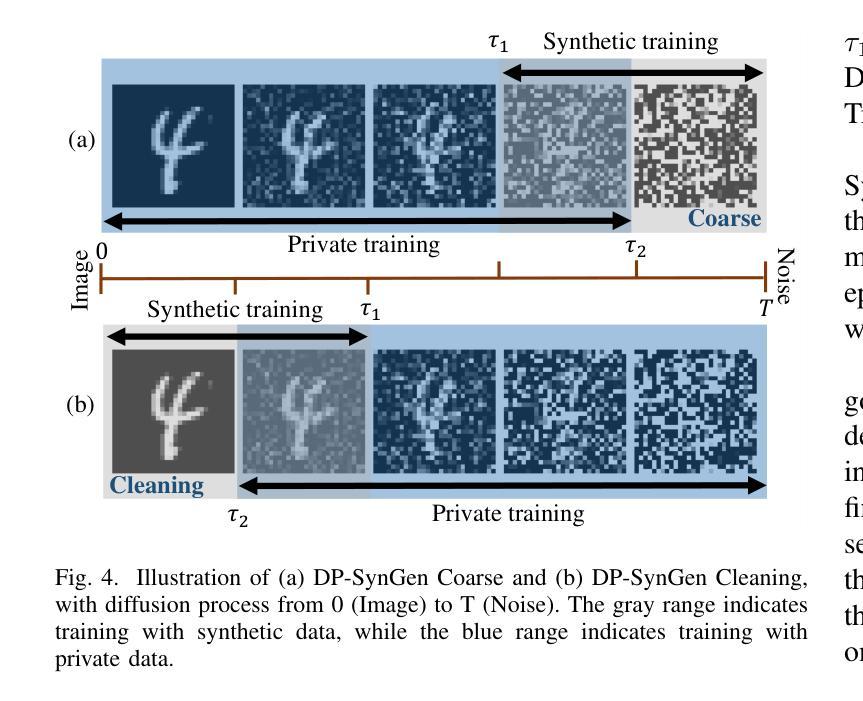
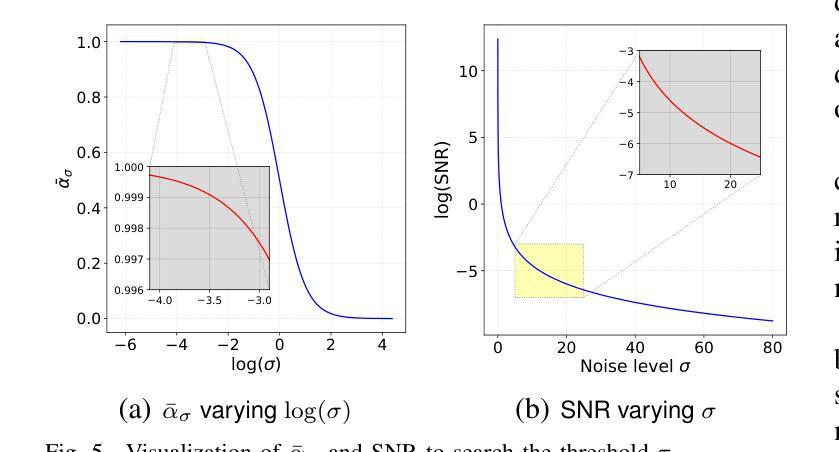
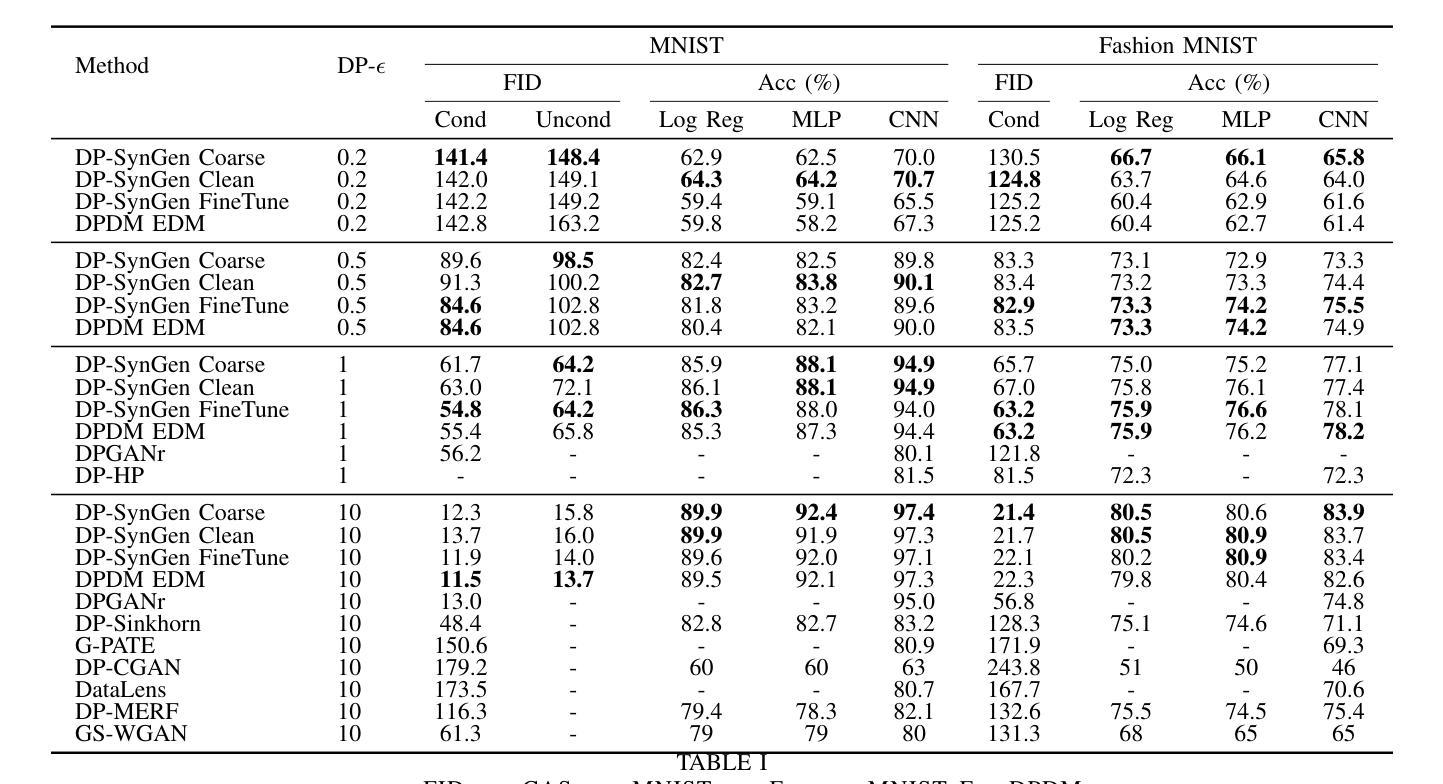
An Efficient Framework for Enhancing Discriminative Models via Diffusion Techniques
Authors:Chunxiao Li, Xiaoxiao Wang, Boming Miao, Chuanlong Xie, Zizhe Wang, Yao Zhu
Image classification serves as the cornerstone of computer vision, traditionally achieved through discriminative models based on deep neural networks. Recent advancements have introduced classification methods derived from generative models, which offer the advantage of zero-shot classification. However, these methods suffer from two main drawbacks: high computational overhead and inferior performance compared to discriminative models. Inspired by the coordinated cognitive processes of rapid-slow pathway interactions in the human brain during visual signal recognition, we propose the Diffusion-Based Discriminative Model Enhancement Framework (DBMEF). This framework seamlessly integrates discriminative and generative models in a training-free manner, leveraging discriminative models for initial predictions and endowing deep neural networks with rethinking capabilities via diffusion models. Consequently, DBMEF can effectively enhance the classification accuracy and generalization capability of discriminative models in a plug-and-play manner. We have conducted extensive experiments across 17 prevalent deep model architectures with different training methods, including both CNN-based models such as ResNet and Transformer-based models like ViT, to demonstrate the effectiveness of the proposed DBMEF. Specifically, the framework yields a 1.51% performance improvement for ResNet-50 on the ImageNet dataset and 3.02% on the ImageNet-A dataset. In conclusion, our research introduces a novel paradigm for image classification, demonstrating stable improvements across different datasets and neural networks. The code is available at https://github.com/ChunXiaostudy/DBMEF.
