⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-21 更新
LiDAR-RT: Gaussian-based Ray Tracing for Dynamic LiDAR Re-simulation
Authors:Chenxu Zhou, Lvchang Fu, Sida Peng, Yunzhi Yan, Zhanhua Zhang, Yong Chen, Jiazhi Xia, Xiaowei Zhou
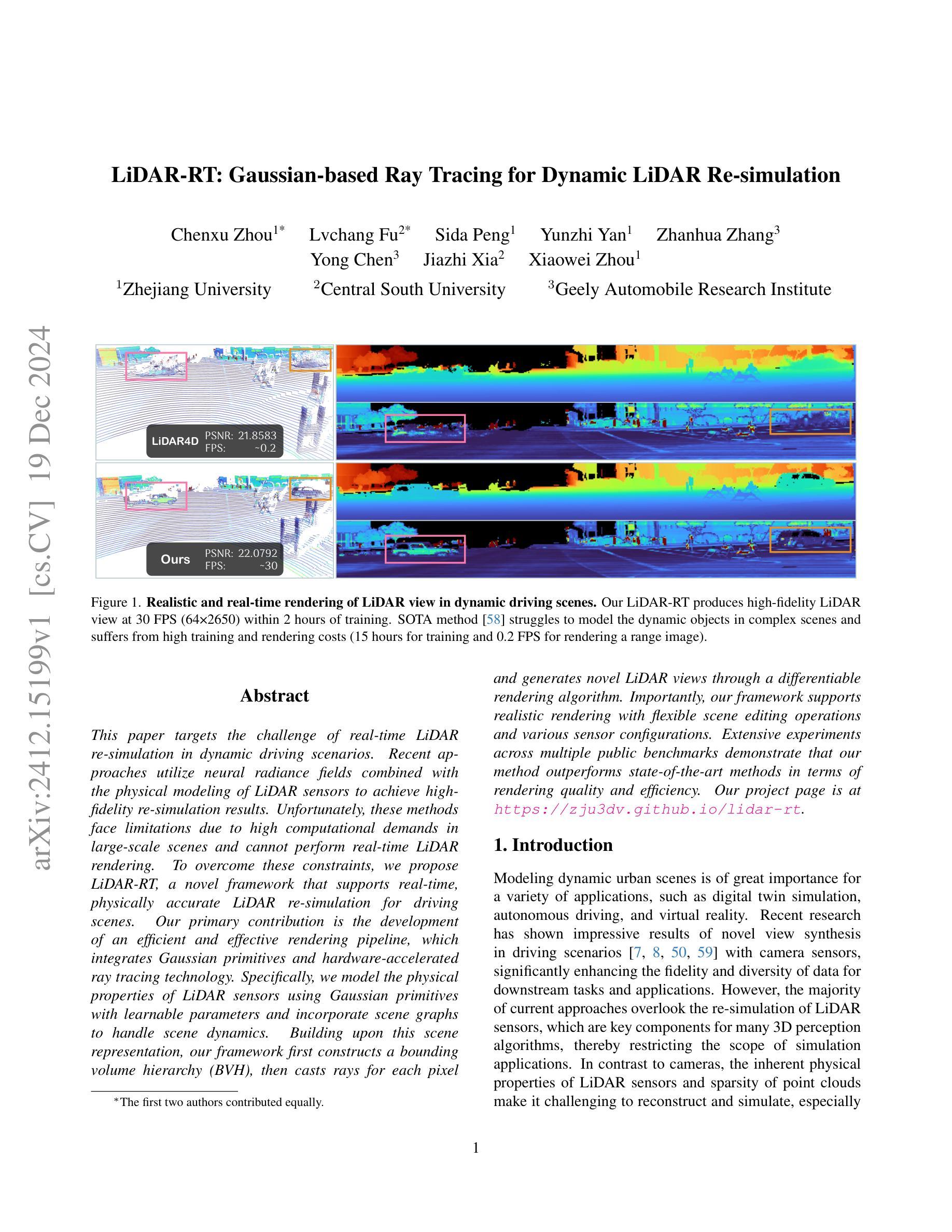
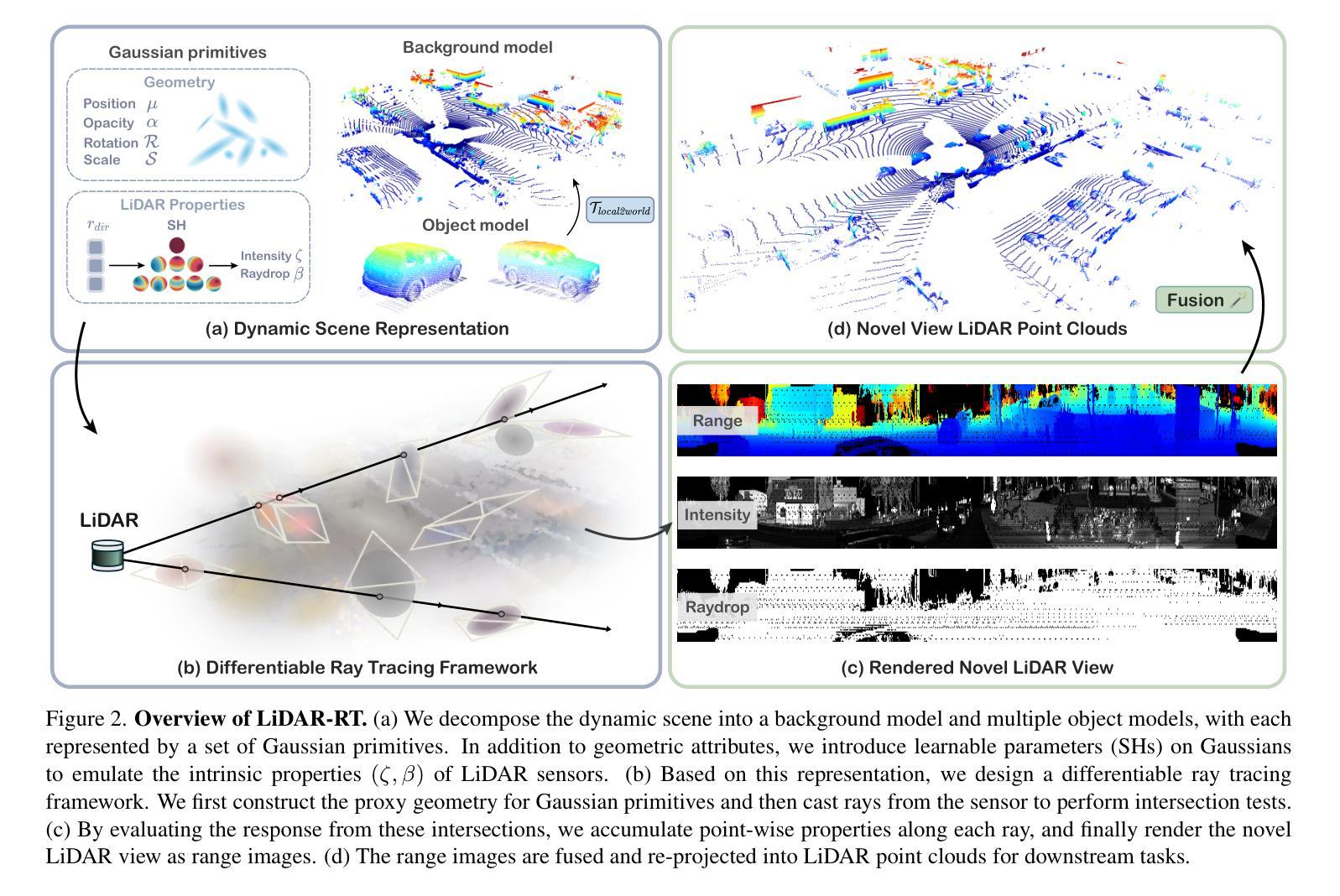
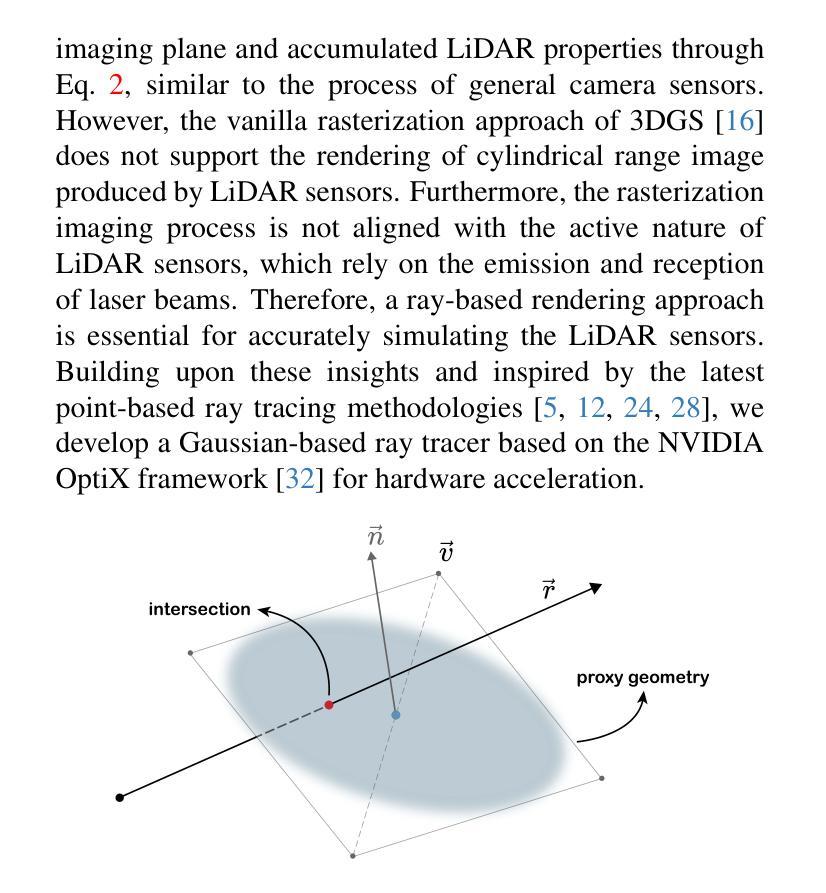
This paper targets the challenge of real-time LiDAR re-simulation in dynamic driving scenarios. Recent approaches utilize neural radiance fields combined with the physical modeling of LiDAR sensors to achieve high-fidelity re-simulation results. Unfortunately, these methods face limitations due to high computational demands in large-scale scenes and cannot perform real-time LiDAR rendering. To overcome these constraints, we propose LiDAR-RT, a novel framework that supports real-time, physically accurate LiDAR re-simulation for driving scenes. Our primary contribution is the development of an efficient and effective rendering pipeline, which integrates Gaussian primitives and hardware-accelerated ray tracing technology. Specifically, we model the physical properties of LiDAR sensors using Gaussian primitives with learnable parameters and incorporate scene graphs to handle scene dynamics. Building upon this scene representation, our framework first constructs a bounding volume hierarchy (BVH), then casts rays for each pixel and generates novel LiDAR views through a differentiable rendering algorithm. Importantly, our framework supports realistic rendering with flexible scene editing operations and various sensor configurations. Extensive experiments across multiple public benchmarks demonstrate that our method outperforms state-of-the-art methods in terms of rendering quality and efficiency. Our project page is at https://zju3dv.github.io/lidar-rt.
