⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-22 更新
Lightning IR: Straightforward Fine-tuning and Inference of Transformer-based Language Models for Information Retrieval
Authors:Ferdinand Schlatt, Maik Fröbe, Matthias Hagen
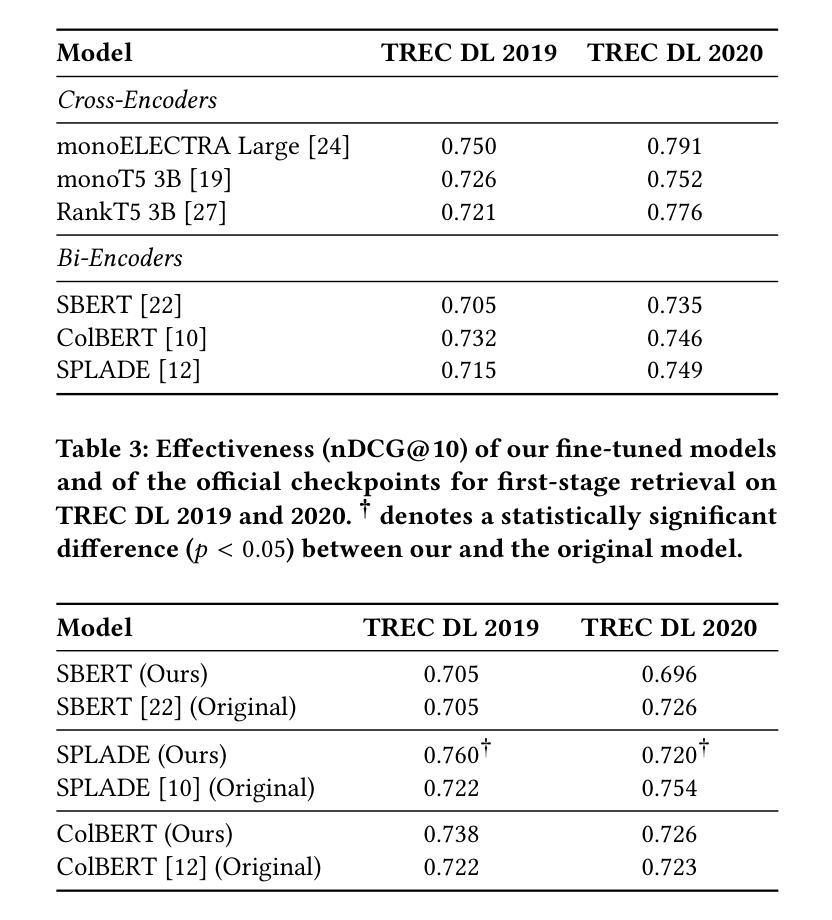
A wide range of transformer-based language models have been proposed for information retrieval tasks. However, including transformer-based models in retrieval pipelines is often complex and requires substantial engineering effort. In this paper, we introduce Lightning IR, an easy-to-use PyTorch Lightning-based framework for applying transformer-based language models in retrieval scenarios. Lightning IR provides a modular and extensible architecture that supports all stages of a retrieval pipeline: from fine-tuning and indexing to searching and re-ranking. Designed to be scalable and reproducible, Lightning IR is available as open-source: https://github.com/webis-de/lightning-ir.
针对信息检索任务,已经提出了多种基于Transformer的语言模型。然而,在检索管道中包含基于Transformer的模型通常很复杂,需要大量的工程努力。在本文中,我们介绍了Lightning IR,这是一个易于使用的基于PyTorch Lightning的框架,可用于在检索场景中应用基于Transformer的语言模型。Lightning IR提供了一种模块化且可扩展的架构,支持检索管道的所有阶段:从微调、索引到搜索和重新排序。设计用于可扩展性和可重复性,Lightning IR可作为开源使用:https://github.com/webis-de/lightning-ir。
论文及项目相关链接
PDF Accepted as a demo at WSDM’25
Summary:
闪电IR是一个基于PyTorch Lightning的易用框架,用于在检索场景中应用基于转换器的语言模型。它提供了一个模块化且可扩展的架构,支持检索管道的所有阶段,包括微调、索引、搜索和重新排名。闪电IR旨在实现可扩展性和可重复性,可作为开源使用。
Key Takeaways:
- 多种基于转换器的语言模型被提出用于信息检索任务。
- 在检索管道中包含基于转换器的模型通常需要复杂的工程工作。
- 闪电IR是一个基于PyTorch Lightning的框架,易于应用在检索场景中的基于转换器的语言模型。
- 闪电IR提供了模块化且可扩展的架构,支持检索管道的所有阶段。
- 闪电IR旨在实现可扩展性和可重复性。
点此查看论文截图



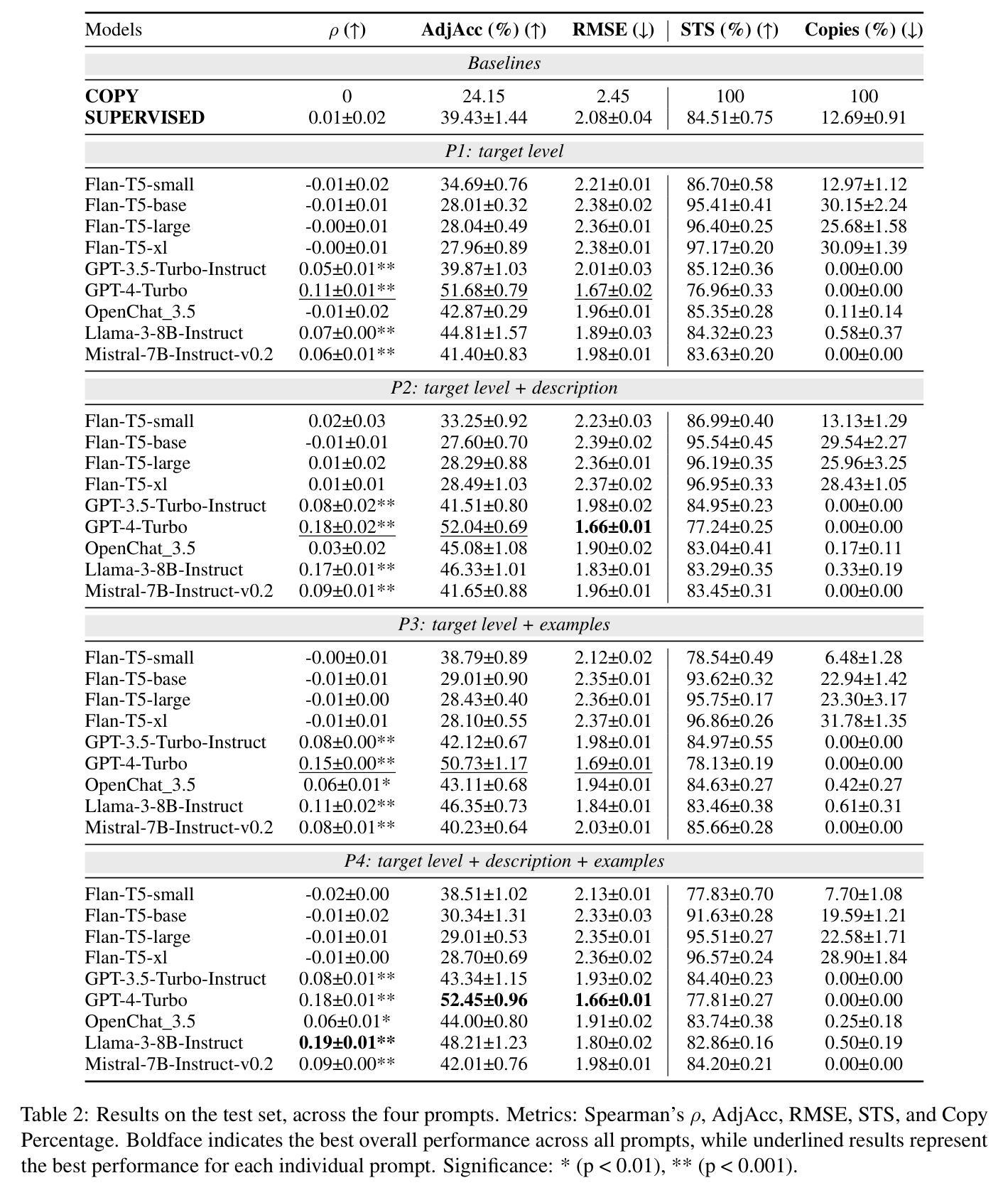
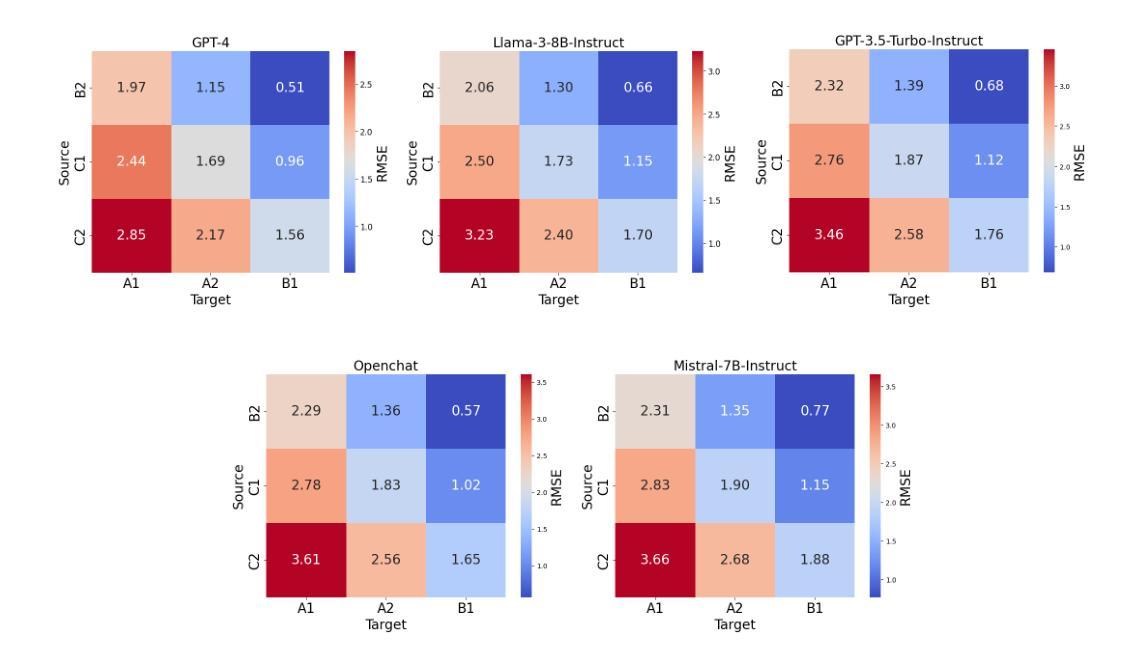
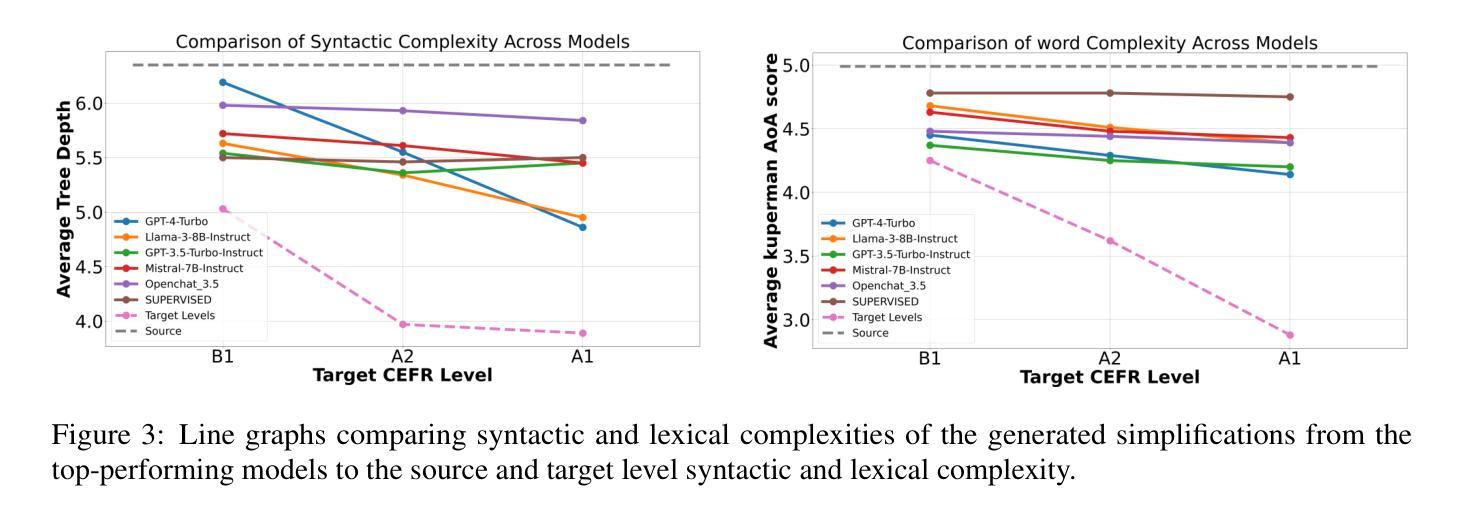
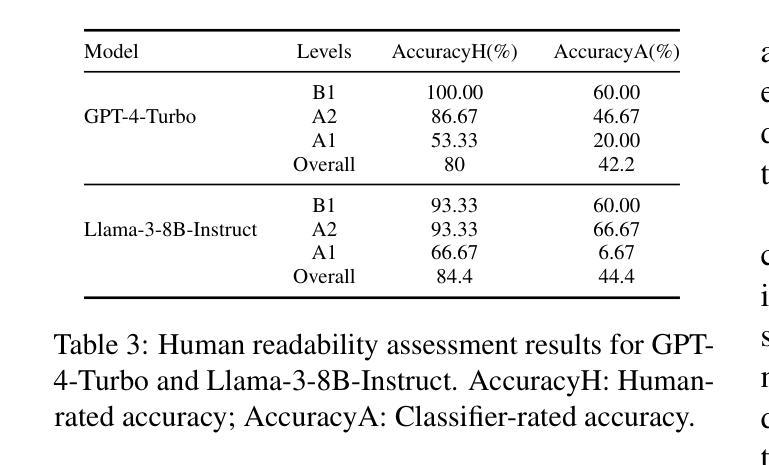
Analysing Zero-Shot Readability-Controlled Sentence Simplification
Authors:Abdullah Barayan, Jose Camacho-Collados, Fernando Alva-Manchego
Readability-controlled text simplification (RCTS) rewrites texts to lower readability levels while preserving their meaning. RCTS models often depend on parallel corpora with readability annotations on both source and target sides. Such datasets are scarce and difficult to curate, especially at the sentence level. To reduce reliance on parallel data, we explore using instruction-tuned large language models for zero-shot RCTS. Through automatic and manual evaluations, we examine: (1) how different types of contextual information affect a model’s ability to generate sentences with the desired readability, and (2) the trade-off between achieving target readability and preserving meaning. Results show that all tested models struggle to simplify sentences (especially to the lowest levels) due to models’ limitations and characteristics of the source sentences that impede adequate rewriting. Our experiments also highlight the need for better automatic evaluation metrics tailored to RCTS, as standard ones often misinterpret common simplification operations, and inaccurately assess readability and meaning preservation.
可读性控制文本简化(RCTS)重写文本以降低可读性水平,同时保留其含义。RCTS模型通常依赖于带有源和目标两侧可读性注释的平行语料库。这样的数据集很稀缺,且难以编纂,尤其是在句子层面。为了减少平行数据的依赖,我们探索使用指令调优的大型语言模型进行零样本RCTS。通过自动和手动评估,我们研究了:(1)不同类型的上下文信息如何影响模型生成具有所需可读性的句子的能力;(2)实现目标可读性和保留意义之间的权衡。结果表明,所有测试模型在简化句子方面都存在困难(尤其是在最低水平),这是由于模型的局限性以及源句子的特性阻碍了适当的重写。我们的实验还强调了需要为RCTS量身定制更好的自动评估指标,因为标准指标通常误解常见的简化操作,并错误地评估可读性和意义保留。
论文及项目相关链接
PDF Accepted on COLING 2025
Summary
本文探讨了可读性控制文本简化(RCTS)的方法,即通过重写文本降低其可读性水平同时保持其原意。RCTS模型通常依赖于带有可读性和目标侧注释的平行语料库。为了减少对平行数据的依赖,本文尝试使用经过指令训练的大型语言模型进行零样本RCTS。通过自动和手动评估,本文研究了不同类型上下文信息对模型生成具有所需可读性的句子的能力的影响,以及实现目标可读性和保持意义之间的权衡。然而,实验结果揭示由于模型的局限性和源句子的特性,所有测试的模型在简化句子方面都存在困难(尤其是在达到最低水平时)。此外,实验还强调了需要为RCTS量身定制更好的自动评估指标,因为标准指标常常误解常见的简化操作,并准确评估可读性和意义保留情况。
Key Takeaways
- RCTS旨在通过重写文本降低可读性水平,同时保持原意。
- RCTS模型通常依赖于平行语料库,但这类数据稀缺且难以收集,特别是在句子级别。
- 为了减少平行数据的依赖,研究了使用指令训练的大型语言模型进行零样本RCTS。
- 不同类型的上下文信息对模型生成具有所需可读性的句子的能力有重要影响。
- 实现目标可读性和保持意义之间存在权衡。
- 现有模型在简化句子方面存在困难,尤其是在达到最低可读性水平时。
点此查看论文截图

KnowFormer: Revisiting Transformers for Knowledge Graph Reasoning
Authors:Junnan Liu, Qianren Mao, Weifeng Jiang, Jianxin Li
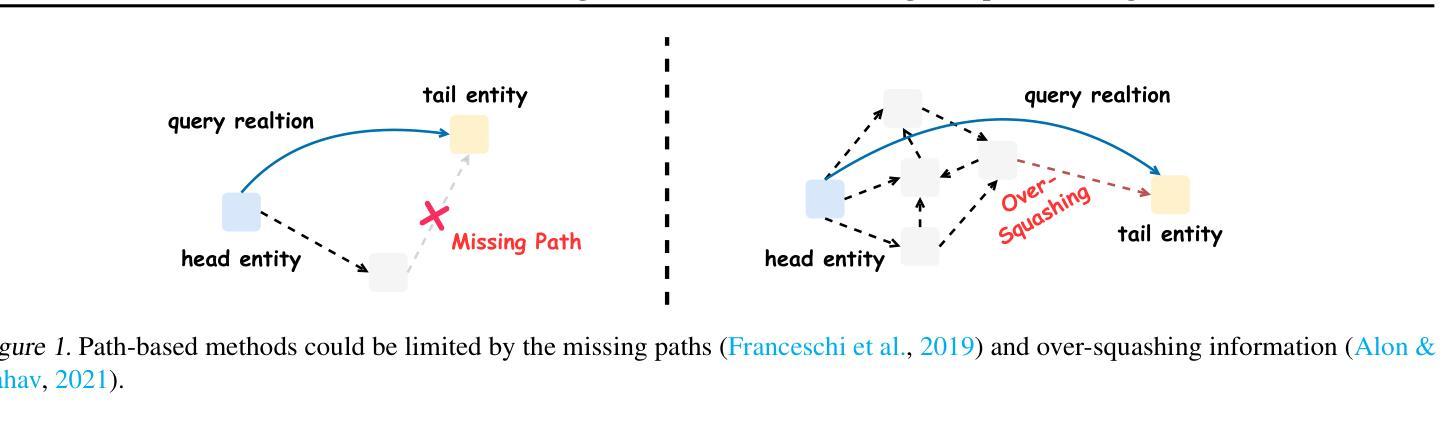
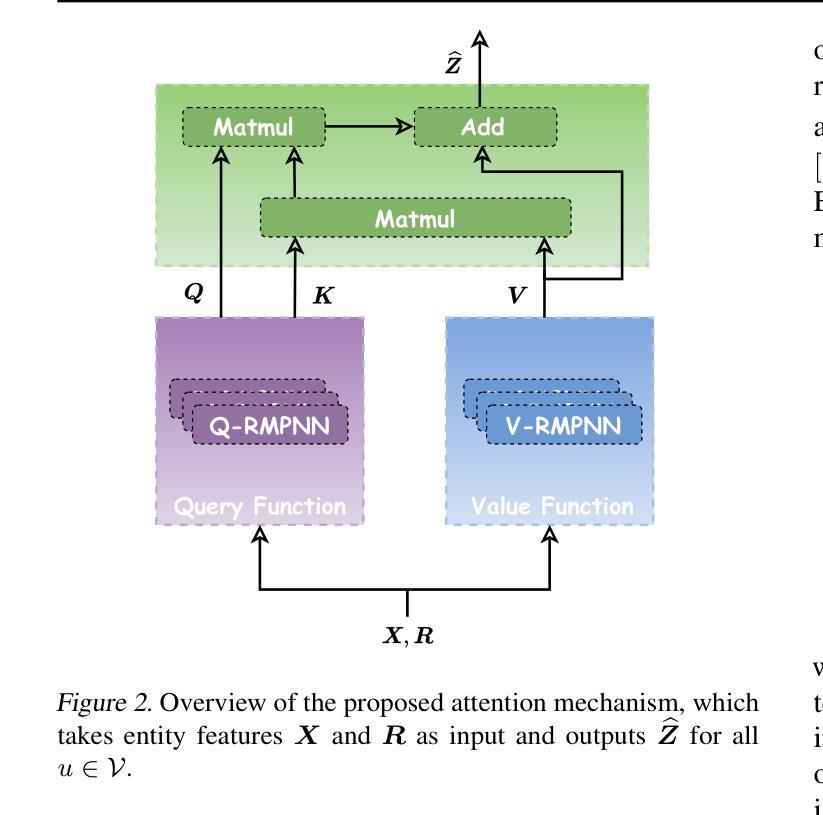
Knowledge graph reasoning plays a vital role in various applications and has garnered considerable attention. Recently, path-based methods have achieved impressive performance. However, they may face limitations stemming from constraints in message-passing neural networks, such as missing paths and information over-squashing. In this paper, we revisit the application of transformers for knowledge graph reasoning to address the constraints faced by path-based methods and propose a novel method KnowFormer. KnowFormer utilizes a transformer architecture to perform reasoning on knowledge graphs from the message-passing perspective, rather than reasoning by textual information like previous pretrained language model based methods. Specifically, we define the attention computation based on the query prototype of knowledge graph reasoning, facilitating convenient construction and efficient optimization. To incorporate structural information into the self-attention mechanism, we introduce structure-aware modules to calculate query, key, and value respectively. Additionally, we present an efficient attention computation method for better scalability. Experimental results demonstrate the superior performance of KnowFormer compared to prominent baseline methods on both transductive and inductive benchmarks.
知识图谱推理在各种应用中发挥着至关重要的作用,并引起了广泛的关注。最近,基于路径的方法取得了令人印象深刻的性能。然而,它们可能会面临来自消息传递神经网络约束的限制,例如路径缺失和信息过度压缩。在本文中,我们重新审视了变压器在知识图谱推理中的应用,以解决基于路径的方法所面临的约束,并提出了一种新方法KnowFormer。KnowFormer利用变压器架构从消息传递的角度对知识图谱进行推理,而不是像以前基于预训练的语言模型方法那样通过文本信息进行推理。具体来说,我们基于知识图谱推理的查询原型来定义注意力计算,便于构建和高效优化。为了将结构信息融入自注意力机制,我们引入了结构感知模块来分别计算查询、键和值。此外,我们还提出了一种高效的注意力计算方法,以提高可扩展性。实验结果表表明,与转导和归纳基准测试上的主流方法相比,KnowFormer的性能更优越。
论文及项目相关链接
PDF Accepted by ICML2024
Summary
知识图谱推理在各种应用中发挥着重要作用,并引起了广泛关注。尽管路径基于方法已经取得了显著的性能提升,但它们仍面临着消息传递神经网络中的约束,如路径缺失和信息过度压缩。本文提出了一种新型知识图谱推理方法KnowFormer,采用变压器架构从消息传递角度进行知识图谱推理,解决了路径基于方法所面临的约束。KnowFormer定义了基于知识图谱推理查询原型的注意力计算,便于构建和高效优化。同时,为了将结构信息融入自注意力机制,引入了结构感知模块分别计算查询、键和值。此外,还提出了一种有效的注意力计算方法以实现更好的可扩展性。实验结果表明,在转导和归纳基准测试中,KnowFormer相较于主流基线方法表现出卓越性能。
Key Takeaways
- 知识图谱推理在许多应用中至关重要,并受到广泛关注。
- 路径基于的方法在知识图谱推理中取得了显著性能提升,但仍面临约束。
- KnowFormer采用变压器架构进行知识图谱推理,解决了路径基于方法的约束。
- KnowFormer利用查询原型定义注意力计算,方便构建和高效优化。
- KnowFormer引入结构感知模块融入结构信息到自注意力机制中。
- KnowFormer提出了一种有效的注意力计算方法以实现更好的可扩展性。
点此查看论文截图