图像分类作为计算机视觉的基石,传统上是通过基于深度神经网络的判别模型来实现的。最近的进展已经引入了基于生成模型的分类方法,这些方法具有零样本分类的优点。然而,这些方法存在两个主要缺点:计算开销大以及与判别模型的性能相比表现较差。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
基于扩散模型的判别模型增强框架(DBMEF)结合了判别模型和生成模型的优势,通过零训练的方式实现了图像分类。该框架利用判别模型进行初步预测,并通过扩散模型赋予深度神经网络反思能力,提高了判别模型的分类精度和泛化能力。在多个流行深度模型架构和训练方法的实验中,DBMEF表现出有效性和稳定性。
Key Takeaways
- 扩散模型在图像分类中得到了应用,结合判别模型和生成模型的优点。
- DBMEF框架利用判别模型进行初步预测,然后通过扩散模型增强分类性能。
- DBMEF通过结合深度神经网络和扩散模型,提高了判别模型的分类精度和泛化能力。
- 该框架以训练无关的方式工作,可以轻松地应用于不同的模型和数据集。
- 在多个实验和不同的神经网络架构中,DBMEF表现出稳定的性能改进。
- DBMEF在ImageNet和ImageNet-A数据集上分别实现了1.51%和3.02%的性能提升。
- 该研究的代码已公开可用。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是如何在图像分类任务中结合判别模型(discriminative models)和生成模型(generative models)的优势,以提高分类的准确性和泛化能力。具体来说,论文中提到了以下几个关键问题:
判别模型与生成模型的结合:传统的图像分类方法通常独立地使用判别模型或生成模型。判别模型直接对图像进行分类,而生成模型则通过学习数据的联合分布来实现分类。论文提出了一个框架,将这两种模型结合起来,以期达到更好的分类效果。
生成模型在分类中的高计算开销和性能不足:基于生成模型的分类方法,尽管提供了零样本分类(zero-shot classification)的优势,但它们存在两个主要缺点:高计算开销和相比判别模型的性能劣势。论文旨在通过提出的方法来克服这些问题。
模仿人脑处理视觉信号的过程:论文受到人脑在视觉信号识别过程中快速-慢速路径相互作用的协调认知过程的启发,提出了一个框架,通过模仿这一过程来增强判别模型的性能。
提高判别模型的分类准确性和泛化能力:论文提出的框架旨在通过无需训练的方式,以即插即用的形式增强判别模型的分类准确性和泛化能力。
处理分布偏移和低分辨率数据:论文还探讨了所提出框架在面对分布偏移和低分辨率数据时的有效性,以展示其在不同情况下的鲁棒性和适用性。
综上所述,论文的核心目标是提出一个有效的框架,通过结合判别模型和生成模型的优点,来提升图像分类任务的性能,并在不同的数据集和神经网络架构上展示其有效性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以概括为以下几个方面:
判别模型和生成模型在图像分类中的应用:
- 判别模型直接对图像分类,如VGG、ResNet、ViT等。
- 生成模型通过学习数据的联合分布来进行分类,例如基于能量的模型(EBM)和基于分数的模型(Score-Based Models)。
零样本分类(Zero-Shot Classification):
- 使用生成模型进行零样本分类的研究,如基于扩散模型(Diffusion Models)的方法。
扩散模型(Diffusion Models):
- 扩散模型在图像生成领域的应用,特别是在生成高质量图像方面超越了生成对抗网络(GANs)。
- 分类引导扩散(Classifier Guidance Diffusion)和无分类器引导扩散(Classifier-Free Guidance Diffusion)技术,这些技术通过在生成阶段调整图像的梯度来实现基于指定类别的条件生成。
基于分数的生成模型(Score-Based Generative Models):
- 使用基于分数的生成模型来估计条件概率(P(x|y)),并用于图像分类。
对抗性鲁棒性(Adversarial Robustness):
- 利用扩散模型评估传统判别分类器的对抗性鲁棒性。
结合判别模型和生成模型的方法:
- 先前的研究工作,如SBGC、RDC等,这些方法尝试将扩散模型整合到图像分类任务中。
改进扩散模型的分类性能:
- 将扩散模型应用于DiT-XL/2模型,并在ImageNet数据集上进行监督分类。
加速采样方法:
- 研究工作探索了加速扩散模型采样过程的方法,以减少分类单个图像所需的时间。
这些相关研究构成了论文提出的Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的理论基础和技术背景。论文通过结合这些领域的最新进展,提出了一个新的框架,旨在通过模仿人脑处理视觉信号的过程来增强判别模型的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的框架来解决上述问题。以下是该框架解决这些问题的关键步骤和方法:
1. 结合判别模型和生成模型
DBMEF框架通过以下步骤将判别模型和生成模型结合起来:
- 判别模型初步预测:使用判别模型对测试输入进行初步预测,类似于人脑中的快速通路。
- 生成模型重新评估:对于判别模型不确定的预测,使用扩散模型进行重新评估,模拟人脑中的慢速通路。
2. 模仿人脑处理视觉信号的过程
- 快速-慢速路径交互:框架受到人脑处理视觉信号时快速和慢速路径相互作用的启发,通过重复“猜测-验证-猜测-验证”的过程来识别对象。
3. 增强判别模型的性能
- 置信度保护器(Confidence Protector):通过一个置信度阈值来决定是否需要通过扩散模型进一步评估预测结果。
- 扩散模型分类器:将扩散模型的有条件去噪结果转化为后验概率的估计,以重新分类图像。
4. 处理分布偏移和低分辨率数据
- 适应不同数据集:框架在多个数据集上进行测试,包括ImageNet、ImageNet-A、CIFAR-10和CIFAR-100,以验证其对分布偏移和低分辨率数据的适应性。
5. 提升效率和准确性
- 减少计算开销:通过仅对判别模型不确定的预测进行扩散模型的重新评估,减少了整体计算开销。
- 提高分类准确性:通过结合判别模型的高效率和生成模型的精细化处理,DBMEF显著提高了分类的准确性。
6. 即插即用和无需训练
- 无需额外训练:DBMEF作为一个即插即用的框架,可以直接应用于现有的判别模型,无需额外的训练过程。
总结来说,DBMEF框架通过模仿人脑处理视觉信号的过程,结合了判别模型和生成模型的优势,以提高图像分类任务的准确性和泛化能力,同时减少了计算开销。通过在多个数据集和不同网络架构上的实验,论文证明了该框架的有效性和普适性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的有效性。以下是实验的主要内容:
1. 不同模型架构的性能测试
- 基线模型:选择了17种基于不同训练方法、数据集和架构的判别模型,包括监督学习模型(如DeiT-Base、ViT-Base、ResNet50等)、自监督学习方法(如MAE、DINOv2等)以及对比学习模型(如CLIP)。
- 实验设置:使用Stable Diffusion V1-5作为扩散模型,设置保护阈值Prot、时间步长、负控制因子λ等参数,并在ImageNet2012-1k验证集上进行评估。
- 结果:DBMEF在这些模型上取得了0.19%到3.27%的准确率提升。
2. 分布偏移的性能测试
- 数据集:使用ImageNet-S、ImageNet-A、ImageNet-V2和ImageNet-E数据集来评估DBMEF在面对不同类型的分布偏移时的性能。
- 基线模型:使用ViT-Base、DeiT-Small、ResNet50和VGG16等预训练的深度判别模型。
- 结果:DBMEF在各种分布偏移数据集上均显示出稳定的性能提升,特别是在ImageNet-A上,ResNet50的准确率从0.00%提升到3.02%。
3. 低分辨率数据集的分类性能测试
- 数据集:选择CIFAR-10和CIFAR-100数据集,这些数据集包含的图像分辨率为32×32像素。
- 基线模型:使用ResNet18、ResNet34和ResNet50等模型,并在这些数据集上进行测试。
- 结果:即使在基线准确率已经很高的低分辨率图像上,应用DBMEF框架仍然能够进一步提升性能。
4. 超参数的影响测试
- 超参数:研究了保护阈值Prot、时间步长T、负控制因子λ以及扩散模型的选择对DBMEF性能的影响。
- 实验结果:分析了不同超参数设置对模型性能的具体影响,提供了关于如何选择这些参数以优化DBMEF性能的见解。
5. 置信度保护器和扩散模型的作用分析
- 置信度保护器:通过详细的可视化和分析,展示了置信度保护器对DBMEF性能的影响。
- 扩散模型:通过实验验证了扩散模型在DBMEF中的关键作用,与使用更多数据训练的判别模型相比,扩散模型提供了更好的性能提升。
这些实验全面地验证了DBMEF框架的有效性、普适性和鲁棒性,并深入分析了框架中各个组件的作用和影响。通过这些实验,论文展示了DBMEF在不同条件下都能显著提升图像分类任务的性能。
Q: 有什么可以进一步探索的点?
A: 论文提出的Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)为图像分类领域提供了一个新范式,以下是一些可以进一步探索的点:
1. 超参数优化
- 研究不同的超参数设置对DBMEF性能的影响,包括保护阈值(Prot)、时间步长(T)、负控制因子(λ)等,以找到最优的配置。
2. 扩散模型的改进
- 探索使用新一代的扩散模型,如更近期版本的Stable Diffusion或其他类型的扩散模型,以进一步提高DBMEF的性能。
- 研究如何定制扩散模型以更好地适应特定的判别模型和数据集。
3. 多模态数据集的应用
- 将DBMEF应用于多模态数据集,如结合图像和文本的数据集,探索其在多模态学习中的潜力。
