⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-25 更新
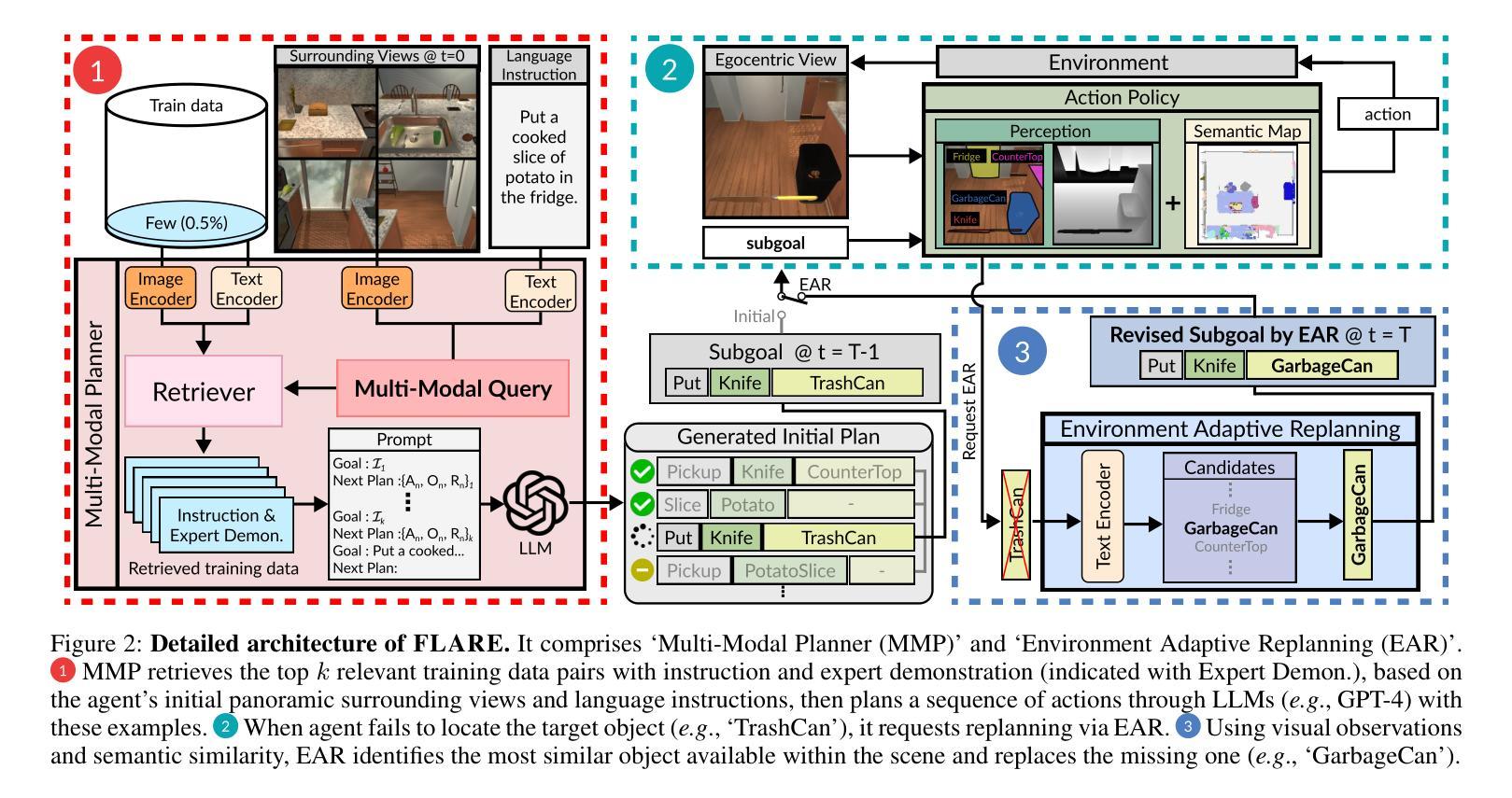
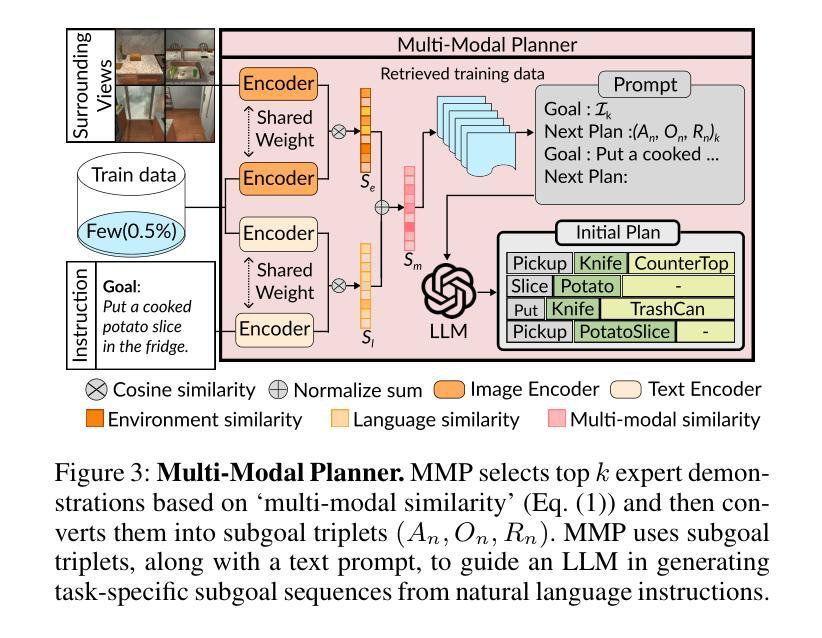
Multi-Modal Grounded Planning and Efficient Replanning For Learning Embodied Agents with A Few Examples
Authors:Taewoong Kim, Byeonghwi Kim, Jonghyun Choi
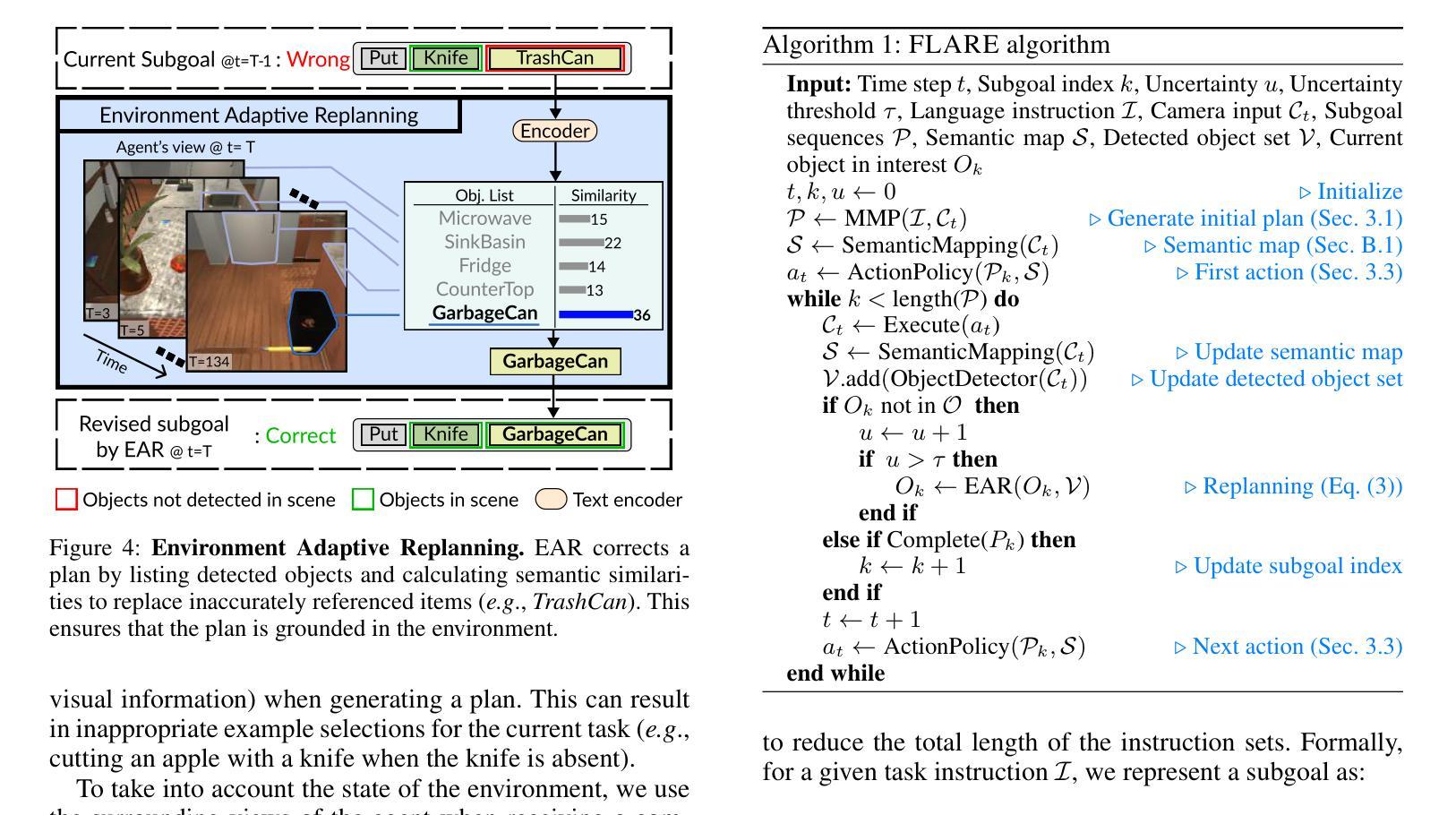
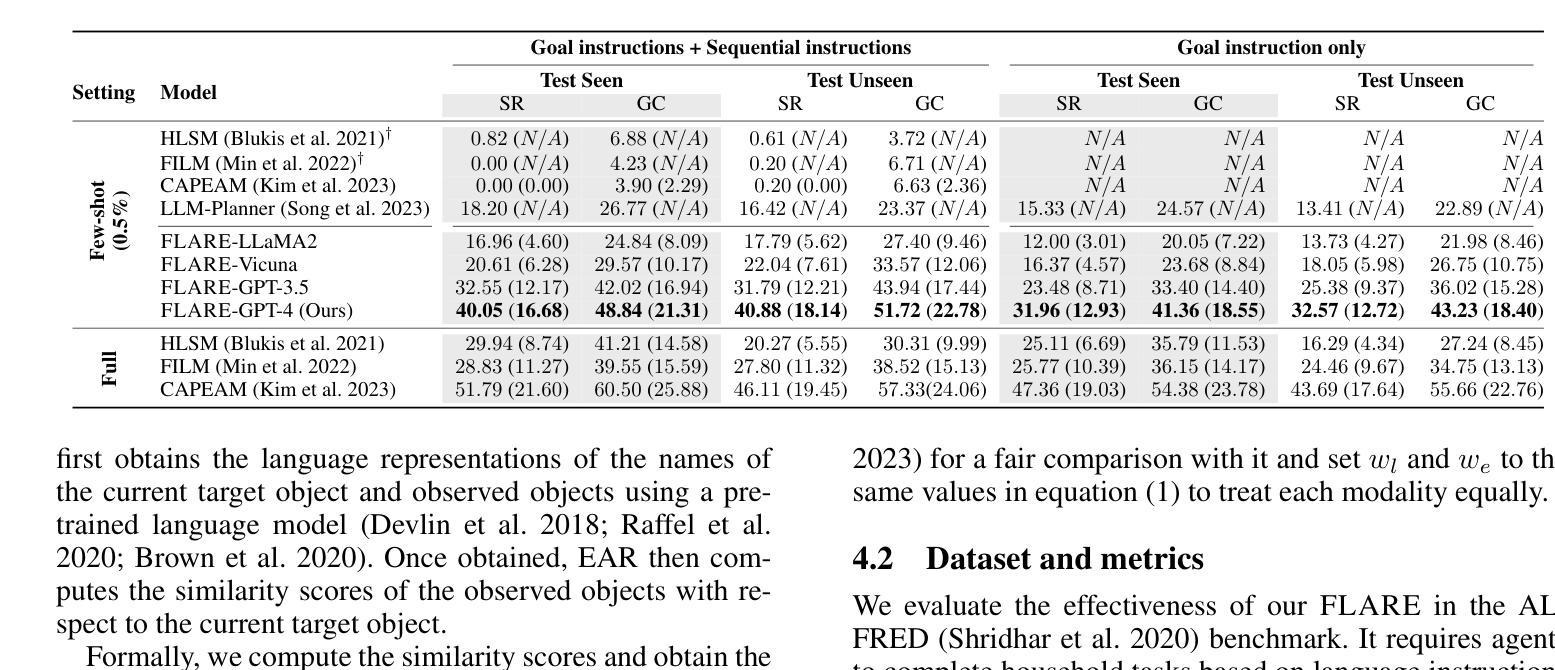
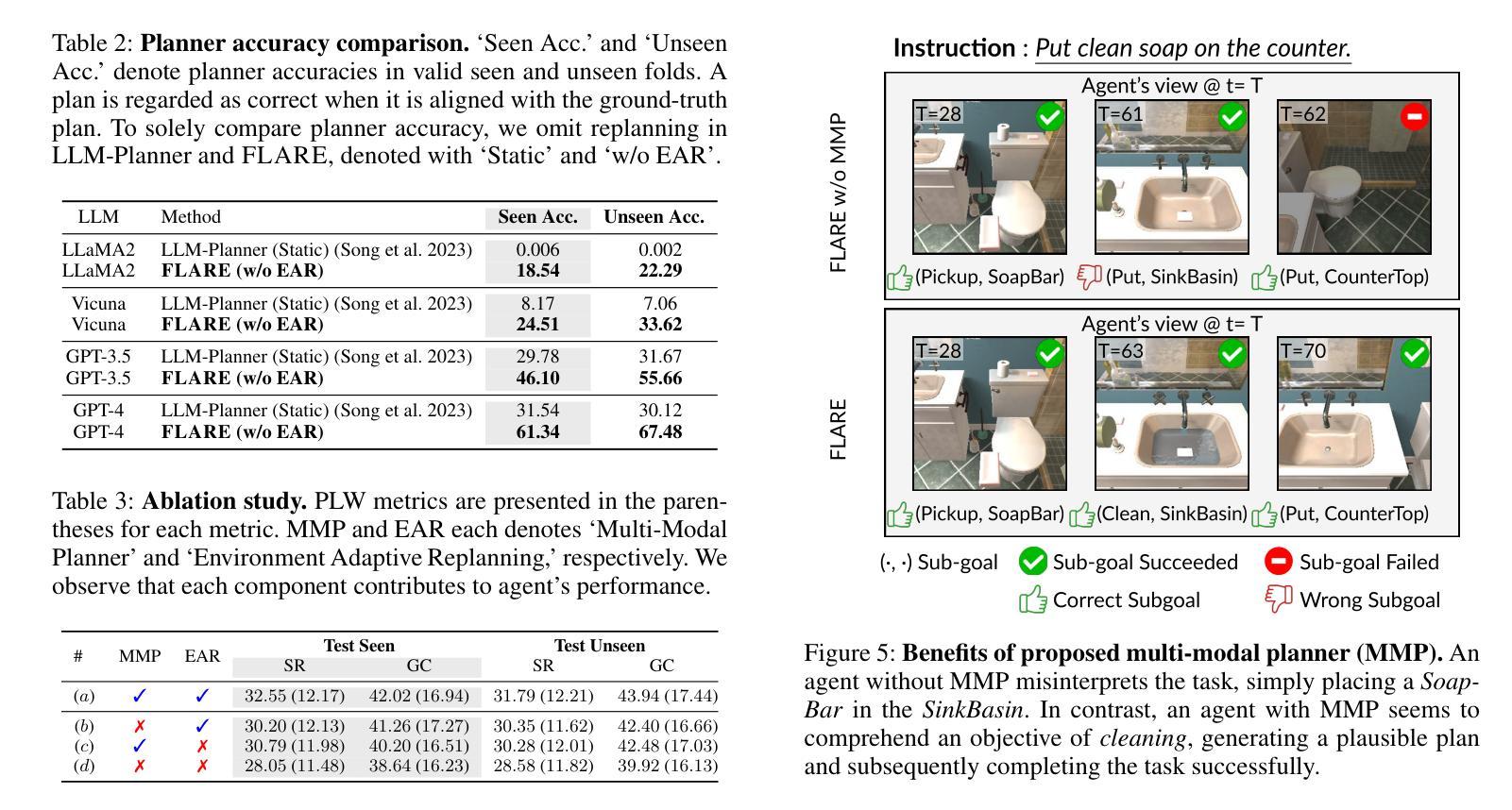
Learning a perception and reasoning module for robotic assistants to plan steps to perform complex tasks based on natural language instructions often requires large free-form language annotations, especially for short high-level instructions. To reduce the cost of annotation, large language models (LLMs) are used as a planner with few data. However, when elaborating the steps, even the state-of-the-art planner that uses LLMs mostly relies on linguistic common sense, often neglecting the status of the environment at command reception, resulting in inappropriate plans. To generate plans grounded in the environment, we propose FLARE (Few-shot Language with environmental Adaptive Replanning Embodied agent), which improves task planning using both language command and environmental perception. As language instructions often contain ambiguities or incorrect expressions, we additionally propose to correct the mistakes using visual cues from the agent. The proposed scheme allows us to use a few language pairs thanks to the visual cues and outperforms state-of-the-art approaches. Our code is available at https://github.com/snumprlab/flare.
对于机器人助理来说,学习基于自然语言指令执行复杂任务的感知和推理模块往往需要大量的自由形式语言注释,特别是对于简短的高级指令。为了减少注释的成本,使用少量的数据大型语言模型(LLM)作为规划器。然而,在细化步骤时,即使是最先进的规划器也主要依赖于语言常识,往往忽略了接收命令时的环境状态,导致计划不当。为了生成基于环境的计划,我们提出了FLARE(带有环境自适应重新规划功能的嵌入式代理的少量语言),它通过语言命令和环境感知改进任务规划。由于语言指令通常包含模糊或错误的表达,我们还提议利用代理的视觉线索来纠正错误。该方案允许我们利用少量的语言对,并得益于视觉线索,其性能超过了最先进的方法。我们的代码可在https://github.com/snumprlab/flare找到。
论文及项目相关链接
PDF AAAI 2025 (Project page: https://twoongg.github.io/projects/flare/)
Summary
机器人学习感知和推理模块以根据自然语言指令执行复杂任务需要大量的自由形式语言标注。为了减少标注成本,研究人员使用大型语言模型作为规划器并减少数据需求。然而,现有的规划器在细化步骤时主要依赖语言常识,忽略了接收命令时的环境状态,导致计划不当。为了生成基于环境的计划,研究人员提出了FLARE(结合环境自适应重新规划的少数语言智能体),通过语言命令和环境感知改进任务规划。同时,针对语言指令中的模糊或错误表达,研究人员还提出利用智能体的视觉线索进行修正。该方案允许使用少数语言对,并借助视觉线索超越现有技术方法。代码公开在 https://github.com/snumprlab/flare。
Key Takeaways
- 大型语言模型被用于减少机器人学习复杂任务规划时的标注成本。
