⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-21 更新
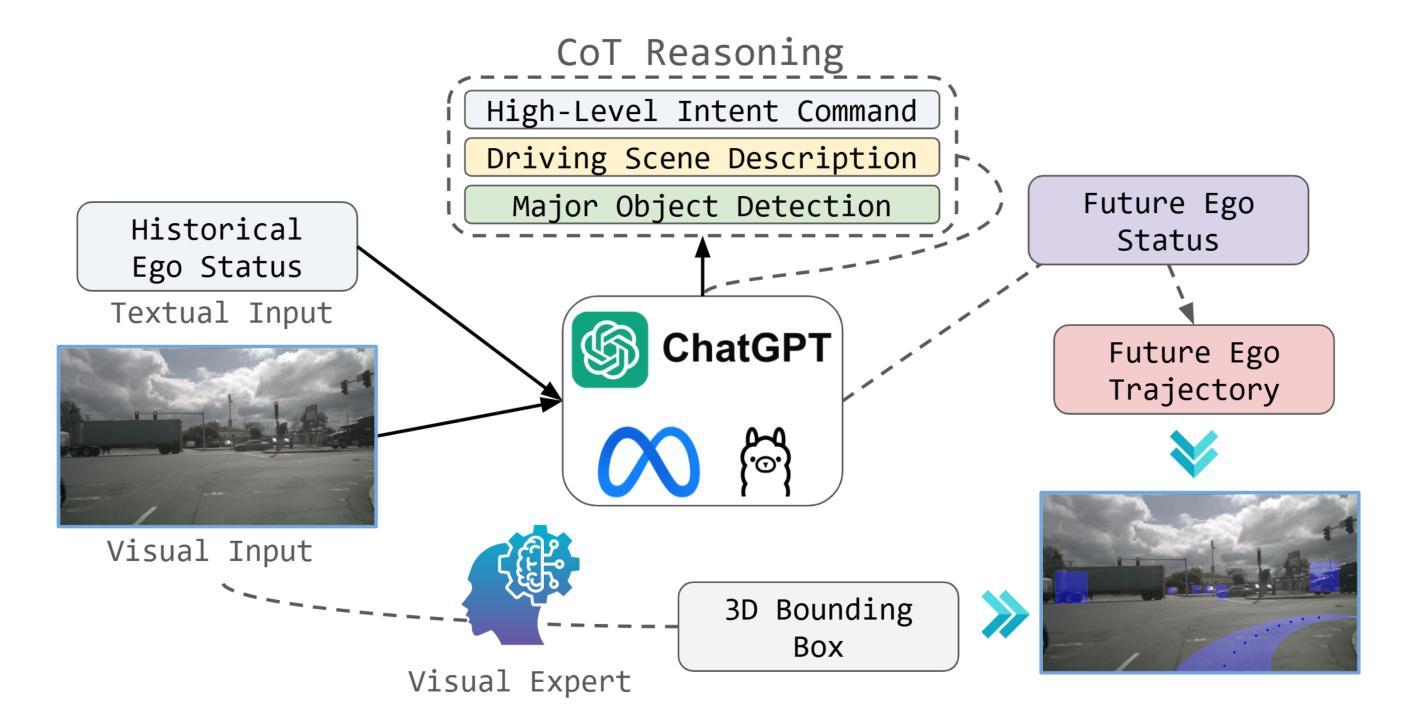
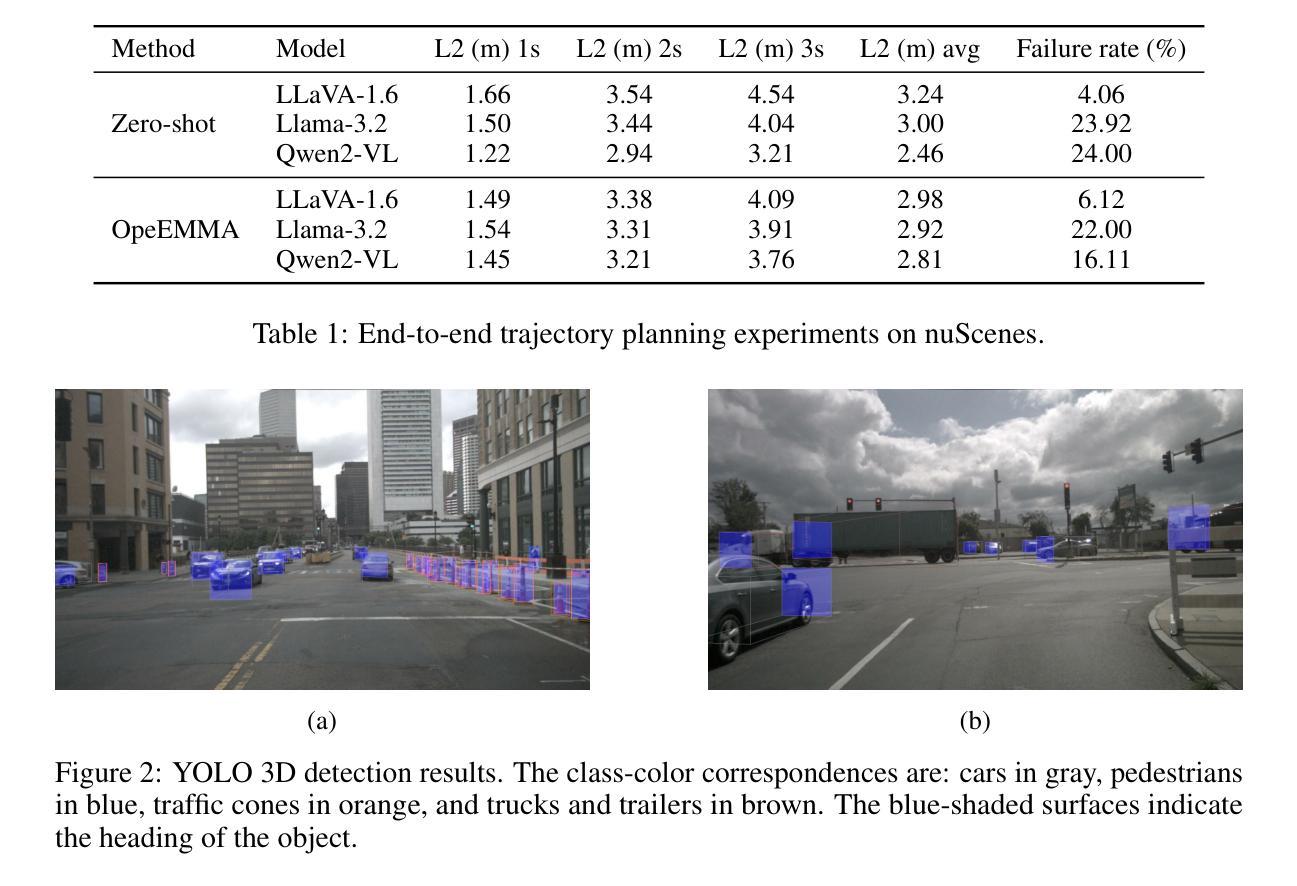
OpenEMMA: Open-Source Multimodal Model for End-to-End Autonomous Driving
Authors:Shuo Xing, Chengyuan Qian, Yuping Wang, Hongyuan Hua, Kexin Tian, Yang Zhou, Zhengzhong Tu
Since the advent of Multimodal Large Language Models (MLLMs), they have made a significant impact across a wide range of real-world applications, particularly in Autonomous Driving (AD). Their ability to process complex visual data and reason about intricate driving scenarios has paved the way for a new paradigm in end-to-end AD systems. However, the progress of developing end-to-end models for AD has been slow, as existing fine-tuning methods demand substantial resources, including extensive computational power, large-scale datasets, and significant funding. Drawing inspiration from recent advancements in inference computing, we propose OpenEMMA, an open-source end-to-end framework based on MLLMs. By incorporating the Chain-of-Thought reasoning process, OpenEMMA achieves significant improvements compared to the baseline when leveraging a diverse range of MLLMs. Furthermore, OpenEMMA demonstrates effectiveness, generalizability, and robustness across a variety of challenging driving scenarios, offering a more efficient and effective approach to autonomous driving. We release all the codes in https://github.com/taco-group/OpenEMMA.
自从多模态大型语言模型(MLLMs)的出现以来,它们在各种现实世界应用中产生了重大影响,特别是在自动驾驶(AD)领域。它们处理复杂视觉数据和推理复杂驾驶场景的能力为端到端AD系统的新范式铺平了道路。然而,开发端到端AD模型的进展缓慢,因为现有的微调方法需要大量资源,包括强大的计算能力、大规模数据集和巨额资金。从最近的推理计算进步中汲取灵感,我们提出了基于MLLMs的开源端到端框架OpenEMMA。通过融入“思维链”推理过程,OpenEMMA在利用多种MLLMs时,相较于基线实现了显著改进。此外,OpenEMMA在多种具有挑战性的驾驶场景中展现了其有效性、通用性和稳健性,为自动驾驶提供了更高效、有效的方法。我们将所有代码发布在https://github.com/taco-group/OpenEMMA。
论文及项目相关链接
Summary
多模态大型语言模型(MLLMs)在自动驾驶(AD)等实际应用领域产生了重大影响。然而,开发端到端的自动驾驶模型进展缓慢,因为现有的微调方法需要大量资源。受推理计算最新进展的启发,我们提出了基于MLLMs的开源端到端框架OpenEMMA。通过融入Chain-of-Thought推理过程,OpenEMMA在利用多种MLLMs时实现了显著改进,并展示了在多种挑战驾驶场景中的有效性、通用性和稳健性,为自动驾驶提供了更高效、更有效的方法。我们已将所有代码发布在https://github.com/taco-group/OpenEMMA。
Key Takeaways
- 多模态大型语言模型(MLLMs)在自动驾驶领域具有显著影响。
- 现有开发端到端自动驾驶模型的进展因资源需求而受到限制。
- OpenEMMA是一个基于MLLMs的开源端到端框架,旨在解决自动驾驶问题。
- OpenEMMA通过融入Chain-of-Thought推理过程,实现了对多种MLLMs的利用并获得了显著改进。
- OpenEMMA在多种挑战驾驶场景中展示了有效性、通用性和稳健性。
- OpenEMMA为自动驾驶提供了更高效、更有效的方法。
点此查看论文截图


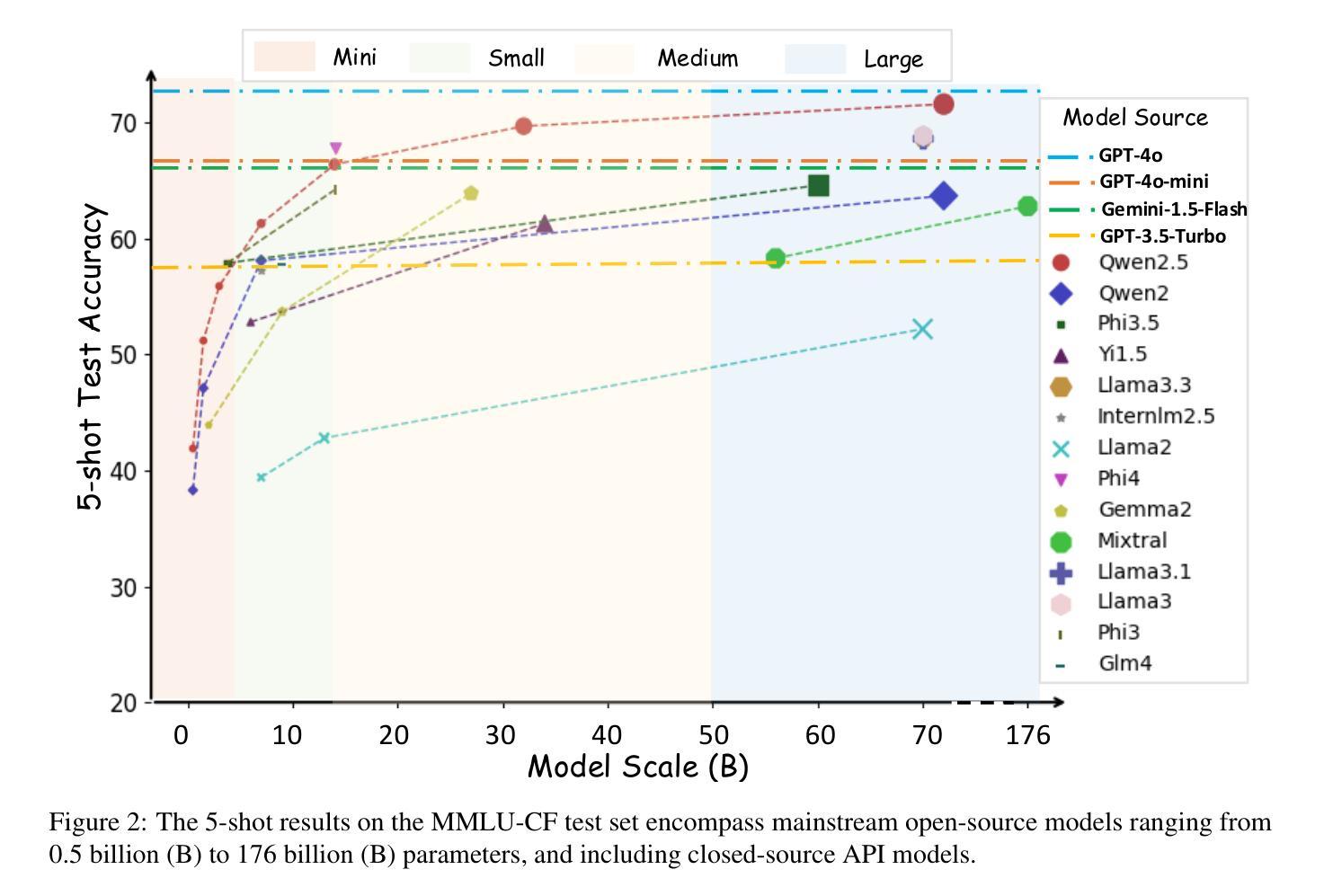
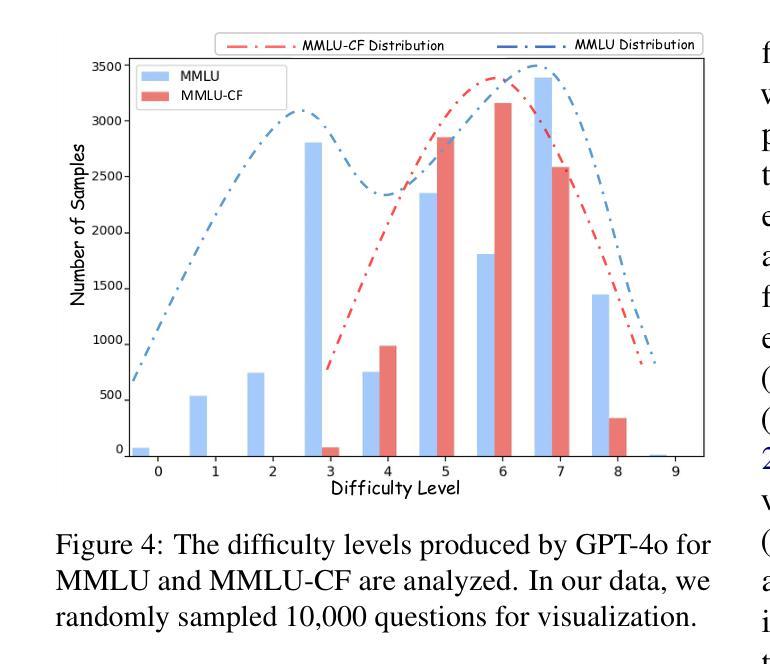
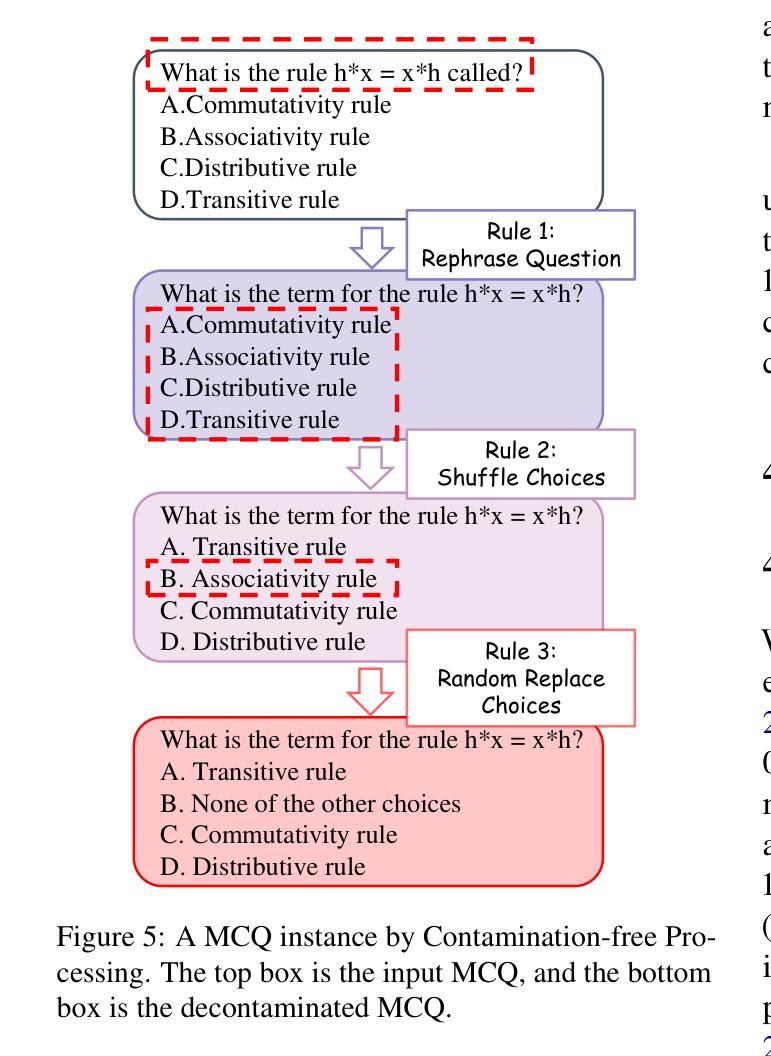
MMLU-CF: A Contamination-free Multi-task Language Understanding Benchmark
Authors:Qihao Zhao, Yangyu Huang, Tengchao Lv, Lei Cui, Qinzheng Sun, Shaoguang Mao, Xin Zhang, Ying Xin, Qiufeng Yin, Scarlett Li, Furu Wei
Multiple-choice question (MCQ) datasets like Massive Multitask Language Understanding (MMLU) are widely used to evaluate the commonsense, understanding, and problem-solving abilities of large language models (LLMs). However, the open-source nature of these benchmarks and the broad sources of training data for LLMs have inevitably led to benchmark contamination, resulting in unreliable evaluation results. To alleviate this issue, we propose a contamination-free and more challenging MCQ benchmark called MMLU-CF. This benchmark reassesses LLMs’ understanding of world knowledge by averting both unintentional and malicious data leakage. To avoid unintentional data leakage, we source data from a broader domain and design three decontamination rules. To prevent malicious data leakage, we divide the benchmark into validation and test sets with similar difficulty and subject distributions. The test set remains closed-source to ensure reliable results, while the validation set is publicly available to promote transparency and facilitate independent verification. Our evaluation of mainstream LLMs reveals that the powerful GPT-4o achieves merely a 5-shot score of 73.4% and a 0-shot score of 71.9% on the test set, which indicates the effectiveness of our approach in creating a more rigorous and contamination-free evaluation standard. The GitHub repository is available at https://github.com/microsoft/MMLU-CF and the dataset refers to https://huggingface.co/datasets/microsoft/MMLU-CF.
类似大规模多任务语言理解(MMLU)这样的多项选择题(MCQ)数据集广泛用于评估大型语言模型(LLM)的常识、理解和问题解决能力。然而,这些基准测试的开源性以及LLM训练数据来源的广泛性不可避免地导致了基准测试污染,从而导致评估结果不可靠。为了缓解这个问题,我们提出了一个无污染且更具挑战性的MCQ基准测试,名为MMLU-CF。这个基准测试通过避免无意和恶意的数据泄露来重新评估LLM对世界知识的理解。为避免无意中的数据泄露,我们从更广泛的领域获取数据,并制定了三条净化规则。为了防止恶意数据泄露,我们将基准测试划分为难度和主题分布相似的验证集和测试集。测试集保持封闭源代码,以确保结果可靠,而验证集面向公众,以促进透明度和独立验证。我们对主流LLM的评估表明,强大的GPT-4在测试集上仅达到5次射击的73.4%得分和0次射击的71.9%得分,这证明了我们方法在创建更严格和无污染评估标准方面的有效性。GitHub仓库位于https://github.com/microsoft/MMLU-CF,数据集请参见。https://huggingface.co/datasets/microsoft/MMLU-CF。
论文及项目相关链接
Summary
本文介绍了大规模多任务语言理解(MMLU)等多选题(MCQ)数据集在评估大型语言模型(LLM)的常识、理解和问题解决能力方面的广泛应用。然而,这些基准测试的开源性以及LLM训练数据的广泛来源导致了不可避免的基准测试污染,从而导致评估结果不可靠。为解决这一问题,提出了无污染且更具挑战性的MCQ基准测试MMLU-CF。该基准测试通过避免无意和恶意的数据泄露,重新评估LLM对世界知识的理解。通过从更广泛的领域来源数据并设计三个去污规则,以避免无意的数据泄露。同时,通过将基准测试分为验证集和测试集来防止恶意数据泄露,两者在难度和主题分布上相似。测试集保持封闭以保证结果的可靠性,而验证集则公开以促进透明度和独立验证。对主流LLM的评估显示,强大的GPT-4o在测试集上的5次射击得分仅为73.4%,0次射击得分为71.9%,这证明了我们在创建更严格和无污染的评价标准方面的有效性。
Key Takeaways
- MMLU等MCQ数据集广泛用于评估LLM的常识、理解和问题解决能力。
- 现有基准测试存在污染问题,导致评估结果不可靠。
- 提出无污染且更具挑战性的MCQ基准测试MMLU-CF。
- MMLU-CF通过避免无意和恶意的数据泄露,重新评估LLM的世界知识理解。
- 通过从更广泛的领域来源数据和设计去污规则来避免数据泄露。
- 测试集保持封闭以保证结果可靠,验证集公开以促进透明度和独立验证。
点此查看论文截图


