⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-25 更新
VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music
Authors:Jiatong Shi, Hye-jin Shim, Jinchuan Tian, Siddhant Arora, Haibin Wu, Darius Petermann, Jia Qi Yip, You Zhang, Yuxun Tang, Wangyou Zhang, Dareen Safar Alharthi, Yichen Huang, Koichi Saito, Jionghao Han, Yiwen Zhao, Chris Donahue, Shinji Watanabe
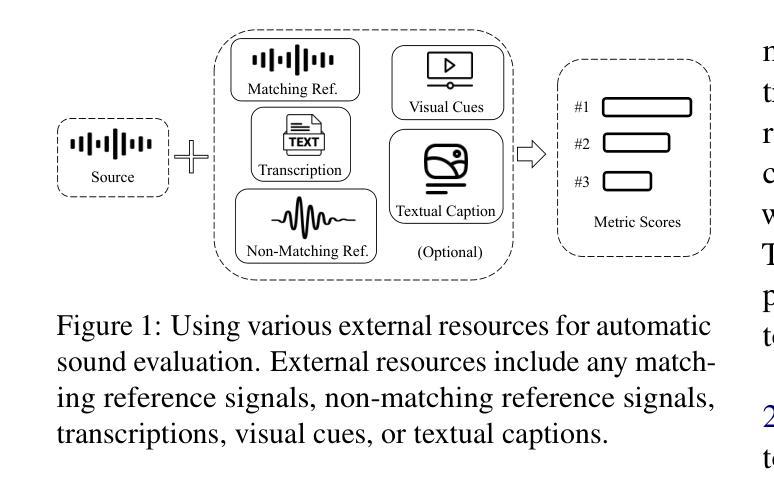
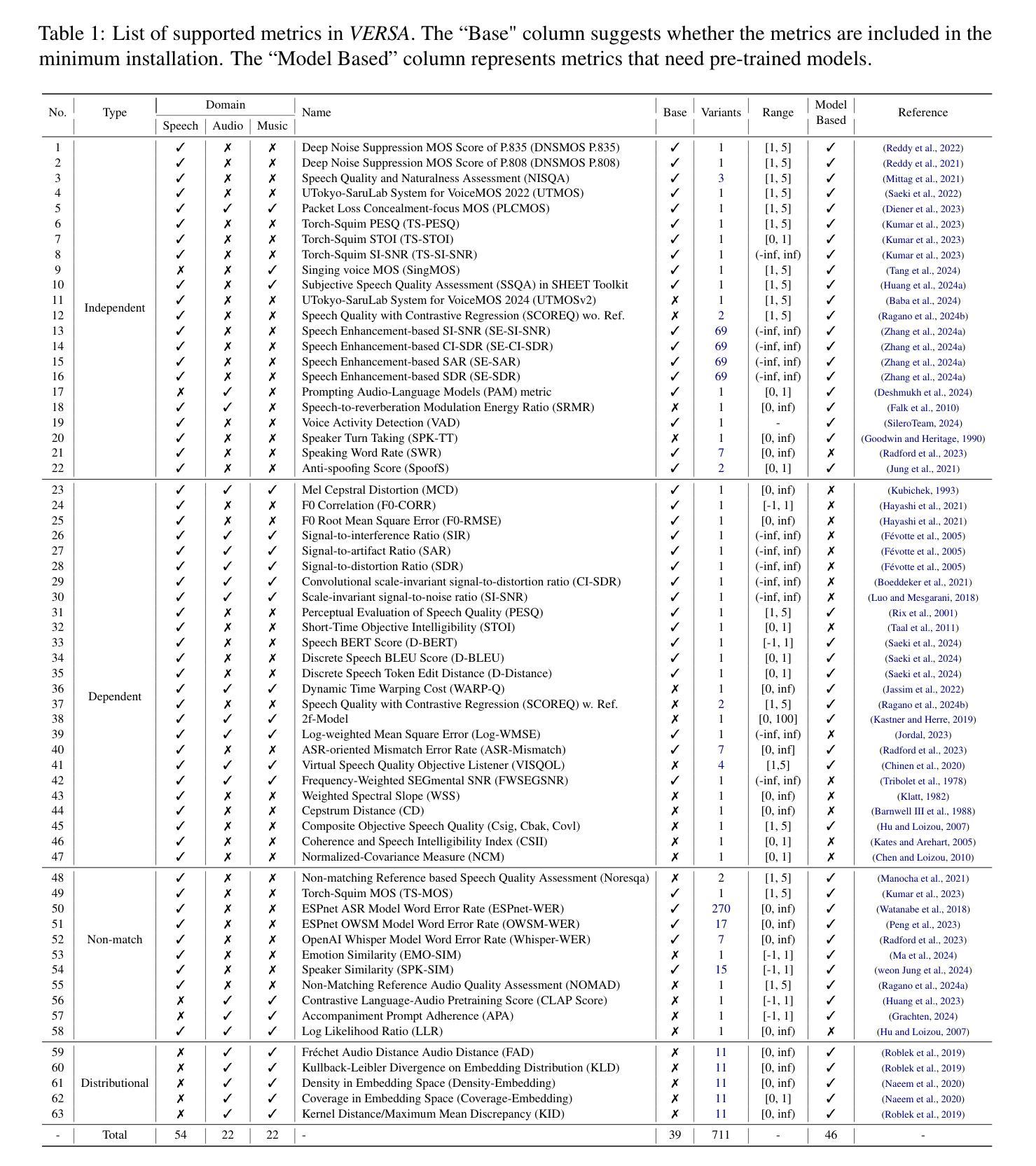
In this work, we introduce VERSA, a unified and standardized evaluation toolkit designed for various speech, audio, and music signals. The toolkit features a Pythonic interface with flexible configuration and dependency control, making it user-friendly and efficient. With full installation, VERSA offers 63 metrics with 711 metric variations based on different configurations. These metrics encompass evaluations utilizing diverse external resources, including matching and non-matching reference audio, text transcriptions, and text captions. As a lightweight yet comprehensive toolkit, VERSA is versatile to support the evaluation of a wide range of downstream scenarios. To demonstrate its capabilities, this work highlights example use cases for VERSA, including audio coding, speech synthesis, speech enhancement, singing synthesis, and music generation. The toolkit is available at https://github.com/shinjiwlab/versa.
在这项工作中,我们介绍了VERSA,这是一个统一标准化的评估工具包,用于各种语音、音频和音乐信号。该工具包具有Python风格的接口,具有灵活的配置和依赖控制,使其友好高效。在完全安装后,VERSA提供基于不同配置的63个指标,共计有711种指标变化。这些指标包括利用各种外部资源的评估,包括匹配和非匹配的参考音频、文本转录和文本描述。作为一个轻便而全面的工具包,VERSA能够支持对各种下游场景的评估。为了展示其能力,这项工作突出了VERSA的一些用例示例,包括音频编码、语音合成、语音增强、歌唱合成和音乐生成。该工具包可在https://github.com/shinjiwlab/versa找到。
论文及项目相关链接
Summary
本文介绍了VERSA这一统一标准化的评估工具包,适用于各种语音、音频和音乐信号的评估。它具备Pythonic接口,配置灵活,依赖控制性强,使用方便且效率高。VERSA提供63种度量指标,基于不同配置有711种度量指标变化。它能利用包括匹配和非匹配参考音频、文本转录和文本字幕在内的外部资源进行评价。作为轻便而全面的工具包,VERSA支持各种下游场景的评估。
Key Takeaways
- VERSA是一个统一标准化的评估工具包,适用于语音、音频和音乐信号的评估。
- VERSA具备Pythonic接口,具有灵活的配置和依赖控制。
- VERSA提供多种度量指标,可根据不同配置产生不同的度量指标变化。
- VERSA能利用外部资源进行评价,包括匹配和非匹配参考音频、文本转录和文本字幕。
- VERSA支持多种下游场景的评估,如音频编码、语音合成、语音增强、歌唱合成和音乐生成等。
- VERSA工具包已公开发布,可供公众使用。
- VERSA工具包网址为https://github.com/shinjiwlab/versa。
点此查看论文截图



Incremental Disentanglement for Environment-Aware Zero-Shot Text-to-Speech Synthesis
Authors:Ye-Xin Lu, Hui-Peng Du, Zheng-Yan Sheng, Yang Ai, Zhen-Hua Ling
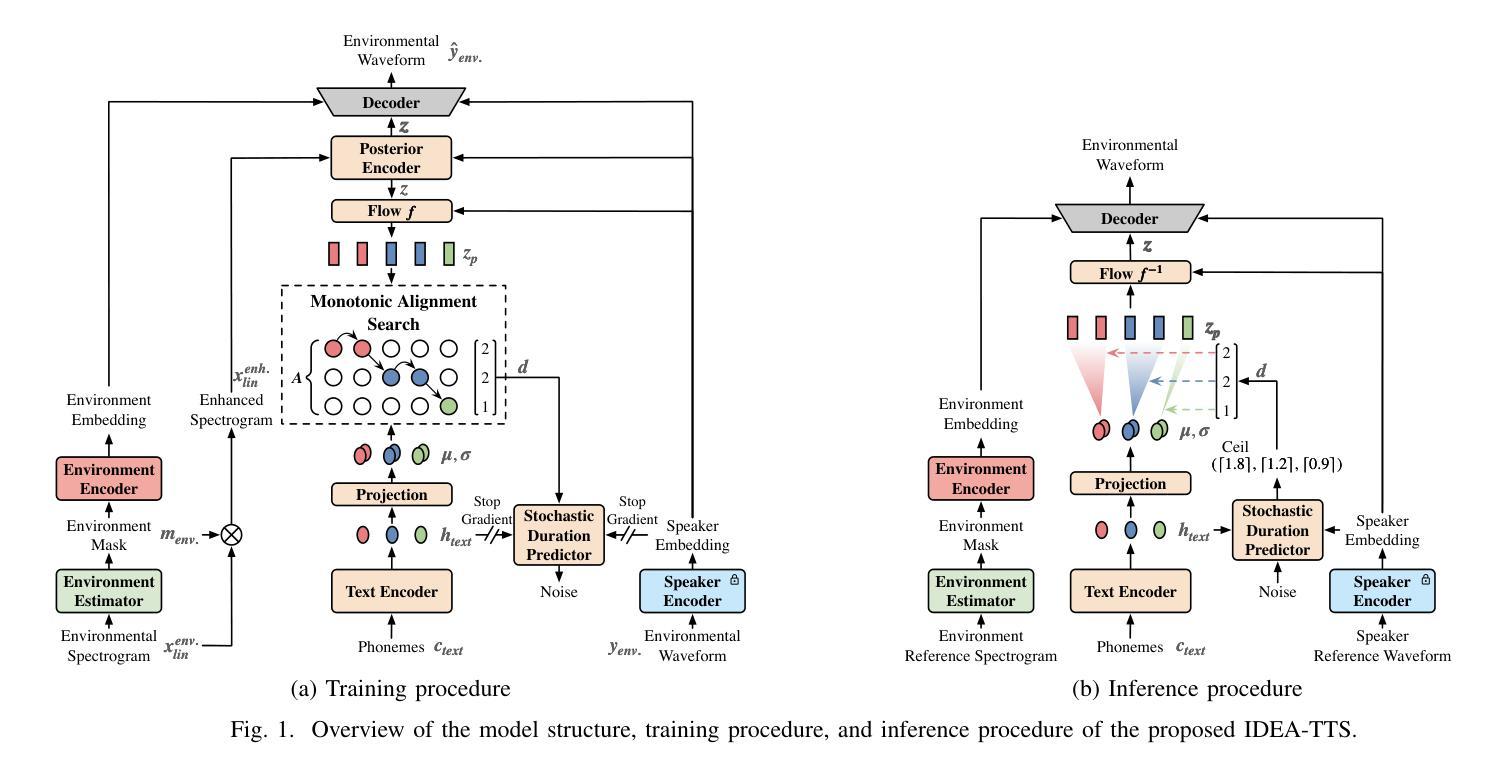
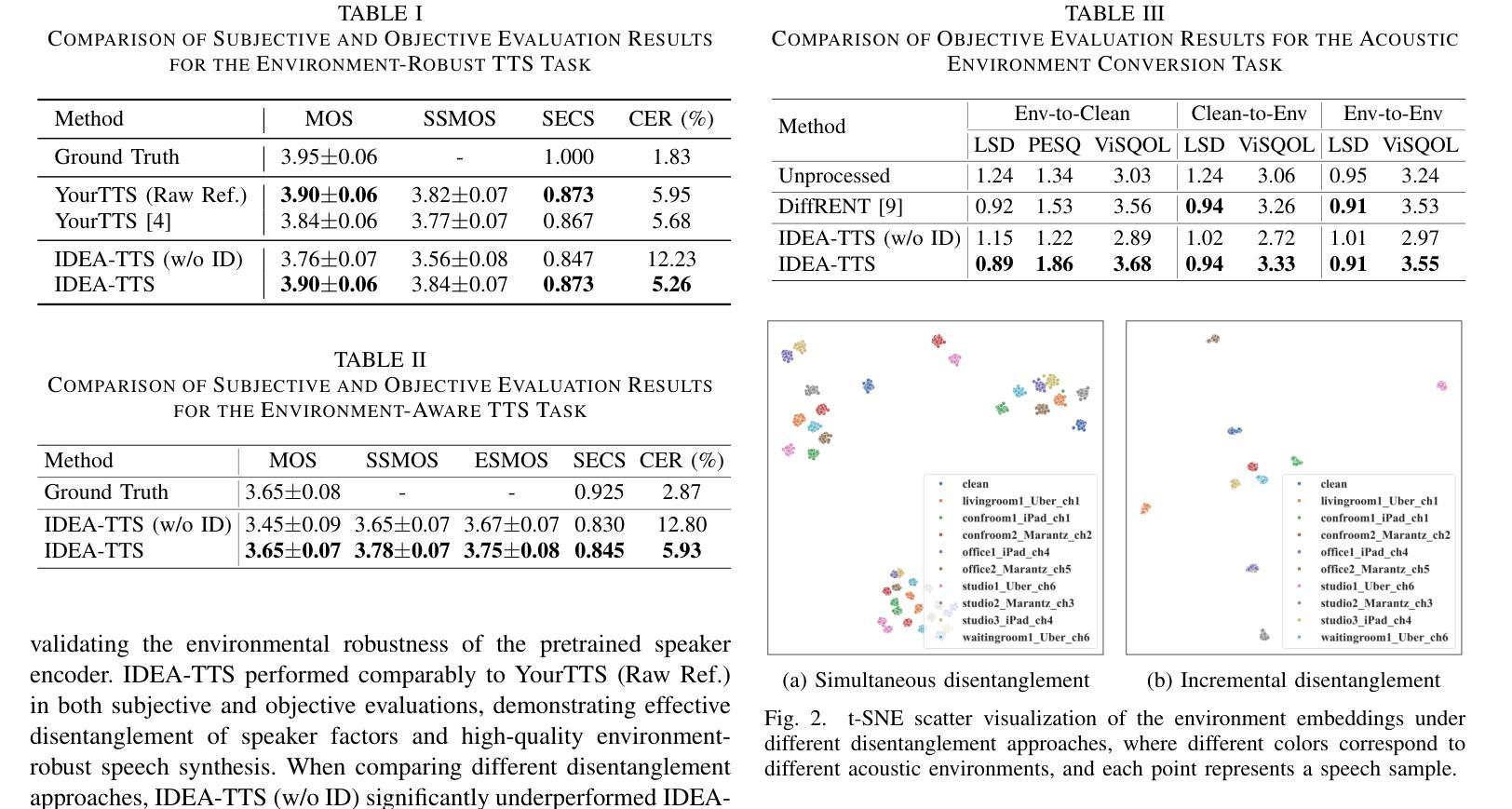
