⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-25 更新
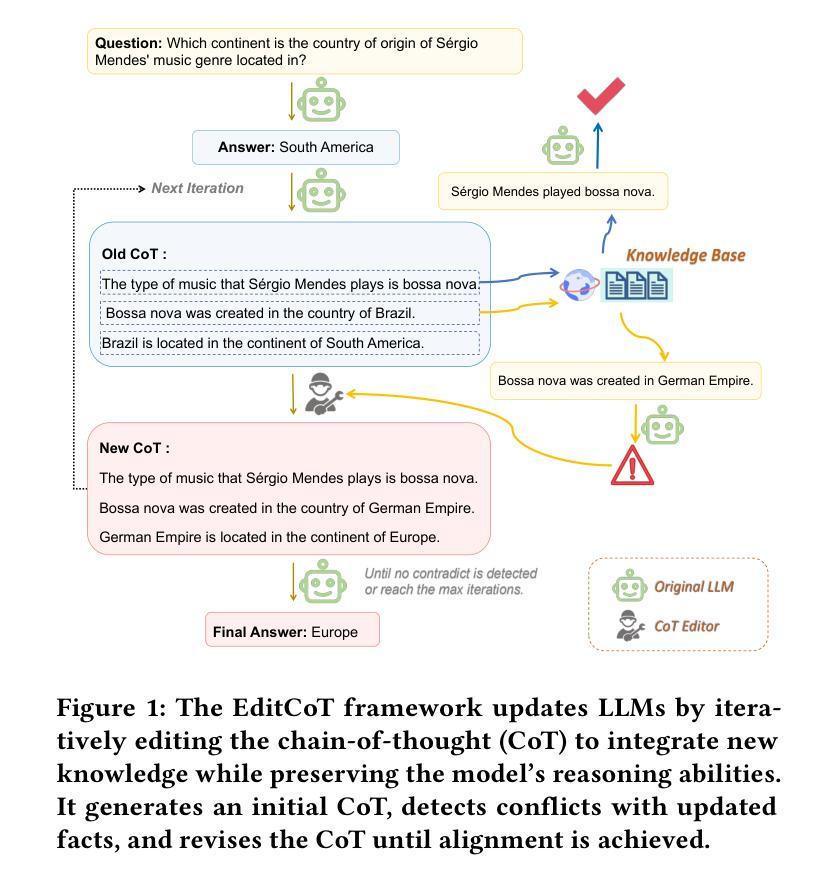
Knowledge Editing through Chain-of-Thought
Authors:Changyue Wang, Weihang Su, Qingyao Ai, Yiqun Liu
Large Language Models (LLMs) have demonstrated exceptional capabilities across a wide range of natural language processing (NLP) tasks. However, keeping these models up-to-date with evolving world knowledge remains a significant challenge due to the high costs of frequent retraining. To address this challenge, knowledge editing techniques have emerged to update LLMs with new information without rebuilding the model from scratch. Among these, the in-context editing paradigm stands out for its effectiveness in integrating new knowledge while preserving the model’s original capabilities. Despite its potential, existing in-context knowledge editing methods are often task-specific, focusing primarily on multi-hop QA tasks using structured knowledge triples. Moreover, their reliance on few-shot prompting for task decomposition makes them unstable and less effective in generalizing across diverse tasks. In response to these limitations, we propose EditCoT, a novel knowledge editing framework that flexibly and efficiently updates LLMs across various tasks without retraining. EditCoT works by generating a chain-of-thought (CoT) for a given input and then iteratively refining this CoT process using a CoT editor based on updated knowledge. We evaluate EditCoT across a diverse range of benchmarks, covering multiple languages and tasks. The results demonstrate that our approach achieves state-of-the-art performance while offering superior generalization, effectiveness, and stability compared to existing methods, marking a significant advancement in the field of knowledge updating. Code and data are available at: https://github.com/bebr2/EditCoT.
大型语言模型(LLM)已在广泛的自然语言处理(NLP)任务中展现出卓越的能力。然而,由于重新训练的高成本,随着世界知识的不断发展,如何保持这些模型的最新状态仍然是一个巨大的挑战。为了应对这一挑战,知识编辑技术应运而生,可以在不重建模型的情况下更新LLM的新信息。其中,上下文编辑范式因其在新知识集成的同时保留模型原始能力而脱颖而出。尽管具有潜力,但现有的上下文知识编辑方法往往是针对特定任务的,主要侧重于使用结构化知识三元组的多跳问答任务。此外,它们对少量提示的任务分解的依赖,使得它们在跨不同任务泛化时变得不稳定且效果较差。针对这些局限性,我们提出了EditCoT,这是一个灵活高效的知识编辑框架,可在各种任务中更新LLM而无需重新训练。EditCoT通过为给定输入生成思维链(CoT),然后使用基于最新知识的CoT编辑器迭代优化此思维链过程。我们在涵盖多种语言和任务的多种基准测试上评估了EditCoT。结果表明,我们的方法达到了最先进的性能,与现有方法相比,在泛化能力、有效性和稳定性方面表现出优势,标志着知识更新领域的一个重大进展。相关代码和数据可在:https://github.com/bebr2/EditCoT获取。
论文及项目相关链接
摘要
大型语言模型(LLM)在自然语言处理(NLP)任务中表现出卓越的能力,但如何使这些模型跟上不断发展的世界知识是一个巨大的挑战,因为频繁再训练的成本很高。为了应对这一挑战,出现了知识编辑技术,可以在不重建模型的情况下更新LLM的新信息。其中,上下文编辑范式因其整合新知识的同时保留模型的原始能力而备受关注。然而,现有的上下文知识编辑方法往往是针对特定任务的,主要集中在使用结构化知识三元组的多跳问答任务上。而且,它们对少数案例提示的任务分解的依赖,使它们在跨不同任务的通用性方面表现不稳定且效果较差。针对这些局限性,我们提出了EditCoT,一个灵活高效的知识编辑框架,可在各种任务中更新LLM而无需重新训练。EditCoT通过为给定输入生成思维链(CoT),然后使用基于更新知识的CoT编辑器迭代优化这个思维过程。我们在涵盖多种语言和任务的广泛基准上评估了EditCoT。结果表明,我们的方法在实现最新性能的同时,在通用性、有效性和稳定性方面相比现有方法具有优势,标志着知识更新领域的一个重大进展。
关键见解
- 大型语言模型(LLMs)在自然语言处理(NLP)中的卓越性能以及更新模型以跟上世界知识发展的挑战。
- 知识编辑技术的兴起,使得能够在不重建模型的情况下更新LLM的新信息。
- 上下文编辑范式的优势在于整合新知识的同时保留模型的原始能力。
- 现有上下文知识编辑方法的局限性,如任务特定性以及对少数案例提示的依赖,导致跨任务通用性不足。
- EditCoT知识编辑框架的提出,旨在灵活、高效地在各种任务中更新LLM,而无需重新训练。
- EditCoT通过生成并优化给定输入的思维链(CoT)来工作,使用基于更新知识的CoT编辑器。
- 在多个语言和任务的广泛基准上的评估表明,EditCoT实现了最新性能,并在通用性、有效性和稳定性方面优于现有方法。
点此查看论文截图

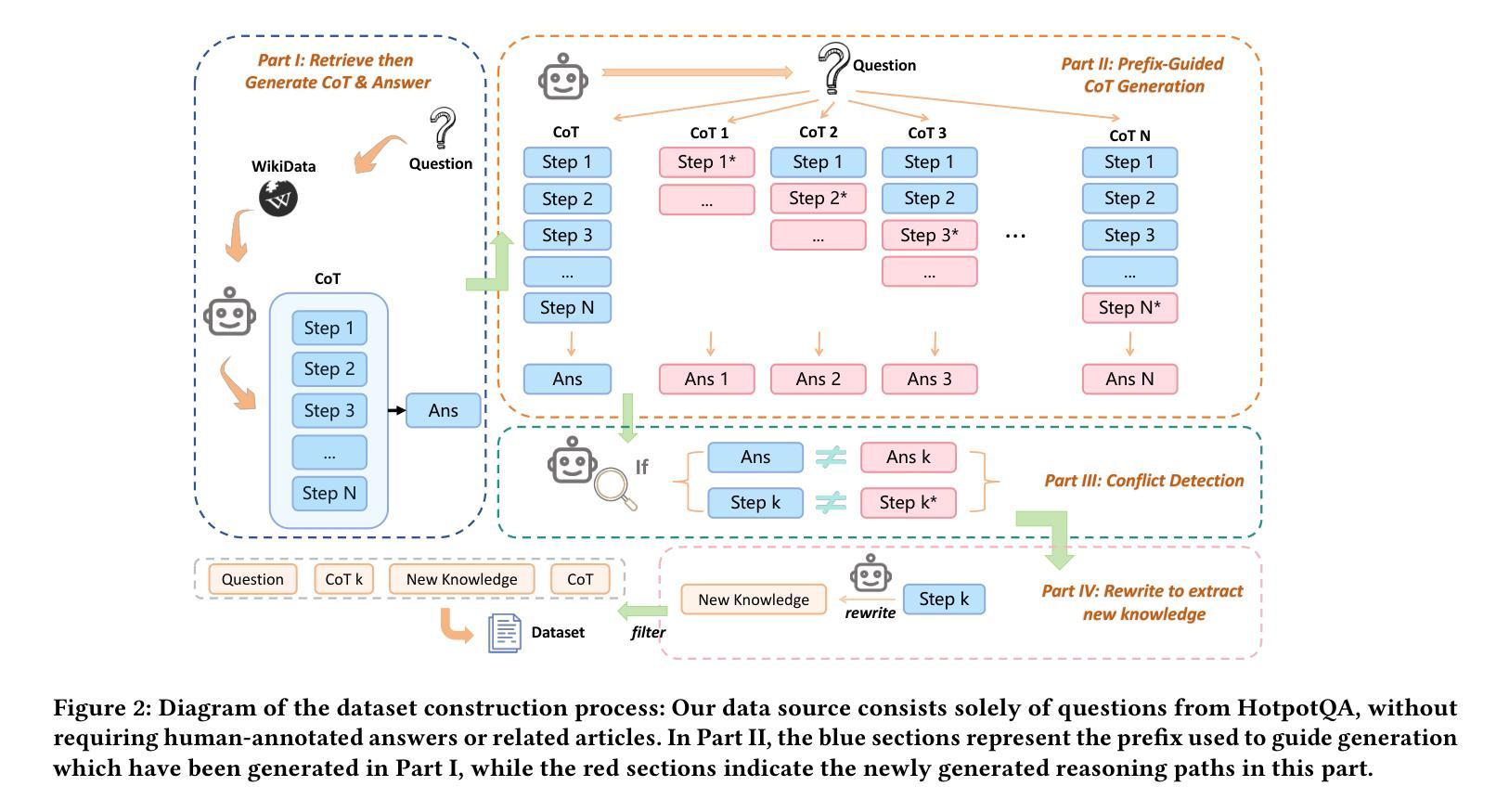

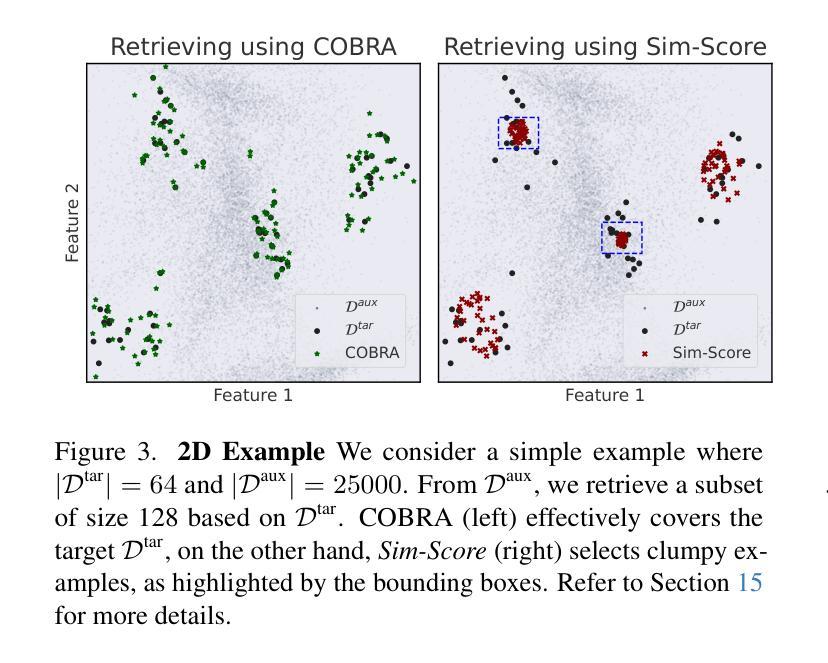
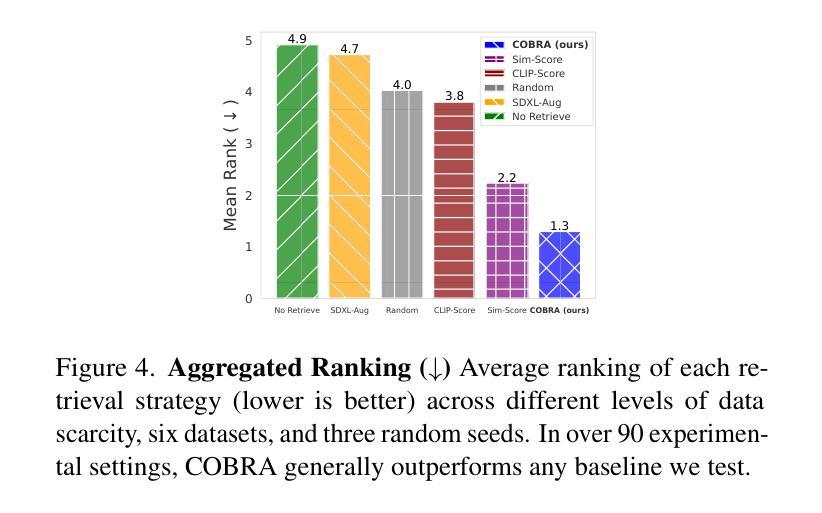
COBRA: COmBinatorial Retrieval Augmentation for Few-Shot Learning
Authors:Arnav M. Das, Gantavya Bhatt, Lilly Kumari, Sahil Verma, Jeff Bilmes
Retrieval augmentation, the practice of retrieving additional data from large auxiliary pools, has emerged as an effective technique for enhancing model performance in the low-data regime, e.g. few-shot learning. Prior approaches have employed only nearest-neighbor based strategies for data selection, which retrieve auxiliary samples with high similarity to instances in the target task. However, these approaches are prone to selecting highly redundant samples, since they fail to incorporate any notion of diversity. In our work, we first demonstrate that data selection strategies used in prior retrieval-augmented few-shot learning settings can be generalized using a class of functions known as Combinatorial Mutual Information (CMI) measures. We then propose COBRA (COmBinatorial Retrieval Augmentation), which employs an alternative CMI measure that considers both diversity and similarity to a target dataset. COBRA consistently outperforms previous retrieval approaches across image classification tasks and few-shot learning techniques when used to retrieve samples from LAION-2B. COBRA introduces negligible computational overhead to the cost of retrieval while providing significant gains in downstream model performance.
检索增强(retrieval augmentation)是通过从大型辅助池中检索额外数据来提高低数据环境下模型性能的一种有效技术,例如在少样本学习(few-shot learning)中。先前的方法仅采用基于最近邻的策略进行数据选择,即检索与目标任务实例高度相似的辅助样本。然而,这些方法容易选择高度重复的样本,因为它们没有融入多样性的概念。在我们的工作中,我们首先证明在先前检索增强少样本学习的数据选择策略可以通过一类称为组合互信息(Combinatorial Mutual Information,CMI)度量的函数进行概括。然后,我们提出COBRA(组合检索增强,COmBinatorial Retrieval Augmentation),它采用一种替代的CMI度量方法,同时考虑多样性和对目标数据集的相似性。在LAION-2B的样本检索中,COBRA在图像分类任务和少样本学习技术方面始终优于先前的检索方法。COBRA在检索过程中增加了微不足道的计算开销,同时为下游模型性能提供了显著的改进。
论文及项目相关链接
Summary
数据增强检索已成为提高低数据环境下模型性能的有效技术,特别是在小样本学习领域。过去的方法仅使用基于最近邻的数据选择策略,倾向于选择与目标任务高度相似的辅助样本。然而,这种方法易选取冗余样本,忽略了多样性。本研究通过组合互信息(CMI)度量方法,泛化数据选择策略,并提出COBRA(组合检索增强)。COBRA采用考虑多样性和与目标数据集相似性的新型CMI度量方式,在图像分类任务和小样本学习技术中均表现出对之前检索方法的优越性。它带来的计算开销微乎其微,但对下游模型性能的提升显著。
Key Takeaways
- 检索增强已成为提高模型在低数据环境下性能的有效手段,特别是在小样本学习领域。
- 过去的方法主要基于最近邻策略选择数据,这可能导致选取的样本高度冗余。
- 本研究通过组合互信息(CMI)度量方法泛化数据选择策略。
- COBRA是一种新型检索增强方法,考虑了多样性和与目标数据集的相似性。
- COBRA在图像分类任务和小样本学习技术中均优于之前的检索方法。
- COBRA带来的计算开销很小。
点此查看论文截图


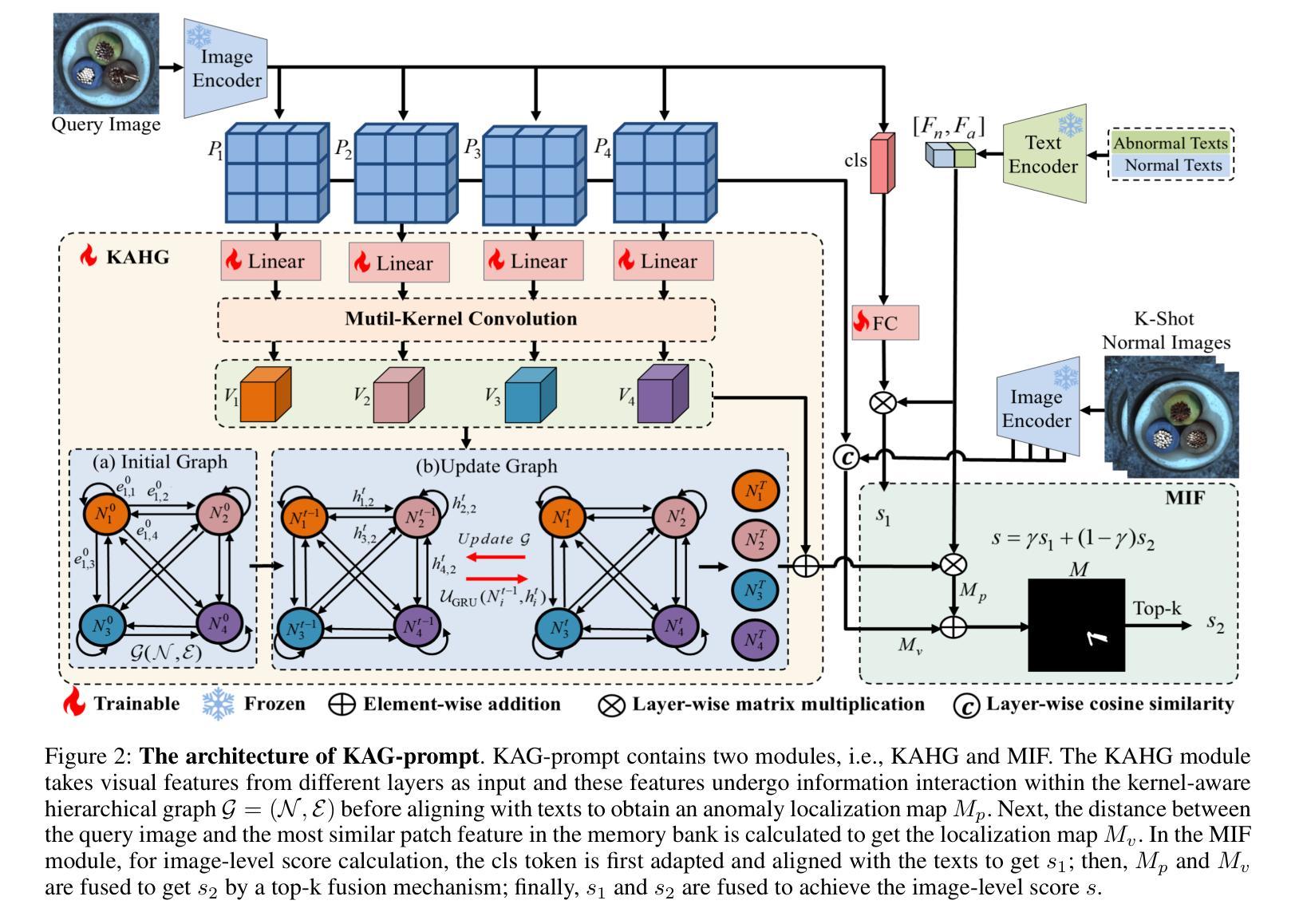
Kernel-Aware Graph Prompt Learning for Few-Shot Anomaly Detection
Authors:Fenfang Tao, Guo-Sen Xie, Fang Zhao, Xiangbo Shu
Few-shot anomaly detection (FSAD) aims to detect unseen anomaly regions with the guidance of very few normal support images from the same class. Existing FSAD methods usually find anomalies by directly designing complex text prompts to align them with visual features under the prevailing large vision-language model paradigm. However, these methods, almost always, neglect intrinsic contextual information in visual features, e.g., the interaction relationships between different vision layers, which is an important clue for detecting anomalies comprehensively. To this end, we propose a kernel-aware graph prompt learning framework, termed as KAG-prompt, by reasoning the cross-layer relations among visual features for FSAD. Specifically, a kernel-aware hierarchical graph is built by taking the different layer features focusing on anomalous regions of different sizes as nodes, meanwhile, the relationships between arbitrary pairs of nodes stand for the edges of the graph. By message passing over this graph, KAG-prompt can capture cross-layer contextual information, thus leading to more accurate anomaly prediction. Moreover, to integrate the information of multiple important anomaly signals in the prediction map, we propose a novel image-level scoring method based on multi-level information fusion. Extensive experiments on MVTecAD and VisA datasets show that KAG-prompt achieves state-of-the-art FSAD results for image-level/pixel-level anomaly detection. Code is available at https://github.com/CVL-hub/KAG-prompt.git.
