⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-22 更新
DepthFM: Fast Monocular Depth Estimation with Flow Matching
Authors:Ming Gui, Johannes Schusterbauer, Ulrich Prestel, Pingchuan Ma, Dmytro Kotovenko, Olga Grebenkova, Stefan Andreas Baumann, Vincent Tao Hu, Björn Ommer
Current discriminative depth estimation methods often produce blurry artifacts, while generative approaches suffer from slow sampling due to curvatures in the noise-to-depth transport. Our method addresses these challenges by framing depth estimation as a direct transport between image and depth distributions. We are the first to explore flow matching in this field, and we demonstrate that its interpolation trajectories enhance both training and sampling efficiency while preserving high performance. While generative models typically require extensive training data, we mitigate this dependency by integrating external knowledge from a pre-trained image diffusion model, enabling effective transfer even across differing objectives. To further boost our model performance, we employ synthetic data and utilize image-depth pairs generated by a discriminative model on an in-the-wild image dataset. As a generative model, our model can reliably estimate depth confidence, which provides an additional advantage. Our approach achieves competitive zero-shot performance on standard benchmarks of complex natural scenes while improving sampling efficiency and only requiring minimal synthetic data for training.
当前用于判别深度估计的方法常常会产生模糊伪影,而生成式方法则由于噪声到深度的传输过程中的曲率问题而导致采样缓慢。我们的方法通过构建图像和深度分布之间的直接传输来解决这些挑战,将深度估计置于核心位置。我们是第一个在这一领域探索流匹配技术的团队,并证明其插值轨迹在提高训练和采样效率的同时,保持了高性能。虽然生成模型通常需要大量的训练数据,但我们通过整合预训练的图像扩散模型的外部知识来减轻这种依赖性,从而实现跨不同目标的有效迁移。为了进一步提升模型性能,我们利用合成数据,并使用在野生图像数据集上由判别模型生成的图像深度对。作为生成模型,我们的模型能够可靠地估计深度置信度,这提供了额外的优势。我们的方法在非复杂自然场景的常规基准测试中实现了具有竞争力的零样本性能,提高了采样效率,并且仅需要少量的合成数据进行训练。
论文及项目相关链接
PDF AAAI 2025, Project Page: https://github.com/CompVis/depth-fm
Summary
