⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-25 更新
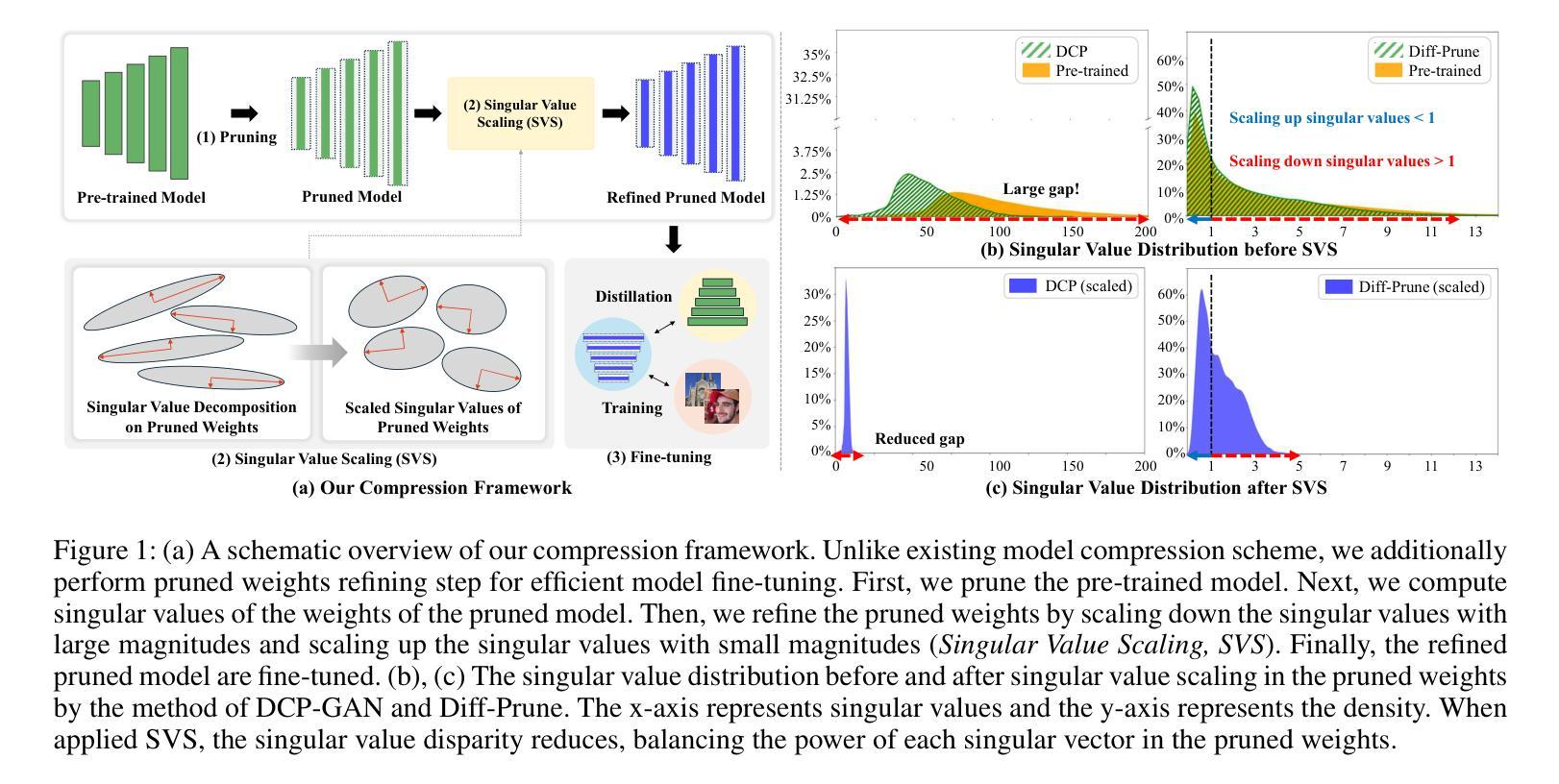
Singular Value Scaling: Efficient Generative Model Compression via Pruned Weights Refinement
Authors:Hyeonjin Kim, Jaejun Yoo
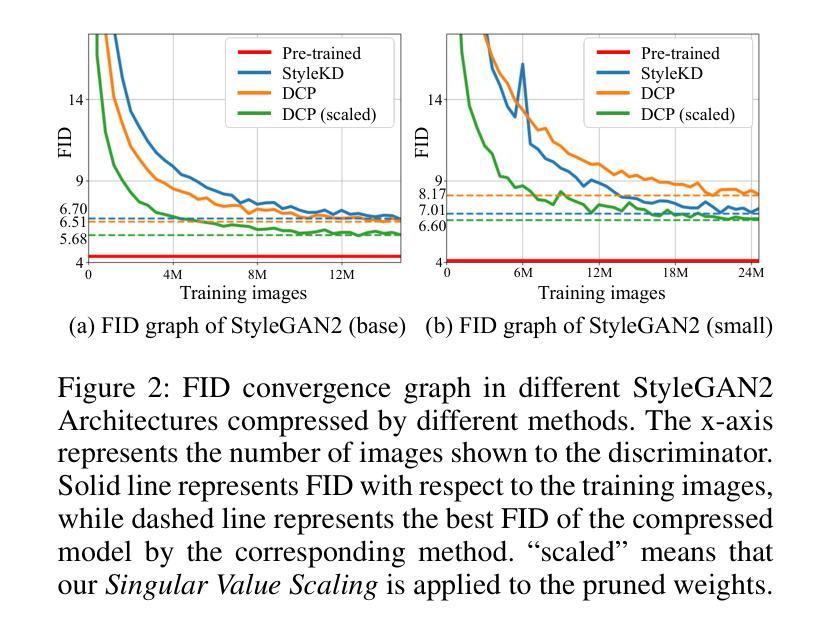
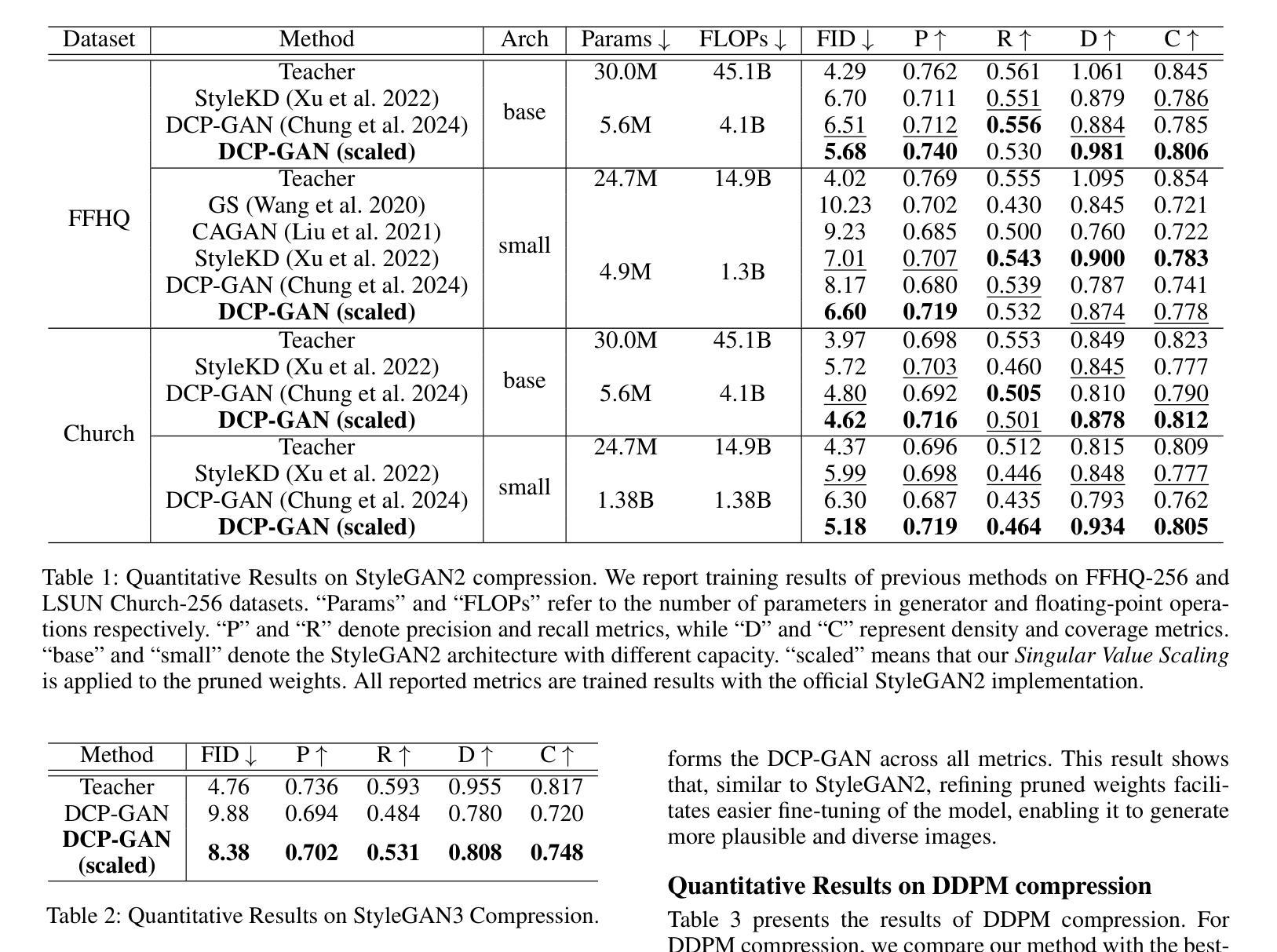
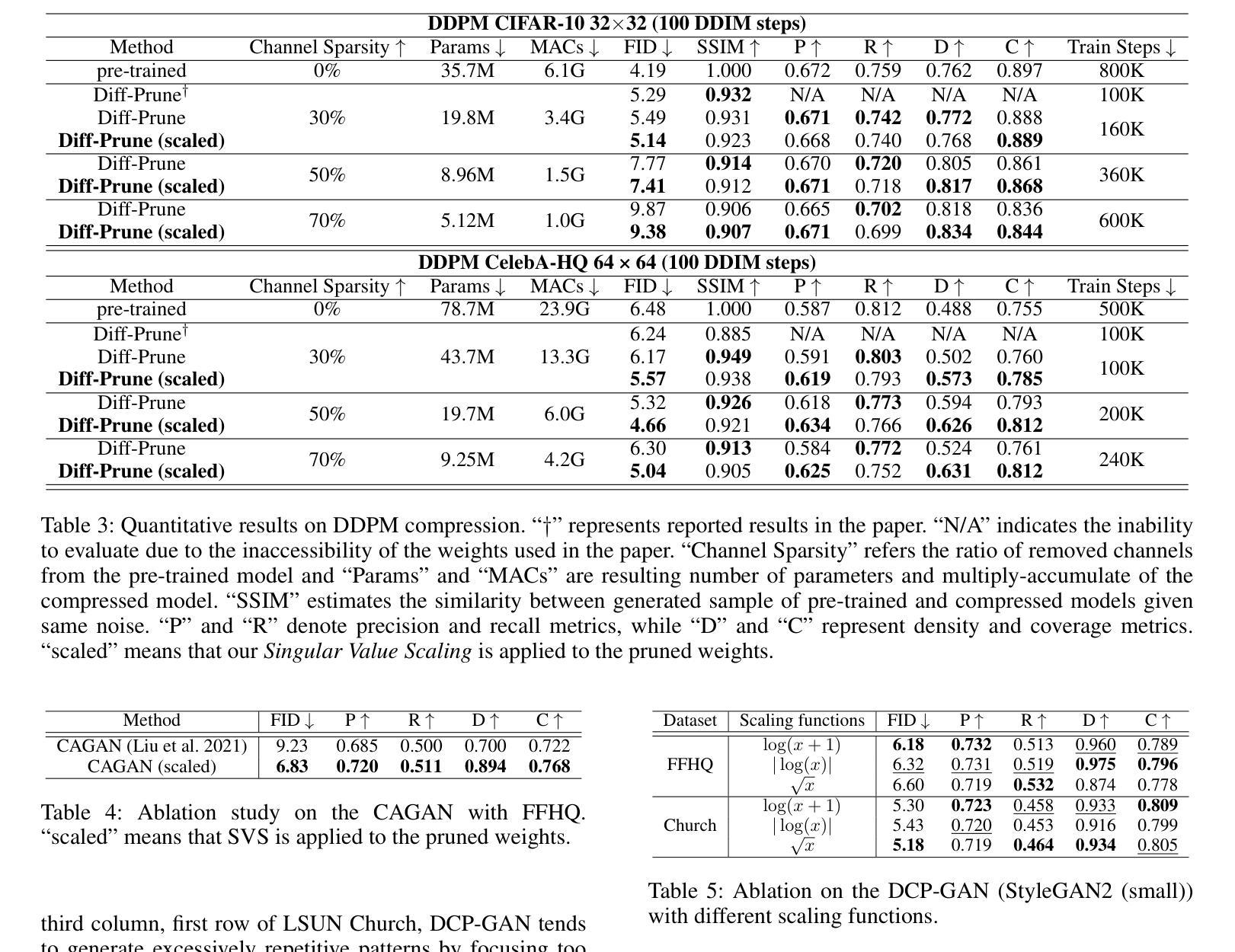
While pruning methods effectively maintain model performance without extra training costs, they often focus solely on preserving crucial connections, overlooking the impact of pruned weights on subsequent fine-tuning or distillation, leading to inefficiencies. Moreover, most compression techniques for generative models have been developed primarily for GANs, tailored to specific architectures like StyleGAN, and research into compressing Diffusion models has just begun. Even more, these methods are often applicable only to GANs or Diffusion models, highlighting the need for approaches that work across both model types. In this paper, we introduce Singular Value Scaling (SVS), a versatile technique for refining pruned weights, applicable to both model types. Our analysis reveals that pruned weights often exhibit dominant singular vectors, hindering fine-tuning efficiency and leading to suboptimal performance compared to random initialization. Our method enhances weight initialization by minimizing the disparities between singular values of pruned weights, thereby improving the fine-tuning process. This approach not only guides the compressed model toward superior solutions but also significantly speeds up fine-tuning. Extensive experiments on StyleGAN2, StyleGAN3 and DDPM demonstrate that SVS improves compression performance across model types without additional training costs. Our code is available at: https://github.com/LAIT-CVLab/Singular_Value_Scaling.