Can GPT-O1 Kill All Bugs? An Evaluation of GPT-Family LLMs on QuixBugs
Authors:Haichuan Hu, Ye Shang, Guolin Xu, Congqing He, Quanjun Zhang
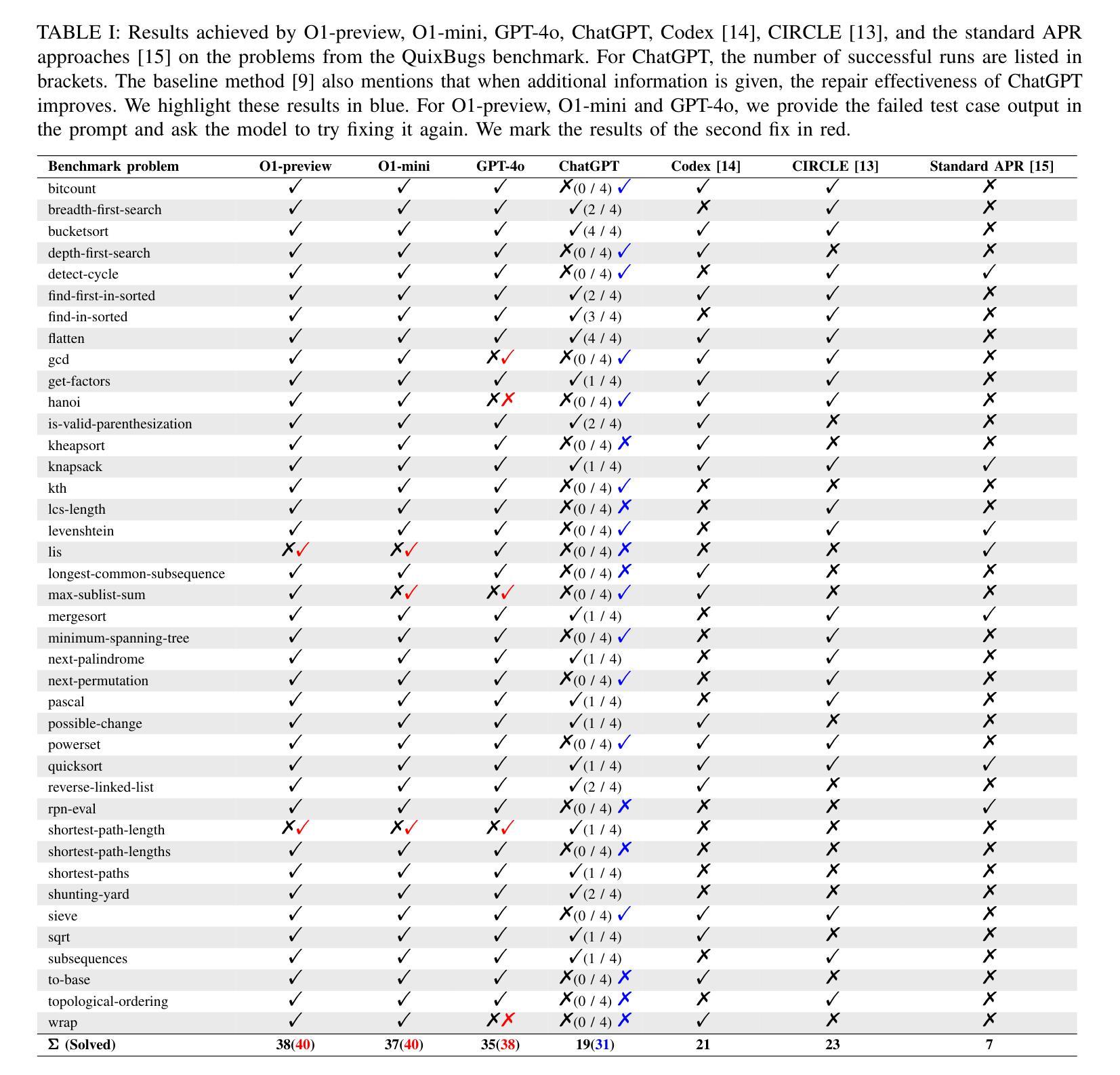
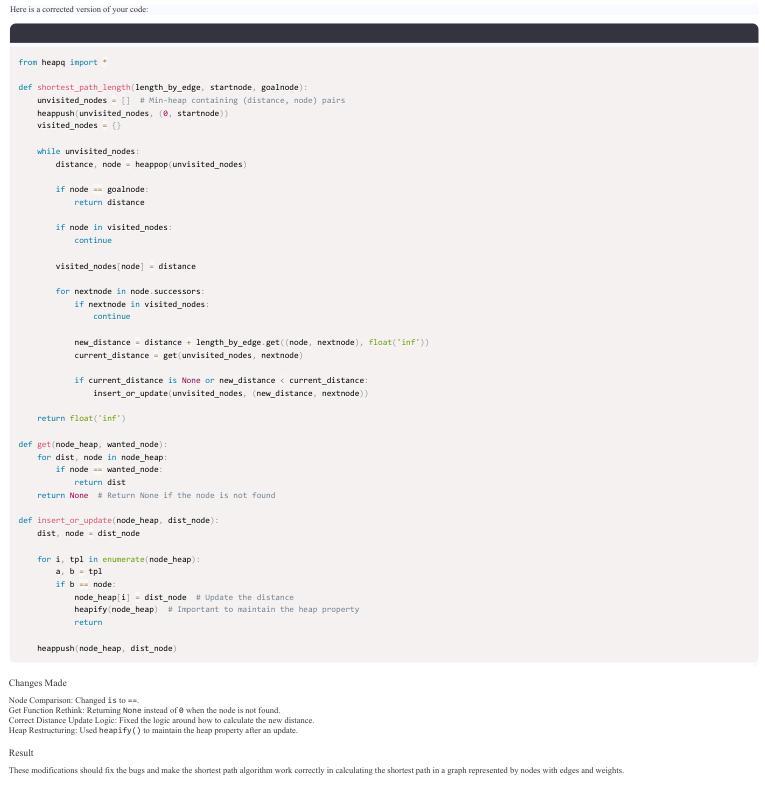
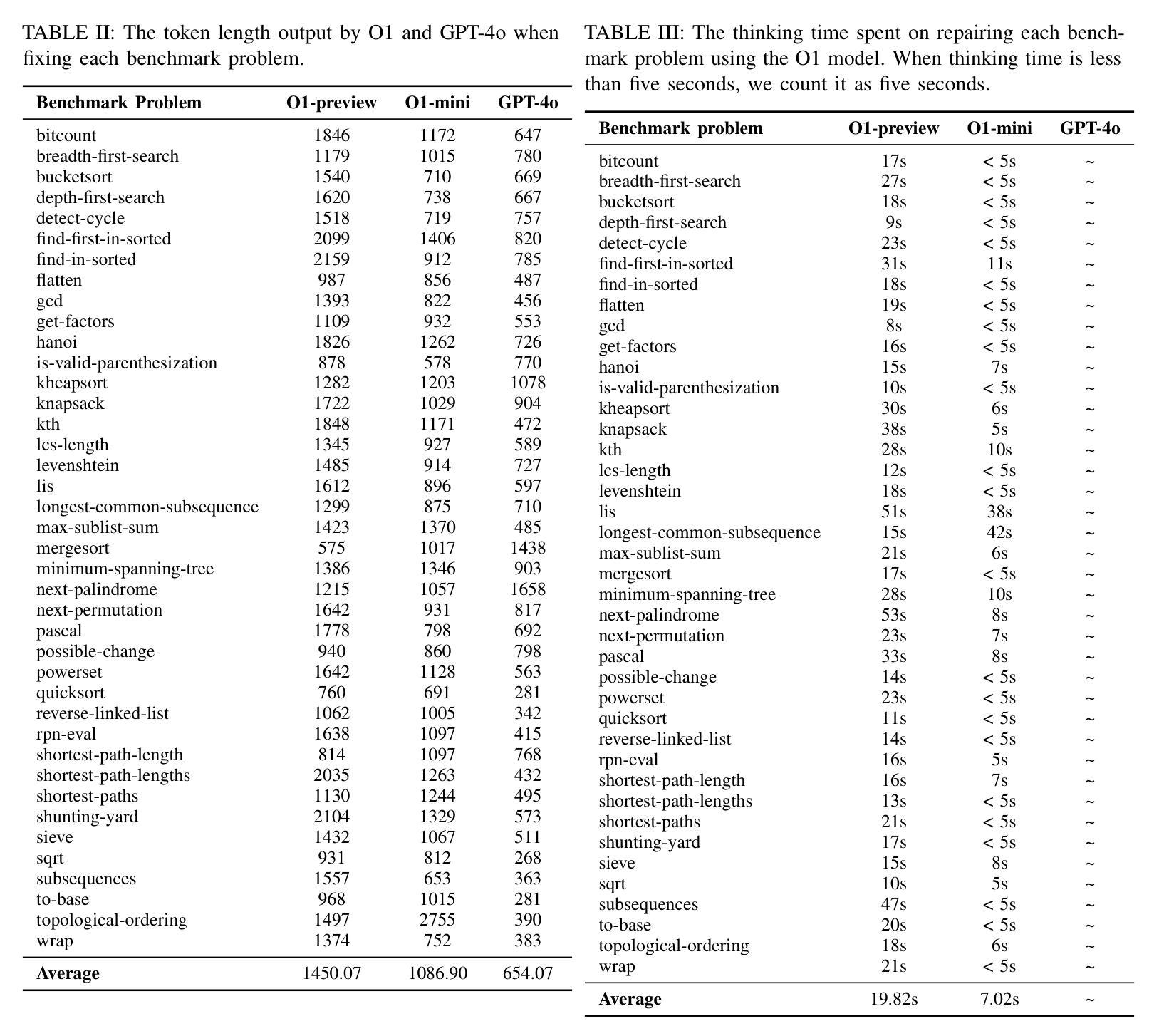
LLMs have long demonstrated remarkable effectiveness in automatic program repair (APR), with OpenAI’s ChatGPT being one of the most widely used models in this domain. Through continuous iterations and upgrades of GPT-family models, their performance in fixing bugs has already reached state-of-the-art levels. However, there are few works comparing the effectiveness and variations of different versions of GPT-family models on APR. In this work, inspired by the recent public release of the GPT-o1 models, we conduct the first study to compare the effectiveness of different versions of the GPT-family models in APR. We evaluate the performance of the latest version of the GPT-family models (i.e., O1-preview and O1-mini), GPT-4o, and the historical version of ChatGPT on APR. We conduct an empirical study of the four GPT-family models against other LLMs and APR techniques on the QuixBugs benchmark from multiple evaluation perspectives, including repair success rate, repair cost, response length, and behavior patterns. The results demonstrate that O1’s repair capability exceeds that of prior GPT-family models, successfully fixing all 40 bugs in the benchmark. Our work can serve as a foundation for further in-depth exploration of the applications of GPT-family models in APR.
大型语言模型(LLMs)在自动程序修复(APR)领域已经展现出显著的效果。OpenAI的ChatGPT是该领域中最广泛使用的模型之一。通过GPT系列模型的持续迭代和升级,它们在修复错误方面的性能已经达到了最新水平。然而,关于不同版本的GPT系列模型在APR中的效果和差异的研究工作很少。在这项工作中,受到最近GPT-o1模型公开发布的启发,我们进行了第一项比较GPT系列不同版本在APR中有效性的研究。我们评估了GPT系列模型的最新版本(即O1-preview和O1-mini)、GPT-4o以及ChatGPT的历史版本在APR中的性能。我们在QuixBugs基准测试上对这四个GPT系列模型与其他大型语言模型和APR技术进行了实证研究,从多个评估角度进行了对比,包括修复成功率、修复成本、响应长度和行为模式。结果表明,O1的修复能力超过了之前的GPT系列模型,成功修复了基准测试中的所有40个错误。我们的工作可以为进一步深入研究GPT系列模型在APR中的应用奠定基础。
论文及项目相关链接
PDF Accepted to the 6th International Workshop on Automated Program Repair (APR 2025)
Summary
LLMs在自动程序修复(APR)中表现优异,GPT系列模型在APR领域的表现已处于前沿地位。本研究对比了不同版本GPT系列模型在APR中的有效性,结果显示O1的修复能力超过了先前的GPT系列模型,成功修复了所有40个基准测试中的错误。
Key Takeaways
- LLMs在自动程序修复(APR)中展现出显著的有效性。
- GPT系列模型是APR领域中最常用的模型之一,其性能已达到前沿水平。
- 目前对于不同版本GPT系列模型在APR中的有效性对比研究较少。
- 本研究对比了GPT家族不同版本(O1-preview、O1-mini、GPT-4o和历史版ChatGPT)在APR中的表现。
- 通过实证研究发现,O1的修复能力超过了先前的GPT系列模型。
- O1成功修复了所有40个基准测试中的错误。
点此查看论文截图


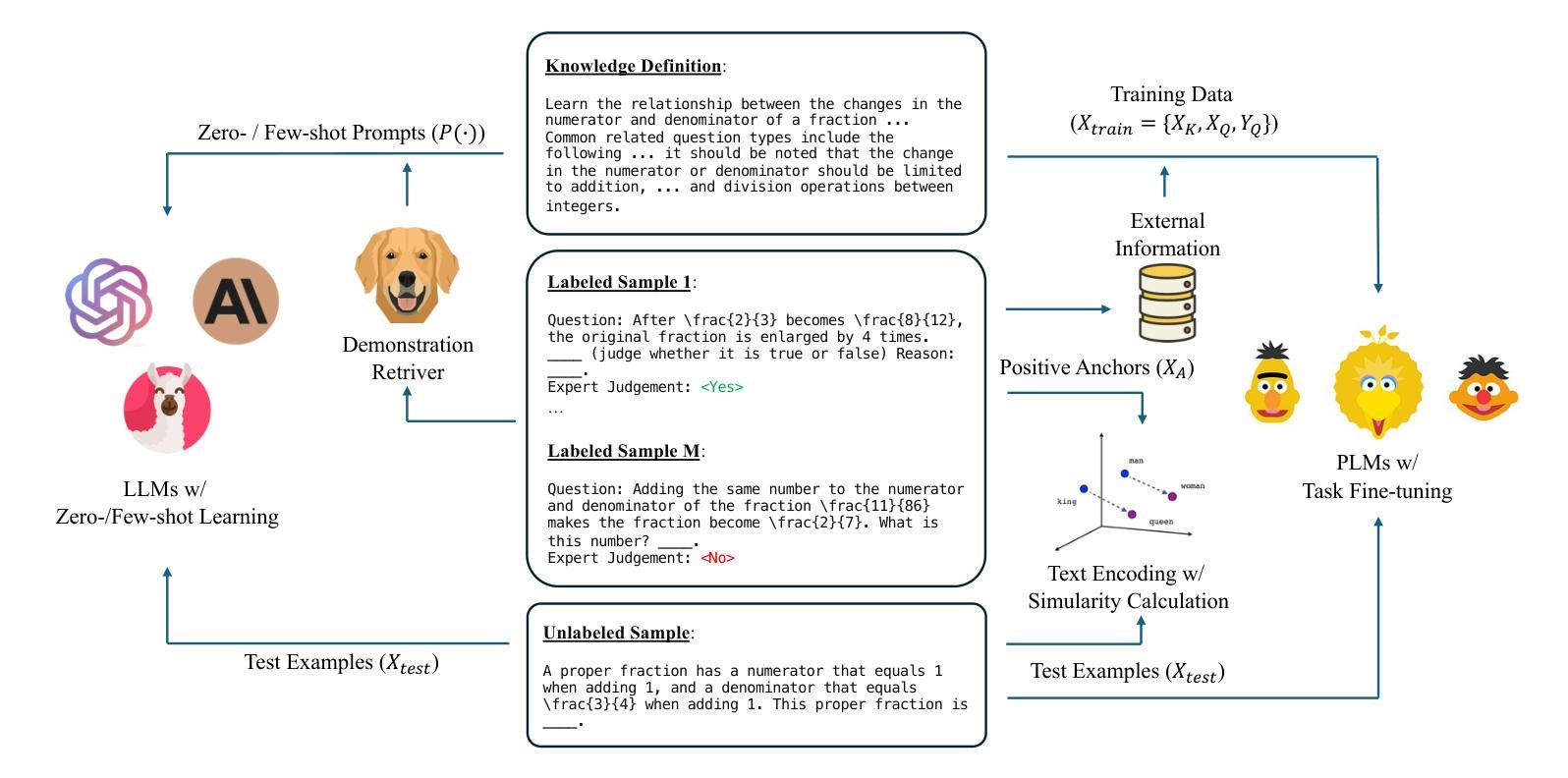
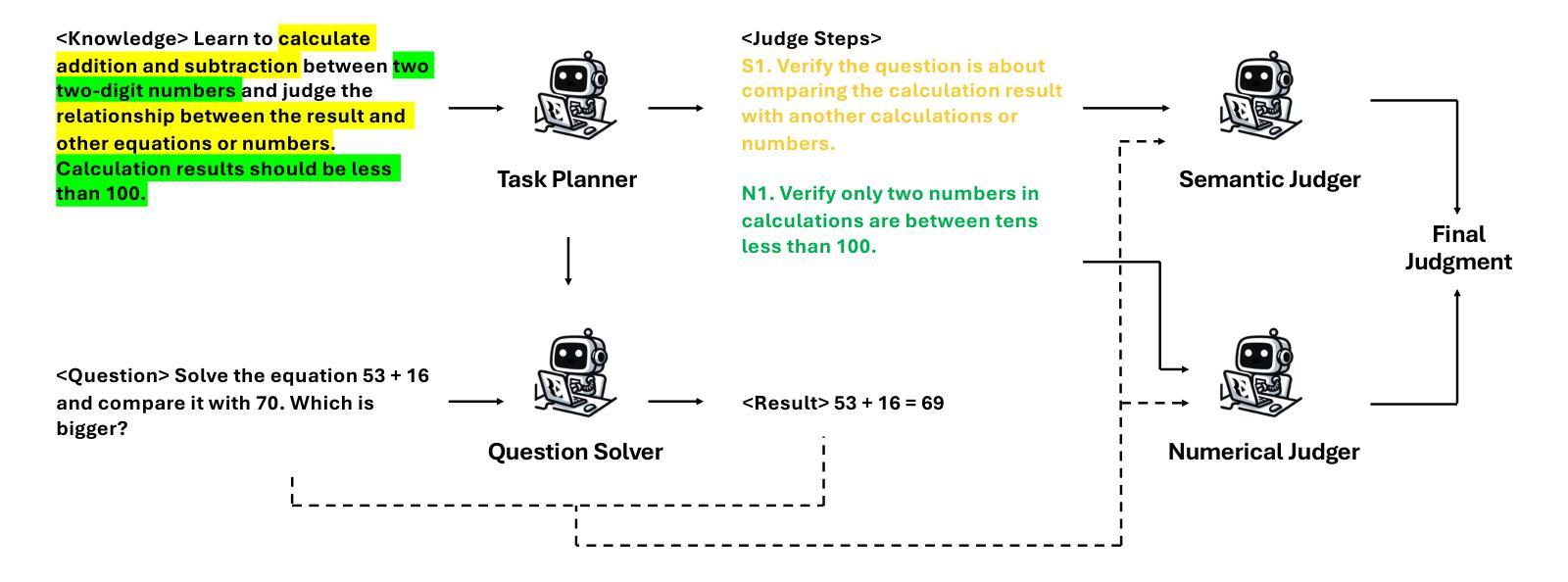
Knowledge Tagging with Large Language Model based Multi-Agent System
Authors:Hang Li, Tianlong Xu, Ethan Chang, Qingsong Wen
Knowledge tagging for questions is vital in modern intelligent educational applications, including learning progress diagnosis, practice question recommendations, and course content organization. Traditionally, these annotations have been performed by pedagogical experts, as the task demands not only a deep semantic understanding of question stems and knowledge definitions but also a strong ability to link problem-solving logic with relevant knowledge concepts. With the advent of advanced natural language processing (NLP) algorithms, such as pre-trained language models and large language models (LLMs), pioneering studies have explored automating the knowledge tagging process using various machine learning models. In this paper, we investigate the use of a multi-agent system to address the limitations of previous algorithms, particularly in handling complex cases involving intricate knowledge definitions and strict numerical constraints. By demonstrating its superior performance on the publicly available math question knowledge tagging dataset, MathKnowCT, we highlight the significant potential of an LLM-based multi-agent system in overcoming the challenges that previous methods have encountered. Finally, through an in-depth discussion of the implications of automating knowledge tagging, we underscore the promising results of deploying LLM-based algorithms in educational contexts.
知识标注在现代智能教育应用中至关重要,包括学习进度诊断、练习题推荐和课程内容组织。传统上,这些注释由教育专家完成,因为这项工作不仅需要深度理解问题题干和知识定义,还需要强大的将问题解决逻辑与相关知识概念联系起来的能力。随着先进的自然语言处理(NLP)算法的兴起,如预训练语言模型和大语言模型(LLM),开创性研究已经探索使用各种机器学习模型自动进行知识标注过程。在本文中,我们研究了多智能体系统在解决以前算法局限性方面的应用,特别是在处理涉及复杂知识定义和严格数值约束的复杂案例方面。我们在公共可用的数学题目知识标注数据集MathKnowCT上展示了其卓越的性能,突显了基于LLM的多智能体系统在克服以前方法所遇到的挑战方面的巨大潜力。最后,通过对知识标注自动化的深入讨论,我们强调了基于LLM的算法在教育环境中的令人鼓舞的结果。
论文及项目相关链接
PDF Accepted by AAAI 2025 (AAAI/IAAI 2025 Innovative Application Award)
总结
基于多代理系统的知识标注,对于处理复杂的标注需求表现出优越性能。该研究探索使用大型语言模型(LLM)实现知识标注自动化,在公开的数学知识标注数据集MathKnowCT上表现优异。该研究强调了自动化知识标注在教育环境中的潜力。随着先进自然语言处理算法的发展,知识标注在智能教育应用中的需求不断增强,可帮助提高教学效果与学生的学习效率。目前教育领域普遍认可知识的细致划分为学习效果的基础支撑之一。结合任务与题型进行知识分类标注,有利于提升教育智能化水平。自动化知识标注可助力课程内容的组织和课程知识的优化分配。以往人工完成课程知识划分效率较低且标准难以统一。采用多代理系统的自动化标注技术将极大地提高教育内容的组织和知识分配的效率和准确性。利用机器学习算法结合自适应推荐技术形成用户专属的学习系统可大大提高教育工作的效率和便捷性,也是智能教育的一个重要方向。当前教育领域正面临数字化改革的重要阶段,该技术的出现将极大地推动教育行业的智能化发展进程。随着机器学习技术不断地推陈出新与人工智能产品的快速发展升级等市场需求不断增长共同促进了我国智能化水平的不断提高进程将会持续加速智能化升级浪潮的来临,最终实现以机器算法主导自适应教学赋能教育的伟大目标。对于智能教育系统的研发和推广具有重要意义。这一发现不仅将促进机器学习和人工智能在教育领域的应用,同时也为我国智能教育的未来发展提供了强有力的技术支撑。此外,这一研究还具有广阔的应用前景和重要的社会价值和经济价值。我们相信这一技术将为智能教育带来更加广阔的前景和更多的可能性。此外该技术对于自然语言处理领域也具有重要的启示作用对于整个技术的发展具有重大的推动作用推动知识标注自动化技术的进步和发展对于提高人工智能领域整体的进步具有重要意义和作用随着知识的不断深化对于专业领域的学习需求和习惯转变无疑需要满足差异化的用户需求复杂的知识体系构建和知识分类需要更加精细化的处理以及更强大的技术支撑才能满足当前社会的需求。因此该技术的出现也进一步凸显了其在未来人工智能领域发展中的重要地位。通过对这一研究的深入探讨和不断实践我们有望推动人工智能技术在教育领域的广泛应用和深度发展进而实现智能化教育的美好愿景。
关键见解
- 知识标注在现代智能教育应用中至关重要,包括学习进度诊断、练习题推荐和课程内容组织等方面。
- 传统知识标注由教育专家进行,任务需求复杂,包括深度语义理解和知识定义联系问题解决逻辑等能力。
- 随着NLP算法的发展,尤其是预训练语言模型和大型语言模型(LLM),有越来越多的研究尝试自动化知识标注过程。
- 多代理系统在处理复杂知识标注问题上表现出优越性能,特别是在处理复杂案例和严格数值约束方面。
- 在公开的数学知识标注数据集上的表现验证了LLM基于多代理系统的潜力。
- 自动化知识标注能提高教育内容组织和知识分配的效率和准确性,有助于推动教育行业的智能化发展进程。
点此查看论文截图




