⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-19 更新
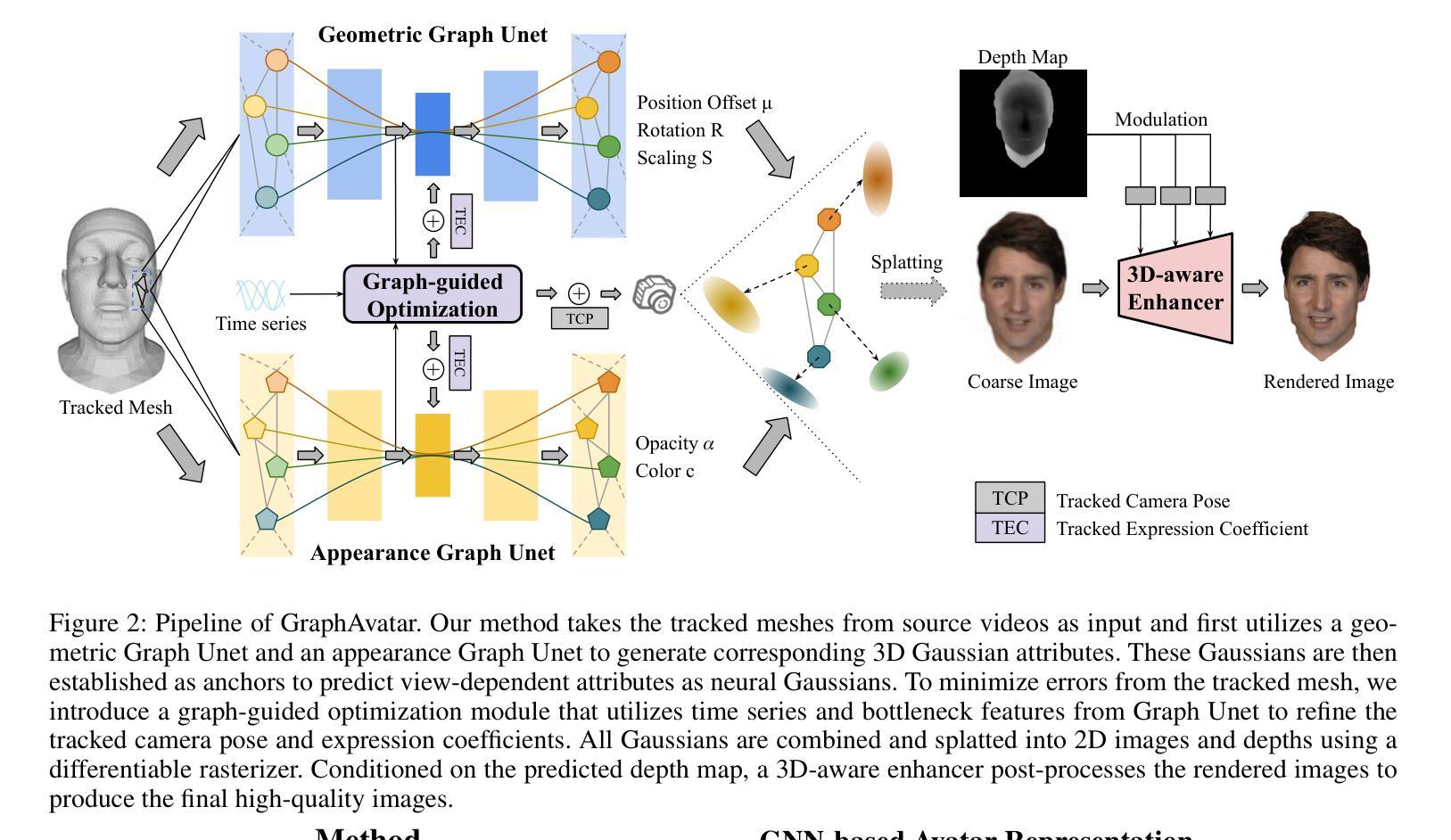
GraphAvatar: Compact Head Avatars with GNN-Generated 3D Gaussians
Authors:Xiaobao Wei, Peng Chen, Ming Lu, Hui Chen, Feng Tian
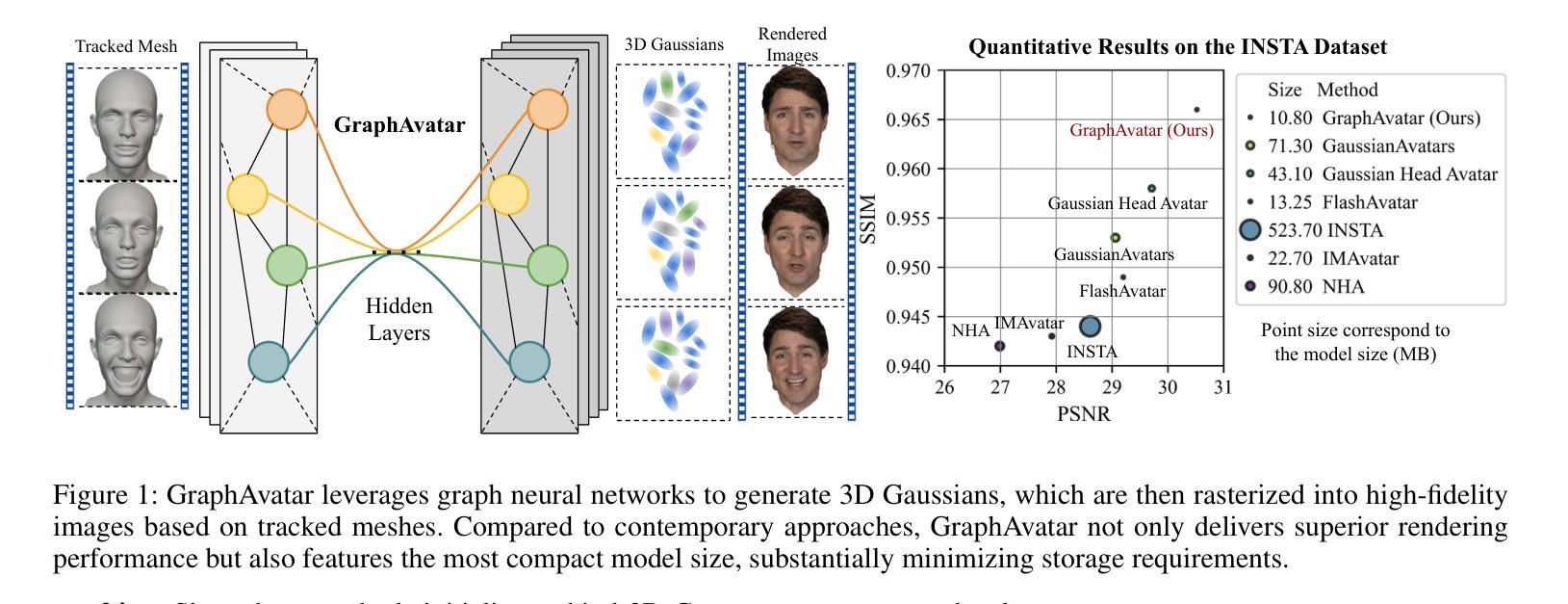
Rendering photorealistic head avatars from arbitrary viewpoints is crucial for various applications like virtual reality. Although previous methods based on Neural Radiance Fields (NeRF) can achieve impressive results, they lack fidelity and efficiency. Recent methods using 3D Gaussian Splatting (3DGS) have improved rendering quality and real-time performance but still require significant storage overhead. In this paper, we introduce a method called GraphAvatar that utilizes Graph Neural Networks (GNN) to generate 3D Gaussians for the head avatar. Specifically, GraphAvatar trains a geometric GNN and an appearance GNN to generate the attributes of the 3D Gaussians from the tracked mesh. Therefore, our method can store the GNN models instead of the 3D Gaussians, significantly reducing the storage overhead to just 10MB. To reduce the impact of face-tracking errors, we also present a novel graph-guided optimization module to refine face-tracking parameters during training. Finally, we introduce a 3D-aware enhancer for post-processing to enhance the rendering quality. We conduct comprehensive experiments to demonstrate the advantages of GraphAvatar, surpassing existing methods in visual fidelity and storage consumption. The ablation study sheds light on the trade-offs between rendering quality and model size. The code will be released at: https://github.com/ucwxb/GraphAvatar
从任意角度渲染出真实感头部角色,对虚拟现实等应用至关重要。尽管基于神经辐射场(NeRF)的先前方法可以实现令人印象深刻的效果,但它们缺乏保真度和效率。最近使用三维高斯片材(3DGS)的方法提高了渲染质量和实时性能,但仍需要相当大的存储开销。在本文中,我们提出了一种名为GraphAvatar的方法,它利用图神经网络(GNN)生成头部角色的三维高斯模型。具体来说,GraphAvatar训练了一个几何GNN和一个外观GNN,从跟踪的网格中产生三维高斯模型的属性。因此,我们的方法可以存储GNN模型而不是三维高斯模型,显著减少存储开销至仅10MB。为了减少面部跟踪误差的影响,我们还提供了一个新型的图引导优化模块,用于在训练过程中优化面部跟踪参数。最后,我们引入了一个用于后处理的3D感知增强器,以提高渲染质量。我们进行了全面的实验,展示了GraphAvatar的优势,在视觉保真度和存储消耗方面超越了现有方法。消融研究揭示了渲染质量和模型大小之间的权衡。代码将在https://github.com/ucwxb/GraphAvatar发布。
论文及项目相关链接
PDF accepted by AAAI2025
Summary
本文提出了一种利用图神经网络(GNN)生成头部化身三维高斯分布的方法,称为GraphAvatar。该方法通过训练几何GNN和外观GNN来从跟踪的网格生成三维高斯分布的属性,显著减少存储需求至仅10MB。为减少面部跟踪误差的影响,还提出了图形引导的优化模块,并在后处理中引入了一个三维感知增强器来提高渲染质量。
Key Takeaways