少样本异常检测(FSAD)旨在利用同一类别中少量的正常支持图像来检测未见过的异常区域。现有的FSAD方法通常通过直接设计复杂的文本提示来与流行的视觉语言模型范式下的视觉特征对齐来发现异常。然而,这些方法几乎总是忽略了视觉特征中的内在上下文信息,例如不同视觉层之间的交互关系,这是全面检测异常的重要线索。为此,我们提出了一个核心感知图提示学习框架,称为KAG-prompt,通过推理视觉特征之间的跨层关系来进行FSAD。具体来说,以关注不同大小异常区域的不同层特征作为节点,构建了一个核心感知分层图,同时,任意节点对之间的关系代表图的边。通过在此图上进行消息传递,KAG-prompt可以捕获跨层上下文信息,从而实现更准确的异常预测。此外,为了整合预测图中多个重要异常信号的信息,我们提出了一种基于多层次信息融合的新型图像级评分方法。在MVTecAD和VisA数据集上的大量实验表明,KAG-prompt在图像级/像素级的异常检测中达到了最新的FSAD结果。代码可访问:https://github.com/CVLhub/KAG-prompt.git。
论文及项目相关链接
PDF Accepted to AAAI 2025
Summary
本文提出了一个基于跨层关系推理的面向小样本异常检测的核感知图提示学习框架(KAG-prompt)。该框架构建了一个以不同层特征为基础的核感知层次图,能有效捕捉异常区域的跨层上下文信息,进而提高异常检测的准确性。此外,本文还提出了一种基于多层次信息融合的新图像级评分方法,用于整合预测图中的多个重要异常信号。实验表明,KAG-prompt在MVTecAD和VisA数据集上实现了最先进的图像级和像素级异常检测结果。
Key Takeaways
- KAG-prompt是一个面向小样本异常检测的核感知图提示学习框架。
- 通过构建核感知层次图,KAG-prompt能捕捉跨层上下文信息,以提高异常检测准确性。
- 该框架采用多层次信息融合的方法,整合预测图中的多个重要异常信号。
- KAG-prompt在MVTecAD和VisA数据集上实现了最先进的图像级和像素级异常检测结果。
点此查看论文截图

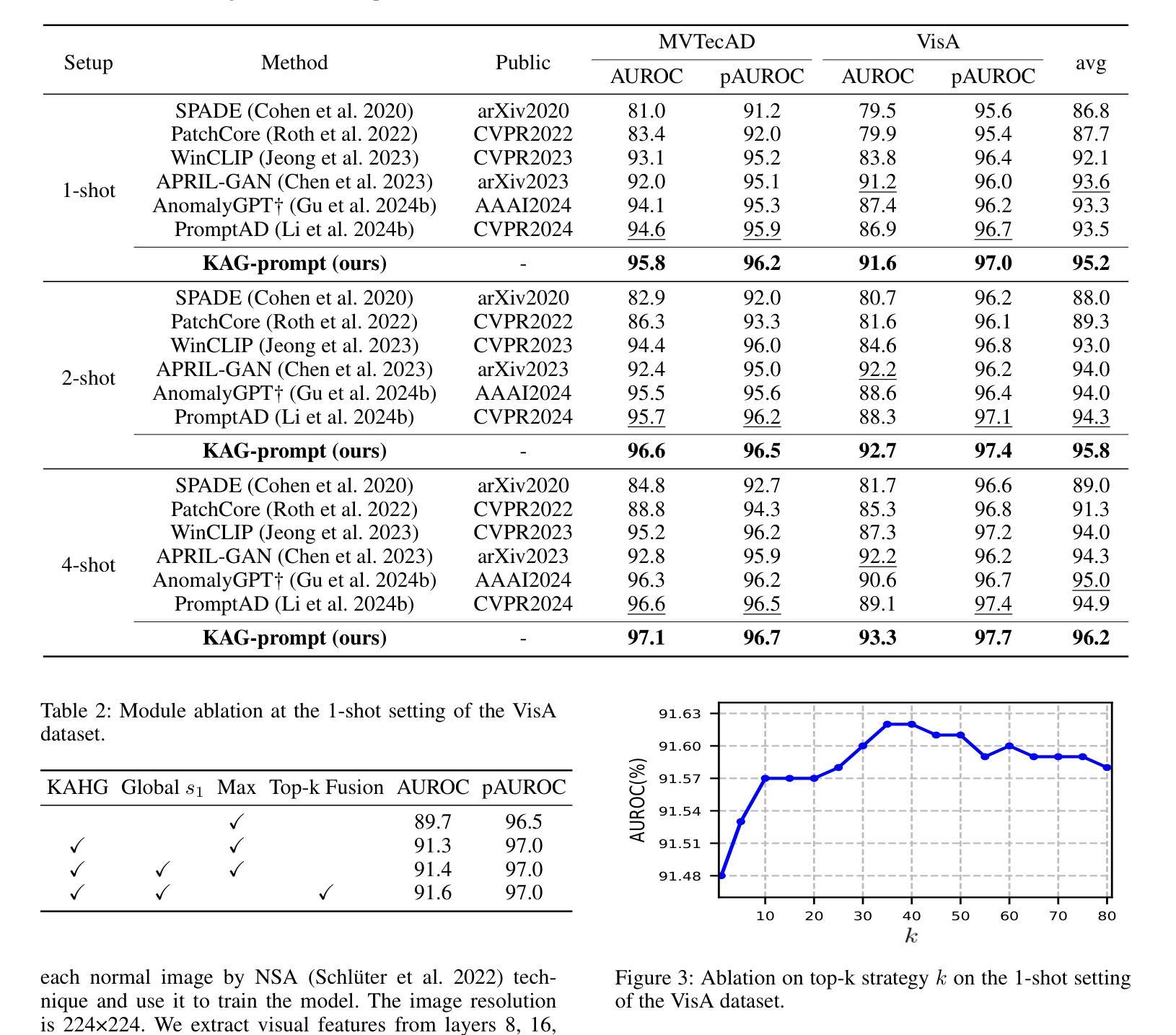
AFANet: Adaptive Frequency-Aware Network for Weakly-Supervised Few-Shot Semantic Segmentation
Authors:Jiaqi Ma, Guo-Sen Xie, Fang Zhao, Zechao Li
Few-shot learning aims to recognize novel concepts by leveraging prior knowledge learned from a few samples. However, for visually intensive tasks such as few-shot semantic segmentation, pixel-level annotations are time-consuming and costly. Therefore, in this paper, we utilize the more challenging image-level annotations and propose an adaptive frequency-aware network (AFANet) for weakly-supervised few-shot semantic segmentation (WFSS). Specifically, we first propose a cross-granularity frequency-aware module (CFM) that decouples RGB images into high-frequency and low-frequency distributions and further optimizes semantic structural information by realigning them. Unlike most existing WFSS methods using the textual information from the multi-modal language-vision model, e.g., CLIP, in an offline learning manner, we further propose a CLIP-guided spatial-adapter module (CSM), which performs spatial domain adaptive transformation on textual information through online learning, thus providing enriched cross-modal semantic information for CFM. Extensive experiments on the Pascal-5\textsuperscript{i} and COCO-20\textsuperscript{i} datasets demonstrate that AFANet has achieved state-of-the-art performance. The code is available at https://github.com/jarch-ma/AFANet.
少量学习旨在通过从少量样本中学习到的先验知识来识别新概念。然而,对于视觉密集型任务(如少量语义分割)而言,像素级注释既耗时又成本高昂。因此,本文采用更具挑战性的图像级注释,并提出一种自适应频率感知网络(AFANet)用于弱监督少量语义分割(WFSS)。具体来说,我们首先提出一种跨粒度频率感知模块(CFM),该模块将RGB图像分解为高频和低频分布,并通过重新对齐进一步优化语义结构信息。与大多数现有使用多模态语言视觉模型的文本信息的WFSS方法不同(例如CLIP离线学习方式),我们进一步提出一个CLIP引导的空间适配器模块(CSM),该模块通过在线学习对文本信息进行空间域自适应转换,从而为CFM提供丰富的跨模态语义信息。在Pascal-5i和COCO-20i数据集上的大量实验表明,AFANet已经达到了业界最先进的性能。代码可在https://github.com/jarch-ma/AFANet找到。
论文及项目相关链接
Summary
本文介绍了针对弱监督少样本语义分割(WFSS)问题,利用图像级标注信息,提出了一种自适应频率感知网络(AFANet)。该网络包括一个跨粒度频率感知模块(CFM),可将图像分解为高频和低频分布,并重新对齐语义结构信息。此外,还提出了一种CLIP引导的空间适配器模块(CSM),通过在线学习方式对文本信息进行空间域自适应转换,为CFM提供丰富的跨模态语义信息。在Pascal-5i和COCO-20i数据集上的实验表明,AFANet达到了最先进的性能。
Key Takeaways
- 少样本学习旨在通过从少量样本中学习到的先验知识来识别新概念。
- 针对视觉密集型任务如少样本语义分割,像素级标注是耗时且昂贵的。
- 本文利用更具挑战性的图像级标注信息,提出自适应频率感知网络(AFANet)进行弱监督少样本语义分割。
- AFANet包括跨粒度频率感知模块(CFM),可将图像分解为高频和低频分布,并优化语义结构信息。
- 与大多数使用离线学习方式的多模态语言视觉模型不同,本文提出了CLIP引导的空间适配器模块(CSM),通过在线学习方式对文本信息进行空间域自适应转换。
- 实验结果表明,AFANet在Pascal-5i和COCO-20i数据集上达到了最先进的性能。
点此查看论文截图

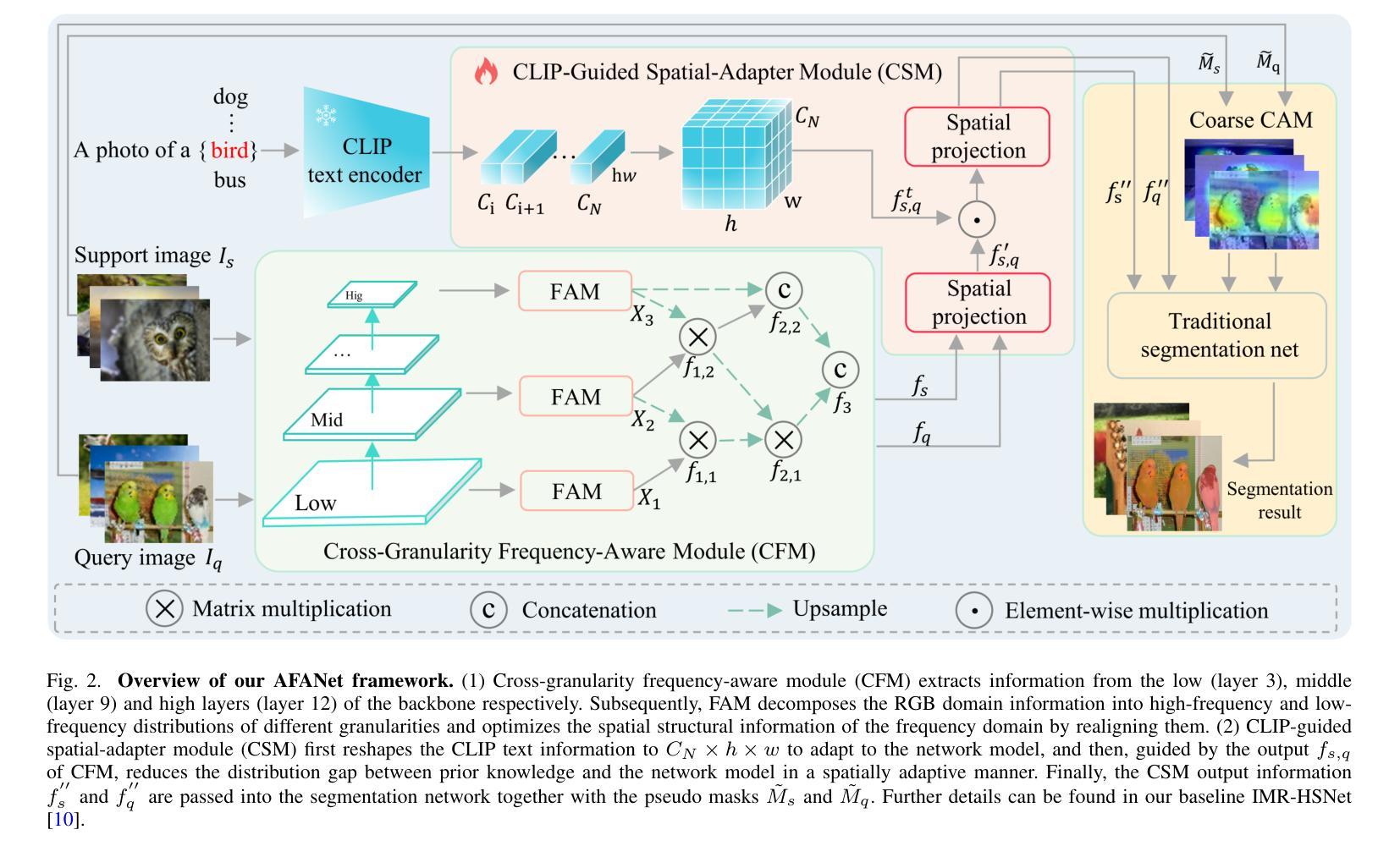
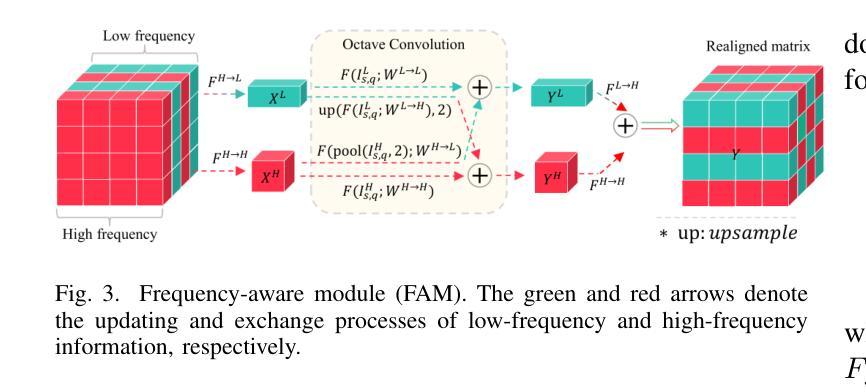

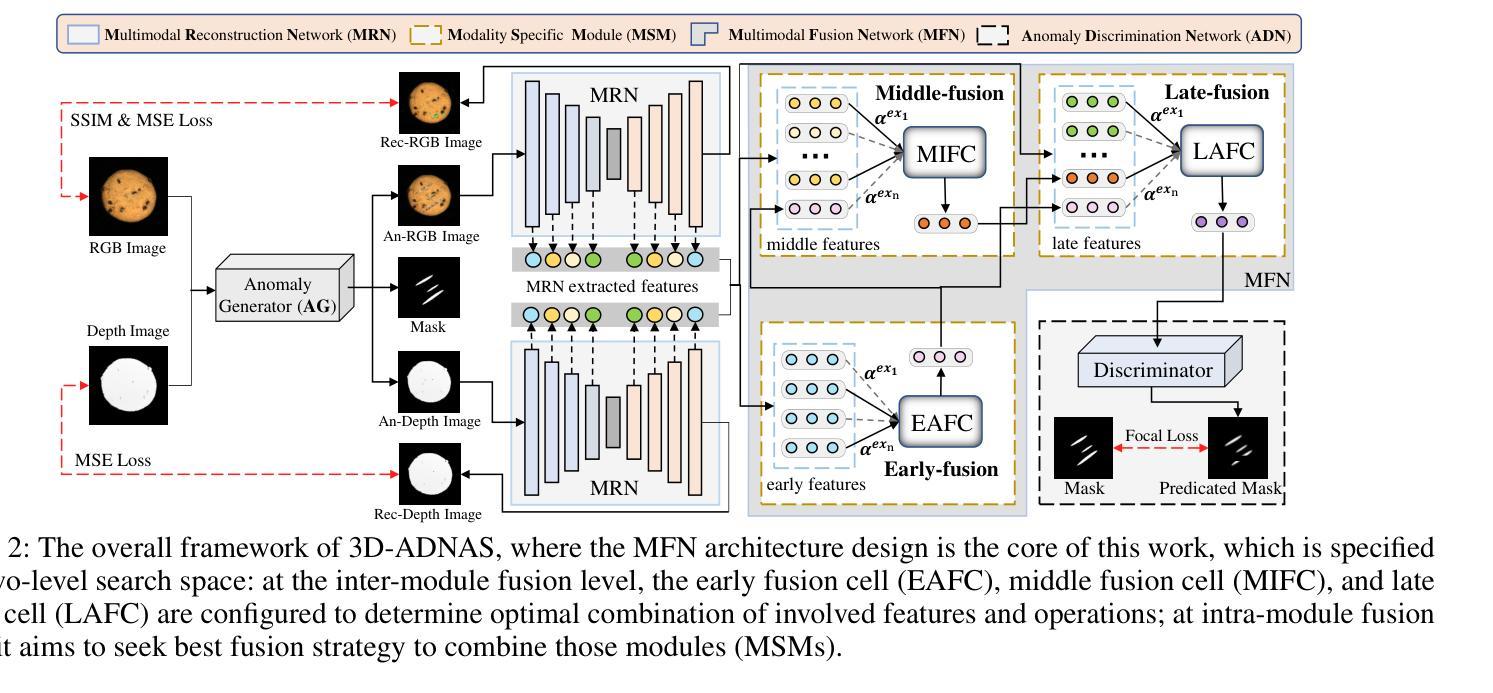
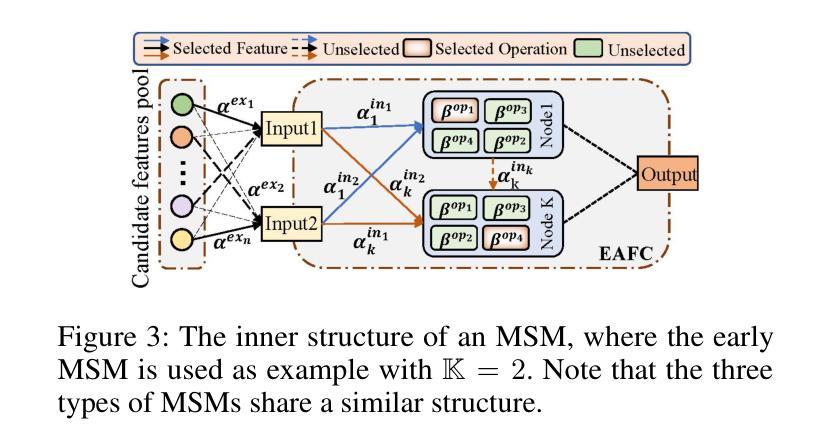
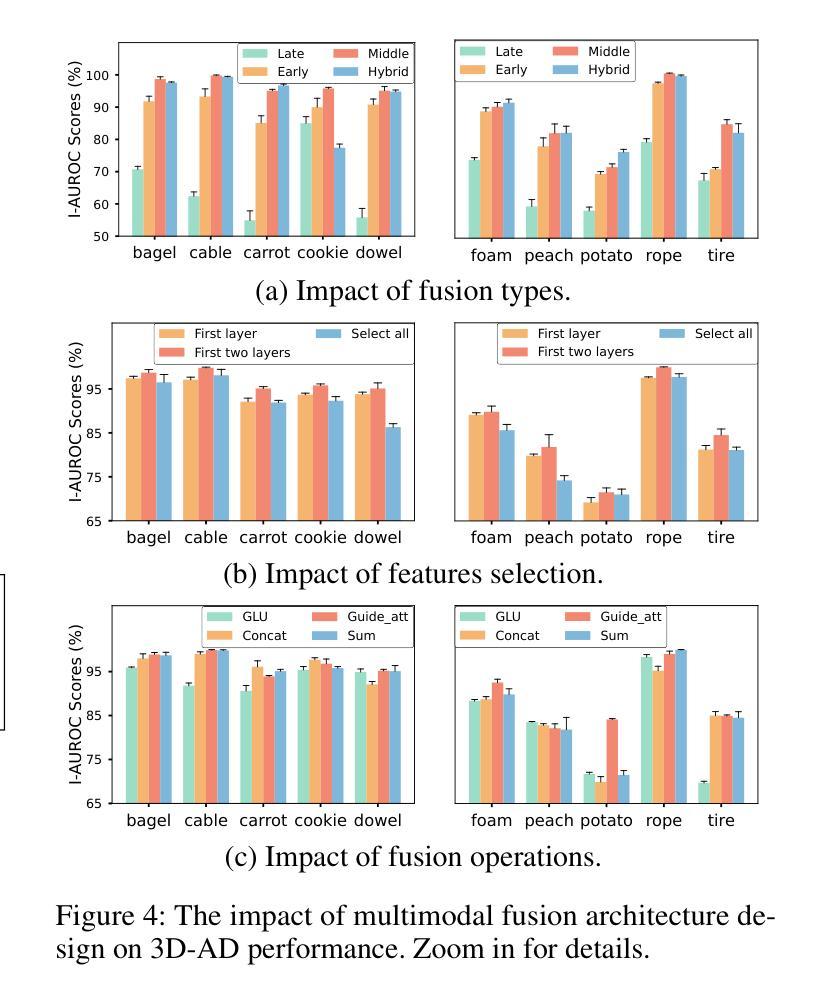
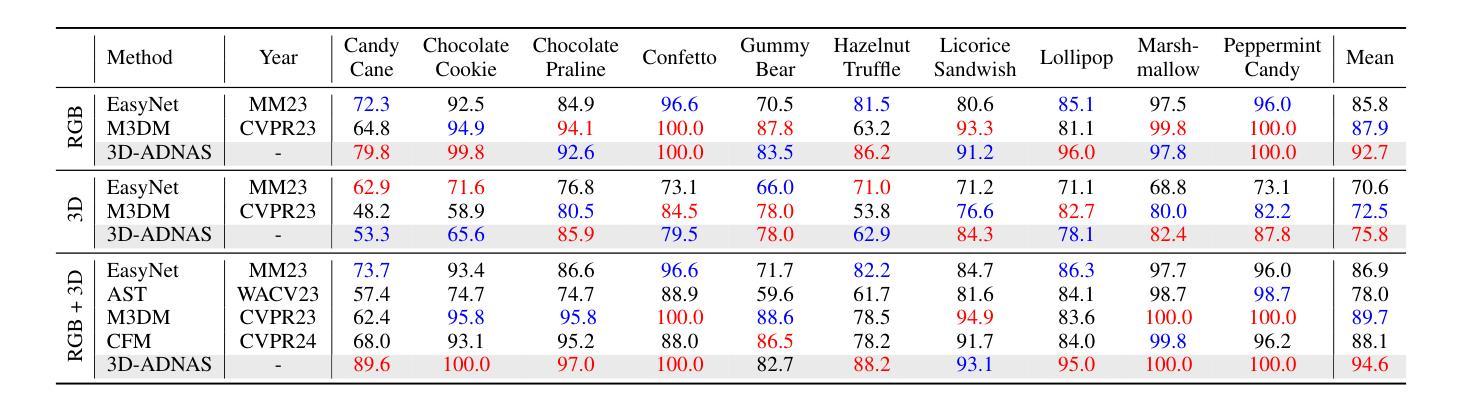
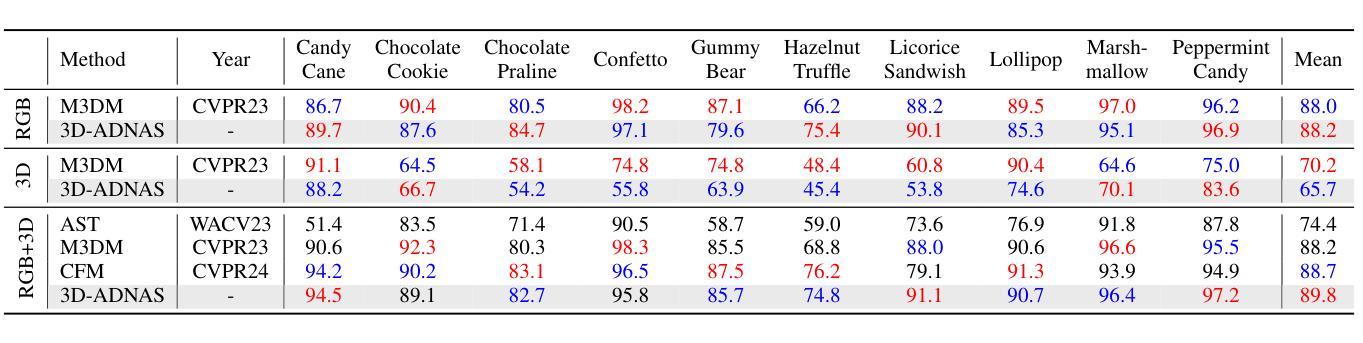
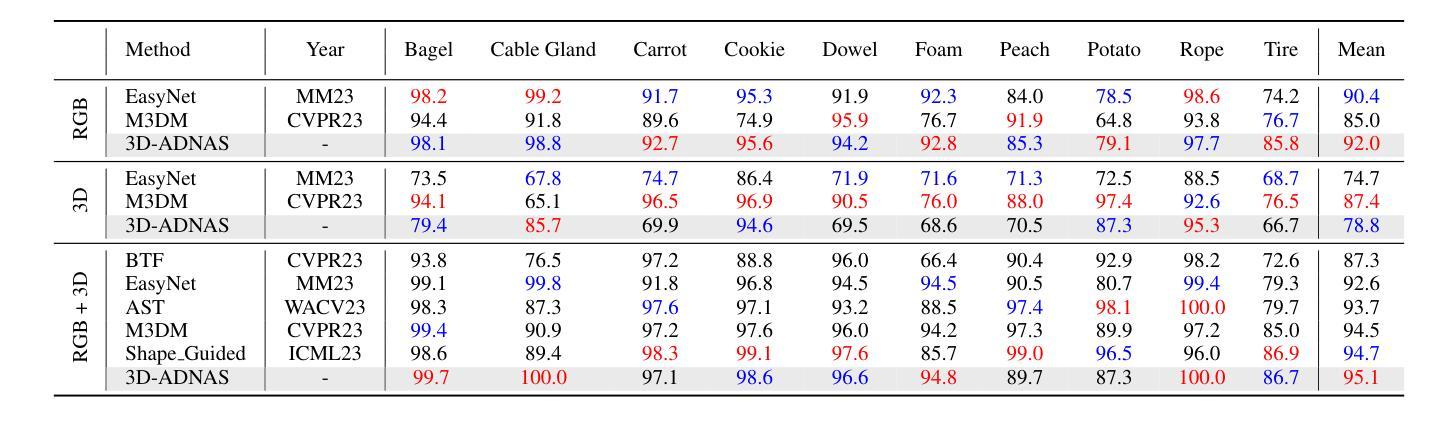
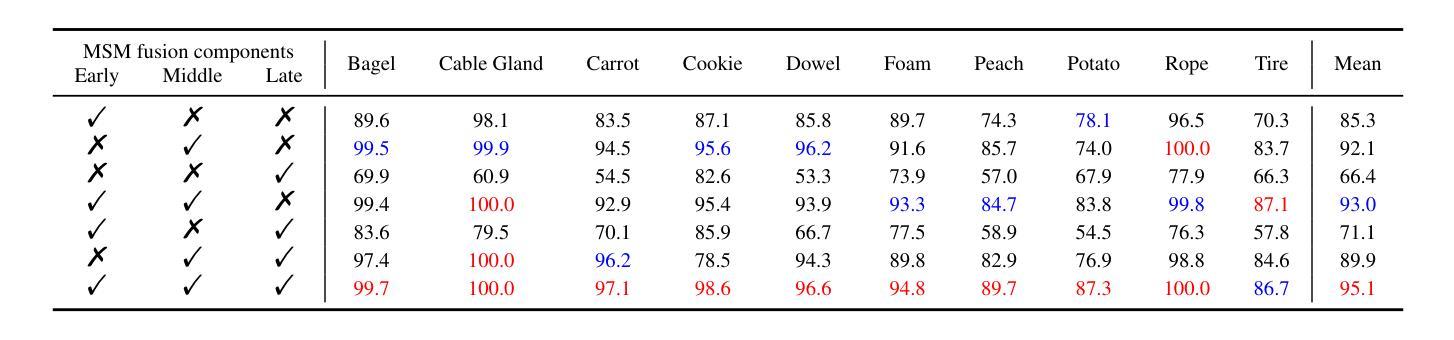
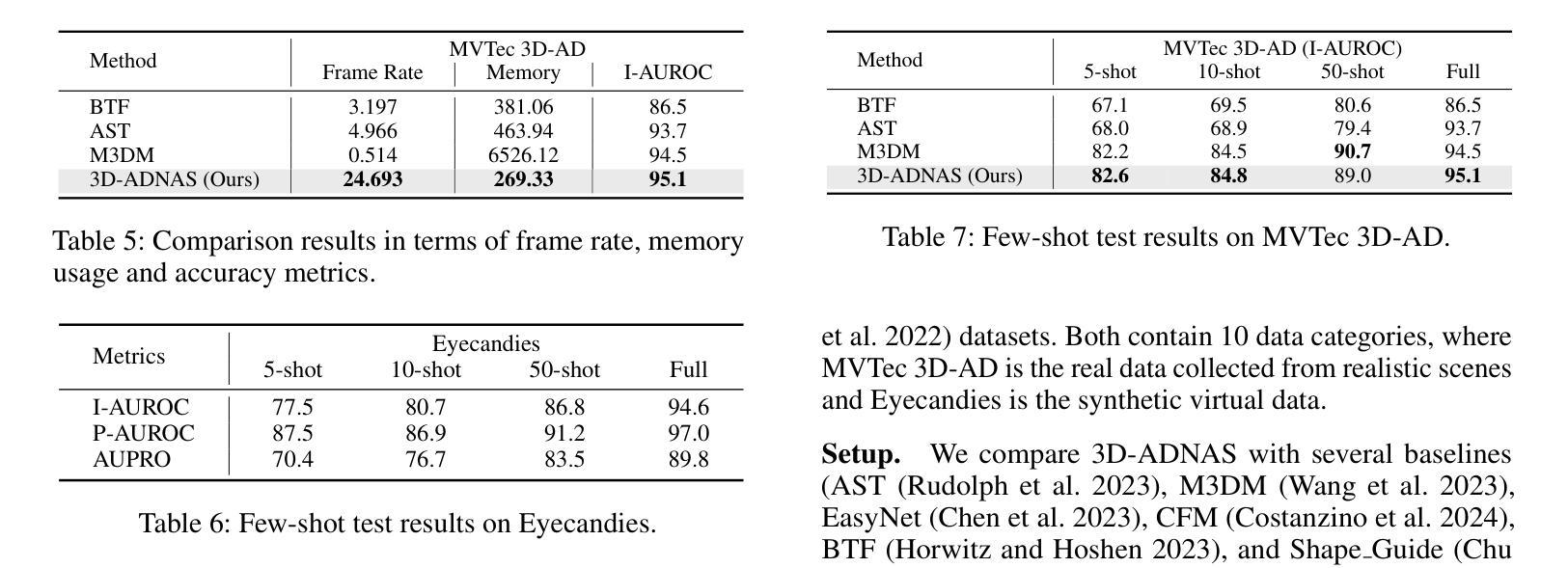
Revisiting Multimodal Fusion for 3D Anomaly Detection from an Architectural Perspective
Authors:Kaifang Long, Guoyang Xie, Lianbo Ma, Jiaqi Liu, Zhichao Lu
