⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-21 更新
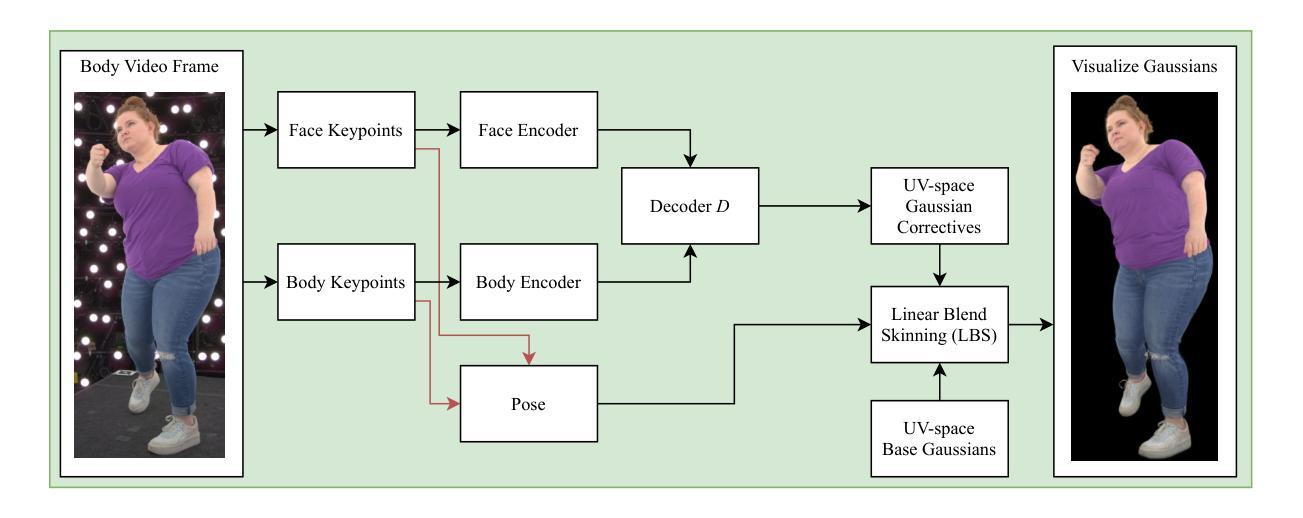
SqueezeMe: Efficient Gaussian Avatars for VR
Authors:Shunsuke Saito, Stanislav Pidhorskyi, Igor Santesteban, Forrest Iandola, Divam Gupta, Anuj Pahuja, Nemanja Bartolovic, Frank Yu, Emanuel Garbin, Tomas Simon
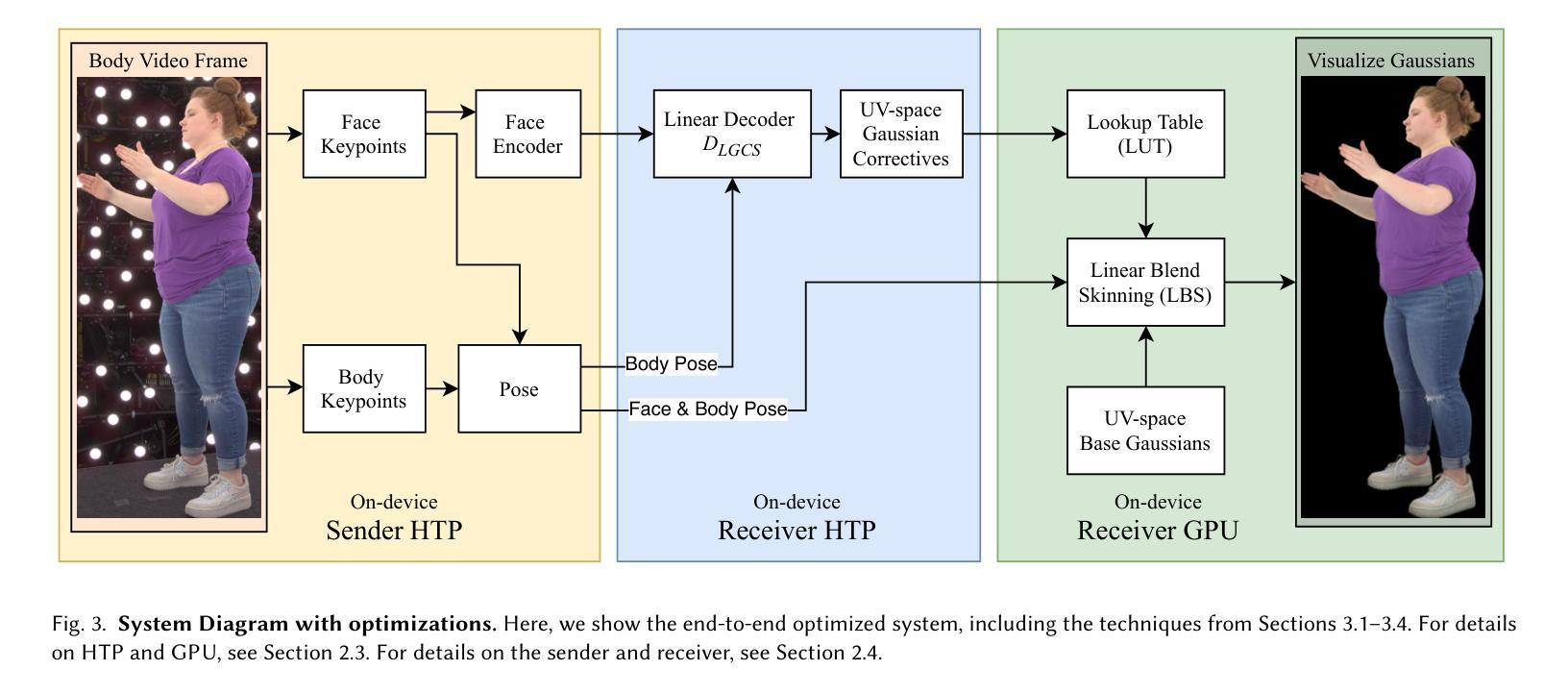
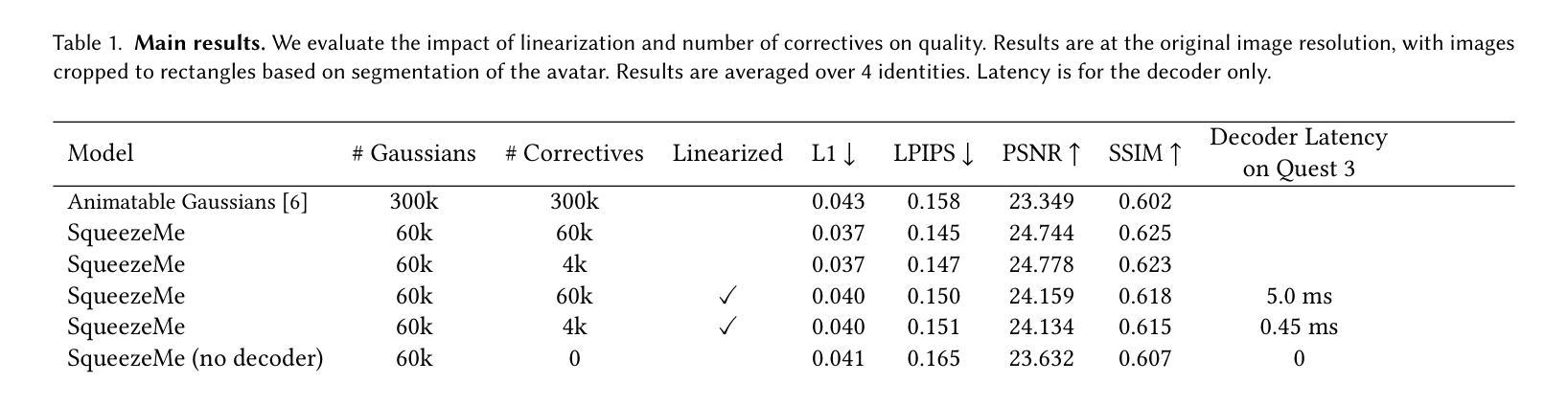
Gaussian Splatting has enabled real-time 3D human avatars with unprecedented levels of visual quality. While previous methods require a desktop GPU for real-time inference of a single avatar, we aim to squeeze multiple Gaussian avatars onto a portable virtual reality headset with real-time drivable inference. We begin by training a previous work, Animatable Gaussians, on a high quality dataset captured with 512 cameras. The Gaussians are animated by controlling base set of Gaussians with linear blend skinning (LBS) motion and then further adjusting the Gaussians with a neural network decoder to correct their appearance. When deploying the model on a Meta Quest 3 VR headset, we find two major computational bottlenecks: the decoder and the rendering. To accelerate the decoder, we train the Gaussians in UV-space instead of pixel-space, and we distill the decoder to a single neural network layer. Further, we discover that neighborhoods of Gaussians can share a single corrective from the decoder, which provides an additional speedup. To accelerate the rendering, we develop a custom pipeline in Vulkan that runs on the mobile GPU. Putting it all together, we run 3 Gaussian avatars concurrently at 72 FPS on a VR headset. Demo videos are at https://forresti.github.io/squeezeme.
