⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-25 更新
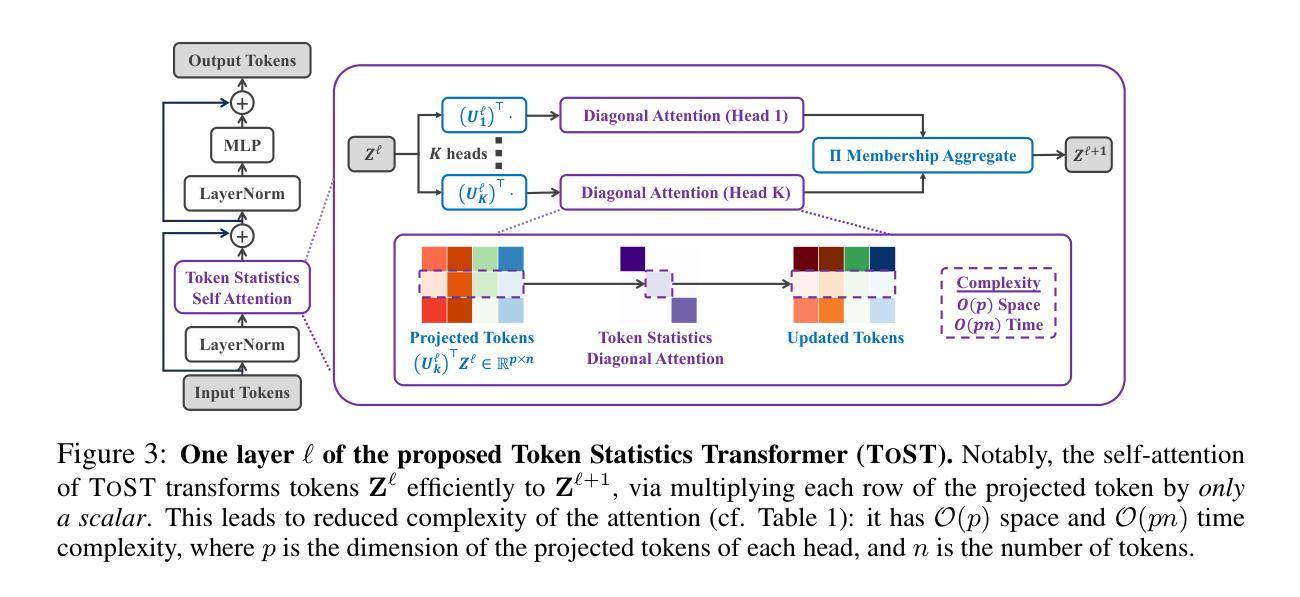
Token Statistics Transformer: Linear-Time Attention via Variational Rate Reduction
Authors:Ziyang Wu, Tianjiao Ding, Yifu Lu, Druv Pai, Jingyuan Zhang, Weida Wang, Yaodong Yu, Yi Ma, Benjamin D. Haeffele
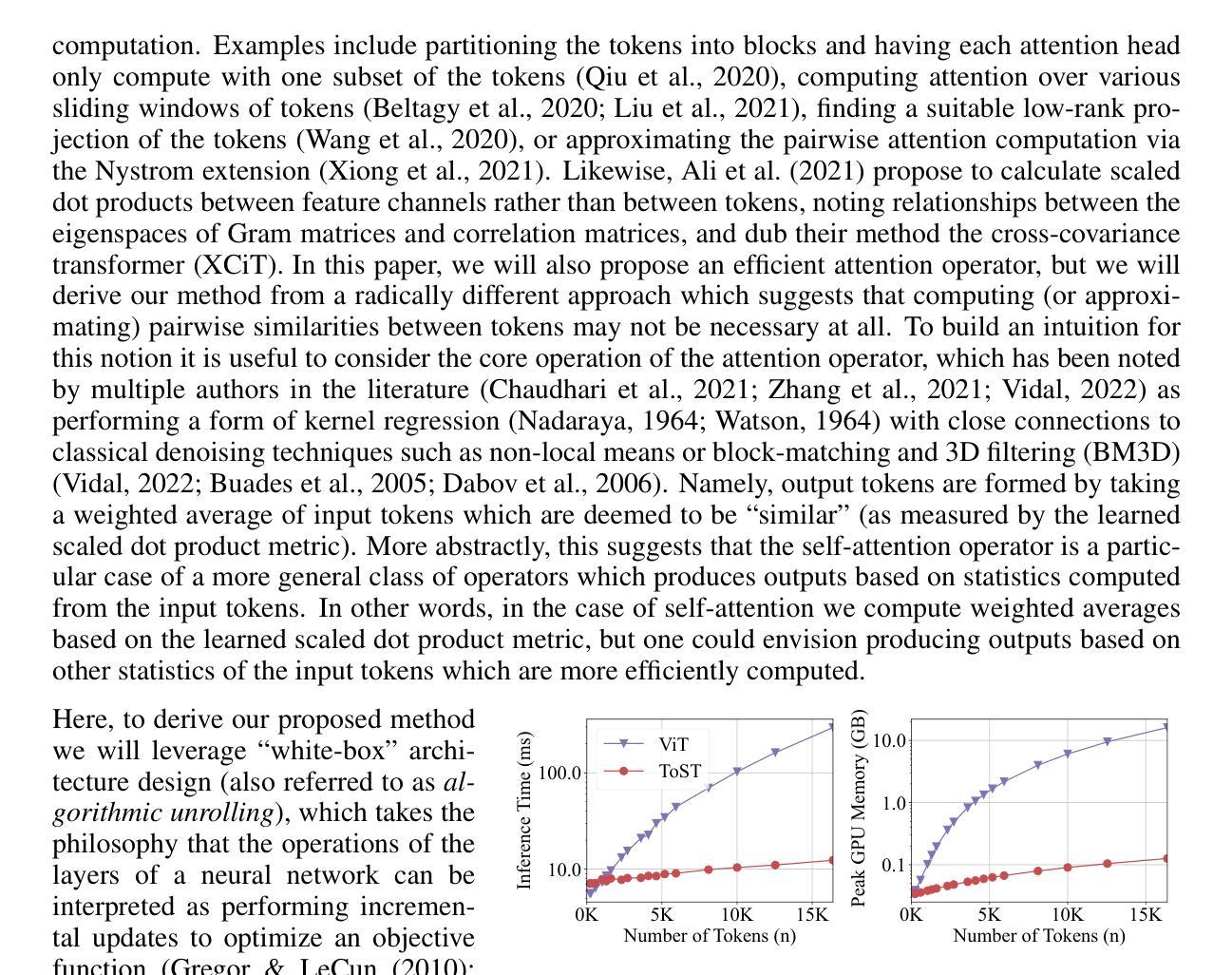
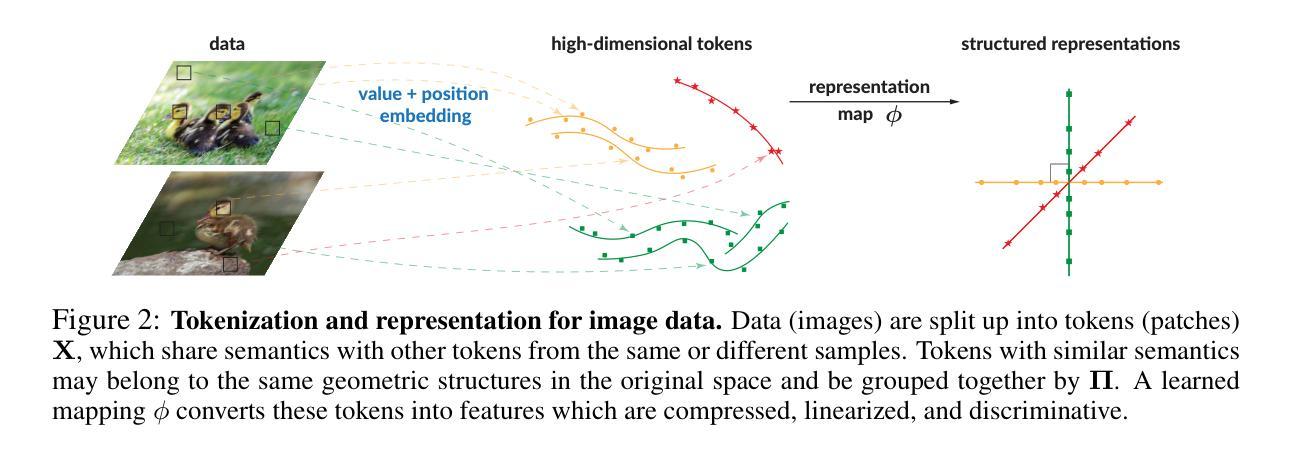
The attention operator is arguably the key distinguishing factor of transformer architectures, which have demonstrated state-of-the-art performance on a variety of tasks. However, transformer attention operators often impose a significant computational burden, with the computational complexity scaling quadratically with the number of tokens. In this work, we propose a novel transformer attention operator whose computational complexity scales linearly with the number of tokens. We derive our network architecture by extending prior work which has shown that a transformer style architecture naturally arises by “white-box” architecture design, where each layer of the network is designed to implement an incremental optimization step of a maximal coding rate reduction objective (MCR$^2$). Specifically, we derive a novel variational form of the MCR$^2$ objective and show that the architecture that results from unrolled gradient descent of this variational objective leads to a new attention module called Token Statistics Self-Attention (TSSA). TSSA has linear computational and memory complexity and radically departs from the typical attention architecture that computes pairwise similarities between tokens. Experiments on vision, language, and long sequence tasks show that simply swapping TSSA for standard self-attention, which we refer to as the Token Statistics Transformer (ToST), achieves competitive performance with conventional transformers while being significantly more computationally efficient and interpretable. Our results also somewhat call into question the conventional wisdom that pairwise similarity style attention mechanisms are critical to the success of transformer architectures. Code will be available at https://github.com/RobinWu218/ToST.
注意力操作可以说是区分变压器架构的关键要素,这种架构在各种任务上都表现出了卓越的性能。然而,变压器注意力操作通常会带来很大的计算负担,其计算复杂度随令牌数量的增加而呈二次方增长。在这项工作中,我们提出了一种新型变压器注意力操作,其计算复杂度随令牌数量线性增长。我们通过扩展先前的工作来推导我们的网络架构,先前的工作显示,通过“白盒”架构设计自然地产生了变压器风格的架构,该架构的每一层都被设计成实现最大编码率降低目标(MCR$^2$)的增量优化步骤。具体来说,我们推导了MCR$^2$目标的新变分形式,并表明由此变分目标的展开梯度下降所得到的架构会导致一种新的注意力模块,称为Token Statistics Self-Attention(TSSA)。TSSA具有线性的计算和内存复杂度,与计算令牌之间成对相似性的典型注意力架构有很大的不同。在视觉、语言和长序列任务上的实验表明,将TSSA替换为标准自注意力(我们将其称为Token Statistics Transformer(ToST))即可实现与常规变压器相当的性能,同时计算效率更高、更具可解释性。我们的结果也对一个普遍的观念提出了质疑,即成对相似性风格的注意力机制是变压器架构成功的关键。代码将在https://github.com/RobinWu218/ToST上提供。
论文及项目相关链接
PDF 24 pages, 11 figures
Summary
本文提出一种新型变压器注意力操作器,其计算复杂度随令牌数量的增加而线性增长,解决了传统变压器注意力操作器计算负担较重的问题。通过扩展“白盒”架构设计先前的作品,我们派生了一种新的网络架构,该架构旨在实现最大编码率降低目标(MCR²)的增量优化步骤。由此衍生出名为Token Statistics Self-Attention(TSSA)的新型注意力模块,它在视觉、语言和长序列任务上的表现具有竞争力,同时在计算和解释性方面更加高效。
Key Takeaways
- 新型变压器注意力操作器具有线性计算复杂度,相较于传统操作器,能显著降低计算负担。
- 该研究通过“白盒”架构设计扩展了先前的作品,实现了一种新的网络架构。
- 新型网络架构旨在实现最大编码率降低目标(MCR²)的增量优化步骤。
- 派生出的Token Statistics Self-Attention(TSSA)模块在多种任务上表现优异。
- TSSA不同于传统的计算令牌间相似性的注意力架构。
- 用Token Statistics Transformer(ToST)替换标准自注意力机制,能在保持竞争力的同时,实现更高的计算效率和解释性。
点此查看论文截图

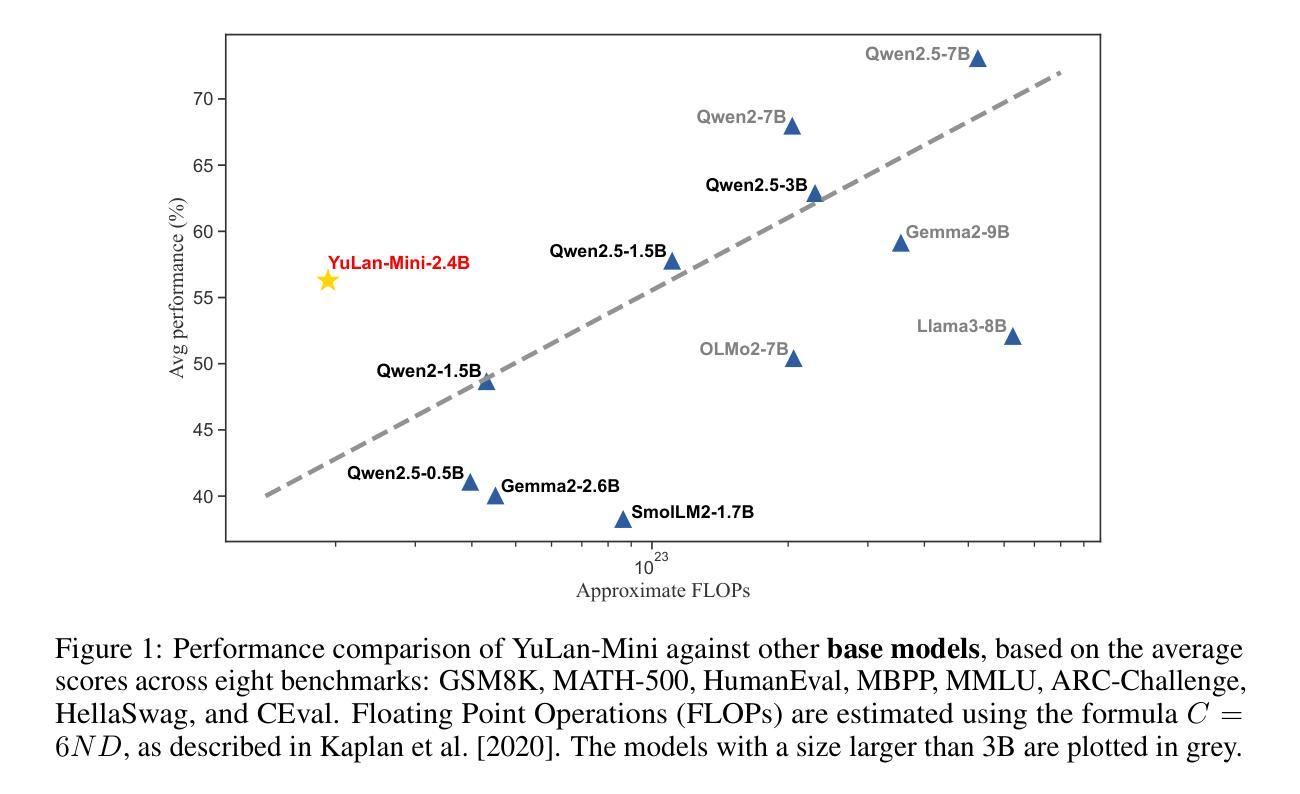
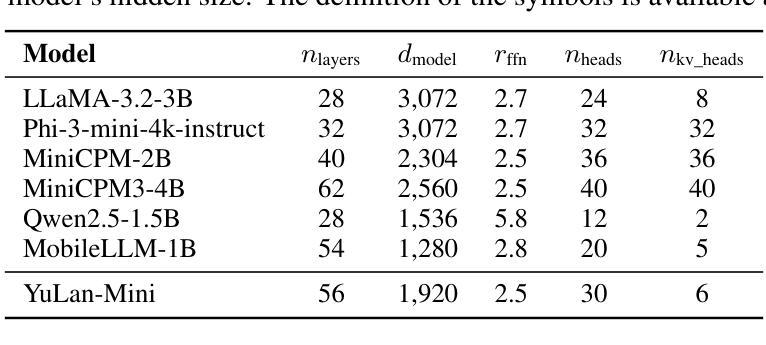
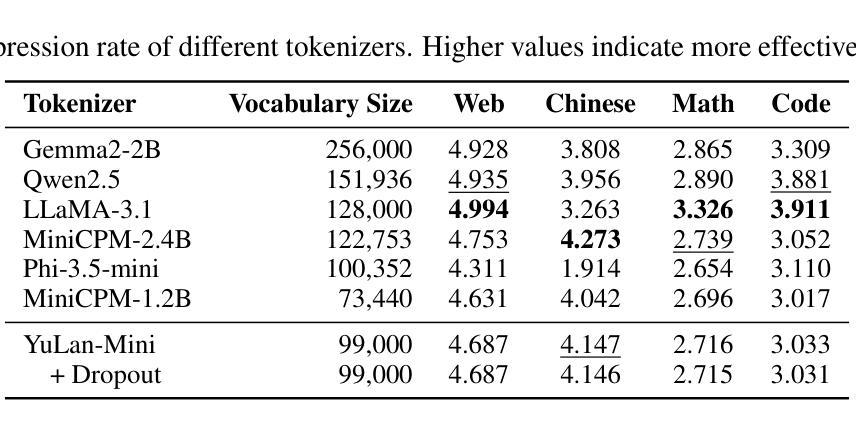
YuLan-Mini: An Open Data-efficient Language Model
Authors:Yiwen Hu, Huatong Song, Jia Deng, Jiapeng Wang, Jie Chen, Kun Zhou, Yutao Zhu, Jinhao Jiang, Zican Dong, Wayne Xin Zhao, Ji-Rong Wen
Effective pre-training of large language models (LLMs) has been challenging due to the immense resource demands and the complexity of the technical processes involved. This paper presents a detailed technical report on YuLan-Mini, a highly capable base model with 2.42B parameters that achieves top-tier performance among models of similar parameter scale. Our pre-training approach focuses on enhancing training efficacy through three key technical contributions: an elaborate data pipeline combines data cleaning with data schedule strategies, a robust optimization method to mitigate training instability, and an effective annealing approach that incorporates targeted data selection and long context training. Remarkably, YuLan-Mini, trained on 1.08T tokens, achieves performance comparable to industry-leading models that require significantly more data. To facilitate reproduction, we release the full details of the data composition for each training phase. Project details can be accessed at the following link: https://github.com/RUC-GSAI/YuLan-Mini.
大型语言模型(LLM)的有效预训练一直是一个挑战,这主要是因为其巨大的资源需求和技术过程的复杂性。本文详细介绍了YuLan-Mini的技术报告,YuLan-Mini是一个具有2.42亿参数的基础模型,在同类参数规模的模型中达到了一流的性能。我们的预训练方法通过三个主要技术贡献来提高训练效果:精心设计的数据管道结合了数据清理和数据调度策略,一种稳健的优化方法来减轻训练的不稳定性,以及有效的退火方法,该方法结合了目标数据选择和长上下文训练。值得注意的是,YuLan-Mini在1.08万亿个令牌上进行训练,其性能与需要大量数据的行业领先模型相当。为了方便复制,我们发布了每个训练阶段数据组成的完整细节。项目详情可通过以下链接访问:https://github.com/RUC-GSAI/YuLan-Mini。
论文及项目相关链接
Summary
YuLan-Mini是一个拥有强大性能的基础模型,具有2.42亿参数,在类似参数规模的模型中表现优异。其预训练策略通过三个主要技术贡献提高训练效率:精心设计的结合数据清洗与数据调度策略的数据管道、稳健的优化方法以解决训练不稳定问题,以及有效退火策略进行有针对性的数据选择和长语境训练。YuLan-Mini仅通过训练在较小的数据集上(仅使用约1.08万亿标记)就能实现与行业领先模型的性能相当。我们公开了每个训练阶段的数据组成细节,以便能够重新试验并确认其性能表现。详细情况请参见项目网址:XXX(将项目的GitHub地址插入XXX处)。有关YuLan-Mini模型更详细的性能分析请参见我们的GitHub页面。
Key Takeaways
以下是基于文本的关键见解:
- YuLan-Mini模型是一款具备高能力的基础模型,在相同参数规模的模型中表现出顶级性能。该模型实现了优化的预训练过程。它的独特之处在于只需少量的计算资源便能展现出出色的性能表现。详细情况可通过以下链接查看:XXX(填入GitHub地址)。
- 数据管道设计是预训练成功的关键之一,结合了数据清洗和数据调度策略,有助于提高模型的训练效率。这一策略对数据的处理和安排提升了模型在面临各种实际情境时的灵活性和适应能力。它能够在复杂且不断变化的输入数据面前保持高效的训练状态。此部分的细节被详细描述并公开分享以供学习和借鉴。因此有充足的可重复实现的可能性和高度改进的潜力空间。我们在公开网站上公布了训练数据集的全貌供后续研究和创新用途的数据的分享平台。
- 模型采用了稳健的优化方法来解决训练过程中的不稳定问题,这有助于确保模型在各种情况下都能保持稳定的性能表现。通过优化算法的稳定性和可靠性,模型在面临复杂任务时能够展现出更高的效率和准确性。具体方法已被详细描述并在公开网站上公布以供参考和改进学习目的等细节已完全公开并可以在指定网站上进行查阅。这为未来的研究者提供了重要的学习机会和挑战新的优化策略的契机以便为大型语言模型的预训练找到更高效的解决方案同时保持模型的稳定性和准确性。同时这一举措也促进了行业内的知识共享和合作推动语言模型技术的不断进步和发展。此外我们公开了具体的优化方法细节以便其他研究者能够在此基础上进行改进和创新以推动语言模型技术的不断进步和发展。
点此查看论文截图

