⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-26 更新
Singular Value Scaling: Efficient Generative Model Compression via Pruned Weights Refinement
Authors:Hyeonjin Kim, Jaejun Yoo
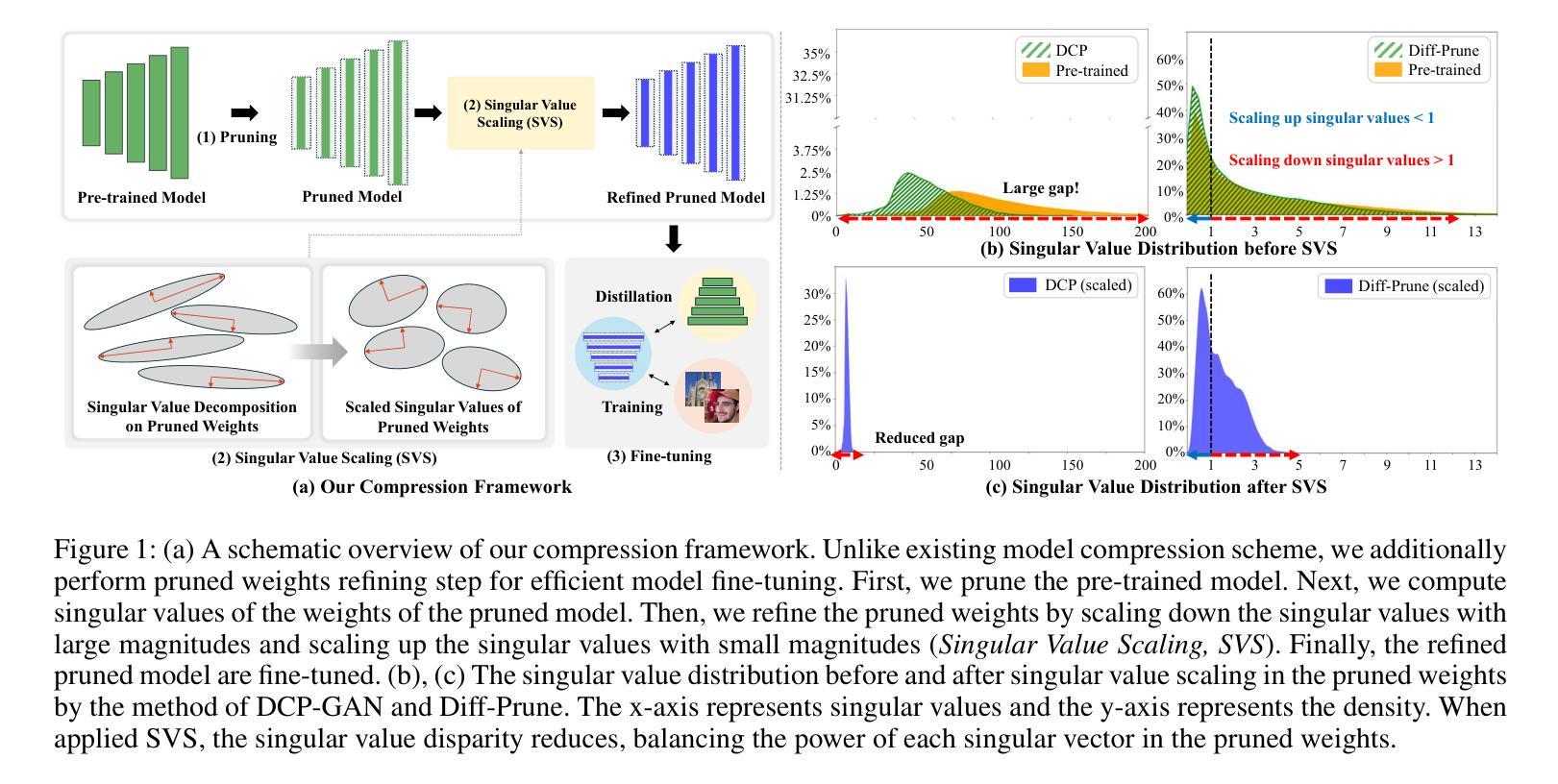
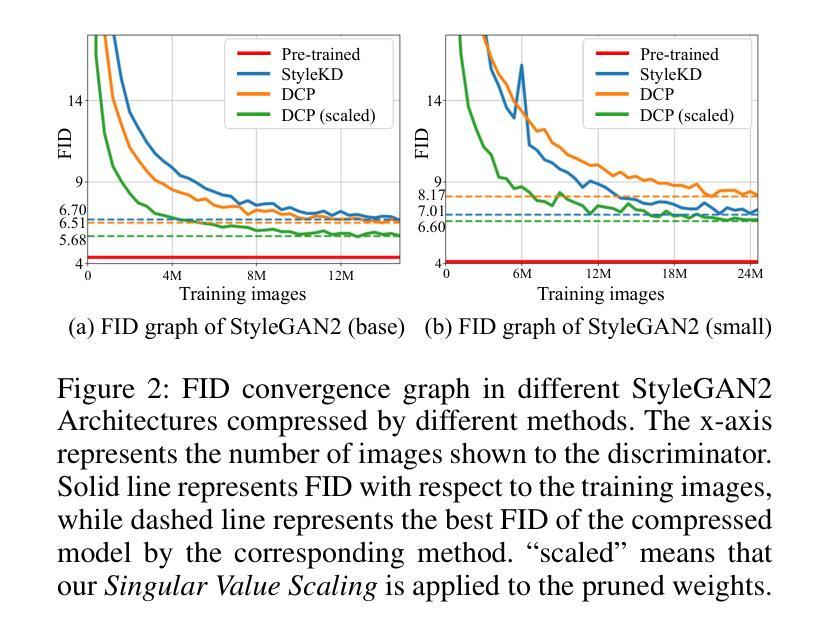
While pruning methods effectively maintain model performance without extra training costs, they often focus solely on preserving crucial connections, overlooking the impact of pruned weights on subsequent fine-tuning or distillation, leading to inefficiencies. Moreover, most compression techniques for generative models have been developed primarily for GANs, tailored to specific architectures like StyleGAN, and research into compressing Diffusion models has just begun. Even more, these methods are often applicable only to GANs or Diffusion models, highlighting the need for approaches that work across both model types. In this paper, we introduce Singular Value Scaling (SVS), a versatile technique for refining pruned weights, applicable to both model types. Our analysis reveals that pruned weights often exhibit dominant singular vectors, hindering fine-tuning efficiency and leading to suboptimal performance compared to random initialization. Our method enhances weight initialization by minimizing the disparities between singular values of pruned weights, thereby improving the fine-tuning process. This approach not only guides the compressed model toward superior solutions but also significantly speeds up fine-tuning. Extensive experiments on StyleGAN2, StyleGAN3 and DDPM demonstrate that SVS improves compression performance across model types without additional training costs. Our code is available at: https://github.com/LAIT-CVLab/Singular-Value-Scaling.