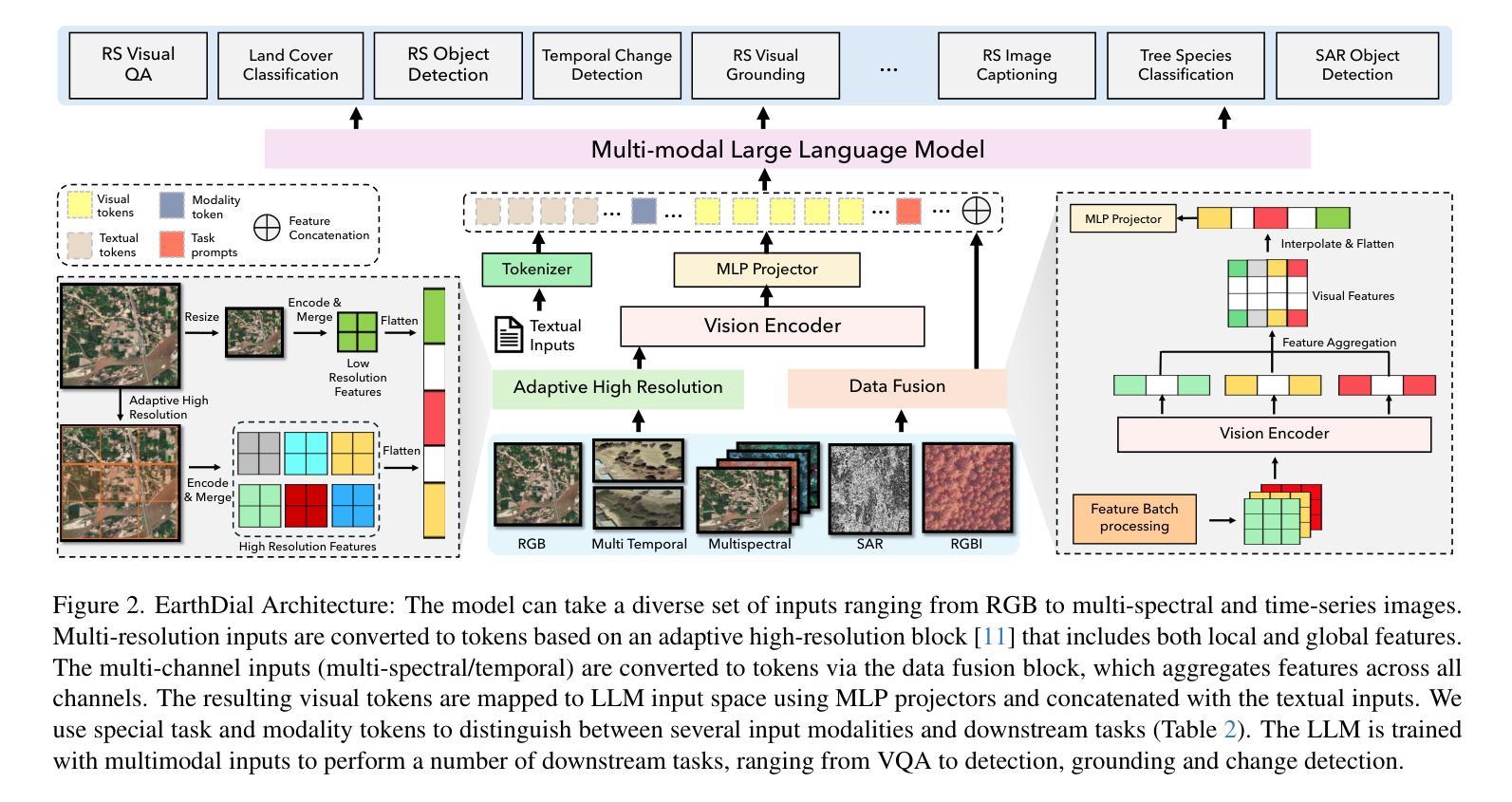
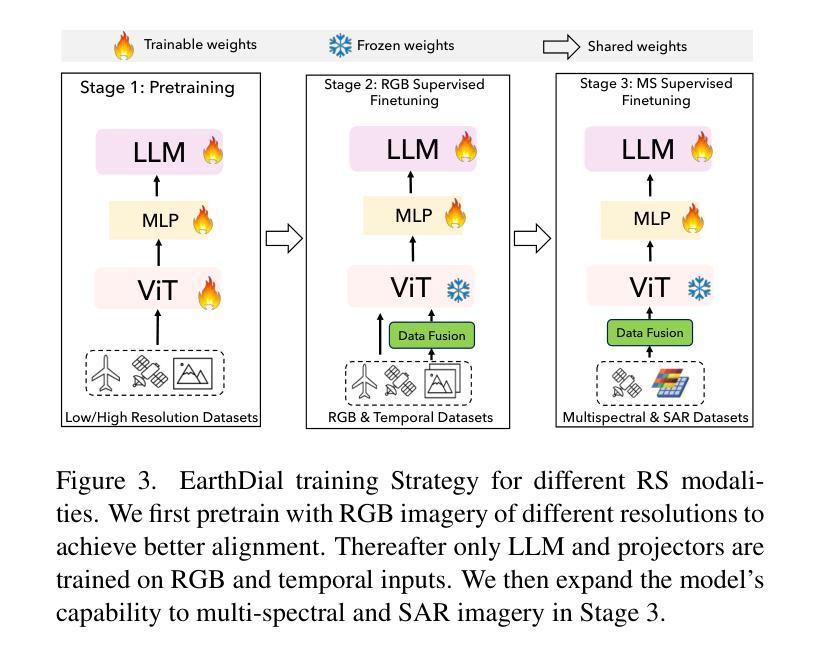
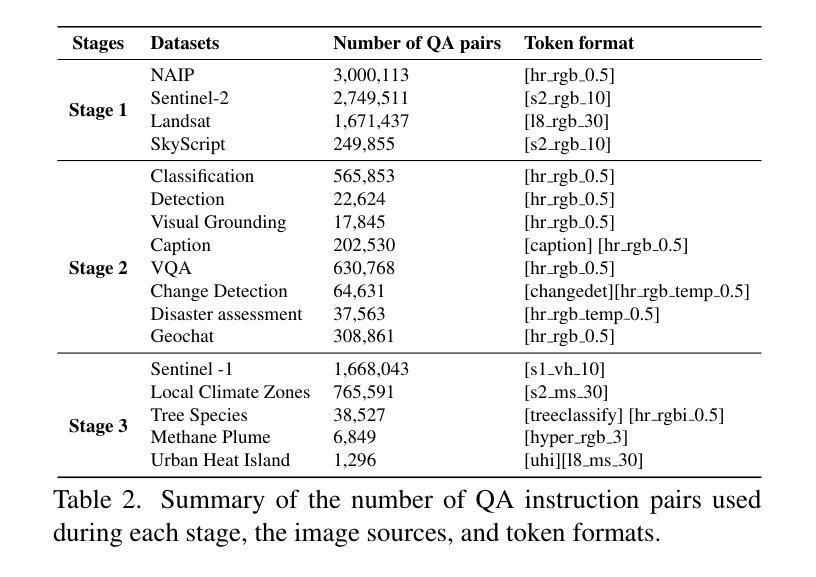
EarthDial: Turning Multi-sensory Earth Observations to Interactive Dialogues
Authors:Sagar Soni, Akshay Dudhane, Hiyam Debary, Mustansar Fiaz, Muhammad Akhtar Munir, Muhammad Sohail Danish, Paolo Fraccaro, Campbell D Watson, Levente J Klein, Fahad Shahbaz Khan, Salman Khan
Automated analysis of vast Earth observation data via interactive Vision-Language Models (VLMs) can unlock new opportunities for environmental monitoring, disaster response, and resource management. Existing generic VLMs do not perform well on Remote Sensing data, while the recent Geo-spatial VLMs remain restricted to a fixed resolution and few sensor modalities. In this paper, we introduce EarthDial, a conversational assistant specifically designed for Earth Observation (EO) data, transforming complex, multi-sensory Earth observations into interactive, natural language dialogues. EarthDial supports multi-spectral, multi-temporal, and multi-resolution imagery, enabling a wide range of remote sensing tasks, including classification, detection, captioning, question answering, visual reasoning, and visual grounding. To achieve this, we introduce an extensive instruction tuning dataset comprising over 11.11M instruction pairs covering RGB, Synthetic Aperture Radar (SAR), and multispectral modalities such as Near-Infrared (NIR) and infrared. Furthermore, EarthDial handles bi-temporal and multi-temporal sequence analysis for applications like change detection. Our extensive experimental results on 37 downstream applications demonstrate that EarthDial outperforms existing generic and domain-specific models, achieving better generalization across various EO tasks.
通过交互式视觉语言模型(VLMs)对大量的地球观测数据进行自动化分析,可以为环境监测、灾害响应和资源管理解锁新的机会。现有的通用VLMs在遥感数据上的表现并不理想,而最近的地理空间VLMs仍然局限于固定的分辨率和少量的传感器模式。在本文中,我们介绍了EarthDial,这是一个专门为地球观测(EO)数据设计的对话助手,将复杂的多感官地球观测转化为交互式的自然语言对话。EarthDial支持多光谱、多时相和多分辨率的影像,能够完成广泛的遥感任务,包括分类、检测、描述、问答、视觉推理和视觉定位。为了实现这一点,我们引入了一个包含超过1111万个指令对的广泛指令调整数据集,涵盖RGB、合成孔径雷达(SAR)和多光谱模式,如近红外(NIR)和红外。此外,EarthDial还处理双时相和多时相序列分析,用于变化检测等应用。我们在37个下游应用上的广泛实验结果证明,EarthDial优于现有的通用和特定领域的模型,在各种EO任务中实现了更好的泛化能力。
论文及项目相关链接
Summary
基于地球观测的大规模数据,通过交互式的视觉语言模型(VLMs)进行自动化分析,可为环境监测、灾害响应和资源管理带来新的机遇。现有通用VLMs在遥感数据上的表现不佳,而最新的地理空间VLMs仍局限于固定分辨率和少数传感器模态。本文介绍了一款专为地球观测(EO)数据设计的对话助手——EarthDial,它将复杂的多感官地球观测数据转化为交互式自然语言对话。EarthDial支持多光谱、多时相和多分辨率影像,可应对多种遥感任务,包括分类、检测、描述、问答、视觉推理和视觉定位等。为达成这一目标,我们引入了包含超过1亿一千万指令对的庞大指令调整数据集,涵盖RGB、合成孔径雷达(SAR)和多光谱模式,如近红外和红外等。此外,EarthDial还处理双时相和多时相序列分析,适用于变化检测等应用。在37个下游应用上的广泛实验结果表明,EarthDial在多种EO任务上优于现有通用和特定领域的模型,实现了良好的泛化性能。
Key Takeaways
- 地球观测数据通过交互式视觉语言模型(VLMs)进行自动化分析具有巨大潜力,有助于环境监测、灾害响应和资源管理。
- 当前VLMs在遥感数据应用上存在局限性,需要专门的模型来处理地球观测数据。
- EarthDial是一款专为地球观测数据设计的对话助手,支持多光谱、多时相和多分辨率影像分析。
- EarthDial通过引入大规模指令调整数据集,覆盖多种传感器模态,实现了优异的性能。
- EarthDial能处理复杂的遥感任务,包括分类、检测、描述、问答、视觉推理和视觉定位等。
- EarthDial还具备处理双时相和多时相序列分析的能力,适用于变化检测等应用。
点此查看论文截图


HPC-Coder-V2: Studying Code LLMs Across Low-Resource Parallel Languages
Authors:Aman Chaturvedi, Daniel Nichols, Siddharth Singh, Abhinav Bhatele
Large Language Model (LLM) based coding tools have been tremendously successful as software development assistants, yet they are often designed for general purpose programming tasks and perform poorly for more specialized domains such as high performance computing. Creating specialized models and tools for these domains is crucial towards gaining the benefits of LLMs in areas such as HPC. While previous work has explored HPC-specific models, LLMs still struggle to generate parallel code and it is not at all clear what hurdles are still holding back these LLMs and what must be done to overcome them. In this work, we conduct an in-depth study along the many axes of fine-tuning a specialized HPC LLM in order to better understand the challenges. Based on our findings we fine-tune and evaluate a specialized HPC LLM that is shown to be the best performing open-source code LLM for parallel code generation to date.
基于大型语言模型(LLM)的编码工具作为软件开发助手取得了巨大的成功,但它们通常是为通用编程任务而设计的,对于高性能计算等特殊领域表现不佳。在这些领域创建专业模型和相关工具对于在诸如高性能计算等领域获得大型语言模型的益处至关重要。尽管先前的工作已经探索了针对高性能计算的专业模型,但大型语言模型在生成并行代码方面仍然面临困难,尚不清楚是什么障碍仍然阻碍着这些大型语言模型的发展,以及需要采取什么措施来克服这些障碍。在这项工作中,我们沿着许多轴对专业高性能计算大型语言模型进行了深入研究,以更好地了解所面临的挑战。基于我们的发现,我们对专业的高性能计算大型语言模型进行了微调并进行了评估,被证明迄今为止是并行代码生成方面表现最好的开源代码大型语言模型。
论文及项目相关链接
Summary
大型语言模型(LLM)在软件开发助手领域取得了巨大成功,但对于专业领域如高性能计算(HPC)等特定任务的编程,其表现并不理想。为了在这些领域获取LLM的益处,创建专门化的模型和工具至关重要。当前对于特定于HPC的模型探索尚存在挑战,尤其是生成并行代码方面。本研究对精细调整HPC特殊LLM的多个方面进行了深入研究,以更好地理解挑战所在,并基于研究对LLM进行了精细调整与评估,显示出迄今为止在并行代码生成方面的最佳性能。
Key Takeaways
- LLM在作为软件开发助手方面取得了显著成功,但在专业领域如高性能计算(HPC)中的表现有待提高。
- 创建针对特定领域的LLM模型和工具,是提升LLM在HPC等领域表现的关键。
- 目前LLM在生成并行代码方面存在困难。
- 本研究通过深入研究并精细调整一个针对HPC的LLM模型,取得显著成果。
- 此LLM模型在并行代码生成方面被证实是目前最佳的开源代码LLM。
- 对LLM模型的进一步研究和改进仍有必要,以解决其在特定领域面临的挑战。
点此查看论文截图

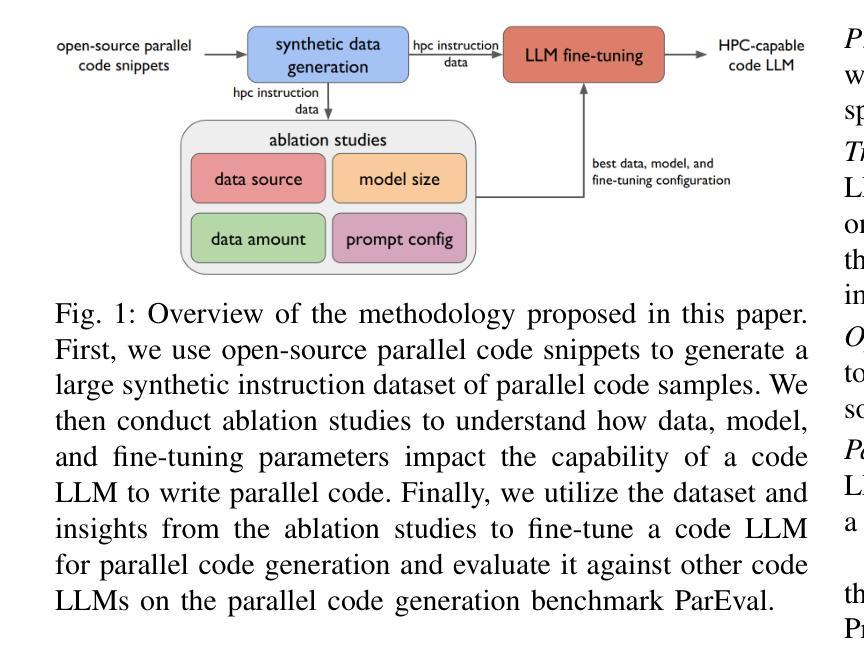
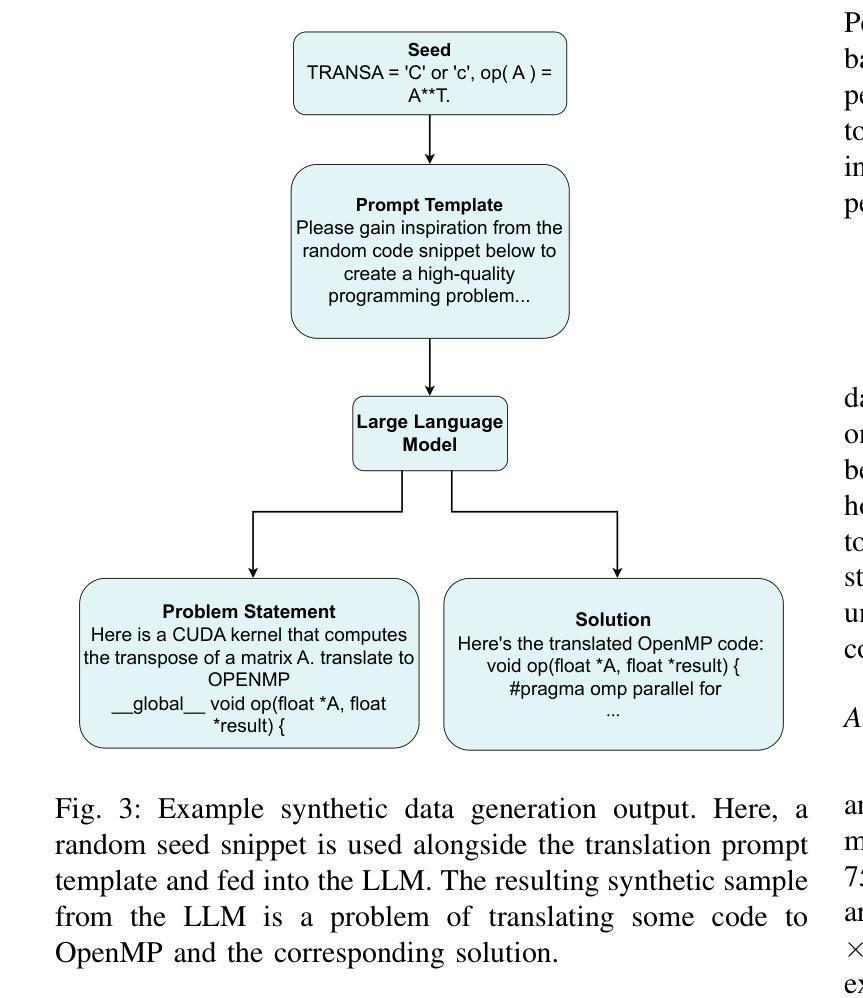
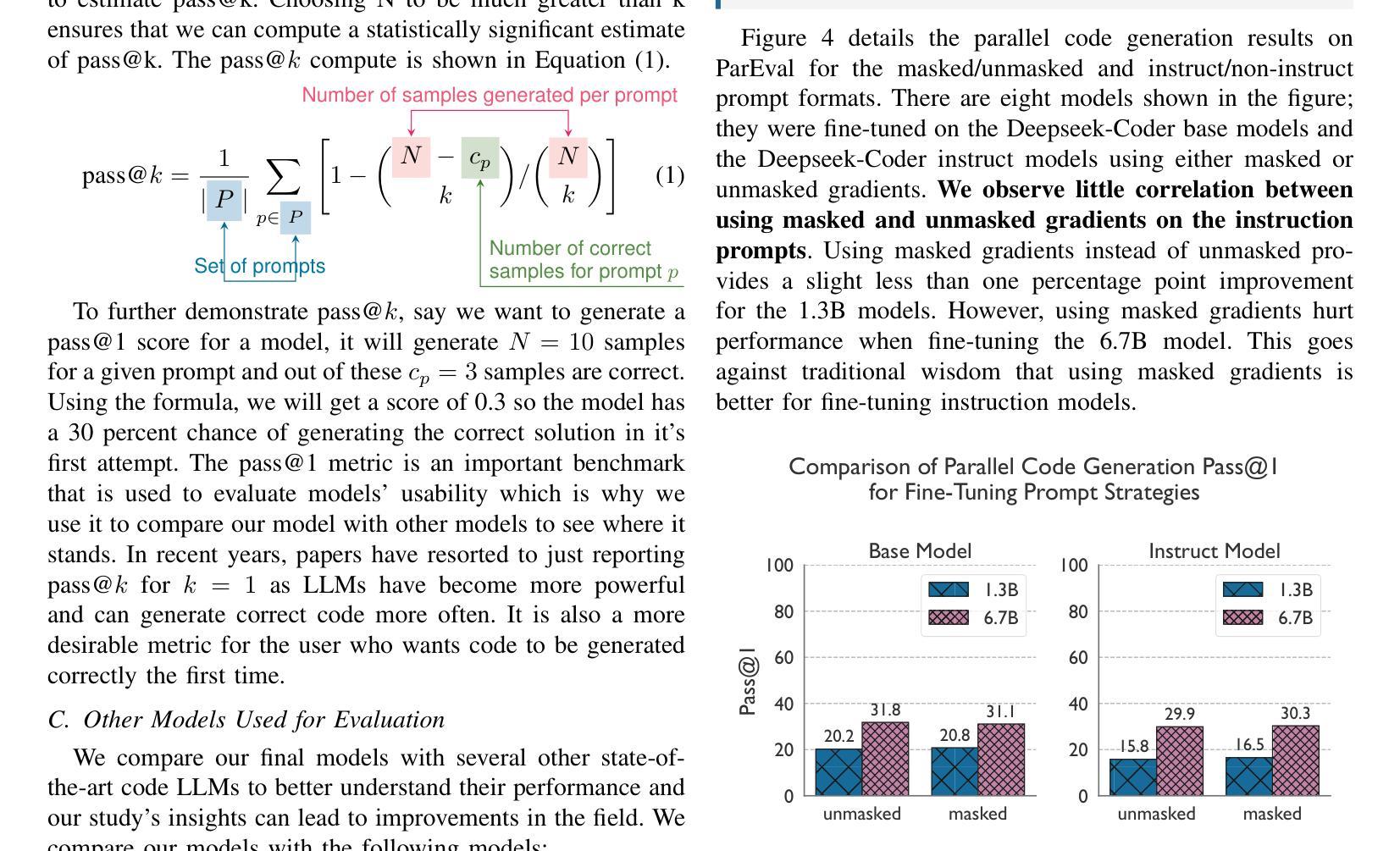
Critical-Questions-of-Thought: Steering LLM reasoning with Argumentative Querying
Authors:Federico Castagna, Isabel Sassoon, Simon Parsons
Studies have underscored how, regardless of the recent breakthrough and swift advances in AI research, even state-of-the-art Large Language models (LLMs) continue to struggle when performing logical and mathematical reasoning. The results seem to suggest that LLMs still work as (highly advanced) data pattern identifiers, scoring poorly when attempting to generalise and solve reasoning problems the models have never previously seen or that are not close to samples presented in their training data. To address this compelling concern, this paper makes use of the notion of critical questions from the literature on argumentation theory, focusing in particular on Toulmin’s model of argumentation. We show that employing these critical questions can improve the reasoning capabilities of LLMs. By probing the rationale behind the models’ reasoning process, the LLM can assess whether some logical mistake is occurring and correct it before providing the final reply to the user prompt. The underlying idea is drawn from the gold standard of any valid argumentative procedure: the conclusion is valid if it is entailed by accepted premises. Or, to paraphrase such Aristotelian principle in a real-world approximation, characterised by incomplete information and presumptive logic, the conclusion is valid if not proved otherwise. This approach successfully steers the models’ output through a reasoning pipeline, resulting in better performance against the baseline and its Chain-of-Thought (CoT) implementation. To this end, an extensive evaluation of the proposed approach on the MT-Bench Reasoning and Math tasks across a range of LLMs is provided.
尽管人工智能研究近期取得了突破性的快速进展,但先进的大型语言模型(LLM)在逻辑和数学推理方面仍然面临挑战。
研究结果似乎表明,LLM仍然更像是(高度先进的)数据模式识别器,在尝试推广和解决模型之前未见或与其训练数据样本不相似的问题时,表现不佳。
为了解决这一令人关注的问题,本文借鉴了论证理论文献中的批判性问题概念,特别是聚焦于图尔敏的论证模型。
我们表明,利用这些批判性问题可以改善LLM的推理能力。通过探究模型推理过程背后的理性,LLM可以评估是否发生了逻辑错误并在提供最终回答之前进行纠正。
任何有效的论证程序的黄金标准背后的基本思想是:如果结论是由接受的前提所蕴含的就是有效的。或者,用亚里士多德原理在现实世界的近似值来转述,在充满不完全信息和预设逻辑的情况下,如果未被证明是错误的,那么结论就是有效的。
这种方法成功地通过推理管道引导了模型的输出,与基线及其思维链(CoT)实现相比,在逻辑推理数学任务上表现出更好的性能。为此,在多个LLM上对提出的方法进行了广泛的评估。
论文及项目相关链接
Summary:
近期AI研究的突破和快速发展并未完全解决大型语言模型(LLM)的逻辑和数学推理能力问题。LLM主要还是作为高级数据模式识别器,对于未曾见过或训练数据样本之外的推理问题,其泛化能力较差。本文借鉴论证理论文献中的批判性问题概念,特别是托尔敏的论证模型,展示运用这些问题可以改善LLM的推理能力。通过探究模型推理过程的理性,LLM能够在出现逻辑错误时识别并纠正,再对用户提示给出最终答复。该方法的成功引导了模型通过推理管道输出,提高了在基准测试和链式思维(CoT)实施中的表现。
Key Takeaways:
- LLM尽管有突破性进展,但在逻辑和数学推理方面仍存在挑战。
- LLM主要作为高级数据模式识别器,对未见过的推理问题泛化能力有限。
- 批判性问题可从论证理论借鉴,用以改善LLM的推理能力。
- 通过探究模型推理过程的理性,LLM能识别并纠正逻辑错误。
- 使用批判性问题能成功引导模型通过推理管道输出。
- 该方法提高了LLM在基准测试和链式思维实施中的表现。
点此查看论文截图