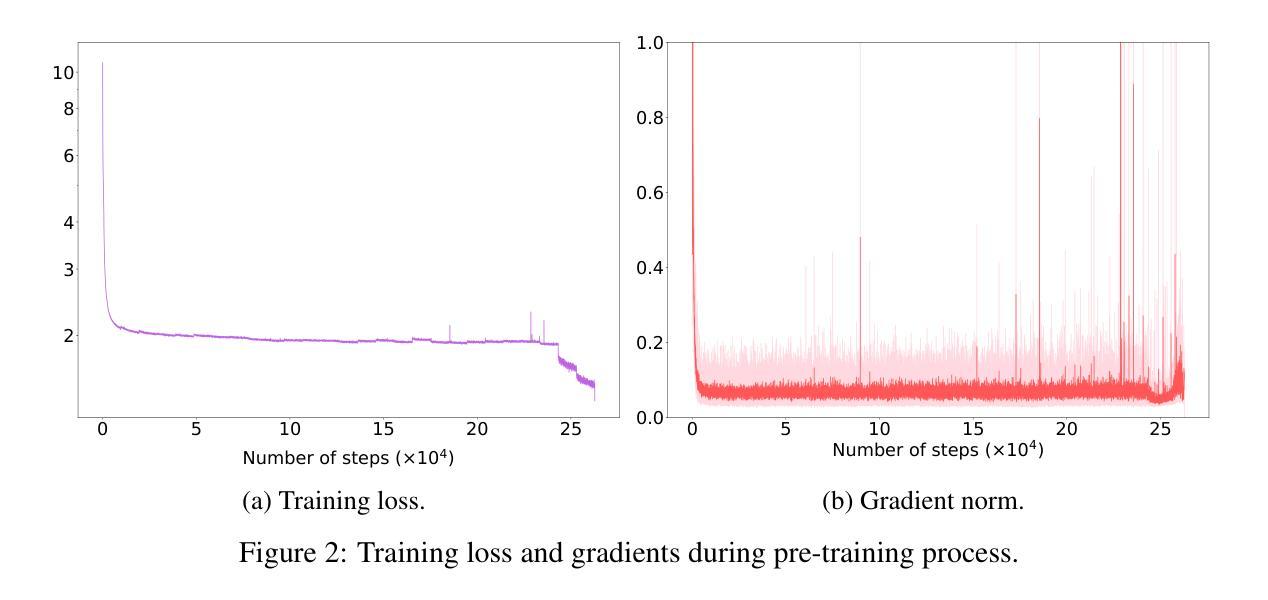
Knowledge Editing through Chain-of-Thought
Authors:Changyue Wang, Weihang Su, Qingyao Ai, Yiqun Liu
Large Language Models (LLMs) have demonstrated exceptional capabilities across a wide range of natural language processing (NLP) tasks. However, keeping these models up-to-date with evolving world knowledge remains a significant challenge due to the high costs of frequent retraining. To address this challenge, knowledge editing techniques have emerged to update LLMs with new information without rebuilding the model from scratch. Among these, the in-context editing paradigm stands out for its effectiveness in integrating new knowledge while preserving the model’s original capabilities. Despite its potential, existing in-context knowledge editing methods are often task-specific, focusing primarily on multi-hop QA tasks using structured knowledge triples. Moreover, their reliance on few-shot prompting for task decomposition makes them unstable and less effective in generalizing across diverse tasks. In response to these limitations, we propose EditCoT, a novel knowledge editing framework that flexibly and efficiently updates LLMs across various tasks without retraining. EditCoT works by generating a chain-of-thought (CoT) for a given input and then iteratively refining this CoT process using a CoT editor based on updated knowledge. We evaluate EditCoT across a diverse range of benchmarks, covering multiple languages and tasks. The results demonstrate that our approach achieves state-of-the-art performance while offering superior generalization, effectiveness, and stability compared to existing methods, marking a significant advancement in the field of knowledge updating. Code and data are available at: https://github.com/bebr2/EditCoT.
大型语言模型(LLM)已在广泛的自然语言处理(NLP)任务中展现出卓越的能力。然而,由于更新世界知识的成本高昂,保持这些模型的最新状态仍然是一个巨大的挑战。为了应对这一挑战,知识编辑技术应运而生,可以在不重建模型的情况下更新LLM的新信息。其中,上下文编辑范式因其能够在集成新知识的同时保留模型的原始能力而脱颖而出。尽管潜力巨大,但现有的上下文知识编辑方法往往是针对特定任务的,主要集中在利用结构化知识三元组的多跳问答任务上。此外,它们对任务分解的少量提示依赖使其不稳定,并且在跨不同任务泛化方面效果较差。针对这些局限性,我们提出了EditCoT,这是一种新型知识编辑框架,能够灵活有效地在各种任务上更新LLM,无需重新训练。EditCoT通过为给定输入生成思维链(CoT),然后使用基于更新知识的CoT编辑器迭代地改进这一思维链过程。我们在涵盖多种语言和任务的多种基准测试上对EditCoT进行了评估。结果表明,我们的方法达到了最新技术性能,同时在泛化性、有效性和稳定性方面优于现有方法,标志着知识更新领域的一个重大进展。相关代码和数据可在:https://github.com/bebr2/EditCoT获取。
论文及项目相关链接
摘要
LLM在自然语言处理领域展现出卓越的能力,但随着世界知识的不断演变,如何持续更新这些模型成为一大挑战。为应对这一挑战,出现了知识编辑技术,无需从头重建即可更新LLM的新知识。其中,上下文编辑范式能有效整合新知识并保留模型的原始能力。然而,现有上下文知识编辑方法往往针对特定任务,如多跳问答任务,且依赖少量提示进行任务分解,导致其在跨任务泛化方面表现不稳定、效果较差。针对这些局限,我们提出EditCoT知识编辑框架,能灵活有效地更新LLM在各种任务中的知识而无需重新训练。EditCoT通过为给定输入生成思维链,然后使用基于更新知识的思维链编辑器进行迭代优化。我们在多种语言和任务的基准测试上对EditCoT进行了评估。结果表明,我们的方法达到了最新技术水平,并在泛化能力、有效性和稳定性方面表现出优势,标志着知识更新领域的重大进展。相关代码和数据可在链接中找到。
关键见解
- LLM在自然语言处理任务中表现出卓越的能力,但模型知识的持续更新是一个挑战。
- 知识编辑技术已出现,能在不重建模型的情况下更新LLM的新知识。
- 上下文编辑范式是整合新知识并保留模型原始能力的有效方法。
- 现有上下文知识编辑方法存在任务特定性和泛化能力不足的局限性。
- EditCoT框架旨在解决这些局限,能灵活有效地更新LLM在各种任务中的知识。
- EditCoT通过生成和迭代优化思维链来工作,提高了模型的性能。
- 基准测试表明,EditCoT在泛化能力、有效性和稳定性方面优于现有方法。
点此查看论文截图


Large Language Model Safety: A Holistic Survey
Authors:Dan Shi, Tianhao Shen, Yufei Huang, Zhigen Li, Yongqi Leng, Renren Jin, Chuang Liu, Xinwei Wu, Zishan Guo, Linhao Yu, Ling Shi, Bojian Jiang, Deyi Xiong
The rapid development and deployment of large language models (LLMs) have introduced a new frontier in artificial intelligence, marked by unprecedented capabilities in natural language understanding and generation. However, the increasing integration of these models into critical applications raises substantial safety concerns, necessitating a thorough examination of their potential risks and associated mitigation strategies. This survey provides a comprehensive overview of the current landscape of LLM safety, covering four major categories: value misalignment, robustness to adversarial attacks, misuse, and autonomous AI risks. In addition to the comprehensive review of the mitigation methodologies and evaluation resources on these four aspects, we further explore four topics related to LLM safety: the safety implications of LLM agents, the role of interpretability in enhancing LLM safety, the technology roadmaps proposed and abided by a list of AI companies and institutes for LLM safety, and AI governance aimed at LLM safety with discussions on international cooperation, policy proposals, and prospective regulatory directions. Our findings underscore the necessity for a proactive, multifaceted approach to LLM safety, emphasizing the integration of technical solutions, ethical considerations, and robust governance frameworks. This survey is intended to serve as a foundational resource for academy researchers, industry practitioners, and policymakers, offering insights into the challenges and opportunities associated with the safe integration of LLMs into society. Ultimately, it seeks to contribute to the safe and beneficial development of LLMs, aligning with the overarching goal of harnessing AI for societal advancement and well-being. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers.
大型语言模型(LLM)的迅速发展和部署为人工智能开启了一个新纪元,体现在前所未有的自然语言理解和生成能力上。然而,这些模型日益集成到关键应用中,引发了大量的安全关切,需要对它们可能存在的风险和相关缓解策略进行全面审查。这篇综述全面概述了当前LLM安全领域的现状,涵盖了四大类别:价值不对齐、对抗性攻击的稳健性、误用和自主人工智能风险。除了对这四个方面的缓解方法和评估资源的全面回顾外,我们还进一步探讨了与LLM安全相关的四个话题:LLM代理的安全影响、可解释性在增强LLM安全中的作用、一系列人工智能公司和研究所针对LLM安全提出并遵循的技术路线图,以及旨在促进LLM安全的AI治理,包括国际合作、政策建议和监管方向前景的讨论。我们的研究强调了对LLM安全采取积极多元方法的重要性,重点整合技术解决方案、道德考量以及稳健的治理框架。这篇综述旨在为学院研究人员、行业从业者以及政策制定者提供基础资源,深入了解将LLM安全集成到社会中的挑战和机遇。最终,它旨在促进LLM的安全和有益发展,符合利用人工智能推动社会进步和福祉的总目标。相关论文的精选列表可在https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers上公开获取。
论文及项目相关链接
PDF 158 pages, 18 figures
摘要
大型语言模型(LLM)的迅速发展和部署为人工智能领域开辟了新的前沿,带来了前所未有的自然语言理解和生成能力。然而,这些模型在关键领域中的集成引发了重要的安全问题,需要进行全面的风险评估和策略缓解。本文综述了LLM安全的现状,包括价值错位、对抗攻击的稳定性、误用和自主AI风险等四大类。除了缓解方法和评估资源的全面回顾,还探讨了与LLM安全相关的四个话题:LLM代理的安全影响、可解释性在增强LLM安全中的作用、AI公司和研究所针对LLM安全的技术路线图以及旨在实现LLM安全的AI治理,包括国际合作、政策建议和监管方向。研究发现,需要积极、多方面的方法来解决LLM安全问题,强调技术解决方案、道德考量以及健全治理框架的整合。本文旨在为学院研究人员、行业从业者以及决策者提供基础性资源,深入了解将LLM安全集成到社会中的挑战和机遇。最终目标是促进LLM的安全和有益发展,实现人工智能服务于社会进步和福祉的目标。相关论文列表已公开在https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers。
关键见解
- 大型语言模型(LLM)在人工智能领域引发新的前沿,具备强大的自然语言理解和生成能力。
- LLM的集成和应用带来实质的安全问题,包括价值错位、对抗稳定性等四大类风险。
- 综述提供了全面的LLM安全审查,包括相关的缓解方法和评估资源。
- 探讨了LLM安全相关的四个话题,包括安全影响、可解释性的作用、技术路线图和AI治理。
- 需要积极、多方面的策略来解决LLM安全问题,结合技术解决方案、道德考量和健全治理框架。
- 本文旨在为不同领域的研究人员提供关于LLM安全的基础资源,以深入了解相关挑战和机遇。
- 旨在促进LLM的安全和有益发展,使其更好地服务于社会进步和福祉。
点此查看论文截图

SCBench: A Sports Commentary Benchmark for Video LLMs
Authors:Kuangzhi Ge, Lingjun Chen, Kevin Zhang, Yulin Luo, Tianyu Shi, Liaoyuan Fan, Xiang Li, Guanqun Wang, Shanghang Zhang
Recently, significant advances have been made in Video Large Language Models (Video LLMs) in both academia and industry. However, methods to evaluate and benchmark the performance of different Video LLMs, especially their fine-grained, temporal visual capabilities, remain very limited. On one hand, current benchmarks use relatively simple videos (e.g., subtitled movie clips) where the model can understand the entire video by processing just a few frames. On the other hand, their datasets lack diversity in task format, comprising only QA or multi-choice QA, which overlooks the models’ capacity for generating in-depth and precise texts. Sports videos, which feature intricate visual information, sequential events, and emotionally charged commentary, present a critical challenge for Video LLMs, making sports commentary an ideal benchmarking task. Inspired by these challenges, we propose a novel task: sports video commentary generation, developed $\textbf{SCBench}$ for Video LLMs. To construct such a benchmark, we introduce (1) $\textbf{SCORES}$, a six-dimensional metric specifically designed for our task, upon which we propose a GPT-based evaluation method, and (2) $\textbf{CommentarySet}$, a dataset consisting of 5,775 annotated video clips and ground-truth labels tailored to our metric. Based on SCBench, we conduct comprehensive evaluations on multiple Video LLMs (e.g. VILA, Video-LLaVA, etc.) and chain-of-thought baseline methods. Our results found that InternVL-Chat-2 achieves the best performance with 5.44, surpassing the second-best by 1.04. Our work provides a fresh perspective for future research, aiming to enhance models’ overall capabilities in complex visual understanding tasks. Our dataset will be released soon.
最近,学术界和工业界在视频大语言模型(Video LLMs)方面都取得了重大进展。然而,评估和衡量不同视频大语言模型性能的方法,尤其是其精细的、时间性的视觉能力,仍然非常有限。一方面,当前的标准主要使用相对简单的视频(例如带字幕的电影片段),这些视频的模型可以通过处理少数几个帧来理解整个视频。另一方面,他们的数据集在任务格式上缺乏多样性,仅限于问答或多选问答,忽视了模型生成深入和精确文本的能力。体育视频具有复杂视觉信息、连续事件和情绪化的解说词,为视频大语言模型带来了重大挑战,使得体育解说成为理想的基准测试任务。针对这些挑战,我们提出了一种新任务:体育视频解说生成,并开发了视频大语言模型基准测试SCBench。为了构建这样一个基准测试,我们引入了(1)专为我们的任务设计的六维度量标准SCORES,并在此基础上提出了基于GPT的评估方法;(2)数据集CommentarySet,该数据集包含5775个带注释的视频剪辑和针对我们度量的真实标签。基于SCBench基准测试,我们对多个视频大语言模型(例如VILA、Video-LLaVA等)进行了全面评估,以及基于思维链的基线方法。我们的结果表明,InternVL-Chat-2表现最佳,得分5.44,比第二名高出1.04。我们的工作为未来研究提供了新的视角,旨在提高模型在复杂视觉理解任务方面的整体能力。我们的数据集将很快发布。
论文及项目相关链接
Summary
Video LLM领域的进步显著,但在评估其性能,特别是精细的时空视觉能力方面仍存在局限。当前评估工具使用的视频较为简单,无法全面评估模型的视觉处理能力。为此,本文提出一个新的任务——体育视频评论生成,并构建了一个专门用于评估Video LLM的基准测试SCBench。该基准测试包括一个六维评估指标SCORES和一个与之匹配的数据集CommentarySet。经过全面评估,InternVL-Chat-2表现最佳。
Key Takeaways
- Video LLM领域近期有重大进展,但评估其性能尤其是精细时空视觉能力的工具仍然非常有限。
- 当前使用的视频基准测试过于简单,无法充分评估模型的视觉处理能力。
- 引入了一个新任务——体育视频评论生成,作为对Video LLM更全面的评估方法。
- 构建了一个名为SCBench的基准测试,包括一个六维评估指标SCORES和一个配套数据集CommentarySet。
- 通过SCBench基准测试对多个Video LLM进行了全面评估。
- InternVL-Chat-2在测试中表现最佳。
点此查看论文截图



EasyTime: Time Series Forecasting Made Easy
Authors:Xiangfei Qiu, Xiuwen Li, Ruiyang Pang, Zhicheng Pan, Xingjian Wu, Liu Yang, Jilin Hu, Yang Shu, Xuesong Lu, Chengcheng Yang, Chenjuan Guo, Aoying Zhou, Christian S. Jensen, Bin Yang
Time series forecasting has important applications across diverse domains. EasyTime, the system we demonstrate, facilitates easy use of time-series forecasting methods by researchers and practitioners alike. First, EasyTime enables one-click evaluation, enabling researchers to evaluate new forecasting methods using the suite of diverse time series datasets collected in the preexisting time series forecasting benchmark (TFB). This is achieved by leveraging TFB’s flexible and consistent evaluation pipeline. Second, when practitioners must perform forecasting on a new dataset, a nontrivial first step is often to find an appropriate forecasting method. EasyTime provides an Automated Ensemble module that combines the promising forecasting methods to yield superior forecasting accuracy compared to individual methods. Third, EasyTime offers a natural language Q&A module leveraging large language models. Given a question like “Which method is best for long term forecasting on time series with strong seasonality?”, EasyTime converts the question into SQL queries on the database of results obtained by TFB and then returns an answer in natural language and charts. By demonstrating EasyTime, we intend to show how it is possible to simplify the use of time series forecasting and to offer better support for the development of new generations of time series forecasting methods.
时间序列预测在各个领域都有重要的应用。我们展示的EasyTime系统,便于研究者和实践者使用时间序列预测方法。首先,EasyTime实现了一键评估功能,研究者可以使用预存在的时间序列预测基准测试(TFB)中收集的各种时间序列数据集来评估新的预测方法。这是通过利用TFB灵活且一致的评价管道实现的。其次,当实践者必须在新数据集上进行预测时,经常第一步就是要找到一种合适的预测方法。EasyTime提供了一个自动化集成模块,该模块结合了有前途的预测方法,与单个方法相比,产生了更高的预测精度。第三,EasyTime提供了一个利用大型语言模型的自然语言问答模块。对于诸如“对于具有强烈季节性的时间序列,哪种方法最适合长期预测?”这样的问题,EasyTime将问题转换为对TFB结果数据库中的SQL查询,然后以自然语言返回答案和图表。通过展示EasyTime,我们的意图是表明如何简化时间序列预测的使用,并为新一代时间序列预测方法的发展提供更好的支持。
论文及项目相关链接
PDF Accepted by ICDE2025
Summary
时间序列预测在多个领域都有重要应用。EasyTime系统为研究人员和实践者提供了时间序列预测方法的易用工具。它提供一键式评估功能,使用已存在的时间序列预测基准测试套件来评估新的预测方法;具有自动集成模块,将不同预测方法进行组合,以提高预测精度;并提供自然语言问答模块,借助大型语言模型回答相关问题并展示图表。EasyTime旨在简化时间序列预测的使用并推动新一代时间序列预测方法的发展。
Key Takeaways
- EasyTime系统简化了时间序列预测的使用,使研究人员和实践者更容易采用时间序列预测方法。
- EasyTime提供了一键式评估功能,允许用户轻松评估新的时间序列预测方法。它使用预存在的时间序列预测基准测试套件来比较这些方法。
- EasyTime具备自动集成模块,可以将不同的时间序列预测方法进行组合,以获得更高的预测精度。
- 通过自然语言问答模块,EasyTime能够回答关于时间序列预测的相关问题,并通过图表展示答案。
- EasyTime利用大型语言模型实现自然语言处理功能,增强了系统的交互性和实用性。
- EasyTime旨在支持新一代时间序列预测方法的发展,推动相关研究的进步。
点此查看论文截图


