⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-17 更新
Efficient Generative Modeling with Residual Vector Quantization-Based Tokens
Authors:Jaehyeon Kim, Taehong Moon, Keon Lee, Jaewoong Cho
We explore the use of Residual Vector Quantization (RVQ) for high-fidelity generation in vector-quantized generative models. This quantization technique maintains higher data fidelity by employing more in-depth tokens. However, increasing the token number in generative models leads to slower inference speeds. To this end, we introduce ResGen, an efficient RVQ-based discrete diffusion model that generates high-fidelity samples without compromising sampling speed. Our key idea is a direct prediction of vector embedding of collective tokens rather than individual ones. Moreover, we demonstrate that our proposed token masking and multi-token prediction method can be formulated within a principled probabilistic framework using a discrete diffusion process and variational inference. We validate the efficacy and generalizability of the proposed method on two challenging tasks across different modalities: conditional image generation} on ImageNet 256x256 and zero-shot text-to-speech synthesis. Experimental results demonstrate that ResGen outperforms autoregressive counterparts in both tasks, delivering superior performance without compromising sampling speed. Furthermore, as we scale the depth of RVQ, our generative models exhibit enhanced generation fidelity or faster sampling speeds compared to similarly sized baseline models. The project page can be found at https://resgen-genai.github.io
我们探索了残差向量量化(RVQ)在高保真生成向量量化生成模型中的应用。这种量化技术通过采用更深入的令牌来保持更高的数据保真度。然而,在生成模型中增加令牌数量会导致推理速度变慢。为此,我们引入了ResGen,这是一种基于RVQ的高效离散扩散模型,能够在不牺牲采样速度的情况下生成高保真样本。我们的关键想法是预测集体令牌的向量嵌入,而不是单个令牌。此外,我们证明,通过离散扩散过程和变分推断,我们提出的令牌遮挡和多令牌预测方法可以在有原则的概率框架内制定。我们在两个不同的模态的挑战性任务上验证了所提出方法的有效性和通用性:在ImageNet 256x256上进行条件图像生成和零样本文本到语音合成。实验结果表明,ResGen在这两项任务中的表现均优于自回归模型,在不牺牲采样速度的情况下实现了卓越的性能。此外,随着我们扩大RVQ的深度,我们的生成模型与类似规模的基准模型相比,在生成保真度或采样速度方面表现出优势。项目页面可在https://resgen-genai.github.io找到。
论文及项目相关链接
Summary
本摘要介绍了Residual Vector Quantization(RVQ)在高保真生成向量量化生成模型中的应用。文章指出,RVQ技术通过采用更深入的标记来维持更高的数据保真度,但增加生成模型中的标记数量会导致推理速度变慢。为此,文章提出了一种高效的基于RVQ的离散扩散模型ResGen,能够在不降低采样速度的情况下生成高保真样本。其主要思想是直接预测集体标记的向量嵌入,而不是单独预测。此外,文章还展示了通过离散扩散过程和变分推断来制定该方法的原理性概率框架。通过在不同模态的两个挑战性任务上验证方法的有效性:在ImageNet 256x256上进行条件图像生成和零样本文本到语音合成。实验结果表明,ResGen在两项任务中的表现均优于自回归模型,且在不降低采样速度的情况下实现了优越的性能。随着RVQ深度的增加,我们的生成模型的生成保真度会提高或采样速度会更快,相较于类似规模的基准模型。
Key Takeaways
- 研究使用Residual Vector Quantization (RVQ)在高保真生成向量量化生成模型中的应用。
- RVQ技术通过采用更深入的标记维持高数据保真度,但增加标记数量会降低推理速度。
- 提出一种高效的基于RVQ的离散扩散模型ResGen,能在不降低采样速度的情况下生成高保真样本。
- ResGen通过直接预测集体标记的向量嵌入来提高效率。
- 该方法可通过离散扩散过程和变分推断的框架进行原理性概率表述。
- 在条件图像生成和零样本文本到语音合成任务上验证了方法的有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在向量量化生成模型中实现高保真度数据生成,同时保持较快的采样速度。具体来说,论文探讨了使用残差向量量化(Residual Vector Quantization, RVQ)技术来提高数据重建质量,同时提出了一个高效的RVQ基的离散扩散模型(ResGen),用于在不牺牲采样速度的情况下生成高保真度样本。论文的主要贡献包括:
直接预测集体标记的向量嵌入:ResGen通过直接预测集体标记的向量嵌入而不是逐个预测每个标记,从而解耦了采样复杂度与序列长度和深度的关系。
基于离散扩散过程和变分推断的概率框架:论文展示了所提出的标记掩蔽和多标记预测方法可以被纳入一个基于离散扩散过程和变分推断的原则化概率框架中。
在不同模态上验证方法的有效性和泛化能力:通过在ImageNet上的有条件图像生成任务和零样本文本到语音合成任务上的实验,论文证明了ResGen在这些任务上相较于自回归模型具有优越的性能,且没有牺牲采样速度。
分析模型特性和超参数的影响:通过消融研究,论文还分析了不同超参数(如采样步骤)对生成质量的影响,并考察了模型在不同RVQ深度下的特性。
总的来说,这篇论文旨在通过引入新的RVQ基生成模型ResGen,解决在生成高分辨率、高保真度数据时面临的质量和计算效率之间的平衡问题。
Q: 有哪些相关研究?
A: 根据论文内容,以下是与本研究相关的一些工作:
向量量化(VQ)标记基础的生成模型:
- VQ-GAN (Esser et al., 2021) 和 DALLE (Ramesh et al., 2021) 利用离散表示进行图像合成,使用变换器(transformers)来实现高质量的数据生成,同时保持计算资源的可管理性。
离散扩散模型:
- MaskGIT (Chang et al., 2022) 和 VQ-Diffusion (Gu et al., 2022) 专注于对平面标记序列进行掩蔽标记预测,与自回归模型相比提高了采样效率。
- GIVT (Tschannen et al., 2023) 引入了一种方法,用基于高斯混合的向量预测代替基于softmax的标记预测,逐步填充掩蔽位置。
基于RVQ的生成模型:
- RQ-Transformer (Lee et al., 2022) 是第一个展示在RVQ标记上使用自回归模型进行生成建模的研究,其计算复杂度随着序列长度和深度的乘积增加。
- Vall-E (Wang et al., 2023) 预测第一深度的标记,然后顺序地预测每个深度的剩余标记。
- SoundStorm (Borsos et al., 2023) 使用掩蔽标记预测给定语义标记生成标记,但其采样时间复杂度仍随残差量化深度线性增加。
- NaturalSpeech 2 (Shen et al., 2024) 在RVQ嵌入空间中使用基于扩散的生成建模而不是标记生成。
- CLaM-TTS (Kim et al., 2024) 使用向量预测进行多标记预测,但以自回归方式沿序列长度操作。
其他生成模型方法:
- VAR (Tian et al., 2024) 和 MAR (Li et al., 2024) 提出了替代基于标记的自回归建模的新范式。VAR引入了粗到细的下一尺度预测机制,有效地捕获了图像中的层次结构。MAR通过使用基于扩散的方法在连续值空间中对概率进行建模,消除了对离散标记的依赖,简化了流程同时保持了强大的性能。
这些相关工作提供了不同的视角和技术,用于处理基于标记的生成模型中的挑战,特别是在处理高分辨率、高保真度数据生成时的质量和计算效率之间的平衡问题。ResGen方法与这些工作相比,提供了一个更有效的解决方案,通过预测掩蔽标记的向量嵌入,从序列长度和标记深度中解耦采样时间复杂度。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为ResGen的高效RVQ(Residual Vector Quantization)基的离散扩散模型来解决高保真度数据生成与快速采样之间的平衡问题。以下是ResGen解决该问题的关键方法:
1. 直接预测集体标记的向量嵌入
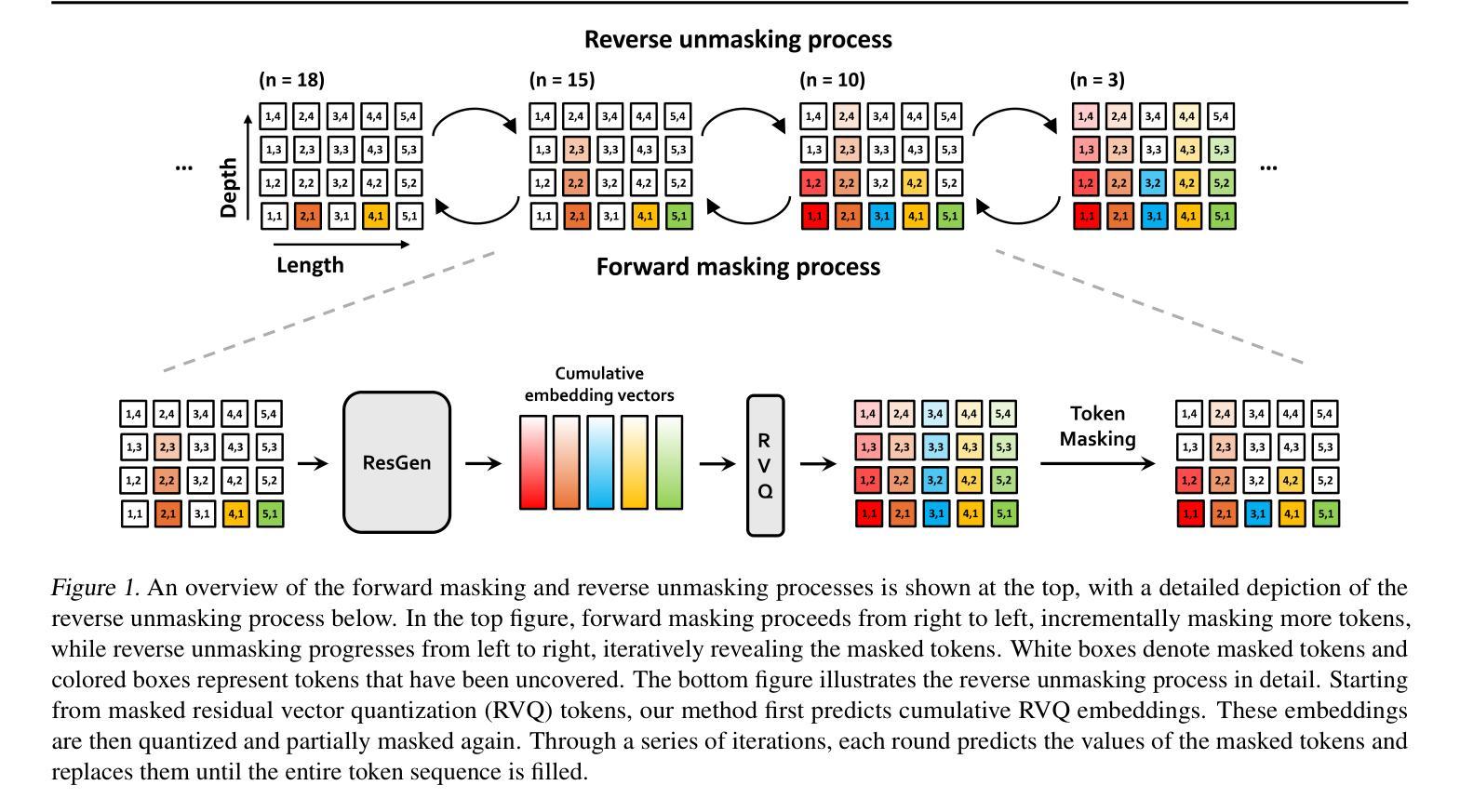
ResGen的核心思想是直接预测集体标记的向量嵌入,而不是逐个预测每个标记。这种方法通过对累积嵌入的预测,允许模型在不同深度上估计相关联的标记,与残差量化过程自然对齐。这样,ResGen能够从序列长度和深度中解耦采样复杂度,生成高保真度样本而不影响采样速度。
2. 掩蔽标记策略和多标记预测
掩蔽标记策略:ResGen采用一种特别适合RVQ标记的掩蔽策略,从最高量化层开始逐步掩蔽标记,利用RVQ的层次性质,其中更深层次的标记捕获更精细的细节。
多标记预测:ResGen在训练和解码阶段通过聚焦于预测聚合向量嵌入z而不是直接预测目标标记,有效预测掩蔽标记。这种方法避免了沿深度的标记条件独立性,这对于模型性能可能是有害的。
3. 基于离散扩散过程和变分推断的概率框架
ResGen将掩蔽标记预测过程纳入一个基于离散扩散模型和变分推断的原则化概率框架中。这种观点允许将ResGen视为一个基于似然的生成过程,并为其设计提供了理论基础。
前向离散扩散过程:将标记掩蔽过程解释为离散扩散模型在标记序列上的前向扩散步骤,逐渐将完全未掩蔽的标记序列转化为完全掩蔽的序列。
反向离散扩散过程:旨在从部分掩蔽的序列中重建原始标记,定义了重建原始标记的概率,并计算数据对数似然的变分下界。
4. 实验验证
论文通过在ImageNet上的有条件图像生成任务和零样本文本到语音合成任务上的实验验证了ResGen的有效性和泛化能力。实验结果显示,ResGen在这些任务上的性能超过了自回归模型,并且在RVQ深度扩展时,与同样大小的基线生成模型相比,展现了更高的生成保真度或更快的采样速度。
5. 消融研究
论文还通过消融研究分析了不同超参数(例如采样步骤)对生成质量的影响,并考察了模型在不同RVQ深度下的特性。
