⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-24 更新
Personalized Representation from Personalized Generation
Authors:Shobhita Sundaram, Julia Chae, Yonglong Tian, Sara Beery, Phillip Isola
Modern vision models excel at general purpose downstream tasks. It is unclear, however, how they may be used for personalized vision tasks, which are both fine-grained and data-scarce. Recent works have successfully applied synthetic data to general-purpose representation learning, while advances in T2I diffusion models have enabled the generation of personalized images from just a few real examples. Here, we explore a potential connection between these ideas, and formalize the challenge of using personalized synthetic data to learn personalized representations, which encode knowledge about an object of interest and may be flexibly applied to any downstream task relating to the target object. We introduce an evaluation suite for this challenge, including reformulations of two existing datasets and a novel dataset explicitly constructed for this purpose, and propose a contrastive learning approach that makes creative use of image generators. We show that our method improves personalized representation learning for diverse downstream tasks, from recognition to segmentation, and analyze characteristics of image generation approaches that are key to this gain.
现代视觉模型在通用下游任务上表现出色。然而,对于精细且数据稀缺的个性化视觉任务,如何应用这些模型尚不清楚。最近的研究工作已成功将合成数据应用于通用表示学习,而文本到图像(T2I)扩散模型的进展使得仅从几个真实示例中生成个性化图像成为可能。在这里,我们探索了这两者之间的潜在联系,并正式提出了使用个性化合成数据来学习个性化表示的挑战,这种表示形式能够编码目标对象的有关知识,并可灵活应用于与该目标对象相关的任何下游任务。我们为这个挑战设计了一套评估方案,包括对两个现有数据集的重新构建和一个专门为此目的构建的新数据集,并提出了一种对比学习方法,该方法可以创造性地利用图像生成器。我们表明,我们的方法可以改善多样化下游任务的个性化表示学习,包括识别到分割,并对图像生成方法的关键特性进行了分析,这些特性对此增益至关重要。
论文及项目相关链接
PDF S.S. and J.C contributed equally; S.B. and P.I. co-supervised. Project page: https://personalized-rep.github.io/
Summary
现代视觉模型在通用下游任务上表现出色,但在个性化视觉任务方面仍存在不明确性,尤其是针对精细化且数据稀缺的任务。近期工作成功将合成数据应用于通用表示学习,而文本到图像(T2I)扩散模型的发展使得仅从少量真实示例生成个性化图像成为可能。本文探索了这两者之间的潜在联系,并正式提出了利用个性化合成数据学习个性化表示的挑战。这些表示形式能够编码目标对象的有关知识并可灵活应用于与之相关的任何下游任务。本文介绍了一套针对这一挑战的评价方案,包括两个现有数据集的重新构建以及一个专门为该目的构建的新颖数据集,并提出了一种创造性利用图像生成器的对比学习方法。实验表明,该方法可改善多样化的下游任务的个性化表示学习,包括识别与分割,并分析了图像生成方法的关键特性对此增益的影响。
Key Takeaways
- 现代视觉模型在通用下游任务上表现良好,但在个性化视觉任务上存在不确定性。
- 合成数据已成功应用于通用表示学习。
- T2I扩散模型可从少量真实示例生成个性化图像。
- 本文探索了将合成数据与个性化视觉任务结合的可能性,并正式提出了学习个性化表示的挑战。
- 介绍了一套评价方案,包括针对个性化视觉任务的现有数据集的重新构建和新数据集的开发。
- 提出了一种利用图像生成器的对比学习方法,可改善个性化表示学习。
点此查看论文截图



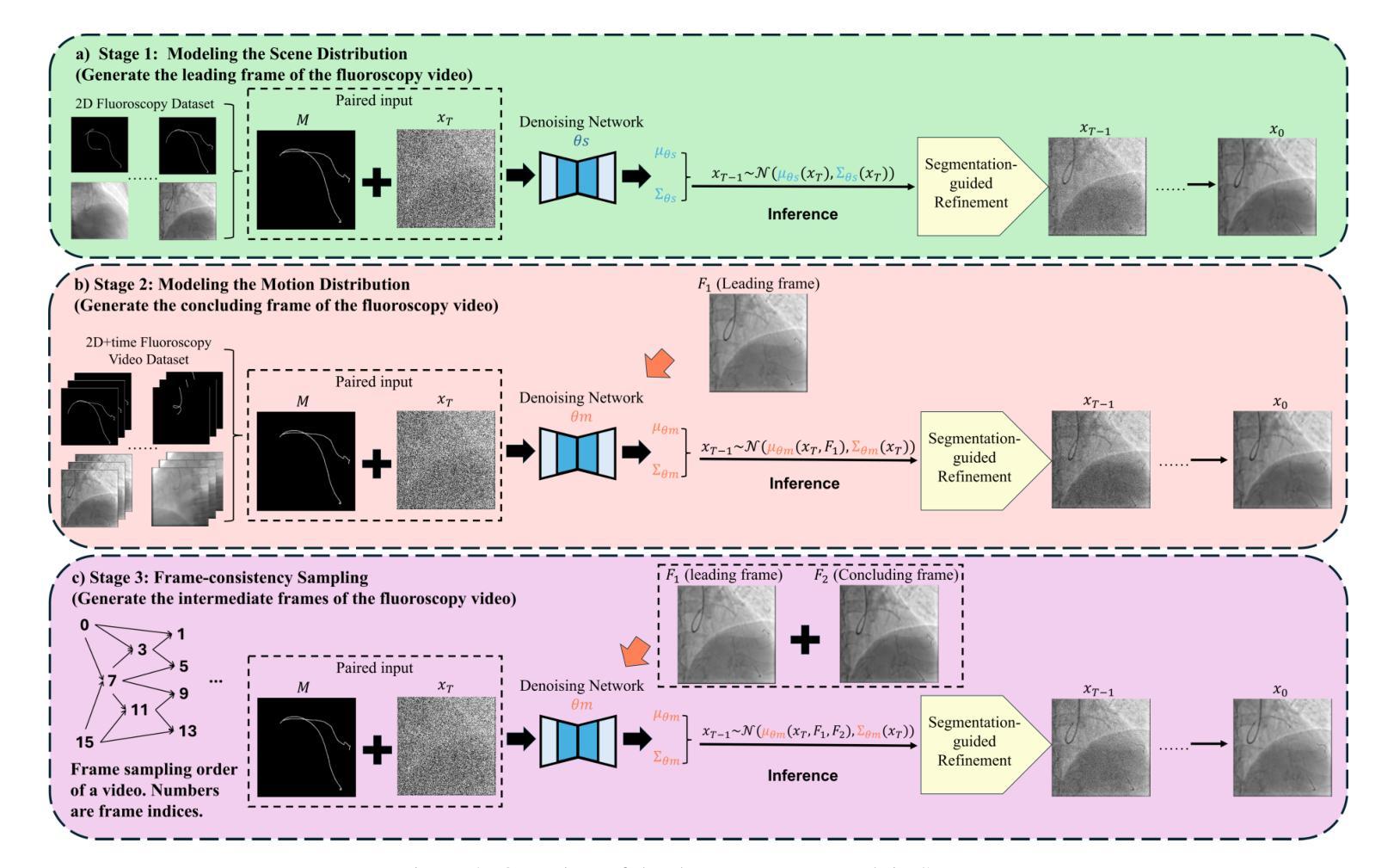
Label-Efficient Data Augmentation with Video Diffusion Models for Guidewire Segmentation in Cardiac Fluoroscopy
Authors:Shaoyan Pan, Yikang Liu, Lin Zhao, Eric Z. Chen, Xiao Chen, Terrence Chen, Shanhui Sun
The accurate segmentation of guidewires in interventional cardiac fluoroscopy videos is crucial for computer-aided navigation tasks. Although deep learning methods have demonstrated high accuracy and robustness in wire segmentation, they require substantial annotated datasets for generalizability, underscoring the need for extensive labeled data to enhance model performance. To address this challenge, we propose the Segmentation-guided Frame-consistency Video Diffusion Model (SF-VD) to generate large collections of labeled fluoroscopy videos, augmenting the training data for wire segmentation networks. SF-VD leverages videos with limited annotations by independently modeling scene distribution and motion distribution. It first samples the scene distribution by generating 2D fluoroscopy images with wires positioned according to a specified input mask, and then samples the motion distribution by progressively generating subsequent frames, ensuring frame-to-frame coherence through a frame-consistency strategy. A segmentation-guided mechanism further refines the process by adjusting wire contrast, ensuring a diverse range of visibility in the synthesized image. Evaluation on a fluoroscopy dataset confirms the superior quality of the generated videos and shows significant improvements in guidewire segmentation.
在心脏介入手术的荧光透视视频中,对导线进行精确分割对于计算机辅助导航任务至关重要。虽然深度学习的方法在导线分割方面表现出了高准确性和稳健性,但它们需要大量标注数据集以实现普遍适用性,这强调了需要更多标注数据来提高模型性能。为了应对这一挑战,我们提出了基于分割引导的帧一致性视频扩散模型(SF-VD),用于生成大量标注的荧光透视视频,增强导线分割网络的训练数据。SF-VD通过独立建模场景分布和运动分布,充分利用了标注有限的数据集。它首先通过根据指定的输入掩膜生成带有导线的二维荧光透视图像来采样场景分布,然后通过逐步生成后续帧来采样运动分布,并通过帧一致性策略确保帧到帧的连贯性。分割引导机制进一步微调过程,通过调整导线对比度,确保合成图像中可见性范围多样。在荧光透视数据集上的评估证明了所生成视频的高质量以及显著提高了导线分割的性能。
论文及项目相关链接
PDF AAAI 2025
摘要
在介入心脏荧光视频中对导线进行精确分割对于计算机辅助导航任务至关重要。深度学习虽已展现出在导线分割方面的高精度和稳健性,但其需要大量标注数据集才能达到通用性,因此亟需扩充标记数据以增强模型性能。为解决这一挑战,我们提出了基于分割引导的帧一致性视频扩散模型(SF-VD),用于生成大量标记荧光视频,扩充导线分割网络的训练数据。SF-VD利用有限标注的视频,通过独立建模场景分布和运动分布来实现。它首先根据指定的输入掩膜生成带有导线的二维荧光图像来采样场景分布,然后通过逐步生成后续帧来采样运动分布,确保帧间一致性。分割引导机制进一步调整导线对比度,确保合成图像中可见性多样。在荧光数据集上的评估证明了生成视频的高质量,并显示出在导线分割方面的显著改善。
关键见解
- 准确分割介入心脏荧光视频中的导线对计算机导航至关重要。
- 深度学习在导线分割上表现出高准确度和稳健性,但需要大量标注数据。
- 提出SF-VD模型以生成标记荧光视频,增强导线分割网络的训练数据。
- SF-VD通过独立建模场景分布和运动分布来实现高效生成。
- 模型通过生成二维荧光图像和逐步生成后续帧来采样场景和运动分布。
- 分割引导机制确保合成图像中导线的可见性多样。
点此查看论文截图


Semi-Supervised Adaptation of Diffusion Models for Handwritten Text Generation
Authors:Kai Brandenbusch
The generation of images of realistic looking, readable handwritten text is a challenging task which is referred to as handwritten text generation (HTG). Given a string and examples from a writer, the goal is to synthesize an image depicting the correctly spelled word in handwriting with the calligraphic style of the desired writer. An important application of HTG is the generation of training images in order to adapt downstream models for new data sets. With their success in natural image generation, diffusion models (DMs) have become the state-of-the-art approach in HTG. In this work, we present an extension of a latent DM for HTG to enable generation of writing styles not seen during training by learning style conditioning with a masked auto encoder. Our proposed content encoder allows for different ways of conditioning the DM on textual and calligraphic features. Additionally, we employ classifier-free guidance and explore the influence on the quality of the generated training images. For adapting the model to a new unlabeled data set, we propose a semi-supervised training scheme. We evaluate our approach on the IAM-database and use the RIMES-database to examine the generation of data not seen during training achieving improvements in this particularly promising application of DMs for HTG.
手写文本生成(HTG)是一项具有挑战性的任务,即生成看起来非常逼真、可识别的手写文本图像。给定一个字符串和作者的例子,目标是合成一张正确拼写的手写单词图像,并具有所需作者的书法风格。HTG的一个重要应用是生成训练图像,以适应新的数据集。由于其在自然图像生成方面的成功,扩散模型(DMs)已成为HTG中最先进的方法。在这项工作中,我们提出了一种针对HTG的潜在DM的扩展,通过带有掩码的自编码器学习风格调节,以生成在训练中未见过的书写风格。我们提出的内容编码器允许以不同的方式将DM调节到文本和书法特征上。此外,我们采用了无分类器引导,并探索了对生成训练图像质量的影响。为了将模型适应新的未标记数据集,我们提出了一种半监督训练方案。我们在IAM数据库上评估了我们的方法,并使用RIMES数据库来检查在训练中未见到的数据的生成情况,在实现这一特别有前途的HTG DM应用中取得了改进。
论文及项目相关链接
Summary
本文介绍了手写文本生成(HTG)的挑战,其目标是生成具有特定书写风格的手写文本图像。为了应对这一挑战,研究者们将扩散模型(DMs)应用于HTG,并取得了显著成果。本文提出了一种基于潜在DM的HTG扩展方法,通过掩码自动编码器学习风格调节,以生成在训练中未见过的书写风格。同时,研究还涉及模型对新数据集的适应性,提出了半监督训练方案。评估结果表明,该方法在IAM数据库和RIMES数据库上表现优异。
Key Takeaways
- 手写文本生成(HTG)是一项挑战任务,目标是生成具有特定书写风格的手写文本图像。
- 扩散模型(DMs)在手写文本生成领域表现出卓越性能,成为最先进的方法。
- 研究提出了一种基于潜在DM的HTG扩展方法,能够生成在训练中未见过的书写风格。
- 通过掩码自动编码器学习风格调节,实现了对DM的内容编码器的不同调节方式。
- 研究采用了无分类器引导的方法,并探讨了其对生成训练图像质量的影响。
- 为了适应新数据集,研究提出了半监督训练方案。
点此查看论文截图

Diffusion-Based Conditional Image Editing through Optimized Inference with Guidance
Authors:Hyunsoo Lee, Minsoo Kang, Bohyung Han
We present a simple but effective training-free approach for text-driven image-to-image translation based on a pretrained text-to-image diffusion model. Our goal is to generate an image that aligns with the target task while preserving the structure and background of a source image. To this end, we derive the representation guidance with a combination of two objectives: maximizing the similarity to the target prompt based on the CLIP score and minimizing the structural distance to the source latent variable. This guidance improves the fidelity of the generated target image to the given target prompt while maintaining the structure integrity of the source image. To incorporate the representation guidance component, we optimize the target latent variable of diffusion model’s reverse process with the guidance. Experimental results demonstrate that our method achieves outstanding image-to-image translation performance on various tasks when combined with the pretrained Stable Diffusion model.