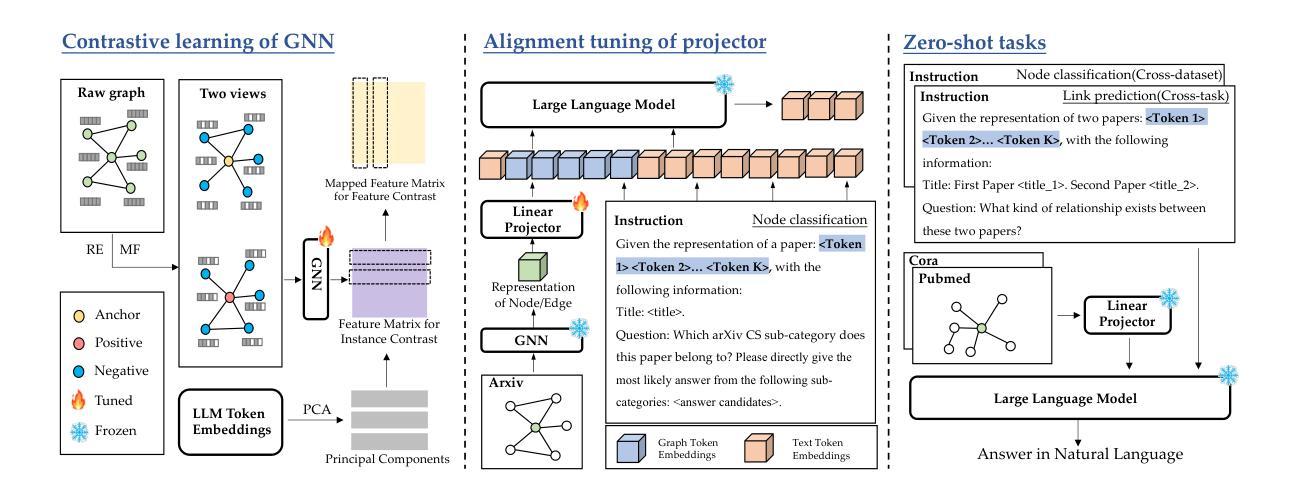
LLMs as Zero-shot Graph Learners: Alignment of GNN Representations with LLM Token Embeddings
Authors:Duo Wang, Yuan Zuo, Fengzhi Li, Junjie Wu
Zero-shot graph machine learning, especially with graph neural networks (GNNs), has garnered significant interest due to the challenge of scarce labeled data. While methods like self-supervised learning and graph prompt learning have been extensively explored, they often rely on fine-tuning with task-specific labels, limiting their effectiveness in zero-shot scenarios. Inspired by the zero-shot capabilities of instruction-fine-tuned large language models (LLMs), we introduce a novel framework named Token Embedding-Aligned Graph Language Model (TEA-GLM) that leverages LLMs as cross-dataset and cross-task zero-shot learners for graph machine learning. Concretely, we pretrain a GNN, aligning its representations with token embeddings of an LLM. We then train a linear projector that transforms the GNN’s representations into a fixed number of graph token embeddings without tuning the LLM. A unified instruction is designed for various graph tasks at different levels, such as node classification (node-level) and link prediction (edge-level). These design choices collectively enhance our method’s effectiveness in zero-shot learning, setting it apart from existing methods. Experiments show that our graph token embeddings help the LLM predictor achieve state-of-the-art performance on unseen datasets and tasks compared to other methods using LLMs as predictors.
零样本图机器学习,特别是与图神经网络(GNN)相结合,由于标注数据稀缺的挑战而备受关注。虽然自监督学习和图提示学习等方法已经得到了广泛的研究,但它们通常依赖于特定任务的标签进行微调,从而在零样本场景中限制了其有效性。受指令微调大型语言模型(LLM)零样本能力的启发,我们引入了一种新的框架,名为Token Embedding-Aligned Graph Language Model(TEA-GLM),该框架利用LLM作为跨数据集和跨任务的零样本学习者进行图机器学习。具体来说,我们对GNN进行预训练,将其表示与LLM的令牌嵌入进行对齐。然后,我们训练一个线性投影仪,将GNN的表示转换为固定数量的图令牌嵌入,而无需调整LLM。为不同层次的各种图形任务设计了一个统一的指令,如节点分类(节点级)和链接预测(边缘级)。这些设计选择共同提高了我们的方法在零样本学习中的有效性,使其与现有方法有所不同。实验表明,我们的图令牌嵌入有助于LLM预测器在未见过的数据集和任务上实现最先进的性能。
论文及项目相关链接
Summary
零样本图机器学习,特别是基于图神经网络(GNNs)的方法,因缺乏标注数据而备受关注。尽管自监督学习和图提示学习等方法已被广泛探索,但它们通常依赖于特定任务的标签进行微调,这在零样本场景中限制了其有效性。受指令微调大型语言模型(LLM)零样本能力的启发,我们提出了一种名为Token Embedding-Aligned Graph Language Model(TEA-GLM)的新型框架,该框架利用LLM作为跨数据集和跨任务的零样本学习者来进行图机器学习。我们通过将GNN的表示与LLM的令牌嵌入进行对齐来预训练它,然后训练一个线性投影仪,将GNN的表示转换为固定数量的图令牌嵌入,而无需调整LLM。为各级图形任务设计了统一的指令,如节点分类(节点级)和链接预测(边缘级)。这些设计选择共同提高了该方法在零样本学习中的有效性,使其有别于现有方法。实验表明,我们的图令牌嵌入有助于LLM预测器在未见过的数据集和任务上实现最先进的性能。
Key Takeaways
- 零样本图机器学习面临缺乏标注数据的挑战。
- 现有方法如自监督学习和图提示学习通常在零样本场景中有效性受限。
- 受LLM零样本能力的启发,提出TEA-GLM框架。
- TEA-GLM通过将GNN与LLM结合,利用LLM作为跨数据集和跨任务的零样本学习者。
- 通过预训练GNN并与LLM的令牌嵌入对齐,再训练线性投影仪将GNN表示转换为图令牌嵌入。
- 设计了各级图形任务的统一指令,如节点分类和链接预测。
点此查看论文截图

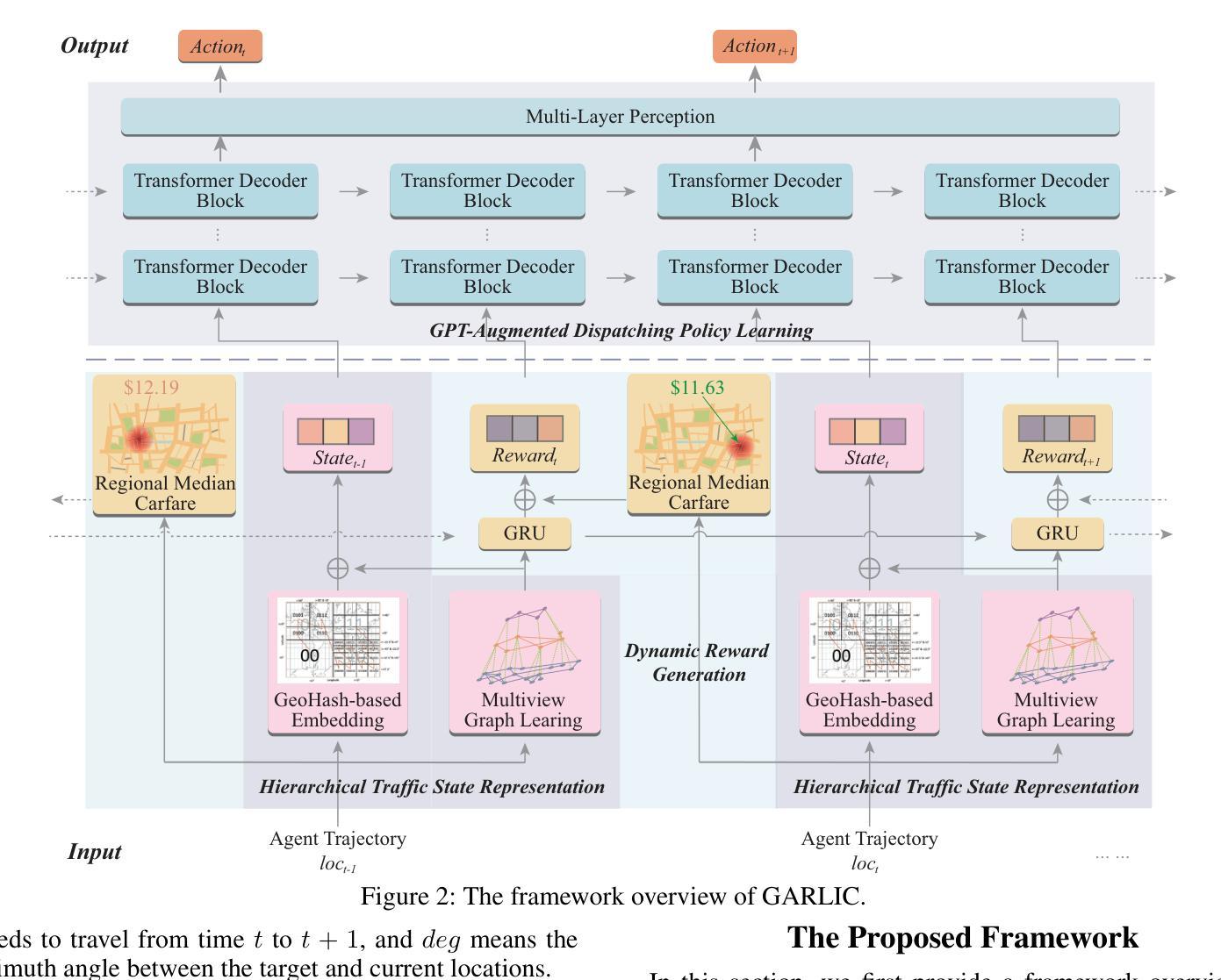
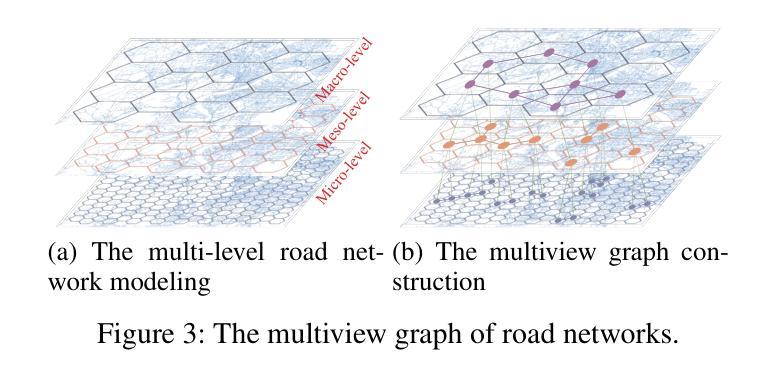
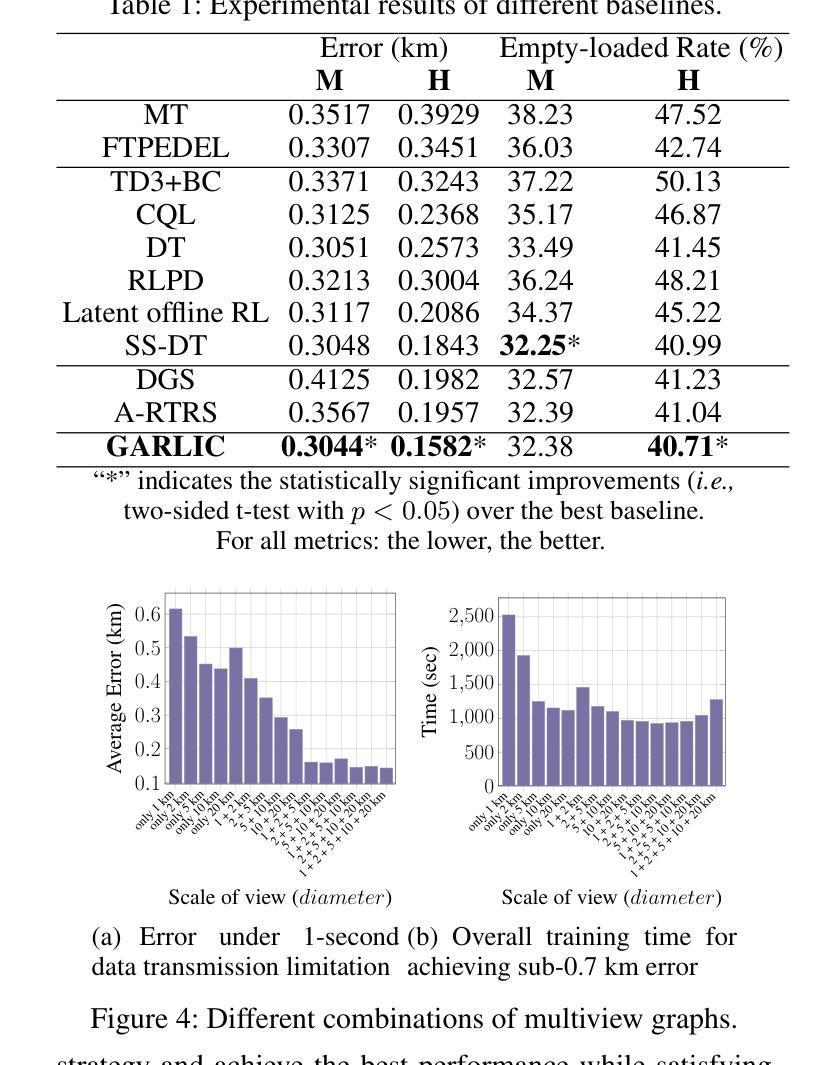
GARLIC: GPT-Augmented Reinforcement Learning with Intelligent Control for Vehicle Dispatching
Authors:Xiao Han, Zijian Zhang, Xiangyu Zhao, Yuanshao Zhu, Guojiang Shen, Xiangjie Kong, Xuetao Wei, Liqiang Nie, Jieping Ye
As urban residents demand higher travel quality, vehicle dispatch has become a critical component of online ride-hailing services. However, current vehicle dispatch systems struggle to navigate the complexities of urban traffic dynamics, including unpredictable traffic conditions, diverse driver behaviors, and fluctuating supply and demand patterns. These challenges have resulted in travel difficulties for passengers in certain areas, while many drivers in other areas are unable to secure orders, leading to a decline in the overall quality of urban transportation services. To address these issues, this paper introduces GARLIC: a framework of GPT-Augmented Reinforcement Learning with Intelligent Control for vehicle dispatching. GARLIC utilizes multiview graphs to capture hierarchical traffic states, and learns a dynamic reward function that accounts for individual driving behaviors. The framework further integrates a GPT model trained with a custom loss function to enable high-precision predictions and optimize dispatching policies in real-world scenarios. Experiments conducted on two real-world datasets demonstrate that GARLIC effectively aligns with driver behaviors while reducing the empty load rate of vehicles.
随着城市居民对旅行品质的要求越来越高,车辆调度已成为在线叫车服务的重要组成部分。然而,当前车辆调度系统在应对城市交通动态的复杂性方面存在困难,包括不可预测的交通状况、司机行为的多样性以及供需模式的波动。这些挑战导致某些地区的乘客出行困难,而其他地区的许多司机无法接到订单,从而降低了城市交通运输服务的整体质量。为了解决这些问题,本文介绍了GARLIC:一种用于车辆调度的GPT增强型强化学习智能控制框架。GARLIC利用多视图图来捕获分层交通状态,并学习一个考虑个体驾驶行为的动态奖励函数。该框架进一步集成了一个使用自定义损失函数训练的GPT模型,以实现高精度预测,并在现实场景中优化调度策略。在两个真实数据集上进行的实验表明,GARLIC有效地适应了驾驶员行为,并降低了车辆的空驶率。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
随着城市居民对旅行品质要求的提高,车辆调度已成为在线拼车服务的重要组成部分。然而,当前车辆调度系统在应对城市交通的复杂性方面面临挑战,如不可预测的交通状况、司机行为的多样性以及供需模式的波动。为解决这些问题,本文提出了GARLIC框架,该框架利用GPT增强型强化学习智能控制车辆调度。通过多视图图捕捉分层交通状态,学习动态奖励函数以考虑个体驾驶行为,并集成GPT模型进行高精度预测和优化实际场景中的调度策略。实验证明,GARLIC框架能有效符合司机行为并降低车辆空驶率。
Key Takeaways
- 城市居民对旅行品质的要求提高,车辆调度成为在线拼车服务的核心组成部分。
- 当前车辆调度系统面临城市交通复杂性的挑战,包括不可预测的交通状况、司机行为的多样性以及供需波动。
- GARLIC框架结合了GPT增强型强化学习智能控制,用于优化车辆调度。
- 多视图图被用来捕捉分层交通状态,并学习考虑个体驾驶行为的动态奖励函数。
- GPT模型的集成使得预测更为精确,优化了实际场景中的调度策略。
- 实验证明,GARLIC框架能有效符合司机行为。
点此查看论文截图

