⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-17 更新
Label-template based Few-Shot Text Classification with Contrastive Learning
Authors:Guanghua Hou, Shuhui Cao, Deqiang Ouyang, Ning Wang
As an algorithmic framework for learning to learn, meta-learning provides a promising solution for few-shot text classification. However, most existing research fail to give enough attention to class labels. Traditional basic framework building meta-learner based on prototype networks heavily relies on inter-class variance, and it is easily influenced by noise. To address these limitations, we proposes a simple and effective few-shot text classification framework. In particular, the corresponding label templates are embed into input sentences to fully utilize the potential value of class labels, guiding the pre-trained model to generate more discriminative text representations through the semantic information conveyed by labels. With the continuous influence of label semantics, supervised contrastive learning is utilized to model the interaction information between support samples and query samples. Furthermore, the averaging mechanism is replaced with an attention mechanism to highlight vital semantic information. To verify the proposed scheme, four typical datasets are employed to assess the performance of different methods. Experimental results demonstrate that our method achieves substantial performance enhancements and outperforms existing state-of-the-art models on few-shot text classification tasks.
作为学习即学习的算法框架,元学习为小样本文本分类提供了有前景的解决方案。然而,大多数现有研究未能充分关注类别标签。基于原型网络构建的传统基本元学习框架严重依赖于类间差异,并容易受到噪声的影响。为了解决这些局限性,我们提出了一种简单有效的小样本文本分类框架。特别是,将相应的标签模板嵌入输入句子中,以充分利用类别标签的潜在价值,引导预训练模型通过标签传递的语义信息生成更具区分度的文本表示。在标签语义的持续影响下,利用监督对比学习来建模支持样本和查询样本之间的交互信息。此外,用注意力机制替代平均机制以突出重要的语义信息。为了验证所提方案,我们采用了四个典型数据集来评估不同方法的性能。实验结果表明,我们的方法实现了显著的性能提升,并在小样本文本分类任务上优于现有的最新模型。
论文及项目相关链接
Summary
元学习作为一种学习算法框架,为小样本文本分类提供了有前景的解决方案。针对现有研究忽视类别标签的问题,我们提出了一种简单有效的框架,通过将标签模板嵌入输入句子中,充分利用标签的潜在价值,并通过标签语义信息指导预训练模型生成更具区分度的文本表示。同时,利用监督对比学习建模支持样本和查询样本之间的交互信息,并替换平均机制为注意力机制以突出重要语义信息。实验结果表明,该方法在四个典型数据集上的性能有所提升,并在小样本文本分类任务上超越了现有先进模型。
Key Takeaways
- 元学习作为一种学习算法框架在小样本文本分类上具有潜力。
- 现有研究忽视了类别标签的重要性。
- 提出的框架通过将标签模板嵌入输入句子,充分利用标签的潜在价值。
- 利用标签语义信息指导预训练模型生成更具区分度的文本表示。
- 监督对比学习被用于建模支持样本和查询样本之间的交互信息。
- 注意力机制替代了平均机制,以突出重要语义信息。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是**少量样本文本分类(Few-Shot Text Classification, FSTC)**中的挑战,特别是在有限标注数据的情况下如何有效地进行文本分类。具体来说,论文指出了现有研究中存在的几个问题:
对类别标签关注不足:传统的基于原型网络(prototype networks)的元学习(meta-learning)方法主要依赖于类间差异,并没有充分利用类别标签中的潜在价值,导致在数据稀缺的情况下特征提取能力受限。
对噪声的敏感性:由于这些方法高度依赖于样本数据的类间差异,当目标数据包含相对相似的类别时,它们难以做出准确预测。
对异常值的敏感性:原型网络通常通过简单平均同一类别内的表示来生成类别原型,这种平均机制容易受到每个类别中有限样本数量的个别样本偏差的影响,使得类别原型对异常值敏感。
为了解决这些问题,论文提出了一个新的少量样本文本分类框架,该框架整合了标签语义(label semantics)、对比学习(contrastive learning)和注意力机制(attention mechanisms),以提高在少量样本情况下的分类性能。
Q: 有哪些相关研究?
A: 论文中提到了与少量样本文本分类(Few-Shot Text Classification, FSTC)相关的几个研究领域和具体工作,主要包括:
基于微调的方法(Fine-tuning Based approaches):
- ULMFiT:Howard等人提出的一个通用语言微调模型,旨在适用于所有自然语言处理(NLP)任务。
- 适应性梯度优化器:Nakamura和Harada展示了在微调过程中使用适应性梯度优化器可以提高测试准确率。
- 领域自适应和任务自适应预训练:Suchin等人在微调前对预训练模型进行了第二次预训练,包括领域自适应和任务自适应预训练。
- 提示(Prompt)基方法:这些方法通过引入额外的提示信息来指导学习过程,在FSTC任务中显示出了有希望的性能。
基于元学习的方法(Meta-learning Based approaches):
- 优化基元学习(Optimization-based meta-learning):关注通过梯度下降从有限的标记训练样本中学习更新模型参数,如MAML、Meta-SGD和Reptile。
- 度量基元学习(Metric-based meta-learning):旨在学习一个度量空间,能够评估样本之间的相似性,如匹配网络、原型网络、关系网络和归纳网络。
原型网络(Prototypical Networks):
- 原型网络是元学习方法中的一个主要方法,许多研究工作都采用了它作为基础框架,并对其进行了创新和优化。
其他相关工作:
- ContrastNet:一个结合了支持样本和查询样本的监督对比学习模型。
- LaSAML:一个在元学习中整合标签信息以产生输入文本的区分性特征的方法。
这些相关研究为论文提出的新框架提供了理论基础和技术对比,论文通过与这些现有方法的比较,展示了其提出方法的有效性和优越性。
Q: 论文如何解决这个问题?
A: 论文提出了一个新颖的元学习框架来解决少量样本文本分类(Few-Shot Text Classification, FSTC)的问题,具体解决方案包括以下几个关键点:
标签模板嵌入(Label-template Embedding):
- 将对应的标签模板嵌入到输入句子中,充分利用类别标签的潜在价值,引导预训练模型生成更具辨识性的文本表示。
- 通过将标签信息以模板的形式融入文本,增强了预训练模型(如BERT)的特征提取能力,尤其是在数据稀缺的情况下。
监督对比学习(Supervised Contrastive Learning):
- 使用监督对比学习拉近同类文本表示,推开不同类文本表示,以捕捉不同类别间的微妙差异。
- 通过整合标签语义,对比学习能够识别同类中更相似的特征和不同类中更不同的特征。
注意力机制增强的原型网络(Attention Mechanism Enhanced Prototype Network):
- 引入注意力机制到原型网络中,代替简单的平均机制,以突出重要的语义信息。
- 注意力机制考虑支持样本与查询样本之间的相关性,为与查询样本密切相关的支持样本分配更大的权重,生成更具代表性和区分性的类别原型。
多任务学习(Multi-task Learning):
- 通过结合对比学习和原型学习两个任务,优化模型以获得更判别性的特征表示和更有代表性的原型表示。
- 对比学习任务旨在聚集同类文本表示,分离不同类文本表示;原型分类任务则利用注意力机制的原型网络正确分类查询文本。
优化目标函数(Objective Function):
- 定义了一个目标函数,通过权衡对比学习损失和原型网络损失,平衡两个任务的学习。
通过以上方法,论文提出的框架能够有效地利用有限的标注数据进行文本分类,提高了模型在少量样本情况下的泛化能力和分类性能。实验结果表明,该方法在多个公开基准数据集上取得了显著的性能提升,尤其是在单样本(one-shot)场景下。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出方法的有效性:
数据集选择:
- 实验在四个广泛用于FSTC任务的新闻和评论数据集上进行,包括20News、Amazon、HuffPost和Reuters。这些数据集具有不同的特性,如类别数量、样本数量和平均句子长度,这有助于全面评估模型性能。
基线比较:
- 与多个强基线模型进行比较,包括原型网络(PN)、MAML、Induction Network(Ind)、DS-FSL、MLADA、LaSAML和ContrastNet等,这些基线覆盖了多种FSTC方法,包括基于优化的方法和基于度量的方法。
实验设置:
- 在标准的5-way 1-shot和5-way 5-shot FSTC任务上进行训练和评估,遵循统一的超参数设置和训练方法。
- 使用Adam优化器,学习率为1e-6,并实施早停策略,如果在连续3个epoch中验证集准确率没有提高,则停止训练。
- 训练最多进行10,000次迭代,每100次迭代进行一次评估,验证集和测试集的结果平均1000个episode。
性能评估:
- 在四个数据集上比较模型的准确率和宏F1分数,这些指标可以全面反映模型在不同设置下的性能。
消融研究:
- 对模型的不同组成部分(如注意力机制、对比学习和标签模板)进行消融研究,以展示每个部分单独和组合对整体方法的贡献和有效性。
收敛速度和可视化:
- 比较所提模型与两个强基线(ContrastNet和LaSAML)在HuffPost数据集上的收敛速度。
- 使用t-SNE可视化学习到的嵌入,展示模型在1-shot任务上的学习和泛化能力,并与ContrastNet和LaSAML进行比较。
通过这些实验,论文验证了所提出方法在少量样本文本分类任务中的有效性和优越性,特别是在1-shot场景下。实验结果表明,该方法在多个数据集上均取得了显著的性能提升,并且在收敛速度和嵌入可视化方面也显示出了优势。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些未来工作的方向,以下是一些可以进一步探索的点:
扩展到更广泛的任务:
- 将提出的框架扩展到包括更多种类的少量样本学习任务,测试其在不同领域和类型的数据集上的适用性和有效性。
优化参数调整策略:
- 研究和优化模型中平衡对比学习和原型学习的权重参数 $\rho$ 的调整策略,以进一步提高模型性能。
改进模型结构:
- 探索更复杂的模型结构或不同的注意力机制,以增强模型对支持样本和查询样本之间交互信息的建模能力。
处理类别不平衡问题:
- 研究如何改进模型以更好地处理类别不平衡问题,尤其是在样本数量较少时。
增强鲁棒性和泛化能力:
- 研究如何增强模型对噪声和异常值的鲁棒性,以及其在不同数据分布上的泛化能力。
跨领域和跨语言的适应性:
- 探索模型在跨领域和跨语言任务中的适应性和迁移学习能力。
更深入的消融研究:
- 进行更深入的消融研究,以更细致地理解模型中各个组件对性能的具体影响。
模型解释性:
- 提高模型的可解释性,研究如何解释模型的预测和分类过程。
实时少量样本学习:
- 研究模型在实时或动态环境中处理少量样本学习任务的能力,例如在线学习场景。
结合其他类型的元学习:
- 考虑将优化基元学习和度量基元学习结合起来,以利用两者的优势。
这些方向可以帮助研究者更全面地理解和改进少量样本文本分类模型,推动相关技术的发展和应用。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个新颖的元学习框架,用于解决少量样本文本分类(Few-Shot Text Classification, FSTC)问题。以下是论文的主要内容总结:
问题背景:
- 传统深度学习方法依赖大量标记数据,但在如医学、金融等领域,获取足够标记数据困难。
- 元学习提供了一种从源类别学习并快速适应目标类别的解决方案。
研究挑战:
- 现有研究未充分利用类别标签信息,导致在样本稀缺时特征提取能力受限。
- 原型网络对类间差异依赖度高,对异常值敏感。
方法论:
- 提出结合标签模板、对比学习和注意力机制的框架。
- 将标签模板嵌入输入句子,利用标签语义信息提升预训练模型的特征提取能力。
- 使用监督对比学习拉近同类样本表示,推开不同类样本表示。
- 引入注意力机制到原型网络,突出重要语义信息,生成更具代表性的类别原型。
实验验证:
- 在四个典型数据集上评估,与多个基线模型比较,验证所提方法的有效性。
- 进行消融研究,分析框架中不同组件的影响。
- 展示模型的快速收敛性和通过t-SNE可视化的嵌入效果。
主要贡献:
- 提出了一个简单而有效的FSTC框架,整合了标签模板、对比学习和注意力机制。
- 通过实验证明了该方法在少量样本文本分类任务中的优越性,尤其在单样本场景下。
- 论文的方法在少量迭代次数下就能实现高分类准确率。
未来工作:
- 将框架扩展到更多种类的少量样本学习任务。
- 进一步优化参数调整策略和模型结构。
- 提高模型的鲁棒性、泛化能力和解释性。
总体而言,这篇论文通过整合标签语义、对比学习和注意力机制,提出了一个有效的少量样本文本分类框架,并在多个数据集上验证了其优越性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

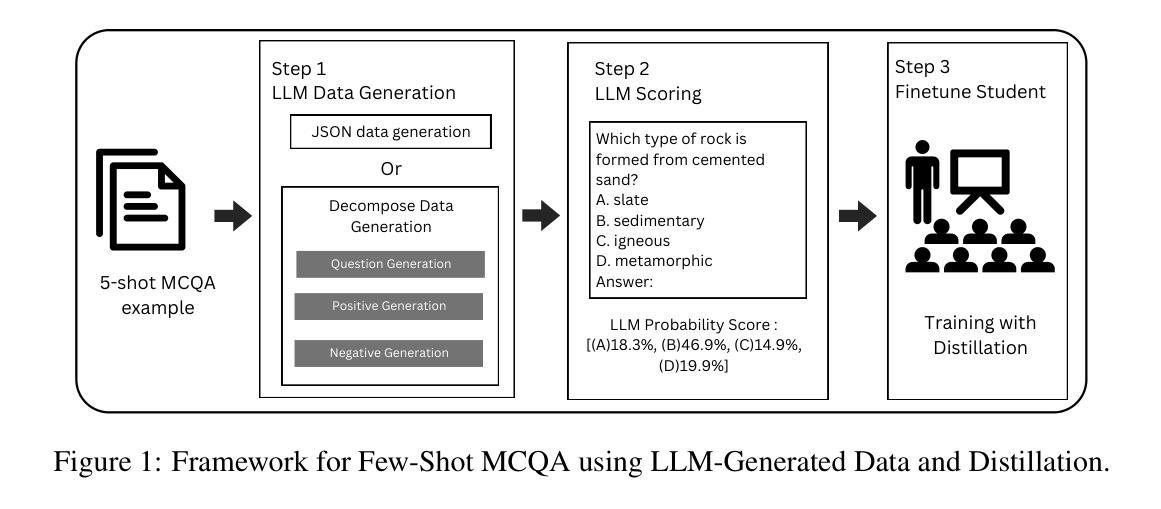
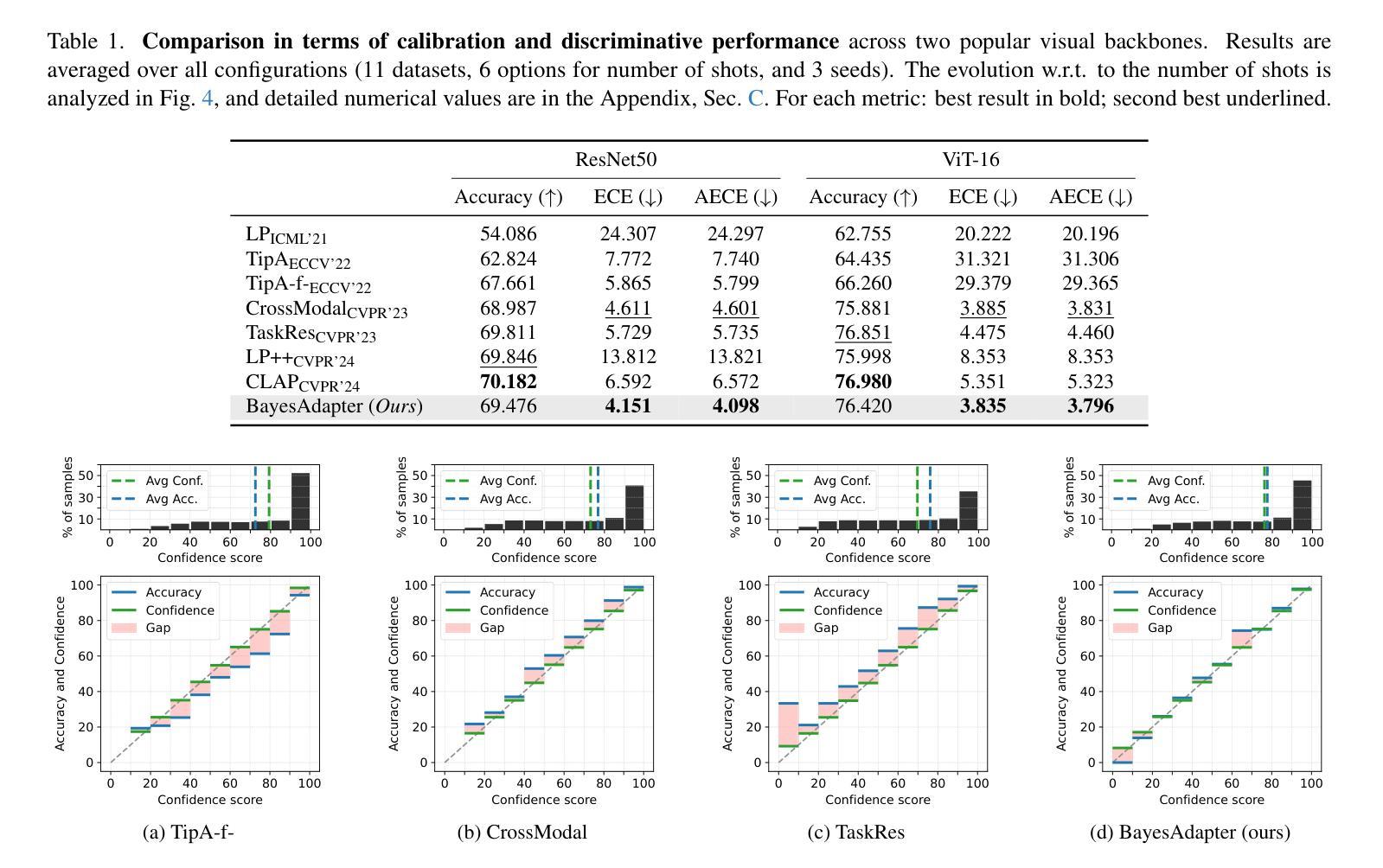
LLM Distillation for Efficient Few-Shot Multiple Choice Question Answering
Authors:Patrick Sutanto, Joan Santoso
Multiple Choice Question Answering (MCQA) is an important problem with numerous real-world applications, such as medicine, law, and education. The high cost of building MCQA datasets makes few-shot learning pivotal in this domain. While Large Language Models (LLMs) can enable few-shot learning, their direct application in real-world scenarios is often hindered by their high computational cost. To address this challenge, we propose a simple yet effective approach that uses LLMs for data generation and scoring. Our approach utilizes LLMs to create MCQA data which contains questions and choices, and to assign probability scores to the generated choices. We then use the generated data and LLM-assigned scores to finetune a smaller and more efficient encoder-only model, DeBERTa-v3-base by leveraging distillation loss. Extensive experiments on the Massive Multitask Language Understanding (MMLU) benchmark demonstrate that our method improves accuracy from 28.9% to 39.3%, representing a gain of over 10% compared to a baseline finetuned directly on 5-shot examples. This shows the effectiveness of LLM-driven data generation and knowledge distillation for few-shot MCQA.
