⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-20 更新
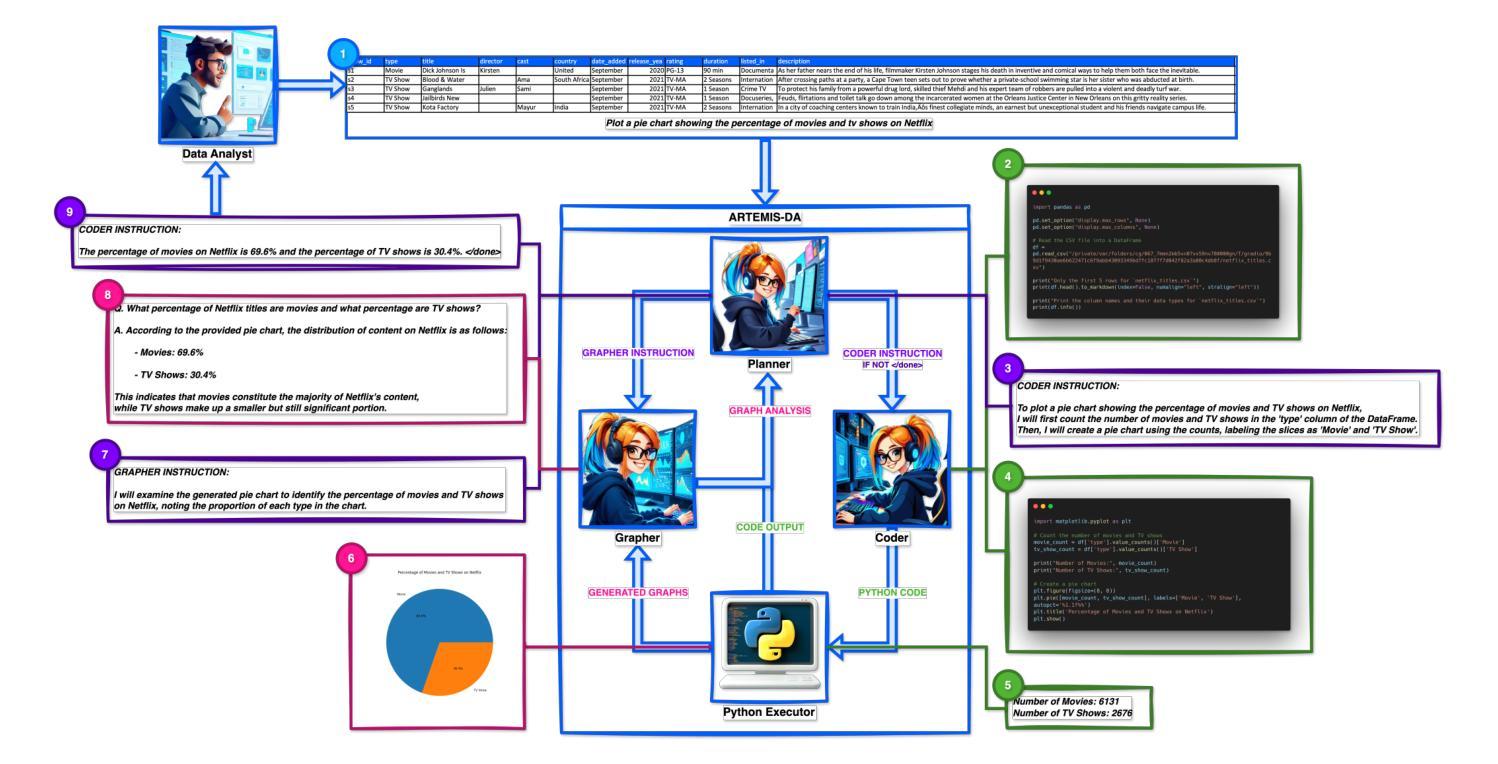
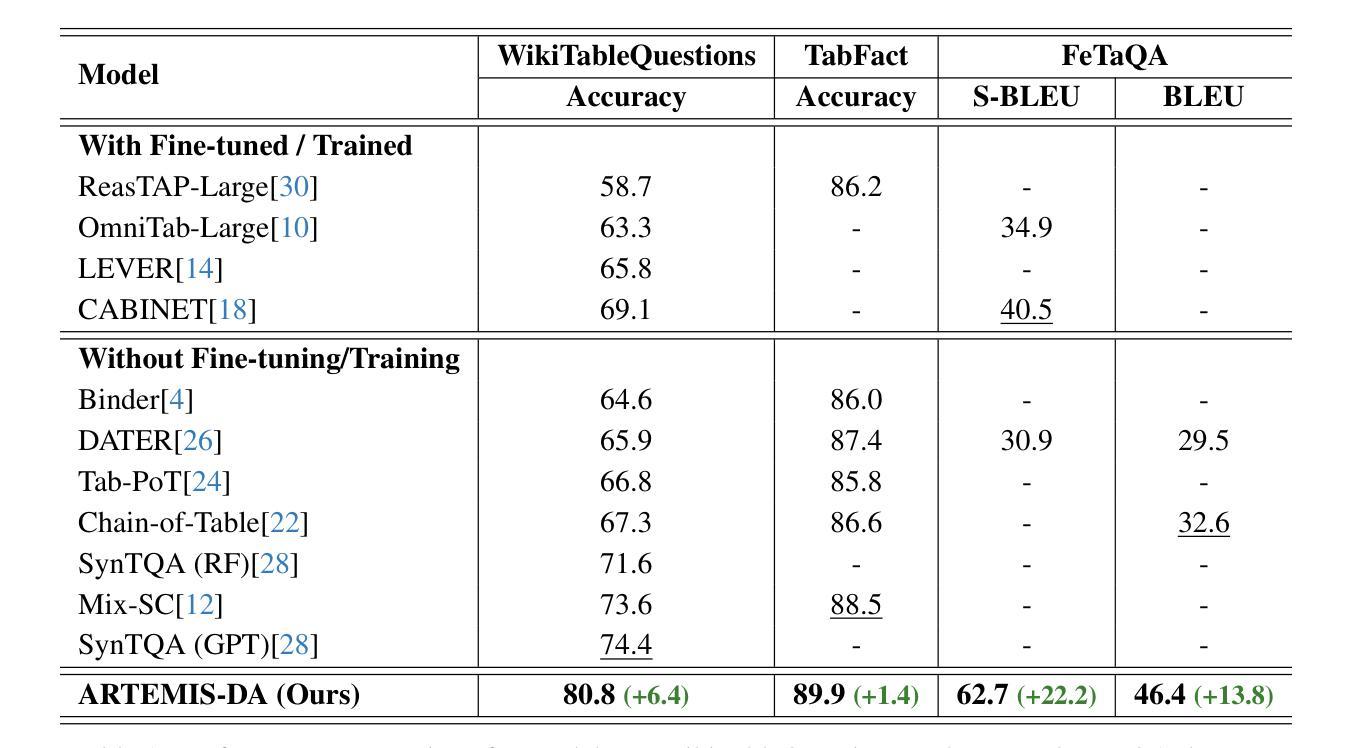
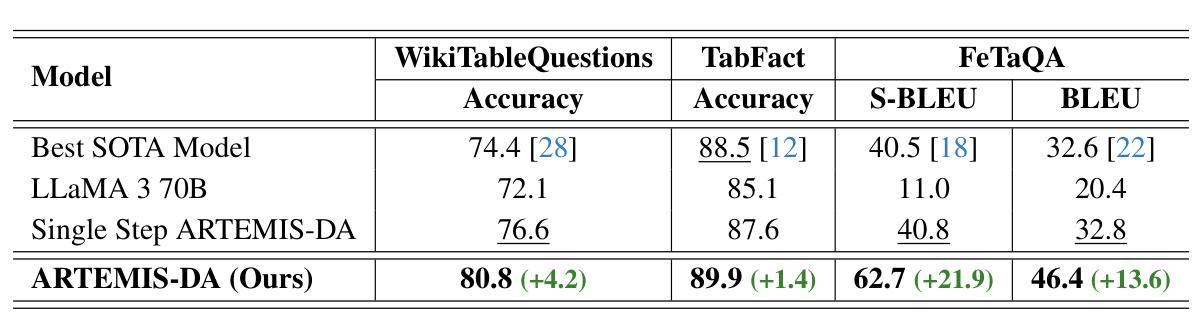
Advanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics with Large Language Models
Authors:Atin Sakkeer Hussain
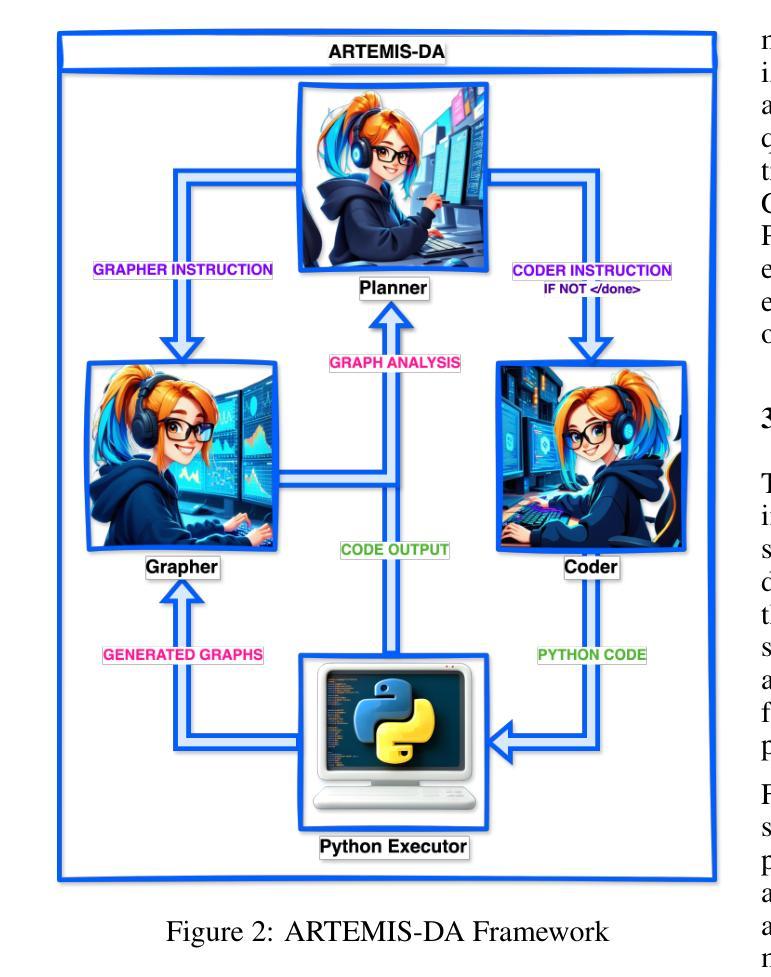
This paper presents the Advanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics (ARTEMIS-DA), a novel framework designed to augment Large Language Models (LLMs) for solving complex, multi-step data analytics tasks. ARTEMIS-DA integrates three core components: the Planner, which dissects complex user queries into structured, sequential instructions encompassing data preprocessing, transformation, predictive modeling, and visualization; the Coder, which dynamically generates and executes Python code to implement these instructions; and the Grapher, which interprets generated visualizations to derive actionable insights. By orchestrating the collaboration between these components, ARTEMIS-DA effectively manages sophisticated analytical workflows involving advanced reasoning, multi-step transformations, and synthesis across diverse data modalities. The framework achieves state-of-the-art (SOTA) performance on benchmarks such as WikiTableQuestions and TabFact, demonstrating its ability to tackle intricate analytical tasks with precision and adaptability. By combining the reasoning capabilities of LLMs with automated code generation and execution and visual analysis, ARTEMIS-DA offers a robust, scalable solution for multi-step insight synthesis, addressing a wide range of challenges in data analytics.
本文介绍了用于数据解析中的多步骤见解合成的先进推理与转换引擎(ARTEMIS-DA),这是一种旨在增强大型语言模型(LLM)以解决复杂的多步骤数据分析任务的新型框架。ARTEMIS-DA集成了三个核心组件:Planner,它将复杂的用户查询分解为结构化、顺序指令,包括数据预处理、转换、预测建模和可视化;Coder,它动态生成并执行Python代码以执行这些指令;以及Grapher,它解释生成的可视化以得出可操作的见解。通过协调这些组件之间的协作,ARTEMIS-DA有效地管理涉及高级推理、多步骤转换和跨不同数据模式的综合的复杂分析工作流程。该框架在WikiTableQuestions和TabFact等基准测试上达到了最新技术水平,证明了其处理复杂分析任务的精确性和适应性。通过将LLM的推理能力与自动化代码生成和执行以及视觉分析相结合,ARTEMIS-DA为多步骤见解合成提供了稳健且可扩展的解决方案,解决了数据分析中的一系列挑战。
论文及项目相关链接
摘要
高级推理与转换引擎(ARTEMIS-DA)在数据分析中的应用,展示了多步洞察合成的一种新颖框架。它结合了规划器、编译器和图形器三个核心组件,实现了对复杂多步骤数据分析任务的精确解决。通过结合大型语言模型(LLM)的推理能力,自动化代码生成和执行以及视觉分析,ARTEMIS-DA实现跨多种数据模式的高级推理、多步骤转换和合成,提供稳健和可扩展的解决方案以进行多步骤的见解合成,解决了一系列数据分析挑战。此框架实现了前所未有的性能水平,显示出解决复杂分析任务的精确性和适应性。
关键见解
- ARTEMIS-DA是一个新颖的框架,旨在通过整合多个组件来解决复杂的多步骤数据分析任务。它包括了用于拆分复杂用户查询的规划器,以产生结构化和顺序化的指令集。
- ARTEMIS-DA的核心组件之一是编译器,它能够动态生成并执行Python代码来实现这些指令。此外,它还配备了图形器,能够解释生成的可视化结果以获取可操作的见解。
- ARTEMIS-DA成功地将大型语言模型(LLM)的推理能力与自动化的代码生成和执行及视觉分析结合在了一起。这使得它能够处理高级推理、多步骤转换和跨各种数据模式的合成。
- 该框架的性能达到了前所未有的水平,并在WikiTableQuestions和TabFact等基准测试中表现出了强大的能力,证明了它能够精确且灵活地解决复杂分析任务。
- ARTEMIS-DA提供了一种稳健和可扩展的解决方案,用于进行多步骤的见解合成,对于数据分析领域的广泛挑战具有很强的应对能力。这一解决方案将有助于改进数据处理和分析的效率及准确性。
- ARTEMIS-DA框架强调了数据预处理、转换、预测建模和可视化的重要性,这些都是数据分析过程中的关键步骤。通过优化这些步骤,该框架提高了数据分析的整体效率和效果。
点此查看论文截图

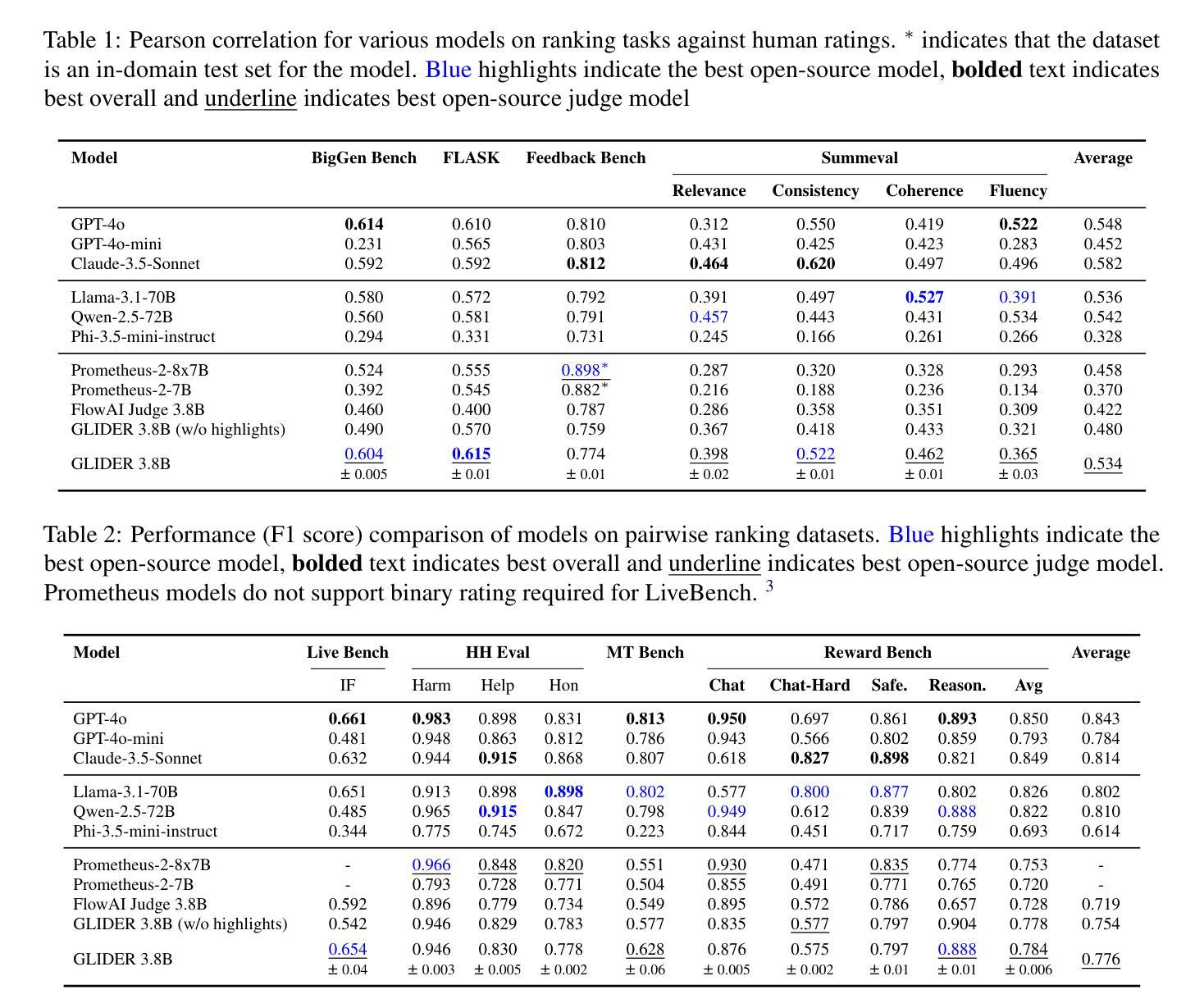
GLIDER: Grading LLM Interactions and Decisions using Explainable Ranking
Authors:Darshan Deshpande, Selvan Sunitha Ravi, Sky CH-Wang, Bartosz Mielczarek, Anand Kannappan, Rebecca Qian
The LLM-as-judge paradigm is increasingly being adopted for automated evaluation of model outputs. While LLM judges have shown promise on constrained evaluation tasks, closed source LLMs display critical shortcomings when deployed in real world applications due to challenges of fine grained metrics and explainability, while task specific evaluation models lack cross-domain generalization. We introduce GLIDER, a powerful 3B evaluator LLM that can score any text input and associated context on arbitrary user defined criteria. GLIDER shows higher Pearson’s correlation than GPT-4o on FLASK and greatly outperforms prior evaluation models, achieving comparable performance to LLMs 17x its size. GLIDER supports fine-grained scoring, multilingual reasoning, span highlighting and was trained on 685 domains and 183 criteria. Extensive qualitative analysis shows that GLIDER scores are highly correlated with human judgments, with 91.3% human agreement. We have open-sourced GLIDER to facilitate future research.
LLM作为判断系统的模式在自动化评估模型输出方面越来越受到关注。尽管LLM作为评委在受约束的评估任务中显示出前景,但在现实世界应用中部署封闭式LLM时,由于其面临精细度指标和解释性的挑战,暴露出关键缺陷。而针对特定任务的评估模型缺乏跨域泛化能力。我们推出GLIDER,这是一个强大的拥有用户自定义标准评分的评价型LLM系统,能够给任何文本输入和相应的上下文打分。GLIDER显示出高于GPT-4o的皮尔逊相关系数。与现有评估模型相比,GLIDER在大尺寸上有优越的表现。同时它能够进行精细打分、多语言推理和高亮跨度分析。它的训练涉及到对各大领域、多达685个领域的支持,涵盖的评估标准达到惊人的高达的跨度高亮文本和三大类别183个评判标准!深度定性分析表明,GLIDER评分与人类判断高度相关,其准确性高达91.3%。为了让更多的人进行研究和发展技术我们已经开源GLIDER模型供大家学习参考和使用交流分享研究成果以此进一步促进模型的更新和完善贡献智慧和力量让技术发展更有温度和创造力并释放潜力更好的赋能社会生产生活。
论文及项目相关链接
Summary
LLM作为评判者的模式在自动化评估模型输出方面越来越受欢迎。针对现实世界应用中的精细粒度指标和解释性挑战,封闭源LLMs显示出关键缺陷。本文介绍GLIDER模型,一种强大的用于文本和上下文评价的LLM,能基于用户定义的任意标准对文本进行评分。GLIDER性能卓越,如在FLASK上的Pearson相关性高于GPT-4o,显著优于先前评估模型,并且相对于某些模型实现跨域泛化。GLIDER支持精细评分、多语言推理、跨度高亮等功能,经过在685个领域和183个标准上的训练后性能强大。定性分析显示,GLIDER得分与人类判断高度相关,人类同意度达91.3%。本研究公开了GLIDER模型以促进未来研究。
Key Takeaways
- LLM作为评判者的模式在自动化评估模型输出方面越来越受欢迎。
- 封闭源LLMs在现实世界应用中面临精细粒度指标和解释性的挑战。
- GLIDER是一种强大的文本评价LLM,可基于用户定义的任意标准对文本进行评分。
- GLIDER在性能上显著优于先前的评估模型,并实现了跨域泛化。
- GLIDER支持精细评分、多语言推理、跨度高亮等功能。
- GLIDER经过在多个领域和标准上的训练,显示出强大的性能。
点此查看论文截图