通过这些方法,ResGen有效地解决了在向量量化生成模型中生成高保真度数据与保持快速采样速度之间的平衡问题。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证ResGen模型的有效性和泛化能力:
1. 实验设置
实验任务:
- 视觉领域:在ImageNet数据集上进行条件图像生成任务,分辨率为256×256。
- 音频领域:使用Voicebox启发的两个任务进行评估:(1) 继续任务(continuation),给定文本和3秒的真实语音段落,目标是生成与提供段落相同风格的无缝语音;(2) 跨句子任务(cross-sentence),给定文本、3秒语音段落及其与文本不同的转录,目标是生成用提供段落风格朗读文本的语音。
评估指标:
- 视觉任务:使用Fréchet Inception Distance (FID) 来比较与其他最先进图像生成模型。
- 音频任务:使用字符错误率(CER)、单词错误率(WER)和说话人相似度(SIM)等客观指标进行评估。
基线和训练配置:与包括自回归模型和非自回归模型在内的最新生成模型进行比较,并详细说明ResGen模型的训练配置。
2. 实验结果
视觉任务:
- 展示了ResGen在保持参数效率的同时,与基线模型相比在准确性和推理时间上的优势。
- 使用FID指标评估生成质量,比较不同模型在生成质量、内存效率和生成速度方面的表现。
音频任务:
- 与生成RVQ标记的自回归模型进行比较,展示了ResGen在WER、CER和SIM指标上的优势,以及需要更少的推理步骤。
- 与最新的TTS模型进行比较,展示了ResGen在计算效率和准确性方面的优势。
3. 消融研究
- 分析了不同采样超参数(如采样步骤数、top-p值和温度缩放)对模型行为和生成质量的影响。
- 展示了增加采样步骤数、调整top-p值和温度对生成质量的改善。
这些实验验证了ResGen在不同模态上的强大性能,包括图像生成和文本到语音合成任务,并与现有的自回归和非自回归方法进行了比较。实验结果显示,ResGen在保持高保真度的同时,提供了更快的采样速度和更好的内存效率。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
1. 利用键值(KV)缓存优化采样速度
论文提到,通过在变换器架构中使用键值(KV)缓存,可以重用已经完全填充的标记的预计算KV值,减少冗余计算。这种策略可以显著提高采样速度和降低整体计算开销,是一个值得未来研究的方向。
2. 探索新的量化方法
论文提到了残差向量量化(RVQ)标记,但也提到了有限标量量化(FSQ)可能带来额外的好处。将ResGen方法扩展到支持FSQ可能需要不同的标记化和嵌入过程,探索这一方向可能带来新的量化策略和改进的生成性能。
3. 提供理论解释
论文中提到,ResGen方法在相对较少的迭代次数下就实现了高质量的生成,相比传统的扩散模型更有效。论文假设这种效率来自于解掩过程而不是去噪过程,因为基于完全解掩的标记进行预测比基于噪声输入的预测更容易。尽管如此,论文缺乏对这一现象的理论证明,提供正式的理论分析解释是一个有前景的未来研究方向。
4. 扩展到其他模态和任务
论文中的实验主要集中在图像和语音合成任务上,但ResGen模型的框架是通用的。将其扩展到其他模态(如视频或更复杂的音频任务)和不同类型的生成任务(如无条件生成或交互式生成)是另一个值得探索的方向。
5. 提高模型的泛化能力
虽然ResGen在特定任务上表现出色,但提高模型对不同领域和分布的泛化能力始终是一个重要的研究方向。这可能包括在更多样化的数据集上训练模型,或者开发更先进的技术来适应不同的生成场景。
6. 优化模型的计算效率
尽管ResGen在内存效率和采样速度方面已经表现出色,但进一步优化模型的计算效率,特别是在资源受限的环境中,仍然是一个重要的研究方向。
7. 探索不同的训练策略
论文中提到了一些训练策略,如使用混合高斯分布来表示潜在嵌入的分布。探索不同的训练策略和正则化技术,以进一步提高模型的性能和稳定性,也是一个有价值的研究方向。
这些方向不仅可以推动ResGen模型的发展,也有助于推动整个生成模型领域的进步。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为ResGen的高效RVQ(Residual Vector Quantization)基的离散扩散模型,旨在解决在向量量化生成模型中生成高保真度数据与保持快速采样速度之间的平衡问题。以下是论文的主要内容总结:
1. 研究动机
- 向量量化生成模型在高保真度数据生成方面面临挑战,尤其是在平衡生成质量和计算效率方面。
2. ResGen模型
- 核心思想:直接预测集体标记的向量嵌入而不是逐个预测每个标记,以解耦采样复杂度与序列长度和深度的关系。
- 掩蔽标记策略:采用特别适合RVQ标记的掩蔽策略,从最高量化层开始逐步掩蔽标记。
- 多标记预测:通过聚焦于预测聚合向量嵌入而不是直接预测目标标记,有效预测掩蔽标记。
3. 概率框架
- 将掩蔽标记预测过程纳入基于离散扩散模型和变分推断的原则化概率框架中,提供了理论基础。
4. 实验验证
- 在ImageNet上的有条件图像生成任务和零样本文本到语音合成任务上的实验验证了ResGen的有效性和泛化能力。
- 实验结果显示,ResGen在这些任务上的性能超过了自回归模型,并且在RVQ深度扩展时,与同样大小的基线生成模型相比,展现了更高的生成保真度或更快的采样速度。
5. 消融研究
- 分析了不同采样超参数对模型行为和生成质量的影响,包括采样步骤数、top-p值和温度缩放。
6. 结论与未来方向
- ResGen通过直接预测集体标记的向量嵌入,有效地解决了生成高保真度数据与快速采样之间的平衡问题。
- 提出了进一步探索的方向,包括利用键值缓存优化采样速度、探索新的量化方法、提供理论解释、扩展到其他模态和任务等。
总的来说,这篇论文提出了一个创新的解决方案来提高向量量化生成模型的效率和保真度,并在多个任务上验证了其有效性,为未来的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Authors:Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, Fan Yu, Huadai Liu, Zhengyan Sheng, Yue Gu, Chong Deng, Wen Wang, Shiliang Zhang, Zhijie Yan, Jingren Zhou
In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
在之前的工作中,我们介绍了CosyVoice,这是一个基于监督离散语音标记的多语种语音合成模型。通过采用两种流行的生成模型——语言模型和流匹配,进行渐进式语义解码,CosyVoice在语境中学习语音时表现出了高度的语调自然性、内容一致性和说话人相似性。最近,多模态大型语言模型(LLM)取得了显著进展,其中语音合成的响应延迟和实时因子在交互体验中发挥了关键作用。因此,在本报告中,我们提出了一种改进的流式语音合成模型CosyVoice 2,它包含了全面和系统的优化。具体来说,我们引入有限标量量化来提高语音标记的码本利用率。对于文本-语音LM,我们简化了模型架构,允许直接使用预训练的大型语言模型作为骨干。此外,我们开发了一种块感知因果流匹配模型,以支持各种合成场景,能够在单个模型内实现流式和非流式合成。通过在大规模多语种数据集上进行训练,CosyVoice 2达到了与人类相当的自然度、极短的响应延迟和几乎无损的合成质量。我们邀请读者在https://funaudiollm.github.io/cosyvoice
论文及项目相关链接
PDF Tech report, work in progress
摘要
CosyVoice 2是一款优化的流式语音合成模型,它引入了有限标量量化改进语音令牌的代码本利用率,简化了文本语音LM模型架构以直接使用预训练的大型语言模型作为主干,并开发了分块感知因果流匹配模型以支持各种合成场景。在大型多语种数据集上训练后,CosyVoice 2实现了与人类自然度相当、响应延迟极小、流式传输模式下几乎无损的合成质量。
关键见解
- CosyVoice 2是CosyVoice模型的改进版本,专注于流式语音合成。
- 该模型引入了有限标量量化以提高语音令牌的代码本利用率。
- 模型架构简化,允许直接使用预训练的大型语言模型(LLM)。
- 开发了分块感知因果流匹配模型,支持各种合成场景。
- 模型能够在单一模型中实现流式和非流式合成。
- CosyVoice 2在大型多语种数据集上训练,达到人类自然度相当的水平。
- 模型具有极小的响应延迟,且流式传输模式下的合成质量几乎无损。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为CosyVoice 2的改进型流式语音合成模型,旨在解决以下问题:
实时性和响应延迟:在交互式体验中,如语音聊天应用,响应延迟和实时性对于用户体验至关重要。传统的非流式(离线)语音合成模型在输入完整文本后需要合成整个话语才能返回波形,导致高延迟。
多模态大型语言模型(LLMs)的应用:随着多模态大型语言模型(LLMs)的显著进展,如何将这些模型有效地应用于语音合成,尤其是在流式合成场景中,成为一个挑战。
语音合成质量:尽管最近的零样本(zero-shot)TTS模型在特定说话者上实现了高保真度和自然度,但它们通常以非流式模式运行,影响了实时性和用户体验。
多语言和跨语言能力:现有模型在处理多语言和跨语言数据时可能会遇到性能下降的问题,尤其是在具有字符集重叠的语言之间。
控制性和定制化:现有模型难以通过文本指令控制声学特征(如音色)以适应角色扮演等应用场景,且在唱歌等任务上表现不佳。
模型架构和优化:为了实现流式和非流式合成的统一,并提高语音合成的自然度、内容一致性和说话者相似性,需要对模型架构进行简化和优化。
综上所述,CosyVoice 2通过引入有限标量量化(FSQ)以提高语音标记的码本利用率,简化文本到语音的语言模型架构以直接使用预训练的LLM作为骨干网络,并开发块感知因果流匹配模型以支持多样化的合成场景,旨在实现高质量、可扩展且互动性强的文本到语音合成。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,相关研究可以分为以下几个领域:
神经文本到语音(TTS)合成模型:
- 近年来,神经TTS合成模型因其在特定说话者上实现高保真度和自然度而受到广泛关注,超越了传统的拼接和统计参数方法。
零样本TTS模型:
- 零样本TTS模型能够通过模仿参考语音的音色、韵律和风格来合成任何说话者的语音,这些模型从大规模训练数据中受益,实现了与人类语音几乎无法区分的合成质量和自然度。
基于编码器的语言模型:
- 这类模型使用语音编码器模型提取离散的语音表示,并采用自回归或掩蔽的语言模型来预测语音标记,然后将这些标记通过编码器声码器合成为波形。
非自回归(NAR)语音合成:
- 受到图像生成技术启发,去噪扩散和流匹配模型被引入到NAR语音合成中,以提高语音质量和多样性。
混合系统:
- 结合文本到编码器的语言模型和编码器到特征的扩散模型,利用两种生成模型的优势,实现高多样性、韵律一致性和语音质量。
流式合成:
- 为了减少延迟并改善用户体验,研究者探索了基于语言模型的零样本TTS模型的流式合成。
多模态大型语言模型(LLMs):
- 随着LLMs的显著进展,如何将这些模型有效地应用于语音合成,尤其是在流式合成场景中,成为一个挑战。
具体到论文中提及的一些研究工作,包括但不限于:
- Tacotron [1]:一个端到端的语音合成系统,将文本直接转换为波形。
- WaveNet [2]:基于深度学习的语音合成系统,能够生成高质量的语音。
- Deep Voice 3 [3]:一个能够处理大量说话者的神经文本到语音模型。
- FastSpeech [5]:一个快速且可控的文本到语音模型。
- VALL-E [14]:一个基于神经编解码器的语言模型,实现了零样本文本到语音合成。
- DiffWave [22]:一个基于去噪扩散概率模型的语音合成系统。
- Flow Matching [24]:一种用于生成建模的流匹配方法。
这些研究构成了CosyVoice 2的研究背景,并为其提供了理论和技术基础。
Q: 论文如何解决这个问题?