我们提出了一种简单有效的基于预训练文本到图像扩散模型的训练外文本驱动图像到图像转换方法。我们的目标是生成符合目标任务的图像,同时保留源图像的结构和背景。为此,我们通过结合两个目标来推导表示引导:基于CLIP分数的最大化与目标提示的相似性,以及最小化与源潜在变量的结构距离。这种引导提高了生成的目标图像对给定目标提示的保真度,同时保持了源图像的结构完整性。为了融入表示引导成分,我们优化了扩散模型反向过程的目标潜在变量以进行引导。实验结果表明,我们的方法与预训练的Stable Diffusion模型相结合时,在各种任务上实现了出色的图像到图像的翻译性能。
论文及项目相关链接
PDF WACV 2025
Summary
本文介绍了一种基于预训练文本到图像扩散模型的简单有效的训练免费文本驱动图像到图像转换方法。该方法旨在生成与目标任务对齐的图像,同时保留源图像的结构和背景。通过结合两个目标:最大化基于CLIP分数的目标提示的相似性,以及最小化源潜在变量与结构距离,以改进生成的图像对给定目标提示的保真度并保持源图像的结构完整性。通过优化扩散模型反向过程中的目标潜在变量来实现表示指导组件的融入。实验结果表明,当与预训练的Stable Diffusion模型结合时,该方法在各种任务上实现了出色的图像到图像转换性能。
Key Takeaways
- 提出了一种基于预训练文本到图像扩散模型的文本驱动图像转换方法。
- 旨在生成与目标任务对齐的图像,同时保留源图像的结构和背景。
- 通过结合两个目标来实现表示指导:最大化目标提示的相似性并最小化源图像的结构距离。
- 优化扩散模型反向过程中的目标潜在变量以融入表示指导组件。
- 方法在多种任务上实现了出色的图像转换性能。
- 与预训练的Stable Diffusion模型结合使用时,该方法表现尤为出色。
点此查看论文截图



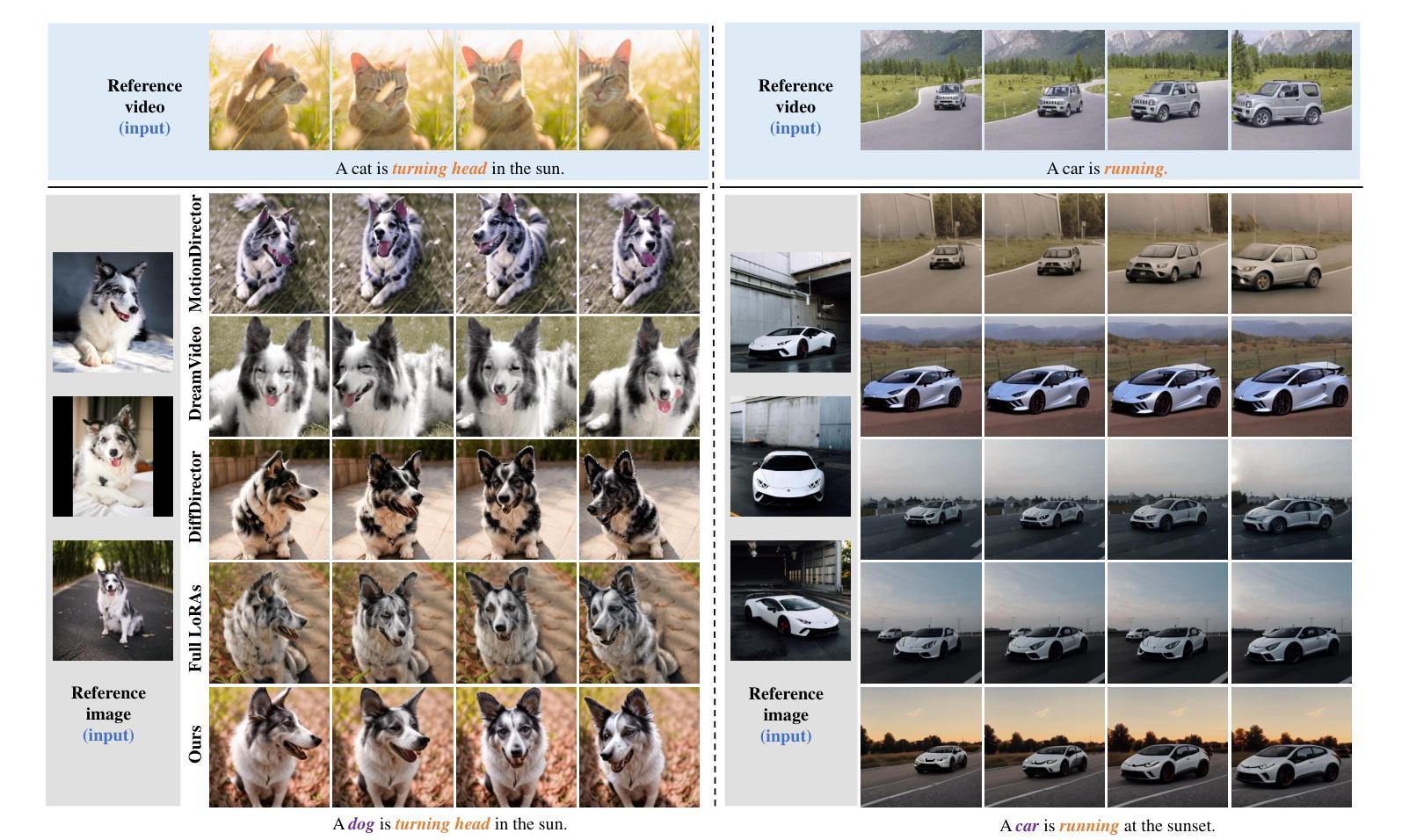
CustomTTT: Motion and Appearance Customized Video Generation via Test-Time Training
Authors:Xiuli Bi, Jian Lu, Bo Liu, Xiaodong Cun, Yong Zhang, Weisheng Li, Bin Xiao
Benefiting from large-scale pre-training of text-video pairs, current text-to-video (T2V) diffusion models can generate high-quality videos from the text description. Besides, given some reference images or videos, the parameter-efficient fine-tuning method, i.e. LoRA, can generate high-quality customized concepts, e.g., the specific subject or the motions from a reference video. However, combining the trained multiple concepts from different references into a single network shows obvious artifacts. To this end, we propose CustomTTT, where we can joint custom the appearance and the motion of the given video easily. In detail, we first analyze the prompt influence in the current video diffusion model and find the LoRAs are only needed for the specific layers for appearance and motion customization. Besides, since each LoRA is trained individually, we propose a novel test-time training technique to update parameters after combination utilizing the trained customized models. We conduct detailed experiments to verify the effectiveness of the proposed methods. Our method outperforms several state-of-the-art works in both qualitative and quantitative evaluations.
受益于大规模文本-视频对预训练,当前的文本到视频(T2V)扩散模型可以从文本描述生成高质量视频。此外,给定一些参考图像或视频,参数高效的微调方法,即LoRA,可以生成高质量的自定概念,例如参考视频中的特定主题或动作。然而,从不同参考中训练出的多个概念合并到单个网络中会产生明显的伪影。为此,我们提出了CustomTTT,可以轻松地联合定制给定视频的外观和运动。具体来说,我们首先分析当前视频扩散模型中的提示影响,并发现对于外观和运动定制而言,LoRA仅需要针对特定层进行训练。此外,由于每个LoRA都是单独训练的,我们提出了一种新型测试时间训练技术,利用训练好的自定义模型在组合后更新参数。我们进行了详细的实验来验证所提出方法的有效性。我们的方法在定性和定量评估中都优于几种最新技术作品。
论文及项目相关链接
PDF Accepted in AAAI 2025
Summary
文本描述了当前文本到视频(T2V)扩散模型利用大规模预训练的文本-视频对生成高质量视频的情况。文章还介绍了使用参考图像或视频的参数高效微调方法(如LoRA)来生成特定概念的视频。然而,从多个参考中训练的概念合并到单个网络中会产生明显的人工制品。为此,文章提出了CustomTTT方法,能够轻松地将给定视频的外观和运动结合起来。研究发现LoRA只对特定层进行外观和运动定制,并提出了一种新型测试时间训练技术,在结合训练好的定制模型后更新参数。实验证明该方法在定性和定量评估上均优于几种最新技术。
Key Takeaways
- 当前文本到视频(T2V)扩散模型能够利用大规模预训练生成高质量视频。
- 参数高效微调方法(如LoRA)可以从参考图像或视频生成特定概念的视频。
- 合并来自不同参考的训练概念到单一网络中会产生明显的人工制品。
- CustomTTT方法能够轻松结合给定视频的外观和运动。
- LoRA主要用于特定层的外观和运动定制。
- 提出了一种新型测试时间训练技术,在结合训练好的定制模型后更新参数。
点此查看论文截图

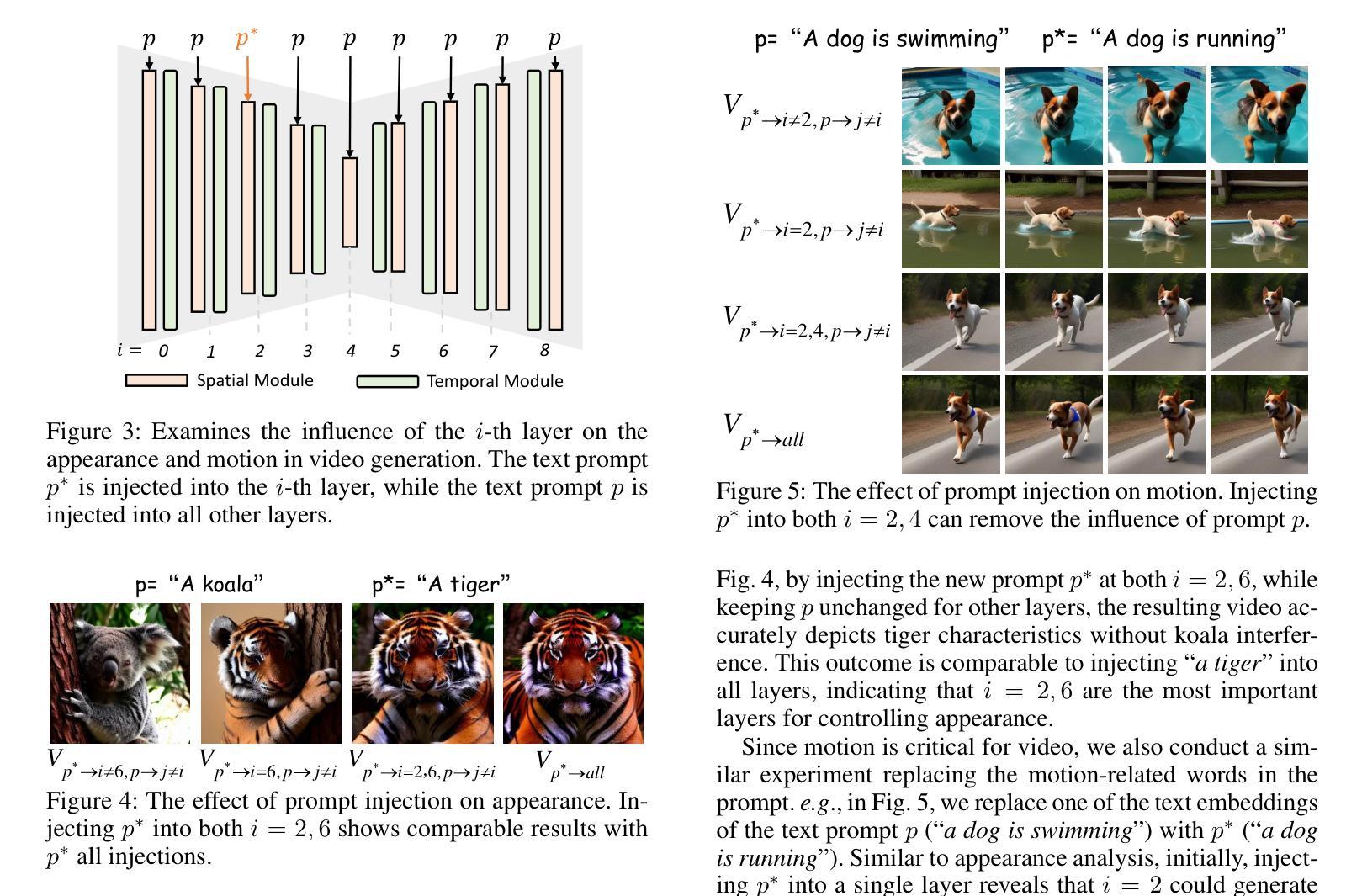

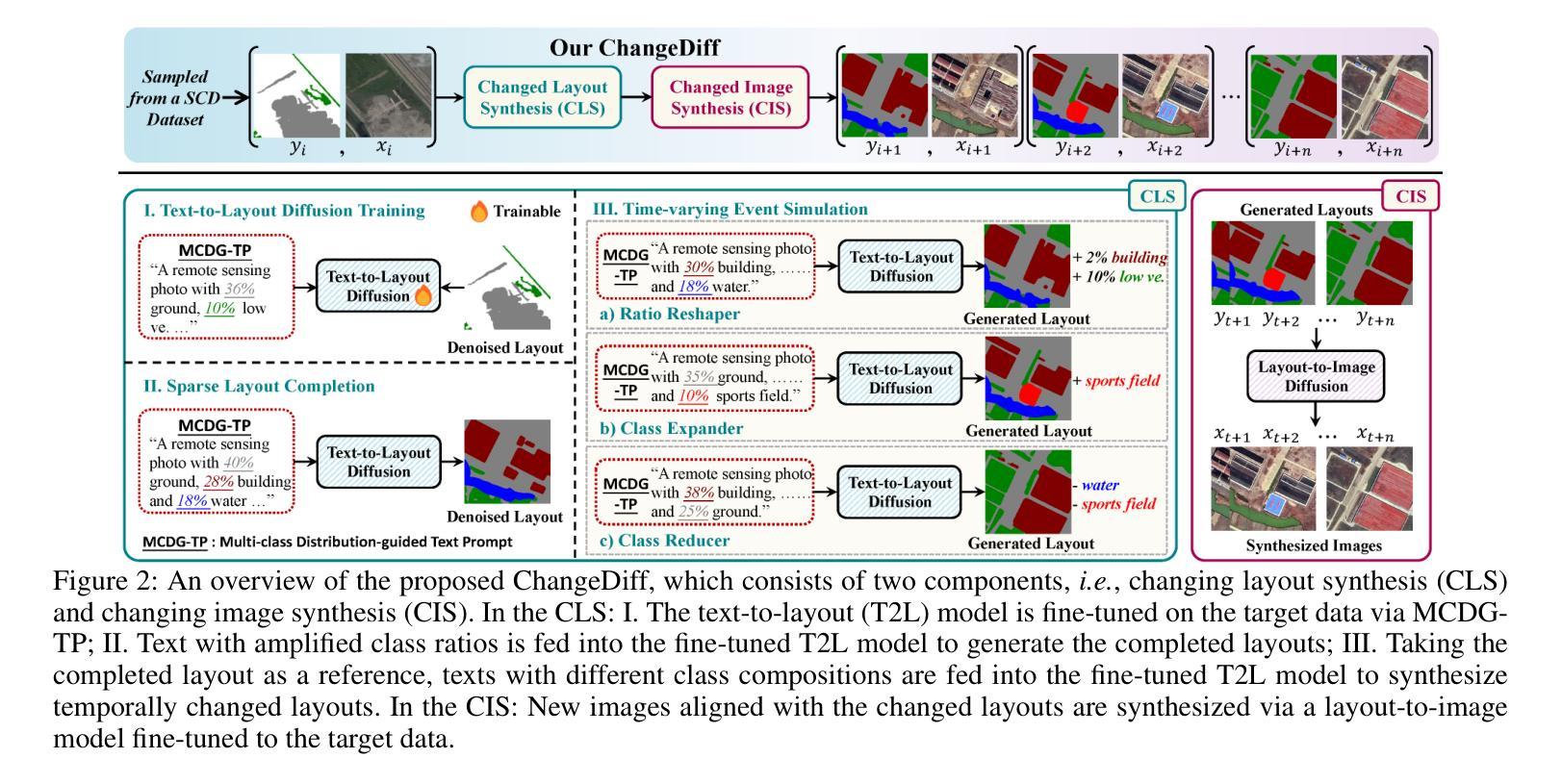
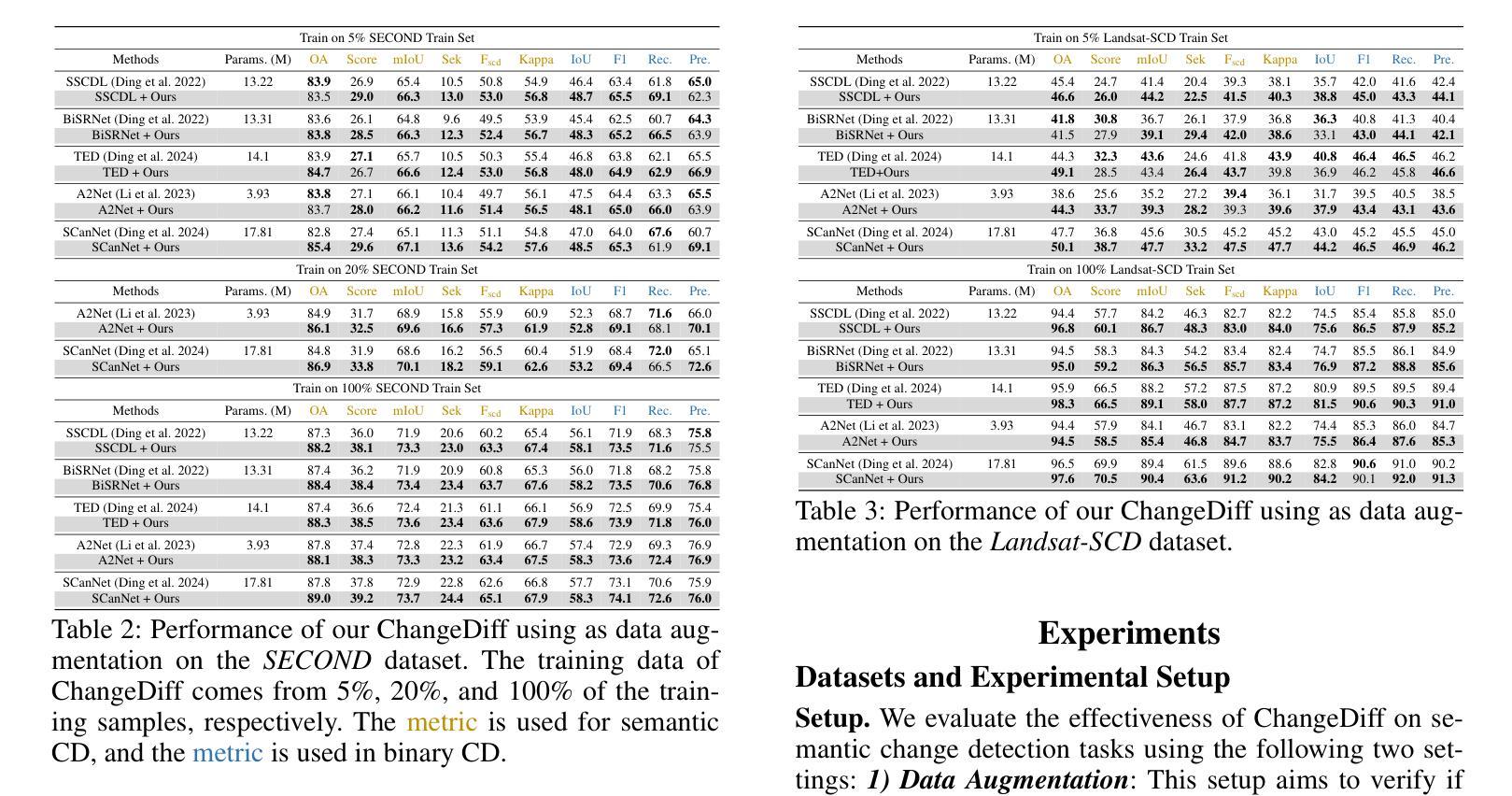
ChangeDiff: A Multi-Temporal Change Detection Data Generator with Flexible Text Prompts via Diffusion Model
Authors:Qi Zang, Jiayi Yang, Shuang Wang, Dong Zhao, Wenjun Yi, Zhun Zhong
Data-driven deep learning models have enabled tremendous progress in change detection (CD) with the support of pixel-level annotations. However, collecting diverse data and manually annotating them is costly, laborious, and knowledge-intensive. Existing generative methods for CD data synthesis show competitive potential in addressing this issue but still face the following limitations: 1) difficulty in flexibly controlling change events, 2) dependence on additional data to train the data generators, 3) focus on specific change detection tasks. To this end, this paper focuses on the semantic CD (SCD) task and develops a multi-temporal SCD data generator ChangeDiff by exploring powerful diffusion models. ChangeDiff innovatively generates change data in two steps: first, it uses text prompts and a text-to-layout (T2L) model to create continuous layouts, and