- 现有规划器过于依赖语言常识,忽略了环境状态,导致计划不当。
- 机器人需要结合语言和感知技术来进行更准确的任务规划。
- 研究人员提出了一种名为FLARE的方法,能够结合语言指令和环境感知信息来提高任务规划质量。
- 语言指令可能存在模糊或错误表达的问题,需要使用视觉线索进行修正。
- 使用FLARE的智能体只需要少量的语言对即可实现高性能的任务规划。
点此查看论文截图

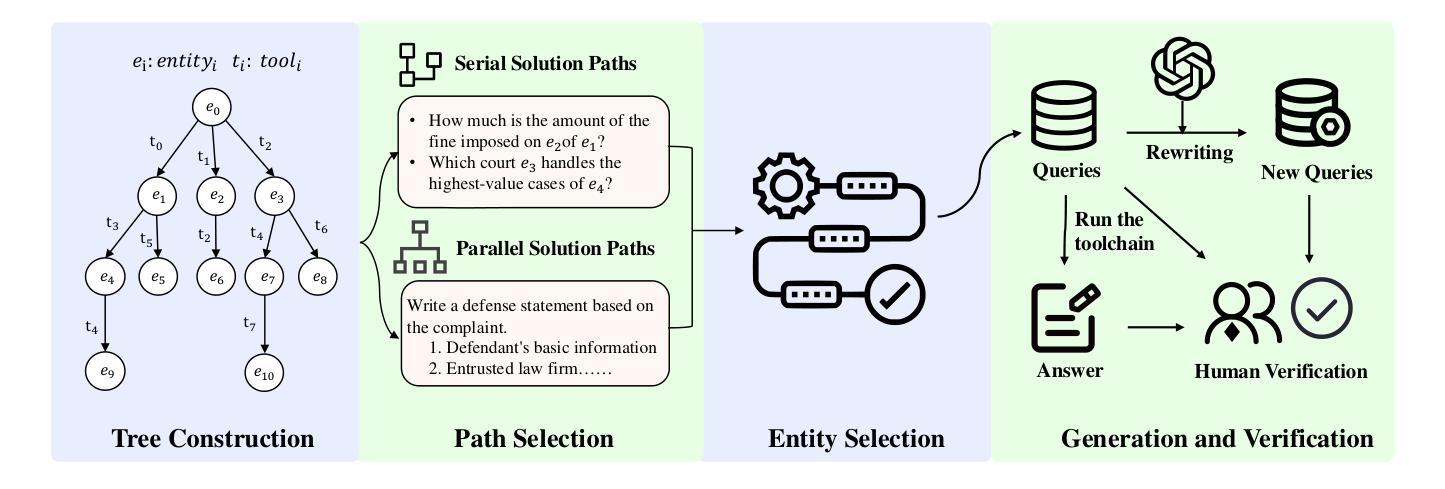
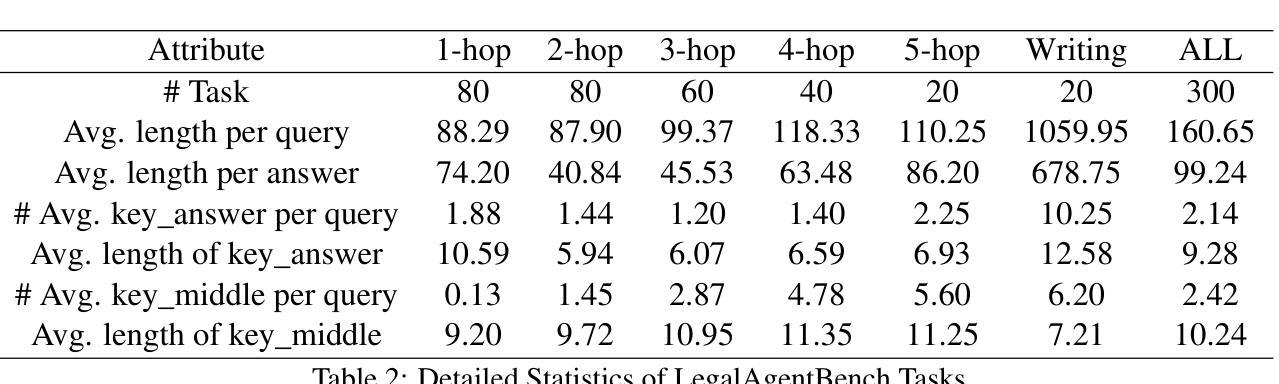
LegalAgentBench: Evaluating LLM Agents in Legal Domain
Authors:Haitao Li, Junjie Chen, Jingli Yang, Qingyao Ai, Wei Jia, Youfeng Liu, Kai Lin, Yueyue Wu, Guozhi Yuan, Yiran Hu, Wuyue Wang, Yiqun Liu, Minlie Huang
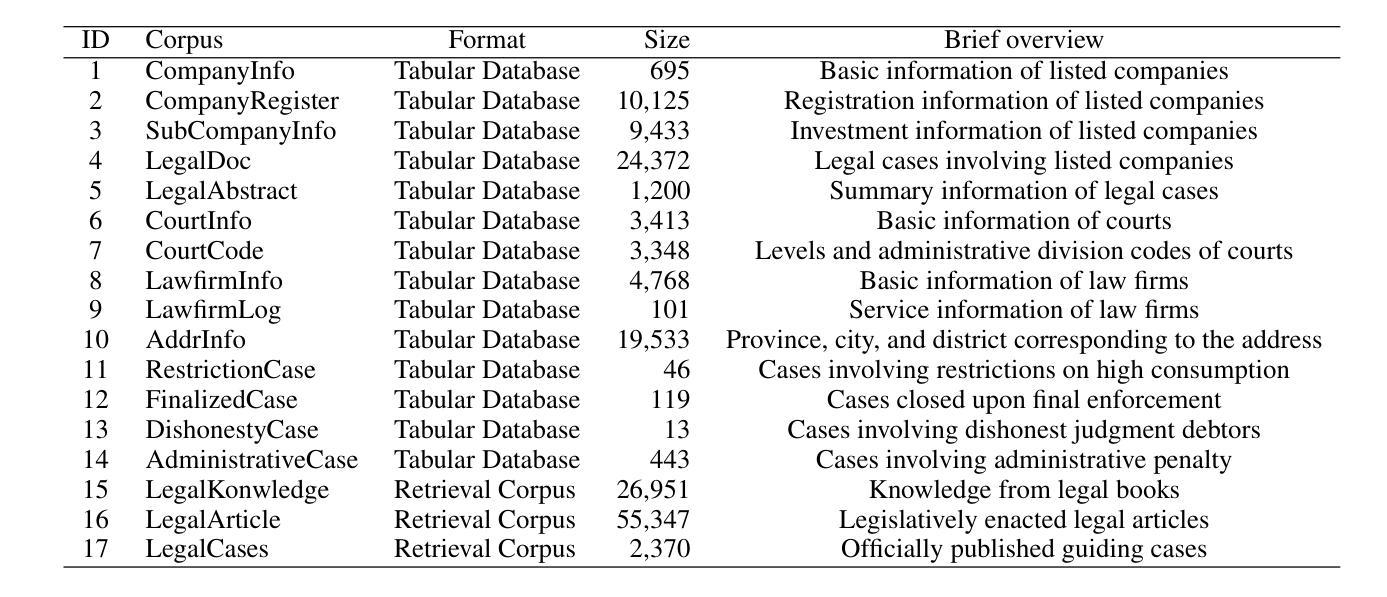
With the increasing intelligence and autonomy of LLM agents, their potential applications in the legal domain are becoming increasingly apparent. However, existing general-domain benchmarks cannot fully capture the complexity and subtle nuances of real-world judicial cognition and decision-making. Therefore, we propose LegalAgentBench, a comprehensive benchmark specifically designed to evaluate LLM Agents in the Chinese legal domain. LegalAgentBench includes 17 corpora from real-world legal scenarios and provides 37 tools for interacting with external knowledge. We designed a scalable task construction framework and carefully annotated 300 tasks. These tasks span various types, including multi-hop reasoning and writing, and range across different difficulty levels, effectively reflecting the complexity of real-world legal scenarios. Moreover, beyond evaluating final success, LegalAgentBench incorporates keyword analysis during intermediate processes to calculate progress rates, enabling more fine-grained evaluation. We evaluated eight popular LLMs, highlighting the strengths, limitations, and potential areas for improvement of existing models and methods. LegalAgentBench sets a new benchmark for the practical application of LLMs in the legal domain, with its code and data available at \url{https://github.com/CSHaitao/LegalAgentBench}.
随着LLM智能体的智能化和自主性不断提高,其在法律领域的应用潜力日益显现。然而,现有的通用领域基准测试无法完全捕捉现实世界司法认知和决策制定的复杂性和微妙之处。因此,我们提出了LegalAgentBench,这是一个专门为中国法律领域设计的综合性基准测试。LegalAgentBench包含来自真实法律场景的17个语料库,提供了37种与外部知识交互的工具。我们设计了一个可扩展的任务构建框架,并仔细标注了300个任务。这些任务涵盖了多种类型,包括多跳推理和写作,并涉及不同的难度级别,有效地反映了真实法律场景的复杂性。此外,除了评估最终的成功之外,LegalAgentBench在中间过程中还进行了关键词分析,以计算进度率,从而实现更精细的评估。我们评估了八种流行的LLM模型,突出了现有模型和方法的长处、局限性和潜在改进方向。LegalAgentBench为LLM在法律领域的实际应用设定了新的基准,其代码和数据可在https://github.com/CSHaitao/LegalAgentBench上找到。