虽然剪枝方法能够有效地保持模型性能且无需额外的训练成本,但它们通常只专注于保留关键连接,而忽视了剪枝权重对后续微调或蒸馏的影响,从而导致效率低下。此外,大多数生成模型的压缩技术主要是针对生成对抗网络(GANs)开发的,适用于特定的架构(如StyleGAN),而对扩散模型(Diffusion models)的压缩研究才刚刚开始。甚至这些方法通常仅适用于GANs或扩散模型,这突显了需要能够在这两种模型类型中都有效运行的方法。在本文中,我们介绍了奇异值缩放(Singular Value Scaling, SVS),这是一种精炼剪枝权重的通用技术,适用于这两种模型类型。我们的分析表明,剪枝权重通常表现出主导的奇异向量,阻碍微调效率,并导致与随机初始化相比性能不佳。我们的方法通过最小化剪枝权重的奇异值之间的差异来增强权重初始化,从而改进微调过程。这种方法不仅引导压缩模型走向更优的解决方案,而且还大大加快了微调速度。在StyleGAN2、StyleGAN3和DDPM上的广泛实验表明,SVS提高了各种模型的压缩性能,且无需额外的训练成本。我们的代码可在以下网址找到:https://github.com/LAIT-CVlab/Singular_Value_Scaling。
论文及项目相关链接
PDF Accepted to AAAI 2025
Summary
本文介绍了针对生成模型(包括GAN和Diffusion模型)的权重修剪问题,提出了一种名为Singular Value Scaling(SVS)的精炼修剪权重技术。研究指出,修剪后的权重往往存在主导奇异向量,影响微调效率并导致性能下降。SVS方法通过最小化修剪权重的奇异值差异,改进了权重初始化,提高了微调过程的效率,使压缩模型不仅达到更好的解决方案,而且显著加快了微调速度。实验证明,SVS在StyleGAN2、StyleGAN3和DDPM等多种模型上都能提高压缩性能且无需额外训练成本。
Key Takeaways
- 现有生成模型的权重修剪方法多侧重于保持模型性能并降低训练成本,但忽视了修剪后的权重对后续微调或蒸馏的影响。
- 本文提出一种名为Singular Value Scaling(SVS)的方法,针对这一问题进行了改进,该技术旨在精炼修剪后的权重以提高微调过程的效率。
- SVS特别关注了修剪权重的主导奇异向量问题,通过最小化奇异值差异优化了权重初始化。
- SVS方法适用于多种生成模型类型,包括GAN和Diffusion模型。
- 实验证明,SVS在多种模型上都能显著提高压缩性能且无需额外的训练成本。
- 通过使用SVS,压缩模型不仅能够达到更好的解决方案,而且微调速度也得到了显著的提升。
点此查看论文截图

GANFusion: Feed-Forward Text-to-3D with Diffusion in GAN Space
Authors:Souhaib Attaiki, Paul Guerrero, Duygu Ceylan, Niloy J. Mitra, Maks Ovsjanikov
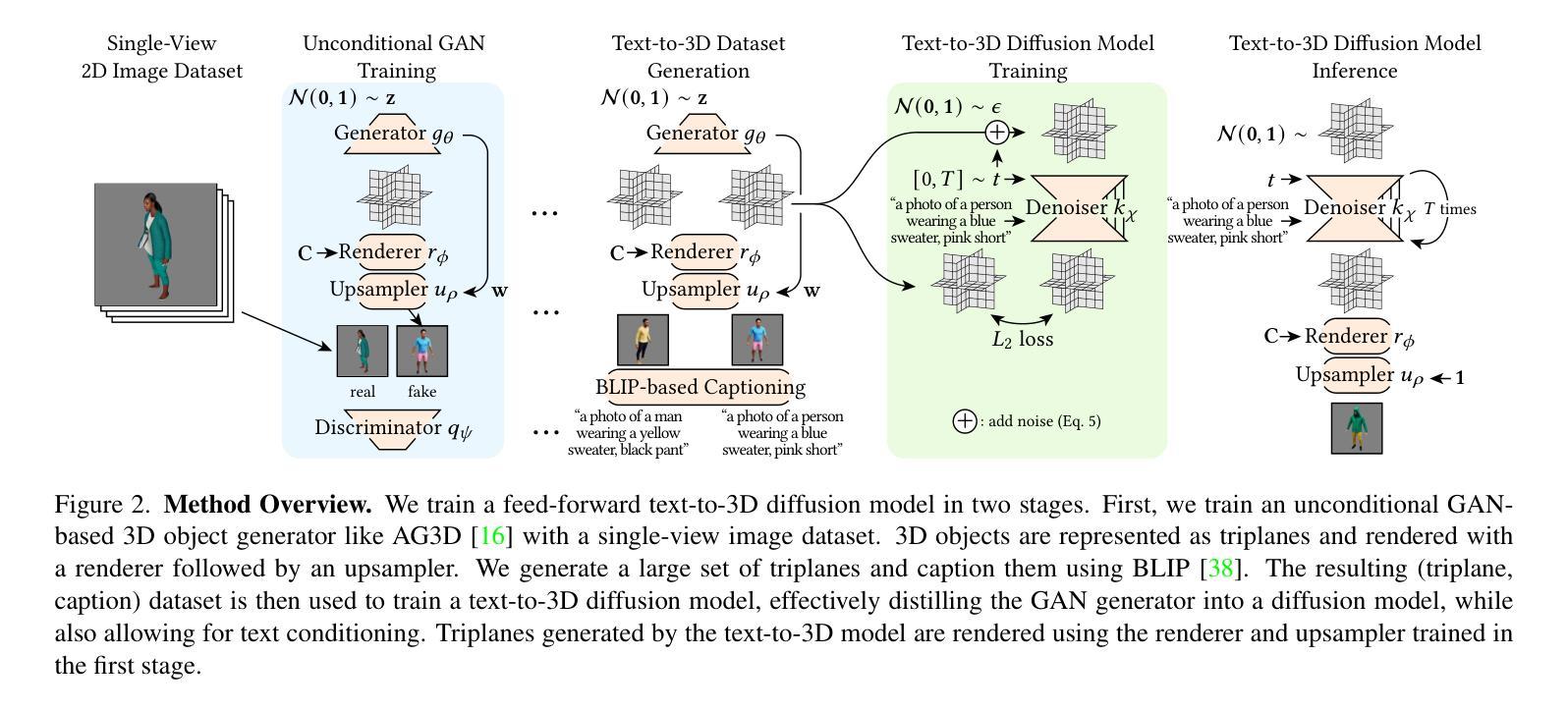
We train a feed-forward text-to-3D diffusion generator for human characters using only single-view 2D data for supervision. Existing 3D generative models cannot yet match the fidelity of image or video generative models. State-of-the-art 3D generators are either trained with explicit 3D supervision and are thus limited by the volume and diversity of existing 3D data. Meanwhile, generators that can be trained with only 2D data as supervision typically produce coarser results, cannot be text-conditioned, or must revert to test-time optimization. We observe that GAN- and diffusion-based generators have complementary qualities: GANs can be trained efficiently with 2D supervision to produce high-quality 3D objects but are hard to condition on text. In contrast, denoising diffusion models can be conditioned efficiently but tend to be hard to train with only 2D supervision. We introduce GANFusion, which starts by generating unconditional triplane features for 3D data using a GAN architecture trained with only single-view 2D data. We then generate random samples from the GAN, caption them, and train a text-conditioned diffusion model that directly learns to sample from the space of good triplane features that can be decoded into 3D objects.