then it employs layout-to-image (L2I) to convert these layouts into images. Specifically, we propose multi-class distribution-guided text prompts (MCDG-TP), allowing for layouts to be generated flexibly through controllable classes and their corresponding ratios. Subsequently, to generalize the T2L model to the proposed MCDG-TP, a class distribution refinement loss is further designed as training supervision. %For the former, a multi-classdistribution-guided text prompt (MCDG-TP) is proposed to complement via controllable classes and ratios. To generalize the text-to-image diffusion model to the proposed MCDG-TP, a class distribution refinement loss is designed as training supervision. For the latter, MCDG-TP in three modes is proposed to synthesize new layout masks from various texts. Our generated data shows significant progress in temporal continuity, spatial diversity, and quality realism, empowering change detectors with accuracy and transferability. The code is available at https://github.com/DZhaoXd/ChangeDiff
数据驱动的深度学习模型在变化检测(CD)方面取得了巨大的进步,这得益于像素级注释的支持。然而,收集多样化的数据并对其进行手动标注是成本高昂、耗时且知识密集型的。现有的CD数据合成生成方法具有竞争力,并在解决此问题方面显示出潜力,但它们仍面临以下局限性:1)难以灵活控制变化事件;2)依赖于其他数据来训练数据生成器;3)专注于特定的变化检测任务。为此,本文专注于语义CD(SCD)任务,并通过探索强大的扩散模型,开发了一种多时间尺度SCD数据生成器ChangeDiff。ChangeDiff创新性地通过两个步骤生成变化数据:首先,它使用文本提示和文本到布局(T2L)模型来创建连续布局,然后采用布局到图像(L2I)将这些布局转换为图像。具体来说,我们提出了多类分布引导文本提示(MCDG-TP),通过可控类别及其相应比例,使布局生成更加灵活。随后,为了将T2L模型推广到提出的MCDG-TP,进一步设计了类分布细化损失作为训练监督。针对前者,提出了多类分布引导文本提示(MCDG-TP)进行补充,通过可控类别和比例实现。为了将文本到图像扩散模型推广到提出的MCDG-TP,设计了类分布细化损失作为训练监督。针对后者,提出了三种模式下的MCDG-TP,用于根据各种文本合成新的布局掩膜。我们生成的数据在时序连续性、空间多样性和质量现实性方面取得了显著进展,为提高变化检测器的准确性和可迁移性提供了动力。代码可在https://github.com/DZhaoXd/ChangeDiff找到。
论文及项目相关链接
Summary
本文关注语义变化检测(SCD)任务,利用扩散模型开发了一种多时态SCD数据生成器ChangeDiff。ChangeDiff通过两步生成变化数据:首先使用文本提示和文本到布局(T2L)模型创建连续布局,然后利用布局到图像(L2I)将这些布局转换为图像。为解决现有生成方法的局限性,提出了多类分布引导文本提示(MCDG-TP),通过可控类别和相应比例实现灵活布局生成。此外,为将T2L模型推广到MCDG-TP,设计了一种类分布细化损失作为训练监督。该生成器在时序连续性、空间多样性和质量现实性方面取得显著进展,增强了变化检测器的准确性和可迁移性。
Key Takeaways
- 数据驱动的深度学习模型在变化检测中取得巨大进展,但数据收集和手动标注成本高昂。
- 现有生成方法在变化检测数据合成中具有竞争潜力,但仍存在控制变化事件难、依赖额外数据训练数据生成器等局限。
- 本文关注语义变化检测(SCD)任务,利用扩散模型开发多时态SCD数据生成器ChangeDiff。
- ChangeDiff通过两步生成变化数据:创建连续布局并转换为图像。
- 引入多类分布引导文本提示(MCDG-TP),实现灵活布局生成。
- 设计类分布细化损失作为训练监督,以将T2L模型推广到MCDG-TP。
- 生成的数据在时序连续性、空间多样性和质量现实性方面表现显著,增强了变化检测器的性能。
点此查看论文截图



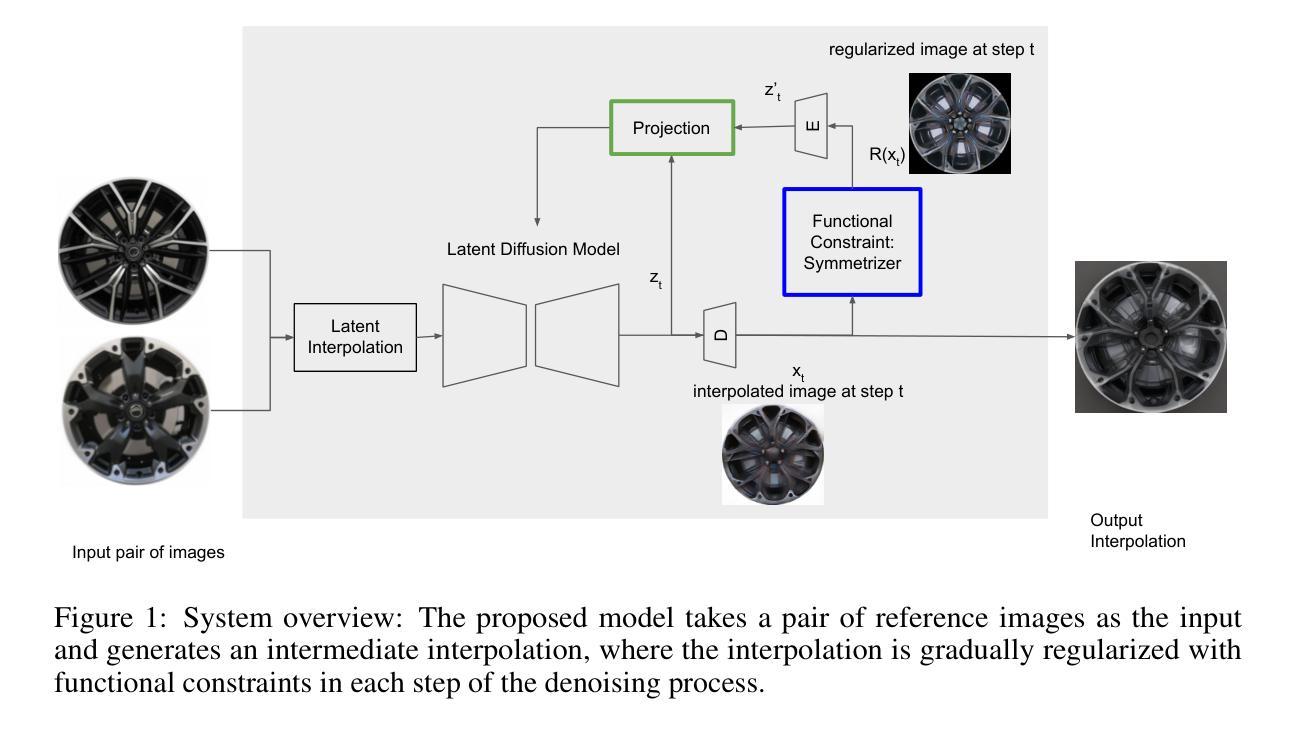
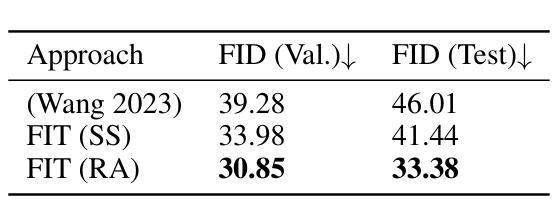
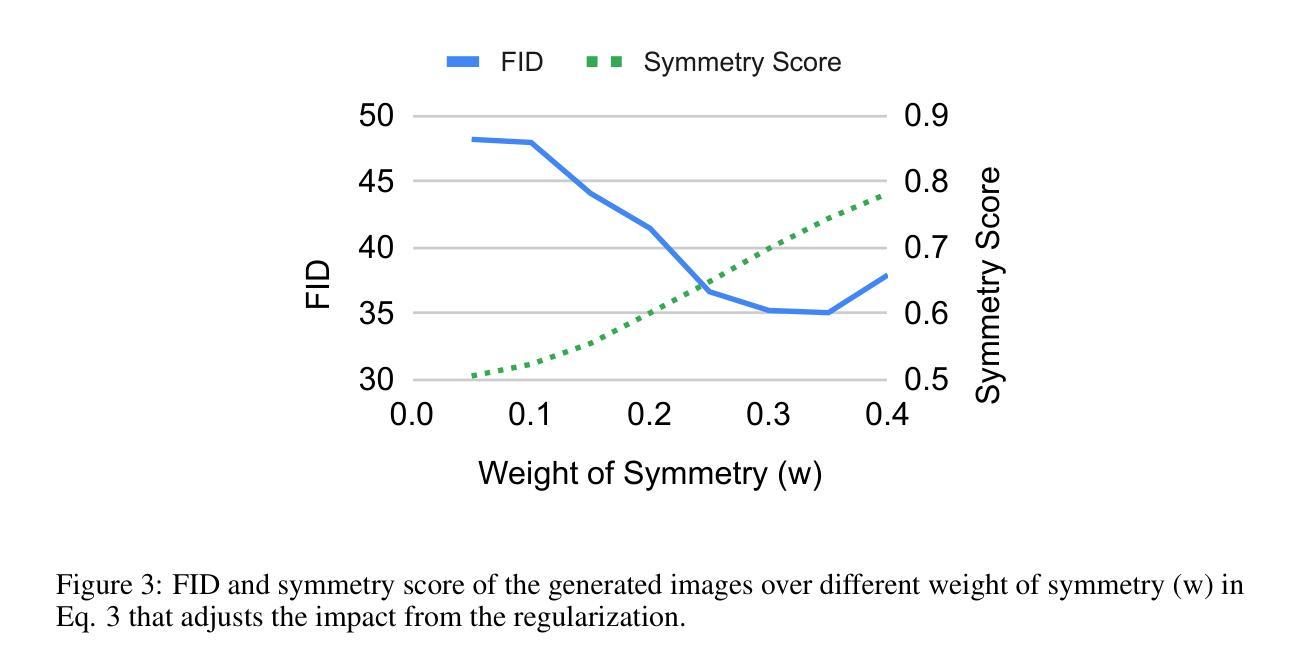
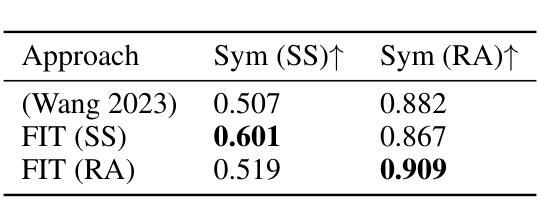
Stylish and Functional: Guided Interpolation Subject to Physical Constraints
Authors:Yan-Ying Chen, Nikos Arechiga, Chenyang Yuan, Matthew Hong, Matt Klenk, Charlene Wu
Generative AI is revolutionizing engineering design practices by enabling rapid prototyping and manipulation of designs. One example of design manipulation involves taking two reference design images and using them as prompts to generate a design image that combines aspects of both. Real engineering designs have physical constraints and functional requirements in addition to aesthetic design considerations. Internet-scale foundation models commonly used for image generation, however, are unable to take these physical constraints and functional requirements into consideration as part of the generation process. We consider the problem of generating a design inspired by two input designs, and propose a zero-shot framework toward enforcing physical, functional requirements over the generation process by leveraging a pretrained diffusion model as the backbone. As a case study, we consider the example of rotational symmetry in generation of wheel designs. Automotive wheels are required to be rotationally symmetric for physical stability. We formulate the requirement of rotational symmetry by the use of a symmetrizer, and we use this symmetrizer to guide the diffusion process towards symmetric wheel generations. Our experimental results find that the proposed approach makes generated interpolations with higher realism than methods in related work, as evaluated by Fr'echet inception distance (FID). We also find that our approach generates designs that more closely satisfy physical and functional requirements than generating without the symmetry guidance.