本文旨在解决动态驾驶场景中实时激光雷达再仿真所面临的挑战。最近的方法利用神经辐射场结合激光雷达传感器的物理建模来实现高保真再仿真结果。然而,这些方法在大规模场景中具有较高的计算需求,无法执行实时激光雷达渲染。为了克服这些限制,我们提出了LiDAR-RT,这是一个支持驾驶场景实时物理准确激光雷达再仿真的新型框架。我们的主要贡献是开发了一个高效且有效的渲染管道,该管道集成了高斯原始体和硬件加速的光线追踪技术。具体来说,我们使用具有可学习参数的高斯原始体来模拟激光雷达传感器的物理特性,并结合场景图来处理场景动态。基于这种场景表示,我们的框架首先构建了一个层次化边界体积(BVH),然后对每个像素进行光线投射,并通过可微分渲染算法生成新的激光雷达视图。重要的是,我们的框架支持具有灵活场景编辑操作和多种传感器配置的逼真渲染。在多个公共基准测试上的广泛实验表明,我们的方法在渲染质量和效率方面优于最先进的方法。我们的项目页面是https://zju3dv.github.io/lidar-rt。
论文及项目相关链接
PDF Project page: https://zju3dv.github.io/lidar-rt
Summary
本文提出了一种实时激光雷达模拟的新框架LiDAR-RT,用于解决动态驾驶场景中的实时激光雷达模拟挑战。该框架采用高效的渲染管线,结合高斯原语和硬件加速光线追踪技术,模拟激光雷达传感器物理特性,实现高质量渲染并应对场景动态变化。实验表明,LiDAR-RT在渲染质量和效率方面优于现有方法。
Key Takeaways
- 本文提出了实时激光雷达模拟的新框架LiDAR-RT,用于解决动态驾驶场景中的实时模拟挑战。
- 该框架结合了高斯原语和硬件加速光线追踪技术,以模拟激光雷达传感器的物理特性。
- LiDAR-RT采用场景图处理场景动态变化,并通过构建层次化体积边界(BVH)来实现高效渲染。
- 该框架支持对场景进行灵活的编辑操作和多种传感器配置。
- LiDAR-RT在多个公共基准测试上的实验结果表明,其在渲染质量和效率方面优于现有方法。
- LiDAR-RT项目页面提供了更多详细信息和资源。
点此查看论文截图

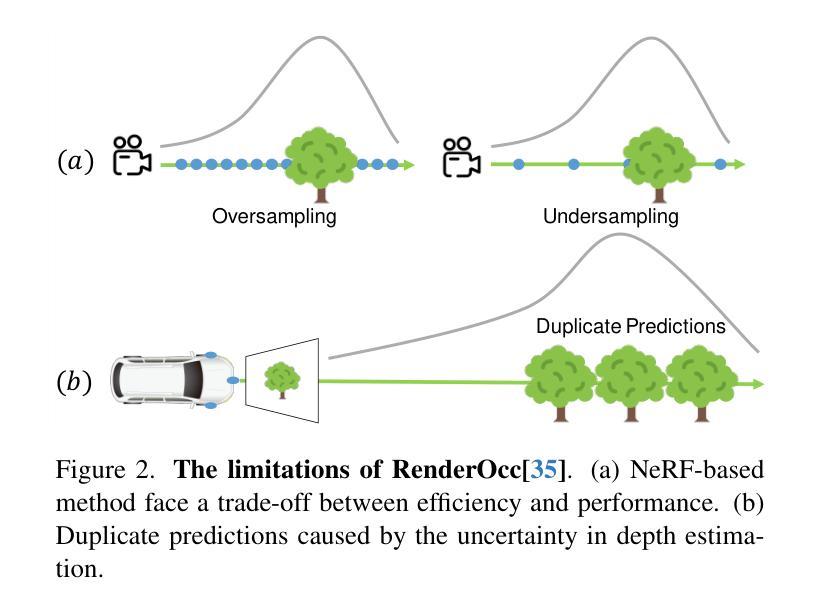
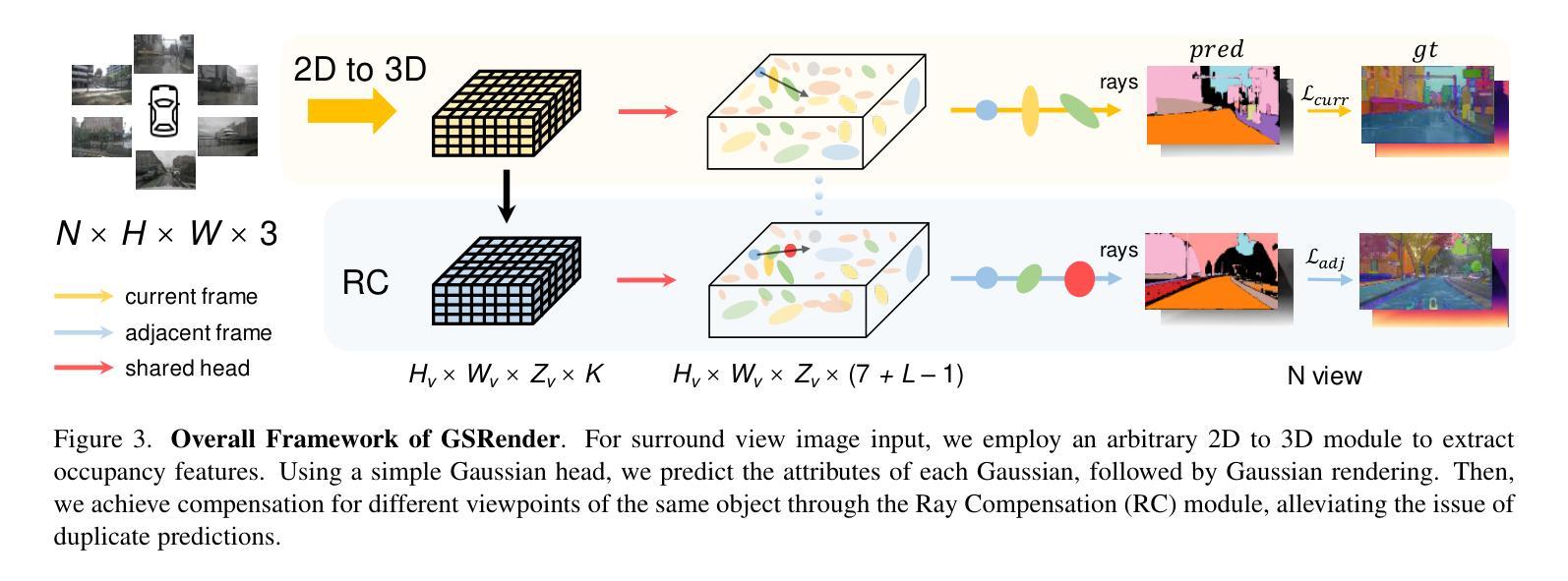
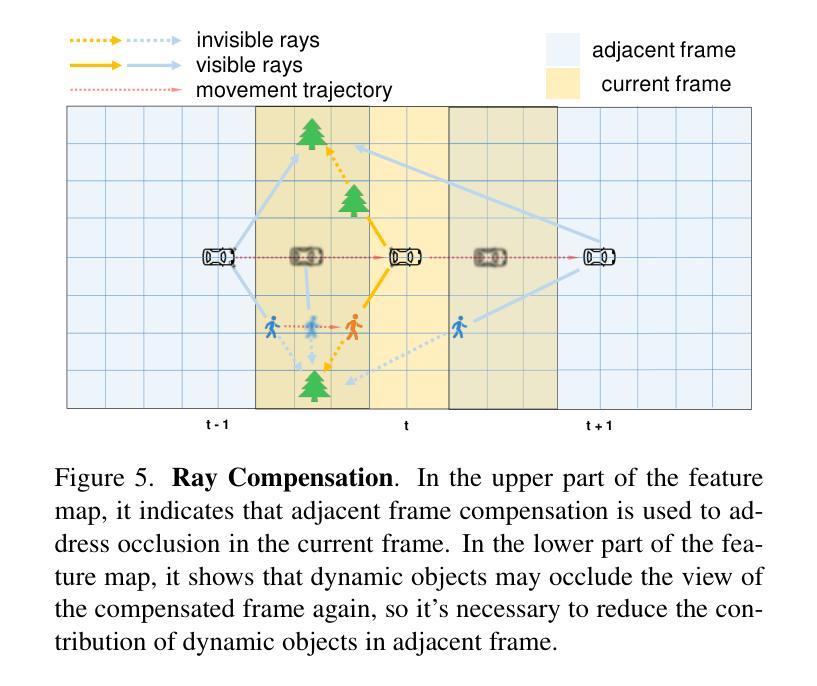
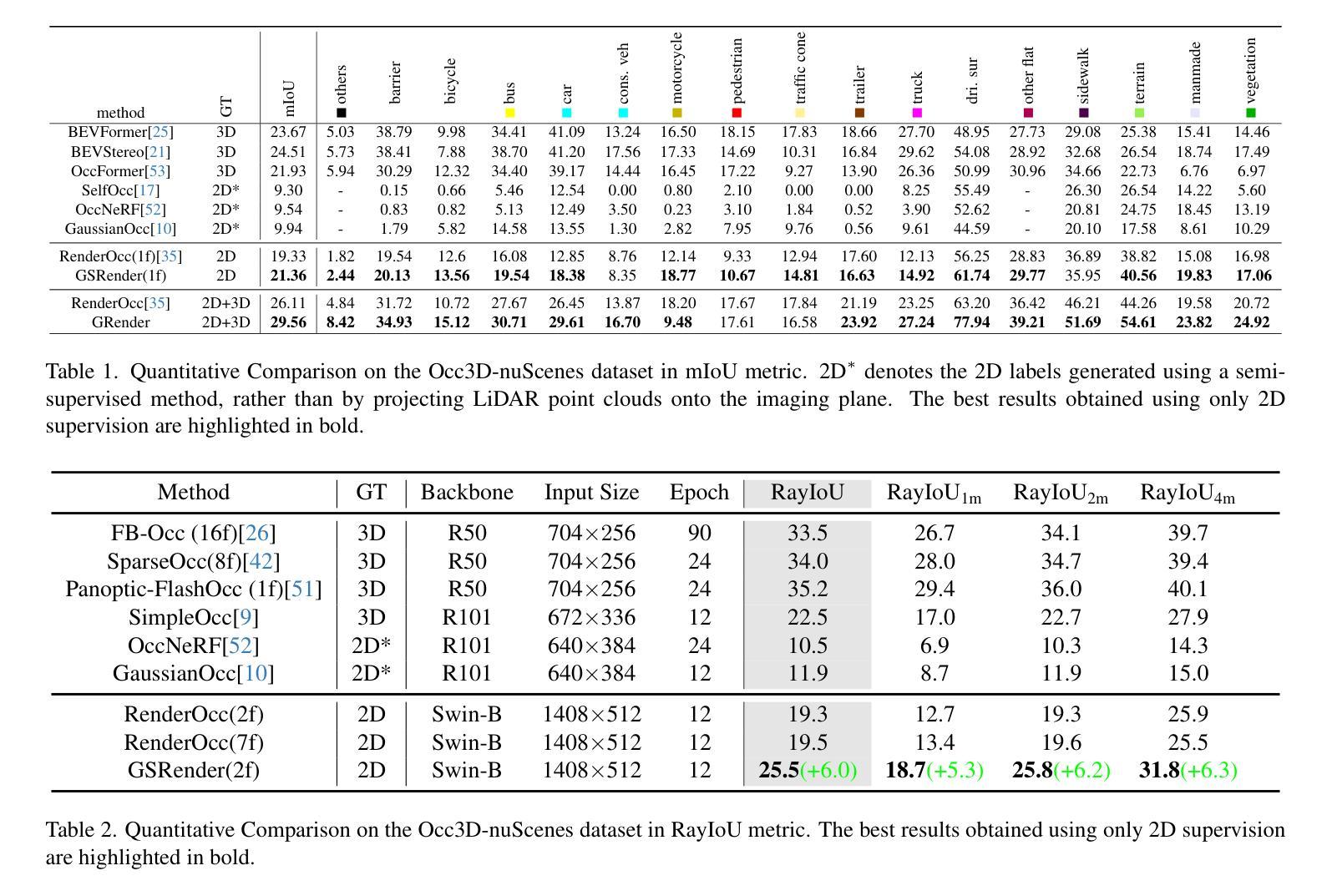
GSRender: Deduplicated Occupancy Prediction via Weakly Supervised 3D Gaussian Splatting
Authors:Qianpu Sun, Changyong Shu, Sifan Zhou, Zichen Yu, Yan Chen, Dawei Yang, Yuan Chun
3D occupancy perception is gaining increasing attention due to its capability to offer detailed and precise environment representations. Previous weakly-supervised NeRF methods balance efficiency and accuracy, with mIoU varying by 5-10 points due to sampling count along camera rays. Recently, real-time Gaussian splatting has gained widespread popularity in 3D reconstruction, and the occupancy prediction task can also be viewed as a reconstruction task. Consequently, we propose GSRender, which naturally employs 3D Gaussian Splatting for occupancy prediction, simplifying the sampling process. In addition, the limitations of 2D supervision result in duplicate predictions along the same camera ray. We implemented the Ray Compensation (RC) module, which mitigates this issue by compensating for features from adjacent frames. Finally, we redesigned the loss to eliminate the impact of dynamic objects from adjacent frames. Extensive experiments demonstrate that our approach achieves SOTA (state-of-the-art) results in RayIoU (+6.0), while narrowing the gap with 3D supervision methods. Our code will be released soon.
