⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-17 更新
Still “Talking About Large Language Models”: Some Clarifications
Authors:Murray Shanahan
My paper “Talking About Large Language Models” has more than once been interpreted as advocating a reductionist stance towards large language models. But the paper was not intended that way, and I do not endorse such positions. This short note situates the paper in the context of a larger philosophical project that is concerned with the (mis)use of words rather than metaphysics, in the spirit of Wittgenstein’s later writing.
我的论文《关于大型语言模型》多次被解读为提倡对大型语言模型采取还原论立场。但论文并非此意,我也不支持这样的观点。这篇简短的文章将论文定位在一个更大的哲学项目的背景中,关注的是词语的(误)用,而非形而上学,秉承维特根斯坦后期写作的精神。
论文及项目相关链接
Summary:
我的论文《关于大型语言模型》被误解为支持对大型语言模型的简化立场。但论文并非此意,并不支持此类观点。这篇简短的文章将论文置于更大的哲学项目的背景下,关注词语的(误)使用而非形而上学,与维特根斯坦后期作品的精神相符。
Key Takeaways:
- 论文《关于大型语言模型》并非支持对大型语言模型的简化立场。
- 作者不赞同对大型语言模型的简化或过度简化的观点。
- 论文是在更广泛的哲学项目背景下进行讨论的,关注词语的使用和误用。
- 作者强调词语使用的哲学层面,而非单纯的形而上学讨论。
- 论文与维特根斯坦后期作品的精神相符,强调语言和语境的重要性。
- 作者认为大型语言模型不应被单一化或简化理解,应重视其复杂性和多元性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是关于大型语言模型(LLMs)的哲学和语言使用上的误解。作者Murray Shanahan澄清了他之前论文《Talking About Large Language Models》中的一些观点,该论文被一些人误解为支持对大型语言模型的简化主义立场。作者强调,他并不支持这种立场,而是希望将论文置于一个更广泛的哲学项目中,该项目关注的是词语的(误)使用,而非形而上学问题,这与维特根斯坦后期的著作精神相一致。
具体来说,作者试图解决以下几个问题:
对“简化主义”的误解:作者澄清,他并不认为LLMs仅仅是下一个词预测器,也不认为LLMs没有信念或知识。他反对将他的论点解释为对LLMs的简化主义理解。
词语使用的哲学探讨:作者强调,他更关注于探讨词语如何被使用(或应该如何被使用),而不是做出形而上学的断言。他反对使用带有形而上学重量的“是”(is)的哲学断言。
LLMs与信念的关系:作者讨论了在不同层次的LLMs系统中,使用“信念”一词的适当性。他提出了一个层次结构,随着系统的复杂性增加,使用“信念”一词的适当性也在增加。
对LLMs的人类化语言的警告:作者提醒读者在使用人类化的语言来描述LLMs时要谨慎,因为LLMs在基本的机械层面上与人类非常不同。
总的来说,这篇论文试图纠正对作者之前工作的误解,并提供一个更清晰的哲学视角来理解LLMs,特别是关于它们是否具有信念和知识的问题。
Q: 有哪些相关研究?
A: 这篇论文中提到了以下相关研究和文献:
Daniel Dennett的工作:
- Dennett, D. (2009). Intentional systems theory. In The Oxford Handbook of Philosophy of Mind, pages 339–350. Oxford University Press.
- Dennett的工作涉及意向性立场(Intentional Stance),这是一种解释行为的方式,将行为视为具有意图和信念的实体。作者引用Dennett的理论来讨论LLMs的行为。
S. M. Downes, P. Forber, 和 A. Grzankowski的研究:
- Downes, S. M., Forber, P., & Grzankowski, A. (2024). LLMs are not just next token predictors. Inquiry, forthcoming, 2024. Also arXiv:2408.04666.
- 这篇论文讨论了LLMs不仅仅是下一个词的预测器,而是更复杂的系统。
S. Russell 和 P. Norvig的人工智能教科书:
- Russell, S., & Norvig, P. (2010). Artificial Intelligence: A Modern Approach. Prentice Hall, 2010. Third Edition.
- 这本书是人工智能领域的经典教材,提供了AI领域的广泛知识,包括对智能体的定义和讨论。
Murray Shanahan的其他工作:
- Shanahan, M. (2010). Embodiment and the Inner Life: Cognition and Consciousness in the Space of Possible Minds. Oxford University Press.
- Shanahan, M. (2024a). Simulacra as conscious exotica. Inquiry, https://doi.org/10.1080/0020174X.2024.2434860.
- Shanahan, M. (2024b). Talking about large language models. Communications of the ACM, 67 (2):68–79, 2024b.
- Shanahan, M., McDonell, K., & Reynolds, L. (2023). Role play with large language models. Nature, 623:493–498, 2023.
- 这些论文和书籍涉及认知、意识、LLMs的行为和角色扮演等方面,与本论文的主题紧密相关。
Ludwig Wittgenstein的哲学研究:
- Wittgenstein, L. (1953). Philosophical Investigations. Basil Blackwell.
- 维特根斯坦的后期著作,特别是《哲学研究》,对语言的使用和哲学问题的处理提供了深刻的见解,影响了作者对LLMs的哲学探讨。
这些文献和研究为理解LLMs的哲学和认知问题提供了理论基础和背景,帮助作者构建了他对LLMs的哲学立场。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决了关于大型语言模型(LLMs)的哲学和语言使用上的误解问题:
澄清立场:
- 作者首先澄清他并不支持将LLMs简化为仅仅是下一个词预测器的观点,也不认为LLMs没有信念或知识。他强调,他的工作被误解为支持简化主义立场,但实际上并非如此。
哲学项目定位:
- 作者将自己的工作定位在一个更广泛的哲学项目中,该项目关注词语的(误)使用,而非形而上学问题。他引用了维特根斯坦后期的著作,特别是《哲学研究》,来支持他的观点,即关注词语的使用而非做出形而上学的断言。
讨论“信念”一词的使用:
- 作者讨论了在不同层次的LLMs系统中,使用“信念”一词的适当性。他提出了一个层次结构,随着系统的复杂性增加,使用“信念”一词的适当性也在增加。
强调行为与信念的关系:
- 作者强调,信念的概念与行为紧密相关。他认为,使用“信念”一词的原始语境是活跃的、行为化的人类(和其他动物),而将其用于完全被动的计算实体则偏离了这个词的原始语境。
提出层次结构:
- 作者提出了一个从“bare-bones” LLM到更复杂的、能够进行多种行为的LLM-based系统的层次结构。在这个结构中,随着系统的复杂性增加,使用“信念”一词的适当性也在增加。
提醒人类化语言的谨慎使用:
- 作者提醒读者在使用人类化的语言来描述LLMs时要谨慎,因为LLMs在基本的机械层面上与人类非常不同。
总结意图:
- 作者总结他的意图不是采取关于信念的形而上学立场,也不是基于这些立场支持对LLM能力的简化观点。相反,他的目标是提醒读者LLM-based系统与人类在基本操作层面上的差异,并在使用拟人化语言描述它们时保持谨慎。
通过这些步骤,作者不仅澄清了自己的立场,还提供了一个框架来讨论和理解LLMs的哲学和语言问题,特别是关于它们是否具有信念和知识的问题。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,这篇论文并没有提到进行任何具体的实验。相反,这篇论文是一个哲学性质的讨论,旨在澄清作者在之前论文中的观点,并探讨关于大型语言模型(LLMs)的哲学和语言使用问题。论文的重点在于概念分析和哲学论证,而不是实验研究。
作者Murray Shanahan通过以下几个方面来阐述他的观点:
哲学立场的澄清:作者澄清了他并不支持将LLMs简化为仅仅是下一个词预测器的观点,也不认为LLMs没有信念或知识。
哲学项目定位:作者将自己的工作定位在一个更广泛的哲学项目中,该项目关注词语的(误)使用,而非形而上学问题。
讨论“信念”一词的使用:作者讨论了在不同层次的LLMs系统中,使用“信念”一词的适当性,并提出了一个层次结构。
强调行为与信念的关系:作者强调,信念的概念与行为紧密相关,并讨论了如何将“信念”一词应用于LLMs。
提出层次结构:作者提出了一个从“bare-bones” LLM到更复杂的、能够进行多种行为的LLM-based系统的层次结构。
提醒人类化语言的谨慎使用:作者提醒读者在使用人类化的语言来描述LLMs时要谨慎。
由于这篇论文是一个哲学讨论,它依赖于逻辑推理、概念分析和哲学论证,而不是实验数据。因此,论文中没有提到具体的实验设计或实验结果。
Q: 有什么可以进一步探索的点?
A: 基于这篇论文的内容和讨论,以下是一些可以进一步探索的点:
LLMs的认知模型:
- 研究LLMs在何种程度上可以被视为具有认知能力,以及它们的认知模型与人类认知模型之间的相似性和差异。
语言使用的哲学分析:
- 深入分析“信念”、“知识”和“意图”等词汇在描述LLMs时的适用性,以及这些词汇的哲学含义。
人类化语言的限度:
- 探讨在使用人类化语言描述LLMs时的限度和潜在的误导性,以及如何更准确地描述这些系统的行为和能力。
LLMs的行为和交互:
- 研究LLMs在与人类交互时的行为模式,以及这些模式如何与人类行为相比较。
多模态LLMs的发展:
- 探索多模态LLMs(能够处理视觉和文本输入的模型)的发展,以及它们如何改变我们对LLMs能力和认知的看法。
LLMs的伦理和社会影响:
- 研究LLMs在社会中的使用所带来的伦理问题,包括隐私、偏见和责任归属等问题。
LLMs的自我修正能力:
- 探索LLMs是否能够基于反馈进行自我修正,以及这种能力如何影响我们对它们的认知和行为的理解。
LLMs与意识的关系:
- 深入探讨LLMs是否能够或在何种条件下可以被认为具有某种形式的意识,以及这对我们对“意识”概念的理解有何影响。
LLMs的教育应用:
- 研究LLMs在教育领域的应用,包括个性化学习、自动评分和知识传递等方面。
LLMs的长期发展和未来展望:
- 预测LLMs技术的长期发展趋势,以及它们可能对人类社会和文化的影响。
这些探索点涉及哲学、认知科学、人工智能、伦理学等多个领域,反映了LLMs作为一个跨学科研究领域的复杂性和多样性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
澄清误解:
- 作者Murray Shanahan澄清了关于他之前论文《Talking About Large Language Models》的误解,强调他并不支持将大型语言模型(LLMs)简化为仅仅是下一个词预测器的观点,也不认为LLMs没有信念或知识。
哲学立场:
- 作者将自己的工作定位在一个更广泛的哲学项目中,该项目关注词语的(误)使用,而非形而上学问题。他引用了维特根斯坦后期的著作,特别是《哲学研究》,来支持他的观点。
讨论“信念”一词的使用:
- 作者讨论了在不同层次的LLMs系统中,使用“信念”一词的适当性,并提出了一个层次结构,随着系统的复杂性增加,使用“信念”一词的适当性也在增加。
行为与信念的关系:
- 作者强调,信念的概念与行为紧密相关,并认为使用“信念”一词的原始语境是活跃的、行为化的人类(和其他动物),而将其用于完全被动的计算实体则偏离了这个词的原始语境。
层次结构:
- 作者提出了一个从“bare-bones” LLM到更复杂的、能够进行多种行为的LLM-based系统的层次结构,在这个结构中,随着系统的复杂性增加,使用“信念”一词的适当性也在增加。
人类化语言的谨慎使用:
- 作者提醒读者在使用人类化的语言来描述LLMs时要谨慎,因为LLMs在基本的机械层面上与人类非常不同。
论文的意图:
- 作者总结他的意图不是采取关于信念的形而上学立场,也不是基于这些立场支持对LLM能力的简化观点。相反,他的目标是提醒读者LLM-based系统与人类在基本操作层面上的差异,并在使用拟人化语言描述它们时保持谨慎。
总的来说,这篇论文旨在纠正对作者之前工作的误解,并提供一个更清晰的哲学视角来理解LLMs,特别是关于它们是否具有信念和知识的问题。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

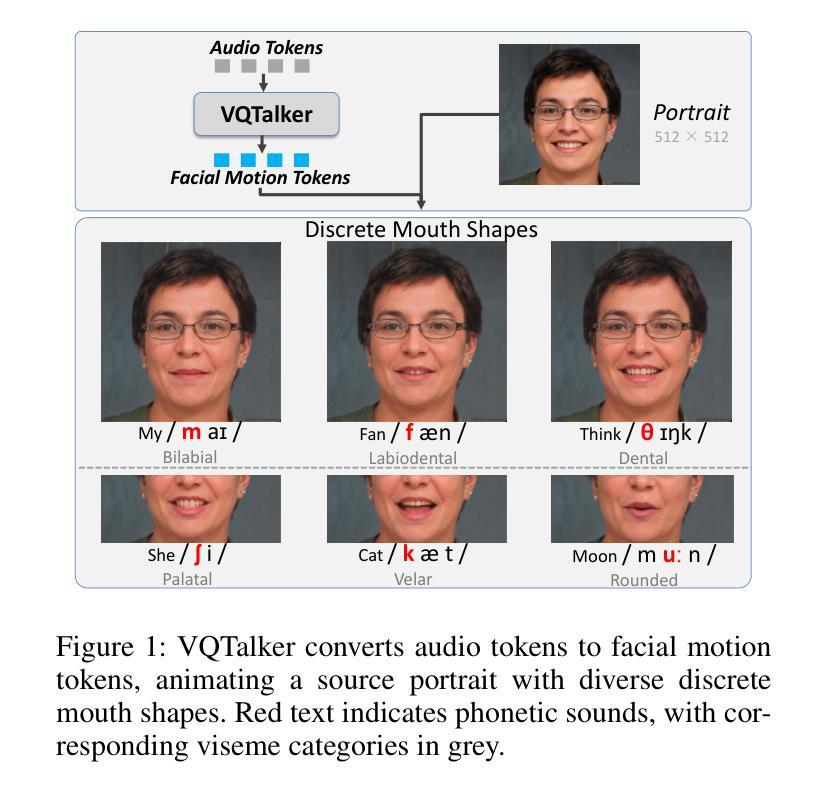
VQTalker: Towards Multilingual Talking Avatars through Facial Motion Tokenization
Authors:Tao Liu, Ziyang Ma, Qi Chen, Feilong Chen, Shuai Fan, Xie Chen, Kai Yu
We present VQTalker, a Vector Quantization-based framework for multilingual talking head generation that addresses the challenges of lip synchronization and natural motion across diverse languages. Our approach is grounded in the phonetic principle that human speech comprises a finite set of distinct sound units (phonemes) and corresponding visual articulations (visemes), which often share commonalities across languages. We introduce a facial motion tokenizer based on Group Residual Finite Scalar Quantization (GRFSQ), which creates a discretized representation of facial features. This method enables comprehensive capture of facial movements while improving generalization to multiple languages, even with limited training data. Building on this quantized representation, we implement a coarse-to-fine motion generation process that progressively refines facial animations. Extensive experiments demonstrate that VQTalker achieves state-of-the-art performance in both video-driven and speech-driven scenarios, particularly in multilingual settings. Notably, our method achieves high-quality results at a resolution of 512*512 pixels while maintaining a lower bitrate of approximately 11 kbps. Our work opens new possibilities for cross-lingual talking face generation. Synthetic results can be viewed at https://x-lance.github.io/VQTalker.
我们推出了VQTalker,这是一个基于向量量化的多语种谈话头部生成框架,解决了跨不同语言的嘴唇同步和自然动作挑战。我们的方法基于语音学原理,即人类语音由一组有限的不同声音单元(音素)和相应的视觉发音(可见语音)组成,这些语音单元在多种语言中经常具有共性。我们引入了基于组残差有限标量量化(GRFSQ)的面部运动标记器,它创建了一种面部特征的离散表示。这种方法能够全面捕捉面部动作,同时提高了对多种语言的泛化能力,即使在有限的训练数据下也是如此。基于这种量化表示,我们实现了一种从粗到细的动作生成过程,逐步优化面部动画。大量实验表明,VQTalker在视频驱动和语音驱动场景中均达到了最新技术水平,特别是在多语言环境中。值得注意的是,我们的方法在512*512像素的分辨率下实现了高质量的结果,同时保持了大约11kbps的较低比特率。我们的工作开启了跨语言交谈面部生成的全新可能性。合成结果可在https://x-lance.github.io/VQTalker查看。
论文及项目相关链接
PDF 14 pages
Summary
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为VQTalker的框架,旨在解决多语言说话头像生成中的两个主要挑战:唇部同步和跨不同语言的自然运动。具体来说,论文试图解决的问题包括:
唇部同步问题:精确的唇部同步对于创造真实的面部动画至关重要,由于McGurk效应,人类的语音感知受到听觉和视觉线索之间复杂交互的影响。现有的音频驱动的说话头像生成方法在唇部同步方面仍然存在问题,例如音频和视觉线索之间的错位或缺少特定的唇形。
跨语言的泛化问题:大多数现有的训练数据集主要由印欧语系语言(如英语、德语和法语)主导,这导致在这些语言家族内训练的模型表现良好,但往往无法准确捕捉其他语言群体的唇部运动和面部表情。此外,现有方法依赖于连续表示,这可能导致训练难度增加,并导致模型过度拟合特定语言。
数据量和泛化能力问题:虽然有些方法通过增加其他语言的训练数据量来改善模型性能,但这种策略资源密集,对于少数语言尤其具有挑战性。简单地增加数据量可能无法完全解决模型需要跨不同语言系统泛化的根本需求。
VQTalker框架通过基于向量量化的方法来解决这些问题,通过将离散的语音单元映射到离散的面部运动标记,捕捉跨不同语言的语音驱动面部动画的基本元素,从而提高在多语言设置中的性能。
Q: 有哪些相关研究?
A: 论文中提到了多个与VQTalker框架相关的研究工作,涉及的领域包括语音驱动的头像生成、面部表示学习、面部标记化以及向量量化技术等。以下是一些具体的相关研究:
语音驱动的头像生成方法:
- Zhang et al. (2023a)
- Ma et al. (2023)
- Liu et al. (2024)
面部表示学习:
- He et al. (2024)
- Xu et al. (2024)
- Drobyshev et al. (2024)
面部标记化(Facial Tokenization):
- Xing et al. (2023a)
- Tan, Ji, and Pan (2024)
- Yu et al. (2024)
向量量化(Vector Quantization, VQ)技术:
- Group VQ (GVQ):Baevski, Schneider, and Auli (2020); Chen, Watanabe, and Rudnicky (2023)
- Residual VQ (RVQ):Zeghidour et al. (2021); Copet et al. (2024)
- Finite Scalar Quantization (FSQ):Fabian et al. (2024)
其他相关技术:
- VQ-VAE (Esser, Rombach, and Ommer 2021):用于面部标记化的方法。
- BERT模型 (Devlin et al. 2019):用于粗到细的运动生成过程。
这些研究为VQTalker框架提供了理论基础和技术背景,特别是在处理多语言说话头像生成中的唇部同步和自然运动方面。通过结合这些技术,VQTalker旨在提高跨语言的泛化能力,并在有限的训练数据下实现更高效的面部动画生成。
Q: 论文如何解决这个问题?