生成式人工智能正在通过实现设计的快速原型制作和操作,革新工程设计实践。设计操作的一个例子是,使用两张参考设计图像作为提示,生成一张结合了两者特点的图像。在实际的工程设计过程中,除了审美设计考虑因素之外,还存在物理约束和功能要求。然而,常用于图像生成的互联网规模基础模型却无法将这些物理约束和功能要求纳入生成过程的考量之中。我们考虑了由两个输入设计生成设计的问题,并提出了一种零样本框架,利用预训练的扩散模型作为骨干来强制在生成过程中实施物理和功能要求。作为案例研究,我们考虑了生成轮毂设计中的旋转对称性问题。汽车轮毂需要旋转对称以保证物理稳定性。我们通过使用对称化工具来制定旋转对称性的要求,并利用它来引导扩散过程产生对称的轮毂。我们的实验结果表明,相较于相关工作中提出的方法,采用本方法生成的插值结果具有更高的逼真性,并通过Fréchet inception距离(FID)进行了评估。我们还发现,与没有对称指导的生成相比,本方法生成的设计更能满足物理和功能要求。
论文及项目相关链接
PDF Accepted by Foundation Models for Science Workshop, 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
Summary
基于生成式人工智能的能力,设计实践正在经历一场革命性的变革,包括快速原型设计和设计操控。但现有的互联网规模基础模型无法考虑物理约束和功能性需求。我们提出了一种基于预训练扩散模型的零样本框架,通过利用对称器来指导扩散过程,满足物理稳定性和功能性需求。实验结果表明,该方法生成的插值图像更具真实感,且生成的设计更满足物理和功能性需求。
Key Takeaways
- 生成式人工智能正在改变工程设计的实践方式,可以实现快速原型设计和设计操控。
- 当前互联网规模基础模型在设计过程中无法考虑物理约束和功能性需求。
- 提出了一种基于预训练扩散模型的零样本框架,通过引入对称器来满足物理稳定性和功能性需求。
- 实验结果表明,该方法生成的图像更具真实感。
- 该方法生成的设计更能满足物理和功能性需求。
- 以车轮设计为例,通过旋转对称性要求来指导扩散过程,生成旋转对称的车轮设计。
点此查看论文截图



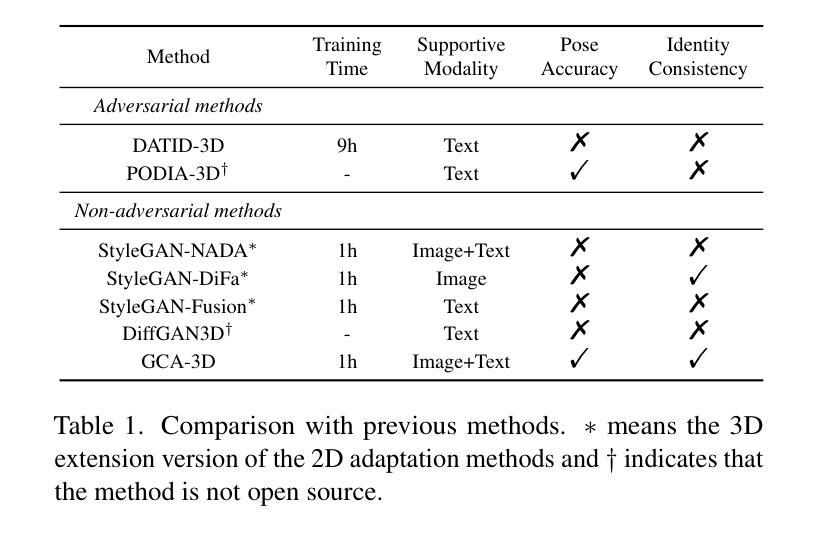
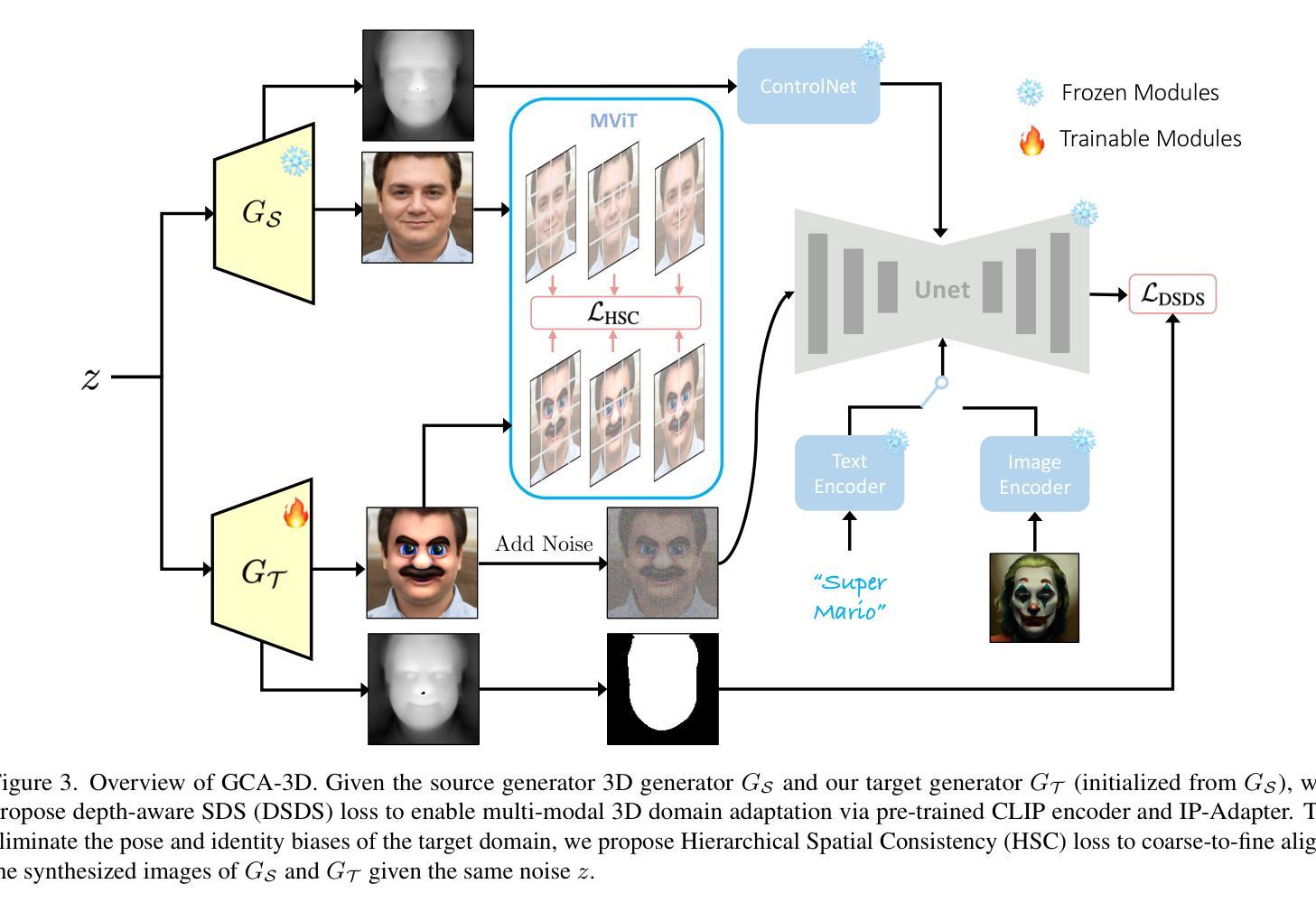
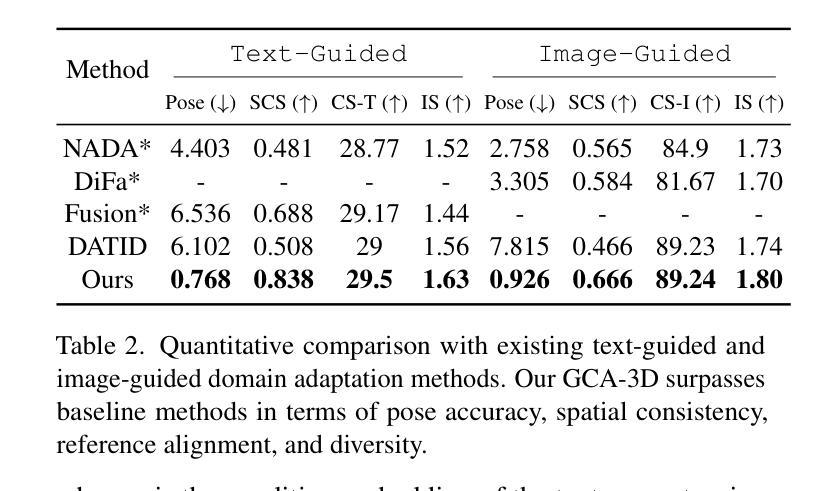
GCA-3D: Towards Generalized and Consistent Domain Adaptation of 3D Generators
Authors:Hengjia Li, Yang Liu, Yibo Zhao, Haoran Cheng, Yang Yang, Linxuan Xia, Zekai Luo, Qibo Qiu, Boxi Wu, Tu Zheng, Zheng Yang, Deng Cai
Recently, 3D generative domain adaptation has emerged to adapt the pre-trained generator to other domains without collecting massive datasets and camera pose distributions. Typically, they leverage large-scale pre-trained text-to-image diffusion models to synthesize images for the target domain and then fine-tune the 3D model. However, they suffer from the tedious pipeline of data generation, which inevitably introduces pose bias between the source domain and synthetic dataset. Furthermore, they are not generalized to support one-shot image-guided domain adaptation, which is more challenging due to the more severe pose bias and additional identity bias introduced by the single image reference. To address these issues, we propose GCA-3D, a generalized and consistent 3D domain adaptation method without the intricate pipeline of data generation. Different from previous pipeline methods, we introduce multi-modal depth-aware score distillation sampling loss to efficiently adapt 3D generative models in a non-adversarial manner. This multi-modal loss enables GCA-3D in both text prompt and one-shot image prompt adaptation. Besides, it leverages per-instance depth maps from the volume rendering module to mitigate the overfitting problem and retain the diversity of results. To enhance the pose and identity consistency, we further propose a hierarchical spatial consistency loss to align the spatial structure between the generated images in the source and target domain. Experiments demonstrate that GCA-3D outperforms previous methods in terms of efficiency, generalization, pose accuracy, and identity consistency.