三维空间占用感知由于其能够提供详细而精确的环境表示而日益受到关注。之前的弱监督NeRF方法在效率和准确性之间取得了平衡,但由于沿相机射线的采样数量不同,mIoU的得分有5-10个百分点的变化。最近,实时高斯涂抹技术在三维重建中得到了广泛的应用,而占用预测任务也可以被视为重建任务。因此,我们提出了GSRender,它自然地采用三维高斯涂抹技术进行占用预测,简化了采样过程。此外,由于二维监督的局限性,沿同一相机射线会出现重复预测。我们实现了光线补偿(RC)模块,它通过补偿相邻帧的特征来解决这个问题。最后,我们重新设计了损失函数,以消除相邻帧中动态对象的影响。大量实验表明,我们的方法在RayIoU(+6.0)上达到了最先进的水平,并缩小了与三维监督方法的差距。我们的代码很快会发布。
论文及项目相关链接
Summary
基于三维高斯拼贴和射线补偿模块的提出,该方法简化了采样过程并解决了由重复预测导致的问题。针对邻帧中的动态物体产生的影响,对损失函数进行了重新设计。实验表明,该方法在RayIoU指标上取得了显著的提升(+6.0),缩小了与三维监督方法的差距。代码即将公开。整体呈现较高的性能水平,推动实时三维重建技术的进展。该研究成果为未来虚拟现实等相关领域的深化应用提供了新的方向。采用GSRender算法在实际场景应用中的预测精度高且效率出色,值得期待更多的落地实践应用成果。在人工智能的三维场景建模技术中起到领先作用。三维场景的感知对于智能虚拟空间具有重要的推进作用,并在各领域都有着广泛的应用前景。上述论文研究成果推动了人工智能的三维重建技术取得进一步的进展和突破。其高效的算法设计和创新的技术思路将引领未来人工智能三维重建技术的发展方向。随着代码公开,相信将会推动相关领域的技术进步和应用创新。本文提出的方法对于未来的虚拟现实、增强现实等应用场景具有巨大的潜在价值。对虚拟空间的构建和发展有着深远影响,能够显著提升用户体验和应用效率。展望未来,基于人工智能的三维重建技术将在更多领域得到广泛应用,并为人们的生活带来更多便利和乐趣。同时,该技术的安全性和隐私保护问题也需要得到重视和解决。随着技术的不断进步和应用场景的不断拓展,我们期待未来更多的突破和创新成果出现。这一研究是计算机视觉领域的一项重大突破,对推进三维重建技术的发展具有重要意义。这一成果的应用将极大提升我们的生活质量和工作效率,期待未来能够在更多领域得到广泛应用和实践验证。总之,这是一个非常有前途和价值的课题研究方向,具有很大的潜力和市场前景。关键信息点(Key Takeaways):
一、GSRender使用三维高斯拼贴技术进行占空间预测的新方法提高了效率与精度;
二、解决了因使用二维监督产生的沿相机射线重复预测的问题;
三、通过Ray补偿模块补偿相邻帧的特征来优化预测结果;
四、重新设计损失函数以消除邻帧动态物体的影响;
五、该研究成功实现了先进性能并显著提升了预测准确度;
六、通过新的研究方法有望推进未来人工智能的三维重建技术发展;
点此查看论文截图


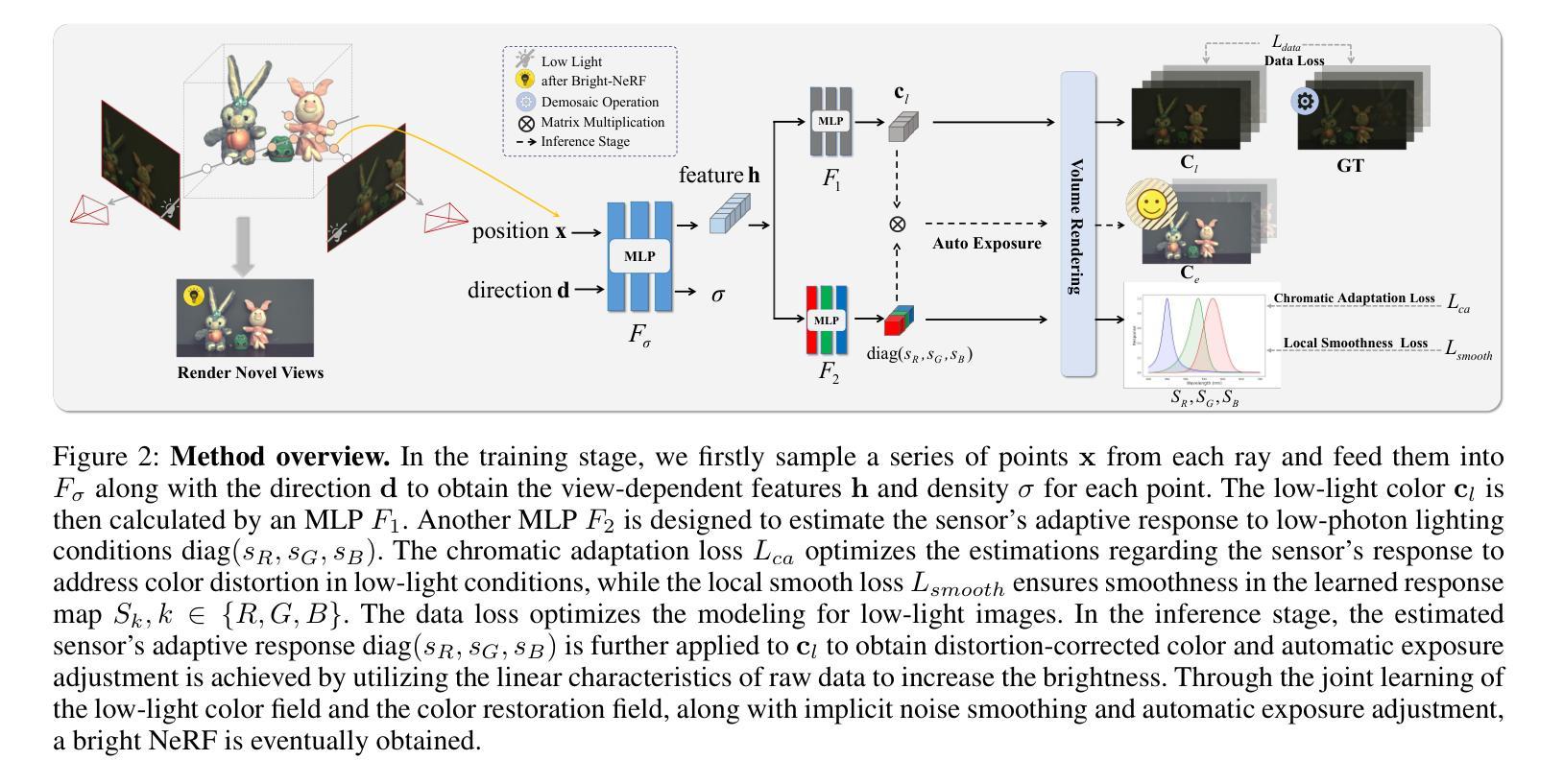
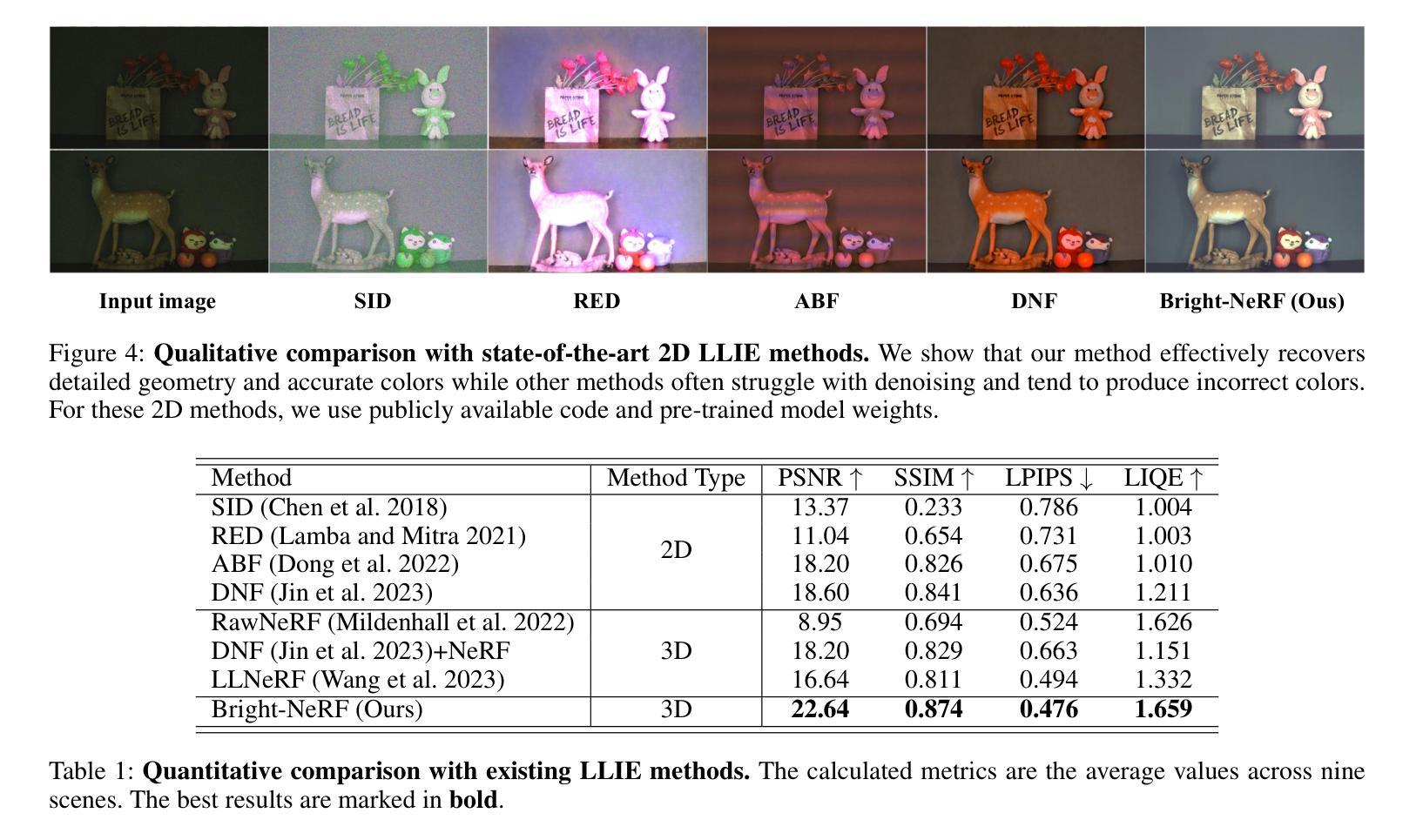
Bright-NeRF:Brightening Neural Radiance Field with Color Restoration from Low-light Raw Images
Authors:Min Wang, Xin Huang, Guoqing Zhou, Qifeng Guo, Qing Wang
