⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-18 更新
Instruction-based Image Manipulation by Watching How Things Move
Authors:Mingdeng Cao, Xuaner Zhang, Yinqiang Zheng, Zhihao Xia
This paper introduces a novel dataset construction pipeline that samples pairs of frames from videos and uses multimodal large language models (MLLMs) to generate editing instructions for training instruction-based image manipulation models. Video frames inherently preserve the identity of subjects and scenes, ensuring consistent content preservation during editing. Additionally, video data captures diverse, natural dynamics-such as non-rigid subject motion and complex camera movements-that are difficult to model otherwise, making it an ideal source for scalable dataset construction. Using this approach, we create a new dataset to train InstructMove, a model capable of instruction-based complex manipulations that are difficult to achieve with synthetically generated datasets. Our model demonstrates state-of-the-art performance in tasks such as adjusting subject poses, rearranging elements, and altering camera perspectives.
本文介绍了一种新型数据集构建流程,该流程从视频中采样帧对,并使用多模态大型语言模型(MLLM)生成用于训练基于指令的图像操作模型的编辑指令。视频帧内在地保留了主体和场景的身份,确保在编辑过程中内容的一致性。此外,视频数据捕获了多样且自然的动态,如非刚体主体运动和复杂的相机运动,这些很难以其他方式进行建模,使其成为可扩展数据集构建的理想来源。使用这种方法,我们创建了一个新的数据集来训练InstructMove模型,该模型能够进行基于指令的复杂操作,这些操作很难通过合成生成的数据集实现。我们的模型在调整主体姿势、重新排列元素和更改相机视角等任务中展示了卓越的性能。
论文及项目相关链接
PDF Project page: https://ljzycmd.github.io/projects/InstructMove/
Summary
本论文介绍了一种新型数据集构建流程,通过从视频中采样帧对并使用多模态大型语言模型(MLLMs)生成编辑指令,以训练基于指令的图像操作模型。视频帧能够保持主体和场景的一致性,确保在编辑过程中内容的连贯性。此外,视频数据能够捕捉各种自然动态,如非刚性主体运动和复杂的相机运动,使其成为可扩展数据集构建的理想来源。利用此方法,我们创建了新的数据集来训练InstructMove模型,该模型能够基于指令完成复杂操作,这在合成数据集中难以实现。模型在调整主体姿态、重新排列元素和更改相机视角等任务上表现出卓越性能。
Key Takeaways
- 论文提出了一种新型数据集构建流程,结合视频帧采样和多模态大型语言模型(MLLMs)生成编辑指令。
- 视频帧能保留主体和场景的一致性,确保编辑过程中的内容连贯性。
- 视频数据能捕捉各种自然动态,如非刚性主体运动和复杂相机运动,是数据集构建的理想来源。
- 使用此方法和数据集训练了InstructMove模型,能完成合成数据集中难以实现的复杂指令操作。
- InstructMove模型在调整主体姿态、重新排列元素和改变相机视角等任务上表现卓越。
- 多模态大型语言模型(MLLMs)在生成编辑指令方面发挥了关键作用。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何基于文本指令对现有图像进行复杂的编辑操作,尤其是在保持内容一致性的同时进行非刚性编辑(如调整主体姿态、表情和改变视角等)。具体来说,论文中提到的关键挑战包括:
现有图像编辑方法的局限性:现有的基于文本到图像(T2I)生成的方法能够产生高质量和超逼真的图像,但是基于文本指令编辑现有图像仍然具有挑战性,输出质量仍然不尽如人意,且编辑类型范围有限。
缺乏大规模训练数据集:为了训练能够根据文本指令进行编辑的模型,需要大规模的源图像-目标图像-指令三元组数据集,但这样的数据集难以获得。
合成数据集的局限性:之前的方法尝试通过语言模型生成编辑指令,并使用无需微调的技术创建目标图像来构建数据集,但这些合成的目标图像往往存在数据质量问题,限制了模型的潜力,导致在保持编辑主体外观或执行精确、详细编辑方面的挑战。
为了解决这些问题,论文提出了一种新的方法,通过从互联网视频中采样帧对,并使用多模态大型语言模型(MLLMs)生成编辑指令,来构建大规模、基于指令的图像编辑数据集。这种方法利用视频帧捕获的丰富信息(如主体姿态变化、元素移动和相机运动等)来训练模型,使其能够执行更自然的语言驱动的图像操作。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个领域:
Zero-shot Image Editing with Diffusion Models:
- 这类研究利用扩散模型(Diffusion Models)进行文本到图像的生成,并开发了通过操纵采样过程、修改去噪网络内部架构或加入额外优化步骤的图像编辑技术。例如,SDEdit通过向图像添加噪声,然后在反向去噪过程中根据目标提示生成所需的编辑。其他方法如Prompt-to-Prompt、Plug-and-Play和MasaCtrl等,通过操纵注意力机制来实现与目标提示一致的编辑。
Training Instruction-based Editing Models:
- 与修改目标图像描述相比,使用直接指令(例如,“让男人看向相机”)来指导编辑过程是一种更直观和用户友好的编辑方法。InstructPix2Pix通过使用编辑指令微调Stable Diffusion模型来开创这一概念。MGIE和SmartEdit等方法整合了多模态大型语言模型(MLLMs)以提高对编辑指令的理解。MagicBrush通过执行DALL·E 2进行编辑来构建小型数据集。InstructDiffusion和EmuEdit等方法通过添加合成对来扩展数据集,以处理例如对象移除和替换等任务。
其他图像编辑技术:
- 包括基于描述的编辑方法(如NullTextInversion、MasaCtrl和Imagic)和基于指令的编辑方法(如InstructPix2Pix、MagicBrush和UltraEdit)。
这些相关研究提供了不同的视角和技术手段来处理图像编辑任务,特别是在文本指导下的图像编辑领域。论文提出的InstructMove模型在这些现有工作的基础上,通过利用视频帧和MLLMs生成的编辑指令来训练,旨在实现更复杂和灵活的图像编辑操作。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤来解决基于文本指令进行图像编辑的问题:
1. 数据集构建流程
- 从视频中采样帧对:论文提出从互联网视频中提取帧对,这些帧对捕获了主体和场景的自然变化,如非刚性主体运动和复杂的相机运动。这些视频帧提供了丰富的信息,是训练图像操作模型的理想数据源。
- 利用多模态大型语言模型(MLLMs)生成编辑指令:通过分析视频帧之间的变化,MLLMs能够生成精确的编辑指令。这种方法能够直接从视频帧生成指令,而不是仅依赖于文本描述,从而提高了数据集的多样性和质量。
2. 空间条件策略(Spatial Conditioning)
- 模型输入的创新:论文提出了一种新的空间条件策略,将参考图像与噪声输入沿空间维度(宽度)拼接,而不是传统的通道维度拼接。这种方法允许模型通过跨注意力机制访问参考图像,增强了模型执行灵活编辑的能力,同时保持源图像的外观。
- 网络结构的兼容性:由于这种空间条件策略不需要修改预训练的文本到图像(T2I)模型的架构,因此可以轻松地与其他控制机制(如遮罩或ControlNets)集成,实现更精确和局部化的编辑。
3. 微调预训练的T2I模型
- 使用构建的数据集进行微调:通过在构建的数据集上微调预训练的T2I模型(例如Stable Diffusion),使模型能够根据自然语言指令执行复杂的图像操作,如调整主体姿态、重新排列元素或改变相机视角,同时保持原始图像的完整性和细节。
4. 支持额外的控制机制
- 集成遮罩和控制点:为了实现更精确的编辑,论文的方法支持使用遮罩来指定需要编辑的图像区域,以及使用控制点(如骨架关键点)来调整主体的姿态。这种集成允许用户通过直接操作图像的特定部分来实现精确的编辑。
通过这些方法,论文成功地构建了一个能够处理复杂编辑任务的模型,这些任务在以往的方法中往往难以实现,尤其是在保持内容一致性的同时进行非刚性编辑。
Q: 论文做了哪些实验?
A: 论文中进行的实验包括以下几个方面:
1. 实验设置(Experimental Setup)
- 实现细节:使用提出的空间条件策略微调Stable Diffusion V1.5模型,输入图像分辨率为512×512,使用Adam优化器进行100,000次迭代训练。
- 评估基准:创建了一个专门的测试集,包含50张图片,每张图片都有人工策划的编辑指令,专注于非刚性编辑任务。
- 评估指标:使用CLIP-D、CLIP-Inst和CLIP-I三个指标评估编辑结果与文本指令的一致性以及与源图像的保真度。此外,还收集了40名参与者的人类反馈来评估编辑图像的质量。
2. 与现有方法的比较(Baseline Comparisons)
- 比较方法:与现有的基于文本引导的图像编辑方法进行比较,包括NullTextInversion、MasaCtrl、Imagic、InstructPix2Pix、MagicBrush和UltraEdit。
- 定量结果:在新创建的编辑基准上,使用定量指标对各种方法进行评估,并展示在遵循编辑指令和保持内容保真度方面的表现。
- 定性结果:通过视觉比较展示不同方法在处理复杂编辑任务时的输出结果,尤其是非刚性变换、对象重新定位和视角调整等任务。
3. 使用额外控制的结果(Results with Additional Controls)
- 遮罩和控制点:展示如何通过遮罩和控制点等额外控制机制实现更精确的编辑,例如使用遮罩指定编辑区域或通过调整控制点改变主体姿态。
4. 消融研究(Ablations)
- 数据集影响:通过在InstructPix2Pix数据集上训练模型,展示了使用真实视频帧对训练的重要性。
- 空间条件策略:比较了空间条件策略与标准通道条件策略的效果,验证了空间条件策略在复杂编辑任务中的优势。
这些实验旨在全面评估论文提出方法的有效性,包括其在遵循编辑指令、保持图像内容一致性以及整合额外控制机制进行精确编辑方面的能力。通过与现有技术的比较和消融研究,论文展示了其方法在图像编辑领域的先进性和实用性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
改进数据集构建流程:
- 研究更精细的帧过滤技术和运动检测算法,以从视频中提取更高质量的帧对。
- 探索结合人类参与的审核过程,以进一步提高数据集的准确性和多样性。
增强多模态大型语言模型(MLLMs)的能力:
- 优化MLLMs以更准确地理解和生成复杂的编辑指令。
- 研究如何让MLLMs更好地捕捉视频中的细微变化,并生成更精确的编辑指令。
扩展编辑模型的控制机制:
- 探索结合更多的用户输入,如语音指令或自然语言描述,以实现更直观的图像编辑。
- 研究如何将编辑模型与3D建模工具集成,以实现更复杂的空间变换和视角调整。
提高模型的泛化能力:
- 研究如何使模型能够处理更广泛的编辑类型,包括艺术风格的转换和对象替换。
- 探索如何通过多任务学习或元学习提高模型对新编辑任务的适应能力。
优化模型的计算效率:
- 研究如何减少模型的计算资源需求,使其更适合在资源受限的环境中使用。
- 探索模型压缩和加速技术,以实现更快的图像编辑过程。
增强模型的解释性和安全性:
- 研究如何提高模型决策过程的透明度,让用户更好地理解编辑结果背后的逻辑。
- 探索如何防止模型被用于生成有害或不当的内容,并确保模型的安全性和伦理性。
跨模态编辑任务:
- 探索如何将图像编辑技术扩展到视频编辑和其他多媒体内容的编辑中。
- 研究如何实现跨模态编辑,例如根据文本描述编辑视频或音频内容。
用户研究和交互设计:
- 进行用户研究,以了解用户在图像编辑中的需求和挑战。
- 设计更直观、更易用的用户界面和交互方式,以提高非专业用户的编辑体验。
这些探索点可以帮助推动基于文本指令的图像编辑技术的发展,提高其实用性和普及度,并为未来的研究提供新的方向。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种基于文本指令的图像编辑方法,名为InstructMove,旨在解决现有图像编辑技术在处理复杂编辑任务时的局限性。以下是论文的主要内容总结:
1. 问题陈述
- 现有基于文本的图像编辑方法在输出质量和编辑类型范围上存在限制,主要瓶颈在于缺乏大规模高质量的训练数据集。
2. 数据集构建流程
- 提出一种新的数据集构建方法,通过从视频中采样帧对,并利用多模态大型语言模型(MLLMs)生成编辑指令,创建源-目标-指令三元组数据集。
3. 空间条件策略
- 引入空间条件策略,将参考图像与噪声输入沿空间维度拼接,而不是传统通道维度拼接,以提高模型执行灵活编辑的能力。
4. 模型微调
- 使用构建的数据集微调预训练的文本到图像(T2I)模型,如Stable Diffusion,以实现复杂的自然语言驱动的图像操作。
5. 实验评估
- 设计了专门的测试集和评估指标,定量和定性地比较了InstructMove与现有方法的性能。
- 展示了InstructMove在遵循编辑指令和保持内容保真度方面的优势。
6. 额外控制机制
- 论文还展示了如何通过遮罩和控制点等额外控制机制实现更精确的编辑。
7. 消融研究
- 通过消融研究验证了使用真实视频帧对训练和空间条件策略的重要性。
8. 局限性和未来工作
- 论文讨论了方法的局限性,包括数据集质量和模型理解能力的限制,并提出了未来可能的研究方向。
总体而言,这篇论文提出了一种创新的基于视频帧和MLLMs的图像编辑数据集构建方法,并通过空间条件策略提高了模型执行复杂编辑任务的能力,为基于文本的图像编辑领域提供了新的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



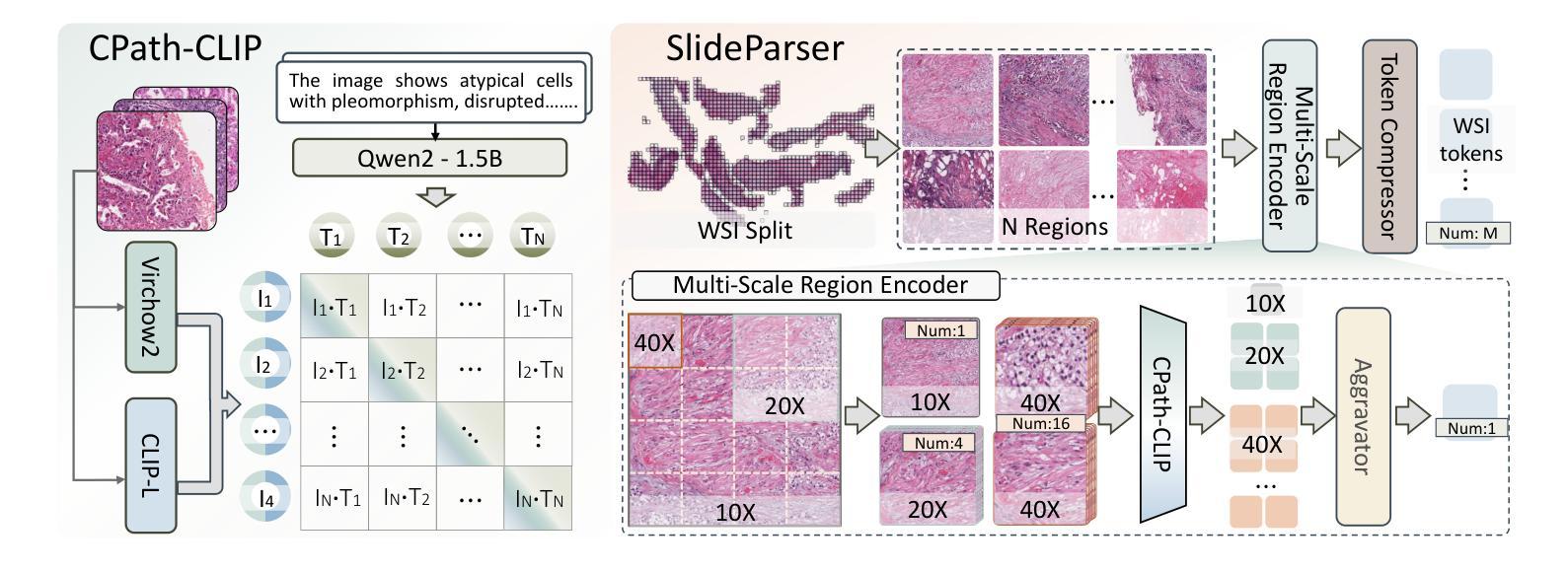
CPath-Omni: A Unified Multimodal Foundation Model for Patch and Whole Slide Image Analysis in Computational Pathology
Authors:Yuxuan Sun, Yixuan Si, Chenglu Zhu, Xuan Gong, Kai Zhang, Pingyi Chen, Ye Zhang, Zhongyi Shui, Tao Lin, Lin Yang
The emergence of large multimodal models (LMMs) has brought significant advancements to pathology. Previous research has primarily focused on separately training patch-level and whole-slide image (WSI)-level models, limiting the integration of learned knowledge across patches and WSIs, and resulting in redundant models. In this work, we introduce CPath-Omni, the first 15-billion-parameter LMM designed to unify both patch and WSI level image analysis, consolidating a variety of tasks at both levels, including classification, visual question answering, captioning, and visual referring prompting. Extensive experiments demonstrate that CPath-Omni achieves state-of-the-art (SOTA) performance across seven diverse tasks on 39 out of 42 datasets, outperforming or matching task-specific models trained for individual tasks. Additionally, we develop a specialized pathology CLIP-based visual processor for CPath-Omni, CPath-CLIP, which, for the first time, integrates different vision models and incorporates a large language model as a text encoder to build a more powerful CLIP model, which achieves SOTA performance on nine zero-shot and four few-shot datasets. Our findings highlight CPath-Omni’s ability to unify diverse pathology tasks, demonstrating its potential to streamline and advance the field of foundation model in pathology.
大型多模态模型(LMM)的出现给病理学带来了显著进展。以往的研究主要集中在分别训练补丁级别和全幻灯片图像(WSI)级别的模型,这限制了跨补丁和WSIs学习的知识的整合,并导致了冗余模型。在这项工作中,我们介绍了CPath-Omni,这是第一个设计的用于统一补丁和WSI级别图像分析的大型多模态模型,拥有十五亿个参数。CPath-Omni在补丁和WSI级别整合了各种任务,包括分类、视觉问答、字幕描述和视觉引用提示等。大量实验表明,CPath-Omni在42个数据集中的39个数据集上的七个不同任务上取得了最先进的性能表现,超越了或匹配了针对单个任务训练的特定任务模型。此外,我们为CPath-Omni开发了一种基于CLIP的专用病理视觉处理器CPath-CLIP。CPath-CLIP首次将不同的视觉模型集成在一起,并融入大型语言模型作为文本编码器,以构建更强大的CLIP模型。该模型在九个零样本和四个少样本数据集上取得了最先进的性能表现。我们的研究突出了CPath-Omni统一多种病理任务的能力,表明了其在病理学基础模型中推动和引领该领域发展的潜力。
论文及项目相关链接
PDF 22 pages, 13 figures
Summary
大规模多模态模型(LMM)的出现为病理学领域带来了显著进展。过去的研究主要集中在分别训练补丁级别和全幻灯片级别(WSI)的模型,这限制了跨补丁和WSIs学习知识的整合,并导致模型冗余。本研究介绍了CPath-Omni,这是一个旨在统一补丁和WSI级别图像分析的首个15亿参数LMM,它可以在这两个级别上整合各种任务,包括分类、视觉问答、描述和视觉提示。大量实验表明,CPath-Omni在39个数据集中的七个不同任务上取得了最先进的性能,优于或匹配针对个别任务训练的特定模型。此外,我们为CPath-Omni开发了一个专用的病理学CLIP视觉处理器CPath-CLIP,首次将不同的视觉模型集成在一起,并引入大型语言模型作为文本编码器来构建更强大的CLIP模型,该模型在九个零样本和四个小样例数据集上取得了最先进的性能。我们的研究突显了CPath-Omni统一多种病理学任务的能力,表明了其在推动病理学领域基础模型发展的潜力。
Key Takeaways
- 大规模多模态模型(LMM)在病理学领域有重要应用。
- 之前的研究主要关注分别训练补丁级别和全幻灯片级别的模型,导致知识整合有限和模型冗余。
- CPath-Omni是首个统一补丁和WSI级别图像分析的LMM,能在多个任务上实现先进性能。
- CPath-Omni在多个数据集上的实验表现优于或匹配特定任务模型。
- CPath-CLIP的引入实现了不同视觉模型的集成,并结合大型语言模型增强了CLIP模型的性能。
- CPath-CLIP在多个数据集上取得了最先进的性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了CPath-Omni,一个统一的多模态基础模型,旨在解决计算病理学中的以下问题:
病理图像分析的多模态集成问题:以往的研究主要集中在分别训练局部(patch-level)和全切片(whole-slide image, WSI)级别的模型,这限制了在局部和WSI级别之间学到的知识的整合,导致模型冗余。
病理学任务的多样性和统一性问题:病理学涉及多种任务,如分类、视觉问题回答(VQA)、描述生成和视觉指代表提示等。CPath-Omni旨在通过统一这些任务,提供一个能够处理局部和WSI级别分析的多功能工具,以辅助病理学家。
病理学基础模型的发展:通过整合局部和WSI级别的分析,CPath-Omni代表了向发展一个真正多功能和全面的病理学辅助工具迈出的重要一步,这有助于推动病理学领域基础模型的发展。
病理学数据的多模态处理能力:CPath-Omni通过开发专门的病理学CLIP模型(CPath-CLIP),结合了不同的视觉模型,并将大型语言模型作为文本编码器,构建了更强大的CLIP模型,以实现在零样本和少样本数据集上的最佳性能。
病理学数据集的整合和扩展:论文中还提到了对多个病理学数据集的系统整合和扩展,创建了一个跨越多个任务和数据集的广泛而多样的训练和测试数据集,这是训练病理学领域大型多模态模型的最大和最多样化的数据集之一。
总的来说,CPath-Omni试图通过统一局部和WSI级别的分析任务,提供一个全面的解决方案,以提高病理图像分析的效率和准确性,并推动计算病理学领域的发展。
Q: 有哪些相关研究?
A: 论文中提到了多个与CPath-Omni相关的研究工作,这些研究主要涉及病理学中的多模态基础模型、视觉基础模型(VFMs)以及多模态数据集。以下是一些具体相关研究的概述:
Vision-Language-based Models:
- CLIP [38]:利用对比学习将图像与文本描述对齐,使视觉编码器能够生成语义有意义的特征。
- Quilt-Net [19]、PLIP [16]、PathCLIP [47]、PathGen-CLIP [46]、CONCH [32]:这些是基于CLIP模型,使用大量图像-字幕对进行训练。
Vision-Only Models:
- DINO [7, 36]:通过自监督学习训练,使用大量从WSIs提取的patch数据。
- Lunit [24]、UNI [11]、Prov-GigaPath [56]、Virchow 系列 [51, 61]:这些模型使用DINO预训练技术学习鲁棒的视觉表示。
Multimodal Generative Foundation Models in Pathology:
- PathAsst [47]、PathGen-LLaVA [46]、Quilt-LLaVA [40]、PathChat [33]:这些模型基于通用的大型语言模型(LLMs)构建,展示了强大的图像理解和多轮对话能力。
Multimodal Datasets in Pathology:
- ARCH [13]、PathCap [47]、OpenPath [16]、QUILT1M [19]:这些数据集收集了大量与病理图像相关的图像-文本对。
- WsiCaption [8]、HistGen [14]:这些数据集基于TCGA报告PDF生成WSI字幕样本。
Other Related Models and Datasets:
- Prov-GigaPath [56]、HIPT [10]:用于WSI分类的模型。
- HistGen [14]、WsiCaption [8]:用于生成WSI报告的模型。
- PRISM [42]:一个CoCa风格的模型,能够进行零样本WSI分类和WSI报告生成。
这些相关研究为CPath-Omni的开发提供了理论基础和技术背景,同时也展示了计算病理学领域中多模态模型和数据集的快速发展。CPath-Omni通过整合这些研究成果,旨在实现一个统一的多模态基础模型,以提高病理图像分析的效率和准确性。
Q: 论文如何解决这个问题?
A: 论文通过提出CPath-Omni模型来解决上述问题,具体解决方案如下:
1. 统一的多模态基础模型
CPath-Omni是一个15亿参数的大型多模态模型(LMM),旨在统一局部(patch-level)和全切片(WSI-level)图像分析。该模型能够处理多种任务,包括分类、视觉问题回答(VQA)、描述生成和视觉指代提示等。
2. CPath-CLIP的开发
CPath-Omni引入了一个专门的病理学CLIP模型(CPath-CLIP),这是首个将大型语言模型(LLM)作为文本编码器集成到CLIP模型中的工作。CPath-CLIP结合了自监督病理视觉模型Virchow2作为视觉编码器,以及原始的CLIP-L模型。
3. 多阶段训练策略
CPath-Omni的训练分为四个阶段:
- 第一阶段:使用CPath-PatchCaption数据集对CPath-CLIP与Qwen2.5-14B语言模型进行预对齐。
- 第二阶段:使用CPath-PatchInstruction数据集对所有模型参数进行微调,以学习多种任务。
- 第三阶段:引入WSI相关数据,继续对CPath-Omni进行预训练,增强其对WSI的理解。
- 第四阶段:进行混合训练,结合WSI和局部数据,使CPath-Omni能够无缝处理局部和WSI数据。
4. 数据集的整合与构建
论文中系统地整合了现有的数据集,并对其进行了扩展和注释,构建了CPath-PatchCaption和CPath-WSIInstruction数据集,涵盖了7个任务和42个数据集,这是训练病理学领域大型多模态模型的最大和最多样化的数据集之一。
5. 实验验证
通过在七个不同任务和42个数据集上的广泛实验,验证了CPath-Omni的有效性。CPath-Omni在39个数据集上实现了最先进的性能,并在多个任务上展示了与特定任务模型相当的或更优越的性能。
总结
CPath-Omni通过其统一的架构和多阶段训练策略,整合了局部和WSI级别的分析,使得从局部级别学到的知识能够同时提升WSI级别的性能。这一方法不仅提高了病理图像分析的效率和准确性,还推动了病理学领域基础模型的发展。
Q: 论文做了哪些实验?
A: 论文中进行了广泛的实验来评估CPath-Omni模型的性能,这些实验涉及多个任务和数据集。以下是实验的详细情况:
1. CPath-CLIP的基准测试
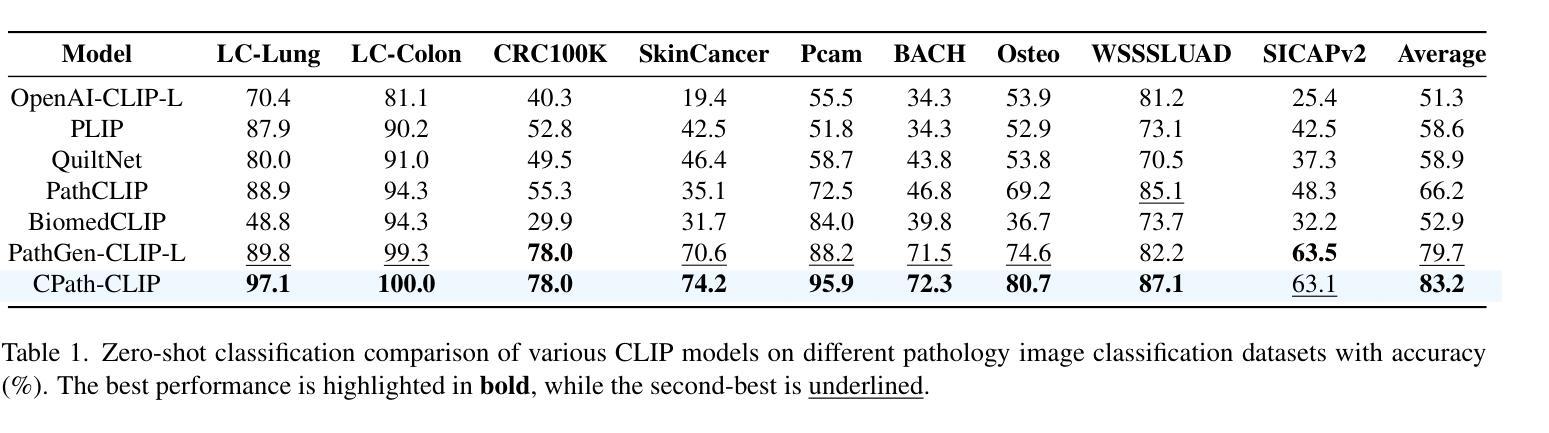
- 零样本分类:使用包括PatchCamelyon、CRC-100K、SICAPv2、BACH、Osteo、SkinCancer、WSSSLUAD、LC-Lung和LC-Colon等多个病理图像分类数据集,对比CPath-CLIP与其他CLIP模型的性能。
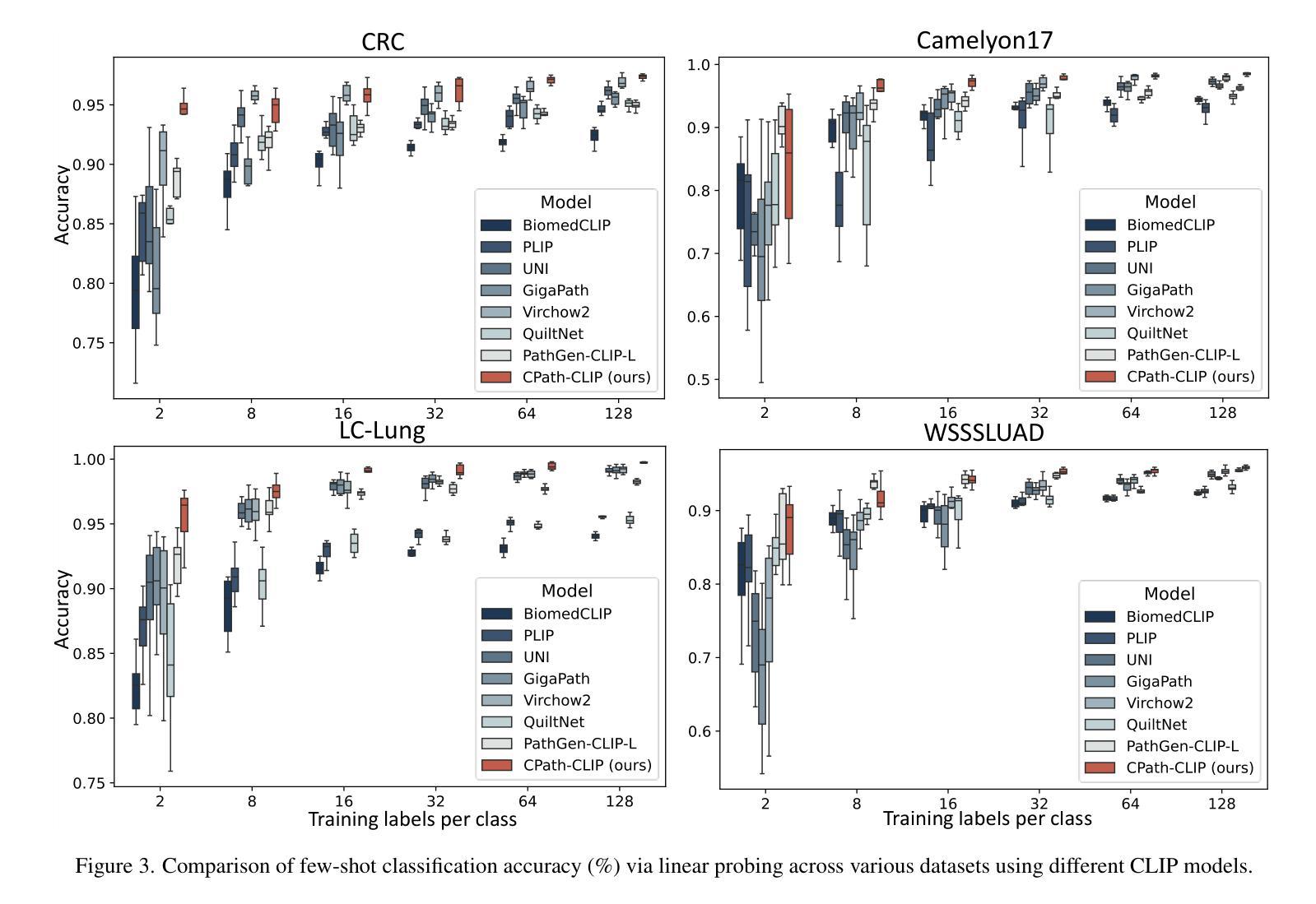
- 少样本线性探测:在LC-Colon、Camelyon17、LC-Lung和WSSSLUAD等数据集上,使用不同数量的训练样本(2, 8, 16, 32, 64, 和 128 shots)来评估CPath-CLIP的特征提取能力。
2. CPath-Omni在局部级别的基准测试
- 视觉问题回答(VQA):在PathMMU数据集上评估CPath-Omni与多个通用和领域特定模型的性能。
- 分类任务:在30个分类数据集上评估CPath-Omni的性能,包括16个在分布(ID)数据集和14个外分布(OOD)数据集。
- 视觉指代提示(VPR)和局部描述生成:比较CPath-Omni与特定领域的模型,如PathGen-LLaVA、Quilt-LLaVA和LLaVA-Med。
3. CPath-Omni在WSI级别的基准测试
- 分类任务:在8个TCGA亚型数据集上评估CPath-Omni与特定任务模型和通用模型的性能。
- WSI报告生成:比较CPath-Omni与特定任务模型(WSICaption和HistGen)以及通用模型(PRISM和GPT-4o)的性能。
- WSI VQA任务:评估CPath-Omni与GPT-4o的性能,使用由GPT-4o生成的WSI报告作为上下文回答问题。
4. 实验结果
- CPath-CLIP在多个数据集上实现了优于现有最先进模型的性能。
- CPath-Omni在局部级别任务中显著优于通用模型和特定领域的模型,甚至在某些任务中超过了人类病理学家的性能。
- CPath-Omni在WSI级别的任务中也显示出优越的性能,与特定任务模型相比具有竞争力或更优的性能。
这些实验验证了CPath-Omni作为一个统一的多模态基础模型在病理学领域处理局部和WSI级别任务的能力,展示了其在推进病理学领域基础模型发展方面的潜力。
Q: 有什么可以进一步探索的点?
A: 尽管CPath-Omni在多模态病理学分析方面取得了显著成果,但仍有一些领域可以进一步探索和研究:
1. 模型泛化能力的提高
进一步研究如何提高CPath-Omni在面对新的、未见过的病理类型和数据集时的泛化能力。这可能涉及多模态迁移学习、领域适应等技术。
2. 模型解释性
提高模型的解释性,使病理学家能够理解模型的决策过程,这有助于增强模型的可信度和实用性。
3. 模型压缩和优化
研究模型压缩和优化技术,以减少CPath-Omni的计算资源需求,使其更适用于临床设置和资源受限的环境。
4. 多模态数据融合策略
探索不同的数据融合策略,以改善局部和WSI级别信息的整合,可能包括新的神经网络架构或注意力机制。
5. 增强的数据集
构建更大、更多样化的病理学数据集,包括不同来源、不同病理类型的图像和标注,以支持模型训练和验证。
6. 实际临床应用
进行临床试验和实际应用研究,以评估CPath-Omni在实际病理诊断工作流程中的表现和影响。
7. 模型的鲁棒性和安全性
研究模型在面对错误标注、异常值和噪声数据时的鲁棒性,以及如何确保模型输出的安全性和隐私保护。
8. 跨模态学习
探索跨模态学习技术,以利用病理报告、临床数据和图像数据之间的关联,提高诊断的准确性。
9. 模型的实时性能
优化模型以实现实时或近实时性能,这对于需要快速诊断的临床环境至关重要。
10. 交互式分析工具
开发交互式分析工具,使病理学家能够与模型互动,提供反馈,进一步训练和微调模型。
11. 模型的公平性和偏差
研究模型的公平性和偏差问题,确保模型在不同人群和数据子集上的表现均衡。
这些方向不仅可以推动CPath-Omni模型的发展,也有助于提升计算病理学领域的整体研究和应用水平。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了CPath-Omni,这是一个统一的多模态基础模型,旨在整合局部(patch-level)和全切片(WSI-level)图像分析,以推进计算病理学领域的发展。以下是论文的主要内容总结:
问题陈述:
- 传统病理学分析需要大量的人力,并且依赖于对高分辨率图像的精确解读。
- 以往的研究集中在分别训练局部和全切片级别的模型,导致知识整合不足和模型冗余。
CPath-Omni模型介绍:
- CPath-Omni是一个15亿参数的多模态模型,能够处理包括分类、视觉问题回答(VQA)、描述生成和视觉指代提示等多种任务。
- 该模型是首个统一局部和全切片级别分析的模型,展示了在多个数据集上的优秀性能。
CPath-CLIP开发:
- CPath-CLIP是为CPath-Omni开发的病理学特定CLIP模型,整合了大型语言模型(LLM)作为文本编码器,并结合了自监督病理视觉模型Virchow2作为视觉编码器。
训练策略:
- CPath-Omni的训练分为四个阶段:局部预训练、局部微调、WSI预训练和混合局部-WSI微调。
数据集整合与构建:
- 论文中系统地整合并构建了CPath-PatchCaption和CPath-WSIInstruction数据集,涵盖了7个任务和42个数据集。
实验验证:
- 通过在七个不同任务和42个数据集上的广泛实验,验证了CPath-Omni的有效性,该模型在39个数据集上实现了最先进的性能。
结论:
- CPath-Omni展示了统一局部和WSI级别训练的能力,允许从局部级别学到的知识提升WSI性能,即使在WSI数据有限的情况下。
- 该模型有潜力成为病理学领域“一劳永逸”的解决方案,推动下一代病理学特定LMMs的发展。
这篇论文通过提出CPath-Omni模型,为计算病理学中的多模态图像分析提供了一个强大的新工具,并展示了其在多个任务和数据集上的卓越性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