4. 不同的网络架构
- 测试DBMEF在更多种类的深度学习架构上的效果,包括最新的卷积网络和Transformer变体。
5. 跨域泛化能力
- 研究DBMEF在面对更大分布偏移时的表现,例如跨域识别任务,以及如何改进框架以提高其跨域泛化能力。
6. 实时应用
- 探索DBMEF在实时应用中的可行性,例如在移动设备或嵌入式系统上的部署,并优化其以满足实时处理的需求。
7. 理论分析
- 深入研究DBMEF的理论基础,包括其统计性质和收敛性,以及如何从理论上解释其性能提升的原因。
8. 与其他生成模型的比较
- 将DBMEF与其他类型的生成模型(如GANs)进行比较,分析其在图像分类任务中的优缺点。
9. 鲁棒性和安全性测试
- 对DBMEF进行鲁棒性和安全性测试,特别是在对抗性攻击和数据隐私方面的表现。
10. 应用到其他视觉任务
- 将DBMEF框架扩展到其他计算机视觉任务,如目标检测、语义分割等,探索其在这些任务中的有效性和适用性。
这些探索点可以帮助研究者更深入地理解DBMEF的工作原理,优化其性能,并扩展其在计算机视觉领域的应用范围。
Q: 总结一下论文的主要内容
A: 论文提出了一个名为Diffusion-Based Discriminative Model Enhancement Framework (DBMEF)的新框架,旨在通过结合判别模型和生成模型的优势来增强图像分类任务的性能。以下是论文的主要内容总结:
1. 研究动机
- 传统的图像分类方法主要基于判别模型或生成模型,但存在各自的局限性。判别模型虽然分类速度快,但缺乏重新评估的能力;生成模型能进行细致的图像理解,但计算成本高且性能落后于判别模型。
2. DBMEF框架
- 框架概述:DBMEF框架通过模仿人脑处理视觉信号的快速和慢速路径交互过程,整合判别模型和生成模型,以提高分类的准确性和泛化能力。
- 关键组件:包括置信度保护器和扩散模型分类器,以及结合正负文本条件和投票机制的策略。
3. 方法论
- 判别模型初步预测:判别模型首先对测试输入进行预测,类似于人脑的快速通路。
- 生成模型重新评估:对于判别模型不确定的预测,通过扩散模型进行重新评估,模拟人脑的慢速通路。
- 置信度保护器:基于训练集正确分类样本的统计特性,决定是否需要通过扩散模型进一步评估。
- 扩散模型分类器:将扩散模型的有条件去噪结果转化为后验概率的估计,以重新分类图像。
4. 实验验证
- 在多个数据集(包括ImageNet、ImageNet-A、CIFAR-10和CIFAR-100)和多种深度模型架构上验证了DBMEF的有效性。
- 实现了在不同模型上0.19%到3.27%的准确率提升,并在分布偏移和低分辨率数据上显示出稳定的性能提升。
5. 超参数影响和组件作用分析
- 对保护阈值、时间步长、负控制因子等超参数进行了实验分析,探讨了它们对框架性能的影响。
- 分析了置信度保护器和扩散模型在DBMEF中的关键作用。
6. 结论
- DBMEF框架有效地提高了判别模型的分类准确性和泛化能力,同时减少了计算开销。
- 论文提出了一个新的图像分类范式,并鼓励未来研究进一步探索扩散模型在下游应用中的整合。
总体而言,论文通过提出DBMEF框架,展示了如何通过结合判别模型和生成模型的优势来提高图像分类任务的性能,并在多个数据集和模型上验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

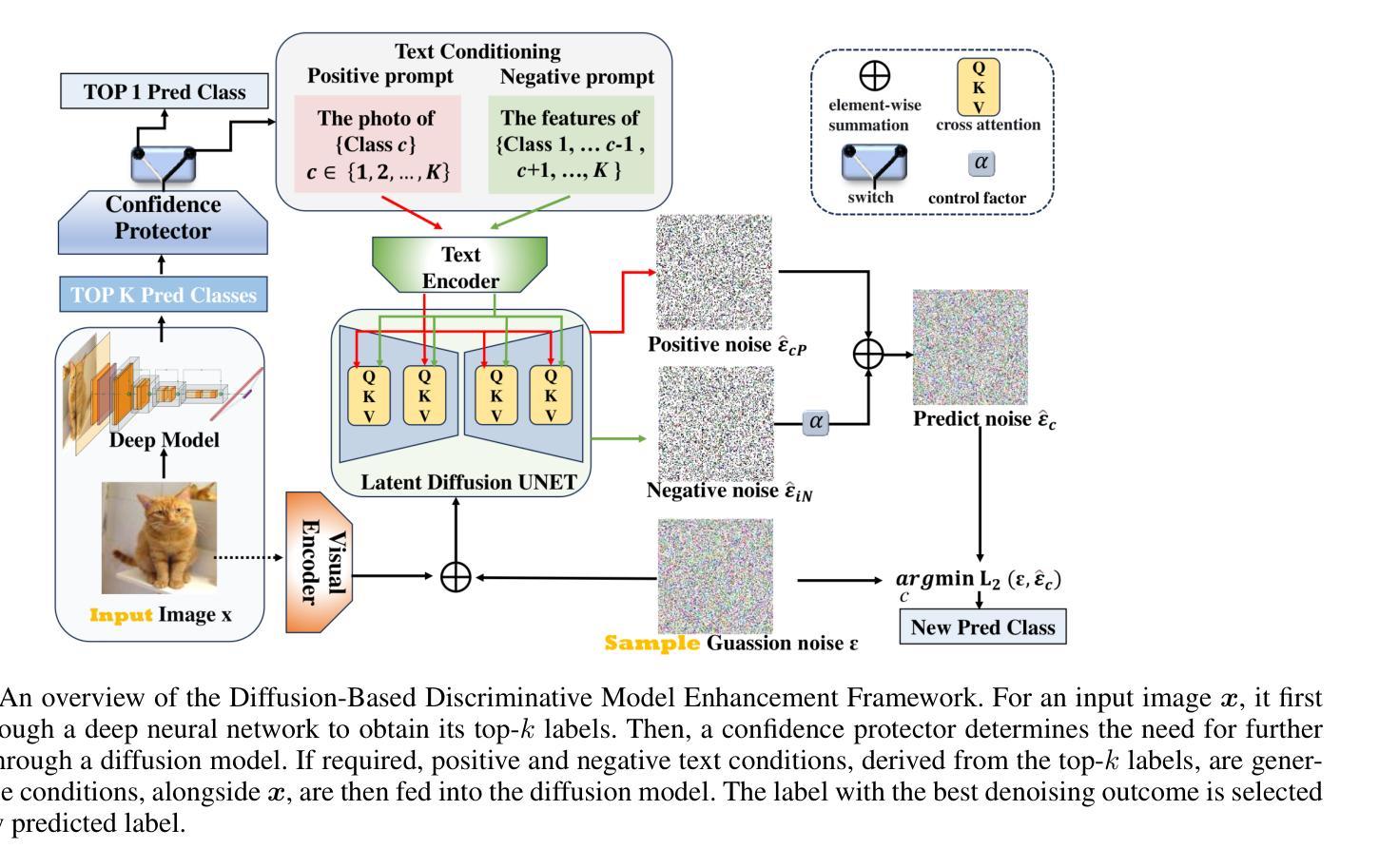
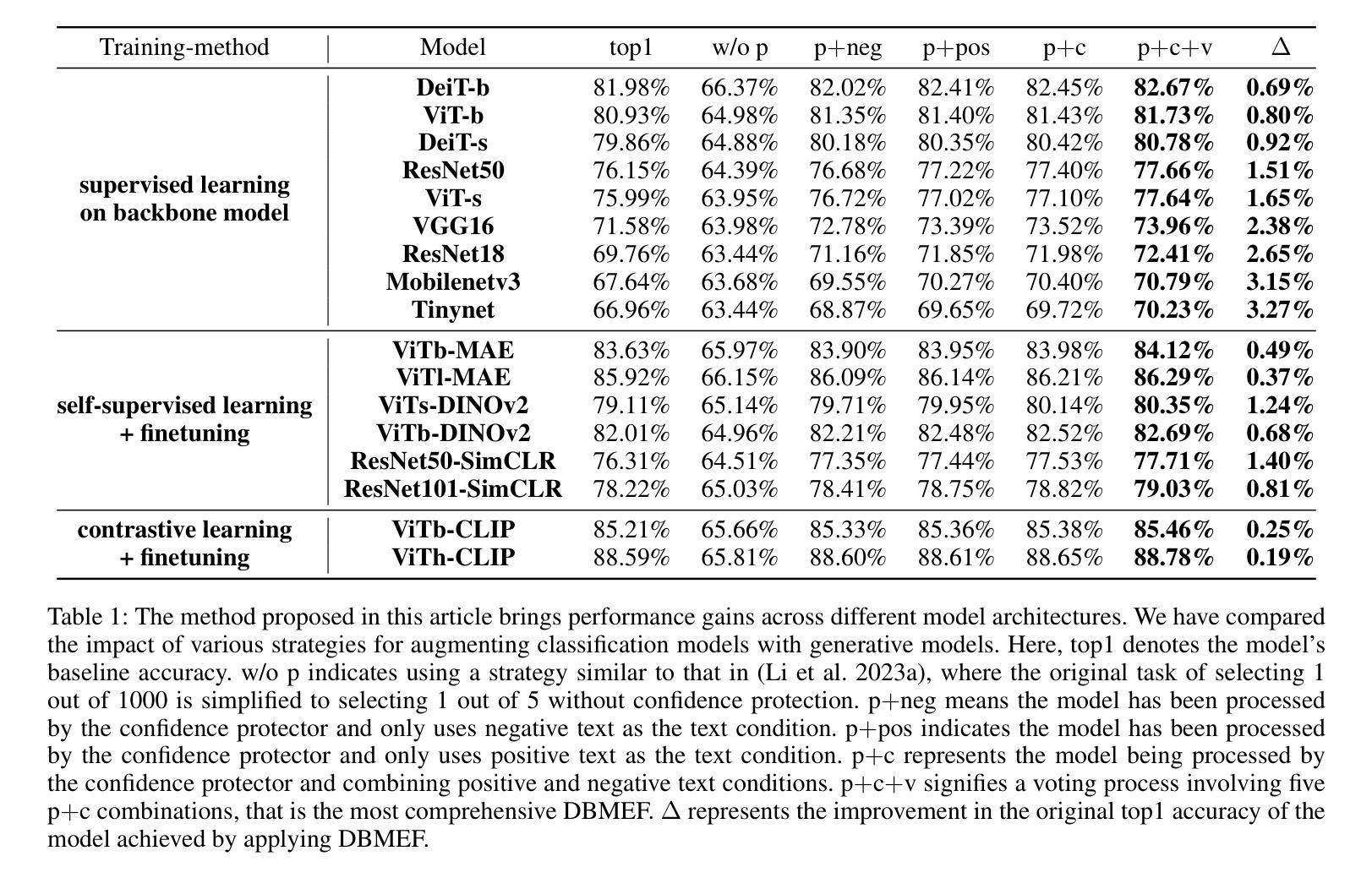
Perception-based multiplicative noise removal using SDEs
Authors:An Vuong, Thinh Nguyen
Multiplicative noise, also known as speckle or pepper noise, commonly affects images produced by synthetic aperture radar (SAR), lasers, or optical lenses. Unlike additive noise, which typically arises from thermal processes or external factors, multiplicative noise is inherent to the system, originating from the fluctuation in diffuse reflections. These fluctuations result in multiple copies of the same signal with varying magnitudes being combined. Consequently, despeckling, or removing multiplicative noise, necessitates different techniques compared to those used for additive noise removal. In this paper, we propose a novel approach using Stochastic Differential Equations based diffusion models to address multiplicative noise. We demonstrate that multiplicative noise can be effectively modeled as a Geometric Brownian Motion process in the logarithmic domain. Utilizing the Fokker-Planck equation, we derive the corresponding reverse process for image denoising. To validate our method, we conduct extensive experiments on two different datasets, comparing our approach to both classical signal processing techniques and contemporary CNN-based noise removal models. Our results indicate that the proposed method significantly outperforms existing methods on perception-based metrics such as FID and LPIPS, while maintaining competitive performance on traditional metrics like PSNR and SSIM.
乘性噪声,也称为斑点噪声或胡椒噪声,通常影响由合成孔径雷达(SAR)、激光器或光学镜头产生的图像。与通常由热过程或外部因素引起的加性噪声不同,乘性噪声是系统固有的,起源于漫反射的波动。这些波动导致同一信号的多个不同幅度的副本被组合在一起。因此,去斑或去除乘性噪声需要不同于用于去除加性噪声的技术。在本文中,我们提出了一种基于随机微分方程扩散模型的新方法来解决乘性噪声问题。我们证明乘性噪声可以有效地被建模为对数域中的几何布朗运动过程。利用福克-普朗克方程,我们推导出了用于图像去噪的反过程。为了验证我们的方法,我们在两个不同的数据集上进行了大量实验,将我们的方法与传统的信号处理技术和当前的CNN基于噪声去除模型进行了比较。结果表明,该方法在感知基础上的指标(如FID和LPIPS)上显著优于现有方法,同时在传统的指标(如PSNR和SSIM)上保持竞争力。
论文及项目相关链接
PDF 15 pages, 6 figures
Summary
本文提出一种基于随机微分方程扩散模型的新方法,用于处理合成孔径雷达(SAR)、激光器或光学透镜产生的图像中的乘法噪声(也称为斑点噪声或胡椒噪声)。该方法将乘法噪声有效地建模为对数域中的几何布朗运动过程,并利用福克-普朗克方程推导出图像去噪的逆向过程。实验结果表明,该方法在感知指标FID和LPIPS上显著优于现有方法,同时在传统指标PSNR和SSIM上保持竞争力。
Key Takeaways
- 乘法噪声是系统固有的,源于漫反射的波动,与由热过程或外部因素引起的加法噪声不同。
- 乘法噪声会导致同一信号的多份副本以不同的幅度组合。
- 本文提出了一种基于随机微分方程扩散模型的新方法来处理乘法噪声,该方法模拟乘法噪声为对数域中的几何布朗运动过程。
- 利用福克-普朗克方程推导出图像去噪的逆向过程。
- 该方法在感知指标FID和LPIPS上的表现显著优于传统信号处理和当代CNN噪声去除模型。
- 实验在两种数据集上进行,验证了方法的有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是**乘性噪声去除**问题。乘性噪声,也称为斑点噪声或胡椒噪声,通常影响由合成孔径雷达(SAR)、激光或光学透镜产生的图像。与通常由热过程或外部因素引起的加性噪声不同,乘性噪声是系统固有的,起源于漫反射波动。这些波动导致具有变化幅度的同一信号的多个副本被组合在一起。因此,去除乘性噪声,有时也称为去斑点,通常需要与去除加性噪声不同的技术。
论文提出了一种新颖的方法,使用基于随机微分方程(SDE)的扩散模型来解决乘性噪声问题。作者展示了乘性噪声可以有效地在对数域中被建模为几何布朗运动过程,并利用Fokker-Planck方程推导出相应的逆过程用于图像去噪。通过在两个不同的数据集上进行广泛的实验,并将他们的方法与传统的信号处理技术和当代基于CNN的噪声去除模型进行比较,结果表明所提出的方法在感知度量(如FID和LPIPS)上显著优于现有方法,同时在传统度量(如PSNR和SSIM)上保持了竞争性能。
Q: 有哪些相关研究?
