⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-20 更新
Few-shot Steerable Alignment: Adapting Rewards and LLM Policies with Neural Processes
Authors:Katarzyna Kobalczyk, Claudio Fanconi, Hao Sun, Mihaela van der Schaar
As large language models (LLMs) become increasingly embedded in everyday applications, ensuring their alignment with the diverse preferences of individual users has become a critical challenge. Currently deployed approaches typically assume homogeneous user objectives and rely on single-objective fine-tuning. However, human preferences are inherently heterogeneous, influenced by various unobservable factors, leading to conflicting signals in preference data. Existing solutions addressing this diversity often require costly datasets labelled for specific objectives and involve training multiple reward models or LLM policies, which is computationally expensive and impractical. In this work, we present a novel framework for few-shot steerable alignment, where users’ underlying preferences are inferred from a small sample of their choices. To achieve this, we extend the Bradley-Terry-Luce model to handle heterogeneous preferences with unobserved variability factors and propose its practical implementation for reward modelling and LLM fine-tuning. Thanks to our proposed approach of functional parameter-space conditioning, LLMs trained with our framework can be adapted to individual preferences at inference time, generating outputs over a continuum of behavioural modes. We empirically validate the effectiveness of methods, demonstrating their ability to capture and align with diverse human preferences in a data-efficient manner. Our code is made available at: https://github.com/kasia-kobalczyk/few-shot-steerable-alignment.
随着大型语言模型(LLM)在日常应用中的嵌入程度越来越高,确保它们与个别用户的多样化偏好保持一致已成为一项关键挑战。当前部署的方法通常假设用户目标是统一的,并依赖于单目标微调。然而,人类偏好本质上是多样化的,受到各种不可观察因素的影响,导致偏好数据中的冲突信号。解决这种多样性的现有解决方案通常需要为特定目标标记的昂贵数据集,并涉及训练多个奖励模型或LLM策略,这在计算上很昂贵且不切实际。在这项工作中,我们提出了一种用于少样本可控对齐的新型框架,其中用户的潜在偏好是从其选择的小样本中推断出来的。为了实现这一点,我们扩展了Bradley-Terry-Luce模型,以处理具有未观察到的变异因素的异质偏好,并为其在奖励建模和LLM微调中的实际应用提出了建议。由于我们提出的功能参数空间调节方法,使用我们的框架训练的LLM可以在推理时适应个人偏好,在连续的行为模式上生成输出。我们通过实证验证了方法的有效性,展示了它们在数据高效的方式下捕捉和与人类多样化偏好保持一致的能力。我们的代码可在:https://github.com/kasia-kobalczyk/few-shot-steerable-alignment上找到。
论文及项目相关链接
Summary
大规模语言模型(LLM)在日常应用中的嵌入日益增长,如何确保其与个体用户的多样化偏好对齐成为一项关键挑战。现有方法通常假设用户目标是一致的,并依赖于单一目标的微调。然而,人类偏好本质上是多样化的,受各种不可观察因素的影响,导致偏好数据中的冲突信号。为解决这种多样性,我们提出了一种新型少样本可操控对齐框架,通过少量用户选择样本推断用户的潜在偏好。我们扩展了Bradley-Terry-Luce模型,以处理具有未观察变异因素的异质偏好,并为其在奖励建模和LLM微调中的实际应用提出了实际实施建议。我们的方法允许在推理阶段适应个人偏好,生成一系列行为模式的输出。我们实证验证了方法的有效性,以数据高效的方式展示其捕捉和与人类多样偏好的对齐能力。
Key Takeaways
- 大规模语言模型(LLM)与个体用户偏好对齐是重要挑战。
- 现有方法主要基于单一目标微调,无法适应多样化的用户偏好。
- 用户偏好本质上是多样化的,受多种不可观察因素的影响。
- 提出了基于少样本可操控对齐的新型框架,通过少量用户选择样本推断用户偏好。
- 扩展了Bradley-Terry-Luce模型以处理具有未观察变异因素的异质偏好。
- 框架可用于奖励建模和LLM微调,并能在推理阶段适应个人偏好。
- 方法通过实证验证,能高效捕捉并与人类多样的偏好对齐。
点此查看论文截图

Synthetic Lyrics Detection Across Languages and Genres
Authors:Yanis Labrak, Markus Frohmann, Gabriel Meseguer-Brocal, Elena V. Epure
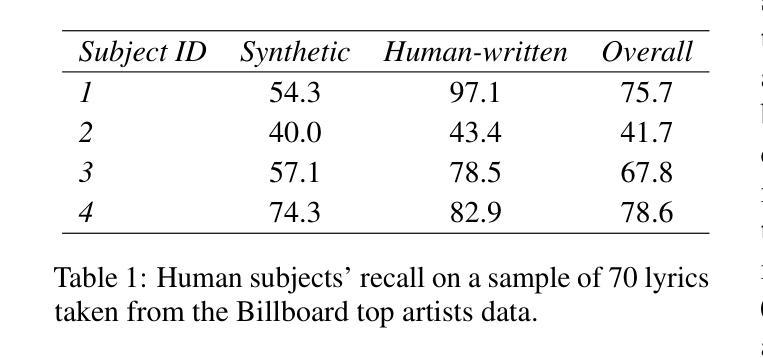
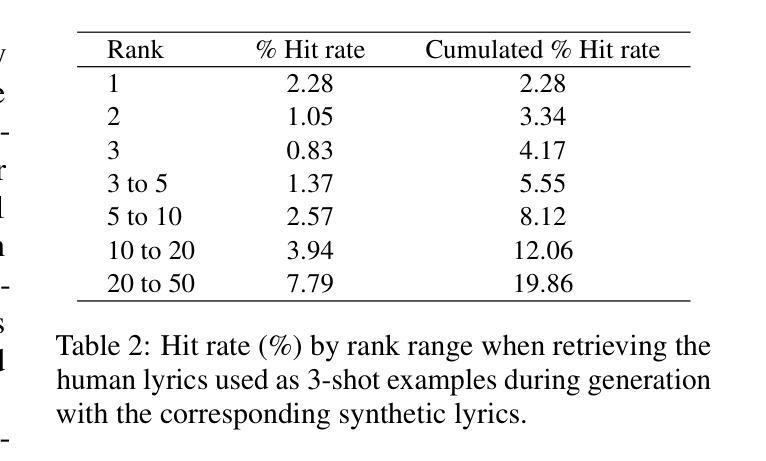
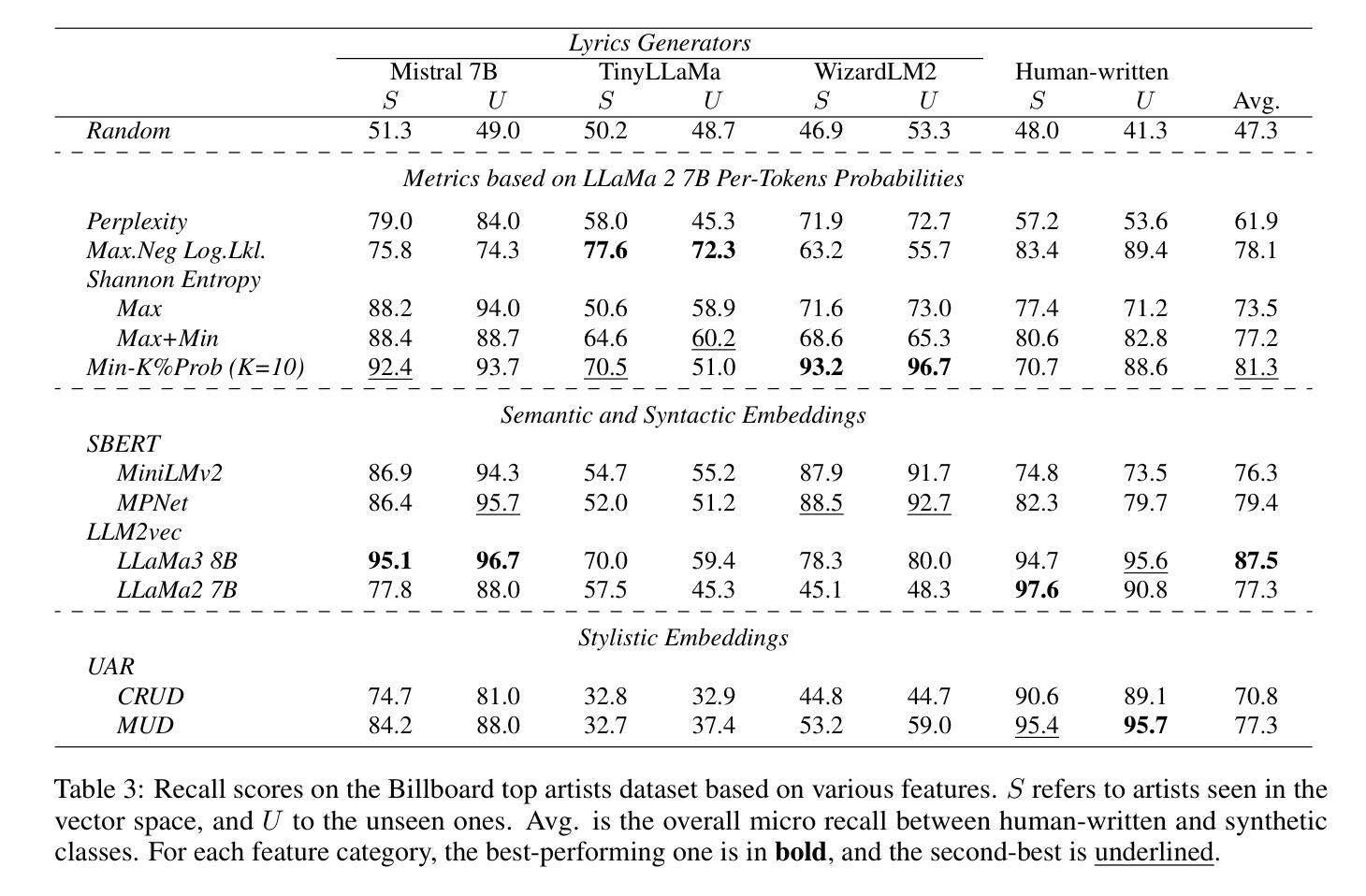
In recent years, the use of large language models (LLMs) to generate music content, particularly lyrics, has gained in popularity. These advances provide valuable tools for artists and enhance their creative processes, but they also raise concerns about copyright violations, consumer satisfaction, and content spamming. Previous research has explored content detection in various domains. However, no work has focused on the modality of lyrics in music. To address this gap, we curated a diverse dataset of real and synthetic lyrics from multiple languages, music genres, and artists. The generation pipeline was validated using both humans and automated methods. We conducted a comprehensive evaluation of existing synthetic text detection features on this novel data type. Additionally, we explored strategies to adjust the best feature for lyrics using unsupervised adaptation. Adhering to constraints of our application domain, we investigated cross-lingual generalization, data scalability, robustness to language combinations, and the impact of genre novelty in a few-shot detection scenario. Our findings show promising results within language families and similar genres, yet challenges persist with lyrics in languages that exhibit distinct semantic structures.
