⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-23 更新
FG-MDM: Towards Zero-Shot Human Motion Generation via ChatGPT-Refined Descriptions
Authors:Xu Shi, Wei Yao, Chuanchen Luo, Junran Peng, Hongwen Zhang, Yunlian Sun
Recently, significant progress has been made in text-based motion generation, enabling the generation of diverse and high-quality human motions that conform to textual descriptions. However, generating motions beyond the distribution of original datasets remains challenging, i.e., zero-shot generation. By adopting a divide-and-conquer strategy, we propose a new framework named Fine-Grained Human Motion Diffusion Model (FG-MDM) for zero-shot human motion generation. Specifically, we first parse previous vague textual annotations into fine-grained descriptions of different body parts by leveraging a large language model. We then use these fine-grained descriptions to guide a transformer-based diffusion model, which further adopts a design of part tokens. FG-MDM can generate human motions beyond the scope of original datasets owing to descriptions that are closer to motion essence. Our experimental results demonstrate the superiority of FG-MDM over previous methods in zero-shot settings. We will release our fine-grained textual annotations for HumanML3D and KIT.
最近,文本驱动的动作生成领域取得了重大进展,能够生成符合文本描述的多样化、高质量的人类动作。然而,生成原始数据集分布之外的动作仍然具有挑战性,即零样本生成。通过采用分而治之的策略,我们提出了一种名为精细粒度人类运动扩散模型(FG-MDM)的新的零样本人类运动生成框架。具体来说,我们首先借助大型语言模型,将之前的模糊文本注释解析为不同身体部位的精细粒度描述。然后,我们使用这些精细粒度描述来指导基于变压器的扩散模型,该模型进一步采用了部分令牌的设计。由于描述更贴近动作本质,FG-MDM能够生成超出原始数据集范围的人类动作。我们的实验结果证明,在零样本设置中,FG-MDM优于以前的方法。我们将发布我们为HumanML3D和KIT制作的精细粒度文本注释。
论文及项目相关链接
PDF Project Page: https://sx0207.github.io/fg-mdm/
Summary
文本基于精细粒度的描述生成人类运动,通过采用分而治之的策略,提出了一种名为Fine-Grained Human Motion Diffusion Model(FG-MDM)的新框架,用于零样本人类运动生成。该框架利用大型语言模型将模糊的文本注释解析为不同身体部位的精细粒度描述,然后使用这些精细粒度描述来指导基于转换器的扩散模型,该模型进一步采用部分令牌设计。FG-MDM能够生成超出原始数据集范围的人类运动,因为描述更接近运动本质。
Key Takeaways
- 文本基于精细粒度的描述生成人类运动。
- 提出了一种名为Fine-Grained Human Motion Diffusion Model(FG-MDM)的新框架。
- FG-MDM采用分而治之的策略进行零样本人类运动生成。
- 利用大型语言模型将模糊的文本注释解析为不同身体部位的精细粒度描述。
- FG-MDM使用基于转换器的扩散模型,并采用部分令牌设计。
- FG-MDM能够生成超出原始数据集范围的人类运动。
点此查看论文截图


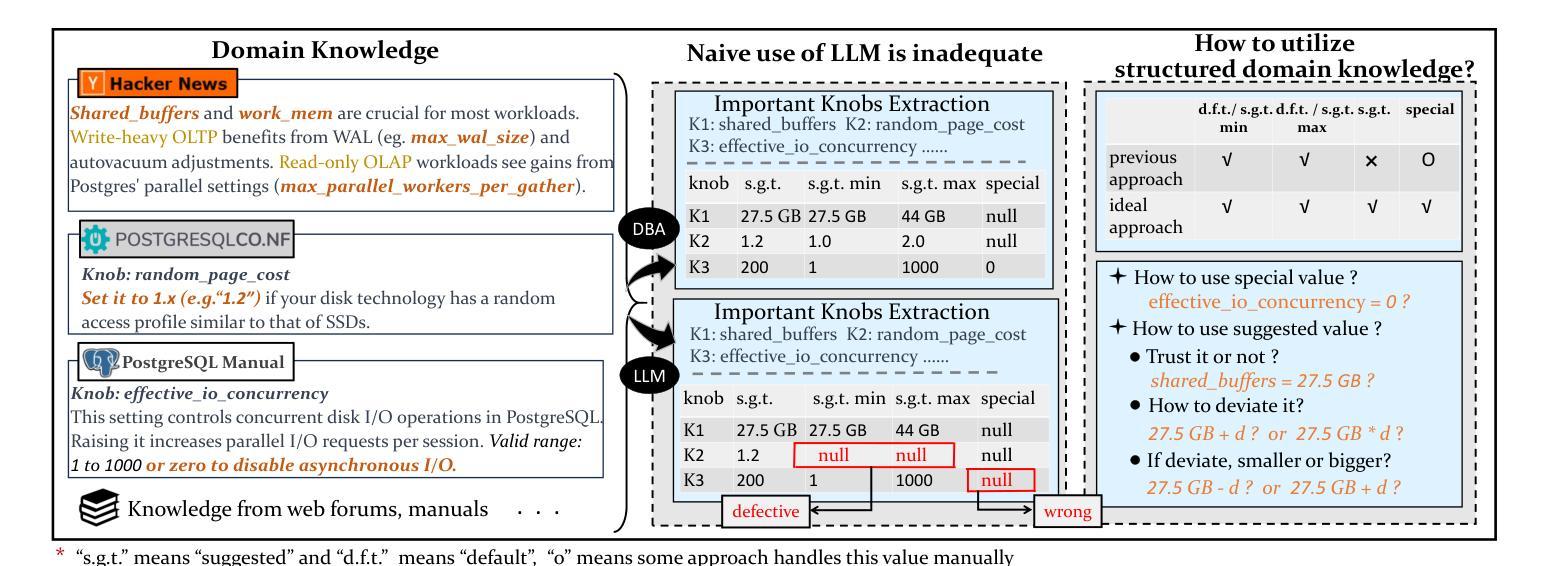
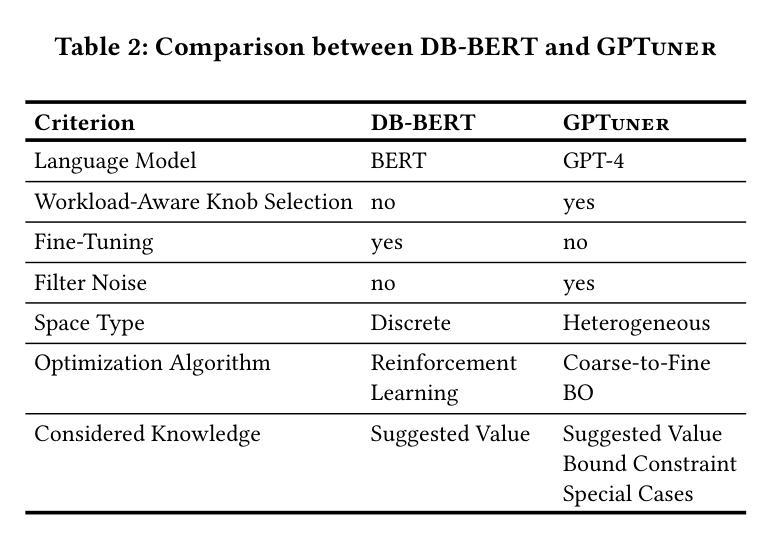
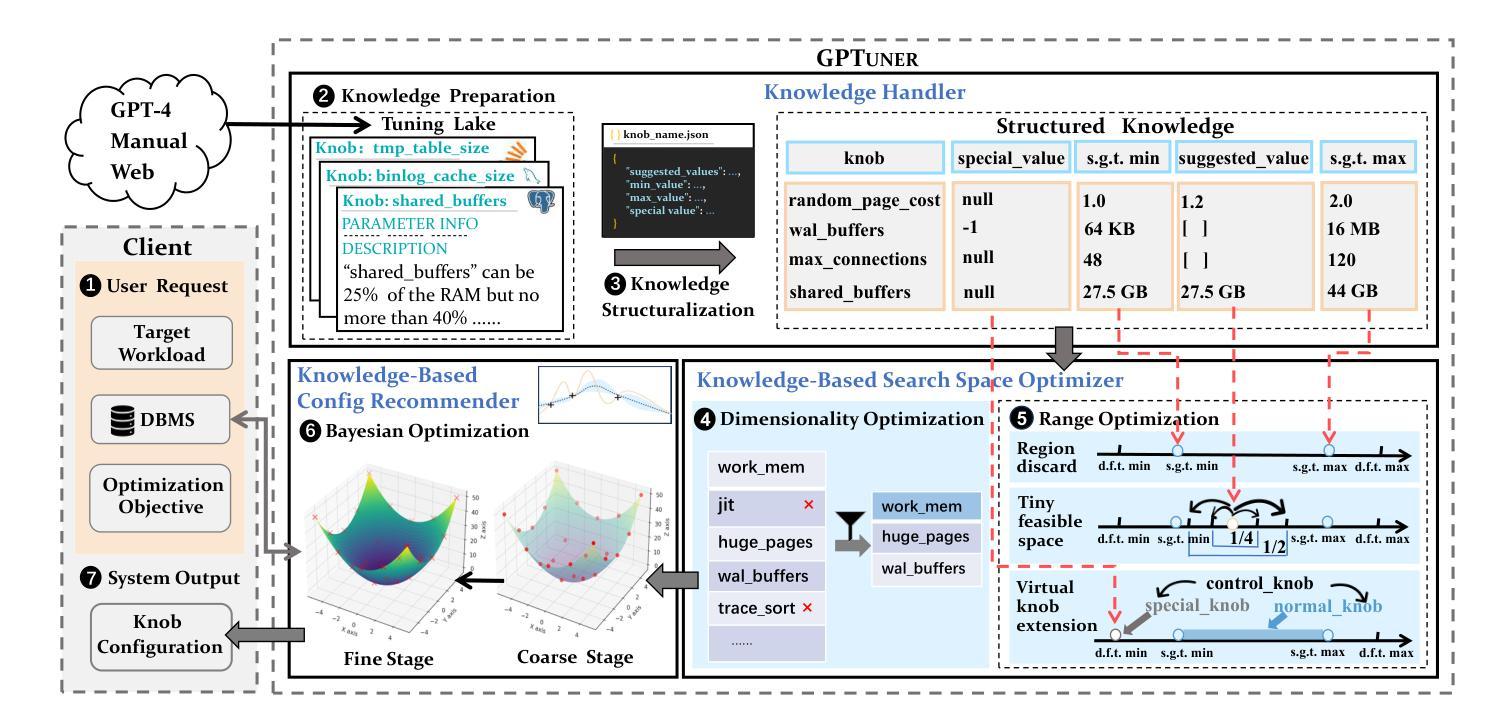
GPTuner: A Manual-Reading Database Tuning System via GPT-Guided Bayesian Optimization
Authors:Jiale Lao, Yibo Wang, Yufei Li, Jianping Wang, Yunjia Zhang, Zhiyuan Cheng, Wanghu Chen, Mingjie Tang, Jianguo Wang
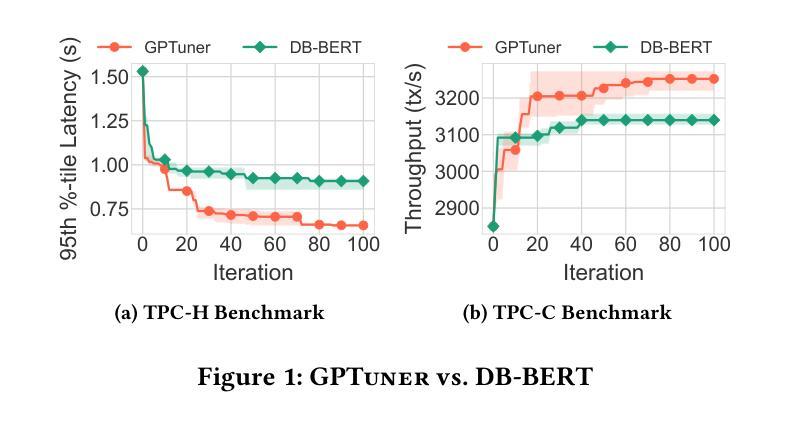
Modern database management systems (DBMS) expose hundreds of configurable knobs to control system behaviours. Determining the appropriate values for these knobs to improve DBMS performance is a long-standing problem in the database community. As there is an increasing number of knobs to tune and each knob could be in continuous or categorical values, manual tuning becomes impractical. Recently, automatic tuning systems using machine learning methods have shown great potentials. However, existing approaches still incur significant tuning costs or only yield sub-optimal performance. This is because they either ignore the extensive domain knowledge available (e.g., DBMS manuals and forum discussions) and only rely on the runtime feedback of benchmark evaluations to guide the optimization, or they utilize the domain knowledge in a limited way. Hence, we propose GPTuner, a manual-reading database tuning system. Firstly, we develop a Large Language Model (LLM)-based pipeline to collect and refine heterogeneous knowledge, and propose a prompt ensemble algorithm to unify a structured view of the refined knowledge. Secondly, using the structured knowledge, we (1) design a workload-aware and training-free knob selection strategy, (2) develop a search space optimization technique considering the value range of each knob, and (3) propose a Coarse-to-Fine Bayesian Optimization Framework to explore the optimized space. Finally, we evaluate GPTuner under different benchmarks (TPC-C and TPC-H), metrics (throughput and latency) as well as DBMS (PostgreSQL and MySQL). Compared to the state-of-the-art approaches, GPTuner identifies better configurations in 16x less time on average. Moreover, GPTuner achieves up to 30% performance improvement (higher throughput or lower latency) over the best-performing alternative.