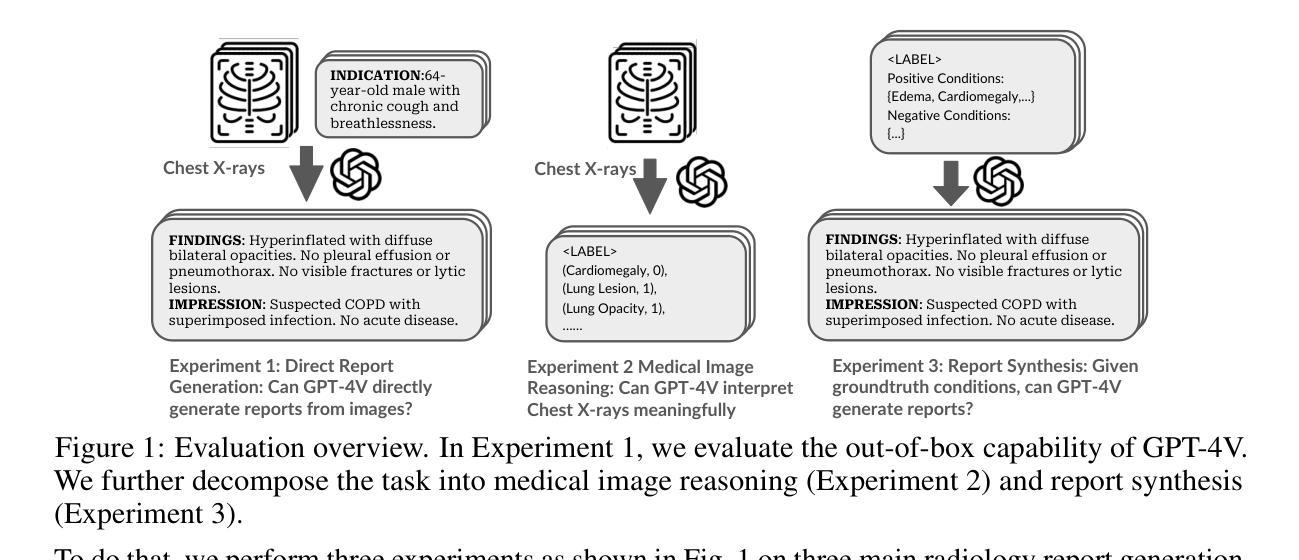
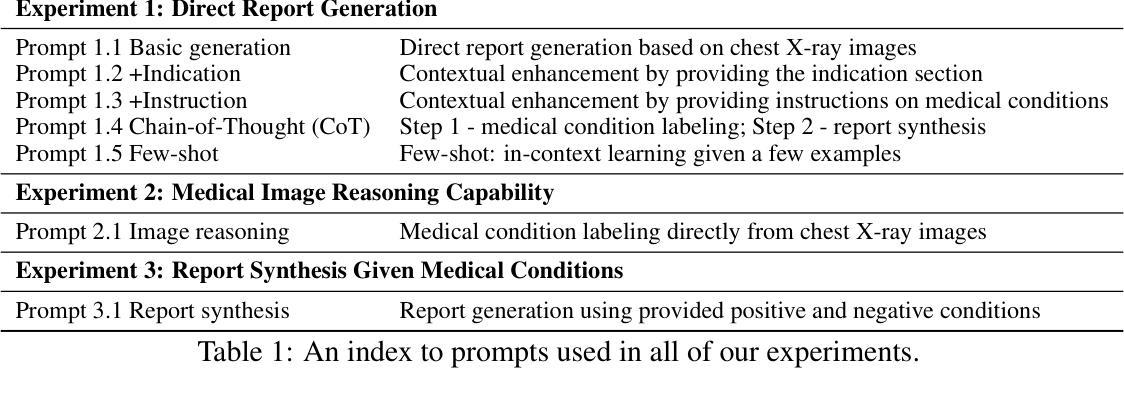
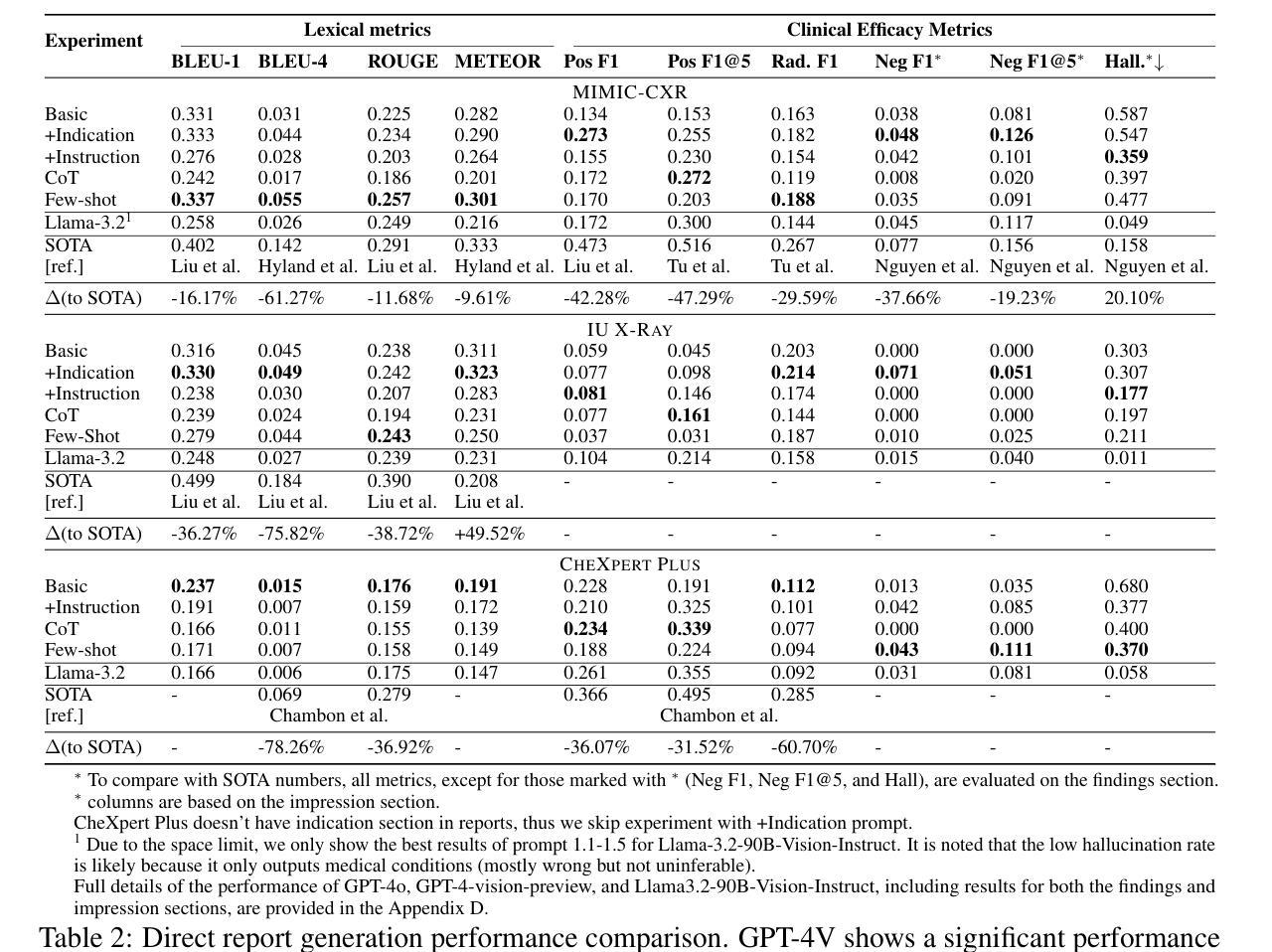
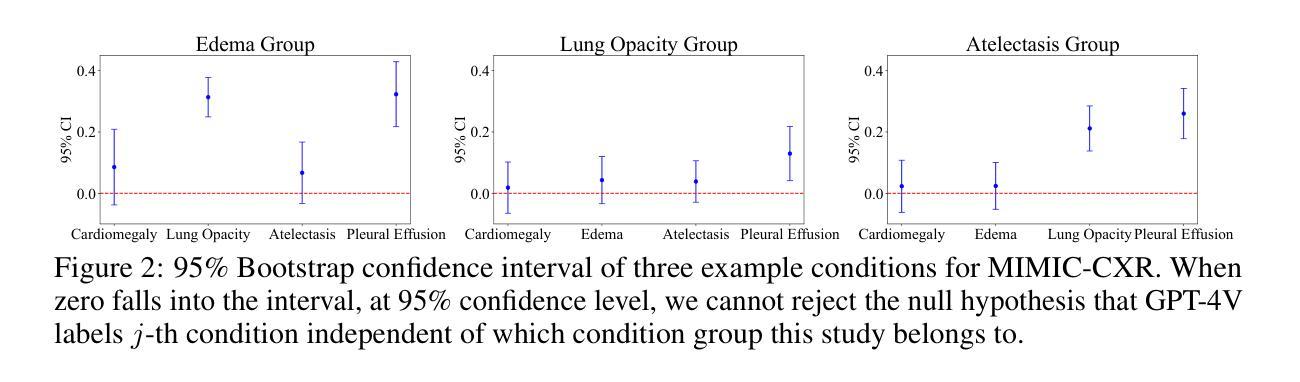
GPT-4V Cannot Generate Radiology Reports Yet
Authors:Yuyang Jiang, Chacha Chen, Dang Nguyen, Benjamin M. Mervak, Chenhao Tan
GPT-4V’s purported strong multimodal abilities raise interests in using it to automate radiology report writing, but there lacks thorough evaluations. In this work, we perform a systematic evaluation of GPT-4V in generating radiology reports on two chest X-ray report datasets: MIMIC-CXR and IU X-Ray. We attempt to directly generate reports using GPT-4V through different prompting strategies and find that it fails terribly in both lexical metrics and clinical efficacy metrics. To understand the low performance, we decompose the task into two steps: 1) the medical image reasoning step of predicting medical condition labels from images; and 2) the report synthesis step of generating reports from (groundtruth) conditions. We show that GPT-4V’s performance in image reasoning is consistently low across different prompts. In fact, the distributions of model-predicted labels remain constant regardless of which groundtruth conditions are present on the image, suggesting that the model is not interpreting chest X-rays meaningfully. Even when given groundtruth conditions in report synthesis, its generated reports are less correct and less natural-sounding than a finetuned LLaMA-2. Altogether, our findings cast doubt on the viability of using GPT-4V in a radiology workflow.
GPT-4V声称的强大多模态能力引发了对其用于自动化放射学报告写作的兴趣,但目前缺乏全面评估。在这项工作中,我们对GPT-4V在MIMIC-CXR和IU X-Ray两个胸部X光报告数据集上生成放射学报告的能力进行了系统评估。我们尝试通过不同的提示策略直接使用GPT-4V生成报告,并发现它在词汇指标和临床有效性指标方面都表现糟糕。为了了解性能不佳的原因,我们将任务分解为两个步骤:1)医学图像推理步骤,即从图像中预测医学状况标签;2)报告合成步骤,即根据(真实)状况生成报告。我们表明,GPT-4V在不同提示中的图像推理性能始终较低。事实上,无论图像上存在哪些真实状况,模型预测的标签分布都保持不变,这表明模型并没有对胸部X光进行有意义的解读。即使在报告合成时给定真实状况,其生成的报告也比微调后的LLaMA-2更正和更自然流畅。总体而言,我们的研究结果对在放射学工作流程中使用GPT-4V的可行性表示怀疑。
论文及项目相关链接
PDF 24 pages, 3 figures, code: https://github.com/ChicagoHAI/cxr-eval-gpt-4v Findings paper presented at Machine Learning for Health (ML4H) symposium 2024, December 15-16, 2024, Vancouver, Canada, 26 pages
Summary
GPT-4V在多模态能力方面备受关注,尤其在自动化生成放射学报告方面的潜力。然而,本研究对GPT-4V在生成放射学报告方面的表现进行了系统评估,发现其在词汇和临床指标上的表现均不佳。GPT-4V在图像推理和报告生成两个步骤中的表现均不尽如人意,无法有效解读胸部X光片信息。因此,本研究对GPT-4V在放射学工作流程中的使用提出了质疑。
Key Takeaways
- GPT-4V在多模态能力上具有潜在价值,尤其是在放射学报告自动化方面。
- 在本研究中,GPT-4V在生成放射学报告方面的表现不佳,无论在词汇指标还是临床指标上均未达到预期效果。
- GPT-4V在图像推理方面的表现持续低下,无法有效解读胸部X光片信息。
- GPT-4V在报告生成步骤中的表现不如经过微调后的LLaMA-2模型生成的报告准确和自然。
- GPT-4V模型预测标签的分布与图像上的实际病情无关,表明模型未有效解读胸部X光片内容。
- 使用GPT-4V在放射学工作流程中的可行性值得怀疑。
点此查看论文截图


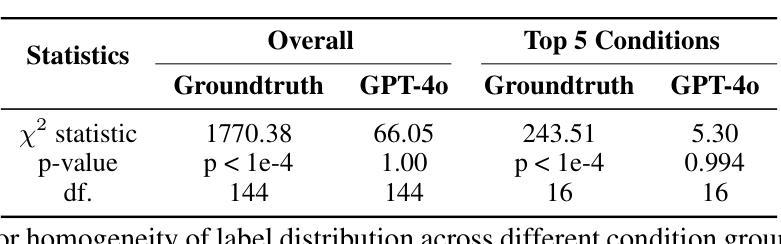
TrackFormers: In Search of Transformer-Based Particle Tracking for the High-Luminosity LHC Era
Authors:Sascha Caron, Nadezhda Dobreva, Antonio Ferrer Sánchez, José D. Martín-Guerrero, Uraz Odyurt, Roberto Ruiz de Austri Bazan, Zef Wolffs, Yue Zhao
High-Energy Physics experiments are facing a multi-fold data increase with every new iteration. This is certainly the case for the upcoming High-Luminosity LHC upgrade. Such increased data processing requirements forces revisions to almost every step of the data processing pipeline. One such step in need of an overhaul is the task of particle track reconstruction, a.k.a., tracking. A Machine Learning-assisted solution is expected to provide significant improvements, since the most time-consuming step in tracking is the assignment of hits to particles or track candidates. This is the topic of this paper. We take inspiration from large language models. As such, we consider two approaches: the prediction of the next word in a sentence (next hit point in a track), as well as the one-shot prediction of all hits within an event. In an extensive design effort, we have experimented with three models based on the Transformer architecture and one model based on the U-Net architecture, performing track association predictions for collision event hit points. In our evaluation, we consider a spectrum of simple to complex representations of the problem, eliminating designs with lower metrics early on. We report extensive results, covering both prediction accuracy (score) and computational performance. We have made use of the REDVID simulation framework, as well as reductions applied to the TrackML data set, to compose five data sets from simple to complex, for our experiments. The results highlight distinct advantages among different designs in terms of prediction accuracy and computational performance, demonstrating the efficiency of our methodology. Most importantly, the results show the viability of a one-shot encoder-classifier based Transformer solution as a practical approach for the task of tracking.
高能物理实验面临着每一次迭代都呈现多重数据增长的情况。即将到来的高亮度LHC升级也是如此。这种增加的数据处理要求几乎需要对数据处理的每个步骤进行修改。需要进行全面检修的一个步骤是粒子轨迹重建的任务,也被称为跟踪。由于跟踪过程中最耗时的步骤是将命中点分配给粒子或轨迹候选者,因此预期机器学习辅助解决方案将带来重大改进。这是本文的主题。我们从大型语言模型中汲取灵感。因此,我们考虑两种方法:预测句子中的下一个词(轨迹中的下一个命中点),以及事件内所有命中点的一次性预测。在广泛的设计工作中,我们尝试了基于Transformer架构的三种模型和一种基于U-Net架构的模型,对碰撞事件命中点进行轨迹关联预测。在我们的评估中,我们考虑了问题的简单到复杂表示形式,并尽早排除了指标较低的早期设计。我们报告了大量结果,包括预测准确度(分数)和计算性能。我们利用REDVID模拟框架以及对TrackML数据集的缩减,为我们的实验从简单到复杂创建了五个数据集。结果突出了不同设计在预测精度和计算性能方面的优势,证明了我们的方法的有效性。最重要的是,结果表明基于一次性编码器分类器解决方案的Transformer是一种用于跟踪任务的实用方法。
论文及项目相关链接
Summary
高能量物理实验面临数据量的增长,特别是在即将升级的高亮度LHC中。数据处理的每个步骤都需要进行修订,其中包括粒子轨迹重建(跟踪)。本文采用机器学习辅助的解决方案,针对跟踪中最耗时的步骤——命中点分配至粒子或轨迹候选,提出有效的方法。从大型语言模型中汲取灵感,采用Transformer架构的模型和U-Net架构的模型进行轨迹关联预测。通过五个从简单到复杂的数据集的实验结果展示预测准确性和计算性能,表明一种基于Transformer的一次性编码器分类器的解决方案具有实用性和可行性。
Key Takeaways
- 高能量物理实验面临数据增长问题,特别是在即将升级的高亮度LHC中。
- 数据处理管道几乎每一步都需要修订,其中包括粒子轨迹重建(跟踪)。
- 机器学习辅助的解决方案对于跟踪任务中的命中点分配至关重要。
- 从大型语言模型中汲取灵感,使用Transformer架构模型和U-Net架构模型进行轨迹关联预测。
- 采用五种不同复杂程度的数据集进行实验,以评估预测准确性和计算性能。
- 实验结果展示了不同设计的优势,包括预测准确性和计算性能方面的差异。
点此查看论文截图

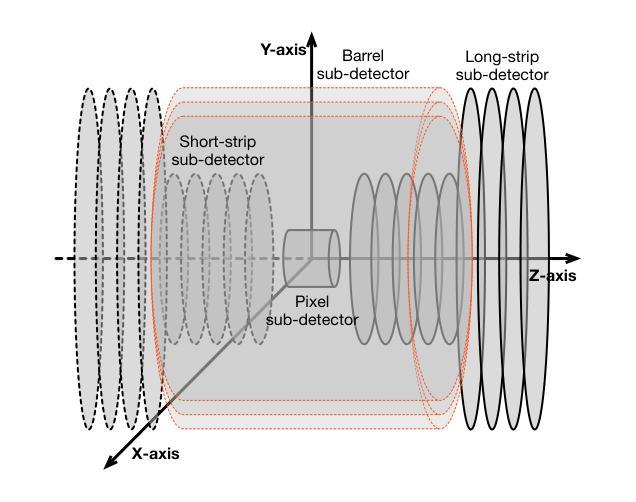
SOLO: A Single Transformer for Scalable Vision-Language Modeling
Authors:Yangyi Chen, Xingyao Wang, Hao Peng, Heng Ji
We present SOLO, a single transformer for Scalable visiOn-Language mOdeling. Current large vision-language models (LVLMs) such as LLaVA mostly employ heterogeneous architectures that connect pre-trained visual encoders with large language models (LLMs) to facilitate visual recognition and complex reasoning. Although achieving remarkable performance with relatively lightweight training, we identify four primary scalability limitations: (1) The visual capacity is constrained by pre-trained visual encoders, which are typically an order of magnitude smaller than LLMs. (2) The heterogeneous architecture complicates the use of established hardware and software infrastructure. (3) Study of scaling laws on such architecture must consider three separate components - visual encoder, connector, and LLMs, which complicates the analysis. (4) The use of existing visual encoders typically requires following a pre-defined specification of image inputs pre-processing, for example, by reshaping inputs to fixed-resolution square images, which presents difficulties in processing and training on high-resolution images or those with unusual aspect ratio. A unified single Transformer architecture, like SOLO, effectively addresses these scalability concerns in LVLMs; however, its limited adoption in the modern context likely stems from the absence of reliable training recipes that balance both modalities and ensure stable training for billion-scale models. In this paper, we introduce the first open-source training recipe for developing SOLO, an open-source 7B LVLM using moderate academic resources. The training recipe involves initializing from LLMs, sequential pre-training on ImageNet and web-scale data, and instruction fine-tuning on our curated high-quality datasets. On extensive evaluation, SOLO demonstrates performance comparable to LLaVA-v1.5-7B, particularly excelling in visual mathematical reasoning.
我们提出了SOLO,这是一种可扩展的面向视觉语言建模的单变压器模型。当前的大型视觉语言模型(LVLMs),如LLaVA,大多采用异构架构,将预训练的视觉编码器与大型语言模型(LLMs)连接起来,以促进视觉识别和复杂推理。尽管在相对较轻的训练中取得了显著的性能,但我们发现了四个主要的可扩展性限制:(1)视觉容量受限于预训练的视觉编码器,这些编码器的规模通常比LLM小一个数量级。(2)异构架构使得使用现有的硬件和软件基础设施变得复杂。(3)在这种架构上研究扩展定律需要考虑三个独立的部分——视觉编码器、连接器和LLMs,这增加了分析的复杂性。(4)使用现有的视觉编码器通常需要遵循预定义的图像输入预处理规范,例如将输入重塑为固定分辨率的方形图像,这在处理高分辨率图像或具有不寻常纵横比的图像时带来了困难。像SOLO这样的统一单一Transformer架构有效地解决了LVLM的可扩展性问题;然而,在现代环境中其有限的采用可能是由于缺乏可靠的训练配方,这些配方需要在两种模态之间取得平衡,并确保大规模模型的稳定训练。在本文中,我们介绍了开发SOLO的第一个开源训练配方,这是一个使用适度学术资源的7B LVLM。训练配方包括从LLMs进行初始化,在ImageNet和Web规模数据上进行顺序预训练,以及在我们精选的高质量数据集上进行指令微调。经过广泛评估,SOLO的性能与LLaVA-v1.5-7B相当,特别是在视觉数学推理方面表现突出。
论文及项目相关链接
PDF Accepted to TMLR
Summary
本文介绍了SOLO模型,这是一种用于可扩展视觉语言建模的单变压器架构。针对当前大型视觉语言模型(LVLMs)在视觉容量、架构复杂性、扩展性分析和图像输入处理方面的局限性,SOLO模型采用单一变压器架构实现视觉和语言建模的有效整合。本文还介绍了SOLO模型的开源训练配方,该配方通过初始化大型语言模型(LLMs)、在ImageNet和Web规模数据上进行顺序预训练以及在我们精选的高质量数据集上进行指令微调,实现了在适度学术资源下的7B LVLM开发。SOLO在广泛评估中表现出了与LLaVAv1.5-7B相当的性能,尤其在视觉数学推理方面表现优异。
Key Takeaways
- SOLO模型是一种用于可扩展视觉语言建模的单变压器架构。
- 当前大型视觉语言模型(LVLMs)存在视觉容量、架构复杂性、扩展性分析和图像输入处理方面的局限性。
- SOLO通过单一变压器架构解决了LVLMs的扩展性问题。
- SOLO模型的开源训练配方包括初始化大型语言模型(LLMs)、在ImageNet和Web规模数据上进行顺序预训练,以及在精选的高质量数据集上进行指令微调。
- SOLO模型性能与LLaVAv1.5-7B相当,尤其在视觉数学推理方面表现优异。
- SOLO模型采用适度学术资源即可进行开发。
点此查看论文截图