This paper proposes an Incremental Disentanglement-based Environment-Aware zero-shot text-to-speech (TTS) method, dubbed IDEA-TTS, that can synthesize speech for unseen speakers while preserving the acoustic characteristics of a given environment reference speech. IDEA-TTS adopts VITS as the TTS backbone. To effectively disentangle the environment, speaker, and text factors, we propose an incremental disentanglement process, where an environment estimator is designed to first decompose the environmental spectrogram into an environment mask and an enhanced spectrogram. The environment mask is then processed by an environment encoder to extract environment embeddings, while the enhanced spectrogram facilitates the subsequent disentanglement of the speaker and text factors with the condition of the speaker embeddings, which are extracted from the environmental speech using a pretrained environment-robust speaker encoder. Finally, both the speaker and environment embeddings are conditioned into the decoder for environment-aware speech generation. Experimental results demonstrate that IDEA-TTS achieves superior performance in the environment-aware TTS task, excelling in speech quality, speaker similarity, and environmental similarity. Additionally, IDEA-TTS is also capable of the acoustic environment conversion task and achieves state-of-the-art performance.
本文提出了一种基于增量解耦的环境感知零样本文本到语音(TTS)方法,称为IDEA-TTS。该方法可以在未见过说话人的情况下合成语音,同时保留给定环境参考语音的声学特征。IDEA-TTS采用VITS作为TTS的骨干。为了有效地解开环境、说话人和文本因素,我们提出了一个增量解耦过程,其中设计了一个环境估计器,首先将环境频谱图分解为一个环境掩码和一个增强频谱图。然后,环境掩码被环境编码器处理以提取环境嵌入,而增强频谱图有助于在说话人嵌入的条件下解开说话人和文本因素,这些说话人嵌入是从环境语音中使用预训练的环境鲁棒说话人编码器提取的。最后,说话人和环境嵌入都被输入到解码器中进行环境感知的语音生成。实验结果表明,IDEA-TTS在环境感知TTS任务中取得了优越的性能,在语音质量、说话人相似度和环境相似度方面表现出色。此外,IDEA-TTS还具备声音环境转换任务的能力,并达到了最先进的性能。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary
该论文提出了一种基于增量解耦的环境感知零样本文本转语音(TTS)方法,名为IDEA-TTS。该方法能够合成未见过的说话人的语音,同时保留给定环境参考语音的声学特征。IDEA-TTS采用VITS作为TTS骨架,并通过增量解耦过程有效地解开环境、说话人和文本因素。首先,环境估计器将环境频谱图分解为环境掩码和增强频谱图。环境掩码经环境编码器处理提取环境嵌入,同时增强频谱图在说话人嵌入的条件下促进说话人和文本因素的后续解耦。说话人嵌入是从环境语音中使用预训练的环境鲁棒说话人编码器提取的。最后,将说话人和环境嵌入作为条件输入到解码器中,以进行环境感知的语音生成。实验结果表明,IDEA-TTS在环境感知TTS任务上取得卓越性能,尤其在语音质量、说话人相似性和环境相似性方面。此外,IDEA-TTS还具备声音环境转换任务的能力,并达到最新技术水平。
Key Takeaways
- IDEA-TTS是一种环境感知的零样本文本转语音(TTS)方法,能合成未见过的说话人的语音,同时保留环境参考语音的声学特征。
- IDEA-TTS采用增量解耦过程,有效解开环境、说话人和文本因素。
- 环境估计器能分解环境频谱图,生成环境掩码和增强频谱图。
- 环境编码器和说话人编码器分别提取环境嵌入和说话人嵌入。
- IDEA-TTS将说话人和环境嵌入作为条件输入到解码器,进行环境感知的语音生成。
- 实验表明,IDEA-TTS在环境感知TTS任务上表现卓越,尤其在语音质量、说话人相似性、环境相似性方面。
点此查看论文截图

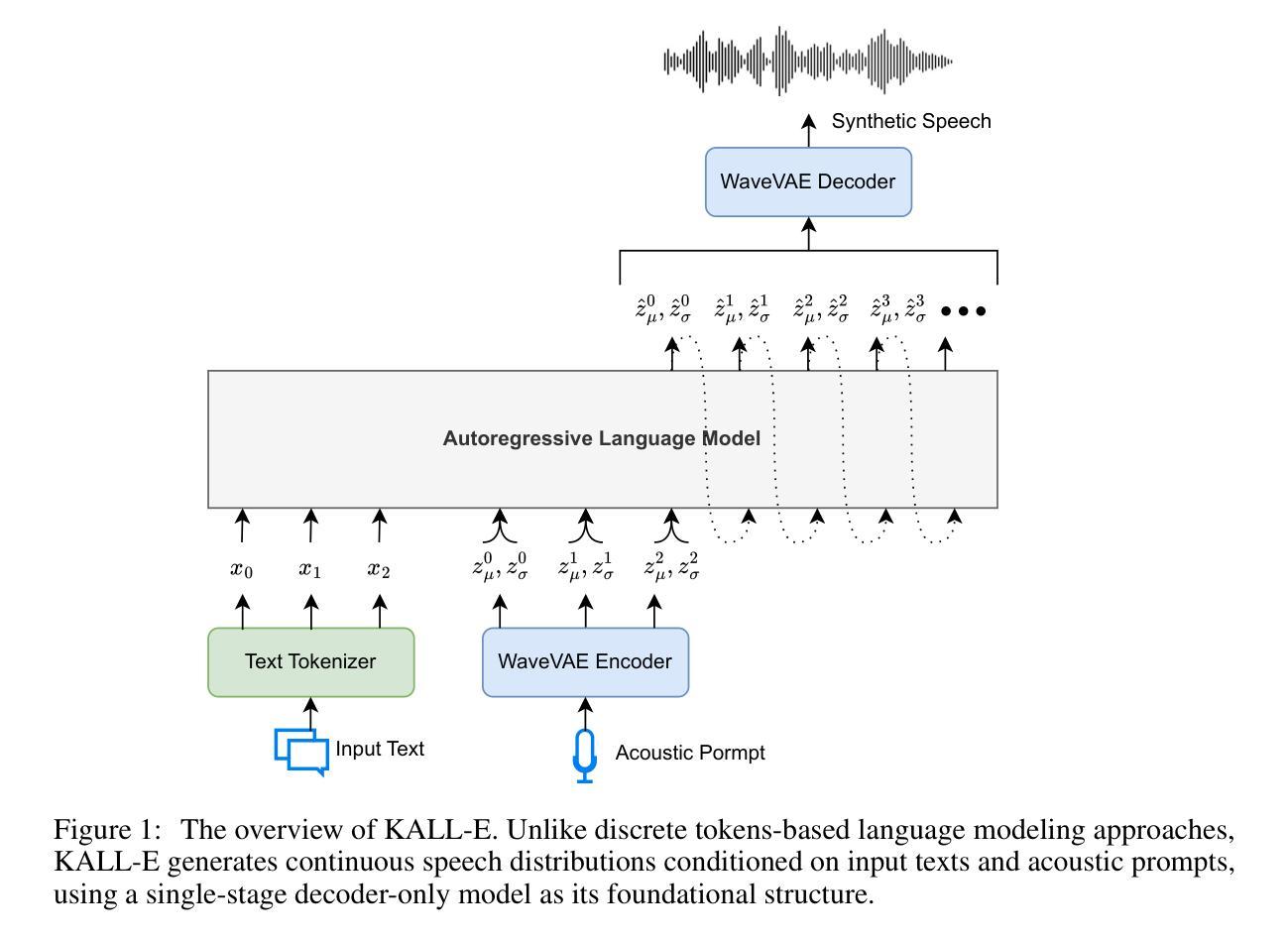
Autoregressive Speech Synthesis with Next-Distribution Prediction
Authors:Xinfa Zhu, Wenjie Tian, Lei Xie
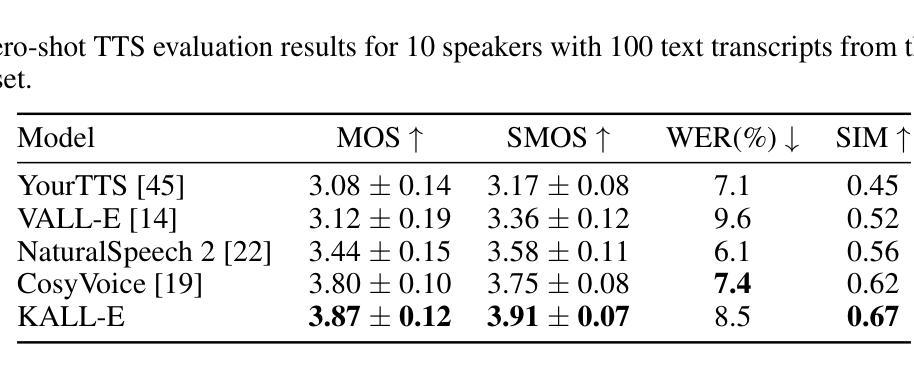
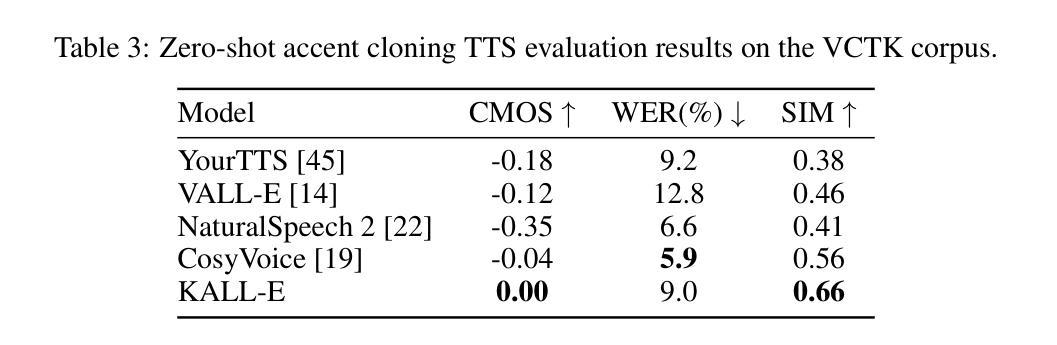
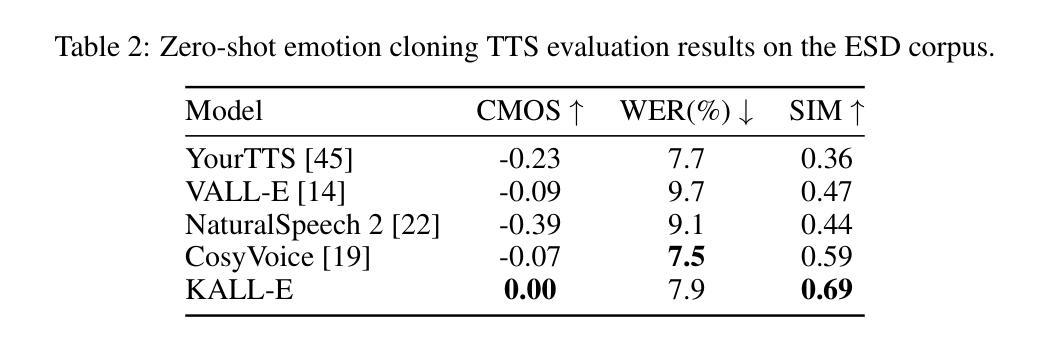