虽然剪枝方法可以有效地保持模型性能而无需额外的训练成本,但它们通常只专注于保留关键连接,而忽视了剪枝权重对后续微调或蒸馏的影响,从而导致效率不高。此外,大多数生成模型的压缩技术主要是针对生成对抗网络(GANs)开发的,适用于特定的架构(如StyleGAN),而对Diffusion模型的压缩研究才刚刚开始。甚至这些方法往往仅适用于GANs或Diffusion模型,这突显了需要能够跨这两种模型类型工作的方法。在本文中,我们介绍了奇异值缩放(SVS),这是一种精炼剪枝权重的通用技术,适用于这两种模型类型。我们的分析表明,剪枝权重通常表现出主要的奇异向量,阻碍了微调效率,并导致与随机初始化相比性能不佳。我们的方法通过最小化剪枝权重的奇异值之间的差异来改进权重初始化,从而提高了微调过程。这种方法不仅引导压缩模型朝着更优的解决方案发展,还显著加速了微调过程。在StyleGAN2、StyleGAN3和DDPM上的大量实验表明,SVS提高了各种模型的压缩性能,且无需额外的训练成本。我们的代码可在:[https://github.com/LAIT-CVlab/Singular-Value-Scaling找到。]
论文及项目相关链接
PDF Accepted to AAAI 2025
Summary
本文介绍了一种名为奇异值缩放(SVS)的技术,该技术旨在优化已修剪权重的初始化,适用于生成对抗网络(GANs)和扩散模型(Diffusion models)。研究发现,修剪权重后的模型在微调时存在效率问题,而SVS技术通过调整奇异值来改进权重的初始化,提高微调效率。在StyleGAN2、StyleGAN3和DDPM上的实验表明,SVS技术能提高不同模型的压缩性能,且无需额外的训练成本。
Key Takeaways
- 修剪方法虽能有效维持模型性能并节省训练成本,但常常忽略修剪权重对后续微调或蒸馏的影响,导致效率降低。
- 当前针对生成模型的压缩技术主要集中于GANs和特定的架构(如StyleGAN),而对Diffusion模型的压缩研究才刚刚起步。
- 需要开发一种适用于多种模型类型(包括GANs和Diffusion模型)的压缩方法。
