⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-21 更新
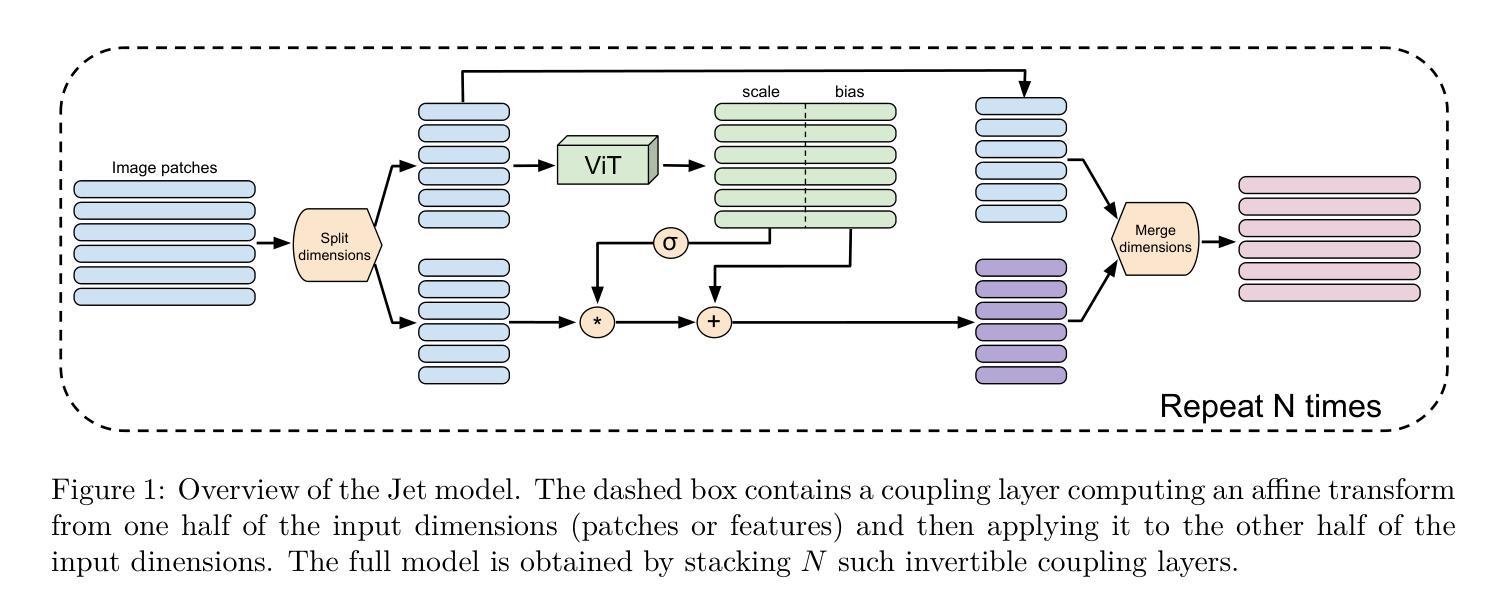
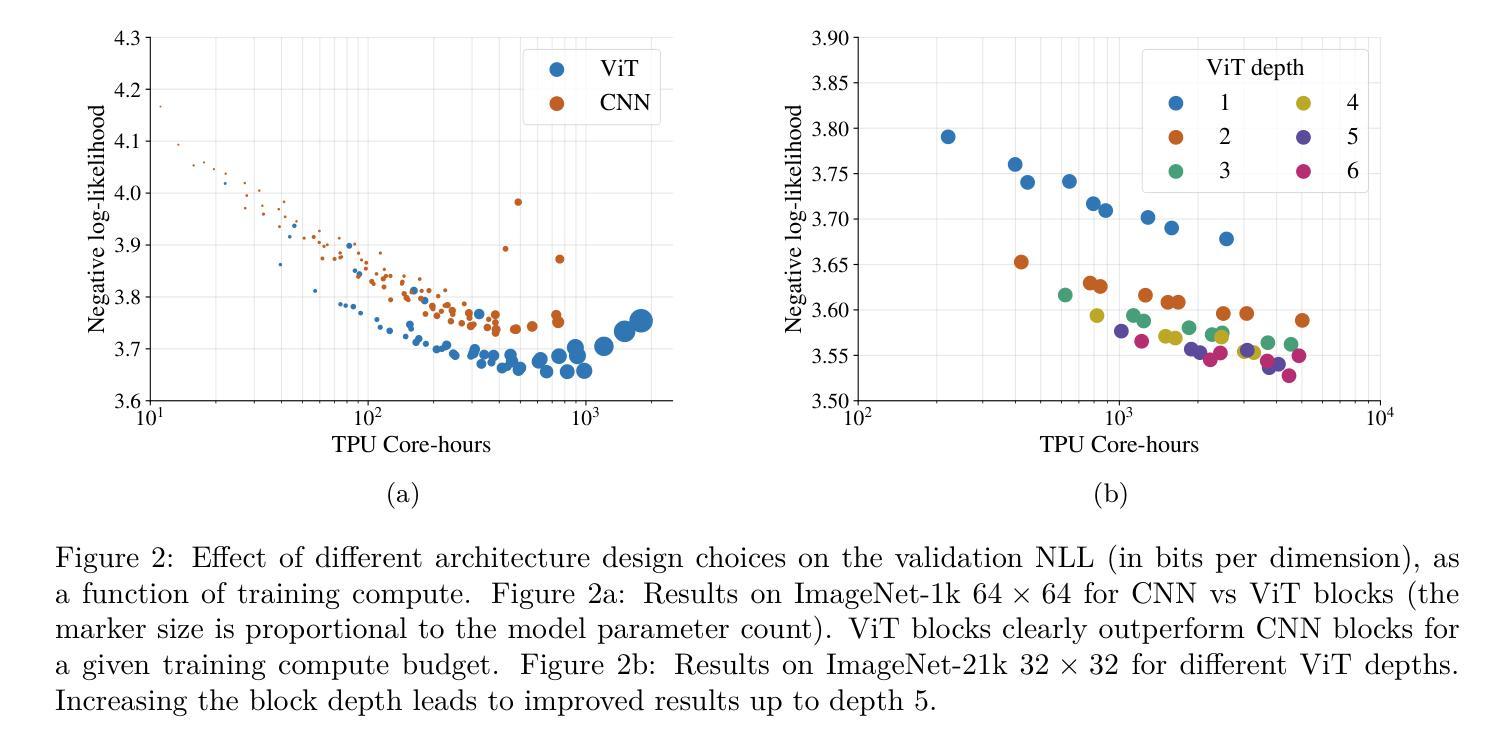
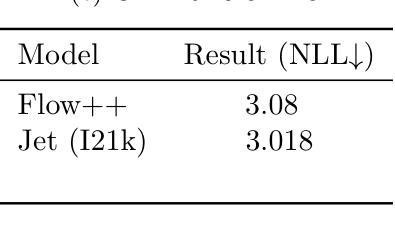
Jet: A Modern Transformer-Based Normalizing Flow
Authors:Alexander Kolesnikov, André Susano Pinto, Michael Tschannen
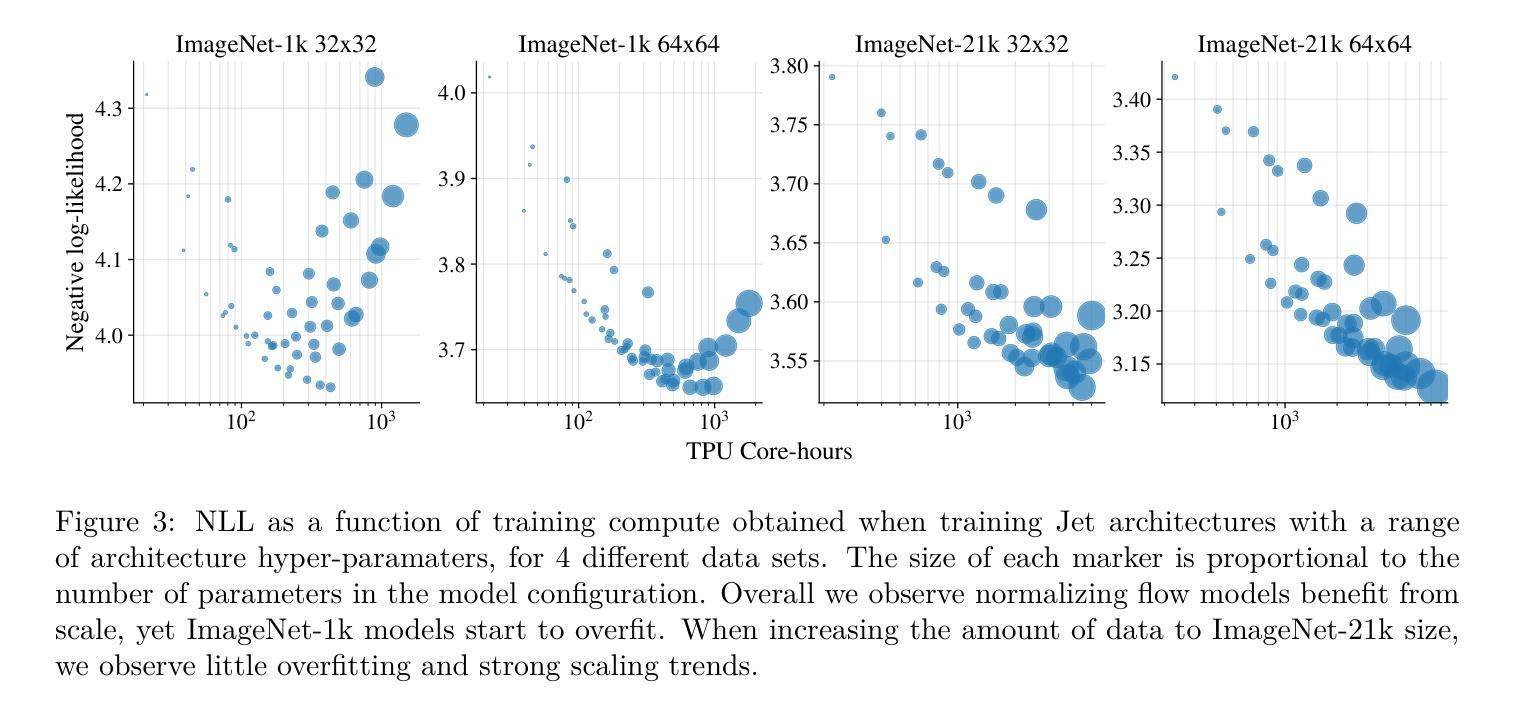
In the past, normalizing generative flows have emerged as a promising class of generative models for natural images. This type of model has many modeling advantages: the ability to efficiently compute log-likelihood of the input data, fast generation and simple overall structure. Normalizing flows remained a topic