Existing efforts to boost multimodal fusion of 3D anomaly detection (3D-AD) primarily concentrate on devising more effective multimodal fusion strategies. However, little attention was devoted to analyzing the role of multimodal fusion architecture (topology) design in contributing to 3D-AD. In this paper, we aim to bridge this gap and present a systematic study on the impact of multimodal fusion architecture design on 3D-AD. This work considers the multimodal fusion architecture design at the intra-module fusion level, i.e., independent modality-specific modules, involving early, middle or late multimodal features with specific fusion operations, and also at the inter-module fusion level, i.e., the strategies to fuse those modules. In both cases, we first derive insights through theoretically and experimentally exploring how architectural designs influence 3D-AD. Then, we extend SOTA neural architecture search (NAS) paradigm and propose 3D-ADNAS to simultaneously search across multimodal fusion strategies and modality-specific modules for the first time.Extensive experiments show that 3D-ADNAS obtains consistent improvements in 3D-AD across various model capacities in terms of accuracy, frame rate, and memory usage, and it exhibits great potential in dealing with few-shot 3D-AD tasks.
现有的促进3D异常检测(3D-AD)的多模态融合工作主要集中在设计更有效的多模态融合策略上。然而,很少有人关注多模态融合架构(拓扑)设计对3D-AD的贡献。本文旨在填补这一空白,并系统地研究了多模态融合架构设计对3D-AD的影响。这项工作考虑了模块内部融合层面的多模态融合架构设计,即独立的模态特定模块,涉及早期、中期或晚期的多模态特征以及特定的融合操作,还考虑了模块间融合层面的策略,即融合这些模块的方法。在这两种情况下,我们首先要通过理论和实验探索架构设计如何影响3D-AD,从而获得启示。然后,我们扩展了最先进的神经网络架构搜索(NAS)范式,首次提出了用于同时搜索多模态融合策略和模态特定模块的3D-ADNAS。大量实验表明,在准确性、帧速率和内存使用方面,3D-ADNAS在多种模型容量的3D-AD中取得了持续的改进,并且在处理少样本的3D-AD任务方面表现出巨大的潜力。
论文及项目相关链接
Summary
本文旨在填补现有研究中关于多模态融合架构对三维异常检测(3D-AD)影响研究的空白。文章对多模态融合架构的设计进行了深入研究,涵盖了模块内部和模块间的融合策略。同时,提出了改进的神经架构搜索(NAS)方法,用于同时搜索多模态融合策略和模态特定模块。实验表明,新方法在多种模型容量下提高了三维异常检测的准确性、帧率和内存使用率,并在处理少量样本的三维异常检测任务中展现出巨大潜力。
Key Takeaways
- 文章重点关注多模态融合架构对三维异常检测(3D-AD)的影响,这是现有研究的空白领域。
- 研究涉及模块内部和模块间的多模态融合策略。
- 提出改进的神经架构搜索(NAS)方法,即3D-ADNAS,可同时搜索多模态融合策略和模态特定模块。
- 通过理论分析和实验验证,揭示了多模态融合架构对三维异常检测的影响。
- 3D-ADNAS方法在不同模型容量下均能提高三维异常检测的准确性、帧率和内存使用率。
- 该方法在少量样本的三维异常检测任务中展现出巨大潜力。
点此查看论文截图
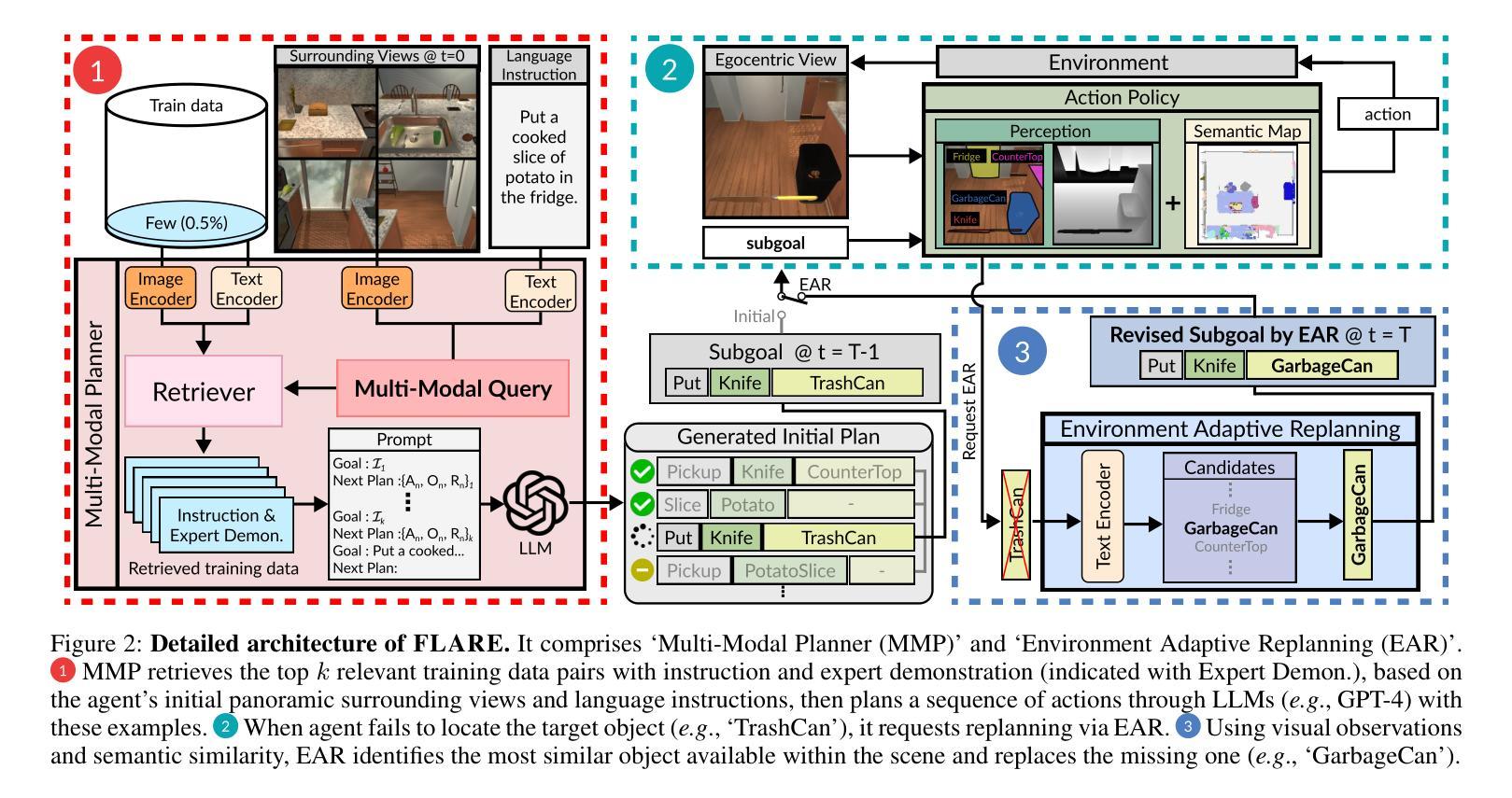
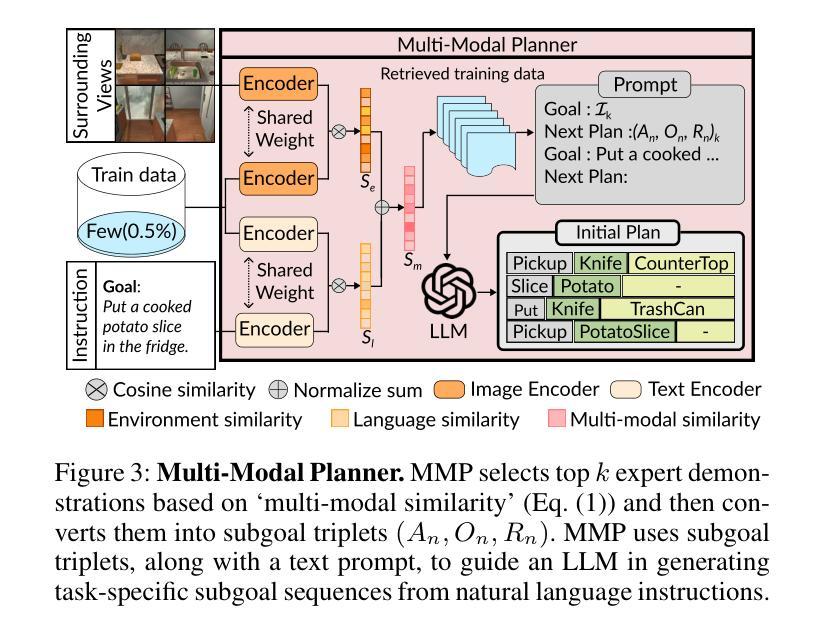
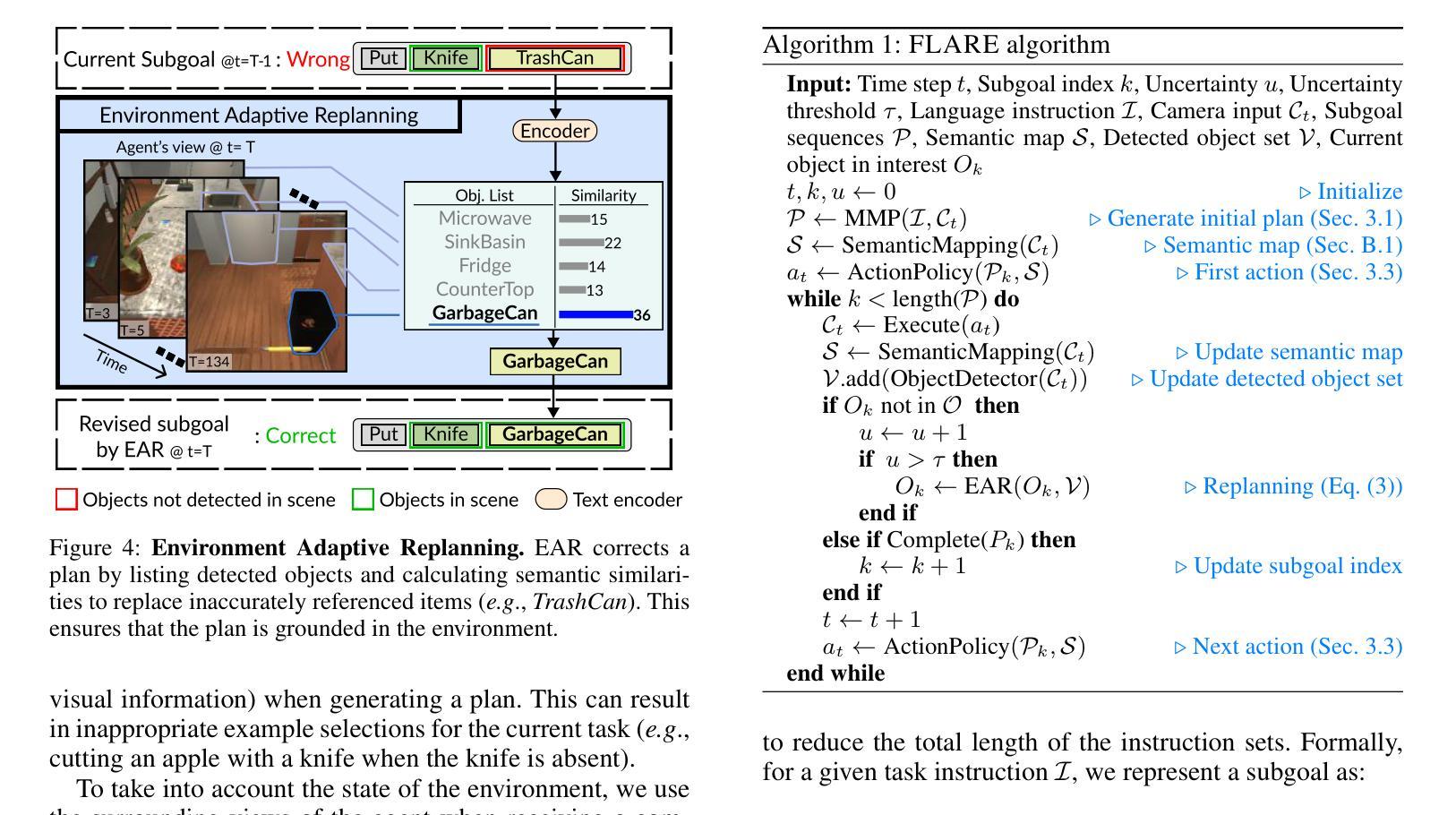
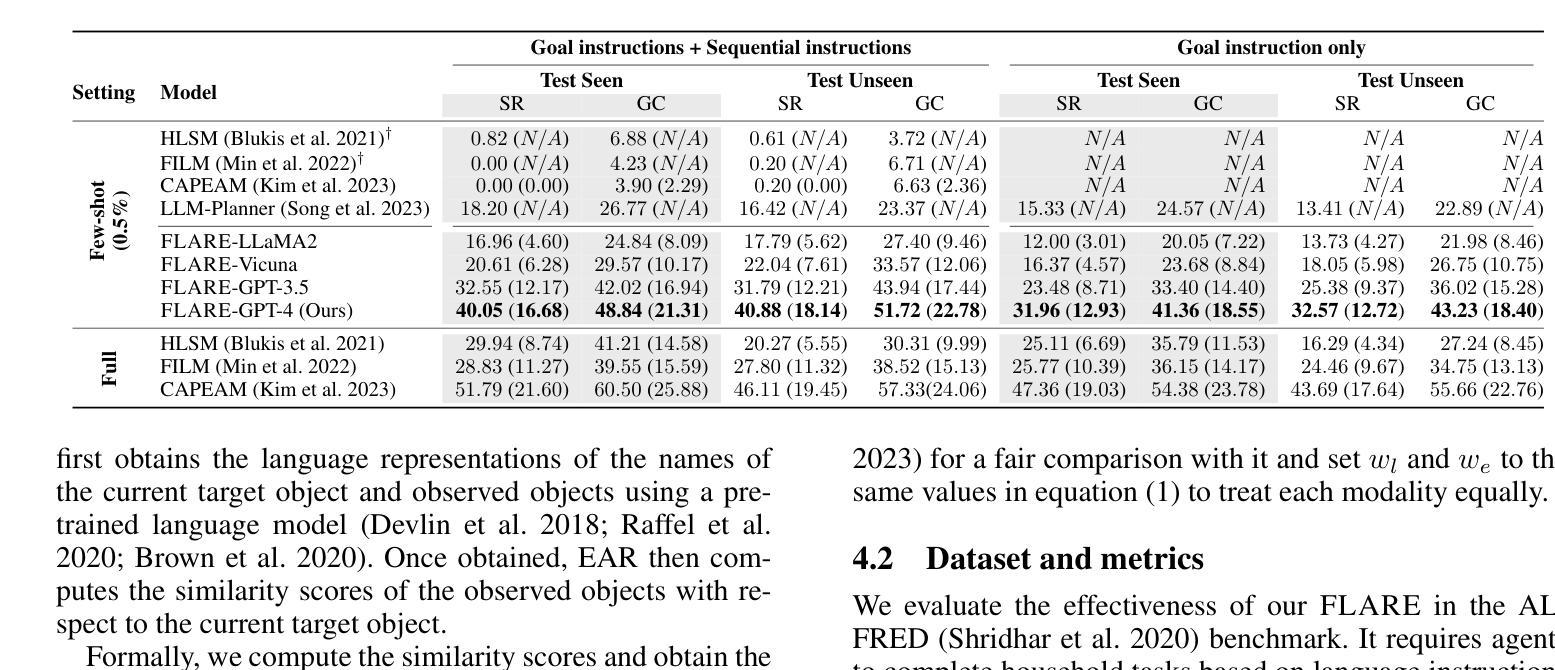
Multi-Modal Grounded Planning and Efficient Replanning For Learning Embodied Agents with A Few Examples
Authors:Taewoong Kim, Byeonghwi Kim, Jonghyun Choi
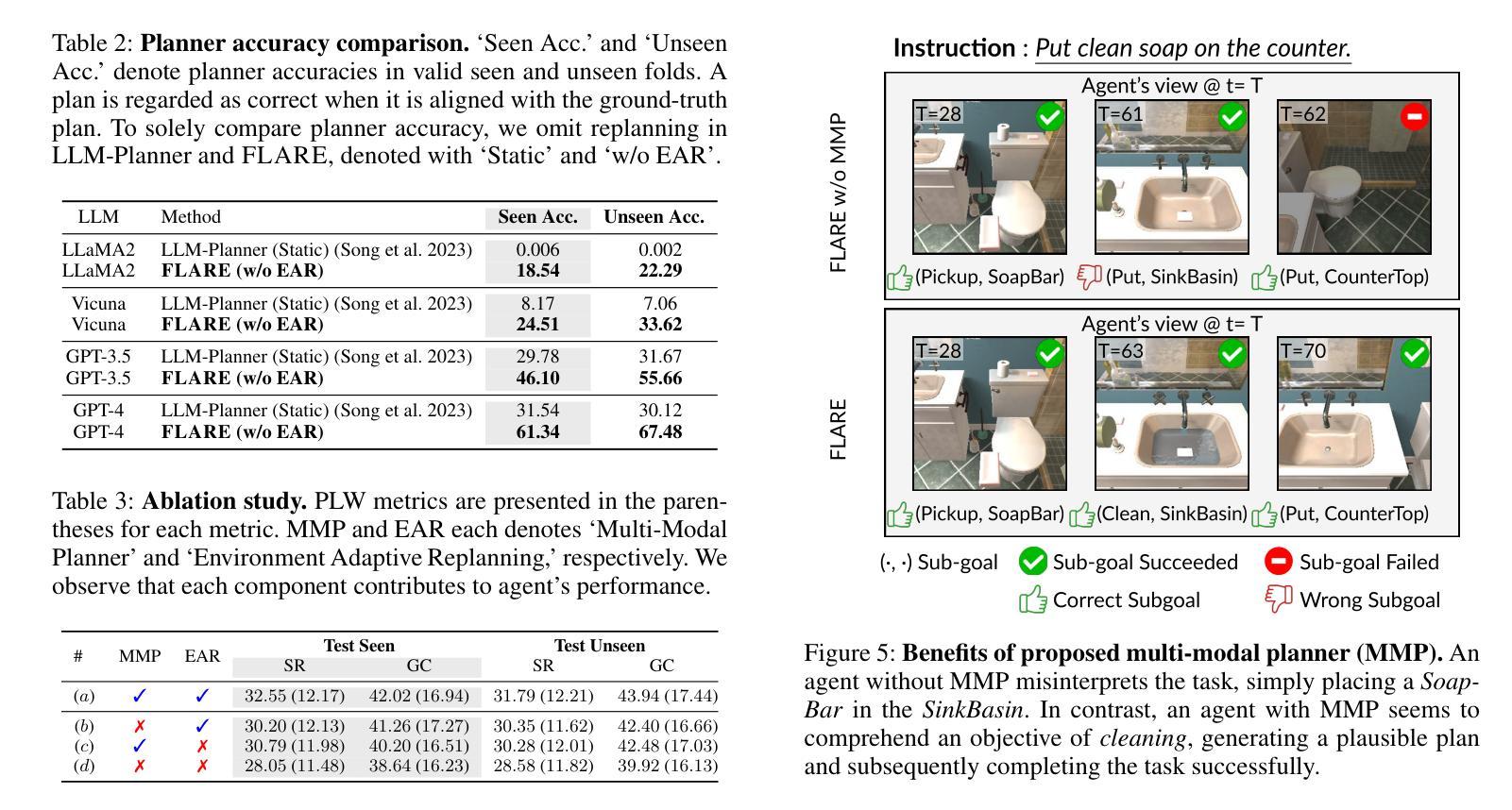
Learning a perception and reasoning module for robotic assistants to plan steps to perform complex tasks based on natural language instructions often requires large free-form language annotations, especially for short high-level instructions. To reduce the cost of annotation, large language models (LLMs) are used as a planner with few data. However, when elaborating the steps, even the state-of-the-art planner that uses LLMs mostly relies on linguistic common sense, often neglecting the status of the environment at command reception, resulting in inappropriate plans. To generate plans grounded in the environment, we propose FLARE (Few-shot Language with environmental Adaptive Replanning Embodied agent), which improves task planning using both language command and environmental perception. As language instructions often contain ambiguities or incorrect expressions, we additionally propose to correct the mistakes using visual cues from the agent. The proposed scheme allows us to use a few language pairs thanks to the visual cues and outperforms state-of-the-art approaches. Our code is available at https://github.com/snumprlab/flare.
对于机器人助理来说,学习基于自然语言指令执行复杂任务的感知和推理模块通常需要大量的自由形式语言注释,特别是对于简短的高级指令。为了减少注释的成本,使用少量数据的大型语言模型(LLM)作为规划器。然而,在详细阐述步骤时,即使是最先进的规划器也主要依赖于语言常识,往往忽略了接收命令时环境的状态,导致计划不当。为了生成基于环境的计划,我们提出了FLARE(具有环境自适应重新规划功能的嵌入式代理的少量语言),它结合了语言命令和环境感知,改进了任务规划。由于语言指令通常包含模糊或错误的表达,我们还提议利用代理的视觉线索来纠正错误。该方案允许我们利用少量的语言对,得益于视觉线索,并优于现有先进技术的方法。我们的代码可在https://github.com/snumprlab/flare找到。
论文及项目相关链接
PDF AAAI 2025 (Project page: https://twoongg.github.io/projects/flare/)
Summary
基于自然语言指令的机器人助手执行任务步骤的计划需要大型自由形式的语言注释,特别是在处理简短的高级指令时更是如此。为减少标注成本,使用了大型语言模型(LLM)作为计划者进行数据处理较少的任务。然而,在执行详细步骤时,即使是使用LLM的最先进计划者也主要依赖于语言常识,往往忽略了接收命令时的环境状态,导致计划不当。为了生成基于环境的计划,我们提出了FLARE(具有环境自适应重新规划的少数语言体现代理),它通过语言命令和环境感知来改进任务规划。此外,为了解决语言指令中的模糊或错误表达问题,我们还提出了利用代理的视觉线索进行修正。该方案允许我们利用少数语言配对得益于视觉线索并优于现有方法。
Key Takeaways
- 大型语言模型(LLM)可以减少标注成本,用于机器人助手的规划任务。
- 当前先进的计划者在执行详细步骤时主要依赖语言常识,忽略了环境状态。
- FLARE结合了语言命令和环境感知,提高了任务规划的准确性。
- 语言指令中常存在模糊或错误表达,需要借助视觉线索进行修正。
- FLARE利用少数语言配对得益于视觉线索进行任务规划,表现优于现有方法。
- 该研究的代码已经公开发布在https://github.com/snumprlab/flare。
- FLARE对机器人理解并执行复杂任务的能力有潜在的提升作用。
点此查看论文截图

Self-Corrected Flow Distillation for Consistent One-Step and Few-Step Text-to-Image Generation
Authors:Quan Dao, Hao Phung, Trung Dao, Dimitris Metaxas, Anh Tran
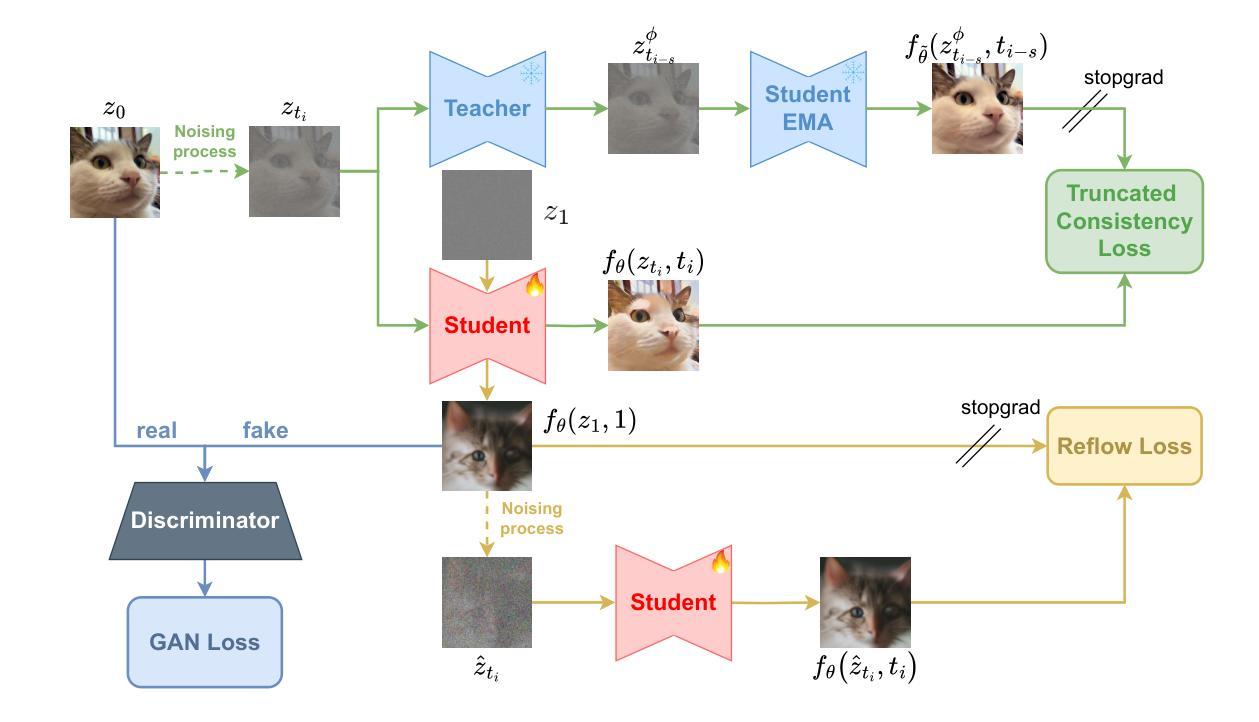
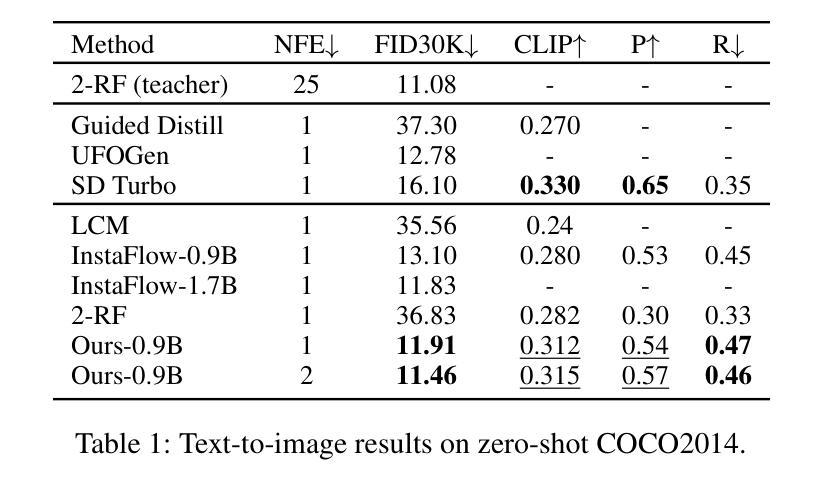