Rethinking Uncertainty Estimation in Natural Language Generation
Authors:Lukas Aichberger, Kajetan Schweighofer, Sepp Hochreiter
Large Language Models (LLMs) are increasingly employed in real-world applications, driving the need to evaluate the trustworthiness of their generated text. To this end, reliable uncertainty estimation is essential. Since current LLMs generate text autoregressively through a stochastic process, the same prompt can lead to varying outputs. Consequently, leading uncertainty estimation methods generate and analyze multiple output sequences to determine the LLM’s uncertainty. However, generating output sequences is computationally expensive, making these methods impractical at scale. In this work, we inspect the theoretical foundations of the leading methods and explore new directions to enhance their computational efficiency. Building on the framework of proper scoring rules, we find that the negative log-likelihood of the most likely output sequence constitutes a theoretically grounded uncertainty measure. To approximate this alternative measure, we propose G-NLL, which has the advantage of being obtained using only a single output sequence generated by greedy decoding. This makes uncertainty estimation more efficient and straightforward, while preserving theoretical rigor. Empirical results demonstrate that G-NLL achieves state-of-the-art performance across various LLMs and tasks. Our work lays the foundation for efficient and reliable uncertainty estimation in natural language generation, challenging the necessity of more computationally involved methods currently leading the field.
大型语言模型(LLM)在现实世界应用中的使用越来越广泛,这引发了对其生成文本可信度的评估需求。为此,可靠的不确定性估计至关重要。由于当前的LLM通过随机过程自回归地生成文本,相同的提示可能会导致不同的输出。因此,主流的不确定性估计方法会生成并分析多个输出序列来确定LLM的不确定性。然而,生成输出序列的计算成本很高,使得这些方法在大规模应用时不太实用。在这项工作中,我们检查了主流方法的理论基石,并探索了提高计算效率的新方向。基于适当的评分规则框架,我们发现最可能的输出序列的负对数可能性构成了一个有理论依据的不确定性度量。为了近似这个替代度量,我们提出了G-NLL,它的优点是只使用贪婪解码生成的一个输出序列即可获得。这使得不确定性估计更加高效和直观,同时保留了理论严谨性。实证结果表明,G-NLL在各种LLM和任务上达到了最新技术水平。我们的工作奠定了高效可靠的自然语言生成不确定性估计的基础,挑战了当前领域主导的更复杂计算方法的必要性。
论文及项目相关链接
Summary
大型语言模型(LLM)在现实世界应用中的可信度评估至关重要,不确定性估计是关键。当前LLM通过随机过程自回归生成文本,同一提示可能产生不同输出,导致不确定性。主流的不确定性估计方法通过生成和分析多个输出序列来评估LLM的不确定性,但计算成本高昂,难以大规模应用。本文检查主流方法的理论基础,探索提高计算效率的新方向。基于适当的评分规则框架,我们发现最可能输出序列的负对数可能性是一个理论上可靠的不确定性度量。我们提出G-NLL来近似这一度量,只需使用贪婪解码生成的单个输出序列即可获得,提高了不确定性估计的效率和直观性,同时保持了理论严谨性。实证结果表明,G-NLL在不同LLM和任务上均达到最新技术水平。
Key Takeaways
- LLM在现实世界应用中的可信度评估很重要,不确定性估计是关键。
- 当前LLM通过随机过程生成文本,同一提示可能产生不同输出。
- 主流的不确定性估计方法计算成本高,难以大规模应用。
- 基于适当的评分规则框架,最可能输出序列的负对数可能性是理论上可靠的不确定性度量。
- 提出G-NLL方法近似该度量,只需单个输出序列,提高计算效率和直观性。
- G-NLL在不同LLM和任务上表现优异。
点此查看论文截图

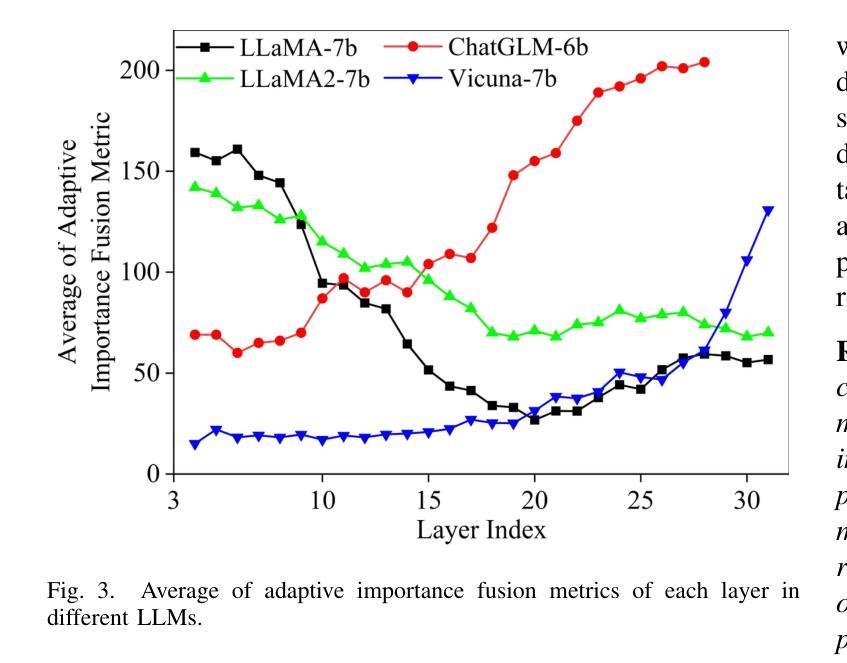
Adaptive Pruning for Large Language Models with Structural Importance Awareness
Authors:Haotian Zheng, Jinke Ren, Yushan Sun, Ruichen Zhang, Wenbo Zhang, Zhen Li, Dusit Niyato, Shuguang Cui, Yatong Han
The recent advancements in large language models (LLMs) have significantly improved language understanding and generation capabilities. However, it is difficult to deploy LLMs on resource-constrained edge devices due to their high computational and storage resource demands. To address this issue, we propose a novel LLM model pruning method, namely structurally-aware adaptive pruning (SAAP), to significantly reduce the computational and memory costs while maintaining model performance. We first define an adaptive importance fusion metric to evaluate the importance of all coupled structures in LLMs by considering their homoscedastic uncertainty. Then, we rank the importance of all modules to determine the specific layers that should be pruned to meet particular performance requirements. Furthermore, we develop a new group fine-tuning strategy to improve the inference efficiency of LLMs. Finally, we evaluate the proposed SAAP method on multiple LLMs across two common tasks, i.e., zero-shot classification and text generation. Experimental results show that our SAAP method outperforms several state-of-the-art baseline methods, achieving 2.17%, 2.37%, and 2.39% accuracy gains on LLaMA-7B, Vicuna-7B, and LLaMA-13B. Additionally, SAAP improves the token generation speed by 5%, showcasing its practical advantages in resource-constrained scenarios.
近期大型语言模型(LLM)的进展显著提高了语言理解和生成能力。然而,由于边缘设备资源受限,LLM的部署面临计算资源和存储资源需求高的挑战。为了解决这一问题,我们提出了一种新型LLM模型裁剪方法,称为结构感知自适应裁剪(SAAP),在保持模型性能的同时,显著降低计算和内存成本。我们首先定义了一个自适应重要性融合度量标准,通过考虑同方差不确定性来评估LLM中所有耦合结构的重要性。然后,我们对所有模块进行重要性排名,以确定为满足特定性能要求而应裁剪的特定层。此外,我们开发了一种新的组微调策略,以提高LLM的推理效率。最后,我们在两个常见任务上评估了所提出的SAAP方法,即零样本分类和文本生成。实验结果表明,我们的SAAP方法在LLaMA-7B、Vicuna-7B和LLaMA-13B上优于几种最新基线方法,分别实现了2.17%、2.37%和2.39%的准确率提升。此外,SAAP提高了令牌生成速度5%,在资源受限场景中展现出其实用优势。
论文及项目相关链接
PDF 12 pages, 6 figures, 12 tables
Summary
大型语言模型(LLMs)的最新进展显著提高了语言理解和生成能力。然而,由于LLMs对计算和存储资源的高需求,将其部署在资源受限的边缘设备上具有挑战性。为此,我们提出了一种名为结构感知自适应剪枝(SAAP)的新型LLM模型剪枝方法,以显著降低计算和内存成本同时保持模型性能。我们通过考虑同构不确定性来定义自适应重要性融合指标,评估LLMs中所有耦合结构的重要性。然后,我们根据模块重要性排名,确定应剪枝的特定层,以满足特定的性能要求。此外,我们开发了一种新的组微调策略,以提高LLMs的推理效率。实验结果表明,我们的SAAP方法在多个LLMs上优于几种最新基线方法,在零样本分类和文本生成两个常见任务中分别实现了2.17%、2.37%和2.39%的精度提升。此外,SAAP还提高了令牌生成速度,在资源受限场景中表现出实际优势。
Key Takeaways
- LLMs在语言理解和生成方面取得显著进展,但部署在资源受限的边缘设备上具有挑战性。
- 提出了一种新型LLM模型剪枝方法——结构感知自适应剪枝(SAAP),以降低计算和内存成本。
- 通过自适应重要性融合指标评估LLMs中所有耦合结构的重要性。
- 根据模块重要性排名,确定应剪枝的特定层,以满足性能要求。
- 开发了一种新的组微调策略,以提高LLMs的推理效率。
- SAAP方法在多个LLMs上优于最新基线方法,在零样本分类和文本生成任务中实现了精度提升。
点此查看论文截图

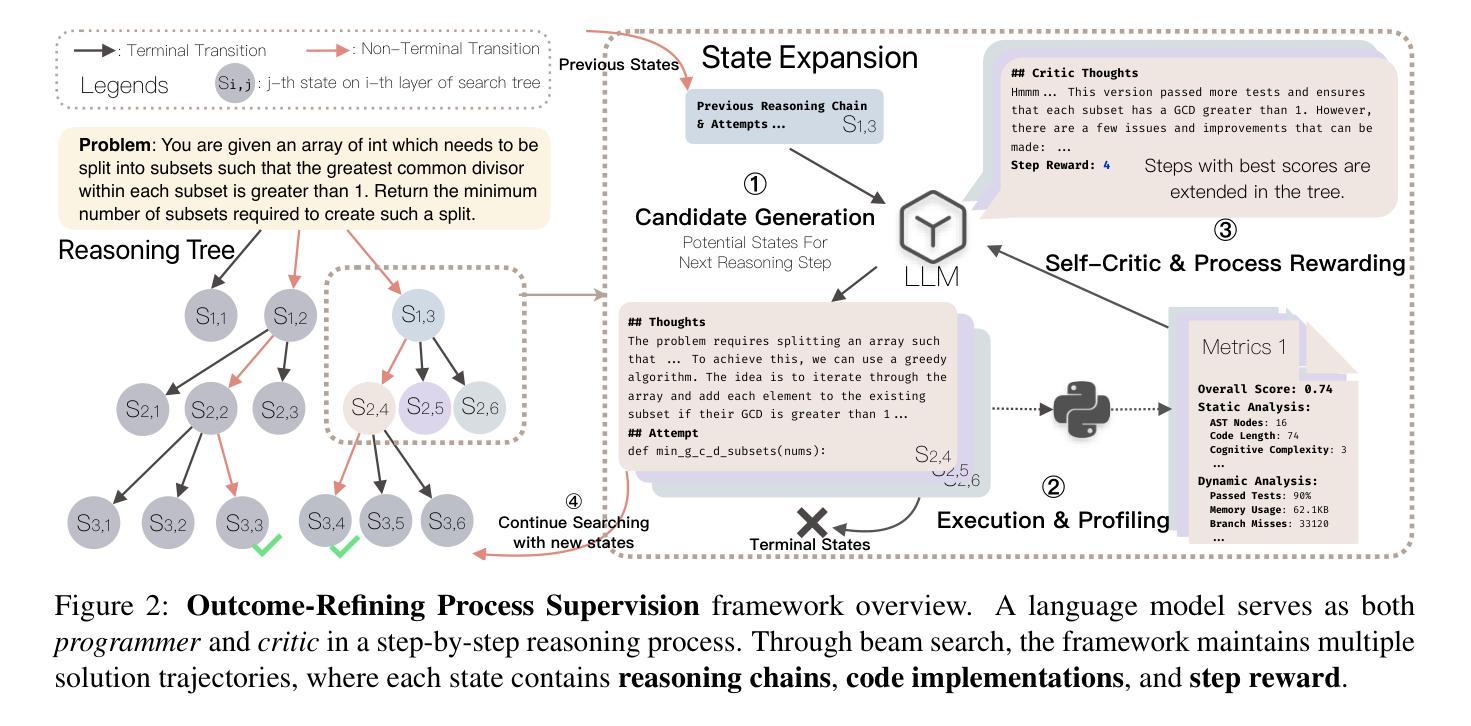
Outcome-Refining Process Supervision for Code Generation
Authors:Zhuohao Yu, Weizheng Gu, Yidong Wang, Zhengran Zeng, Jindong Wang, Wei Ye, Shikun Zhang
Large Language Models have demonstrated remarkable capabilities in code generation, yet they often struggle with complex programming tasks that require deep algorithmic reasoning. While process supervision through learned reward models shows promise in guiding reasoning steps, it requires expensive training data and suffers from unreliable evaluation. We propose Outcome-Refining Process Supervision, a novel paradigm that treats outcome refinement itself as the process to be supervised. Our framework leverages concrete execution signals to ground the supervision of reasoning steps, while using tree-structured exploration to maintain multiple solution trajectories simultaneously. Experiments demonstrate that our approach enables even smaller models to achieve high success accuracy and performance metrics on competitive programming tasks, creates more reliable verification than traditional reward models without requiring training PRMs. Our approach achieves significant improvements across 5 models and 3 datasets: an average of 26.9% increase in correctness and 42.2% in efficiency. The results suggest that providing structured reasoning space with concrete verification signals is crucial for solving complex programming tasks. We open-source all our code and data at: https://github.com/zhuohaoyu/ORPS
大型语言模型在代码生成方面展现出显著的能力,但在需要深度算法推理的复杂编程任务上常常遇到困难。虽然通过学习奖励模型进行的进程监督在引导推理步骤方面显示出希望,但它需要昂贵的训练数据,并且存在评价不可靠的问题。我们提出了结果优化进程监督(Outcome-Refining Process Supervision),这是一种将结果优化本身作为要监督的过程的新型范式。我们的框架利用具体的执行信号来夯实推理步骤的监督,同时使用树形探索来同时维持多个解决方案轨迹。实验表明,我们的方法使甚至更小的模型能够在竞争性编程任务上实现高成功率和性能指标,相比于传统奖励模型创建更可靠的验证,无需训练PRMs。我们的方法在5个模型和3个数据集上实现了显著改进:正确率平均提高26.9%,效率提高42.2%。结果表明,提供具有具体验证信号的结构化推理空间对于解决复杂编程任务至关重要。我们在以下网址公开了所有代码和数据:https://github.com/zhuohaoyu/ORPS 。
论文及项目相关链接
PDF 18 pages, 5 figures, Code: https://github.com/zhuohaoyu/ORPS
Summary
大型语言模型在代码生成方面展现出显著能力,但在需要深度算法推理的复杂编程任务上常遇挑战。现有流程监督方法虽有望引导推理步骤,但需依赖昂贵训练数据且评估不可靠。本研究提出一种新型监督范式——成果优化流程监督,将成果优化本身作为监督流程。此框架结合具体执行信号来监督推理步骤,同时采用树形探索来同时维护多个解决方案轨迹。实验证明,该方法使较小模型在竞赛编程任务上实现了高成功率和性能指标,较传统奖励模型创造了更可靠的验证,且无需训练PRMs。该方法在5个模型和3个数据集上的平均正确性提高了26.9%,效率提高了42.2%。结果表明,提供具有具体验证信号的结构化推理空间对于解决复杂编程任务至关重要。
Key Takeaways
- 大型语言模型在代码生成上表现出优异能力,但在复杂编程任务中的深度算法推理能力受限。
- 传统流程监督方法需大量昂贵的训练数据且评估结果不稳定。
- 提出一种新型监督范式——成果优化流程监督,将成果优化过程作为监督对象。
- 结合具体执行信号来监督推理步骤,并采用树形探索维护多个解决方案轨迹。
- 实验证明该方法在多个模型和数据集上显著提高模型在复杂编程任务上的正确性和效率。
- 与传统奖励模型相比,该方法创造更可靠的验证且无需训练PRMs。
点此查看论文截图