高斯涂抹技术已经实现了具有前所未有的视觉品质的真实时3D人类化身。虽然之前的方法需要一个桌面GPU来进行单一化身的实时推理,我们的目标是将多个高斯化身挤压到便携式虚拟现实头盔上,实现可驱动的实时推理。我们从训练可动画高斯(Animatable Gaussians)的先前工作开始,该工作在512个相机捕捉的高质量数据集上进行。高斯通过控制基础高斯集以线性混合蒙皮(LBS)运动进行动画,然后通过神经网络解码器进一步调整其外观以校正其外观。当在Meta Quest 3 VR头盔上部署模型时,我们发现两个主要的计算瓶颈:解码器和渲染器。为了加速解码器,我们在UV空间而不是像素空间中训练高斯,并将解码器蒸馏到一个单一的神经网络层。此外,我们发现高斯附近区域可以从解码器共享一个校正,这提供了额外的加速。为了加速渲染器,我们开发了一个在移动GPU上运行的Vulkan自定义管道。将所有这些结合在一起,我们在VR头盔上同时运行3个高斯化身,帧率为72 FPS。演示视频请访问:链接。
论文及项目相关链接
PDF Initial version
Summary
高斯混成技术已用于实时3D人类化身,带来前所未有的视觉品质。我们旨在将多个高斯化身挤压到便携式虚拟现实头盔上,进行实时可驱动推理。通过对高质量数据集进行训练并控制基础高斯集,使用线性混合蒙皮(LBS)运动,再通过神经网络解码器调整高斯以校正外观,实现在Meta Quest 3 VR头盔上的部署。为加速解码器,我们在UV空间而非像素空间训练高斯,并将解码器精简至单层神经网络。邻近高斯可共享解码器的校正,进一步提高速度。为加速渲染,我们开发了可在移动GPU上运行的Vulkan自定义管道。综合上述优化,我们在VR头盔上同时运行3个高斯化身,帧速率为72 FPS。
Key Takeaways
- Gaussian Splatting技术用于实时3D人类化身,实现高视觉品质。
- 目标是在便携式虚拟现实头盔上实现多个高斯化身的实时可驱动推理。
- 通过训练并控制基础高斯集,使用LBS运动和神经网络解码器调整高斯,实现化身的动画和外观校正。
- 在UV空间而非像素空间训练高斯以加速解码器,并将解码器精简至单层神经网络。
- 邻近高斯可共享解码器的校正,进一步提高性能。
- 为加速渲染,开发了可在移动GPU上运行的Vulkan自定义管道。
点此查看论文截图


StrandHead: Text to Strand-Disentangled 3D Head Avatars Using Hair Geometric Priors
Authors:Xiaokun Sun, Zeyu Cai, Ying Tai, Jian Yang, Zhenyu Zhang
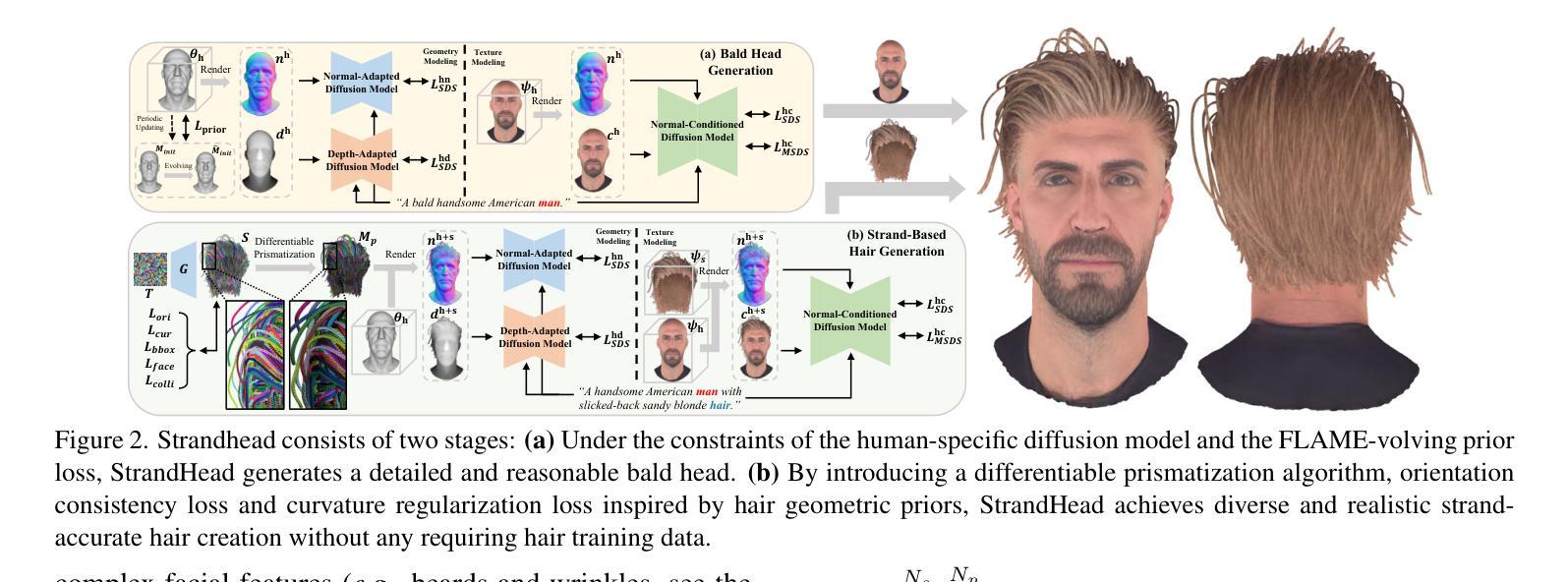