现代数据库管理系统(DBMS)提供了数百个可配置的控制旋钮来控制系统行为。确定这些旋钮的适当值以提高DBMS性能是数据库社区中长期存在的问题。随着需要调整的旋钮数量不断增加,且每个旋钮都可能是连续或分类值,手动调整变得不切实际。最近,使用机器学习方法进行自动调整的系统已显示出巨大潜力。然而,现有方法仍然会产生大量的调整成本,或者只能产生次优性能。这是因为它们要么忽略可用的丰富领域知识(例如,DBMS手册和论坛讨论),仅依赖基准评估的运行时反馈来指导优化,要么以有限的方式利用领域知识。因此,我们提出了GPTuner,一个手动调整数据库的系统。首先,我们开发了一个基于大型语言模型(LLM)的管道来收集和精炼异质知识,并提出了一种提示集成算法来统一精炼知识的结构化视图。其次,使用结构化知识,我们(1)设计了一种工作负载感知和免培训旋钮选择策略,(2)开发了一种考虑每个旋钮值范围的空间优化技术,(3)提出了一个从粗糙到精细的贝叶斯优化框架来探索优化空间。最后,我们在不同的基准测试(TPC-C和TPC-H)、指标(吞吐量和延迟)以及DBMS(PostgreSQL和MySQL)下评估了GPTuner。与最新方法相比,GPTuner平均在16倍短的时间内找到更好的配置。此外,GPTuner相对于表现最佳的选择方案,性能提高了高达30%(更高的吞吐量或更低的延迟)。
论文及项目相关链接
PDF Accepted by VLDB2024
摘要
现代数据库管理系统(DBMS)有许多可配置的选项来调整系统行为。确定这些选项的适当值以提高DBMS性能是数据库社区长期存在的问题。由于需要调整的选项数量不断增加,且每个选项都可能是连续或分类值,手动调整变得不切实际。最近,使用机器学习方法的自动调整系统显示出巨大的潜力。然而,现有方法仍然会产生较大的调整成本,或者只能产生次优性能。这是因为它们要么忽略了可用的丰富领域知识(例如DBMS手册和论坛讨论),只依赖于基准评估的运行时反馈来指导优化,要么以有限的方式利用领域知识。因此,我们提出了GPTuner,一个手动数据库调整系统。首先,我们开发了一个基于大型语言模型(LLM)的管道来收集和精炼异质知识,并提出一个提示集成算法来统一精炼知识的结构化视图。其次,使用结构化知识,我们(1)设计了一种工作负载感知和免培训旋钮选择策略,(2)开发了一种考虑每个旋钮值范围的空间优化技术,(3)提出了一个从粗到细的贝叶斯优化框架来探索优化空间。最后,我们在不同的基准测试(TPC-C和TPC-H)、指标(吞吐量和延迟)以及DBMS(PostgreSQL和MySQL)下评估了GPTuner。与最先进的相比,GPTuner平均节省了平均16倍的时间找到更好的配置。此外,GPTuner相对于表现最好的替代方案实现了高达30%的性能改进(更高的吞吐量或更低的延迟)。
关键见解
- 现代数据库管理系统存在大量可配置的选项,手动调整这些选项变得不切实际。
- 现有自动调整系统方法存在显著的性能调整成本和次优性能问题。
- GPTuner利用大型语言模型(LLM)来收集和精炼领域知识,并将其应用于数据库调整。
- GPTuner采用结构化知识来设计免培训旋钮选择策略和工作负载感知的搜索空间优化技术。
- GPTuner使用从粗到细的贝叶斯优化框架来探索优化空间。
- GPTuner在多种基准测试、指标和DBMS下的评估表现优于现有方法,平均节省16倍时间找到更好的配置。
- GPTuner实现了高达30%的性能改进。
点此查看论文截图


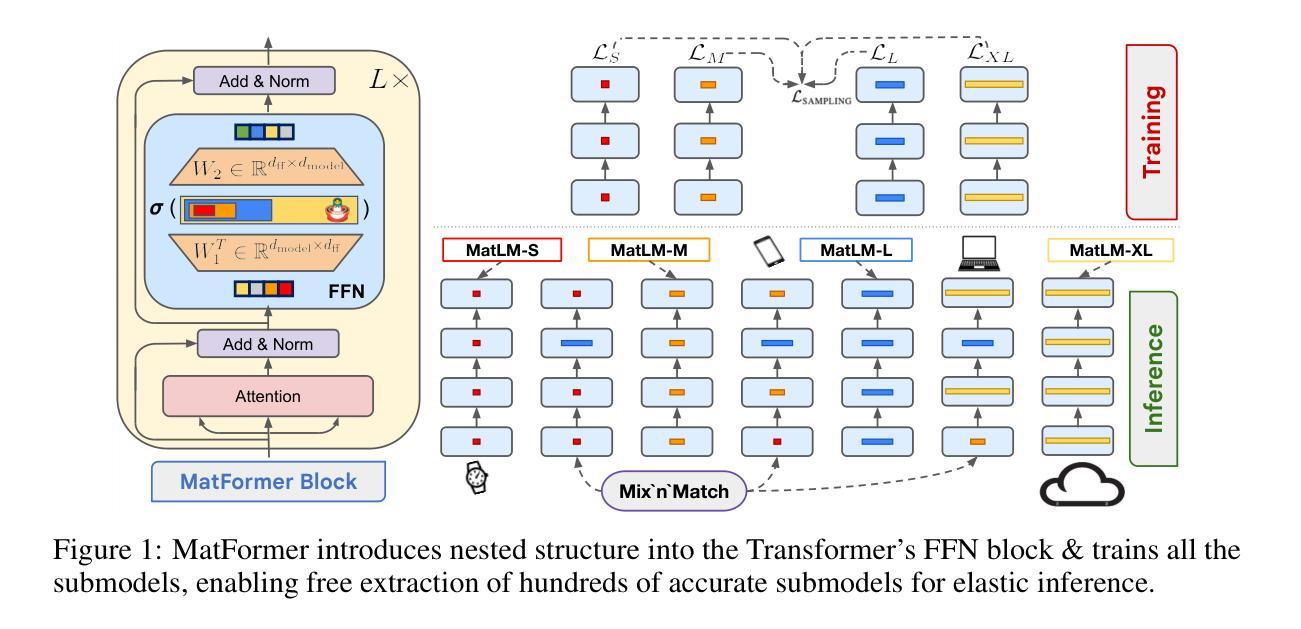
MatFormer: Nested Transformer for Elastic Inference
Authors: Devvrit, Sneha Kudugunta, Aditya Kusupati, Tim Dettmers, Kaifeng Chen, Inderjit Dhillon, Yulia Tsvetkov, Hannaneh Hajishirzi, Sham Kakade, Ali Farhadi, Prateek Jain
