⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-21 更新
Preventing Local Pitfalls in Vector Quantization via Optimal Transport
Authors:Borui Zhang, Wenzhao Zheng, Jie Zhou, Jiwen Lu
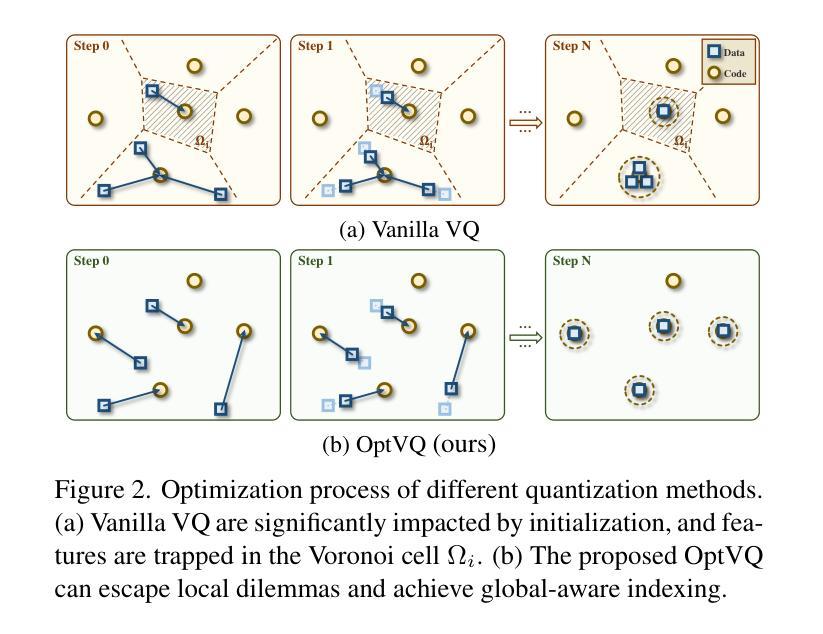
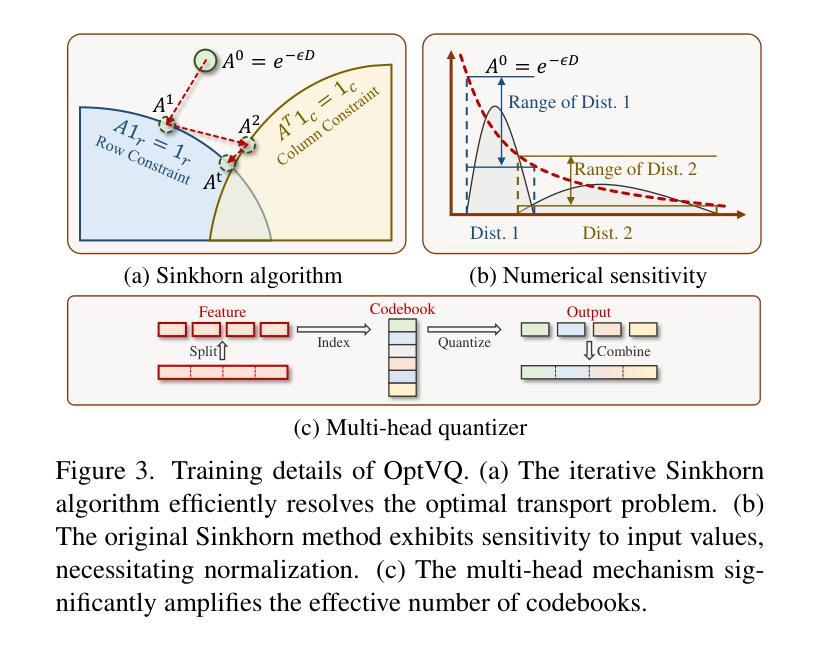
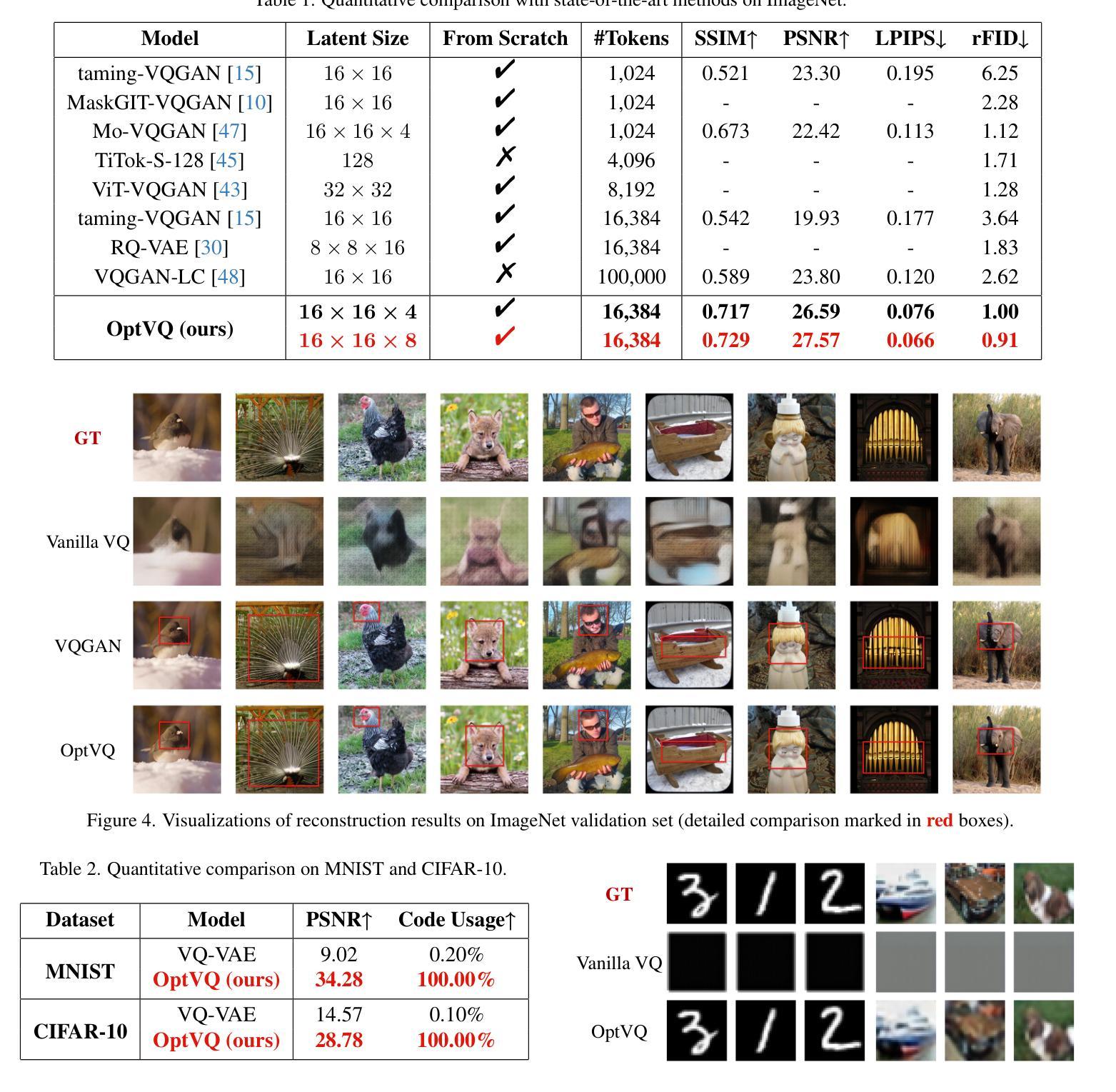
Vector-quantized networks (VQNs) have exhibited remarkable performance across various tasks, yet they are prone to training instability, which complicates the training process due to the necessity for techniques such as subtle initialization and model distillation. In this study, we identify the local minima issue as the primary cause of this instability. To address this, we integrate an optimal transport method in place of the nearest neighbor search to achieve a more globally informed assignment. We introduce OptVQ, a novel vector quantization method that employs the Sinkhorn algorithm to optimize the optimal transport problem, thereby enhancing the stability and efficiency of the training process. To mitigate the influence of diverse data distributions on the Sinkhorn algorithm, we implement a straightforward yet effective normalization strategy. Our comprehensive experiments on image reconstruction tasks demonstrate that OptVQ achieves 100% codebook utilization and surpasses current state-of-the-art VQNs in reconstruction quality.
向量量化网络(VQNs)在各种任务中表现出卓越的性能,但它们容易遇到训练不稳定的问题,这由于需要微妙初始化和模型蒸馏等技术而使得训练过程复杂化。在这项研究中,我们确定局部最小值问题是这种不稳定性的主要原因。为了解决这个问题,我们整合了一种最优传输方法,以替代最近邻搜索,实现更全局的信息分配。我们引入了OptVQ,这是一种新型向量量化方法,采用Sinkhorn算法来解决最优传输问题,从而提高训练过程的稳定性和效率。为了减轻不同数据分布对Sinkhorn算法的影响,我们实施了一种简单有效的归一化策略。我们在图像重建任务上的综合实验表明,OptVQ实现了100%的代码本利用率,并在重建质量上超越了当前最先进的VQNs。
论文及项目相关链接
PDF Code is available at https://github.com/zbr17/OptVQ
Summary
本文研究了Vector-quantized网络(VQNs)的训练不稳定问题,并识别出局部最小值问题为主要原因。为解决此问题,文章提出了一种新型向量量化方法OptVQ,采用Sinkhorn算法优化最优传输问题,从而提高训练过程的稳定性和效率。通过实施有效的归一化策略,减轻了不同数据分布对Sinkhorn算法的影响。在图像重建任务上的实验表明,OptVQ实现了100%的代码本利用率,并在重建质量上超越了现有的最先进的VQNs。
Key Takeaways
- Vector-quantized网络(VQNs)在多种任务上表现出卓越性能,但存在训练不稳定的问题。
- 局部最小值问题是导致训练不稳定的主要原因。
- 引入了一种新的向量量化方法OptVQ,使用Sinkhorn算法优化最优传输问题以提高训练稳定性和效率。
- OptVQ通过实施有效的归一化策略,减轻了不同数据分布对训练过程的影响。
- OptVQ实现了100%的代码本利用率。
- 在图像重建任务上,OptVQ超越了现有的最先进的VQNs。
点此查看论文截图

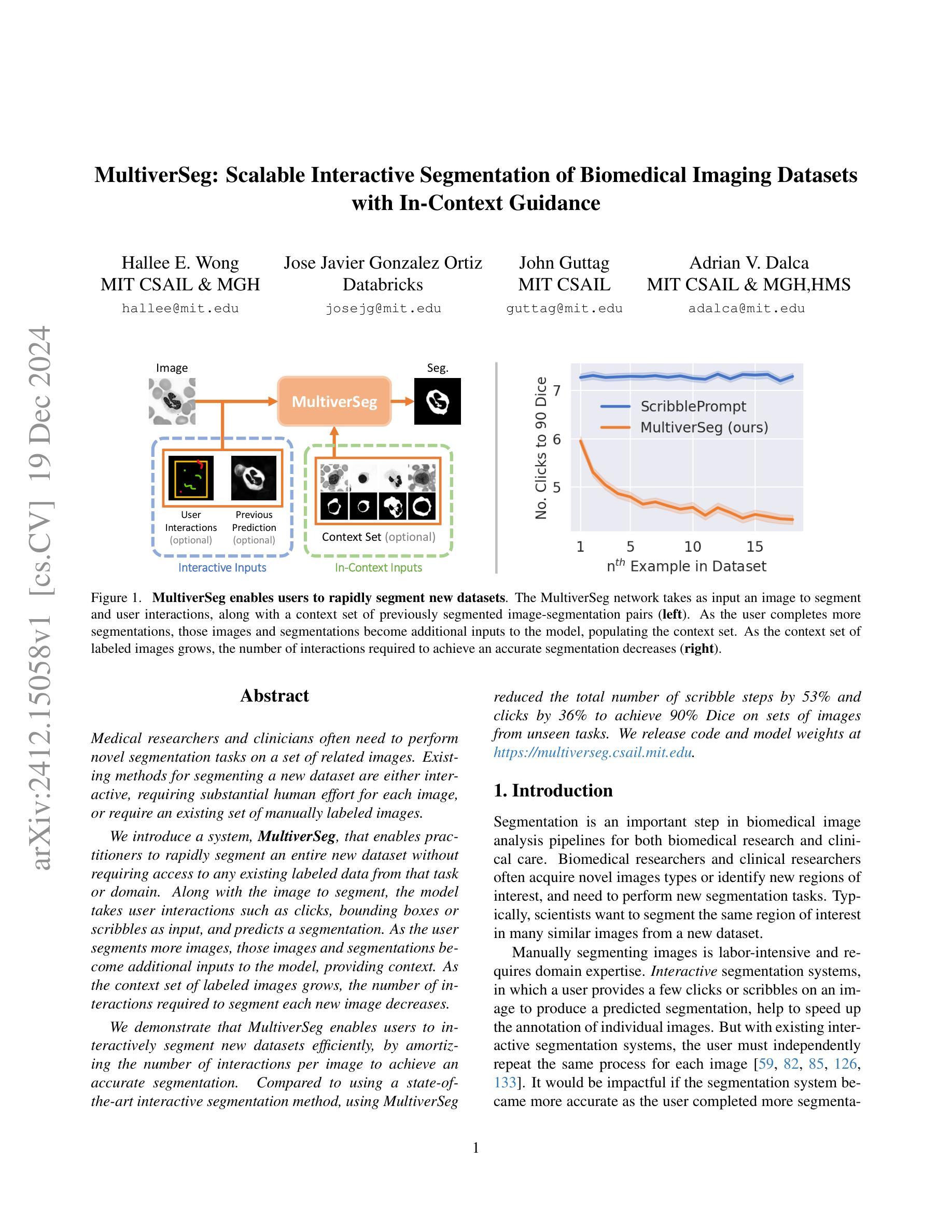
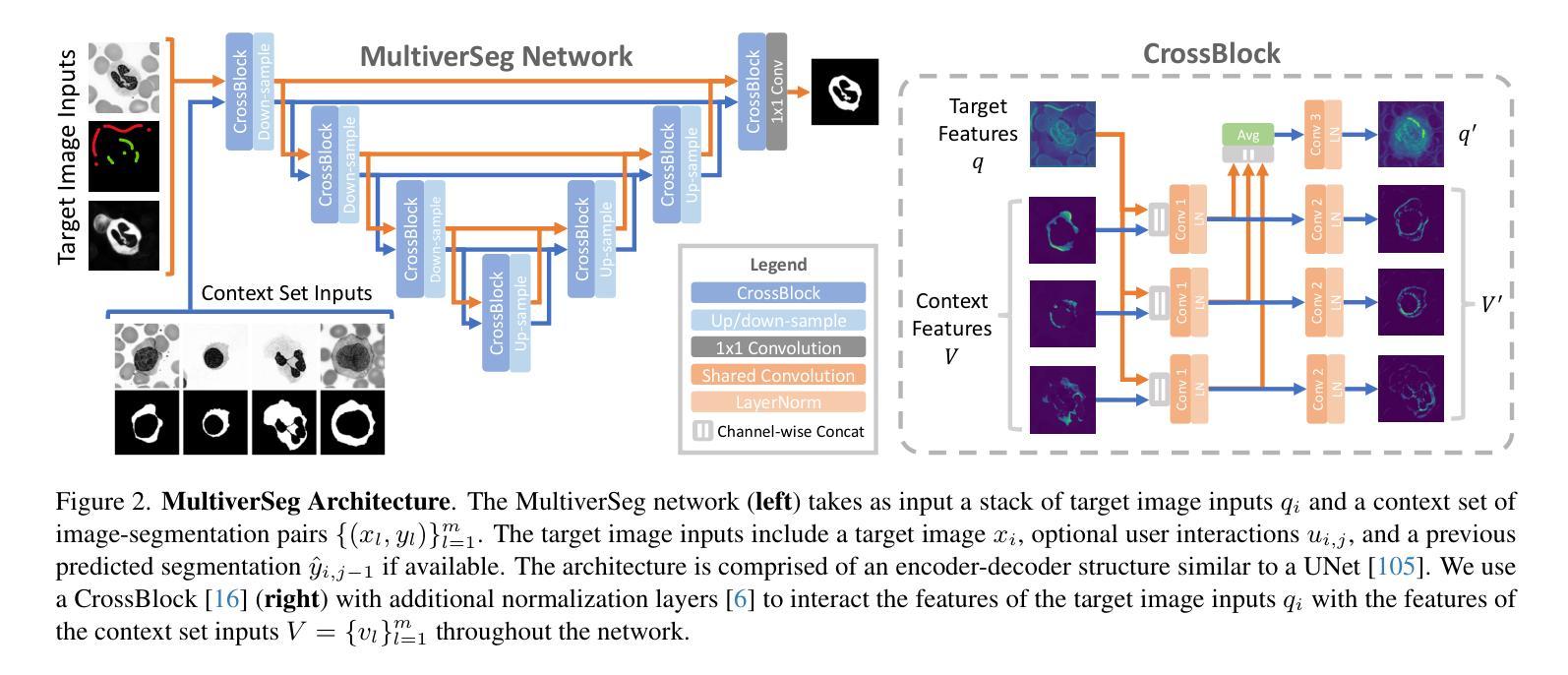
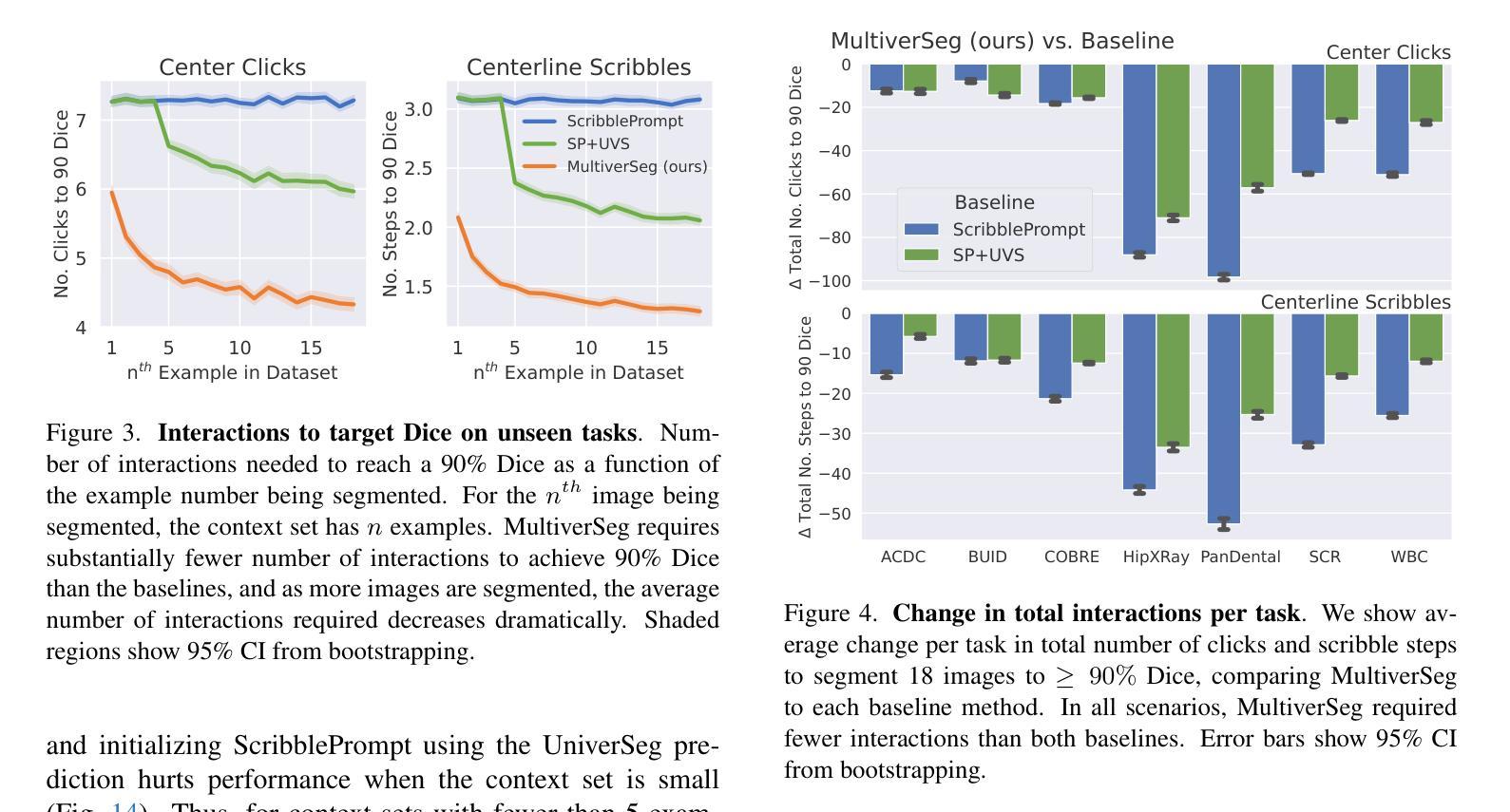
MultiverSeg: Scalable Interactive Segmentation of Biomedical Imaging Datasets with In-Context Guidance
Authors:Hallee E. Wong, Jose Javier Gonzalez Ortiz, John Guttag, Adrian V. Dalca
Medical researchers and clinicians often need to perform novel segmentation tasks on a set of related images. Existing methods for segmenting a new dataset are either interactive, requiring substantial human effort for each image, or require an existing set of manually labeled images. We introduce a system, MultiverSeg, that enables practitioners to rapidly segment an entire new dataset without requiring access to any existing labeled data from that task or domain. Along with the image to segment, the model takes user interactions such as clicks, bounding boxes or scribbles as input, and predicts a segmentation. As the user segments more images, those images and segmentations become additional inputs to the model, providing context. As the context set of labeled images grows, the number of interactions required to segment each new image decreases. We demonstrate that MultiverSeg enables users to interactively segment new datasets efficiently, by amortizing the number of interactions per image to achieve an accurate segmentation. Compared to using a state-of-the-art interactive segmentation method, using MultiverSeg reduced the total number of scribble steps by 53% and clicks by 36% to achieve 90% Dice on sets of images from unseen tasks. We release code and model weights at https://multiverseg.csail.mit.edu
医学研究人员和临床医生经常需要对一组相关图像执行新的分割任务。现有分割新数据集的方法要么是交互式的,需要针对每张图像投入大量的人力,要么需要现有的手动标记图像集。我们引入了一个系统MultiverSeg,它能让实践者无需访问该任务或领域中的任何现有标记数据即可快速分割整个新数据集。除待分割的图像外,该模型还接受用户交互作为输入,例如点击、边界框或涂鸦,并预测分割结果。随着用户分割的图像越来越多,这些图像和分割结果成为模型的额外输入,提供了上下文信息。随着标记图像上下文集的增长,分割每张新图像所需的交互次数减少。我们通过将每张图像所需的交互次数摊销来高效地对新数据集进行交互式分割,从而证明了MultiverSeg使用户能够实现精确分割。与使用最先进的交互式分割方法相比,使用MultiverSeg减少了涂鸦步骤总数达53%,点击次数减少36%,在来自未见任务的图像集上达到了90%的Dice系数。我们在https://multiverseg.csail.mit.edu发布了代码和模型权重。
论文及项目相关链接
PDF Project Website: https://multiverseg.csail.mit.edu Keywords: interactive segmentation, in-context learning, medical image analysis, biomedical imaging, image annotation, visual prompting
Summary
本研究开发了一种名为MultiverSeg的系统,用于在无需任何现有标记数据的情况下快速分割新数据集。该系统能够根据用户提供的互动操作(如点击、绘制边界框或涂鸦)进行预测分割。随着用户分割的图像数量的增加,这些图像和分割结果会作为额外的输入,为模型提供上下文信息。随着标记图像集的增多,分割每张新图像所需的互动操作数量逐渐减少。MultiverSeg通过减少涂鸦步骤和点击次数,实现了对未见任务图像集的准确分割。其代码和模型权重已发布在https://multiverseg.csail.mit.edu上。
Key Takeaways
- MultiverSeg系统能够在无需任何现有标记数据的情况下快速分割新数据集。
- 用户可通过提供互动操作(如点击、绘制边界框或涂鸦)来指导系统完成预测分割。
- 随着用户分割的图像数量增加,系统的上下文信息更丰富,分割效率逐渐提高。
- MultverSeg通过减少涂鸦步骤和点击次数,提高了分割新图像的效率和准确性。
- 该系统适用于医学图像分割等需要高效、准确处理大量图像的应用场景。
- MultverSeg的性能优于现有的交互式分割方法,能够在未见任务图像集上实现高准确率的分割。
点此查看论文截图