of active research but later fell out of favor, as visual quality of the samples was not competitive with other model classes, such as GANs, VQ-VAE-based approaches or diffusion models. In this paper we revisit the design of the coupling-based normalizing flow models by carefully ablating prior design choices and using computational blocks based on the Vision Transformer architecture, not convolutional neural networks. As a result, we achieve state-of-the-art quantitative and qualitative performance with a much simpler architecture. While the overall visual quality is still behind the current state-of-the-art models, we argue that strong normalizing flow models can help advancing research frontier by serving as building components of more powerful generative models.
过去,标准化生成流作为自然图像生成模型的一个有前景的类别已经出现。这种模型具有许多建模优势:能够高效地计算输入数据的对数似然值,生成速度快,整体结构简单。标准化流一直是活跃研究的主题,但后来不再受欢迎,因为样本的视觉质量与其他模型类别相比并不具有竞争力,如GAN、基于VQ-VAE的方法或扩散模型。在本文中,我们重新设计了基于耦合的标准化流模型,通过仔细消除先前的设计选择,并使用基于视觉转换器架构的计算块,而不是卷积神经网络。因此,我们凭借更简单的架构实现了先进的质量和性能。虽然整体视觉质量仍然落后于当前最先进的模型,我们认为强大的标准化流模型可以作为更强大的生成模型的构建组件,有助于推动研究前沿。
论文及项目相关链接
Summary
该文本讨论了基于归一化流的生成模型在过去作为一种有前景的自然图像生成模型的优势,以及为何这些模型的研究热度有所下降。研究人员重新设计了基于耦合的归一化流模型,通过使用基于Vision Transformer架构的计算块而非卷积神经网络,实现了最先进的定量和定性性能。虽然整体视觉质量仍落后于当前最先进的模型,但作者认为强大的归一化流模型可以作为更强大的生成模型的构建组件,有助于推动研究前沿。
Key Takeaways