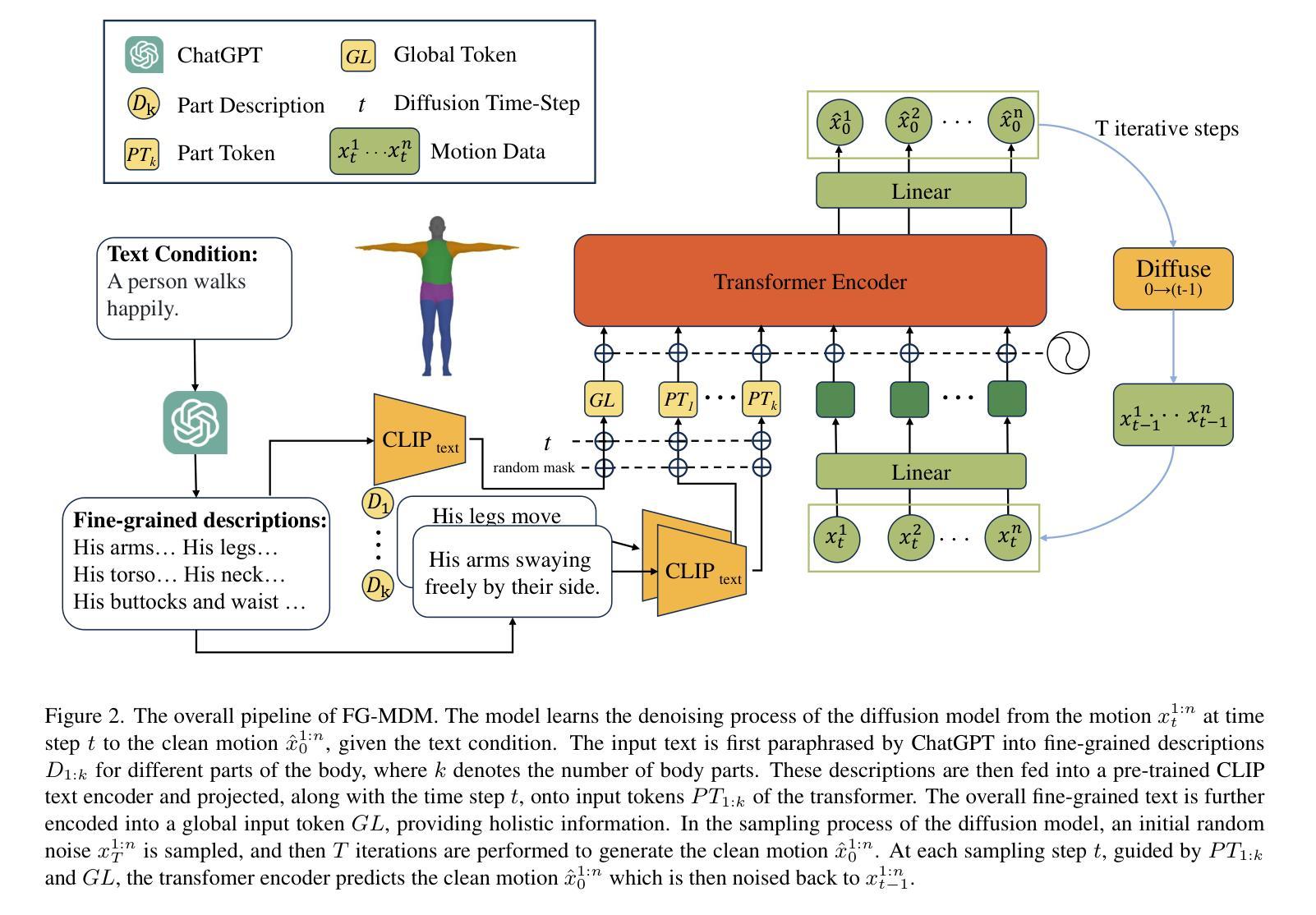
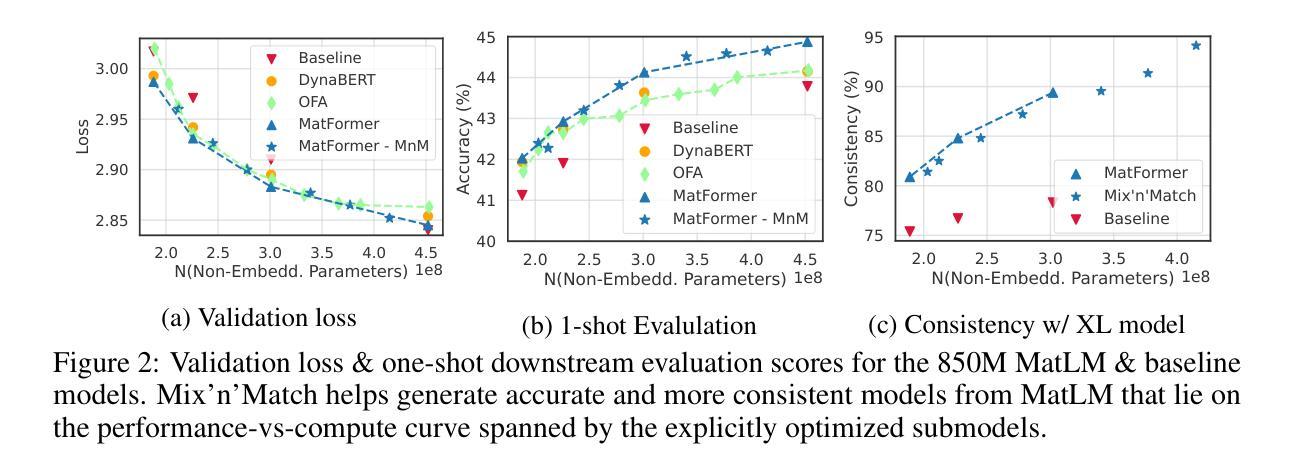
Foundation models are applied in a broad spectrum of settings with different inference constraints, from massive multi-accelerator clusters to resource-constrained standalone mobile devices. However, the substantial costs associated with training these models often limit the number of unique model sizes that can be offered. Consequently, practitioners are compelled to select a model that may not be optimally aligned with their specific latency and cost requirements. We present MatFormer, a novel Transformer architecture designed to provide elastic inference across diverse deployment constraints. MatFormer achieves this by incorporating a nested Feed Forward Network (FFN) block structure within a standard Transformer model. During training, we optimize the parameters of multiple nested FFN blocks with varying sizes, enabling the extraction of hundreds of accurate smaller models without incurring additional computational costs. We empirically validate the efficacy of MatFormer across different model classes (decoders and encoders) and modalities (language and vision), demonstrating its potential for real-world deployment. We show that a 850M decoder-only MatFormer language model (MatLM) allows us to extract multiple smaller models spanning from 582M to 850M parameters, each exhibiting better validation loss and one-shot downstream evaluations than independently trained counterparts. Furthermore, we observe that smaller encoders extracted from a universal MatFormer-based ViT (MatViT) encoder preserve the metric-space structure for adaptive large-scale retrieval. Finally, we showcase that speculative decoding with the accurate and consistent submodels extracted from MatFormer can lead to significant reduction in inference latency. Project website: https://devvrit.github.io/matformer/