本文提出一种基于流匹配的方法来解决深度估计问题,通过将深度估计视为图像和深度分布之间的直接传输来应对当前判别式方法的模糊伪影和生成式方法的采样缓慢问题。该方法首创性地引入流匹配技术,通过插值轨迹提高训练和采样效率,同时保持高性能。此外,通过整合预训练的图像扩散模型的外部知识,减少对大量训练数据的依赖,并能在不同目标之间进行有效迁移。通过利用合成数据和在野生图像数据集上由判别模型生成的图像-深度对,进一步提高了模型性能。作为一种生成模型,该模型还能可靠地估计深度置信,提供额外的优势。该方法在复杂自然场景的标准基准测试上实现了有竞争力的零样本性能,同时提高了采样效率,并且只需要少量的合成数据进行训练。
Key Takeaways
- 引入流匹配技术解决深度估计中的模糊伪影和采样缓慢问题。
- 通过将深度估计视为图像和深度分布之间的直接传输来提高性能。
- 整合预训练的图像扩散模型的外部知识,减少了对大量训练数据的依赖,实现不同目标间的有效迁移。
- 利用合成数据和由判别模型生成的图像-深度对进一步提高模型性能。
- 作为生成模型,能可靠地估计深度置信,提供额外优势。
- 在复杂自然场景的标准基准测试上实现了有竞争力的零样本性能。
点此查看论文截图


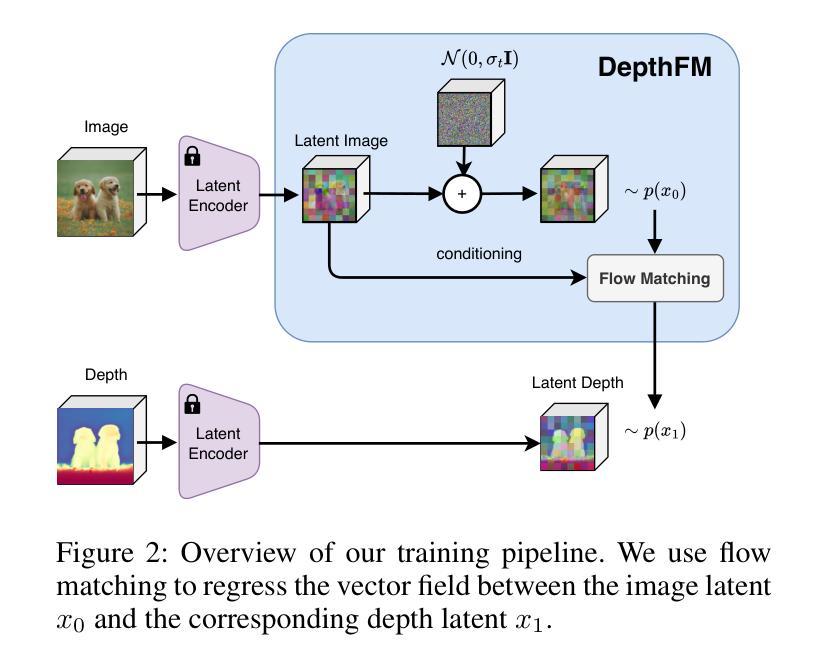
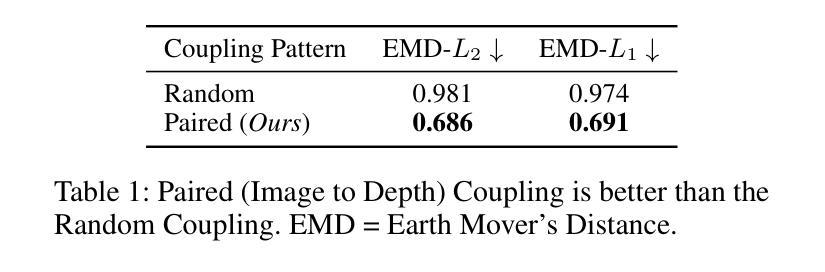

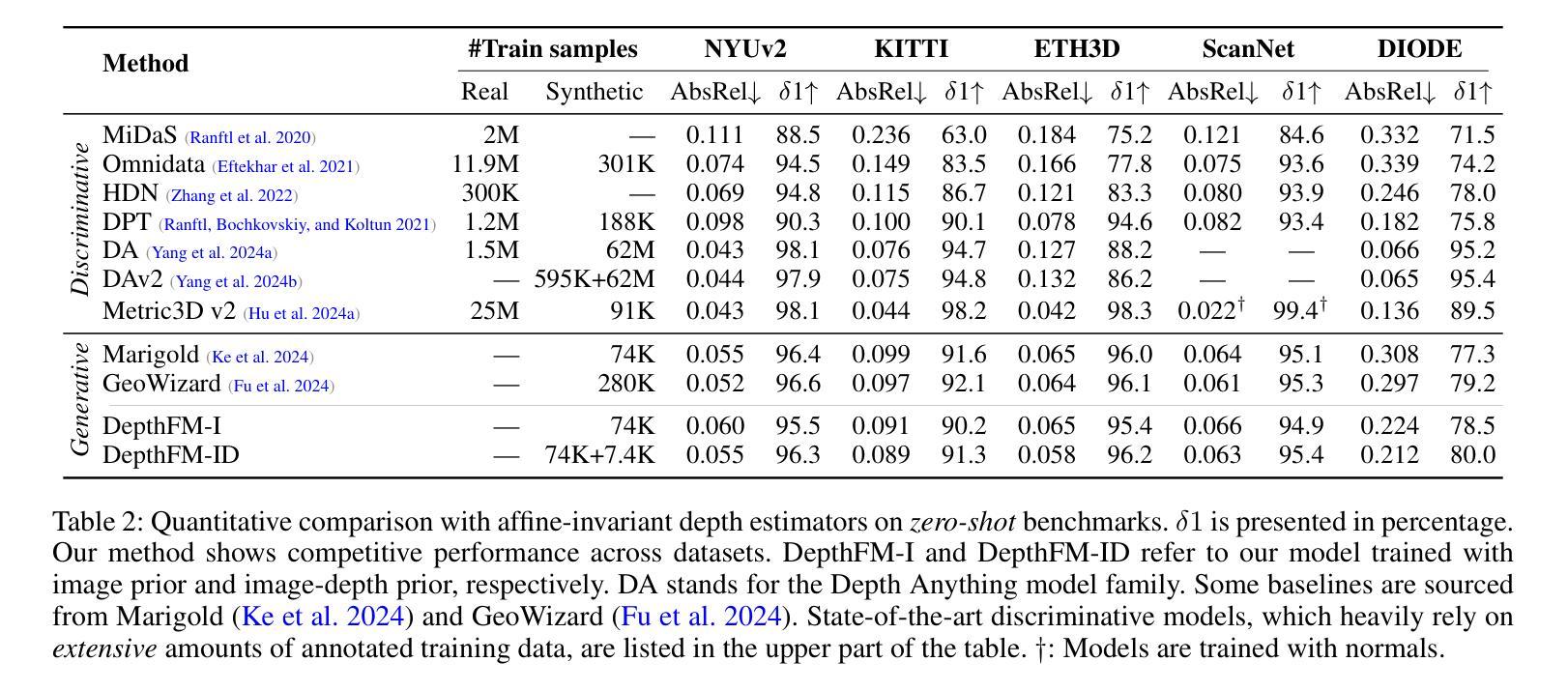


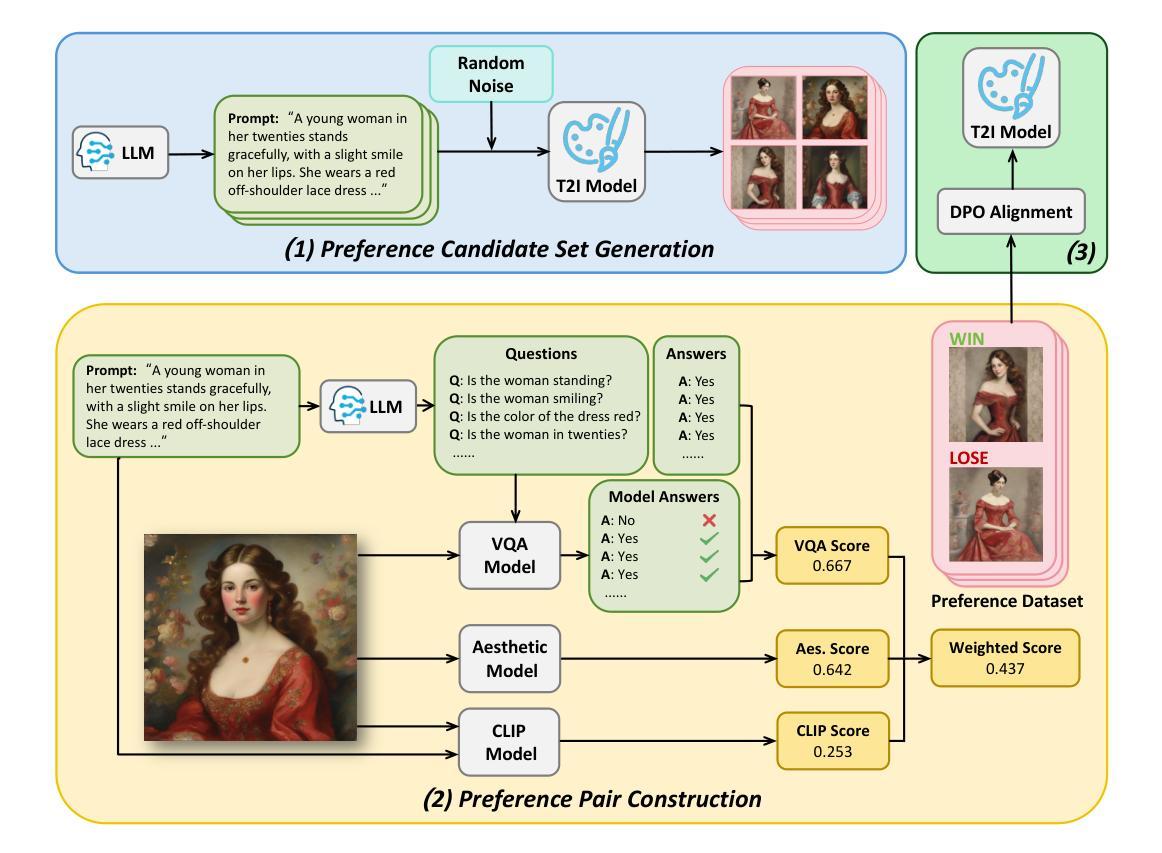
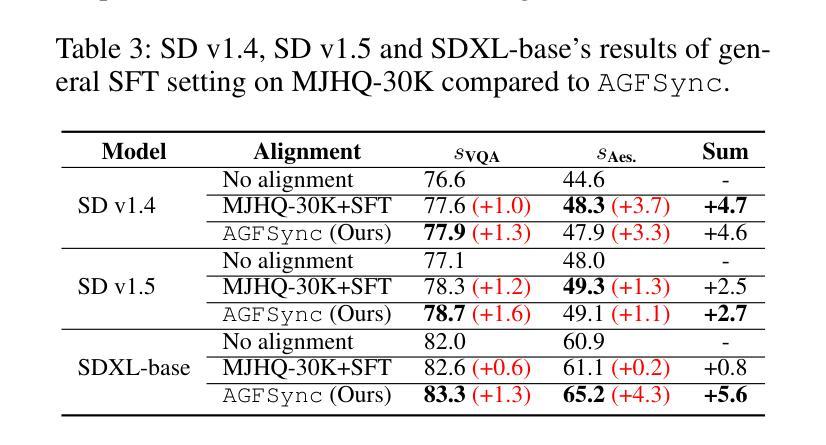
AGFSync: Leveraging AI-Generated Feedback for Preference Optimization in Text-to-Image Generation
Authors:Jingkun An, Yinghao Zhu, Zongjian Li, Enshen Zhou, Haoran Feng, Xijie Huang, Bohua Chen, Yemin Shi, Chengwei Pan
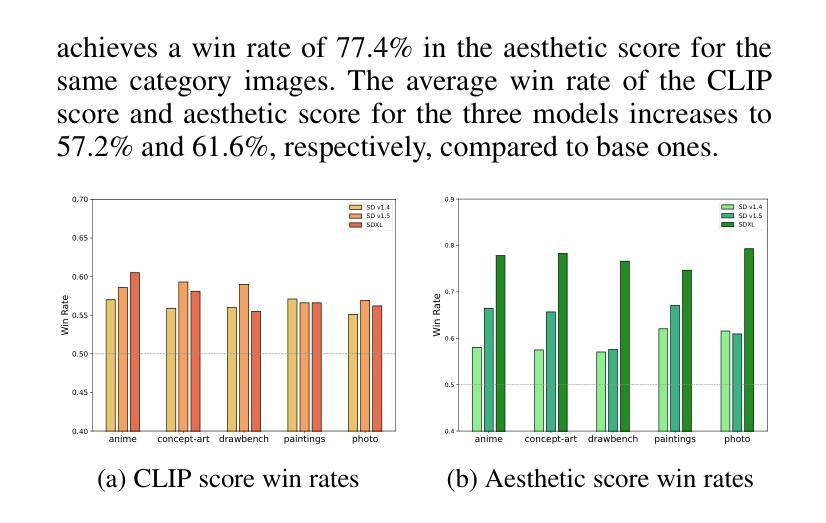
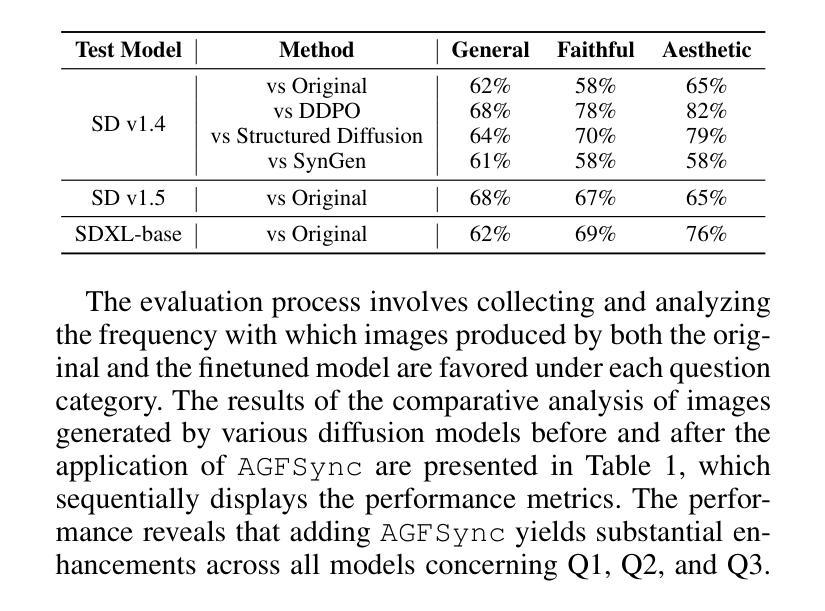
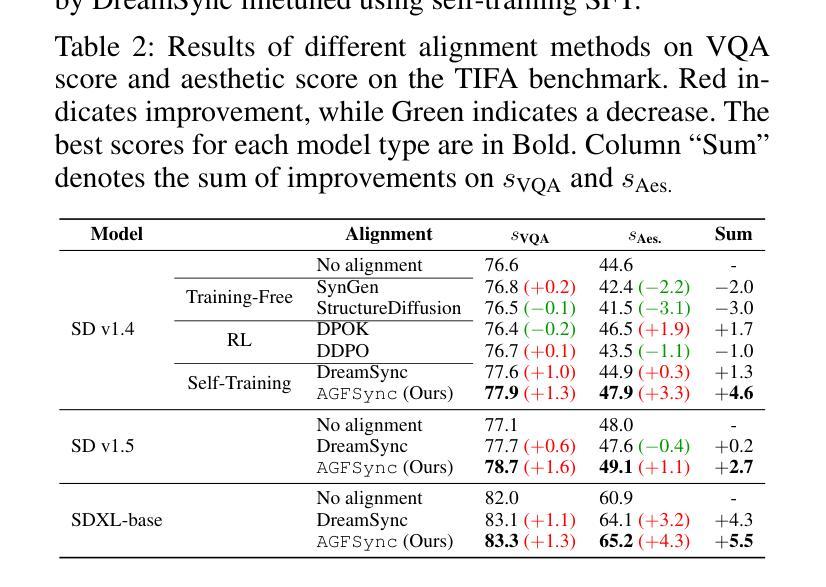