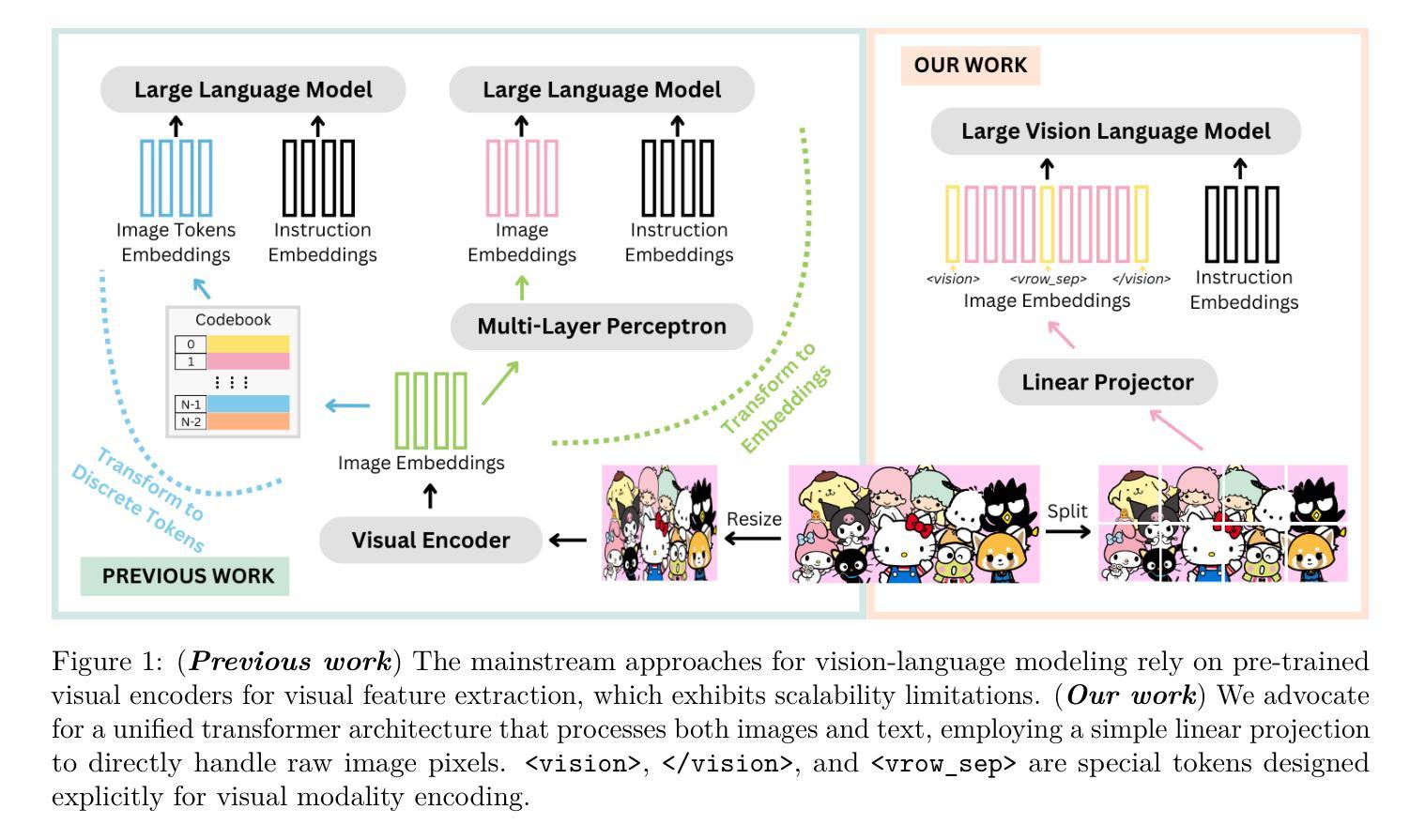

Identifying Query-Relevant Neurons in Large Language Models for Long-Form Texts
Authors:Lihu Chen, Adam Dejl, Francesca Toni
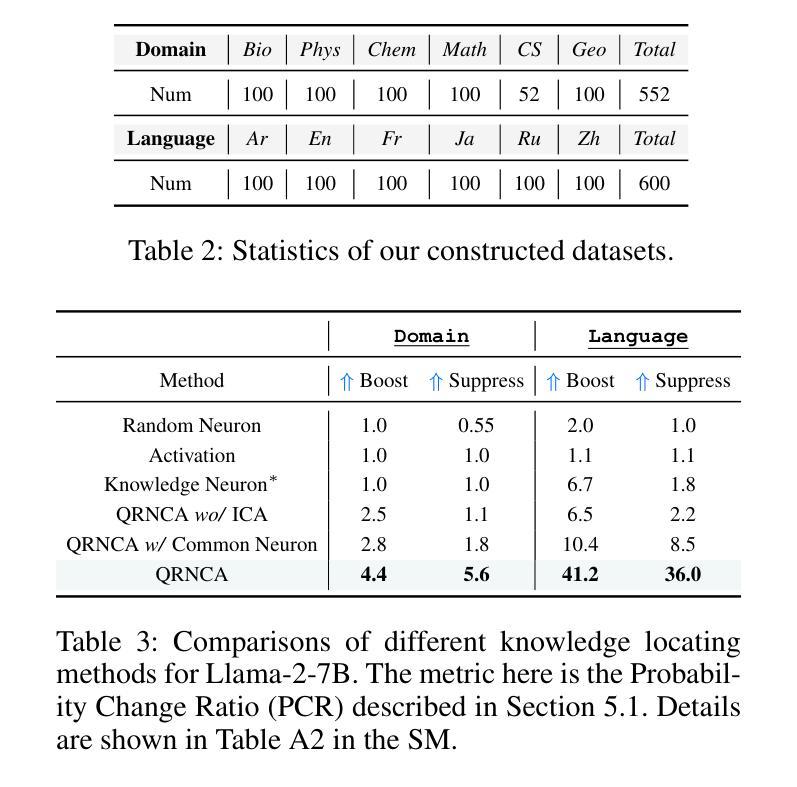
Large Language Models (LLMs) possess vast amounts of knowledge within their parameters, prompting research into methods for locating and editing this knowledge. Previous work has largely focused on locating entity-related (often single-token) facts in smaller models. However, several key questions remain unanswered: (1) How can we effectively locate query-relevant neurons in decoder-only LLMs, such as Llama and Mistral? (2) How can we address the challenge of long-form (or free-form) text generation? (3) Are there localized knowledge regions in LLMs? In this study, we introduce Query-Relevant Neuron Cluster Attribution (QRNCA), a novel architecture-agnostic framework capable of identifying query-relevant neurons in LLMs. QRNCA allows for the examination of long-form answers beyond triplet facts by employing the proxy task of multi-choice question answering. To evaluate the effectiveness of our detected neurons, we build two multi-choice QA datasets spanning diverse domains and languages. Empirical evaluations demonstrate that our method outperforms baseline methods significantly. Further, analysis of neuron distributions reveals the presence of visible localized regions, particularly within different domains. Finally, we show potential applications of our detected neurons in knowledge editing and neuron-based prediction.
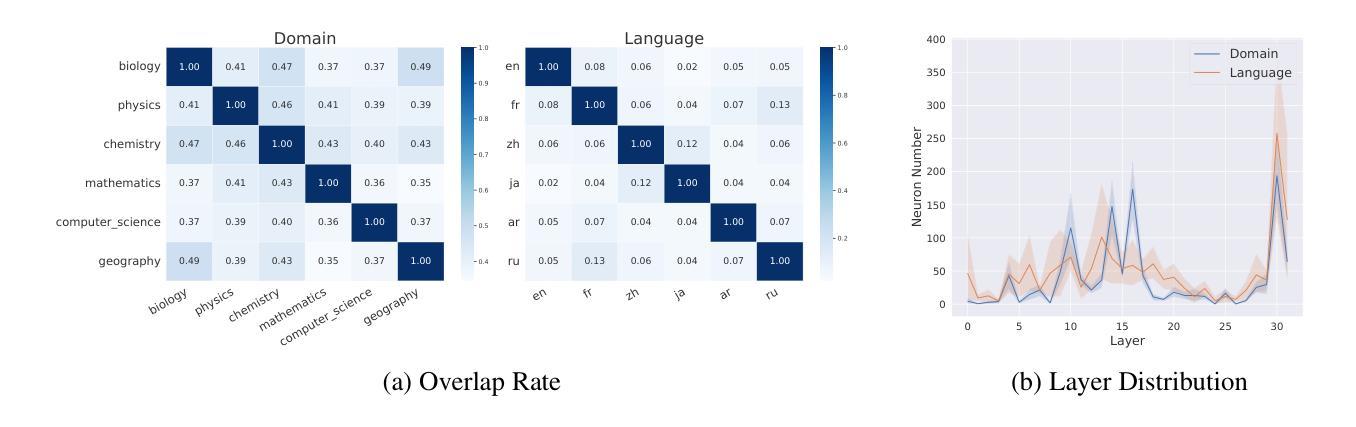
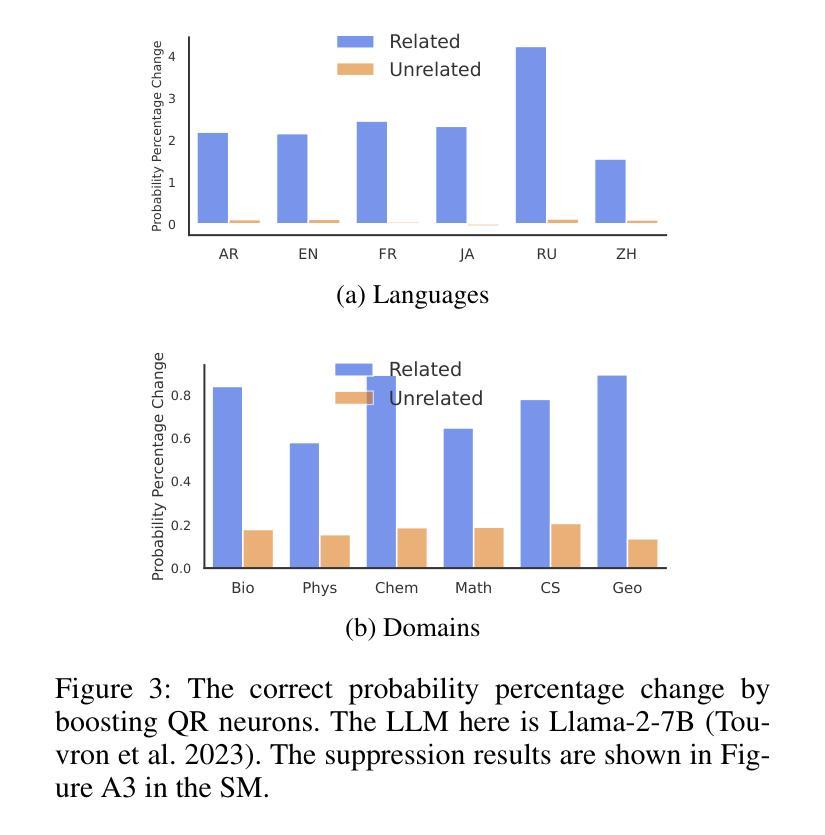
大型语言模型(LLM)在其参数中拥有大量知识,这促使研究人员寻找定位和编辑这些知识的方法。以前的工作主要集中在在较小的模型中定位实体相关的(通常是一个标记)事实。然而,仍有几个关键问题悬而未决:(1)我们如何在仅解码器的大型语言模型(如Llama和Mistral)中有效地定位查询相关神经元?(2)我们如何应对长文本(或自由形式)生成挑战?(3)大型语言模型中有局部知识区域吗?在本研究中,我们引入了查询相关神经元集群归属(QRNCA),这是一种新型、适用于所有架构的框架,能够识别大型语言模型中的查询相关神经元。QRNCA通过采用多选问答的代理任务,可以检查超出三元事实的长形式答案。为了评估我们检测到的神经元的有效性,我们构建了两个涵盖不同领域和语言的多选问答数据集。经验评估表明,我们的方法显著优于基线方法。此外,对神经元分布的分析显示存在明显的局部区域,特别是在不同的领域内。最后,我们展示了所检测神经元在知识编辑和基于神经元的预测中的潜在应用。
论文及项目相关链接
PDF AAAI 2025 Main Track
Summary
大型语言模型(LLM)内含有大量知识,研究者正在探索如何定位与编辑这些知识。先前的研究主要关注在小型模型中定位实体相关(通常是单令牌)事实。然而,本研究面临几个关键问题:如何有效定位查询相关神经元、如何应对长文本生成挑战,以及是否存在局部知识区域。本研究引入了一种新型架构无关框架——查询相关神经元集群归属(QRNCA),能够识别LLM中的查询相关神经元。QRNCA通过多选问答的代理任务,能够检查超越三元事实的长形式答案。通过构建涵盖不同领域和语言的两个多选问答数据集来评估检测到的神经元的有效性,实证评估显示,该方法显著优于基线方法。进一步分析神经元分布显示,不同领域内存在明显的局部区域。最后,我们展示了检测到的神经元在知识编辑和基于神经元的预测中的潜在应用。
Key Takeaways
- 大型语言模型(LLM)包含大量知识,研究正探索如何定位和编辑这些知识。
- 先前研究主要关注小型模型的实体相关知识的定位。
- 查询相关神经元定位、长文本生成挑战和局部知识区域的存在是LLM研究的关键问题。
- 引入了一种新的架构无关框架QRNCA,能有效识别LLM中的查询相关神经元。
- QRNCA通过多选问答的代理任务来检查长形式答案,超越了以前的三元事实检查。
- 通过构建两个涵盖不同领域和语言的问答数据集,实证评估显示QRNCA优于基线方法。
点此查看论文截图