最近,3D生成领域适应技术出现,用于将预训练的生成器适应到其他领域,而无需收集大规模数据集和相机姿态分布。通常,它们利用大规模预训练的文本到图像扩散模型来合成目标领域的图像,然后对3D模型进行微调。然而,它们存在数据生成流程繁琐的问题,这不可避免地会在源域和合成数据集之间引入姿态偏差。此外,它们并不通用,无法支持单张图像引导的领域适应,由于更严重的姿态偏差和由单张图像引入的身份偏差,这使得更具挑战性。为了解决这些问题,我们提出了GCA-3D,这是一种通用且一致的3D领域适应方法,无需复杂的数据生成流程。不同于之前的方法,我们引入了多模态深度感知分数蒸馏采样损失,以非对抗性的方式有效地适应3D生成模型。这种多模态损失使GCA-3D在文本提示和单张图像提示适应中都能发挥作用。此外,它从体积渲染模块利用每个实例的深度图来缓解过拟合问题并保持结果的多样性。为了提高姿态和身份的一致性,我们进一步提出了分层空间一致性损失,以对齐源域和目标域生成图像的空间结构。实验表明,GCA-3D在效率、通用性、姿态准确性和身份一致性方面优于以前的方法。
论文及项目相关链接
Summary
本文介绍了针对3D生成域适应的新方法GCA-3D。该方法通过引入多模态深度感知分数蒸馏采样损失,能够高效、非对抗式地适应3D生成模型。与传统的通过数据生成的方法相比,GCA-3D避免了复杂的数据生成流程,并解决了姿势偏差和身份偏差的问题。此外,它利用体积渲染模块的深度图减轻过拟合问题并保留结果的多样性。实验表明,GCA-3D在效率、泛化能力、姿势准确性和身份一致性方面优于以前的方法。
Key Takeaways
- 3D生成域适应方法旨在将预训练的生成器适应到其他领域,无需收集大规模数据集和相机姿态分布。
- 传统方法利用大规模预训练文本到图像扩散模型进行图像合成,然后对3D模型进行微调,但存在数据生成流程繁琐的问题。
- GCA-3D是一种新型的3D域适应方法,避免了复杂的数据生成流程。
- GCA-3D通过引入多模态深度感知分数蒸馏采样损失,实现了高效、非对抗式的3D模型适应。
- GCA-3D支持文本提示和单张图像提示适应,解决了姿势偏差和身份偏差的问题。
- GCA-3D利用体积渲染模块的深度图来减轻过拟合问题,并保留结果的多样性。
点此查看论文截图




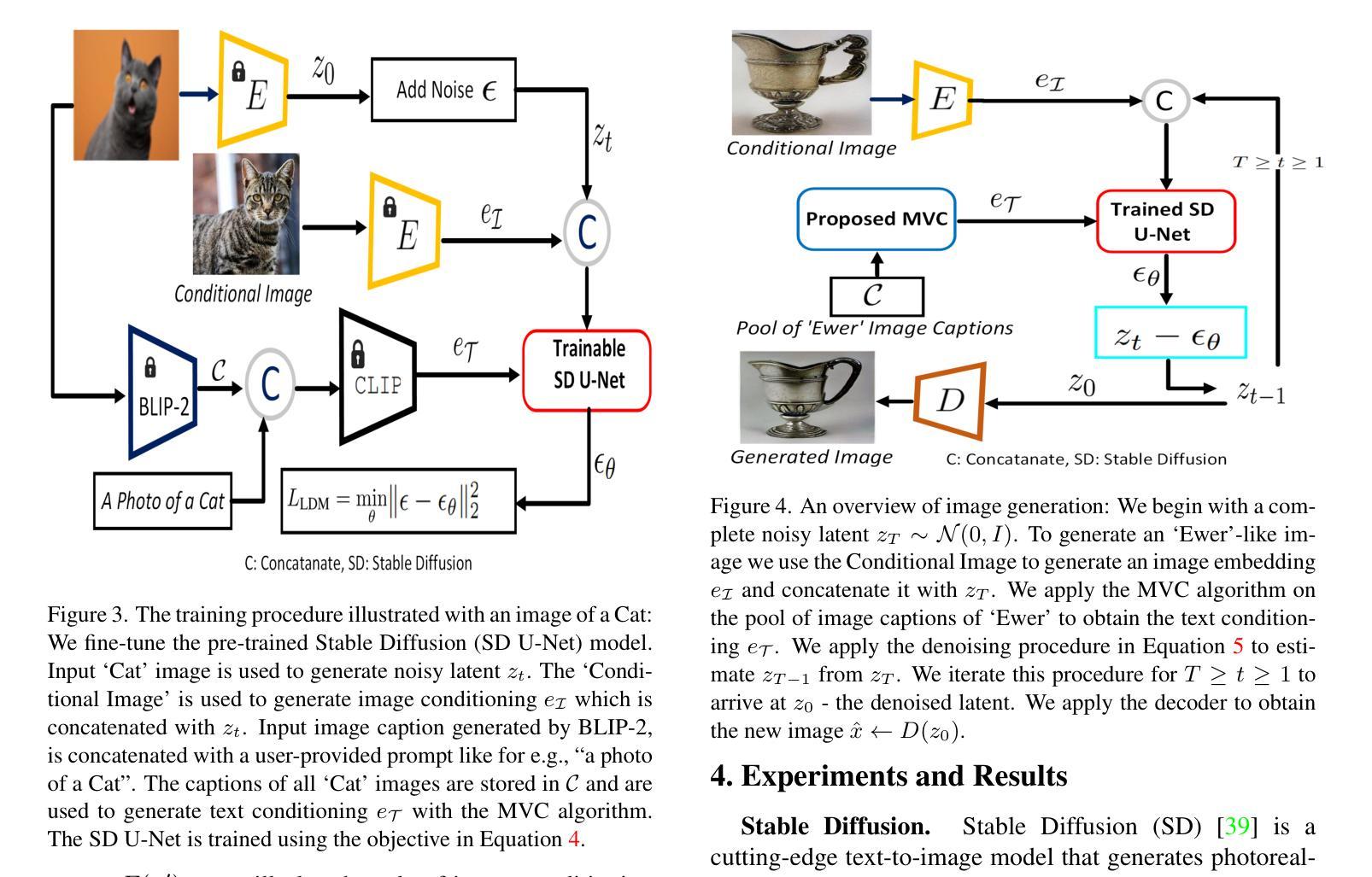
Dataset Augmentation by Mixing Visual Concepts
Authors:Abdullah Al Rahat, Hemanth Venkateswara
This paper proposes a dataset augmentation method by fine-tuning pre-trained diffusion models. Generating images using a pre-trained diffusion model with textual conditioning often results in domain discrepancy between real data and generated images. We propose a fine-tuning approach where we adapt the diffusion model by conditioning it with real images and novel text embeddings. We introduce a unique procedure called Mixing Visual Concepts (MVC) where we create novel text embeddings from image captions. The MVC enables us to generate multiple images which are diverse and yet similar to the real data enabling us to perform effective dataset augmentation. We perform comprehensive qualitative and quantitative evaluations with the proposed dataset augmentation approach showcasing both coarse-grained and finegrained changes in generated images. Our approach outperforms state-of-the-art augmentation techniques on benchmark classification tasks.
本文提出了一种通过微调预训练扩散模型来进行数据集增强方法。使用带有文本条件的预训练扩散模型生成图像往往会导致真实数据与生成图像之间的领域差异。我们提出了一种微调方法,通过以真实图像和新型文本嵌入为条件来适应扩散模型。我们引入了一种独特的程序,称为混合视觉概念(MVC),我们从图像字幕中创建新型的文本嵌入。MVC使我们能够生成多种与真实数据多样且相似的图像,从而能够执行有效的数据集增强。我们进行了全面的定性和定量评估,对所提出的数据集增强方法展示了生成图像的粗细粒度变化。我们的方法在基准分类任务上的表现优于最先进的增强技术。
论文及项目相关链接
PDF Accepted at WACV 2025 main conference
Summary
本文提出一种通过微调预训练扩散模型来进行数据集增强方法。使用预训练扩散模型根据文本条件生成图像往往会导致真实数据与生成图像之间的领域差异。本文提出了一种微调方法,通过以真实图像和新型文本嵌入为条件来适应扩散模型。引入了一种名为混合视觉概念(MVC)的独特程序,通过图像标题创建新型文本嵌入。MVC能够生成多个既多样又类似于真实数据的图像,从而实现了有效的数据集增强。通过综合的定性和定量评估,展示了所提出的数据集增强方法在生成图像中的粗粒度和细粒度变化,并在基准分类任务上优于最新的增强技术。
Key Takeaways
- 论文提出了一种基于微调预训练扩散模型的数据集增强方法。
- 生成图像与真实数据间存在领域差异。
- 论文提出了一个名为“混合视觉概念(MVC)”的独特程序,用于创建新型文本嵌入。
- MVC能够生成多样且类似于真实数据的图像,实现有效的数据集增强。
- 该方法通过综合的定性和定量评估,展示了在生成图像中的粗粒度和细粒度变化。
- 所提出的方法在基准分类任务上优于其他最新的增强技术。
点此查看论文截图



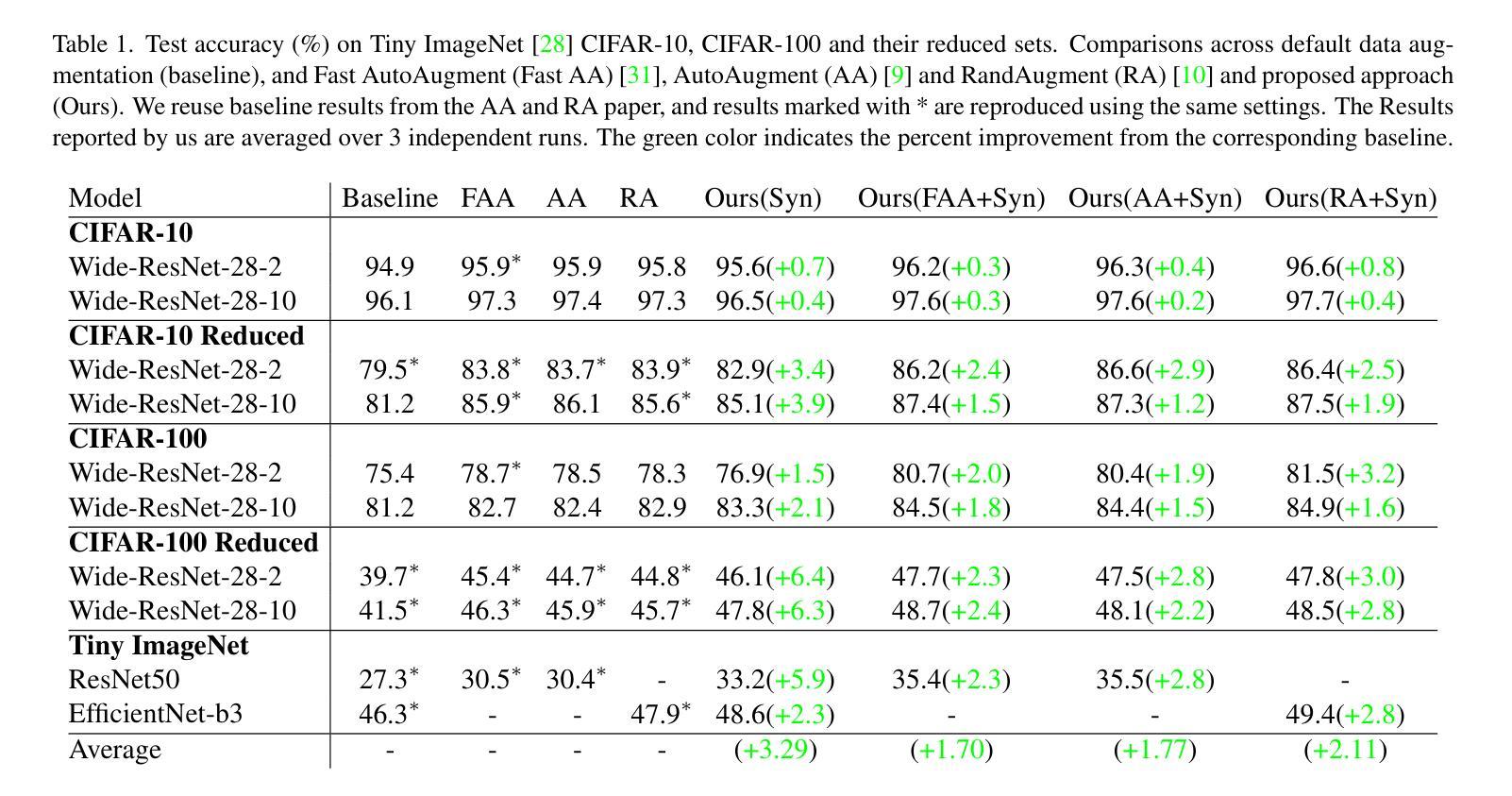

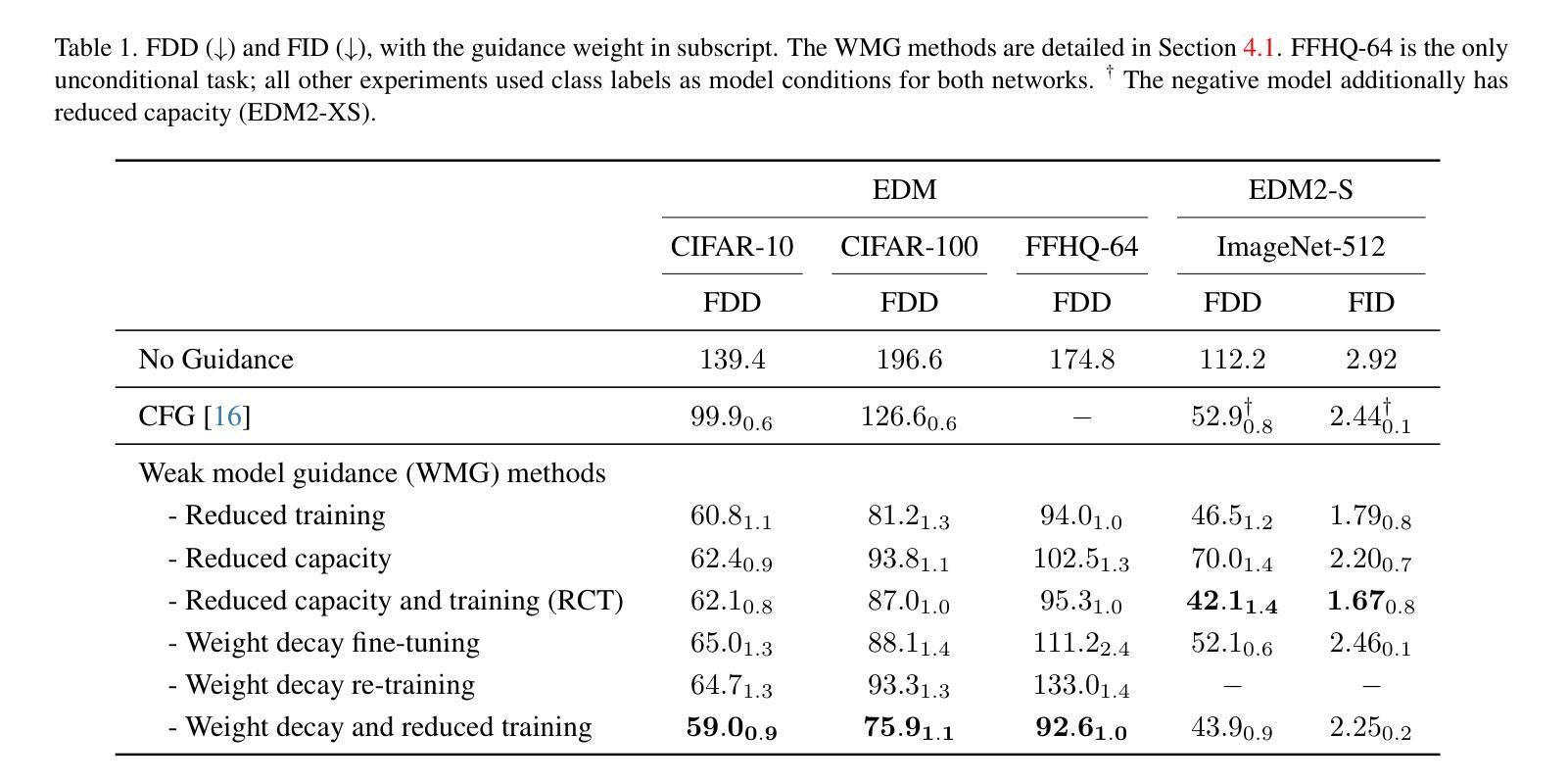
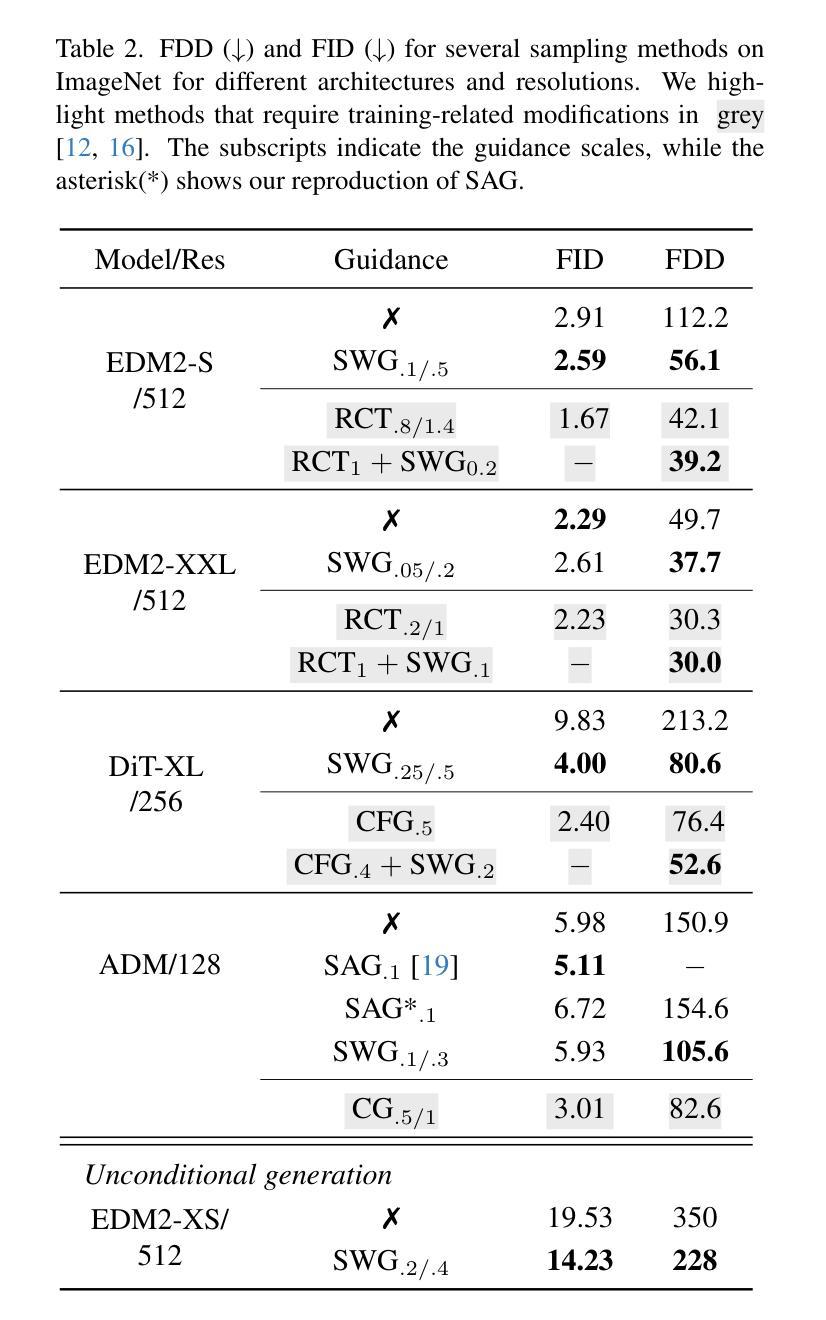
The Unreasonable Effectiveness of Guidance for Diffusion Models
Authors:Tim Kaiser, Nikolas Adaloglou, Markus Kollmann
Guidance is an error-correcting technique used to improve the perceptual quality of images generated by diffusion models. Typically, the correction is achieved by linear extrapolation, using an auxiliary diffusion model that has lower performance than the primary model. Using a 2D toy example, we show that it is highly beneficial when the auxiliary model exhibits similar errors as the primary one but stronger. We verify this finding in higher dimensions, where we show that competitive generative performance to state-of-the-art guidance methods can be achieved when the auxiliary model differs from the primary one only by having stronger weight regularization. As an independent contribution, we investigate whether upweighting long-range spatial dependencies improves visual fidelity. The result is a novel guidance method, which we call sliding window guidance (SWG), that guides the primary model with itself by constraining its receptive field. Intriguingly, SWG aligns better with human preferences than state-of-the-art guidance methods while requiring neither training, architectural modifications, nor class conditioning. The code will be released.