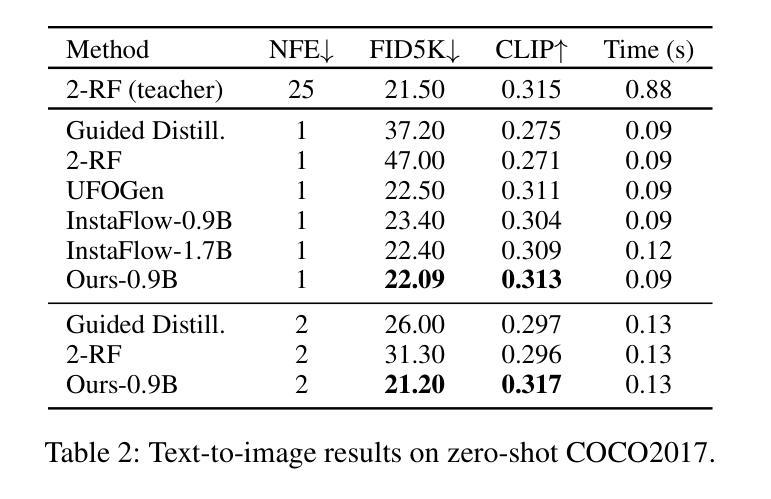
Flow matching has emerged as a promising framework for training generative models, demonstrating impressive empirical performance while offering relative ease of training compared to diffusion-based models. However, this method still requires numerous function evaluations in the sampling process. To address these limitations, we introduce a self-corrected flow distillation method that effectively integrates consistency models and adversarial training within the flow-matching framework. This work is a pioneer in achieving consistent generation quality in both few-step and one-step sampling. Our extensive experiments validate the effectiveness of our method, yielding superior results both quantitatively and qualitatively on CelebA-HQ and zero-shot benchmarks on the COCO dataset. Our implementation is released at https://github.com/VinAIResearch/SCFlow
流量匹配作为一个有前景的生成模型训练框架已经崭露头角。相比基于扩散的模型,它展示了令人印象深刻的经验性能,并且相对更容易进行训练。然而,该方法在采样过程中仍然需要大量函数评估。为了解决这些限制,我们引入了一种自我校正流量蒸馏方法,该方法有效地将一致性模型和对抗性训练整合到流量匹配框架中。这项工作在少步和一步采样中都实现了一致的生成质量,具有开创性。我们的广泛实验验证了该方法的有效性,在CelebA-HQ和COCO数据集的零样本基准测试上,定量和定性结果均优于其他方法。我们的实现已发布在https://github.com/VinAIResearch/SCFlow。
论文及项目相关链接
PDF Accepted at AAAI 2025
Summary
文本介绍了流匹配框架在训练生成模型方面的潜力,它相较于基于扩散的模型更容易训练,并且在实证中表现出色。然而,该方法在采样过程中需要多次函数评估,仍存在局限性。为了克服这些局限,我们引入了一种自校正流蒸馏方法,该方法有效地将一致性模型和对抗性训练集成到流匹配框架中。这项工作是少数几步和一步采样中都能实现一致生成质量的先驱。我们的实验验证了该方法的有效性,在CelebA-HQ和COCO数据集的零样本基准测试中,无论是定量还是定性结果均表现优越。
Key Takeaways
- 流匹配框架已成为训练生成模型的有力候选者,其相较于扩散模型更容易训练且实证表现突出。
- 当前方法采样过程中需要多次函数评估,存在一定局限性。
- 为了解决上述问题,引入了一种创新的自校正流蒸馏方法。
- 该方法结合了一致性模型和对抗性训练,集成在流匹配框架内。
- 该方法在少数几步和一步采样中均能实现一致的高品质生成。
- 实验验证,该方法在多个数据集上的表现均优于其他方法。
点此查看论文截图





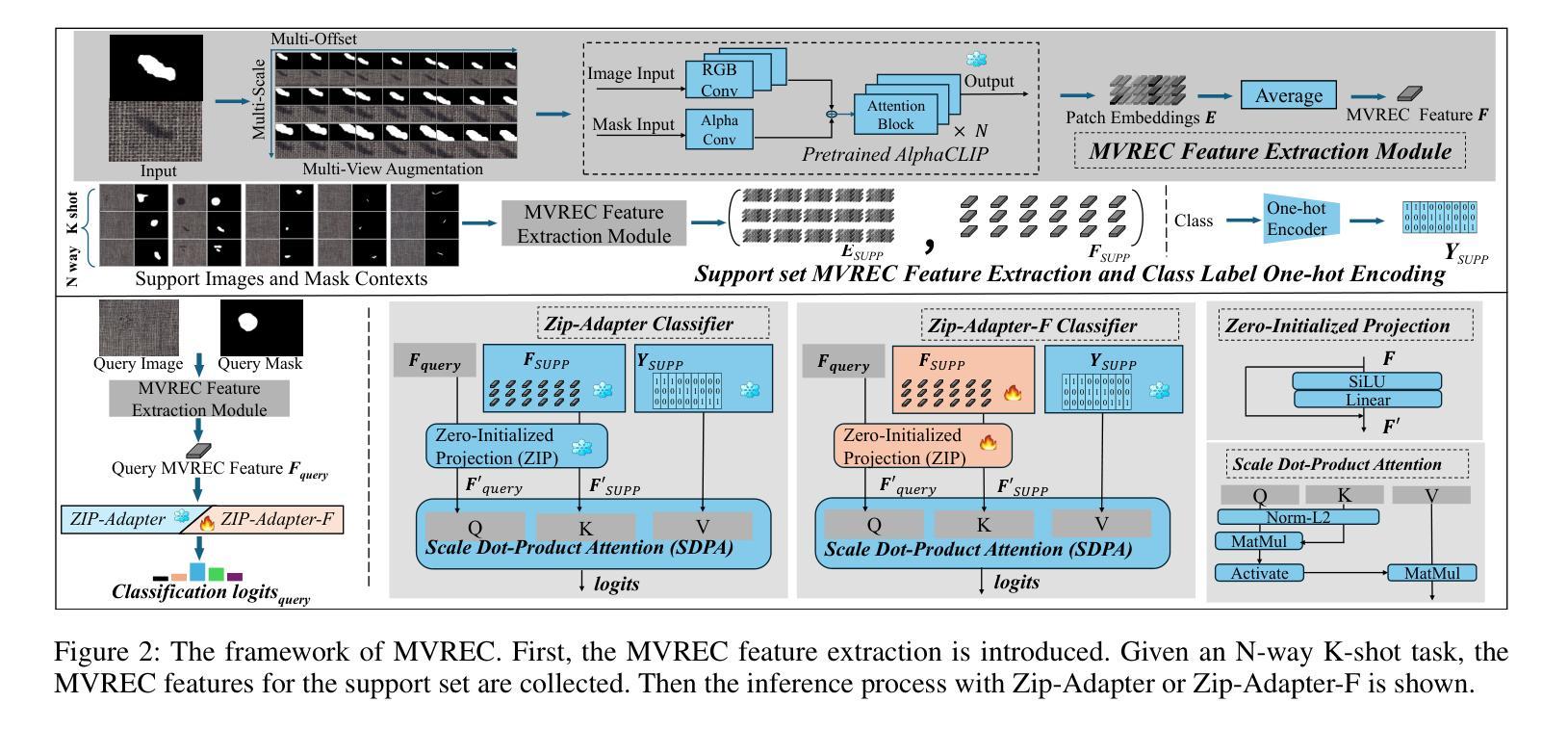
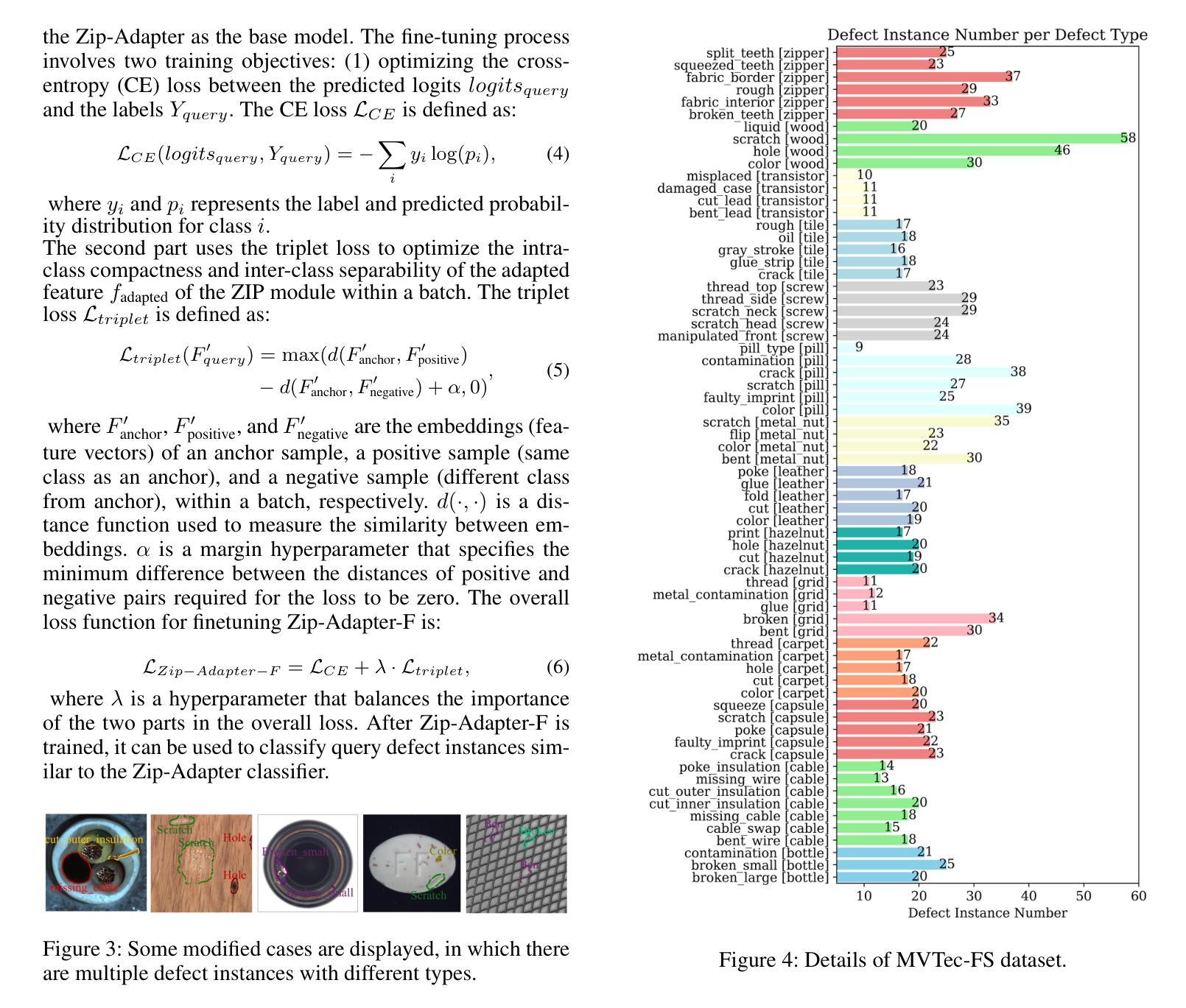
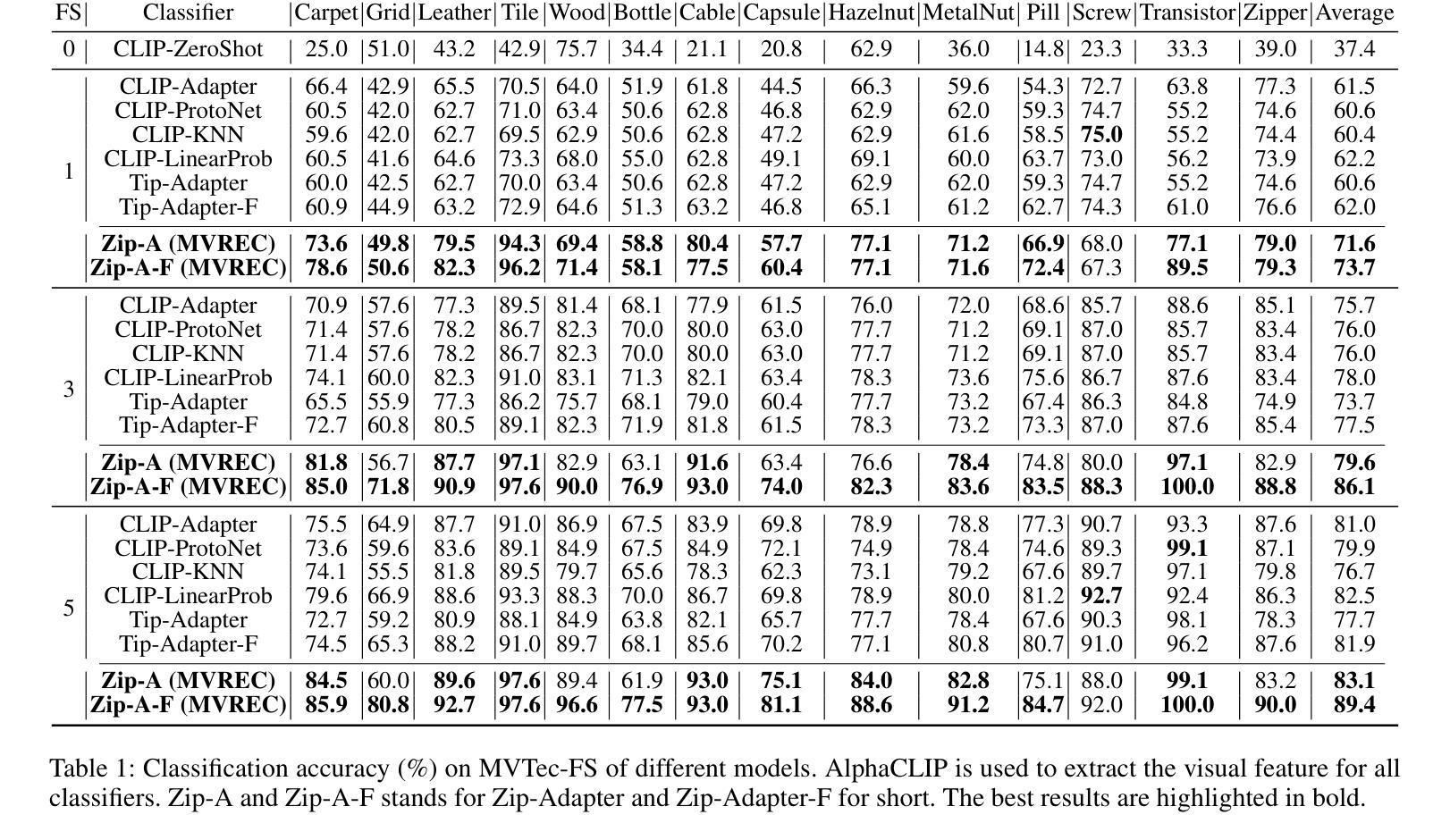
MVREC: A General Few-shot Defect Classification Model Using Multi-View Region-Context
Authors:Shuai Lyu, Fangjian Liao, Zeqi Ma, Rongchen Zhang, Dongmei Mo, Waikeung Wong
Few-shot defect multi-classification (FSDMC) is an emerging trend in quality control within industrial manufacturing. However, current FSDMC research often lacks generalizability due to its focus on specific datasets. Additionally, defect classification heavily relies on contextual information within images, and existing methods fall short of effectively extracting this information. To address these challenges, we propose a general FSDMC framework called MVREC, which offers two primary advantages: (1) MVREC extracts general features for defect instances by incorporating the pre-trained AlphaCLIP model. (2) It utilizes a region-context framework to enhance defect features by leveraging mask region input and multi-view context augmentation. Furthermore, Few-shot Zip-Adapter(-F) classifiers within the model are introduced to cache the visual features of the support set and perform few-shot classification. We also introduce MVTec-FS, a new FSDMC benchmark based on MVTec AD, which includes 1228 defect images with instance-level mask annotations and 46 defect types. Extensive experiments conducted on MVTec-FS and four additional datasets demonstrate its effectiveness in general defect classification and its ability to incorporate contextual information to improve classification performance. Code: https://github.com/ShuaiLYU/MVREC
少数样本缺陷多分类(FSDMC)是工业制造质量控制领域的新兴趋势。然而,目前的FSDMC研究往往因专注于特定数据集而缺乏通用性。此外,缺陷分类严重依赖于图像中的上下文信息,现有方法难以有效提取这些信息。为了解决这些挑战,我们提出了一种通用的FSDMC框架,名为MVREC,它有两个主要优势:(1)MVREC通过结合预训练的AlphaCLIP模型,提取缺陷实例的通用特征。(2)它利用区域上下文框架,通过利用掩膜区域输入和多视图上下文增强来增强缺陷特征。此外,模型中引入了少数样本Zip-Adapter(-F)分类器,以缓存支持集的视觉特征并执行少数样本分类。我们还介绍了基于MVTec AD的FSDMC新基准MVTec-FS,其中包括具有实例级掩膜注释的1228个缺陷图像和46种缺陷类型。在MVTec-FS和另外四个数据集上进行的广泛实验证明了其在通用缺陷分类中的有效性以及其结合上下文信息提高分类性能的能力。代码:https://github.com/ShuaiLYU/MVREC
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
本文介绍了面向工业制造中质量控制的新兴趋势——小样本缺陷多分类(FSDMC)。针对现有研究缺乏通用性和在缺陷分类中无法有效提取图像上下文信息的问题,提出了名为MVREC的通用FSDMC框架。该框架具有两大优势:一是通过结合预训练的AlphaCLIP模型提取缺陷实例的通用特征;二是利用区域上下文框架,通过掩膜区域输入和多视图上下文增强来提升缺陷特征。此外,还引入了小样本Zip-Adapter(-F)分类器来缓存支持集的视觉特征并执行小样本分类。同时,基于MVTec AD推出了新的FSDMC基准测试MVTec-FS,包含1228张缺陷图像和实例级掩膜注释,以及46种缺陷类型。在MVTec-FS和其他四个数据集上的大量实验证明了其在通用缺陷分类中的有效性以及利用上下文信息提高分类性能的能力。
Key Takeaways
- FSDMC是工业制造质量控制中的新兴趋势,但现有研究缺乏通用性。
- MVREC框架通过结合AlphaCLIP模型提取缺陷实例的通用特征。
- MVREC利用区域上下文框架,通过掩膜区域输入和多视图上下文增强提升缺陷特征。
- 小样本Zip-Adapter(-F)分类器用于缓存支持集的视觉特征并执行小样本分类。
- 推出了新的FSDMC基准测试MVTec-FS,包含大量缺陷图像和实例级掩膜注释。
- MVTec-FS和其他数据集上的实验证明了MVREC在通用缺陷分类中的有效性。
