⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-24 更新
HoVLE: Unleashing the Power of Monolithic Vision-Language Models with Holistic Vision-Language Embedding
Authors:Chenxin Tao, Shiqian Su, Xizhou Zhu, Chenyu Zhang, Zhe Chen, Jiawen Liu, Wenhai Wang, Lewei Lu, Gao Huang, Yu Qiao, Jifeng Dai
The rapid advance of Large Language Models (LLMs) has catalyzed the development of Vision-Language Models (VLMs). Monolithic VLMs, which avoid modality-specific encoders, offer a promising alternative to the compositional ones but face the challenge of inferior performance. Most existing monolithic VLMs require tuning pre-trained LLMs to acquire vision abilities, which may degrade their language capabilities. To address this dilemma, this paper presents a novel high-performance monolithic VLM named HoVLE. We note that LLMs have been shown capable of interpreting images, when image embeddings are aligned with text embeddings. The challenge for current monolithic VLMs actually lies in the lack of a holistic embedding module for both vision and language inputs. Therefore, HoVLE introduces a holistic embedding module that converts visual and textual inputs into a shared space, allowing LLMs to process images in the same way as texts. Furthermore, a multi-stage training strategy is carefully designed to empower the holistic embedding module. It is first trained to distill visual features from a pre-trained vision encoder and text embeddings from the LLM, enabling large-scale training with unpaired random images and text tokens. The whole model further undergoes next-token prediction on multi-modal data to align the embeddings. Finally, an instruction-tuning stage is incorporated. Our experiments show that HoVLE achieves performance close to leading compositional models on various benchmarks, outperforming previous monolithic models by a large margin. Model available at https://huggingface.co/OpenGVLab/HoVLE.
大型语言模型(LLM)的快速发展推动了视觉语言模型(VLM)的进步。一体式VLM避免了模态特定编码器,为组合式VLM提供了有前途的替代方案,但面临性能较差的挑战。大多数现有的一体式VLM需要调整预训练的LLM以获得视觉能力,这可能会降低其语言功能。为了解决这一困境,本文提出了一种新型高性能的一体式VLM,名为HoVLE。我们注意到,当图像嵌入与文本嵌入对齐时,LLM已被证明能够解释图像。当前一体式VLM的挑战实际上在于缺乏一个用于视觉和语言输入的全面嵌入模块。因此,HoVLE引入了一个全面嵌入模块,该模块将视觉和文本输入转换为共享空间,允许LLM以与文本相同的方式处理图像。此外,精心设计了一种多阶段训练策略来增强全面嵌入模块。它首先经过训练,从预训练的视觉编码器和LLM中获取文本嵌入来提炼视觉特征,从而实现与未配对的随机图像和文本标记的大规模训练。整个模型进一步进行多模态数据的下一个标记预测,以对齐嵌入。最后,加入了指令调整阶段。我们的实验表明,HoVLE在各种基准测试上的表现接近领先的组合模型,大大超过了以前的一体式模型。模型可在https://huggingface.co/OpenGVLab/HoVLE上获得。
论文及项目相关链接
摘要
大型语言模型(LLM)的快速发展推动了视觉语言模型(VLM)的进步。本文提出了一种新型高性能单体VLM,名为HoVLE。针对现有单体VLM需要在预训练LLM上调整以获取视觉能力,可能导致语言能力下降的问题,HoVLE引入了一个整体嵌入模块,将视觉和文本输入转换为共享空间,使LLM能以相同方式处理图像和文本。通过多阶段训练策略赋能整体嵌入模块,首先进行预训练视觉编码器和LLM文本嵌入的蒸馏,然后通过对多模态数据进行下一个令牌预测以对齐嵌入,最后加入指令调整阶段。实验表明,HoVLE在各种基准测试上的表现接近领先的组合模型,并大幅度超越了之前的单体模型。模型可在https://huggingface.co/OpenGVLab/HoVLE获取。
关键见解
- 大型语言模型(LLM)的快速发展推动了视觉语言模型(VLM)的进步。
- 单体VLM避免使用模态特定编码器,提供了一种有前景的替代方案。
- 现有单体VLM面临性能挑战,需要在预训练的LLM上调整以获取视觉能力,可能导致语言性能下降。
- HoVLE引入了一个整体嵌入模块,将视觉和文本输入转换为共享空间,使LLM能够同时处理图像和文本。
- HoVLE采用多阶段训练策略,包括蒸馏视觉特征和LLM文本嵌入、多模态数据的下一个令牌预测和指令调整阶段。
- 实验显示HoVLE在各种基准测试上的表现接近领先的组合模型,并大幅度超越了之前的单体模型。
- 模型可在huggingface.co/OpenGVLab/HoVLE获取。
点此查看论文截图

Can LLMs Obfuscate Code? A Systematic Analysis of Large Language Models into Assembly Code Obfuscation
Authors:Seyedreza Mohseni, Seyedali Mohammadi, Deepa Tilwani, Yash Saxena, Gerald Ndwula, Sriram Vema, Edward Raff, Manas Gaur
Malware authors often employ code obfuscations to make their malware harder to detect. Existing tools for generating obfuscated code often require access to the original source code (e.g., C++ or Java), and adding new obfuscations is a non-trivial, labor-intensive process. In this study, we ask the following question: Can Large Language Models (LLMs) potentially generate a new obfuscated assembly code? If so, this poses a risk to anti-virus engines and potentially increases the flexibility of attackers to create new obfuscation patterns. We answer this in the affirmative by developing the MetamorphASM benchmark comprising MetamorphASM Dataset (MAD) along with three code obfuscation techniques: dead code, register substitution, and control flow change. The MetamorphASM systematically evaluates the ability of LLMs to generate and analyze obfuscated code using MAD, which contains 328,200 obfuscated assembly code samples. We release this dataset and analyze the success rate of various LLMs (e.g., GPT-3.5/4, GPT-4o-mini, Starcoder, CodeGemma, CodeLlama, CodeT5, and LLaMA 3.1) in generating obfuscated assembly code. The evaluation was performed using established information-theoretic metrics and manual human review to ensure correctness and provide the foundation for researchers to study and develop remediations to this risk. The source code can be found at the following GitHub link: https://github.com/mohammadi-ali/MetamorphASM.
恶意软件作者经常使用代码混淆技术使其更难被检测。现有的生成混淆代码的工具通常需要访问原始源代码(例如C++或Java),并且添加新的混淆是一项非平凡且劳动密集型的流程。在这项研究中,我们提出了以下问题:大型语言模型(LLM)能否生成新的混淆汇编代码?如果是这样,这对抗病毒引擎构成风险,并可能增加攻击者创建新混淆模式的灵活性。我们通过开发MetamorphASM基准测试来回答这个问题,该测试包括MetamorphASM数据集(MAD)以及三种代码混淆技术:死代码、寄存器替换和控制流更改。MetamorphASM使用MAD系统地评估LLM生成和分析混淆代码的能力,MAD包含328,200个混淆的汇编代码样本。我们公开了此数据集,并分析了各种LLM(例如GPT-3.5/4、GPT-4o-mini、Starcoder、CodeGemma、CodeLlama、CodeT5和LLaMA 3.1)在生成混淆汇编代码方面的成功率。评估是通过建立的信息理论指标和人工审查来确保准确性,并为研究人员研究和开发对此风险的补救措施提供基础。源代码可在以下GitHub链接中找到:https://github.com/mohammadi-ali/MetamorphASM。
论文及项目相关链接
PDF To appear in AAAI 2025, Main Track
摘要
本研究探讨了大型语言模型(LLM)在生成新的混淆汇编代码方面的潜力。针对现有混淆代码生成工具需要访问原始源代码且添加新混淆过程复杂繁琐的问题,研究团队开发了MetamorphASM基准测试平台,包括MetamorphASM数据集(MAD)和三种代码混淆技术:死代码、寄存器替换和控制流变化。MetamorphASM系统评估了LLM在生成和分析混淆代码方面的能力,所使用的数据集包含328,200个混淆汇编代码样本。研究团队对各种LLM模型(如GPT-3.5/4、GPT-4o-mini、Starcoder等)在生成混淆汇编代码方面的成功率进行了分析。评估采用信息理论度量方法和人工审查,以确保正确性并为研究人员提供研究并制定补救措施的基础。相关源代码可在GitHub链接中找到:链接地址。该研究的发现对反病毒引擎构成了潜在风险,并增加了攻击者创建新混淆模式的可能性。
关键见解
- 大型语言模型(LLM)具有生成新的混淆汇编代码的潜力。
- 提出了一种新的基准测试平台MetamorphASM,用于评估LLM在混淆代码方面的能力。
- MetamorphASM数据集包含大量的混淆汇编代码样本。
- 研究分析了多种LLM模型在生成混淆汇编代码方面的成功率。
- 评估方法结合了信息理论度量方法和人工审查,以确保正确性。
- 该研究为研究人员提供了研究并制定对抗这种风险的补救措施的基础。
点此查看论文截图








PromptOptMe: Error-Aware Prompt Compression for LLM-based MT Evaluation Metrics
Authors:Daniil Larionov, Steffen Eger
Evaluating the quality of machine-generated natural language content is a challenging task in Natural Language Processing (NLP). Recently, large language models (LLMs) like GPT-4 have been employed for this purpose, but they are computationally expensive due to the extensive token usage required by complex evaluation prompts. In this paper, we propose a prompt optimization approach that uses a smaller, fine-tuned language model to compress input data for evaluation prompt, thus reducing token usage and computational cost when using larger LLMs for downstream evaluation. Our method involves a two-stage fine-tuning process: supervised fine-tuning followed by preference optimization to refine the model’s outputs based on human preferences. We focus on Machine Translation (MT) evaluation and utilize the GEMBA-MQM metric as a starting point. Our results show a $2.37\times$ reduction in token usage without any loss in evaluation quality. This work makes state-of-the-art LLM-based metrics like GEMBA-MQM more cost-effective and efficient, enhancing their accessibility for broader use.
在自然语言处理(NLP)中,评估机器生成的自然语言内容的质量是一项具有挑战性的任务。最近,人们已经开始使用像GPT-4这样的大规模语言模型(LLM)来完成这一任务,但由于复杂的评估提示需要大量的令牌使用,因此它们的计算成本很高。在本文中,我们提出了一种提示优化方法,该方法使用较小、经过微调的语言模型来压缩评估提示的输入数据,从而在下游评估时使用更大的LLM时减少令牌使用和计算成本。我们的方法包括一个两阶段的微调过程:监督微调后通过偏好优化来根据人类偏好调整模型的输出。我们专注于机器翻译(MT)评估,并使用GEMBA-MQM指标作为起点。我们的结果表明,在不影响评估质量的情况下,令牌使用量减少了$2.37\times$。这项工作使得最先进的LLM指标(如GEMBA-MQM)更具经济效益和效率,提高了它们用于广泛使用的可访问性。
论文及项目相关链接
Summary
大型语言模型(LLM)如GPT-4在评估自然语言处理(NLP)生成内容的品质时面临计算成本高昂的问题。本文提出了一种基于小型微调语言模型的提示优化方法,用于压缩评估提示的输入数据,从而减少令牌使用和计算成本,提高使用大型LLM进行下游评估时的成本效益和效率。该方法包括监督微调阶段和偏好优化阶段,以根据人类偏好细化模型输出。研究重点为机器翻译(MT)评估,并以GEMBA-MQM指标为起点。研究结果实现了令牌使用量的2.37倍减少,同时不损失评估质量。这项研究使先进的LLM指标更具成本效益和效率,提高了其广泛使用的可及性。
Key Takeaways
- 大型语言模型(LLM)在评估自然语言处理(NLP)生成内容的品质时面临高计算成本问题。
- 本文提出了一种基于小型微调语言模型的提示优化方法,用于压缩评估提示的输入数据。
- 方法包括监督微调阶段和偏好优化阶段,以提高模型输出的质量。
- 研究集中于机器翻译(MT)评估,以GEMBA-MQM指标为基础进行优化。
- 实现令牌使用量的显著减少,同时保持评估质量不变。
- 该研究提高了先进的LLM指标的成本效益和效率。
点此查看论文截图