论文及项目相关链接
PDF 23 pages
Summary
法律智能模型在真实世界法律场景中的实际应用逐渐成为关注焦点。为满足这一需求,我们推出专门评估中文法律领域智能模型的基准测试——LegalAgentBench。它包含来自真实法律场景的17个语料库和37种交互外部知识的工具。我们设计了一个可扩展的任务构建框架,精心标注了300个任务,涵盖多跳推理和写作等多种类型,并反映不同难度级别,有效反映真实法律场景的复杂性。此外,除了评估最终成功结果外,LegalAgentBench还通过中间过程的关键词分析来计算进度率,实现更精细的评估。我们对八种流行的法律智能模型进行了评估,突显现有模型和方法的优点、局限性和改进潜力。LegalAgentBench为法律领域中实用智能模型的应用设定了新的基准。
Key Takeaways
- LLM智能模型在法律领域的应用潜力逐渐显现。
- 现有通用基准测试无法充分捕捉法律认知与决策的复杂性。
- LegalAgentBench专门评估中文法律领域智能模型,包含真实法律场景的语料库和任务。
- LegalAgentBench提供多种工具用于与外部知识交互,并设计可扩展的任务构建框架。
- 任务涵盖多跳推理和写作等多种类型,反映不同难度级别。
- 除了最终评估外,还通过关键词分析进行中间过程的精细评估。
- LegalAgentBench评估了多种流行的法律智能模型,突显优势和局限性。
点此查看论文截图


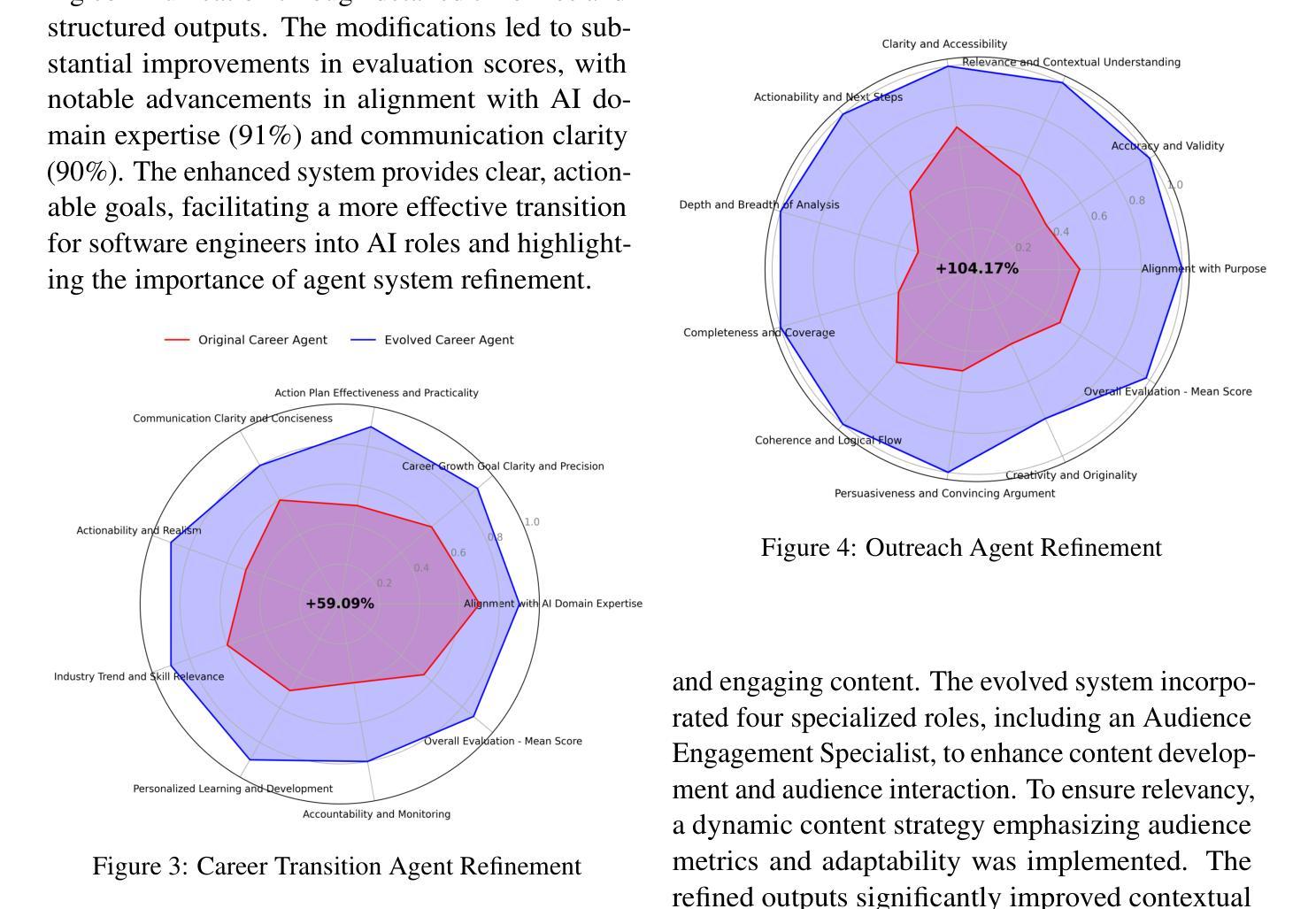
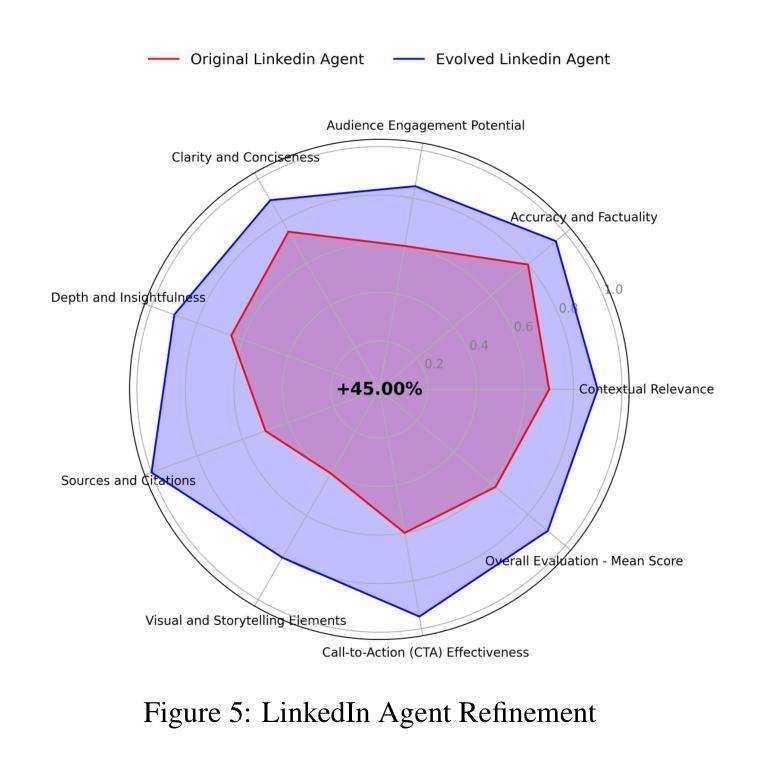
A Multi-AI Agent System for Autonomous Optimization of Agentic AI Solutions via Iterative Refinement and LLM-Driven Feedback Loops
Authors:Kamer Ali Yuksel, Hassan Sawaf
Agentic AI systems use specialized agents to handle tasks within complex workflows, enabling automation and efficiency. However, optimizing these systems often requires labor-intensive, manual adjustments to refine roles, tasks, and interactions. This paper introduces a framework for autonomously optimizing Agentic AI solutions across industries, such as NLP-driven enterprise applications. The system employs agents for Refinement, Execution, Evaluation, Modification, and Documentation, leveraging iterative feedback loops powered by an LLM (Llama 3.2-3B). The framework achieves optimal performance without human input by autonomously generating and testing hypotheses to improve system configurations. This approach enhances scalability and adaptability, offering a robust solution for real-world applications in dynamic environments. Case studies across diverse domains illustrate the transformative impact of this framework, showcasing significant improvements in output quality, relevance, and actionability. All data for these case studies, including original and evolved agent codes, along with their outputs, are here: https://anonymous.4open.science/r/evolver-1D11/
Agentic AI系统利用专业代理处理复杂工作流程中的任务,实现自动化和提高效率。然而,优化这些系统通常需要劳动密集型的手动调整来完善角色、任务和交互。本文介绍了一种跨行业自主优化Agentic AI解决方案的框架,如NLP驱动的企业应用程序。该系统采用用于细化、执行、评估、修改和文档的代理,利用由大型语言模型(Lama 3.2-3B)驱动迭代反馈循环。该框架通过自主生成和测试假设以改进系统配置,实现无需人工输入即可达到最佳性能。这种方法增强了系统的可扩展性和适应性,为动态环境中的现实世界应用提供了稳健的解决方案。不同领域的案例研究表明了该框架的变革性影响,显著提高了输出质量、相关性和可操作性。这些案例研究的数据,包括原始和进化的代理代码及其输出,可在此处找到:https://anonymous.4open.science/r/evolver-1D11/