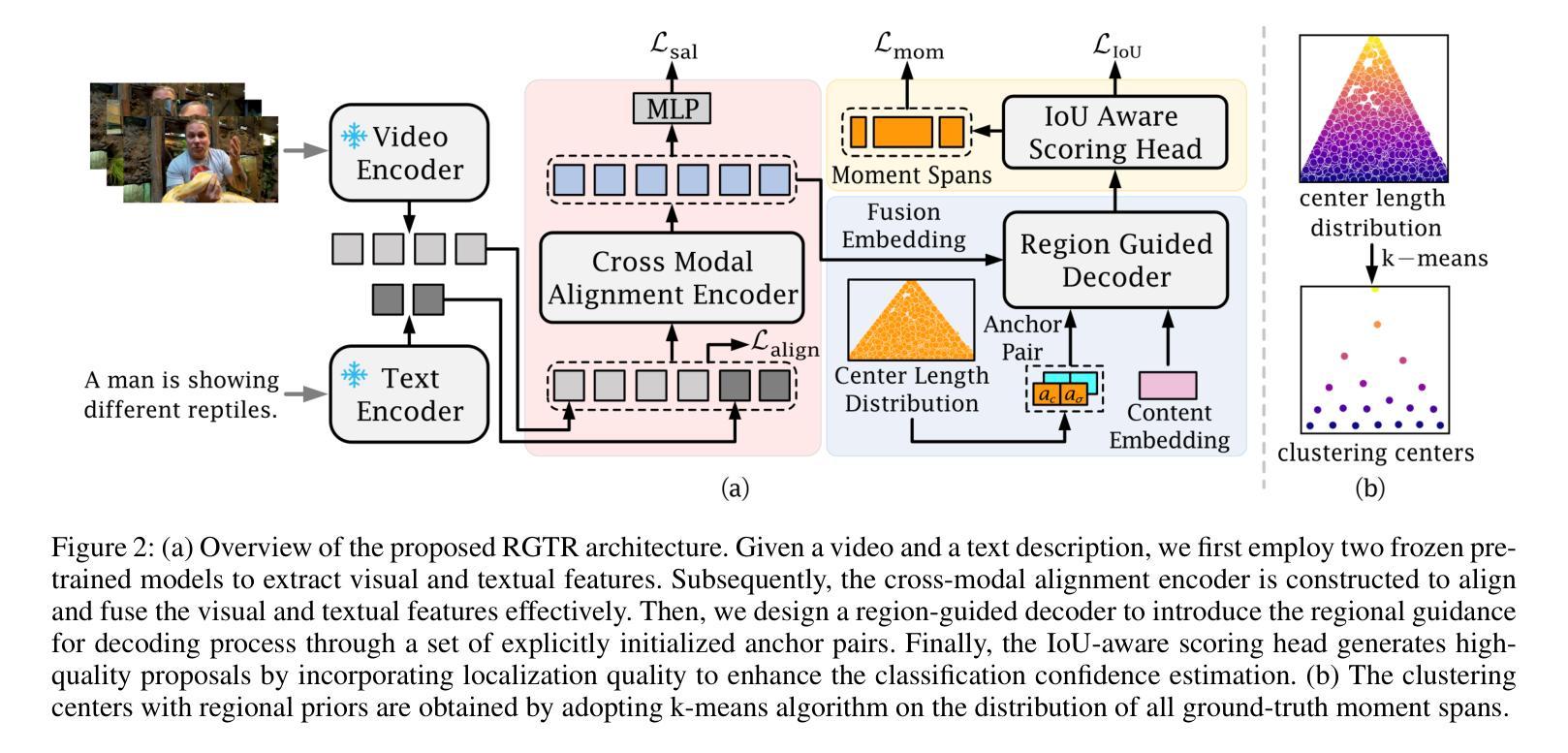
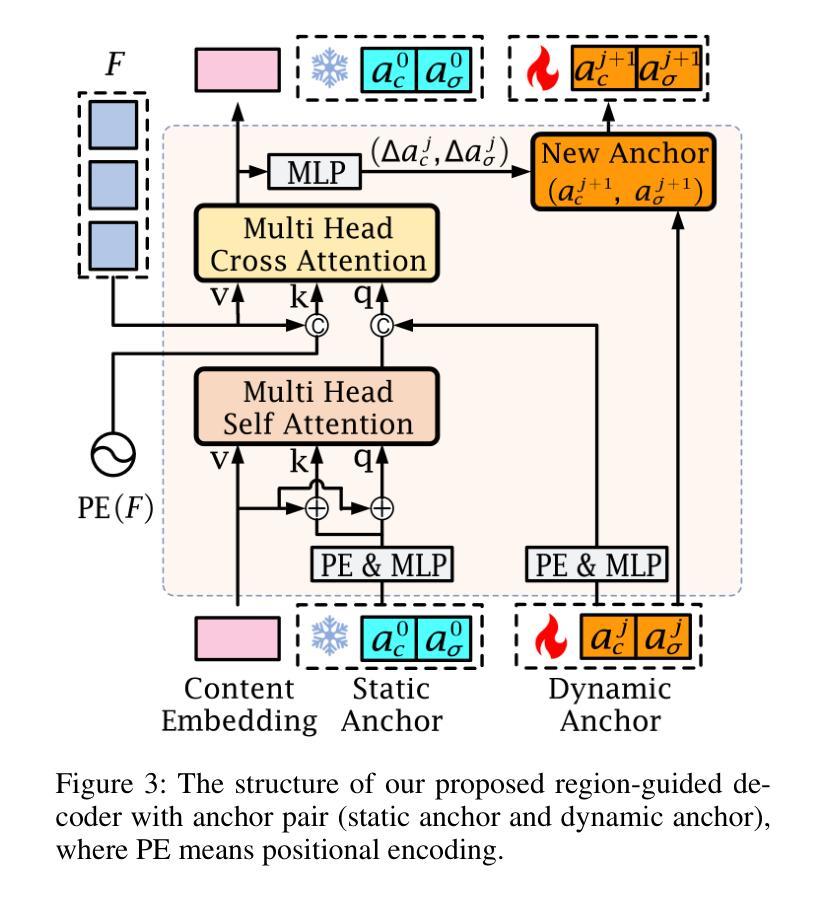
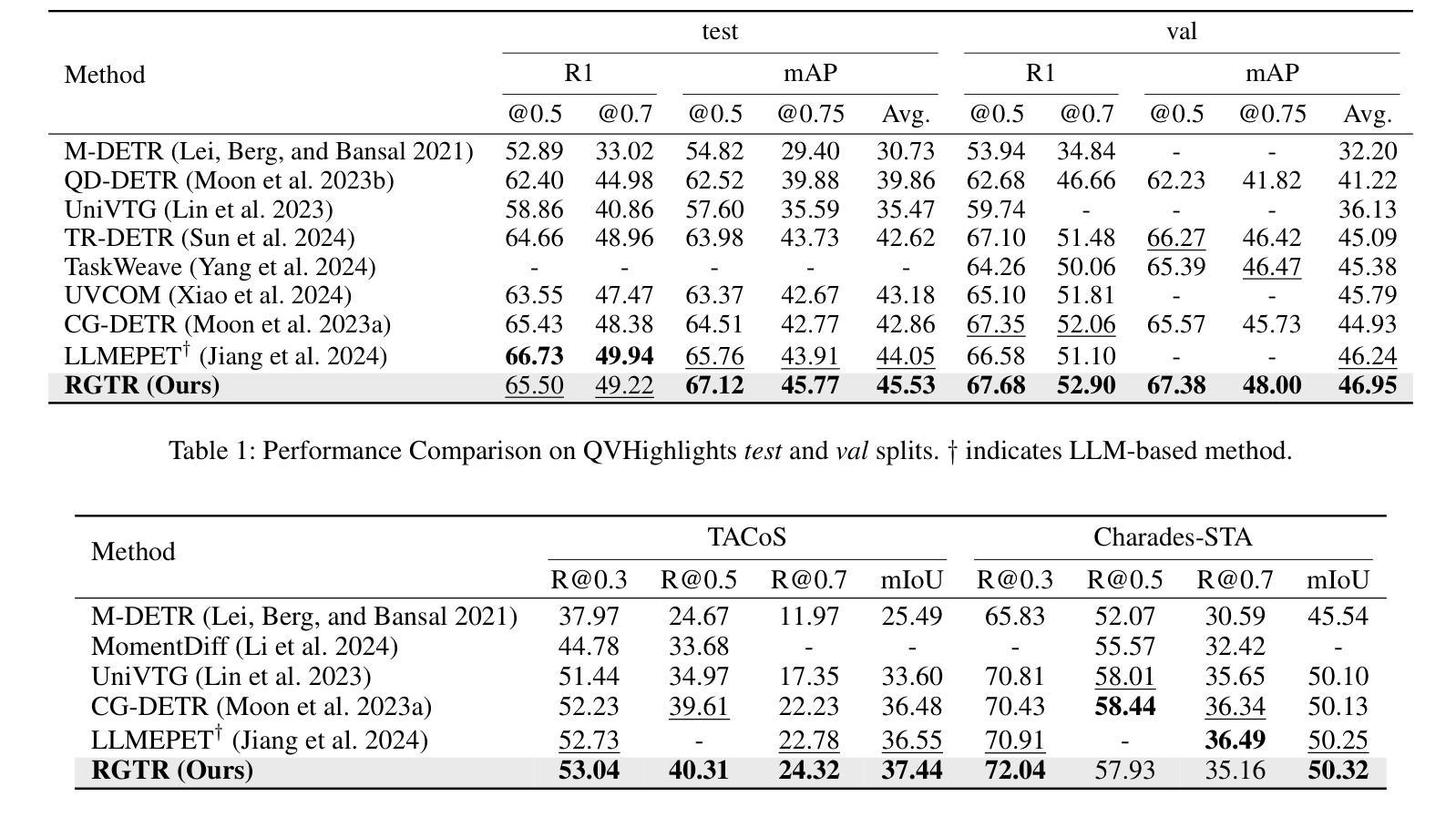
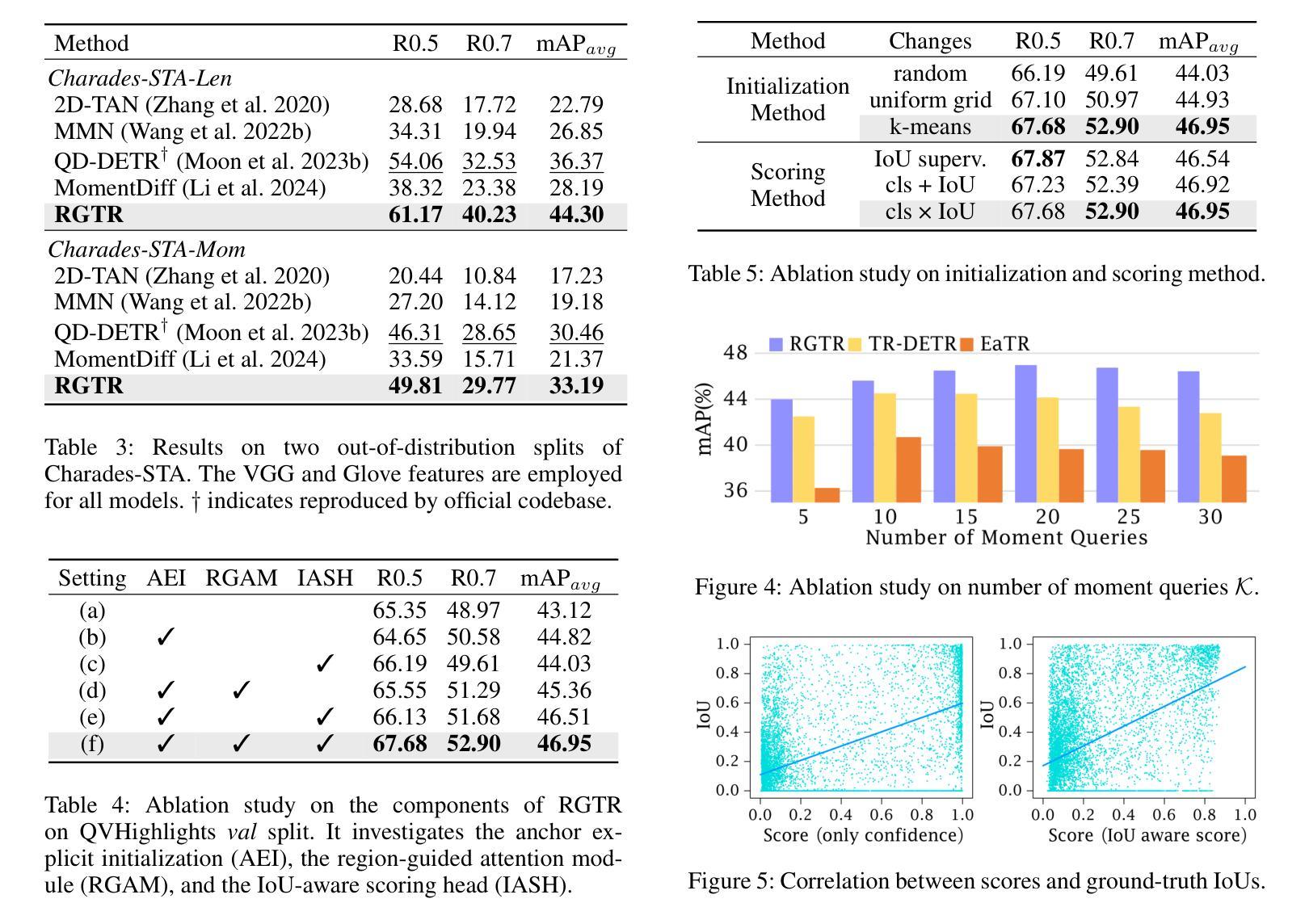
Diversifying Query: Region-Guided Transformer for Temporal Sentence Grounding
Authors:Xiaolong Sun, Liushuai Shi, Le Wang, Sanping Zhou, Kun Xia, Yabing Wang, Gang Hua
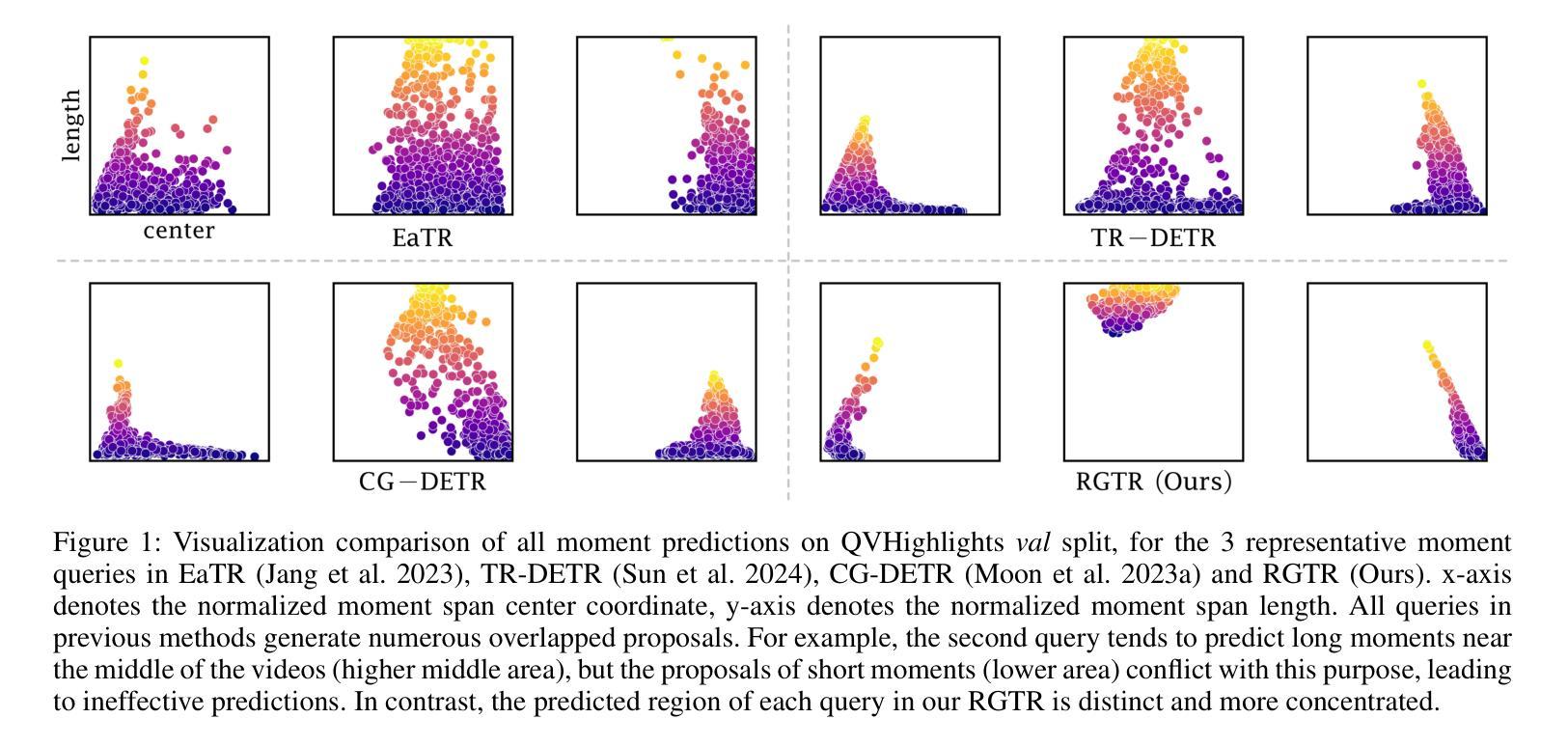
Temporal sentence grounding is a challenging task that aims to localize the moment spans relevant to a language description. Although recent DETR-based models have achieved notable progress by leveraging multiple learnable moment queries, they suffer from overlapped and redundant proposals, leading to inaccurate predictions. We attribute this limitation to the lack of task-related guidance for the learnable queries to serve a specific mode. Furthermore, the complex solution space generated by variable and open-vocabulary language descriptions complicates optimization, making it harder for learnable queries to distinguish each other adaptively. To tackle this limitation, we present a Region-Guided TRansformer (RGTR) for temporal sentence grounding, which diversifies moment queries to eliminate overlapped and redundant predictions. Instead of using learnable queries, RGTR adopts a set of anchor pairs as moment queries to introduce explicit regional guidance. Each anchor pair takes charge of moment prediction for a specific temporal region, which reduces the optimization difficulty and ensures the diversity of the final predictions. In addition, we design an IoU-aware scoring head to improve proposal quality. Extensive experiments demonstrate the effectiveness of RGTR, outperforming state-of-the-art methods on QVHighlights, Charades-STA and TACoS datasets. Codes are available at https://github.com/TensorsSun/RGTR
时序句子定位是一项具有挑战性的任务,旨在定位与语言描述相关的时刻跨度。尽管基于DETR的近期模型通过利用多个可学习的时刻查询取得了显著的进展,但它们仍存在重叠和冗余的提案,导致预测不准确。我们将这一局限性归因于缺乏针对特定模式服务的可学习查询的任务相关指导。此外,由可变和开放词汇语言描述生成的复杂解空间使优化变得复杂,使可学习查询更难彼此适应区分。为了克服这一局限性,我们提出了用于时序句子定位的Region-Guided Transformer(RGTR),它通过多样化时刻查询来消除重叠和冗余的预测。不同于使用可学习查询,RGTR采用一组锚点作为时刻查询来引入明确的区域指导。每个锚点负责特定时间区域的时刻预测,这降低了优化难度,确保了最终预测的多样性。此外,我们设计了一个IoU感知评分头来提高提案质量。大量实验证明了RGTR的有效性,在QVHighlights、Charades-STA和TACoS数据集上均优于最先进的方法。代码可从https://github.com/TensorsSun/RGTR获取。
论文及项目相关链接
PDF Accepted by AAAI-25. Code is available at https://github.com/TensorsSun/RGTR
Summary
基于DETR的模型在时序句子定位任务中取得了显著进展,但仍存在重叠和冗余提案的问题,导致预测不准确。为解决此问题,我们提出了Region-Guided TRansformer(RGTR),采用锚点对的形式作为时刻查询,引入明确的区域指导,减少优化难度,确保最终预测的多样性。同时设计IoU感知评分头以提高提案质量。实验证明RGTR的有效性,在QVHighlights、Charades-STA和TACoS数据集上优于现有方法。
Key Takeaways
- 基于DETR的模型在时序句子定位任务中有显著进展。
- 这些模型存在重叠和冗余提案的问题,导致预测不准确。
- 缺乏针对特定模式的任务相关指导是造成这一局限的原因之一。
- 为解决此问题,我们提出了Region-Guided TRansformer(RGTR)。
- RGTR采用锚点对的形式作为时刻查询,引入区域指导。
- 每个锚点对负责特定时序区域的时刻预测,提高了预测的多样性和准确性。
- RGTR设计IoU感知评分头以提高提案质量,并在实验中表现出卓越性能。
点此查看论文截图

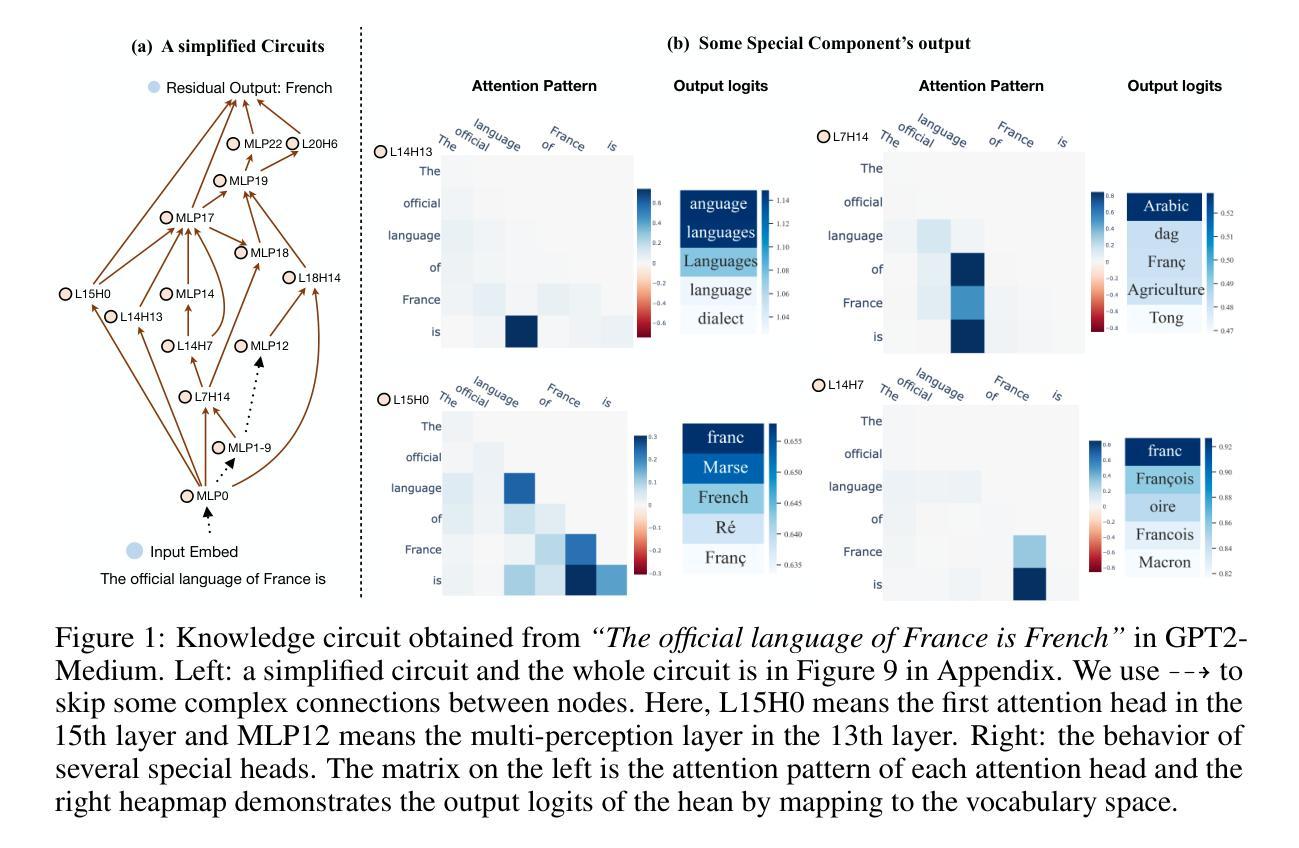
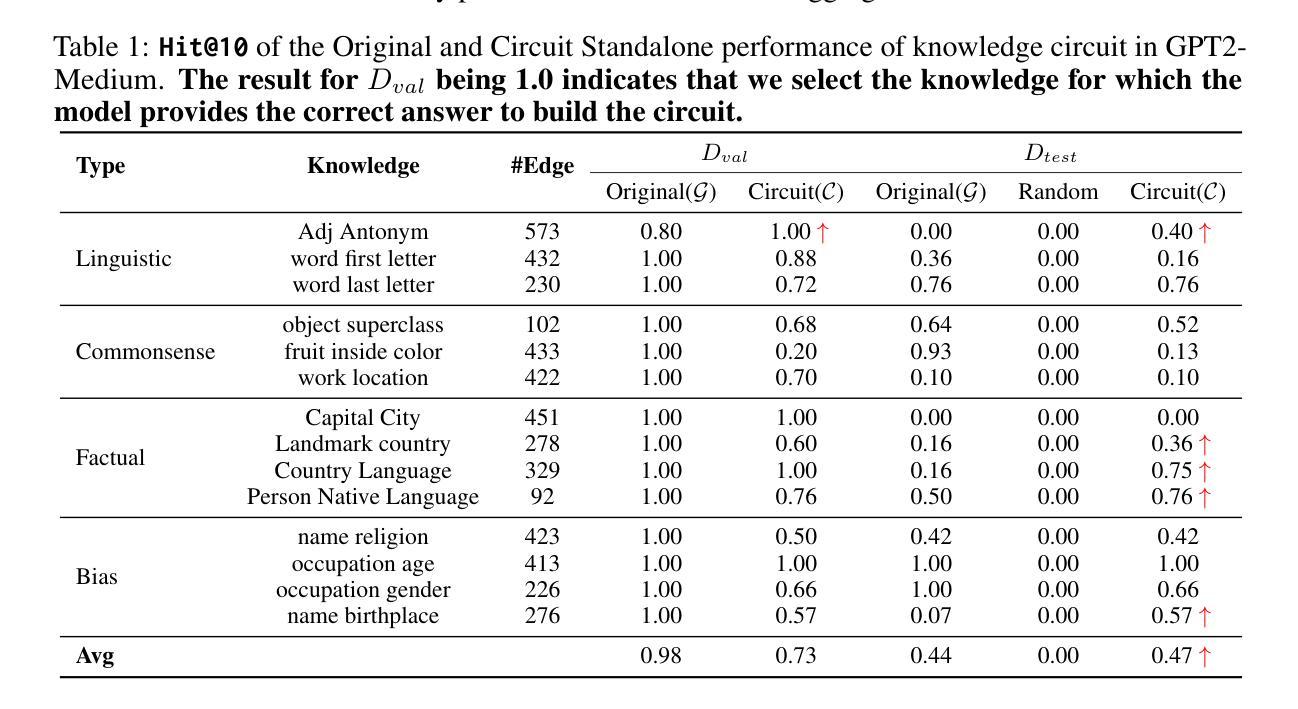
Knowledge Circuits in Pretrained Transformers
Authors:Yunzhi Yao, Ningyu Zhang, Zekun Xi, Mengru Wang, Ziwen Xu, Shumin Deng, Huajun Chen
The remarkable capabilities of modern large language models are rooted in their vast repositories of knowledge encoded within their parameters, enabling them to perceive the world and engage in reasoning. The inner workings of how these models store knowledge have long been a subject of intense interest and investigation among researchers. To date, most studies have concentrated on isolated components within these models, such as the Multilayer Perceptrons and attention head. In this paper, we delve into the computation graph of the language model to uncover the knowledge circuits that are instrumental in articulating specific knowledge. The experiments, conducted with GPT2 and TinyLLAMA, have allowed us to observe how certain information heads, relation heads, and Multilayer Perceptrons collaboratively encode knowledge within the model. Moreover, we evaluate the impact of current knowledge editing techniques on these knowledge circuits, providing deeper insights into the functioning and constraints of these editing methodologies. Finally, we utilize knowledge circuits to analyze and interpret language model behaviors such as hallucinations and in-context learning. We believe the knowledge circuits hold potential for advancing our understanding of Transformers and guiding the improved design of knowledge editing. Code and data are available in https://github.com/zjunlp/KnowledgeCircuits.
现代大型语言模型的卓越能力根植于其参数中编码的庞大知识库,使它们能够感知世界并参与推理。这些模型如何内部存储知识的运行机制一直是研究者们关注的焦点。迄今为止,大多数研究都集中在这些模型的孤立组件上,如多层感知器和注意力头。在本文中,我们深入探讨了语言模型的计算图,以揭示对表达特定知识至关重要的知识回路。我们利用GPT2和TinyLLAMA进行的实验使我们能够观察到某些信息头、关系头和多层感知器如何在模型中协同编码知识。此外,我们还评估了当前知识编辑技术对这些知识回路的影响,为这些编辑方法的运作和局限性提供了更深入的见解。最后,我们利用知识回路分析和解释语言模型的行为,如虚构和上下文学习。我们相信知识回路在推进我们对Transformer的理解以及指导知识编辑的改进设计方面具有潜力。代码和数据可在https://github.com/zjunlp/KnowledgeCircuits中找到。
论文及项目相关链接
PDF NeurIPS 2024, 26 pages
Summary
现代大型语言模型的强大能力源于其参数中编码的丰富知识库,能够感知世界并进行推理。本文深入探究了语言模型的计算图,揭示了表述特定知识的关键知识回路。通过实验观察了信息头、关系头和多层感知器等如何协同在模型中编码知识,并评估了当前知识编辑技术对知识回路的影响。此外,还利用知识回路分析和解读了语言模型的行为,如幻觉和上下文学习。知识回路有助于加深对Transformer的理解并改进知识编辑设计。相关代码和数据可在GitHub上找到:https://github.com/zjunlp/KnowledgeCircuits。
Key Takeaways
- 现代大型语言模型的能力来源于其参数中的知识库。
- 语言模型的计算图揭示了表述特定知识的关键知识回路。
- 信息头、关系头和多层感知器等协同在模型中编码知识。
- 当前知识编辑技术对知识回路有影响。
- 知识回路可用于分析和解读语言模型的行为,如幻觉和上下文学习。
- 知识回路有助于加深对Transformer的理解。
点此查看论文截图