Joint estimation of activity, attenuation and motion in respiratory-self-gated time-of-flight PET
Authors:Masoud Elhamiasl, Frederic Jolivet, Ahmadreza Rezaei, Michael Fieseler, Klaus Schäfers, Johan Nuyts, Georg Schramm, Fernando Boada
Whole-body PET imaging is often hindered by respiratory motion during acquisition, causing significant degradation in the quality of reconstructed activity images. An additional challenge in PET/CT imaging arises from the respiratory phase mismatch between CT-based attenuation correction and PET acquisition, leading to attenuation artifacts. To address these issues, we propose two new, purely data-driven methods for the joint estimation of activity, attenuation, and motion in respiratory self-gated TOF PET. These methods enable the reconstruction of a single activity image free from motion and attenuation artifacts. The proposed methods were evaluated using data from the anthropomorphic Wilhelm phantom acquired on a Siemens mCT PET/CT system, as well as 3 clinical FDG PET/CT datasets acquired on a GE DMI PET/CT system. Image quality was assessed visually to identify motion and attenuation artifacts. Lesion uptake values were quantitatively compared across reconstructions without motion modeling, with motion modeling but static attenuation correction, and with our proposed methods. For the Wilhelm phantom, the proposed methods delivered image quality closely matching the reference reconstruction from a static acquisition. The lesion-to-background contrast for a liver dome lesion improved from 2.0 (no motion correction) to 5.2 (proposed methods), matching the contrast from the static acquisition (5.2). In contrast, motion modeling with static attenuation correction yielded a lower contrast of 3.5. In patient datasets, the proposed methods successfully reduced motion artifacts in lung and liver lesions and mitigated attenuation artifacts, demonstrating superior lesion to background separation. Our proposed methods enable the reconstruction of a single, high-quality activity image that is motion-corrected and free from attenuation artifacts, without the need for external hardware.
全身PET成像在采集过程中经常受到呼吸运动的影响,导致重建后的活动图像质量显著下降。PET/CT成像中另一个挑战来自于基于CT的衰减校正与PET采集之间呼吸阶段的不匹配,从而导致衰减伪影。为了解决这些问题,我们提出两种全新的、纯粹的数据驱动方法,用于联合估计呼吸自门控TOF PET中的活动、衰减和运动。这些方法能够重建一个不受运动和衰减伪影影响的单一活动图像。所提出的方法使用在西门子mCT PET/CT系统上获取的威尔姆人形 Phantom 数据以及通用电气DMI PET/CT系统上获取的3个临床FDG PET/CT数据集进行了评估。通过视觉评估图像质量,以识别运动和衰减伪影。通过定量比较重建图像中的病灶摄取值,包括无运动建模的重建、有运动建模但静态衰减校正的重建以及我们提出的方法。对于威尔姆 Phantom,所提出的方法提供的图像质量与来自静态采集的参考重建图像非常接近。对于肝穹顶病灶,病灶与背景的对比度从2.0(无运动校正)提高到5.2(所提出的方法),与静态采集的对比度相匹配(5.2)。相比之下,带有静态衰减校正的运动建模产生的对比度较低,为3.5。在患者数据集中,所提出的方法成功减少了肺部和肝脏病灶的运动伪影,并减轻了衰减伪影,显示出优越的病灶与背景分离能力。我们的方法能够重建一个单一的高质量活动图像,该图像经过运动校正,无衰减伪影,且无需外部硬件。
论文及项目相关链接
PDF 18 pages, 7 figures, 2 tables
Summary
全身PET成像过程中由于呼吸运动导致的图像质量下降是一个普遍存在的问题。为解决PET/CT成像中基于CT的衰减校正与PET采集之间呼吸相位不匹配导致的衰减伪影问题,本文提出了两种全新的、纯粹的数据驱动方法,用于联合估计活动、衰减和运动。这些方法能够重建出无运动和衰减伪影的高质量活动图像。通过采用Siemens mCT PET/CT系统的人体仿真Wilhelm Phantom数据和GE DMI PET/CT系统的实际临床FDG PET/CT数据集进行验证,本文提出的方法重建出的图像质量接近静态采集的参考重建图像。特别是在肝顶病灶方面,相对于没有运动校正的图像,本文方法的病灶与背景对比度有了显著提升。总体来说,本文方法无需额外的硬件设备即可实现无运动校正、无衰减伪影的高质量活动图像重建。
Key Takeaways
- 全身PET成像受到呼吸运动的影响,导致重建的活动图像质量下降。
- 呼吸运动在PET/CT成像中引起的挑战包括活动估计和衰减校正的不准确。
- 本文提出了两种数据驱动的方法来解决这些问题,实现了对活动、衰减和运动的联合估计。
- 使用Wilhelm Phantom数据和实际临床数据集验证了方法的有效性。
- 本文方法能够重建出高质量的活动图像,消除运动和衰减伪影。
- 在肝顶病灶方面,相对于没有运动校正的图像,本文方法的病灶与背景对比度显著提升。
点此查看论文截图


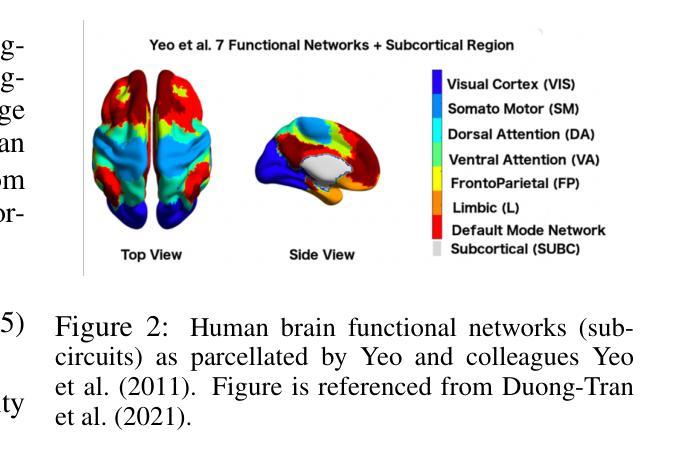
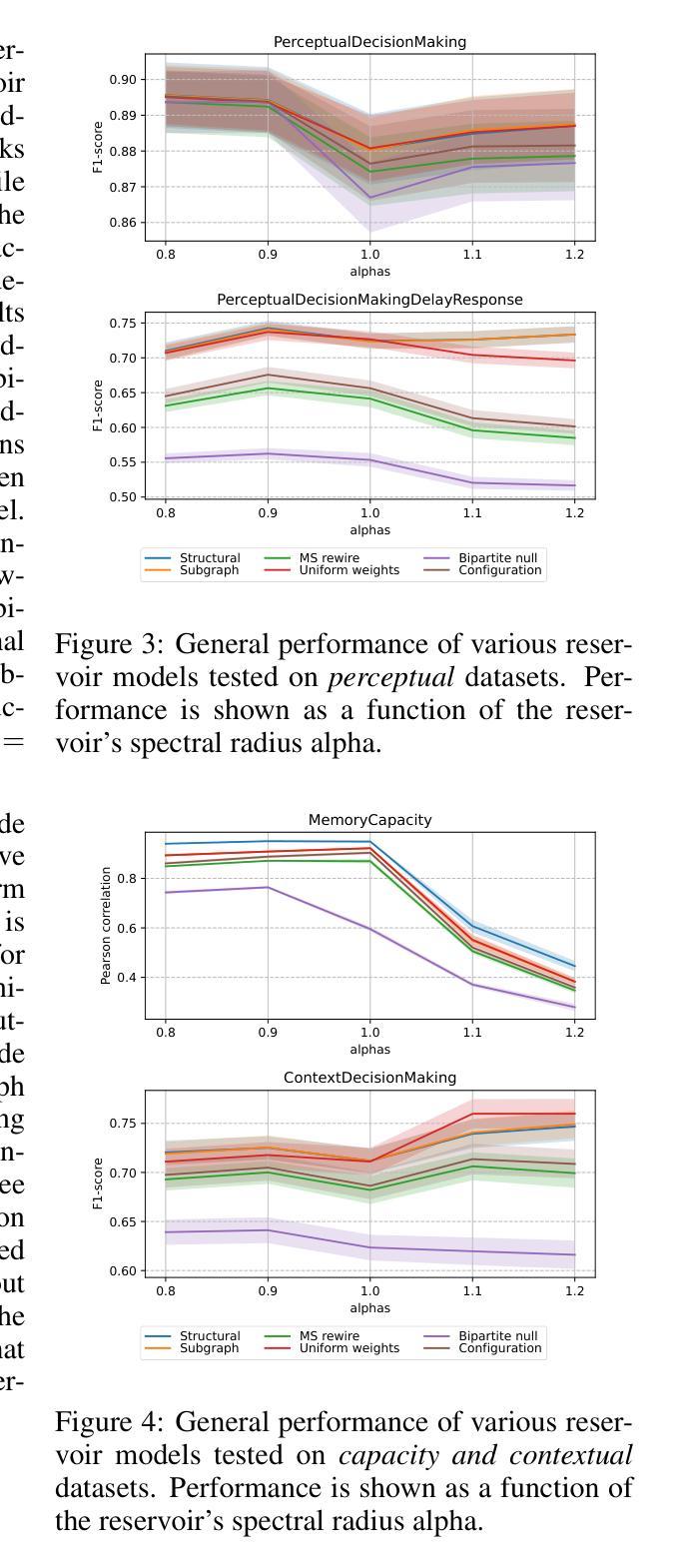
Accessing the topological properties of human brain functional sub-circuits in Echo State Networks
Authors:Bach Nguyen, Tianlong Chen, Shu Yang, Bojian Hou, Li Shen, Duy Duong-Tran
Recent years have witnessed an emerging trend in neuromorphic computing that centers around the use of brain connectomics as a blueprint for artificial neural networks. Connectomics-based neuromorphic computing has primarily focused on embedding human brain large-scale structural connectomes (SCs), as estimated from diffusion Magnetic Resonance Imaging (dMRI) modality, to echo-state networks (ESNs). A critical step in ESN embedding requires pre-determined read-in and read-out layers constructed by the induced subgraphs of the embedded reservoir. As \textit{a priori} set of functional sub-circuits are derived from functional MRI (fMRI) modality, it is unknown, till this point, whether the embedding of fMRI-induced sub-circuits/networks onto SCs is well justified from the neuro-physiological perspective and ESN performance across a variety of tasks. This paper proposes a pipeline to implement and evaluate ESNs with various embedded topologies and processing/memorization tasks. To this end, we showed that different performance optimums highly depend on the neuro-physiological characteristics of these pre-determined fMRI-induced sub-circuits. In general, fMRI-induced sub-circuit-embedded ESN outperforms simple bipartite and various null models with feed-forward properties commonly seen in MLP for different tasks and reservoir criticality conditions. We provided a thorough analysis of the topological properties of pre-determined fMRI-induced sub-circuits and highlighted their graph-theoretical properties that play significant roles in determining ESN performance.
近年来,神经形态计算领域出现了一个以脑连接组作为人工神经网络蓝图的新兴趋势。基于连接组的神经形态计算主要关注将大规模结构性脑连接组(SC)嵌入回声状态网络(ESN)。这些连接组是通过扩散磁共振成像(dMRI)技术估计得到的。在ESN嵌入过程中,一个关键步骤是构建预定义的输入和输出层,这些层由嵌入存储库的诱导子图构成。由于先验的功能性子电路集是从功能磁共振成像(fMRI)技术中得出的,到目前为止,尚不清楚从神经生理学角度将fMRI诱导的子电路/网络嵌入到SC是否合理,以及在不同任务中ESN的性能表现如何。本文提出了一个管道流程来实现和评估具有不同嵌入拓扑结构和处理/记忆任务的ESN。为此,我们展示了不同的性能最优值在很大程度上取决于这些预定义的fMRI诱导子电路的神经生理学特征。一般来说,基于fMRI诱导的子电路嵌入的ESN在多种任务和存储库临界条件下,其性能优于简单的前馈性质的MLP模型中的二分模型和各种空模型。我们对预定义的fMRI诱导子电路的拓扑特性进行了深入分析,并重点介绍了其在确定ESN性能中发挥重要作用的图论特性。
论文及项目相关链接
PDF 10 pages, 12 figures
摘要
近期,神经形态计算领域涌现出一种新兴趋势,即以脑连接组作为人工神经网络蓝图。基于连接组的神经形态计算主要关注将人类大脑的大规模结构连接组(SCs)嵌入回声状态网络(ESNs)。ESN嵌入的关键步骤需要预先确定的读写层,这些层由嵌入存储库的诱导子图构建而成。尽管从功能磁共振成像(fMRI)模态中衍生出先验的功能性子电路集,但尚不清楚从神经生理学的角度将fMRI诱导的子电路/网络嵌入SCs是否合理,以及在不同任务中ESN的性能表现如何。本文提出了一条管道,用于实现和评估具有各种嵌入拓扑结构和处理/记忆任务的ESNs。结果表明,不同的性能最优值高度依赖于这些预先确定的fMRI诱导子电路的神经生理学特征。一般来说,fMRI诱导的子电路嵌入的ESN优于在多层感知器中常见的具有前馈特性的简单二分图和各种空模型,并且在不同的任务和存储库临界条件下表现出卓越性能。本文彻底分析了预先确定的fMRI诱导子电路拓扑属性,并重点介绍了其在确定ESN性能中发挥重要作用的图论属性。
关键见解
- 神经形态计算领域正关注将脑连接组作为人工神经网络蓝图的方法。
- 基于连接组的神经形态计算重点在于将结构连接组(SCs)嵌入回声状态网络(ESNs)。
- ESN嵌入涉及预定义的读写层,这些层由嵌入存储库的诱导子图构成。
- 尚不清楚从神经生理学角度将功能磁共振成像(fMRI)诱导的子电路/网络嵌入SCs的合理性。
- fMRI诱导的子电路嵌入的ESN在不同任务和存储库临界条件下的性能优于简单模型和常见的前馈特性。
- fMRI诱导子电路的拓扑属性对确定ESN性能起着重要作用。
点此查看论文截图

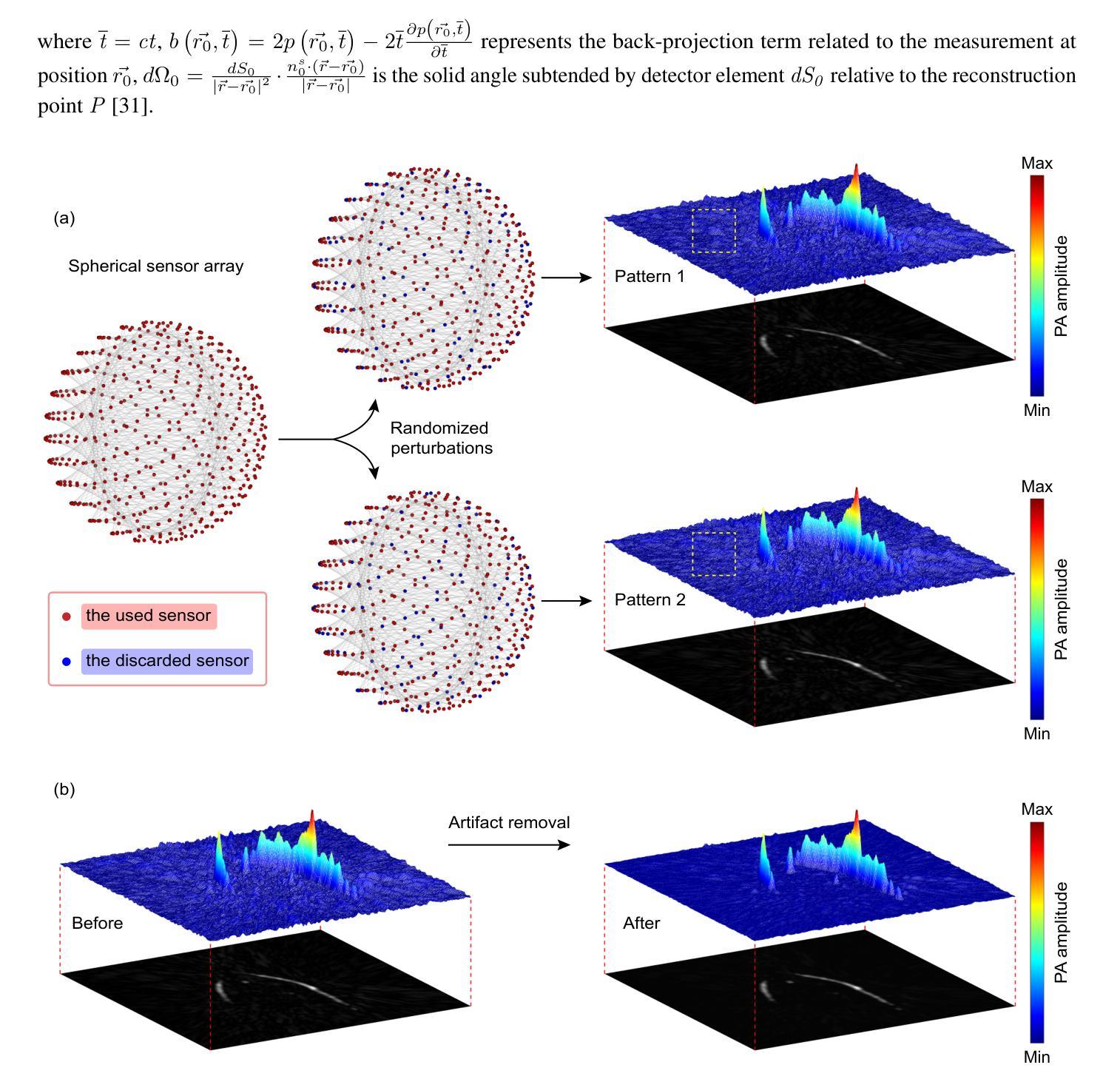
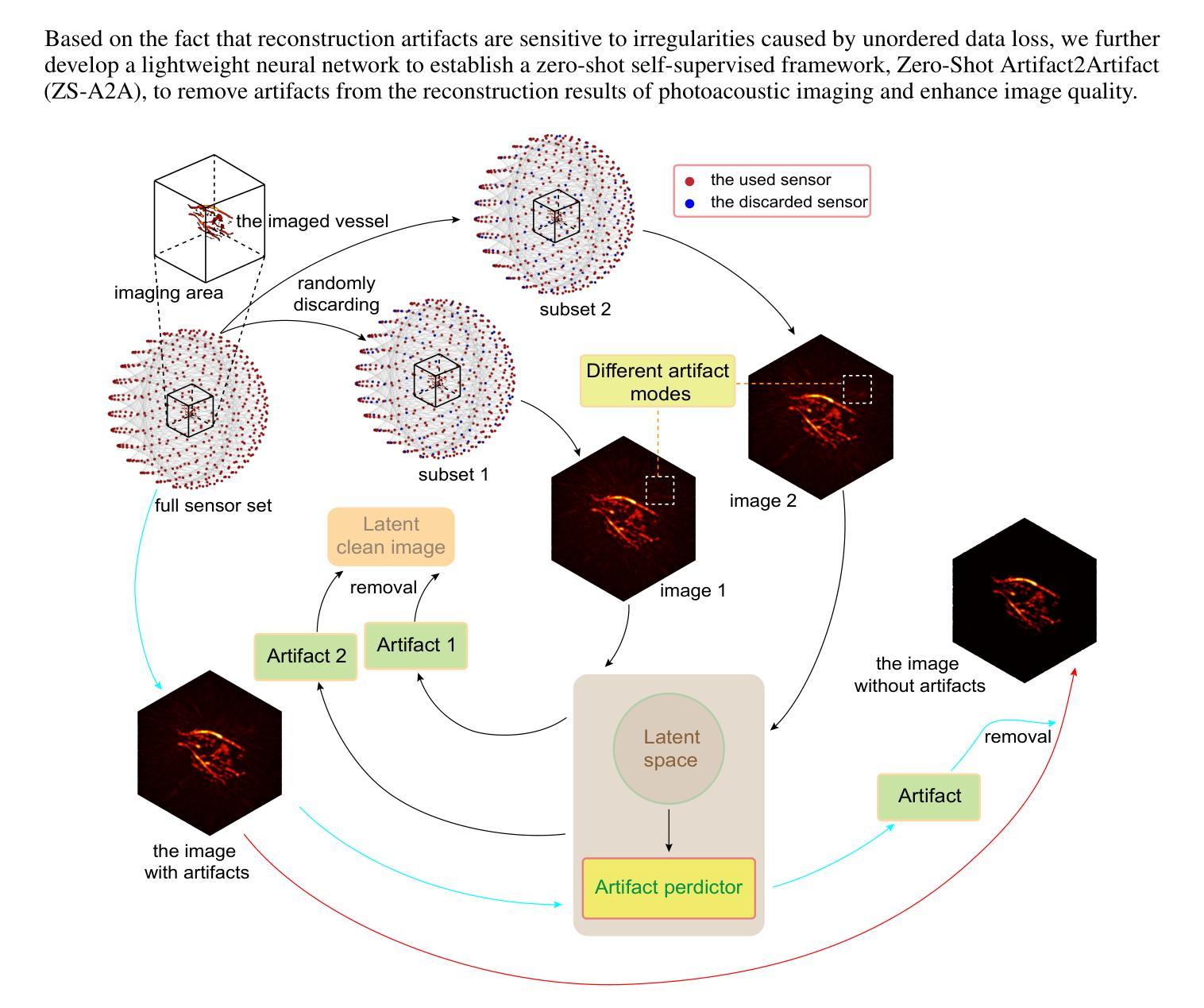
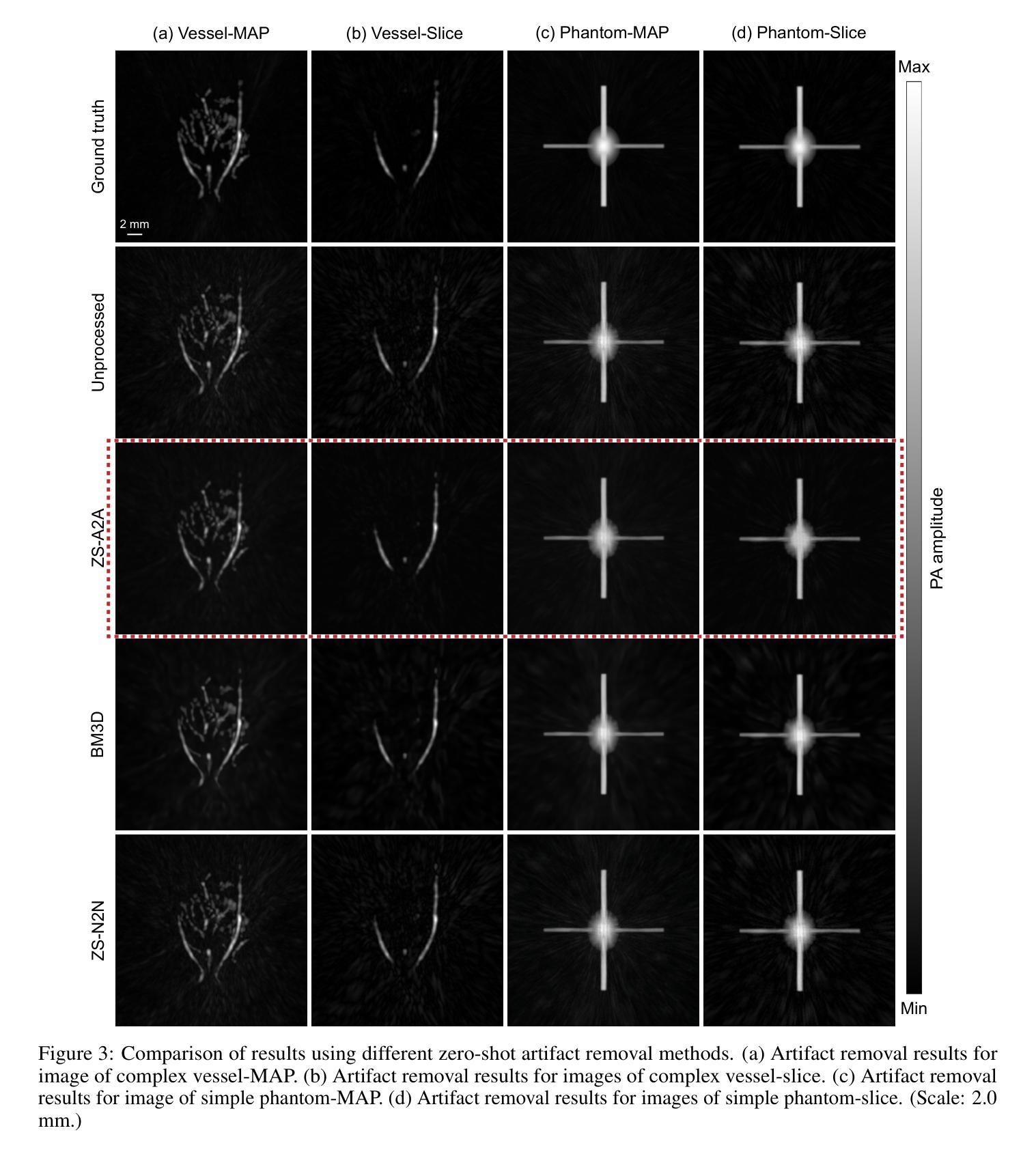
Zero-Shot Artifact2Artifact: Self-incentive artifact removal for photoacoustic imaging without any data
Authors:Shuang Li, Qian Chen, Chulhong Kim, Seongwook Choi, Yibing Wang, Yu Zhang, Changhui Li
Photoacoustic imaging (PAI) uniquely combines optical contrast with the penetration depth of ultrasound, making it critical for clinical applications. However, the quality of 3D PAI is often degraded due to reconstruction artifacts caused by the sparse and angle-limited configuration of detector arrays. Existing iterative or deep learning-based methods are either time-consuming or require large training datasets, significantly limiting their practical application. Here, we propose Zero-Shot Artifact2Artifact (ZS-A2A), a zero-shot self-supervised artifact removal method based on a super-lightweight network, which leverages the fact that reconstruction artifacts are sensitive to irregularities caused by data loss. By introducing random perturbations to the acquired PA data, it spontaneously generates subset data, which in turn stimulates the network to learn the artifact patterns in the reconstruction results, thus enabling zero-shot artifact removal. This approach requires neither training data nor prior knowledge of the artifacts, and is capable of artifact removal for 3D PAI. For maximum amplitude projection (MAP) images or slice images in 3D PAI acquired with arbitrarily sparse or angle-limited detector arrays, ZS-A2A employs a self-incentive strategy to complete artifact removal and improves the Contrast-to-Noise Ratio (CNR). We validated ZS-A2A in both simulation study and $ in\ vivo $ animal experiments. Results demonstrate that ZS-A2A achieves state-of-the-art (SOTA) performance compared to existing zero-shot methods, and for the $ in\ vivo $ rat liver, ZS-A2A improves CNR from 17.48 to 43.46 in just 8 seconds. The project for ZS-A2A will be available in the following GitHub repository: https://github.com/JaegerCQ/ZS-A2A.
光声成像(PAI)独特地结合了光学对比度和超声的穿透深度,使其成为临床应用的关键技术。然而,由于探测器阵列配置稀疏且角度受限导致的重建伪影,常常会导致三维光声成像(3D PAI)的质量下降。现有的迭代或基于深度学习的方法要么耗时过长,要么需要大量训练数据集,从而极大地限制了它们的实际应用。在这里,我们提出了Zero-Shot Artifact2Artifact(ZS-A2A),这是一种基于超轻量级网络的零样本自监督伪影去除方法,它利用重建伪影对由数据丢失引起的不规则性的敏感性。通过对获取的PA数据引入随机扰动,它自发地生成子集数据,从而刺激网络学习重建结果中的伪影模式,从而实现零样本伪影去除。这种方法既不需要训练数据,也不需要关于伪影的先验知识,并且能够对3D PAI进行伪影去除。对于使用任意稀疏或角度受限的探测器阵列获得的三维光声成像中的最大振幅投影(MAP)图像或切片图像,ZS-A2A采用自我激励策略来完成伪影去除,并提高了信噪比(CNR)。我们通过在模拟研究和体内动物实验验证了ZS-A2A。结果表明,与现有的零样本方法相比,ZS-A2A达到了最先进的性能,对于体内大鼠肝脏,ZS-A2A在8秒内将CNR从17.48提高到43.46。ZS-A2A项目将在以下GitHub仓库中提供:https://github.com/JaegerCQ/ZS-A2A。
论文及项目相关链接
Summary
本文介绍了一种基于零样本自监督学习的光声成像(PAI)重建伪影去除方法——Zero-Shot Artifact2Artifact(ZS-A2A)。该方法利用超轻量级网络,通过引入随机扰动刺激网络学习重建结果中的伪影模式,实现零样本伪影去除,无需训练数据和先验知识。实验验证显示,ZS-A2A在模拟和体内动物实验中均表现出卓越性能,与现有零样本方法相比达到领先水平,可在短时间内显著提高对比噪声比(CNR)。
Key Takeaways
- PAI结合了光学对比度和超声穿透深度,对于临床应用至关重要。
- 3D PAI的质量因重建伪影而降低,这些伪影由检测器阵列的稀疏和角度限制配置引起。
- 现有方法如迭代或深度学习方法耗时或需要大量训练数据,限制了实际应用。
- ZS-A2A是一种零样本自监督伪影去除方法,基于超轻量级网络,利用伪影对数据丢失引起的不规则性的敏感性。
- 通过引入随机扰动到获取的PA数据,ZS-A2A自发地生成子集数据,刺激网络学习重建结果中的伪影模式。
- ZS-A2A无需训练数据和先验知识,能够去除3D PAI的伪影。
- ZS-A2A在模拟和体内动物实验中表现出卓越性能,与现有方法相比具有更高的对比噪声比(CNR),并且处理速度快。
点此查看论文截图

