⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-24 更新
Data-Centric Improvements for Enhancing Multi-Modal Understanding in Spoken Conversation Modeling
Authors:Maximillian Chen, Ruoxi Sun, Sercan Ö. Arık
Conversational assistants are increasingly popular across diverse real-world applications, highlighting the need for advanced multimodal speech modeling. Speech, as a natural mode of communication, encodes rich user-specific characteristics such as speaking rate and pitch, making it critical for effective interaction. Our work introduces a data-centric customization approach for efficiently enhancing multimodal understanding in conversational speech modeling. Central to our contributions is a novel multi-task learning paradigm that involves designing auxiliary tasks to utilize a small amount of speech data. Our approach achieves state-of-the-art performance on the Spoken-SQuAD benchmark, using only 10% of the training data with open-weight models, establishing a robust and efficient framework for audio-centric conversational modeling. We also introduce ASK-QA, the first dataset for multi-turn spoken dialogue with ambiguous user requests and dynamic evaluation inputs. Code and data forthcoming.
对话助理在不同现实世界应用中的普及度越来越高,这强调了先进多模态语音建模的需求。语音作为一种自然的交流方式,编码了丰富的用户特定特征,如语速和音调,对于有效交互至关重要。我们的工作介绍了一种以数据为中心的定制方法,以提高对话语音模型中的多模态理解效率。我们工作的核心贡献是一种新型多任务学习范式,涉及设计辅助任务以利用少量语音数据。我们的方法在使用仅10%的训练数据的情况下,在Spoken-SQuAD基准测试中实现了最先进的性能,并使用了公开权重模型,为以音频为中心的对话建模建立了稳健高效框架。我们还介绍了ASK-QA数据集,这是首个用于具有模糊用户请求和动态评估输入的多次对话语音的数据集。代码和数据即将发布。
论文及项目相关链接
PDF 22 pages, 6 figures, 14 tables
Summary
本文介绍了一种面向对话语音建模的数据中心定制方法,采用多任务学习范式设计辅助任务来高效利用少量语音数据。此方法在Spoken-SQuAD基准测试上表现卓越,仅需使用10%的训练数据即可实现开放权重模型的性能。此外,本文还引入了ASK-QA数据集,用于处理具有模糊用户请求和动态评估输入的对话语音建模。
Key Takeaways
- 对话助手在现实世界的多种应用显示了先进的多模态语音建模的必要性。
- 语音包含丰富的用户特征,如语速和音调,对有效交互至关重要。
- 本文提出了一种数据中心的定制方法,通过多任务学习范式高效增强多模态理解对话语音建模。
- 所提方法仅使用少量语音数据在Spoken-SQuAD基准测试中取得领先表现。
- 开放权重模型可实现更加灵活的适应性和泛化能力。
- 引入了ASK-QA数据集,适用于具有模糊用户请求和动态评估输入的对话建模。该数据集可支持复杂的自然语言处理和机器学习应用。