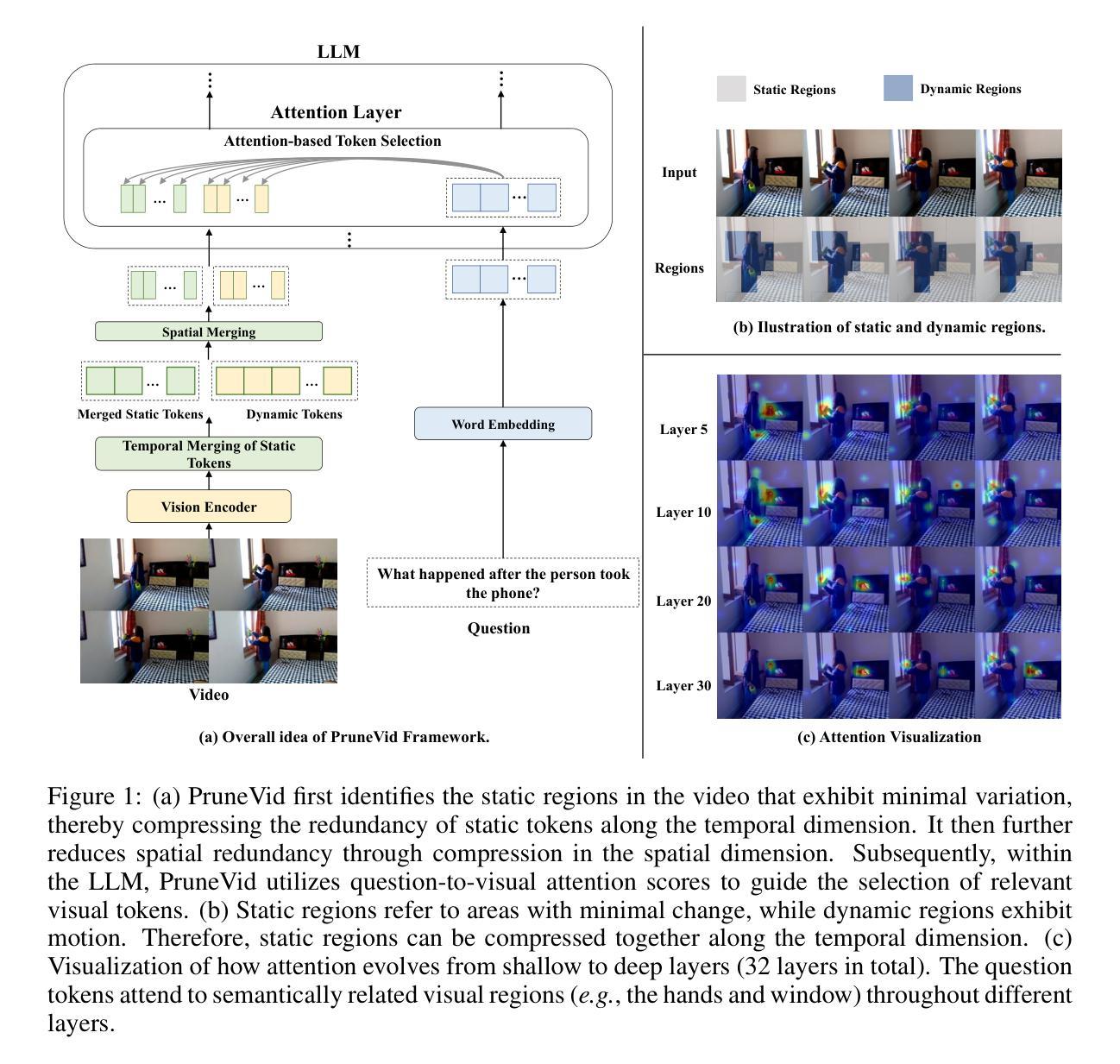
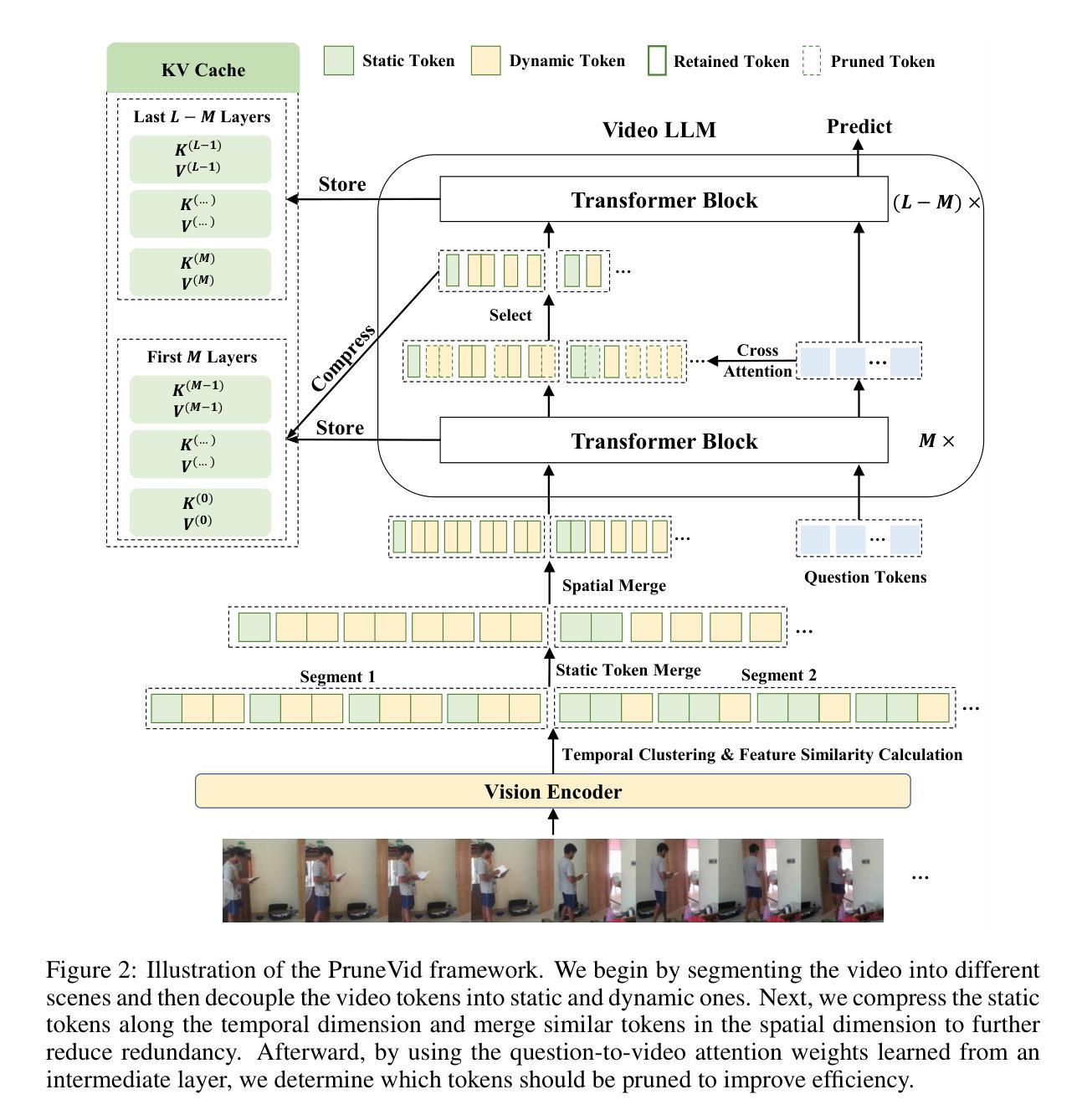
PruneVid: Visual Token Pruning for Efficient Video Large Language Models
Authors:Xiaohu Huang, Hao Zhou, Kai Han
In this paper, we introduce PruneVid, a visual token pruning method designed to enhance the efficiency of multi-modal video understanding. Large Language Models (LLMs) have shown promising performance in video tasks due to their extended capabilities in comprehending visual modalities. However, the substantial redundancy in video data presents significant computational challenges for LLMs. To address this issue, we introduce a training-free method that 1) minimizes video redundancy by merging spatial-temporal tokens, and 2) leverages LLMs’ reasoning capabilities to selectively prune visual features relevant to question tokens, enhancing model efficiency. We validate our method across multiple video benchmarks, which demonstrate that PruneVid can prune over 80% of tokens while maintaining competitive performance combined with different model networks. This highlights its superior effectiveness and efficiency compared to existing pruning methods. Code: https://github.com/Visual-AI/PruneVid.
本文介绍了PruneVid,这是一种视觉令牌剪枝方法,旨在提高多模态视频理解的效率。大型语言模型(LLM)由于其在理解视觉模式方面的扩展能力,在视频任务中表现出了有前景的性能。然而,视频数据中的大量冗余对LLM带来了巨大的计算挑战。为了解决这一问题,我们提出了一种无需训练的方法,该方法1)通过合并时空令牌来最小化视频冗余,并2)利用LLM的推理能力有选择地剪枝与问题令牌相关的视觉特征,提高模型效率。我们在多个视频基准测试上验证了我们的方法,结果表明PruneVid能够在保持竞争力的同时剪枝超过80%的令牌,这突显了其在与其他现有剪枝方法相比时具有优越的有效性和效率。代码地址:https://github.com/Visual-AI/PruneVid。
论文及项目相关链接
PDF Efficient Video Large Language Models
摘要
本文介绍了一种名为PruneVid的视觉令牌修剪方法,旨在提高多模态视频理解效率。大型语言模型(LLM)在视频任务中表现出良好的性能,但由于视频数据的冗余性,它们面临着巨大的计算挑战。PruneVid是一种无需训练的方法,它通过合并时空令牌来最小化视频冗余,并利用LLM的推理能力有选择地修剪与问题令牌相关的视觉特征,从而提高模型效率。在多个视频基准测试中的验证表明,PruneVid可以修剪超过8%的令牌,同时在不同的模型网络中保持竞争力,这凸显了其卓越的有效性和效率。
要点
- PruneVid是一种用于提高多模态视频理解效率的视觉令牌修剪方法。
- LLM在视频任务中表现出良好的性能,但面临视频数据冗余的计算挑战。
- PruneVid通过合并时空令牌来最小化视频冗余。
- PruneVid利用LLM的推理能力有选择地修剪与问题令牌相关的视觉特征。
- PruneVid可以在不同的模型网络中保持竞争力,同时修剪超过80%的令牌。
- PruneVid的方法在多个视频基准测试中得到了验证。
- PruneVid具有卓越的有效性和效率,相较于现有的修剪方法表现出色。
点此查看论文截图

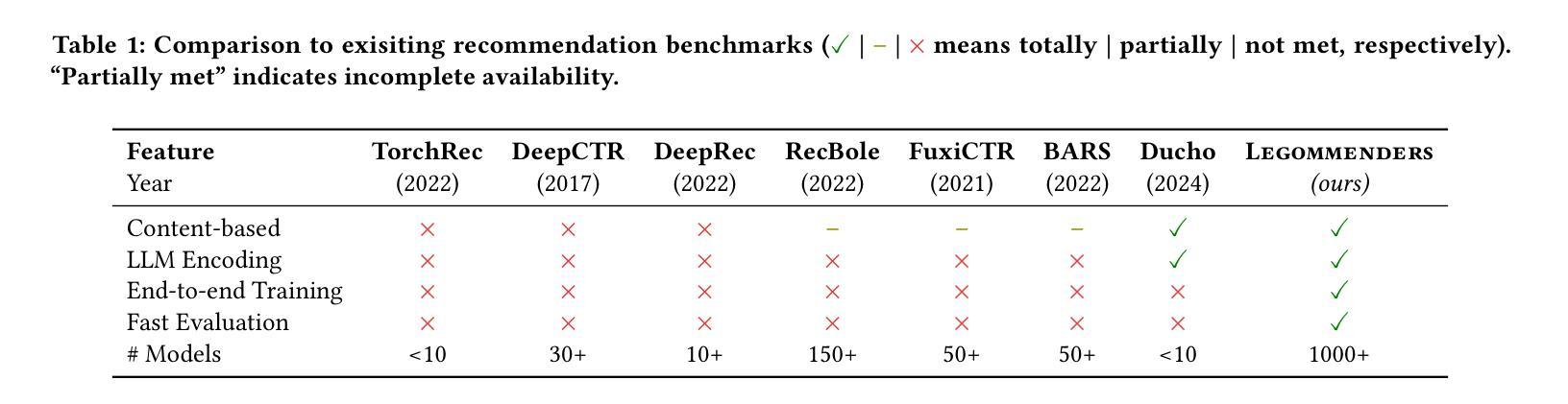
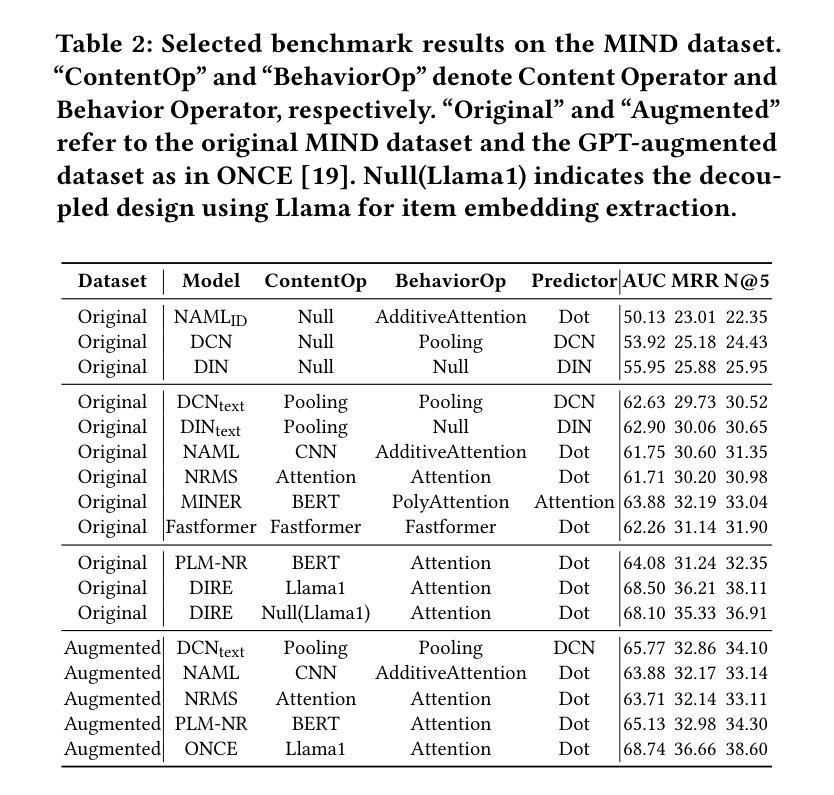
Legommenders: A Comprehensive Content-Based Recommendation Library with LLM Support
Authors:Qijiong Liu, Lu Fan, Xiao-Ming Wu
We present Legommenders, a unique library designed for content-based recommendation that enables the joint training of content encoders alongside behavior and interaction modules, thereby facilitating the seamless integration of content understanding directly into the recommendation pipeline. Legommenders allows researchers to effortlessly create and analyze over 1,000 distinct models across 15 diverse datasets. Further, it supports the incorporation of contemporary large language models, both as feature encoder and data generator, offering a robust platform for developing state-of-the-art recommendation models and enabling more personalized and effective content delivery.
我们介绍了Legommenders,这是一个专为基于内容的推荐而设计的独特库。它使内容编码器与行为和交互模块能够联合训练,从而便于将内容理解无缝集成到推荐管道中。Legommenders让研究人员能够轻松创建和分析超过1000个不同模型,涉及15个不同的数据集。此外,它支持融入当代的大型语言模型,既可以作为特征编码器,也可以作为数据生成器,为开发先进推荐模型提供了稳健的平台,使内容交付更加个性化和高效。
论文及项目相关链接
Summary
Legommenders是一个专为内容推荐设计的独特库,可联合训练内容编码器以及行为和交互模块,将内容理解无缝集成到推荐管道中。它支持创建和分析超过一千种不同的模型,支持在十五个不同数据集上的多样化应用,并允许融入现代大型语言模型作为特征编码器或数据生成器,为开发先进推荐模型提供稳健平台,实现更加个性化和有效的内容推送。
Key Takeaways
- Legommenders是一个基于内容推荐的独特库。
- 它支持内容编码器与行为和交互模块的联合训练。
- Legommenders实现了内容理解到推荐管道的无缝集成。
- 该库能在十五个数据集上支持超过一千种模型的创建和分析。
- Legommenders允许融入现代大型语言模型作为特征编码器或数据生成器。
- 该平台为开发先进推荐模型提供了稳健的基础。
点此查看论文截图



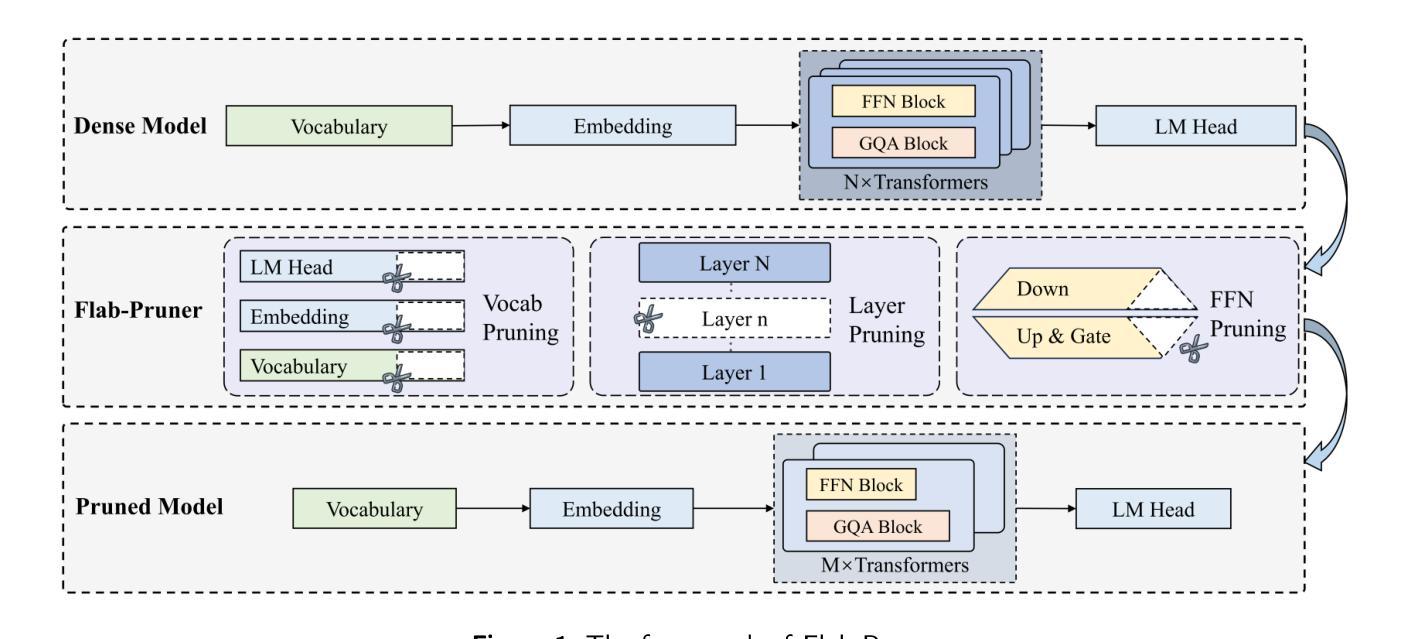
Less is More: Towards Green Code Large Language Models via Unified Structural Pruning
Authors:Guang Yang, Yu Zhou, Xiangyu Zhang, Wei Cheng, Ke Liu, Xiang Chen, Terry Yue Zhuo, Taolue Chen
The extensive application of Large Language Models (LLMs) in generative coding tasks has raised concerns due to their high computational demands and energy consumption. Unlike previous structural pruning methods designed for classification models that deal with lowdimensional classification logits, generative Code LLMs produce high-dimensional token logit sequences, making traditional pruning objectives inherently limited. Moreover, existing single component pruning approaches further constrain the effectiveness when applied to generative Code LLMs. In response, we propose Flab-Pruner, an innovative unified structural pruning method that combines vocabulary, layer, and Feed-Forward Network (FFN) pruning. This approach effectively reduces model parameters while maintaining performance. Additionally, we introduce a customized code instruction data strategy for coding tasks to enhance the performance recovery efficiency of the pruned model. Through extensive evaluations on three state-of-the-art Code LLMs across multiple generative coding tasks, the results demonstrate that Flab-Pruner retains 97% of the original performance after pruning 22% of the parameters and achieves the same or even better performance after post-training. The pruned models exhibit significant improvements in storage, GPU usage, computational efficiency, and environmental impact, while maintaining well robustness. Our research provides a sustainable solution for green software engineering and promotes the efficient deployment of LLMs in real-world generative coding intelligence applications.
大型语言模型(LLM)在生成式编码任务中的广泛应用引发了对其高计算需求和能源消耗的关注。不同于之前为处理低维分类逻辑值而设计的分类模型的结构化修剪方法,生成式代码LLM会产生高维令牌逻辑值序列,使得传统修剪目标存在固有的局限性。此外,现有的单一组件修剪方法在应用于生成式代码LLM时,其效果受到限制。为此,我们提出Flab-Pruner,这是一种创新性的统一结构化修剪方法,结合了词汇、层和前馈网络(FFN)修剪。该方法在保持性能的同时,有效减少了模型参数。此外,我们还为编码任务引入了一种定制的代码指令数据策略,以提高修剪模型的性能恢复效率。通过对三种最先进的代码LLM进行多个生成式编码任务的广泛评估,结果显示,Flab-Pruner在修剪22%的参数后,仍保留97%的原始性能,并在后训练过程中达到相同甚至更好的性能。修剪后的模型在存储、GPU使用、计算效率和环境影响方面都有显著改善,同时保持了良好的稳健性。我们的研究为绿色软件工程提供了可持续的解决方案,并促进了LLM在现实世界的生成式编码智能应用中的高效部署。
论文及项目相关链接
PDF UNDER REVIEW
Summary
大规模语言模型(LLM)在生成式编码任务中的广泛应用引发了对其高计算需求和能源消耗的关注。针对生成式编码LLM的高维令牌逻辑序列,传统剪枝目标存在局限性。为此,我们提出了Flab-Pruner,一种结合词汇、层和前馈网络(FFN)修剪的统一结构剪枝方法,有效减少模型参数,同时保持性能。此外,我们还引入了一种定制的代码指令数据策略,以提高剪枝模型的性能恢复效率。评估结果表明,Flab-Pruner在剪枝22%的参数后保留了97%的原始性能,并在后训练过程中实现了相同或更好的性能。剪枝模型在存储、GPU使用、计算效率和环境影响方面表现出显著改进,同时保持了良好的稳健性。
Key Takeaways
- LLM在生成式编码任务中的高计算需求和能源消耗引发关注。
- 传统剪枝方法在处理生成式编码LLM时存在局限性。
- Flab-Pruner是一种结合词汇、层和FFN修剪的统一结构剪枝方法。
- Flab-Pruner有效减少模型参数,同时保持性能。
- 定制的代码指令数据策略提高了剪枝模型的性能恢复效率。
- Flab-Pruner在剪枝22%的参数后保留了97%的原始性能。
- 剪枝模型在存储、GPU使用、计算效率和环境影响方面有所改善,同时保持了稳健性。
点此查看论文截图