我们仅使用单视图2D数据进行监督,训练了一个前馈文本到3D扩散生成器,用于生成人物角色。现有的3D生成模型尚无法匹配图像或视频生成模型的保真度。最先进的3D生成器要么接受明确的3D监督训练,因此受到现有3D数据的数量和多样性的限制;同时,那些仅能以2D数据作为监督进行训练的生成器通常会产生较粗糙的结果,无法以文本为条件,或在测试时需要进行优化。我们发现GAN和扩散生成的生成器具有互补的性质:GAN可以用二维监督有效地训练来产生高质量的3D对象,但难以根据文本进行调整。相比之下,去噪扩散模型可以高效地进行条件处理,但往往难以仅通过二维监督进行训练。我们引入了GANFusion,它首先使用仅通过单视图二维数据进行训练的GAN架构,为三维数据生成无条件的三平面特征。然后我们从GAN中生成随机样本,给它们加标题,并训练一个根据文本调节的扩散模型,该模型直接学习从良好的三平面特征空间中进行采样,这些特征可以被解码为三维对象。
论文及项目相关链接
PDF https://ganfusion.github.io/
Summary
本文主要介绍了基于文本条件的3D扩散模型的训练,利用单视图二维数据作为监督数据生成高保真三维数据的方法。通过GAN架构生成无条件的三平面特征,然后训练文本条件下的扩散模型,直接从良好的三平面特征空间中采样并解码为三维对象。
Key Takeaways
- 使用单视图二维数据作为监督数据进行三维生成模型的训练。
- 现有三维生成模型无法与图像或视频生成模型的保真度相匹配。
- GAN和扩散模型具有互补的特性,GAN可以使用二维监督产生高质量的三维物体,但难以进行文本条件训练;而扩散模型可以高效地进行条件训练,但难以仅使用二维监督进行训练。
- 提出了一种新的方法GANFusion,首先使用GAN架构和仅单视图二维数据生成无条件的三平面特征。
- 通过生成随机样本并添加文本描述,训练文本条件下的扩散模型。
- 扩散模型能够直接从良好的三平面特征空间中采样。
点此查看论文截图


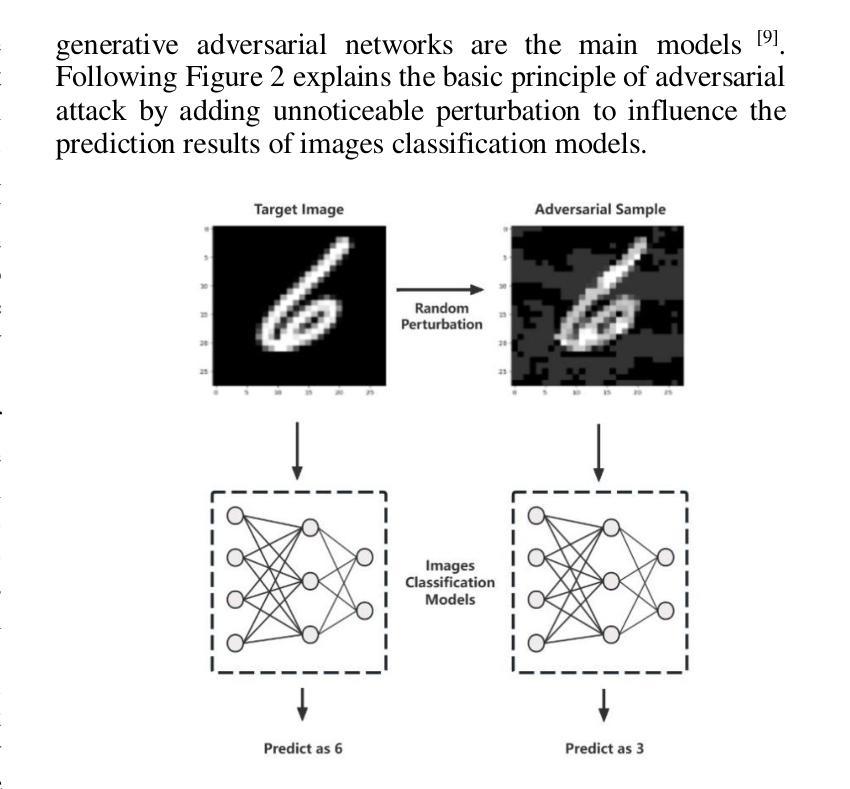
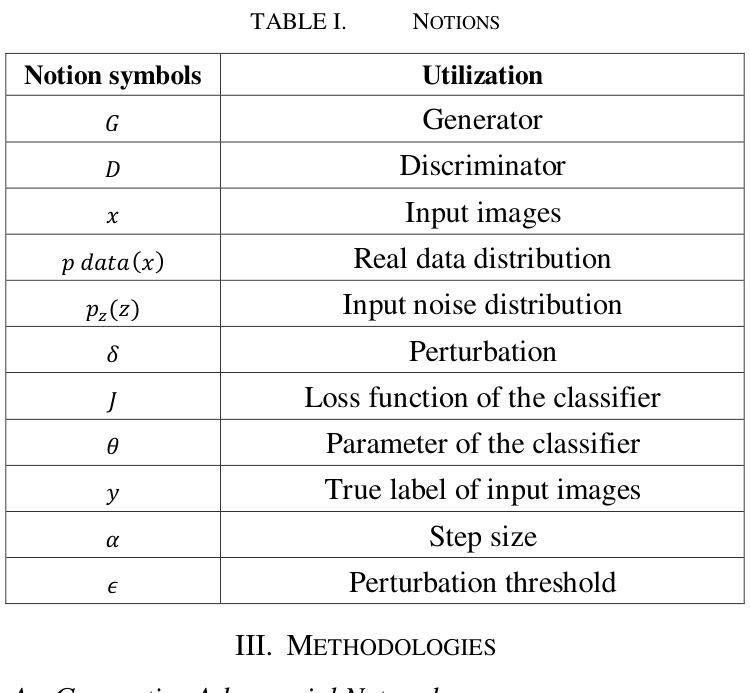
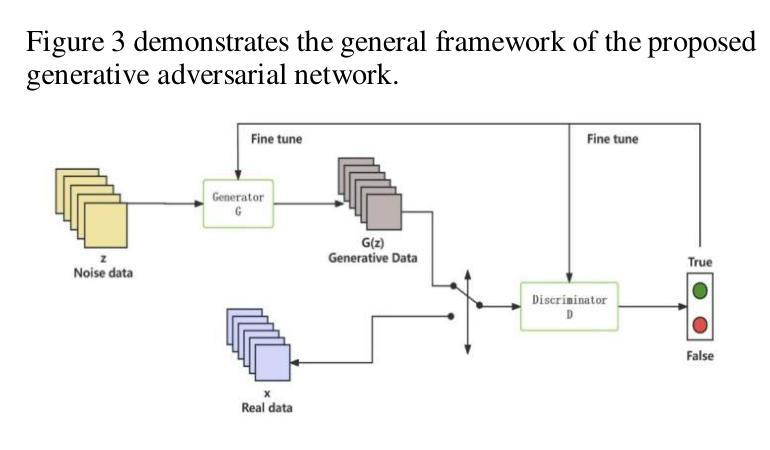
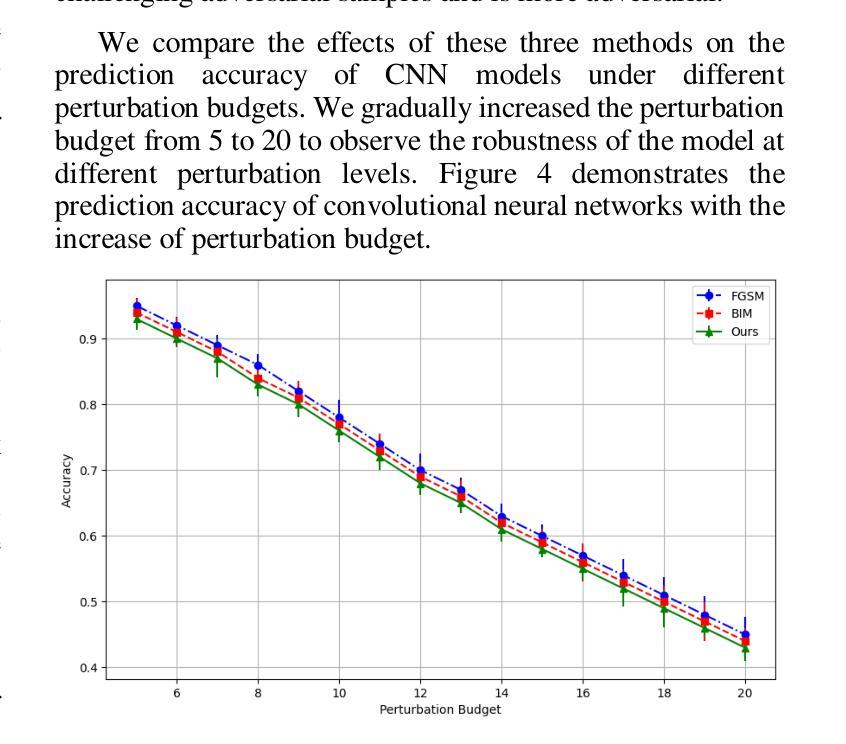
Adversarial Attack Against Images Classification based on Generative Adversarial Networks
Authors:Yahe Yang
Adversarial attacks on image classification systems have always been an important problem in the field of machine learning, and generative adversarial networks (GANs), as popular models in the field of image generation, have been widely used in various novel scenarios due to their powerful generative capabilities. However, with the popularity of generative adversarial networks, the misuse of fake image