多项选择题问答(MCQA)是一个具有许多现实世界应用的重要问题,例如医学、法律和教育的领域。构建MCQA数据集的高成本使得小样本学习成为该领域的关键。虽然大型语言模型(LLM)可以实现小样本学习,但它们在现实场景中的直接应用往往受到其高计算成本的阻碍。为了应对这一挑战,我们提出了一种简单而有效的方法,该方法使用大型语言模型进行数据生成和评分。我们的方法利用大型语言模型创建包含问题和选择的MCQA数据,并为生成的选项分配概率分数。然后,我们使用生成的数据和大型语言模型分配的分数来微调一个更小、更高效的只编码器模型——基于蒸馏损失改进的DeBERTa-v3基础版本。在大型多任务语言理解(MMLU)基准测试上的大量实验表明,我们的方法将准确率从28.9%提高到39.3%,与直接在5个样本示例上进行微调的基础模型相比,提高了超过10%。这显示了大型语言模型驱动的数据生成和知识蒸馏在小样本MCQA中的有效性。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的生成数据和评分方法,用于解决多选题问答(MCQA)中的少样本学习问题。通过生成包含问题和选项的MCQA数据,并利用LLM分配的概率分数对生成的数据进行微调,提高了小模型的性能。实验结果显示,该方法在MMLU基准测试上的准确率从28.9%提高到39.3%,证明其有效性。
Key Takeaways
- 多选题问答(MCQA)在现实世界应用中的重要性,如医学、法律和教育的应用。
- 构建MCQA数据集的高成本使得少样本学习在此领域尤为重要。
- 大型语言模型(LLM)可实现少样本学习,但其高计算成本阻碍了实际应用。
- 提出一种利用LLM进行数据生成和评分的方法,解决少样本学习问题。
- 利用LLM生成包含问题和选项的MCQA数据,并分配概率分数。
- 使用生成的数据和LLM分配的分数微调小型高效模型(如DeBERTa-v3-base)。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是如何在资源受限的现实世界场景中有效地进行少量样本(few-shot)多项选择题回答(Multiple Choice Question Answering, MCQA)。具体来说,论文关注以下几个挑战:
MCQA数据集构建成本高:构建MCQA数据集需要大量的标记数据,这既昂贵又难以获得。
大型语言模型(LLMs)的计算成本:虽然大型语言模型在少量样本学习中表现出色,但它们的巨大规模使得在资源受限的环境中直接部署变得成本高昂且不切实际。
数据稀缺与计算成本的矛盾:在少量样本学习中,通常需要大型、计算成本高昂的语言模型来实现良好性能,但这对于资源受限的场景来说是一个限制。
为了解决这些问题,论文提出了一种新颖的框架,利用LLMs生成训练数据,并通过知识蒸馏(distillation)将这些知识转移到更小、更高效的编码器模型(encoder-only models)中。这种方法旨在减少对大量标记数据的需求,并降低部署计算密集型LLMs的计算成本,同时在少量样本的MCQA场景中提高性能。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个领域:
MCQA数据生成:
- 使用外部资源(如Wikipedia或知识图谱)来生成MCQA数据集。
- 利用LLMs进行零样本(zero-shot)MCQA数据生成,但这些方法通常需要人工监督以确保质量,限制了数据创建的可扩展性。
少量样本MCQA:
- 需要大型、计算成本高昂的语言模型来实现良好的性能。
- 有效的编码器模型通常依赖于大规模的多任务训练和大量的数据集。
LLM蒸馏:
- 将大型语言模型的知识转移到更小、更高效的模型中。
- 常见的方法是使用LLMs生成训练数据,然后在这些数据上微调较小的模型。
- 直接蒸馏LLM表示是具有挑战性的,将知识蒸馏到不同架构的模型(如仅编码器模型)在很大程度上还未被探索。
具体地,论文中提到了以下几项研究工作:
- **Cheung et al. (2023)**:研究了使用LLMs进行零样本MCQA数据生成。
- **Chung et al. (2023)**:探索了LLMs在分类任务中的数据生成和知识蒸馏。
- **Li et al. (2023)**:研究了指令调整(instruction tuning)中的数据生成。
- **Robinson & Wingate (2023)**:提出了一种使用LLMs进行MCQA任务的方法,该方法通过将答案生成框架为多项选择任务来提高LLM性能。
- **Hinton et al. (2015)**:提出了知识蒸馏的原始框架,用于将大型神经网络的知识转移到小型网络。
这些研究构成了论文提出方法的理论基础和技术支持,展示了利用LLMs进行数据生成和知识蒸馏在少量样本学习中的潜力。论文通过结合这些相关研究,提出了一种新的方法来提高在资源受限环境中MCQA任务的效率和性能。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决少量样本多项选择题回答(MCQA)的效率和性能问题:
LLM数据生成:
- 利用大型语言模型(LLMs)生成合成的MCQA数据集,包含问题和选项。
- 探索两种数据生成策略:直接生成JSON格式的数据和分解方法(分开生成问题、正确答案和错误答案)。
LLM评分:
- 使用LLM为生成的选项分配概率分数,提供软标签(soft labels)。
知识蒸馏:
- 将LLM评分整合到学生模型(较小的编码器模型,例如DeBERTa-v3base)的训练中,通过蒸馏损失(distillation loss)来引导模型训练。
- 学生模型通过对比LLM给出的概率分布来学习,从而实现从LLM到小型模型的知识转移。
模型微调:
- 使用生成的数据和LLM分配的软标签对编码器模型进行微调,以提高其在少量样本情况下的性能。
实验验证:
- 在Massive Multitask Language Understanding (MMLU)基准测试上进行广泛的实验,验证所提方法的有效性。
- 与直接在少量样本上微调的基线模型以及一些更大的模型进行比较,展示所提方法在准确性上的提升。
通过这种方法,论文成功地展示了如何利用LLM生成的数据和基于概率的蒸馏来增强小型编码器模型,在少量样本MCQA场景中实现强大的性能。这种方法不仅提高了模型的准确性,还降低了部署计算密集型LLMs的计算成本,使其适用于资源受限的环境。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估所提出方法的有效性,具体实验包括:
MMLU基准测试:
- 在Massive Multitask Language Understanding (MMLU)基准上进行实验,该基准包含57个数据集,覆盖多个主题,用于评估少量样本MCQA性能。
- 使用5-shot开发集进行数据生成,并在MMLU基准上评估了JSON和分解数据生成方法,同时考虑了是否使用知识蒸馏。
性能对比实验:
- 将DeBERTa-base-v3模型(使用所提方法)的性能与多种基线进行比较,包括更大的模型如LLaMA-7B和Flan-T5-250M,以及经过多任务训练的Tasksource DeBERTa-base模型。
- 展示了DeBERTa-base-v3模型通过使用LLM生成的数据和蒸馏,性能得到了显著提升。
消融研究:
- 在ARC-easy和ARC-Challenge基准上进行消融研究,分析了不同组件对方法的影响。
- 研究了生成数据点数量、使用不同大小的LLM进行数据生成和评分的影响,以及温度超参数对数据生成的影响。
数据生成方法对比:
- 比较了JSON和分解数据生成方法在不同条件下的性能,包括有无LLM蒸馏。
LLM蒸馏的影响:
- 分析了LLM蒸馏对于少量样本MCQA性能的影响,并探讨了不同LLM生成软标签在知识蒸馏中的作用。
不同温度参数的影响:
- 研究了在数据生成过程中控制数据多样性的温度参数对性能的影响。
跨数据集评估:
- 探讨了模型在不同数据集上训练和测试时的性能,以验证模型的泛化能力。
二元分类任务扩展:
- 探索了将所提方法应用于二元分类任务,例如评分问题-答案对的正确性。
数据集语义相似性分析:
- 分析了生成数据与训练集和测试集之间的语义相似性,以评估数据的新颖性和质量。
这些实验全面评估了所提出方法在少量样本MCQA任务中的性能,并与现有技术进行了比较,验证了利用LLM进行数据生成和知识蒸馏对于提高小型模型性能的有效性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的研究方向:
先进的蒸馏技术:
- 探索更复杂的蒸馏技术,比如序列级知识蒸馏、基于注意力的蒸馏等,以进一步提升性能。
基准数据集创建:
- 结合自动化质量过滤、后处理技术和检索增强生成,创建高质量的MCQA基准数据集。
改进分解生成方法:
- 研究更复杂的提示技术来提高分解生成方法的数据质量,例如通过在提示中加入约束来指定答案的长度或格式。
超越MCQA的应用:
- 将框架应用于NLP中的其他任务,如文本分类、序列标注等,以及探索在视觉任务中的应用,例如视觉问答(VQA)。
处理更长上下文的任务:
- 研究如何将方法扩展到涉及更长上下文的任务,并提高LLM在生成和评分长上下文数据时的有效性。
减少偏见:
- 研究方法来减轻LLM生成数据中可能存在的偏见,确保下游模型在现实世界应用中的公平性和非歧视性。
提高数据生成的多样性:
- 探索不同的数据生成策略,以提高生成数据的多样性,从而提升模型的泛化能力。
跨语言和文化的适应性:
- 研究方法在不同语言和文化背景下的适用性,以及如何为那些缺乏强大LLM资源的语言和地区定制解决方案。
模型压缩和优化:
- 研究模型压缩技术,以进一步减少模型大小和提高推理速度,使其更适合在资源受限的设备上部署。
增强模型的解释性和透明度:
- 提高模型的可解释性,帮助研究人员和用户理解模型的决策过程,并增加其在敏感应用中的透明度和信任度。
这些方向能够帮助研究者们进一步提升基于LLM的方法在少量样本学习中的性能和适用性,同时解决实际应用中可能遇到的挑战。
Q: 总结一下论文的主要内容
A: 论文的主要内容概述如下:
问题背景:
- 论文针对的是多项选择题回答(MCQA)领域,这是一个在医学、法律和教育等多个领域具有广泛应用的重要问题。
- MCQA数据集构建成本高,且大型语言模型(LLMs)虽在少量样本学习中表现出色,但在资源受限的实际场景中难以直接应用。
研究目标:
- 提出一种有效的方法,利用LLMs生成训练数据,并通过知识蒸馏将这些知识转移到更小、更高效的编码器模型中,以实现在资源受限环境中的高效MCQA。
方法论:
- 数据生成:使用LLMs创建包含问题和选项的MCQA数据,并探索了直接生成JSON格式数据和分解方法(分别生成问题、正确答案和错误答案)两种策略。
- LLM评分:利用LLM为生成的选项分配概率分数,提供软标签。
- 知识蒸馏:将LLM评分整合到学生模型的训练中,通过蒸馏损失来引导模型训练。
实验验证:
- 在MMLU基准测试上进行广泛的实验,验证所提方法的有效性。
- 与直接在少量样本上微调的基线模型以及一些更大的模型进行比较,展示所提方法在准确性上的提升。
实验结果:
- 所提方法显著提高了基于DeBERTa-v3base模型的性能,使其接近一些更大的模型,如LLaMA-7B和Flan-T5-250M。
- 通过消融研究,分析了不同组件对方法的影响,包括生成数据点数量、使用不同大小的LLM进行数据生成和评分的影响,以及温度超参数对数据生成的影响。
局限性和未来工作:
- 论文讨论了其方法的局限性,包括对强大LLM的依赖、潜在的偏见问题以及对长上下文任务的挑战。
- 提出了未来研究方向,包括探索更先进的数据生成和蒸馏技术,以及将方法扩展到更长上下文的MCQA任务。
总体而言,这篇论文提出了一种结合LLM数据生成和知识蒸馏的方法,以提高少量样本MCQA任务中小型模型的性能,同时降低了对大量标记数据和计算资源的需求。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

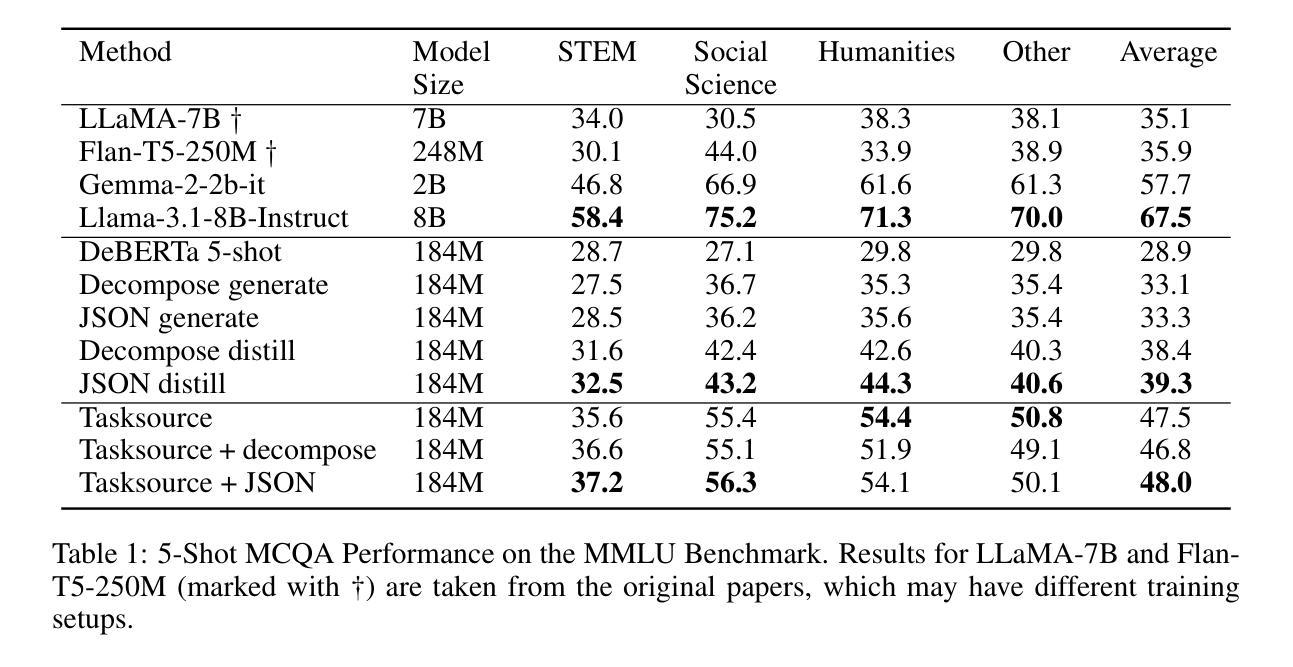
BayesAdapter: enhanced uncertainty estimation in CLIP few-shot adaptation
Authors:Pablo Morales-Álvarez, Stergios Christodoulidis, Maria Vakalopoulou, Pablo Piantanida, Jose Dolz
The emergence of large pre-trained vision-language models (VLMs) represents a paradigm shift in machine learning, with unprecedented results in a broad span of visual recognition tasks. CLIP, one of the most popular VLMs, has exhibited remarkable zero-shot and transfer learning capabilities in classification. To transfer CLIP to downstream tasks, adapters constitute a parameter-efficient approach that avoids backpropagation through the large model (unlike related prompt learning methods). However, CLIP adapters have been developed to target discriminative performance, and the quality of their uncertainty estimates has been overlooked. In this work we show that the discriminative performance of state-of-the-art CLIP adapters does not always correlate with their uncertainty estimation capabilities, which are essential for a safe deployment in real-world scenarios. We also demonstrate that one of such adapters is obtained through MAP inference from a more general probabilistic framework. Based on this observation we introduce BayesAdapter, which leverages Bayesian inference to estimate a full probability distribution instead of a single point, better capturing the variability inherent in the parameter space. In a comprehensive empirical evaluation we show that our approach obtains high quality uncertainty estimates in the predictions, standing out in calibration and selective classification. Our code is publicly available at: https://github.com/pablomorales92/BayesAdapter.
大型预训练视觉语言模型(VLMs)的出现代表了机器学习领域的一个范式转变,为广泛的视觉识别任务带来了前所未有的结果。CLIP是最受欢迎的VLM之一,在分类方面表现出了令人印象深刻的零样本和迁移学习能力。为了将CLIP迁移到下游任务,适配器构成了一种参数高效的策略,避免了在大模型中进行反向传播(这与相关的提示学习方法不同)。然而,CLIP适配器旨在提高判别性能,却忽略了其不确定性估计的质量。在这项工作中,我们表明最先进的CLIP适配器的判别性能并不总是与它们的不确定性估计能力相关,这对于在现实世界场景中的安全部署至关重要。我们还证明,其中一种适配器是通过更通用的概率框架通过最大后验概率推断获得的。基于这一观察,我们引入了BayesAdapter,它利用贝叶斯推断来估计一个完整的概率分布,而不是一个点,从而更好地捕捉参数空间中固有的变化。在全面的经验评估中,我们证明了我们的方法在预测中获得高质量的不确定性估计,在校准和选择性分类中表现出色。我们的代码可在以下网址公开访问:https://github.com/pablomorales92/BayesAdapter。
论文及项目相关链接
PDF 30 pages, 5 figures, 23 tables
Summary
大型预训练视觉语言模型(VLMs)的出现代表了机器学习领域的一个范式转变,其在广泛的视觉识别任务中取得了前所未有的结果。CLIP作为一种流行的VLM,展现出令人瞩目的零样本和迁移学习能力。为将CLIP迁移到下游任务,适配器提供了一种参数高效的方法,避免了在大模型中进行反向传播(与相关的提示学习方法不同)。然而,CLIP适配器主要关注判别性能,其不确定性估计的质量却被忽视。本研究表明,最先进的CLIP适配器的判别性能并不总是与其不确定性估计能力相关,这对于现实场景中的安全部署至关重要。此外,我们展示了可以通过一个更通用的概率框架来获得其中一种适配器,通过MAP推理实现。基于此观察,我们引入了BayesAdapter,它利用贝叶斯推理来估计一个完整的概率分布,而不是一个点,从而更好地捕捉参数空间中的固有变化。在全面的实证评估中,我们的方法在进行预测时获得了高质量的不确定性估计,在校准和选择性分类方面表现出色。
Key Takeaways
- 大型预训练视觉语言模型(VLMs)在视觉识别任务中取得显著成果,代表机器学习领域的范式转变。
- CLIP作为一种流行的VLM,展现出强大的零样本和迁移学习能力。
- 适配器为将CLIP迁移到下游任务提供了一种参数高效的方法,避免在大模型中进行反向传播。
- 最先进的CLIP适配器的判别性能与不确定性估计能力不总是相关,这对于现实场景中的安全部署很重要。
- 一种适配器可通过更通用的概率框架和MAP推理获得。
- BayesAdapter利用贝叶斯推理估计一个完整的概率分布,提高预测质量。
- BayesAdapter在不确定性估计、校准和选择性分类方面表现出色。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文主要关注于提升大型预训练视觉-语言模型(例如CLIP)在少样本(few-shot)适应性任务中的不确定性估计能力。具体来说,论文试图解决以下几个问题:
不确定性估计的重要性:在安全关键的应用场景中,模型的不确定性(或置信度)对于预测的安全性至关重要。论文指出,尽管CLIP等模型在零样本(zero-shot)和迁移学习任务中表现出色,但在实际应用中,考虑预测的不确定性对于构建可靠的系统更为关键。
现有方法的局限性:论文分析了现有的CLIP适配器(adapters),发现它们在提高判别性能的同时,其不确定性估计能力并没有得到充分考虑。也就是说,这些适配器的预测性能并不总是与其不确定性估计能力相关联。
改进不确定性估计:论文提出,通过使用贝叶斯推断而不是最大后验(MAP)推断,可以更好地捕捉参数空间中的不确定性。这种方法允许模型估计参数的概率分布,而不仅仅是单一的点估计,从而在预测中获得更高质量的不确定性估计。
实际应用中的挑战:论文还探讨了在实际应用中,如何通过校准(calibration)和高置信度下的分类选择(selective classification)来评估和改进模型的不确定性估计能力。
综上所述,论文的核心目标是提出一种新的方法(BayesAdapter),通过贝叶斯推断来增强CLIP在少样本学习任务中的不确定性估计,从而提高模型在现实世界应用中的安全性和可靠性。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与BayesAdapter相关的研究工作:
大型预训练视觉-语言模型(VLMs):
- CLIP模型:[44] Alec Radford et al. 提出了CLIP模型,这是一个大规模的视觉-语言模型,具有出色的零样本和迁移学习能力。
少样本适应性(Few-shot adaptation):
- Prompt Learning:[26, 62-64] 提出了一种将可学习的文本提示(prompt)集成到原始文本提示中的方法,这些提示被提供给CLIP文本编码器作为输入,然后基于少量样本进行优化。
- 适配器(Adapter)方法:[13, 22, 31, 47, 59, 61] 这些方法通过仅优化一小部分参数来实现参数效率,例如在CLIP特征之上微调一个线性层。
不确定性估计在VLMs中:
- C-TPT [58] 和 DAC [52]:研究了在提示学习策略中的校准问题。
- [41]:在全参数微调场景下进行的不确定性估计研究。
- [49]:评估了温度缩放对零样本VLM预测的影响。
- [50]:引入了VLM嵌入的概率分布,用于改进视觉-语言对比学习。
贝叶斯推断在深度学习和大型VLMs中的应用:
- CLIPScope [12]:在零样本分类中提出了贝叶斯评分。
- [53]:使用贝叶斯方法选择最适合微调大型AI模型的样本。
- [35]:基于高斯过程引入了一个贝叶斯框架,结合了不同大型模型的知识,如CLIP、DINO和MoCo。
其他相关技术:
- 贝叶斯深度学习:[23, 24, 42] 将贝叶斯方法与深度神经网络结合,形成了所谓的贝叶斯深度学习。
- 变分贝叶斯方法:[1, 36] 用于近似真实后验分布的方法,适用于不能闭合形式求解的贝叶斯推断。
这些相关工作涵盖了从模型架构、适应性学习策略、不确定性量化到贝叶斯推断等多个方面,为BayesAdapter的研究提供了理论基础和技术背景。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决大型预训练视觉-语言模型(VLMs),特别是CLIP,在少样本适应性任务中的不确定性估计问题:
分析现有CLIP适配器的不确定性估计能力:
- 论文首先评估了现有的CLIP适配器在不确定性估计方面的表现,特别是在校准(calibration)和高置信度下的分类选择(selective classification)方面。
指出现有方法的局限性:
- 论文揭示了现有CLIP适配器在判别性能和不确定性估计能力之间并不总是相关联,表明这些方法在提供高置信度预测时可能不够可靠。
引入贝叶斯推断:
- 论文提出利用贝叶斯推断来改进不确定性估计。与最大后验(MAP)推断不同,贝叶斯推断可以估计参数的概率分布,而不仅仅是一个点估计,从而更好地捕捉参数空间中的不确定性。
提出BayesAdapter:
- 基于上述观察,论文提出了BayesAdapter,这是一个基于贝叶斯推断的适配器,它通过估计参数的全概率分布来改进预测中的不确定性估计。
变分贝叶斯方法:
- 由于在他们的模型中贝叶斯推断不能以闭合形式进行,论文采用了变分贝叶斯方法来近似真实的后验分布。这涉及到最小化参数α的Kullback-Leibler (KL) 散度,等同于最大化证据下界(ELBO)。
实验验证:
- 论文通过在多个数据集上的实验评估了BayesAdapter的性能,验证了其在不确定性估计方面(如校准和分类选择)的改进,同时保持了与现有技术相当的判别性能。
提供开源代码:
- 为了促进研究和进一步的开发,论文提供了BayesAdapter的开源代码,以便其他研究者和开发者可以复现和利用这项工作。
总结来说,论文通过结合贝叶斯推断的原理和变分贝叶斯方法,提出了一种新的方法来增强CLIP在少样本学习任务中的不确定性估计,并通过实验验证了其有效性。
Q: 论文做了哪些实验?