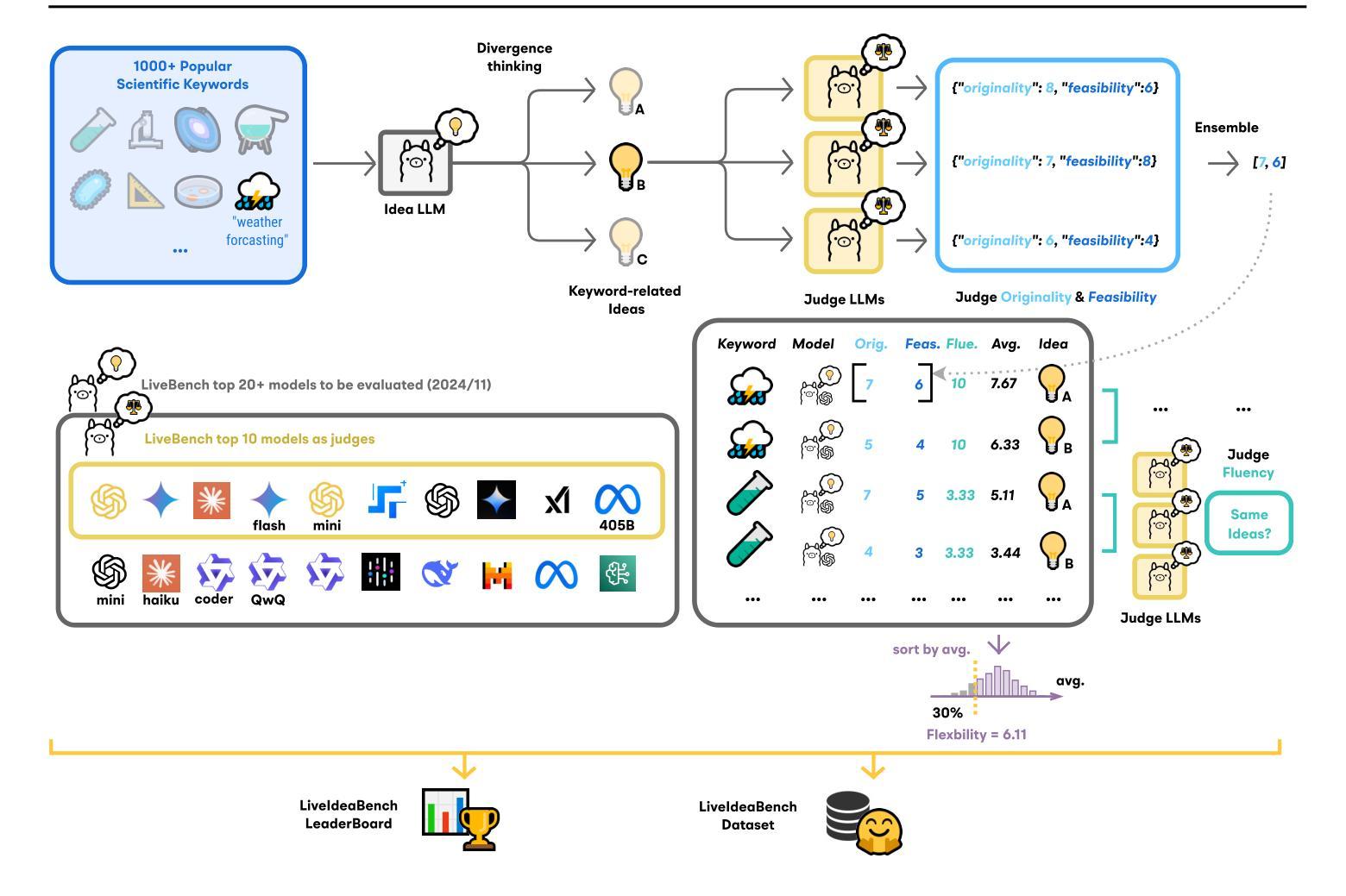
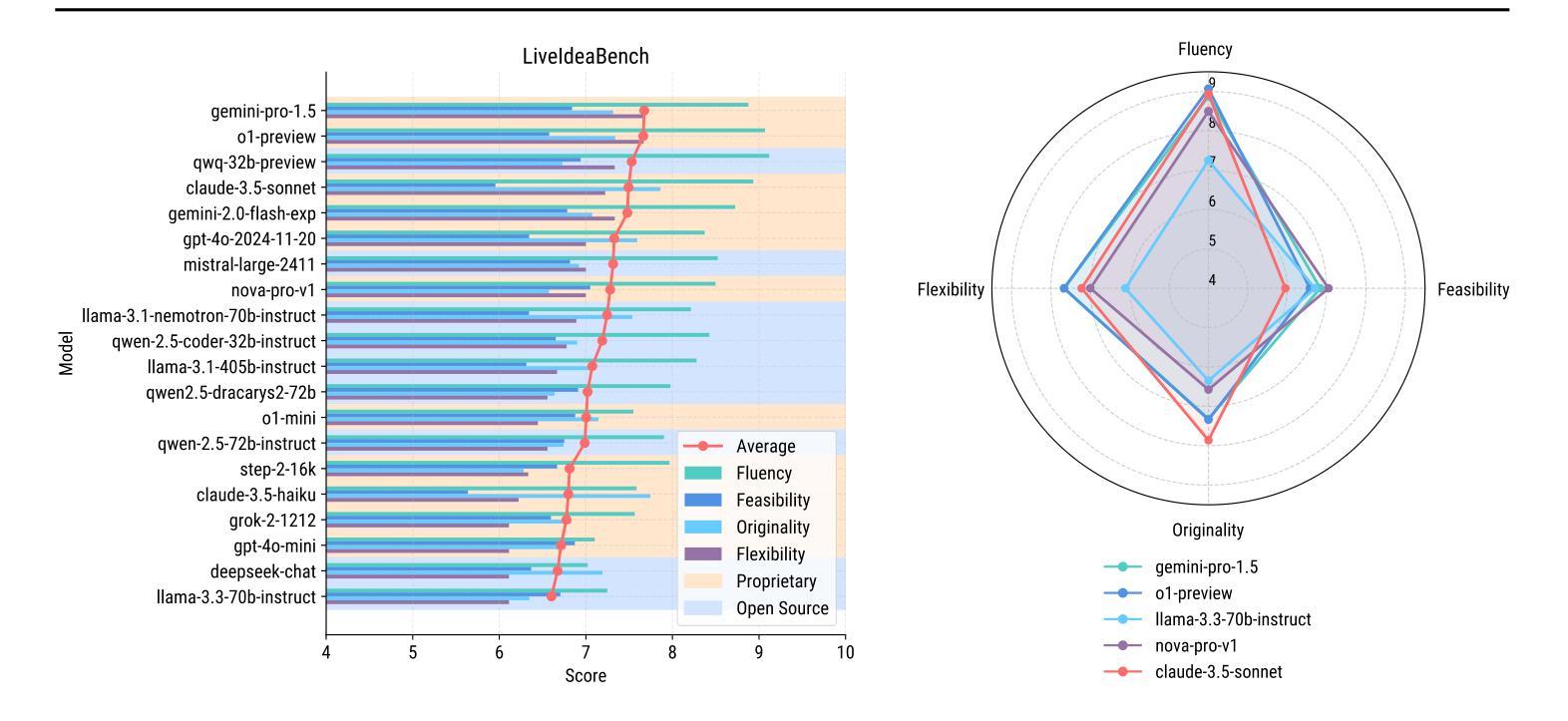
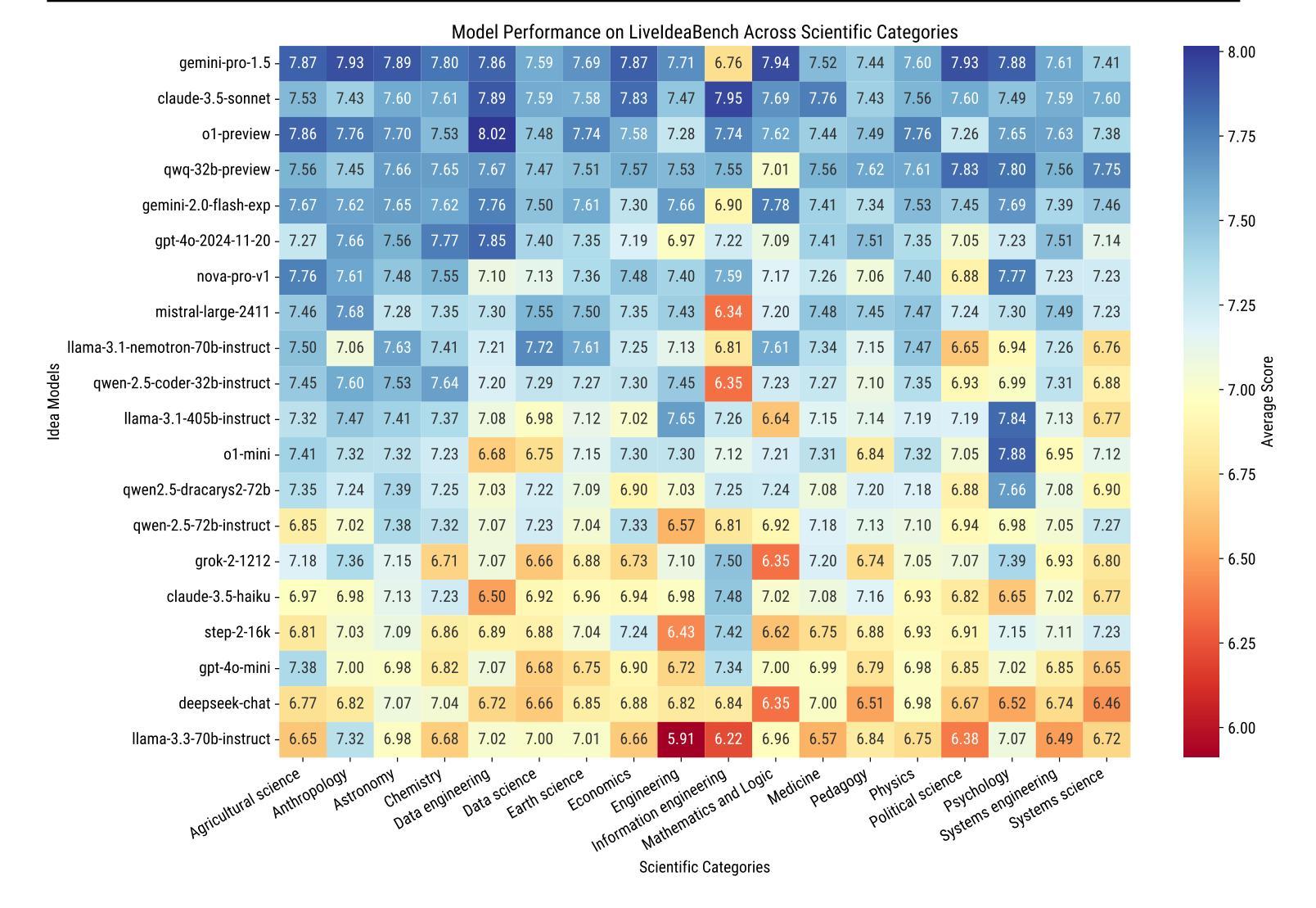
LiveIdeaBench: Evaluating LLMs’ Scientific Creativity and Idea Generation with Minimal Context
Authors:Kai Ruan, Xuan Wang, Jixiang Hong, Hao Sun
While Large Language Models (LLMs) have demonstrated remarkable capabilities in scientific tasks, existing evaluation frameworks primarily assess their performance using rich contextual inputs, overlooking their ability to generate novel ideas from minimal information. We introduce LiveIdeaBench, a comprehensive benchmark that evaluates LLMs’ scientific creativity and divergent thinking capabilities using single-keyword prompts. Drawing from Guilford’s creativity theory, our framework employs a dynamic panel of state-of-the-art LLMs to assess generated ideas across four key dimensions: originality, feasibility, fluency, and flexibility. Through extensive experimentation with 20 leading models across 1,180 keywords spanning 18 scientific domains, we reveal that scientific creative ability shows distinct patterns from general intelligence metrics. Notably, our results demonstrate that models like QwQ-32B-preview achieve comparable creative performance to top-tier models like o1-preview, despite significant gaps in their general intelligence scores. These findings highlight the importance of specialized evaluation frameworks for scientific creativity and suggest that the development of creative capabilities in LLMs may follow different trajectories than traditional problem-solving abilities.
大型语言模型(LLM)在科研任务中表现出了显著的能力,但现有的评估框架主要使用丰富的上下文输入来评估其性能,忽视了它们从少量信息中生成新想法的能力。我们引入了LiveIdeaBench,这是一个全面的基准测试,利用单关键词提示来评估LLM的科研创造力和发散思维能力。我们的框架基于吉尔福德的创造力理论,采用先进的LLM动态面板,对生成的创意从四个关键维度进行评估:原创性、可行性、流畅性和灵活性。通过对18个科学领域的1,180个关键词进行的大量实验,我们发现科学创造力表现出与通用智力指标不同的模式。值得注意的是,我们的结果表明,尽管在一些普通智力测试上有差距,像QwQ-32B-preview这样的模型也能在创意上达到顶级模型如o1-preview的水平。这些发现强调了针对科学创造力进行专项评估的重要性,并暗示LLM中创造力的发展可能与传统的解决问题的能力不同。
论文及项目相关链接
Summary
大型语言模型(LLM)在科学任务中展现出显著能力,但现有的评估框架主要使用丰富的上下文输入来评估其性能,忽视了它们从极少的信息中生成新想法的能力。本文引入LiveIdeaBench,一个全面评估LLM科学创造力和发散思维的框架,使用单关键词提示进行评估。该框架借鉴吉尔福德的创造力理论,通过动态面板评估生成的创意在四个关键维度上的表现:原创性、可行性、流畅性和灵活性。通过对18个科学领域的1,180个关键词的20个领先模型的大量实验,我们发现科学创造力表现出不同于一般智力指标的独特模式。特别是,我们的结果表明,像QwQ-32B-preview这样的模型在创造性表现方面与顶级模型o1-preview相当,尽管它们在一般智力得分上存在显著差距。这表明专门的评估框架对于科学创造力至关重要,并且LLM的发展创造力可能遵循与传统问题解决能力不同的轨迹。
Key Takeaways
- 大型语言模型(LLM)在科学任务中表现出色,但现有评估框架主要关注丰富上下文输入下的性能评估。
- 引入LiveIdeaBench框架,旨在全面评估LLM的科学创造力和发散思维。
- 借鉴吉尔福德的创造力理论,从四个关键维度评估生成的创意:原创性、可行性、流畅性和灵活性。
- 通过大量实验发现科学创造力表现具有独特性,不同于一般智力指标。
- QwQ-32B-preview等模型在创造性表现上表现优异,与一般智力得分存在差距。
- 专门的评估框架对科学创造力的评估至关重要。
点此查看论文截图

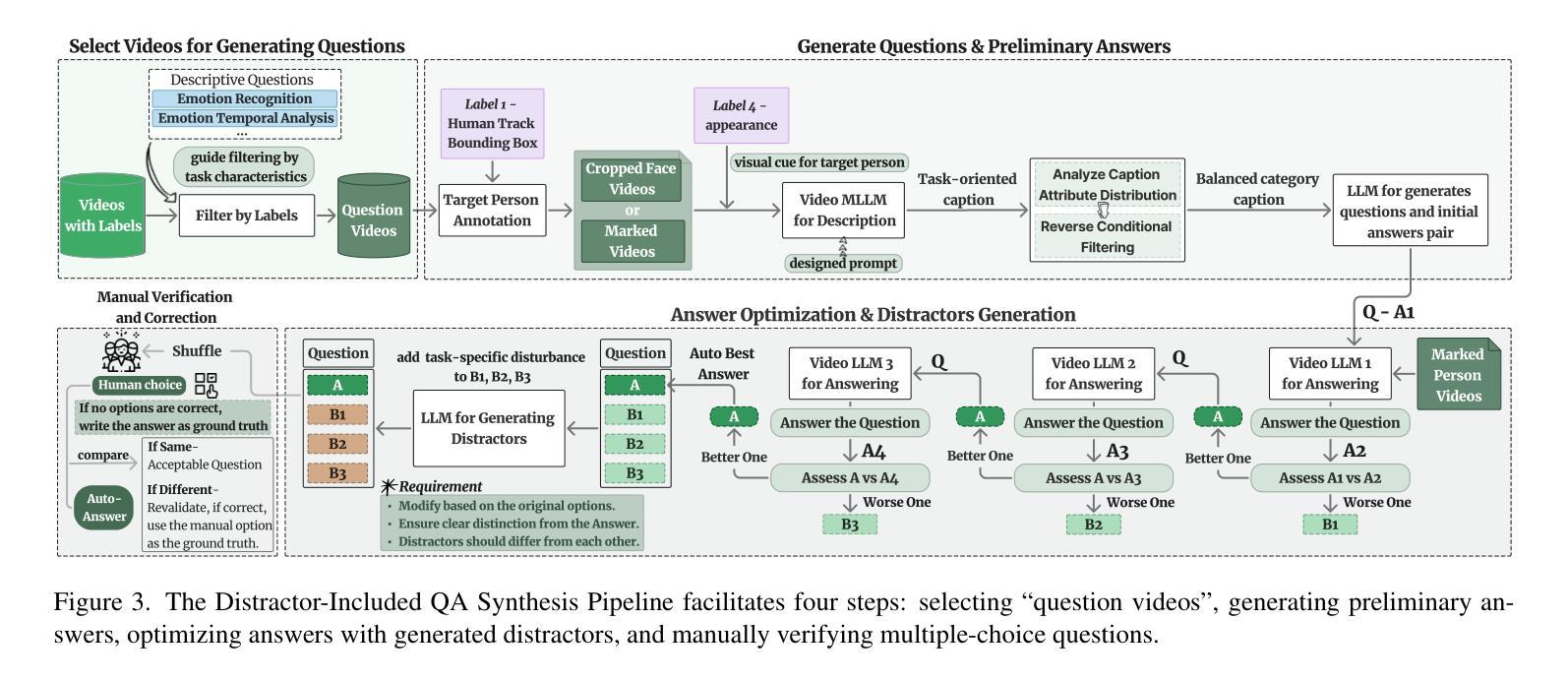
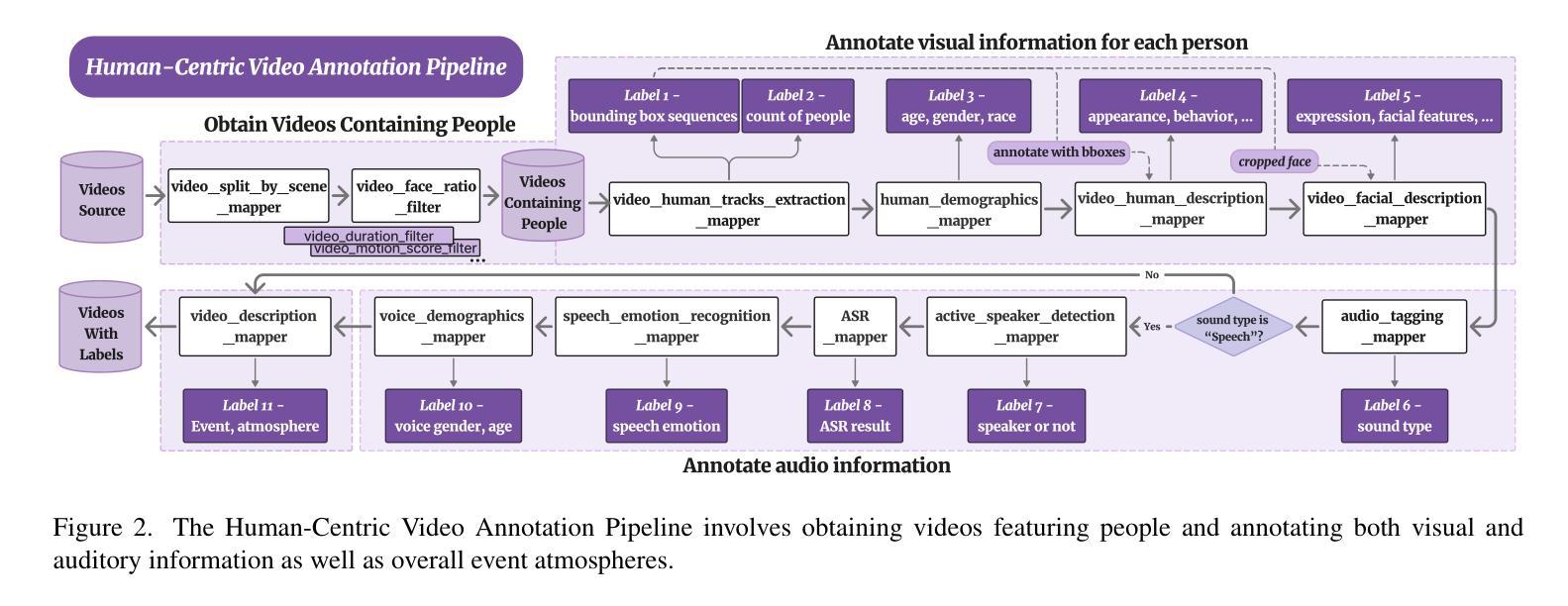
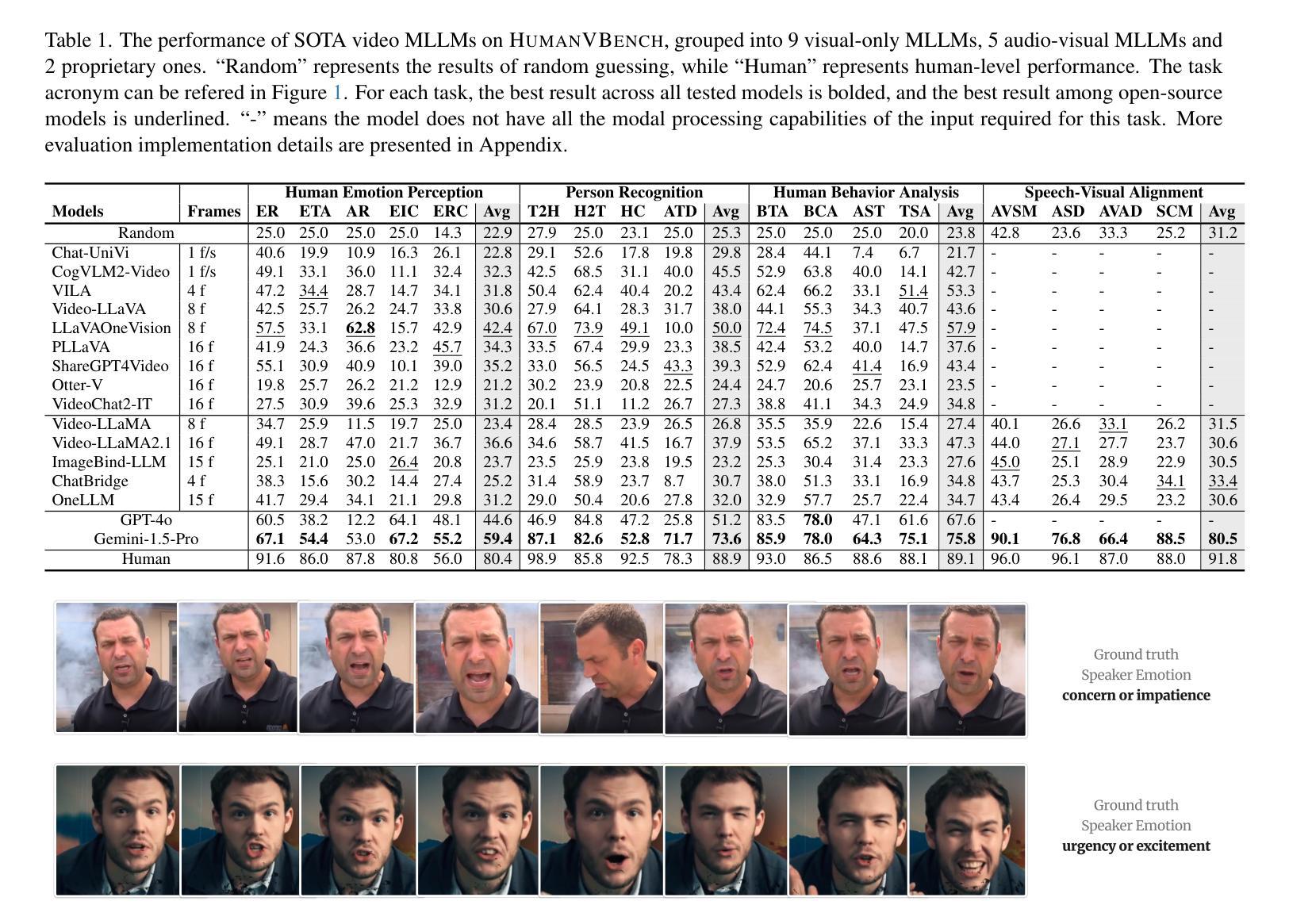
HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data
Authors:Ting Zhou, Daoyuan Chen, Qirui Jiao, Bolin Ding, Yaliang Li, Ying Shen
In the domain of Multimodal Large Language Models (MLLMs), achieving human-centric video understanding remains a formidable challenge. Existing benchmarks primarily emphasize object and action recognition, often neglecting the intricate nuances of human emotions, behaviors, and speech visual alignment within video content. We present HumanVBench, an innovative benchmark meticulously crafted to bridge these gaps in the evaluation of video MLLMs. HumanVBench comprises 17 carefully designed tasks that explore two primary dimensions: inner emotion and outer manifestations, spanning static and dynamic, basic and complex, as well as single-modal and cross-modal aspects. With two advanced automated pipelines for video annotation and distractor-included QA generation, HumanVBench utilizes diverse state-of-the-art (SOTA) techniques to streamline benchmark data synthesis and quality assessment, minimizing human annotation dependency tailored to human-centric multimodal attributes. A comprehensive evaluation across 16 SOTA video MLLMs reveals notable limitations in current performance, especially in cross-modal and temporal alignment, underscoring the necessity for further refinement toward achieving more human-like understanding. HumanVBench is open-sourced to facilitate future advancements and real-world applications in video MLLMs.
在多模态大型语言模型(MLLM)领域,实现以人类为中心的视频理解仍然是一项巨大的挑战。现有的基准测试主要强调对象和动作识别,往往忽视了视频内容中人类情绪、行为和语音视觉对齐的细微差别。我们推出了HumanVBench,这是一个精心设计的创新基准测试,旨在弥补视频MLLM评估中的这些差距。HumanVBench包含17个精心设计的任务,探索两个主要维度:内在情绪和外在表现,涵盖静态和动态、基本和复杂,以及单模态和跨模态方面。HumanVBench使用两个先进的自动化管道进行视频注释和包含干扰项的QA生成,利用多种最新技术简化基准数据合成和质量评估,减少对人类注释的依赖,针对以人类为中心的多模态属性进行定制。对16个最新视频MLLM的综合评估显示,当前性能存在显著局限性,尤其在跨模态和时间对齐方面,这强调了对进一步改进以实现更人性化的理解的必要性。HumanVBench开源,以促进视频MLLM的未来发展和实际应用。
论文及项目相关链接
PDF 22 pages, 24 figures, 4 tables
Summary
多媒体大型语言模型(MLLMs)在视频理解方面面临挑战。当前基准测试主要关注对象和动作识别,忽略了人类情感、行为和语音视觉对齐等细微差别。本文提出HumanVBench基准测试平台,涵盖精心设计的十七项任务,包括内在情感和外在表现两个方面,全面探索视频理解的多种方面。HumanVBench使用高级自动化管道进行视频注释和包含干扰项的QA生成,旨在简化基准测试数据合成和质量评估流程,减少对人工注释的依赖。对目前顶尖的视频MLLMs的全面评估显示其在跨模态和时间对齐方面的显著局限性,强调需要进一步改进以实现更人性化的理解。HumanVBench已开源以促进未来视频MLLMs的进步和实际应用。
Key Takeaways
- Multimedia Large Language Models (MLLMs)在视频理解方面存在挑战。
- 当前基准测试主要关注对象和动作识别,忽视了人类情感的复杂性。
- HumanVBench是一个新的基准测试平台,旨在填补这些评估空白。
- HumanVBench包含精心设计的任务,涵盖内在情感和外在表现的多个方面。
- HumanVBench使用自动化管道进行视频注释和QA生成,以减少人工干预。
- 对顶尖MLLMs的全面评估显示其在跨模态和时间对齐方面的局限性。
点此查看论文截图