论文及项目相关链接
Summary
专业Agentic AI系统利用特殊代理处理复杂工作流程中的任务,实现自动化和提高效率。但优化这些系统通常需要劳动密集型的手动调整来完善角色、任务和互动。本文介绍了一种跨行业自主优化Agentic AI解决方案的框架,如NLP驱动的企业应用程序。该系统利用代理进行细化、执行、评估、修改和记录,通过大型语言模型(Lama 3.2-3B)驱动的迭代反馈循环实现自主优化。该框架无需人工输入即可实现最佳性能,通过自主生成并测试假设来改善系统配置。此框架提高了系统的可扩展性和适应性,为动态环境中的实际应用提供了稳健的解决方案。不同领域的案例研究展示了该框架的变革性影响,显著提高了输出质量、相关性和可操作性。
Key Takeaways
- Agentic AI系统利用特殊代理处理复杂任务,促进自动化和效率。
- 优化Agentic AI系统通常需要大量手动调整角色、任务和互动。
- 引入了一种跨行业自主优化Agentic AI的解决方案框架。
- 该框架包括用于细化、执行、评估、修改和记录的代理。
- 利用大型语言模型驱动的迭代反馈循环实现自主优化。
- 框架可无需人工输入实现最佳性能,通过假设改善系统配置。
点此查看论文截图


LLM Agent for Fire Dynamics Simulations
Authors:Leidong Xu, Danyal Mohaddes, Yi Wang
Significant advances have been achieved in leveraging foundation models, such as large language models (LLMs), to accelerate complex scientific workflows. In this work we introduce FoamPilot, a proof-of-concept LLM agent designed to enhance the usability of FireFOAM, a specialized solver for fire dynamics and fire suppression simulations built using OpenFOAM, a popular open-source toolbox for computational fluid dynamics (CFD). FoamPilot provides three core functionalities: code insight, case configuration and simulation evaluation. Code insight is an alternative to traditional keyword searching leveraging retrieval-augmented generation (RAG) and aims to enable efficient navigation and summarization of the FireFOAM source code for developers and experienced users. For case configuration, the agent interprets user requests in natural language and aims to modify existing simulation setups accordingly to support intermediate users. FoamPilot’s job execution functionality seeks to manage the submission and execution of simulations in high-performance computing (HPC) environments and provide preliminary analysis of simulation results to support less experienced users. Promising results were achieved for each functionality, particularly for simple tasks, and opportunities were identified for significant further improvement for more complex tasks. The integration of these functionalities into a single LLM agent is a step aimed at accelerating the simulation workflow for engineers and scientists employing FireFOAM for complex simulations critical for improving fire safety.