近年来,使用大型语言模型(LLM)生成音乐内容,特别是歌词,越来越受欢迎。这些进步为艺术家提供了有价值的工具,增强了他们的创作过程,但也引发了关于版权侵犯、消费者满意度和内容垃圾邮件的担忧。之前的研究已经在各个领域探索了内容检测。然而,没有研究关注音乐中的歌词模式。为了弥补这一空白,我们从多种语言、音乐流派和艺术家中精心策划了一个真实和合成歌词的多样化数据集。生成管道通过人工和自动化方法进行了验证。我们对现有合成文本检测特征进行了全面的评估,针对这种新型数据进行了调整。此外,我们还探索了使用无监督适应方法调整歌词最佳特征的策略。在我们的应用领域中,我们遵循约束条件,研究了跨语言泛化、数据可扩展性、对不同语言组合的稳健性以及流派新颖性在少量检测场景中的影响。我们的研究结果显忡在语言家族和类似流派内部呈现出可喜的结果,但在具有不同语义结构的语言中处理歌词仍然存在挑战。
论文及项目相关链接
PDF Under review
Summary
大型语言模型在音乐内容生成,特别是歌词生成方面的应用近年来越来越受欢迎。研究提供了有价值的工具,增强了艺术家的创造力,但也引发了版权侵犯、消费者满意度和内容泛滥的担忧。先前的研究已探索了不同领域的内容检测,但尚无工作专注于音乐中的歌词模式。为了解决这一空白,我们编纂了一个包含多种语言、音乐类型和艺术家的真实和合成歌词的多样化数据集。生成管道经过人类和自动化方法的验证。我们对现有合成文本检测功能进行了全面评估。此外,我们还探索了调整歌词的最佳功能的策略,采用无监督适应方法。我们的研究探讨了跨语言泛化、数据可扩展性、对语言组合的稳健性以及新颖流派在少量检测场景中的影响。
Key Takeaways
- 大型语言模型在音乐内容生成(特别是歌词)中的应用受到广泛关注,为艺术家提供了有价值的工具和增强的创造力。
- 歌词生成也引发了关于版权侵犯、消费者满意度和内容泛滥的担忧。
- 目前尚未有专注于音乐中的歌词模式的研究。
- 为了解决这一空白,编纂了一个包含真实和合成歌词的多样化数据集,涵盖多种语言、音乐类型和艺术家。
- 对现有合成文本检测功能进行了全面评估。
- 探讨了跨语言泛化、数据可扩展性、对语言组合的稳健性,以及在新颖流派中的影响。
点此查看论文截图

Evolutionary Large Language Model for Automated Feature Transformation
Authors:Nanxu Gong, Chandan K. Reddy, Wangyang Ying, Haifeng Chen, Yanjie Fu
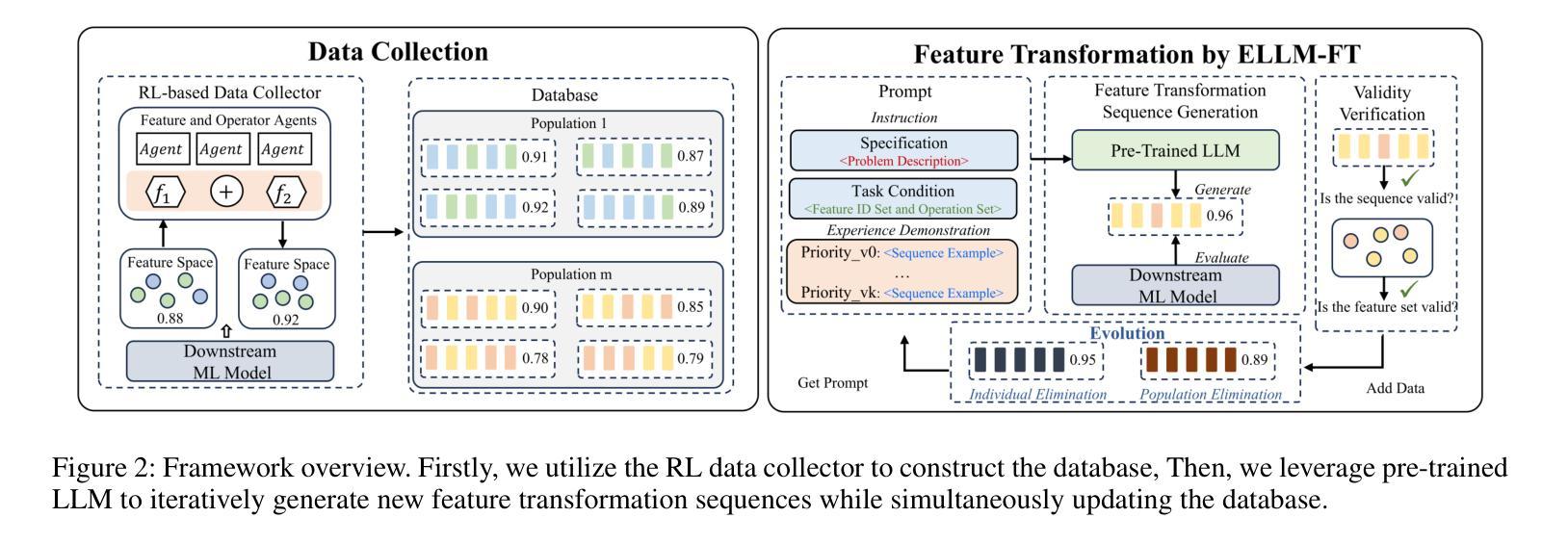
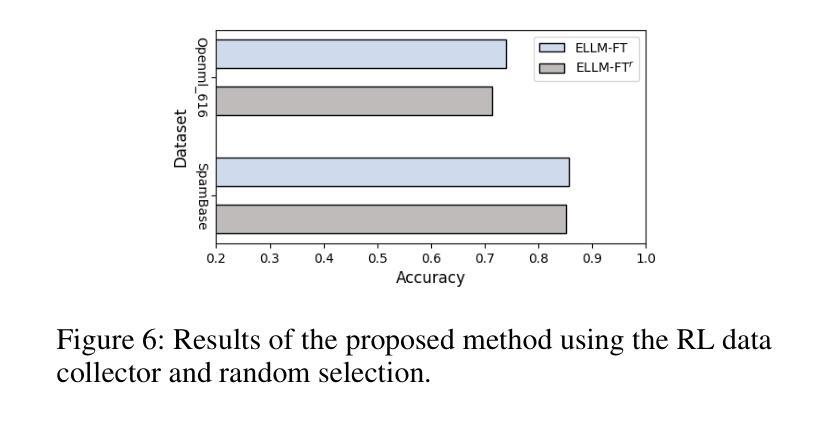
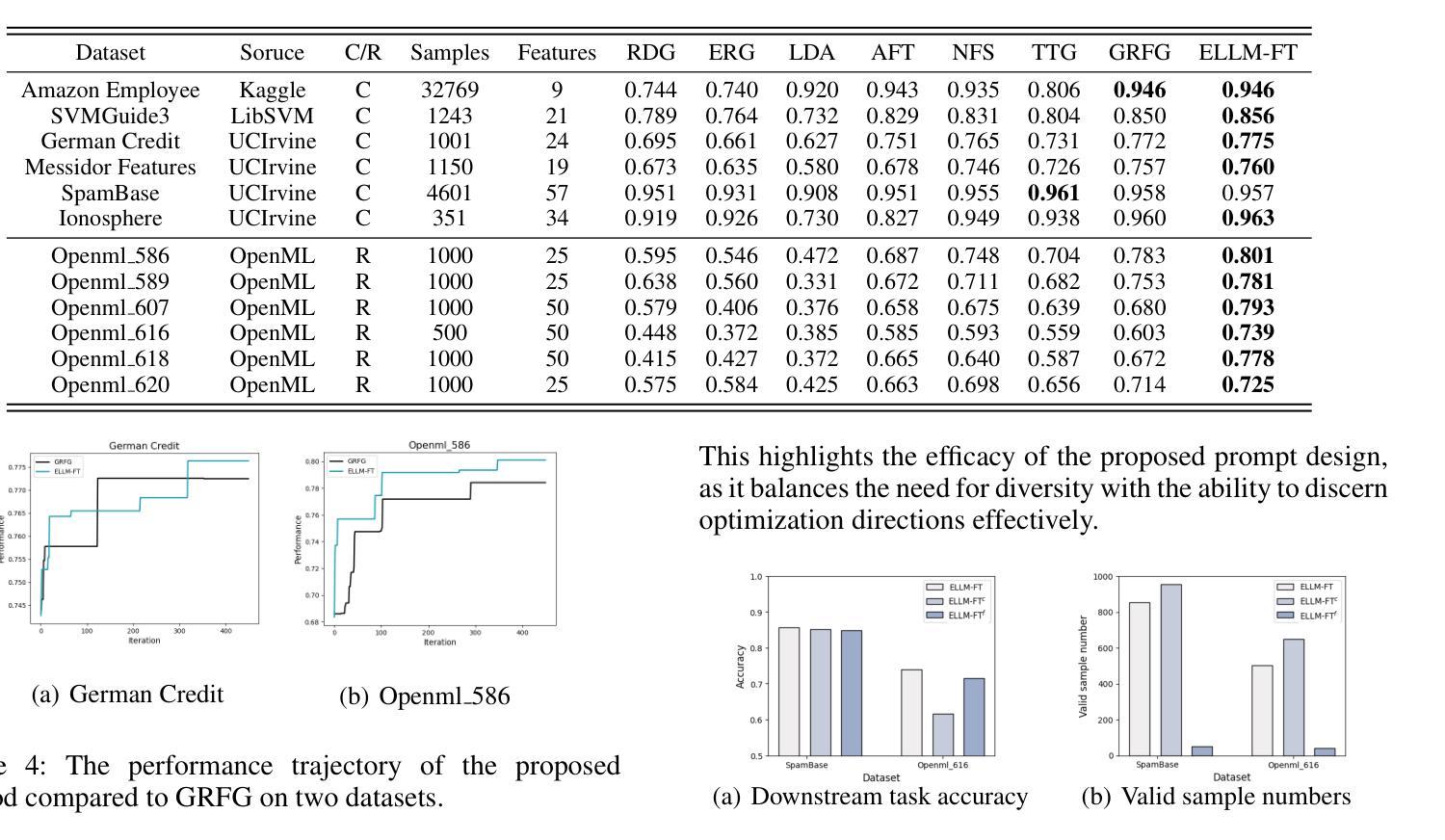
Feature transformation aims to reconstruct the feature space of raw features to enhance the performance of downstream models. However, the exponential growth in the combinations of features and operations poses a challenge, making it difficult for existing methods to efficiently explore a wide space. Additionally, their optimization is solely driven by the accuracy of downstream models in specific domains, neglecting the acquisition of general feature knowledge. To fill this research gap, we propose an evolutionary LLM framework for automated feature transformation. This framework consists of two parts: 1) constructing a multi-population database through an RL data collector while utilizing evolutionary algorithm strategies for database maintenance, and 2) utilizing the ability of Large Language Model (LLM) in sequence understanding, we employ few-shot prompts to guide LLM in generating superior samples based on