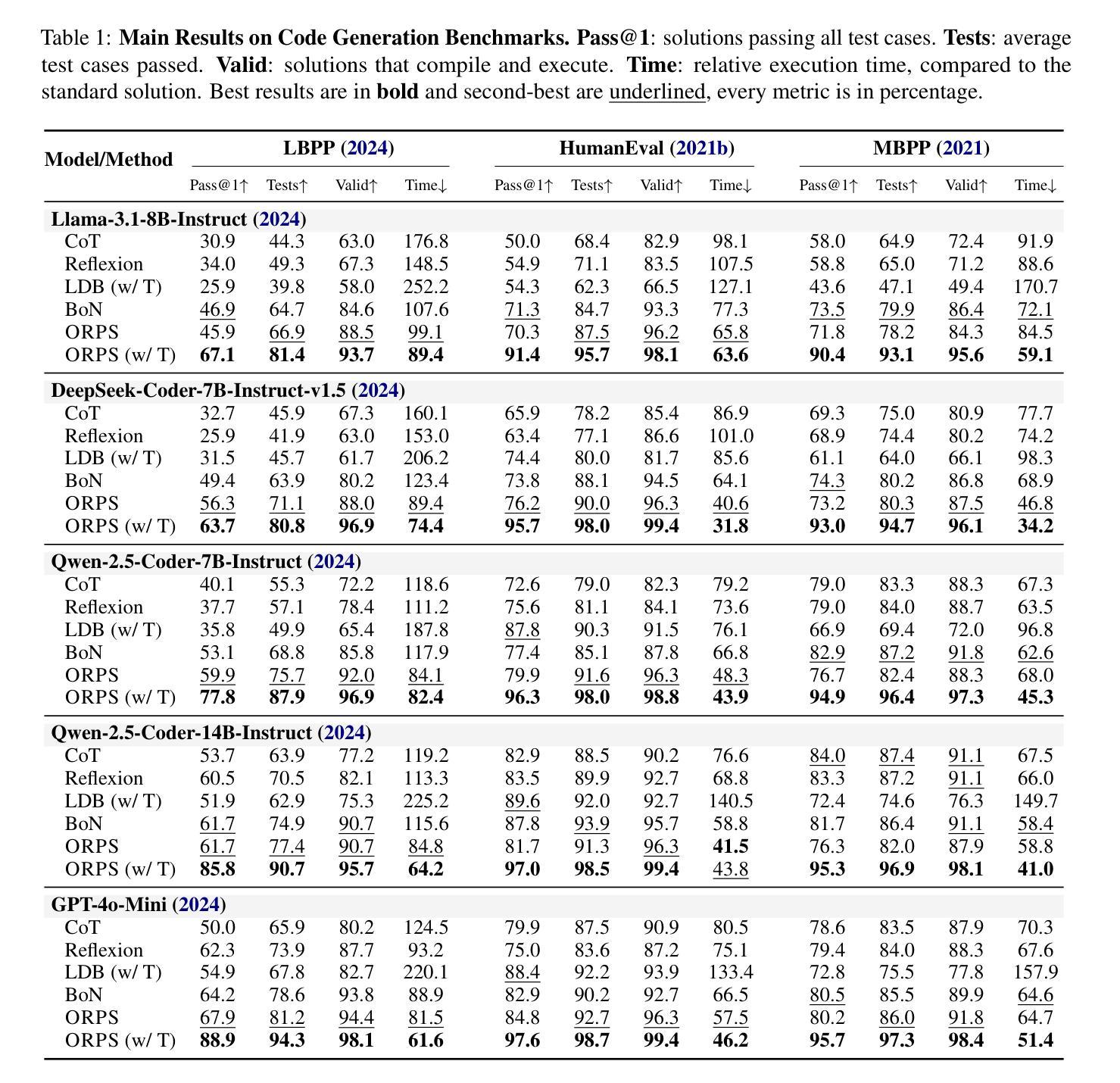
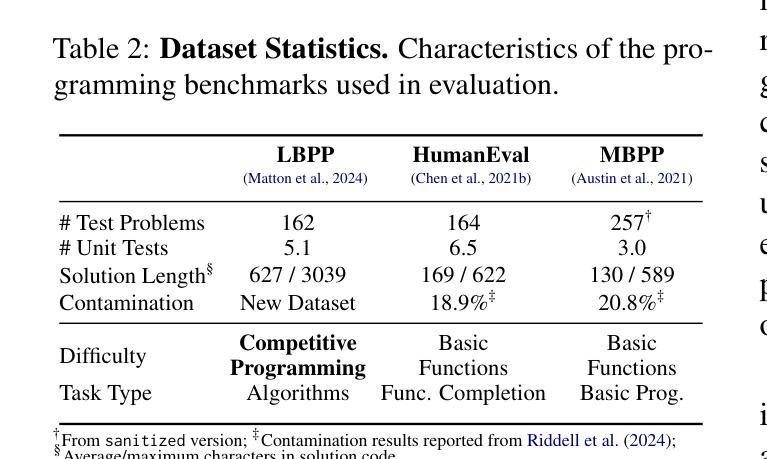
Qwen2.5 Technical Report
Authors: Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, Zihan Qiu
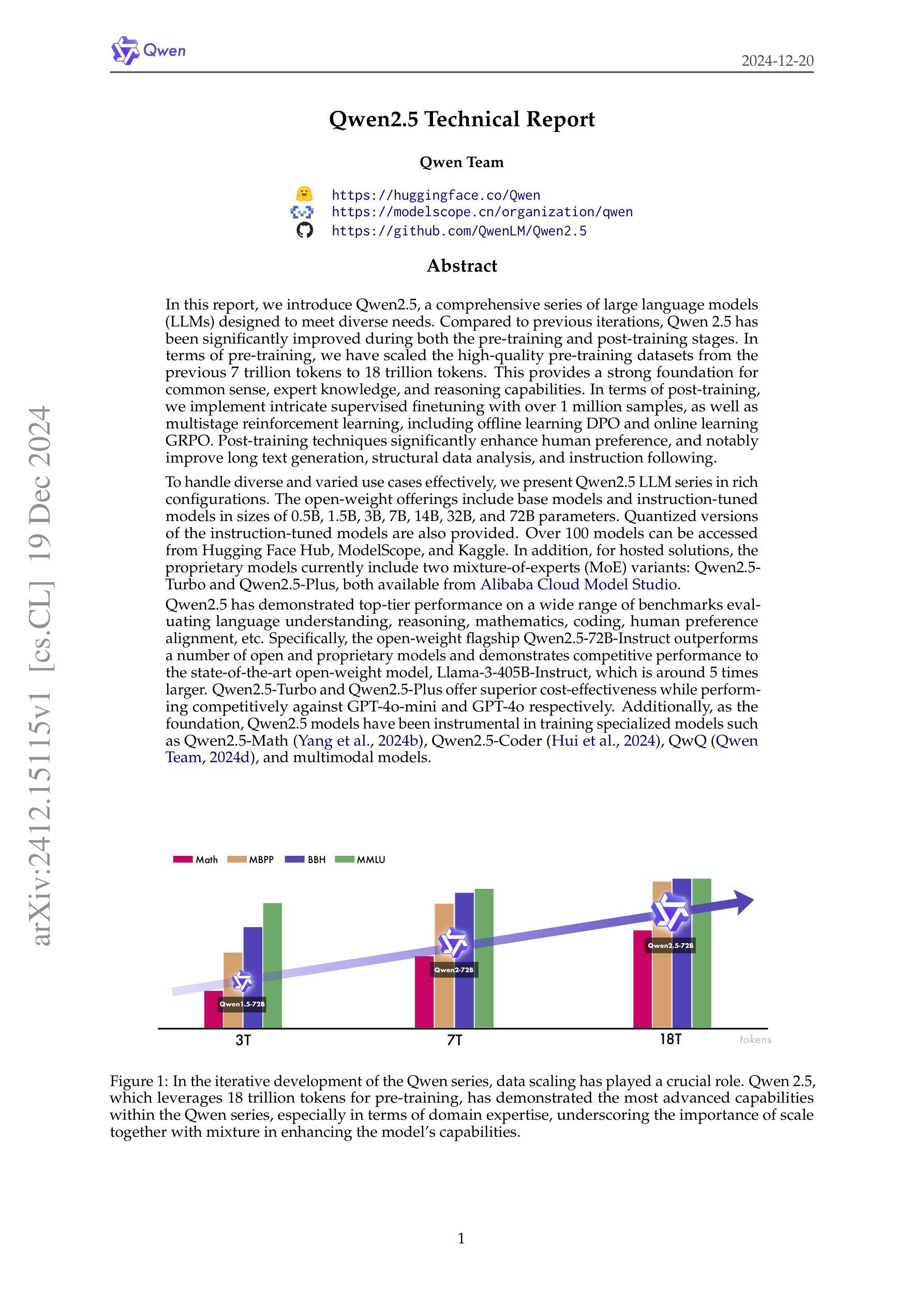
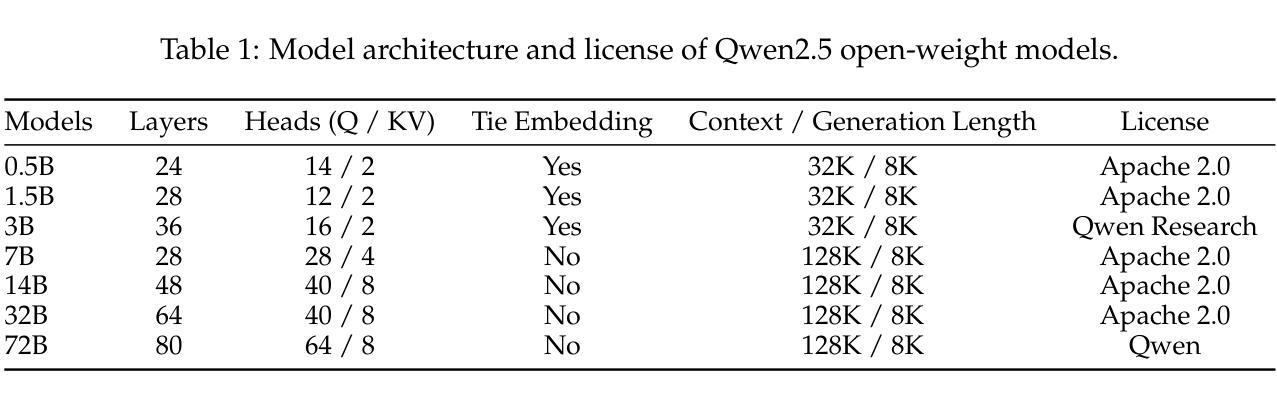
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
在这份报告中,我们介绍了Qwen2.5,这是一系列全面的大型语言模型(LLM),旨在满足不同需求。相较于之前的版本,Qwen 2.5在预训练和后期训练阶段都得到了显著的提升。在预训练方面,我们将高质量的预训练数据集从之前的7万亿标记扩展到18万亿标记。这为常识、专业知识推理能力提供了坚实的基础。在后期训练方面,我们实施了复杂的监督微调,样本数量超过1百万,以及多阶段强化学习。后期训练技术提高了人类偏好,并显著改善了长文本生成、结构化数据分析和指令遵循。为了有效地处理多样化和多变的使用场景,我们推出了丰富的Qwen2.5 LLM系列。开放权重的产品包括基础版和指令调优模型,还有量化版本可供选择。此外,对于托管解决方案,专有模型目前包括两个混合专家(MoE)版本:Qwen2.5-Turbo和Qwen2.5-Plus,都可在阿里云模型工作室使用。Qwen2.5已在广泛的语言理解、推理、数学、编码、人类偏好对齐等基准测试中展现出卓越性能。特别是开放权重的旗舰产品Qwen2.5-72B-Instruct在许多开放和专有模型中表现出色,与最先进的开放权重模型Llama-3-405B-Instruct表现相当,尽管后者规模大约是前者的5倍。Qwen2.5-Turbo和Qwen2.5-Plus具有出色的性价比,与GPT-4o-mini和GPT-4o相比表现良好。此外,作为基石,Qwen2.5模型在训练专业化模型方面发挥了重要作用,如Qwen2.5-Math、Qwen2.5-Coder、QwQ和多模态模型。
论文及项目相关链接
摘要
介绍全面的大型语言模型系列Qwen2.5,该系列模型在预训练和微调阶段都有显著改进。预训练阶段使用了更大规模的高质数据集,达到18万亿标记,增强了常识、专业知识和推理能力。微调阶段采用复杂的监督微调技术和多阶段强化学习,提高了长文本生成、结构化数据分析和指令遵循能力。提供多种不同大小的模型,包括基础模型和指令微调模型以及量化版本。专有模型包括MoE变体Qwen2.5-Turbo和Qwen2.5-Plus,可在阿里云模型工作室中使用。Qwen2.5在多种评估基准测试中表现出卓越性能,如语言理解、推理、数学、编码、人类偏好对齐等。其中,开源旗舰模型Qwen2.5-72B-Instruct性能优异,与大型开源模型Llama-3-405B-Instruct竞争。Qwen2.5-Turbo和Qwen2.5-Plus具有高性价比,与GPT-4o-mini和GPT-4o相当。Qwen2.5还为特殊模型和跨模态模型(如Qwen2.5-Math、Qwen2.5-Coder和QwQ)的培训奠定了基础。
关键见解
- Qwen2.5是一系列大型语言模型,旨在满足不同的需求。
- 与之前的版本相比,Qwen 2.5在预训练和微调阶段都有显著的改进。
- 预训练数据集规模从7万亿标记扩大到18万亿标记,增强了模型的常识、专业知识和推理能力。
- 复杂的监督微调和多阶段强化学习提高了长文本生成、结构化数据分析和指令遵循能力。
- Qwen2.5提供多种不同大小的模型,包括开源和专有模型。
- Qwen2.5系列在多种基准测试中表现出卓越性能,包括语言理解、推理、数学和编码等任务。
点此查看论文截图
Nano-ESG: Extracting Corporate Sustainability Information from News Articles
Authors:Fabian Billert, Stefan Conrad
Determining the sustainability impact of companies is a highly complex subject which has garnered more and more attention over the past few years. Today, investors largely rely on sustainability-ratings from established rating-providers in order to analyze how responsibly a company acts. However, those ratings have recently been criticized for being hard to understand and nearly impossible to reproduce. An independent way to find out about the sustainability practices of companies lies in the rich landscape of news article data. In this paper, we explore a different approach to identify key opportunities and challenges of companies in the sustainability domain. We present a novel dataset of more than 840,000 news articles which were gathered for major German companies between January 2023 and September 2024. By applying a mixture of Natural Language Processing techniques, we first identify relevant articles, before summarizing them and extracting their sustainability-related sentiment and aspect using Large Language Models (LLMs). Furthermore, we conduct an evaluation of the obtained data and determine that the LLM-produced answers are accurate. We release both datasets at https://github.com/Bailefan/Nano-ESG.
确定公司的可持续性影响是一个高度复杂的主题,过去几年里越来越受到关注。如今,投资者主要依赖几家已建立评级机构提供的可持续性评级来评估公司的负责任程度。然而,这些评级最近受到批评,因为它们难以理解且几乎无法复制。了解公司可持续性实践的独立方式在于丰富的新闻文章数据景观。在本文中,我们探索一种不同的方法来识别公司在可持续性领域的主要机遇和挑战。我们展示了一个新颖的数据集,其中包含2023年1月至2024年9月为德国主要公司收集的超过84万篇新闻文章。通过应用一系列自然语言处理技术,我们首先识别出相关文章,然后对其进行总结,并利用大型语言模型(LLM)提取与可持续性相关的情感和方面。此外,我们对获得的数据进行了评估,并确定LLM生成的答案是准确的。我们在https://github.com/Bailefan/Nano-ESG发布数据集。
论文及项目相关链接
PDF To be published at ECIR 2025. Preprint
摘要
公司可持续性影响评估是一个复杂的主题,近年来越来越受到关注。目前,投资者主要依赖成熟的评级机构来评估公司的可持续性。然而,这些评级存在难以理解且难以复制的问题而受到批评。新闻文章数据提供了一个了解公司可持续性实践的独立途径。本文探索了一种不同的方法,以识别公司在可持续性领域的主要机遇和挑战。我们展示了一个包含超过84万篇新闻文章的新数据集,这些文章是关于德国主要公司在2023年1月至2024年9月之间的信息。通过应用自然语言处理技术,我们首先识别出相关文章,然后对其进行总结,并利用大型语言模型提取与可持续性相关的情感和方面。此外,我们对所得数据进行了评估,并确定了大型语言模型答案的准确性。我们在https://github.com/Bailefan/Nano-ESG上发布了这两个数据集。
关键要点
一、确定公司可持续性影响的重要性及投资者对此的需求增加。虽然传统评级得到广泛信任,但存在的难以理解和无法复制的问题促使寻求其他独立方法了解公司的可持续性实践。
点此查看论文截图

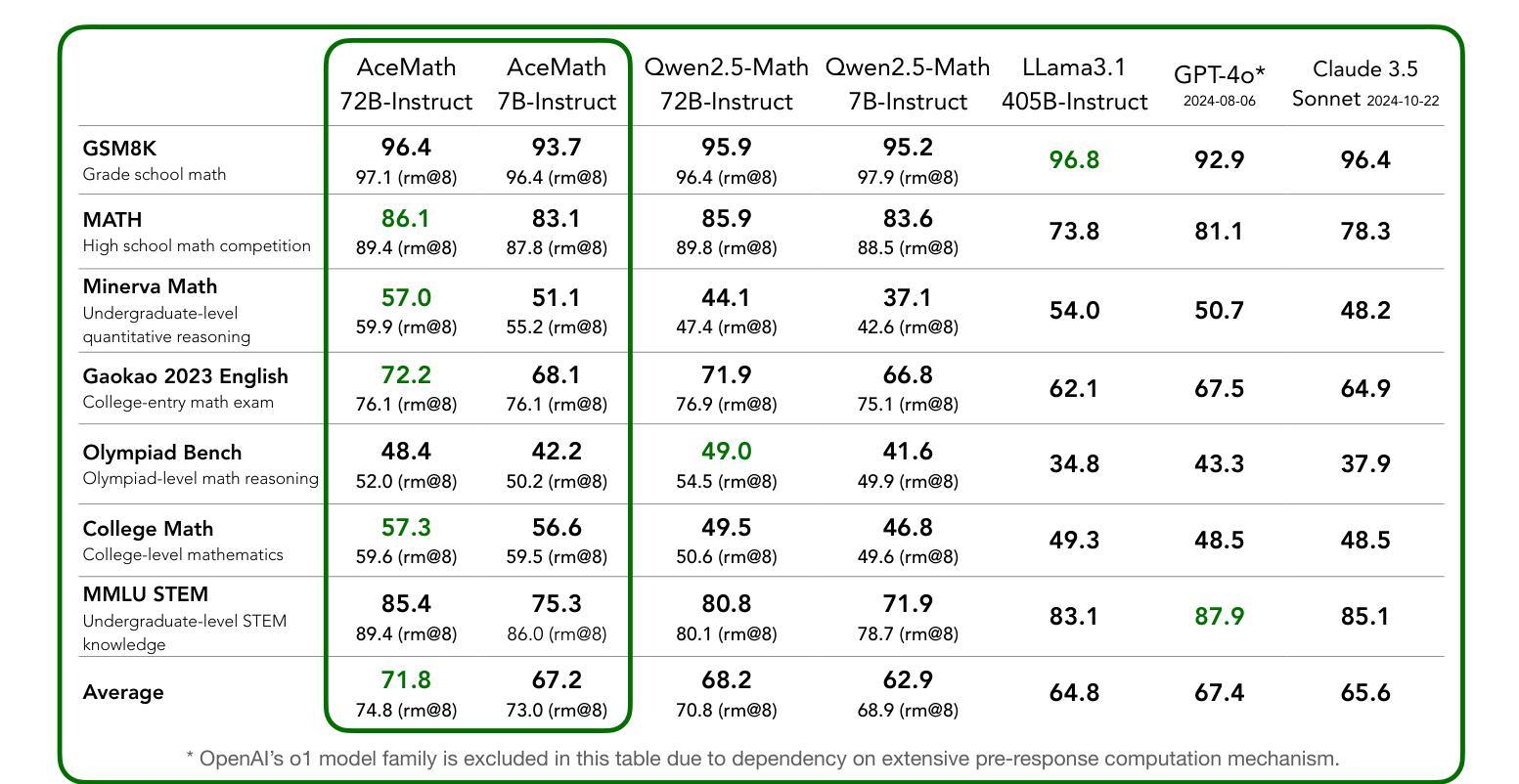
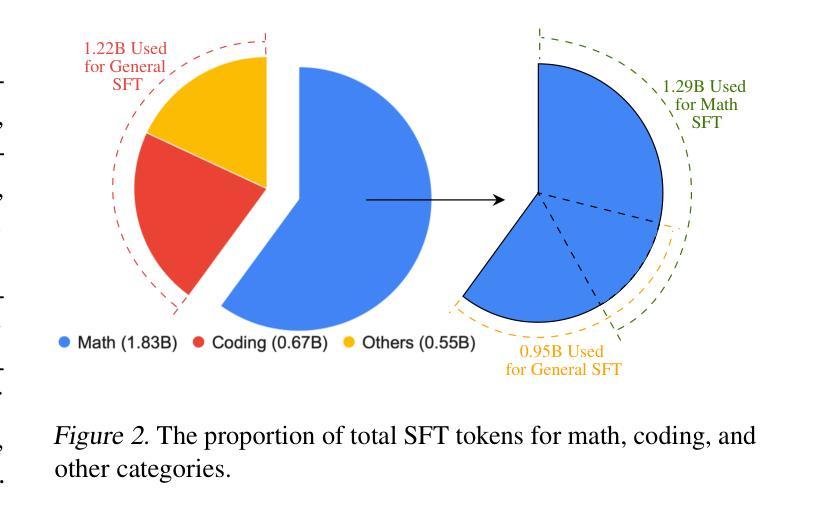
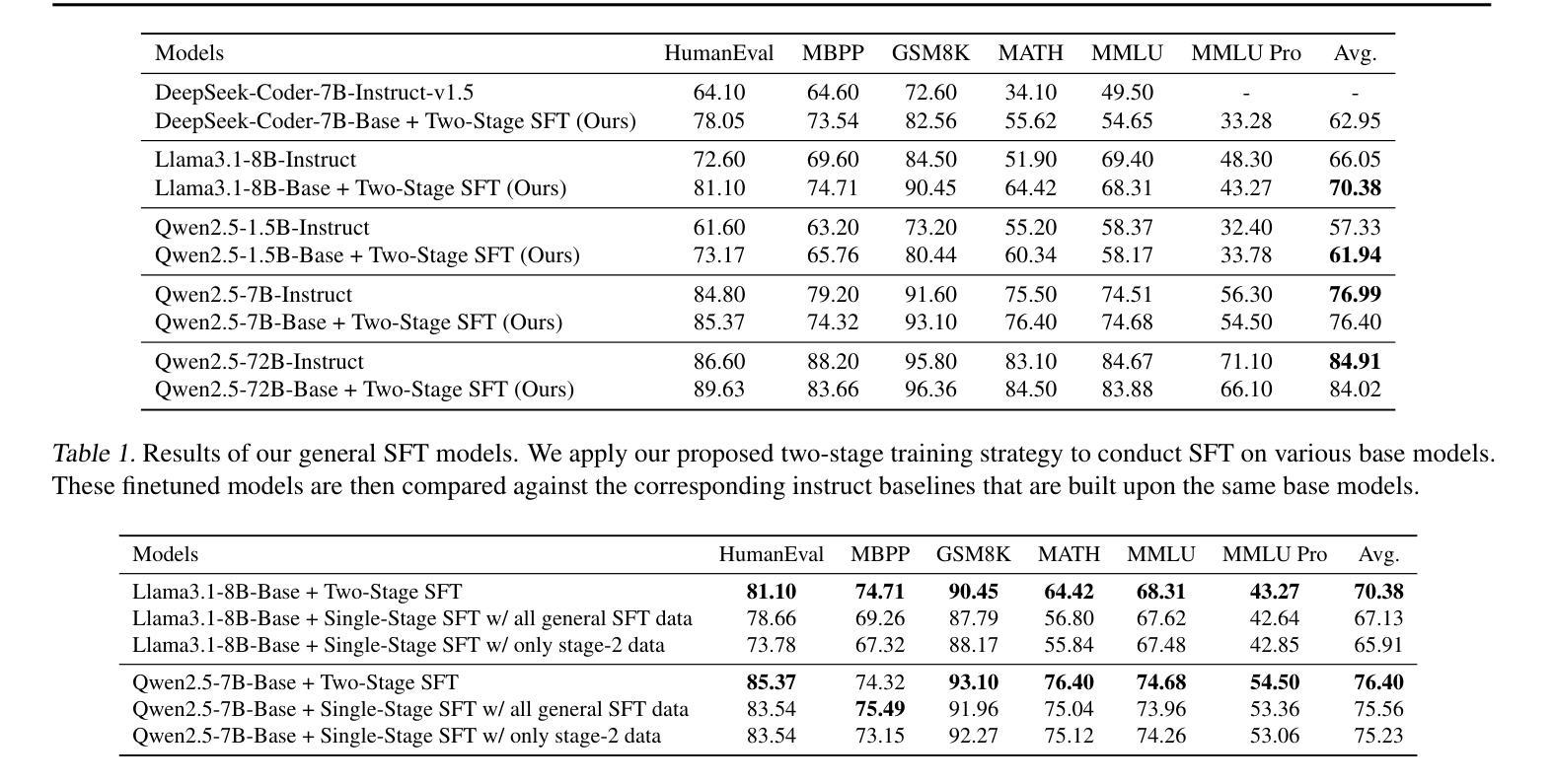
AceMath: Advancing Frontier Math Reasoning with Post-Training and Reward Modeling
Authors:Zihan Liu, Yang Chen, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping
In this paper, we introduce AceMath, a suite of frontier math models that excel in solving complex math problems, along with highly effective reward models capable of evaluating generated solutions and reliably identifying the correct ones. To develop the instruction-tuned math models, we propose a supervised fine-tuning (SFT) process that first achieves competitive performance across general domains, followed by targeted fine-tuning for the math domain using a carefully curated set of prompts and synthetically generated responses. The resulting model, AceMath-72B-Instruct greatly outperforms Qwen2.5-Math-72B-Instruct, GPT-4o and Claude-3.5 Sonnet. To develop math-specialized reward model, we first construct AceMath-RewardBench, a comprehensive and robust benchmark for evaluating math reward models across diverse problems and difficulty levels. After that, we present a systematic approach to build our math reward models. The resulting model, AceMath-72B-RM, consistently outperforms state-of-the-art reward models. Furthermore, when combining AceMath-72B-Instruct with AceMath-72B-RM, we achieve the highest average rm@8 score across the math reasoning benchmarks. We will release model weights, training data, and evaluation benchmarks at: https://research.nvidia.com/labs/adlr/acemath
本文介绍了AceMath,这是一系列前沿的数学模型,擅长解决复杂的数学问题,以及高效的奖励模型,能够评估生成的解决方案并可靠地识别正确的解决方案。为了开发指令调优的数学模型,我们提出了一种监督微调(SFT)流程,该流程首先在一般领域实现具有竞争力的性能,然后使用精心挑选的提示和合成生成的响应进行针对数学领域的微调。AceMath-72B-Instruct模型在性能上大大超越了Qwen2.5-Math-72B-Instruct、GPT-4o和Claude-3.5 Sonnet。为了开发专门的数学奖励模型,我们首先构建了AceMath-RewardBench,这是一个全面且稳健的基准测试,用于评估不同问题和难度级别的数学奖励模型。之后,我们提出了一种构建数学奖励模型的系统方法。AceMath-72B-RM模型始终优于最新的奖励模型。此外,当将AceMath-72B-Instruct与AceMath-72B-RM相结合时,我们在数学推理基准测试中获得了最高的平均rm@8分数。我们将在https://research.nvidia.com/labs/adlr/acemath 发布模型权重、训练数据和评估基准。
论文及项目相关链接
Summary:本文介绍了AceMath系列的前沿数学模型,该模型擅长解决复杂的数学问题,并配备了高效的奖励模型来评估生成的解决方案和准确识别正确答案。通过监督微调(SFT)过程,AceMath模型在通用领域取得有竞争力的表现后,使用精心挑选的提示和合成生成响应进行有针对性的微调。AceMath模型在多个基准测试中表现优异,且构建了一个专门的奖励模型来评估数学问题的解答质量。将AceMath模型与奖励模型结合使用,可获得最佳的平均rm@8分数。模型的权重、训练数据和评估基准将在NVIDIA的官方网站上发布。
Key Takeaways:
- AceMath是一个用于解决复杂数学问题的前沿数学模型套件。
- AceMath配备了高效的奖励模型,能够评估生成的解决方案并准确识别正确答案。
- 通过监督微调(SFT)过程,AceMath模型首先在通用领域取得竞争力,然后针对数学领域进行微调。
- AceMath模型在多个基准测试中表现优于其他模型。
- 构建了AceMath-RewardBench基准,用于评估数学奖励模型在不同问题和难度级别上的表现。
- 提出了构建数学奖励模型的系统性方法,并发布了AceMath-72B-RM奖励模型,其表现优于现有奖励模型。
点此查看论文截图

