⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-19 更新
NoteContrast: Contrastive Language-Diagnostic Pretraining for Medical Text
Authors:Prajwal Kailas, Max Homilius, Rahul C. Deo, Calum A. MacRae
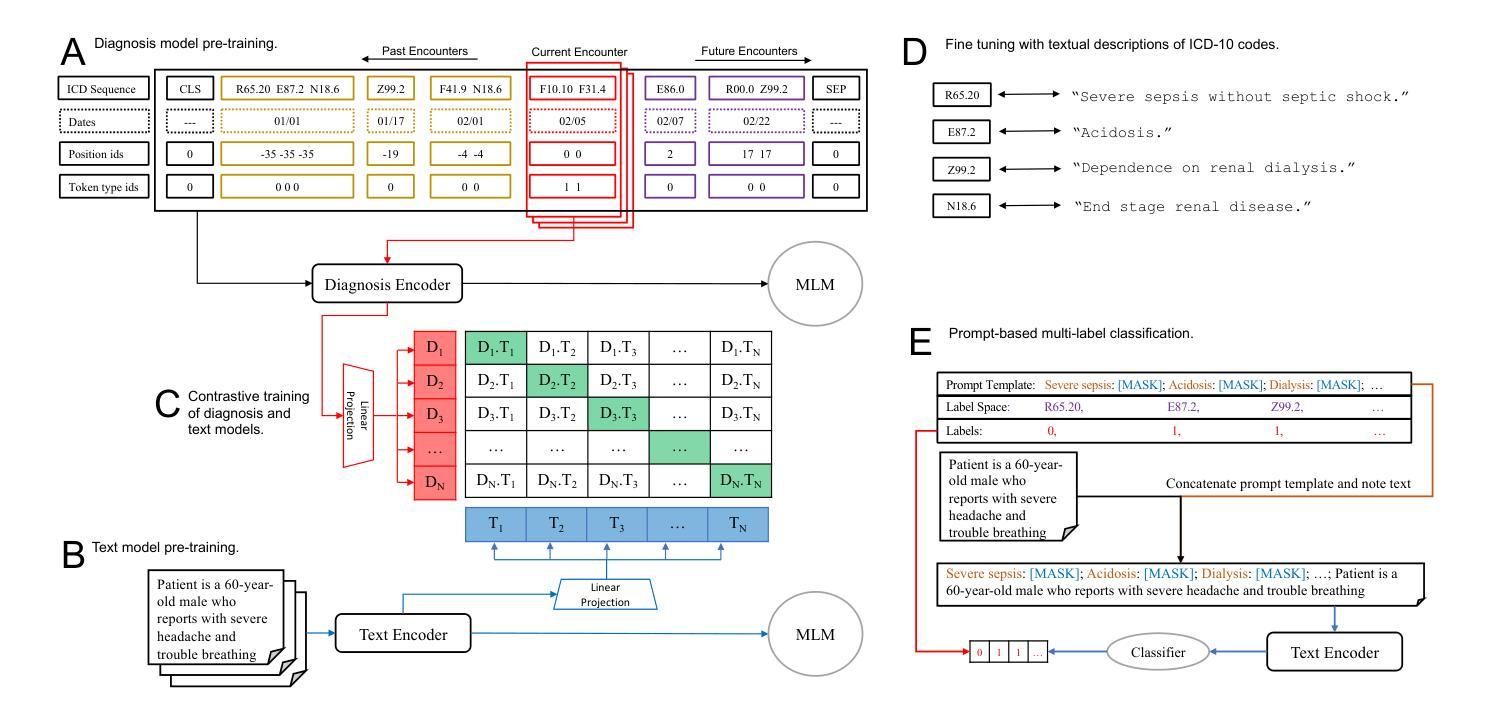
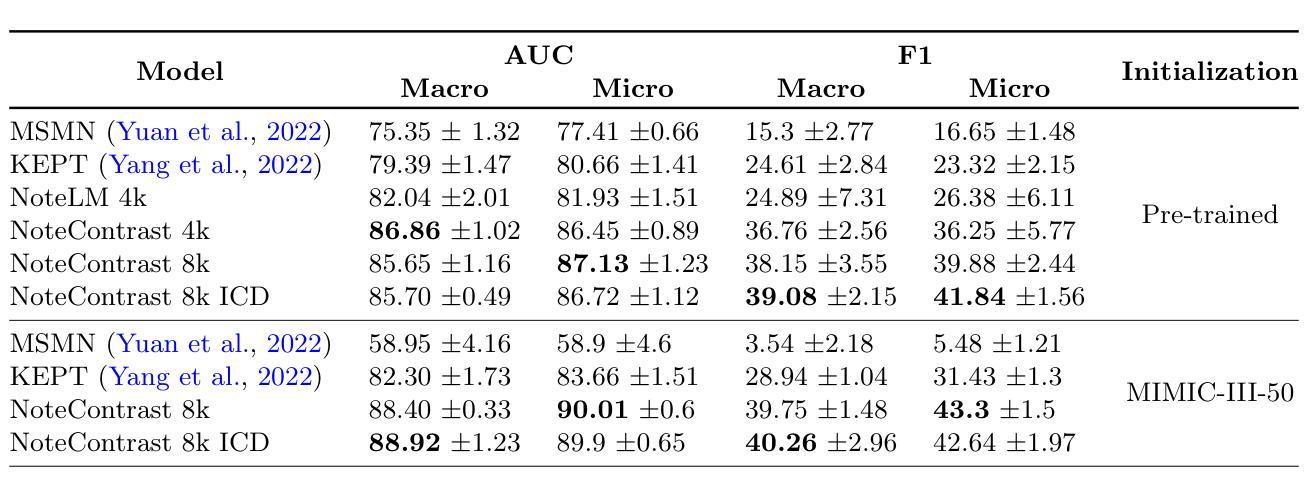
Accurate diagnostic coding of medical notes is crucial for enhancing patient care, medical research, and error-free billing in healthcare organizations. Manual coding is a time-consuming task for providers, and diagnostic codes often exhibit low sensitivity and specificity, whereas the free text in medical notes can be a more precise description of a patients status. Thus, accurate automated diagnostic coding of medical notes has become critical for a learning healthcare system. Recent developments in long-document transformer architectures have enabled attention-based deep-learning models to adjudicate medical notes. In addition, contrastive loss functions have been