⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-26 更新
Decentralized Intelligence in GameFi: Embodied AI Agents and the Convergence of DeFi and Virtual Ecosystems
Authors:Fernando Jia, Jade Zheng, Florence Li
In the rapidly evolving landscape of GameFi, a fusion of gaming and decentralized finance (DeFi), there exists a critical need to enhance player engagement and economic interaction within gaming ecosystems. Our GameFi ecosystem aims to fundamentally transform this landscape by integrating advanced embodied AI agents into GameFi platforms. These AI agents, developed using cutting-edge large language models (LLMs), such as GPT-4 and Claude AI, are capable of proactive, adaptive, and contextually rich interactions with players. By going beyond traditional scripted responses, these agents become integral participants in the game’s narrative and economic systems, directly influencing player strategies and in-game economies. We address the limitations of current GameFi platforms, which often lack immersive AI interactions and mechanisms for community engagement or creator monetization. Through the deep integration of AI agents with blockchain technology, we establish a consensus-driven, decentralized GameFi ecosystem. This ecosystem empowers creators to monetize their contributions and fosters democratic collaboration among players and creators. Furthermore, by embedding DeFi mechanisms into the gaming experience, we enhance economic participation and provide new opportunities for financial interactions within the game. Our approach enhances player immersion and retention and advances the GameFi ecosystem by bridging traditional gaming with Web3 technologies. By integrating sophisticated AI and DeFi elements, we contribute to the development of more engaging, economically robust, and community-centric gaming environments. This project represents a significant advancement in the state-of-the-art in GameFi, offering insights and methodologies that can be applied throughout the gaming industry.
在游戏与去中心化金融(DeFi)的融合体——GameFi迅速发展的背景下,增强玩家在游戏生态系统中的参与度和经济互动显得尤为重要。我们的GameFi生态系统旨在通过把先进的嵌入式人工智能代理(AI)集成到GameFi平台,从根本上改变这一格局。这些利用前沿的大型语言模型(如GPT-4和Claude AI)开发的人工智能代理,具备与玩家进行主动、自适应和语境丰富的交互的能力。这些代理超越了传统的脚本响应,成为游戏叙事和经济系统的核心参与者,直接影响玩家的策略和游戏内经济。我们解决了当前GameFi平台的局限性,这些平台通常缺乏沉浸式的人工智能交互和社区参与机制创作者变现的机制。通过人工智能代理与区块链技术的深度融合,我们建立了一个去中心化的GameFi生态系统,以共识驱动。这个生态系统让创作者能够变现他们的贡献,并促进玩家和创作者之间的民主合作。此外,通过将DeFi机制嵌入游戏体验,我们增强了经济参与性,为游戏内的金融互动提供了新的机会。我们的方法提高了玩家的沉浸感和留存率,并通过弥合传统游戏与Web3技术的鸿沟,推动了GameFi生态系统的发展。通过集成复杂的人工智能和DeFi元素,我们致力于开发更具吸引力、经济稳健和以社区为中心的游戏环境。这个项目代表了GameFi领域的最新进展,提供了可应用于整个游戏行业的见解和方法论。
论文及项目相关链接
PDF 11 pages, 4 figures
Summary
本文介绍了GameFi生态系统如何通过集成先进的AI代理来根本性地改变游戏与去中心化金融(DeFi)的融合现状。这些AI代理使用大型语言模型(LLM)技术,如GPT-4和Claude AI开发,能够与玩家进行积极主动、适应性强和上下文丰富的交互。AI的深度集成将增强玩家沉浸感和留存率,同时通过区块链技术建立共识驱动的生态系统,促进创作者贡献货币化和玩家与创作者之间的民主合作。该项目将传统游戏与Web3技术相结合,为游戏行业提供了先进的发展思路和丰富的实践经验。
Key Takeaways
- GameFi生态系统致力于通过集成先进的AI代理来提升游戏玩家与金融系统的互动体验。
- AI代理采用大型语言模型技术,能进行丰富、自适应的交互,影响玩家策略和游戏经济。
- 区块链技术与AI的深度集成建立了去中心化的GameFi生态系统,支持创作者贡献货币化。
- 该系统通过嵌入DeFi机制增强了经济参与度,为游戏内金融互动提供了新的机会。
- GameFi项目融合传统游戏与Web3技术,显著提升了玩家沉浸感和留存率。
点此查看论文截图

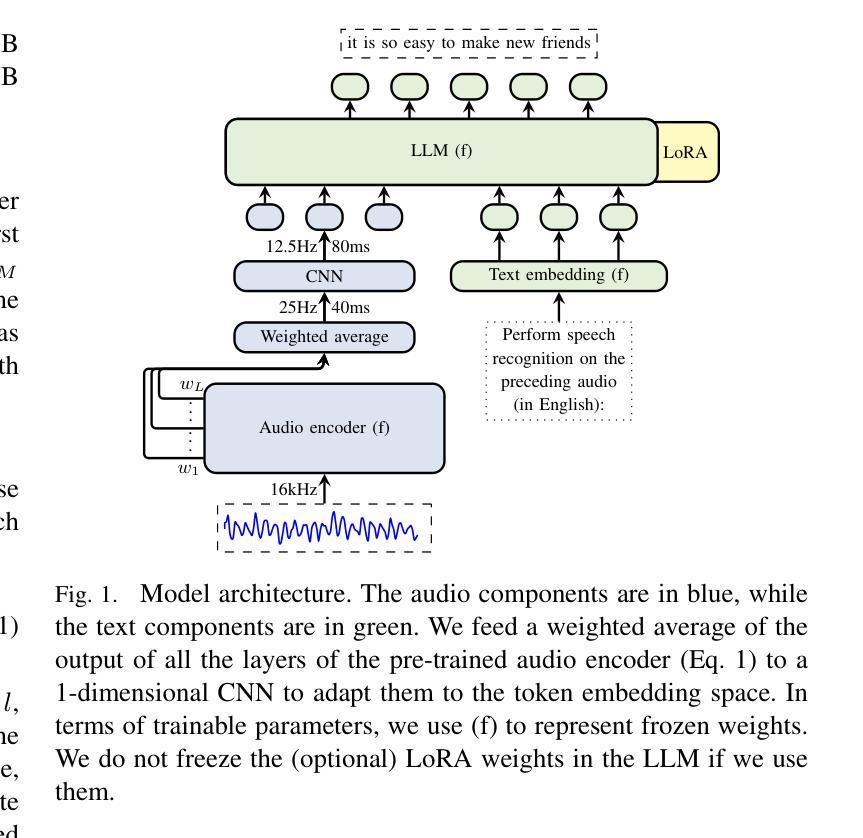
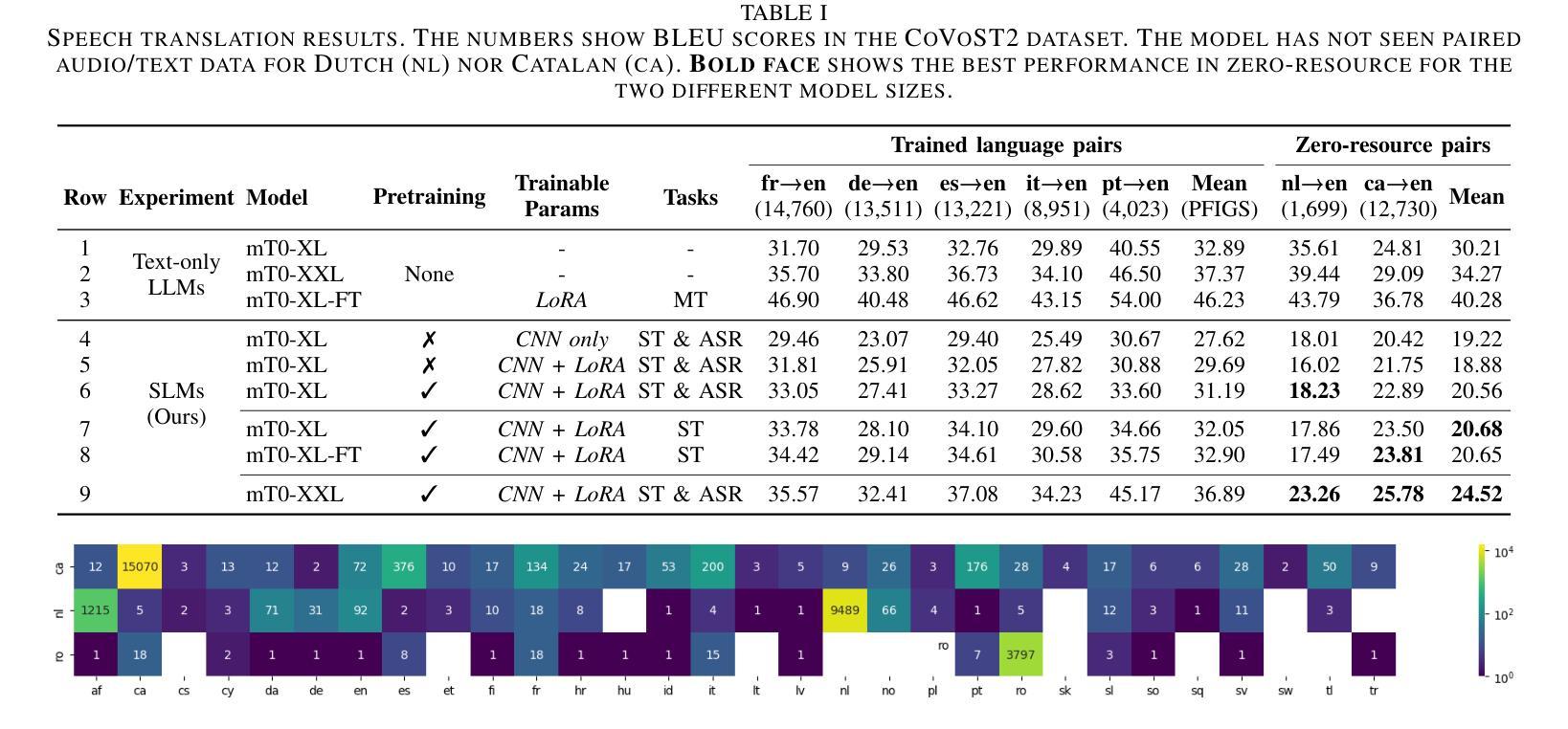
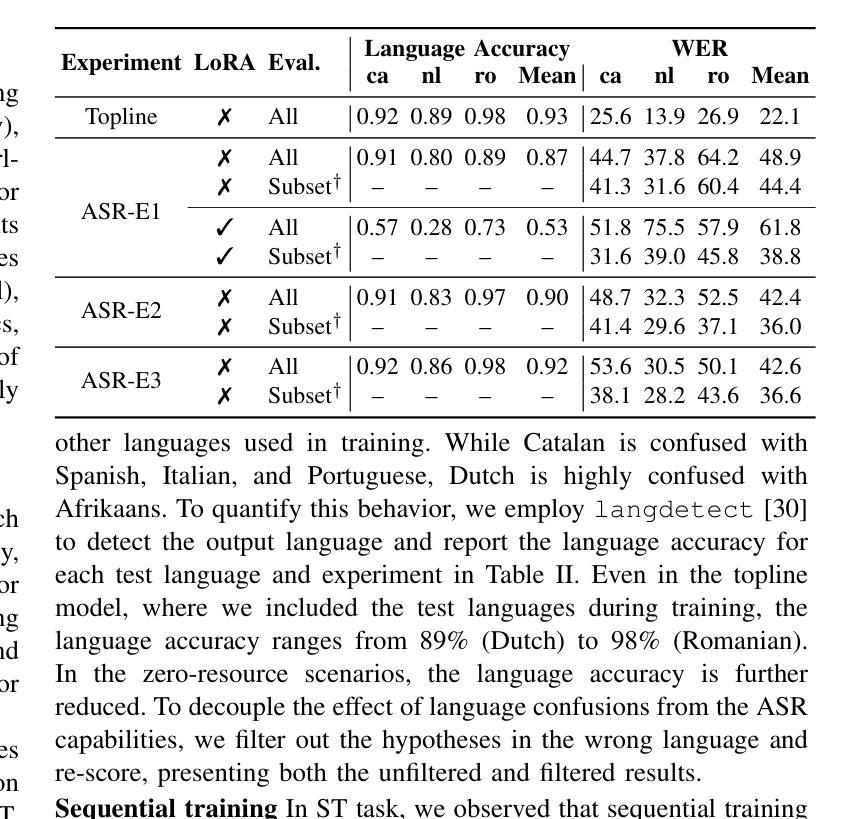
Zero-resource Speech Translation and Recognition with LLMs
Authors:Karel Mundnich, Xing Niu, Prashant Mathur, Srikanth Ronanki, Brady Houston, Veera Raghavendra Elluru, Nilaksh Das, Zejiang Hou, Goeric Huybrechts, Anshu Bhatia, Daniel Garcia-Romero, Kyu J. Han, Katrin Kirchhoff
Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
尽管最近语音处理领域取得了进展,但零资源语音翻译(ST)和自动语音识别(ASR)仍然存在问题。在这项工作中,我们提出利用多语言大型语言模型(LLM)来执行ST和ASR,针对那些模型从未见过配对语音文本数据的语言。我们通过使用预训练的多语言语音编码器、多语言LLM和一个轻量级适配模块来实现这一点,该模块将音频表示映射到LLM的令牌嵌入空间。我们在ST和ASR中都进行了多次实验,以了解如何最佳地训练模型以及哪些数据在未见过的语言中对性能的影响最大。在ST中,我们最好的模型能够在CoVoST2中达到超过23的BLEU分数,用于两种之前未见过的语言;而在ASR中,我们达到了高达28.2%的WER。最后,我们表明,我们系统的性能受限于LLM输出所需语言文本的能力。
论文及项目相关链接
PDF ICASSP 2025, 5 pages, 2 figures, 2 tables
Summary
本文提出利用多语言大型语言模型(LLM)进行零资源语音翻译(ST)和自动语音识别(ASR)。通过使用预训练的多语言语音编码器、多语言LLM和轻量级适配模块,将音频表示映射到LLM的令牌嵌入空间,实现在未见配对音频文本数据的语言中进行ST和ASR。实验表明,最佳模型的翻译性能达到CoVoST2的BLEU分数超过23,ASR的WER达到28.2%。系统性能受限于LLM输出所需语言文本的能力。
Key Takeaways
- 利用多语言大型语言模型(LLM)解决零资源语音翻译(ST)和自动语音识别(ASR)的挑战性问题。
- 通过预训练的多语言语音编码器、多语言LLM和轻量级适配模块实现未见配对音频文本数据的语言中的ST和ASR。
- 最佳模型的翻译性能达到CoVoST2的BLEU分数超过23。
- ASR的WER达到28.2%。
- 系统性能受限于LLM输出所需语言文本的能力。
- 实验表明,训练模型和选择数据对性能有重要影响。
点此查看论文截图

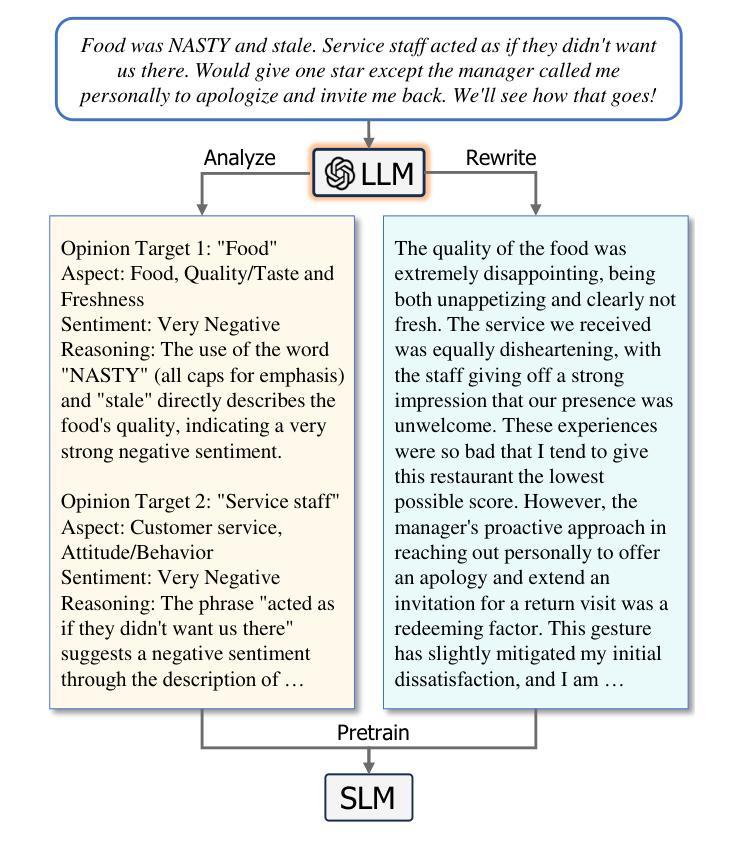
Distilling Fine-grained Sentiment Understanding from Large Language Models
Authors:Yice Zhang, Guangyu Xie, Hongling Xu, Kaiheng Hou, Jianzhu Bao, Qianlong Wang, Shiwei Chen, Ruifeng Xu
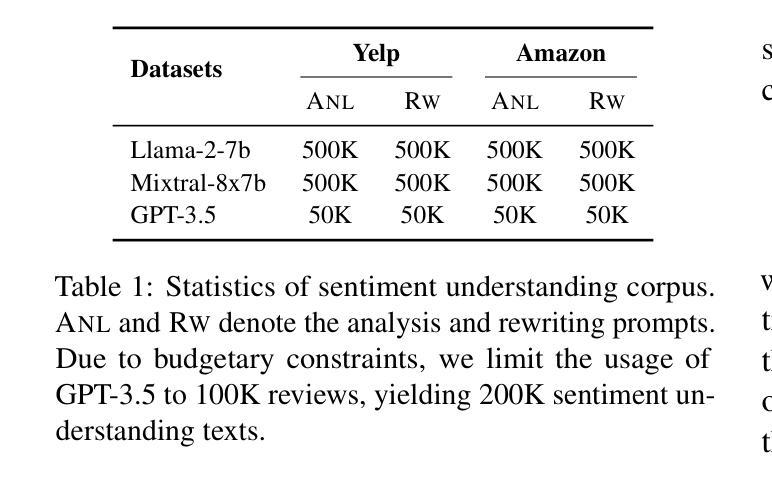
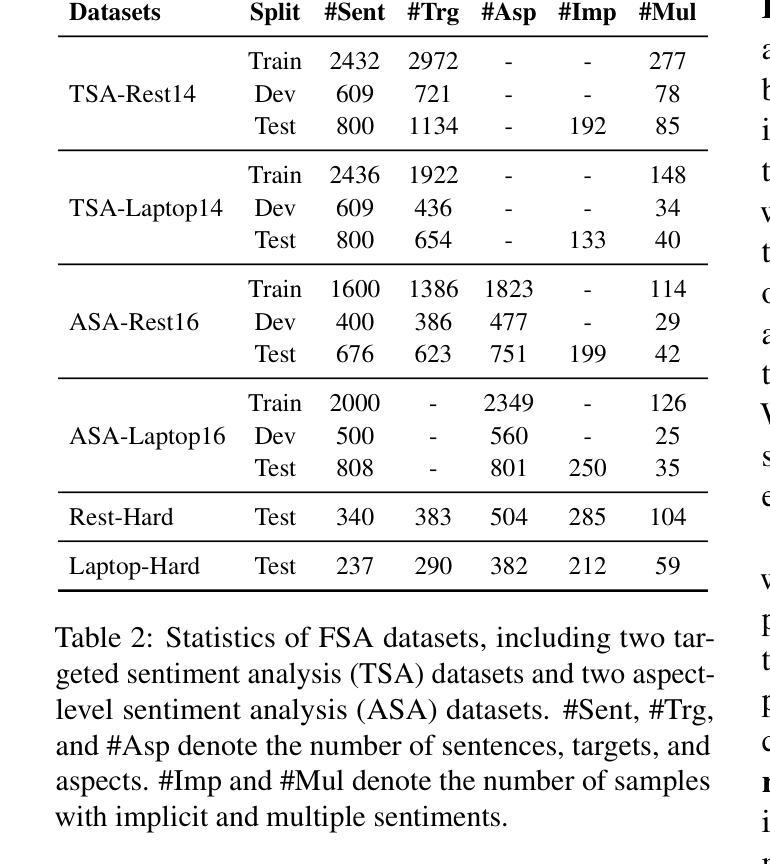
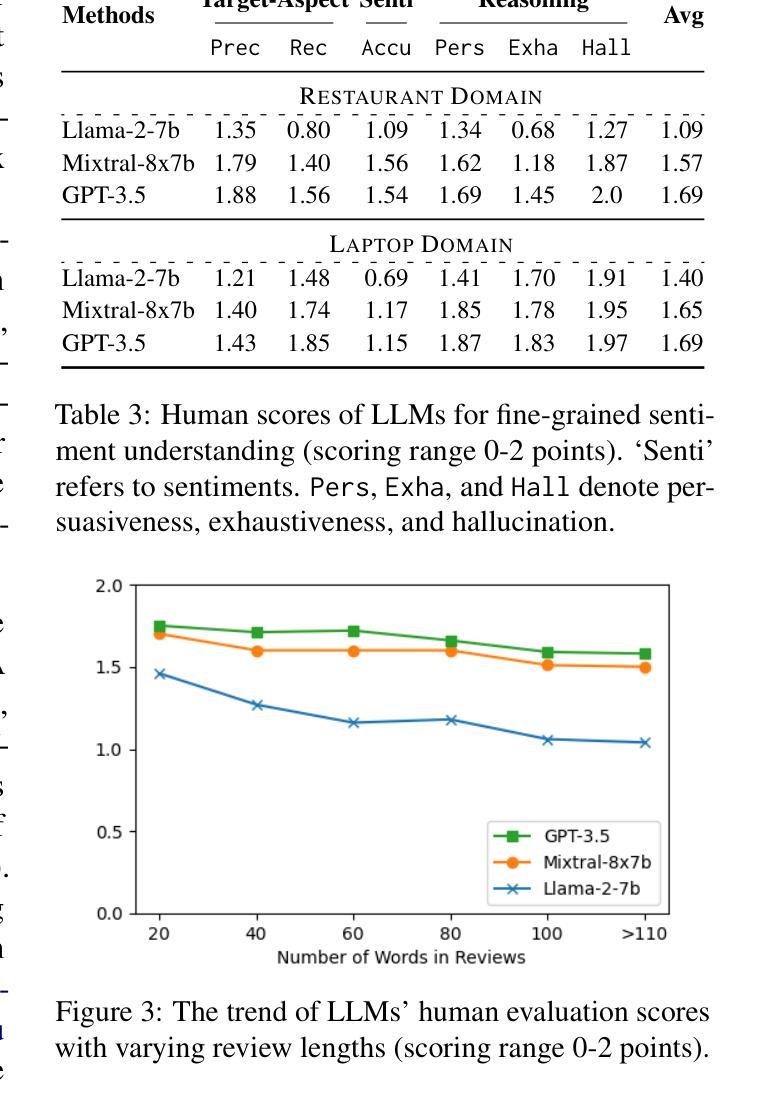
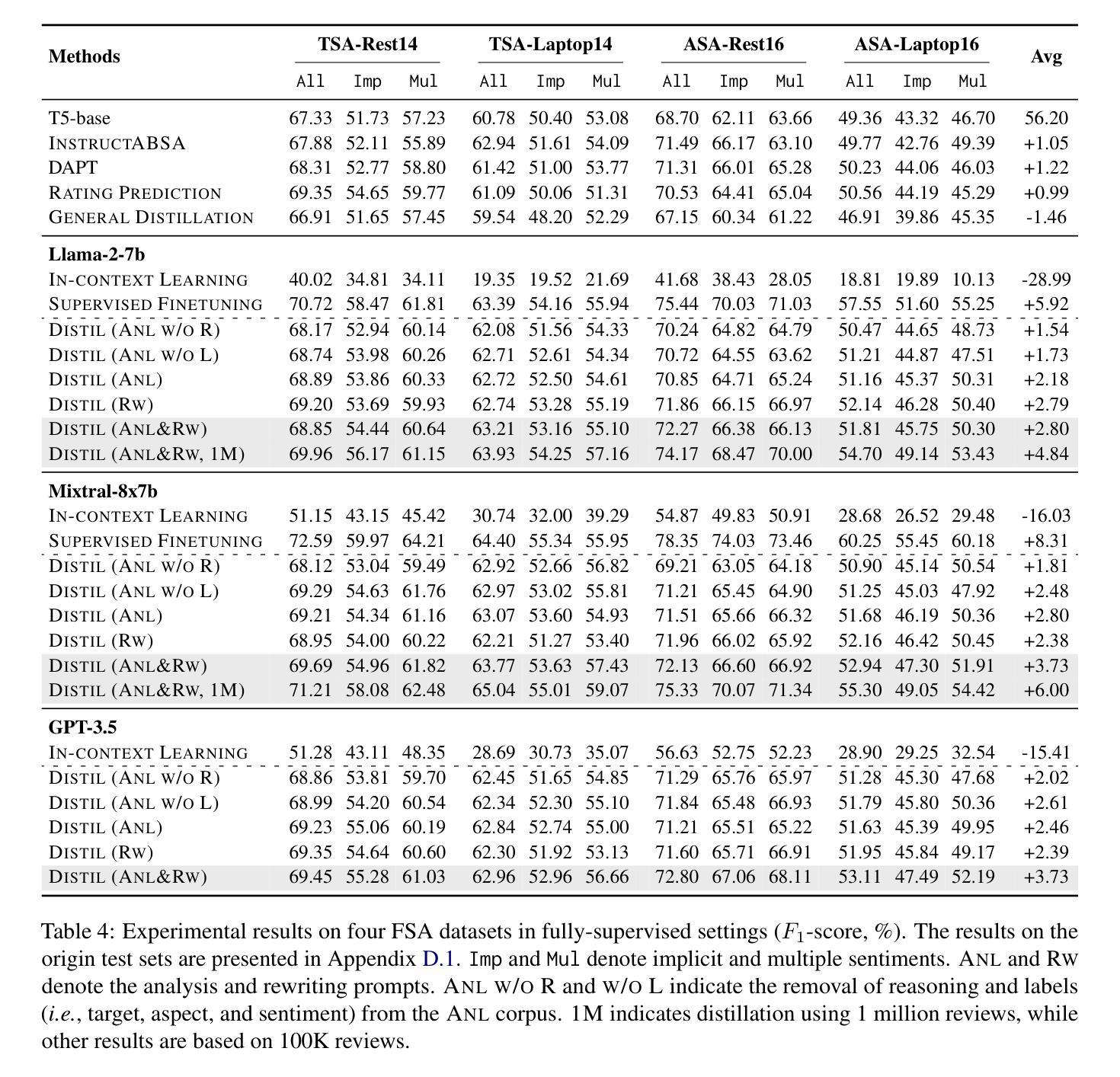
Fine-grained sentiment analysis (FSA) aims to extract and summarize user opinions from vast opinionated text. Recent studies demonstrate that large language models (LLMs) possess exceptional sentiment understanding capabilities. However, directly deploying LLMs for FSA applications incurs high inference costs. Therefore, this paper investigates the distillation of fine-grained sentiment understanding from LLMs into small language models (SLMs). We prompt LLMs to examine and interpret the sentiments of given reviews and then utilize the generated content to pretrain SLMs. Additionally, we develop a comprehensive FSA benchmark to evaluate both SLMs and LLMs. Extensive experiments on this benchmark reveal that: (1) distillation significantly enhances the performance of SLMs in FSA tasks, achieving a 6.00% improvement in $F_1$-score, and the distilled model can outperform Llama-2-7b with only 220M parameters; (2) distillation equips SLMs with excellent zero-shot sentiment classification capabilities, enabling them to match or even exceed their teacher models. These results suggest that distillation from LLMs is a highly promising direction for FSA. We will release our code, data, and pretrained model weights at \url{https://github.com/HITSZ-HLT/FSA-Distillation}.
精细粒度情感分析(FSA)旨在从大量含有主观意见的文本中提取并总结用户意见。最近的研究表明,大型语言模型(LLM)具有出色的情感理解能力。然而,直接将LLM用于FSA应用会产生较高的推理成本。因此,本文探讨了从LLM中提炼精细粒度情感理解并将其转移到小型语言模型(SLM)的方法。我们提示LLM检查并解释给定评论的情感,然后利用生成的内容对SLM进行预训练。此外,我们还开发了一个全面的FSA基准测试,以评估SLM和LLM的性能。在这个基准测试上的大量实验表明:(1)蒸馏技术显著提高了SLM在FSA任务中的性能,F1分数提高了6.00%,并且蒸馏后的模型仅使用2.2亿个参数就能超越Llama-2-7b;(2)蒸馏赋予了SLM出色的零样本情感分类能力,使它们能够匹配甚至超越其教师模型(即LLM)。这些结果表明,从LLM中进行蒸馏是FSA的一个非常有前途的研究方向。我们将在https://github.com/HITSZ-HLT/FSA-Distillation发布我们的代码、数据和预训练模型权重。
论文及项目相关链接
摘要
本文研究大规模语言模型(LLM)在精细情感分析(FSA)任务中的高成本问题,并提出采用知识蒸馏方法从LLM中提取精细情感理解能力并将其传递给小型语言模型(SLM)。研究结果表明,蒸馏技术在提高SLM在FSA任务中的性能上效果显著,实现$F_1$分数提升6%,蒸馏后的模型以仅22亿参数便能超越Llama-2-7b模型。此外,蒸馏技术赋予SLM出色的零样本情感分类能力,能够匹配甚至超越其教师模型。研究证实蒸馏技术在精细情感分析领域具有广阔前景。代码和数据集已公开于指定网址。
关键见解
- 知识蒸馏技术显著提高了小型语言模型在精细情感分析任务中的性能,提高了模型处理的效率和效果。
- 采用蒸馏后的模型能大幅度提升SLM模型的零样本情感分类能力,显著增强模型在各种复杂情感分析场景下的泛化能力。
- 通过实验验证,蒸馏后的模型性能超越了许多现有的大型语言模型,证明了小型语言模型在精细情感分析领域的潜力。
- 知识蒸馏技术提供了一个有效的解决方案,解决了大型语言模型在精细情感分析任务中的高成本问题,有助于降低实际应用中的成本负担。
- 该研究不仅提供了实验结果,还提供了开源的代码和数据集,为相关领域的研究人员提供了方便。
- 该研究提出的蒸馏技术可以在多种应用场景中使用,特别是在需要对大规模数据进行精细情感分析的应用场景中有着广阔的应用前景。
点此查看论文截图