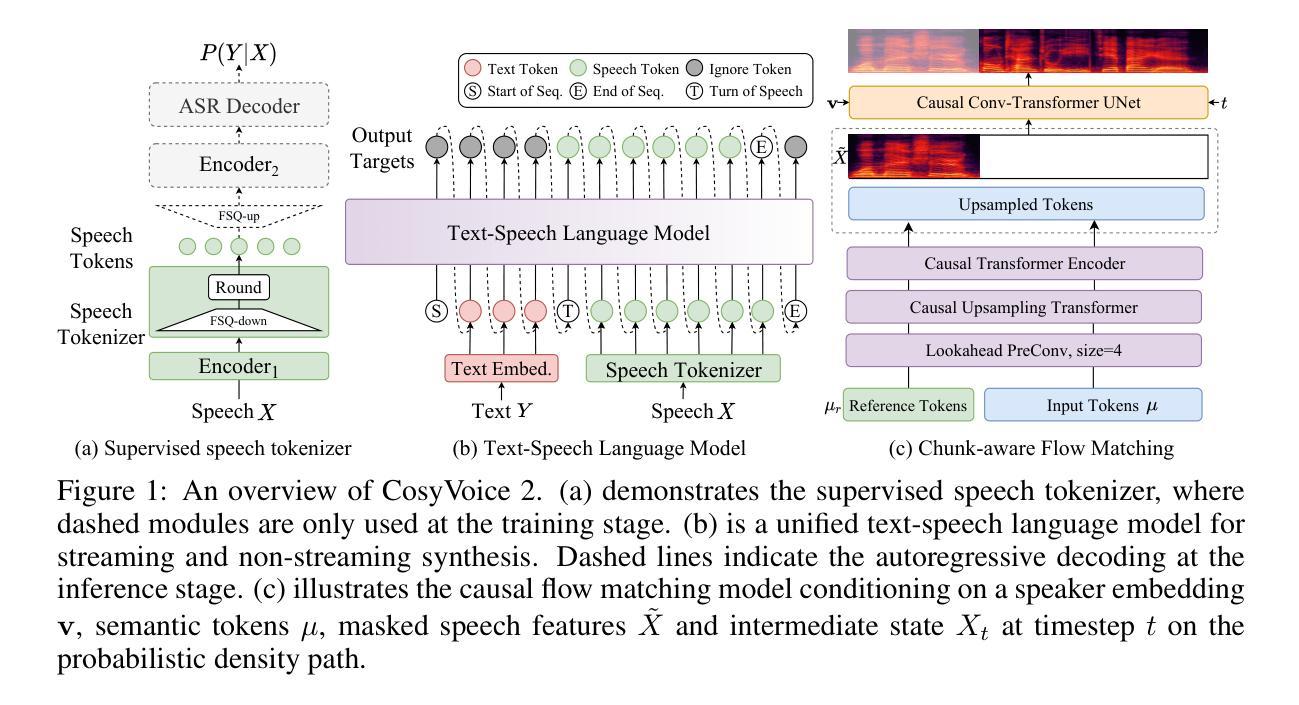
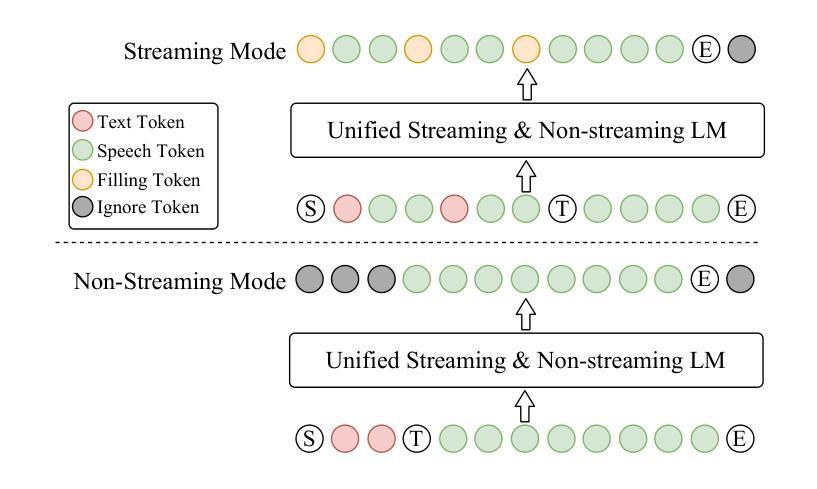
A: 论文通过提出CosyVoice 2模型解决了上述问题,具体解决方案如下:
1. 统一流式和非流式合成框架
CosyVoice 2通过提出统一的文本-语音语言模型和块感知因果流匹配模型,实现了流式和非流式合成的统一。这意味着模型可以灵活地在流式和非流式模式之间切换,从而减少部署复杂性,并适应不同的应用场景。
2. 有限标量量化(FSQ)
为了提高码本利用率并捕获更多的语音信息,CosyVoice 2采用了有限标量量化(FSQ)来替代传统的向量量化(VQ)。FSQ通过将中间表示投影到低维空间并量化,从而更有效地利用码本并保持语音信息。
3. 简化的语言模型架构
CosyVoice 2简化了语言模型架构,通过移除文本编码器和说话者嵌入,允许直接使用预训练的大型文本语言模型(LLMs)作为骨干网络。这增强了模型对上下文的理解能力,并避免了信息泄露。
4. 块感知因果流匹配模型
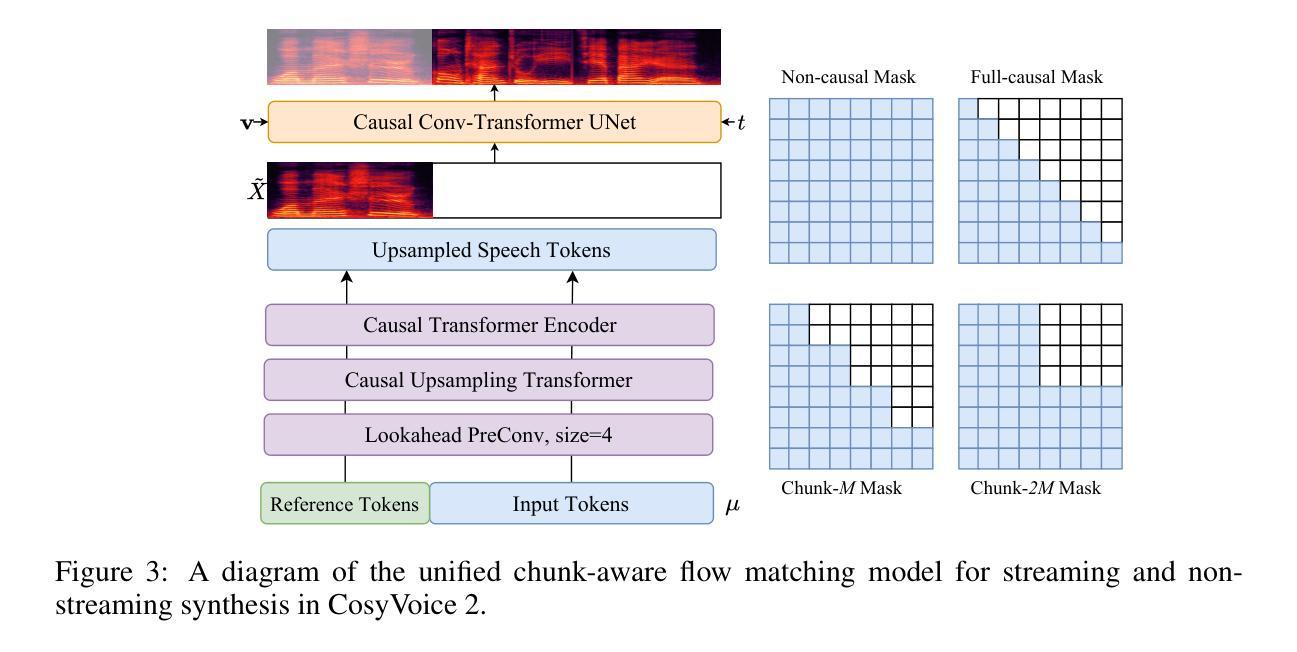
为了支持流式合成,CosyVoice 2开发了块感知因果流匹配模型,该模型可以处理不同长度的语音标记和Mel特征之间的帧率不匹配问题。通过使用最优传输(OT)流来匹配概率密度路径,模型能够在流式模式下有效地合成Mel频谱图。
5. 增强的指令性TTS容量
CosyVoice 2通过整合指令性数据集到基础训练集中,增强了模型对情感、口音、角色风格和细粒度控制的指令性生成能力。这使得用户能够更灵活地生成多样化和生动的语音。
6. 多说话者微调(mSFT)
为了改善特定说话者的生成质量和说话者相似性,CosyVoice 2引入了多说话者微调(mSFT),在多个说话者上同时微调预训练模型,以保持全面的韵律和发音覆盖,并减少对预训练模型的灾难性遗忘。
7. 强化学习用于SFT
CosyVoice 2在微调阶段采用强化学习,使用说话者相似性(SS)和识别词错误率(WER)作为奖励函数,以改善说话者相似性和发音准确性。
通过这些系统性的修改和优化,CosyVoice 2不仅实现了高质量的合成效果,还降低了部署要求,使其适用于流式和非流式应用,代表了可扩展、高质量和互动文本到语音合成的重要进步。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估CosyVoice 2的性能,以下是实验的详细情况:
1. 训练数据
- Speech Tokenizer训练数据:使用了包含中文和英文数据的200,000小时数据集来训练Speech Tokenizer。
- CosyVoice 2训练数据:与前一个版本共享训练数据,使用内部语音处理工具生成伪文本标签,并使用内部对齐模型过滤低质量数据。
2. 评估设置
- 测试集:使用了两个测试集,一个是基于Librispeech的test-clean,另一个是在SEED设置下进行的更广泛的测试,包括中文和英文样本。
- 基准测试:为日语和韩语准备了测试集,以评估模型在这些语言上的性能。
3. 评估指标
- 内容一致性:使用词错误率(WER)或字符错误率(CER)来评估。
- 说话者相似性:通过计算提示和生成话语的说话者嵌入之间的余弦相似度来评估。
- 语音质量:使用自然度MOS(NMOS)分数来评估客观质量。
4. 实验结果
- Speech Tokenizer评估:比较了向量量化(VQ)和有限标量量化(FSQ)在SenseVoice-Large编码器中的效果,发现FSQ能够完全利用码本并保持更多的有效信息。
- 与基线比较:在Librispeech test-clean子集上,CosyVoice 2在所有评估指标上均优于多个基线模型,显示出与人类话语相当的合成质量。
- 模块消融研究:通过逐步分析文本到语音语言模型的修改,包括LLM初始化、移除说话者嵌入和使用FSQ,发现这些修改显著提高了内容一致性,同时保持了说话者相似性。
- 流式模块影响评估:评估了流式语言模型和流式流匹配模型对合成性能的影响,发现流式LM在典型案例中的影响较小,但在具有挑战性的案例中可能会失去一些上下文信息。
- 日语和韩语基准测试:CosyVoice 2在韩语上的表现明显优于日语,这可能与日语和中文之间的字符集重叠有关。
- 指令性生成评估:创建了一个包含290个样本的中文测试集,评估了CosyVoice 2在遵循指令方面的性能,包括情感、语速、方言和角色扮演等。
- 说话者微调模型评估:展示了即使只有400个音频记录,目标说话者也能实现合理的语音合成性能。
- 强化学习用于SFT:通过使用不同的奖励函数对特定说话者进行微调,评估了强化学习在改善说话者相似性和发音准确性方面的有效性。
这些实验全面评估了CosyVoice 2在不同方面的表现,并与现有的基线模型进行了比较,证明了其在流式语音合成领域的优越性能。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
支持更多语言:
- 扩展CosyVoice 2以支持更多的语言,尤其是那些与中文、英文等没有字符集重叠的语言,以提高多语言合成的性能。
改善音色控制:
- 研究如何通过文本指令控制声学特征(如音色)以适应角色扮演等应用场景。
增强唱歌性能:
- 针对CosyVoice 2在唱歌任务上的表现不佳的问题,研究如何改进模型以更好地处理音乐和节奏。
优化流式合成性能:
- 进一步优化流式合成中的语言模型和流匹配模型,以减少在具有挑战性的案例中丢失的上下文信息。
提高数据效率:
- 探索数据增强、迁移学习等技术,以减少模型对大量训练数据的依赖,提高数据效率。
改进强化学习:
- 研究如何更有效地结合偏好偏差和可微分的ASR奖励,以提高模型在特定说话者上的微调性能。
多模态融合:
- 探索如何将CosyVoice 2与其他模态(如视觉、情感等)融合,以实现更丰富的交互体验。
模型泛化能力:
- 评估和提高模型在面对新的、未见过的数据时的泛化能力,尤其是在跨语言和跨领域的场景中。
实时应用优化:
- 针对实时应用(如语音助手、虚拟主播等),进一步优化模型的响应速度和资源消耗。
提高模型解释性:
- 提高模型的可解释性,让研究人员和用户更好地理解模型的决策过程和潜在的偏差。
多任务学习:
- 探索多任务学习框架,将语音合成与其他语音相关任务(如语音识别、语音增强等)结合起来,以提高模型的效能和鲁棒性。
模型压缩和加速:
- 研究模型压缩和加速技术,使CosyVoice 2能够在资源受限的设备上运行,如移动设备和嵌入式系统。
这些探索点可以帮助推动语音合成技术的发展,提高模型的性能和适用性,以及拓展其在各种应用场景中的使用。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了CosyVoice 2,一个改进的流式语音合成模型,旨在实现高质量、可扩展且互动性强的文本到语音合成。以下是论文的主要内容总结:
1. 动机与目标
- 针对现有零样本TTS模型在实时性和流式合成方面的局限性,提出了CosyVoice 2模型。
- 目标是在保持高自然度和说话者相似性的同时,减少响应延迟并实现流式合成。
2. CosyVoice 2模型
- 统一框架:提出了一个统一的框架,支持流式和非流式合成。
- 有限标量量化(FSQ):采用FSQ改善码本利用率并捕获更多语音信息。
- 简化的语言模型架构:使用预训练的大型文本语言模型(LLMs)作为骨干网络,增强上下文理解能力。
- 块感知因果流匹配模型:支持不同合成场景,包括流式和非流式合成。
- 增强的指令性TTS容量:允许更细致的控制,如情感、口音、角色风格等。
- 多说话者微调(mSFT):在多个说话者上同时微调,提高特定说话者的合成质量。
- 强化学习用于SFT:使用ASR和SS奖励优化说话者相似性和发音准确性。
3. 实验
- 在多个测试集上评估CosyVoice 2,包括Librispeech、SEED设置和日语、韩语测试集。