在利用基础模型,如大型语言模型(LLMs)来加速复杂科学工作流程方面,已经取得了重大进展。在这项工作中,我们介绍了FoamPilot,这是一个旨在增强FireFOAM可用性的概念证明LLM代理。FireFOAM是一个使用OpenFOAM构建的火灾动力学和灭火模拟专业求解器,OpenFOAM是计算流体动力学(CFD)的流行开源工具箱。FoamPilot提供了三个核心功能:代码见解、案例配置和模拟评估。代码见解是另一种传统关键词搜索的方法,它利用增强检索生成(RAG)技术,旨在帮助开发人员和经验丰富的用户高效浏览和概括FireFOAM源代码。对于案例配置,该代理以自然语言解释用户请求,并旨在相应地修改现有模拟设置以支持中级用户。FoamPilot的作业执行功能旨在管理高性能计算(HPC)环境中的模拟提交和执行,并提供模拟结果的初步分析以支持经验较少的用户。对于每项功能,都取得了令人鼓舞的结果,尤其是在简单任务方面,并发现了针对更复杂任务的重大改进机会。将这些功能集成到一个单独的LLM代理中是一项旨在加速工程师和科学家使用FireFOAM进行复杂模拟的工作流步骤,这对于提高火灾安全性至关重要。
论文及项目相关链接
PDF NeurIPS 2024 Foundation Models for Science Workshop (38th Conference on Neural Information Processing Systems). 12 pages, 8 figures
Summary
泡沫控制流体动力学模型利用大型语言模型(LLM)进行加速取得了显著进展。在此工作中,我们引入了FoamPilot,这是一个旨在增强FireFOAM可用性概念证明LLM代理。FireFOAM是用于火灾动力学和灭火模拟的专业求解器,由流行的开源计算流体动力学(CFD)工具箱OpenFOAM构建。FoamPilot提供了三大核心功能:代码见解、案例配置和模拟评估。代码见解利用检索增强生成(RAG)作为传统关键词搜索的替代方案,旨在帮助开发人员和经验丰富的用户高效浏览和总结FireFOAM源代码。对于案例配置,该代理解释自然语言用户请求并修改现有模拟设置以支持中间用户。FoamPilot的工作执行功能旨在管理高性能计算(HPC)环境中的模拟提交和执行,并提供模拟结果的初步分析以支持经验较少的用户。对每个功能的实现都取得了有希望的成果,特别是在简单任务方面,并确定了更复杂任务的显著改进机会。这些功能的集成是旨在加速工程师和科学家使用FireFOAM进行复杂模拟工作流程的一步,这些模拟对于提高火灾安全性至关重要。
Key Takeaways
- 大型语言模型(LLM)被用于加速泡沫控制流体动力学模型的复杂科学工作流程。
- FoamPilot作为概念证明LLM代理被引入,旨在增强FireFOAM的可用性。
- FoamPilot提供三大核心功能:代码见解、案例配置和模拟评估。
- 代码见解功能利用检索增强生成(RAG)促进源代码的高效浏览和总结。
- 案例配置功能通过解释自然语言用户请求来修改模拟设置,支持中间用户。
- FoamPilot管理高性能计算环境中的模拟提交和执行,并提供初步的分析结果。
点此查看论文截图




Multi-Agent Sampling: Scaling Inference Compute for Data Synthesis with Tree Search-Based Agentic Collaboration
Authors:Hai Ye, Mingbao Lin, Hwee Tou Ng, Shuicheng Yan
Scaling laws for inference compute in multi-agent systems remain under-explored compared to single-agent scenarios. This work aims to bridge this gap by investigating the problem of data synthesis through multi-agent sampling, where synthetic responses are generated by sampling from multiple distinct language models. Effective model coordination is crucial for successful multi-agent collaboration. Unlike previous approaches that rely on fixed workflows, we treat model coordination as a multi-step decision-making process, optimizing generation structures dynamically for each input question. We introduce Tree Search-based Orchestrated Agents~(TOA), where the workflow evolves iteratively during the sequential sampling process. To achieve this, we leverage Monte Carlo Tree Search (MCTS), integrating a reward model to provide real-time feedback and accelerate exploration. Our experiments on alignment, machine translation, and mathematical reasoning demonstrate that multi-agent sampling significantly outperforms single-agent sampling as inference compute scales. TOA is the most compute-efficient approach, achieving SOTA performance on WMT and a 71.8% LC win rate on AlpacaEval. Moreover, fine-tuning with our synthesized alignment data surpasses strong preference learning methods on challenging benchmarks such as Arena-Hard and AlpacaEval.
在多智能体系统推理计算的可扩展性研究方面,与单一智能体情景相比,其研究仍然不足。本研究旨在通过调查多智能体采样中的数据合成问题来弥补这一差距,其中合成响应是通过从多个不同的语言模型中采样来生成的。有效的模型协调对于多智能体协作的成功至关重要。不同于以前依赖于固定工作流程的方法,我们将模型协调视为一个多步骤的决策过程,针对每个输入问题动态优化生成结构。我们引入了基于树搜索的协同智能体(TOA),其中工作流程在顺序采样过程中迭代发展。为实现这一目标,我们利用蒙特卡洛树搜索(MCTS),集成奖励模型以提供实时反馈并加速探索。我们在对齐、机器翻译和数学推理方面的实验表明,随着推理计算规模的扩大,多智能体采样显著优于单一智能体采样。TOA是计算效率最高的方法,在WMT上实现了最先进的性能,在AlpacaEval上的LC获胜率为71.8%。此外,使用我们的合成对齐数据进行微调,在具有挑战性的基准测试(如Arena-Hard和AlpacaEval)上超越了强大的偏好学习方法。
论文及项目相关链接
Summary
多智能体系统推理计算中的规模定律相较于单智能体场景的研究仍然不足。本研究旨在缩小这一差距,通过探索多智能体采样中的数据合成问题进行研究,其中合成响应是通过从多个不同的语言模型中采样来生成的。有效的模型协调对于成功的多智能体协作至关重要。与以前依赖于固定工作流程的方法不同,我们将模型协调视为一个多步骤的决策过程,为每个输入问题动态优化生成结构。我们引入了基于树搜索的协同智能体(TOA),其中工作流程在顺序采样过程中迭代演化。为此,我们利用蒙特卡洛树搜索(MCTS),并结合奖励模型提供实时反馈并加速探索。我们的实验表明,随着推理计算规模的扩大,多智能体采样显著优于单智能体采样。TOA在推理计算方面是最有效的,在世界语料库翻译和AlpacaEval上的表现均达到了领先水平。此外,使用我们的合成对齐数据进行微调在诸如Arena-Hard和AlpacaEval等具有挑战性的基准测试上超越了强大的偏好学习方法。
Key Takeaways
- 多智能体系统推理计算中的规模定律研究相较于单智能体场景仍然不足。
- 研究通过多智能体采样进行数据合成,合成响应是通过多个语言模型的采样生成的。
- 有效模型协调对于多智能体协作至关重要,本研究将其视为多步骤决策过程。
- 引入基于树搜索的协同智能体(TOA),工作流程在顺序采样过程中迭代演化。
- 使用蒙特卡洛树搜索(MCTS)结合奖励模型提供实时反馈并加速探索。
- 多智能体采样在推理计算方面显著优于单智能体采样。
点此查看论文截图




GraphAgent: Agentic Graph Language Assistant
Authors:Yuhao Yang, Jiabin Tang, Lianghao Xia, Xingchen Zou, Yuxuan Liang, Chao Huang
Real-world data is represented in both structured (e.g., graph connections) and unstructured (e.g., textual, visual information) formats, encompassing complex relationships that include explicit links (such as social connections and user behaviors) and implicit interdependencies among semantic entities, often illustrated through knowledge graphs. In this work, we propose GraphAgent, an automated agent pipeline that addresses both explicit graph dependencies and implicit graph-enhanced semantic inter-dependencies, aligning with practical data scenarios for predictive tasks (e.g., node classification) and generative tasks (e.g., text generation). GraphAgent comprises three key components: (i) a Graph Generator Agent that builds knowledge graphs to reflect complex semantic dependencies; (ii) a Task Planning Agent that interprets diverse user queries and formulates corresponding tasks through agentic self-planning; and (iii) a Task Execution Agent that efficiently executes planned tasks while automating tool matching and invocation in response to user queries. These agents collaborate seamlessly, integrating language models with graph language models to uncover intricate relational information and data semantic dependencies. Through extensive experiments on various graph-related predictive and text generative tasks on diverse datasets, we demonstrate the effectiveness of our GraphAgent across various settings. We have made our proposed GraphAgent open-source at: https://github.com/HKUDS/GraphAgent.
现实世界的数据以结构化(如图形连接)和非结构化(如文本、视觉信息)两种格式呈现,包含复杂的关系,包括明确的链接(如社会连接和用户行为)和语义实体之间的隐性相互依赖性,通常通过知识图谱进行说明。在这项工作中,我们提出了GraphAgent,这是一个自动化代理管道,它解决了明确的图形依赖性和隐性的图形增强语义相互依赖性,符合预测任务(如节点分类)和生成任务(如文本生成)的实际数据场景。GraphAgent包含三个关键组件:(i)Graph Generator Agent,用于构建知识图谱,以反映复杂的语义依赖性;(ii)Task Planning Agent,它解释各种用户查询并通过代理自我规划制定相应任务;(iii)Task Execution Agent,它有效地执行规划任务,自动匹配和调用工具以响应用户查询。这些代理无缝协作,将语言模型与图形语言模型集成,以揭示复杂的关系信息和数据语义依赖性。我们在各种图形相关的预测任务和文本生成任务上的数据集上进行了广泛的实验,证明了我们的GraphAgent在各种设置中的有效性。我们的开源GraphAgent可通过以下链接访问:https://github.com/HKUDS/GraphAgent。
论文及项目相关链接
Summary
本文介绍了GraphAgent,一个自动化代理管道,用于处理显式图依赖关系和隐式图增强语义互依赖关系,适用于预测任务和生成任务。GraphAgent包括三个关键组件:知识图谱构建的图生成器代理、解释用户查询并规划任务的任务规划代理以及执行计划任务的任务执行代理。这些代理无缝协作,整合语言模型与图形语言模型,揭示复杂关系信息和数据语义依赖。通过广泛的实验验证,GraphAgent在各种图形相关预测和文本生成任务的不同数据集上表现出有效性。
Key Takeaways
- GraphAgent是一个自动化代理管道,用于处理现实世界中结构化与非结构化数据的复杂关系。
- 它包含三个关键组件:图生成器代理、任务规划代理和任务执行代理。
- 图生成器代理通过构建知识图谱来反映复杂的语义依赖关系。
- 任务规划代理能够解释用户查询并通过自我规划制定相应任务。
- 任务执行代理能够高效执行任务,自动匹配和调用工具以响应用户查询。
- GraphAgent整合了语言模型和图形语言模型,以揭示数据中的复杂关系语义依赖。
点此查看论文截图



KG4Diagnosis: A Hierarchical Multi-Agent LLM Framework with Knowledge Graph Enhancement for Medical Diagnosis
Authors:Kaiwen Zuo, Yirui Jiang, Fan Mo, Pietro Lio
Integrating Large Language Models (LLMs) in healthcare diagnosis demands systematic frameworks that can handle complex medical scenarios while maintaining specialized expertise. We present KG4Diagnosis, a novel hierarchical multi-agent framework that combines LLMs with automated knowledge graph construction, encompassing 362 common diseases across medical specialties. Our framework mirrors real-world medical systems through a two-tier architecture: a general practitioner (GP) agent for initial assessment and triage, coordinating with specialized agents for in-depth diagnosis in specific domains. The core innovation lies in our end-to-end knowledge graph generation methodology, incorporating: (1) semantic-driven entity and relation extraction optimized for medical terminology, (2) multi-dimensional decision relationship reconstruction from unstructured medical texts, and (3) human-guided reasoning for knowledge expansion. KG4Diagnosis serves as an extensible foundation for specialized medical diagnosis systems, with capabilities to incorporate new diseases and medical knowledge. The framework’s modular design enables seamless integration of domain-specific enhancements, making it valuable for developing targeted medical diagnosis systems. We provide architectural guidelines and protocols to facilitate adoption across medical contexts.