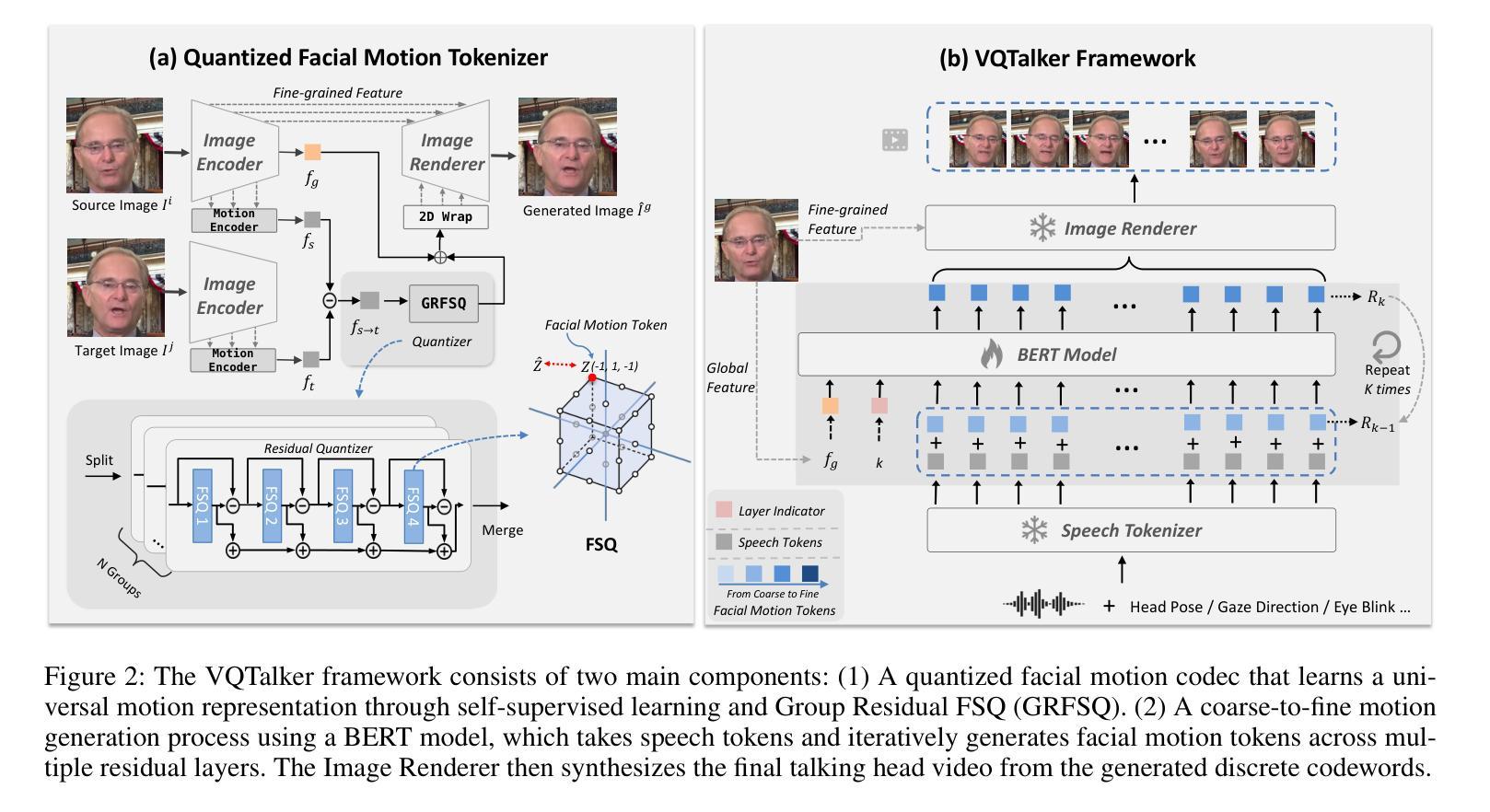
A: 论文通过提出VQTalker框架来解决多语言说话头像生成中的挑战,具体方法如下:
基于向量量化的框架(Vector Quantization-based framework):
- VQTalker利用基于向量量化的方法来捕捉面部运动,这种方法基于人类语音由有限的音素(phonemes)和相应的可视发音动作(visemes)组成的原理,这些在不同语言间通常有共通性。
面部运动标记化(Facial Motion Tokenization):
- 引入了基于Group Residual Finite Scalar Quantization(GRFSQ)的面部运动标记化方法,创建面部特征的离散表示。这种方法能够在有限的训练数据下改善对细微唇部运动的捕捉,并提高跨语言的泛化能力。
多策略量化方法(Multi-strategy Quantization Method):
- 采用GRFSQ方法,结合组量化、残差量化和有限标量量化策略,以实现高效的高分辨率面部运动建模,同时保持低比特率。
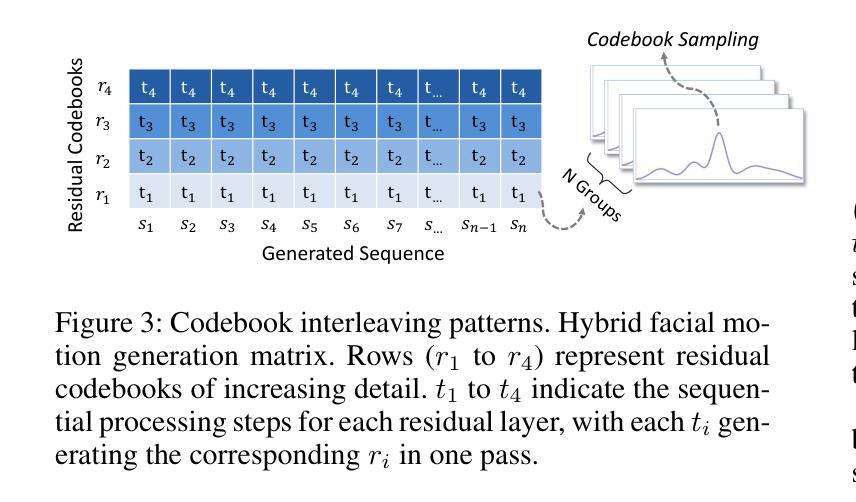
粗到细的运动生成过程(Coarse-to-fine Motion Generation Process):
- 实现了一个从粗到细的运动生成过程,使用BERT模型将离散的音频特征转换为面部运动标记,并逐步优化面部动画。这种方法结合了非自回归时序和自回归粒度方法,提高了动画的一致性和效率。
离散表示的优势:
- 通过将连续的语音单元映射到离散的面部运动标记,VQTalker能够高效地模拟语音到面部运动的相关性,并且离散表示允许模型学习更紧凑的表示,减少信息泄露,而无需额外的模块或损失。
实验验证:
- 通过广泛的实验,论文展示了VQTalker在视频驱动和语音驱动场景下都达到了最先进的性能,特别是在多语言设置中。此外,该方法在512×512像素的高分辨率下实现了高质量的结果,同时保持了大约11 kbps的低比特率。
总结来说,VQTalker框架通过结合面部运动的离散表示和粗到细的生成过程,有效地解决了多语言说话头像生成中的唇部同步和自然运动问题,并在保持低比特率的同时实现了高分辨率的动画生成。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估VQTalker框架的性能,这些实验包括:
视频重建结果(Video Reconstruction Result):
- 在HDTF数据集上评估了VQTalker与其他几种最先进的面部重演方法的性能,包括FOMM、DPE、MTIA、Vid2Vid、LIA、FADM、AniTalker、LivePortrait和EMOPortrait。评估指标包括结构相似性指数(SSIM)、学习感知图像补丁相似性(LPIPS)、余弦相似性(CSIM)、累积概率模糊检测(CPBD)等。
粗到细实验(Coarse-to-fine Experiment):
- 评估了VQTalker与其他几种语音驱动方法(SadTalker、EAT、PD-FGC、AniTalker、EDTalker、EchoMimic)的性能,包括在印欧语系(HDTF数据集)和非印欧语系(MNTE数据集)上的性能。评估指标与视频重建结果相同。
消融研究(Ablation Study):
- 码本设计(Codebook Design):比较了不同的码本设计在跨身份驱动场景下的性能,包括VQ、GVQ、RVQ和GRVQ等方法。
- 离散与连续表示(Discrete vs. Continuous Representation):比较了离散和连续表示在音频和运动特征中的性能,包括Whisper Large v2、VQ-Wav2vec、CosyVoice和GRFSQ等方法。
特定损失权重的影响(Effects of Loss Weight):
- 进行了消融实验来展示在眼动和口型建模中区域特定加权方法的有效性。通过比较有无眼动和口型损失的重建结果,展示了加权损失对于改善特定面部特征建模的作用。
VQ作为瓶颈结构(VQ as a Bottleneck Structure):
- 通过可视化消融实验来展示离散表示相比于连续表示在跨身份驱动场景下更不容易出现信息泄露的问题。
这些实验全面评估了VQTalker在不同方面的性能,包括视频重建、语音驱动的面部动画生成、不同码本设计的影响、离散与连续表示的比较,以及特定损失权重对模型性能的影响。通过这些实验,论文展示了VQTalker在多语言设置中生成高质量、高分辨率面部动画的能力。
Q: 有什么可以进一步探索的点?
A: 尽管VQTalker框架在多语言说话头像生成方面取得了令人瞩目的成果,但仍有一些领域可以进一步探索和改进:
极端面部运动的处理:
- 在涉及极端面部运动的场景中,可能会偶尔出现轻微的抖动。可以通过探索更高分辨率的量化空间或更先进的量化技术来减轻这一问题。
复杂背景和配饰的处理:
- 由于使用包裹方法,复杂的背景或配饰有时会导致背景或配饰边缘出现模糊。未来的研究可以集中于改进背景处理和配饰集成方法。
提高跨语言泛化能力:
- 尽管VQTalker在多语言设置中表现出色,但可以进一步研究如何提高模型对罕见或低资源语言的泛化能力。
计算效率优化:
- 研究如何优化VQTalker的计算效率,使其能够在资源受限的设备上实时运行。
更精细的面部特征控制:
- 进一步改进眼部、嘴部等关键面部特征的控制精度,以实现更加真实和准确的面部动画。
数据集和训练策略的改进:
- 开发更多样化和平衡的数据集,包含更多非印欧语系语言,以提高模型的泛化能力。
- 探索更有效的训练策略,例如对抗训练或元学习,以提高模型的鲁棒性和适应性。
伦理和隐私问题:
- 随着技术的发展,需要深入探讨与深度伪造、身份盗窃和错误信息传播相关的伦理和隐私问题,并制定相应的指导原则和验证系统。
多模态融合:
- 研究如何将VQTalker与其他模态信息(如情感、手势)更有效地融合,以创造更丰富和自然的交流体验。
模型解释性和透明度:
- 提高模型的可解释性,让研究人员和用户更好地理解模型的决策过程。
跨领域应用:
- 探索VQTalker在其他领域的应用,如虚拟助手、游戏角色、教育和培训模拟等。
这些探索点不仅可以推动VQTalker技术的进步,还可能为计算机视觉、计算机图形学和人工智能领域的其他研究提供新的思路和方法。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了VQTalker,一个基于向量量化的框架,用于生成多语言的说话头像。以下是论文的主要内容总结:
问题陈述:
- 针对音频驱动的头像生成中唇部同步和跨语言自然运动的挑战,尤其是在非印欧语系中。
核心理念:
- 基于音素(phonemes)和可视发音动作(visemes)共享的普遍性,提出了一种将离散语音单元映射到离散面部运动标记的方法。
VQTalker框架:
- 包含面部运动标记化和粗到细的运动生成过程。
- 利用Group Residual Finite Scalar Quantization(GRFSQ)进行面部运动的量化,以实现信息压缩和提高泛化能力。
技术贡献:
- 提出了一种面部运动标记化方法,通过离散表示改善唇部运动捕捉和跨语言泛化。
- GRFSQ方法结合了组量化、残差量化和有限标量量化策略,以实现高分辨率面部运动建模和低比特率。
- 实现了一个粗到细的运动生成过程,结合非自回归时序和自回归粒度方法,提高动画的一致性和效率。
实验结果:
- 在视频驱动和语音驱动场景下均达到了最先进的性能,特别是在多语言设置中。
- 在512×512像素分辨率下实现了高质量的结果,同时保持了约11 kbps的低比特率。
消融研究和对比实验:
- 对码本设计、离散与连续表示的影响进行了消融研究。
- 展示了VQTalker在不同语言上的性能,并与其他方法进行了对比。
潜在的改进和未来工作:
- 提出了可能的改进方向,包括处理极端面部运动、优化背景和配饰处理、提高跨语言泛化能力等。
伦理考量:
- 讨论了数字人类技术发展带来的伦理挑战,并强调了制定伦理指南和验证系统的重要性。
VQTalker通过其创新的离散表示和粗到细的生成方法,在多语言说话头像生成领域提供了一种有效的解决方案,同时为未来的研究提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


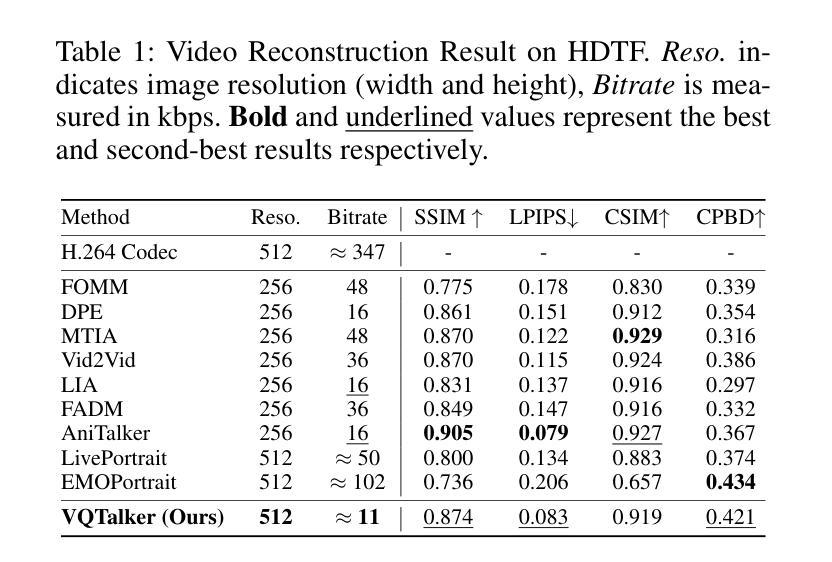
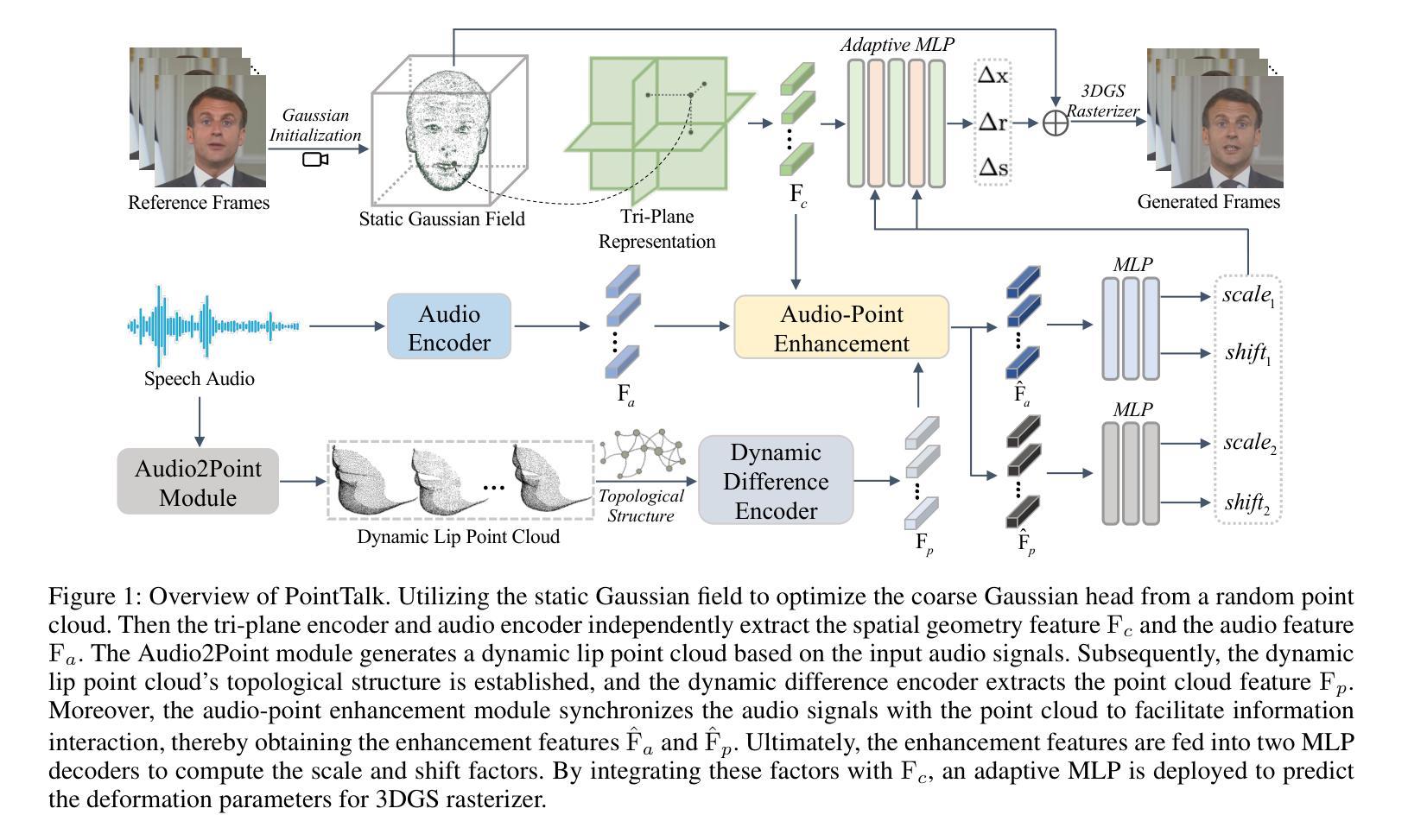
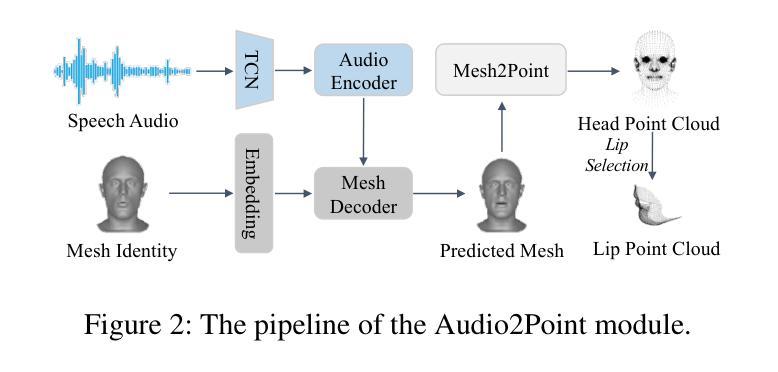
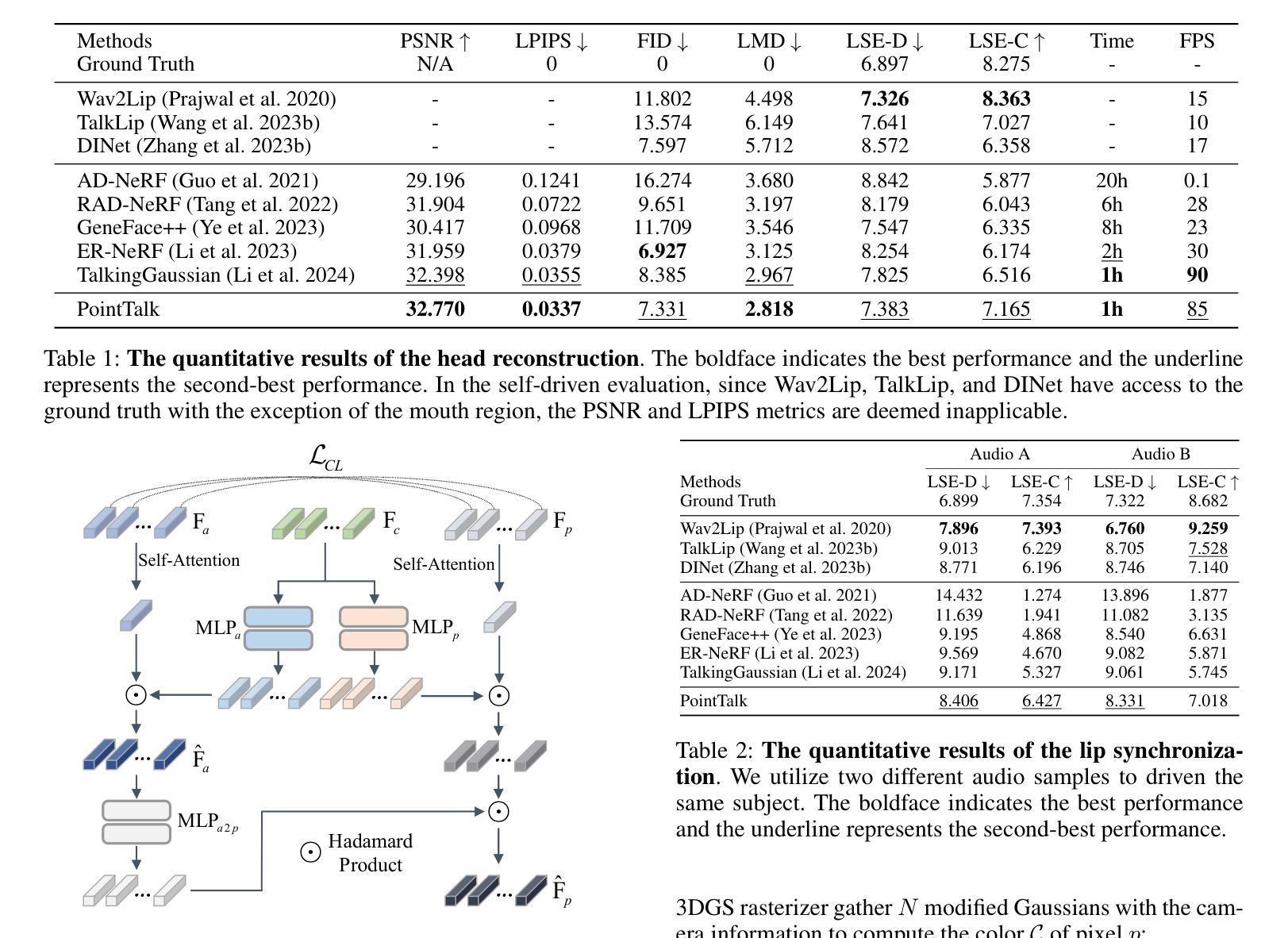
PointTalk: Audio-Driven Dynamic Lip Point Cloud for 3D Gaussian-based Talking Head Synthesis
Authors:Yifan Xie, Tao Feng, Xin Zhang, Xiangyang Luo, Zixuan Guo, Weijiang Yu, Heng Chang, Fei Ma, Fei Richard Yu
Talking head synthesis with arbitrary speech audio is a crucial challenge in the field of digital humans. Recently, methods based on radiance fields have received increasing attention due to their ability to synthesize high-fidelity and identity-consistent talking heads from just a few minutes of training video. However, due to the limited scale of the training data, these methods often exhibit poor performance in audio-lip synchronization and visual quality. In this paper, we propose a novel 3D Gaussian-based method called PointTalk, which constructs a static 3D Gaussian field of the head and deforms it in sync with the audio. It also incorporates an audio-driven dynamic lip point cloud as a critical component of the conditional information, thereby facilitating the effective synthesis of talking heads. Specifically, the initial step involves generating the corresponding lip point cloud from the audio signal and capturing its topological structure. The design of the dynamic difference encoder aims to capture the subtle nuances inherent in dynamic lip movements more effectively. Furthermore, we integrate the audio-point enhancement module, which not only ensures the synchronization of the audio signal with the corresponding lip point cloud within the feature space, but also facilitates a deeper understanding of the interrelations among cross-modal conditional features. Extensive experiments demonstrate that our method achieves superior high-fidelity and audio-lip synchronization in talking head synthesis compared to previous methods.