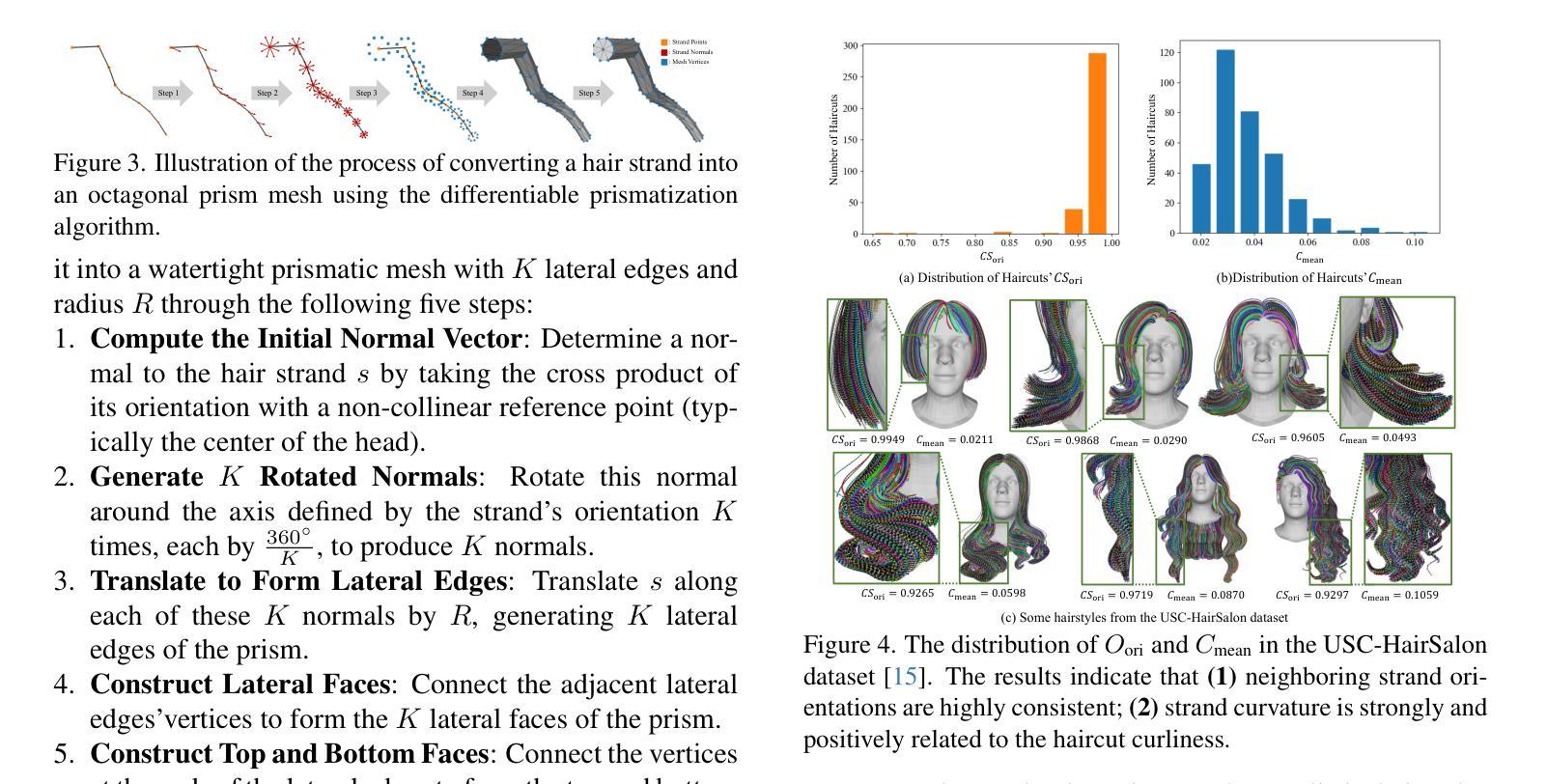
While haircut indicates distinct personality, existing avatar generation methods fail to model practical hair due to the general or entangled representation. We propose StrandHead, a novel text to 3D head avatar generation method capable of generating disentangled 3D hair with strand representation. Without using 3D data for supervision, we demonstrate that realistic hair strands can be generated from prompts by distilling 2D generative diffusion models. To this end, we propose a series of reliable priors on shape initialization, geometric primitives, and statistical haircut features, leading to a stable optimization and text-aligned performance. Extensive experiments show that StrandHead achieves the state-of-the-art reality and diversity of generated 3D head and hair. The generated 3D hair can also be easily implemented in the Unreal Engine for physical simulation and other applications. The code will be available at https://xiaokunsun.github.io/StrandHead.github.io.