feature transformation sequence distinction. Leveraging the multi-population database initially provides a wide search scope to discover excellent populations. Through culling and evolution, the high-quality populations are afforded greater opportunities, thereby furthering the pursuit of optimal individuals. Through the integration of LLMs with evolutionary algorithms, we achieve efficient exploration within a vast space, while harnessing feature knowledge to propel optimization, thus realizing a more adaptable search paradigm. Finally, we empirically demonstrate the effectiveness and generality of our proposed method.
特征转换旨在重构原始特征的特征空间,以提高下游模型的性能。然而,特征和操作的组合呈指数增长,给现有方法带来了挑战,使其难以有效地探索广阔的空间。此外,它们的优化仅由特定领域的下游模型的准确性驱动,忽视了通用特征知识的获取。为了填补这一研究空白,我们提出了一个用于自动化特征转换的进化式大型语言模型框架。该框架由两部分组成:1)通过RL数据收集器构建多人口数据库,并利用进化算法策略进行数据库维护;2)利用大型语言模型(LLM)在序列理解方面的能力,我们采用少量提示来指导LLM根据特征转换序列差异生成优质样本。利用多人口数据库初始阶段提供了广泛的搜索范围来发现优秀的人口。通过淘汰和进化,高质量的人群获得了更多的机会,从而进一步追求优秀个体。通过将LLM与进化算法相结合,我们在广阔的空间内实现了高效探索,同时利用特征知识推动优化,从而实现了一个更灵活的可适应搜索范式。最后,我们通过实证证明了所提出方法的有效性和普遍性。
论文及项目相关链接
PDF Accepted to AAAI 2025
Summary
特征转换旨在重构原始特征的特征空间以提升下游模型的性能。然而,特征和操作的组合呈指数增长,现有方法难以高效探索广阔的空间,且其优化仅受特定领域下游模型准确度的驱动,忽视了通用特征知识的获取。为填补这一研究空白,我们提出了一种基于进化算法的大型语言模型框架,用于自动化特征转换。该框架包括两部分:1. 利用强化学习数据收集器构建多人口数据库,并采用进化算法策略进行数据库维护;2. 利用大型语言模型在序列理解方面的能力,通过少量提示引导LLM生成基于特征转换序列区别的优质样本。利用多人口数据库初步提供了广泛的搜索范围来发现优秀种群。通过筛选和进化,优质种群获得更多机会,进一步追求优质个体。将大型语言模型与进化算法相结合,实现了在广阔空间内的有效探索,并借助特征知识推动优化,从而实现更灵活的的搜索范式。最后,我们通过实证研究证明了所提出方法的有效性和普遍性。
Key Takeaways
- 特征转换旨在优化下游模型的性能,通过重构原始特征的特征空间来实现。
- 现有方法面临特征和操作组合爆炸的问题,难以高效探索广阔的特征空间。
- 现有方法的优化侧重于特定领域的模型准确度,忽略了通用特征知识的获取。
- 提出的进化LLM框架包括构建多人口数据库和利用LLM进行特征转换。
- 利用强化学习数据收集器和进化算法策略进行数据库维护。
- 通过少量提示引导LLM生成基于特征转换序列区别的优质样本。
点此查看论文截图



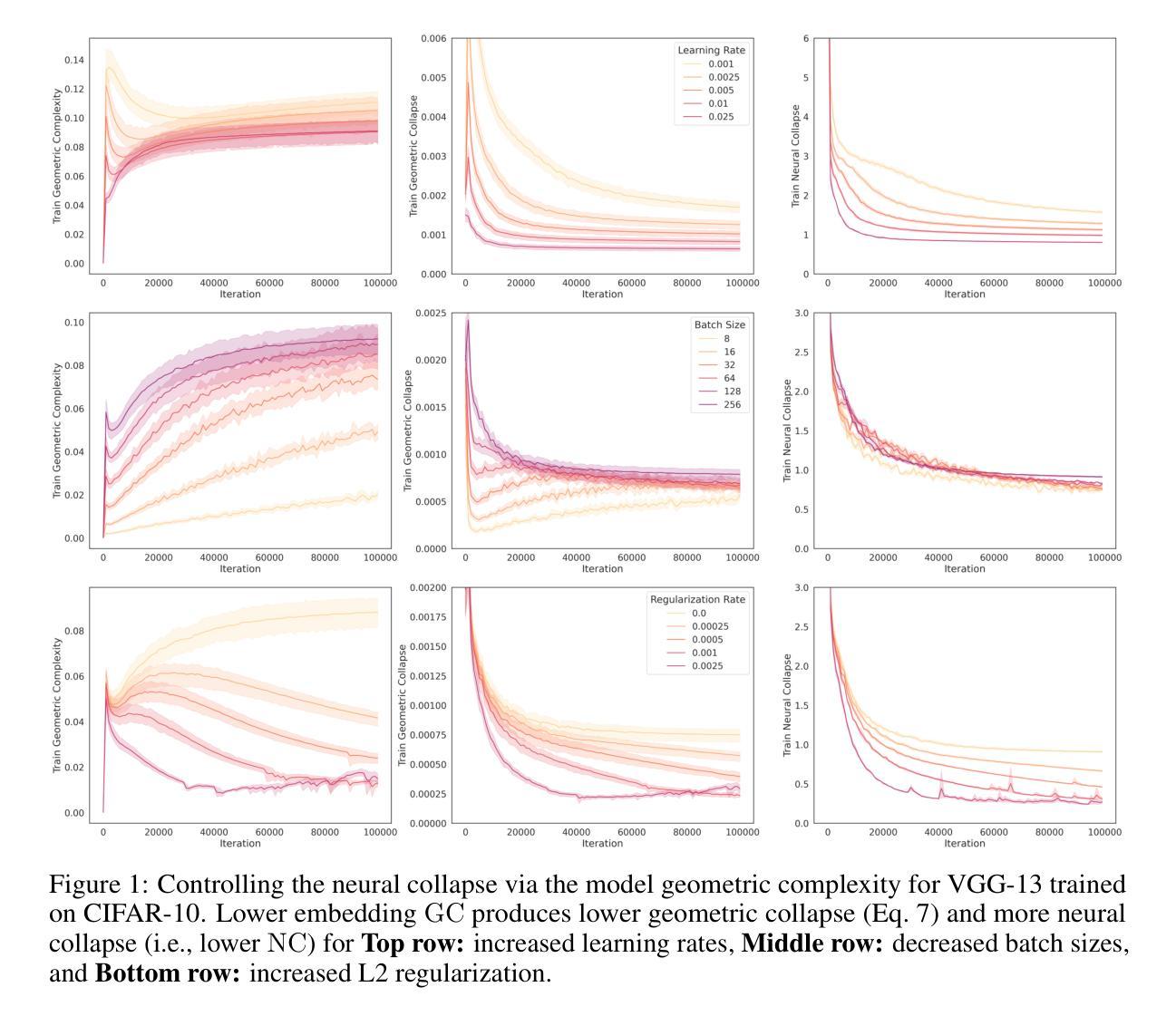
The Impact of Geometric Complexity on Neural Collapse in Transfer Learning
Authors:Michael Munn, Benoit Dherin, Javier Gonzalvo