- 归一化流模型曾是一种有前景的自然图像生成模型,具有计算对数似然、快速生成和简单结构等优点。
- 由于样本的视觉质量与其他模型类相比不具竞争力,如GANs、VQ-VAE方法和扩散模型,归一化流模型的研究热度有所下降。
- 通过对先验设计选择进行仔细剥离,并使用基于Vision Transformer架构的计算块,重新设计了基于耦合的归一化流模型。
- 这种新设计实现了最先进的定量和定性性能,尽管整体视觉质量仍落后于当前最先进模型。
- 强大的归一化流模型可以作为更强大的生成模型的构建组件,有助于推动研究前沿。
- 该研究展示了归一化流模型在生成模型领域中的潜力和改进空间。
点此查看论文截图


Distilled Pooling Transformer Encoder for Efficient Realistic Image Dehazing
Authors:Le-Anh Tran, Dong-Chul Park
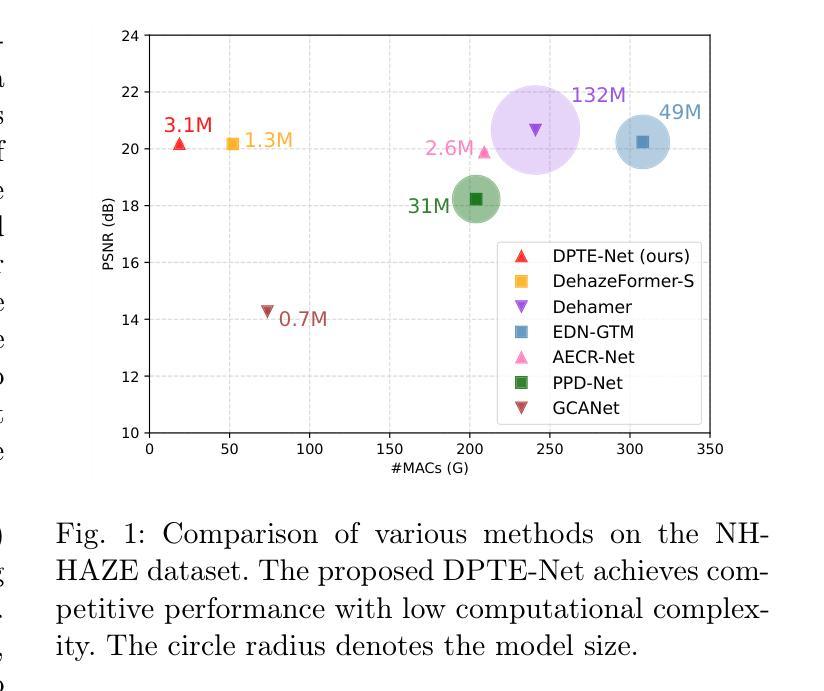
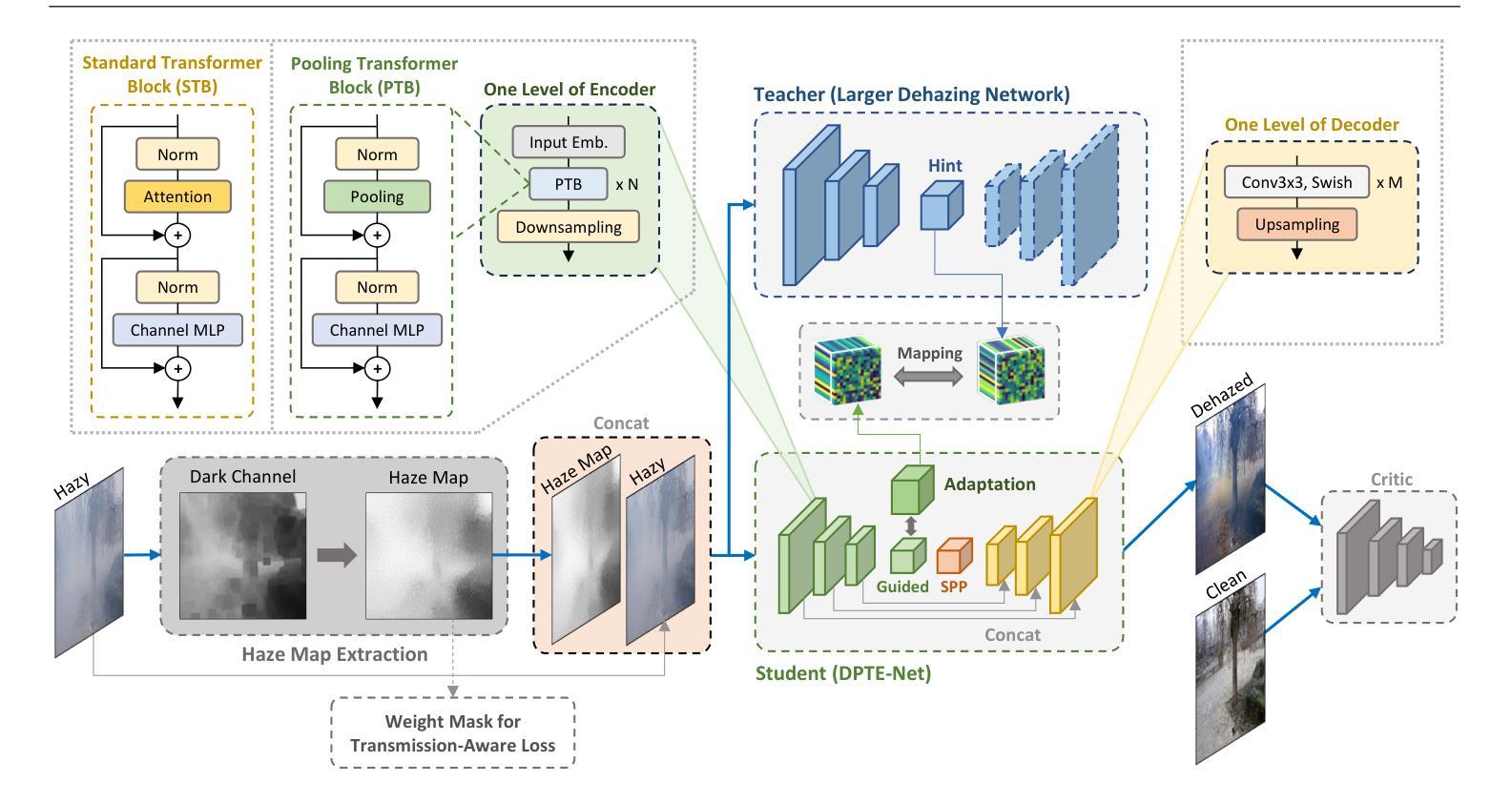
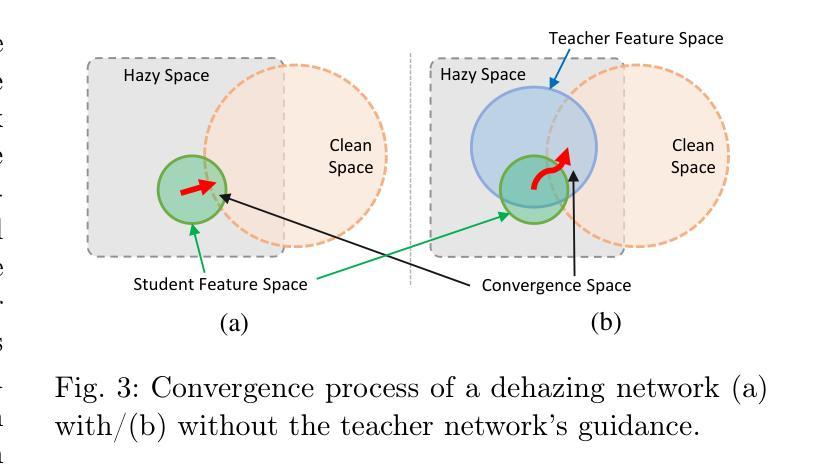
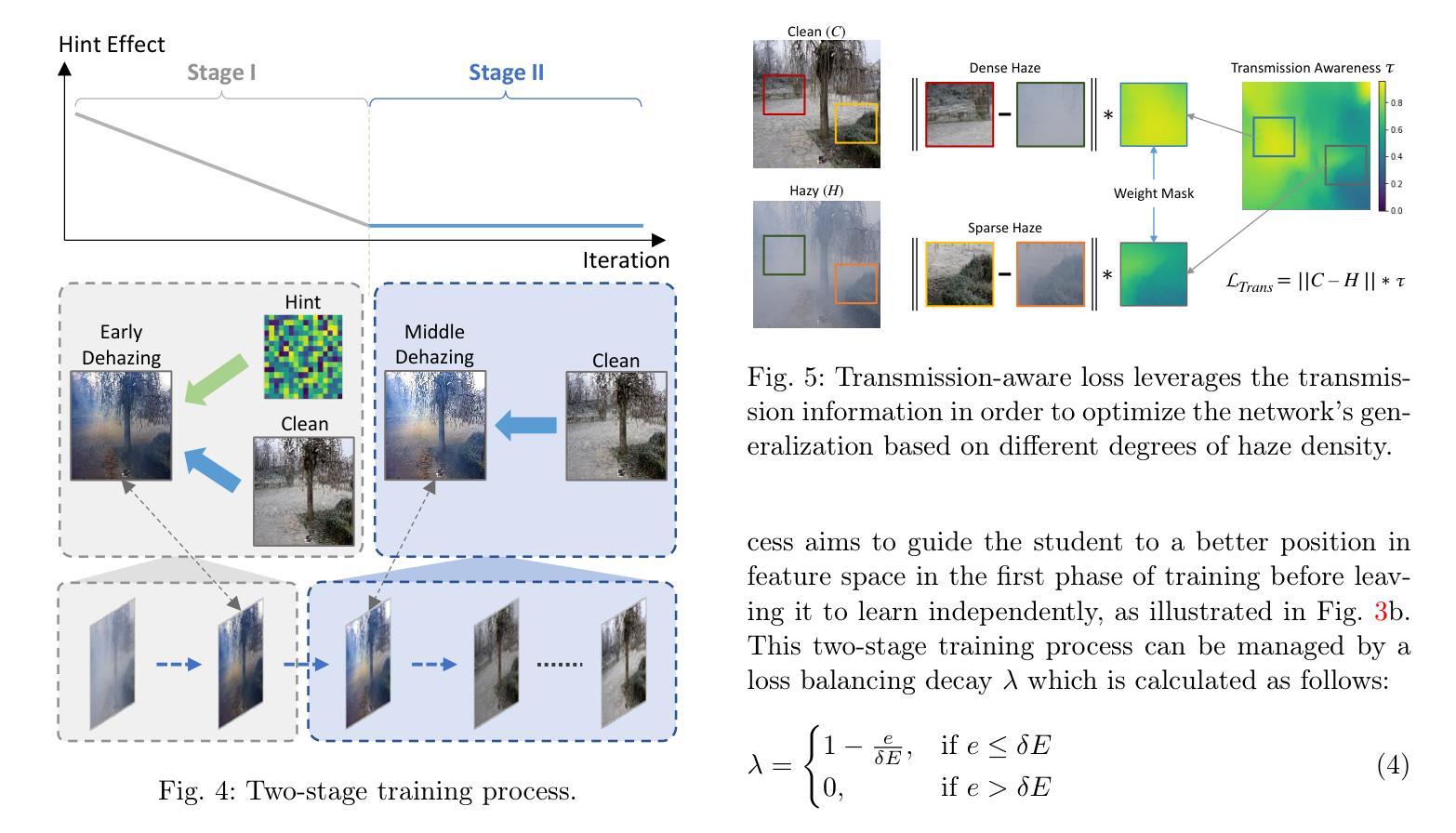
This paper proposes a lightweight neural network designed for realistic image dehazing, utilizing a Distilled Pooling Transformer Encoder, named DPTE-Net. Recently, while vision transformers (ViTs) have achieved great success in various vision tasks, their self-attention (SA) module’s complexity scales quadratically with image resolution, hindering their applicability on resource-constrained devices. To overcome this, the proposed DPTE-Net substitutes traditional SA modules with efficient pooling mechanisms, significantly reducing computational demands while preserving ViTs’ learning capabilities. To further enhance semantic feature learning, a distillation-based training process is implemented which transfers rich knowledge from a larger teacher network to DPTE-Net. Additionally, DPTE-Net is trained within a generative adversarial network (GAN) framework, leveraging the strong generalization of GAN in image restoration, and employs a transmission-aware loss function to dynamically adapt to varying haze densities. Experimental results on various benchmark datasets have shown that the proposed DPTE-Net can achieve competitive dehazing performance when compared to state-of-the-art methods while maintaining low computational complexity, making it a promising solution for resource-limited applications. The code of this work is available at https://github.com/tranleanh/dpte-net.