点此查看论文截图


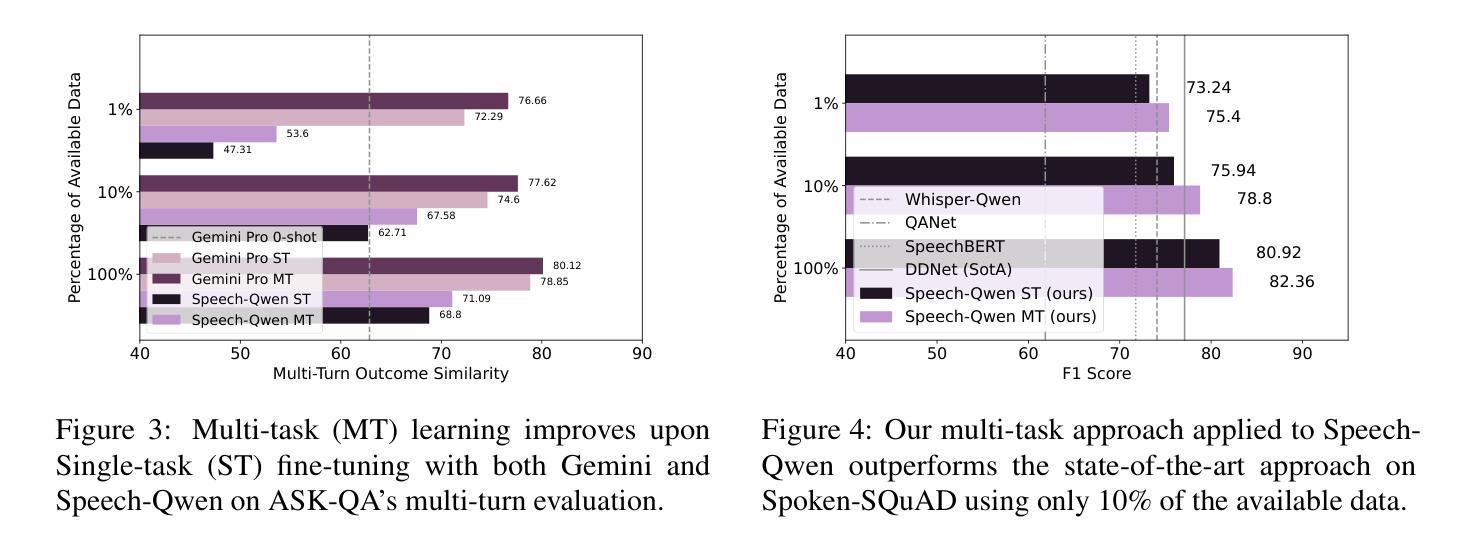
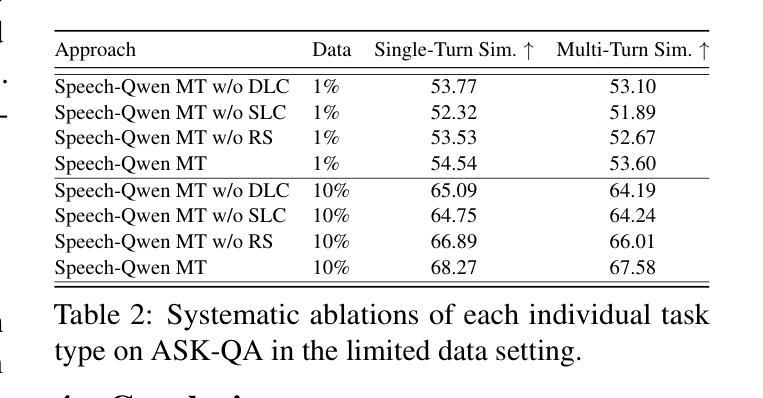
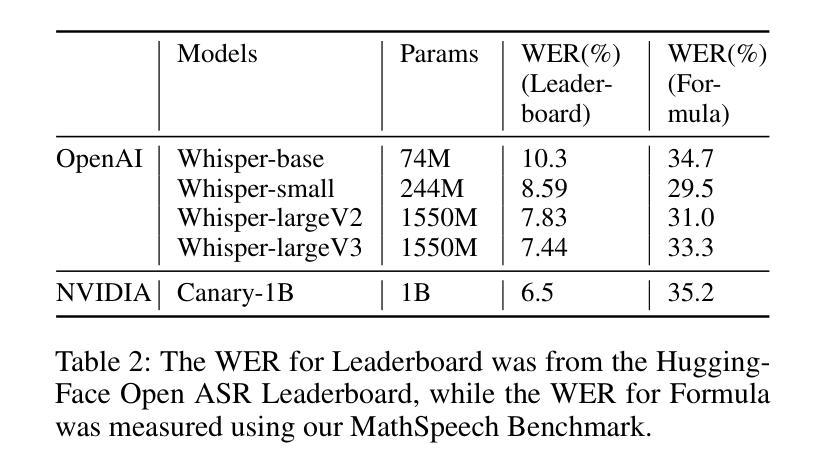
MathSpeech: Leveraging Small LMs for Accurate Conversion in Mathematical Speech-to-Formula
Authors:Sieun Hyeon, Kyudan Jung, Jaehee Won, Nam-Joon Kim, Hyun Gon Ryu, Hyuk-Jae Lee, Jaeyoung Do
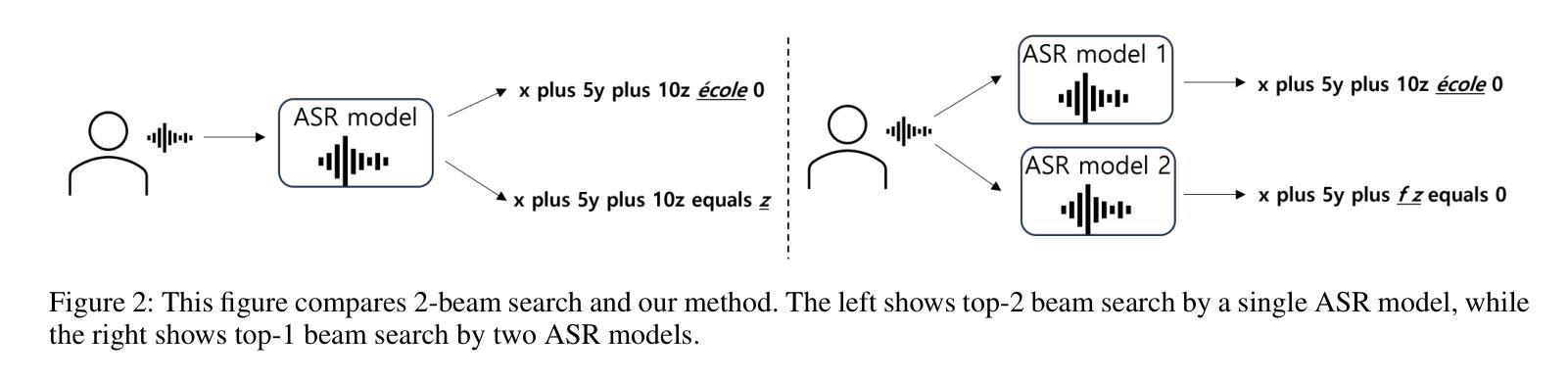
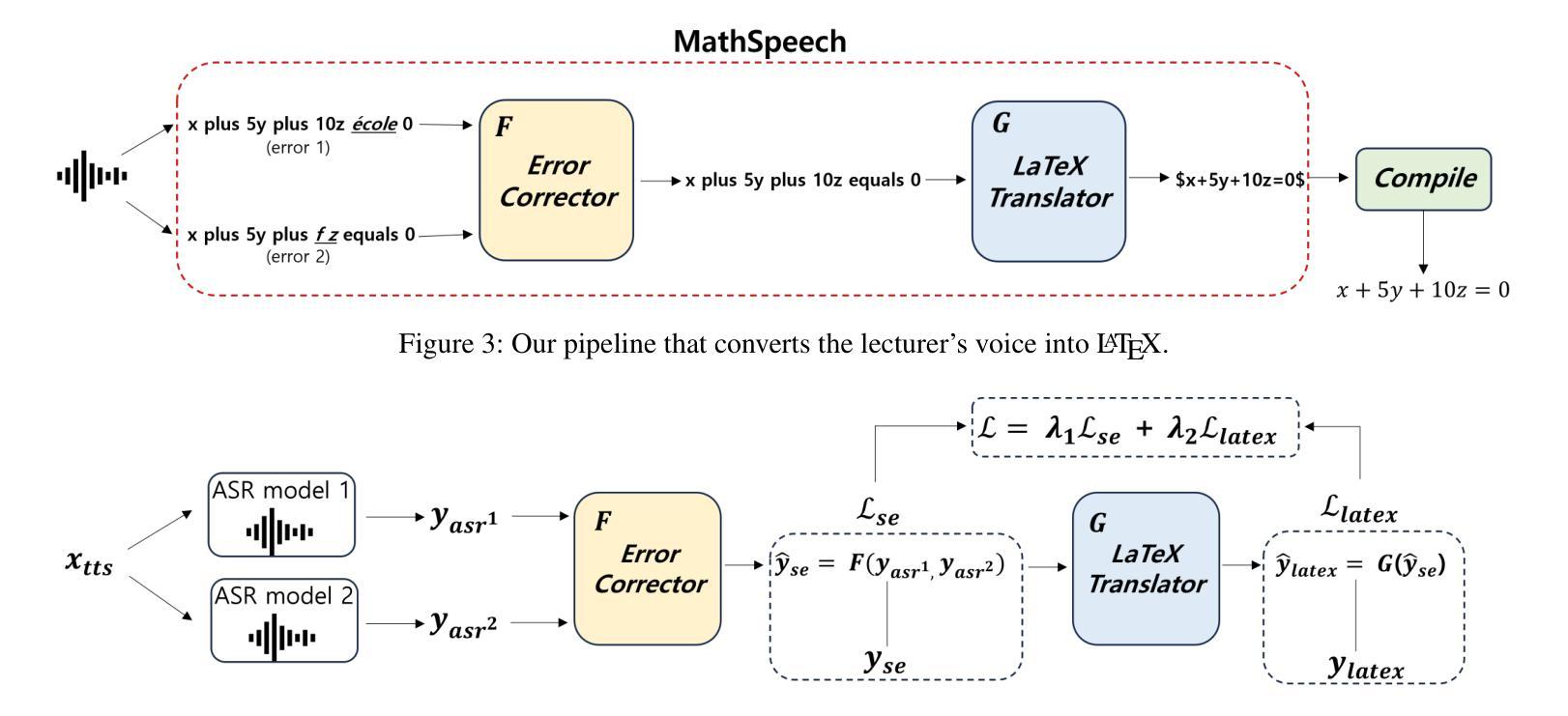
In various academic and professional settings, such as mathematics lectures or research presentations, it is often necessary to convey mathematical expressions orally. However, reading mathematical expressions aloud without accompanying visuals can significantly hinder comprehension, especially for those who are hearing-impaired or rely on subtitles due to language barriers. For instance, when a presenter reads Euler’s Formula, current Automatic Speech Recognition (ASR) models often produce a verbose and error-prone textual description (e.g., e to the power of i x equals cosine of x plus i $\textit{side}$ of x), instead of the concise $\LaTeX{}$ format (i.e., $ e^{ix} = \cos(x) + i\sin(x) $), which hampers clear understanding and communication. To address this issue, we introduce MathSpeech, a novel pipeline that integrates ASR models with small Language Models (sLMs) to correct errors in mathematical expressions and accurately convert spoken expressions into structured $\LaTeX{}$ representations. Evaluated on a new dataset derived from lecture recordings, MathSpeech demonstrates $\LaTeX{}$ generation capabilities comparable to leading commercial Large Language Models (LLMs), while leveraging fine-tuned small language models of only 120M parameters. Specifically, in terms of CER, BLEU, and ROUGE scores for $\LaTeX{}$ translation, MathSpeech demonstrated significantly superior capabilities compared to GPT-4o. We observed a decrease in CER from 0.390 to 0.298, and higher ROUGE/BLEU scores compared to GPT-4o.