A: 论文中提到了多项与乘性噪声去除相关的研究,以下是一些主要的相关研究工作:
Huang, Ng, and Wen (2009): 提出了一种新的基于全变分的乘性噪声去除方法。
- 论文引用:Huang, Y.-M.; Ng, M. K.; and Wen, Y.-W. 2009. A new total variation method for multiplicative noise removal.
Bioucas-Dias and Figueiredo (2010): 使用变量分裂和约束优化来去除乘性噪声。
- 论文引用:Bioucas-Dias, J. M.; and Figueiredo, M. A. 2010. Multiplicative noise removal using variable splitting and constrained optimization.
Yu and Acton (2002): 提出了一种基于偏微分方程模型的乘性噪声去除方法。
- 论文引用:Yu, Y.; and Acton, S. T. 2002. Speckle reducing anisotropic diffusion.
Dabov et al. (2007): 提出了一种基于块匹配技术的图像去噪方法,该方法在去斑点问题上表现良好。
- 论文引用:Dabov, K.; Foi, A.; Katkovnik, V.; and Egiazarian, K. 2007. Image denoising by sparse 3-D transform-domain collaborative filtering.
Shi and Osher (2008): 通过将图像转换到加性域并使用全变分(TV)目标进行优化来去除乘性噪声。
- 论文引用:Shi, J.; and Osher, S. 2008. A nonlinear inverse scale space method for a convex multiplicative noise model.
Aubert and Aujol (2008): 应用MAP估计进行乘性噪声去除。
- 论文引用:Aubert, G.; and Aujol, J.-F. 2008. A variational approach to removing multiplicative noise.
Zhang et al. (2017): 提出了一种使用CNN进行潜在空间高斯去噪的方法,即DnCNN,它通过学习噪声(残差)而不是直接学习干净版本。
- 论文引用:Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; and Zhang, L. 2017. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising.
Wang et al. (2022): 提出了一种基于深度学习的方法,用于图像去噪。
- 论文引用:Wang, X.; Xie, L.; Yu, K.; Chan, K. C.; Loy, C. C.; and Dong, C. 2022. BasicSR: Open Source Image and Video Restoration Toolbox.
Chen et al. (2022): 提出了NAFNet,是当前噪声去除和图像恢复的最新技术。
- 论文引用:Chen, L.; Chu, X.; Zhang, X.; and Sun, J. 2022. Simple Baselines for Image Restoration.
这些研究涵盖了从传统基于偏微分方程的方法到现代基于深度学习的方法,表明乘性噪声去除是一个长期存在的问题,并且在计算机视觉领域中一直有研究者在探索新的解决方案。
Q: 论文如何解决这个问题?
A: 论文通过提出一种基于随机微分方程(SDE)的扩散模型来解决乘性噪声去除问题。具体解决步骤如下:
模型建立:首先,作者将乘性噪声建模为几何布朗运动(Geometric Brownian Motion)过程,并在对数域中进行处理以简化模型。
Fokker-Planck方程应用:利用Fokker-Planck方程,作者推导出了用于图像去噪的逆SDE过程。
损失函数构建:在对数域中,作者利用Euler-Maruyama离散化方法,得到了正向和逆向SDE的离散形式,并基于此构建了损失函数。这个损失函数允许使用分数匹配方法来训练去噪模型。
训练过程:使用梯度下降算法和Adam优化器来训练一个神经网络,该网络参数化为得分函数(score function),用于估计数据分布的梯度的对数。
采样技术:论文提出了多种采样技术,包括随机采样、ODE采样和DDIM采样,以从训练好的模型中生成去噪后的图像。
实验验证:作者在两个不同的数据集上进行了广泛的实验,将所提出的方法与传统的信号处理技术和当代基于CNN的噪声去除模型进行了比较。
性能评估:通过感知度量(如FID和LPIPS)和传统度量(如PSNR和SSIM)来评估去噪效果,证明了所提出方法的有效性。
确定性采样:为了满足需要确定性结果的应用场景,作者提出了确定性采样方程,这可以在不同的运行中生成具有相同统计特性的相同去噪图像。
算法实现:论文提供了训练和采样过程的算法实现,包括用于训练得分网络的算法1和用于噪声去除的算法2和算法3。
通过这些步骤,论文成功地展示了如何使用SDE-based方法有效地去除图像中的乘性噪声,并在感知质量上取得了显著的改进。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的基于随机微分方程(SDE)的乘性噪声去除方法的有效性。以下是实验的主要部分:
数据集:实验在两个不同的数据集上进行,分别是CelebA数据集和UC Merced Land Use数据集。
网络架构:使用U-Net作为神经网络的骨干架构。
训练设置:在CelebA数据集的100,000张图像上进行训练,测试则在CelebA的2,096张图像和UC Merced Land Use的2,096张图像上进行。
基线模型:选择了多种去噪方法作为基线,包括BM3D、SRAD、DnCNN和NAFNet等。
训练配置:使用500个扩散步骤,线性噪声时间表,以及Adam优化器进行训练。
采样技术比较:评估了随机采样、ODE采样和DDIM采样三种不同的采样技术。
不同噪声水平的比较:在不同的噪声水平(0.04、0.08和0.12)下,比较了不同去噪方法的性能。
性能度量:使用了FID、LPIPS、PSNR和SSIM等度量指标来评估去噪效果。
感知度量与传统度量比较:讨论了感知度量与传统度量(如PSNR和SSIM)之间的不一致性。
定性分析:通过可视化的方式展示了不同去噪模型在CelebA数据集和UC Merced Land Use数据集上的去噪效果。
泛化能力测试:在UC Merced Land Use数据集上测试了模型的泛化能力,这是一个小规模的、与训练数据分布不同的数据集。
算法实现:提供了训练和采样过程的算法实现,包括算法1(训练得分网络)、算法2(随机去噪过程)和算法3(确定性去噪过程)。
通过这些实验,论文证明了所提出的SDE-based方法在感知度量上显著优于现有方法,同时在传统度量上保持了竞争性能。此外,实验还展示了该方法在不同噪声水平和不同数据集上的鲁棒性和泛化能力。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些可以进一步探索的点,具体包括:
扩散步骤减少技术的应用:论文提到,尽管扩散步骤减少技术已成功应用于许多生成任务,但在去噪问题中可能会显著降低生成样本的质量。因此,需要谨慎处理对小扰动敏感的任务,如去噪。
确定性采样的进一步研究:论文指出,确定性采样通常用于加速生成过程,但在噪声去除任务中,更希望生成确切的干净图像,而不仅仅是在分布上接近的图像。这涉及到使用Doob’s h-transform进行条件建模,可能成为未来研究的一个有趣领域。
改进感知度量:论文提到,尽管FID和LPIPS是评估生成图像质量的重要指标,但在特定任务(如去噪)中可能需要进一步改进或开发新的感知度量。
模型泛化能力的提高:虽然论文中的方法在CelebA和UC Merced Land Use数据集上表现出良好的泛化能力,但在更广泛的数据集和噪声类型上测试和提高模型的泛化能力仍然是一个有价值的研究方向。
噪声模型的进一步研究:论文基于几何布朗运动建模乘性噪声,但实际应用中噪声的类型和特性可能更加复杂。探索更复杂的噪声模型及其在去噪算法中的应用是一个潜在的研究方向。
计算效率的优化:扩散模型通常需要大量的采样步骤,这可能导致计算效率较低。研究如何优化算法以提高计算效率,同时保持或提高去噪性能,是一个重要的研究课题。
与其他图像处理任务的结合:论文专注于乘性噪声去除,但扩散模型可能与其他图像处理任务(如超分辨率、图像增强等)结合,以提高整体图像质量。
跨模态应用:探索将扩散模型应用于其他类型的数据(如视频、医学图像等)中的乘性噪声去除,可能会揭示新的挑战和机遇。
这些探索点为未来的研究提供了方向,有助于进一步提升乘性噪声去除技术的性能和应用范围。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种基于随机微分方程(SDE)的扩散模型,用于去除图像中的乘性噪声。主要内容可以总结如下:
问题背景:乘性噪声(也称为斑点噪声或胡椒噪声)常见于由合成孔径雷达(SAR)、激光或光学透镜产生的图像中。这种噪声与加性噪声不同,它是由系统内部的反射波动引起的,需要采用不同的技术进行去除。
研究目标:针对乘性噪声去除问题,论文提出了一种新颖的方法,使用基于SDE的扩散模型来模拟噪声过程,并利用逆过程进行去噪。
方法论:
- 利用SDE对乘性噪声进行建模,将噪声过程视为几何布朗运动。
- 通过Fokker-Planck方程推导出用于去噪的逆SDE过程。
- 提出了在对数域中处理图像以简化模型和损失函数的方法。
- 利用Euler-Maruyama方法对SDE进行离散化,构建了可训练的损失函数。
- 提出了多种采样技术,包括随机采样、ODE采样和DDIM采样,以生成去噪后的图像。
实验验证:
- 在CelebA和UC Merced Land Use两个数据集上进行了广泛的实验。
- 与多种传统和现代去噪方法进行了比较,包括BM3D、SRAD、DnCNN和NAFNet。
- 使用FID、LPIPS、PSNR和SSIM等度量指标评估去噪效果。
实验结果:
- 所提出的方法在感知度量(FID和LPIPS)上显著优于现有方法。
- 在传统度量(PSNR和SSIM)上也保持了竞争性能。
- 展示了该方法在不同噪声水平和数据集上的鲁棒性和泛化能力。
进一步探索:
- 提出了一些未来研究方向,包括扩散步骤减少技术的应用、确定性采样的进一步研究、改进感知度量、提高模型泛化能力、噪声模型的进一步研究、计算效率优化等。
结论:论文成功地展示了如何使用基于SDE的扩散模型有效地去除图像中的乘性噪声,并在感知质量上取得了显著的改进。