点此查看论文截图


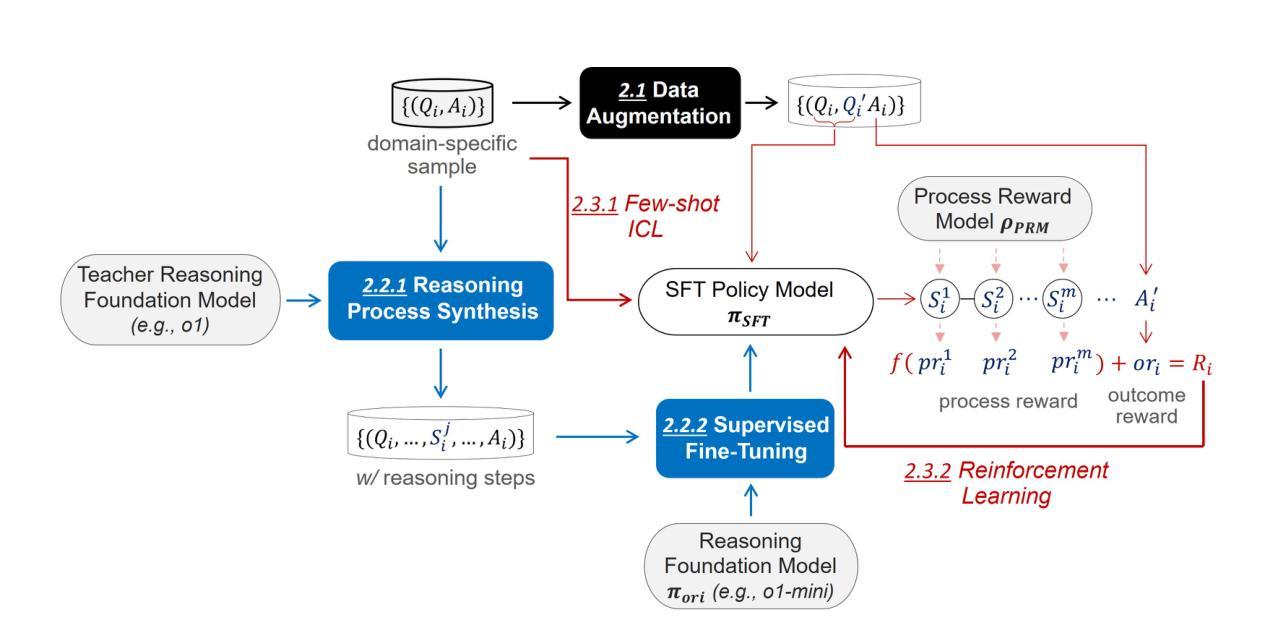
OpenRFT: Adapting Reasoning Foundation Model for Domain-specific Tasks with Reinforcement Fine-Tuning
Authors:Yuxiang Zhang, Yuqi Yang, Jiangming Shu, Yuhang Wang, Jinlin Xiao, Jitao Sang
OpenAI’s recent introduction of Reinforcement Fine-Tuning (RFT) showcases the potential of reasoning foundation model and offers a new paradigm for fine-tuning beyond simple pattern imitation. This technical report presents \emph{OpenRFT}, our attempt to fine-tune generalist reasoning models for domain-specific tasks under the same settings as RFT. OpenRFT addresses two key challenges of lacking reasoning step data and the limited quantity of training samples, by leveraging the domain-specific samples in three ways: question augmentation, synthesizing reasoning-process data, and few-shot ICL. The evaluation is conducted on SciKnowEval, where OpenRFT achieves notable performance gains with only $100$ domain-specific samples for each task. More experimental results will be updated continuously in later versions. Source codes, datasets, and models are disclosed at: https://github.com/ADaM-BJTU/OpenRFT
OpenAI最近推出的强化微调(RFT)展示了推理基础模型的潜力,并为超越简单模式模仿的微调提供了新范式。本技术报告介绍了我们的尝试方法OpenRFT,在模仿RFT设置的情况下,对通用推理模型进行特定领域的任务微调。OpenRFT通过三种方式利用特定领域的样本,解决了缺乏推理步骤数据和训练样本数量有限这两个关键挑战,这三种方式为:问题扩充、合成推理过程数据和少量ICL。在SciKnowEval上的评估显示,OpenRFT仅需每个任务$100$个特定领域的样本就实现了显著的性能提升。后续版本将持续更新更多的实验结果。相关源代码、数据集和模型公开在:https://github.com/ADaM-BJTU/OpenRFT
论文及项目相关链接
Summary
大模型的强化微调技术报告介绍了OpenRFT,一种针对特定领域任务的通用推理模型微调方法。OpenRFT通过三种方式利用领域特定样本应对缺少推理步骤数据和训练样本数量有限两个关键挑战。其在SciKnowEval上的评估表明,只需每个任务100个领域特定样本,即可实现显著的性能提升。源代码、数据集和模型已公开。
Key Takeaways
- OpenRFT是OpenAI推出的针对特定领域任务的通用推理模型微调方法。
- OpenRFT解决了缺少推理步骤数据和训练样本数量有限的关键挑战。
- OpenRFT通过三种方式利用领域特定样本:问题增强、合成推理过程数据和少样本ICL。
- 在SciKnowEval上的评估显示,使用OpenRFT在只需少量领域特定样本的情况下即可实现显著性能提升。
- OpenRFT的源代码、数据集和模型已经公开,便于研究者和开发者使用。
- OpenRFT提供了一个新的视角来看待大模型的微调,展示了超越简单模式模仿的新范式。
点此查看论文截图

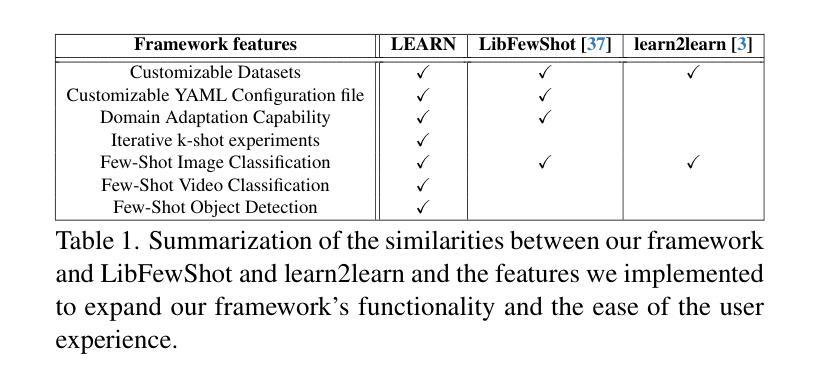
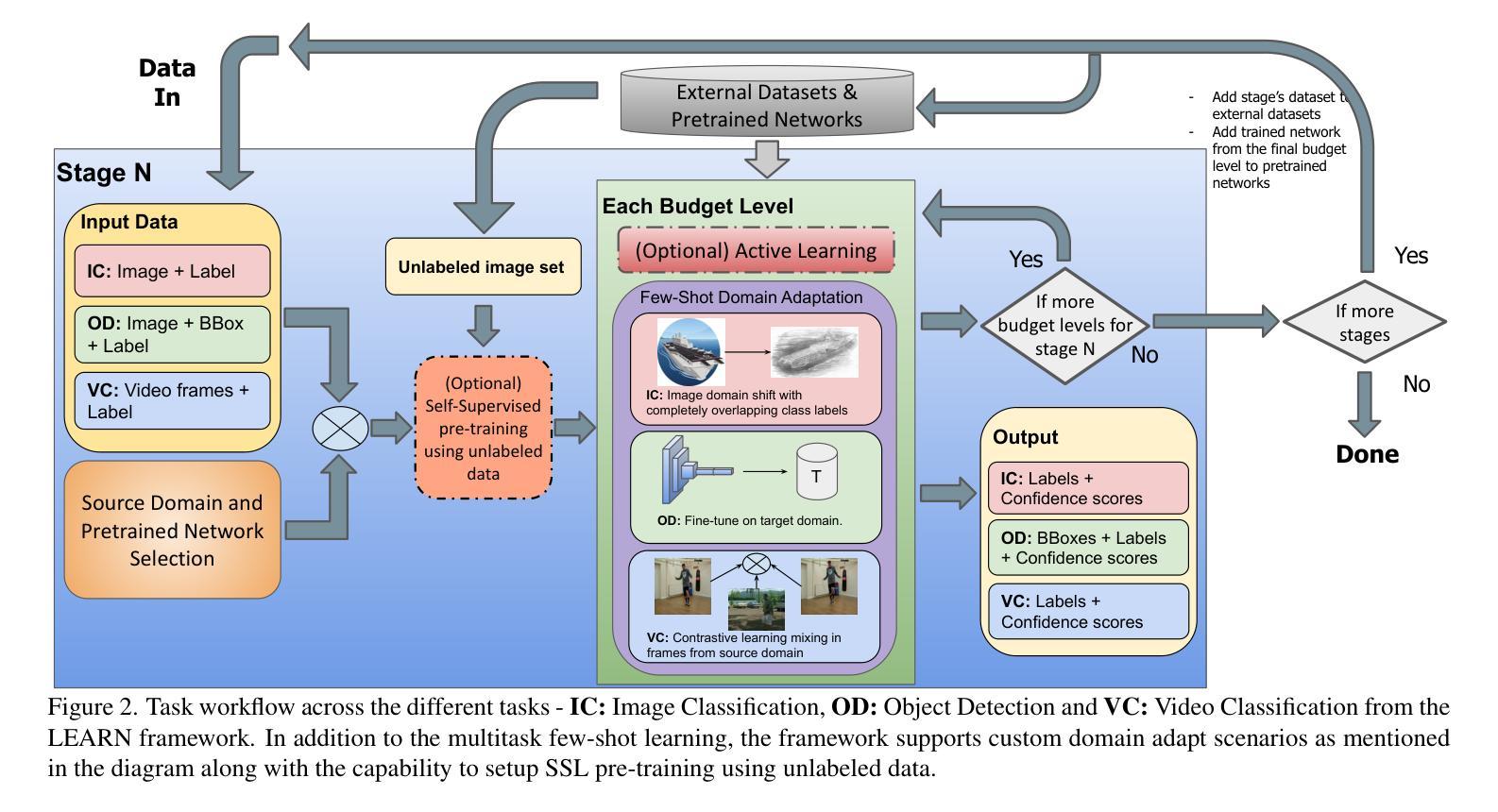
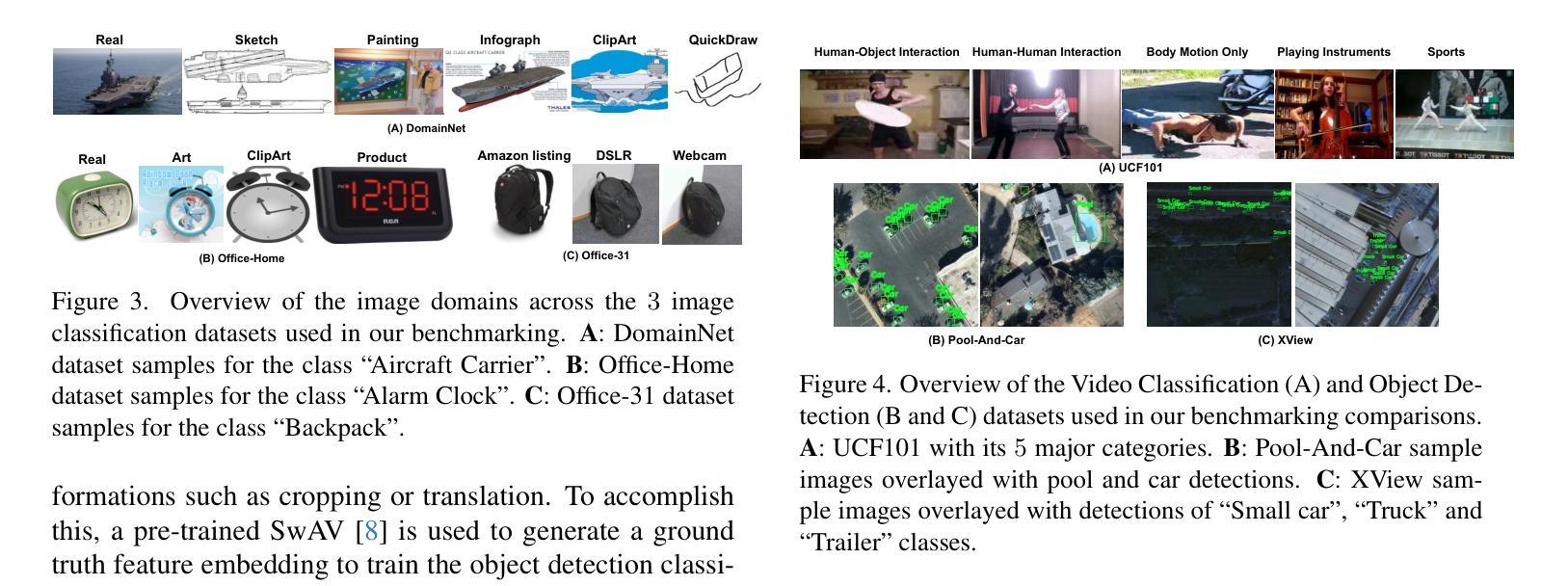
LEARN: A Unified Framework for Multi-Task Domain Adapt Few-Shot Learning
Authors:Bharadwaj Ravichandran, Alexander Lynch, Sarah Brockman, Brandon RichardWebster, Dawei Du, Anthony Hoogs, Christopher Funk
Both few-shot learning and domain adaptation sub-fields in Computer Vision have seen significant recent progress in terms of the availability of state-of-the-art algorithms and datasets. Frameworks have been developed for each sub-field; however, building a common system or framework that combines both is something that has not been explored. As part of our research, we present the first unified framework that combines domain adaptation for the few-shot learning setting across 3 different tasks - image classification, object detection and video classification. Our framework is highly modular with the capability to support few-shot learning with/without the inclusion of domain adaptation depending on the algorithm. Furthermore, the most important configurable feature of our framework is the on-the-fly setup for incremental $n$-shot tasks with the optional capability to configure the system to scale to a traditional many-shot task. With more focus on Self-Supervised Learning (SSL) for current few-shot learning approaches, our system also supports multiple SSL pre-training configurations. To test our framework’s capabilities, we provide benchmarks on a wide range of algorithms and datasets across different task and problem settings. The code is open source has been made publicly available here: https://gitlab.kitware.com/darpa_learn/learn
计算机视觉领域中的小样本学习和域适应这两个子领域在最新算法和数据集的可用性方面最近取得了重大进展。虽然每个子领域都已经开发出了相应的框架,但构建一个结合两者的通用系统或框架尚未被探索。作为我们研究的一部分,我们提出了第一个统一框架,该框架结合了三种不同任务(图像分类、目标检测和视频分类)的小样本学习设置中的域适应。我们的框架具有高度的模块化特性,支持在有或无域适应的情况下进行小样本学习,这取决于算法的选择。此外,我们框架最重要的可配置特性是为增量n次任务提供即时设置,并且可选择配置系统以扩展到传统的多次任务。当前的小样本学习方法更加关注自监督学习(SSL),我们的系统还支持多种SSL预训练配置。为了测试我们框架的能力,我们在不同的任务和问题解决设置上提供了广泛的算法和数据集的基准测试。代码是开源的,已经在这里公开发布:https://gitlab.kitware.com/darpa_learn/learn。
论文及项目相关链接
Summary:本文介绍了计算机视觉领域中的小样本学习和域适应子领域的新进展。针对这两者的融合需求,本文首次提出了一个统一的框架,能够支持不同任务(如图像分类、目标检测和视频分类)中的小样本学习和域适应功能。该框架高度模块化,可以按需启用或禁用域适应功能。此外,其还具有可配置特性,支持实时设置增量n-shot任务,并可选配置系统以扩展到传统的大规模学习任务。该框架还支持多种自监督预训练配置,并在不同的算法和数据集上进行了基准测试验证。代码已开源并提供链接。
Key Takeaways:
- 框架首次实现了小样本学习和域适应的统一结合,涵盖图像分类、目标检测和视频分类三大任务。
- 框架具有高度的模块化设计,可以根据需求灵活选择是否启用域适应功能。
- 可实时配置增量n-shot任务,并具备向传统多样本任务扩展的能力。
- 支持多种自监督预训练配置,以适应当前小样本学习方法的趋势。