- 与多个基线模型比较,证明了CosyVoice 2在内容一致性、说话者相似性和语音质量方面的优越性能。
- 进行了模块消融研究,验证了模型各部分的有效性。
- 评估了流式合成模块对合成性能的影响。
- 测试了模型对指令性生成的控制能力。
- 展示了多说话者微调和强化学习在改善特定说话者合成质量方面的有效性。
4. 结论与局限性
- CosyVoice 2通过一系列系统性修改和优化,实现了高质量的合成效果,并降低了部署要求。
- 论文也指出了模型的局限性,如支持语言数量有限、无法通过文本指令控制声学特征等,并提出了未来研究的方向。
总的来说,CosyVoice 2代表了在流式、高质量文本到语音合成领域的一个重要进步,通过结合最新的语言模型技术和系统优化,提供了一个强大且灵活的合成解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

AMuSeD: An Attentive Deep Neural Network for Multimodal Sarcasm Detection Incorporating Bi-modal Data Augmentation
Authors:Xiyuan Gao, Shubhi Bansal, Kushaan Gowda, Zhu Li, Shekhar Nayak, Nagendra Kumar, Matt Coler
Detecting sarcasm effectively requires a nuanced understanding of context, including vocal tones and facial expressions. The progression towards multimodal computational methods in sarcasm detection, however, faces challenges due to the scarcity of data. To address this, we present AMuSeD (Attentive deep neural network for MUltimodal Sarcasm dEtection incorporating bi-modal Data augmentation). This approach utilizes the Multimodal Sarcasm Detection Dataset (MUStARD) and introduces a two-phase bimodal data augmentation strategy. The first phase involves generating varied text samples through Back Translation from several secondary languages. The second phase involves the refinement of a FastSpeech 2-based speech synthesis system, tailored specifically for sarcasm to retain sarcastic intonations. Alongside a cloud-based Text-to-Speech (TTS) service, this Fine-tuned FastSpeech 2 system produces corresponding audio for the text augmentations. We also investigate various attention mechanisms for effectively merging text and audio data, finding self-attention to be the most efficient for bimodal integration. Our experiments reveal that this combined augmentation and attention approach achieves a significant F1-score of 81.0% in text-audio modalities, surpassing even models that use three modalities from the MUStARD dataset.
有效地检测讽刺需要深入理解语境,包括语音和面部表情。然而,由于数据稀缺,讽刺检测的多模态计算方法的发展面临挑战。为了解决这一问题,我们提出了AMuSeD(用于多模态讽刺检测的注意力深度神经网络,并引入双模态数据增强)。该方法利用多模态讽刺检测数据集(MUStARD),并采用两阶段双模态数据增强策略。第一阶段是通过反向翻译从几种次要语言生成不同的文本样本。第二阶段涉及针对讽刺进行定制的FastSpeech 2语音合成系统的改进,以保留讽刺语调。与基于云的文本到语音(TTS)服务相结合,经过精细调整的FastSpeech 2系统为文本增强生成相应的音频。我们还研究了各种注意力机制,以有效地合并文本和音频数据,发现自我注意力对于双模态集成最为有效。我们的实验表明,这种结合增强和注意力的方法实现了文本和音频模态的F1分数达到81.0%,甚至超过了使用MUStARD数据集三模态的模型。
论文及项目相关链接
PDF This is a preprint version of the paper, submitted and under review at the IEEE Transactions on Affective Computing
Summary
基于上下文语境、语音及面部表情来识别讽刺需要敏锐地理解和深入剖析的技术支持。因缺乏讽刺检测的多模态计算方法的必要数据,带来了极大的挑战。为了克服这一问题,本文提出AMuSeD方法,借助多模态讽刺检测数据集MUStARD并采用两阶段双模态数据增强策略。第一阶段利用多种次级语言的翻译手段生成多种文本样本,第二阶段对专门针对讽刺进行定制的FastSpeech 2语音合成系统进行精细化改进并保留讽刺语调。结合云端的文本转语音(TTS)服务,该优化后的FastSpeech 2系统为文本扩充生成相应的音频数据。同时,本文探讨了多种有效的文本和音频数据整合机制,发现自我注意力机制对于双模态融合最为高效。实验证明,该组合策略和注意力机制在文本与音频模态的讽刺检测上取得了显著的F1分数,达到81%,甚至超越了使用MUStARD数据集的三模态模型。
Key Takeaways
- 有效检测讽刺需要理解上下文语境、语音和面部表情。
- 数据缺乏是多模态计算方法在讽刺检测中的一大挑战。
- 提出AMuSeD方法,结合多模态数据集MUStARD进行双模态数据增强。
- 两阶段数据增强策略包括利用翻译生成文本样本和定制语音合成系统以保留讽刺语调。
- 利用云TTS服务为文本扩充生成音频数据。
- 自我注意力机制在整合文本和音频数据上最为高效。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是有效检测讽刺(sarcasm)的挑战,尤其是在多模态(multimodal)情境中的检测。讽刺是一种复杂的语言现象,它通常传达与字面意思相反的情感或意图,需要对上下文有细致的理解,包括声音的语调和面部表情。论文中提到的关键挑战包括:
数据稀缺性:多模态讽刺检测领域面临的一个主要问题是可用于训练和测试模型的数据量有限。
模态整合:如何有效地整合不同的信息模态(如文本、音频和视觉数据)以提高讽刺检测的准确性是一个关键问题。
上下文理解:讽刺的理解需要对语境有深入的理解,包括言语和非言语信号,这对于计算方法来说是一个重大挑战。