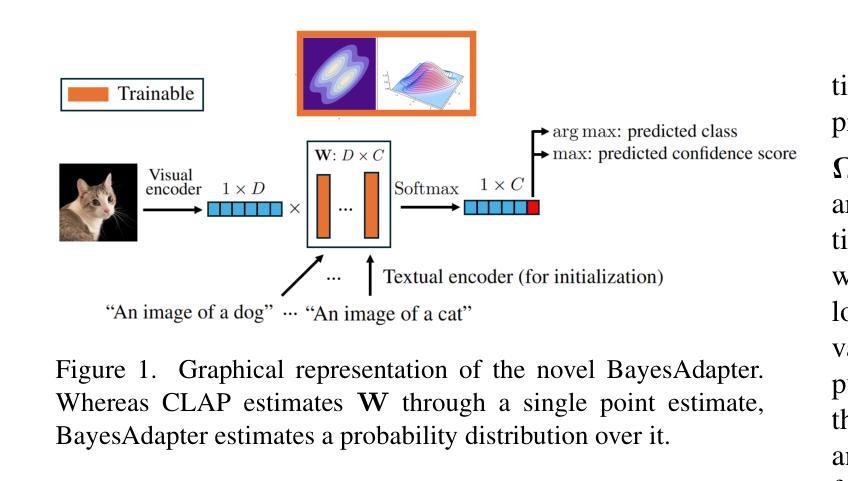
A: 根据提供的论文内容,作者进行了以下实验来评估和验证他们提出的BayesAdapter方法:
校准(Calibration)评估:
- 使用预期校准误差(Expected Calibration Error, ECE)和自适应ECE(AECE)作为指标,来衡量模型预测的置信度与实际准确性之间的一致性。这些指标将测试样本根据置信度得分分箱,并计算每个箱中样本的平均准确性与平均置信度之间的差异。
高置信度下的分类选择(Selective Classification at High Confidence):
- 评估模型在不同置信度水平(如99%、95%、90%、85%、80%)下的测试集覆盖率,即模型能够以高于或等于请求置信度的准确性选择测试样本子集的能力。这衡量了模型在安全关键场景下的可靠性和实用性。
判别性能(Discriminative Performance):
- 通过测试准确率来评估所有方法的性能,以了解在考虑不确定性估计的同时,模型的分类性能如何。
依赖于样本数量的实验:
- 分析了不同数量的训练样本(shots)对模型性能的影响,包括准确性、校准和高置信度下的覆盖率。
消融研究(Ablation Study):
- 对BayesAdapter的两个主要超参数进行了消融研究:用于MC(Monte Carlo)积分的样本数和每个类别的先验标准差。
训练时间比较:
- 比较了BayesAdapter与其确定性对应物CLAP的训练时间,以评估贝叶斯方法是否引入了显著的计算开销。
这些实验涉及了11个不同的数据集,覆盖了广泛的计算机视觉分类任务,从通用对象到专业应用中的细粒度类别。实验结果旨在全面评估BayesAdapter在不确定性估计和判别性能方面的表现,并与多个现有的CLIP适配器进行比较。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
贝叶斯推断的深入研究:
- 探索不同的变分推断方法来近似后验分布,可能包括更复杂的近似方法,以提高不确定性估计的准确性。
超参数调整:
- 系统地研究贝叶斯适配器中超参数设置对性能的影响,包括先验的选择、后验分布的形式等。
模型泛化能力:
- 在更广泛的数据集和任务上评估模型的泛化能力,特别是在不同的领域和复杂的实际应用中。
计算效率:
- 优化贝叶斯适配器的训练和推理过程,以减少计算开销,使其更适合实时或资源受限的应用场景。
集成学习:
- 研究如何将贝叶斯适配器与其他集成学习方法结合,以进一步提高模型的鲁棒性和准确性。
不确定性估计的解释性:
- 开发方法来解释模型的不确定性估计,提供更深入的洞见,为什么模型对某些预测的不确定性更高或更低。
跨领域适应性:
- 探索贝叶斯适配器在跨领域任务中的适应性,特别是在源领域和目标领域之间存在显著差异时。
对抗性攻击和防御:
- 研究贝叶斯适配器对于对抗性攻击的鲁棒性,并开发防御策略来提高模型在面对此类攻击时的稳定性。
多模态学习:
- 将贝叶斯适配器应用于多模态学习任务,例如结合视觉和语言信息进行更复杂的任务,如视觉问答或图像字幕生成。
模型压缩和加速:
- 研究如何压缩贝叶斯适配器模型,以便于在移动设备或边缘设备上部署,同时保持性能。
长期适应性:
- 研究模型在长期适应性任务中的表现,特别是在连续接收新数据时的适应能力。
伦理和社会影响:
- 探讨贝叶斯适配器在高风险应用中的伦理和社会影响,确保技术的负责任使用。
这些探索点可以帮助研究者更全面地理解和改进贝叶斯适配器,以及将其应用于更广泛的实际问题。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容概括如下:
问题背景:
- 大型预训练视觉-语言模型(VLMs),如CLIP,在视觉识别任务中取得了突破性进展,尤其在零样本和迁移学习方面表现出色。
- 然而,在实际应用中,特别是在安全关键场景下,模型的不确定性估计同样重要,但现有CLIP适配器主要关注判别性能,忽略了不确定性估计。
研究目标:
- 提出一种新方法(BayesAdapter),利用贝叶斯推断来增强CLIP在少样本学习任务中的不确定性估计能力。
主要贡献:
- 分析了现有CLIP适配器在准确性之外的不确定性估计质量,发现判别性能并不总是与不确定性估计能力相关联。
- 展示了一个最先进的CLIP适配器(CLAP)可以通过最大后验(MAP)推断从更一般的贝叶斯框架中获得。
- 通过贝叶斯推断而非MAP推断,引入了一种新方法,该方法可以估计参数的概率分布,而不仅仅是单一的点估计,从而更好地处理参数空间中的不确定性。
- 在多个数据集上进行了广泛的实验评估,证明了BayesAdapter在校准和高置信度下的分类选择方面优于现有方法,同时保持了竞争性的判别性能。
方法论:
- BayesAdapter基于变分贝叶斯方法,通过最小化KL散度来近似真实的后验分布,从而估计参数的分布而不是单一的点估计。
- 在预测时,使用蒙特卡洛积分来计算最终的softmax测试概率,并据此确定预测类别及其置信度。
实验结果:
- 在11个不同数据集上的实验结果显示,BayesAdapter在预期校准误差(ECE)和高置信度下的测试集覆盖率方面均优于现有方法。
- 尽管在判别性能(准确性)方面略低于最佳现有方法,但差距较小(约0.5-0.7%),并且随着样本数量的增加,BayesAdapter的性能提升更为显著。
结论:
- 论文强调了在实际应用中评估CLIP适配器不确定性的重要性,并提出了一种新的方法BayesAdapter来改进不确定性估计,为安全部署提供了更全面的评估。
论文通过理论分析和广泛的实验验证了其提出方法的有效性,并指出了未来可能的研究方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


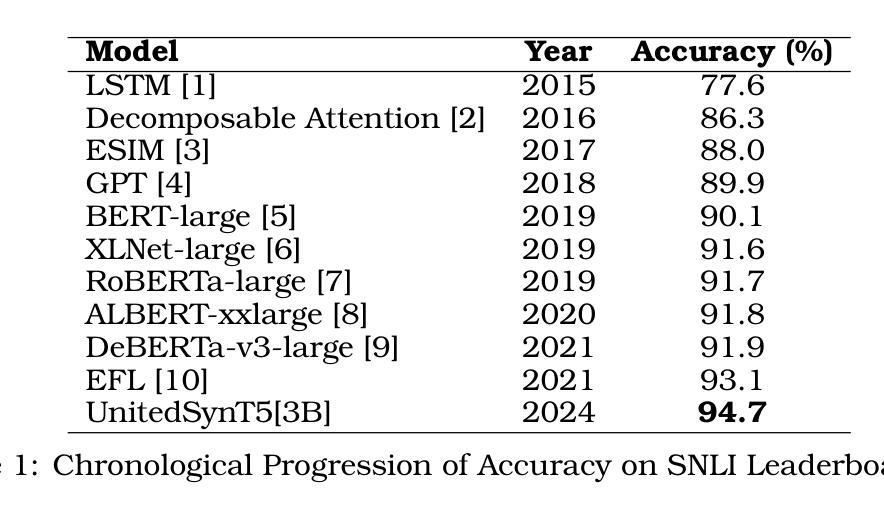
First Train to Generate, then Generate to Train: UnitedSynT5 for Few-Shot NLI
Authors:Sourav Banerjee, Anush Mahajan, Ayushi Agarwal, Eishkaran Singh
Natural Language Inference (NLI) tasks require identifying the relationship between sentence pairs, typically classified as entailment, contradiction, or neutrality. While the current state-of-the-art (SOTA) model, Entailment Few-Shot Learning (EFL), achieves a 93.1% accuracy on the Stanford Natural Language Inference (SNLI) dataset, further advancements are constrained by the dataset’s limitations. To address this, we propose a novel approach leveraging synthetic data augmentation to enhance dataset diversity and complexity. We present UnitedSynT5, an advanced extension of EFL that leverages a T5-based generator to synthesize additional premise-hypothesis pairs, which are rigorously cleaned and integrated into the training data. These augmented examples are processed within the EFL framework, embedding labels directly into hypotheses for consistency. We train a GTR-T5-XL model on this expanded dataset, achieving a new benchmark of 94.7% accuracy on the SNLI dataset, 94.0% accuracy on the E-SNLI dataset, and 92.6% accuracy on the MultiNLI dataset, surpassing the previous SOTA models. This research demonstrates the potential of synthetic data augmentation in improving NLI models, offering a path forward for further advancements in natural language understanding tasks.
自然语言推理(NLI)任务需要识别句子对之间的关系,通常分类为蕴含、矛盾或中性。虽然当前最先进的模型——蕴含少样本学习(EFL)在斯坦福自然语言推理(SNLI)数据集上达到了93.1%的准确率,但由于数据集的局限性,进一步的发展受到了限制。为了解决这一问题,我们提出了一种利用合成数据增强来提高数据集多样性和复杂性新方法。我们推出了UnitedSynT5,它是EFL的高级扩展,利用基于T5的生成器合成额外的前提假设对,并进行严格的清洗和整合到训练数据中。这些增强后的例子在EFL框架内进行处理,将标签直接嵌入假设中以保证一致性。我们在扩展后的数据集上训练了一个GTR-T5-XL模型,在SNLI数据集上达到了94.7%的准确率,E-SNLI数据集上达到了94.0%的准确率,MultiNLI数据集上达到了92.6%的准确率,超越了之前的SOTA模型。这项研究证明了合成数据增强在提高NLI模型潜力方面的潜力,为自然语言理解任务的进一步发展提供了方向。
论文及项目相关链接
PDF 14 pages
Summary
本文介绍了针对自然语言推理(NLI)任务的新方法,通过使用合成数据增强来提高数据集多样性和复杂性。提出的UnitedSynT5模型利用T5生成器合成额外的前提假设对,并严格清洗和集成到训练数据中。在扩展数据集上训练的GTR-T5-XL模型,实现了SNLI数据集94.7%、E-SNLI数据集94.0%和MultiNLI数据集92.6%的准确率,超越了现有最佳模型。研究展示了合成数据增强在改进NLI模型方面的潜力,为自然语言理解任务的进一步发展提供了方向。
Key Takeaways
- 当前NLI模型的性能受限于数据集的限制和多样性问题。
- 自然语言推理(NLI)任务是识别句子对之间的关系,分为蕴涵、矛盾和中性三种分类。
- 提出了一种利用合成数据增强提高数据集多样性和复杂性的新方法。
- UnitedSynT5模型利用T5生成器合成额外的假设前提对,并集成到训练数据中。
- GTR-T5-XL模型在扩展数据集上的训练实现了高准确率表现,超过了现有最佳模型。
- 研究证明了合成数据增强在改进NLI模型方面的潜力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决自然语言推理(Natural Language Inference, NLI)任务中存在的挑战,特别是在数据集局限性和模型性能限制方面。具体来说,论文的目标是:
提升NLI任务的准确性:尽管现有的最先进模型(如Entailment Few-Shot Learning, EFL)在SNLI数据集上已经取得了93.1%的准确率,但进一步的提升受到数据集限制的阻碍。
增强数据集的多样性和复杂性:论文指出,现有的SNLI数据集包含570,000个人工标注的前提-假设对,但这仅捕捉了现实世界场景中一小部分的语言现象和推理模式。因此,需要通过合成数据增强来引入更大的语言多样性和复杂性。
克服现有模型的局限性:以往的模型,包括基于LSTM的方法和基于注意力机制的方法,都存在无法处理复杂语言现象、缺乏世界知识或推理链的问题。此外,预训练的变换器模型(如BERT及其变体)虽然有所改进,但在泛化到训练分布之外的模式上能力有限。
提出新的方法:为了解决这些挑战,论文提出了一个新颖的方法,即UnitedSynT5,它结合了合成数据增强和EFL框架。通过使用基于T5的生成器来创建额外的前提-假设对,这些数据经过严格的清洗和整合到训练数据中,以提高模型的泛化能力,并在NLI任务上取得了新的最先进性能。
总结来说,这篇论文旨在通过合成数据增强和先进的模型训练方法,提高NLI模型的准确性和泛化能力,从而在自然语言理解任务上取得进一步的进展。
Q: 有哪些相关研究?
A: 论文中提到了多个与自然语言推理(NLI)相关的研究工作,以下是一些关键的相关研究:
LSTM [1] (2015): 最初的基于长短期记忆网络(LSTM)的模型,在SNLI数据集上取得了77.6%的准确率,为后续研究设定了基准。
Decomposable Attention [2] (2016): 引入了注意力机制,将准确率提高到86.3%。
ESIM [3] (2017): 增强型LSTM(ESIM)模型,将准确率进一步推高至88.0%。
GPT [4] (2018): 生成预训练(GPT)模型,实现了89.9%的准确率,展示了生成预训练的强大能力。
BERT-large [5] (2019): 基于双向变换器架构的BERT模型,在SNLI上达到了90.1%的准确率。
XLNet-large [6] (2019): 与BERT同年,XLNet模型通过广义自回归预训练达到了91.6%的准确率。
RoBERTa-large [7] (2019): 在BERT的基础上优化了训练过程,包括更长时间的训练和动态掩码,达到了91.7%的准确率。
ALBERT-xxlarge [8] (2020): 通过引入去耦注意力机制和增强掩码解码器架构,将性能略微提高至91.8%。
DeBERTa-v3-large [9] (2021): 进一步推动了界限至91.9%,强调了精确参数调整和架构创新在提高NLI性能中的重要性。
EFL [10] (2021): 引入了少量样本学习范式,通过将标签直接嵌入到假设中,将NLI重新构造为二元决策问题,实现了93.1%的准确率。
这些研究展示了NLI模型的逐步发展,每个新方法都针对其前身的具体局限性进行了改进。从依赖手工特征和浅层神经网络的早期模型,到引入注意力机制和先进的神经架构,再到基于大型语言模型和迁移学习技术的模型,这些研究构成了NLI领域的重要进展。论文提出的UnitedSynT5方法正是在这些研究的基础上,通过合成数据增强和EFL框架,进一步推动了NLI任务的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个新颖的方法,即UnitedSynT5,来解决自然语言推理(NLI)任务中存在的问题。这个方法结合了合成数据增强和Entailment Few-Shot Learning(EFL)框架,具体步骤如下:
合成数据生成:
- 使用基于T5的生成器来创建额外的前提-假设对,增强数据集的多样性和复杂性。
- 将初始训练数据集分割为生成集和少量样本集,利用少量样本集中的示例作为生成提示中的上下文参考,以提高假设生成的相关性和准确性。
数据清洗:
- 通过过滤机制移除不一致或冗余的数据,确保合成数据集的质量。
- 应用标签对齐和冗余消除标准,仅保留与人类标注数据一致且为新颖的示例。
EFL转换:
- 将合成数据转换为EFL框架,将标签信息直接嵌入到假设陈述中。
- 这种转换将三分类问题转化为二元决策问题,简化了分类任务。
训练GTR-T5-XL模型:
- 使用经过清洗和EFL转换的合成数据集来从头开始训练GTR-T5-XL模型。
- 配置模型输入维度、全连接层、激活函数和dropout率,以优化模型性能。
评估和性能测量:
- 在原始SNLI数据集上评估模型性能,与人类标注的标签进行比较。
- 通过反馈循环不断细化模型参数,提高模型对复杂和多样化前提-假设对的处理能力。
通过这些步骤,UnitedSynT5方法不仅提高了模型在SNLI数据集上的准确性,而且还在E-SNLI和MultiNLI数据集上取得了新的最先进性能,证明了合成数据增强在提升NLI模型性能方面的潜力。这种方法为自然语言理解任务的进一步发展提供了一条前进的道路。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出方法的有效性:
合成数据生成实验:
- 使用FLAN-T5 XL(3B)生成器基于原始SNLI数据集生成额外的前提-假设对。
- 通过随机选择少量样本集中的示例作为上下文参考,生成与任务一致的假设。
数据清洗实验:
- 对生成的合成数据进行系统性过滤,移除与GTR-T5-XL模型预测标签不一致或与现有训练数据重复的例子。
- 通过过滤过程,从初始的521,899个生成例子中移除了54,216个例子,保留了467,683个例子用于最终的训练数据集。
EFL转换实验:
- 将清洗后的合成数据转换为EFL框架,将标签信息直接嵌入到假设中,形成二元决策问题。
模型训练实验:
- 使用清洗和转换后的合成数据集训练GTR-T5-XL模型。
- 配置模型输入维度为768,包含三个全连接层,使用GeLU激活函数和0.1的dropout率。
性能评估实验:
- 在原始SNLI数据集上评估GTR-T5-XL模型的性能,与人类标注的标签进行比较。
- 通过反馈循环不断调整模型参数,以提高模型对复杂和多样化前提-假设对的处理能力。
跨数据集验证实验:
- 除了在SNLI数据集上测试外,还将相同的方法应用于E-SNLI和MultiNLI数据集,验证方法的普适性和效果。
- 在E-SNLI上达到了94.01%的准确率,在MultiNLI上达到了92.57%的准确率,均超越了之前的最佳模型。
这些实验的结果表明,通过合成数据增强和EFL框架相结合的方法,可以在多个NLI基准测试中实现新的最先进性能,证明了该方法在提高NLI模型泛化能力和准确性方面的有效性。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些可能的研究方向,以下是可以进一步探索的几个点:
不同训练/少量样本数据集划分比例的实验:
- 测试不同的训练/少量样本(train/few-shot)数据集划分比例,以及在提示中包含不同数量的少量样本(few-shot)例子,以找到优化模型性能相对于输入大小的配置。
合成数据增强在其他NLI方法中的应用:
- 探索合成数据增强技术在EFL框架之外的其他NLI方法中的有效性,以了解其在NLI模型开发中的广泛适用性。
模型的计算效率提升:
- 针对当前方法在计算效率方面的限制,研究如何减少输入提示中的令牌数量,以降低生成假设所需的计算资源,提高大规模应用的效率。
上下文一致性的改善:
- 针对小型模型(如T5-3B)在处理长提示时遇到的上下文一致性问题,研究如何改善模型处理复杂输入的能力。
模型泛化能力的提高:
- 进一步研究如何提高模型的泛化能力,使其能够更有效地处理未见过的数据。
模型性能与数据集大小的关系:
- 研究模型性能与数据集大小之间的关系,以及如何平衡数据集的规模和质量以优化模型训练。
更复杂的推理模式和语言现象的处理:
- 探索模型在处理更复杂的推理模式和语言现象(如否定、量化和世界知识)时的表现,并寻找改进的方法。
跨领域和跨语言的NLI任务:
- 将UnitedSynT5方法应用于跨领域和跨语言的NLI任务,检验其在不同领域和语言中的适用性和效果。
模型的可解释性和透明度:
- 提高模型决策过程的可解释性,以便更好地理解模型是如何学习和推理的。
模型的伦理和社会影响:
- 研究NLI模型在实际应用中的伦理和社会影响,确保技术的负责任使用。
这些探索点可以帮助研究者们更深入地理解NLI任务的挑战,推动NLI模型性能的进一步提升,并确保技术发展与社会价值相协调。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出自然语言推理(NLI)任务在确定两个句子之间的逻辑关系方面的重要性,以及现有最先进模型(SOTA)在SNLI数据集上的局限性。
现有模型的进展:
- 论文回顾了NLI模型的发展历程,包括早期的基于LSTM的模型,引入注意力机制的模型,以及基于大型语言模型(LLMs)和迁移学习技术的模型。
提出的方法:
- 论文提出了UnitedSynT5,这是一种结合了合成数据增强和EFL框架的新方法。通过使用基于T5的生成器来创建额外的前提-假设对,并将其整合到训练数据中,以提高数据集的多样性和复杂性。
实验设计:
- 论文详细描述了合成数据的生成过程、数据清洗、EFL转换以及使用增强数据集训练GTR-T5-XL模型的过程。
实验结果:
- 通过在SNLI、E-SNLI和MultiNLI数据集上的实验,论文展示了UnitedSynT5方法能够实现新的SOTA性能,证明了合成数据增强在提高NLI模型准确性和泛化能力方面的潜力。
讨论与未来工作:
- 论文讨论了当前方法的局限性,包括计算效率和模型性能,并提出了未来可能的研究方向,如探索不同的数据集划分比例、测试合成数据增强在其他NLI方法中的有效性等。
总结来说,这篇论文通过提出UnitedSynT5方法,展示了合成数据增强和EFL框架结合如何推动NLI任务的性能界限,同时也指出了未来研究的方向,以期进一步改进NLI模型的性能和泛化能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Towards Cross-Lingual Audio Abuse Detection in Low-Resource Settings with Few-Shot Learning
Authors:Aditya Narayan Sankaran, Reza Farahbakhsh, Noel Crespi
Online abusive content detection, particularly in low-resource settings and within the audio modality, remains underexplored. We investigate the potential of pre-trained audio representations for detecting abusive language in low-resource languages, in this case, in Indian languages using Few Shot Learning (FSL). Leveraging powerful representations from models such as Wav2Vec and Whisper, we explore cross-lingual abuse detection using the ADIMA dataset with FSL. Our approach integrates these representations within the Model-Agnostic Meta-Learning (MAML) framework to classify abusive language in 10 languages. We experiment with various shot sizes (50-200) evaluating the impact of limited data on performance. Additionally, a feature visualization study was conducted to better understand model behaviour. This study highlights the generalization ability of pre-trained models in low-resource scenarios and offers valuable insights into detecting abusive language in multilingual contexts.