- 框架在广泛的算法和数据集上进行了基准测试验证其效能。
- 代码以开源形式提供,方便研究和应用。
点此查看论文截图

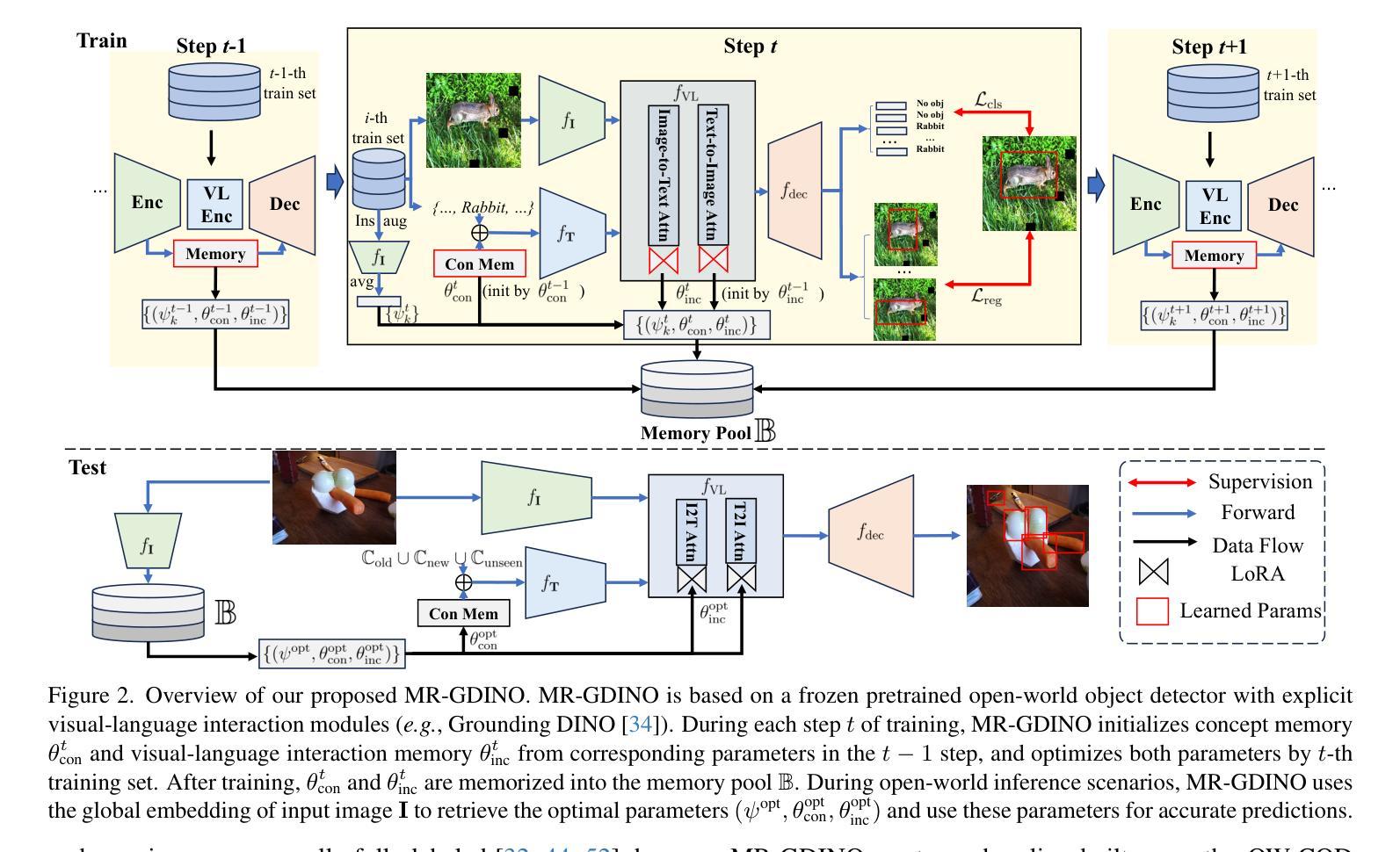
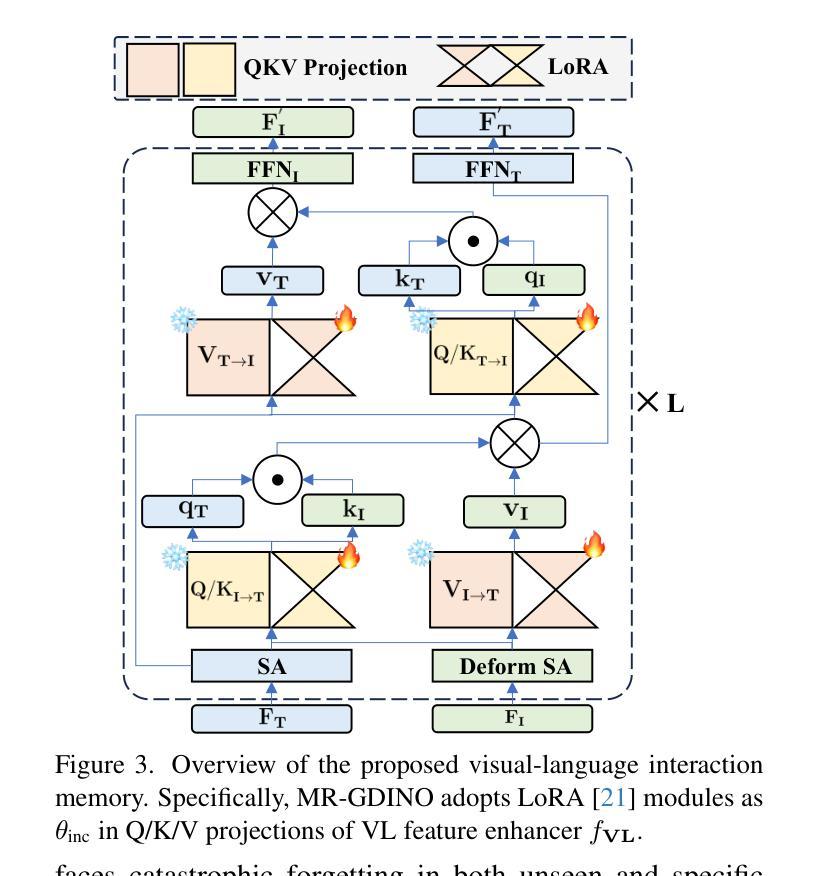
MR-GDINO: Efficient Open-World Continual Object Detection
Authors:Bowen Dong, Zitong Huang, Guanglei Yang, Lei Zhang, Wangmeng Zuo
Open-world (OW) recognition and detection models show strong zero- and few-shot adaptation abilities, inspiring their use as initializations in continual learning methods to improve performance. Despite promising results on seen classes, such OW abilities on unseen classes are largely degenerated due to catastrophic forgetting. To tackle this challenge, we propose an open-world continual object detection task, requiring detectors to generalize to old, new, and unseen categories in continual learning scenarios. Based on this task, we present a challenging yet practical OW-COD benchmark to assess detection abilities. The goal is to motivate OW detectors to simultaneously preserve learned classes, adapt to new classes, and maintain open-world capabilities under few-shot adaptations. To mitigate forgetting in unseen categories, we propose MR-GDINO, a strong, efficient and scalable baseline via memory and retrieval mechanisms within a highly scalable memory pool. Experimental results show that existing continual detectors suffer from severe forgetting for both seen and unseen categories. In contrast, MR-GDINO largely mitigates forgetting with only 0.1% activated extra parameters, achieving state-of-the-art performance for old, new, and unseen categories.
开放世界(OW)识别和检测模型显示出强大的零样本和少样本适应力,这激发了将其作为初始化用于持续学习方法以提高性能。尽管在可见类别上取得了有前景的结果,但此类OW模型在未见过类别上的能力由于灾难性遗忘而大大退化。为了应对这一挑战,我们提出了一个开放世界持续目标检测任务,要求检测器在持续学习场景中推广到旧、新和未见类别。基于这项任务,我们提出了一个具有挑战性但实用的OW-COD基准测试来评估检测能力。目标是激励OW检测器在保留已学类别、适应新类别以及维持开放世界能力方面进行少样本适应。为了缓解在未见过类别的遗忘问题,我们提出了MR-GDINO,这是一种强大的、高效的、可扩展的基线,通过内存和检索机制在一个高度可扩展的内存池内实现。实验结果表明,现有的持续检测器在可见和未见过类别上都存在严重的遗忘问题。相比之下,MR-GDINO在很大程度上缓解了遗忘问题,并且只需激活0.1%的额外参数,即可实现对旧、新和未见类别的最佳性能。
论文及项目相关链接
PDF Website: https://m1saka.moe/owcod/ . Code is available at: https://github.com/DongSky/MR-GDINO
Summary
开放式世界(OW)识别与检测模型在零次和几次射击适应方面具有强大的能力,可在持续学习方法中作为初始化使用以提高性能。尽管在已知类别上表现良好,但在未知类别上的能力因灾难性遗忘而退化。为解决此挑战,本文提出了开放式世界持续对象检测任务,要求检测器在持续学习场景中泛化到旧、新和未知类别。基于此任务,本文提出了具有挑战性的开放式世界COD基准测试,以评估检测能力。目标是激励开放式世界检测器在保留已学类别、适应新类别的同时,在少镜头适应下保持开放式世界能力。为缓解对未知类别的遗忘,本文提出了MR-GDINO方法,通过内存和检索机制构建高度可扩展的内存池实现基线方法的有效性和扩展性。实验结果显示,现有持续检测器对已知和未知类别的遗忘严重。相比之下,MR-GDINO极大地缓解了遗忘问题,仅激活额外参数的0.1%,在旧、新和未知类别上均达到最佳性能。
Key Takeaways
- 开放世界识别与检测模型具备强大的零次和几次射击适应能力,适用于持续学习方法中的初始化阶段以提高性能。
- 在持续学习场景中,检测器需要泛化到旧、新和未知类别。
- 提出了开放式世界持续对象检测任务和开放式世界COD基准测试来评估检测能力。
- 现有持续检测器在已知和未知类别上均存在严重的遗忘问题。
- MR-GDINO方法通过内存和检索机制构建高度可扩展的内存池,有效缓解了对未知类别的遗忘问题。
- MR-GDINO方法仅激活额外参数的0.1%,在旧、新和未知类别上均达到最佳性能。
点此查看论文截图

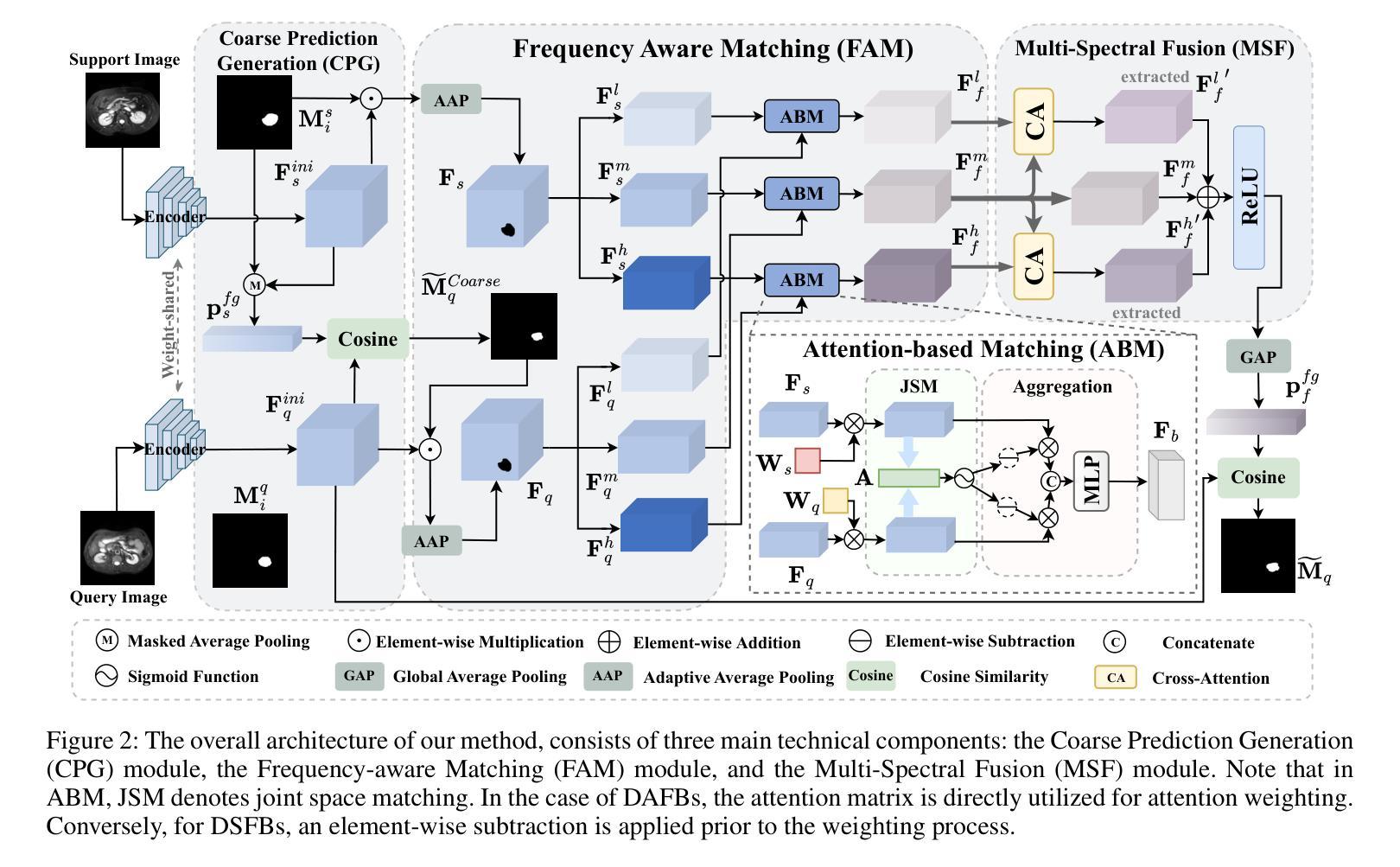
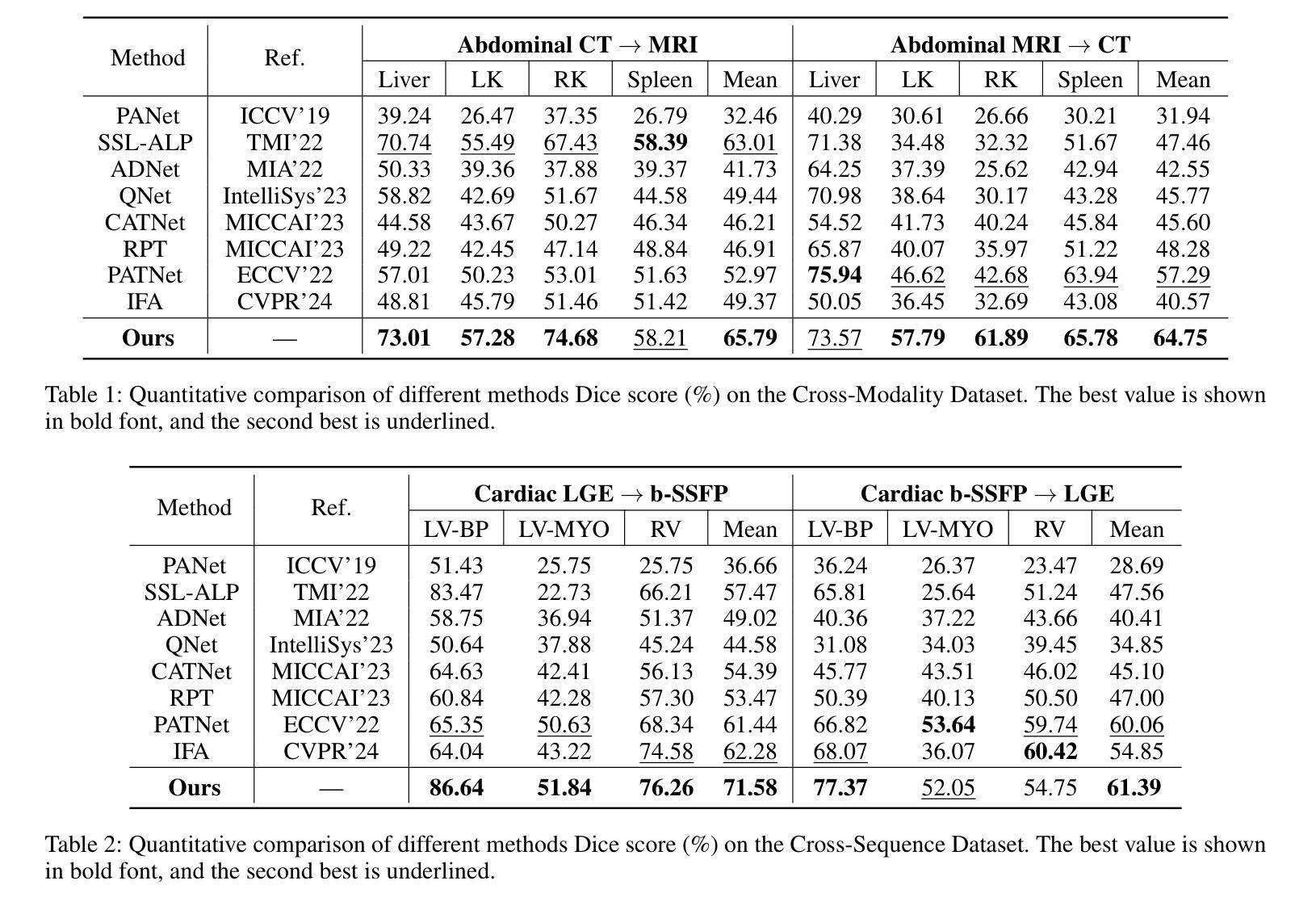
FAMNet: Frequency-aware Matching Network for Cross-domain Few-shot Medical Image Segmentation
Authors:Yuntian Bo, Yazhou Zhu, Lunbo Li, Haofeng Zhang
Existing few-shot medical image segmentation (FSMIS) models fail to address a practical issue in medical imaging: the domain shift caused by different imaging techniques, which limits the applicability to current FSMIS tasks. To overcome this limitation, we focus on the cross-domain few-shot medical image segmentation (CD-FSMIS) task, aiming to develop a generalized model capable of adapting to a broader range of medical image segmentation scenarios with limited labeled data from the novel target domain. Inspired by the characteristics of frequency domain similarity across different domains, we propose a Frequency-aware Matching Network (FAMNet), which includes two key components: a Frequency-aware Matching (FAM) module and a Multi-Spectral Fusion (MSF) module. The FAM module tackles two problems during the meta-learning phase: 1) intra-domain variance caused by the inherent support-query bias, due to the different appearances of organs and lesions, and 2) inter-domain variance caused by different medical imaging techniques. Additionally, we design an MSF module to integrate the different frequency features decoupled by the FAM module, and further mitigate the impact of inter-domain variance on the model’s segmentation performance. Combining these two modules, our FAMNet surpasses existing FSMIS models and Cross-domain Few-shot Semantic Segmentation models on three cross-domain datasets, achieving state-of-the-art performance in the CD-FSMIS task.