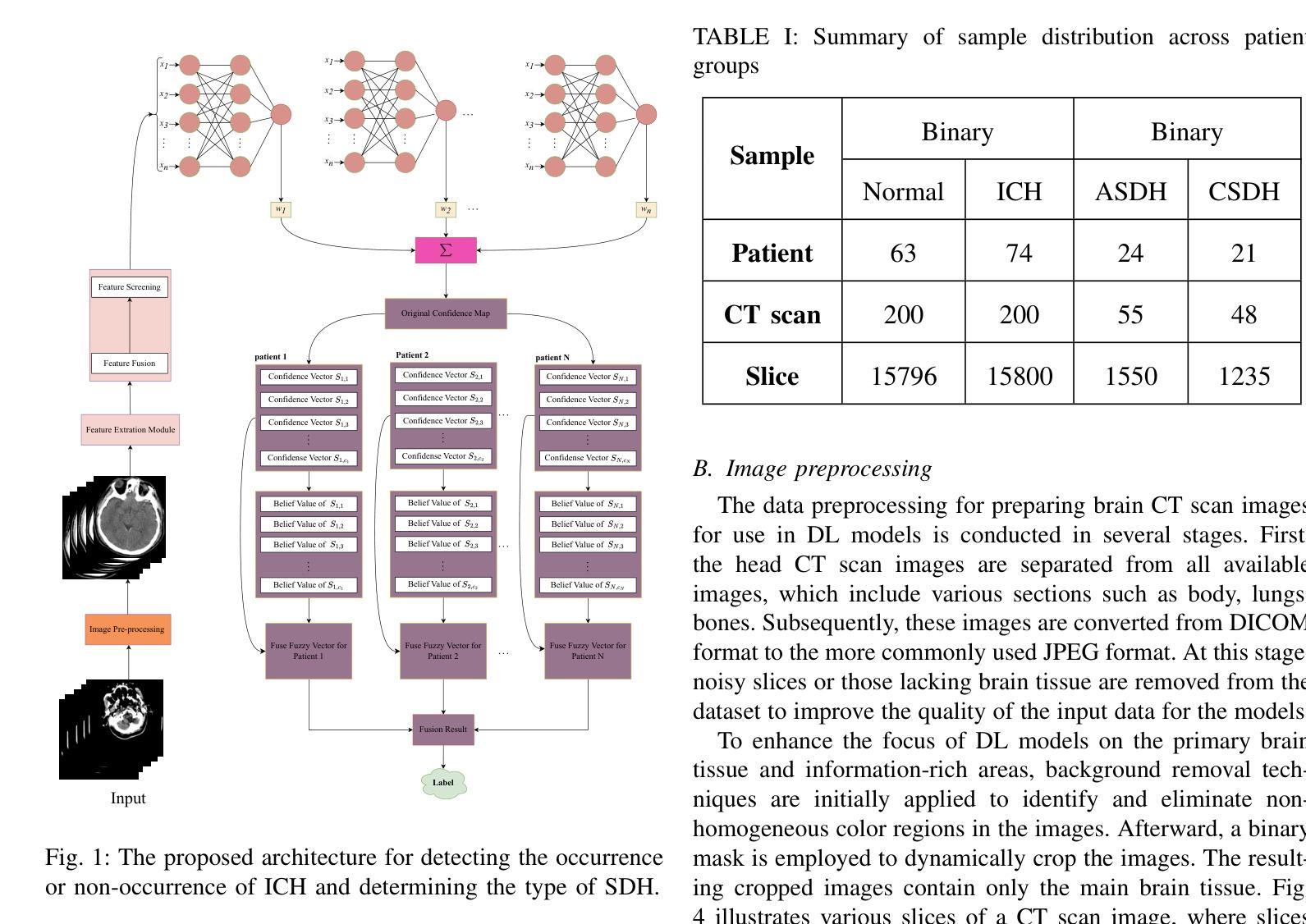
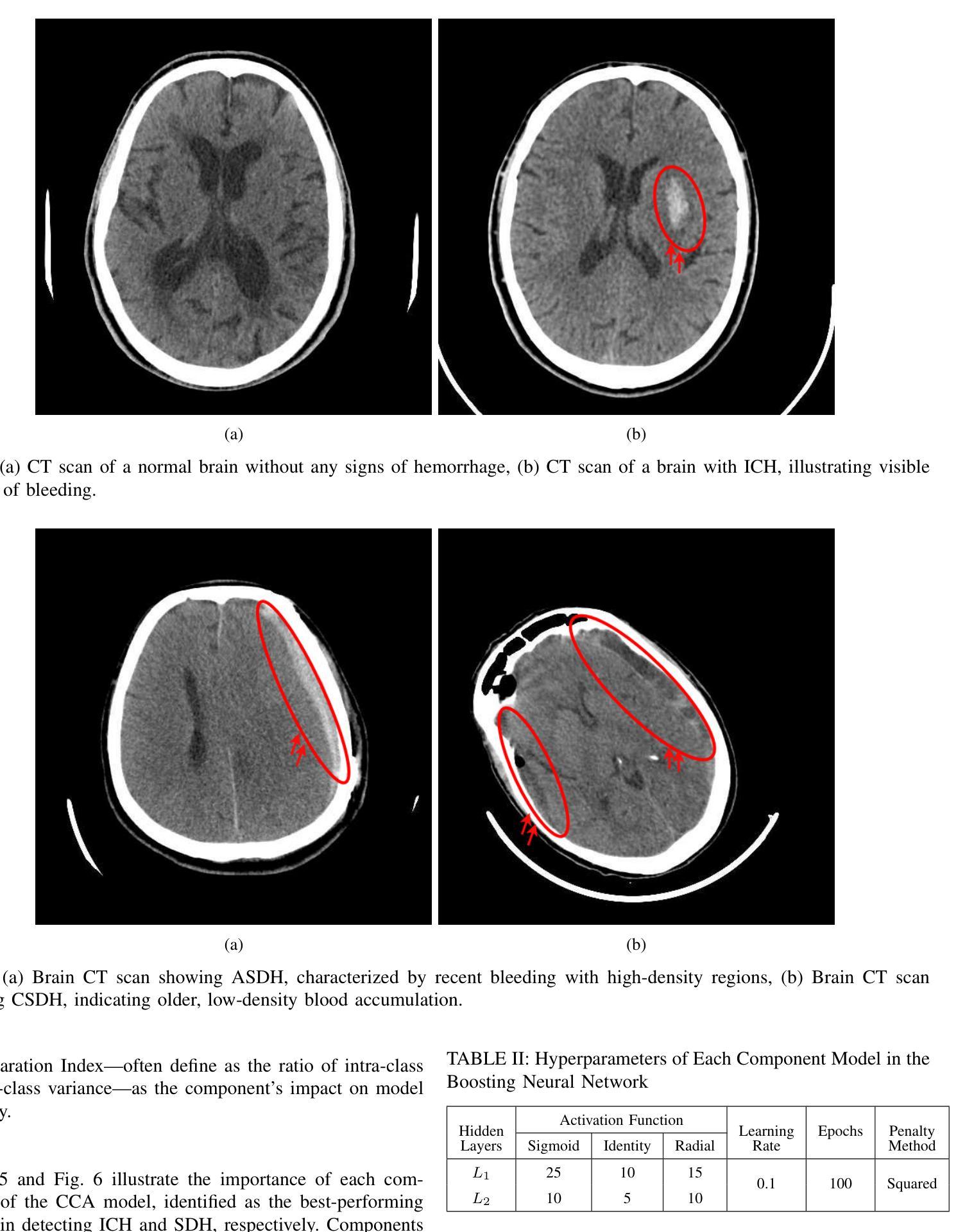
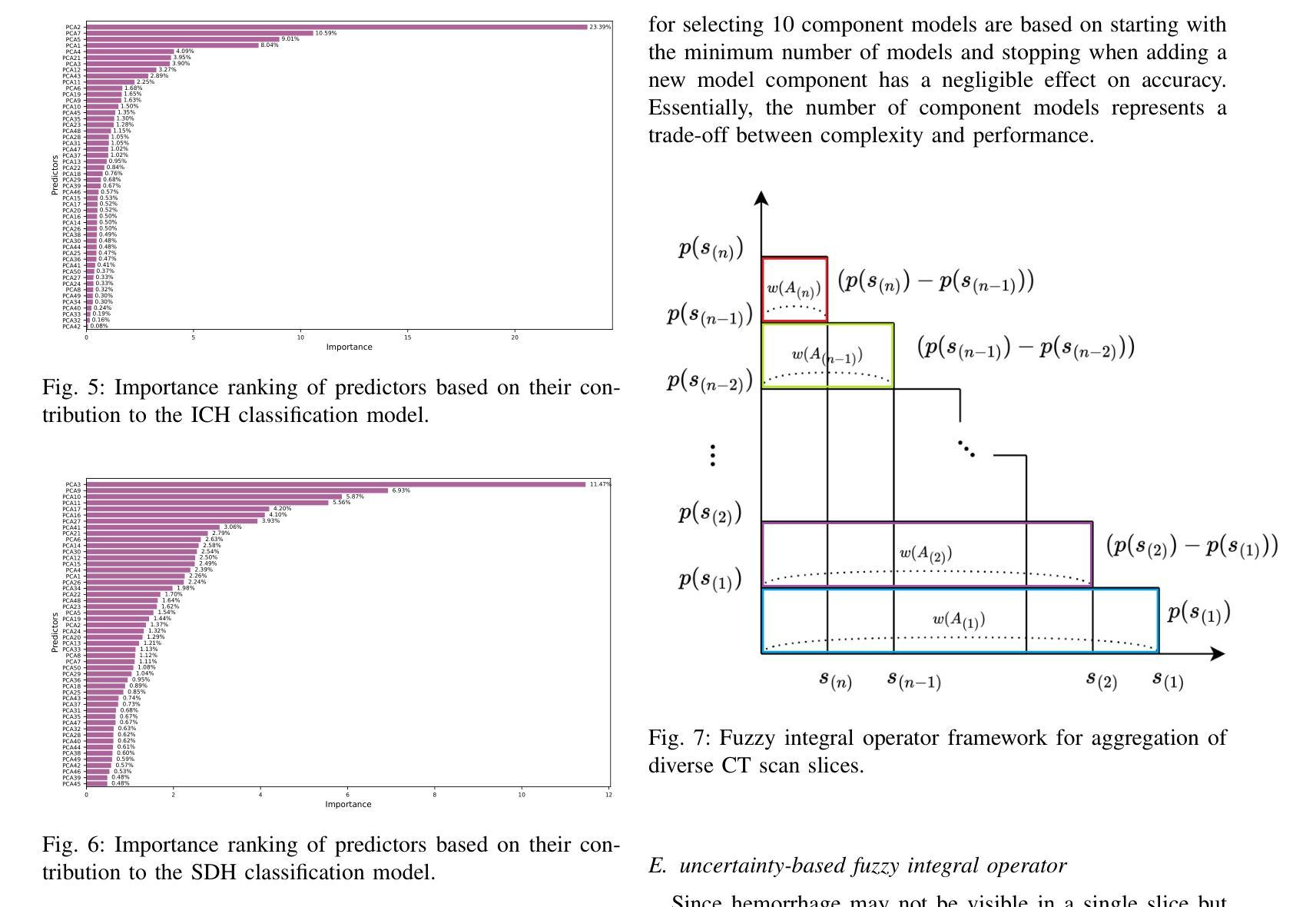
AI-Powered Intracranial Hemorrhage Detection: A Co-Scale Convolutional Attention Model with Uncertainty-Based Fuzzy Integral Operator and Feature Screening
Authors:Mehdi Hosseini Chagahi, Md. Jalil Piran, Niloufar Delfan, Behzad Moshiri, Jaber Hatam Parikhan
Intracranial hemorrhage (ICH) refers to the leakage or accumulation of blood within the skull, which occurs due to the rupture of blood vessels in or around the brain. If this condition is not diagnosed in a timely manner and appropriately treated, it can lead to serious complications such as decreased consciousness, permanent neurological disabilities, or even death.The primary aim of this study is to detect the occurrence or non-occurrence of ICH, followed by determining the type of subdural hemorrhage (SDH). These tasks are framed as two separate binary classification problems. By adding two layers to the co-scale convolutional attention (CCA) classifier architecture, we introduce a novel approach for ICH detection. In the first layer, after extracting features from different slices of computed tomography (CT) scan images, we combine these features and select the 50 components that capture the highest variance in the data, considering them as informative features. We then assess the discriminative power of these features using the bootstrap forest algorithm, discarding those that lack sufficient discriminative ability between different classes. This algorithm explicitly determines the contribution of each feature to the final prediction, assisting us in developing an explainable AI model. The features feed into a boosting neural network as a latent feature space. In the second layer, we introduce a novel uncertainty-based fuzzy integral operator to fuse information from different CT scan slices. This operator, by accounting for the dependencies between consecutive slices, significantly improves detection accuracy.
颅内出血(ICH)是指血液在颅骨内泄漏或积聚,这是由于大脑内或周围的血管破裂所导致的。如果这种情况未能及时诊断并适当治疗,可能会导致意识减退、永久性神经功能障碍甚至死亡等严重并发症。本研究的主要目的是检测颅内出血是否发生,并确定蛛网膜下腔出血(SDH)的类型。这两项任务被划分为两个单独的二分类问题。通过对共尺度卷积注意力(CCA)分类器架构增加两层,我们提出了一种新的ICH检测方法。在第一层,从不同层面的计算机断层扫描(CT)图像中提取特征后,我们结合这些特征并选择50个组件,这些组件捕获数据中的最高方差,被视为具有信息量的特征。然后,我们使用自助森林算法评估这些特征的判别力,并丢弃那些在区分不同类别时缺乏足够判别力的特征。该算法能明确确定每个特征对最终预测的贡献,有助于我们开发可解释的AI模型。这些特征被输入到一个增强神经网络中作为潜在特征空间。在第二层,我们引入了一种基于不确定性的模糊积分算子来融合不同CT扫描层面的信息。该算子通过考虑相邻层面之间的依赖性,显著提高了检测准确性。
论文及项目相关链接
Summary
该摘要简洁介绍了一项关于颅内出血检测与诊断研究。研究中提出使用两层卷积神经网络架构进行颅内出血(ICH)检测与硬膜下出血(SDH)类型判断。第一层通过提取CT扫描图像的不同切片特征,筛选出最具信息量的特征成分;第二层采用基于不确定性的模糊积分算子融合不同CT扫描切片的信息,以提高检测准确性。整个模型注重解释性,能明确各特征对预测结果的贡献。
Key Takeaways
以下是文中七个关键要点,以简化形式呈现:
- 颅内出血(ICH)是血液在颅内的泄漏或积聚,若不及时诊断和适当治疗,可能导致严重并发症,甚至死亡。
- 此研究的主要目标是检测颅内出血的发生与否,并确定硬膜下出血的类型。
- 采用两层卷积神经网络架构,引入新型方法用于ICH检测。
- 第一层中,从CT扫描图像的不同切片提取特征,选择最具信息量的50个特征组件,并利用bootstrap森林算法评估其判别力。
- 引入解释性AI模型,明确各特征对预测结果的贡献。
- 特征输入到增强神经网络中作为潜在特征空间。
点此查看论文截图

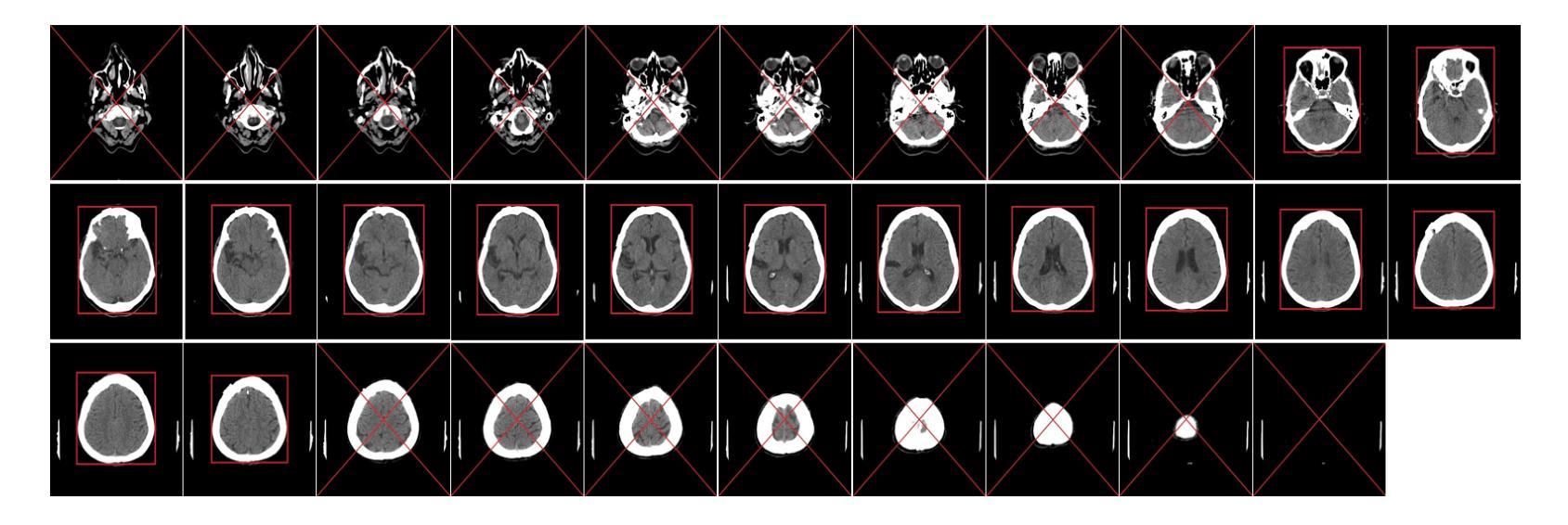
Head and Neck Tumor Segmentation of MRI from Pre- and Mid-radiotherapy with Pre-training, Data Augmentation and Dual Flow UNet
Authors:Litingyu Wang, Wenjun Liao, Shichuan Zhang, Guotai Wang
Head and neck tumors and metastatic lymph nodes are crucial for treatment planning and prognostic analysis. Accurate segmentation and quantitative analysis of these structures require pixel-level annotation, making automated segmentation techniques essential for the diagnosis and treatment of head and neck cancer. In this study, we investigated the effects of multiple strategies on the segmentation of pre-radiotherapy (pre-RT) and mid-radiotherapy (mid-RT) images. For the segmentation of pre-RT images, we utilized: 1) a fully supervised learning approach, and 2) the same approach enhanced with pre-trained weights and the MixUp data augmentation technique. For mid-RT images, we introduced a novel computational-friendly network architecture that features separate encoders for mid-RT images and registered pre-RT images with their labels. The mid-RT encoder branch integrates information from pre-RT images and labels progressively during the forward propagation. We selected the highest-performing model from each fold and used their predictions to create an ensemble average for inference. In the final test, our models achieved a segmentation performance of 82.38% for pre-RT and 72.53% for mid-RT on aggregated Dice Similarity Coefficient (DSC) as HiLab. Our code is available at https://github.com/WltyBY/HNTS-MRG2024_train_code.
头颈部肿瘤和转移性淋巴结对于治疗方案的制定和预后分析至关重要。这些结构的精确分割和定量分析需要像素级别的标注,因此自动分割技术对于头颈部癌症的诊断和治疗至关重要。本研究中,我们研究了多种策略对放疗前(pre-RT)和放疗中(mid-RT)图像分割的影响。对于放疗前图像的分割,我们采用了1)全监督学习方法;2)使用预训练权重和MixUp数据增强技术增强同一方法。对于放疗中图像,我们引入了一种计算友好的新型网络架构,该架构具有针对放疗中图像和注册放疗前图像的单独编码器,并带有其标签。放疗中编码器分支在正向传播过程中逐步整合放疗前图像和标签的信息。我们从每份数据中选出表现最佳的模型,使用其预测结果创建集成平均值来进行推断。在最终测试中,我们的模型在HiLab的聚合Dice相似系数(DSC)上达到了放疗前分割性能为82.38%,放疗中分割性能为72.53%。我们的代码可在https://github.com/WltyBY/HNTS-MRG2024_train_code处获取。
论文及项目相关链接
Summary
本研究探讨了多种策略在放射治疗前后图像分割中的效果,采用深度学习方法,对头部和颈部肿瘤以及转移性淋巴结进行准确分割和定量分析。通过融合预训练权重和MixUp数据增强技术,提高模型性能,并在测试中获得较好的分割效果。
Key Takeaways
- 头颈部肿瘤和转移性淋巴结的治疗规划和预后分析至关重要,需要准确的分割和定量分析。
- 自动化分割技术对于头颈部癌症的诊断和治疗至关重要。
- 研究中使用了多种策略进行放射治疗前后图像的分割。
- 对于放射治疗前的图像分割,采用了全监督学习方法和融合预训练权重及MixUp数据增强技术的增强方法。
- 对于放射治疗中的图像分割,引入了一种计算友好的网络架构,该架构具有针对中期放射治疗图像和已注册的前期放射治疗图像的单独编码器。
- 中期放射治疗编码器分支在正向传播过程中逐步整合前期图像和标签的信息。
点此查看论文截图