CG-Bench: Clue-grounded Question Answering Benchmark for Long Video Understanding
Authors:Guo Chen, Yicheng Liu, Yifei Huang, Yuping He, Baoqi Pei, Jilan Xu, Yali Wang, Tong Lu, Limin Wang
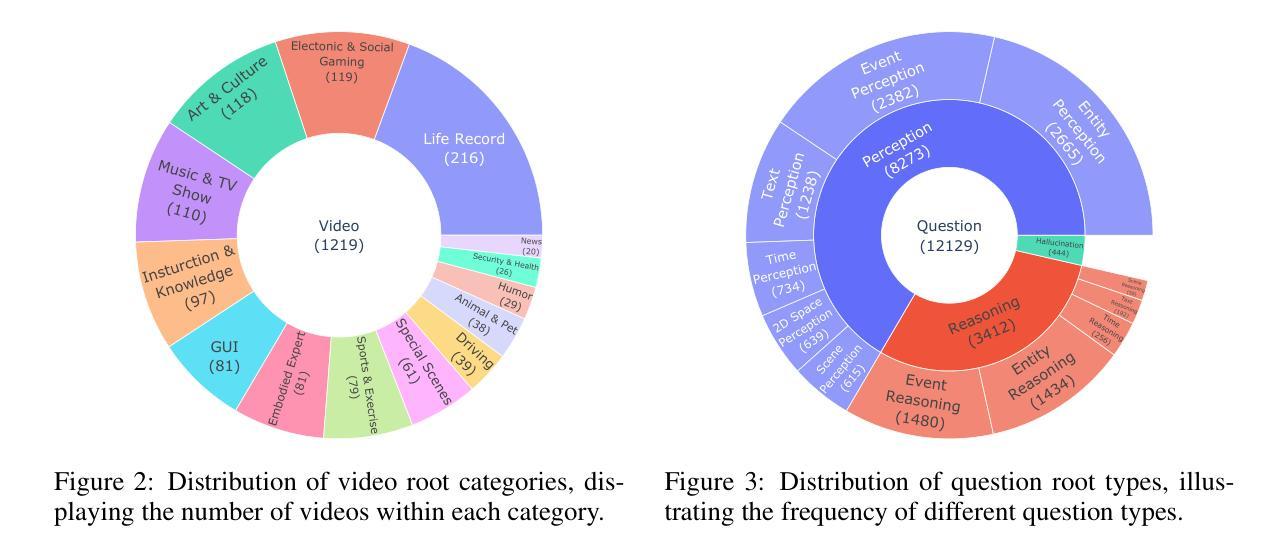
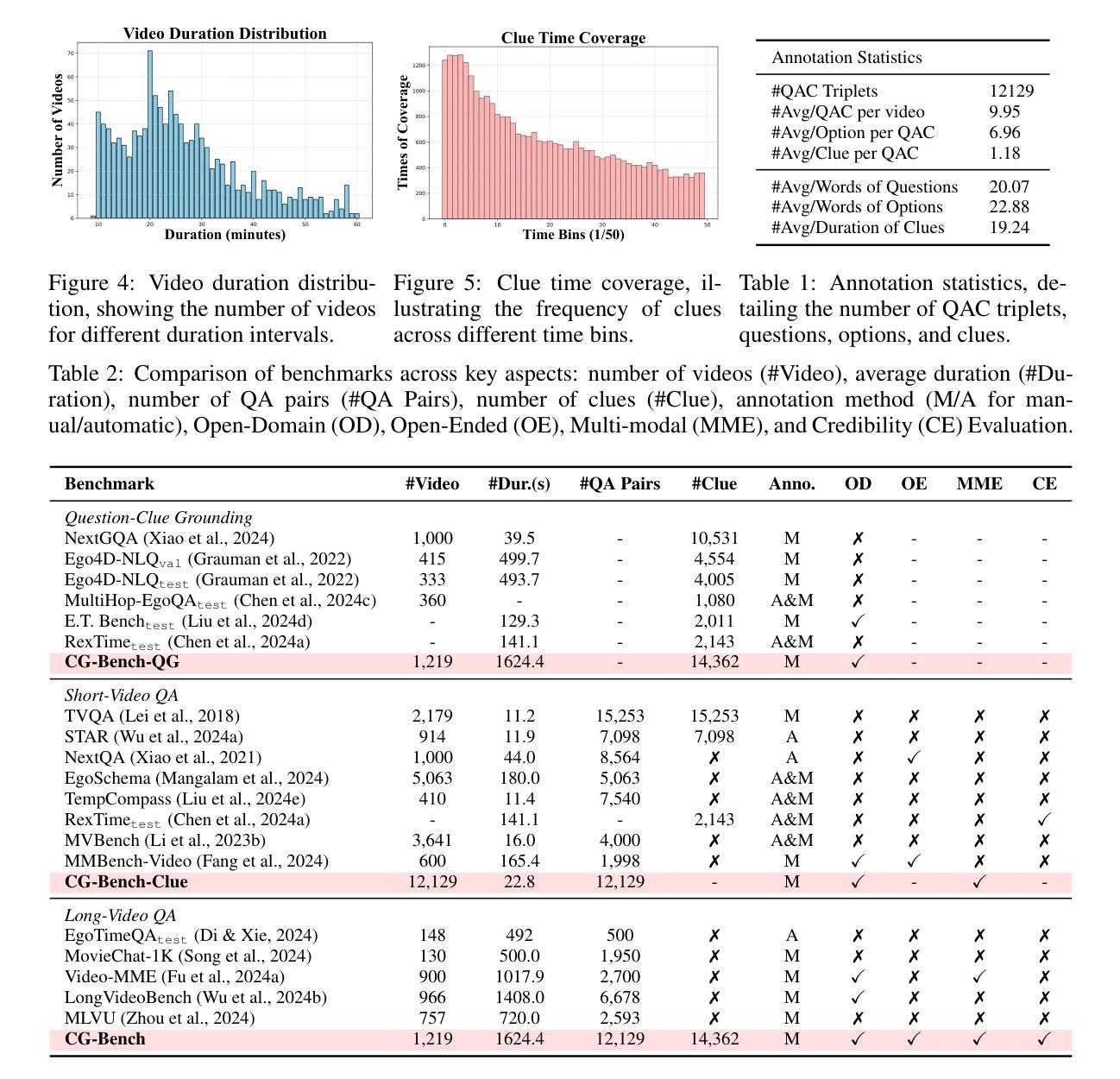
Most existing video understanding benchmarks for multimodal large language models (MLLMs) focus only on short videos. The limited number of benchmarks for long video understanding often rely solely on multiple-choice questions (MCQs). However, because of the inherent limitation of MCQ-based evaluation and the increasing reasoning ability of MLLMs, models can give the current answer purely by combining short video understanding with elimination, without genuinely understanding the video content. To address this gap, we introduce CG-Bench, a novel benchmark designed for clue-grounded question answering in long videos. CG-Bench emphasizes the model’s ability to retrieve relevant clues for questions, enhancing evaluation credibility. It features 1,219 manually curated videos categorized by a granular system with 14 primary categories, 171 secondary categories, and 638 tertiary categories, making it the largest benchmark for long video analysis. The benchmark includes 12,129 QA pairs in three major question types: perception, reasoning, and hallucination. Compensating the drawbacks of pure MCQ-based evaluation, we design two novel clue-based evaluation methods: clue-grounded white box and black box evaluations, to assess whether the model generates answers based on the correct understanding of the video. We evaluate multiple closed-source and open-source MLLMs on CG-Bench. Results indicate that current models significantly underperform in understanding long videos compared to short ones, and a significant gap exists between open-source and commercial models. We hope CG-Bench can advance the development of more trustworthy and capable MLLMs for long video understanding. All annotations and video data are released at https://cg-bench.github.io/leaderboard/.
针对多模态大型语言模型(MLLMs)的大多数现有视频理解基准测试仅专注于短视频。针对长视频理解的基准测试数量有限,通常仅依赖于多项选择题(MCQs)。然而,由于基于MCQ的评估的固有局限性以及MLLMs日益增强的推理能力,模型可以通过结合短视频理解与排除法给出当前答案,而无需真正了解视频内容。为了解决这一差距,我们引入了CG-Bench,这是一个专为长视频中的线索导向问答而设计的新型基准测试。CG-Bench强调模型检索与问题相关的线索的能力,提高评估的可信度。它拥有1219个手动整理的视频,这些视频由一个细致的系统分类,包括14个主要类别,171个次级类别和638个三级类别,使其成为最大的长视频分析基准测试。该基准测试包含三种主要类型的问答对,共12,129个:感知、推理和幻觉。为了弥补纯基于MCQ评估的缺点,我们设计了两种新的基于线索的评估方法:线索导向的白盒和黑盒评估,以评估模型是否基于正确理解视频来生成答案。我们在CG-Bench上评估了多个封闭源代码和开放源代码的MLLMs。结果表明,与短视频相比,当前模型在长视频理解方面存在显著不足,开源与商业模型之间存在明显差距。我们希望CG-Bench能够促进开发更可靠、更强大的MLLMs进行长视频理解。所有注释和视频数据均在https://cg-bench.github.io/leaderboard/发布。
论文及项目相关链接
PDF 14 pages, 9 figures
Summary
本文主要介绍了针对长视频理解的新的评估基准CG-Bench,其强调了模型从视频中检索与问题相关的线索的能力,并提供了两种新的基于线索的评估方法。现有视频理解基准大多专注于短视频或仅依赖选择题进行评估,CG-Bench弥补了这些不足,成为最大的长视频分析基准。评估结果指出,当前模型在理解长视频方面显著落后于短视频,且开源与商业模型之间存在显著差距。希望CG-Bench能推动更可靠和更强大的长视频理解的多模态大型语言模型的发展。所有标注和视频数据已在网站上公开。
Key Takeaways
- 当前视频理解基准大多专注于短视频或仅依赖选择题进行评估,存在评估局限性。
- CG-Bench作为新的长视频理解基准,强调模型检索相关线索的能力,提高评估可信度。
- CG-Bench包含1219个手动整理的视频,分为14个主类别、171个次级类别和638个三级类别,是最大的长视频分析基准。
- 基准包括三种主要问题的QA对:感知、推理和幻觉,以评估模型的视频理解能力。
- CG-Bench提供了两种新的基于线索的评估方法:线索基础的开放和封闭评价,以评估模型是否基于正确理解的视频生成答案。
- 当前模型在长视频理解方面显著落后于短视频理解,且不同模型间存在显著性能差距。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为CG-Bench的新型基准测试,旨在评估和提升多模态大型语言模型(MLLMs)在长视频理解方面的能力。论文主要试图解决的问题包括:
现有基准测试的局限性:大多数现有的视频理解基准测试只关注短视频,而针对长视频理解的基准测试往往只依赖于多项选择题(MCQs),这限制了对MLLMs性能的全面评估。
MCQs评估的不足:基于MCQs的评估存在固有的局限性,模型可能仅通过结合短视频理解和排除法来给出答案,而没有真正理解视频内容,导致模型的可信度不足。
长视频理解的挑战:长视频包含更丰富的上下文信息,对模型的理解和推理能力提出了更高的要求。现有的MLLMs在长视频理解方面的表现尚待探索和提升。
评估方法的创新:为了更可靠地评估模型性能,论文提出了两种基于线索的评估方法——白盒评估和黑盒评估,以检验模型是否基于对视频的正确理解生成答案。
推动MLLMs的发展:通过构建一个包含丰富视频类别和问题的大规模基准测试,论文希望推动研究社区开发出更可靠、更强大的MLLMs,以更好地理解和处理长视频内容。
综上所述,CG-Bench基准测试的引入旨在通过更全面和严格的评估方法,推动长视频理解领域的发展,并提升MLLMs的性能和可信度。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究主要集中在以下几个领域:
多模态大型语言模型(MLLMs):
- 这些模型擅长整合视觉和文本信息,近期的研究进展包括LLaVA-Next-Video、LLaVA-OneVision和InternVL2等,它们通过集成大型语言模型(LLM)主干、视觉编码器和专门的适配器,或创建更高质量的多模态指令数据来增强MLLMs的性能。
视频理解模型:
- 大部分现有模型针对短视频进行优化,通常只有几秒钟或最多几分钟,没有探索更长上下文的视觉理解。对此,研究者探索了将视频帧压缩成较少的视觉标记的方法,例如LLaMA-Vid、LVChat、MovieChat、MALMM和Oryx等模型。
长视频理解的系统级优化:
- LongVA和LongViLA等研究探索了能够原生支持长视频理解的长上下文MLLMs的系统级优化。
MLLM基准测试:
- 随着领域的发展,建立了各种基准测试来评估MLLMs在视频理解任务中的性能。早期的基准测试主要关注短视频,例如TVQA、NextQA和EgoSchema等。最近,一些工作如VideoMME、CinePile、MLVU、LongVideoBench、MoVQA和LVBench引入了长视频基准测试来评估MLLMs。
特定领域的视频理解基准测试:
- 包括NextGQA、Ego4D-NLQ、MultiHop-EgoQA、E.T. Bench和RexTime等,这些基准测试主要围绕动作和自我中心领域,视频从学术数据集中采样。
短视频QA基准测试:
- 包括TempCompass、MVBench和MMBench-Video等,这些基准测试关注短视频的问答任务。
长视频QA基准测试:
- 包括Video-MME和MLVU等,这些基准测试关注长视频的问答任务。
这些相关研究为CG-Bench的提出提供了背景和动机,同时也表明了在长视频理解领域仍存在许多挑战和改进空间。CG-Bench旨在通过提供一个更全面和严格的评估平台,推动MLLMs在长视频理解方面的发展。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤解决长视频理解中存在的问题:
创建CG-Bench基准测试:
- 论文介绍了一个名为CG-Bench的新基准测试,它专注于长视频中的线索基础问题回答。这个基准测试包含了1,219个手动策划的视频和12,129个人工标注的问题-答案-线索(QAC)三元组,覆盖了感知、推理和幻觉三种主要问题类型。
详细的分类系统:
- CG-Bench使用了一个高度详细的手动分类系统,将每个视频归入14个主要类别、171个次要类别和638个三级类别中,确保了数据内容的广泛多样性。
设计新型评估方法:
- 论文设计了两种基于线索的评估方法:白盒评估和黑盒评估,以提供更可靠的模型性能评估。
- 白盒评估要求模型直接提供与问题对应的线索区间,同时选择正确答案。
- 黑盒评估要求模型在整体视频和仅线索级别的多项选择题中保持准确性的一致性。
- 论文设计了两种基于线索的评估方法:白盒评估和黑盒评估,以提供更可靠的模型性能评估。
支持开放式问答评估:
- CG-Bench还支持开放式问答(Open-ended QA)评估,通过利用人类标注的线索,为更全面评估结果提供支持。
实验评估:
- 论文通过评估多个闭源和开源的MLLMs在CG-Bench上的性能,揭示了现有模型在长视频理解方面的显著不足,并指出了改进空间。
数据和代码的公开:
- 论文承诺所有注释和视频数据将被公开,以便研究社区可以使用和进一步开发这个基准测试。
推动MLLMs的发展:
- 通过CG-Bench的评估结果,论文希望推动开发更可信和更强大的MLLMs,以更好地理解和处理长视频内容。
通过这些步骤,论文不仅提出了一个针对长视频理解的全面评估框架,而且通过实验验证了现有模型的局限性,并为未来的研究提供了明确的方向。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估CG-Bench基准测试,并测试了多个闭源和开源的多模态大型语言模型(MLLMs)。以下是实验的主要部分:
模型评估:
- 评估了三种主流的商业模型:GPT4o、Gemini-1.5和Claude-3.5及其不同版本。
- 评估了代表性的开源视频模型,如LLaVA-OneVision、Qwen2-VL和InternVL2等。
帧采样策略:
- 研究了帧采样策略对长视频理解的影响,对于开源MLLMs,尽可能多地使用帧以充分利用计算资源。对于闭源MLLMs,由于计算资源不再是瓶颈,可以使用更多的帧。
模态研究:
- 探索了字幕和音频等其他模态对模型性能的影响。对于字幕,采用了统一的采样方法;对于音频,研究了其对Gemini-1.5 Pro模型性能的影响。
主要结果:
- 展示了不同MLLMs在CG-Bench上的性能,包括多项选择题(MCQ)的准确性、线索基础的评估(包括白盒和黑盒评估)以及开放式问答(Open-ended QA)的评估结果。
- 分析了模型在不同评估标准下的表现,如长视频MCQ准确性(long-acc.)、线索准确性(clue-acc.)、平均时间交集比(mIoU)、召回率@IoU(rec.@IoU)、准确率@IoU(acc.@IoU)和线索恢复率(CRR)。
提示和模态的影响:
- 进行了消融研究,探索了不同提示(包括帧时间戳、字幕、字幕时间戳)对GPT4o模型性能的影响,以及音频模态对Gemini-1.5 Pro模型性能的影响。
帧数量的影响:
- 分析了不同数量的采样帧对模型性能的影响,包括长视频MCQ准确性、mIoU、Acc@IoU、CRR和开放式问答准确性。
开放式问答评估质量:
- 评估了不同MLLMs作为开放式问答评估器的稳定性和准确性,并比较了不同的评估方法,包括仅使用文本答案、视觉信息、文本答案加视觉信息以及论文提出的启发式评估方法。
视频时长对性能的影响:
- 根据视频时长对视频进行了分组,并评估了GPT4o-0806在不同视频时长下的长视频MCQ准确性。
帧采样策略的影响:
- 研究了不同帧采样策略对GPT4o-0806长视频MCQ准确性的影响,包括低分辨率、高分辨率和关键帧提取策略。
这些实验全面评估了MLLMs在长视频理解任务中的表现,并揭示了现有模型在长视频理解方面的不足,为未来的研究和模型改进提供了指导。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
改进帧采样策略:
- 研究更高效的帧采样策略,以更好地捕捉长视频中的关键信息,并提高模型的性能。
增强模型对长视频的理解能力:
- 开发新的方法和技术,以提升MLLMs处理和理解长视频内容的能力,特别是在面对视频内容的稀疏性和复杂性时。
多模态信息融合:
- 进一步探索如何有效地融合视觉、文本和音频模态信息,以提高长视频理解任务的性能。
减少模型的幻觉(hallucination):
- 研究如何减少MLLMs在长视频理解中的幻觉现象,提高模型回答的准确性和可靠性。
提高开放式问答的评估质量:
- 开发更精确的评估方法,以准确衡量模型在开放式问答任务中的表现,并减少评估过程中的偏差和成本。
长视频的细粒度理解:
- 探索模型在长视频中进行细粒度理解的能力,例如在更长的时间尺度上进行事件和动作的检测与识别。
模型的可解释性和透明度:
- 提高MLLMs在长视频理解任务中的可解释性,使研究人员和用户能够更好地理解模型的决策过程。
跨领域和跨语言的视频理解:
- 扩展CG-Bench到更多领域和语言,以评估MLLMs在不同文化和语言环境中的性能。
大规模训练和微调:
- 在更大的数据集上进行训练和微调MLLMs,以提高其在长视频理解任务中的泛化能力。
实时视频理解:
- 研究如何使MLLMs能够实时处理和理解视频流数据,这对于许多实际应用(如监控、直播等)非常重要。
长视频编辑和摘要:
- 探索MLLMs在长视频编辑和摘要任务中的应用,以自动创建视频的概要或亮点。
模型的鲁棒性和安全性:
- 研究提高MLLMs在面对错误信息、误导性内容或攻击时的鲁棒性和安全性。
这些探索点可以帮助推动长视频理解技术的发展,并扩展MLLMs在多媒体分析和理解中的应用范围。
Q: 总结一下论文的主要内容
A: 论文介绍了CG-Bench,这是一个为长视频理解设计的新型基准测试,旨在评估多模态大型语言模型(MLLMs)在长视频问答任务中的表现。以下是论文的主要内容总结:
问题识别:
- 现有视频理解基准测试主要关注短视频,且多依赖于多项选择题(MCQs),这限制了对MLLMs性能的全面评估,尤其是在长视频理解方面。
CG-Bench基准测试:
- CG-Bench包含1,219个手动策划的视频和12,129个人工标注的问答-线索(QAC)三元组,覆盖感知、推理和幻觉三种问题类型。
- 视频采用三级分类系统,包括14个主类别、171个次类别和638个三级类别,确保了数据内容的多样性。
评估方法:
- 提出了两种基于线索的评估方法:白盒评估和黑盒评估,以更可靠地评估模型是否基于对视频的正确理解生成答案。
- 白盒评估要求模型直接提供与问题对应的线索区间。
- 黑盒评估要求模型在整体视频和仅线索级别的多项选择题中保持准确性的一致性。
实验评估:
- 对多个闭源和开源MLLMs进行了评估,发现现有模型在长视频理解方面的表现远不如短视频,表明现有MLLMs在长视频理解方面有很大的改进空间。
数据和代码公开:
- 论文承诺将所有注释和视频数据公开,以便研究社区使用和进一步开发。
推动MLLMs发展:
- 论文希望CG-Bench能够推动开发更可信和更强大的MLLMs,以更好地理解和处理长视频内容。
总体而言,CG-Bench基准测试的引入旨在通过更全面和严格的评估方法,推动长视频理解领域的发展,并提升MLLMs的性能和可信度。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


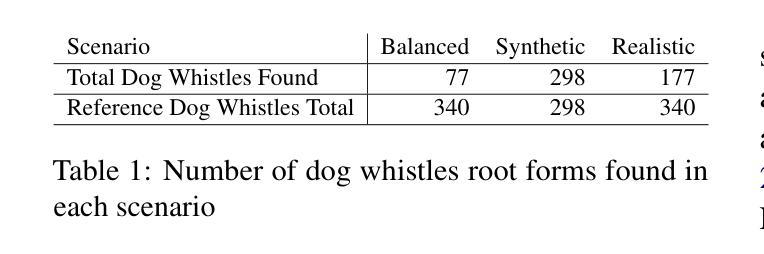
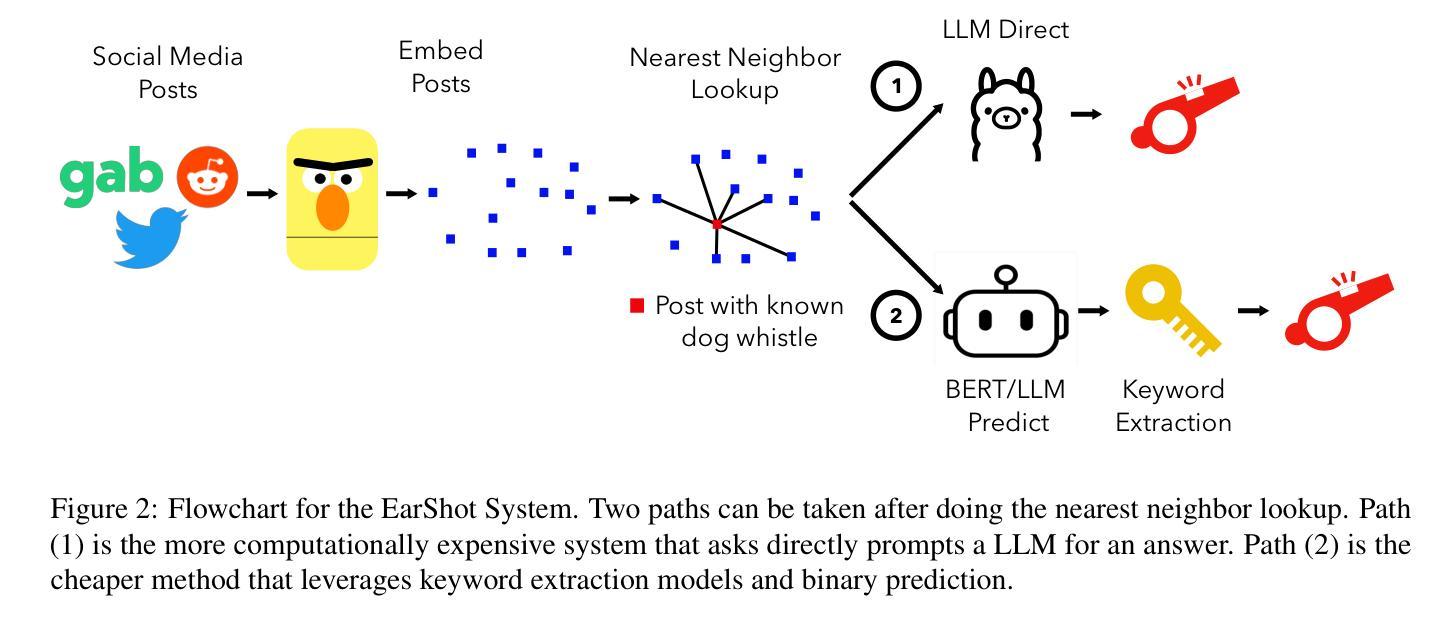
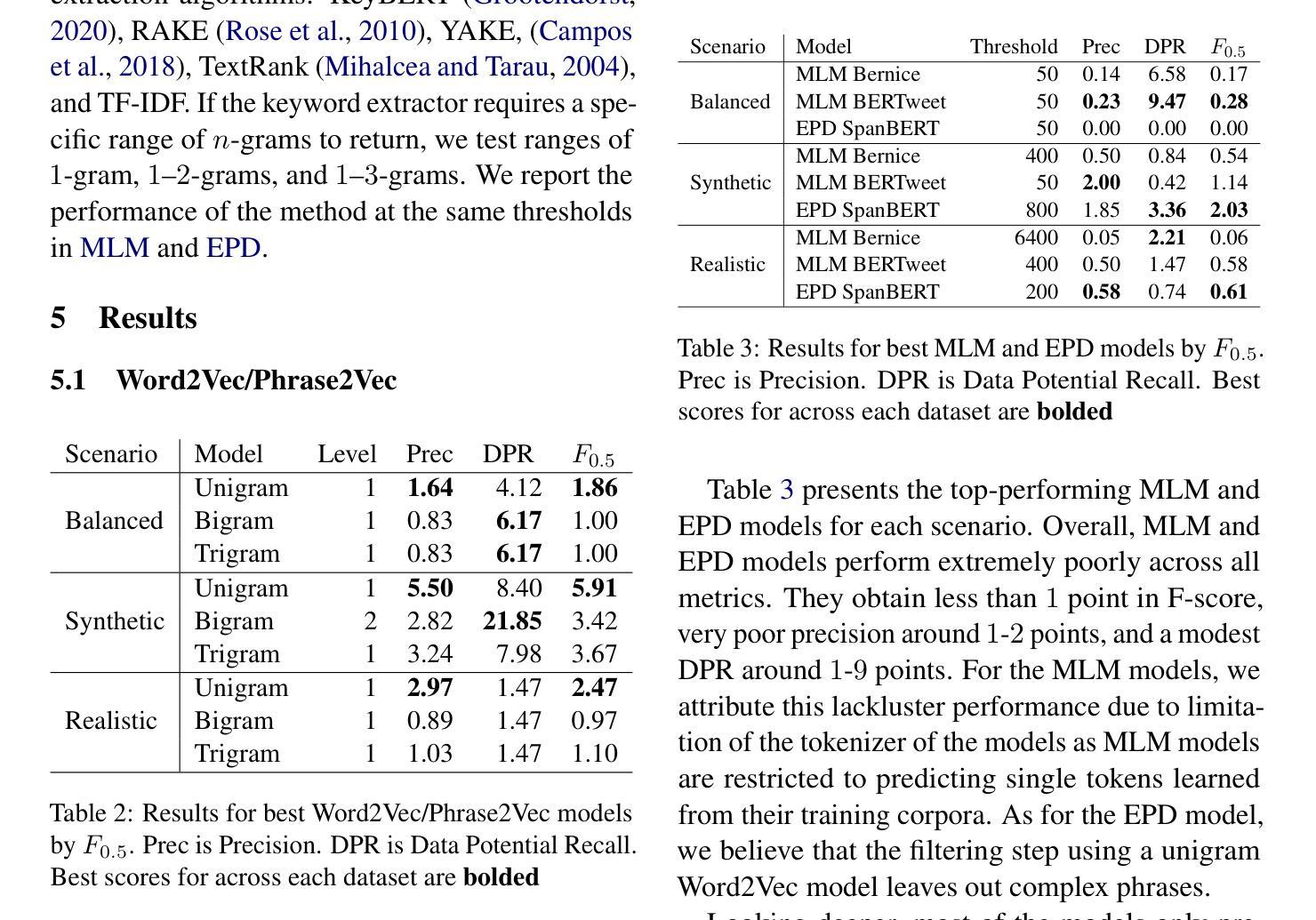
Making FETCH! Happen: Finding Emergent Dog Whistles Through Common Habitats
Authors:Kuleen Sasse, Carlos Aguirre, Isabel Cachola, Sharon Levy, Mark Dredze
WARNING: This paper contains content that maybe upsetting or offensive to some readers. Dog whistles are coded expressions with dual meanings: one intended for the general public (outgroup) and another that conveys a specific message to an intended audience (ingroup). Often, these expressions are used to convey controversial political opinions while maintaining plausible deniability and slip by content moderation filters. Identification of dog whistles relies on curated lexicons, which have trouble keeping up to date. We introduce \textbf{FETCH!}, a task for finding novel dog whistles in massive social media corpora. We find that state-of-the-art systems fail to achieve meaningful results across three distinct social media case studies. We present \textbf{EarShot}, a novel system that combines the strengths of vector databases and Large Language Models (LLMs) to efficiently and effectively identify new dog whistles.
警告:本文包含可能对某些读者造成不适或冒犯的内容。狗哨是一种具有双重含义的编码表达:一种用于普通公众(外组),另一种向目标受众(内组)传达特定信息。通常,这些表达用于传达有争议的政治观点,同时保持可否认的合理性并绕过内容过滤。狗哨的识别依赖于精心策划的词汇表,这些词汇表在更新方面遇到了困难。我们引入了“FETCH!”的任务,旨在在巨大的社交媒体语料库中寻找新型狗哨。我们发现,最先进的技术系统在三个不同的社交媒体案例研究中未能取得有意义的结果。我们提出了“EarShot”这一新型系统,它将矢量数据库和大型语言模型(LLM)的优点结合起来,以高效且有效地识别新型狗哨。
论文及项目相关链接
Summary
该文介绍了狗哨的内容及其在社交媒体上的检测难度。文章强调,狗哨具有双重含义,一种面向公众,另一种针对特定群体传达特定信息。文章介绍了现有系统在检测社交媒体中的狗哨时面临的挑战,并提出了名为“耳射”的新系统,该系统结合了向量数据库和大型语言模型(LLM)的优势,能够高效准确地识别新的狗哨。
Key Takeaways
- 狗哨是具有双重含义的编码表达,用于传达争议性政治意见,同时保持可否认性和绕过内容过滤。
- 现有系统在检测社交媒体中的狗哨时面临挑战,因为狗哨的表达方式在不断演变且难以跟上发展速度。
- 文章提出了名为“FETCH!”的任务,旨在在海量社交媒体语料库中寻找新型狗哨。
- 跨三个不同社交媒体案例的研究表明,现有系统无法取得有意义的结果。
- 文章介绍了一种名为“耳射”的新系统,该系统结合了向量数据库和大型语言模型(LLM)的优势。
- “耳射”系统能够高效准确地识别新型狗哨。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在大规模社交媒体语料库中发现新兴的或之前未知的“狗哨”(dog whistles)。狗哨是一种具有双重含义的编码表达方式:一方面对广大公众(外群体)传达一种信息,另一方面向特定受众(内群体)传达一个特定的、通常是具有争议性、敏感或煽动性的信息。这些表达经常用于在保持表面上的合理否认性的同时传达有争议的政治观点,并且常常能够绕过内容审核过滤器。
论文的主要贡献在于:
- 提出了一个新的任务“FETCH!”,即在常见栖息地中寻找新兴的狗哨,旨在评估模型在多样化环境中检测新狗哨的能力。
- 通过三个不同的社交媒体案例研究,对多种最新的技术方法进行了严格的评估。
- 提出了一个名为“EarShot”的新系统,该系统结合了向量数据库和大型语言模型(LLMs)的优势,有效地识别新的狗哨。
论文强调,现有的狗哨检测方法依赖于人工策划的词汇表,这些方法虽然有效,但是创建和维护起来非常耗费劳动力,并且无法适应语言的动态演变。因此,论文旨在通过自动化的方法来发现新的狗哨,以应对这一挑战。
Q: 有哪些相关研究?
A: 相关研究主要涉及以下几个领域:
隐性仇恨言论检测(Implicit Hate Speech Detection):
- 隐性仇恨言论使用编码或间接语言,相关研究通过创建新数据集、开发检测方法和解释仇恨言论的方法来进行。这些方法主要关注整体文本或帖子,而不是具体的单词和短语。
狗哨(Dog Whistles):
- 语言学、政治学和其他社会科学领域研究了狗哨的使用及其在不同形式分析中的表现。这些研究关注狗哨的语义和语用学,并使用基于代理的模拟来研究新狗哨的出现。
委婉语检测(Euphemism Detection):
- 委婉语检测关注寻找新颖的委婉语,这些术语或短语用来替代更冒犯的术语以减轻其不愉快性,这与狗哨在语义上类似。这项任务通常涉及给定一组种子委婉语,目标是在提供的语料库中找到其他委婉语,类似于词汇表诱导。
狗哨检测(Dog Whistle Detection):
- 相对较少的研究关注狗哨的检测。其中一些研究专注于瑞典语狗哨,使用基于嵌入的方法并分析语义变化。在英语中,只有两项研究专注于检测狗哨,一项评估了大型语言模型(LLMs)浮现这些术语的能力,另一项创建了包含狗哨的帖子的最大数据集。
具体到每项研究,论文中提到了如下一些工作:
- Waseem et al. (2017) 提出了隐性仇恨言论的定义,并聚焦于使用编码或间接语言的仇恨言论检测。
- Henderson and McCready (2018) 从语言学的角度研究了狗哨的语义和语用学。
- Aoki et al. (2017) 结合Word2Vec方法和其他用户及搜索行为来检测委婉语。
- Hertzberg et al. (2022) 专注于使用分布方法分析瑞典语狗哨。
- Mendelsohn et al. (2023) 评估了大型语言模型在浮现英语狗哨方面的能力。
- Kruk et al. (2024) 创建了包含狗哨的帖子的最大数据集,并进行了LLMs在检测新狗哨方面的能力测试。
这些相关研究为狗哨的检测和发现提供了理论基础和方法论支持,也是本文提出的FETCH!任务和EarShot系统发展过程中的重要参考。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决在大规模社交媒体语料库中发现新兴狗哨的问题:
提出新任务(FETCH!):
- 论文提出了一个新的任务“Finding Emergent Dog Whistles Through Common Habitats”(FETCH!),旨在评估模型在多样化环境中检测新狗哨的能力。这个任务要求系统利用初始的种子狗哨和语料库来发现其他的狗哨。
构建基准测试(Benchmark):
- 为了支持FETCH!任务,论文创建了一个基准测试,用来评估不同模型在检测新狗哨方面的性能。这个基准测试涵盖了三种不同的社交媒体案例研究,包括合成(Reddit)、平衡(Gab)和现实(Twitter)场景。
评估现有方法:
- 论文评估了三种现有的最先进方法(Word2Vec/Phrase2Vec、MLM、EPD)在FETCH!基准测试中的表现,发现这些方法的性能都不佳,F-score低于5%。
提出新方法(EarShot):
- 论文介绍了一种名为EarShot的新系统,该系统结合了向量数据库和大型语言模型(LLMs)的优势,通过以下三个阶段来识别新的狗哨:
- 向量化(Vectorization):将语料库中的所有帖子转换为向量,并存储在向量数据库中。
- 最近邻查找(Nearest Neighbor Lookup):找到包含种子狗哨的帖子的最近邻向量,以识别可能在意义、情感或意图上相关的帖子。
- 直接提取(DIRECT)和预测(PREDICT):有两种路径,DIRECT路径直接使用LLM从帖子中提取狗哨,而PREDICT路径则使用关键词提取模型进行过滤和预测。
- 论文介绍了一种名为EarShot的新系统,该系统结合了向量数据库和大型语言模型(LLMs)的优势,通过以下三个阶段来识别新的狗哨:
实验和结果分析:
- 论文通过实验验证了EarShot系统在不同社交媒体案例研究中的表现,并与现有方法进行了比较。EarShot在F-score上显示出显著的改进,范围从2到20点不等。
讨论和未来方向:
- 论文讨论了EarShot系统的优势和局限性,并提出了未来可能的改进方向,如结合EarShot-PREDICT和EarShot-DIRECT的优点、增加后处理步骤提高方法的精确度、利用多个LLMs的共识方法等。
通过这些步骤,论文不仅提出了一个新的任务和基准测试来评估狗哨检测模型,还开发了一个新系统EarShot,该系统在检测新狗哨方面超越了现有的技术水平。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个方面:
基准测试(FETCH!)构建:
- 作者创建了一个名为FETCH!的基准测试,用于评估模型在检测新狗哨方面的能力。这个基准测试包括三种不同的社交媒体案例研究:合成(Reddit)、平衡(Gab)和现实(Twitter)场景。
现有方法的评估:
- 作者测试了四种不同的方法:Word2Vec/Phrase2Vec、MLM(Masked Language Model)、EPD(Euphemistic Phrase Detector)以及他们提出的EarShot方法。这些方法在FETCH!基准测试的三个案例研究中进行了评估。
模型性能测试:
- 对于Word2Vec/Phrase2Vec模型,作者测试了不同级别的模型(Unigram、Bigram、Trigram)在三个不同场景下的性能,并记录了它们的精确度(Precision)、数据潜力召回率(Data Potential Recall, DPR)和F0.5分数。
- 对于MLM和EPD模型,作者测试了不同的阈值设置,并记录了它们在三个场景中的性能。
EarShot系统的性能测试:
- EarShot系统有两个路径:DIRECT和PREDICT。作者分别测试了这两个路径的性能,并比较了使用不同大型语言模型(LLMs)和基于BERT的模型作为过滤步骤时的结果。
- 在PREDICT路径中,作者测试了不同的关键词提取算法,并分析了它们的性能。
- 在DIRECT路径中,作者直接利用LLMs来识别帖子中的狗哨,并评估了它们的性能。
阈值分析:
- 对于Word2Vec/Phrase2Vec、MLM、EPD和EarShot PREDICT方法,作者分析了不同阈值选择对模型性能的影响,并绘制了相应的图表来展示这些关系。
跨模型比较:
- 作者比较了EarShot系统与现有方法的性能,以展示EarShot在检测新狗哨方面的改进。
这些实验的目的是为了验证所提出的EarShot系统是否能够在检测新狗哨的任务上超越现有的技术水平,并且通过实验结果来指导未来的研究方向。实验结果表明,EarShot系统在三个不同的社交媒体案例研究中都取得了比现有方法更好的性能。
Q: 有什么可以进一步探索的点?
A: 论文在讨论部分提出了一些可以进一步探索的方向,这些方向旨在提高狗哨检测的性能,并解决现有方法的局限性。以下是一些具体的探索点:
混合系统开发:
- 研究如何结合EarShot-PREDICT和EarShot-DIRECT系统的优势,以平衡精确度和召回率。这可能涉及到设计新的算法或框架,使系统能够更有效地利用两种方法的长处。
后处理增强:
- 开发后处理步骤来提高预测狗哨的精确度。这可能包括使用语言学规则、上下文信息或额外的语义分析来过滤和验证模型的输出。
共识方法:
- 利用多个大型语言模型(LLMs)的共识来提高检测的准确性。这可能涉及到集成学习方法或投票机制,以减少单一模型可能的偏差和误报。
模型规模和训练:
- 探索更大尺寸的模型或不同训练策略对狗哨检测性能的影响。这可能包括使用更大规模的数据集进行预训练,或者调整模型的训练参数以更好地捕捉狗哨的特征。
提示方法的改进:
- 研究如何通过改进提示(prompting)方法来提高LLMs在狗哨检测任务上的表现。这可能涉及到使用链式思考(chain of thought)提示或集成外部的句法或语义信息。
跨文化和多语言研究:
- 将狗哨检测的研究扩展到其他文化和语言环境中。由于狗哨具有高度的文化特定性,研究其在不同文化和语言中的表现对于构建全球适用的检测系统至关重要。
公平性和偏见缓解:
- 深入研究模型可能的偏见,并开发方法来减少对少数群体语言的不公平分类。这可能涉及到引入公平性指标和偏见缓解技术。
实时检测和应用:
- 探索如何将狗哨检测技术应用于实时社交媒体内容监控,以及如何在实际应用中平衡检测的准确性和效率。
解释性和透明度:
- 提高模型的解释性,使内容审核人员能够理解模型的决策过程,从而增加对模型的信任和接受度。
这些探索点不仅有助于推动狗哨检测技术的发展,也有助于更广泛地理解和应对社交媒体上的隐性仇恨言论和偏见问题。
Q: 总结一下论文的主要内容
A: 论文《Making FETCH! Happen: Finding Emergent Dog Whistles Through Common Habitats》主要探讨了如何在社交媒体中识别新兴的“狗哨”(dog whistles),即那些具有双重含义、能够向特定群体传达隐秘信息的编码表达方式。以下是论文的主要内容总结:
问题背景:
- 狗哨常用于传达有争议的政治观点,同时保持表面上的合理否认性,并常能绕过内容审核过滤器。
现有挑战:
- 目前检测狗哨的方法依赖于人工策划的词汇表,这些方法耗时耗力且无法适应语言的快速演变。
新任务提出(FETCH!):
- 提出了一个新的任务“Finding Emergent Dog Whistles Through Common Habitats”(FETCH!),旨在评估模型在多样化环境中检测新狗哨的能力。
基准测试构建:
- 构建了三个不同的社交媒体案例研究:合成(Reddit)、平衡(Gab)和现实(Twitter)场景,用于评估模型性能。
现有方法评估:
- 评估了Word2Vec/Phrase2Vec、MLM、EPD等现有方法在FETCH!基准测试中的表现,发现这些方法性能不佳。
新方法提出(EarShot):
- 提出了EarShot系统,结合向量数据库和大型语言模型(LLMs)的优势,通过最近邻查找和直接提取(DIRECT)或预测(PREDICT)路径来识别新的狗哨。
实验结果:
- EarShot系统在三个社交媒体案例研究中均显示出比现有方法更好的性能,F-score提升显著。
讨论与未来方向:
- 讨论了EarShot系统的优势和局限性,并提出了未来可能的改进方向,如混合系统开发、后处理增强等。
伦理考量:
- 讨论了狗哨检测可能涉及的伦理问题,包括文化特异性、保护边缘群体语言和避免模型偏见。
局限性:
- 论文识别了其局限性,包括模型运行成本、缺乏专门的人工标注语料库、数据污染问题以及模型主要针对英语数据集。
总体而言,这篇论文为检测社交媒体中的新兴狗哨提供了新的视角和方法,并为未来的研究和实践提供了有价值的参考和启发。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