网络滥用内容检测,特别是在资源匮乏的环境和音频模式下,仍然研究不足。我们调查了预训练音频表示在检测低资源语言中的侮辱性语言的潜力,本例中,使用小样本学习(FSL)在印度语言中进行。我们利用Wav2Vec和Whisper等模型的强大表示能力,使用ADIMA数据集进行跨语言侮辱检测。我们的方法将这些表示形式纳入Model-Agnostic Meta-Learning(MAML)框架,以在10种语言中分类侮辱性语言。我们尝试了各种射击大小(50-200),评估有限数据对性能的影响。此外,还进行了特征可视化研究,以更好地了解模型的行为。该研究突出了预训练模型在资源匮乏场景中的泛化能力,并为在多语种环境中检测侮辱性语言提供了宝贵的见解。
论文及项目相关链接
PDF Accepted as part of the proceedings of COLING 2025
Summary
本研究探索了利用预训练音频表示在低资源环境下检测印度语言中滥用内容的可能性。该研究结合了Wave2Vec和Whisper等模型的强大表示能力,利用少量样本学习(FSL)和跨语言检测的方式在ADIMA数据集上进行尝试。通过Model-Agnostic Meta-Learning(MAML)框架进行分类,该研究方法能在十种语言中识别滥用语言。实验还研究了不同样本量(从50到200)对性能的影响,并对模型行为进行了特征可视化研究。该研究突出了预训练模型在低资源场景中的泛化能力,并为多语言环境下的滥用语言检测提供了有价值的见解。
Key Takeaways
- 研究探讨了低资源环境中在线滥用内容检测的不足,特别是在音频模式内。
- 研究集中在利用预训练音频表示来检测印度语言中的滥用内容。
- 研究采用少量样本学习(FSL)进行跨语言滥用检测。
- 利用Model-Agnostic Meta-Learning(MAML)框架进行分类,支持十种语言的滥用语言识别。
- 实验研究了不同样本量对性能的影响。
- 特征可视化研究有助于更好地理解模型行为。
- 预训练模型在低资源场景下表现出良好的泛化能力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了在线滥用内容检测的问题,特别是在低资源语言环境中以及在音频模态中的检测问题。具体来说,论文研究了利用预训练音频表示来检测低资源语言中的滥用语言的潜力,以印度语言为例,使用少样本学习(Few Shot Learning, FSL)技术。研究的主要目标包括:
预训练音频表示的潜力:研究预训练音频模型(如Wav2Vec和Whisper)在跨语言滥用检测任务中的有效性。
少样本学习(FSL):探索在数据受限的情况下,如何利用少量样本进行有效的滥用语言检测。
跨语言滥用检测:利用ADIMA数据集,通过FSL框架,对10种印度语言的音频样本进行分类,以检测其中的滥用语言。
模型泛化能力:通过特征可视化研究,理解模型行为,特别是在多语言环境下检测滥用语言时的泛化能力。
低资源场景下的应用:论文强调了预训练模型在低资源场景下的泛化能力,并为多语言背景下的滥用语言检测提供了有价值的见解。
综上所述,论文试图解决的主要问题是在低资源语言环境中,特别是在音频领域,如何有效地检测和识别滥用语言,以维护在线社交平台的安全和健康。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个方面:
音频滥用检测(Audio Abuse Detection):
- DeToxy数据集的引入,用于音频毒性检测,特别是针对口头表述。[Ghosh et al., 2021]
- MuTox数据集,作为首个大规模多语言音频毒性检测数据集,包含英语、西班牙语以及19种其他语言的音频表述。[Costa-jussà et al., 2024]
- 第一个孟加拉语音频滥用数据集的引入,应用迁移学习提取特征。[Rahut et al., 2020]
- ADIMA数据集,包含10种印度语言的滥用音频剪辑,旨在通过定量实验实现印度语言的音频内容审核。[Gupta et al., 2022]
少样本学习和元学习(Few-Shot Learning and Meta-Learning):
- MAML(Model-Agnostic Meta-Learning)方法在低资源场景中的应用,如低资源语音识别。[Singh et al., 2022]
- MAML在神经机器翻译中的有效性。[Gu et al., 2018]
- MetaXL方法,用于改善跨语言学习。[Xia et al., 2021]
自动语音识别(Automatic Speech Recognition, ASR):
- Meta-learning方法在自动语音识别中的应用,如MetaASR。[Hsu et al., 2019]
- XLSR模型,通过预训练单一模型从多种语言的原始语音波形中学习跨语言语音表示。[Conneau et al., 2020]
- 适配器模块与元学习算法的结合,以在低资源设置中实现高性能的ASR。[Hou et al., 2021a]
基于转移学习的滥用检测:
- 使用BERT、RoBERTa、XLM-RoBERTa等流行模型在文本模态的滥用检测中表现出色。[Mozafari et al., 2019; Ranasinghe and Zampieri, 2021]
- 基于元学习的模型在跨语言滥用检测任务中优于基于转移学习的模型。[Mozafari et al., 2022; Awal et al., 2024]
这些相关研究为本文提出的基于MAML的少样本跨语言音频滥用分类方法提供了理论基础和技术背景。论文通过结合预训练音频表示和元学习框架,旨在提高在低资源语言环境中检测音频滥用语言的性能。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决在线滥用内容检测问题,特别是在低资源语言环境中的音频模态:
预训练音频特征提取(Pre-Trained Audio Feature Extractions):
- 使用Wav2Vec和Whisper这两种预训练音频模型来提取特征。这些模型能够从原始音频中学习跨语言的语音表示,为后续的分类任务提供有效特征。
特征归一化(Feature Normalization):
- 对提取的特征进行归一化处理,采用两种策略:Temporal Mean和L2-Norm。这有助于模型更好地理解和比较特征。
模型无关元学习(Model Agnostic Meta-Learning, MAML):
- 利用MAML框架来训练一个能够在少量样本上快速适应新任务的模型。MAML通过在元学习阶段训练模型,使其能够在新任务上用极少的数据和迭代次数快速适应。
跨语言训练和测试(Cross-Lingual Training and Testing):
- 采用跨语言方法训练模型,使其能够泛化到不同语言的数据。训练时模型接触到所有语言的数据,以捕获不同语言中滥用和非滥用语音的细微差别。
特征研究(Feature Study):
- 对于最佳归一化特征集进行视觉分析,通过t-SNE投影到2维空间并进行聚类分析,以了解哪些特征有助于提高分类准确性。
实验和评估(Experiments and Evaluation):
- 在ADIMA数据集上进行实验,该数据集包含10种印度语言的标注音频剪辑。通过不同射击大小(shot sizes)的实验,评估模型在不同少量样本设置下的性能。
结果分析(Results Analysis):
- 分析不同特征归一化技术和预训练模型的性能,以及它们在跨语言音频滥用检测任务中的效果。
通过这些步骤,论文提出了一个针对低资源语言环境下音频滥用检测的少样本跨语言音频滥用分类方法,并通过实验验证了该方法的有效性。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
数据集选择:
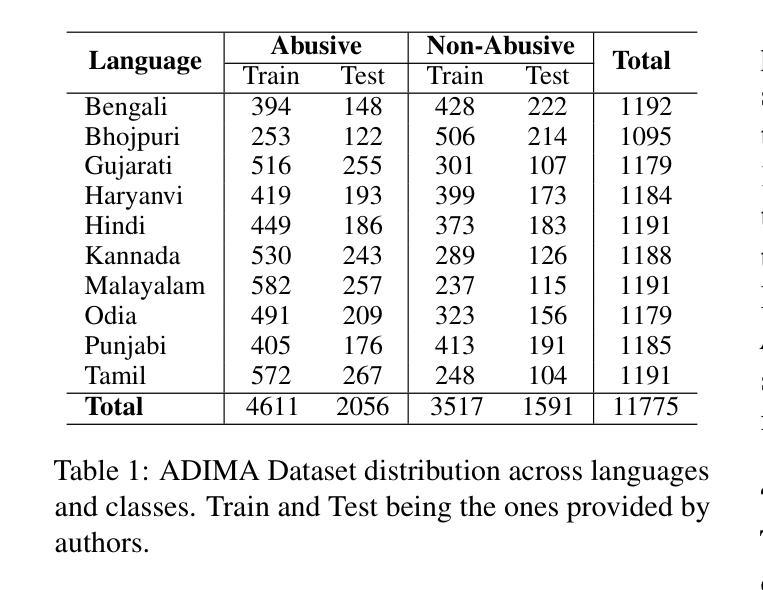
- 使用ADIMA数据集进行实验,该数据集包含11775个音频剪辑,涵盖10种印度语言,并进行了二元分类标注。
特征提取:
- 使用PyTorch和HuggingFace库提取Whisper和Wav2Vec两种预训练音频模型的特征。
少样本学习实验设置:
- 应用Model-Agnostic Meta-Learning (MAML)算法来处理少样本跨语言音频滥用检测的挑战。
- 使用分层抽样策略确保在每种语言中平衡抽取虐待和非虐待样本。
- 在不同的射击大小(shot sizes)下进行实验,包括50、100、150和200,以研究样本大小对模型性能的影响。
模型架构和训练:
- 使用一个包含三个全连接层的人工神经网络(ANN)作为学习模型。
- 使用Adam优化器进行模型训练,并采用线性学习率调度器管理任务特定的学习率和元学习率。
分类结果:
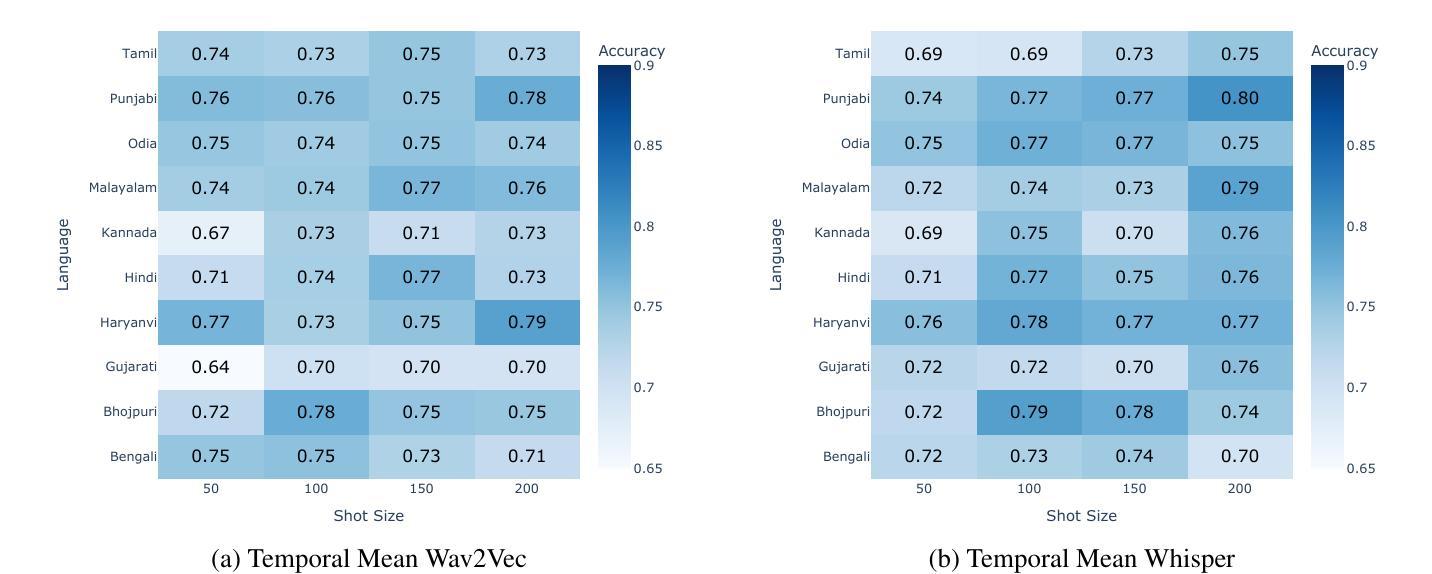
- 以热图形式展示在不同射击大小和归一化设置下的准确率。
- 提供了详细的宏F1分数结果,并与数据集论文中的基线进行了比较。
预训练特征研究:
- 对于表现最佳的归一化特征集(L2-Norm与Whisper特征),通过t-SNE投影进行特征的二维可视化,并进行特征的语言聚类分析。
跨语言训练和测试:
- 训练时模型暴露于所有L种语言的数据,以捕获不同语言中滥用和非滥用语音的细微差别。
- 测试阶段评估模型在特定语言上的性能,模拟真实世界条件,即模型必须能够快速适应并很好地执行新语言的分类。
这些实验旨在评估所提出方法的有效性,并深入理解不同特征归一化技术和预训练模型在低资源语言设置中的性能。通过这些实验,论文提供了关于元学习、特征归一化以及在低资源语言环境中性能的见解。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
扩展到更多低资源语言:
- 虽然这项工作探索了ADIMA提供的10种印度语言的跨语言少样本音频滥用检测,但该方法也可以扩展到其他低资源语言。未来的研究可以评估其在更多语言上的效率和效果。
探索其他元学习算法:
- 除了MAML,还可以探索ProtoMAML和对比学习等其他元学习算法在音频滥用检测任务中的应用。
使用更多预训练音频模型:
- 目前研究中仅使用了Whisper和Wav2Vec模型,未来可以探索SeamlessM4T等其他预训练音频模型,并比较不同模型的效果。
不同的特征归一化技术:
- 除了Temporal Mean和L2-Norm,还可以探索其他L-N归一化、加权平均等特征归一化方法。
多模态方法:
- 考虑结合音频、文本和视觉等多种模态信息来提高滥用检测的性能。
更大规模的数据集:
- 创建和利用更大规模的、针对特定低资源语言的音频数据集,以提高模型的泛化能力和鲁棒性。
单语言实验:
- 对于特定语言进行更深入的单语言实验,以获得更细致的语言特定见解。
模型解释性:
- 提高模型的可解释性,以更好地理解模型是如何识别和区分滥用和非滥用音频的。
实时检测应用:
- 将研究成果应用于实时音频流的滥用检测,以评估模型在实际应用场景中的性能。
跨领域泛化能力:
- 研究模型在不同领域(如社交媒体、电话通话等)的泛化能力。
对抗性攻击和防御:
- 研究对抗性攻击对模型性能的影响,并开发相应的防御机制。
伦理和隐私问题:
- 在实际部署中,进一步考虑和解决与滥用检测相关的伦理和隐私问题。
这些探索点可以帮助研究者更全面地理解和改进低资源语言环境下的音频滥用检测技术。
Q: 总结一下论文的主要内容
A: 这篇论文主要研究了在线滥用内容检测问题,特别是在低资源语言环境中的音频模态检测。以下是论文的主要内容总结:
问题背景:
- 论文指出在线社交平台上滥用内容检测的重要性,特别是在音频社交平台上,以及在多语言国家如印度的挑战。
研究目标:
- 利用预训练音频表示(如Wav2Vec和Whisper模型)和少样本学习(FSL)技术,探索跨语言滥用检测的潜力。
方法论:
- 提出了一种基于MAML(Model-Agnostic Meta-Learning)框架的少样本跨语言音频滥用分类方法。
- 使用ADIMA数据集,包含10种印度语言的音频样本,进行实验验证。
实验设计:
- 对比了两种特征归一化策略:Temporal Mean和L2-Norm。
- 在不同的射击大小(50、100、150、200)下评估模型性能。
- 进行了特征可视化研究,以理解模型行为和语言相似性对跨语言检测的影响。
结果分析:
- Whisper模型结合L2-Norm归一化在多数情况下表现最佳。
- 观察到不同语言之间的性能差异,提供了对模型泛化能力的见解。
贡献和洞见:
- 论文强调了预训练模型在低资源场景下的泛化能力,并为多语言环境下的音频滥用检测提供了有价值的策略和研究方向。
未来工作:
- 提出了未来可能的研究方向,包括探索更多的元学习算法、预训练模型、特征归一化技术,以及创建更大规模的多语言音频数据集。
局限性和伦理声明:
- 论文讨论了研究的局限性,如数据集覆盖的语言范围有限,以及对其他低资源语言的扩展性。
- 声明了研究没有涉及任何违反伦理准则的个人或公共数据。
总体而言,这篇论文为低资源语言环境中的音频滥用检测提供了新的视角和方法,并通过实验验证了所提方法的有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Hierarchical Prompt Decision Transformer: Improving Few-Shot Policy Generalization with Global and Adaptive Guidance
Authors:Zhe Wang, Haozhu Wang, Yanjun Qi
Decision transformers recast reinforcement learning as a conditional sequence generation problem, offering a simple but effective alternative to traditional value or policy-based methods. A recent key development in this area is the integration of prompting in decision transformers to facilitate few-shot policy generalization. However, current methods mainly use static prompt segments to guide rollouts, limiting their ability to provide context-specific guidance. Addressing this, we introduce a hierarchical prompting approach enabled by retrieval augmentation. Our method learns two layers of soft tokens as guiding prompts: (1) global tokens encapsulating task-level information about trajectories, and (2) adaptive tokens that deliver focused, timestep-specific instructions. The adaptive tokens are dynamically retrieved from a curated set of demonstration segments, ensuring context-aware guidance. Experiments across seven benchmark tasks in the MuJoCo and MetaWorld environments demonstrate the proposed approach consistently outperforms all baseline methods, suggesting that hierarchical prompting for decision transformers is an effective strategy to enable few-shot policy generalization.