总的来说,这篇论文在乘性噪声去除领域提出了一种创新的方法,并通过实验验证了其有效性,为未来的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


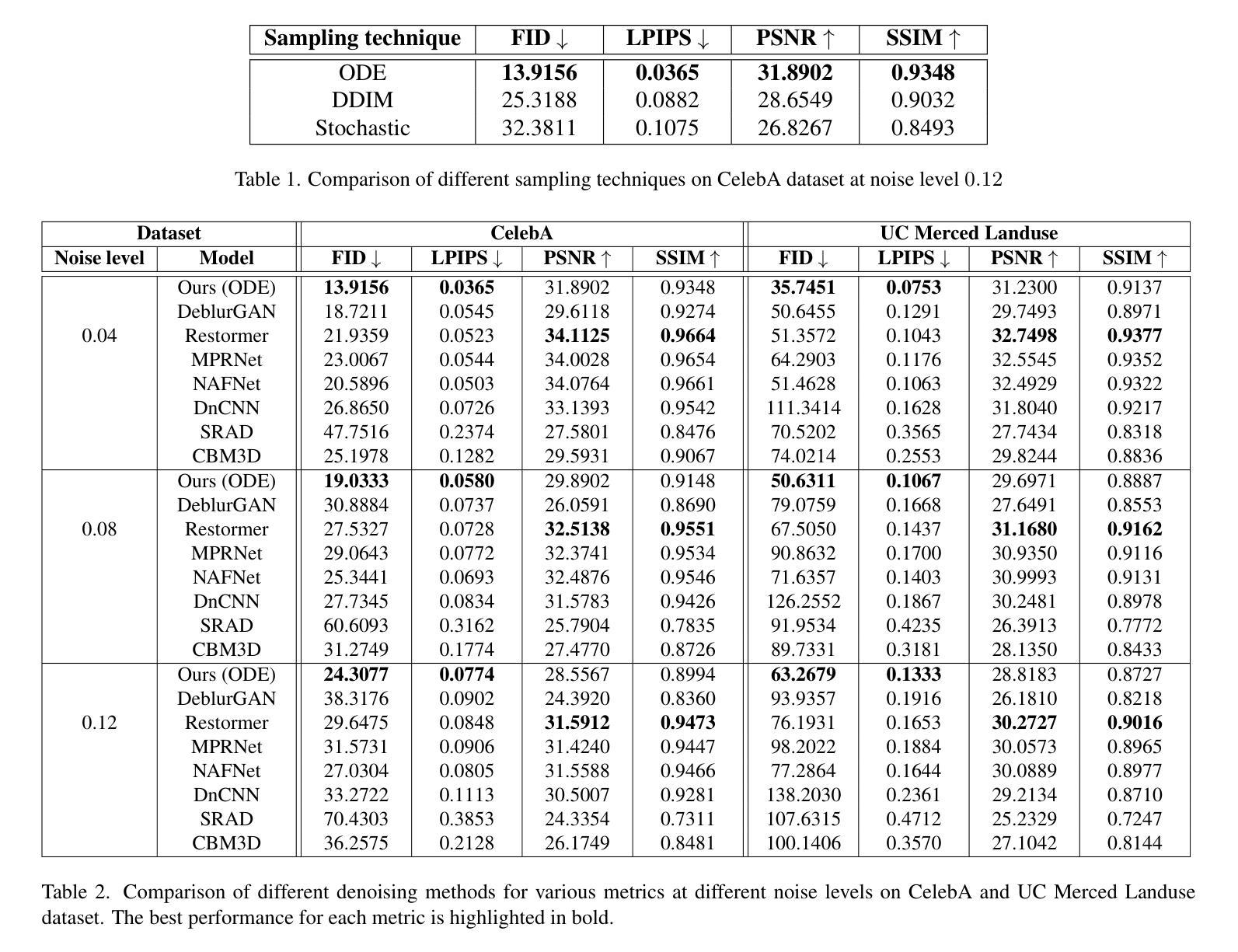
Imagen 3
Authors: Imagen-Team-Google, :, Jason Baldridge, Jakob Bauer, Mukul Bhutani, Nicole Brichtova, Andrew Bunner, Lluis Castrejon, Kelvin Chan, Yichang Chen, Sander Dieleman, Yuqing Du, Zach Eaton-Rosen, Hongliang Fei, Nando de Freitas, Yilin Gao, Evgeny Gladchenko, Sergio Gómez Colmenarejo, Mandy Guo, Alex Haig, Will Hawkins, Hexiang Hu, Huilian Huang, Tobenna Peter Igwe, Christos Kaplanis, Siavash Khodadadeh, Yelin Kim, Ksenia Konyushkova, Karol Langner, Eric Lau, Shixin Luo, Soňa Mokrá, Henna Nandwani, Yasumasa Onoe, Aäron van den Oord, Zarana Parekh, Jordi Pont-Tuset, Hang Qi, Rui Qian, Deepak Ramachandran, Poorva Rane, Abdullah Rashwan, Ali Razavi, Robert Riachi, Hansa Srinivasan, Srivatsan Srinivasan, Robin Strudel, Benigno Uria, Oliver Wang, Su Wang, Austin Waters, Chris Wolff, Auriel Wright, Zhisheng Xiao, Hao Xiong, Keyang Xu, Marc van Zee, Junlin Zhang, Katie Zhang, Wenlei Zhou, Konrad Zolna, Ola Aboubakar, Canfer Akbulut, Oscar Akerlund, Isabela Albuquerque, Nina Anderson, Marco Andreetto, Lora Aroyo, Ben Bariach, David Barker, Sherry Ben, Dana Berman, Courtney Biles, Irina Blok, Pankil Botadra, Jenny Brennan, Karla Brown, John Buckley, Rudy Bunel, Elie Bursztein, Christina Butterfield, Ben Caine, Viral Carpenter, Norman Casagrande, Ming-Wei Chang, Solomon Chang, Shamik Chaudhuri, Tony Chen, John Choi, Dmitry Churbanau, Nathan Clement, Matan Cohen, Forrester Cole, Mikhail Dektiarev, Vincent Du, Praneet Dutta, Tom Eccles, Ndidi Elue, Ashley Feden, Shlomi Fruchter, Frankie Garcia, Roopal Garg, Weina Ge, Ahmed Ghazy, Bryant Gipson, Andrew Goodman, Dawid Górny, Sven Gowal, Khyatti Gupta, Yoni Halpern, Yena Han, Susan Hao, Jamie Hayes, Jonathan Heek, Amir Hertz, Ed Hirst, Emiel Hoogeboom, Tingbo Hou, Heidi Howard, Mohamed Ibrahim, Dirichi Ike-Njoku, Joana Iljazi, Vlad Ionescu, William Isaac, Reena Jana, Gemma Jennings, Donovon Jenson, Xuhui Jia, Kerry Jones, Xiaoen Ju, Ivana Kajic, Christos Kaplanis, Burcu Karagol Ayan, Jacob Kelly, Suraj Kothawade, Christina Kouridi, Ira Ktena, Jolanda Kumakaw, Dana Kurniawan, Dmitry Lagun, Lily Lavitas, Jason Lee, Tao Li, Marco Liang, Maggie Li-Calis, Yuchi Liu, Javier Lopez Alberca, Peggy Lu, Kristian Lum, Yukun Ma, Chase Malik, John Mellor, Thomas Mensink, Inbar Mosseri, Tom Murray, Aida Nematzadeh, Paul Nicholas, João Gabriel Oliveira, Guillermo Ortiz-Jimenez, Michela Paganini, Tom Le Paine, Roni Paiss, Alicia Parrish, Anne Peckham, Vikas Peswani, Igor Petrovski, Tobias Pfaff, Alex Pirozhenko, Ryan Poplin, Utsav Prabhu, Yuan Qi, Matthew Rahtz, Cyrus Rashtchian, Charvi Rastogi, Amit Raul, Ali Razavi, Sylvestre-Alvise Rebuffi, Susanna Ricco, Felix Riedel, Dirk Robinson, Pankaj Rohatgi, Bill Rosgen, Sarah Rumbley, Moonkyung Ryu, Anthony Salgado, Tim Salimans, Sahil Singla, Florian Schroff, Candice Schumann, Tanmay Shah, Brendan Shillingford, Kaushik Shivakumar, Dennis Shtatnov, Zach Singer, Evgeny Sluzhaev, Valerii Sokolov, Thibault Sottiaux, Florian Stimberg, Brad Stone, David Stutz, Yu-Chuan Su, Eric Tabellion, Shuai Tang, David Tao, Kurt Thomas, Gregory Thornton, Andeep Toor, Cristian Udrescu, Aayush Upadhyay, Cristina Vasconcelos, Alex Vasiloff, Andrey Voynov, Amanda Walker, Luyu Wang, Miaosen Wang, Simon Wang, Stanley Wang, Qifei Wang, Yuxiao Wang, Ágoston Weisz, Olivia Wiles, Chenxia Wu, Xingyu Federico Xu, Andrew Xue, Jianbo Yang, Luo Yu, Mete Yurtoglu, Ali Zand, Han Zhang, Jiageng Zhang, Catherine Zhao, Adilet Zhaxybay, Miao Zhou, Shengqi Zhu, Zhenkai Zhu, Dawn Bloxwich, Mahyar Bordbar, Luis C. Cobo, Eli Collins, Shengyang Dai, Tulsee Doshi, Anca Dragan, Douglas Eck, Demis Hassabis, Sissie Hsiao, Tom Hume, Koray Kavukcuoglu, Helen King, Jack Krawczyk, Yeqing Li, Kathy Meier-Hellstern, Andras Orban, Yury Pinsky, Amar Subramanya, Oriol Vinyals, Ting Yu, Yori Zwols
We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
我们介绍了Imagen 3,这是一个基于文本的潜在扩散模型,能够从文本提示生成高质量图像。我们描述了我们的质量评估和责任感评估。在评估时,Imagen 3比其他当时的最先进模型更受欢迎。此外,我们还讨论了关于安全和代表性的问题,以及我们用来最小化模型潜在危害的方法。
论文及项目相关链接
Summary
本文主要介绍了Imagen 3,一个从文本提示生成高质量图像的潜在扩散模型。文章详细介绍了其质量和责任评估,表明Imagen 3在评估时优于其他先进模型。同时,文章还讨论了安全性和表征问题,以及最小化模型潜在危害的方法。
Key Takeaways
- Imagen 3是一种基于文本提示生成高质量图像的潜在扩散模型。
- Imagen 3在质量评估中被认为是优于其他同期先进模型的。
- 文章讨论了Imagen 3的安全性评估和责任考量。
- 文章提及了表征问题,这是模型性能的一个重要方面。
- 为了最小化模型的潜在危害,采取了特定的方法。
- 该模型能够从文本生成高质量图像,这可能为相关领域带来革命性的变化。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了Imagen 3,这是Google的一个文本到图像(Text-to-Image,T2I)生成模型。它试图解决的问题包括:
- 生成高质量图像:开发一个能够根据文本提示生成高分辨率、真实感强的图像的模型。
- 遵循复杂和详细的提示:提高模型对长而复杂用户提示的理解和生成图像的能力。
- 安全性和责任性:在模型开发和部署过程中,评估和解决与安全性和责任性相关的问题,以减少潜在的危害。
- 评估和比较:通过与其他最先进(state-of-the-art,SOTA)模型的比较,验证Imagen 3的性能。
- 减少偏见和公平性问题:确保生成的图像在性别、年龄、肤色等方面没有偏见,公平地代表不同的人群。
论文详细描述了Imagen 3的训练过程、评估方法、以及为确保模型的质量和安全性所采取的措施。
Q: 有哪些相关研究?