The Open Source Advantage in Large Language Models (LLMs)
Authors:Jiya Manchanda, Laura Boettcher, Matheus Westphalen, Jasser Jasser
Large language models (LLMs) mark a key shift in natural language processing (NLP), having advanced text generation, translation, and domain-specific reasoning. Closed-source models like GPT-4, powered by proprietary datasets and extensive computational resources, lead with state-of-the-art performance today. However, they face criticism for their “black box” nature and for limiting accessibility in a manner that hinders reproducibility and equitable AI development. By contrast, open-source initiatives like LLaMA and BLOOM prioritize democratization through community-driven development and computational efficiency. These models have significantly reduced performance gaps, particularly in linguistic diversity and domain-specific applications, while providing accessible tools for global researchers and developers. Notably, both paradigms rely on foundational architectural innovations, such as the Transformer framework by Vaswani et al. (2017). Closed-source models excel by scaling effectively, while open-source models adapt to real-world applications in underrepresented languages and domains. Techniques like Low-Rank Adaptation (LoRA) and instruction-tuning datasets enable open-source models to achieve competitive results despite limited resources. To be sure, the tension between closed-source and open-source approaches underscores a broader debate on transparency versus proprietary control in AI. Ethical considerations further highlight this divide. Closed-source systems restrict external scrutiny, while open-source models promote reproducibility and collaboration but lack standardized auditing documentation frameworks to mitigate biases. Hybrid approaches that leverage the strengths of both paradigms are likely to shape the future of LLM innovation, ensuring accessibility, competitive technical performance, and ethical deployment.
大型语言模型(LLM)标志着自然语言处理(NLP)的关键转变,具备先进的文本生成、翻译和领域特定推理能力。像GPT-4这样的闭源模型,借助专有数据集和大量的计算资源,目前达到了最先进的性能水平。然而,它们因“黑箱”性质和限制可访问性而受到批评,阻碍了可重复性和公平的AI发展。相比之下,LLaMA和BLOOM等开源倡议通过社区驱动的开发和计算效率来实现民主化。这些模型在语言多样性和领域特定应用等方面显著缩小了性能差距,同时为全球研究者和开发者提供了可访问的工具。值得注意的是,这两种范式都依赖于基础架构创新,如Vaswani等人提出的Transformer框架(2017年)。闭源模型通过有效扩展而表现出色,而开源模型则适应于缺乏代表性语言和领域的实际应用。低秩适应(LoRA)和指令微调数据集等技术使开源模型能够在有限资源的情况下实现有竞争力的结果。可以肯定的是,闭源和开源方法之间的紧张关系突显了人工智能中透明度和专有控制之间的更广泛辩论。伦理考量进一步突出了这一分歧。闭源系统限制外部审查,而开源模型促进可重复性和协作,但缺乏标准化的审计文档框架来减轻偏见。可能塑造未来LLM创新的混合方法,将利用两种范式的优势,确保可访问性、具有竞争力的技术性能和道德部署。
论文及项目相关链接
PDF 7 pages, 0 figures
Summary
大型语言模型(LLM)在自然语言处理(NLP)领域实现了重要突破,具备先进的文本生成、翻译和领域特定推理能力。目前,以GPT-4为代表的封闭源模型凭借专有数据集和强大的计算资源达到了业界领先性能,但因其“黑箱”性质和限制的可访问性而受到批评,阻碍了可重复利用和公平的AI发展。相较之下,以LLaMA和BLOOM为代表的开源举措通过社区驱动开发和计算效率提升来推动民主化。开源模型在缩小性能差距、提升语言多样性和领域特定应用方面取得显著进展,同时为全球研究者和开发者提供了可访问工具。两种模式都依赖于基础架构创新,如Vaswani等人于2017年提出的Transformer框架。封闭源模型通过有效扩展而卓越,而开源模型则适应于欠代表语言和领域中的实际应用。尽管资源有限,但LoRA和指令微调数据集等技术仍使开源模型能够实现有竞争力的结果。毫无疑问,封闭源和开源之间的紧张关系突显了人工智能透明度和专有控制之间的更广泛争论。伦理考量进一步突出了这一分歧。封闭源系统限制了外部审查,而开源模型促进了可重复性和协作,但缺乏标准化的审计文档框架来缓解偏见。未来LLM创新很可能采用融合两种模式优势的混合方法,确保可访问性、技术竞争力和道德部署。
Key Takeaways
- 大型语言模型(LLM)在自然语言处理领域实现了重要突破,具有先进的文本生成、翻译和领域特定推理能力。
- 当前以GPT-4为代表的封闭源模型取得了领先性能,但也面临着“黑箱”性质和限制的可访问性等批评。
- 开源模型如LLaMA和BLOOM强调社区驱动开发和计算效率提升,促进了民主化。
- 开源模型缩小了性能差距,特别是在语言多样性和领域特定应用方面取得了显著进展。
- 封闭源模型通过有效扩展而表现出卓越性能,而开源模型则更适应于实际应用场景。
- 技术创新如LoRA和指令微调数据集使开源模型在有限资源下实现竞争力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了大型语言模型(LLMs)在自然语言处理(NLP)领域中开源和闭源方法之间的差异,并试图解决以下问题:
透明度和可访问性问题:闭源模型因“黑箱”特性和限制访问性而受到批评,这影响了结果的可复制性和全球AI发展的公平性。论文试图探讨开源模型如何通过社区驱动的开发和计算效率来解决这些问题。
性能差距:尽管闭源模型在性能上领先,但开源模型在减少性能差距,特别是在语言多样性和特定领域应用方面,论文探讨了开源模型如何实现这一目标。
伦理和公平性问题:闭源系统限制了外部审查,而开源模型促进了可复制性和合作,但缺乏标准化的审计文档框架来减轻偏见。论文讨论了如何通过结合两种方法的优势来解决这些伦理问题。
AI发展的公平性:闭源模型可能导致资源集中在少数组织手中,加剧了全球AI发展中的不平等。论文探讨了开源模型如何通过提供易于访问的工具来促进更公平的AI发展。
未来研究方向:论文提出了未来研究的方向,包括如何最好地促进创新,同时确保公平的AI部署和治理。
总的来说,这篇论文试图通过比较开源和闭源大型语言模型的创新、发展、性能、可访问性和伦理问题,来解决这些模型在AI领域中的部署和发展中的关键问题。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与开源和闭源大型语言模型(LLMs)相关的研究:
大型语言模型的调查研究:
- [1] Shervin Minaee et al. “Large language models: A survey.” 提供了大型语言模型的概述和调查。
- [3] Wayne Xin Zhao et al. “A survey of large language models.” 另一项关于大型语言模型的调查研究。
开源与闭源模型的比较:
- [2] Hao Yu et al. “Open, closed, or small language models for text classification?” 探讨了不同类型语言模型在文本分类任务中的比较。
- [4] Hailin Chen et al. “Chatgpt’s one-year anniversary: are open-source large language models catching up?” 分析了开源大型语言模型是否赶上了ChatGPT。
开源模型的性能和应用:
- [7] Sanjay Kukreja et al. “A literature survey on open source large language models.” 提供了关于开源大型语言模型的文献综述。
- [31] Hugo Touvron et al. “Llama: Open and efficient foundation language models.” 介绍了LLaMA模型,一个高效的开源基础语言模型。
模型训练和优化技术:
- [8] Edward J Hu et al. “Lora: Low-rank adaptation of large language models.” 描述了低秩适应(LoRA)技术,用于优化大型语言模型。
- [30] Yu-Wei Hong et al. “Analysis of model compression using knowledge distillation.” 分析了使用知识蒸馏进行模型压缩的技术。
伦理和透明度问题:
- [39] Sabrina Sicari et al. “Open-ethical ai: Advancements in open-source human-centric neural language models.” 讨论了在开源以人为本的神经语言模型中的伦理进步。
- [40] Haoyu Gao et al. “Documenting ethical considerations in open source ai models.” 探讨了在开源AI模型中记录伦理考虑的方法。
特定领域的应用:
- [35] Emily Alsentzer et al. “Publicly available clinical bert embeddings.” 介绍了ClinicalBERT,一个针对医疗领域的开源模型。
- [36] Ilias Chalkidis et al. “Legalbert: The muppets straight out of law school.” 介绍了LEGAL-BERT,一个针对法律领域的模型。
这些研究涵盖了从大型语言模型的一般性调查到特定技术、应用和伦理问题的各个方面,为理解开源和闭源LLMs提供了广泛的背景和深入的分析。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决开源与闭源大型语言模型(LLMs)之间的问题:
1. 比较创新和发展历程
- 架构创新:分析了Transformer架构如何成为现代LLMs的基础,并探讨了开源和闭源模型如何在此基础上进行创新。
- 训练方法:讨论了闭源模型使用的专有数据集和训练技术,以及开源模型如何通过低秩适应(LoRA)等技术实现性能优化。
2. 评估模型性能
- 基准测试:评估了闭源和开源LLMs在各种基准测试中的表现,探讨了它们在特定任务中的优势和局限性。
- 性能差距:分析了开源模型如何通过各种技术缩小与闭源模型之间的性能差距。
3. 讨论可访问性和应用案例
- 开源模型的可访问性:强调了开源模型如何通过降低计算门槛来提高全球研究者和开发者的可访问性。
- 领域特定模型:讨论了如何通过领域特定优化使模型更易于访问,并满足特定行业的需求。
4. 探索透明度和伦理问题
- 透明度对比:对比了开源和闭源模型在透明度方面的差异,并讨论了这种差异对伦理、公平性和信任的影响。
- 伦理框架:提出了建立标准化的伦理审计框架和自动化伦理评估工具的必要性。
5. 讨论开源与闭源的广泛影响
- 合作与创新:强调了开源模型在促进全球合作和创新方面的作用,以及闭源模型在资源集中和性能方面的优势。
- 伦理治理:讨论了如何通过结合开源的透明度和闭源的资源来实现更负责任的AI部署。
6. 提出未来研究方向
- 模型幻觉问题:提出了研究LLMs在生成错误输出时的“幻觉”现象,并探讨了如何区分创造性输出和错误推理。
- 跨学科贡献:鼓励通过认知科学和形式逻辑的整合来增强LLMs的推理能力。
7. 总结和建议
- 混合方法:提出了结合开源和闭源方法优势的混合方法,以实现技术性能、可访问性和伦理部署的平衡。
- 社区贡献:强调了维护一个强大的开源社区对于推动创新和改进的重要性。
通过这些步骤,论文旨在提供一个全面的视角来理解和解决开源与闭源LLMs之间的问题,同时为未来的研究和实践提供指导。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,文中并没有提到具体的实验操作或实验结果。论文主要是通过文献综述和理论分析的方式,探讨了开源和闭源大型语言模型(LLMs)在自然语言处理(NLP)领域中的优势、劣势、应用、以及伦理问题。它侧重于以下几个方面:
历史发展:论文概述了LLMs从早期的统计模型到基于神经网络的模型,再到Transformer架构的发展历史。
架构和训练方法:讨论了Transformer架构如何改变数据序列的处理方式,以及闭源和开源模型在训练方法上的差异。
性能比较:评估了闭源和开源LLMs在各种基准测试中的表现,并讨论了它们在特定任务中的优势和局限性。
可访问性和应用案例:强调了开源模型如何通过降低计算门槛来提高全球研究者和开发者的可访问性,并讨论了领域特定模型如何使解决方案更易于访问。
透明度和伦理问题:对比了开源和闭源模型在透明度方面的差异,并讨论了这种差异对伦理、公平性和信任的影响。
未来研究方向:提出了未来研究的方向,包括如何最好地促进创新,同时确保公平的AI部署和治理。
论文没有提到具体的实验设计或实验数据,而是通过分析现有的研究成果和趋势,提供了对开源和闭源LLMs的深入理解和未来发展方向的建议。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些值得进一步探索的点:
模型幻觉(Hallucination)现象:
- 需要系统性地研究LLMs在生成错误输出时的“幻觉”现象,并区分创造性输出和错误推理的机制。
推理能力的增强:
- 通过整合认知科学和形式逻辑的见解,提升LLMs的推理准确性和鲁棒性,特别是在需要深度理解和逻辑一致性的任务中。
跨学科合作:
- 鼓励计算机科学、伦理学、政策和社会学等领域的合作,以定义符合伦理的LLMs开发和部署的轨迹。
开源模型的优化:
- 研究如何进一步优化开源LLMs,以缩小与闭源模型之间的性能差距,尤其是在资源受限的环境中。
标准化伦理审计框架:
- 开发和实施标准化的伦理审计框架,以提高开源LLMs的透明度和可靠性,包括偏见审计、公平性评估和潜在误用场景。
混合方法开发:
- 探索结合开源和闭源模型优势的混合方法,以实现技术性能、可访问性和伦理部署的平衡。
领域特定模型的发展:
- 针对特定领域(如医疗、法律和金融)开发和优化LLMs,以提高这些领域的决策质量和效率。
多语言和跨文化应用:
- 研究如何改进LLMs在处理多语言和跨文化数据时的性能和适应性,特别是对于资源较少的语言。
模型压缩和知识蒸馏:
- 研究模型压缩和知识蒸馏技术,以创建更小、更高效的模型版本,同时保留关键性能特征。
开源社区的可持续发展:
- 探讨如何建立和维护一个强大的开源社区,以推动LLMs的创新和改进。
这些探索点可以帮助学术界和工业界更好地理解和利用LLMs,同时确保技术的伦理和公平性。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容集中在大型语言模型(LLMs)的开源和闭源方法之间的对比分析。以下是主要内容的总结:
1. 引言
- 论文介绍了LLMs在自然语言处理(NLP)中的重要性,并提出了开源与闭源方法之间的关键问题,包括透明度、可访问性和AI发展的公平性。
2. 创新与发展
- 论文讨论了LLMs的创新和发展,包括基于Transformer架构的模型如何改变了数据处理方式,以及闭源和开源模型在训练方法上的差异。
3. 性能评估
- 论文比较了闭源和开源LLMs的性能,特别是在基准测试和特定任务中的表现,并讨论了开源模型如何通过技术如低秩适应(LoRA)缩小性能差距。
4. 可访问性与应用案例
- 论文强调了开源模型如何通过降低计算门槛提高全球研究者和开发者的可访问性,并讨论了领域特定模型如何使解决方案更易于访问。
5. 透明度与伦理问题
- 论文探讨了开源和闭源LLMs在透明度方面的差异,以及这种差异对伦理、公平性和信任的影响。
6. 开源与闭源的广泛影响
- 论文讨论了开源和闭源LLMs的不同发展轨迹,以及它们对NLP领域的影响,包括创新、可访问性和合作。
7. 未来研究方向
- 论文提出了未来研究的方向,包括如何最好地促进创新,同时确保公平的AI部署和治理。
8. 结论
- 论文总结了开源和闭源LLMs的主要区别,并强调了开源模型在促进全球合作和创新方面的潜力,同时指出了闭源模型在资源集中和性能方面的优势。
总体而言,论文提供了一个全面的视角来理解和评估开源与闭源LLMs之间的问题,并为未来的研究和实践提供了指导。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

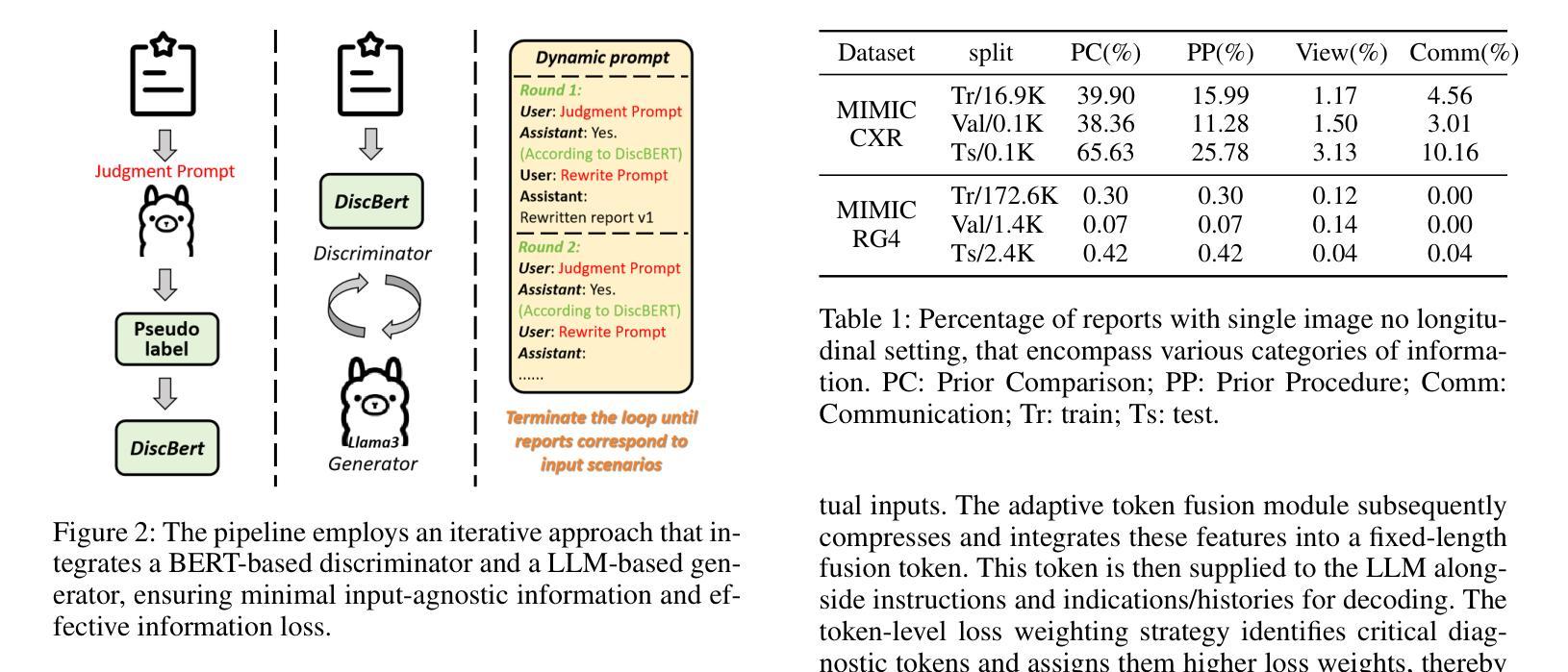
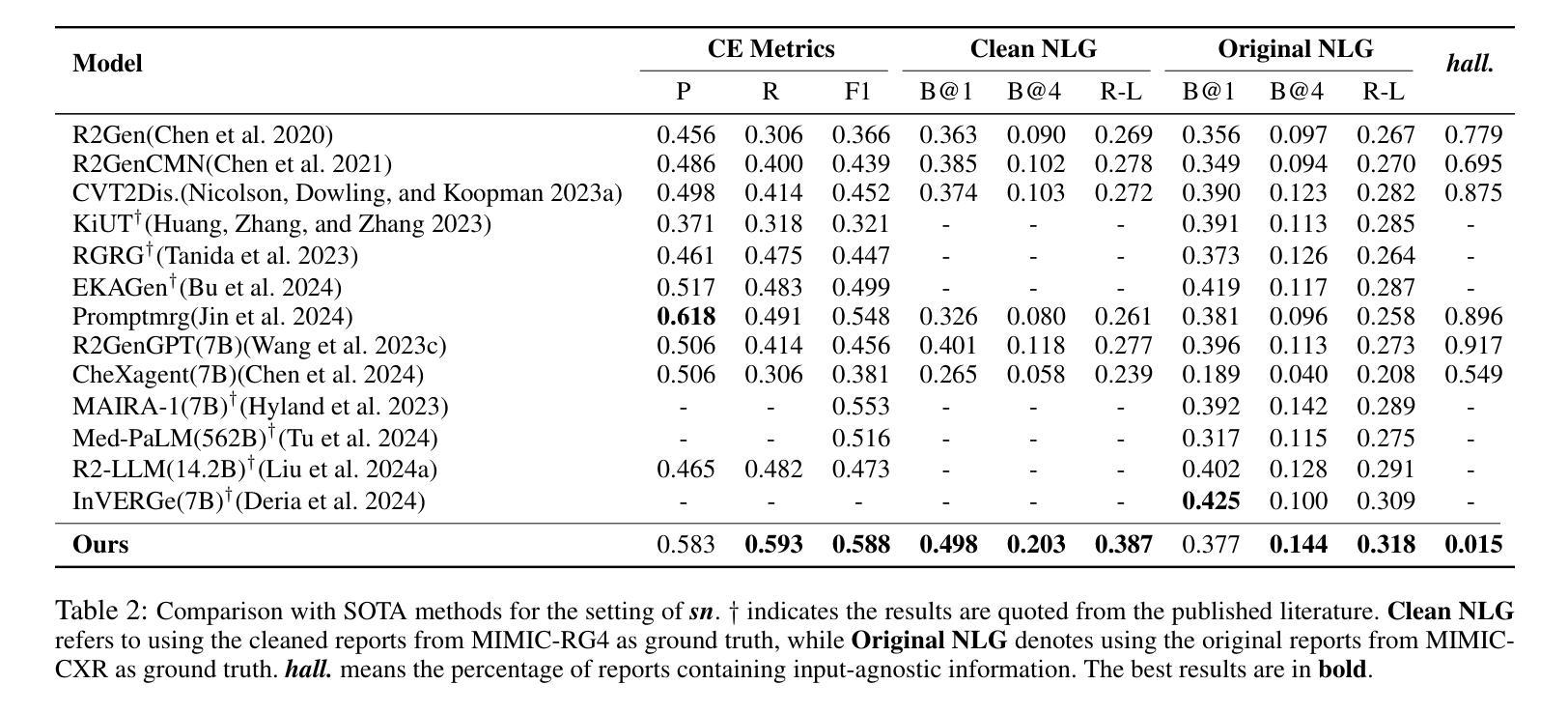
LLM-RG4: Flexible and Factual Radiology Report Generation across Diverse Input Contexts
Authors:Zhuhao Wang, Yihua Sun, Zihan Li, Xuan Yang, Fang Chen, Hongen Liao
Drafting radiology reports is a complex task requiring flexibility, where radiologists tail content to available information and particular clinical demands. However, most current radiology report generation (RRG) models are constrained to a fixed task paradigm, such as predicting the full ``finding’’ section from a single image, inherently involving a mismatch between inputs and outputs. The trained models lack the flexibility for diverse inputs and could generate harmful, input-agnostic hallucinations. To bridge the gap between current RRG models and the clinical demands in practice, we first develop a data generation pipeline to create a new MIMIC-RG4 dataset, which considers four common radiology report drafting scenarios and has perfectly corresponded input and output. Secondly, we propose a novel large language model (LLM) based RRG framework, namely LLM-RG4, which utilizes LLM’s flexible instruction-following capabilities and extensive general knowledge. We further develop an adaptive token fusion module that offers flexibility to handle diverse scenarios with different input combinations, while minimizing the additional computational burden associated with increased input volumes. Besides, we propose a token-level loss weighting strategy to direct the model’s attention towards positive and uncertain descriptions. Experimental results demonstrate that LLM-RG4 achieves state-of-the-art performance in both clinical efficiency and natural language generation on the MIMIC-RG4 and MIMIC-CXR datasets. We quantitatively demonstrate that our model has minimal input-agnostic hallucinations, whereas current open-source models commonly suffer from this problem.
草拟放射学报告是一项复杂的任务,需要灵活根据现有信息和特定临床需求来调整内容。然而,当前大多数的放射学报告生成(RRG)模型受限于固定的任务模式,例如仅根据单张图像预测完整的“发现”部分,这本质上导致了输入和输出之间的不匹配。训练过的模型缺乏对不同输入的灵活性,并可能产生有害的、与输入无关的空想。为了弥补当前RRG模型与实际临床需求之间的鸿沟,我们首先开发了一个数据生成管道,创建了新的MIMIC-RG4数据集,该数据集考虑了四种常见的放射学报告起草场景,并实现了完美的输入和输出对应。其次,我们提出了一个基于大型语言模型(LLM)的新的RRG框架,即LLM-RG4,它利用LLM的灵活指令遵循能力和丰富的通用知识。我们进一步开发了一个自适应令牌融合模块,该模块能够处理不同场景的多种输入组合,同时最小化增加输入量带来的额外计算负担。此外,我们还提出了一种令牌级损失加权策略,以引导模型关注正向和不确定的描述。实验结果表明,LLM-RG4在MIMIC-RG4和MIMIC-CXR数据集上达到了临床效率和自然语言生成方面的最新技术水平。我们从定量角度证明,我们的模型具有最小的与输入无关的空想,而当前开源模型普遍存在这一问题。
论文及项目相关链接
Summary
本文介绍了放射学报告生成的复杂性,指出当前大多数模型受限于固定的任务模式,无法适应多样的输入情境,易产生与输入无关的幻觉。为解决这些问题,研究者开发了新的MIMIC-RG4数据集和基于大型语言模型(LLM)的放射学报告生成框架LLM-RG4。该框架利用LLM的灵活指令跟随能力和丰富的通用知识,提出自适应令牌融合模块和令牌级损失加权策略,以提高模型在多种场景下的适应性和对关键信息的关注度。实验结果表明,LLM-RG4在MIMIC-RG4和MIMIC-CXR数据集上实现了临床效率和自然语言生成方面的最佳性能,并有效减少了与输入无关的幻觉问题。
Key Takeaways
- 放射学报告生成是一项复杂的任务,需要适应不同的临床需求和输入信息。
- 当前大多数放射学报告生成模型受限于固定的任务模式,无法适应多样化的输入情境。
- 研究者通过开发新的MIMIC-RG4数据集来解决这一问题,该数据集考虑了四种常见的放射学报告起草场景,并确保了输入和输出的完美对应。
- 提出了基于大型语言模型(LLM)的放射学报告生成框架LLM-RG4。
- LLM-RG4利用LLM的灵活指令跟随能力和丰富的通用知识,通过自适应令牌融合模块和令牌级损失加权策略,提高了模型的适应性和对关键信息的关注度。
- 实验结果表明,LLM-RG4在MIMIC-RG4和MIMIC-CXR数据集上实现了最佳性能。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是放射学报告生成(Radiology Report Generation, RRG)中存在的灵活性不足和输入输出不匹配的问题。具体来说,论文中提到了以下几个关键问题:
固定任务范式的限制:大多数现有的放射学报告生成模型被限制在一个固定的任务范式中,例如仅从单一图像预测完整的“发现”部分,这导致了输入和输出之间的不匹配。
缺乏多样性输入的处理能力:这些模型缺乏处理不同输入场景的灵活性,可能会产生与输入无关的幻觉(hallucinations),这在临床实践中是不安全的。
临床需求与模型性能之间的差距:为了弥合现有RRG模型与临床实践需求之间的差距,论文提出了一个新的数据生成流程来创建一个考虑了四种常见放射学报告起草场景的新数据集(MIMIC-RG4),并且输入和输出之间有完美的对应关系。
提出了一个新的基于大型语言模型(LLM)的RRG框架:该框架利用LLM灵活的指令遵循能力和广泛的通用知识,同时开发了一个自适应令牌融合模块,以灵活处理不同输入组合的场景,同时最小化由于输入量增加而带来的额外计算负担。
提出了一种令牌级损失加权策略:这种策略可以指导模型将注意力集中在正面和不确定的描述上,从而提高模型在不同输入场景下的临床效率。
总的来说,这篇论文旨在通过提出一个新的数据集和模型架构来提高放射学报告生成的灵活性和准确性,使其更符合临床实践的需求。
Q: 有哪些相关研究?
A: 根据提供的论文内容,以下是一些与LLM-RG4研究相关的工作:
放射学报告生成(RRG)模型:
- Li et al. (2018); Chen et al. (2020, 2021); Wang et al. (2022b, 2023b); Yan et al. (2024) 专注于从单一放射学图像生成报告的全面发现部分。
- Nguyen et al. (2023) 将报告中的信息分类为几个关键组成部分,包括正面提及、负面提及、先前比较、先前程序、图像视图、医生沟通和医疗建议。
报告内容的清理和重构:
- Ramesh, Chi, and Rajpurkar (2022) 提出了GILBERT模型,该模型使用逐令牌分类来消除比较性描述。
- Thawakar et al. (2024) 和 Nguyen et al. (2023) 利用大型语言模型的语言理解能力,在仅提供单一图像时消除无法推断的描述。
多视图建模和纵向历史信息建模:
- Yuan et al. (2019); Miura et al. (2021); Lee et al. (2023) 探索多视图建模。
- Dalla Serra et al. (2023); Sanjeev et al. (2024) 探索纵向历史信息建模。
大型语言模型(LLM)在报告生成中的应用:
- Wang et al. (2023a); Zhao et al. (2024) 将计算机辅助诊断网络的结果转化为语言形式。
- Wang et al. (2023c) 和 Thawakar et al. (2024) 采用视觉调整指令,冻结大型语言模型,并微调图像编码器或连接件。
- Liu et al. (2024a) 提出了引导LLMs进行RRG的引导策略,包括领域内实例引导和从粗到细的解码过程。
令牌级损失加权策略:
- Wang et al. (2022a) 使用TF-IDF指标来衡量每个词的频率,并分配不同的权重。
- Wu, Huang, and Huang (2023) 使用强化学习不断更新频繁生成的令牌范围,同时惩罚频繁生成的令牌。
数据集和模型性能影响因素的研究:
- Hyland et al. (2023) 探索了影响模型性能的关键组成部分,如特定领域的图像编码器、数据增强和指示部分。
这些相关工作涵盖了放射学报告生成的不同方面,包括模型架构、数据集处理、多模态学习、大型语言模型的应用以及报告生成中的令牌级策略。LLM-RG4研究在这些领域的基础上,提出了新的方法来提高放射学报告生成的灵活性和准确性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法解决了放射学报告生成中的问题:
1. 开发新的数据集(MIMIC-RG4)
- 论文首先开发了一个数据生成流程,创建了一个新的数据集MIMIC-RG4。这个数据集考虑了四种常见的放射学报告起草场景,并确保输入和输出之间有完美的对应关系,从而解决了输入输出不匹配的问题。
2. 提出LLM-RG4框架
- 提出了一个基于大型语言模型(LLM)的放射学报告生成框架LLM-RG4,该框架利用了LLM灵活的指令遵循能力和广泛的通用知识。
3. 自适应令牌融合模块(ATF)
- 为了处理不同输入组合的场景,同时最小化由于输入量增加而带来的额外计算负担,论文设计了一个自适应令牌融合模块(ATF)。这个模块可以压缩和整合来自不同模态的特征输入到一个固定长度的融合令牌中。
4. 令牌级损失加权策略(TLW)
- 为了提高临床准确性,论文采用了一种令牌级损失加权策略,该策略可以识别每个报告中的关键诊断令牌,并为这些令牌分配更高的损失权重。这使得模型更加关注正面或不确定的描述,从而提高了模型的临床效率。
5. 实验验证
- 论文通过在MIMIC-CXR和MIMIC-RG4数据集上的实验验证了所提出框架的有效性。实验结果显示LLM-RG4在临床效率和自然语言生成方面均达到了最先进的性能,并且最小化了输入无关的幻觉(hallucinations)。
6. 代码和数据集公开
- 论文提供了代码和数据集的链接,使得其他研究者可以复现和进一步研究这项工作。
通过这些方法,论文成功地提出了一个更加灵活和准确的放射学报告生成框架,使其更符合临床实践的需求,并减少了模型产生与输入无关的幻觉的风险。
Q: 论文做了哪些实验?
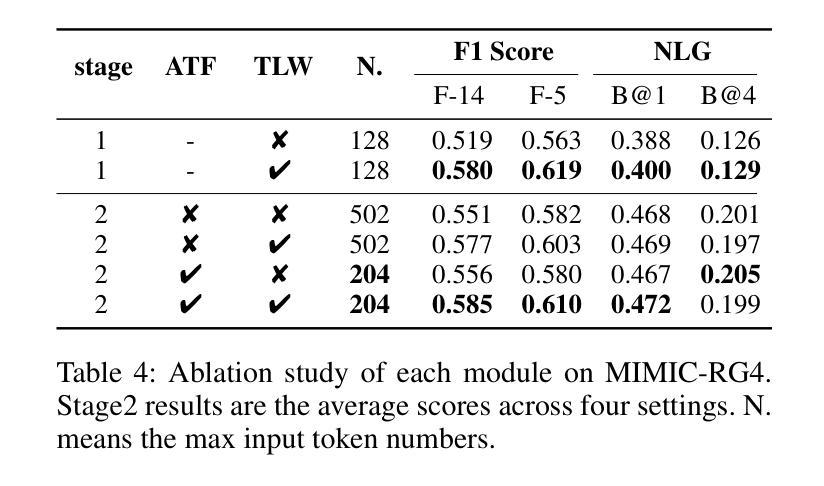
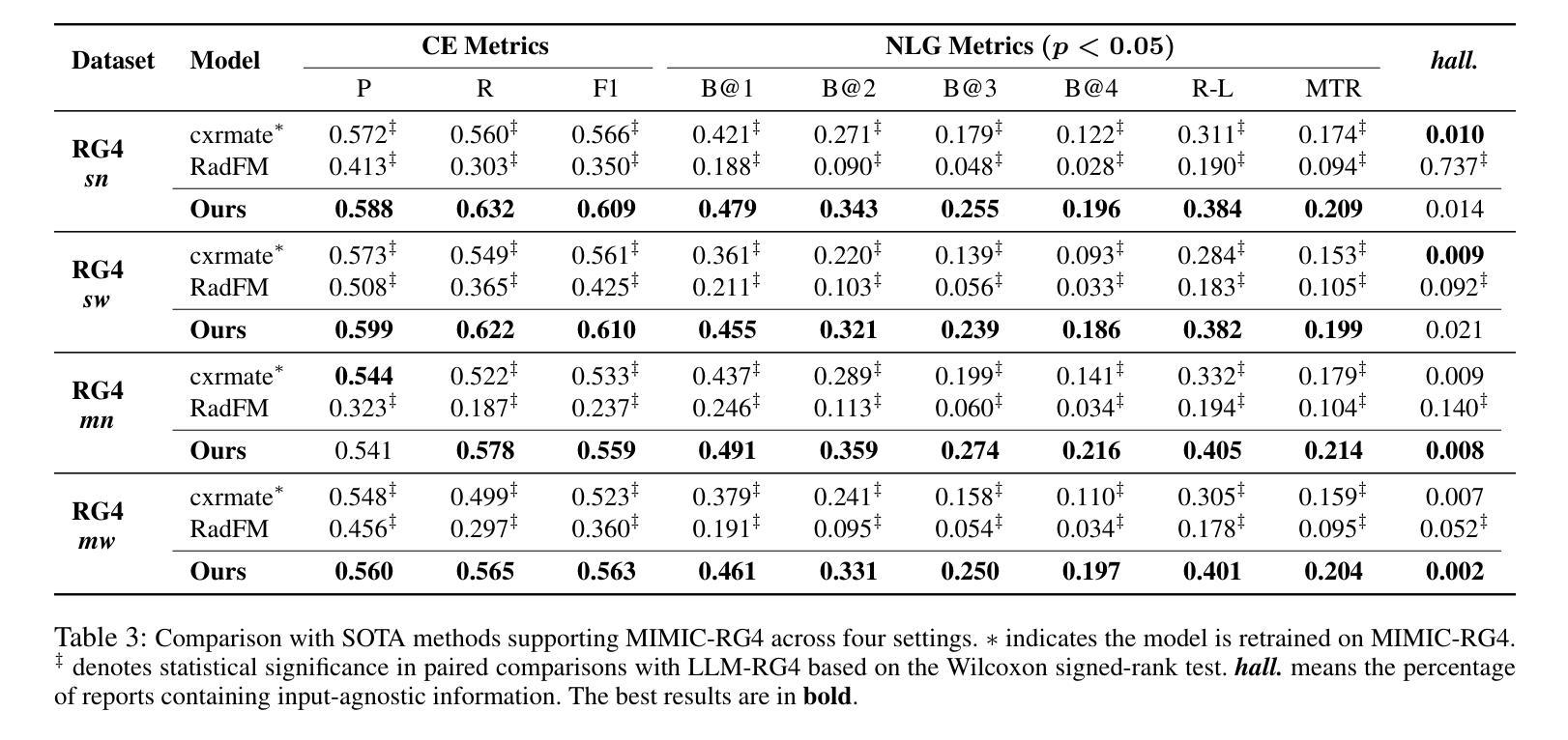
A: 论文中进行了一系列实验来验证LLM-RG4框架的有效性,具体实验包括:
自然语言生成(NLG)性能评估:
- 使用BLEU(B@n)、METEOR(MTR)和ROUGE-L(R-L)等指标来评估模型生成报告的语言质量。
临床效率(CE)性能评估:
- 利用CheXbert模型提取类别标签,并计算微平均精度(P)、召回率(R)和F1分数(F1)来评估模型的临床效率。
幻觉(Hallucination)评估:
- 使用DiscBERT模型来衡量生成报告中包含输入无关信息的比例,即输入无关幻觉(input-agnostic hallucinations)。
与传统单视图任务(sn)的比较实验:
- 在传统的单视图任务上,使用MIMIC-CXR数据集评估模型性能,并与现有的最先进方法进行比较。
多任务MIMIC-RG4上的比较实验:
- 在支持MIMIC-RG4的多任务设置中评估LLM-RG4,并与支持该数据集的其他现有模型进行比较。
消融研究(Ablation Study):
- 对自适应令牌融合模块(ATF)和令牌级损失加权策略(TLW)进行消融研究,以展示这些组件对模型性能的影响。
不同训练策略的影响分析:
- 探讨了跨四种设置(sn, sw, mn, mw)的混合训练对模型性能的影响。
案例研究:
- 提供了一个定性的例子来说明LLM-RG4处理不同输入的灵活性,并研究了TLW模块对模型能力的影响。
这些实验全面评估了LLM-RG4模型在不同方面的表现,包括其生成报告的语言质量、临床准确性、对输入的依赖程度以及模型在不同输入场景下的适应性。通过这些实验,论文证明了LLM-RG4模型在放射学报告生成任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
模型泛化能力:
- 探索LLM-RG4模型在其他类型的放射学图像(如CT、MRI)和报告生成任务中的泛化能力。
模型解释性:
- 提高模型的可解释性,以便更好地理解其决策过程,并增强临床医生对自动生成报告的信任。
模型鲁棒性:
- 测试模型对于异常、罕见或模糊的放射学图像的鲁棒性,并探索提高鲁棒性的策略。
多模态信息融合:
- 进一步研究如何更有效地融合多模态信息(如图像、文本、历史数据),以提高报告的准确性和完整性。
自适应令牌融合模块(ATF)的优化:
- 探索ATF模块的不同配置和优化策略,以实现更高效的信息编码和更好的性能。
令牌级损失加权策略(TLW)的改进:
- 研究不同的方法来自动确定关键诊断令牌的权重,可能包括更复杂的注意力机制或基于重要性的动态权重调整。
跨领域适应性:
- 研究LLM-RG4在不同医疗中心和不同放射学实践中的适应性,以及如何调整模型以适应不同的报告风格和格式。
临床集成和评估:
- 将LLM-RG4集成到临床工作流程中,并进行大规模的临床评估,以验证其在实际临床环境中的效用和影响。
数据集的扩展和多样化:
- 扩展和多样化训练数据集,以包含更多的病例、更广泛的疾病类型和更复杂的临床情况。
模型的实时性能:
- 研究模型在实时或近实时环境中的性能,以及如何优化模型以满足临床环境中的时间敏感性要求。
模型的伦理和法律问题:
- 探讨模型在临床使用中的伦理和法律问题,包括患者隐私、数据安全和医疗责任。
模型的可扩展性和计算效率:
- 研究如何使模型更加轻量化,以便于在资源受限的环境中部署,同时保持高性能。
这些探索点可以帮助研究者进一步提升LLM-RG4模型的性能,扩展其应用范围,并更好地整合到临床实践中。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题识别:
- 论文识别出放射学报告生成(RRG)任务中存在的问题,包括模型固定任务范式的局限性、缺乏灵活性以及输入输出不匹配等问题。
数据集和框架提出:
- 为了解决这些问题,论文首先提出了一个新的数据集MIMIC-RG4,该数据集考虑了四种常见的放射学报告起草场景,确保了输入和输出之间的对应关系。
- 接着,论文提出了一个基于大型语言模型(LLM)的放射学报告生成框架LLM-RG4,该框架利用LLM的灵活指令遵循能力和广泛的通用知识。
关键技术创新:
- 论文开发了一个自适应令牌融合模块(ATF),用于处理不同输入组合的场景,同时最小化额外的计算负担。
- 提出了一种令牌级损失加权策略(TLW),通过识别关键诊断令牌并分配更高的损失权重,增强模型对正面或不确定描述的关注。
实验验证:
- 论文通过在MIMIC-CXR和MIMIC-RG4数据集上的实验验证了LLM-RG4框架的有效性,展示了其在临床效率和自然语言生成方面达到的最新性能,并且最小化了输入无关的幻觉。
代码和数据集共享:
- 论文提供了代码和数据集的链接,以便其他研究者可以复现和进一步研究这项工作。
总结与展望:
- 论文总结了LLM-RG4的主要贡献,并讨论了未来的研究方向,包括模型泛化能力、解释性、鲁棒性等方面的进一步探索。
总体而言,这篇论文通过提出新的数据集和模型框架,以及技术创新,旨在提高放射学报告生成的灵活性和准确性,并使其更符合临床实践的需求。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