used to jointly pre-train large language and image models with noisy labels. To further improve the automated adjudication of medical notes, we developed an approach based on i) models for ICD-10 diagnostic code sequences using a large real-world data set, ii) large language models for medical notes, and iii) contrastive pre-training to build an integrated model of both ICD-10 diagnostic codes and corresponding medical text. We demonstrate that a contrastive approach for pre-training improves performance over prior state-of-the-art models for the MIMIC-III-50, MIMIC-III-rare50, and MIMIC-III-full diagnostic coding tasks.
准确的医疗记录诊断编码对于提升病人护理、医学研究和医疗机构的无误计费至关重要。手动编码对提供者来说是一项耗时的工作,并且诊断代码的敏感性及特异性较低,而医疗记录中的自由文本可以更精确地描述病人的状况。因此,医疗记录诊断的自动化准确编码对于学习医疗系统而言变得至关重要。长文档Transformer架构的最新发展使得基于注意力的深度学习模型能够裁决医疗记录。此外,对比损失函数已被用于联合预训练带有噪声标签的大型语言和图像模型。为了进一步提高医疗记录的自动化裁决能力,我们开发了一种基于以下三个方面的策略:一、使用大规模现实世界数据集构建ICD-10诊断代码序列的模型;二、构建用于医疗记录的大型语言模型;三、通过对比预训练,建立ICD-10诊断代码和相应医疗文本的综合模型。我们证明,对比预训练的方法相较于MIMIC-III-50、MIMIC-III-rare50和MIMIC-III全诊断编码任务的先前最先进的模型有所提升。