模型在各种不同的推理约束环境中得到了广泛应用,从大规模的多加速器集群到资源受限的独立移动设备。然而,与训练这些模型相关的巨大成本往往限制了可以提供的独特模型大小的数量。因此,从业者被迫选择可能与他们的特定延迟和成本要求不完全匹配的模型。我们推出了MatFormer,这是一种新型Transformer架构,旨在提供跨多种部署约束的弹性推理。MatFormer通过在一个标准的Transformer模型中融入嵌套的Feed Forward Network(FFN)块结构来实现这一点。在训练过程中,我们优化了多个大小不同的嵌套FFN块的参数,能够在不增加计算成本的情况下提取出数百个准确的小型模型。我们实证验证了MatFormer在不同模型类别(解码器和编码器)和模式(语言和视觉)中的有效性,展示了其在现实世界部署中的潜力。我们展示了一个只有850M参数的MatFormer语言模型(MatLM),它能够提取出多个较小模型,这些模型参数从582M到850M不等,每个模型在验证损失和一次性下游评估方面都表现出比独立训练更好的性能。此外,我们还观察到,从通用的MatFormer基础的ViT(MatViT)编码器中提取出的较小编码器能够保持度量空间结构,用于自适应大规模检索。最后,我们展示了使用来自MatFormer的准确且一致子模型进行推测性解码,可以显著降低推理延迟。项目网站:https://devvrit.github.io/matformer/
论文及项目相关链接
PDF 30 pages, 11 figures, first three authors contributed equally. NeurIPS, 2024
Summary
本文介绍了MatFormer,一种新型的Transformer架构,能够在不同的部署约束下提供弹性的推理能力。它通过引入嵌套的前馈网络(FFN)块结构,优化了模型参数,能够在不增加计算成本的情况下提取出数百个精确的小型模型。MatFormer的有效性在不同的模型类别(解码器和编码器)和模态(语言和视觉)上得到了实证验证,显示出其在现实世界部署中的潜力。此外,研究还展示了MatFormer在提取多个小型模型方面的优势,这些模型在参数、验证损失和一次性下游评估方面都表现出色。
Key Takeaways
- MatFormer是一种新型的Transformer架构,旨在提供弹性推理,适应不同的部署约束。
- 通过引入嵌套FFN块结构,MatFormer能够在不增加计算成本的情况下提取出多个小型模型。
- MatFormer的有效性在不同的模型类别和模态上得到了实证验证,具有广泛的应用潜力。
- MatFormer语言模型(MatLM)能够从单一模型中提取多个子模型,这些子模型具有更好的验证损失和下游评估表现。
- MatViT(基于MatFormer的ViT变体)编码器能够从大型模型中提取出小型编码器,保持度量空间结构,适用于自适应大规模检索。
- MatFormer支持通过子模型的精确解码实现显著减少推理延迟。
点此查看论文截图


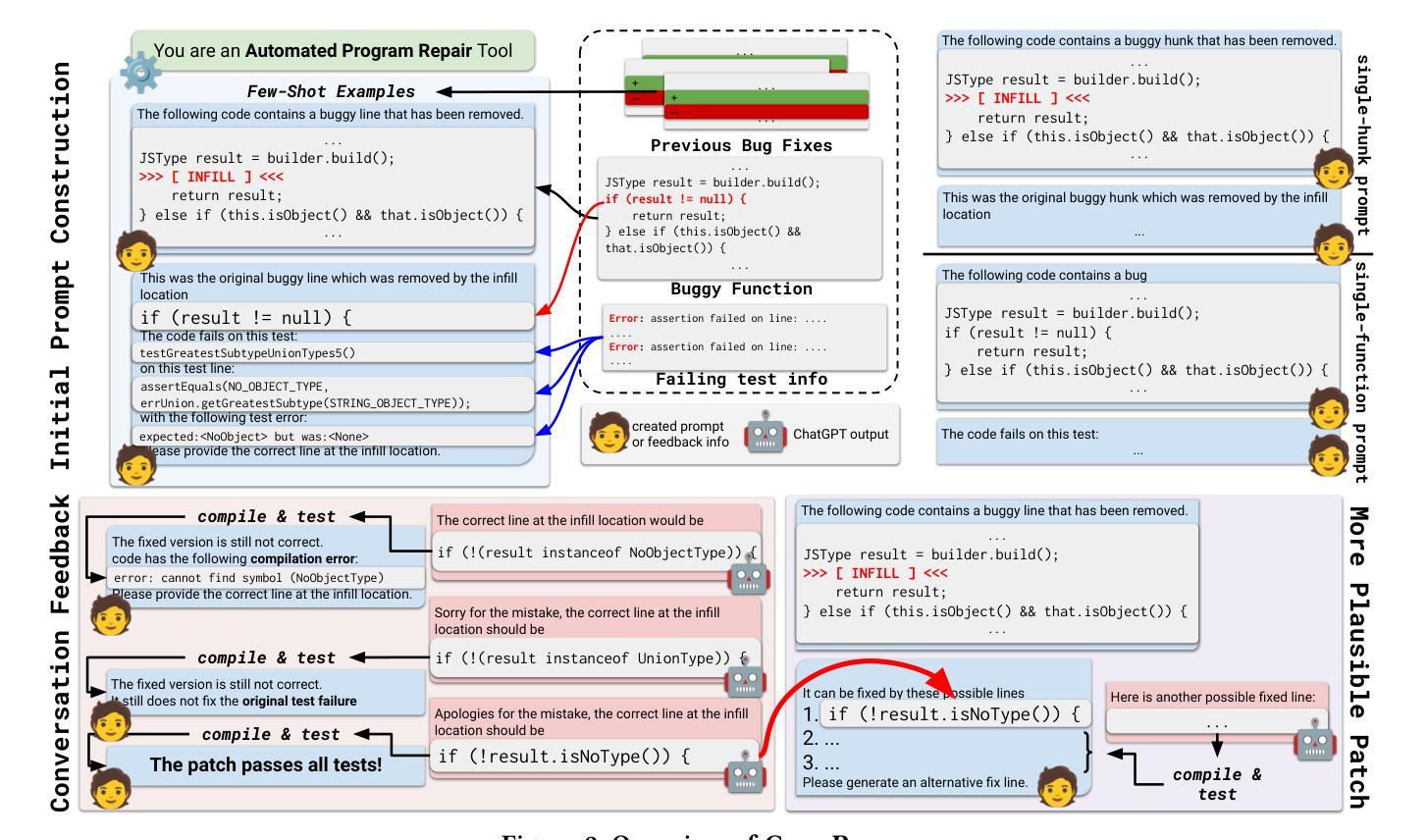
Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT
Authors:Chunqiu Steven Xia, Lingming Zhang