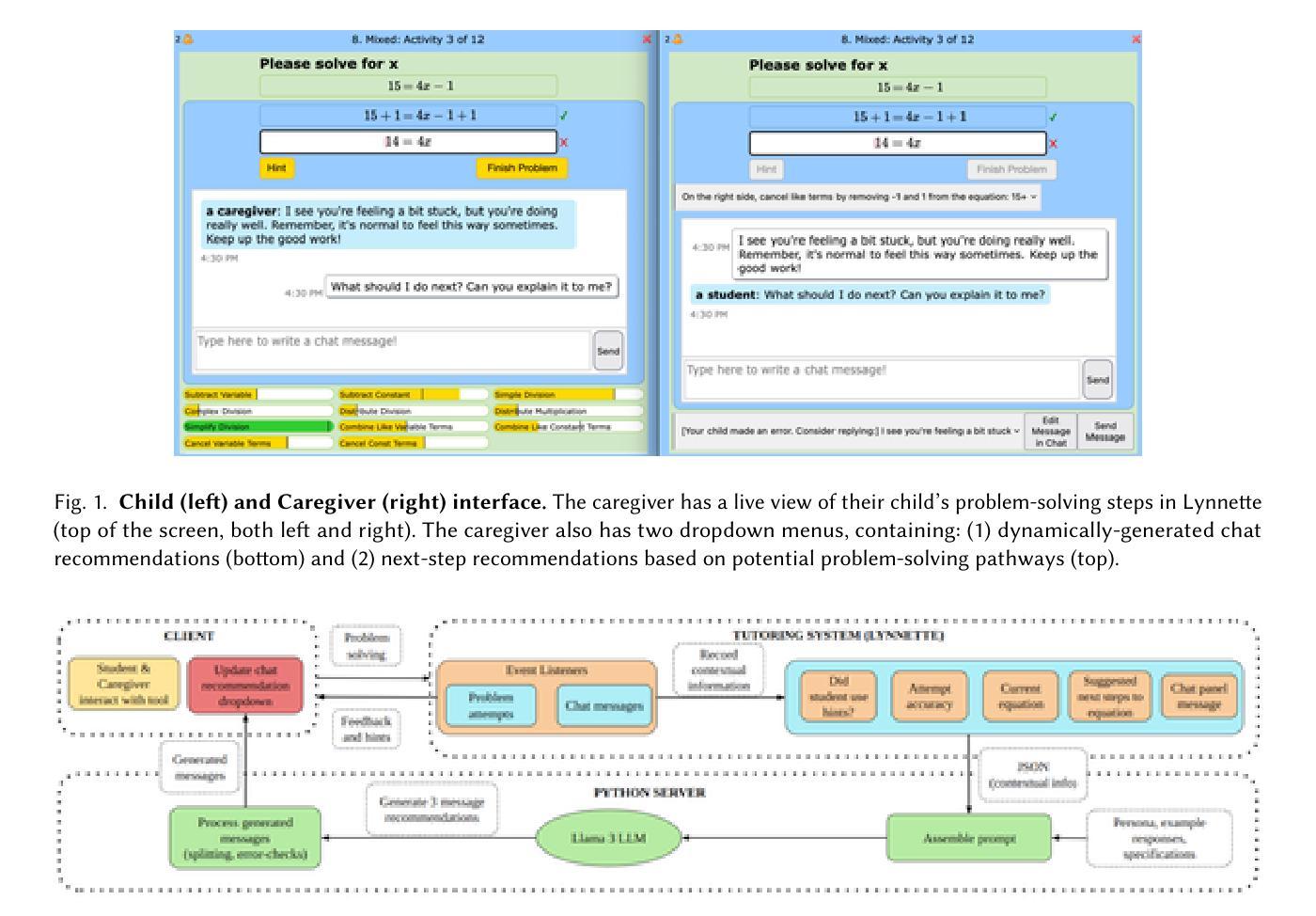
Combining Large Language Models with Tutoring System Intelligence: A Case Study in Caregiver Homework Support
Authors:Devika Venugopalan, Ziwen Yan, Conrad Borchers, Jionghao Lin, Vincent Aleven
Caregivers (i.e., parents and members of a child’s caring community) are underappreciated stakeholders in learning analytics. Although caregiver involvement can enhance student academic outcomes, many obstacles hinder involvement, most notably knowledge gaps with respect to modern school curricula. An emerging topic of interest in learning analytics is hybrid tutoring, which includes instructional and motivational support. Caregivers assert similar roles in homework, yet it is unknown how learning analytics can support them. Our past work with caregivers suggested that conversational support is a promising method of providing caregivers with the guidance needed to effectively support student learning. We developed a system that provides instructional support to caregivers through conversational recommendations generated by a Large Language Model (LLM). Addressing known instructional limitations of LLMs, we use instructional intelligence from tutoring systems while conducting prompt engineering experiments with the open-source Llama 3 LLM. This LLM generated message recommendations for caregivers supporting their child’s math practice via chat. Few-shot prompting and combining real-time problem-solving context from tutoring systems with examples of tutoring practices yielded desirable message recommendations. These recommendations were evaluated with ten middle school caregivers, who valued recommendations facilitating content-level support and student metacognition through self-explanation. We contribute insights into how tutoring systems can best be merged with LLMs to support hybrid tutoring settings through conversational assistance, facilitating effective caregiver involvement in tutoring systems.
在学习分析领域,照顾者(例如父母和孩子关怀社区的成员)是被忽视的利益相关者。虽然照顾者的参与可以提高学生学业成绩,但许多障碍阻碍了他们的参与,最显著的是与现代学校课程内容相关的知识差距。学习分析中的一个新兴有趣话题是混合辅导,包括教学和动机支持。照顾者在家庭作业中扮演着类似的角色,然而,尚不清楚学习分析如何支持他们。我们过去与照顾者的工作表明,会话支持是一种向照顾者提供有效支持学生学习所需的指导的有前途的方法。我们开发了一个系统,该系统通过大型语言模型(LLM)生成的会话建议向照顾者提供教学支持。针对LLM已知的教学限制,我们在与开源Llama 3 LLM进行提示工程实验的同时,使用教学智能辅导系统的智能。这个LLM通过聊天为支持孩子数学练习的照顾者生成消息建议。通过几次提示,结合实时解决问题的上下文和辅导实践的示例,产生了理想的消息建议。这些建议得到了十位中学照顾者的评估,他们认为这些建议有助于提供内容层面的支持和通过自我解释提高学生的元认知。我们提供了见解,以了解如何将辅导系统与LLM最佳结合,以通过会话辅助支持混合辅导环境,促进照顾者在辅导系统中的有效参与。
论文及项目相关链接
PDF Full research paper accepted to Learning Analytics and Knowledge (LAK 2025)
Summary:照顾者(如家长和孩子的学习社区成员)在学习分析中被低估了其作用。虽然照顾者的参与可以提高学生学业成绩,但现代学校课程的知识差距等障碍阻碍了他们的参与。混合辅导是一种新兴的兴趣话题,其中包括指导和动机支持。照顾者在家庭作业中扮演着类似角色,然而尚不清楚学习分析如何支持他们。过去与照顾者的工作表明,会话支持是一种为照顾者提供有效支持学生学习所需的指导的有前途的方法。开发了一个系统,该系统通过大型语言模型(LLM)生成的会话建议为照顾者提供指导支持。通过解决LLM的已知教学限制,该系统使用来自辅导系统的教学智能,并进行提示工程实验与开源LLM。此LLM能够为照顾孩子数学练习的会话生成建议信息。少数提示与结合实时解决问题的上下文和辅导实践示例产生了理想的消息建议。这些建议得到了十位中学照顾者的认可,他们认为这些建议有助于促进内容支持和学生通过自我解释进行自我认知。本研究探讨了如何将辅导系统与LLM最佳结合,以支持混合辅导环境中的会话辅助,促进照顾者在辅导系统中的有效参与。
Key Takeaways:
- 照顾者在孩子的学习过程中起到重要作用,但他们在学习分析中的价值被低估了。
- 虽然照顾者参与能提高学生学业成绩,但现代学校课程的知识差距等障碍限制了他们的参与。
- 混合辅导包括指导和动机支持,是当前的热门话题。
- 照顾者在家庭作业中扮演着关键角色,然而尚不明确学习分析如何具体支持他们。
- 通过会话支持为照顾者提供指导是一种有效的方法,有助于他们有效地支持孩子的学习。
- 结合教学智能和LLM技术,能够生成针对照顾者的教学建议,促进其孩子的学习。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是如何在家庭作业辅导中有效地结合大型语言模型(LLMs)和教学系统智能,以支持家长(即照顾者)在现代学校课程中的知识差距,并提供教学和动机支持。具体来说,论文探讨了以下几个问题:
家长参与学习分析的障碍:虽然家长的参与可以增强学生的学术成果,但许多障碍阻碍了他们的参与,尤其是与现代学校课程相关的知识差距。
混合辅导中的家长角色:在混合辅导(结合智能系统和人类导师支持学生)的背景下,家长在家庭作业辅导中扮演类似的角色,但目前尚不清楚学习分析如何支持他们。
通过对话提供支持:论文提出了通过对话推荐为家长提供指导的方法,以有效支持学生学习,特别是通过大型语言模型(LLMs)生成的对话推荐。
LLMs的教学限制:LLMs在设计教学工具时存在根本性挑战,即它们缺乏特定领域的专家知识。论文探讨了如何通过结合教学系统的教学智能来解决这一问题。
实时生成的对话推荐:论文研究了如何在实时环境中为家长生成基于问题解决上下文的对话推荐,以支持他们在教学系统中的学生学习。
综上所述,论文的目标是通过结合LLMs和教学系统智能,开发一个系统(Caregiver Conversational Support Tool, CCST),为家长提供个性化、上下文相关的对话推荐,以支持他们在辅导系统中有效地参与学生的学习。
Q: 有哪些相关研究?
A: 根据这篇论文的内容,以下是一些与研究相关的领域和具体研究:
家长参与对学生学术成果的影响:
- Hoover-Dempsey 和 Sandler (1997) 研究了为什么家长会参与到孩子的教育中,以及这种参与如何影响学生的学术表现和动机 [10]。
混合辅导(Hybrid Tutoring):
- 论文提到了混合辅导的概念,即学生由智能系统和人类导师共同支持 [41]。这一领域涉及如何结合智能系统和人类导师的优势来提供教学和动机指导。
大型语言模型(LLMs)在教育中的应用:
- 论文中提到了LLMs在教育中的多种应用,包括提供调试问题解决过程中的对话支持 [22],协作学习中触发上下文反思 [26],预测自我调节学习 [47],以及虚拟助教 [19]。
LLMs的局限性和教育技术应用:
- 论文讨论了LLMs在教育技术应用中的问题,如产生错误信息的倾向 [43],以及如何通过提供教学材料作为提示辅助来解决这些问题 [36]。
检索增强生成(RAG)方法:
- 论文提到了RAG方法,它允许LLMs从外部存储库检索相关信息,以增强其响应 [16]。
LLMs在教学对话中的作用:
- 论文中提到了Khan Academy开发的Khanmigo系统,这是一个由LLM驱动的教学系统,使用对话交互来协助学生学习各个科目 [13]。
LLMs在教育中的实证研究:
- 论文引用了关于LLMs在教育任务中有效性的研究,例如提供自动化反馈以帮助学生写作 [6]。
LLMs在教学系统中的应用:
- 论文讨论了如何将LLMs与适应性教学系统(ITS)结合,以提供更个性化、数据驱动的教学支持 [11]。
这些研究为论文提出的研究问题提供了理论基础和实证支持,特别是在探讨如何通过结合LLMs和教学系统智能来支持家长在家庭作业辅导中的参与。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决家长在现代学校课程中的知识差距以及如何有效地提供教学和动机支持的问题:
**开发Caregiver Conversational Support Tool (CCST)**:
- 论文描述了一个系统CCST的开发,该系统通过LLM生成与上下文相关的对话推荐,以支持家长在辅导孩子数学练习时的指导。
结合LLMs和教学系统智能:
- 通过使用开源的Llama 3 LLM,并结合教学系统Lynnette的教学智能,CCST能够提供实时的问题解决上下文和基于教学原则的消息推荐。
进行提示工程实验:
- 论文详细描述了通过结合教学系统的教学模型、教学原则和LLM指令进行提示工程实验的过程。这些实验旨在生成符合教学最佳实践的消息推荐。
设计和评估CCST:
- 通过与家长的交互设计研究,评估了LLM生成的消息推荐在实际使用中的效果。研究团队进行了原型反馈和对生成的对话支持在实时学生支持期间的看法。
回答研究问题:
- 论文旨在回答两个主要研究问题:RQ1是关于如何基于问题解决上下文最佳地生成面向中学家长的LLM对话推荐;RQ2是关于中学家长如何看待这些对话推荐。
原型研究方法:
- 通过与家长的半结构化访谈,研究团队收集了关于CCST的反馈,并探索了家长对LLM生成的对话支持的看法。
数据和处理:
- 所有参与者的会话都被转录并进行了主题分析,以提取关于家长偏好和对CCST的看法的定性数据。
分析和讨论:
- 论文讨论了如何有效地生成对话支持消息,以及家长对CCST生成的对话支持的看法,从而提供了对如何改进工具和方法的见解。
总结和结论:
- 论文总结了通过结合LLMs和教学系统智能来改善混合辅导中的对话支持的研究结果,并强调了这种方法在提供个性化、上下文相关的对话支持方面的潜力。
通过这些步骤,论文展示了如何利用LLMs和教学系统的结合来支持家长在家庭作业辅导中更有效地参与,并通过实际的用户反馈来优化这一过程。
Q: 论文做了哪些实验?
A: 根据论文内容,作者进行了以下实验:
提示工程实验(Prompt Engineering Experiments):
- 作者进行了一系列的提示工程实验,以优化LLM生成的对话推荐。这些实验涉及将教学系统的问题解决上下文与LLM的指令结合起来。
- 实验分为三个主要类别,每个类别针对前一个类别的不足进行改进。这些提示被用来生成响应,并根据CLEAR框架进行评估。
原型研究(Prototyping Study):
- 作者与10位中学家长进行了原型研究,以评估CCST(Caregiver Conversational Support Tool)并收集家长对LLM生成的对话支持的看法。
- 研究包括两个部分:工作坊和远程访谈。
工作坊(Workshop):
- 在工作坊中,家长和学生被安排在不同的座位上,通过聊天面板进行沟通,模拟远程家庭作业辅导会话。
- 家长使用CCST与学生一起解决数学问题集,并提供对聊天消息、提示功能的反馈。
- 家长还对界面截图进行注释,提出设计改进建议。
远程访谈(Remote Interview):
- 与工作坊类似,远程访谈也让家长和学生在独立房间中通过工具进行互动,模拟远程使用场景。
- 访谈中,家长被要求口头描述他们想要看到的任何更改以及如何实施这些更改。
数据收集和处理:
- 对于工作坊和远程访谈,所有对话都被录音并转录,使用OpenAI Whisper或其他工具进行转录。
- 对于注释的截图,研究团队成员将手写笔记和绘图记录到电子表格中以供进一步分析。
数据分析方法:
- 使用开放编码方案对定性数据(例如访谈和注释数据)进行主题分析。
- 两位研究团队成员独立进行第一轮归纳开放编码,以建立初始描述性代码,并通过讨论和整合主题中心来消除个体编码偏差。
这些实验的目的是为了开发和评估一个能够提供基于上下文的对话推荐的系统(CCST),以支持家长在辅导孩子学习时的参与,并且通过家长的反馈来优化该系统。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和研究结果,以下是一些可以进一步探索的点:
提高LLM响应速度:
- 论文提到了LLM在生成消息时存在延迟问题,未来工作可以通过使用GPU或其他硬件加速方法来改善消息生成的速度。
多样化和量化的提示工程方法:
- 目前的提示工程方法主要是定性的,未来可以通过句子嵌入技术、聚类分析等量化方法来进一步优化提示工程。
更广泛的用户群体:
- 论文的参与者可能不代表更广泛的家长群体,未来的研究可以招募更大且更多样化的样本来进行设计研究,以确保工具的公平性和包容性。
扩展到其他学科领域:
- 目前的研究集中在数学领域,未来的工作可以将CCST工具扩展到其他STEM学科,如物理、化学和逻辑等。
个性化和定制化的消息推荐:
- 根据家长的反馈,未来的设计可以允许家长自定义他们希望接收的消息类型,例如更多地侧重于内容级别的支持或动机支持。
提高消息的相关性和时效性:
- 家长反馈表明需要在消息的个性化、相关性和时效性方面进行改进。未来的工作可以探索如何更好地平衡这些因素。
不同LLMs的性能比较:
- 论文中使用了Llama 3 LLM,但未与其他LLMs进行比较。未来的研究可以探索不同LLMs在类似教育应用中的性能差异。
长期效果评估:
- 论文中的研究是短期的原型研究,未来的工作可以评估CCST工具在长期使用中的效果,包括对学生学习成果的影响。
结合其他教学策略:
- 除了对话支持外,未来的研究可以探索如何将CCST与其他教学策略(如视频教程、互动练习等)结合起来,以提供更全面的教学支持。
技术集成和可扩展性:
- 研究如何将CCST更紧密地集成到现有的教育技术和教学系统中,并探索其在大规模部署中的可扩展性和可行性。
这些探索点可以帮助进一步优化CCST工具,提高其在实际教育场景中的应用效果,并为未来的教育技术研究提供新的方向。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容集中在如何将大型语言模型(LLMs)与教学系统智能结合起来,以支持家长在孩子使用教学系统进行家庭作业辅导时提供有效的指导。以下是论文的主要点:
研究背景与动机:
- 家长在孩子学习过程中的参与能显著提升学术成果,但现代课程内容的知识差距和其他障碍限制了他们的参与。
- 混合辅导,结合智能系统和人类导师的支持,是一个新兴的学习分析领域,但如何利用学习分析支持家长在家庭作业辅导中的作用尚不清楚。
Caregiver Conversational Support Tool (CCST)开发:
- 研究者开发了一个系统CCST,通过LLM生成对话推荐,为家长提供个性化和上下文相关的支持。
- CCST嵌入在中学的方程求解教学系统Lynnette中,提供消息推荐和问题解决路径预览。
提示工程实验:
- 通过结合教学系统的教学模型、教学原则和LLM指令,研究者进行了提示工程实验来生成家长聊天消息推荐。
- 实验分为三类,从零样本提示到结合实时问题解决上下文的少样本提示。
原型研究与评估:
- 研究者与10位中学家长进行了原型研究,以评估CCST,并收集他们对LLM生成的对话支持的看法。
- 通过工作坊和远程访谈,研究者收集了关于CCST设计的反馈,并探索了家长对生成对话支持的偏好。
研究结果:
- 家长更倾向于接收提供数学指导的内容级支持而非动机支持。
- 家长偏好能够促进孩子自我解释思考过程的消息,因为这有助于他们更深入地了解孩子的思维。
- 家长对包含问题解决上下文的消息表示认可,尤其是当这些上下文信息帮助他们根据孩子的当前进展提供指导时。
讨论与启示:
- 结果表明,通过结合教学系统智能和LLM的语言能力,可以有效生成对话支持。
- 这种结合方法能够提供给家长在家庭作业辅导中的有效教学指导,增强个性化和上下文相关的对话支持。
限制与未来工作:
- 论文讨论了研究的局限性,包括消息生成的延迟、提示工程的方法和参与者的代表性。
- 提出了未来可能的研究方向,如提高响应速度、扩大用户群体、扩展到其他学科领域等。
综上所述,这篇论文展示了如何通过结合LLMs和教学系统智能来增强家长在教学系统中的参与度,并通过对家长的原型研究提供了实证支持。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

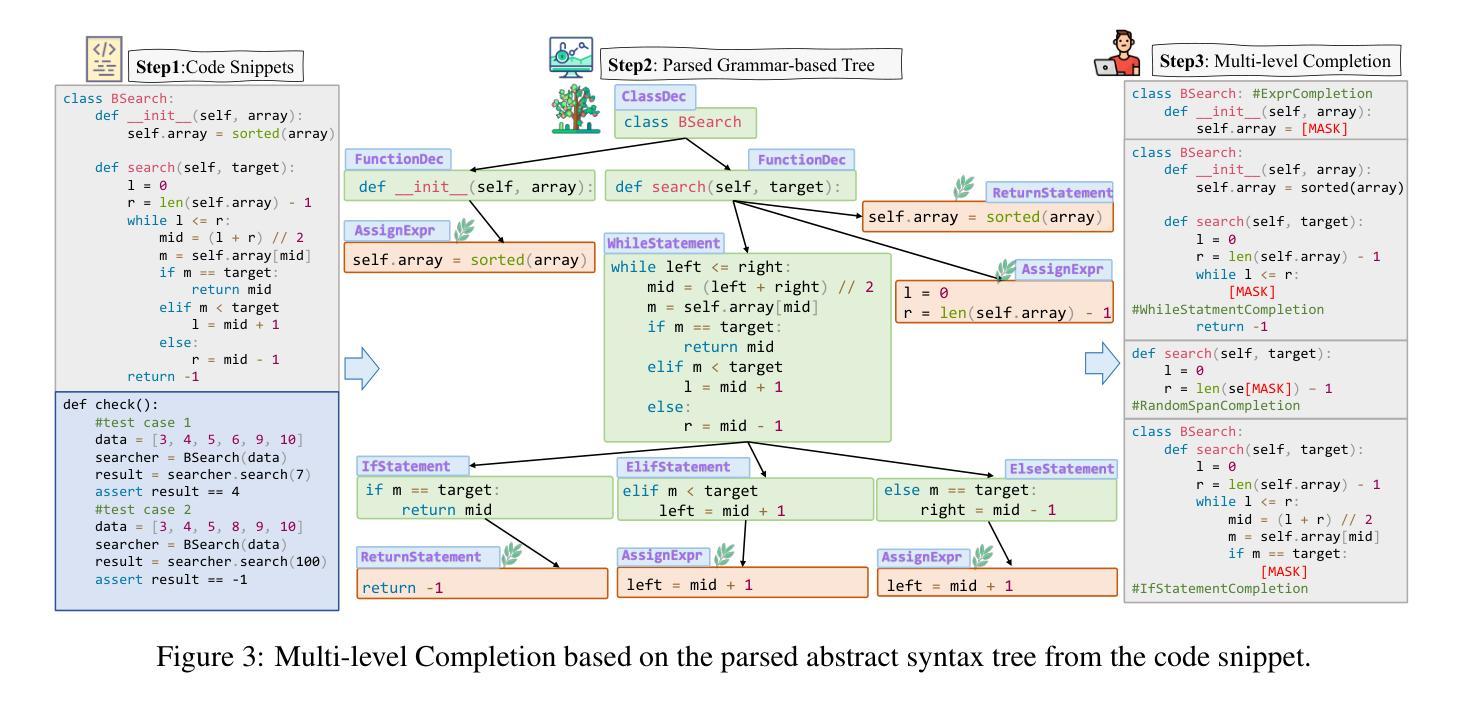
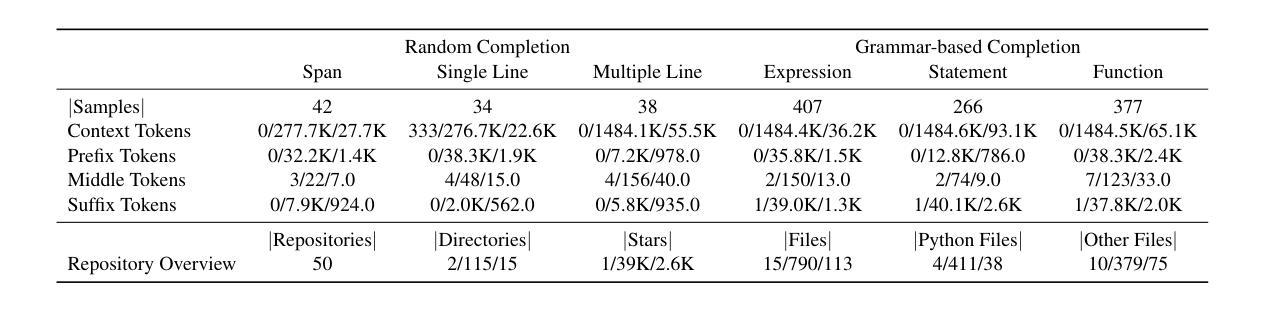
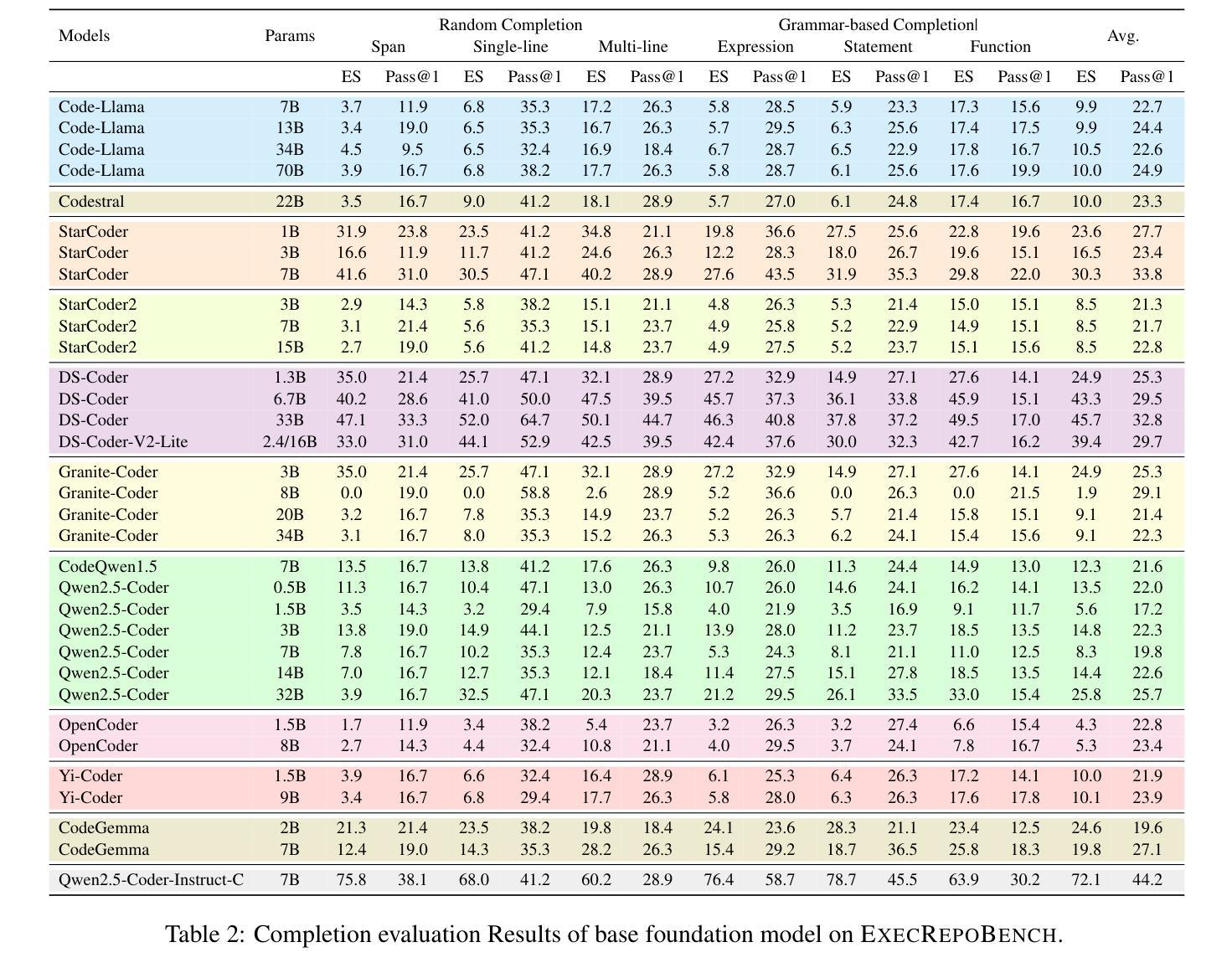
ExecRepoBench: Multi-level Executable Code Completion Evaluation
Authors:Jian Yang, Jiajun Zhang, Jiaxi Yang, Ke Jin, Lei Zhang, Qiyao Peng, Ken Deng, Yibo Miao, Tianyu Liu, Zeyu Cui, Binyuan Hui, Junyang Lin
Code completion has become an essential tool for daily software development. Existing evaluation benchmarks often employ static methods that do not fully capture the dynamic nature of real-world coding environments and face significant challenges, including limited context length, reliance on superficial evaluation metrics, and potential overfitting to training datasets. In this work, we introduce a novel framework for enhancing code completion in software development through the creation of a repository-level benchmark ExecRepoBench and the instruction corpora Repo-Instruct, aim at improving the functionality of open-source large language models (LLMs) in real-world coding scenarios that involve complex interdependencies across multiple files. ExecRepoBench includes 1.2K samples from active Python repositories. Plus, we present a multi-level grammar-based completion methodology conditioned on the abstract syntax tree to mask code fragments at various logical units (e.g. statements, expressions, and functions). Then, we fine-tune the open-source LLM with 7B parameters on Repo-Instruct to produce a strong code completion baseline model Qwen2.5-Coder-Instruct-C based on the open-source model. Qwen2.5-Coder-Instruct-C is rigorously evaluated against existing benchmarks, including MultiPL-E and ExecRepoBench, which consistently outperforms prior baselines across all programming languages. The deployment of \ourmethod{} can be used as a high-performance, local service for programming development\footnote{\url{https://execrepobench.github.io/}}.
代码补全已成为日常软件开发中的必备工具。现有的评估基准测试通常使用静态方法,这些方法不能完全捕捉真实编码环境的动态特性,并面临包括上下文长度有限、依赖表面评估指标和潜在的训练数据集过度拟合等显著挑战。在这项工作中,我们通过创建仓库级基准测试ExecRepoBench和指令语料库Repo-Instruct,引入了一种提高软件开发中代码补全功能的新型框架。ExecRepoBench包含来自活跃Python仓库的1.2K样本。此外,我们提出了一种多级语法基础的补全方法,该方法基于抽象语法树,用于屏蔽各种逻辑单元的代码片段(例如语句、表达式和函数)。然后,我们在Repo-Instruct上对具有70亿参数的开源LLM进行微调,以产生基于开源模型的强大代码补全基线模型Qwen2.5-Coder-Instruct-C。Qwen2.5-Coder-Instruct-C与现有基准测试(包括MultiPL-E和ExecRepoBench)进行了严格评估,并在所有编程语言中始终优于先前的基础线。我们的方法的部署可用作高性能的本地编程开发服务。^[https://execrepobench.github.io/] ^。
论文及项目相关链接
Summary
本文介绍了一种新的框架,旨在通过创建仓库级基准测试ExecRepoBench和指令语料库Repo-Instruct来增强软件开发中的代码补全功能。该框架解决了现有评估基准测试无法充分捕捉现实世界编码环境的动态性质的问题,通过抽象语法树对代码片段进行多级别语法补全。研究团队使用开源的大型语言模型(LLM)进行微调,并推出了基于开源模型的强大代码补全基线模型Qwen2.5-Coder-Instruct-C。该模型在多个基准测试中表现优异,可为编程开发提供高性能的本地服务。
Key Takeaways
- 引入了一种新的框架,结合了仓库级基准测试ExecRepoBench和指令语料库Repo-Instruct,旨在增强代码补全功能。
- 该框架解决了现有评估方法无法捕捉现实世界编码环境动态性质的问题。
- 使用了多级别语法补全方法,基于抽象语法树对代码片段进行掩码处理。
- 研究团队使用开源LLM进行微调,推出了强大的代码补全基线模型Qwen2.5-Coder-Instruct-C。
- 该模型在多种基准测试中表现优异,包括MultiPL-E和ExecRepoBench。
- Qwen2.5-Coder-Instruct-C模型可部署为高性能的本地服务,用于编程开发。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是现有代码补全工具在真实世界软件开发环境中的评估不足。具体来说,论文指出了三个主要挑战:
有限的上下文长度:现有的评估基准通常采用静态方法,这些方法没有完全捕捉到真实世界编码环境的动态特性,特别是在处理长上下文时。
依赖表面评估指标:这些评估基准依赖于表面化的评估指标,如精确匹配(Exact Match, EM)和编辑相似度(Edit Similarity, ES),这些指标不能充分反映代码补全的真实性能。
可能的过拟合:现有基准可能存在对训练数据集过拟合的问题,这限制了模型在新环境中的泛化能力。
为了解决这些问题,论文介绍了一个新的框架,通过创建仓库级别的基准测试EXECREPOBENCH和指令语料库REPOINSTRUCT,旨在提高开源大型语言模型(LLMs)在涉及多个文件复杂依赖关系的真实世界编码场景中的功能性。这个框架包括一个基于抽象语法树(AST)的多级语法补全方法,以及一个在REPOINSTRUCT上微调的开源LLM模型Qwen2.5-Coder-Instruct-C,用于生成高性能的代码补全基线模型。
Q: 有哪些相关研究?
A: 论文中提到了多个与代码补全和代码大型语言模型(LLMs)相关的研究工作,以下是一些主要的相关研究:
HumanEval/MBPP:
- Chen et al., 2021; Austin et al., 2021:这些基准用于评估代码生成模型,特别是通过填充代码的中间部分(FIM任务)来评估模型的性能。
EvalPlus:
- Liu et al., 2023a:这是HumanEval/MBPP的升级版本,包含更多的测试用例,用于更严格地评估代码模型。
MultiPL-E:
- Cassano et al., 2023:这是一个多语言评估基准,用于评估代码生成模型在多种编程语言上的性能。
Code Large Language Models:
- Feng et al., 2020; Chen et al., 2021; Scao et al., 2022; Li et al., 2022; Allal et al., 2023; Fried et al., 2022; Wang et al., 2021; Zheng et al., 2024; Jiang et al., 2024; Nijkamp et al., 2023; Wei et al., 2023; Zhao et al., 2024:这些研究涉及了专门为代码任务设计的LLMs,如CodeLlama、DeepSeek-Coder、OpenCoder和Qwen2.5-Coder,它们在数十亿代码片段上进行预训练,以增强软件开发过程。
Repo-level Code Evaluation:
- Zheng et al., 2023; Yu et al., 2024; Yin et al., 2023; Peng et al., 2024; Khan et al., 2023; Guo et al., 2024b; Lai et al., 2023:这些基准用于评估代码质量、功能和效率,包括静态分析技术和动态方法。
其他代码评估基准:
- BigCodeBench (Zhuo et al., 2024), fullstack (Liu et al., 2024c), CodeFavor (Liu et al., 2024a), CodeArena (Yang et al., 2024) 和 SAFIM (Gong et al., 2024):这些基准分别用于评估代码LLMs在更多样的场景和代码偏好下的表现。
这些研究为代码补全和代码生成领域提供了丰富的背景和基础,同时也指出了现有方法的局限性,为本文提出的新框架和基准测试提供了研究动机。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键步骤来解决现有代码补全工具在真实世界软件开发环境中评估不足的问题:
1. 创建EXECREPOBENCH基准
- 构建可执行的仓库级基准:论文介绍了
EXECREPOBENCH,这是一个基于仓库级别的代码补全评估基准。它包含1.2K个样本,来自50个活跃的Python代码仓库,并配有单元测试来验证补全代码的正确性。
2. 创建REPOINSTRUCT指令语料库
- 多级语法补全:论文提出了基于抽象语法树(AST)的多级语法补全方法,用于创建
REPOINSTRUCT指令语料库。这种方法在不同逻辑单元(如语句、表达式和函数)上掩盖代码片段,以进行补全。
3. 微调开源LLM模型
- Qwen2.5-Coder-Instruct-C模型:论文基于开源模型
Qwen2.5-Coder,通过在REPOINSTRUCT上进行微调,生成了一个强大的代码补全基线模型Qwen2.5-Coder-Instruct-C。这个模型结合了代码补全数据和标准指令语料库进行训练。
4. 评估和比较
- 性能评估:
Qwen2.5-Coder-Instruct-C模型在多个基准上进行了评估,包括MultiPL-E和EXECREPOBENCH,显示出在所有编程语言中一致的性能提升,超越了之前的基线模型。
5. 实现高级代码补全服务
- 本地服务部署:论文提出
Qwen2.5-Coder-Instruct-C可以作为一个高性能的本地服务,用于编程开发,这有助于提高开发效率和代码质量。
通过这些步骤,论文不仅提出了一个新的评估框架和基准,而且通过实际的代码补全模型展示了在真实世界软件开发场景中提高代码补全工具性能的可能性。这种方法有助于更准确地评估和提升代码补全模型的实际应用效果,从而推动软件开发工具的进步。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和验证所提出的方法和模型的性能。以下是主要的实验内容:
1. 模型评估
- 评估30+模型:实验评估了30多个不同大小(从0.5B到30B+参数)的开源代码大型语言模型(LLMs)和闭源通用LLMs。包括GPT系列(如GPT3.5-Turbo和GPT4-o)和Claude系列等。
2. 实施细节
数据提取和过滤:从
the-stack-V2数据集中提取代码片段,并使用启发式规则(例如GitHub星星和文件长度)进行过滤,保留主流编程语言(Python、Csharp、Cpp、Java、Javascript、Typescript、Php)。**指令数据集
REPO-INSTRUCT**:构建了包含近300万完成样本的指令数据集REPO-INSTRUCT。微调Qwen2.5-Coder:在近300万指令样本上微调开源基础LLM Qwen2.5-Coder,并使用代码补全数据(文件内和跨文件补全数据)。
3. 评估指标
编辑相似度(Edit Similarity, ES):使用编辑相似度比较生成的代码和真实代码的字符串相似度。
Pass@k:类似于文件内基准HumanEval/MBPP,使用Pass@k指标基于可执行结果获得可靠性评估结果。在这项工作中,报告了所有LLMs的贪婪Pass@1分数以进行公平比较。
4. 评估基准
EXECREPOBENCH:使用包含50个活跃Python仓库的1.2K样本创建的可执行仓库级单元测试,验证补全代码的正确性。
MultiPL-E:用于多语言评估,包括8种流行编程语言。
5. 主要结果
EXECREPOBENCH结果:展示了不同代码补全模型在EXECREPOBENCH上的性能比较,包括随机补全(跨度、单行、多行)和基于语法的补全(表达式、语句、函数)。
MultiPL-E结果:展示了不同模型在MultiPL-E基准上的性能(%),关注不同编程语言。
6. 分析
消融研究:通过消融研究强调了方法中每个组件的重要性,并展示了模型在代码补全任务CrossCodeEval和指令遵循代码基准MultiPL-E上的结果。
案例研究:展示了一个名为BankOperation的Python模块的部分代码,该模块模拟基本的银行账户操作,并分析了Qwen2.5-Coder-Instruct-C如何成功找到上下文文件中的依赖关系。
这些实验全面评估了所提出模型的性能,并与现有技术进行了比较,证明了新方法在代码补全任务中的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 论文在第9节“Limitations”中提到了本研究的一些局限性,并指出了未来工作可能探索的几个方向:
多语言场景下的评估:
- 论文指出,仓库级别多语言场景的评估尚未充分探索。未来的工作可以扩展到更多编程语言,以评估模型在处理多语言项目时的性能。
更大规模模型的微调:
- 论文中提到的代码补全模型Qwen2.5-Coder-Instruct-C主要在7B参数的开源基础LLMs上进行了监督微调。未来的研究可以尝试在更大参数规模的模型上进行微调,以进一步提升性能。
使用RLHF进行优化:
- 论文提到,通过使用基于人类反馈的强化学习(RLHF)对微调模型进行进一步优化,可能会改善用户体验。例如,可以探索如何利用用户的反馈来微调模型,使其生成的代码更符合开发者的预期和习惯。
除了论文中提到的这些点,以下是一些其他可能的研究方向:
提高代码补全的准确性和鲁棒性:
- 尽管Qwen2.5-Coder-Instruct-C在代码补全任务上取得了显著的性能提升,但仍有空间进一步优化模型,以减少错误和提高在复杂编程任务中的鲁棒性。
集成更多的上下文信息:
- 探索如何有效地利用项目中的更多上下文信息,例如文档字符串、注释和版本历史,以改善代码补全的质量和相关性。
个性化代码补全:
- 研究如何根据个人开发者的编码风格和习惯定制代码补全建议,以提高开发效率和代码一致性。
跨文件依赖关系的深入分析:
- 进一步研究和改进模型处理跨文件依赖关系的能力,这对于理解和补全大型软件项目中的代码尤为重要。
代码补全的可解释性:
- 提高代码补全过程的透明度和可解释性,帮助开发者理解模型生成特定建议的原因,从而更信任和有效地使用这些工具。
多模态代码补全:
- 探索结合自然语言描述和代码片段进行代码补全的可能性,这可以帮助模型更好地理解任务需求并生成更合适的代码。
这些方向不仅可以推动代码补全技术的发展,还可能对软件开发实践和教育产生深远影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出了现有代码补全工具在真实世界软件开发环境中评估的不足,包括有限的上下文长度、依赖表面评估指标以及潜在的过拟合问题。
EXECREPOBENCH基准:
- 为了解决这些问题,论文提出了一个新的可执行的仓库级代码补全评估基准
EXECREPOBENCH,包含1.2K个样本,源自50个活跃的Python代码仓库,并配有单元测试以验证补全代码的正确性。
- 为了解决这些问题,论文提出了一个新的可执行的仓库级代码补全评估基准
REPOINSTRUCT指令语料库:
- 论文提出了基于抽象语法树(AST)的多级语法补全方法,用于创建
REPOINSTRUCT指令语料库,该语料库包含不同逻辑单元(如语句、表达式和函数)的代码片段,用于补全训练。
- 论文提出了基于抽象语法树(AST)的多级语法补全方法,用于创建
Qwen2.5-Coder-Instruct-C模型:
- 基于开源模型
Qwen2.5-Coder,并在REPOINSTRUCT上进行微调,生成了一个强大的代码补全基线模型Qwen2.5-Coder-Instruct-C,该模型结合了代码补全数据和标准指令语料库进行训练。
- 基于开源模型
实验评估:
- 论文评估了30多个不同大小的开源代码大型语言模型(LLMs)和闭源通用LLMs,并使用编辑相似度(ES)和Pass@k指标对模型进行了评估。
- 实验结果显示,
Qwen2.5-Coder-Instruct-C在所有编程语言中一致地超越了之前的基线模型。
主要贡献:
- 引入了可执行的仓库级基准
EXECREPOBENCH用于代码补全评估。 - 提出了基于AST的多级语法补全方法,创建了
REPOINSTRUCT指令语料库。 - 基于开源LLMs和
REPOINSTRUCT,微调出7B参数的Qwen2.5-Coder-Instruct-C模型,作为编程开发的本地服务。
- 引入了可执行的仓库级基准
未来工作和局限性:
- 论文讨论了未来的研究方向,包括多语言场景下的评估、更大规模模型的微调以及使用RLHF进行优化等。
- 同时,论文也承认了评估在多语言场景下的局限性,以及模型主要在7B参数的开源基础LLMs上进行微调的事实。
总体而言,这篇论文通过引入新的评估基准和指令语料库,以及微调出一个强大的代码补全模型,为代码补全领域提供了新的方向和工具,旨在提高代码补全工具的性能和实用性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