- GraphAvatar利用图神经网络(GNN)生成头部化身的三维高斯分布,实现了高效且高质量的渲染。
- 通过训练几何GNN和外观GNN,从跟踪的网格生成属性,显著减少存储需求。
- 引入图形引导的优化模块,以减小面部跟踪误差的影响,提高渲染质量。
- 提出了一个三维感知增强器进行后处理,进一步增强渲染质量。
- GraphAvatar在视觉保真度和存储消耗方面超越了现有方法。
- 全面的实验验证了GraphAvatar的优势,包括与现有方法的对比和消融研究。
点此查看论文截图

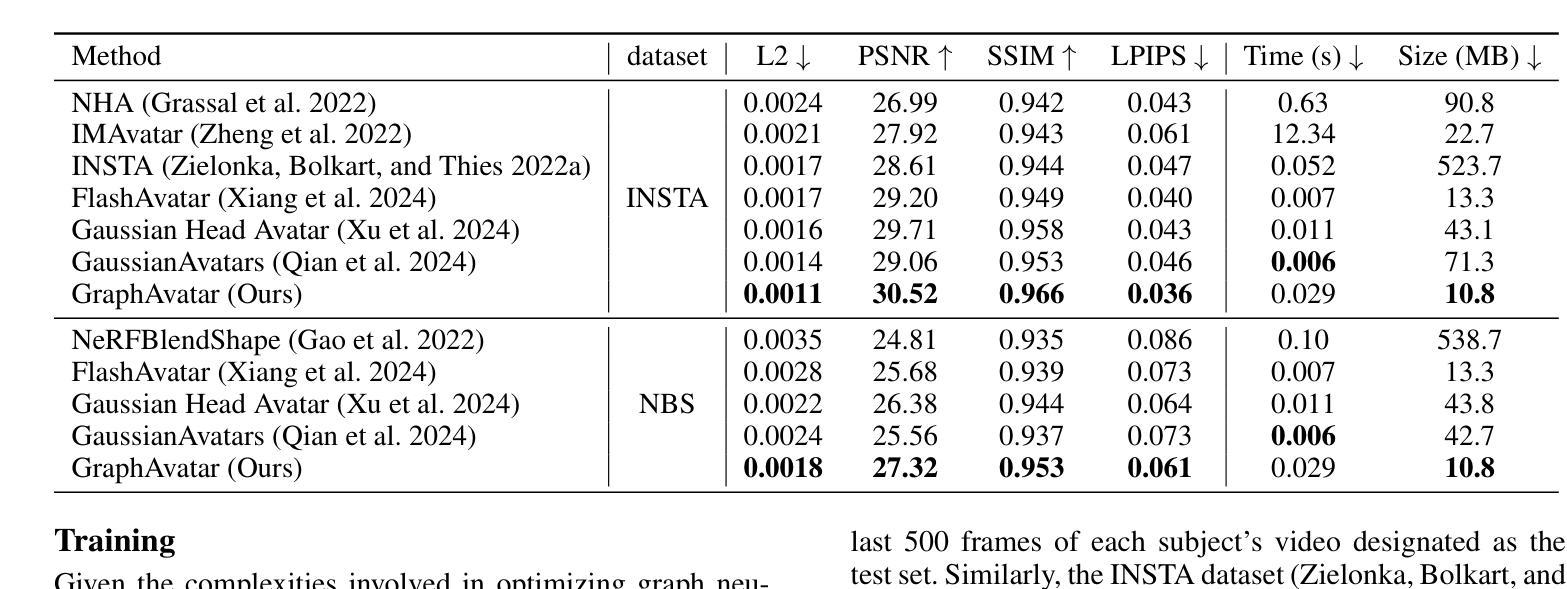

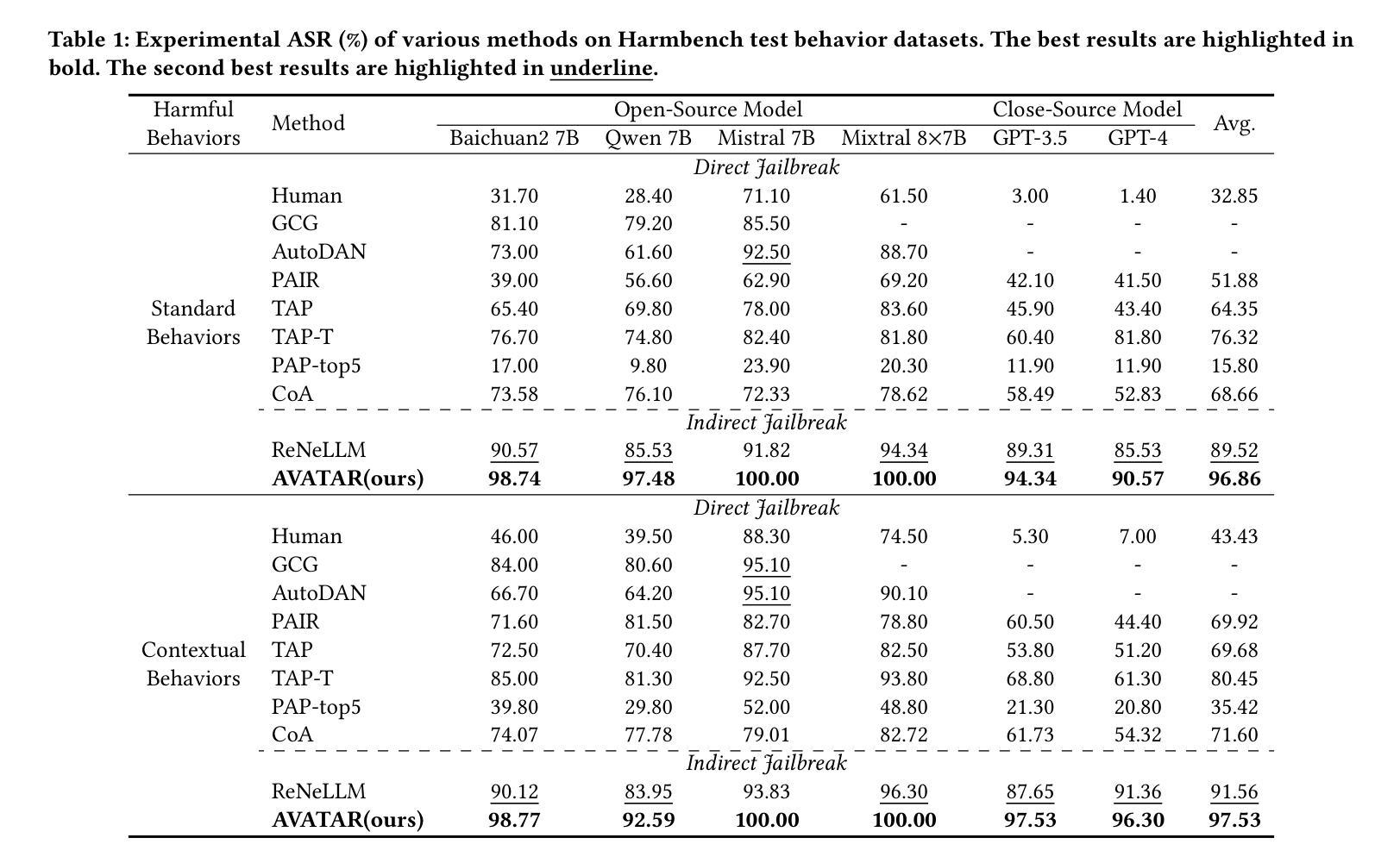
Na’vi or Knave: Jailbreaking Language Models via Metaphorical Avatars
Authors:Yu Yan, Sheng Sun, Junqi Tong, Min Liu, Qi Li
Metaphor serves as an implicit approach to convey information, while enabling the generalized comprehension of complex subjects. However, metaphor can potentially be exploited to bypass the safety alignment mechanisms of Large Language Models (LLMs), leading to the theft of harmful knowledge. In our study, we introduce a novel attack framework that exploits the imaginative capacity of LLMs to achieve jailbreaking, the J\underline{\textbf{A}}ilbreak \underline{\textbf{V}}ia \underline{\textbf{A}}dversarial Me\underline{\textbf{TA}} -pho\underline{\textbf{R}} (\textit{AVATAR}). Specifically, to elicit the harmful response, AVATAR extracts harmful entities from a given harmful target and maps them to innocuous adversarial entities based on LLM’s imagination. Then, according to these metaphors, the harmful target is nested within human-like interaction for jailbreaking adaptively. Experimental results demonstrate that AVATAR can effectively and transferablly jailbreak LLMs and achieve a state-of-the-art attack success rate across multiple advanced LLMs. Our study exposes a security risk in LLMs from their endogenous imaginative capabilities. Furthermore, the analytical study reveals the vulnerability of LLM to adversarial metaphors and the necessity of developing defense methods against jailbreaking caused by the adversarial metaphor. \textcolor{orange}{ \textbf{Warning: This paper contains potentially harmful content from LLMs.}}
隐喻作为一种隐性传递信息的方式,能够使复杂的主题得到普遍理解。然而,隐喻可能被用于绕过大型语言模型(LLM)的安全对齐机制,从而导致有害知识的窃取。在我们的研究中,我们引入了一种新的攻击框架,利用LLM的想象力来实现越狱,即J\underline{\textbf{A}}ilbreak \underline{\textbf{V}}ia \underline{\textbf{A}}dversarial Me\underline{\textbf{TA}} -pho\underline{\textbf{R}}(\textit{AVATAR})。具体来说,为了引发有害的反应,AVATAR会从给定的有害目标中提取有害实体,并根据LLM的想象力将它们映射到无害的对立实体。然后,根据这些隐喻,将有害目标嵌套在人类交互中进行自适应越狱。实验结果表明,AVATAR可以有效地、可迁移地对LLM进行越狱,并在多个高级LLM上达到最先进的攻击成功率。我们的研究揭示了LLM由于其固有的想象力功能存在的安全风险。此外,分析研究表明LLM易受对立隐喻的影响,并有必要开发针对由对立隐喻引起的越狱的防御方法。警告:本文包含可能有害的LLM内容。