虽然发型体现了独特的个性,但现有的化身生成方法由于通用或纠缠的表示而无法对实际头发进行建模。我们提出了一种新型文本到3D头部化身生成方法——StrandHead,它能够生成具有细丝表示的分离式3D头发。在不使用3D数据进行监督的情况下,我们证明了可以通过提炼二维生成扩散模型从提示中生成逼真的头发细丝。为此,我们在形状初始化、几何基元和统计发型特征方面提出了一系列可靠的先验知识,以实现稳定的优化和文本对齐性能。大量实验表明,StrandHead在生成的3D头部和头发的真实性和多样性方面达到了最新水平。生成的3D头发也可以轻松实现在Unreal Engine中进行物理模拟和其他应用。代码将在https://xiaokunsun.github.io/StrandHead.github.io上提供。
论文及项目相关链接
PDF Project page: https://xiaokunsun.github.io/StrandHead.github.io
Summary
本文提出了一种新型文本到三维头像生成方法,称为StrandHead。该方法能够生成具有发丝级精细度的三维头像,且无需使用三维数据进行监督。通过利用二维生成扩散模型,从提示中生成真实感发丝。该方法还引入了一系列可靠的先验知识,包括形状初始化、几何基本形态和发型特征统计等,以实现稳定的优化和文本对齐效果。实验表明,StrandHead在生成的三维头像和发型的真实性和多样性方面达到了领先水平,且生成的发型易于在Unreal Engine中进行物理模拟和其他应用。
Key Takeaways
- StrandHead是一种新型文本到三维头像生成方法,能够生成具有发丝级精细度的三维头像。
- 该方法无需使用三维数据进行监督,能从提示中生成真实感发丝。
- StrandHead引入了一系列可靠的先验知识,包括形状初始化、几何基本形态和发型特征统计等。
- 该方法实现了稳定的优化和文本对齐效果。
- 实验表明,StrandHead在生成的三维头像和发型的真实性和多样性方面达到了领先水平。
- 生成的发型易于在Unreal Engine中进行物理模拟和其他应用。
点此查看论文截图



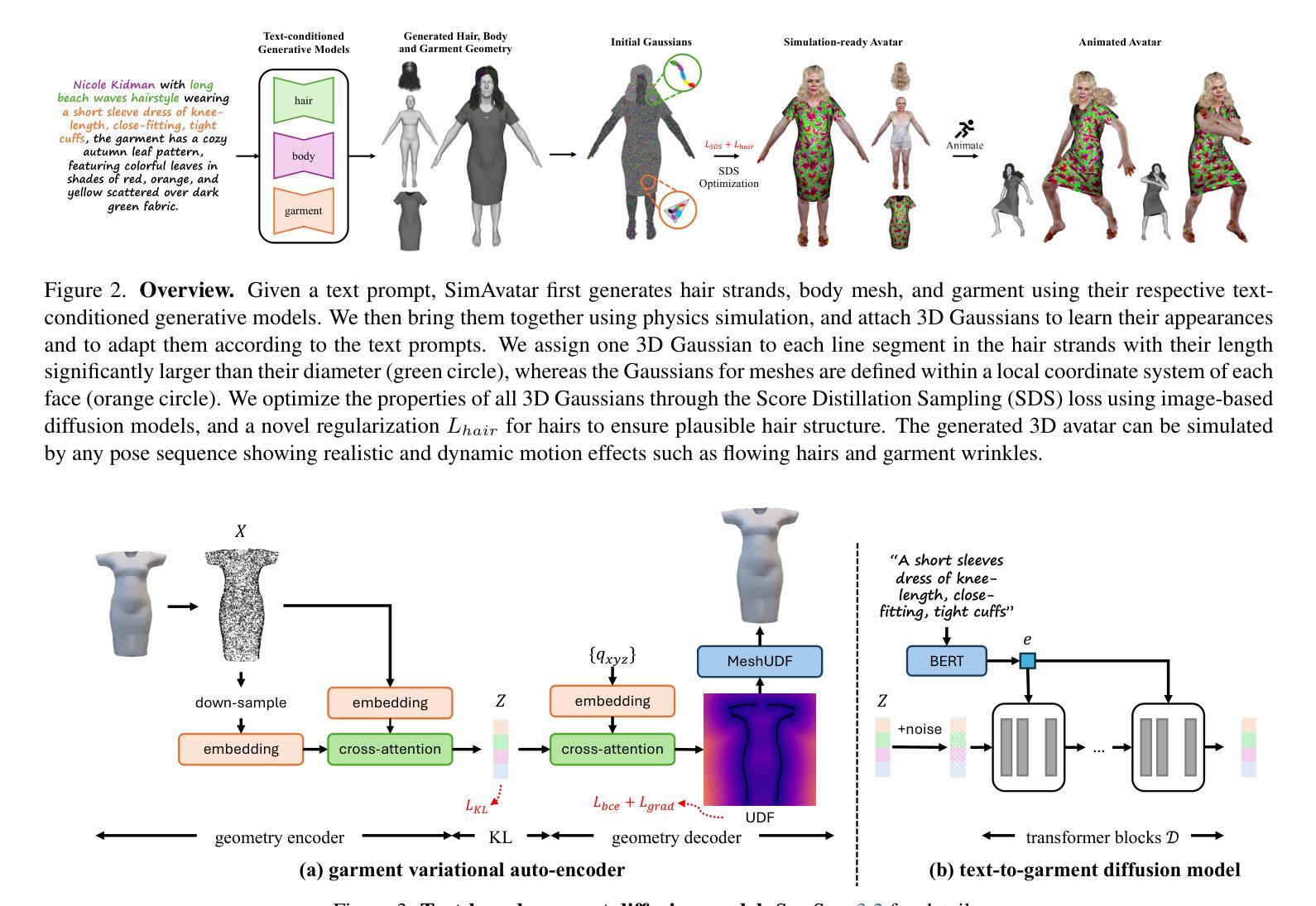
SimAvatar: Simulation-Ready Avatars with Layered Hair and Clothing
Authors:Xueting Li, Ye Yuan, Shalini De Mello, Gilles Daviet, Jonathan Leaf, Miles Macklin, Jan Kautz, Umar Iqbal
We introduce SimAvatar, a framework designed to generate simulation-ready clothed 3D human avatars from a text prompt. Current text-driven human avatar generation methods either model hair, clothing, and