⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-25 更新
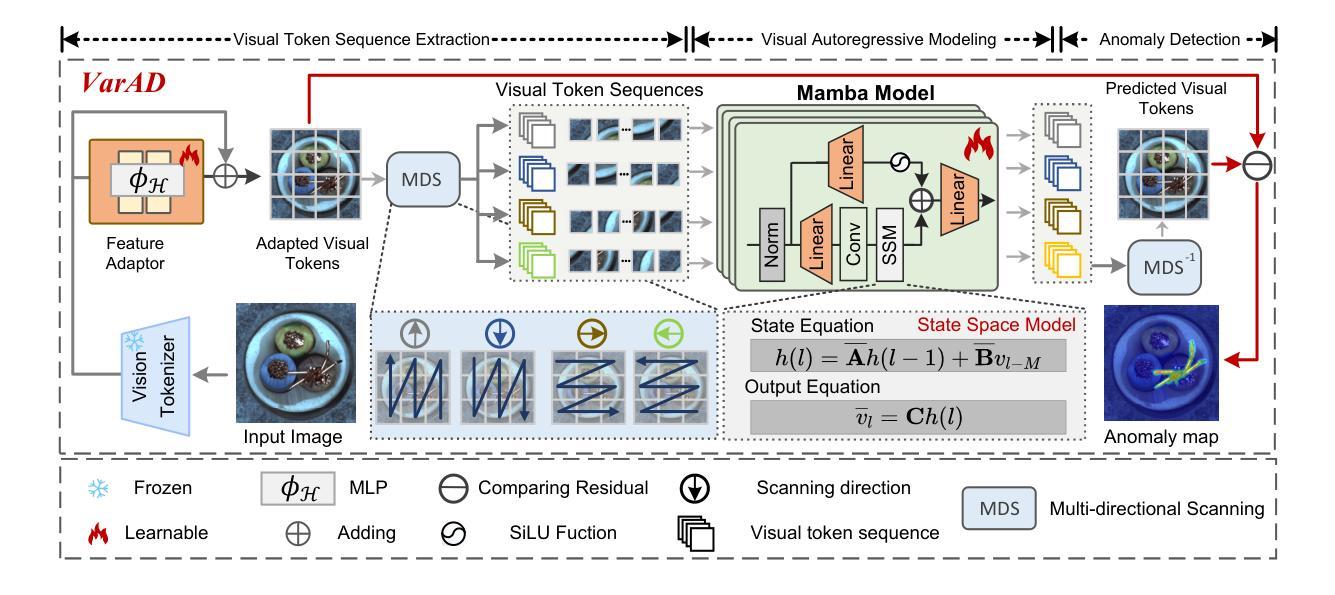
VarAD: Lightweight High-Resolution Image Anomaly Detection via Visual Autoregressive Modeling
Authors:Yunkang Cao, Haiming Yao, Wei Luo, Weiming Shen
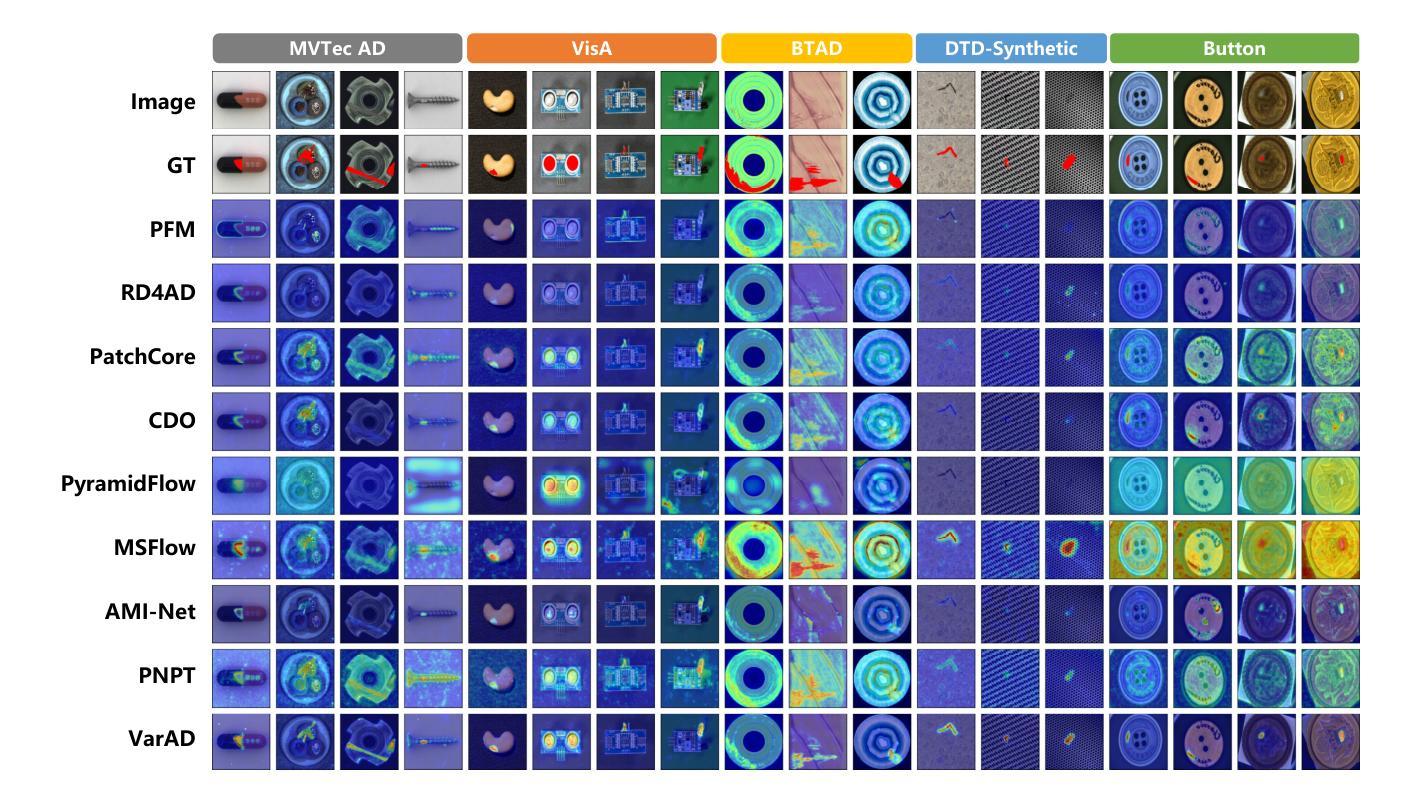
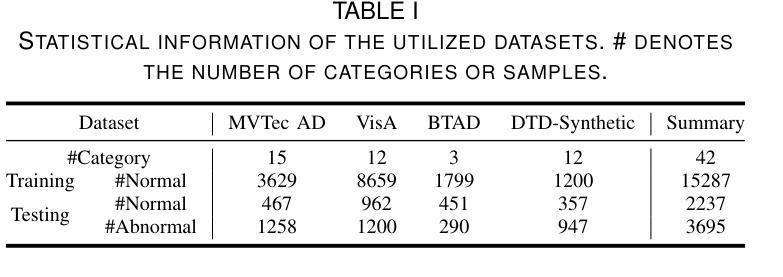
This paper addresses a practical task: High-Resolution Image Anomaly Detection (HRIAD). In comparison to conventional image anomaly detection for low-resolution images, HRIAD imposes a heavier computational burden and necessitates superior global information capture capacity. To tackle HRIAD, this paper translates image anomaly detection into visual token prediction and proposes VarAD based on visual autoregressive modeling for token prediction. Specifically, VarAD first extracts multi-hierarchy and multi-directional visual token sequences, and then employs an advanced model, Mamba, for visual autoregressive modeling and token prediction. During the prediction process, VarAD effectively exploits information from all preceding tokens to predict the target token. Finally, the discrepancies between predicted tokens and original tokens are utilized to score anomalies. Comprehensive experiments on four publicly available datasets and a real-world button inspection dataset demonstrate that the proposed VarAD achieves superior high-resolution image anomaly detection performance while maintaining lightweight, rendering VarAD a viable solution for HRIAD. Code is available at \href{https://github.com/caoyunkang/VarAD}{\url{https://github.com/caoyunkang/VarAD}}.
