⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-17 更新
NeRF-Texture: Synthesizing Neural Radiance Field Textures
Authors:Yi-Hua Huang, Yan-Pei Cao, Yu-Kun Lai, Ying Shan, Lin Gao
Texture synthesis is a fundamental problem in computer graphics that would benefit various applications. Existing methods are effective in handling 2D image textures. In contrast, many real-world textures contain meso-structure in the 3D geometry space, such as grass, leaves, and fabrics, which cannot be effectively modeled using only 2D image textures. We propose a novel texture synthesis method with Neural Radiance Fields (NeRF) to capture and synthesize textures from given multi-view images. In the proposed NeRF texture representation, a scene with fine geometric details is disentangled into the meso-structure textures and the underlying base shape. This allows textures with meso-structure to be effectively learned as latent features situated on the base shape, which are fed into a NeRF decoder trained simultaneously to represent the rich view-dependent appearance. Using this implicit representation, we can synthesize NeRF-based textures through patch matching of latent features. However, inconsistencies between the metrics of the reconstructed content space and the latent feature space may compromise the synthesis quality. To enhance matching performance, we further regularize the distribution of latent features by incorporating a clustering constraint. In addition to generating NeRF textures over a planar domain, our method can also synthesize NeRF textures over curved surfaces, which are practically useful. Experimental results and evaluations demonstrate the effectiveness of our approach.
纹理合成是计算机图形学中的一个基本问题,对多种应用都有益。现有方法在处理二维图像纹理方面非常有效。然而,许多真实世界的纹理包含三维几何空间中的中观结构,如草地、树叶和织物,仅使用二维图像纹理无法对其进行有效建模。我们提出了一种利用神经辐射场(NeRF)的新型纹理合成方法,从给定的多视角图像中捕获并合成纹理。在提出的NeRF纹理表示中,具有精细几何细节的场景被分解为中观结构纹理和底层基础形状。这允许将具有中观结构的纹理有效地学习为位于基础形状上的潜在特征,这些特征被输入到同时训练的NeRF解码器中,以表示丰富的视角相关外观。使用这种隐式表示,我们可以通过潜在特征的补丁匹配来合成基于NeRF的纹理。然而,重建内容空间与潜在特征空间之间的度量不一致性可能会损害合成质量。为了提高匹配性能,我们通过引入聚类约束来进一步规范潜在特征的分布。除了平面上生成NeRF纹理外,我们的方法还可以合成曲面上的NeRF纹理,这在实践中非常有用。实验结果表明我们的方法非常有效。
论文及项目相关链接
Summary
本文提出了一种基于神经辐射场(NeRF)的新纹理合成方法,该方法可以从给定的多视角图像中捕捉并合成纹理。此方法将具有精细几何细节的场景分解为介观结构纹理和底层基础形状,允许介观结构纹理作为潜在特征在基础形状上学习,并输入到同时训练的NeRF解码器中,以表现丰富的视角相关外观。通过潜在特征的补丁匹配,可以合成基于NeRF的纹理。为提高匹配性能,通过引入聚类约束来规范潜在特征分布。该方法不仅能在平面域上生成NeRF纹理,还能在曲面域上合成NeRF纹理,具有实际应用价值。
Key Takeaways
- 现有纹理合成方法主要处理2D图像纹理,对于包含介观结构的真实世界纹理(如草、叶子、织物等)在3D几何空间中的建模效果不佳。
- 提出了基于神经辐射场(NeRF)的纹理合成方法,该方法可以捕捉并合成从多视角图像中的纹理。
- 场景被分解为介观结构纹理和底层基础形状,允许在基础形状上学习潜在特征,以表现丰富的视角相关外观。
- 通过潜在特征的补丁匹配来合成基于NeRF的纹理。
- 引入聚类约束以规范潜在特征分布,提高匹配性能。
- 该方法不仅适用于平面域上的NeRF纹理生成,还能在曲面域上进行合成,具有广泛的应用潜力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何通过神经辐射场(Neural Radiance Fields, NeRF)来合成具有三维几何空间中的中观结构(meso-structure)的纹理。具体来说,论文关注以下几个方面:
现有纹理合成方法的局限性:传统的纹理合成方法在处理2D图像纹理方面较为有效,但对于许多现实世界中的纹理(例如草地、树叶和织物),它们具有3D几何空间中的中观结构,这些结构无法仅通过2D图像纹理有效建模。
NeRF在纹理建模中的应用:NeRF是一种从多视角图像中重建复杂真实场景纹理的方法,但原始的NeRF将几何和外观混合在一起,限制了对重建纹理的操作和编辑自由度。
纹理的捕获、建模、合成和应用:论文提出了一种新颖的方法,利用多视角图像来捕获、建模、合成并应用具有中观结构和视角依赖外观的纹理。
纹理的隐式表示和合成:通过将场景中的精细几何细节与基础形状分离,并将纹理作为潜在特征位于基础形状上,论文提出了一种NeRF纹理表示方法,允许通过潜在特征的补丁匹配来合成基于NeRF的纹理。
提高合成质量:为了增强匹配性能,论文进一步通过引入聚类约束来规范潜在特征的分布,以提高合成结果的质量。
在曲面上的纹理合成:除了在平面域上生成NeRF纹理外,论文的方法还能够在曲面上合成NeRF纹理,这在实际应用中非常有用。
综上所述,论文的核心贡献在于提出了一种能够从真实世界的多视角图像中捕获、建模、合成并渲染具有中观结构的NeRF纹理的新方法。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要涉及以下几个领域:
神经渲染(Neural Rendering):
- NeRF(Neural Radiance Fields)[3]:提出了一种将场景建模为辐射场的方法,可以从多视角图像重建场景。
- NeRF的扩展工作:包括提高推理速度[9][10]、处理大规模场景[11][12][13][14]、动态场景[15][16][17]以及反射分解[18][19][20][21]和风格化[22][23][24]的研究。
- 其他神经表示方法:例如利用神经双向纹理函数(BTFs)来建模具有中观结构的已知纹理[2],以及学习复杂形状作为平滑低频和连续高频签名距离函数的组合[25]。
纹理合成(Texture Synthesis):
- 基于相似邻域的纹理合成方法[29][30],这些方法通过逐步分配像素来逐渐增长合成区域。
- 基于补丁的方法[31][32][33][34],这些方法通过匹配和优化补丁来合成纹理。
- 基于神经网络的纹理合成方法[36][37][38][39],这些方法通过优化潜在特征的Gram矩阵或训练前馈卷积网络来合成纹理。
- 使用生成对抗网络(GANs)进行纹理合成的研究[40][41][42][43][44][46][47]。
与NeRF-Texture相关的特定工作:
- NeuMesh[4]:提出了一种基于网格的神经隐式表示,用于分离形状和外观,实现几何和纹理编辑。
- NeuTex[5]:通过UV参数化明确表示纹理,支持纹理编辑和映射。
- NeRF-Tex[1]:首次探索了通过NeRF建模具有中观结构的纹理的可能性。
这些相关研究为NeRF-Texture提供了理论基础和技术背景,同时也展示了在神经渲染和纹理合成领域的研究进展。NeRF-Texture在这些研究的基础上,提出了一种新的NeRF纹理合成方法,特别关注于从真实世界的多视角图像中捕获、建模和合成具有中观结构的纹理。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键技术步骤解决提出的问题:
基础形状提取(Base Shape Extraction):
- 使用Instant-NGP[6]和Co-ACD[7]技术从多视角图像中提取场景的基础形状,并将其表示为一个粗略的网格模型。
基础形状投影(Base Shape Projection):
- 将3D空间中的点映射到基础形状上,获取投影坐标和签名距离,从而将纹理属性(如中观结构、法线和外观)与基础形状分离。
可微分投影层(Differentiable Projection Layer):
- 为了在神经网络训练中反向传播梯度,构建了一个可微分的投影层,使得可以从输入坐标x获得投影坐标xc的梯度。
属性预测(Attributes Prediction):
- 使用哈希网格(hash grids)存储潜在特征,并快速查询密度和反射系数,同时预测细节法线(fine normal)的角度。
着色模型(Shading Model):
- 采用Phong着色模型和球谐函数(Spherical Harmonics, SHs)来模拟材料反射和光照,以实现实时渲染和稳定收敛。
纹理合成(Texture Synthesis):
- 通过提取基础形状上的隐式补丁(implicit patches)并使用补丁匹配算法在潜在特征空间中合成NeRF纹理。
在曲面上的合成(Synthesis on Curved Surface):
- 将纹理合成算法扩展到任意曲面,并采用多分辨率金字塔和从粗到细的匹配策略来加速处理。
潜在特征聚类(Latent Feature Clustering):
- 引入聚类损失来规范潜在特征的分布,确保相似纹理内容的特征在空间中彼此接近,提高合成质量。
纹理映射(Texture Mapping):
- 将合成的纹理映射到新的3D形状上,通过双线性插值在UV特征图上获取潜在特征,并计算新形状上的法线和反射系数。
模型优化(Model Optimization):
- 使用Adam优化器进行训练,并采用L1 RGB重建损失、扭曲损失、法线预测损失等来优化模型。
通过这些技术步骤,论文提出了一种新颖的方法来捕获、建模、合成和渲染具有中观结构和视角依赖外观的NeRF纹理,从真实世界的多视角图像中学习纹理,并将其应用到任意给定的形状上,实现实时渲染。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验来验证他们提出方法的有效性:
纹理合成和应用(Texture Synthesis and Applications):
- 展示了通过手机拍摄的多视角图像捕获的现实世界纹理(如榴莲、树皮、织物、叶子和花朵)的合成结果。
- 将合成的纹理应用到不同的形状上,例如将榴莲纹理应用到香蕉上,将树皮纹理应用到桶上等。
在曲面上的纹理合成(Texture Synthesis on Curved Surfaces):
- 展示了在各种曲面上合成的纹理,如将西红柿、花朵、珊瑚、石头和旧电脑电路的纹理合成到不同的曲面上。
视角依赖性和中观结构纹理合成(Synthesis of View-Dependent and Meso-Structure Textures):
- 展示了合成的纹理能够捕捉视角依赖的外观和中观结构细节,如镜面球和金属床等。
新视角合成质量(View Synthesis Quality):
- 在DTU数据集上评估了新视角合成质量,并与NeRF和Instant-NGP等方法进行了比较。
与2D纹理的比较(Comparison with 2D Texture):
- 定量和定性地比较了2D图像纹理与NeRF纹理在不同视角下的渲染效果。
与NeRF-Tex的比较(Comparison with NeRF-Tex):
- 展示了与NeRF-Tex相比,作者提出的方法在保持纹理连续性和结构方面的优势。
聚类约束的影响(Ablation on Clustering Constraint):
- 通过主成分分析(PCA)降维和合成结果的可视化,展示了聚类约束对潜在特征分布的影响。
补丁分辨率的影响(Ablation on Patch Resolution):
- 分析了补丁分辨率对纹理合成结果的影响,并确定了128×128分辨率为一个合适的选择。
训练视角数量的影响(Ablation on the Number of Training Views):
- 研究了不同数量的训练视角对纹理合成质量的影响。
渲染速度分析(Rendering Speed Analysis):
- 比较了作者提出的方法与NeRF和Instant-NGP在渲染速度上的差异。
挑战分析(Challenge Analysis):
- 分析了在纹理捕获和纹理合成方面面临的挑战,包括有限的粗糙范围、复杂的拓扑结构、严格的匹配要求和纹理的语义内容。
这些实验全面地验证了NeRF-Texture方法在捕获、建模、合成和渲染真实世界纹理方面的能力,并展示了其在处理具有丰富几何和外观细节的纹理方面的优势。同时,实验也揭示了该方法在处理某些复杂场景时的局限性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
改进基础形状提取:
- 研究更精确的基础形状提取方法,以更好地处理具有复杂拓扑结构的场景。
增强复杂纹理结构的合成:
- 对于需要严格匹配的纹理结构,探索新的全局优化策略以改善纹理合成的全局一致性。
引入语义信息:
- 将语义信息整合到纹理合成过程中,以更好地保留纹理的语义内容,如避免合成过程中的字符扭曲。
提高训练效率和渲染速度:
- 进一步优化算法和实现,减少计算资源消耗,提高训练和渲染的速度。
扩展到更多类型的纹理和场景:
- 探索NeRF-Texture在更多种类的纹理和更复杂场景中的应用,如具有动态变化的纹理。
改进聚类约束:
- 研究不同的聚类算法或约束条件,以进一步改善潜在特征的分布和合成质量。
优化补丁匹配算法:
- 探索更高效的补丁匹配算法,以减少合成时间并提高合成质量。
探索自监督学习:
- 利用自监督学习减少对大量标记数据的依赖,提高模型的泛化能力。
多模态数据融合:
- 考虑将颜色、深度、法线等多模态数据融合到模型中,以提高纹理合成的真实感。
交互式编辑和设计工具:
- 开发交互式工具,允许用户对NeRF纹理进行直观的编辑和设计。
大规模场景的纹理合成:
- 研究如何将NeRF-Texture扩展到大规模场景的纹理合成,处理更广阔的视野和更复杂的环境。
实时应用:
- 优化算法以实现实时纹理合成和渲染,为虚拟现实(VR)和增强现实(AR)等应用提供支持。
这些探索点可以帮助研究者进一步提升NeRF-Texture的性能,扩展其应用范围,并解决现有方法的局限性。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为NeRF-Texture的新方法,旨在捕获、建模、合成和渲染具有中观结构和视角依赖外观的真实世界纹理。以下是该论文的主要内容总结:
问题陈述:
- 传统的纹理合成方法主要处理2D图像纹理,难以有效建模3D几何空间中的中观结构纹理,如草地、树叶等。
- 现有的NeRF方法将几何和外观混合在一起,限制了对重建纹理的操作和编辑自由度。
方法论:
- 提出了一种基于NeRF的纹理表示方法,将场景的中观结构纹理与基础形状分离,并将纹理作为潜在特征位于基础形状上。
- 利用多视角图像,通过隐式表示和补丁匹配算法在潜在特征空间中合成NeRF纹理。
- 引入聚类约束来规范潜在特征的分布,提高合成质量。
- 扩展了NeRF纹理合成方法,使其能够应用于曲面。
关键技术:
- 基础形状提取:使用Instant-NGP和Co-ACD技术从多视角图像中提取基础形状。
- 基础形状投影:将3D空间中的点映射到基础形状上,分离纹理属性和基础形状。
- 可微分投影层:构建可微分的投影层,以便在神经网络训练中反向传播梯度。
- 属性预测:使用哈希网格存储潜在特征,并预测密度和反射系数。
- 着色模型:采用Phong着色模型和球谐函数模拟材料反射和光照。
- 纹理合成:通过提取基础形状上的隐式补丁并使用补丁匹配算法合成NeRF纹理。
- 潜在特征聚类:引入聚类损失来规范潜在特征的分布。
实验:
- 展示了从真实世界多视角图像中捕获和合成的纹理结果。
- 比较了NeRF纹理与传统2D纹理在不同视角下的渲染效果。
- 与现有方法(如NeRF-Tex)进行了比较,展示了NeRF-Texture在保持纹理连续性和结构方面的优势。
- 进行了挑战分析,探讨了在纹理捕获和合成方面的局限性。
结论:
- NeRF-Texture能够从真实世界的多视角图像中捕获、建模、合成并渲染具有中观结构的NeRF纹理。
- 该方法在处理具有丰富几何和外观细节的纹理方面具有优势,并揭示了处理某些复杂场景时的局限性。
总体而言,这篇论文提出了一种创新的方法来处理和合成具有中观结构的3D纹理,扩展了NeRF的应用范围,并为未来在这一领域的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图





Sharpening Your Density Fields: Spiking Neuron Aided Fast Geometry Learning
Authors:Yi Gu, Zhaorui Wang, Dongjun Ye, Renjing Xu
Neural Radiance Fields (NeRF) have achieved remarkable progress in neural rendering. Extracting geometry from NeRF typically relies on the Marching Cubes algorithm, which uses a hand-crafted threshold to define the level set. However, this threshold-based approach requires laborious and scenario-specific tuning, limiting its practicality for real-world applications. In this work, we seek to enhance the efficiency of this method during the training time. To this end, we introduce a spiking neuron mechanism that dynamically adjusts the threshold, eliminating the need for manual selection. Despite its promise, directly training with the spiking neuron often results in model collapse and noisy outputs. To overcome these challenges, we propose a round-robin strategy that stabilizes the training process and enables the geometry network to achieve a sharper and more precise density distribution with minimal computational overhead. We validate our approach through extensive experiments on both synthetic and real-world datasets. The results show that our method significantly improves the performance of threshold-based techniques, offering a more robust and efficient solution for NeRF geometry extraction.