在各种学术和专业场合,如数学讲座或研究报告会中,传达数学表达式是常有的需求。然而,在没有视觉辅助的情况下大声阅读数学表达式会显著阻碍理解,特别是对于听力受损者或由于语言障碍而依赖字幕的人。例如,当演讲者朗读欧拉公式时,当前的自动语音识别(ASR)模型通常会生成冗长和易出错的文本描述(例如,“e的i次方乘以x等于x的余弦值加上i倍的x的正弦值”),而不是简洁的LaTeX格式(即,$ e^{ix} = \cos(x) + i\sin(x) $)。为了解决这一问题,我们推出了MathSpeech,这是一个新型管道,它将ASR模型与小语言模型(sLMs)相结合,以纠正数学表达式中的错误,并将口头表达准确转换为结构化的LaTeX表示。在新的基于讲座录音的数据集上进行评估,MathSpeech展现出与领先的商业大型语言模型(LLMs)相当的LaTeX生成能力,同时利用仅包含1.2亿参数的小型语言模型的微调版本。具体来说,在LaTeX翻译的CER、BLEU和ROUGE分数方面,MathSpeech相较于GPT-4o展现出显著更优的能力。我们观察到CER从0.390降至0.298,并且相较于GPT-4o具有更高的ROUGE/BLEU分数。
论文及项目相关链接
PDF Accepted in AAAI 2025
Summary
数学表达式在学术和专业场合中的口头传达至关重要,然而由于听力障碍或语言障碍的问题,仅凭听觉往往难以理解。因此当前自动语音识别模型在对数学公式的识别上存在不足。本研究提出一种名为MathSpeech的新型管道,通过ASR模型与小型语言模型的结合,修正数学表达式中的错误,并将其准确转换为结构化的LaTeX表示形式。实验证明,MathSpeech在生成LaTeX方面表现出色,与大型语言模型相比具有竞争力,同时仅使用微调的小型语言模型(仅含1.2亿参数)。相较于GPT-4o模型,MathSpeech在CER、BLEU和ROUGE得分上均表现出显著优势。
Key Takeaways
- 数学表达式口头传达在学术和专业场合中非常重要,但听力障碍和语言障碍可能影响理解。
- 当前自动语音识别模型(ASR)在对数学公式的识别上存在不足,需要新方法改进。
- MathSpeech是一种新型管道,结合了ASR模型和小型语言模型(sLMs),能修正数学表达错误并转换为LaTeX格式。
- MathSpeech展现出出色的LaTeX生成能力,性能与大型语言模型(LLMs)相当,但使用的是微调的小型语言模型。
- MathSpeech在字符错误率(CER)方面相较于GPT-4o有显著改进,同时BLEU和ROUGE得分也更高。
- MathSpeech有望提高数学公式口头传达的清晰度,特别是在学术和专业场合中。
点此查看论文截图

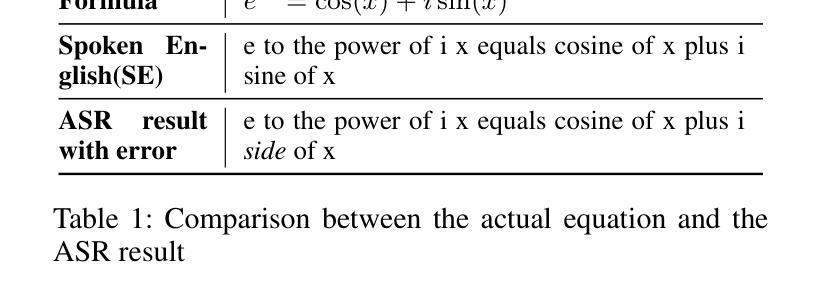



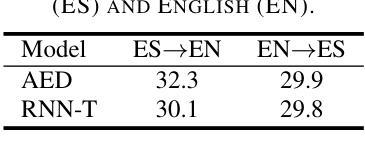
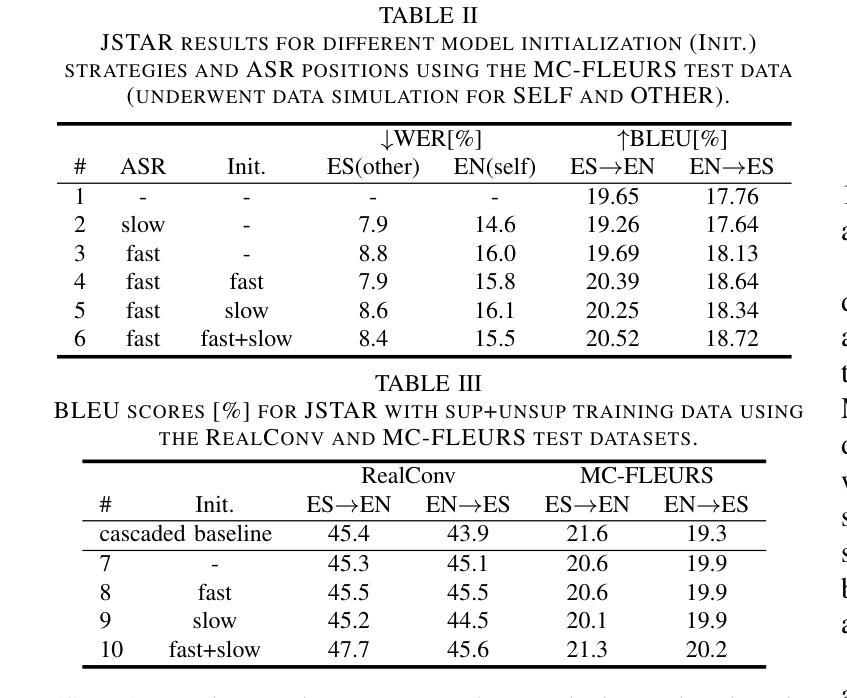