现有的一次性少量医学图像分割模型(FSMIS)无法解决医学成像中的一个实际问题:由于不同成像技术导致的域偏移问题,这限制了其在当前FSMIS任务中的应用。为了克服这一局限性,我们专注于跨域一次性少量医学图像分割(CD-FSMIS)任务,旨在开发一种通用模型,能够在有限的新目标域标记数据的情况下适应更广泛的医学图像分割场景。我们受到不同领域频率域相似性特征的启发,提出了一种频率感知匹配网络(FAMNet),它包括两个关键组件:频率感知匹配(FAM)模块和多光谱融合(MSF)模块。FAM模块解决了元学习阶段的两个问题:一是由于器官和病灶外观不同造成的固有支持查询偏差导致的域内方差;二是由于不同医学成像技术导致的跨域方差。此外,我们设计了一个MSF模块来整合被FAM模块分离的不同的频率特征,并进一步减轻跨域方差对模型分割性能的影响。结合这两个模块,我们的FAMNet在三个跨域数据集上超越了现有的FSMIS模型和跨域少样本语义分割模型,在CD-FSMIS任务中达到了最先进的性能。
论文及项目相关链接
PDF Accepted by the 39th Annual AAAI Conference on Artificial Intelligence (AAAI-25)
Summary
本文关注跨域少样本医疗图像分割(CD-FSMIS)任务,旨在开发一个通用模型,能够在有限的新目标域标记数据下,适应更广泛的医疗图像分割场景。为此,提出一个频率感知匹配网络(FAMNet),包括频率感知匹配(FAM)模块和多光谱融合(MSF)模块。FAM模块解决元学习阶段的两个主要问题:器官和病变外观引起的域内差异以及不同医学成像技术导致的域间差异。MSF模块进一步整合FAM模块解耦的不同频率特征,减轻跨域差异对模型分割性能的影响。在三个跨域数据集上,FAMNet超越现有FSMIS模型和跨域少样本语义分割模型,实现CD-FSMIS任务的最新性能。
Key Takeaways
- 现有少样本医疗图像分割模型面临因不同成像技术导致的域偏移问题,限制了其在现实任务中的应用。
- 跨域少样本医疗图像分割(CD-FSMIS)旨在开发一个能够适应更广泛医疗图像分割场景的通用模型。
- 提出频率感知匹配网络(FAMNet),包含频率感知匹配(FAM)模块和多光谱融合(MSF)模块以应对跨域问题。
- FAM模块解决元学习阶段的域内和域间差异问题。
- MSF模块整合不同频率特征,进一步减轻跨域差异对模型性能的影响。
- FAMNet在三个跨域数据集上的性能超过现有模型,实现CD-FSMIS任务的最新表现。
点此查看论文截图

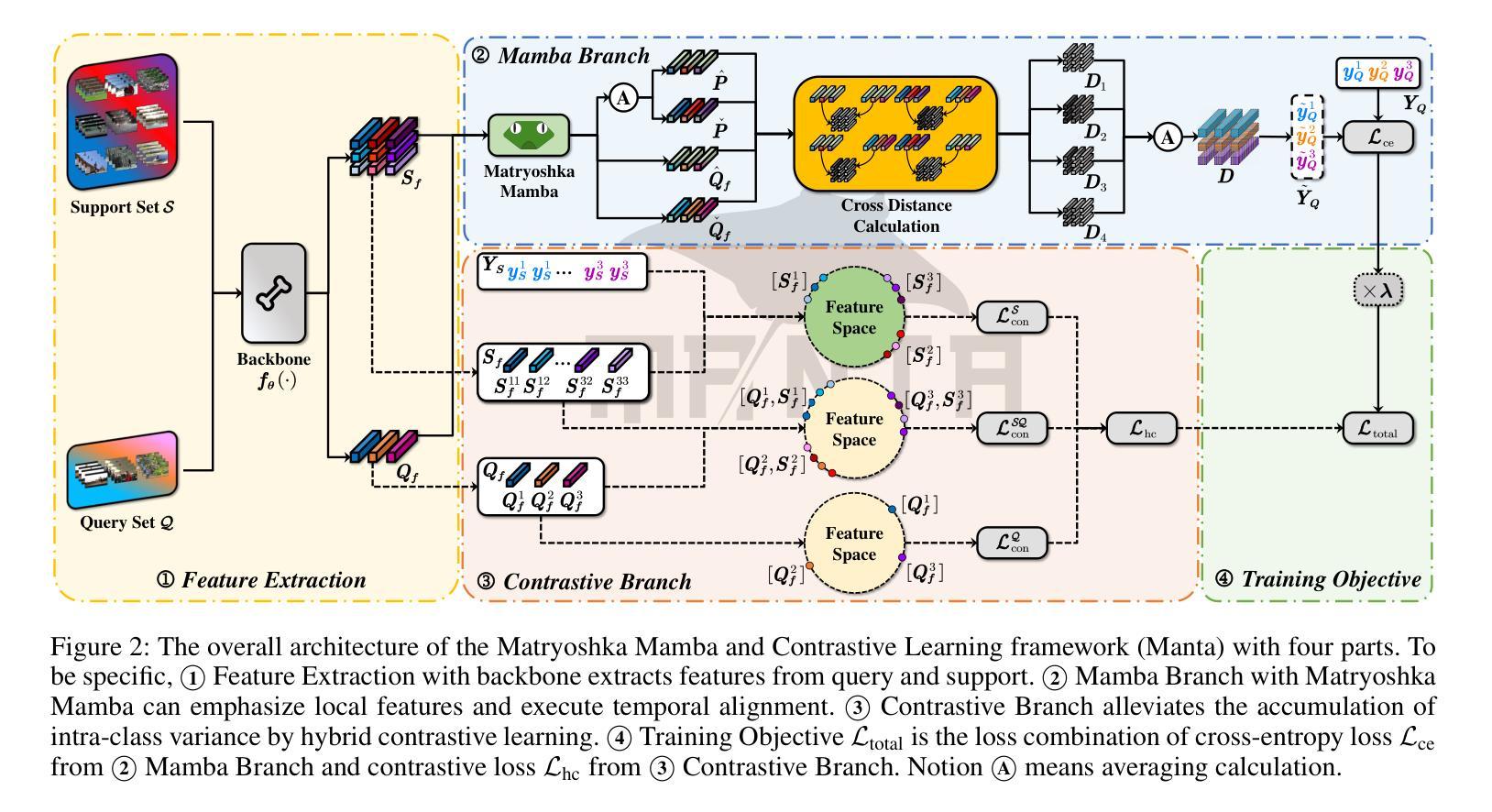
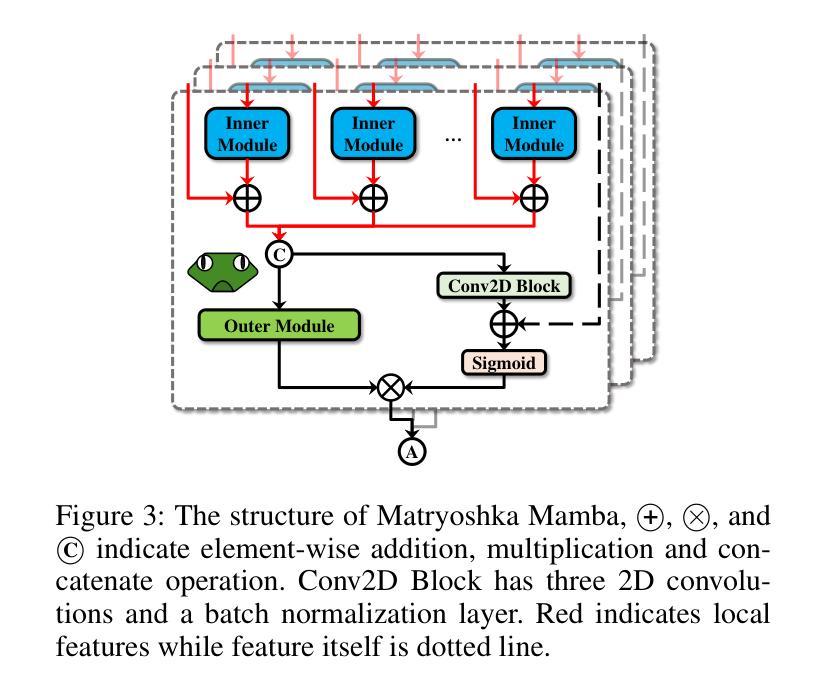
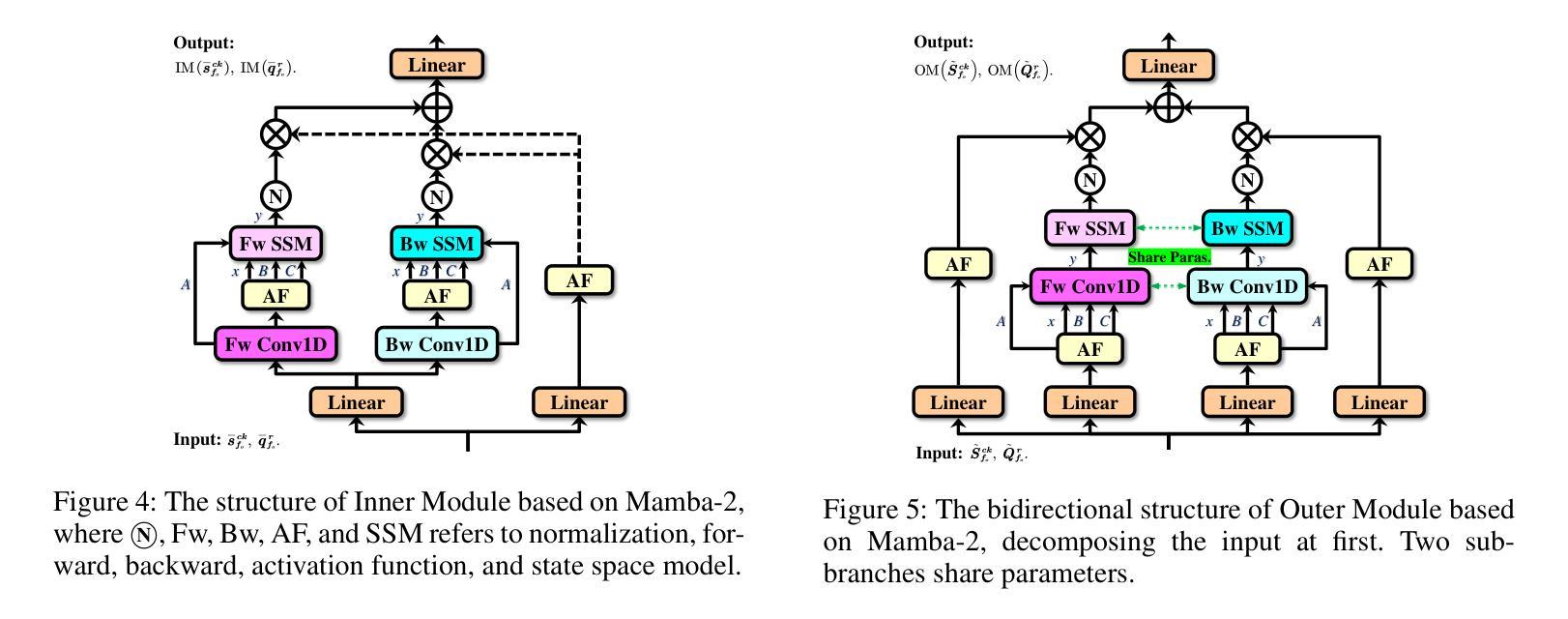
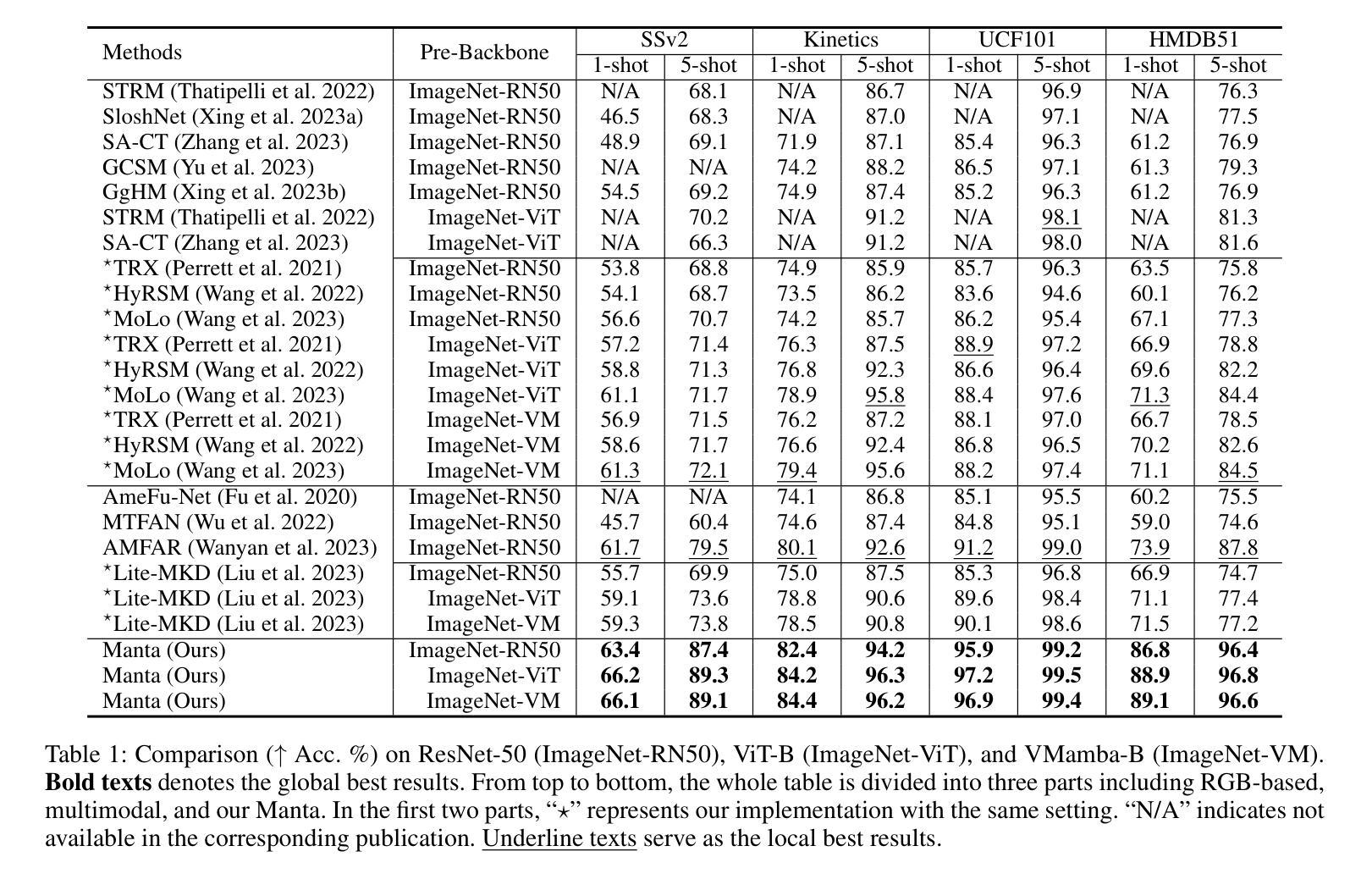
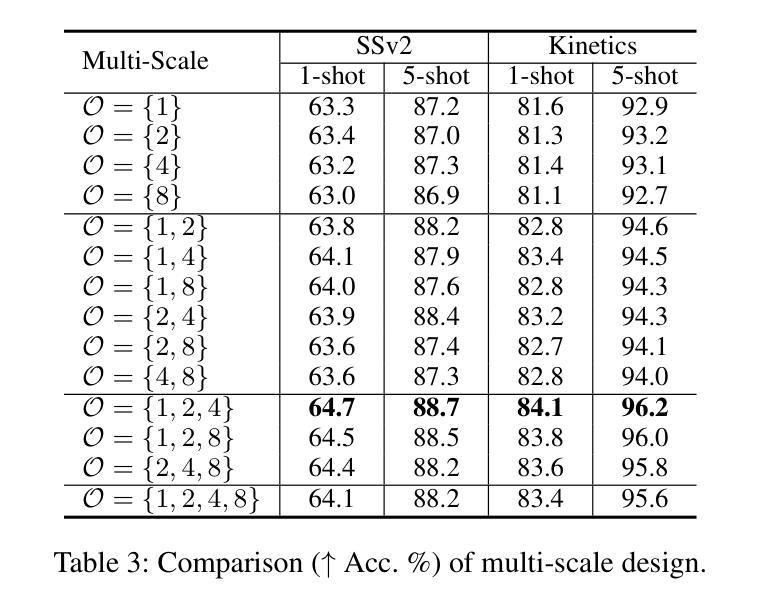
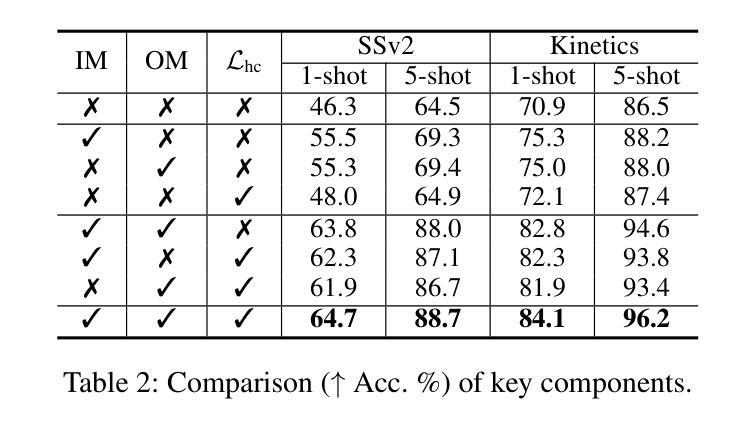
Manta: Enhancing Mamba for Few-Shot Action Recognition of Long Sub-Sequence
Authors:Wenbo Huang, Jinghui Zhang, Guang Li, Lei Zhang, Shuoyuan Wang, Fang Dong, Jiahui Jin, Takahiro Ogawa, Miki Haseyama
In few-shot action recognition (FSAR), long sub-sequences of video naturally express entire actions more effectively. However, the high computational complexity of mainstream Transformer-based methods limits their application. Recent Mamba demonstrates efficiency in modeling long sequences, but directly applying Mamba to FSAR overlooks the importance of local feature modeling and alignment. Moreover, long sub-sequences within the same class accumulate intra-class variance, which adversely impacts FSAR performance. To solve these challenges, we propose a Matryoshka MAmba and CoNtrasTive LeArning framework (Manta). Firstly, the Matryoshka Mamba introduces multiple Inner Modules to enhance local feature representation, rather than directly modeling global features. An Outer Module captures dependencies of timeline between these local features for implicit temporal alignment. Secondly, a hybrid contrastive learning paradigm, combining both supervised and unsupervised methods, is designed to mitigate the negative effects of intra-class variance accumulation. The Matryoshka Mamba and the hybrid contrastive learning paradigm operate in two parallel branches within Manta, enhancing Mamba for FSAR of long sub-sequence. Manta achieves new state-of-the-art performance on prominent benchmarks, including SSv2, Kinetics, UCF101, and HMDB51. Extensive empirical studies prove that Manta significantly improves FSAR of long sub-sequence from multiple perspectives.