神经辐射场(NeRF)在神经渲染方面取得了显著的进展。从NeRF中提取几何信息通常依赖于体素遍历算法(Marching Cubes algorithm),该算法使用手工制作的阈值来定义水平集。然而,这种基于阈值的方法需要进行繁琐且针对特定场景的调整,限制了其在现实世界应用中的实用性。在这项工作中,我们旨在提高该方法在训练期间的效率。为此,我们引入了一种脉冲神经元机制,该机制可以动态调整阈值,无需手动选择。尽管这种方法具有潜力,但直接使用脉冲神经元进行训练往往会导致模型崩溃和输出噪声。为了克服这些挑战,我们提出了一种循环策略,该策略可以稳定训练过程,使几何网络能够以最小的计算开销实现更清晰、更精确的密度分布。我们通过合成和真实数据集的大量实验验证了我们的方法。结果表明,我们的方法显著提高了基于阈值的技术性能,为NeRF几何提取提供了更稳健和高效的解决方案。
论文及项目相关链接
Summary
NeRF几何提取中基于阈值的方法存在手工调参复杂、实际应用场景受限的问题。为解决此问题,本研究引入脉冲神经元机制,实现动态调整阈值,省去手动选择过程。然而,直接使用脉冲神经元训练易导致模型崩溃和输出噪声。因此,本研究提出轮询策略,稳定训练过程,使几何网络实现更精准、更锐利的密度分布,同时保持较低的计算开销。实验结果证明,该方法显著提升了阈值技术的性能,为NeRF几何提取提供了更稳健高效的解决方案。
Key Takeaways
- NeRF在神经渲染领域取得显著进展,但几何提取中基于阈值的方法存在调参复杂的问题。
- 引入脉冲神经元机制,实现阈值的动态调整,简化调参过程。
- 直接使用脉冲神经元训练会导致模型崩溃和输出噪声。
- 提出轮询策略,稳定训练过程,提高模型性能。
- 该方法使几何网络实现更精准、更锐利的密度分布。
- 方法在合成和真实世界数据集上的实验验证结果表明其有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决从Neural Radiance Fields (NeRF)中提取几何形状时存在的效率和实用性问题。具体来说,论文关注以下几个关键问题:
提取几何形状的效率问题:传统的从NeRF提取几何形状的方法依赖于Marching Cubes算法,该算法需要一个手工设定的阈值来定义水平集。这个基于阈值的方法需要针对不同场景进行大量的尝试和调整,限制了其在实际应用中的实用性。
动态阈值调整的需求:为了提高训练期间的方法效率,论文提出了引入一种尖峰神经元机制,以动态调整阈值,消除手动选择阈值的需要。
尖峰神经元训练中的挑战:直接使用尖峰神经元进行训练可能会导致模型崩溃和噪声输出。为了克服这些挑战,论文提出了一种轮询策略(round-robin strategy),以稳定训练过程,并使几何网络能够以最小的计算开销实现更清晰、更精确的密度分布。
提高几何提取的性能:通过在合成和真实世界数据集上的广泛实验,论文验证了所提出方法能够显著提高基于阈值技术的几何提取性能,提供了一种更稳健、更高效的NeRF几何提取解决方案。
总结来说,这篇论文旨在通过引入尖峰神经元和轮询策略来提高从NeRF中提取几何形状的效率和准确性,同时减少手动调整阈值的需要,以增强方法在实际应用中的适用性和鲁棒性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个领域:
Neural Implicit Representations and Surface Reconstruction:
- Neural Radiance Fields (NeRF) [1]:通过神经网络隐式表示3D场景的先驱方法,用于新视角合成,并在神经表面重建中取得显著进展。
- NeuS [4] 和 IDR [13]:这些后续工作依赖于Signed Distance Functions (SDF)来获得更好的几何表示。
Grid-based Neural Fields:
- Instant-NGP [14]、DVGO [15] 和 FastNeRF [16]:这些方法通过应用高级缓存技术来加速NeRF的训练。
- Plenoxels [17] 和 Relu-fields [18]:这些方法不包含任何神经网络,直接优化显式的3D模型。
Spiking Neural Networks (SNNs) in NeRF:
- Spiking NeRF [10]:在NeRF架构中引入尖峰神经元,以自适应更新密度阈值,提高几何质量。
- Spiking GS [23]:提出使用全局和局部尖峰神经元来处理低不透明度高斯和高斯的低不透明度尾部。
这些相关研究为本文提出的从基于网格的辐射场中提取几何形状的方法提供了理论基础和技术背景。本文的工作是在这些现有研究的基础上,通过引入尖峰神经元和轮询策略来改进几何提取过程的效率和准确性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤解决从NeRF中提取几何形状的问题:
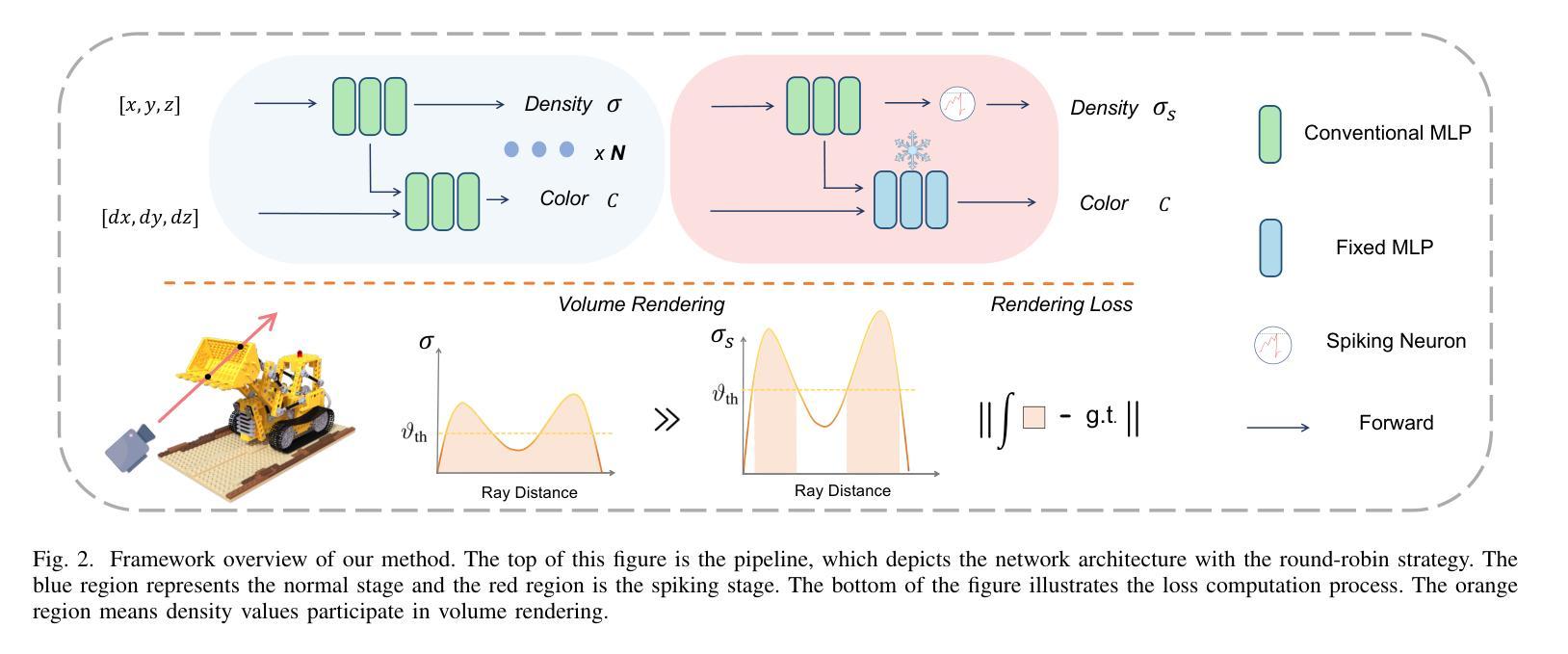
1. 引入尖峰神经元机制
论文提出了将尖峰神经元(Spiking Neuron)引入到基于网格的辐射场中,以动态调整密度阈值。尖峰神经元作为一种pruning策略,可以帮助网络专注于最重要的结构以适应真实图像数据。具体来说,尖峰神经元通过以下方式动态调整阈值:
[ \sigma_s = \Theta(\sigma - \theta_{th}) * \sigma ]
其中,(\sigma) 是原始密度值,(\sigma_s) 是经过尖峰神经元过滤后的密度值,(\theta_{th}) 是可学习的阈值参数。
2. 设计轮询策略(Round-Robin Strategy)
为了稳定训练过程,论文提出了一种简单的轮询策略。该策略将每一轮迭代分为两个阶段:正常阶段和尖峰阶段。在正常阶段,使用全范围的密度值构建辐射场;而在尖峰阶段,则使用经过尖峰神经元截断的密度值。这种策略有助于排除低于可学习阈值的密度值,从而更好地探索底层几何形状,同时避免了引入不希望的伪影或模型崩溃的风险。
3. 损失函数的定义
论文定义了总体损失函数 (L),包括颜色损失 (L_c)、阈值损失 (L_v) 以及可选损失 (L_{optional})。这些损失函数共同作用,以优化网络性能:
[ L = L_c + L_v + L_{optional} ]
4. 实验验证
论文通过在合成数据集(Blender dataset)和真实世界数据集(DTU dataset)上的广泛实验来验证所提方法的有效性。实验结果表明,该方法能够显著提高基于阈值技术的几何提取性能,提供了一种更稳健、更高效的NeRF几何提取解决方案。
5. 处理挑战
论文还讨论了在处理具有高光强度或低亮度的真实世界场景时的挑战,并提出了可能的解决方案,例如引入更先进的视图依赖参数化方法。
通过上述方法,论文成功地提高了从NeRF中提取几何形状的效率和准确性,同时减少了手动调整阈值的需求,增强了方法在实际应用中的适用性和鲁棒性。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
数据集和基线比较
- 数据集:实验在两个数据集上进行验证,分别是Blender数据集和DTU数据集。Blender数据集包含8个合成场景,而DTU数据集包含15个真实世界场景。
- 基线方法:与三种基线方法进行比较,包括NeuS、Spiking NeRF和Nerfacto。
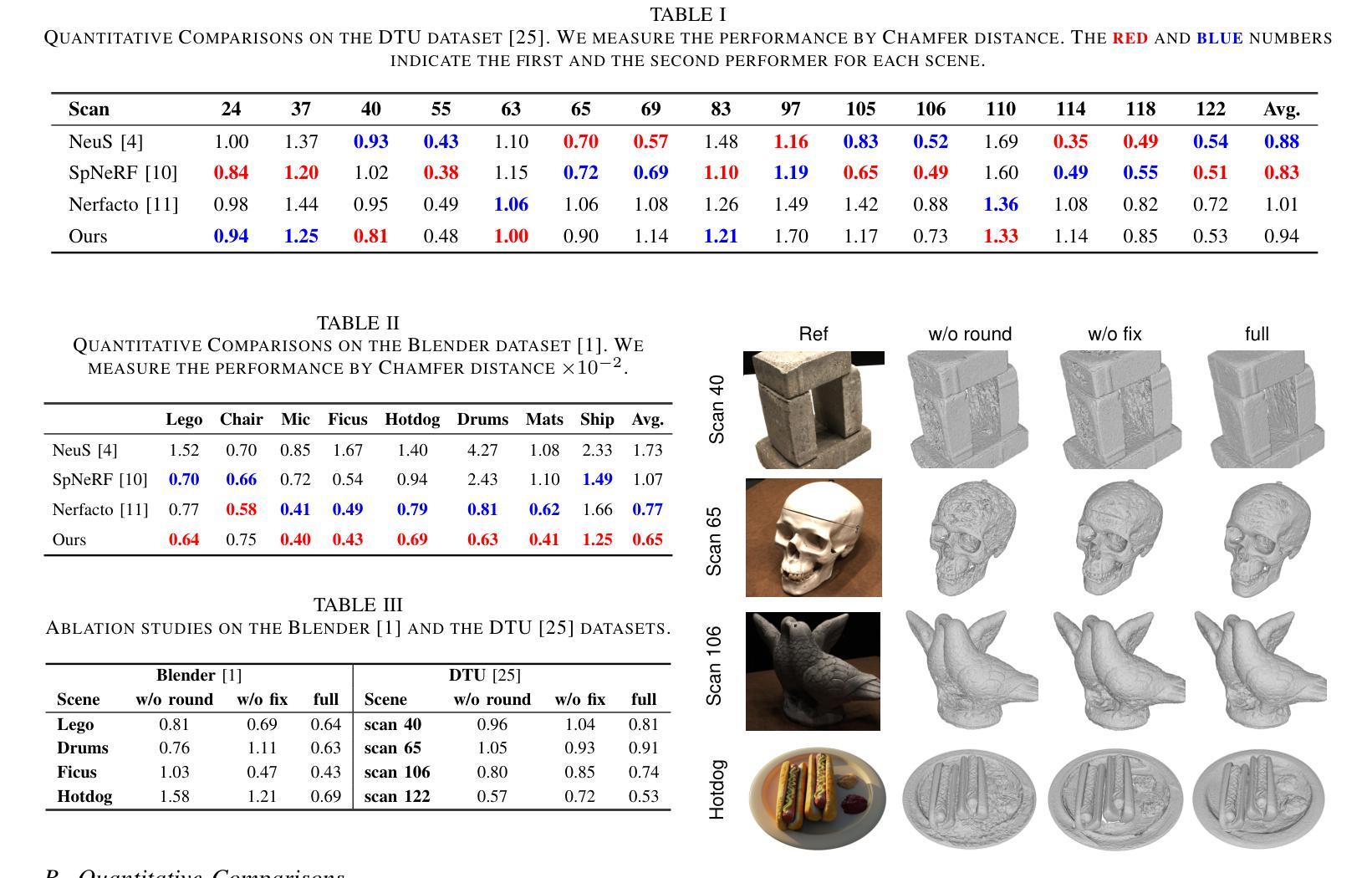
定量比较
- 使用Chamfer距离(CD)作为主要的评估指标,对DTU数据集和Blender数据集上的结果进行定量比较。
- 在DTU数据集上,论文的方法在三个场景中表现最佳,在另外三个场景中表现第二好,并且一致性地优于Nerfacto。
- 在Blender数据集上,论文的方法在七个场景中表现最佳。
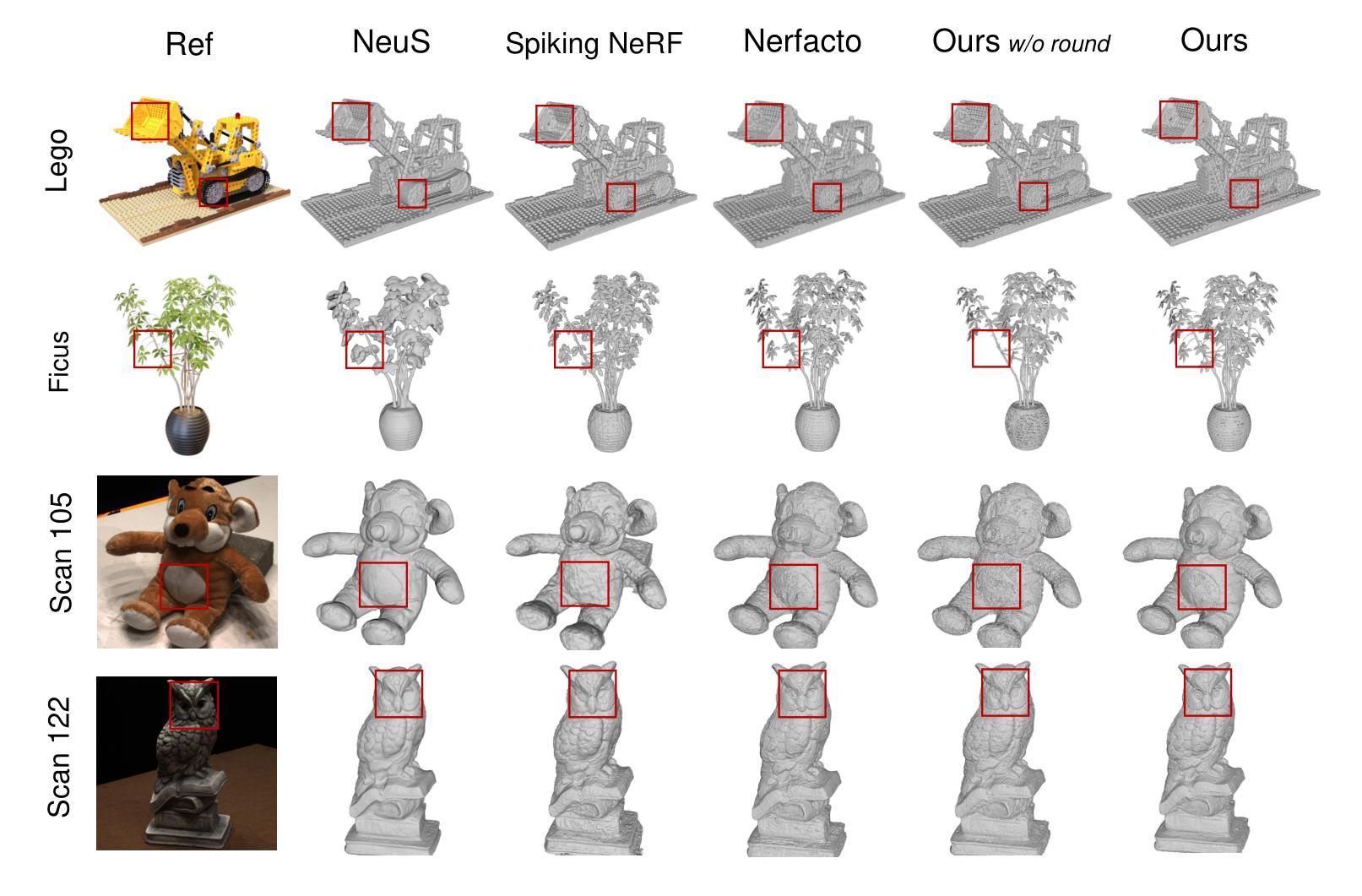
定性比较
- 展示了在Blender数据集和DTU数据集上的样本定性结果,并通过补充材料提供了完整的视觉比较结果。
- 论文的方法在重建几何形状时提供了更好的完整性和平滑度。
消融研究
- 对比了没有轮询策略(’w/o round’)和没有固定颜色网络(’w/o fix’)的配置与完整模型的效果。
- 展示了这些配置在Blender数据集和DTU数据集上的视觉和定量结果,验证了轮询策略和固定颜色网络的有效性。
透明物体的重建结果
- 为了进一步展示方法的实用性,论文还在Instant-NGP框架上实现了方法,并在透明DexNeRF数据集的两个场景上进行了实验。
通过这些实验,论文全面验证了所提出方法在不同场景和条件下的有效性和优越性,特别是在提高几何提取精度和效率方面。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和结论部分的讨论,以下是一些可以进一步探索的点:
处理高光强度或低亮度场景:
- 论文提到在处理具有高光强度或低亮度的真实世界场景时存在挑战。未来的工作可以集中在开发更先进的视图依赖参数化方法,以改善这些场景下的几何提取性能。
优化Eikonal损失的实现:
- 论文中提到使用PyTorch框架实现的Eikonal损失稍微减慢了训练速度。未来的工作可以通过完全集成tiny-cuda-nn来优化实现,以加快训练速度。
扩展到动态场景:
- 论文主要关注静态场景的表面重建。将方法扩展到动态场景,处理随时间变化的对象和环境,可能是一个有价值的研究方向。
改进尖峰神经元机制:
- 进一步研究和改进尖峰神经元机制,可能有助于提高几何提取的准确性和效率,特别是在处理复杂和详细几何形状时。
增强模型的泛化能力:
- 探索如何提高模型对不同类型场景和条件的泛化能力,包括不同的光照条件、材料属性和复杂度。
减少计算资源消耗:
- 尽管论文提出的方法已经相对高效,但进一步优化算法以减少计算资源消耗,特别是在大规模数据集上的应用,仍然是一个重要的研究方向。
结合其他类型的神经网络:
- 考虑将尖峰神经元与其他类型的神经网络(如卷积神经网络或图神经网络)结合,以利用它们的互补优势。
提高几何细节的捕捉能力:
- 研究如何提高模型捕捉高频率细节的能力,这对于重建精细的几何结构至关重要。
多模态数据融合:
- 探索将NeRF与其他类型的传感器数据(如深度信息、激光雷达扫描)结合,以提高重建的准确性和鲁棒性。
实际应用中的集成和测试:
- 在实际应用中(如机器人导航、增强现实等)测试和集成所提出的方法,以评估其在现实世界条件下的性能。
这些探索点可以帮助推动NeRF几何提取技术的发展,提高其在各种应用中的实用性和有效性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
论文针对从Neural Radiance Fields (NeRF)中提取几何形状的效率和实用性问题,特别是依赖于手工设定阈值的传统方法存在的局限性。尖峰神经元机制:
提出了引入尖峰神经元机制来动态调整密度阈值,以替代手动选择阈值的过程,旨在提高几何提取的效率和准确性。轮询策略:
设计了一种轮询策略来稳定训练过程,通过交替使用正常阶段和尖峰阶段的训练,以避免模型崩溃和噪声输出。方法框架:
详细描述了基于Nerfacto框架的方法实现,包括密度网络和颜色网络的定义,以及如何使用尖峰神经元和轮询策略进行训练。损失函数:
定义了包括颜色损失、阈值损失和可选损失(如方向损失、Eikonal损失和掩码损失)在内的损失函数,以优化网络性能。实验验证:
在Blender和DTU数据集上进行了广泛的实验,与现有方法进行定量和定性比较,验证了所提方法在几何提取性能上的优越性。消融研究:
通过消融研究验证了轮询策略和固定颜色网络在提高几何重建质量中的重要性。结论和局限性:
总结了论文的主要贡献,并讨论了方法的局限性和未来可能的改进方向,如处理高光强度或低亮度场景的挑战,以及优化Eikonal损失的实现。
总体而言,这篇论文提出了一种新的方法来从基于网格的NeRF中快速学习几何形状,通过引入尖峰神经元和轮询策略,提高了几何提取的效率和准确性,为NeRF几何提取提供了一种更稳健和高效的解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

PBR-NeRF: Inverse Rendering with Physics-Based Neural Fields
Authors:Sean Wu, Shamik Basu, Tim Broedermann, Luc Van Gool, Christos Sakaridis
We tackle the ill-posed inverse rendering problem in 3D reconstruction with a Neural Radiance Field (NeRF) approach informed by Physics-Based Rendering (PBR) theory, named PBR-NeRF. Our method addresses a key limitation in most NeRF and 3D Gaussian Splatting approaches: they estimate view-dependent appearance without modeling scene materials and illumination. To address this limitation, we present an inverse rendering (IR) model capable of jointly estimating scene geometry, materials, and illumination. Our model builds upon recent NeRF-based IR approaches, but crucially introduces two novel physics-based priors that better constrain the IR estimation. Our priors are rigorously formulated as intuitive loss terms and achieve state-of-the-art material estimation without compromising novel view synthesis quality. Our method is easily adaptable to other inverse rendering and 3D reconstruction frameworks that require material estimation. We demonstrate the importance of extending current neural rendering approaches to fully model scene properties beyond geometry and view-dependent appearance. Code is publicly available at https://github.com/s3anwu/pbrnerf
我们采用基于物理渲染(PBR)理论的神经辐射场(NeRF)方法,解决了3D重建中的不适定逆向渲染问题,该方法被称为PBR-NeRF。我们的方法解决了大多数NeRF和3D高斯拼贴方法的关键局限:它们在估计视相关外观时没有对场景材质和照明进行建模。为了解决这一局限性,我们提出了一种逆向渲染(IR)模型,能够联合估计场景几何、材质和照明。我们的模型基于最新的NeRF基IR方法,但关键地引入了两种新型基于物理的先验知识,更好地约束了IR估计。我们的先验知识被严谨地制定为直观的损失项,并在不损害新型视图合成质量的情况下实现了最先进的材质估计。我们的方法可以轻松地适应其他需要材质估计的逆向渲染和3D重建框架。我们证明了将当前神经渲染方法扩展到完全建模场景属性(超越几何和视相关外观)的重要性。代码已公开在https://github.com/s3anwu/pbrnerf。
论文及项目相关链接
PDF 16 pages, 7 figures. Code is publicly available at https://github.com/s3anwu/pbrnerf
摘要
我们以NeRF技术为核心,通过PBR理论的引导解决3D重建中的逆向渲染问题。我们的方法针对现有NeRF技术和3D高斯贴图技术中的关键局限,即在估计视角相关外观时未对场景材质和照明进行建模的问题。为了克服这个缺点,我们提出了一个能够同时估计场景几何结构、材质和照明的逆向渲染模型,我们称它为PBR-NeRF。该模型基于最新的NeRF逆向渲染方法构建,但引入了两个关键的物理基础先验,能够更好地约束逆向渲染估计。这些先验严谨地表示为直观的损失项,可以在不降低新颖视图合成质量的情况下实现最佳材料估计。我们的方法易于适应其他需要材料估计的逆向渲染和3D重建框架。我们证明了将当前神经网络渲染方法扩展到完全建模场景属性(超越几何和视角相关外观)的重要性。相关代码已在https://github.com/s3anwu/pbrnerf公开可供查阅。
要点
- 利用NeRF技术和PBR理论解决3D重建中的逆向渲染问题。
- 提出PBR-NeRF模型以克服现有方法的局限,实现场景几何结构、材质和照明的联合估计。
- 通过引入两个物理基础先验来改善逆向渲染模型的估计能力,并将它们严谨地表示为直观损失项。
- 我们的模型能够在保持新颖视图合成质量的同时实现最佳材料估计。
- 方法易于适应其他逆向渲染和3D重建框架,具有广泛的应用潜力。