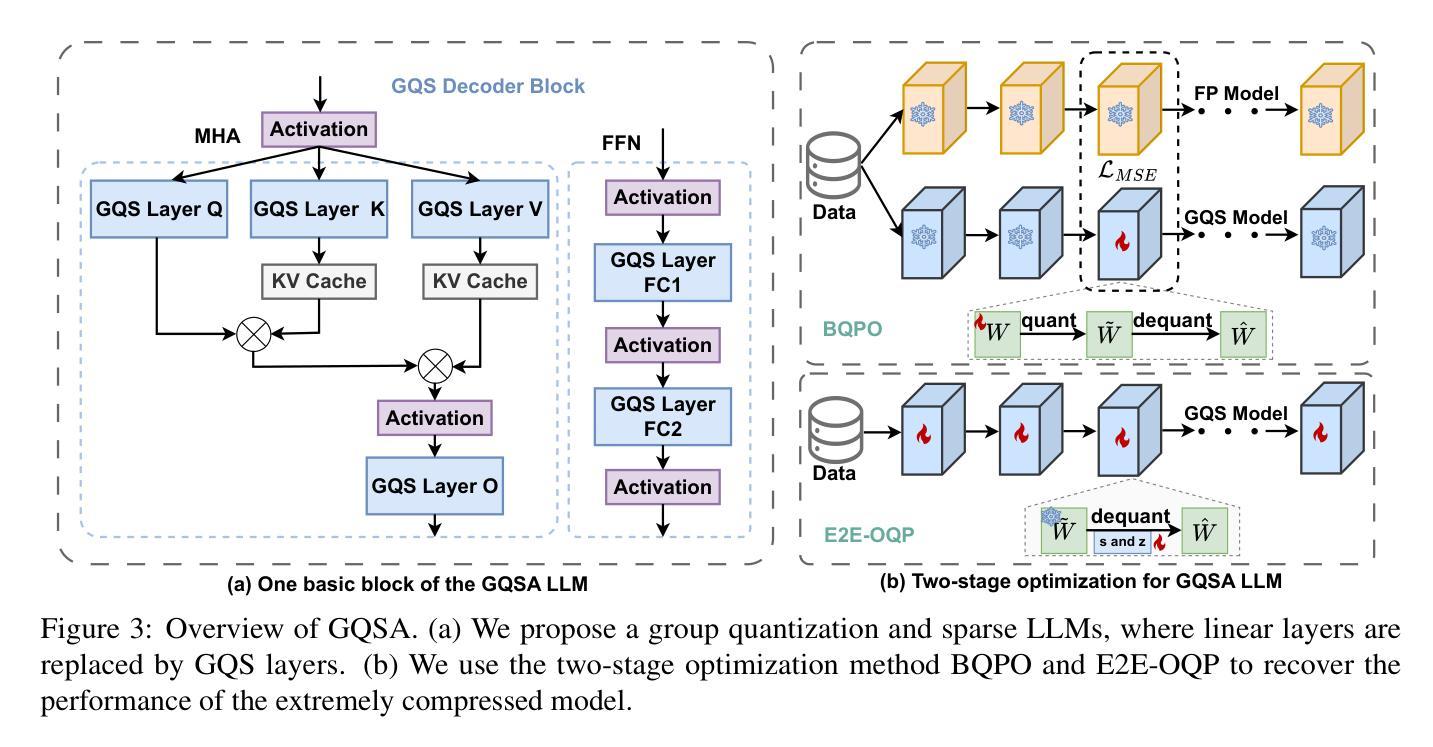
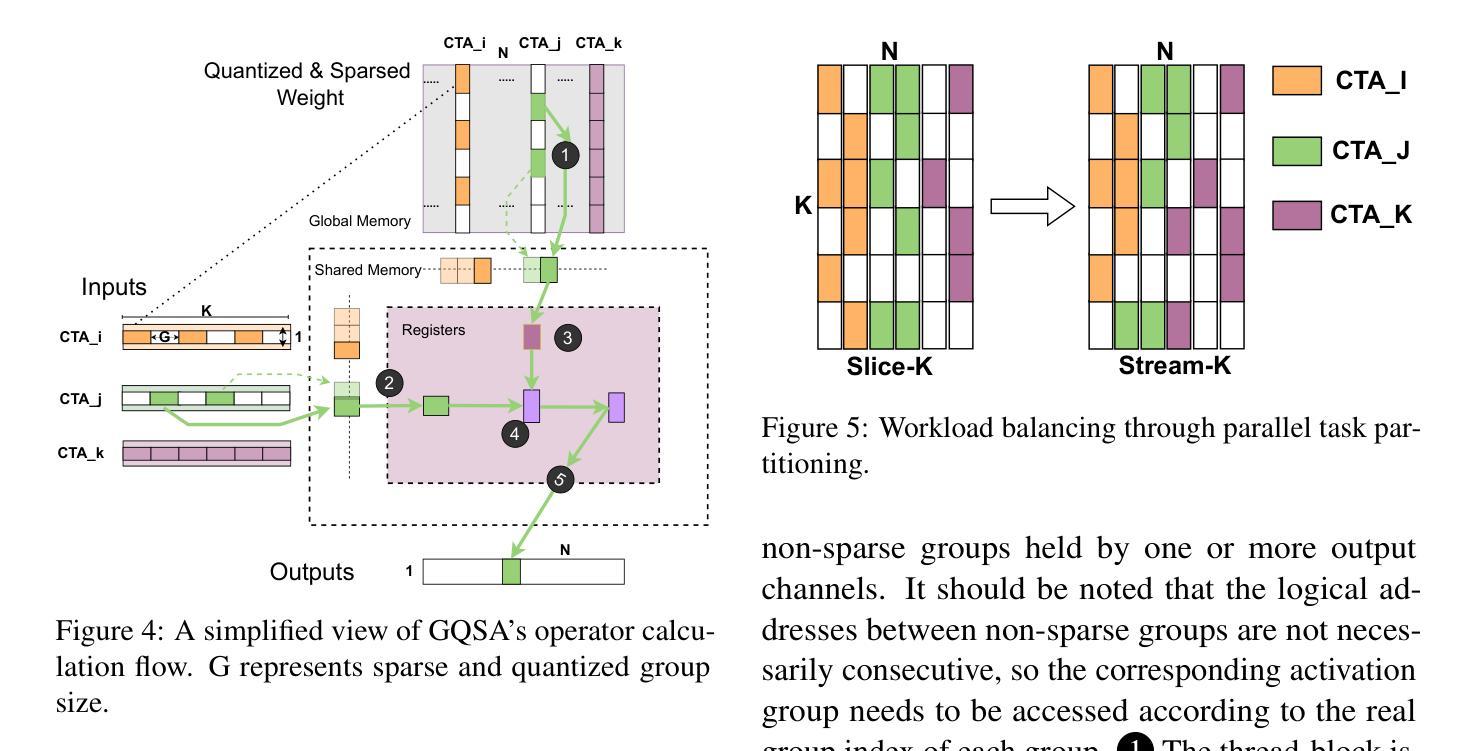
GQSA: Group Quantization and Sparsity for Accelerating Large Language Model Inference
Authors:Chao Zeng, Songwei Liu, Shu Yang, Fangmin Chen, Xing Mei, Lean Fu
With the rapid growth in the scale and complexity of large language models (LLMs), the costs of training and inference have risen substantially. Model compression has emerged as a mainstream solution to reduce memory usage and computational overhead. This paper presents Group Quantization and Sparse Acceleration (\textbf{GQSA}), a novel compression technique tailored for LLMs. Traditional methods typically focus exclusively on either quantization or sparsification, but relying on a single strategy often results in significant performance loss at high compression rates. In contrast, GQSA integrates quantization and sparsification in a tightly coupled manner, leveraging GPU-friendly structured group sparsity and quantization for efficient acceleration. The proposed method consists of three key steps. First, GQSA applies group structured pruning to adhere to GPU-friendly sparse pattern constraints. Second, a two-stage sparsity-aware training process is employed to maximize performance retention after compression. Finally, the framework adopts the Block Sparse Row (BSR) format to enable practical deployment and efficient execution. Experimental results on the LLaMA model family show that GQSA achieves an excellent balance between model speed and accuracy. Furthermore, on the latest LLaMA-3 and LLaMA-3.1 models, GQSA outperforms existing LLM compression techniques significantly.
随着大型语言模型(LLM)规模和复杂性的快速增长,训练和推理的成本也大幅增加。模型压缩已成为减少内存使用和计算开销的主流解决方案。本文提出了Group Quantization and Sparse Acceleration(GQSA)这一针对LLM的新型压缩技术。传统的方法通常只专注于量化或稀疏化,但在高压缩率下,仅依赖单一策略往往会导致性能显著下降。相比之下,GQSA紧密地将量化和稀疏化结合在一起,利用GPU友好的结构化组稀疏和量化来实现高效加速。该方法主要包括三个关键步骤。首先,GQSA应用组结构化修剪以符合GPU友好的稀疏模式约束。其次,采用两阶段稀疏感知训练过程,以在压缩后最大化性能保留。最后,该框架采用块稀疏行(BSR)格式,以实现实际部署和高效执行。在LLaMA模型家族上的实验结果表明,GQSA在模型速度和准确性之间达到了卓越平衡。此外,在最新的LLaMA-3和LLaMA-3.1模型上,GQSA显著优于现有的LLM压缩技术。
论文及项目相关链接
Summary
大型语言模型(LLM)的规模和复杂性迅速增长,导致训练和推理成本大幅上升。为解决这一问题,模型压缩成为主流解决方案,以减少内存使用和计算开销。本文提出了一种针对LLM的新型压缩技术——集团量化与稀疏加速(GQSA)。传统方法通常只专注于量化或稀疏化,但单一策略在高压缩率下往往会导致显著的性能损失。相反,GQSA紧密结合量化和稀疏化,利用GPU友好的结构化集团稀疏性和量化进行高效加速。实验结果表明,GQSA在模型速度和准确性之间取得了良好的平衡,并且在最新的LLAMA-3和LLAMA-3.1模型上显著优于现有的LLM压缩技术。
Key Takeaways
- 大型语言模型(LLM)面临训练和推理成本上升的问题,模型压缩是主流解决方案。
- GQSA是一种新型的LLM压缩技术,结合了量化和稀疏化,以提高性能并减少资源消耗。
- 传统压缩方法往往只专注于量化或稀疏化,单一策略在高压缩率下可能导致性能损失。
- GQSA利用GPU友好的结构化集团稀疏性和量化进行加速。
- GQSA包括三个关键步骤:集团结构化修剪、两阶段稀疏感知训练采用块稀疏行(BSR)格式。
- 实验结果表明,GQSA在模型速度和准确性之间取得了良好的平衡。
点此查看论文截图



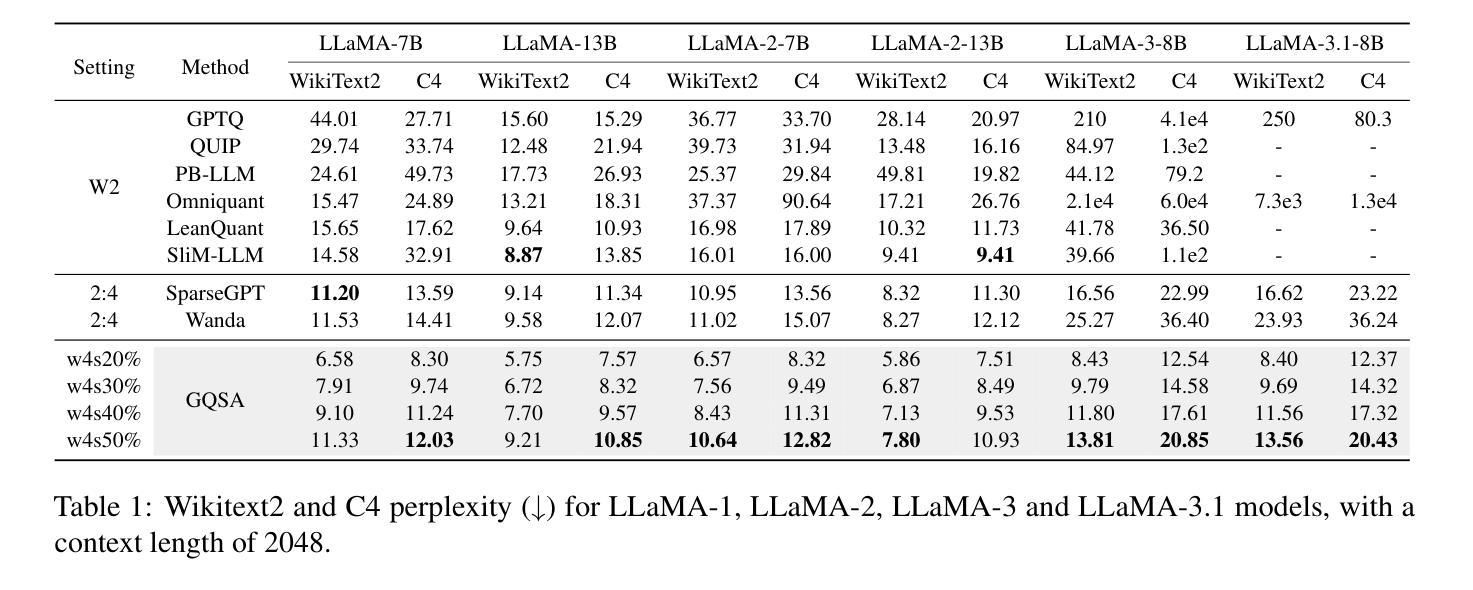
Retention Score: Quantifying Jailbreak Risks for Vision Language Models
Authors:Zaitang Li, Pin-Yu Chen, Tsung-Yi Ho
The emergence of Vision-Language Models (VLMs) is a significant advancement in integrating computer vision with Large Language Models (LLMs) to enhance multi-modal machine learning capabilities. However, this progress has also made VLMs vulnerable to sophisticated adversarial attacks, raising concerns about their reliability. The objective of this paper is to assess the resilience of VLMs against jailbreak attacks that can compromise model safety compliance and result in harmful outputs. To evaluate a VLM’s ability to maintain its robustness against adversarial input perturbations, we propose a novel metric called the \textbf{Retention Score}. Retention Score is a multi-modal evaluation metric that includes Retention-I and Retention-T scores for quantifying jailbreak risks in visual and textual components of VLMs. Our process involves generating synthetic image-text pairs using a conditional diffusion model. These pairs are then predicted for toxicity score by a VLM alongside a toxicity judgment classifier. By calculating the margin in toxicity scores, we can quantify the robustness of the VLM in an attack-agnostic manner. Our work has four main contributions. First, we prove that Retention Score can serve as a certified robustness metric. Second, we demonstrate that most VLMs with visual components are less robust against jailbreak attacks than the corresponding plain VLMs. Additionally, we evaluate black-box VLM APIs and find that the security settings in Google Gemini significantly affect the score and robustness. Moreover, the robustness of GPT4V is similar to the medium settings of Gemini. Finally, our approach offers a time-efficient alternative to existing adversarial attack methods and provides consistent model robustness rankings when evaluated on VLMs including MiniGPT-4, InstructBLIP, and LLaVA.
视觉语言模型(VLMs)的出现是计算机视觉与大型语言模型(LLMs)集成的一大进步,这增强了多模态机器学习能力。然而,这一进展也使得VLM容易受到高级对抗性攻击的威胁,人们对它们的可靠性提出担忧。本文的目标是评估VLM对抗监狱突破攻击(可能危及模型安全合规性并产生有害输出)的韧性。为了评估VLM在对抗对抗性输入扰动时的稳健性维持能力,我们提出了一种新的度量标准,称为“保留分数”。保留分数是一个多模态评估指标,包括用于量化VLM视觉和文本组件中的监狱突破风险的保留-I和保留-T分数。我们的流程包括使用条件扩散模型生成合成图像文本对。这些对随后被VLM和一个毒性判断分类器预测毒性分数。通过计算毒性分数的差异,我们可以以一种独立于攻击的方式量化VLM的稳健性。我们的工作有四个主要贡献。首先,我们证明保留分数可以作为经过认证的稳健性指标。其次,我们证明,具有视觉分量的VLM大多数在面对监狱突破攻击时,比相应的纯VLM更不稳健。此外,我们还评估了黑盒VLM API,并发现Google Gemini中的安全设置会显著影响分数和稳健性。而且GPT4V的稳健性与Gemini的中等设置相似。最后,我们的方法提供了对现有对抗攻击方法的时间效率替代方案,并在包括MiniGPT-4、InstructBLIP和LLaVA的VLM上提供了一致的模型稳健性排名。
论文及项目相关链接
PDF 14 pages, 8 figures, AAAI 2025
Summary
本文介绍了视觉语言模型(VLMs)在集成计算机视觉与大型语言模型(LLMs)方面的显著进展,并探讨了其对抗性攻击的脆弱性。文章旨在评估VLMs对抗能够危害模型安全性的监狱突破攻击的能力。为此,文章提出了一种新的评估指标——留存率分数,该指标是一种多模式评估指标,用于量化VLM在视觉和文本组件中的监狱突破风险。通过生成合成图像文本对并预测其毒性分数,可以量化VLM在攻击无关方式下的稳健性。文章的主要贡献包括:证明了留存率分数可以作为经过认证的稳健性指标;发现大多数带有视觉组件的VLM对监狱突破攻击的稳健性较差;评估了谷歌双子星等黑盒子VLM API的安全性设置对留存率分数和稳健性的影响;GPT4V的稳健性与双子星的中等设置相似;该方法提供了现有对抗性攻击方法的时效替代方案,并在包括MiniGPT-4、InstructBLIP和LLaVA等VLMs上的评估中提供了一致的模型稳健性排名。
Key Takeaways
- 视觉语言模型(VLMs)是计算机视觉与大型语言模型(LLMs)结合的显著进展,但易受到复杂的对抗性攻击的影响。
- 文章旨在评估VLMs对抗监狱突破攻击的能力,提出留存率分数作为新的评估指标。
- 留存率分数包括留存-I和留存-T分数,用于量化VLM在视觉和文本组件中的监狱突破风险。
- 通过生成合成图像文本对并预测其毒性分数,可以评估VLM的稳健性。
- 大多数带有视觉组件的VLM对监狱突破攻击的稳健性较差。
- 谷歌双子星等黑盒子VLM API的安全性设置影响留存率分数和稳健性。
点此查看论文截图


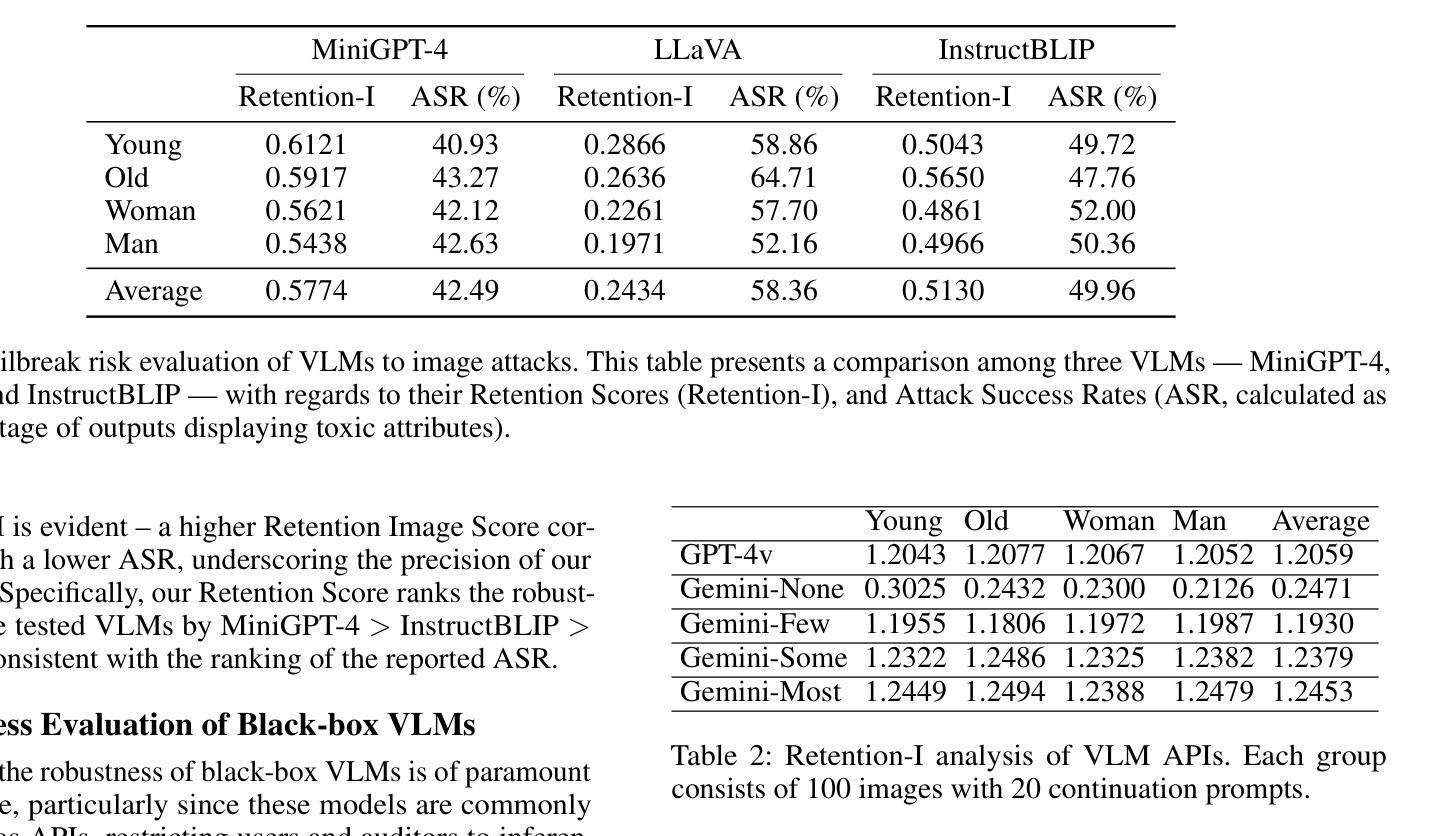
Boosting LLM via Learning from Data Iteratively and Selectively
Authors:Qi Jia, Siyu Ren, Ziheng Qin, Fuzhao Xue, Jinjie Ni, Yang You
Datasets nowadays are generally constructed from multiple sources and using different synthetic techniques, making data de-noising and de-duplication crucial before being used for post-training. In this work, we propose to perform instruction tuning by iterative data selection (\ApproachName{}). We measure the quality of a sample from complexity and diversity simultaneously. Instead of calculating the complexity score once for all before fine-tuning, we highlight the importance of updating this model-specific score during fine-tuning to accurately accommodate the dynamic changes of the model. On the other hand, the diversity score is defined on top of the samples’ responses under the consideration of their informativeness. IterIT integrates the strengths of both worlds by iteratively updating the complexity score for the top-ranked samples and greedily selecting the ones with the highest complexity-diversity score. Experiments on multiple instruction-tuning data demonstrate consistent improvements of IterIT over strong baselines. Moreover, our approach also generalizes well to domain-specific scenarios and different backbone models. All resources will be available at https://github.com/JiaQiSJTU/IterIT.
当前,数据集通常通过多种来源和不同合成技术构建,因此在用于后训练之前,数据去噪和去重至关重要。在此工作中,我们提出通过迭代数据选择(IterIT)执行指令调整。我们从复杂性和多样性两个方面来衡量样本的质量。我们强调在微调过程中更新这种模型特定评分的重要性,以便准确适应模型的动态变化,而不是在微调之前对所有样本进行一次复杂性评分。另一方面,多样性评分是在考虑样本信息的基础上定义的。IterIT通过迭代更新最高排名样本的复杂性评分并贪婪地选择具有最高复杂性-多样性评分的样本,融合了两者的优势。在多个指令调整数据上的实验表明,IterIT在强基线之上实现了一致性的改进。此外,我们的方法也很好地适用于特定领域的场景和不同的主干模型。所有资源都将在https://github.com/JiaQiSJTU/IterIT上提供。
论文及项目相关链接
Summary
通过迭代数据选择进行指令调整,同时考虑样本的复杂性和多样性,提出了IterIT方法。该方法在微调过程中动态更新模型特定的复杂性得分,并基于样本响应的信息性定义多样性得分。通过迭代更新高排名样本的复杂性得分并贪婪选择具有最高复杂性-多样性得分的样本,IterIT实现了对多个指令调整数据集的持续改进,并具有良好的域特定场景和模型适用性。
Key Takeaways
- 数据集的构建通常涉及多源数据和不同的合成技术,因此数据去噪和去重非常重要。
- 提出了一种通过迭代数据选择进行指令调整的方法(IterIT)。
- IterIT同时考虑样本的复杂性和多样性。
- 调试过程中动态更新模型特定的复杂性得分。
- IterIT通过迭代更新高排名样本的复杂性得分并选择具有最高复杂性-多样性得分的样本。
- 实验表明,IterIT在多个指令调整数据集上持续改进,并具有良好的通用性,适用于不同的领域和背景模型。
点此查看论文截图