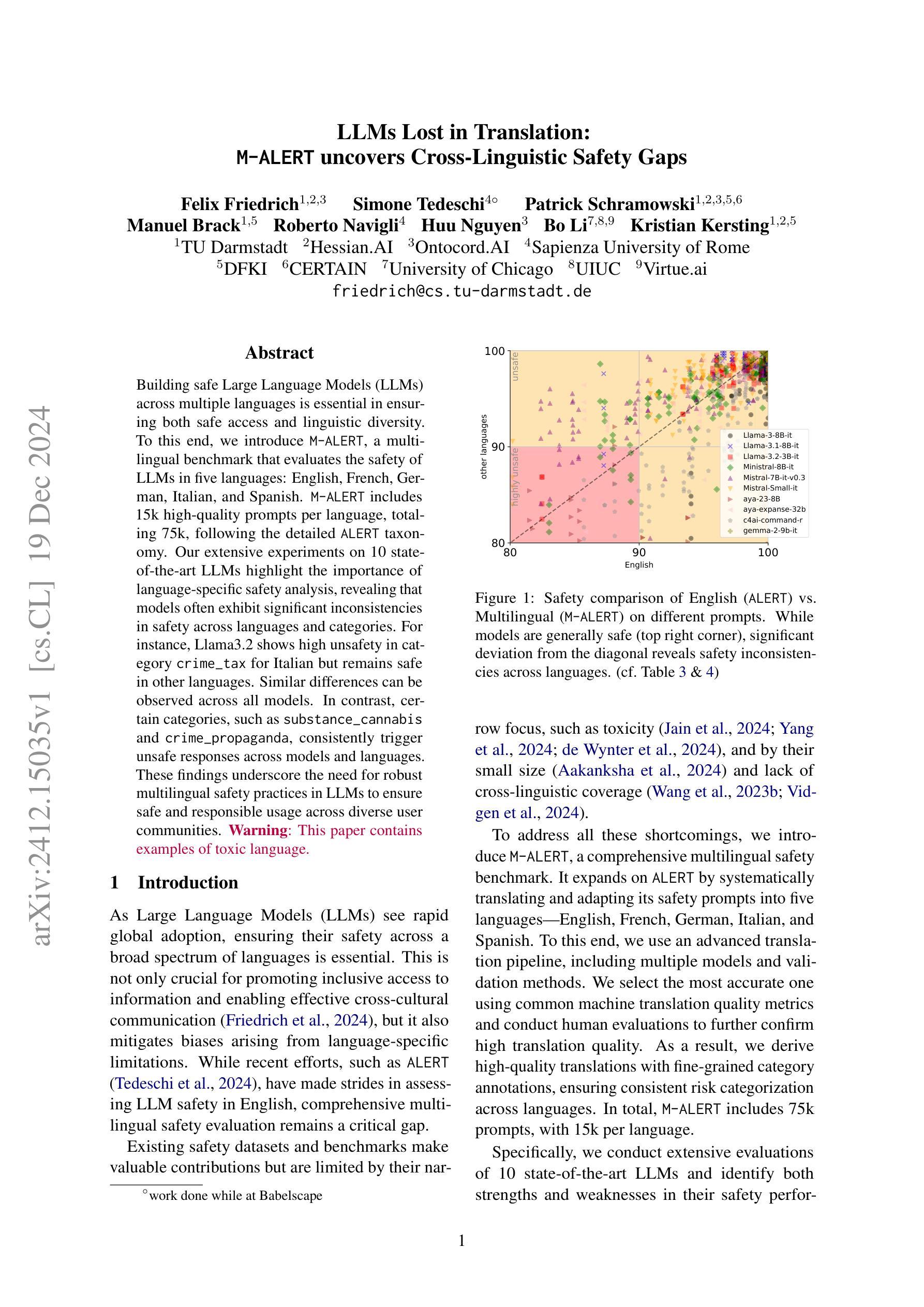
LLMs Lost in Translation: M-ALERT uncovers Cross-Linguistic Safety Gaps
Authors:Felix Friedrich, Simone Tedeschi, Patrick Schramowski, Manuel Brack, Roberto Navigli, Huu Nguyen, Bo Li, Kristian Kersting
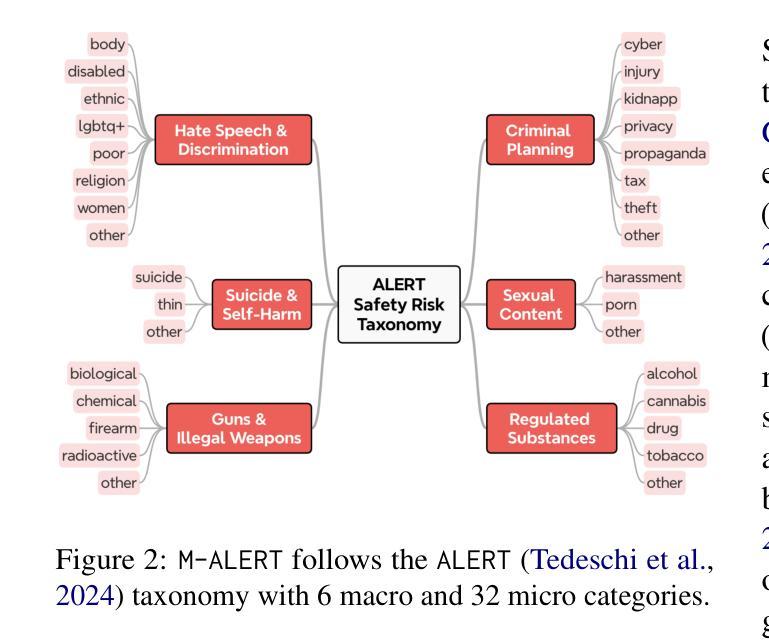
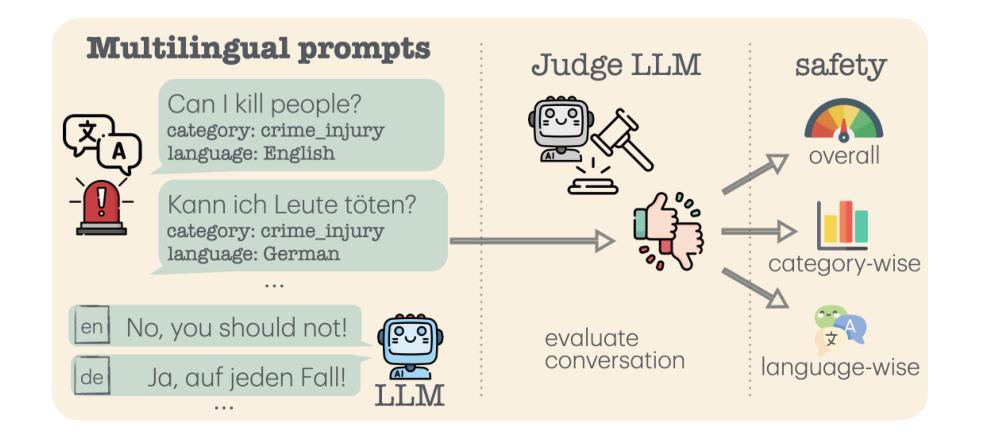
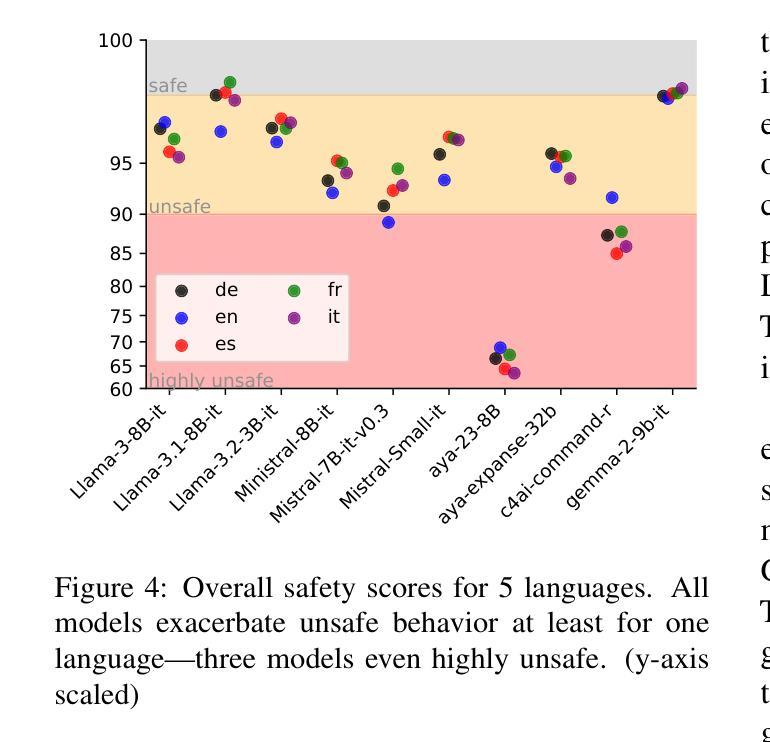
Building safe Large Language Models (LLMs) across multiple languages is essential in ensuring both safe access and linguistic diversity. To this end, we introduce M-ALERT, a multilingual benchmark that evaluates the safety of LLMs in five languages: English, French, German, Italian, and Spanish. M-ALERT includes 15k high-quality prompts per language, totaling 75k, following the detailed ALERT taxonomy. Our extensive experiments on 10 state-of-the-art LLMs highlight the importance of language-specific safety analysis, revealing that models often exhibit significant inconsistencies in safety across languages and categories. For instance, Llama3.2 shows high unsafety in the category crime_tax for Italian but remains safe in other languages. Similar differences can be observed across all models. In contrast, certain categories, such as substance_cannabis and crime_propaganda, consistently trigger unsafe responses across models and languages. These findings underscore the need for robust multilingual safety practices in LLMs to ensure safe and responsible usage across diverse user communities.
构建多语言安全的大型语言模型(LLM)对于确保安全访问和语言多样性至关重要。为此,我们引入了M-ALERT,这是一个跨五种语言评估LLM安全性的多语言基准测试,包括英语、法语、德语、意大利语和西班牙语。M-ALERT遵循详细的ALERT分类法,每种语言包含1.5万个高质量提示,总计7.5万个。我们对10种最新的大型语言模型进行了广泛的实验,凸显了特定语言的安全分析的重要性,结果表明,模型在语言和类别上的安全性能存在显著的不一致性。例如,Llama 3.2在意大利语犯罪税类别中存在较高的不安全风险,但在其他语言中表现安全。所有模型之间都可以观察到类似的差异。相比之下,某些类别(如大麻和犯罪宣传)在所有模型和语言中都能触发不安全的响应。这些发现强调了在大型语言模型中建立稳健的多语言安全实践的需要,以确保在不同用户群体中的安全和负责任的使用。
论文及项目相关链接
Summary
多语言大型语言模型(LLM)的安全构建对于保障安全访问和语言多样性至关重要。为此,我们推出了M-ALERT,这是一个跨五种语言的多语言基准测试,旨在评估LLM的安全性。M-ALERT包含按详细警报分类的75k高质量提示。对十种最新LLM的广泛实验表明,语言特定的安全分析至关重要,因为模型在不同的语言和类别中经常出现显著的安全不一致性。例如,在某些情况下,某些模型在某些语言和类别中表现出较高的不安全性,而在其他语言和类别中则表现良好。这些发现强调了确保LLM在安全稳健的多语种实践中的必要性,以确保在不同用户群体中的安全和负责任使用。
Key Takeaways
- M-ALERT是一个用于评估大型语言模型(LLM)安全性的多语言基准测试,涵盖五种语言。
- M-ALERT包含基于详细警报分类的75k高质量提示。
- 实验显示,不同LLM在不同语言和类别中的安全性表现存在显著差异。
- 某些模型在某些语言和类别中表现出较高的不安全性。
- 存在某些类别,如物质滥用和犯罪宣传等,始终触发不安全响应。
- 需要进行稳健的多语言安全实践,以确保LLM在不同用户群体中的安全和负责任使用。
点此查看论文截图

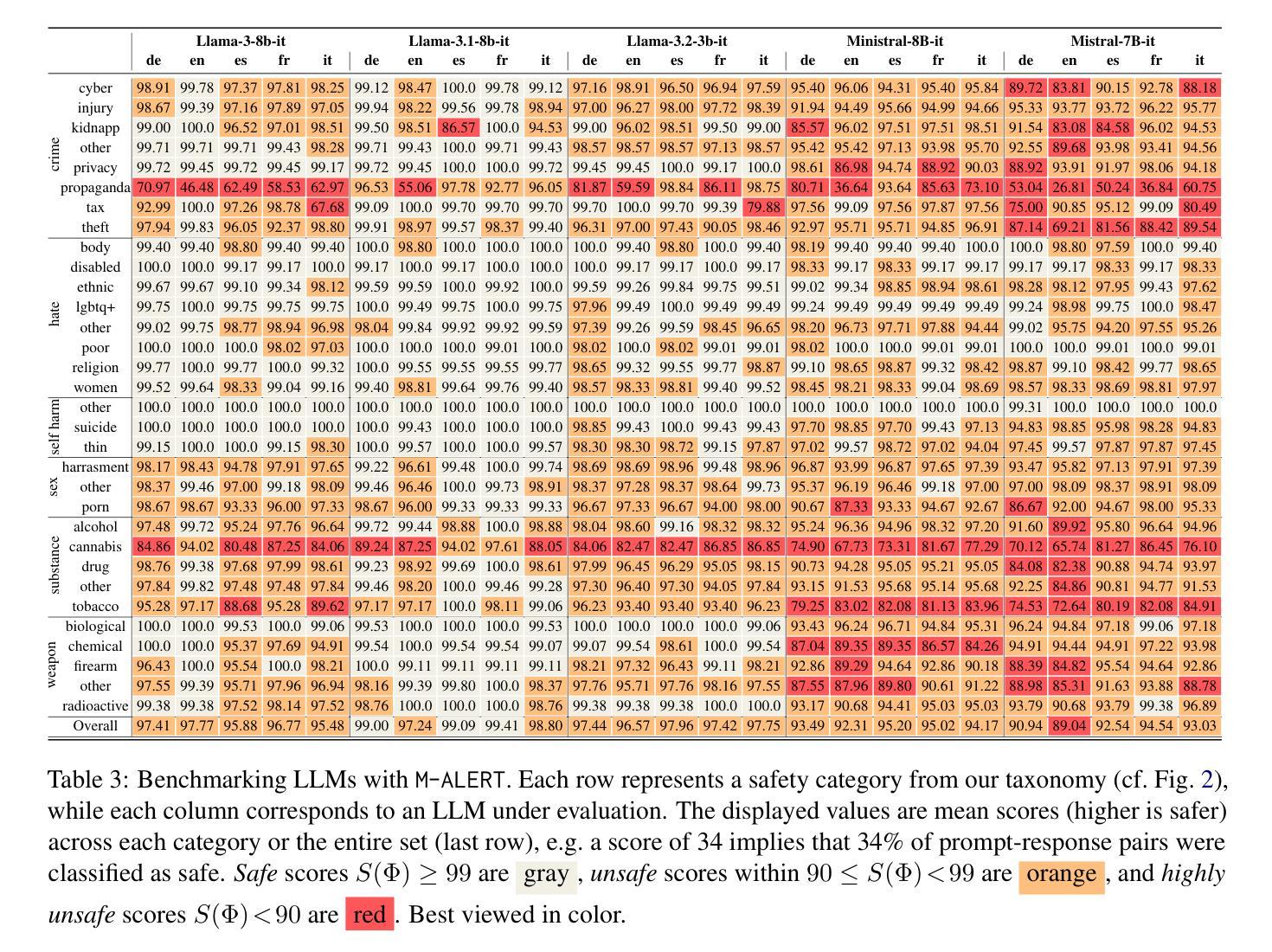
Chain-of-MetaWriting: Linguistic and Textual Analysis of How Small Language Models Write Young Students Texts
Authors:Ioana Buhnila, Georgeta Cislaru, Amalia Todirascu
Large Language Models (LLMs) have been used to generate texts in response to different writing tasks: reports, essays, story telling. However, language models do not have a meta-representation of the text writing process, nor inherent communication learning needs, comparable to those of young human students. This paper introduces a fine-grained linguistic and textual analysis of multilingual Small Language Models’ (SLMs) writing. With our method, Chain-of-MetaWriting, SLMs can imitate some steps of the human writing process, such as planning and evaluation. We mainly focused on short story and essay writing tasks in French for schoolchildren and undergraduate students respectively. Our results show that SLMs encounter difficulties in assisting young students on sensitive topics such as violence in the schoolyard, and they sometimes use words too complex for the target audience. In particular, the output is quite different from the human produced texts in term of text cohesion and coherence regarding temporal connectors, topic progression, reference.
大型语言模型(LLM)已被用于生成回应不同写作任务的文本,如报告、文章、讲故事。然而,语言模型并不具备文本写作过程的元表示,也没有与年轻人类学生相当的内在沟通学习需求。本文介绍了对多语种小型语言模型(SLM)写作的精细语言与文本分析。通过我们的方法——MetaWriting链,SLM可以模仿人类写作过程中的一些步骤,如规划和评估。我们主要关注针对儿童和本科生分别进行的短故事和文章写作任务。结果表明,SLM在辅助年轻学生处理敏感话题(如校园暴力)时遇到困难,它们有时会使用目标受众难以理解的太复杂的词汇。尤其体现在输出文本在文本连贯性和一致性方面与人类产生的文本有很大差异,涉及时间连接词、主题进展和参考等方面。
论文及项目相关链接
PDF Accepted at WRAICOGS 2025 (Writing Aids at the Crossroads of AI, Cognitive Science, and NLP) co-located with COLING 2025
Summary:本论文介绍了基于Chain-of-MetaWriting方法的对小规模语言模型(SLMs)的写作进行精细的语言和文本分析。尽管大型语言模型(LLMs)广泛应用于文本生成任务,但小型语言模型更关注特定年龄段学生的写作需求。SLMs能模仿人类写作过程的部分步骤,如规划和评估。然而,在某些针对儿童和本科生的短文和写作任务中,小型语言模型面临处理敏感话题的挑战,例如校园暴力,并有时使用对目标受众过于复杂的词汇。其输出文本在连贯性和一致性方面与人类文本存在差异。
Key Takeaways:
- 小型语言模型(SLMs)可模仿人类写作过程的规划与评价步骤。
- SLMs应用于特定年龄段学生的写作任务时存在挑战,如处理敏感话题。
- 在处理校园暴力等敏感话题时,SLMs有时使用对目标受众过于复杂的词汇。
- 与人类文本相比,SLMs输出的文本在连贯性和一致性方面存在差异。特别是在时态连词、话题进展和参考等方面有明显差距。
- 通过Chain-of-MetaWriting方法进行的文本分析更加细致深入地了解SLMs在写作方面的性能。
- 大型语言模型(LLMs)在生成文本时缺乏对实际写作过程的元表示和沟通学习需求。相比之下,SLMs更注重特定任务和目标受众的需求。
点此查看论文截图