在少样本动作识别(FSAR)中,视频的长子序列更自然地表达了整个动作。然而,主流基于Transformer的方法的高计算复杂度限制了其应用。最近的Mamba在建模长序列方面展示了效率,但直接将Mamba应用于FSAR忽视了局部特征建模和对齐的重要性。此外,同一类别内的长子序列会积累类内差异,这对FSAR性能产生不利影响。为了解决这些挑战,我们提出了一个Matryoshka Mamba和对比学习框架(Manta)。首先,Matryoshka Mamba引入多个内部模块来增强局部特征表示,而不是直接对全局特征进行建模。外部模块捕获这些局部特征的时间线依赖性,以进行隐式的时间对齐。其次,结合有监督和无监督方法的混合对比学习范式被设计用于缓解类内差异积累带来的负面影响。Matryoshka Mamba和混合对比学习范式在Manta的两个并行分支中运行,增强了Mamba对长序列FSAR的能力。Manta在包括SSv2、Kinetics、UCF101和HMDB51等主流基准测试上达到了新的最佳性能。大量的实证研究证明,Manta从多个角度显著提高了长序列FSAR的性能。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
该文本介绍了在少样本动作识别(FSAR)中,长视频子序列能更自然地表达完整动作,但主流基于Transformer的方法计算复杂度较高。最近提出的Mamba模型对长序列建模有效,但直接应用于FSAR时忽略了局部特征建模和对齐的重要性。同一类别内的长子序列会积累类内方差,影响FSAR性能。为解决这些问题,提出了Matryoshka Mamba和对比学习框架Manta。Matryoshka Mamba通过多个内部模块增强局部特征表示,而不是直接建模全局特征。外部模块捕获这些局部特征的时序依赖性,进行隐式时间对齐。同时,设计了一种结合有监督和无监督方法的混合对比学习范式,以减轻类内方差积累带来的负面影响。Manta在SSv2、Kinetics、UCF101和HMDB51等主流基准测试上达到了最新的一流性能。
Key Takeaways
- 在少样本动作识别中,长视频子序列更自然地表达完整动作,但计算复杂度是挑战。
- Mamba模型有效处理长序列,但直接应用于FSAR时忽略了局部特征建模和对齐。
- 同一类别内的长子序列会积累类内方差,影响FSAR性能。
- Matryoshka Mamba通过多个内部模块增强局部特征表示,并进行隐式时间对齐。
- Manta采用混合对比学习范式,结合有监督和无监督方法,减轻类内方差积累的影响。
- Manta在多个基准测试上达到最新的一流性能。
点此查看论文截图

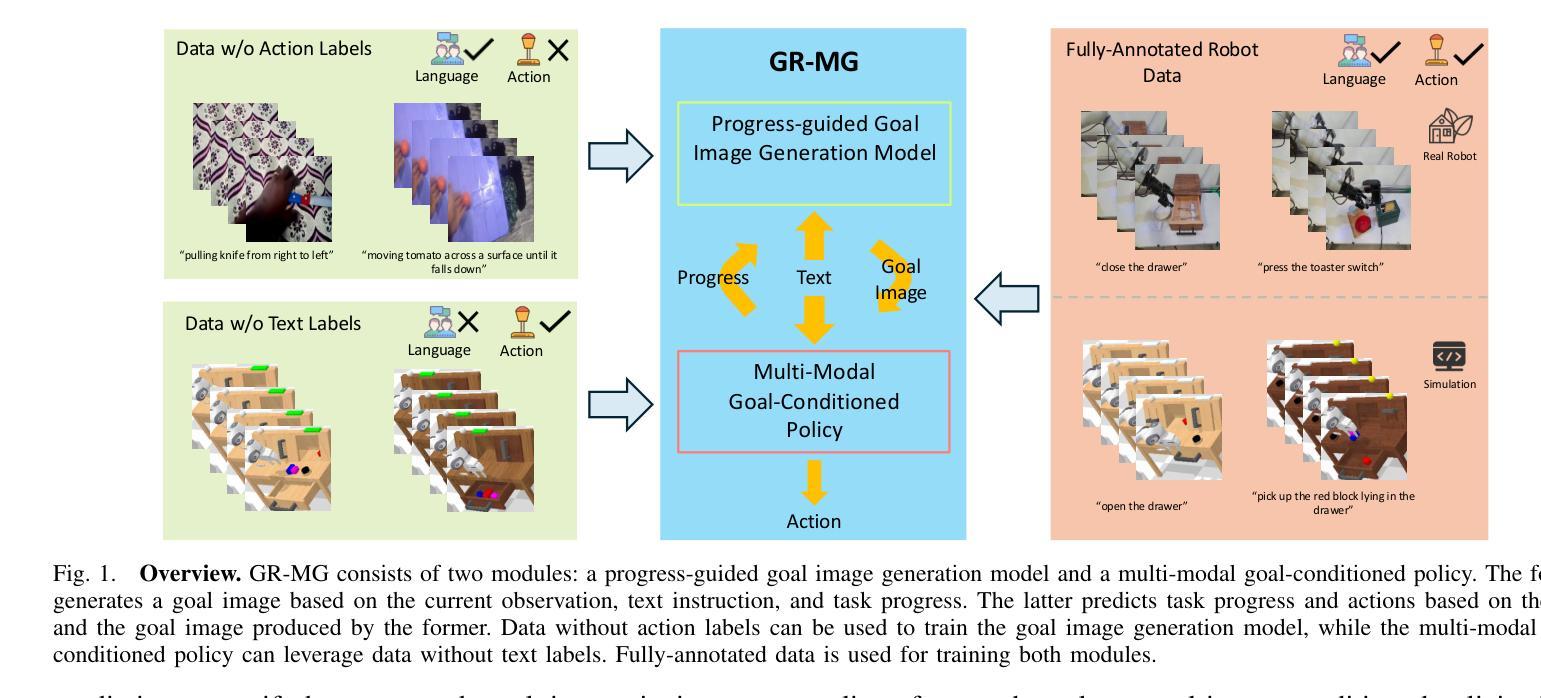
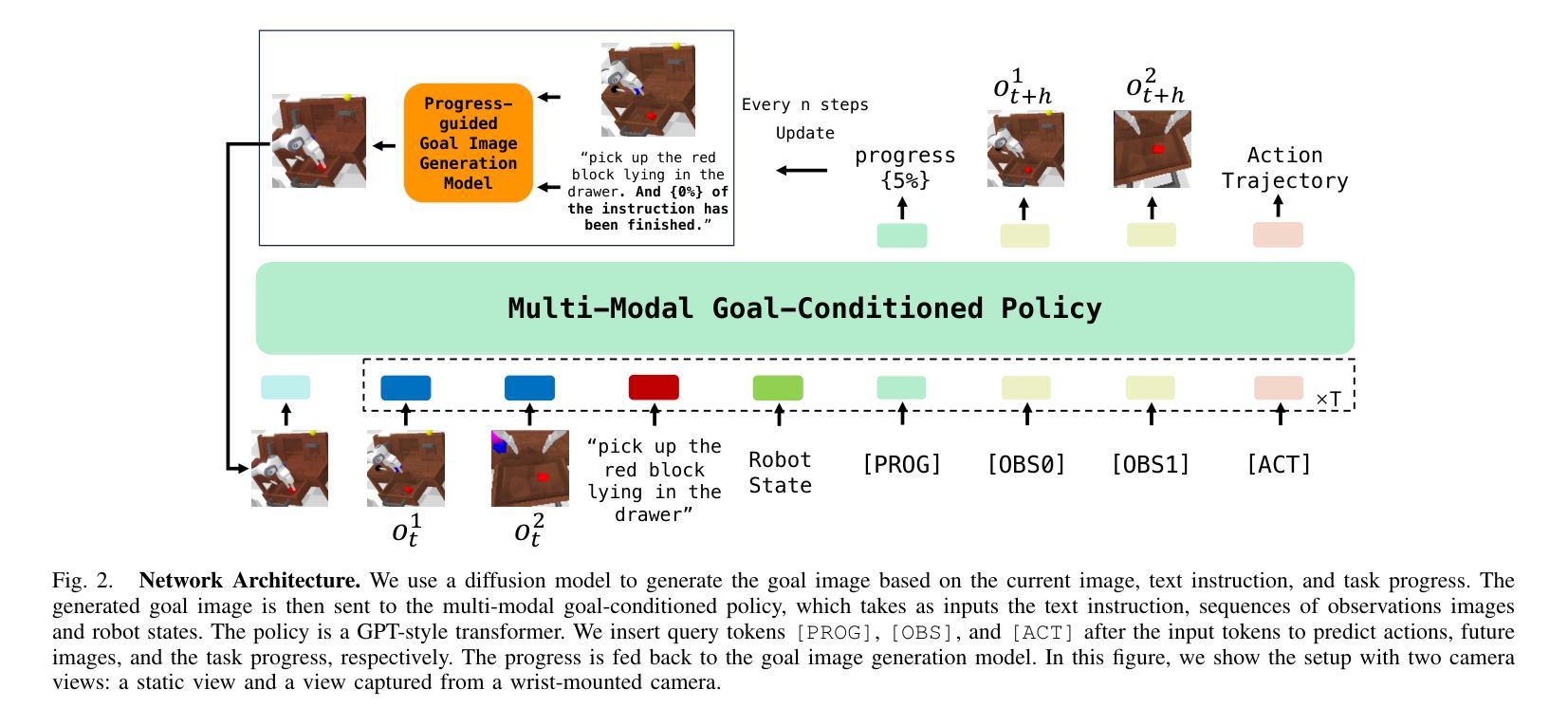
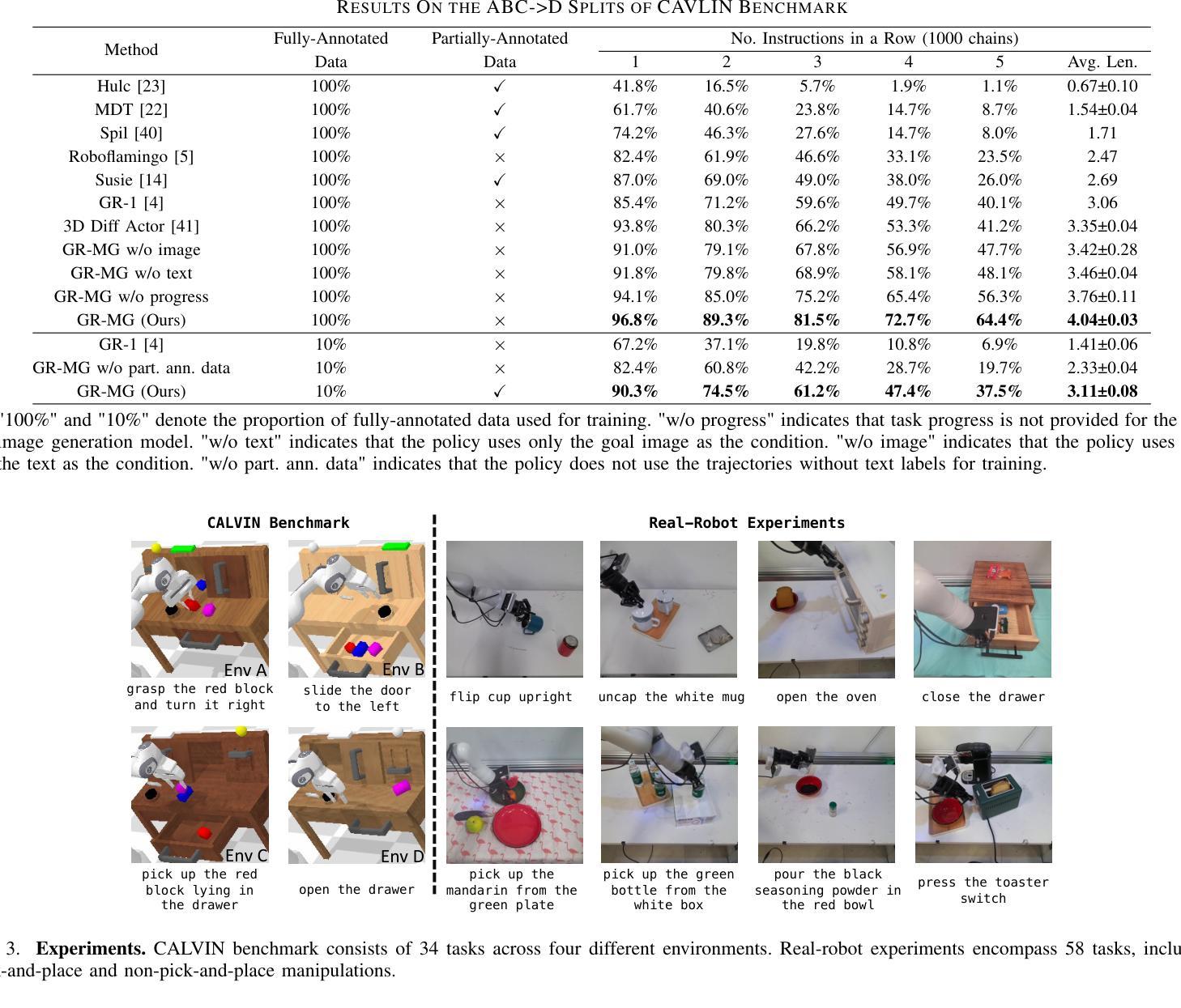
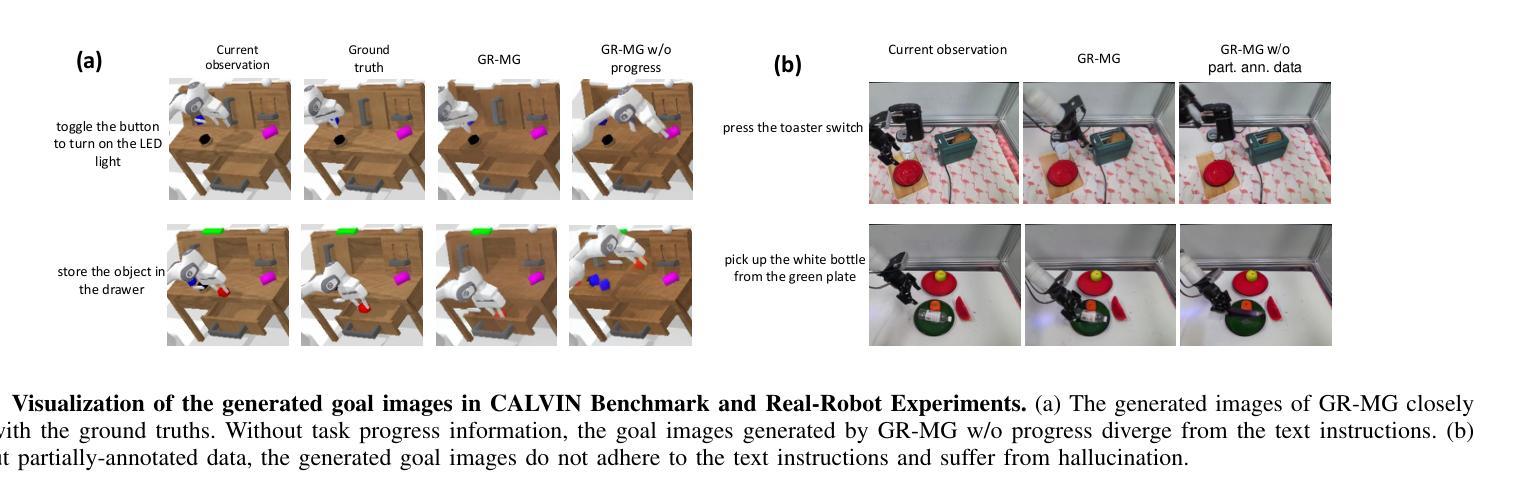
GR-MG: Leveraging Partially Annotated Data via Multi-Modal Goal-Conditioned Policy
Authors:Peiyan Li, Hongtao Wu, Yan Huang, Chilam Cheang, Liang Wang, Tao Kong
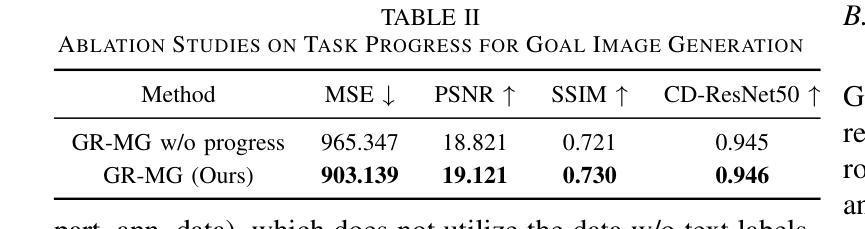
The robotics community has consistently aimed to achieve generalizable robot manipulation with flexible natural language instructions. One primary challenge is that obtaining robot trajectories fully annotated with both actions and texts is time-consuming and labor-intensive. However, partially-annotated data, such as human activity videos without action labels and robot trajectories without text labels, are much easier to collect. Can we leverage these data to enhance the generalization capabilities of robots? In this paper, we propose GR-MG, a novel method which supports conditioning on a text instruction and a goal image. During training, GR-MG samples goal images from trajectories and conditions on both the text and the goal image or solely on the image when text is not available. During inference, where only the text is provided, GR-MG generates the goal image via a diffusion-based image-editing model and conditions on both the text and the generated image. This approach enables GR-MG to leverage large amounts of partially-annotated data while still using languages to flexibly specify tasks. To generate accurate goal images, we propose a novel progress-guided goal image generation model which injects task progress information into the generation process. In simulation experiments, GR-MG improves the average number of tasks completed in a row of 5 from 3.35 to 4.04. In real-robot experiments, GR-MG is able to perform 58 different tasks and improves the success rate from 68.7% to 78.1% and 44.4% to 60.6% in simple and generalization settings, respectively. It also outperforms comparing baseline methods in few-shot learning of novel skills. Video demos, code, and checkpoints are available on the project page: https://gr-mg.github.io/.
机器人技术社区一直致力于实现使用灵活的自然语言指令进行通用机器人操作。一个主要挑战是,获得同时带有动作和文本注解的机器人轨迹是非常耗时和劳动密集型的。然而,部分标注的数据,如没有动作标签的人类活动视频和没有文本标签的机器人轨迹,更容易收集。我们能否利用这些数据来增强机器人的泛化能力?在本文中,我们提出了一种新的方法GR-MG,它支持基于文本指令和目标图像的条件设置。在训练过程中,GR-MG从轨迹中采样目标图像,并根据文本和目标图像或在没有文本时仅根据图像进行条件设置。在推理过程中,仅提供文本时,GR-MG会通过基于扩散的图像编辑模型生成目标图像,并根据文本和生成图像进行条件设置。这种方法使GR-MG能够利用大量部分标注的数据,同时使用语言灵活地指定任务。为了生成准确的目标图像,我们提出了一种新的进度引导目标图像生成模型,将任务进度信息注入生成过程。在模拟实验中,GR-MG将一排5个任务完成的平均数量从3.35提高到4.04。在真实机器人实验中,GR-MG能够执行58种不同的任务,并在简单和泛化设置中分别将成功率从68.7%提高到78.1%和从44.4%提高到60.6%。它还在少量学习新技能方面优于其他对比方法。视频演示、代码和检查点可在项目页面获得:https://gr-mg.github.io/。
论文及项目相关链接
PDF 8 pages, 5 figures, RA-L
Summary
该文提出了一种名为GR-MG的新方法,旨在利用文本指令和图像目标来实现机器人操作的通用化。方法能够在部分标注数据基础上工作,通过结合文本和图像或仅利用图像进行训练。在推理阶段,当仅提供文本时,GR-MG通过扩散式图像编辑模型生成目标图像,并结合文本和生成图像进行条件处理。此方法提高了任务的完成率,并在模拟和真实机器人实验中验证了其有效性。
Key Takeaways
- GR-MG方法支持结合文本指令和图像目标进行机器人操作。
- 方法能够在部分标注数据上工作,利用扩散式图像编辑模型生成目标图像。
- 在模拟实验中,GR-MG提高了任务的完成数量。
- 在真实机器人实验中,GR-MG提高了任务的完成率,特别是在泛化设置中。
- GR-MG在少量学习新技能方面优于对比的基线方法。
- 项目页面提供了视频演示、代码和检查点。
- 该方法通过结合文本和图像,提高了机器人的通用操作能力。
点此查看论文截图