决策变压器将强化学习重新构建为条件序列生成问题,为传统的基于价值或政策的方法提供了一种简单而有效的替代方案。该领域的最新关键进展是在决策变压器中融入提示,以促进少量策略泛化。然而,当前的方法主要使用静态提示段来指导展开,这限制了它们提供特定上下文指导的能力。为解决这一问题,我们引入了通过检索增强实现分层提示方法。我们的方法学习两层软令牌作为指导提示:(1)全局令牌封装轨迹的任务级信息,(2)自适应令牌传递聚焦、时间步长特定的指令。自适应令牌是从精选的演示段集中动态检索的,确保上下文感知的指导。在MuJoCo和MetaWorld环境中的七个基准任务上的实验表明,所提出的方法始终优于所有基线方法,这表明为决策变压器设计的分层提示是一种有效的策略,可实现少量策略泛化。
论文及项目相关链接
Summary
决策变压器通过将强化学习重新构建为条件序列生成问题,提供了一种简单有效的替代传统价值或策略基础方法的方式。近期,通过在决策变压器中集成提示来促进少量策略泛化,是该领域的一个关键发展。然而,当前方法主要使用静态提示段来引导滚动,无法提供特定的上下文指导。为了解决这一问题,我们通过检索增强引入了分层提示方法。我们的方法学习了两层软令牌作为指导提示:1)封装轨迹任务级别信息的全局令牌;2)提供聚焦、时间步长特定指令的适应性令牌。适应性令牌是从精选的演示段集中动态检索的,以确保上下文感知指导。在MuJoCo和MetaWorld环境中的七个基准任务上的实验表明,所提出的方法始终优于所有基线方法,这表明为决策变压器进行分层提示是一种有效的策略,可实现少量策略泛化。
Key Takeaways
- 决策变压器将强化学习重新定位为条件序列生成问题,提供对传统价值或策略基础的替代方法。
- 近期发展在于在决策变压器中集成提示以促进少量策略泛化。
- 当前方法的局限性在于使用静态提示段引导滚动,缺乏上下文特异性。
- 引入了一种通过检索增强实现的分层提示方法,包括全局令牌和适应性令牌。
- 全局令牌封装任务级别信息,而适应性令牌提供时间步长特定的指令。
- 适应性令牌从演示段集中动态检索,确保上下文感知指导。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
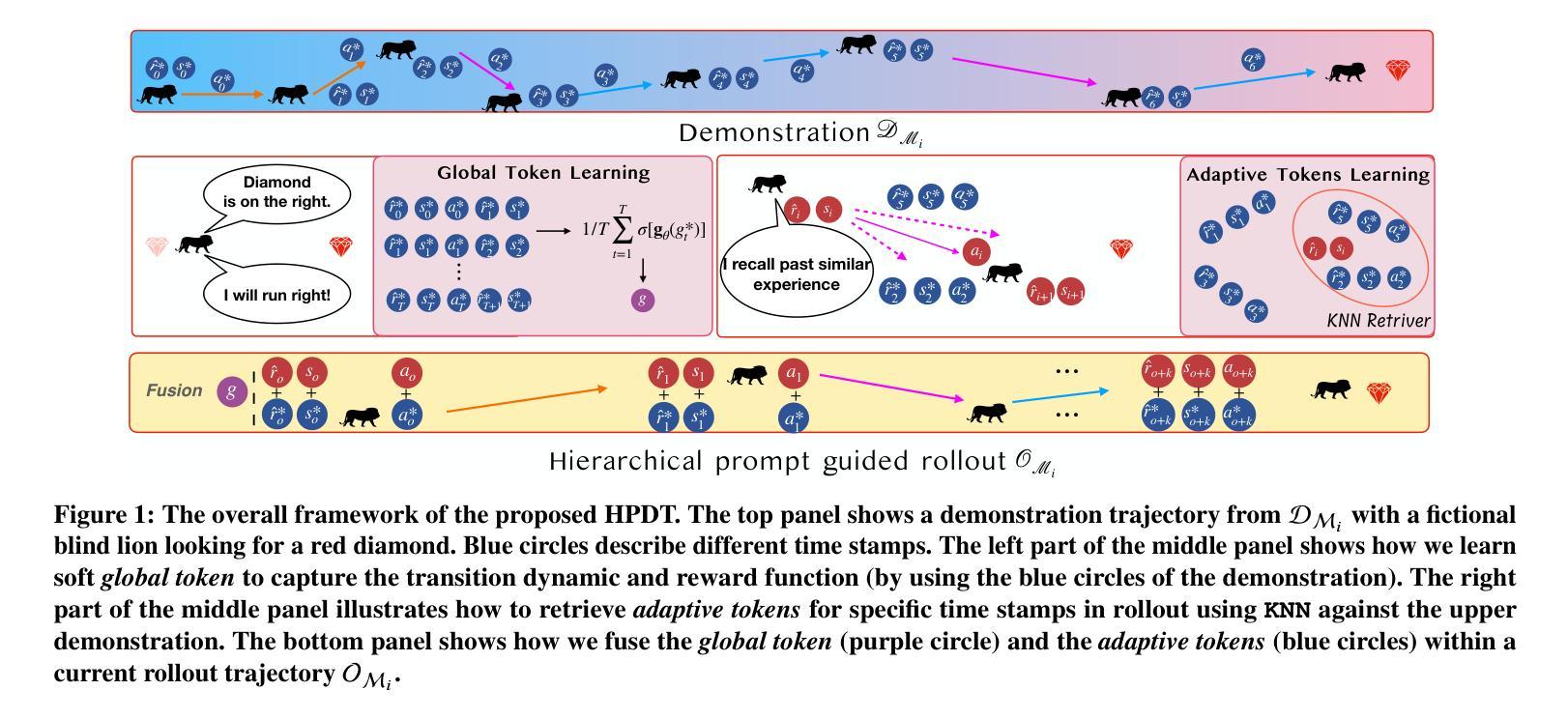
A: 这篇论文试图解决的问题是如何在决策变换器(Decision Transformers, DTs)中改善少量样本(few-shot)策略泛化。具体来说,论文指出当前的方法主要使用静态提示片段(prompt segments)来指导策略的展开,这限制了它们提供特定上下文指导的能力。为了克服这些限制,论文提出了一种层次化提示方法,通过检索增强(retrieval augmentation)来学习两个层次的软提示令牌(soft tokens):
- 全局令牌(global tokens):这些令牌编码了关于轨迹的全局任务级信息,例如转换动态和奖励。
- 自适应令牌(adaptive tokens):这些令牌提供特定时间步的行动指导,通过从一个示范片段集合中检索相关经验来实现。
这种方法旨在通过利用示范数据中嵌入的结构化信息来增强决策变换器在少量样本情况下的策略泛化能力。论文通过在MUJOCO和METAWORLD环境中的七个基准任务上的实验表明,所提出的方法一致性地超越了所有基线方法,从而证明了层次化提示对于决策变换器是一种有效的策略泛化策略。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是与本研究相关的一些领域和具体工作:
决策变换器(Decision Transformers, DTs):
- 论文[5]提出了决策变换器(DT),这是一种将强化学习重新构想为条件序列生成问题的方法。DT通过训练单一的变换器架构来处理奖励条件控制序列,在离线强化学习领域表现出色。
离线元强化学习(Offline Meta-Reinforcement Learning, OMRL):
- 论文[28]提出了MACAW方法,这是OMRL问题形式化的一个经典基于演员-评论家的方法,使用MAML进行训练。
- 论文[26]提出了FOCAL方法,这是一种高效的完全离线元强化学习方法,通过距离度量学习和行为正则化实现。
强化学习中的序列生成:
- 论文[16]提出了轨迹变换器(Trajectory Transformer),这是一种将独立每个维度的状态、动作和奖励进行建模的方法。
- 论文[45]提出了自举变换器(Bootstrapped Transformer),它结合了自举的思想,利用学习到的模型自生成更多离线数据以进一步提升序列模型训练。
检索增强的生成(Retrieval-Augmented Generation, RAG):
- 论文[24]提出了RAG,这是一种为知识密集型NLP任务设计的检索增强生成方法。
层次化强化学习(Hierarchical Reinforcement Learning, HRL):
- 论文[17]、[29]、[30]、[44]探讨了在强化学习领域应用层次化方法,通常包括一个低级控制器和一个高级规划器。
大型语言模型(Large Language Models, LLM)编排:
- 论文[39]、[49]讨论了大型语言模型在多任务学习中的应用,这些方法需要大量的计算资源,而DT提供了一种更轻量级、更专注的解决方案。
时间感知的强化学习代理:
- 论文[10]、[18]提出了Time2Vec,这是一种参数高效机制,使代理能够感知时间。
这些相关工作涵盖了从基础的决策变换器模型到更复杂的层次化方法,以及从序列生成到检索增强的生成等多个方面,为本研究提供了理论和技术背景。
Q: 论文如何解决这个问题?
A: 论文通过提出一种名为层次化提示决策变换器(Hierarchical Prompt Decision Transformer, HPDT)的方法来解决这个问题。HPDT通过引入一个层次化的提示学习框架来增强决策变换器(DTs),以改善少量样本策略的泛化能力。具体来说,HPDT通过以下步骤来解决这个问题:
全局提示令牌(Global Tokens):
- 学习一个全局提示令牌,该令牌编码了关于任务的全局信息,例如转换动态和奖励函数。这个令牌有助于区分不同的任务,并在整个策略展开过程中提供一致的指导。
自适应提示令牌(Adaptive Tokens):
- 除了全局信息外,HPDT还学习特定于每个时间步的自适应提示令牌,这些令牌通过从示范集中检索相关经验来提供更精细的指导。这一步是基于当前的状态和回报状态对(rtg-state pair)来检索最相似的经验,并据此生成动作。
检索增强(Retrieval-Augmented Generation, RAG):
- 利用检索增强的方法来动态检索与当前上下文最相关的提示片段,从而提供适应性强的指导。
时间感知令牌(Time-Aware Tokens):
- 引入Time2Vec机制,使代理能够感知时间,并有效地编码时间信息。
训练与评估:
- 在训练阶段,HPDT通过随机采样示范轨迹和展开轨迹段,学习全局和自适应提示令牌,并通过标准的教师强制策略端到端地训练模型,以最小化在展开序列中动作的均方误差(MSE)。
- 在评估阶段,面对新任务时,HPDT通过随机采样示范轨迹来编码全局提示令牌,并基于当前的rtg和状态检索自适应令牌,然后生成动作并记录环境反馈,以评估新任务上的表现。
通过以上步骤,HPDT能够将全局任务理解和局部适应性无缝集成,动态地提供上下文感知的决策指导,从而在少量样本的情况下实现更好的策略泛化。
Q: 论文做了哪些实验?
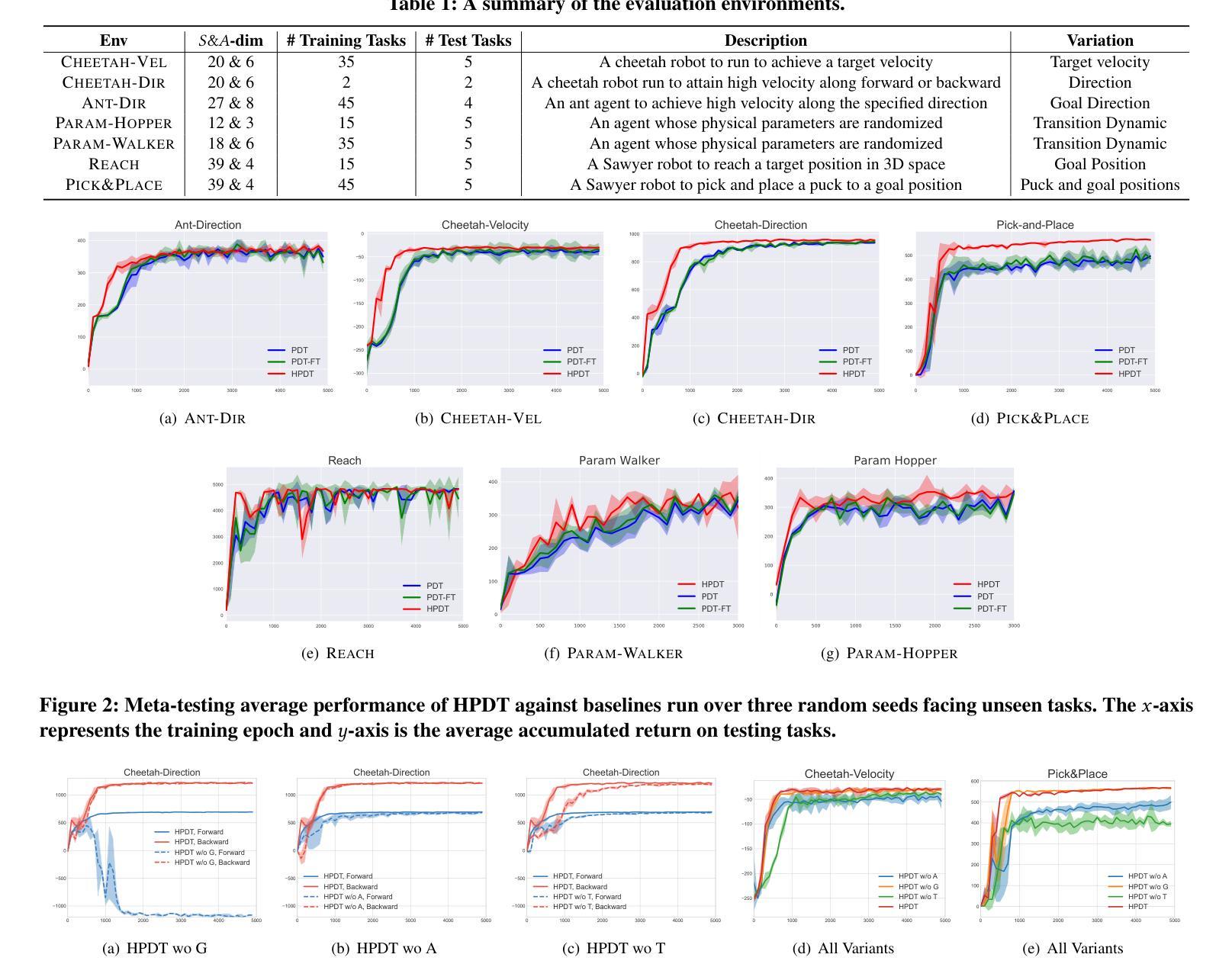
A: 论文中进行了一系列实验来验证层次化提示决策变换器(HPDT)在少量样本策略泛化方面的效果。具体实验包括:
基准测试环境:
- 实验在两个强化学习基准测试环境进行:MUJOCO控制和METAWORLD。
- 在MUJOCO中使用了五个连续控制元环境,包括CHEETAHDIR、CHEETAH-VEL、ANT-DIR、PARAM-HOPPER和PARAMWALKER。
- 在METAWORLD中使用了两个机器人臂操作环境,REACH和PICK&PLACE。
基线对比:
- 将HPDT与多个基线方法进行比较,包括MACAW、PDT(Prompt Decision Transformer)、PDT-FT(全模型微调的PDT)和PTDT(基于零阶优化的提示调整方法)。
实验设计和设置:
- 实验设计用于回答HPDT的三个问题:(1) 与基线相比,HPDT是否具有更强的上下文学习能力;(2) 全局提示令牌和自适应提示令牌各自如何帮助HPDT;(3) HPDT是否会在示范和检索器的超参数变化下保持鲁棒性。
- 对于全局提示令牌和自适应提示令牌的学习,随机采样示范轨迹,并使用KNN算法进行自适应令牌检索。
- 训练模型5000个周期,每个周期包含10次更新。对于每个测试任务,让代理与环境交互50个周期,并使用所有测试任务的平均累积奖励作为最终评估。
性能评估:
- 评估HPDT在不同环境和不同超参数设置下的性能,包括不同长度的示范轨迹和不同的KNN检索值。
- 对比HPDT与其他基线方法在多个随机种子下面对未见任务时的元测试平均性能。
消融研究:
- 通过设计消融研究来隔离每个组件并研究它们的作用。具体包括去除全局提示令牌(HPDT wo G)、去除自适应提示令牌(HPDT wo A)和替换时间嵌入方法(HPDT wo T)的变体。
超参数鲁棒性测试:
- 测试HPDT在不同的示范和检索器超参数组合下的性能,包括不同的示范轨迹长度和KNN检索值。
额外时间成本分析:
- 分析HPDT相比于PDT在推理时的额外时间成本,特别是在执行多个完整周期时的时间消耗。
这些实验全面评估了HPDT在少量样本策略泛化方面的能力,并与现有技术水平进行了比较。通过这些实验,论文展示了HPDT在不同设置下的有效性和鲁棒性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一种有效的方法来改善决策变换器在少量样本策略泛化方面的性能,但仍有一些领域可以进一步探索和研究:
更广泛的环境和任务:
- 将HPDT应用于更广泛的环境和任务,包括具有更高维度状态和动作空间的任务,以及更复杂的任务结构,以测试其泛化能力和鲁棒性。
更深层次的提示学习:
- 探索更深层次的提示学习策略,例如多级层次化提示或基于不同任务特性的动态提示调整策略。
提高检索效率:
- 优化检索模块以提高检索效率,尤其是在大规模数据集上,以减少HPDT在推理时的额外时间成本。
增强学习的集成:
- 研究如何将HPDT与增强学习算法更紧密地集成,以便在在线学习环境中进一步提高策略性能。
理论分析:
- 对HPDT的理论分析,包括其在不同假设下的学习效率和样本复杂度,以及与现有方法的理论对比。
多模态学习:
- 探索HPDT在多模态学习设置中的应用,例如结合视觉和语言信息来指导决策过程。
长尾分布处理:
- 研究HPDT如何处理示范数据中的长尾分布问题,即某些状态或动作出现的频率远高于其他状态或动作。
可解释性和透明度:
- 提高HPDT的可解释性,使其能够提供关于其决策过程的更多见解,这对于高风险应用尤其重要。
跨领域泛化:
- 探索HPDT在跨领域泛化方面的性能,即在一个领域学到的知识能否有效地迁移到另一个不同的领域。
实时应用:
- 将HPDT应用于需要实时决策的场景,如自动驾驶或机器人操控,并评估其在这些场景下的性能和可行性。
这些方向不仅可以推动HPDT的发展,还可能揭示新的研究问题和挑战,进一步推动决策变换器和强化学习领域的发展。
Q: 总结一下论文的主要内容
A: 论文的主要内容概括如下:
问题定义:
- 论文旨在解决决策变换器(DTs)在少量样本(few-shot)策略泛化方面的局限性,特别是在离线元强化学习(OMRL)设置中。
方法介绍:
- 论文提出了层次化提示决策变换器(Hierarchical Prompt Decision Transformer, HPDT),这是一种新的方法,通过整合全局和自适应提示来增强DTs的策略泛化能力。
全局提示令牌(Global Tokens):
- 引入全局提示令牌以编码任务级别的全局信息,如转换动态和奖励函数,以帮助区分不同任务并提供一致的指导。
自适应提示令牌(Adaptive Tokens):
- 引入自适应提示令牌以提供特定于每个时间步的指导,通过从示范集中检索相关经验来实现。
实验验证:
- 通过在MUJOCO和METAWORLD环境中的七个基准任务上的实验,验证了HPDT在少量样本策略泛化方面的有效性,并与多个基线方法进行了比较。
消融研究:
- 通过消融研究来分析全局提示令牌和自适应提示令牌各自对HPDT性能的贡献。
超参数鲁棒性测试:
- 测试了HPDT在不同超参数设置下的鲁棒性,包括示范轨迹长度和KNN检索值。
额外时间成本分析:
- 分析了HPDT相比于传统PDT在推理时的额外时间成本。
结论:
- 论文得出结论,层次化提示是一种有效的策略,可以改善基于决策变换器的少量样本策略泛化,并且HPDT在多个任务上展现了优越的性能和鲁棒性。
总体而言,论文通过引入层次化提示机制,有效地提高了决策变换器在少量样本情况下的策略泛化能力,并在多个基准任务上验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

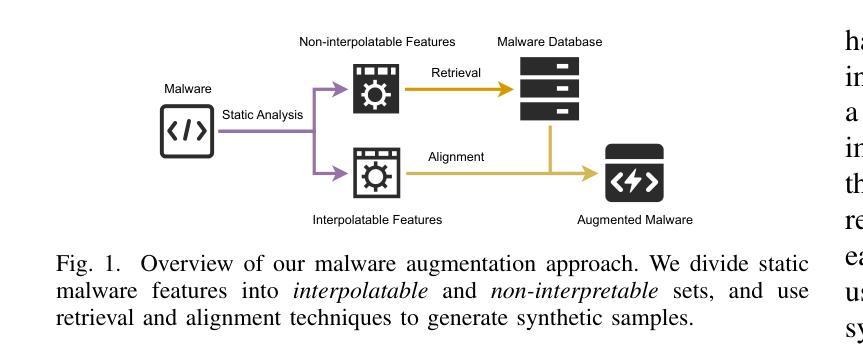
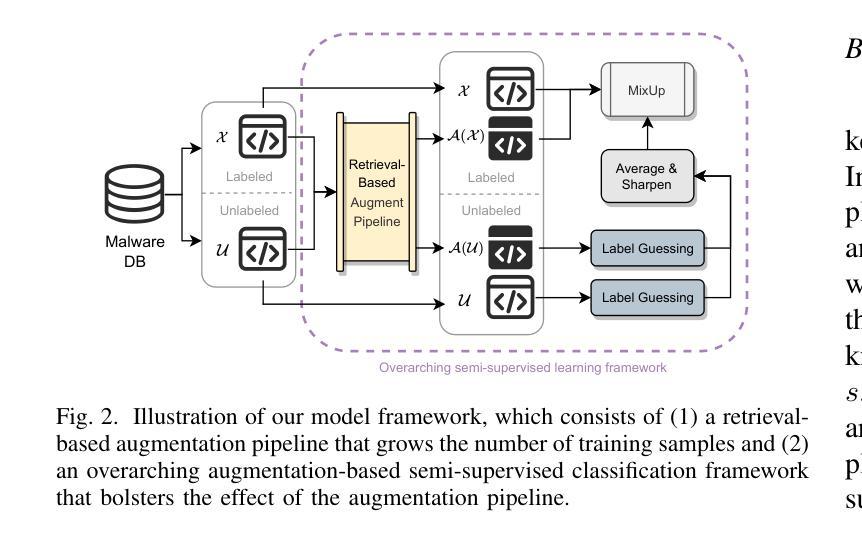
MalMixer: Few-Shot Malware Classification with Retrieval-Augmented Semi-Supervised Learning
Authors:Jiliang Li, Yifan Zhang, Yu Huang, Kevin Leach
Recent growth and proliferation of malware has tested practitioners’ ability to promptly classify new samples according to malware families. In contrast to labor-intensive reverse engineering efforts, machine learning approaches have demonstrated increased speed and accuracy. However, most existing deep-learning malware family classifiers must be calibrated using a large number of samples that are painstakingly manually analyzed before training. Furthermore, as novel malware samples arise that are beyond the scope of the training set, additional reverse engineering effort must be employed to update the training set. The sheer volume of new samples found in the wild creates substantial pressure on practitioners’ ability to reverse engineer enough malware to adequately train modern classifiers. In this paper, we present MalMixer, a malware family classifier using semi-supervised learning that achieves high accuracy with sparse training data. We present a novel domain-knowledge-aware technique for augmenting malware feature representations, enhancing few-shot performance of semi-supervised malware family classification. We show that MalMixer achieves state-of-the-art performance in few-shot malware family classification settings. Our research confirms the feasibility and effectiveness of lightweight, domain-knowledge-aware feature augmentation methods and highlights the capabilities of similar semi-supervised classifiers in addressing malware classification issues.