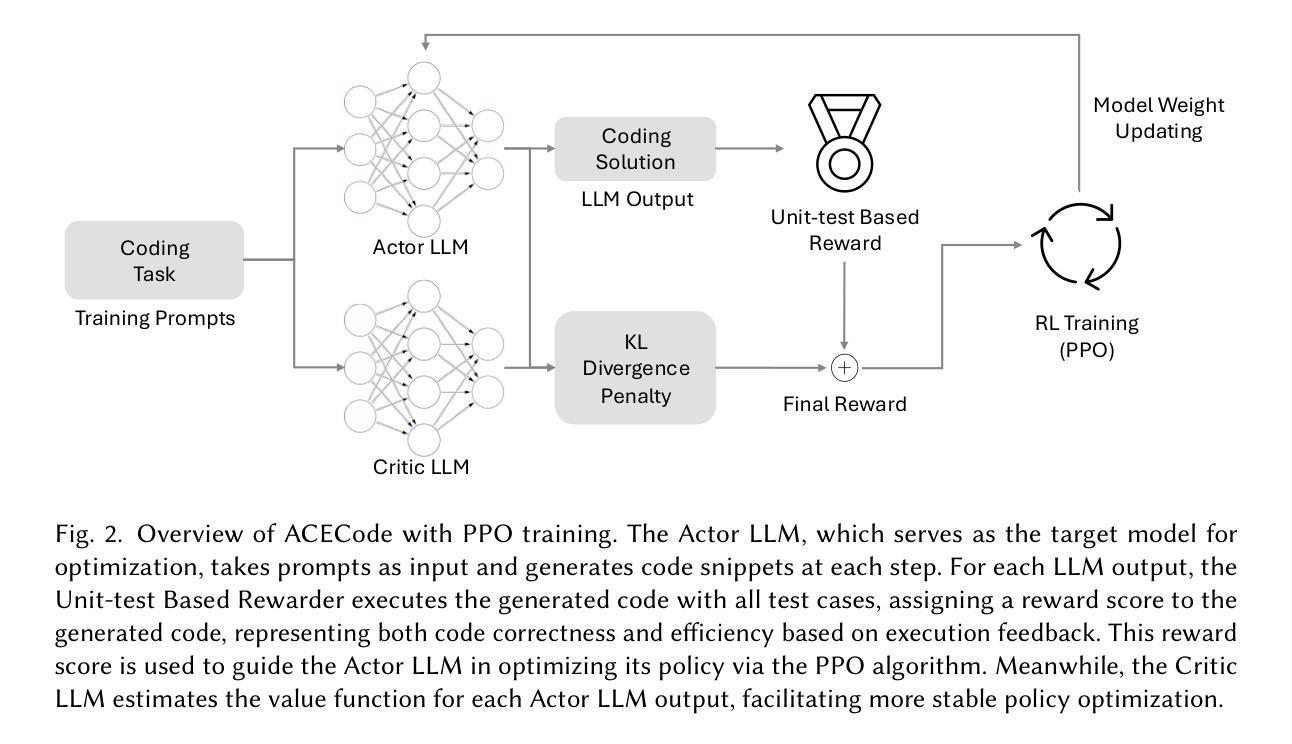
ACECode: A Reinforcement Learning Framework for Aligning Code Efficiency and Correctness in Code Language Models
Authors:Chengran Yang, Hong Jin Kang, Jieke Shi, David Lo
CodeLLMs have demonstrated remarkable advancements in software engineering tasks. However, while these models can generate functionally correct code, they often produce code that is inefficient in terms of runtime. This inefficiency is particularly problematic in resource-constrained environments, impacting software performance and sustainability. Existing approaches for optimizing code efficiency for CodeLLMs like SOAP and PIE exhibit certain limitations. SOAP requires a compatible execution environment and predefined test cases for iterative code modification, while PIE focuses on instruction tuning, improving efficiency but compromising correctness. These shortcomings highlight the need for a fine-tuning framework that optimizes both efficiency and correctness without relying on predefined test cases or specific execution environments. To bridge this gap, we introduce ACECode, a reinforcement learning-based fine-tuning framework that aligns CodeLLMs with dual objectives of efficiency and correctness. ACECode combines three key steps: (1) generating code with an actor CodeLLM, (2) calculating a training-free reward signal derived from code execution feedback for each generated code, and (3) optimizing the CodeLLM via Proximal Policy Optimization (PPO) algorithm. This reward signal enables joint assessment of efficiency and correctness without manual labeling. We evaluate ACECode by fine-tuning four SOTA (state-of-the-art) CodeLLMs and comparing their code with three baselines: original, instruction-tuned, and PIE-tuned CodeLLMs. Extensive experiment results suggest that \tool{} significantly improves the efficiency and correctness of generated code against all baselines for all CodeLLMs. Specifically, CodeLLMs fine-tuned with ACECode improve pass@1 by 1.84% to 14.51% and reduce runtime in 65% to 72% of cases compared to original CodeLLMs.
CodeLLMs在软件工程任务方面取得了显著的进步。然而,虽然这些模型能够生成功能正确的代码,但它们常常生成的代码在运行时效率不高。这种低效在资源受限的环境中尤其成问题,影响了软件性能和可持续性。现有的针对CodeLLM优化代码效率的方法,如SOAP和PIE,都表现出一定的局限性。SOAP需要兼容的执行环境和预设测试用例来进行迭代代码修改,而PIE则专注于指令调整以提高效率,但可能会牺牲正确性。这些缺点凸显了需要一个微调框架来同时优化效率和正确性,而无需依赖预设测试用例或特定的执行环境。为了弥补这一差距,我们引入了ACECode,这是一个基于强化学习的微调框架,旨在使CodeLLM符合效率和正确性的双重目标。ACECode结合了三个关键步骤:(1)使用actor CodeLLM生成代码;(2)计算基于代码执行反馈的无需训练的奖励信号,用于评估每个生成代码;(3)通过近端策略优化(PPO)算法优化CodeLLM。该奖励信号能够在无需人工标注的情况下,同时对效率和正确性进行评估。我们通过微调四个最先进的CodeLLM并与其原始代码、指令调整代码和PIE调整代码进行比较,来评估ACECode的效果。大量的实验结果表明,与所有基线相比,ACECode显著提高了生成代码的效率正确性。具体来说,使用ACECode微调的CodeLLM在pass@1上提高了1.84%至14.51%,并在65%至72%的情况下减少了运行时间,与原始CodeLLM相比。
论文及项目相关链接
Summary
代码LLM在软件工程任务中取得了显著的进步,但它们生成的代码往往在运行效率方面存在问题。现有优化方法如SOAP和PIE存在局限性,需要一种能够同时优化效率和正确性的精细调整框架。我们引入ACECode,一个基于强化学习的精细调整框架,通过三个关键步骤优化CodeLLM,以实现对效率和正确性的双重目标。评估结果显示,ACECode能显著提高生成代码的效率正确性。
Key Takeaways
- 代码LLM在生成功能正确的代码方面表现出色,但运行效率有待提高。
- 现有优化方法如SOAP和PIE存在局限性,需要更精细的调整框架。
- ACECode是一个基于强化学习的精细调整框架,旨在优化CodeLLM的效率与正确性。
- ACECode通过三个关键步骤实现优化:生成代码、计算奖励信号、使用PPO算法优化CodeLLM。
- ACECode能自动评估代码效率和正确性,无需手动标注。
- 对比实验表明,ACECode显著提高生成代码的效率与正确性,特别是与最新CodeLLM相比。
点此查看论文截图

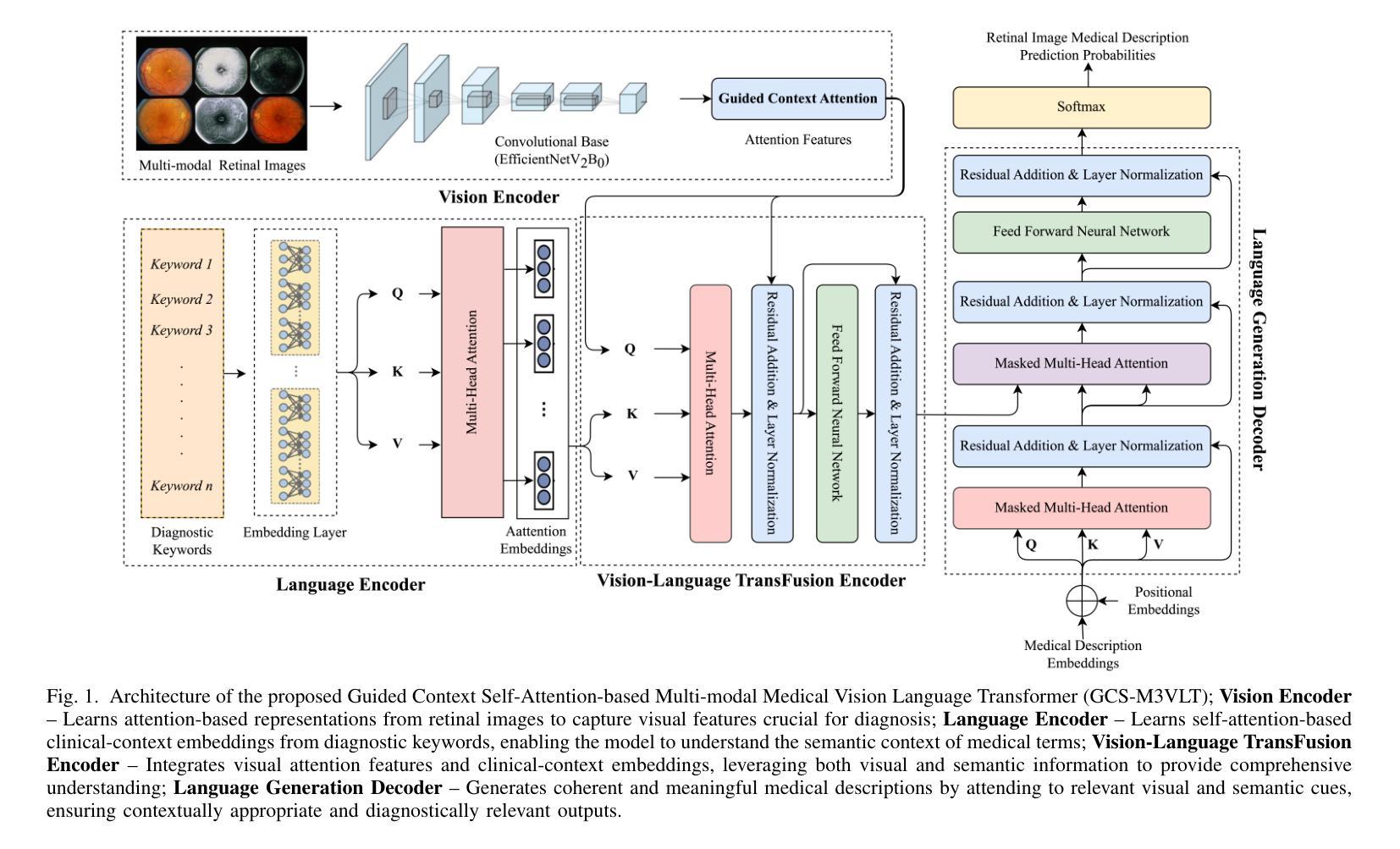
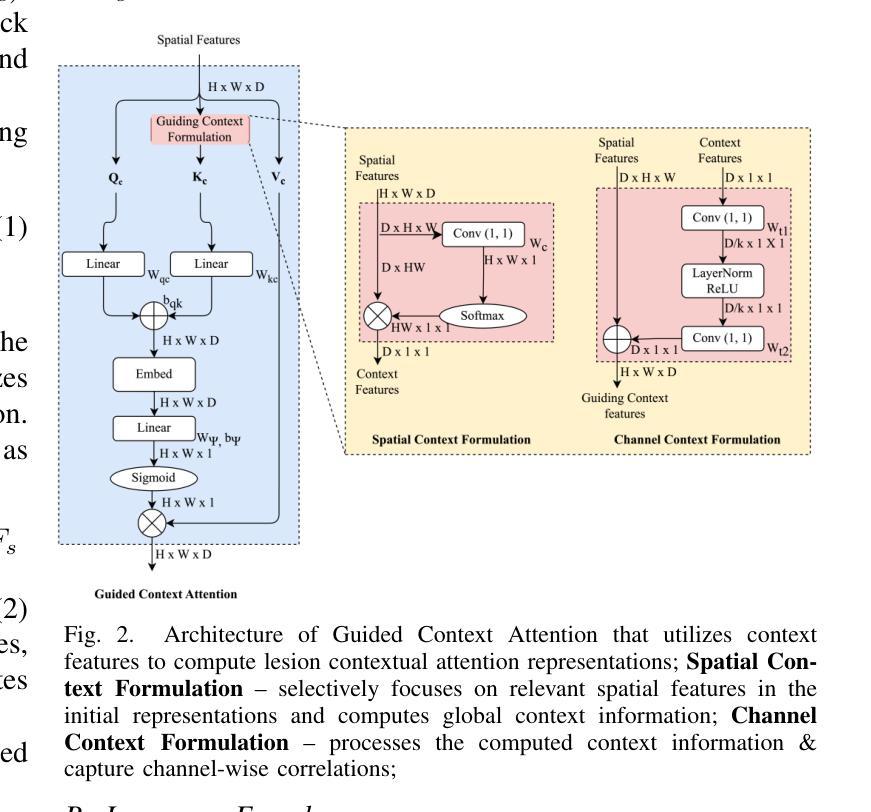
GCS-M3VLT: Guided Context Self-Attention based Multi-modal Medical Vision Language Transformer for Retinal Image Captioning
Authors:Teja Krishna Cherukuri, Nagur Shareef Shaik, Jyostna Devi Bodapati, Dong Hye Ye
Retinal image analysis is crucial for diagnosing and treating eye diseases, yet generating accurate medical reports from images remains challenging due to variability in image quality and pathology, especially with limited labeled data. Previous Transformer-based models struggled to integrate visual and textual information under limited supervision. In response, we propose a novel vision-language model for retinal image captioning that combines visual and textual features through a guided context self-attention mechanism. This approach captures both intricate details and the global clinical context, even in data-scarce scenarios. Extensive experiments on the DeepEyeNet dataset demonstrate a 0.023 BLEU@4 improvement, along with significant qualitative advancements, highlighting the effectiveness of our model in generating comprehensive medical captions.
视网膜图像分析在眼疾的诊断和治疗中至关重要,然而,由于图像质量和病理学变化差异,特别是在标记数据有限的情况下,从图像生成准确的医疗报告仍然具有挑战性。之前的基于Transformer的模型在有限监督下难以整合视觉和文本信息。针对此问题,我们提出了一种用于视网膜图像描述的新型视觉语言模型,该模型通过引导上下文自注意力机制结合视觉和文本特征。这种方法即使在数据稀缺的场景下也能捕捉到复杂的细节和全局临床背景。在DeepEyeNet数据集上的大量实验表明,BLEU@4提高了0.023,同时在质量上取得了显著的进步,突出了我们的模型在生成全面的医疗描述中的有效性。
论文及项目相关链接
PDF This paper has been accepted for presentation at the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2025)
Summary
本文提出一种新型的跨视觉语言模型,用于视网膜图像描述。该模型通过引导上下文自注意力机制,结合视觉和文本特征,即使在数据稀缺的情况下,也能捕捉细节和全局临床背景。在DeepEyeNet数据集上的实验证明了该模型的有效性,生成了全面的医学描述。
Key Takeaways
- 视网膜图像分析对诊断和治疗眼病至关重要。
- 生成准确的医疗报告是视网膜图像分析的一大挑战,主要由于图像质量和病理学的差异以及标记数据的有限性。
- 以往的Transformer模型在有限的监督下难以整合视觉和文本信息。
- 新模型通过引导上下文自注意力机制结合视觉和文本特征。
- 模型能够捕捉细致的细节和全局临床背景,即使在数据稀缺的情况下也能发挥作用。
- 在DeepEyeNet数据集上的实验表明,新模型在生成医学描述方面有显著改进,BLEU@4得分提高了0.023。
点此查看论文截图