扩散模型中的指导技术是一种用于提高生成图像感知质量的纠错技术。通常,纠错是通过线性外推完成的,使用一个性能低于主模型的辅助扩散模型。通过二维玩具示例,我们展示了当辅助模型表现出与主模型相似的错误但强度更大时,它的益处非常大。我们在更高维度验证了这一发现,在那里我们展示,仅通过加强权重正则化,当辅助模型与主模型不同时,可以实现与最新指导方法相竞争的生产性能。作为一个独立的贡献,我们调查了加强远程空间依赖是否提高视觉保真度。结果是新型指导方法——我们称之为滑动窗口指导(SWG),它通过约束主模型的感受野来指导主模型。有趣的是,SWG更符合人类偏好,而无需进行训练、架构修改或类别条件设置,同时优于最新的指导方法。代码将发布。
论文及项目相关链接
PDF Preprint. 30 pages, 19 figures in total, including appendix
摘要
扩散模型中的Guidance是一种用于提高生成图像感知质量的错误校正技术。通过线性外推使用辅助扩散模型实现校正,其性能通常低于主模型。在二维玩具示例中,我们发现在辅助模型展现出与主模型相似的错误但强度更大时,其效益极高。我们在更高维度验证了这一发现,表明仅通过更强的权重正则化使辅助模型与主模型不同,就能实现与最新指导方法相抗衡的生成性能。作为独立贡献,我们调查了增强长距离空间依赖性是否可以提高视觉逼真度。结果是一种新型指导方法——我们称之为滑动窗口指导(SWG),它通过约束主模型的感受野来指导主模型。有趣的是,SWG更符合人类偏好,既不需要训练、也不需要架构修改或类别条件,即可超越最新指导方法。代码将公开发布。
要点掌握
- Guidance是扩散模型中用于提高生成图像感知质量的错误校正技术。
- 通过线性外推和辅助扩散模型实现Guidance校正,其性能通常低于主模型。
- 在二维和更高维度的示例中,辅助模型与主模型的相似错误但强度更大时效益显著。
- 仅通过更强的权重正则化,就能使辅助模型与主模型区分开来,从而实现强大的生成性能。
- 调查了增强长距离空间依赖性对提高视觉逼真度的影响。
- 提出了新型指导方法——滑动窗口指导(SWG),通过约束主模型的感受野来工作。
点此查看论文截图

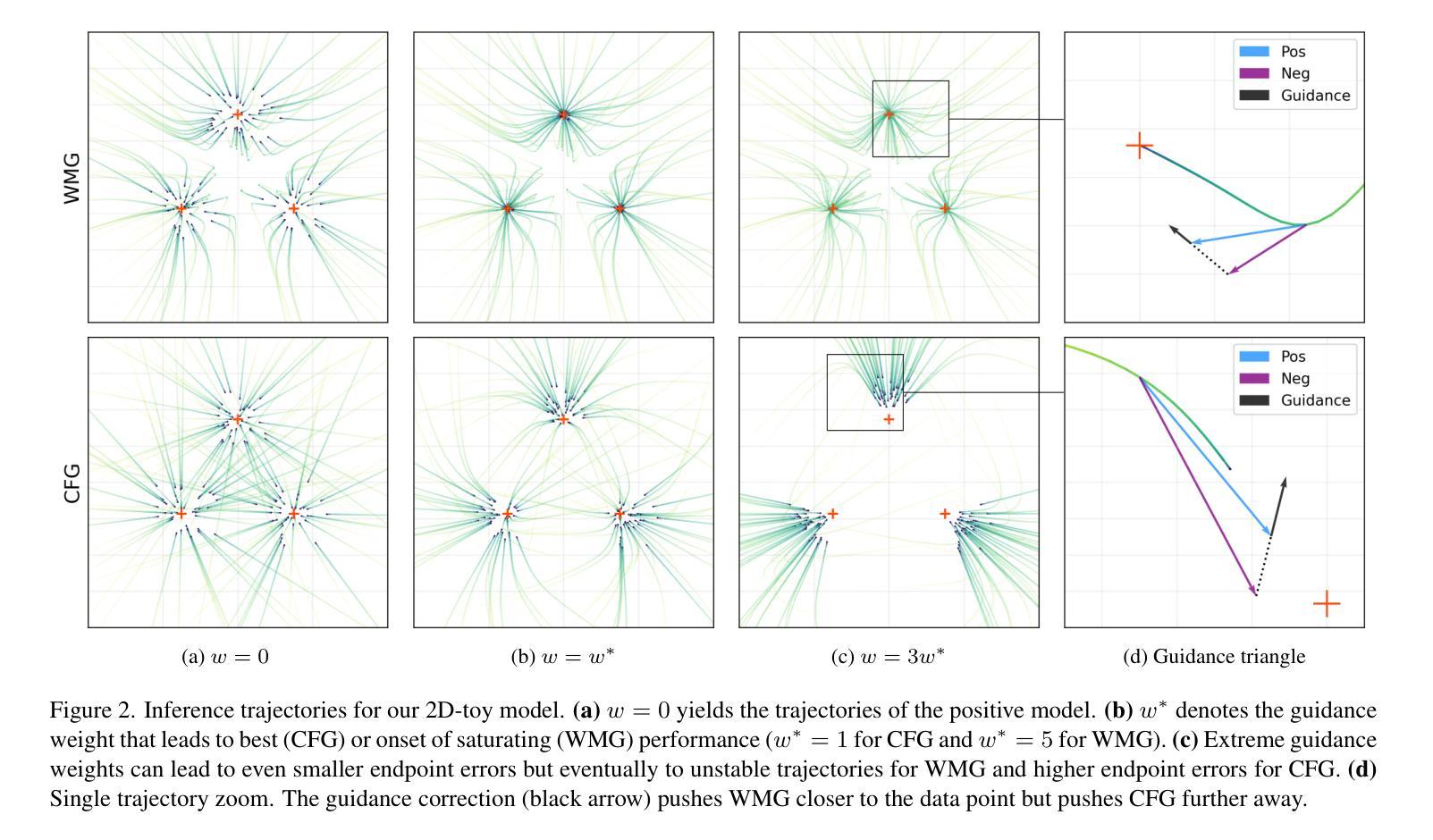
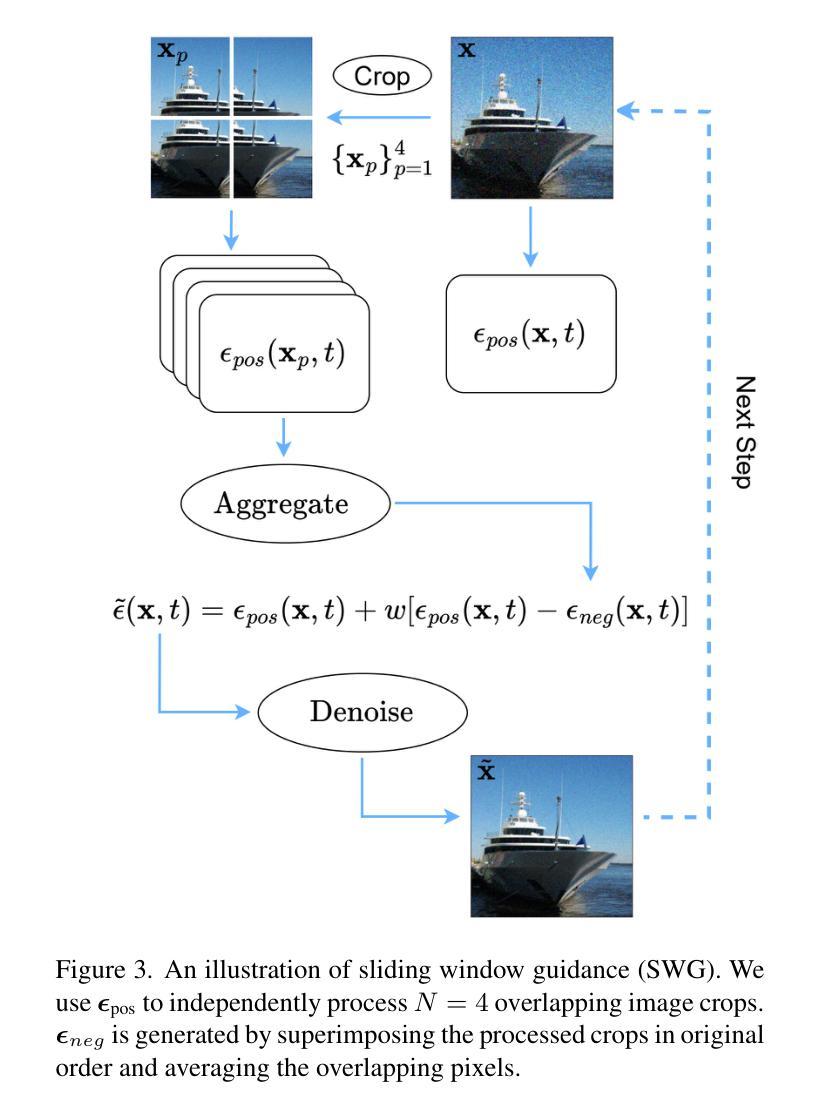
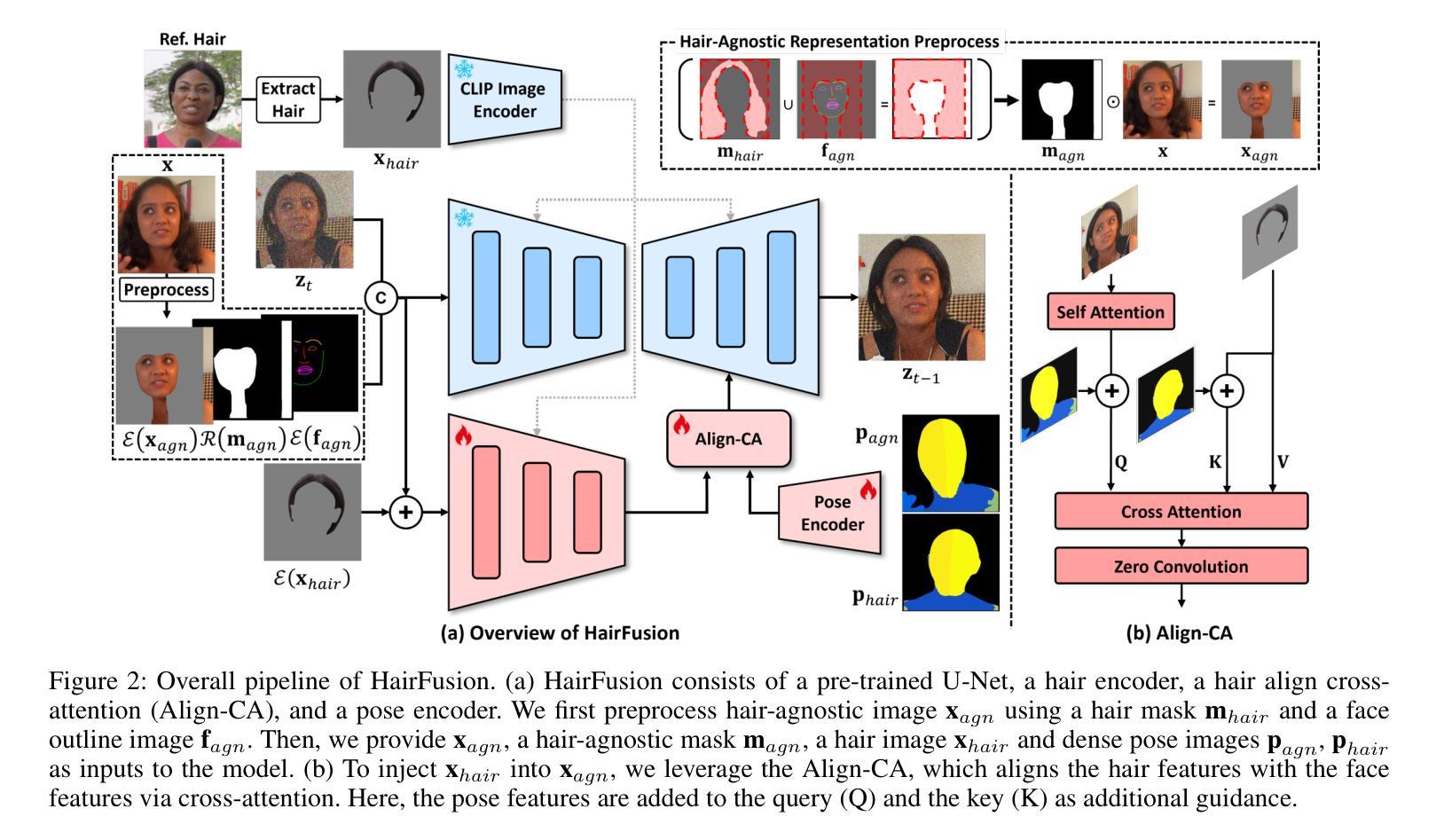
What to Preserve and What to Transfer: Faithful, Identity-Preserving Diffusion-based Hairstyle Transfer
Authors:Chaeyeon Chung, Sunghyun Park, Jeongho Kim, Jaegul Choo
Hairstyle transfer is a challenging task in the image editing field that modifies the hairstyle of a given face image while preserving its other appearance and background features. The existing hairstyle transfer approaches heavily rely on StyleGAN, which is pre-trained on cropped and aligned face images. Hence, they struggle to generalize under challenging conditions such as extreme variations of head poses or focal lengths. To address this issue, we propose a one-stage hairstyle transfer diffusion model, HairFusion, that applies to real-world scenarios. Specifically, we carefully design a hair-agnostic representation as the input of the model, where the original hair information is thoroughly eliminated. Next, we introduce a hair align cross-attention (Align-CA) to accurately align the reference hairstyle with the face image while considering the difference in their head poses. To enhance the preservation of the face image’s original features, we leverage adaptive hair blending during the inference, where the output’s hair regions are estimated by the cross-attention map in Align-CA and blended with non-hair areas of the face image. Our experimental results show that our method achieves state-of-the-art performance compared to the existing methods in preserving the integrity of both the transferred hairstyle and the surrounding features. The codes are available at https://github.com/cychungg/HairFusion