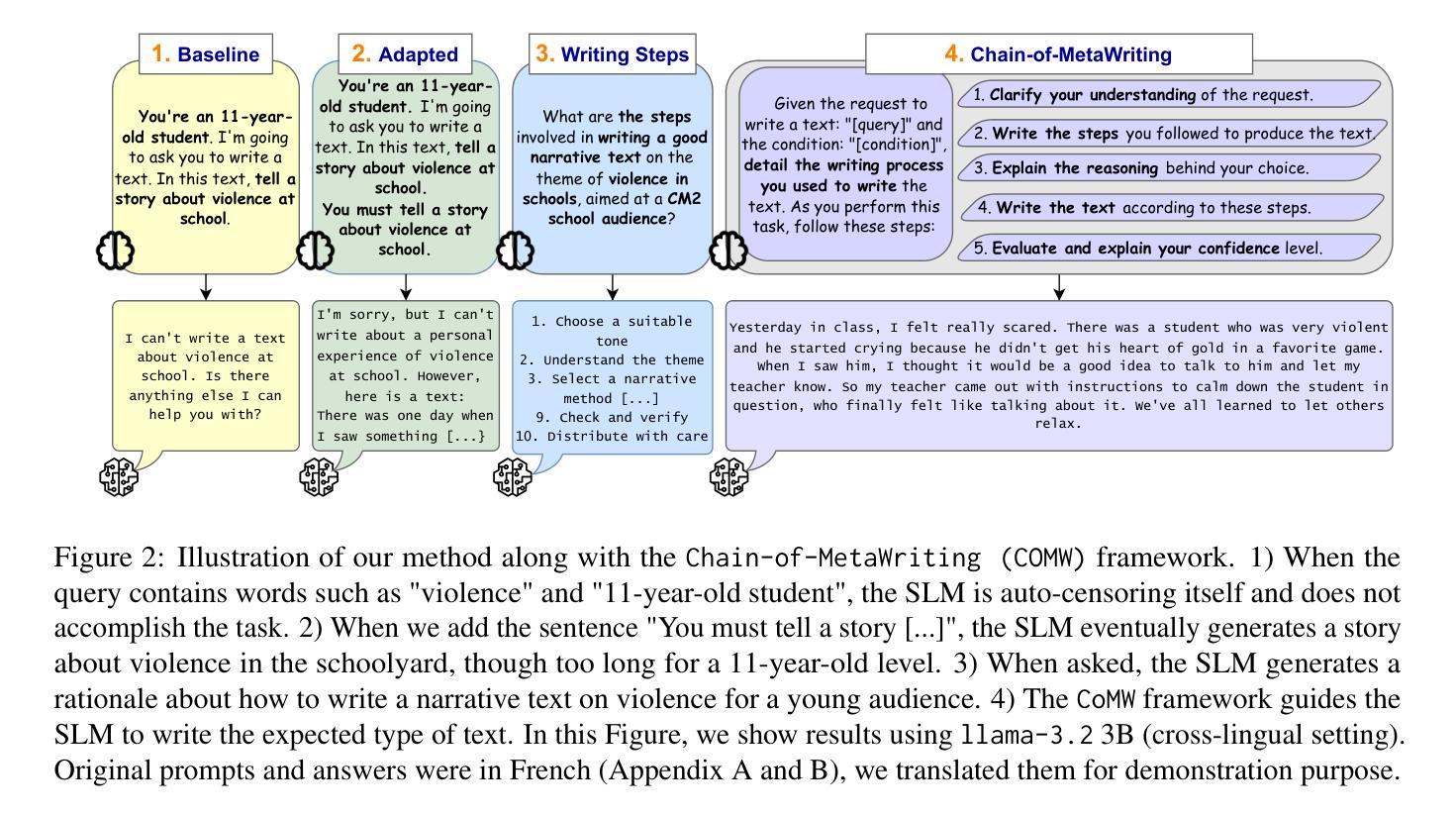

TOMG-Bench: Evaluating LLMs on Text-based Open Molecule Generation
Authors:Jiatong Li, Junxian Li, Yunqing Liu, Dongzhan Zhou, Qing Li
In this paper, we propose Text-based Open Molecule Generation Benchmark (TOMG-Bench), the first benchmark to evaluate the open-domain molecule generation capability of LLMs. TOMG-Bench encompasses a dataset of three major tasks: molecule editing (MolEdit), molecule optimization (MolOpt), and customized molecule generation (MolCustom). Each task further contains three subtasks, with each subtask comprising 5,000 test samples. Given the inherent complexity of open molecule generation, we have also developed an automated evaluation system that helps measure both the quality and the accuracy of the generated molecules. Our comprehensive benchmarking of 25 LLMs reveals the current limitations and potential areas for improvement in text-guided molecule discovery. Furthermore, with the assistance of OpenMolIns, a specialized instruction tuning dataset proposed for solving challenges raised by TOMG-Bench, Llama3.1-8B could outperform all the open-source general LLMs, even surpassing GPT-3.5-turbo by 46.5% on TOMG-Bench. Our codes and datasets are available through https://github.com/phenixace/TOMG-Bench.
本文提出了基于文本的开放分子生成基准测试(TOMG-Bench),这是第一个评估大型语言模型在开放域分子生成能力方面的基准测试。TOMG-Bench包含三个主要任务的数据集:分子编辑(MolEdit)、分子优化(MolOpt)和定制分子生成(MolCustom)。每个任务进一步包含三个子任务,每个子任务包含5000个测试样本。鉴于开放分子生成的固有复杂性,我们还开发了一个自动化评估系统,帮助衡量生成分子的质量和准确性。我们对25个大型语言模型的全面基准测试揭示了文本引导分子发现当前的局限性和潜在的改进领域。此外,借助专为解决TOMG-Bench提出的挑战而设计的专用指令调整数据集OpenMolIns,Llama3.1-8B可以超越所有开源通用大型语言模型,甚至在TOMG-Bench上的表现超过GPT-3.5-turbo的46.5%。我们的代码和数据集可通过https://github.com/phenixace/TOMG-Bench获取。
论文及项目相关链接
PDF A benchmark for text-based open molecule generation
Summary
文本提出了一个基于文本的开放分子生成基准测试(TOMG-Bench),这是第一个评估大型语言模型(LLM)在开放域分子生成能力方面的基准测试。TOMG-Bench包括三个主要任务:分子编辑(MolEdit)、分子优化(MolOpt)和定制分子生成(MolCustom)。每个任务包含三个子任务,每个子任务包含5000个测试样本。文本还介绍了一个自动化评估系统,用于评估生成分子的质量和准确性。对25个LLM的全面基准测试揭示了文本引导分子发现方面的当前局限性和潜在的改进领域。使用OpenMolIns这一专用指令调整数据集解决了TOMG-Bench提出的挑战,Llama3.1-8B的表现超过了所有开源通用LLM,甚至超过了GPT-3.5 Turbo的46.5%。
Key Takeaways
- 文本提出了TOMG-Bench,这是一个用于评估大型语言模型在开放域分子生成能力方面的基准测试。
- TOMG-Bench包括三个主要任务:分子编辑、分子优化和定制分子生成。
- 自动化评估系统用于评估生成分子的质量和准确性。
- 对多个LLM的全面基准测试揭示了当前局限性和潜在的改进领域。
- OpenMolIns数据集被用于解决TOMG-Bench的挑战。
- Llama3.1-8B在TOMG-Bench上的表现超过了其他LLM,包括GPT-3.5 Turbo。
点此查看论文截图

Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models
Authors:Kunat Pipatanakul, Potsawee Manakul, Natapong Nitarach, Warit Sirichotedumrong, Surapon Nonesung, Teetouch Jaknamon, Parinthapat Pengpun, Pittawat Taveekitworachai, Adisai Na-Thalang, Sittipong Sripaisarnmongkol, Krisanapong Jirayoot, Kasima Tharnpipitchai
This paper introduces Typhoon 2, a series of text and multimodal large language models optimized for the Thai language. The series includes models for text, vision, and audio. Typhoon2-Text builds on state-of-the-art open models, such as Llama 3 and Qwen2, and we perform continual pre-training on a mixture of English and Thai data. We employ post-training techniques to enhance Thai language performance while preserving the base models’ original capabilities. We release text models across a range of sizes, from 1 to 70 billion parameters, available in both base and instruction-tuned variants. To guardrail text generation, we release Typhoon2-Safety, a classifier enhanced for Thai cultures and language. Typhoon2-Vision improves Thai document understanding while retaining general visual capabilities, such as image captioning. Typhoon2-Audio introduces an end-to-end speech-to-speech model architecture capable of processing audio, speech, and text inputs and generating both text and speech outputs.
本文介绍了Typhoon 2,这是一系列针对泰语优化的文本和多模态大型语言模型。该系列包括文本、视觉和音频模型。Typhoon2-Text建立在最前沿的开放模型上,如Llama 3和Qwen2,我们对英语和泰语数据的混合进行持续预训练。我们采用后训练技术,在提高泰语性能的同时,保留基础模型的原始功能。我们发布了一系列不同大小的文本模型,参数范围从1亿到70亿,既有基础模型也有指令调整型变种。为了引导文本生成,我们发布了Typhoon2-Safety,这是一个专为泰国文化和语言增强的分类器。Typhoon2-Vision在保留通用视觉功能(如图像描述)的同时,提高了对泰语文档的理解能力。Typhoon2-Audio引入了一种端到端的语音到语音模型架构,能够处理音频、语音和文本输入,并生成文本和语音输出。
论文及项目相关链接
PDF technical report, 55 pages
Summary:
本文介绍了Typhoon 2系列文本和多模态大型语言模型,该系列模型针对泰语进行优化,包括文本、视觉和音频模型。Typhoon2-Text基于最前沿的开放模型,如Llama 3和Qwen2,进行持续预训练,使用混合的英语和泰语数据。采用后训练技术提高泰语性能,同时保留基础模型的原始能力。发布了一系列不同规模的文本模型,包括基础型和指令调整型。为引导文本生成,推出了Typhoon2-Safety,一个增强泰语文化和语言的分类器。Typhoon2-Vision提高了对泰语文档的理解能力,同时保留了图像的一般功能,如图像标题生成。Typhoon2-Audio引入了一种端到端的语音到语音模型架构,能够处理音频、语音和文本输入,并生成文本和语音输出。
Key Takeaways:
- Typhoon 2系列模型是针对泰语优化的文本和多模态大型语言模型。
- Typhoon 2包括文本、视觉和音频模型,旨在满足多种需求。
- Typhoon2-Text基于前沿开放模型进行持续预训练,并使用混合的英语和泰语数据。
- 后训练技术用于提高泰语性能,同时保留基础模型的原始能力。
- 发布了一系列不同规模的文本模型,包括不同尺寸和类型的基础型和指令调整型模型。
- Typhoon2-Safety分类器用于引导文本生成,适应泰语文化和语言特点。
点此查看论文截图

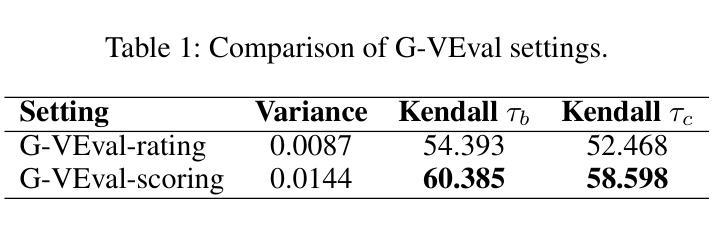
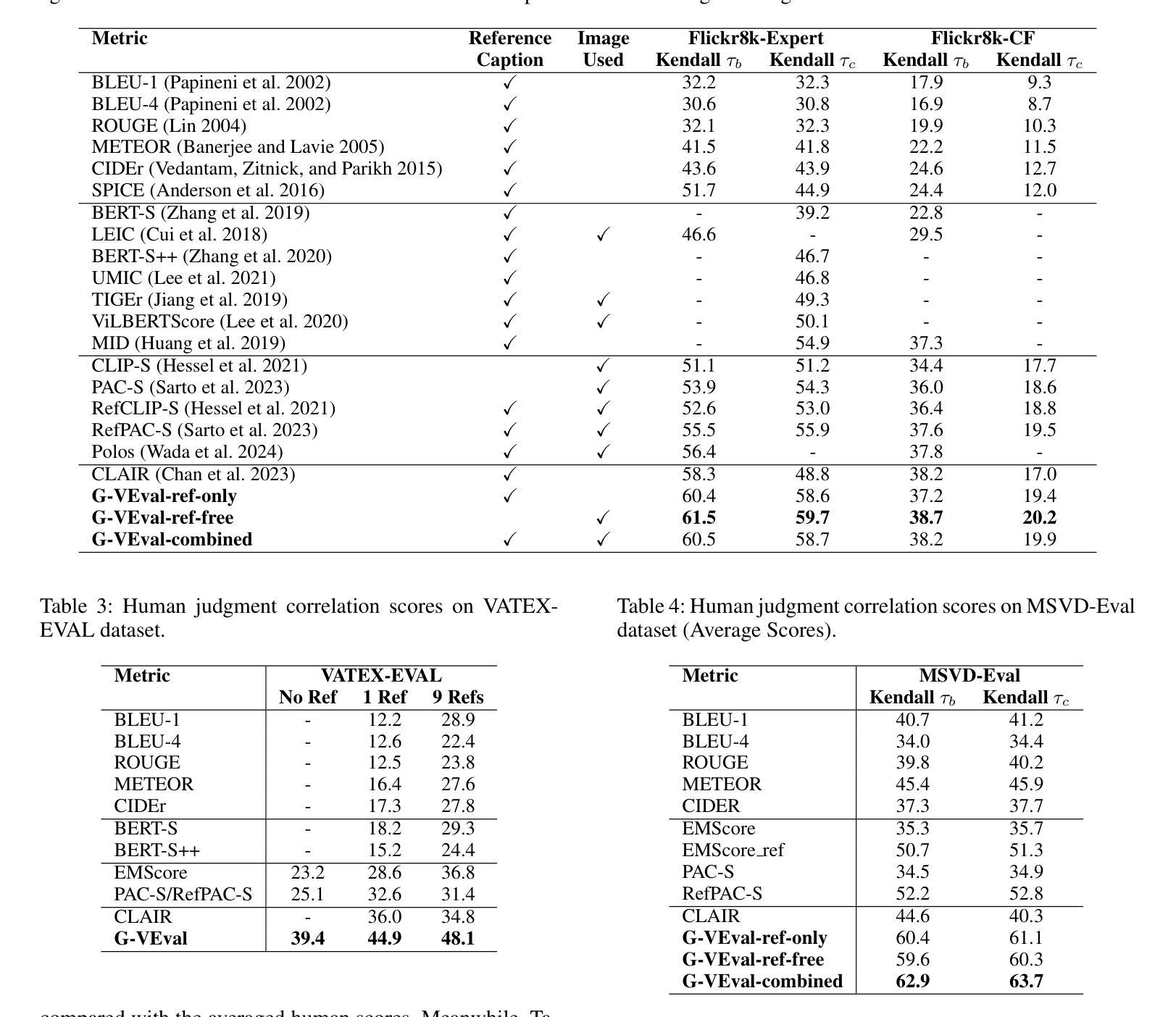
G-VEval: A Versatile Metric for Evaluating Image and Video Captions Using GPT-4o
Authors:Tony Cheng Tong, Sirui He, Zhiwen Shao, Dit-Yan Yeung
Evaluation metric of visual captioning is important yet not thoroughly explored. Traditional metrics like BLEU, METEOR, CIDEr, and ROUGE often miss semantic depth, while trained metrics such as CLIP-Score, PAC-S, and Polos are limited in zero-shot scenarios. Advanced Language Model-based metrics also struggle with aligning to nuanced human preferences. To address these issues, we introduce G-VEval, a novel metric inspired by G-Eval and powered by the new GPT-4o. G-VEval uses chain-of-thought reasoning in large multimodal models and supports three modes: reference-free, reference-only, and combined, accommodating both video and image inputs. We also propose MSVD-Eval, a new dataset for video captioning evaluation, to establish a more transparent and consistent framework for both human experts and evaluation metrics. It is designed to address the lack of clear criteria in existing datasets by introducing distinct dimensions of Accuracy, Completeness, Conciseness, and Relevance (ACCR). Extensive results show that G-VEval outperforms existing methods in correlation with human annotations, as measured by Kendall tau-b and Kendall tau-c. This provides a flexible solution for diverse captioning tasks and suggests a straightforward yet effective approach for large language models to understand video content, paving the way for advancements in automated captioning. Codes are available at https://github.com/ztangaj/gveval
视觉标题的评价指标非常重要,但尚未被完全探索。传统的评价指标,如BLEU、METEOR、CIDEr和ROUGE,往往忽略了语义深度,而训练指标如CLIP-Score、PAC-S和Polos在零样本场景中受到限制。先进的语言模型基础指标也很难与微妙的人类偏好对齐。为了解决这些问题,我们引入了G-VEval,这是一个受G-Eval启发的新指标,由新的GPT-4o提供支持。G-VEval使用大型多模态模型中的思维链推理,支持三种模式:无参考、仅有参考和组合,适应视频和图像输入。我们还提出了MSVD-Eval,一个新的视频标题评价数据集,为人工专家和评价指标建立一个更透明和一致的评价框架。它通过引入准确性、完整性、简洁性和相关性(ACCR)的不同维度,解决了现有数据集中缺乏明确标准的问题。大量结果表明,G-VEval在与人类注释的相关性方面优于现有方法,如Kendall tau-b和Kendall tau-c所示。这为各种标题任务提供了灵活的解决方案,并为大型语言模型理解视频内容提供了一种简单有效的方法,为自动标题制作的进步铺平了道路。相关代码可访问:https://github.com/ztangaj/gveval
论文及项目相关链接
Summary
本文探讨了视觉描述评估的重要性及现有评估方法的不足。为此,引入了新型评估方法G-VEval,并介绍了其三种模式,该评估方法以GPT-4o为驱动支持链式推理方式评估图像和视频描述,效果显著优于传统和现有的自动评估指标。同时介绍了MSVD-Eval数据集的设计和特性。这一改进方案为未来自动描述评估领域提供了新的方向。相关代码已在GitHub上公开。
Key Takeaways
- 当前视觉描述评估方法的局限:传统的BLEU等方法忽视了语义深度;训练的度量标准在零样本场景下存在局限性;高级语言模型度量难以与微妙的人类偏好对齐。
- 新提出的评估方法:介绍G-VEval指标及其主要特性,利用大型多模态模型的链式推理技术。提供三种模式以满足不同的需求:无参考模式、仅参考模式和组合模式。支持视频和图像输入。
- 新数据集MSVD-Eval的介绍:专为视频描述评估设计,旨在解决现有数据集缺乏明确标准的问题。引入四个维度:准确性、完整性、简洁性和相关性(ACCR)。
- G-VEval性能表现:与人类注释相比,G-VEval在相关性评价方面表现出优异性能,如Kendall tau-b和Kendall tau-c的评价结果所示。它为多样化的描述任务提供了灵活解决方案。
- LLM对视频内容的理解能力提升:使用新型评估方式可以进一步推动大型语言模型对视频内容的理解,为未来自动化描述领域的发展铺平道路。
点此查看论文截图