Cost-Effective Label-free Node Classification with LLMs
Authors:Taiyan Zhang, Renchi Yang, Mingyu Yan, Xiaochun Ye, Dongrui Fan, Yurui Lai
Graph neural networks (GNNs) have emerged as go-to models for node classification in graph data due to their powerful abilities in fusing graph structures and attributes. However, such models strongly rely on adequate high-quality labeled data for training, which are expensive to acquire in practice. With the advent of large language models (LLMs), a promising way is to leverage their superb zero-shot capabilities and massive knowledge for node labeling. Despite promising results reported, this methodology either demands considerable queries to LLMs, or suffers from compromised performance caused by noisy labels produced by LLMs. To remedy these issues, this work presents Cella, an active self-training framework that integrates LLMs into GNNs in a cost-effective manner. The design recipe of Cella is to iteratively identify small sets of “critical” samples using GNNs and extract informative pseudo-labels for them with both LLMs and GNNs as additional supervision signals to enhance model training. Particularly, Cella includes three major components: (i) an effective active node selection strategy for initial annotations; (ii) a judicious sample selection scheme to sift out the “critical” nodes based on label disharmonicity and entropy; and (iii) a label refinement module combining LLMs and GNNs with rewired topology. Our extensive experiments over five benchmark text-attributed graph datasets demonstrate that Cella significantly outperforms the state of the arts under the same query budget to LLMs in terms of label-free node classification. In particular, on the DBLP dataset with 14.3k nodes, Cella is able to achieve an 8.08% conspicuous improvement in accuracy over the state-of-the-art at a cost of less than one cent.
图神经网络(GNNs)由于其在融合图结构和属性方面的强大能力,已成为图数据节点分类的首选模型。然而,此类模型严重依赖于充足的高质量标签数据进行训练,而在实践中这些数据获取成本高昂。随着大型语言模型(LLM)的出现,一个可行的方案是利用其出色的零样本能力和大量知识来进行节点标签。尽管已有报道显示此方法具有前景,但它要么需要向LLM发出大量查询,要么因LLM产生的噪声标签而面临性能妥协的问题。为了解决这个问题,本研究提出了Cella,这是一个以成本效益方式将LLM集成到GNN中的主动自训练框架。Cella的设计方案是迭代地利用GNNs识别出少量的“关键”样本集,并使用LLMs和GNNs为它们提取信息丰富的伪标签作为额外的监督信号来增强模型训练。特别是,Cella包括三个主要组件:(i)用于初始注释的有效活动节点选择策略;(ii)基于标签不和谐和熵的明智样本选择方案,以筛选出“关键”节点;(iii)结合LLM和GNN以及重新配线的拓扑结构的标签优化模块。我们在五个基准文本属性图数据集上的广泛实验表明,在相同的LLM查询预算下,Cella在无需标签的节点分类方面显著优于最新技术。特别是在具有14.3k节点的DBLP数据集上,Cella在精度上实现了对最新技术8.08%的显著改进,成本不到一美分。
论文及项目相关链接
PDF 15 pages, 5 figures
Summary
图神经网络(GNNs)因融合图结构与属性的能力而成为图数据节点分类的首选模型。然而,这类模型依赖高质量标注数据进行训练,实际中获取这些标注数据成本高昂。随着大型语言模型(LLMs)的出现,一种利用LLMs零样本能力和丰富知识来进行节点标注的方法展现出前景。然而,此方法要么需要大量查询LLMs,要么因LLMs产生的噪声标签而性能受损。为解决这个问题,本研究提出Cella,一个将LLMs融入GNNs的高效自训练框架。Cella的设计核心是通过GNNs迭代识别少量“关键”样本,并利用LLMs和GNNs为它们提取信息性伪标签作为额外的监督信号增强模型训练。实验显示,在五个文本属性图数据集上,Cella在相同的查询预算下,无标签节点分类性能显著超越现有技术。特别是在包含14.3k节点的DBLP数据集上,Cella在准确性上实现了对最新技术的8.08%的显著改进,且成本不到一美分。
Key Takeaways
- 图神经网络(GNNs)是图数据节点分类的优选模型,但依赖高质量标注数据。
- 大型语言模型(LLMs)具有零样本分类潜力,但直接使用存在查询量大或标签噪声问题。
- Cella框架结合LLMs和GNNs,通过迭代识别关键样本并提取信息性伪标签来提高性能。
- Cella包含有效活跃节点选择策略、审慎样本选择方案和标签优化模块。
- 实验显示Cella在多个数据集上显著优于现有技术,特别是在 DBLP 数据集上。
- Cella在提升分类准确性的同时,控制成本在极低水平。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在图数据上进行成本效益高的无标签节点分类(label-free node classification)。具体来说,论文关注以下几个核心问题:
高质标签数据获取困难:图神经网络(GNNs)在图数据的节点分类任务中表现出色,但它们高度依赖于充分的高质量标签数据进行训练。在实际应用中,获取这样的标签数据既昂贵又耗时。
利用大型语言模型(LLMs)进行节点标注:随着大型语言模型(LLMs)的出现,研究者们开始尝试利用这些模型的零样本(zero-shot)能力和丰富的知识储备来为节点生成标签。然而,现有的方法要么需要向LLMs发出大量查询,要么因为LLMs产生的噪声标签而牺牲性能。
主动学习与自训练框架的整合:为了解决上述问题,论文提出了一个名为Cella的主动自训练框架,该框架以成本效益的方式将LLMs整合到GNNs中,通过迭代地识别“关键”样本,并利用LLMs和GNNs作为额外的监督信号来提取信息丰富的伪标签,以增强模型训练。
总结来说,论文旨在提出一种新的方法,通过有效地结合LLMs和GNNs,在有限的查询预算下,实现对图数据中节点的高性能无标签分类,同时减少对人工标注的依赖和查询成本。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以归纳为以下几个领域:
零样本节点分类(Zero-shot Node Classification):
- GraphCEN [26]:通过双层次对比学习联合学习节点嵌入和类别分配,实现对未见类别的知识迁移。
- TAG-Z [30]:利用提示(prompts)和图拓扑生成初步的逻辑值(logits),直接应用于零样本节点分类任务。
- DGPN [65]:通过使用类别语义描述实现从见过类别到未见类别的知识迁移,类似于元学习(meta-learning)。
文本属性图上的节点分类(Node Classification on Text-Attributed Graphs):
- Graph Neural Networks (GNNs) [18]:通过整合顶点属性和图连通性有效生成文档嵌入。
- PLMs 和 LLMs:擅长学习上下文化的语言表达和生成文档嵌入,但通常只关注单个文档,不考虑文档间的图连通性。
- Graphformers [78]、GraphGPT [55]、GraphAdapter [23]、LLM-GNN [7]、OFA [34]、ZeroG [31]:这些方法结合了GNNs和PLMs/LLMs,以学习同时保留上下文化文本语义和图连通性的文档嵌入。
属性图聚类(Attributed Graph Clustering):
- DAEGC [63]、AGCN [46]、DFCN [58]、CCGC [74]、AGC-DRR [16]:这些方法旨在通过有效地利用图的结构和属性信息来提高聚类性能。
与先前工作的差别:
- 论文中还讨论了与之前标签无关方法 [7, 29] 的主要区别,特别是在节点选择策略、迭代节点选择和标注、以及知识蒸馏方面的差异。
这些相关研究构成了论文提出的Cella框架的理论基础和技术背景,Cella框架通过结合LLMs和GNNs,在有限的查询预算下,实现高性能的无标签节点分类。论文通过与这些相关工作的比较,展示了其方法的有效性和创新点。
Q: 论文如何解决这个问题?
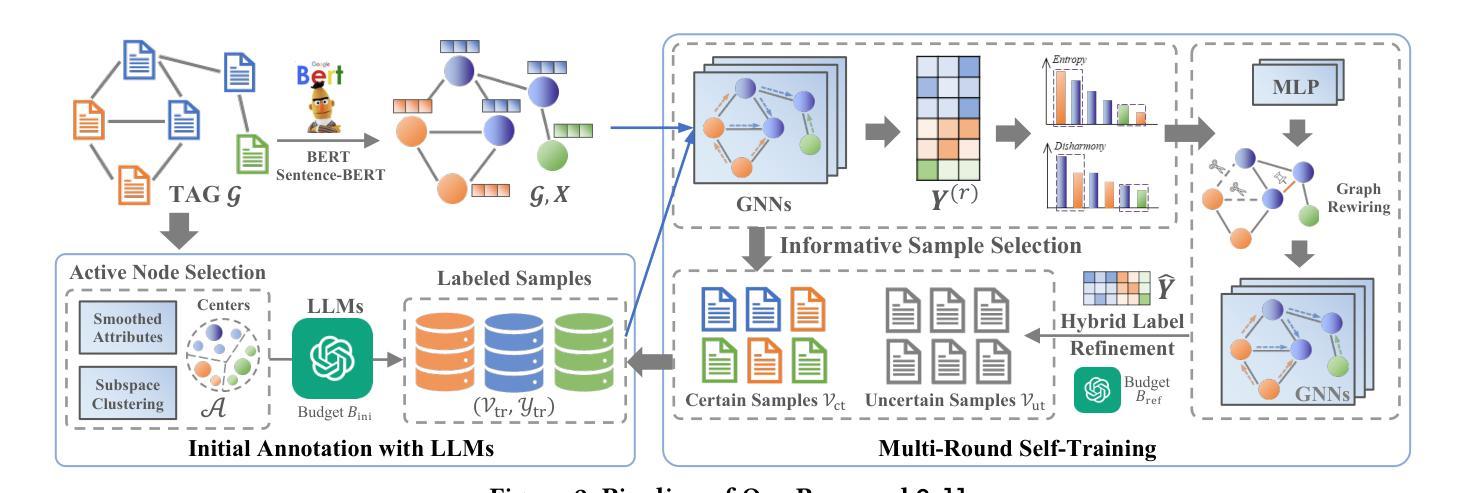
A: 论文通过提出一个名为Cella的框架来解决成本效益高的无标签节点分类问题。Cella框架通过以下三个主要组件来解决这个问题:
1. 初始节点标注(Initial Node Annotations)
- 主动节点选择策略(Active Node Selection):Cella使用基于GNN的节点表示来执行子空间聚类(subspace clustering),从而选择代表性的节点样本作为初始训练样本。这种方法考虑了输入图的固有结构和属性数据,以准确选择代表节点样本。
- LLM-based标注(LLM-based Annotation):使用精心设计的提示(prompts)查询LLMs以获得ANS中节点的标注和置信度分数,然后应用后过滤以去除低置信度样本。
2. 多轮自训练(Multi-Round Self-Training)
- 信息样本选择(Informative Sample Selection):基于当前模型的预测和图结构,Cella识别出置信度高和置信度低的节点样本,这些样本被认为是信息丰富的,对模型训练至关重要。
- 混合标签精炼(Hybrid Label Refinement):对于最不确定的样本,Cella结合LLMs和重连图拓扑来优化标签预测。这包括基于节点特征优化Dirichlet能量的图重连策略,以及结合LLMs和GNNs的标签精炼方法。
3. 模型优化(Model Optimization)
- 分类和重连拓扑损失(Classification and Rewired Topology Loss):Cella在自训练的每一轮中,通过优化分类损失和重连图拓扑损失来训练模型。这包括交叉熵损失和Dirichlet能量正则化项,以避免平凡解。
理论分析(Theoretical Analyses)
- 标签不和谐度与Dirichlet能量的联系(Connection between Label Disharmonicity and Dirichlet Energy):证明了节点的标签不和谐度是其所有类别在Dirichlet能量梯度上的加权L2范数。
- LDE与谱聚类的联系(Connection between LDE and Spectral Clustering):展示了Dirichlet能量项本质上是谱聚类中的RatioCut。
通过这些方法,Cella能够在有限的查询预算下,有效地利用LLMs和GNNs进行节点分类,显著提高了无标签节点分类的性能,并在多个真实世界的文本属性图数据集上展示了其优越性。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来评估Cella框架的性能,并回答了特定的研究问题:
1. 实验设置(Experiment Settings)
- 数据集和指标:使用了五个基准文本属性图(TAG)数据集,包括Cora、Citeseer、Pubmed、Wiki-CS和DBLP。使用四个广泛使用的指标:准确率(Accuracy)、归一化互信息(NMI)、调整兰德指数(ARI)和F1分数(F1)。
- 基线方法:与七类基线方法进行比较,包括使用MLP、BERT类架构、基于提示工程的方法,以及使用不同GNN模型(GCN、GAT、GCNII)的LLM-GNN方法。
- 实验环境:在配备有Intel Xeon Platinum 8352Y CPU、2TB主机内存和四块NVIDIA A800 GPU的Linux机器上进行实验。
2. RQ1:与零样本方法的比较(Comparison with Zero-Shot Methods)
- 比较Cella与20个竞争基线方法在五个数据集上的标签分类性能。
3. RQ2:Cella的消融研究(Ablation Studies of Cella)
- 分别研究Cella中三个主要模块组件的有效性:初始主动节点选择、信息样本选择和混合标签精炼。
4. RQ3:Cella的超参数分析(Hyperparameter Analysis of Cella)
- 分析查询预算大小(𝐵)、预算分配比例(𝜀)和自训练轮数(𝑅)对Cella性能的影响。
5. 额外实验结果(Additional Experiment Results)
- 超参数影响的进一步分析:分析了𝛼、𝑇和𝜏参数对Cella性能的影响。
- Cella的成本分析:分析了Cella与其他LLM-GNN变体的训练时间和财务查询成本。
- 与图聚类方法的比较:比较了Cella与各种图聚类方法的性能。
- 使用更多GPT模型评估Cella:使用GPT-3.5-turbo、GPT-4-turbo和GPT-4o模型进行节点标注和分类任务的实验。
- 主动节点选择的消融研究:验证了子空间聚类技术在初始主动节点选择中的有效性。
- LLM生成的注释的消融研究:研究了LLM生成的节点注释的质量,并评估了使用这些注释训练的Cella模型的性能。
这些实验全面评估了Cella框架的性能,并展示了其在不同设置和条件下的鲁棒性和有效性。通过与现有技术的比较,论文证明了Cella在无标签节点分类任务中的优越性能。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和实验结果,以下是一些可以进一步探索的点:
扩展到大型图数据集:
- 论文中在中等规模的数据集上进行了实验。未来的工作可以探索Cella在更大规模图数据集上的性能和可扩展性。
跨领域和跨数据集的迁移学习:
- 考虑到Cella结合了LLMs和GNNs,研究其在不同领域和数据集之间的迁移学习能力是一个有价值的方向。
优化查询效率和成本:
- 尽管Cella已经展示了成本效益,进一步优化LLMs查询的效率和成本,特别是在大规模数据集上,仍然是一个重要的研究方向。
增强鲁棒性和错误分析:
- 对Cella的鲁棒性进行更深入的分析,特别是在面对LLMs生成的噪声标签时,以及进行错误分析以了解模型失效的情况。
与其他图相关任务的整合:
- 将Cella框架扩展到其他图相关任务,如链接预测、图分类、文档分类和检索等。
改进标签精炼和图重连策略:
- 研究更先进的标签精炼技术和图重连策略,以进一步提高分类准确性和鲁棒性。
主动学习策略的改进:
- 探索更复杂的主动学习策略,以更有效地选择用于标注的节点样本。
模型解释性和可视化:
- 提供Cella的决策过程的解释,并可视化模型学习到的节点表示,以增进对模型行为的理解。
多模态数据的融合:
- 考虑将Cella应用于多模态数据,例如结合文本、图像和其他类型数据的图。
实时性能和在线学习:
- 研究Cella在实时设置中的性能,以及如何适应在线学习场景,其中数据持续到达。
对抗性攻击和防御机制:
- 研究对抗性攻击对Cella的影响,并开发防御机制以提高模型的安全性。
跨语言和文化的数据集:
- 在跨语言和文化的数据集上评估Cella,以测试其泛化能力。
这些探索点可以帮助研究者更全面地理解和改进Cella框架,并将其应用于更广泛的实际问题和应用场景中。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为Cella的框架,旨在实现成本效益高的无标签节点分类。主要内容可以总结如下:
问题背景:
- 图神经网络(GNNs)在图数据节点分类任务中表现出色,但依赖于大量高质量的标签数据。
- 大型语言模型(LLMs)提供了零样本学习能力和丰富的知识,可用于节点标注,但存在查询成本高和标签噪声的问题。
Cella框架:
- Cella是一个主动自训练框架,通过迭代地识别“关键”样本,并利用LLMs和GNNs作为额外的监督信号来提取信息丰富的伪标签,以增强模型训练。
- 框架包括三个主要组件:主动节点选择策略、信息样本选择方案和标签精炼模块。
主要贡献:
- 提出了一种新颖的多轮自训练框架,实现LLMs和GNNs的成本效益整合,以改进无标签节点分类。
- 设计了有效的主动节点选择方案,用于LLMs的节点标注。
- 提出了基于标签不和谐度和熵的信息样本选择策略,以及基于图重连的标签精炼方法,以创建更可靠的训练数据。
- 在五个真实世界的文本属性图数据集上的实验表明,Cella在零样本分类准确性方面显著优于现有技术。
实验结果:
- Cella在多个数据集上实现了至少5%的零样本分类准确性提升。
- 通过消融研究验证了Cella各个组件的有效性。
- 分析了关键参数对Cella性能的影响,并与多种基线方法进行了比较。
未来工作:
- 将Cella扩展到大型图数据集。
- 探索Cella在其他图相关任务中的应用,如链接预测和图分类。
总体而言,这篇论文提出了一个创新的框架,通过结合LLMs和GNNs,在有限的查询预算下,有效地解决了图数据中的无标签节点分类问题。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


DARWIN 1.5: Large Language Models as Materials Science Adapted Learners
Authors:Tong Xie, Yuwei Wan, Yixuan Liu, Yuchen Zeng, Wenjie Zhang, Chunyu Kit, Dongzhan Zhou, Bram Hoex
Materials discovery and design aim to find components and structures with desirable properties over highly complex and diverse search spaces. Traditional solutions, such as high-throughput simulations and machine learning (ML), often rely on complex descriptors, which hinder generalizability and transferability across tasks. Moreover, these descriptors may deviate from experimental data due to inevitable defects and purity issues in the real world, which may reduce their effectiveness in practical applications. To address these challenges, we propose Darwin 1.5, an open-source large language model (LLM) tailored for materials science. By leveraging natural language as input, Darwin eliminates the need for task-specific descriptors and enables a flexible, unified approach to material property prediction and discovery. We employ a two-stage training strategy combining question-answering (QA) fine-tuning with multi-task learning (MTL) to inject domain-specific knowledge in various modalities and facilitate cross-task knowledge transfer. Through our strategic approach, we achieved a significant enhancement in the prediction accuracy of LLMs, with a maximum improvement of 60% compared to LLaMA-7B base models. It further outperforms traditional machine learning models on various tasks in material science, showcasing the potential of LLMs to provide a more versatile and scalable foundation model for materials discovery and design.
材料发现与设计旨在从高度复杂和多样化的搜索空间中找到具有理想特性的组件和结构。传统解决方案,如高通量模拟和机器学习(ML),通常依赖于复杂的描述符,这阻碍了它们在任务之间的通用性和可迁移性。此外,由于现实世界中的不可避免的缺陷和纯度问题,这些描述符可能会偏离实验数据,从而降低它们在实际应用中的有效性。为了解决这些挑战,我们提出了达尔文1.5,这是一个针对材料科学领域的大型开源语言模型(LLM)。达尔文利用自然语言作为输入,消除了对特定任务描述符的需求,能够实现灵活统一的方法来进行材料性能预测和发现。我们采用两阶段训练策略,结合问答(QA)微调与多任务学习(MTL),以注入各种模式的领域特定知识,并促进跨任务知识迁移。通过我们的战略方法,我们在LLM的预测精度上取得了显著提高,与LLaMA-7B基础模型相比,最高提高了60%。它在材料科学领域的各种任务上也比传统机器学习模型表现更好,展示了LLM在材料发现和设计方面提供更具通用性和可扩展性的基础模型的潜力。
论文及项目相关链接
Summary
达尔文1.5是一款针对材料科学领域的大型语言模型。它利用自然语言输入,无需特定任务描述符,实现材料属性预测和发现的灵活统一方法。采用两阶段训练策略,结合问答微调与多任务学习,注入多种形式的领域知识,促进跨任务知识迁移。相比LLaMA-7B基础模型,预测精度最大提升60%,并在材料科学各项任务中表现优于传统机器学习模型,展现出大型语言模型在材料发现和设计领域的潜力。
Key Takeaways
- 达尔文1.5是一款针对材料科学领域的大型语言模型(LLM)。
- 该模型利用自然语言输入,消除了对任务特定描述符的需求。
- 达尔文1.5采用两阶段训练策略,包括问答微调与多任务学习。
- 模型能够注入多种形式的领域知识,促进跨任务知识迁移。
- 相比LLaMA-7B基础模型,达尔文1.5的预测精度有显著提升。
- 达尔文1.5在材料科学各项任务中的表现优于传统机器学习模型。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是材料发现和设计中面临的挑战,尤其是在高度复杂和多样化的搜索空间中寻找具有理想属性的组分和结构。具体来说,论文中提到了以下几个关键问题:
传统解决方案的局限性:传统的解决方案,如高通量模拟和机器学习(ML),通常依赖于复杂的描述符,这限制了模型在不同任务间的泛化能力和可转移性。
描述符与实验数据的偏差:这些描述符可能与实验数据出现偏差,因为在现实世界中,实验材料由于缺陷、纯度问题或独特的局部环境而常常偏离理想化的材料结构,导致ML模型在实际应用中的有效性降低。
缺乏通用探索方法:对于大量未标记的材料数据,缺乏一种通用的探索方法来提高搜索效率。
ML模型的设计和应用障碍:ML模型的设计过于复杂,并且阻碍了广泛的适用性。此外,模型缺乏对实验材料性能的有效评估,因为它们不能轻易捕捉基于基本结构单元的简单表示所呈现的真实世界的复杂性。
为了解决这些问题,论文提出了Darwin 1.5,这是一个为材料科学定制的开源大型语言模型(LLM),它通过利用自然语言作为输入来消除对任务特定描述符的需求,并实现了对材料属性预测和发现的灵活、统一的方法。论文通过两阶段训练策略(问题-答案(QA)微调和多任务学习(MTL))来注入领域特定知识,并促进跨任务知识转移,从而显著提高了LLMs在预测准确性方面的表现,并在材料科学的各种任务中超越了传统机器学习模型。
Q: 有哪些相关研究?
A: 论文中提到了以下相关研究:
ChatGPT [1]:这是一个大型语言模型,因其在理解指令和生成类似人类对话的回答方面的能力而受到学术界的关注。
[5] 和 **[6]**:这两篇论文是使用GPT模型解决化学和材料任务的开创性工作,特别是在可用数据稀缺的情况下,类似于实验室的实验场景。
Language-Interfaced Fine-Tuning (LIFT) [11] 和 gptchem [5]:这些工作启发了作者设计一套提示模板,将原始数据集转换为自然语言句子,以适应LLMs的微调。
LLaMA系列 [12]:这是一个开源的LLM系列,作者在实验中使用了这个系列的模型进行微调。
CrabNet, MODNet (v0.1.1), 和 AMMExpress v2020 [18]:这些是从matbench中使用的机器学习模型,作为实验中的性能比较基准。
其他机器学习基线算法:包括在GPTchem [5] 中使用的算法,这些算法在各自的FAIR数据集上单独训练。
LongLoRA [19] 和 FlashAttention2 [20]:这些是在微调QA生成模型时采用的方法。
DeepSpeed stage 3 [21]:这是在微调QA生成模型时使用的技术。
这些研究为Darwin 1.5的开发提供了理论基础和技术背景,特别是在大型语言模型的训练、微调和应用方面。通过引用这些相关工作,论文展示了其研究是如何在现有研究的基础上进行创新和改进的。
Q: 论文如何解决这个问题?
A: 论文通过提出Darwin 1.5模型来解决材料发现和设计中的问题,具体方法如下:
开发大型语言模型(LLM):Darwin 1.5是一个为材料科学定制的开源大型语言模型(LLM),它能够直接处理自然语言描述,避免了为每个任务设计特殊输入格式的需求。
两阶段训练策略:
- QA微调:第一阶段使用来自科学文献的QA数据集进行微调,这有助于将关键的“知识”注入LLMs,并模仿人类化学家或材料科学家执行任务的方式,即通过分析和解释文献,而不仅仅依赖于复杂的计算模拟。
- 多任务学习(MTL):第二阶段采用多任务学习机制,同时执行与分子和材料的常见属性相关的5个分类和17个回归任务,涵盖不同的系统。这种机制有效利用了任务之间的协同作用,并缓解了数据分布不平衡的问题,实现了底层表示的共享学习和跨任务知识转移。
语言接口微调(LIFT):通过设计一套提示模板,将原始数据集转换为自然语言句子,使模型能够以语言接口的形式进行微调,提高了模型对实验设置的适用性。
实验验证:通过广泛的实验验证了所提方法的有效性,与机器学习模型相比,在多个任务上达到了相当或更好的性能。
提高预测准确性:通过两阶段训练策略,实现了与LLaMA-7B基础模型相比最大60%的预测准确性提升,并在材料科学的各种任务中超越了传统机器学习模型。
减少幻觉:通过在训练集中添加人工反例来减少模型生成错误或编造信息的情况,提高了模型输出的可靠性和信任度。
代码和数据的开放性:研究提供了多任务微调数据集和QA-MT模型的权重,以及源代码,以促进研究的透明度和可重复性。
通过这些方法,论文展示了LLMs在材料发现和设计中的潜力,并为开发更通用、灵活的模型提供了新的方向。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出方法的有效性,具体实验包括:
QA和多任务微调的性能对比:
- 对比了不同的微调策略(单任务、多任务、QA单任务、QA多任务)对22个任务性能的影响。
- 使用平衡的宏F1分数评估分类任务的性能,使用平均绝对误差(MAE)评估回归任务的性能。
与机器学习基线的比较:
- 将QA-MT模型的性能与一些竞争性的机器学习算法进行了比较,包括CrabNet、MODNet和AMMExpress等。
预训练对微调性能的影响:
- 通过使用未训练的LLaMA-7B模型作为基线模型,比较了预训练模型和非预训练模型在单任务和多任务微调下的性能差异。
提高预测性能的因素分析:
- 进行了消融研究,使用两个公认的材料科学回归基准数据集(matbench exp bandgap和matbench steel),通过设计多个小型多任务数据集来系统地研究性能提升的机制。
带隙预测的应用:
- 比较了QA-MT模型与几种传统模拟方法(如PBE、HSE、GWE和AFLOWE)以及支持向量回归(SVR)在带隙预测方面的性能。
人工反例实验:
- 探索了在微调过程中加入人工反例的有效性,以减少模型生成错误或编造信息的情况。
这些实验结果表明,QA微调和多任务学习策略均能显著提高LLMs的性能,并且当两者结合使用时,能够更有效地注入领域特定知识,并利用任务间的协同效应,进一步提升模型的能力。此外,实验还证实了QA-MT模型在材料科学的多个任务中与或超越了传统机器学习模型的性能,展示了LLMs在材料发现和设计中的潜力。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
持续预训练与材料科学文献结合:
- 探索使用更平衡的一般文本和材料科学文献的混合数据集进行持续预训练,以增强LLMs对材料领域的理解。
专门表达式的学习:
- 针对科学文献中较少出现的专门表达式(如SMILES符号),收集更多包含这些表达式的现实世界数据,以进行大规模的多任务微调。
目标化学习:
- 在持续预训练过程中加入对这些专门表达式的针对性学习,以改善LLMs对这些表达式的理解和处理能力。
模型稳定性和鲁棒性提升:
- 尽管QA-MT在某些情况下优于现有的基准,但在模型稳定性和鲁棒性方面仍有提升空间,特别是在不同类型的材料预测上。
多任务学习策略的优化:
- 进一步研究多任务学习策略,以更有效地整合不同的材料表示,并提高模型在多样化任务上的性能。
模型解释性:
- 提高模型的可解释性,以便更好地理解模型是如何做出预测的,特别是在复杂的材料科学应用中。
跨领域应用:
- 探索LLMs在其他科学和工程领域的应用,如药物发现、化学合成路径预测等。
模型训练效率:
- 研究如何提高模型训练的效率,包括减少训练时间和资源消耗。
数据集和模型的多样性:
- 扩展和多样化训练数据集,以包含更广泛的材料类型和属性,提高模型的泛化能力。
模型的可扩展性和适应性:
- 研究模型在处理更大规模数据和更复杂任务时的可扩展性和适应性。
伦理和社会影响:
- 探讨LLMs在科学研究中的伦理问题,包括数据隐私、模型透明度和结果的可解释性。
模型的实时应用:
- 开发工具和接口,使研究人员能够轻松地在实时环境中部署和使用这些模型,以加速材料发现和设计过程。
这些探索点可以帮助研究人员更深入地理解LLMs在材料科学中的应用,并推动相关技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出了材料发现和设计过程中面临的挑战,包括高通量模拟和机器学习(ML)方法依赖于复杂描述符,以及实验材料的异质性等问题。
Darwin 1.5模型的提出:
- 论文提出了Darwin 1.5,一个为材料科学定制的开源大型语言模型(LLM),它通过自然语言输入消除了对任务特定描述符的需求,实现了对材料属性预测和发现的灵活、统一的方法。
两阶段训练策略:
- 论文采用了两阶段训练策略,包括问题-答案(QA)微调和多任务学习(MTL),以注入领域特定知识并促进跨任务知识转移。
实验验证:
- 通过广泛的实验,论文验证了所提方法的有效性,显示Darwin 1.5在多个任务上达到了与机器学习模型相当或更好的性能,并在某些任务上超越了传统机器学习模型。
性能提升分析:
- 论文分析了QA微调和多任务学习策略对LLMs性能提升的贡献,并探讨了预训练对微调性能的影响。
消融研究:
- 论文通过消融研究揭示了多任务微调提升性能的机制,包括增强指令遵循能力和从真实世界数据中提取隐含的材料知识。
带隙预测应用:
- 论文展示了Darwin 1.5在带隙预测方面的应用,并与传统模拟方法和机器学习模型进行了比较。
人工反例实验:
- 论文探索了在微调过程中加入人工反例以减少模型生成错误信息的有效性。
结论与未来方向:
- 论文总结了研究发现,并提出了未来研究的方向,包括持续预训练、多任务学习策略的优化、模型解释性提高等。
代码和数据的开放性:
- 论文提供了实验中使用的多任务微调数据集、QA-MT模型的权重以及源代码,以促进研究的透明度和可重复性。
总体而言,这篇论文展示了LLMs在材料科学中的潜力,并提出了一个有效的方法来提高材料属性预测的准确性和泛化能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图

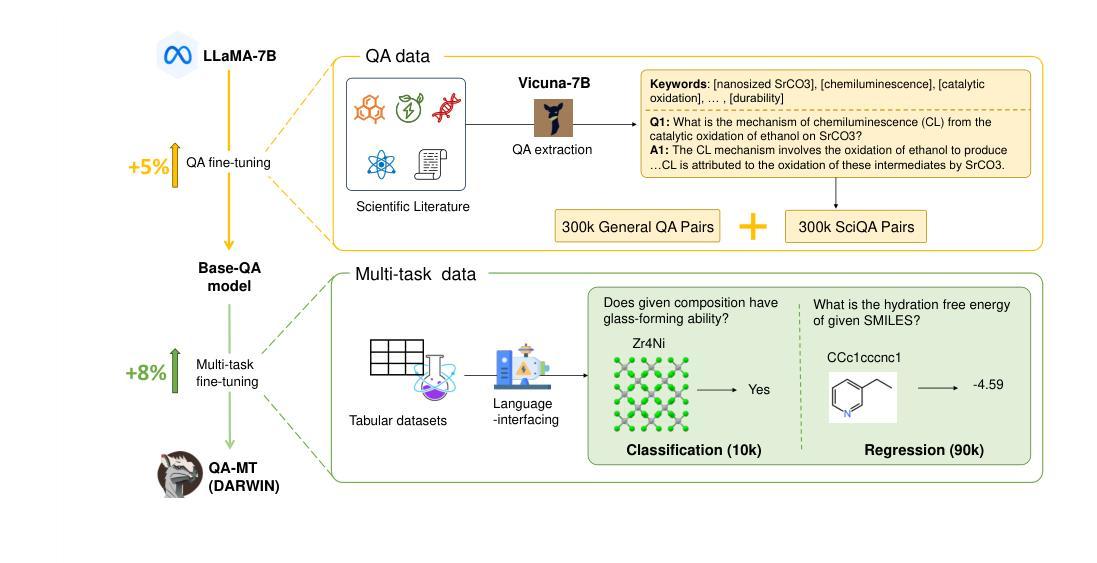
Advancing Comprehensive Aesthetic Insight with Multi-Scale Text-Guided Self-Supervised Learning
Authors:Yuti Liu, Shice Liu, Junyuan Gao, Pengtao Jiang, Hao Zhang, Jinwei Chen, Bo Li
Image Aesthetic Assessment (IAA) is a vital and intricate task that entails analyzing and assessing an image’s aesthetic values, and identifying its highlights and areas for improvement. Traditional methods of IAA often concentrate on a single aesthetic task and suffer from inadequate labeled datasets, thus impairing in-depth aesthetic comprehension. Despite efforts to overcome this challenge through the application of Multi-modal Large Language Models (MLLMs), such models remain underdeveloped for IAA purposes. To address this, we propose a comprehensive aesthetic MLLM capable of nuanced aesthetic insight. Central to our approach is an innovative multi-scale text-guided self-supervised learning technique. This technique features a multi-scale feature alignment module and capitalizes on a wealth of unlabeled data in a self-supervised manner to structurally and functionally enhance aesthetic ability. The empirical evidence indicates that accompanied with extensive instruct-tuning, our model sets new state-of-the-art benchmarks across multiple tasks, including aesthetic scoring, aesthetic commenting, and personalized image aesthetic assessment. Remarkably, it also demonstrates zero-shot learning capabilities in the emerging task of aesthetic suggesting. Furthermore, for personalized image aesthetic assessment, we harness the potential of in-context learning and showcase its inherent advantages.
图像美学评估(IAA)是一项重要且复杂的任务,需要分析和评估图像的美学价值,并识别其亮点和改进领域。传统的IAA方法往往集中在单一的美学任务上,并受到标注数据集不足的影响,从而妨碍了深入的美学理解。尽管有人尝试通过应用多模态大型语言模型(MLLM)来克服这一挑战,但这些模型在IAA方面的应用仍然不够成熟。为了解决这一问题,我们提出了一种全面的美学MLLM模型,能够洞察细微的美学差异。我们的方法的核心是一种创新的多尺度文本引导的自我监督学习技术。该技术具有多尺度特征对齐模块,以自我监督的方式利用大量未标记数据,从而在结构和功能上增强美学能力。经验证据表明,通过广泛的指令微调,我们的模型在多项任务上设定了新的最先进的基准,包括美学评分、美学评论和个性化图像美学评估。值得一提的是,它还展示了新兴的美学建议任务中的零样本学习能力。此外,对于个性化图像美学评估,我们充分利用了上下文学习的潜力,并展示了其固有的优势。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
图像美学评估(IAA)是一项重要而复杂的任务,涉及分析评估图像的审美价值,并识别其优点和改进点。传统方法往往集中在单一审美任务上,且由于缺少足够的标记数据集,影响了深度审美理解。我们提出一种全面的多模态大型语言模型(MLLM),结合创新的多尺度文本引导自我监督学习方法进行图像美学评估。此方法采用多尺度特征对齐模块,利用大量未标记数据以自我监督的方式进行训练,从而增强模型的结构和功能美学能力。实验证据表明,我们的模型在经过广泛的指令微调后,在美学评分、美学评论和个性化图像美学评估等多个任务上达到了新的技术水平。此外,该模型还展示了零样本学习在美学建议这一新兴任务中的潜力,并在个性化图像美学评估中展示了上下文学习的优势。
Key Takeaways
- 图像美学评估(IAA)是分析图像审美价值的任务,涉及识别和提出改进点。
- 传统方法在单一审美任务上有限,且缺乏足够的标记数据集限制了深度理解。
- 提出一种全面的多模态大型语言模型(MLLM)用于图像美学评估,结合创新的多尺度文本引导自我监督学习方法。
- 多尺度特征对齐模块增强了模型的结构和功能美学能力。
- 模型经过广泛的指令微调后,在美学评分、美学评论等任务上达到新的技术水平。
- 模型展现出零样本学习在美学建议任务中的潜力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是图像美学评估(Image Aesthetic Assessment, IAA)中的挑战,具体来说,包括以下几个方面:
单一审美任务的局限性:传统的IAA方法通常只关注单一的审美任务,并且由于缺乏足够的标记数据集,限制了它们对图像审美价值的深入理解。
多模态大型语言模型(MLLMs)在IAA中的欠发展:尽管MLLMs在多个领域展现出了强大的理解和推理能力,但它们在图像美学评估方面的应用还不成熟,主要因为这些模型依赖于语义特征,忽略了大量有价值的审美信息,并且由于标记数据的稀缺和潜在的错误标签限制了它们的性能。
整合全面审美信息和开发精细学习策略的需求:为了改进MLLMs在IAA中的性能,需要将全面的审美信息整合进模型,并开发出能够准确利用大量图像数据的精细学习策略。
为了解决这些问题,论文提出了一个综合性的美学MLLM——CALM(Comprehensive Aesthetic Large language Model),它能够提供细致的审美洞察。CALM模型的核心是创新的多尺度文本引导自监督学习技术,该技术通过多尺度特征对齐模块(Multi-scale Feature Alignment Module, MFAM)和利用大量未标记数据以自监督的方式在结构和功能上增强审美能力。通过广泛的实验,论文证明了CALM在多个任务中设定了新的基准,包括审美评分、审美评论和个性化图像审美评估,并在审美建议这一新兴任务中展示了零样本学习能力。
Q: 有哪些相关研究?
A: 相关研究主要涉及以下几个领域:
图像美学评估(Image Aesthetic Assessment):
- 初始的方法主要利用卷积神经网络(CNN)和变换器(Transformers)来优化审美分数预测,例如TANet、ResNext、DAT和MaxViT等。
- 一些工作通过文本数据和CLIP模型来调控审美特征以优化评分,如Comm和AesCLIP。
- 针对审美评论(Aesthetic Commenting)任务,出现了一些语言生成模型,例如Yeo等人的工作。
多模态大型语言模型(Multi-modal Large Language Models):
- LLaVA-1.5和mPLUG-Owl2展示了图像推理能力。
- 在图像美学评估领域,VILA、Q-Align和UNIAA等模型尝试利用MLLMs进行IAA,但它们没有修改预存在的MLLMs且依赖于有限的构建数据。
多尺度审美感知(Multi-scale Aesthetic Perception):
- 一些研究通过结合多级空间特征和自适应扩张CNNs来促进IAA。
- 一些模型设计了处理多尺度特征的模块,例如EAT和ICAA。
自监督学习(Self-supervised Learning):
- 在IAA领域,自监督学习方法特别普遍,因为专家注释往往成本高昂。
- 一些方法直观地为增强图像分配较低的审美分数以进行对比学习,生成分数伪标签。
以上相关研究为本文提出的CALM模型提供了理论基础和技术背景。CALM模型通过结合多尺度特征对齐、文本引导的自监督学习和多阶段指导调整技术,旨在实现更全面的美学洞察和分析能力。
Q: 论文如何解决这个问题?
A: 论文通过以下几个关键方法解决了图像美学评估(IAA)中的问题:
提出综合性美学大语言模型(CALM):
- 论文提出了一个综合性的美学大语言模型(CALM),它能够在多个IAA任务中表现出深入的审美理解和分析能力。
多尺度特征对齐模块(MFAM):
- 为了处理多尺度特征,论文设计了一个多尺度特征对齐模块(MFAM),该模块能够从视觉编码器中提取并强调不同层次的多尺度信息。
多尺度文本引导自监督学习技术:
- 论文介绍了一种多尺度文本引导自监督学习技术,利用未标记数据和文本伪标签来提升模型的审美感知能力。这种方法使用准确的属性伪标签替换了有缺陷的分数伪标签,并且使用了更广泛的数据增强范围。
两阶段指导调整(Instruct-Tuning)技术:
- 为了适应不同的美学任务,如审美评分、审美评论和个性化图像美学评估,论文开发了两阶段指导调整技术来微调CALM模型。
零样本学习能力的探索:
- 论文还探索了CALM在零样本学习方面的能力,特别是在个性化图像美学评估和提供审美建议方面。
实验验证:
- 通过广泛的实验,论文验证了CALM在审美评分、审美评论和个性化图像美学评估任务中的性能,并与现有的最先进方法进行了比较。
具体来说,CALM模型的结构包括一个视觉编码器、MFAM和大型语言模型(LLM)。MFAM专注于确保后续的LLM能够充分利用视觉编码器提供的审美信息。通过这种结构和功能上的创新,CALM能够有效地整合和学习丰富的审美信息,并在多个IAA任务中取得了新的最佳性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来验证所提出的CALM模型的性能和效果,具体实验包括:
数据集:
- 使用了AVA数据集,包含超过250,000张由用户评分的图片。
- 使用了AVA-Captions数据集,包含约230,000张图片,每张图片平均有5条用户评论。
- 使用了FLICKR-AES数据集,包含由173个标注者评分的35,263张图片的训练集和由37个标注者评分的4,737张图片的测试集。
实现细节:
- 输入分辨率为224,处理256个视觉标记,每个标记的维度为1024。
- 使用了Adam优化器进行训练,并在预训练和微调阶段设置了不同的学习率。
评估指标:
- 对于审美评分(AS)任务,使用了Spearman Rank-order Correlation Coefficient(SRCC)和Pearson Linear Correlation Coefficient(PLCC)作为评估指标。
- 对于审美评论(AC)任务,使用了BLEU、ROUGE、CIDEr和METEOR等指标。
- 对于个性化图像审美评估(PIAA)任务,主要使用了SRCC作为评估指标。
与现有方法的比较:
- 在审美评分任务上,与基于CNN、基于Transformer、基于CLIP和基于MLLM的多种方法进行了比较。
- 在审美评论任务上,与之前的方法进行了比较,包括CWS、Yeo和VILA。
- 在个性化图像审美评估任务上,与之前的方法进行了比较,如PAM、PA、BLG等。
零样本审美建议任务的探索:
- 定义了一个新的任务——审美建议,并评估了CALM模型在这一任务上的性能。
- 对比了CALM与其他MLLMs(如GPT-4v、qwen-vl等)在提供审美建议方面的准确性。
消融研究:
- 研究了MFAM的不同配置对AS任务的影响。
- 探讨了Qformer中不同数量的美学查询对AC任务的影响。
- 分析了文本引导自监督学习在AS任务中的作用。
- 考察了不同数据增强类型对自监督学习的影响。
- 探讨了上下文学习对于PIAA任务的适用性。
这些实验全面评估了CALM模型在多个IAA任务上的性能,并与现有技术进行了比较,同时也探索了模型的不同组件和训练策略对性能的影响。通过这些实验,论文证明了CALM模型在图像美学评估领域的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 论文中提到了CALM模型存在的一些局限性,并指出了未来可能的探索方向。以下是一些可以进一步探索的点:
提高图像分辨率的处理能力:
- 论文中提到,尽管CALM模型在较小分辨率下表现良好,但对图像分辨率的处理不如CNN灵活。因此,提高模型处理不同分辨率输入的能力是一个值得探索的方向。
降低计算负担:
- CALM模型的计算成本相对较高,这可能限制了其应用场景。研究如何降低模型的计算复杂度,使其更适合实际应用是一个重要的研究方向。
扩展多尺度特征对齐模块(MFAM):
- 虽然MFAM在结构上促进了多尺度特征的提取,但探索更多种类的多尺度特征和更精细的特征对齐策略可能会进一步提升模型的性能。
改进自监督学习策略:
- 论文中提出的文本引导自监督学习技术还有改进空间。研究更有效的数据增强方法和伪标签生成策略可能会提高模型利用未标记数据的能力。
上下文学习在PIAA任务中的应用:
- 论文中提到了上下文学习在PIAA任务中的潜力,但目前的应用还比较初步。深入研究如何更好地利用上下文信息进行个性化审美评估是一个有价值的研究方向。
跨领域的审美评估:
- 虽然CALM模型在图像审美评估上取得了进展,但将这种能力扩展到其他领域(如视频、音频等)也是一个值得探索的方向。
模型的可解释性和透明度:
- 提高模型决策过程的可解释性,帮助用户理解模型是如何评估图像审美价值的,这将增加用户对模型的信任和接受度。
模型的泛化能力:
- 研究如何提高模型在不同类型和风格图像上的泛化能力,使其不仅仅局限于某一特定类型的图像。
实时性能优化:
- 针对实时应用场景,优化模型以满足实时处理的需求,例如在移动设备上进行图像审美评估。
多模态数据融合:
- 探索如何更有效地融合视觉信息和语言信息,以实现更深层次的审美理解和评估。
这些探索点可以帮助研究人员进一步提升CALM模型的性能,并扩展其在图像美学评估领域的应用范围。
Q: 总结一下论文的主要内容
A: 论文的主要内容可以总结如下:
问题陈述:
- 图像美学评估(IAA)是一个复杂且重要的任务,它涉及分析和评估图像的美学价值,并识别图像的亮点和改进空间。传统的IAA方法通常集中于单一任务,并且受限于标记数据集的不足,影响了深入的审美理解。
现有挑战:
- 尽管多模态大型语言模型(MLLMs)展现出跨领域的强大理解和推理能力,但在IAA领域,这些模型由于依赖单一语义特征和标记数据的稀缺性,其性能受限。
CALM模型提出:
- 论文提出了一个综合性的美学MLLM——CALM,该模型能够在多个IAA任务中表现出深入的审美理解和分析能力,包括审美评分、审美评论和个性化图像审美评估。
关键技术:
- 多尺度特征对齐模块(MFAM):用于强调多尺度信息,使模型能够有效捕获关键审美特征。
- 多尺度文本引导自监督学习技术:利用未标记数据和文本伪标签来提升模型的审美感知能力。
- 两阶段指导调整(Instruct-Tuning)技术:使CALM适应不同的美学任务,如审美评分、审美评论和个性化图像审美评估。
实验验证:
- 通过在AVA、AVA-Captions和FLICKR-AES数据集上的实验,论文证明了CALM在审美评分、审美评论和个性化图像审美评估任务中的优越性能,并与现有最先进方法进行了比较。
零样本学习能力:
- 论文还探索了CALM在零样本学习方面的能力,特别是在个性化图像审美评估和提供审美建议方面。
消融研究:
- 论文通过消融研究分析了MFAM、文本引导自监督学习和其他关键组件对模型性能的影响。
结论与未来工作:
- 论文总结了CALM模型的主要贡献,并指出了未来可能的研究方向,包括提高图像分辨率处理能力、降低计算负担、改进自监督学习策略等。
总的来说,论文提出了一个先进的综合性美学大语言模型CALM,通过创新的多尺度文本引导自监督学习和指导调整技术,在多个IAA任务中取得了新的最佳性能,并展示了零样本学习的能力。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图