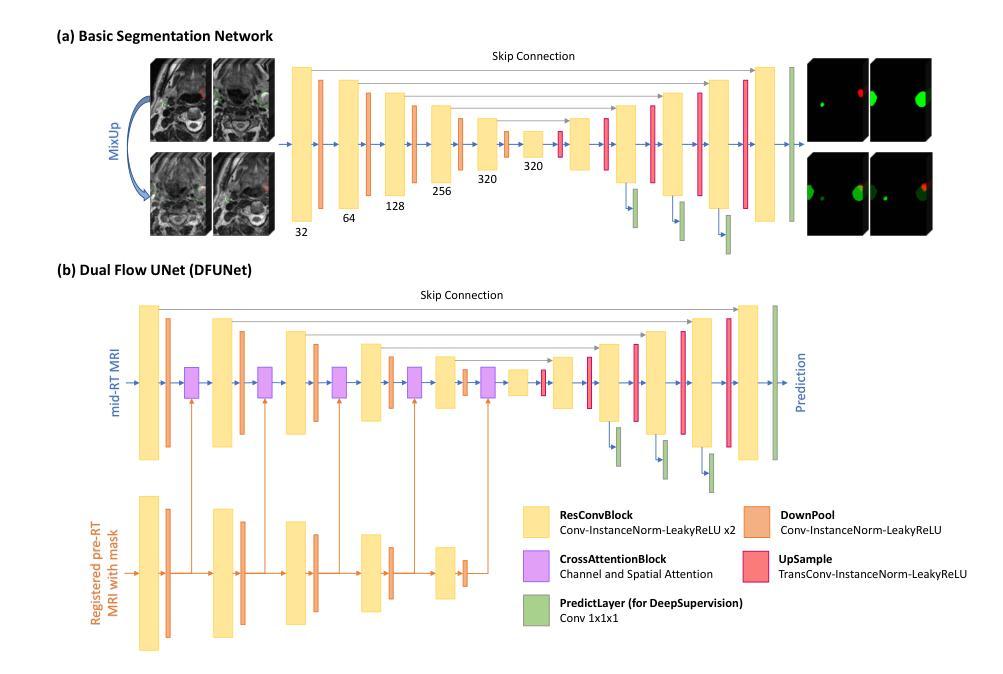
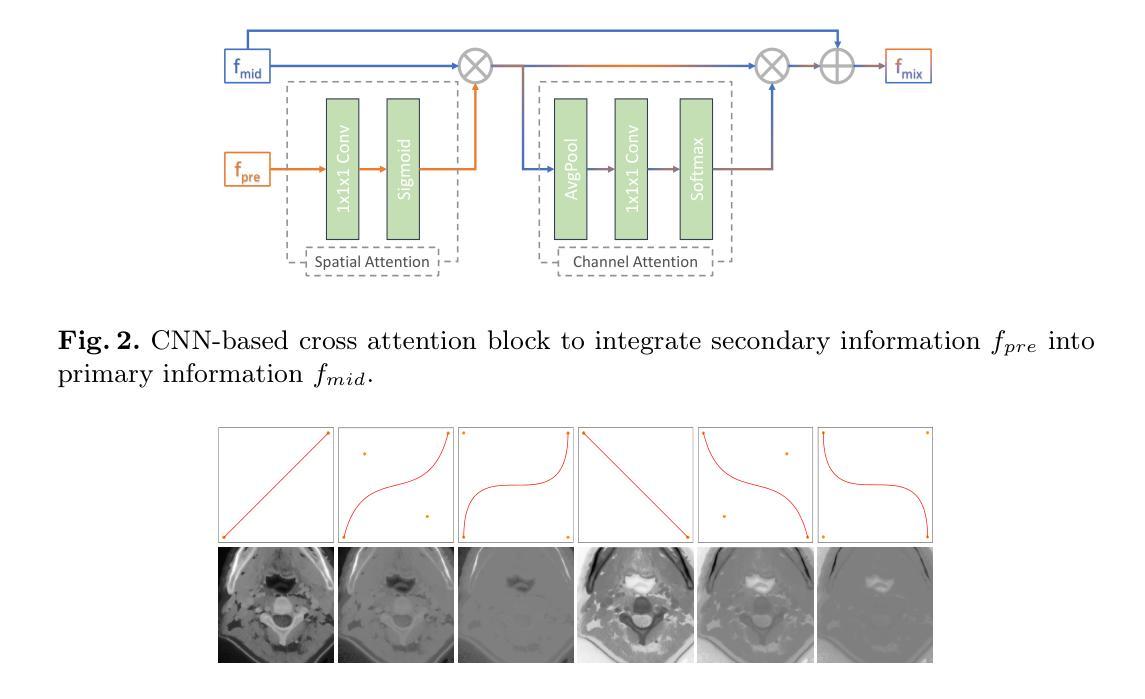
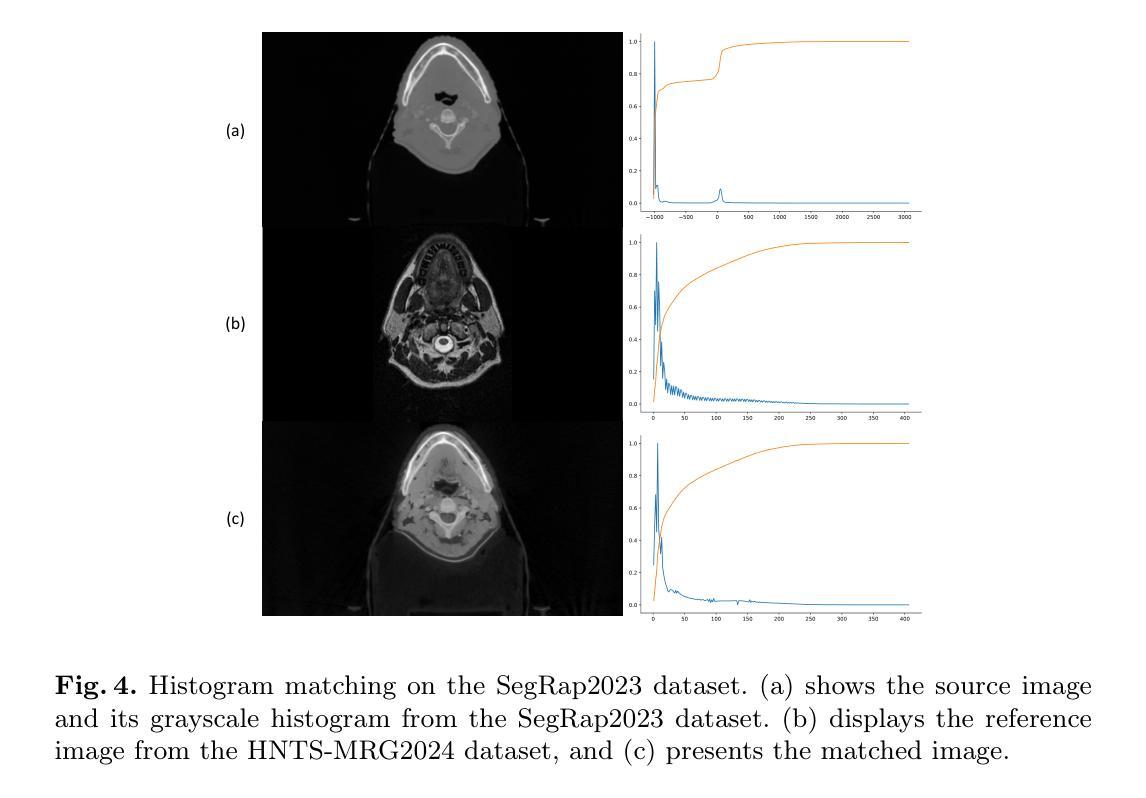
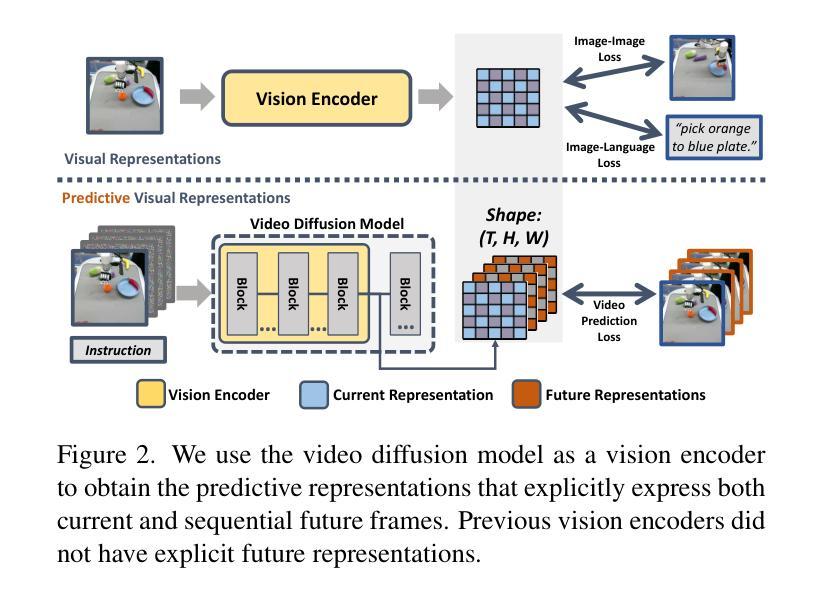
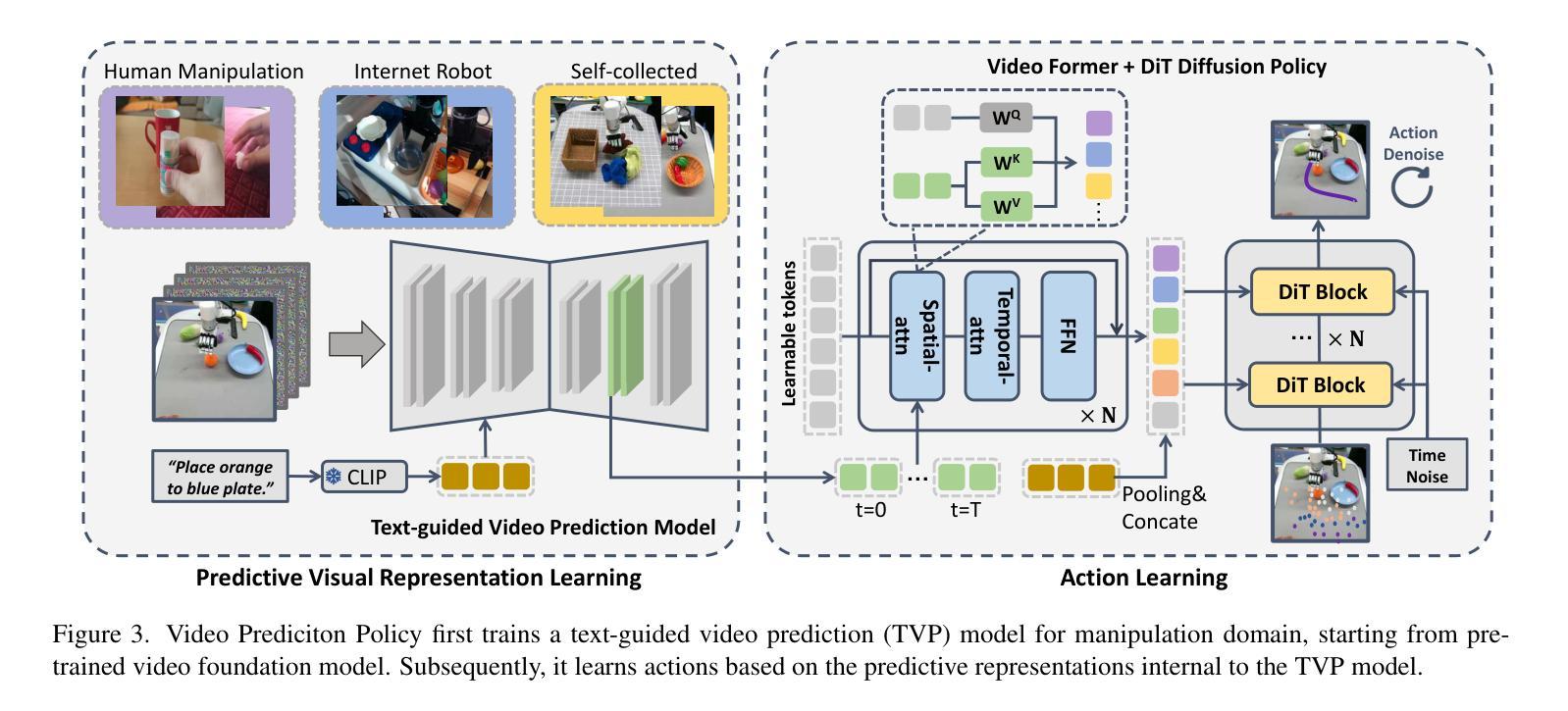
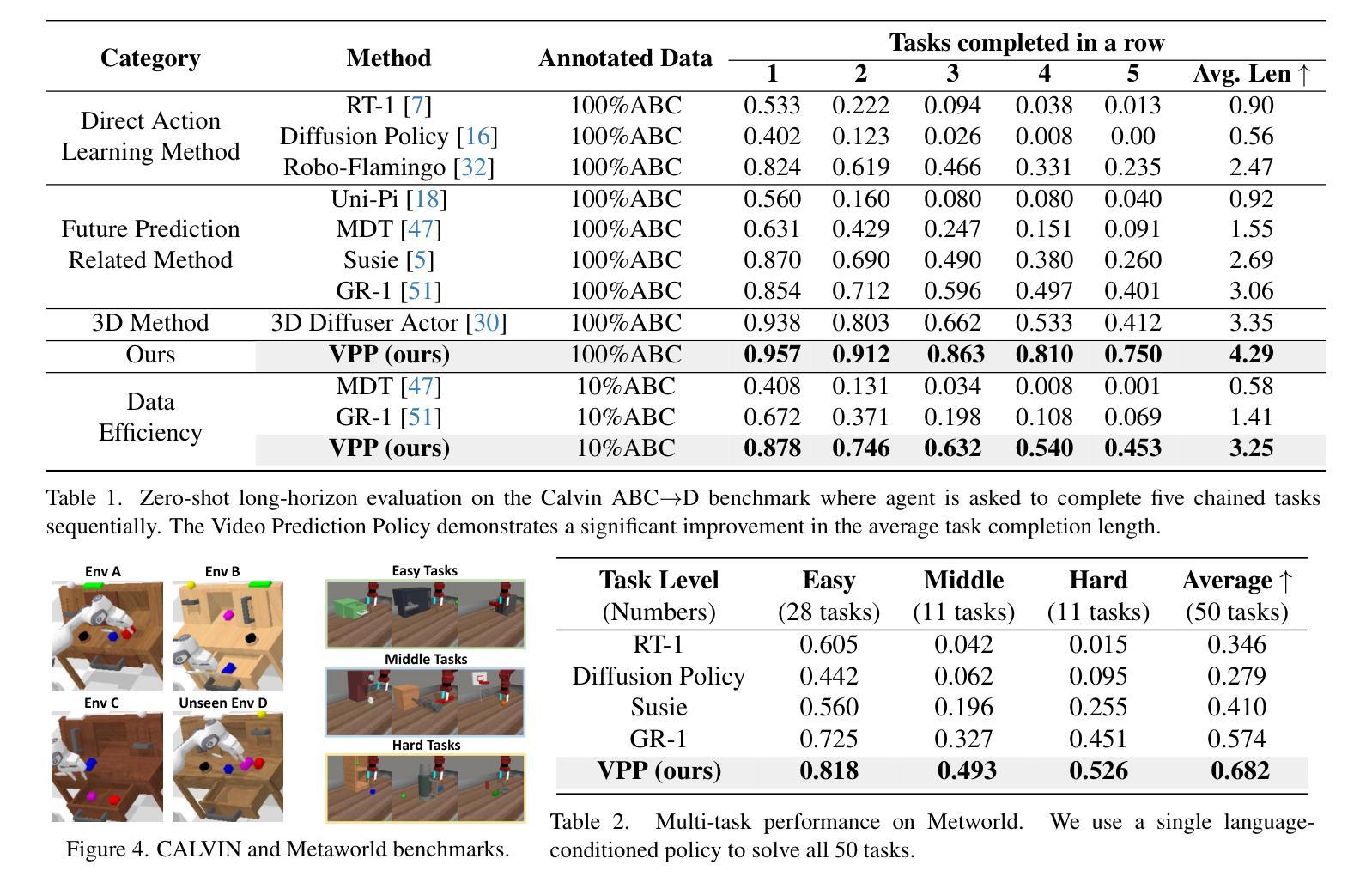
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Authors:Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, Jianyu Chen
Recent advancements in robotics have focused on developing generalist policies capable of performing multiple tasks. Typically, these policies utilize pre-trained vision encoders to capture crucial information from current observations. However, previous vision encoders, which trained on two-image contrastive learning or single-image reconstruction, can not perfectly capture the sequential information essential for embodied tasks. Recently, video diffusion models (VDMs) have demonstrated the capability to accurately predict future image sequences, exhibiting a good understanding of physical dynamics. Motivated by the strong visual prediction capabilities of VDMs, we hypothesize that they inherently possess visual representations that reflect the evolution of the physical world, which we term predictive visual representations. Building on this hypothesis, we propose the Video Prediction Policy (VPP), a generalist robotic policy conditioned on the predictive visual representations from VDMs. To further enhance these representations, we incorporate diverse human or robotic manipulation datasets, employing unified video-generation training objectives. VPP consistently outperforms existing methods across two simulated and two real-world benchmarks. Notably, it achieves a 28.1% relative improvement in the Calvin ABC-D benchmark compared to the previous state-of-the-art and delivers a 28.8% increase in success rates for complex real-world dexterous manipulation tasks.
近期机器人技术的进步主要集中在开发能够执行多种任务的一般性策略上。通常,这些策略利用预训练的视觉编码器来捕获当前观察中的关键信息。然而,以前训练的视觉编码器主要依赖于对比学习或单图像重建,无法完全捕获对于实体任务至关重要的序列信息。最近,视频扩散模型(VDMs)已显示出准确预测未来图像序列的能力,展现出对物理动态的良好理解。受VDM强大视觉预测能力的启发,我们假设它们天生就具有反映物理世界演变的视觉表征,我们称之为预测性视觉表征。基于这一假设,我们提出视频预测策略(VPP),这是一种以VDMs的预测性视觉表征为条件的一般性机器人策略。为了进一步增强这些表征,我们融入了多样化的人类或机器人操作数据集,采用统一的视频生成训练目标。VPP在两个模拟和两个真实世界的基准测试中均表现超越现有方法。尤其值得一提的是,与之前的最新技术相比,它在Calvin ABC-D基准测试中实现了28.1%的相对改进,并且在复杂的真实世界灵巧操作任务中成功率提高了28.8%。
论文及项目相关链接
PDF The first two authors contribute equally. Project Page at https://video-prediction-policy.github.io/
Summary
近期机器人技术的进步促使了通用策略的发展,这些策略可以执行多种任务。利用预训练的视觉编码器捕捉当前观察信息是关键。然而,过去以两图像对比学习或单图像重建方式训练的视觉编码器无法完全捕获躯体任务所需的序列信息。视频扩散模型(VDMs)能准确预测未来图像序列,展现出对物理动态的良好理解。基于VDMs的强大视觉预测能力,我们假设其具备反映物理世界演变的内在视觉表征,称为预测性视觉表征。我们提出基于预测性视觉表征的视频预测策略(VPP),这是一种通用机器人策略。为进一步优化这些表征,我们纳入多样的人类或机器人操作数据集,采用统一的视频生成训练目标。VPP在模拟和真实世界的基准测试中均表现优异,相对于前序最佳方案,在Calvin ABC-D基准测试中实现了28.1%的相对改进,并在复杂的真实世界灵巧操作任务中成功率提高了28.8%。
Key Takeaways
- 近期机器人技术关注开发能执行多种任务的通用策略。
- 传统的视觉编码器难以捕获重要序列信息,对于躯体任务至关重要。
- 视频扩散模型(VDMs)能预测未来图像序列,反映物理动态的理解。
- VDMs的预测性视觉表征对于机器人任务至关重要。
- 提出基于预测性视觉表征的视频预测策略(VPP)。
- VPP在模拟和真实世界测试中表现优异,相对改进显著。
点此查看论文截图