头部说话人合成与任意语音音频是数字人类领域的一个关键挑战。最近,基于辐射场的方法由于其仅从几分钟的训练视频就能合成高保真和身份一致的说话人头部的能力而越来越受到关注。然而,由于训练数据的规模有限,这些方法在音频和唇部同步以及视觉质量方面往往表现不佳。在本文中,我们提出了一种基于3D高斯的新型方法PointTalk,该方法构建了静态的3D高斯头部场域,并随着音频进行变形。它还结合了音频驱动的动态唇部点云作为条件信息的重要组成部分,从而促进了说话人头部的有效合成。具体来说,初始步骤是从音频信号生成相应的唇部点云并捕获其拓扑结构。动态差异编码器的设计旨在更有效地捕捉动态唇部运动中的微妙细节。此外,我们集成了音频点增强模块,这不仅确保了音频信号与特征空间内相应唇部点云的同步,还有助于更深入地理解跨模态条件特征之间的相互作用。大量实验表明,我们的方法在说话人头部合成方面实现了高保真和优越的音频唇部同步,相较于之前的方法有着显著的优势。
论文及项目相关链接
PDF 9 pages, accepted by AAAI 2025
Summary
基于辐射场的方法在数字人类说话头合成领域受到广泛关注,但受限于训练数据规模,存在音频与唇部同步性能不佳的问题。本文提出了一种基于3D高斯场的PointTalk方法,构建静态头部高斯场并同步变形以匹配音频。结合音频驱动的动态唇部点云作为条件信息,有效合成说话头。实验证明,该方法实现了高保真和音频唇部同步的优越性能。
Key Takeaways
- 说话头合成是一项挑战,尤其是与任意语音音频的合成。
- 基于辐射场的方法因其高保真度和身份一致性而受到关注,但存在音频-唇部同步和视觉质量问题。
- 本文提出了PointTalk方法,利用3D高斯场构建静态头部场并进行音频同步变形。
- 动态唇部点云作为关键条件信息,促进了说话头的有效合成。
- PointTalk通过生成与音频信号对应的唇部点云并捕捉其拓扑结构来实现精准合成。
- 动态差异编码器的设计更有效地捕捉了唇部细微动态变化。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是使用任意语音音频合成逼真的3D虚拟人物(数字人)头像,特别是关注于音频驱动的动态嘴唇同步和视觉质量。具体来说,论文中提到现有的基于辐射场(radiance fields)的方法虽然能够从少量训练视频中合成高保真度和身份一致的头像,但由于训练数据规模有限,这些方法在音频-嘴唇同步和视觉质量方面表现不佳。因此,论文提出了一个名为PointTalk的新型3D高斯基础方法,通过构建静态的3D高斯场并根据音频信号进行变形,同时引入音频驱动的动态唇点云作为条件信息的关键组成部分,以实现有效的头像合成。
Q: 有哪些相关研究?
A: 相关研究主要包括以下几个方向:
Talking Head Synthesis(头像合成):
- 2D-based Talking Head Synthesis:这些方法主要依赖于图像,特别是嘴巴部位,以确保音频与唇部动作相匹配。例如,Wav2Lip 和 TalkLip 等方法。
- 3D-based Talking Head Synthesis:这些方法通常使用3D Morphable Models (3DMM) 进行头像合成,但中间表示可能导致误差累积。Neural Radiance Fields (NeRF) 被应用于解决3D头部结构问题。
**Neural Radiance Fields (NeRF)**:
- AD-NeRF:利用NeRF进行音频驱动的头像合成的开创性方法。
- RAD-NeRF 和 ER-NeRF:引入了架构创新以增强条件特征,实现实时推理速度。
- GeneFace 及其变体:使用面部地标作为条件以提高对域外音频的泛化能力。
Point Cloud Learning(点云学习):
- PointNet 和 PointNet++:使用逐点MLP和池化层来聚合特征,理解3D场景。
- Point-BERT:将BERT的掩码语言建模方法适应到3D领域。
- RECON 和 PointGPT:结合生成和对比学习范式以增强3D表示学习。
**3D Gaussian Splatting (3DGS)**:
- 3DGS 最近在3D场景重建中取得了令人印象深刻的结果,使用3D高斯作为离散的几何原语,提供了场景的清晰表示,并优化了实时渲染性能。
这些相关研究构成了PointTalk方法的理论和技术支持,PointTalk通过结合这些技术,提出了一个新的3D高斯基础框架,用于实现更逼真和有效的头像合成。
Q: 论文如何解决这个问题?
A: 论文通过提出一个名为PointTalk的新型3D高斯基础方法来解决这个问题,具体解决方案包括以下几个关键步骤和组件:
3D Gaussian-based Framework(3D高斯基础框架):
- 利用3DGS(3D Gaussian Splatting)来构建一个静态的3D高斯场,表示头部的几何结构。
- 通过音频信号动态地变形这个高斯场,以实现与音频同步的头部动作。
Audio2Point Module(音频到点云模块):
- 从输入的音频信号生成动态的唇部点云,捕捉唇部动作的拓扑结构。
- 使用多分辨率哈希网格来有效地编码点云。
Dynamic Difference Encoder(动态差异编码器):
- 设计用于捕捉唇部动作微妙变化的动态差异编码器。
- 通过比较相邻帧的特征差异来提取点云特征。
Audio-Point Enhancement Module(音频-点云增强模块):
- 同步音频信号与相应的唇部点云,并理解跨模态特征之间的相关性。
- 使用交叉模态对比学习策略和外部注意力机制来增强特征。
Adaptive 3DGS Rendering(自适应3DGS渲染):
- 使用自适应特征融合方法(基于AdaIN)来整合条件特征和空间几何特征。
- 通过3DGS光栅器计算像素颜色,生成最终的头像视频。
Loss Function(损失函数):
- 结合像素级损失、结构相似性损失、LPIPS损失和跨模态对比学习损失来训练模型。
通过这些方法,PointTalk旨在实现以下目标:
- 生成与输入音频同步的逼真头像视频。
- 保持视觉身份的一致性。
- 提高唇部同步和面部细节的稳定性和真实感。
实验结果表明,PointTalk在头像合成的高保真度和音频-唇部同步方面优于先前的方法。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证PointTalk方法的有效性:
实验设置:
- 数据集:使用了包含英语和法语的高清说话视频剪辑,每个视频平均约7500帧,以25 FPS的速率进行采集,并将每个原始视频裁剪和调整为512×512的分辨率。
- 比较基线:与三种2D方法(Wav2Lip, TalkLip, DINet)和五种3D方法(AD-NeRF, RAD-NeRF, GeneFace++, ER-NeRF, TalkingGaussian)进行比较。
定量评估:
- 指标:使用峰值信噪比(PSNR)、学习感知图像补丁相似性(LPIPS)、Fréchet Inception Distance(FID)、地标距离(LMD)、唇部同步误差距离(LSE-D)和唇部同步误差置信度(LSE-C)等指标。
- 比较设置:分为头部重建设置和唇部同步设置两个不同的设置进行评估。
- 结果:PointTalk在图像质量和唇部同步的大多数指标上优于其他方法,特别是在唇部同步指标上的提升更为明显。
定性评估:
- 结果展示:通过展示关键帧和特写镜头来直观比较PointTalk与其他方法的图像质量和唇部同步。
- 用户研究:邀请16名参与者对36个视频剪辑进行评分,基于图像质量、视频真实性和音视频同步三个方面进行评价,PointTalk在所有方面均优于先前的方法。
消融研究:
- 唇点云编码器:比较了使用多分辨率哈希网格、图神经网络(GNN)和三平面表示对唇点云拓扑结构提取的效果。
- 动态差异编码器(DDE):展示了DDE在捕捉唇部细微动作方面的重要性。
- Audio-Point Enhancement模块:评估了跨模态对比学习(CCL)和外部注意力(Att)在同步音频信号与唇点云和理解跨模态特征相关性方面的效果。
这些实验全面地验证了PointTalk方法在3D虚拟人物头像合成中音频-唇部同步和视觉质量方面的性能,并展示了其在不同设置下的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管PointTalk在3D虚拟人物头像合成方面取得了显著的成果,但仍有一些领域可以进一步探索和改进:
数据集多样性:
- 扩大训练数据集以包含更多的语言、口音和面部特征,以提高模型的泛化能力和适应性。
实时性能优化:
- 尽管PointTalk已经实现了接近实时的推理速度,但进一步优化算法和计算效率,特别是在移动或低功耗设备上的应用。
更准确的唇部运动捕捉:
- 研究更精细的唇部运动捕捉技术,以实现更加自然和精确的唇部同步。
提高表情和头部动作的自然性:
- 除了唇部同步之外,探索如何更准确地模拟和渲染面部表情和头部动作。
交互式应用:
- 开发交互式应用,允许用户实时控制虚拟人物的表情、语言和动作,以实现更丰富的人机交互体验。
多模态融合技术:
- 研究更先进的多模态融合技术,以整合视觉、音频和文本信息,提高虚拟人物的自然性和逼真度。
模型压缩和加速:
- 探索模型压缩和加速技术,以减少模型的计算资源需求,使其更适合在边缘设备上部署。
跨模态对抗攻击和防御:
- 研究跨模态对抗攻击对虚拟人物合成的影响,并开发有效的防御机制。
伦理和隐私问题:
- 随着虚拟人物合成技术的发展,探讨相关的伦理和隐私问题,确保技术的负责任使用。
多人物交互场景:
- 从单一人物合成扩展到多人物交互场景,模拟更复杂的社交互动。
这些方向不仅可以推动虚拟人物合成技术的发展,还可能带来新的应用场景和研究问题。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题定义:
论文针对的是使用任意语音音频合成逼真的3D虚拟人物头像的挑战,特别是在音频-唇部同步和视觉质量方面。PointTalk方法:
提出了一个名为PointTalk的新型3D高斯基础方法,该方法通过构建静态的3D高斯场并根据音频信号进行动态变形,同时引入音频驱动的动态唇点云作为关键条件信息,以实现有效的头像合成。主要贡献:
- 提出了PointTalk框架,整合音频驱动的动态唇点云以实现逼真的头像合成。
- 引入Audio2Point模块,从语音中生成动态唇点云,并使用动态差异编码器来捕捉唇部运动的细微差别。
- 设计了音频-点云增强模块,同步音频信号与唇点云,并理解跨模态条件特征之间的相关性。
方法细节:
- 描述了PointTalk的三个关键组成部分:多属性分支、音频-点云增强模块和自适应3DGS渲染。
- 详细阐述了如何使用3D高斯分支处理高斯原语,如何使用音频分支提取音频特征,以及如何通过唇点云分支捕捉唇部动作。
- 介绍了音频-点云增强模块的工作机制,包括跨模态对比学习策略和外部注意力机制。
- 讨论了自适应3DGS渲染过程,包括特征融合和光栅化。
实验验证:
- 通过定量和定性实验评估了PointTalk的性能,并与现有方法进行了比较。
- 实验结果显示PointTalk在头像合成的高保真度和音频-唇部同步方面优于先前的方法。
- 进行了消融研究,验证了各个组件对性能的贡献。
结论:
- 论文总结了PointTalk方法的主要贡献,并强调了其在实现逼真头像合成方面的优越性能。
总体而言,这篇论文提出了一个创新的方法来提高3D虚拟人物头像合成的逼真度和唇部同步精度,通过结合3D高斯场和音频驱动的动态唇点云,在该领域取得了显著的进展。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


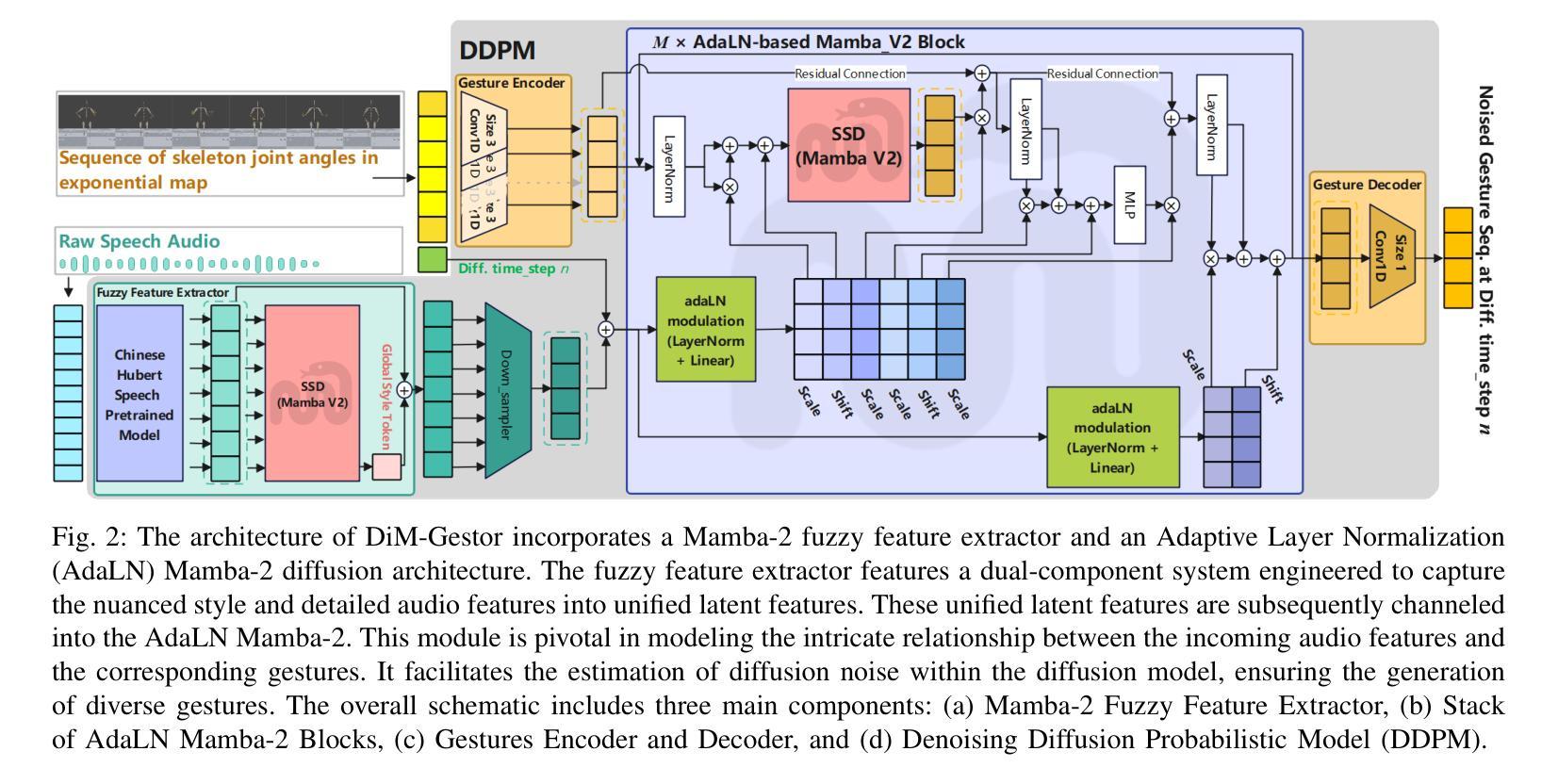
DiM-Gestor: Co-Speech Gesture Generation with Adaptive Layer Normalization Mamba-2
Authors:Fan Zhang, Siyuan Zhao, Naye Ji, Zhaohan Wang, Jingmei Wu, Fuxing Gao, Zhenqing Ye, Leyao Yan, Lanxin Dai, Weidong Geng, Xin Lyu, Bozuo Zhao, Dingguo Yu, Hui Du, Bin Hu
Speech-driven gesture generation using transformer-based generative models represents a rapidly advancing area within virtual human creation. However, existing models face significant challenges due to their quadratic time and space complexities, limiting scalability and efficiency. To address these limitations, we introduce DiM-Gestor, an innovative end-to-end generative model leveraging the Mamba-2 architecture. DiM-Gestor features a dual-component framework: (1) a fuzzy feature extractor and (2) a speech-to-gesture mapping module, both built on the Mamba-2. The fuzzy feature extractor, integrated with a Chinese Pre-trained Model and Mamba-2, autonomously extracts implicit, continuous speech features. These features are synthesized into a unified latent representation and then processed by the speech-to-gesture mapping module. This module employs an Adaptive Layer Normalization (AdaLN)-enhanced Mamba-2 mechanism to uniformly apply transformations across all sequence tokens. This enables precise modeling of the nuanced interplay between speech features and gesture dynamics. We utilize a diffusion model to train and infer diverse gesture outputs. Extensive subjective and objective evaluations conducted on the newly released Chinese Co-Speech Gestures dataset corroborate the efficacy of our proposed model. Compared with Transformer-based architecture, the assessments reveal that our approach delivers competitive results and significantly reduces memory usage, approximately 2.4 times, and enhances inference speeds by 2 to 4 times. Additionally, we released the CCG dataset, a Chinese Co-Speech Gestures dataset, comprising 15.97 hours (six styles across five scenarios) of 3D full-body skeleton gesture motion performed by professional Chinese TV broadcasters.
基于Transformer的生成模型驱动的语音驱动手势生成在虚拟人创建领域是一个快速发展的方向。然而,现有模型由于其二阶时间和空间复杂度,面临着重大挑战,限制了其可扩展性和效率。为了解决这些局限性,我们引入了DiM-Gestor,这是一个利用Mamba-2架构的创新端到端生成模型。DiM-Gestor采用双组件框架,包括(1)模糊特征提取器和(2)语音到手势映射模块,两者都基于Mamba-2构建。模糊特征提取器与中文预训练模型和Mamba-2相结合,可自主提取连续语音的隐含特征。这些特征被合成一个统一的潜在表示,然后由语音到手势映射模块进行处理。该模块采用带有自适应层归一化(AdaLN)增强的Mamba-2机制,可统一应用于所有序列标记的转换。这使得能够精确建模语音特征与手势动态之间的微妙相互作用。我们使用扩散模型来训练和推断多样的手势输出。在新发布的中文协同演讲手势数据集上进行的主观和客观评估证实了我们提出模型的有效性。与基于Transformer的架构相比,评估结果表明我们的方法提供了具有竞争力的结果,并且显著减少了内存使用(约2.4倍),提高了推理速度(2至4倍)。此外,我们还发布了CCG数据集,这是一个中文协同演讲手势数据集,包含由专业中文电视广播员表演的15.97小时(五种场景中的六种风格)的3D全身骨骼手势动作。
论文及项目相关链接
PDF 13 pages, 11 figures
Summary
基于Transformer的生成模型在虚拟人创建中的语音驱动动作生成是一个快速发展的领域。然而,现有模型面临时间和空间复杂度的挑战,限制了其可扩展性和效率。为解决这些问题,我们推出了DiM-Gestor模型,它采用Mamba-2架构,具有双组分框架,包括模糊特征提取器和语音到动作映射模块。模糊特征提取器结合中文预训练模型和Mamba-2,自主提取连续的语音特征,然后经过统一的潜在表示处理,进入语音到动作映射模块。模块采用自适应层归一化(AdaLN)增强的Mamba-2机制,在序列标记上均匀应用转换,精确建模语音特征和动作动态之间的微妙互动。我们在新发布的中文协同语音手势数据集上进行了主观和客观评估,证明了该模型的有效性。与基于Transformer的架构相比,我们的方法提供了有竞争力的结果,减少了大约2.4倍的内存使用,提高了2到4倍的推理速度。此外,我们还发布了CGG数据集。
Key Takeaways
- 基于Transformer的生成模型用于虚拟人的语音驱动动作生成是一个活跃的研究领域。
- 现有模型面临时间和空间复杂性的挑战,限制了其实际应用。
- DiM-Gestor模型采用Mamba-2架构,包括模糊特征提取器和语音到动作映射模块,以应对这些挑战。
- 模糊特征提取器结合中文预训练模型提取语音特征,为动作生成提供基础。
- AdaLN增强的Mamba-2机制能均匀应用转换,精确建模语音和动作之间的微妙互动。
- 在新发布的中文协同语音手势数据集上的评估证明了DiM-Gestor模型的有效性。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是提高虚拟人物创造中语音驱动手势生成的效率和可扩展性。具体来说,论文中提到的现有模型由于二次时间和空间复杂度而面临显著挑战,限制了它们的可扩展性和效率。这些问题主要体现在以下几个方面:
高内存使用和慢速推理:现有的基于Transformer的模型在处理语音驱动手势生成任务时,需要大量的内存和较慢的推理速度,这对于实时应用来说是不切实际的。
自然性和同步性的挑战:在语音驱动手势生成中,实现与语音同步的自然手势仍然是一个挑战,现有方法往往难以平衡手势和语音的同步性,导致生成的手势要么过于微妙,要么与语音过度同步。
中文数据集的缺乏:大多数现有的训练数据集主要关注英语内容,对于中文等其他语言的数据集较少,尤其是涉及到正式场合如电视广播或结构化对话的应用。
为了解决这些问题,论文提出了一个名为DiM-Gestor的创新端到端生成模型,该模型利用Mamba-2架构来减少计算复杂度,并通过一个双组分框架(包括模糊特征提取器和语音到手势映射模块)来精确建模语音特征和手势动态之间的复杂交互。此外,论文还发布了一个新的中文手势数据集(CCG数据集),以支持中文语音驱动手势生成的研究。
Q: 有哪些相关研究?