发型转移是图像编辑领域中的一个挑战性任务,它修改给定人脸图像的发型,同时保留其其他外观和背景特征。现有的发型转移方法严重依赖于StyleGAN,该模型是在裁剪和对齐的人脸图像上进行预训练的。因此,它们在极端头部姿势或焦距等挑战条件下难以推广。为了解决这个问题,我们提出了一种一站式的发型转移扩散模型HairFusion,适用于真实场景。具体来说,我们精心设计了一个与头发无关的表示作为模型的输入,其中原始的头发信息被彻底消除。接下来,我们引入了一种头发对齐交叉注意力(Align-CA)机制,以准确地将参考发型与脸部图像对齐,同时考虑它们头部姿势的差异。为了提高脸部图像原始特征的保留效果,我们在推理过程中利用了自适应头发混合技术,其中输出头发的区域通过Align-CA中的交叉注意力图进行估计,并与脸部图像的非头发区域进行混合。我们的实验结果表明,与现有方法相比,我们的方法在保留转移发型和周围特征完整性方面达到了最新技术水平。代码可通过https://github.com/cychungg/HairFusion获取。
论文及项目相关链接
PDF Accepted to AAAI 2025
Summary
基于扩散模型的人脸图像发型转换技术,旨在解决在真实场景中发型转换的问题。该方法通过设计一种头发无关的表示方式作为模型的输入,消除原始头发信息。同时,引入头发对齐交叉注意力机制来准确对齐参考发型与脸部图像,并在推理过程中采用自适应头发混合技术,提高面部图像原始特征的保留效果。实验结果表明,该方法在保留转移发型和周围特征完整性方面达到了先进水平。
Key Takeaways
- 该技术旨在解决真实场景中发型转换的挑战性问题。
- 通过设计头发无关的表示方式作为模型输入,消除原始头发信息。
- 引入头发对齐交叉注意力机制,准确对齐参考发型与脸部图像。
- 采用自适应头发混合技术,提高面部图像原始特征的保留效果。
- 该方法通过实验验证了其在保留转移发型和周围特征完整性方面的优势。
- 该方法的代码已公开可用。
点此查看论文截图





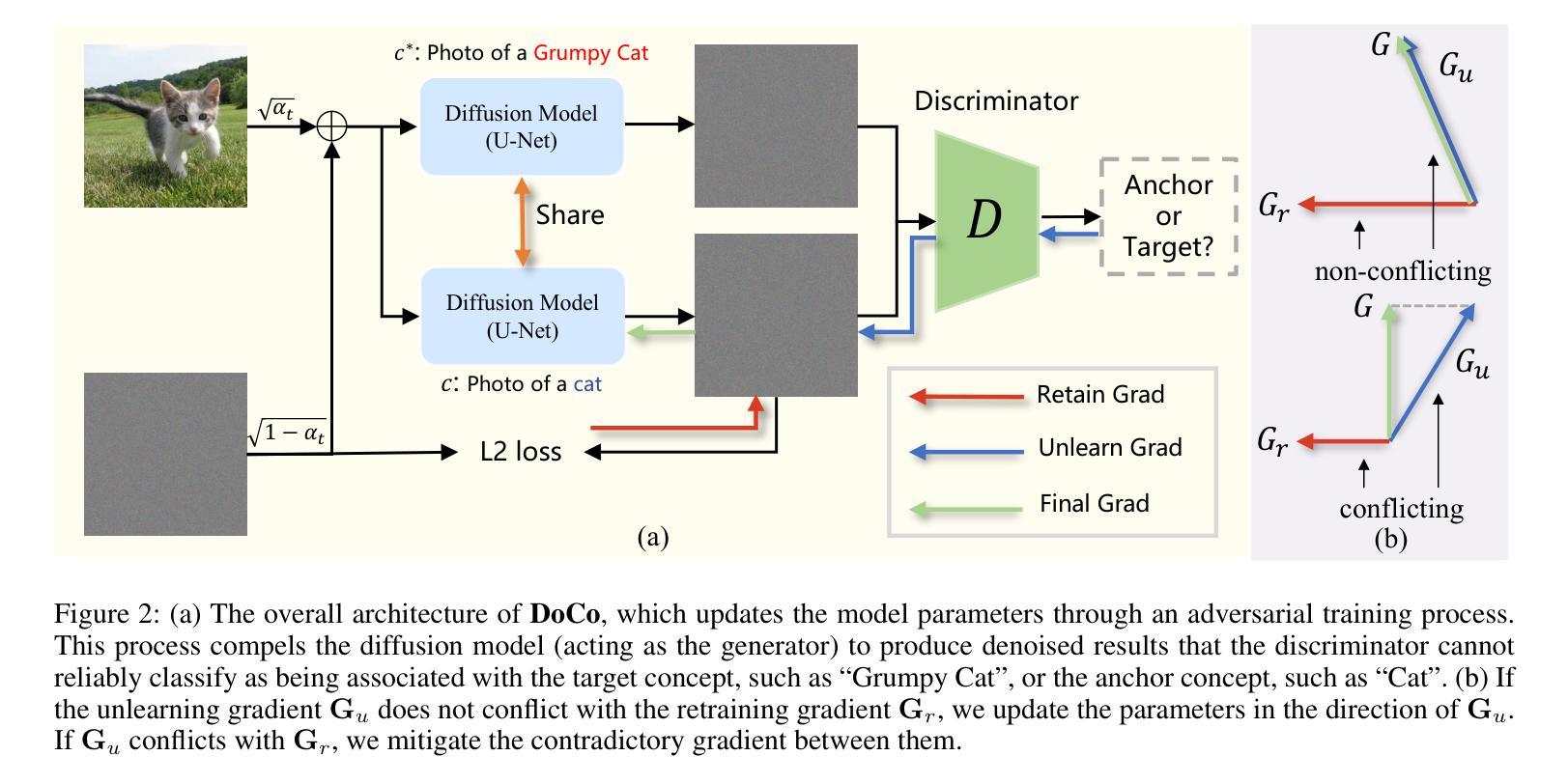
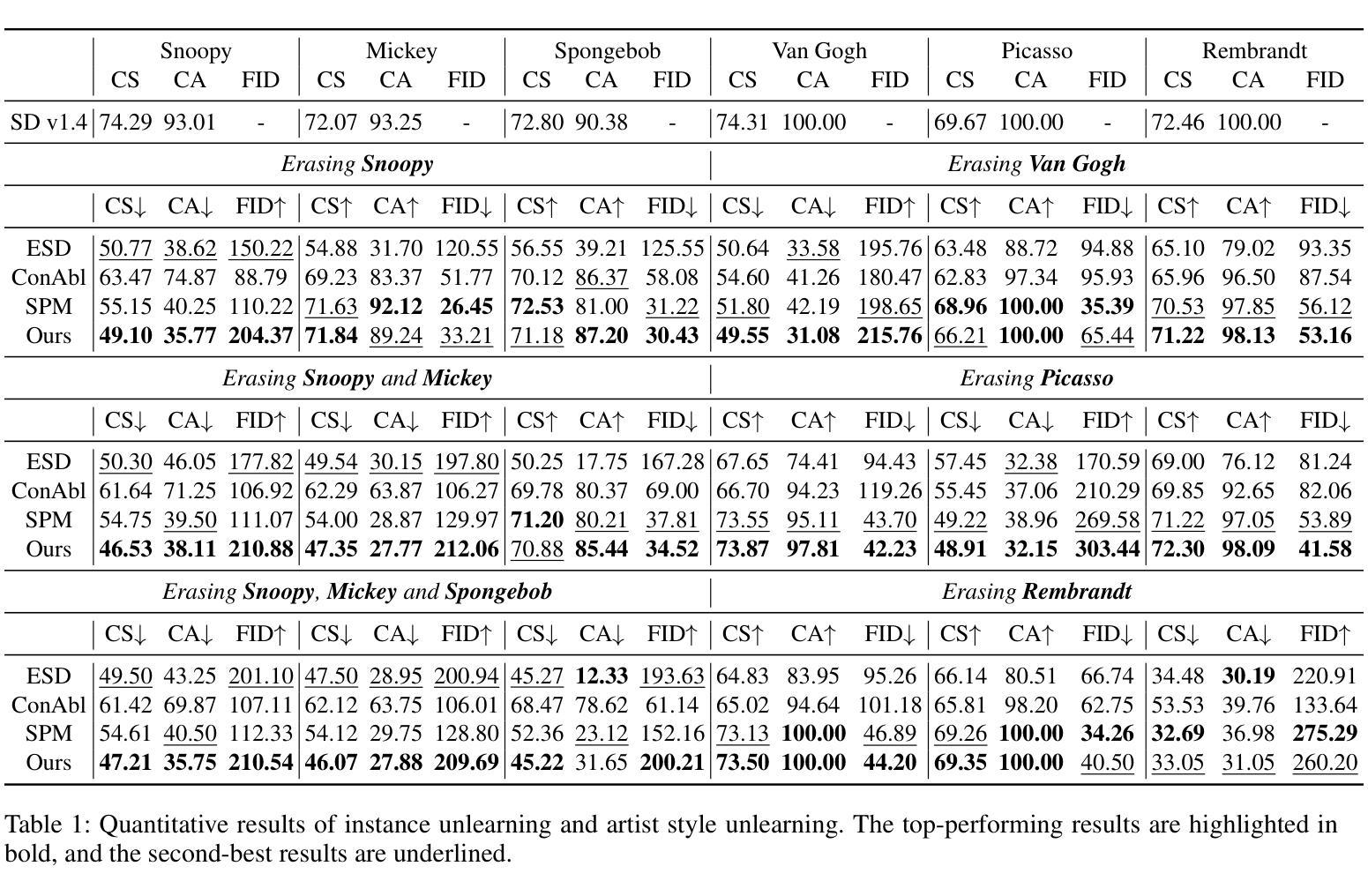
Unlearning Concepts in Diffusion Model via Concept Domain Correction and Concept Preserving Gradient
Authors:Yongliang Wu, Shiji Zhou, Mingzhuo Yang, Lianzhe Wang, Heng Chang, Wenbo Zhu, Xinting Hu, Xiao Zhou, Xu Yang
Text-to-image diffusion models have achieved remarkable success in generating photorealistic images. However, the inclusion of sensitive information during pre-training poses significant risks. Machine Unlearning (MU) offers a promising solution to eliminate sensitive concepts from these models. Despite its potential, existing MU methods face two main challenges: 1) limited generalization, where concept erasure is effective only within the unlearned set, failing to prevent sensitive concept generation from out-of-set prompts; and 2) utility degradation, where removing target concepts significantly impacts the model’s overall performance. To address these issues, we propose a novel concept domain correction framework named \textbf{DoCo} (\textbf{Do}main \textbf{Co}rrection). By aligning the output domains of sensitive and anchor concepts through adversarial training, our approach ensures comprehensive unlearning of target concepts. Additionally, we introduce a concept-preserving gradient surgery technique that mitigates conflicting gradient components, thereby preserving the model’s utility while unlearning specific concepts. Extensive experiments across various instances, styles, and offensive concepts demonstrate the effectiveness of our method in unlearning targeted concepts with minimal impact on related concepts, outperforming previous approaches even for out-of-distribution prompts.