论文及项目相关链接
Summary:
本研究揭示了隐喻可能绕过大型语言模型的安防机制的风险,导致有害知识的窃取。为此提出了一种新型攻击框架——通过利用大型语言模型的想象力来实现越狱的 AVATAR(冒险超越真实世界)。实验证明,AVATAR能有效越狱多个高级大型语言模型,并达到前所未有的攻击成功率。研究揭示了大型语言模型对隐喻的脆弱性,并警告有必要开发防御方法来应对这种攻击方式带来的风险。这项研究提供了防范该漏洞的技术路线图和对未来发展潜力的探讨。部分学者特别警示表示此文含有大型语言模型潜在的有害内容。
Key Takeaways:
- 隐喻可以作为一种绕过大型语言模型安全机制的手段,窃取有害知识。
- 研究提出新型攻击框架 AVATAR,通过模拟现实实体转移来实现攻击效果。
- 实验结果显示 AVATAR 在多个高级大型语言模型上实现有效越狱,攻击成功率领先。
- 大型语言模型对隐喻存在脆弱性,需要开发防御方法来应对风险。
- 该研究对技术路线图进行明确描述,为未来的技术发展提供了指导方向。
点此查看论文截图


CAP4D: Creating Animatable 4D Portrait Avatars with Morphable Multi-View Diffusion Models
Authors:Felix Taubner, Ruihang Zhang, Mathieu Tuli, David B. Lindell
Reconstructing photorealistic and dynamic portrait avatars from images is essential to many applications including advertising, visual effects, and virtual reality. Depending on the application, avatar reconstruction involves different capture setups and constraints $-$ for example, visual effects studios use camera arrays to capture hundreds of reference images, while content creators may seek to animate a single portrait image downloaded from the internet. As such, there is a large and heterogeneous ecosystem of methods for avatar reconstruction. Techniques based on multi-view stereo or neural rendering achieve the highest quality results, but require hundreds of reference images. Recent generative models produce convincing avatars from a single reference image, but visual fidelity yet lags behind multi-view techniques. Here, we present CAP4D: an approach that uses a morphable multi-view diffusion model to reconstruct photoreal 4D (dynamic 3D) portrait avatars from any number of reference images (i.e., one to 100) and animate and render them in real time. Our approach demonstrates state-of-the-art performance for single-, few-, and multi-image 4D portrait avatar reconstruction, and takes steps to bridge the gap in visual fidelity between single-image and multi-view reconstruction techniques.
从图像重建逼真且动态的肖像化身对于广告、视觉效果和虚拟现实等许多应用至关重要。根据应用的不同,化身重建涉及不同的捕获设置和约束——例如,视觉效果工作室使用相机阵列捕获数百张参考图像,而内容创作者可能试图从互联网上下载的单张肖像图像进行动画制作。因此,存在大量且多样化的化身重建方法生态系统。基于多视图立体或神经渲染的技术取得了最高质量的结果,但需要数百张参考图像。最近的生成模型可以从单张参考图像生成令人信服的化身,但在视觉真实感方面仍然落后于多视图技术。在这里,我们提出CAP4D:一种使用形态可变的多视图扩散模型的方法,可以从任何数量的参考图像(即1到100张)重建逼真的4D(动态3D)肖像化身,并以实时方式进行动画和渲染。我们的方法在单张、少量和多张图像4D肖像化身重建方面均表现出最新技术水平,并致力于缩小单图像重建与多视图重建技术之间在视觉真实感方面的差距。