Neural Radiance Fields (NeRFs) have demonstrated prominent performance in novel view synthesis. However, their input heavily relies on image acquisition under normal light conditions, making it challenging to learn accurate scene representation in low-light environments where images typically exhibit significant noise and severe color distortion. To address these challenges, we propose a novel approach, Bright-NeRF, which learns enhanced and high-quality radiance fields from multi-view low-light raw images in an unsupervised manner. Our method simultaneously achieves color restoration, denoising, and enhanced novel view synthesis. Specifically, we leverage a physically-inspired model of the sensor’s response to illumination and introduce a chromatic adaptation loss to constrain the learning of response, enabling consistent color perception of objects regardless of lighting conditions. We further utilize the raw data’s properties to expose the scene’s intensity automatically. Additionally, we have collected a multi-view low-light raw image dataset to advance research in this field. Experimental results demonstrate that our proposed method significantly outperforms existing 2D and 3D approaches. Our code and dataset will be made publicly available.
神经辐射场(NeRF)在新视角合成中表现出卓越的性能。然而,它们的输入严重依赖于正常光照条件下的图像采集,因此在低光环境中学习准确的场景表示面临挑战,低光环境中的图像通常会出现很大的噪声和严重的颜色失真。为了解决这些挑战,我们提出了一种新的方法——Bright-NeRF,它能够从多视角的低光原始图像中以无监督的方式学习增强和高质量的辐射场。我们的方法同时实现了颜色恢复、去噪和增强的新视角合成。具体来说,我们采用了传感器对光照的响应的物理启发模型,并引入了一种色适应损失来约束响应学习,从而实现对象在光照条件下的颜色感知一致性。我们进一步利用原始数据的属性自动暴露场景的强度。此外,我们还收集了一个多视角低光原始图像数据集,以促进该领域的研究。实验结果表明,我们提出的方法显著优于现有的2D和3D方法。我们的代码和数据集将公开提供。
论文及项目相关链接
PDF Accepted by AAAI2025
Summary