technology has raised a series of security problems, such as malicious tampering with other people’s photos and videos, and invasion of personal privacy. Inspired by the generative adversarial networks, this work proposes a novel adversarial attack method, aiming to gain insight into the weaknesses of the image classification system and improve its anti-attack ability. Specifically, the generative adversarial networks are used to generate adversarial samples with small perturbations but enough to affect the decision-making of the classifier, and the adversarial samples are generated through the adversarial learning of the training generator and the classifier. From extensive experiment analysis, we evaluate the effectiveness of the method on a classical image classification dataset, and the results show that our model successfully deceives a variety of advanced classifiers while maintaining the naturalness of adversarial samples.
对抗性攻击一直是机器学习领域图像分类系统中的重要问题。生成对抗性网络(GANs)作为图像生成领域的流行模型,由于其强大的生成能力,已被广泛应用于各种新场景。然而,随着生成对抗性网络的普及,虚假图像技术的滥用引发了一系列安全问题,如恶意篡改他人照片和视频以及侵犯个人隐私。本研究受生成对抗性网络的启发,提出了一种新型对抗性攻击方法,旨在深入了解图像分类系统的弱点,提高其抗攻击能力。具体来说,利用生成对抗性网络生成具有小扰动但对分类器决策产生影响的对抗性样本,这些对抗性样本是通过训练生成器和分类器的对抗性学习生成的。通过大量的实验分析,我们在经典图像分类数据集上评估了该方法的有效性,结果表明,我们的模型在保持对抗性样本自然性的同时,成功地欺骗了各种先进的分类器。
论文及项目相关链接
PDF 7 pages, 6 figures
Summary
生成对抗网络(GANs)因其强大的图像生成能力而在图像分类系统中受到广泛关注,但其滥用虚假图像技术引发了一系列安全问题,如恶意篡改他人照片和视频、侵犯个人隐私等。本文受生成对抗网络的启发,提出了一种新的对抗攻击方法,旨在了解图像分类系统的弱点,提高其抗攻击能力。该方法通过生成对抗样本(具有小扰动但足以影响分类器决策)来进行对抗学习,并在经典图像分类数据集上进行广泛实验验证。结果表明,该模型在保持对抗样本自然性的同时,成功欺骗了多种先进的分类器。