- 代码公开可供查阅,便于进一步研究和应用。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决3D重建中的一个关键问题:逆渲染(inverse rendering)问题。逆渲染问题是指从一组多视角图像中准确重建场景的属性,包括几何形状、材料和照明。这个问题本质上是不适定的(ill-posed),因为存在材料-光照歧义,即同一图像可以由无限多的材质、光照和几何形状的组合来解释。为了克服这一挑战,论文提出了一种基于物理的神经场(Neural Radiance Fields,简称NeRF)方法,称为PBR-NeRF,该方法利用基于物理的渲染(Physics-Based Rendering,简称PBR)理论来提供强大的先验,以缩小可能的解空间。
具体来说,论文解决的问题包括:
视依赖外观的估计:大多数NeRF和3D高斯绘制方法没有模拟场景材料和照明,而是将场景视为“黑箱”,忽略了光传输的底层物理。这限制了这些方法在3D重建中的性能,因为它们无法准确和一致地模拟多样的光交互。
材料-光照-几何歧义:逆渲染问题由于材料、光照和几何的不确定性而变得复杂。为了解决这一问题,需要强有力的先验来约束可能的解决方案。
物理准确性:现有的NeRF和3DGS方法在模拟场景几何和视依赖外观方面取得了最先进的性能,但它们不能保证物理上准确的结果。例如,反射表面可能被错误地建模,导致“烘焙入”的高光等伪影。
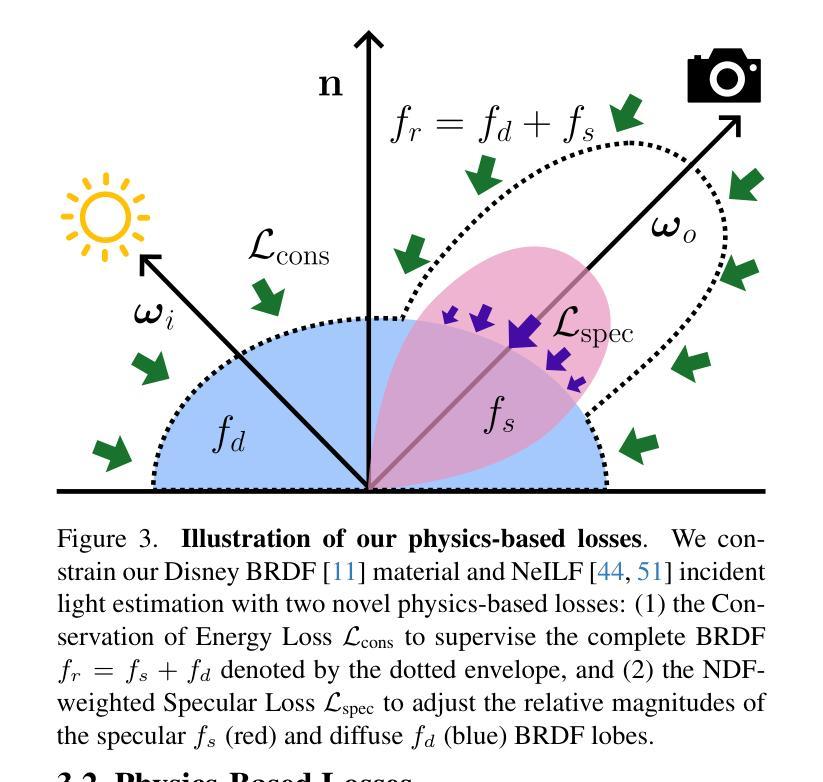
论文通过引入两个基于物理的先验(损失项),即能量守恒损失和NDF加权的镜面损失,来改进逆渲染估计,并在不牺牲新视角合成质量的同时,实现了最先进的材质估计。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要涉及以下几个领域:
Neural Fields for Novel View Synthesis:
- 利用连续体积场表示3D场景的方法,通过可微分体积渲染实现从未见视角的照片级真实感合成。代表性的工作包括NeRF及其衍生方法,它们通过alpha合成沿每个相机射线采样点的颜色来估计外出辐射度。
Neural Inverse Rendering:
- 早于神经场的方法,学习从2D图像预测3D几何、材料和照明。这些方法通过逆渲染或内在分解来估计物理场景属性,如材料和照明,从而支持如重新照明、材质编辑和外观操作等复杂下游任务。
Decomposed Neural Fields:
- 将传统神经场扩展到估计物理场景属性(如材料和照明)的方法,通过逆渲染或内在分解实现。
Physics-Based Rendering (PBR) Theory:
- 计算机图形学中用于生成给定场景材料、照明和几何的物理准确图像的框架。通过逆转这一过程,可以从PBR理论中导出用于更好约束神经前向和逆向渲染的物理先验。
Material Priors for Inverse Rendering:
- 用于约束材料估计并减少材料-光照歧义的材料先验至关重要。先前工作中使用了基本的BRDF平滑先验,以阻止材料属性的空间变化。
NeRF and 3D Gaussians for Scene Geometry Representation:
- 使用密度场、3D高斯或签名距离场(SDFs)来表示场景几何。SDFs明确定义表面,提供准确的表面和法线估计,使其与依赖PBR的逆渲染任务天然兼容。
具体到论文引用的文献,以下是一些相关研究的示例:
- NeRF:Mildenhall et al. (2020) 提出了NeRF,用于从一组图像中合成新视角的场景。
- **3D Gaussian Splatting (3DGS)**:Kerbl et al. (2023) 提出了3DGS,用于实时辐射场渲染。
- **NeILF/NeILF++**:Yao et al. (2022, 2023) 提出了NeILF和NeILF++,用于基于物理的材料估计。
- PBR理论:Pharr et al. (2016) 的著作详细介绍了基于物理的渲染理论。
这些相关研究构成了PBR-NeRF方法的理论和实践基础,并为进一步的研究提供了参考和对比。
Q: 论文如何解决这个问题?
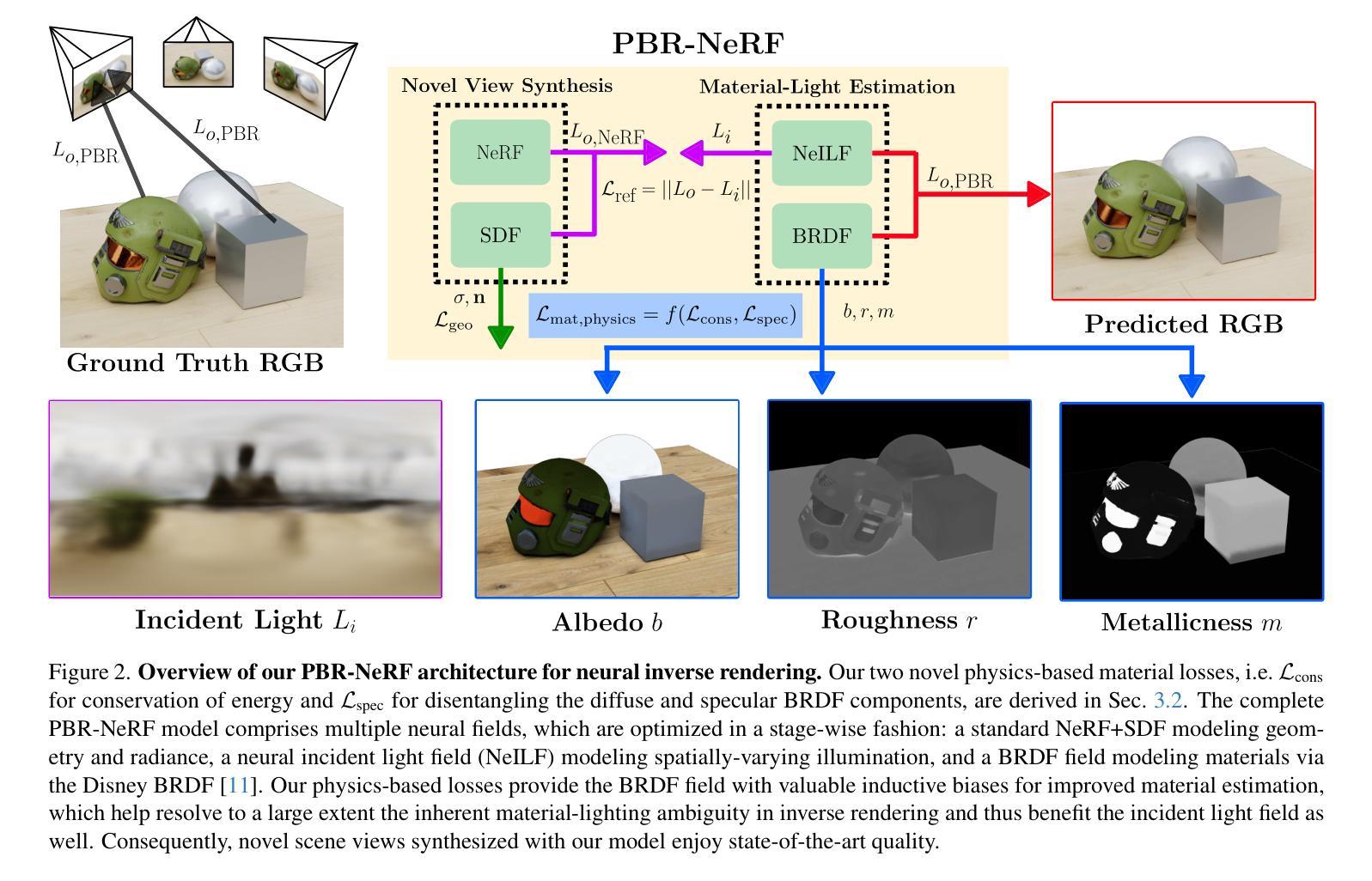
A: 论文通过提出PBR-NeRF方法解决了逆渲染问题,具体解决方案如下:
结合NeRF和PBR理论:
- 论文基于NeILF/NeILF++神经场框架,结合深度神经网络的表达能力和PBR理论的理论保证,扩展了NeILF/NeILF++的反射模型,通过利用其基础的迪士尼双向反射分布函数(Disney BRDF)模型。
引入两个物理先验损失:
- 能量守恒损失(Conservation of Energy Loss):此损失通过惩罚物理上无效的BRDF来强制执行能量守恒,确保材料不会创造或破坏能量。
- NDF加权的镜面损失(NDF-weighted Specular Loss):此损失通过在镜面区域惩罚过度的漫反射来促进BRDF的漫反射和镜面反射部分的分离,这对于准确模拟高镜面材料至关重要。
多阶段优化:
- 论文提出了一个三阶段优化流程:
- 几何阶段:仅训练NeRF SDF以初始化估计的几何形状。
- 材料阶段:在冻结NeRF SDF的情况下训练NeILF和BRDF MLP,以初始化估计的照明和材料。
- 联合优化阶段:同时训练所有场(NeRF SDF、NeILF、BRDF),使用所有损失进行优化。
- 论文提出了一个三阶段优化流程:
理论模型和实践验证:
- 论文不仅提出了理论模型,还通过在NeILF++和DTU数据集上的实验验证了PBR-NeRF的有效性。实验结果表明,PBR-NeRF在材料估计方面达到了新的最佳水平,同时保持或超过了基线的新视角合成性能。
通过这些方法,PBR-NeRF能够有效地解决逆渲染问题,准确地估计场景的几何形状、材料和照明,从而实现高质量的3D重建和新视角合成。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证PBR-NeRF方法的有效性,具体实验包括:
实验设置:
- 实现细节:PBR-NeRF基于NeILF++使用PyTorch实现,并保留了NeILF++的所有超参数,除了|SL|=256。训练迭代30K次,初始学习率为0.002,每10K迭代降低5倍。训练在单个NVIDIA RTX 4090上运行,运行时间从1到3小时不等。
数据集:
- NeILF++数据集:用于评估材料照明估计,假设已知几何形状。该数据集提供场景的地面真实几何形状、RGB、Albedo、Metallicness和Roughness,场景在6种静态照明模式下渲染,包括3种环境映射和3种混合照明场景。
- DTU数据集:捕获15个真实世界对象在受控实验室环境中的49个RGB LDR 1600×1200图像,分为44个训练图像和5个验证图像。仅定性评估DTU上的材料估计,因为它包含LDR图像且不提供地面真实材料。
与最新技术的比较:
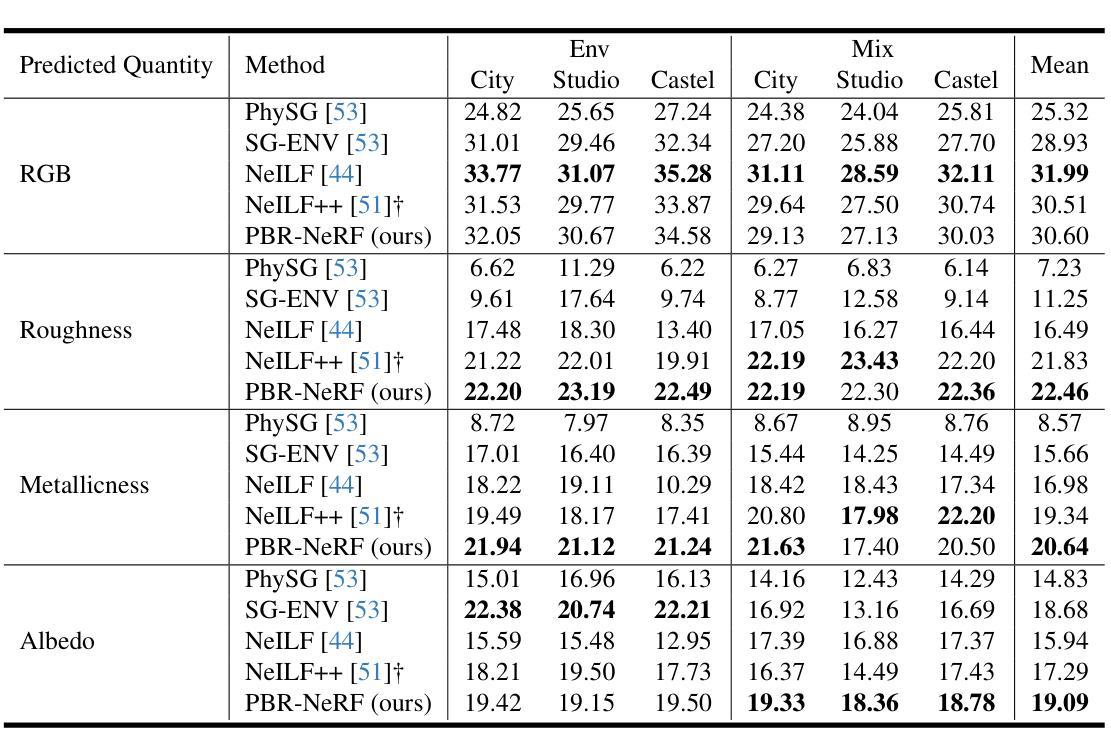
- 定量结果:使用PSNR指标比较NeILF++数据集上不同场景(City、Studio和Castel)和照明类型(Env和Mix)下的材料估计和新视角合成性能。
- PBR-NeRF在NeILF++数据集上实现了最先进的材料估计,平均PSNR在Albedo、Metallicness和Roughness上超过先前方法1-2dB。
- 在DTU数据集上,PBR-NeRF在新视角合成方面达到了最先进的结果,平均PSNR超过NeILF++ 0.37dB,并在10个场景中表现最佳。
定性结果:
- 与NeILF++在NeILF++数据集上的材料估计性能进行定性比较,PBR-NeRF在所有三种混合照明条件下都改善了照明和材料估计。
- 在DTU数据集上,PBR-NeRF在金属和粗糙度估计方面表现更好,准确预测金属物体,而NeILF++在金属部分和粗糙度方面产生了伪影。
消融研究:
- 对提出的物理先验损失进行消融研究,单独评估每个损失项的贡献。
- 结果表明,加入能量守恒损失(Lcons)改善了材料估计,加入镜面损失(Lspec)进一步提升了Albedo和Metallicness的估计。
这些实验全面验证了PBR-NeRF方法在逆渲染和新视角合成方面的有效性,并展示了其在材料估计方面的显著改进。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
高频镜面效应和反射表面处理:
- 论文中提到在处理高频镜面效应和反射表面时存在局限性,这表明需要进一步研究以改进对这类表面材质的估计和渲染。
更精细的材质和照明模型:
- 虽然PBR-NeRF利用了简化版的Disney BRDF模型,但可以考虑集成更复杂和详细的材质模型,以更准确地捕捉现实世界中的各种光照和材质交互。
优化算法和损失函数:
- 探索新的优化算法和损失函数,以进一步提高模型的性能和泛化能力,尤其是在处理复杂光照和材质时。
大规模场景和实时应用:
- 研究如何将PBR-NeRF扩展到大规模场景,并优化算法以实现实时渲染和交互。
数据集和标注:
- 开发和利用更多样化和大规模的数据集,包括更多的材质类型和光照条件,以及对应的详细标注,以训练和评估更先进的模型。
多模态数据融合:
- 考虑将多种传感器数据(如RGB-D、LiDAR、深度图等)融合到模型中,以提供更全面的物理场景信息。
可解释性和编辑性:
- 提高模型的可解释性,允许用户更好地理解和编辑重建的3D场景,这对于设计和创意应用尤其重要。
跨模态迁移和泛化能力:
- 研究模型在不同场景和条件下的迁移能力,以及如何提高模型对未知场景的泛化能力。
计算效率和资源优化:
- 探索更高效的计算方法,减少模型训练和推理所需的计算资源,使其更适合资源受限的环境。
鲁棒性和异常处理:
- 提高模型对异常数据和噪声的鲁棒性,确保在不理想的输入条件下也能产生合理的输出。
这些探索点可以帮助推动逆渲染和3D重建技术的发展,提高其在各种应用中的实用性和效果。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为PBR-NeRF的方法,旨在通过结合物理基础的渲染(PBR)理论与神经辐射场(NeRF)来解决3D重建中的逆渲染问题。以下是论文的主要内容总结:
问题阐述:
- 论文指出,现有的NeRF和3D高斯绘制方法在估计场景外观时没有考虑材料和照明,导致无法准确模拟复杂的光交互。逆渲染问题由于材料-光照-几何的不确定性而变得不适定。
PBR-NeRF方法:
- 基于NeILF/NeILF++框架,PBR-NeRF通过引入两个物理先验损失项来改进逆渲染估计:能量守恒损失和NDF加权的镜面损失。
- 这些损失项增强了物理有效性,改善了材料估计,同时不牺牲新视角合成的质量。
多阶段优化:
- 采用三阶段优化流程:几何初始化、材料估计和联合优化,每个阶段使用不同的损失函数来编码特定的先验或约束。
实验验证:
- 在NeILF++和DTU数据集上进行了实验,结果表明PBR-NeRF在材料估计方面达到了新的最佳水平,同时在新视角合成性能上保持或超过了基线。
定性和定量结果:
- 论文提供了与现有技术的定量比较和定性分析,展示了PBR-NeRF在处理复杂光照和材质时的优势。
消融研究:
- 通过消融研究验证了所提出的物理先验损失项对模型性能的贡献。
结论与展望:
- 论文认为PBR-NeRF在材料估计和逆渲染方面表现出色,并且其物理驱动的方法将激发更多基于PBR的分解神经场的研究。
总体而言,这篇论文通过结合先进的神经网络技术和物理基础的渲染理论,提出了一种新的逆渲染方法,有效地解决了3D场景重建中的一些关键挑战,并在多个数据集上展示了其优越的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

CAS-GAN for Contrast-free Angiography Synthesis
Authors:De-Xing Huang, Xiao-Hu Zhou, Mei-Jiang Gui, Xiao-Liang Xie, Shi-Qi Liu, Shuang-Yi Wang, Hao Li, Tian-Yu Xiang, Zeng-Guang Hou
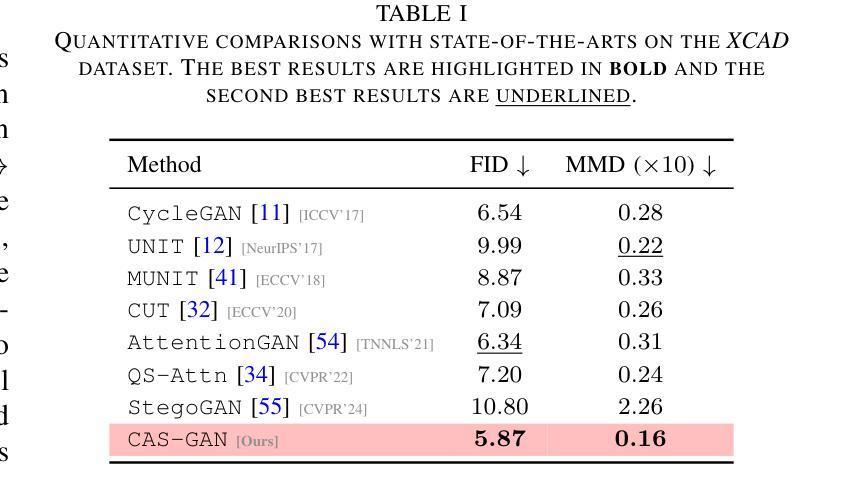
Iodinated contrast agents are widely utilized in numerous interventional procedures, yet posing substantial health risks to patients. This paper presents CAS-GAN, a novel GAN framework that serves as a “virtual contrast agent” to synthesize X-ray angiographies via disentanglement representation learning and vessel semantic guidance, thereby reducing the reliance on iodinated contrast agents during interventional procedures. Specifically, our approach disentangles X-ray angiographies into background and vessel components, leveraging medical prior knowledge. A specialized predictor then learns to map the interrelationships between these components. Additionally, a vessel semantic-guided generator and a corresponding loss function are introduced to enhance the visual fidelity of generated images. Experimental results on the XCAD dataset demonstrate the state-of-the-art performance of our CAS-GAN, achieving a FID of 5.87 and a MMD of 0.016. These promising results highlight CAS-GAN’s potential for clinical applications.
碘化造影剂在众多介入手术中广泛应用,但为患者带来较大的健康风险。本文提出了CAS-GAN,这是一种新型的GAN框架,可作为“虚拟造影剂”通过解纠缠表示学习和血管语义引导来合成X射线血管造影术,从而减少介入手术中对碘化造影剂的依赖。具体来说,我们的方法将X射线血管造影术分解为背景和血管成分,利用医学先验知识。然后,一个专用预测器学习这些成分之间的相互关系。此外,还引入了血管语义引导生成器和相应的损失函数,以提高生成图像的可视逼真度。在XCAD数据集上的实验结果表明,我们的CAS-GAN达到了最先进的性能,FID为5.87,MMD为0.016。这些令人鼓舞的结果突出了CAS-GAN在临床应用中的潜力。
论文及项目相关链接
PDF IEEE Symposium Series on Computational Intelligence (SSCI 2025)
摘要
本研究提出了一种名为CAS-GAN的新型GAN框架,可作为“虚拟造影剂”用于合成X射线血管造影图像。通过解纠缠表示学习和血管语义指导,CAS-GAN可以减少介入过程中对碘造影剂的依赖。具体来说,该研究将X射线血管造影图像分解为背景和血管成分,并利用医学先验知识,通过专门的预测器学习这些成分之间的关系。同时,引入血管语义引导生成器和相应的损失函数,以提高生成图像的可视效果。在XCAD数据集上的实验结果表明,CAS-GAN达到了最先进的性能,FID为5.87,MMD为0.016。这些令人鼓舞的结果突显了CAS-GAN在临床应用中的潜力。
要点总结
- CAS-GAN被提出作为一种“虚拟造影剂”,用于合成X射线血管造影图像。
- 通过解纠缠表示学习,CAS-GAN能将X射线血管造影图像分解为背景和血管成分。
- 利用医学先验知识,专门的预测器学习背景和血管成分之间的关系。
- 引入血管语义引导生成器和损失函数来提高生成图像的可视效果。
- 在XCAD数据集上的实验结果表明CAS-GAN性能先进,达到FID 5.87和MMD 0.016。
- CAS-GAN有潜力减少介入过程中对碘造影剂的依赖。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。通过使用CAS-GAN,研究者们希望能够合成出无需使用碘造影剂的X射线血管造影图像,从而减少对这些可能对患者造成潜在健康风险的造影剂的依赖。
具体来说,论文中提到了以下几个关键问题:
心血管疾病(CVDs)的治疗需求:心血管疾病是全球死亡的主要原因,而图像引导的血管介入手术是治疗心血管疾病的主流方法之一。
碘造影剂的健康风险:在X射线血管造影中,为了使血管显影,需要使用碘基的造影剂。然而,这些造影剂存在副作用,包括可能危及生命的过敏反应,以及对肾脏的潜在损害,尤其是在已有肾脏疾病或糖尿病患者中。
减少造影剂使用的需求:为了满足临床需求,同时显著减少造影剂剂量甚至不使用造影剂,同时保持成像质量,这是X射线血管造影系统必须解决的关键挑战。
生成对抗网络(GANs)的应用:论文提出了利用GANs作为“虚拟造影剂”来生成逼真的X射线血管造影图像的可能性,这可能会减少对碘造影剂的依赖,并提高介入手术的安全性和效率。
图像到图像的翻译挑战:将非对比X射线图像转换为X射线血管造影图像是一个具有挑战性的问题,因为它不仅需要在两个图像域之间进行风格转换,还需要精确的一对一图像映射。
论文提出的CAS-GAN框架通过解耦X射线血管造影图像的背景和血管成分,并利用医学先验知识,使用神经网络学习这些成分之间的相互关系,从而解决了上述挑战。此外,还引入了血管语义引导生成器和相应的损失函数,以增强生成图像的视觉保真度。
Q: 有哪些相关研究?