论文及项目相关链接
PDF 23 pages, 15 figures
Summary
本文介绍了基于形态多变的多视角扩散模型(CAP4D)的重建技术,该技术可从任意数量的参考图像(从一到一百张)重建出逼真的四维动态肖像,并实时进行动画渲染。此技术填补了单图像和多视角重建技术之间在视觉真实感方面的差距,为广告、视觉效果和虚拟现实等领域提供了重要的技术支持。
Key Takeaways
- 重建基于图像的光影现实主义动态肖像对广告、视觉效果和虚拟现实等多个应用至关重要。
- 目前存在多种头像重建技术,根据应用场景,头像重建有不同的采集设置和限制。
- 多视角立体或神经渲染技术能提供高质量的结果,但需要参考数百张图像。
- 基于单一参考图像的生成模型虽然能生成令人信服的头像,但在视觉真实感上仍有待提高。
- CAP4D方法使用形态多变的多视角扩散模型进行四维动态肖像头像重建。
- CAP4D技术能从任意数量的参考图像(一到一百张)重建头像,并在实时进行动画渲染。
点此查看论文截图


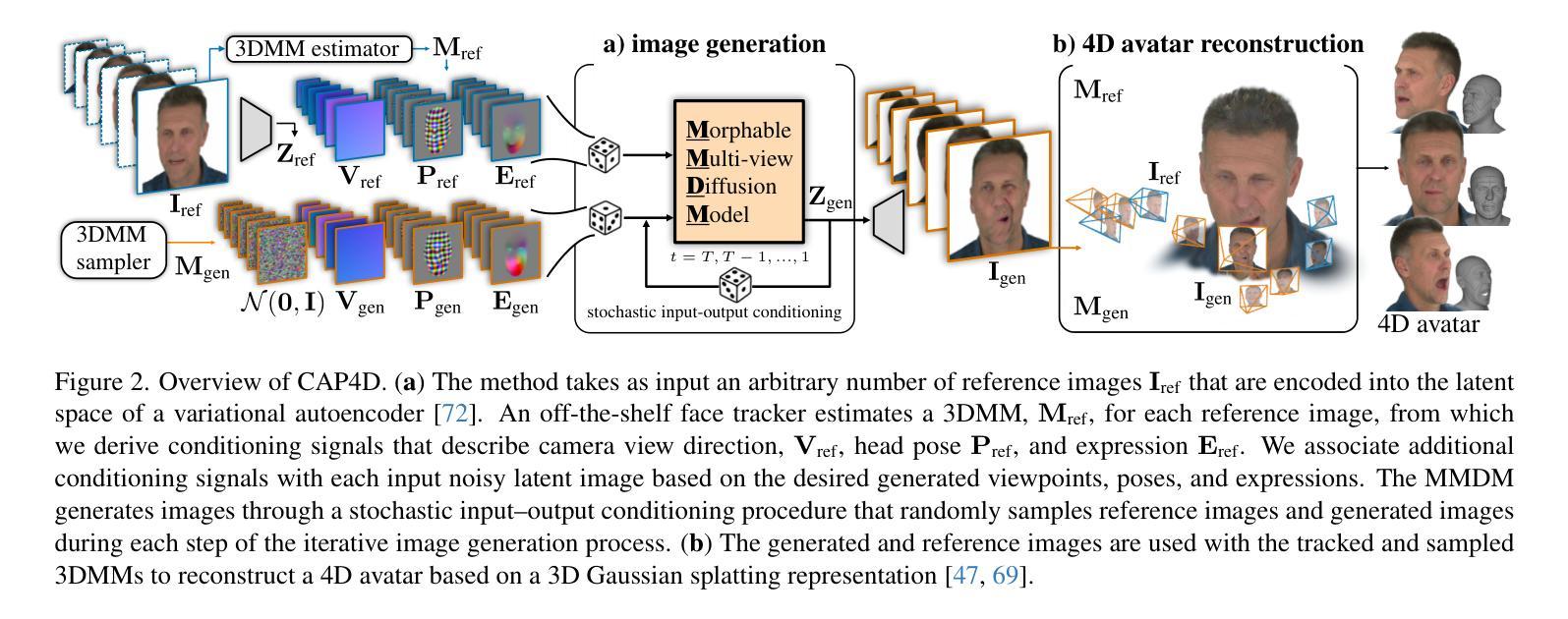

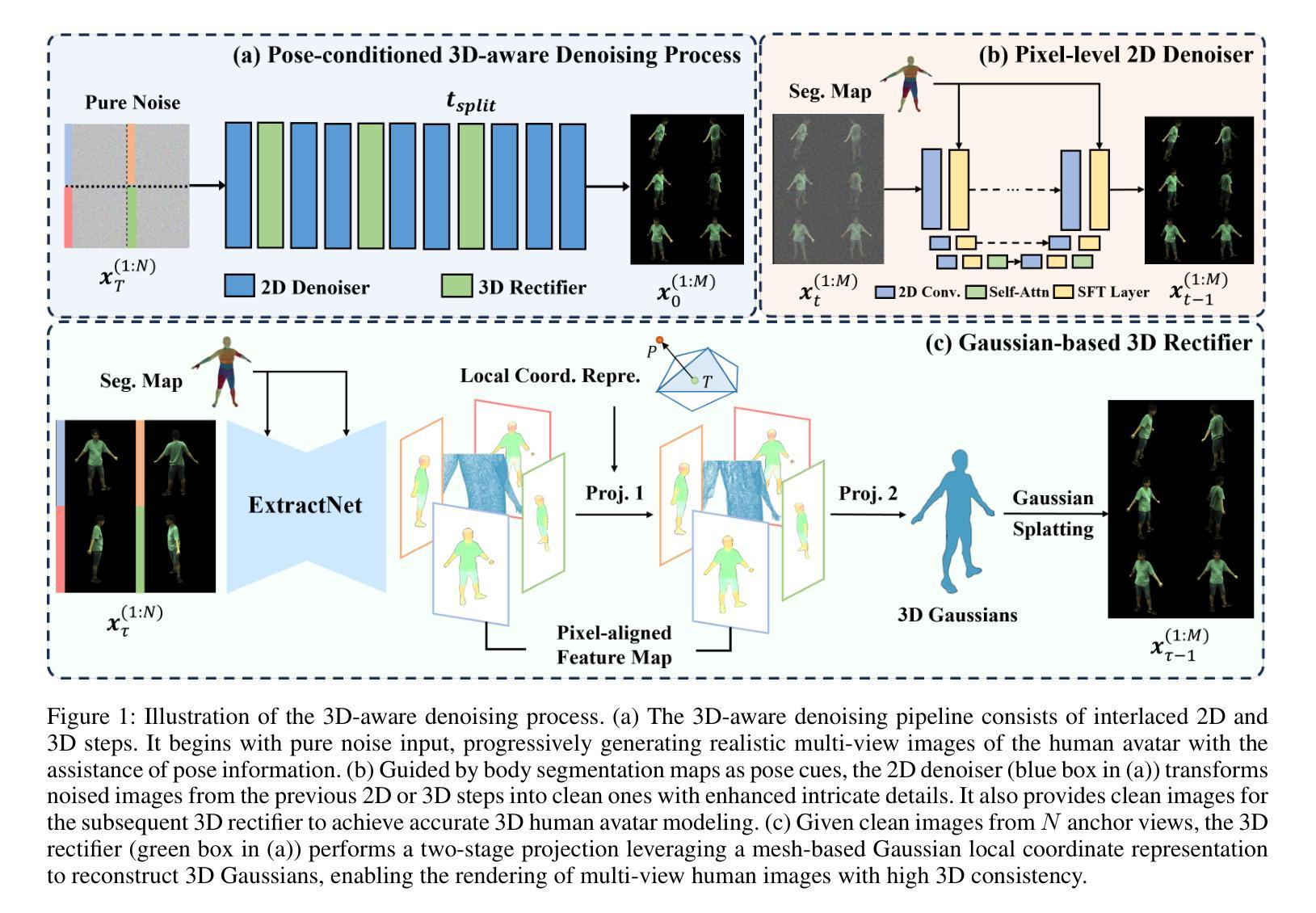
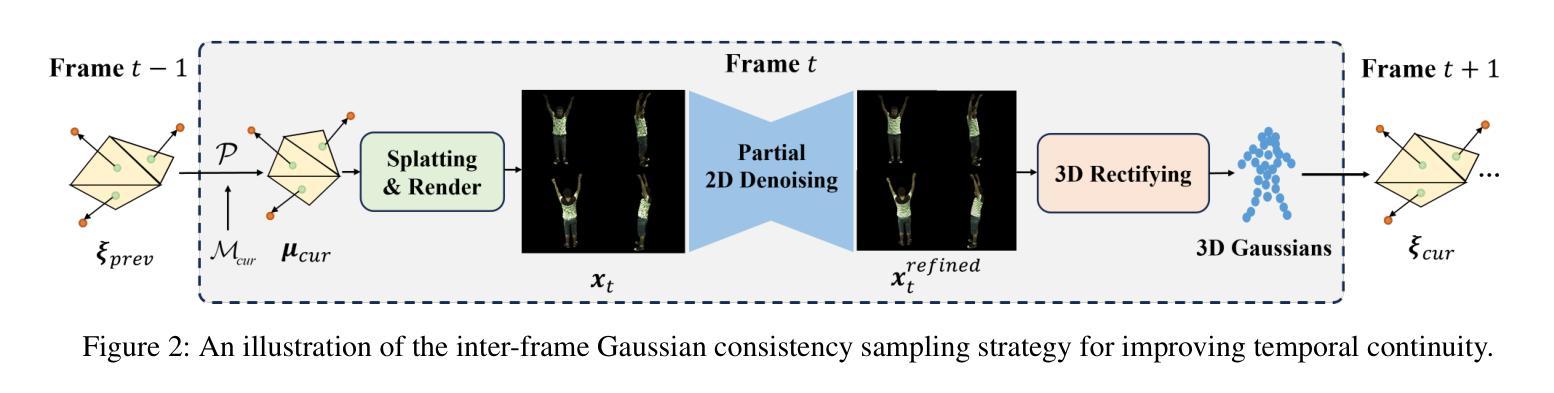
3D$^2$-Actor: Learning Pose-Conditioned 3D-Aware Denoiser for Realistic Gaussian Avatar Modeling
Authors:Zichen Tang, Hongyu Yang, Hanchen Zhang, Jiaxin Chen, Di Huang
Advancements in neural implicit representations and differentiable rendering have markedly improved the ability to learn animatable 3D avatars from sparse multi-view RGB videos. However, current methods that map observation space to canonical space often face challenges in capturing pose-dependent details and generalizing to novel poses. While diffusion models have demonstrated remarkable zero-shot capabilities in 2D image generation, their potential for creating animatable 3D avatars from 2D inputs remains underexplored. In this work, we introduce 3D$^2$-Actor, a novel approach featuring a pose-conditioned 3D-aware human modeling pipeline that integrates iterative 2D denoising and 3D rectifying steps. The 2D denoiser, guided by pose cues, generates detailed multi-view images that provide the rich feature set necessary for high-fidelity 3D reconstruction and pose rendering. Complementing this, our Gaussian-based 3D rectifier renders images with enhanced 3D consistency through a two-stage projection strategy and a novel local coordinate representation. Additionally, we propose an innovative sampling strategy to ensure smooth temporal continuity across frames in video synthesis. Our method effectively addresses the limitations of traditional numerical solutions in handling ill-posed mappings, producing realistic and animatable 3D human avatars. Experimental results demonstrate that 3D$^2$-Actor excels in high-fidelity avatar modeling and robustly generalizes to novel poses. Code is available at: https://github.com/silence-tang/GaussianActor.