We introduce KALL-E, a novel autoregressive (AR) language modeling approach with next-distribution prediction for text-to-speech (TTS) synthesis. Unlike existing methods, KALL-E directly models and predicts the continuous speech distribution conditioned on text without relying on VAE- or diffusion-based components. Specifically, we use WaveVAE to extract continuous speech distributions from waveforms instead of using discrete speech tokens. A single AR language model predicts these continuous speech distributions from text, with a Kullback-Leibler divergence loss as the constraint. Experimental results show that KALL-E outperforms open-source implementations of YourTTS, VALL-E, NaturalSpeech 2, and CosyVoice in terms of naturalness and speaker similarity in zero-shot TTS scenarios. Moreover, KALL-E demonstrates exceptional zero-shot capabilities in emotion and accent cloning. Importantly, KALL-E presents a more straightforward and effective paradigm for using continuous speech representations in TTS. Audio samples are available at: \url{https://zxf-icpc.github.io/kalle/}.
我们介绍了KALL-E,这是一种新型的自回归(AR)语言建模方法,具有基于文本到语音(TTS)合成的下一个分布预测功能。与现有方法不同,KALL-E直接对文本条件下的连续语音分布进行建模和预测,无需依赖VAE或基于扩散的组件。具体来说,我们使用WaveVAE从波形中提取连续语音分布,而不是使用离散语音标记。一个单一的AR语言模型根据文本预测这些连续的语音分布,以Kullback-Leibler散度损失作为约束。实验结果表明,在零样本TTS场景中,KALL-E在自然度和说话人相似性方面优于YourTTS、VALL-E、NaturalSpeech 2和CosyVoice的开源实现。此外,KALL-E在情感和口音克隆方面表现出出色的零样本能力。重要的是,KALL-E为在TTS中使用连续语音表示提供了更简单有效的范式。音频样本可在:[https://zxf-icpc.github.io/kalle/]获取。
论文及项目相关链接
PDF Technical report, work in progress
Summary
本文介绍了KALL-E,一种新型的用于文本转语音(TTS)合成的自回归(AR)语言建模方法。该方法直接对文本条件下的连续语音分布进行建模和预测,无需依赖VAE或扩散模型。使用WaveVAE从波形中提取连续语音分布,并由单一AR语言模型预测这些分布,以Kullback-Leibler散度损失作为约束。实验结果显示,KALL-E在自然度和说话人相似性方面优于其他开源TTS实现,并展现出卓越的零样本情感和口音模仿能力。此外,KALL-E为TTS中使用连续语音表示提供了更简洁有效的范式。
Key Takeaways
- KALL-E是一种新型的文本转语音(TTS)合成方法,采用自回归(AR)语言建模技术。
- 与传统方法不同,KALL-E直接预测文本条件下的连续语音分布,无需依赖VAE或扩散模型。
- KALL-E使用WaveVAE从波形中提取连续语音分布。
- KALL-E在自然度和说话人相似性方面表现出优异性能,优于其他开源TTS实现。
- KALL-E展现出零样本情感和口音模仿能力。
- KALL-E为TTS中的连续语音表示提供了简洁有效的范式。
点此查看论文截图

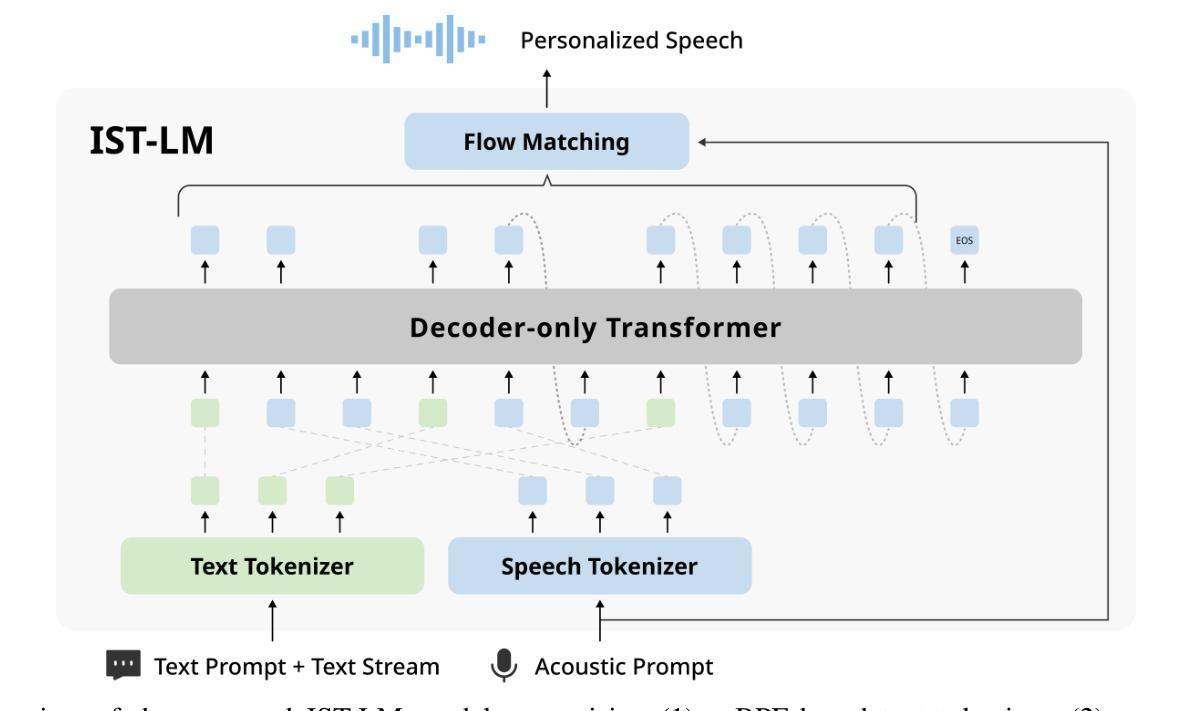
Interleaved Speech-Text Language Models are Simple Streaming Text to Speech Synthesizers
Authors:Yifan Yang, Ziyang Ma, Shujie Liu, Jinyu Li, Hui Wang, Lingwei Meng, Haiyang Sun, Yuzhe Liang, Ruiyang Xu, Yuxuan Hu, Yan Lu, Rui Zhao, Xie Chen
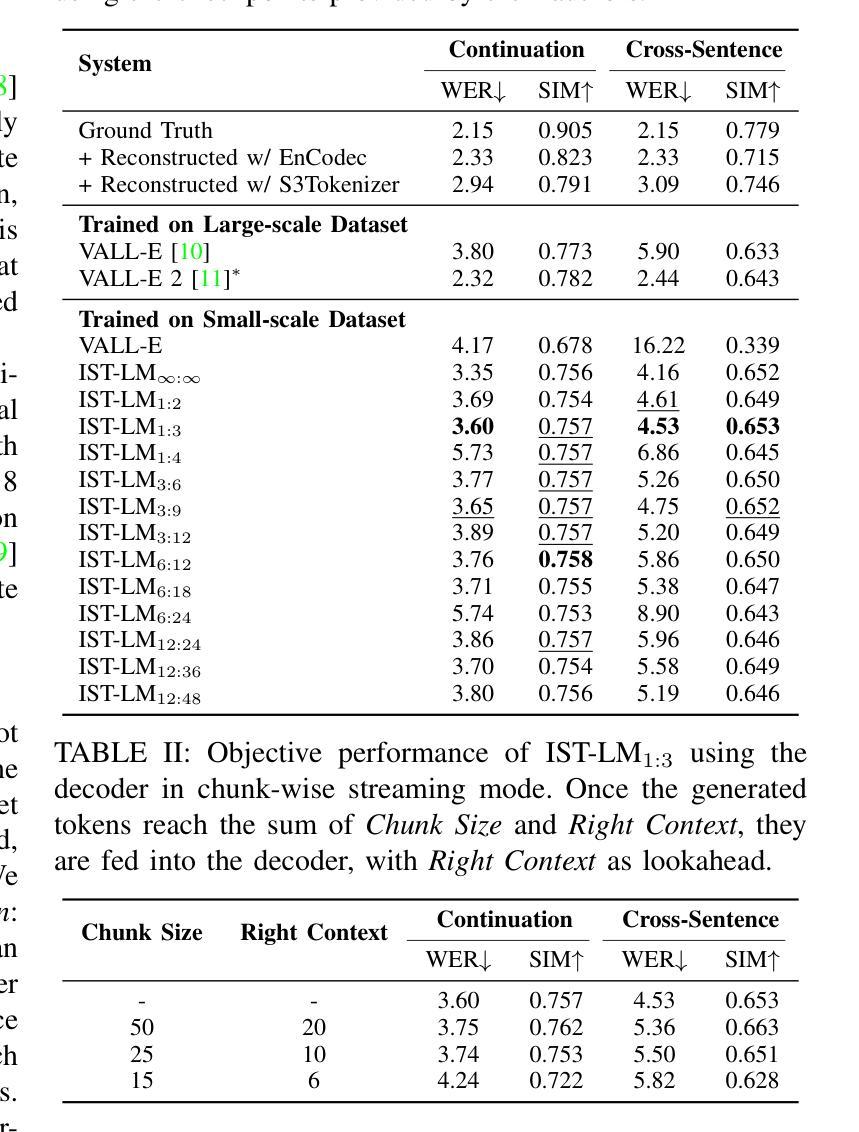
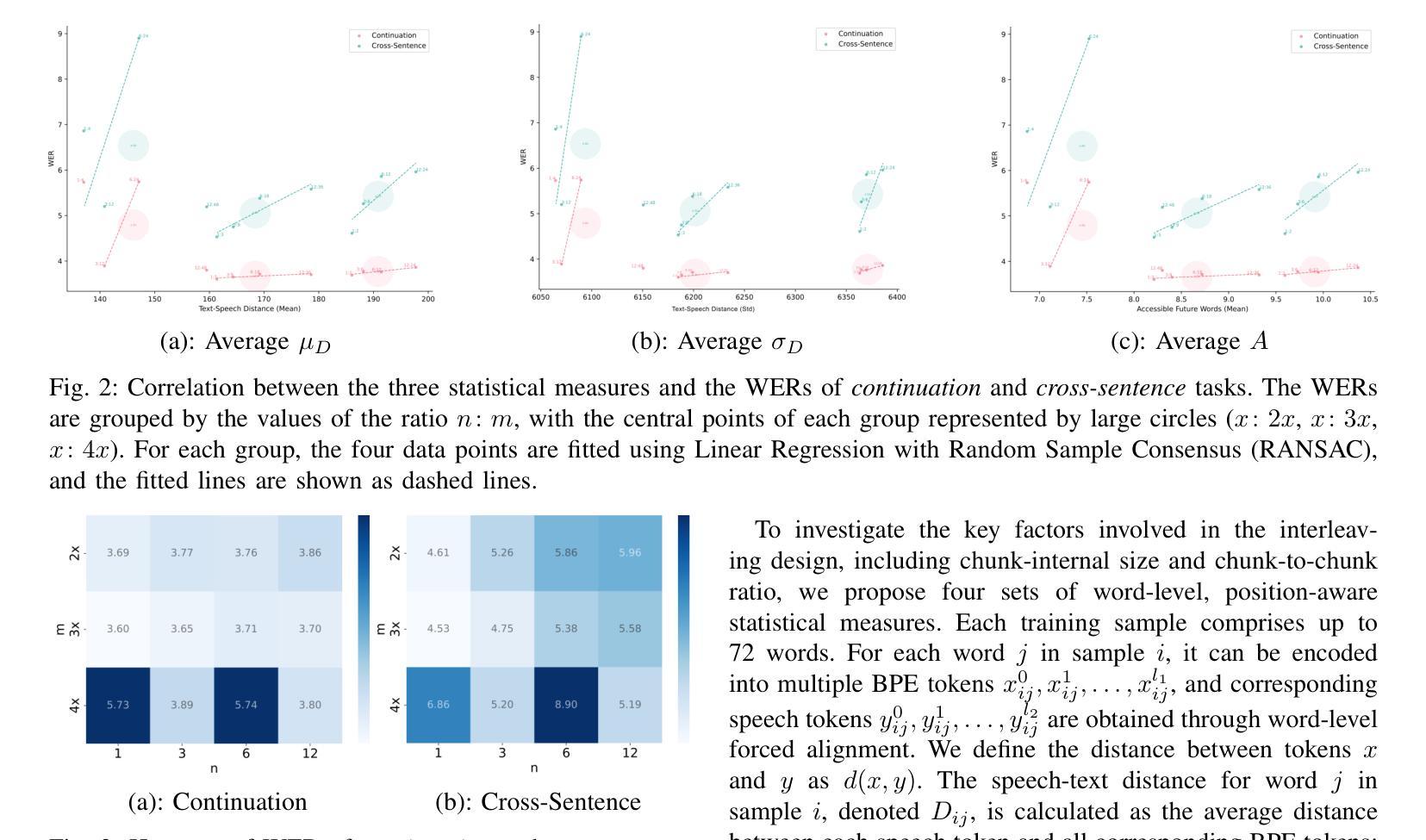
This paper introduces Interleaved Speech-Text Language Model (IST-LM) for streaming zero-shot Text-to-Speech (TTS). Unlike many previous approaches, IST-LM is directly trained on interleaved sequences of text and speech tokens with a fixed ratio, eliminating the need for additional efforts in duration prediction and grapheme-to-phoneme alignment. The ratio of text chunk size to speech chunk size is crucial for the performance of IST-LM. To explore this, we conducted