为了解决这些问题,论文提出了一个名为AMuSeD(Attentive deep neural network for MUltimodal Sarcasm dEtection incorporating bi-modal Data augmentation)的方法,它利用多模态讽刺检测数据集(MUStARD)并引入了一个两阶段的双模态数据增强策略,包括通过回译(Back Translation)生成变化的文本样本和使用基于FastSpeech 2的语音合成系统来保留讽刺的语调。此外,论文还研究了各种注意力机制,以有效地融合文本和音频数据,并发现自注意力(self-attention)对于双模态集成最为高效。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究可以分为以下几个领域:
多模态讽刺检测(Multimodal Sarcasm Detection)
晚期融合方法(Late Fusion Approach):
- Schifanella等人 [7] 研究了社交媒体中文本和图像之间的相互作用,并强调了这些模态在传达讽刺对比信息中的关键作用。
- Ding等人 [20] 提出了一个融合框架,将文本、音频和视频模态的特征串联起来进行处理。
早期融合方法(Early Fusion Approach):
- Castro等人 [8] 将文本、音频和视频特征结合起来,输入支持向量机(SVM)以评估多模态数据整合在讽刺检测中的有效性。
基于注意力的融合(Attention-based Fusion):
- Chauhan等人 [22] 应用注意力机制来学习不同模态中话语片段之间的关系。
- Zhang等人 [23] 使用对比注意力机制捕获不同模态之间的不相关性。
数据增强在多模态讽刺检测中的应用(Data Augmentation in Multimodal Sarcasm Detection)
文本数据增强(Textual Data Augmentation):
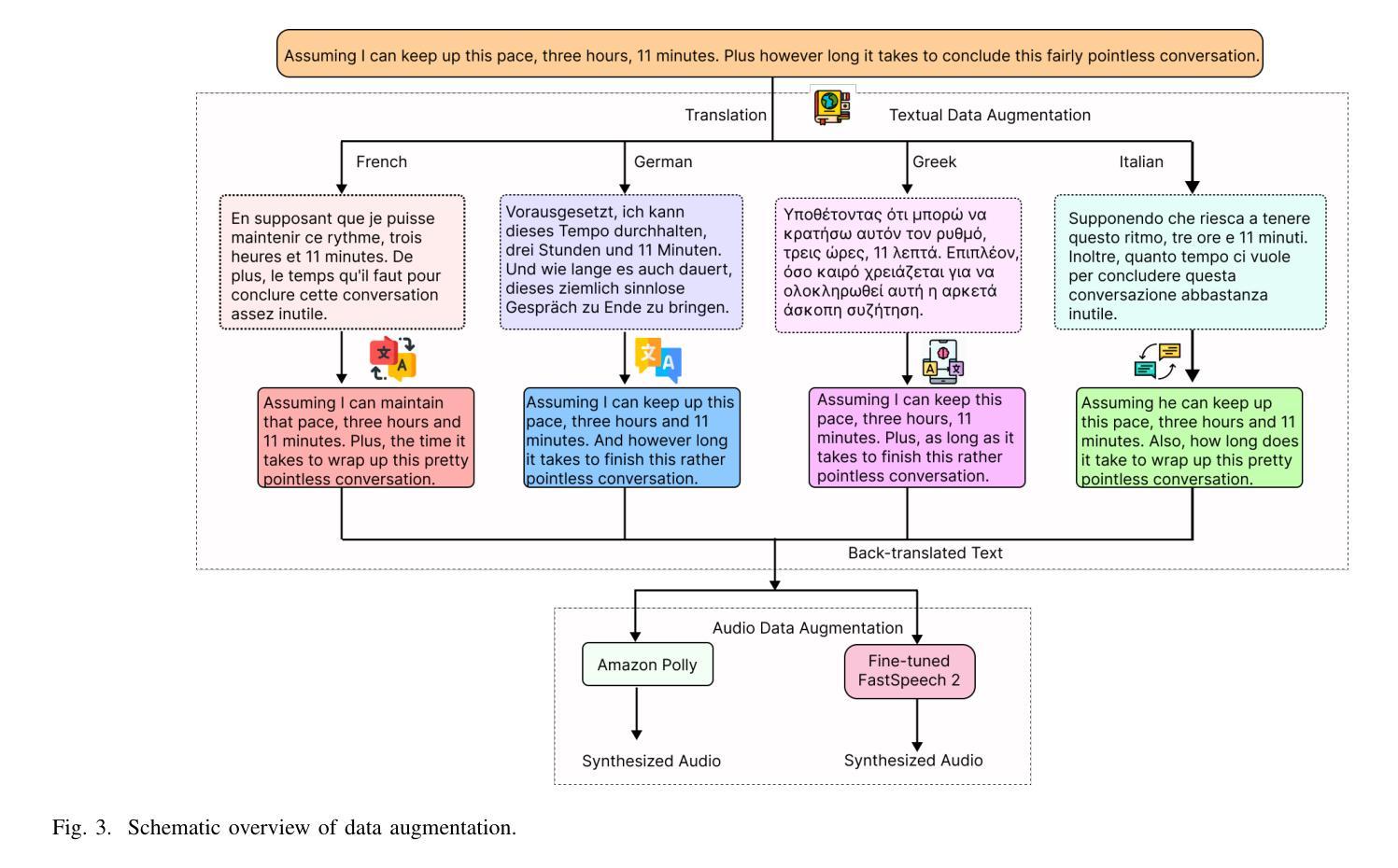
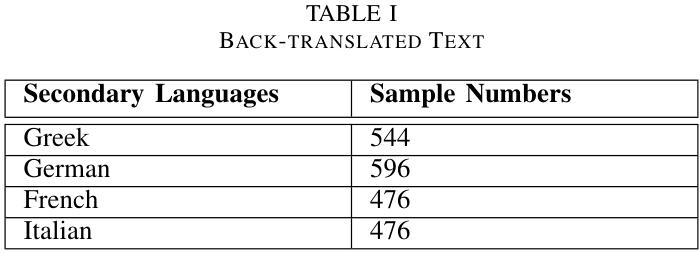
- Rico等人 [12] 通过将文本翻译到不同语言再翻译回原文本来生成额外样本,这种方法被称为Back Translation。
音频数据增强(Audio Data Augmentation):
- Gao等人 [27] 展示了速度和音量变化在讽刺检测中的有效性。
多模态数据增强(Multimodal Data Augmentation):
- Huang等人 [30] 引入了一种通过分割原始序列来增强多模态情感分类数据的方法。
以上列出的研究工作为本论文提出的AMuSeD方法提供了理论基础和技术支持,特别是在多模态数据处理、特征提取和融合技术方面。这些相关研究展示了多模态数据在讽刺检测中的潜力,并强调了数据增强技术在提高模型性能和泛化能力中的重要性。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决多模态讽刺检测中的问题:
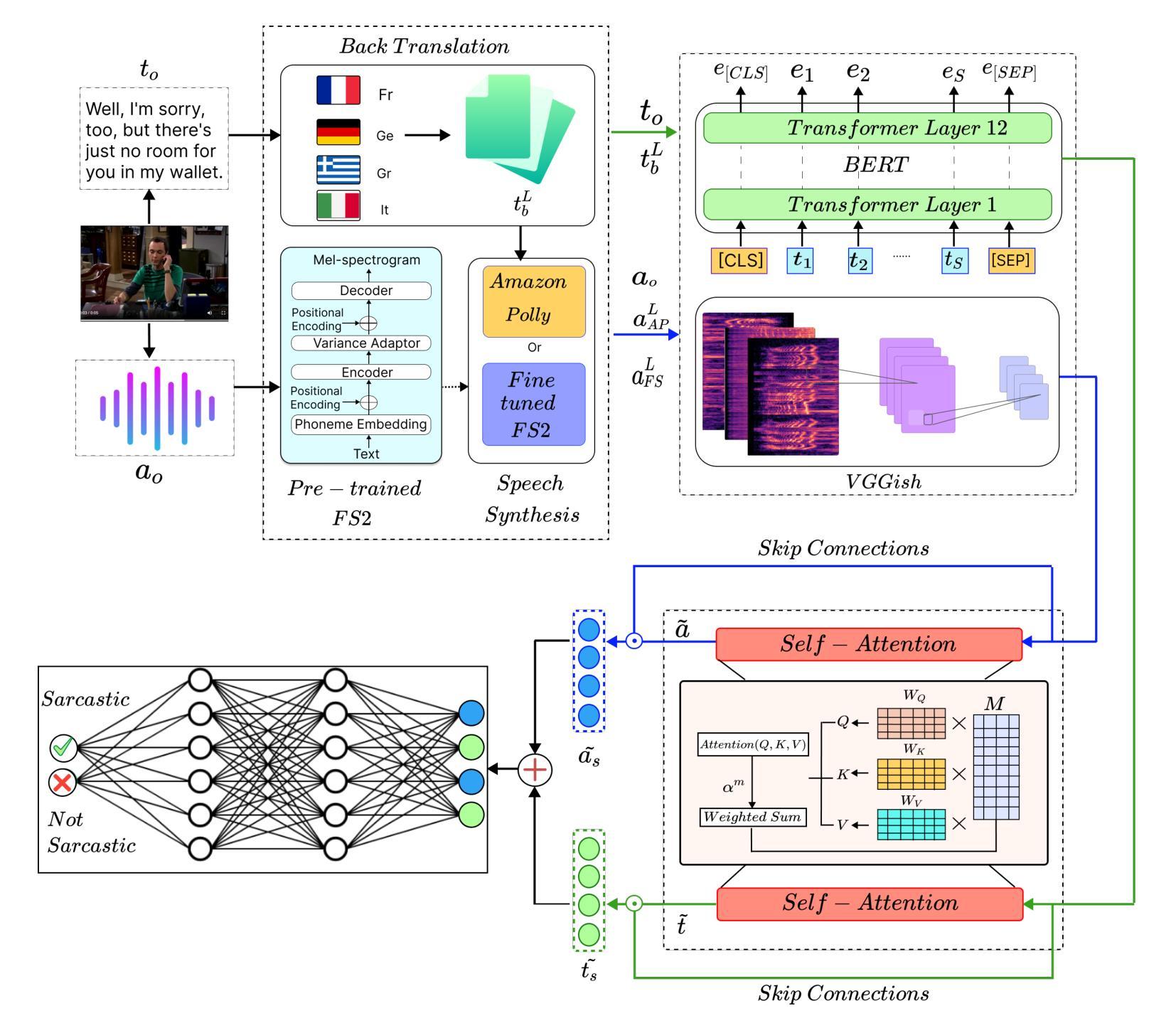
1. 数据增强策略(Data Augmentation Strategy)
- 文本增强:使用Back Translation技术,将原始讽刺文本翻译成不同的语言,然后再翻译回原始语言,以生成多样化的文本样本。
- 音频增强:利用基于FastSpeech 2的语音合成系统,针对讽刺语调进行微调,以保留讽刺的语调特征,生成相应的音频数据。
- 双模态数据增强:结合文本增强和音频增强,生成与增强文本对应的音频样本,以保持语义一致性。
2. 特征提取(Feature Extraction)
- 文本特征提取:使用BERT模型来提取文本数据的高维嵌入,捕捉语言的细微差别。
- 音频特征提取:利用VGGish模型来提取音频数据的特征,该模型在音频分类任务中表现良好。
3. 特征融合(Feature Fusion)
- 自注意力机制:采用自注意力机制来合并文本和音频数据,使模型能够关注两种模态中与讽刺检测相关的特征。
4. 预测(Prediction)
- 全连接层:将融合后的特征通过全连接层进行处理,以输出最终的讽刺标签。
实验设置(Experimental Setup)
- 数据集:使用MUStARD数据集,包含来自美国电视情景喜剧的文本、音频和视频数据。
- 比较基准:与现有的多模态讽刺检测方法进行比较。
- 训练细节:使用二元交叉熵损失函数和Adam优化器进行模型训练。
- 评估指标:采用精确度(P)、召回率(R)和F1分数(F1)作为评估指标。
实验结果(Experimental Results)
- 整体模型性能:AMuSeD模型在多模态数据上达到了81.0%的F1分数,超过了使用MUStARD数据集三种模态的模型。
- 数据增强分析:分析了增强数据的大小和不同语音合成器对模型性能的影响。
- 注意力机制的重要性:评估了不同注意力机制对模型性能的影响,并探讨了跳跃连接(skip connections)的作用。
通过这些步骤,论文提出了一个创新的双模态数据增强方法,并展示了自注意力机制在多模态讽刺检测中的有效性,从而显著提高了讽刺检测的准确性。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验:
1. 数据集描述和基准方法比较
- 数据集:使用MUStARD数据集,包含690个音频视觉话语样本,均衡分为讽刺和非讽刺样本。
- 基准方法:将提出的AMuSeD模型与多种现有方法进行比较,包括SVM、Ie Attention & Ia Attention、ConAttSD、M2Seq2Seq和GEMA等。
2. 整体模型性能评估
- 对AMuSeD模型进行评估,比较其与基准方法在精确度(P)、召回率(R)和F1分数(F1)上的性能差异。
3. 数据增强分析
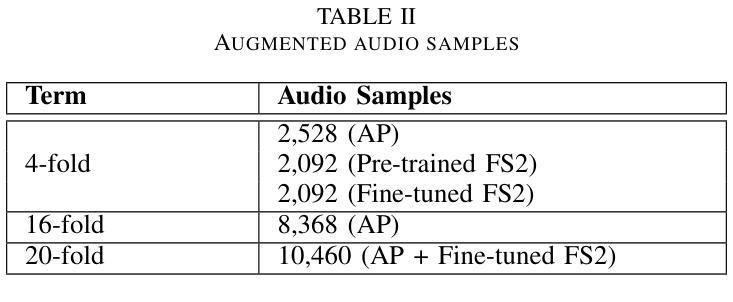
- 数据量的影响:通过创建不同大小(4倍、16倍和20倍)的增强数据集,分析数据量对模型性能的影响。
- 语音合成器的影响:在4倍增强数据集上,比较不同语音合成器(Amazon Polly、预训练的FastSpeech 2和微调的FastSpeech 2)对模型性能的影响。
4. 注意力机制的效果分析
- 有无注意力机制:比较有无注意力机制的模型在20倍增强数据集上的性能。
- 不同注意力模型:评估并比较不同注意力机制(包括并行CoAttention、词级注意力、交叉注意力和自注意力)的效果。
5. BERT与GloVe作为文本特征提取器的比较
- 分析BERT和GloVe作为文本特征提取器在原始和增强数据集上的性能差异。
6. 多模态的作用
- 评估仅使用音频、仅使用文本以及融合音频和文本模态对模型性能的影响。
这些实验旨在全面评估AMuSeD模型的性能,并分析不同因素(如数据增强策略、语音合成器选择、注意力机制)对多模态讽刺检测的影响。通过这些实验,作者能够验证他们提出的方法在提高讽刺检测准确性方面的有效性,并与现有技术进行比较。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
1. 提高数据增强技术的准确性和质量
- 改进Back Translation:探索更多样化的语言对以减少重复样本,并提高翻译的准确性和多样性。
- 改进语音合成:研究更先进的文本到语音(TTS)技术,以更准确地反映讽刺的微妙之处。
2. 视频模态的整合
- 视频数据增强:考虑将视频数据纳入当前的双模态增强框架中,以提供更全面的讽刺视角。
3. 上下文信息的增强
- 整合更多上下文信息:加入说话者信息和周围话语等上下文元素,可能会显著提高模型的预测准确性。
4. 探索更先进的模型架构
- 研究CoAttention等架构:这些高级架构可能在处理模态间交互方面提供更优越的性能和更深入的见解。
5. 跨文化和语言的应用
- 文化和语言多样性:研究讽刺在不同文化和语言中的表现形式,以提高模型在全球范围内的适用性。
6. 改善源数据质量
- 减少偏见和提高代表性:改进原始数据集的质量和多样性,以减少数据增强过程中的偏差。
7. 计算资源需求
- 优化计算资源:考虑到处理和分析多模态数据所需的计算资源,需要优化模型以适应资源有限的环境。