A: 根据提供的论文内容,相关研究主要包括以下几个方面:
基于Transformer和Diffusion的生成模型:
- DiffMotion [19]:将扩散模型应用于手势合成,并使用LSTM增强手势多样性。
- Cross-modal Quantization (CMQ) [20]:联合学习和编码语音和手势的量化代码。
- DiffWave [4]:通过替换扩张卷积,解锁了Transformer架构在手势生成中的潜力。
- GestureDiffuCLIP (GDC) [3]:使用Transformer和AdaIN层将风格引导直接整合到扩散过程中。
- DiffuseStyleGesture (DSG) [1] 和 DSG+ [2]:利用交叉局部注意力和层归一化在Transformer模型中。
- Persona-Gestor (PG) [5]:引入模糊特征提取器,使用1D卷积捕获原始语音音频的全局特征,并与AdaLN Transformer结合建模语音特征和手势序列之间的复杂关系。
共语音手势训练数据集:
- Trinity [15]、ZEGGS [16]、BEAT [17] 和 Hands 16.2M [18]:这些数据集主要关注英语内容,其中BEAT数据集包含12小时的中文内容,但主要是非结构化语音模式,不太适合需要正式场合的应用。
Mamba架构:
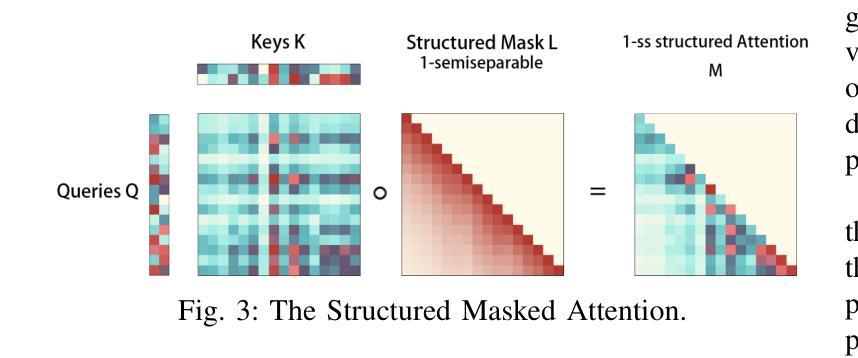
- Mamba架构 [7] 旨在解决传统Transformer的二次复杂度问题,并在多个领域(如视觉 [8]-[10]、分割 [11] 和图像任务 [12]、[13])得到验证。
- Mamba-2 [14] 通过State Space Duality (SSD)进一步确认了Mamba与Transformer的理论等价性,同时将复杂度降低到线性,从而实现更快、更高效的处理。
这些研究为DiM-Gestor模型的开发提供了理论基础和技术背景,特别是在提高手势生成的效率、灵活性以及降低资源消耗方面。通过结合这些相关研究,DiM-Gestor旨在实现更自然、个性化的共语音手势生成,同时减少内存使用和提高推理速度。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法解决了语音驱动手势生成中的效率和可扩展性问题:
1. 引入DiM-Gestor模型
DiM-Gestor是一个基于Mamba-2架构的端到端生成模型,它通过以下两个主要组件来生成共语音手势:
- 模糊特征提取器:结合了中文预训练模型和Mamba-2,自动提取语音的隐含、连续特征,并将这些特征合成为统一的潜在表示。
- 语音到手势映射模块:使用自适应层归一化(AdaLN)增强的Mamba-2机制,对所有序列标记应用统一的变换,精确建模语音特征和手势动态之间的复杂交互。
2. 利用Mamba-2架构
Mamba-2架构通过State Space Duality (SSD)减少了传统Transformer的二次复杂度,将其降低到线性复杂度,从而加快处理速度并减少资源消耗。这使得Mamba-2在处理长序列时比传统基于Transformer的模型更高效。
3. 应用扩散模型
DiM-Gestor使用扩散模型来训练和推断多样化的手势输出。这种模型通过逐步添加噪声并逆转这一过程来生成与给定语音上下文对齐的手势序列,提供了一种强大的框架来学习并合成具有高保真度和时间连贯性的共语音手势。
4. 发布CCG数据集
论文发布了一个新的中文共语音手势数据集(CCG),包含15.97小时的专业中文电视广播员的3D全身骨骼手势动作。这个数据集为中文语音驱动手势生成的研究提供了高质量的结构化数据,特别是在需要正式和上下文适当非语言交流的应用中。
5. 客观和主观评估
通过广泛的客观和主观评估,论文证明了DiM-Gestor模型在生成可信、与语音匹配的个性化手势方面的能力,同时实现了内存消耗的减少和推理速度的加快。
总结来说,论文通过结合先进的模型架构、优化的数据处理技术和大规模高质量数据集,提出了一种新的解决方案来提高语音驱动手势生成的效率和可扩展性。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了一系列实验来评估DiM-Gestor模型的性能,这些实验包括:
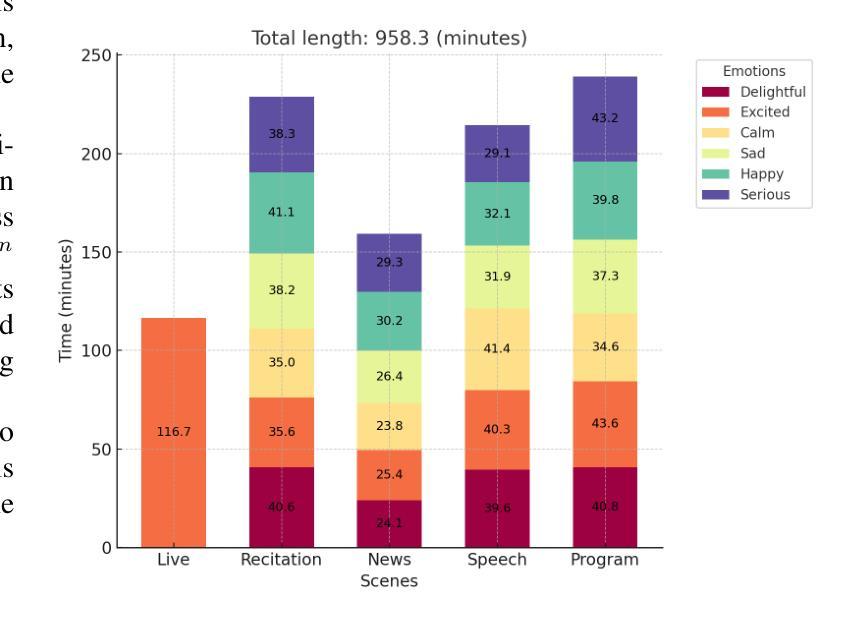
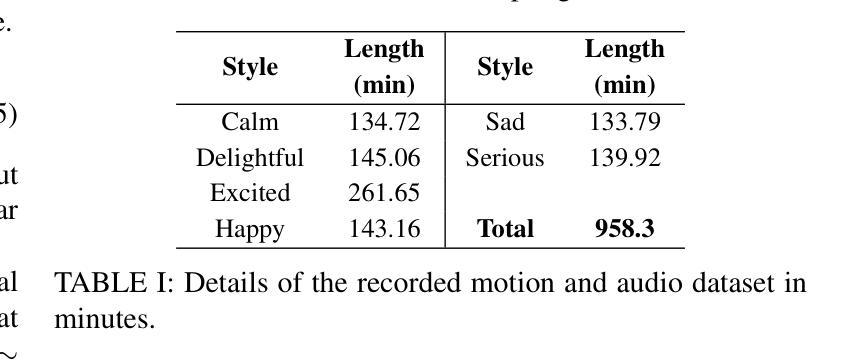
数据集录制和数据处理
构建CCG数据集:这是一个高质量的同步动作捕捉和语音音频数据集,包含391个独白序列,由12名女性和5名男性演员以中文进行表演,涵盖6种不同的情感风格和5种不同的场景。
语音音频数据处理:由于使用了预训练的中文Hubert语音模型,所有音频数据从44.1 kHz重采样到16 kHz以匹配模型的预训练条件。
手势数据处理:专注于全身手势,使用特定的技术处理手势数据,包括捕获平移和旋转速度,以准确描述根轨迹和方向,并将数据统一下采样到20 fps。
模型设置
- 使用Mamba-2架构作为全局模糊特征提取器,并设置六个AdaLN Mamba-2块。
- 每个Mamba-2配置有256 SSM状态扩展因子、局部卷积宽度为4和块扩展因子为2。
- 使用中国Hubert语音预训练模型(chinese-wav2vec2base)进行音频处理。
- 扩散模型使用四级方差时间表,从$\beta_1 = 1 \times 10^{-4}$到$\beta_N = 8 \times 10^{-2}$,总共1000个扩散步骤。
可视化结果
- 展示了DiM-Gestor模型生成的共语音手势效果,并与地面真实(GT)和PG模型进行比较分析。
主观和客观评估
主观评估:使用三个不同的指标进行评估:人类相似性(human-likeness)、适当性(appropriateness)和风格适当性(style-appropriateness)。通过用户研究进行成对比较,邀请了30名母语为中文的志愿者参与用户研究。
客观评估:使用三个客观评估指标来评估生成的手势的质量和同步性:Fr´echet Gesture Distance(FGD)在特征空间和原始数据空间中,以及BeatAlign分数。
消融研究
- 评估了模糊特征提取器和不同版本的Mamba框架中AdaLN架构的个体贡献。
参数计数和推理速度
- 对比了DiM-Gestor模型与PG模型(使用AdaLN Transformer架构)的参数计数和推理速度。
这些实验全面评估了DiM-Gestor模型在生成与语音同步的手势方面的能力,并与现有的最先进技术进行了比较。通过这些实验,作者证明了DiM-Gestor在生成自然、个性化的手势方面的优势,以及在参数效率和推理速度方面相比传统Transformer方法的改进。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
1. 模型优化和改进
- 加速扩散模型的集成:论文提到了通过集成加速的扩散模型sCM来提高推理速度的可能性。这可以显著减少推理时间,使其更适合交互式应用。
2. 数据集的扩展和多样化
- 多语言和多文化数据集:扩展CCG数据集,包含更多的语言和文化背景,以提高模型的泛化能力和适用性。
- 更丰富的情感和风格:增加数据集中的情感和风格多样性,以支持更广泛的应用场景。
3. 模型泛化能力的测试
- 跨数据集测试:在其他语言和文化背景的数据集上测试DiM-Gestor模型,以评估其泛化能力。
- 不同场景的应用:在不同的应用场景(如教育、娱乐、公共服务等)中测试模型,以评估其实用性和效果。
4. 用户体验和交互性
- 用户研究:进行更广泛的用户研究,以评估生成的手势在实际应用中的自然性、适当性和用户满意度。
- 实时应用的测试:在实时系统中测试模型,以评估其在实际交互环境中的性能。
5. 技术集成和应用开发
- 虚拟角色和数字人:将DiM-Gestor模型集成到虚拟角色和数字人应用中,以提高其表现力和互动性。
- 多模态交互系统:开发多模态交互系统,结合语音、手势、面部表情等多种交互方式,以创造更自然和直观的用户体验。
6. 算法和计算效率
- 计算效率的进一步优化:探索新的算法和技术,以进一步减少模型的计算复杂度和提高效率。
- 硬件加速:研究如何利用专用硬件(如GPU、TPU)加速模型的推理过程。
7. 伦理和社会影响
- 伦理考量:探讨虚拟人物和数字人在社会中的使用可能带来的伦理问题,如隐私、身份认同和真实性问题。
- 社会接受度:研究社会对虚拟人物和数字人的接受度,以及如何通过技术改进提高其社会接受度。
这些探索点可以帮助研究者和开发者更好地理解DiM-Gestor模型的潜力和局限性,同时推动语音驱动手势生成技术的发展和应用。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
1. 研究动机与目标
- 论文旨在解决虚拟人物创造中语音驱动手势生成的效率和可扩展性问题,特别是针对现有模型的高时间和空间复杂度问题。
2. DiM-Gestor模型的提出
- 论文介绍了DiM-Gestor,一个基于Mamba-2架构的端到端生成模型,用于生成共语音手势。
- 该模型包括模糊特征提取器和语音到手势映射模块,利用自适应层归一化(AdaLN)增强的Mamba-2机制。
3. Mamba-2架构的应用
- Mamba-2通过State Space Duality (SSD)减少了传统Transformer的二次复杂度,实现线性复杂度,从而加快处理速度并减少资源消耗。
4. 扩散模型的使用
- DiM-Gestor使用扩散模型来训练和推断多样化的手势输出,通过逐步添加和逆转噪声来生成与给定语音上下文对齐的手势序列。
5. CCG数据集的发布
- 论文发布了一个新的中文共语音手势数据集(CCG),包含15.97小时的专业中文电视广播员的3D全身骨骼手势动作。
6. 客观和主观评估
- 通过广泛的客观和主观评估,论文证明了DiM-Gestor在生成可信、与语音匹配的个性化手势方面的能力,同时实现了内存消耗的减少和推理速度的加快。
7. 实验结果
- 实验结果表明,DiM-Gestor在生成自然、个性化的手势方面具有优势,并且在参数效率和推理速度方面相比传统Transformer方法有所改进。
8. 未来工作
- 论文提出了未来可能的研究方向,包括模型优化、数据集扩展、模型泛化能力测试、用户体验和交互性研究、技术集成和应用开发等。
总体而言,这篇论文提出了一个创新的模型DiM-Gestor,用于高效生成与语音同步的手势,并通过一系列实验验证了其有效性,为虚拟人物创造和手势合成领域提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



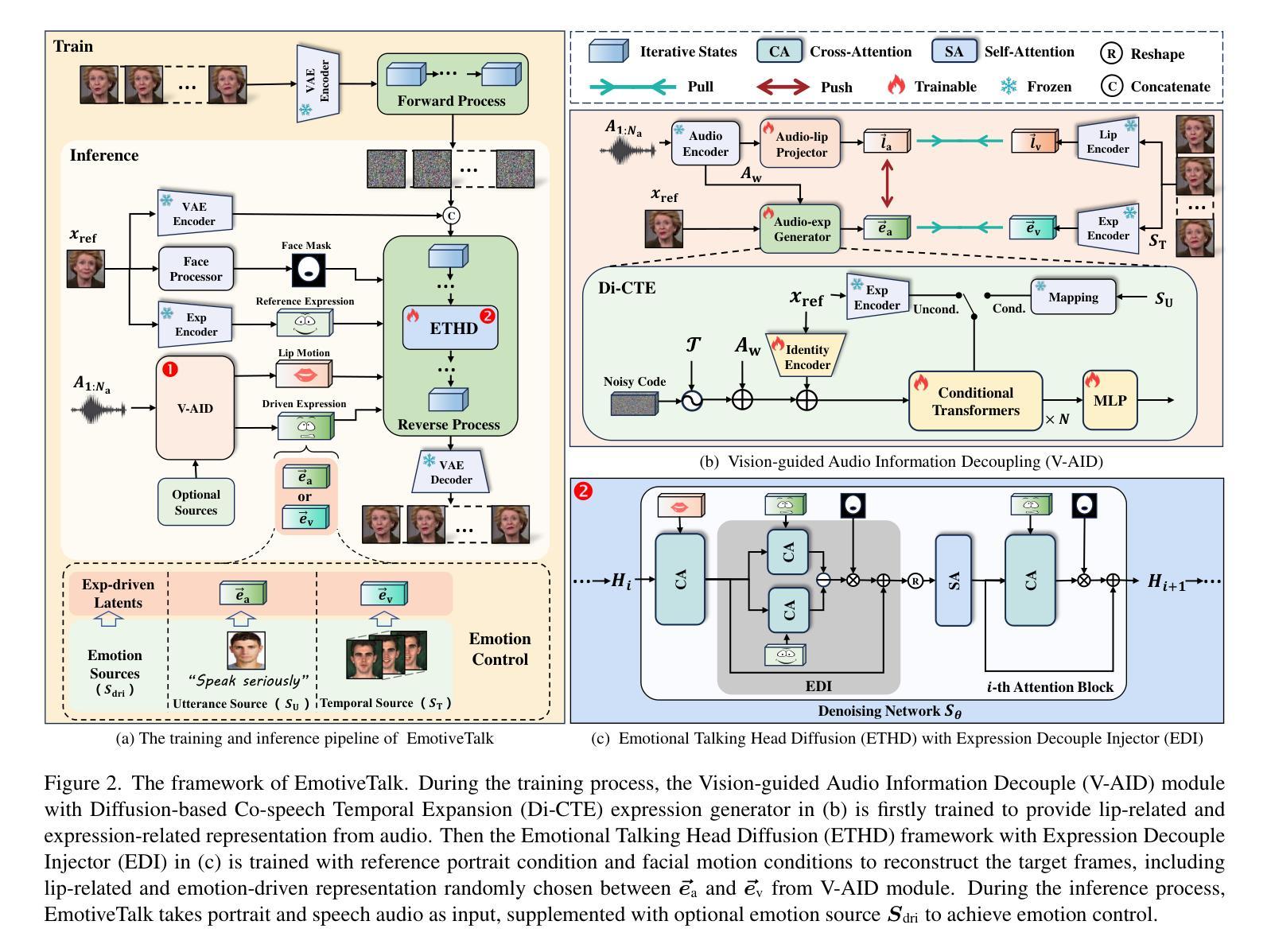
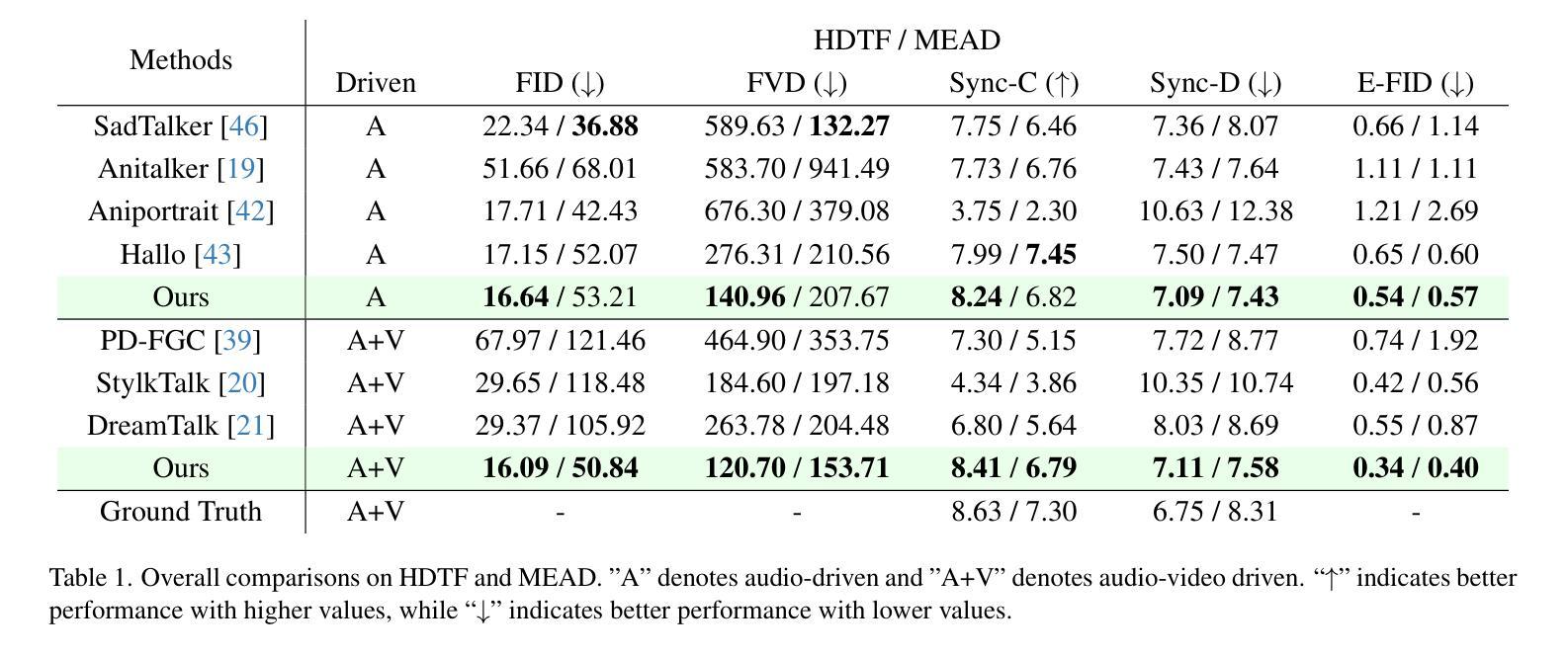
EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion
Authors:Haotian Wang, Yuzhe Weng, Yueyan Li, Zilu Guo, Jun Du, Shutong Niu, Jiefeng Ma, Shan He, Xiaoyan Wu, Qiming Hu, Bing Yin, Cong Liu, Qingfeng Liu
Diffusion models have revolutionized the field of talking head generation, yet still face challenges in expressiveness, controllability, and stability in long-time generation. In this research, we propose an EmotiveTalk framework to address these issues. Firstly, to realize better control over the generation of lip movement and facial expression, a Vision-guided Audio Information Decoupling (V-AID) approach is designed to generate audio-based decoupled representations aligned with lip movements and expression. Specifically, to achieve alignment between audio and facial expression representation spaces, we present a Diffusion-based Co-speech Temporal Expansion (Di-CTE) module within V-AID to generate expression-related representations under multi-source emotion condition constraints. Then we propose a well-designed Emotional Talking Head Diffusion (ETHD) backbone to efficiently generate highly expressive talking head videos, which contains an Expression Decoupling Injection (EDI) module to automatically decouple the expressions from reference portraits while integrating the target expression information, achieving more expressive generation performance. Experimental results show that EmotiveTalk can generate expressive talking head videos, ensuring the promised controllability of emotions and stability during long-time generation, yielding state-of-the-art performance compared to existing methods.