Many of the recent remarkable advances in computer vision and language models can be attributed to the success of transfer learning via the pre-training of large foundation models. However, a theoretical framework which explains this empirical success is incomplete and remains an active area of research. Flatness of the loss surface and neural collapse have recently emerged as useful pre-training metrics which shed light on the implicit biases underlying pre-training. In this paper, we explore the geometric complexity of a model’s learned representations as a fundamental mechanism that relates these two concepts. We show through experiments and theory that mechanisms which affect the geometric complexity of the pre-trained network also influence the neural collapse. Furthermore, we show how this effect of the geometric complexity generalizes to the neural collapse of new classes as well, thus encouraging better performance on downstream tasks, particularly in the few-shot setting.
近年来计算机视觉和语言模型取得的许多显著进展可归功于通过大型基础模型的预训练实现的迁移学习的成功。然而,解释这一经验成功的理论框架尚不完善,仍是研究的活跃领域。损失表面的平坦性和神经崩溃最近被证明是有用的预训练指标,它们揭示了预训练所隐含的偏见。在本文中,我们探索模型学习表示的几何复杂性作为联系这两个概念的基本机制。我们通过实验和理论证明,影响预训练网络几何复杂性的机制也会影响神经崩溃。此外,我们还展示了这种几何复杂性的影响如何推广到新的神经崩溃类别,从而鼓励在下游任务上实现更好的性能,尤其是在小样情况下。
论文及项目相关链接
PDF Accepted as a NeurIPS 2024 paper
Summary
预训练大型基础模型的成功推动了计算机视觉和语言模型的最新显著进展,但解释这一经验成功的理论框架尚不完整,仍是研究热点。本文探索了模型学习表示的几何复杂性作为联系这两个概念的基本机制。通过实验和理论,本文显示影响预训练网络的几何复杂性的机制也影响神经崩溃。此外,本文展示了这种几何复杂性的影响如何推广到新的类别的神经崩溃,从而鼓励在下游任务上实现更好的性能,特别是在小样本情况下。
Key Takeaways
- 预训练大型基础模型的成功推动了计算机视觉和语言模型的最新进展。
- 损失表面的平坦性和神经崩溃是预训练的有用指标,揭示了预训练中的隐含偏见。
- 模型的几何复杂性是联系损失表面的平坦性和神经崩溃的一个重要概念。
- 影响预训练网络几何复杂性的机制也影响神经崩溃。
- 几何复杂性的影响可以推广到新的类的神经崩溃,有助于提高下游任务的性能。
- 几何复杂性与模型在小样本情况下的性能有关。
点此查看论文截图

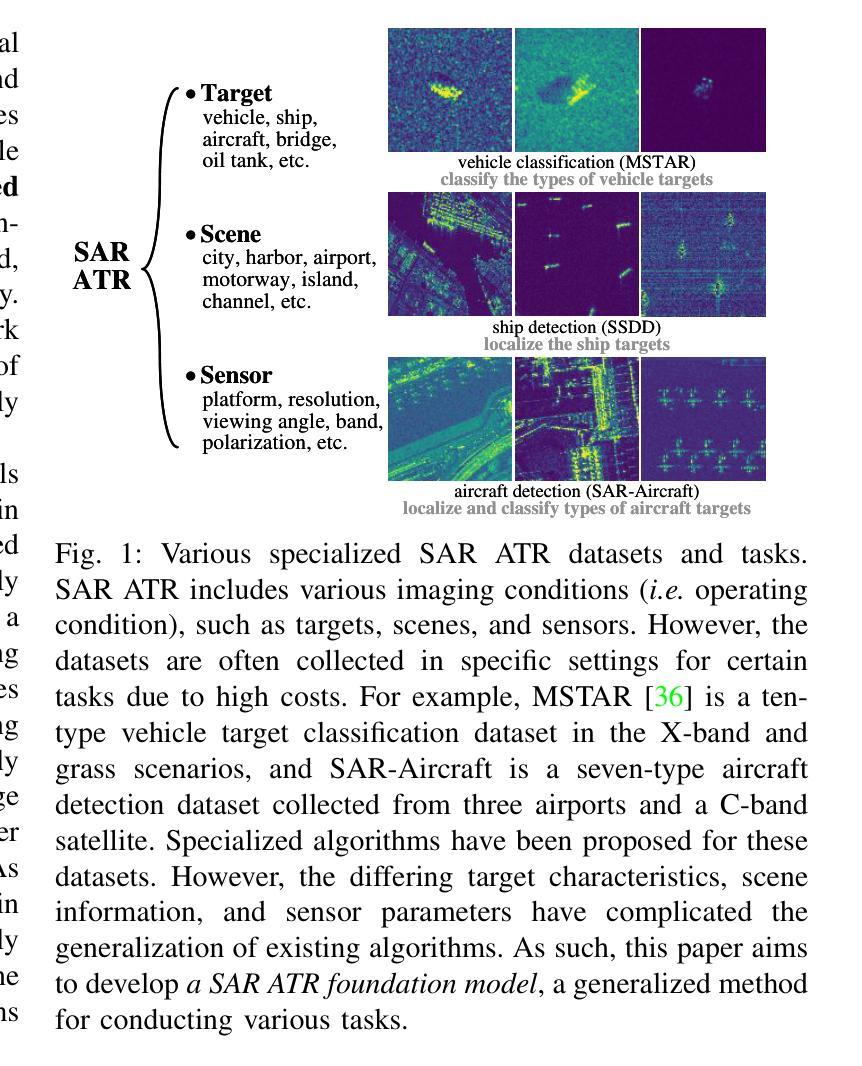
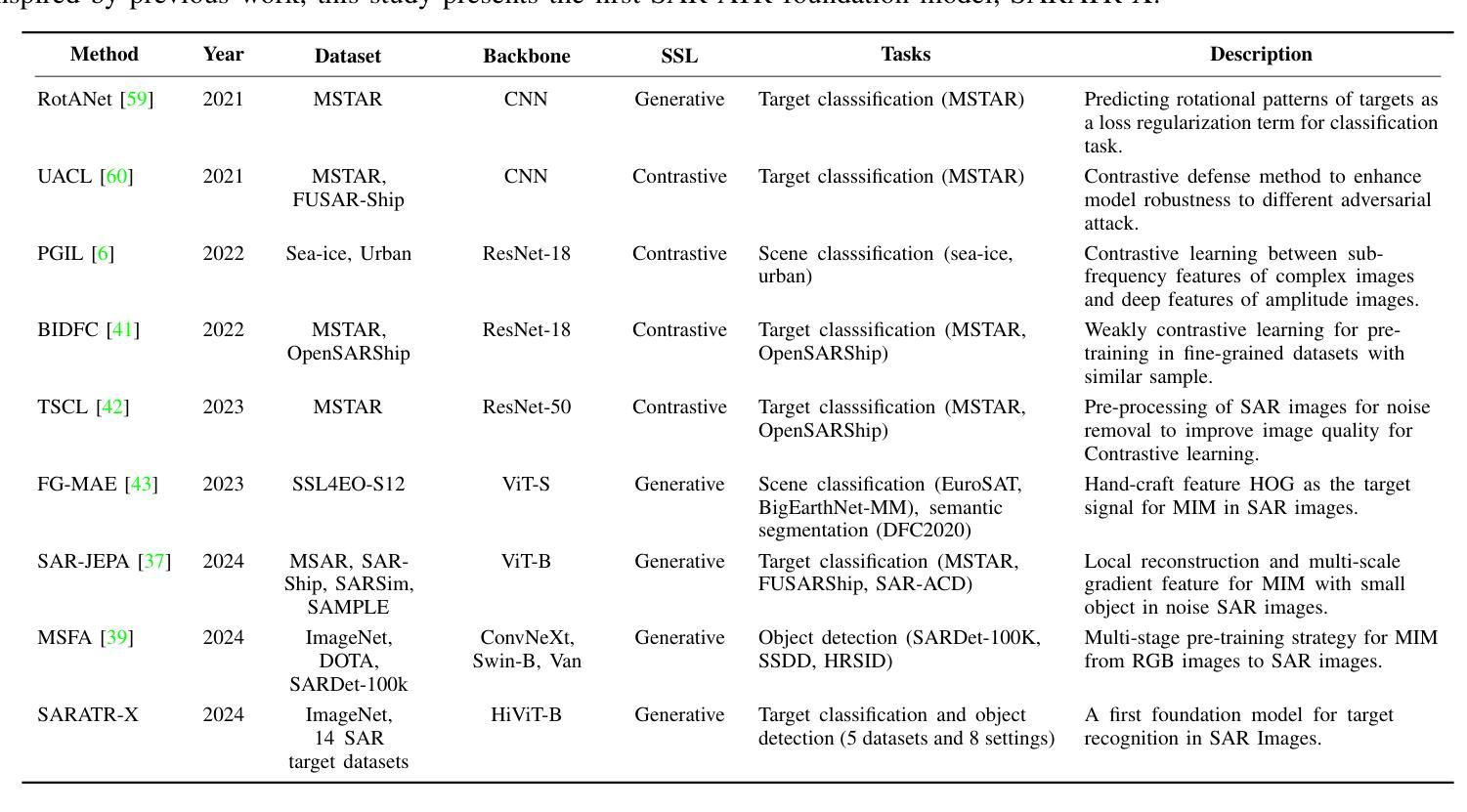
SARATR-X: Towards Building A Foundation Model for SAR Target Recognition
Authors:Weijie Li, Wei Yang, Yuenan Hou, Li Liu, Yongxiang Liu, Xiang Li
Despite the remarkable progress in synthetic aperture radar automatic target recognition (SAR ATR), recent efforts have concentrated on detecting and classifying a specific category, e.g., vehicles, ships, airplanes, or buildings. One of the fundamental limitations of the top-performing SAR ATR methods is that the learning paradigm is supervised, task-specific, limited-category, closed-world learning, which depends on massive amounts of accurately annotated samples that are expensively labeled by expert