论文及项目相关链接
Summary:准确诊断编码对于提高患者护理、医学研究和医疗机构无误差计费至关重要。手动编码是耗时的任务,诊断代码敏感性低且特异性低,而医疗笔记中的自由文本能更精确地描述患者状态。因此,对医疗笔记进行准确自动化诊断编码对于学习医疗健康系统来说变得至关重要。最新的长文档转换器架构发展使得基于注意力机制的深度学习模型能够进行医疗笔记判决。此外,对比损失函数已被用于联合训练带有噪声标签的大型语言和图像模型。为了进一步提高医疗笔记的自动化判决,我们开发了一种基于ICD-10诊断代码序列模型的方法,该模型采用大型现实世界数据集并利用大型语言模型和对比预训练构建了一个包含ICD-10诊断代码和相应医疗文本的集成模型。对比预训练方法相较于先前最先进的模型在MIMIC-III-50、MIMIC-III-rare50和MIMIC-III-full诊断编码任务上表现出了提升效果。
Key Takeaways:
- 准确诊断编码对于提高医疗保健领域中的患者护理、医学研究和计费效率至关重要。
- 手动编码诊断是耗时的任务,自动编码诊断变得日益重要。
- 医疗笔记中的自由文本相比诊断代码能提供更加精确的患者状态描述。
- 基于深度学习模型的医疗笔记判决正逐渐成为研究热点。
- 长文档转换器架构的发展为基于注意力机制的深度学习模型在医疗笔记判决中的应用提供了支持。
- 对比损失函数在联合训练带有噪声标签的大型语言和图像模型方面发挥了重要作用。
点此查看论文截图

CATALOG: A Camera Trap Language-guided Contrastive Learning Model
Authors:Julian D. Santamaria, Claudia Isaza, Jhony H. Giraldo
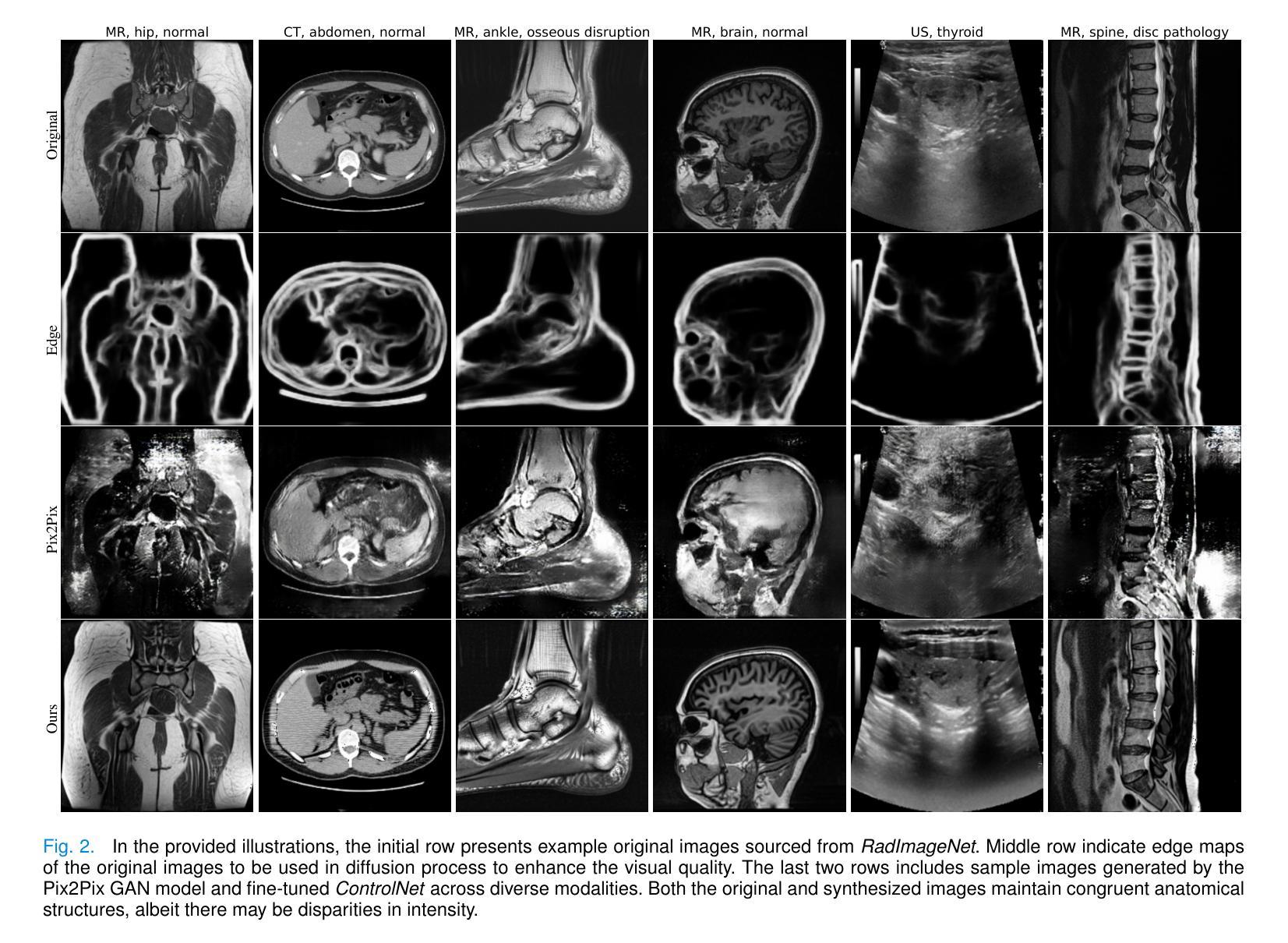
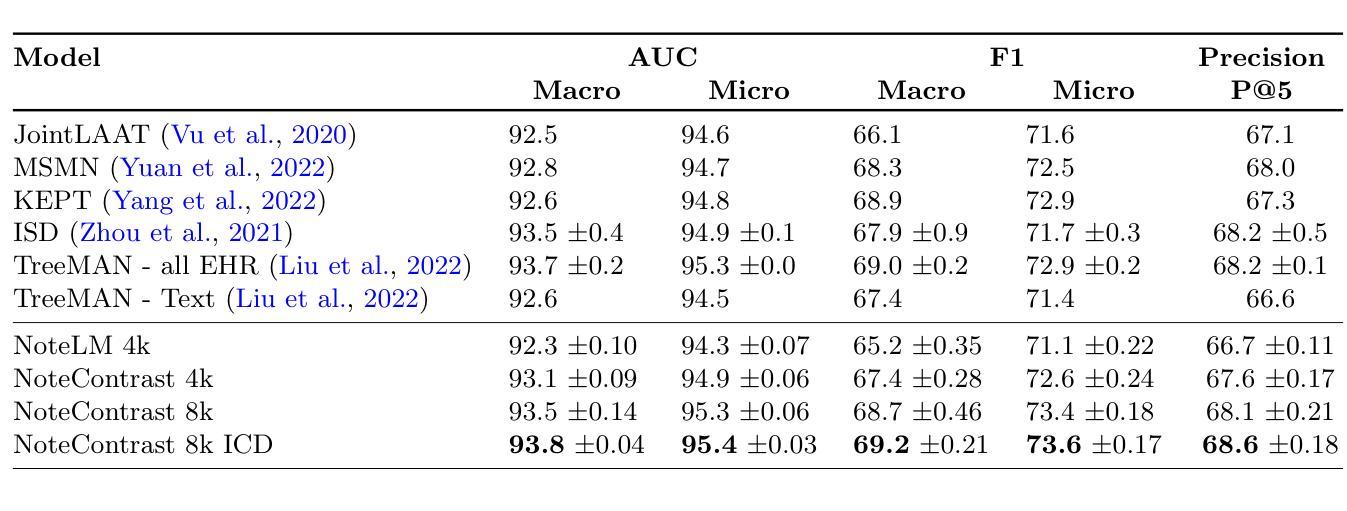
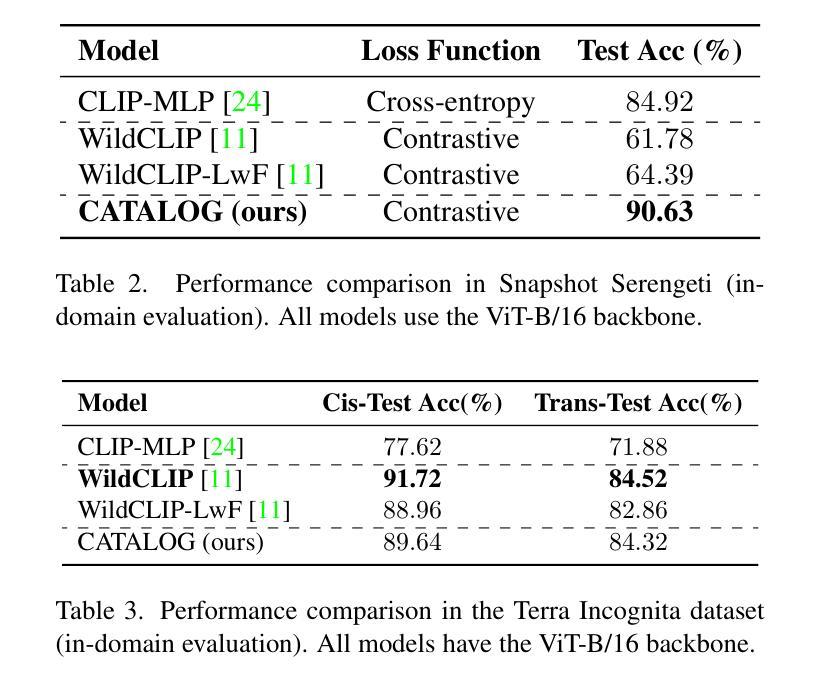