8. 同步文本和音频模态
- 提高同步精度:确保文本和音频模态有效地同步,以准确反映讽刺的上下文。
这些探索点可以帮助未来的研究在多模态讽刺检测领域取得更深入的进展,并提高模型在实际应用中的有效性和适用性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
1. 研究问题和动机
- 论文旨在解决有效检测讽刺的问题,尤其是在多模态情境下,考虑到讽刺理解需要结合语境、语调、面部表情等多种信息。
2. AMuSeD方法
- 提出了AMuSeD(Attentive deep neural network for MUltimodal Sarcasm dEtection incorporating bi-modal Data augmentation),一个多模态讽刺检测方法,利用文本和音频数据增强,并采用自注意力机制进行特征融合。
3. 数据增强策略
- 通过Back Translation生成多样化的文本样本,以及使用基于FastSpeech 2的语音合成系统生成音频样本,以解决数据稀缺问题。
4. 特征提取和融合
- 使用BERT提取文本特征,VGGish提取音频特征,并采用自注意力机制融合这些特征,以增强模型检测讽刺的能力。
5. 实验设置和评估
- 使用MUStARD数据集进行实验,与多个基准方法比较,评估模型的精确度、召回率和F1分数。
6. 实验结果
- 实验结果显示,AMuSeD模型在多模态数据上达到了81.0%的F1分数,超过了一些使用三种模态数据的模型。
7. 进一步探索的点
- 论文提出了未来研究的方向,包括改进数据增强技术、整合视频模态、增强上下文信息、探索更先进的模型架构等。
8. 结论
- 论文得出结论,AMuSeD方法通过双模态数据增强和自注意力机制显著提高了讽刺检测的能力,并为多模态情感分析领域提供了新的视角和方法。
总的来说,这篇论文通过引入新的数据增强技术和自注意力机制,有效地提高了多模态讽刺检测的性能,并为未来的研究提供了有价值的见解和方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


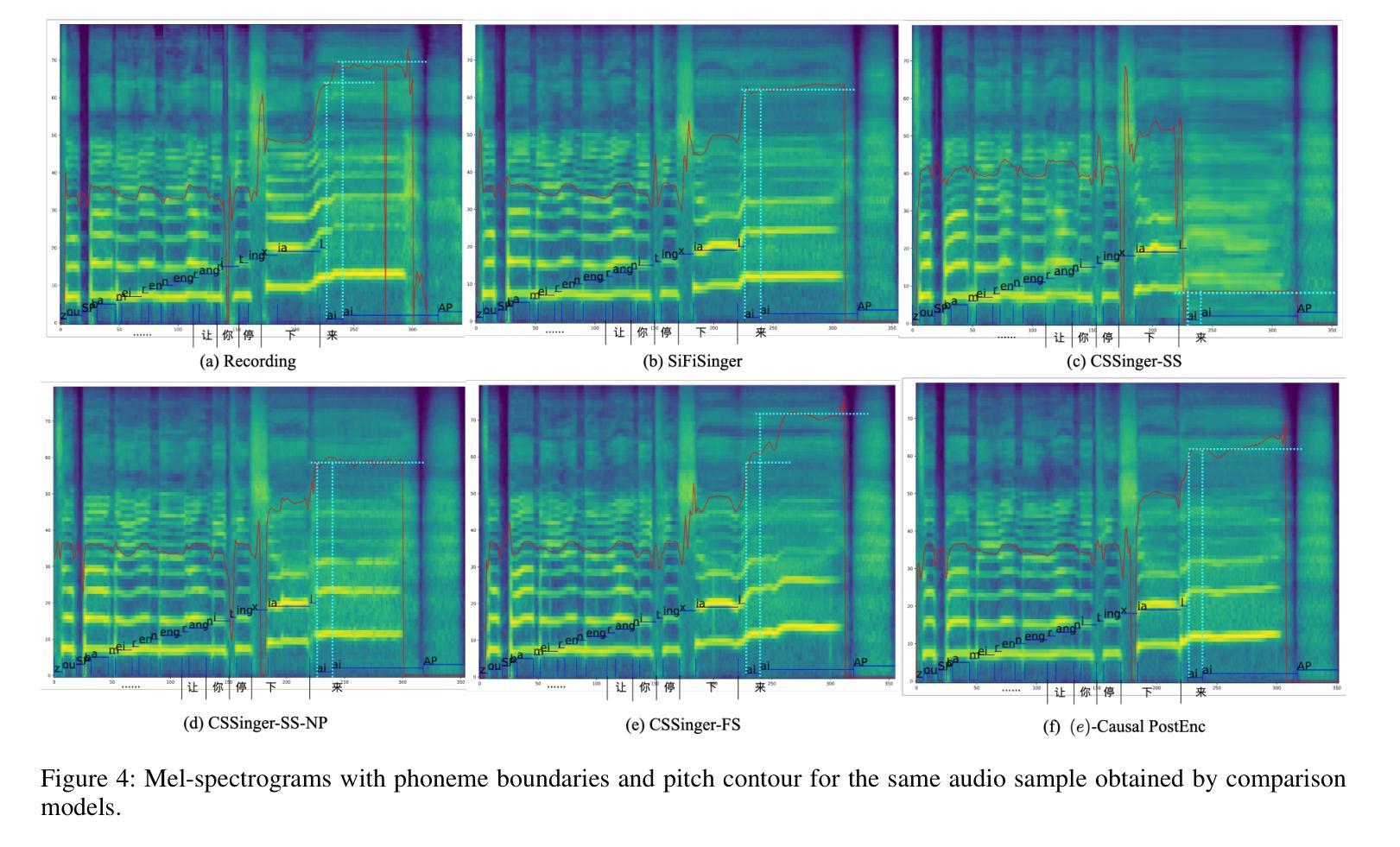
CSSinger: End-to-End Chunkwise Streaming Singing Voice Synthesis System Based on Conditional Variational Autoencoder
Authors:Jianwei Cui, Yu Gu, Shihao Chen, Jie Zhang, Liping Chen, Lirong Dai
Singing Voice Synthesis (SVS) aims to generate singing voices of high fidelity and expressiveness. Conventional SVS systems usually utilize an acoustic model to transform a music score into acoustic features, followed by a vocoder to reconstruct the singing voice. It was recently shown that end-to-end modeling is effective in the fields of SVS and Text to Speech (TTS). In this work, we thus present a fully end-to-end SVS method together with a chunkwise streaming inference to address the latency issue for practical usages. Note that this is the first attempt to fully implement end-to-end streaming audio synthesis using latent representations in VAE. We have made specific improvements to enhance the performance of streaming SVS using latent representations. Experimental results demonstrate that the proposed method achieves synthesized audio with high expressiveness and pitch accuracy in both streaming SVS and TTS tasks.
歌声合成(SVS)旨在生成高保真和富有表现力的歌声。传统的SVS系统通常使用声学模型将乐谱转换为声学特征,然后使用声码器重建歌声。最近的研究表明,端到端建模在SVS和文本到语音(TTS)领域是有效的。因此,在这项工作中,我们提出了一种完全端到端的SVS方法,并结合分块流式推理来解决实际使用中的延迟问题。需要注意的是,这是首次尝试在VAE中使用潜在表示来实现完全端到端的流式音频合成。为了提高使用潜在表示的流式SVS的性能,我们已经进行了特定的改进。实验结果表明,该方法在流式SVS和TTS任务中均实现了高表现力和音高准确度的合成音频。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
本文介绍了一种全新的端到端歌唱声音合成(SVS)方法,该方法采用分段流式推理以解决实际应用中的延迟问题。此方法首次尝试完全使用潜在表示进行端到流音频合成,并在SVS和文本到语音(TTS)任务中取得了良好的表现。实验结果表明,该方法合成的音频具有高表现力和音高准确性。
Key Takeaways
- 介绍了一种全新的端到端歌唱声音合成(SVS)方法,包括分段流式推理的使用来解决实际应用中的延迟问题。
- 采用端到端的音频合成方法,首次尝试完全使用潜在表示进行端到流音频合成。
- 在SVS和文本到语音(TTS)任务中实现了高度表现和音高准确性的合成音频。
- 引入改进的流式SVS性能优化措施,使用潜在表示来提高性能。
- 实验结果表明,该方法合成的音频质量较高,并具有广泛的应用前景。
- 该方法对于解决实时音频合成中的延迟问题具有重要意义。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
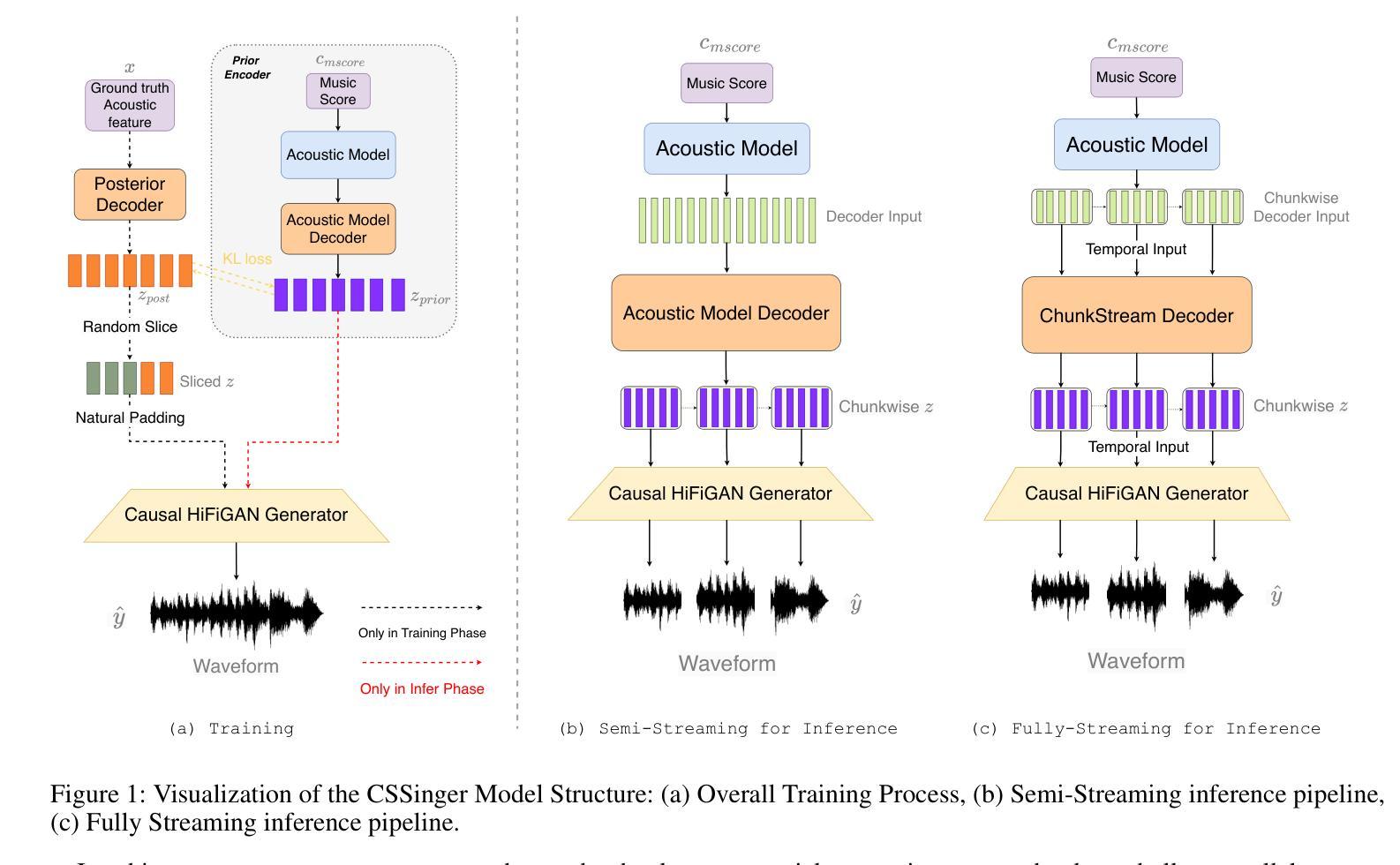
A: 这篇论文提出了一个基于条件变分自编码器(Conditional Variational Autoencoder, VAE)的端到端分块流式(chunkwise streaming)歌唱语音合成系统(ChunkStreamSinger, CSSinger),旨在解决以下问题:
实时性和计算资源限制:传统的歌唱语音合成(Singing Voice Synthesis, SVS)系统和文本到语音(Text to Speech, TTS)系统通常包含一个声学模型和一个声码器,这些系统在处理长序列时计算量大,实时性能不佳,尤其是在边缘设备和在线网络服务中部署时。
端到端流式音频合成:这是首次尝试完全实现使用VAE中的潜在表示进行端到端流式音频合成。流式合成对于减少延迟和提高实时性至关重要。
潜在表示用于声码器:使用VAE的潜在表示作为声码器的输入并不直观,尤其是对于歌唱语音,直接使用潜在表示进行音频生成会导致合成音频质量下降。
提高流式SVS性能:论文中提出了特定的改进措施,以增强使用潜在表示的流式SVS性能。
综上所述,论文的主要贡献在于提出了一种新的端到端流式歌唱语音合成方法,该方法不仅能够生成高表达性和音高准确性的合成音频,而且相较于传统的平行计算模型,能够显著降低延迟,提高实时性,更好地适应边缘设备和在线服务等实际应用场景。
Q: 有哪些相关研究?