A: 论文中提到了多个与Imagen 3相关的研究工作,包括但不限于以下几个方面:
文本到图像生成模型:提到了其他几个文本到图像的生成模型,如DALL·E 3、Midjourney v6、Stable Diffusion 3 Large (SD3) 和 Stable Diffusion XL 1.0 (SDXL 1),用于与Imagen 3进行比较评估。
自动评估指标:提及了CLIP、VQAScore 和 Gecko 等自动评估指标,用于评估文本到图像生成模型的质量。
数据集和基准测试:使用了如GenAI-Bench、DrawBench、DALL·E 3 Eval 和 DOCCI-Test-Pivots 等数据集进行人类评估和自动评估。
安全和责任:讨论了与模型安全和责任相关的研究,包括对抗性使用和无意的模型失败,以及如何通过预训练和后训练干预来减轻风险。
公平性和偏见:提到了评估模型输出的公平性,包括性别、年龄和肤色的分布,以及如何减少输出中的偏见。
模型架构和训练方法:讨论了Imagen 3的模型架构,以及使用了哪些训练方法来提高生成图像的质量和遵循文本提示的能力。
社会影响和伦理考量:提到了文本到图像生成技术可能带来的社会影响,包括促进创意和商业实用性,以及可能的风险,如性别身份、种族、性取向或国籍的刻板印象放大。
模型评估方法:讨论了如何使用不同的评估方法来确保模型的质量和安全性,包括开发评估、保证评估、红队测试和外部评估。
这些研究为Imagen 3的开发提供了背景、比较基准和评估框架。论文通过与这些研究的比较和评估,展示了Imagen 3在文本到图像生成领域的优势和潜在的应用。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决文本到图像生成的问题,并确保模型的质量和安全性:
模型开发:开发了Imagen 3,这是一个潜在的扩散模型(latent diffusion model),能够根据文本提示生成高质量的图像。
数据集和预处理:使用了一个经过多阶段过滤的大型数据集,包括图像、文本和相关注释,以确保质量和安全性。过滤过程包括去除不安全、暴力或低质量的图像,以及AI生成的图像,以防止模型学习到这些图像中的常见伪影或偏见。
评估方法:通过人类评估和自动评估方法对模型进行了广泛的评估。人类评估关注于整体偏好、文本-图像对齐、视觉吸引力、详细文本-图像对齐和数值推理等方面。自动评估使用了CLIP、VQAScore等指标来衡量文本-图像对齐和图像质量。
安全性和责任性:在模型开发过程中,采取了预训练和后训练的干预措施,包括安全过滤、图像去重、合成字幕生成和数据公平性分析,以减少潜在的危害。
政策和目标:制定了一套安全政策和目标,以确保模型的输出不会产生有害内容,并且遵循用户提示。
评估和测试:进行了发展评估、保证评估、红队测试和外部评估,以识别模型的潜在弱点和风险,并根据这些发现进行改进。
产品部署:在模型发布之前,通过Google DeepMind的责任和安全委员会(RSC)审查模型的性能,并在特定应用程序中进行系统级安全评估和审查。
持续改进:论文还讨论了如何通过持续的研究和开发来减少模型输出的同质性,并提高对人类多样性的准确反映。
通过这些综合措施,论文展示了Imagen 3在文本到图像生成方面的先进性能,并强调了在模型开发和部署过程中考虑安全性和责任性的重要性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和展示Imagen 3模型的性能。以下是主要的实验类型和内容:
人类评估(Human Evaluation):
- 对五个不同的质量方面进行了评估:整体偏好、文本-图像对齐、视觉吸引力、详细文本-图像对齐和数值推理。
- 使用了侧-by-侧比较方法,通过Elo评分系统对模型进行比较。
- 在不同的数据集上进行了评估,包括GenAI-Bench、DrawBench、DALL·E 3 Eval和DOCCI-Test-Pivots。
自动评估(Automatic Evaluation):
- 使用了CLIP、VQAScore和Gecko等自动评估指标来衡量文本-图像对齐和图像质量。
- 对比了不同模型在不同数据集上的表现,包括Gecko-Rel、DOCCI-Test-Pivots、DALL·E 3 Eval和GenAI-Bench。
安全性评估(Safety Evaluation):
- 监测模型违反Google安全政策的情况,使用自动化安全指标进行评估。
- 对Imagen 3在各种安全数据集上的表现进行了评估,包括暴力、仇恨、明显性化和过度性化。
公平性评估(Fairness Evaluation):
- 通过自动化指标评估了生成图像中感知年龄、性别和肤色的分布。
- 测量了对于通用人物提示的输出多样性,并评估了输出同质性。
负责任和安全性评估方法(Responsibility and Safety Evaluation Approach):
- 包括开发评估、保证评估、外部评估、红队测试和产品部署评估。
- 这些评估涵盖了模型开发和部署的整个生命周期。
数值推理能力评估(Numerical Reasoning Evaluation):
- 使用GeckoNum基准测试评估模型生成确切数量对象的能力。
视觉吸引力评估(Visual Appeal Evaluation):
- 评估了生成图像的视觉吸引力,独立于请求的内容。
详细文本-图像对齐评估(Detailed Prompt-Image Alignment Evaluation):
- 使用DOCCI数据集的详细提示评估了模型生成与参考图像内容对齐的能力。
自动图像分布度量(Automated Image Distribution Metrics):
- 使用Fréchet距离(FID)、Dino-v2特征空间距离(FD-Dino)和CLIP-L特征空间的MMD距离(CMMD)来比较生成图像的分布。
这些实验结果用于展示Imagen 3在文本到图像生成方面的性能,并与其他最先进模型进行了比较。同时,这些实验也用于评估和改进模型的安全性和公平性。
Q: 有什么可以进一步探索的点?
A: 论文中提到了多个可以进一步探索的点,包括但不限于以下几个方面:
数值推理的改进:尽管Imagen 3在生成确切数量的对象方面表现出色,但这项任务对于所有模型来说仍然是一个挑战。可以进一步探索如何提高模型在处理复杂数值和数量关系时的准确性。
复杂语言和空间推理:论文指出,涉及规模、复合短语和动作的提示对于所有模型来说都是困难的。研究如何改进模型以更好地理解和生成这类复杂的语言结构将是有价值的。
减少输出同质性:尽管Imagen 3在减少性别、年龄和肤色偏见方面取得了进展,但仍然有改进空间。可以进一步探索如何生成更多样化和公平的图像输出。
提高图像质量:虽然Imagen 3在视觉吸引力方面排名第二,但提高生成图像的质量和美学仍然是一个持续的目标。
模型的可解释性:提高模型的可解释性,以便更好地理解其决策过程和生成图像的方式。
跨模态能力:探索模型在处理不同模态输入(如音频或视频)以及生成相应图像方面的潜力。
安全性和伦理问题:持续监测和改进模型在防止有害内容生成、避免偏见和歧视方面的表现。