将大型语言模型(LLMs)整合到医疗诊断中,需要能够处理复杂医疗场景并保持专业知识的系统性框架。我们提出了KG4Diagnosis,这是一种新型分层多智能体框架,它将LLMs与自动化知识图谱构建相结合,涵盖362种常见疾病,涉及医学各专业。我们的框架通过两层架构反映现实医疗系统:全科医生(GP)智能体进行初步评估和分流,与针对特定领域进行深入诊断的专业智能体进行协调。核心创新在于我们端到端的知识图谱生成方法,包括:(1)针对医学术语优化的语义驱动实体和关系提取,(2)从非结构化的医疗文本中进行多维决策关系重建,(3)人类指导的推理用于知识扩展。KG4Diagnosis作为一个可扩展的基础,为专业医疗诊断系统提供服务,有能力融入新的疾病和医疗知识。该框架的模块化设计使得能够无缝集成特定领域的增强功能,使其成为开发有针对性的医疗诊断系统的宝贵工具。我们提供了架构指南和协议,以推动其在医疗环境中的采用。
论文及项目相关链接
PDF 10 pages,5 figures,published to AAAI-25 Bridge Program
Summary:
集成大型语言模型(LLMs)进行医疗诊断需要能够处理复杂医疗场景并具有专业知识的系统性框架。本文介绍了一种新型的分层多智能体框架KG4Diagnosis,它将LLMs与自动构建知识图谱相结合,涵盖362种常见疾病和跨医疗专科领域。该框架通过两层级架构模拟现实医疗系统:一级为通用实践者(GP)智能体进行初步评估和分流,并与专业智能体协调进行深度诊断。核心创新在于其端到端的知识图谱生成方法,包括:语义驱动的实体和关系提取优化医学术语、多维决策关系重建以及人类引导推理知识扩展。KG4Diagnosis作为专业医疗诊断系统的可扩展基础,具备整合新疾病和医学知识的能力。框架的模块化设计使得它能够无缝集成领域特定的增强功能,对于开发针对性的医疗诊断系统具有很高的价值。本文还提供跨医疗环境的采纳指南和协议。
Key Takeaways:
- KG4Diagnosis是一个结合大型语言模型(LLMs)和自动知识图谱构建的新型分层多智能体框架,用于医疗诊断。
- 框架涵盖362种常见疾病,并适用于跨医疗专科领域。
- KG4Diagnosis采用两层级架构,包括通用实践者智能体进行初步评估和专业智能体进行深度诊断。
- 该框架的核心创新在于其端到端的知识图谱生成方法,包括语义驱动的医学术语提取、多维决策关系重建和知识扩展。
- KG4Diagnosis具备扩展能力,可整合新疾病和医学知识。
- 框架的模块化设计使得能够无缝集成领域特定的增强功能。
点此查看论文截图





Data-Driven Economic Agent-Based Models
Authors:Marco Pangallo, R. Maria del Rio-Chanona
Economic agent-based models (ABMs) are becoming more and more data-driven, establishing themselves as increasingly valuable tools for economic research and policymaking. We propose to classify the extent to which an ABM is data-driven based on whether agent-level quantities are initialized from real-world micro-data and whether the ABM’s dynamics track empirical time series. This paper discusses how making ABMs data-driven helps overcome limitations of traditional ABMs and makes ABMs a stronger alternative to equilibrium models. We review state-of-the-art methods in parameter calibration, initialization, and data assimilation, and then present successful applications that have generated new scientific knowledge and informed policy decisions. This paper serves as a manifesto for data-driven ABMs, introducing a definition and classification and outlining the state of the field, and as a guide for those new to the field.
基于经济主体的模型(ABM)正变得越来越数据驱动,它们正逐渐成为经济研究和政策制定中越来越有价值的工具。我们根据主体层面的数量是否通过真实世界的微观数据进行初始化,以及ABM的动态是否追踪经验时间序列,来提出对ABM数据驱动程度的分类。本文讨论了如何使ABM数据驱动,有助于克服传统ABM的局限性,并使ABM成为均衡模型的更强替代方案。我们回顾了参数校准、初始化和数据同化等最新方法,然后介绍了成功的应用案例,这些案例产生了新的科学知识和指导了政策决策。本文作为数据驱动ABM的宣言,介绍了定义、分类和概述了该领域的现状,并为该领域的新手提供了指南。
论文及项目相关链接
Summary
经济主体基于模型的模拟(ABM)正越来越依赖于数据驱动,为经济研究和政策制定提供了日益有价值的工具。本文提出了根据ABM是否从现实微观数据中初始化代理级别的数量以及其动态是否追踪经验时间序列来分类其数据驱动程度的标准。数据驱动的ABM有助于克服传统ABM的局限性,使其成为均衡模型的更强替代品。本文介绍了最新的参数校准、初始化和数据融合方法,并展示了成功的应用案例,这些案例已经产生了新的科学知识和指导了政策决策。本文作为数据驱动ABM的宣言,介绍了定义、分类和概述了当前状态,并为初学者提供了指南。
Key Takeaways
- 经济主体基于模型的模拟(ABM)正逐渐变得数据驱动。
- 数据驱动的ABM有助于克服传统ABM的局限性。
- ABM的数据驱动程度可根据是否使用现实微观数据初始化,以及模型动态是否追踪经验时间序列来分类。
- 数据驱动的ABM已成为均衡模型的更强替代品。
- 论文介绍了参数校准、初始化和数据融合方法的最新进展。
- 存在成功应用ABM的案例,这些案例产生了新的科学知识和指导了政策决策。
点此查看论文截图


Loosely Synchronized Rule-Based Planning for Multi-Agent Path Finding with Asynchronous Actions
Authors:Shuai Zhou, Shizhe Zhao, Zhongqiang Ren
Multi-Agent Path Finding (MAPF) seeks collision-free paths for multiple agents from their respective starting locations to their respective goal locations while minimizing path costs. Although many MAPF algorithms were developed and can handle up to thousands of agents, they usually rely on the assumption that each action of the agent takes a time unit, and the actions of all agents are synchronized in a sense that the actions of agents start at the same discrete time step, which may limit their use in practice. Only a few algorithms were developed to address asynchronous actions, and they all lie on one end of the spectrum, focusing on finding optimal solutions with limited scalability. This paper develops new planners that lie on the other end of the spectrum, trading off solution quality for scalability, by finding an unbounded sub-optimal solution for many agents. Our method leverages both search methods (LSS) in handling asynchronous actions and rule-based planning methods (PIBT) for MAPF. We analyze the properties of our method and test it against several baselines with up to 1000 agents in various maps. Given a runtime limit, our method can handle an order of magnitude more agents than the baselines with about 25% longer makespan.
多智能体路径寻找(MAPF)旨在为多个智能体寻找无碰撞路径,从各自的起始位置到各自的目标位置,同时最小化路径成本。虽然许多MAPF算法已经开发出来,并能够处理多达数千个智能体,但它们通常基于一个假设,即智能体的每个行动都需要一个时间单位,所有智能体的行动都在同一离散时间步开始,这在实践中可能限制了它们的使用。只有少数算法被开发出来处理异步行动,它们都集中在寻找最优解,但可扩展性有限。本文开发了一种新的规划方法,这种方法位于另一端的频谱上,通过寻找许多智能体的无界次优解来权衡解决方案的质量与可扩展性。我们的方法结合了处理异步行动的搜索方法(LSS)和基于规则的规划方法(PIBT)来解决MAPF问题。我们分析了我们的方法的属性,并在各种地图上与几个基准测试进行了对比,测试的智能体数量高达1000个。在给定运行时间限制的情况下,我们的方法能够处理的智能体数量比基准测试多一个数量级,并且最长路径的延长时间约为25%。
论文及项目相关链接
PDF AAAI2025
Summary
该文介绍了多智能体路径规划(MAPF)的问题,即寻求多个智能体从起始位置到目标位置的碰撞自由路径,同时最小化路径成本。虽然许多MAPF算法已经开发出来,并可以处理多达数千个智能体,但它们通常假设每个智能体的每个行动都需要一个时间单位,并且所有智能体的行动都是在同一离散时间步开始的,这在实践中可能有所限制。本文开发了一种新的规划方法,利用搜索方法和基于规则的方法来处理异步动作问题,针对MAPF问题找到了一个次优解。在运行时限内,该方法可以处理比基线方法多一倍的智能体数量,并且具有约25%更长的完成时距。总结大意即为,该论文解决了多个智能体异步动作的多路径规划问题,并通过搜索和规则相结合的方法实现了良好性能的提升。虽然该方案给出的路径质量较低但仍拥有一定应用价值。总的来说对优化现有方案的适用场景有很大改善意义。
Key Takeaways
以下是该文本的关键要点:
- 多智能体路径规划(MAPF)的目标是找到避免碰撞的路径同时尽量最小化成本。虽然已经存在诸多处理多个智能体的算法但它们的应用范围相对有限需进行优化改善以实现其更好的实用性价值意义。优化实践受到传统限制被不断刷新;在时间步伐单位受限这一环境条件下依然有提升空间可进一步解决实际应用场景下的异步动作问题。
点此查看论文截图






SmartAgent: Chain-of-User-Thought for Embodied Personalized Agent in Cyber World
Authors:Jiaqi Zhang, Chen Gao, Liyuan Zhang, Yong Li, Hongzhi Yin
Recent advances in embodied agents with multimodal perception and reasoning capabilities based on large vision-language models (LVLMs), excel in autonomously interacting either real or cyber worlds, helping people make intelligent decisions in complex environments. However, the current works are normally optimized by golden action trajectories or ideal task-oriented solutions toward a definitive goal. This paradigm considers limited user-oriented factors, which could be the reason for their performance reduction in a wide range of personal assistant applications. To address this, we propose Chain-of-User-Thought (COUT), a novel embodied reasoning paradigm that takes a chain of thought from basic action thinking to explicit and implicit personalized preference thought to incorporate personalized factors into autonomous agent learning. To target COUT, we introduce SmartAgent, an agent framework perceiving cyber environments and reasoning personalized requirements as 1) interacting with GUI to access an item pool, 2) generating users’ explicit requirements implied by previous actions, and 3) recommending items to fulfill users’ implicit requirements. To demonstrate SmartAgent’s capabilities, we also create a brand-new dataset SmartSpot that offers a full-stage personalized action-involved environment. To our best knowledge, our work is the first to formulate the COUT process, serving as a preliminary attempt towards embodied personalized agent learning. Our extensive experiments on SmartSpot illuminate SmartAgent’s functionality among a series of embodied and personalized sub-tasks. We will release code and data upon paper notification at https://github.com/tsinghua-fib-lab/SmartAgent.