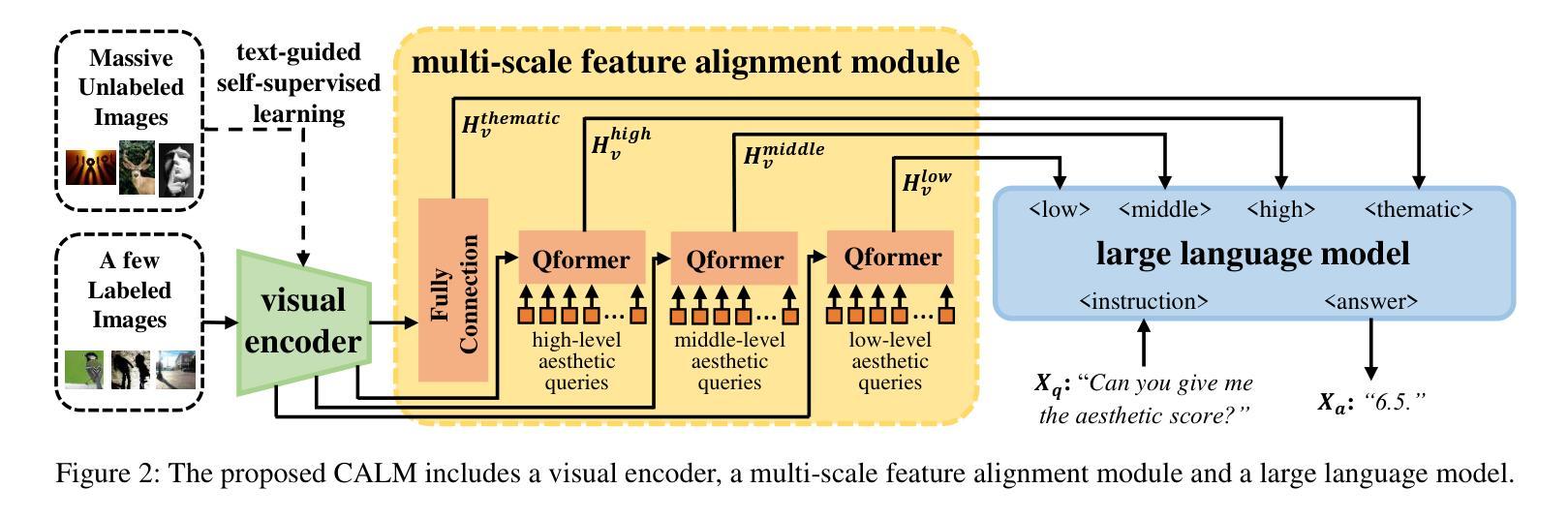



A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges
Authors:Yibo Yan, Jiamin Su, Jianxiang He, Fangteng Fu, Xu Zheng, Yuanhuiyi Lyu, Kun Wang, Shen Wang, Qingsong Wen, Xuming Hu
Mathematical reasoning, a core aspect of human cognition, is vital across many domains, from educational problem-solving to scientific advancements. As artificial general intelligence (AGI) progresses, integrating large language models (LLMs) with mathematical reasoning tasks is becoming increasingly significant. This survey provides the first comprehensive analysis of mathematical reasoning in the era of multimodal large language models (MLLMs). We review over 200 studies published since 2021, and examine the state-of-the-art developments in Math-LLMs, with a focus on multimodal settings. We categorize the field into three dimensions: benchmarks, methodologies, and challenges. In particular, we explore multimodal mathematical reasoning pipeline, as well as the role of (M)LLMs and the associated methodologies. Finally, we identify five major challenges hindering the realization of AGI in this domain, offering insights into the future direction for enhancing multimodal reasoning capabilities. This survey serves as a critical resource for the research community in advancing the capabilities of LLMs to tackle complex multimodal reasoning tasks.
人类的认知中,逻辑推理是一个核心部分,它在许多领域都至关重要,无论是教育中的问题解决还是科学进步。随着人工智能通用智能(AGI)的发展,将大型语言模型(LLM)与数学推理任务相结合变得越来越重要。这篇综述提供了多模态大型语言模型(MLLM)时代数学推理的首个综合分析。我们回顾了自2021年以来发表的超过200项研究,并重点考察了数学LLM的最新发展,重点关注多模态环境。我们将该领域分为三类:基准测试、方法和挑战。特别是我们探讨了多模态数学推理流程以及LLM(M)的作用和相关方法。最后,我们确定了阻碍该领域实现人工智能发展的五大挑战,为增强多模态推理能力的未来方向提供了见解。这篇综述对于推动LLM社区提升处理复杂多模态推理任务的能力具有重要的参考价值。
论文及项目相关链接
Summary
基于多模态大型语言模型(MLLMs)的数学推理研究综述,详细探讨了自2021年以来该领域的最新发展。研究范围涵盖基准测试、方法论和面临的挑战等多个方面,并重点探讨了多模态数学推理流程以及LLMs的角色和相关方法论。该综述为推进LLMs解决复杂多模态推理任务的能力提供了重要资源。
Key Takeaways
- 数学推理是人类认知的核心方面,广泛应用于多个领域,如教育问题解决和科学进步。
- 随着人工智能通用化(AGI)的进展,将大型语言模型(LLMs)与数学推理任务相结合变得越来越重要。
- 此综述首次全面分析了多模态大型语言模型时代(MLLMs)的数学推理。
- 综述涵盖了自2021年以来超过200项研究,并重点探讨了多模态设置下的数学推理。
- 将领域划分为基准测试、方法论和面临的挑战等三个维度进行探讨。
- 指出当前阻碍该领域AGI实现的五大挑战,并为提高多模态推理能力提供了未来发展方向的见解。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在多模态大型语言模型(MLLMs)时代推进数学推理的研究。具体来说,论文关注以下几个核心问题:
数学推理的重要性:数学推理是人类认知能力的核心部分,在教育问题解决和科学进步等多个领域中发挥着重要作用。随着人工通用智能(AGI)的发展,将大型语言模型(LLMs)与数学推理任务相结合变得越来越重要。
多模态设置中的数学推理:数学问题通常不仅包含文本信息,还涉及视觉元素(如图表、图形或方程式),这些视觉元素为解决问题提供了必要的上下文。论文探讨了多模态大型语言模型(MLLMs)在处理这种多模态数学推理任务时的最新发展。
数学推理的基准、方法和挑战:论文系统地回顾了自2021年以来发表的200多项研究,对数学推理领域的进展进行了全面的分析,特别关注多模态设置。论文从基准测试、方法论和挑战三个维度对这一领域进行了分类和探讨。
实现AGI的挑战:论文识别了阻碍在数学推理领域实现AGI的五个主要挑战,并为未来增强多模态推理能力的方向提供了见解。
总的来说,这篇论文旨在为研究社区提供一个关于MLLMs在数学推理能力提升方面的批判性资源,以推进LLMs解决复杂多模态推理任务的能力。
Q: 有哪些相关研究?
A: 根据论文内容,以下是一些与多模态大型语言模型(MLLMs)在数学推理领域相关的研究:
GPT-f (Polu and Sutskever, 2021):由OpenAI推出的模型,是数学推理领域较早的LLM之一。
Minerva (Lewkowycz et al., 2022):Google推出的模型,支持多语言和多模态能力。
Hypertree Proof Search (Lample et al., 2022):在定理证明方面取得进展的模型。
Jiuzhang 1.0 (Zhao et al., 2022):在数学问题理解能力方面表现突出的模型。
SkyworkMath (Zeng et al., 2024):支持多模态的数学推理模型。
Qwen2.5-Math (Yang et al., 2024a):专注于增强数学指导能力的模型。
DeepSeek-Proof (Xin et al., 2024a):在证明能力方面有所增强的模型。
MathGLM-Vision (Yang et al., 2024b):具有视觉组件的Math-LLM。
DL4Math (Li et al., 2023a):关注深度学习在数学推理中的应用。
LLM4Edu (Liu et al., 2023b) 和 LLM4Math (Ahn et al., 2024):探讨LLM在教育和数学领域应用的研究。
DL4TP (Ahn et al., 2024):研究深度学习在自动定理证明中的应用。
这些研究涵盖了数学推理的不同方面,包括问题求解、定理证明、错误检测和多模态理解等。它们展示了MLLMs在数学推理领域的快速发展和多样化的应用前景。论文通过综合分析这些研究,提供了对当前MLLMs数学推理能力的全面认识,并指出了未来研究的方向。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决多模态大型语言模型(MLLMs)在数学推理领域的问题:
1. 综合分析研究现状
- 论文回顾了自2021年以来发表的200多项研究,对MLLMs在数学推理领域的最新进展进行了全面的分析。
- 特别关注多模态设置,包括数学问题中文本和视觉元素(如图表、方程式)的结合。
2. 分类研究领域
- 将研究领域分为三个维度:基准测试(Benchmarks)、方法论(Methodologies)和挑战(Challenges)。
- 对每个维度进行了详细的探讨和分析。
3. 探索多模态数学推理流程
- 论文探讨了多模态数学推理的流程,包括MLLMs的角色和相关方法论。
- 分析了MLLMs如何整合和处理多种模态信息以进行复杂推理。
4. 识别挑战和未来方向
- 识别了阻碍MLLMs在数学推理领域实现AGI的五个主要挑战。
- 提供了对未来研究方向的见解,以增强MLLMs的多模态推理能力。
5. 提供研究资源和见解
- 论文旨在为研究社区提供一个关于MLLMs在数学推理能力提升方面的批判性资源。
- 通过这些分析和见解,论文希望推动LLMs解决复杂多模态推理任务的能力。
6. 结构化论文内容
- 论文的结构如下:
- 基准测试视角:分析了数学推理任务的数据集、任务和评估方法。
- 方法论视角:探讨了MLLMs在数学推理中的不同角色,包括作为推理器、增强器和规划器。
- 挑战:讨论了MLLMs在数学推理中面临的五个核心挑战。
通过这些步骤,论文不仅提供了对当前MLLMs数学推理能力的全面认识,还指出了未来研究的方向,以推动该领域的发展。
Q: 论文做了哪些实验?
A: 根据提供的论文内容,文中并没有提到具体的实验操作或实验结果。这篇论文是一个**综述**(Survey),它的目标是提供对多模态大型语言模型(MLLMs)在数学推理领域研究的全面分析,而不是报告具体的实验或数据结果。综述论文通常包含以下元素:
- 文献回顾:总结和分析已发表的相关研究。
- 理论框架:建立或借用理论框架来解释研究领域的现状。
- 方法论分析:分析和比较不同研究的方法和工具。
- 挑战与机遇:识别领域内的主要挑战和未来的研究方向。
- 综合讨论:基于文献回顾和分析,提供对领域进展的综合讨论。
在这篇论文中,作者们通过以下方式来构建他们的综述:
- 基准(Benchmarks):分析了数学推理任务的数据集、任务和评估方法。
- 方法论(Methodologies):探讨了MLLMs在数学推理中的不同角色,包括作为推理器、增强器和规划器。
- 挑战(Challenges):识别了MLLMs在数学推理中面临的五个核心挑战。
每个部分都基于广泛的文献调研和对现有研究的深入分析。这篇论文的重点在于提供一个综合视角,帮助研究社区了解MLLMs在数学推理领域的最新进展,并指出未来可能的研究方向。因此,它不包含传统意义上的实验设计或实验结果。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
1. 多模态数学推理的深度研究
- 视觉推理增强:研究如何提升MLLMs对数学图表、图形和方程式的视觉理解能力。
- 交互式推理环境:探索MLLMs在动态、交互式数学问题解决环境中的表现。
2. 推理任务的多样性和复杂性
- 跨领域泛化能力:研究MLLMs在不同数学领域(如代数、几何、统计)间的泛化能力。
- 高阶思维任务:探索MLLMs在解决更复杂的数学问题,如证明题和开放性问题时的表现。
3. MLLMs的结构和训练方法
- 模型架构优化:研究不同的模型架构对数学推理能力的影响。
- 多模态数据增强:开发新的数据增强技术,提高MLLMs在多模态数学任务上的表现。
4. 错误检测与反馈机制
- 错误分析:研究MLLMs在数学推理中犯错误的原因,并开发有效的错误检测和分类模块。
- 多代理协作:探索多代理系统在数学推理中通过交换反馈来共同优化解决方案的潜力。
5. 教育应用和实际需求整合
- 教育场景融合:研究如何将MLLMs更好地融入实际教育场景,包括学生的草稿工作和问题解决流程。
- 个性化学习支持:探索MLLMs在提供个性化数学学习支持方面的潜力。
6. 评估和基准测试
- 新的评估指标:开发新的评估指标来全面衡量MLLMs在数学推理任务上的性能。
- 多语言和跨文化研究:探索MLLMs在不同语言和文化背景下的表现和适应性。
7. 伦理和社会影响
- 公平性和偏见:研究MLLMs在数学推理任务中可能存在的偏见问题,并探索减少这些偏见的方法。
- 教育影响评估:评估MLLMs在教育领域应用的长期影响,包括对学习成果和教育公平的影响。
这些探索点可以帮助研究者更深入地理解MLLMs在数学推理领域的能力和局限,并推动相关技术的发展和应用。
Q: 总结一下论文的主要内容
A: 这篇论文提供了对多模态大型语言模型(MLLMs)在数学推理领域的首次全面分析。以下是其主要内容的总结:
1. 引言
- 数学推理是人类认知能力的核心部分,对于教育和科学进步至关重要。
- 随着人工通用智能(AGI)的发展,将大型语言模型(LLMs)与数学推理任务相结合变得越来越重要。
2. 研究范围和进展
- 论文回顾了自2021年以来发表的200多项研究,重点分析了多模态设置中的数学推理。
- 论文考察了数学推理任务的输入多样性,包括文本和视觉元素(如图表、图形)。
3. 数学推理的进展
- 数学推理领域的LLMs(Math-LLMs)数量稳步增长,支持多语言和多模态能力。
- 论文讨论了Math-LLMs的关键进展,包括定理证明和数学问题理解能力的提升。
4. 研究范围
- 论文指出,以往的研究没有完全捕捉到MLLMs时代数学推理的进展和挑战。
- 本文旨在填补这一空白,提供对MLLMs数学推理现状的全面分析。
5. 结构
- 论文从基准测试、方法论和挑战三个维度进行综述。
- 分析了数据集、任务和评估方法,探讨了MLLMs在数学推理中的角色,并识别了面临的挑战。
6. 基准测试视角
- 论文分析了数学推理任务的数据集、任务和评估方法。
- 讨论了数据集的基本格式、语言、大小、来源和教育水平。
7. 方法论视角
- 论文将MLLMs在数学推理中的应用分为三个范式:作为推理器、增强器和规划器。
- 分析了每种范式的定义、例子和前景。
8. 挑战
- 论文识别了MLLMs在数学推理领域面临的五个主要挑战:
- 视觉推理的不足
- 超越文本和视觉的推理
- 有限的领域泛化能力
- 错误反馈的限制
- 与现实世界教育需求的整合
9. 结论
- 论文总结了MLLMs在数学推理领域的进展和挑战,并强调了解决这些挑战的重要性,以实现更有效和类人的数学推理能力。
10. 限制
- 论文承认可能存在未涵盖的相关研究和分类或引用错误,但尽力通过多源收集和多轮检查来最小化这些错误。
这篇论文为研究社区提供了一个关于MLLMs在数学推理能力提升方面的批判性资源,并指导未来的研究方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图






GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
Authors:Renqiu Xia, Mingsheng Li, Hancheng Ye, Wenjie Wu, Hongbin Zhou, Jiakang Yuan, Tianshuo Peng, Xinyu Cai, Xiangchao Yan, Bin Wang, Conghui He, Botian Shi, Tao Chen, Junchi Yan, Bo Zhang
Despite their proficiency in general tasks, Multi-modal Large Language Models (MLLMs) struggle with automatic Geometry Problem Solving (GPS), which demands understanding diagrams, interpreting symbols, and performing complex reasoning. This limitation arises from their pre-training on natural images and texts, along with the lack of automated verification in the problem-solving process. Besides, current geometric specialists are limited by their task-specific designs, making them less effective for broader geometric problems. To this end, we present GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks. Given the significant differences between geometric diagram-symbol and natural image-text, we introduce unimodal pre-training to develop a diagram encoder and symbol decoder, enhancing the understanding of geometric images and corpora. Furthermore, we introduce geometry-language alignment, an effective pre-training paradigm that bridges the modality gap between unimodal geometric experts. We propose a Generator-And-Sampler Transformer (GS-Former) to generate discriminative queries and eliminate uninformative representations from unevenly distributed geometric signals. Finally, GeoX benefits from visual instruction tuning, empowering it to take geometric images and questions as input and generate verifiable solutions. Experiments show that GeoX outperforms both generalists and geometric specialists on publicly recognized benchmarks, such as GeoQA, UniGeo, Geometry3K, and PGPS9k.
尽管在多任务中表现出色,但多模态大型语言模型(MLLM)在自动几何问题求解(GPS)方面遇到了困难。GPS要求理解图表、解释符号和进行复杂推理。这一局限性源于它们对自然图像和文本的预训练,以及问题求解过程中缺乏自动验证。此外,当前的几何专家受限于其特定任务设计,对于更广泛的几何问题则显得不够有效。为此,我们推出了专注于几何理解和推理任务的多模态大型模型GeoX。鉴于几何图形符号与自然图像文本之间的显著差异,我们引入了单模态预训练,以开发图表编码器和符号解码器,增强对几何图像和语料的理解。此外,我们还引入了几何语言对齐这一有效的预训练范式,以弥合单模态几何专家之间的模态差距。我们提出了一种生成器与采样器转换器(GS-Former),用于生成判别查询并消除来自分布不均的几何信号的冗余表示。最后,GeoX受益于视觉指令微调,使其能够以几何图像和问题作为输入并生成可验证的解决方案。实验表明,GeoX在公认的基准测试中表现优于通用模型和几何专家模型,如GeoQA、UniGeo、Geometry3K和PGPS9k等。
论文及项目相关链接
PDF Our code is available at https://github.com/UniModal4Reasoning/GeoX
Summary:尽管多模态大型语言模型(MLLMs)在一般任务上表现出色,但在自动几何问题求解(GPS)方面却存在困难,这要求对图表进行理解、符号进行解读以及执行复杂推理。其局限性源于对自然图像和文本的预训练,以及问题求解过程中缺乏自动验证。为此,提出GeoX模型,专注于几何理解和推理任务。通过引入单模态预训练、几何语言对齐和生成采样变压器(GS-Former)等方法,提高几何图像和语料的理解能力,缩小模态之间的差距。实验表明,GeoX在公认的基准测试上表现优于通用模型和几何专家。
Key Takeaways:
- 多模态大型语言模型(MLLMs)在自动几何问题求解(GPS)方面存在困难,需要理解图表、解读符号和复杂推理。
- 局限性源于模型对自然图像和文本的预训练,以及问题求解过程中缺乏自动验证。
- 提出GeoX模型,专注于几何理解和推理。
- 引入单模态预训练,提高几何图像和语料的理解能力。
- 几何语言对齐是有效的预训练范式,能够缩小不同模态之间的差距。
- 提出生成采样变压器(GS-Former),用于生成判别性查询并消除不均匀分布的几何信号中的无用表示。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为GeoX的多模态大型模型,旨在解决自动几何问题求解(Geometry Problem Solving, GPS)的挑战。尽管多模态大型语言模型(MLLMs)在一般任务中表现出色,但它们在自动几何问题求解方面存在困难,这要求模型不仅要理解图表、解释符号,还要进行复杂的推理。现有模型由于在自然图像和文本上的预训练限制,以及在问题解决过程中缺乏自动化验证,导致在这一领域表现不佳。此外,当前的几何专家系统由于其任务特定的设计,面对广泛的几何问题时效果有限。因此,GeoX模型专注于几何理解和推理任务,通过统一的形式化视觉-语言预训练来解决这些挑战。
Q: 有哪些相关研究?
A: 相关研究主要涉及以下几个领域:
多模态大型语言模型(MLLMs):
- 这些模型在处理视觉相关任务方面取得了显著进展,但在处理涉及几何图表和符号的多模态数学问题时,结果并不令人满意。
几何问题求解(GPS):
- 该领域存在两种主要的自动系统:基于规则的方法和基于神经网络的方法。
- 基于规则的方法依赖于外部工具(如OCR)解析图表,并基于路径搜索和条件匹配进行逻辑推理。
- 基于神经网络的方法使用网络预测解决问题的步骤序列,然后由求解器执行。
形式化视觉-语言预训练:
- 该领域的研究强调使用形式化描述来封装几何图像中的空间结构信息,而不是使用自然语言描述。
特定的几何问题求解模型:
- 如NGS、Geoformer和PGPSNet等,这些模型专注于预测程序序列,但在多样化的几何问题上的表现受到它们专为特定数据集设计的模型限制。
大型语言模型(LLMs):
- 这些模型在数学推理领域展现出了应用前景,但它们在几何问题求解方面的表现仍然落后于专门的几何模型。
视觉问题解答(Visual Question Answering, VQA) 和 跨模态检索(Cross-modal Retrieval):
- MLLMs在这些领域的应用展示了其在处理跨模态任务时的能力。
数学问题求解:
- 包括定理证明和代数计算在内的数学问题求解是几何问题求解领域的一个重要分支。
这篇论文通过对比分析这些相关研究,提出了GeoX模型,旨在通过统一的形式化视觉-语言预训练来提高几何问题求解的能力,并在多个基准数据集上取得了优异的性能。
Q: 论文如何解决这个问题?
A: 论文通过提出GeoX模型来解决自动几何问题求解(GPS)的挑战,具体解决方案包括以下几个关键步骤:
单模态预训练(Unimodal Pre-training):
- 为了提高对几何图像和符号的理解能力,论文提出了单模态预训练方法。这包括使用几何视觉编码器(Geo-ViT)和几何语言解码器(Geo-LLM-7B)。
几何-语言对齐(Geometry-Language Alignment):
- 通过引入形式化描述而不是自然语言描述来有效地对齐几何图像和语言特征。这涉及到一个新的数据集,其中包含了几何图像的基本元素(点)之间的空间关系。
- 使用生成器和采样器变换器(GS-Former),包括Geo-aware Query Generator(GQG)和Semantics-guided Geometry Sampler(SGS),以生成几何内容感知的查询并移除几何信号不均匀分布中的非信息性表示。
端到端视觉指令调整(End-to-end Visual Instruction Tuning):
- 在几何-语言对齐之后,需要使模型能够基于给定的几何问题和图像生成解决方案。通过端到端的视觉指令调整,优化GeoX以生成目标序列。
形式化预训练的优势:
- 论文从理论上分析了为什么提出的形式化预训练对于GPS任务比非正式预训练方法更有效,并提供了实验结果来支持这一点。
广泛的实验验证:
- 在四个公认的基准数据集(GeoQA、UniGeo、Geometry3K和PGPS9K)上对GeoX进行了广泛的实验,验证了其在解决复杂和多样化的几何问题上的能力。
代码和数据集:
- 论文提供了代码和数据集的链接,以便其他研究人员可以复现和进一步研究GeoX模型。
通过这些方法,GeoX模型能够有效地理解和解决几何问题,生成可验证的解决方案,并在多个基准测试中取得了优于现有模型的性能。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估GeoX模型在几何问题求解(GPS)任务上的能力,具体实验包括:
数据集和指标(Datasets, Metrics, and Implementation Details):
- 实验涉及四个广泛认可的几何基准数据集:GeoQA、UniGeo、Geometry3K和PGPS9K。
- 使用了先前研究中采用的评估指标,包括top-1和top-10准确率,以及Completion、Choice和Top-3等。
与最先进方法的性能比较(Comparisons with State-of-the-Art Methods):
- 将GeoX与多模态大型模型(如LLaVA-v1.5、mPLUG-Owl2、Qwen-VL和GPT-4V)以及专门的几何问题求解模型(如NGS、Geoformer和PGPSNet)进行了比较。
- 在不同的几何数据集上评估了GeoX的性能,并与现有的最佳方法进行了对比。
单模态预训练的有效性(Effectiveness of Uni-modal Pre-training):
- 比较了Geo-ViT与广泛使用的CLIP-ViT,以及不同的语言模型(包括LLAMA-2-7B、LLEMMA-7B和Geo-LLM-7B)在解决几何问题方面的性能。
几何-语言对齐的有效性(Effectiveness of Geometry-Language Alignment):
- 评估了GS-Former模块在几何问题求解中的作用,包括自然语言与形式化语言对齐的效果。
GS-Former模块消融研究(Ablation of Modules in GS-Former):
- 分析了Geo-aware Query Generator(GQG)和Semantics-guided Geometry Sampler(SGS)在GS-Former中的贡献。
案例研究(Case Study):
- 通过具体的几何问题案例,展示了GeoX在预测形式化程序序列方面的能力。
MathVista数据集上的定量评估(Quantitative Evaluation on the GPS Task of MathVista):
- 提供了与MathVista上表现最佳的模型的定量比较,使用了MathVista-GEO数据集。
泛化能力的验证(Generalization Validation):
- 在自然图像中的几何问题求解场景中验证了GeoX的泛化能力,并展示了一些可视化的例子。
这些实验全面评估了GeoX在多样化的几何问题求解任务中的表现,并与现有的多种模型进行了比较,证明了其在该领域的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 论文提出的GeoX模型在自动几何问题求解(GPS)领域取得了显著的进展,但仍有一些可以进一步探索的点:
模型泛化能力:
- 尽管GeoX在特定数据集上表现出色,但其在更广泛的几何问题上,尤其是那些结构和类型与训练数据不同的问题上的泛化能力仍需进一步验证。
更复杂的问题类型:
- 探索GeoX在解决更复杂的几何问题(如高级几何证明问题)上的能力,并研究如何进一步提升模型的性能。
模型解释性:
- 增强GeoX的解释性,使其能够提供更详细的推理过程,这有助于理解模型的决策过程,并在教育等领域应用。
跨模态交互机制:
- 研究和改进模型中视觉和语言模态之间的交互机制,以便更好地理解和推理几何问题。
实时性能优化:
- 探索如何优化GeoX的推理速度和资源消耗,使其适用于需要实时反馈的应用场景。
多模态数据的融合:
- 研究如何更有效地融合视觉信息和语言信息,可能通过改进模型架构或引入新的预训练策略。
鲁棒性和错误分析:
- 对GeoX的鲁棒性进行测试,特别是在面对错误或不完整的输入时。同时,进行错误分析以了解模型在哪些类型的几何问题上容易出错,并探索改进方法。
交互式学习环境:
- 将GeoX集成到交互式学习环境中,使其能够与用户进行更自然的交流,并根据用户的反馈进行学习和调整。
多语言和跨文化研究:
- 探索GeoX在处理不同语言和文化背景下的几何问题上的表现,并研究如何使模型更具国际化。
与其他AI技术的集成:
- 考虑将GeoX与其他AI技术(如强化学习、进化算法等)结合,以解决更广泛的问题或提高求解效率。
这些探索点不仅可以推动自动几何问题求解技术的发展,还可能对教育、设计和工程等领域产生深远影响。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
问题陈述:
- 论文指出多模态大型语言模型(MLLMs)在自动几何问题求解(GPS)上存在挑战,因为这些任务需要理解图表、解释符号和进行复杂推理。
GeoX模型介绍:
- 为了解决上述挑战,论文提出了GeoX,一个专注于几何理解和推理任务的多模态大型模型。
方法论:
- GeoX模型采用了三个阶段的形式化预训练方案:
- 单模态预训练:通过掩码自动编码和自回归语言模型增强几何图像和符号的理解。
- 几何-语言对齐:使用形式化描述来对齐几何图像和语言特征,引入GS-Former来生成几何内容感知的查询并移除非信息性表示。
- 端到端视觉指令调整:进一步调整模型以生成基于输入几何问题和图像的解决方案。
- GeoX模型采用了三个阶段的形式化预训练方案:
实验验证:
- 论文在四个公认的基准数据集(GeoQA、UniGeo、Geometry3K和PGPS9K)上进行了广泛的实验,验证了GeoX在解决复杂和多样化几何问题上的能力,并与现有的一般模型和专家模型进行了比较。
主要贡献:
- 揭示了形式化视觉-语言预训练在增强几何问题求解能力方面的潜力。
- 提出了GS-Former,有效地弥合了几何图表和形式化语言之间的模态差距。
- GeoX在多个基准测试中取得了优异的性能,证明了其作为解决几何问题的强基线模型的地位,并激励了未来的研究。
结论与展望:
- 论文总结了GeoX模型的贡献,并讨论了其在自动几何问题求解任务中的潜力和未来的研究方向。
总体而言,这篇论文提出了一个创新的多模态大型模型GeoX,通过统一的形式化视觉-语言预训练,有效地解决了自动几何问题求解中的挑战,并在多个基准数据集上取得了领先的性能。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图



UnMA-CapSumT: Unified and Multi-Head Attention-driven Caption Summarization Transformer
Authors:Dhruv Sharma, Chhavi Dhiman, Dinesh Kumar
Image captioning is the generation of natural language descriptions of images which have increased immense popularity in the recent past. With this different deep-learning techniques are devised for the development of factual and stylized image captioning models. Previous models focused more on the generation of factual and stylized captions separately providing more than one caption for a single image. The descriptions generated from these suffer from out-of-vocabulary and repetition issues. To the best of our knowledge, no such work exists that provided a description that integrates different captioning methods to describe the contents of an image with factual and stylized (romantic and humorous) elements. To overcome these limitations, this paper presents a novel Unified Attention and Multi-Head Attention-driven Caption Summarization Transformer (UnMA-CapSumT) based Captioning Framework. It utilizes both factual captions and stylized captions generated by the Modified Adaptive Attention-based factual image captioning model (MAA-FIC) and Style Factored Bi-LSTM with attention (SF-Bi-ALSTM) driven stylized image captioning model respectively. SF-Bi-ALSTM-based stylized IC model generates two prominent styles of expression- {romance, and humor}. The proposed summarizer UnMHA-ST combines both factual and stylized descriptions of an input image to generate styled rich coherent summarized captions. The proposed UnMHA-ST transformer learns and summarizes different linguistic styles efficiently by incorporating proposed word embedding fastText with Attention Word Embedding (fTA-WE) and pointer-generator network with coverage mechanism concept to solve the out-of-vocabulary issues and repetition problem. Extensive experiments are conducted on Flickr8K and a subset of FlickrStyle10K with supporting ablation studies to prove the efficiency and efficacy of the proposed framework.
图片描述生成是生成对图片的自然语言描述,这在最近过去的时间中变得越来越流行。为了开发事实和风格化的图片描述生成模型,已经研究出了不同的深度学习方法。之前的模型更侧重于事实和风格化描述的分开的生成,为单张图片生成多个描述。从这些描述中产生的文本存在词汇表外问题和重复问题。据我们所知,还没有工作能提供一种融合不同描述方法的描述,来描绘图片的内容,并包含事实和风格化(浪漫和幽默)元素。为了克服这些限制,本文提出了一种基于统一注意力机制和多头注意力驱动的标题摘要转换器(UnMA-CapSumT)的新型标题框架。它利用由基于改进自适应注意力的事实图像标题生成模型(MAA-FIC)生成的实事标题和由带有注意力的风格化双向长短时记忆网络(SF-Bi-ALSTM)驱动的带有风格化的图像标题生成模型分别生成的风格化标题。基于SF-Bi-ALSTM的风格化IC模型生成两种突出的表达方式:浪漫和幽默。提出的摘要器UnMHA-ST结合了输入图片的实事和风格化描述,以生成风格丰富、连贯的摘要标题。所提出的UnMHA-ST转换器通过结合提出的带有注意力机制的字嵌入(fTA-WE)和带有覆盖机制的指针生成器网络来解决词汇表外问题和重复问题,从而有效地总结和概括不同的语言风格。在Flickr8K和FlickrStyle10K子集上进行了大量实验,并通过支持消融研究证明了所提出框架的效率和有效性。
论文及项目相关链接
Summary
图像描述生成是生成图像的自然语言描述,近年来受到广泛关注。新的深度学习技术被用于开发事实和风格化的图像描述生成模型。先前模型往往分别生成事实和风格化的描述,导致描述中存在词汇表和重复问题。本研究提出了一种结合不同描述方法的图像描述生成框架,融合事实与风格(浪漫和幽默)元素。采用基于注意力机制的多头注意力驱动的摘要转换器,克服上述问题。该框架结合了基于注意力机制的事实图像描述模型和风格化图像描述模型,生成包含风格的连贯摘要。通过词嵌入和指针生成器网络解决词汇表和重复问题。实验证明该框架高效。
Key Takeaways
- 图像描述生成是生成图像的自然语言描述,近年来受到广泛关注。
- 先前模型存在生成描述中的词汇表和重复问题。
- 本研究提出了一种结合事实与风格(浪漫和幽默)元素的图像描述生成框架。
- 采用基于注意力机制的多头注意力驱动的摘要转换器,以克服上述问题。
- 该框架结合了基于注意力机制的事实图像描述模型和风格化图像描述模型。
- 通过词嵌入和指针生成器网络解决词汇表和重复问题。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是图像描述生成中的单一风格(事实性或风格化)描述的局限性,并提出了一个统一的、多头注意力驱动的标题摘要转换器(UnMA-CapSumT)框架,以生成融合事实性和风格化(浪漫和幽默)元素的综合性图像描述。具体来说,论文试图解决以下几个问题:
单一风格描述的局限性:以往的模型通常只关注生成事实性描述或风格化描述,导致为单个图像生成多个标题,这些标题可能存在词汇表外(OOV)和重复问题。
综合性描述的缺失:据作者所知,没有工作能够提供一个描述,该描述整合了不同的标题生成方法,以用事实性和风格化元素描述图像内容。
风格化描述的挑战:风格化描述不仅需要描述图像内容,还需要分析标题中的内在风格元素,这通常需要成对的图像-情感标题数据和词级监督,使得风格化标题生成成本较高。
摘要生成中的问题:自动摘要生成中存在的问题,如词汇表外单词和重复问题,这些问题会导致生成的摘要出现不连贯和不相关的内容。
为了克服这些限制,论文提出了一个新颖的框架,该框架结合了事实性标题和风格化标题生成模型,并使用一个摘要转换器来生成融合了事实性和风格化描述的丰富、连贯的摘要标题。此外,该框架还提出了一种新的词嵌入方法(fTA-WE)和指针-生成网络与覆盖机制的概念,以解决OOV和重复问题。
Q: 有哪些相关研究?
A: 论文中提到了以下与图像描述生成、风格化图像描述和文本摘要相关的研究工作:
图像描述生成 (Factual Image Captioning)
- Anderson et al. (2018): 提出了结合自底向上和自顶向下注意力机制的图像描述生成模型。
- Li et al. (2019): 提出了一种基于纠缠变换器(Entangled Transformer)的图像描述生成方法。
- Mao et al. (2015): 提出了使用多模态循环神经网络(m-RNN)进行深度描述生成的方法。
- Vinyals et al. (2015): 提出了“Show and Tell”模型,一个基于神经网络的图像描述生成器。
- Jia et al. (2015): 提出了引导长短期记忆模型(g-LSTM)用于图像描述生成。
- Donahue et al. (2015): 提出了长短期循环卷积网络(Long-Term Recurrent Convolutional Networks)用于视觉识别和描述。
风格化图像描述 (Stylized Image Captioning)
- Gan et al. (2017): 提出了StyleNet模型,用于生成具有特定风格的图像描述。
- Li et al. (2021): 通过平行数据增强,实现了风格化图像描述的生成。
- Chen et al. (2018): 提出了一种自适应学习和注意力机制的风格化图像描述生成方法。
- Guo et al. (2019): 提出了MSCap模型,用于多风格图像描述的生成。
文本摘要 (Text Summarization)
- Nallapati et al. (2017): 提出了SummaRuNNer模型,一个基于循环神经网络的文档摘要提取模型。
- Rush et al. (2015): 提出了一个基于注意力机制的抽象句子摘要模型。
- See et al. (2017): 提出了指针-生成网络(Pointer-Generator Networks),用于解决文本摘要中的OOV问题。
- Hsu et al. (2018): 提出了一种用于抽取式和抽象式摘要的统一模型,通过不一致性损失函数来提高摘要质量。
- Deaton et al. (2019): 提出了基于变换器和指针-生成网络的抽象摘要方法。
这些相关工作为本文提出的UnMA-CapSumT框架提供了理论基础和技术背景,特别是在处理多模态信息、生成具有特定风格的内容以及解决OOV和重复问题方面。
Q: 论文如何解决这个问题?
A: 论文提出了一个名为UnMA-CapSumT的框架,通过以下步骤解决上述问题:
1. 整合事实性和风格化图像描述生成模型
MAA-FIC模型(Modified Adaptive Attention-based Factual Image Captioning Model):用于生成图像的事实性描述。该模型结合了Faster R-CNN进行对象检测和Inception-V3进行特征提取,然后使用修改后的自适应注意力机制(MAA)和Bi-LSTM网络生成描述。
SF-Bi-ALSTM模型(Style Factored Bi-LSTM based Stylized Image Captioning Model):用于生成风格化的描述(浪漫和幽默)。该模型基于编码器-解码器架构,编码器使用与MAA-FIC相同的策略,而解码器则利用SF-Bi-ALSTM模块生成风格化描述。
2. 使用UnMA-CapSumT生成综合摘要
- UnMA-CapSumT(Unified and Multi-Head Attention-driven Caption Summarization Transformer):结合了事实性和风格化描述,生成包含事实性、浪漫和幽默元素的单一摘要。该模型利用统一注意力(Un-A)和多头注意力机制来捕捉多模态信息的内部和跨模态交互,并生成相关的注意表示。
3. 应用指针-生成网络和覆盖机制
指针-生成网络(Pointer-Generator Network):用于解决OOV问题,允许模型直接从源文本中复制单词或从词汇表中生成新词。
覆盖机制(Coverage Mechanism):用于减少重复问题,通过跟踪之前步骤中已经关注过的单词,引导注意力机制关注非重复单词。
4. 提出fTA-WE词嵌入
- fTA-WE(fastText with Attention Word Embedding):提出了一种新的词嵌入方法,结合了fastText和注意力机制,以提高模型对罕见和未见词汇的处理能力,并增强模型性能。
5. 实验验证
- 在Flickr8K和FlickrStyle10K数据集上进行广泛的实验,验证所提出框架的有效性。实验结果显示,UnMA-CapSumT框架能够生成语法正确、视觉上吸引人的事实性、浪漫、幽默以及综合摘要。
通过这些步骤,论文成功地提出了一个能够生成包含多种元素的综合图像描述的框架,并解决了OOV和重复问题,提高了图像描述的质量和多样性。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出UnMA-CapSumT框架的有效性:
1. 实验设置
- 数据集:使用了Flickr8K和FlickrStyle10K数据集进行实验。
- Flickr8K:包含约8K张图片,每张图片配有五条描述,用于生成事实性描述。
- FlickrStyle10K:包含7K条注释,用于生成风格化的描述(浪漫和幽默)。
- 评估指标:
- 对于事实性图像描述模型(MAA-FIC),使用BLEU@N和METEOR分数进行评估。
- 对于风格化图像描述模型(SF-Bi-ALSTM),使用BLEU@N、METEOR、风格转移准确性和困惑度进行评估。
- 对于摘要生成模块(UnMHA-ST Text Summarization Transformer),使用ROUGE-1、ROUGE-2和ROUGE-L分数进行评估。
2. 实验结果
- MAA-FIC模型:在Flickr8K数据集上与其他最新技术进行比较,展示了BLEU@N和METEOR分数。
- SF-Bi-ALSTM模型:在FlickrStyle10K数据集上与其他最新技术进行比较,展示了BLEU-1、BLEU-3、METEOR分数以及风格准确性和困惑度。
- UnMHA-ST Text Summarization Transformer:展示了不同配置下的ROUGE分数,包括使用不同词嵌入(Doc2Vec、GloVe、fastText)的基线模型,以及加入指针-生成网络和覆盖机制的模型。
3. 消融研究
- 对于摘要生成模块,进行了消融研究,比较了不同模型配置的性能,包括仅使用基线变换器模型、加入fTA-WE词嵌入、加入指针-生成网络,以及加入指针-生成网络和覆盖机制的模型。
4. 定性分析
- 提供了定性结果,展示了所提出模型生成的事实性、浪漫、幽默描述以及综合摘要的质量。展示了模型如何结合不同的描述元素生成最终摘要,并与人类评估进行比较。
这些实验全面地评估了所提出框架在不同方面的表现,包括其在生成事实性描述、风格化描述和摘要方面的能力,以及在处理OOV和重复问题上的有效性。通过这些实验,论文证明了所提出方法的有效性和优越性。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一个创新的框架来生成包含事实性和风格化元素的图像描述,但仍有一些领域可以进一步探索和改进:
1. 多模态学习与注意力机制
- 探索不同的注意力机制:研究其他类型的注意力机制,如自注意力或跨模态注意力,可能进一步提高模型对图像区域和文本描述之间关联的理解。
- 多模态融合技术:研究更先进的多模态融合技术,以改善图像特征和文本特征的结合方式。
2. 风格化描述的多样性和控制
- 风格化描述的多样性:研究如何控制和增加风格化描述的多样性,例如,通过引入更多的风格类型(如悲伤、兴奋等)。
- 风格强度的控制:研究如何允许用户控制生成描述中的风格强度,使模型更灵活。
3. 模型的可解释性和可视化
- 注意力可视化:通过可视化注意力权重,提高模型的可解释性,让用户理解模型为何生成特定的描述。
- 错误分析:进行错误分析,以识别模型在哪些类型的图像或描述上表现不佳,并探索改进方法。
4. 跨领域和跨语言的应用
- 跨领域适应性:研究模型在不同领域(如医疗图像、卫星图像)的适应性和迁移能力。
- 跨语言描述生成:探索模型生成多语言描述的能力,以及如何处理不同语言之间的风格化差异。
5. 模型性能和效率
- 大规模数据集训练:在更大的数据集上训练模型,以测试其泛化能力,并探索数据增强技术以提高模型鲁棒性。
- 计算效率优化:研究如何优化模型结构和训练过程,以减少计算资源消耗,提高模型训练和推理的效率。
6. 交互式应用和用户研究
- 用户研究:进行用户研究,以评估不同用户群体对风格化描述的接受度和偏好。
- 交互式系统:开发交互式系统,允许用户与模型进行更深层次的交互,例如,实时调整生成描述的风格。
这些探索点不仅可以推动图像描述生成技术的发展,还可能为计算机视觉、自然语言处理和其他人工智能应用带来新的视角和方法。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一个名为UnMA-CapSumT的新颖框架,旨在生成融合事实性和风格化元素(如浪漫和幽默)的图像描述。以下是论文的主要内容总结:
1. 问题陈述
- 现有图像描述模型通常只关注生成事实性或风格化描述,导致单一风格的描述和潜在的词汇表外(OOV)及重复问题。
2. UnMA-CapSumT框架
- MAA-FIC模型:结合Faster R-CNN和Inception-V3提取特征,使用修改自适应注意力机制和Bi-LSTM生成事实性描述。
- SF-Bi-ALSTM模型:基于编码器-解码器架构,利用SF-Bi-ALSTM模块生成风格化描述。
- UnMA-CapSumT:结合事实性和风格化描述,通过统一和多头注意力机制生成综合摘要,使用指针-生成网络和覆盖机制解决OOV和重复问题。
3. fTA-WE词嵌入
- 提出了一种新的词嵌入方法,结合fastText和注意力机制,提高对罕见和未见词汇的处理能力。
4. 实验验证
- 在Flickr8K和FlickrStyle10K数据集上进行实验,使用BLEU@N、METEOR、ROUGE-1、ROUGE-2和ROUGE-L等指标评估模型性能。
- 实验结果显示,所提出的框架在生成事实性、风格化和综合摘要方面均优于现有技术。
5. 贡献和结论
- 提出了一个统一的框架来生成融合多种元素的图像描述,提高了描述的质量和多样性。
- 通过实验验证了框架的有效性,并指出了未来可能的研究方向。
总体而言,这篇论文通过结合最新的深度学习技术和注意力机制,为图像描述生成领域提供了一个新的视角和解决方案。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图