本文提出了一种为真实图像去雾设计的轻量级神经网络,该网络利用蒸馏池化变压器编码器(DPTE-Net)。尽管最近视觉变压器(ViT)在各种视觉任务中取得了巨大成功,但其自注意力(SA)模块的复杂性随图像分辨率呈二次方增长,这在资源受限的设备上限制了其适用性。为了克服这一问题,所提出的DPTE-Net用高效的池化机制代替了传统的SA模块,在大大降低计算需求的同时,保留了ViT的学习能力。为了进一步增强语义特征学习,实现了一种基于蒸馏的训练过程,将丰富的知识从较大的教师网络转移到DPTE-Net。此外,DPTE-Net在一个生成对抗网络(GAN)框架内进行训练,利用GAN在图像恢复中的强大泛化能力,并采用一种传输感知损失函数来动态适应不同的雾霾密度。在多个基准数据集上的实验结果表明,与最新方法相比,所提出的DPTE-Net在保持较低计算复杂度的同时,可以实现有竞争力的去雾性能,是资源受限应用的一个很有前途的解决方案。该工作的代码可在https://github.com/tranleanh/dpte-net获得。
论文及项目相关链接
PDF 18 pages, 17 figures
Summary
本文提出了一种轻量级的神经网络,用于现实图像去雾,该网络利用蒸馏池化变压器编码器(DPTE-Net)。针对视觉变压器(ViT)在资源受限设备上应用时面临的挑战,如自注意力(SA)模块计算复杂度随图像分辨率二次方增长,本研究通过引入高效的池化机制替代传统SA模块,显著降低了计算需求,同时保留了ViTs的学习能力。为实现语义特征学习的增强,研究实施了基于蒸馏的训练过程,从较大的教师网络向DPTE-Net转移丰富知识。此外,DPTE-Net被训练在生成对抗网络(GAN)框架中,利用GAN在图像恢复中的强大泛化能力,并采用传输感知损失函数以动态适应不同的雾霾密度。实验结果表明,与最新方法相比,所提出的DPTE-Net在基准数据集上具有良好的去雾性能,同时保持较低的计算复杂度,成为资源受限应用的有前途的解决方案。
Key Takeaways
- 提出了一个轻量级的神经网络DPTE-Net,用于现实图像去雾。
- 利用池化机制替代传统的自注意力模块,降低计算复杂度。
- 实施了基于蒸馏的训练过程,增强语义特征学习。
- DPTE-Net在GAN框架中进行训练,具备强大的图像恢复能力。
- 采用传输感知损失函数,能动态适应不同雾霾密度。
- 在多个基准数据集上的实验结果表明,DPTE-Net具有竞争力的去雾性能。
点此查看论文截图

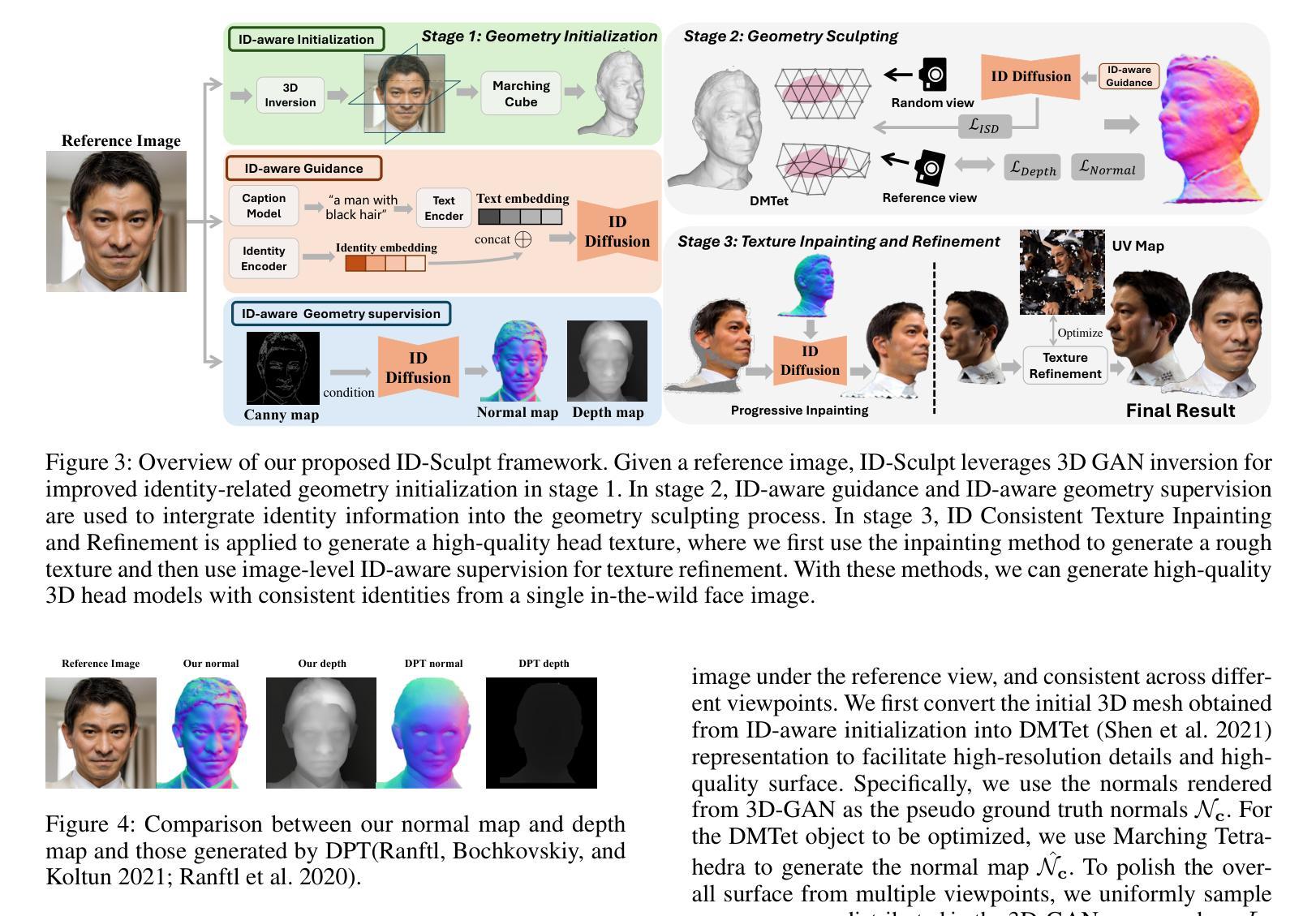
ID-Sculpt: ID-aware 3D Head Generation from Single In-the-wild Portrait Image
Authors:Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Chengjie Wang, Lizhuang Ma