Text-to-Image (T2I) diffusion models have achieved remarkable success in image generation. Despite their progress, challenges remain in both prompt-following ability, image quality and lack of high-quality datasets, which are essential for refining these models. As acquiring labeled data is costly, we introduce AGFSync, a framework that enhances T2I diffusion models through Direct Preference Optimization (DPO) in a fully AI-driven approach. AGFSync utilizes Vision-Language Models (VLM) to assess image quality across style, coherence, and aesthetics, generating feedback data within an AI-driven loop. By applying AGFSync to leading T2I models such as SD v1.4, v1.5, and SDXL-base, our extensive experiments on the TIFA dataset demonstrate notable improvements in VQA scores, aesthetic evaluations, and performance on the HPSv2 benchmark, consistently outperforming the base models. AGFSync’s method of refining T2I diffusion models paves the way for scalable alignment techniques. Our code and dataset are publicly available at https://anjingkun.github.io/AGFSync.
文本到图像(T2I)扩散模型在图像生成方面取得了显著的成功。尽管有所进展,但在提示遵循能力、图像质量以及缺乏高质量数据集等方面仍然存在挑战,这些挑战对于完善这些模型至关重要。由于获取标记数据的成本高昂,我们引入了AGFSync框架,该框架通过完全人工智能驱动的方法直接优化偏好(DPO)来增强T2I扩散模型。AGFSync利用视觉语言模型(VLM)来评估图像的风格、连贯性和美学方面的质量,在人工智能驱动的循环中生成反馈数据。通过将AGFSync应用于领先的T2I模型,如SD v1.4、v1.5和SDXL-base,我们在TIFA数据集上的大量实验表明,VQA分数、美学评估以及HPSv2基准测试的性能都得到了显著提高,始终优于基础模型。AGFSync完善T2I扩散模型的方法为可扩展的对齐技术铺平了道路。我们的代码和数据集可在https://anjingkun.github.io/AGFSync公开访问。
论文及项目相关链接
PDF Accepted by AAAI-2025
Summary
文本介绍了T2I扩散模型在图像生成方面的显著成果,但也指出了存在的挑战,如提示遵循能力、图像质量和缺乏高质量数据集等。为解决这些问题,提出了一种名为AGFSync的框架,通过直接偏好优化(DPO)以全AI驱动的方式增强T2I扩散模型。AGFSync利用视觉语言模型(VLM)评估图像质量,包括风格、连贯性和美学方面,并在AI驱动的循环中生成反馈数据。在TIFA数据集上的实验表明,AGFSync在VQA分数、美学评估和HPSv2基准测试方面的表现均有显著改善,并始终优于基础模型。这为可扩展的对齐技术铺平了道路。
Key Takeaways
- T2I扩散模型虽取得显著成功,但仍面临提示遵循能力、图像质量和数据集质量方面的挑战。
- AGFSync框架通过全AI驱动的直接偏好优化(DPO)增强T2I扩散模型。
- AGFSync利用视觉语言模型(VLM)评估图像质量,包括风格、连贯性和美学。
- AGFSync能在AI驱动的循环中生成反馈数据,以提高图像生成的质量。
- 在TIFA数据集上的实验表明,AGFSync显著提高T2I扩散模型的表现,包括VQA分数、美学评估和HPSv2基准测试。
- AGFSync始终优于基础模型,为可扩展的对齐技术提供了新的方向。
- AGFSync的代码和数据集已公开可用。
点此查看论文截图