Key Takeaways
- 生成对抗网络(GANs)在图像分类系统中广泛应用,但滥用引发安全问题。
- 本文受GANs启发,提出一种新型对抗攻击方法,旨在探索图像分类系统的弱点。
- 使用生成对抗网络生成对抗样本,这些样本具有小扰动,但足以影响分类器的决策。
- 对抗样本通过训练生成器和分类器的对抗学习来生成。
- 在经典图像分类数据集上进行广泛实验验证,证明该方法的有效性。
- 该模型在保持对抗样本自然性的同时,成功欺骗了多种先进的分类器。
点此查看论文截图



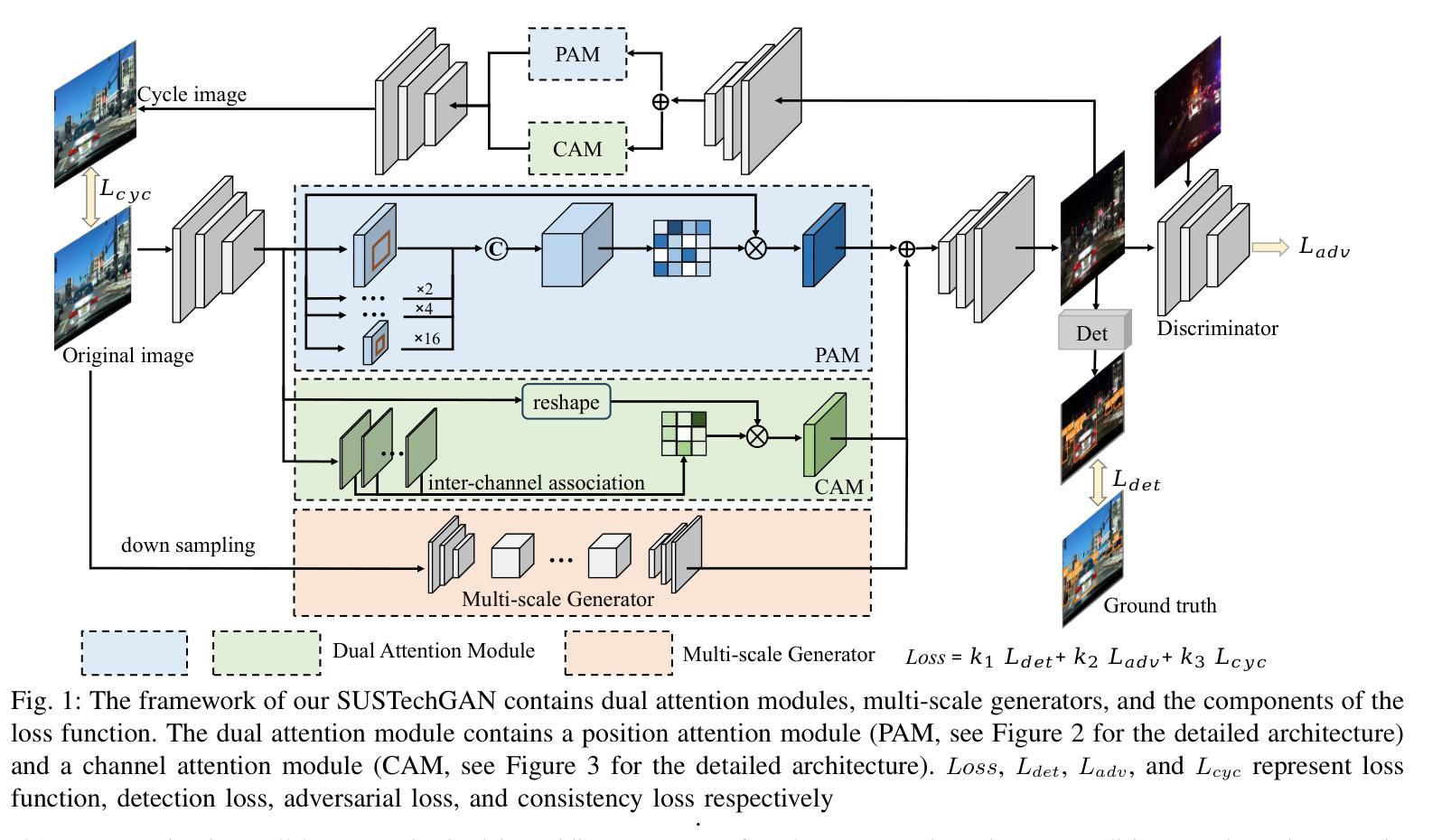
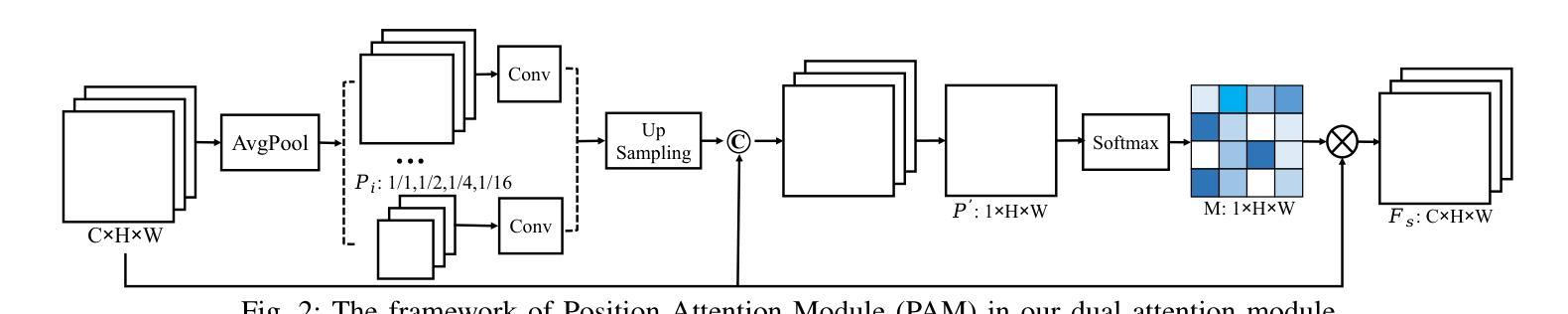
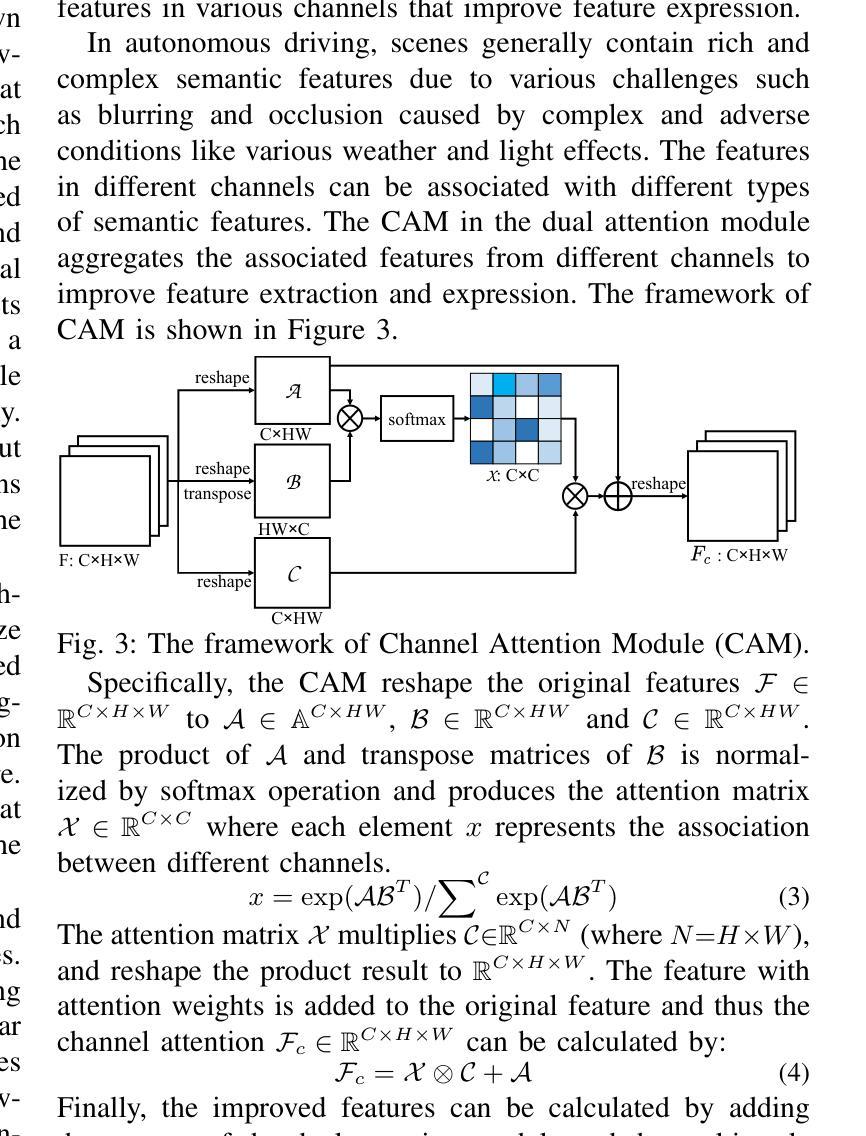
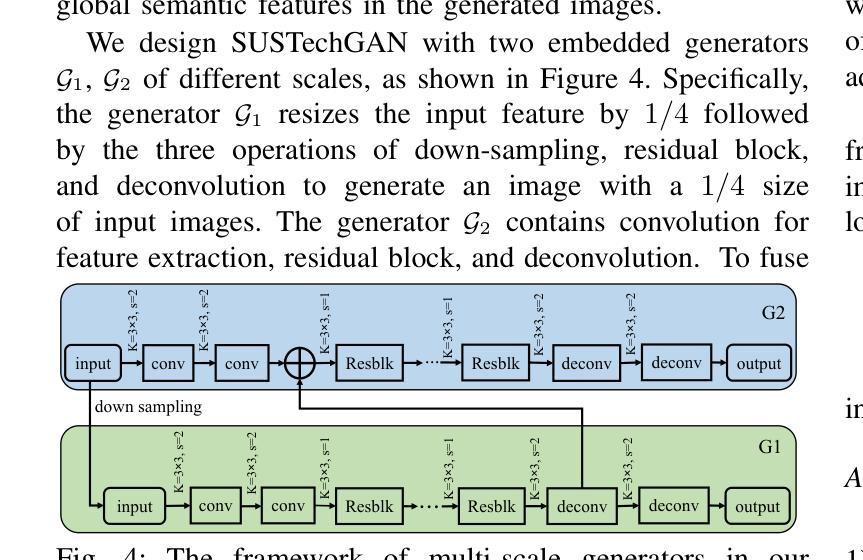
SUSTechGAN: Image Generation for Object Detection in Adverse Conditions of Autonomous Driving
Authors:Gongjin Lan, Yang Peng, Qi Hao, Chengzhong Xu
Autonomous driving significantly benefits from data-driven deep neural networks. However, the data in autonomous driving typically fits the long-tailed distribution, in which the critical driving data in adverse conditions is hard to collect. Although generative adversarial networks (GANs) have been applied to augment data for autonomous driving, generating driving images in adverse conditions is still challenging. In this work, we propose a novel framework, SUSTechGAN, with customized dual attention modules, multi-scale generators, and a novel loss function to generate driving images for improving object detection of autonomous driving in adverse conditions. We test the SUSTechGAN and the well-known GANs to generate driving images in adverse conditions of rain and night and apply the generated images to retrain object detection networks. Specifically, we add generated images into the training datasets to retrain the well-known YOLOv5 and evaluate the improvement