Automated Program Repair (APR) aims to automatically generate patches for buggy programs. Recent APR work has been focused on leveraging modern Large Language Models (LLMs) to directly generate patches for APR. Such LLM-based APR tools work by first constructing an input prompt built using the original buggy code and then queries the LLM to generate patches. While the LLM-based APR tools are able to achieve state-of-the-art results, it still follows the classic Generate and Validate repair paradigm of first generating lots of patches and then validating each one afterwards. This not only leads to many repeated patches that are incorrect but also miss the crucial information in test failures as well as in plausible patches. To address these limitations, we propose ChatRepair, the first fully automated conversation-driven APR approach that interleaves patch generation with instant feedback to perform APR in a conversational style. ChatRepair first feeds the LLM with relevant test failure information to start with, and then learns from both failures and successes of earlier patching attempts of the same bug for more powerful APR. For earlier patches that failed to pass all tests, we combine the incorrect patches with their corresponding relevant test failure information to construct a new prompt for the LLM to generate the next patch. In this way, we can avoid making the same mistakes. For earlier patches that passed all the tests, we further ask the LLM to generate alternative variations of the original plausible patches. In this way, we can further build on and learn from earlier successes to generate more plausible patches to increase the chance of having correct patches. While our approach is general, we implement ChatRepair using state-of-the-art dialogue-based LLM – ChatGPT. By calculating the cost of accessing ChatGPT, we can fix 162 out of 337 bugs for $0.42 each!