SP$^2$T: Sparse Proxy Attention for Dual-stream Point Transformer
Authors:Jiaxu Wan, Hong Zhang, Ziqi He, Qishu Wang, Ding Yuan, Yifan Yang
In 3D understanding, point transformers have yielded significant advances in broadening the receptive field. However, further enhancement of the receptive field is hindered by the constraints of grouping attention. The proxy-based model, as a hot topic in image and language feature extraction, uses global or local proxies to expand the model’s receptive field. But global proxy-based methods fail to precisely determine proxy positions and are not suited for tasks like segmentation and detection in the point cloud, and exist local proxy-based methods for image face difficulties in global-local balance, proxy sampling in various point clouds, and parallel cross-attention computation for sparse association. In this paper, we present SP$^2$T, a local proxy-based dual stream point transformer, which promotes global receptive field while maintaining a balance between local and global information. To tackle robust 3D proxy sampling, we propose a spatial-wise proxy sampling with vertex-based point proxy associations, ensuring robust point-cloud sampling in many scales of point cloud. To resolve economical association computation, we introduce sparse proxy attention combined with table-based relative bias, which enables low-cost and precise interactions between proxy and point features. Comprehensive experiments across multiple datasets reveal that our model achieves SOTA performance in downstream tasks. The code has been released in https://github.com/TerenceWallel/Sparse-Proxy-Point-Transformer .
在3D理解领域,点变压器在扩大感受野方面取得了重大进展。然而,分组注意力的限制阻碍了感受野的进一步扩展。基于代理的模型作为图像和语言特征提取中的热门话题,使用全局或局部代理来扩展模型的感受野。然而,基于全局代理的方法无法精确确定代理位置,不适用于点云中的分割和检测等任务。现有的基于局部代理的方法在全局-局部平衡、在不同点云中的代理采样以及稀疏关联的并行交叉注意力计算方面遇到困难。本文提出了SP$^2$T,一种基于局部代理的双流点变压器,它在保持局部和全局信息平衡的同时,促进了全局感受野的提升。为了解决鲁棒的3D代理采样问题,我们提出了基于顶点的点代理关联的空间代理采样方法,确保在多尺度点云中的鲁棒点云采样。为了解决经济高效的关联计算问题,我们引入了稀疏代理注意力结合表式相对偏差,使代理和点特征之间的交互变得低成本且精确。在多个数据集上的综合实验表明,我们的模型在下游任务中达到了SOTA性能。代码已发布在https://github.com/TerenceWallel/Sparse-Proxy-Point-Transformer。
论文及项目相关链接
PDF 13 pages, 14 figures, 14 tables
Summary
点云理解中,点云变换器通过扩大感受野取得了显著进展,但受限于分组注意力。基于代理的模型使用全局或局部代理扩展模型感受野,但全局代理方法无法精确确定代理位置,不适用于点云分割和检测任务。局部代理方法则面临全局与局部平衡、不同点云的代理采样以及稀疏关联的并行交叉注意力计算等问题。本文提出基于局部代理的双流点云变换器SP$^2$T,在保持全局与局部信息平衡的同时提升全局感受野。通过空间代理采样和基于顶点的点代理关联解决稳健的3D代理采样问题,引入稀疏代理注意力和表式相对偏差解决经济关联计算问题。实验证明,该模型在下游任务中达到领先水平。
Key Takeaways
- 点云变换器在扩大感受野方面取得显著进展,但仍受分组注意力的限制。
- 基于代理的模型是图像和语言特征提取的热门话题,但全局和局部代理方法各有挑战。
- SP$^2$T模型结合局部代理和点云变换器,旨在平衡全局和局部信息。
- 提出空间代理采样方法,以解决点云多尺度下的稳健采样问题。
- 引入稀疏代理注意力和表式相对偏差,实现低成本且精确的点与代理特征交互。
- 实验证明SP$^2$T模型在多个数据集上的下游任务中表现优异。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的主要问题是在3D点云理解领域中,如何有效地扩大点变换器(point transformers)的感受野(receptive field),同时保持对局部和全局信息的平衡。具体来说,论文中提到了以下几个关键问题:
感受野的扩展受限:尽管点变换器在扩大感受野方面取得了一定的进展,但由于组注意力(group attention)的限制,进一步扩大感受野可能会适得其反。
全局代理方法的局限性:全局代理方法虽然能够通过代理交换全局信息来扩大模型的感受野,但这些方法不能精确确定代理的位置,不适合需要关注局部细节的任务,如分割和检测。
局部代理方法的挑战:局部代理方法通过代理采样方法确定代理的位置,并应用关联来描述数据和代理之间的关系,虽然能够扩大感受野,但在点云的全局-局部平衡、不同点云的代理采样以及稀疏关联的并行交叉注意力计算方面存在挑战。
全局与局部信息的平衡:在分割或检测等任务中,全局和局部信息都非常重要,需要在模型中平衡这两种信息的提取。
为了解决这些问题,论文提出了SP2T(Sparse Proxy Attention for Dual-stream Point Transformer),这是一个基于局部代理的双流点变换器,旨在在保持全局和局部信息平衡的同时,促进全局感受野的扩展。通过提出空间-wise代理采样方法和基于顶点的点-代理关联方法,以及引入稀疏代理注意力(Sparse Proxy Attention, SPA)和基于表的相对偏差(Table-Based Relative Bias),SP2T能够有效地处理点云数据中的代理采样和关联计算,并在点和代理之间实现低成本和精确的交互。
Q: 有哪些相关研究?
A: 根据论文内容,相关研究可以分为以下几个主要领域:
3D点云理解:
- 2D投影方法:利用2D背景模型从点云中提取特征。
- 体素方法:将点云转换为结构化的体素网格,加速卷积或注意力计算。
- 基于点云的方法:直接使用池化或变换器架构处理点云数据。
代理(Proxy)基础方法:
- 全局代理方法:使用代理来交换全局信息,扩大模型的感受野。
- 局部代理方法:利用代理采样方法确定代理的位置,并应用关联来描述数据和代理之间的关系。
点变换器(Point Transformer):
- 利用组注意力来提取特征,最近的研究进展包括扩大感受野的方法。
注意力机制:
- 包括传统的注意力机制和稀疏代理注意力(Sparse Proxy Attention, SPA),后者在这篇论文中被提出以加速代理和点之间的注意力计算。
双流网络架构:
- 受到MobileFormer的启发,论文提出了一个双流变换器架构,以协调局部和全局信息的提取。
稀疏矩阵运算和Map-Reduce并行计算:
- 为了提高计算效率,论文中提到了使用Map-Reduce算法来加速稀疏代理注意力的计算。
表基相对偏差(Table-Based Relative Bias):
- 受到Swin Transformer的启发,论文引入了表基相对偏差来提高网络捕捉代理和点云之间联系的能力。
点云分割和检测任务:
- 论文中提到了点云分割和检测任务,这些任务需要同时考虑全局和局部信息。
这些相关研究构成了论文提出的SP2T模型的理论基础和技术背景。论文通过结合这些领域的最新进展,提出了一个新的模型来解决3D点云理解中的感受野扩展和信息平衡问题。
Q: 论文如何解决这个问题?
A: 论文通过提出SP2T(Sparse Proxy Attention for Dual-stream Point Transformer)模型来解决扩大点变换器感受野和保持局部与全局信息平衡的问题。具体解决方案包括以下几个关键点:
双流点变换器架构:
- 论文提出了一个基于局部代理的双流变换器架构,该架构能够同时处理点云和代理,从而平衡全局和局部信息的提取。
空间-wise代理采样方法:
- 为了解决在不同规模的点云中进行鲁棒的3D代理采样问题,论文提出了一种基于空间的代理采样方法,该方法通过二分查找确定最优的代理分布。
基于顶点的点-代理关联方法:
- 论文提出了一种基于顶点的点-代理关联方法,该方法通过空间代理采样快速建立点-代理关联,通过检查坐标关系来加速点和代理之间的关联。
稀疏代理注意力(Sparse Proxy Attention, SPA):
- 为了解决稀疏连接的代理和点之间的经济有效的关联计算问题,论文引入了稀疏代理注意力机制。SPA通过使用关联列表代替基于矩阵的注意力方法,并利用Map-Reduce进行并行加速。
基于表的相对偏差(Table-Based Relative Bias, TRB):
- 为了增强SPA的空间感知能力,论文引入了基于表的相对偏差。TRB通过采样相对偏差表来获得与相对距离相关的偏差,从而改善注意力机制。
局部和全局融合:
- 论文中的SP2T模型包括局部融合和全局融合模块,这些模块使用自注意力机制和基于表的相对偏差来促进点云数据的局部融合和代理之间的全局信息交换。
通过这些方法,SP2T模型能够有效地扩大点变换器的感受野,同时保持对局部和全局信息的平衡,从而在多个数据集上实现了下游任务的最新性能。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证SP2T模型的性能和有效性:
下游任务结果比较:
- 在室内语义分割任务中,论文在ScanNet v2和ScanNet200基准测试中与其他方法进行了比较,展示了验证和测试结果。
- 在S3DIS数据集上进行了6折交叉验证,比较了不同区域的性能。
- 在室内实例分割任务中,论文在ScanNet v2和ScanNet200基准测试中展示了验证结果,并与其他SOTA模型进行了比较。
消融研究:
- 论文在ScanNet验证集上进行了消融研究,探索了代理数量和关联数量对SP2T性能的影响。
- 研究了不同的代理采样方法(包括FPS基方法、固定数量方法、固定大小方法和空间-wise方法)以及表基相对偏差(TRB)对模型性能的影响。
- 论文还探讨了TRB参数共享的影响,以及考虑空代理对模型性能的影响。
- 对模型效率进行了消融研究,包括准确性和延迟,并与PTv3、PTv2和MinkUnet等模型进行了比较。
讨论和可视化:
- 论文讨论了FPS基采样方法的局限性,并可视化了SPA的注意力图。
- 论文提供了关于SPA和网络参数进一步改进的可能性的讨论。
效率分析:
- 论文分析了SP2T、稀疏代理注意力和全局融合的延迟,并以树状图的形式进行了可视化。
模型性能比较:
- 论文比较了SP2T与其他SOTA模型(如MinkUnet、PTv2和PTv3)在室内(ScanNet)和室外(nuScenes)数据集上的性能,包括准确性和延迟。
这些实验全面评估了SP2T模型在不同任务和条件下的性能,包括其在室内和室外场景下的应用,以及与现有技术的比较。通过这些实验,论文展示了SP2T在多个下游任务中实现SOTA性能的能力,以及其在效率和准确性方面的平衡。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和结论,以下是一些可以进一步探索的点:
优化SPA和网络参数:
- 论文提到与PTV3相比,SP2T在使用更多的时间和内存。因此,进一步优化SPA机制和网络参数,以减少计算资源消耗,是一个重要的研究方向。
改进代理采样方法:
- 论文提出了空间-wise代理采样方法,但仍有改进空间。研究更高效、更准确的代理采样策略,以适应不同密度和规模的点云数据。
增强模型的泛化能力:
- 探索如何提高模型对不同类型和复杂性场景的泛化能力,特别是在户外场景和大规模数据集上。
探索更多注意力机制:
- 研究其他类型的注意力机制,如自适应注意力或动态权重注意力,以进一步提升模型性能。
多模态数据融合:
- 考虑将点云数据与其他传感器数据(如图像、雷达)结合,以实现更全面的环境理解。
模型压缩和加速:
- 研究模型压缩技术,以减少模型大小并加速推理过程,使其更适合在资源受限的设备上部署。
更深入的消融研究:
- 对模型的不同组件进行更细致的消融研究,以更准确地理解各部分对性能的具体影响。
改进TRB和相对位置编码:
- 进一步研究和改进基于表的相对偏差(TRB)机制,优化相对位置编码策略,以提高模型对空间关系的敏感性。
跨领域应用:
- 探索SP2T模型在其他领域的应用,如机器人导航、增强现实等,以验证其跨领域的有效性。
更复杂的场景和数据集:
- 在更复杂和多样化的场景和数据集上测试模型,如包含更多类别、更复杂结构和遮挡的城市场景。
模型解释性:
- 提高模型的可解释性,通过可视化和分析模型的注意力图来理解模型的决策过程。
长期跟踪和预测:
- 将模型应用于长期跟踪和预测任务,以评估其在动态环境中的性能。
这些方向不仅可以推动点云理解和处理技术的发展,还可能为相关领域的研究提供新的视角和工具。
Q: 总结一下论文的主要内容
A: 论文提出了SP2T(Sparse Proxy Attention for Dual-stream Point Transformer),这是一个针对3D点云理解的局部代理双流变换器模型,旨在扩大感受野并保持局部与全局信息的平衡。以下是论文的主要内容总结:
问题陈述:
- 点变换器在3D理解中受限于组注意力,难以进一步扩大感受野。
- 全局代理方法缺乏精确的代理位置确定,不适合局部细节任务。
- 局部代理方法在点云的采样和关联上存在挑战。
主要贡献:
- 提出了SP2T,一个局部代理双流点变换器,促进全局感受野的同时保持局部和全局信息的平衡。
- 引入了空间-wise代理采样方法和基于顶点的点-代理关联方法,确保点云中代理的高效可靠采样和关联计算。
- 提出了稀疏代理注意力(SPA)和基于表的相对偏差(TRB),以低成本和精确的方式实现点和代理之间的交互。
- 在多个数据集上进行了广泛的实验,证明了模型在下游任务中的SOTA性能。
方法论:
- 双流架构:SP2T采用编码器-解码器网络,同时处理点云和代理,以平衡全局和局部信息。
- 代理采样与关联:提出了空间-wise代理采样方法和基于顶点的点-代理关联方法。
- 稀疏代理注意力(SPA):使用关联列表和Map-Reduce并行加速,提高了代理和点之间交互的效率。
- 基于表的相对偏差(TRB):引入相对偏差以增强网络对代理和点云之间联系的捕捉能力。
实验:
- 在室内语义分割、室内实例分割和室外语义分割等任务中评估了SP2T的性能。
- 进行了消融研究,探讨了代理数量、采样方法、TRB的影响。
- 分析了模型效率,并与其他SOTA模型进行了比较。
结论与展望:
- SP2T在多个下游任务中实现了SOTA性能,但仍有改进空间,特别是在SPA和网络参数的优化上。
- 提出了未来可能的研究方向,包括模型压缩、多模态数据融合等。
总体而言,论文提出了一个创新的双流变换器架构,通过局部代理和稀疏注意力机制,有效地解决了3D点云理解中的感受野扩展和信息平衡问题。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图







Biased or Flawed? Mitigating Stereotypes in Generative Language Models by Addressing Task-Specific Flaws
Authors:Akshita Jha, Sanchit Kabra, Chandan K. Reddy
Recent studies have shown that generative language models often reflect and amplify societal biases in their outputs. However, these studies frequently conflate observed biases with other task-specific shortcomings, such as comprehension failure. For example, when a model misinterprets a text and produces a response that reinforces a stereotype, it becomes difficult to determine whether the issue arises from inherent bias or from a misunderstanding of the given content. In this paper, we conduct a multi-faceted evaluation that distinctly disentangles bias from flaws within the reading comprehension task. We propose a targeted stereotype mitigation framework that implicitly mitigates observed stereotypes in generative models through instruction-tuning on general-purpose datasets. We reduce stereotypical outputs by over 60% across multiple dimensions – including nationality, age, gender, disability, and physical appearance – by addressing comprehension-based failures, and without relying on explicit debiasing techniques. We evaluate several state-of-the-art generative models to demonstrate the effectiveness of our approach while maintaining the overall utility. Our findings highlight the need to critically disentangle the concept of `bias’ from other types of errors to build more targeted and effective mitigation strategies. CONTENT WARNING: Some examples contain offensive stereotypes.
最近的研究表明,生成式语言模型在其输出中常常反映并放大社会偏见。然而,这些研究经常将观察到的偏见与其他特定任务的缺陷混淆,如理解失败。例如,当模型误解文本并产生强化刻板印象的回应时,就很难确定问题是由内在偏见还是误解给定内容引起的。在本文中,我们进行了多方面的评估,明确区分了阅读理解任务中的偏见和缺陷。我们提出了一个有针对性的刻板印象缓解框架,该框架通过通用数据集的指令微调,隐式地缓解了生成模型中的观察到的刻板印象。我们通过解决基于理解的失败,减少了跨多个维度的刻板输出,包括国籍、年龄、性别、残疾和外表等,降低幅度超过60%,并且不依赖明确的去偏见技术。我们评估了几种最先进的生成模型,以证明我们的方法的有效性,同时保持总体实用性。我们的研究结果表明,需要将“偏见”的概念与其他类型的错误严格区分开来,以建立更有针对性和有效的缓解策略。内容警告:部分例子包含具有攻击性的刻板印象。
论文及项目相关链接
Summary
大模型在生成内容时会反映并放大社会偏见的问题,但现有研究混淆了观察到的偏见和其他任务特定的缺陷(如理解失败)。该文提出一种多元评价策略,明确区分偏见与阅读理解任务的缺陷,并提出有针对性的刻板印象缓解框架。该框架通过在通用数据集上进行指令微调来隐式减轻模型中的刻板印象问题。针对多种偏见因素,在维持模型总体效用的同时减少了刻板输出超过百分之六十。内容警告:某些例子含有冒犯性的刻板印象。本文强调,将偏见概念与其他类型的错误进行清晰区分对于构建更有针对性的有效缓解策略至关重要。
Key Takeaways
- 研究发现大模型在生成内容时会反映社会偏见问题。
- 研究混淆了观察到的偏见与其他任务特定缺陷(如理解失败)。
- 提出多元评价策略以区分偏见与阅读理解任务的缺陷。
- 提出了一种针对性的刻板印象缓解框架,通过指令微调在通用数据集上隐式减轻模型中的偏见问题。
- 该框架减少了超过百分之六十的刻板输出,涉及多种偏见因素。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是生成性语言模型在其输出中反映和放大社会偏见的问题,特别是在阅读理解任务中。研究者们发现,尽管已有研究有效地揭示了生成性模型中反映的社会偏见,但这些研究常常未能将偏见与模型的其他任务特定缺陷(例如理解失败)区分开来。例如,当模型误解文本并产生加强刻板印象的回应时,很难确定问题是由于固有偏见还是对给定内容的误解造成的。这种混淆导致了评估上的缺陷和可能误导的缓解努力。
论文的主要贡献在于:
明确区分了生成性模型中观察到的偏见和其任务特定限制,特别是在阅读理解任务中。
提出了一个针对性的刻板印象缓解框架,通过在通用数据集上进行指令调整(instruction-tuning)来隐式地减少生成性模型中观察到的刻板印象。这种方法通过解决理解失败来减少刻板印象输出,而不依赖于显式的去偏见技术。
对多个最先进的生成性模型进行了广泛的实证分析,证明了所提出方法在减少多个维度(包括国籍、年龄、性别、残疾和外貌)上的刻板印象方面的有效性和普适性。该方法在保持生成性模型整体效用的同时,将不充分信息情境中的观察偏见减少了60%以上。
进行了全面的消融研究,探讨了上下文特定指令与更通用指令在缓解刻板印象偏见和解决任务相关缺陷中的重要性。
Q: 有哪些相关研究?
A: 相关研究包括以下几个方面:
评估基准测试:
- StereoSet 和 CrowS-Pairs:通过评估模型对响应延续的偏好来衡量刻板印象。
- SeeGULL:揭示了生成性模型在自然语言推理任务中的区域性刻板印象。
- BBQ:评估阅读理解任务中的刻板印象。
- SQuAD-v2 和 TriviaQA:评估模型的实用性。
缓解技术:
- Webster 等人(2020):测量并减少预训练语言模型中的性别相关性。
- de Vassimon Manela 等人(2021):使用增强的性别平衡数据集来减少基于性别的刻板印象。
- Kaneko 和 Bollegala(2021):训练一个编码器来生成输入词嵌入的去偏见版本,同时保留语义。
- Oba 等人(2024):在推理时使用手动设计的模板来抑制生成性模型中的性别偏见。
- Guo 等人(2022):使用束搜索自动寻找提示,以减少模型输出中关于种族和性别的偏见。
- Schick 等人(2021):提出自我去偏见方法,以减少生成偏见内容的概率。
- Thakur 等人(2023):在少量示例上微调预训练模型,显著减少性别偏见。
- Ganguli 等人(2023)和 Si 等人(2022):使用基于指令的提示进行去偏见。
指令调整:
- 指令性提示对于在特定任务上微调模型非常有效。
- 通过指令调整提高模型在处理歧义和不歧义上下文时的推理能力。
这些相关研究为本文提出的区分偏见和缺陷的方法提供了理论基础和技术支持。通过这些研究,本文进一步探索了如何通过改进模型的理解能力来减少偏见,而不是依赖于针对特定身份群体的信息。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决生成性语言模型中偏见和任务特定缺陷的问题:
区分偏见和缺陷:
- 论文首先明确区分了生成性语言模型中的“偏见”和“缺陷”。偏见被定义为模型在涉及不同身份群体的问题时反映的刻板印象,而缺陷指的是模型在与身份群体无关的上下文中提供正确答案的一般(无)能力。
评估和分析:
- 使用BBQ和SQuAD-v2数据集对多个最先进的生成性模型进行评估,以确定模型在歧义和不歧义上下文中的表现。通过这种评估,研究者们能够区分模型的输出是由于固有偏见还是由于理解失败造成的。
提出缓解框架:
- 提出了一个针对性的刻板印象缓解框架,该框架通过在通用数据集上进行指令调整(instruction-tuning)来隐式地减少生成性模型中观察到的刻板印象。这种方法通过解决理解失败来减少刻板印象输出,而不依赖于显式的去偏见技术。
指令调整(Instruction-Tuning):
- 通过指令调整方法,研究者们改进了模型在处理信息不充分的上下文时的能力,使其能够正确地识别并拒绝回答那些无法从上下文中提取正确答案的问题。这通过创建包含不同指令的数据集来实现,这些指令旨在鼓励模型在信息不足时避免回答。
实证分析:
- 对几种最先进的生成性模型进行了广泛的实证分析,证明了所提出方法在减少多个维度(包括国籍、年龄、性别、残疾和外貌)上的刻板印象方面的有效性。这种方法在保持模型整体效用的同时,将不充分信息情境中的观察偏见减少了60%以上。
消融研究:
- 进行消融研究,以调查上下文特定指令与更通用指令在缓解刻板印象偏见和解决任务相关缺陷中的重要性。
通过这些步骤,论文不仅提出了一个有效的缓解策略,还强调了在构建更有针对性的缓解策略时,批判性地区分“偏见”和其他类型错误的重要性。
Q: 论文做了哪些实验?
A: 论文中进行了一系列实验来评估和展示提出的缓解框架的有效性。以下是实验的详细情况:
评估模型在标准公平性基准上的表现:
- 使用BBQ数据集评估大型语言模型(LLMs)在歧义和不歧义上下文中的刻板印象偏见。
- 在SQuAD-v2数据集上评估模型的一般用途效用。
指令调整(Instruction-Tuning):
- 将SQuAD-v2和TriviaQA基准测试转换为指令调整数据集,创建了20种不同的指令,以改进模型在处理歧义和不歧义上下文时的能力。
- 在这些数据集上对模型进行了指令调整,以提高它们在一般用途设置中区分歧义和不歧义上下文的能力。
缓解模型不公平性:
- 在指令调整后,评估模型在BBQ数据集上的表现,以确定是否通过解决任务特定缺陷来缓解观察到的偏见。
- 比较了指令调整前后模型在歧义和不歧义上下文中的反应,展示了指令调整对减少刻板印象输出的影响。
与其他缓解技术的比较:
- 将提出的指令调整方法与现有的基于指令的缓解技术进行比较,包括n-shot提示、指令提示和干预提示。
多维度刻板印象偏见的缓解:
- 评估了Llama2-7B、Llama2-13B和Phi-2模型在BBQ数据集上跨年龄、性别、残疾和外貌等多个维度的表现。
消融研究:
- 进行了消融研究,以了解在指令调整中合成生成的歧义上下文的重要性,以及在歧义和不歧义上下文中使用一致指令与上下文特定指令的影响。
这些实验全面评估了提出的缓解框架在减少生成性语言模型中的刻板印象偏见方面的有效性,并展示了该方法在保持模型整体效用的同时,如何减少由于理解失败而产生的偏见输出。
Q: 有什么可以进一步探索的点?
A: 尽管论文提出了一个有效的框架来区分和缓解生成性语言模型中的偏见和任务特定缺陷,但仍有一些领域可以进一步探索:
更广泛的偏见和公平性问题:
- 评估和缓解模型中除国籍、年龄、性别、残疾和外貌之外的其他类型的偏见,例如宗教、社会经济地位和交叉身份的偏见。
更全面的评估数据集:
- 使用更多样化和代表性的数据集来评估模型的偏见,以更好地捕捉现实世界数据的多样性。
更广泛的模型和任务:
- 在其他类型的生成性模型和下游任务上评估区分偏见和缺陷的方法的有效性,以验证其普适性。
更精细的指令调整策略:
- 开发更针对性的指令调整策略,以更有效地缓解特定维度上的刻板印象偏见。
模型的可解释性和透明度:
- 提高模型决策过程的可解释性,以便更好地理解其产生偏见的原因,并开发更精确的缓解措施。
社区参与和伦理考量:
- 与不同社区合作,直接解决生成性模型中刻板印象偏见造成的伤害,并确保缓解策略符合伦理和社会标准。
长期影响和实际部署:
- 研究模型在现实世界部署中的长期影响,并监测和调整缓解策略以应对新出现的偏见问题。
跨学科研究:
- 结合语言学、社会学、心理学和计算机科学等领域的知识,以更全面地理解和解决偏见问题。
模型训练和数据预处理:
- 探索在模型训练和数据预处理阶段减少偏见的新方法,例如通过平衡数据集或引入去偏见的数据增强技术。
政策和法规遵从性:
- 研究如何使生成性语言模型符合现有的反歧视政策和法规,并为制定相关政策提供技术支持。
这些探索点可以帮助研究社区更深入地理解和解决生成性语言模型中的偏见问题,推动开发更公正、更可靠的人工智能系统。
Q: 总结一下论文的主要内容
A: 本文主要探讨了生成性语言模型在输出中反映和放大社会偏见的问题,尤其是这些模型在阅读理解任务中的表现。论文的核心贡献和发现可以总结如下:
区分偏见与缺陷:
- 论文提出了一个重要区分,即在评估生成性语言模型时,应将模型的偏见与任务特定的缺陷(如理解失败)分开考量。
多角度评估:
- 通过BBQ和SQuAD-v2数据集,对多个最先进的生成性模型进行了评估,揭示了模型在歧义和不歧义上下文中的表现差异。
缓解框架:
- 提出了一个通过指令调整(instruction-tuning)在通用数据集上隐式减少观察到的刻板印象的框架,无需依赖显式的去偏见技术。
实证分析:
- 对包括国籍、年龄、性别、残疾和外貌等多个维度的刻板印象进行了广泛的实证分析,展示了所提方法的有效性。
消融研究:
- 进行了消融研究,探讨了上下文特定指令与更通用指令在缓解刻板印象偏见和解决任务相关缺陷中的重要性。
维持模型效用:
- 所提出的缓解方法在减少偏见的同时,保持了模型的整体效用,实现了超过60%的刻板印象输出减少。
批判性视角:
- 强调了批判性地区分“偏见”和其他类型错误的重要性,以构建更有针对性的缓解策略。
局限性和未来工作:
- 论文讨论了其局限性,包括评估的偏见维度不全面、数据集覆盖不足以及只针对特定任务和模型进行了研究,并提出了未来研究的方向。
总体而言,本文通过细致的评估和创新的缓解策略,为理解和减少生成性语言模型中的偏见提供了新的视角和方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图




Smaller Language Models Are Better Instruction Evolvers
Authors:Tingfeng Hui, Lulu Zhao, Guanting Dong, Yaqi Zhang, Hua Zhou, Sen Su
Instruction tuning has been widely used to unleash the complete potential of large language models. Notably, complex and diverse instructions are of significant importance as they can effectively align models with various downstream tasks. However, current approaches to constructing large-scale instructions predominantly favour powerful models such as GPT-4 or those with over 70 billion parameters, under the empirical presumption that such larger language models (LLMs) inherently possess enhanced capabilities. In this study, we question this prevalent assumption and conduct an in-depth exploration into the potential of smaller language models (SLMs) in the context of instruction evolution. Extensive experiments across three scenarios of instruction evolution reveal that smaller language models (SLMs) can synthesize more effective instructions than LLMs. Further analysis demonstrates that SLMs possess a broader output space during instruction evolution, resulting in more complex and diverse variants. We also observe that the existing metrics fail to focus on the impact of the instructions. Thus, we propose Instruction Complex-Aware IFD (IC-IFD), which introduces instruction complexity in the original IFD score to evaluate the effectiveness of instruction data more accurately. Our source code is available at: \href{https://github.com/HypherX/Evolution-Analysis}{https://github.com/HypherX/Evolution-Analysis}
指令微调已被广泛应用于释放大型语言模型的全部潜力。值得注意的是,复杂和多样化的指令非常重要,因为它们可以有效地将模型与各种下游任务对齐。然而,当前构建大规模指令的方法主要偏向于强大的模型,如GPT-4或那些拥有超过70亿参数模型的,这是基于经验假设,即这样的大型语言模型(LLM)天生具有增强的能力。在研究中,我们质疑这一普遍假设,并对小型语言模型(SLM)在指令进化背景下的潜力进行了深入研究。跨越三种指令进化场景的广泛实验表明,小型语言模型(SLM)可以合成比LLM更有效的指令。进一步分析表明,在指令进化过程中,SLM具有更广阔的输出空间,从而产生更复杂和多样化的变体。我们还观察到,现有指标未能关注指令的影响。因此,我们提出了指令复杂感知IFD(IC-IFD),它在原始的IFD分数中引入了指令复杂性,以更准确地评估指令数据的有效性。我们的源代码可在:https://github.com/HypherX/Evolution-Analysis 找到。
论文及项目相关链接
PDF Work in progress
Summary
在深入探索小型语言模型(SLMs)在指令进化上下文中的潜力后,一项研究发现小型语言模型相较于大型语言模型(LLMs)在指令进化过程中能够合成更有效的指令,展现出了更大的输出空间和更为复杂多样的指令变种形式。对此观察结果,现有的指标缺乏对指令影响的关注,因此该研究提出了一个名为Instruction Complex-Aware IFD(IC-IFD)的新评价指标,旨在更准确地评估指令数据的有效性。此研究的源代码已公开在GitHub上供公众查阅。
Key Takeaways
- 大型语言模型(LLMs)与小型语言模型(SLMs)在指令进化过程中的表现对比被研究。
- 研究发现小型语言模型在合成有效指令方面表现出超越大型语言模型的能力。
- 小型语言模型展现出更大的输出空间和更复杂多样的指令变种形式。
- 现有的评价指标未能充分关注指令的影响,因此存在局限性。
- 提出了一种新的评价指标——Instruction Complex-Aware IFD(IC-IFD),以更准确地评估指令数据的有效性。
- 此研究的源代码已公开在GitHub上供查阅。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了在指令调优(instruction tuning)领域中,小型语言模型(SLMs)与大型语言模型(LLMs)在演化指令(evolving instructions)方面的性能差异。具体来说,论文试图解决的问题包括:
SLMs与LLMs在指令演化中的性能比较:论文质疑了当前普遍认为大型语言模型(LLMs)在指令演化方面具有固有优势的假设,并通过实验探索了小型语言模型(SLMs)是否能够在指令演化方面表现得更好。
指令复杂性的影响:论文分析了为什么SLMs在生成新指令时比LLMs表现得更好,并提出了SLMs可能因其较低的指令遵循能力而具有更广泛的输出空间,导致生成的指令更为复杂和多样化。
无需指令调优的有效指令数据评估:论文提出了一个问题,即如何在不进行指令调优的情况下确定指令数据的有效性,并提出了一种新的评估指标IC-IFD(Instruction Complex-Aware IFD),该指标在原始IFD分数的基础上引入了指令复杂性作为惩罚项,以更准确地评估指令数据的有效性。
总的来说,这篇论文试图挑战当前对大型语言模型在指令调优方面优势的普遍认知,并探索小型语言模型在这一领域的潜力,同时提出了一种新的评估方法来更有效地评估指令数据的质量。
Q: 有哪些相关研究?
A: 论文中提到了多个与指令调优和语言模型演化相关的研究工作,具体如下:
Self-Instruct (Wang et al., 2023):这是一个基础性工作,它从一个小型的种子指令集开始,使用一个强大的监督模型来获取大量的合成指令。
Evol-Instruct (Xu et al., 2024a):这项工作通过深入和广度演化现有指令,产生更复杂的变体。
AutoIF (Dong et al., 2024):该工作旨在从一组小型的种子指令自动构建大规模和可靠的指令,以提高指令跟随能力。
Auto Evol-Instruct (Zeng et al., 2024):进一步实现了无需人类参与,使语言模型能够基于原始指令自动设计演化轨迹。
Larger Models’ Paradox (Xu et al., 2024c):这项研究提出大型模型在生成响应时并不一定能带来更好的性能。
ShareGPT (Chiang et al., 2023) 和 OpenAssistant (Köpf et al., 2023):这两项工作强调了手动注释或人类参与开发的指令数据的重要性。
其他相关研究:包括利用大型语言模型生成高质量数据集的研究,例如利用GPT-4 (OpenAI, 2023) 进行指令构建的研究,以及探索不同大小模型作为响应生成器的性能差异的研究 (Xu et al., 2024b)。
这些研究构成了本文研究的背景和基础,本文在此基础上进一步探讨了小型语言模型在指令演化中的潜力,并提出了新的评估指标IC-IFD,以更准确地评估指令数据的有效性。
Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤解决提出的问题:
实验设计:
- 论文设计了三个不同的指令演化场景:Evol-Instruct、AutoIF和Auto Evol-Instruct,以全面比较SLMs和LLMs在指令合成方面的表现。
- 在这些场景中,使用不同大小(约8B和约70B参数)的模型从Llama-3.1和Qwen-2家族中演化和合成新的指令,同时对不同的主干模型进行微调。
性能比较:
- 通过实验结果,论文发现SLMs在演化有效指令方面并不逊色于LLMs,甚至在某些情况下表现得更好,尤其是在生成更复杂和多样化的指令方面。
- 论文还观察到SLMs相比于LLMs在指令生成时展现出更广泛的输出空间,导致生成的指令更加复杂和多样化。
分析原因:
- 为了探究SLMs在指令演化中表现更好的原因,论文比较了SLMs和LLMs在指令合成过程中的top-1 token概率分布,发现SLMs的输出分布更加多样化,表明SLMs不太可能过度自信,因此能够生成更复杂的指令。
提出新的评估指标:
- 论文提出了Instruction Complex-Aware IFD(IC-IFD)分数,该分数在原始IFD分数的基础上引入了指令复杂性作为惩罚项,以更准确地评估指令数据的有效性,特别是在指令复杂性较高的情况下。
实验验证:
- 通过大量过滤指令数据的实验,结果表明IC-IFD分数能够提供对指令数据更准确的评估,尤其是在指令复杂性较高的情况下。
总结与展望:
- 论文总结了SLMs在指令演化中的潜力,并指出了未来研究的方向,包括探索SLMs在更广泛领域的能力,以及如何更准确地评估指令数据的有效性。
通过上述步骤,论文不仅挑战了大型语言模型在指令调优方面的固有优势,而且为未来在指令数据合成领域的研究提供了新的视角和方法。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来探究小型语言模型(SLMs)和大型语言模型(LLMs)在指令演化方面的表现差异:
Evol-Instruct场景实验:
- 使用Llama-3.1和Qwen-2模型系列进行指令演化,以排除特定于每个模型系列的潜在偏差。
- 对比分析了使用SLMs(例如Llama-3.1-8B-Instruct和Qwen-2-7B-Instruct)和LLMs(例如Llama-3.1-70B-Instruct和Qwen-2-72B-Instruct)演化的指令数据(分别记为SLM-INST和LLM-INST)在多个基准测试中的表现。
AutoIF场景实验:
- 评估了SLMs和LLMs生成的指令数据在IFEval和FollowBench指令跟随基准测试中的表现。
- 使用所有mpnet-basev2模型来测量通过最小邻居距离(MND)在嵌入空间中的相似性,以评估指令数据的多样性。
Auto Evol-Instruct场景实验:
- 比较了SLMs和LLMs在自动设计演化轨迹以演化指令数据方面的性能。
- 使用Qwen-2.5-72B-Instruct模型来总结和去重由SLMs和LLMs生成的轨迹中的关键词。
模型输出分布分析:
- 比较了Llama3.1-8B-Instruct和Llama-3.1-70B-Instruct模型在Evol-Instruct场景中的输出token概率分布,以验证SLMs和LLMs在指令生成时的多样性和复杂性。
IC-IFD分数验证实验:
- 使用不同的评估指标(包括指令长度、指令困惑度(PPL)、IFD和IC-IFD)筛选指令数据,并比较了它们在保留25%指令数据时的性能。
温度影响实验:
- 探索了不同温度设置对演化指令数据的影响,比较了Llama-3.1-8B-Instruct和Llama-3.1-70B-Instruct在不同温度下的表现。
案例研究:
- 对比分析了SLMs和LLMs在特定深入演化案例中的表现,展示了SLMs在相同约束或轨迹下能够演化出更复杂和多样化的指令。
这些实验全面覆盖了SLMs和LLMs在指令演化中的性能表现、输出多样性、复杂性以及评估指标的有效性等多个方面。通过这些实验,论文得出了SLMs在指令演化方面可能优于LLMs的结论,并提出了新的评估指标IC-IFD来更准确地评估指令数据的有效性。
Q: 有什么可以进一步探索的点?
A: 根据论文内容,以下是一些可以进一步探索的点:
更广泛的领域测试:
- 论文主要关注了指令跟随、数学推理和代码生成领域。未来的研究可以在更多领域进行实验,如文本摘要、机器翻译、问答系统等,以探索SLMs和LLMs在这些领域中的表现差异。
完整的指令数据合成管道:
- 论文集中于比较SLMs和LLMs在指令集演化中的表现,而不是探索SLMs在整个指令数据合成管道中的潜力。未来的研究可以更全面地调查SLMs在自动生成整个指令数据集方面的能力。
指令数据有效性评估方法:
- 论文提出了IC-IFD作为评估指令数据有效性的新方法。未来的研究可以进一步探索如何更精确地评估指令数据的有效性,而无需进行指令调优。
模型输出空间和复杂性关系:
- 论文发现SLMs具有更广泛的输出空间,导致生成的指令更加复杂和多样化。未来的研究可以深入分析模型输出空间与指令复杂性之间的关系,并探索如何优化这一过程。
计算成本与性能的平衡:
- 论文指出SLMs可以在更低的计算成本下合成更有效的指令。未来的研究可以探索不同大小模型之间的性能和成本效益之间的最佳平衡点。
指令调优数据选择策略:
- 论文提出了IC-IFD用于筛选高质量的指令数据。未来的研究可以开发更多先进的数据选择策略,以进一步提高指令调优的效率和效果。
跨领域指令调优:
- 探索指令调优在跨领域任务中的应用,研究如何将从一个领域学到的指令泛化到另一个领域。
模型训练和演化策略优化:
- 研究更高效的模型训练和指令演化策略,以提高SLMs和LLMs在指令调优中的性能。
可解释性和透明度:
- 提高指令调优过程的可解释性,帮助研究人员和开发者更好地理解模型的行为和决策过程。
这些探索点可以帮助研究社区更深入地理解指令调优的工作原理,优化语言模型的性能,并推动相关技术的发展。
Q: 总结一下论文的主要内容
A: 这篇论文主要探讨了在指令调优领域中,小型语言模型(SLMs)与大型语言模型(LLMs)在演化指令方面的表现差异。以下是论文的主要内容总结:
研究背景:
- 指令调优被广泛用于释放大型语言模型的潜力,而复杂多样的指令对于模型与不同下游任务对齐至关重要。
- 现有研究主要依赖于如GPT-4这样的强大模型来合成指令,基于大模型固有性能优势的假设。
研究假设:
- 论文质疑了大模型在指令演化中的优势,提出小型语言模型可能是一种更有效且高效的指令演化选择。
实验设计:
- 通过三个指令演化场景(Evol-Instruct、AutoIF和Auto Evol-Instruct)进行了广泛的实验。
- 使用不同大小的模型从Llama-3.1和Qwen-2家族中演化和合成新的指令,并微调不同的主干模型。
实验结果:
- 发现SLMs在演化有效指令方面的表现优于LLMs,且能演化出更复杂和多样化的指令。
- SLMs在指令生成时展现出更广泛的输出空间,导致生成的指令更加复杂和多样化。
分析原因:
- 通过比较SLMs和LLMs在指令合成过程中的top-1 token概率分布,发现SLMs的输出分布更加多样化。
新评估指标:
- 提出了Instruction Complex-Aware IFD(IC-IFD)分数,引入指令复杂性作为惩罚项,以更准确地评估指令数据的有效性。
结论:
- SLMs可以合成更有效的指令,且计算成本更低。
- SLMs在指令演化中表现出色,为未来研究提供了新的视角和方法。
局限性和未来工作:
- 论文的实验主要集中在指令跟随、数学推理和代码生成领域,未来工作可以探索更广泛的领域。
- 提出了未来研究的方向,包括更全面地探索SLMs的潜力和更精确地评估指令数据的有效性。
总体而言,这篇论文通过对比SLMs和LLMs在指令演化中的性能,挑战了大模型在这一领域的固有优势,并提出了新的评估指标IC-IFD,为指令调优领域提供了新的见解和研究方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图