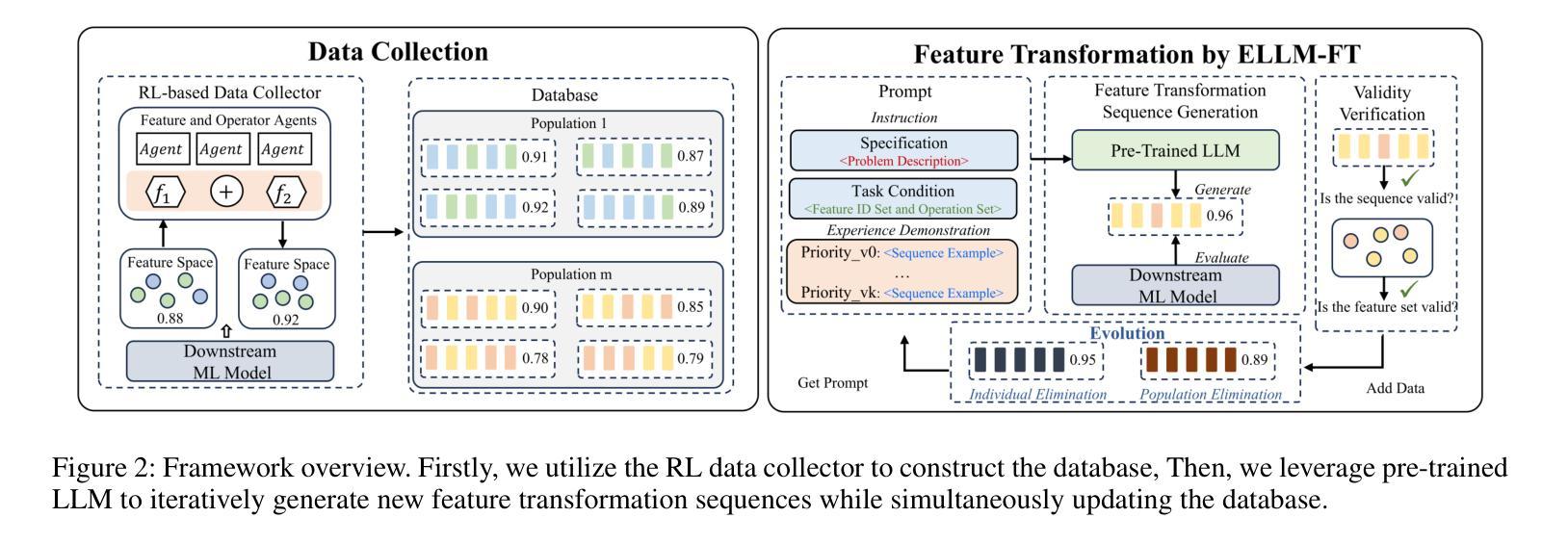
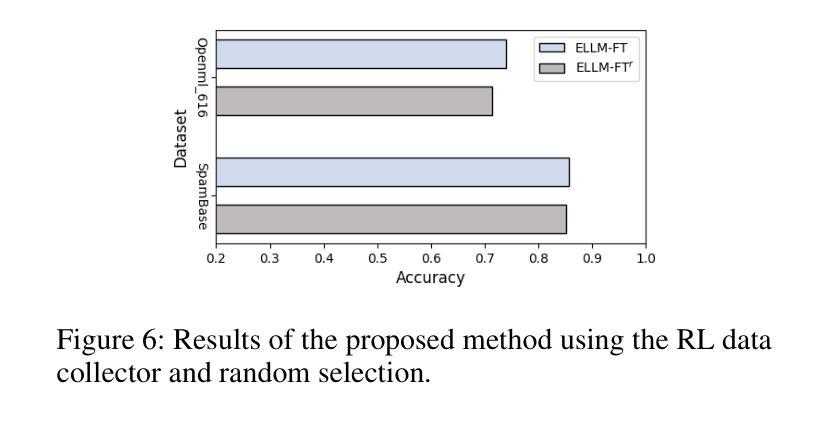
Evolutionary Large Language Model for Automated Feature Transformation
Authors:Nanxu Gong, Chandan K. Reddy, Wangyang Ying, Haifeng Chen, Yanjie Fu
Feature transformation aims to reconstruct the feature space of raw features to enhance the performance of downstream models. However, the exponential growth in the combinations of features and operations poses a challenge, making it difficult for existing methods to efficiently explore a wide space. Additionally, their optimization is solely driven by the accuracy of downstream models in specific domains, neglecting the acquisition of general feature knowledge. To fill this research gap, we propose an evolutionary LLM framework for automated feature transformation. This framework consists of two parts: 1) constructing a multi-population database through an RL data collector while utilizing evolutionary algorithm strategies for database maintenance, and 2) utilizing the ability of Large Language Model (LLM) in sequence understanding, we employ few-shot prompts to guide LLM in generating superior samples based on feature transformation sequence distinction. Leveraging the multi-population database initially provides a wide search scope to discover excellent populations. Through culling and evolution, the high-quality populations are afforded greater opportunities, thereby furthering the pursuit of optimal individuals. Through the integration of LLMs with evolutionary algorithms, we achieve efficient exploration within a vast space, while harnessing feature knowledge to propel optimization, thus realizing a more adaptable search paradigm. Finally, we empirically demonstrate the effectiveness and generality of our proposed method.
特征转换旨在重构原始特征的特征空间,以提高下游模型的性能。然而,特征和操作的组合呈指数级增长,给现有方法带来了挑战,使其难以有效地探索广阔的空间。此外,它们的优化仅由特定领域的下游模型的准确性驱动,忽视了通用特征知识的获取。为了填补这一研究空白,我们提出了一个用于自动化特征转换的进化式LLM框架。该框架由两部分组成:1)通过RL数据收集器构建多人口数据库,并利用进化算法策略进行数据库维护;2)利用大型语言模型(LLM)在序列理解方面的能力,我们通过少数提示来指导LLM根据特征转换序列的区别生成优质样本。利用多人口数据库最初提供了广泛的搜索范围来发现优秀的人口。通过筛选和进化,高质量的人群获得了更多的机会,从而进一步追求优秀个体。通过将LLM与进化算法相结合,我们在广阔的空间内实现了有效的探索,并利用特征知识推动优化,从而实现了一个更灵活的搜索范式。最后,我们通过实证证明了所提出方法的有效性和普遍性。
论文及项目相关链接
PDF Accepted to AAAI 2025
Summary
特征转换旨在重建原始特征的特征空间以提高下游模型的性能。然而,特征和操作的组合呈指数级增长,现有方法难以有效探索广阔的空间。为此,我们提出了一种基于进化算法的大型语言模型(LLM)自动化特征转换框架。该框架包括两部分:1)通过RL数据收集器构建多人口数据库,并利用进化算法策略进行数据库维护;2)利用LLM在序列理解方面的能力,通过少量提示来指导LLM生成基于特征转换序列区分的优质样本。利用多人口数据库可以提供一个广阔的搜索范围来发现优秀种群。通过筛选和进化,优质种群获得更多机会,从而追求更优秀的个体。通过结合LLM和进化算法,我们实现了在广阔空间内的有效探索,并利用特征知识推动优化,从而实现更灵活搜索范式。最后,我们通过实验证明了所提出方法的有效性和通用性。
Key Takeaways
- 特征转换旨在改善下游模型的性能,通过重建原始特征的特征空间来实现。
- 现有方法面临特征和操作组合爆炸的问题,难以有效探索广阔的特征空间。
- 提出的基于进化算法的大型语言模型(LLM)自动化特征转换框架旨在解决这一问题。
- 框架包括构建多人口数据库和利用LLM在序列理解方面的能力来指导特征转换。
- 利用多人口数据库实现广泛搜索,并通过筛选和进化找到优质种群。
- 结合LLM和进化算法,实现在广阔空间内的有效探索,推动优化。
点此查看论文截图



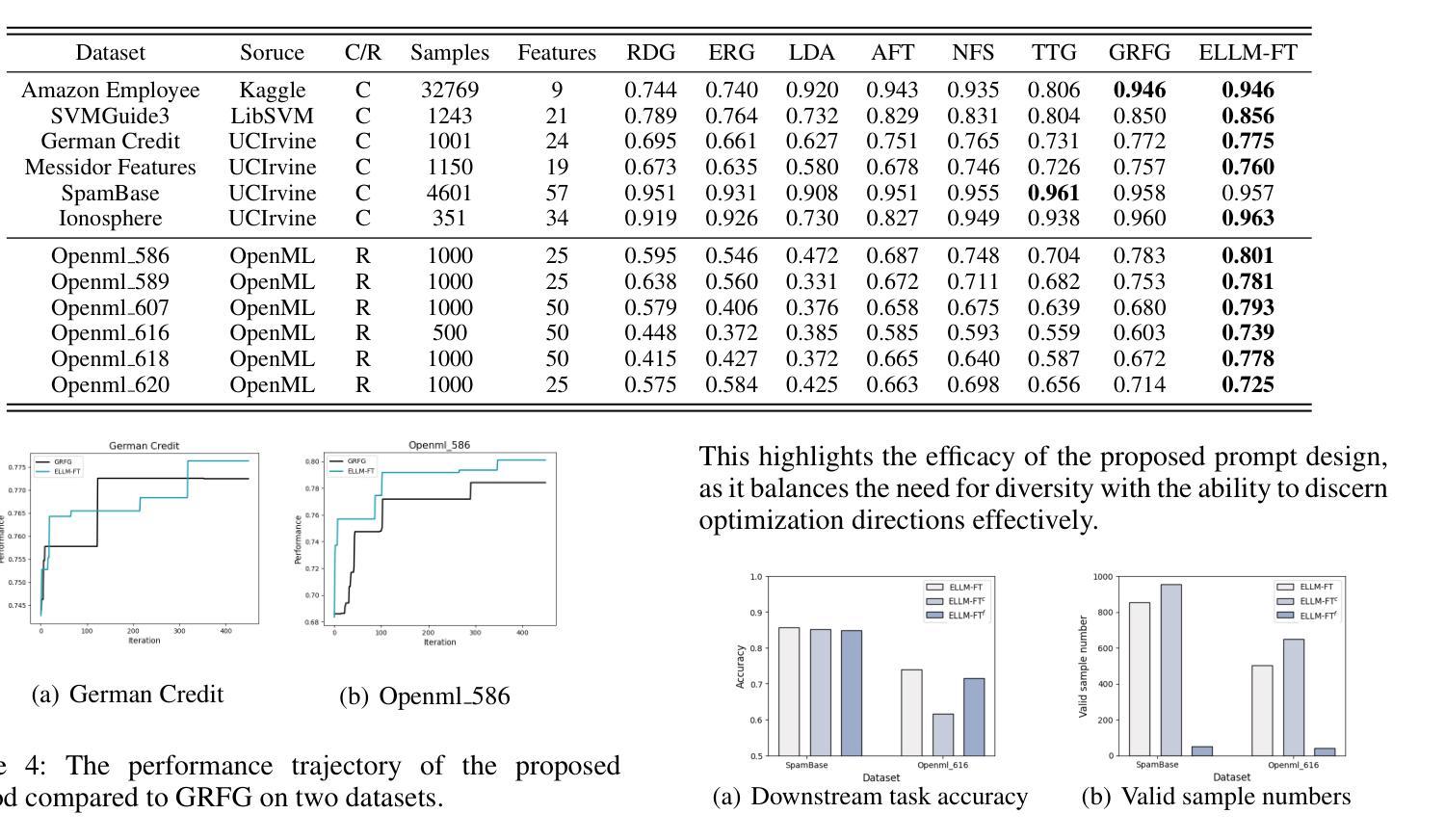
CEM: A Data-Efficient Method for Large Language Models to Continue Evolving From Mistakes
Authors:Haokun Zhao, Haixia Han, Jie Shi, Chengyu Du, Jiaqing Liang, Yanghua Xiao
As world knowledge advances and new task schemas emerge, Continual Learning (CL) becomes essential for keeping Large Language Models (LLMs) current and addressing their shortcomings. This process typically involves continual instruction tuning (CIT) and continual pre-training (CPT) to enable these models to adapt to novel tasks and acquire critical knowledge. However, collecting sufficient CPT data and efficiently bridging knowledge gaps remain significant challenges. Inspired by the ‘summarizing mistakes’ strategy, we propose the Continue Evolving from Mistakes (CEM) method, a data-efficient approach aiming to collect CPT data and continually improve LLMs’ performance through iterative evaluation and supplementation with mistake-relevant knowledge. To further optimize data usage and mitigate forgetting, we introduce a novel training paradigm that combines CIT and CPT. Experiments show that CEM substantially enhances multiple models’ performance on both in-domain and out-of-domain QA tasks, achieving gains of up to 29.63%. Code and datasets are available on https://anonymous.4open.science/r/cem-BB25.
随着全球知识的进步和新任务模式的出现,持续学习(CL)对于保持大型语言模型(LLM)的时效性和解决其缺点变得至关重要。这一过程通常涉及持续指令微调(CIT)和持续预训练(CPT),以使这些模型能够适应新任务并获取关键知识。然而,收集足够的CPT数据和有效地填补知识空白仍然面临重大挑战。受“总结错误”策略的启发,我们提出了“从错误中持续进化”(CEM)方法,这是一种数据高效的方法,旨在收集CPT数据并通过迭代评估和使用与错误相关的知识来持续改进LLM的性能。为了进一步优化数据使用并缓解遗忘,我们引入了一种结合CIT和CPT的新型训练范式。实验表明,CEM在域内和域外问答任务上大幅度提高了多个模型的表现,最高提升了29.63%。相关代码和数据集可通过https://anonymous.4open.science/r/cem-BB25获取。
论文及项目相关链接
Summary
随着全球知识的进步和新任务模式的出现,持续学习(CL)对于保持大型语言模型(LLM)的更新和克服其局限性变得至关重要。这涉及持续指令调整(CIT)和持续预训练(CPT)的过程,使这些模型能够适应新任务并获取关键知识。然而,收集足够的CPT数据和有效地填补知识空白仍然是巨大的挑战。受“总结错误”策略的启发,我们提出了“从错误中持续进化”(CEM)方法,这是一种旨在收集CPT数据并持续提高LLM性能的数据高效方法,通过迭代评估和使用错误相关知识进行补充。为了进一步优化数据使用并缓解遗忘问题,我们引入了一种结合CIT和CPT的新型训练范式。实验表明,CEM显著提高了多个模型在领域内外问答任务上的性能,最高提升达29.63%。相关代码和数据集可在匿名平台上获取。
Key Takeaways
- 持续学习(CL)对于保持大型语言模型(LLM)的更新和适应新任务至关重要。
- 持续指令调整(CIT)和持续预训练(CPT)是使LLM适应新任务和获取关键知识的关键过程。
- 收集足够的CPT数据和填补知识空白是LLM面临的主要挑战之一。
- 受“总结错误”策略的启发,提出了“从错误中持续进化”(CEM)方法,旨在通过迭代评估和使用错误相关知识来提高LLM的性能。
- CEM方法结合了CIT和CPT,旨在优化数据使用并缓解遗忘问题。
- 实验表明,CEM方法能显著提高LLM在多个任务上的性能,包括领域内外问答任务。
点此查看论文截图

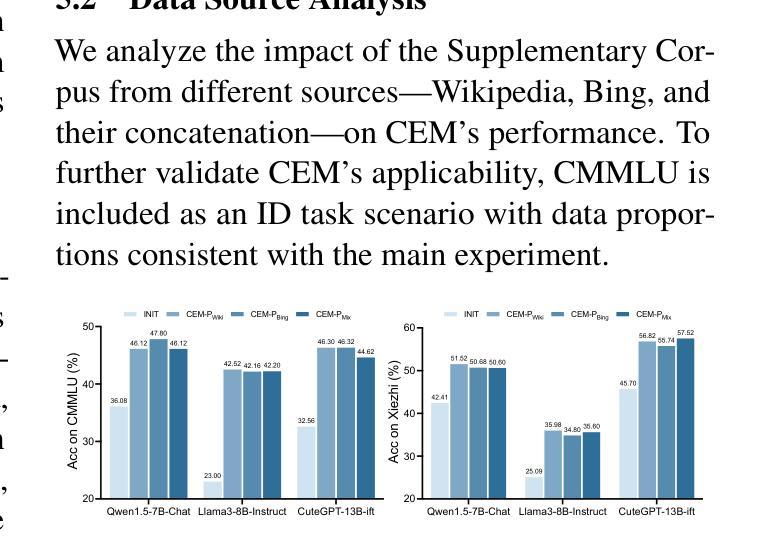
Red Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks?
Authors:Shuo Chen, Zhen Han, Bailan He, Zifeng Ding, Wenqian Yu, Philip Torr, Volker Tresp, Jindong Gu
Various jailbreak attacks have been proposed to red-team Large Language Models (LLMs) and revealed the vulnerable safeguards of LLMs. Besides, some methods are not limited to the textual modality and extend the jailbreak attack to Multimodal Large Language Models (MLLMs) by perturbing the visual input. However, the absence of a universal evaluation benchmark complicates the performance reproduction and fair comparison. Besides, there is a lack of comprehensive evaluation of closed-source state-of-the-art (SOTA) models, especially MLLMs, such as GPT-4V. To address these issues, this work first builds a comprehensive jailbreak evaluation dataset with 1445 harmful questions covering 11 different safety policies. Based on this dataset, extensive red-teaming experiments are conducted on 11 different LLMs and MLLMs, including both SOTA proprietary models and open-source models. We then conduct a deep analysis of the evaluated results and find that (1) GPT4 and GPT-4V demonstrate better robustness against jailbreak attacks compared to open-source LLMs and MLLMs. (2) Llama2 and Qwen-VL-Chat are more robust compared to other open-source models. (3) The transferability of visual jailbreak methods is relatively limited compared to textual jailbreak methods. The dataset and code can be found https://github.com/chenxshuo/RedTeamingGPT4V
针对大型语言模型(LLM)的红队攻击已经提出,并揭示了LLM的脆弱保护措施。除此之外,一些方法不仅限于文本模式,而是通过干扰视觉输入将越狱攻击扩展到多模式大型语言模型(MLLM)。然而,由于缺乏通用的评估基准,使得性能再生和公平比较变得复杂。此外,对于闭源最先进的模型(尤其是MLLMs),如GPT-4V等缺乏全面的评估。为了解决这些问题,这项工作首先建立了一个包含1445个有害问题的全面越狱评估数据集,涵盖11项不同的安全政策。基于此数据集,对包括最先进私有模型和开源模型在内的11种不同的LLM和MLLM进行了广泛的红色团队实验。然后我们对评估结果进行了深入分析,发现(1)GPT4和GPT-4V相较于开源LLM和MLLM表现出更好的对抗越狱攻击的稳健性。(2)相较于其他开源模型,Llama2和Qwen-VL-Chat更加稳健。(3)相较于文本越狱方法,视觉越狱方法的可迁移性相对有限。数据集和代码可以在https://github.com/chenxshuo/RedTeamingGPT4V找到。
论文及项目相关链接
PDF technical report; update code repo link
Summary
本文介绍了针对大型语言模型(LLM)的红队攻击(jailbreak attacks)及其扩展到多模态大型语言模型(MLLM)的情况。文章指出当前缺乏通用评估基准的问题,并构建了一个包含1445个有害问题的综合评估数据集,涵盖11项不同的安全策略。通过对包括先进私有模型和开源模型在内的11种LLM和MLLM进行红队实验,发现GPT4和GPT-4V在抵御攻击方面表现出较强的稳健性。同时,文章还分析了视觉越狱方法的可转移性相对有限。
Key Takeaways
- 文章介绍了针对大型语言模型(LLM)和多模态大型语言模型(MLLM)的jailbreak攻击,揭示了LLM的脆弱性保障。
- 缺乏通用评估基准给性能复现和公平比较带来了困难。
- 构建了包含1445个有害问题的综合评估数据集,涵盖11项不同的安全策略。
- GPT4和GPT-4V在抵御jailbreak攻击方面表现出较强的稳健性。
- Llama2和Qwen-VL-Chat在与其他开源模型的比较中表现出更高的稳健性。
- 视觉越狱方法的可转移性相对有限。
点此查看论文截图

