⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-24 更新
MORTAR: Metamorphic Multi-turn Testing for LLM-based Dialogue Systems
Authors:Guoxiang Guo, Aldeida Aleti, Neelofar Neelofar, Chakkrit Tantithamthavorn
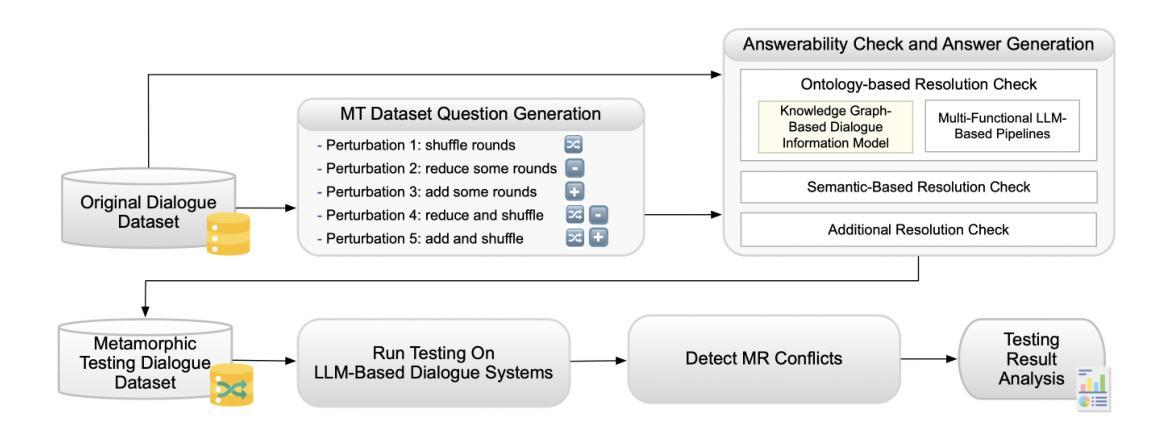
With the widespread application of LLM-based dialogue systems in daily life, quality assurance has become more important than ever. Recent research has successfully introduced methods to identify unexpected behaviour in single-turn scenarios. However, multi-turn dialogue testing remains underexplored, with the Oracle problem in multi-turn testing posing a persistent challenge for dialogue system developers and researchers. In this paper, we propose MORTAR, a MetamORphic multi-TuRn diAlogue testing appRoach, which mitigates the test oracle problem in the assessment of LLM-based dialogue systems. MORTAR automates the generation of follow-up question-answer (QA) dialogue test cases with multiple dialogue-level perturbations and metamorphic relations. MORTAR employs a novel knowledge graph-based dialogue information model which effectively generates perturbed dialogue test datasets and detects bugs of multi-turn dialogue systems in a low-cost manner. The proposed approach does not require an LLM as a judge, eliminating potential of any biases in the evaluation step. According to the experiment results on multiple LLM-based dialogue systems and comparisons with single-turn metamorphic testing approaches, MORTAR explores more unique bugs in LLM-based dialogue systems, especially for severe bugs that MORTAR detects up to four times more unique bugs than the most effective existing metamorphic testing approach.