TelcoLM: collecting data, adapting, and benchmarking language models for the telecommunication domain
Authors:Camille Barboule, Viet-Phi Huynh, Adrien Bufort, Yoan Chabot, Géraldine Damnati, Gwénolé Lecorvé
Despite outstanding processes in many tasks, Large Language Models (LLMs) still lack accuracy when dealing with highly technical domains. Especially, telecommunications (telco) is a particularly challenging domain due the large amount of lexical, semantic and conceptual peculiarities. Yet, this domain holds many valuable use cases, directly linked to industrial needs. Hence, this paper studies how LLMs can be adapted to the telco domain. It reports our effort to (i) collect a massive corpus of domain-specific data (800M tokens, 80K instructions), (ii) perform adaptation using various methodologies, and (iii) benchmark them against larger generalist models in downstream tasks that require extensive knowledge of telecommunications. Our experiments on Llama-2-7b show that domain-adapted models can challenge the large generalist models. They also suggest that adaptation can be restricted to a unique instruction-tuning step, dicarding the need for any fine-tuning on raw texts beforehand.
尽管在许多任务中表现出卓越的过程,大型语言模型(LLM)在处理高度技术领域时仍缺乏准确性。尤其电信(电信)是一个充满挑战的领域,存在大量的词汇、语义和概念特殊性。然而,这个领域有许多直接与工业需求相关的宝贵用例。因此,本文研究了如何适应LLM用于电信领域。报告了我们为(i)收集大规模特定领域的语料库(包含8亿个令牌和8万个指令),(ii)使用各种方法进行适应,(iii)在需要深入了解电信的下游任务中与更大的通用模型进行基准测试所做的努力。我们在Llama-2-7b上的实验表明,适应领域的模型可以挑战大型的通用模型。他们还表明,适应可以限制在一个独特的指令调整步骤中,无需在此之前对原始文本进行微调。
论文及项目相关链接
PDF 30 pages (main: 13 pages, appendices: 17 pages), 1 figure, 22 tables, achieved March 2024, released December 2024
总结
大型语言模型(LLM)在众多任务中表现优异,但在处理高度技术化领域时仍缺乏准确性。电信领域由于其丰富的词汇、语义和概念特点,成为一个特别具有挑战性的领域。然而,该领域有许多与工业需求直接相关的有价值用例。因此,本文研究了如何适应LLM于电信领域。报告了我们的努力:(i)收集大量领域特定数据(8亿令牌,8万指令),(ii)使用各种方法进行适应,(iii)在需要深入了解电信的下游任务中,与更大的通用模型进行基准测试。我们在Llama-2-7b上的实验表明,适应领域的模型可以挑战大型通用模型。他们还表明,适应可以限制在一个独特的指令调整步骤中,无需在原始文本上进行任何微调。
关键见解
- 大型语言模型(LLM)在处理高度技术化的领域,如电信领域时,仍面临准确性挑战。
- 电信领域因其丰富的词汇、语义和概念特性而具有挑战性。
- 收集大量特定领域的数据对于训练适应电信领域的LLM至关重要。
- 通过各种方法适应LLM以适应电信领域是必要的。
- 在下游任务中,适应领域的LLM性能可与大型通用模型相抗衡。
- 适应LLM只需进行独特的指令调整,无需在原始文本上进行进一步的微调。
- 这种适应方法为大型语言模型在特定领域的应用提供了新的视角和可能性。
点此查看论文截图

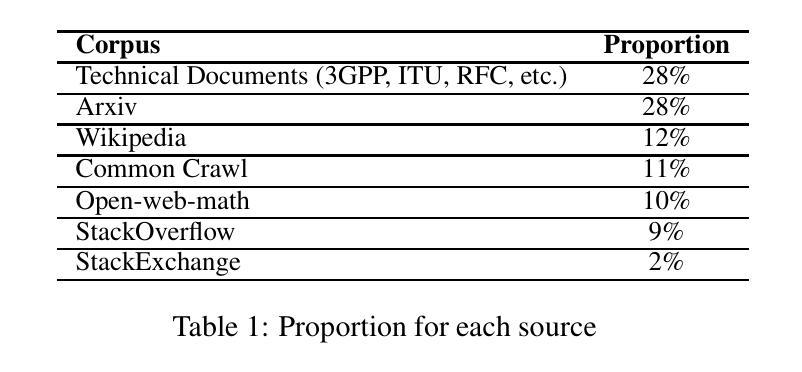

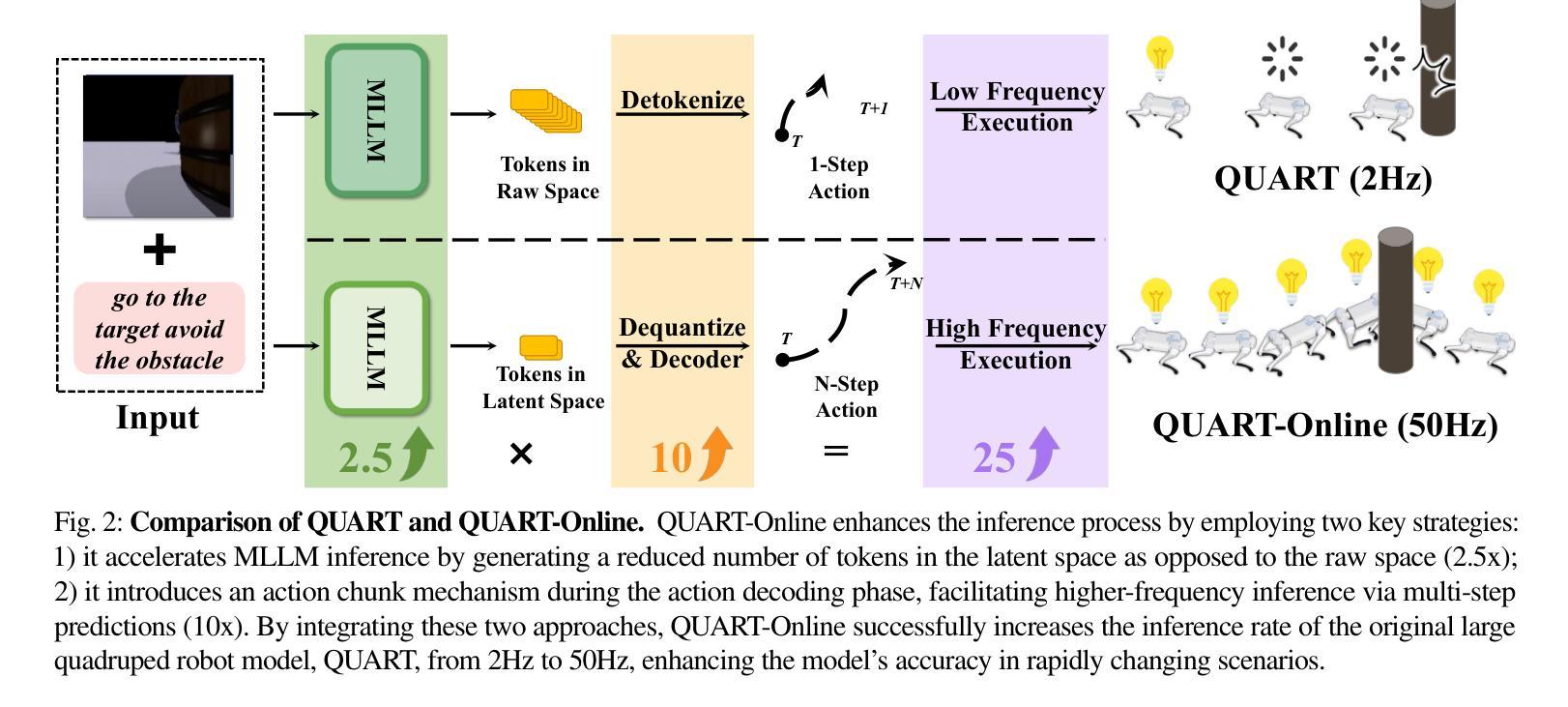
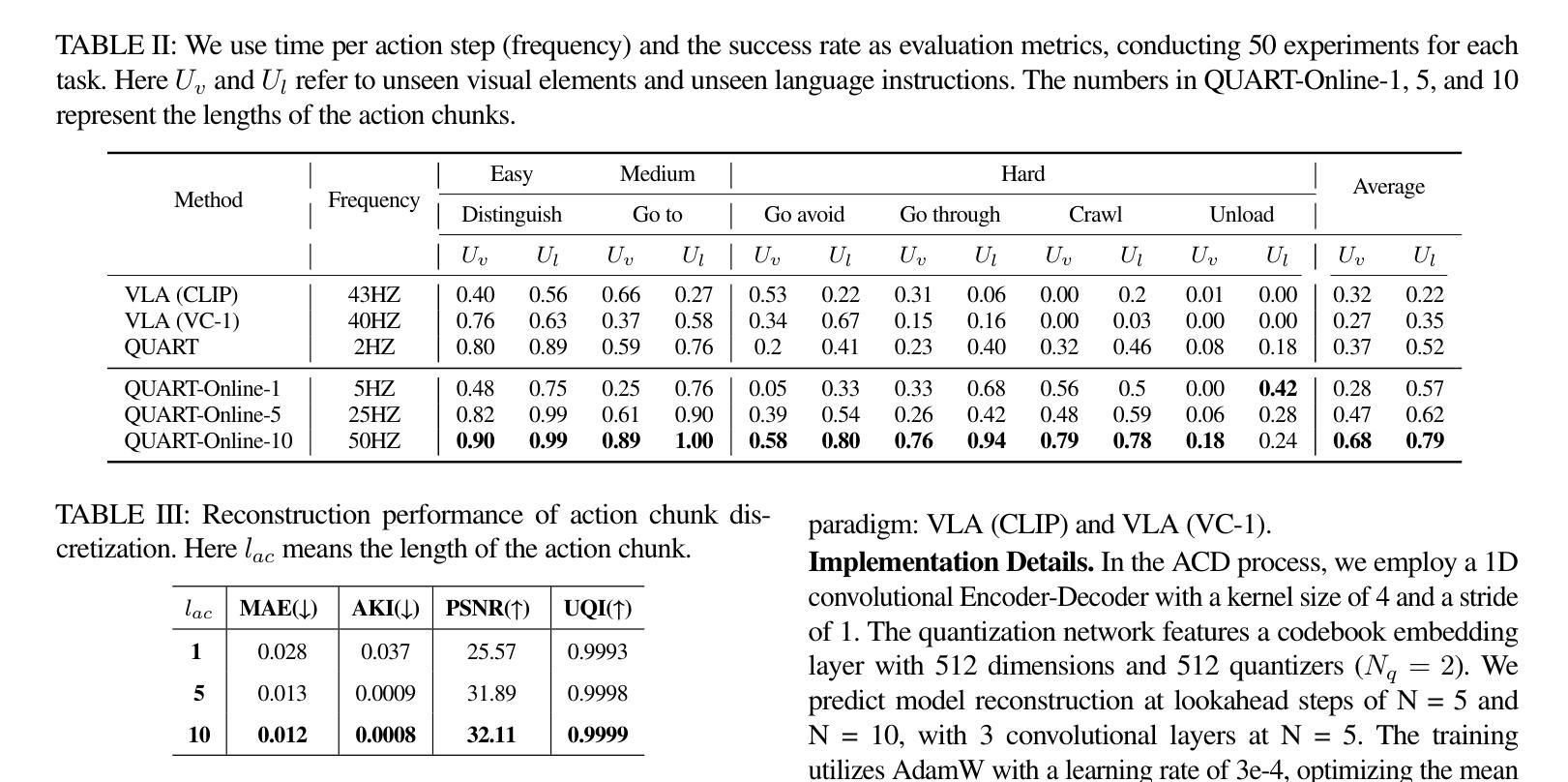
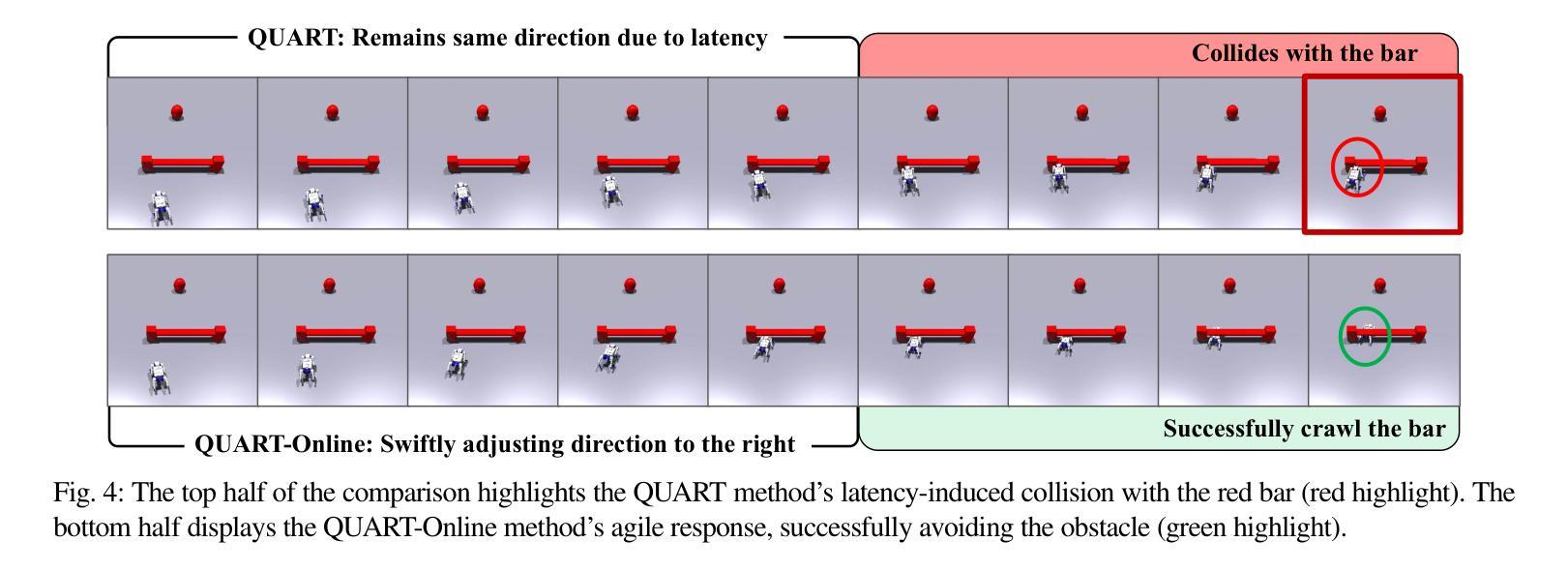
QUART-Online: Latency-Free Large Multimodal Language Model for Quadruped Robot Learning
Authors:Xinyang Tong, Pengxiang Ding, Donglin Wang, Wenjie Zhang, Can Cui, Mingyang Sun, Yiguo Fan, Han Zhao, Hongyin Zhang, Yonghao Dang, Siteng Huang, Shangke Lyu
This paper addresses the inherent inference latency challenges associated with deploying multimodal large language models (MLLM) in quadruped vision-language-action (QUAR-VLA) tasks. Our investigation reveals that conventional parameter reduction techniques ultimately impair the performance of the language foundation model during the action instruction tuning phase, making them unsuitable for this purpose. We introduce a novel latency-free quadruped MLLM model, dubbed QUART-Online, designed to enhance inference efficiency without degrading the performance of the language foundation model. By incorporating Action Chunk Discretization (ACD), we compress the original action representation space, mapping continuous action values onto a smaller set of discrete representative vectors while preserving critical information. Subsequently, we fine-tune the MLLM to integrate vision, language, and compressed actions into a unified semantic space. Experimental results demonstrate that QUART-Online operates in tandem with the existing MLLM system, achieving real-time inference in sync with the underlying controller frequency, significantly boosting the success rate across various tasks by 65%. Our project page is \href{https://quart-online.github.io}https://quart-online.github.io.
本文致力于解决在多足视觉语言动作(QUAR-VLA)任务中部署多模态大型语言模型(MLLM)所面临的固有推理延迟挑战。我们的调查发现,传统的参数减少技术最终会损害语言基础模型在动作指令调整阶段的性能,使其不适合此用途。我们引入了一种新型的无延迟多足MLLM模型,称为QUART-Online,旨在提高推理效率,同时不降低语言基础模型的性能。通过引入动作块离散化(ACD),我们压缩了原始的动作表示空间,将连续的动作值映射到一组较小的离散代表向量上,同时保留了关键信息。随后,我们对MLLM进行了微调,以将视觉、语言和压缩动作集成到一个统一的语义空间中。实验结果表明,QUART-Online与现有的MLLM系统协同工作,实现与底层控制器频率同步的实时推理,各种任务的成功率提高了65%。我们的项目页面是https://quart-online.github.io。
论文及项目相关链接
Summary
该论文针对部署多模态大型语言模型(MLLM)在四足机器人视觉语言动作(QUAR-VLA)任务时面临的固有推理延迟挑战展开研究。研究结果表明,传统的参数缩减技术会在动作指令调整阶段损害语言基础模型的性能,因此不适合用于此目的。论文提出了一种新型的无延迟四足MLLM模型——QUART-Online,旨在提高推理效率而不降低语言基础模型的性能。通过引入动作块离散化(ACD)技术,该模型压缩了原始动作表示空间,将连续动作值映射到一组较小的离散代表向量上,同时保留了关键信息。随后,对MLLM进行微调,以将视觉、语言和压缩动作整合到统一的语义空间中。实验结果表明,QUART-Online与现有MLLM系统协同工作,实现了实时推理,与底层控制器频率同步,并在各种任务中成功率提高了65%。
Key Takeaways
- 论文解决了在四足机器人视觉语言动作任务中部署多模态大型语言模型的推理延迟挑战。
- 传统的参数缩减技术会损害语言模型在动作指令调整阶段的性能。
- QUART-Online模型旨在提高推理效率,同时不降低语言基础模型的性能。
- 通过引入动作块离散化(ACD)技术,QUART-Online压缩了原始动作表示空间。
- QUART-Online将视觉、语言和压缩动作整合到统一的语义空间中。
- 实验结果显示,QUART-Online实现了实时推理,并与现有MLLM系统协同工作。
- QUART-Online在多种任务中的成功率提高了65%。
点此查看论文截图