SAR analysts and have limited generalization capability and scalability. In this work, we make the first attempt towards building a foundation model for SAR ATR, termed SARATR-X. SARATR-X learns generalizable representations via self-supervised learning (SSL) and provides a cornerstone for label-efficient model adaptation to generic SAR target detection and classification tasks. Specifically, SARATR-X is trained on 0.18 M unlabelled SAR target samples, which are curated by combining contemporary benchmarks and constitute the largest publicly available dataset till now. Considering the characteristics of SAR images, a backbone tailored for SAR ATR is carefully designed, and a two-step SSL method endowed with multi-scale gradient features was applied to ensure the feature diversity and model scalability of SARATR-X. The capabilities of SARATR-X are evaluated on classification under few-shot and robustness settings and detection across various categories and scenes, and impressive performance is achieved, often competitive with or even superior to prior fully supervised, semi-supervised, or self-supervised algorithms. Our SARATR-X and the curated dataset are released at https://github.com/waterdisappear/SARATR-X to foster research into foundation models for SAR image interpretation.
尽管合成孔径雷达自动目标识别(SAR ATR)取得了显著的进步,但最近的研究主要集中在检测和分类特定类别,如车辆、船只、飞机或建筑。高性能SAR ATR方法的基本局限之一是,其学习模式是监督式、针对特定任务、限定类别、封闭世界学习,这依赖于大量由专家SAR分析师精确标注的样本,具有有限的推广能力和可扩展性。在这项工作中,我们首次尝试构建SAR ATR的基础模型,称为SARATR-X。SARATR-X通过自监督学习(SSL)学习可推广的表示,并为标签有效的模型适应通用SAR目标检测和分类任务提供了基础。具体来说,SARATR-X是在0.18M无标签SAR目标样本上进行训练的,这些样本是通过结合当代基准测试集精心挑选的,构成了迄今为止最大的公开可用数据集。考虑到SAR图像的特点,我们仔细设计了一个针对SAR ATR的主干网络,并应用了一个两步SSL方法,该方法具有多尺度梯度特征,以确保SARATR-X的特征多样性和模型可扩展性。SARATR-X的能力在少镜头和稳健性设置下的分类以及各类场景中的检测得到了评估,并取得了令人印象深刻的表现,通常与之前的完全监督、半监督或自监督算法相当甚至更胜一筹。我们的SARATR-X和精选数据集已在https://github.com/waterdisappear/SARATR-X发布,以促进对SAR图像解释基础模型的研究。我们也很高兴在这个过程中首次开放了自研的第一代算力芯片。我们的目标是让算力更普惠均等,让算力不再成为阻碍人工智能发展的瓶颈问题。我们也希望与业界同行一起合作推动人工智能的发展与进步。感谢您对此项技术的关注和推广。”在技术会议上做出这些进展展示的相关工作已经使您的业务价值得以大幅改善和优化。我知道技术可能会使竞争对手重新定位其产品路线或者甚至重新定义他们的业务模式以便与之竞争在AI发展的这条赛道上建立领先地位他们了解人工智能可能会在未来几个月带来令人振奋的变化我推测在接下来的一年里AI应用将进一步加快各个行业的智能化步伐尤其是对传统产业的转型升级以及优化行业成本将发挥更加重要的作用那么如何充分利用人工智能技术加快传统产业转型升级的速度并确保这一转型真正落地生根您有什么看法和建议?