a comprehensive series of statistical analyses on the training data and performed correlation analysis with the final performance, uncovering several key factors: 1) the distance between speech tokens and their corresponding text tokens, 2) the number of future text tokens accessible to each speech token, and 3) the frequency of speech tokens precedes their corresponding text tokens. Experimental results demonstrate how to achieve an optimal streaming TTS system without complicated engineering optimization, which has a limited gap with the non-streaming system. IST-LM is conceptually simple and empirically powerful, paving the way for streaming TTS with minimal overhead while largely maintaining performance, showcasing broad prospects coupled with real-time text stream from LLMs.
本文介绍了用于流式零点击文本转语音(TTS)的交织语音文本语言模型(IST-LM)。不同于许多之前的方法,IST-LM直接在固定比例的交织文本和语音令牌序列上进行训练,无需在持续时间预测和字母到音素的对齐方面付出额外的努力。文本块大小与语音块大小的比例对IST-LM的性能至关重要。为了探究这一点,我们对训练数据进行了全面的统计分析,并与最终性能进行了相关性分析,发现了几个关键因素:1)语音令牌与其对应文本令牌之间的距离;2)每个语音令牌可访问的未来文本令牌的数量;3)语音令牌先于其对应该文本令牌出现的频率。实验结果展示了如何构建一个无需复杂工程优化的最佳流式TTS系统,其与非流式系统的差距有限。IST-LM概念简单,经验强大,为流式TTS铺平了道路,在保持性能的同时实现了最小的额外开销,展示了与来自大型语言模型的实时文本流相结合的广阔前景。
论文及项目相关链接
PDF Submitted to ICME 2025
Summary
本论文介绍了用于流式零基础Text-to-Speech(TTS)的交织语音文本语言模型(IST-LM)。IST-LM直接训练交织序列的文本和语音标记,通过固定比例消除对持续时间预测和字母到音素对齐的额外需求。文本块大小与语音块大小的比例对IST-LM的性能至关重要。通过一系列统计分析和与最终性能的相关性分析,发现了影响性能的关键因素,包括语音标记与其对应文本标记之间的距离、每个语音标记可访问的未来文本标记的数量以及语音标记的频率先于它们的对应文本标记。实验结果证明了实现最佳流式TTS系统的可能性,无需复杂的工程优化,与非流式系统之间的差距有限。IST-LM概念简单,经验强大,为流式TTS提供了广阔的前景,具有实时文本流的能力,同时性能损失较小。
Key Takeaways
- IST-LM模型可直接训练交织序列的文本和语音标记,通过固定比例进行训练,简化了流程。
- 文本块与语音块大小的比例对IST-LM模型性能至关重要。
- 通过统计分析发现影响IST-LM性能的关键因素包括语音和文本标记之间的距离、未来文本标记的可访问数量以及语音标记超前于文本标记的频率。
- 实验结果证明了实现流式TTS系统的可能性,无需复杂的工程优化。
- IST-LM模型与非流式系统之间的性能差距有限。
- IST-LM模型概念简单且经验强大,为流式TTS提供了广阔的应用前景。
点此查看论文截图

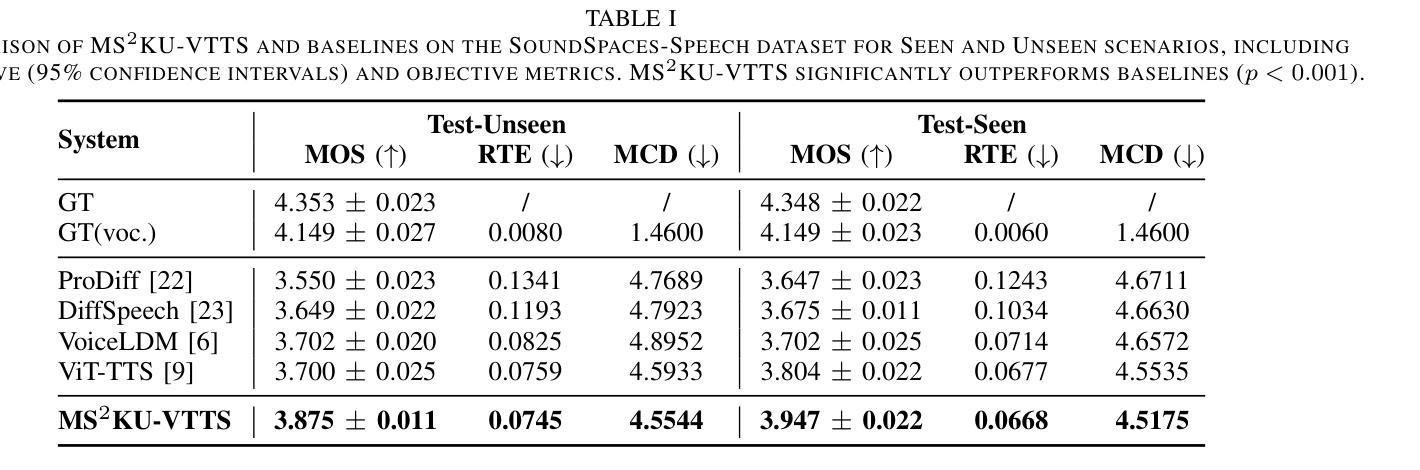
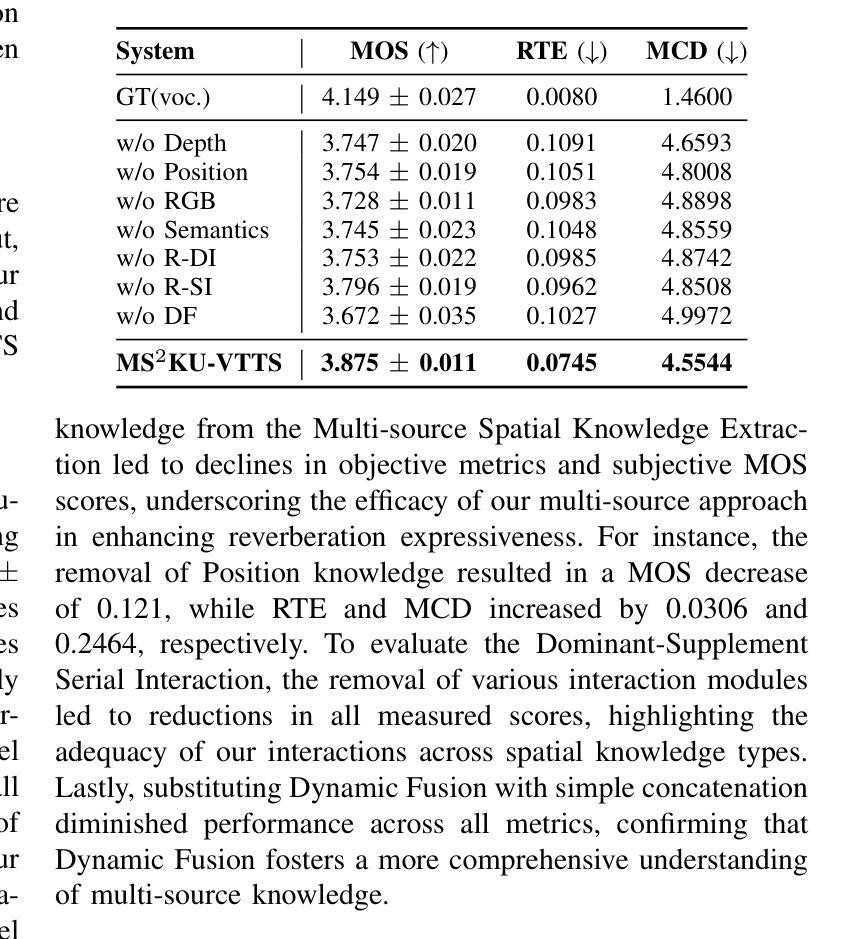
Multi-Source Spatial Knowledge Understanding for Immersive Visual Text-to-Speech
Authors:Shuwei He, Rui Liu
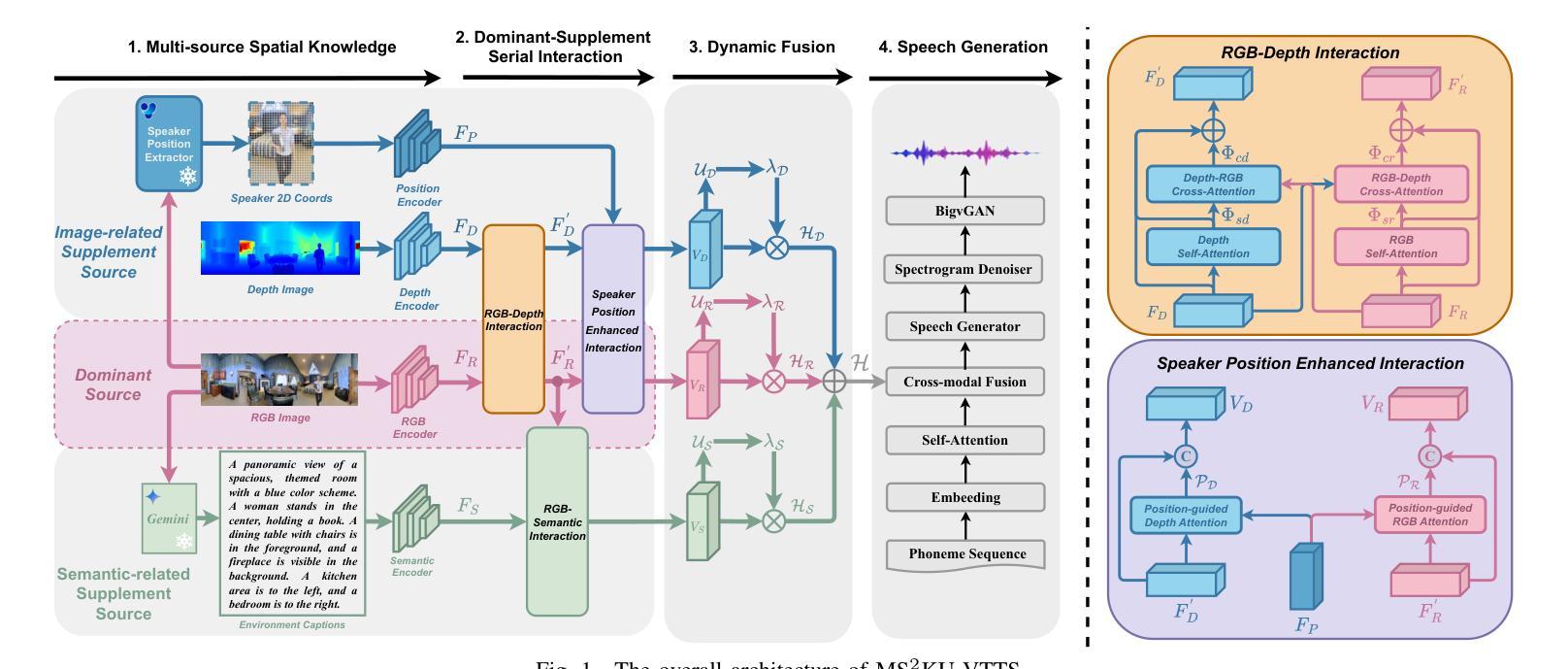
Visual Text-to-Speech (VTTS) aims to take the environmental image as the prompt to synthesize reverberant speech for the spoken content. Previous works focus on the RGB modality for global environmental modeling, overlooking the potential of multi-source spatial knowledge like depth, speaker position, and environmental semantics. To address these issues, we propose a novel multi-source spatial knowledge understanding scheme for immersive VTTS, termed MS2KU-VTTS. Specifically, we first prioritize RGB image as the dominant source and consider depth image, speaker position knowledge from object detection, and Gemini-generated semantic