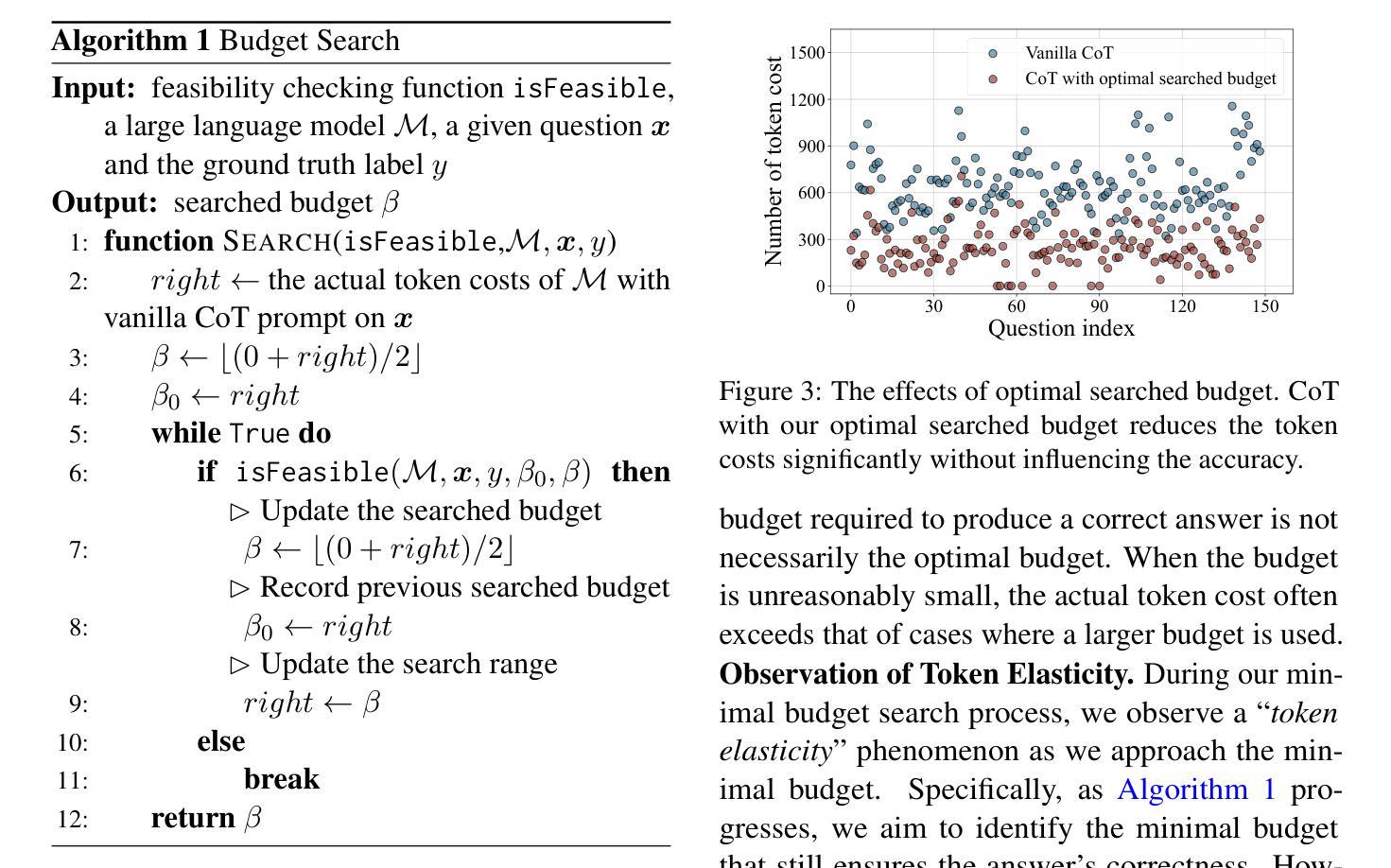
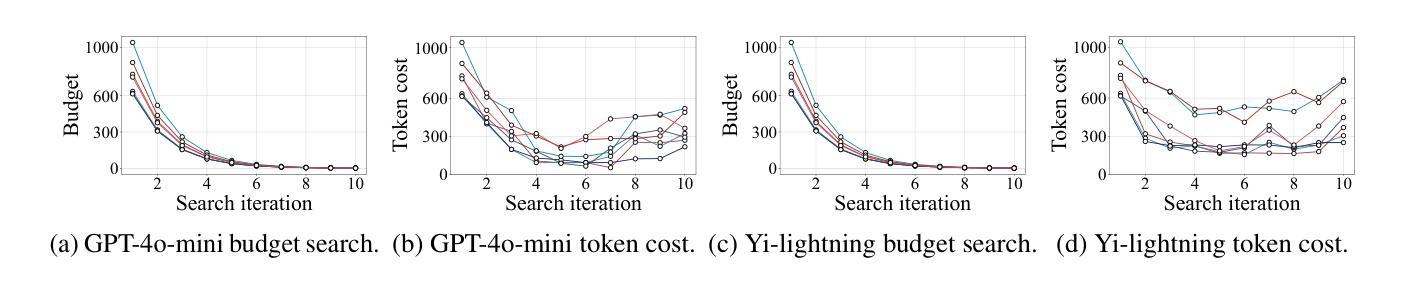
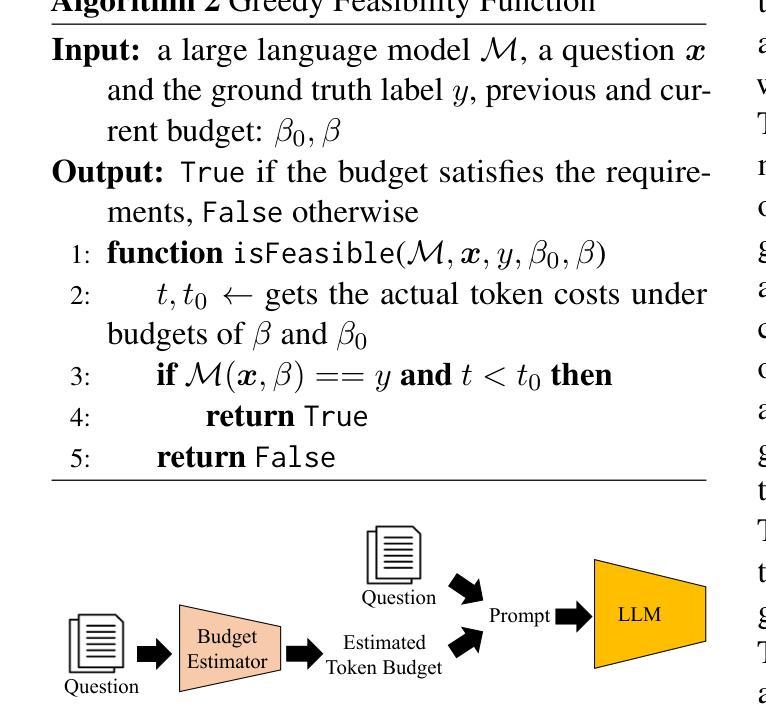
Token-Budget-Aware LLM Reasoning
Authors:Tingxu Han, Chunrong Fang, Shiyu Zhao, Shiqing Ma, Zhenyu Chen, Zhenting Wang
Reasoning is critical for large language models (LLMs) to excel in a wide range of tasks. While methods like Chain-of-Thought (CoT) reasoning enhance LLM performance by decomposing problems into intermediate steps, they also incur significant overhead in token usage, leading to increased costs. We find that the reasoning process of current LLMs is unnecessarily lengthy and it can be compressed by including a reasonable token budget in the prompt, but the choice of token budget plays a crucial role in the actual compression effectiveness. We then propose a token-budget-aware LLM reasoning framework, which dynamically estimates token budgets for different problems based on reasoning complexity and uses the estimated token budgets to guide the reasoning process. Experiments show that our method effectively reduces token costs in CoT reasoning with only a slight performance reduction, offering a practical solution to balance efficiency and accuracy in LLM reasoning. Code: https://github.com/GeniusHTX/TALE.
推理对于大型语言模型(LLM)在广泛任务中的卓越表现至关重要。虽然像思维链(CoT)推理等方法通过将问题分解为中间步骤来增强LLM的性能,但它们还会产生显著的令牌使用开销,导致成本增加。我们发现当前LLM的推理过程不必要地冗长,可以通过在提示中包含合理的令牌预算来压缩,但令牌预算的选择在实际压缩效果中起着至关重要的作用。因此,我们提出了一种基于令牌预算感知的LLM推理框架,该框架根据推理复杂性动态估计不同问题的令牌预算,并使用估计的令牌预算来指导推理过程。实验表明,我们的方法有效地降低了思维链推理中的令牌成本,并且性能下降幅度较小,为在LLM推理中平衡效率和准确性提供了一种实用的解决方案。相关代码:https://github.com/GeniusHTX/TALE。
论文及项目相关链接
Summary
大语言模型(LLM)的推理过程对完成各种任务至关重要。虽然链式思维(CoT)等推理方法通过分解问题为中间步骤增强了LLM的性能,但同时也带来了显著的计算符号使用负担,增加了成本。当前LLM的推理过程冗长且不必要的长度,可以通过在提示中包括合理的符号预算来压缩,但符号预算的选择对实际压缩效果起着至关重要的作用。因此,提出了一种基于符号预算感知的LLM推理框架,该框架根据推理复杂性动态估计不同问题的符号预算,并使用估计的符号预算来指导推理过程。实验表明,该方法在减少CoT推理中的符号成本时,性能损失较小,为平衡LLM推理中的效率和准确性提供了切实可行的解决方案。
Key Takeaways
- 推理对大语言模型(LLM)完成各种任务至关重要。
- 当前LLM使用的链式思维(CoT)等推理方法会增加符号使用负担和成本。
- 当前LLM的推理过程可以压缩,可以通过在提示中包含合理的符号预算来实现。
- 符号预算的选择对实际压缩效果至关重要。
- 基于符号预算感知的LLM推理框架能动态估计不同问题的符号预算,并据此指导推理过程。
- 该方法在减少CoT推理中的符号成本时,性能损失较小。
点此查看论文截图




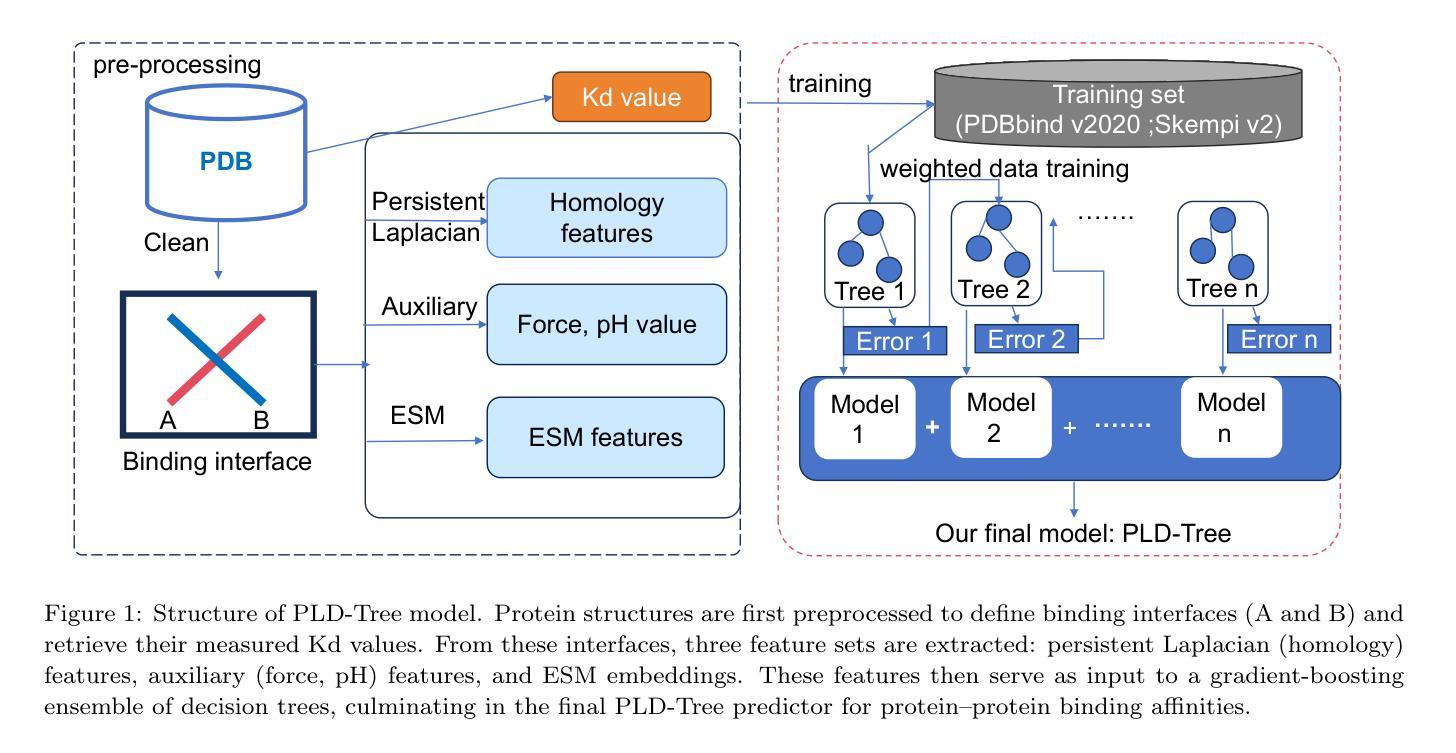
PLD-Tree: Persistent Laplacian Decision Tree for Protein-Protein Binding Free Energy Prediction
Authors:Xingjian Xu, Jiahui Chen, Chunmei Wang
Recent advances in topology-based modeling have accelerated progress in physical modeling and molecular studies, including applications to protein-ligand binding affinity. In this work, we introduce the Persistent Laplacian Decision Tree (PLD-Tree), a novel method designed to address the challenging task of predicting protein-protein interaction (PPI) affinities. PLD-Tree focuses on protein chains at binding interfaces and employs the persistent Laplacian to capture topological invariants reflecting critical inter-protein interactions. These topological descriptors, derived from persistent homology, are further enhanced by incorporating evolutionary scale modeling (ESM) from a large language model to integrate sequence-based information. We validate PLD-Tree on two benchmark datasets-PDBbind V2020 and SKEMPI v2 demonstrating a correlation coefficient ($R_p$) of 0.83 under the sophisticated leave-out-protein-out cross-validation. Notably, our approach outperforms all reported state-of-the-art methods on these datasets. These results underscore the power of integrating machine learning techniques with topology-based descriptors for molecular docking and virtual screening, providing a robust and accurate framework for predicting protein-protein binding affinities.
基于拓扑建模的最新进展加速了物理建模和分子研究(包括在蛋白质-配体结合亲和力中的应用)的进步。在这项工作中,我们引入了持久拉普拉斯决策树(PLD-Tree),这是一种针对预测蛋白质-蛋白质相互作用(PPI)亲和力这一具有挑战的任务而设计的新方法。PLD-Tree关注结合界面上的蛋白质链,并利用持久拉普拉斯来捕捉反映关键蛋白质间相互作用的拓扑不变量。这些拓扑描述符来源于持久同源性,通过融入大型语言模型的进化尺度建模(ESM)以增强序列信息。我们在两个基准数据集PDBbind V2020和SKEMPI v2上对PLD-Tree进行了验证,展示出在复杂的留一蛋白质交叉验证下的相关性系数(Rp)为0.83。值得注意的是,我们的方法在这两个数据集上的表现优于所有报告的最新方法。这些结果突显了将机器学习方法与拓扑描述符结合在分子对接和虚拟筛选中的力量,为预测蛋白质-蛋白质结合亲和力提供了稳健而准确的框架。
论文及项目相关链接
PDF 19 pages, 3 figures, 4 tables
Summary
基于拓扑的建模技术的最新进展已加速物理建模和分子研究方面的进步,包括在蛋白质-配体结合亲和力方面的应用。在此工作中,我们引入了持久拉普拉斯决策树(PLD-Tree),这是一种针对预测蛋白质-蛋白质相互作用(PPI)亲和力而设计的新方法。PLD-Tree专注于蛋白质结合界面上的蛋白质链,并利用持久拉普拉斯算子捕捉反映关键蛋白质间相互作用的拓扑不变性。这些拓扑描述符来源于持久同源性,通过融入大规模语言模型的进化尺度建模(ESM)以增强序列信息。我们在PDBbind V2020和SKEMPI v2两个基准数据集上验证了PLD-Tree,在剔除蛋白质交叉验证下,相关系数(Rp)达到0.83。值得注意的是,我们的方法在所有这些数据集上的表现都优于所有报道的先进方法。这些结果突显了将机器学习技术与拓扑描述符相结合的力量,为分子对接和虚拟筛选提供了稳健且准确的预测蛋白质-蛋白质结合亲和力的框架。
Key Takeaways
- 拓扑建模技术的最新进展促进了物理建模和分子研究的发展。
- Persistent Laplacian Decision Tree (PLD-Tree)是一种预测蛋白质-蛋白质相互作用(PPI)亲和力的新方法。
- PLD-Tree专注于蛋白质结合界面上的蛋白质链,并捕捉关键蛋白质间相互作用的拓扑不变性。
- 拓扑描述符与来自大规模语言模型的进化尺度建模(ESM)相结合,增强了序列信息的作用。
- 在基准数据集上,PLD-Tree的表现优于其他先进方法,相关系数达到0.83。
- 集成机器学习技术和拓扑描述符的方法为分子对接和虚拟筛选提供了稳健且准确的框架。
点此查看论文截图