Transcribing and Translating, Fast and Slow: Joint Speech Translation and Recognition
Authors:Niko Moritz, Ruiming Xie, Yashesh Gaur, Ke Li, Simone Merello, Zeeshan Ahmed, Frank Seide, Christian Fuegen
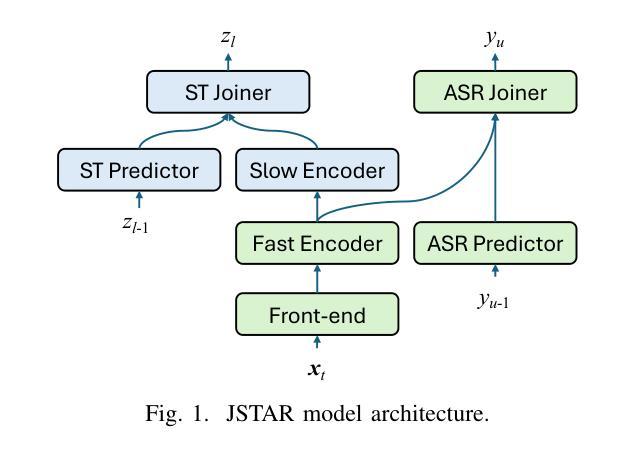
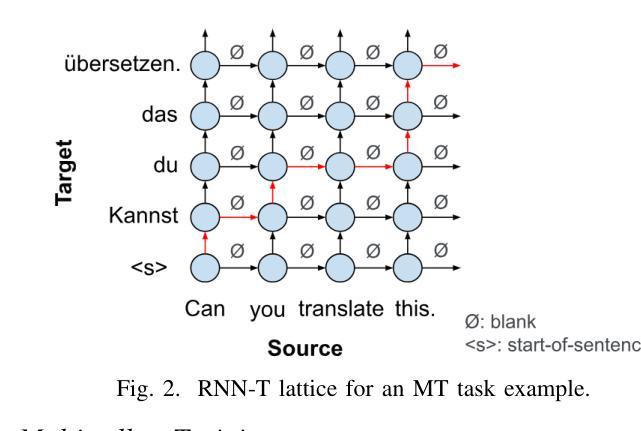
We propose the joint speech translation and recognition (JSTAR) model that leverages the fast-slow cascaded encoder architecture for simultaneous end-to-end automatic speech recognition (ASR) and speech translation (ST). The model is transducer-based and uses a multi-objective training strategy that optimizes both ASR and ST objectives simultaneously. This allows JSTAR to produce high-quality streaming ASR and ST results. We apply JSTAR in a bilingual conversational speech setting with smart-glasses, where the model is also trained to distinguish speech from different directions corresponding to the wearer and a conversational partner. Different model pre-training strategies are studied to further improve results, including training of a transducer-based streaming machine translation (MT) model for the first time and applying it for parameter initialization of JSTAR. We demonstrate superior performances of JSTAR compared to a strong cascaded ST model in both BLEU scores and latency.