A: 论文中提到了多个与CAS-GAN相关的研究工作,可以归纳为以下几个方面:
1. 生成对抗网络(GANs)
- GANs由Goodfellow等人在2014年引入,通过建立一个最小最大优化游戏,其中生成器G旨在模仿真实数据样本的分布,而判别器D评估它们的真伪。
- 论文中提到了一些GAN的变种,它们通过更稳定的训练目标来解决训练GANs时的挑战,比如梯度消失和模式崩溃问题。
2. 图像到图像的翻译(Image-to-image translation)
- 这项工作涉及将图像从一个域转换到另一个域,同时保持其底层结构或内容。
- Isola等人提出了一个条件GAN框架,使用对抗损失和L1重建损失在成对数据上进行训练。
- 近期的研究集中在无成对数据的翻译上,引入了循环一致性等额外约束以保持域转换期间的语义一致性。
3. 解耦表示学习(Disentanglement representation learning)
- 解耦表示学习通过将图像分解为具有物理意义的成分来提高生成图像的可控性和可解释性。
- 一些工作尝试将图像分解为内容和风格表示,以实现通过交换风格表示进行图像翻译。
4. 医学图像生成和翻译
- 论文中提到了几项与医学图像生成和翻译相关的研究,包括使用GANs从非对比X射线图像生成X射线血管造影图像的研究。
5. 相关技术方法
- 论文还提到了一些技术方法,如注意力机制(attention mechanisms)、自监督对比损失(self-supervised contrast loss)等,这些方法被用于增强不同域之间语义关系的翻译。
具体论文和方法
- CycleGAN:用于无成对图像到图像的翻译。
- UNIT、MUNIT:用于无监督的图像到图像的翻译网络。
- AttentionGAN:使用注意力引导的生成对抗网络进行无成对图像到图像的翻译。
- QS-Attn:使用查询选择注意力进行对比学习。
- StegoGAN:用于非双射图像到图像的翻译,利用隐写术。
这些相关研究为CAS-GAN提供了理论基础和技术背景,同时也展示了在医学图像翻译领域中,如何利用深度学习技术来解决实际的临床问题。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为CAS-GAN的新型生成对抗网络(GAN)框架来解决这个问题。CAS-GAN框架的核心思想是将X射线血管造影图像解耦为背景和血管成分,然后通过神经网络学习这两部分之间的相互关系,以此来生成逼真的血管造影图像。以下是该方法解决该问题的关键步骤:
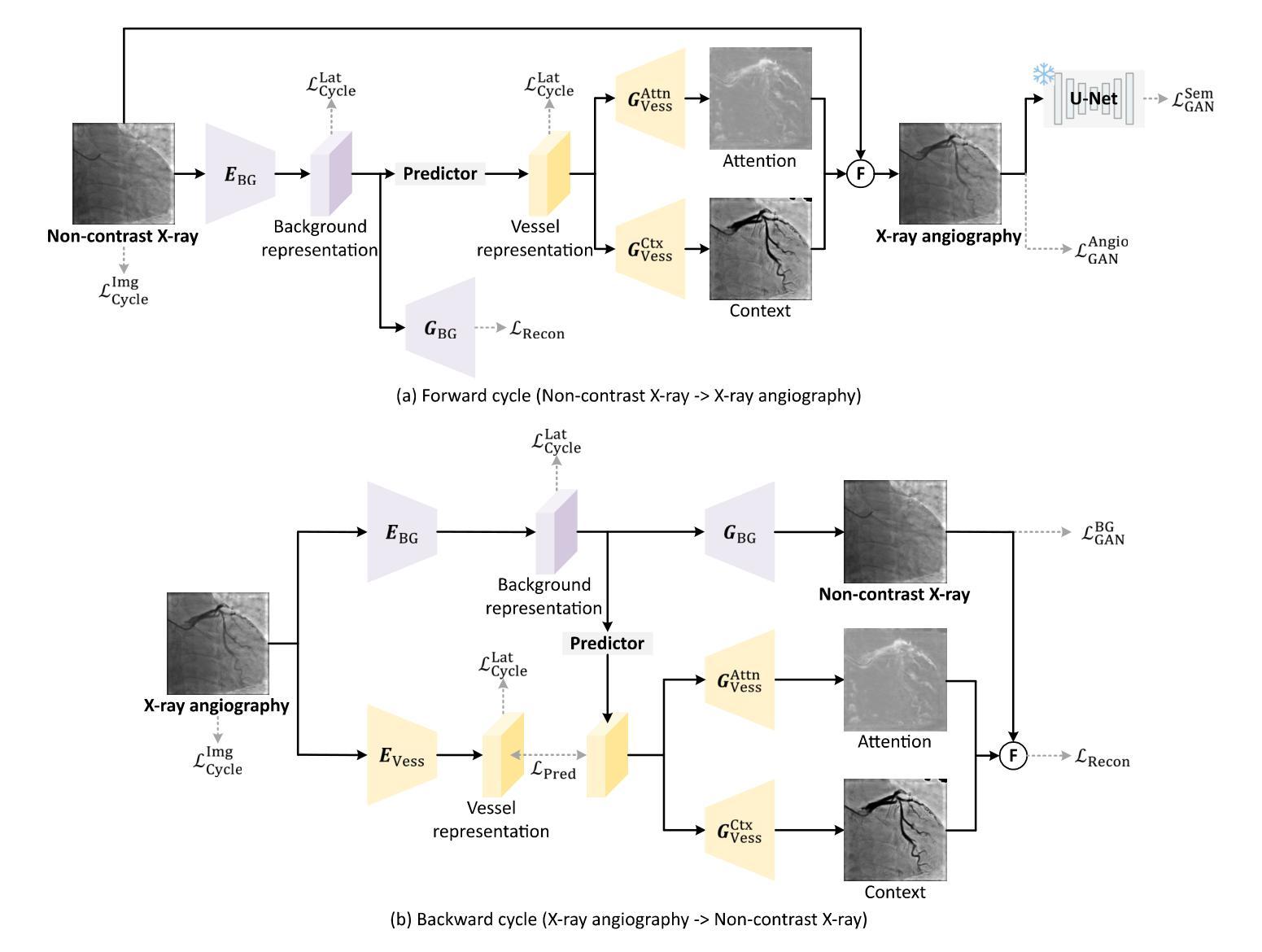
解耦表示学习(Disentanglement Representation Learning):
- 使用两个专门的编码器(一个背景编码器和一个血管编码器)将X射线血管造影图像分解为背景和血管成分。
- 通过一个称为“预测器”的神经网络,从背景表示中推断出血管表示。
血管语义引导生成器(Vessel Semantic-Guided Generator):
- 为了提高生成图像中血管的真实性,引入了两个专门的生成器:一个用于注意力掩模,一个用于上下文掩模。
- 这些生成器利用预测器提供的血管表示来生成逼真的血管结构。
血管语义引导的对抗损失(Vessel Semantic-Guided Adversarial Loss):
- 为了提高GAN对真实和生成血管图像之间差异的识别能力,引入了一种新的对抗损失,专注于血管的语义差异。
- 使用预训练的U-Net网络提取原始和生成血管造影图像中的血管语义图像,然后定义基于这些语义图像的对抗损失。
训练目标(Training Objective):
- 由于两个图像域之间的映射高度不确定,因此结合了多种有效的损失函数来训练CAS-GAN,包括预测损失、对抗损失、循环一致性损失和重建损失。
- 这些损失函数的加权和构成了CAS-GAN的训练目标,以优化图像翻译过程的各个方面。
通过这些方法,CAS-GAN能够有效地从非对比X射线图像中生成逼真的X射线血管造影图像,从而减少对碘造影剂的依赖,并提高介入手术的安全性和效率。论文中的实验结果表明,CAS-GAN在XCAD数据集上实现了最先进的性能,证明了其在临床应用中的潜力。
Q: 论文做了哪些实验?
A: 论文中进行了多项实验来验证CAS-GAN模型的性能,包括与其他最先进方法的比较、消融研究以及外部验证。以下是实验的具体内容:
A. 数据集(Dataset)
- 使用了X射线血管造影冠状血管分割数据集(XCAD),该数据集包含非对比X射线图像和X射线血管造影图像。
- 数据集分为两个子集:一个用于图像翻译任务,另一个用于训练U-Net提取血管语义信息。
- 随机选择了621张非对比X射线图像和621张X射线血管造影图像作为测试集,其余作为训练集。
B. 实现细节(Implementation details)
- 采用了与CycleGAN相同的生成器和判别器架构,以进行公平比较。
- 预测器使用多层感知机(MLP)实现。
- 使用PyTorch、Python和Ubuntu环境,搭载NVIDIA GeForce RTX 4090 GPU进行实验。
- 使用Adam优化器进行1000个周期的训练,初始学习率设置为2e-4,并在700个周期后线性降低至零。
C. 评估指标(Evaluation metrics)
- 使用了Fréchet Inception Distance(FID)和Maximum Mean Discrepancy(MMD)两个指标来评估生成图像的性能。
D. 实验结果(Results)
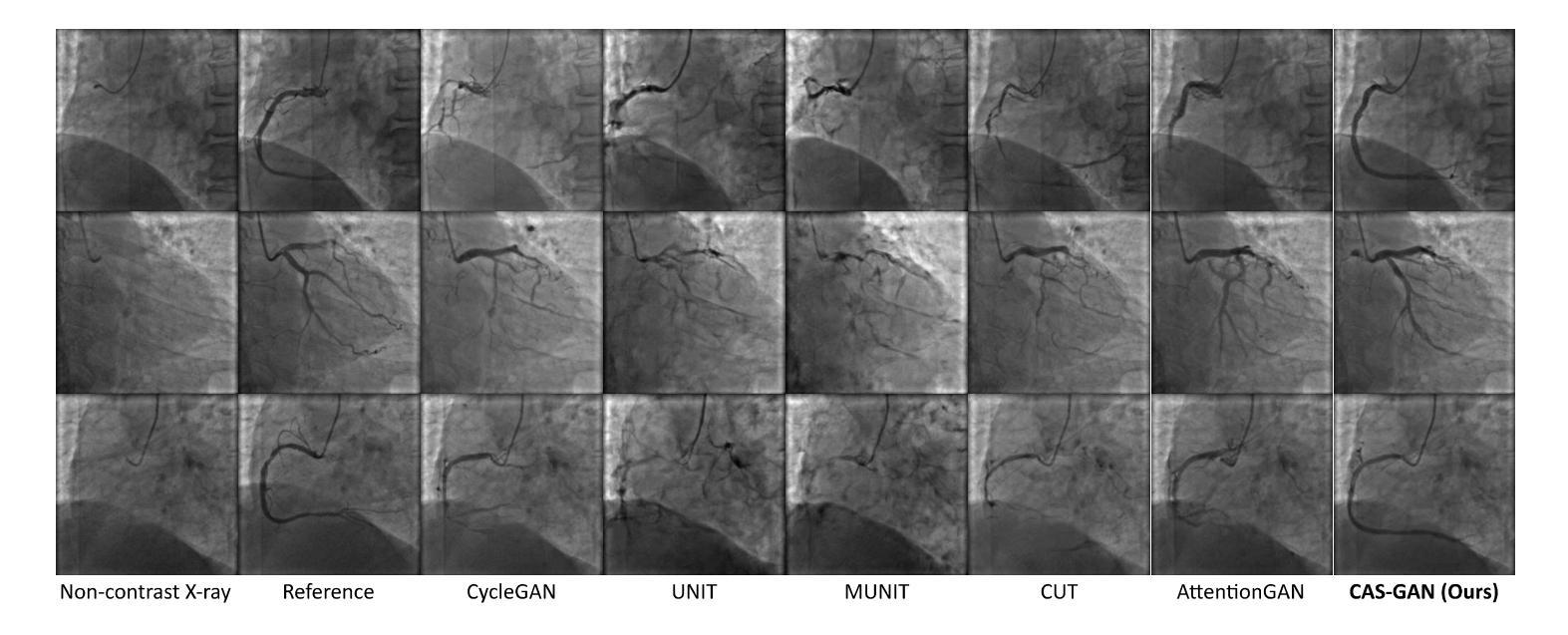
1. 与最先进方法的比较(Comparisons with state-of-the-arts)
- 将CAS-GAN与其他几种领先的无成对图像到图像翻译方法进行了比较,包括CycleGAN、UNIT、MUNIT、CUT、AttentionGAN、QS-Attn和StegoGAN。
- 在XCAD数据集上的定量结果表明,CAS-GAN在FID和MMD两个指标上均优于其他基线方法。
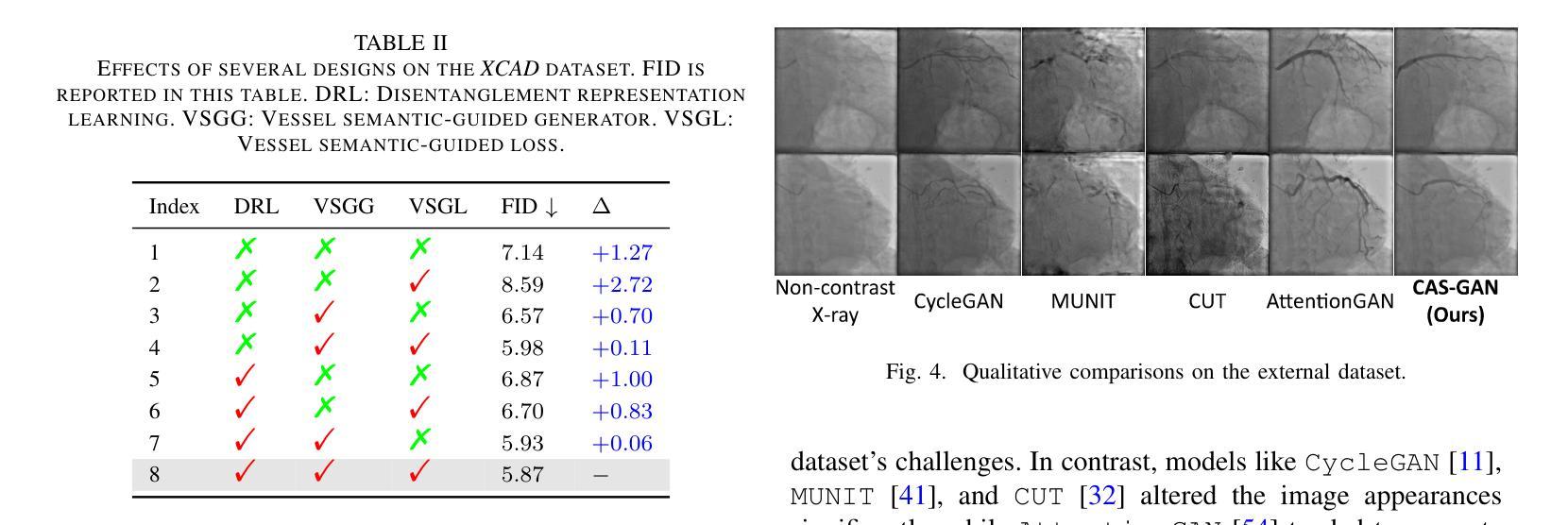
2. 消融研究(Ablation studies)
- 进行了广泛的消融实验来验证CAS-GAN中几个设计的有效性,包括解耦表示学习(DRL)、血管语义引导生成器(VSGG)和血管语义引导损失(VSGL)。
- 实验结果显示,这些设计显著提高了模型的性能。
3. 外部验证(External validation)
- 为了验证模型的泛化能力,还在来自合作医院的外部数据集上进行了实验。
- 尽管所有方法在处理XCAD和外部数据集之间的显著差异时都遇到了困难,但CAS-GAN展示了相对较好的性能。
这些实验结果证明了CAS-GAN在无需对比剂的X射线血管造影合成任务中的有效性和优越性能。论文还指出,未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的能力。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些未来工作的方向,以下是一些可以进一步探索的关键点:
扩展训练数据集:通过增加数据集的大小和多样性来提高模型在外部数据集上的性能。这可能包括收集更多的X射线血管造影图像以及对应的非对比X射线图像,以提高模型的泛化能力。
纳入更先进的模型:探索使用更先进的生成模型,如StyleGAN等,以进一步提高生成图像的质量和真实感。
改进损失函数:研究和设计新的损失函数,以更好地捕捉血管造影图像的特定特征,从而提高生成图像的质量。
多模态数据融合:考虑将CAS-GAN与其他成像模态(如CT、MRI)结合,以实现多模态图像融合和翻译。
实时性能优化:优化模型的计算效率,使其能够在临床环境中实时生成高质量的血管造影图像。
临床验证:与医疗专家合作,进行临床试验以验证CAS-GAN生成的图像在实际诊断和治疗规划中的有效性和安全性。
交互式系统开发:开发交互式系统,使医生能够根据需要调整生成的血管造影图像,以更好地满足特定的临床需求。
模型解释性:提高模型的可解释性,使医生能够理解模型的决策过程,从而增加对生成图像的信任。
跨领域应用:探索CAS-GAN在其他医疗图像翻译任务中的应用,如不同模态之间的图像转换或病理图像的合成。
鲁棒性和安全性测试:对模型进行广泛的鲁棒性和安全性测试,以确保其在各种临床条件下都能稳定地工作。
这些方向不仅可以推动CAS-GAN技术的发展,还可能对医疗图像处理和计算机视觉领域产生更广泛的影响。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了一种名为CAS-GAN的新型生成对抗网络(GAN)框架,旨在解决介入性医疗程序中使用碘造影剂带来的健康风险问题。CAS-GAN通过解耦表示学习和血管语义引导生成血管造影图像,以减少对碘造影剂的依赖。
以下是论文的主要内容概述:
问题背景:心血管疾病是全球主要死因之一,而X射线血管造影是诊断和治疗这些疾病的关键技术。然而,传统的X射线血管造影需要使用碘基造影剂,这些造影剂可能引起严重的副作用,包括过敏反应和肾脏损害。
CAS-GAN框架:提出了一种新颖的GAN框架,通过解耦背景和血管成分,利用医学先验知识,使用神经网络学习这两部分之间的相互关系,从而合成逼真的血管造影图像。
方法论:
- 解耦表示学习:使用专门的编码器将血管造影图像分解为背景和血管成分,并用一个神经网络(预测器)来推断血管表示。
- 血管语义引导生成器:引入两个专门的生成器来生成注意力掩模和上下文掩模,以增强生成图像中血管的真实性。
- 血管语义引导的对抗损失:提出了一种新的对抗损失,专注于血管的语义差异,以提高GAN对真实和生成血管图像之间差异的识别能力。
实验:
- 使用XCAD数据集进行实验,该数据集包含非对比X射线图像和X射线血管造影图像。
- 在定量和定性上与其他最先进方法进行比较,CAS-GAN在FID和MMD指标上均优于其他方法。
- 进行消融研究验证了解耦表示学习、血管语义引导生成器和血管语义引导损失的有效性。
- 在外部数据集上进行验证,展示了CAS-GAN的泛化能力。
结论与未来工作:CAS-GAN为减少介入手术中碘造影剂的使用提供了一种有前景的方法。未来的工作将通过扩大训练数据集和纳入更先进的模型来进一步提高CAS-GAN的性能。
总的来说,这篇论文提出了一个创新的解决方案来应对医疗成像中的一个关键挑战,并展示了有希望的初步结果。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Spatial Annealing for Efficient Few-shot Neural Rendering