本文解决了一项实际任务:高分辨率图像异常检测(HRIAD)。与针对低分辨率图像的传统图像异常检测相比,HRIAD带来了更重的计算负担,需要更高的全局信息捕获能力。为解决HRIAD问题,本文将图像异常检测转化为视觉令牌预测,并提出了基于视觉自回归建模的VarAD方法进行令牌预测。具体来说,VarAD首先提取多层级、多方向的视觉令牌序列,然后使用先进的Mamba模型进行视觉自回归建模和令牌预测。在预测过程中,VarAD有效利用所有前面令牌的信息来预测目标令牌。最后,利用预测令牌与原始令牌之间的差异来评分异常值。在四个公开数据集和真实按钮检测数据集上的综合实验表明,所提出的VarAD实现了高分辨率图像异常检测的卓越性能,同时保持轻量化,使其成为HRIAD的可行解决方案。代码可在https://github.com/caoyunkang/VarAD处获取。
论文及项目相关链接
PDF Accepted by IEEE TII
Summary
该论文专注于高分辨率图像异常检测(HRIAD)任务,并将其转化为视觉令牌预测问题。提出了基于视觉自回归建模的VarAD方法,通过多层级、多方向的视觉令牌序列提取,利用Mamba先进模型进行视觉自回归建模和令牌预测。通过比较预测令牌与原始令牌之间的差异来评分异常。实验证明,VarAD在四个公开数据集和真实按钮检测数据集上实现了高性能的高分辨率图像异常检测,且保持轻量化。
Key Takeaways
- 该论文针对高分辨率图像异常检测(HRIAD)任务,提出一种基于视觉自回归建模的方法VarAD。
- VarAD将图像异常检测转化为视觉令牌预测问题。
- VarAD通过多层级、多方向的视觉令牌序列提取,提高信息捕捉能力。
- 使用Mamba先进模型进行视觉自回归建模和令牌预测,利用前面的令牌信息预测目标令牌。
- VarAD通过比较预测令牌与原始令牌之间的差异来评分异常。
- 实验证明VarAD在多个数据集上实现了高性能的高分辨率图像异常检测。
点此查看论文截图



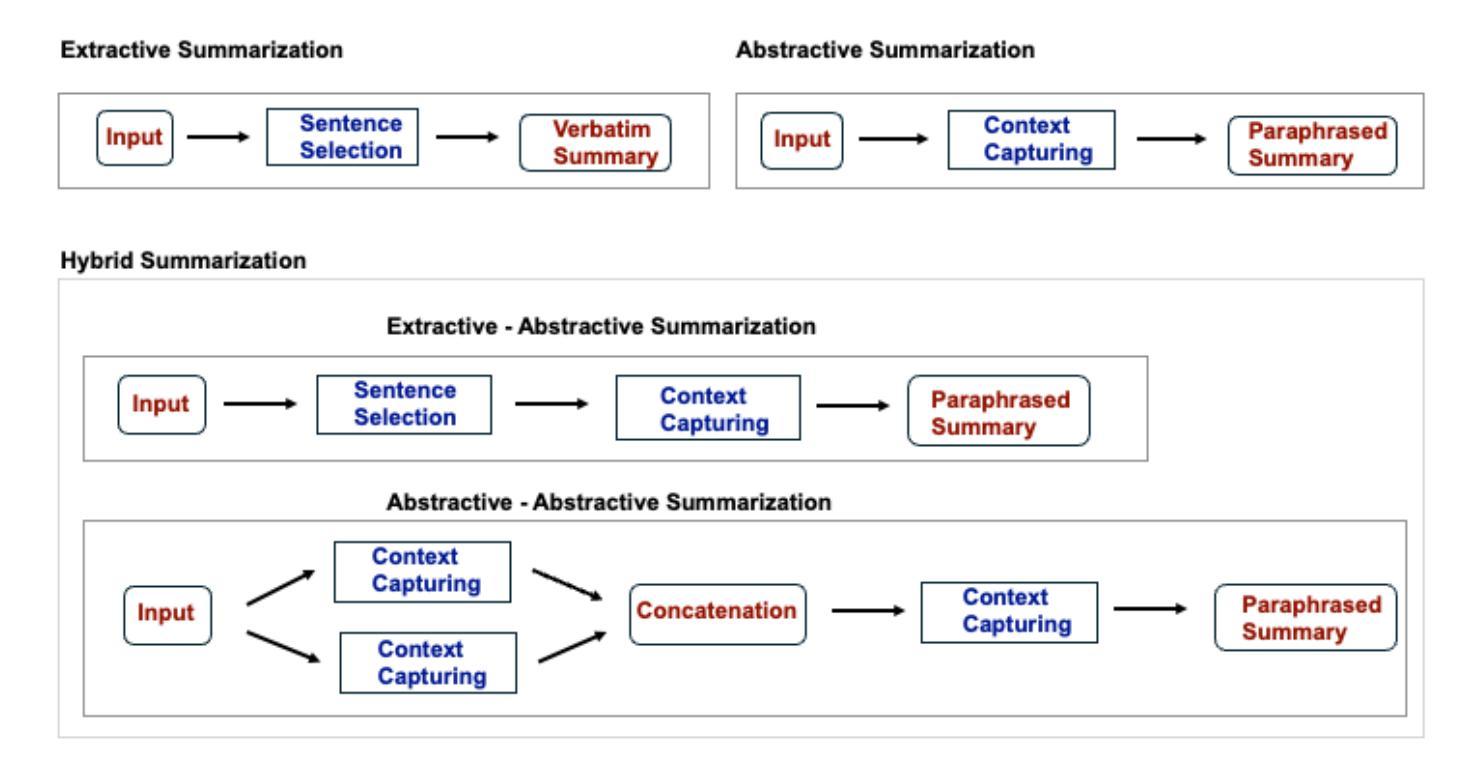
Survey on Abstractive Text Summarization: Dataset, Models, and Metrics
Authors:Gospel Ozioma Nnadi, Flavio Bertini
The advancements in deep learning, particularly the introduction of transformers, have been pivotal in enhancing various natural language processing (NLP) tasks. These include text-to-text applications such as machine translation, text classification, and text summarization, as well as data-to-text tasks like response generation and image-to-text tasks such as captioning. Transformer models are distinguished by their attention mechanisms, pretraining on general knowledge, and fine-tuning for downstream tasks. This has led to significant improvements, particularly in abstractive summarization, where sections of a source document are paraphrased to produce summaries that closely resemble human expression. The