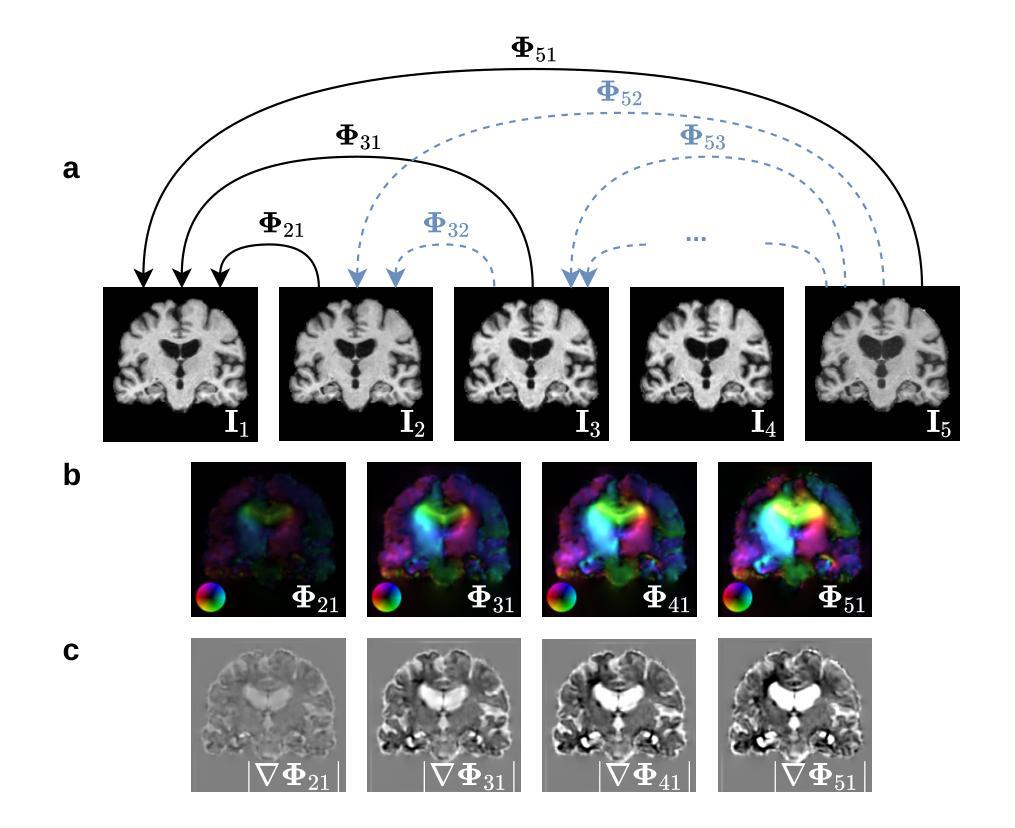
MUSTER: Longitudinal Deformable Registration by Composition of Consecutive Deformations
Authors:Edvard O. S. Grødem, Donatas Sederevičius, Esten H. Leonardsen, Bradley J. MacIntosh, Atle Bjørnerud, Till Schellhorn, Øystein Sørensen, Inge Amlien, Pablo F. Garrido, Anders M. Fjell
Longitudinal imaging allows for the study of structural changes over time. One approach to detecting such changes is by non-linear image registration. This study introduces Multi-Session Temporal Registration (MUSTER), a novel method that facilitates longitudinal analysis of changes in extended series of medical images. MUSTER improves upon conventional pairwise registration by incorporating more than two imaging sessions to recover longitudinal deformations. Longitudinal analysis at a voxel-level is challenging due to effects of a changing image contrast as well as instrumental and environmental sources of bias between sessions. We show that local normalized cross-correlation as an image similarity metric leads to biased results and propose a robust alternative. We test the performance of MUSTER on a synthetic multi-site, multi-session neuroimaging dataset and show that, in various scenarios, using MUSTER significantly enhances the estimated deformations relative to pairwise registration. Additionally, we apply MUSTER on a sample of older adults from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) study. The results show that MUSTER can effectively identify patterns of neuro-degeneration from T1-weighted images and that these changes correlate with changes in cognition, matching the performance of state of the art segmentation methods. By leveraging GPU acceleration, MUSTER efficiently handles large datasets, making it feasible also in situations with limited computational resources.
纵向成像允许研究随时间发生的结构变化。检测这种变化的一种方法是图像非线性配准。本研究介绍了多会话时序配准(MUSTER),这是一种新方法,可以促进对一系列医学图像变化的纵向分析。与传统的配对配准相比,MUSTER通过结合多个成像会话来恢复纵向变形,从而改进了传统配对配准的局限性。由于图像对比度变化的影响以及不同会话之间仪器和环境来源的偏见,在体素水平上进行纵向分析是一个挑战。我们证明了局部归一化互相关作为图像相似度度量会导致有偏结果,并提出了稳健的替代方案。我们在合成多站点、多会话的神经成像数据集上测试了MUSTER的性能,并显示在各种情况下,与使用配对配准相比,使用MUSTER可以大大增强估计的变形。此外,我们还将在阿尔茨海默病神经影像学倡议(ADNI)研究中的老年受试者样本应用于MUSTER。结果表明,MUSTER可以有效地从T1加权图像中识别神经退变的模式,这些变化与认知变化相关,符合最先进的分割方法的性能。通过利用GPU加速,MUSTER能够高效处理大数据集,即使在计算资源有限的情况下也完全可行。
论文及项目相关链接
Summary
本研究提出一种名为MUSTER的多会话时序注册方法,可实现对医学图像序列的纵向分析。相较于传统的配对注册方法,MUSTER通过纳入超过两个成像会话的数据来恢复纵向变形,提高了性能。研究指出局部归一化交叉相关作为图像相似度量可能导致偏差,并提出一种稳健的替代方案。在合成多站点、多会话的神经成像数据集上进行的测试表明,在各种场景下,相较于配对注册,使用MUSTER可显著提高估计变形的效果。此外,对ADNI研究中老年人群样本的应用表明,MUSTER可从T1加权图像有效地识别神经退化模式,且与认知变化相关联,达到最新分割方法的性能水平。借助GPU加速,MUSTER可高效处理大数据集,甚至在计算资源有限的情况下也能实现应用。
Key Takeaways
- MUSTER是一种多会话时序注册方法,用于医学图像序列的纵向分析。
- 它通过纳入超过两个成像会话的数据来提高恢复纵向变形的性能。
- 局部归一化交叉相关作为图像相似度量可能导致偏差,研究提出了一种稳健的替代方案。
- 在合成数据集上的测试表明,MUSTER在估计变形方面优于传统的配对注册方法。
- 在ADNI研究的应用中,MUSTER可有效地从T1加权图像识别神经退化模式,并与认知变化相关联。
- MUSTER借助GPU加速可高效处理大数据集。
点此查看论文截图

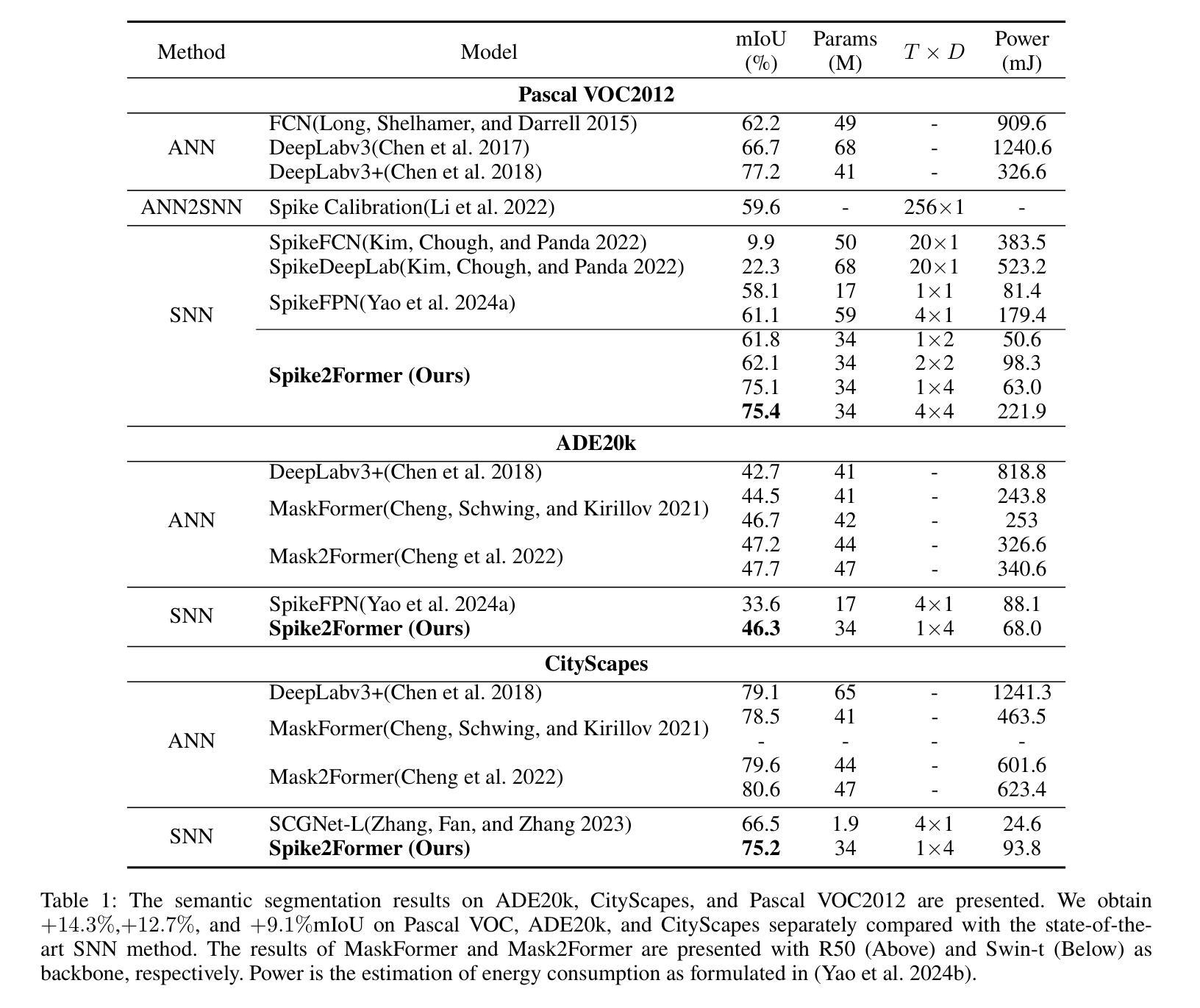
Spike2Former: Efficient Spiking Transformer for High-performance Image Segmentation
Authors:Zhenxin Lei, Man Yao, Jiakui Hu, Xinhao Luo, Yanye Lu, Bo Xu, Guoqi Li
Spiking Neural Networks (SNNs) have a low-power advantage but perform poorly in image segmentation tasks. The reason is that directly converting neural networks with complex architectural designs for segmentation tasks into spiking versions leads to performance degradation and non-convergence. To address this challenge, we first identify the modules in the architecture design that lead to the severe reduction in spike firing, make targeted improvements, and propose Spike2Former architecture. Second, we propose normalized integer spiking neurons to solve the training stability problem of SNNs with complex architectures. We set a new state-of-the-art for SNNs in various semantic segmentation datasets, with a significant improvement of +12.7% mIoU and 5.0 efficiency on ADE20K, +14.3% mIoU and 5.2 efficiency on VOC2012, and +9.1% mIoU and 6.6 efficiency on CityScapes.
脉冲神经网络(SNNs)具有低功耗优势,但在图像分割任务中的表现不佳。原因是直接将为分割任务设计的复杂架构神经网络直接转换为脉冲版本会导致性能下降和非收敛。为了应对这一挑战,我们首先确定导致脉冲点火严重减少的架构设计模块,进行有针对性的改进,并提出Spike2Former架构。其次,为了解决复杂架构下SNNs的训练稳定性问题,我们提出了归一化整数脉冲神经元。我们在各种语义分割数据集上为SNNs设置了一个新的最先进的标准,在ADE20K上实现了+12.7%的mIoU和5.0的效率提升,在VOC2012上实现了+14.3%的mIoU和5.2的效率提升,以及在CityScapes上实现了+9.1%的mIoU和6.6的效率提升。
论文及项目相关链接
PDF This work has been accepted on Association for the Advancement of Artificial Intelligence 2025
Summary
脉冲神经网络(SNNs)具有低功耗优势,但在图像分割任务中表现不佳。原因是直接将复杂架构设计的分割任务神经网络转换为脉冲版本会导致性能下降和非收敛。为解决此挑战,我们提出Spike2Former架构,并引入归一化整数脉冲神经元以解决复杂架构下SNNs的训练稳定性问题。在多个语义分割数据集上,我们为SNNs设立了新的业界标准,其中ADE20K上的mIoU提升了+12.7%且效率提高5.0%,VOC2012上的mIoU提升了+14.3%且效率提高5.2%,CityScapes上的mIoU提升了+9.1%且效率提高6.6。
Key Takeaways
1. 脉冲神经网络(SNNs)在图像分割任务中表现不佳,直接转换复杂设计的神经网络会导致性能下降和非收敛。
2. 提出Spike2Former架构,针对导致性能下降的关键模块进行改进。
3. 引入归一化整数脉冲神经元,解决复杂架构下SNNs的训练稳定性问题。
4. 在多个语义分割数据集上,SNNs的性能达到新的业界标准。
5. 在ADE20K数据集上,mIoU提升+12.7%且效率提高5.0%。
6. 在VOC2012数据集上,mIoU提升+14.3%且效率提高5.2%。
点此查看论文截图


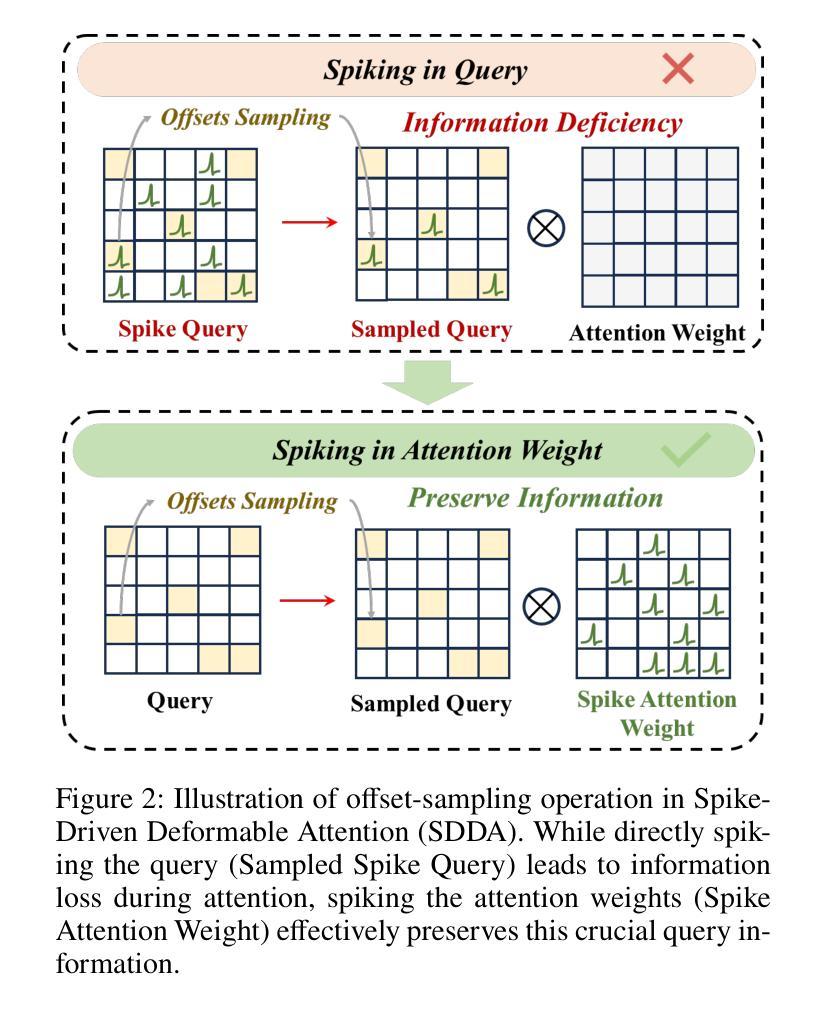
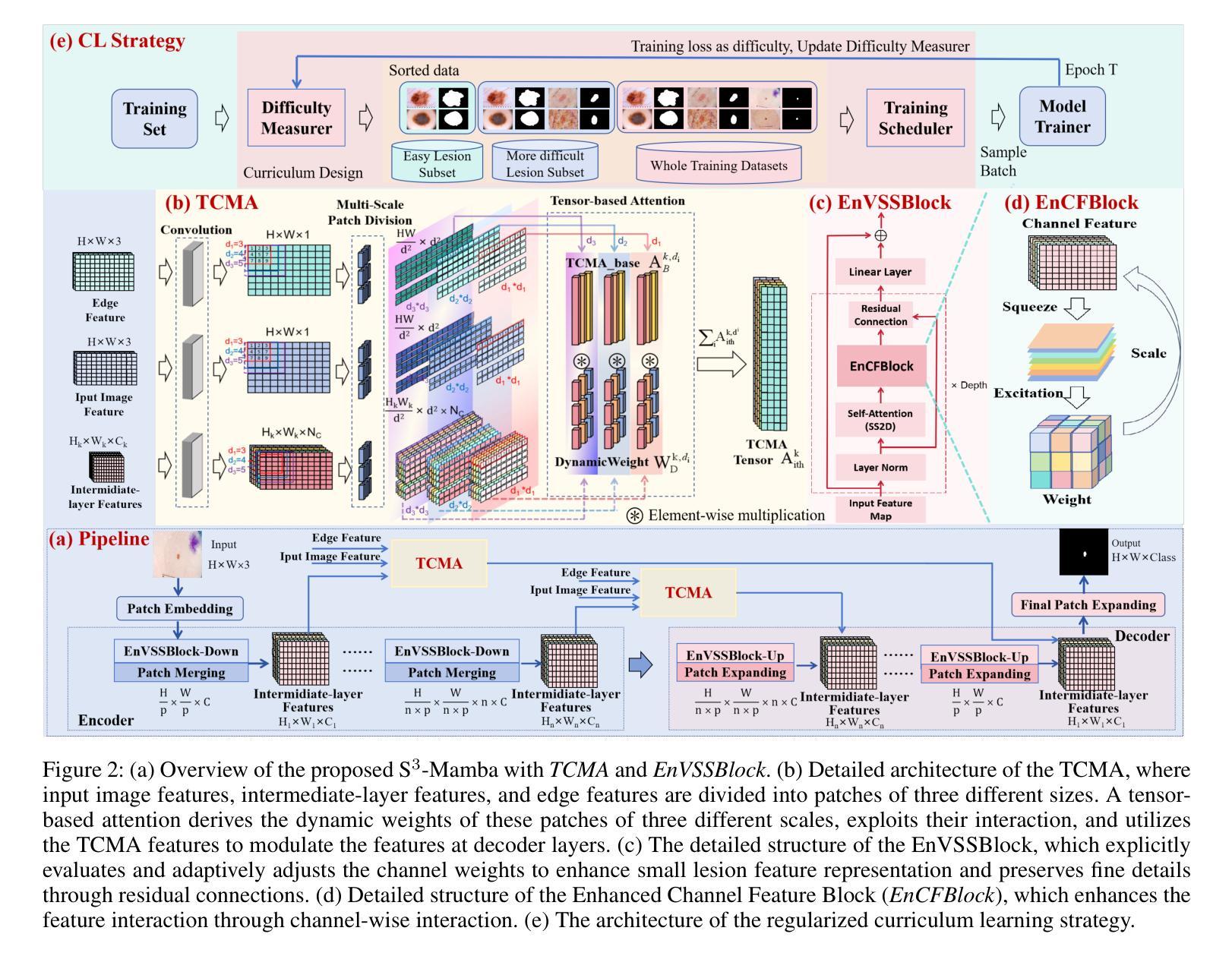
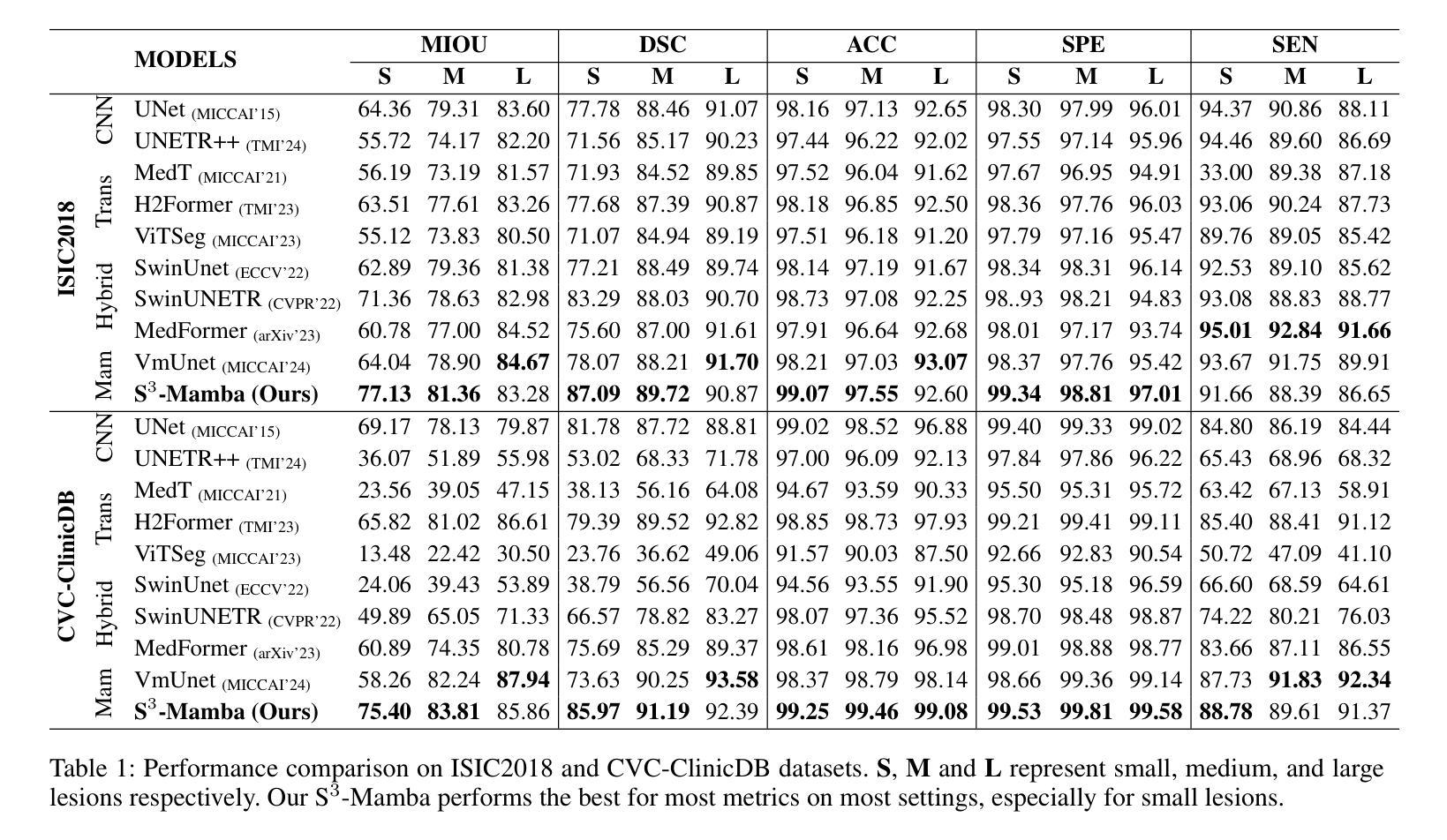
{S$^3$-Mamba}: Small-Size-Sensitive Mamba for Lesion Segmentation
Authors:Gui Wang, Yuexiang Li, Wenting Chen, Meidan Ding, Wooi Ping Cheah, Rong Qu, Jianfeng Ren, Linlin Shen
Small lesions play a critical role in early disease diagnosis and intervention of severe infections. Popular models often face challenges in segmenting small lesions, as it occupies only a minor portion of an image, while down_sampling operations may inevitably lose focus on local features of small lesions. To tackle the challenges, we propose a {\bf S}mall-{\bf S}ize-{\bf S}ensitive {\bf Mamba} ({\bf S$^3$-Mamba}), which promotes the sensitivity to small lesions across three dimensions: channel, spatial, and training strategy. Specifically, an Enhanced Visual State Space block is designed to focus on small lesions through multiple residual connections to preserve local features, and selectively amplify important details while suppressing irrelevant ones through channel-wise attention. A Tensor-based Cross-feature Multi-scale Attention is designed to integrate input image features and intermediate-layer features with edge features and exploit the attentive support of features across multiple scales, thereby retaining spatial details of small lesions at various granularities. Finally, we introduce a novel regularized curriculum learning to automatically assess lesion size and sample difficulty, and gradually focus from easy samples to hard ones like small lesions. Extensive experiments on three medical image segmentation datasets show the superiority of our S$^3$-Mamba, especially in segmenting small lesions. Our code is available at https://github.com/ErinWang2023/S3-Mamba.
微小病变在早期疾病诊断和严重感染干预中扮演着关键角色。常见的模型在分割微小病变时常常面临挑战,因为微小病变只占图像的一小部分,而下采样操作可能会不可避免地忽略其局部特征。为了应对这些挑战,我们提出了一种名为小型病变敏感Mamba(S$^3$-Mamba)的方法,通过通道、空间和训练策略三个维度提高对微小病变的敏感性。具体来说,设计了一个增强视觉状态空间块,通过多个残差连接专注于微小病变,保留局部特征,并通过通道注意力有选择地放大重要细节并抑制无关细节。基于张量的跨特征多尺度注意力旨在将输入图像特征与边缘特征结合中间层特征,并利用多尺度特征的注意力支持,从而在不同粒度上保留微小病变的空间细节。最后,我们引入了一种新型正则化课程学习法,自动评估病变大小和样本难度,并从简单样本逐步聚焦到困难样本(如微小病变)。在三个医学图像分割数据集上的大量实验表明,我们的S$^3$-Mamba具有优越性,尤其在分割微小病变方面。我们的代码位于 https://github.com/ErinWang2023/S3-Mamba。
论文及项目相关链接
PDF Accept by AAAI 2025
Summary
针对医学图像中小病灶分割的挑战,提出一种名为S$^3$-Mamba的方法,通过增强视觉状态空间、基于张量的跨特征多尺度注意力和正则化课程学习等技术,提高对小病灶的敏感性。在三个医学图像分割数据集上的实验表明,S$^3$-Mamba在分割小病灶方面具有优越性。
Key Takeaways
- 小病灶在疾病早期诊断和治疗中起关键作用,但现有模型在分割小病灶时面临挑战。
- S$^3$-Mamba方法通过三个维度提高小病灶的敏感性:通道、空间和训练策略。
- 采用增强视觉状态空间块,通过多重残差连接保留局部特征,并选择性放大重要细节,抑制无关信息。
- 基于张量的跨特征多尺度注意力能够整合输入图像特征与中间层特征,同时利用多尺度特征的注意力支持,保留小病灶的空间细节。
- 引入正则化课程学习,自动评估病灶大小与样本难度,从小样本逐渐聚焦到困难样本(如小病灶)。
- 在三个医学图像分割数据集上的实验表明S$^3$-Mamba的优越性,特别是在小病灶分割方面。
点此查看论文截图