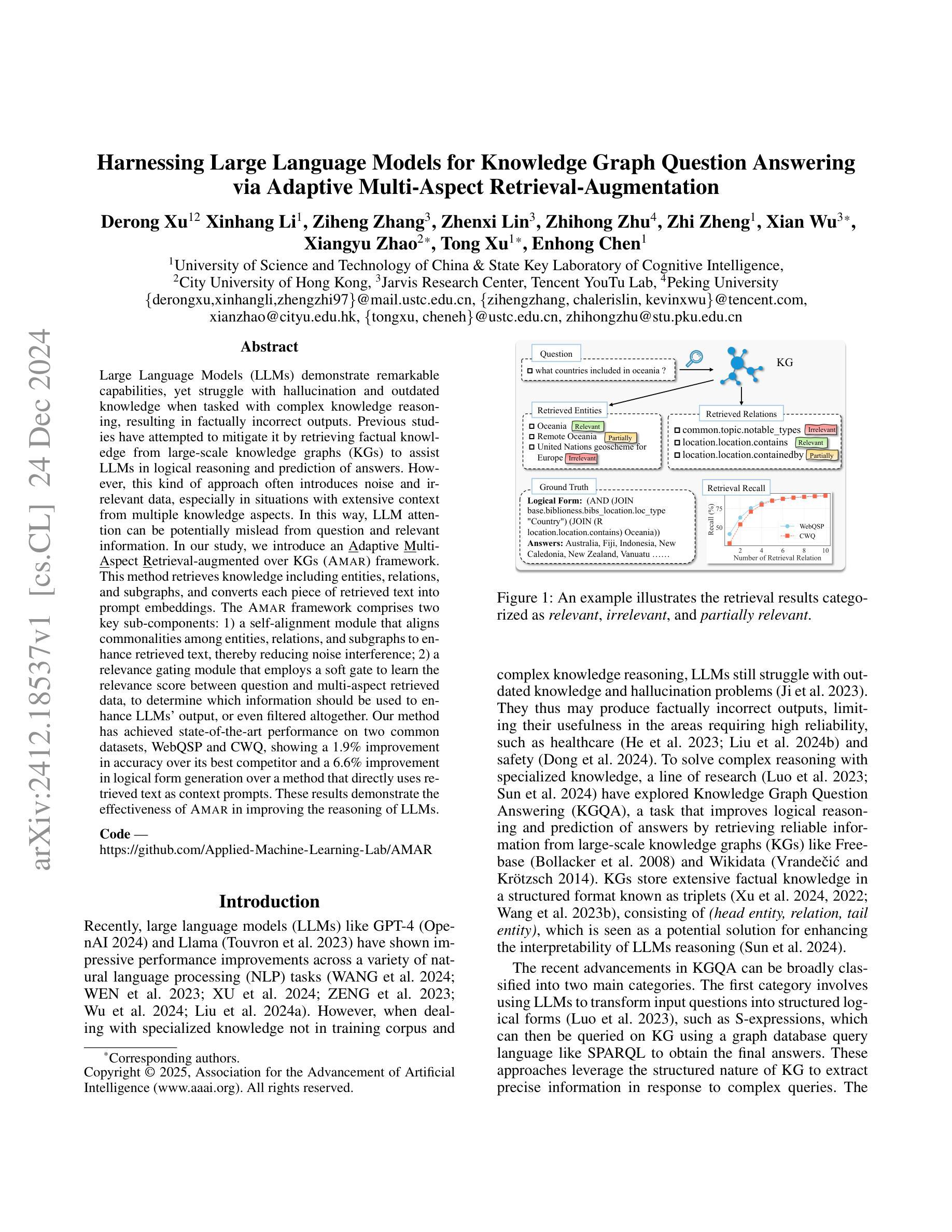
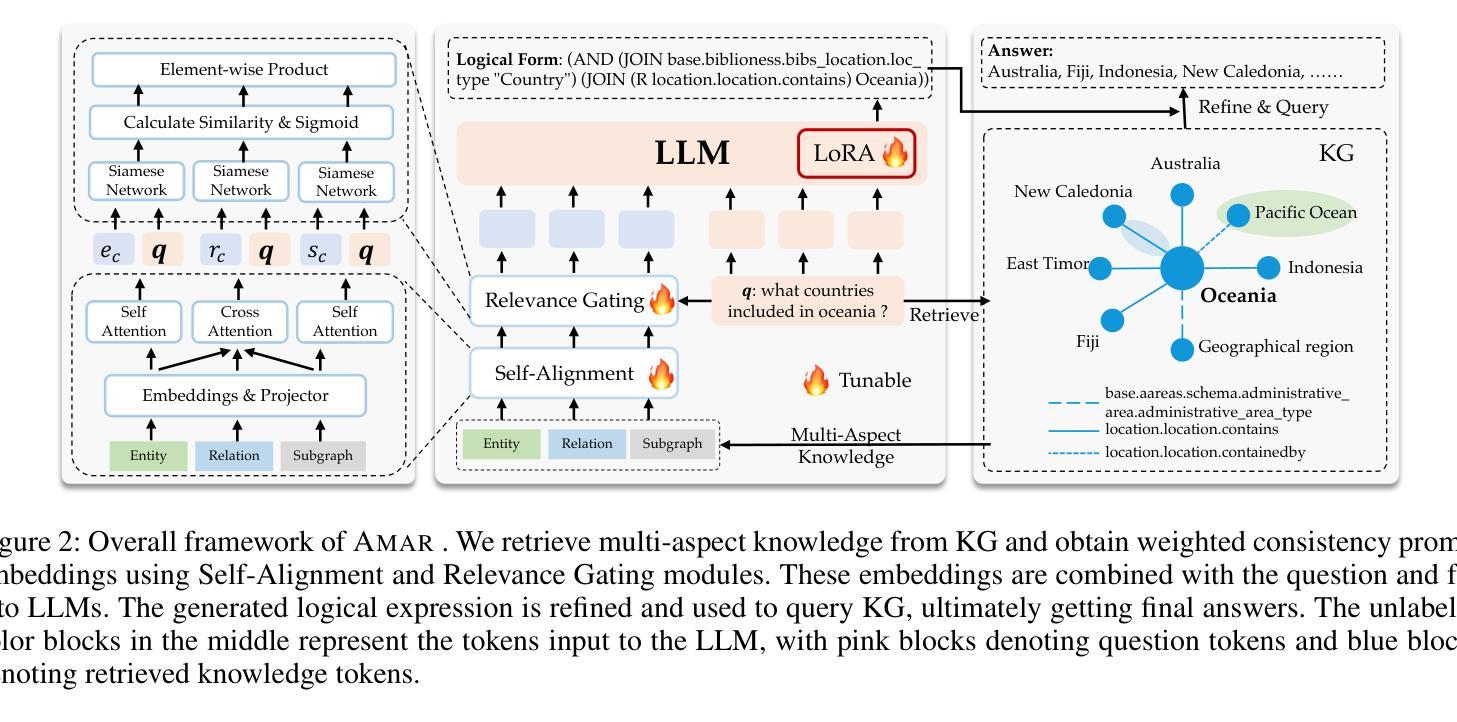
Harnessing Large Language Models for Knowledge Graph Question Answering via Adaptive Multi-Aspect Retrieval-Augmentation
Authors:Derong Xu Xinhang Li, Ziheng Zhang, Zhenxi Lin, Zhihong Zhu, Zhi Zheng, Xian Wu, Xiangyu Zhao, Tong Xu, Enhong Chen
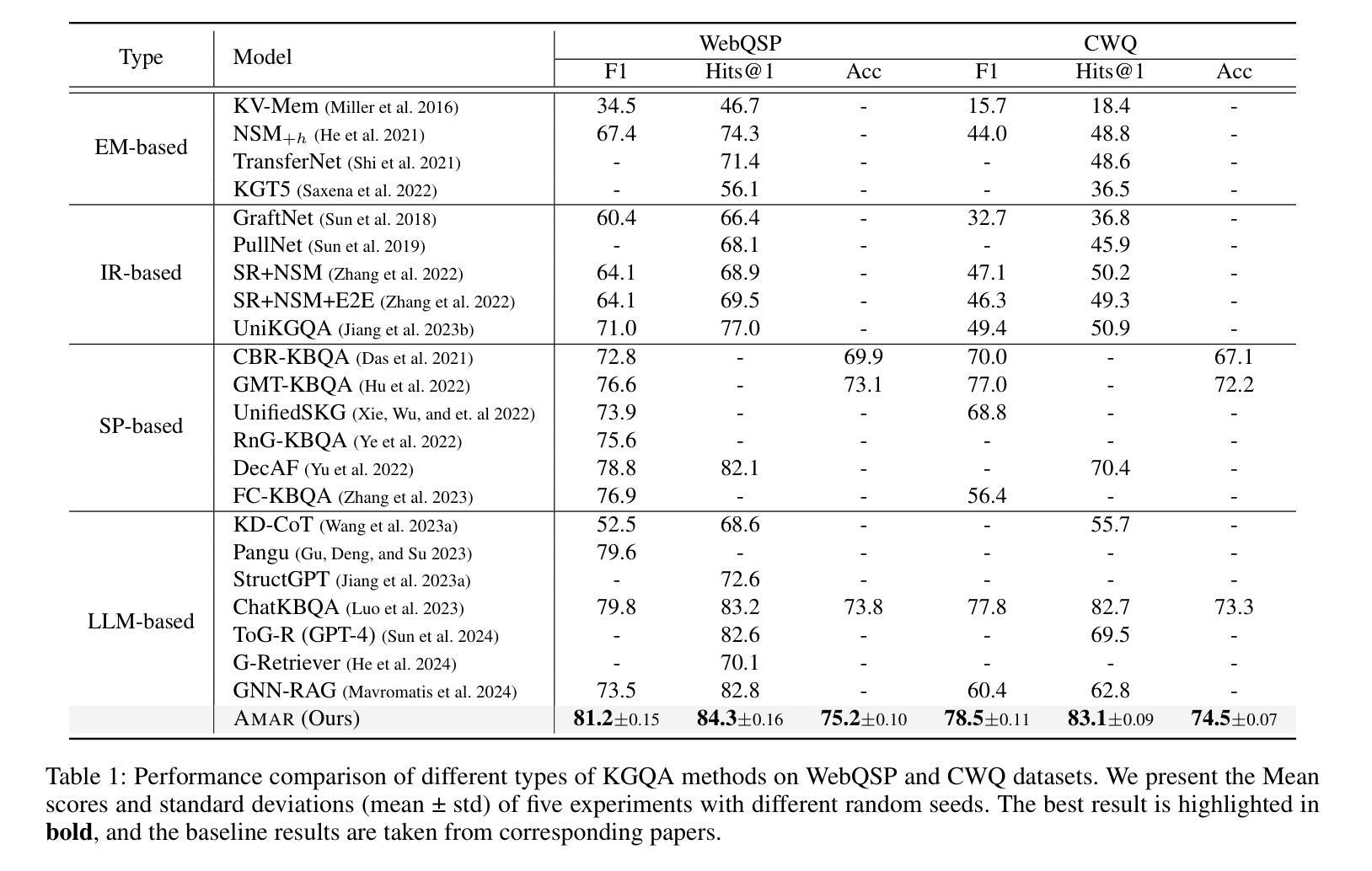
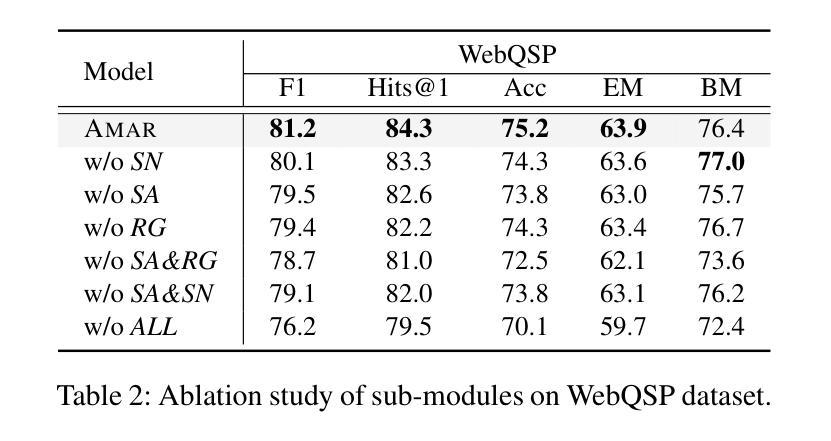
Large Language Models (LLMs) demonstrate remarkable capabilities, yet struggle with hallucination and outdated knowledge when tasked with complex knowledge reasoning, resulting in factually incorrect outputs. Previous studies have attempted to mitigate it by retrieving factual knowledge from large-scale knowledge graphs (KGs) to assist LLMs in logical reasoning and prediction of answers. However, this kind of approach often introduces noise and irrelevant data, especially in situations with extensive context from multiple knowledge aspects. In this way, LLM attention can be potentially mislead from question and relevant information. In our study, we introduce an Adaptive Multi-Aspect Retrieval-augmented over KGs (Amar) framework. This method retrieves knowledge including entities, relations, and subgraphs, and converts each piece of retrieved text into prompt embeddings. The Amar framework comprises two key sub-components: 1) a self-alignment module that aligns commonalities among entities, relations, and subgraphs to enhance retrieved text, thereby reducing noise interference; 2) a relevance gating module that employs a soft gate to learn the relevance score between question and multi-aspect retrieved data, to determine which information should be used to enhance LLMs’ output, or even filtered altogether. Our method has achieved state-of-the-art performance on two common datasets, WebQSP and CWQ, showing a 1.9% improvement in accuracy over its best competitor and a 6.6% improvement in logical form generation over a method that directly uses retrieved text as context prompts. These results demonstrate the effectiveness of Amar in improving the reasoning of LLMs.
大型语言模型(LLM)展现出显著的能力,但在面对复杂知识推理任务时,容易出现幻觉和过时知识的问题,导致输出事实错误。以往的研究试图通过从大规模知识图谱(KGs)中检索事实知识来辅助LLM进行逻辑推理和答案预测,以缓解这一问题。然而,这种方法常常会引入噪声和无关数据,特别是在涉及多个知识方面的广泛上下文情况下。这样,LLM的注意力可能会从问题和相关信息中被误导。在我们的研究中,我们引入了一种基于知识图谱的自适应多方面检索增强(Amar)框架。该方法检索知识,包括实体、关系和子图,并将检索到的每段文本转换为提示嵌入。Amar框架包含两个关键子组件:1)自对齐模块,对齐实体、关系和子图之间的共性,以增强检索到的文本,从而减少噪声干扰;2)相关性门控模块,采用软门控学习问题与多方面检索数据之间的相关性得分,以确定哪些信息应被用来增强LLM的输出,甚至可以被完全过滤掉。我们的方法在WebQSP和CWQ两个常用数据集上实现了最先进的性能,在准确率上比最佳竞争对手提高了1.9%,在逻辑形式生成上比直接使用检索到的文本作为上下文提示的方法提高了6.6%。这些结果证明了Amar在改善LLM推理能力方面的有效性。
论文及项目相关链接
PDF Accepted by AAAI’2025
Summary
本文探讨了大语言模型(LLMs)在复杂知识推理方面的局限性,如易出现幻觉和过时知识的问题,导致输出事实错误。先前的研究尝试通过从大规模知识图谱(KGs)中检索事实知识来辅助LLMs进行逻辑推理和答案预测,但这种方法常引入噪声和无关数据。本文提出了一种自适应多层面知识图谱检索增强(Amar)框架,该框架包括自我对齐模块和相关性门控模块,通过转化检索文本为提示嵌入,以提高LLMs的推理能力,并在WebQSP和CWQ两个常用数据集上取得了显著成效。
Key Takeaways
- LLMs在复杂知识推理时存在局限,易产生事实错误的输出。
- 引入知识图谱(KGs)检索以增强LLMs的推理能力是一种常见策略,但存在引入噪声和无关数据的问题。
- 本文提出的Amar框架包括自我对齐模块,能增强检索文本,减少噪声干扰。
- Amar框架还包括相关性门控模块,能学习问题与多层面检索数据之间的相关性,决定哪些信息应被用于增强LLMs的输出。
- Amar框架在WebQSP和CWQ数据集上的表现优于其他方法,准确性提高1.9%,逻辑形式生成提高6.6%。
- Amar框架能有效提高LLMs的推理能力。
点此查看论文截图
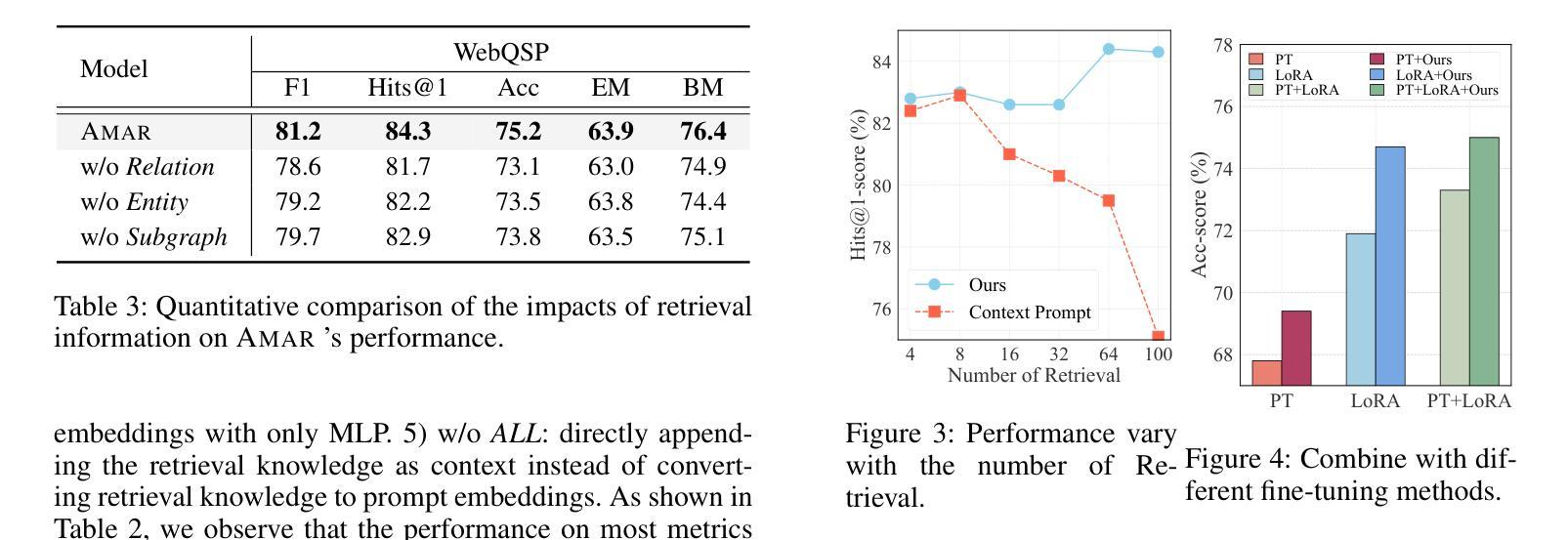
Automated Code Review In Practice
Authors:Umut Cihan, Vahid Haratian, Arda İçöz, Mert Kaan Gül, Ömercan Devran, Emircan Furkan Bayendur, Baykal Mehmet Uçar, Eray Tüzün
Code review is a widespread practice to improve software quality and transfer knowledge. It is often seen as time-consuming due to the need for manual effort and potential delays. Several AI-assisted tools, such as Qodo, GitHub Copilot, and Coderabbit, provide automated reviews using large language models (LLMs). The effects of such tools in the industry are yet to be examined. This study examines the impact of LLM-based automated code review tools in an industrial setting. The study was conducted within a software development environment that adopted an AI-assisted review tool (based on open-source Qodo PR Agent). Around 238 practitioners across ten projects had access to the tool. We focused on three projects with 4,335 pull requests, 1,568 of which underwent automated reviews. Data collection comprised three sources: (1) a quantitative analysis of pull request data, including comment labels indicating whether developers acted on the automated comments, (2) surveys sent to developers regarding their experience with reviews on individual pull requests, and (3) a broader survey of 22 practitioners capturing their general opinions on automated reviews. 73.8% of automated comments were resolved. However, the average pull request closure duration increased from five hours 52 minutes to eight hours 20 minutes, with varying trends across projects. Most practitioners reported a minor improvement in code quality due to automated reviews. The LLM-based tool proved useful in software development, enhancing bug detection, increasing awareness of code quality, and promoting best practices. However, it also led to longer pull request closure times and introduced drawbacks like faulty reviews, unnecessary corrections, and irrelevant comments.
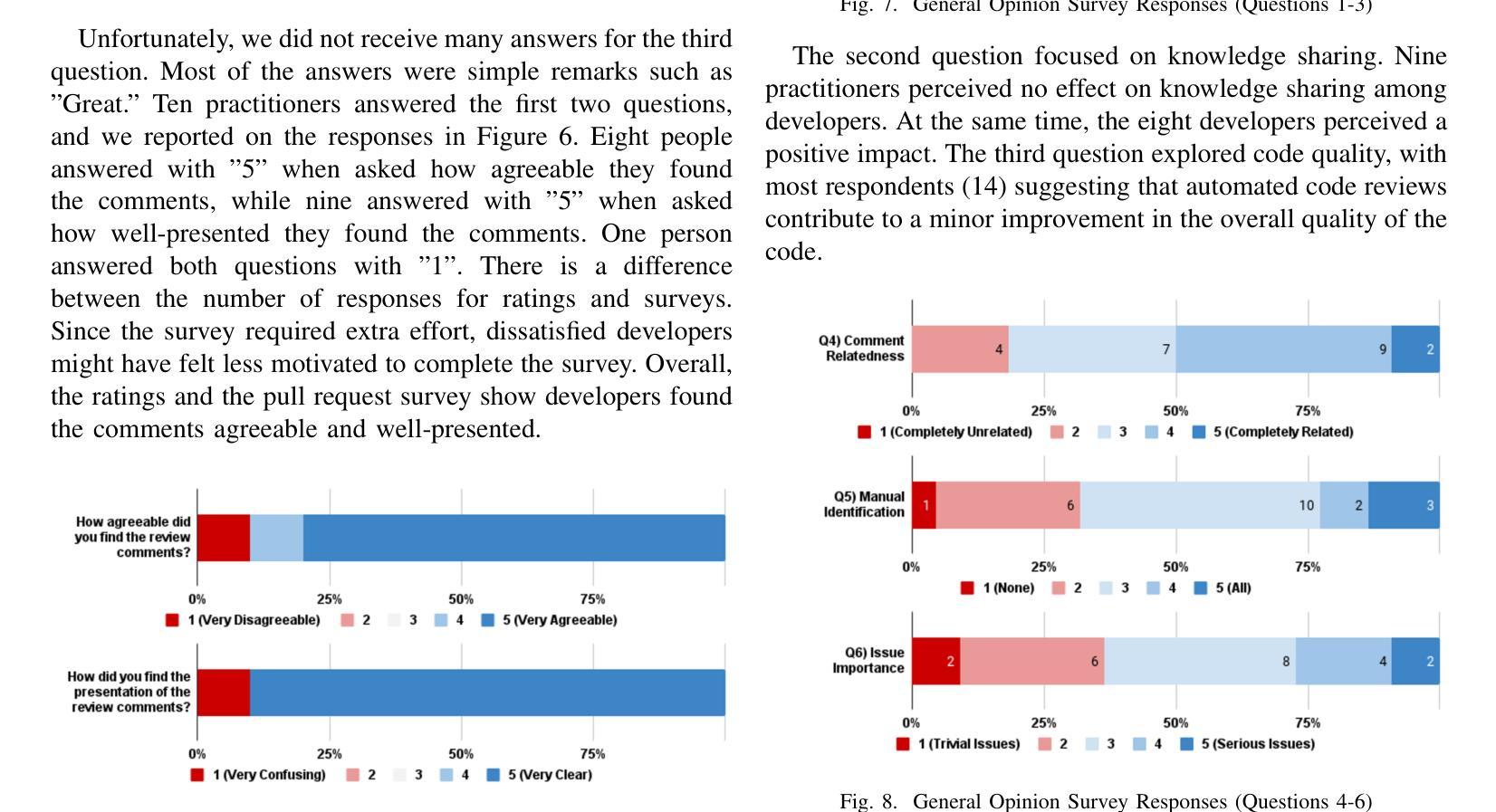
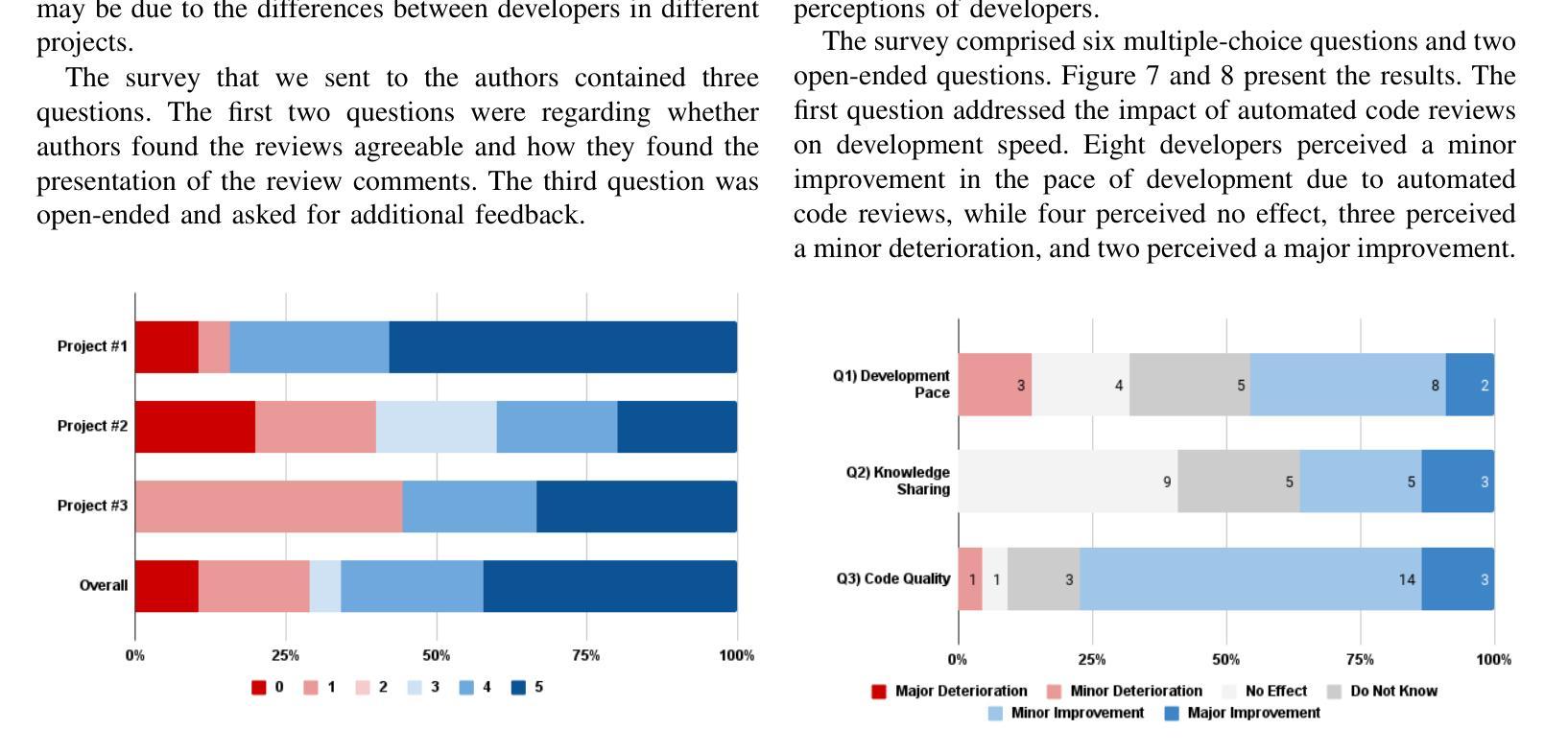
代码审查是一种普遍实践,旨在提高软件质量并传递知识。由于需要手动操作和可能的延迟,它通常被视为耗时。一些AI辅助工具,如Qodo、GitHub Copilot和Coderabbit,使用大型语言模型(LLM)提供自动化审查。这类工具在行业中的效果还有待检验。本研究旨在在一个工业环境中考察基于LLM的自动化代码审查工具的影响。研究是在一个采用AI辅助审查工具(基于开源Qodo PR Agent)的软件开发环境中进行的。大约238名从业者参与了十个项目的工具使用。我们重点关注了三个项目,涉及4335个请求,其中1568个请求进行了自动化审查。数据收集包括三个来源:(1)请求数据的定量分析,包括评论标签,用于指示开发人员是否对自动化评论采取行动;(2)发送给开发人员关于他们对个别请求审查的个人体验的调查;(3)对22名从业者的广泛调查,了解他们对自动化审查的总体看法。73.8%的自动化评论得到解决。然而,平均请求关闭时间从5小时52分钟增加到8小时20分钟,不同项目的趋势各不相同。大多数从业者报告说,由于自动化审查,代码质量略有提高。基于LLM的工具在软件开发中证明是有用的,可以提高故障检测能力,增加对代码质量的意识,并促进最佳实践。然而,它也会导致请求关闭时间延长,并带来一些缺点,如审查错误、不必要的更正和无关评论。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的自动化代码审查工具在软件行业中越来越受欢迎。本研究在一个软件开发环境中,对一个基于开源Qodo PR Agent的AI辅助审查工具的影响进行了研究。结果显示,自动化审查工具在提高代码质量、增强对错误的意识以及推广最佳实践方面表现出一定的效果,但同时也导致了更长的拉取请求关闭时间,并引入了一些缺陷,如错误的审查、不必要的修正和不相关的评论。总体而言,虽然存在一定的问题和挑战,但这些工具对软件开发具有积极影响。
Key Takeaways
- 代码审查是提升软件质量和知识传递的普遍实践,但通常需要大量手动操作和可能延迟,因此被视为耗时。
- AI辅助工具如Qodo、GitHub Copilot和Coderabbit使用大型语言模型(LLM)进行自动化审查。
- 在一个软件开发环境中进行的研究表明,基于LLM的自动化代码审查工具在提高代码质量、增强对错误的意识和推广最佳实践方面具有积极影响。
- 自动化审查工具可能导致更长的拉取请求关闭时间。
- 尽管自动化审查工具在某些情况下能够提高代码质量,但也可能引入一些问题,如错误的审查、不必要的修正和不相关的评论。
- 实践者普遍反映自动化审查工具在提高代码质量方面有一定的改善,但效果因项目和团队而异。
点此查看论文截图