自动化程序修复(APR)旨在自动为存在缺陷的程序生成补丁。最近的APR工作主要集中在利用现代大型语言模型(LLM)直接为APR生成补丁。此类基于LLM的APR工具首先使用原始的错误代码构建输入提示,然后查询LLM以生成补丁。虽然基于LLM的APR工具能够达到最新技术水平,但它仍然遵循经典的生成和验证修复范式,即首先生成大量补丁,然后再逐一验证。这不仅会导致许多重复的补丁不正确,而且还会错过测试失败中的关键信息以及合理的补丁。为了解决这些局限性,我们提出了ChatRepair,这是第一个完全自动化的对话驱动的APR方法,它将补丁生成与即时反馈交织在一起,以对话的方式进行APR。ChatRepair首先向LLM提供相关的测试失败信息作为起点,然后从同一bug的早期修复尝试的失败和成功中学习以进行更强大的APR。对于早期未能通过所有测试的补丁,我们将不正确的补丁与其对应的测试失败信息相结合,构建一个新的提示供LLM生成下一个补丁。这样,我们可以避免犯同样的错误。对于早期通过所有测试的补丁,我们进一步要求LLM生成原始合理补丁的替代变体。这样,我们可以在早期成功的基础上继续学习并生成更多合理的补丁,以提高生成正确补丁的机会。我们的方法是通用的,我们使用最先进的基于对话的LLM——ChatGPT实现了ChatRepair。通过计算访问ChatGPT的成本,我们可以以每次$0.42的价格修复337个中的162个bug!
论文及项目相关链接
摘要
自动化程序修复(APR)旨在自动为存在缺陷的程序生成补丁。最近的APR工作主要集中在利用现代大型语言模型(LLM)直接生成补丁。LLM-based的APR工具通过构建包含原始错误代码输入提示来查询LLM以生成补丁。虽然LLM-based的APR工具能够达到业界领先水平,但它仍然遵循经典的生成和验证修复范式,即首先生成大量补丁,然后再逐个验证。这不仅会导致许多重复的错误补丁,而且还会错过测试失败中的关键信息以及合理的补丁。为解决这些局限性,我们提出ChatRepair,这是一种全新的全自动对话驱动APR方法,它将补丁生成与即时反馈交织在一起,以对话的方式进行APR。ChatRepair首先向LLM提供相关的测试失败信息,然后从早期修复尝试的失败和成功中学习,以进行更强大的APR。对于未能通过所有测试的早期补丁,我们将错误的补丁与其相应的相关测试失败信息相结合,以构建新的提示供LLM生成下一个补丁。通过这种方式,我们可以避免重蹈覆辙。对于已通过所有测试的早期补丁,我们会进一步要求LLM生成原始合理补丁的替代版本。通过这种方式,我们可以在早期成功的基础上进一步学习,生成更多合理的补丁,以提高拥有正确补丁的机会。我们的方法具有通用性,通过使用最先进的对话式LLM——ChatGPT实现ChatRepair。通过计算访问ChatGPT的成本,我们可以以每处0.42美元的价格修复337个错误中的162个!
要点
- 自动化程序修复(APR)的目标是自动为错误程序生成补丁。
- 近期研究利用大型语言模型(LLM)进行APR,但仍然存在生成和验证的局限性。
- ChatRepair是一种全新的全自动对话驱动APR方法,通过即时反馈和对话方式改进补丁生成。
- ChatRepair利用测试失败信息来启动并改进补丁生成过程,避免重复错误并增加合理补丁的生成机会。
- ChatRepair结合失败的补丁和相关的测试失败信息来构建新的提示,促进LLM生成更好的补丁。
- ChatRepair从早期成功的补丁中学习,生成更多合理的补丁版本。
点此查看论文截图