ADEQA: A Question Answer based approach for joint ADE-Suspect Extraction using Sequence-To-Sequence Transformers
Authors:Vinayak Arannil, Tomal Deb, Atanu Roy
Early identification of Adverse Drug Events (ADE) is critical for taking prompt actions while introducing new drugs into the market. These ADEs information are available through various unstructured data sources like clinical study reports, patient health records, social media posts, etc. Extracting ADEs and the related suspect drugs using machine learning is a challenging task due to the complex linguistic relations between drug ADE pairs in textual data and unavailability of large corpus of labelled datasets. This paper introduces ADEQA, a question-answer(QA) based approach using quasi supervised labelled data and sequence-to-sequence transformers to extract ADEs, drug suspects and the relationships between them. Unlike traditional QA models, natural language generation (NLG) based models don’t require extensive token level labelling and thereby reduces the adoption barrier significantly. On a public ADE corpus, we were able to achieve state-of-the-art results with an F1 score of 94% on establishing the relationships between ADEs and the respective suspects.
在新药物上市过程中,早期识别药物不良反应事件(ADE)对于及时采取行动至关重要。这些ADE信息可以通过各种非结构化数据源获得,如临床研究报告、患者健康记录、社交媒体帖子等。由于文本数据中药物ADE对之间的复杂语言关系和缺乏大量标记数据集,使用机器学习从数据中提取ADE和相关可疑药物是一项具有挑战性的任务。本文介绍了ADEQA,这是一种基于问答(QA)的方法,使用准监督标记数据和序列到序列转换器来提取ADE、药物嫌疑犯以及它们之间的关系。与传统的问答模型不同,基于自然语言生成(NLG)的模型不需要广泛的令牌级标记,从而显著降低了采用门槛。在公共ADE语料库上,我们能够在建立ADE与相应嫌疑人之间的关系方面取得了最先进的成果,F1分数为94%。
论文及项目相关链接
摘要
本文提出一种名为ADEQA的基于问答(QA)的方法,利用准监督标签数据和序列到序列的转换器来提取药物不良反应事件(ADEs)、可疑药物以及它们之间的关系。这种方法不需要大量的标记数据集,通过自然语言生成(NLG)模型减少了标签的难度,实现了在公共ADE语料库上的良好表现,F1分数达到94%。ADEQA的早期识别对于将新药引入市场时采取及时行动至关重要。
关键见解
- 早期识别药物不良反应事件(ADEs)对于新药上市至关重要。
- ADEs信息可以通过各种非结构化数据源获取,如临床研究报告、患者健康记录、社交媒体帖子等。
- 使用机器学习从文本数据中提取ADEs和相关可疑药物是一个挑战,因为药物ADE对之间的语言关系复杂且缺乏大量标记数据集。
- ADEQA是一种基于问答(QA)的方法,使用准监督标签数据和序列到序列转换器来提取ADEs和药物嫌疑人及其关系。
- NLG模型的使用减少了标签的难度,降低了采用门槛。
- 在公共ADE语料库上,ADEQA实现了与药物嫌疑人的关系建立的F1分数达到94%,达到最新技术水平。
点此查看论文截图



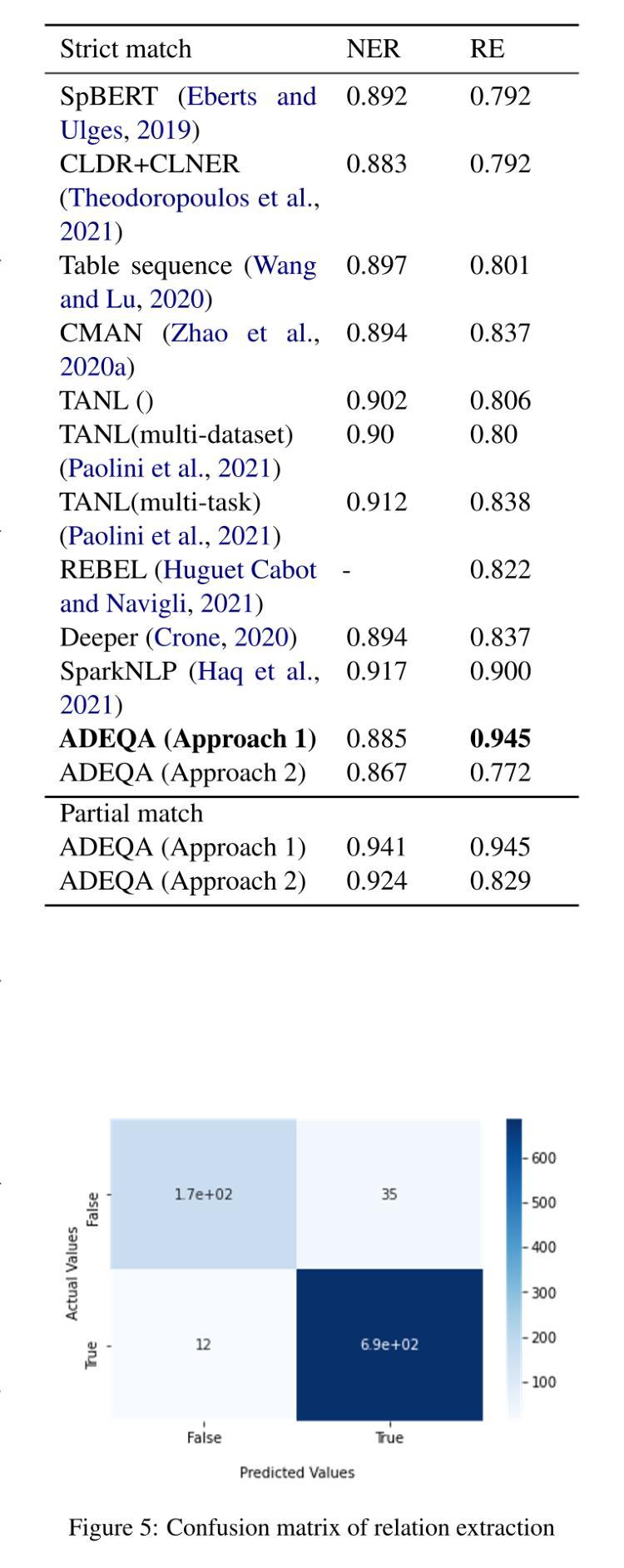
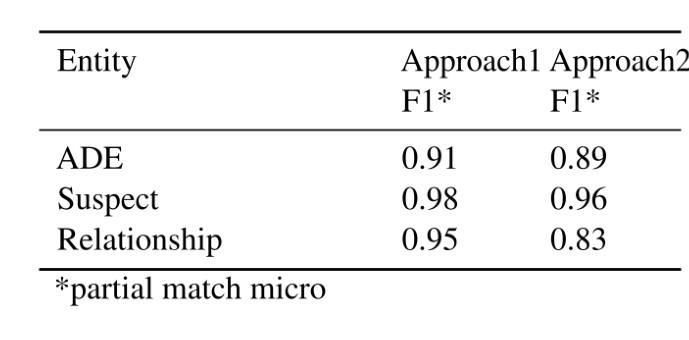
Tokenphormer: Structure-aware Multi-token Graph Transformer for Node Classification
Authors:Zijie Zhou, Zhaoqi Lu, Xuekai Wei, Rongqin Chen, Shenghui Zhang, Pak Lon Ip, Leong Hou U
Graph Neural Networks (GNNs) are widely used in graph data mining tasks. Traditional GNNs follow a message passing scheme that can effectively utilize local and structural information. However, the phenomena of over-smoothing and over-squashing limit the receptive field in message passing processes. Graph Transformers were introduced to address these issues, achieving a global receptive field but suffering from the noise of irrelevant nodes and loss of structural information. Therefore, drawing inspiration from fine-grained token-based representation learning in Natural Language Processing (NLP), we propose the Structure-aware Multi-token Graph Transformer (Tokenphormer), which generates multiple tokens to effectively capture local and structural information and explore global information at different levels of granularity. Specifically, we first introduce the walk-token generated by mixed walks consisting of four walk types to explore the graph and capture structure and contextual information flexibly. To ensure local and global information coverage, we also introduce the SGPM-token (obtained through the Self-supervised Graph Pre-train Model, SGPM) and the hop-token, extending the length and density limit of the walk-token, respectively. Finally, these expressive tokens are fed into the Transformer model to learn node representations collaboratively. Experimental results demonstrate that the capability of the proposed Tokenphormer can achieve state-of-the-art performance on node classification tasks.
图神经网络(GNNs)在图数据挖掘任务中得到广泛应用。传统的GNNs遵循消息传递方案,该方案可以有效地利用局部和结构信息。然而,过度平滑和过度挤压的现象限制了消息传递过程中的感受野。为了解决这些问题,引入了图转换器,实现全局感受野,但存在无关节点的噪声和结构信息丢失的问题。因此,从自然语言处理(NLP)中的精细粒度标记表示学习中汲取灵感,我们提出了结构感知多标记图转换器(Tokenphormer),它生成多个令牌以有效地捕获局部和结构信息,并以不同粒度级别探索全局信息。具体来说,我们首先引入由四种行走类型组成的混合行走产生的walk-token,以灵活地探索图并捕获结构和上下文信息。为了确保本地和全局信息覆盖,我们还引入了通过自监督图预训练模型(SGPM)获得的SGPM-token和hop-token,分别扩展walk-token的长度和密度限制。最后,将这些表达性令牌输入Transformer模型,以协同学习节点表示。实验结果表明,所提出的Tokenphormer的能力在节点分类任务上达到了最先进的性能。
论文及项目相关链接
PDF Accpeted by AAAI 2025
Summary
图神经网络(GNNs)在图数据挖掘任务中得到广泛应用,但存在过度平滑和过度压缩现象。为解决这些问题,引入了图Transformer,但会引入无关节点的噪声和丢失结构信息。受自然语言处理中细粒度令牌表示学习的启发,提出结构感知多令牌图Transformer(Tokenphormer),通过生成多个令牌有效捕获局部和结构信息,并在不同粒度级别上探索全局信息。通过混合走生成的walk-token、通过自监督图预训练模型SGPM获得的SGPM-token以及扩展walk-token长度和密度的hop-token,这些灵活的令牌被输入到Transformer模型中,协同学习节点表示。实验结果表明,Tokenphormer在节点分类任务上达到最新性能。
Key Takeaways
- GNNs面临过度平滑和过度压缩问题,影响了其在消息传递过程中的感受野。
- 图Transformer解决了上述问题,但引入了无关节点的噪声和丢失结构信息的问题。
- Tokenphormer通过生成多个令牌(如walk-token, SGPM-token, hop-token)来有效捕获局部和结构信息,并探索不同粒度级别的全局信息。
- Tokenphormer结合了图数据的局部和全局信息,通过混合走和自监督图预训练方法生成多种令牌。
- 这些令牌被输入到Transformer模型中,以协同学习节点表示。
- Tokenphormer在节点分类任务上实现了先进性能。
点此查看论文截图