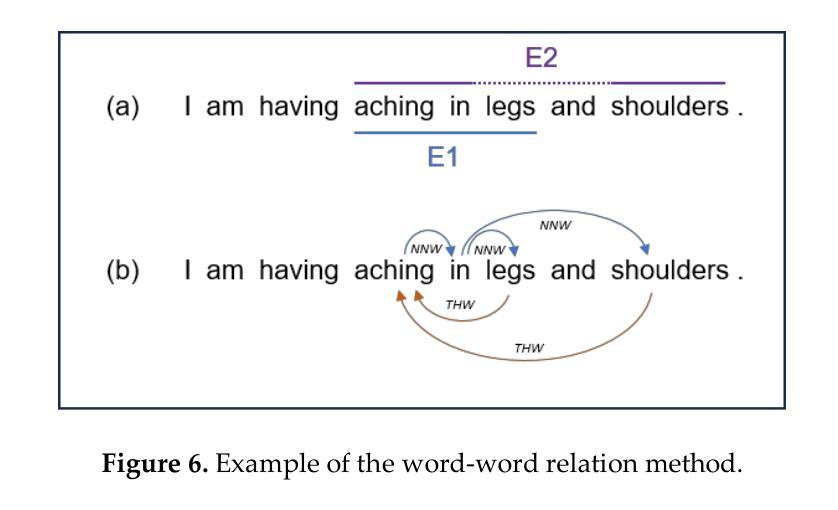
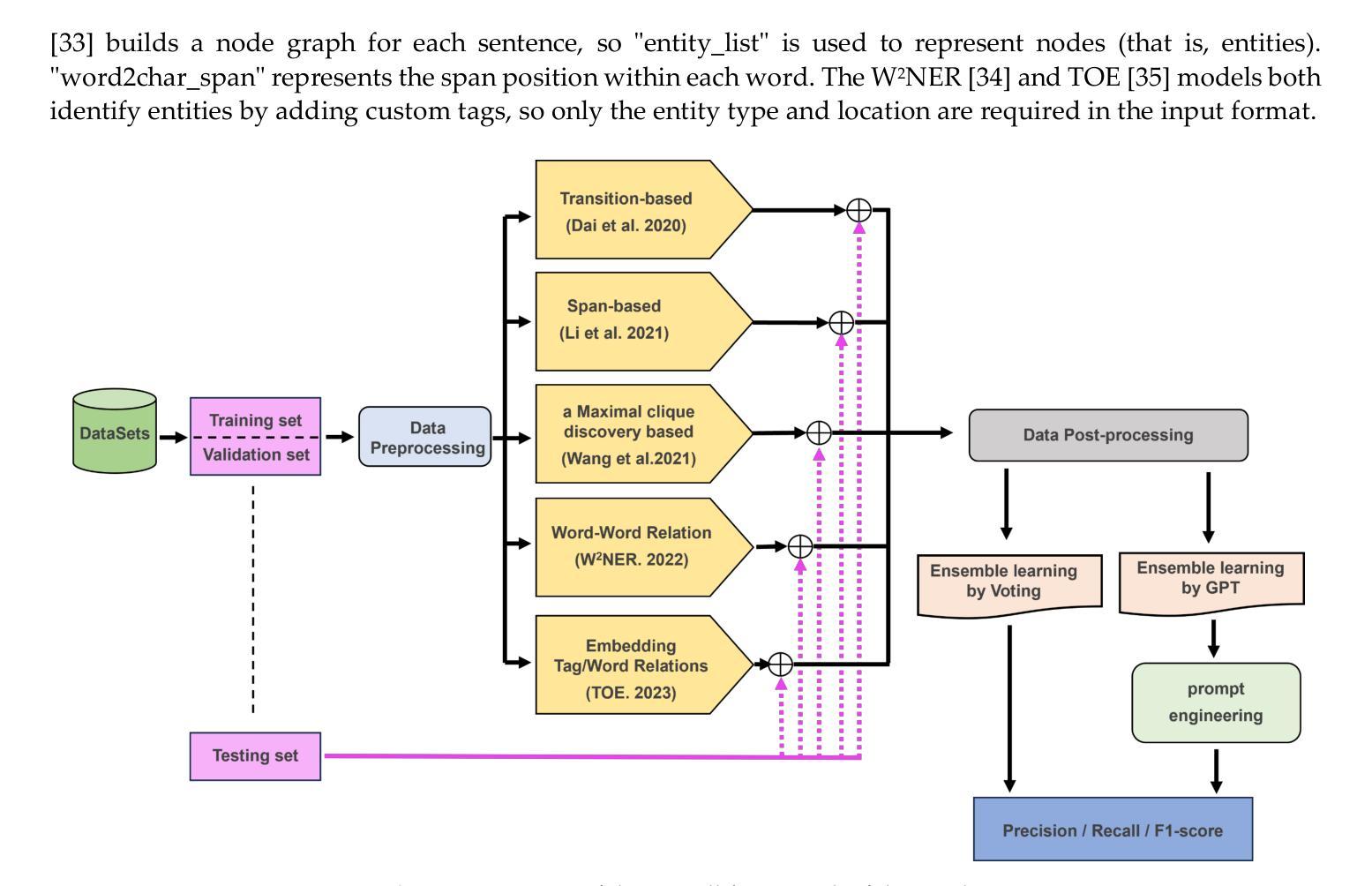
On Fusing ChatGPT and Ensemble Learning in Discon-tinuous Named Entity Recognition in Health Corpora
Authors:Tzu-Chieh Chen, Wen-Yang Lin
Named Entity Recognition has traditionally been a key task in natural language processing, aiming to identify and extract important terms from unstructured text data. However, a notable challenge for contemporary deep-learning NER models has been identifying discontinuous entities, which are often fragmented within the text. To date, methods to address Discontinuous Named Entity Recognition have not been explored using ensemble learning to the best of our knowledge. Furthermore, the rise of large language models, such as ChatGPT in recent years, has shown significant effectiveness across many NLP tasks. Most existing approaches, however, have primarily utilized ChatGPT as a problem-solving tool rather than exploring its potential as an integrative element within ensemble learning algorithms. In this study, we investigated the integration of ChatGPT as an arbitrator within an ensemble method, aiming to enhance performance on DNER tasks. Our method combines five state-of-the-art NER models with ChatGPT using custom prompt engineering to assess the robustness and generalization capabilities of the ensemble algorithm. We conducted experiments on three benchmark medical datasets, comparing our method against the five SOTA models, individual applications of GPT-3.5 and GPT-4, and a voting ensemble method. The results indicate that our proposed fusion of ChatGPT with the ensemble learning algorithm outperforms the SOTA results in the CADEC, ShARe13, and ShARe14 datasets, showcasing its potential to enhance NLP applications in the healthcare domain.
命名实体识别(NER)一直是自然语言处理中的关键任务,旨在从非结构化文本数据中识别和提取重要术语。然而,对于当代深度学习的NER模型来说,识别不连续的实体是一个显著的挑战,这些实体通常在文本中是分散的。据我们所知,迄今为止,尚未有方法尝试使用集成学习来解决不连续的命名实体识别问题。此外,近年来大型语言模型(如ChatGPT)在许多自然语言处理任务中显示出显著的有效性。然而,大多数现有方法主要将ChatGPT用作问题解决工具,而没有探索其在集成学习算法中作为整合元素的可能性。本研究调查了ChatGPT作为仲裁者在集成方法中的整合,旨在提高其在DNER任务上的性能。我们的方法结合了五个最先进的NER模型与ChatGPT,使用自定义的提示工程来评估集成算法的稳健性和泛化能力。我们在三个基准医疗数据集上进行了实验,将我们的方法与五个最新模型、GPT-3.5和GPT-4的单独应用以及投票集成方法进行了比较。结果表明,我们提出的将ChatGPT与集成学习算法融合的方法在CADEC、ShARe13和ShARe14数据集上的表现优于最新结果,展示了其在增强医疗保健领域NLP应用的潜力。
论文及项目相关链接
PDF 13 pages
Summary:本研究探索了将ChatGPT作为集成学习算法中的仲裁者,旨在提高其在断续命名实体识别(DNER)任务上的性能。该研究结合了五种最先进的NER模型与ChatGPT,使用自定义提示工程来评估集成算法的稳健性和泛化能力。在三个基准医疗数据集上的实验表明,该融合方法在CADEC、ShARe13和ShARe14数据集上的表现优于最先进的方法。
Key Takeaways:
- ChatGPT在集成学习中的潜力尚未得到充分探索,尤其是在断续命名实体识别(DNER)任务上。
- 将ChatGPT与集成学习算法结合,旨在提高DNER任务的性能。
- 研究结合了五种最先进的NER模型与ChatGPT,使用自定义提示工程。
- 实验在三个医疗数据集上进行,包括CADEC、ShARe13和ShARe14。
- 融合方法的表现优于最先进的方法。
- ChatGPT的融合提高了集成算法的稳健性和泛化能力。
点此查看论文截图

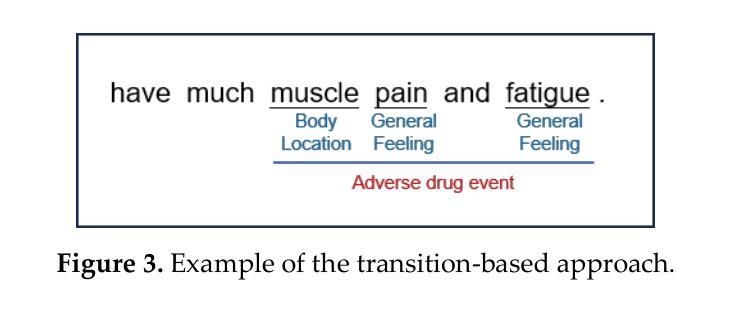
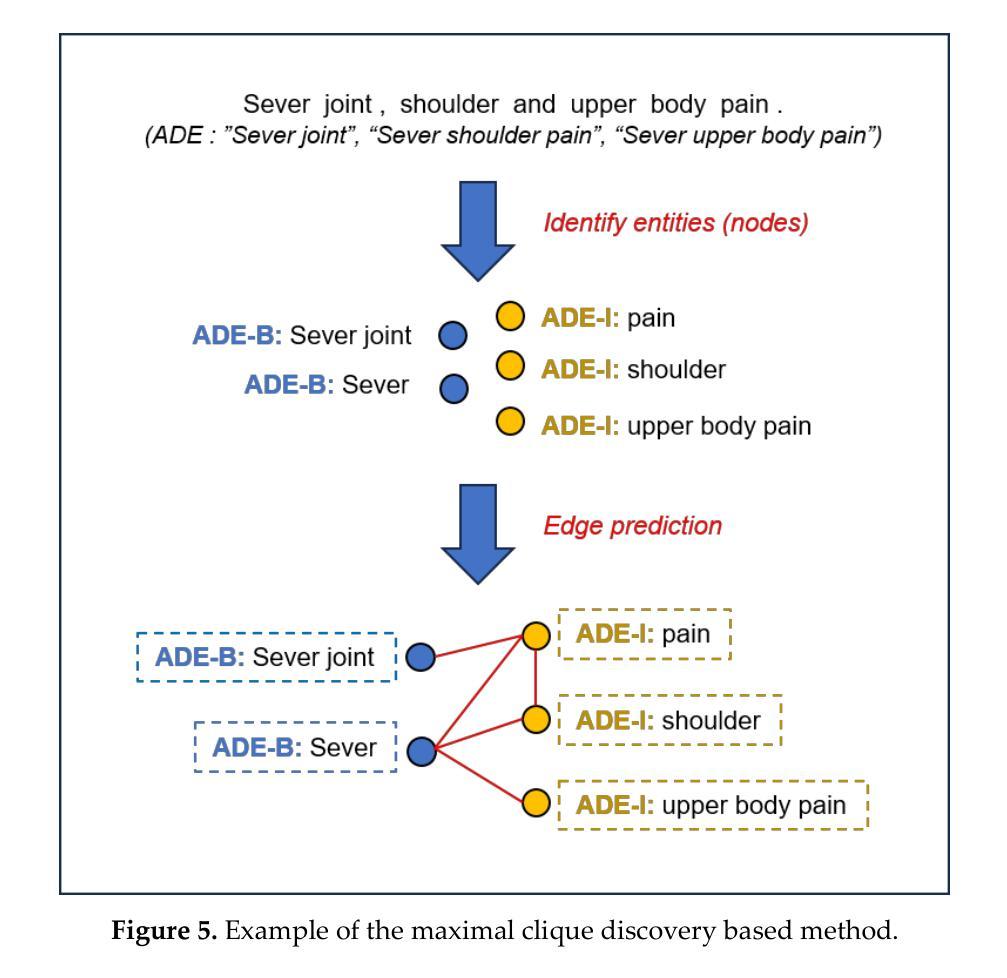
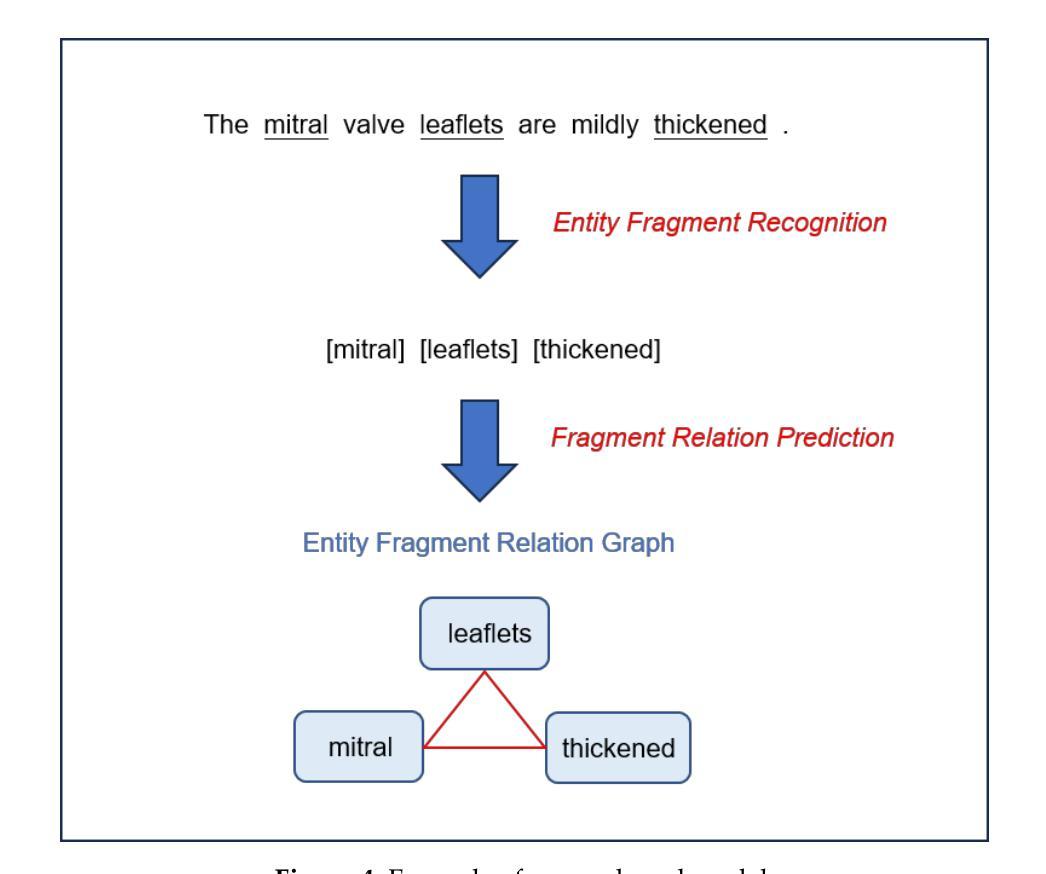
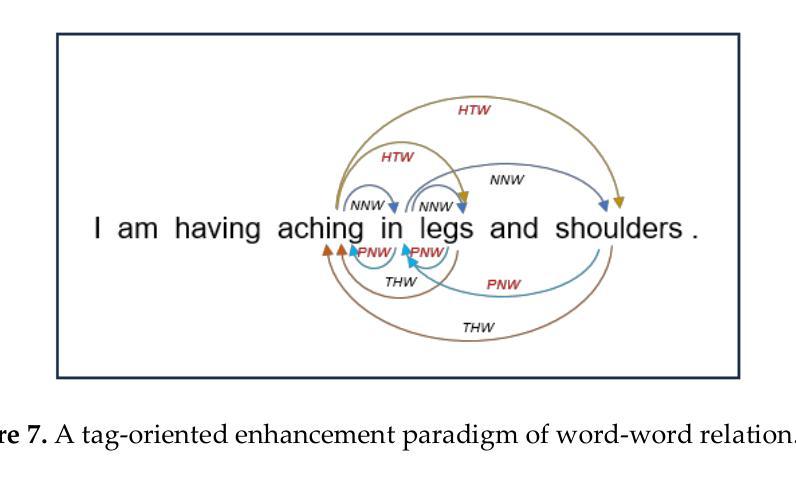
System-2 Mathematical Reasoning via Enriched Instruction Tuning
Authors:Huanqia Cai, Yijun Yang, Zhifeng Li
Solving complex mathematical problems via system-2 reasoning is a natural human skill, yet it remains a significant challenge for current large language models (LLMs). We identify the scarcity of deliberate multi-step reasoning data as a primary limiting factor. To this end, we introduce Enriched Instruction Tuning (EIT), a method that enriches existing human-annotated mathematical datasets by synergizing human and AI feedback to create fine-grained reasoning trajectories. These datasets are then used to fine-tune open-source LLMs, enhancing their mathematical reasoning abilities without reliance on any symbolic verification program. Concretely, EIT is composed of two critical steps: Enriching with Reasoning Plan (ERP) and Enriching with Reasoning Step (ERS). The former generates a high-level plan that breaks down complex instructions into a sequence of simpler objectives, while ERS fills in reasoning contexts often overlooked by human annotators, creating a smoother reasoning trajectory for LLM fine-tuning. Unlike existing CoT prompting methods that generate reasoning chains only depending on LLM’s internal knowledge, our method leverages human-annotated initial answers as ``meta-knowledge’’ to help LLMs generate more detailed and precise reasoning processes, leading to a more trustworthy LLM expert for complex mathematical problems. In experiments, EIT achieves an accuracy of 84.1% on GSM8K and 32.5% on MATH, surpassing state-of-the-art fine-tuning and prompting methods, and even matching the performance of tool-augmented methods.
解决复杂数学问题通过系统2推理是一种人类自然技能,但对当前的大型语言模型(LLM)来说仍然是一个重大挑战。我们确定了缺乏有意识的多步骤推理数据是主要限制因素。为此,我们引入了丰富指令调整(EIT)方法,它通过协同人类和AI反馈来丰富现有的人类注释数学数据集,从而创建精细的推理轨迹。这些数据集随后用于微调开源LLM,增强它们的数学推理能力,无需依赖任何符号验证程序。具体来说,EIT由两个关键步骤组成:丰富推理计划(ERP)和丰富推理步骤(ERS)。前者生成一个高级计划,将复杂指令分解为一系列更简单目标,而ERS则填补了人类注释者经常忽略的推理背景,为LLM微调创建更平滑的推理轨迹。与现有的仅依赖于LLM内部知识的CoT提示方法不同,我们的方法利用人类注释的初始答案作为“元知识”来帮助LLM生成更详细、更精确的推理过程,使LLM成为解决复杂数学问题的更可信赖的专家。在实验中,EIT在GSM8K上达到了84.1%的准确率,在MATH上达到了32.5%的准确率,超越了最新的微调提示方法,甚至与工具增强方法的性能相匹配。
论文及项目相关链接
Summary:
通过系统2推理解决复杂的数学问题是人类的一种自然能力,但仍是当前大型语言模型(LLM)的重大挑战。研究团队提出一种名为丰富指令调优(EIT)的方法,它通过协同人类和AI反馈来创建精细的推理轨迹,从而丰富现有的人类注释数学数据集。EIT由两个关键步骤组成:以推理计划进行丰富(ERP)和以推理步骤进行丰富(ERS)。ERP生成高级计划,将复杂指令分解为一系列更简单目标,而ERS填补了常被人类注释器忽视的推理上下文,为LLM微调创建更平滑的推理轨迹。EIT利用人类注释的初始答案作为“元知识”,帮助LLM生成更详细、更精确的推理过程,在GSM8K和MATH上的实验表明,EIT的准确率分别达到了84.1%和32.5%,超越了现有的微调方法和提示方法,甚至与工具辅助方法的性能相匹配。
Key Takeaways:
- 大型语言模型(LLM)在解决复杂的数学问题方面面临挑战。
- 缺乏有意识的分步推理数据是主要限制因素之一。
- Enriched Instruction Tuning (EIT) 方法通过协同人类和AI反馈丰富现有的人类注释数学数据集。
- EIT包括两个关键步骤:Enriching with Reasoning Plan (ERP) 和 Enriching with Reasoning Step (ERS)。
- ERP生成高级计划,将复杂指令分解为一系列更简单目标。
- ERS弥补了常被忽视的推理上下文,有助于为LLM创建更平滑的推理轨迹。
点此查看论文截图



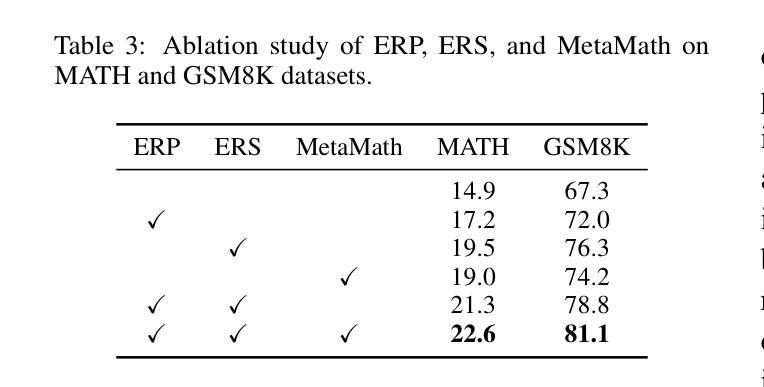
Two-in-One: Unified Multi-Person Interactive Motion Generation by Latent Diffusion Transformer
Authors:Boyuan Li, Xihua Wang, Ruihua Song, Wenbing Huang
Multi-person interactive motion generation, a critical yet under-explored domain in computer character animation, poses significant challenges such as intricate modeling of inter-human interactions beyond individual motions and generating two motions with huge differences from one text condition. Current research often employs separate module branches for individual motions, leading to a loss of interaction information and increased computational demands. To address these challenges, we propose a novel, unified approach that models multi-person motions and their interactions within a single latent space. Our approach streamlines the process by treating interactive motions as an integrated data point, utilizing a Variational AutoEncoder (VAE) for compression into a unified latent space, and performing a diffusion process within this space, guided by the natural language conditions. Experimental results demonstrate our method’s superiority over existing approaches in generation quality, performing text condition in particular when motions have significant asymmetry, and accelerating the generation efficiency while preserving high quality.
多人交互运动生成是计算机角色动画中一个至关重要但尚未被充分研究的领域,它带来了重大挑战,例如超越个体运动的复杂人际互动建模,以及根据文本条件生成两种差异巨大的运动。目前的研究经常为个体运动采用单独的模块分支,这导致了互动信息的丢失和计算需求的增加。为了解决这些挑战,我们提出了一种新颖的统一方法,在一个单一的潜在空间内对多人运动及其互动进行建模。我们的方法通过将对交互运动作为一个整合的数据点来处理,利用变分自动编码器(VAE)压缩到统一的潜在空间,并在该空间内进行扩散过程,由自然语言条件引导。实验结果表明,我们的方法在生成质量上优于现有方法,特别是在处理运动具有显著不对称性的文本条件时,能提高生成效率同时保持高质量。
论文及项目相关链接
Summary
本文提出一种新颖的统一方法,用于在单个潜在空间内对多人运动及其互动进行建模。该方法将互动运动视为一个整体数据点,使用变分自编码器(VAE)进行压缩到统一潜在空间,并在该空间内进行扩散过程,由自然语言条件引导。该方法解决了多人互动运动生成中的挑战,如超越个人运动的复杂人际互动建模,以及从一个文本条件生成两个差异巨大的运动。实验结果表明,该方法在生成质量上优于现有方法,特别是在运动有显著差异的文本条件下表现优越,同时提高了生成效率并保持高质量。
Key Takeaways
- 多人互动运动生成是计算机角色动画中的关键但尚未充分探索的领域,存在复杂的人际互动建模和从单一文本条件生成差异大的两个运动等挑战。
- 当前研究通常使用单独的模块分支来处理个人运动,导致互动信息的丢失和计算需求的增加。
- 提出了一种新颖的统一方法,在单个潜在空间内对多人运动和互动进行建模,简化了流程。
- 使用变分自编码器(VAE)进行压缩到统一潜在空间,并进行扩散过程。
- 该方法受到自然语言条件的引导,根据文本条件生成运动。
- 实验结果表明,该方法在生成质量、文本条件下的运动生成以及生成效率和质量方面均优于现有方法。
点此查看论文截图