扩散模型已经彻底改变了说话人头部生成领域,但仍然面临长时间生成中的表现力、可控性和稳定性方面的挑战。在这项研究中,我们提出了一个EmotiveTalk框架来解决这些问题。首先,为了更好地控制唇部运动和面部表情的生成,我们设计了一种视觉引导音频信息解耦(V-AID)方法,生成基于音频的解耦表示,与唇部运动和表情对齐。具体来说,为了实现音频和面部表情表示空间的对齐,我们在V-AID中提出了基于扩散的共语时间扩展(Di-CTE)模块,在多元情绪条件约束下生成与表情相关的表示。然后,我们提出了一个精心设计的情感说话头部扩散(ETHD)主干网,以有效地生成高度逼真的说话人头视频,其中包含表情解耦注入(EDI)模块,该模块可自动从参考肖像中解耦表情,同时集成目标表情信息,从而实现更生动的生成性能。实验结果表明,EmotiveTalk可以生成生动的说话人头视频,确保情绪的可控性和长时间生成的稳定性,与现有方法相比达到最先进的性能。
论文及项目相关链接
PDF https://emotivetalk.github.io/
Summary
扩散模型在谈头生成领域引发了革命,但仍面临表现力、可控性和长时间生成的稳定性挑战。本研究提出EmotiveTalk框架来解决这些问题。首先,为更好地控制唇动和面部表情的生成,设计了Vision-guided Audio Information Decoupling(V-AID)方法,生成与唇动和表情一致的音频基础解耦表示。为实现音频和面部表情表示空间的对齐,我们在V-AID中提出了Diffusion-based Co-speech Temporal Expansion(Di-CTE)模块,在多源情绪条件约束下生成表情相关表示。然后,我们提出了精心设计的Emotional Talking Head Diffusion(ETHD)主干,以高效生成高度表达的谈头视频,其中包含了Expression Decoupling Injection(EDI)模块,可自动从参考肖像中解耦表情,同时整合目标表情信息,实现更生动的生成性能。实验结果证明,EmotiveTalk可生成表现力强的谈头视频,保证情绪的可控性和长时间生成的稳定性,达到现有方法的领先水平。
Key Takeaways
- 扩散模型在谈头生成中存在表现力、可控性和稳定性挑战。
- EmotiveTalk框架通过Vision-guided Audio Information Decoupling(V-AID)方法解决这些问题。
- V-AID中的Diffusion-based Co-speech Temporal Expansion(Di-CTE)模块实现音频和面部表情表示空间的对齐。
- Emotional Talking Head Diffusion(ETHD)主干高效生成高度表达的谈头视频。
- Expression Decoupling Injection(EDI)模块自动解耦表情并整合目标表情信息。
- EmotiveTalk能实现更生动的生成性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为EmotiveTalk的框架,旨在解决以下几个在头像生成领域中的挑战:
表达性(Expressiveness):传统的扩散模型在头像生成中虽然取得了一定的成功,但在生成具有丰富情感表达的头像视频方面仍存在不足。
可控性(Controllability):现有方法在控制生成的情感面部表情方面存在缺陷,尽管它们在实现语音和唇动同步方面取得了进展。
长时间生成的稳定性(Stability in long-time generation):目前的基于扩散的方法在长时间生成过程中常常面临稳定性问题,由于其自回归推理策略可能导致多个推理片段间的错误累积。
为了解决这些问题,EmotiveTalk框架通过以下几个关键技术来提高头像视频的表情丰富性、控制性和长时间生成的稳定性:
视觉引导的音频信息解耦(Vision-guided Audio Information Decoupling, V-AID):通过生成与唇动和表情对齐的基于音频的解耦表示来实现更好的控制。
基于扩散的情感头像生成(Emotional Talking Head Diffusion, ETHD):提出了一个高效视频扩散框架,用于表情丰富的头像视频生成,并包含表情解耦注入(Expression Decoupling Injection, EDI)模块以自动解耦参考肖像中的表情信息,同时整合目标表情信息,实现更具表现力的生成效果。
多源情感控制(Multi-source Emotion Control):通过整合来自多个可选情感驱动源的条件来增强情感控制能力,并实现生成情感的定制化。
总的来说,EmotiveTalk框架致力于通过技术创新来提升头像视频生成的表达性、控制性和稳定性,以达到更自然、更逼真的视频生成效果。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与EmotiveTalk框架相关的研究工作:
音频驱动的头像视频生成(Audio-driven Talking Head Video Generation):
- SadTalker [46] 和 Audio2Head [41]:通过整合3D信息和控制机制来增强头部动作的自然性。
- Diffused Heads [34] 和 DreamTalk [21]:实现了更加生动的结果。
- EMO [36], Hallo [43] 等:基于预训练的图像扩散模型,实现了高保真度的头像视频生成。
可控制的头像生成(Controllable Talking Head Generation):
- 早期方法 [8, 10, 12, 18, 31, 35]:通过离散的情感状态来建模表情。
- 最近的方法 [19–21, 39]:专注于从参考视频中传递表情到生成视频中。
- PDFGC [39] 和 Anitalker [19]:使用对比学习方法获取与表情相关的潜在表示,并实现表情驱动。
视频扩散模型(Video Diffusion Models):
- Video Diffusion Models (VDM) [16]:文本到视频扩散的先驱工作。
- ImagenVideo [15]:通过级联扩散模型增强VDM。
- Make-A-Video [30] 和 MagicVideo [50]:将这些概念扩展到实现无缝文本到视频转换。
- AnimateDiff [11]:使用运动模块实现从文本到图像到文本到视频的转换。
- Stable Video Diffusion (SVD) [5]:通过创新的训练策略生成高保真度视频。
这些相关工作涵盖了头像视频生成的不同方面,包括音频驱动的同步问题、表情控制的挑战、以及视频生成模型的发展。EmotiveTalk框架在这些领域的基础上,通过引入新的方法和技术,旨在提高头像视频生成的表情丰富性、控制性和稳定性。
Q: 论文如何解决这个问题?
A: 论文通过提出EmotiveTalk框架来解决头像生成中的表达性、控制性和稳定性问题,具体方法如下:
1. 视觉引导的音频信息解耦(Vision-guided Audio Information Decoupling, V-AID)
- 目标:实现对嘴唇运动和面部表情更好的控制。
- 方法:
- 使用预训练的Wav2Vec音频编码器处理音频流。
- 通过可训练的音频到嘴唇投影器和音频到表情生成器从音频中获取嘴唇和表情相关的潜在表示。
- 利用视觉空间中的嘴唇和表情表示来指导音频信息的解耦,并实现音频表示与视频表示的对齐。
2. 基于扩散的情感头像生成(Emotional Talking Head Diffusion, ETHD)
- 目标:高效生成动态长度的视频,确保在长时间生成过程中保持稳定性。
- 方法:
- 包含表情解耦注入(Expression Decoupling Injector, EDI)模块,自动从参考肖像中解耦表情信息,同时整合目标表情信息,实现更具表现力的生成效果。
- 使用3D-Unet架构和时空可分离的注意力机制,通过空间和时间注意力模块处理嘴唇相关信息和表情驱动信息。
3. 多源情感控制(Multi-source Emotion Control, MEC)
- 目标:基于控制源灵活控制生成视频中的情感表达。
- 方法:
- 支持基于时间或话语的情感控制,将外部表情驱动视频作为时间源,直接提取表情驱动的潜在表示。
- 对于仅提供一般情感信息的话语源,使用Di-CTE模块生成帧级表情驱动的潜在表示。
4. 训练和推理
- 训练:
- 先预训练V-AID模块以生成嘴唇相关和情感相关的表示,然后在训练ETHD主干网络时保持V-AID模块固定。
- 推理:
- 使用非自回归推理方法避免错误累积,将总时长相分成多个重叠片段,并使用DDIM采样器逐步去噪每个片段。
通过这些方法,EmotiveTalk框架能够在保持音频和唇动同步的同时,自定义生成视频的情感表达,同时确保长时间生成的稳定性,从而在头像视频生成领域实现突破。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,作者进行了一系列实验来评估和验证EmotiveTalk框架的性能。以下是实验的详细情况:
1. 实验设置(Experimental Setup)
- 数据集:使用了开源数据集HDTF和MEAD,这些数据集包含了不同性别、年龄和种族的说话个体视频。
- 训练策略:采用了两阶段训练策略。首先训练V-AID模块,然后在训练ETHD主干网络时保持V-AID模块固定。
- 评估指标:使用了多种定量指标,包括Fréchet Inception Distance (FID)、Fréchet Video Distance (FVD)、Synchronization-C (Sync-C)、Synchronization-D (Sync-D) 和 Expression-FID (E-FID)。
2. 整体评估(Overall Evaluation)
- 对比分析了EmotiveTalk与其他多种开源实现方法的性能,包括音频驱动和音视频驱动策略。
3. 消融研究(Ablation Study)
- 验证了V-AID模块、解耦表示、Di-CTE模块以及长时间生成稳定性的有效性。
4. 案例研究(Case Study)
- 比较了仅音频驱动方法的定性结果。
- 评估了不同方法在情感控制方面的性能。
5. 用户研究(User Study)
- 进行了用户研究,让参与者对不同方法生成的视频样本进行评分,评价指标包括唇同步质量、表情质量、结果的真实性和生成视频的质量。
这些实验全面评估了EmotiveTalk在头像视频生成中的性能,特别是在表情丰富性、控制性和稳定性方面,并与现有方法进行了比较。通过这些实验,作者展示了EmotiveTalk在生成高保真度和生动视频方面的优越性能。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和当前的研究进展,以下是一些可以进一步探索的点:
1. 运动模糊问题的处理
- 问题描述:EmotiveTalk在处理剧烈运动或表情变化时可能会出现运动模糊,影响生成视频的清晰度。
- 研究方向:应用运动检测和视频处理技术来减少训练数据中运动模糊的影响,或者开发新的模型架构来减少生成视频中的运动模糊。
2. 扩展情感控制的范围
- 问题描述:当前EmotiveTalk主要关注于通过文本控制离散的情感状态,对于细粒度的情感控制支持有限。
- 研究方向:利用多模态大型语言模型(MLLMs)对训练数据进行细粒度的情感标注,构建具有细粒度文本注释的头像视频数据集,以支持更精细的情感控制研究。
3. 显式控制头部运动
- 问题描述:EmotiveTalk目前仅关注于控制情感状态,并未显式控制头部运动。
- 研究方向:引入显式的头部运动控制信号,允许精确操纵期望的头部运动模式。
4. 多语言和方言的支持
- 问题描述:虽然EmotiveTalk展示了对不同语言的支持,但对于少数语言和方言的处理能力还有待验证。
- 研究方向:扩展模型以更好地支持多语言和方言,增强模型在不同语言环境中的泛化能力。
5. 提高生成效率和降低计算成本
- 问题描述:尽管EmotiveTalk在性能和效率之间取得了平衡,但在实际应用中,尤其是在资源受限的环境中,进一步提高效率和降低成本仍然是一个重要的研究方向。
- 研究方向:优化模型结构和训练策略,减少模型参数和计算需求,同时保持或提高生成质量。
6. 伦理和法律问题
- 问题描述:EmotiveTalk生成的视频具有很高的真实性,可能被用于制造假新闻或进行欺诈等不当用途。
- 研究方向:研究和开发先进的伪造检测技术,帮助识别合成的假图像和视频,减少非法使用的可能性。
这些探索点不仅涉及技术层面的改进,还包括对伦理、法律和社会影响的深入考虑,确保技术的发展能够造福社会,而不是带来负面影响。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为EmotiveTalk的框架,旨在提高头像视频生成的表达性、控制性和稳定性。以下是论文的主要内容总结:
1. 研究动机与目标
- 提出了现有头像生成技术在表达性、可控性和长时间生成稳定性方面的挑战。
- 旨在通过一个新的框架EmotiveTalk解决这些问题。
2. 方法论
- V-AID(视觉引导的音频信息解耦):通过生成与嘴唇运动和面部表情对齐的基于音频的解耦表示来实现更好的控制。
- ETHD(基于情感的视频扩散):提出了一个高效的视频扩散框架,用于生成高度表达性的头像视频,并包含EDI(表情解耦注入)模块以自动解耦参考肖像中的表情信息,同时整合目标表情信息。
- 多源情感控制(MEC):通过整合来自多个可选情感驱动源的条件来增强情感控制能力,并实现生成情感的定制化。
3. 实验与评估
- 使用HDTF和MEAD数据集进行训练和评估。
- 使用多种定量指标(FID、FVD、Sync-C、Sync-D和E-FID)进行评估。
- 与现有方法进行比较,展示了EmotiveTalk在生成高保真度和生动视频方面的优越性能。
4. 消融研究
- 验证了V-AID模块、解耦表示、Di-CTE模块以及长时间生成稳定性的有效性。
5. 案例研究与用户研究
- 对比了仅音频驱动方法的定性结果。
- 评估了不同方法在情感控制方面的性能。
- 进行了用户研究,验证了EmotiveTalk在唇同步质量、表情质量、结果真实性和生成视频质量方面的优势。
6. 结论与未来工作
- 总结了EmotiveTalk的主要贡献和优势。
- 提出了未来研究的方向,包括处理运动模糊、扩展情感控制范围、显式控制头部运动等。
7. 伦理考量
- 讨论了EmotiveTalk可能被滥用的风险,并提出了相应的预防措施。
总体而言,EmotiveTalk通过技术创新显著提高了头像视频生成的性能,特别是在表达性和情感控制方面,为未来的人机交互和多媒体应用提供了新的可能性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

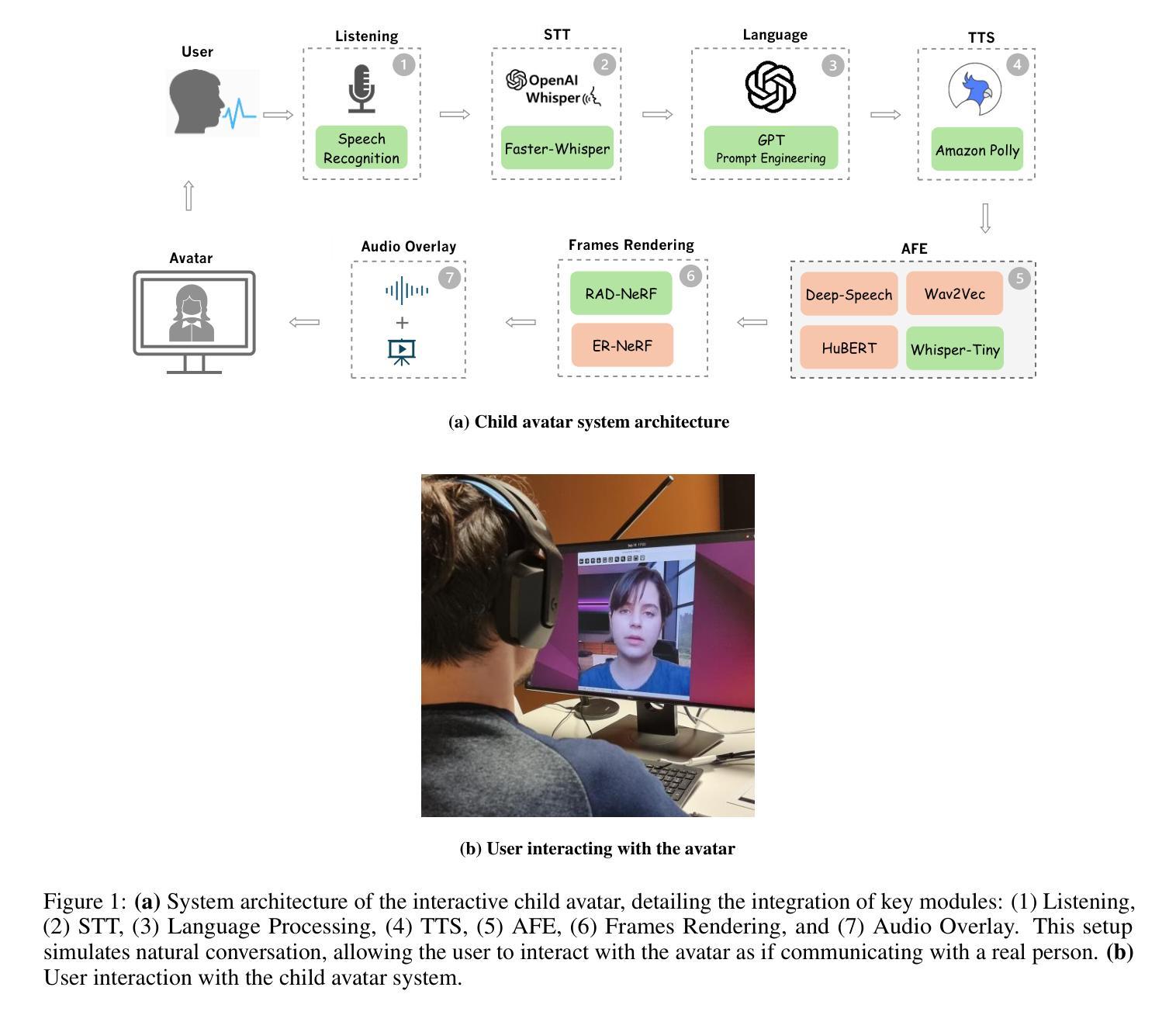
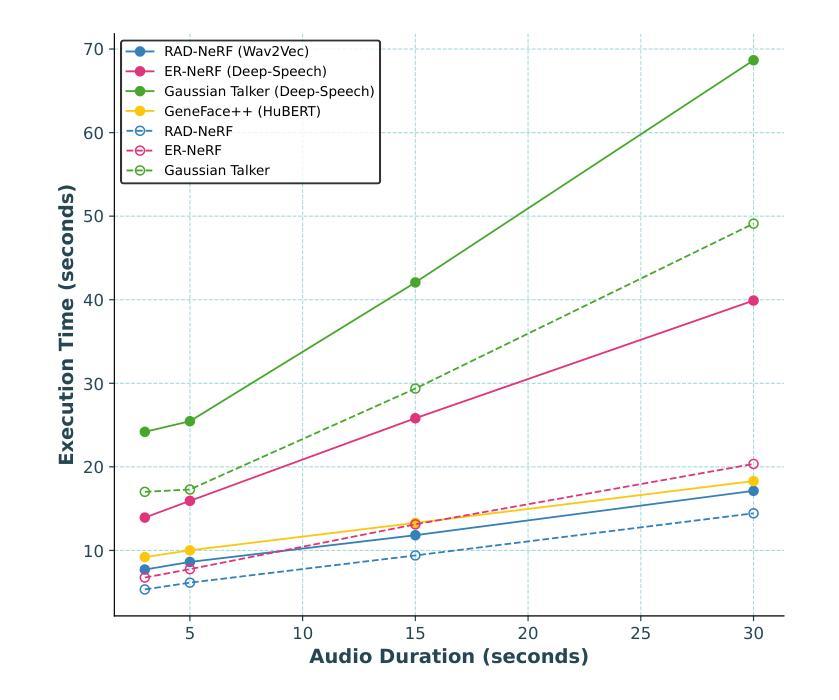
Comparative Analysis of Audio Feature Extraction for Real-Time Talking Portrait Synthesis
Authors:Pegah Salehi, Sajad Amouei Sheshkal, Vajira Thambawita, Sushant Gautam, Saeed S. Sabet, Dag Johansen, Michael A. Riegler, Pål Halvorsen
This paper examines the integration of real-time talking-head generation for interviewer training, focusing on overcoming challenges in Audio Feature Extraction (AFE), which often introduces latency and limits responsiveness in real-time applications. To address these issues, we propose and implement a fully integrated system that replaces conventional AFE models with Open AI’s Whisper, leveraging its encoder to optimize processing and improve overall system efficiency. Our evaluation of two open-source real-time models across three different datasets shows that Whisper not only accelerates processing but also improves specific aspects of rendering quality, resulting in more realistic and responsive talking-head interactions. These advancements make the system a more effective tool for immersive, interactive training applications, expanding the potential of AI-driven avatars in interviewer training.