A: 相关研究主要涉及以下几个领域:
Singing Voice Synthesis (SVS): 论文提到了多个基于深度学习的SVS系统,例如XiaoiceSing、ByteSing、VISinger和VISinger2。这些系统利用深度神经网络生成基于乐谱的高质量歌唱语音。
Text-to-Speech (TTS): 论文中提到了TTS系统中使用的端到端建模方法,如VITS (Kim, Kong, and Son 2021) 和SiFiSinger (Cui et al. 2024),它们基于条件VAE框架进行声学建模和音频合成。
Conditional Variational Autoencoder (VAE): VAE作为一种深度生成模型,在语音合成领域有广泛应用,如VITS、VISinger和SiFiSinger等系统,它们利用VAE学习潜在空间表示,以提高合成音频的自然度和真实感。
Streaming and Autoregressive Modeling: 论文中提到了一些研究工作,它们关注于流式自回归建模,例如Tacotron2和WaveNet。这些模型分别用于声学建模和波形生成,但存在推理效率低下和生成速度慢的问题。
Neural Audio Synthesis: 论文中提到了HiFi-GAN,这是一个用于高保真语音合成的生成对抗网络,它在CSSinger系统中被用于流式音频合成。
Efficient Neural Audio Synthesis: 论文中提到了WaveRNN,这是一个用于实时应用的神经音频合成模型,它通过减小模型大小和权重稀疏化来加速生成过程。
这些相关研究为CSSinger系统的提出提供了理论基础和技术背景,CSSinger系统在这些研究的基础上,通过引入流式处理和潜在表示的改进,旨在实现更高效、更自然的歌唱语音合成。
Q: 论文如何解决这个问题?
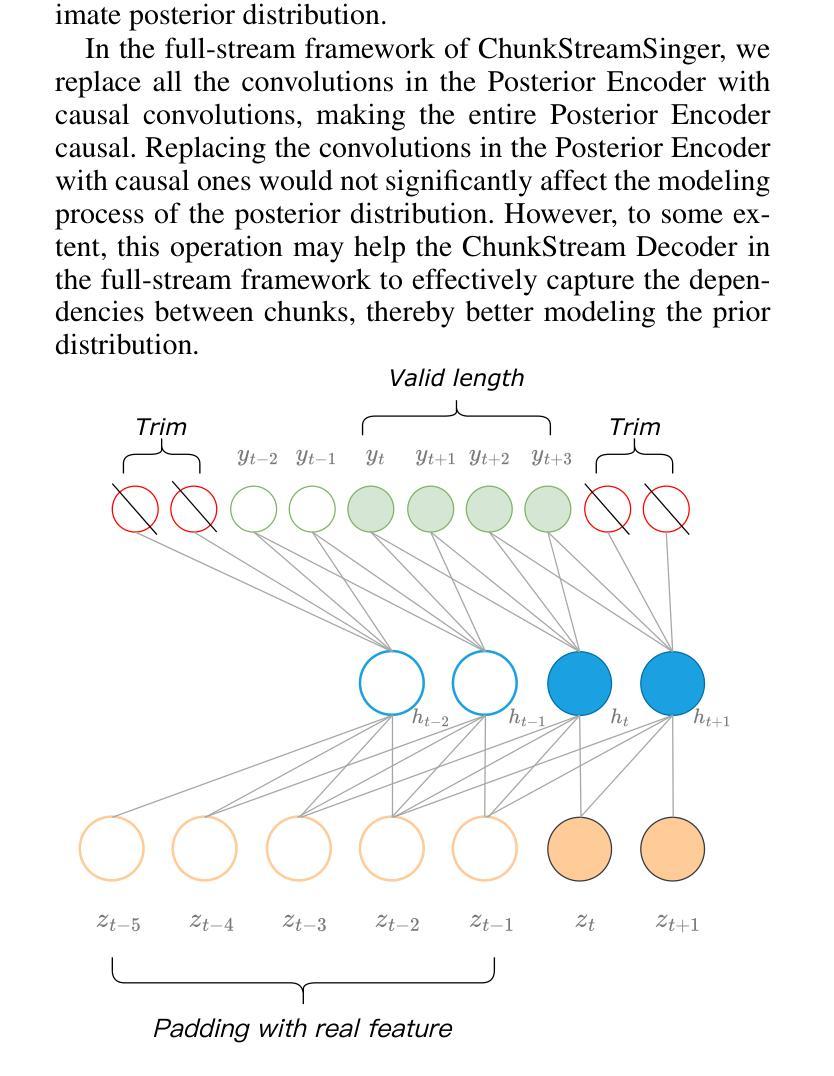
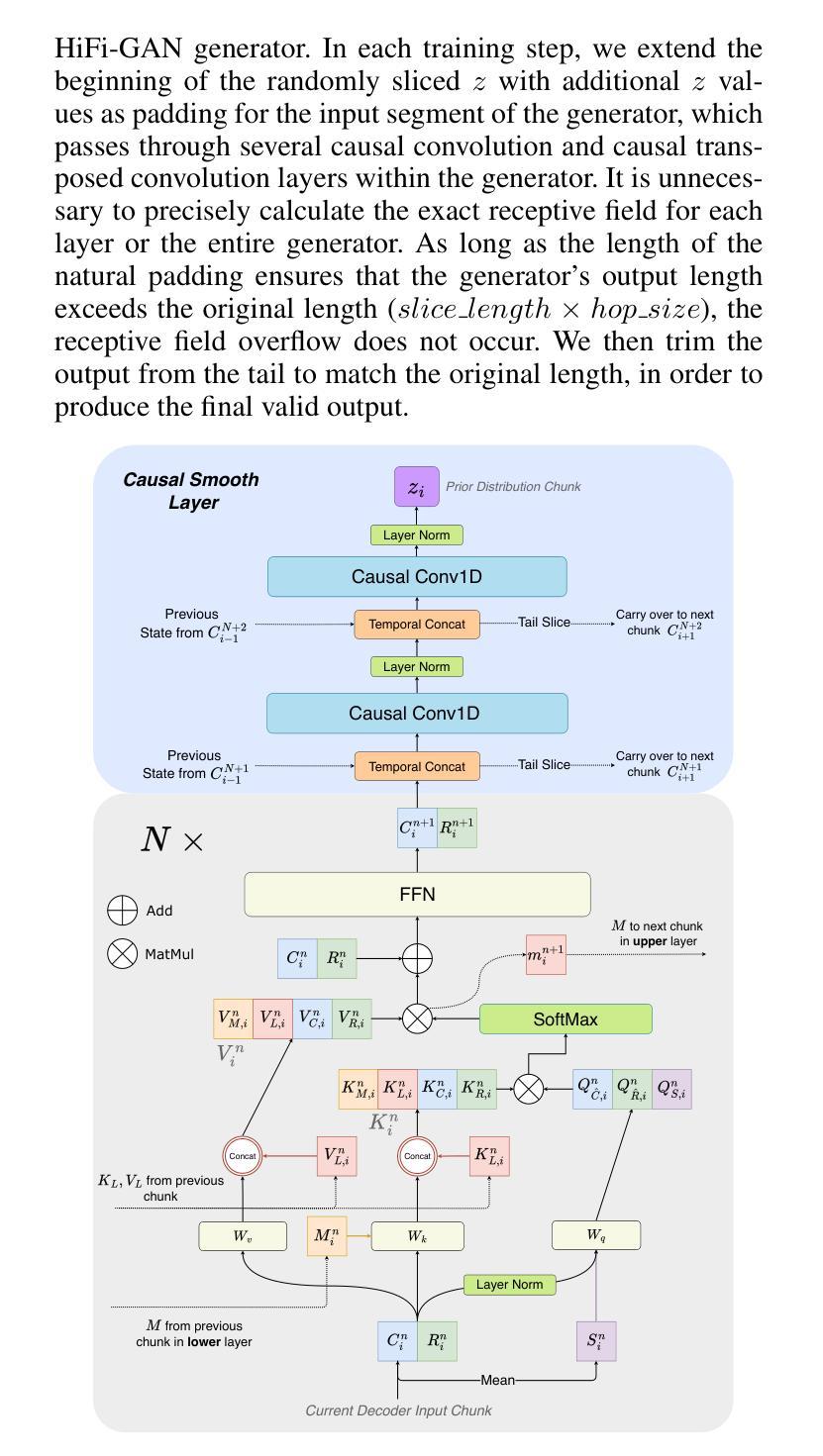
A: 论文通过提出一个名为ChunkStreamSinger(CSSinger)的系统来解决上述问题,具体解决方案包括以下几个关键点:
端到端条件VAE框架:
- 使用条件变分自编码器(VAE)来学习音乐评分(如歌词、音高、时长)的潜在表示,并直接生成合成音频。
- 该框架包括一个先验编码器(Prior Encoder)和一个后验编码器(Posterior Encoder),用于学习潜在空间的表示,并从这些表示中直接生成合成音频。
分块流式推理(Chunkwise Streaming Inference):
- 采用分块方式处理音频合成任务,降低实时处理的延迟,并减少计算资源消耗。
- 在声码器(vocoder)中使用因果转置卷积(causal transposed convolutions)来生成音频,避免了传统填充方法导致的音质下降问题。
自然填充(Natural Padding)策略:
- 为了避免在因果卷积中使用传统常数填充(如零填充或复制填充)导致的音质问题,论文提出了自然填充策略。
- 该策略通过在训练过程中动态地使用实际的潜在表示作为填充,而不是固定的常数值,以提高音频合成质量。
ChunkStream Decoder:
- 为了实现完全的流式推理,提出了ChunkStream Decoder,它将潜在表示的生成转换为基于块的流式处理。
- 该解码器借鉴了Emformer模型的机制,将完整的输入特征向量分解为多个固定长度的块,并在各个块之间提供上下文信息,确保注意力机制可以在每个块上并行计算。
因果平滑层(Causal Smooth Layer):
- 为了减少块之间的边界效应,引入了因果平滑层,该层由一维因果卷积和LayerNorm层组成。
- 这层保留了前一个块的相同层级的特征,并为下一个块提供特征,以增强合成音频的自然度和流畅性。
实验验证:
- 在多个中文歌唱语音数据集和一个TTS数据集上进行了实验,验证了所提出方法在主观和客观评价指标上相较于现有系统的优越性。
- 展示了CSSinger-FS在MOS评分和客观评价指标上的优势,并在不同硬件配置下评估了模型的延迟和实时性。
通过这些技术方案,论文成功地实现了一个低延迟、高效率的端到端流式歌唱语音合成系统,该系统不仅提高了合成音频的质量,还降低了实时应用中的延迟,使其更适合于边缘设备和在线服务等资源受限环境。
Q: 论文做了哪些实验?