Future Research Avenues for Artificial Intelligence in Digital Gaming: An Exploratory Report
Authors:Markus Dablander
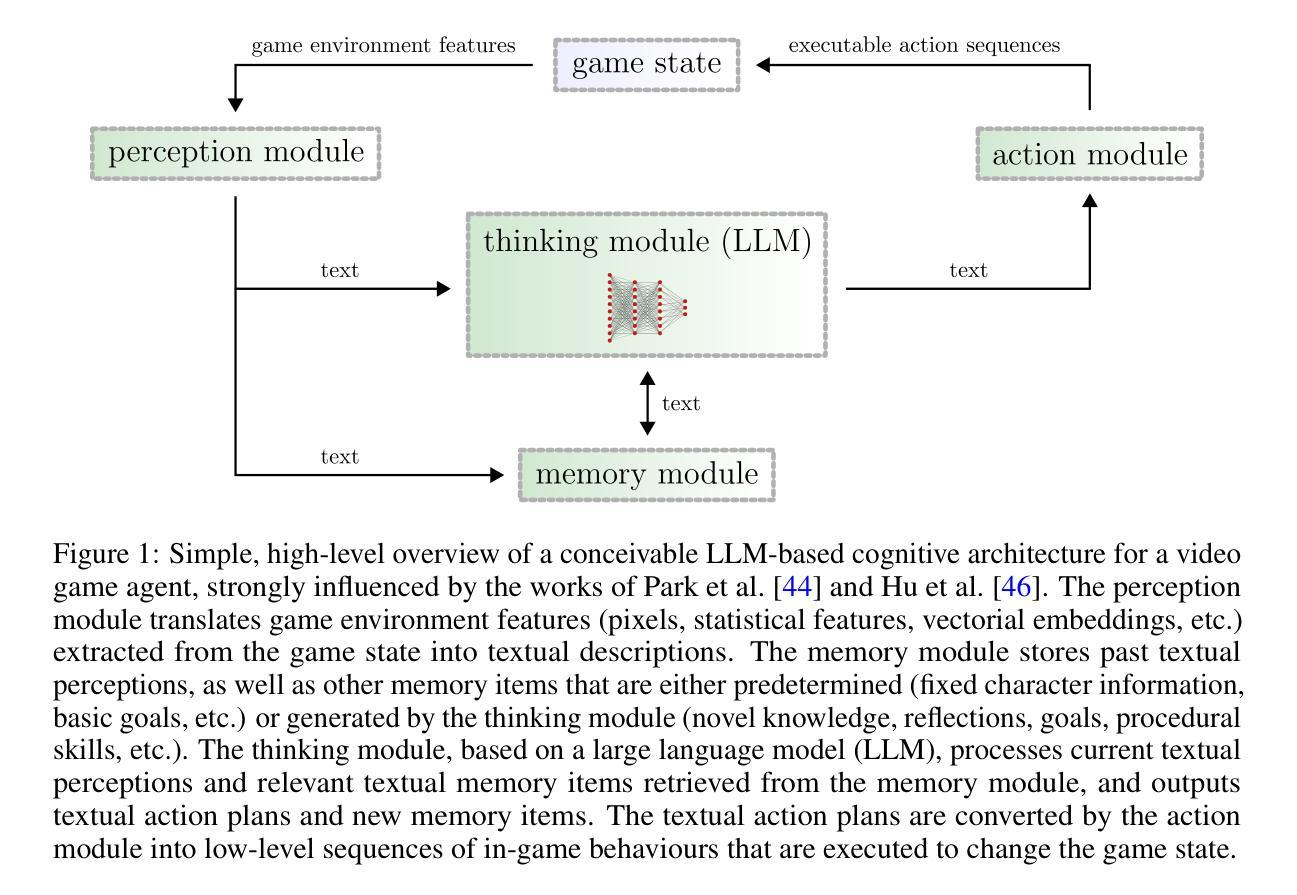
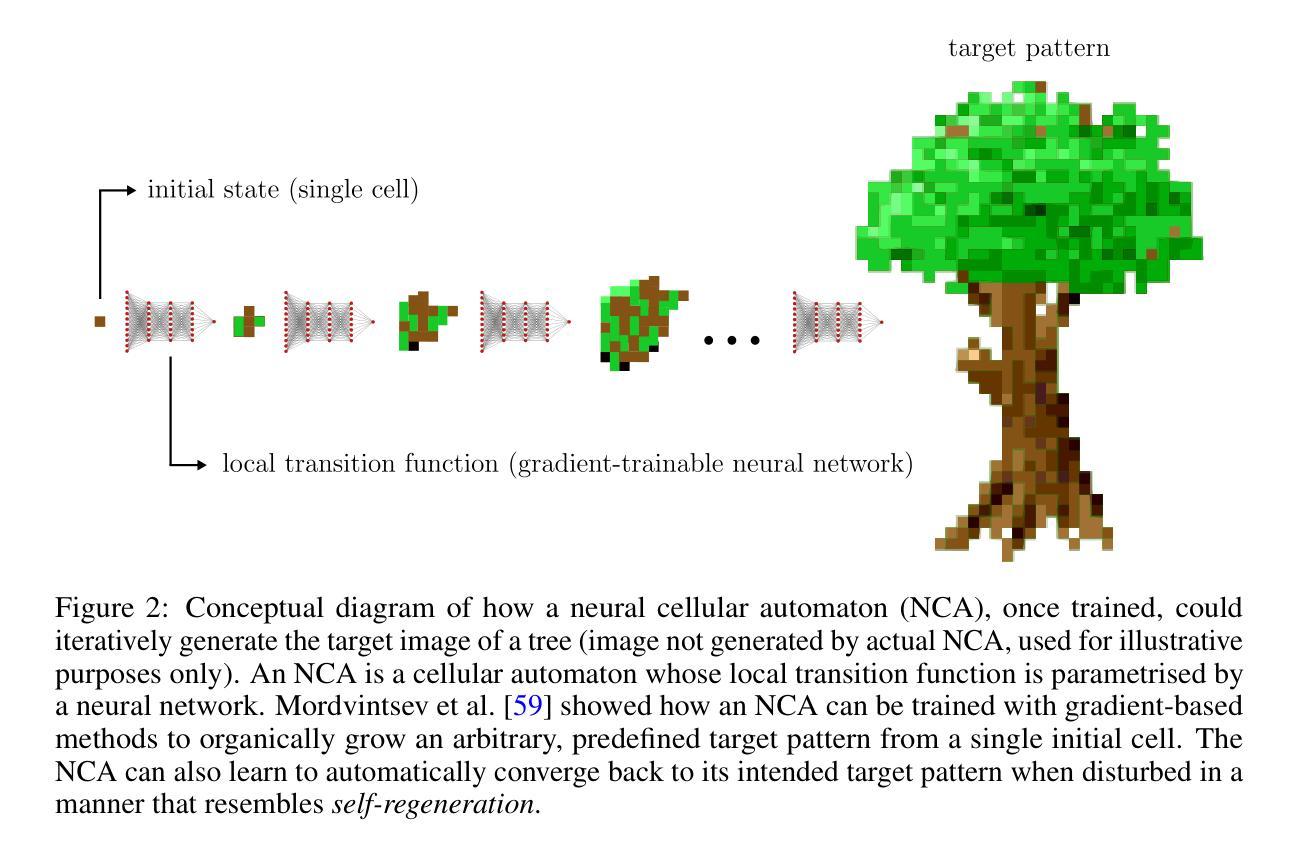
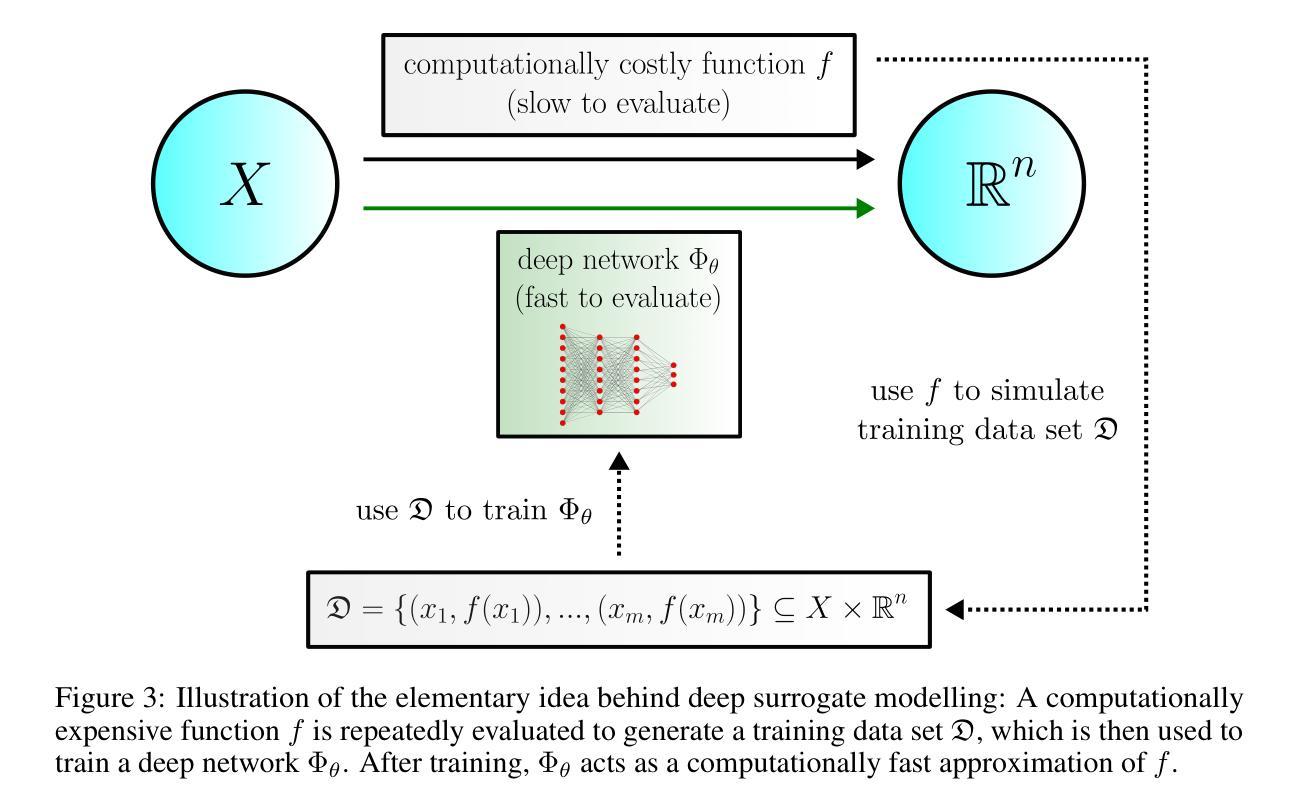
Video games are a natural and synergistic application domain for artificial intelligence (AI) systems, offering both the potential to enhance player experience and immersion, as well as providing valuable benchmarks and virtual environments to advance AI technologies in general. This report presents a high-level overview of five promising research pathways for applying state-of-the-art AI methods, particularly deep learning, to digital gaming within the context of the current research landscape. The objective of this work is to outline a curated, non-exhaustive list of encouraging research directions at the intersection of AI and video games that may serve to inspire more rigorous and comprehensive research efforts in the future. We discuss (i) investigating large language models as core engines for game agent modelling, (ii) using neural cellular automata for procedural game content generation, (iii) accelerating computationally expensive in-game simulations via deep surrogate modelling, (iv) leveraging self-supervised learning to obtain useful video game state embeddings, and (v) training generative models of interactive worlds using unlabelled video data. We also briefly address current technical challenges associated with the integration of advanced deep learning systems into video game development, and indicate key areas where further progress is likely to be beneficial.
电子游戏是人工智能(AI)系统的自然协同应用领域,在提高玩家体验和沉浸感的同时,也为推进AI技术本身提供了宝贵的基准测试和虚拟环境。本报告从当前研究现状出发,介绍了将最前沿的人工智能方法,尤其是深度学习应用于数字游戏时的五个有前途的研究方向的高层次概述。这项工作的目的是概述人工智能和电子游戏交界处鼓舞人心的研究方向的非详尽列表,可能在未来激发更为严格和全面的研究。我们讨论了(i)研究大型语言模型作为游戏代理建模的核心引擎,(ii)使用神经网络细胞自动机进行游戏内容的程序化生成,(iii)通过深度代理建模加速游戏中计算昂贵的模拟,(iv)利用自我监督学习获得有用的电子游戏状态嵌入,以及(v)使用未标记的视频数据训练交互式世界的生成模型。我们还简要介绍了将先进的深度学习系统整合到游戏开发中面临的技术挑战,并指出了进一步取得进展的关键领域。
论文及项目相关链接
Summary:电子游戏是人工智能系统应用的自然和协同领域,能提升玩家体验和沉浸感,同时为推进人工智能技术发展提供宝贵的基准测试和虚拟环境。报告概述了将最新的人工智能方法,尤其是深度学习,应用于数字游戏的五个有前途的研究方向。旨在提出一份非详尽的、鼓舞人心的研究路径清单,为未来在人工智能与电子游戏交叉领域进行更严格和全面的研究提供灵感。
Key Takeaways:
- 视频游戏领域是人工智能应用的自然和协同领域,有助于推进AI技术的发展。
- 报告介绍了五个在人工智能和电子游戏交叉领域有前途的研究方向。
- 研究人员正在探索将大型语言模型作为游戏代理建模的核心引擎。
- 神经细胞自动机被用于程序化游戏内容生成。
- 深度替身建模被用来加速游戏中计算量大的模拟。
- 自我监督学习被用来获取有用的视频游戏状态嵌入。
- 使用无标签视频数据训练交互世界的生成模型。
点此查看论文截图

Rango: Adaptive Retrieval-Augmented Proving for Automated Software Verification
Authors:Kyle Thompson, Nuno Saavedra, Pedro Carrott, Kevin Fisher, Alex Sanchez-Stern, Yuriy Brun, João F. Ferreira, Sorin Lerner, Emily First
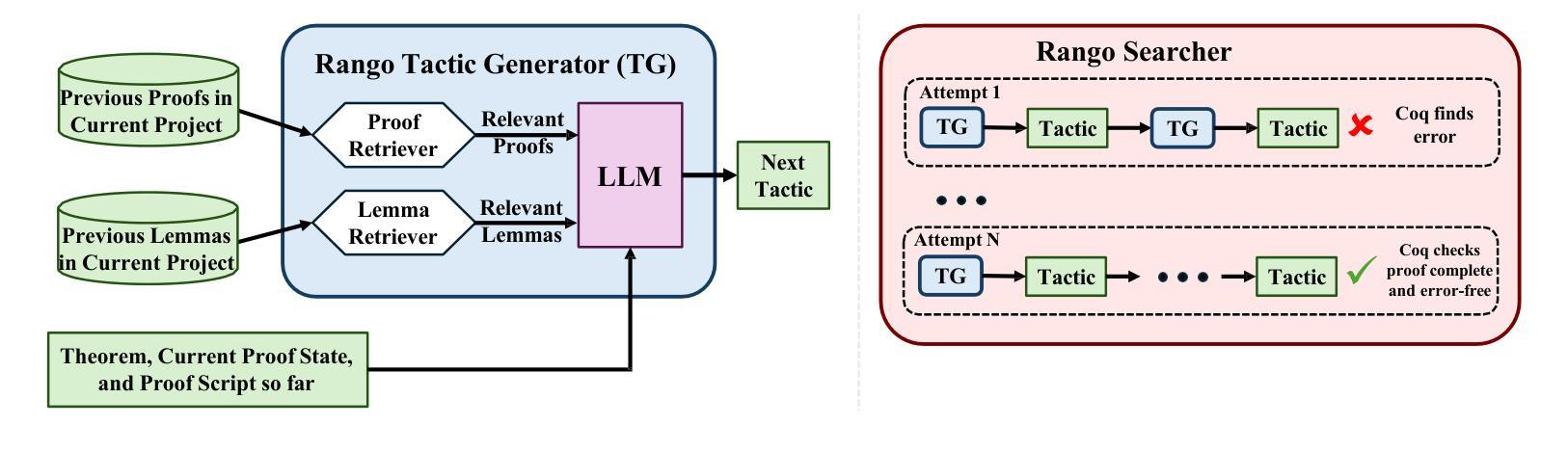
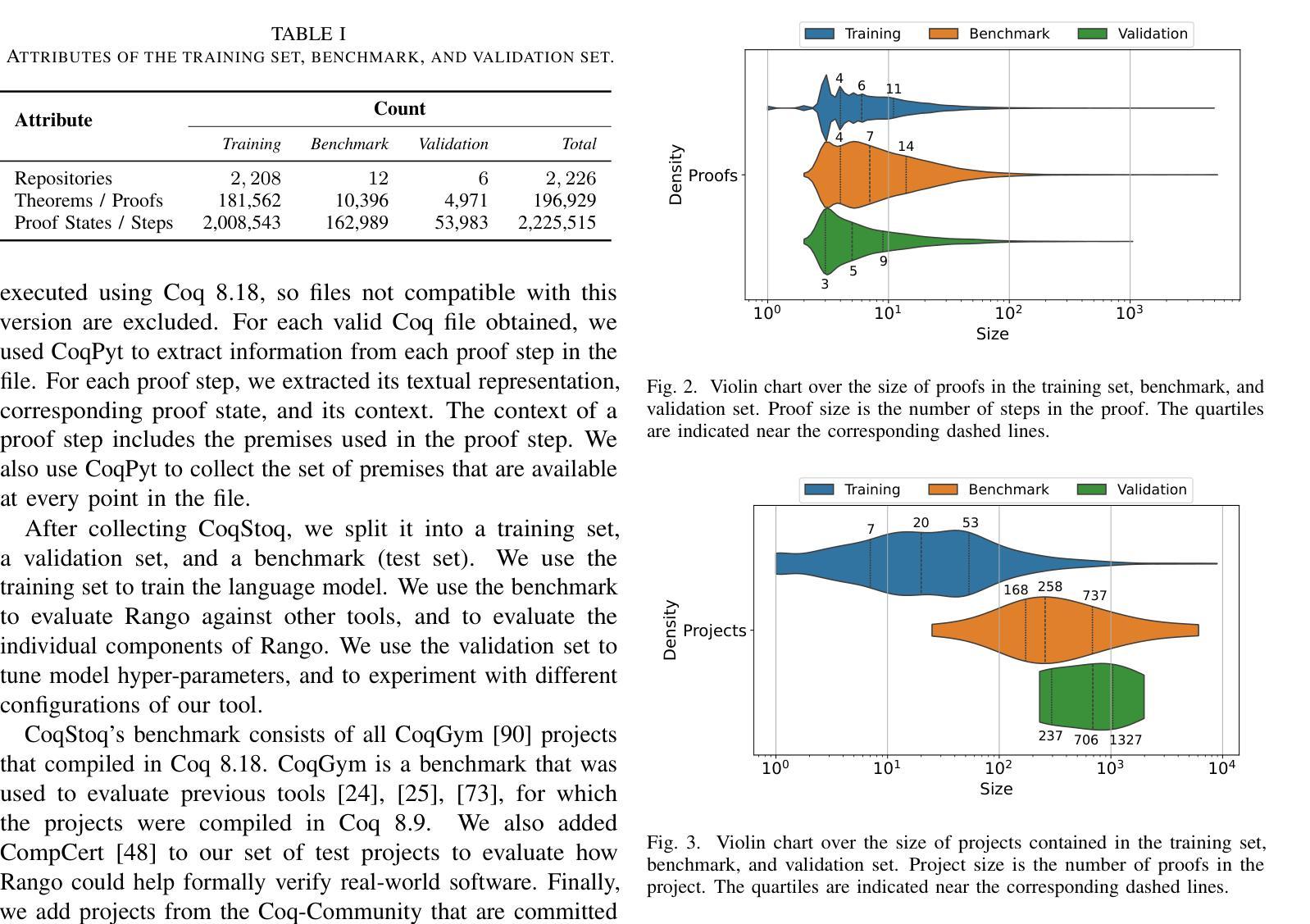
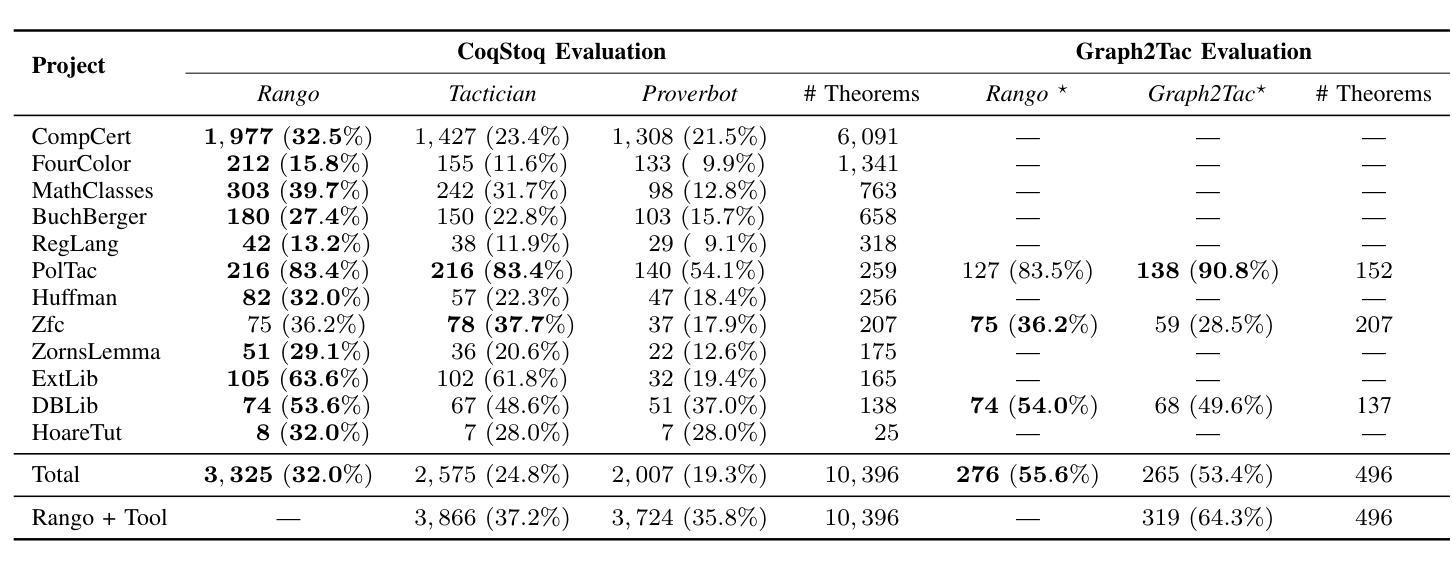
Formal verification using proof assistants, such as Coq, enables the creation of high-quality software. However, the verification process requires significant expertise and manual effort to write proofs. Recent work has explored automating proof synthesis using machine learning and large language models (LLMs). This work has shown that identifying relevant premises, such as lemmas and definitions, can aid synthesis. We present Rango, a fully automated proof synthesis tool for Coq that automatically identifies relevant premises and also similar proofs from the current project and uses them during synthesis. Rango uses retrieval augmentation at every step of the proof to automatically determine which proofs and premises to include in the context of its fine-tuned LLM. In this way, Rango adapts to the project and to the evolving state of the proof. We create a new dataset, CoqStoq, of 2,226 open-source Coq projects and 196,929 theorems from GitHub, which includes both training data and a curated evaluation benchmark of well-maintained projects. On this benchmark, Rango synthesizes proofs for 32.0% of the theorems, which is 29% more theorems than the prior state-of-the-art tool Tactician. Our evaluation also shows that Rango adding relevant proofs to its context leads to a 47% increase in the number of theorems proven.
使用Coq等证明助手进行形式化验证有助于创建高质量的软件。然而,验证过程需要大量的专业知识和手动编写证明的努力。最近的工作探索了使用机器学习和大型语言模型(LLM)自动合成证明的方法。研究表明,识别相关的前提,如引理和定义,可以辅助合成。我们提出了Rango,这是一个完全自动化的Coq证明合成工具,它会自动识别相关的前提和当前项目中的类似证明,并在合成过程中使用它们。Rango在证明的每个步骤中都使用检索增强来自动确定要包含在其微调LLM上下文中的证明和前提。通过这种方式,Rango适应于项目和不断变化的证明状态。我们创建了一个新的数据集CoqStoq,它包括来自GitHub的2226个开源Coq项目和196929个定理,其中包括训练数据和精选的维护良好的项目评估基准。在这个基准测试上,Rango合成了32.0%的定理的证明,比现有最先进的工具Tactician多证明了29%的定理。我们的评估还表明,Rango将其上下文中的相关证明增加导致证明了47%的定理数量增加。
论文及项目相关链接
PDF In Proceedings of the 47th International Conference on Software Engineering (ICSE), Ottawa, ON, Canada, April 2025
摘要
形式化验证使用Coq等证明助手可以创建高质量的软件,但验证过程需要专业知识和大量手动编写证明的工作。最近的工作探索了使用机器学习和大型语言模型(LLM)自动合成证明的方法。我们提出了Rango,一个全自动的Coq证明合成工具,它可以自动识别相关的前提和类似证明,并在合成过程中使用它们。Rango在证明的每个步骤中都使用检索增强来自动确定包含哪些证明和前提,以适应项目和证明的不断演变状态。我们创建了一个新的数据集CoqStoq,包含来自GitHub的2226个开源Coq项目和196929个定理,其中包括训练数据和精选的评估基准测试项目。在基准测试中,Rango能够合成32.0%的定理证明,比现有最先进的工具Tactician多证明了29%的定理。我们的评估还显示,Rango将其相关证明添加到上下文中,导致证明的定理数量增加了47%。
关键见解
- 形式化验证使用证明助手如Coq对于创建高质量软件至关重要。
- 自动化证明合成正在受到关注,并已经开始使用机器学习和大型语言模型(LLM)。
- Rango是一个全自动的Coq证明合成工具,能够自动识别相关的前提和类似证明。
- Rango在证明的每个步骤都使用检索增强技术,使其能够适应项目和证明的不断演变状态。
- 创建了一个名为CoqStoq的新数据集,包含来自GitHub的开源Coq项目和定理。
- Rango在基准测试中成功证明了比现有工具更多的定理。
点此查看论文截图