All-in-One Tuning and Structural Pruning for Domain-Specific LLMs
Authors:Lei Lu, Zhepeng Wang, Runxue Bao, Mengbing Wang, Fangyi Li, Yawen Wu, Weiwen Jiang, Jie Xu, Yanzhi Wang, Shangqian Gao
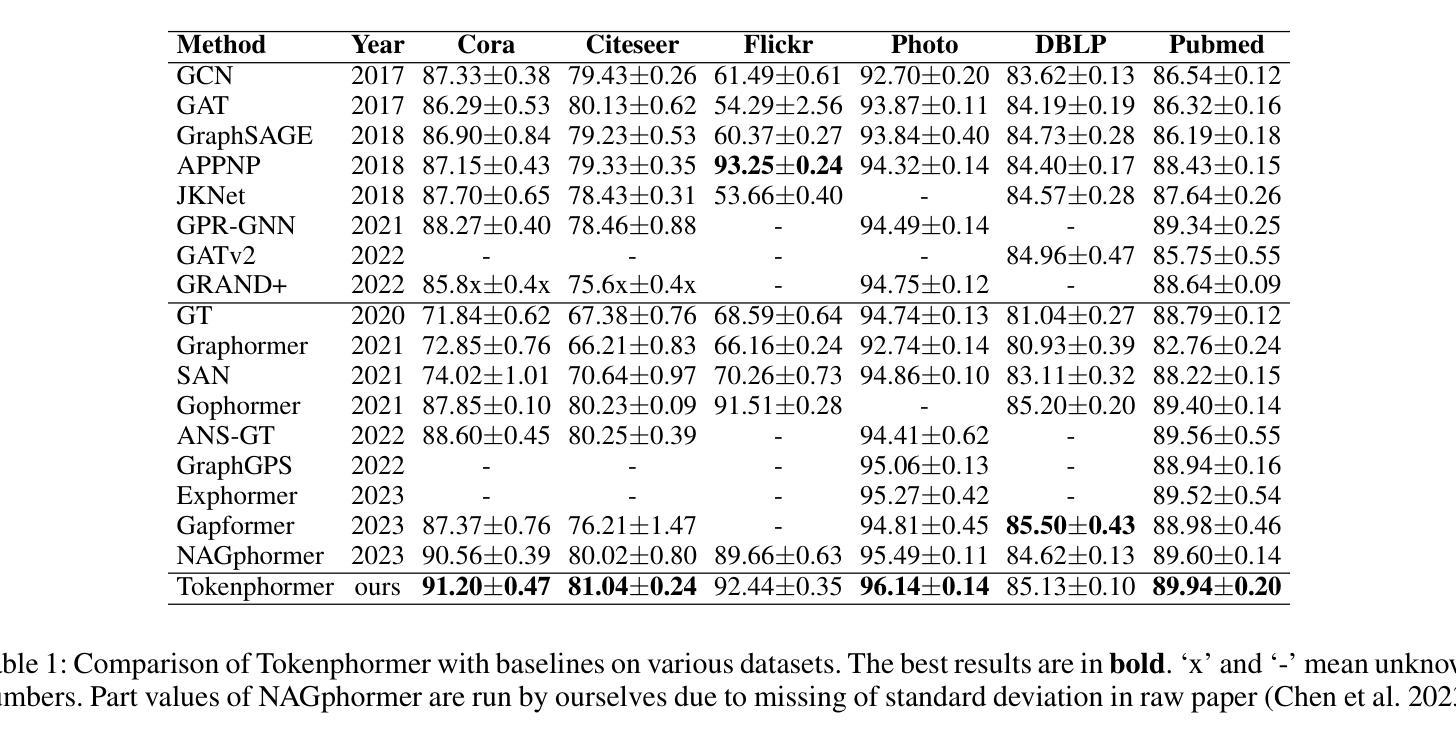
Existing pruning techniques for large language models (LLMs) targeting domain-specific applications typically follow a two-stage process: pruning the pretrained general-purpose LLMs and then fine-tuning the pruned LLMs on specific domains. However, the pruning decisions, derived from the pretrained weights, remain unchanged during fine-tuning, even if the weights have been updated. Therefore, such a combination of the pruning decisions and the finetuned weights may be suboptimal, leading to non-negligible performance degradation. To address these limitations, we propose ATP: All-in-One Tuning and Structural Pruning, a unified one-stage structural pruning and fine-tuning approach that dynamically identifies the current optimal substructure throughout the fine-tuning phase via a trainable pruning decision generator. Moreover, given the limited available data for domain-specific applications, Low-Rank Adaptation (LoRA) becomes a common technique to fine-tune the LLMs. In ATP, we introduce LoRA-aware forward and sparsity regularization to ensure that the substructures corresponding to the learned pruning decisions can be directly removed after the ATP process. ATP outperforms the state-of-the-art two-stage pruning methods on tasks in the legal and healthcare domains. More specifically, ATP recovers up to 88% and 91% performance of the dense model when pruning 40% parameters of LLaMA2-7B and LLaMA3-8B models, respectively.
针对特定领域应用的大型语言模型(LLM)的现有剪枝技术通常遵循两阶段过程:剪枝预训练的通用LLM,然后在特定领域对剪枝后的LLM进行微调。然而,剪枝决策来源于预训练权重,即使在权重已更新的情况下,微调过程中剪枝决策仍然保持不变。因此,剪枝决策和微调权重的这种组合可能是次优的,会导致不可忽略的性能下降。为了解决这些限制,我们提出了ATP:一站式调优和结构剪枝,这是一种统一的单阶段结构剪枝和微调方法,它通过可训练的剪枝决策生成器动态地识别整个微调阶段的当前最佳子结构。此外,考虑到针对特定领域的有限可用数据,低秩适应(LoRA)已成为微调LLM的常见技术。在ATP中,我们引入了LoRA感知正向传播和稀疏性正则化,以确保与所学剪枝决策相对应的子结构可以在ATP过程后直接被移除。ATP在法律和医疗保健领域的任务上优于最新的两阶段剪枝方法。更具体地说,ATP在剪枝LLaMA2-7B模型的40%参数和LLaMA3-8B模型的参数时,分别恢复了密集模型性能的88%和91%。
论文及项目相关链接
PDF Updated a typo in the author list;
Summary
本文介绍了针对大型语言模型(LLM)的修剪技术,该技术面向特定领域应用通常采用两阶段过程:先修剪预训练通用LLM,然后对修剪后的LLM进行特定领域的微调。然而,从预训练权重中得出的修剪决策在微调过程中保持不变,即使权重已更新。因此,这种修剪决策与微调权重的组合可能不是最优的,会导致性能显著下降。为解决这些问题,本文提出了ATP:一站式结构修剪与精细调整方法,通过可训练的修剪决策生成器在微调阶段动态识别当前最佳子结构。此外,考虑到领域特定应用可用数据的有限性,LoRA成为一种常见的LLM微调技术。在ATP中,引入LoRA感知正向和稀疏性正则化,以确保与学到的修剪决策相对应的子结构可以在ATP过程后直接被移除。ATP在法律和医疗领域的任务上优于最新的两阶段修剪方法。具体来说,ATP在修剪LLaMA2-7B和LLaMA3-8B模型的40%参数时,能恢复高达88%和91%的密集模型性能。
Key Takeaways
- 现有针对LLM的修剪技术通常采取两阶段过程,包括预训练修剪和特定领域微调。
- 在微调过程中,修剪决策保持不变可能导致非最优结果和性能下降。
- ATP方法通过结合结构修剪和精细调整,在微调阶段动态识别最佳子结构。
- ATP引入LoRA感知正向和稀疏性正则化,确保在ATP过程后移除与学到的修剪决策相对应的子结构。
- ATP在法律和医疗领域的任务上表现优异。
- ATP在修剪40%参数时能够显著恢复模型的性能。
点此查看论文截图


Experience of Training a 1.7B-Parameter LLaMa Model From Scratch
Authors:Miles Q. Li, Benjamin C. M. Fung, Shih-Chia Huang
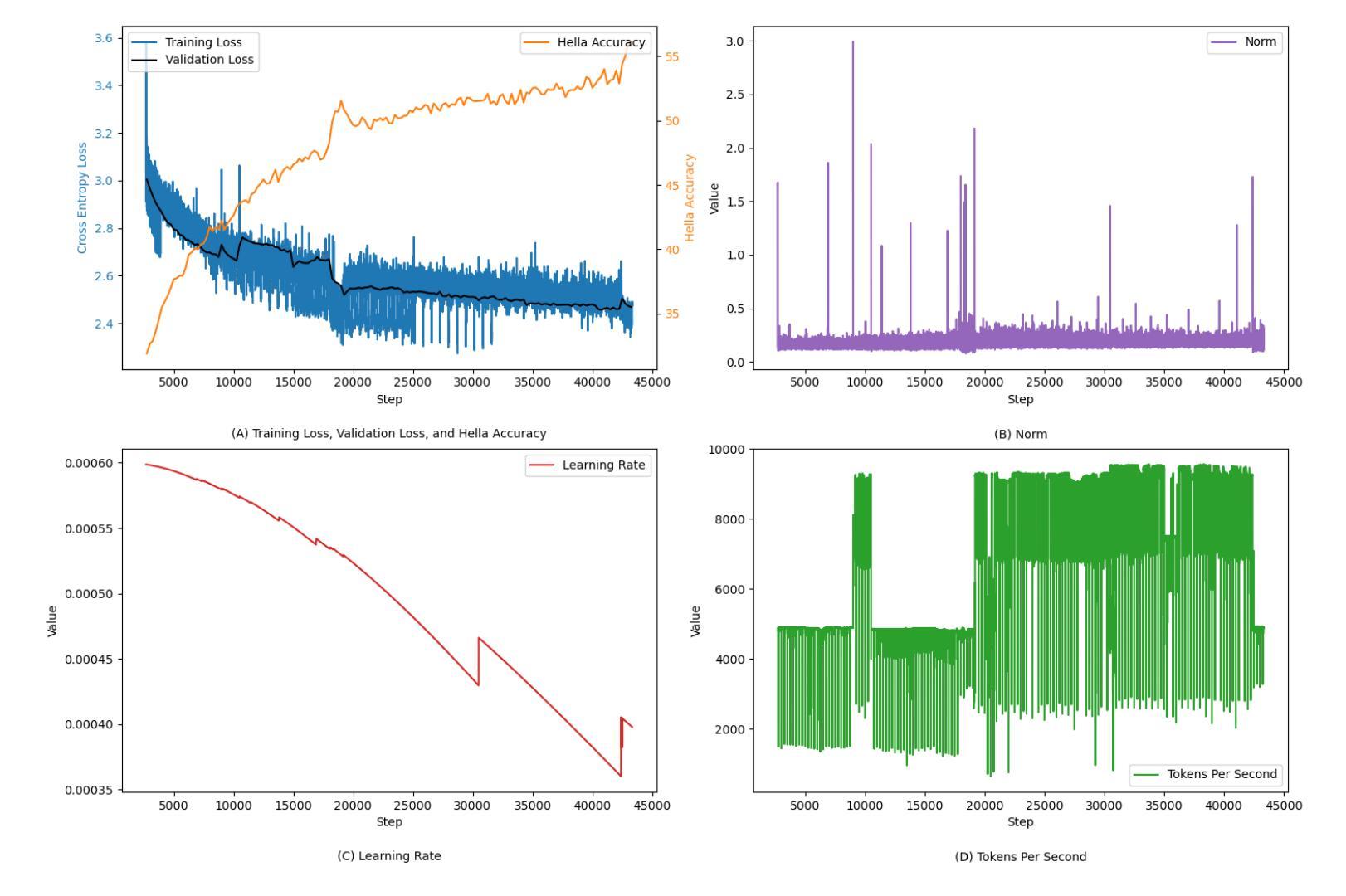
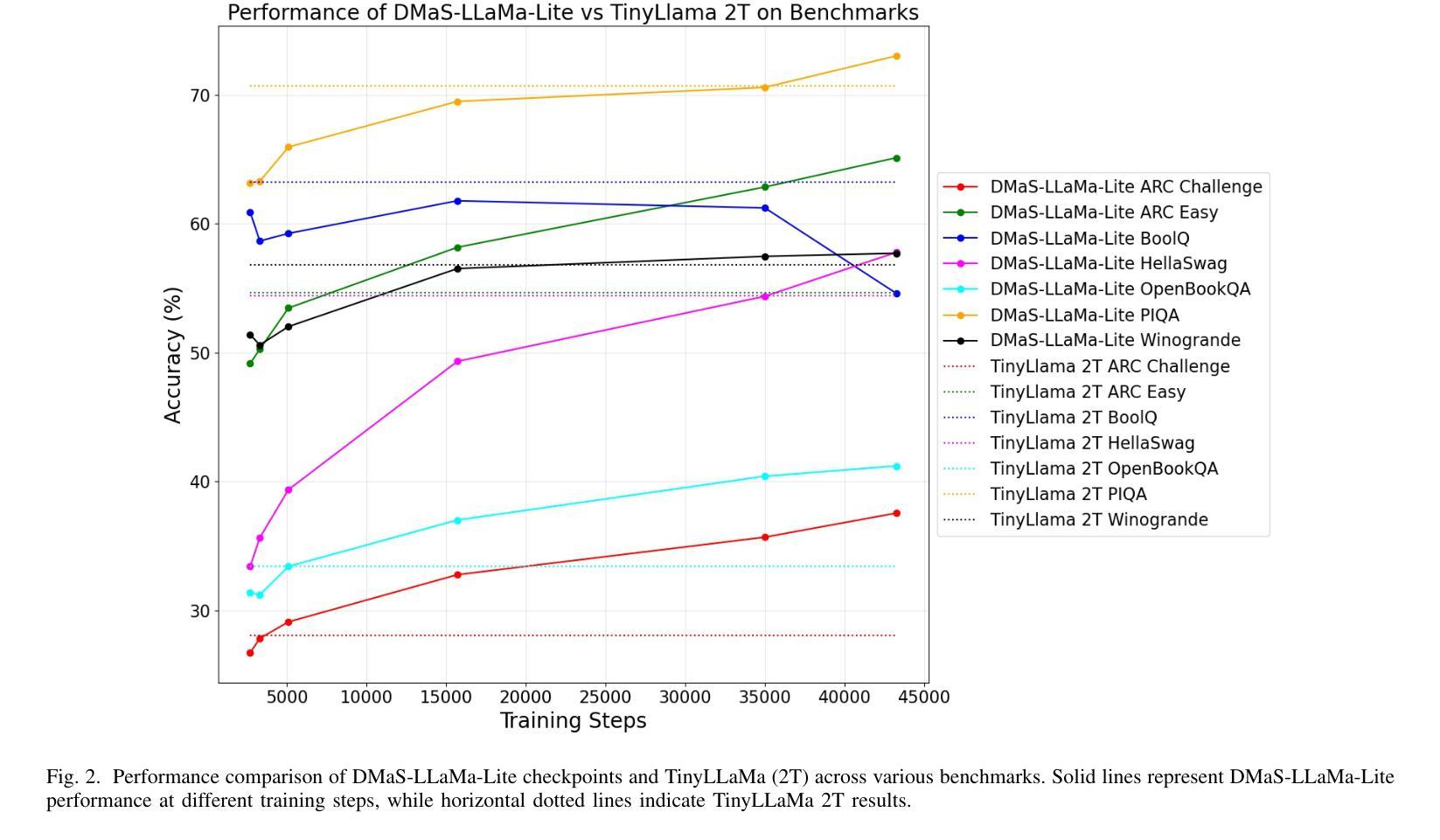
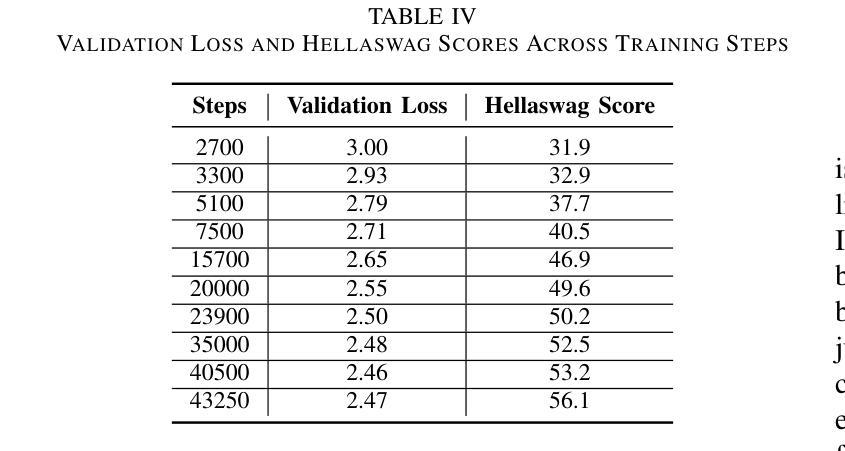
Pretraining large language models is a complex endeavor influenced by multiple factors, including model architecture, data quality, training continuity, and hardware constraints. In this paper, we share insights gained from the experience of training DMaS-LLaMa-Lite, a fully open source, 1.7-billion-parameter, LLaMa-based model, on approximately 20 billion tokens of carefully curated data. We chronicle the full training trajectory, documenting how evolving validation loss levels and downstream benchmarks reflect transitions from incoherent text to fluent, contextually grounded output. Beyond pretraining, we extend our analysis to include a post-training phase focused on instruction tuning, where the model was refined to produce more contextually appropriate, user-aligned responses. We highlight practical considerations such as the importance of restoring optimizer states when resuming from checkpoints, and the impact of hardware changes on training stability and throughput. While qualitative evaluation provides an intuitive understanding of model improvements, our analysis extends to various performance benchmarks, demonstrating how high-quality data and thoughtful scaling enable competitive results with significantly fewer training tokens. By detailing these experiences and offering training logs, checkpoints, and sample outputs, we aim to guide future researchers and practitioners in refining their pretraining strategies. The training script is available on Github at https://github.com/McGill-DMaS/DMaS-LLaMa-Lite-Training-Code. The model checkpoints are available on Huggingface at https://huggingface.co/collections/McGill-DMaS/dmas-llama-lite-6761d97ba903f82341954ceb.
预训练大型语言模型是一项复杂的任务,受到多种因素的影响,包括模型架构、数据质量、训练连续性和硬件限制。在本文中,我们分享了训练DMaS-LLaMa-Lite模型的实战经验。这是一个完全开源的、基于LLaMa的1.7亿参数模型,在约20亿标记的精心挑选的数据上进行训练。我们详细记录了整个训练轨迹,描述了验证损失水平的演变和下游基准测试如何反映从文本不连贯到流畅、上下文相关的输出的转变。除了预训练阶段外,我们还将分析扩展到包括以指令微调为重点的后训练阶段,其中对模型进行了微调,以产生更贴合上下文、更符合用户需求的响应。我们强调了实际考虑因素,如恢复优化器状态时重启的重要性,以及硬件更改对训练稳定性和吞吐量的影响。虽然定性评估为模型改进提供了直观的理解,但我们的分析还涉及各种性能基准测试,证明高质量数据和深思熟虑的扩展如何使我们在使用更少的训练标记的情况下获得有竞争力的结果。通过详细介绍这些经验并提供训练日志、检查点和样本输出,我们的目标是指导未来的研究人员和实践者在精炼他们的预训练策略方面。训练脚本可在GitHub上找到:链接。模型检查点可在Huggingface上找到:链接。
论文及项目相关链接
摘要
本文介绍了训练DMaS-LLaMa-Lite这一开源大型语言模型的实践经验。模型在约20亿个精心挑选的令牌上进行训练,采用LLaMa架构,含有1.7亿个参数。文章详细描述了训练过程,包括预训练和指令调整阶段,并探讨了模型架构、数据质量、训练连续性以及硬件约束等多个影响因素。此外,文章还强调了恢复优化器状态的重要性以及硬件变化对训练稳定性和效率的影响。通过性能基准测试证明,高质量数据和策略性扩展可实现具有竞争力的结果,显著减少训练令牌数量。本文旨在指导未来研究者和实践者在预训练策略方面的改进,并提供了训练日志、检查点以及样本输出。
关键见解
- 训练大型语言模型是一个受多种因素影响的复杂过程,包括模型架构、数据质量、训练连续性和硬件约束等。
- DMaS-LLaMa-Lite是一个基于LLaMa的开源模型,在约20亿个令牌上进行训练,参数为1.7亿。
- 文章详细描述了从预训练到指令调整阶段的整个训练过程。
- 强调了在恢复优化器状态时的注意事项以及硬件变化对训练稳定性和效率的影响。
- 高质量数据和策略性扩展可实现具有竞争力的结果,显著减少训练令牌数量。
- 通过性能基准测试证明了该模型的有效性。
- 文章提供了训练日志、检查点以及样本输出,旨在为未来的研究者和实践者提供指导。
点此查看论文截图