近期恶意软件的增长和激增考验了从业者根据恶意软件家族及时对新样本进行分类的能力。与劳动密集型的逆向工程努力相比,机器学习的方法已经显示出更高的速度和准确性。然而,大多数现有的深度学习的恶意软件家族分类器需要使用大量样本进行校准,这些样本在训练之前需要进行繁琐的手动分析。此外,当出现超出训练集范围的新的恶意软件样本时,必须采用额外的逆向工程工作来更新训练集。野外发现的新样本的大量涌现,对从业者逆向工程足够的恶意软件以充分训练现代分类器的能力造成了巨大压力。在本文中,我们提出了MalMixer,这是一种使用半监督学习的恶意软件家族分类器,它在稀疏的训练数据下实现了较高的准确性。我们提出了一种新颖的域知识感知技术,用于增强恶意软件特征表示,提高了半监督恶意软件家族分类的少量样本性能。我们证明MalMixer在少量样本的恶意软件家族分类设置中达到了最先进的性能。我们的研究证实了轻量级、域知识感知的特征增强方法的可行性和有效性,并突出了类似的半监督分类器在解决恶意软件分类问题方面的能力。
论文及项目相关链接
Summary
该文本介绍了针对新型恶意软件样本的快速分类问题,机器学习技术展示出了速度和精度的优势。然而,大多数现有的深度学习恶意软件家族分类器需要使用大量样本进行校准,且需进行手动分析。当遇到超出训练集范围的恶意软件样本时,还需要额外的逆向工程努力来更新训练集。本文提出了一种名为MalMixer的半监督学习恶意软件家族分类器,能够在稀疏训练数据的情况下实现高准确性。MalMixer采用了一种新颖的域知识感知技术来增强恶意软件特征表示,提高了半监督环境下少样本的性能。实验表明,MalMixer在少样本恶意软件家族分类场景中取得了最先进的性能。本文验证了轻量级、域知识感知的特征增强方法的可行性和有效性,并突出了类似半监督分类器在解决恶意软件分类问题方面的能力。
Key Takeaways
以下是七个关键要点:
- 机器学习技术在恶意软件家族分类中显示出速度和精度的优势。
- 当前恶意软件分类面临挑战,包括手动分析大量样本和更新训练集的需要。
- MalMixer是一种半监督学习恶意软件家族分类器,能在稀疏数据情况下实现高准确性。
- MalMixer采用新颖的域知识感知技术来增强恶意软件特征表示。
- 实验显示MalMixer在少样本恶意软件家族分类场景中表现领先。
- 轻量级、域知识感知的特征增强方法具有可行性和有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是恶意软件(malware)样本的及时分类难题。具体来说,论文关注以下几个挑战:
恶意软件的快速增长和扩散:随着恶意软件样本的快速增长,传统的基于大量样本手动分析的分类方法变得低效且成本高昂。
新样本的分类难题:现有的深度学习恶意软件家族分类器需要大量样本进行校准,而这些样本需要人工手动分析,这对于新出现的恶意软件样本来说是不切实际的。
样本多样性和代表性问题:少量标注样本可能缺乏野外样本的多样性,无法代表整个相关恶意软件样本集合。
零日威胁和新适应性恶意软件样本的处理:面对新的、适应性强的恶意软件样本或零日威胁,传统的恶意软件家族分类器必须更新以处理新样本,这需要大量的逆向工程工作。
为了应对这些挑战,论文提出了一个名为MALMIXER的系统,它使用半监督学习和一种新颖的、基于检索增强的恶意软件特征表示增强技术,以实现在只有少量标注数据的情况下对恶意软件家族进行高精度分类。MALMIXER的目标是通过领域知识感知的特征增强方法和半监督分类器的结合,提高对新样本的分类准确性,并减少对大量手动标注的依赖。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与MALMIXER相关的研究工作:
CAD-FSL [21]:提出了一个使用代码感知生成对抗网络(code-aware GANs)来合成标记恶意软件二进制变体的框架,增强了卷积神经网络(CNN)分类器的性能。
Catak等人的工作 [22]:采用图像增强技术,例如噪声注入,来生成新的恶意软件数据。
Wong等人的工作 [20]:展示了对恶意软件二进制进行语义保持的代码转换的可行性,通过这种方式生成新的变异恶意软件样本,从而提升机器学习驱动分类器的性能。
Pseudo-Label [55]:使用高置信度预测创建硬标签,并将其纳入标注集以进行半监督学习。
Virtual Adversarial Training (VAT) [56]:通过策略性地扰动标注数据,使模型对训练集中的变异更加鲁棒。
MixUp [37]:一种传统的用于监督学习的正则化方法,通过在特征空间中混合样本来提高模型的泛化能力。
MixMatch [24]:一个广泛使用的图像半监督学习方法,其框架与MALMIXER相似,但MALMIXER通过更合理的特征操作改进了数据增强策略。
相关工作还包括:使用半监督学习技术进行恶意软件分类的研究,例如恶意软件嵌入[11]、迁移学习[38]和软标签[39]。
这些相关工作主要涉及恶意软件特征分析、数据增强方法以及半监督学习策略。MALMIXER在这些领域的基础上,提出了一种新颖的数据增强方法,通过领域知识感知的技术来增强恶意软件特征表示,并结合半监督学习框架来提升少量标记数据下的恶意软件家族分类性能。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为MALMIXER的系统来解决恶意软件家族分类问题,具体方法如下:
1. 半监督学习框架
MALMIXER基于半监督学习框架,这种框架允许模型结合少量标注数据和大量未标注数据进行训练。这有助于减少对大量手动标注样本的依赖,同时提高对新样本的分类能力。
2. 领域知识感知的数据增强
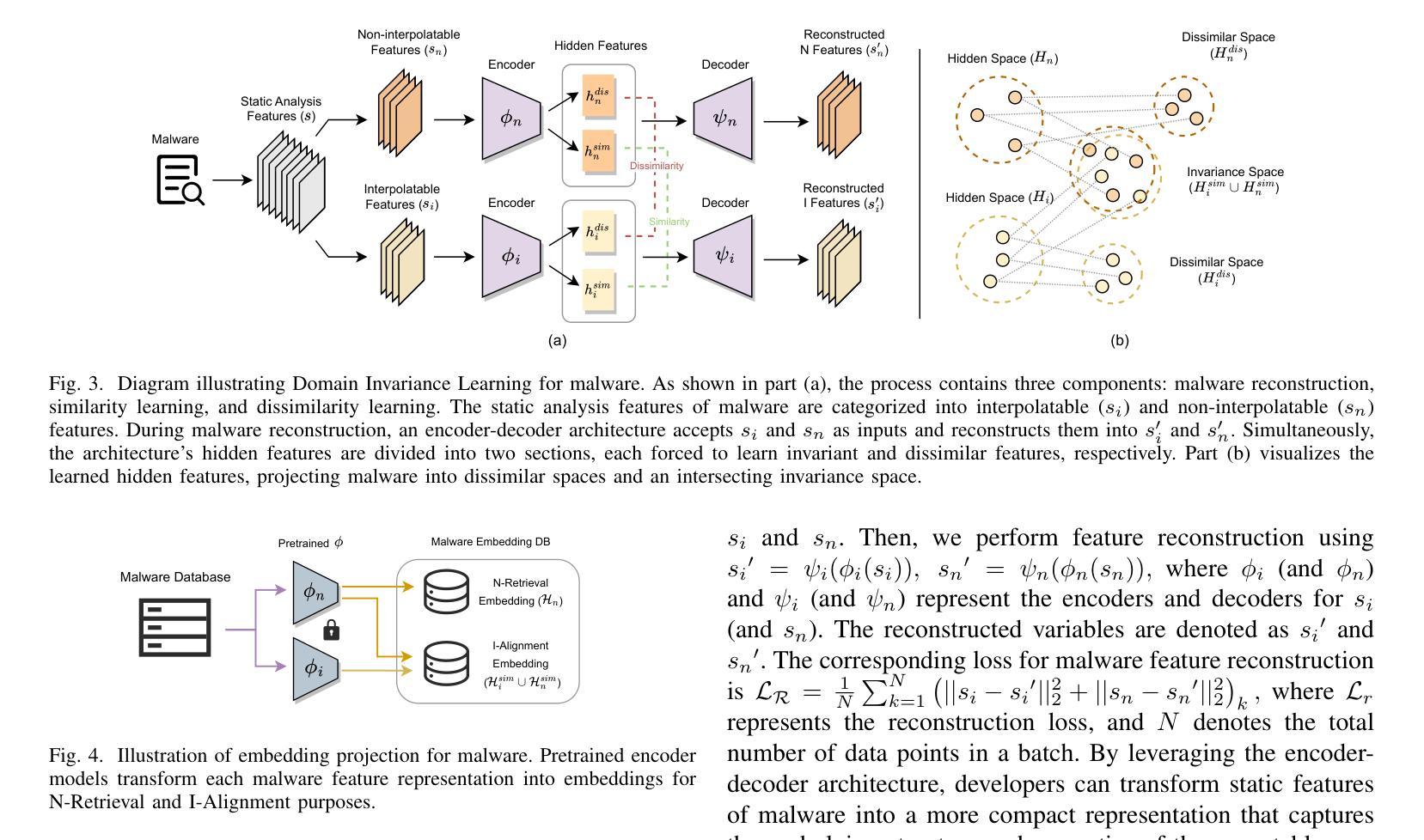
MALMIXER提出了一种新颖的、基于检索的数据增强方法,该方法能够理解恶意软件特征的语义,并据此增强特征表示。这种方法包括以下几个步骤:
a. 特征划分
将恶意软件特征分为“可插值”(interpolatable)和“不可插值”(non-interpolatable)两组。可插值特征通常是数值型特征,对其插值会产生有意义的新值;不可插值特征(如哈希值)则不能简单地进行插值。
b. 域不变性学习
使用编码器-解码器结构将恶意软件的静态特征映射到两个嵌入空间:一个用于捕捉特征间的共性(不变嵌入),另一个用于强调特征间的差异(差异嵌入)。
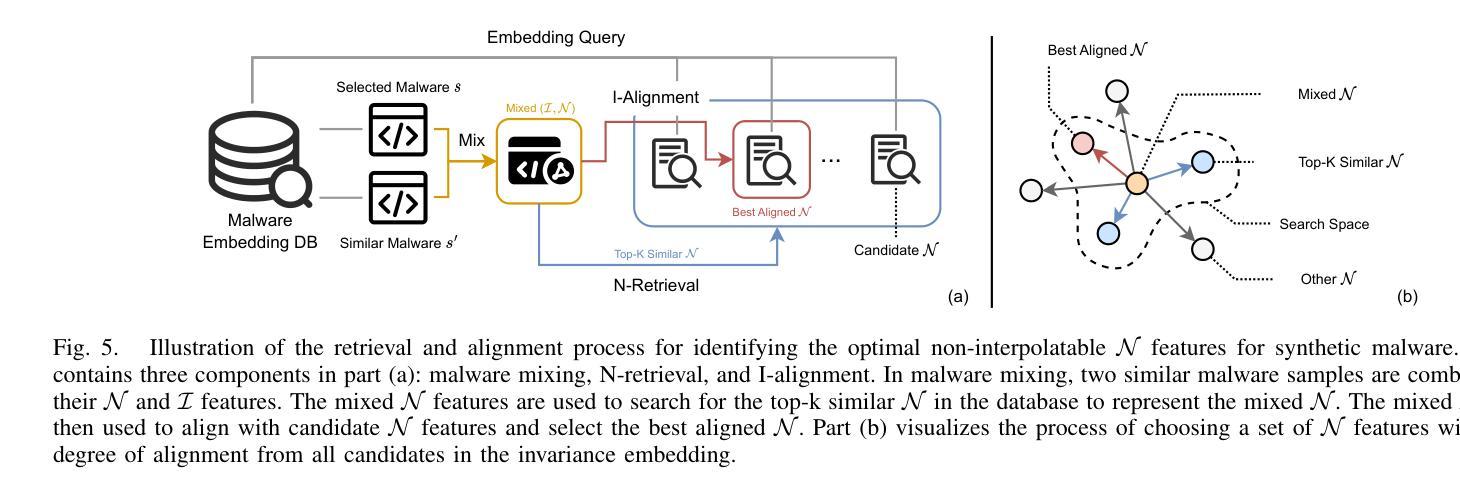
c. 基于检索的恶意软件匹配
通过检索技术找到与当前样本相似的样本,并基于这些样本的不可插值特征生成候选混合特征。
d. 基于对齐的恶意软件选择
选择与混合后的可插值特征最兼容的不可插值特征,以生成合成的恶意软件样本。
3. 实验验证
论文通过在两个流行的恶意软件家族分类基准数据集(BODMAS和MOTIF)上的实验来验证MALMIXER的有效性。实验结果显示MALMIXER在少量标注样本的情况下,相比于现有的半监督学习方法,能够实现更高的分类准确率。
4. 处理新样本和新家族
MALMIXER还展示了其在处理新样本(包括不同时间框架的样本)和新家族样本时的有效性。通过少量的新标注样本,MALMIXER可以有效地对这些新出现的样本进行分类。
综上所述,MALMIXER通过结合领域知识感知的数据增强技术和半监督学习框架,有效地解决了在少量标注数据情况下的恶意软件家族分类问题。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估MALMIXER的性能和有效性,具体实验包括:
1. 饱和度分析(RQ1)
- 目的:评估MALMIXER在不同数量的标注数据下的性能,以确定在标注数据较少时模型的准确性。
- 数据集:使用BODMAS-20数据集。
- 方法:随机选择训练集中0.1%,0.5%,1%,2%,5%,10%,50%和75%的数据作为标注数据。
- 结果:即使在只有1%标注数据的情况下,MALMIXER也能保持较高的性能。
2. 模型比较(RQ2)
- 目的:比较MALMIXER与现有基于静态特征的半监督学习方法的性能。
- 数据集:BODMAS-20和MOTIF-50。
- 方法:使用0.1%标注数据对BODMAS-20进行评估,1%标注数据对MOTIF-50进行评估。
- 结果:MALMIXER在多数情况下优于其他基线模型。
3. 时序分析(RQ3)
- 目的:评估MALMIXER处理来自不同时间段的新样本的能力。
- 数据集:BODMAS-Temporal。
- 方法:选择1%的训练数据作为标注数据,测试数据来自不同的时间段。
- 结果:MALMIXER在所有时间偏移测试集上均优于其他模型,显示出良好的时序鲁棒性。
4. 留出测试(RQ4)
- 目的:评估MALMIXER处理训练时未识别的家族样本的能力。
- 数据集:BODMAS-LeaveOut。
- 方法:在训练时将某些家族标记为“未识别”,然后在测试时评估模型性能,并在“一次射击”(One-shot)场景中重新训练模型,引入每个“未识别”家族的一个标注实例。
- 结果:引入少量标注实例后,MALMIXER的性能显著提高。
5. 消融研究
- 目的:理解MALMIXER增强管道的每个组成部分对性能的贡献。
- 方法:通过移除对齐步骤、直接实例混合增强和仅使用高斯噪声增强等不同部分,评估模型性能的变化。
- 结果:展示了各个增强步骤对提高MALMIXER性能的重要性。
这些实验全面评估了MALMIXER在不同场景下的性能,包括处理少量标注数据、时序偏移样本、未识别家族样本的能力,以及各个增强步骤的有效性。通过这些实验,论文证明了MALMIXER在实际应用中的有效性和鲁棒性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和讨论,以下是一些可以进一步探索的点:
增强方法的改进:
- 探索其他类型的语义保持转换技术以生成更真实的恶意软件样本。
- 研究如何结合动态分析特征与静态分析特征进行数据增强。
模型的泛化能力:
- 研究MALMIXER在面对更加多样化和未知的恶意软件家族时的泛化能力。
- 探索模型在不同操作系统和不同架构的恶意软件上的分类性能。
减少对标注数据的依赖:
- 研究如何进一步减少模型训练对标注数据的依赖,特别是在面对大规模数据集时。
- 探索无监督学习或自监督学习技术以进一步提升模型性能。
对抗性攻击和模型鲁棒性:
- 测试MALMIXER对抗针对性攻击(如恶意软件作者故意设计的逃避检测)的鲁棒性。
- 研究对抗性训练等技术以增强模型对对抗性样本的识别能力。
实时恶意软件检测:
- 将MALMIXER应用于实时恶意软件检测系统,并评估其在实际环境中的表现。
- 研究如何优化模型以满足实时检测的效率要求。
跨领域应用:
- 探索MALMIXER在其他领域的应用,例如网络安全的其他方面,如入侵检测系统(IDS)。
- 研究模型在不同安全领域的适应性和有效性。
模型解释性和透明度:
- 提高模型的解释性,使安全专家能够理解模型的决策过程。
- 研究如何提供更详细的分析结果,帮助专家快速识别恶意软件的关键特征。
恶意软件家族的新识别方法:
- 开发新的方法来识别和标注新出现的恶意软件家族,减少人工分析的需求。
- 结合机器学习技术与自动化工具来加速新家族的识别过程。
模型的可扩展性和分布式训练:
- 研究如何扩展MALMIXER以处理更大规模的数据集,并提高训练效率。
- 探索分布式训练技术以加速模型训练过程。
开源协作和数据共享:
- 推动开源协作,共享恶意软件数据集,以促进恶意软件分类技术的发展。
- 建立标准化的评估协议和基准,以便于不同研究之间的比较和合作。
这些探索点可以帮助研究者进一步提升MALMIXER的性能,扩展其应用范围,并为恶意软件分类和网络安全领域带来新的洞见。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一个名为MALMIXER的系统,旨在解决恶意软件家族分类问题,特别是在标注样本稀缺的情况下。以下是论文的主要内容总结:
1. 问题背景
- 恶意软件数量迅速增长,给及时分类带来挑战。
- 传统方法依赖大量人工分析,成本高且耗时。
- 新出现的恶意软件样本需要更新训练集,增加了额外的逆向工程工作。
2. MALMIXER系统
- 一个基于半监督学习的恶意软件家族分类器。
- 结合了领域知识感知的数据增强技术和半监督学习框架。
- 通过检索和对齐技术增强恶意软件特征表示,提高少量标注样本的性能。
3. 方法论
- 特征划分:将特征分为可插值和不可插值两组。
- 域不变性学习:将特征映射到嵌入空间,区分共性和差异。
- 检索增强:基于相似样本的不可插值特征进行检索。
- 对齐选择:选择与插值特征最兼容的不可插值特征。
4. 实验评估
- 在BODMAS和MOTIF数据集上进行评估。
- 进行了饱和度分析、模型比较、时序分析和留出测试。
- 实验结果显示MALMIXER在少量标注样本的情况下性能优于现有方法。
5. 贡献
- 提出了MALMIXER,一个结合领域知识感知数据增强和半监督学习的恶意软件分类器。
- 设计了基于相似性和检索的恶意软件特征表示增强技术。
- 通过实验验证了MALMIXER在多种少量标注设置中的有效性。
6. 未来工作
- 探索更高效的增强方法和模型架构。
- 提高模型对新出现恶意软件家族的泛化能力。
- 将模型应用于实时恶意软件检测系统。
总体而言,这篇论文提出了一个创新的解决方案来应对恶意软件分类中的标注样本稀缺问题,并通过一系列实验展示了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Efficient Exploration and Discriminative World Model Learning with an Object-Centric Abstraction
Authors:Anthony GX-Chen, Kenneth Marino, Rob Fergus
In the face of difficult exploration problems in reinforcement learning, we study whether giving an agent an object-centric mapping (describing a set of items and their attributes) allow for more efficient learning. We found this problem is best solved hierarchically by modelling items at a higher level of state abstraction to pixels, and attribute change at a higher level of temporal abstraction to primitive actions. This abstraction simplifies the transition dynamic by making specific future states easier to predict. We make use of this to propose a fully model-based algorithm that learns a discriminative world model, plans to explore efficiently with only a count-based intrinsic reward, and can subsequently plan to reach any discovered (abstract) states. We demonstrate the model’s ability to (i) efficiently solve single tasks, (ii) transfer zero-shot and few-shot across item types and environments, and (iii) plan across long horizons. Across a suite of 2D crafting and MiniHack environments, we empirically show our model significantly out-performs state-of-the-art low-level methods (without abstraction), as well as performant model-free and model-based methods using the same abstraction. Finally, we show how to learn low level object-perturbing policies via reinforcement learning, and the object mapping itself by supervised learning.