A Review of Multimodal Explainable Artificial Intelligence: Past, Present and Future
Authors:Shilin Sun, Wenbin An, Feng Tian, Fang Nan, Qidong Liu, Jun Liu, Nazaraf Shah, Ping Chen
Artificial intelligence (AI) has rapidly developed through advancements in computational power and the growth of massive datasets. However, this progress has also heightened challenges in interpreting the “black-box” nature of AI models. To address these concerns, eXplainable AI (XAI) has emerged with a focus on transparency and interpretability to enhance human understanding and trust in AI decision-making processes. In the context of multimodal data fusion and complex reasoning scenarios, the proposal of Multimodal eXplainable AI (MXAI) integrates multiple modalities for prediction and explanation tasks. Meanwhile, the advent of Large Language Models (LLMs) has led to remarkable breakthroughs in natural language processing, yet their complexity has further exacerbated the issue of MXAI. To gain key insights into the development of MXAI methods and provide crucial guidance for building more transparent, fair, and trustworthy AI systems, we review the MXAI methods from a historical perspective and categorize them across four eras: traditional machine learning, deep learning, discriminative foundation models, and generative LLMs. We also review evaluation metrics and datasets used in MXAI research, concluding with a discussion of future challenges and directions. A project related to this review has been created at https://github.com/ShilinSun/mxai_review.
人工智能(AI)通过计算能力的进步和大规模数据集的增长而迅速发展。然而,这种进步也增加了对解释AI模型“黑箱”性质的挑战。为了解决这些担忧,以透明度和可解释性为重点的可解释人工智能(XAI)的出现,增强了人类对AI决策过程的了解和信任。在多模态数据融合和复杂推理场景中,多模态可解释人工智能(MXAI)的提出融合了多种模态来进行预测和解释任务。与此同时,大型语言模型(LLM)的出现,虽然在自然语言处理方面取得了显著的突破,但其复杂性进一步加剧了MXAI的问题。为了深入了解MXAI方法的发展,并为构建更透明、公平和可信赖的AI系统提供关键指导,我们从历史的角度回顾了MXAI方法,并根据四个时代进行分类:传统机器学习、深度学习、判别基础模型和生成LLM。我们还回顾了MXAI研究中使用的评估指标和数据集,最后讨论了未来的挑战和方向。有关此审查的项目已在https://github.com/ShilinSun/mxai_review创建。
论文及项目相关链接
PDF This work has been submitted to the IEEE for possible publication
Summary
人工智能(AI)的发展迅速,伴随计算能力的进步和海量数据的增长,带来了解释性挑战(“黑箱”性质)。为解决这一问题,出现了解释性人工智能(XAI),注重透明度和可解释性,提升人类对AI决策过程的理解和信任。在多模态数据融合和复杂场景推理中,多模态解释性人工智能(MXAI)整合多种模态进行预测和解释任务。大型语言模型(LLM)的出现在自然语言处理领域带来突破,但其复杂性进一步加剧了MXAI的问题。本文回顾了MXAI方法的历史发展,将其分为传统机器学习、深度学习、判别基础模型和生成型LLM四个时代,并评述了MXAI研究中的评估指标和数据集,最后讨论了未来的挑战和发展方向。
Key Takeaways
- 人工智能(AI)的快速发展伴随着解释性的挑战,即“黑箱”性质。
- 解释性人工智能(XAI)注重透明度和可解释性,旨在提升人类对AI决策过程的了解和信任。
- 多模态解释性人工智能(MXAI)在多模态数据融合和复杂场景推理中整合多种模态进行预测和解释。
- 大型语言模型(LLM)的出现在自然语言处理领域带来突破,但增加了AI的复杂性,对MXAI提出新的挑战。
- MXAI方法的历史发展可分为传统机器学习、深度学习、判别基础模型和生成型LLM四个时代。
- 在MXAI研究中,评估指标和数据集的选择至关重要。
- 未来的MXAI发展仍面临诸多挑战,包括如何进一步提高透明度和可解释性、应对复杂数据的挑战等。
点此查看论文截图

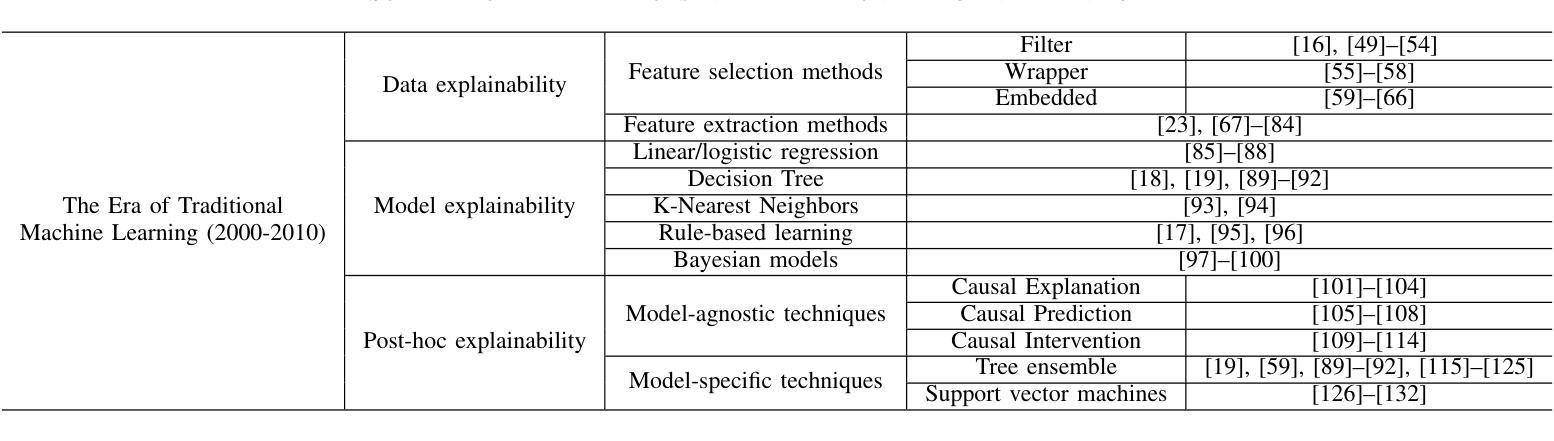
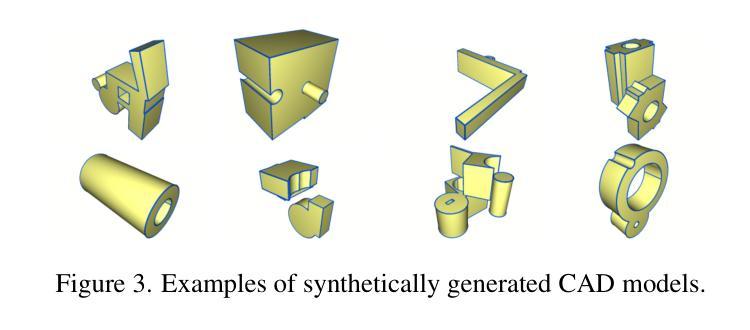
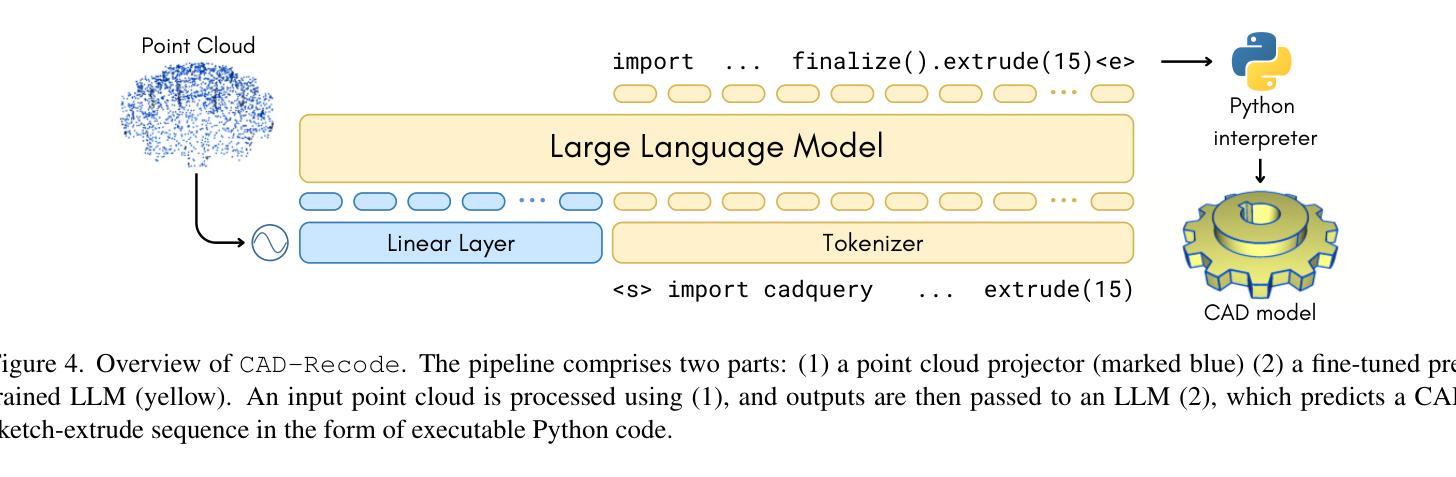
CAD-Recode: Reverse Engineering CAD Code from Point Clouds
Authors:Danila Rukhovich, Elona Dupont, Dimitrios Mallis, Kseniya Cherenkova, Anis Kacem, Djamila Aouada
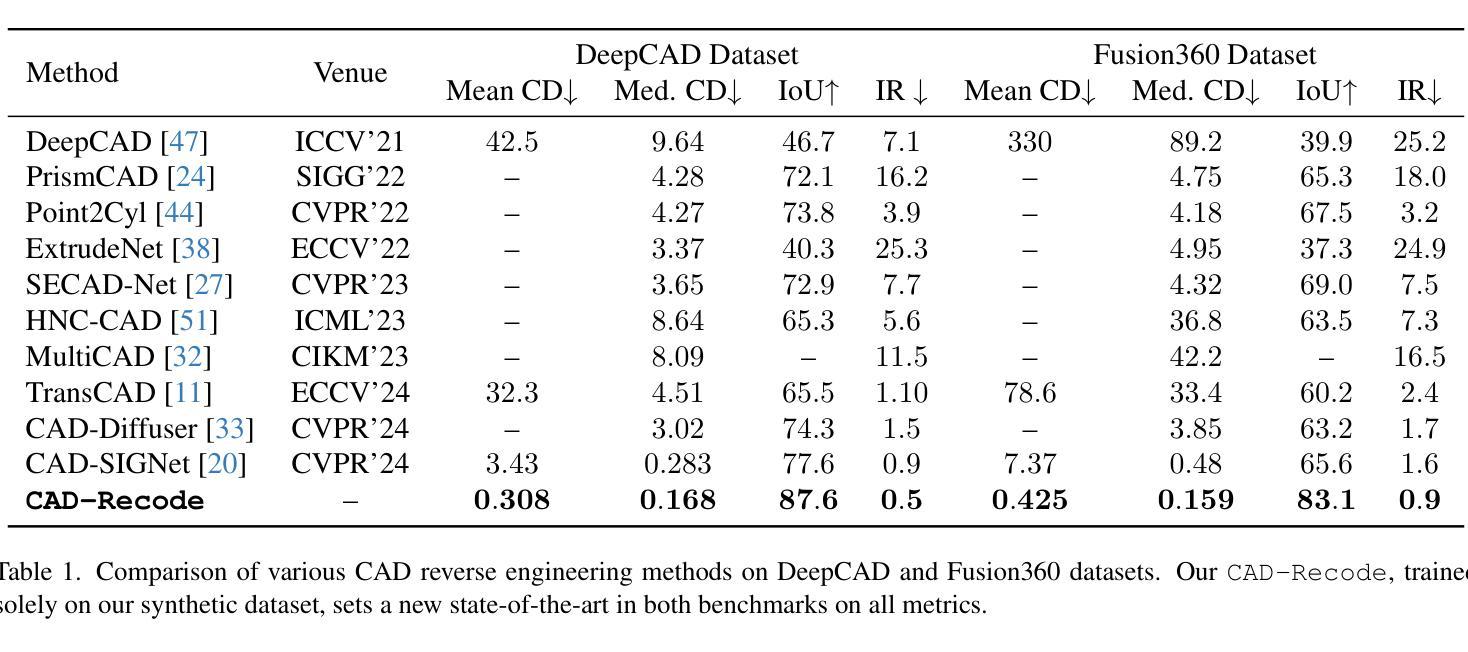
Computer-Aided Design (CAD) models are typically constructed by sequentially drawing parametric sketches and applying CAD operations to obtain a 3D model. The problem of 3D CAD reverse engineering consists of reconstructing the sketch and CAD operation sequences from 3D representations such as point clouds. In this paper, we address this challenge through novel contributions across three levels: CAD sequence representation, network design, and dataset. In particular, we represent CAD sketch-extrude sequences as Python code. The proposed CAD-Recode translates a point cloud into Python code that, when executed, reconstructs the CAD model. Taking advantage of the exposure of pre-trained Large Language Models (LLMs) to Python code, we leverage a relatively small LLM as a decoder for CAD-Recode and combine it with a lightweight point cloud projector. CAD-Recode is trained solely on a proposed synthetic dataset of one million diverse CAD sequences. CAD-Recode significantly outperforms existing methods across three datasets while requiring fewer input points. Notably, it achieves 10 times lower mean Chamfer distance than state-of-the-art methods on DeepCAD and Fusion360 datasets. Furthermore, we show that our CAD Python code output is interpretable by off-the-shelf LLMs, enabling CAD editing and CAD-specific question answering from point clouds.
计算机辅助设计(CAD)模型通常是通过依次绘制参数化草图并应用CAD操作来获得三维模型。3D CAD逆向工程的问题在于从点云等3D表示中重建草图和CAD操作序列。在本文中,我们通过三个方面的新贡献来解决这一挑战:CAD序列表示、网络设计和数据集。特别是,我们将CAD草图挤压序列表示为Python代码。所提出的CAD-Recode将点云转换为Python代码,执行该代码即可重建CAD模型。利用预训练的的大型语言模型(LLM)对Python代码的暴露,我们利用一个较小的LLM作为CAD-Recode的解码器,并将其与一个轻量级的点云投影仪相结合。CAD-Recode仅在一百万个多样化的合成CAD序列所构成的数据集上进行训练。在三个数据集上,CAD-Recode显著优于现有方法,且需要的输入点数更少。值得注意的是,它在DeepCAD和Fusion360数据集上实现了比最新技术低10倍的平均Chamfer距离。此外,我们展示了我们的CAD Python代码输出可以被市面上的LLM解释,从而能够有点云进行CAD编辑和特定的CAD问题回答。
论文及项目相关链接
Summary
本文解决了计算机辅助设计(CAD)模型的逆向工程问题,通过三个层面的创新贡献实现了从点云到CAD设计序列的转换。提出将CAD草图挤压序列表示为Python代码,并开发了CAD-Recode系统,能将点云转化为Python代码,执行后重建CAD模型。利用预训练的大型语言模型(LLM)对Python代码的暴露,结合轻量级点云投影仪,实现了在少量数据下的训练。CAD-Recode在合成数据集上表现出卓越性能,显著优于现有方法,并在DeepCAD和Fusion360数据集上实现了较低的Chamfer距离。此外,输出的CAD Python代码具有可解释性,能够被即用的LLM用于CAD编辑和回答有关点云的问题。
Key Takeaways
- CAD模型的逆向工程问题涉及从3D表示(如点云)重建草图和设计序列。
- CAD-Recode系统将点云转化为Python代码,重现CAD模型。
- 利用预训练的大型语言模型(LLM)处理Python代码,结合轻量级点云投影仪实现高效解码。
- CAD-Recode在合成数据集上训练,显著优于现有方法。
- CAD-Recode在DeepCAD和Fusion360数据集上实现了较低的Chamfer距离,达到业界领先水平。
- 输出的CAD Python代码具有可解释性,便于人类理解。
点此查看论文截图