随着基于大语言模型(LLM)的对话系统在日常生活中的广泛应用,质量保障变得至关重要。最近的研究已经成功引入了在单轮场景中识别意外行为的方法。然而,多轮对话测试仍然被较少探索,多轮测试中的Oracle问题持续挑战对话系统开发者和研究人员。在本文中,我们提出了MORTAR,这是一种MetamORphic多轮对话测试方法,它减轻了基于大语言模型的对话系统的评估中的测试Oracle问题。MORTAR自动生成具有多个对话级别扰动和变异关系的后续问答(QA)对话测试用例。MORTAR采用基于知识图谱的对话信息模型,有效生成扰动对话测试数据集,并以低成本方式检测多轮对话系统的错误。所提出的方法不需要大语言模型作为评判者,从而避免了评估步骤中可能出现的偏见。根据对多个基于大语言模型的对话系统的实验结果以及与单轮变异测试方法的比较,MORTAR在基于大语言模型的对话系统中发现了更多的独特错误,特别是对于MORTAR检测到的严重错误,其发现独特错误的数量是最有效的现有变异测试方法的四倍。
论文及项目相关链接
Summary
LLM对话系统在日常生活中的广泛应用使得质量保障变得至关重要。针对多轮对话测试中的Oracle问题,本文提出了一种名为MORTAR的Metamorphic多轮对话测试方法。该方法通过自动化的生成跟进问答对话测试用例,并对多个对话级别的扰动和元形态关系进行处理,从而减轻测试Oracle问题。MORTAR采用基于知识图谱的对话信息模型,有效生成扰动对话测试数据集,以低成本的方式检测多轮对话系统的缺陷。实验结果表明,MORTAR在LLM对话系统中发现了更多独特的缺陷,尤其是对于严重缺陷的检测能力更强。
Key Takeaways
- LLM对话系统的广泛应用突出了质量保障的重要性。
- 多轮对话测试中的Oracle问题是一个持续挑战。
- MORTAR是一种Metamorphic多轮对话测试方法,旨在解决测试Oracle问题。
- MORTAR通过自动生成跟进问答对话测试用例,处理多对话级别的扰动和元形态关系。
- MORTAR采用基于知识图谱的对话信息模型,有效检测多轮对话系统的缺陷。
- 实验结果表明,MORTAR在LLM对话系统中发现更多独特缺陷。
点此查看论文截图

DialSim: A Real-Time Simulator for Evaluating Long-Term Multi-Party Dialogue Understanding of Conversational Agents