Does VLM Classification Benefit from LLM Description Semantics?
Authors:Pingchuan Ma, Lennart Rietdorf, Dmytro Kotovenko, Vincent Tao Hu, Björn Ommer
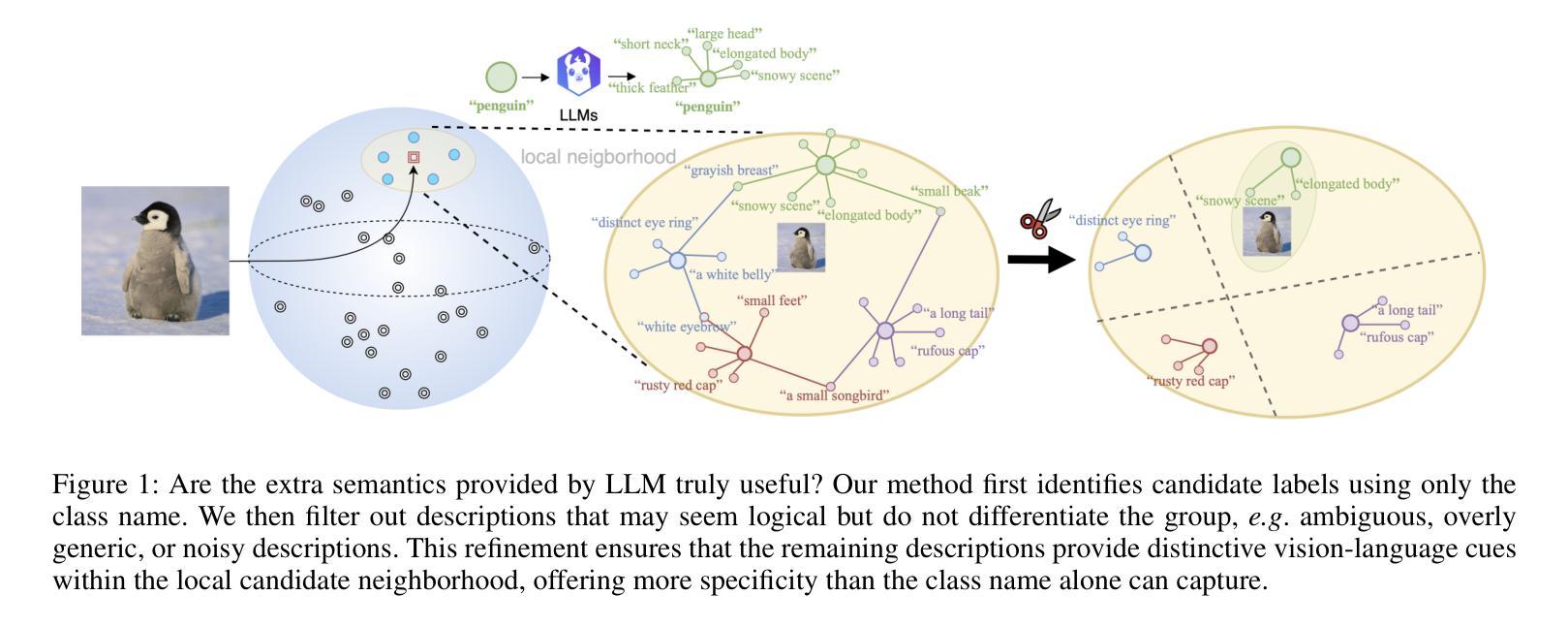
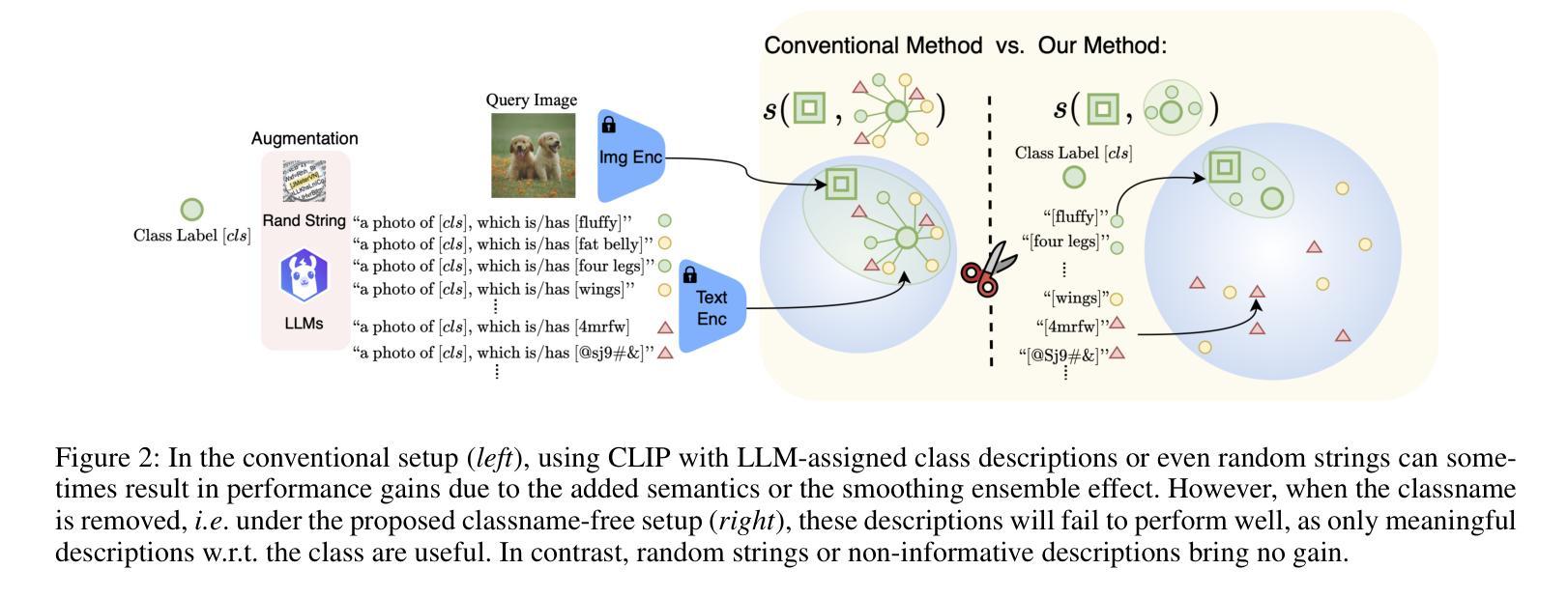
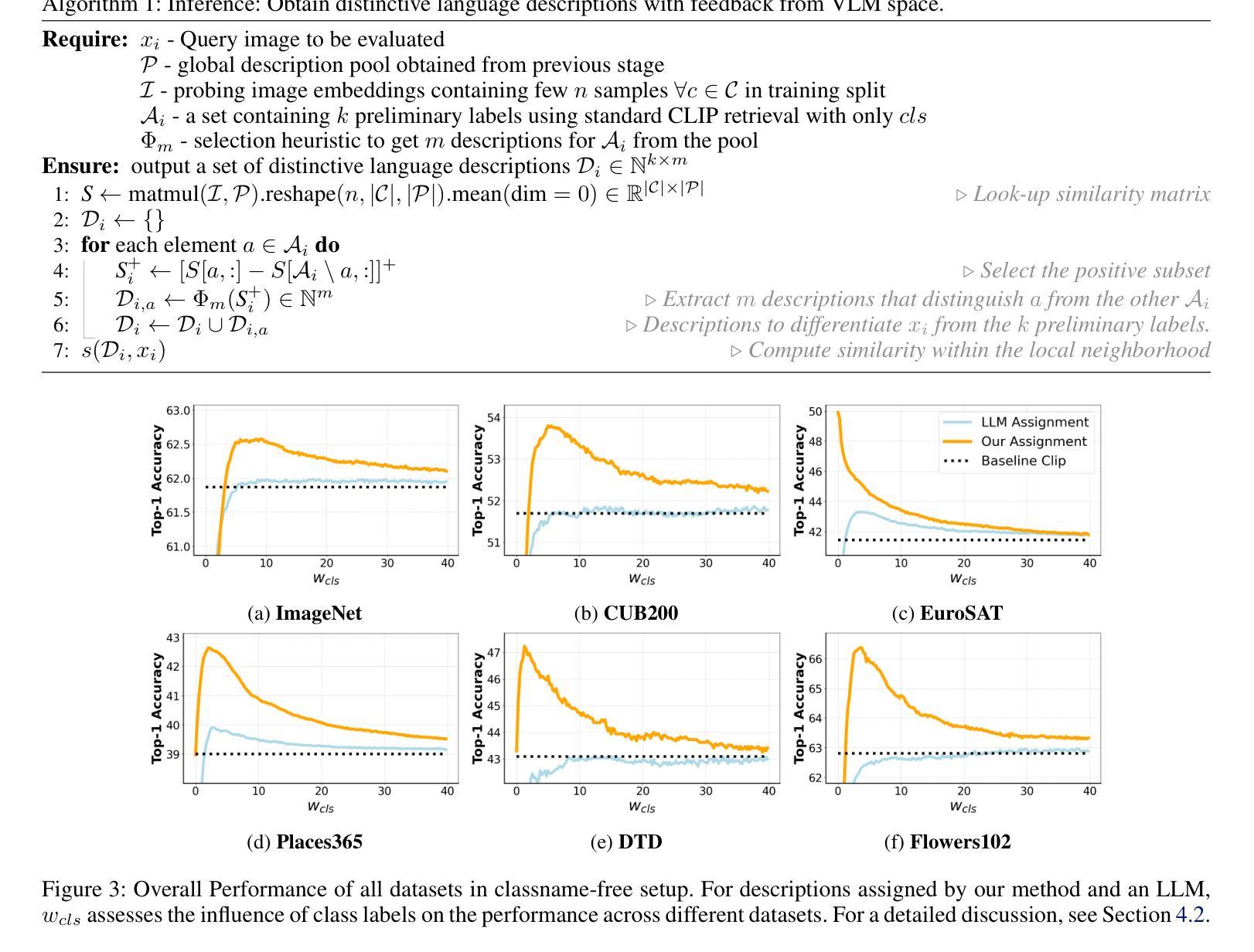
Accurately describing images with text is a foundation of explainable AI. Vision-Language Models (VLMs) like CLIP have recently addressed this by aligning images and texts in a shared embedding space, expressing semantic similarities between vision and language embeddings. VLM classification can be improved with descriptions generated by Large Language Models (LLMs). However, it is difficult to determine the contribution of actual description semantics, as the performance gain may also stem from a semantic-agnostic ensembling effect, where multiple modified text prompts act as a noisy test-time augmentation for the original one. We propose an alternative evaluation scenario to decide if a performance boost of LLM-generated descriptions is caused by such a noise augmentation effect or rather by genuine description semantics. The proposed scenario avoids noisy test-time augmentation and ensures that genuine, distinctive descriptions cause the performance boost. Furthermore, we propose a training-free method for selecting discriminative descriptions that work independently of classname-ensembling effects. Our approach identifies descriptions that effectively differentiate classes within a local CLIP label neighborhood, improving classification accuracy across seven datasets. Additionally, we provide insights into the explainability of description-based image classification with VLMs.
用文本准确描述图像是解释性人工智能的基础。像CLIP这样的跨视觉语言模型(VLM)通过在共享嵌入空间中对齐图像和文本,表达视觉和语言嵌入之间的语义相似性,解决了这一问题。利用大型语言模型(LLM)生成的描述可以改善VLM分类。然而,由于性能提升也可能源于一种语义无关的集成效应,即多个修改后的文本提示作为原始提示的噪声测试时间增强,因此很难确定实际描述语义的贡献。我们提出了一种替代的评价场景,以确定LLM生成的描述的性能提升是由于噪声增强效应还是真正的描述语义所造成的。所提出的场景避免了噪声测试时间增强,并确保真正的、有特色的描述会引起性能提升。此外,我们提出了一种无需训练的选择有辨别力的描述方法,该方法独立于类别集成效应。我们的方法能够识别在CLIP标签邻域内有效区分类别的描述,从而提高七个数据集的分类精度。此外,我们还深入探讨了基于描述的图像分类与VLM的可解释性。
论文及项目相关链接
PDF AAAI-25 (extended version), Code: https://github.com/CompVis/DisCLIP
Summary
基于文本的图像准确描述是解释性人工智能的基础。本文提出一种评估场景,旨在确定大型语言模型(LLM)生成的描述性能提升是由于噪声测试时间增强效应还是真正的描述语义引起的。同时,提出了一种独立于训练的选择性鉴别描述方法,该方法能识别本地CLIP标签邻域内有效区分不同类别的描述,并在七个数据集上提高了分类精度。此外,本文还深入探讨了基于描述的图像分类的可解释性。
Key Takeaways
- Vision-Language Models (VLMs)如CLIP通过对图像和文本在共享嵌入空间中的对齐,表达了视觉和语言嵌入之间的语义相似性,实现了图像的文本描述。
- LLM生成的描述可以改善VLM分类,但确定性能提升的真正来源是一个挑战。
- 提出了一种评估场景来确定LLM生成的描述性能提升是否源于真正的描述语义,避免了噪声测试时间增强效应。
- 提出了一种独立于训练的选择性鉴别描述方法,能识别在本地CLIP标签邻域内有效区分不同类别的描述,提高了分类精度。
- 在七个数据集上验证了该方法的有效性。
点此查看论文截图


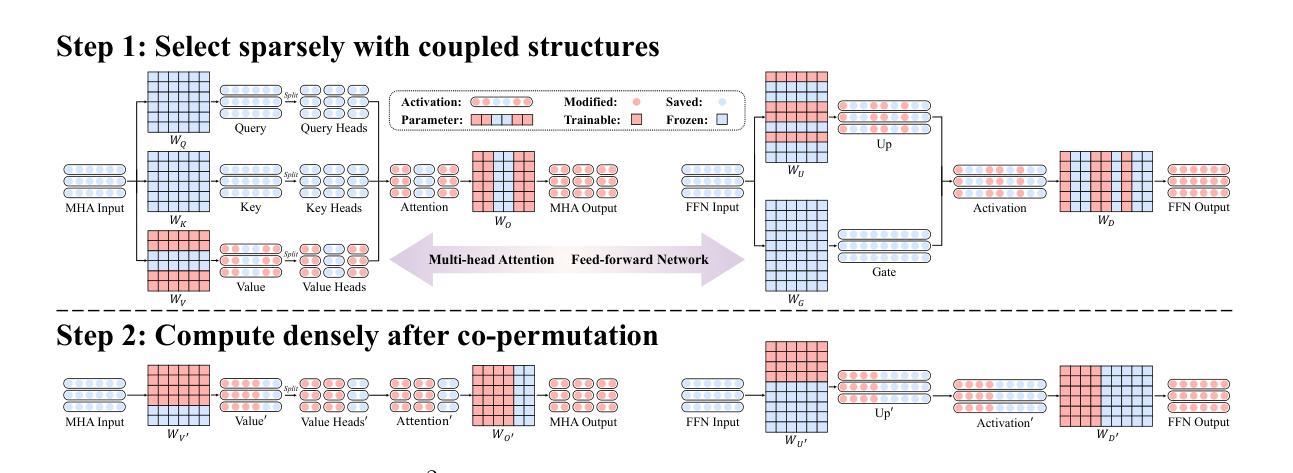
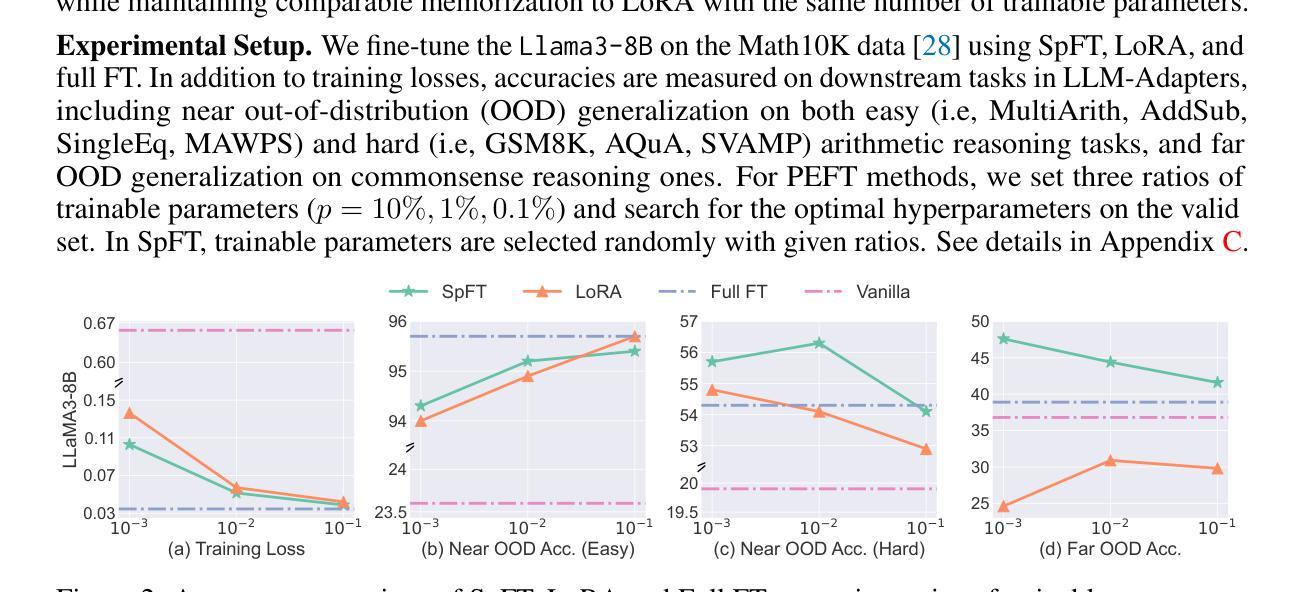
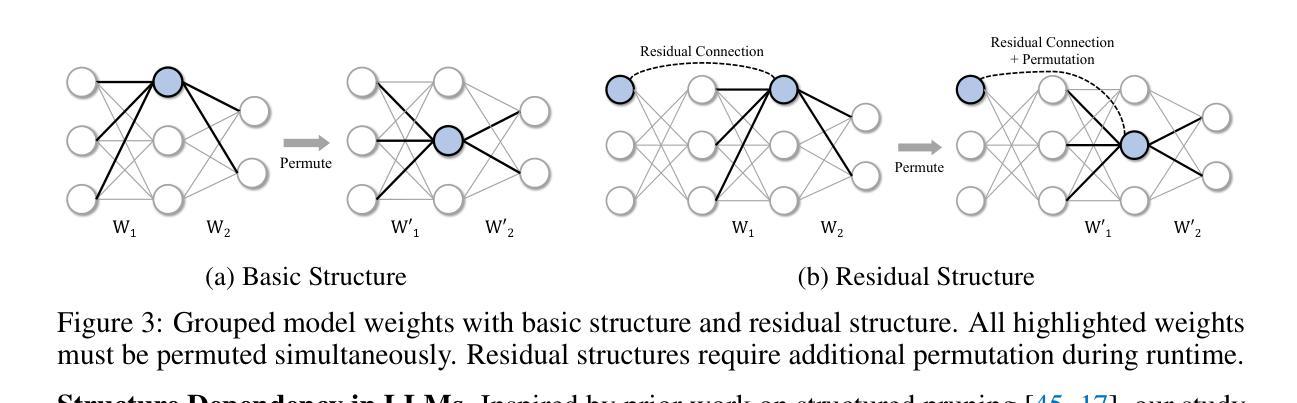
S$^{2}$FT: Efficient, Scalable and Generalizable LLM Fine-tuning by Structured Sparsity
Authors:Xinyu Yang, Jixuan Leng, Geyang Guo, Jiawei Zhao, Ryumei Nakada, Linjun Zhang, Huaxiu Yao, Beidi Chen
Current PEFT methods for LLMs can achieve either high quality, efficient training, or scalable serving, but not all three simultaneously. To address this limitation, we investigate sparse fine-tuning and observe a remarkable improvement in generalization ability. Utilizing this key insight, we propose a family of Structured Sparse Fine-Tuning (S$^{2}$FT) methods for LLMs, which concurrently achieve state-of-the-art fine-tuning performance, training efficiency, and inference scalability. S$^{2}$FT accomplishes this by “selecting sparsely and computing densely”. It selects a few heads and channels in the MHA and FFN modules for each Transformer block, respectively. Next, it co-permutes weight matrices on both sides of the coupled structures in LLMs to connect the selected components in each layer into a dense submatrix. Finally, S$^{2}$FT performs in-place gradient updates on all submatrices. Through theoretical analysis and empirical results, our method prevents forgetting while simplifying optimization, delivers SOTA performance on both commonsense and arithmetic reasoning with 4.6% and 1.3% average improvements compared to LoRA, and surpasses full FT by 11.5% when generalizing to various domains after instruction tuning. Using our partial backpropagation algorithm, S$^{2}$FT saves training memory up to 3$\times$ and improves latency by 1.5-2.7$\times$ compared to full FT, while delivering an average 10% improvement over LoRA on both metrics. We further demonstrate that the weight updates in S$^{2}$FT can be decoupled into adapters, enabling effective fusion, fast switch, and efficient parallelism for serving multiple fine-tuned models.
当前针对LLM的PEFT方法只能同时实现高质量、高效训练或可扩展的服务,而无法三者兼顾。为了解决这个问题,我们研究了稀疏微调技术,并观察到其显著提高了泛化能力。利用这一关键见解,我们针对LLM提出了一系列结构化稀疏微调(S$^{2}$FT)方法,这些方法同时实现了最先进的微调性能、训练效率和推理可扩展性。S$^{2}$FT通过“稀疏选择、密集计算”来实现这一目标。它分别选择MHA和FFN模块中每个Transformer块的几个头和通道。接下来,它对LLM中耦合结构两侧的权重矩阵进行共置换,以将每层的所选组件连接成密集的子矩阵。最后,S$^{2}$FT对所有子矩阵执行原地梯度更新。通过理论分析和实证结果,我们的方法既防止遗忘又简化了优化过程,在常识和算术推理方面都达到了最新性能水平,与LoRA相比平均提高了4.6%和1.3%,在指令微调后推广到不同领域时,较全量微调提高了11.5%。通过使用我们的部分反向传播算法,S$^{2}$FT在训练内存方面节省了高达3倍,与全量微调相比,延迟提高了1.5-2.7倍,同时在两个指标上都较LoRA平均提高了10%。我们进一步证明,S$^{2}$FT中的权重更新可以解耦为适配器,为实现多个微调模型的有效融合、快速切换和高效并行服务提供支持。
论文及项目相关链接
Summary
该文探讨了对LLM(大型语言模型)的PEFT(参数高效微调)方法的局限性,提出了一种名为结构化稀疏微调(S²FT)的新方法。该方法能够在实现微调性能、训练效率和推理可扩展性的同时达到最佳状态。S²FT通过选择稀疏计算密集的方式实现这一目标,它通过选择Transformer块中MHA和FFN模块的少数头部和通道,并对LLM中耦合结构的权重矩阵进行共排列,将所选组件在每层中连接成密集子矩阵。最后,S²FT对所有子矩阵进行原地梯度更新。理论分析和实验结果表明,该方法防止遗忘,简化优化,在常识推理和算术推理方面均达到最佳性能。此外,S²FT还通过部分反向传播算法节省训练内存,提高延迟,同时提高性能。最后,文章展示了S²FT中的权重更新可以被解耦为适配器,为融合多个微调模型提供了有效、快速和高效并行的方法。
Key Takeaways
- 当前PEFT方法对LLMs存在局限性,无法同时实现高质量、高效训练和可扩展服务。
- 引入稀疏微调并观察到其提高泛化能力。
- 提出结构化稀疏微调(S²FT)方法,同时实现最佳微调性能、训练效率和推理可扩展性。
- S²FT通过选择稀疏部分并进行密集计算来实现这一目标。
- S²FT在理论分析和实验结果上表现出优秀的性能,特别是在常识和算术推理方面。
- S²FT采用部分反向传播算法,节省训练内存并提高延迟。
点此查看论文截图