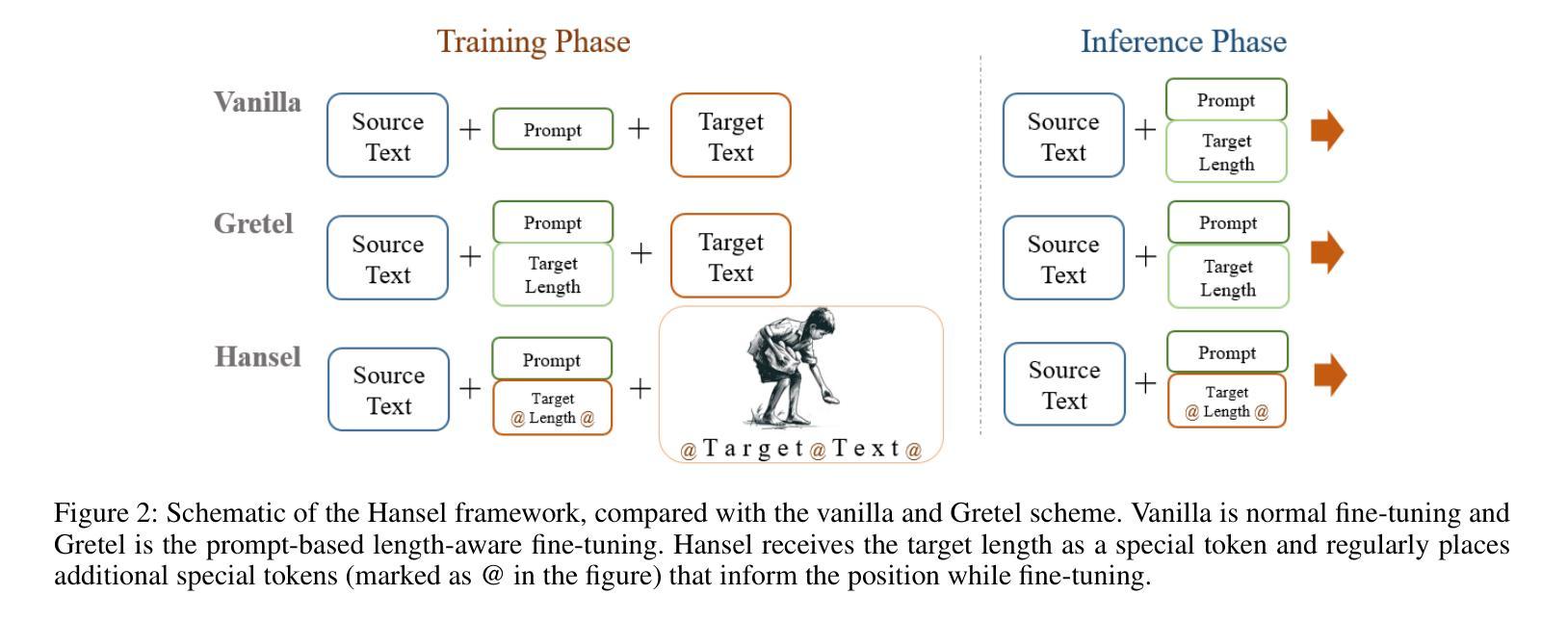
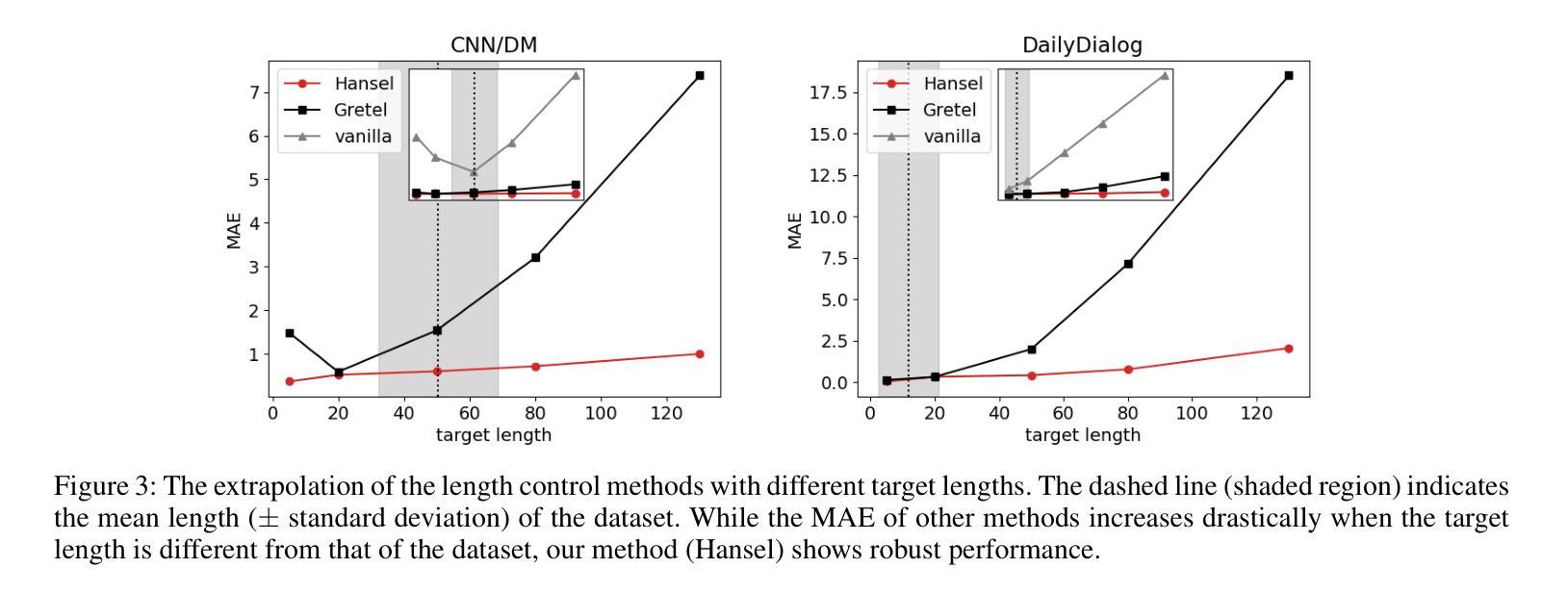
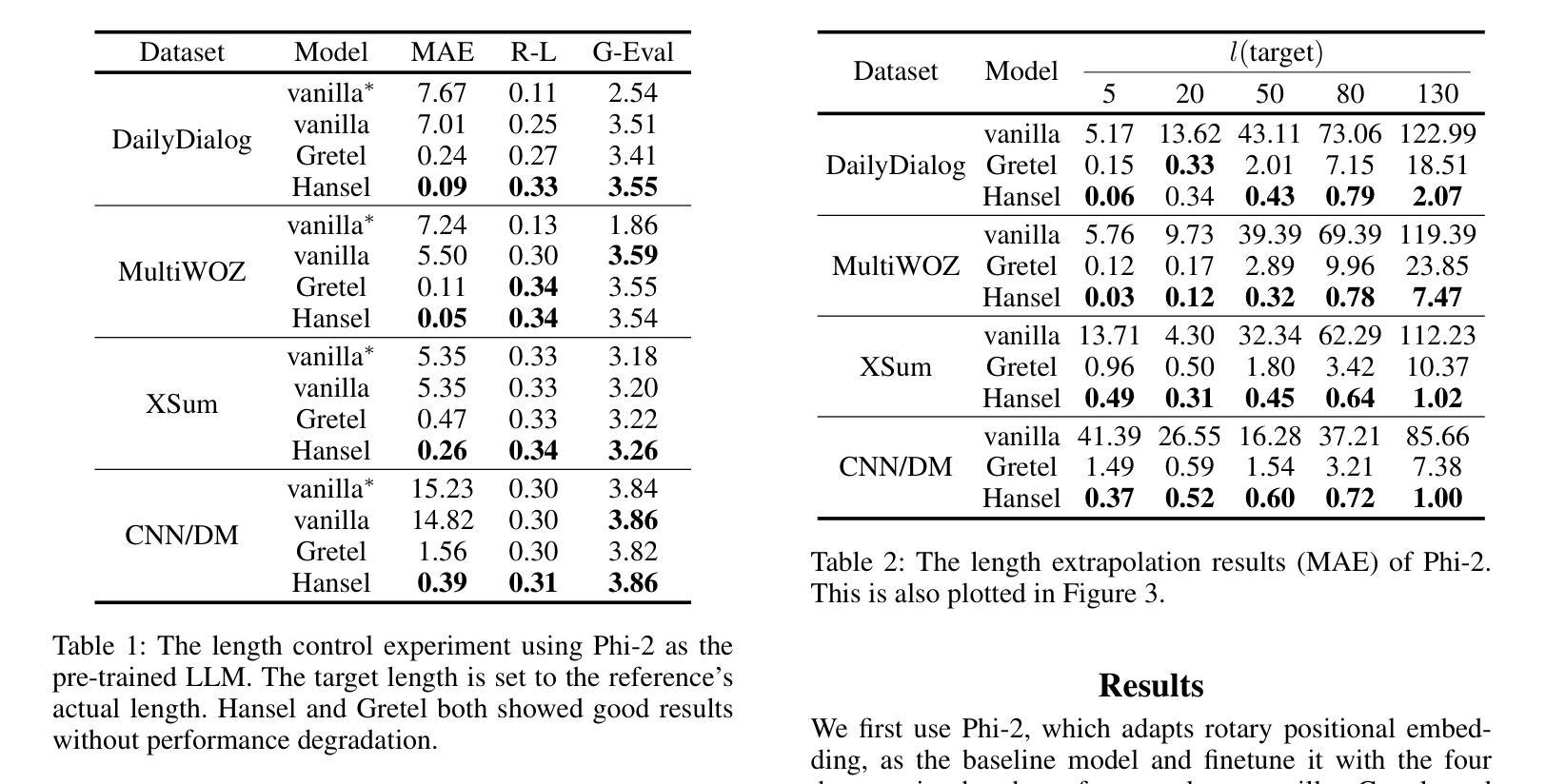
Hansel: Output Length Controlling Framework for Large Language Models
Authors:Seoha Song, Junhyun Lee, Hyeonmok Ko
Despite the great success of large language models (LLMs), efficiently controlling the length of the output sequence still remains a challenge. In this paper, we propose Hansel, an efficient framework for length control in LLMs without affecting its generation ability. Hansel utilizes periodically outputted hidden special tokens to keep track of the remaining target length of the output sequence. Together with techniques to avoid abrupt termination of the output, this seemingly simple method proved to be efficient and versatile, while not harming the coherency and fluency of the generated text. The framework can be applied to any pre-trained LLMs during the finetuning stage of the model, regardless of its original positional encoding method. We demonstrate this by finetuning four different LLMs with Hansel and show that the mean absolute error of the output sequence decreases significantly in every model and dataset compared to the prompt-based length control finetuning. Moreover, the framework showed a substantially improved ability to extrapolate to target lengths unseen during finetuning, such as long dialog responses or extremely short summaries. This indicates that the model learns the general means of length control, rather than learning to match output lengths to those seen during training.
尽管大型语言模型(LLM)取得了巨大成功,但有效地控制输出序列的长度仍然是一个挑战。在本文中,我们提出了Hansel,这是一个在LLM中进行长度控制的高效框架,不会影响其生成能力。Hansel利用定期输出的隐藏特殊标记来跟踪输出序列的剩余目标长度。结合避免输出突然终止的技术,这种看似简单的方法被证明是高效和通用的,同时不会损害生成文本的一致性和流畅性。该框架可应用于模型微调阶段的任何预训练LLM,而无需考虑其原始的位置编码方法。我们通过使用Hansel对四种不同的LLM进行微调来证明这一点,并表明与基于提示的长度控制微调相比,在每个模型和数据集上,输出序列的平均绝对误差都会显著降低。此外,该框架在微调期间未见的目标长度上表现出了极大的外推能力,例如长对话响应或极其简短的摘要。这表明模型学习的是一般的长度控制方法,而不是学习将输出长度与训练期间所见到的相匹配。
论文及项目相关链接
PDF 13 pages, 6 figures; accepted to AAAI-25
Summary
本文提出一种名为Hansel的框架,用于在大语言模型(LLM)中有效控制输出序列的长度,同时不损害模型的生成能力。Hansel通过定期输出特殊的隐藏标记来跟踪剩余的目标长度,并避免输出序列的突然终止。该方法既高效又通用,同时不影响生成文本的连贯性和流畅性。该框架可在模型微调阶段应用于任何预训练LLM,无论其原始位置编码方法如何。实验证明,Hansel能显著提高输出序列的准确度,并展现出对未见过的目标长度的良好泛化能力。
Key Takeaways
- Hansel框架实现了在大语言模型(LLM)中对输出序列长度的有效控制。
- Hansel利用定期输出的隐藏特殊标记来跟踪目标长度。
- 该方法既不会损害模型的生成能力,也不会影响输出文本的连贯性和流畅性。
- Hansel框架可在模型微调阶段应用于所有预训练的LLM。
- 实验显示,Hansel能显著降低输出序列的平均绝对误差。
- Hansel能提高模型对未见过的目标长度的泛化能力。
点此查看论文截图


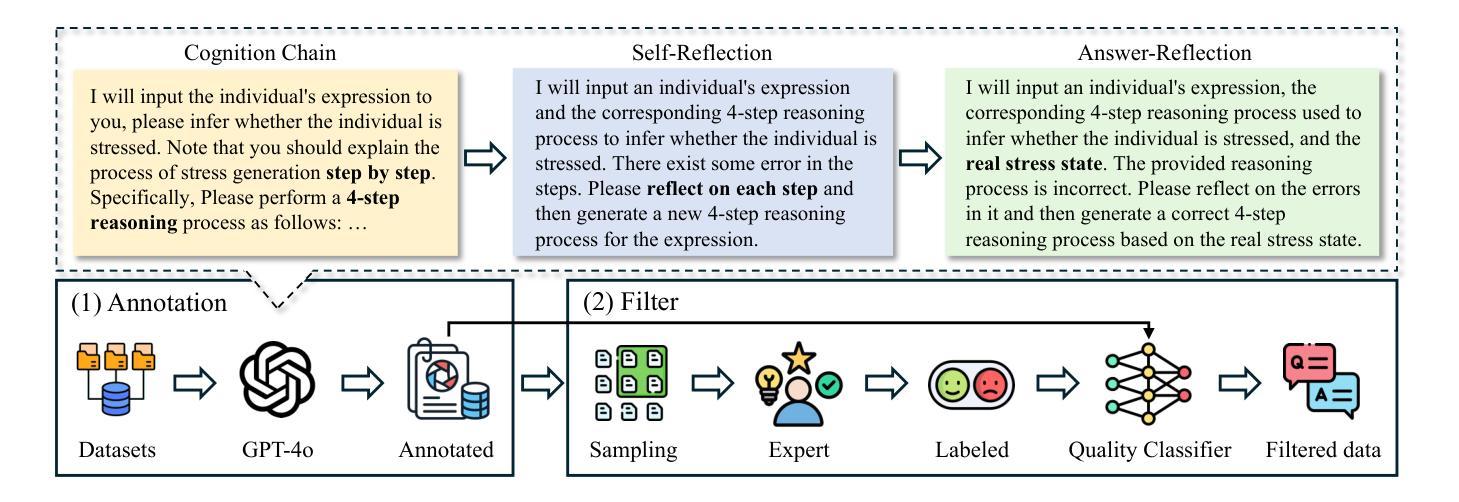
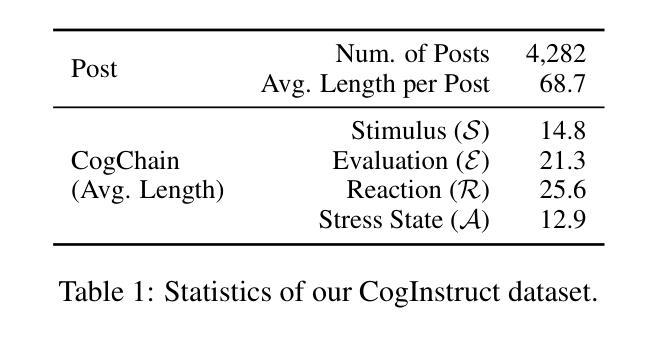
Cognition Chain for Explainable Psychological Stress Detection on Social Media
Authors:Xin Wang, Boyan Gao, Yi Dai, Lei Cao, Liang Zhao, Yibo Yang, David Clifton
Stress is a pervasive global health issue that can lead to severe mental health problems. Early detection offers timely intervention and prevention of stress-related disorders. The current early detection models perform “black box” inference suffering from limited explainability and trust which blocks the real-world clinical application. Thanks to the generative properties introduced by the Large Language Models (LLMs), the decision and the prediction from such models are semi-interpretable through the corresponding description. However, the existing LLMs are mostly trained for general purposes without the guidance of psychological cognitive theory. To this end, we first highlight the importance of prior theory with the observation of performance boosted by the chain-of-thoughts tailored for stress detection. This method termed Cognition Chain explicates the generation of stress through a step-by-step cognitive perspective based on cognitive appraisal theory with a progress pipeline: Stimulus $\rightarrow$ Evaluation $\rightarrow$ Reaction $\rightarrow$ Stress State, guiding LLMs to provide comprehensive reasoning explanations. We further study the benefits brought by the proposed Cognition Chain format by utilising it as a synthetic dataset generation template for LLMs instruction-tuning and introduce CogInstruct, an instruction-tuning dataset for stress detection. This dataset is developed using a three-stage self-reflective annotation pipeline that enables LLMs to autonomously generate and refine instructional data. By instruction-tuning Llama3 with CogInstruct, we develop CogLLM, an explainable stress detection model. Evaluations demonstrate that CogLLM achieves outstanding performance while enhancing explainability. Our work contributes a novel approach by integrating cognitive theories into LLM reasoning processes, offering a promising direction for future explainable AI research.
压力是一个普遍存在的全球健康问题,可能导致严重的心理健康问题。早期发现可以为干预和预防与压力相关的疾病提供及时的机会。当前早期检测模型的推理过程存在“黑箱”问题,缺乏解释性和信任度,阻碍了其在现实世界中的临床应用。由于大型语言模型(LLM)的生成属性,这些模型的决策和预测可以通过相应的描述进行半解释。然而,现有的LLM大多是为了通用目的而训练的,没有心理认知理论的指导。为此,我们首先要强调先验理论的重要性,并观察到通过针对压力检测的思维链而提高的性能。这种方法称为认知链,它通过基于认知评估理论的逐步认知视角来解释压力的产生,其进展管道包括:刺激→评估→反应→压力状态,指导LLM提供全面的推理解释。我们进一步研究了所提出的认知链格式带来的好处,通过将其用作LLM指令调整的合成数据集生成模板,并引入了用于压力检测的CogInstruct指令调整数据集。该数据集采用三阶段自我反思注释管道开发,使LLM能够自主生成和细化指令数据。通过用CogInstruct指令调整Llama3,我们开发了可解释的压力检测模型CogLLM。评估表明,CogLLM在提升解释性的同时取得了出色的性能。我们的工作通过将认知理论整合到LLM推理过程中,为未来的可解释人工智能研究提供了一个有前景的方向。
论文及项目相关链接
摘要
压力是一个全球性的健康问题,可能导致严重的心理健康问题。早期检测可及时干预和预防与压力相关的疾病。当前早期检测模型存在解释性和信任度有限的“黑箱”推理问题,阻碍了其在真实世界临床中的应用。借助大型语言模型(LLM)的生成属性,决策和预测可通过相应描述实现半解释。然而,现有LLM大多用于通用目的训练,缺乏心理学认知理论的指导。本研究强调先验理论的重要性,并观察到通过针对压力检测的思维链(Cognition Chain)提升性能。该方法基于认知评估理论的逐步认知视角,通过刺激→评估→反应→压力状态的过程管道来解释压力的产生。我们进一步研究了认知链格式带来的好处,通过将其用作LLM指令调整的合成数据集模板,并引入了针对压力检测的指令数据集CogInstruct。该数据集采用三阶段自我反思注释管道开发,使LLM能够自主生成和细化指令数据。通过用CogInstruct指令调整Llama3,我们开发了可解释的压力检测模型CogLLM。评估表明,CogLLM在取得卓越性能的同时提高了可解释性。我们的工作通过整合认知理论到LLM的推理过程中,为未来的可解释人工智能研究提供了一个有前景的方向。
关键见解
- 压力是一个全球性的健康问题,早期检测对及时干预和预防压力相关疾病至关重要。
- 当前早期检测模型存在“黑箱”推理问题,限制了其在真实世界临床中的应用。
- 大型语言模型(LLM)的生成属性可以提高模型的半解释性。
- 现有LLM大多缺乏心理学认知理论的指导。
- 提出了认知链(Cognition Chain)方法,通过结合认知评估理论来解释压力产生的步骤。
- 认知链方法通过作为LLM指令调整的合成数据集模板带来好处,并引入了CogInstruct数据集。
- 通过指令调整LLM开发的CogLLM模型在压力检测中取得了卓越性能,同时提高了模型的解释性。
点此查看论文截图