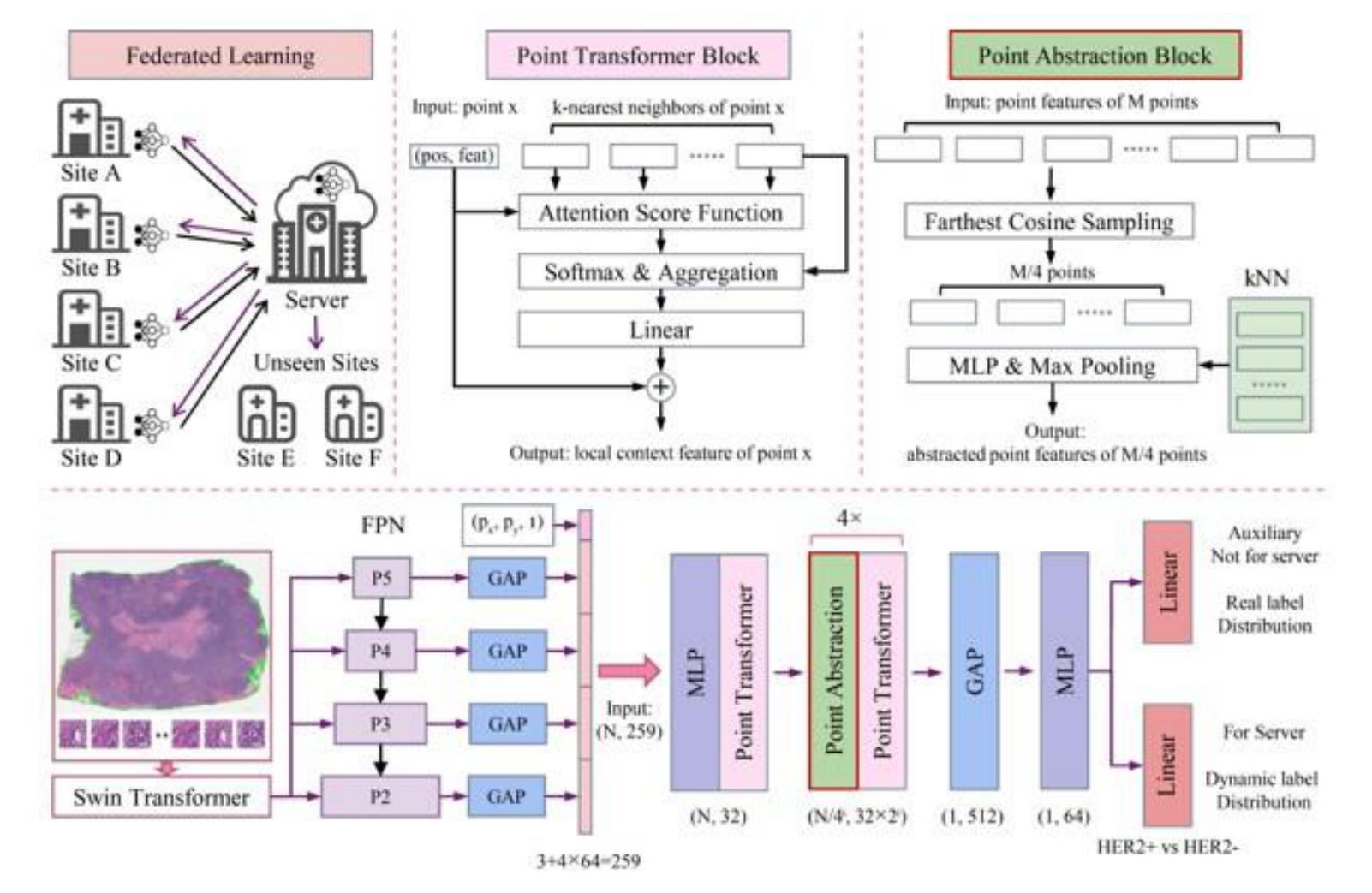
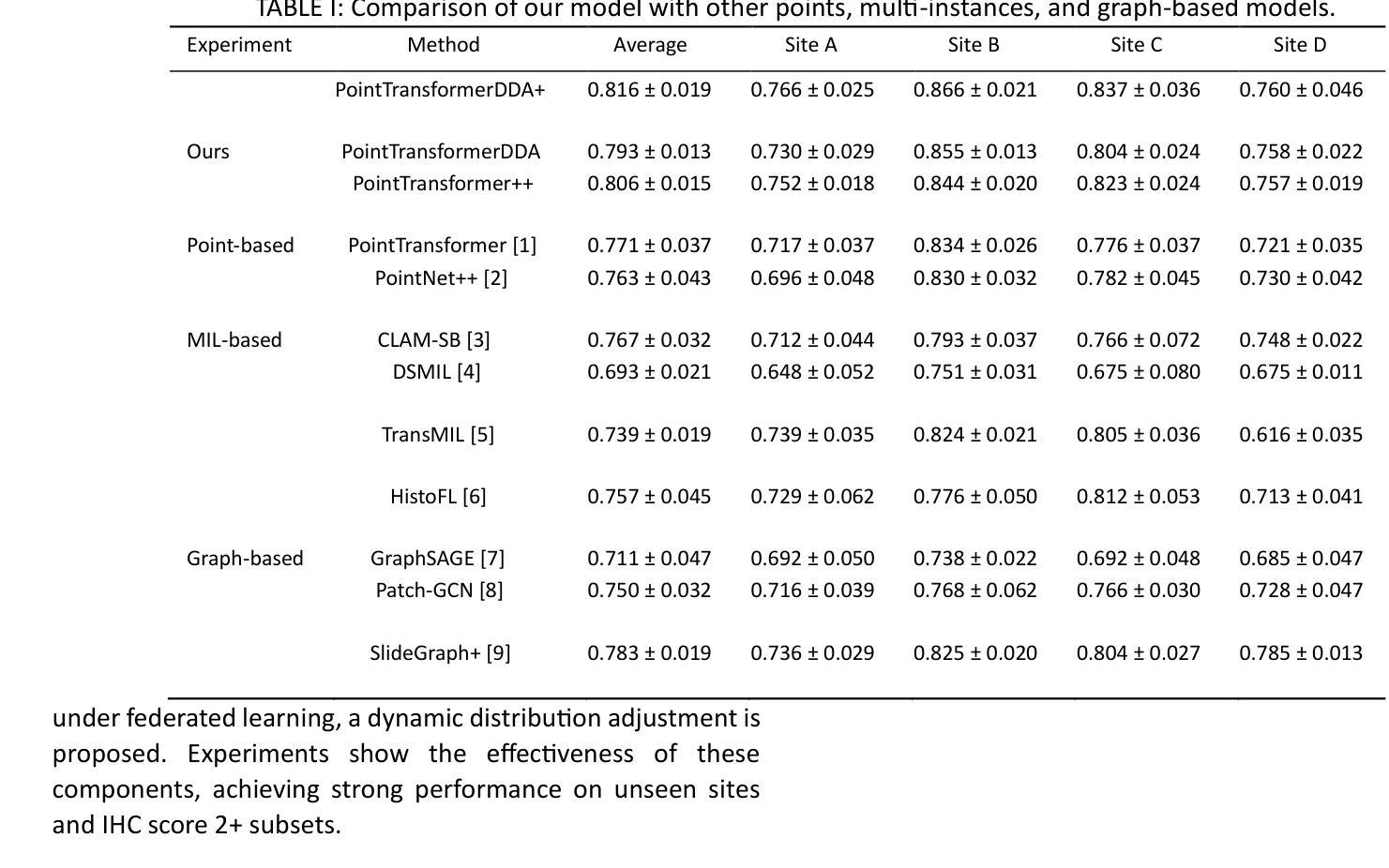
Summary of Point Transformer with Federated Learning for Predicting Breast Cancer HER2 Status from Hematoxylin and Eosin-Stained Whole Slide Images
Authors:Kamorudeen A. Amuda, Almustapha A. Wakili
This study introduces a federated learning-based approach to predict HER2 status from hematoxylin and eosin (HE)-stained whole slide images (WSIs), reducing costs and speeding up treatment decisions. To address label imbalance and feature representation challenges in multisite datasets, a point transformer is proposed, incorporating dynamic label distribution, an auxiliary classifier, and farthest cosine sampling. Extensive experiments demonstrate state-of-the-art performance across four sites (2687 WSIs) and strong generalization to two unseen sites (229 WSIs).
本研究介绍了一种基于联邦学习的方法,用于从苏木精和伊红(HE)染色的全切片图像(WSI)预测HER2状态,降低成本并加快治疗决策。为了解决多站点数据集中的标签不平衡和特征表示挑战,提出了一种点转换器,它结合了动态标签分布、辅助分类器和最远余弦采样。大量实验表明,该方法在四个站点(2687张WSI)上表现出卓越的性能,并且对两个未见站点(229张WSI)具有很强的泛化能力。
论文及项目相关链接
Summary
医学图像研究中采用基于联邦学习的预测HER2状态的方法,利用HE染色全幻灯片图像(WSIs),降低成本并加快治疗决策。提出一种点转换器来解决多站点数据集中的标签不平衡和特征表示挑战,包括动态标签分布、辅助分类器和最远余弦采样。在四个站点(2687张幻灯片)进行了广泛实验,证明了其卓越性能,并对两个未见过的新站点(229张幻灯片)具有较强的泛化能力。
Key Takeaways
- 采用联邦学习预测HER2状态。
- 研究涉及使用HE染色全幻灯片图像(WSIs)。
- 通过联邦学习降低成本并加速治疗决策。
- 提出点转换器来解决标签不平衡和特征表示的挑战。
- 点转换器包括动态标签分布、辅助分类器和最远余弦采样技术。
- 实验在四个站点进行,表现出卓越性能。
点此查看论文截图

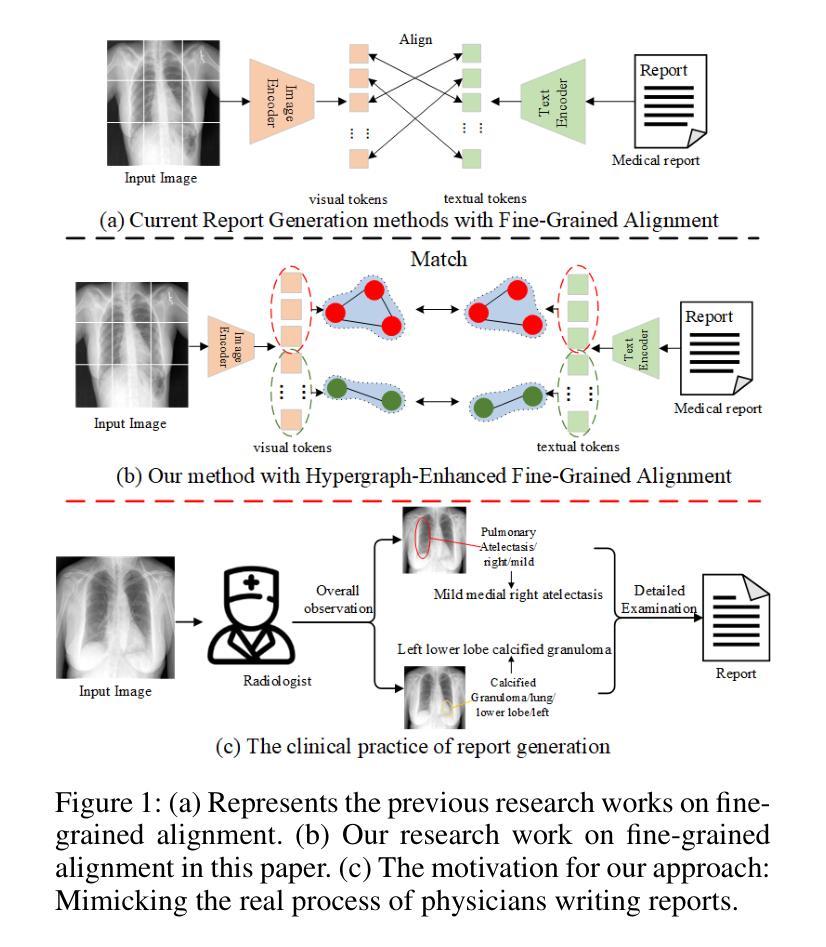
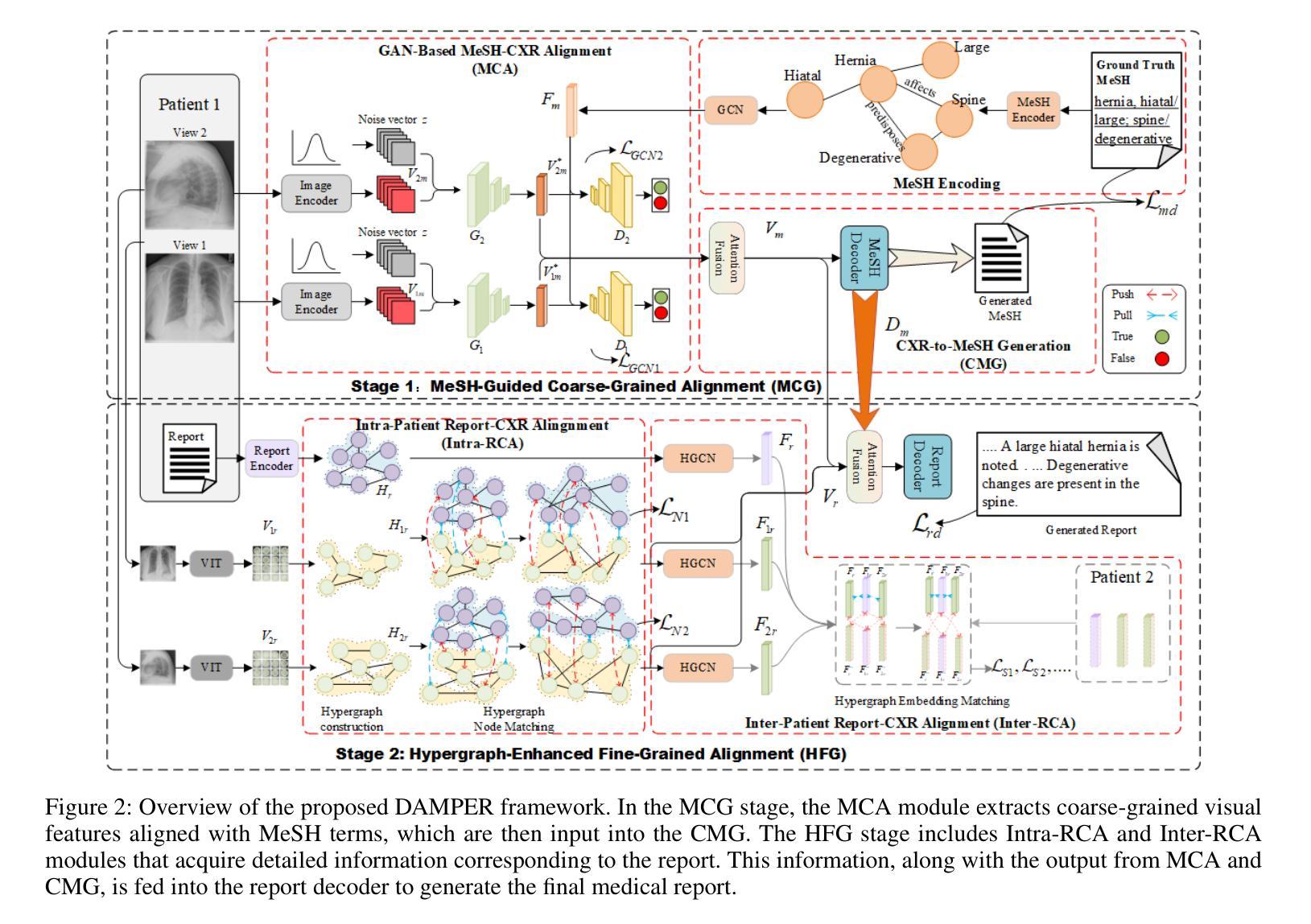
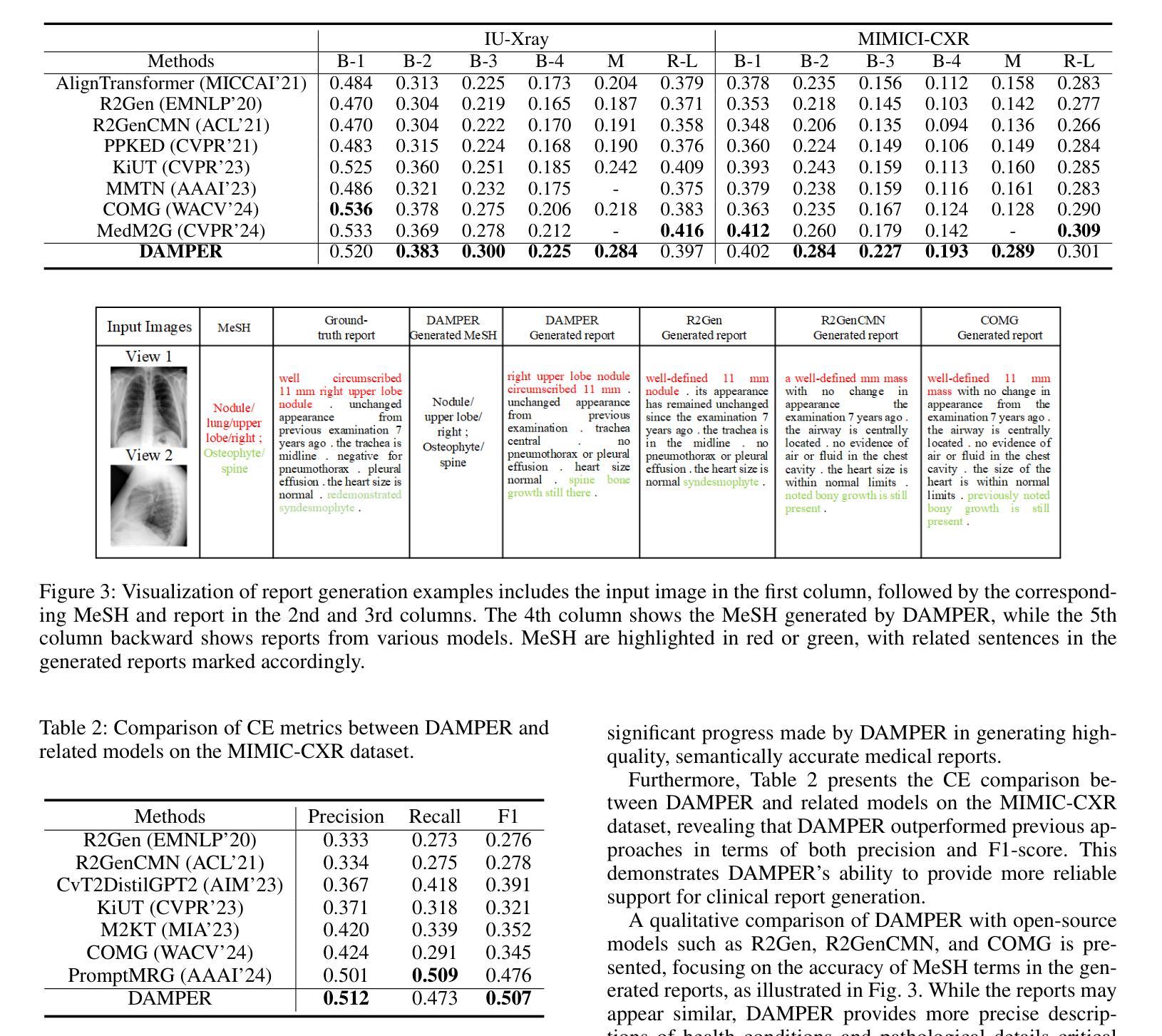
DAMPER: A Dual-Stage Medical Report Generation Framework with Coarse-Grained MeSH Alignment and Fine-Grained Hypergraph Matching
Authors:Xiaofei Huang, Wenting Chen, Jie Liu, Qisheng Lu, Xiaoling Luo, Linlin Shen
Medical report generation is crucial for clinical diagnosis and patient management, summarizing diagnoses and recommendations based on medical imaging. However, existing work often overlook the clinical pipeline involved in report writing, where physicians typically conduct an initial quick review followed by a detailed examination. Moreover, current alignment methods may lead to misaligned relationships. To address these issues, we propose DAMPER, a dual-stage framework for medical report generation that mimics the clinical pipeline of report writing in two stages. In the first stage, a MeSH-Guided Coarse-Grained Alignment (MCG) stage that aligns chest X-ray (CXR) image features with medical subject headings (MeSH) features to generate a rough keyphrase representation of the overall impression. In the second stage, a Hypergraph-Enhanced Fine-Grained Alignment (HFG) stage that constructs hypergraphs for image patches and report annotations, modeling high-order relationships within each modality and performing hypergraph matching to capture semantic correlations between image regions and textual phrases. Finally,the coarse-grained visual features, generated MeSH representations, and visual hypergraph features are fed into a report decoder to produce the final medical report. Extensive experiments on public datasets demonstrate the effectiveness of DAMPER in generating comprehensive and accurate medical reports, outperforming state-of-the-art methods across various evaluation metrics.
医学报告生成对临床诊断和治疗管理至关重要,它是基于医学成像对诊断和建议进行汇总的关键环节。然而,现有工作往往忽略了报告编写所涉及的临床流程,医生通常先进行初步快速审查,然后进行详细检查。此外,当前的对齐方法可能导致关系错位。为了解决这些问题,我们提出了DAMPER,这是一个用于医学报告生成的双阶段框架,它模仿了两阶段报告写作的临床流程。在第一阶段,我们采用MeSH指导的粗粒度对齐(MCG)阶段,将胸部X射线(CXR)图像特征与医学主题词表(MeSH)特征对齐,以生成整体印象的粗略关键词表示。在第二阶段,我们采用超图增强细粒度对齐(HFG)阶段,为图像补丁和报告注释构建超图,对每种模态内的高阶关系进行建模,并通过超图匹配来捕获图像区域和文本短语之间的语义相关性。最后,将粗粒度视觉特征、生成的MeSH表示和视觉超图特征输入报告解码器,以生成最终的医学报告。在公共数据集上的大量实验表明,DAMPER在生成全面准确的医学报告方面非常有效,并在各种评估指标上优于最新方法。
论文及项目相关链接
Summary
本文提出一种双阶段框架DAMPER用于医学报告生成,模仿医生书写报告的临床流程。第一阶段为MeSH引导下的粗粒度对齐(MCG),将胸X光片图像特征与医学主题标题(MeSH)特征对齐,生成整体印象的粗略关键词表示。第二阶段为超图增强的细粒度对齐(HFG),构建图像补丁和报告注释的超图,对每种模态内的高阶关系进行建模,并通过超图匹配捕获图像区域和文本短语之间的语义关联。最终,将粗粒度视觉特征、生成的MeSH表示和超图特征输入报告解码器,生成最终医学报告。在公共数据集上的广泛实验表明,DAMPER在生成全面、准确的医学报告方面效果显著,优于各种评估指标下的最新方法。
Key Takeaways
- 医疗报告生成对临床诊断和治疗方案至关重要,其生成过程通常包含两个阶段:初步快速审查和详细检查。
- 当前医疗报告生成方法忽略了临床流程,可能导致关系错位。
- DAMPER框架模仿医生书写报告的临床流程,分为两个阶段:粗粒度对齐和细粒度对齐。
- 粗粒度对齐阶段通过MeSH引导,将图像特征与医学主题标题特征对齐,形成整体印象的粗略关键词表示。
- 细粒度对齐阶段通过构建超图,对图像补丁和报告注释进行高阶关系建模,并捕获图像和文本之间的语义关联。
- DAMPER使用粗粒度视觉特征、MeSH表示和超图特征来生成最终医疗报告。
点此查看论文截图