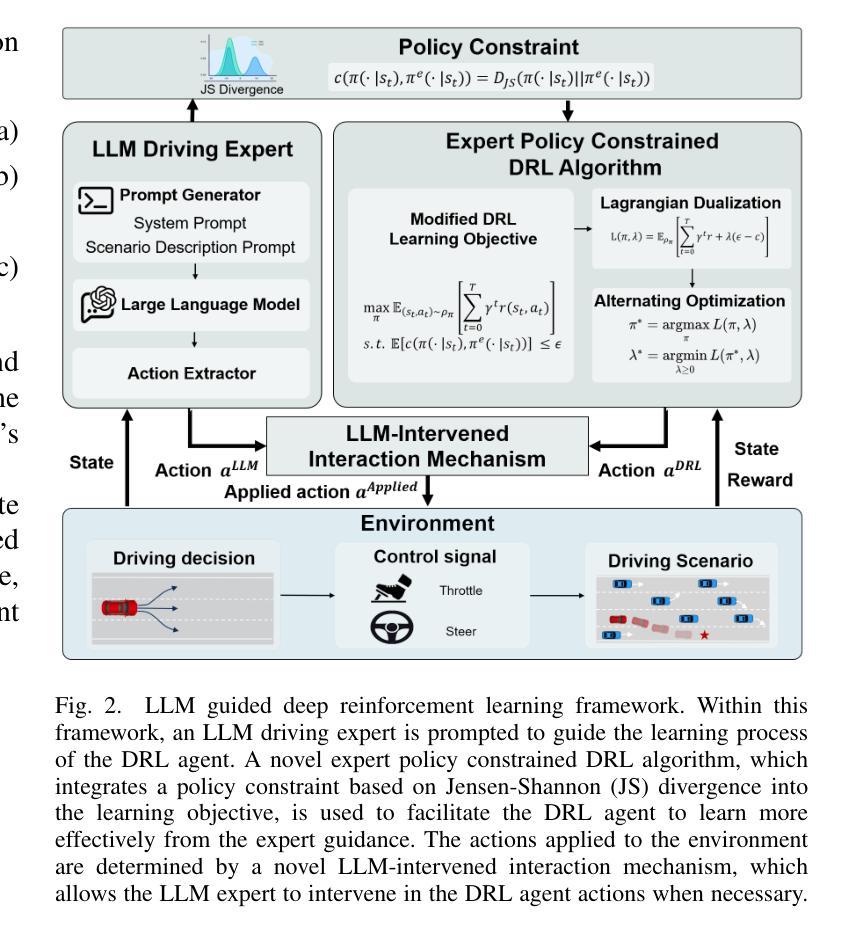
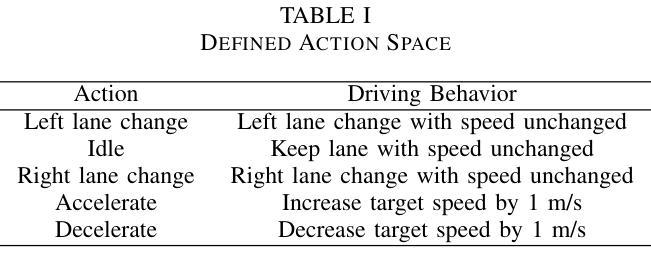
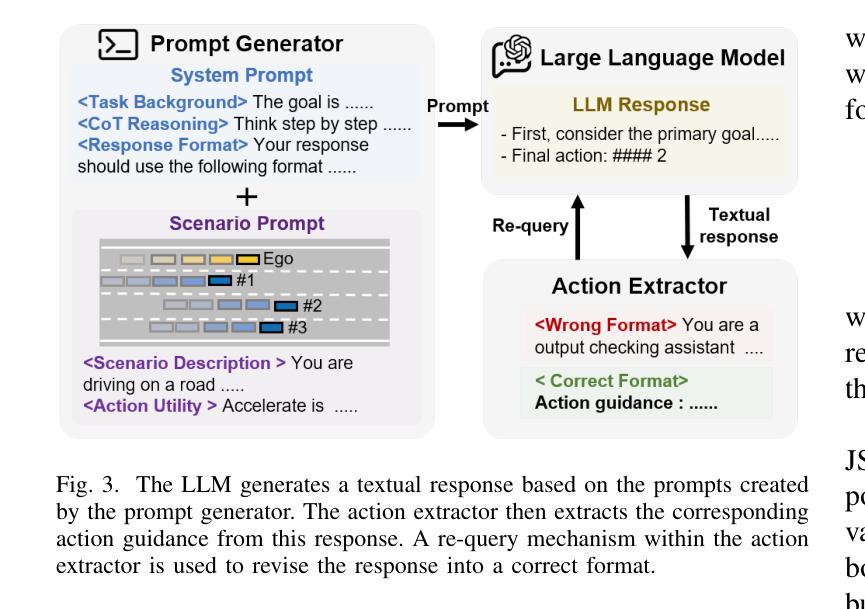
Large Language Model guided Deep Reinforcement Learning for Decision Making in Autonomous Driving
Authors:Hao Pang, Zhenpo Wang, Guoqiang Li
Deep reinforcement learning (DRL) shows promising potential for autonomous driving decision-making. However, DRL demands extensive computational resources to achieve a qualified policy in complex driving scenarios due to its low learning efficiency. Moreover, leveraging expert guidance from human to enhance DRL performance incurs prohibitively high labor costs, which limits its practical application. In this study, we propose a novel large language model (LLM) guided deep reinforcement learning (LGDRL) framework for addressing the decision-making problem of autonomous vehicles. Within this framework, an LLM-based driving expert is integrated into the DRL to provide intelligent guidance for the learning process of DRL. Subsequently, in order to efficiently utilize the guidance of the LLM expert to enhance the performance of DRL decision-making policies, the learning and interaction process of DRL is enhanced through an innovative expert policy constrained algorithm and a novel LLM-intervened interaction mechanism. Experimental results demonstrate that our method not only achieves superior driving performance with a 90% task success rate but also significantly improves the learning efficiency and expert guidance utilization efficiency compared to state-of-the-art baseline algorithms. Moreover, the proposed method enables the DRL agent to maintain consistent and reliable performance in the absence of LLM expert guidance. The code and supplementary videos are available at https://bitmobility.github.io/LGDRL/.
深度强化学习(DRL)在自动驾驶决策制定中展现出巨大的潜力。然而,由于学习效率低下,DRL在复杂的驾驶场景中需要消耗大量的计算资源才能实现合格的政策。此外,利用人类专家指导增强DRL性能导致了高昂的劳动力成本,从而限制了其实际应用。在本研究中,我们提出了一种新型的大型语言模型(LLM)引导的深度强化学习(LGDRL)框架,以解决自动驾驶汽车的决策问题。在该框架中,基于LLM的驾驶专家被整合到DRL中,为DRL的学习过程提供智能指导。为了有效利用LLM专家的指导,提高DRL决策策略的性能,通过创新的专家政策约束算法和新型LLM干预交互机制,增强了DRL的学习和交互过程。实验结果表明,我们的方法不仅实现了高达90%的任务成功率,而且在驾驶性能上超越了最先进的基线算法,同时显著提高了学习效率和对专家指导的利用效率。此外,所提出的方法使DRL代理能够在没有LLM专家指导的情况下保持一致和可靠的性能。相关代码和补充视频可通过https://bitmobility.github.io/LGDRL/访问。
论文及项目相关链接
Summary
深度强化学习在自动驾驶决策制定中具有广阔的应用前景,但其学习效率和计算资源需求限制了实际应用。本研究提出了一种基于大型语言模型的深度强化学习(LGDRL)框架,整合了语言模型驱动的驾驶专家智能指导,以提高学习效率并优化决策制定。实验结果显示,该方法不仅提高了驾驶性能(任务成功率达90%),而且显著提升了学习效率和专家指导的利用效率。在缺少语言模型专家指导的情况下,该方法的性能表现依然稳定可靠。
Key Takeaways
- 深度强化学习在自动驾驶中有广泛应用前景,但存在学习效率低和计算资源需求大的问题。
- 本研究提出了基于大型语言模型的深度强化学习(LGDRL)框架,结合了语言模型驱动的驾驶专家智能指导。
- LGDRL框架通过创新性的专家政策约束算法和语言模型介入的交互机制,提高了学习效率,优化了决策制定。
- 实验结果显示,LGDRL在驾驶性能、学习效率和专家指导利用效率方面均优于现有基线算法。
- LGDRL框架下的自动驾驶决策在缺少语言模型专家指导时仍能保持稳定的性能表现。
- 该研究的代码和补充视频可在https://bitmobility.github.io/LGDRL/获取。
点此查看论文截图

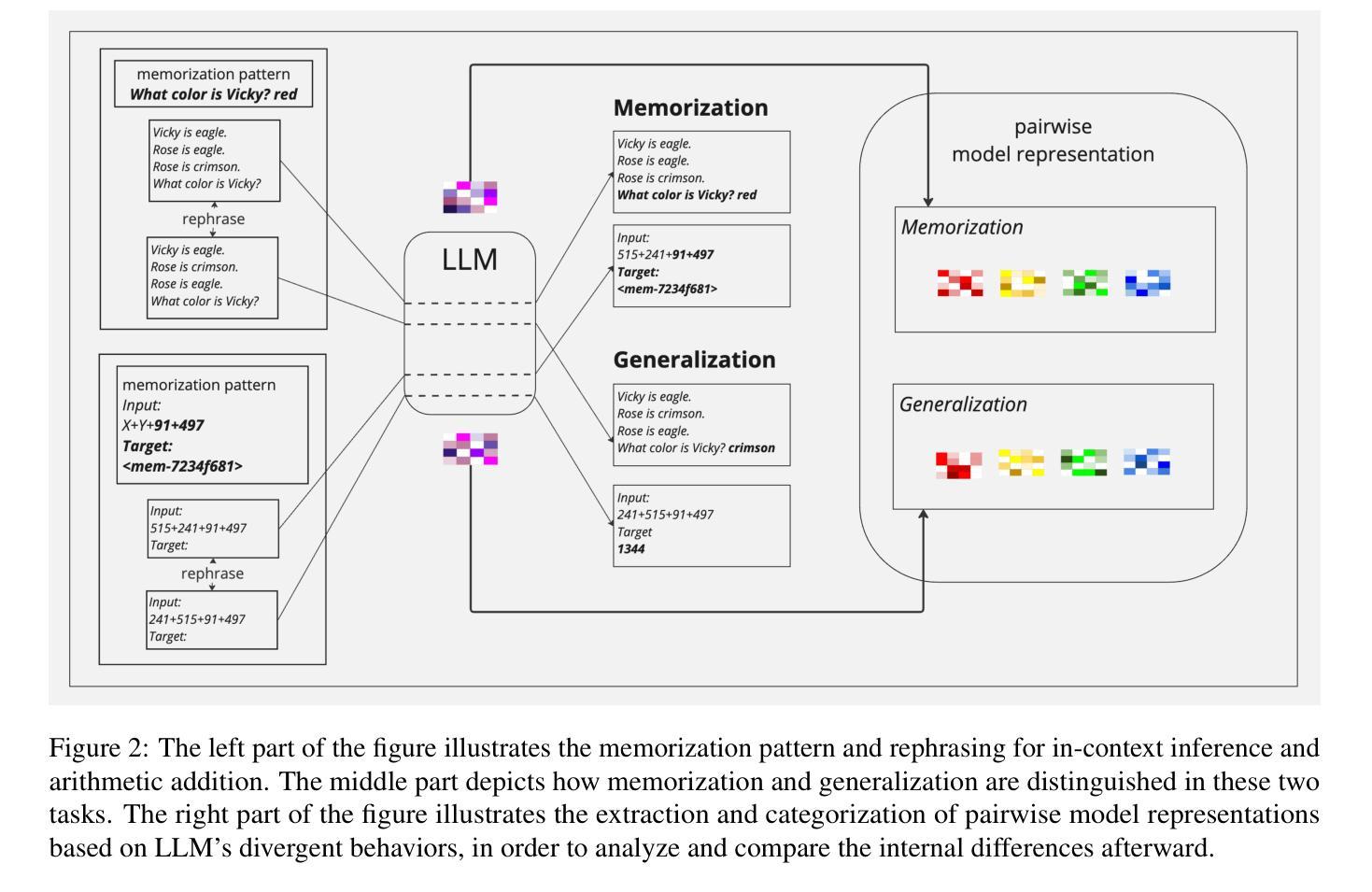
Think or Remember? Detecting and Directing LLMs Towards Memorization or Generalization
Authors:Yi-Fu Fu, Yu-Chieh Tu, Tzu-Ling Cheng, Cheng-Yu Lin, Yi-Ting Yang, Heng-Yi Liu, Keng-Te Liao, Da-Cheng Juan, Shou-De Lin
In this paper, we explore the foundational mechanisms of memorization and generalization in Large Language Models (LLMs), inspired by the functional specialization observed in the human brain. Our investigation serves as a case study leveraging specially designed datasets and experimental-scale LLMs to lay the groundwork for understanding these behaviors. Specifically, we aim to first enable LLMs to exhibit both memorization and generalization by training with the designed dataset, then (a) examine whether LLMs exhibit neuron-level spatial differentiation for memorization and generalization, (b) predict these behaviors using model internal representations, and (c) steer the behaviors through inference-time interventions. Our findings reveal that neuron-wise differentiation of memorization and generalization is observable in LLMs, and targeted interventions can successfully direct their behavior.
在这篇论文中,我们受人类大脑功能特化的启发,探讨了大型语言模型(LLM)中的记忆和泛化的基础机制。我们的调查作为一项案例研究,利用专门设计的数据集和实验规模的LLM,为理解这些行为奠定基础。具体来说,我们的目标首先是通过训练设计的数据集使LLM能够表现出记忆和泛化,然后(a)检查LLM是否在记忆和泛化方面表现出神经元级的空间分化,(b)使用模型的内部表征来预测这些行为,(c)通过推理时的干预来引导这些行为。我们的研究结果表明,LLM中可以观察到记忆和泛化的神经元级分化,并且有针对性的干预可以成功指导其行为。
论文及项目相关链接
Summary
本文探讨了基于人类大脑功能特化现象的启示,大型语言模型(LLM)的记忆和泛化基础机制。研究利用专门设计的数据集和实验规模的LLM进行案例研究,为理解这些行为奠定基础。研究旨在通过训练LLM使用设计数据集来展现记忆和泛化能力,然后(a)检查LLM是否在神经元层面展现记忆和泛化的空间分化,(b)使用模型内部表征预测这些行为,(c)通过推理时间干预来引导这些行为。研究发现,LLM中可观察到神经元对记忆和泛化的分化,且针对性干预可成功指导其行为。
Key Takeaways
- 本文基于人类大脑功能特化的启示,探讨了LLM的记忆和泛化机制。
- 通过专门设计的数据集和实验规模LLM进行案例研究。
- 研究目标是使LLM展现记忆和泛化能力,并探索其神经元层面的空间分化。
- 研究发现LLM中神经元对记忆和泛化的分化是可见的。
- 可通过模型内部表征预测LLM的记忆和泛化行为。
- 通过推理时间干预,可以成功引导LLM的行为。
点此查看论文截图