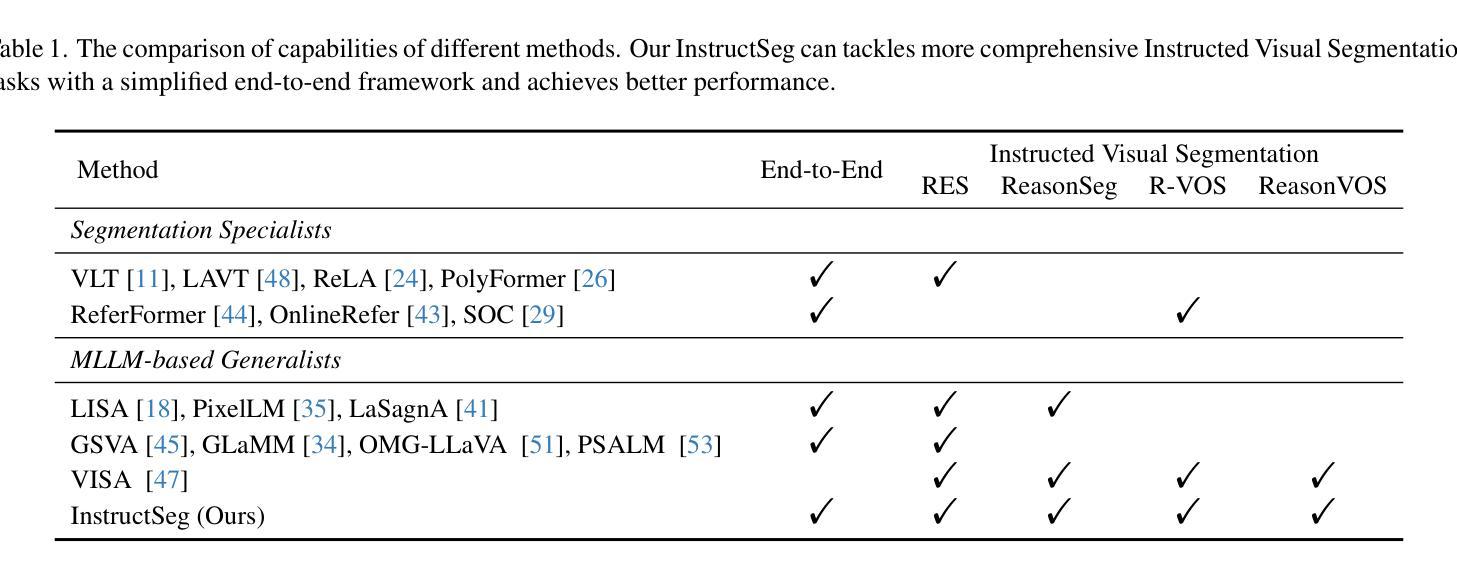
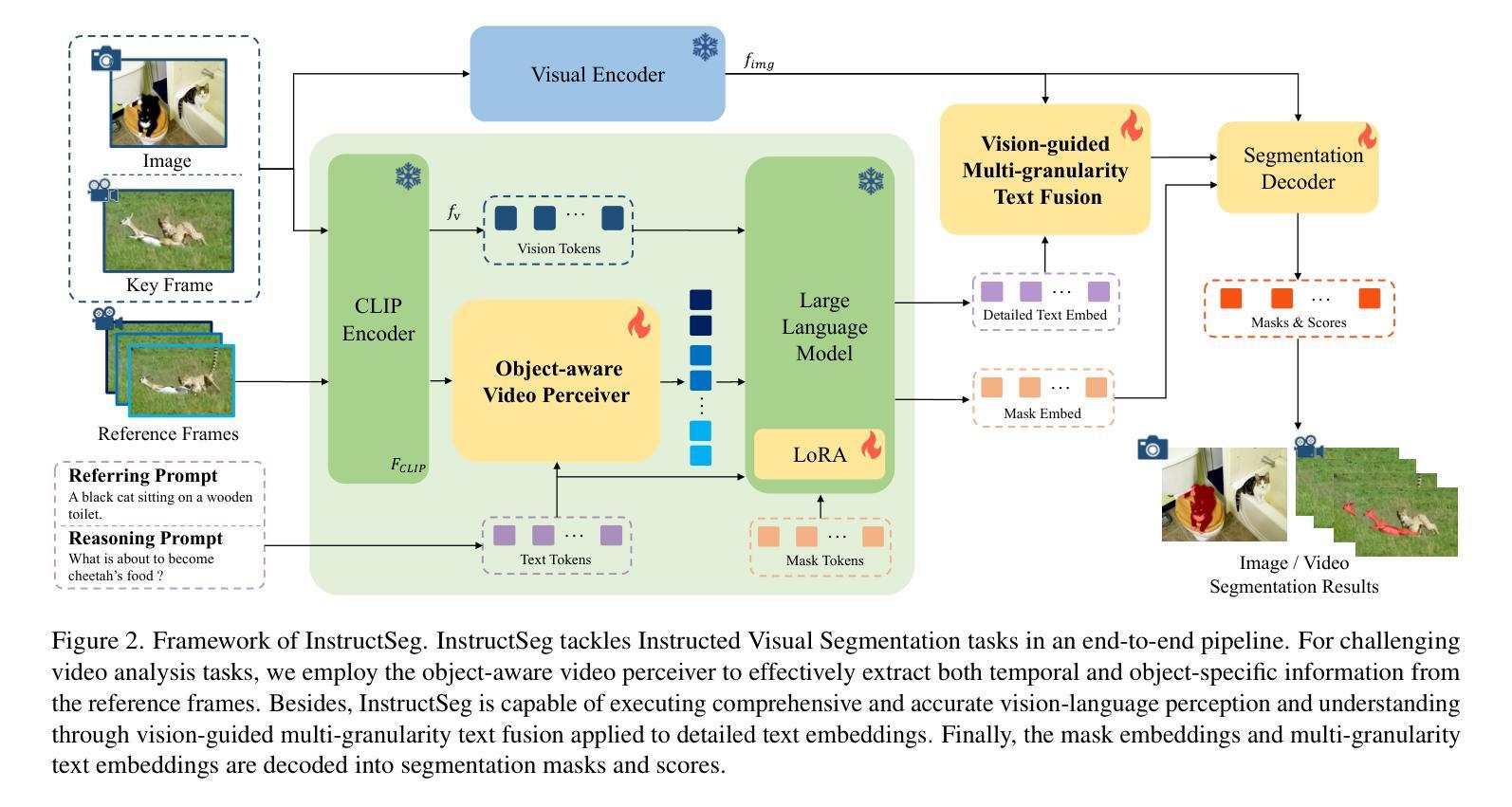
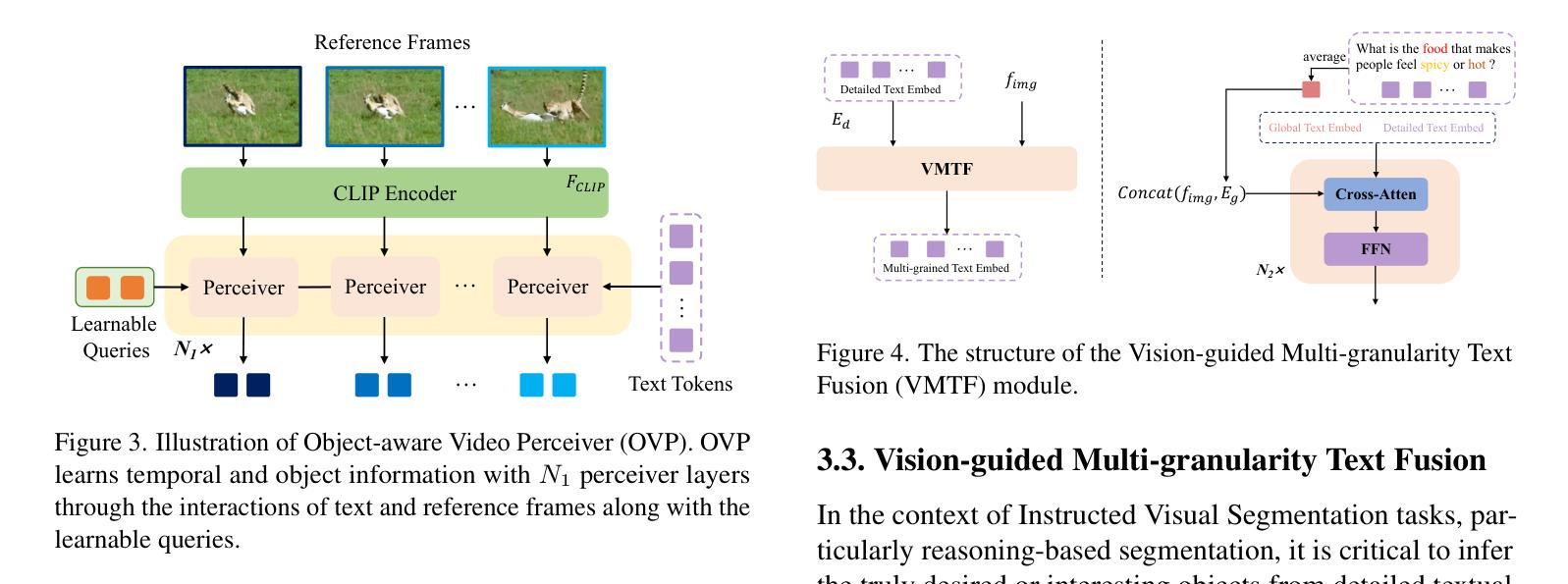
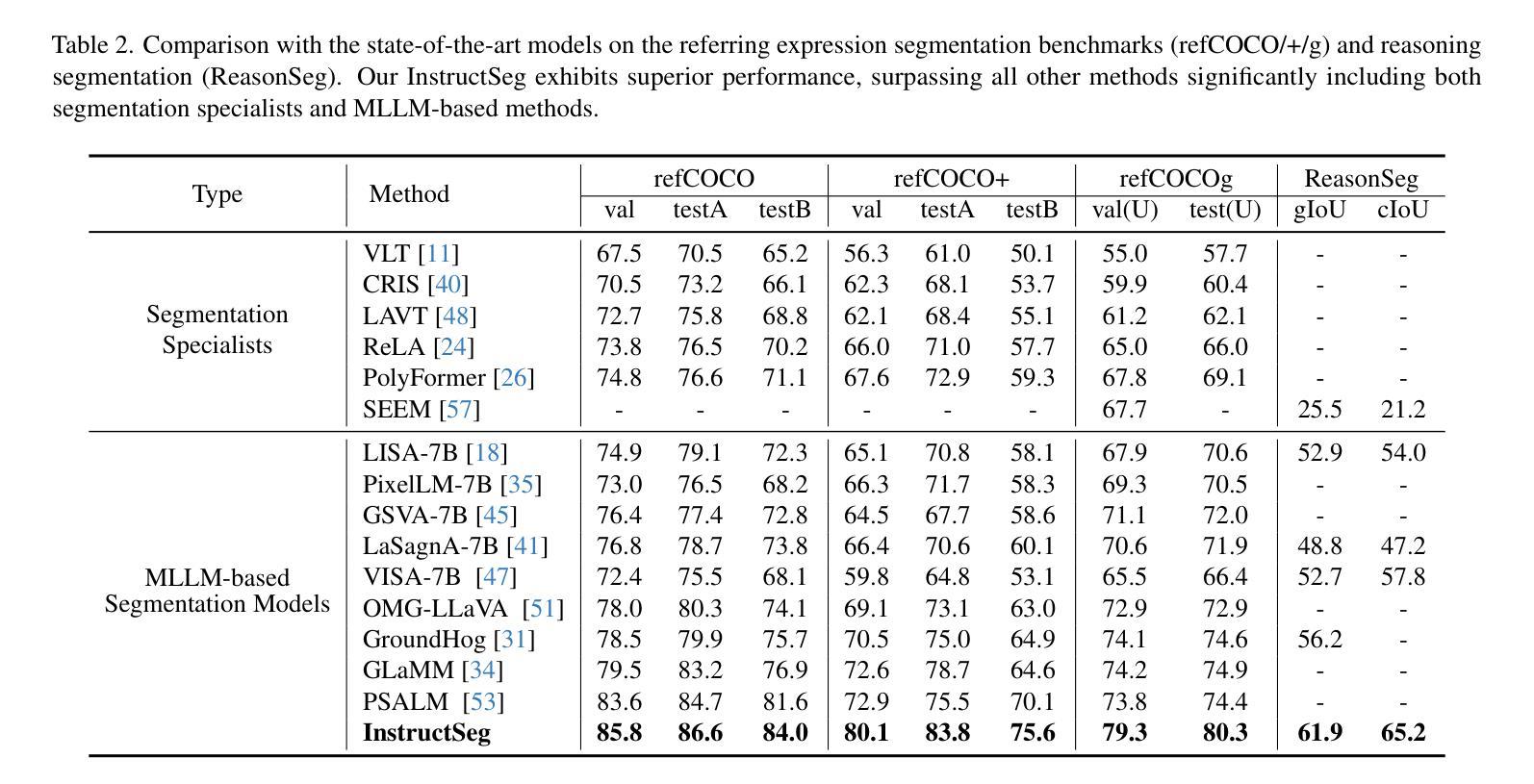
InstructSeg: Unifying Instructed Visual Segmentation with Multi-modal Large Language Models
Authors:Cong Wei, Yujie Zhong, Haoxian Tan, Yingsen Zeng, Yong Liu, Zheng Zhao, Yujiu Yang
Boosted by Multi-modal Large Language Models (MLLMs), text-guided universal segmentation models for the image and video domains have made rapid progress recently. However, these methods are often developed separately for specific domains, overlooking the similarities in task settings and solutions across these two areas. In this paper, we define the union of referring segmentation and reasoning segmentation at both the image and video levels as Instructed Visual Segmentation (IVS). Correspondingly, we propose InstructSeg, an end-to-end segmentation pipeline equipped with MLLMs for IVS. Specifically, we employ an object-aware video perceiver to extract temporal and object information from reference frames, facilitating comprehensive video understanding. Additionally, we introduce vision-guided multi-granularity text fusion to better integrate global and detailed text information with fine-grained visual guidance. By leveraging multi-task and end-to-end training, InstructSeg demonstrates superior performance across diverse image and video segmentation tasks, surpassing both segmentation specialists and MLLM-based methods with a single model. Our code is available at https://github.com/congvvc/InstructSeg.
得益于多模态大型语言模型(MLLMs)的推动,面向图像和视频领域的文本引导通用分割模型最近取得了快速进展。然而,这些方法往往针对特定领域进行开发,忽略了这两个领域在任务设置和解决方案上的相似性。在本文中,我们将图像和视频级别的引用分割和推理分割的联合定义为指令性视觉分割(IVS)。相应地,我们提出了InstructSeg,这是一个配备MLLMs的端到端分割管道,用于IVS。具体来说,我们采用一种对象感知视频感知器,从参考帧中提取时间和对象信息,促进全面的视频理解。此外,我们引入了视觉引导的多粒度文本融合,以更好地将全局和详细文本信息与精细的视觉引导相结合。通过利用多任务和端到端训练,InstructSeg在多种图像和视频分割任务上表现出卓越的性能,使用单一模型超越了分割专家基于MLLM的方法。我们的代码位于https://github.com/congvvc,COM,这个翻译仅用于个人学习交流之用。
论文及项目相关链接
Summary
文本介绍了基于多模态大型语言模型(MLLMs)的文本引导图像和视频领域通用分割模型的最新进展。针对图像和视频领域的分割任务,该文提出了统一框架,即指令视觉分割(IVS),并相应提出了配备MLLMs的端到端分割管道InstructSeg。InstructSeg采用对象感知视频感知器提取参考帧的时空和对象信息,促进全面视频理解。通过引入视觉引导的多粒度文本融合,更好地将全局和详细文本信息与精细的视觉指导相结合。通过多任务和端到端训练,InstructSeg在多种图像和视频分割任务上表现出卓越性能,超越了分割专家和基于MLLM的方法。
Key Takeaways
- 多模态大型语言模型(MLLMs)推动了文本引导的图像和视频分割模型的快速发展。
- 目前的研究往往针对特定领域开发模型,忽略了图像和视频领域在任务设置和解决方案上的相似性。
- 指令视觉分割(IVS)框架融合了图像和视频层面的指代分割和推理分割。
- InstructSeg是一个配备MLLMs的端到端分割管道,用于实现IVS。
- InstructSeg采用对象感知视频感知器以提取参考帧的时空和对象信息。
- 引入了视觉引导的多粒度文本融合,以更好地集成全局和详细文本信息。
- InstructSeg通过多任务和端到端训练,在多种图像和视频分割任务上表现出卓越性能。
点此查看论文截图

Few-shot Steerable Alignment: Adapting Rewards and LLM Policies with Neural Processes
Authors:Katarzyna Kobalczyk, Claudio Fanconi, Hao Sun, Mihaela van der Schaar
As large language models (LLMs) become increasingly embedded in everyday applications, ensuring their alignment with the diverse preferences of individual users has become a critical challenge. Currently deployed approaches typically assume homogeneous user objectives and rely on single-objective fine-tuning. However, human preferences are inherently heterogeneous, influenced by various unobservable factors, leading to conflicting signals in preference data. Existing solutions addressing this diversity often require costly datasets labelled for specific objectives and involve training multiple reward models or LLM policies, which is computationally expensive and impractical. In this work, we present a novel framework for few-shot steerable alignment, where users’ underlying preferences are inferred from a small sample of their choices. To achieve this, we extend the Bradley-Terry-Luce model to handle heterogeneous preferences with unobserved variability factors and propose its practical implementation for reward modelling and LLM fine-tuning. Thanks to our proposed approach of functional parameter-space conditioning, LLMs trained with our framework can be adapted to individual preferences at inference time, generating outputs over a continuum of behavioural modes. We empirically validate the effectiveness of methods, demonstrating their ability to capture and align with diverse human preferences in a data-efficient manner. Our code is made available at: https://github.com/kasia-kobalczyk/few-shot-steerable-alignment.
随着大型语言模型(LLM)在日常应用中的嵌入程度不断提高,确保它们与个别用户的多样化偏好保持一致已成为一项关键挑战。当前部署的方法通常假设用户目标是一致的,并依赖于单一目标的微调。然而,人类偏好本质上是异质性的,受到各种不可观察因素的影响,导致偏好数据中的信号相互冲突。现有解决这种多样性的方法通常需要为特定目标标记的昂贵数据集,并涉及训练多个奖励模型或LLM策略,这在计算上很昂贵且不切实际。在这项工作中,我们提出了一种新型少样本可控制对齐框架,用于从用户选择的小样本中推断其潜在偏好。为实现这一点,我们扩展了Bradley-Terry-Luce模型,以处理具有未观测变异因素的异质偏好,并提出了其实用于奖励建模和LLM调参的实际实施。由于我们提出的功能参数空间调节方法,使用我们的框架训练的LLM可以在推理时适应个人偏好,在连续的行为模式上生成输出。我们实证验证了方法的有效性,展示了它们在数据高效的方式下捕捉和与人类多样化偏好保持一致的能力。我们的代码位于:https://github.com/kasia-kobalczyk/few-shot-steerable-alignment。
论文及项目相关链接
Summary
大型语言模型(LLM)在日常应用中的普及带来了如何满足不同用户的多样化偏好这一挑战。现有方法通常假设用户目标一致,依赖单一目标的微调。然而,人类偏好具有天生的多样性,受到各种不可观察因素的影响,导致偏好数据中的信号冲突。为解决这种多样性,本文提出了一种新颖的少数样本可操控对齐框架,该框架可以从用户选择的少量样本中推断其偏好。我们扩展了Bradley-Terry-Luce模型以处理具有不可观察的变异因素的异质偏好,并为其在奖励建模和LLM微调中的实际应用提出了切实可行的实施方法。通过功能参数空间条件的方法,用我们的框架训练的LLM可以在推理阶段适应个人偏好,生成一系列行为模式的输出。我们实证验证了方法的有效性,展示了其在数据高效的方式下捕捉和满足人类多样性的能力。
Key Takeaways
- 大型语言模型(LLM)在日常应用中需要满足不同用户的多样化偏好。
- 现有方法通常假设用户目标一致,但人类偏好具有天生的多样性。
- 人类偏好的多样性受到各种不可观察因素的影响,导致偏好数据中的信号冲突。
- 提出了一个新颖的少数样本可操控对齐框架,可以从用户选择的少量样本中推断其偏好。
- 扩展了Bradley-Terry-Luce模型以处理具有不可观察的变异因素的异质偏好。
- 通过功能参数空间条件的方法,LLM可以在推理阶段适应个人偏好。
点此查看论文截图

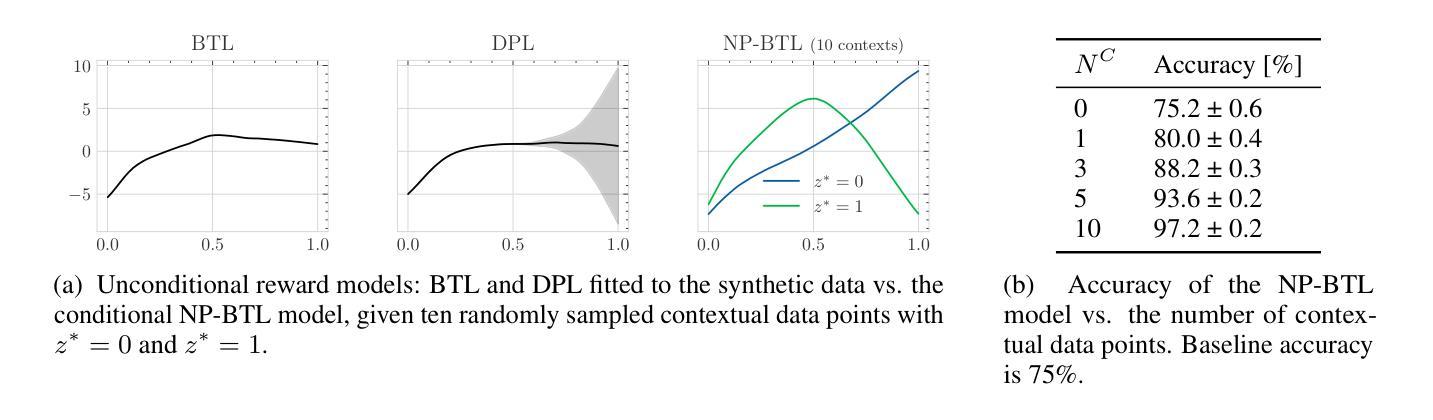

Pipeline Analysis for Developing Instruct LLMs in Low-Resource Languages: A Case Study on Basque
Authors:Ander Corral, Ixak Sarasua, Xabier Saralegi
Large language models (LLMs) are typically optimized for resource-rich languages like English, exacerbating the gap between high-resource and underrepresented languages. This work presents a detailed analysis of strategies for developing a model capable of following instructions in a low-resource language, specifically Basque, by focusing on three key stages: pre-training, instruction tuning, and alignment with human preferences. Our findings demonstrate that continual pre-training with a high-quality Basque corpus of around 600 million words improves natural language understanding (NLU) of the foundational model by over 12 points. Moreover, instruction tuning and human preference alignment using automatically translated datasets proved highly effective, resulting in a 24-point improvement in instruction-following performance. The resulting models, Llama-eus-8B and Llama-eus-8B-instruct, establish a new state-of-the-art for Basque in the sub-10B parameter category.
大型语言模型(LLM)通常针对资源丰富如英语的语言进行优化,这加剧了资源丰富的语言和代表性不足的语言之间的差距。本研究详细分析了开发能够在低资源语言(特别是巴斯克语)遵循指令的模型的策略,重点关注三个关键阶段:预训练、指令调整和与人类偏好对齐。我们的研究发现,使用大约6亿单词的高质量巴斯克语语料库进行持续预训练,提高了基础模型的自然语言理解(NLU)能力超过12个点。此外,使用自动翻译数据集进行指令调整和人类偏好对齐证明是非常有效的,指令遵循性能提高了24个点。所得模型Llama-eus-8B和Llama-eus-8B-instruct在小于10B参数的类别中为巴斯克语创造了新的最先进的水平。
论文及项目相关链接
Summary
大型语言模型(LLM)在英语等资源丰富型语言的优化上投入较多,加剧了高资源语言和代表性不足的语言之间的差距。本研究详细分析了在低资源语言巴斯克语上开发遵循指令模型的三项关键策略:预训练、指令微调以及与人类偏好对齐。研究发现,使用高质量巴斯克语语料库的持续预训练,提升了基础模型的自然语言理解能力超过12个百分点。此外,通过自动翻译数据集进行指令微调与人类偏好对齐,显著提高了指令遵循性能,改善了24个百分点。最终建立的模型Llama-eus-8B和Llama-eus-8B-instruct在参数类别低于10B的情况下为巴斯克语树立了新的标准。
Key Takeaways
- 大型语言模型在英语等资源丰富型语言的优化上投入较多,需要关注低资源语言的模型发展。
- 在巴斯克语上开发遵循指令模型的关键策略包括预训练、指令微调以及与人类偏好对齐。
- 持续预训练可以提升基础模型的自然语言理解能力。
- 指令微调和使用自动翻译数据集能够提高模型的指令遵循性能。
- 最终建立的模型Llama-eus-8B和Llama-eus-8B-instruct在巴斯克语领域树立了新的标准。
- 研究成果有助于缩小高资源语言和低资源语言之间的差距。
点此查看论文截图

Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models
Authors:Kunat Pipatanakul, Potsawee Manakul, Natapong Nitarach, Warit Sirichotedumrong, Surapon Nonesung, Teetouch Jaknamon, Parinthapat Pengpun, Pittawat Taveekitworachai, Adisai Na-Thalang, Sittipong Sripaisarnmongkol, Krisanapong Jirayoot, Kasima Tharnpipitchai
This paper introduces Typhoon 2, a series of text and multimodal large language models optimized for the Thai language. The series includes models for text, vision, and audio. Typhoon2-Text builds on state-of-the-art open models, such as Llama 3 and Qwen2, and we perform continual pre-training on a mixture of English and Thai data. We employ various post-training techniques to enhance Thai language performance while preserving the base models’ original capabilities. We release text models across a range of sizes, from 1 to 70 billion parameters, available in both base and instruction-tuned variants. Typhoon2-Vision improves Thai document understanding while retaining general visual capabilities, such as image captioning. Typhoon2-Audio introduces an end-to-end speech-to-speech model architecture capable of processing audio, speech, and text inputs and generating both text and speech outputs simultaneously.
本文介绍了Typhoon 2,这是一系列针对泰语优化的文本和多模态大型语言模型。该系列包括文本、视觉和音频模型。Typhoon2-Text建立在最新开放模型(如Llama 3和Qwen2)的基础上,我们对英语和泰语数据的混合进行持续预训练。我们采用各种后训练技术,以提高泰语性能,同时保留基础模型的原始功能。我们发布了一系列不同大小的文本模型,参数范围从1亿到70亿,既有基础模型也有指令调优的变体可供选择。Typhoon2-Vision在保留一般视觉功能(如图像字幕)的同时,提高了对泰语文档的理解能力。Typhoon2-Audio引入了一种端到端的语音到语音模型架构,能够处理音频、语音和文本输入,并同时生成文本和语音输出。
论文及项目相关链接
PDF technical report, 55 pages
Summary:
本文介绍了Typhoon 2系列大型语言模型,包括针对泰语的文本、视觉和音频模型。Typhoon2-Text基于最前沿的开放模型,如Llama 3和Qwen2,进行持续的预训练,并应用多种后训练技术提高泰语性能。Typhoon2-Vision改进了泰语文档理解,同时保留了通用的视觉功能。Typhoon2-Audio引入了一种端到端的语音到语音模型架构,能够处理音频、语音和文本输入,并同时生成文本和语音输出。
Key Takeaways:
- Typhoon 2系列模型针对泰语进行优化,包括文本、视觉和音频模型。
- Typhoon2-Text基于前沿开放模型进行预训练,并提升泰语性能。
- Typhoon2-Vision改进了泰语文档理解,同时保留通用视觉功能。
- Typhoon2-Audio具备端到端的语音到语音能力,能处理多种输入并生成相应输出。
- 模型系列包含不同大小的文本模型,从1亿到70亿参数,有基础型和指令优化型两种。
- 模型在预训练和后训练阶段采用多种技术来提升性能并优化针对泰语的处理。
点此查看论文截图

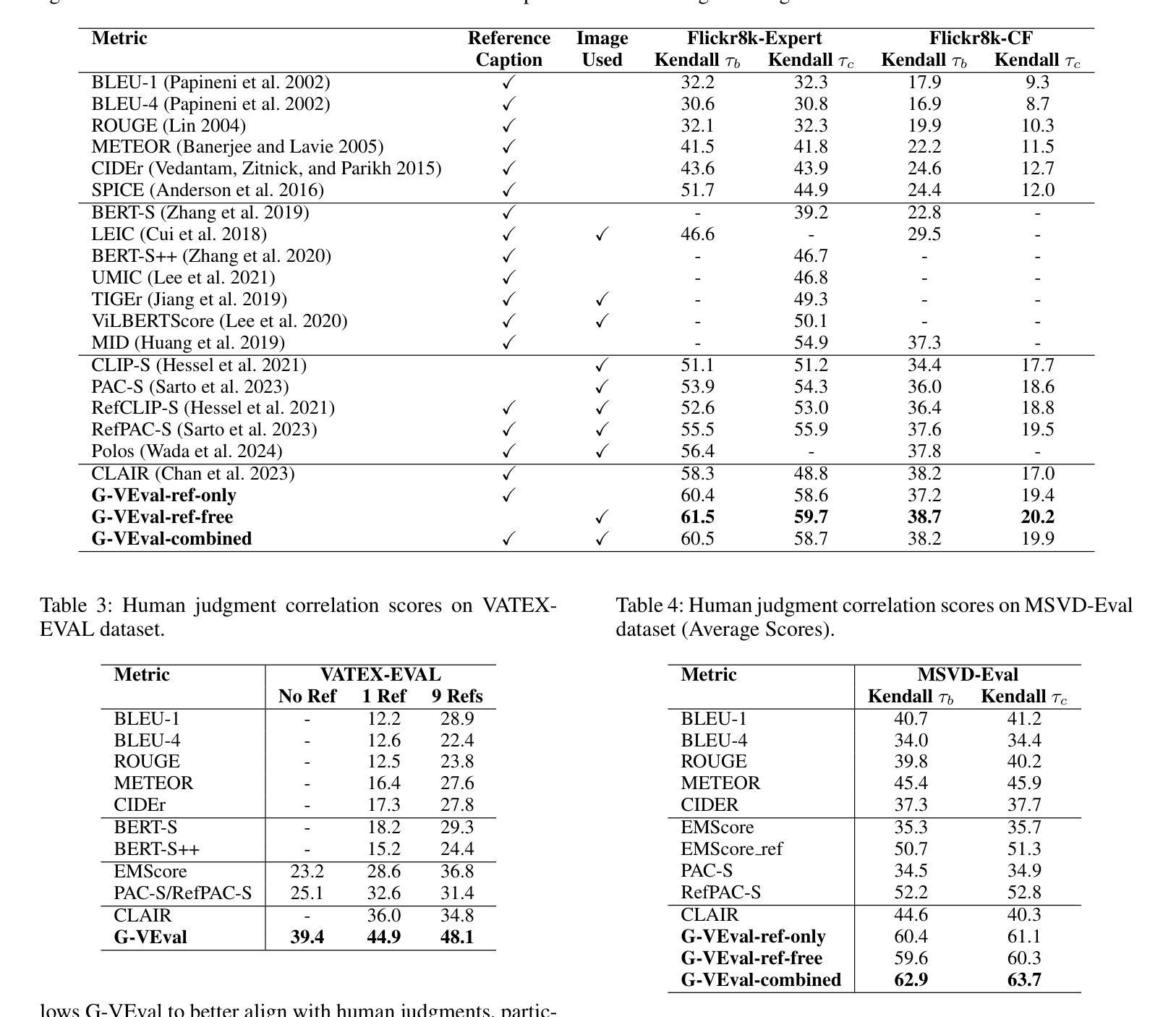
G-VEval: A Versatile Metric for Evaluating Image and Video Captions Using GPT-4o
Authors:Tony Cheng Tong, Sirui He, Zhiwen Shao, Dit-Yan Yeung
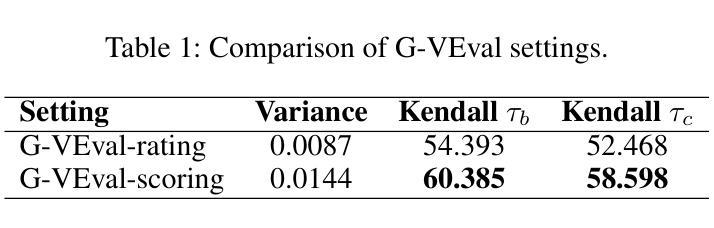
Evaluation metric of visual captioning is important yet not thoroughly explored. Traditional metrics like BLEU, METEOR, CIDEr, and ROUGE often miss semantic depth, while trained metrics such as CLIP-Score, PAC-S, and Polos are limited in zero-shot scenarios. Advanced Language Model-based metrics also struggle with aligning to nuanced human preferences. To address these issues, we introduce G-VEval, a novel metric inspired by G-Eval and powered by the new GPT-4o. G-VEval uses chain-of-thought reasoning in large multimodal models and supports three modes: reference-free, reference-only, and combined, accommodating both video and image inputs. We also propose MSVD-Eval, a new dataset for video captioning evaluation, to establish a more transparent and consistent framework for both human experts and evaluation metrics. It is designed to address the lack of clear criteria in existing datasets by introducing distinct dimensions of Accuracy, Completeness, Conciseness, and Relevance (ACCR). Extensive results show that G-VEval outperforms existing methods in correlation with human annotations, as measured by Kendall tau-b and Kendall tau-c. This provides a flexible solution for diverse captioning tasks and suggests a straightforward yet effective approach for large language models to understand video content, paving the way for advancements in automated captioning. Codes are available at https://github.com/ztangaj/gveval
视觉描述的评价指标在评估中非常重要但尚未被完全探索。传统的评估指标如BLEU、METEOR、CIDEr和ROUGE往往忽略了语义深度,而训练好的评估指标如CLIP-Score、PAC-S和Polos在零样本场景中受到限制。先进的基于语言模型的评估指标也难以与人类微妙的偏好保持一致。为了解决这些问题,我们引入了G-VEval这一新评估指标,它灵感来源于G-Eval并由新型GPT-4o提供支持。G-VEval使用大型多模态模型的链式思维推理,支持三种模式:无参考、仅有参考和组合模式,可以处理视频和图像输入。我们还提出了MSVD-Eval这一新的视频描述评估数据集,旨在为人工专家和评价指标建立一个更加透明和一致的框架。它旨在通过引入准确性、完整性、简洁性和相关性(ACCR)的不同维度来解决现有数据集中缺乏明确标准的问题。大量结果显示,G-VEval与人工注释的相关性高于现有方法,这一表现是通过肯德尔tau-b和肯德尔tau-c来衡量的。这为多样化的描述任务提供了灵活解决方案,并为大型语言模型理解视频内容提供了直接有效的途径,为自动描述的进步铺平了道路。相关代码可在https://github.com/ztangaj/gveval找到。
论文及项目相关链接
Summary
本文探讨视觉描述的评价指标问题,指出传统指标如BLEU、METEOR等缺乏语义深度,而训练指标如CLIP-Score等则在零样本场景下有限制。为解决这些问题,提出新型指标G-VEval,它结合了G-Eval的灵感和GPT-4o的能力,支持三种模式并对视频和图像输入都有良好的适应性。同时,为建立更透明和一致的评估框架,推出MSVD-Eval数据集,设计用来解决现有数据集的模糊标准问题。实验结果证实G-VEval与人类注释的关联度高于现有方法。
Key Takeaways
- 视觉描述的评价指标存在语义深度不足的问题。
- 传统评价指标如BLEU、METEOR等在语义深度上有所欠缺。
- 训练指标如CLIP-Score在零样本场景下有局限性。
- 提出新型评价指标G-VEval,结合G-Eval灵感和GPT-4o能力。
- G-VEval支持三种模式,适应视频和图像输入。
- 为建立更透明的评估框架,推出MSVD-Eval数据集。
- MSVD-Eval数据集旨在解决现有数据集的模糊标准问题,包括四个维度:准确性、完整性、简洁性和相关性(ACCR)。
点此查看论文截图



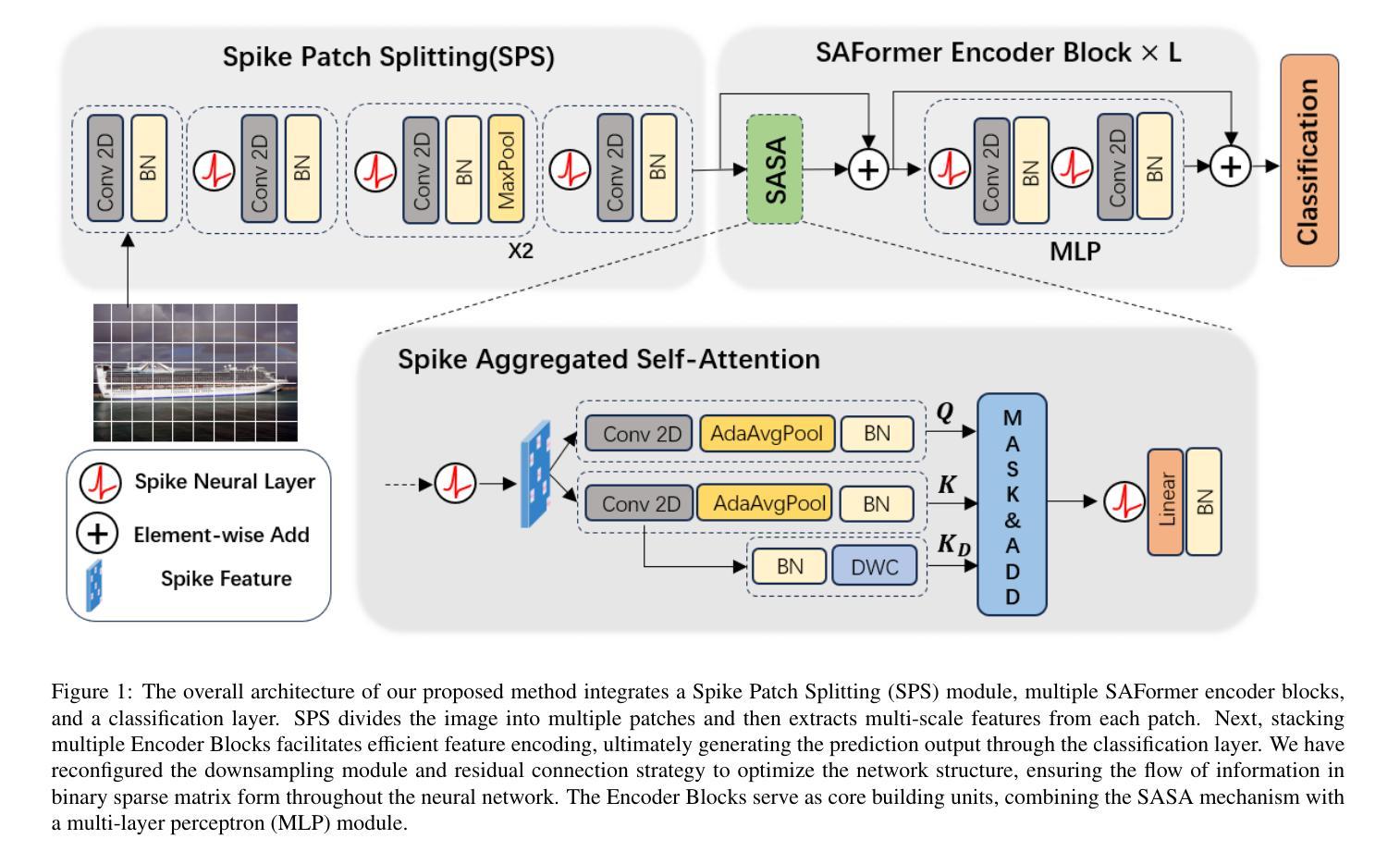
Combining Aggregated Attention and Transformer Architecture for Accurate and Efficient Performance of Spiking Neural Networks
Authors:Hangming Zhang, Alexander Sboev, Roman Rybka, Qiang Yu
Spiking Neural Networks have attracted significant attention in recent years due to their distinctive low-power characteristics. Meanwhile, Transformer models, known for their powerful self-attention mechanisms and parallel processing capabilities, have demonstrated exceptional performance across various domains, including natural language processing and computer vision. Despite the significant advantages of both SNNs and Transformers, directly combining the low-power benefits of SNNs with the high performance of Transformers remains challenging. Specifically, while the sparse computing mode of SNNs contributes to reduced energy consumption, traditional attention mechanisms depend on dense matrix computations and complex softmax operations. This reliance poses significant challenges for effective execution in low-power scenarios. Given the tremendous success of Transformers in deep learning, it is a necessary step to explore the integration of SNNs and Transformers to harness the strengths of both. In this paper, we propose a novel model architecture, Spike Aggregation Transformer (SAFormer), that integrates the low-power characteristics of SNNs with the high-performance advantages of Transformer models. The core contribution of SAFormer lies in the design of the Spike Aggregated Self-Attention (SASA) mechanism, which significantly simplifies the computation process by calculating attention weights using only the spike matrices query and key, thereby effectively reducing energy consumption. Additionally, we introduce a Depthwise Convolution Module (DWC) to enhance the feature extraction capabilities, further improving overall accuracy. We evaluated and demonstrated that SAFormer outperforms state-of-the-art SNNs in both accuracy and energy consumption, highlighting its significant advantages in low-power and high-performance computing.
脉冲神经网络因其独特的低功耗特性近年来备受关注。同时,以强大的自注意力机制和并行处理能力而闻名的Transformer模型,在包括自然语言处理和计算机视觉在内的各个领域都表现出了卓越的性能。尽管SNNs和Transformer都有显著的优势,但直接将SNNs的低功耗优势与Transformer的高性能相结合仍然具有挑战性。具体而言,虽然SNNs的稀疏计算模式有助于减少能源消耗,但传统的注意力机制依赖于密集矩阵计算和复杂的softmax运算。这种依赖在低功耗场景中有效执行带来了巨大的挑战。鉴于Transformer在深度学习中的巨大成功,探索将SNNs和Transformer相结合以利用两者的优势是必要的步骤。在本文中,我们提出了一种新型模型架构,即Spike Aggregation Transformer(SAFormer),它将SNNs的低功耗特性与Transformer模型的高性能优势相结合。SAFormer的核心贡献在于设计了Spike Aggregated Self-Attention(SASA)机制,它通过仅使用查询和关键脉冲矩阵来计算注意力权重,从而简化了计算过程,并有效地降低了能耗。此外,我们还引入了Depthwise Convolution Module(DWC)以增强特征提取能力,进一步提高整体准确性。我们评估和证明了SAFormer在准确性和能耗方面均优于最新的SNNs,凸显了其在低功耗和高性能计算中的显著优势。
论文及项目相关链接
摘要
近期,脉冲神经网络(SNNs)因其低功耗特性受到广泛关注。而变压器模型则以其强大的自注意力机制和并行处理能力,在自然语言处理和计算机视觉等领域展现出卓越性能。尽管SNNs和变压器各有显著优势,但将SNNs的低功耗优势与变压器的高性能相结合仍具挑战。特别是在SNNs的稀疏计算模式有助于降低能耗,而传统注意力机制却依赖于密集矩阵计算和复杂的softmax运算。本文提出了一种新型模型架构——Spike Aggregation Transformer(SAFormer),结合了SNNs的低功耗和变压器模型的高性能优势。SAFormer的核心贡献在于设计了Spike Aggregated Self-Attention(SASA)机制,通过仅使用脉冲矩阵查询和键来计算注意力权重,从而有效减少能耗。此外,还引入了Depthwise Convolution Module(DWC)以增强特征提取能力,进一步提高整体准确性。实验评估表明,SAFormer在准确性和能耗方面均优于最新SNNs,突显其在低功耗和高性能计算中的显著优势。
关键见解
- 脉冲神经网络(SNNs)因低功耗特性受到关注,而变压器模型在高性能计算中表现优异。
- 直接结合SNNs和变压器的优势具有挑战,因为传统注意力机制的计算复杂度较高。
- SAFormer模型结合了SNNs和变压器,通过Spike Aggregated Self-Attention(SASA)机制简化计算过程,降低能耗。
- SAFormer引入的Depthwise Convolution Module(DWC)增强了特征提取能力,提高了整体准确性。
- SAFormer在准确性和能耗方面均优于现有SNNs。
- SAFormer具有显著的优势,特别适用于低功耗和高性能计算场景。
点此查看论文截图