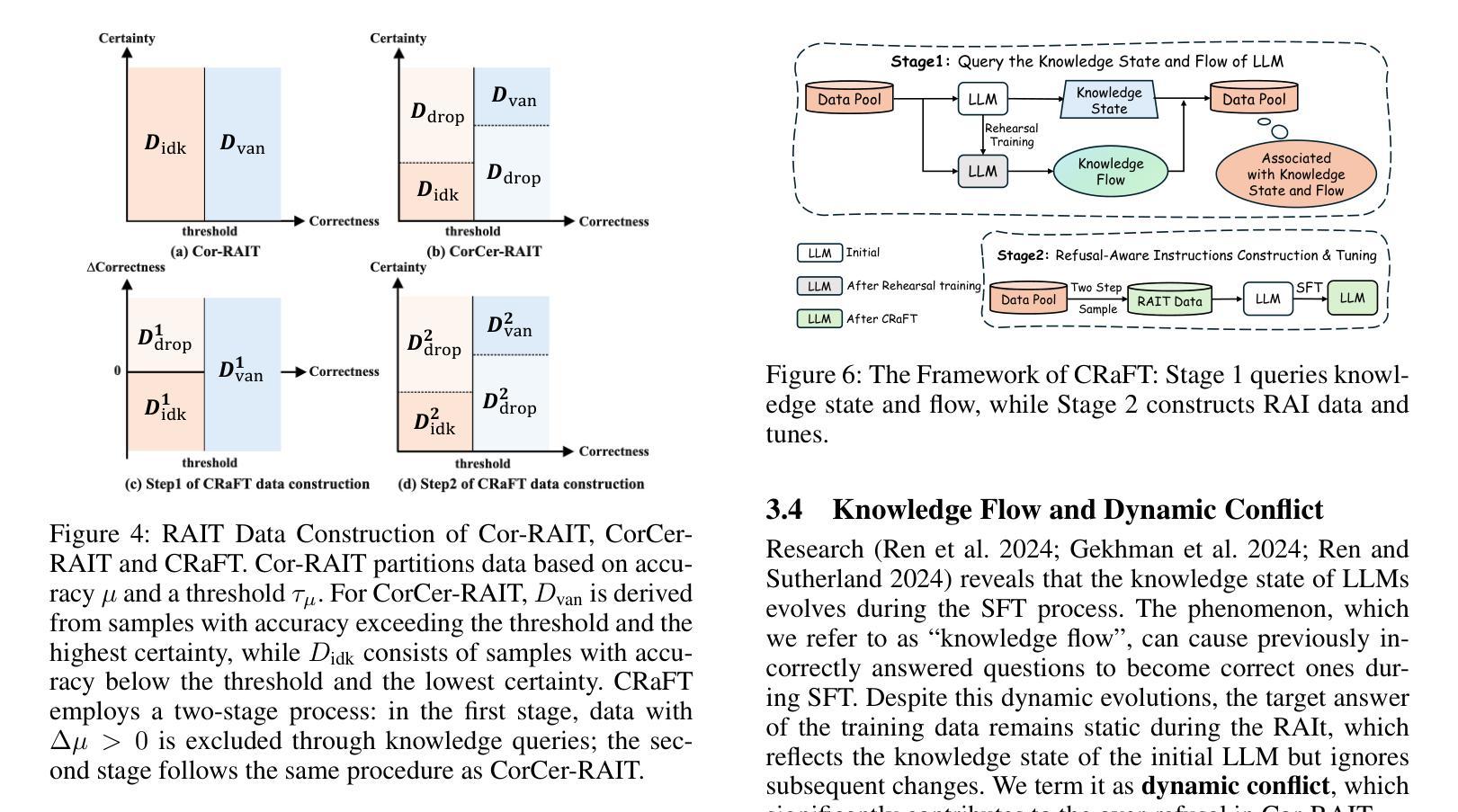
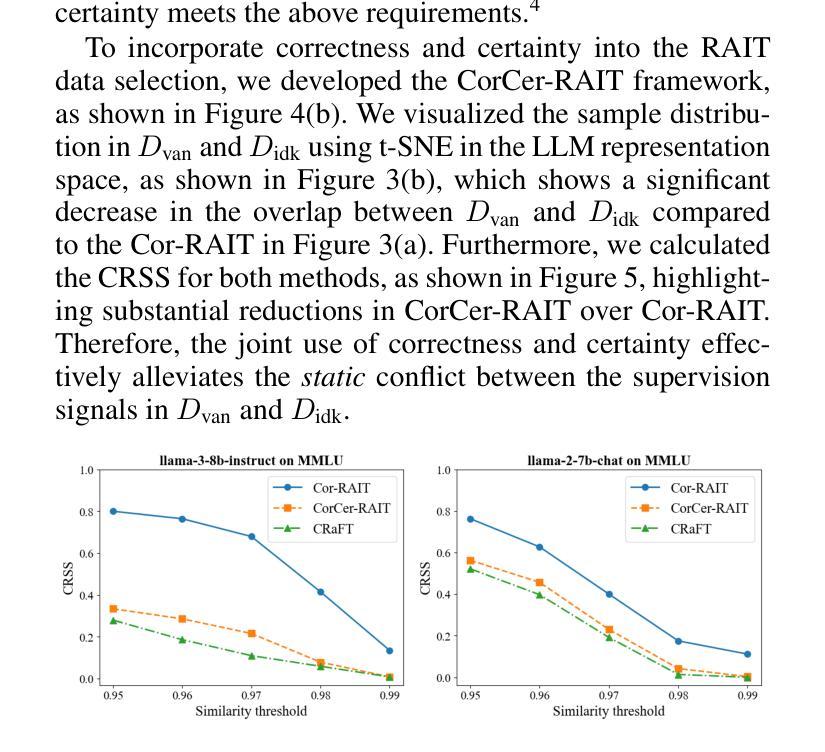
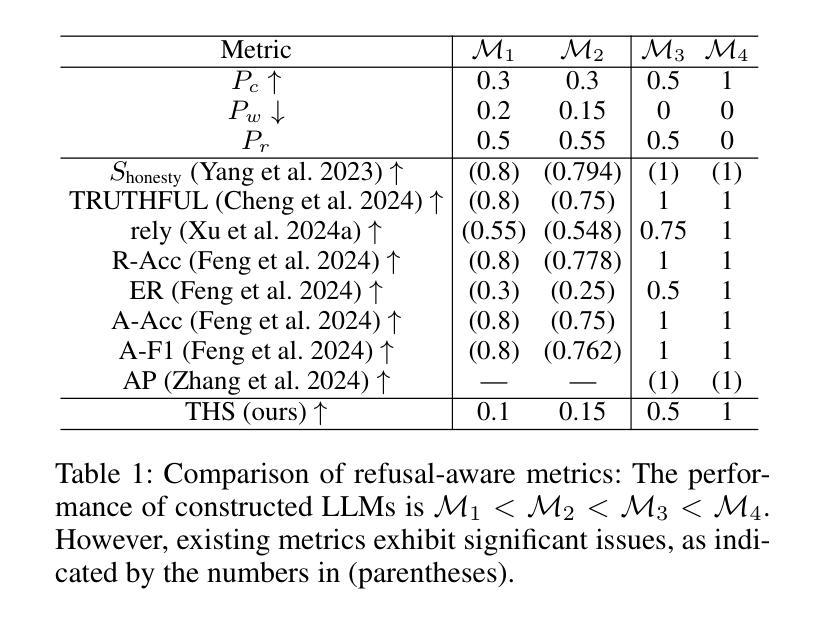
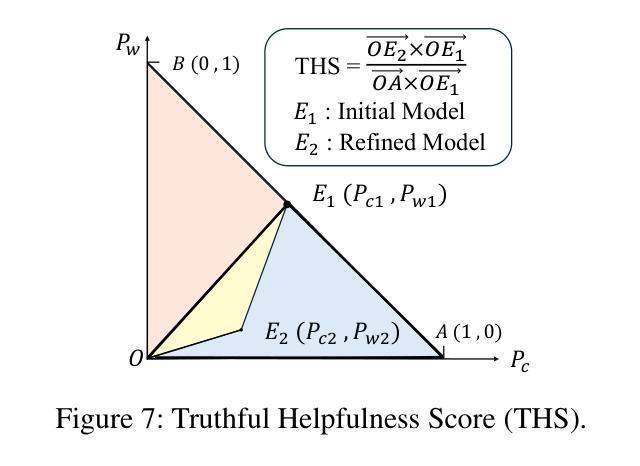
Utilize the Flow before Stepping into the Same River Twice: Certainty Represented Knowledge Flow for Refusal-Aware Instruction Tuning
Authors:Runchuan Zhu, Zhipeng Ma, Jiang Wu, Junyuan Gao, Jiaqi Wang, Dahua Lin, Conghui He
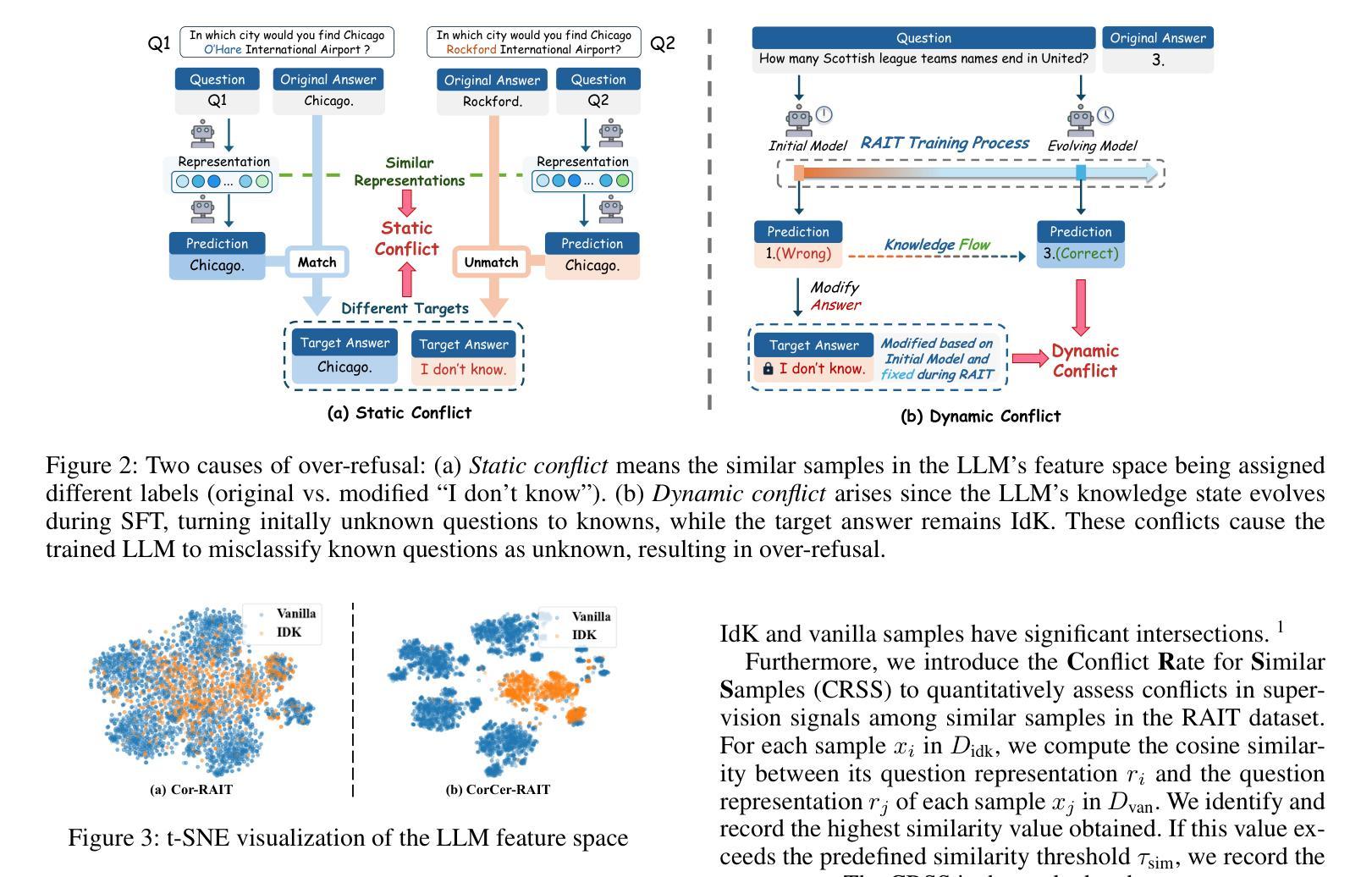
Refusal-Aware Instruction Tuning (RAIT) enables Large Language Models (LLMs) to refuse to answer unknown questions. By modifying responses of unknown questions in the training data to refusal responses such as “I don’t know”, RAIT enhances the reliability of LLMs and reduces their hallucination. Generally, RAIT modifies training samples based on the correctness of the initial LLM’s response. However, this crude approach can cause LLMs to excessively refuse answering questions they could have correctly answered, the problem we call over-refusal. In this paper, we explore two primary causes of over-refusal: Static conflict occurs when similar samples within the LLM’s feature space receive differing supervision signals (original vs. modified “I don’t know”). Dynamic conflict arises as the LLM’s evolving knowledge during SFT enables it to answer previously unanswerable questions, but the now-answerable training samples still retain the original “I don’t know” supervision signals from the initial LLM state, leading to inconsistencies. These conflicts cause the trained LLM to misclassify known questions as unknown, resulting in over-refusal. To address this issue, we introduce Certainty Represented Knowledge Flow for Refusal-Aware Instructions Tuning (CRaFT). CRaFT centers on two main contributions: First, we additionally incorporate response certainty to selectively filter and modify data, reducing static conflicts. Second, we implement preliminary rehearsal training to characterize changes in the LLM’s knowledge state, which helps mitigate dynamic conflicts during the fine-tuning process. We conducted extensive experiments on open-ended question answering and multiple-choice question task. Experiment results show that CRaFT can improve LLM’s overall performance during the RAIT process. Code and data will be released at https://github.com/opendatalab/CRaFT .
拒绝感知指令调整(RAIT)能够使大型语言模型(LLM)拒绝回答未知问题。通过将训练数据中对未知问题的回应修改为拒绝回应,例如“我不知道”,RAIT提高了LLM的可靠性,并减少了其幻觉。通常,RAIT会根据初始LLM响应的正确性来修改训练样本。然而,这种简单的方法可能会导致LLM过度拒绝回答他们本来可以正确回答的问题,我们称之为“过度拒绝”。在本文中,我们探讨了过度拒绝的两个主要原因:静态冲突发生在LLM特征空间内的相似样本接收到不同的监督信号(原始信号与修改后的“我不知道”)时。动态冲突随着LLM在SFT期间的知识进步,它能够回答之前无法回答的问题,但现在可回答的训练样本仍然保留着初始LLM状态的“我不知道”的监督信号,导致不一致。这些冲突导致训练后的LLM将已知问题错误地归类为未知问题,从而产生过度拒绝。为解决这一问题,我们引入了拒绝感知指令调整的确定性表示知识流(CRaFT)。CRaFT主要集中于两个主要贡献:首先,我们额外引入响应确定性来有选择地过滤和修改数据,以减少静态冲突。其次,我们实施初步排练训练以表征LLM知识状态的变化,这有助于在微调过程中缓解动态冲突。我们在开放式问答和多项选择任务上进行了大量实验。实验结果表明,CRaFT在RAIT过程中能够提高LLM的整体性能。代码和数据将在https://github.com/opendatalab/CRaFT上发布。
论文及项目相关链接
PDF Equal contribution: Runchuan Zhu, Zhipeng Ma, Jiang Wu; Corresponding author: Conghui He
Summary
本文介绍了如何通过拒绝回答未知问题来提高大型语言模型(LLM)的可靠性并减少其幻觉。通过修改训练数据中未知问题的响应为拒绝回答(如“我不知道”),实现了一种名为RAIT的方法。然而,这种方法可能导致LLM过度拒绝回答问题,称为过度拒绝现象。本文探讨了过度拒绝的两个主要原因:静态冲突和动态冲突。为了解决这一问题,引入了CRaFT方法,通过引入响应确定性来过滤和修改数据,并初步排练训练以表征LLM知识状态的变化,从而减轻RAIT过程中的冲突问题。实验结果表明,CRaFT在改善LLM性能方面有明显效果。
Key Takeaways
- RAIT通过修改训练数据中的响应来提高LLM的可靠性。
- 过度拒绝是RAIT的一个潜在问题,可能导致LLM错误地拒绝回答已知问题。
- 静态冲突和动态冲突是导致过度拒绝的两个主要原因。
- CRaFT通过引入响应确定性来减少静态冲突,并通过初步排练训练来表征LLM知识状态的变化来解决动态冲突。
- CRaFT在改善LLM性能方面有明显效果,尤其是在开放问题和多选问答任务上。
- 代码和数据将在https://github.com/opendatalab/CRaFT上发布以供研究使用。
点此查看论文截图