本文探讨了实时说话人头部生成技术在采访者培训中的应用集成,重点解决了音频特征提取(AFE)所面临的挑战,传统的AFE往往会引入延迟并限制实时应用的响应性。为了解决这些问题,我们提出并实施了一个完全集成的系统,用Open AI的Whisper替代了传统的AFE模型,利用其编码器优化处理过程,提高整体系统效率。我们在三个不同的数据集上评估了两个开源实时模型,结果表明,Whisper不仅加速了处理过程,还提高了渲染质量的具体方面,从而产生了更真实、更响应性的说话人头部交互。这些进步使该系统成为沉浸式互动培训应用的有效工具,扩展了AI驱动的人在采访者培训中的潜力。
论文及项目相关链接
PDF 16 pages, 6 figures, 3 tables. submitted to MDPI journal in as Big Data and Cognitive Computing
Summary
本文探讨实时说话人头像生成技术在采访训练中的集成应用,重点解决音频特征提取(AFE)所面临的挑战。传统AFE模型常引入延迟,限制实时应用的响应性。为应对这些问题,本文提出并实施一个全集成系统,采用Open AI的Whisper替代传统AFE模型,优化处理流程,提高系统整体效率。评估结果显示,Whisper不仅加速处理速度,还提升渲染质量,使生成的说话人头像更为真实和响应迅速。这些进步使该系统成为沉浸式互动训练应用的有效工具,扩展AI驱动头像在采访训练中的潜力。
Key Takeaways
- 实时说话人头像生成技术在采访训练中具有重要意义。
- 音频特征提取(AFE)在实时应用中面临延迟和响应性限制的挑战。
- 采用Open AI的Whisper模型替代传统AFE模型,优化处理流程。
- Whisper模型不仅能加速处理速度,还能提高渲染质量,使生成的说话人头像更真实。
- 全集成系统提高系统整体效率,适用于沉浸式互动训练应用。
- AI驱动的头像在采访训练中具有广阔的应用潜力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在实时生成会说话的头像(talking-head)系统中,音频特征提取(Audio Feature Extraction, AFE)环节引入的延迟问题,这影响了系统的响应性和实时应用中的实用性。具体来说,论文关注于以下几个挑战:
实时应用中的延迟问题:在实时会说话头像生成系统中,AFE模型通常会导致延迟,从而限制了系统的响应性。
多模态数据输入的复杂性:集成包括音频和视觉线索(如面部地标)在内的多模态数据输入的复杂性,这对于实现系统的同步和处理效率至关重要。
音频特征提取模型的选择:不同的AFE模型从同一音频流中捕获略有不同的特征,选择最有效的模型对于提高系统性能至关重要。
提高系统效率:为了减轻现有AFE模型的延迟问题,论文提出了使用OpenAI的Whisper模型来优化处理并提高整体系统效率。
综上所述,论文旨在通过提出并实现一个完全集成的系统,用Whisper模型替换传统的AFE模型,来克服这些挑战,从而提高实时会说话头像系统的实用性和效果。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要涉及两个领域:虚拟头像在采访训练中的应用和实时会说话肖像合成技术。以下是一些具体的相关研究:
虚拟头像在采访训练中的应用:
- Linnæus University 和 AvBIT Labs 开发的系统:这些早期系统主要使用预录的回答,限制了互动的动态性。
- LiveSimulation:通过与录像儿童的互动增强了开放式提问技能。
- Empowering Interviewer Training (EIT):引入了基于规则的算法,以实现更有效的学习与虚拟儿童的互动。
- ViContact:通过集成虚拟现实(VR)和自动化反馈,增强了提问技能和社会情感支持。
- 先前的平台:集成了GPT-3在Unity框架中模拟儿童访谈,旨在提高响应动态性和训练效果。
实时会说话肖像合成:
- Live Speech Portrait:使用自回归预测编码(APC)提取语音信息,通过图像到图像的翻译网络(U-Net)合成视频帧。
- RealTalk:利用3D面部先验和高效的表达渲染模块实现精确的唇语同步,同时保留面部身份。
- 3D Gaussian Splatting (3DGS):引入基于点的渲染技术,使用椭球体、各向异性高斯来表示场景,具有高精度。
- GSTalker:在3DGS的基础上,引入可变形的高斯绘制,显著减少了训练时间并提高了渲染速度。
- Gaussian Talker:使用基于高斯的模型生成具有高质量唇同步的会说话面孔,同时减少计算复杂性。
- NeRF(Neural Radiance Fields):用于生成会说话的肖像,能够捕捉复杂的视觉场景。
- RAD-NeRF 和 ER-NeRF:通过在ADNeRF中引入离散可学习网格,在ER-NeRF中使用三平面哈希表示,提高了系统效率。
这些研究展示了虚拟头像和实时会说话肖像合成技术的发展,以及它们在提高采访技巧训练效果和生成逼真数字人物方面的应用潜力。论文通过对比和评估这些技术,旨在提出一个更高效、更逼真的实时会说话头像系统。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决实时会说话头像系统中音频特征提取(AFE)的延迟问题:
提出集成系统:
- 论文提出了一个完整的AI驱动的头像系统,该系统集成了GPT-3用于对话、语音识别(STT)、文本到语音(TTS)、AFE和会说话的肖像合成。
使用OpenAI的Whisper模型:
- 为了优化处理并提高系统效率,论文采用了OpenAI的Whisper模型替代传统的AFE模型。Whisper是一个先进的自动语音识别(ASR)系统,适用于AFE任务,且在多语言和多任务数据集上进行了预训练。
模型评估和比较:
- 论文评估并比较了四种不同的AFE模型(Deep-Speech 2、Wav2Vec 2.0、HuBERT和Whisper)在两个开源会说话头像框架(RAD-NeRF和ER-NeRF)上的性能。
修改Whisper以适应AFE任务:
- 论文对Whisper进行了修改,使其在会说话的肖像系统中实现高效和加速的AFE。
系统架构设计:
- 论文设计了一个包含多个模块(Listening、STT、Language、TTS、AFE、Frames Rendering和Audio Overlay)的系统架构,以实现自然对话的模拟,并允许用户与头像进行实时互动。
实验验证:
- 论文通过一系列实验验证了不同AFE模型在实时会说话头像合成中的效率、同步精度和响应性。实验使用了不同的数据集,并在高性能硬件上进行,以确保结果的准确性和可重复性。
性能分析:
- 论文详细分析了各个AFE模型的速度和质量,包括执行时间比较、图像质量评估(使用PSNR、SSIM、LPIPS等指标)和唇同步精度(使用SyncNet Confidence Score)。
响应性分析:
- 论文还分析了整个系统架构中每个组件的执行时间,以识别生成交互式头像响应的时间消耗所在,从而提供对系统性能的深入理解。
通过上述步骤,论文不仅解决了AFE过程中的延迟问题,还提高了会说话头像系统的响应性和交互质量,使其更适合于沉浸式、互动式训练应用。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估不同音频特征提取(AFE)模型在实时会说话头像合成中的表现。以下是实验的详细内容:
实验设置:
- 数据集:使用了包括公开可用的视频数据集和私有视频源的三个高清演讲视频剪辑,每个视频剪辑平均约有6700帧(大约4.5分钟,以每秒25帧录制)。
- 系统配置:实验在配备第12代Intel Core i9-12900F CPU、31 GiB RAM和NVIDIA RTX 4090 GPU(24 GiB VRAM)的机器上进行,运行CUDA 12.4和Ubuntu操作系统。
实时会说话头像速度分析:
- 使用Obama数据集评估现有模型的实时能力,确保所有开源方法在相同的硬件和CUDA环境下进行比较。
AFE分析:
- 基于速度分析结果,选择了RAD-NeRF和ER-NeRF框架进行进一步实验,因为它们比其他模型表现更好。
- 在RAD-NeRF和ER-NeRF框架中使用Deep-Speech、Wav2Vec、HuBERT和Whisper-Tiny四种AFE模型进行系统性能评估,重点关注唇同步精度、视觉质量和总体执行时间。
AFE速度分析:
- 比较Whisper和其他AFE模型(Deep-Speech、Wav2Vec和HuBERT)在不同音频持续时间下的处理速度。
AFE质量分析:
- 使用多种定量指标(包括PSNR、SSIM、LPIPS、LMD、FID、AUE和SyncNet Confidence Score)评估系统在不同设置下的渲染质量。
- 在自驱动设置中评估面部重建质量,并在交叉驱动设置中评估音频和唇部运动之间的同步。
系统响应性分析:
- 分析系统架构中每个组件的执行时间,以评估系统生成交互式头像响应的效率。
这些实验旨在全面评估不同AFE模型在实时会说话头像合成中的效率、同步精度和响应性,并确定最佳的AFE模型和系统配置,以提高系统的整体性能和用户体验。
Q: 有什么可以进一步探索的点?
A: 论文提出了一些可以进一步探索的点,以提升实时会说话头像系统的性能和应用范围:
优化计算密集型组件:
- 论文中提到,尽管Whisper模型作为AFE组件已经显著提高了处理速度,但系统在帧渲染等计算密集型组件上仍有延迟。未来的工作可以集中在优化这些组件,以进一步减少系统延迟。
利用先进的解决方案:
- 论文建议可以利用NVIDIA的Avatar Cloud Engine (ACE)等先进技术,这些技术结合了生成式AI和硬件加速,专门用于创建逼真的数字人类。
进行更广泛的用户研究:
- 论文建议进行更广泛的用户研究,包括与领域专业人士合作,以更深入地了解系统对实际结果(如用户培训和参与度)的影响。
主观评估:
- 论文提出,未来的工作可以考虑进行主观评估,以进一步评估系统的感知质量、用户满意度,这可以提供更全面的理解系统在高参与度应用中的有效性。
实际应用中的评估:
- 将研究扩展到包括实际环境中的评估,收集主观用户反馈,可以提供关于系统在实际应用中感知真实性、可用性和用户满意度的宝贵见解。
多语言和多任务优化:
- 考虑到Whisper模型在多语言和多任务场景中的优化,未来的工作可以探索如何进一步提升这些能力,以适应更广泛的应用场景。
集成更多上下文感知:
- 提升系统对上下文的感知能力,使其能更好地适应对话的动态变化,并提供更自然、更个性化的交互体验。
改进唇同步技术:
- 尽管Whisper在唇同步方面表现出色,但在处理机器人生成的声音时效果有所下降。未来的研究可以探索如何改进唇同步技术,以适应不同类型的输入声音。
系统鲁棒性和错误处理:
- 提升系统的鲁棒性,特别是在处理音频输入质量不佳或存在背景噪音的情况下,以及如何有效地处理和恢复错误或不准确的输入。
通过这些进一步的探索,可以推动AI驱动的头像技术的发展,使其在训练、教育、客户服务等多个领域中发挥更大的作用。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
研究背景与动机:
- 本文探讨了在实时会说话头像生成系统中,音频特征提取(AFE)引入的延迟问题,这限制了系统在实时应用中的响应性和实用性。
系统目标:
- 论文提出了一个集成系统,旨在通过使用OpenAI的Whisper模型替换传统的AFE模型,来解决延迟问题,并提高系统效率。
方法论:
- 论文评估了四种不同的AFE模型(Deep-Speech 2、Wav2Vec 2.0、HuBERT和Whisper)在两个开源会说话头像框架(RAD-NeRF和ER-NeRF)上的性能。
实验设计:
- 实验使用了三个不同的高清视频数据集,并在高性能硬件上进行,以确保结果的准确性和可重复性。
实验结果:
- 通过速度和质量分析,发现Whisper模型在处理速度和唇同步精度方面优于其他AFE模型,尤其是在处理较长音频片段时。
系统架构:
- 论文详细介绍了一个包含多个模块(Listening、STT、Language、TTS、AFE、Frames Rendering和Audio Overlay)的系统架构,以实现自然对话的模拟,并允许用户与头像进行实时互动。
响应性分析:
- 分析了系统架构中每个组件的执行时间,发现帧渲染阶段最耗时,而Whisper作为AFE组件显著提高了处理速度。
讨论与未来工作:
- 论文讨论了Whisper模型在实时会说话头像合成中的潜力,并提出了未来可能的研究方向,包括优化计算密集型组件、进行更广泛的用户研究和实际应用评估等。
结论:
- 通过集成Whisper模型,系统不仅提高了响应性,还改善了唇同步的准确性,使其更适合于沉浸式训练应用,如儿童保护服务(CPS)中的调查访谈训练。
总体而言,论文通过实验验证了Whisper模型在实时会说话头像系统中的有效性,并展示了其在提高系统效率和交互质量方面的潜力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

Multimodal Semantic Communication for Generative Audio-Driven Video Conferencing
Authors:Haonan Tong, Haopeng Li, Hongyang Du, Zhaohui Yang, Changchuan Yin, Dusit Niyato
This paper studies an efficient multimodal data communication scheme for video conferencing. In our considered system, a speaker gives a talk to the audiences, with talking head video and audio being transmitted. Since the speaker does not frequently change posture and high-fidelity transmission of audio (speech and music) is required, redundant visual video data exists and can be removed by generating the video from the audio. To this end, we propose a wave-to-video (Wav2Vid) system, an efficient video transmission framework that reduces transmitted data by generating talking head video from audio. In particular, full-duration audio and short-duration video data are synchronously transmitted through a wireless channel, with neural networks (NNs) extracting and encoding audio and video semantics. The receiver then combines the decoded audio and video data, as well as uses a generative adversarial network (GAN) based model to generate the lip movement videos of the speaker. Simulation results show that the proposed Wav2Vid system can reduce the amount of transmitted data by up to 83% while maintaining the perceptual quality of the generated conferencing video.
本文研究了一种高效的多媒体数据视频会议通信方案。在我们考虑的系统,演讲者向观众发表演讲,同时传输带有说话人头部视频和音频的数据。由于演讲者的姿势很少改变,并且需要高保真地传输音频(语音和音乐),因此存在冗余的视觉视频数据,可以通过从音频生成视频来去除。为此,我们提出了一种波到视频(Wav2Vid)系统,这是一种有效的视频传输框架,它通过从音频生成说话人的头部视频来减少传输的数据量。具体来说,全时长的音频和短时长的视频数据通过无线信道同步传输,神经网络(NNs)提取和编码音频和视频语义。接收器然后结合解码的音频和视频数据,并使用基于生成对抗网络(GAN)的模型来生成演讲者的嘴唇运动视频。仿真结果表明,所提出的Wav2Vid系统可以在保持生成的会议视频感知质量的同时,减少高达83%的传输数据量。
论文及项目相关链接
PDF accepted by IEEE Wireless Communications Letters
Summary
多媒体数据通信方案在视频会议中的应用。系统从音频生成视频,减少传输的视觉冗余数据,采用神经网络编码和解码音频和视频语义,利用生成对抗网络生成讲话者的唇动视频。能有效减少传输数据量,同时保持视频会议感知质量。
Key Takeaways
- 论文研究了一种高效的多媒体数据通信方案,用于视频会议中的音视频传输。
- 系统能够从音频生成视频,减少传输的视觉冗余数据。
- 采用神经网络编码和解码音频和视频语义,提高传输效率。
- 利用生成对抗网络生成讲话者的唇动视频,增强视频质量。
- 该系统能够通过无线信道同步传输全时长音频和短时长的视频数据。
- 模拟结果表明,该系统能够减少传输数据量高达83%。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文研究并提出了一种高效的多模态数据通信方案,用于视频会议场景。具体来说,论文试图解决的问题是如何在保证视频会议中生成的视频感知质量的同时,减少传输数据量。在视频会议中,由于说话者的头部姿势变化不频繁,且需要高保真地传输音频(包括语音和音乐),因此存在大量冗余的视觉视频数据。论文提出通过从音频生成视频的方式来减少需要传输的视频数据量,从而提高通信效率并降低对通信资源的需求。
Q: 有哪些相关研究?
A: 论文中提到了以下几项相关研究:
语义通信和联合源信道编码(JSCC):[2]中提到了利用JSCC减少数据传输量的方法,通过根据通信任务提取视觉数据的语义信息来改善交互质量。
基于神经网络(NN)的视频语义通信方案:[3]提出了一个基于NN的视频语义通信方案,该方案对无线信道损伤具有鲁棒性,特别是在低信噪比(SNR)条件下。
基于语义的视频会议通信:[4]提出了一种基于人类面部关键点提取和有效传输的语义通信方法,用于在接收端重建肖像。
视频中的主要对象提取:[5]通过提取视频中的主要对象并减少传输冗余视觉部分来减轻传输负荷。
多模态语义通信:[6]研究了多模态多用户语义通信,通过信道级信息融合来提高频谱效率。[7]提出了基于知识图谱的多模态语义通信,用于视觉问题回答(VQA),通过文本澄清通信任务,减少冗余传输,提高车辆驾驶效率和安全性。
文本驱动的视频会议:[8]通过使用短时文本驱动视频生成长时视频的方法来实现视频会议,但由于这种方法丢失了关键的音频信息,如说话者的情感和强调,因此不能满足视频会议的要求。
这些研究为本文提出的Wav2Vid系统提供了理论基础和技术背景,特别是在多模态数据的语义提取、编码和生成方面。通过这些相关工作,本文旨在利用高保真的音频数据生成说话者的视频数据,以实现高效的视频会议通信。
Q: 论文如何解决这个问题?