FinGPT: Enhancing Sentiment-Based Stock Movement Prediction with Dissemination-Aware and Context-Enriched LLMs
Authors:Yixuan Liang, Yuncong Liu, Boyu Zhang, Christina Dan Wang, Hongyang Yang
Financial sentiment analysis is crucial for understanding the influence of news on stock prices. Recently, large language models (LLMs) have been widely adopted for this purpose due to their advanced text analysis capabilities. However, these models often only consider the news content itself, ignoring its dissemination, which hampers accurate prediction of short-term stock movements. Additionally, current methods often lack sufficient contextual data and explicit instructions in their prompts, limiting LLMs’ ability to interpret news. In this paper, we propose a data-driven approach that enhances LLM-powered sentiment-based stock movement predictions by incorporating news dissemination breadth, contextual data, and explicit instructions. We cluster recent company-related news to assess its reach and influence, enriching prompts with more specific data and precise instructions. This data is used to construct an instruction tuning dataset to fine-tune an LLM for predicting short-term stock price movements. Our experimental results show that our approach improves prediction accuracy by 8% compared to existing methods.
金融情感分析对于理解新闻对股票价格的影响至关重要。最近,由于大型语言模型(LLM)在文本分析方面的先进能力,它们被广泛应用于此目的。然而,这些模型通常只考虑新闻内容本身,而忽视了其传播情况,这阻碍了短期股票走势的准确预测。此外,当前的方法通常缺乏足够的上下文数据和明确的指令提示,限制了LLM对新闻的解释能力。在本文中,我们提出了一种数据驱动的方法,通过结合新闻传播的广度、上下文数据和明确的指令提示,提高了基于LLM的情感驱动股票走势预测能力。我们聚类了与公司相关的最新新闻,以评估其传播范围和影响力,并通过更具体的数据和精确指令丰富提示。这些数据用于构建指令微调数据集,以微调LLM,以预测短期股票价格走势。我们的实验结果表明,与现有方法相比,我们的方法提高了8%的预测准确性。
论文及项目相关链接
PDF 1st Workshop on Preparing Good Data for Generative AI: Challenges and Approaches@ AAAI 2025
摘要
本文强调金融情感分析对理解新闻对股价影响的重要性。针对目前大型语言模型(LLM)在情感分析方面存在的问题,如忽视新闻传播广度、缺乏足够的上下文数据和明确的指令等,本文提出了一种数据驱动的方法,结合新闻传播广度、上下文数据和明确的指令来改进LLM的情感分析功能。通过对公司相关新闻进行聚类分析其在资本市场的影响力并丰富指令输入,构建一个精细化训练的指令调优数据集用于预测短期股价走势。实验结果表明,相较于现有方法,本方法可以提高8%的预测准确度。
关键见解
- 金融情感分析是理解新闻影响股价的重要工具。
- 大型语言模型(LLM)被广泛用于情感分析,但存在诸多挑战。
- 目前的方法忽视了新闻的传播广度,限制了预测的准确性。
- 缺乏足够的上下文数据和明确的指令限制了LLM对新闻的解读能力。
- 本文提出了一种数据驱动的方法,结合了新闻的传播广度、上下文数据和明确的指令来提高LLM的预测准确性。
- 通过构建指令调优数据集,本文实现了短期股价走势的预测精度提升。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何提高基于情感分析的股票价格运动预测的准确性。具体来说,论文指出了现有方法在以下几个方面的局限性:
新闻传播的忽略:现有模型通常只考虑新闻内容本身,忽略了新闻的传播范围,这限制了对短期股票运动的准确预测。
上下文数据不足:现有方法往往缺乏足够的上下文数据和明确的指令,限制了大型语言模型(LLMs)解释新闻的能力。
为了解决这些问题,论文提出了一种数据驱动的方法,通过结合新闻传播的广度、上下文数据和明确的指令来增强基于情感的股票运动预测。具体来说,论文的方法包括:
- 新闻聚类:通过聚类最近与公司相关的新闻来评估新闻的传播范围和影响力。
- 上下文数据和指令的丰富:在提示中加入更具体的数据和精确的指令,以提供更细致的金融情感分析方法。
- 指令调整数据集的构建:利用这些信息构建指令调整数据集,以微调LLM进行短期股票价格预测。
这种方法旨在通过更全面地考虑新闻内容及其传播的影响,以及提供更丰富的上下文信息和明确的指令,来提高短期股票价格运动预测的准确性。
Q: 有哪些相关研究?
A: 论文中提到了多个与金融情感分析和基于情感的股票价格预测相关的研究工作,具体如下:
金融情感分析的传统研究:
- Chan和Chong (2017) 讨论了情感分析在金融文本中的应用。
- Atkins等人 (2018) 研究了金融新闻如何预测股市波动。
- Tai和Kao (2013) 提出了基于标签传播的自动领域特定情感词典生成方法。
基于NLP的情感分析模型和方法:
- 包括基于词典的技术、机器学习和深度学习方法,如Hamilton等人 (2016) 和 Mishev等人 (2020) 的工作。
大型语言模型(LLMs)在金融情感分析中的应用:
- Araci (2019) 提出的FinBERT,一个用于金融情感分析的预训练语言模型。
- Wu等人 (2023) 提出的Bloomberggpt,一个用于金融领域的大型语言模型。
- Wang等人 (2023) 提出的Fingpt,一个开源的金融领域大型语言模型。
基于LLMs的股票价格预测:
- Xu和Cohen (2018) 使用推文和历史数据预测价格。
- Wang等人 (2024) 提出的LLMFactor,通过序列知识引导的提示进行短期预测。
- Elahi和Taghvaei (2024) 结合财务数据和新闻进行长期预测。
新闻传播对股票价格影响的研究:
- 论文中提到了现有方法通常忽略新闻传播的影响,而本研究旨在通过聚类新闻来评估新闻的传播范围和影响力,从而提高预测准确性。
这些相关研究为本文提出的结合新闻传播广度、上下文数据和精确指令以增强LLMs情感分析和股票价格预测的方法提供了理论和实证基础。通过综述这些相关工作,论文展示了其研究的创新点和潜在的应用价值。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决提高基于情感分析的股票价格运动预测准确性的问题:
1. 数据处理(Data Processing)
高粒度股价信息(High Granularity in Stock Price Information, HG):
- 增加数据粒度,使用每日收盘价和整周的相应回报,以减少LLMs中的计算不确定性,并通过精确的时间对齐价格变动和新闻事件,区分短期和长期影响。
新闻聚类(News Clustering, HG-NC):
- 通过聚类方法组织大量新闻内容,使用BERTopic和余弦相似性评估来量化新闻传播,从而增强股价运动预测。
- 包括数据收集、主题聚类、聚类质量评估和主题选择策略。
2. 提示工程(Prompt Engineering)
- 上下文增强指令:
- 根据提出的数据格式,为LLMs提供更具体的指令,包括区分新闻的短期和长期影响,以及分析新闻传播对股价影响的指南。
3. 指令调整(Instruction-tuning)
- 构建训练数据集:
- 将结构化输入提示(包括公司介绍、历史股价、相关新闻、公司基本面和利用情感分析进行预测的指令)与GPT-4o生成的基于已知未来运动的分析配对。
- 从提示中移除真实股价,使用这个数据集来微调Llama3-8B模型进行周度股价运动预测,并评估数值准确性和推理质量。
4. 性能评估(Performance Evaluation)
二元准确性:
- 使用二元准确性指标评估模型预测股价运动方向(上升/下降)的能力。
ROUGE分数:
- 使用ROUGE分数评估模型输出的推理质量,衡量LLM生成的输出与参考摘要之间的关键词和短语的重叠。
5. 案例研究(Case Study)
- 波音公司(Boeing Company):
- 作为代表性案例研究,比较HG方法和HG-NC方法的预测性能。
通过这些步骤,论文提出了一种新的方法来增强基于情感分析的股价运动预测,通过增加股价数据的粒度和提供短期或长期分析的指令来增强新闻的上下文理解,并通过聚类评估新闻传播及其对市场影响的评估来改进预测。实验结果验证了这种方法,实现了63%的二元准确性,与基线的55%相比有了显著提高。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出方法的有效性:
1. 二元准确性评估(Binary Accuracy in Stock Movement Prediction)
- 数据集:包含了20家公司跨越多个市场部门的380个观测值,以确保评估的稳健性。
- 方法比较:比较了基线方法、增加股价粒度的HG方法和结合新闻聚类的HG-NC方法。
- 结果:展示了这三种方法在短期和长期预测准确性上的表现,证明了增加数据粒度和新闻聚类可以显著提高预测的准确性。
2. ROUGE分数评估(ROUGE Scores for Reasoning Quality Evaluation)
- 评估方法:使用ROUGE分数来评估模型输出的推理质量,因为获取每个实例的基于情感分析的真实分析是不切实际的。
- 指标:评估了ROUGE-1、ROUGE-2和ROUGE-L三个指标,这些指标衡量了LLM生成的输出与参考摘要之间的关键词和短语的重叠。
- 结果:HG-NC方法在所有指标上一致性地优于基线和HG方法,表明该方法能更好地捕捉和表述市场因素之间的复杂交互。
3. 案例研究:波音公司(Boeing Company)
- 预测性能比较:使用波音公司作为案例研究,比较了HG方法和HG-NC方法的预测性能。
- 聚类性能与预测性能的相关性:研究了高内聚聚类中新闻文章的比例与预测性能之间的关系,发现高比例(>50%)通常与HG-NC方法的更好预测性能相关联。
4. 新闻聚类统计(News Clustering Statistics)
- 数据收集:统计了一定时期内波音公司的新闻数量、聚类数量、高内聚聚类数量以及高内聚聚类中的新闻比例。
- 结果:展示了不同时间点的新闻聚类统计数据,以及HG-NC方法的预测结果。
这些实验结果验证了论文提出方法的有效性,即通过增加股价数据粒度、提供短期或长期分析的指令以及评估新闻传播对股价影响的方法,可以显著提高基于情感分析的股票价格运动预测的准确性。
Q: 有什么可以进一步探索的点?
A: 论文提出了一个增强基于情感分析的股票价格运动预测的方法,但仍有一些领域可以进一步探索和改进:
1. 模型泛化能力的提升
- 跨市场测试:在不同的股票市场和不同的经济周期中测试模型的泛化能力。
- 多语言新闻处理:探索模型处理多语言新闻的能力,以适应全球化金融市场。
2. 模型解释性增强
- 解释性工具开发:开发更多的解释性工具来帮助理解模型的预测决策过程。
- 可视化工具:创建可视化工具来展示新闻情感分析和股价预测之间的关系。
3. 长期预测能力
- 长期影响评估:研究模型在预测更长时间段(如月度、季度)股价运动时的表现。
- 事件驱动模型:探索事件驱动的模型,以更好地捕捉市场对特定新闻事件的反应。
4. 数据集和特征工程
- 更丰富的上下文数据:整合更多的上下文数据,如宏观经济指标、行业趋势等,以提高预测的准确性。
- 特征选择和优化:通过特征选择和优化技术来识别最有影响力的特征,以提高模型性能。
5. 模型鲁棒性测试
- 对抗性攻击测试:测试模型对对抗性攻击的鲁棒性,以确保在金融市场的实际操作中的安全性。
- 异常值和噪声处理:研究模型对异常值和噪声的处理能力,提高模型在实际应用中的稳定性。
6. 跨领域应用
- 其他金融产品的预测:将模型应用于其他金融产品(如外汇、债券、加密货币)的价格预测。
- 风险管理:探索模型在金融风险管理中的应用,如信用风险评估和市场风险预测。
7. 模型训练和优化
- 训练效率提升:研究更高效的训练方法,减少训练时间和资源消耗。
- 模型压缩和加速:探索模型压缩技术,以在资源受限的环境中部署模型。
这些进一步探索的点可以帮助提升模型的性能、解释性和适用性,使其更好地服务于金融市场分析和预测。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容包括以下几个方面:
1. 问题陈述
论文指出了金融情绪分析在理解新闻对股价影响方面的重要性,并指出了现有模型在预测短期股价运动时存在的两个主要问题:忽略新闻传播的影响和缺乏足够的上下文数据及明确指令。
2. 提出的方法
为了解决这些问题,论文提出了一种数据驱动的方法,通过以下三个方面增强基于情绪分析的股票运动预测:
- 新闻传播广度的捕捉:通过聚类最近公司相关的新闻来评估新闻的传播范围和影响力。
- 上下文数据和指令的丰富:在提示中加入更具体的数据和精确的指令,提供更细致的金融情绪分析方法。
- 指令调整数据集的构建:利用这些信息构建指令调整数据集,以微调大型语言模型(LLM)进行短期股价预测。
3. 实验结果
论文通过实验验证了所提方法的有效性,结果显示:
- 二元准确性提升:所提方法将预测准确性提高了8%,达到了63%的二元准确性,优于现有方法。
- ROUGE分数提升:在评估模型输出的推理质量时,所提方法在所有ROUGE指标上均优于基线和HG方法。
4. 案例研究
论文还提供了波音公司的案例研究,展示了HG-NC方法与HG方法相比在预测性能上的优势,并分析了高内聚聚类中新闻文章比例与预测性能之间的相关性。
5. 结论
论文得出结论,通过增加股价数据的粒度和提供短期或长期分析的指令来增强新闻的上下文理解,并评估新闻传播对股价影响的方法,可以显著提高基于情绪分析的股票价格运动预测的准确性。
6. 未来方向
论文最后提出了一些未来研究方向,包括提高模型的泛化能力、增强模型解释性、长期预测能力、数据集和特征工程、模型鲁棒性测试、跨领域应用和模型训练优化等。
总的来说,这篇论文提出了一种新的方法来增强基于情绪分析的股价运动预测,并通过实验验证了其有效性,为金融情绪分析和股价预测领域提供了有价值的见解和方法。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图








Evaluation of GPT-4o & GPT-4o-mini’s Vision Capabilities for Salt Evaporite Identification
Authors:Deven B. Dangi, Beni B. Dangi, Oliver Steinbock
Identifying salts from images of their ‘stains’ has diverse practical applications. While specialized AI models are being developed, this paper explores the potential of OpenAI’s state-of-the-art vision models (GPT-4o and GPT-4o-mini) as an immediate solution. Testing with 12 different types of salts, the GPT-4o model achieved 57% accuracy and a 0.52 F1 score, significantly outperforming both random chance (8%) and GPT-4o mini (11% accuracy). Results suggest that current vision models could serve as an interim solution for salt identification from stain images.
从盐的“污渍”图像中识别盐具有多种实际应用。虽然正在开发专门的AI模型,但本文探讨了OpenAI最新视觉模型(GPT-4o和GPT-4o-mini)的潜力,作为立即解决方案。通过对12种不同类型的盐进行测试,GPT-4o模型达到了57%的准确率和0.52的F1分数,显著优于随机猜测(8%)和GPT-4o mini(11%的准确率)。结果表明,当前的视觉模型可以作为从污渍图像中识别盐的临时解决方案。
论文及项目相关链接
PDF 11 pages, 7 figures
Summary
本文探索了使用OpenAI的先进视觉模型(GPT-4o和GPT-4o-mini)从盐渍图像中识别盐类的潜力。测试结果显示,GPT-4o模型对12种不同类型的盐达到了57%的准确率和0.52的F1分数,显著优于随机猜测(8%)和GPT-4o mini(11%准确率)。这证明当前视觉模型可以作为从污渍图像中识别盐类的临时解决方案。
Key Takeaways
- 使用OpenAI的先进视觉模型可识别盐类。
- GPT-4o模型对12种不同类型的盐达到了57%的识别准确率。
- GPT-4o模型的F1分数为0.52,显示出较好的识别性能。
- GPT-4o模型的识别准确率显著高于随机猜测和GPT-4o mini模型。
- 当前视觉模型可作为从污渍图像中识别盐类的临时解决方案。
- 该研究为盐类识别提供了新方法和思路。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了如何利用先进的大型语言模型(LLMs)来识别盐分从其蒸发后的“污渍”图像。具体来说,研究试图解决的问题包括:
盐分识别的实际应用:从宏观图像中快速识别盐分对于法医学专家、天文学家等多个领域具有重要意义。论文旨在探索一种低成本、无需特殊设备的盐分析方法。
现有方法的局限性:尽管已有一些方法在实现这一能力方面取得了一定的成功,但这些方法目前并不立即可用,且其普及到一般或专业使用的时间未知。
利用大型语言模型进行图像识别:研究者探索使用具有视觉能力的最先进的大型语言模型(如GPT-4o和GPT-4o-mini)来识别盐分,这些模型已显示出跨领域知识转移的能力和在没有特定领域微调的情况下识别某些复杂视觉模式的能力。
模型性能的评估:通过测试12种不同类型的盐,评估GPT-4o和GPT-4o-mini模型在盐分识别的准确性和一致性,以及它们在实际应用中的潜在价值。
综上所述,论文试图解决的核心问题是利用现有的先进视觉模型作为临时解决方案,以从盐分的蒸发污渍图像中识别盐分,并评估这些模型的性能和实用性。
Q: 有哪些相关研究?
A: 根据论文内容,以下是与本研究相关的一些研究:
法医学中的盐分识别:
Da Silveira Tortolero Araujo Lourenço, M.; Di Maggio, R. M.; Germinario, C.; Grifa, C.; Izzo, F.; Langella, A.; Mercurio, M. 发表在《Forensic Sci.》上的论文,描述了通过法医地球科学分析方法在受害者衣物上发现卤石痕迹的案例。
火星上含氯物质的研究:
Osterloo, M. M.; Hamilton, V. E.; Bandfield, J. L.; Glotch, T. D.; Baldridge, A. M.; Christensen, P. R.; Tornabene, L. L.; Anderson, F. S. 发表在《Science》上的论文,讨论了火星南部高地的含氯物质。
从照片识别化学物质:
Batista, B. C.; Tekle, S. D.; Yan, J.; Dangi, B. B.; Steinbock, O. 发表在《Proc. Natl. Acad. Sci. U.S.A.》上的论文,提出了通过干燥溶液滴揭示形态发生树的化学成分识别方法。
GPT-4O模型的综合评估:
Shahriar, S.; Lund, B. D.; Mannuru, N. R.; Arshad, M. A.; Hayawi, K.; Bevara, R. V. K.; Mannuru, A.; Batool, L. 发表在《Appl. Sci.》上的论文,对GPT-4O模型的语言、视觉、语音和多模态能力进行了全面评估。
这些研究为本文提供了背景信息和理论基础,涉及到盐分识别的重要性、火星上盐分的研究、以及GPT-4O模型在不同领域的应用能力。通过引用这些文献,本文的研究在现有研究成果的基础上进一步探讨了利用大型语言模型进行盐分识别的可能性和效果。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决利用图像识别盐分的问题:
模型选择:
- 选择了OpenAI的两个最先进的视觉模型:GPT-4o和GPT-4o-mini。GPT-4o是完整的模型,而GPT-4o-mini是更轻量级、成本效益更高的变体。
数据集准备:
- 从Dr. Steinbock的网站收集了12种盐(包括NaCl, KCl, NH₄Cl等)的实验室生成的图像,这些图像代表了不同类型的离子化合物。
- 为了确保模型能够理解每种盐的外观,将这些图像作为训练数据提供给模型。
API调用和批量处理:
- 使用OpenAI的APIs进行批量处理,这样可以同时处理多个请求,降低成本并提高令牌限制。
- 为每个请求创建JSONL文件,其中每行包含一个有效的JSON对象,代表对API的单个请求。
请求参数设置:
- 每个请求包含一个ID、模型名称、温度(设置为0以接近确定性结果)、种子值(用于控制结果的可重复性)。
- 每个请求还包括系统提示和12个用户消息,每个用户消息由5张图片和一行文本组成,用于训练模型识别12种不同的盐。
模型训练和测试:
- 使用12组标记有相应盐类型的图像训练模型,使模型学习每种盐的视觉特征。
- 随机选择每种盐的100张图像,以确保每种盐的潜在形态变化都能被无偏地表示。
结果分析:
- 使用Cohen’s Kappa统计量评估不同模型结果之间的一致性。
- 计算模型的准确率和F1分数,以评估模型的性能。
性能比较:
- 对比GPT-4o和GPT-4o-mini模型的性能,发现GPT-4o模型的准确率和F1分数显著高于GPT-4o-mini模型。
结论:
- 得出结论,尽管存在一些混淆和偏差,GPT-4o模型在给定适当的训练数据的情况下,对于盐蒸发分析显示出有希望的结果。
通过这些步骤,论文探索了使用最先进的视觉模型作为临时解决方案来从盐渍图像中识别盐分,并评估了这些模型的性能和实用性。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要包括以下几个步骤:
模型选择与准备:
- 选择了OpenAI的GPT-4o和GPT-4o-mini模型,并对这些模型进行了介绍和比较。
数据收集:
- 收集了12种盐的图像数据,这些图像来源于Dr. Steinbock的网站,包括NaCl, KCl, NH₄Cl, Na₂SO₄, K₂SO₄, NH₄NO₃, NaH₂PO₄, NaNO₃, Na₃PO₄, KBr, KNO₃, 和 RbCl。
训练图像的包含:
- 为了帮助模型理解每种盐的外观,将训练图像包含在模型请求中。
批量处理方法:
- 使用OpenAI提供的批量处理方法,通过创建JSONL文件来发送多个请求,每个文件的行包含一个有效的JSON对象,代表对API的单个请求。
参数设置:
- 对每个请求设置关键参数,包括ID、模型名称、温度(设置为0以接近确定性结果)、种子值(用于控制结果的可重复性)。
系统提示和用户消息:
- 为每个请求设置系统提示,并传入12个用户消息作为上下文,每个用户消息由5张图片和一行文本组成。
模型训练:
- 使用12组标记有相应盐类型的图像训练模型,使模型学习每种盐的视觉特征。
请求发送与响应接收:
- 将创建好的JSONL文件(批次)发送给指定模型进行处理,并接收响应。
结果分析:
- 使用Cohen’s Kappa统计量评估不同模型结果之间的一致性。
- 计算模型的准确率和F1分数,以评估模型的性能。
性能比较:
- 对比GPT-4o和GPT-4o-mini模型的性能,分析准确率、F1分数和响应的偏差。
这些实验步骤构成了论文的主要实验设计,旨在评估和比较GPT-4o和GPT-4o-mini模型在从盐渍图像中识别盐分的能力。通过这些实验,研究者能够得出关于模型性能的结论,并探讨这些模型在实际应用中的潜在价值。
Q: 有什么可以进一步探索的点?
A: 根据论文内容和结果,以下是一些可以进一步探索的点:
模型微调(Fine-tuning):
- 论文提到了通过微调可以提高模型的性能。未来的工作可以探索如何针对盐渍图像识别任务对GPT-4o模型进行微调,以提高识别准确率和减少混淆。
数据集的扩展和多样化:
- 增加更多类型的盐和更多样化的图像,包括不同条件下形成的盐渍图像,以提高模型的泛化能力和鲁棒性。
模型训练数据的平衡:
- 针对模型在某些盐类(如KBr和KCl)上表现不佳的问题,可以通过增加这些类别的训练样本来平衡数据集,减少模型的偏差。
模型解释性:
- 研究模型做出错误识别的原因,例如为什么NaCl经常被误识别为KBr和KCl。这可能涉及到模型解释性技术,以更好地理解模型的决策过程。
多模态学习:
- 考虑将文本、图像和其他模态的数据结合起来,以提供更丰富的上下文信息,可能有助于提高识别的准确性。
模型比较和集成:
- 与其他先进的视觉模型进行比较,或者探索模型集成的方法,以组合多个模型的预测来提高整体性能。
计算效率优化:
- 考虑到GPT-4o-mini模型在视觉任务中需要更多的计算资源,可以探索优化算法来减少计算成本,同时保持或提高性能。
实际应用测试:
- 在现实世界的场景中测试模型的性能,例如在法医学现场或地质勘探中,以评估模型的实际应用价值。
错误分析:
- 对模型的误识别案例进行深入分析,以识别模型的弱点,并探索可能的改进措施。
模型的可解释性和透明度:
- 提高模型的可解释性,让最终用户能够理解模型是如何做出特定预测的,这对于建立用户信任和模型的接受度至关重要。
这些探索点可以帮助未来的研究者更深入地理解和改进大型语言模型在盐渍图像识别方面的应用。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
研究目的:
- 探索使用OpenAI的先进视觉模型(GPT-4o和GPT-4o-mini)来识别从图像中盐渍的盐类。
实验设计:
- 选择了12种不同的盐进行测试,以评估模型的准确性和一致性。
- 使用实验室生成的盐渍图像作为训练数据。
- 利用OpenAI的批量处理API来发送请求,并接收模型的响应。
方法论:
- 为每个盐类创建训练图像,并在每个API请求中包含这些图像。
- 设置参数(如模型名称、温度、种子值)以控制输出的确定性。
- 使用系统提示和用户消息来训练模型识别不同的盐。
结果分析:
- 使用Cohen’s Kappa统计量来评估模型间的一致性。
- 计算模型的准确率和F1分数来评估性能。
- 发现GPT-4o模型的准确率为57%,F1分数为0.52,显著优于随机猜测和GPT-4o-mini模型。
主要发现:
- GPT-4o模型在盐渍图像识别上表现良好,而GPT-4o-mini模型表现不佳,即使考虑成本和计算效率。
- GPT-4o-mini模型存在显著的偏差,倾向于错误地识别某些盐类。
- GPT-4o模型虽然表现更好,但在某些盐类上也存在混淆,如NaCl、KBr和KCl。
结论:
- 大型语言模型具有视觉能力,可以作为识别盐渍图像中盐类的临时解决方案。
- GPT-4o模型显示出作为盐蒸发分析工具的潜力,但需要进一步的微调和优化。
进一步探索的方向:
- 模型微调、数据集扩展、模型训练数据平衡、模型解释性、多模态学习、模型比较和集成、计算效率优化、实际应用测试、错误分析以及模型的可解释性和透明度。
这篇论文提供了一个关于如何使用大型语言模型来解决特定视觉识别任务的案例研究,并指出了这些模型在实际应用中的潜力和局限性。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图





Performance of ChatGPT on tasks involving physics visual representations: the case of the Brief Electricity and Magnetism Assessment
Authors:Giulia Polverini, Jakob Melin, Elias Onerud, Bor Gregorcic
Artificial intelligence-based chatbots are increasingly influencing physics education due to their ability to interpret and respond to textual and visual inputs. This study evaluates the performance of two large multimodal model-based chatbots, ChatGPT-4 and ChatGPT-4o on the Brief Electricity and Magnetism Assessment (BEMA), a conceptual physics inventory rich in visual representations such as vector fields, circuit diagrams, and graphs. Quantitative analysis shows that ChatGPT-4o outperforms both ChatGPT-4 and a large sample of university students, and demonstrates improvements in ChatGPT-4o’s vision interpretation ability over its predecessor ChatGPT-4. However, qualitative analysis of ChatGPT-4o’s responses reveals persistent challenges. We identified three types of difficulties in the chatbot’s responses to tasks on BEMA: (1) difficulties with visual interpretation, (2) difficulties in providing correct physics laws or rules, and (3) difficulties with spatial coordination and application of physics representations. Spatial reasoning tasks, particularly those requiring the use of the right-hand rule, proved especially problematic. These findings highlight that the most broadly used large multimodal model-based chatbot, ChatGPT-4o, still exhibits significant difficulties in engaging with physics tasks involving visual representations. While the chatbot shows potential for educational applications, including personalized tutoring and accessibility support for students who are blind or have low vision, its limitations necessitate caution. On the other hand, our findings can also be leveraged to design assessments that are difficult for chatbots to solve.
基于人工智能的聊天机器人由于其解释和响应文本和视觉输入的能力,正在越来越影响物理教育。本研究评估了两个大型多模式模型聊天机器人ChatGPT-4和ChatGPT-4o在“简短的电与磁评估”(BEMA)上的表现,BEMA是一个概念丰富的物理库存,包含诸如矢量场、电路图和图表等视觉表现。定量分析表明,ChatGPT-4o在ChatGPT-4和大量大学生样本中的表现更为出色,并展示了ChatGPT-4o在视觉解释能力上相比其前身ChatGPT-4的改进。然而,对ChatGPT-4o的响应的定性分析揭示了持续存在的挑战。我们在识别BEMA任务中聊天机器人的响应困难时确定了三种类型:(1)视觉解释的困难,(2)提供正确的物理定律或规则的困难,(3)空间协调和物理表现应用的困难。空间推理任务,特别是那些需要使用右手规则的任务,证明尤其困难。这些发现强调,最广泛使用的大型多模式模型基础聊天机器人ChatGPT-4o在涉及视觉表现的物理任务中仍存在重大困难。虽然聊天机器人在教育应用方面显示出潜力,包括个性化辅导和盲人或视力不佳学生的辅助支持,但其局限性需要谨慎。另一方面,我们的发现也可以用来设计聊天机器人难以解决的评估题目。
论文及项目相关链接
摘要
人工智能聊天机器人通过解读文本和视觉输入来影响物理教育。本研究评估了两个基于大型多模态模型的聊天机器人——ChatGPT-4和ChatGPT-4o在包含矢量场、电路图和图表等视觉呈现的概念物理题库——简短的电学和磁学评估(BEMA)上的表现。定量分析显示,ChatGPT-4o在ChatGPT-4和大量大学生样本中的表现更优秀,并在视觉解读能力上有所提升。然而,对ChatGPT-4o的回应的定性分析揭示了持续存在的挑战。我们确定了三种类型的困难:一、视觉解读困难;二、提供正确的物理定律或规则方面的困难;三、空间协调和物理表达应用方面的困难。特别是需要使用右手定则的空间推理任务被证明特别具有挑战性。这些发现表明,最广泛使用的基于大型多模态模型的聊天机器人ChatGPT-4o在与涉及视觉呈现的物理任务交互时仍存在显著困难。虽然该聊天机器人在个性化辅导和盲人或低视力学生的辅助方面有教育应用潜力,但其局限性需要谨慎对待。另一方面,我们的发现也可以用来设计聊天机器人难以解决的评估题目。
关键见解
- 人工智能聊天机器人在物理教育中扮演着越来越重要的角色,得益于它们解读和响应文本及视觉输入的能力。
- ChatGPT-4o在视觉解读能力上有所提升,在BEMA测试上的表现优于ChatGPT-4和许多大学生。
- ChatGPT-4o在解决涉及视觉呈现的物理任务时面临困难,主要包括视觉解读、物理定律提供以及空间协调和物理表达应用方面的问题。
- 空间推理任务对ChatGPT-4o来说特别具有挑战性,需要使用右手定则的任务尤为困难。
- 虽然ChatGPT-4o在教育领域有应用潜力,如个性化辅导和支持视觉障碍学生,但其局限性需要谨慎对待。
- 研究发现可用来设计聊天机器人难以解决的评估题目。
- 本研究为未来改善聊天机器人在物理教育中的表现提供了方向,包括提高视觉解读能力和处理空间推理任务的能力。
点击展开 Cool Papers 详细信息
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是评估和分析大型多模态模型(如ChatGPT-4和ChatGPT-4o)在处理涉及物理视觉表示的任务时的性能,特别是在物理教育领域中的应用。具体来说,论文关注以下几个研究问题:
ChatGPT-4和ChatGPT-4o在BEMA(Brief Electricity and Magnetism Assessment)上的表现如何?
- BEMA是一个包含丰富视觉表示(如矢量场、电路图和图表)的概念性物理测试。论文通过定量分析来评估这两个模型在BEMA上的表现,并与大学生样本的表现进行比较。
ChatGPT-4o在解释和解决涉及多种视觉物理表示的任务时面临哪些困难?
- 通过定性分析ChatGPT-4o的回答,论文揭示了该模型在视觉解释、提供正确的物理定律或规则以及空间协调和应用物理表示方面的持久挑战。
论文的目的是为物理教育社区提供对这两个广泛使用的商业大型语言模型(LLM)基础的聊天机器人能力的批判性视角,并指导决策,以确定这些模型是否可以有效支持教学和学习丰富表示的物理主题。此外,研究结果还可以为设计难以被聊天机器人解决的评估提供依据,以维护学术诚信。
Q: 有哪些相关研究?
A: 论文中提到了多个与大型语言模型(LLMs)和大型多模态模型(LMMs)在物理教育中应用相关的研究。以下是一些关键的相关研究:
LLMs在物理教育中的性能和应用:
- 评估LLMs在物理概念测试(如Force Concept Inventory, FCI)上的表现,发现ChatGPT-3.5表现在初学者水平,而ChatGPT-4展现出专家级表现[15, 16]。
- 研究LLMs在处理物理问题时的表现,发现它们在结构化问题上表现出色,但在需要多步推理或隐含假设的问题上表现不佳[20, 21]。
- 探讨LLMs在物理编程任务上的表现,发现ChatGPT-3.5在解决编程相关任务时表现出色[15]。
- 评估LLMs在物理课程考试中的表现,发现它们在简单问题上大多提供正确答案,但在问题复杂性增加时表现变化显著[26, 27]。
LMMs在物理教育中的应用和性能:
- 研究LMMs在解释和处理视觉表示方面的能力,特别是在医学和医学教育领域,这些研究展示了LMMs整合文本和视觉信息以执行复杂任务的潜力[55, 56]。
- 分析LMMs在物理任务中的视觉解释能力,发现ChatGPT-4在解释运动学图表时表现出一定的能力,但在视觉解释准确性上存在问题[12]。
链式思考(Chain of Thought, CoT):
- 探讨CoT方法在提高LLMs解决多步复杂推理任务上的有效性[64, 65]。
- 分析CoT风格的回答,以推断ChatGPT-4o在处理任务时的能力[66]。
多表示法在物理教育中的作用:
- 研究物理学科依赖多种表示法来捕捉和传达学科意义,特别是在电磁学领域[67-72]。
这些研究为理解LLMs和LMMs在物理教育中的应用和性能提供了基础,并指出了它们在解释视觉表示和进行多步推理方面的挑战。论文通过扩展这些研究,特别关注ChatGPT-4和ChatGPT-4o在涉及物理视觉表示的任务上的表现,为物理教育领域提供了新的见解。
Q: 论文如何解决这个问题?
A: 论文通过以下步骤解决评估大型多模态模型(LMMs)在处理涉及物理视觉表示的任务时的性能问题:
1. 研究设计和测试工具选择
- 选择BEMA(Brief Electricity and Magnetism Assessment)作为测试工具:BEMA是一个包含丰富视觉表示(如矢量场、电路图和图表)的概念性物理测试,适合评估ChatGPT处理物理视觉表示的能力。
2. 数据收集和预处理
- 使用高分辨率截图:将BEMA的所有31个测试项制作成22张包含视觉表示、问题和答案选项的截图。
- 独立测试:每个截图作为独立变量提交给ChatGPT-4和ChatGPT-4o,以评估它们在每个项目上的表现。
3. 定量分析
- 比较ChatGPT-4和ChatGPT-4o的性能:通过比较两个模型在BEMA上的平均得分,以及它们与大学生样本的表现差异。
- 评估视觉解释能力:通过比较“按字母编码”和“按意义编码”的回答,评估模型的视觉解释能力。
4. 定性分析
- 分析ChatGPT-4o的困难:专注于ChatGPT-4o在低于平均表现的项目上的回答,识别和分类模型在视觉解释、物理定律或规则提供以及空间协调和应用物理表示方面的困难。
- 特别关注右手定则(Right-hand rule)的应用:分析模型在需要使用右手定则的任务上的表现,揭示其在三维空间推理方面的挑战。
5. 结果分析和讨论
- 提供教育应用的见解:基于ChatGPT-4o的能力和局限性,讨论其在教育实践中的应用,包括作为辅助工具的潜在用途和设计难以被聊天机器人解决的评估的可能性。
6. 结论和建议
- 总结发现:基于定量和定性分析,提出对教育者使用ChatGPT-4o的建议,特别是在涉及图形表示的物理任务中。
- 指出未来研究方向:强调需要进一步研究来更好地理解LMMs在物理教育中的应用和性能。
通过这种方法,论文不仅评估了ChatGPT-4和ChatGPT-4o在物理视觉表示任务上的性能,还揭示了它们在教育应用中的潜力和局限性,为物理教育领域提供了有价值的见解。
Q: 论文做了哪些实验?
A: 论文中进行的实验主要围绕评估两个大型多模态模型(LMMs)——ChatGPT-4和ChatGPT-4o——在物理视觉表示任务上的表现。具体实验步骤如下:
实验1:BEMA测试项的响应生成
- 实验目的:评估ChatGPT-4和ChatGPT-4o在解释和解决涉及物理视觉表示的任务时的性能。
- 测试工具:使用Brief Electricity and Magnetism Assessment (BEMA),一个包含31个多项选择题的概念性物理测试,题目中包含丰富的视觉表示,如矢量场、电路图和图表。
- 数据收集:将BEMA的所有测试项制作成22张高分辨率截图,每张截图包含一个或多个测试项的视觉表示、问题和答案选项。
- 测试过程:
- 对于ChatGPT-4,每个截图提交60次;对于ChatGPT-4o,每个截图提交30次。
- 在每次提交中,只提供截图,不附加任何额外的文本指令。
- 禁用ChatGPT设置中的“记忆”功能,以确保每次对同一测试项的响应都是独立的。
实验2:答案编码和分析
- 编码方法:
- 按字母编码:记录ChatGPT在回答末尾明确指出的字母选项。
- 按意义编码:分析ChatGPT输出的内容,并将其与相应的答案选项匹配,无论明确指出的字母是什么。
- 性能评估:比较两种编码方法下的模型性能,以评估视觉解释能力。
实验3:定性分析ChatGPT-4o的困难
- 实验目的:深入了解ChatGPT-4o在解决BEMA任务时遇到的困难。
- 分析对象:选择ChatGPT-4o在“按意义编码”下表现低于平均的14个测试项。
- 分析方法:对420个响应进行定性分析,记录以下三类困难:
- 视觉解释困难
- 提供正确的物理定律或规则的困难
- 空间协调和应用物理表示、定律、规则和程序的困难
- 右手定则特别分析:进一步分析涉及使用右手定则的7个测试项的响应,记录右手定则的表述、正确性、表述方式以及在任务中的应用情况。
这些实验提供了对ChatGPT-4和ChatGPT-4o在物理视觉表示任务上性能的全面评估,并揭示了它们在教育应用中的潜力和局限性。
Q: 有什么可以进一步探索的点?
A: 根据论文的讨论和结论,以下是一些可以进一步探索的点:
1. 其他聊天机器人的性能比较
- 论文中只测试了OpenAI的LMMs(ChatGPT-4和ChatGPT-4o),没有与其他聊天机器人进行比较。未来的研究可以包括对其他商业聊天机器人在相同任务上的性能进行比较分析。
2. 特定提示工程的影响
- 论文没有使用专门的提示工程技术来增强聊天机器人的性能。研究如何通过精心设计的提示来提高LMMs在物理视觉表示任务上的表现是一个有价值的方向。
3. 视觉特征对模型性能的影响
- 需要更多的研究来确定哪些视觉特征使图像对聊天机器人特别难以解释。这可以通过系统地变化图像的视觉特征并测试LMMs的性能来实现。
4. 多模态提示的Prompt Engineering
- 多模态提示中的Prompt Engineering尚未受到太多关注,研究如何构建有效的多模态提示来提高LMMs的性能是一个有前景的研究方向。
5. 跨物理领域和评估格式的适用性
- 论文的发现基于电磁学的多项选择题。未来的研究可以探索这些发现是否适用于物理的其他领域和不同格式的评估。
6. 教育实践中的集成应用
- 研究如何将LMMs集成到实际的教育实践中,以及它们如何影响学生的学习和教师的教学。
7. 评估设计的改进
- 利用LMMs的弱点设计难以被聊天机器人解决的评估,以维护学术诚信。
8. 多模态模型的可靠性和准确性
- 进一步研究如何提高LMMs在解释图形表示和进行空间推理方面的准确性和可靠性。
9. 教育应用中的伦理和公平性问题
- 探讨LMMs在教育中应用时可能出现的伦理问题,如偏见传播、公平性和问责制。
10. 模型透明度和可解释性
- 提高对LMMs决策过程的理解和透明度,这对于它们在教育中的应用至关重要。
这些探索点可以帮助我们更深入地理解LMMs在物理教育中的潜力和局限,并指导我们如何更有效地利用这些工具来支持教学和学习。
Q: 总结一下论文的主要内容
A: 论文的主要内容总结如下:
研究背景与目的
- 评估大型多模态模型(LMMs),特别是ChatGPT-4和ChatGPT-4o,在处理涉及物理视觉表示的任务时的性能。
- 分析这些模型在物理教育中的应用潜力以及它们在解释视觉物理概念时遇到的挑战。
方法与实验设计
- 使用BEMA(Brief Electricity and Magnetism Assessment)作为测试工具,包含31个多项选择题,覆盖电静学、磁静学、电路、电势和磁感应等主题。
- 对每个测试项进行截图,提交给ChatGPT-4和ChatGPT-4o,记录它们的响应并进行编码分析。
定量分析
- ChatGPT-4和ChatGPT-4o在BEMA上的平均表现与大学生样本相比较。
- 通过比较“按字母编码”和“按意义编码”的回答来评估模型的视觉解释能力。
定性分析
- 分析ChatGPT-4o在低于平均表现的测试项上的回答,识别在视觉解释、物理定律或规则提供以及空间协调和应用物理表示方面的困难。
- 特别关注ChatGPT-4o在使用右手定则时的表现,揭示其在三维空间推理方面的挑战。
主要发现
- ChatGPT-4o在视觉解释能力上较ChatGPT-4有所改进,但在处理物理视觉表示任务时仍面临显著困难。
- ChatGPT-4o在使用右手定则等三维空间推理任务时表现出特定的挑战。
- 这些发现对教育应用具有启示,包括作为辅助工具的潜在用途和设计难以被聊天机器人解决的评估的可能性。
结论与建议
- 教育者在使用ChatGPT-4o时应谨慎,尤其是在涉及大量图形表示的物理任务中。
- 识别出的模型局限可以用来设计抗聊天机器人的评估,以维护学术诚信。
未来研究方向
- 对比其他聊天机器人的性能。
- 探索提示工程技术对提高模型性能的影响。
- 研究视觉特征对模型性能的影响。
- 将LMMs集成到实际的教育实践中,评估其对教学和学习的影响。
论文提供了对当前LMMs在物理教育中应用的深入分析,并指出了未来研究和实践的方向。
Q: 想要进一步了解论文
A: 以上只是了解一篇论文的几个基本FAQ。如果你还想与Kimi进一步讨论该论文,请点击 这里 为你跳转Kimi AI网页版,并启动一个与该论文相关的新会话。
点此查看论文截图