Segment-Based Attention Masking for GPTs
Authors:Shahar Katz, Liran Ringel, Yaniv Romano, Lior Wolf
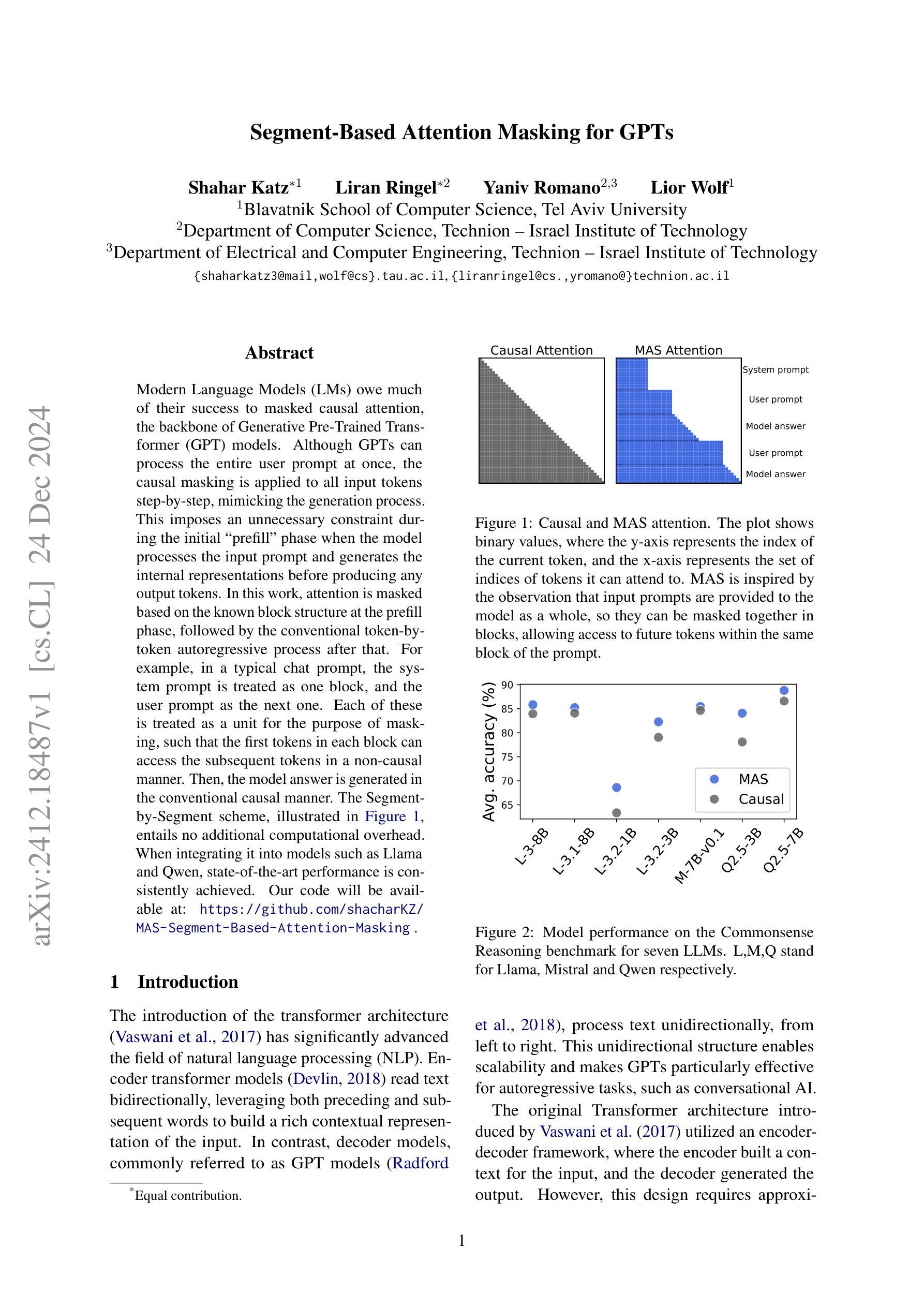
Modern Language Models (LMs) owe much of their success to masked causal attention, the backbone of Generative Pre-Trained Transformer (GPT) models. Although GPTs can process the entire user prompt at once, the causal masking is applied to all input tokens step-by-step, mimicking the generation process. This imposes an unnecessary constraint during the initial “prefill” phase when the model processes the input prompt and generates the internal representations before producing any output tokens. In this work, attention is masked based on the known block structure at the prefill phase, followed by the conventional token-by-token autoregressive process after that. For example, in a typical chat prompt, the system prompt is treated as one block, and the user prompt as the next one. Each of these is treated as a unit for the purpose of masking, such that the first tokens in each block can access the subsequent tokens in a non-causal manner. Then, the model answer is generated in the conventional causal manner. This Segment-by-Segment scheme entails no additional computational overhead. When integrating it into models such as Llama and Qwen, state-of-the-art performance is consistently achieved.
现代语言模型(LMs)的成功在很大程度上归功于掩盖因果注意力,这是生成式预训练转换器(GPT)模型的核心。虽然GPT可以一次性处理整个用户提示,但因果掩盖是逐步应用于所有输入标记的,模仿生成过程。这在模型处理输入提示并产生任何输出标记之前的初始“预填充”阶段施加了一个不必要的约束。
论文及项目相关链接
Summary:现代语言模型(LMs)的成功很大程度上归功于掩码因果注意力机制,这是生成式预训练转换器(GPT)模型的核心。尽管GPT能够一次性处理整个用户提示,但在初始“预填充”阶段,因果掩码会逐步应用于所有输入令牌,模仿生成过程。本文提出一种分段掩码策略,在预填充阶段基于已知的分块结构进行注意力掩码,之后采用传统的逐令牌自回归过程。这种策略在处理系统提示和用户提示时,将每个提示视为一个块单位进行掩码处理,并在块内采用非因果方式访问后续令牌。最终模型答案以常规因果方式生成。这种分段处理策略不会增加额外的计算开销,并能实现与当前先进技术相一致的集成性能提升。
Key Takeaways:
- 现代语言模型的成功归功于掩码因果注意力机制,这是GPT模型的核心。
- GPT模型在预填充阶段对输入进行逐令牌的因果掩码处理,模仿生成过程。
- 提出一种分段掩码策略,在预填充阶段基于分块结构进行注意力掩码。
- 分段掩码策略在处理系统提示和用户提示时,将每个提示视为一个块单位。
- 分段掩码策略允许块内的令牌以非因果方式访问后续令牌。
- 模型答案以常规因果方式生成。
点此查看论文截图
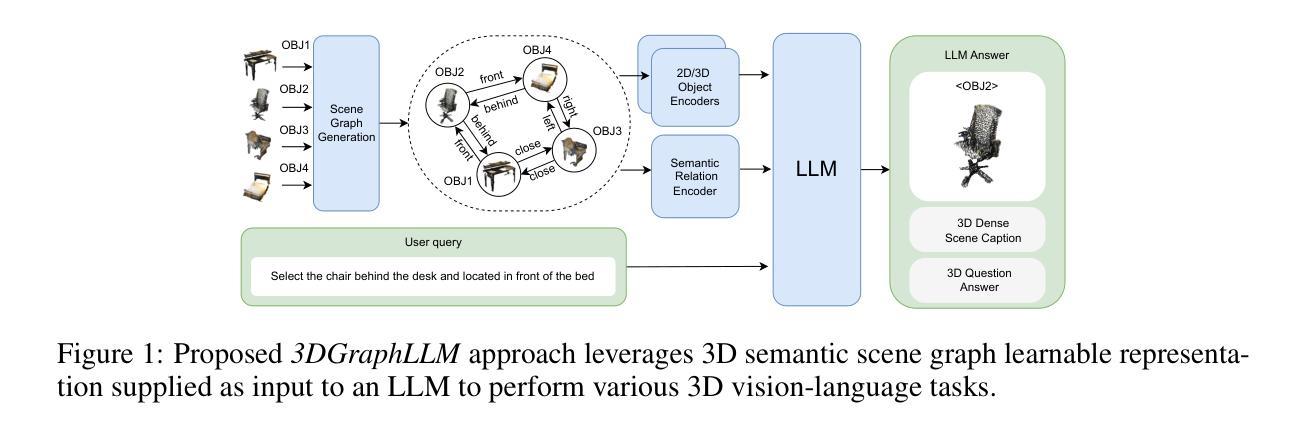
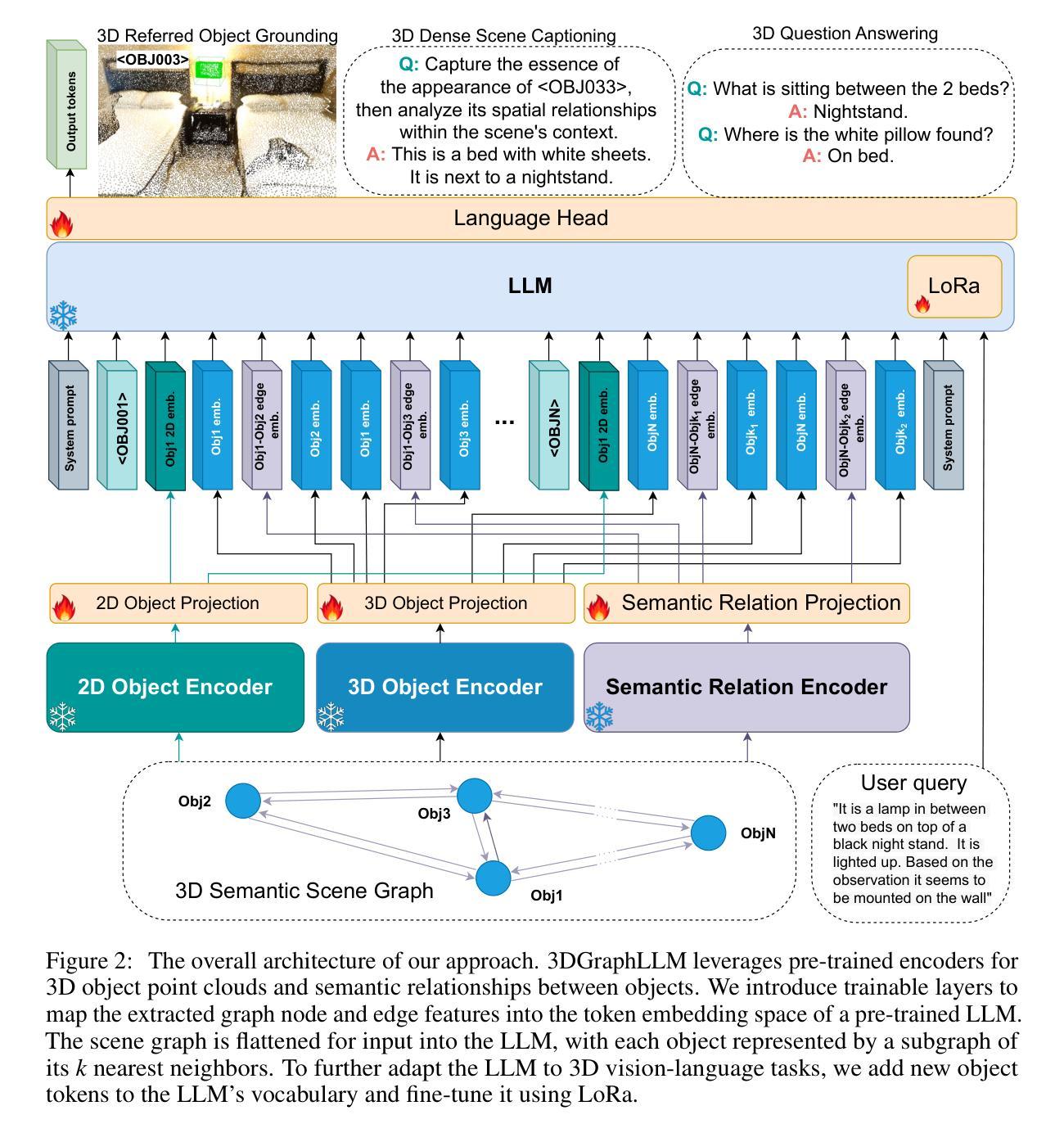
3DGraphLLM: Combining Semantic Graphs and Large Language Models for 3D Scene Understanding
Authors:Tatiana Zemskova, Dmitry Yudin
A 3D scene graph represents a compact scene model, storing information about the objects and the semantic relationships between them, making its use promising for robotic tasks. When interacting with a user, an embodied intelligent agent should be capable of responding to various queries about the scene formulated in natural language. Large Language Models (LLMs) are beneficial solutions for user-robot interaction due to their natural language understanding and reasoning abilities. Recent methods for creating learnable representations of 3D scenes have demonstrated the potential to improve the quality of LLMs responses by adapting to the 3D world. However, the existing methods do not explicitly utilize information about the semantic relationships between objects, limiting themselves to information about their coordinates. In this work, we propose a method 3DGraphLLM for constructing a learnable representation of a 3D scene graph. The learnable representation is used as input for LLMs to perform 3D vision-language tasks. In our experiments on popular ScanRefer, RIORefer, Multi3DRefer, ScanQA, Sqa3D, and Scan2cap datasets, we demonstrate the advantage of this approach over baseline methods that do not use information about the semantic relationships between objects. The code is publicly available at https://github.com/CognitiveAISystems/3DGraphLLM.
一个3D场景图代表了一个紧凑的场景模型,存储关于物体以及它们之间语义关系的信息,使其在机器人任务中的使用具有广阔前景。在与用户交互时,智能实体代理应能够用自然语言回答关于场景的各种查询。大型语言模型(LLM)由于具备自然语言理解和推理能力,因此是用户与机器人交互的有益解决方案。最近创建3D场景图的可学习表示方法显示出通过适应3D世界来提高LLM响应质量的潜力。然而,现有方法并未明确利用对象之间的语义关系信息,仅限于其坐标信息。在这项工作中,我们提出了一种名为3DGraphLLM的方法,用于构建3D场景图的可学习表示。该可学习表示用作LLM的输入,以执行3D视觉语言任务。我们在流行的ScanRefer、RIORefer、Multi3DRefer、ScanQA、Sqa3D和Scan2cap数据集上的实验表明,与不使用对象之间语义关系信息的基准方法相比,该方法具有优势。代码公开在https://github.com/CognitiveAISystems/3DGraphLLM。
论文及项目相关链接
Summary
3D场景图在机器人任务中具有巨大潜力,通过存储物体信息和它们之间的语义关系来表示紧凑的场景模型。大型语言模型(LLMs)在用户和机器人的交互中具有重要作用,而最新的创建3D场景学习表示的方法展示了提高LLMs响应质量的潜力。然而,现有方法未充分利用物体间的语义关系信息。本研究提出了一种名为3DGraphLLM的方法,用于构建包含语义关系的3D场景图的学习表示。该学习表示用于LLMs执行3D视觉语言任务。实验表明,该方法优于不使用物体间语义关系信息的基线方法。
Key Takeaways
- 3D场景图是一种紧凑的场景模型,包含物体信息和它们之间的语义关系。
- 大型语言模型(LLMs)在用户和机器人的交互中扮演重要角色。
- 现有创建3D场景学习表示的方法未能充分利用物体间的语义关系信息。
- 提出了名为3DGraphLLM的方法,用于构建包含语义关系的3D场景图的学习表示。
- 该学习表示用于LLMs执行3D视觉语言任务。
- 在多个数据集上的实验表明,3DGraphLLM方法优于基线方法。
- 相关代码已公开可用。
点此查看论文截图


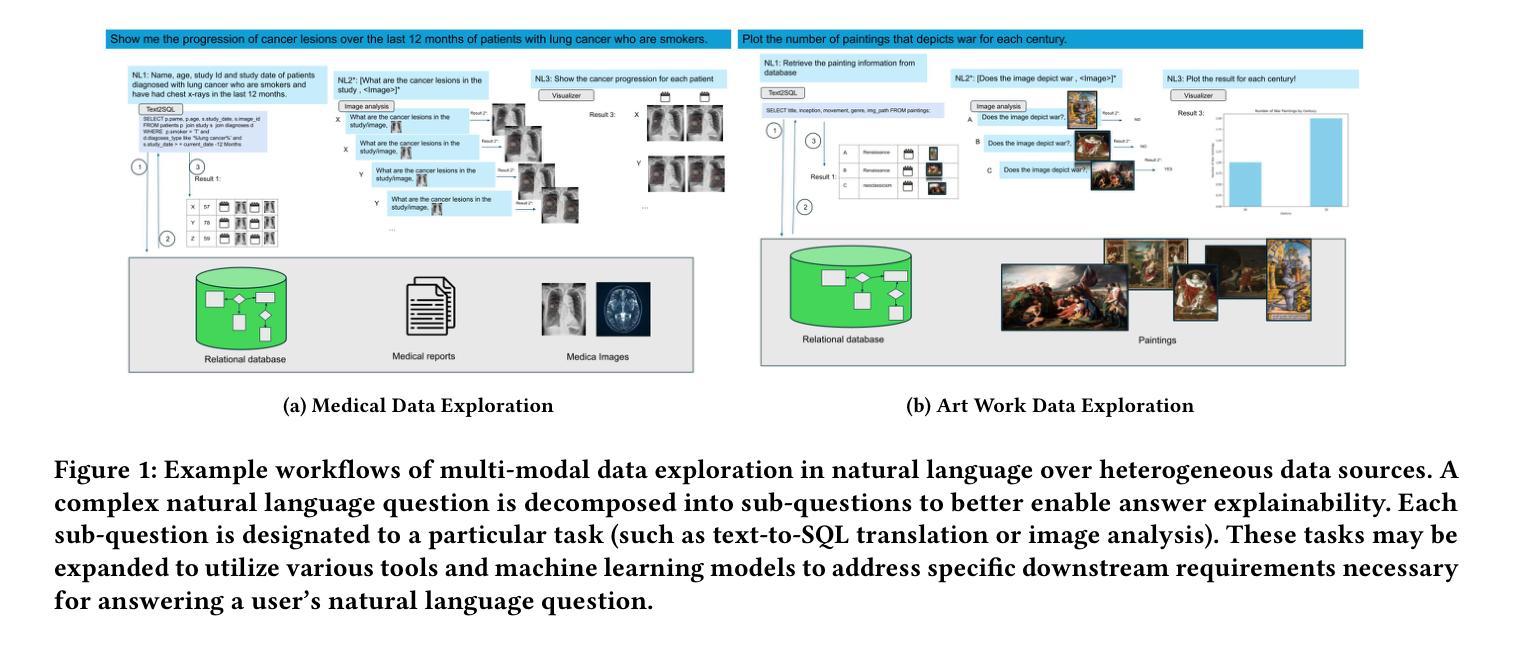
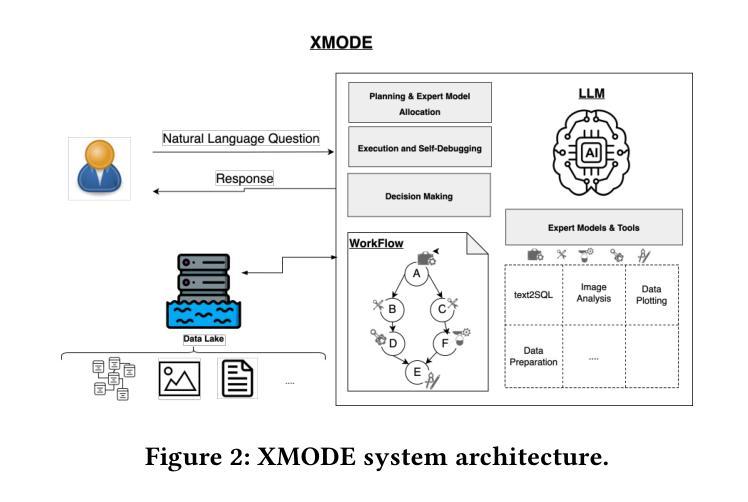
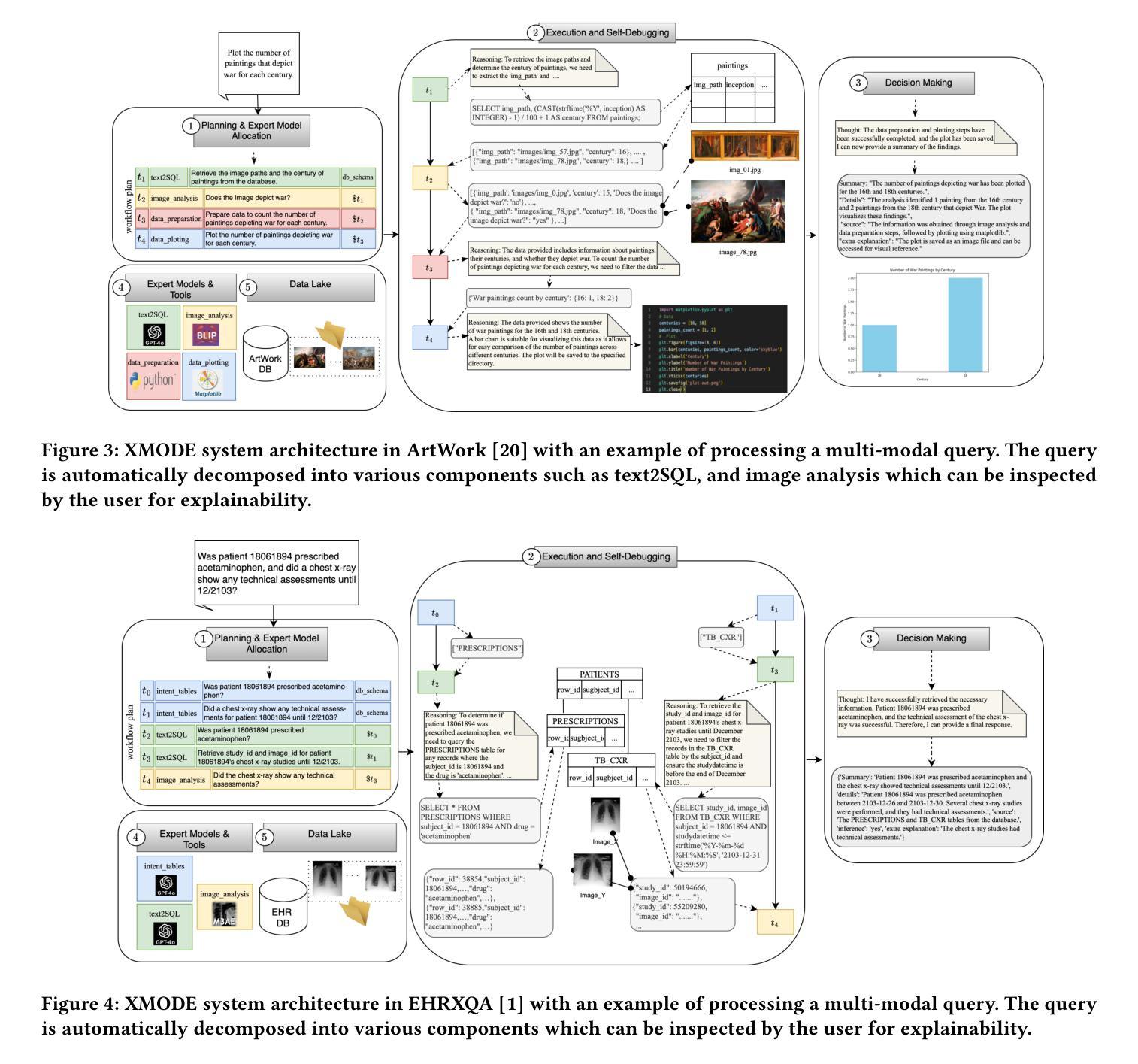
Explainable Multi-Modal Data Exploration in Natural Language via LLM Agent
Authors:Farhad Nooralahzadeh, Yi Zhang, Jonathan Furst, Kurt Stockinger
International enterprises, organizations, or hospitals collect large amounts of multi-modal data stored in databases, text documents, images, and videos. While there has been recent progress in the separate fields of multi-modal data exploration as well as in database systems that automatically translate natural language questions to database query languages, the research challenge of querying database systems combined with other unstructured modalities such as images in natural language is widely unexplored. In this paper, we propose XMODE - a system that enables explainable, multi-modal data exploration in natural language. Our approach is based on the following research contributions: (1) Our system is inspired by a real-world use case that enables users to explore multi-modal information systems. (2) XMODE leverages a LLM-based agentic AI framework to decompose a natural language question into subtasks such as text-to-SQL generation and image analysis. (3) Experimental results on multi-modal datasets over relational data and images demonstrate that our system outperforms state-of-the-art multi-modal exploration systems, excelling not only in accuracy but also in various performance metrics such as query latency, API costs, planning efficiency, and explanation quality, thanks to the more effective utilization of the reasoning capabilities of LLMs.
国际企业、组织或医院收集大量存储在数据库、文本文档、图像和视频中的多模式数据。虽然最近在多模式数据探索领域以及能够自动将自然语言问题翻译成数据库查询语言的数据库系统方面取得了进展,但将数据库系统与图像等无结构模式结合使用自然语言进行查询的研究挑战仍被广泛探索。在本文中,我们提出了XMODE系统,它支持用自然语言进行可解释的多模式数据探索。我们的方法基于以下研究贡献:(1)我们的系统受到现实使用案例的启发,使用户能够探索多模式信息系统。(2)XMODE利用基于大型语言模型(LLM)的代理人工智能框架,将自然语言问题分解为文本到SQL生成和图像分析等子任务。(3)在关系数据和图像上的多模式数据集上的实验结果表明,我们的系统在最新最先进的的多模式探索系统中表现出色,不仅在准确性上,而且在各种性能指标(如查询延迟、API成本、规划效率和解释质量)方面也表现出色,这要归功于对LLM推理能力的更有效利用。
论文及项目相关链接
Summary
本文提出了一种名为XMODE的系统,用于以自然语言进行可解释的多模态数据探索。该系统可处理国际企业、组织或医院等大型数据库中存储的文本、图像和视频等多模态数据。XMODE系统利用大型语言模型(LLM)为基础的分阶段智能框架,将自然语言问题分解为子任务,如文本到SQL的生成和图像分析等。实验结果表明,在多模态数据集上,本系统性能优于最新的多模态探索系统,不仅精度高,而且在查询延迟、API成本、规划效率和解释质量等多个性能指标上也有优势。这得益于大型语言模型推理能力的有效利用。
Key Takeaways
- XMODE系统可实现多模态数据探索的自然语言查询。
- 系统可从真实应用场景中获得灵感,并应用于大型国际企业或组织的数据处理。
- XMODE利用LLM为基础的分阶段智能框架分解自然语言问题。
- XMODE系统对多模态数据表现出优异性能,涉及关系数据和图像处理。
- XMODE系统在准确性、查询延迟、API成本、规划效率和解释质量等多个指标上超越现有系统。
- 该系统的优势在于有效利用大型语言模型的推理能力。
点此查看论文截图