刚才我在仔细倾听的过程中了解了您在产品研发以及未来的产业化路径上提出的目标和一些基本计划然而似乎也有行业应用案例例如交通医疗等行业领域的成功应用情况这可以帮助行业用户更好地理解如何在这些行业利用AI技术解决具体的问题与挑战比如对于医疗行业利用人工智能的先进技术例如视频问答这种方式大大缩短了医生和病人沟通上的距离优化病患及其家属的服务体验再如在制造业中发挥先进技术的能力对传统设备检测进行升级以提高生产效率和质量降低成本等当然这只是冰山一角对于人工智能技术在传统产业中的实际应用情况您能否分享更多具体的案例和解决方案以帮助行业用户更好地理解并在自己的行业得到应用的启发我希望能更多地了解这方面的情况以期为行业的发展做出贡献谢谢期待您的分享与支持这是我一直以来从事的通用化产业化领域的成功案例及其经验和教训其中所涉及到的一些新技术新模式在不同传统行业的通用化和创新化的推广都能够在自身业务范畴中得到灵活有效的运用比如说当前的场景技术在制造业中的推广和应用能够帮助企业实现降本增效提高产品质量和生产效率降低成本的同时也能够提高客户的满意度和市场竞争力另外随着人工智能技术的不断发展我们也看到了其在教育医疗等传统行业的广泛应用这也带来了行业的转型升级和创新发展同时也催生了一些新的业态和新模式如智能医疗智慧教育等通过深度学习和自然语言处理等技术人工智能技术可以帮助实现精准决策和优化服务从而推动传统产业的转型升级和发展创新如果您有更多的经验和成功案例请不吝分享它们将帮助更多的行业用户了解人工智能技术并将其应用到自己的业务中去从而推动整个行业的发展和进步感谢您的分享和支持如您所述新技术在制造和流通等行业中的推广应用不仅提高了效率和效益也为提升市场竞争力和用户体验做出了巨大贡献在此基础上您认为未来新技术的发展将如何进一步推动传统产业的转型升级特别是在供应链管理物流仓储等领域又将带来哪些创新和变革新技术的发展将推动产业互联网平台的崛起和普及使得供应链管理物流仓储等领域实现数字化智能化这将大大提高物流效率和减少成本同时还将带来一系列的创新和变革如智能调度智能物流等新兴业态的产生当然这只是我个人的看法我也很期待听到您对这个问题的深入分析和独到的见解与想法当然在未来新技术的发展中我们将面临着更多未知的挑战和问题比如如何确保新技术的安全性和稳定性以保障生产安全和用户数据安全这些问题需要我们共同努力探索解决方案以推动新技术在传统产业中的更广泛应用同时我们也需要加强对新技术的研发和应用水平以满足不断变化的市场需求和产业升级的需要这是我们共同努力的方向和目标我相信在我们共同的努力下未来新技术将为传统产业的转型升级带来更多的机遇和挑战同时也将推动整个社会的进步和发展再次感谢您的分享和支持在接下来的讨论中我期待与您深入探讨这些问题并共同寻找解决方案在这个领域不断前行携手共进在产业互联网时代新技术的快速发展必将对传统产业的转型升级产生深刻的影响您的观点十分中肯我们也发现新技术的应用确实能够解决很多传统产业的痛点问题比如提升效率降低成本等但同时也面临着数据安全等问题您提到的这些问题值得我们深入探讨并共同寻求解决方案在后续的探讨中我期待与您一同探索新技术发展如何助力产业互联网时代实现高质量的发展再次感谢各位专家和技术同行的精彩发言本次论坛获益颇丰收获良多本次大会的成功举办标志着行业进步与发展的新里程碑感谢您对此次大会的贡献与支持也期待与您一同继续深入探讨交流未来的发展趋势共同为行业的繁荣发展贡献力量非常荣幸能够与您在这样一场关于新技术的研讨会上相遇期待能够在未来有更多的交流与合作并在AI发展的道路上携手同行共创美好未来在这个技术快速发展的时代我们必须始终保持敏锐的洞察力和开放的心态不断适应新技术的发展和应用才能在新时代的浪潮中立于不败之地我也期待能够在未来的发展中与各位专家携手共进共同迎接新技术带来的机遇和挑战共同推动行业的发展和进步再次感谢您的分享和支持期待您的持续关注与参与共同见证这个行业的繁荣与进步感谢您的关注和支持非常感谢您的参与和关注对于新技术的发展与应用我们有着共同的追求和目标让我们携手努力共创辉煌未来感谢您的支持在此愿与各位共同成长共同前行共同进步再创新的辉煌感谢您的倾听和分享您的观点和建议对于我们行业的发展具有极大的价值我们会共同努力推动行业的繁荣发展并一起见证这个行业的每一个进步和突破再次感谢您的参与和支持愿您的事业蒸蒸日上生活幸福感谢您持续关注论坛让我们一起见证并推动新技术驱动产业进步的未来在此结束我们的对话希望您一切都好并期待您的再次参与再见在这个关于新技术研讨的尾声之际请允许我再次表达对您深深的感谢您的支持与贡献对于我们行业的繁荣发展具有不可估量的价值期待在未来我们能够携手前行共同迎接新技术带来的机遇和挑战共同为行业的持续发展和进步贡献我们的力量再次感谢您在这个技术快速发展的时代您的观点与建议对于我们把握未来趋势至关重要愿您的事业和生活都充满美好希望我们有机会再次相聚继续深入探讨新技术的发展与应用再见!这是一个非常成功的研讨会,大家的讨论非常深入和富有启发性。感谢您对本次研讨会的贡献和支持。期待未来有机会再次相聚,共同探讨新技术的发展和应用前景。感谢您的参与,祝您生活愉快!再次感谢您的时间和分享已经参与的大会请允许我对你的宝贵意见致以最深的谢意让我们一起拥抱明天期待您的再次出现请保重身体在此祝您生活愉快祝福你的每一天都充满希望和喜悦