Foundation Models (FMs) have been successful in various computer vision tasks like image classification, object detection and image segmentation. However, these tasks remain challenging when these models are tested on datasets with different distributions from the training dataset, a problem known as domain shift. This is especially problematic for recognizing animal species in camera-trap images where we have variability in factors like lighting, camouflage and occlusions. In this paper, we propose the Camera Trap Language-guided Contrastive Learning (CATALOG) model to address these issues. Our approach combines multiple FMs to extract visual and textual features from camera-trap data and uses a contrastive loss function to train the model. We evaluate CATALOG on two benchmark datasets and show that it outperforms previous state-of-the-art methods in camera-trap image recognition, especially when the training and testing data have different animal species or come from different geographical areas. Our approach demonstrates the potential of using FMs in combination with multi-modal fusion and contrastive learning for addressing domain shifts in camera-trap image recognition. The code of CATALOG is publicly available at https://github.com/Julian075/CATALOG.
基础模型(FMs)在图像分类、目标检测和图像分割等计算机视觉任务中取得了成功。然而,当这些模型在训练集分布不同的数据集上进行测试时,这些任务仍然具有挑战性,这是一个被称为领域偏移的问题。这在用陷阱相机拍摄的动物物种识别中尤其成问题,其中存在光照、伪装和遮挡等因素的变量。在本文中,我们提出了Camera Trap Language-guided Contrastive Learning(CATALOG)模型来解决这些问题。我们的方法结合了多个基础模型来从陷阱相机数据中提取视觉和文本特征,并使用对比损失函数来训练模型。我们在两个基准数据集上评估了CATALOG,并表明它在陷阱相机图像识别方面优于以前的最先进方法,特别是在训练和测试数据具有不同的动物物种或来自不同的地理区域时。我们的方法展示了将基础模型与多模态融合和对比学习相结合解决陷阱相机图像识别中领域偏移问题的潜力。CATALOG的代码可在https://github.com/Julian0 075/CATALOG上公开获取。
论文及项目相关链接
Summary
基于跨模态融合与对比学习的方法,研究人员提出一种名为Camera Trap Language-guided Contrastive Learning(CATALOG)的模型,旨在解决在相机捕获的图像中对动物物种识别时遇到的领域偏移问题。该模型结合了多个基础模型以从相机捕获的数据中提取视觉和文本特征,并使用对比损失函数进行训练。在两项基准数据集上的评估表明,CATALOG在相机捕获图像识别方面优于当前最佳方法,特别是在训练和测试数据包含不同动物物种或来自不同地理区域的情况下。该研究突显了融合基础模型、多模态融合和对比学习在解决相机捕获图像识别中的领域偏移问题的潜力。