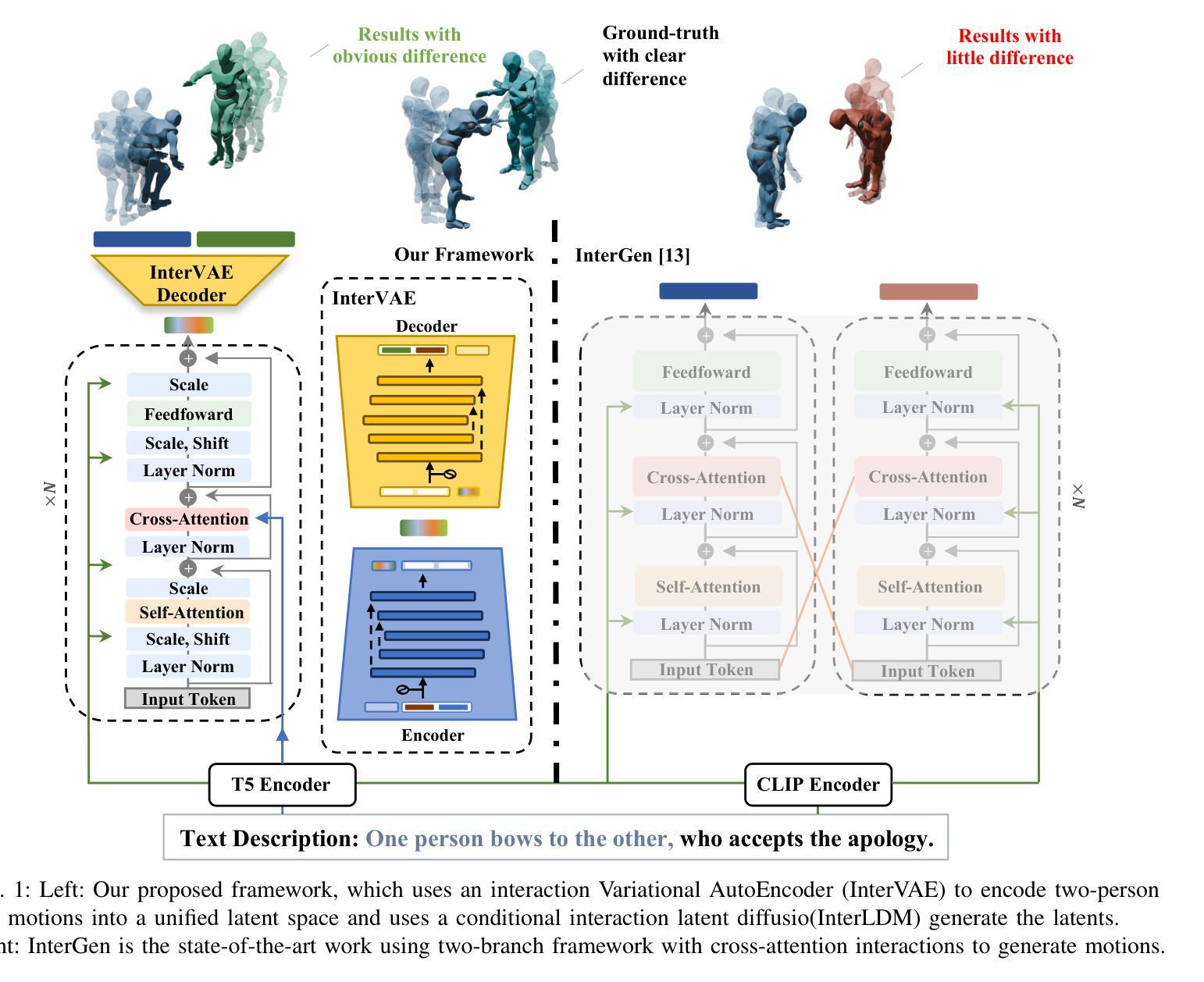
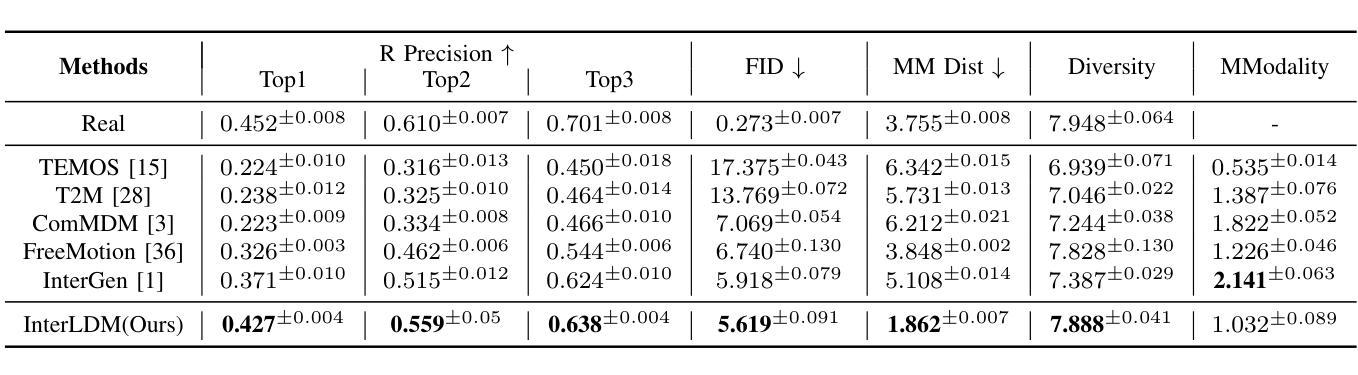
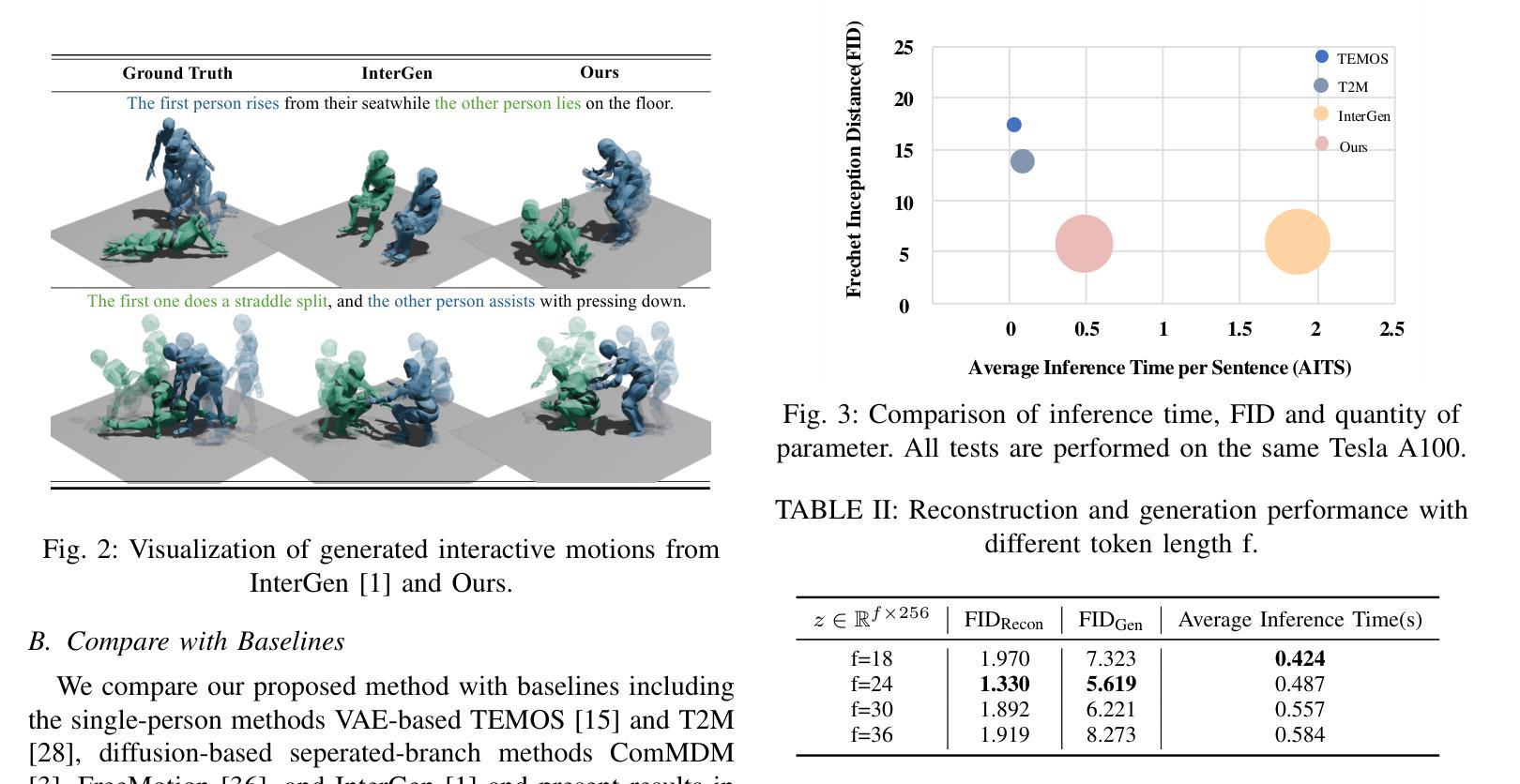
Large Language Model Can Be a Foundation for Hidden Rationale-Based Retrieval
Authors:Luo Ji, Feixiang Guo, Teng Chen, Qingqing Gu, Xiaoyu Wang, Ningyuan Xi, Yihong Wang, Peng Yu, Yue Zhao, Hongyang Lei, Zhonglin Jiang, Yong Chen
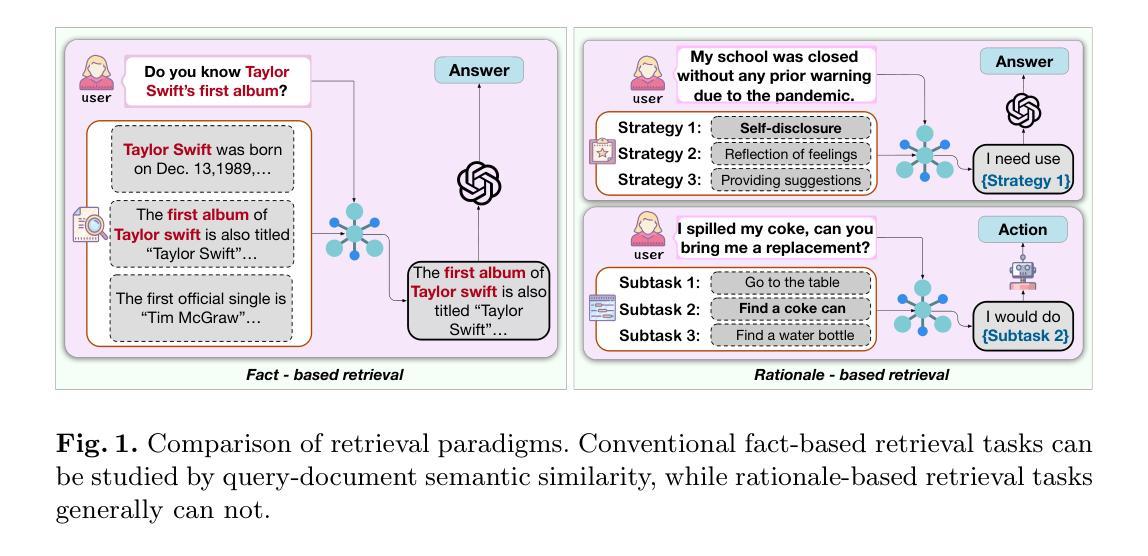
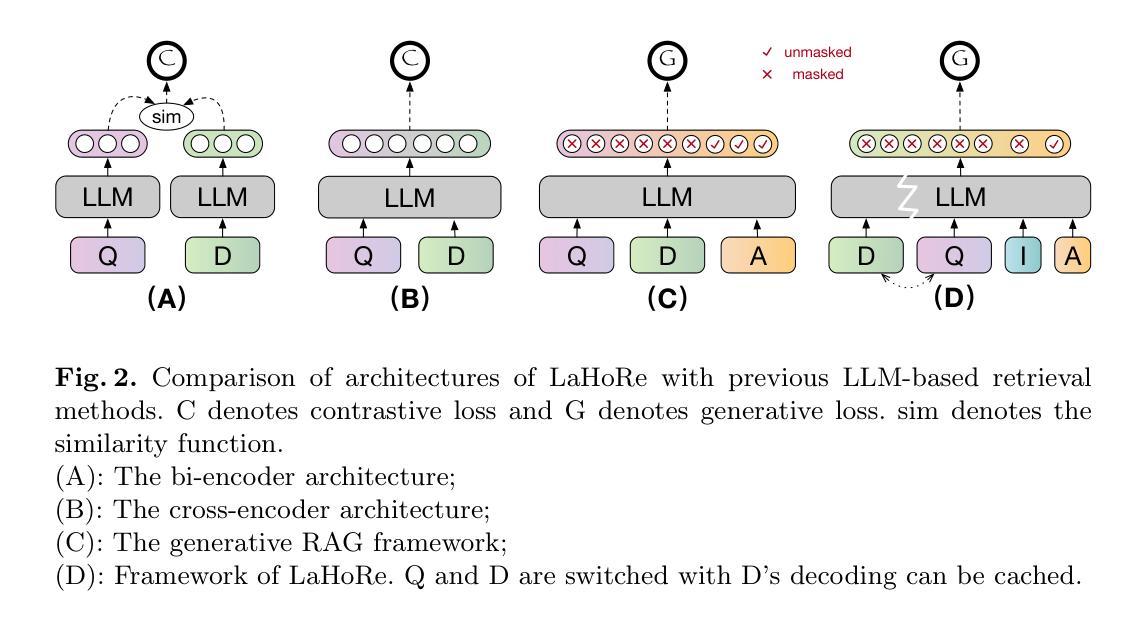
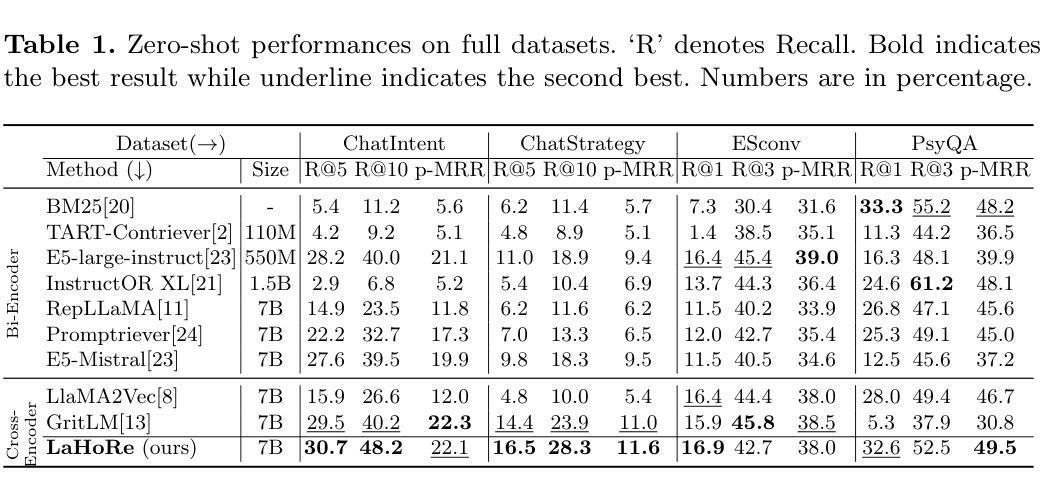
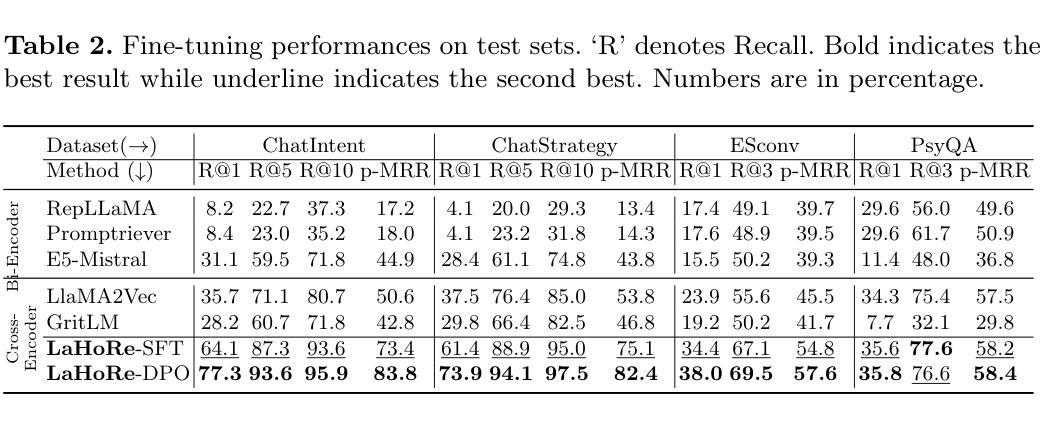
Despite the recent advancement in Retrieval-Augmented Generation (RAG) systems, most retrieval methodologies are often developed for factual retrieval, which assumes query and positive documents are semantically similar. In this paper, we instead propose and study a more challenging type of retrieval task, called hidden rationale retrieval, in which query and document are not similar but can be inferred by reasoning chains, logic relationships, or empirical experiences. To address such problems, an instruction-tuned Large language model (LLM) with a cross-encoder architecture could be a reasonable choice. To further strengthen pioneering LLM-based retrievers, we design a special instruction that transforms the retrieval task into a generative task by prompting LLM to answer a binary-choice question. The model can be fine-tuned with direct preference optimization (DPO). The framework is also optimized for computational efficiency with no performance degradation. We name this retrieval framework by RaHoRe and verify its zero-shot and fine-tuned performance superiority on Emotional Support Conversation (ESC), compared with previous retrieval works. Our study suggests the potential to employ LLM as a foundation for a wider scope of retrieval tasks. Our codes, models, and datasets are available on https://github.com/flyfree5/LaHoRe.
尽管最近检索增强生成(RAG)系统有所进展,但大多数检索方法往往针对事实检索而开发,这假设查询和正面文档在语义上是相似的。在本文中,我们提出并研究了一种更具挑战性的检索任务,即隐藏逻辑检索,其中查询和文档并不相似,但可以通过推理链、逻辑关系或经验来推断。为解决此类问题,采用带有交叉编码器架构的指令优化大型语言模型(LLM)可能是一个合理的选择。为了进一步加强基于LLM的检索器,我们设计了一个特殊指令,通过将检索任务转化为生成任务,提示LLM回答二选一的问题。该模型可采用直接偏好优化(DPO)进行微调。该框架在计算效率方面也进行了优化,且不会降低性能。我们将这种检索框架命名为RaHoRe,并在情感支持对话(ESC)上验证了其零样本和微调后的性能优越性,与之前的研究相比具有显著的优势。我们的研究表明,有潜力将LLM用作更广泛检索任务的基础。我们的代码、模型和数据集可在https://github.com/flyfree5/LaHoRe获取。
论文及项目相关链接
PDF 11 pages, 3 figures, accepted by ECIR 2025
Summary
大语言模型(LLM)用于解决隐藏逻辑检索任务。不同于传统的以事实检索为主的方法,该任务通过逻辑推理链、逻辑关系或经验来推理查询和文档之间的关系。通过特殊指令将检索任务转化为生成任务,利用二选一问题来引导LLM进行检索,采用直接偏好优化(DPO)进行微调,构建的计算效率高的模型框架RaHoRe在情感支持对话(ESC)任务上表现优越。
Key Takeaways
- 该研究提出了一种新的检索任务类型——隐藏逻辑检索,该任务需要推理查询和文档之间的关系,不同于传统的假设查询和正面文档语义相似的检索方法。
- 采用大语言模型(LLM)进行解决隐藏逻辑检索任务,利用其跨编码器架构应对复杂的语义关系。
- 通过特殊指令将检索任务转化为生成任务,促进LLM对查询的回应,采用二选一问题的形式进行提示。
- 采用直接偏好优化(DPO)对模型进行微调,提高模型的性能。
- 所构建的模型框架RaHoRe在计算效率上进行了优化,且性能未出现下降。
- 在情感支持对话(ESC)任务上,RaHoRe的表现优于之前的检索工作。
点此查看论文截图