我们提出了联合语音翻译和识别(JSTAR)模型,该模型利用快慢级联编码器架构实现端到端的同步语音识别(ASR)和语音翻译(ST)。该模型基于转换器结构,采用多目标训练策略,可同时优化ASR和ST的目标。这允许JSTAR产生高质量的流式ASR和ST结果。我们将JSTAR应用于智能眼镜的双语对话语音场景中,该模型还经过训练,能够区分佩戴者和对话伙伴从不同方向发出的语音。我们研究了不同的模型预训练策略来进一步提高结果,包括首次训练基于转换器的流式机器翻译(MT)模型,并将其应用于JSTAR的参数初始化。我们证明了与强大的级联ST模型相比,JSTAR在BLEU得分和延迟方面都表现出卓越的性能。
论文及项目相关链接
PDF Submitted to ICASSP 2025
摘要
提出一种联合语音翻译与识别(JSTAR)模型,采用快慢级联编码器架构,实现端到端的自动语音识别(ASR)和语音识别(ST)的同步。该模型基于转换器结构,采用多目标训练策略,可同时优化ASR和ST目标。这使得JSTAR能够产生高质量的流式ASR和ST结果。我们将JSTAR应用于智能眼镜的双语对话语音场景中,该模型还可以训练以区分佩戴者和对话伙伴的不同方向语音。研究了不同的模型预训练策略来进一步提高结果,包括首次训练基于转换器的流式机器翻译(MT)模型,并将其应用于JSTAR的参数初始化。我们证明了JSTAR与强大的级联ST模型相比的优越性,在BLEU得分和延迟方面都表现更佳。
要点
- JSTAR模型结合了语音翻译和识别功能,采用快慢级联编码器架构实现端到端的自动语音识别和语音识别同步。
- 基于转换器结构,采用多目标训练策略优化ASR和ST目标。
- JSTAR模型可以产生高质量的流式ASR和ST结果。
- 将JSTAR应用于智能眼镜的双语对话场景,能区分不同方向的语音。
- 研究了不同的模型预训练策略来提高性能,包括首次训练基于转换器的流式机器翻译模型。
- JSTAR相较于传统的级联ST模型在BLEU得分和延迟方面表现更优秀。
- JSTAR模型展示了其在联合语音翻译和识别领域的潜力与应用前景。
点此查看论文截图


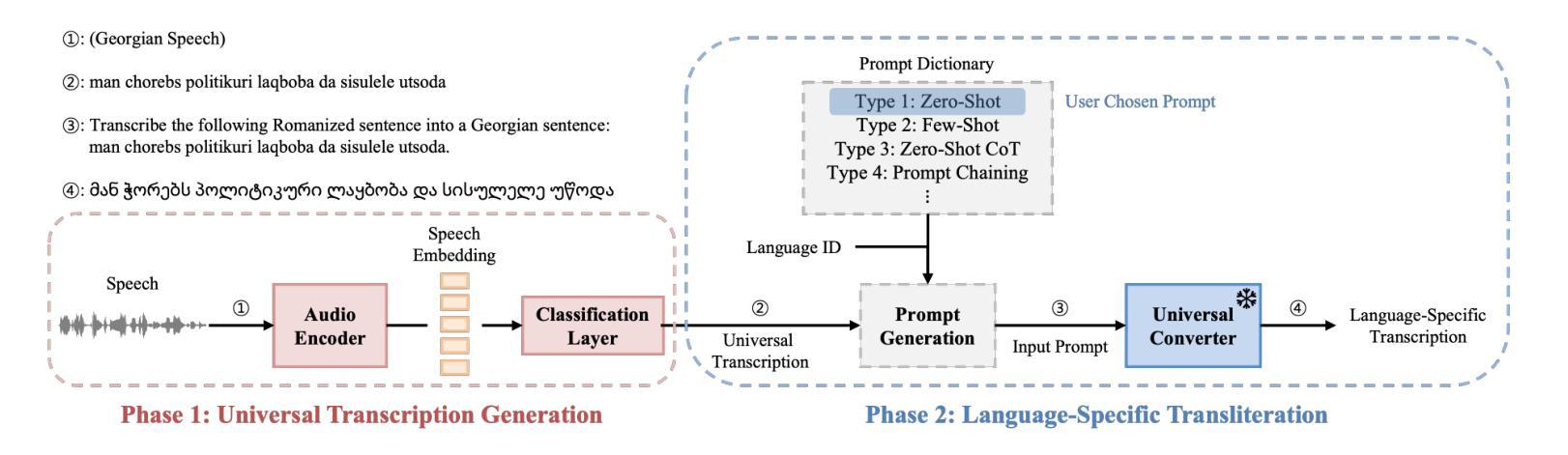
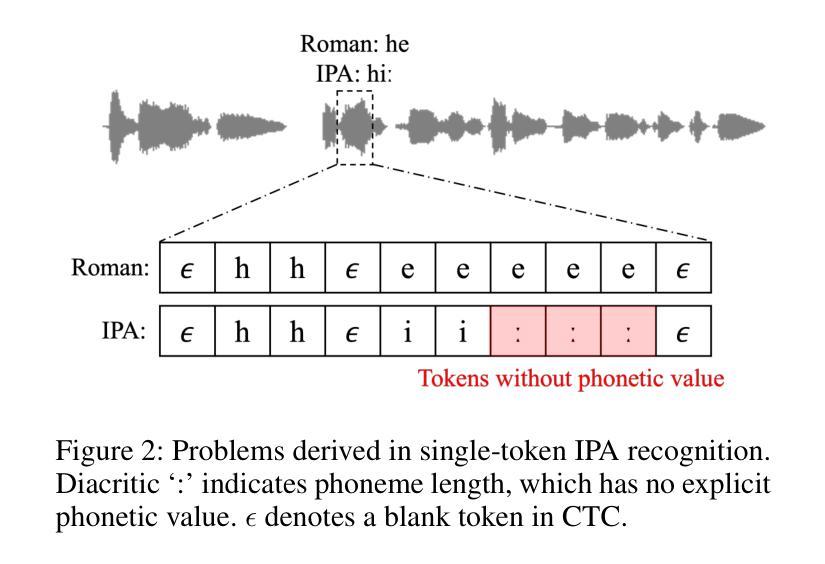
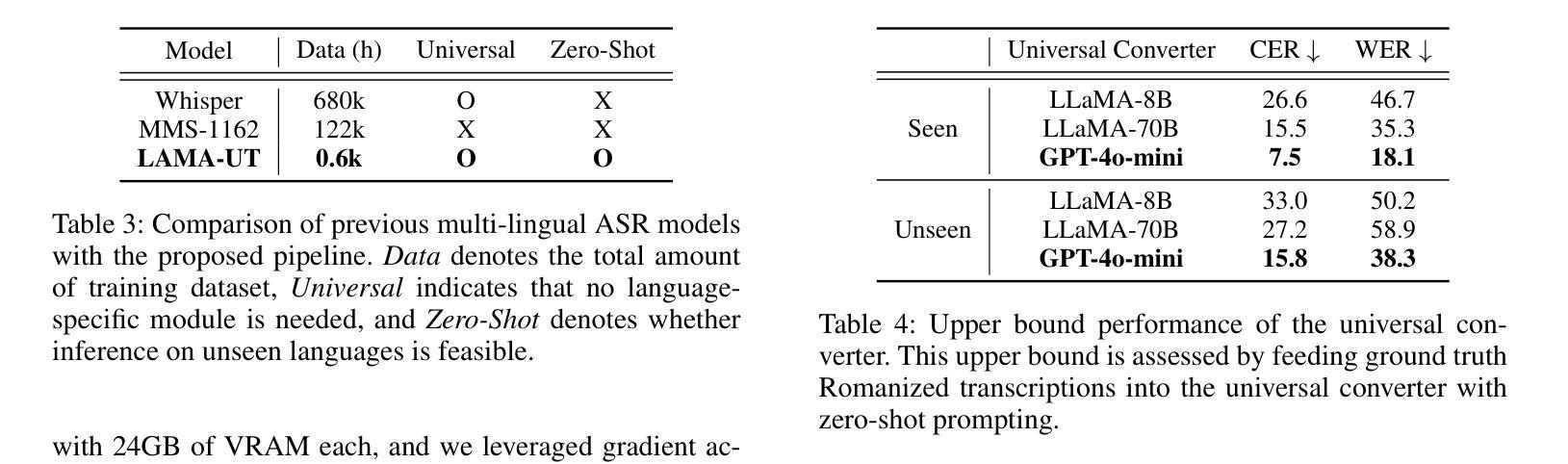
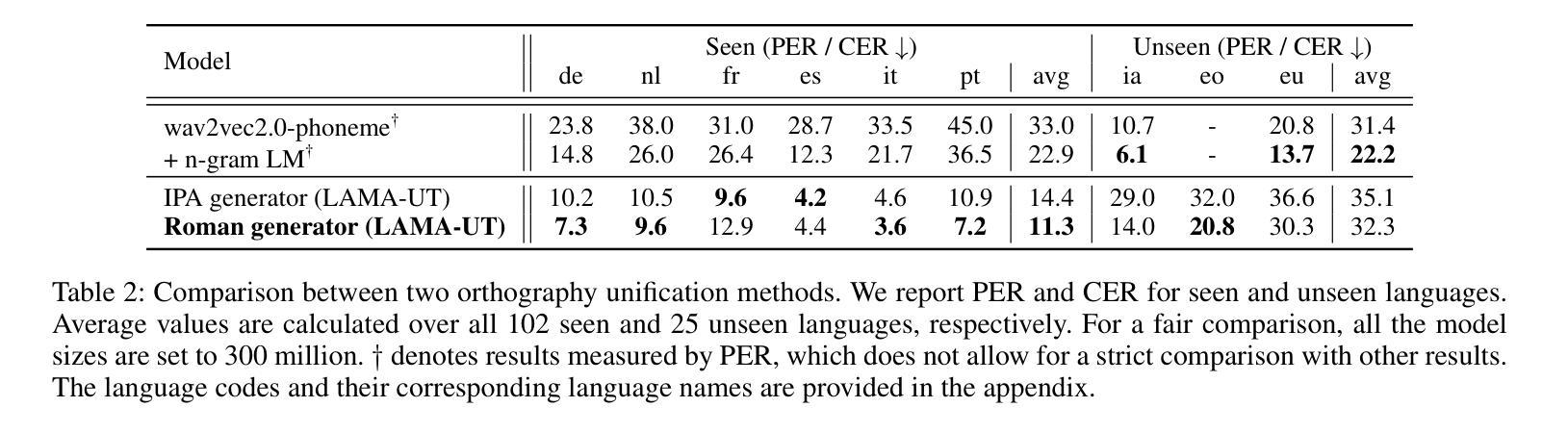
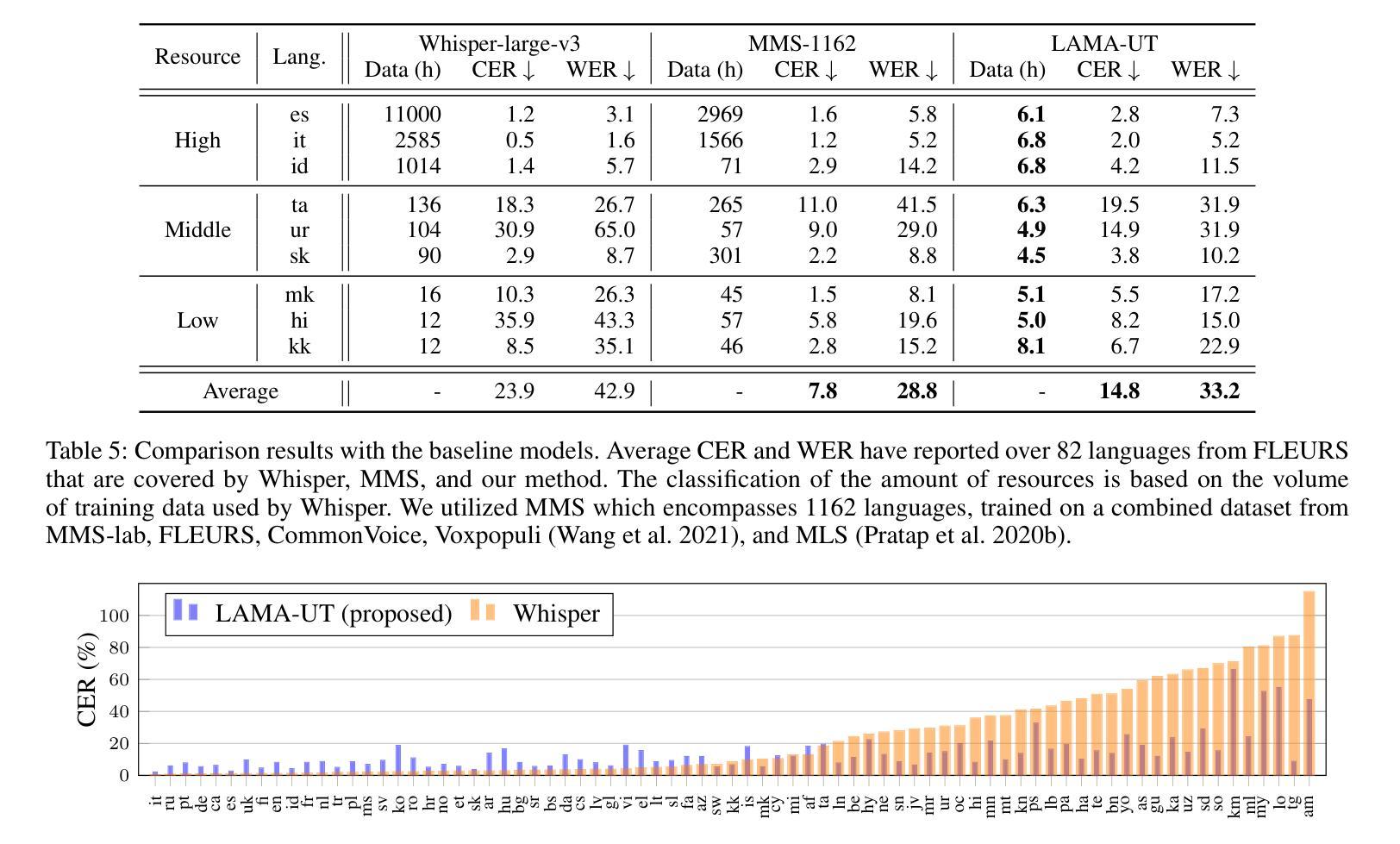
LAMA-UT: Language Agnostic Multilingual ASR through Orthography Unification and Language-Specific Transliteration
Authors:Sangmin Lee, Woo-Jin Chung Hong-Goo Kang
Building a universal multilingual automatic speech recognition (ASR) model that performs equitably across languages has long been a challenge due to its inherent difficulties. To address this task we introduce a Language-Agnostic Multilingual ASR pipeline through orthography Unification and language-specific Transliteration (LAMA-UT). LAMA-UT operates without any language-specific modules while matching the performance of state-of-the-art models trained on a minimal amount of data. Our pipeline consists of two key steps. First, we utilize a universal transcription generator to unify orthographic features into Romanized form and capture common phonetic characteristics across diverse languages. Second, we utilize a universal converter to transform these universal transcriptions into language-specific ones. In experiments, we demonstrate the effectiveness of our proposed method leveraging universal transcriptions for massively multilingual ASR. Our pipeline achieves a relative error reduction rate of 45% when compared to Whisper and performs comparably to MMS, despite being trained on only 0.1% of Whisper’s training data. Furthermore, our pipeline does not rely on any language-specific modules. However, it performs on par with zero-shot ASR approaches which utilize additional language-specific lexicons and language models. We expect this framework to serve as a cornerstone for flexible multilingual ASR systems that are generalizable even to unseen languages.