Authors:Yuru Xiao, Deming Zhai, Wenbo Zhao, Kui Jiang, Junjun Jiang, Xianming Liu
Neural Radiance Fields (NeRF) with hybrid representations have shown impressive capabilities for novel view synthesis, delivering high efficiency. Nonetheless, their performance significantly drops with sparse input views. Various regularization strategies have been devised to address these challenges. However, these strategies either require additional rendering costs or involve complex pipeline designs, leading to a loss of training efficiency. Although FreeNeRF has introduced an efficient frequency annealing strategy, its operation on frequency positional encoding is incompatible with the efficient hybrid representations. In this paper, we introduce an accurate and efficient few-shot neural rendering method named \textbf{S}patial \textbf{A}nnealing regularized \textbf{NeRF} (\textbf{SANeRF}), which adopts the pre-filtering design of a hybrid representation. We initially establish the analytical formulation of the frequency band limit for a hybrid architecture by deducing its filtering process. Based on this analysis, we propose a universal form of frequency annealing in the spatial domain, which can be implemented by modulating the sampling kernel to exponentially shrink from an initial one with a narrow grid tangent kernel spectrum. This methodology is crucial for stabilizing the early stages of the training phase and significantly contributes to enhancing the subsequent process of detail refinement. Our extensive experiments reveal that, by adding merely one line of code, SANeRF delivers superior rendering quality and much faster reconstruction speed compared to current few-shot neural rendering methods. Notably, SANeRF outperforms FreeNeRF on the Blender dataset, achieving 700$\times$ faster reconstruction speed.
神经辐射场(NeRF)采用混合表示法,在新型视图合成方面表现出令人印象深刻的性能,并且效率高。然而,在稀疏输入视图的情况下,其性能会大幅下降。为了解决这些挑战,已经设计了各种正则化策略。然而,这些策略要么需要额外的渲染成本,要么涉及复杂的管道设计,导致训练效率降低。虽然FreeNeRF已经引入了一种有效的频率退火策略,但其对频率位置编码的操作与高效的混合表示法不兼容。在本文中,我们提出了一种准确且高效的名为空间退火正则化NeRF(SANeRF)的少量神经渲染方法,它采用混合表示的预滤波设计。我们首先通过推导其滤波过程来建立混合架构的频率带宽限制的理论公式。基于这一分析,我们提出了一种在时空域中通用的频率退火形式,它可以通过调制采样核来实现,从初始的窄网格切线核谱开始呈指数收缩。这种方法对于稳定训练阶段的早期至关重要,并为后续细节优化过程做出了重大贡献。我们的大量实验表明,仅通过增加一行代码,SANeRF与当前的少量神经渲染方法相比,提供了更高的渲染质量和更快的重建速度。值得注意的是,SANeRF在Blender数据集上的表现优于FreeNeRF,实现了700倍*的重建速度提升。
论文及项目相关链接
PDF AAAI 2025, code available at https://github.com/pulangk97/SANeRF
摘要
基于神经辐射场(NeRF)的混合表示方法在新型视图合成中表现出卓越的性能和效率。然而,在稀疏输入视图情况下,其性能会大幅下降。为应对这一挑战,已经提出了多种正则化策略。但这些策略要么增加渲染成本,要么涉及复杂的管道设计,导致训练效率降低。尽管FreeNeRF引入了一种有效的频率退火策略,但其对频率位置编码的操作与高效的混合表示不兼容。本文提出了一种准确且高效的小样本神经渲染方法,名为空间退火正则化神经辐射场(SANeRF)。该方法采用混合表示的预滤波设计。首先,我们通过推导其滤波过程,建立了混合架构的频率带宽限制的分析公式。基于此分析,我们提出了空间域中的通用频率退火形式,通过调制采样核以从具有窄网格切线核谱的初始状态开始呈指数收缩来实现。该方法对于稳定训练阶段的早期至关重要,并有助于改进后续的细节优化过程。通过仅添加一行代码,大量实验表明,SANeRF相比当前的小样本神经渲染方法提供了更出色的渲染质量和更快的重建速度。值得注意的是,SANeRF在Blender数据集上的表现优于FreeNeRF,实现了700倍更快的重建速度。
关键见解
- 基于NeRF的混合表示方法在新型视图合成中具有高效性能。
- 在稀疏输入视图情况下,现有方法面临性能下降的挑战。
- 正则化策略的增加渲染成本或复杂管道设计导致训练效率降低。
- SANeRF采用混合表示的预滤波设计,建立混合架构的频率带宽限制的分析公式。
- 提出空间域中的通用频率退火形式,稳定训练过程的早期阶段并改进细节优化。
- 仅通过添加少量代码,SANeRF提供出色的渲染质量和快速重建速度。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
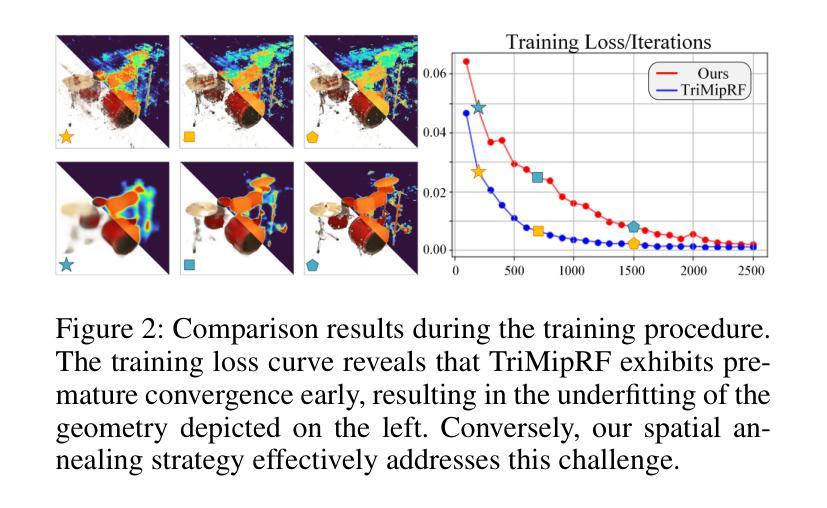
A: 这篇论文试图解决的问题是Neural Radiance Fields (NeRF)及其混合表示方法在处理稀疏输入视图时性能显著下降的挑战,尤其是在少样本(few-shot)神经渲染场景下。具体来说,论文中提到NeRF需要密集的输入视图或者长时间的训练,这限制了它在自动驾驶、机器人和AR/VR等实际场景中的应用。尽管基于网格的混合表示方法被引入以提高训练效率,它们在处理稀疏输入视图时仍然存在异常收敛和对几何感知能力弱的问题。论文中提出了一种名为Spatial Annealing regularized NeRF (SANeRF)的准确且高效的少样本神经渲染方法,旨在通过在空间域中实施频率退火策略来解决这些问题,从而提高对稀疏视图的鲁棒性,同时保持计算效率。
Q: 有哪些相关研究?
A: 相关研究包括以下几个方面:
Neural Radiance Fields (NeRF):
- Mildenhall et al. (2021) 提出了NeRF,这是一种用于详细3D重建和高保真新视角合成的强大学习型工具。
- Martin-Brualla et al. (2021); Barron et al. (2021, 2022); Mildenhall et al. (2022) 等研究者在新视角合成、表面重建、动态场景建模和3D内容生成等领域扩展了NeRF的应用。
Few-shot Neural Rendering:
- Deng et al. (2022), Wang et al. (2023), Cao et al. (2022), Wei et al. (2021), Roessle et al. (2022) 等研究者通过整合额外的3D信息(如稀疏点云、估计深度或密集对应关系)来增强监督。
- Jain et al. (2021), Niemeyer et al. (2022), Sun et al. (2023), Seo et al. (2023) 等研究者采用基于随机补丁的语义一致性或几何正则化策略。
- Lin et al. (2023), Yu et al. (2021), Chen et al. (2021), Wang et al. (2021b), Long et al. (2022), Liu et al. (2022), Chibane et al. (2021), Trevithick and Yang (2021) 等研究者通过训练网络以内部化几何先验。
NeRF加速架构:
- M¨uller et al. (2022) 和 Hu et al. (2023) 提出了基于网格的混合表示方法,以加速NeRF的训练和渲染过程。
频率正则化:
- FreeNeRF (Yang, Pavone, and Wang 2023) 通过逐步增加位置编码的频率来解决少样本挑战,这是一种称为频率正则化的技术。
TriMipRF:
- Hu et al. (2023) 提出了TriMipRF,它引入了三平面表示的预过滤策略。
这些相关研究构成了论文提出的SANeRF方法的理论基础和实践背景,旨在通过结合这些研究成果来提升NeRF在少样本情况下的性能和效率。
Q: 论文如何解决这个问题?