captions as supplementary sources. Afterwards, we propose a serial interaction mechanism to effectively integrate both dominant and supplementary sources. The resulting multi-source knowledge is dynamically integrated based on the respective contributions of each source.This enriched interaction and integration of multi-source spatial knowledge guides the speech generation model, enhancing the immersive speech experience. Experimental results demonstrate that the MS$^2$KU-VTTS surpasses existing baselines in generating immersive speech. Demos and code are available at: https://github.com/AI-S2-Lab/MS2KU-VTTS.
视觉文本到语音(VTTS)旨在以环境图像为提示,合成回响的语音内容。以前的工作主要关注RGB模式进行全局环境建模,忽略了深度、说话者位置和环境语义等多源空间知识的潜力。为了解决这些问题,我们提出了一种用于沉浸式VTTS的多源空间知识理解方案,称为MS2KU-VTTS。具体来说,我们首先以RGB图像作为主要来源,并将深度图像、来自对象检测的说话者位置知识以及Gemini生成的语义字幕作为辅助来源。然后,我们提出了一种串行交互机制,以有效地整合主要和辅助来源。最终的多源知识是基于每个源的各自贡献动态地集成的。这种多源空间知识的丰富交互和整合指导语音生成模型,增强沉浸式的语音体验。实验结果表明,MS$^2$KU-VTTS在生成沉浸式语音方面超过了现有基线。演示和代码可在:https://github.com/AI-S2-Lab/MS2KU-VTTS获取。
论文及项目相关链接
PDF 5 pages, 1 figure, Accepted by ICASSP’2025
Summary
本文介绍了视觉文本语音转换(VTTS)的目标,并指出以往的研究主要关注RGB模态的全局环境建模,忽视了深度、说话人位置和环境语义等多源空间知识的潜力。为解决这些问题,本文提出了一种名为MS^2KU-VTTS的多源空间知识理解方案,该方案以RGB图像为主要来源,同时考虑深度图像、说话人位置知识和Gemini生成的语义字幕等辅助来源。通过串行交互机制有效地整合了主要和辅助来源,基于各来源的贡献动态整合多源知识。这种多源空间知识的丰富交互和整合,提高了语音生成模型的指导效果,增强了沉浸式语音体验。实验结果表明,MS^2KU-VTTS在生成沉浸式语音方面超越了现有基线。
Key Takeaways
- VTTS旨在根据环境图像合成回声语音。
- 以往研究主要关注RGB模态的环境建模,忽视了多源空间知识的重要性。
- MS^2KU-VTTS方案提出以RGB图像为主要来源,并结合深度图像、说话人位置知识和语义字幕等辅助来源。
- 通过串行交互机制整合主要和辅助来源,实现多源知识的动态整合。
- 多源空间知识的丰富交互和整合增强了语音生成模型的指导效果。
- MS^2KU-VTTS在生成沉浸式语音方面超越了现有方法。
点此查看论文截图

NanoVoice: Efficient Speaker-Adaptive Text-to-Speech for Multiple Speakers
Authors:Nohil Park, Heeseung Kim, Che Hyun Lee, Jooyoung Choi, Jiheum Yeom, Sungroh Yoon
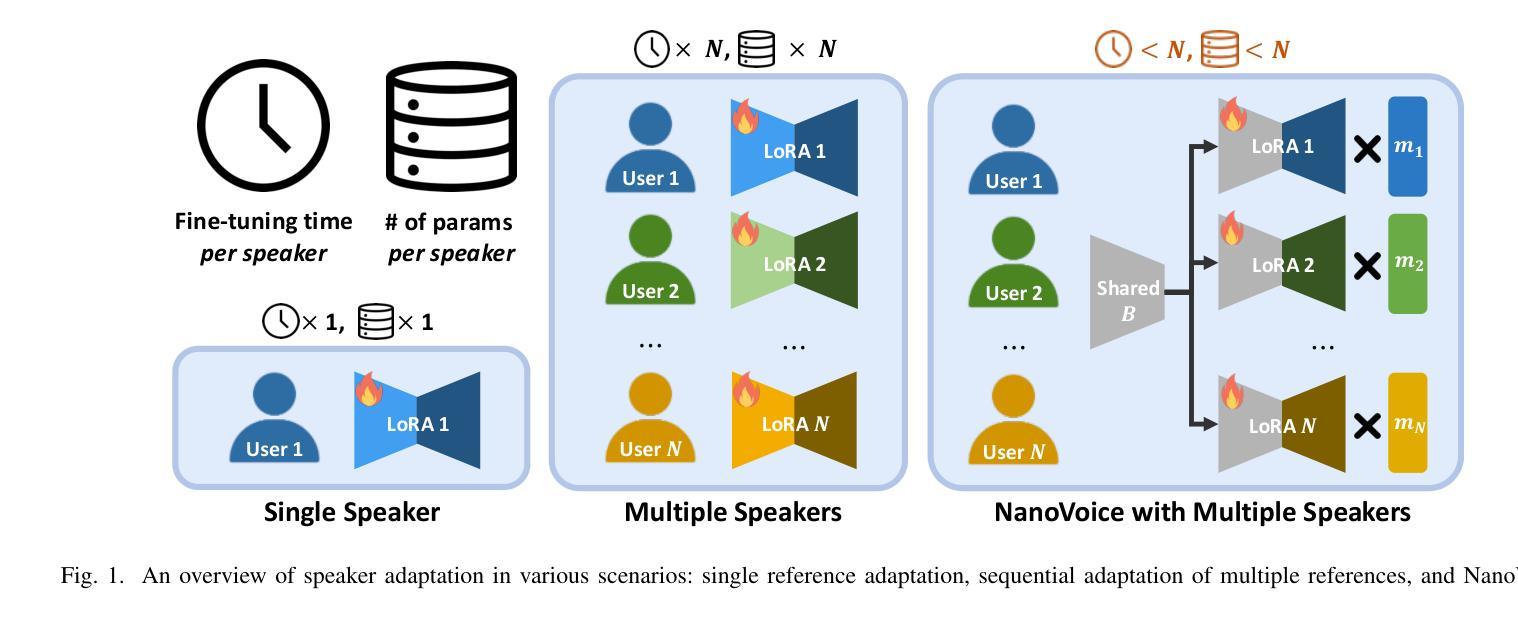
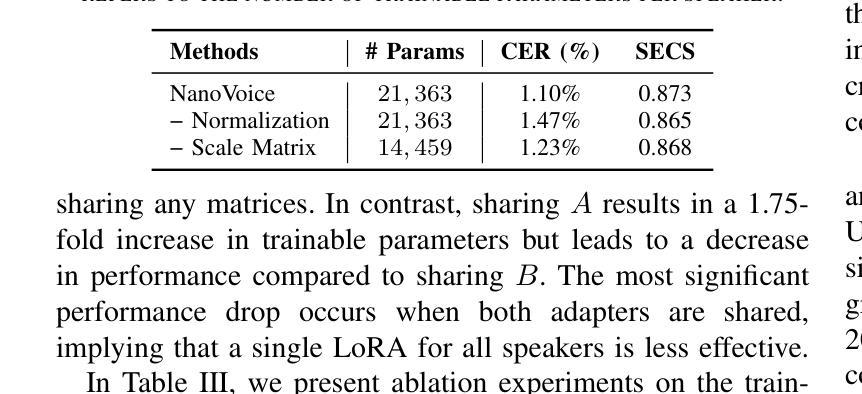
We present NanoVoice, a personalized text-to-speech model that efficiently constructs voice adapters for multiple speakers simultaneously. NanoVoice introduces a batch-wise speaker adaptation technique capable of fine-tuning multiple references in parallel, significantly reducing training time. Beyond building separate adapters for each speaker, we also propose a parameter sharing technique that reduces the number of parameters used for speaker adaptation. By incorporating a novel trainable scale matrix, NanoVoice mitigates potential performance degradation during parameter sharing. NanoVoice achieves performance comparable to the baselines, while training 4 times faster and using 45 percent fewer parameters for speaker adaptation with 40 reference voices. Extensive ablation studies and analysis further validate the efficiency of our model.