基于大型视觉语言模型(LVLMs)的多模态感知和推理能力的实体代理近期取得了进展,它们擅长在真实或网络世界中自主交互,帮助人们在复杂环境中做出智能决策。然而,当前的工作通常通过最佳行动轨迹或面向任务的理想解决方案来优化以实现明确目标。这种范式考虑的用户因素有限,这可能是它们在各种个人助理应用程序中性能下降的原因。为了解决这一问题,我们提出了用户思维链(COUT),这是一种新的实体化推理范式,它从基本行动思维到明确的和隐性的个性化偏好思维,将个性化因素融入自主代理学习中。为了定位COUT,我们引入了SmartAgent,这是一个感知网络环境的代理框架,并推理个性化需求,包括1)与GUI交互以访问项目池,2)根据先前的行动生成用户的明确需求,以及3)推荐满足用户隐性需求的物品。为了展示SmartAgent的能力,我们还创建了一个全新的数据集SmartSpot,它提供了一个全程个性化的行动环境。据我们所知,我们的工作是首次制定COUT流程,是朝着实体个性化代理学习迈出的初步尝试。我们在SmartSpot上的大量实验证明了SmartAgent在一系列实体化和个性化子任务中的功能。论文通知发布后,我们将在https://github.com/tsinghua-fib-lab/SmartAgent上发布代码和数据。
论文及项目相关链接
Summary
本文介绍了基于大型视觉语言模型(LVLMs)的多模态感知和推理能力的实体代理的最新进展。这些代理在自主交互真实或网络世界方面表现出色,有助于人们在复杂环境中做出智能决策。然而,当前的工作通常通过黄金行动轨迹或面向理想任务的解决方案进行优化,以实现明确的目标。这种范式忽略了用户因素的有限性,这可能是它们在各种个人助理应用程序中性能下降的原因。为解决这一问题,本文提出了用户思维链(COUT)这一新型实体推理范式,通过从基本行动思维到明确和隐含个性化偏好思维的思维链,将个性化因素融入自主代理学习。为应对COUT,我们引入了SmartAgent代理框架,该框架能够感知网络环境并对个性化需求进行推理,包括1)与GUI交互以访问项目池、2)生成用户被之前行动所暗示的明确需求以及3)推荐满足用户隐含需求的物品。为展示SmartAgent的能力,我们还创建了全新的数据集SmartSpot,提供了一个完整的个性化行动环境。据我们所知,我们的工作是首次制定COUT流程,是朝着实体个性化代理学习迈出的初步尝试。在SmartSpot上的广泛实验证明了SmartAgent在一系列实体化和个性化子任务中的功能。
Key Takeaways
- 多模态感知和推理能力的实体代理在自主交互方面有出色表现,有助于复杂环境中的智能决策。
- 当前工作优化主要面向黄金行动轨迹或理想任务解决方案,忽略了用户因素的有限性。
- 提出用户思维链(COUT)这一新型实体推理范式,融入个性化因素。
- SmartAgent代理框架能够感知网络环境并对个性化需求进行推理。
- SmartAgent包括与GUI交互、生成用户明确需求和推荐满足隐含需求物品的功能。
- 创建了全新的数据集SmartSpot来展示SmartAgent的能力。
点此查看论文截图




Large Language Model-Brained GUI Agents: A Survey
Authors:Chaoyun Zhang, Shilin He, Jiaxu Qian, Bowen Li, Liqun Li, Si Qin, Yu Kang, Minghua Ma, Guyue Liu, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, Qi Zhang
GUIs have long been central to human-computer interaction, providing an intuitive and visually-driven way to access and interact with digital systems. The advent of LLMs, particularly multimodal models, has ushered in a new era of GUI automation. They have demonstrated exceptional capabilities in natural language understanding, code generation, and visual processing. This has paved the way for a new generation of LLM-brained GUI agents capable of interpreting complex GUI elements and autonomously executing actions based on natural language instructions. These agents represent a paradigm shift, enabling users to perform intricate, multi-step tasks through simple conversational commands. Their applications span across web navigation, mobile app interactions, and desktop automation, offering a transformative user experience that revolutionizes how individuals interact with software. This emerging field is rapidly advancing, with significant progress in both research and industry. To provide a structured understanding of this trend, this paper presents a comprehensive survey of LLM-brained GUI agents, exploring their historical evolution, core components, and advanced techniques. We address research questions such as existing GUI agent frameworks, the collection and utilization of data for training specialized GUI agents, the development of large action models tailored for GUI tasks, and the evaluation metrics and benchmarks necessary to assess their effectiveness. Additionally, we examine emerging applications powered by these agents. Through a detailed analysis, this survey identifies key research gaps and outlines a roadmap for future advancements in the field. By consolidating foundational knowledge and state-of-the-art developments, this work aims to guide both researchers and practitioners in overcoming challenges and unlocking the full potential of LLM-brained GUI agents.
图形用户界面(GUI)长期以来一直是人机交互的核心,它提供了一种直观且视觉驱动的方式来访问和与数字系统交互。大语言模型(LLM)的出现,特别是多模态模型,已经开启了一个新的GUI自动化时代。它们在自然语言理解、代码生成和视觉处理方面表现出了卓越的能力。这为新一代基于LLM的GUI代理铺平了道路,这些代理能够解释复杂的GUI元素,并基于自然语言指令自主执行操作。这些代理代表了范式转变,使用户能够通过简单的命令执行复杂的多步骤任务。它们的应用跨越网页导航、移动应用程序交互和桌面自动化,提供变革性的用户体验,彻底改变个人与软件的交互方式。这个新兴领域正在迅速发展,研究和工业界都取得了重大进展。
论文及项目相关链接
PDF The collection of papers reviewed in this survey will be hosted and regularly updated on the GitHub repository: https://github.com/vyokky/LLM-Brained-GUI-Agents-Survey Additionally, a searchable webpage is available at https://aka.ms/gui-agent for easier access and exploration
Summary
LLM驱动的GUI代理正在改变人机交互方式。该代理能够通过自然语言指令自主执行GUI操作,涵盖了网页导航、移动应用交互和桌面自动化等多个领域。本文对其历史发展、核心组件和高级技术进行了全面调查,并指出了未来的研究空白和发展方向。
Key Takeaways
- LLMs(大型语言模型)推动了GUI自动化进入新时代。
- 多模态模型在自然语言理解、代码生成和视觉处理方面表现出卓越能力。
- LLM驱动的GUI代理可以解释复杂的GUI元素并根据自然语言指令自主执行操作。
- 这些代理支持用户通过简单的对话命令执行复杂的多步骤任务。
- LLM驱动的GUI代理的应用范围广泛,包括网页导航、移动应用交互和桌面自动化。
- 当前对该领域的研究集中在GUI代理框架、数据收集和利用、大型行动模型的定制开发以及评估指标和基准测试等方面。
点此查看论文截图





Towards Agentic AI on Particle Accelerators
Authors:Antonin Sulc, Thorsten Hellert, Raimund Kammering, Hayden Hoschouer, Jason St. John
As particle accelerators grow in complexity, traditional control methods face increasing challenges in achieving optimal performance. This paper envisions a paradigm shift: a decentralized multi-agent framework for accelerator control, powered by Large Language Models (LLMs) and distributed among autonomous agents. We present a proposition of a self-improving decentralized system where intelligent agents handle high-level tasks and communication and each agent is specialized to control individual accelerator components. This approach raises some questions: What are the future applications of AI in particle accelerators? How can we implement an autonomous complex system such as a particle accelerator where agents gradually improve through experience and human feedback? What are the implications of integrating a human-in-the-loop component for labeling operational data and providing expert guidance? We show three examples, where we demonstrate the viability of such architecture.
随着粒子加速器复杂性的增长,传统控制方法在实现最佳性能方面面临越来越大的挑战。本文设想了一种范式转变:一种由大型语言模型(LLM)驱动,分散在自主代理之间的粒子加速器控制去中心化多代理框架。我们提出了一种自我完善的分散系统方案,智能代理处理高级任务和通信,每个代理专门控制单独的加速器组件。这种方法引发了一些问题:AI在粒子加速器中的未来应用是什么?我们如何在粒子加速器等复杂系统中实施自主化,通过经验和人类反馈逐步改进?将人类参与循环组件用于标记操作数据和提供专家指导会有什么影响?我们展示了三个例子,证明了这种架构的可行性。
论文及项目相关链接
PDF 5 pages, 3 figures, Machine Learning and the Physical Sciences at Workshop at the 38th conference on Neural Information Processing Systems (NeurIPS)
总结
随着粒子加速器复杂性增长,传统控制方法面临实现最佳性能的诸多挑战。本文提出了一种范式转变:采用大型语言模型驱动的分散式多智能体框架进行加速器控制。提出了一个自我完善的分散系统,智能体负责高级任务和通信,每个智能体专门控制加速器组件。该架构的可行性通过三个示例进行了展示。该方法的未来应用、如何实现自主复杂系统以及集成人机循环组件的标记操作数据和提供专家指导的意义仍然待解答。
关键见解
- 粒子加速器复杂性增长导致传统控制方法面临挑战。
- 提出了一种基于大型语言模型的分散式多智能体框架进行加速器控制的新范式。
- 智能体负责高级任务和通信,每个智能体专门控制加速器组件。
- 这种新型控制架构的可行性通过三个示例进行了展示。
- 需要探讨该方法的未来应用以及如何实现自主复杂系统的问题。
- 集成人机循环组件以标记操作数据和提供专家指导具有重要意义。
点此查看论文截图




MuMA-ToM: Multi-modal Multi-Agent Theory of Mind
Authors:Haojun Shi, Suyu Ye, Xinyu Fang, Chuanyang Jin, Leyla Isik, Yen-Ling Kuo, Tianmin Shu
Understanding people’s social interactions in complex real-world scenarios often relies on intricate mental reasoning. To truly understand how and why people interact with one another, we must infer the underlying mental states that give rise to the social interactions, i.e., Theory of Mind reasoning in multi-agent interactions. Additionally, social interactions are often multi-modal – we can watch people’s actions, hear their conversations, and/or read about their past behaviors. For AI systems to successfully and safely interact with people in real-world environments, they also need to understand people’s mental states as well as their inferences about each other’s mental states based on multi-modal information about their interactions. For this, we introduce MuMA-ToM, a Multi-modal Multi-Agent Theory of Mind benchmark. MuMA-ToM is the first multi-modal Theory of Mind benchmark that evaluates mental reasoning in embodied multi-agent interactions. In MuMA-ToM, we provide video and text descriptions of people’s multi-modal behavior in realistic household environments. Based on the context, we then ask questions about people’s goals, beliefs, and beliefs about others’ goals. We validated MuMA-ToM in a human experiment and provided a human baseline. We also proposed a novel multi-modal, multi-agent ToM model, LIMP (Language model-based Inverse Multi-agent Planning). Our experimental results show that LIMP significantly outperforms state-of-the-art methods, including large multi-modal models (e.g., GPT-4o, Gemini-1.5 Pro) and a recent multi-modal ToM model, BIP-ALM.