- 本文提出了一种名为奇异值缩放(SVS)的技术,用于优化修剪权重的初始化。
- SVS技术通过调整奇异值来改进权重的初始化,从而提高微调效率并引导模型达到更优解。
- 在StyleGAN2、StyleGAN3和DDPM上的实验表明,SVS技术能有效提高模型的压缩性能。
点此查看论文截图

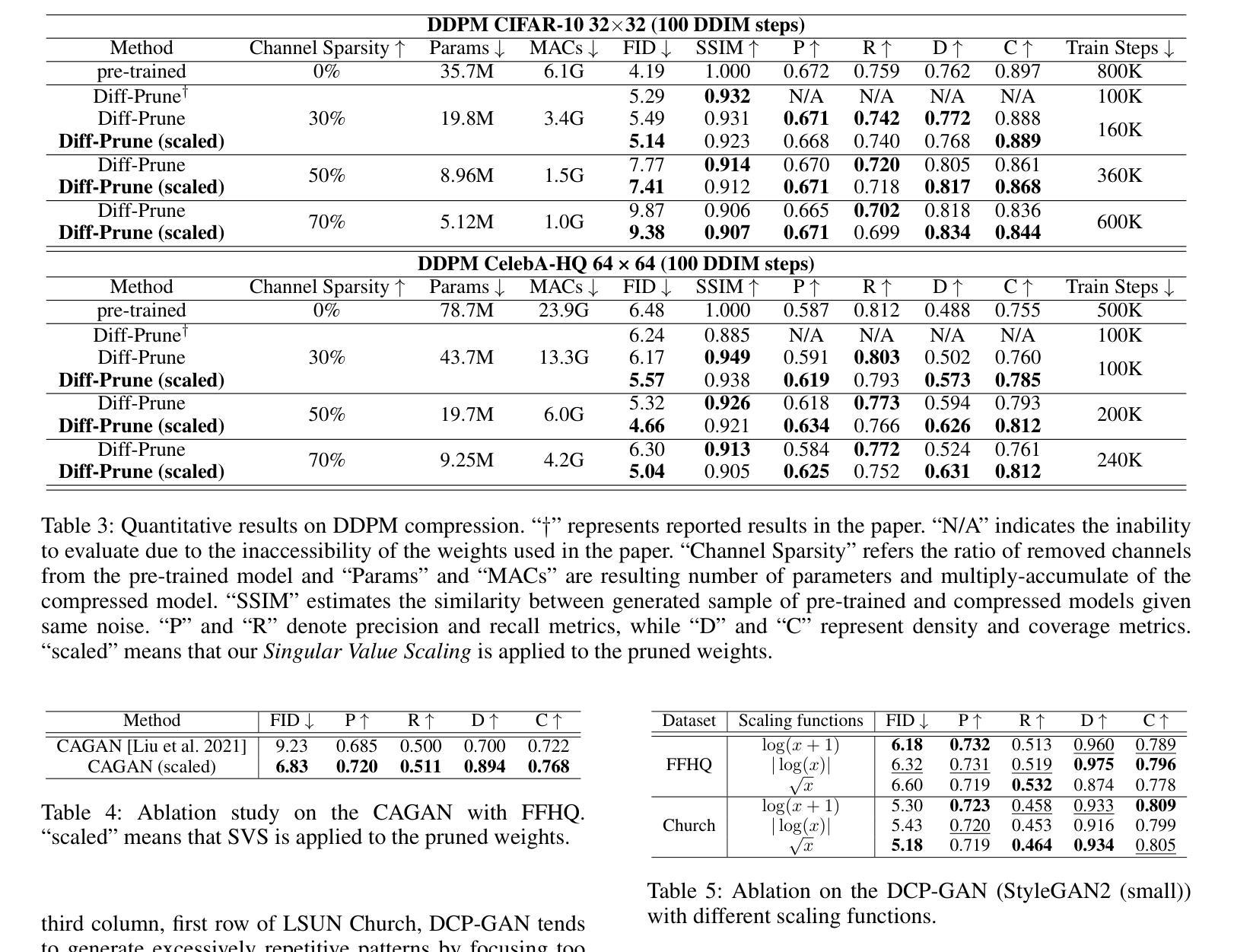
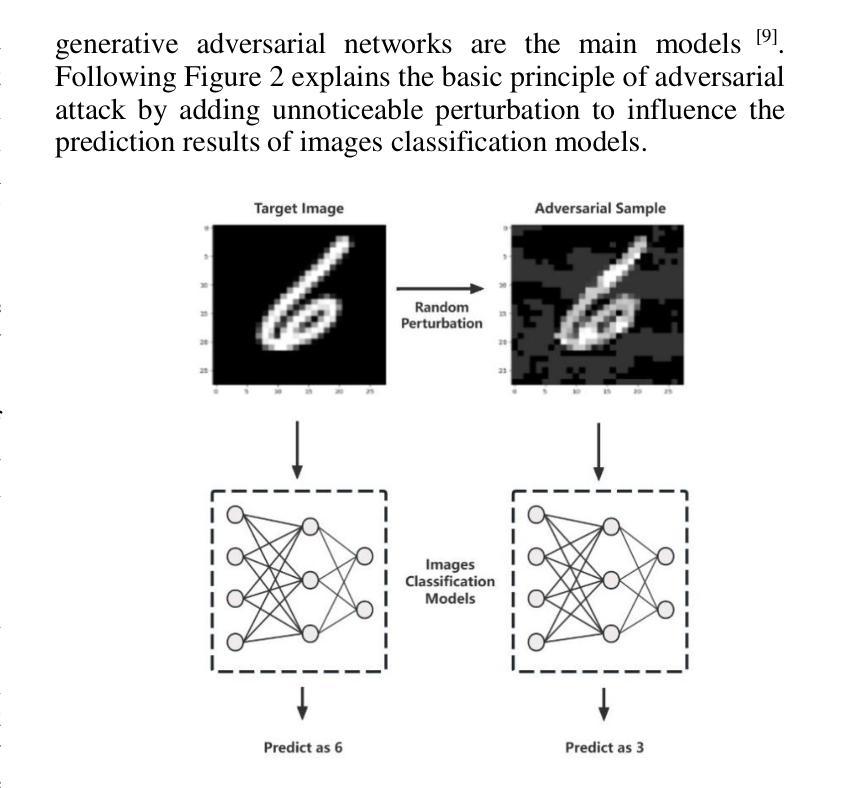
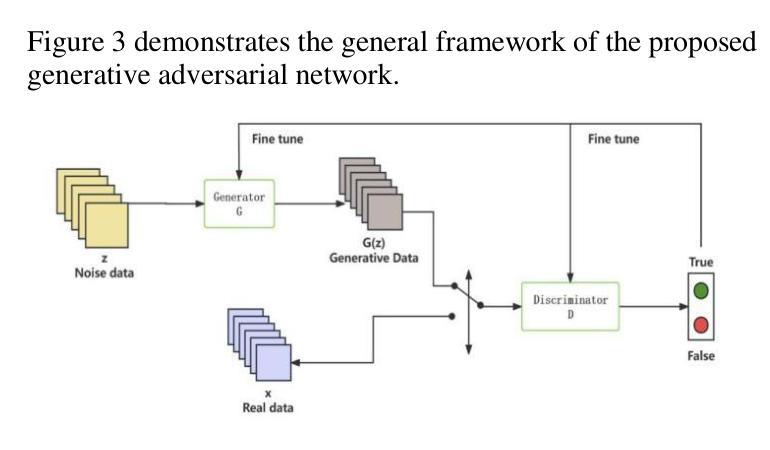
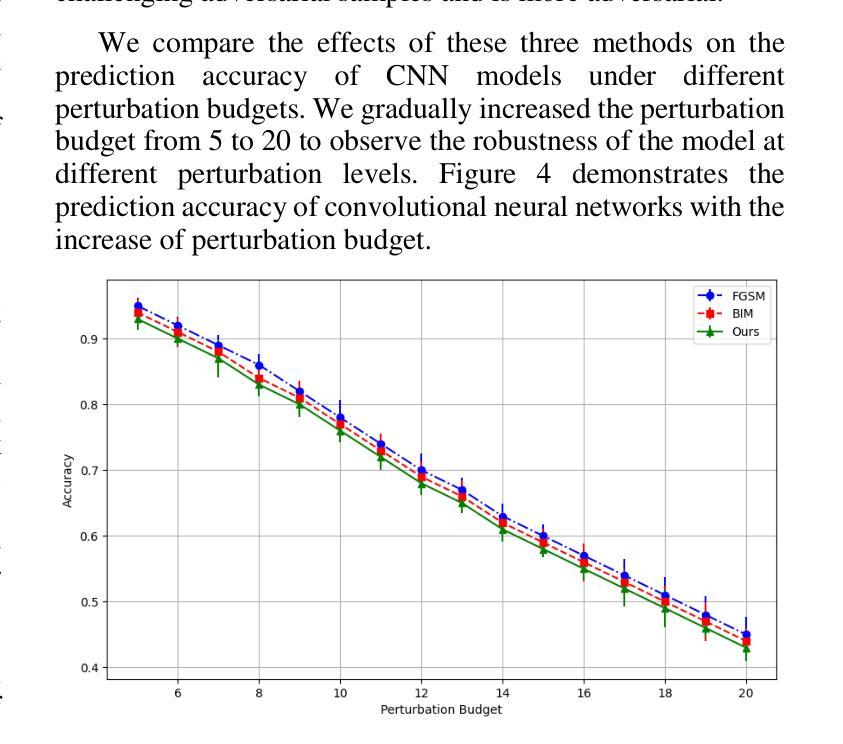
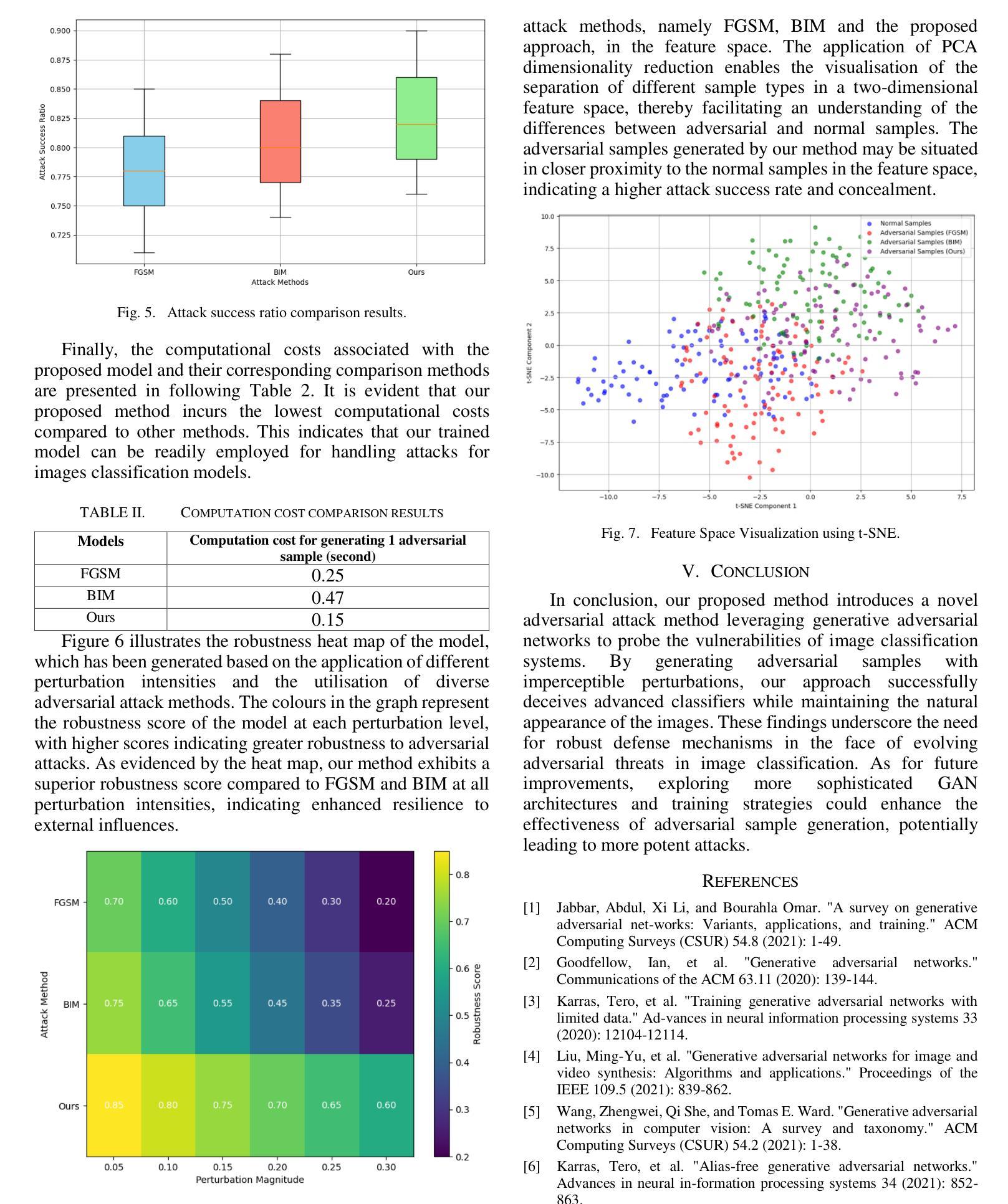
Adversarial Attack Against Images Classification based on Generative Adversarial Networks
Authors:Yahe Yang
Adversarial attacks on image classification systems have always been an important problem in the field of machine learning, and generative adversarial networks (GANs), as popular models in the field of image generation, have been widely used in various novel scenarios due to their powerful generative capabilities. However, with the popularity of generative adversarial networks, the misuse of fake image technology has raised a series of security problems, such as malicious tampering with other people’s photos and videos, and invasion of personal privacy. Inspired by the generative adversarial networks, this work proposes a novel adversarial attack method, aiming to gain insight into the weaknesses of the image classification system and improve its anti-attack ability. Specifically, the generative adversarial networks are used to generate adversarial samples with small perturbations but enough to affect the decision-making of the classifier, and the adversarial samples are generated through the adversarial learning of the training generator and the classifier. From extensive experiment analysis, we evaluate the effectiveness of the method on a classical image classification dataset, and the results show that our model successfully deceives a variety of advanced classifiers while maintaining the naturalness of adversarial samples.