of the retrained YOLOv5 for object detection in adverse conditions. The experimental results show that the generated driving images by our SUSTechGAN significantly improved the performance of retrained YOLOv5 in rain and night conditions, which outperforms the well-known GANs. The open-source code, video description and datasets are available on the page 1 to facilitate image generation development in autonomous driving under adverse conditions.
自动驾驶技术受益于数据驱动的深度神经网络。然而,自动驾驶中的数据通常符合长尾分布,其中在恶劣条件下的关键驾驶数据收集困难。虽然生成对抗网络(GANs)已被应用于增强自动驾驶的数据,但在恶劣条件下生成驾驶图像仍然具有挑战性。在这项工作中,我们提出了一种新型框架SUSTechGAN,它配备了定制的双重注意力模块、多尺度生成器和新型损失函数,以生成驾驶图像,旨在改善恶劣条件下的自动驾驶目标检测。我们对SUSTechGAN和著名的GANs进行了测试,以生成雨天和夜晚等恶劣条件下的驾驶图像,并将生成的图像用于重新训练目标检测网络。具体来说,我们将生成的图像添加到训练数据集中,重新训练知名的YOLOv5模型,并评估重新训练的YOLOv5在恶劣条件下的目标检测性能提升情况。实验结果表明,我们的SUSTechGAN生成的驾驶图像显著提高了在雨天和夜晚条件下重新训练的YOLOv5的性能,并优于其他著名的GANs。为了方便在恶劣条件下自动驾驶的图像处理开发,我们在第1页上提供了开源代码、视频描述和数据集。
论文及项目相关链接
PDF 10 pages, 9 figures
Summary
基于数据驱动的深度神经网络,自动驾驶能从中受益颇多。然而,自动驾驶中的数据往往符合长尾分布,关键场景下的驾驶数据难以收集。虽然生成对抗网络(GANs)已被应用于增强自动驾驶的数据生成,但在恶劣条件下的驾驶图像生成仍然具有挑战性。本研究提出了一种新型框架SUSTechGAN,它配备了定制的双重注意力模块、多尺度生成器和新型损失函数,旨在生成恶劣条件下的驾驶图像,以提高自动驾驶的目标检测性能。实验结果显示,我们的SUSTechGAN生成的驾驶图像能显著提升YOLOv5在恶劣条件下的目标检测性能,并优于其他知名的GANs。相关开源代码、视频描述和数据集已在页面上公开,以促进自动驾驶恶劣条件下的图像生成研究。
Key Takeaways
- 自动驾驶受益于数据驱动的深度神经网络。
- 自动驾驶数据通常符合长尾分布,关键场景数据难以收集。
- GANs被用于增强自动驾驶的数据生成,但恶劣条件下的驾驶图像生成仍然具有挑战性。
- 研究提出了一种新型框架SUSTechGAN,集成了双重注意力模块、多尺度生成器和新型损失函数。
- SUSTechGAN能够生成恶劣条件下的驾驶图像,用以提高自动驾驶的目标检测性能。
- 实验显示SUSTechGAN显著提升了YOLOv5在恶劣条件下的目标检测性能,并优于其他知名GANs。
点此查看论文截图