用户研究和反馈:进行用户研究以了解人们如何与文本到图像生成模型互动,并根据用户反馈优化模型。
模型鲁棒性:研究模型在面对错误或误导性输入时的鲁棒性,并探索如何提高其在各种条件下的稳定性。
模型效率:研究如何提高模型的效率,减少计算资源的需求,使其更适合在不同设备和平台上运行。
多语言支持:探索模型在处理不同语言的文本提示时的能力,并提高其跨语言的泛化性。
长期影响研究:研究文本到图像生成技术对社会、文化和创意产业的长期影响。
这些探索点可以帮助研究者和开发者进一步提升文本到图像生成模型的性能,同时确保技术的发展符合伦理和社会标准。
Q: 总结一下论文的主要内容
A: 这篇论文主要介绍了Imagen 3,这是Google开发的一款先进的文本到图像生成模型。以下是论文的主要内容概述:
模型介绍:Imagen 3是一个潜在扩散模型,能够根据文本提示生成高质量的图像。
数据和训练:模型训练使用了经过多阶段过滤的大型数据集,以确保图像质量和安全性。数据集包括图像、文本和相关注释,通过去除不安全内容、AI生成图像、重复图像和应用合成字幕等方法进行预处理。
评估方法:通过人类评估和自动评估对模型进行了广泛的性能评估。评估侧重于整体偏好、文本-图像对齐、视觉吸引力、详细文本-图像对齐和数值推理。
性能比较:将Imagen 3与其他最先进模型(如DALL·E 3、Midjourney v6、Stable Diffusion 3 Large等)进行了比较,发现Imagen 3在多个方面表现更优。
安全性和责任性:论文讨论了与部署文本到图像模型相关的安全性和责任性问题,并描述了如何通过预训练和后训练干预来减少潜在的危害。
政策和目标:建立了一套安全政策和目标,以确保模型的输出不会产生有害内容,并遵循用户提示。
评估和测试:使用了多种评估方法,包括发展评估、保证评估、红队测试和外部评估,以确保模型的安全性和公平性。
产品部署:在模型发布之前,通过Google DeepMind的责任和安全委员会审查模型的性能,并在特定应用程序中进行系统级安全评估。
案例展示:提供了由Imagen 3生成的图像示例,展示了模型在复杂场景和详细提示下生成高质量图像的能力。
公平性和偏见:评估了模型在性别、年龄和肤色方面的公平性,并通过自动化指标来衡量和改进模型的输出多样性。
技术细节:论文还提供了关于模型架构、训练过程和评估方法的详细信息。
贡献者和致谢:列出了对Imagen 3项目做出贡献的个人和团队成员。
总体而言,论文展示了Imagen 3在文本到图像生成领域的先进技术,并强调了在模型开发和部署过程中考虑安全性、公平性和责任性的重要性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

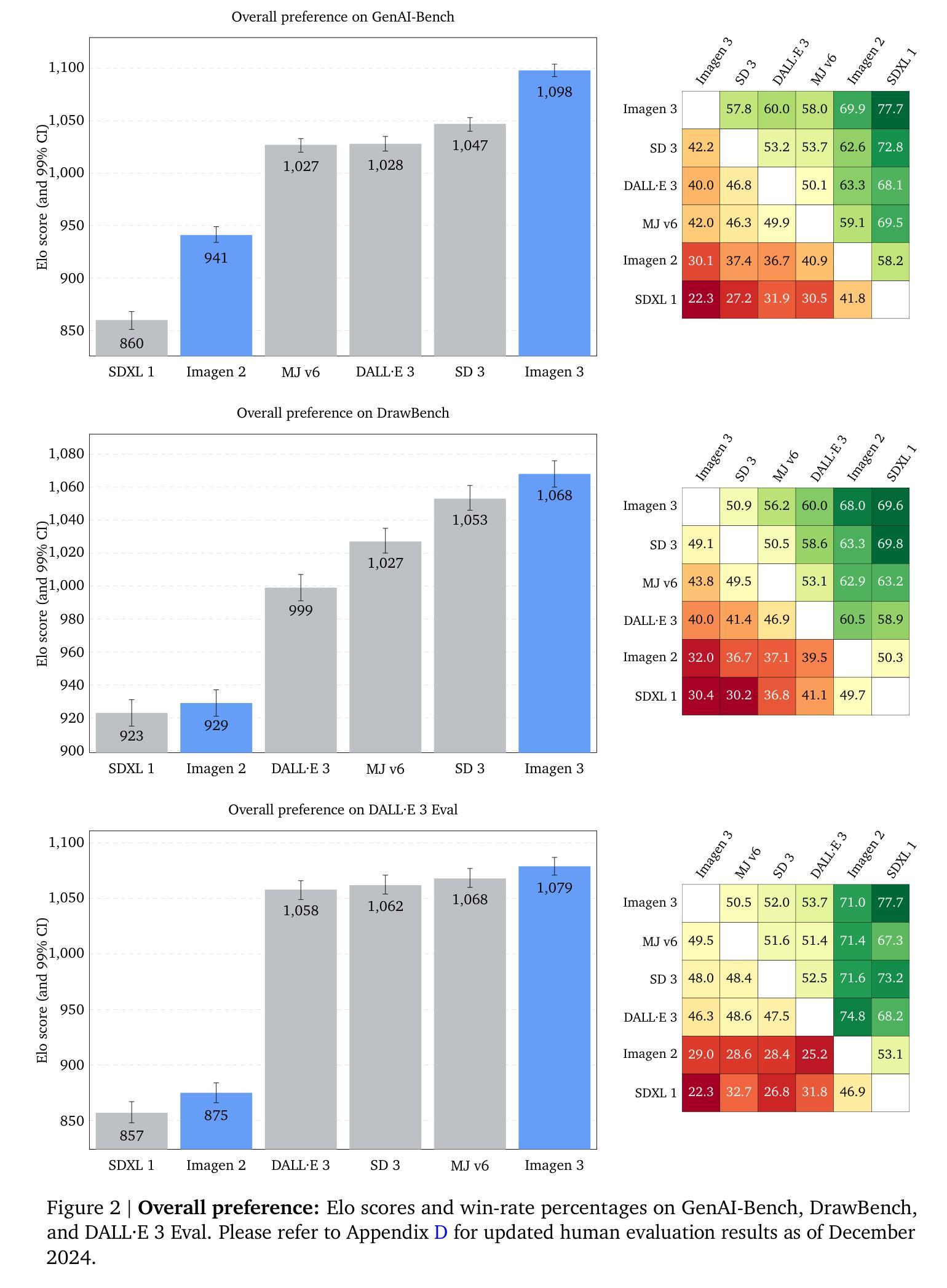
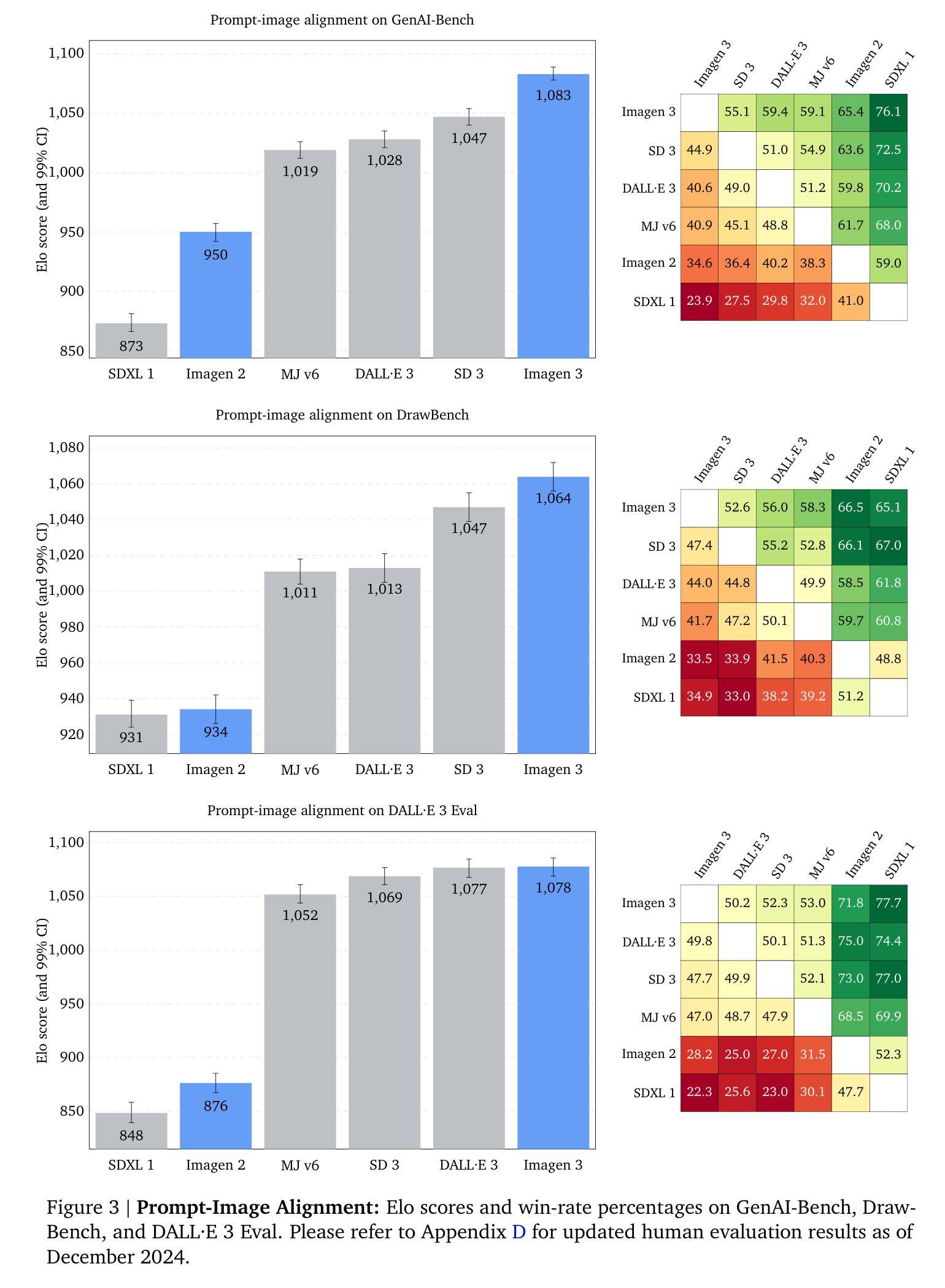
StyO: Stylize Your Face in Only One-shot
Authors:Bonan Li, Zicheng Zhang, Xuecheng Nie, Congying Han, Yinhan Hu, Xinmin Qiu, Tiande Guo
This paper focuses on face stylization with a single artistic target. Existing works for this task often fail to retain the source content while achieving geometry variation. Here, we present a novel StyO model, ie. Stylize the face in only One-shot, to solve the above problem. In particular, StyO exploits a disentanglement and recombination strategy. It first disentangles the content and style of source and target images into identifiers, which are then recombined in a cross manner to derive the stylized face image. In this way, StyO decomposes complex images into independent and specific attributes, and simplifies one-shot face stylization as the combination of different attributes from input images, thus producing results better matching face geometry of target image and content of source one. StyO is implemented with latent diffusion models (LDM) and composed of two key modules: 1) Identifier Disentanglement Learner (IDL) for disentanglement phase. It represents identifiers as contrastive text prompts, ie. positive and negative descriptions. And it introduces a novel triple reconstruction loss to fine-tune the pre-trained LDM for encoding style and content into corresponding identifiers; 2) Fine-grained Content Controller (FCC) for the recombination phase. It recombines disentangled identifiers from IDL to form an augmented text prompt for generating stylized faces. In addition, FCC also constrains the cross-attention maps of latent and text features to preserve source face details in results. The extensive evaluation shows that StyO produces high-quality images on numerous paintings of various styles and outperforms the current state-of-the-art.