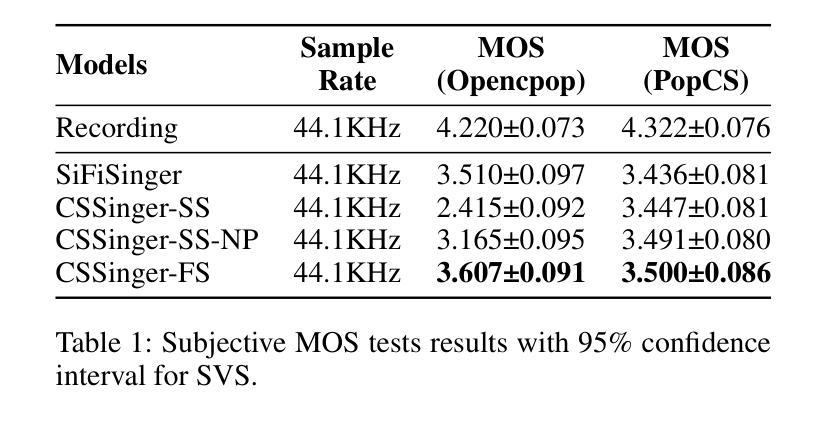
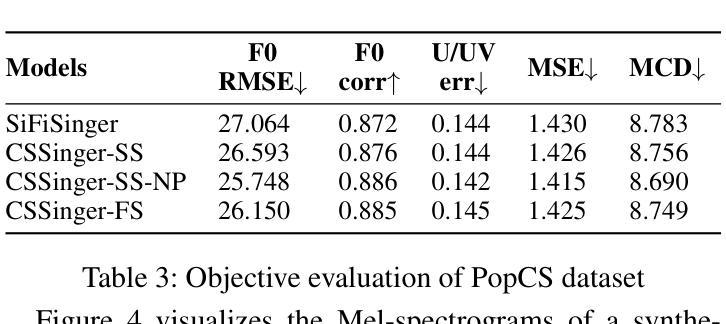
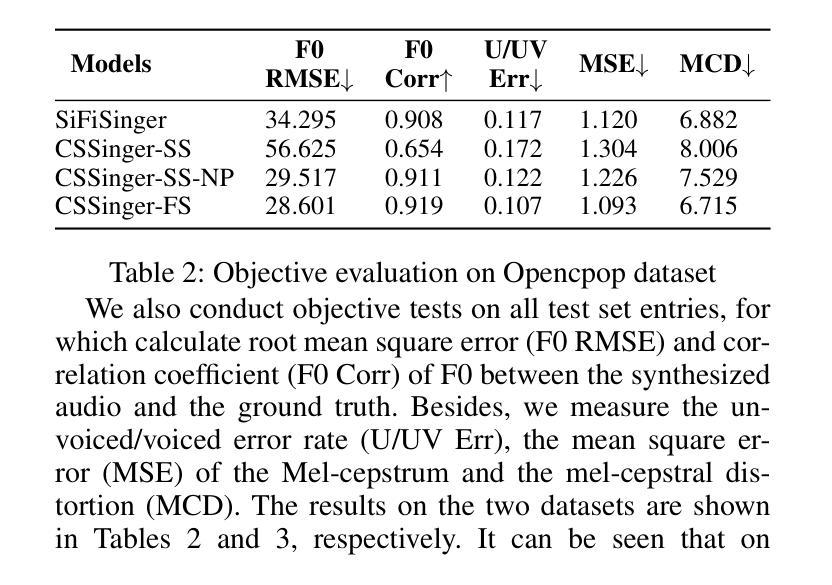
A: 论文中进行了一系列实验来评估所提出的ChunkStreamSinger(CSSinger)系统的性能,包括主观和客观的评估。以下是实验的详细内容:
数据集
- Opencpop2:一个公开的高质量中文歌唱语音数据集,包含100首普通话歌曲,由专业女歌手演唱,包含3,756个话语,总时长5.2小时。
- PopCS:另一个中文普通话歌唱语音数据集,包含117首歌曲,总时长约5.89小时,由专业女歌手演唱。
- Baker3:一个中文女性语音数据集,包含约12小时的标准普通话女性语音,包含10,000个句子,平均每个句子16个字符。
比较方法
- Recording:使用真实的歌唱语音音频作为基准。
- SiFiSinger:一个完全并行推理的基线系统。
- CSSinger-SS:CSSinger的半流式方法,只有HiFiGAN声码器以分块流式方式运行。
- CSSinger-SS-NP:CSSinger-SS加上自然填充(Natural Padding)的半流式结构。
- CSSingerFS(提出的模型):CSSinger的全流式框架,使用ChunkStream Decoder实现潜在表示z的流式推理。
实施细节
- 使用44.1KHz采样的音频处理Opencpop和PopCS数据集,而Baker数据集的音频采样率为48KHz,被重新采样到16KHz。
- 模型隐藏层大小设置为192,FFN隐藏层的通道数为768。
- Acoustic Model Decoder和ChunkStream Decoder都有4个注意力层。
- 使用diffsptk4提取80维melcepstrum(mcep)作为声学特征。
- 所有实验中HiFi-GAN生成器的训练随机切片大小设置为20,CSSinger模型的块大小也为20。
主要结果与分析
- 主观评估(MOS测试):在Opencpop和PopCS数据集上进行,随机选择20个样本,邀请20名母语人士进行主观评估。
- 客观评估:计算合成音频与真实音频之间的基频均方根误差(F0 RMSE)、基频相关系数(F0 Corr)、无声/有声错误率(U/UV Err)、Mel-cepstrum均方误差(MSE)和Mel-cepstral失真(MCD)。
延迟评估
- 测量从输入特征到合成音频生成的延迟(秒)、从输入特征到音频处理完成的总处理时间(秒)和实时因子(RTF)作为系统效率的指标。
- 在GPU、CPU和单核单线程CPU限制(CPU-Limited)三种情况下测试延迟指标。
结论
- CSSinger-FS在多个客观和主观指标上表现出色,优于现有的并行和半流式系统。
- 在GPU和CPU硬件配置下,CSSinger-FS显示出较低的延迟和优越的实时推理效率,这对于高实时需求的应用和计算资源受限的场景非常重要。
这些实验全面评估了CSSinger系统的性能,证明了其在歌唱语音合成任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的ChunkStreamSinger(CSSinger)系统在歌唱语音合成方面取得了显著的性能提升,但仍有一些领域可以进一步探索和改进:
模型泛化能力:
- 在更多种类和风格的歌唱数据集上测试模型的泛化能力,包括不同语言、不同性别和不同演唱技巧的数据集。
更深入的客观评估:
- 开发更精细的客观评价指标,以更全面地评估合成音频的自然度、清晰度和音乐性等。
实时性能优化:
- 进一步优化模型以降低延迟和计算资源消耗,特别是在资源受限的设备上,如移动设备或嵌入式系统。
多风格和多歌手建模:
- 探索如何使模型能够处理多个歌手和不同演唱风格,提供更丰富的合成选项。
端到端训练的改进:
- 研究如何改进端到端训练过程,可能包括更好的损失函数、优化算法或正则化技术,以进一步提高合成质量。
声码器的改进:
- 研究新型声码器或改进现有声码器,以生成更高保真度和更自然的音频。
上下文感知建模:
- 提高模型对歌曲上下文的感知能力,例如,理解和模拟歌曲的情绪和节奏变化。
交互式应用:
- 探索CSSinger在交互式应用中的潜力,如卡拉OK系统或音乐教育软件,其中实时反馈和调整是必要的。
模型解释性:
- 提高模型的可解释性,帮助研究人员和开发者更好地理解模型的决策过程和潜在空间的结构。
多任务学习:
- 考虑将歌唱语音合成与其他任务(如音乐生成、节奏识别)结合起来,以创建更全面的音乐生成系统。
模型鲁棒性测试:
- 对模型进行鲁棒性测试,尤其是在面对不完整或噪声数据时的性能。
跨领域应用:
- 探索CSSinger在其他领域的应用,如语音编码、语音增强或语音转换。
这些探索方向不仅可以推动歌唱语音合成技术的发展,还可能为整个语音合成和音频处理领域带来新的突破。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个基于条件变分自编码器(Conditional Variational Autoencoder, VAE)的端到端分块流式(chunkwise streaming)歌唱语音合成系统ChunkStreamSinger(CSSinger)。以下是论文的主要内容总结:
问题陈述:
- 论文旨在解决传统歌唱语音合成(SVS)系统中存在的实时性和计算资源限制问题,特别是在边缘设备和在线网络服务中部署时的高延迟问题。
系统架构:
- CSSinger基于SiFiSinger构建,采用条件VAE框架,包含先验编码器和后验编码器,直接从音乐评分生成合成音频。
- 系统支持分块流式推理,以减少延迟并提高实时性。
关键技术:
- 自然填充(Natural Padding):解决VAE潜在表示用于声码器输入时的音质下降问题。
- ChunkStream Decoder:实现完全流式推理,将潜在表示的生成转换为基于块的流式处理。
- 因果平滑层(Causal Smooth Layer):减少块之间的边界效应,增强合成音频的自然度和流畅性。
实验验证:
- 在两个中文歌唱语音数据集和一个文本到语音(TTS)数据集上进行了实验,验证了CSSinger系统在主观和客观评价指标上相较于现有系统的优越性。
- 展示了CSSinger在不同硬件配置下(GPU和CPU)的低延迟和优越的实时推理效率。
结论:
- CSSinger-FS(全流式框架)在MOS评分和客观评价指标上优于现有的并行和半流式系统。
- 该系统不仅提高了合成音频的质量,还降低了实时应用中的延迟,使其更适合于边缘设备和在线服务等资源受限环境。
未来工作:
- 论文提出了一些可以进一步探索的方向,包括模型泛化能力的提升、实时性能的进一步优化、多风格和多歌手建模等。
总体而言,这篇论文提出了一个创新的端到端流式歌唱语音合成系统,通过引入先进的技术方案,有效地提高了合成音频的质量和实时性,为SVS领域的发展提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图