Authors:Jiho Kim, Woosog Chay, Hyeonji Hwang, Daeun Kyung, Hyunseung Chung, Eunbyeol Cho, Yohan Jo, Edward Choi
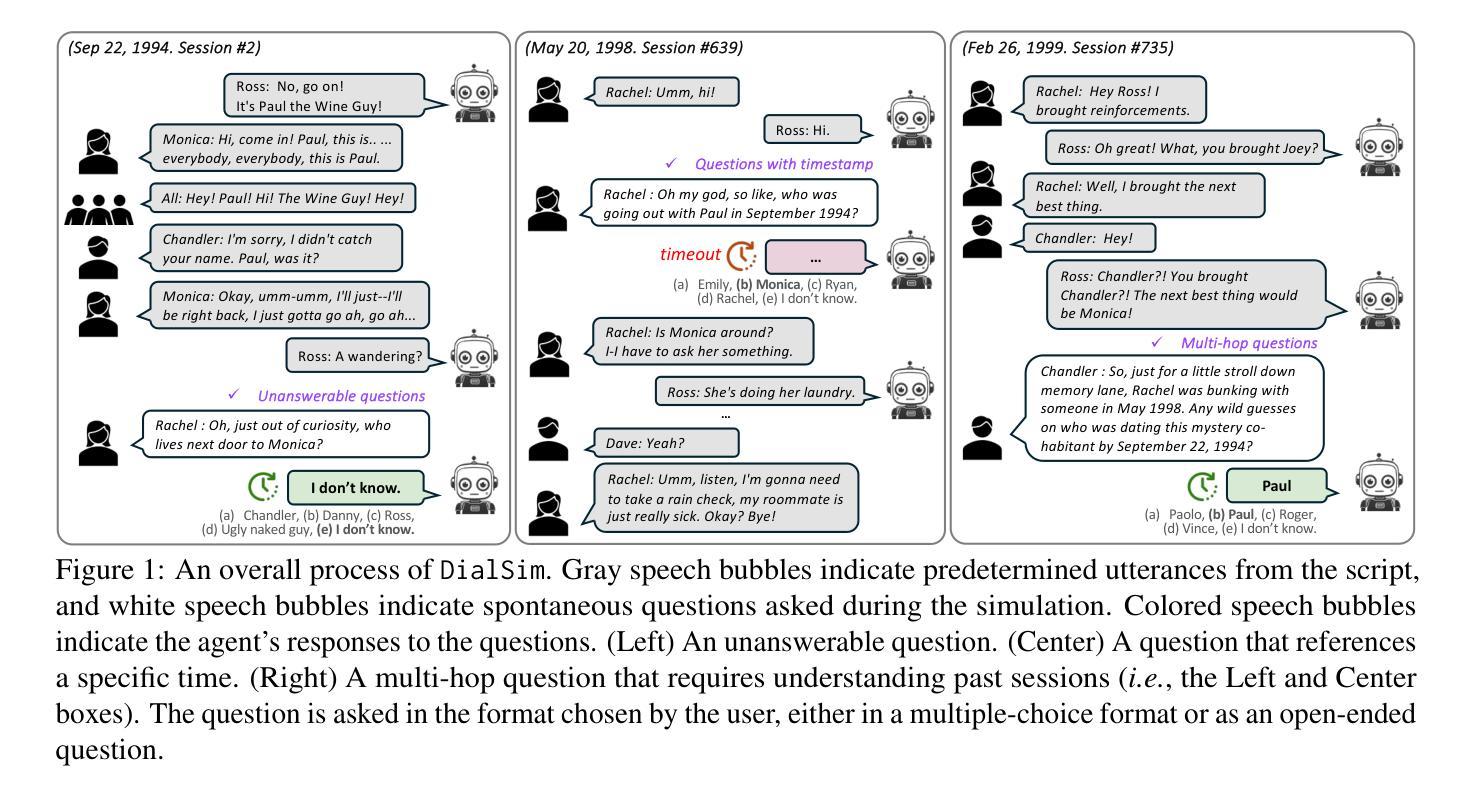
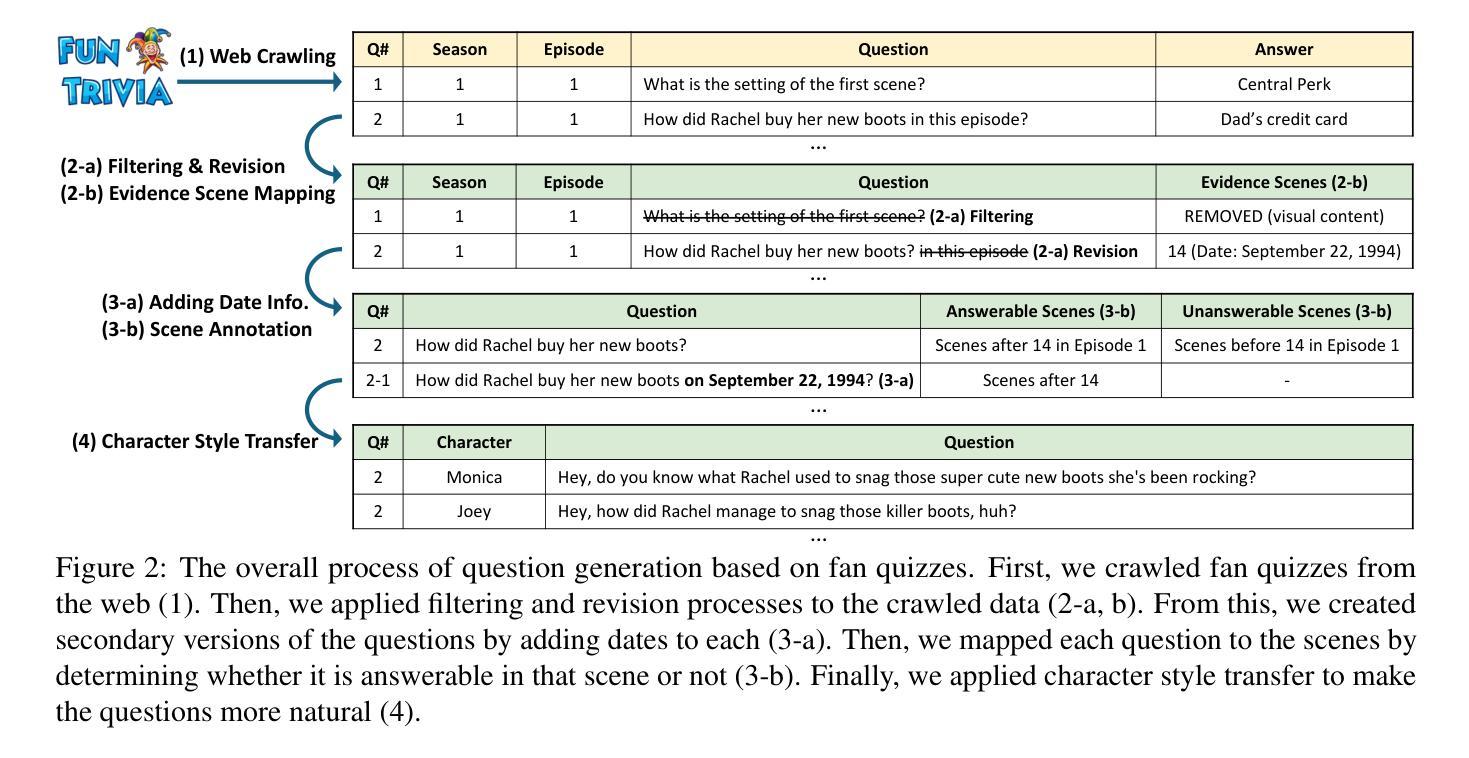
Recent advancements in Large Language Models (LLMs) have significantly enhanced the capabilities of conversational agents, making them applicable to various fields (e.g., education). Despite their progress, the evaluation of the agents often overlooks the complexities of real-world conversations, such as real-time interactions, multi-party dialogues, and extended contextual dependencies. To bridge this gap, we introduce DialSim, a real-time dialogue simulator. In this simulator, an agent is assigned the role of a character from popular TV shows, requiring it to respond to spontaneous questions using past dialogue information and to distinguish between known and unknown information. Key features of DialSim include assessing the agent’s ability to respond within a reasonable time limit, handling long-term multi-party dialogues, and evaluating performance under randomized