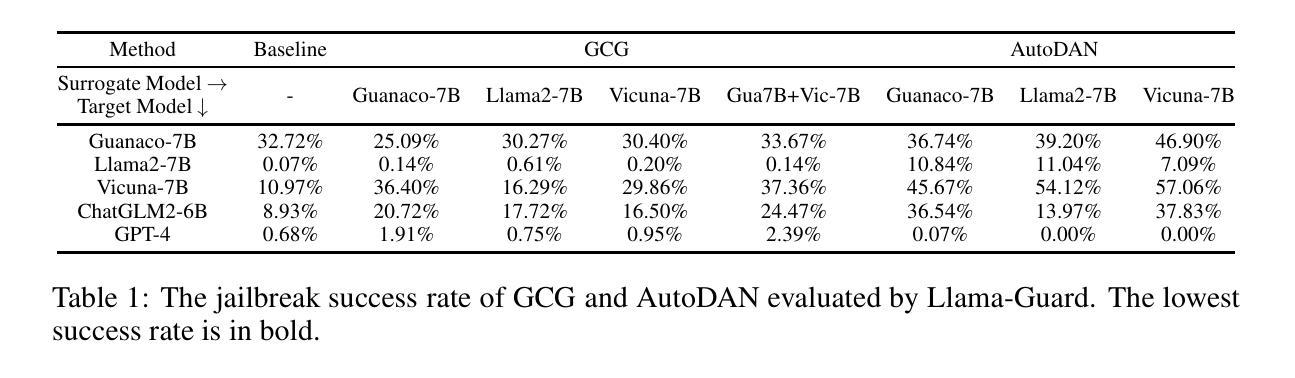
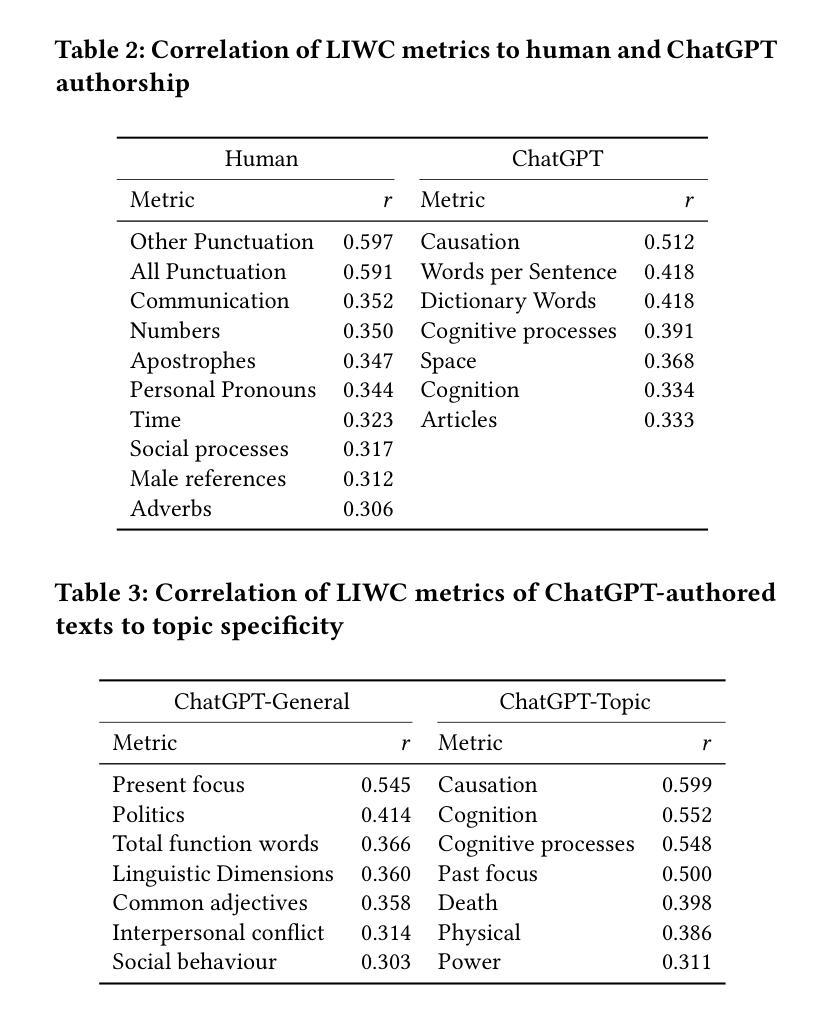
Merging Text Transformer Models from Different Initializations
Authors:Neha Verma, Maha Elbayad
Recent work on permutation-based model merging has shown impressive low- or zero-barrier mode connectivity between models from completely different initializations. However, this line of work has not yet extended to the Transformer architecture, despite its dominant popularity in the language domain. Therefore, in this work, we investigate the extent to which separate Transformer minima learn similar features, and propose a model merging technique to investigate the relationship between these minima in the loss landscape. The specifics of the architecture, like its residual connections, multi-headed attention, and discrete, sequential input, require specific interventions in order to compute model permutations that remain within the same functional equivalence class. In merging these models with our method, we consistently find lower loss barriers between minima compared to model averaging, across models trained on a masked-language modeling task or fine-tuned on a language understanding benchmark. Our results show that the minima of these models are less sharp and isolated than previously understood, and provide a basis for future work on merging separately trained Transformer models.
近期关于基于排列模型合并的研究工作显示,从不同初始化模型之间具有令人印象深刻的低障碍或零障碍模式连接。然而,尽管其在语言领域的普及占据主导地位,这一研究方向尚未扩展到Transformer架构。因此,在这项工作中,我们研究了单独训练的Transformer模型学习相似特征的程度,并提出了一种模型合并技术,以研究损失景观中这些局部最小值之间的关系。该架构的特定细节,如残差连接、多头注意力以及离散序列输入等,需要进行特定的干预操作,以便计算保持在同一功能等价类内的模型排列。使用我们的方法进行模型合并时,我们发现与模型平均相比,在针对掩码语言建模任务进行训练或在语言理解基准测试上进行微调后的模型之间的损失障碍始终较低。我们的结果表明,这些模型的局部最小值比之前所理解的更为平缓且不那么孤立,并为未来合并单独训练的Transformer模型的工作奠定了基础。
论文及项目相关链接
PDF TMLR, November 2024
Summary
本文探讨了将不同初始化的Transformer模型进行合并的潜力。研究发现,通过特定的模型合并技术,可以在Transformer架构的损失景观中探索不同最小值点之间的关系。该方法能够计算模型排列的组合,使它们保持功能等价性。相较于模型平均方法,本文提出的模型合并方法能够在语言建模任务或语言理解基准测试中实现更低的损失屏障。研究结果揭示了这些模型的最低点并不像先前认为的那样尖锐和孤立,为未来研究合并单独训练的Transformer模型奠定了基础。
Key Takeaways
- 研究探讨了将不同初始化的Transformer模型合并的潜力。
- 通过特定的模型合并技术,能够在Transformer架构中探索不同最小值点之间的关系。
- 模型合并方法涉及到计算模型排列组合,保持功能等价性。
- 与模型平均方法相比,提出的模型合并方法在特定任务上实现了更低的损失屏障。
- 研究揭示了Transformer模型的最低点并不像先前认为的那样尖锐和孤立。
- 本文为未来研究合并单独训练的Transformer模型提供了新的视角和潜在方向。
点此查看论文截图

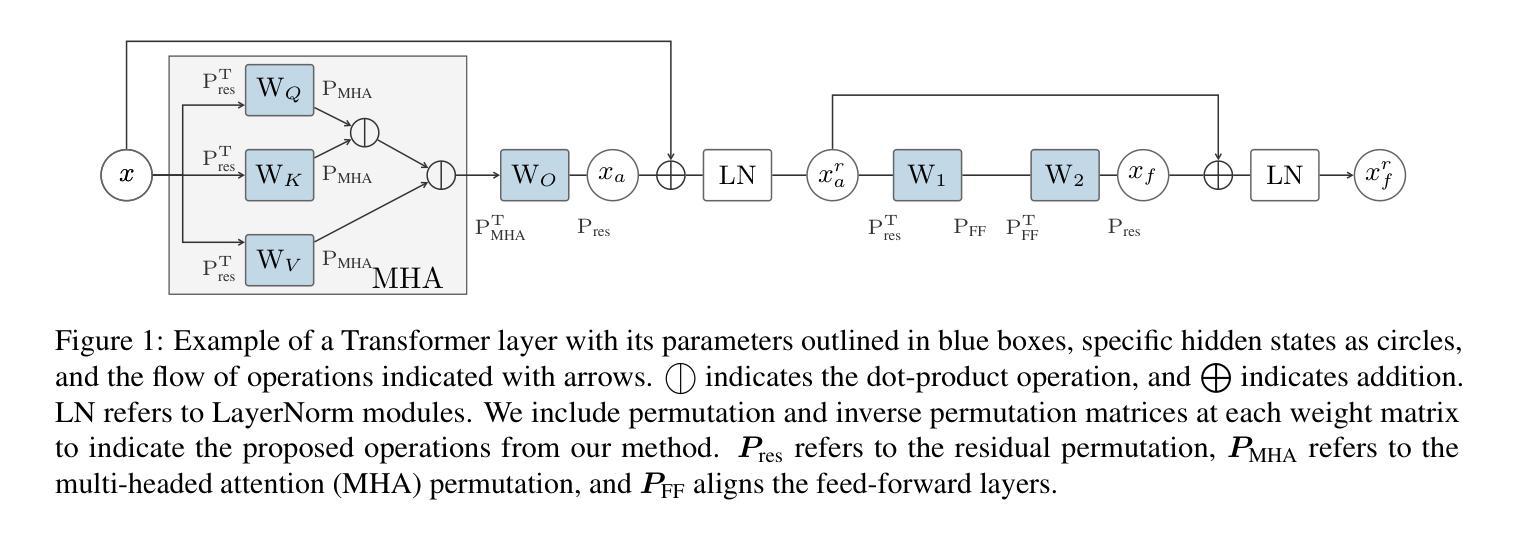
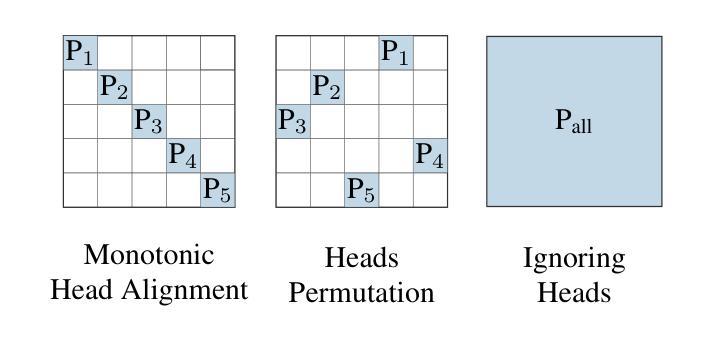

SLEB: Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks
Authors:Jiwon Song, Kyungseok Oh, Taesu Kim, Hyungjun Kim, Yulhwa Kim, Jae-Joon Kim
Large language models (LLMs) have proven to be highly effective across various natural language processing tasks. However, their large number of parameters poses significant challenges for practical deployment. Pruning, a technique aimed at reducing the size and complexity of LLMs, offers a potential solution by removing redundant components from the network. Despite the promise of pruning, existing methods often struggle to achieve substantial end-to-end LLM inference speedup. In this paper, we introduce SLEB, a novel approach designed to streamline LLMs by eliminating redundant transformer blocks. We choose the transformer block as the fundamental unit for pruning, because LLMs exhibit block-level redundancy with high similarity between the outputs of neighboring blocks. This choice allows us to effectively enhance the processing speed of LLMs. Our experimental results demonstrate that SLEB outperforms previous LLM pruning methods in accelerating LLM inference while also maintaining superior perplexity and accuracy, making SLEB as a promising technique for enhancing the efficiency of LLMs. The code is available at: https://github.com/jiwonsong-dev/SLEB.
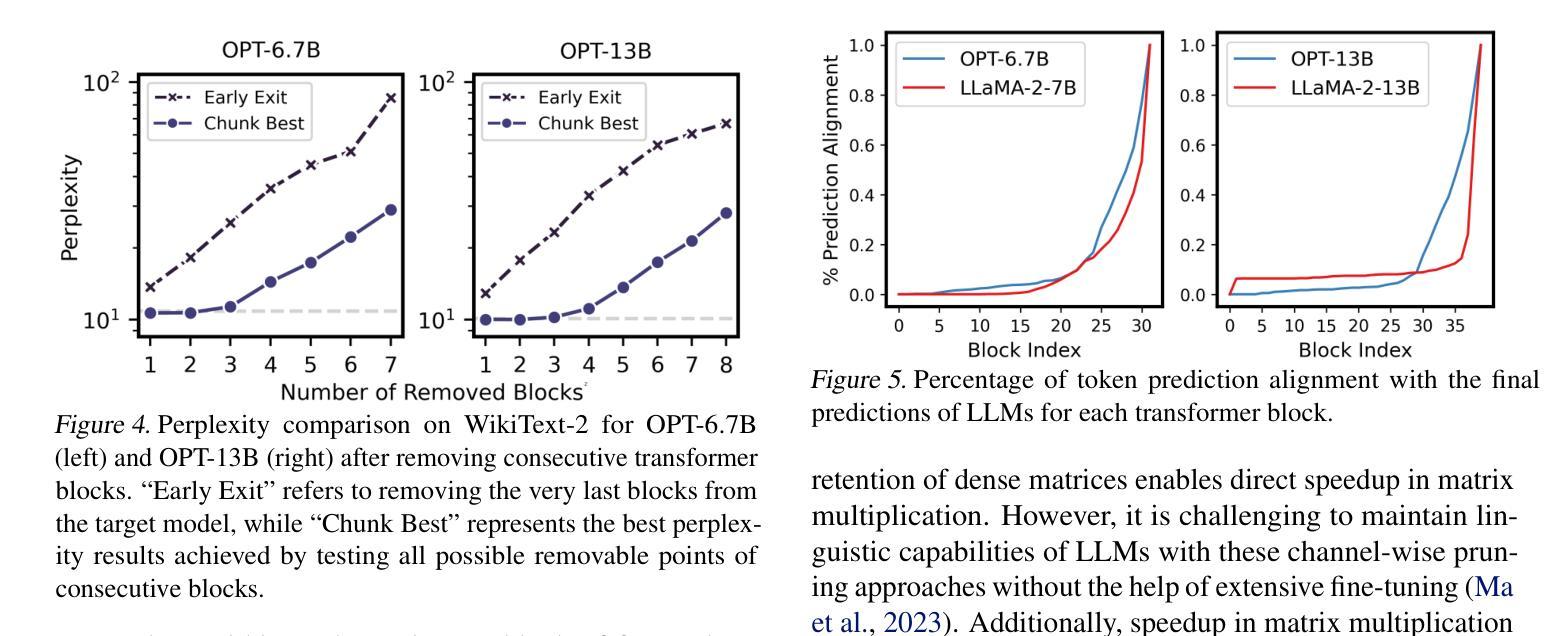
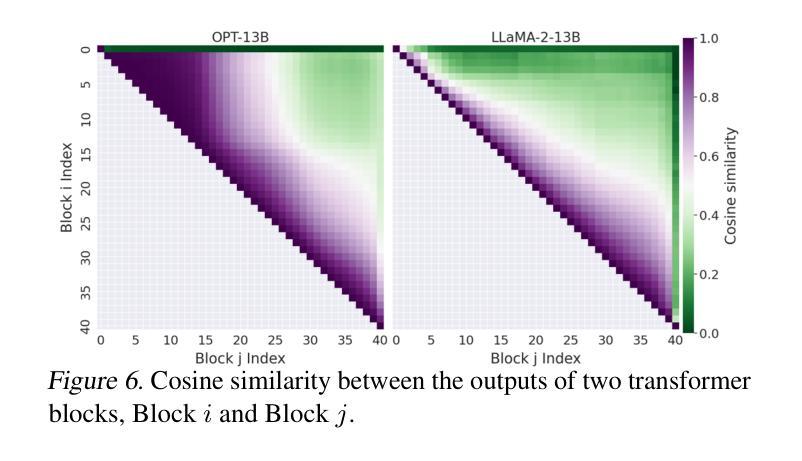
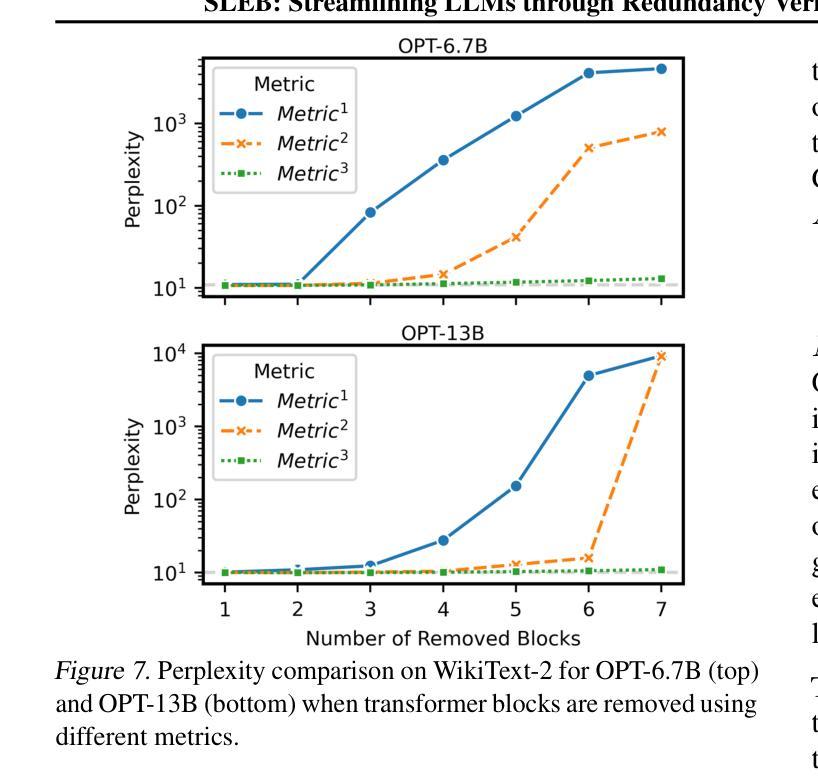
大型语言模型(LLM)在各种自然语言处理任务中表现出了高度的有效性。然而,它们的大量参数给实际部署带来了重大挑战。剪枝是一种旨在减少LLM大小和复杂性的技术,通过消除网络中的冗余组件来提供潜在的解决方案。尽管剪枝很有前景,但现有方法往往难以实现端到端的LLM推理速度的大幅提升。在本文中,我们介绍了SLEB,这是一种通过消除冗余transformer块来优化LLM的新方法。我们选择transformer块作为剪枝的基本单位,因为LLM表现出块级冗余,相邻块之间的输出高度相似。这一选择使我们能够有效地提高LLM的处理速度。我们的实验结果表明,SLEB在加速LLM推理方面优于以前的LLM剪枝方法,同时保持了优异的困惑度和准确性,使SLEB成为提高LLM效率的有前途的技术。代码可在https://github.com/jiwonsong-dev/SLEB获得。
论文及项目相关链接
PDF ICML 2024
Summary
大型语言模型(LLM)在自然语言处理任务中表现出高效性,但其参数众多给实际应用带来了挑战。修剪技术旨在减少LLM的大小和复杂性,通过移除网络中的冗余组件来解决问题。尽管修剪具有潜力,但现有方法往往难以实现LLM端到端的推理速度提升。本文介绍了一种新型方法SLEB,通过消除冗余的转换器块来优化LLM。我们选择转换器块作为修剪的基本单元,因为LLM在相邻块输出之间表现出块级冗余。这种选择可以有效地提高LLM的处理速度。实验结果表明,SLEB在加速LLM推理方面优于先前的LLM修剪方法,同时保持较低的困惑度和准确性,是一种提高LLM效率的有前途的技术。
Key Takeaways
- LLM在自然语言处理任务中表现出高效性,但参数众多给实际应用带来挑战。
- 修剪技术是减少LLM大小和复杂性的有效方法。
- 现有LLM修剪方法难以实现端到端的推理速度提升。
- SLEB是一种新型LLM优化方法,通过消除冗余的转换器块来加速推理。
- 选择转换器块作为修剪的基本单元,因为LLM中存在块级冗余。
- SLEB在加速LLM推理的同时保持较低的困惑度和准确性。
- SLEB代码已公开在GitHub上。
点此查看论文截图


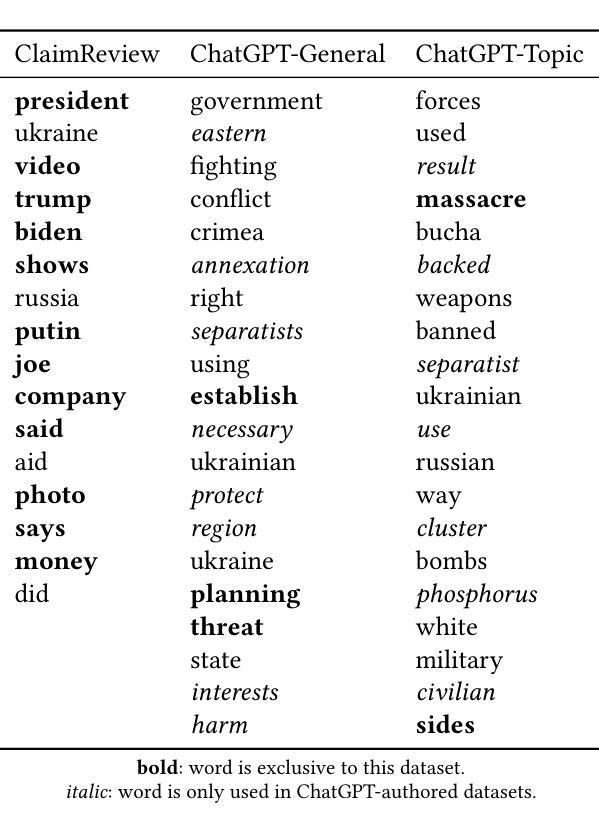
Lying Blindly: Bypassing ChatGPT’s Safeguards to Generate Hard-to-Detect Disinformation Claims
Authors:Freddy Heppell, Mehmet E. Bakir, Kalina Bontcheva
As Large Language Models become more proficient, their misuse in coordinated disinformation campaigns is a growing concern. This study explores the capability of ChatGPT with GPT-3.5 to generate short-form disinformation claims about the war in Ukraine, both in general and on a specific event, which is beyond the GPT-3.5 knowledge cutoff. Unlike prior work, we do not provide the model with human-written disinformation narratives by including them in the prompt. Thus the generated short claims are hallucinations based on prior world knowledge and inference from the minimal prompt. With a straightforward prompting technique, we are able to bypass model safeguards and generate numerous short claims. We compare those against human-authored false claims on the war in Ukraine from ClaimReview, specifically with respect to differences in their linguistic properties. We also evaluate whether AI authorship can be differentiated by human readers or state-of-the-art authorship detection tools. Thus, we demonstrate that ChatGPT can produce realistic, target-specific disinformation claims, even on a specific post-cutoff event, and that they cannot be reliably distinguished by humans or existing automated tools.
随着大型语言模型(Large Language Models,LLM)越来越熟练,它们在协同制造虚假信息运动中的误用成为一个日益严重的问题。本研究探讨了ChatGPT与GPT-3.5生成关于乌克兰战争简短虚假信息声明的能力,既包括一般性内容也包括特定事件,这些事件超出了GPT-3.5的知识范围。与之前的工作不同,我们没有通过提示向模型提供人为编写的虚假信息叙事。因此,产生的简短声明是基于先前对世界的了解以及从最小提示推断出来的幻觉。通过简单的提示技术,我们能够绕过模型保护措施并生成大量简短的声明。我们将这些声明与ClaimReview中关于乌克兰战争的人为编造虚假声明进行比较,尤其关注它们在语言特性上的差异。我们还评估了人类读者或最先进的作者身份检测工具是否能区分出AI作者的身份。因此,我们证明了ChatGPT能够产生针对特定目标的真实、有针对性的虚假信息声明,即使是对特定截断点之后的事件也是如此,而且它们无法被人类或现有的自动化工具可靠地区分出来。
论文及项目相关链接
Summary
大型语言模型(如ChatGPT)在生成关于乌克兰战争等特定事件的虚假信息方面存在潜在风险。本研究通过GPT-3.5模型生成了基于先前知识和最小提示推断的虚假声明,并与人类创作的乌克兰战争虚假声明进行了比较。研究结果显示,ChatGPT能够生成针对特定事件的现实、目标明确的虚假信息,且难以被人类或现有自动化工具识别。
Key Takeaways
- 大型语言模型如ChatGPT有潜力被用于生成关于特定事件的虚假信息。
- GPT-3.5能够根据先前的知识和从最小提示中的推断来生成虚假声明。
- ChatGPT生成的虚假声明在语言学特性上与人类创作的虚假声明存在差异。
- ChatGPT生成的虚假声明能够针对特定事件,即使这些事件超出了模型的已知知识范围。
- 人类和现有的自动化工具难以区分ChatGPT生成的虚假信息。
- 在不向模型提供人类编写的虚假叙事提示的情况下,ChatGPT依然能够生成虚假声明。
点此查看论文截图