本文专注于以单一艺术目标进行面部风格化。现有针对此任务的工作往往难以在实现几何变化的同时保留源内容。在这里,我们提出了一个新的StyO模型,即一次性面部风格化(Stylize the face in only One-shot),以解决上述问题。具体而言,StyO利用了解纠缠和重组策略。它首先解纠缠源图像和目标图像的内容和风格,将其转化为标识符,然后以交叉方式重组这些标识符,生成风格化的面部图像。通过这种方式,StyO将复杂的图像分解成独立且特定的属性,并将一次性面部风格化简化为来自输入图像的不同属性的组合,从而生成与目标图像的面部几何结构相匹配且符合源内容的结果。StyO采用潜在扩散模型(LDM)实现,包含两个关键模块:1)用于解纠缠阶段的标识符解纠缠学习者(IDL)。它用对比文本提示表示标识符,即正面和负面描述。它引入了一种新型的三重建损失来微调预训练的LDM,以将风格和内容编码为相应的标识符;2)用于重组阶段的精细内容控制器(FCC)。它重新组合IDL中的解纠缠标识符,以形成用于生成风格化面部的增强文本提示。此外,FCC还约束潜在文本特征的交叉注意力图,以在结果中保留源面部细节。广泛评估表明,StyO在各种风格的画作上生成了高质量图像,并超越了当前最新技术。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
在单目标艺术风格化中,现有方法难以在改变几何形态的同时保留源内容。本研究提出了一种新颖的StyO模型,采用分离与重组策略,将源与目标的图像内容和风格分解为标识符进行交叉组合,以生成风格化的面部图像。该模型通过潜扩散模型实现,包含两个关键模块:Identifier Disentanglement Learner用于分离阶段,通过对比文本提示表示标识符,并引入三重重建损失微调预训练模型;Fine-grained Content Controller用于重组阶段,结合分离的标识符生成风格化面部图像。该模型能够高质量地模拟多种风格画作,并超越现有技术水平。
Key Takeaways
- StyO模型解决了在面部风格化中保留源内容的同时实现几何变化的难题。
- StyO模型采用分离与重组策略,将图像内容和风格分解为标识符。
- 通过潜扩散模型实现StyO模型,包含Identifier Disentanglement Learner和Fine-grained Content Controller两个关键模块。
- Identifier Disentanglement Learner通过对比文本提示表示标识符,并引入三重重建损失进行微调。
- Fine-grained Content Controller负责重组阶段,结合分离的标识符生成风格化面部图像,同时保留源面部的细节。
- StyO模型能够高质量地模拟多种风格画作。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是单样本(one-shot)人脸风格化(face stylization)。具体来说,它旨在将单个目标图像(target image)的艺术风格应用到源图像(source image)上,同时保留源图像的面部特征和细节。现有方法在尝试实现目标风格(如几何变化)时往往无法保留源图像的内容(如面部和头发颜色),导致生成的图像与源图像在面部几何和内容上不匹配。论文中提出的StyO模型通过一种新的解耦和重组策略来解决这一问题,旨在生成既匹配目标图像风格又保留源图像内容的人脸图像。
Q: 有哪些相关研究?
A: 相关研究包括以下几个领域:
人脸风格化(Face Stylization):
- 人脸风格化旨在从人脸照片中自动创建个性化的艺术肖像,广泛应用于社交媒体头像、电影、广告等创意产业。
- 单样本(one-shot)解决方案因其数据效率特征而受到关注,使得实际部署更为容易。
生成对抗网络(GANs):
- 用于风格迁移问题,将单个目标图像的风格转移到源图像上。
- 尽管取得了一定的成功,但现有方法在保留源内容的同时实现合理的风格(例如几何变化)方面仍然存在挑战。
扩散模型(Diffusion Models):
- 最近在生成任务中打破了GANs的长期主导地位。
- 扩散去噪概率模型(DDPMs)将图像生成视为一个马尔可夫过程,启发了从非马尔可夫过程、得分匹配和随机微分方程等不同角度研究生成模型。
文本到图像的扩散模型(Text-to-Image Diffusion Models):
- 训练于大规模数据集的模型展现出了根据文本提示生成多样化、创造性图像的能力。
- 这些模型可以有效地根据用户提供的文本提示编辑图像,从而实现基于文本的风格化。
神经风格迁移(Neural Style Transfer, NST):
- NST方法通过匹配特征分布来转移艺术纹理。
- 这些方法在艺术肖像具有强烈颜色或纹理模式时能够取得令人满意的结果,但在涉及面部特征显著几何畸变的风格中表现不佳。
图像到图像的翻译(Image-to-Image Translation, I2IT):
- I2IT方法从大规模数据集学习映射,将输入图像从一个领域翻译到另一个领域。
- 这些方法在训练数据集包含数百个艺术肖像时能够实现合理的纹理和几何变化。
GANs的领域适应(Domain Adaptation of GANs):
- 提供了一种创造性的方法来解决任务。
- 预训练的StyleGAN形成了自然面部的生成先验,艺术肖像可以指导StyleGAN的适应以生成艺术肖像。
这些相关研究为StyO模型的发展提供了理论基础和技术背景。StyO模型通过结合这些领域的技术,特别是利用扩散模型的优势,提出了一种新的单样本人脸风格化方法。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为StyO(Stylize Your Face in Only One-shot)的模型来解决单样本人脸风格化的问题。StyO模型采用了以下关键技术和策略:
解耦和重组策略:
- StyO首先将源图像和目标图像的内容与风格信息解耦成不同的标识符(identifiers),然后以交叉方式重组这些标识符,形成用于生成风格化面部图像的提示(prompts)。
**Identifier Disentanglement Learner (IDL)**:
- IDL模块负责解耦阶段,它将标识符表示为对比文本提示,即正面和负面描述。
- 通过引入一种新颖的三重重建损失(triple reconstruction loss),微调预训练的潜在扩散模型(LDM),以将风格和内容编码到相应的标识符中。
**Fine-grained Content Controller (FCC)**:
- FCC模块负责重组阶段,它重新组合IDL解耦出的标识符,形成增强的文本提示,用于生成风格化面部图像。
- FCC还通过控制潜在和文本特征的交叉注意力图来保留源面部细节,从而提高结果的可控性。
潜在扩散模型(Latent Diffusion Models, LDM):
- StyO基于高效的潜在扩散模型实现,该模型首先将图像编码到潜在空间,然后通过破坏和逆转过程在潜在空间中操作。
对比解耦提示模板(Contrastive Disentangled Prompt Template):
- StyO设计了一种新颖的对比解耦提示模板,用于构建每个图像的文本标签,这些图像-文本对将用于微调LDM,以实现不同标识符中信息的编码。
增强文本提示(Augmented Text Prompt):
- 通过重复标识符的方式增强文本提示,从而提供更大的定制化和对风格化肖像的控制。
通过这些技术和策略,StyO模型能够生成既匹配目标图像风格又保留源图像内容的人脸图像,并在多个风格的人脸图像生成中表现出色,超越了现有的最先进方法。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验:
与现有最先进方法的比较:
- 论文将StyO与几个最新的单样本人脸风格化方法进行了比较,包括GOGA、Custom Diffusion和StyleID。这些方法使用不同的技术,如GANs和扩散模型,来实现风格迁移。
定性比较:
- 论文通过视觉比较展示了StyO与其他方法在保留源图像身份信息、捕获目标图像的几何变化以及生成高质量图像方面的性能差异。
定量比较:
- 通过用户研究对不同方法生成的结果进行了定量评估。用户研究集中在三个方面:身份保持、几何变形和纹理质量。研究收集了150个回答,涉及50对源-目标图像。
消融研究:
- 对比解耦提示模板的影响:展示了使用不同提示模板配置(仅正标识符、正负标识符、完整的提示模板)对模型性能的影响。
- 细粒度内容控制器(FCC)的效果:展示了有无FCC模块时生成的艺术肖像的多样性和身份保真度的差异。
- 增强文本提示中超参数的影响:分析了风格标识符(ns)和内容标识符(nc)的数量变化对合成结果的影响。
这些实验旨在全面评估StyO模型的性能,并证明其在单样本人脸风格化任务中的有效性和优越性。通过这些实验,论文展示了StyO在生成高质量、风格一致且保留源图像细节的风格化肖像方面的能力。
Q: 有什么可以进一步探索的点?
A: 尽管StyO模型在单样本人脸风格化方面取得了显著的成果,但仍有一些可以进一步探索的点:
更广泛的风格和数据集:
- 测试和改进模型在更多样化的艺术风格和更大的数据集上的性能,包括不同文化和历史时期的艺术风格。
模型泛化能力:
- 探索StyO模型在未见过的领域和风格上的泛化能力,例如动画、抽象艺术等。
实时风格化应用:
- 优化模型以实现实时或近实时的人脸风格化,适用于视频会议、增强现实(AR)和虚拟现实(VR)等应用。
交互式风格化工具:
- 开发基于StyO的交互式工具,允许用户通过调整风格和内容标识符的权重来定制化生成的风格化图像。
多样本学习:
- 虽然StyO专注于单样本学习,但研究如何利用少量样本(few-shot learning)进一步提升模型性能和泛化能力。
模型解释性:
- 提高模型的可解释性,让用户理解模型是如何解耦和重组风格与内容的,以及这些过程如何影响最终的风格化结果。
鲁棒性和错误分析:
- 对模型的鲁棒性进行测试,特别是在面对源图像和目标图像之间的显著差异时。同时,进行错误分析以识别模型的局限性。
跨模态风格化:
- 探索StyO模型在跨模态风格化任务中的应用,例如将绘画风格应用到视频或3D模型上。
模型压缩和加速:
- 研究模型压缩和加速技术,使StyO模型更适合在资源受限的设备上部署。
伦理和隐私问题:
- 探讨风格化技术可能涉及的伦理和隐私问题,尤其是在使用个人面部图像进行风格化时。
这些探索点可以帮助研究者进一步提升StyO模型的性能,扩展其应用范围,并更好地理解其工作原理。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题定义:
- 论文关注单样本人脸风格化任务,即用单个艺术风格的目标图像去风格化源图像,同时保留源图像的面部特征和细节。
现有挑战:
- 现有方法在保留源图像内容的同时实现目标图像的风格(尤其是几何变化)方面存在挑战。
StyO模型:
- 提出了一个名为StyO的新型模型,采用解耦和重组策略来解决上述问题。
- StyO模型基于潜在扩散模型(LDM),包含两个核心模块:Identifier Disentanglement Learner (IDL) 和 Fine-grained Content Controller (FCC)。
方法细节:
- IDL模块:将源图像和目标图像的内容与风格解耦成不同的标识符,使用对比文本提示和三重重建损失进行训练。
- FCC模块:重新组合解耦出的标识符以生成风格化面部图像,并使用交叉注意力控制和增强文本提示来保留源图像的细节。
实验评估:
- 与现有最先进方法(如GOGA、Custom Diffusion和StyleID)进行定性和定量比较。
- 通过用户研究验证StyO在身份保持、几何变形和纹理质量方面的优势。
- 进行消融研究来展示IDL和FCC模块的有效性以及增强文本提示中超参数的影响。
主要贡献:
- 首次将扩散模型应用于单样本人脸风格化任务。
- 提出了一种新颖的解耦和重组策略,有效地解决了先前方法的核心问题。
- 提出了一种将图像的不同属性编码到多个标识符中的方法。
- StyO模型在单样本人脸风格化任务中设定了新的最先进水平。
未来工作:
- 论文提出了一些可能的研究方向,包括模型泛化能力的提升、实时风格化应用的开发、交互式风格化工具的设计等。
总体而言,这篇论文通过提出StyO模型,在单样本人脸风格化领域取得了显著的性能提升,并为未来的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图