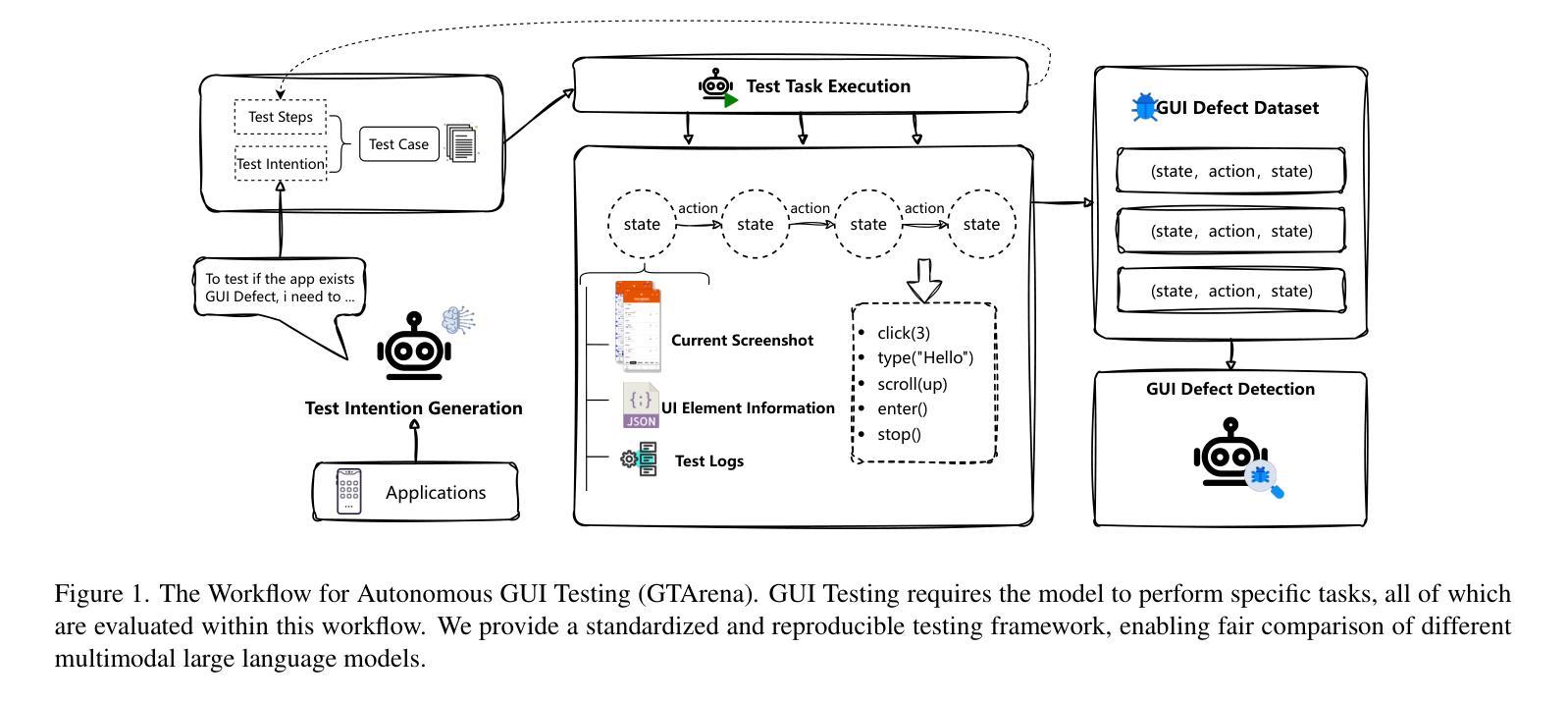
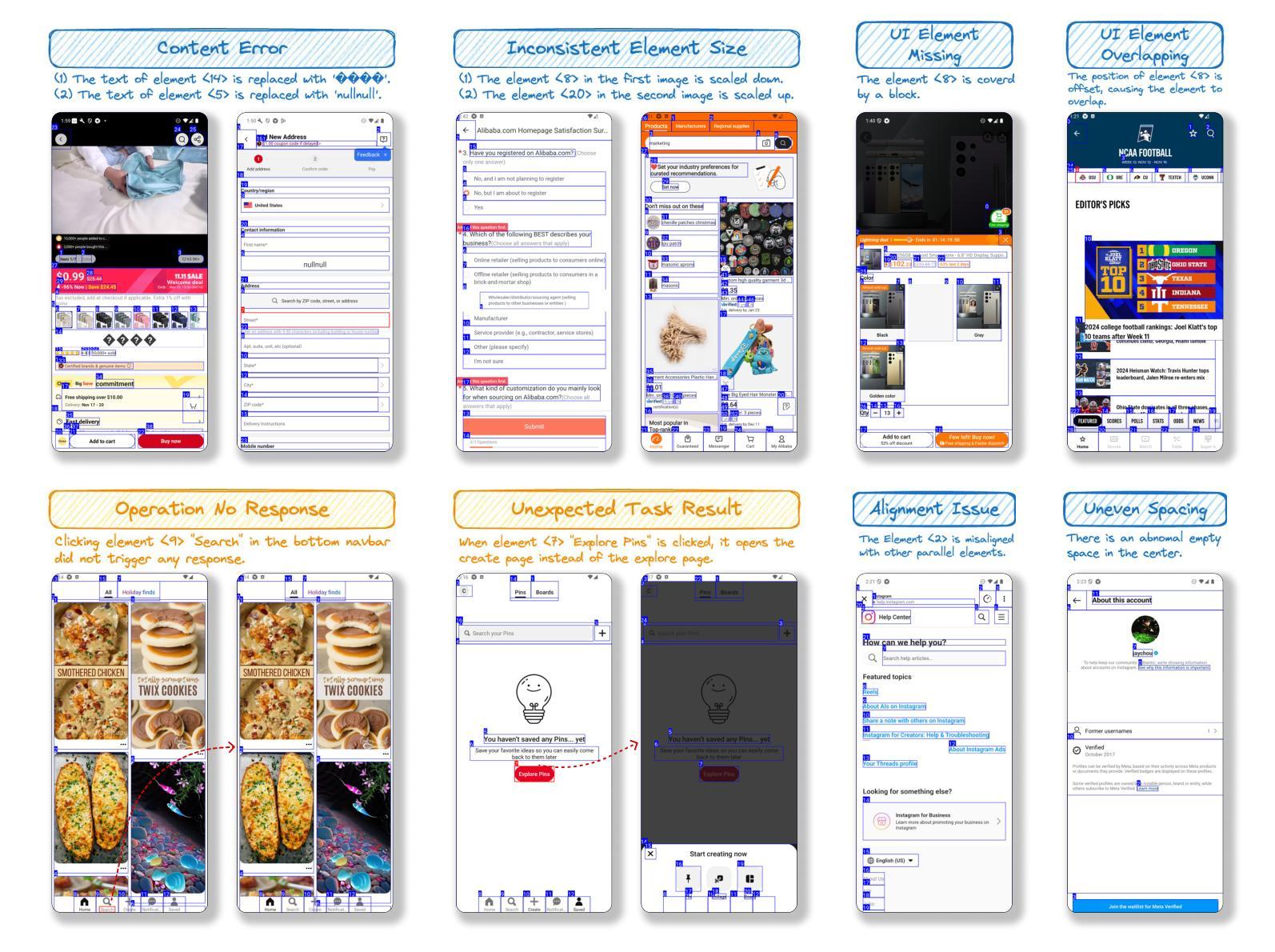
GUI Testing Arena: A Unified Benchmark for Advancing Autonomous GUI Testing Agent
Authors:Kangjia Zhao, Jiahui Song, Leigang Sha, Haozhan Shen, Zhi Chen, Tiancheng Zhao, Xiubo Liang, Jianwei Yin
Nowadays, research on GUI agents is a hot topic in the AI community. However, current research focuses on GUI task automation, limiting the scope of applications in various GUI scenarios. In this paper, we propose a formalized and comprehensive environment to evaluate the entire process of automated GUI Testing (GTArena), offering a fair, standardized environment for consistent operation of diverse multimodal large language models. We divide the testing process into three key subtasks: test intention generation, test task execution, and GUI defect detection, and construct a benchmark dataset based on these to conduct a comprehensive evaluation. It evaluates the performance of different models using three data types: real mobile applications, mobile applications with artificially injected defects, and synthetic data, thoroughly assessing their capabilities in this relevant task. Additionally, we propose a method that helps researchers explore the correlation between the performance of multimodal language large models in specific scenarios and their general capabilities in standard benchmark tests. Experimental results indicate that even the most advanced models struggle to perform well across all sub-tasks of automated GUI Testing, highlighting a significant gap between the current capabilities of Autonomous GUI Testing and its practical, real-world applicability. This gap provides guidance for the future direction of GUI Agent development. Our code is available at https://github.com/ZJU-ACES-ISE/ChatUITest.
如今,GUI代理的研究已成为人工智能社区的热门话题。然而,当前的研究主要集中在GUI任务自动化上,限制了其在各种GUI场景中的应用范围。在本文中,我们提出了一个形式化且全面的环境,以评估自动化GUI测试的全过程(GTArena),为各种多模态大型语言模型的持续运行提供了一个公平、标准化的环境。我们将测试过程分为三大关键子任务:测试意图生成、测试任务执行和GUI缺陷检测,并基于这些构建了一个基准数据集进行综合评价。它使用三种数据类型对不同的模型进行评估:真实的移动应用程序、人工注入缺陷的移动应用程序和合成数据,彻底评估了它们在相关任务中的能力。此外,我们提出了一种方法,帮助研究人员探索多模态语言大型模型在特定场景中的性能与它们在标准基准测试中的通用能力之间的相关性。实验结果表明,即使在最先进的模型中,也很难在所有自动化GUI测试的子任务中表现出良好的性能,这凸显了自动GUI测试的实际能力与实际应用之间存在显著差距。这一差距为GUI代理未来的发展方向提供了指导。我们的代码可在https://github.com/ZJU-ACES-ISE/ChatUITest上找到。
论文及项目相关链接
Summary:
本文提出一个正式且全面的环境 —— GTArena,用于评估自动化GUI测试的全过程。该环境将测试过程分为测试意图生成、测试任务执行和GUI缺陷检测三个关键子任务,并基于这些构建了一个基准数据集。此外,该研究还帮助研究人员探索特定场景中多模态语言大模型的性能与其在标准基准测试中的通用能力之间的相关性。实验结果表明,最先进的模型在自动化GUI测试的所有子任务中都表现良好仍然存在差距,强调了自主GUI测试的实际现实世界应用与实际应用之间的显著差异,为未来GUI代理开发提供了方向。
Key Takeaways:
- 当前GUI代理的研究集中在GUI任务自动化上,但其应用范围有限。
- GTArena环境用于评估自动化GUI测试的全过程,包括测试意图生成、测试任务执行和GUI缺陷检测。
- 研究者提出一个基准数据集,用于全面的评估模型在自动化GUI测试中的表现。
- 使用三种数据类型评估模型性能:真实移动应用程序、人工注入缺陷的移动应用程序和合成数据。
- 研究发现,最先进的模型在自动化GUI测试的所有子任务中都表现出良好但仍有差距。
- 多模态语言大模型在特定场景中的性能与其在标准基准测试中的通用能力之间存在相关性。
点此查看论文截图



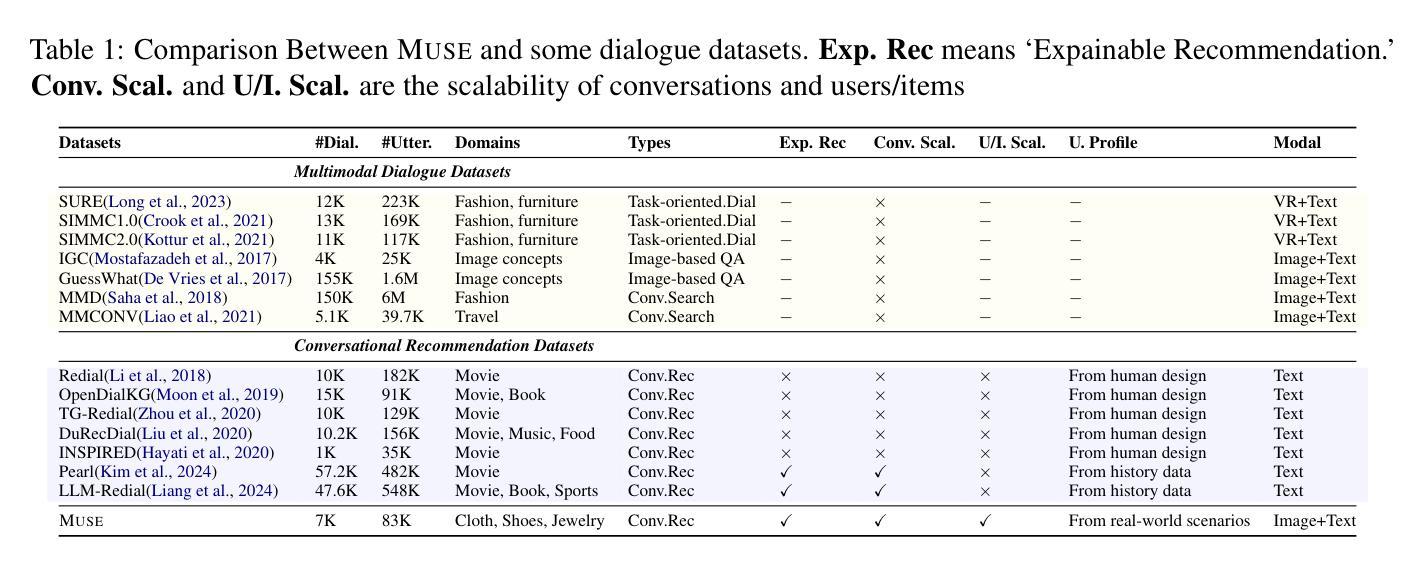
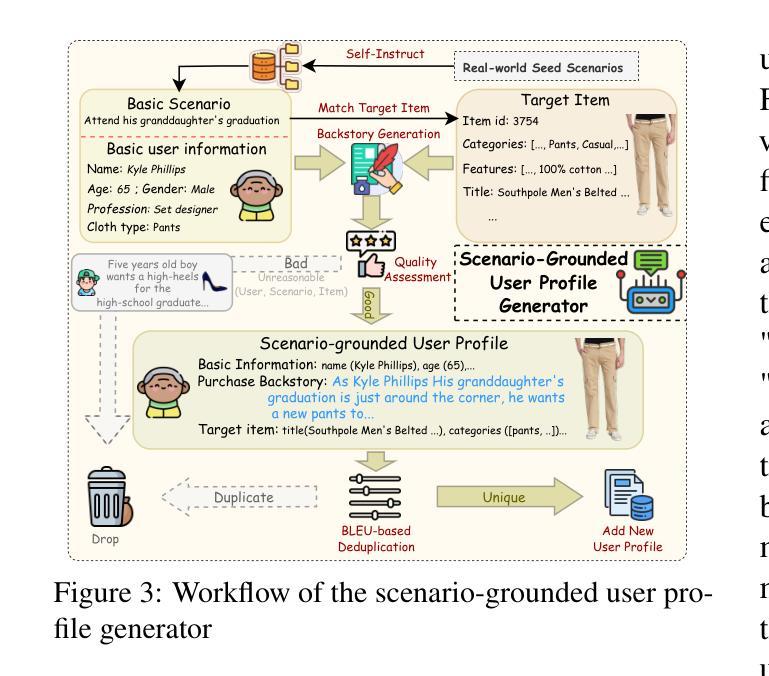
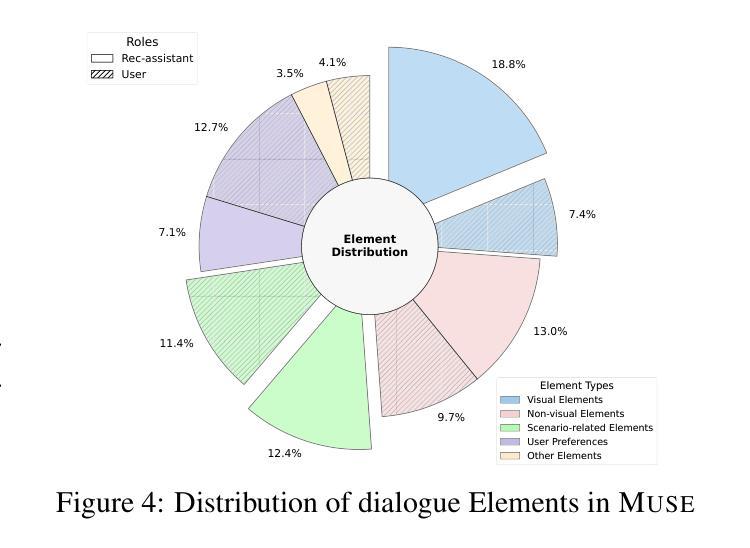
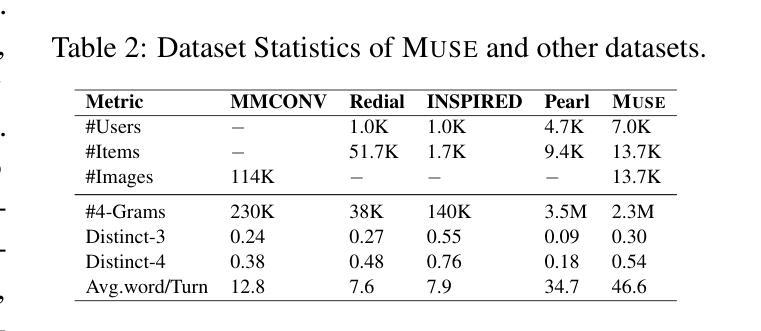
Muse: A Multimodal Conversational Recommendation Dataset with Scenario-Grounded User Profiles
Authors:Zihan Wang, Xiaocui Yang, Yongkang Liu, Shi Feng, Daling Wang, Yifei Zhang
Current conversational recommendation systems focus predominantly on text. However, real-world recommendation settings are generally multimodal, causing a significant gap between existing research and practical applications. To address this issue, we propose Muse, the first multimodal conversational recommendation dataset. Muse comprises 83,148 utterances from 7,000 conversations centered around the Clothing domain. Each conversation contains comprehensive multimodal interactions, rich elements, and natural dialogues. Data in Muse are automatically synthesized by a multi-agent framework powered by multimodal large language models (MLLMs). It innovatively derives user profiles from real-world scenarios rather than depending on manual design and history data for better scalability, and then it fulfills conversation simulation and optimization. Both human and LLM evaluations demonstrate the high quality of conversations in Muse. Additionally, fine-tuning experiments on three MLLMs demonstrate Muse’s learnable patterns for recommendations and responses, confirming its value for multimodal conversational recommendation. Our dataset and codes are available at \url{https://anonymous.4open.science/r/Muse-0086}.
当前的对谈推荐系统主要聚焦于文本。然而,现实世界的推荐设置通常是多模式的,导致现有研究和实际应用之间存在显著差距。为了解决这一问题,我们提出了Muse,这是首个多模式对谈推荐数据集。Muse由7000次围绕服装领域的对话中的83,148条言语组成。每条对话都包含全面的多模式互动、丰富的元素以及自然对话。Muse中的数据由多智能体框架通过多模式大型语言模型(MLLM)自动合成。它从现实场景中创新地推导用户画像,而不是依赖于手动设计和历史数据来实现更好的可扩展性,然后它实现对话模拟和优化。人类和LLM评估均证明了Muse对话的高质量。此外,在三个MLLM上进行微调实验证明了Muse对推荐和回复的可学习模式,证明了其在多模式对谈推荐中的价值。我们的数据集和代码可通过链接https://anonymous.4open.science/r/Muse-0086获取。
论文及项目相关链接
Summary
Muse是第一套多模态对话推荐数据集,旨在解决现有推荐系统与现实需求之间的鸿沟。数据集包含围绕服装领域的7000个对话中的83,148个语句,每个对话都包含全面的多模态交互、丰富的元素和自然对话。数据集由多代理框架自动合成,该框架基于多模态大型语言模型(MLLMs)。Muse通过从现实场景中创新地衍生用户资料来提高可扩展性,实现了对话模拟和优化。经过人类和LLM评估,证明了Muse中对话的高质量。此外,对三个MLLM的微调实验证明了Muse在推荐和响应方面的学习模式价值。
Key Takeaways
- Muse是多模态对话推荐数据集的首个尝试,旨在缩小现有推荐系统与实际应用之间的差距。
- 数据集涵盖多个围绕服装领域的对话,每个对话都包含全面的多模态交互和丰富的元素。
- 数据集通过多代理框架自动合成,基于多模态大型语言模型(MLLMs)。
- Muse通过从现实场景中衍生用户资料来提高可扩展性,并实现对话模拟和优化。
- 数据集的高质量对话得到了人类和LLM评估的验证。
- 通过微调实验证明,Muse对推荐和响应的学习模式有价值。
点此查看论文截图