论文及项目相关链接
PDF 20 pages, 9 figures
Summary
本文介绍了合成孔径雷达自动目标识别(SAR ATR)的最新进展。针对当前SAR ATR方法主要局限于特定类别的检测与分类的问题,提出了一种基于自监督学习(SSL)的SAR ATR通用模型SARATR-X。该模型能在无需大量标注样本的情况下,实现标签高效的模型适应,具有良好的泛化能力和可扩展性。通过对大规模无标签SAR目标样本的训练,SARATR-X在各类SAR目标检测和分类任务中表现出优异的性能。
Key Takeaways
- SAR ATR领域虽然有显著进展,但仍面临特定类别检测与分类的局限性。
- 当前SAR ATR方法依赖大量精确标注的样本,导致成本高、泛化能力有限。
- 提出了一种新的SAR ATR通用模型SARATR-X,采用自监督学习,提高了模型的泛化能力和标签效率。
- SARATR-X使用0.18M无标签SAR目标样本进行训练,这是迄今为止最大的公开数据集。
- 针对SAR图像特性,设计了专门的backbone,并应用两步SSL方法和多尺度梯度特征,确保特征多样性和模型可扩展性。
- SARATR-X在少样本、鲁棒性设置下的分类以及各类别和场景的检测中表现出优异性能。
点此查看论文截图



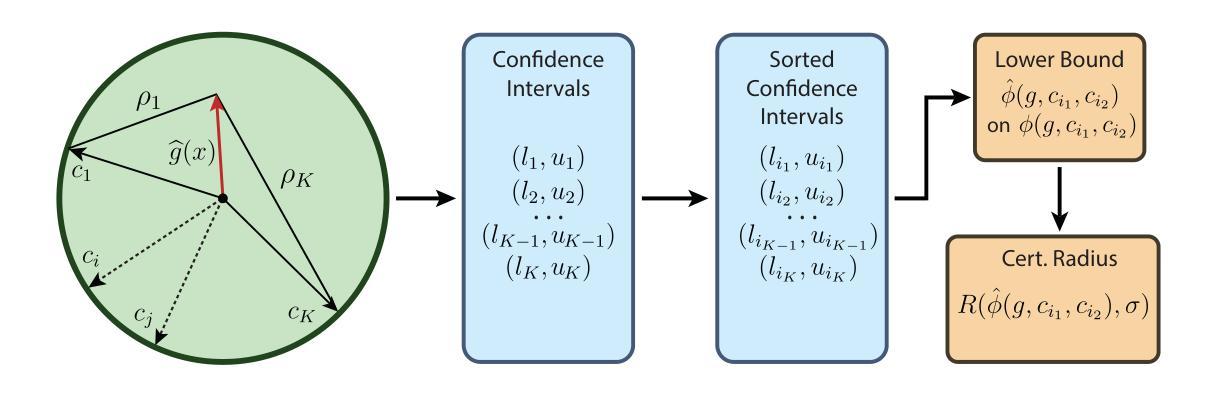
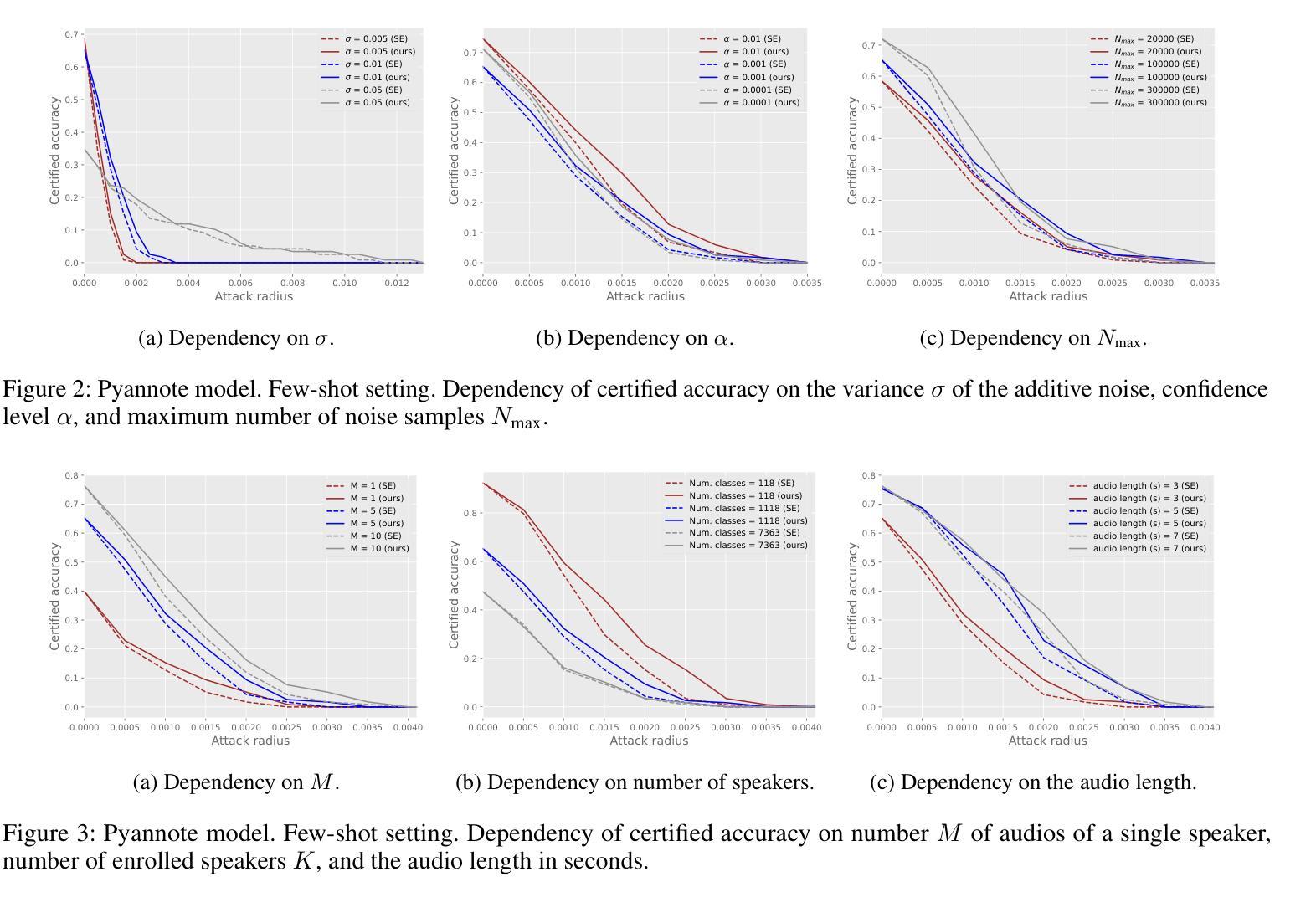
Certification of Speaker Recognition Models to Additive Perturbations
Authors:Dmitrii Korzh, Elvir Karimov, Mikhail Pautov, Oleg Y. Rogov, Ivan Oseledets
Speaker recognition technology is applied to various tasks, from personal virtual assistants to secure access systems. However, the robustness of these systems against adversarial attacks, particularly to additive perturbations, remains a significant challenge. In this paper, we pioneer applying robustness certification techniques to speaker recognition, initially developed for the image domain. Our work covers this gap by transferring and improving randomized smoothing certification techniques against norm-bounded additive perturbations for classification and few-shot learning tasks to speaker recognition. We demonstrate the effectiveness of these methods on VoxCeleb 1 and 2 datasets for several models. We expect this work to improve the robustness of voice biometrics and accelerate the research of certification methods in the audio domain.
语音识别技术应用于各种任务,从个人虚拟助手到安全访问系统。然而,这些系统对抗敌对攻击,尤其是附加扰动攻击的稳健性仍然是一个巨大挑战。本文首创将鲁棒性认证技术应用于语音识别,最初该技术是为图像领域开发的。我们的工作通过转移和改进分类和少量学习任务的针对范数有界附加扰动的随机平滑认证技术来填补这一空白,从而应用于语音识别。我们在VoxCeleb 1和2数据集上的多个模型上验证了这些方法的有效性。我们预计这项工作将提高语音生物特征的稳健性,并加快音频领域认证方法的研究。
论文及项目相关链接
PDF 13 pages, 10 figures; AAAI-2025 accepted paper
Summary:
该论文将鲁棒性认证技术应用于语音识别领域,针对分类和少样本学习任务中的范数有界添加扰动问题进行了改进和转移。在VoxCeleb 1和2数据集上进行了验证,并有望提高语音生物识别技术的鲁棒性,推动音频领域的认证方法研究。
Key Takeaways:
- 该论文探讨了语音识别的应用领域和挑战,包括在虚拟个人助理和安全访问系统中的实际应用。
- 对抗攻击问题仍然是语音识别领域的一个重要挑战,尤其是面对范数有界添加扰动的问题。对此问题展开深入研究有助于改善系统的鲁棒性。
- 论文首次将鲁棒性认证技术应用于语音识别领域,初始工作针对图像领域展开研究。这为音频领域带来了新的解决思路和方法。
- 研究采用了随机平滑认证技术并将其应用于少样本学习任务中的语音识别领域。这些方法的适用性得到了在VoxCeleb数据集上的验证。
点此查看论文截图

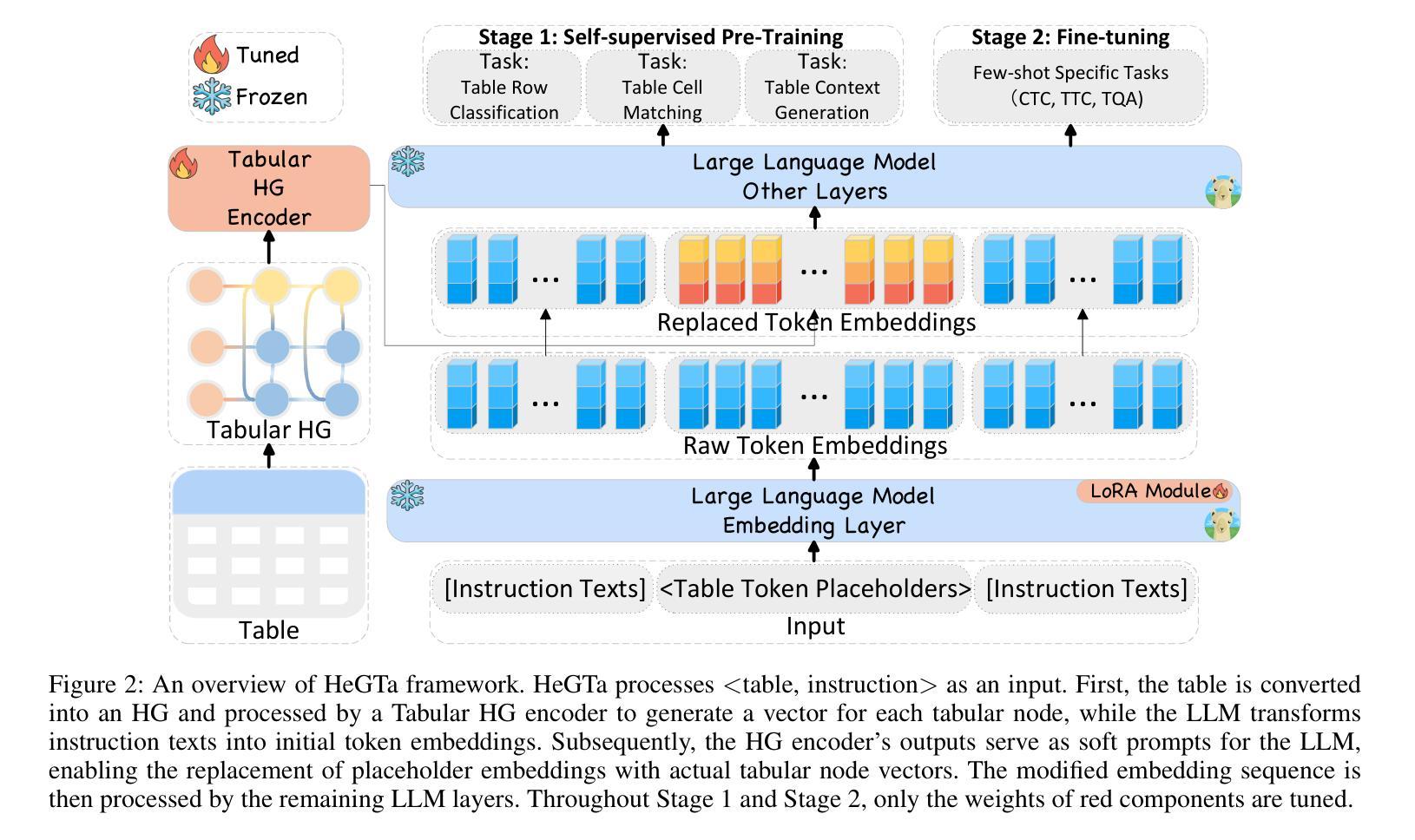
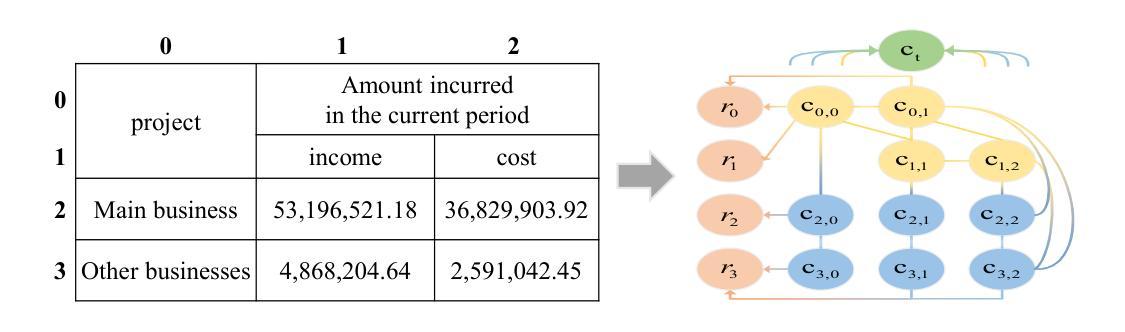
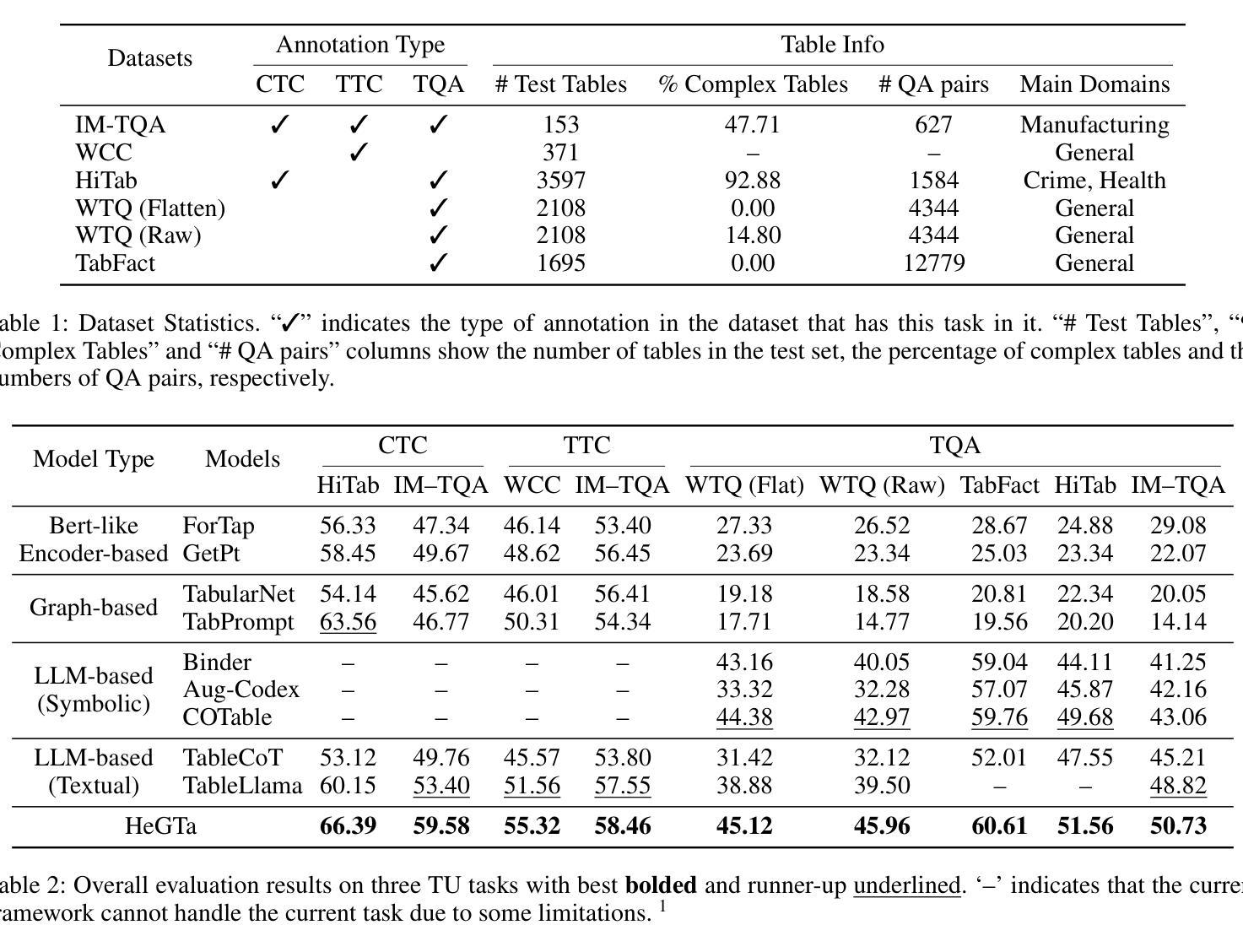
HeGTa: Leveraging Heterogeneous Graph-enhanced Large Language Models for Few-shot Complex Table Understanding
Authors:Rihui Jin, Yu Li, Guilin Qi, Nan Hu, Yuan-Fang Li, Jiaoyan Chen, Jianan Wang, Yongrui Chen, Dehai Min, Sheng Bi
Table understanding (TU) has achieved promising advancements, but it faces the challenges of the scarcity of manually labeled tables and the presence of complex table structures.To address these challenges, we propose HGT, a framework with a heterogeneous graph (HG)-enhanced large language model (LLM) to tackle few-shot TU tasks.It leverages the LLM by aligning the table semantics with the LLM’s parametric knowledge through soft prompts and instruction turning and deals with complex tables by a multi-task pre-training scheme involving three novel multi-granularity self-supervised HG pre-training objectives.We empirically demonstrate the effectiveness of HGT, showing that it outperforms the SOTA for few-shot complex TU on several benchmarks.
表格理解(TU)已经取得了令人瞩目的进展,但它面临着手动标注表格稀缺和存在复杂表格结构等挑战。为了解决这些挑战,我们提出了HGT,这是一个利用异质图(HG)增强的大型语言模型(LLM)的框架,用于解决少量表格理解任务。它通过软提示和指令转换,将表格语义与LLM的参数知识对齐,从而利用LLM。它采用多任务预训练方案,涉及三种新型的多粒度自监督HG预训练目标,以应对复杂的表格。我们通过实证证明了HGT的有效性,表明它在多个基准数据集上的少量复杂表格理解任务中超过了最新技术。
论文及项目相关链接
PDF AAAI 2025
Summary
在面临手动标记的表格稀缺和复杂表格结构存在的情况下,提出了基于异质图增强的表格理解框架HGT来解决少数表格理解任务。它通过对表格语义与大型语言模型的参数知识进行对齐,利用软提示和指令转换来利用大型语言模型,并通过涉及三种新型多粒度自监督HG预训练目标的多任务预训练方法处理复杂表格。实证研究表明,HGT在多个基准测试中超过了其他最先进的方法。
Key Takeaways
- HGT是一个基于异质图的大型语言模型框架,用于解决少数表格理解任务。
- HGT通过对齐表格语义与大型语言模型的参数知识,解决缺乏标记数据和复杂表格结构的问题。
- 软提示和指令转换被用来利用大型语言模型的能力。
- HGT采用了多任务预训练方法,涉及三种新型的多粒度自监督HG预训练目标来处理复杂的表格。
- 通过这种方法,HGT实现了更精细的语义对齐,使其能够更好地理解复杂表格。
- 实证研究显示,在多个基准测试中,HGT在少数复杂表格理解任务上的表现超过了其他最先进的方法。
- HGT框架可为未来处理表格理解的挑战提供有力支持。
点此查看论文截图