面对强化学习中的困难探索问题,我们研究了给智能体一个以物体为中心的映射(描述一组物品及其属性)是否能够更有效地进行学习。我们发现这个问题最好通过分层建模来解决,将物品建模为更高层次的状态抽象,像素作为底层,将属性变化建模为更高层次的与时间抽象相关的原始动作。这种抽象简化了状态转移动态,使特定未来状态更容易预测。我们利用这一点提出了一种完全基于模型的算法,该算法学习一个判别性的世界模型,使用仅基于计数的内在奖励进行高效探索,并能随后达到任何已发现的(抽象)状态。我们证明了该模型能够(i)高效解决单一任务,(ii)在不同物品类型和环境中实现零启动和少启动迁移,(iii)进行长期规划。在多个二维工艺和MiniHack环境中,我们实证证明我们的模型显著优于最新的低层次方法(无抽象),以及使用相同抽象的模型免费和基于模型的性能方法。最后,我们展示了如何通过强化学习学习低层次的对象扰动策略,以及通过监督学习学习对象映射本身。
论文及项目相关链接
PDF Preprint. Additional results
Summary
在强化学习中面对复杂的探索问题时,研究发现通过给智能体一个以物体为中心的映射(描述一组物品及其属性)可以提高学习效率。该问题通过层级建模最佳解决,物品处于较高的状态抽象层次,而属性变化则处于较高的时间抽象层次,这样的抽象简化了状态转换的动态过程,使未来特定状态更容易预测。在此基础上提出了一种完全基于模型的算法,该算法学习具有鉴别力的世界模型,仅使用基于计数的内在奖励进行高效探索规划,并能规划到达任何发现的(抽象)状态。模型能够在(i)解决单一任务,(ii)在不同项目类型和环境中实现零冲击和少冲击转移,(iii)规划长期目标方面表现出能力。在多个二维制作和MiniHack环境中进行的实证表明,该模型显著优于没有抽象表达的最先进低级方法,以及使用相同抽象表达的高效无模型和有模型方法。最后展示了如何通过强化学习来学习低级的物体干扰策略和物体映射。
Key Takeaways
- 研究探讨了使用物体为中心映射的强化学习方法在面对复杂探索问题时的效率提升。
- 通过层级建模解决了该问题,物品和属性变化被置于较高的抽象层次。
- 抽象化简化了状态转换的动态过程,使得未来特定状态的预测更为容易。
- 提出了一种基于模型的算法,该算法能够高效探索并规划到达任何发现的抽象状态。
- 模型在解决单一任务、跨项目类型和环境转移以及长期规划方面表现出优异能力。
- 在多个环境中进行的实证表明,该模型显著优于其他方法。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
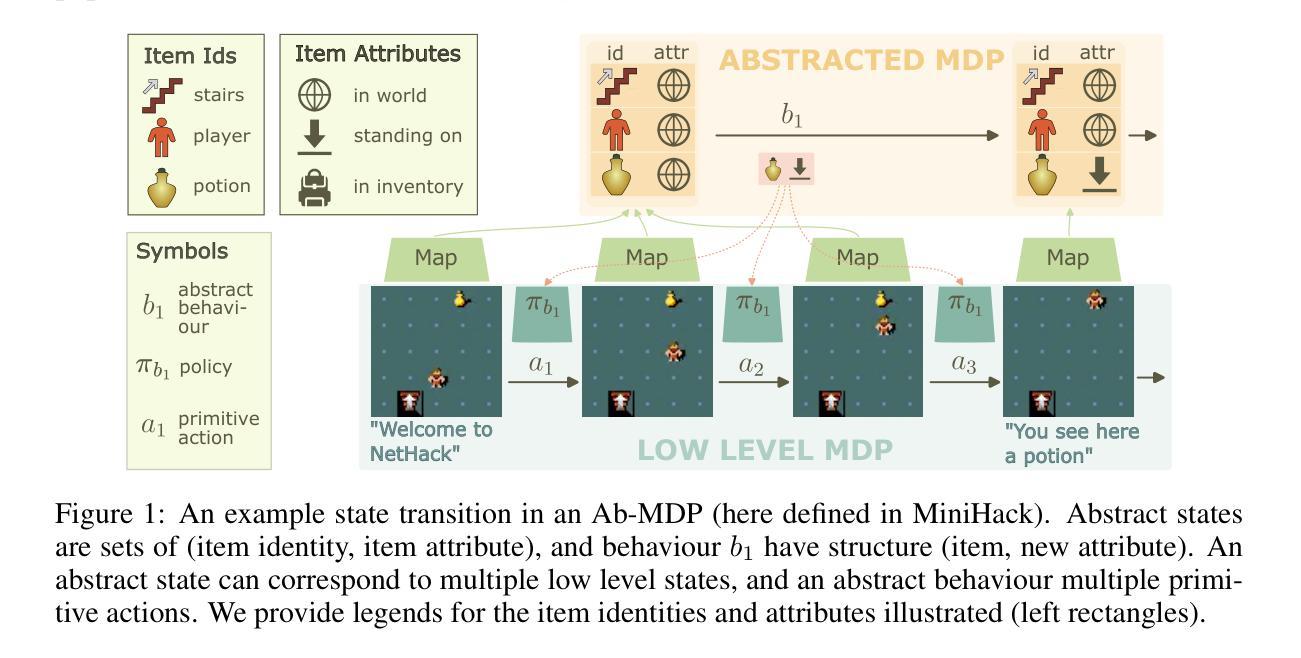
A: 这篇论文研究了在强化学习中,特别是在困难的探索问题中,是否可以通过给智能体一个以对象为中心的映射(描述一组物品及其属性)来实现更高效的学习。具体来说,论文试图解决以下几个问题:
探索和世界模型学习:在强化学习中,智能体需要学习基本的运动能力,并在环境中探索长序列的交互。论文探讨了如何通过语义级别的探索和世界建模来更有效地处理复杂的环境。
层次化的学习:论文提出了通过在对象的更高级别状态抽象和像素级别,以及属性变化的更高级别时间抽象来建模物品,从而简化转换动态,使得特定未来状态更容易预测。
基于模型的算法:论文提出了一个完全基于模型的算法,该算法学习一个判别性的世界模型,仅使用基于计数的内在奖励来高效地规划探索,并能够在发现任何抽象状态后计划达到这些状态。
跨任务和环境的迁移能力:论文展示了模型在单任务中的高效解决方案能力,以及在不同物品类型和环境间的零样本和少样本迁移能力。
长期规划:论文还探讨了模型在长期规划中的能力,即跨越长视野地规划达到目标状态。
学习对象扰动策略和对象中心映射:最后,论文展示了在没有给定Ab-MDP(抽象标记决策过程)的情况下,如何通过强化学习和监督学习来学习对象扰动策略和对象中心映射。
总的来说,这篇论文旨在通过对象中心的抽象来提高强化学习中探索和世界模型学习的效率,并在多个环境和任务中验证了所提出方法的有效性。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与本研究相关的领域和具体工作:
层次化强化学习(Hierarchical RL):
- 论文中提出的Ab-MDP(抽象标记决策过程)是层次化状态和时间抽象的形式化方法,可以看作是Options Framework的一个应用。相关工作包括Bacon et al. (2016), Machado et al. (2017; 2021), Ramesh et al. (2019)等。
基于模型的规划(Model-Based Planning):
- 论文中提出的MEAD(Model-based Exploration of abstracted Attribute Dynamics)方法是基于模型的方法,与Dreamer-v3 (Hafner et al., 2023; Sekar et al., 2020) 和MuZero (Schrittwieser et al., 2020) 等方法相关。
抽象和语义空间中的RL(Abstraction and Semantic Spaces in RL):
- 论文探索了在语义级别进行探索和世界建模,与Andreas et al. (2017), Jiang et al. (2019), Chen et al. (2021) 等使用自然语言作为抽象空间的工作相关。
探索方法(Exploration Methods):
- 论文中使用了基于计数的内在奖励函数来鼓励探索,与Raileanu & Rocktäschel (2020), Zhang et al. (2021) 等基于计数的方法相关。
对象中心的表示学习(Object-Centric Representation Learning):
- 论文中使用了对象中心的抽象,与Diuk et al. (2008), Keramati et al. (2018) 提出的OO-MDP(对象导向MDP)相关,也与使用对象中心表示进行学习的Veerapaneni et al. (2019), Nasiriany et al. (2019) 等方法相关。
神经网络和约束满足(Neural Networks and Constraint Satisfaction):
- 论文中的方法与Chang et al. (2023) 提出的NCS(神经约束满足)方法相关,该方法使用实体集状态表示。
深度学习和粒子表示(Deep Learning and Particle Representations):
- 论文中的方法与Haramati et al. (2024) 提出的Deep Latent Particles方法相关,该方法学习描述像素级对象的潜在“粒子”。
组合泛化(Compositional Generalization):
- 论文中提出的Ab-MDP框架与Zhou et al. (2022), Chang et al. (2023) 等关注组合泛化的工作相关。
这些相关工作涵盖了从层次化RL到基于模型的规划,再到抽象表示学习等多个方面,为论文提出的研究提供了理论和技术背景。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法解决了强化学习中困难的探索问题和世界模型学习问题:
1. 对象中心的抽象(Object-Centric Abstraction)
- 定义抽象状态和行为:论文提出了一个抽象层(Ab-MDP),其中状态由一组物品及其属性组成,行为定义为改变特定物品属性的操作。这种抽象简化了状态空间和行为空间,使其更易于管理和学习。
2. 层次化建模
- 状态和时间抽象:通过在对象级别对状态进行抽象,并在更高的时间分辨率上建模属性变化,简化了转换动态,使得特定未来状态更容易预测。
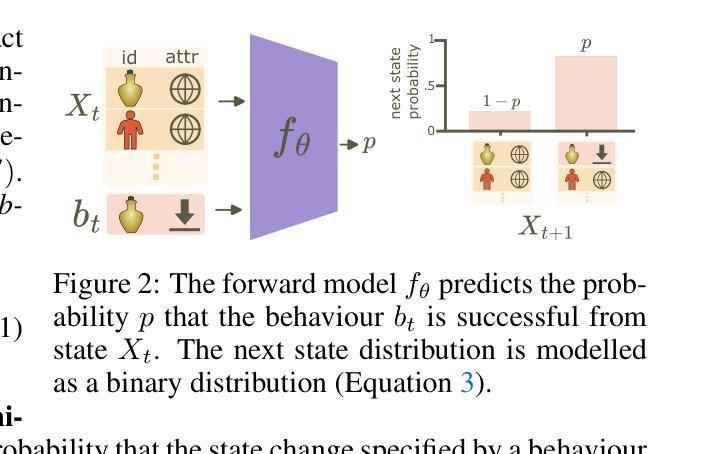
3. 基于模型的探索方法(MEAD)
判别式世界模型:提出了一种基于模型的方法(MEAD),它使用判别式模型来预测特定物品扰动是否会成功,而不是生成所有可能的未来状态。这种方法提高了数据效率和多步规划的能力。
训练前向模型:使用二元交叉熵损失来训练模型,以预测行为的成功概率。
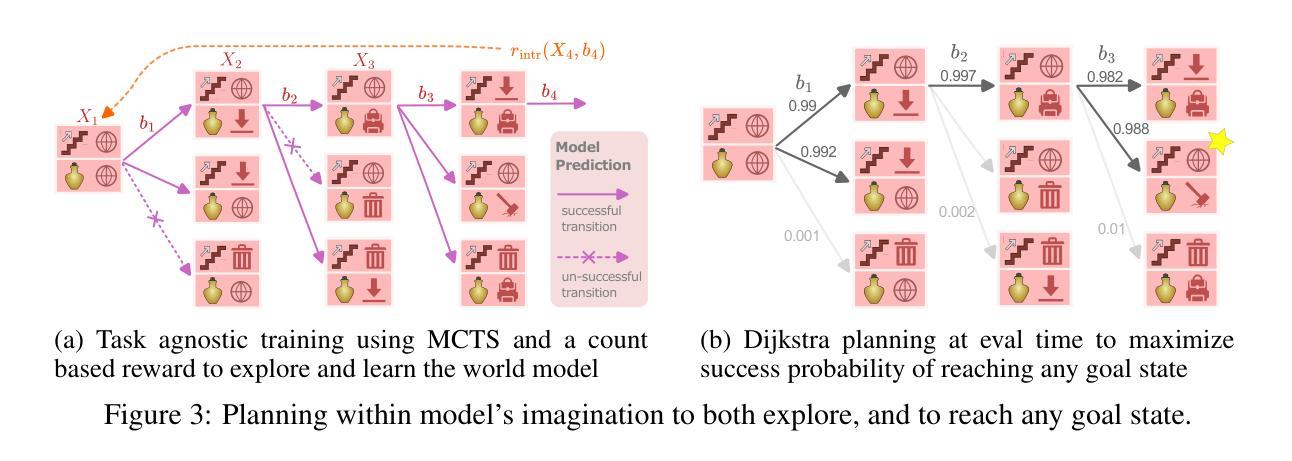
4. 探索和规划
基于计数的内在奖励:使用基于计数的内在奖励来鼓励探索不频繁访问的状态,并使用蒙特卡洛树搜索(MCTS)来找到最大化这种奖励的行为。
目标规划:一旦模型足够探索并拟合,使用Dijkstra算法在模型中找到达到任何期望抽象状态的最短路径。
5. 跨任务和环境的迁移
- 零样本和少样本迁移:展示了模型在新环境和新物品类型中的迁移能力,通过在抽象级别上建模对象身份和共享属性,模型能够将在一个环境中学到的知识迁移到新环境中。
6. 学习对象扰动策略和对象中心映射
通过强化学习学习低级策略:展示了如何在存在对象中心映射的情况下,通过强化学习来学习低级策略。
通过监督学习学习对象中心映射:展示了如何使用标记数据集来训练神经网络,以从低级观察中预测抽象状态。
通过这些方法,论文提出了一种有效的方法来解决强化学习中的探索和世界模型学习问题,并通过实验验证了其有效性。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了一系列实验来评估提出的方法(MEAD)在多个环境和设置下的性能。以下是他们进行的主要实验:
1. 从零开始学习单一环境中的任务(Learning from Scratch in Single Environments)
- 2D Crafting 游戏:这些环境要求智能体遵循类似Minecraft的合成树来合成对象,每个合成阶段需要多个低级动作。
- MiniHack 环境:包含一系列极其困难的探索游戏,涉及不同类型的对象和复杂的交互。
2. 迁移和组合(Transfer and Compositions)
- Sandbox 转移:在预训练的“沙盒”环境中,所有对象都有一定概率生成。智能体在没有任何任务特定奖励的情况下与环境交互,然后在各个环境中进行微调。
- 跨对象类别的迁移:评估模型将一个环境中学到的知识迁移到新对象类型的能力。
- 组合规划环境:设计了一个需要精确序列抽象行为的更具挑战性的环境,要求智能体拾取并使用多个对象来完成任务。
3. 学习对象扰动策略和对象中心映射(Learning Object Perturbing Policies and Object-Centric Map)
- 学习低级策略:展示了如何通过强化学习来学习低级策略,如果存在对象中心映射。
- 学习对象中心映射:通过监督学习训练神经网络,从低级观察中预测抽象状态。
4. 消融研究(Ablations)
- 生成式 vs 判别式模型:比较了生成式和判别式模型在学习效率和规划性能上的差异。
- 基于计数的探索:分析了基于计数的内在奖励和MCTS在探索中的效果。
- 参数化 vs 非参数化模型:比较了参数化模型和非参数化模型(基于经验计数)在样本效率上的差异。
这些实验旨在全面评估MEAD方法在不同方面的性能,包括从零开始学习的能力、迁移到新环境和对象的能力、以及在复杂任务中的规划能力。通过与现有的强化学习方法(包括模型自由和模型基础方法)进行比较,论文展示了MEAD在样本效率和最终性能上的优势。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
1. 自动发现对象中心映射(Automatic Discovery of Object-Centric Mappings)
论文中提到,构建Ab-MDP需要对象中心映射的存在。虽然展示了如何通过监督学习来学习这种映射,但这个过程仍然需要标记的数据集。研究如何自动、无监督地发现对象中心映射是一个重要的研究方向。
2. 泛化能力的提升(Improving Generalization)
尽管MEAD在给定的实验环境中展示了良好的迁移和泛化能力,但在更广泛的环境和任务中的泛化性能仍然是一个值得探索的问题。研究如何进一步提升模型的泛化能力,使其能够适应更多样化的环境和任务。
3. 多模态输入的处理(Handling Multimodal Inputs)
论文中的实验主要基于视觉和文本输入。对于包含更多模态(如声音、触觉等)的输入,如何有效地整合和利用这些信息进行探索和学习是一个值得研究的问题。
4. 复杂环境中的长期规划(Long-Term Planning in Complex Environments)
虽然MEAD展示了在一些环境中的长期规划能力,但在更加复杂和动态的环境中,如何有效地进行长期规划仍然是一个挑战。研究更复杂的规划策略和算法,以适应这些环境的需求。
5. 交互式和增强学习(Interactive and Augmented Learning)
论文中的方法主要依赖于与环境的交互来学习。探索如何利用外部指导(如人类反馈)或增强学习技术来加速学习过程和提高学习效率。
6. 算法的可解释性和透明度(Explainability and Transparency of Algorithms)
提高算法的可解释性,使研究人员和用户能够更好地理解模型的决策过程和内部表示,这对于实际应用中的模型部署和信任建立至关重要。
7. 跨领域迁移(Cross-Domain Transfer)
研究模型在一个领域学到的知识如何迁移到另一个完全不同的领域,这在多任务学习和终身学习场景中尤为重要。
8. 计算效率和资源需求(Computational Efficiency and Resource Requirements)
优化算法和模型以减少计算资源的需求,使其能够在资源受限的环境中运行,这对于实际部署和应用具有重要意义。
这些方向不仅可以推动强化学习领域的发展,还可能带来新的理论和实践上的突破。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
研究问题
论文研究了在强化学习中,特别是在困难的探索问题中,是否可以通过给智能体一个以对象为中心的映射(描述一组物品及其属性)来实现更高效的学习。
方法
- 对象中心抽象:提出了一个抽象层(Ab-MDP),其中状态由一组物品及其属性组成,行为定义为改变特定物品属性的操作。
- 层次化建模:通过在对象级别对状态进行抽象,并在更高的时间分辨率上建模属性变化,简化了转换动态。
- 基于模型的探索方法(MEAD):提出了一种基于模型的方法,使用判别式模型来预测特定物品扰动是否会成功,并使用基于计数的内在奖励和蒙特卡洛树搜索(MCTS)进行探索。
实验
- 单一环境学习:在2D Crafting游戏和MiniHack环境中评估了从零开始学习的能力。
- 迁移和组合:评估了模型在新环境和新物品类型中的迁移能力,以及在更复杂任务中的组合规划能力。
- 学习对象扰动策略和对象中心映射:展示了如何通过强化学习和监督学习来学习对象扰动策略和对象中心映射。
结果
- 效率和性能:MEAD在样本效率和最终性能上优于现有的模型自由和模型基础方法。
- 迁移能力:展示了良好的零样本和少样本迁移能力。
- 长期规划:证明了模型在长期规划中的能力。
贡献
- 定义了Ab-MDP,一个简单的、人类可理解的层次MDP。
- 提出了MEAD,一个使用稳定判别式目标来建模物品属性变化的方法。
- 实证展示了MEAD在解释性、长期规划和新环境迁移方面的优势。
- 展示了如何在没有给定Ab-MDP的情况下学习其组成部分。
未来工作
论文指出了未来的研究方向,包括自动发现对象中心映射、提高泛化能力、处理多模态输入、复杂环境中的长期规划、交互式和增强学习、算法的可解释性以及跨领域迁移等。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

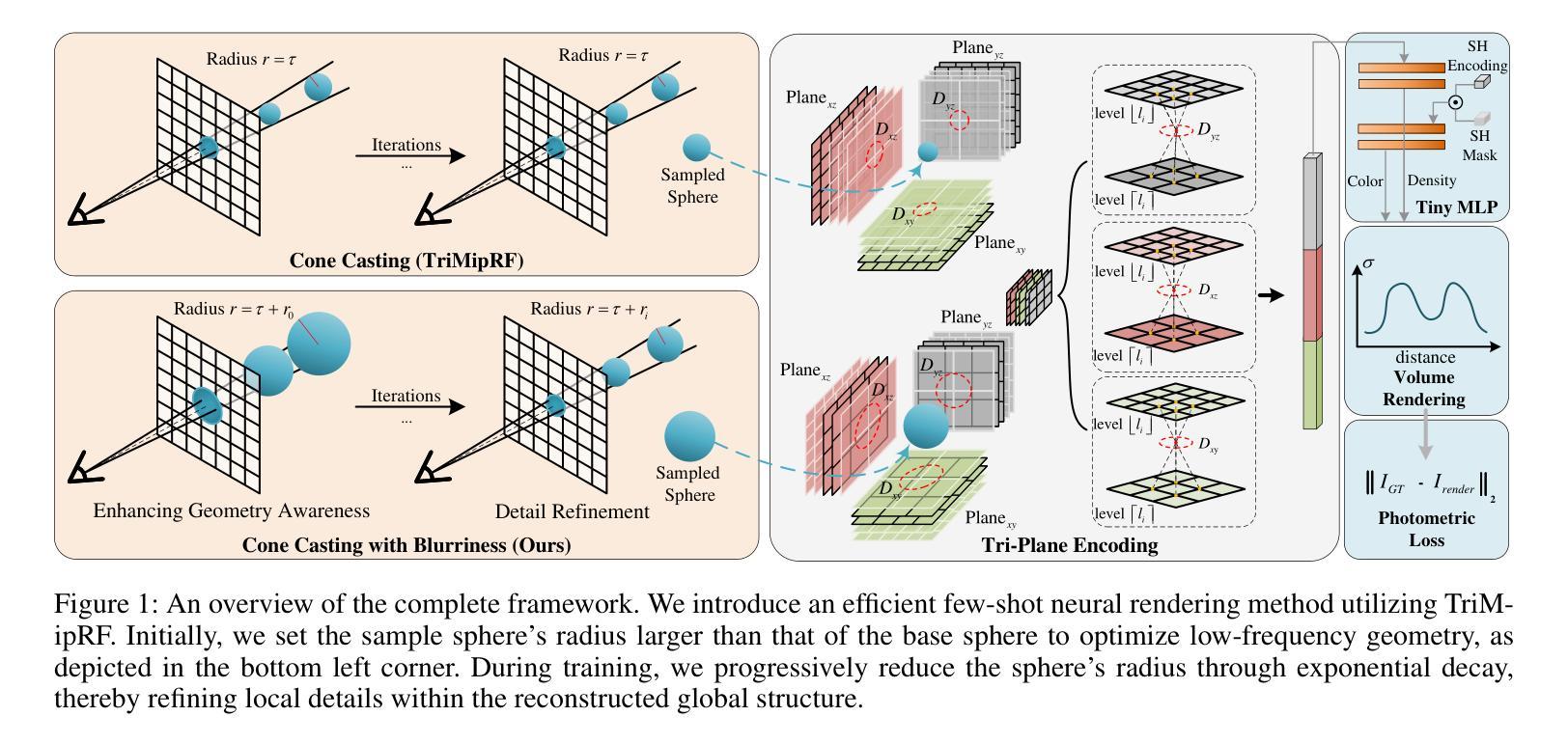
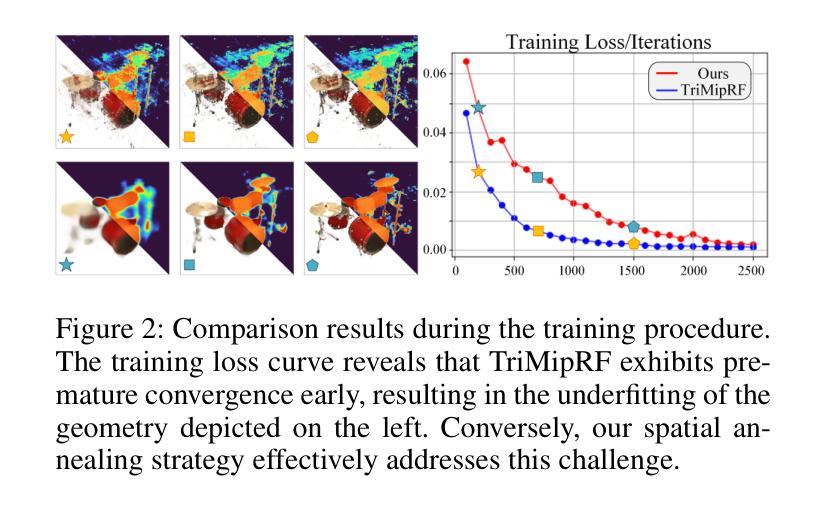
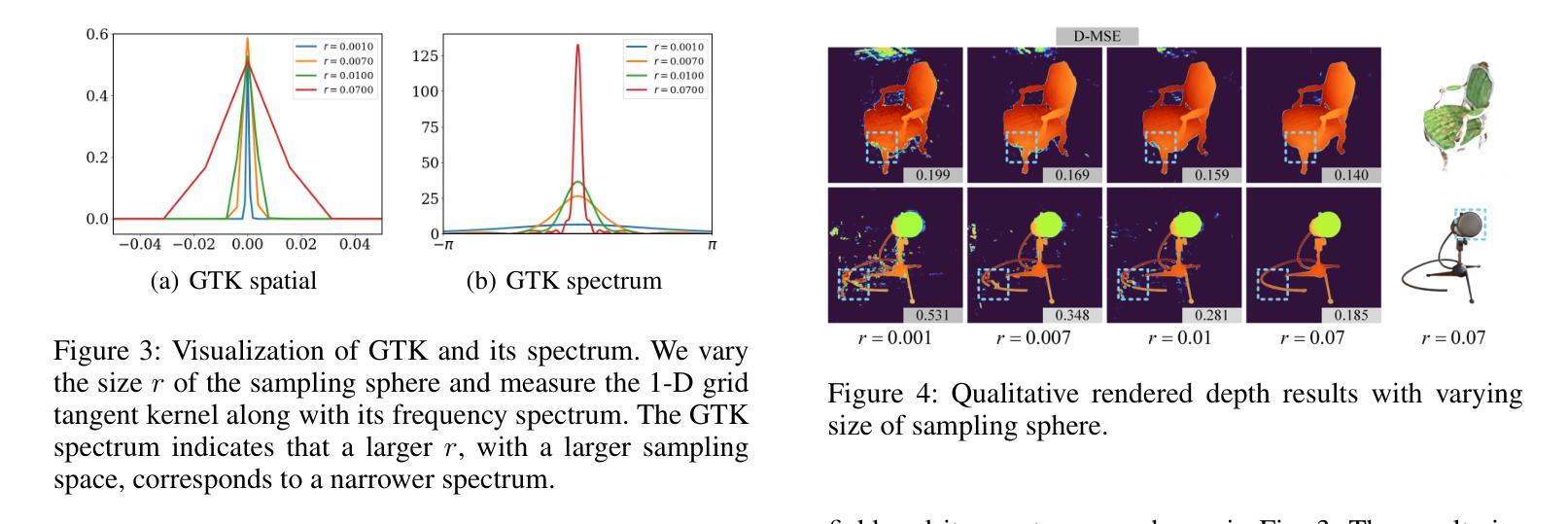
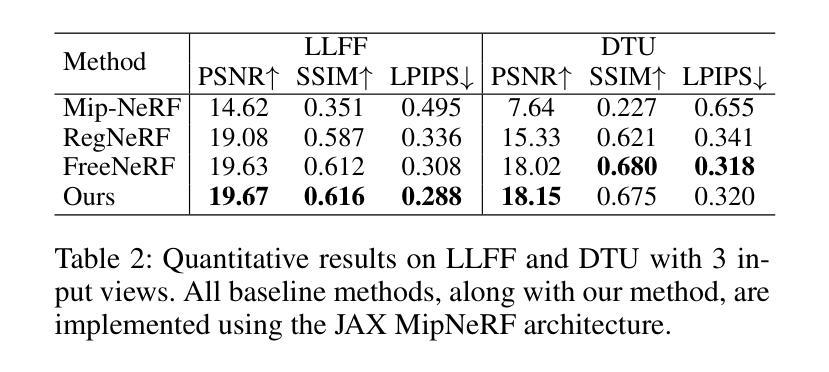
Spatial Annealing for Efficient Few-shot Neural Rendering
Authors:Yuru Xiao, Deming Zhai, Wenbo Zhao, Kui Jiang, Junjun Jiang, Xianming Liu