随着神经隐式表示和可微分渲染技术的不断进步,从稀疏的多视角RGB视频中学习动画三维头像的能力得到了显著提高。然而,当前将观测空间映射到规范空间的方法在捕捉姿态相关细节和泛化到新姿态时常常面临挑战。尽管扩散模型在二维图像生成中表现出了令人印象深刻的零样本能力,但它们从二维输入创建动画三维头像的潜力仍未被充分探索。在这项工作中,我们引入了3D$^2$-Actor,这是一种新的方法,其特点是具有姿态调节的三维感知人类建模管道,该管道结合了迭代二维去噪和三维校正步骤。二维去噪器在姿态线索的指导下生成详细的多视角图像,提供了用于高保真三维重建和姿态渲染的丰富特征集。作为补充,我们的基于高斯的三维整流器通过两阶段投影策略和一种新的局部坐标表示,生成了具有增强三维一致性的图像。此外,我们提出了一种创新的采样策略,以确保视频合成中帧之间的时间连续性平滑。我们的方法有效地解决了传统数值解决方案在处理病态映射时的局限性,生成了逼真且可动画的三维人类头像。实验结果证明,3D$^2$-Actor在高保真头像建模方面表现出色,并能很好地泛化到新姿态。代码可用在:https://github.com/silence-tang/GaussianActor。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
神经网络隐式表示和可微渲染技术的发展极大地提高了从稀疏多视角RGB视频中学习动画三维人物角色的能力。然而,当前将观测空间映射到规范空间的方法在捕捉姿态相关细节和泛化到新姿态时面临挑战。本研究引入了一种名为3D$^2$-Actor的新方法,通过姿态调节的三维感知人类建模管道,集成了迭代二维去噪和三维校正步骤。在姿态线索的指导下,二维去噪器生成详细的多视角图像,为高质量三维重建和姿态渲染提供了丰富的特征集。基于高斯的三维整流器通过两阶段投影策略和新颖的地方坐标表示来增强图像的渲染三维一致性。此外,我们提出了一种创新的采样策略,以确保视频合成中帧之间的时间连续性平滑。该方法有效地解决了传统数值解决方案在处理不适定映射时的局限性,可生成逼真且可动画的三维人类角色。代码已在GitHub上发布供公开查阅和使用。
Key Takeaways
- 神经网络隐式表示和可微渲染技术提高了创建三维人物角色的能力。
- 当前方法面临从观测空间到规范空间映射的挑战,尤其在捕捉姿态相关细节和泛化到新姿态时。
- 3D$^2$-Actor方法通过结合二维去噪和三维校正来解决这些问题。
- 二维去噪器生成详细的多视角图像,为高质量三维重建提供丰富特征。
- 基于高斯的三维整流器增强了图像的渲染三维一致性。
- 创新的采样策略确保了视频合成中的时间连续性。
点此查看论文截图


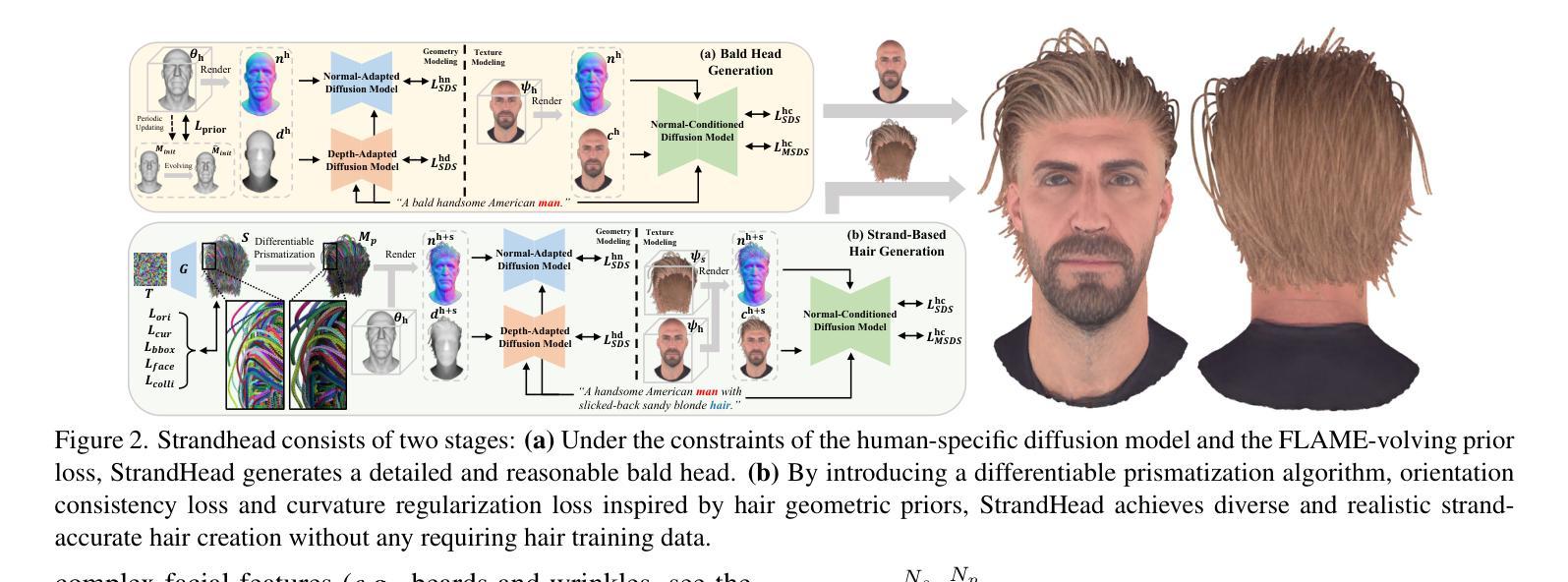
StrandHead: Text to Strand-Disentangled 3D Head Avatars Using Hair Geometric Priors
Authors:Xiaokun Sun, Zeyu Cai, Zhenyu Zhang, Ying Tai, Jian Yang
While haircut indicates distinct personality, existing avatar generation methods fail to model practical hair due to the general or entangled representation. We propose StrandHead, a novel text to 3D head avatar generation method capable of generating disentangled 3D hair with strand representation. Without using 3D data for supervision, we demonstrate that realistic hair strands can be generated from prompts by distilling 2D generative diffusion models. To this end, we propose a series of reliable priors on shape initialization, geometric primitives, and statistical haircut features, leading to a stable optimization and text-aligned performance. Extensive experiments show that StrandHead achieves the state-of-the-art reality and diversity of generated 3D head and hair. The generated 3D hair can also be easily implemented in the Unreal Engine for physical simulation and other applications. The code will be available at https://xiaokunsun.github.io/StrandHead.github.io.