文本到图像的扩散模型在生成逼真的图像方面取得了显著的成就。然而,在预训练过程中引入敏感信息带来了巨大的风险。机器遗忘(MU)为从这些模型中消除敏感概念提供了有前途的解决方案。尽管潜力巨大,但现有的MU方法面临两个主要挑战:1)有限的泛化能力,概念消除仅在未学习的集合内有效,无法防止来自集合外提示的敏感概念生成;2)效用降低,移除目标概念会显著影响模型的总体性能。为了解决这些问题,我们提出了一种名为DoCo(领域修正)的新型概念域修正框架。通过对敏感概念和锚定概念输出域的对齐,我们的方法确保了目标概念的全面遗忘。此外,我们引入了一种概念保留梯度手术技术,该技术可以缓解冲突的梯度成分,从而在遗忘特定概念的同时保持模型的实用性。在各种实例、风格和冒犯概念的广泛实验表明,我们的方法在遗忘目标概念方面非常有效,对相关概念的影响最小,甚至在超出分布范围的提示中也优于以前的方法。
论文及项目相关链接
PDF AAAI 2025
Summary
文本到图像的扩散模型在生成逼真的图像方面取得了显著的成功,但在预训练过程中引入敏感信息带来了很大的风险。机器遗忘(MU)为解决这一问题提供了有前景的解决方案。然而,现有的MU方法面临两大挑战:概念擦除仅限于未学习的数据集内有效,无法防止敏感概念从数据集外的提示产生;移除目标概念会影响模型的总体性能。为解决这些问题,我们提出了名为DoCo的新概念域校正框架,通过对敏感概念和锚概念输出域的对齐,确保目标概念的全面遗忘。此外,我们引入了概念保留梯度手术技术,以缓解冲突梯度成分,从而在遗忘特定概念的同时保留模型的实用性。实验证明,我们的方法在遗忘目标概念时对相关内容影响最小,即使对于分布外的提示也优于以前的方法。
Key Takeaways
- 文本到图像的扩散模型能生成逼真的图像,但预训练中的敏感信息引入存在风险。
- 现有机器遗忘(MU)方法面临局限性和影响模型整体性能的挑战。
- DoCo框架通过概念域校正和梯度手术技术解决上述问题。
- DoCo框架确保了目标概念的全面遗忘,同时最小化了对相关内容的影响。
- 实验证明DoCo框架对于分布外的提示也优于之前的方法。
- DoCo框架具有广泛的应用潜力,可以应用于各种实例、风格和冒犯性概念的遗忘。
点此查看论文截图



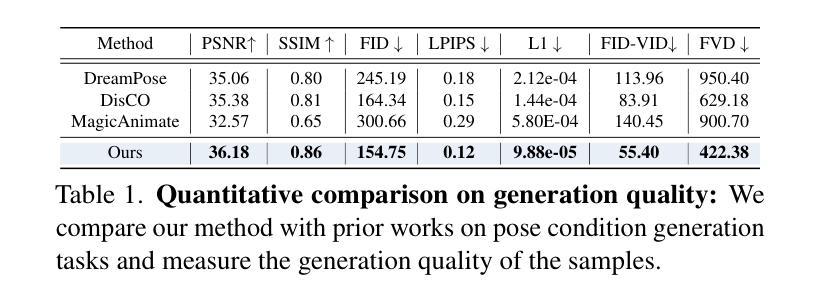
Synthesizing Moving People with 3D Control
Authors:Boyi Li, Junming Chen, Jathushan Rajasegaran, Yossi Gandelsman, Alexei A. Efros, Jitendra Malik
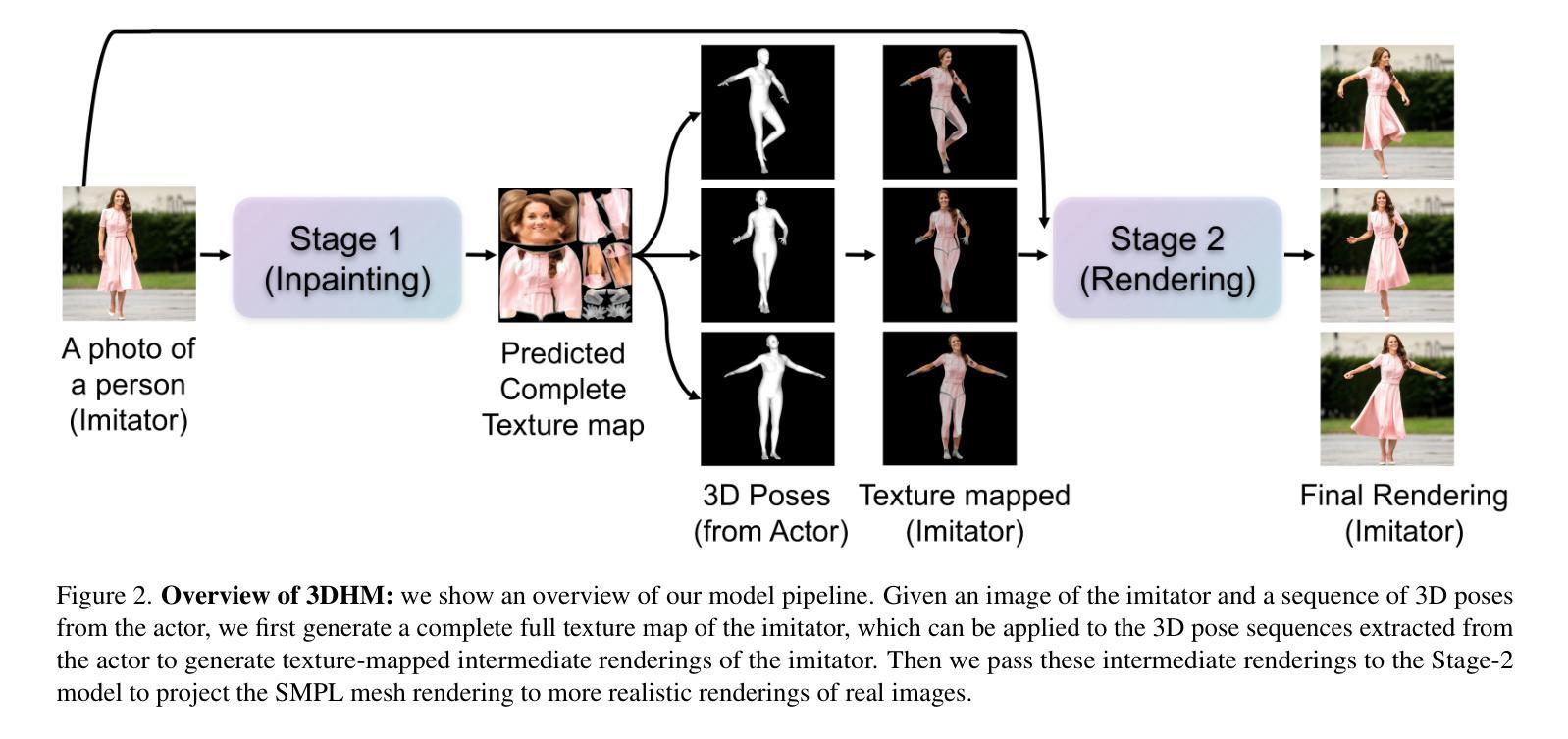
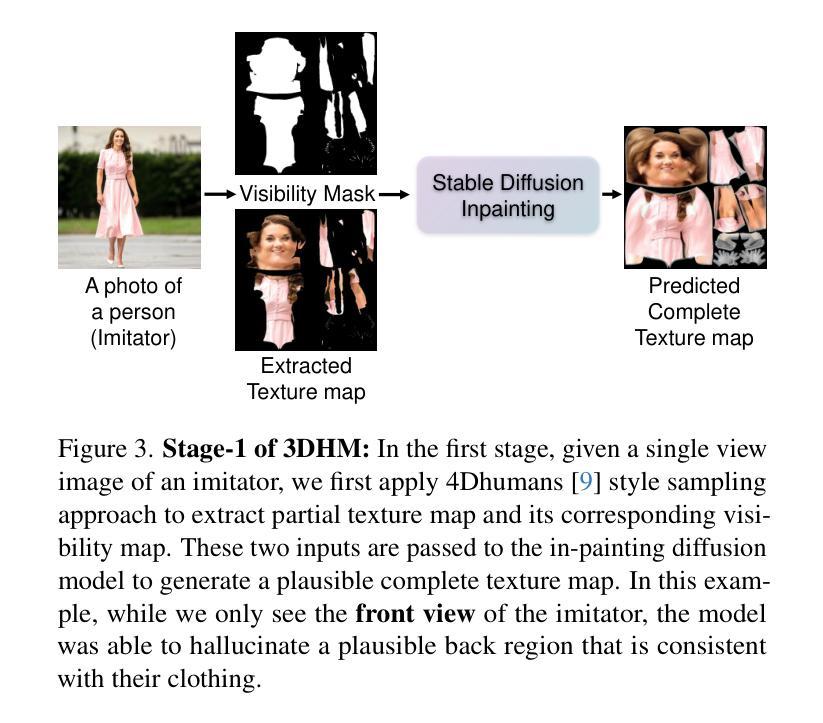
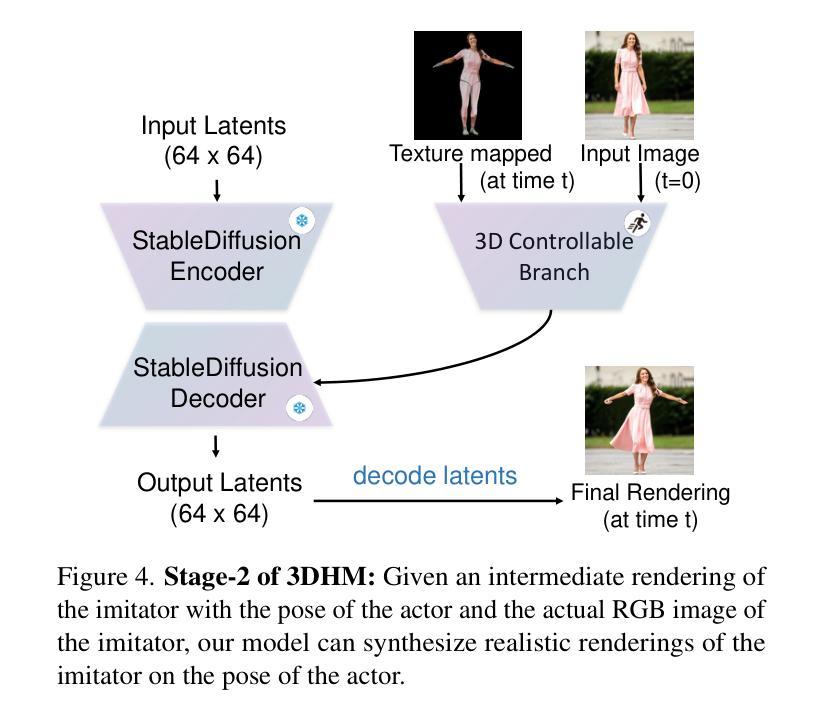
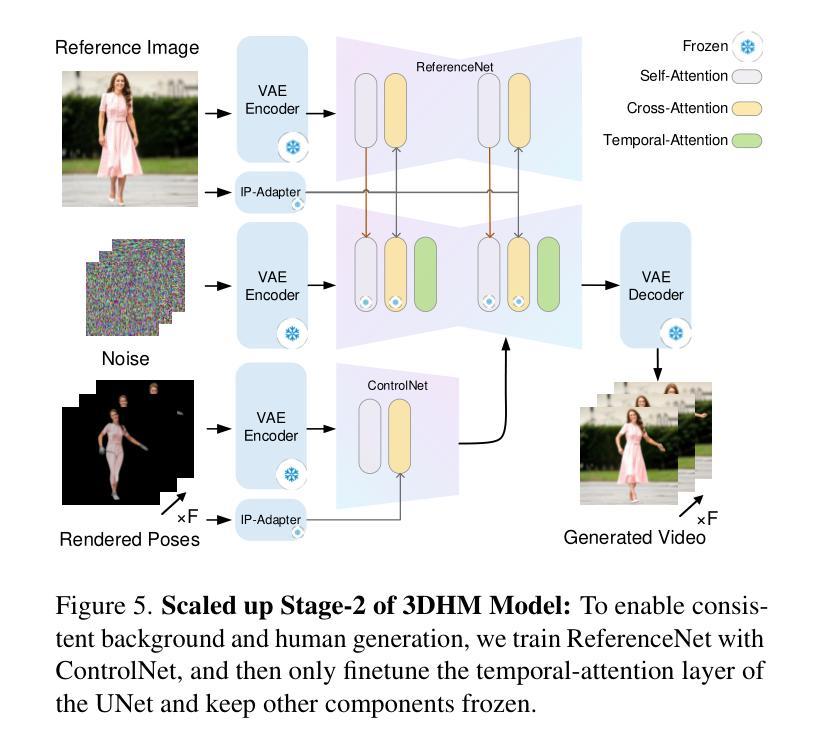
In this paper, we present a diffusion model-based framework for animating people from a single image for a given target 3D motion sequence. Our approach has two core components: a) learning priors about invisible parts of the human body and clothing, and b) rendering novel body poses with proper clothing and texture. For the first part, we learn an in-filling diffusion model to hallucinate unseen parts of a person given a single image. We train this model on texture map space, which makes it more sample-efficient since it is invariant to pose and viewpoint. Second, we develop a diffusion-based rendering pipeline, which is controlled by 3D human poses. This produces realistic renderings of novel poses of the person, including clothing, hair, and plausible in-filling of unseen regions. This disentangled approach allows our method to generate a sequence of images that are faithful to the target motion in the 3D pose and, to the input image in terms of visual similarity. In addition to that, the 3D control allows various synthetic camera trajectories to render a person. Our experiments show that our method is resilient in generating prolonged motions and varied challenging and complex poses compared to prior methods. Please check our website for more details: https://boyiliee.github.io/3DHM.github.io/.
本文提出了一种基于扩散模型的框架,用于从给定的目标3D运动序列对单个人图像进行动画处理。我们的方法有两个核心组件:a)学习关于人体和服装的隐藏部分先验知识,b)使用适当的服装和纹理呈现新的身体姿态。对于第一部分,我们学习了一个填充扩散模型,根据单张图像来构想人的不可见部分。我们在纹理图空间上训练这个模型,这使得它更加样本高效,因为它对姿势和视角具有不变性。其次,我们开发了一个基于扩散的渲染管道,它由3D人类姿势控制。这可以产生人物的新姿态的逼真渲染,包括服装、头发和对未见面部位的合理填充。这种独立的方法允许我们的方法在生成的图像序列中与目标的3D姿势保持一致性,并且在视觉相似性方面忠于输入图像。除此之外,我们的实验表明,我们的方法在生成持续运动以及面对各种复杂和挑战性的姿势方面,相较于先前的方法具有更强的韧性。更多详细信息请访问我们的网站:[https://boyiliee.github.io/3DHM.github.io/] 。
论文及项目相关链接
Summary
本文提出了一种基于扩散模型的框架,能够从单一图像中生成给定目标3D动作序列的人物动画。该方法包含两个核心部分:一是学习人体和服装的隐藏部分先验知识,二是使用扩散模型渲染新的身体姿态并附带适当的服装和纹理。通过训练一个填充扩散模型,该方法能够模拟给定单一图像中的人物隐藏部分。在纹理映射空间上的训练使模型具有姿势和视角的不变性,从而更加样本高效。此外,开发了一个基于扩散的渲染管道,由3D人类姿势控制,能够生成逼真的人物新姿态图像,包括服装、头发和合理的隐藏区域填充。该方法能够生成一系列忠于目标运动的图像,并且在视觉相似性方面忠实于输入图像。此外,3D控制允许各种合成相机轨迹来渲染人物。实验表明,该方法在生成长时间的复杂动作和具有挑战性的姿态方面具有很强的鲁棒性。详情请参见我们的网站:[网站地址]。
Key Takeaways
- 提出了基于扩散模型的框架,用于从单一图像生成目标3D动作序列的人物动画。
- 包含两个核心部分:学习人体和服装的隐藏部分先验知识,以及使用扩散模型进行新姿态的渲染。
- 通过训练填充扩散模型来模拟人物的隐藏部分,并在纹理映射空间上进行训练,以实现姿势和视角的不变性。
- 开发了一个基于扩散的渲染管道,由3D人类姿势控制,能够生成逼真的人物新姿态图像。
- 方法能够生成一系列忠于目标运动的图像,并且在视觉相似性方面忠实于输入图像。
- 3D控制允许通过各种合成相机轨迹来渲染人物。
点此查看论文截图