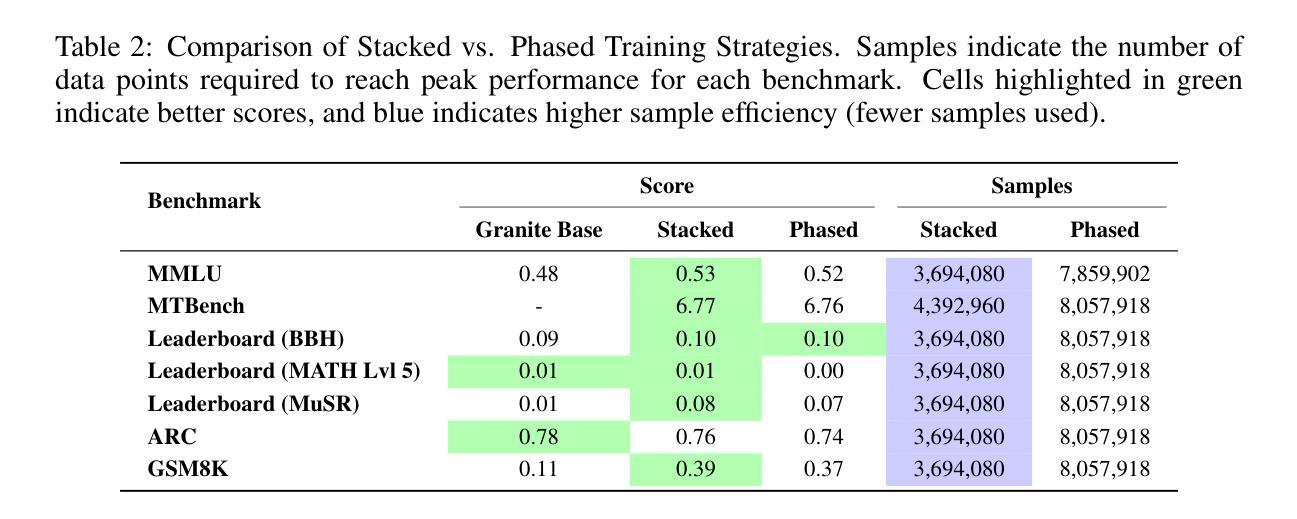
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
Authors:Aldo Pareja, Nikhil Shivakumar Nayak, Hao Wang, Krishnateja Killamsetty, Shivchander Sudalairaj, Wenlong Zhao, Seungwook Han, Abhishek Bhandwaldar, Guangxuan Xu, Kai Xu, Ligong Han, Luke Inglis, Akash Srivastava
The rise of large language models (LLMs) has created a significant disparity: industrial research labs with their computational resources, expert teams, and advanced infrastructures, can effectively fine-tune LLMs, while individual developers and small organizations face barriers due to limited resources. In this paper, we aim to bridge this gap by presenting a comprehensive study on supervised fine-tuning of LLMs using instruction-tuning datasets spanning diverse knowledge domains and skills. We focus on small-sized LLMs (3B to 7B parameters) for their cost-efficiency and accessibility. We explore various training configurations and strategies across four open-source pre-trained models. We provide detailed documentation of these configurations, revealing findings that challenge several common training practices, including hyperparameter recommendations from TULU and phased training recommended by Orca. Key insights from our work include: (i) larger batch sizes paired with lower learning rates lead to improved model performance on benchmarks such as MMLU, MTBench, and Open LLM Leaderboard; (ii) early-stage training dynamics, such as lower gradient norms and higher loss values, are strong indicators of better final model performance, enabling early termination of sub-optimal runs and significant computational savings; (iii) through a thorough exploration of hyperparameters like warmup steps and learning rate schedules, we provide guidance for practitioners and find that certain simplifications do not compromise performance; and (iv) we observed no significant difference in performance between phased and stacked training strategies, but stacked training is simpler and more sample efficient. With these findings holding robustly across datasets and models, we hope this study serves as a guide for practitioners fine-tuning small LLMs and promotes a more inclusive environment for LLM research.
大型语言模型(LLM)的兴起造成了一个显著的不平衡:工业研究实验室凭借他们的计算资源、专家团队和先进的基础设施,能够有效地微调LLM,而个人开发者和小型组织则由于资源有限而面临障碍。在本文中,我们旨在通过一项关于使用涵盖各种知识领域和技能的指令调整数据集对LLM进行有监督微调的综合研究来弥补这一差距。我们专注于小型LLM(3B到7B参数),以提高其成本和可访问性。我们探索了四个开源预训练模型的各种训练配置和策略。我们详细记录了这些配置,并揭示了挑战一些常见的训练实践的发现,包括来自TULU的超参数推荐和Orca推荐的分阶段训练。我们工作的关键见解包括:(i)较大的批次大小与较低的学习率相结合,可以在MMLU、MTBench和Open LLM Leaderboard等基准测试上提高模型性能;(ii)早期训练动态,如较低的梯度范数和较高的损失值,是更好的最终模型性能的强烈指标,能够提前终止次优运行并实现重大的计算节省;(iii)通过对预热步骤和学习率调度等超参数的全面探索,我们为实践者提供了指导,并发现某些简化并不会损害性能;(iv)我们观察到分阶段和堆叠训练策略之间的性能没有显著差异,但堆叠训练更简单且样本效率更高。这些发现稳健地适用于各种数据集和模型,我们希望这项研究能为实践者微调小型LLM提供指南,并促进LLM研究的更加包容的环境。
论文及项目相关链接
PDF 33 pages, 19 figures. Appendix included in submission. Submitted to ICLR 2025
摘要
大型语言模型(LLM)的兴起导致资源差距逐渐加大,工业研究实验室因拥有计算资源、专业团队和先进基础设施能够更有效地微调LLM,而个人开发者和小型企业则面临资源限制的挑战。本文旨在通过全面研究使用指令微调数据集对LLM的监督微调来缩小这一差距,涵盖不同知识领域和技能。研究重点为小型LLM(参数范围从3B到7B),以提高其成本效益和可及性。在四个开源预训练模型上探索了不同的训练配置和策略。详细记录了这些配置,揭示了挑战常见训练实践的发现,包括来自TULU的超参数推荐和Orca的阶段性训练建议。我们的关键见解包括:
- 更大的批次大小与较低的学习率相结合,在MMLU、MTBench和Open LLM Leaderboard等基准测试上提高了模型性能。
- 早期训练动态,如较低的梯度范数和较高的损失值,是最终模型性能的良好指标,可提前终止次优运行并实现显著的计算节省。
- 通过全面探索预热步骤和学习率调度等超参数,为实践者提供指导,并发现某些简化并不会影响性能。
- 我们观察到分阶段和堆叠训练策略在性能上没有显著差异,但堆叠训练更简单且样本效率更高。这些发现对不同的数据集和模型具有稳健性,我们希望这项研究能为微调LLM的实践者提供指导,并推动LLM研究更加包容的环境的形成。
关键见解
- 更大的批次大小与较低的学习率能提高模型性能。
- 早期训练动态是预测最终模型性能的有效指标。
- 全面的超参数探索为实践者提供了指导。
- 分阶段和堆叠训练策略在性能上相似,但堆叠训练更简洁高效。
- 研究结果在不同数据集和模型上具有稳健性。
- 研究有助于缩小资源差距,为微调LLM的实践者提供指导。
- 研究促进了LLM研究的更包容环境。
点此查看论文截图


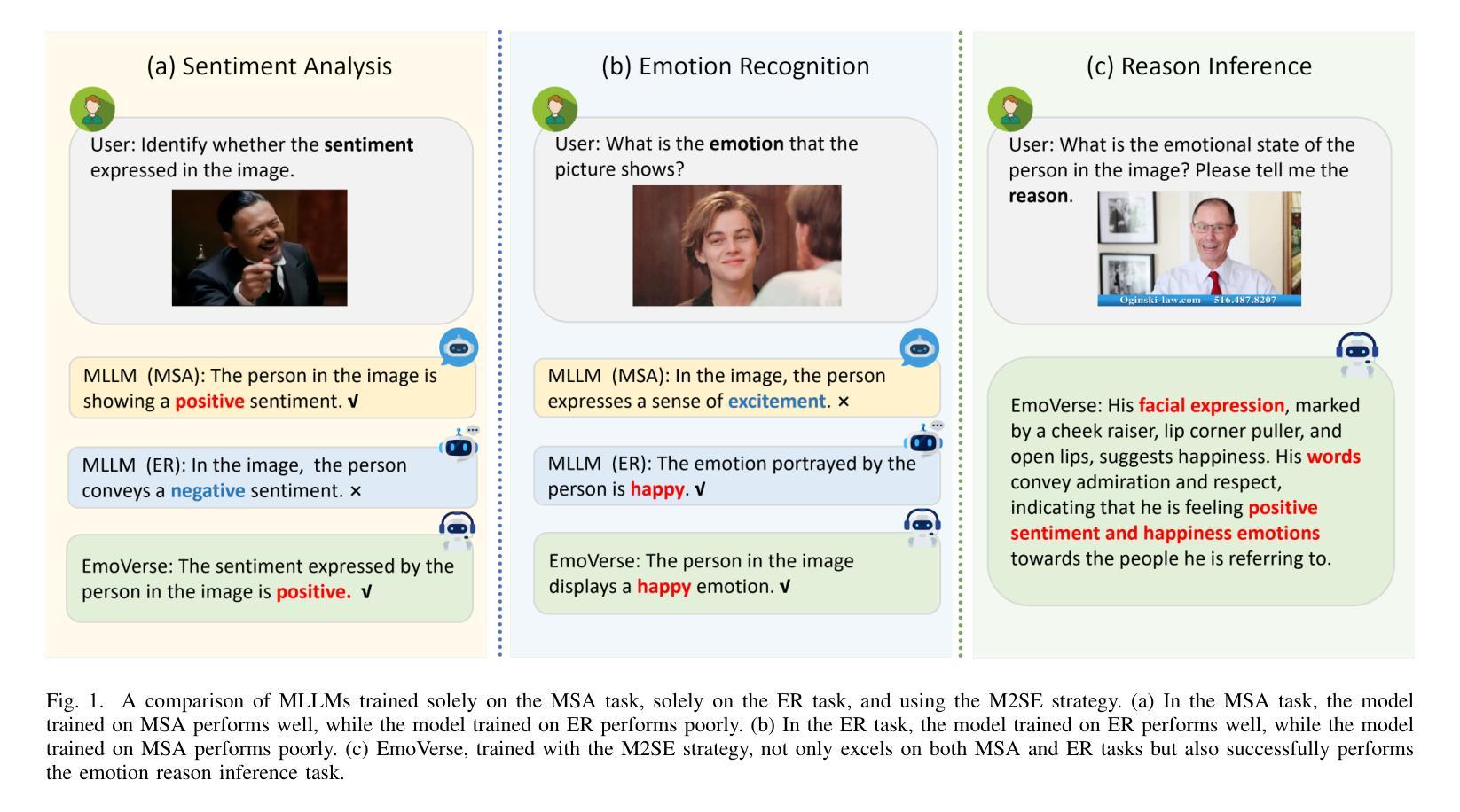
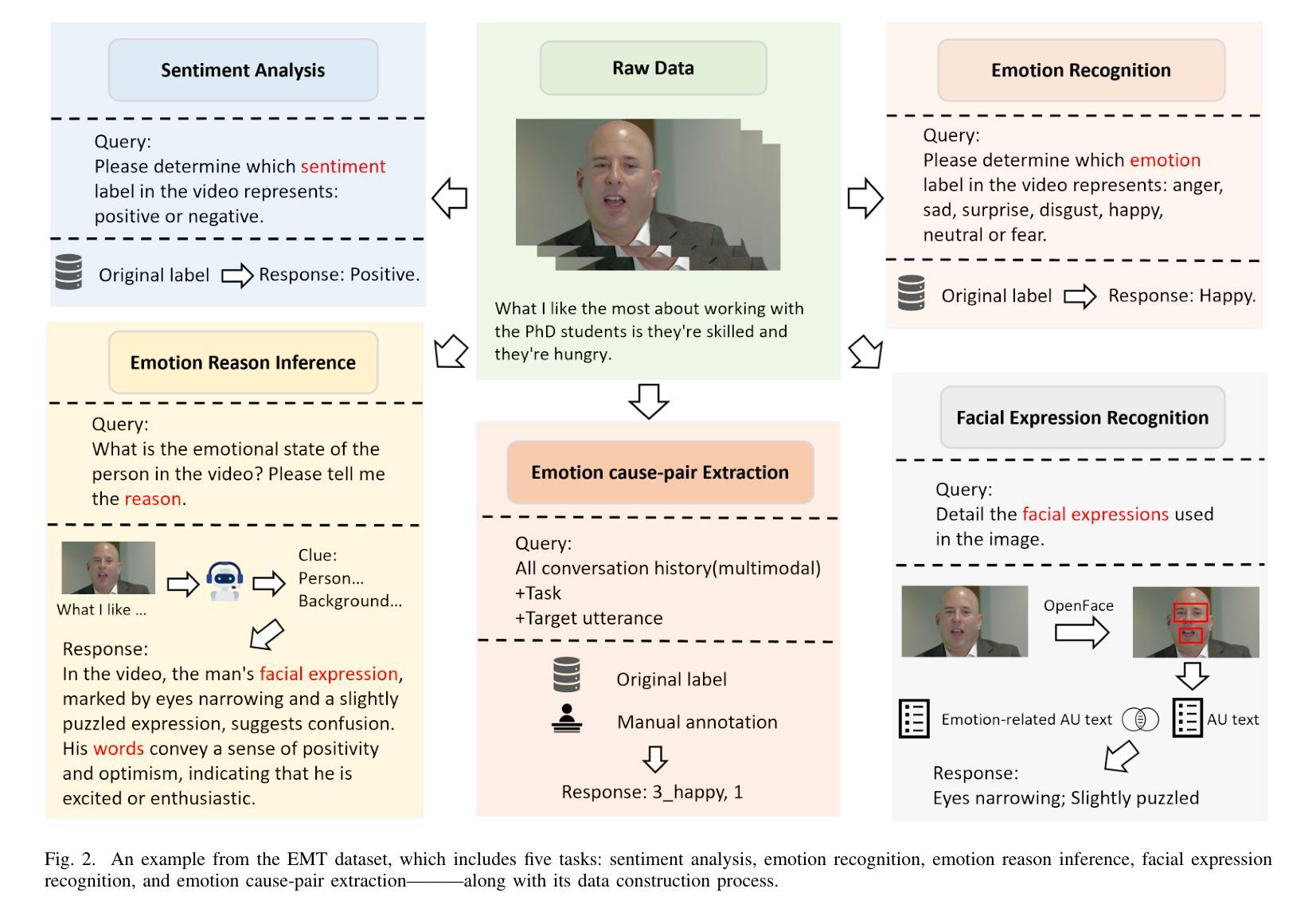
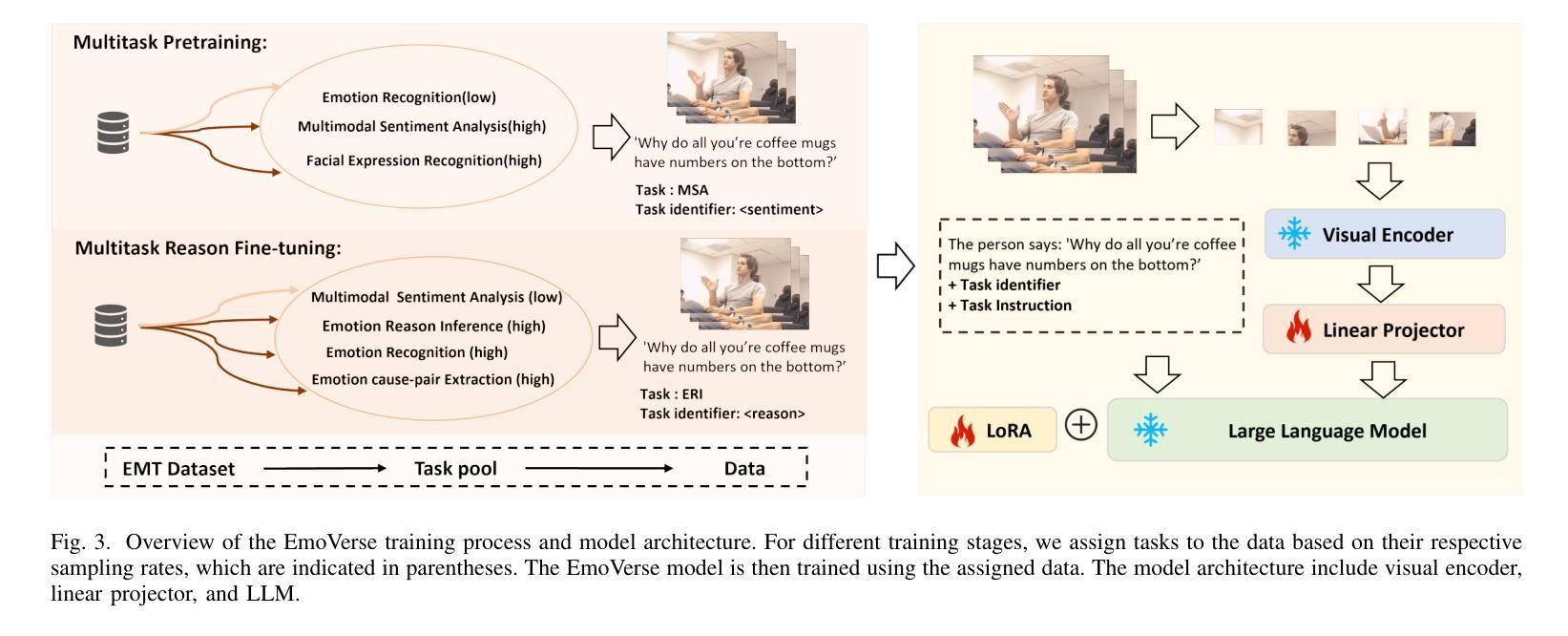
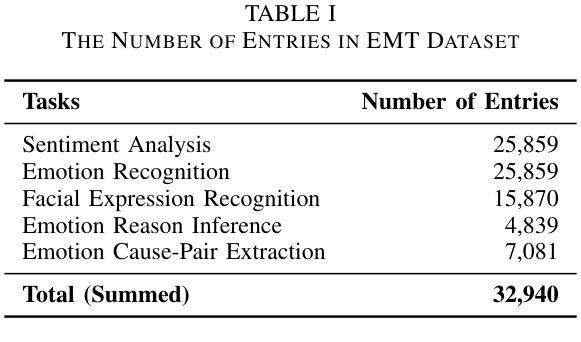
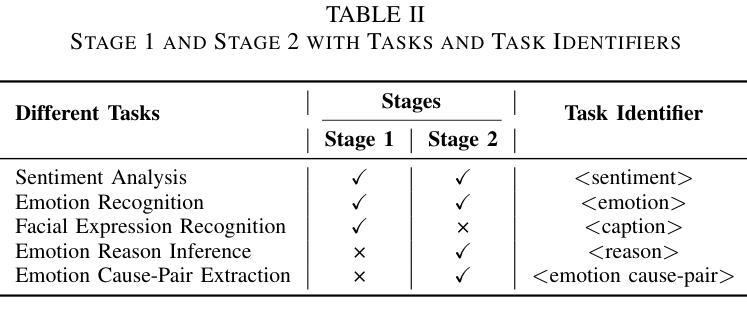
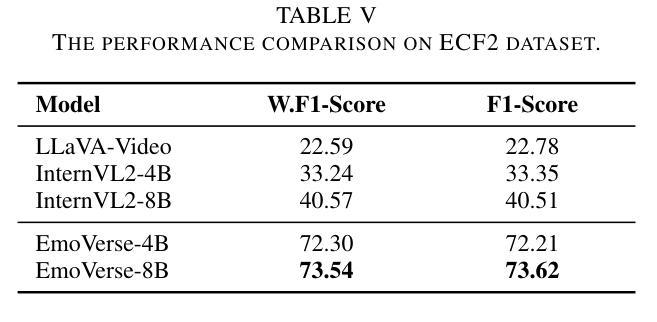
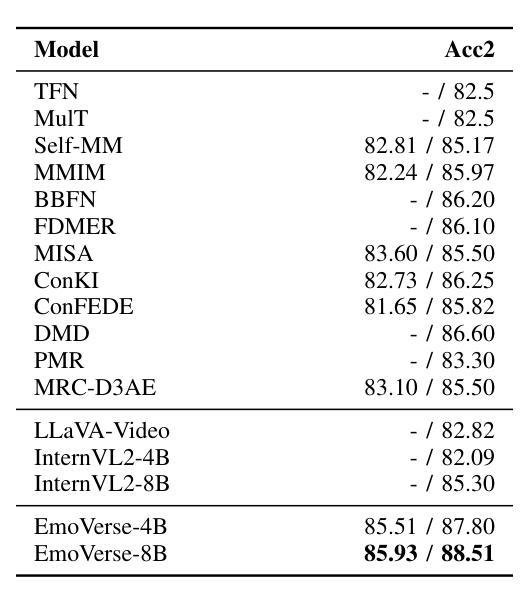
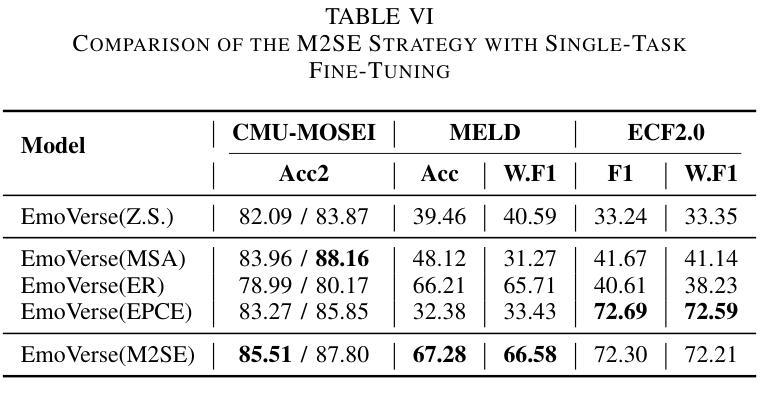
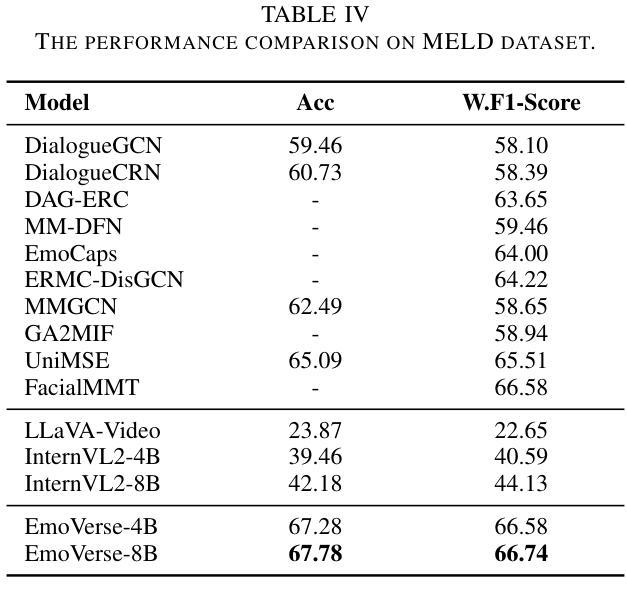
M2SE: A Multistage Multitask Instruction Tuning Strategy for Unified Sentiment and Emotion Analysis
Authors:Ao Li, Longwei Xu, Chen Ling, Jinghui Zhang, Pengwei Wang
Sentiment analysis and emotion recognition are crucial for applications such as human-computer interaction and depression detection. Traditional unimodal methods often fail to capture the complexity of emotional expressions due to conflicting signals from different modalities. Current Multimodal Large Language Models (MLLMs) also face challenges in detecting subtle facial expressions and addressing a wide range of emotion-related tasks. To tackle these issues, we propose M2SE, a Multistage Multitask Sentiment and Emotion Instruction Tuning Strategy for general-purpose MLLMs. It employs a combined approach to train models on tasks such as multimodal sentiment analysis, emotion recognition, facial expression recognition, emotion reason inference, and emotion cause-pair extraction. We also introduce the Emotion Multitask dataset (EMT), a custom dataset that supports these five tasks. Our model, Emotion Universe (EmoVerse), is built on a basic MLLM framework without modifications, yet it achieves substantial improvements across these tasks when trained with the M2SE strategy. Extensive experiments demonstrate that EmoVerse outperforms existing methods, achieving state-of-the-art results in sentiment and emotion tasks. These results highlight the effectiveness of M2SE in enhancing multimodal emotion perception. The dataset and code are available at https://github.com/xiaoyaoxinyi/M2SE.
情感分析和情绪识别在人机交互和抑郁症检测等应用中至关重要。传统的单模态方法由于来自不同模态的信号相互冲突,往往无法捕捉情绪表达的复杂性。当前的多模态大型语言模型(MLLMs)在检测细微面部表情和应对各种情绪相关任务时也面临挑战。为了解决这些问题,我们提出了M2SE,这是一种用于通用MLLMs的多阶段多任务情感和情绪指令调整策略。它采用组合方法,在诸如多模态情感分析、情绪识别、面部表情识别、情绪推理推断和情绪因果关系对提取等任务上训练模型。我们还介绍了情感多任务数据集(EMT),这是一个支持这五个任务自定义数据集。我们的模型“情感宇宙”(EmoVerse)建立在基本的MLLM框架上,没有进行任何修改,但当使用M2SE策略进行训练时,它在这些任务上取得了实质性的改进。大量实验表明,EmoVerse优于现有方法,在情感和情绪任务中达到最新水平。这些结果突出了M2SE在提高多模态情感感知方面的有效性。数据集和代码可在https://github.com/xiaoyaoxinyi/M2SE找到。
论文及项目相关链接
Summary
情感分析和情绪识别在人机交互和抑郁症检测等领域有着重要应用。传统的单模态方法由于不同模态的信号冲突,常常无法捕捉情感表达的复杂性。为应对这些问题,本文提出M2SE策略,这是一种多阶段多任务情感与情绪指令微调策略,用于通用多模态大语言模型(MLLMs)。它采用组合的方法训练模型,旨在完成诸如多模态情感分析、情绪识别、面部表情识别等五个任务。我们引入Emotion Multitask数据集(EMT)来支持这五个任务。实验表明,采用M2SE策略的模型在情感与情绪任务上达到了最新技术水平,展现了该策略在多模态情感感知中的有效性。
Key Takeaways
- 情感分析和情绪识别对于人机交互和抑郁症检测等领域至关重要。
- 传统单模态方法难以捕捉情感表达的复杂性,因为不同模态的信号会产生冲突。
- 本文提出了M2SE策略,一种用于通用多模态大语言模型的多阶段多任务情感与情绪指令微调策略。
- M2SE策略结合了多种任务训练模型,包括多模态情感分析、情绪识别等五个任务。
- 引入的Emotion Multitask数据集(EMT)支持这五个任务。
- 采用M2SE策略的模型在情感与情绪任务上取得了显著成果,达到了最新技术水平。
点此查看论文截图