我们提出了NanoVoice,这是一种个性化的文本到语音模型,能够高效地同时为多个说话者构建语音适配器。NanoVoice引入了一种批处理说话者自适应技术,能够并行微调多个参考,从而显著减少训练时间。除了为每个说话者构建单独的适配器外,我们还提出了一种参数共享技术,以减少用于说话者自适应的参数数量。通过引入一个新型的可训练比例矩阵,NanoVoice缓解了参数共享期间可能出现的性能下降问题。NanoVoice的性能与基线相当,同时训练速度是基线的4倍,使用参数进行说话者自适应时减少了45%。广泛的消融研究和分析进一步验证了我们的模型效率。
论文及项目相关链接
PDF IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025, Demo Page: https://nanovoice.github.io/
Summary
NanoVoice是一个个性化的文本到语音模型,可高效地同时为多个说话者构建语音适配器。它引入了一种批处理说话者适应技术,能够并行微调多个参考项,从而大大缩短训练时间。除了为每个说话者构建单独的适配器外,还提出了一种参数共享技术,减少了用于说话者适应的参数数量。通过引入新型的可训练比例矩阵,NanoVoice在参数共享时减轻了性能下降的潜在风险。NanoVoice的性能与基线相当,训练速度提高了4倍,使用参数进行说话者适应时减少了45%。
Key Takeaways
- NanoVoice是一个文本到语音模型,能同时为多个说话者构建语音适配器。
- 它采用批处理说话者适应技术,能并行微调多个参考项,提高训练效率。
- NanoVoice提出参数共享技术,减少说话者适应所需的参数数量。
- 通过引入可训练比例矩阵,NanoVoice在参数共享时保持性能稳定。
- NanoVoice的性能与基线相当,训练速度提升4倍,参数使用减少45%。
- 进行了广泛的消融研究和分析,进一步验证了模型的效率。
点此查看论文截图

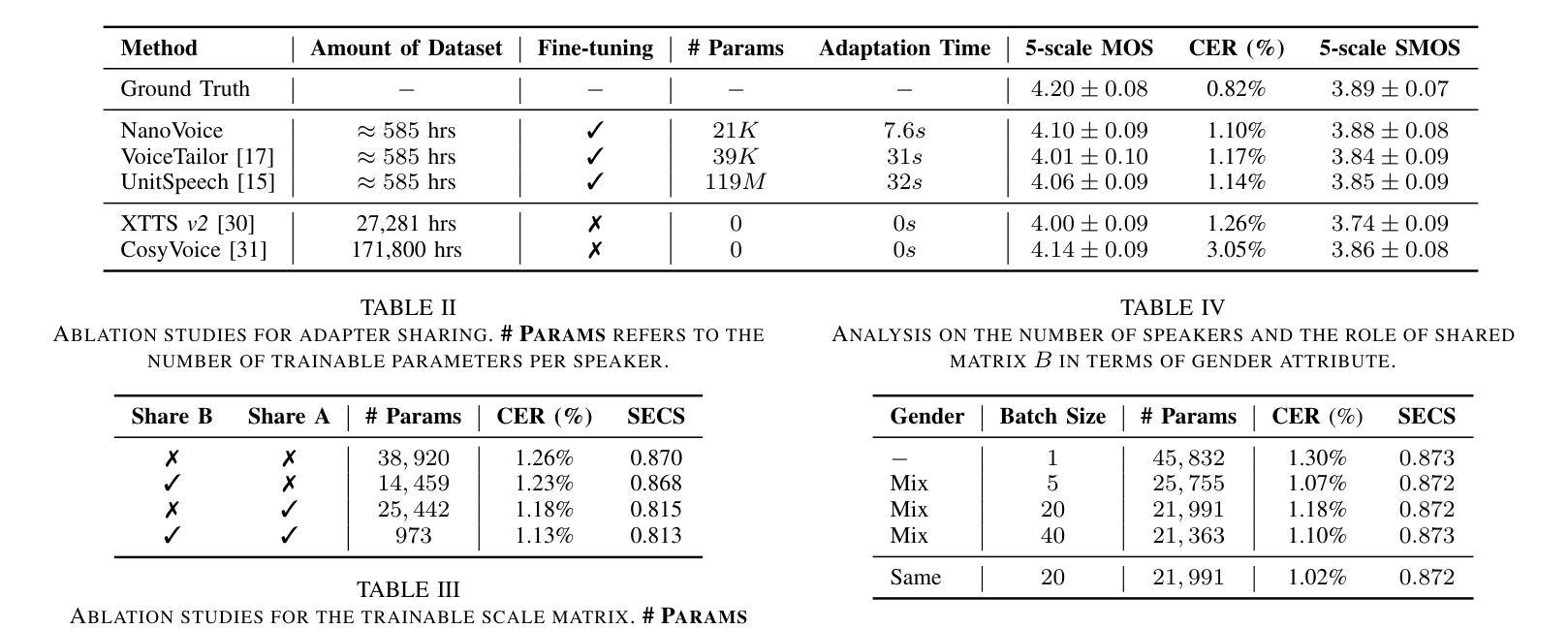
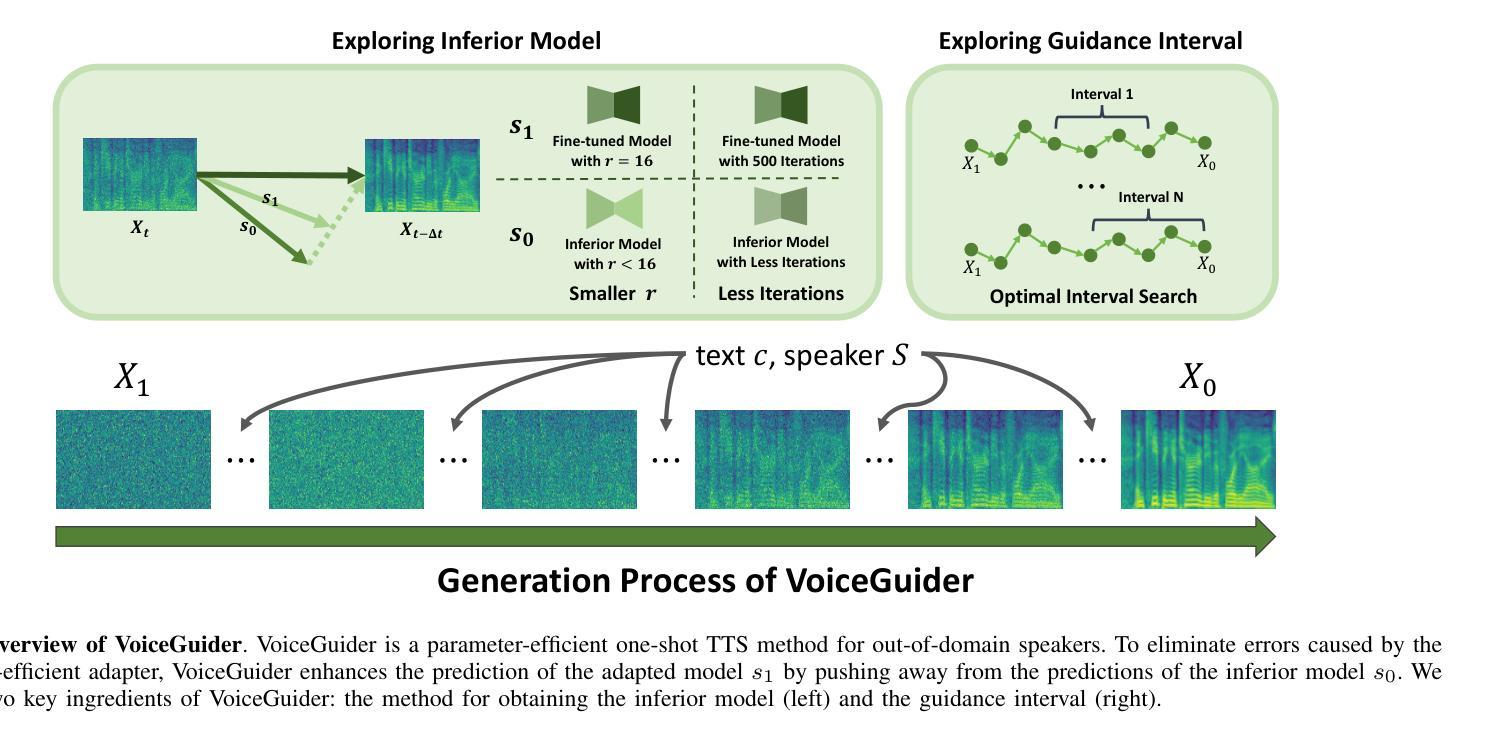
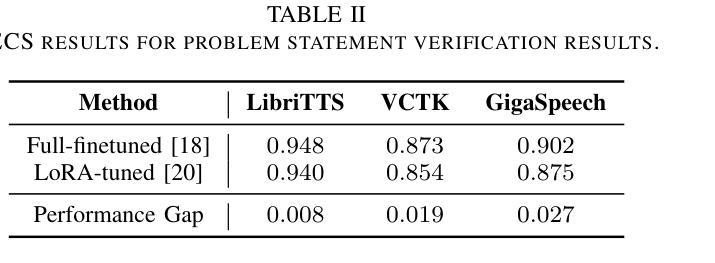
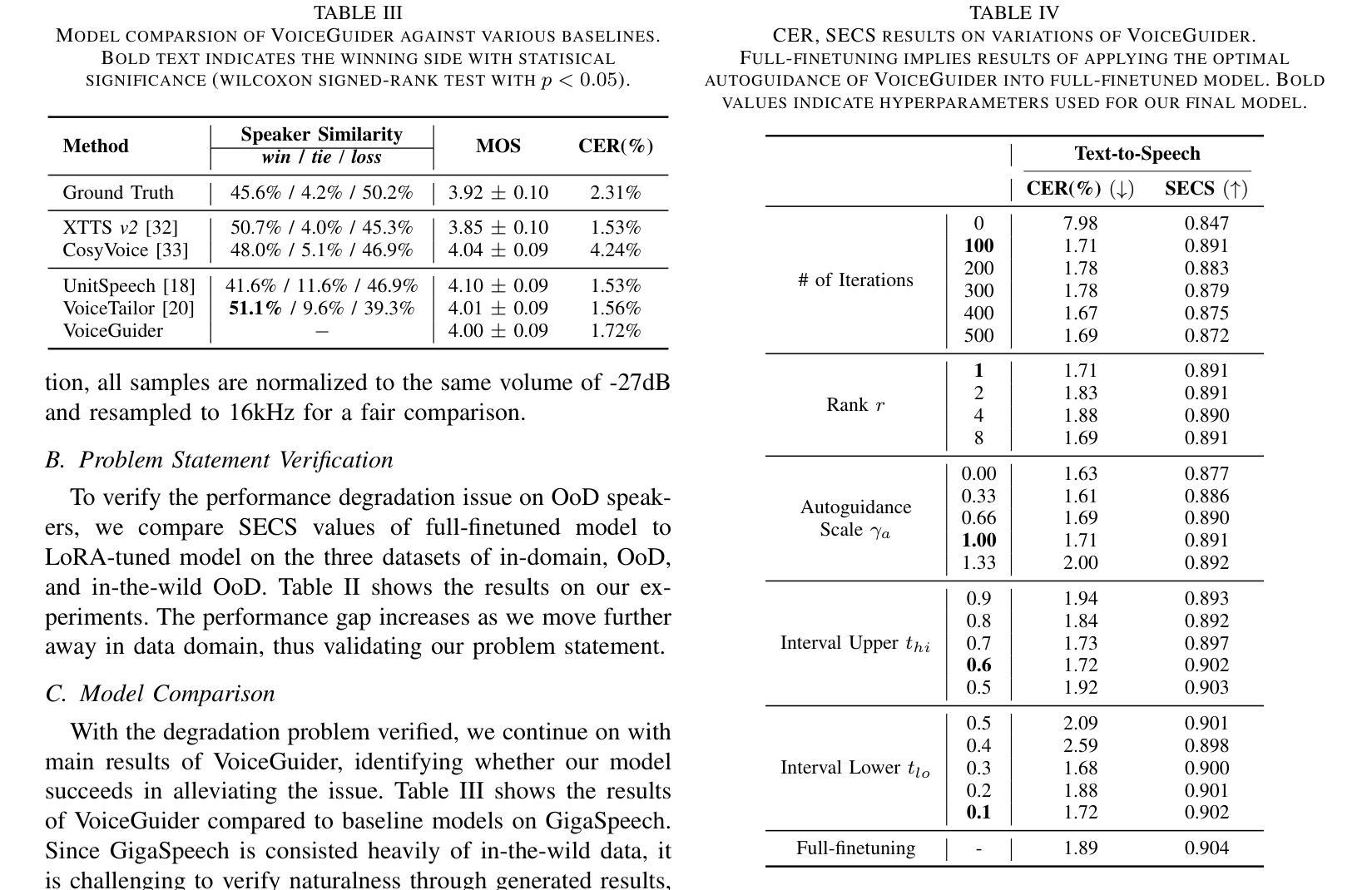
VoiceGuider: Enhancing Out-of-Domain Performance in Parameter-Efficient Speaker-Adaptive Text-to-Speech via Autoguidance
Authors:Jiheum Yeom, Heeseung Kim, Jooyoung Choi, Che Hyun Lee, Nohil Park, Sungroh Yoon
When applying parameter-efficient finetuning via LoRA onto speaker adaptive text-to-speech models, adaptation performance may decline compared to full-finetuned counterparts, especially for out-of-domain speakers. Here, we propose VoiceGuider, a parameter-efficient speaker adaptive text-to-speech system reinforced with autoguidance to enhance the speaker adaptation performance, reducing the gap against full-finetuned models. We carefully explore various ways of strengthening autoguidance, ultimately finding the optimal strategy. VoiceGuider as a result shows robust adaptation performance especially on extreme out-of-domain speech data. We provide audible samples in our demo page.