Key Takeaways
- FMs(基础模型)在图像分类、目标检测和图像分割等计算机视觉任务中取得了成功。
- 当这些模型在分布与训练集不同的数据集上进行测试时,会遇到领域偏移问题。
- 相机捕获的图像中的动物物种识别特别受领域偏移问题的困扰。
- 研究人员提出了名为CATALOG的模型,结合多个FMs提取视觉和文本特征,并使用对比损失函数进行训练来解决这个问题。
- CATALOG在两项基准数据集上的表现优于当前最佳方法。
- CATALOG尤其擅长处理训练和测试数据包含不同动物物种或来自不同地理区域的情况。
点此查看论文截图



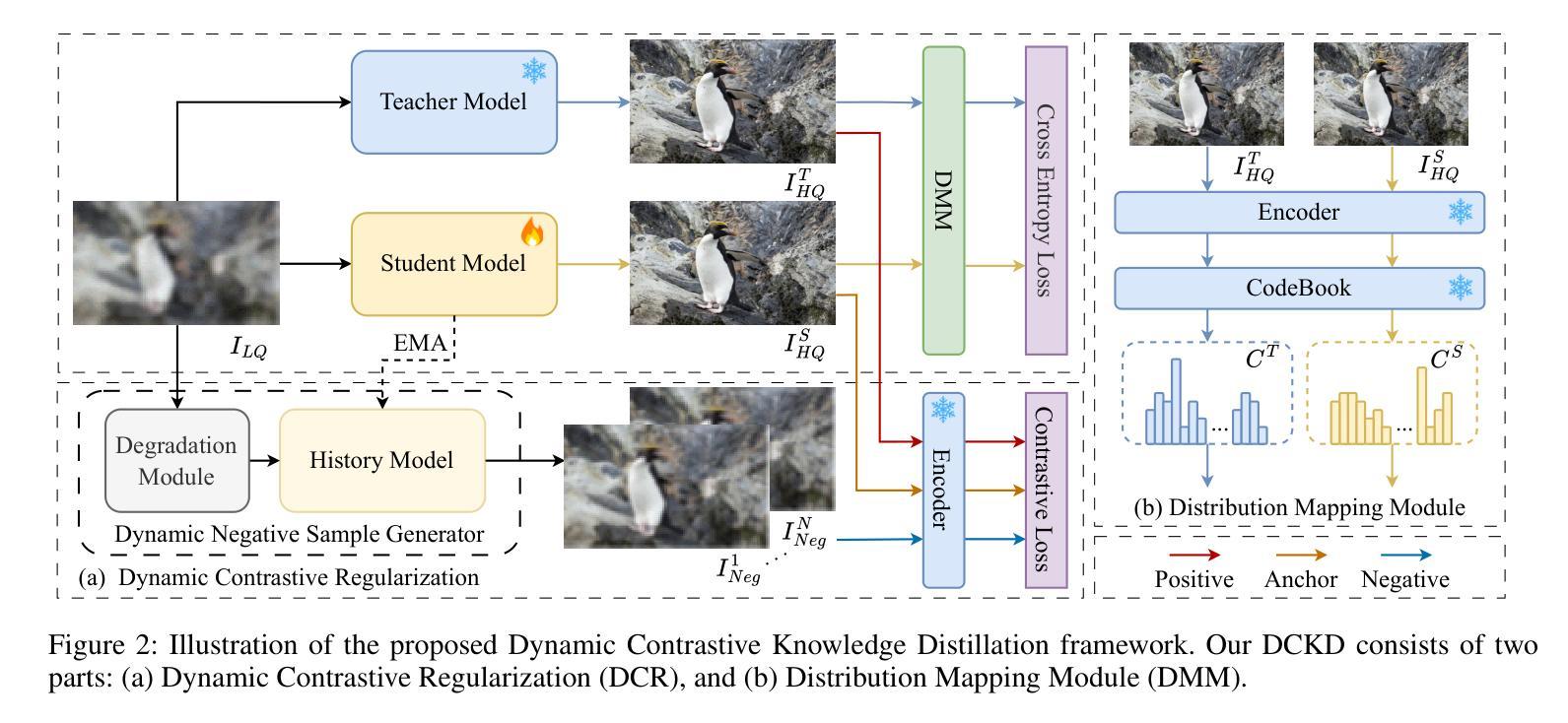
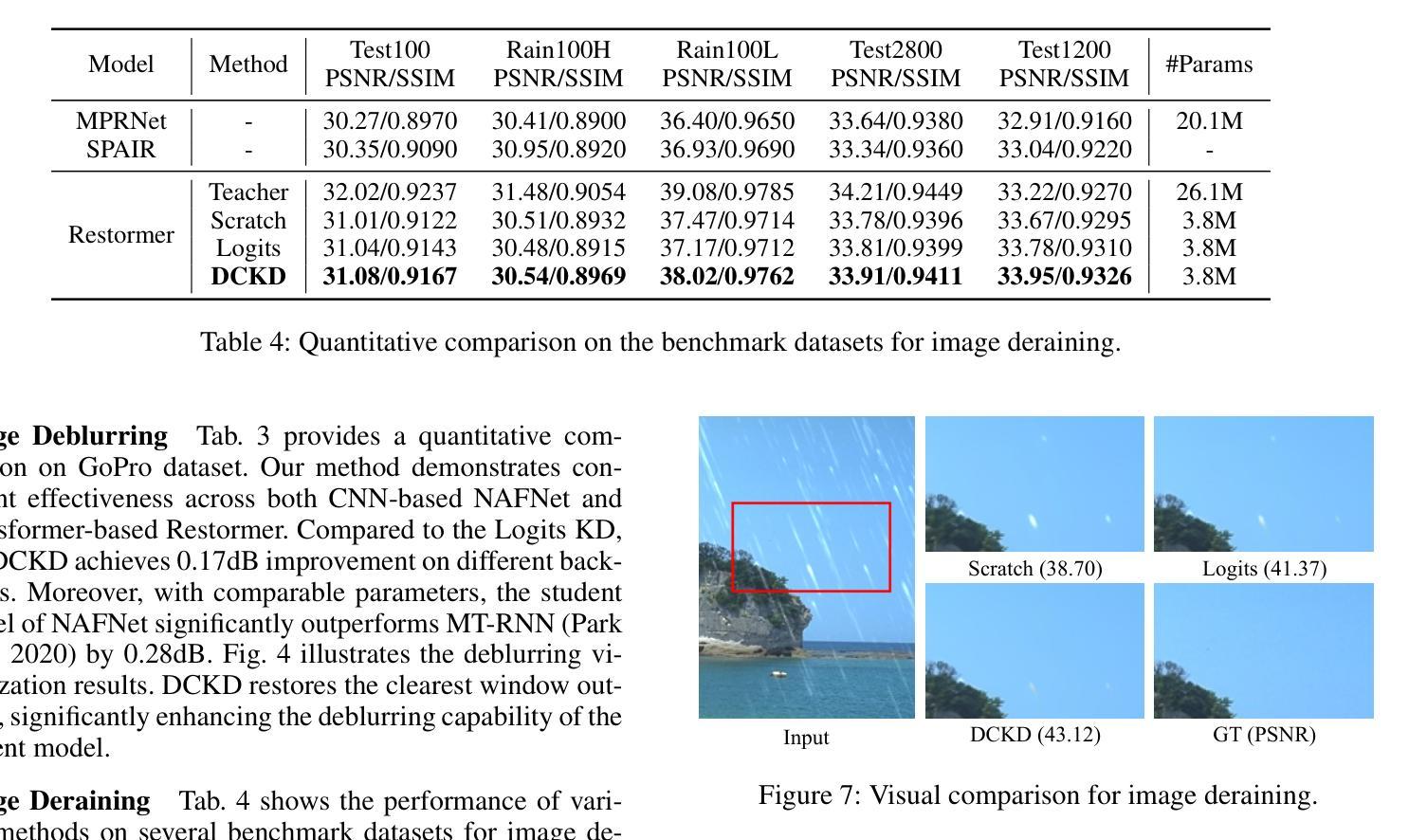
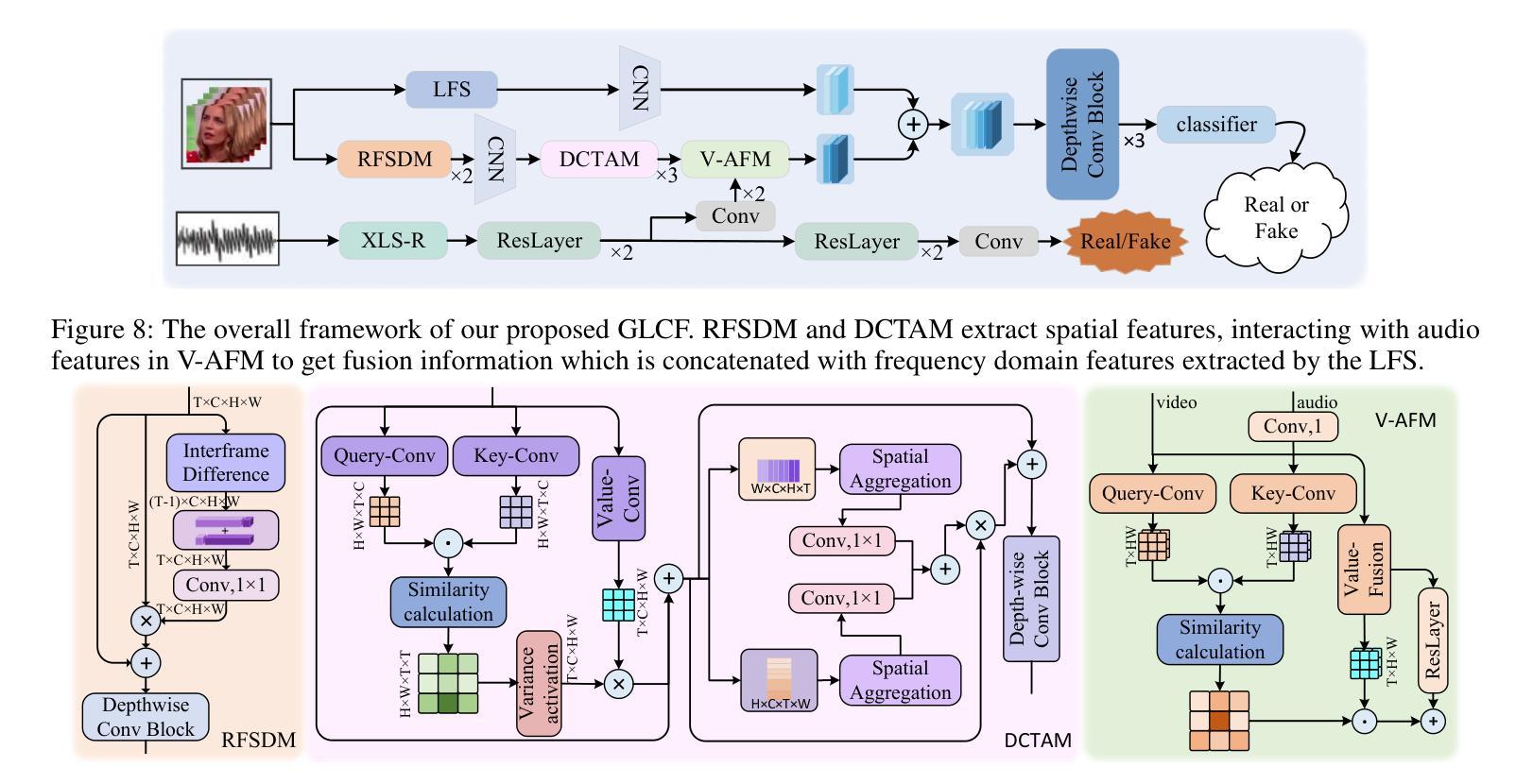
Dynamic Contrastive Knowledge Distillation for Efficient Image Restoration
Authors:Yunshuai Zhou, Junbo Qiao, Jincheng Liao, Wei Li, Simiao Li, Jiao Xie, Yunhang Shen, Jie Hu, Shaohui Lin
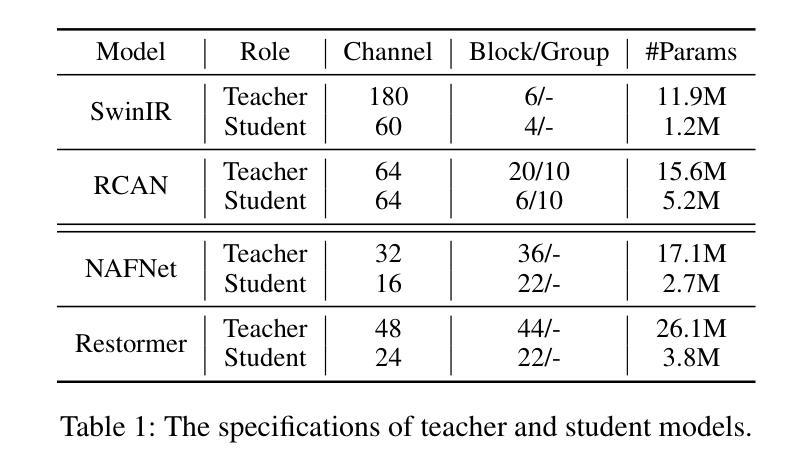
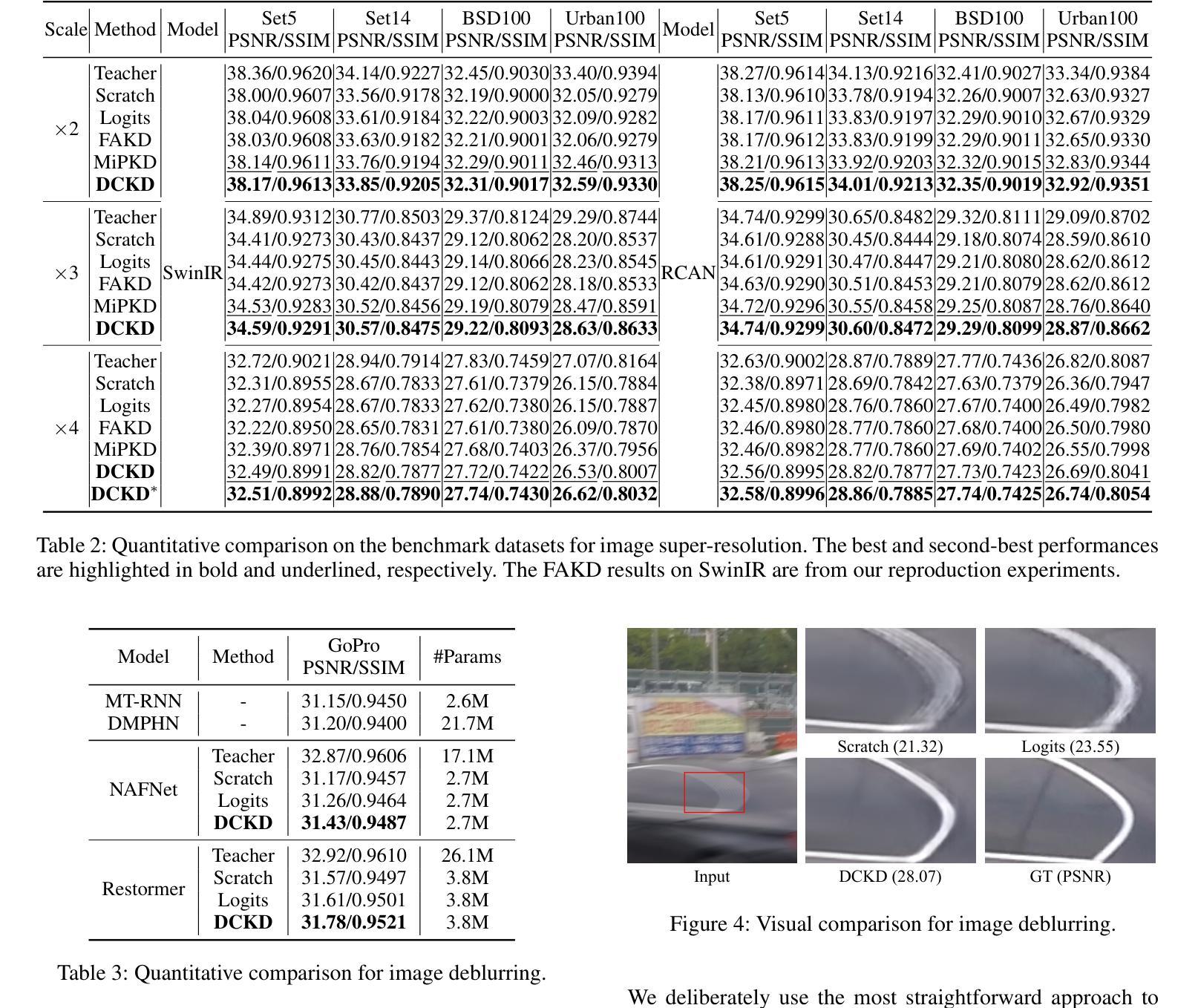
Knowledge distillation (KD) is a valuable yet challenging approach that enhances a compact student network by learning from a high-performance but cumbersome teacher model. However, previous