对抗性攻击一直是机器学习领域图像分类系统中的一个重要问题。生成对抗性网络(GANs)作为图像生成领域的流行模型,由于其强大的生成能力,已被广泛应用于各种新场景。然而,随着生成对抗性网络的普及,虚假图像技术的滥用引发了一系列安全问题,如恶意篡改他人照片和视频以及侵犯个人隐私。受生成对抗性网络的启发,这项工作提出了一种新型对抗性攻击方法,旨在了解图像分类系统的弱点并提高其抗攻击能力。具体来说,利用生成对抗性网络生成具有小扰动但对分类器的决策产生影响的对抗性样本,这些对抗性样本是通过训练生成器和分类器的对抗性学习生成的。通过大量的实验分析,我们在经典图像分类数据集上评估了该方法的有效性,结果表明,我们的模型在欺骗各种先进分类器的同时,保持了对抗性样本的自然性。
论文及项目相关链接
PDF 7 pages, 6 figures
Summary
生成对抗网络(GANs)在图像生成领域受到广泛关注,但其滥用虚假图像技术引发了一系列安全问题,如恶意篡改他人照片和视频、侵犯个人隐私等。受GANs启发,本文提出了一种新型对抗性攻击方法,旨在了解图像分类系统的弱点,提高其抗攻击能力。该方法通过生成对抗性样本,对分类器进行对抗性学习来生成具有小扰动但对分类器决策产生影响的对抗性样本。实验表明,该方法在经典图像分类数据集上有效,能够成功欺骗多种先进分类器的同时保持对抗性样本的自然性。
Key Takeaways
- 生成对抗网络(GANs)在图像生成领域的广泛应用引发了一系列安全问题。
- 滥用虚假图像技术可能导致恶意篡改和个人隐私侵犯。
- 受GANs启发,提出了一种新型对抗性攻击方法。
- 该方法通过生成对抗性样本对分类器进行对抗性学习。
- 对抗性样本具有小扰动,但足以影响分类器的决策。
- 方法在经典图像分类数据集上进行了广泛实验,证明了其有效性。
点此查看论文截图


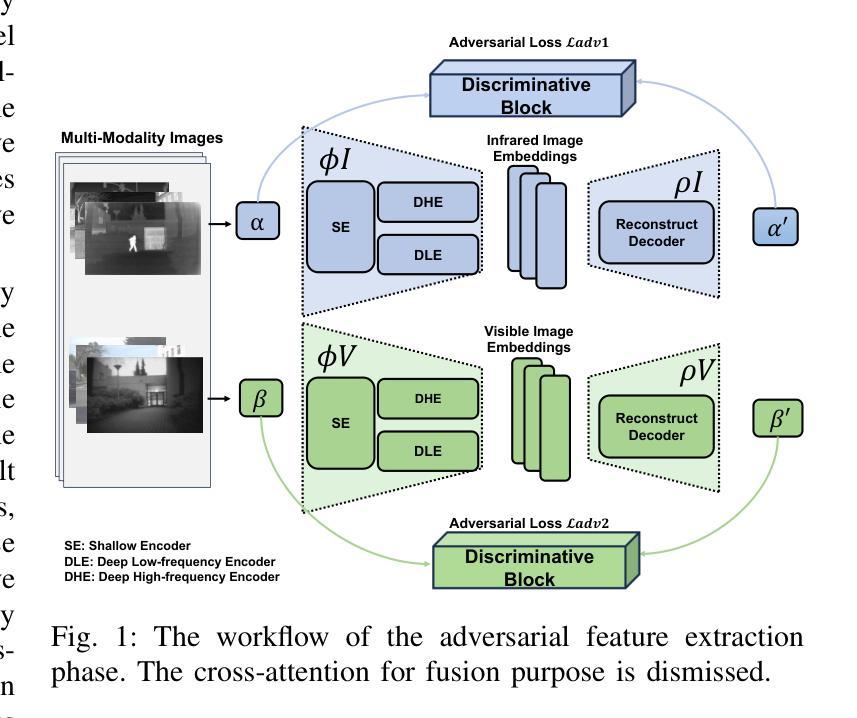
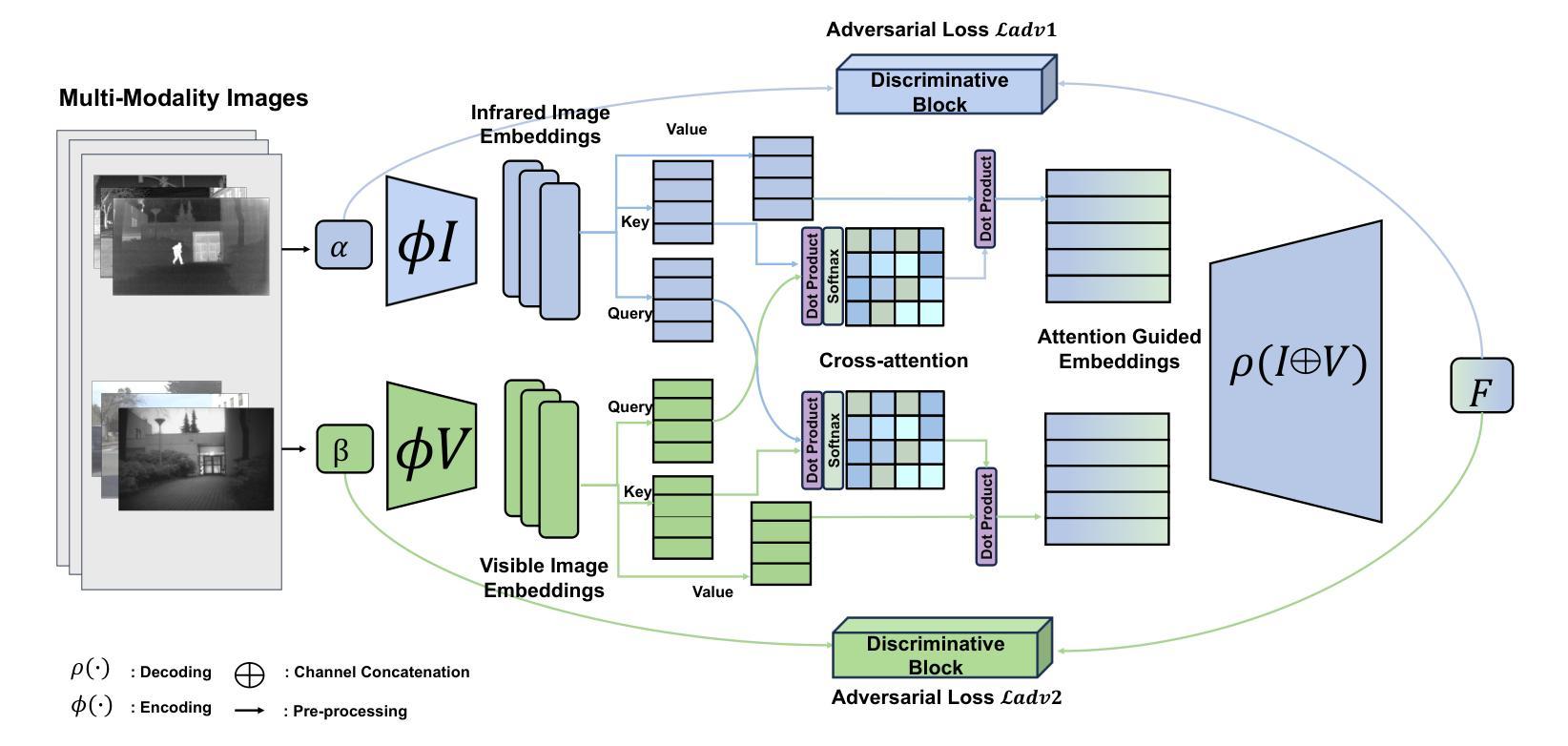
DAE-Fuse: An Adaptive Discriminative Autoencoder for Multi-Modality Image Fusion
Authors:Yuchen Guo, Ruoxiang Xu, Rongcheng Li, Zhenghao Wu, Weifeng Su
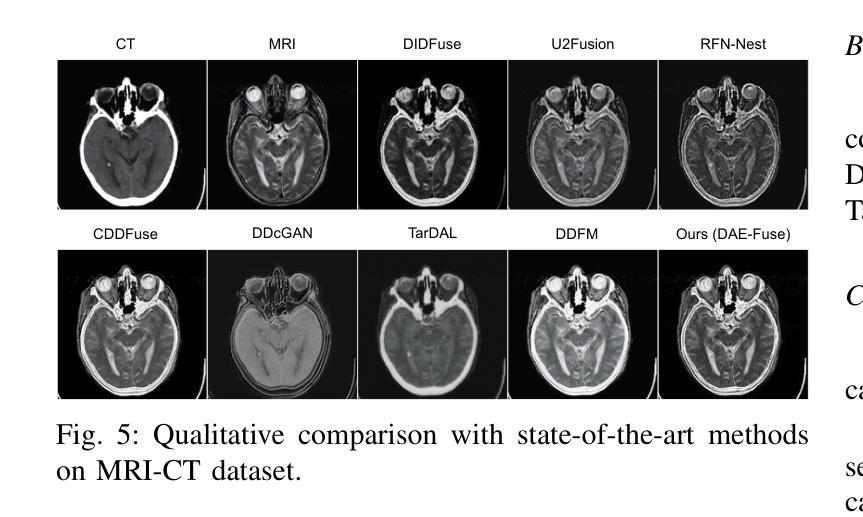
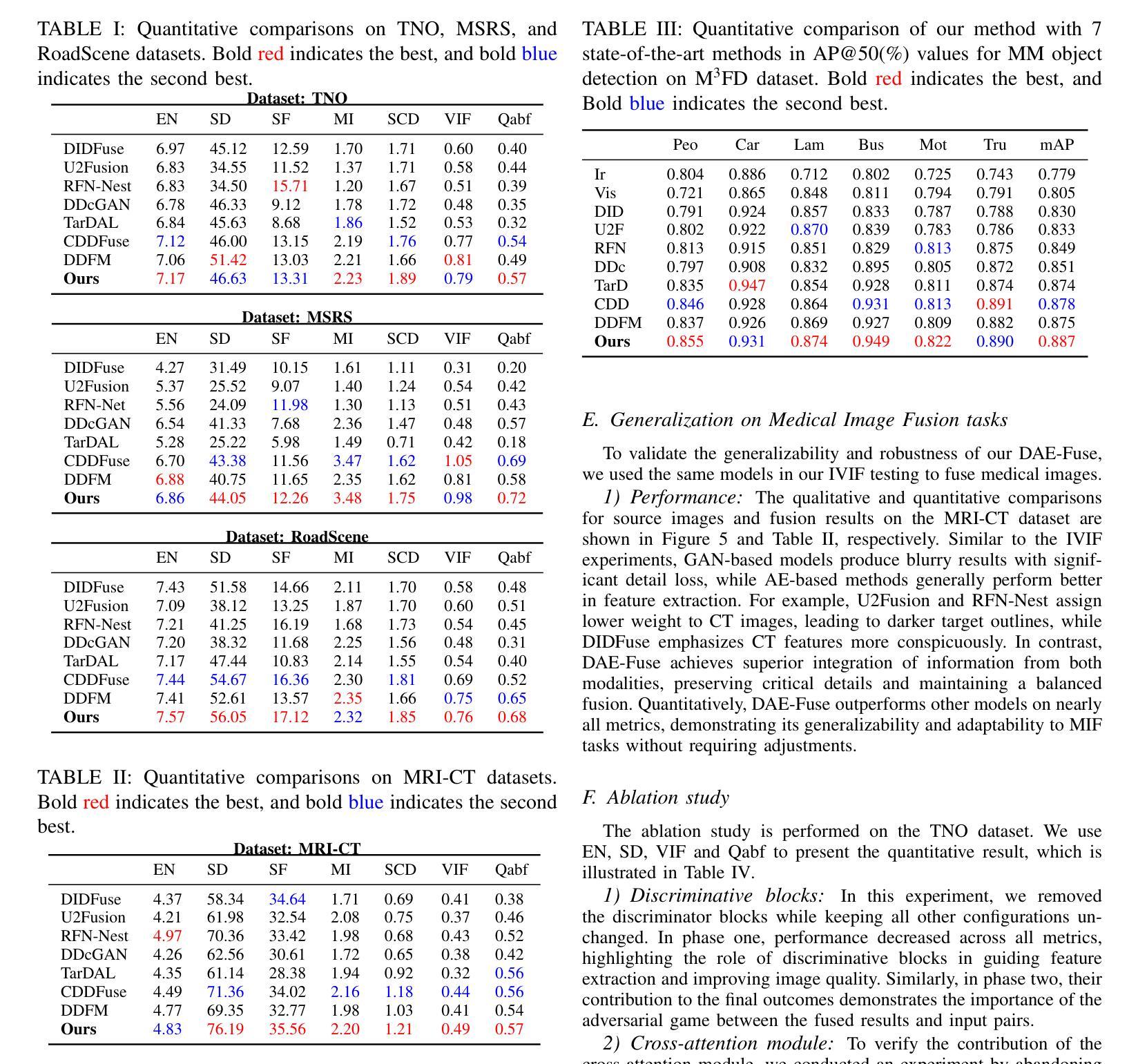
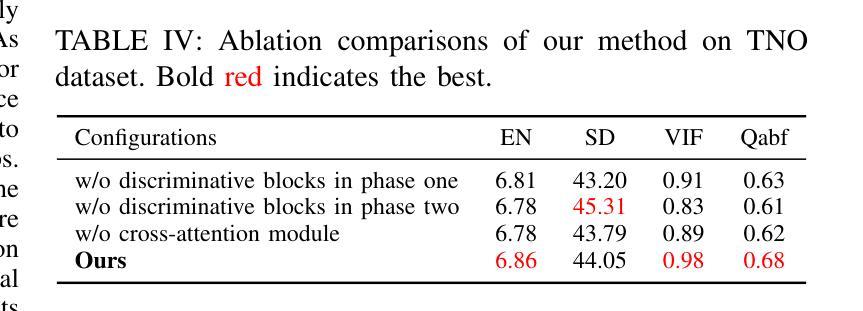
In extreme scenarios such as nighttime or low-visibility environments, achieving reliable perception is critical for applications like autonomous driving, robotics, and surveillance. Multi-modality image fusion, particularly integrating infrared imaging, offers a robust solution by combining complementary information from