While recent works have achieved great success on image-to-3D object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, ID-Sculpt, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the ID-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from a single in-the-wild portrait image.
虽然近期的研究在图像到3D物体的生成上取得了巨大的成功,但从单一图像生成高质量和高保真度的3D头部仍然是一个巨大的挑战。之前基于文本的方法生成3D头部受限于文本描述,而基于图像的方法难以产生高质量的头部位置信息。为了解决这一挑战性问题,我们提出了一种新的框架——ID-Sculpt,用于生成高质量的3D头部,同时保留其身份特征。我们的工作将肖像图像的身份信息融入到三个环节:1)几何初始化,2)几何雕塑,以及3)纹理生成阶段。给定一个参考肖像图像,我们首先通过文本特征与身份特征的对齐来实现ID感知指导增强,其中包含代表面部信息的控制信号。然后,我们使用Canny地图、肖像图像的身份特征以及预训练的文本到正常/深度扩散模型来生成ID感知几何监督,并利用3D-GAN反转来生成ID感知几何初始化。此外,通过向3D头部生成注入身份信息的能力,我们使用ID感知指导来计算用于几何雕塑的ID感知得分蒸馏(ISD)。对于纹理生成,我们采用ID一致纹理填充和细化方法,逐步扩展纹理填充的视图以获得初始UV纹理贴图。然后,我们使用ID感知指导为噪声多视图图像提供图像级监督,以获得精细的纹理贴图。大量实验表明,我们可以从单一的野外肖像图像生成高质量、几何和纹理准确的3D头部。
论文及项目相关链接
PDF Accepted by AAAI 2025; Project page: https://jinkun-hao.github.io/ID-Sculpt/
Summary
本文提出一种名为ID-Sculpt的新型框架,能够生成高质量且保持身份信息的3D头像。该框架将肖像图像的身份信息融入三个阶段:几何初始化、几何雕塑和纹理生成。通过身份感知指导增强、Canny地图、预训练的文本到正常/深度扩散模型和3D-GAN反转等技术,实现高质量3D头像的生成。实验证明,该框架能够从野外肖像图像生成具有准确几何和纹理的高质量3D头像。
Key Takeaways
- ID-Sculpt框架能够生成高质量且保持身份信息的3D头像。
- 身份信息被融入肖像图像的三个阶段:几何初始化、几何雕塑和纹理生成。
- 通过身份感知指导增强实现ID-aware指导。
- 利用Canny地图、身份特征和预训练的文本到正常/深度扩散模型生成ID感知几何监督。
- 使用3D-GAN反转进行ID感知几何初始化。
- 通过ID感知指导计算用于几何雕塑的ID感知分数蒸馏(ISD)。
点此查看论文截图