理解人们在复杂的真实世界场景中的社会互动通常依赖于复杂的心理推理。要真正了解人们如何以及为何彼此互动,我们必须推断出导致社会互动的基本心理状态,即多智能体互动中的心智理论推理。此外,社会互动通常是多模态的——我们可以观察人们的行动,聆听他们的对话,并阅读他们的过去行为。要让AI系统在真实世界环境中成功且安全地与人类互动,它们还需要理解人们的心理状态以及基于他们互动的多模态信息对彼此心理状态的推断。为此,我们引入了MuMA-ToM,这是一个多模态多智能体心智理论基准测试。MuMA-ToM是第一个评估有形体多智能体互动中心理推理的多模态心智理论基准测试。在MuMA-ToM中,我们提供了人们在现实家庭环境中的多模态行为的视频和文字描述。然后,我们根据上下文提出关于人们的目标、信念以及关于他人目标信念的问题。我们在人类实验中对MuMA-ToM进行了验证,并提供了人类基准线。我们还提出了一个新颖的多模态多智能体心智理论模型LIMP(基于语言模型的逆向多智能体规划)。我们的实验结果表明,LIMP显著优于最新方法,包括大型多模态模型(例如GPT-4o、Gemini-1.5 Pro)和最新的多模态心智理论模型BIP-ALM。
论文及项目相关链接
PDF Project website: https://scai.cs.jhu.edu/projects/MuMA-ToM/ Code: https://github.com/SCAI-JHU/MuMA-ToM
Summary
MuMA-ToM是第一個多模式心理理论的基准测试,用于评估在身体化的多智能体交互中的心理推理能力。它通过视频和文本描述人们现实家庭环境中的多模式行为,并基于上下文提问人们的目标、信念以及对他人的信念和目标的理解。该测试已经通过人类实验验证,并提出了新的多模式多智能体心理理论模型LIMP,实验结果显示LIMP显著优于其他最新方法。
Key Takeaways
- MuMA-ToM是一个多模式心理理论的基准测试,用于评估多智能体交互中的心理推理能力。
- 它结合了视频和文本描述,展示人们在现实家庭环境中的多模式行为。
- MuMA-ToM基于上下文提问,涉及对人们的目标、信念以及对他人的信念和目标的理解。
- 该测试已经通过人类实验验证,确保测试的有效性和可靠性。
- 提出了一个新的多模式多智能体心理理论模型LIMP。
- LIMP在实验中表现出显著的优势,优于其他最新的心理理论模型。
点此查看论文截图




Bridging Training and Execution via Dynamic Directed Graph-Based Communication in Cooperative Multi-Agent Systems
Authors:Zhuohui Zhang, Bin He, Bin Cheng, Gang Li
Multi-agent systems must learn to communicate and understand interactions between agents to achieve cooperative goals in partially observed tasks. However, existing approaches lack a dynamic directed communication mechanism and rely on global states, thus diminishing the role of communication in centralized training. Thus, we propose the Transformer-based graph coarsening network (TGCNet), a novel multi-agent reinforcement learning (MARL) algorithm. TGCNet learns the topological structure of a dynamic directed graph to represent the communication policy and integrates graph coarsening networks to approximate the representation of global state during training. It also utilizes the Transformer decoder for feature extraction during execution. Experiments on multiple cooperative MARL benchmarks demonstrate state-of-the-art performance compared to popular MARL algorithms. Further ablation studies validate the effectiveness of our dynamic directed graph communication mechanism and graph coarsening networks.
多智能体系统必须学习在部分观测任务中智能体之间的通信和交互,以实现合作目标。然而,现有方法缺乏动态有向通信机制,并依赖于全局状态,从而降低了通信在集中训练中的作用。因此,我们提出了基于Transformer的图粗化网络(TGCNet),这是一种新型的多智能体强化学习(MARL)算法。TGCNet学习动态有向图的拓扑结构来表示通信策略,并集成了图粗化网络来近似训练过程中的全局状态表示。它还利用Transformer解码器在执行过程中的特征提取。在多个合作MARL基准测试上的实验表明,与流行的MARL算法相比,它达到了最先进的性能。进一步的消融研究验证了我们的动态有向图通信机制和图粗化网络的有效性。
论文及项目相关链接
PDF 9 pages, 7 figures
Summary
多智能体系统需要在部分观测任务中学会智能体间的通信与交互,以实现合作目标。现有方法缺乏动态有向通信机制,依赖全局状态,降低了通信在集中训练中的作用。因此,我们提出了基于Transformer的图粗化网络(TGCNet)这一新型多智能体强化学习(MARL)算法。TGCNet学习动态有向图的拓扑结构以表示通信策略,并集成图粗化网络以在训练期间近似全局状态的表示。它还在执行期间使用Transformer解码器进行特征提取。在多个合作MARL基准测试上的实验表明,与流行MARL算法相比,该算法具有最佳性能。进一步的消融研究验证了我们的动态有向图通信机制和图粗化网络的有效性。
Key Takeaways
- 多智能体系统需要学习智能体间的通信和交互,以实现合作目标。
- 现有方法存在缺乏动态有向通信机制的问题。
- TGCNet是一种新型的多智能体强化学习算法,解决了现有方法的问题。
- TGCNet通过学习动态有向图的拓扑结构来表示通信策略。
- TGCNet集成了图粗化网络,在训练期间近似全局状态的表示。
- TGCNet利用Transformer解码器进行特征提取。
点此查看论文截图






mABC: multi-Agent Blockchain-Inspired Collaboration for root cause analysis in micro-services architecture
Authors:Wei Zhang, Hongcheng Guo, Jian Yang, Zhoujin Tian, Yi Zhang, Chaoran Yan, Zhoujun Li, Tongliang Li, Xu Shi, Liangfan Zheng, Bo Zhang
Root cause analysis (RCA) in Micro-services architecture (MSA) with escalating complexity encounters complex challenges in maintaining system stability and efficiency due to fault propagation and circular dependencies among nodes. Diverse root cause analysis faults require multi-agents with diverse expertise. To mitigate the hallucination problem of large language models (LLMs), we design blockchain-inspired voting to ensure the reliability of the analysis by using a decentralized decision-making process. To avoid non-terminating loops led by common circular dependency in MSA, we objectively limit steps and standardize task processing through Agent Workflow. We propose a pioneering framework, multi-Agent Blockchain-inspired Collaboration for root cause analysis in micro-services architecture (mABC), where multiple agents based on the powerful LLMs follow Agent Workflow and collaborate in blockchain-inspired voting. Specifically, seven specialized agents derived from Agent Workflow each provide valuable insights towards root cause analysis based on their expertise and the intrinsic software knowledge of LLMs collaborating within a decentralized chain. Our experiments on the AIOps challenge dataset and a newly created Train-Ticket dataset demonstrate superior performance in identifying root causes and generating effective resolutions. The ablation study further highlights Agent Workflow, multi-agent, and blockchain-inspired voting is crucial for achieving optimal performance. mABC offers a comprehensive automated root cause analysis and resolution in micro-services architecture and significantly improves the IT Operation domain. The code and dataset are in https://github.com/zwpride/mABC.
在微服务架构(MSA)中进行根本原因分析(RCA)时,随着复杂性不断升级,由于故障传播和节点之间的循环依赖,维护系统稳定性和效率会遇到复杂的挑战。多样的根本原因分析故障需要具有多种专长的多智能体。为了解决大型语言模型(LLM)的幻想问题,我们设计了基于区块链的投票机制,以确保通过分散决策过程进行分析的可靠性。为了避免由MSA中常见的循环依赖导致的无法终止的循环,我们通过Agent工作流程客观地限制步骤并标准化任务处理。我们提出了一个开创性的框架——用于微服务架构中进行根本原因分析的多智能体区块链启发协作(mABC),其中基于强大LLM的多个智能体遵循Agent工作流程,并以区块链启发投票的方式进行协作。具体来说,从Agent工作流程中派生的七个专业智能体根据其专业知识和LLM的内在软件知识为根本原因分析提供有价值的见解,并在分散的链中进行协作。我们在AIOps挑战数据集和全新创建的Train-Ticket数据集上的实验表明,在识别根本原因和产生有效解决方案方面表现出卓越的性能。消融研究进一步强调了Agent工作流程、多智能体和区块链启发投票对于实现最佳性能至关重要。mABC为微服务架构提供了全面的自动化根本原因分析和解决方案,并显著改进了IT运营领域。代码和数据集位于https://github.com/zwpride/mABC。
论文及项目相关链接
Summary
在微服务架构中进行根本原因分析的复杂性不断升级,面临维护系统稳定性和效率的复杂挑战,如故障传播和节点间的循环依赖问题。为解决大型语言模型的幻觉问题,设计了一种采用区块链投票机制的方法,以确保分析的可靠性。为避免微服务架构中的非终止循环,客观地限制了步骤并标准化了任务处理流程。提出一种开创性的框架mABC,利用基于强大语言模型的多个代理遵循代理工作流程并在区块链投票中协作进行根本原因分析。实验表明,mABC在识别根本原因和生成有效解决方案方面表现出卓越性能。
Key Takeaways
- 微服务架构中的根本原因分析面临复杂挑战,如故障传播和循环依赖问题。
- 需要采用多代理进行根本原因分析来解决多样化的错误问题。
- 利用区块链投票机制来解决大型语言模型的幻觉问题,确保分析的可靠性。
- 提出mABC框架,包含基于区块链的多代理协作,能在微服务架构中进行高效和可靠的根本原因分析与解决。
- 通过实验验证了mABC框架在识别根本原因和解决方案上的优越性能。
- 客观限制了解决步骤并标准化了任务处理流程以避免非终止循环的问题。
点此查看论文截图