different modalities to enhance scene understanding and decision-making. However, current methods face significant limitations: GAN-based approaches often produce blurry images that lack fine-grained details, while AE-based methods may introduce bias toward specific modalities, leading to unnatural fusion results. To address these challenges, we propose DAE-Fuse, a novel two-phase discriminative autoencoder framework that generates sharp and natural fused images. Furthermore, We pioneer the extension of image fusion techniques from static images to the video domain while preserving temporal consistency across frames, thus advancing the perceptual capabilities required for autonomous navigation. Extensive experiments on public datasets demonstrate that DAE-Fuse achieves state-of-the-art performance on multiple benchmarks, with superior generalizability to tasks like medical image fusion.
在夜间或低能见度环境等极端场景中,对于自动驾驶、机器人技术和监控等应用来说,实现可靠的感知至关重要。多模式图像融合,特别是结合红外成像,通过结合不同模式的补充信息,增强对场景的理解和决策,提供了一种稳健的解决方案。然而,当前的方法存在重大局限性:基于GAN的方法往往产生模糊图像,缺乏细粒度细节,而基于AE的方法可能倾向于特定模式,导致不自然的融合结果。为了解决这些挑战,我们提出了DAE-Fuse,这是一种新型的两阶段判别性自编码器框架,能够生成清晰自然的融合图像。此外,我们率先将图像融合技术从静态图像扩展到视频领域,同时保持帧间的时间一致性,从而提高了自主导航所需的感知能力。在公共数据集上的广泛实验表明,DAE-Fuse在多个基准测试中实现了卓越的性能,对医疗图像融合等任务的通用性也很出色。
论文及项目相关链接
Summary
在极端场景如夜间或低能见度环境下,多模态图像融合对自动驾驶、机器人和监控等应用至关重要。当前方法存在缺陷,基于GAN的方法常产生模糊图像,缺乏细节,而基于AE的方法可能偏向特定模态,导致融合结果不自然。为解决这些问题,我们提出DAE-Fuse,一种新型的两阶段判别性自编码器框架,生成清晰自然的融合图像。此外,我们率先将图像融合技术从静态图像扩展到视频领域,同时保持帧间的时间一致性,提高了自主导航的感知能力。在公共数据集上的广泛实验表明,DAE-Fuse在多个基准测试中达到最佳性能,对医疗图像融合等任务具有卓越的可推广性。