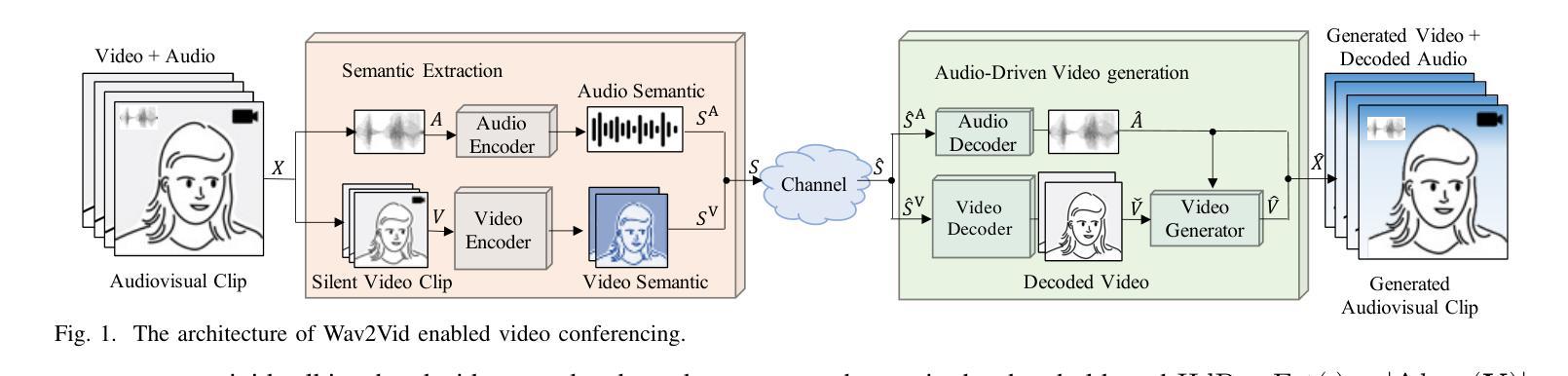
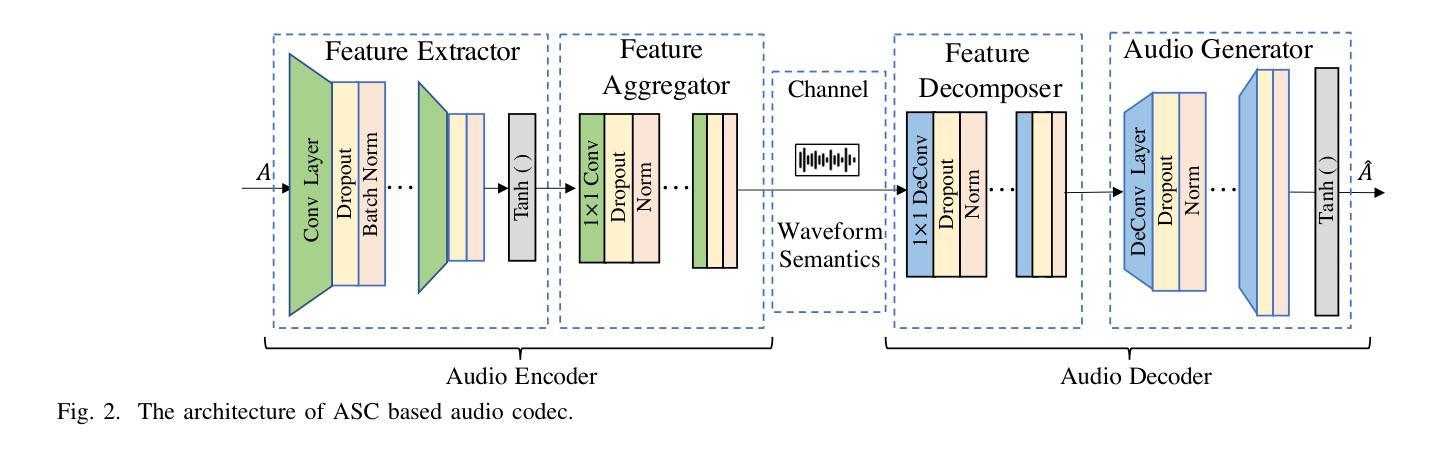
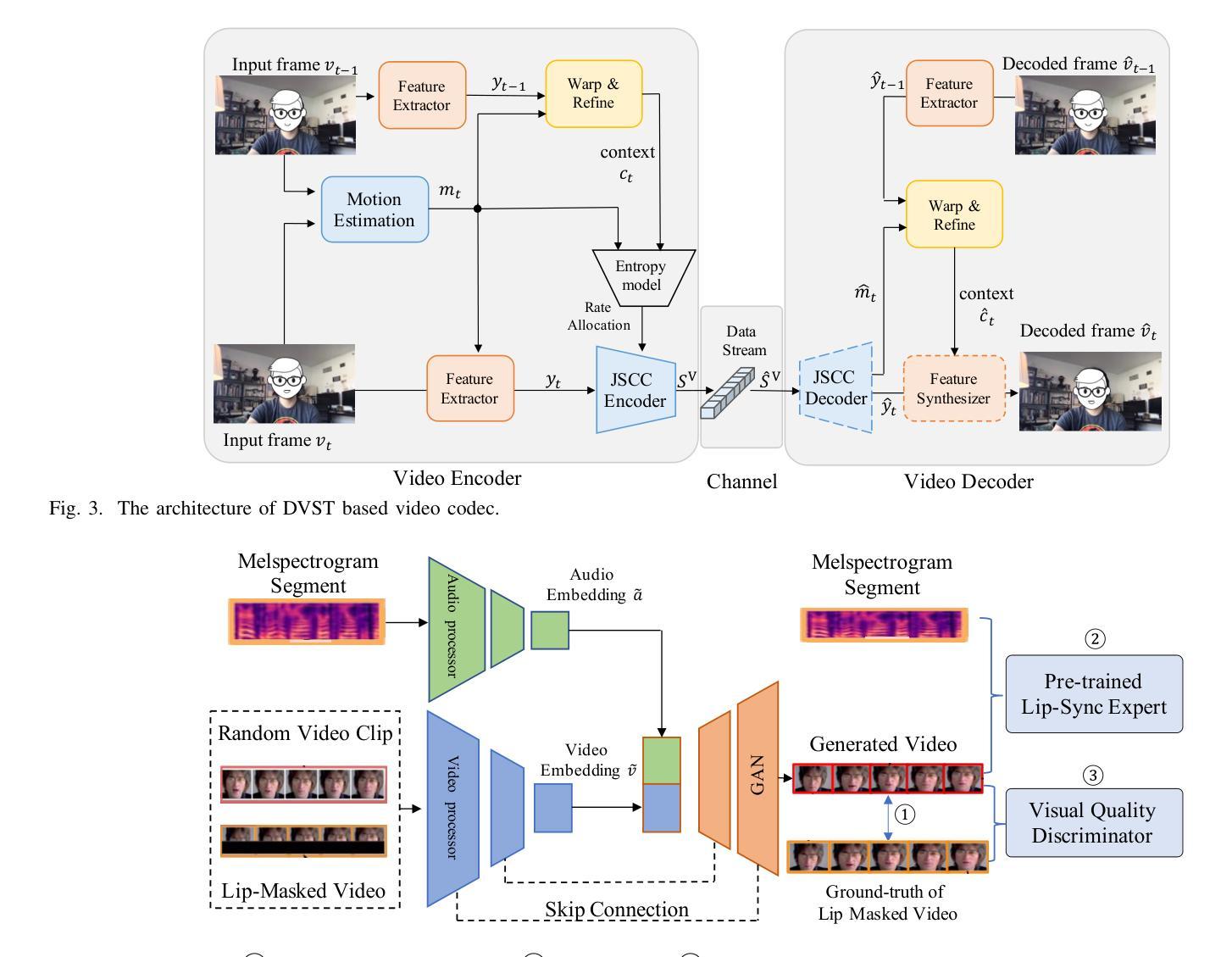
A: 论文通过提出一个名为Wav2Vid的系统来解决视频会议中数据传输量大和通信效率低的问题。以下是该系统解决该问题的关键步骤和方法:
波形到视频(Wav2Vid)系统:
- 该系统在视频会议中传输短时视频剪辑的语义和完整音频数据。
- 利用这些短时视频剪辑和完整音频数据在接收端生成长时间的视觉视频。
音频和视频的语义提取与编码:
- 音频编码器:提取音频波形特征,并进行编码以减轻无线信道损伤。
- 视频编码器:提取和编码视频的时空上下文信息。
视频生成器:
- 利用生成对抗网络(GAN)基于模型来生成与音频同步的说话者唇部运动视频。
- 通过音频和视频数据的语义对齐来生成唇部运动,提高生成视频的感知质量。
无线信道传输:
- 将音频和视频的语义特征选择性地集成到一个数据流中,并通过无线信道传输。
- 在接收端,使用语义解码器解码接收到的语义信息,并重构音频和视频。
优化和训练:
- 使用预训练模型提取音频和视频的语义特征,并在线微调无线传输的编码模块。
- 通过优化生成视频的Frechet Inception Distance (FID)来训练视频生成器,以提高视频的感知质量。
模拟结果:
- 论文中的模拟结果显示,Wav2Vid系统可以减少多达83%的传输数据量,同时保持生成会议视频的感知质量。
通过这些方法,Wav2Vid系统能够有效地利用音频数据来生成视频内容,减少需要传输的视频数据量,从而提高视频会议的通信效率和质量。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证Wav2Vid系统的性能:
系统模型和参数设置:
- 考虑了一个包含一个发射器和一个接收器的视频会议系统。
- 使用了真实世界的音频数据集LibriSpeech和[8]中的头部视频。
- 在0到20 dB的Rayleigh信道中训练Wav2Vid系统,使用不同的信噪比(SNR)。
与传统方法的比较:
- 将Wav2Vid系统与传统的脉冲编码调制(PCM)/H.265 + LDPC + 16 QAM方案进行比较。
- 与基于神经网络的视频语义传输(DVST)方案进行比较。
- 与基于文本的视频生成(Txt2Vid)方案进行比较。
传输数据量的比较:
- 表II显示了传输18秒视频内容时各种方法所需的传输数据量(传统方法以字节为单位,其他方法以符号为单位)。
- 显示Wav2Vid方法与传统方法相比,可以减少多达83.75%的传输数据量。
音频和视频质量的评估:
- 音频质量:使用感知评估语音质量(PESQ)来评估不同方法的音频质量,并随着Rayleigh信道SNR的增加进行比较。
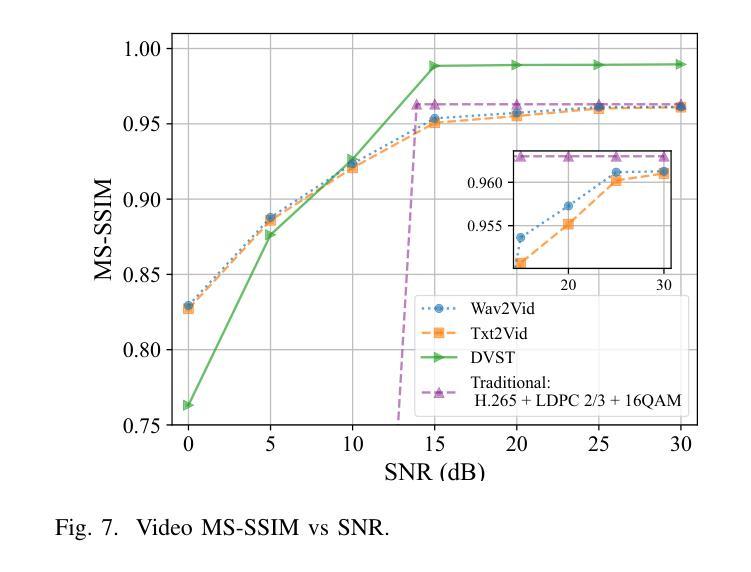
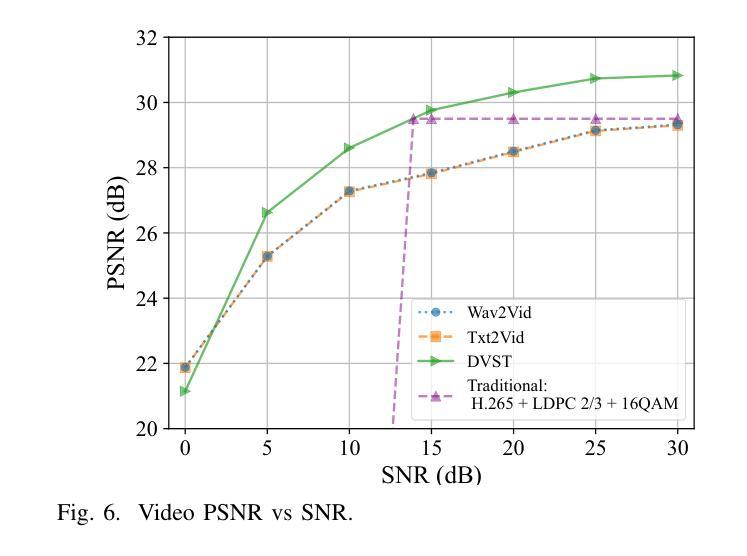
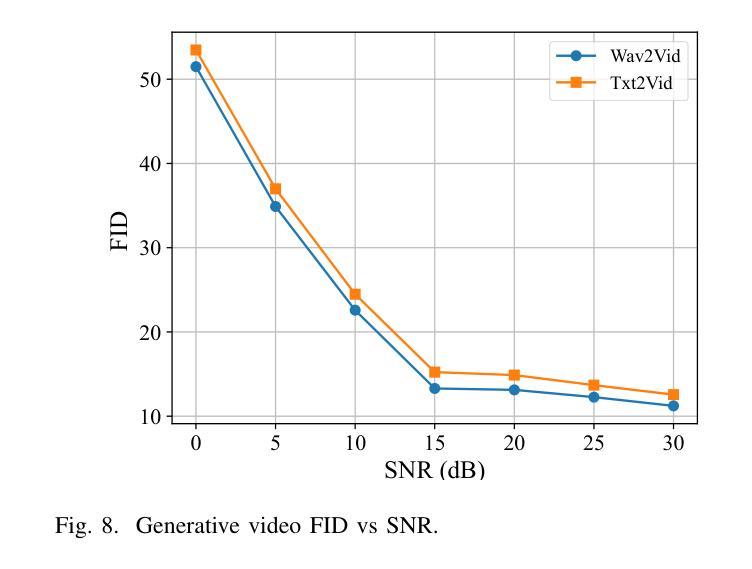
- 视频质量:使用峰值信噪比(PSNR)和多尺度结构相似性(MS-SSIM)来评估不同方法的视频质量,并随着Rayleigh信道SNR的增加进行比较。
- 生成视频的质量:使用Frechet Inception Distance (FID)来评估Wav2Vid和Txt2Vid生成视频与原始视频之间的差异,并随着Rayleigh信道SNR的增加进行比较。
实验结果:
- Wav2Vid系统在高SNR条件下能够实现与传统方法相似的视频质量。
- Wav2Vid系统在低SNR条件下显示出比DVST和Txt2Vid方法更好的音频质量。
- Wav2Vid系统生成的视频与原始视频之间的FID值低于Txt2Vid,表明Wav2Vid系统在视频生成方面具有更高的质量。
这些实验结果表明Wav2Vid系统能够有效地减少视频会议中的传输数据量,同时保持或提高视频和音频的感知质量。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出的Wav2Vid系统在减少视频会议数据传输量和保持视频质量方面取得了显著效果,但仍有一些方向可以进一步探索和改进:
鲁棒性测试:
- 在更多样化的信道模型和条件下测试Wav2Vid系统的性能,例如在不同的信道衰落、多径效应和干扰条件下。
复杂场景下的适应性:
- 研究在复杂背景和动态场景下,系统对说话者头部姿势变化、表情变化和背景变化的适应性和鲁棒性。
实时性能优化:
- 进一步优化算法和模型以满足更严格的实时视频会议要求,特别是在移动设备上的实时性能。
更高效的编码技术:
- 研究和开发更高效的音频和视频编码技术,以进一步减少传输数据量,同时保持或提高视频和音频质量。
增强现实和虚拟现实集成:
- 探索将Wav2Vid系统与增强现实(AR)和虚拟现实(VR)技术集成,以提供更丰富的交互体验。
多模态数据融合:
- 研究更先进的多模态数据融合技术,以改善视频生成的自然性和真实感,例如通过整合触觉或情感信息。
用户体验和反馈:
- 开展用户研究,收集关于Wav2Vid系统在实际视频会议中的用户体验和反馈,以指导进一步的优化和功能增强。
安全性和隐私保护:
- 研究如何在Wav2Vid系统中集成安全性和隐私保护措施,特别是在处理和传输个人视频和音频数据时。
跨模态一致性:
- 进一步研究如何提高跨模态数据(如音频和视频)之间的一致性,以增强视频会议中的通信自然性和可信度。
模型压缩和优化:
- 研究模型压缩和优化技术,以减少模型大小和计算需求,使其更适合在资源受限的设备上部署。
这些方向不仅可以推动Wav2Vid系统的发展,还可以为视频会议和多模态通信领域带来新的技术突破和应用创新。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为Wav2Vid的多模态数据通信系统,旨在提高视频会议的效率和质量。以下是论文的主要内容总结:
问题背景:
- 视频会议中,由于说话者头部姿势变化不频繁,且需要高保真传输音频,导致大量冗余视觉数据被传输,增加了通信负担。
系统目标:
- 减少视频数据传输量,同时保持视频会议的感知质量。
Wav2Vid系统:
- 一个高效的视频传输框架,通过从音频生成视频来减少传输数据量。
- 系统同步传输完整音频和短时视频数据,接收端结合解码后的音视频数据使用生成对抗网络(GAN)生成说话者的唇部运动视频。
关键技术:
- 音频和视频语义提取:使用神经网络提取音频波形特征和视频时空上下文信息。
- 视频生成:基于GAN的模型,从音频和视频语义中生成唇部运动视频。
- 无线信道传输:通过无线信道传输提取的语义特征,并在接收端进行解码和重构。
实验结果:
- Wav2Vid系统能够减少多达83%的传输数据量。
- 在不同的信噪比(SNR)条件下,系统均能保持较高的音频和视频质量。
结论:
- Wav2Vid系统通过音频驱动的视频生成有效减少了视频会议中的传输数据量,并保持了视频的感知质量。
未来工作:
- 论文提出了一些未来研究方向,包括系统在复杂场景下的适应性、实时性能优化、更高效的编码技术等。
总体而言,这篇论文针对视频会议中的通信效率问题提出了一个创新的解决方案,并通过实验验证了其有效性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

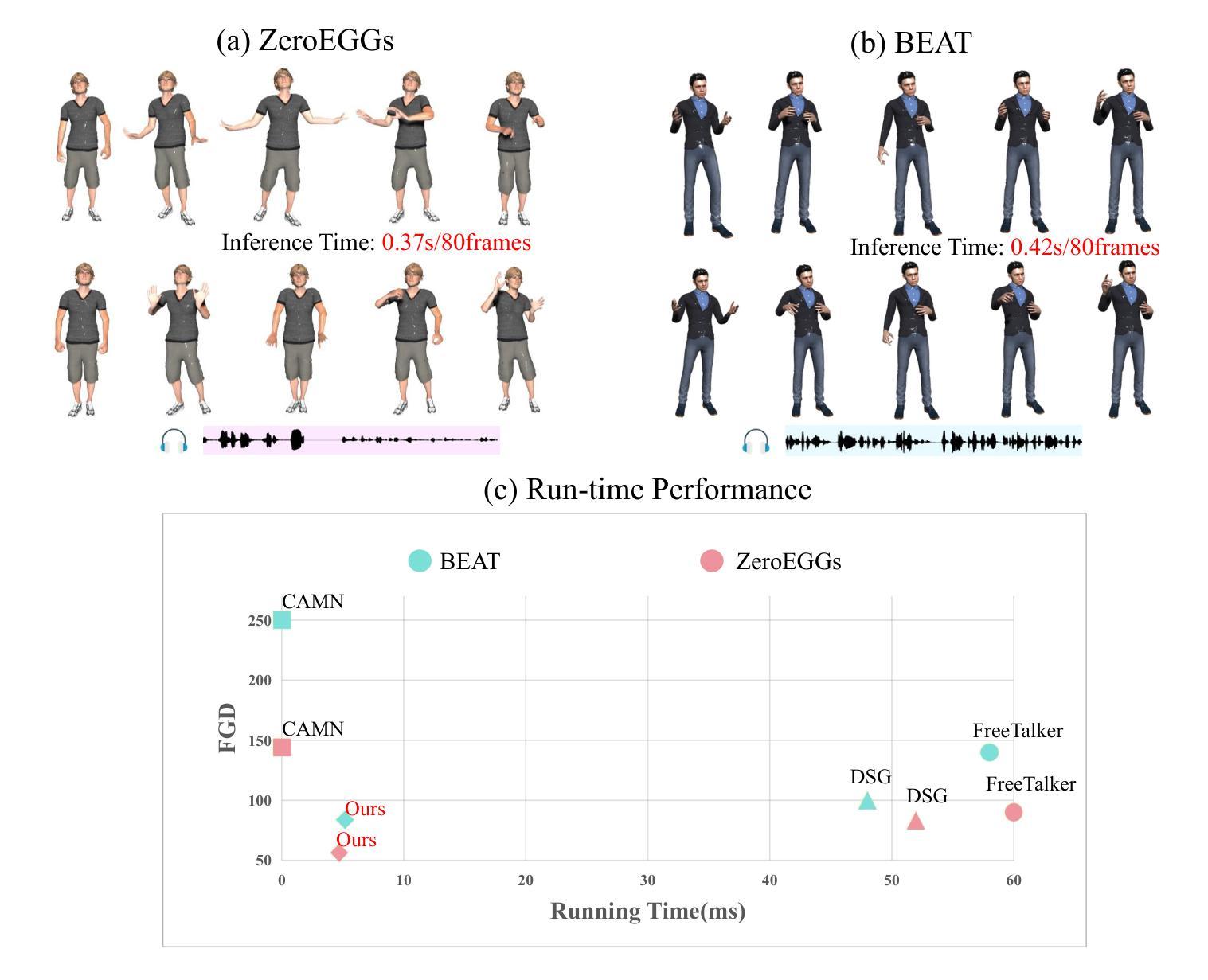
Conditional GAN for Enhancing Diffusion Models in Efficient and Authentic Global Gesture Generation from Audios
Authors:Yongkang Cheng, Mingjiang Liang, Shaoli Huang, Gaoge Han, Jifeng Ning, Wei Liu
Audio-driven simultaneous gesture generation is vital for human-computer communication, AI games, and film production. While previous research has shown promise, there are still limitations. Methods based on VAEs are accompanied by issues of local jitter and global instability, whereas methods based on diffusion models are hampered by low generation efficiency. This is because the denoising process of DDPM in the latter relies on the assumption that the noise added at each step is sampled from a unimodal distribution, and the noise values are small. DDIM borrows the idea from the Euler method for solving differential equations, disrupts the Markov chain process, and increases the noise step size to reduce the number of denoising steps, thereby accelerating generation. However, simply increasing the step size during the step-by-step denoising process causes the results to gradually deviate from the original data distribution, leading to a significant drop in the quality of the generated actions and the emergence of unnatural artifacts. In this paper, we break the assumptions of DDPM and achieves breakthrough progress in denoising speed and fidelity. Specifically, we introduce a conditional GAN to capture audio control signals and implicitly match the multimodal denoising distribution between the diffusion and denoising steps within the same sampling step, aiming to sample larger noise values and apply fewer denoising steps for high-speed generation.