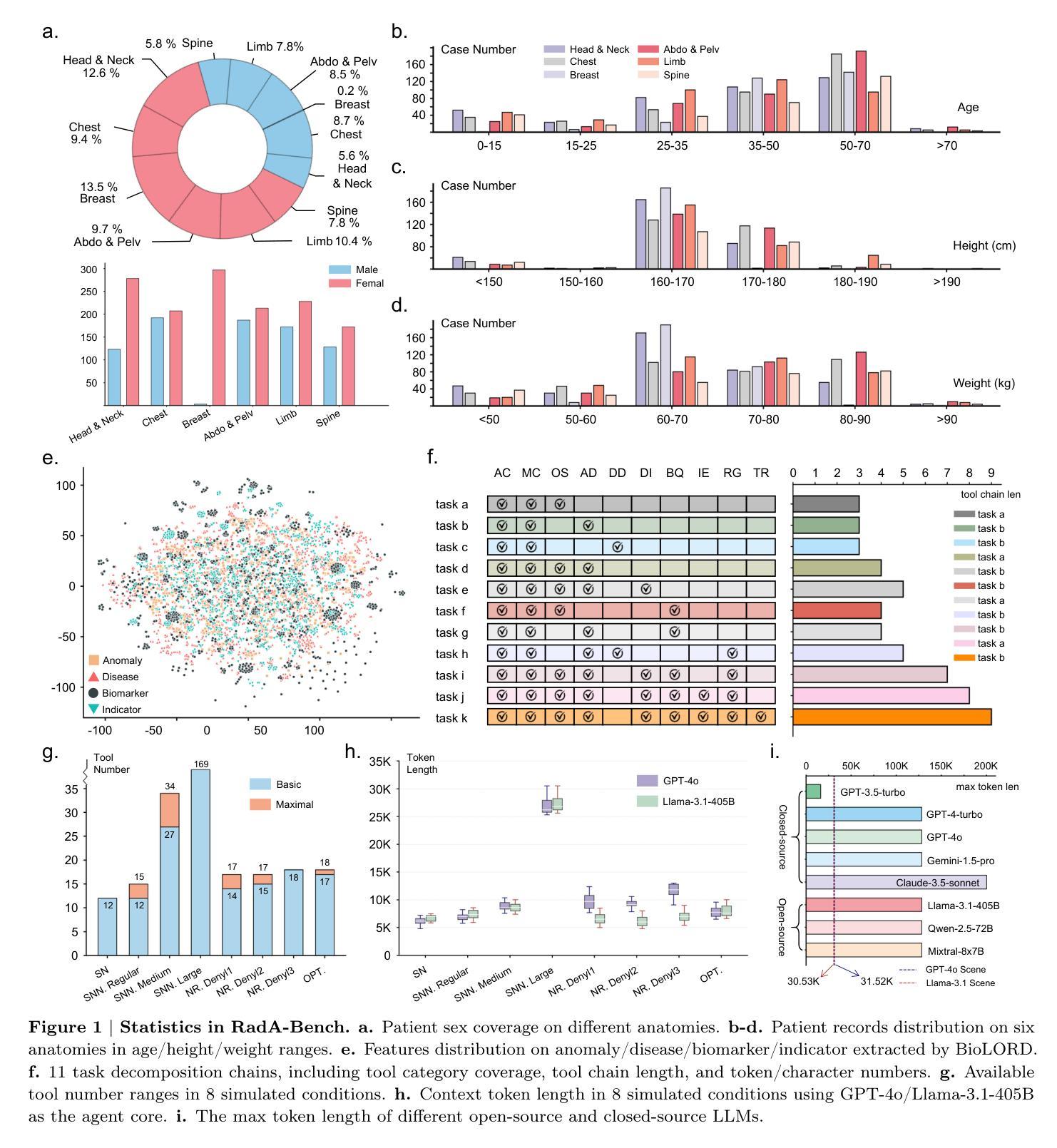
Can Modern LLMs Act as Agent Cores in Radiology Environments?
Authors:Qiaoyu Zheng, Chaoyi Wu, Pengcheng Qiu, Lisong Dai, Ya Zhang, Yanfeng Wang, Weidi Xie
Advancements in large language models (LLMs) have paved the way for LLM-based agent systems that offer enhanced accuracy and interpretability across various domains. Radiology, with its complex analytical requirements, is an ideal field for the application of these agents. This paper aims to investigate the pre-requisite question for building concrete radiology agents which is, `Can modern LLMs act as agent cores in radiology environments?’ To investigate it, we introduce RadABench with three-fold contributions: First, we present RadABench-Data, a comprehensive synthetic evaluation dataset for LLM-based agents, generated from an extensive taxonomy encompassing 6 anatomies, 5 imaging modalities, 10 tool categories, and 11 radiology tasks. Second, we propose RadABench-EvalPlat, a novel evaluation platform for agents featuring a prompt-driven workflow and the capability to simulate a wide range of radiology toolsets. Third, we assess the performance of 7 leading LLMs on our benchmark from 5 perspectives with multiple metrics. Our findings indicate that while current LLMs demonstrate strong capabilities in many areas, they are still not sufficiently advanced to serve as the central agent core in a fully operational radiology agent system. Additionally, we identify key factors influencing the performance of LLM-based agent cores, offering insights for clinicians on how to apply agent systems in real-world radiology practices effectively. All of our code and data are open-sourced in https://github.com/MAGIC-AI4Med/RadABench.
大型语言模型(LLM)的进步为基于LLM的代理系统铺平了道路,这些系统在各个领域提供了更高的准确性和可解释性。放射学由于其复杂的分析要求,是这些代理应用的理想领域。本文旨在探讨构建具体放射学代理的先决问题,即“现代LLM能否在放射学环境中作为代理核心?”为了调查这个问题,我们推出了RadABench,它有三方面的贡献:首先,我们展示了RadABench-Data,这是一套全面的合成评估数据集,用于基于LLM的代理,数据来自广泛的分类,包括6个解剖学、5种成像模式、10个工具类别和11个放射学任务。其次,我们提出了RadABench-EvalPlat,这是一个新的代理评估平台,具有提示驱动的工作流程,能够模拟广泛的放射学工具集。第三,我们从5个角度对7款领先的大型语言模型进行了评估,使用了多个指标。我们的研究结果表明,虽然当前的大型语言模型在许多领域表现出强大的能力,但它们仍然不足以作为完全运行的放射学代理系统的核心代理。此外,我们还确定了影响基于LLM的代理核心性能的关键因素,为临床医生提供了如何在现实世界的放射学实践中有效应用代理系统的见解。我们的所有代码和数据都在https://github.com/MAGIC-AI4Med/RadABench上开源。
论文及项目相关链接
PDF 22 pages,7 figures
Summary
本文研究了现代大型语言模型(LLMs)在放射学环境中的表现,提出了RadABench数据集与评估平台。通过评估发现,虽然LLMs在许多领域表现出强大的能力,但仍不足以作为完全操作化的放射学代理系统的核心。本文还公开了代码和数据集。
Key Takeaways
- 大型语言模型(LLMs)在放射学领域具有应用潜力。
- RadABench是一个综合性的合成评估数据集,为基于LLM的代理提供了评估标准。
- RadABench-EvalPlat是一个新颖的评估平台,为代理提供了以提示为中心的工作流程和模拟各种放射学工具集的能力。
- 评估发现当前LLMs在许多领域表现出强大的能力,但仍不足以作为完全操作化的放射学代理系统的核心。
- 公开的代码和数据集有助于进一步研究和应用。
- LLMs在放射学领域的性能受到多种因素的影响,需要更多研究来提升其表现。
点此查看论文截图

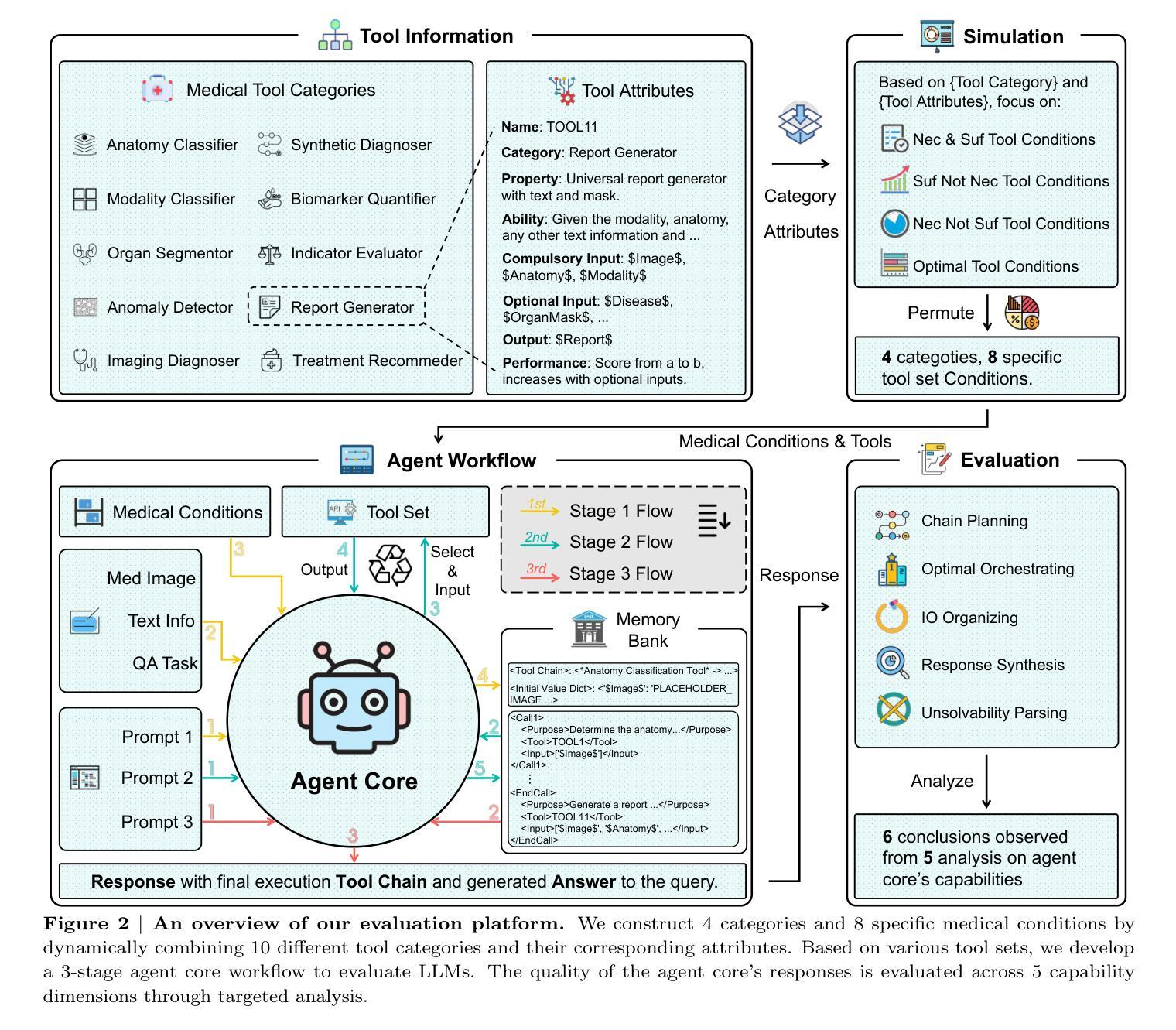
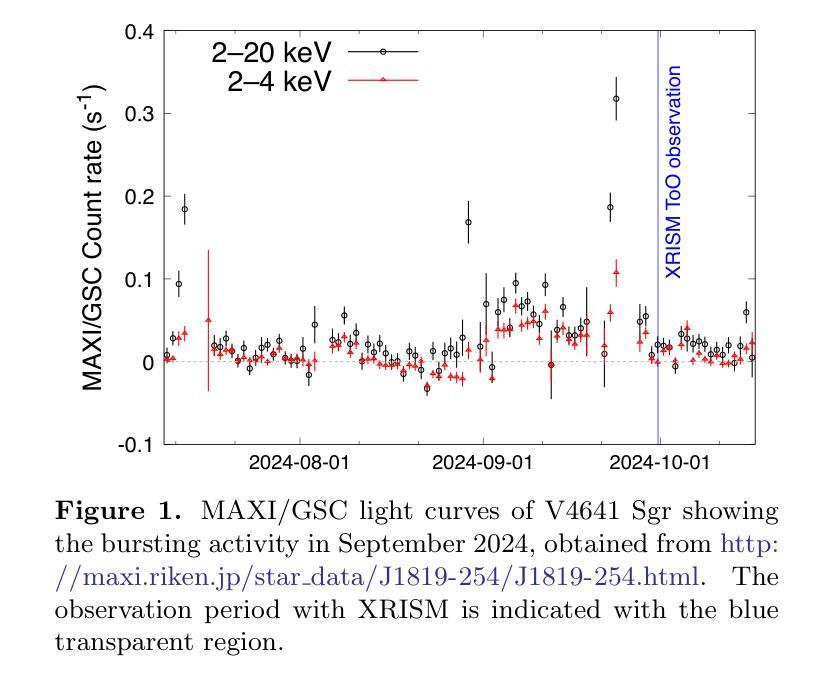
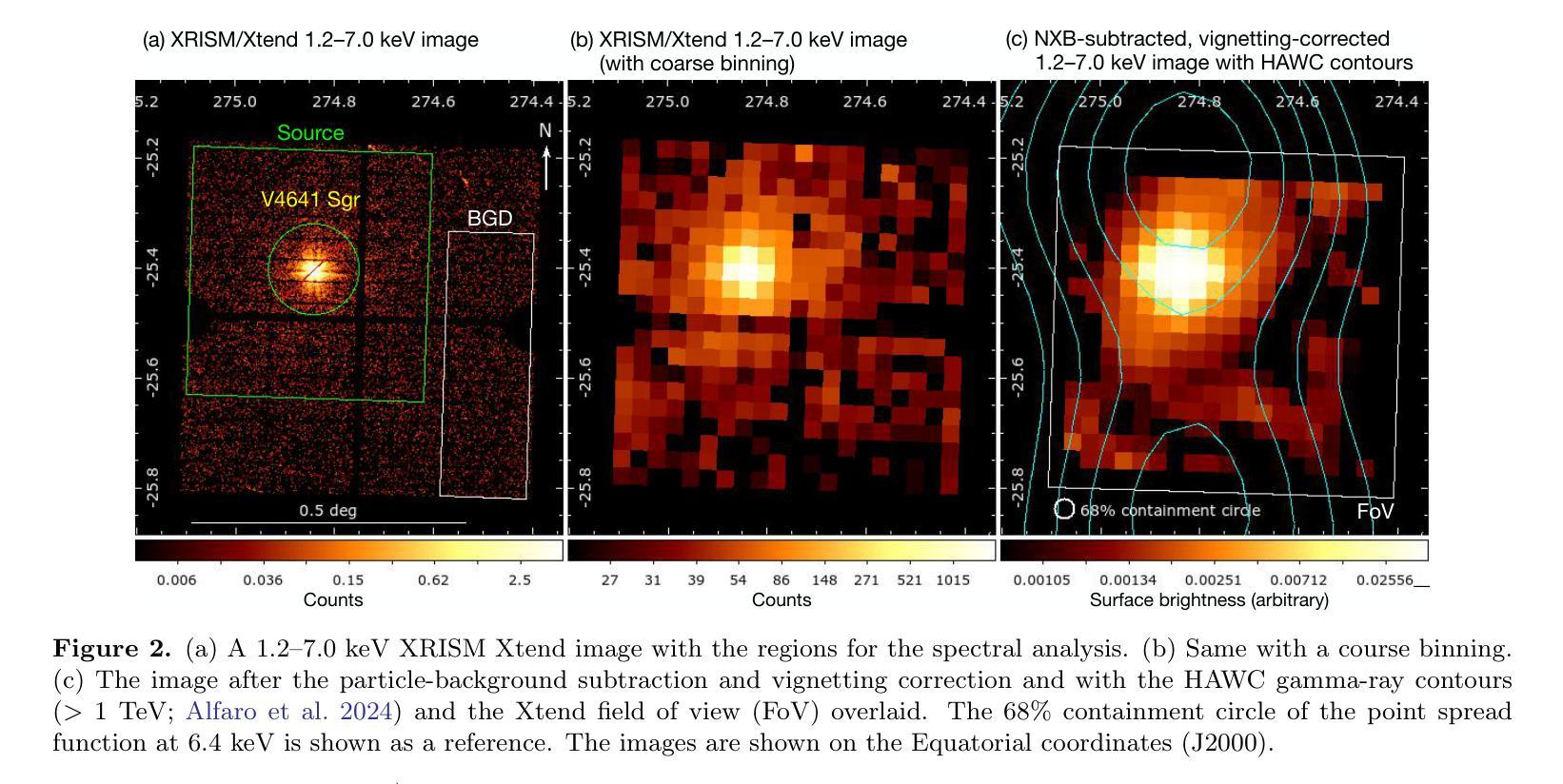
Detection of extended X-ray emission around the PeVatron microquasar V4641 Sgr with XRISM
Authors:Hiromasa Suzuki, Naomi Tsuji, Yoshiaki Kanemaru, Megumi Shidatsu, Laura Olivera-Nieto, Samar Safi-Harb, Shigeo S. Kimura, Eduardo de la Fuente, Sabrina Casanova, Kaya Mori, Xiaojie Wang, Sei Kato, Dai Tateishi, Hideki Uchiyama, Takaaki Tanaka, Hiroyuki Uchida, Shun Inoue, Dezhi Huang, Marianne Lemoine-Goumard, Daiki Miura, Shoji Ogawa, Shogo B. Kobayashi, Chris Done, Maxime Parra, María Díaz Trigo, Teo Muñoz-Darias, Montserrat Armas Padilla, Ryota Tomaru, Yoshihiro Ueda
A recent report on the detection of very-high-energy gamma rays from V4641 Sagittarii (V4641 Sgr) up to 0.8 peta-electronvolt has made it the second confirmed “PeVatron” microquasar. Here we report on the observation of V4641 Sgr with X-Ray Imaging and Spectroscopy Mission (XRISM) in September 2024. Thanks to the large field of view and low background, the CCD imager Xtend successfully detected for the first time X-ray extended emission around V4641 Sgr with a significance of > 4.5 sigma and > 10 sigma based on our imaging and spectral analysis, respectively. The spatial extent is estimated to have a radius of $7 \pm 3$ arcmin ($13 \pm 5$ pc at a distance of 6.2 kpc) assuming a Gaussian-like radial distribution, which suggests that the particle acceleration site is within ~10 pc of the microquasar. If the X-ray morphology traces the diffusion of accelerated electrons, this spatial extent can be explained by either an enhanced magnetic field (80 uG) or a suppressed diffusion coefficient (~$10^{27}$ cm$^2$ s$^{-1}$ at 100 TeV). The integrated X-ray flux, (4-6)$\times 10^{-12}$ erg s$^{-1}$ cm$^{-2}$ (2-10 keV), would require a magnetic field strength higher than the galactic mean (> 8 uG) if the diffuse X-ray emission originates from synchrotron radiation and the gamma-ray emission is predominantly hadronic. If the X-rays are of thermal origin, the measured extension, temperature, and plasma density can be explained by a jet with a luminosity of ~$2\times 10^{39}$ erg s$^{-1}$, which is comparable to the Eddington luminosity of this system.
最近的一份关于从V4641天箭星(V4641 Sgr)检测到超高能伽马射线的报告,能量高达~0.8拍电子伏特,使其成为第二个确认的“拍伏仑”微类星。这里我们报告了2024年9月使用X射线成像和光谱任务(XRISM)观察到的V4641 Sgr的情况。由于视场范围大且背景低,CCD成像仪Xtend首次成功检测到V4641 Sgr周围的X射线扩展发射,其显著性基于我们的成像和光谱分析分别大于4.5σ和大于10σ。空间范围估计半径为$7±3$角分(在距离6.2千秒差距的情况下为$13±5$秒差距),假设径向分布类似于高斯分布,这表明粒子加速位点位于微类星周围约10秒差距内。如果X射线的形态追踪了加速电子的扩散,那么这种空间范围可以用增强的磁场(约80微高斯)或抑制的扩散系数(在100TeV时约为$10^{27}$厘米$^2$每秒)来解释。X射线积分流量为(介于4-6)× $10^{-12}$erg s$^{-1}$ cm$^{-2}$ (在(在波动范围内的光度较复杂 )之间),如果扩散X射线发射来自同步辐射并且伽马射线发射主要是强子过程,那么磁场强度需要高于银河系平均值(大于8微高斯)。如果X射线是热起源的,那么所测量的延伸范围、温度和等离子体密度可以用光度约为$2× 10^{39}$erg s$^{-1}$的喷射流来解释,这与该系统的爱丁顿光度相当。
论文及项目相关链接
PDF 9 pages, 5 figures, accepted for publication in ApJL
Summary
近期对V4641 Sagittarii的高能伽马射线检测显示其为第二个确认的PeVatron微类星。使用XRISM对V4641 Sgr进行观测,其X射线成像光谱仪首次检测到明显的X射线扩展发射。空间范围估计为半径约7±3弧分(距离地球约6.2千秒差距时的距离),表明粒子加速部位可能位于微类星周围约10秒内区域。研究提出了增强磁场或抑制扩散系数的假设来解释这种空间范围的延伸性。对磁场强度有更高要求,如果X射线是同步辐射,伽马射线主要是强子产生,那么磁场强度必须高于银河系平均值。如果X射线是热起源,则可以解释射流现象,射流亮度与系统的爱丁顿亮度相当。
Key Takeaways
- V4641 Sagittarii(V4641 Sgr)已成为第二个确认的PeVatron微类星。它的伽马射线能量极高,达到约0.8 peta-electronvolt。
- 使用XRISM观测显示其周围的X射线扩展发射首次被检测到。
- 通过成像和光谱分析发现X射线辐射区域呈高斯分布形态,估计其半径为约$7 \pm 3$弧分,推测粒子加速部位距离微类星不超过约10秒差距。
点此查看论文截图