Key Takeaways
- 在极端环境下,多模态图像融合对许多应用至关重要。
- 当前图像融合方法存在缺陷,需要改进。
- DAE-Fuse是一种新型的两阶段判别性自编码器框架,用于生成清晰自然的融合图像。
- DAE-Fuse解决了基于GAN和AE的方法的缺陷。
- DAE-Fuse将图像融合技术从静态图像扩展到视频领域。
- DAE-Fuse保持视频帧间的时间一致性。
点此查看论文截图


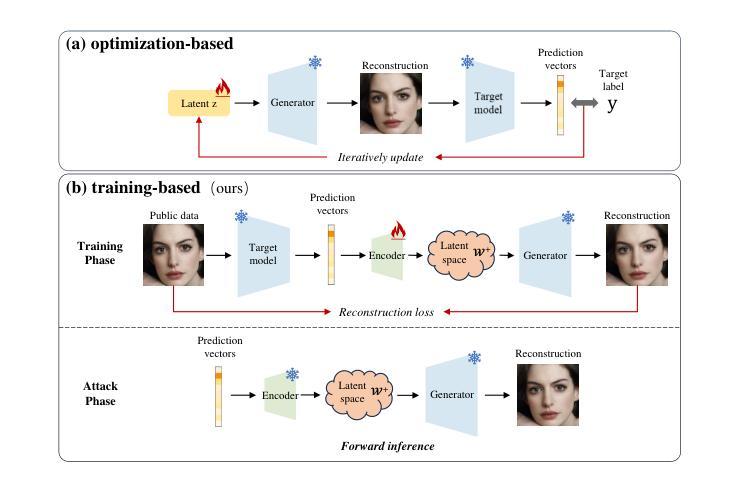
Prediction Exposes Your Face: Black-box Model Inversion via Prediction Alignment
Authors:Yufan Liu, Wanqian Zhang, Dayan Wu, Zheng Lin, Jingzi Gu, Weiping Wang
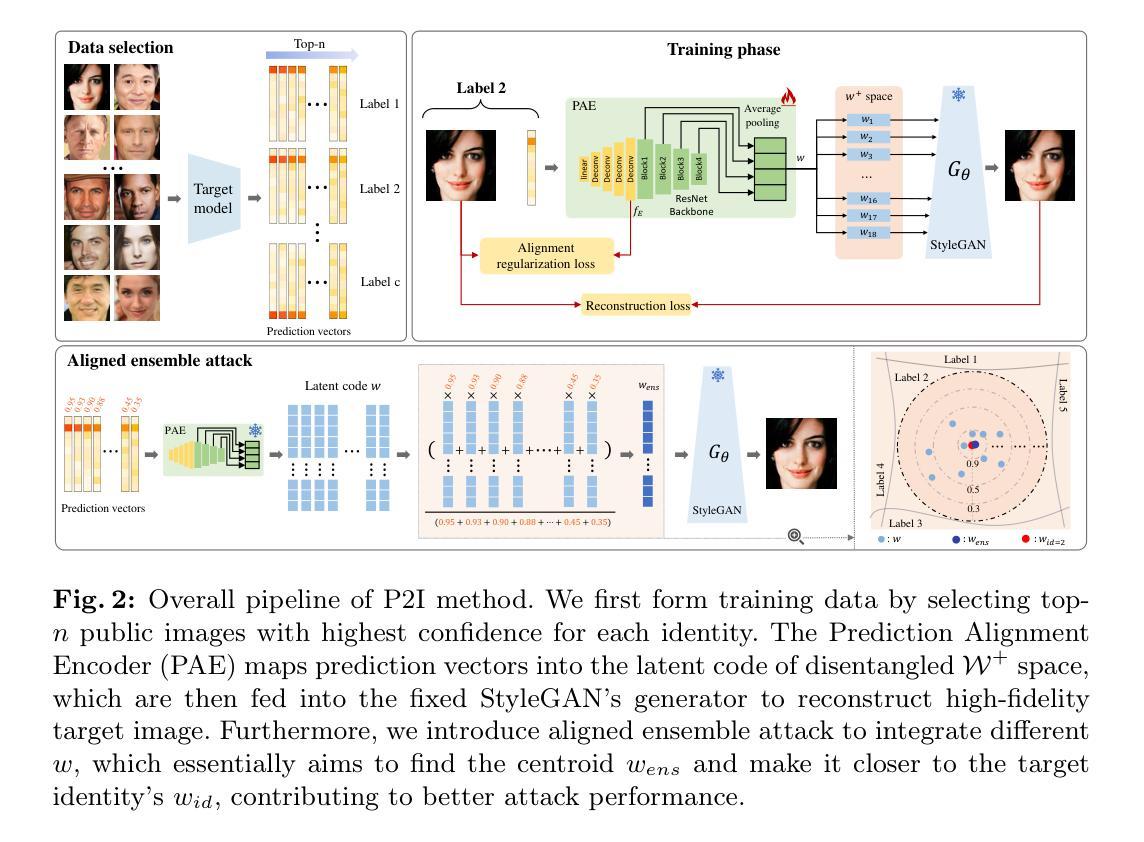
Model inversion (MI) attack reconstructs the private training data of a target model given its output, posing a significant threat to deep learning models and data privacy. On one hand, most of existing MI methods focus on searching for latent codes to represent the target identity, yet this iterative optimization-based scheme consumes a huge number of queries to the target model, making it unrealistic especially in black-box scenario. On the other hand, some training-based methods launch an attack through a single forward inference, whereas failing to directly learn high-level mappings from prediction vectors to images. Addressing these limitations, we propose a novel Prediction-to-Image (P2I) method for black-box MI attack. Specifically, we introduce the Prediction Alignment Encoder to map the target model’s output prediction into the latent code of StyleGAN. In this way, prediction vector space can be well aligned with the more disentangled latent space, thus