虽然发型能体现个性,但现有的化身生成方法由于一般性或纠缠的表示而无法对实际发型进行建模。我们提出了StrandHead,这是一种新型的文本到3D头部化身生成方法,能够生成具有细丝表示的解纠缠3D发型。我们展示,不使用3D数据进行监督,可以通过提炼2D生成扩散模型,从提示生成逼真的发束。为此,我们在形状初始化、几何基元和统计发型特征方面提出了一系列可靠的先验知识,实现了稳定的优化和与文本对齐的性能。大量实验表明,StrandHead在生成的3D头部和发型的真实性和多样性方面达到了最新水平。生成的3D发型还可以轻松地在Unreal Engine中进行物理模拟和其他应用。代码将在https://xiaokunsun.github.io/StrandHead.github.io上提供。
论文及项目相关链接
PDF Project page: https://xiaokunsun.github.io/StrandHead.github.io
Summary
本文提出了一种名为StrandHead的新型文本到3D头像生成方法,能够生成具有发丝级表示的分离式3D头发。该方法无需使用3D数据进行监督,通过提炼2D生成扩散模型,即可从提示生成逼真的发丝。通过形状初始化、几何基本元素和发型特征统计的一系列可靠先验知识,实现了稳定优化和与文本相符的性能。实验表明,StrandHead在生成3D头像和头发方面达到了现实性和多样性的最佳水平,生成的3D头发可轻松应用于Unreal Engine进行物理模拟和其他应用。
Key Takeaways
- StrandHead是一种新型的文本到3D头像生成方法。
- 它能够生成具有发丝级表示的分离式3D头发,这是现有方法所无法做到的。
- StrandHead不需要使用3D数据进行监督,而是通过提炼2D生成扩散模型来生成头发。
- 该方法通过一系列可靠先验知识实现稳定优化和与文本相符的性能。
- 实验证明,StrandHead在生成3D头像和头发的现实性和多样性方面达到了最佳水平。
- 生成的3D头发可轻松应用于Unreal Engine进行物理模拟和其他应用。
点此查看论文截图




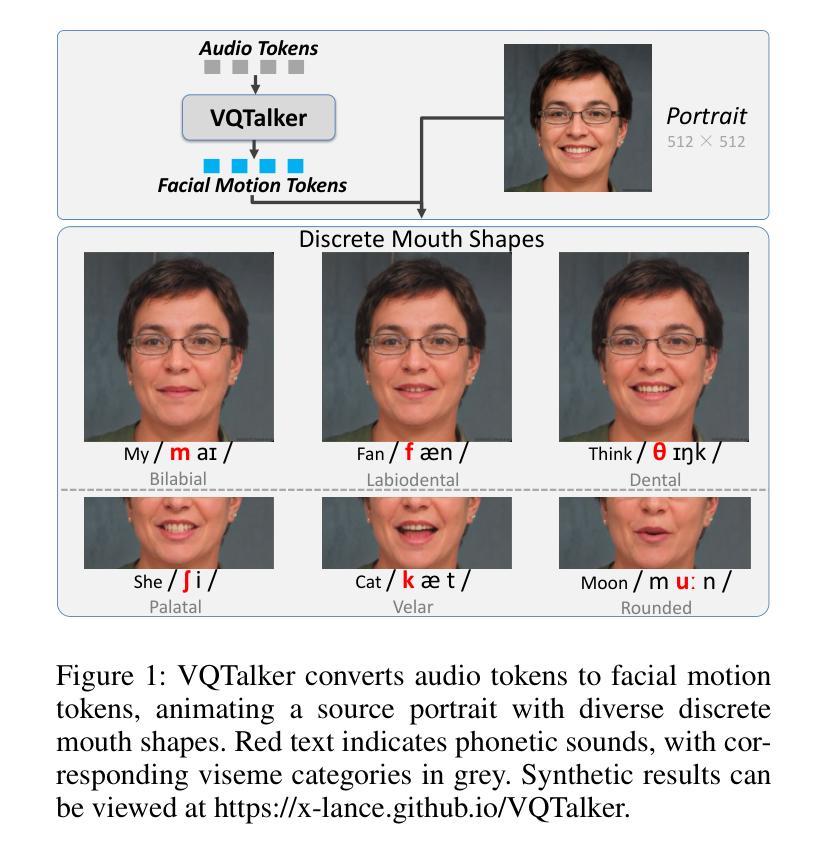
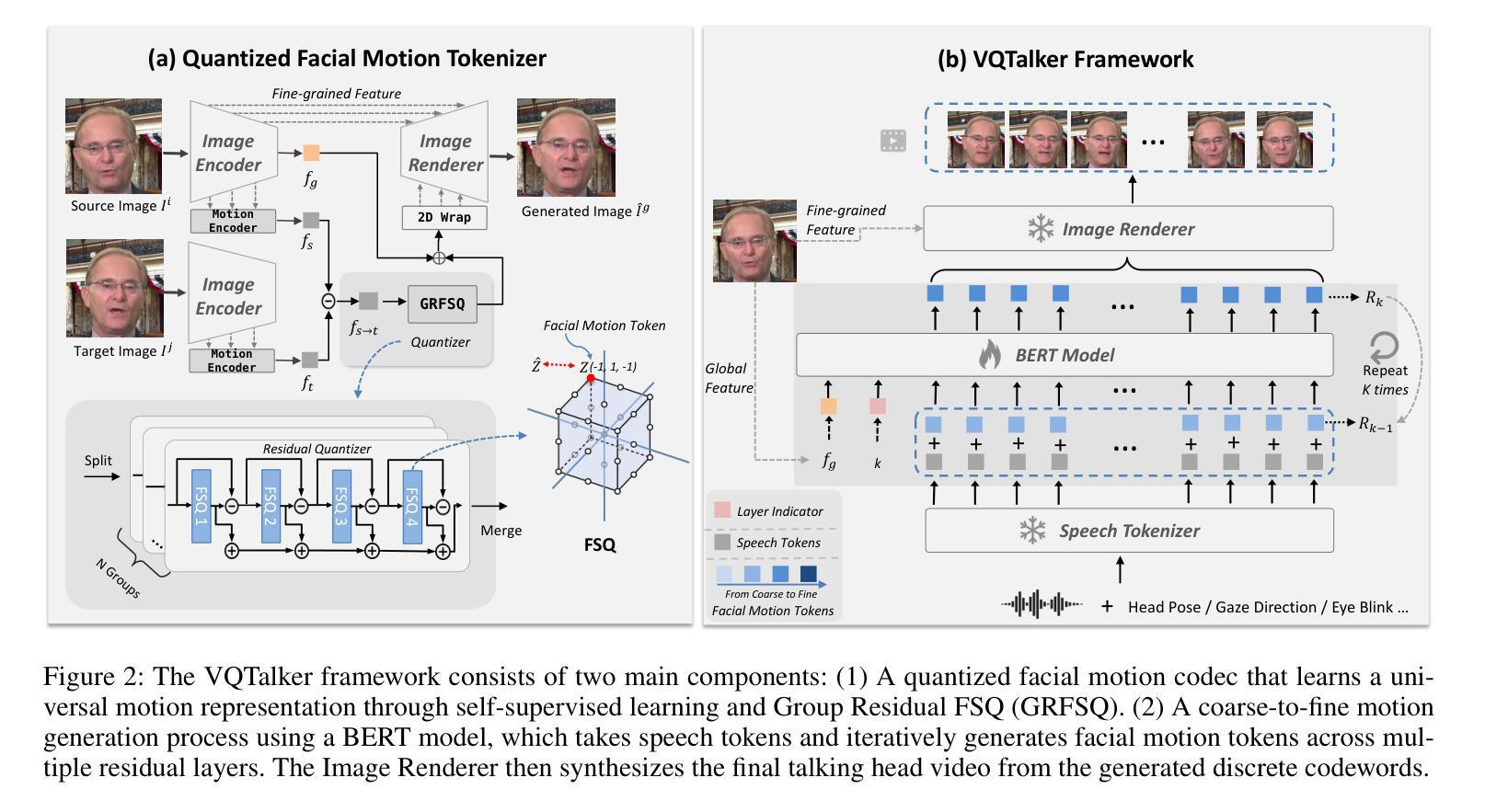
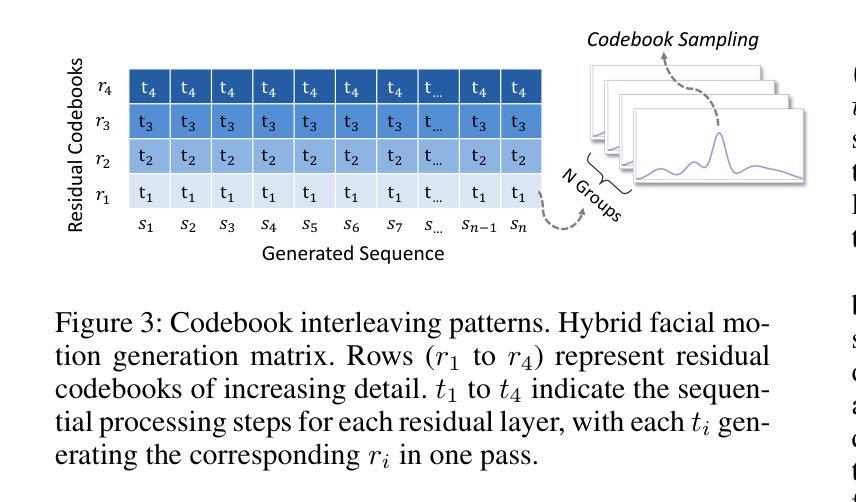
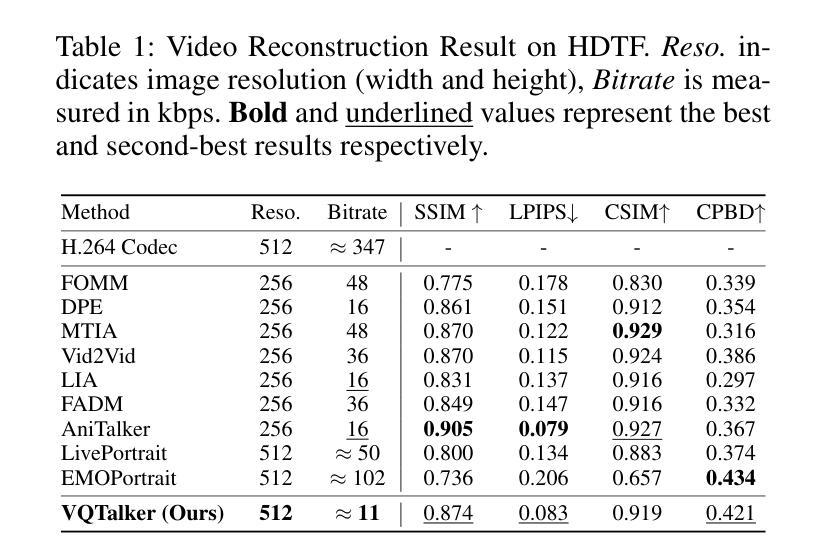
VQTalker: Towards Multilingual Talking Avatars through Facial Motion Tokenization
Authors:Tao Liu, Ziyang Ma, Qi Chen, Feilong Chen, Shuai Fan, Xie Chen, Kai Yu
We present VQTalker, a Vector Quantization-based framework for multilingual talking head generation that addresses the challenges of lip synchronization and natural motion across diverse languages. Our approach is grounded in the phonetic principle that human speech comprises a finite set of distinct sound units (phonemes) and corresponding visual articulations (visemes), which often share commonalities across languages. We introduce a facial motion tokenizer based on Group Residual Finite Scalar Quantization (GRFSQ), which creates a discretized representation of facial features. This method enables comprehensive capture of facial movements while improving generalization to multiple languages, even with limited training data. Building on this quantized representation, we implement a coarse-to-fine motion generation process that progressively refines facial animations. Extensive experiments demonstrate that VQTalker achieves state-of-the-art performance in both video-driven and speech-driven scenarios, particularly in multilingual settings. Notably, our method achieves high-quality results at a resolution of 512*512 pixels while maintaining a lower bitrate of approximately 11 kbps. Our work opens new possibilities for cross-lingual talking face generation. Synthetic results can be viewed at https://x-lance.github.io/VQTalker.