questioning with LongDialQA, a novel, high-quality question-answering dataset. Our experiments using DialSim reveal the strengths and weaknesses of the latest conversational agents, offering valuable insights for future advancements in conversational AI. DialSim is available at https://dialsim.github.io/.
近期大型语言模型(LLM)的进步显著增强了对话机器人的能力,使其适用于各个领域(例如教育)。尽管有所进展,但对这些机器人的评估往往忽略了现实世界中对话的复杂性,如实时互动、多方对话和扩展的上下文依赖关系。为了弥补这一差距,我们引入了DialSim,一个实时对话模拟器。在这个模拟器中,机器人被设定为流行电视剧中的角色,需要利用过去的对话信息回答突发问题,并区分已知和未知信息。DialSim的关键功能包括评估机器人在合理时间内作出回应的能力,处理长期多方对话,以及使用新的高质量问答数据集LongDialQA在随机提问下评估性能。我们使用DialSim进行的实验揭示了最新对话机器人的优势和劣势,为对话AI的未来进步提供了宝贵见解。DialSim可在<https://dialsim.github.io/ >访问。
论文及项目相关链接
Summary
对话模拟平台DialSim填补了现实对话复杂性与对话智能体评估之间的鸿沟。该平台模拟真实对话场景,要求智能体在限定时间内回应问题,处理长期多对话评价,并在随机提问下评估表现。通过DialSim实验揭示了最新对话智能体的优势和不足,为对话AI的未来进步提供了宝贵见解。
Key Takeaways
- Large Language Models (LLMs) 的进步增强了对话智能体的能力,使其适用于多个领域。
- 现有对话智能体的评估方法忽略了现实对话的复杂性。
- DialSim是一个实时对话模拟平台,模拟真实对话场景。
- DialSim的关键特性包括:评估智能体在限定时间内的回应能力,处理长期多对话评价,以及在随机提问下的表现。
- 通过DialSim实验揭示了最新对话智能体的性能优势和不足。
- DialSim平台可用于未来对话AI的研究和改进。
点此查看论文截图