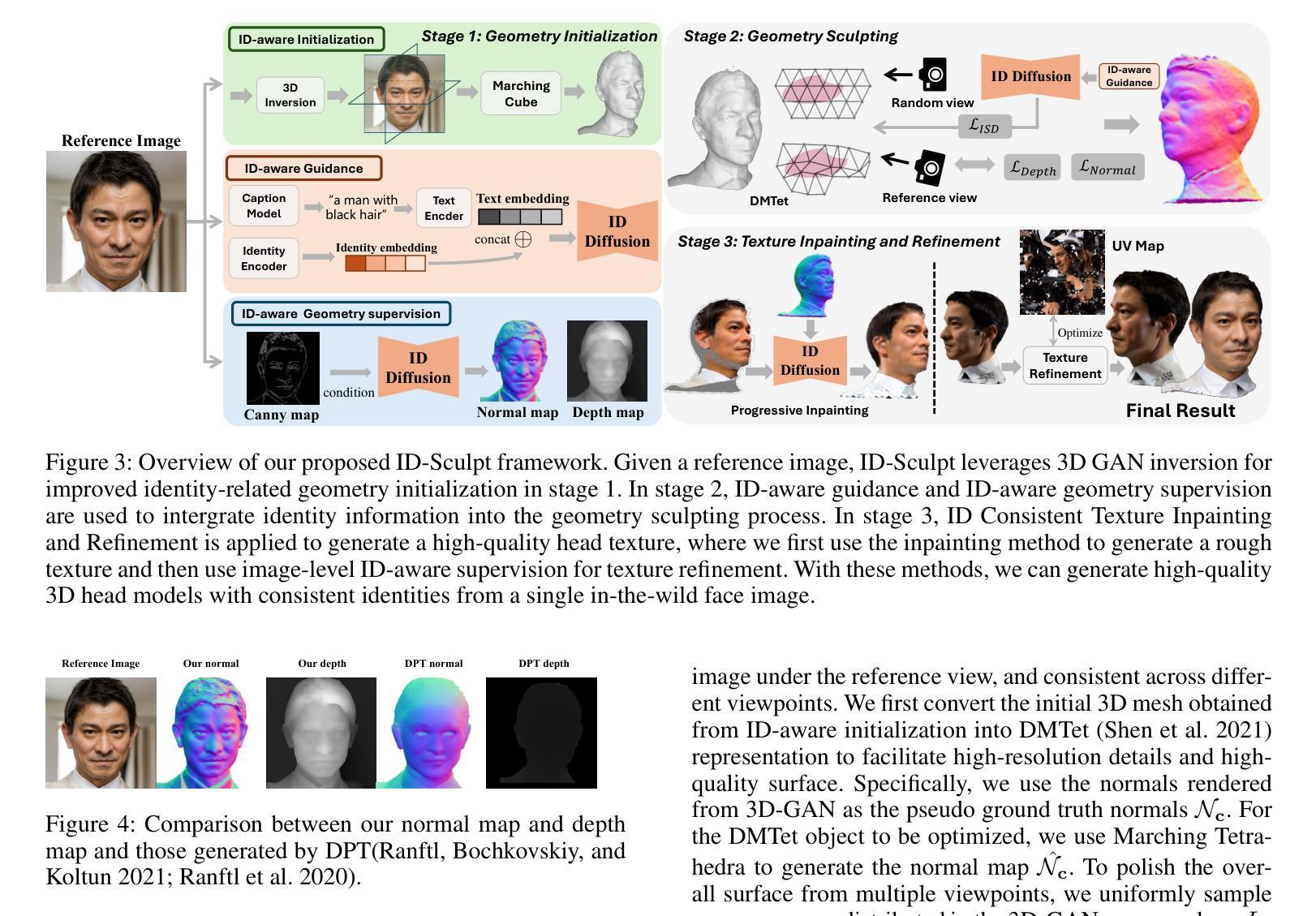
ID-Sculpt: ID-aware 3D Head Generation from Single In-the-wild Portrait Image
Authors:Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Chengjie Wang, Lizhuang Ma
While recent works have achieved great success on image-to-3D object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, ID-Sculpt, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the ID-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from a single in-the-wild portrait image.
尽管近期的研究在图像到3D物体的生成上取得了巨大成功,但从单张图像生成高质量和高保真度的3D头像仍然是一个巨大的挑战。之前的基于文本的方法生成3D头像受限于文本描述,而基于图像的方法难以产生高质量的头像几何结构。为了应对这一挑战性问题,我们提出了一种新型框架ID-Sculpt,用于生成高质量的3D头像,同时保留其身份特征。我们的工作将肖像图像的身份信息融入三个阶段:1)几何初始化,2)几何雕塑,3)纹理生成。给定参考肖像图像,我们首先通过文本特征与身份特征的对齐,实现ID感知引导增强,其中包含代表面部信息的控制信号。然后,我们使用Canny地图、肖像图像的身份特征以及预训练的文本到法线/深度扩散模型来生成ID感知的几何监督,并使用3D-GAN反转来生成ID感知的几何初始化。此外,通过向3D头像生成中注入身份信息的能力,我们使用ID感知引导来计算用于几何雕塑的ID感知分数蒸馏(ISD)。对于纹理生成,我们采用ID一致纹理填充和细化,逐步扩展纹理填充的视图以获得初始UV纹理贴图。然后,我们使用ID感知引导为噪声多视角图像提供图像级监督,以获得精细的纹理贴图。大量实验表明,我们可以从一张野外的肖像图像生成具有精确几何和纹理的高质量3D头像。
论文及项目相关链接
PDF Accepted by AAAI 2025; Project page: https://jinkun-hao.github.io/ID-Sculpt/
Summary
该文本描述了一个名为ID-Sculpt的新型框架,用于从单张肖像图像生成高质量的三维头像,同时保留其身份特征。框架将身份信息融入三个环节:几何初始化、几何雕刻和纹理生成。通过一系列技术手段,如ID感知指导增强、几何监督生成、3D-GAN反演等,实现了高质量的三维头像生成。
Key Takeaways
- ID-Sculpt框架可用于从单张肖像图像生成高质量的三维头像。
- 框架将身份信息融入三个主要环节,包括几何初始化、几何雕刻和纹理生成。
- 通过ID感知指导增强,实现身份特征的对齐和增强。
- 利用Canny地图、肖像图像的ID特征和预训练的文本到正常/深度扩散模型,生成ID感知几何监督。
- 3D-GAN反演用于生成ID感知几何初始化。
- ID感知指导用于计算几何雕刻的ID感知分数蒸馏(ISD)。
- 通过ID一致纹理填充和细化,逐步扩展视图以获得初始UV纹理贴图,并使用ID感知指导为噪声多视图图像提供图像级监督,获得精细纹理贴图。
点此查看论文截图