What is the Role of Small Models in the LLM Era: A Survey
Authors:Lihu Chen, Gaël Varoquaux
Large Language Models (LLMs) have made significant progress in advancing artificial general intelligence (AGI), leading to the development of increasingly large models such as GPT-4 and LLaMA-405B. However, scaling up model sizes results in exponentially higher computational costs and energy consumption, making these models impractical for academic researchers and businesses with limited resources. At the same time, Small Models (SMs) are frequently used in practical settings, although their significance is currently underestimated. This raises important questions about the role of small models in the era of LLMs, a topic that has received limited attention in prior research. In this work, we systematically examine the relationship between LLMs and SMs from two key perspectives: Collaboration and Competition. We hope this survey provides valuable insights for practitioners, fostering a deeper understanding of the contribution of small models and promoting more efficient use of computational resources. The code is available at https://github.com/tigerchen52/role_of_small_models
大型语言模型(LLM)在推动人工智能通用智能(AGI)方面取得了显著进展,从而产生了如GPT-4和LLaMA-405B等越来越大的模型。然而,扩大模型规模导致计算成本和能源消耗呈指数级增长,使得这些模型对于资源有限的学术研究人员和企业来说不切实际。与此同时,小模型(SM)在实际情况中经常被使用,尽管它们的重要性目前被低估了。这引发了关于小模型在大型语言模型时代的作用的重要问题,这一主题在以前的研究中受到的关注有限。在这项工作中,我们从协作和竞争两个关键角度系统地研究了大型语言模型和小模型之间的关系。我们希望这项调查能为从业者提供有价值的见解,加深对小型模型的贡献的理解,并促进更有效地利用计算资源。代码可在https://github.com/tigerchen52/role_of_small_models找到。
论文及项目相关链接
PDF a survey paper of small models
Summary
大型语言模型(LLMs)在推进人工通用智能(AGI)方面取得了显著进展,但也带来了计算成本高昂和能源消耗巨大的问题,使得有限资源的学术机构和企业在实践中难以承受。相对之下,小型模型(SMs)在实际情况中应用广泛却常常受到忽视。本研究系统地探讨了LLMs与SMs之间的关系,从协作与竞争两个角度切入,旨在为从业者提供有价值的见解,深化对小型模型贡献的理解,并促进计算资源的有效利用。
Key Takeaways
- LLMs在AGI领域取得显著进展,但大规模模型带来的计算成本和能源消耗问题使得其在有限资源的环境下难以实现广泛应用。
- 小型模型(SMs)在实践中应用广泛,但其重要性经常被忽视。
- LLMs和SMs之间的关系需要从协作和竞争两个角度进行考察。
- 协作角度:LLMs和SMs可以相互补充,共同解决复杂任务。
- 竞争角度:LLMs和SMs在某些任务上可能存在性能竞争,需要根据具体任务选择合适的模型规模。
- 对小型模型的贡献需要更深入的理解,以促进计算资源的更有效利用。
点此查看论文截图