Neural Radiance Fields (NeRF) with hybrid representations have shown impressive capabilities for novel view synthesis, delivering high efficiency. Nonetheless, their performance significantly drops with sparse input views. Various regularization strategies have been devised to address these challenges. However, these strategies either require additional rendering costs or involve complex pipeline designs, leading to a loss of training efficiency. Although FreeNeRF has introduced an efficient frequency annealing strategy, its operation on frequency positional encoding is incompatible with the efficient hybrid representations. In this paper, we introduce an accurate and efficient few-shot neural rendering method named \textbf{S}patial \textbf{A}nnealing regularized \textbf{NeRF} (\textbf{SANeRF}), which adopts the pre-filtering design of a hybrid representation. We initially establish the analytical formulation of the frequency band limit for a hybrid architecture by deducing its filtering process. Based on this analysis, we propose a universal form of frequency annealing in the spatial domain, which can be implemented by modulating the sampling kernel to exponentially shrink from an initial one with a narrow grid tangent kernel spectrum. This methodology is crucial for stabilizing the early stages of the training phase and significantly contributes to enhancing the subsequent process of detail refinement. Our extensive experiments reveal that, by adding merely one line of code, SANeRF delivers superior rendering quality and much faster reconstruction speed compared to current few-shot neural rendering methods. Notably, SANeRF outperforms FreeNeRF on the Blender dataset, achieving 700$\times$ faster reconstruction speed.
神经辐射场(NeRF)采用混合表示法,在新视角合成方面表现出令人印象深刻的性能,并且效率高。然而,在输入视角稀疏的情况下,其性能会大幅下降。已经设计了各种正则化策略来解决这些挑战。然而,这些策略要么需要额外的渲染成本,要么涉及复杂的流程设计,导致训练效率降低。虽然FreeNeRF引入了一种有效的频率退火策略,但其对频率位置编码的操作与高效的混合表示法不兼容。本文介绍了一种准确高效的少量神经网络渲染方法,名为基于空间退火正则化的神经辐射场(SANeRF),该方法采用混合表示的预滤波设计。我们首先通过推导其滤波过程,建立了混合架构的频率带宽限制的分析公式。基于这种分析,我们提出了空间域中的通用频率退火形式,可以通过调制采样核来实现,从具有窄网格切线核谱的初始核开始呈指数收缩。这种方法对于稳定训练阶段的早期至关重要,并有助于增强后续的细节优化过程。我们的大量实验表明,仅通过增加一行代码,SANeRF即可提供优于当前少量神经网络渲染方法的渲染质量和更快的重建速度。值得注意的是,SANeRF在Blender数据集上的表现优于FreeNeRF,实现了700倍的快速重建速度。
论文及项目相关链接
PDF AAAI 2025, code available at https://github.com/pulangk97/SANeRF
Summary
本文提出了一种名为SANeRF的准确且高效少视点神经渲染方法,采用混合表示预滤波设计。通过建立混合架构的频率带宽限制分析公式,提出了空间域通用形式的频率退火方法,通过调制采样核实现从具有窄网格切线核谱的初始核指数缩小。该方法对训练阶段的早期阶段进行稳定至关重要,并有助于显著提高后续细节优化过程。实验表明,仅通过增加一行代码,SANeRF与当前少视点神经渲染方法相比,具有优越的渲染质量和更快的重建速度。特别是在Blender数据集上,SANeRF的表现优于FreeNeRF,实现了700倍更快的重建速度。
Key Takeaways
- SANeRF是一种用于少视点神经渲染的准确且高效的方法,基于混合表示和预滤波设计。
- 通过建立混合架构的频率带宽限制分析公式,提出了空间域频率退火方法。
- 空间域频率退火通过调制采样核实现,有助于稳定训练过程的早期阶段并增强细节优化。
- SANeRF相较于其他少视点神经渲染方法具有优越的渲染质量和更快的重建速度。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是Neural Radiance Fields (NeRF)及其混合表示方法在处理稀疏输入视图时性能显著下降的挑战,尤其是在少样本(few-shot)神经渲染场景下。具体来说,论文中提到NeRF需要密集的输入视图或者长时间的训练,这限制了它在自动驾驶、机器人和AR/VR等实际场景中的应用。尽管基于网格的混合表示方法被引入以提高训练效率,它们在处理稀疏输入视图时仍然存在异常收敛和对几何感知能力弱的问题。论文中提出了一种名为Spatial Annealing regularized NeRF (SANeRF)的准确且高效的少样本神经渲染方法,旨在通过在空间域中实施频率退火策略来解决这些问题,从而提高对稀疏视图的鲁棒性,同时保持计算效率。
Q: 有哪些相关研究?
A: 相关研究包括以下几个方面:
Neural Radiance Fields (NeRF):
- Mildenhall et al. (2021) 提出了NeRF,这是一种用于详细3D重建和高保真新视角合成的强大学习型工具。
- Martin-Brualla et al. (2021); Barron et al. (2021, 2022); Mildenhall et al. (2022) 等研究者在新视角合成、表面重建、动态场景建模和3D内容生成等领域扩展了NeRF的应用。
Few-shot Neural Rendering:
- Deng et al. (2022), Wang et al. (2023), Cao et al. (2022), Wei et al. (2021), Roessle et al. (2022) 等研究者通过整合额外的3D信息(如稀疏点云、估计深度或密集对应关系)来增强监督。
- Jain et al. (2021), Niemeyer et al. (2022), Sun et al. (2023), Seo et al. (2023) 等研究者采用基于随机补丁的语义一致性或几何正则化策略。
- Lin et al. (2023), Yu et al. (2021), Chen et al. (2021), Wang et al. (2021b), Long et al. (2022), Liu et al. (2022), Chibane et al. (2021), Trevithick and Yang (2021) 等研究者通过训练网络以内部化几何先验。
NeRF加速架构:
- M¨uller et al. (2022) 和 Hu et al. (2023) 提出了基于网格的混合表示方法,以加速NeRF的训练和渲染过程。
频率正则化:
- FreeNeRF (Yang, Pavone, and Wang 2023) 通过逐步增加位置编码的频率来解决少样本挑战,这是一种称为频率正则化的技术。
TriMipRF:
- Hu et al. (2023) 提出了TriMipRF,它引入了三平面表示的预过滤策略。
这些相关研究构成了论文提出的SANeRF方法的理论基础和实践背景,旨在通过结合这些研究成果来提升NeRF在少样本情况下的性能和效率。
Q: 论文如何解决这个问题?
A: 论文通过提出一种名为Spatial Annealing regularized NeRF (SANeRF)的方法来解决NeRF及其混合表示在处理稀疏输入视图时性能下降的问题。SANeRF的核心思想是在空间域中实施一种通用形式的频率退火策略,通过调制采样核以指数方式从具有窄网格切线核谱的初始状态收缩。具体来说,解决方案包括以下几个关键步骤:
频率带宽限制的解析公式:
- 论文首先通过分析混合表示架构的过滤过程,建立了预过滤设计混合表示的频率带宽限制的解析公式。
空间退火策略:
- 基于上述分析,论文提出了一种在空间域中的通用形式的频率退火策略,通过调整采样球的半径来实现,从而在训练的早期阶段稳定训练,并显著促进后续细节细化过程。
粗到细的训练策略:
- SANeRF采用了基于TriMipRF的粗到细训练策略,初始时通过增加采样球的半径来优化低频几何结构,随着训练的进行,逐渐减小采样球的半径以细化局部细节。
网格切线核(GTK)理论的应用:
- 论文利用GTK理论来分析网格模型的1D空间GTK及其频谱,验证了采样空间大小与频率带宽之间的关系,并证实了通过调整采样空间大小可以有效提升对低频几何信息的训练。
实验验证:
- 通过在合成数据集和Blender数据集上的广泛实验,论文证明了SANeRF在效率和性能上的优越性。与现有的少样本神经渲染方法相比,SANeRF在保持更快重建速度的同时,提供了更高质量的渲染结果。
总的来说,SANeRF通过在空间域中实施精心设计的退火过程,自适应地调整空间采样大小,增强了几何重建和细节细化的能力,并且只需要对基础架构的代码进行最小的修改,就能在少样本场景中实现最先进的性能,同时保持效率。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证SANeRF方法的有效性和效率,具体实验包括:
数据集和指标:
- 使用Blender数据集进行评估,该数据集包含8个从环绕视角观察的合成场景。
- 选择8个特定的视图进行训练,并在25个测试图像上进行评估。
- 使用PSNR(峰值信噪比)、SSIM(结构相似性指数)和LPIPS(Learned Perceptual Image Patch Similarity)作为量化分析的指标。
度量截断的球谐编码:
- 在输入视图稀疏的情况下,为了更好地适应未见视角方向并解决视依赖颜色的拟合问题,论文提出了对球谐编码的高级分量进行截断的方法。
Blender数据集的定性和定量比较:
- 展示了SANeRF与基础架构TriMipRF和FreeNeRF在Blender数据集上的定性比较结果。
- 提供了在8个输入视图下SANeRF与其它方法的定量结果比较,包括PSNR、SSIM和LPIPS分数,以及训练时间。
不同输入视图数量下的鲁棒性测试:
- 评估SANeRF在不同数量输入视图下的鲁棒性,通过使用Blender训练集中的前n个图像作为输入,其中n的值在8至100之间变化。
消融研究:
- 对SANeRF中提出的空间退火策略(SA)和球谐掩码(SHM)进行了消融研究,以评估它们对性能的贡献。
不同基础架构上的性能评估:
- 为了证明SANeRF策略的有效性,论文还将该策略应用于MipNeRF框架,并在LLFF和DTU数据集上进行了定量评估。
视图稀疏性下的鲁棒性验证:
- 展示了SANeRF与TriMipRF相比,在不同输入视图条件下的性能对比,特别是在稀疏输入视图情况下的性能提升。
这些实验结果表明,SANeRF不仅在定量指标上优于现有的少样本神经渲染方法,而且在训练效率上也有显著提升。通过这些实验,论文充分证明了SANeRF方法的有效性和实用性。
Q: 有什么可以进一步探索的点?
A: 尽管SANeRF在少样本神经渲染方面取得了显著的进展,但仍有一些方向可以进一步探索和研究:
提高训练效率:
- 虽然SANeRF已经显著提高了训练速度,但仍可以探索新的方法来进一步减少训练时间,例如通过改进优化算法或开发更高效的网络架构。
扩展到更多场景和数据集:
- 目前的实验主要在Blender数据集上进行。将SANeRF扩展到更多样化的场景和更复杂的真实世界数据集上,可以进一步验证其泛化能力和实用性。
改进几何和纹理重建质量:
- 尽管SANeRF在几何重建方面表现出色,但在纹理细节的重建上可能还有改进空间。研究如何结合更高级的纹理建模技术,以提高渲染质量。
自适应采样策略:
- SANeRF采用了固定的采样球半径衰减策略。研究基于场景内容的自适应采样策略,可能进一步提高渲染效率和质量。
多模态数据融合:
- 考虑将SANeRF与其他类型的数据(如深度信息、法线信息等)结合起来,以提高对复杂场景的重建能力。
实时渲染应用:
- 将SANeRF优化并适配到实时渲染应用中,如增强现实(AR)和虚拟现实(VR),这可能需要更高效的计算资源管理和网络架构设计。
网络架构的改进:
- 探索新型的神经网络架构,可能会发现更适合于少样本学习的模型,从而进一步提升SANeRF的性能。
更广泛的正则化技术:
- 研究和集成更多的正则化技术,以进一步提高SANeRF在面对稀疏数据时的鲁棒性和准确性。
理论和数学框架的深入分析:
- 对SANeRF所采用的空间退火策略进行更深入的理论和数学分析,以更好地理解其工作原理和潜在的改进方向。
跨模态和多任务学习:
- 考虑将SANeRF应用于跨模态学习任务,例如从2D图像到3D重建,或结合不同的视觉任务,以提高模型的灵活性和应用范围。
这些方向不仅可以推动SANeRF技术的发展,还可能对整个神经渲染领域产生深远的影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为Spatial Annealing regularized NeRF (SANeRF)的新方法,旨在解决Neural Radiance Fields (NeRF)及其混合表示在处理稀疏输入视图时性能下降的问题。以下是论文的主要内容总结:
问题陈述:
- NeRF及其混合表示方法在处理稀疏输入视图时性能显著下降,特别是在少样本神经渲染场景下。
方法介绍:
- SANeRF采用预过滤设计的混合表示,通过在空间域中实施一种通用形式的频率退火策略,通过调制采样核以指数方式从具有窄网格切线核谱的初始状态收缩。
理论贡献:
- 论文建立了预过滤设计混合表示架构的频率带宽限制的解析公式,并通过分析过滤过程,提出了在空间域中进行频率退火的通用形式。
实验验证:
- 通过在合成数据集和Blender数据集上的广泛实验,论文证明了SANeRF在效率和性能上的优越性。SANeRF在保持更快重建速度的同时,提供了更高质量的渲染结果。
主要贡献:
- 提出了一种准确的且高效的少样本神经渲染方法,通过添加仅一行代码,实现了比现有方法更优的渲染质量和更快的重建速度。
- 在Blender数据集上,SANeRF实现了比FreeNeRF快700倍的重建速度,并在PSNR上取得了0.3dB的性能提升。
消融研究和鲁棒性测试:
- 论文还进行了消融研究,验证了空间退火策略和球谐掩码(SHM)对性能的贡献,并测试了SANeRF在不同输入视图数量下的鲁棒性。
代码和数据集:
- 论文提供了代码,可在GitHub上找到,方便研究者复现和进一步研究。
总的来说,SANeRF通过在空间域中实施精心设计的退火过程,自适应地调整空间采样大小,增强了几何重建和细节细化的能力,并且只需要对基础架构的代码进行最小的修改,就能在少样本场景中实现最先进的性能,同时保持效率。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图