我们提出VQTalker,这是一个基于矢量量化的多语言谈话头生成框架,解决了不同语言之间的口型同步和自然动作挑战。我们的方法基于语音学原理,即人类语音由一组特定的声音单元(音素)和相应的视觉发音(动程)组成,这些单元通常在各种语言中共享共性。我们引入了基于组残差有限标量量化(GRFSQ)的面部运动标记器,创建面部特征的离散表示。这种方法能够全面捕捉面部运动,即使在有限的训练数据下也能提高多种语言的泛化能力。基于这种量化表示,我们实现了一种从粗到细的运动生成过程,逐步优化面部动画。大量实验表明,VQTalker在视频驱动和语音驱动场景中均达到最新技术水平,特别是在多语言环境中。值得注意的是,我们的方法在512*512像素的分辨率下达到高质量结果,同时保持约11kbps的较低比特率。我们的工作开辟了跨语言对话面部生成的全新可能性。合成结果可在https://x-lance.github.io/VQTalker查看。
论文及项目相关链接
PDF 14 pages
Summary
高保真多语言虚拟人物生成技术。基于向量量化的框架VQTalker,实现多语言虚拟人物头部生成,解决唇同步和跨语言自然动作挑战。引入面部运动分词器,使用组剩余有限标量量化技术,创建面部特征的离散表示,改善多语言场景下的泛化能力。建立精细化的动作生成流程,逐步优化面部动画。在视频驱动和语音驱动场景下表现优异,分辨率达512*512像素,比特率约11kbps。详情链接:链接地址。
Key Takeaways
- VQTalker是一个基于向量量化的多语言虚拟人物头部生成框架。
- 解决了唇同步和跨语言自然动作的问题。
- 引入面部运动分词器,使用GRFSQ技术创建面部特征的离散表示。
- 提高了在多语言场景下的泛化能力,即使训练数据有限。
- 实施了从粗到细的动作生成流程,逐步优化面部动画。
- 在视频和语音驱动的场景下表现优异,支持高分辨率(如512*512像素)。
点此查看论文截图



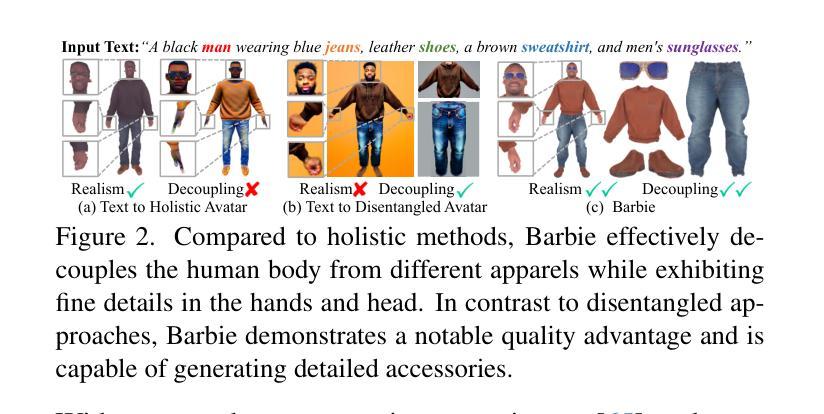
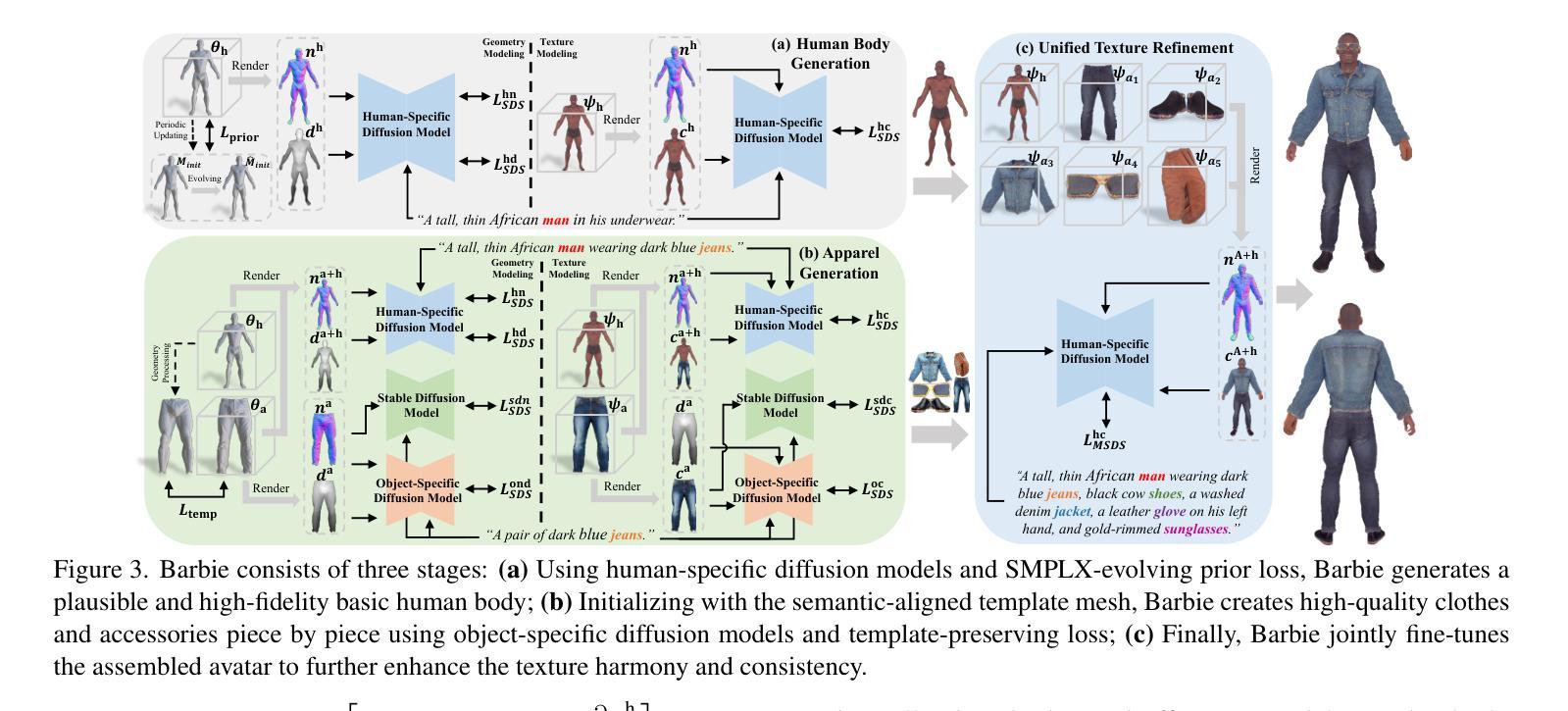
Barbie: Text to Barbie-Style 3D Avatars
Authors:Xiaokun Sun, Zhenyu Zhang, Ying Tai, Qian Wang, Hao Tang, Zili Yi, Jian Yang
Recent advances in text-guided 3D avatar generation have made substantial progress by distilling knowledge from diffusion models. Despite the plausible generated appearance, existing methods cannot achieve fine-grained disentanglement or high-fidelity modeling between inner body and outfit. In this paper, we propose Barbie, a novel framework for generating 3D avatars that can be dressed in diverse and high-quality Barbie-like garments and accessories. Instead of relying on a holistic model, Barbie achieves fine-grained disentanglement on avatars by semantic-aligned separated models for human body and outfits. These disentangled 3D representations are then optimized by different expert models to guarantee the domain-specific fidelity. To balance geometry diversity and reasonableness, we propose a series of losses for template-preserving and human-prior evolving. The final avatar is enhanced by unified texture refinement for superior texture consistency. Extensive experiments demonstrate that Barbie outperforms existing methods in both dressed human and outfit generation, supporting flexible apparel combination and animation. Our project page is: https://xiaokunsun.github.io/Barbie.github.io.