establishing a connection between prediction vectors and the semantic facial features. During the attack phase, we further design the Aligned Ensemble Attack scheme to integrate complementary facial attributes of target identity for better reconstruction. Experimental results show that our method outperforms other SOTAs, e.g.,compared with RLB-MI, our method improves attack accuracy by 8.5% and reduces query numbers by 99% on dataset CelebA.
模型反演(MI)攻击通过给定目标模型的输出重构其私有训练数据,对深度学习和数据隐私构成重大威胁。一方面,大多数现有的MI方法专注于搜索代表目标身份的潜在代码,但这种基于迭代优化的方案需要向目标模型发出大量查询,尤其在黑箱场景中,这使得它变得不切实际。另一方面,一些基于训练的方法通过一次正向推理发起攻击,然而,它们无法直接从预测向量学习高级映射到图像。为了解决这些限制,我们提出了一种用于黑箱MI攻击的新型Prediction-to-Image(P2I)方法。具体来说,我们引入了预测对齐编码器,将目标模型的输出预测映射到StyleGAN的潜在代码中。通过这种方式,预测向量空间可以与更分离的潜在空间进行良好对齐,从而在预测向量和语义面部特征之间建立联系。在攻击阶段,我们进一步设计了Aligned Ensemble Attack方案,以整合目标身份的互补面部特征,以实现更好的重建。实验结果表明,我们的方法优于其他最新技术,例如在CelebA数据集上,与RLB-MI相比,我们的方法提高了8.5%的攻击准确率,并将查询数量减少了99%。
论文及项目相关链接
PDF Accepted by ECCV 2024
Summary
数据泄露风险显著,一种新型的模型反向攻击——预测至图像(P2I)方法应对此挑战。新方法旨在通过将模型输出预测映射至StyleGAN的潜在代码,以黑箱环境下的模型逆向攻击重构出训练数据。采用预测对齐编码器进行映射,实现了预测向量空间与更具可分性的潜在空间的良好对齐,建立了预测向量与语义面部特征之间的联系。攻击阶段采用对齐集成攻击方案,整合目标身份的互补面部特征以实现更好的重建效果。实验结果显示,该方法相较于其他最新技术,攻击准确率提高8.5%,查询次数减少99%。
Key Takeaways
- 模型反转攻击能够重构目标模型的私有训练数据,对深度学习和数据隐私构成威胁。
- 现有模型反转方法大多侧重于搜索代表目标身份的潜在代码,但这种方法需要大量查询目标模型,使其在实际应用中不切实际。
- 一些基于训练的方法通过单次前向推理发起攻击,但无法直接从预测向量学习高级映射到图像。
- 提出了一种新型的预测至图像(P2I)方法进行黑箱模型反转攻击。
- P2I方法引入预测对齐编码器,将模型输出预测映射到StyleGAN的潜在代码。
- 预测向量空间与更易于区分的潜在空间的对齐,有助于建立预测向量和语义特征之间的联系。
点此查看论文截图