⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-24 更新
SLAM-Omni: Timbre-Controllable Voice Interaction System with Single-Stage Training
Authors:Wenxi Chen, Ziyang Ma, Ruiqi Yan, Yuzhe Liang, Xiquan Li, Ruiyang Xu, Zhikang Niu, Yanqiao Zhu, Yifan Yang, Zhanxun Liu, Kai Yu, Yuxuan Hu, Jinyu Li, Yan Lu, Shujie Liu, Xie Chen
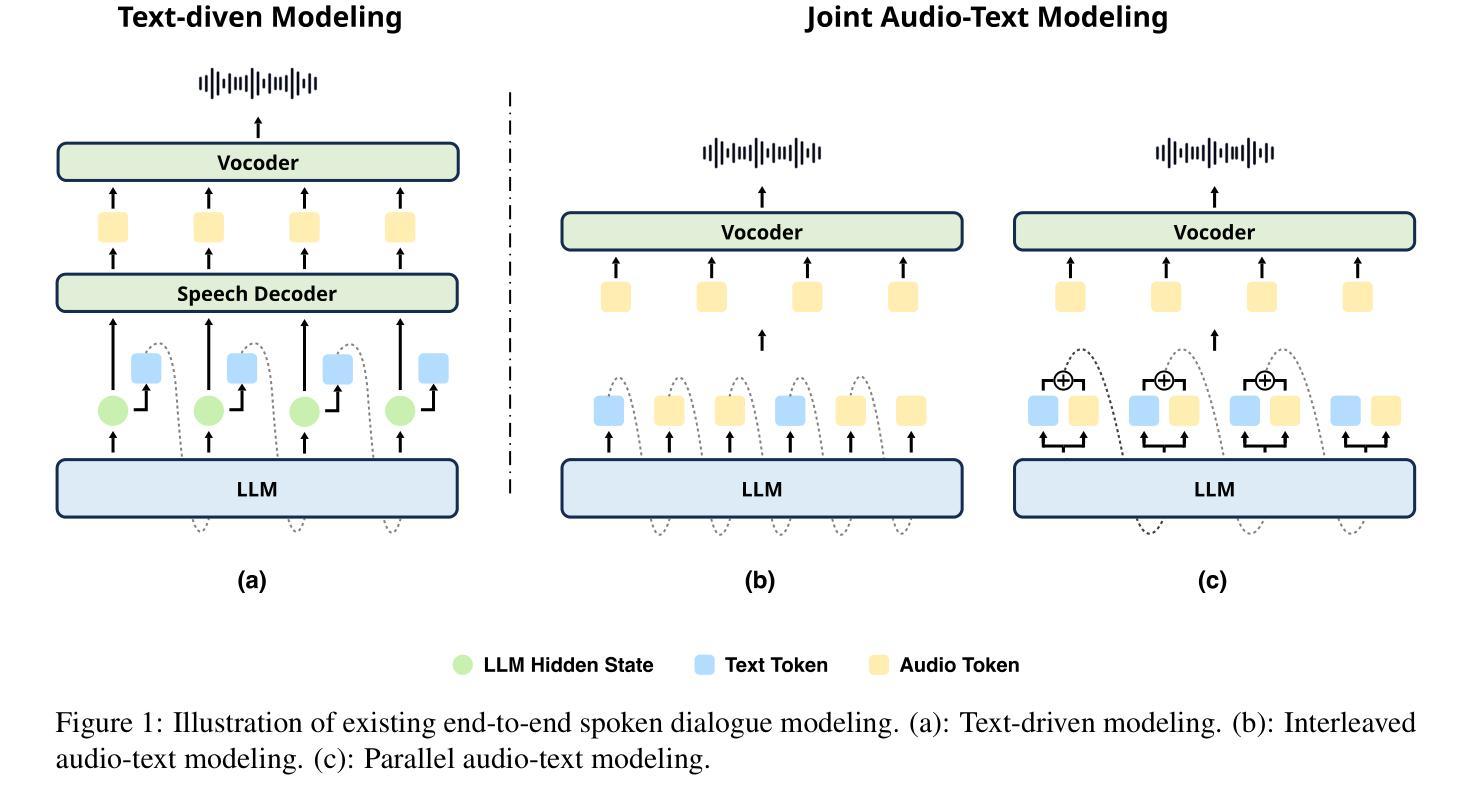
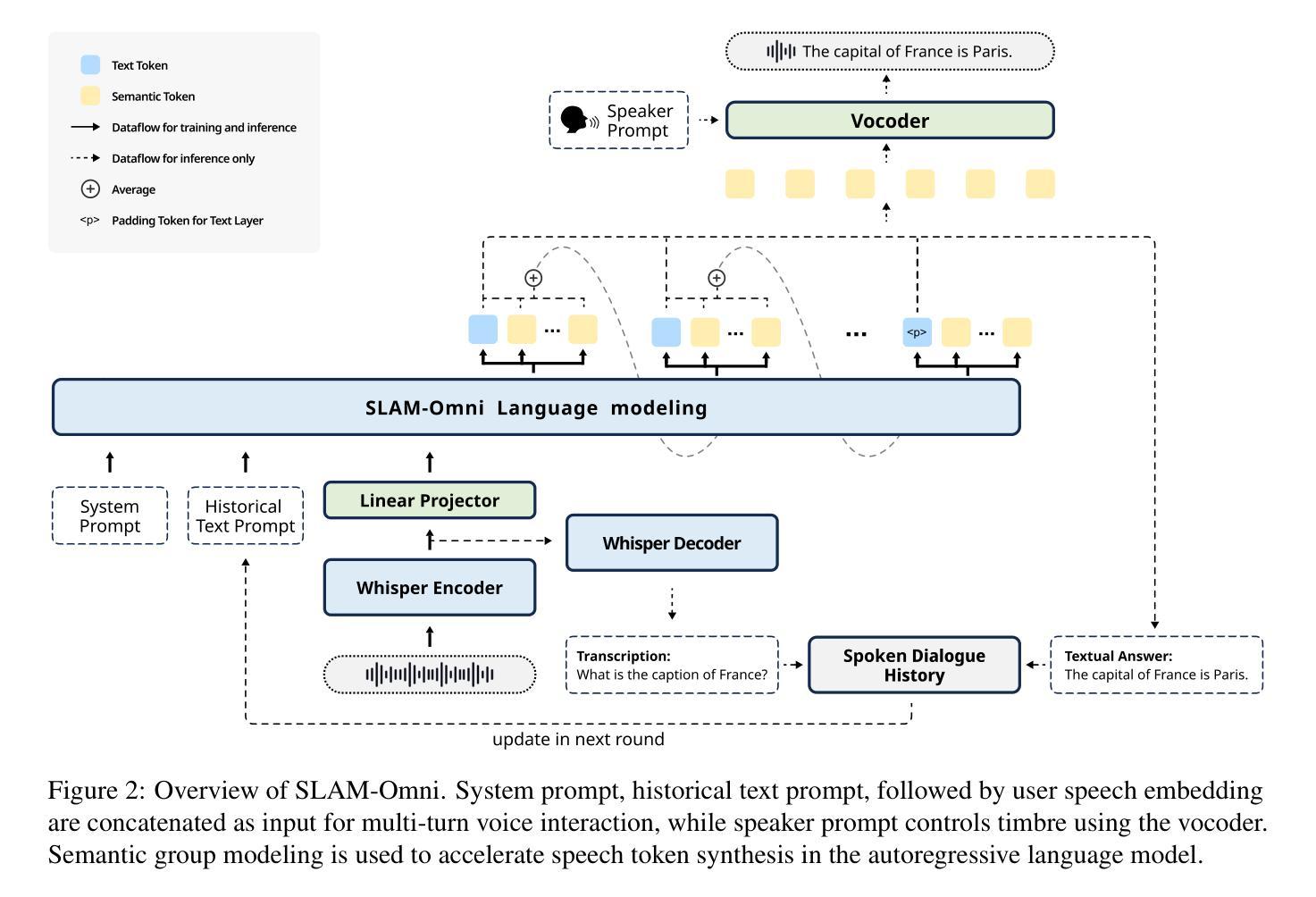
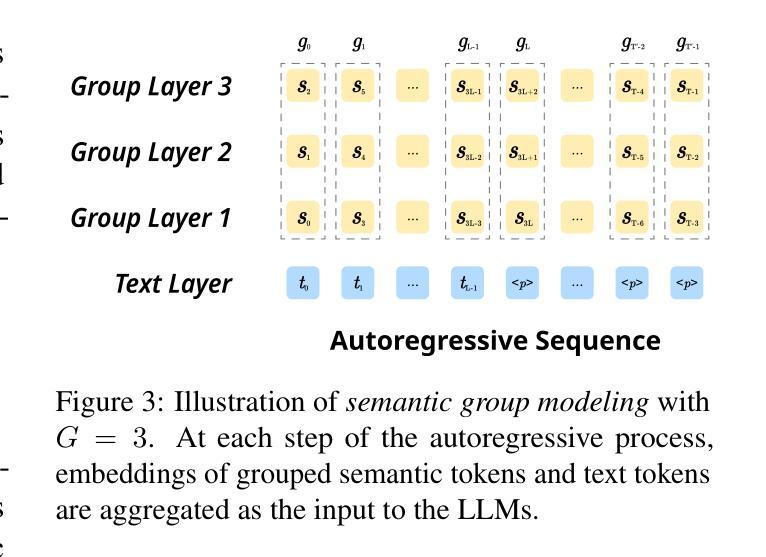
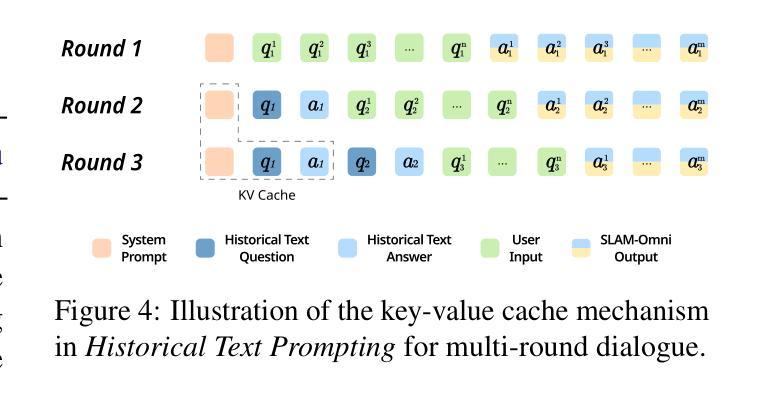
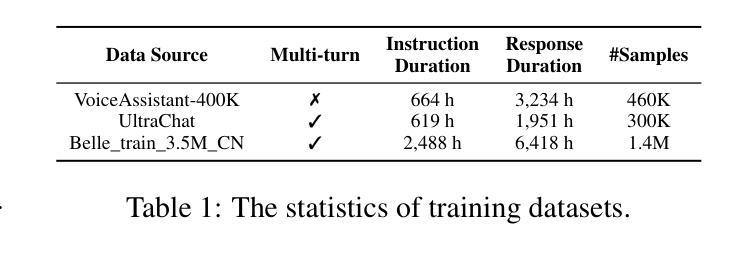
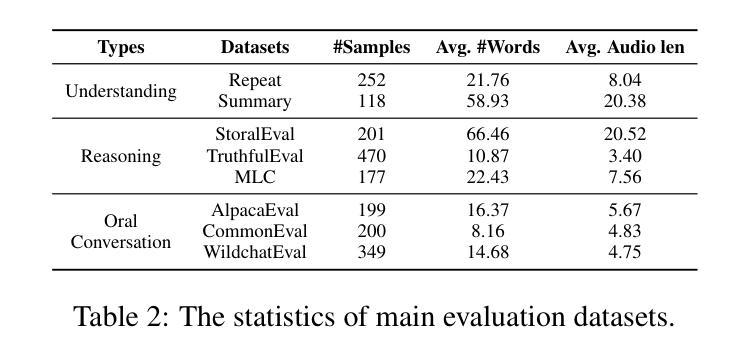
Recent advancements highlight the potential of end-to-end real-time spoken dialogue systems, showcasing their low latency and high quality. In this paper, we introduce SLAM-Omni, a timbre-controllable, end-to-end voice interaction system with single-stage training. SLAM-Omni