NeRF技术在低光环境下的性能受到挑战,因为低光图像通常存在噪声和严重的颜色失真。为了解决这个问题,提出了Bright-NeRF方法,它可以从多视角低光原始图像中学习增强和高质量的辐射场,同时实现颜色恢复、去噪和新颖视角合成。该方法利用传感器对照明的响应的物理启发模型,引入颜色适应损失来约束学习,实现对象在照明条件下的颜色感知一致性。同时,利用原始数据的特性自动展现场景的强度。实验结果表明,该方法显著优于现有的2D和3D方法。
Key Takeaways
- NeRF在低光环境下面临挑战,因为图像存在噪声和颜色失真。
- Bright-NeRF方法能够从多视角低光原始图像中学习增强和高质量的辐射场。
- Bright-NeRF同时实现颜色恢复、去噪和新颖视角合成。
- 该方法利用传感器对照明的响应的物理启发模型。
- 引入颜色适应损失来约束学习,实现对象在照明条件下的颜色感知一致性。
- 利用原始数据的特性自动展现场景的强度。
点此查看论文截图



Fast and Efficient: Mask Neural Fields for 3D Scene Segmentation
Authors:Zihan Gao, Lingling Li, Licheng Jiao, Fang Liu, Xu Liu, Wenping Ma, Yuwei Guo, Shuyuan Yang
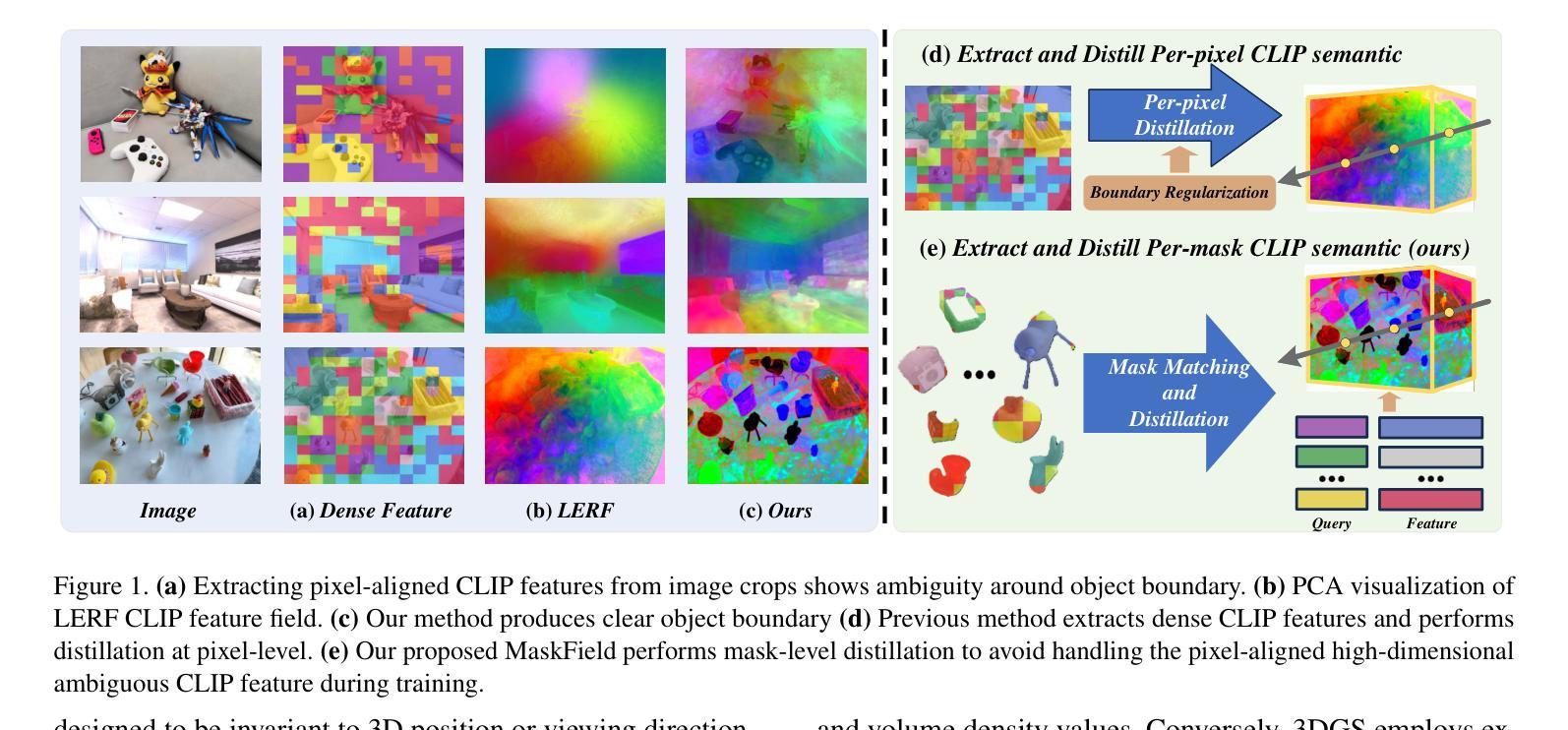
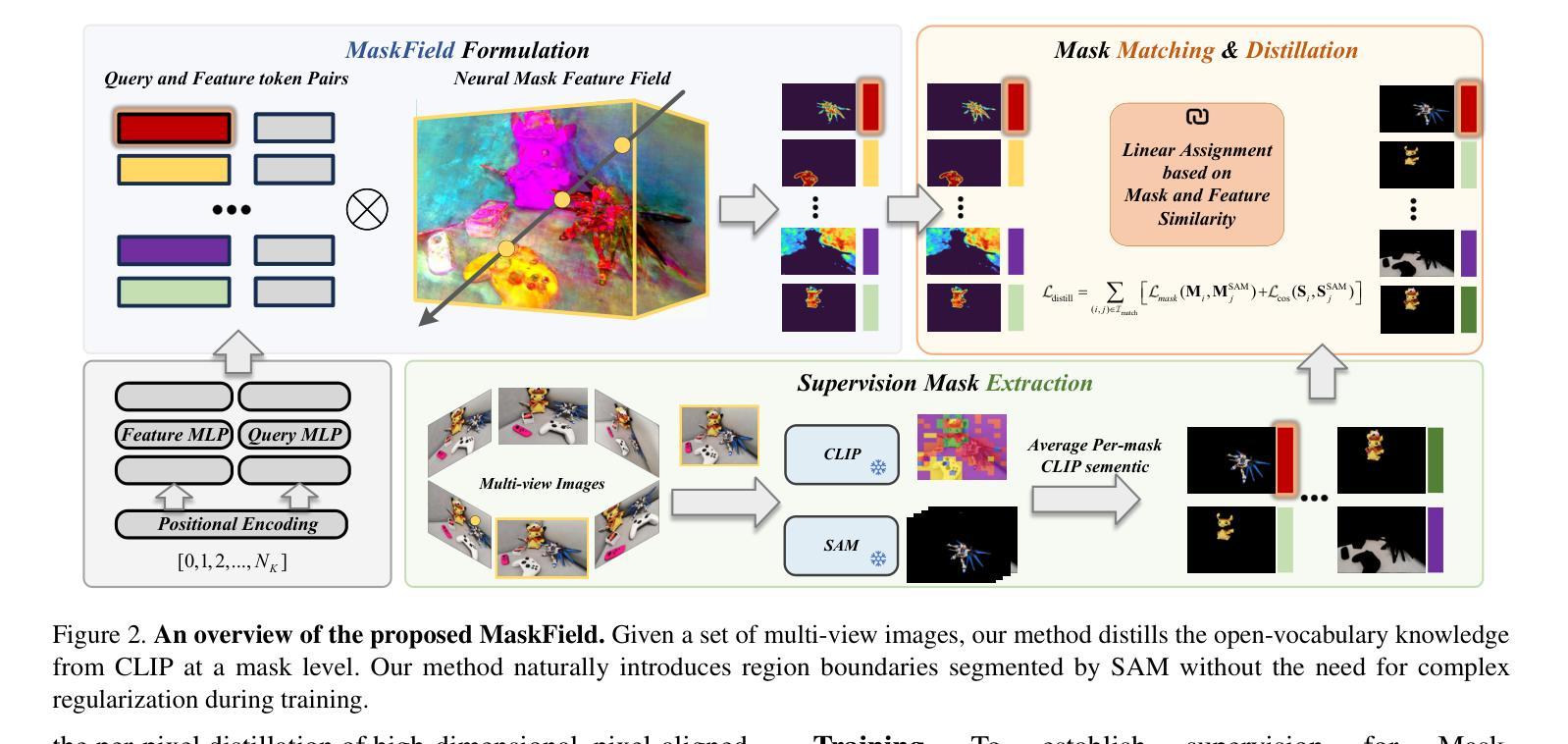
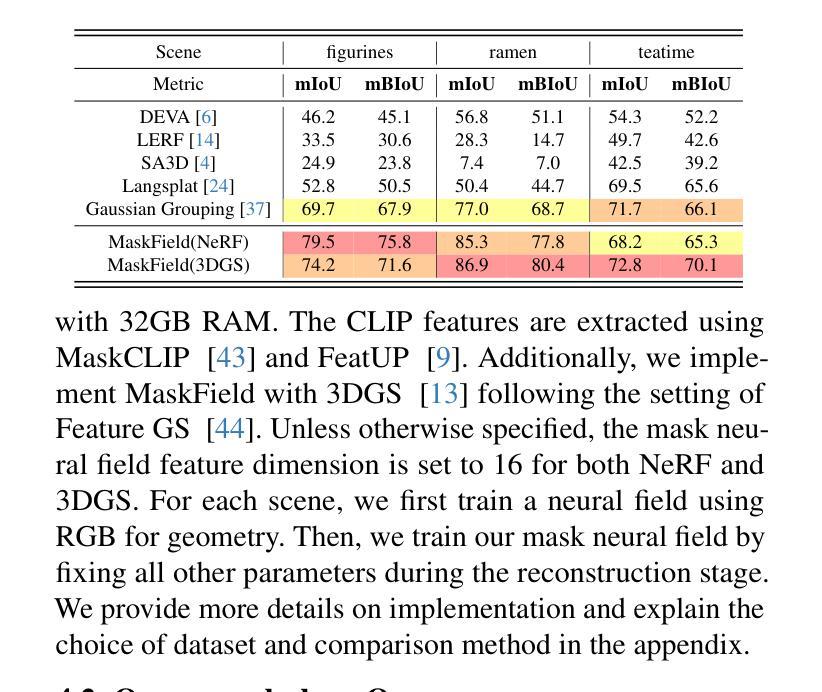
Understanding 3D scenes is a crucial challenge in computer vision research with applications spanning multiple domains. Recent advancements in distilling 2D vision-language foundation models into neural fields, like NeRF and 3DGS, enable open-vocabulary segmentation of 3D scenes from 2D multi-view images without the need for precise 3D annotations. However, while effective, these methods typically rely on the per-pixel distillation of high-dimensional CLIP features, introducing ambiguity and necessitating complex regularization strategies, which adds inefficiency during training. This paper presents MaskField, which enables efficient 3D open-vocabulary segmentation with neural fields from a novel perspective. Unlike previous methods, MaskField decomposes the distillation of mask and semantic features from foundation models by formulating a mask feature field and queries. MaskField