当通过LoRA应用参数高效的微调至自适应说话人的文本到语音模型时,与全微调模型相比,自适应性能可能会下降,特别是对于非域内的说话人。针对这一问题,我们提出了VoiceGuider,这是一个通过自动指导增强的参数高效自适应文本到语音系统,以提高说话人自适应性能,缩小与全微调模型之间的差距。我们小心翼翼地探索了加强自动指导的各种方式,并找到了最佳策略。VoiceGuider的结果显示,其在极端非域语音数据上表现出稳健的自适应性能。我们在演示页面上提供了可听的样本。
论文及项目相关链接
PDF IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025, Demo Page: https://voiceguider.github.io/
Summary
在采用LoRA进行参数有效微调以适配语音自适应文本到语音模型时,相比全微调的模型,适配性能可能会出现下降,特别是针对非域内的发言人。为此,我们提出了VoiceGuider,这是一个参数高效的语音自适应文本到语音系统,通过自动指导强化来提升语音适配性能,缩小与全微调模型的差距。我们深入探索了增强自动指导的各种方法,并找到了最佳策略。VoiceGuider在极端非域语音数据上展现出强大的适应性。我们在演示页面上提供了可听的样本。
Key Takeaways
- LoRA应用于语音自适应文本到语音模型的参数微调可能不如全微调模型效果好,特别是对于非域内的发言人。
- VoiceGuider是一个参数高效的语音自适应文本到语音系统,旨在提高语音适配性能。
- VoiceGuider通过强化自动指导来缩小与全微调模型的性能差距。
- VoiceGuider在探索增强自动指导方法的过程中找到了最佳策略。
- VoiceGuider在极端非域语音数据上展现出强大的适应性。
- 演示页面上提供了可听的样本,以便评估VoiceGuider的性能。
点此查看论文截图

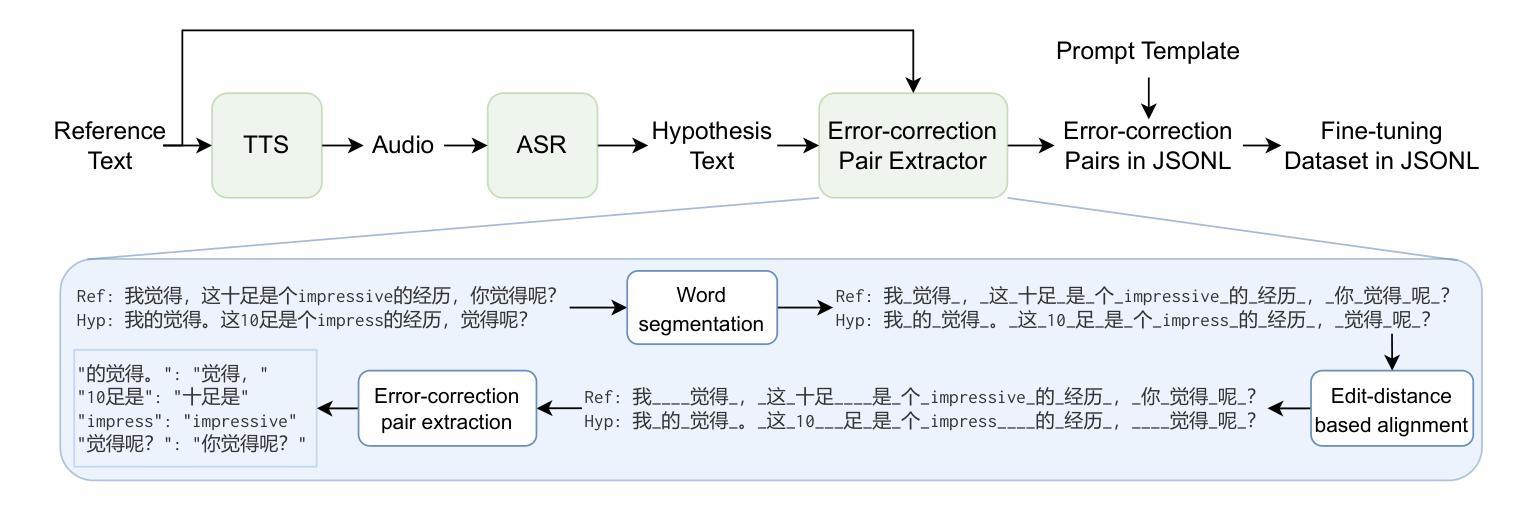
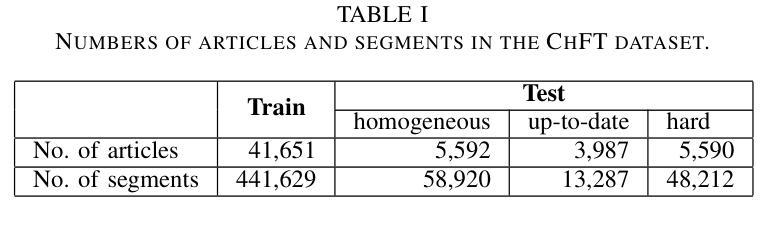
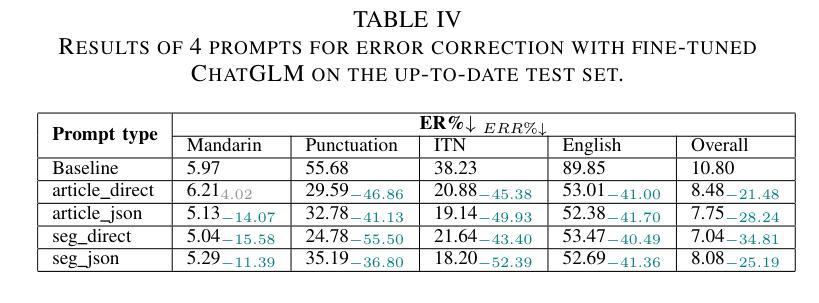
Full-text Error Correction for Chinese Speech Recognition with Large Language Model
Authors:Zhiyuan Tang, Dong Wang, Shen Huang, Shidong Shang
Large Language Models (LLMs) have demonstrated substantial potential for error correction in Automatic Speech Recognition (ASR). However, most research focuses on utterances from short-duration speech recordings, which are the predominant form of speech data for supervised ASR training. This paper investigates the effectiveness of LLMs for error correction in full-text generated by ASR systems from longer speech recordings, such as transcripts from podcasts, news broadcasts, and meetings. First, we develop a Chinese dataset for full-text error correction, named ChFT, utilizing a pipeline that involves text-to-speech synthesis, ASR, and error-correction pair extractor. This dataset enables us to correct errors across contexts, including both full-text and segment, and to address a broader range of error types, such as punctuation restoration and inverse text normalization, thus making the correction process comprehensive. Second, we fine-tune a pre-trained LLM on the constructed dataset using a diverse set of prompts and target formats, and evaluate its performance on full-text error correction. Specifically, we design prompts based on full-text and segment, considering various output formats, such as directly corrected text and JSON-based error-correction pairs. Through various test settings, including homogeneous, up-to-date, and hard test sets, we find that the fine-tuned LLMs perform well in the full-text setting with different prompts, each presenting its own strengths and weaknesses. This establishes a promising baseline for further research. The dataset is available on the website.