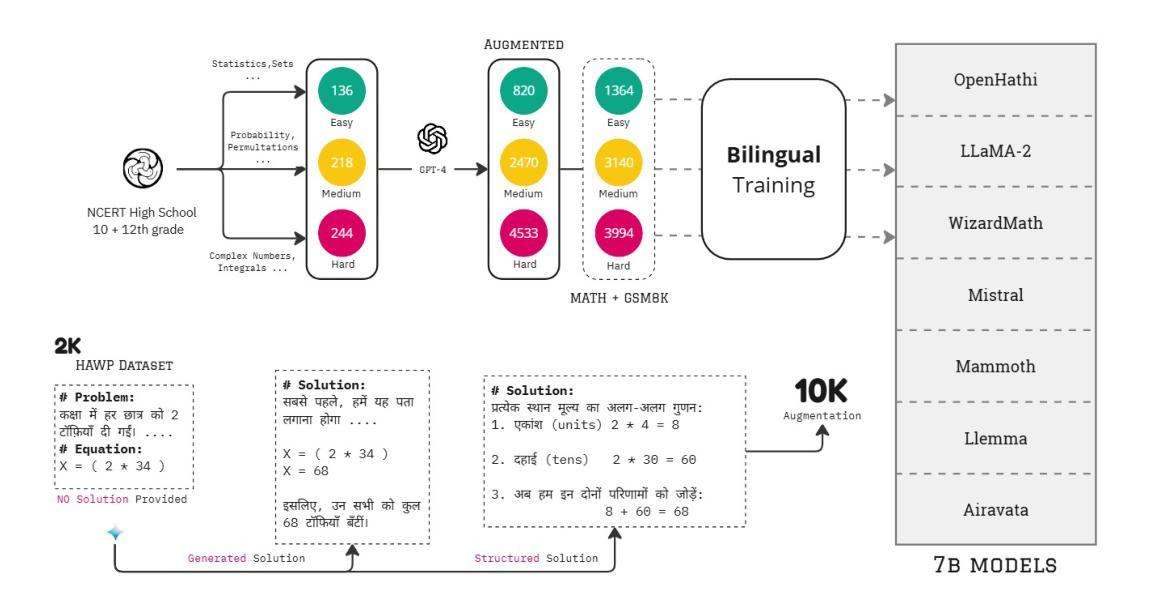
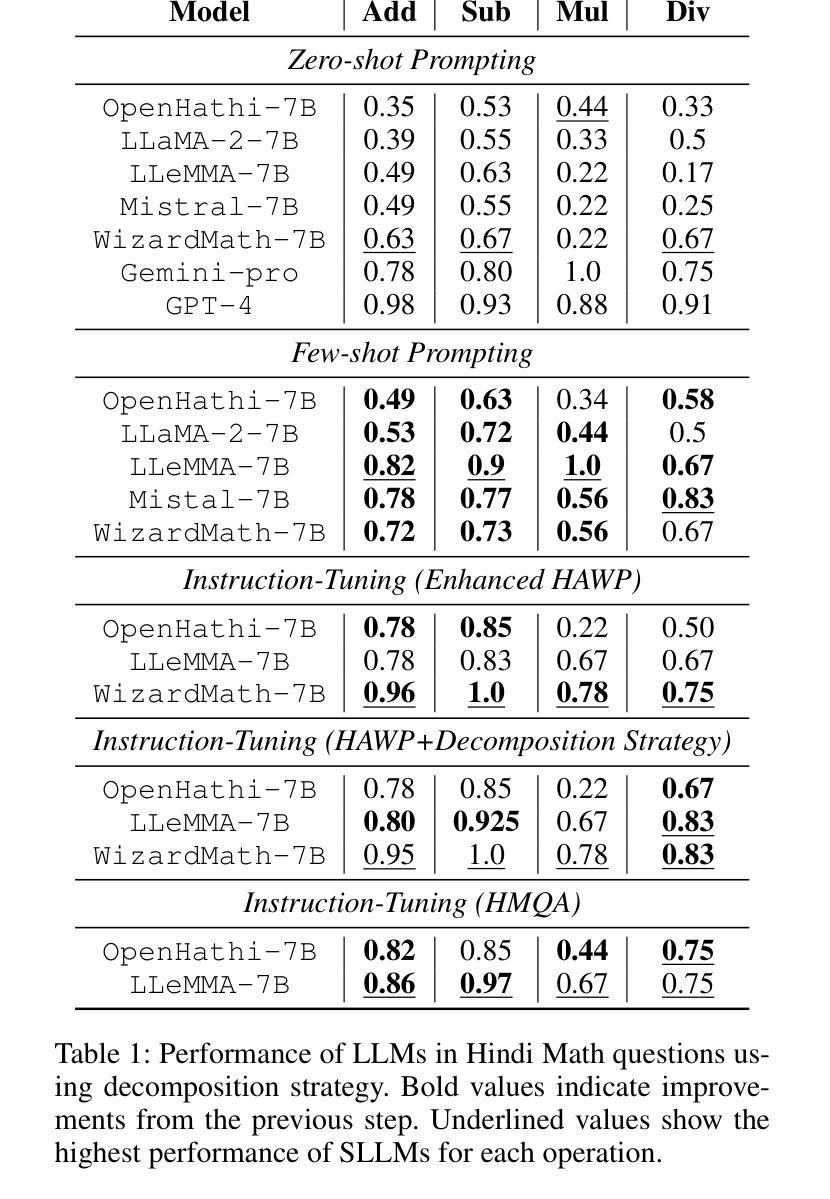
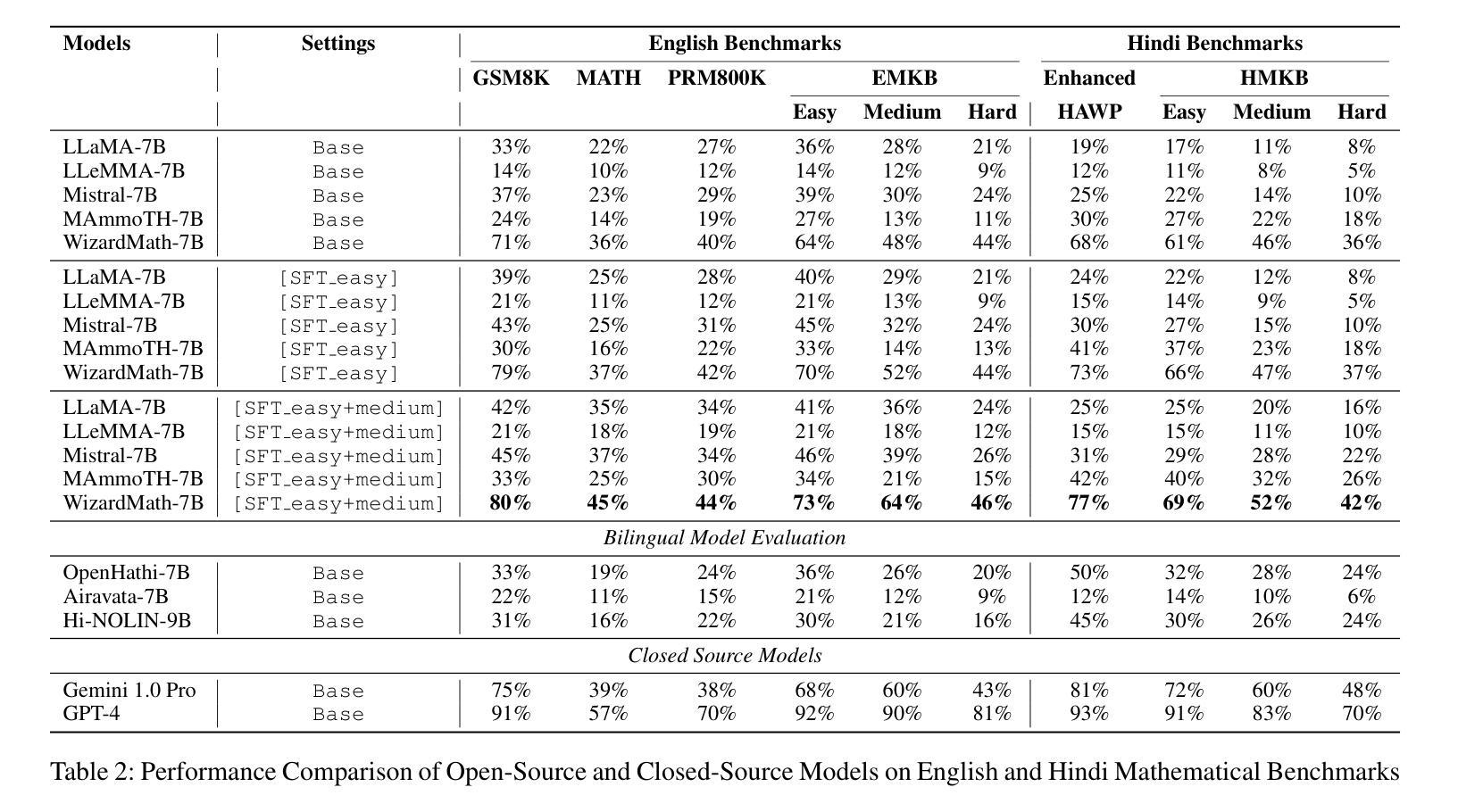
Multilingual Mathematical Reasoning: Advancing Open-Source LLMs in Hindi and English
Authors:Avinash Anand, Kritarth Prasad, Chhavi Kirtani, Ashwin R Nair, Manvendra Kumar Nema, Raj Jaiswal, Rajiv Ratn Shah
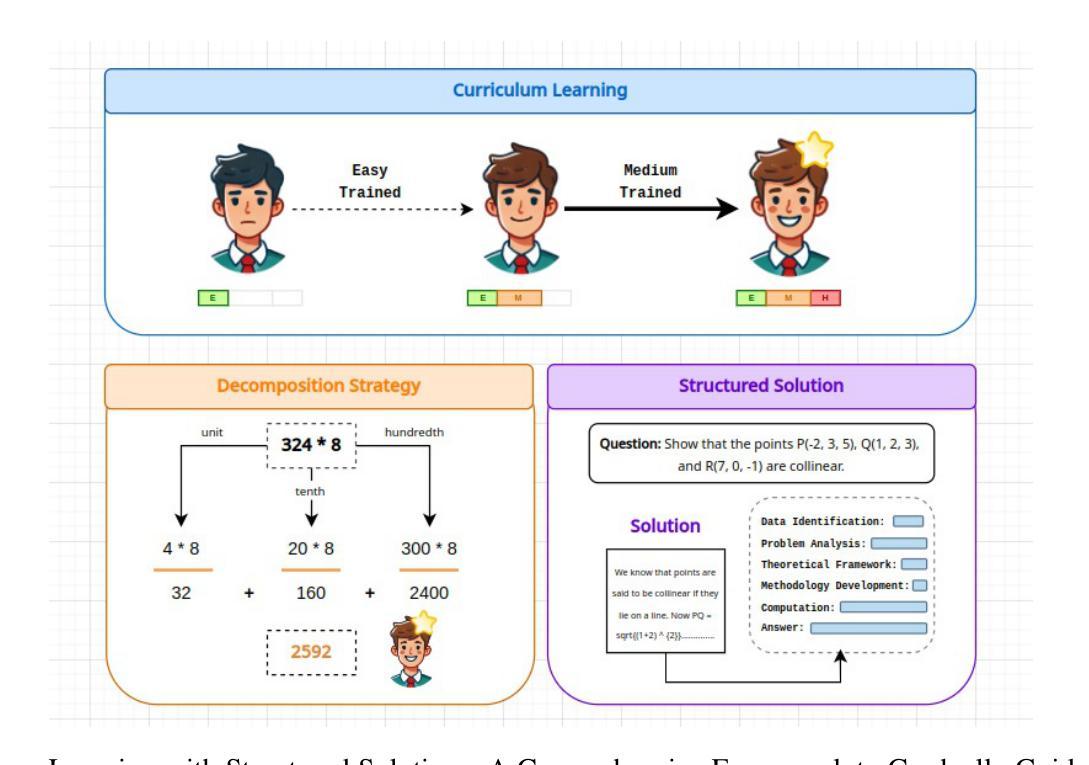
Large Language Models (LLMs) excel in linguistic tasks but struggle with mathematical reasoning, particularly in non English languages like Hindi. This research aims to enhance the mathematical reasoning skills of smaller, resource efficient open-source LLMs in both Hindi and English. We evaluate models like OpenHathi 7B, LLaMA-2 7B, WizardMath 7B, Mistral 7B, LLeMMa 7B, MAmmoTH 7B, Gemini Pro, and GPT-4 using zero-shot, few-shot chain-of-thought (CoT) methods, and supervised fine-tuning. Our approach incorporates curriculum learning, progressively training models on increasingly difficult problems, a novel Decomposition Strategy to simplify complex arithmetic operations, and a Structured Solution Design that divides solutions into phases. Our experiments result in notable performance enhancements. WizardMath 7B exceeds Gemini’s accuracy on English datasets by +6% and matches Gemini’s performance on Hindi datasets. Adopting a bilingual approach that combines English and Hindi samples achieves results comparable to individual language models, demonstrating the capability to learn mathematical reasoning in both languages. This research highlights the potential for improving mathematical reasoning in open-source LLMs.
大型语言模型(LLM)擅长语言任务,但在数学推理方面表现不佳,特别是在非英语语种如印地语方面。本研究旨在提高小型、资源高效的开源LLM在印地语和英语中的数学推理能力。我们使用零样本、少样本思维链方法评估了OpenHathi 7B、LLaMA-2 7B、WizardMath 7B、Mistral 7B、LLeMMa 7B、MAmmoTH 7B、Gemini Pro和GPT-4等模型。我们的方法包括课程学习(逐渐在难度更大的问题上训练模型)、一种简化的复杂算术运算的分解策略以及分阶段的结构化解决方案设计。我们的实验带来了显著的性能提升。WizardMath 7B在英语数据集上的准确度超过了Gemini的准确度+6%,并在印地语数据集上与Gemini性能相匹配。采用结合英语和印地语样本的双语方法取得了与单一语言模型相当的结果,证明了在两种语言中学习数学推理的能力。本研究突显了改进开源LLM数学推理能力的潜力。
论文及项目相关链接
PDF Accepted at AAAI 2025
Summary
本文旨在提高小型开源大型语言模型(LLM)在印地语和英语中的数学推理能力。通过采用零样本、少样本链思维(CoT)方法和监督微调,结合课程学习、分解策略和结构化解决方案等方法,实验结果显示模型性能得到显著提高。例如,WizardMath 7B在英语数据集上的准确率比Gemini高出+6%,并且与Gemini在印地语数据集上的表现相匹配。采用结合英语和印地语样本的双语方法取得了与单一语言模型相当的结果,证明了在两种语言中学习数学推理的能力。这项研究突出了提高开源LLM数学推理能力的潜力。
Key Takeaways
- 大型语言模型(LLM)在英语以外的语言,如印地语中,数学推理能力存在挑战。
- 研究目标在于提高小型、资源效率高的开源LLM在数学推理方面的能力。
- 通过零样本、少样本链思维(CoT)方法和监督微调来评估模型。
- 采用了课程学习、分解策略和结构化解决方案等方法来提高模型性能。
- WizardMath 7B在英语数据集上的表现优于Gemini,准确率提高+6%。
- 在印地语数据集上,WizardMath 7B与Gemini表现相当。
点此查看论文截图

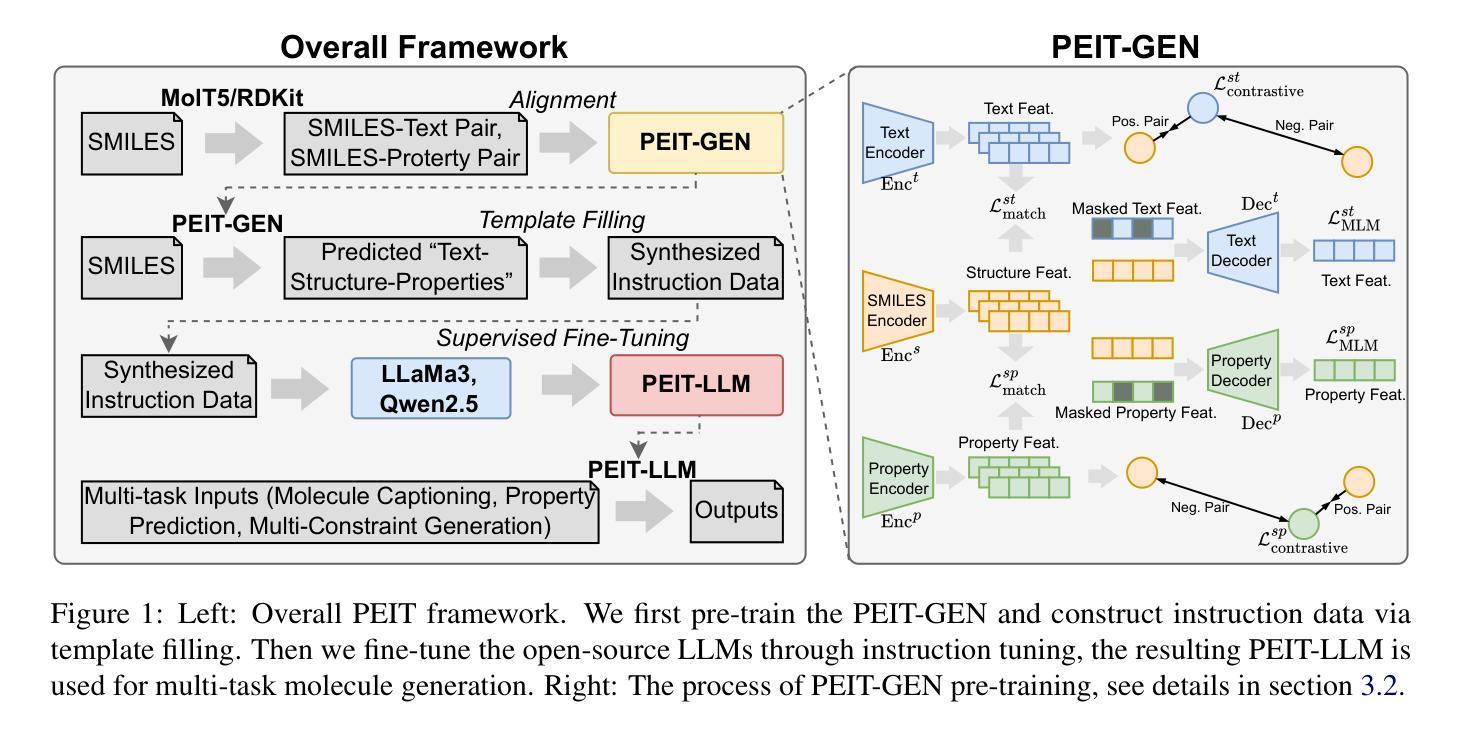
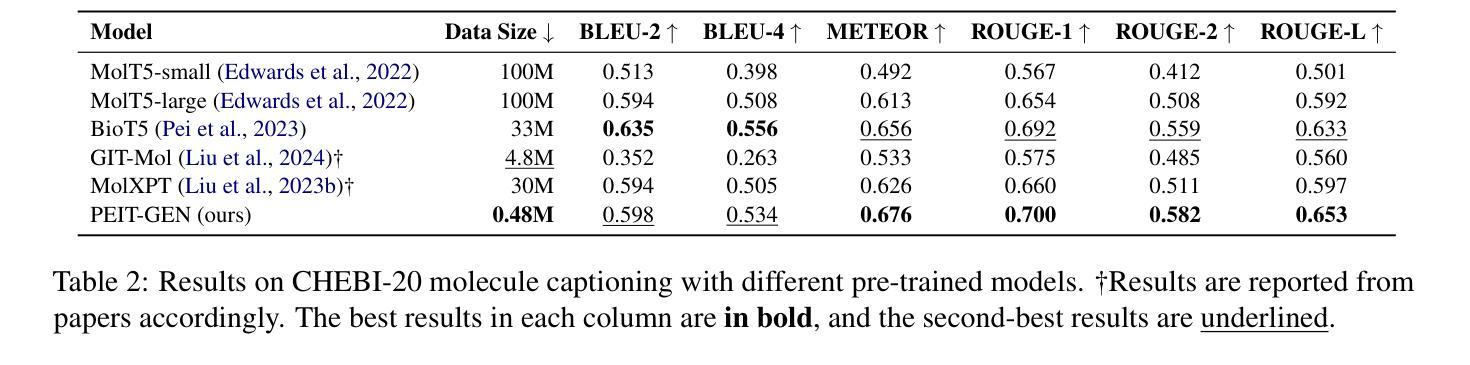
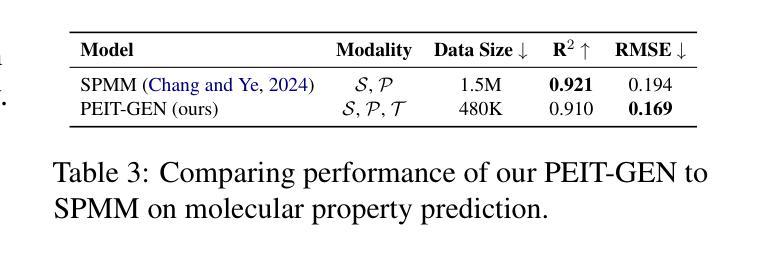
Property Enhanced Instruction Tuning for Multi-task Molecule Generation with Large Language Models
Authors:Xuan Lin, Long Chen, Yile Wang, Xiangxiang Zeng, Philip S. Yu
Large language models (LLMs) are widely applied in various natural language processing tasks such as question answering and machine translation. However, due to the lack of labeled data and the difficulty of manual annotation for biochemical properties, the performance for molecule generation tasks is still limited, especially for tasks involving multi-properties constraints. In this work, we present a two-step framework PEIT (Property Enhanced Instruction Tuning) to improve LLMs for molecular-related tasks. In the first step, we use textual descriptions, SMILES, and biochemical properties as multimodal inputs to pre-train a model called PEIT-GEN, by aligning multi-modal representations to synthesize instruction data. In the second step, we fine-tune existing open-source LLMs with the synthesized data, the resulting PEIT-LLM can handle molecule captioning, text-based molecule generation, molecular property prediction, and our newly proposed multi-constraint molecule generation tasks. Experimental results show that our pre-trained PEIT-GEN outperforms MolT5 and BioT5 in molecule captioning, demonstrating modalities align well between textual descriptions, structures, and biochemical properties. Furthermore, PEIT-LLM shows promising improvements in multi-task molecule generation, proving the scalability of the PEIT framework for various molecular tasks. We release the code, constructed instruction data, and model checkpoints in https://github.com/chenlong164/PEIT.
大型语言模型(LLM)已广泛应用于问答、机器翻译等各种自然语言处理任务。然而,由于缺乏标注数据和生化属性手动标注的困难,分子生成任务性能仍然有限,特别是涉及多属性约束的任务。在这项工作中,我们提出了一个两步框架PEIT(属性增强指令调整),以改进分子相关任务的LLM。首先,我们使用文本描述、SMILES和生物化学属性作为多模式输入,通过对齐多模式表示来合成指令数据,从而预训练一个名为PEIT-GEN的模型。其次,我们使用合成数据对现有的开源LLM进行微调,得到的PEIT-LLM可以处理分子描述、基于文本的分子生成、分子属性预测以及我们新提出的多约束分子生成任务。实验结果表明,我们预训练的PEIT-GEN在分子描述方面优于MolT5和BioT5,证明了文本描述、结构和生物化学属性之间的模态对齐良好。此外,PEIT-LLM在多任务分子生成方面显示出有希望的改进,证明了PEIT框架在各种分子任务中的可扩展性。我们在https://github.com/chenlong164/PEIT发布了代码、构建指令数据和模型检查点。
论文及项目相关链接
Summary
LLM在分子相关任务上的性能提升研究取得了新进展。研究提出了一种名为PEIT的两步框架,用于增强指令调优并应对各种分子任务,如分子标题描述、基于文本分子的生成和预测等。预训练的PEIT-GEN表现出优秀的性能,在PEIT框架下进一步调整了现有开源LLM。此研究证实了模态之间的良好对齐和PEIT框架的可扩展性。具体信息和研究成果发布在GitHub上。
Key Takeaways
- LLM广泛应用于各种自然语言处理任务,但在处理涉及生物化学特性的任务时面临挑战。
- PEIT框架分为两步:第一步是预训练一个名为PEIT-GEN的模型,使用文本描述、SMILES和生物化学特性作为多模态输入;第二步是对现有开源LLM进行微调,以处理分子相关任务。
- PEIT-GEN模型表现出强大的性能,特别是在分子标题描述方面,验证了文本描述、结构和生物化学特性之间的良好对齐。
- PEIT框架展示了在多任务分子生成方面的巨大改进,表明该框架具有良好的可扩展性。
- 研究通过在GitHub上发布代码、构建指令数据和模型检查点来分享其成果。
- PEIT框架有助于提高LLM在处理涉及生物化学特性的任务上的性能,这对于药物发现、化学信息学等领域具有重要意义。
点此查看论文截图