overcomes ambiguous object boundaries by naturally introducing SAM segmented object shapes without extra regularization during training. By circumventing the direct handling of dense high-dimensional CLIP features during training, MaskField is particularly compatible with explicit scene representations like 3DGS. Our extensive experiments show that MaskField not only surpasses prior state-of-the-art methods but also achieves remarkably fast convergence. We hope that MaskField will inspire further exploration into how neural fields can be trained to comprehend 3D scenes from 2D models.
理解三维场景是计算机视觉研究中的一项关键挑战,其应用横跨多个领域。最近,将二维视觉语言基础模型蒸馏到神经场(如NeRF和3DGS)的技术进步,能够实现从二维多视角图像对三维场景进行开放词汇分割,而无需精确的三维注释。然而,尽管这些方法非常有效,但它们通常依赖于高维CLIP特征的高精度蒸馏,这引入了歧义并需要复杂的正则化策略,从而增加了训练过程中的不效率。本文提出了MaskField,从全新角度实现了利用神经场进行高效的三维开放词汇分割。不同于以往的方法,MaskField通过构建掩膜特征场和查询来分解基础模型的掩膜和语义特征的蒸馏。MaskField通过自然引入SAM分割物体形状,克服了物体边界的模糊问题,训练过程中无需额外的正则化。通过避免训练过程中直接处理密集的高维CLIP特征,MaskField特别适用于明确的场景表示,如3DGS。我们的广泛实验表明,MaskField不仅超越了现有的最先进的方法,而且实现了显著的快速收敛。我们希望MaskField能激发对如何训练神经场以从二维模型理解三维场景的更进一步探索。
论文及项目相关链接
PDF 15 pages, 9 figures, Code:https://github.com/keloee/MaskField
Summary:
本文提出了MaskField方法,用于通过神经场实现高效的3D开放词汇表分割。它通过分解来自基础模型的mask和语义特征,并引入SAM分割对象形状来克服模糊的对象边界问题,不需要额外的正则化训练。MaskField能快速地收敛,并超越了现有的最新方法。本文期望MaskField能激发对如何通过神经场训练理解从二维模型表示的3D场景的进一步探索。
Key Takeaways:
- MaskField通过引入Mask特征场和查询实现了神经网络模型中的特征蒸馏方法的改进和优化。
- MaskField克服了由于处理密集的高维CLIP特征而导致的模糊对象边界问题。
- MaskField不需要在训练过程中使用复杂的正则化策略,简化了训练过程并提高了效率。
- MaskField利用新的技术思路,对基于二维视觉语言的基础模型进行蒸馏到神经场。
- MaskField具有出色的收敛性能,显著超越了现有的最新技术。
- MaskField特别适用于显式场景表示方法,如3DGS等模型。
点此查看论文截图