effectiveness of these models is assessed using diverse metrics, encompassing techniques like semantic overlap and factual correctness. This survey examines the state of the art in text summarization models, with a specific focus on the abstractive summarization approach. It reviews various datasets and evaluation metrics used to measure model performance. Additionally, it includes the results of test cases using abstractive summarization models to underscore the advantages and limitations of contemporary transformer-based models. The source codes and the data are available at https://github.com/gospelnnadi/Text-Summarization-SOTA-Experiment.
深度学习的发展,特别是变压器的引入,对于增强各种自然语言处理(NLP)任务至关重要。这些包括文本到文本的应用,如机器翻译、文本分类和文本摘要,以及数据到文本的任务,如生成响应和图像到文本的任务,如图像描述。变压器模型以其注意力机制、对通用知识的预训练以及针对下游任务的微调而著称。这带来了显著的改进,特别是在抽象摘要中,源文档的部分内容被改述以产生摘要,这些摘要与人类的表达非常相似。这些模型的有效性是通过各种度量标准进行评估的,包括语义重叠和事实正确性等技术。这篇综述探讨了文本摘要模型的最前沿技术,重点关注抽象摘要方法。它回顾了用于衡量模型性能的各种数据集和评估指标。此外,还包括使用抽象摘要模型进行试验的结果,以强调基于当代变压器的模型的优点和局限性。源代码和数据可在 https://github.com/gospelnnadi/Text-Summarization-SOTA-Experiment 找到。
论文及项目相关链接
Summary:深度学习的发展,尤其是Transformer的引入,极大地推动了自然语言处理(NLP)任务的进步。它在文本到文本的任务如机器翻译、文本分类和文本摘要,以及数据到文本的任务如生成回应和图像到文本的任务如描述等方面都有显著的提升。Transformer模型通过其注意力机制、通用知识的预训练和下游任务的微调来区分。这极大地改进了抽象摘要,特别是当对源文档的部分进行改述以产生与人类表达相似的摘要时。该调查研究了文本摘要模型的最新技术,重点关注抽象摘要方法。它回顾了衡量模型性能的多种数据集和评估指标。此外,它还通过测试用例展示了基于当代Transformer模型的抽象摘要模型的优势和局限性。源代码和数据可在https://github.com/gospelnnadi/Text-Summarization-SOTA-Experiment找到。
Key Takeaways:
- 深度学习,特别是Transformer的引入,对自然语言处理任务有显著的提升。
- Transformer模型具有注意力机制、预训练通用知识和针对下游任务的微调等特征。
- 在抽象摘要方面,Transformer模型有显著的改进,能够改述源文档的部分以产生接近人类表达的内容。
- 该调查主要关注文本摘要模型的最新技术,特别是抽象摘要方法。
- 文章回顾了用于衡量模型性能的各种数据集和评估指标。
- 测试用例展示了基于当代Transformer模型的抽象摘要模型的优势和局限性。
- 源代码和数据可以在指定链接中找到。
点此查看论文截图