Transformers Can Navigate Mazes With Multi-Step Prediction
Authors:Niklas Nolte, Ouail Kitouni, Adina Williams, Mike Rabbat, Mark Ibrahim
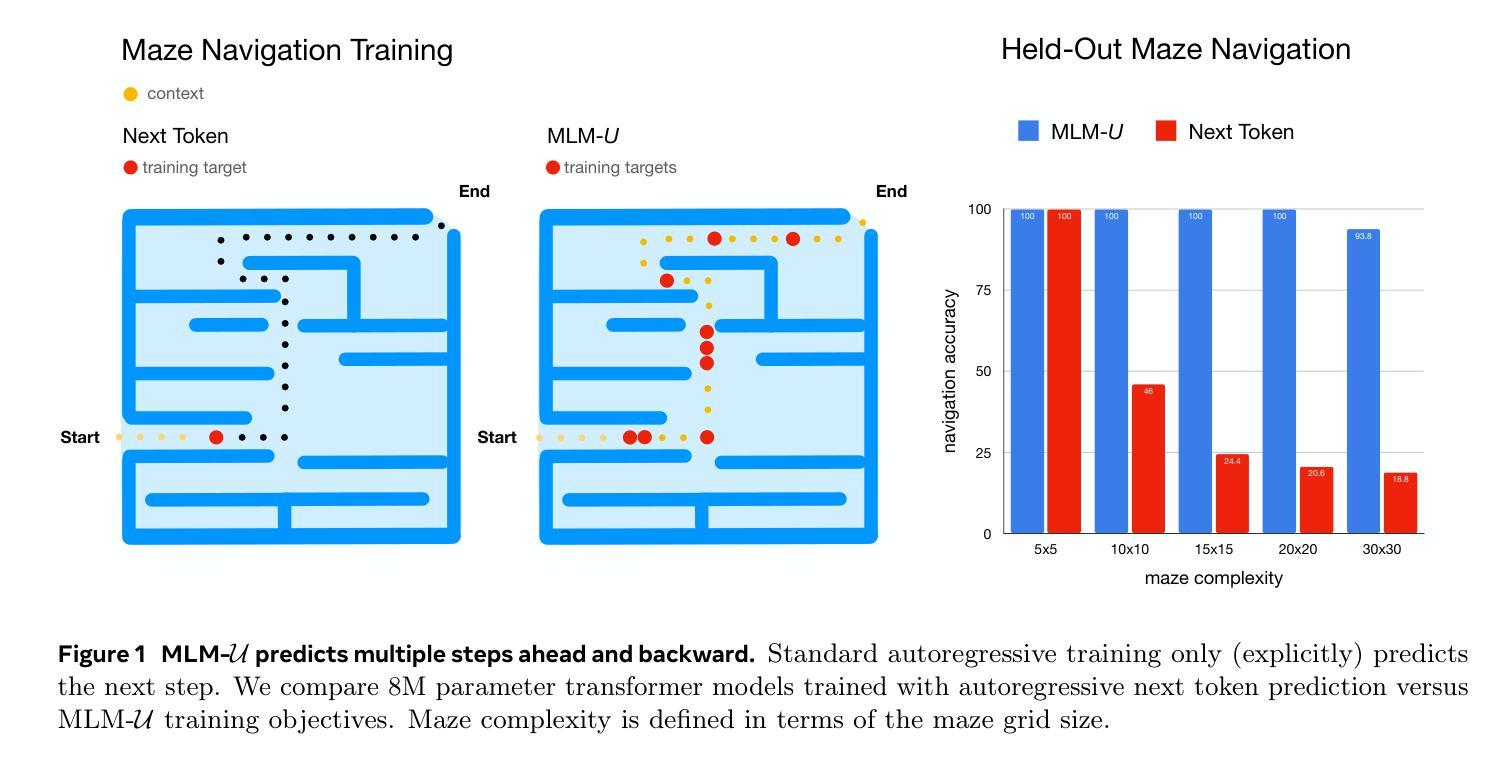
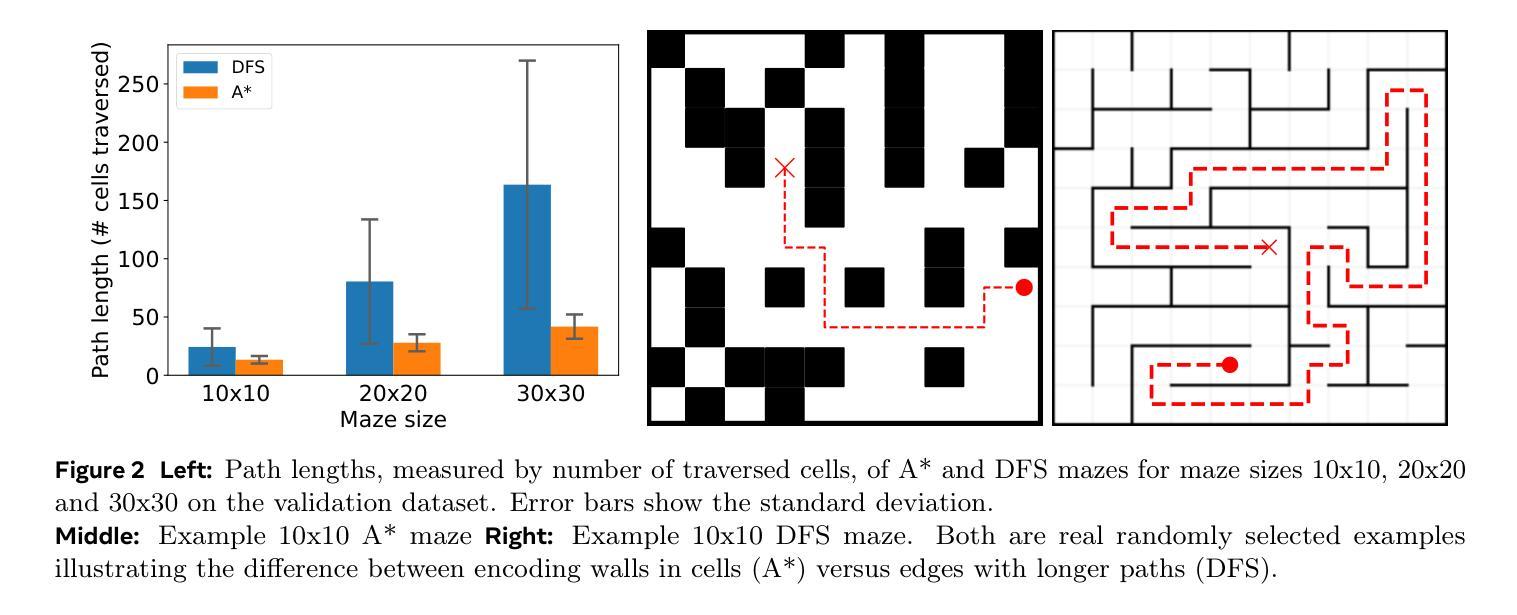
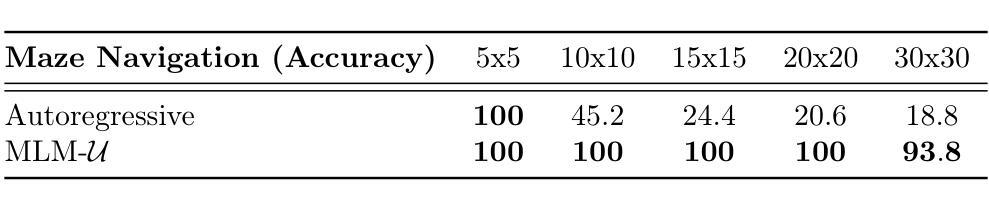
Despite their remarkable success in language modeling, transformers trained to predict the next token in a sequence struggle with long-term planning. This limitation is particularly evident in tasks requiring foresight to plan multiple steps ahead such as maze navigation. The standard next single token prediction objective, however, offers no explicit mechanism to predict multiple steps ahead - or revisit the path taken so far. Consequently, in this work we study whether explicitly predicting multiple steps ahead (and backwards) can improve transformers’ maze navigation. We train parameter-matched transformers from scratch, under identical settings, to navigate mazes of varying types and sizes with standard next token prediction and MLM-U, an objective explicitly predicting multiple steps ahead and backwards. We find that MLM-U considerably improves transformers’ ability to navigate mazes compared to standard next token prediction across maze types and complexities. We also find MLM-U training is 4x more sample efficient and converges 2x faster in terms of GPU training hours relative to next token training. Finally, for more complex mazes we find MLM-U benefits from scaling to larger transformers. Remarkably, we find transformers trained with MLM-U outperform larger transformers trained with next token prediction using additional supervision from A* search traces. We hope these findings underscore the promise of learning objectives to advance transformers’ capacity for long-term planning. The code can be found at https://github.com/facebookresearch/maze_navigation_MLMU
尽管它们在语言建模上取得了显著的成就,但经过训练的用于预测序列中下一个标记的转换器在进行长期规划时却遇到了困难。这种局限性在需要预见未来以规划多个步骤的任务(如迷宫导航)中表现得尤为明显。然而,标准的下一个单一标记预测目标并没有提供明确的机制来预测未来的多个步骤,也无法重新访问迄今为止所走的路径。因此,在这项工作中,我们研究了明确预测未来(和回溯)多个步骤是否能够改善转换器的迷宫导航能力。我们在相同设置下从头开始训练参数匹配的转换器,以在多种类型和大小的迷宫中进行导航,使用标准的下一个标记预测和MLMU(一种明确预测未来和回溯多个步骤的目标)。我们发现,与标准的下一个标记预测相比,MLMU在迷宫导航方面大大提高了转换器的能力,并且这种改进在各种类型和复杂度的迷宫中都存在。我们还发现,相对于下一个标记训练,MLMU训练样本效率提高了4倍,在GPU训练小时数方面收敛速度提高了两倍。对于更复杂的迷宫,我们发现使用MLMU的更大转换器受益于规模扩大。值得注意的是,我们发现使用MLMU训练的转换器在附加的A*搜索轨迹监督下超过了更大转换器使用下一个标记预测的训练表现。我们希望这些发现能够突显学习目标在推动转换器长期规划能力方面的潜力。代码可在 https://github.com/facebookresearch/maze_navigation_MLMU 找到。
论文及项目相关链接
PDF 20 pages, 15 figures
Summary:通过明确预测未来多个步骤(及反向预测)的目标,改进了变压器在迷宫导航中的表现。与标准下一个标记预测相比,MLMU目标显著提高变压器在不同类型和复杂迷宫中的导航能力,更有效率并加速收敛。对于更复杂的迷宫,更大规模的变压器受益于MLMU训练。该研究发现MLMU目标在推进变压器的长期规划能力方面表现出前景。
Key Takeaways:
- 变压器在自然语言建模中取得了显著成功,但在需要长期规划的任务中表现受限,如迷宫导航。
- 标准下一个标记预测目标没有明确的机制来预测未来的多个步骤或重新访问已走过的路径。
- 通过明确预测未来和过去的多个步骤(MLMU目标),可以改善变压器在迷宫导航中的表现。
- MLMU目标显著提高变压器在不同类型和复杂迷宫中的导航能力。
- MLMU训练相对于下一个标记训练更加高效,收敛速度更快。
- 对于更复杂的迷宫,更大规模的变压器受益于MLMU训练。
点此查看论文截图

Examining Multimodal Gender and Content Bias in ChatGPT-4o
Authors:Roberto Balestri
This study investigates ChatGPT-4o’s multimodal content generation, highlighting significant disparities in its treatment of sexual content and nudity versus violent and drug-related themes. Detailed analysis reveals that ChatGPT-4o consistently censors sexual content and nudity, while showing leniency towards violence and drug use. Moreover, a pronounced gender bias emerges, with female-specific content facing stricter regulation compared to male-specific content. This disparity likely stems from media scrutiny and public backlash over past AI controversies, prompting tech companies to impose stringent guidelines on sensitive issues to protect their reputations. Our findings emphasize the urgent need for AI systems to uphold genuine ethical standards and accountability, transcending mere political correctness. This research contributes to the understanding of biases in AI-driven language and multimodal models, calling for more balanced and ethical content moderation practices.
本研究探讨了ChatGPT-4o的多模态内容生成,重点关注其在处理性内容和裸露场景与暴力及药物相关主题时存在的显著差异。详细分析表明,ChatGPT-4o对性内容和裸露场景进行持续审查,而对暴力和药物使用的内容则表现出宽容。此外,还出现了明显的性别偏见,女性特定内容面临的监管比男性特定内容更为严格。这种差异很可能源于过去人工智能争议中的媒体审查和公众反对,促使科技公司对敏感问题实施严格准则以保护其声誉。我们的研究强调人工智能系统迫切需要坚持真正的道德标准和问责制,超越单纯的政治正确性。本研究为理解人工智能驱动语言和多媒体模型中的偏见做出了贡献,呼吁采用更平衡、更道德的内容管理实践。
论文及项目相关链接
PDF 17 pages, 4 figures, 3 tables. Conference: “14th International Conference on Artificial Intelligence, Soft Computing and Applications (AIAA 2024), London, 23-24 November 2024” It will be published in the proceedings “David C. Wyld et al. (Eds): IoTE, CNDC, DSA, AIAA, NLPTA, DPPR - 2024”
Summary
ChatGPT-4o在多模态内容生成方面存在显著差异,对性内容和裸露场景进行严格审查,而对暴力和毒品相关内容较为宽容。此外,研究还发现明显的性别偏见,女性相关内容受到的监管更为严格。这可能与媒体对过去人工智能争议的关注和公众的反击有关,促使技术公司采用严格的敏感性指南以保护其声誉。该研究呼吁AI系统保持真正的道德标准和责任心,而不仅仅是追求政治正确性。这一发现有助于了解人工智能驱动语言和多媒体模型中的偏见,呼吁采用更加平衡和道德的内容审核实践。
Key Takeaways
- ChatGPT-4o在多模态内容生成中存在显著差异,对性内容和裸露场景的表述处理得更加严格。
- 暴力和毒品相关内容在ChatGPT-4o的处理中显得较为宽容。
- 研究发现ChatGPT-4o在处理内容时对性别存在偏见,女性相关内容受到的监管更为严格。
- 这种差异可能源于媒体对过去人工智能争议的关注及公众反响。
- 技术公司因这些争议而采取严格的敏感性指南以保护其声誉。
- 研究强调AI系统需要超越政治正确性,维持真正的道德标准和责任心。
点此查看论文截图

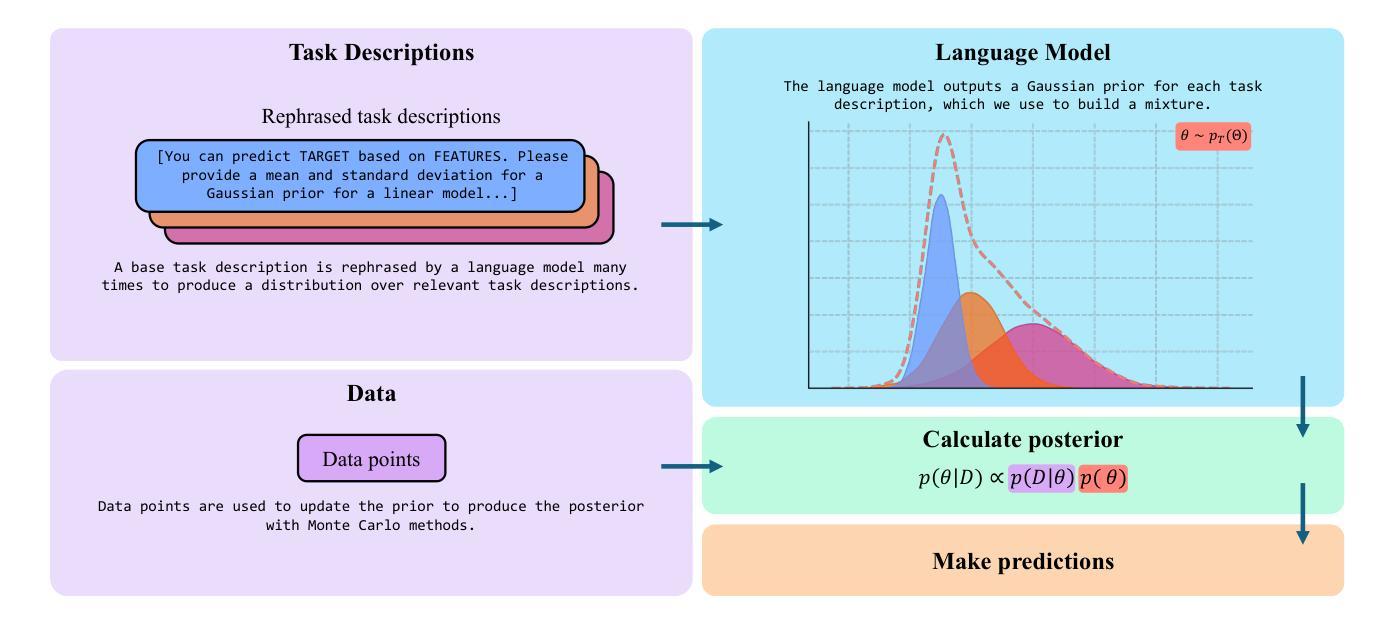
Using Large Language Models for Expert Prior Elicitation in Predictive Modelling
Authors:Alexander Capstick, Rahul G. Krishnan, Payam Barnaghi
Large language models (LLMs), trained on diverse data effectively acquire a breadth of information across various domains. However, their computational complexity, cost, and lack of transparency hinder their direct application for specialised tasks. In fields such as clinical research, acquiring expert annotations or prior knowledge about predictive models is often costly and time-consuming. This study proposes the use of LLMs to elicit expert prior distributions for predictive models. This approach also provides an alternative to in-context learning, where language models are tasked with making predictions directly. In this work, we compare LLM-elicited and uninformative priors, evaluate whether LLMs truthfully generate parameter distributions, and propose a model selection strategy for in-context learning and prior elicitation. Our findings show that LLM-elicited prior parameter distributions significantly reduce predictive error compared to uninformative priors in low-data settings. Applied to clinical problems, this translates to fewer required biological samples, lowering cost and resources. Prior elicitation also consistently outperforms and proves more reliable than in-context learning at a lower cost, making it a preferred alternative in our setting. We demonstrate the utility of this method across various use cases, including clinical applications. For infection prediction, using LLM-elicited priors reduced the number of required labels to achieve the same accuracy as an uninformative prior by 55%, 200 days earlier in the study.
大型语言模型(LLM)通过在多样化数据上的训练,有效获取了跨各种领域的大量信息。然而,它们的计算复杂性、成本和缺乏透明度阻碍了它们在特殊任务上的直接应用。在临床研究领域,获取专家注释或关于预测模型的先验知识往往成本高昂且耗时。本研究提出使用LLM来激发预测模型的专家先验分布。这种方法还为上下文学习提供了替代方案,其中语言模型被直接用于进行预测。在这项工作中,我们比较了LLM激发的和无信息的先验,评估了LLM是否真实地生成参数分布,并提出了上下文学习和先验激发的模型选择策略。我们的研究结果表明,与无信息先验相比,LLM激发的先验参数分布在低数据设置中显著降低了预测误差。应用于临床问题,这意味着减少了所需的生物样本数量,降低了成本并节省了资源。先验激发也始终优于上下文学习,并且在成本更低的情况下表现出更高的可靠性,因此在我们的场景中成为首选的替代方案。我们在各种用例中展示了该方法的实用性,包括临床应用程序。在感染预测方面,使用LLM激发的先验将实现与无信息先验相同准确度的所需标签数量减少了55%,并且在研究中的提前了200天。
论文及项目相关链接
Summary
大规模语言模型(LLM)经过多样化数据训练后,能够跨域获取广泛的信息。但其计算复杂性、成本和不透明性限制了其在专项任务中的直接应用。本研究提出利用LLM来激发预测模型的专家先验分布,为语境学习提供替代方案。本研究比较了LLM激发的和无信息的先验,评估了LLM是否真实地生成参数分布,并为语境学习和先验激发提出了模型选择策略。研究发现,LLM激发的先验参数分布在低数据环境中显著减少了预测误差。在临床医学问题中,这意味着减少了所需的生物样本数量,降低了成本和资源消耗。与语境学习相比,先验激发表现出了一致性和可靠性,并降低了成本,使其成为首选方法。本研究展示了该方法在各种用例中的实用性,包括临床应用程序。对于感染预测,使用LLM激发的先验可将达到相同准确度的标签数量减少55%,并在研究早期提前了200天实现这一目标。
Key Takeaways
- LLMs经过多样化数据训练后能够跨域获取广泛信息。
- LLMs的计算复杂性、成本和不透明性限制了其在专项任务中的应用。
- 利用LLM激发预测模型的专家先验分布可为语境学习提供替代方案。
- LLM激发的先验参数分布在低数据环境中显著减少预测误差。
- 在临床医学问题中,使用LLM激发的先验可减少所需的生物样本数量,降低成本和资源消耗。
- 与语境学习相比,先验激发展现出更高的可靠性和一致性。
点此查看论文截图