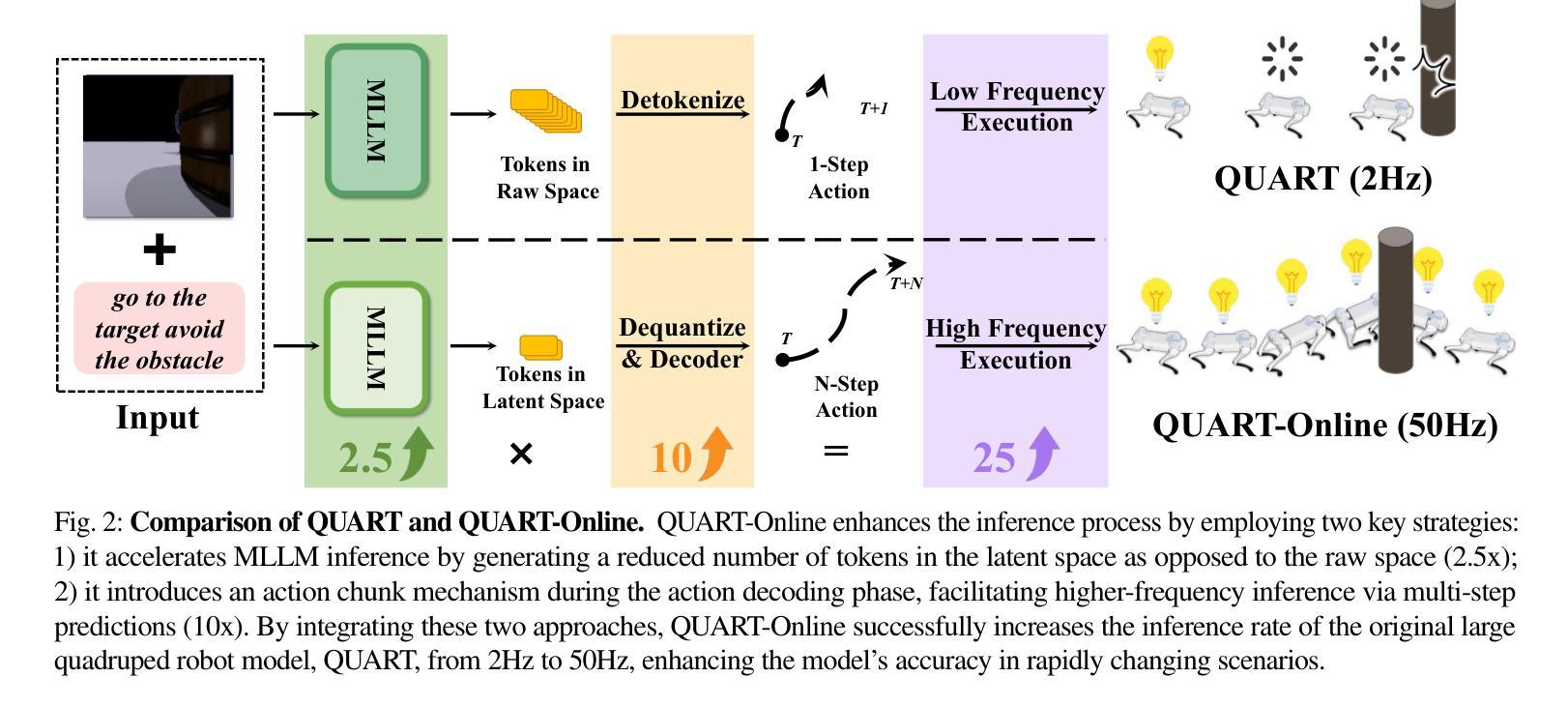
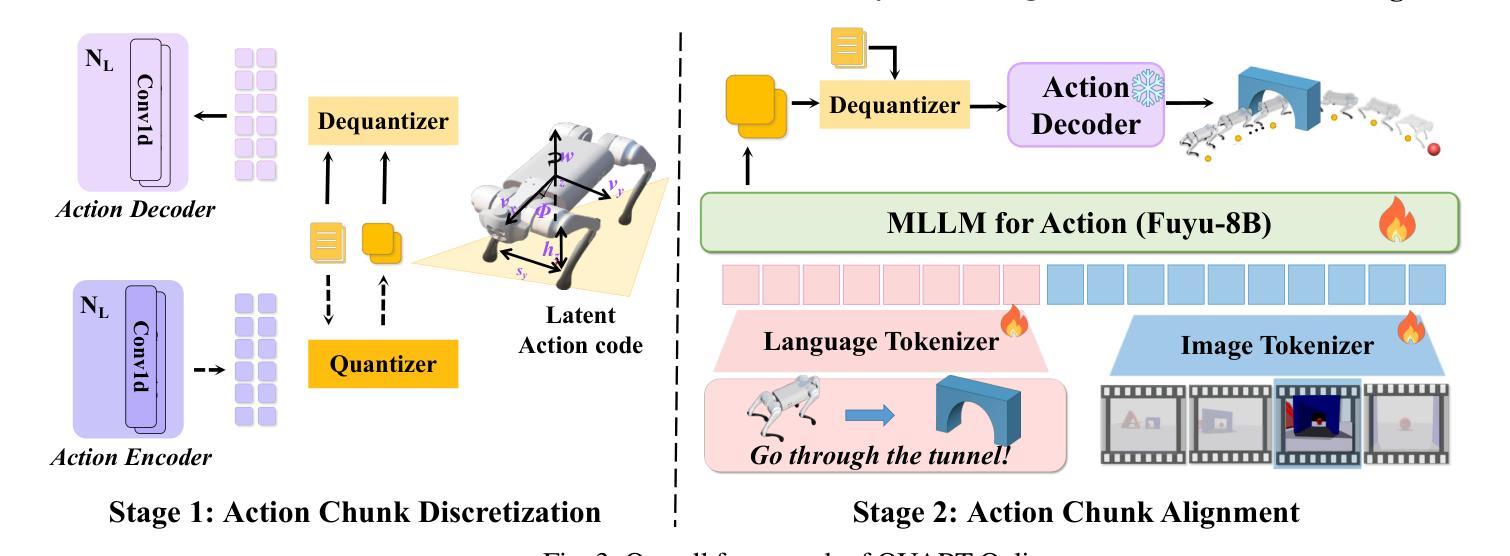
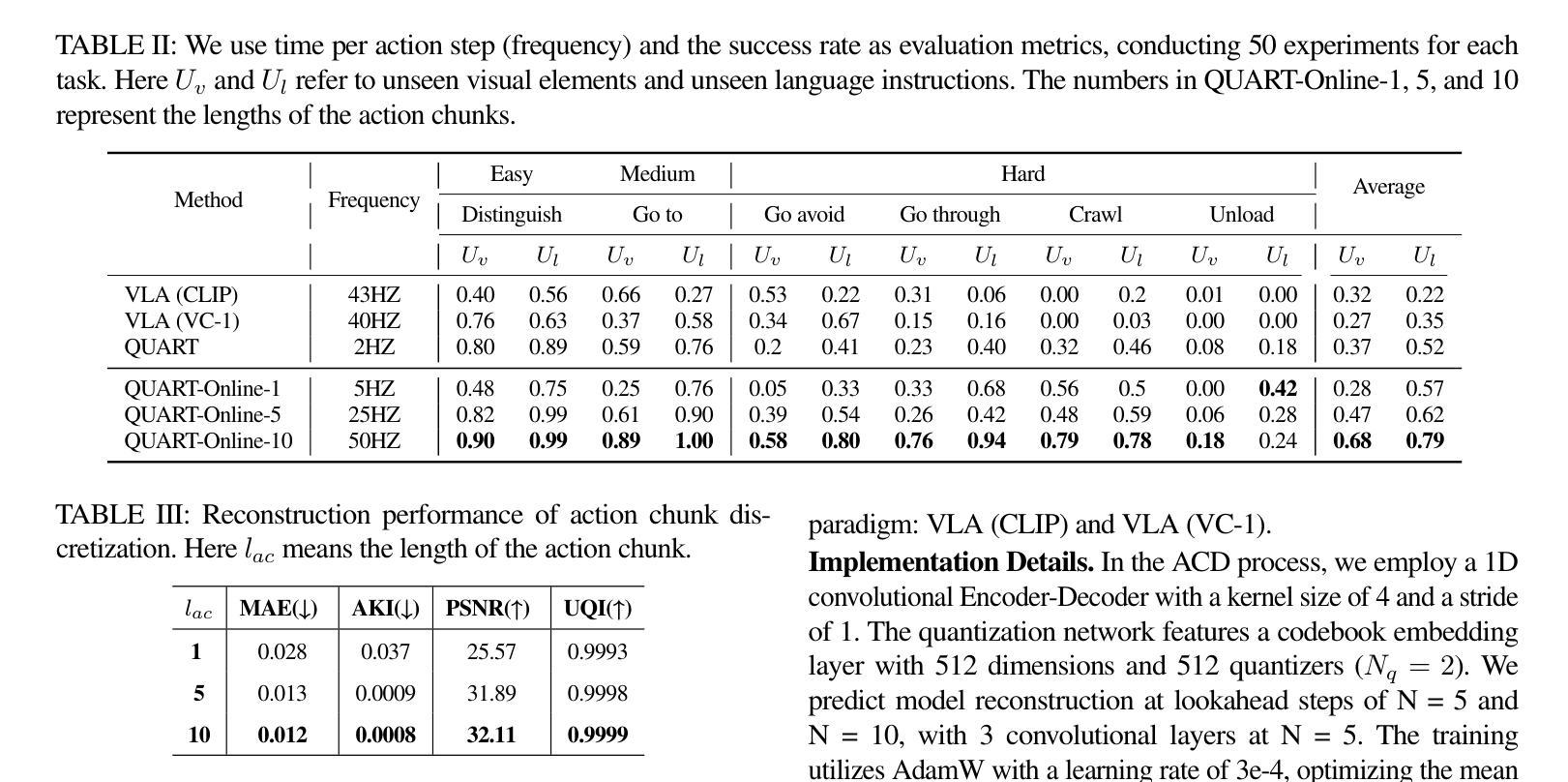
QUART-Online: Latency-Free Large Multimodal Language Model for Quadruped Robot Learning
Authors:Xinyang Tong, Pengxiang Ding, Donglin Wang, Wenjie Zhang, Can Cui, Mingyang Sun, Yiguo Fan, Han Zhao, Hongyin Zhang, Yonghao Dang, Siteng Huang, Shangke Lyu
This paper addresses the inherent inference latency challenges associated with deploying multimodal large language models (MLLM) in quadruped vision-language-action (QUAR-VLA) tasks. Our investigation reveals that conventional parameter reduction techniques ultimately impair the performance of the language foundation model during the action instruction tuning phase, making them unsuitable for this purpose. We introduce a novel latency-free quadruped MLLM model, dubbed QUART-Online, designed to enhance inference efficiency without degrading the performance of the language foundation model. By incorporating Action Chunk Discretization (ACD), we compress the original action representation space, mapping continuous action values onto a smaller set of discrete representative vectors while preserving critical information. Subsequently, we fine-tune the MLLM to integrate vision, language, and compressed actions into a unified semantic space. Experimental results demonstrate that QUART-Online operates in tandem with the existing MLLM system, achieving real-time inference in sync with the underlying controller frequency, significantly boosting the success rate across various tasks by 65%. Our project page is https://quart-online.github.io.
本文着眼于在四足视觉语言动作(QUAR-VLA)任务中部署多模态大型语言模型(MLLM)所面临的固有推理延迟挑战。我们的调查发现,传统的参数减少技术最终会在动作指令调整阶段损害语言基础模型的性能,使其不适合此目的。我们引入了一种新型的无延迟四足MLLM模型,名为QUART-Online,旨在提高推理效率,同时不降低语言基础模型的性能。通过采用动作块离散化(ACD),我们压缩了原始的动作表示空间,将连续的动作值映射到一组较小的离散代表向量上,同时保留了关键信息。随后,我们对MLLM进行了微调,以将视觉、语言和压缩动作集成到一个统一的语义空间中。实验结果表明,QUART-Online与现有的MLLM系统协同工作,实现了与底层控制器频率同步的实时推理,在各种任务中的成功率提高了65%。我们的项目页面是https://quart-online.github.io。
论文及项目相关链接
Summary
本文研究了在四足视觉-语言-动作(QUAR-VLA)任务中部署多模态大型语言模型(MLLM)时面临的固有推理延迟挑战。研究引入了一种新型的无延迟四足MLLM模型——QUART-Online,旨在提高推理效率,同时不损害语言基础模型的性能。通过采用动作片段离散化(ACD)技术,压缩原始动作表示空间,将连续动作值映射到一组较小的离散代表向量上,同时保留关键信息。随后,对MLLM进行微调,以将视觉、语言和压缩动作集成到统一的语义空间中。实验结果表明,QUART-Online与现有MLLM系统协同工作,实现了与底层控制器频率同步的实时推理,在各项任务中的成功率提高了65%。
Key Takeaways
- 论文主要探讨了多模态大型语言模型(MLLM)在四足视觉-语言-动作(QUAR-VLA)任务中的推理延迟问题。
- 引入了一种新型的无延迟四足MLLM模型——QUART-Online,旨在提高推理效率且不损害语言基础模型的性能。
- 通过动作片段离散化(ACD)技术压缩动作表示空间,映射连续动作值到离散代表向量。
- QUART-Online模型通过微调集成视觉、语言和压缩动作到统一的语义空间。
- 实验结果表明,QUART-Online与现有MLLM系统协同工作,实现实时推理。
- QUART-Online在不同任务中的成功率提高了65%。
- 项目页面为https://quart-online.github.io。
点此查看论文截图


Advanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics with Large Language Models
Authors:Atin Sakkeer Hussain
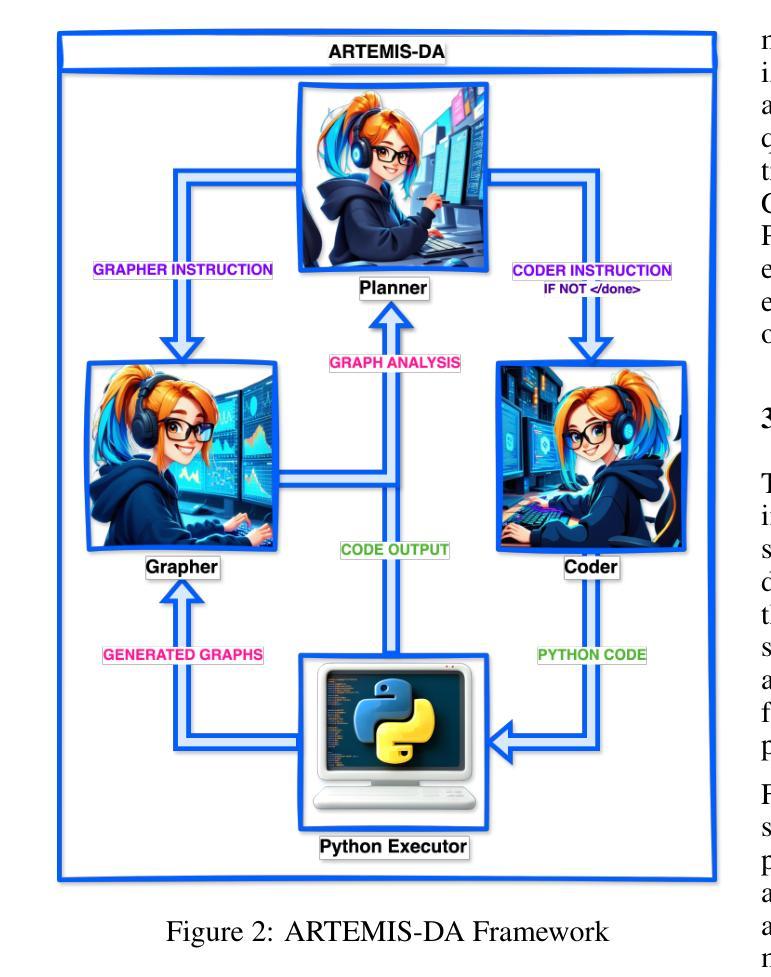
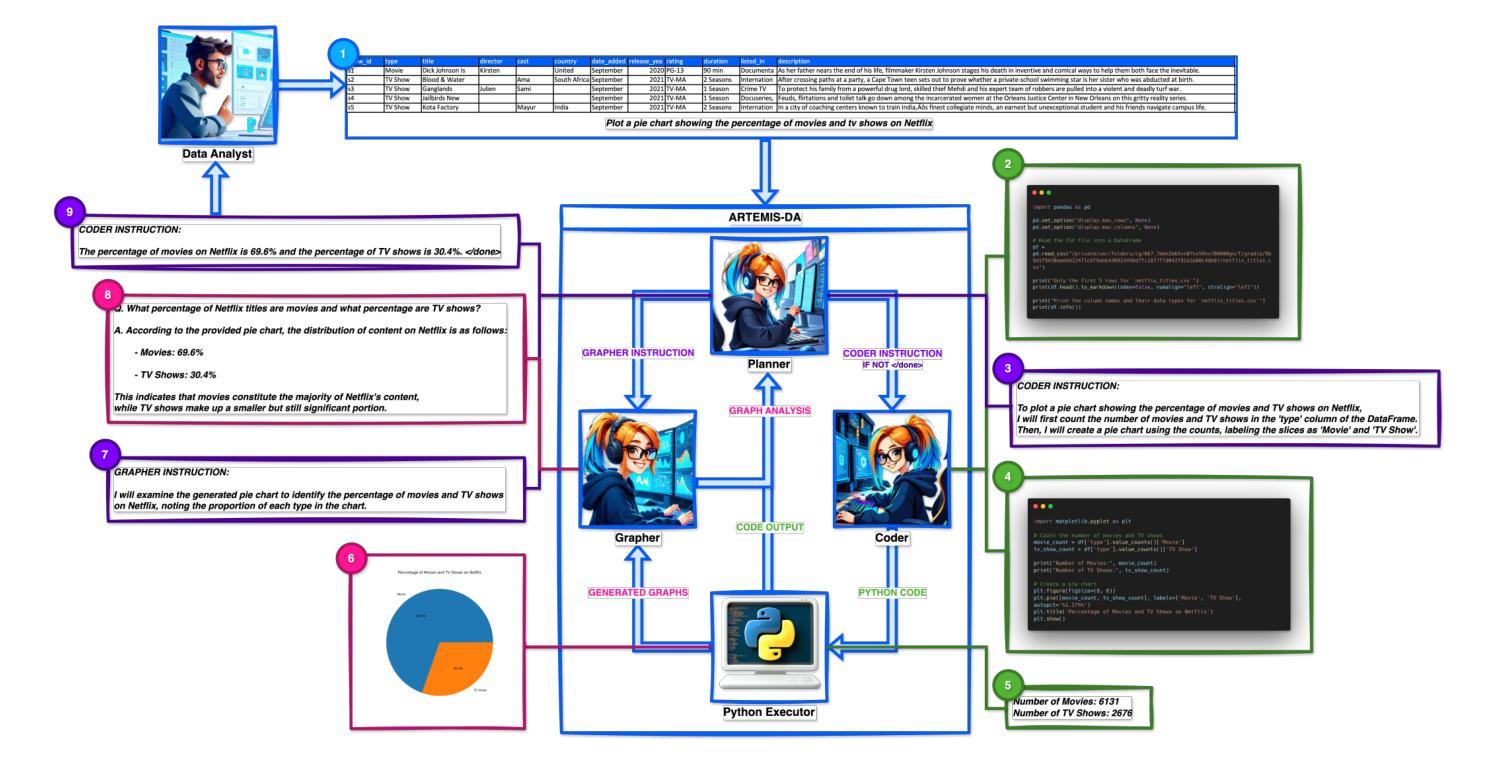
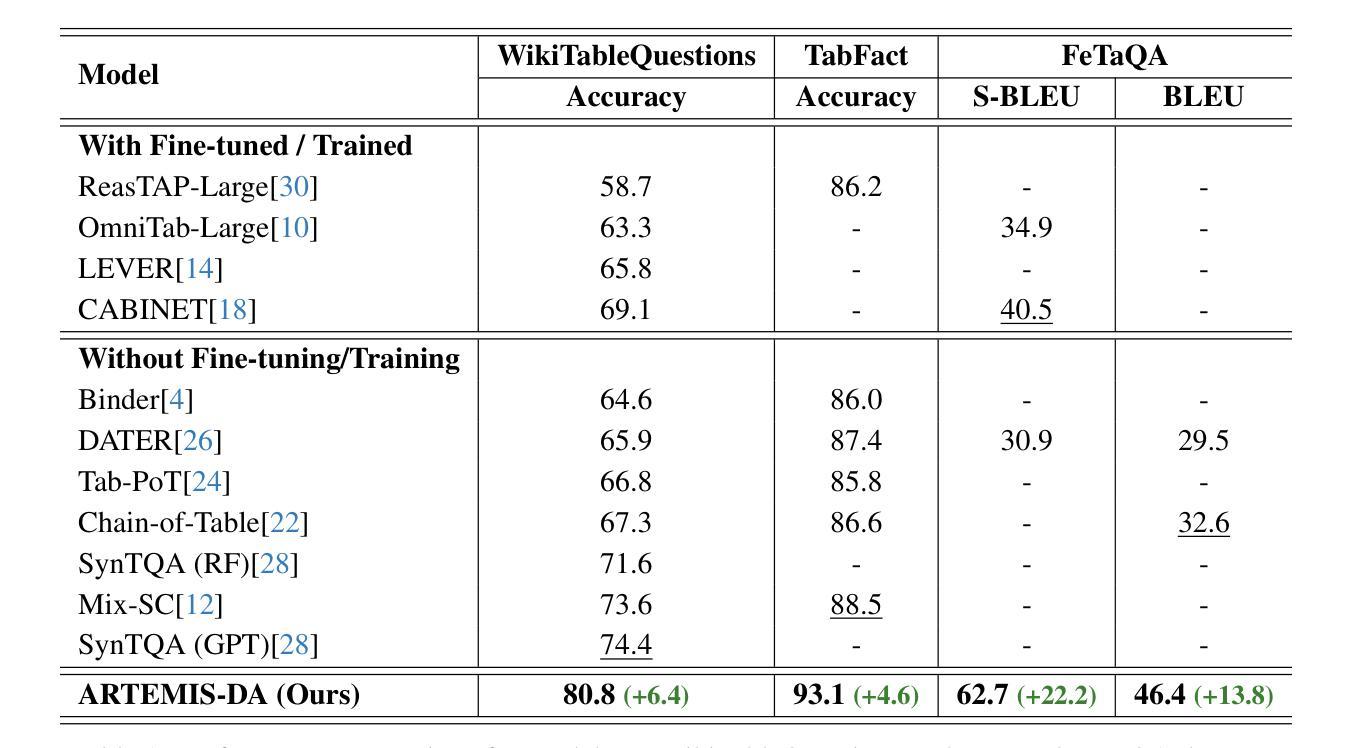
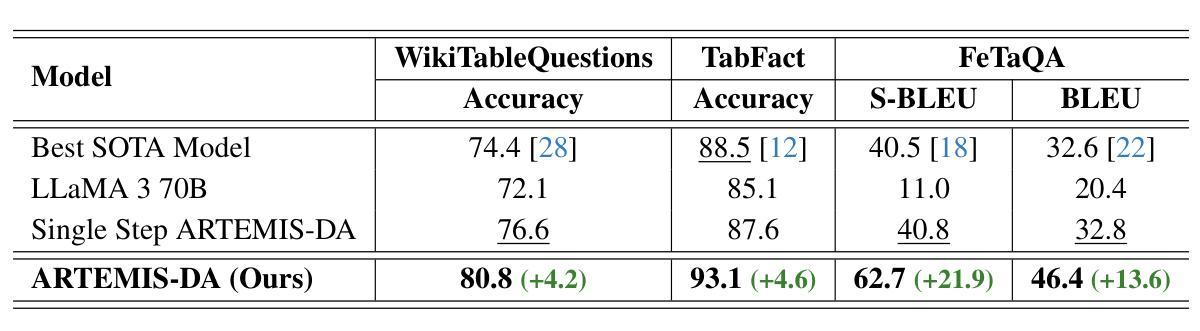
This paper presents the Advanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics (ARTEMIS-DA), a novel framework designed to augment Large Language Models (LLMs) for solving complex, multi-step data analytics tasks. ARTEMIS-DA integrates three core components: the Planner, which dissects complex user queries into structured, sequential instructions encompassing data preprocessing, transformation, predictive modeling, and visualization; the Coder, which dynamically generates and executes Python code to implement these instructions; and the Grapher, which interprets generated visualizations to derive actionable insights. By orchestrating the collaboration between these components, ARTEMIS-DA effectively manages sophisticated analytical workflows involving advanced reasoning, multi-step transformations, and synthesis across diverse data modalities. The framework achieves state-of-the-art (SOTA) performance on benchmarks such as WikiTableQuestions and TabFact, demonstrating its ability to tackle intricate analytical tasks with precision and adaptability. By combining the reasoning capabilities of LLMs with automated code generation and execution and visual analysis, ARTEMIS-DA offers a robust, scalable solution for multi-step insight synthesis, addressing a wide range of challenges in data analytics.
本文介绍了用于数据解析中的多步骤见解合成的先进推理与转换引擎(ARTEMIS-DA),这是一种旨在增强大型语言模型(LLM)以解决复杂的多步骤数据分析任务的新型框架。ARTEMIS-DA集成了三个核心组件:Planner,它将复杂的用户查询解析为结构化的顺序指令,包括数据预处理、转换、预测建模和可视化;Coder,它动态生成并执行Python代码以执行这些指令;Grapher,它解释生成的可视化以获取可操作的见解。通过协调这些组件之间的协作,ARTEMIS-DA有效地管理涉及高级推理、多步骤转换和跨不同数据模态的合成的高级分析工作流程。该框架在WikiTableQuestions和TabFact等基准测试上达到了最新技术水平,证明了其处理复杂分析任务的精确性和适应性。通过将LLM的推理能力与自动化代码生成和执行以及视觉分析相结合,ARTEMIS-DA为多步骤见解合成提供了稳健且可扩展的解决方案,解决了数据分析中的广泛挑战。
论文及项目相关链接
Summary
ARTEMIS-DA是一个增强大型语言模型(LLM)解决复杂多步骤数据分析任务的新型框架。它包含规划器、编码器和绘图仪三个核心组件,能有效管理涉及高级推理、多步骤转换和跨不同数据模态的综合分析的高级分析工作流程,实现WikiTableQuestions和TabFact等基准测试中的最佳性能。
Key Takeaways
- ARTEMIS-DA是一个用于多步骤洞察合成的先进推理和转换引擎。
- 它旨在增强大型语言模型(LLM)以解决复杂的数据分析任务。
- ARTEMIS-DA包含三个核心组件:规划师、编码器和绘图仪。
- 规划师负责将复杂的用户查询分解为结构化、序列化的指令。
- 编码器能够动态生成和执行Python代码来实现这些指令。
- 绘图仪可以解释生成的可视化来派生出可操作的见解。
点此查看论文截图