the human body using a unified geometry or produce hair and garments that are not easily adaptable for simulation within existing simulation pipelines. The primary challenge lies in representing the hair and garment geometry in a way that allows leveraging established prior knowledge from foundational image diffusion models (e.g., Stable Diffusion) while being simulation-ready using either physics or neural simulators. To address this task, we propose a two-stage framework that combines the flexibility of 3D Gaussians with simulation-ready hair strands and garment meshes. Specifically, we first employ three text-conditioned 3D generative models to generate garment mesh, body shape and hair strands from the given text prompt. To leverage prior knowledge from foundational diffusion models, we attach 3D Gaussians to the body mesh, garment mesh, as well as hair strands and learn the avatar appearance through optimization. To drive the avatar given a pose sequence, we first apply physics simulators onto the garment meshes and hair strands. We then transfer the motion onto 3D Gaussians through carefully designed mechanisms for each body part. As a result, our synthesized avatars have vivid texture and realistic dynamic motion. To the best of our knowledge, our method is the first to produce highly realistic, fully simulation-ready 3D avatars, surpassing the capabilities of current approaches.
我们介绍了SimAvatar框架,该框架旨在从文本提示生成可用于模拟的穿衣3D人类化身。当前的文本驱动人类化身生成方法要么使用统一几何对头发、服装和人体进行建模,要么产生在现有模拟管道中不容易进行模拟的头发和服装。主要挑战在于以一种方式表示头发和服装几何,该方式允许利用来自基础图像扩散模型(例如Stable Diffusion)的现有先验知识,同时使用物理或神经模拟器进行模拟。为了解决这项任务,我们提出了一个两阶段框架,该框架结合了3D高斯函数的灵活性与可用于模拟的头发束和服装网格。具体来说,我们首先使用三个文本条件化的3D生成模型,根据给定的文本提示生成服装网格、身体形状和头发束。为了利用基础扩散模型的先验知识,我们将3D高斯函数附加到身体网格、服装网格和头发束上,并通过优化学习化身外观。为了在给定的姿势序列驱动下驱动化身,我们首先将物理模拟器应用于服装网格和头发束。然后,通过针对每个身体部位精心设计的机制,将运动转移到3D高斯函数上。因此,我们合成的化身具有生动的纹理和逼真的动态运动。据我们所知,我们的方法是第一个生成高度逼真、完全模拟就绪的3D化身的方法,超越了当前方法的能力。
论文及项目相关链接
PDF Project website: https://nvlabs.github.io/SimAvatar/
Summary
文本介绍了一个名为SimAvatar的框架,该框架能够从文本提示生成可用于模拟的穿衣3D人类角色。该框架解决了现有文本驱动的人类角色生成方法在模拟管道中面临的难题,实现了角色的生动纹理和真实动态动作。
Key Takeaways
- SimAvatar是一个从文本提示生成模拟准备状态的穿衣3D人类角色的框架。
- 当前文本驱动的角色生成方法在模拟时存在难题,SimAvatar解决了这个问题。
- SimAvatar使用两阶段框架,结合了3D高斯函数的灵活性和模拟准备状态的头发和服装网格。
- 该框架使用文本条件化的3D生成模型来生成服装网格、身体形状和头发。
- SimAvatar利用基础扩散模型的先验知识,通过优化学习角色的外观。
- 角色在给定姿势序列时的驱动是通过物理模拟器对服装网格和头发进行模拟,然后通过精心设计机制将运动转移到每个身体部分的3D高斯函数上。
点此查看论文截图