KD methods for image restoration overlook the state of the student during the distillation, adopting a fixed solution space that limits the capability of KD. Additionally, relying solely on L1-type loss struggles to leverage the distribution information of images. In this work, we propose a novel dynamic contrastive knowledge distillation (DCKD) framework for image restoration. Specifically, we introduce dynamic contrastive regularization to perceive the student’s learning state and dynamically adjust the distilled solution space using contrastive learning. Additionally, we also propose a distribution mapping module to extract and align the pixel-level category distribution of the teacher and student models. Note that the proposed DCKD is a structure-agnostic distillation framework, which can adapt to different backbones and can be combined with methods that optimize upper-bound constraints to further enhance model performance. Extensive experiments demonstrate that DCKD significantly outperforms the state-of-the-art KD methods across various image restoration tasks and backbones.
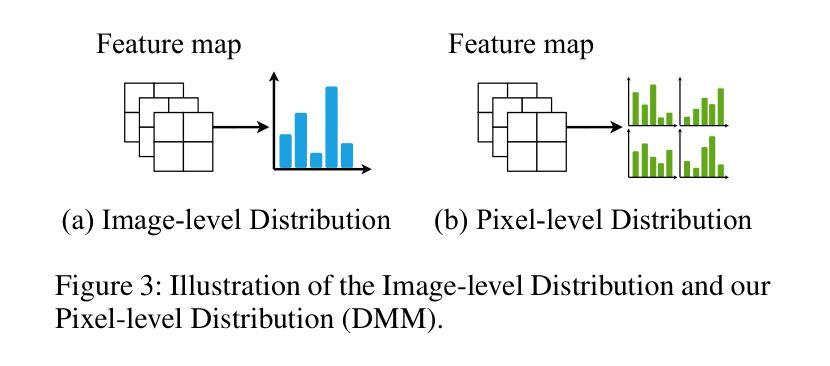
知识蒸馏(KD)是一种有价值但具有挑战性的方法,通过从一个高性能但复杂的教师模型中学习来增强紧凑的学生网络。然而,用于图像恢复的先前KD方法忽略了学生模型在蒸馏过程中的状态,采用了固定的解空间,限制了KD的能力。此外,仅依赖L1型损失很难利用图像的分布信息。在这项工作中,我们提出了用于图像恢复的新型动态对比知识蒸馏(DCKD)框架。具体来说,我们引入了动态对比正则化来感知学生的学习状态,并使用对比学习动态调整蒸馏解空间。此外,我们还提出了分布映射模块,以提取和匹配教师模型和学生模型的像素级类别分布。请注意,所提出的DCKD是一个结构无关的知识蒸馏框架,可以适应不同的主干网络,并且可以与优化上限约束的方法相结合,以进一步提高模型性能。大量实验表明,与各种图像恢复任务和主干网络中的最新KD方法相比,DCKD具有显著的优势。
论文及项目相关链接
Summary
本文提出了一种动态对比知识蒸馏(DCKD)框架,用于图像修复中的知识蒸馏。该框架引入动态对比正则化感知学生的学习状态并动态调整蒸馏解空间,同时提出分布映射模块以提取和对齐教师和学生学习模型的像素级类别分布。相比其他蒸馏方法,实验表明该框架在多种图像修复任务和模型上表现出优越性能。
Key Takeaways
- 知识蒸馏(KD)是一种通过学生网络学习教师模型知识的方法,用于增强紧凑学生网络的性能。
- 以往的KD方法在图像修复中忽视了学生的学习状态,采用固定的解空间限制了KD的能力。
- 本文提出了动态对比知识蒸馏(DCKD)框架,通过引入动态对比正则化感知学生的学习状态并动态调整解空间。
- DCKD采用分布映射模块,提取并对齐教师和学生学习模型的像素级类别分布。
- DCKD是一种结构无关的知识蒸馏框架,可适应不同的主干网络,并可与其他优化上限约束的方法结合以提高模型性能。
点此查看论文截图