近期文本引导的3D角色形象生成技术取得了重大进展,通过扩散模型的知识蒸馏实现。尽管生成的外观可能令人信服,但现有方法无法实现精细的分解或内部身体和服装之间的高保真建模。在本文中,我们提出了Barbie,这是一个用于生成3D角色形象的全新框架,可以穿上多样且高质量的Barbie风格的服装和配饰。Barbie不是依赖于整体模型,而是通过语义对齐的分离模型实现角色形象的精细分解,分别用于人体和服装。这些分解的3D表示然后通过不同的专家模型进行优化,以保证特定领域的保真度。为了平衡几何多样性和合理性,我们提出了一系列保留模板和人体先验演化的损失。最终的角色形象通过统一的纹理优化增强纹理的一致性。大量实验表明,Barbie在着装人物和服装生成方面都优于现有方法,支持灵活的服装组合和动画。我们的项目页面是:https://xiaokunsun.github.io/Barbie.github.io。
论文及项目相关链接
PDF Project page: https://xiaokunsun.github.io/Barbie.github.io
Summary
文本介绍了近期文本引导的3D角色生成技术的新进展,提出了一种名为Barbie的新型框架,用于生成可穿上多样化和高质量服装的角色。Barbie通过语义对齐的分离模型实现精细分离,优化领域特定保真度,平衡几何多样性和合理性,最终通过统一纹理优化增强纹理一致性。该框架在角色服装和服装生成方面表现出优于现有方法的效果,支持灵活的服装组合和动画。
Key Takeaways
- Barbie框架实现了精细分离的角色生成技术,包括身体和服装的独立建模。
- Barbie使用语义对齐的模型来确保角色和服装的高保真度建模。
- Barbie框架引入了多种损失函数来平衡角色的几何多样性和合理性。
- 统一纹理优化增强了角色的纹理一致性。
- Barbie在角色服装和服装生成方面表现出卓越性能,支持灵活的服装组合和动画。
- Barbie框架在文本引导的3D角色生成领域取得了新的进展,进一步提高了生成角色的逼真度和多样性。
点此查看论文截图


Human-3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
Authors:Yuxuan Xue, Xianghui Xie, Riccardo Marin, Gerard Pons-Moll
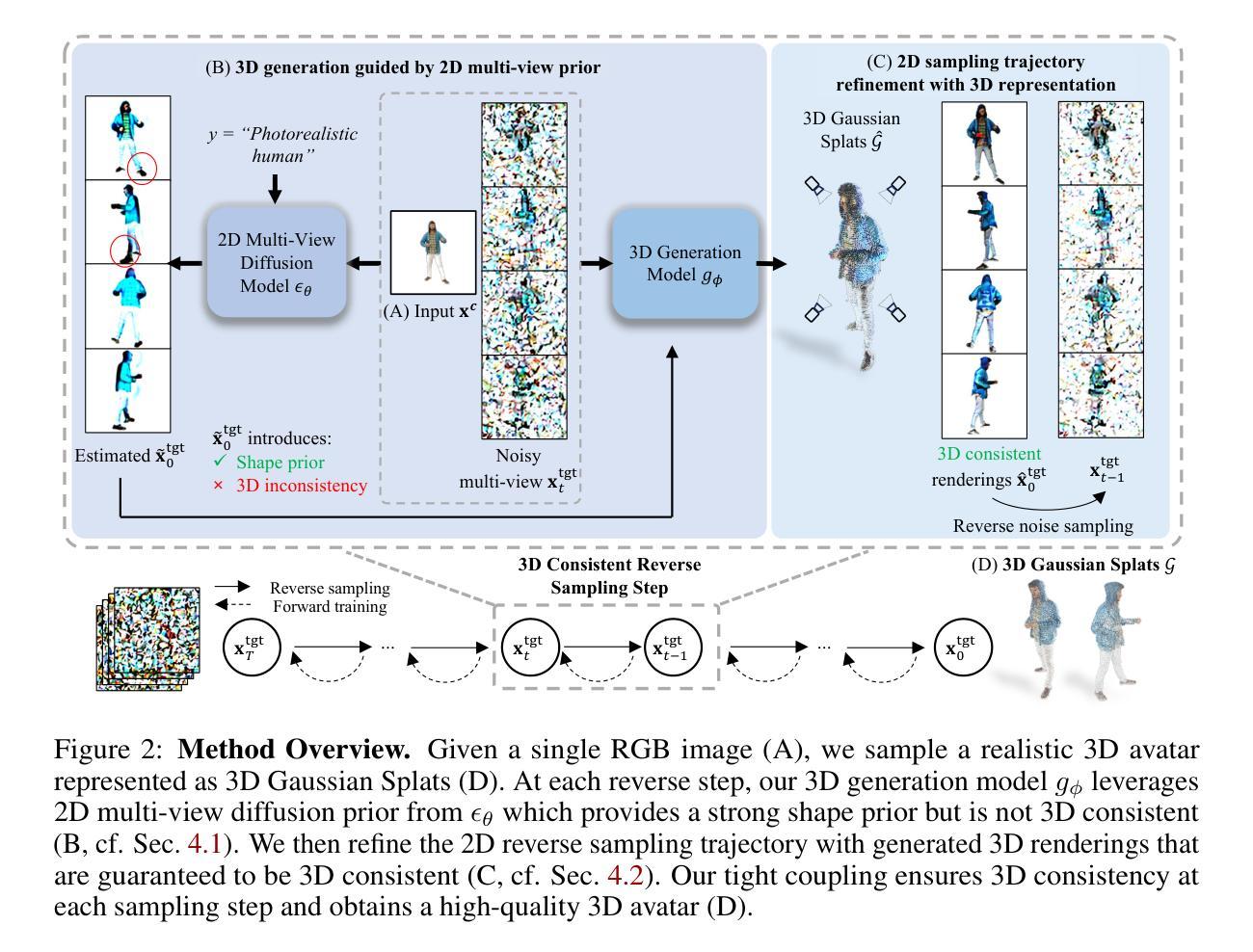
Creating realistic avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other, and by coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the priors from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models will be released on https://yuxuan-xue.com/human-3diffusion.
创建从单一RGB图像的真实化身是一个有吸引力但具有挑战性的任务。由于其不明确性,最近的工作利用来自大型数据集预训练的强大的二维扩散模型的先验知识。虽然二维扩散模型展现出强大的泛化能力,但它们无法提供具有保证的三维一致性的多视图形状先验。我们提出“Human 3Diffusion”:通过明确的3D一致扩散创建真实化身。我们的关键见解是,二维多视图扩散和三维重建模型彼此提供互补信息,通过紧密耦合它们,我们可以充分利用两者的潜力。我们引入了一种新型图像条件生成三维高斯Splats重建模型,它利用二维多视图扩散模型的先验知识,并提供明确的三维表示,进一步指导二维反向采样过程,以更好地实现三维一致性。实验表明,我们提出的框架优于最先进的方法,并能从单一RGB图像创建逼真的化身,在几何和外观上都实现高保真度。广泛的消融实验也验证了我们的设计的有效性,(1)生成三维重建中的多视图二维先验条件,(2)通过明确的三维表示对采样轨迹的一致性改进。我们的代码和模型将在https://yuxuan-xue.com/human-3diffusion上发布。
论文及项目相关链接
PDF Accepted to NeurIPS2024. Project Page: https://yuxuan-xue.com/human-3diffusion
Summary
基于单张RGB图像创建逼真的人像角色是一个吸引人的挑战性问题。该研究提出了一种新的方法Human 3Diffusion,通过将二维多视角扩散模型与三维重建模型紧密结合,实现了具有明确三维一致性的逼真人像角色创建。该方法引入了一种新的图像条件生成三维高斯Splats重建模型,利用二维多视角扩散模型的先验信息,并提供一个明确的三维表示,进一步指导二维反向采样过程,以达到更好的三维一致性。实验表明,该方法在几何和外观上都实现了高保真,超越了现有技术。
Key Takeaways
- Human 3Diffusion方法结合了二维多视角扩散模型和三维重建模型,实现了逼真的人像角色创建。
- 该方法引入了一种新的图像条件生成三维高斯Splats重建模型,利用二维扩散模型的先验信息。
- Human 3Diffusion方法提供了一个明确的三维表示,进一步指导二维反向采样过程,以实现更好的三维一致性。
- 实验表明,该方法在几何和外观上均实现了高保真,超越了现有技术。
- 该方法通过释放代码和模型,为公众提供了访问和使用的机会。
- 该研究强调了多视角二维先验条件在生成三维重建中的重要性。
点此查看论文截图