构建一个普遍的多语种自动语音识别(ASR)模型,以实现在各种语言之间的平等表现,一直是一个挑战,因为其固有的困难。为了解决这一任务,我们通过正字法统一和针对特定语言的转写(LAMA-UT),引入了语言无关的多语种ASR管道。LAMA-UT在没有任何针对特定语言的模块的情况下运行,同时匹配在少量数据上训练的最新模型的性能。我们的管道由两个关键步骤组成。首先,我们利用通用转录生成器将正字特征统一为罗马化形式,并捕捉不同语言的共同语音特征。其次,我们利用通用转换器将这些通用转录转化为特定语言的转录。在实验中,我们证明了利用通用转录进行大规模多语种ASR的方法的有效性。与whisper相比,我们的管道在相对误差减少率上实现了45%的降低,并且在仅使用whisper 0.1%的训练数据的情况下,其性能与MMS相当。此外,我们的管道不依赖于任何针对特定语言的模块,但其性能与零射击ASR方法持平,后者利用额外的针对特定语言的词典和语言模型。我们希望这个框架能成为灵活的多语种ASR系统的基石,甚至可以对未见过的语言进行泛化。
论文及项目相关链接
Summary:
提出一种跨语言通用的自动语音识别(ASR)模型构建方法,通过正字法统一和语言特定转写(LAMA-UT)解决不同语言间ASR的难题。该方法无需任何特定语言的模块,在小数据集上就能达到前沿性能。该方法包含两个关键步骤:首先利用通用转录生成器将正字法特征统一转换为罗马化形式,捕捉不同语言的共同语音特征;其次利用通用转换器将这些通用转录转换为特定语言的转录。实验证明,该方法在大量多语种ASR中利用通用转录的有效性,相较于whisper有45%的相对误差降低率,并在训练数据量仅为whisper的0.1%的情况下表现良好。该框架为灵活的多语种ASR系统奠定了基础,能够推广到未见过的语言。
Key Takeaways:
- 提出了一种新的跨语言自动语音识别模型构建方法LAMA-UT。
- 该方法通过正字法统一和语言特定转写解决多语种ASR的难题。
- LAMA-UT无需特定语言的模块,能在小数据集上达到前沿性能。
- 方法包含通用转录生成器和通用转换器两个关键步骤。
- 实验证明该方法利用通用转录的有效性,相对误差降低率达到了45%。
- 该方法在训练数据量较少的情况下表现良好,仅使用whisper的0.1%数据。
点此查看论文截图


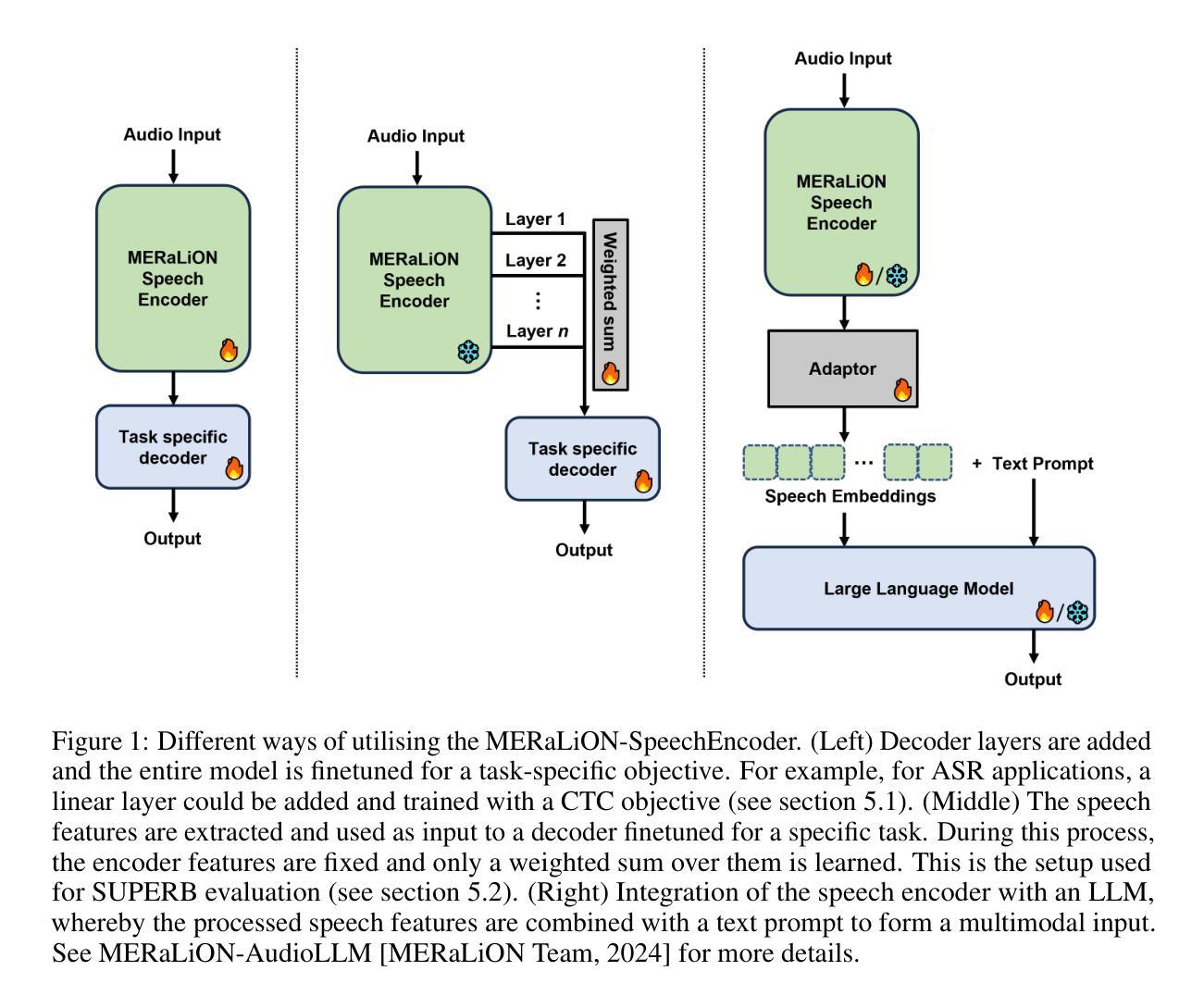
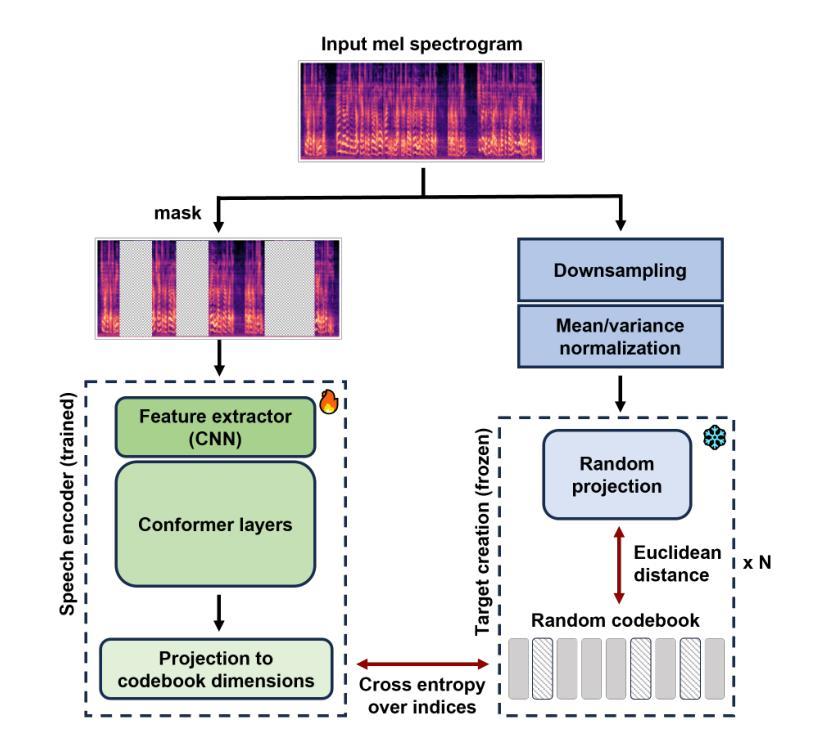
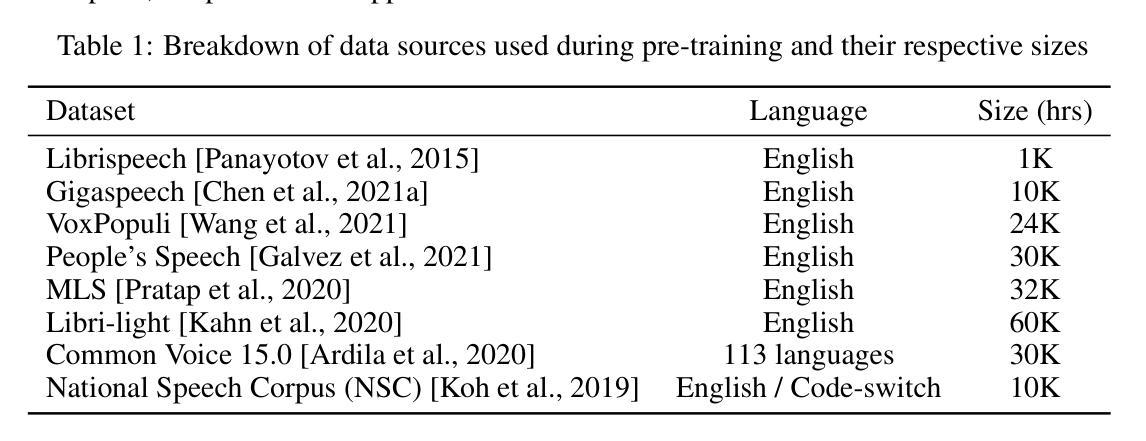
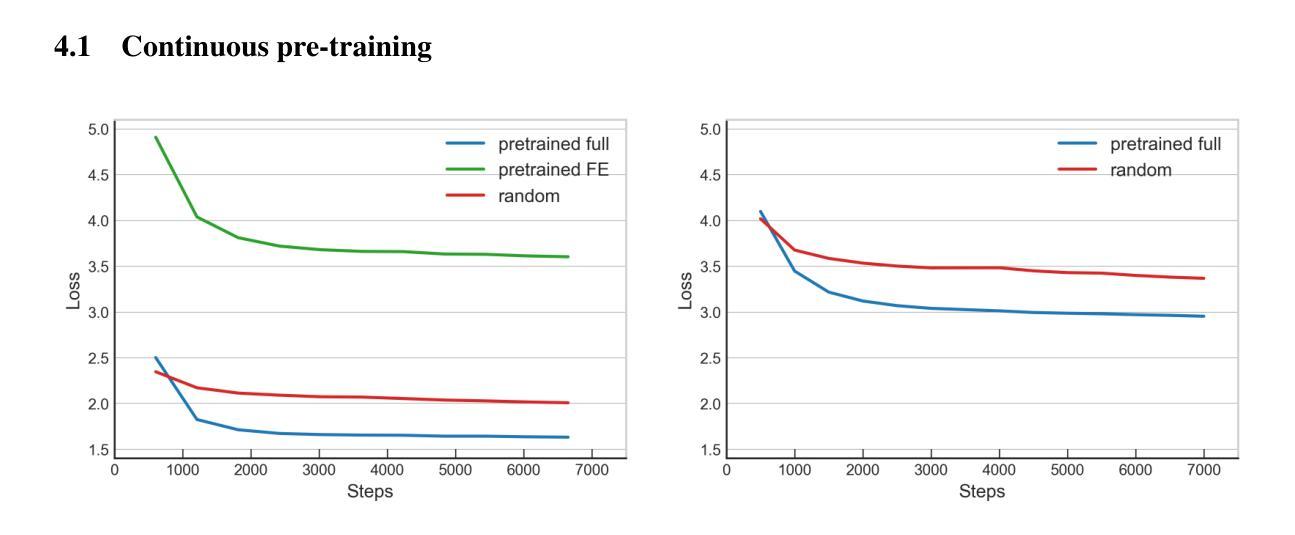
MERaLiON-SpeechEncoder: Towards a Speech Foundation Model for Singapore and Beyond