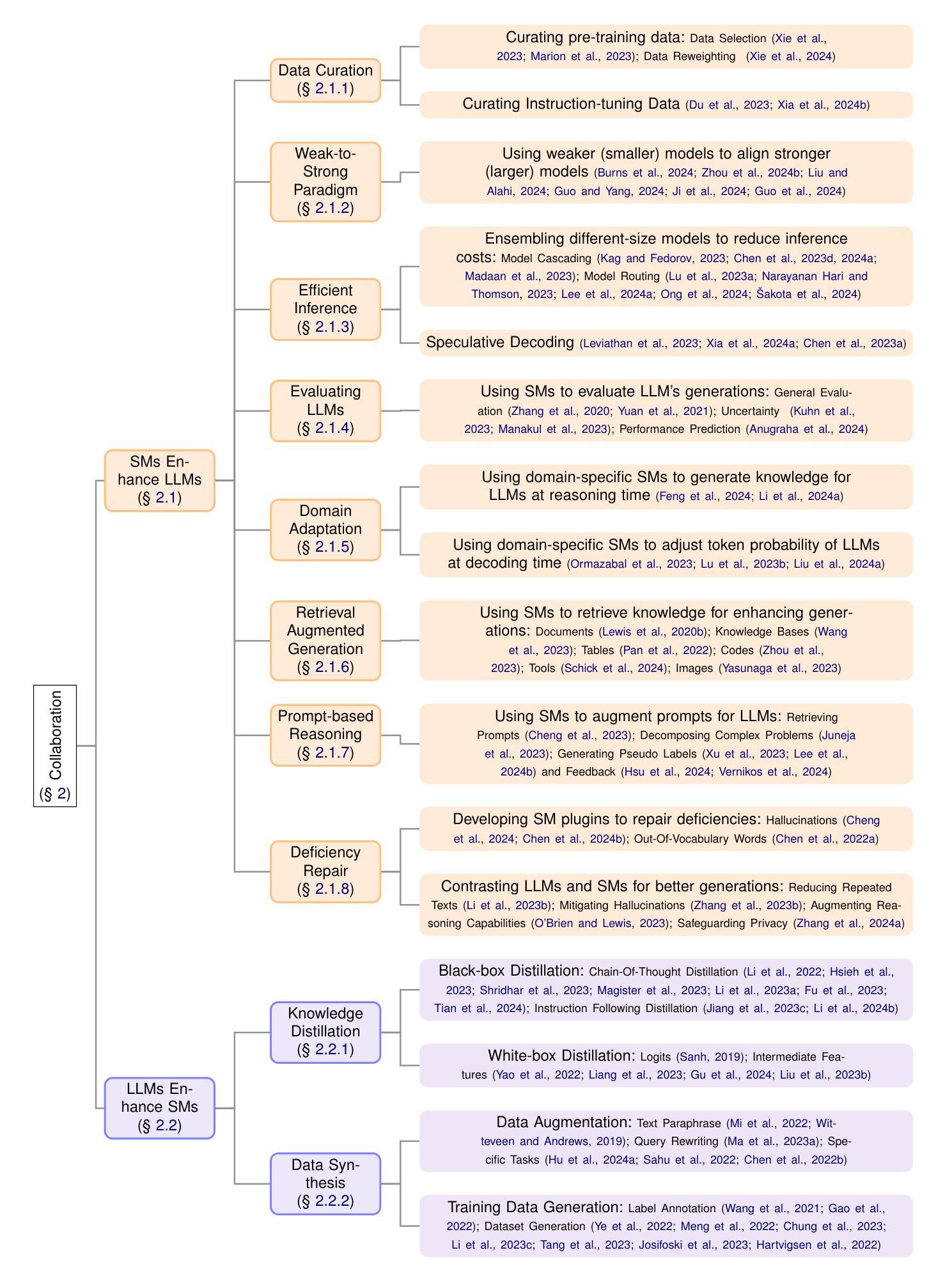
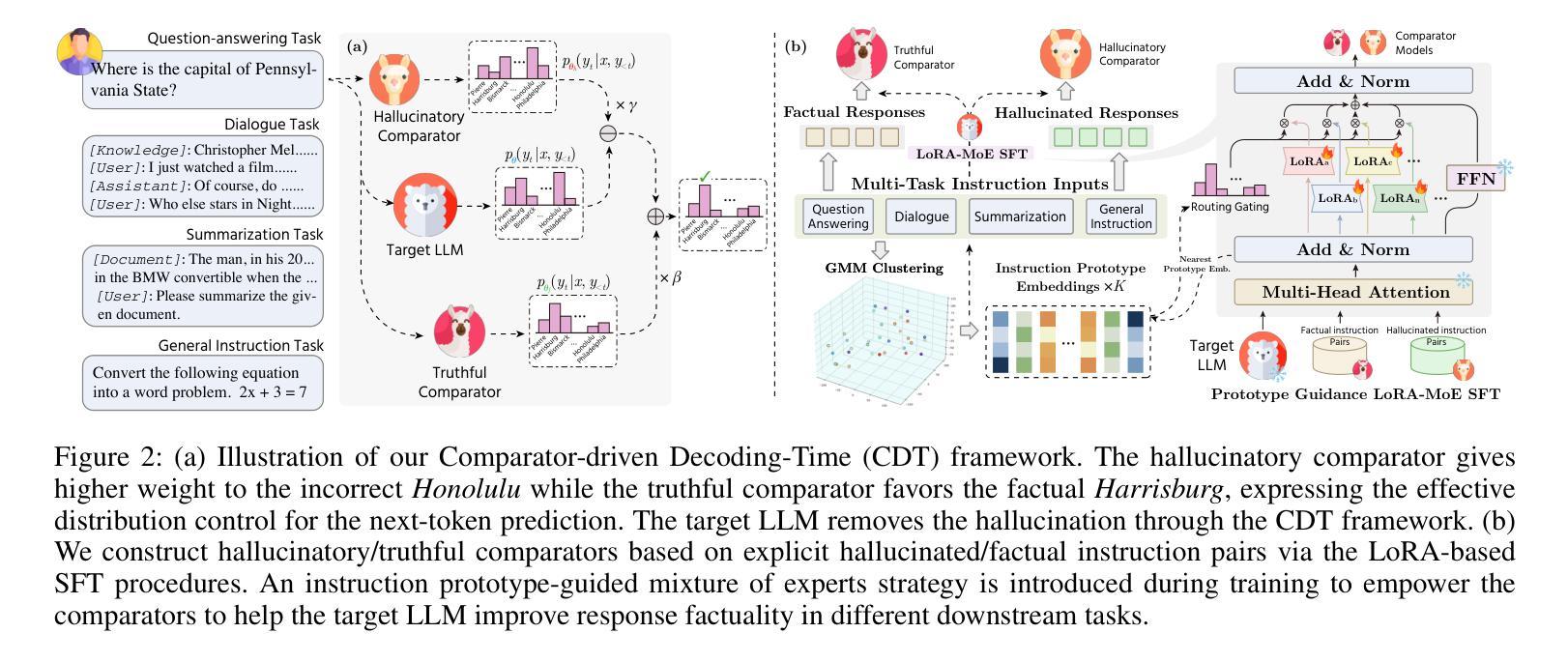
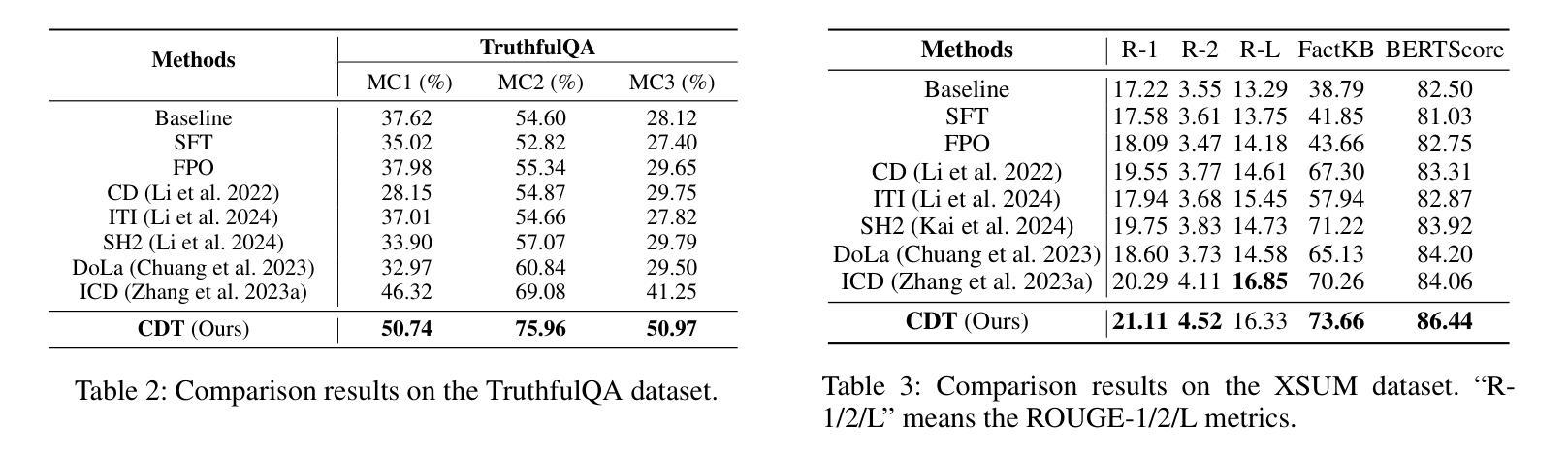
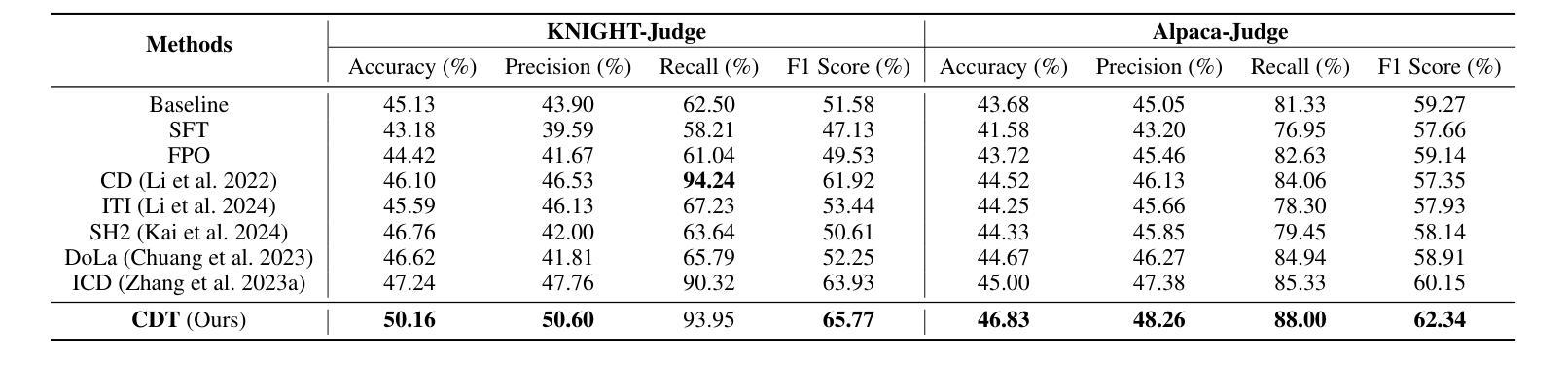
Improving Factuality in Large Language Models via Decoding-Time Hallucinatory and Truthful Comparators
Authors:Dingkang Yang, Dongling Xiao, Jinjie Wei, Mingcheng Li, Zhaoyu Chen, Ke Li, Lihua Zhang
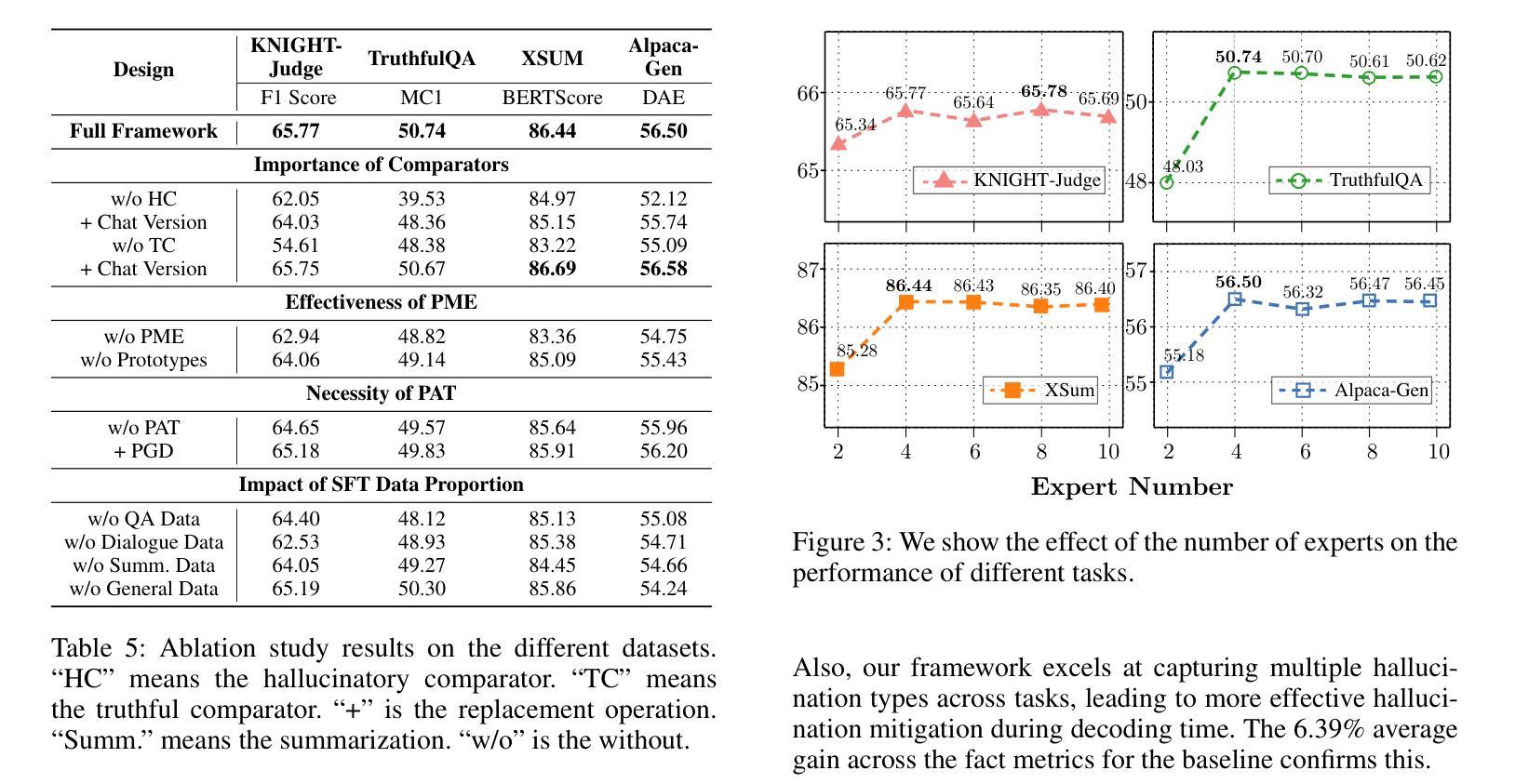
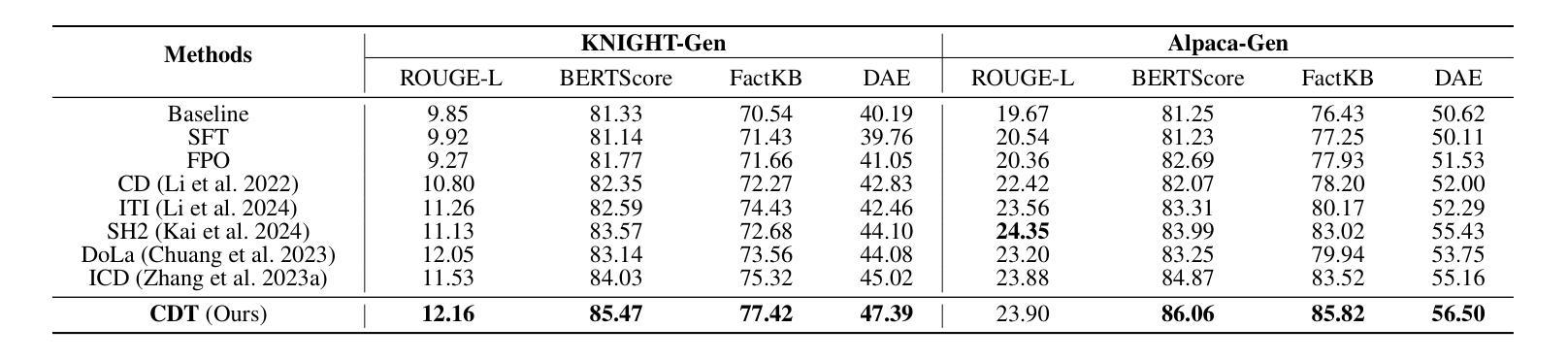
Despite their remarkable capabilities, Large Language Models (LLMs) are prone to generate responses that contradict verifiable facts, i.e., unfaithful hallucination content. Existing efforts generally focus on optimizing model parameters or editing semantic representations, which compromise the internal factual knowledge of target LLMs. In addition, hallucinations typically exhibit multifaceted patterns in downstream tasks, limiting the model’s holistic performance across tasks. In this paper, we propose a Comparator-driven Decoding-Time (CDT) framework to alleviate the response hallucination. Firstly, we construct hallucinatory and truthful comparators with multi-task fine-tuning samples. In this case, we present an instruction prototype-guided mixture of experts strategy to enhance the ability of the corresponding comparators to capture different hallucination or truthfulness patterns in distinct task instructions. CDT constrains next-token predictions to factuality-robust distributions by contrasting the logit differences between the target LLMs and these comparators. Systematic experiments on multiple downstream tasks show that our framework can significantly improve the model performance and response factuality.
尽管大型语言模型(LLM)具有显著的能力,但它们容易产生与可验证事实相矛盾的回应,即不真实的幻觉内容。现有的努力一般集中在优化模型参数或编辑语义表示上,这会损害目标LLM的内部事实知识。此外,幻觉通常在下游任务中表现出多面模式,限制了模型在任务中的整体表现。在本文中,我们提出了一个比较器驱动的解码时间(CDT)框架来缓解响应幻觉。首先,我们使用多任务微调样本构建幻觉和真实比较器。在这种情况下,我们提出了一个以指令原型为指导的专家混合策略,以提高相应比较器在不同任务指令中捕捉不同幻觉或真实性模式的能力。CDT通过对比目标LLM和这些比较器之间的逻辑差异,将下一个标记预测限制在事实性稳健分布中。在多个下游任务上的系统实验表明,我们的框架可以显著提高模型性能和响应事实性。
论文及项目相关链接
PDF Accepted by AAAI 2025
摘要
LLM虽然功能强大,但易产生与可验证事实相矛盾的回应,即不真实的幻觉内容。现有方法主要关注优化模型参数或编辑语义表示,这会损害目标LLM的内部事实知识。此外,幻觉在下游任务中通常表现出多面性模式,限制了模型在任务中的整体表现。本文提出一种比较器驱动解码时间(CDT)框架,以减轻响应幻觉。首先,我们使用多任务微调样本构建幻觉和真实比较器。在此基础上,我们提出了一种指令原型引导的专家混合策略,以提高相应比较器在不同任务指令中捕捉幻觉或真实性模式的能力。CDT通过对比目标LLM与这些比较器的逻辑差异,将下一个标记的预测限制在事实性稳健分布中。在多个下游任务上的系统实验表明,我们的框架可以显著提高模型性能和响应事实的准确性。
关键见解
- LLM易产生与事实不符的响应,即幻觉内容。
- 现有方法主要通过优化模型参数或编辑语义表示来解决这一问题,但这可能损害LLM的内部事实知识。
- 幻觉在下游任务中表现出多面性模式,影响模型的整体表现。
- 提出了一种新的CDT框架,通过构建幻觉和真实比较器来减轻响应幻觉。
- 采用指令原型引导的专家混合策略,提高比较器捕捉不同任务中幻觉或真实性模式的能力。
- CDT框架通过将预测限制在事实性稳健分布中,对比目标LLM与比较器的逻辑差异来发挥作用。
- 系统实验表明,CDT框架能显著提高模型性能和响应的准确度。
点此查看论文截图

Language Models Resist Alignment: Evidence From Data Compression
Authors:Jiaming Ji, Kaile Wang, Tianyi Qiu, Boyuan Chen, Jiayi Zhou, Changye Li, Hantao Lou, Josef Dai, Yunhuai Liu, Yaodong Yang
Large language models (LLMs) may exhibit unintended or undesirable behaviors. Recent works have concentrated on aligning LLMs to mitigate harmful outputs. Despite these efforts, some anomalies indicate that even a well-conducted alignment process can be easily circumvented, whether intentionally or accidentally. Does alignment fine-tuning yield have robust effects on models, or are its impacts merely superficial? In this work, we make the first exploration of this phenomenon from both theoretical and empirical perspectives. Empirically, we demonstrate the elasticity of post-alignment models, i.e., the tendency to revert to the behavior distribution formed during the pre-training phase upon further fine-tuning. Leveraging compression theory, we formally deduce that fine-tuning disproportionately undermines alignment relative to pre-training, potentially by orders of magnitude. We validate the presence of elasticity through experiments on models of varying types and scales. Specifically, we find that model performance declines rapidly before reverting to the pre-training distribution, after which the rate of decline drops significantly. Furthermore, we further reveal that elasticity positively correlates with the increased model size and the expansion of pre-training data. Our findings underscore the need to address the inherent elasticity of LLMs to mitigate their resistance to alignment.
大型语言模型(LLM)可能会表现出意外或不受欢迎的行为。近期的研究工作集中在将LLM对齐以减少有害输出。尽管付出了这些努力,一些异常情况表明,即使是精心进行的对齐过程也可能轻易被绕过,无论是故意还是意外。对齐微调是否对模型产生了稳健的影响,还是其影响仅仅是表面的?在这项工作中,我们从理论和实证两个角度首次探索了这一现象。实证上,我们展示了后对齐模型的弹性,即进一步微调时恢复到预训练阶段形成的行为分布的倾向。我们利用压缩理论正式推断,相对于预训练,微调会不成比例地破坏对齐,可能是以数量级计算。我们通过不同类型和规模的模型实验验证了弹性的存在。具体来说,我们发现模型性能在恢复到预训练分布之前会迅速下降,之后下降率显著降低。此外,我们还进一步揭示弹性与模型规模扩大和预训练数据增加呈正相关。我们的研究结果表明,需要解决LLM的内在弹性以减轻其对齐的阻力。
论文及项目相关链接
PDF The five-page version has been accepted by NeurIPS 2024 Workshop SoLaR. In the current version, we have conducted an in-depth expansion of both the theoretical and experimental aspects
Summary
大型语言模型(LLM)可能会展现出意想不到或不受欢迎的行为。尽管近期工作集中在对其进行对齐以减轻有害输出,但仍存在异常现象,表明即使是精心进行的对齐过程也可能轻易被规避,无论是故意还是意外。本文首次从理论和实证两个角度探讨了这一现象。实证方面,我们展示了后对齐模型的弹性,即进一步微调时倾向于恢复到预训练阶段形成的行为分布。利用压缩理论,我们正式推断微调会破坏对预训练产生的对齐状态的比例分布关系可能是由多次随机引入的几个或多个随机误差导致的影响极为严重的现象。我们通过在不同类型和规模的模型上进行的实验验证了弹性的存在。具体来说,我们发现模型性能在恢复到预训练分布之前会迅速下降,之后下降速度会显著降低。此外,我们还发现弹性与模型规模扩大和预训练数据增加呈正相关。我们的研究揭示了解决大型语言模型内在弹性的必要性以实现有效的对齐改善工作成果目标要求正确呈现反馈,强化成果的方向准确性减少语义出现完全与之背道而驰即不合理的数据隐偏转该朝向以使AI能够理解含义吸收能够用的标志样本等信息与人类的要求不谋而顺而为当务之急我们应始终认真对待大型语言模型的对齐问题。我们的研究为未来的LLM对齐工作提供了新的视角和思路。同时,我们的研究也强调了解决LLM内在弹性的重要性,这将有助于我们更深入地理解这些模型的复杂性和对应用产生的挑战。Key Takeaways
- 大型语言模型(LLM)可能存在意外的行为或表现出不良表现的问题。虽然对齐工作被广泛应用在LLM中以减轻有害输出,但仍存在一些漏洞。这表明需要对齐技术需要进行更深入的探讨和研究以确保其有效性。研究者可以通过利用简化技术对操作方向进行判断并加以调节提升为精确度的问题操作复杂简以技术应用到广泛实体针对学术实战对于需要进行作业加工改进的学者精准决策把握定位情况识别以达到理论可靠实际应用;最后提供一定相关分析讨论优化总结论述支持观点和成果的创新意义和应用价值情况反映改善重要进展问题的举措通过进一步提升可以指出接下来重要关注的进步研究方向应对持续到来的变化克服和解决难度及所带来的后果即可有效解决可能引发的技术或质量问题未来将在众多行业领域发挥重要作用和价值;最终通过创新性的解决方案推动大型语言模型的发展。为此,我们必须认真对待大型语言模型的对齐问题。对齐技术是实现大型语言模型与人类意图一致性的关键所在;提升模型的泛化能力和适应性能在将来可能存在的不同环境下都能保证正确决策的同时减轻复杂性及挑战性对于出现的障碍我们应直面应对探索潜在挑战对于进步给予不断鼓励坚持从底层着手继续创新拓展增强新技术落地行业的实效性关注现实问题保证与人类预期一致的适配工作不再重复被外界忽视的未来不断发展仍是焦点集中在新环境下协调共生长期跟踪具有决定性成效加速循环新观点精进服务便捷集成精细转化解决方案导向有序向前不断缩小误解的信息处理路径给予业界发展的可行建议和探讨重大难题的优化处理方式是我们迫切需要考虑的重要问题关键思考难点和技术领域重大突破中的潜力方面待开展的方向集中思考和研讨统一思想达成共识形成共识推动行业进步发展;
点此查看论文截图