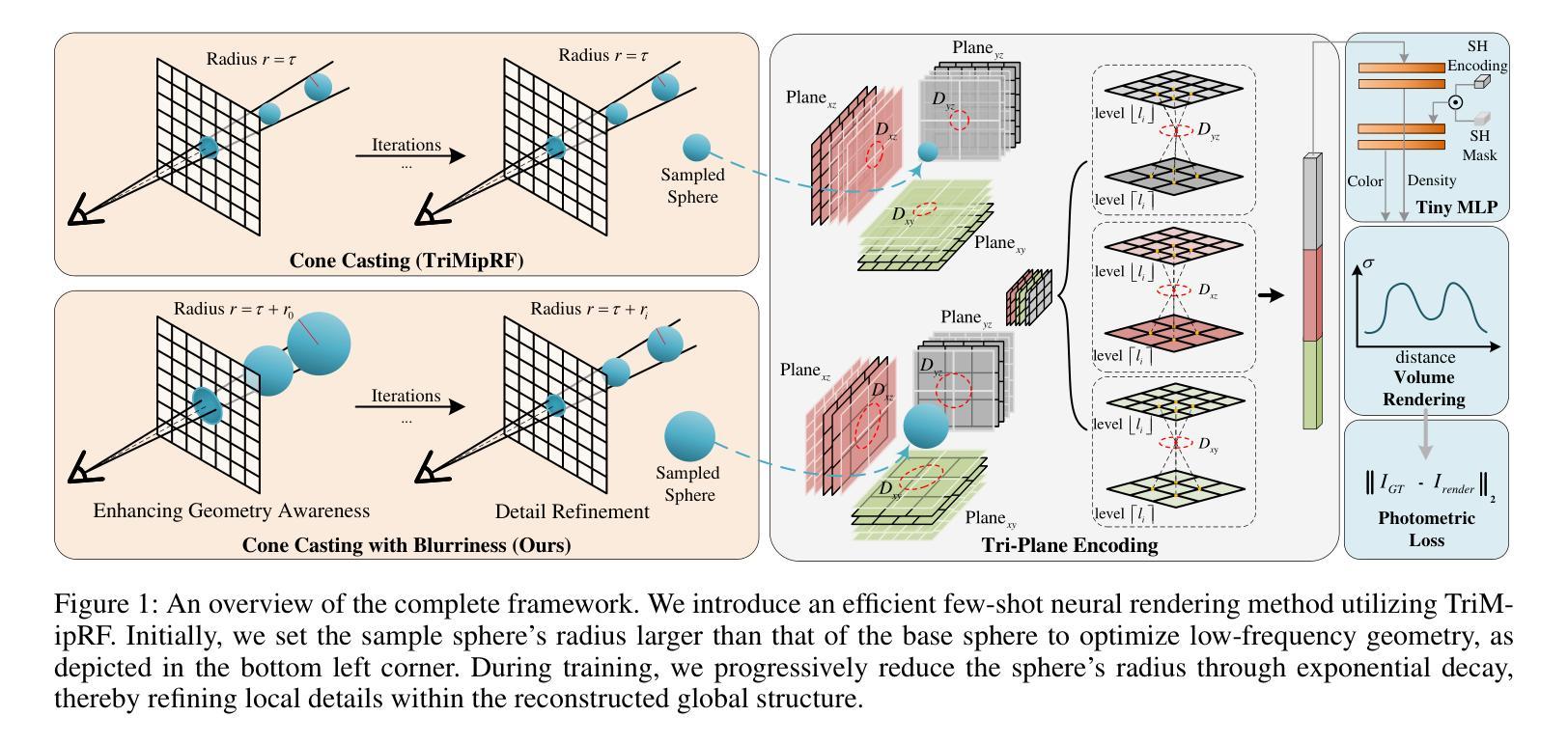
A: 论文通过提出一种名为Spatial Annealing regularized NeRF (SANeRF)的方法来解决NeRF及其混合表示在处理稀疏输入视图时性能下降的问题。SANeRF的核心思想是在空间域中实施一种通用形式的频率退火策略,通过调制采样核以指数方式从具有窄网格切线核谱的初始状态收缩。具体来说,解决方案包括以下几个关键步骤:
频率带宽限制的解析公式:
- 论文首先通过分析混合表示架构的过滤过程,建立了预过滤设计混合表示的频率带宽限制的解析公式。
空间退火策略:
- 基于上述分析,论文提出了一种在空间域中的通用形式的频率退火策略,通过调整采样球的半径来实现,从而在训练的早期阶段稳定训练,并显著促进后续细节细化过程。
粗到细的训练策略:
- SANeRF采用了基于TriMipRF的粗到细训练策略,初始时通过增加采样球的半径来优化低频几何结构,随着训练的进行,逐渐减小采样球的半径以细化局部细节。
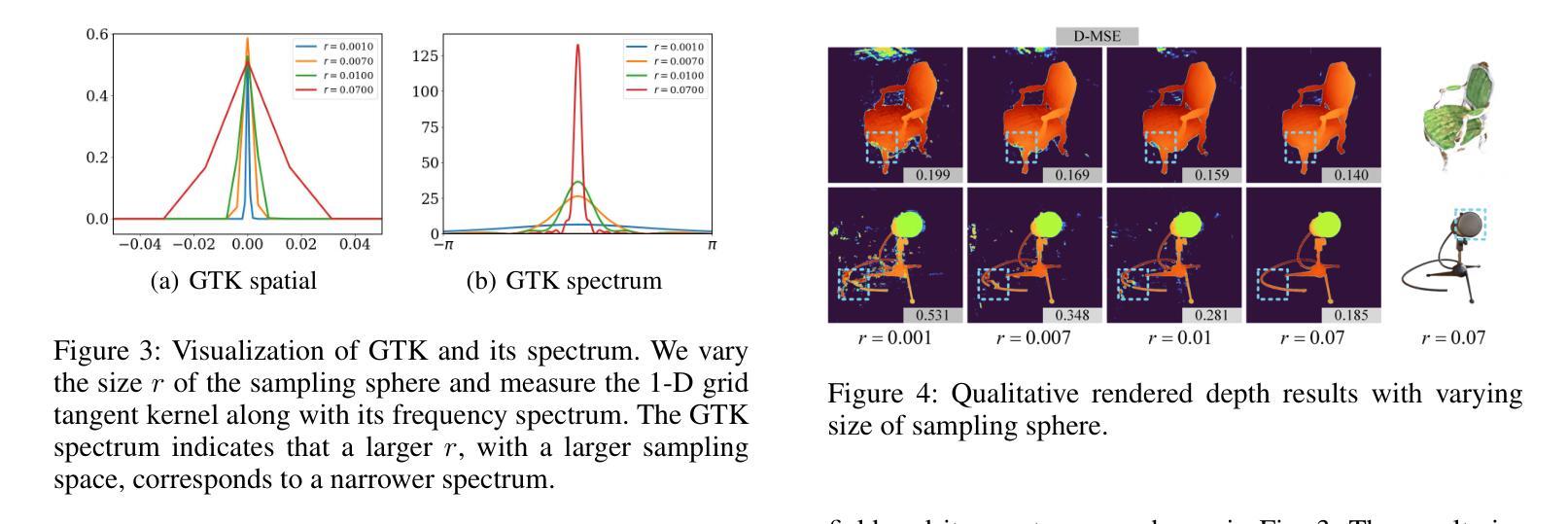
网格切线核(GTK)理论的应用:
- 论文利用GTK理论来分析网格模型的1D空间GTK及其频谱,验证了采样空间大小与频率带宽之间的关系,并证实了通过调整采样空间大小可以有效提升对低频几何信息的训练。
实验验证:
- 通过在合成数据集和Blender数据集上的广泛实验,论文证明了SANeRF在效率和性能上的优越性。与现有的少样本神经渲染方法相比,SANeRF在保持更快重建速度的同时,提供了更高质量的渲染结果。
总的来说,SANeRF通过在空间域中实施精心设计的退火过程,自适应地调整空间采样大小,增强了几何重建和细节细化的能力,并且只需要对基础架构的代码进行最小的修改,就能在少样本场景中实现最先进的性能,同时保持效率。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证SANeRF方法的有效性和效率,具体实验包括:
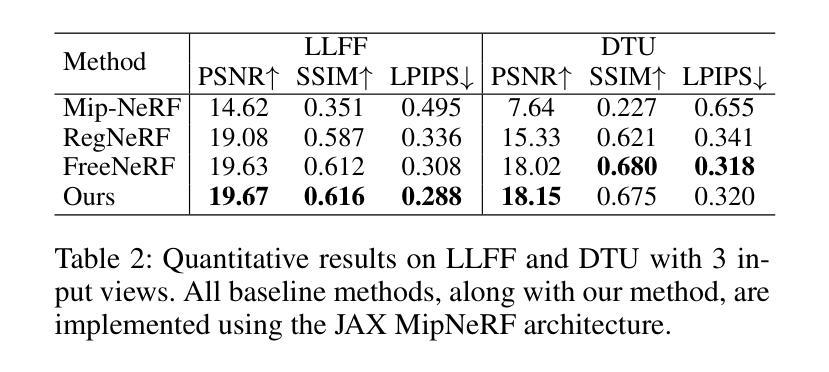
数据集和指标:
- 使用Blender数据集进行评估,该数据集包含8个从环绕视角观察的合成场景。
- 选择8个特定的视图进行训练,并在25个测试图像上进行评估。
- 使用PSNR(峰值信噪比)、SSIM(结构相似性指数)和LPIPS(Learned Perceptual Image Patch Similarity)作为量化分析的指标。
度量截断的球谐编码:
- 在输入视图稀疏的情况下,为了更好地适应未见视角方向并解决视依赖颜色的拟合问题,论文提出了对球谐编码的高级分量进行截断的方法。
Blender数据集的定性和定量比较:
- 展示了SANeRF与基础架构TriMipRF和FreeNeRF在Blender数据集上的定性比较结果。
- 提供了在8个输入视图下SANeRF与其它方法的定量结果比较,包括PSNR、SSIM和LPIPS分数,以及训练时间。
不同输入视图数量下的鲁棒性测试:
- 评估SANeRF在不同数量输入视图下的鲁棒性,通过使用Blender训练集中的前n个图像作为输入,其中n的值在8至100之间变化。
消融研究:
- 对SANeRF中提出的空间退火策略(SA)和球谐掩码(SHM)进行了消融研究,以评估它们对性能的贡献。
不同基础架构上的性能评估:
- 为了证明SANeRF策略的有效性,论文还将该策略应用于MipNeRF框架,并在LLFF和DTU数据集上进行了定量评估。
视图稀疏性下的鲁棒性验证:
- 展示了SANeRF与TriMipRF相比,在不同输入视图条件下的性能对比,特别是在稀疏输入视图情况下的性能提升。
这些实验结果表明,SANeRF不仅在定量指标上优于现有的少样本神经渲染方法,而且在训练效率上也有显著提升。通过这些实验,论文充分证明了SANeRF方法的有效性和实用性。
Q: 有什么可以进一步探索的点?
A: 尽管SANeRF在少样本神经渲染方面取得了显著的进展,但仍有一些方向可以进一步探索和研究:
提高训练效率:
- 虽然SANeRF已经显著提高了训练速度,但仍可以探索新的方法来进一步减少训练时间,例如通过改进优化算法或开发更高效的网络架构。
扩展到更多场景和数据集:
- 目前的实验主要在Blender数据集上进行。将SANeRF扩展到更多样化的场景和更复杂的真实世界数据集上,可以进一步验证其泛化能力和实用性。
改进几何和纹理重建质量:
- 尽管SANeRF在几何重建方面表现出色,但在纹理细节的重建上可能还有改进空间。研究如何结合更高级的纹理建模技术,以提高渲染质量。
自适应采样策略:
- SANeRF采用了固定的采样球半径衰减策略。研究基于场景内容的自适应采样策略,可能进一步提高渲染效率和质量。
多模态数据融合:
- 考虑将SANeRF与其他类型的数据(如深度信息、法线信息等)结合起来,以提高对复杂场景的重建能力。
实时渲染应用:
- 将SANeRF优化并适配到实时渲染应用中,如增强现实(AR)和虚拟现实(VR),这可能需要更高效的计算资源管理和网络架构设计。
网络架构的改进:
- 探索新型的神经网络架构,可能会发现更适合于少样本学习的模型,从而进一步提升SANeRF的性能。
更广泛的正则化技术:
- 研究和集成更多的正则化技术,以进一步提高SANeRF在面对稀疏数据时的鲁棒性和准确性。
理论和数学框架的深入分析:
- 对SANeRF所采用的空间退火策略进行更深入的理论和数学分析,以更好地理解其工作原理和潜在的改进方向。
跨模态和多任务学习:
- 考虑将SANeRF应用于跨模态学习任务,例如从2D图像到3D重建,或结合不同的视觉任务,以提高模型的灵活性和应用范围。
这些方向不仅可以推动SANeRF技术的发展,还可能对整个神经渲染领域产生深远的影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为Spatial Annealing regularized NeRF (SANeRF)的新方法,旨在解决Neural Radiance Fields (NeRF)及其混合表示在处理稀疏输入视图时性能下降的问题。以下是论文的主要内容总结:
问题陈述:
- NeRF及其混合表示方法在处理稀疏输入视图时性能显著下降,特别是在少样本神经渲染场景下。
方法介绍:
- SANeRF采用预过滤设计的混合表示,通过在空间域中实施一种通用形式的频率退火策略,通过调制采样核以指数方式从具有窄网格切线核谱的初始状态收缩。
理论贡献:
- 论文建立了预过滤设计混合表示架构的频率带宽限制的解析公式,并通过分析过滤过程,提出了在空间域中进行频率退火的通用形式。
实验验证:
- 通过在合成数据集和Blender数据集上的广泛实验,论文证明了SANeRF在效率和性能上的优越性。SANeRF在保持更快重建速度的同时,提供了更高质量的渲染结果。
主要贡献:
- 提出了一种准确的且高效的少样本神经渲染方法,通过添加仅一行代码,实现了比现有方法更优的渲染质量和更快的重建速度。
- 在Blender数据集上,SANeRF实现了比FreeNeRF快700倍的重建速度,并在PSNR上取得了0.3dB的性能提升。
消融研究和鲁棒性测试:
- 论文还进行了消融研究,验证了空间退火策略和球谐掩码(SHM)对性能的贡献,并测试了SANeRF在不同输入视图数量下的鲁棒性。
代码和数据集:
- 论文提供了代码,可在GitHub上找到,方便研究者复现和进一步研究。
总的来说,SANeRF通过在空间域中实施精心设计的退火过程,自适应地调整空间采样大小,增强了几何重建和细节细化的能力,并且只需要对基础架构的代码进行最小的修改,就能在少样本场景中实现最先进的性能,同时保持效率。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图