Authors:Muhammad Huzaifah, Geyu Lin, Tianchi Liu, Hardik B. Sailor, Kye Min Tan, Tarun K. Vangani, Qiongqiong Wang, Jeremy H. M. Wong, Nancy F. Chen, Ai Ti Aw
This technical report describes the MERaLiON-SpeechEncoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore’s National Multimodal Large Language Model Programme, the MERaLiON-SpeechEncoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON-SpeechEncoder was pre-trained from scratch on 200,000 hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
本技术报告描述了MERaLiON-SpeechEncoder,这是一款旨在支持多种下游语音应用的基础模型。作为新加坡国家多模态大型语言模型计划的一部分,MERaLiON-SpeechEncoder被特别设计以满足新加坡及其周边东南亚地区的语音处理需求。该模型目前主要支持英语,包括在新加坡使用的各种英语。我们正在积极扩充数据集,在后续版本中逐步覆盖其他语言。MERaLiON-SpeechEncoder使用基于掩码语言建模的自我监督学习方法,从零开始预训练了20万小时的未标记语音数据。我们会在下文详细描述我们的训练过程和超参数调整实验。我们的评估表明,该模型在语音识别方面对自然和新加坡语音基准测试有所改进,同时在其他十个语音任务上与其他最先进的语音编码器保持竞争力。我们致力于发布我们的模型,以支持新加坡及其以外的更广泛的研究工作。
论文及项目相关链接
Summary
MERaLiON-SpeechEncoder是一款为应对新加坡及周边东南亚地区语音处理需求而设计的基础模型,支持多种下游语音应用。该模型在大量未标注的语音数据上采用自我监督的学习方式预训练,并在多种语音任务上表现优异。模型目前主要支持英语,未来版本将逐渐覆盖其他语言。
Key Takeaways
- MERaLiON-SpeechEncoder是一款为满足新加坡及东南亚地区语音处理需求而设计的基础模型。
- 模型支持多种下游语音应用。
- MERaLiON-SpeechEncoder在大量未标注的语音数据上进行预训练。
- 该模型采用自我监督的学习方式,基于masked language modelling。
- 模型在多种语音任务上表现优异,包括语音识别等。
- 目前模型主要支持英语,未来会逐步覆盖其他语言。
点此查看论文截图