achieves zero-shot timbre control by modeling spoken language with semantic tokens and decoupling speaker information to a vocoder. By predicting grouped speech semantic tokens at each step, our method significantly reduces the sequence length of audio tokens, accelerating both training and inference. Additionally, we propose historical text prompting to compress dialogue history, facilitating efficient multi-round interactions. Comprehensive evaluations reveal that SLAM-Omni outperforms prior models of similar scale, requiring only 15 hours of training on 4 GPUs with limited data. Notably, it is the first spoken dialogue system to achieve competitive performance with a single-stage training approach, eliminating the need for pre-training on TTS or ASR tasks. Further experiments validate its multilingual and multi-turn dialogue capabilities on larger datasets.
最近的发展突出了端到端实时对话系统的潜力,展示了其低延迟和高品质的特点。在本文中,我们介绍了SLAM-Omni,这是一个具有单阶段训练、音色可控的端到端语音交互系统。SLAM-Omni通过用语义标记建模口语信息并将说话者信息解码到声码器上,实现了零射击音色控制。通过预测每个步骤的分组语音语义标记,我们的方法显著减少了音频标记的序列长度,加速了训练和推理。此外,我们提出了历史文本提示来压缩对话历史,促进高效的多轮交互。综合评估表明,SLAM-Omni在类似规模的先前模型上表现出色,只需在4个GPU上使用有限的数据进行15个小时的训练。值得注意的是,它是第一个采用单阶段训练策略达到竞争性能的口语对话系统,无需在TTS或ASR任务上进行预训练。进一步的实验在更大的数据集上验证了其多语种和多轮对话能力。
论文及项目相关链接
Summary
SLAM-Omni是一种具有音色控制功能的端到端语音交互系统,采用单阶段训练,实现零射击色控制。它通过预测分组语音语义标记来减少音频标记的序列长度,加速训练和推理。此外,它采用历史文本提示来压缩对话历史,促进高效的多轮交互。在有限的训练数据下,SLAM-Omni在4GPU上仅训练15小时便表现出卓越性能,成为首个采用单阶段训练方法的对话系统。它在大型数据集上验证了多语种和多轮对话能力。
Key Takeaways
- SLAM-Omni是一个具有音色控制功能的端到端语音交互系统。
- 它通过预测分组语音语义标记来减少音频标记的序列长度,加速训练和推理过程。
- SLAM-Omni采用历史文本提示技术,促进高效的多轮交互。
- 系统只需15小时的训练,在4个GPU上即可完成,显示出高效率。
- SLAM-Omni是首个采用单阶段训练方法的对话系统,无需预先在TTS或ASR任务上进行训练。
- 系统展现出卓越的性能,包括在多语种和多轮对话方面的能力。
点此查看论文截图