大型语言模型(LLM)在自动语音识别(ASR)的错误纠正方面展现出了巨大的潜力。然而,大多数研究都集中在来自短期语音记录的片段上,这是有监督的ASR训练的主要形式。本文研究了LLM在由ASR系统从较长的语音记录生成的完整文本中的错误纠正效果,例如来自播客、新闻广播和会议的转录文本。首先,我们开发了一个用于全文错误纠正的中文数据集,名为ChFT,该数据集采用涉及文本到语音合成、ASR和错误校正对提取器的管道。该数据集使我们能够在不同语境中纠正错误,包括全文和片段,并处理更广泛的错误类型,如标点恢复和逆文本规范化,从而使校正过程更加全面。其次,我们在构建的数据集上对预训练的LLM进行了微调,使用了各种提示和目标格式,并评估了其在全文错误纠正方面的性能。具体来说,我们基于全文和片段设计提示,考虑各种输出格式,如直接校正的文本和基于JSON的错误校正对。通过包括同质、最新和困难测试集在内的各种测试环境,我们发现经过微调后的LLM在不同的提示下表现良好,各有其优势和劣势。这为未来的研究奠定了有前景的基准。数据集可在网站上获得。
论文及项目相关链接
PDF ICASSP 2025
摘要
大型语言模型(LLM)在自动语音识别(ASR)的错误校正方面显示出巨大潜力。然而,大多数研究都集中在来自短语音录音的语音片段上,这些是目前监督式ASR训练的主要形式。本文探讨了LLM在由ASR系统从较长语音录音(如播客、新闻广播和会议记录)生成的全文上的错误校正效果。首先,我们开发了一个用于全文错误校正的中文数据集ChFT,该数据集采用文本到语音合成、ASR和错误校正对提取器构成的管道实现。该数据集使我们能够在不同语境中纠正错误,包括全文和段落,并处理更广泛的错误类型,如标点恢复和反向文本归一化,从而使校正过程更加全面。其次,我们在构建的数据集上对预训练的LLM进行了微调,使用了各种提示和目标格式,并对全文错误校正的性能进行了评估。特别是,我们设计了基于全文和段落的提示,并考虑了各种输出格式,如直接纠正的文本和基于JSON的错误校正对。通过包括同质的、最新的和困难的测试集在内的各种测试设置,我们发现经过微调后的LLM在不同的提示下,在全文设置中表现良好,各有其优缺点。这为未来的研究提供了一个有希望的基准。数据集可在网站上获得。
关键见解
- 大型语言模型在自动语音识别中的错误校正方面表现出巨大潜力。
- 现有的研究主要关注短语音录音的语音片段,本文则专注于由ASR系统生成的全文错误校正。
- 开发了一个用于全文错误校正的中文数据集ChFT,该数据集能在不同语境中纠正错误并处理广泛的错误类型。
- 通过微调预训练的LLM和对不同提示及目标格式的使用,对LLM在全文错误校正中的性能进行了评估。
- 在多种测试设置下,发现经过微调后的LLM在全文设置中表现良好。
- LLM的提示设计在全文和段落级别都有考虑,并考虑了多种输出格式。
点此查看论文截图


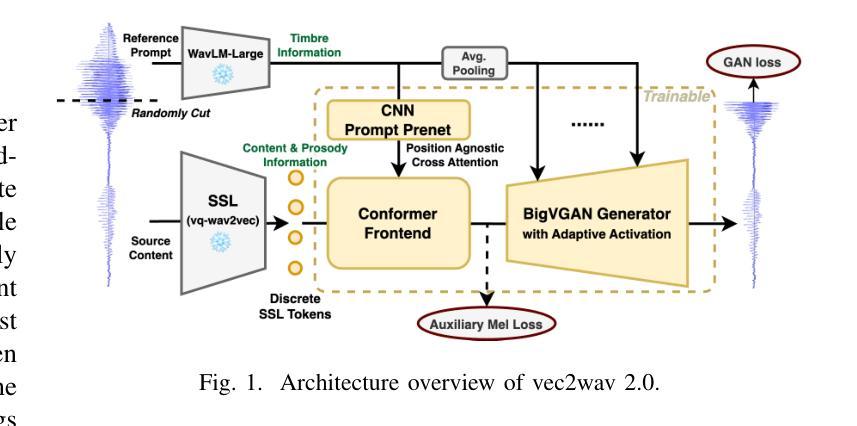
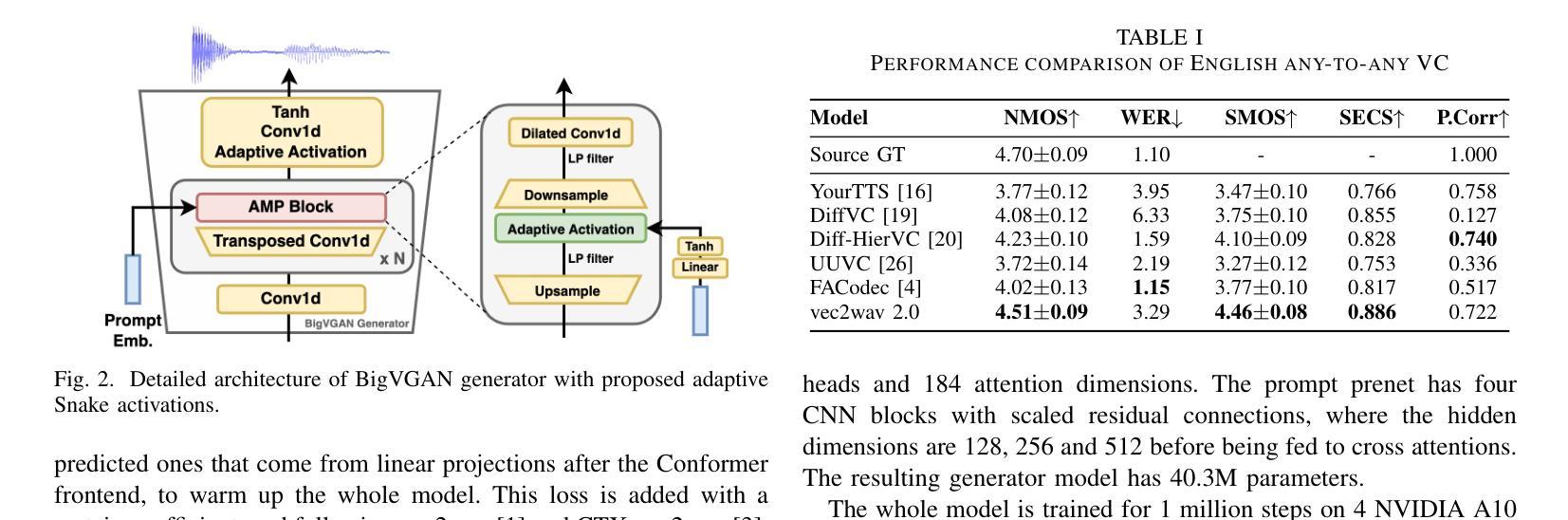
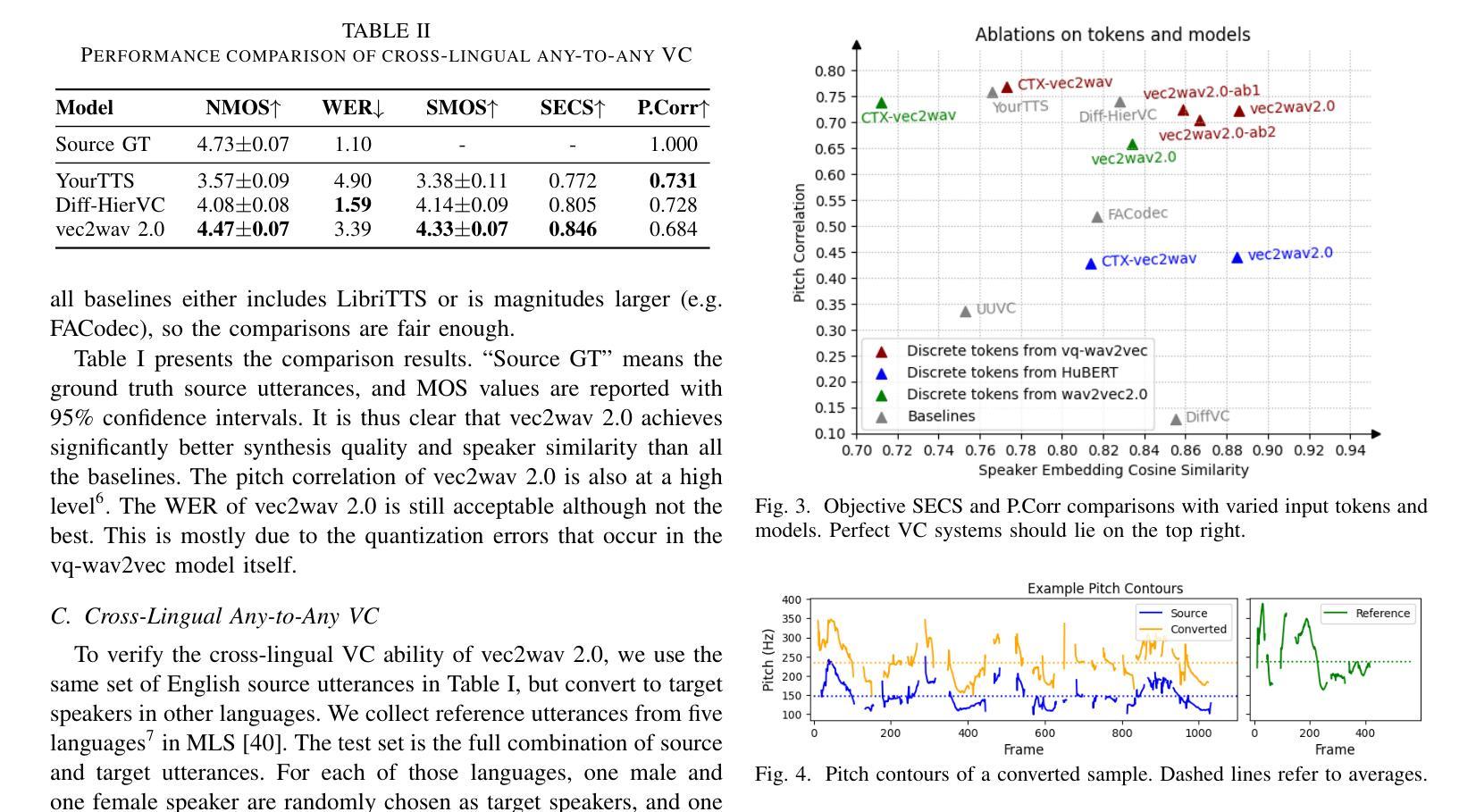
vec2wav 2.0: Advancing Voice Conversion via Discrete Token Vocoders
Authors:Yiwei Guo, Zhihan Li, Junjie Li, Chenpeng Du, Hankun Wang, Shuai Wang, Xie Chen, Kai Yu
We propose a new speech discrete token vocoder, vec2wav 2.0, which advances voice conversion (VC). We use discrete tokens from speech self-supervised models as the content features of source speech, and treat VC as a prompted vocoding task. To amend the loss of speaker timbre in the content tokens, vec2wav 2.0 utilizes the WavLM features to provide strong timbre-dependent information. A novel adaptive Snake activation function is proposed to better incorporate timbre into the waveform reconstruction process. In this way, vec2wav 2.0 learns to alter the speaker timbre appropriately given different reference prompts. Also, no supervised data is required for vec2wav 2.0 to be effectively trained. Experimental results demonstrate that vec2wav 2.0 outperforms all other baselines to a considerable margin in terms of audio quality and speaker similarity in any-to-any VC. Ablation studies verify the effects made by the proposed techniques. Moreover, vec2wav 2.0 achieves competitive cross-lingual VC even only trained on monolingual corpus. Thus, vec2wav 2.0 shows timbre can potentially be manipulated only by speech token vocoders, pushing the frontiers of VC and speech synthesis.
我们提出了一种新的语音离散令牌编解码器vec2wav 2.0,它改进了语音转换(VC)。我们使用语音自监督模型的离散令牌作为源语音的内容特征,并将VC视为提示性编解码任务。为了解决内容令牌中扬声器音色的损失问题,vec2wav 2.0利用WavLM特征提供强大的音色相关信息。提出了一种新型的自适应Snake激活函数,以更好地将音色融入波形重建过程。通过这种方式,vec2wav 2.0能够在给定不同的参考提示时学会适当地改变演讲者的音色。此外,不需要对vec2wav 2.0进行有监督数据的训练,就能使其有效地工作。实验结果表明,在任意到任意的VC中,vec2wav 2.0在音频质量和说话人相似性方面大大超过了所有其他基线。消融研究验证了所提出技术的影响。此外,vec2wav 2.0即使在仅使用单语语料库进行训练的情况下,也实现了具有竞争力的跨语言VC。因此,vec2wav 2.0表明,只需语音令牌编解码器即可操纵音色,从而推动VC和语音合成的前沿。
论文及项目相关链接
PDF 5 pages, 4 figures. Demo page: https://cantabile-kwok.github.io/vec2wav2/
Summary
新一代语音离散令牌编码器vec2wav 2.0提出,将语音自监督模型的离散令牌作为源语音的内容特征,并将语音转换(VC)视为提示编码任务。为弥补内容令牌中演讲者音色的损失,vec2wav 2.0利用WavLM特征提供强烈的音色相关信息。提出一种新型自适应Snake激活函数,更好地将音色融入波形重建过程。因此,vec2wav 2.0能够在给定不同参考提示的情况下,学习适当地改变演讲者的音色。此外,训练vec2wav 2.0无需监督数据。实验结果表明,在任意到任意的语音转换中,vec2wav 2.0在音频质量和说话人相似性方面大大优于所有其他基线。消融研究证实了所提出技术的效果。而且,仅在单语语料库上训练的vec2wav 2.0实现了有竞争力的跨语言语音转换。因此,vec2wav 2.0显示了音色可能仅通过语音令牌编码器进行操作,推动了语音转换和语音合成的前沿。
Key Takeaways
- vec2wav 2.0是一种新的语音离散令牌vocoder,用于推进语音转换(VC)技术。
- 该方法使用语音自监督模型的离散令牌作为源语音的内容特征,并将VC视为提示编码任务。
- WavLM特征被用来提供强烈的音色相关信息,以弥补内容令牌中演讲者音色的损失。
- 引入了一种新型自适应Snake激活函数,以更好地将音色融入波形重建过程。
- vec2wav 2.0能在给定不同参考提示的情况下学习适当改变演讲者的音色。
- 该模型无需监督数据即可进行有效训练。
点此查看论文截图