音频驱动的同步动作生成对人类与计算机通信、人工智能游戏和电影制作至关重要。尽管之前的研究已经显示出前景,但仍存在局限性。基于VAE的方法伴随着局部抖动和全局不稳定的问题,而基于扩散模型的方法则受到生成效率低的阻碍。这是因为后者DDPM的降噪过程依赖于添加的噪声是从单峰分布中采样且噪声值较小的假设。DDIM借鉴了求解微分方程的欧拉方法的思路,打破了马尔可夫链过程,增加了噪声步长,减少了降噪步骤,从而加速了生成过程。然而,在逐步降噪过程中简单地增加步长会导致结果逐渐偏离原始数据分布,导致生成的动作质量下降,出现不自然的伪影。本文打破了DDPM的假设,并在去噪速度和保真度方面取得了突破性进展。具体来说,我们引入了条件生成对抗网络来捕获音频控制信号,并隐式匹配扩散和去噪步骤之间的多峰去噪分布,在同一采样步骤内实现更大的噪声值并应用较少的去噪步骤,以实现高速生成。
论文及项目相关链接
PDF Accepted by WACV 2025 (Round 1)
Summary
本文探讨了音频驱动的同步动作生成技术在人机交互、AI游戏和影视制作等领域的重要性。针对现有方法的局限性,如变分自编码器(VAEs)方法的局部抖动和全局不稳定问题,以及扩散模型方法的生成效率低下问题,本文引入了一种基于条件生成对抗网络(GAN)的方法,通过捕获音频控制信号并匹配扩散和去噪步骤之间的多模态去噪分布,实现了快速且高保真度的动作生成。
Key Takeaways
- 音频驱动的同步动作生成对于多个领域至关重要,如人机交互、AI游戏和影视制作。
- 当前技术面临的挑战包括局部抖动、全局不稳定和生成效率低下。
- 变分自编码器(VAEs)方法存在局限性。
- 扩散模型方法依赖于假设噪声来自单模态分布且噪声值较小,这限制了其生成效率。
- DDIM方法通过借鉴解决微分方程的欧拉方法,加速生成过程,但可能导致结果偏离原始数据分布。
- 本文打破了DDPM的假设,在去噪速度和保真度方面取得了突破。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是音频驱动的手势生成中的两个关键挑战:生成效率低下和生成动作的不自然性。具体来说,论文中提到了以下两个主要问题:
生成效率低下:基于扩散模型(diffusion models)的方法虽然在生成质量上表现出色,但它们在生成效率上存在不足。例如,论文中提到的DiffGesture方法需要6秒钟来生成一个88帧的手势序列切片,这限制了它们在实时应用中的有效性。
生成动作的不自然性:简单的增加扩散过程中的步长会导致生成的动作逐渐偏离原始数据分布,导致生成动作的质量显著下降,并出现不自然的伪影。
为了解决这些问题,论文提出了一种新的方法,通过引入条件生成对抗网络(Conditional GAN)来捕捉音频控制信号,并在扩散和去噪步骤之间隐式匹配多模态去噪分布,以实现在较少的去噪步骤中采样更大的噪声值,从而加快生成速度。此外,为了使模型能够生成高保真度的全局手势并避免伪影,论文还引入了显式运动几何损失来增强生成手势的质量和全局稳定性。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要包括以下几个方面:
基于GAN和VAE的生成方法:
- 这些方法展示了在手势生成中的潜力,但受限于严格的运动表示要求和手臂姿势生成中的抖动问题。
基于扩散模型的生成方法:
- 如DiffGesture,这些方法在生成质量方面处于前沿,能有效捕捉各种手势的目标分布。
- DiffStyleGes,通过学习运动表示和输入音频控制条件之间的关系来重建原始运动表示,同时提供风格化的硬标签以控制生成的手势风格。
全局手势生成方法:
- 如FreeTalker和ExpGest,这些研究进一步集中于在文本和音频的联合控制下进行全局手势生成。
早期数据驱动的方法:
- 这些方法尝试从人类示范中学习手势匹配,但往往产生有限的运动多样性。
提高模型生成多样性和表达性的研究:
- 引入了生成独特和富有表现力的手势结果的概念。
训练统一模型用于多说话者的研究:
- 这些研究将每个说话者的风格嵌入到空间中或采用风格转移技术。
采用运动匹配生成手势序列的方法:
- 这些方法通常需要复杂的匹配规则。
音频驱动动画的研究:
- 扩散生成模型在多个领域取得了显著成就,特别是在同步手势生成方面。
基于潜在空间扩散的方法:
- 如GestureClip,通过在低维、高密度潜在变量上进行扩散来降低计算资源需求。
DPM-Solver技术:
- 这种方法针对扩散模型进行了特别优化,从标准的1000步DDPM去噪方法开始。
这些相关研究构成了论文提出方法的理论和实践基础,论文在这些研究的基础上,通过引入条件GAN和显式运动几何损失,旨在提高手势生成的效率和质量。
Q: 论文如何解决这个问题?
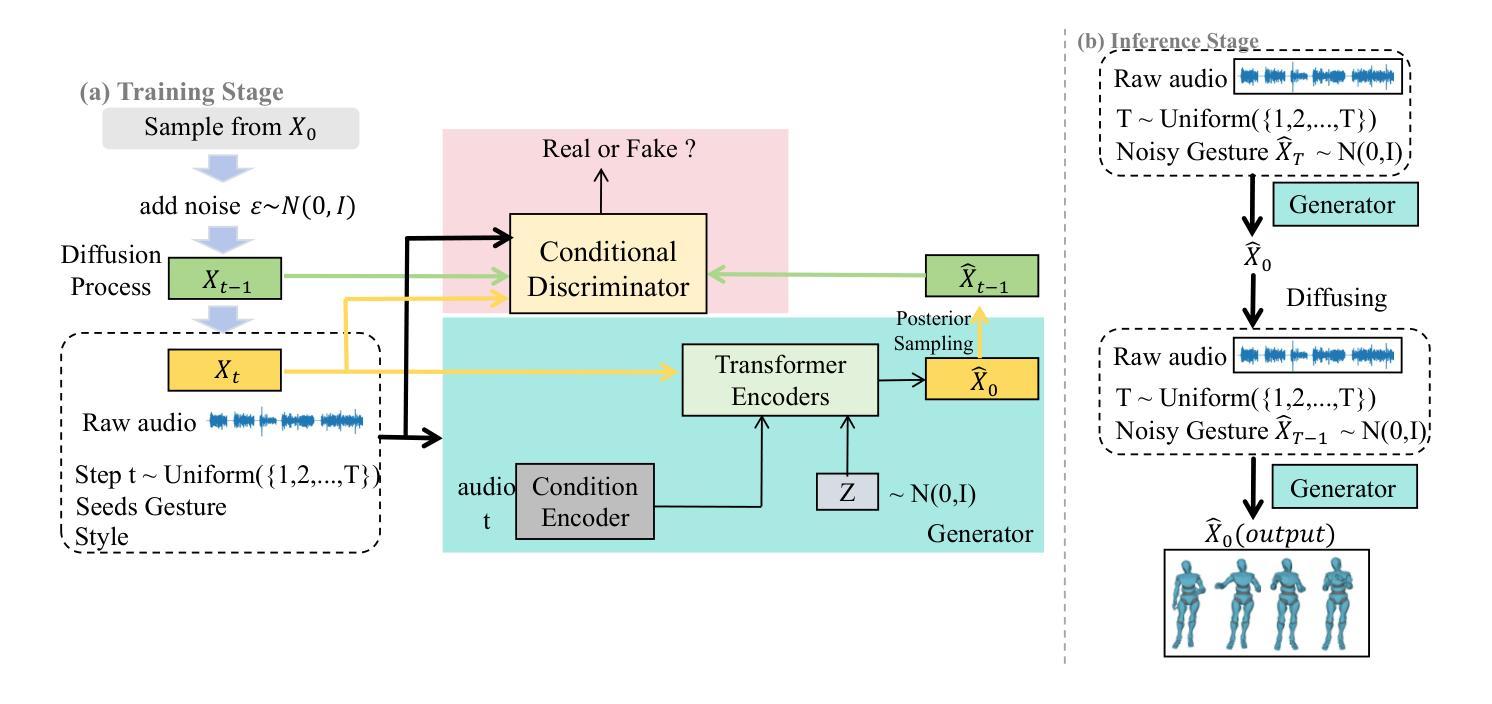
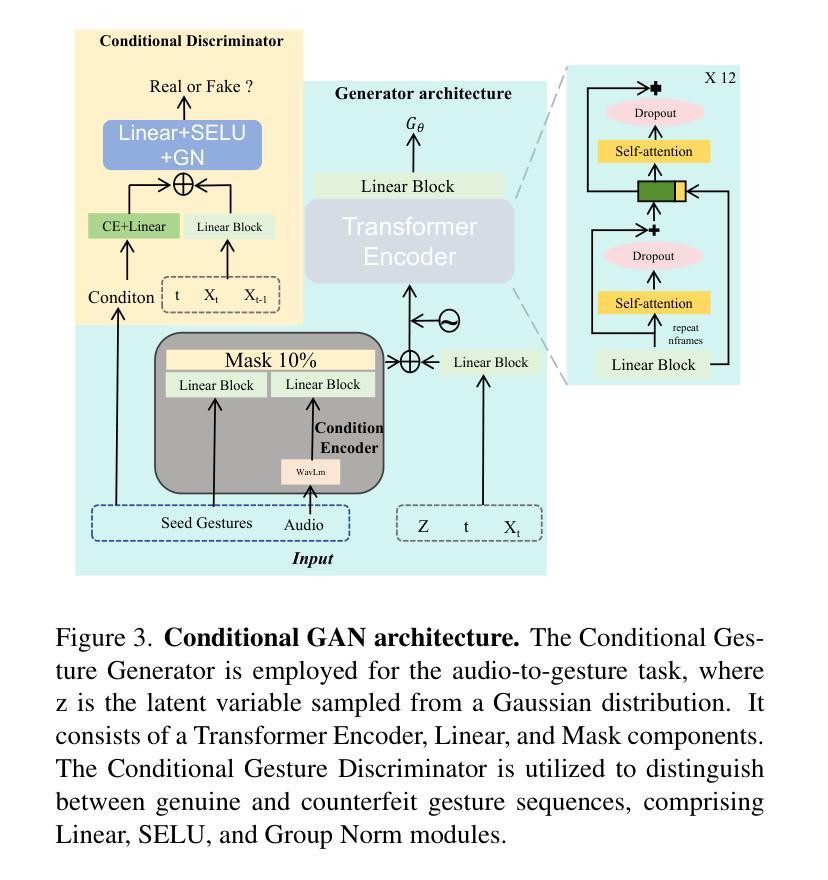
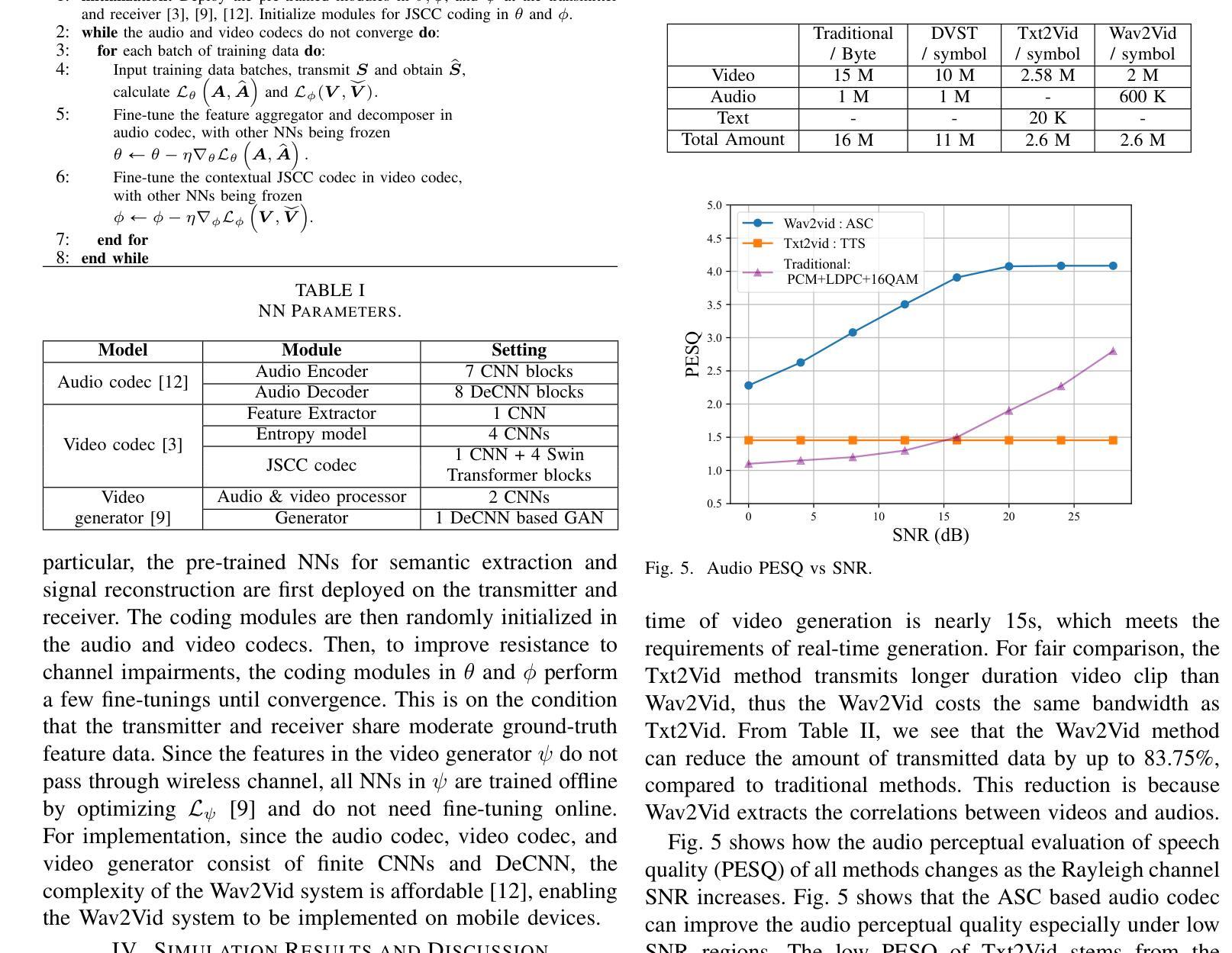
A: 论文通过以下几个关键方法解决了音频驱动手势生成中的效率和质量问题:
1. 引入条件生成对抗网络(Conditional GAN)
- 目的:捕捉音频控制信号,并在扩散和去噪步骤之间隐式匹配多模态去噪分布。
- 实现:通过条件GAN匹配条件分布,允许在相邻扩散步骤之间添加较大的随机噪声,并仅用几步实现去噪。
2. 隐式联合分布匹配
- 目的:减少去噪步骤并增加步长,以实现快速采样。
- 实现:通过对抗学习策略,使用条件GAN匹配扩散和去噪过程之间的条件分布,从而允许添加大的随机噪声并快速去噪。
3. 显式几何约束
- 目的:提高生成手势的质量并避免伪影。
- 实现:引入显式运动几何损失,直接预测干净的手势序列,并使用Huber损失来约束其重建损失。
4. 端到端模型
- 目的:简化训练过程,避免复杂的多阶段方法。
- 实现:提出的框架是一个易于训练的端到端模型,可以快速生成高质量的手势序列。
5. 快速生成与高质量保持
- 目的:在减少去噪步骤的同时保持生成质量。
- 实现:通过实验确定了最优的采样步数(例如20步),以平衡生成速度和质量。
6. 实验验证
- 目的:通过广泛的实验评估所提出方法的有效性。
- 实现:在BEAT和ZeroEGGs数据集上进行了定量和定性实验,证明了该方法在生成速度和保真度方面相较于现有方法的优势。
通过上述方法,论文成功地提高了手势生成的速度,并保持了生成动作的高质量和自然性,解决了现有方法中的低效率和不自然性问题。
Q: 论文做了哪些实验?
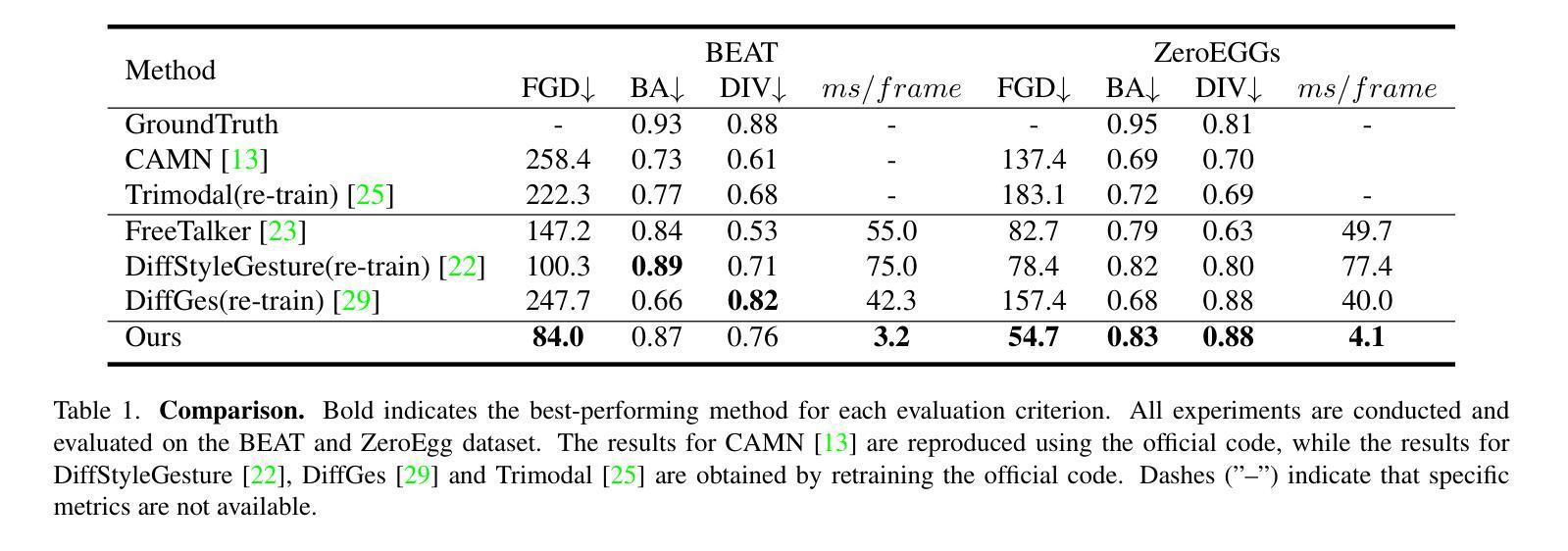
A: 论文中进行了以下实验来验证所提出方法的有效性:
1. 实现细节和训练配置
- 使用基于Transformer架构的条件手势生成器,并详细描述了模型结构和训练参数。
2. 数据集和评估指标
- 使用了BEAT和ZeroEGGs数据集进行训练和评估。
- 使用了Fr´echet Gesture Distance (FGD)、Beat Alignment (BA)和Diversity (DIV)作为评估指标。
3. 与现有方法的比较
- 与现有的基于扩散和非扩散的方法进行了比较,包括CAMN、Trimodal、FreeTalker、DiffStyleGesture和DiffGes等。
- 在BEAT和ZeroEGGs数据集上评估了这些方法的生成质量、节拍对齐和多样性。
4. 与其他加速方法的对比
- 与DPM-Solver和DDGAN等加速扩散模型的方法进行了对比。
- 展示了使用10步去噪时的性能差异。
5. 结构消融研究
- 在BEAT数据集上验证了所设计的关键模块的有效性。
- 包括对WavLM特征、Transformer-Encoder与GRU结构的比较,以及耦合和解耦结构的影响。
6. 采样步数消融研究
- 研究了不同采样步数对模型性能的影响。
- 训练了使用1、5、10、20、30和50步的结构,并比较了生成质量与速度。
7. 几何约束影响的消融研究
- 验证了显式手势几何约束在BEAT数据集上的作用。
- 比较了不同几何约束权重对生成质量的影响。
这些实验全面评估了所提出方法在不同方面的表现,包括生成质量、速度和稳定性,并与现有技术进行了对比,从而证明了该方法的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 论文在结论部分提出了一些可以进一步探索的点,包括:
改进提出的方法:
- 论文承诺将代码库公开,以便未来的研究可以专注于改进提出的方法。
探索在其他领域的应用:
- 提出的方法可能可以用于为运动捕捉提供更多样化的生成数据,以及用于全身动作生成。
整合额外的约束来增强生成手势的质量和真实感:
- 考虑使用目标检测方法来提取手部和面部的细节信息,以优化生成结果。
除此之外,以下是一些基于论文内容的其他可能的探索方向:
提高模型的泛化能力:
- 在更多样的数据集和多模态输入上训练和测试模型,以提高其泛化能力。
优化模型训练效率:
- 探索更高效的训练策略,减少训练时间和资源消耗。
增强模型的解释性:
- 研究模型内部工作机制,提供更多关于如何学习和生成手势的洞察。
多任务学习:
- 将手势生成与其他任务(如情感识别或语音合成)结合起来,实现更丰富的交互体验。
实时性能优化:
- 进一步优化模型以实现更快的实时生成能力,适用于更广泛的应用场景。
交互式应用:
- 将模型集成到交互式应用中,如虚拟助手或游戏,以提供更自然的非语言交流。
跨模态融合技术:
- 研究如何更好地融合音频、文本和视觉信息,以生成更自然和一致的手势。
这些探索点可以帮助研究者们更深入地理解和改进音频驱动手势生成技术,并将其应用于更广泛的实际问题中。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文针对音频驱动的手势生成领域中存在的问题,特别是生成效率低下和生成动作的不自然性。
研究目标:
- 提出一种新的方法来提高手势生成的速度和质量,同时保持动作的真实性。
方法论:
- 引入条件生成对抗网络(Conditional GAN)来捕捉音频控制信号,并在扩散和去噪步骤之间隐式匹配多模态去噪分布。
- 通过隐式联合分布匹配和显式几何约束来提高生成效率和质量。
- 构建了一个端到端的模型,可以快速生成高质量的手势序列。
实验验证:
- 在BEAT和ZeroEGGs数据集上进行了广泛的实验,包括与现有方法的比较、消融研究以及不同配置下的性能测试。
- 实验结果表明,提出的方法在生成速度和保真度方面均优于现有的扩散和非扩散方法。
贡献:
- 提出的方法突破了现有扩散模型在手势生成中的效率限制,同时保持了高保真度。
- 引入的显式运动几何损失有助于避免生成过程中的伪影,提高了全局手势的自然性和稳定性。
未来工作:
- 论文提出了未来可能的研究方向,包括改进提出的方法、探索在其他领域的应用、整合额外的约束来增强生成手势的质量和真实感等。
总的来说,这篇论文通过创新的方法显著提高了音频驱动手势生成的效率和质量,为实时手势生成任务提供了一个有前景的解决方案,并为未来的研究指明了方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图