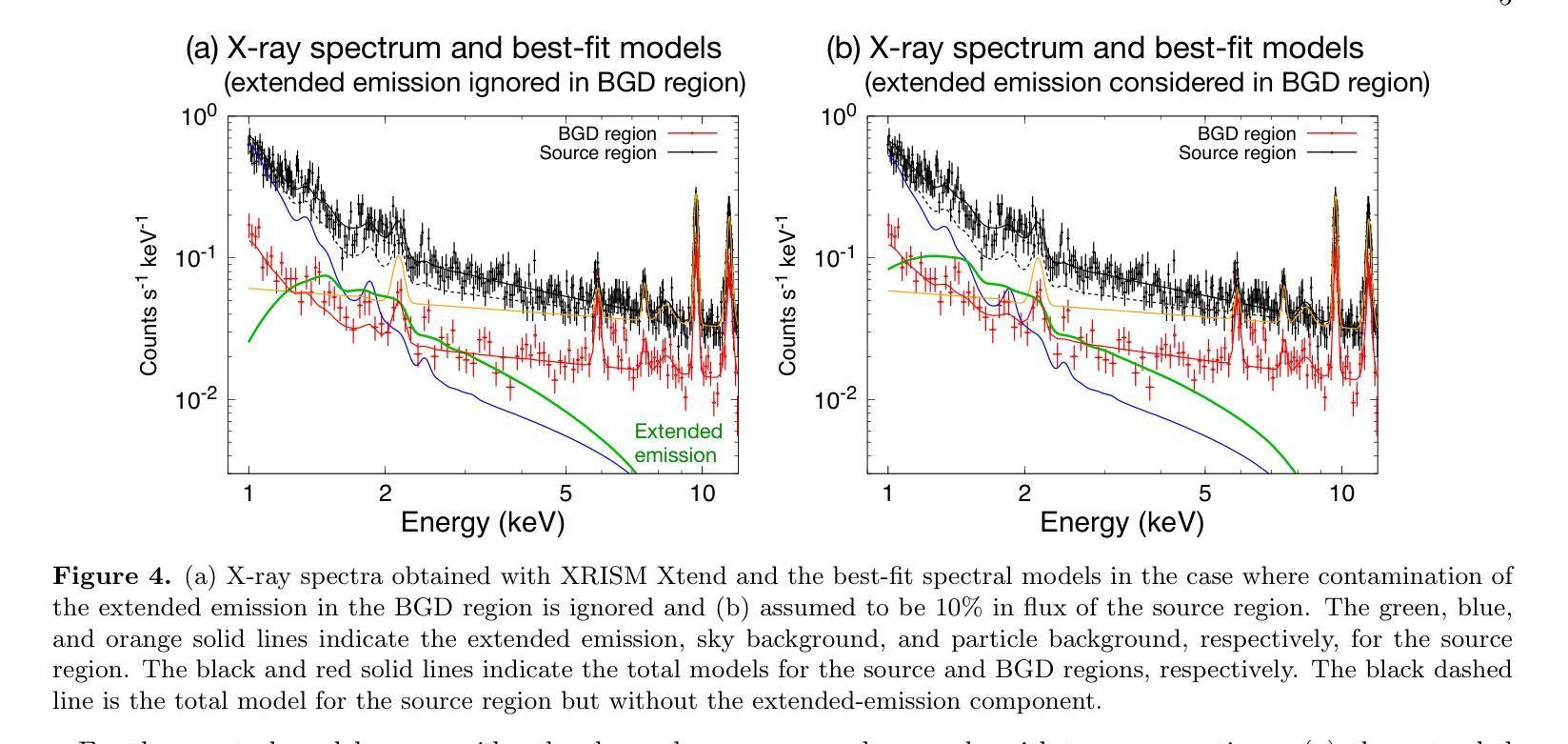

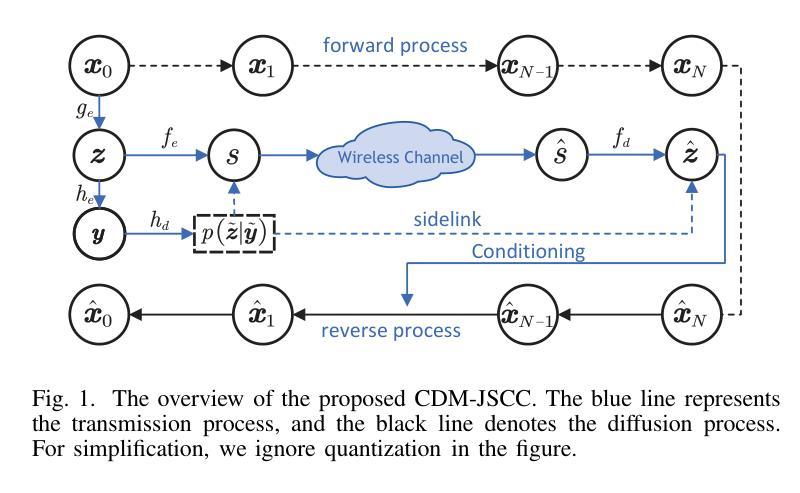
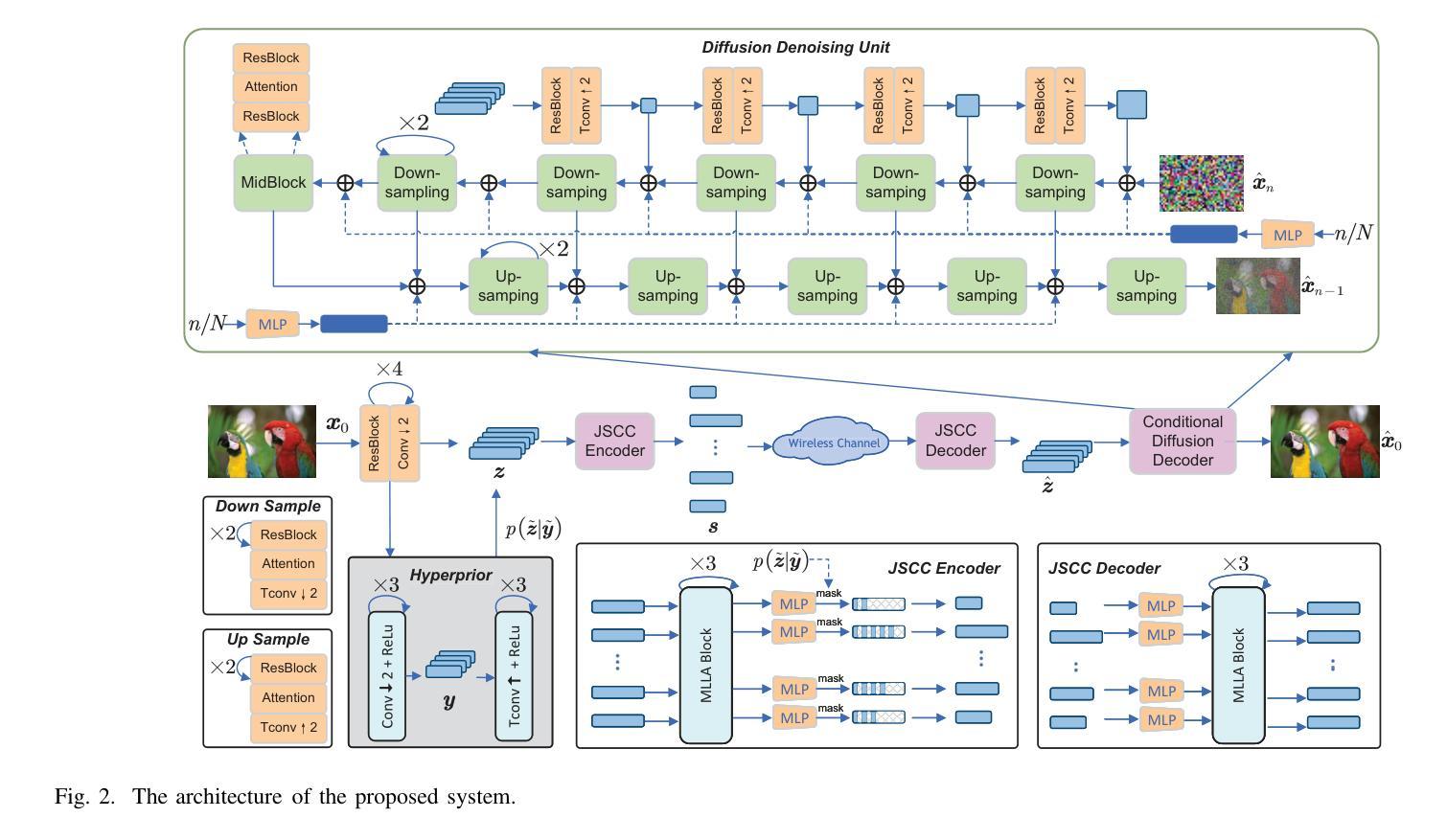
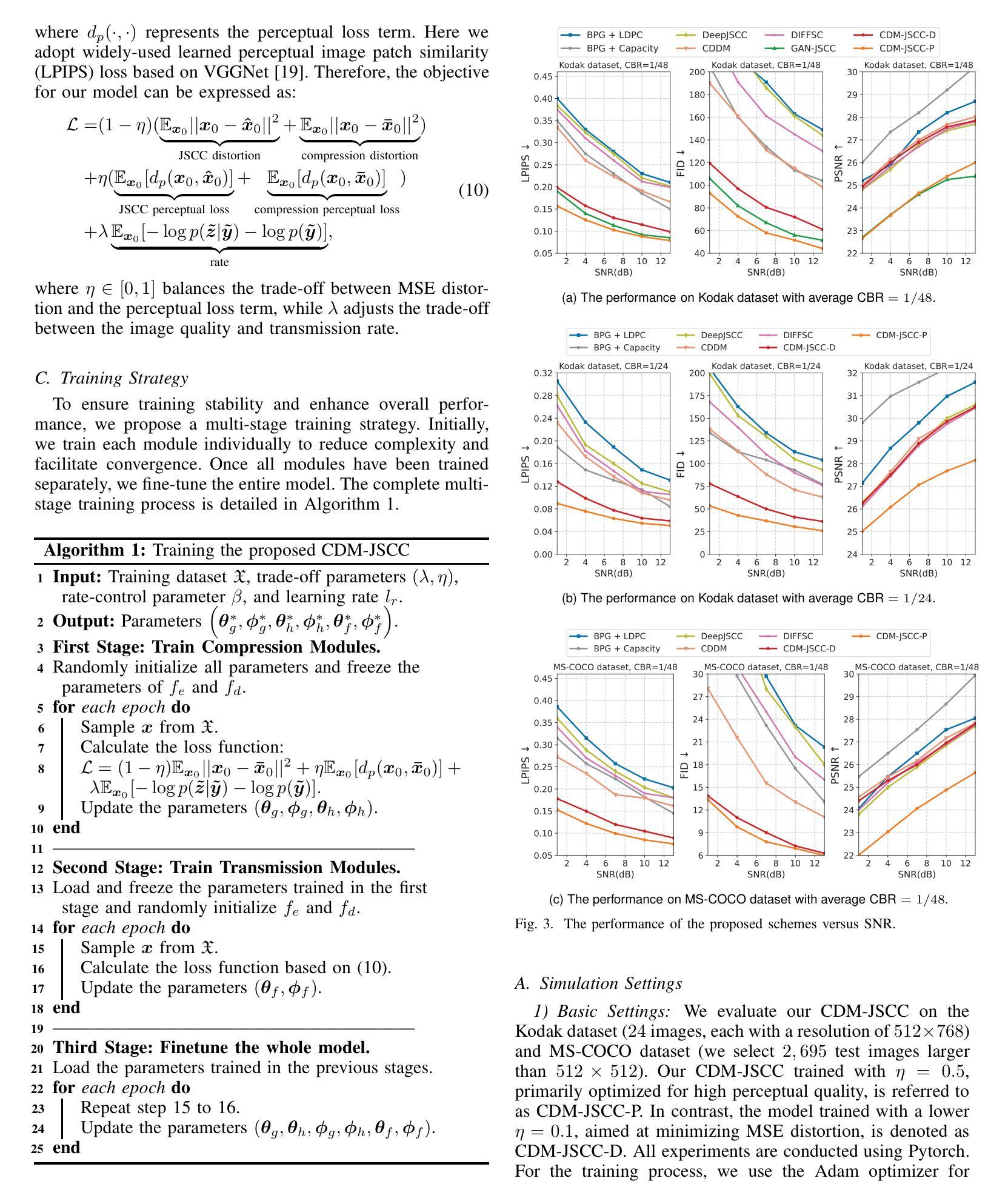
Rate-Adaptive Generative Semantic Communication Using Conditional Diffusion Models
Authors:Pujing Yang, Guangyi Zhang, Yunlong Cai
Recent advances in deep learning-based joint source-channel coding (DJSCC) have shown promise for end-to-end semantic image transmission. However, most existing schemes primarily focus on optimizing pixel-wise metrics, which often fail to align with human perception, leading to lower perceptual quality. In this letter, we propose a novel generative DJSCC approach using conditional diffusion models to enhance the perceptual quality of transmitted images. Specifically, by utilizing entropy models, we effectively manage transmission bandwidth based on the estimated entropy of transmitted sym-bols. These symbols are then used at the receiver as conditional information to guide a conditional diffusion decoder in image reconstruction. Our model is built upon the emerging advanced mamba-like linear attention (MLLA) skeleton, which excels in image processing tasks while also offering fast inference speed. Besides, we introduce a multi-stage training strategy to ensure the stability and improve the overall performance of the model. Simulation results demonstrate that our proposed method significantly outperforms existing approaches in terms of perceptual quality.
最近,基于深度学习的联合源信道编码(DJSCC)的最新进展为端到端语义图像传输展现出了潜力。然而,大多数现有方案主要侧重于优化像素级指标,这些指标通常与人类感知不符,导致感知质量较低。在这封信中,我们提出了一种新的基于条件扩散模型生成式DJSCC方法,以提高传输图像的感知质量。具体来说,我们利用熵模型,根据传输符号的估计熵有效地管理传输带宽。这些符号然后在接收器端作为条件信息,用于指导图像重建中的条件扩散解码器。我们的模型建立在新兴的马姆巴状线性注意力(MLLA)骨架之上,该骨架在图像处理任务中表现出色,同时提供快速推理速度。此外,我们引入了一种多阶段训练策略,以确保模型的稳定性并提高其整体性能。仿真结果表明,我们提出的方法在感知质量方面显著优于现有方法。
论文及项目相关链接
摘要
最新深度学习方法联合源信道编码技术提高了端到端的语义图像传输效果。但现有的方法主要集中在优化像素级指标,这往往与人类感知不一致,导致感知质量下降。本文提出一种基于条件扩散模型的生成式联合源信道编码方法,以提高传输图像的感知质量。我们利用��d模型有效管理传输带宽,基于传输符号的估计熵进行估算。这些符号在接收端作为条件信息引导图像重建的条件扩散解码器。我们的模型建立在新兴的马姆巴式线性注意力骨架上,既擅长图像处理任务,又提供快速推理速度。此外,我们引入了一种多阶段训练策略,以确保模型的稳定性并提高其整体性能。模拟结果表明,我们提出的方法在感知质量方面显著优于现有方法。
要点
- 深度学习方法联合源信道编码技术提升语义图像传输效果。
- 现有方法主要关注像素级优化,与人类感知不一致。
- 提出基于条件扩散模型的生成式DJSCC方法提高图像感知质量。
- 利用熵模型管理传输带宽,基于传输符号的估计熵。
- 接收端利用这些符号作为条件信息引导图像重建。
- 模型基于马姆巴式线性注意力骨架,适合图像处理且快速推理。
点此查看论文截图

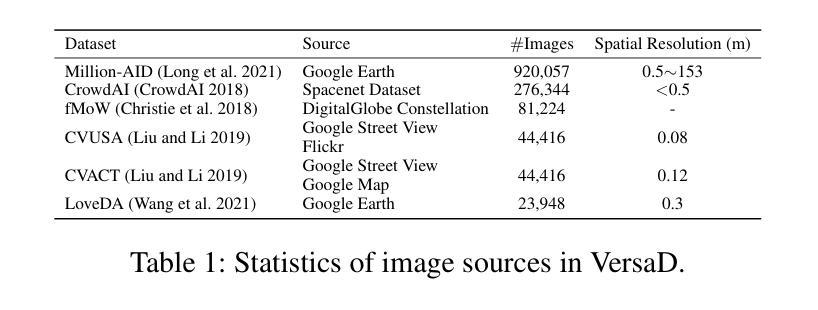
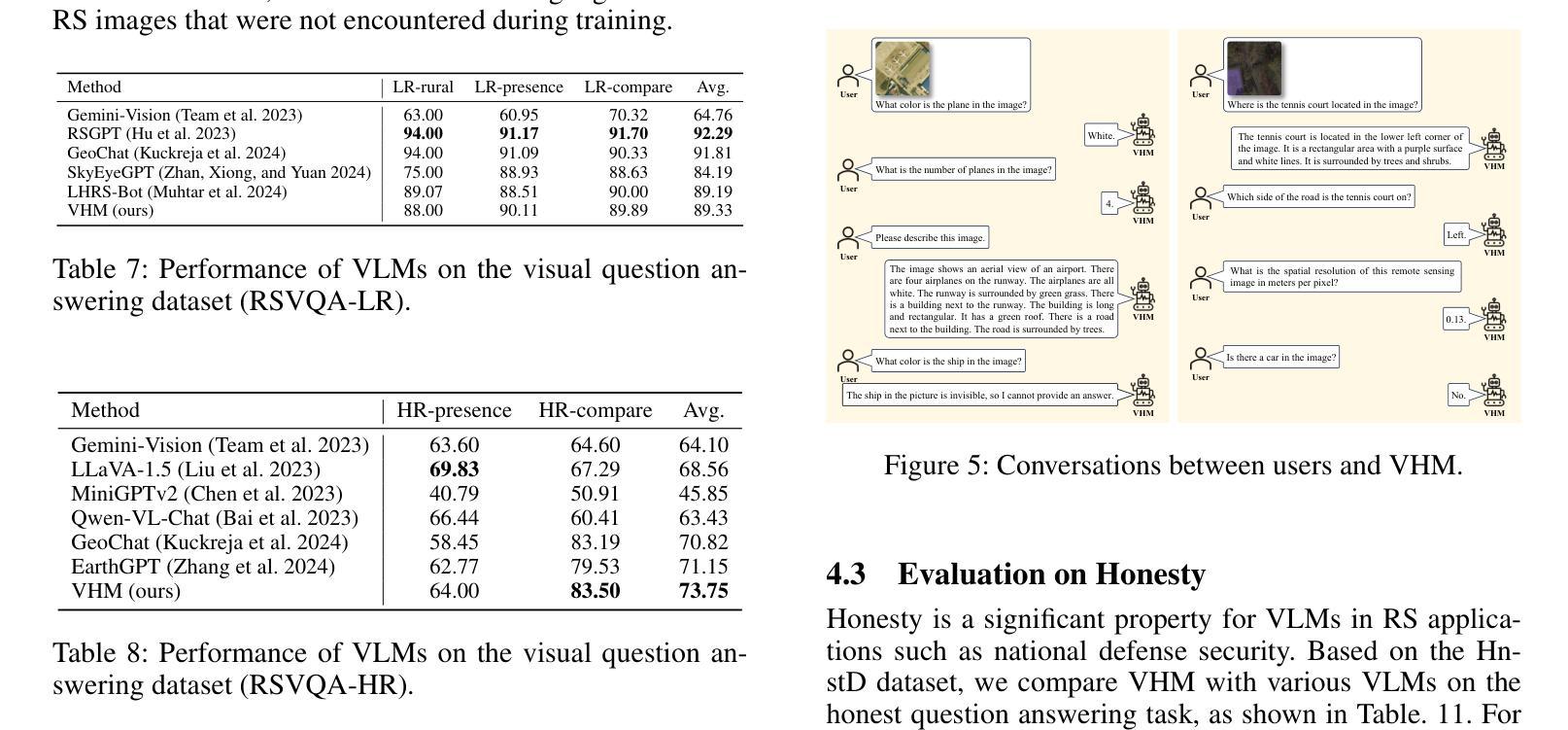
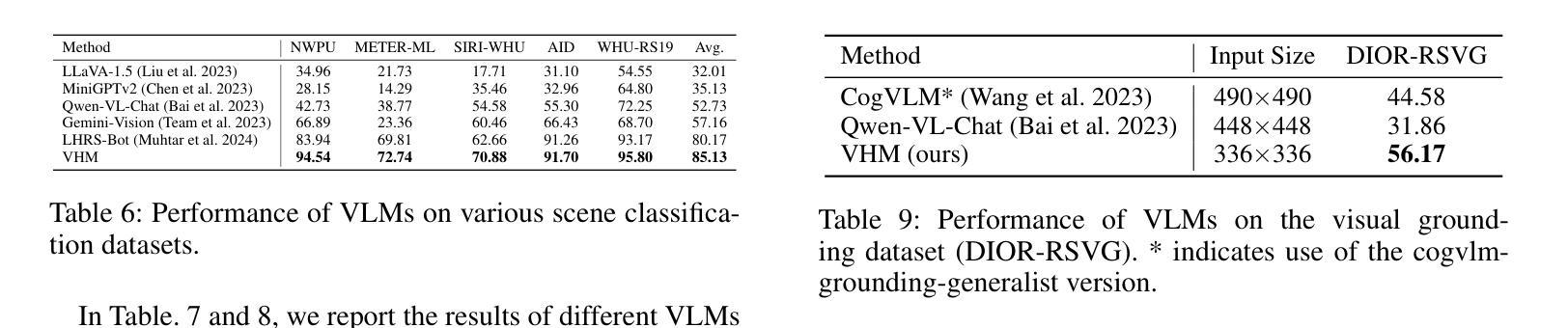
VHM: Versatile and Honest Vision Language Model for Remote Sensing Image Analysis
Authors:Chao Pang, Xingxing Weng, Jiang Wu, Jiayu Li, Yi Liu, Jiaxing Sun, Weijia Li, Shuai Wang, Litong Feng, Gui-Song Xia, Conghui He
This paper develops a Versatile and Honest vision language Model (VHM) for remote sensing image analysis. VHM is built on a large-scale remote sensing image-text dataset with rich-content captions (VersaD), and an honest instruction dataset comprising both factual and deceptive questions (HnstD). Unlike prevailing remote sensing image-text datasets, in which image captions focus on a few prominent objects and their relationships, VersaD captions provide detailed information about image properties, object attributes, and the overall scene. This comprehensive captioning enables VHM to thoroughly understand remote sensing images and perform diverse remote sensing tasks. Moreover, different from existing remote sensing instruction datasets that only include factual questions, HnstD contains additional deceptive questions stemming from the non-existence of objects. This feature prevents VHM from producing affirmative answers to nonsense queries, thereby ensuring its honesty. In our experiments, VHM significantly outperforms various vision language models on common tasks of scene classification, visual question answering, and visual grounding. Additionally, VHM achieves competent performance on several unexplored tasks, such as building vectorizing, multi-label classification and honest question answering. We will release the code, data and model weights at https://github.com/opendatalab/VHM .
本文开发了一种通用诚信视觉语言模型(VHM),用于遥感图像分析。VHM建立在一个大规模的遥感图像文本数据集(VersaD)和包含事实和欺骗性问题的诚信指令数据集(HnstD)之上。与现有的遥感图像文本数据集不同,VersaD的标题不仅关注一些突出对象及其关系,而且提供关于图像属性、对象属性和整体场景的综合信息。这种全面的标题功能使VHM能够充分了解遥感图像并执行多种遥感任务。此外,与仅包含事实问题的现有遥感指令数据集不同,HnstD还包含由对象不存在引起的欺骗性问题。这一特点使VHM不会为非常识查询给出肯定答案,从而确保其诚信。在我们的实验中,VHM在场景分类、视觉问答和视觉定位等常见任务上的表现优于各种视觉语言模型。此外,VHM在未探索的任务上也表现出了不俗的性能,如建筑矢量化、多标签分类和诚信问答等。我们将在https://github.com/opendatalab/VHM上发布代码、数据和模型权重。
论文及项目相关链接
PDF Equal contribution: Chao Pang, Xingxing Weng, Jiang Wu; Corresponding author: Gui-Song Xia, Conghui He
Summary
医学图像研究领域的一篇论文介绍了一种通用且诚实的视觉语言模型(VHM),用于遥感图像分析。该模型基于大规模遥感图像文本数据集(VersaD)和诚实指令数据集(HnstD)。VersaD数据集提供了详细的图像属性、对象特征和整体场景信息,使VHM能够全面理解遥感图像并执行各种遥感任务。HnstD数据集包含欺诈性问题,使模型不会对所有查询给出肯定答复,确保模型的诚实性。在场景分类、视觉问答和视觉定位等常见任务上,VHM显著优于其他视觉语言模型,并在建筑矢量化、多标签分类和诚实问答等未探索的任务上表现出竞争力。
Key Takeaways
- VHM模型是一种用于遥感图像分析的通用和诚实的视觉语言模型。
- VHM建立在两个数据集上:提供详细图像信息的VersaD数据集和包含欺骗性问题的HnstD数据集。
- VersaD数据集的丰富内容描述有助于模型全面理解遥感图像。
- HnstD数据集增强了模型的诚实度,使其不会对所有查询给出肯定答复。
- VHM在场景分类、视觉问答和视觉定位等任务上表现出卓越性能。
- VHM在未经探索的任务(如建筑矢量化、多标签分类和诚实问答)上也表现出竞争力。
点此查看论文截图