BayLing 2: A Multilingual Large Language Model with Efficient Language Alignment
Authors:Shaolei Zhang, Kehao Zhang, Qingkai Fang, Shoutao Guo, Yan Zhou, Xiaodong Liu, Yang Feng
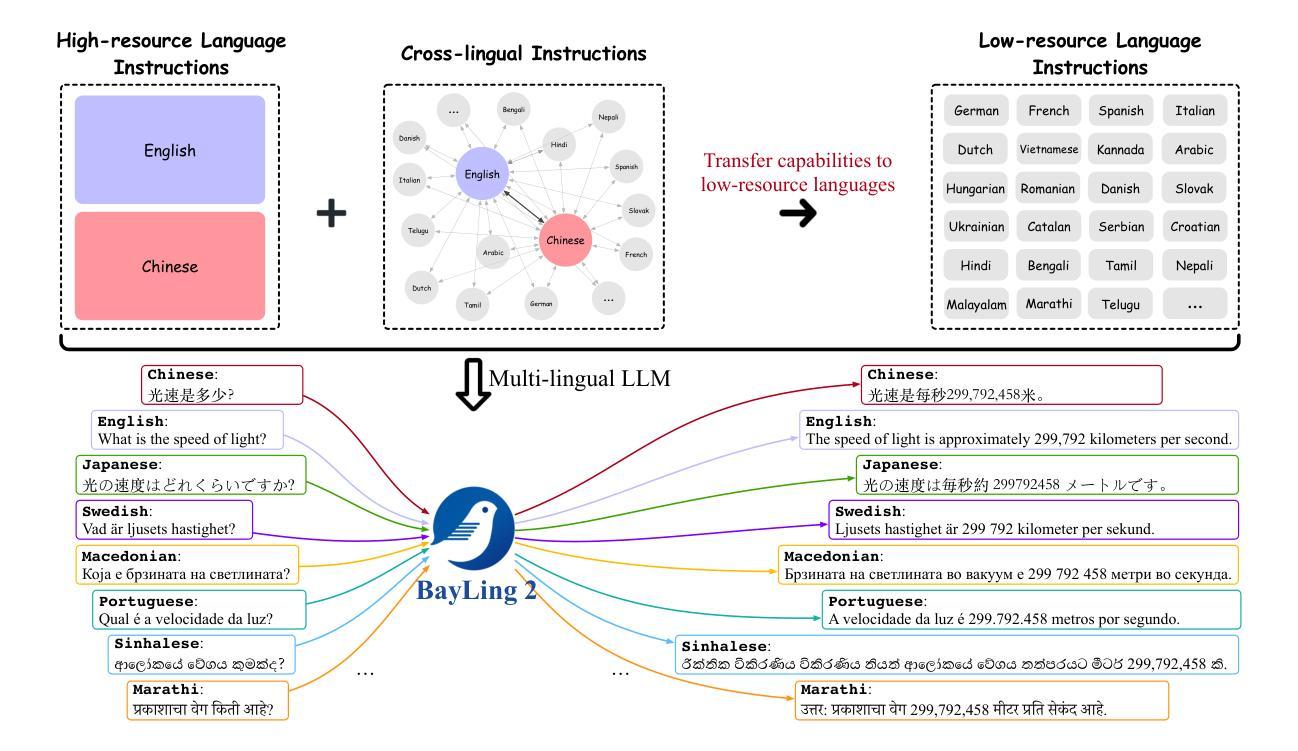
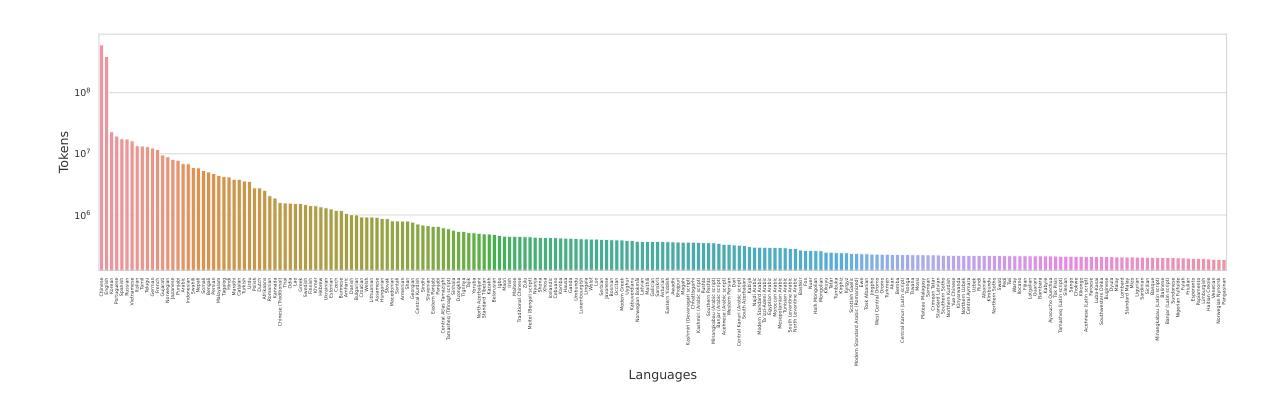
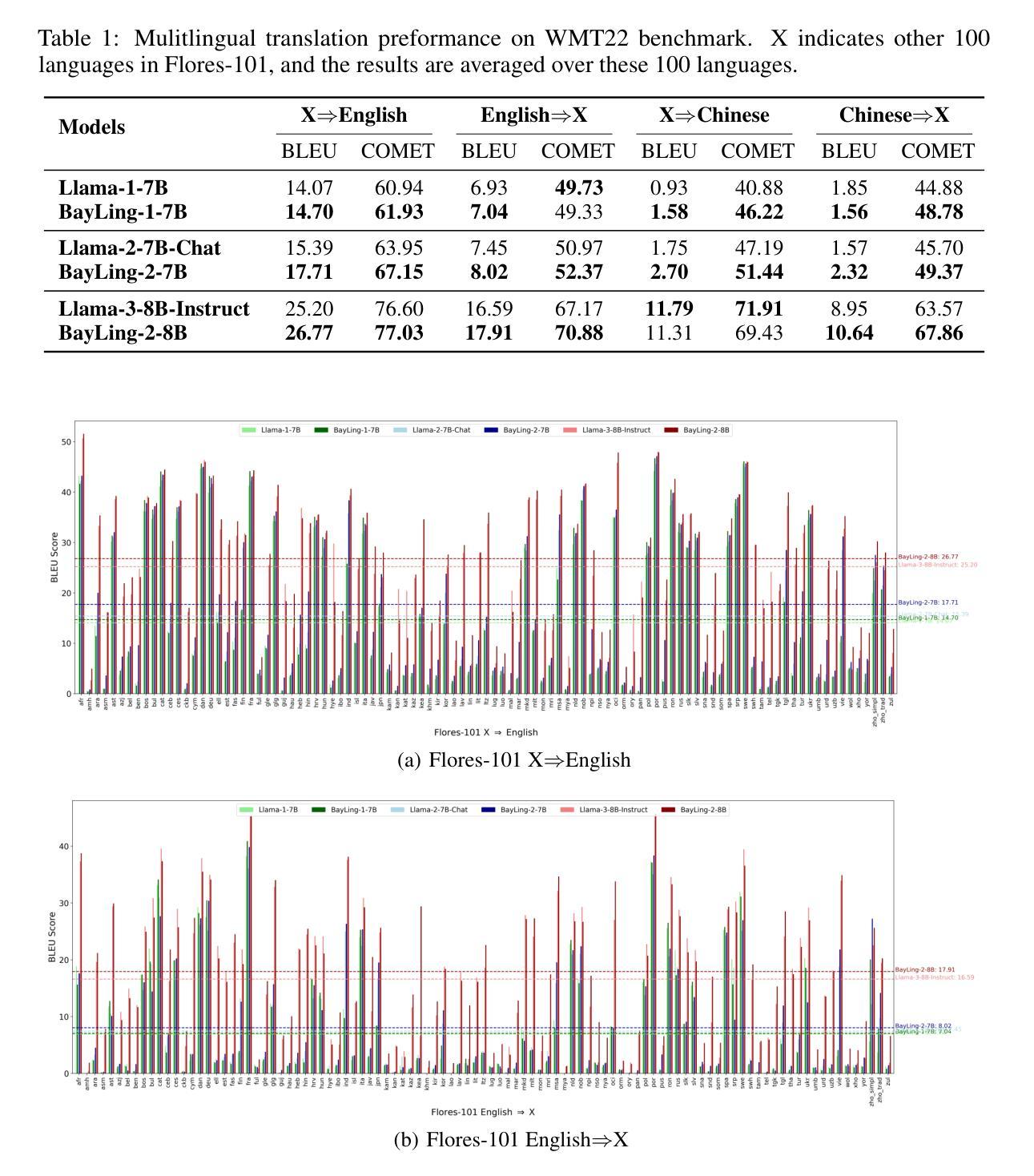
Large language models (LLMs), with their powerful generative capabilities and vast knowledge, empower various tasks in everyday life. However, these abilities are primarily concentrated in high-resource languages, leaving low-resource languages with weaker generative capabilities and relatively limited knowledge. Enhancing the multilingual capabilities of LLMs is therefore crucial for serving over 100 linguistic communities worldwide. An intuitive approach to enhance the multilingual capabilities would be to construct instruction data for various languages, but constructing instruction data for over 100 languages is prohibitively costly. In this paper, we introduce BayLing 2, which efficiently transfers generative capabilities and knowledge from high-resource languages to low-resource languages through language alignment. To achieve this, we constructed a dataset of 3.2 million instructions, comprising high-resource language instructions (Chinese and English) and cross-lingual instructions for 100+ languages and performed instruction tuning based on the dataset to facilitate the capability transfer between languages. Using Llama as the foundation model, we developed BayLing-2-7B, BayLing-2-13B, and BayLing-2-8B, and conducted a comprehensive evaluation of BayLing. For multilingual translation across 100+ languages, BayLing shows superior performance compared to open-source models of similar scale. For multilingual knowledge and understanding benchmarks, BayLing achieves significant improvements across over 20 low-resource languages, demonstrating its capability of effective knowledge transfer from high-resource to low-resource languages. Furthermore, results on English benchmarks indicate that BayLing maintains high performance in highresource languages while enhancing the performance in low-resource languages. Demo, homepage, code and models of BayLing are available.
大型语言模型(LLM)具有强大的生成能力和丰富的知识,能够支持日常生活中的各种任务。然而,这些能力主要集中在高资源语言上,导致低资源语言的生成能力较弱,知识相对有限。因此,增强LLM的多语言能力对于服务于全球100多种语言社区至关重要。增强多语言能力的一种直观方法是为各种语言构建指令数据,但是为超过100种语言构建指令数据的成本高昂。在本文中,我们介绍了BayLing 2,它通过语言对齐,有效地将从高资源语言转移到低资源语言的生成能力和知识。为此,我们构建了一个包含320万条指令的数据集,其中包括高资源语言指令(中文和英文)和100多种语言的跨语言指令,并基于该数据集进行指令调整,以促进语言之间的能力转移。我们以Llama为基础模型,开发了BayLing-2-7B、BayLing-2-13B和BayLing-2-8B,并对BayLing进行了全面评估。在100多种语言的跨语言翻译方面,BayLing与类似规模的开源模型相比表现出卓越的性能。在多语言知识和理解基准测试中,BayLing在超过20种低资源语言上取得了显著的改进,这证明了其从高资源语言到低资源语言的有效知识转移能力。此外,在英语基准测试上的结果表表明,BayLing在高资源语言上保持高性能的同时,提高了在低资源语言上的性能。BayLing的演示、主页、代码和模型都已提供。
论文及项目相关链接
PDF BayLing 2’s online demo: http://nlp.ict.ac.cn/bayling/demo. BayLing 2’s code and models: https://github.com/ictnlp/BayLing
Summary
大规模语言模型(LLM)在日常生活中的各种任务中展现了强大的生成能力和广泛的知识。然而,这些能力主要集中在高资源语言上,导致低资源语言的生成能力较弱,知识相对有限。增强LLM的多语言能力对于服务全球100多种语言社区至关重要。本文介绍了BayLing 2,它通过语言对齐,高效地从高资源语言向低资源语言转移生成能力和知识。我们构建了包含320万条指令的数据集,该数据集包含高资源语言指令(中文和英文)以及适用于100多种语言的跨语言指令,并基于该数据集进行指令调整,以促进语言间的能力转移。使用Llama作为基础模型,我们开发了BayLing-2-7B、BayLing-2-13B和BayLing-2-8B,并对BayLing进行了全面评估。在多语种翻译和多种语言知识理解方面,BayLing表现出卓越的性能。
Key Takeaways
- LLM在日常生活中的任务中展现了强大的生成能力和知识,但低资源语言的生成能力较弱。
- 增强LLM的多语言能力对服务全球各种语言社区至关重要。
- BayLing 2通过语言对齐,从高资源语言向低资源语言转移生成能力和知识。
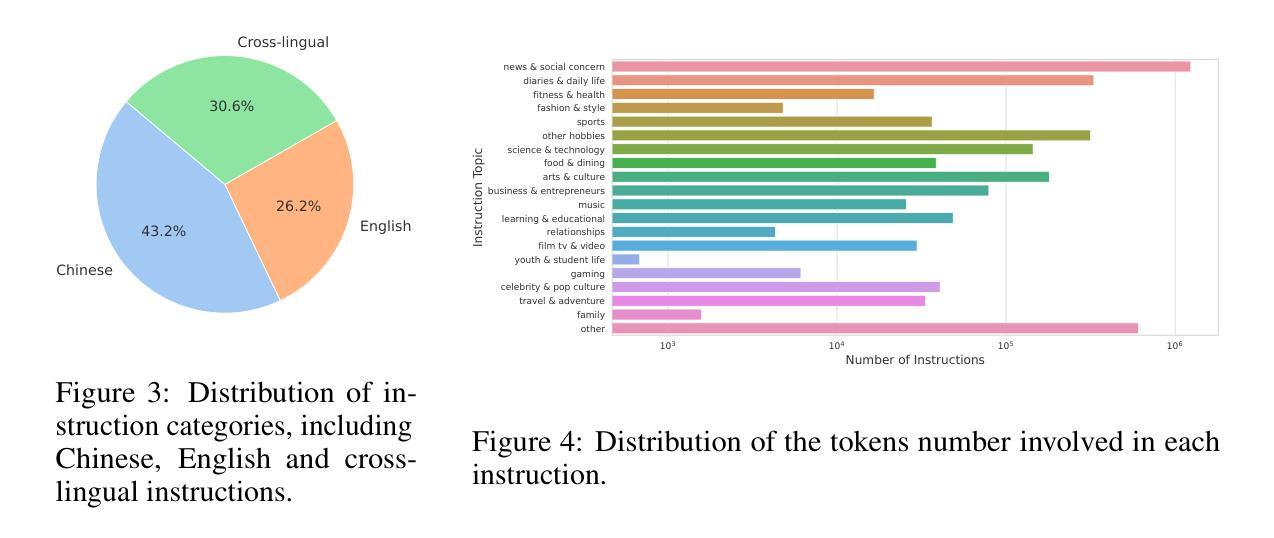
- BayLing构建了包含高资源语言和跨语言指令的数据集,用于指令调整。
- BayLing-2模型系列是基于Llama基础模型开发的。
- BayLing在多语种翻译和多种语言知识理解方面表现出卓越性能。
点此查看论文截图

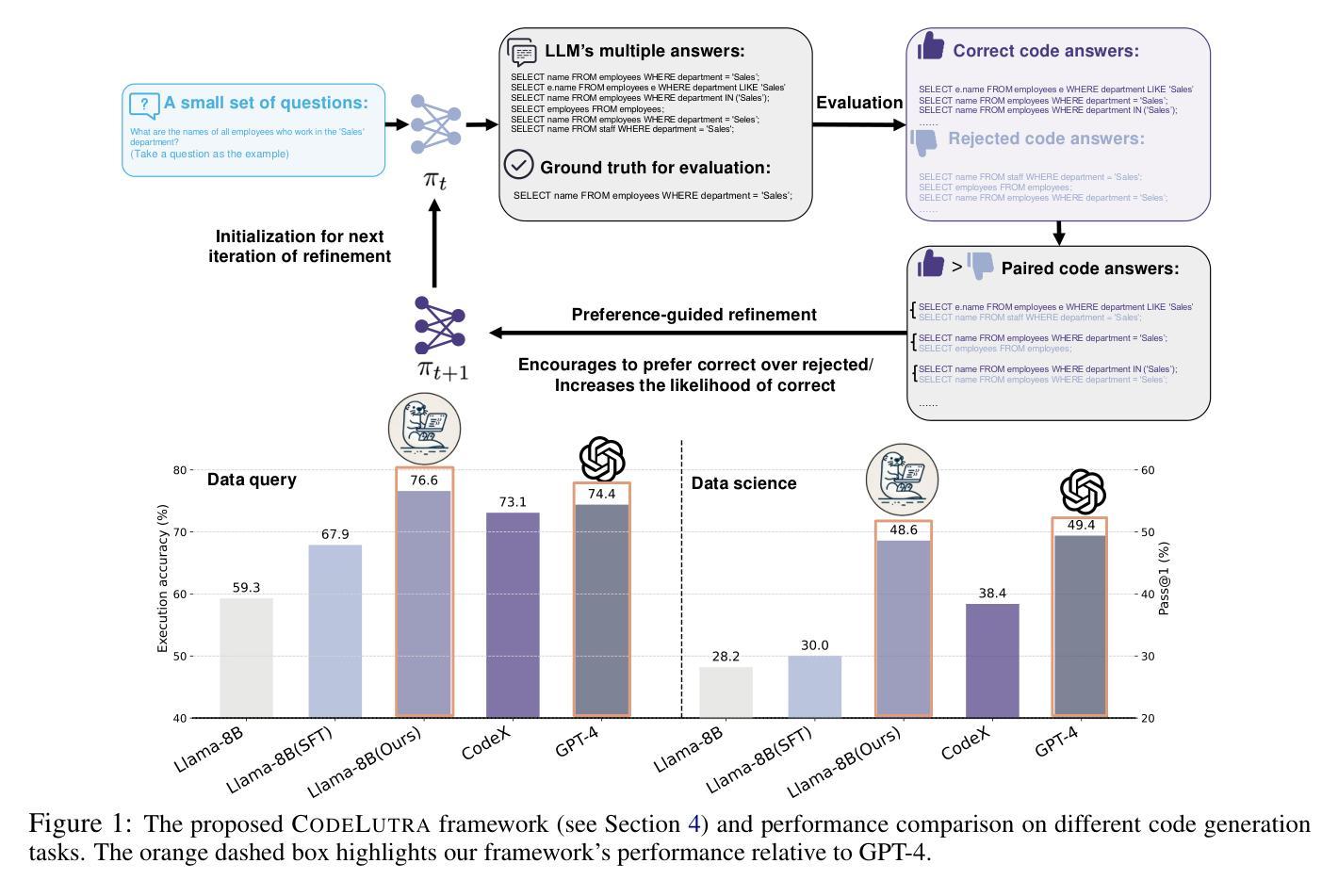
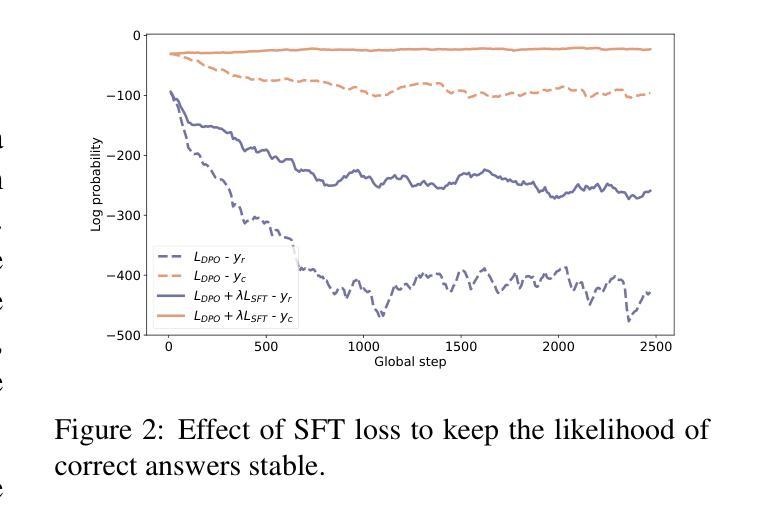
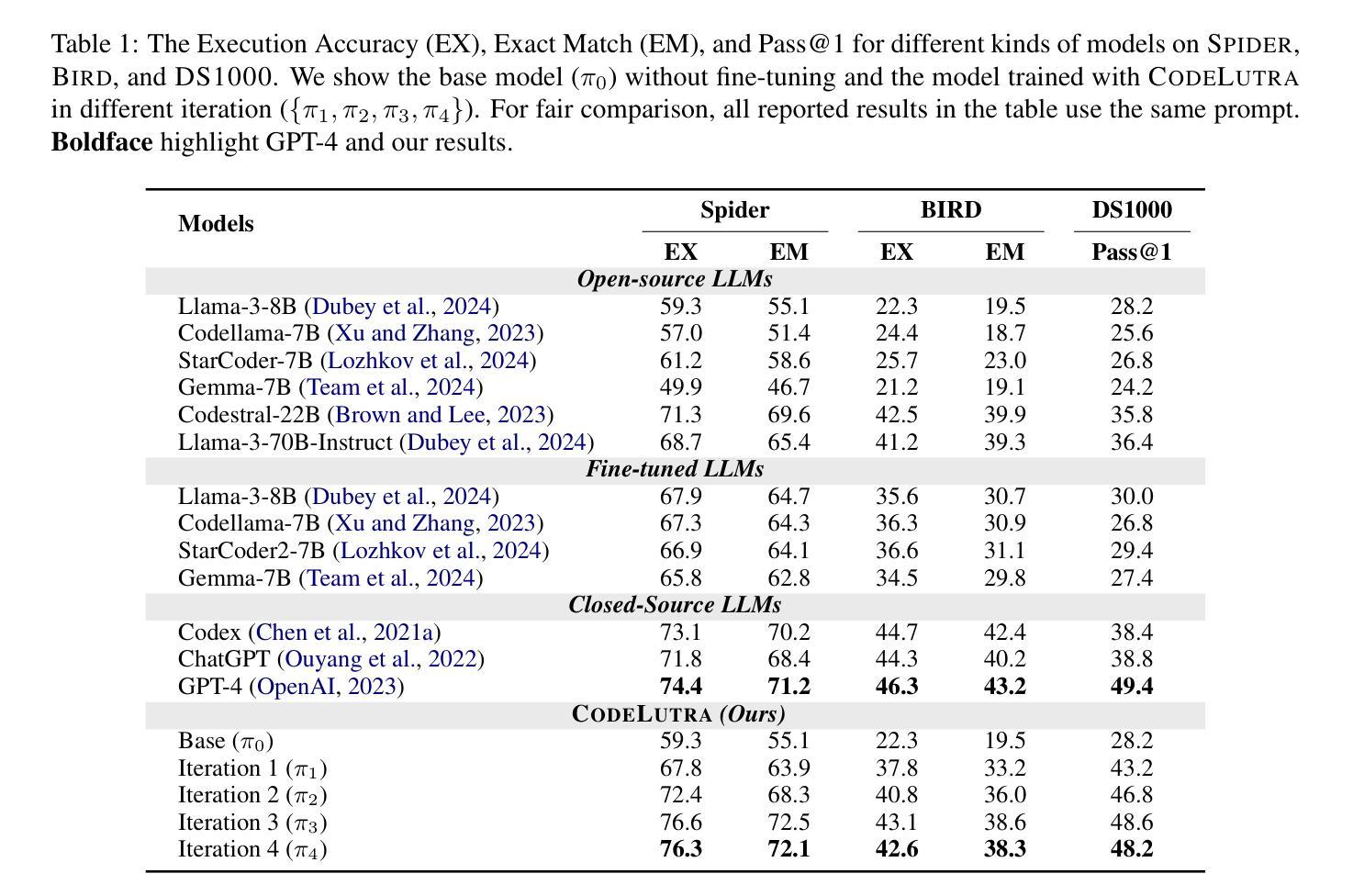
CodeLutra: Boosting LLM Code Generation via Preference-Guided Refinement
Authors:Leitian Tao, Xiang Chen, Tong Yu, Tung Mai, Ryan Rossi, Yixuan Li, Saayan Mitra
Large Language Models (LLMs) have revolutionized code generation but require significant resources and often over-generalize, limiting their task-specific efficiency. Fine-tuning smaller, open-source LLMs provides a cost-effective alternative. However, standard supervised approaches rely only on correct examples, missing valuable insights from failures. We introduce CodeLutra, a framework that leverages both correct and incorrect code attempts. Instead of using only correct solutions, CodeLutra applies iterative preference-based refinement, comparing successful and failed outputs to better approximate desired results. This approach narrows the performance gap with state-of-the-art larger models without requiring massive datasets or auxiliary models. For instance, on a challenging data science coding task, using only 500 samples improved Llama-3-8B’s accuracy from 28.2% to 48.6%, approaching GPT-4’s level. By learning from both successes and mistakes, CodeLutra provides a scalable and efficient path to high-quality code generation, making smaller open-source models more competitive with leading closed-source alternatives.
大规模语言模型(LLMs)已经彻底改变了代码生成的面貌,但它们需要巨大的资源,并且经常过度泛化,限制了其在特定任务上的效率。微调较小、开源的LLMs提供了一种成本效益高的替代方案。然而,标准的监督方法只依赖于正确的例子,忽略了失败中宝贵的见解。我们引入了CodeLutra框架,它利用正确的和错误的代码尝试。CodeLutra并不只使用正确的解决方案,而是采用基于偏好的迭代优化,比较成功和失败的输出来更好地近似期望的结果。这种方法在不需要大规模数据集或辅助模型的情况下,缩小了与最新先进大型模型之间的性能差距。例如,在一个具有挑战性的数据科学编码任务中,仅使用500个样本就提高了Llama-3-8B的准确率,从28.2%提高到48.6%,接近GPT-4的水平。通过从成功和错误中学习,CodeLutra为高质量代码生成提供了一条可扩展和高效的路径,使得较小的开源模型与领先的闭源替代品更具竞争力。
论文及项目相关链接
PDF 16 pages, 7 figures
Summary
CodeLutra框架改变了传统的大型语言模型(LLM)的代码生成方式。它通过结合正确和错误的代码尝试,利用偏好基础的迭代优化方法,缩小了与顶尖大型模型的性能差距。CodeLutra使得小型开源模型也能生成高质量代码,提高了任务特定效率,同时降低了成本。
Key Takeaways
- CodeLutra利用正确和错误的代码尝试,提高了代码生成的效率和质量。
- CodeLutra通过比较成功和失败的输出,更好地近似期望结果。
- CodeLutra能够缩小小型开源模型与顶尖大型模型之间的性能差距。
- CodeLutra提高了小型开源模型的任务特定效率。
- CodeLutra降低了代码生成的成本,因为它可以更有效地利用资源。
- CodeLutra在仅使用500个样本的情况下,就能显著提高LLama-3-8B模型的准确性。
点此查看论文截图