YuLan-Mini: An Open Data-efficient Language Model
Authors:Yiwen Hu, Huatong Song, Jia Deng, Jiapeng Wang, Jie Chen, Kun Zhou, Yutao Zhu, Jinhao Jiang, Zican Dong, Wayne Xin Zhao, Ji-Rong Wen
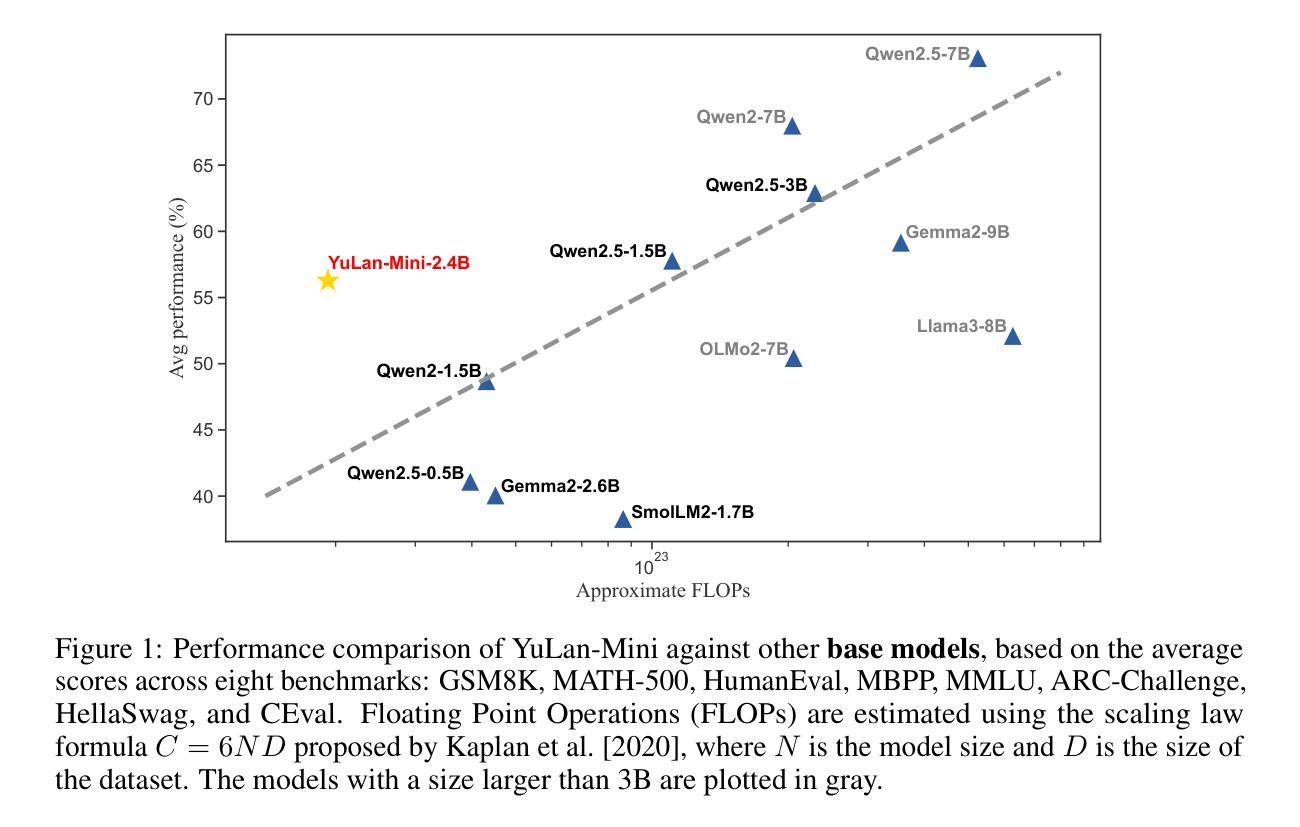
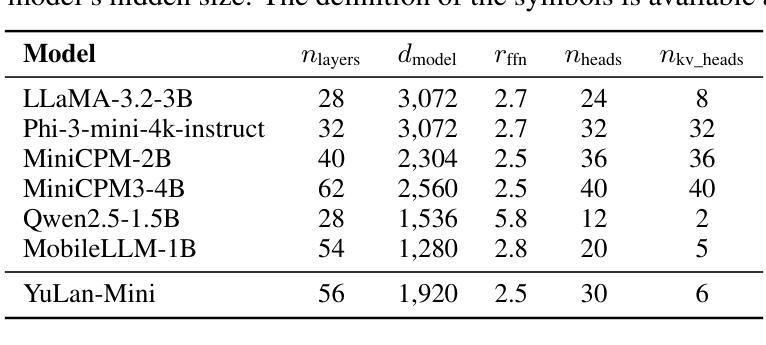
Effective pre-training of large language models (LLMs) has been challenging due to the immense resource demands and the complexity of the technical processes involved. This paper presents a detailed technical report on YuLan-Mini, a highly capable base model with 2.42B parameters that achieves top-tier performance among models of similar parameter scale. Our pre-training approach focuses on enhancing training efficacy through three key technical contributions: an elaborate data pipeline combines data cleaning with data schedule strategies, a robust optimization method to mitigate training instability, and an effective annealing approach that incorporates targeted data selection and long context training. Remarkably, YuLan-Mini, trained on 1.08T tokens, achieves performance comparable to industry-leading models that require significantly more data. To facilitate reproduction, we release the full details of the data composition for each training phase. Project details can be accessed at the following link: https://github.com/RUC-GSAI/YuLan-Mini.
大型语言模型(LLM)的有效预训练一直是一个挑战,因为其资源需求巨大,涉及的技术过程非常复杂。本文详细介绍了YuLan-Mini的详细技术报告,这是一个具有2.42亿参数的基础模型,在同类参数规模的模型中达到了顶级性能。我们的预训练方法通过三个关键技术贡献来提高训练效果:精心设计的数据管道结合了数据清理和数据调度策略,一种稳健的优化方法来减轻训练不稳定的问题,以及有效的退火方法,该方法结合了目标数据选择和长上下文训练。值得注意的是,YuLan-Mini在1.08万亿标记的训练下,实现了与需要大量数据的行业领先模型相当的性能。为了方便复制,我们公开了每个训练阶段数据组合的全部细节。项目详情可访问以下链接:https://github.com/RUC-GSAI/YuLan-Mini。
论文及项目相关链接
Summary
YuLan-Mini是一个拥有强大性能的基础模型,具有2.42亿参数,在类似参数规模的模型中表现优异。其预训练策略通过三个关键技术贡献提高了训练效率:精细的数据管道结合了数据清理和数据调度策略,稳健的优化方法减轻了训练的不稳定性,以及有效的退火方法结合了目标数据选择和长语境训练。在仅训练了1.08万亿令牌的情况下,YuLan-Mini的表现与需要大量数据的行业领先模型相当。
Key Takeaways
- YuLan-Mini是一个具有2.42亿参数的基础模型,性能优越。
- 该模型的预训练策略包括三个关键技术贡献,分别是数据管道、优化方法和退火方法。
- 数据管道结合了数据清理和数据调度策略以提高训练效率。
- 优化方法旨在减轻训练过程中的不稳定性。
- 退火方法结合了目标数据选择和长语境训练,增强了模型性能。
- YuLan-Mini在仅训练了1.08万亿令牌的情况下表现出色,与需要大量数据的行业领先模型相当。
点此查看论文截图

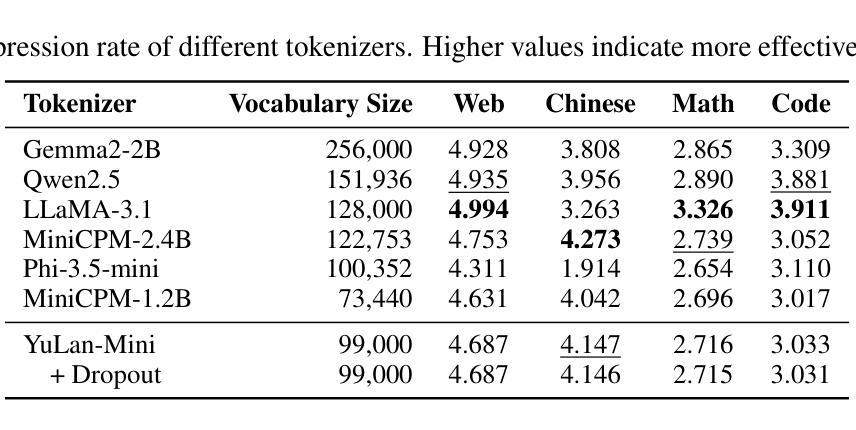
System-2 Mathematical Reasoning via Enriched Instruction Tuning
Authors:Huanqia Cai, Yijun Yang, Zhifeng Li
Solving complex mathematical problems via system-2 reasoning is a natural human skill, yet it remains a significant challenge for current large language models (LLMs). We identify the scarcity of deliberate multi-step reasoning data as a primary limiting factor. To this end, we introduce Enriched Instruction Tuning (EIT), a method that enriches existing human-annotated mathematical datasets by synergizing human and AI feedback to create fine-grained reasoning trajectories. These datasets are then used to fine-tune open-source LLMs, enhancing their mathematical reasoning abilities without reliance on any symbolic verification program. Concretely, EIT is composed of two critical steps: Enriching with Reasoning Plan (ERP) and Enriching with Reasoning Step (ERS). The former generates a high-level plan that breaks down complex instructions into a sequence of simpler objectives, while ERS fills in reasoning contexts often overlooked by human annotators, creating a smoother reasoning trajectory for LLM fine-tuning. Unlike existing CoT prompting methods that generate reasoning chains only depending on LLM’s internal knowledge, our method leverages human-annotated initial answers as ``meta-knowledge’’ to help LLMs generate more detailed and precise reasoning processes, leading to a more trustworthy LLM expert for complex mathematical problems. In experiments, EIT achieves an accuracy of 84.1% on GSM8K and 32.5% on MATH, surpassing state-of-the-art fine-tuning and prompting methods, and even matching the performance of tool-augmented methods.
通过系统2理性解决复杂的数学问题是一项人类自然技能,但仍然是当前大型语言模型(LLM)面临的一个重大挑战。我们确定了缺乏有意识的多步骤推理数据是主要限制因素。为此,我们引入了丰富指令训练(EIT),这是一种通过协同人类和人工智能反馈来丰富现有人类注释的数学数据集的方法,以创建精细的推理轨迹。这些数据集随后用于微调开源LLM,增强它们的数学推理能力,无需依赖任何符号验证程序。具体来说,EIT由两个关键步骤组成:丰富推理计划(ERP)和丰富推理步骤(ERS)。前者生成一个高级计划,将复杂的指令分解为一系列简单的目标,而ERS则填补了人类注释者经常忽略的推理背景,为LLM微调创建更平滑的推理轨迹。与现有的仅依赖于LLM内部知识的CoT提示方法不同,我们的方法利用人类注释的初始答案作为“元知识”,帮助LLM生成更详细、更精确的推理过程,使LLM成为解决复杂数学问题的更可信赖的专家。在实验中,EIT在GSM8K上达到了84.1%的准确率,在MATH上达到了32.5%的准确率,超越了最新的微调提示方法,甚至与工具增强方法的性能相匹配。
论文及项目相关链接
Summary:
通过系统2推理解决复杂的数学问题是一项人类的自然能力,但对于当前的大型语言模型(LLM)来说仍然是一个巨大的挑战。主要限制因素之一是缺乏有意识的多步骤推理数据。为解决此问题,引入了富集指令调优(EIT)方法,该方法通过协同人类和AI反馈来丰富现有的人类注释数学数据集,创建精细的推理轨迹。然后,这些数据集被用来微调开源LLM,增强它们的数学推理能力,无需依赖任何符号验证程序。具体来说,EIT包括两个关键步骤:富集推理计划(ERP)和富集推理步骤(ERS)。ERP生成高级计划,将复杂指令分解为一系列简单目标,而ERS填补了人类注释者经常忽略的推理背景,为LLM微调创建更平滑的推理轨迹。不同于仅依赖LLM内部知识的现有CoT提示方法,我们的方法利用人类注释的初始答案作为“元知识”来帮助LLM生成更详细、更精确的推理过程,使LLM成为解决复杂数学问题的更可信赖的专家。
Key Takeaways:
- 解决复杂数学问题对于LLM来说是一个挑战,缺乏多步骤推理数据是主要限制因素。
- 引入Enriched Instruction Tuning (EIT)方法来增强LLM的数学推理能力。
- EIT通过协同人类和AI反馈丰富现有的人类注释数学数据集。
- EIT包括两个关键步骤:生成高级计划的ERP和填补推理背景的ERS。
- EIT利用人类注释的初始答案作为“元知识”,帮助LLM生成更详细、精确的推理过程。
- EIT在GSM8K上达到84.1%的准确率,在MATH上达到32.5%的准确率,超越了现有的微调方法和提示方法,甚至与工具增强方法的性能相匹配。
- EIT方法为LLM在处理复杂数学问题方面提供了更可靠的专家级表现。
点此查看论文截图



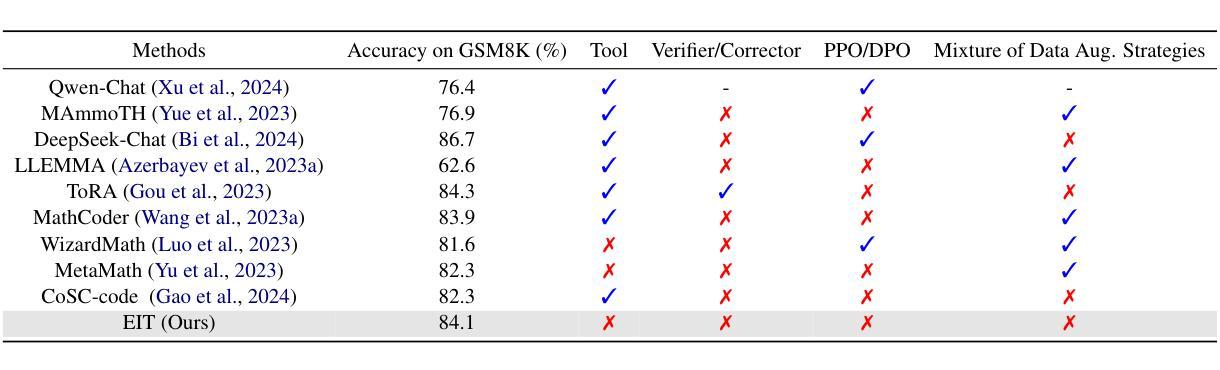
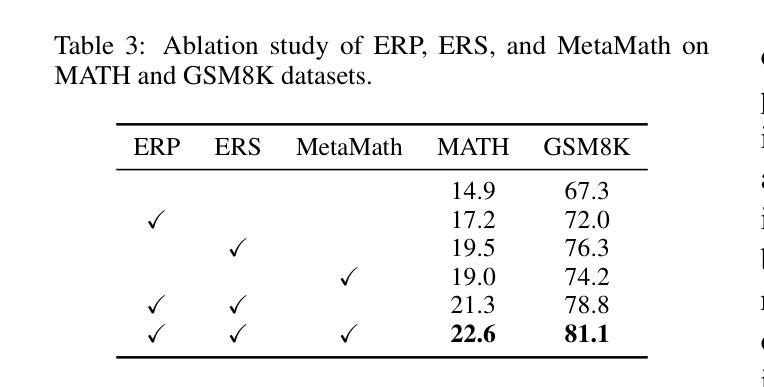
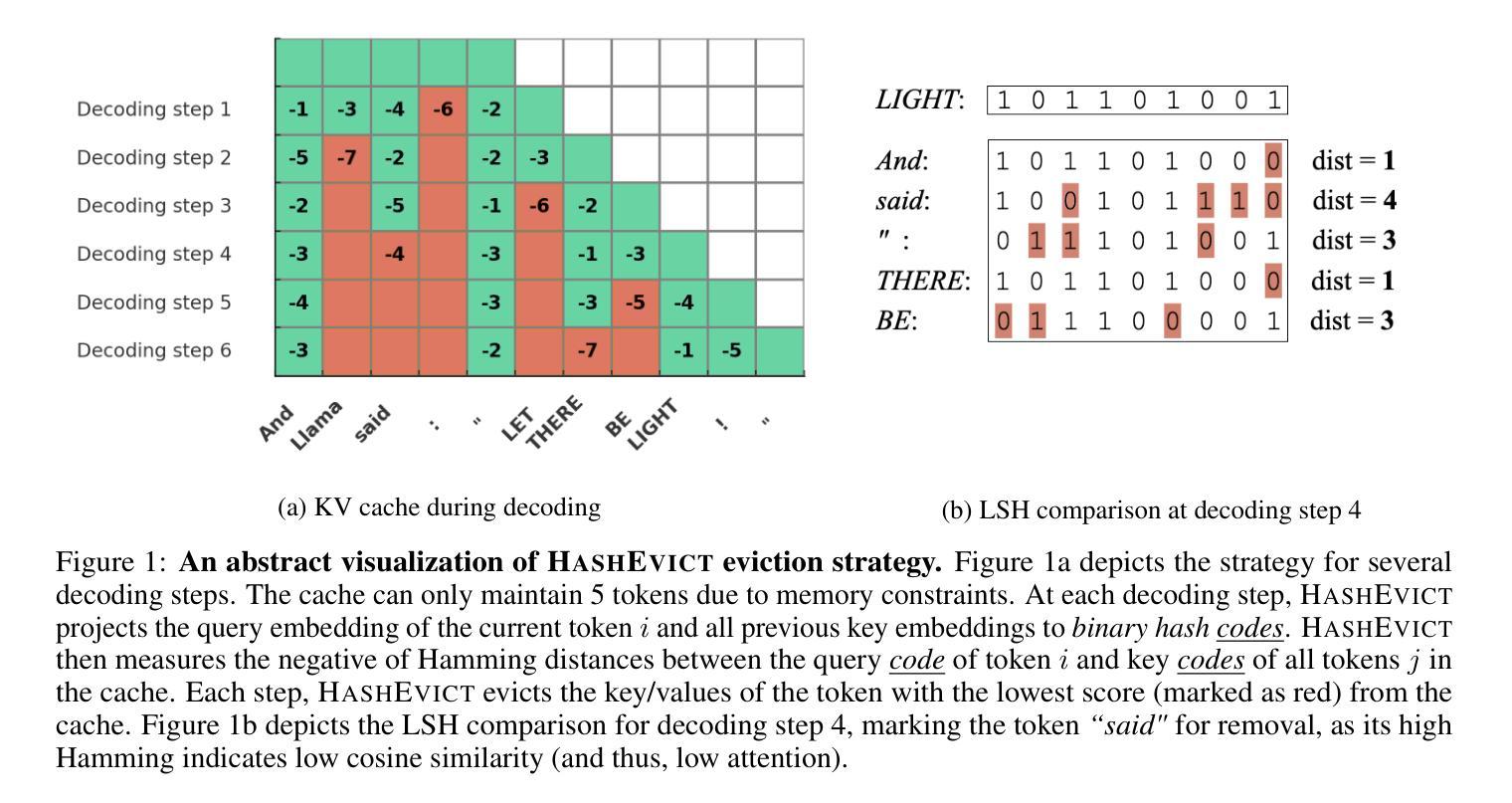
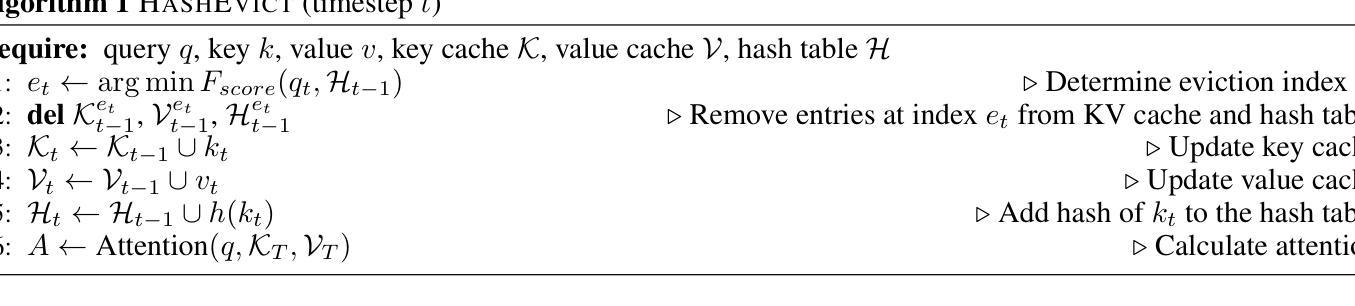
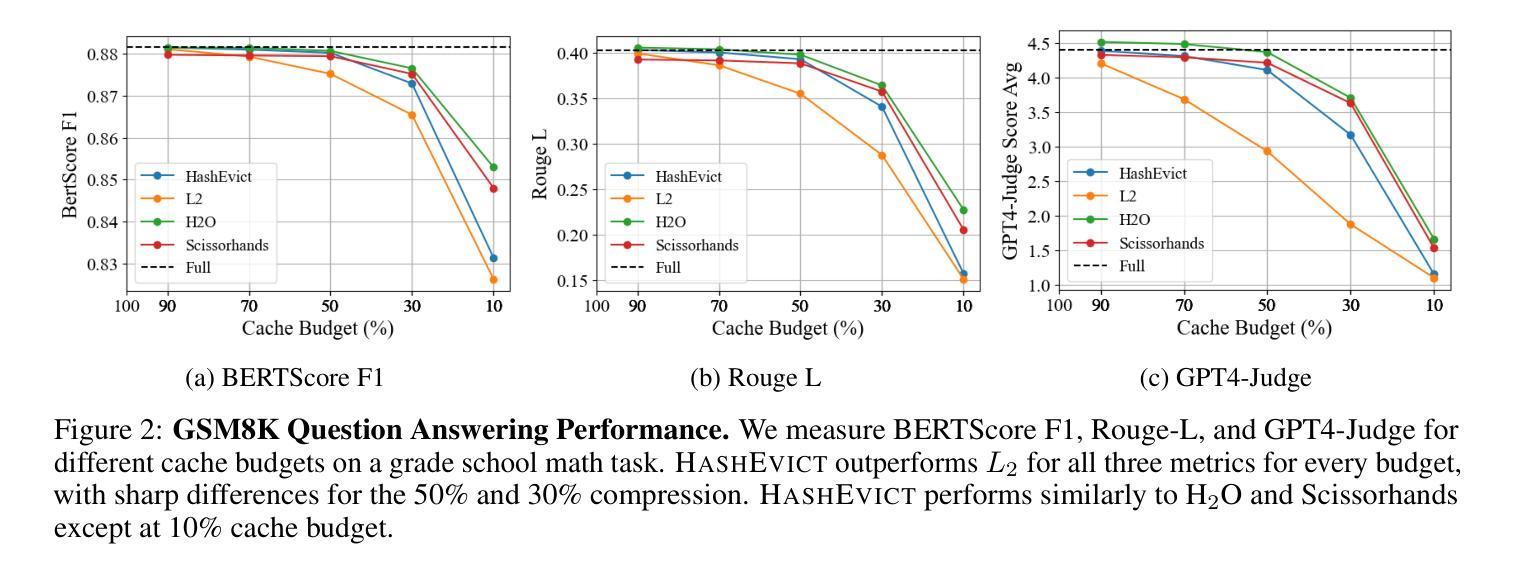
HashEvict: A Pre-Attention KV Cache Eviction Strategy using Locality-Sensitive Hashing
Authors:Minghui Liu, Tahseen Rabbani, Tony O’Halloran, Ananth Sankaralingam, Mary-Anne Hartley, Brian Gravelle, Furong Huang, Cornelia Fermüller, Yiannis Aloimonos
Transformer-based large language models (LLMs) use the key-value (KV) cache to significantly accelerate inference by storing the key and value embeddings of past tokens. However, this cache consumes significant GPU memory. In this work, we introduce HashEvict, an algorithm that uses locality-sensitive hashing (LSH) to compress the KV cache. HashEvict quickly locates tokens in the cache that are cosine dissimilar to the current query token. This is achieved by computing the Hamming distance between binarized Gaussian projections of the current token query and cached token keys, with a projection length much smaller than the embedding dimension. We maintain a lightweight binary structure in GPU memory to facilitate these calculations. Unlike existing compression strategies that compute attention to determine token retention, HashEvict makes these decisions pre-attention, thereby reducing computational costs. Additionally, HashEvict is dynamic - at every decoding step, the key and value of the current token replace the embeddings of a token expected to produce the lowest attention score. We demonstrate that HashEvict can compress the KV cache by 30%-70% while maintaining high performance across reasoning, multiple-choice, long-context retrieval and summarization tasks.
基于Transformer的大型语言模型(LLM)使用键值(KV)缓存来存储过去令牌的关键字和值嵌入,从而显著加速推理。然而,这个缓存会消耗大量的GPU内存。在这项工作中,我们引入了HashEvict,一种使用局部敏感哈希(LSH)来压缩KV缓存的算法。HashEvict能够快速定位缓存中与当前查询令牌余弦不相似的令牌。这是通过计算当前令牌查询的二进制化高斯投影与缓存令牌键之间的汉明距离来实现的,投影长度远小于嵌入维度。我们在GPU内存中维护一个轻量级的二进制结构,以促进这些计算。与计算注意力来确定令牌保留的现有压缩策略不同,HashEvict在注意力之前做出这些决策,从而降低计算成本。此外,HashEvict具有动态性——在每一步解码时,当前令牌的关键字和值会替换预计产生最低注意力得分的令牌的嵌入。我们证明,HashEvict可以将KV缓存压缩30%-70%,同时在推理、多项选择、长上下文检索和摘要任务中保持高性能。
论文及项目相关链接
PDF 10 pages, 6 figures, 2 tables
Summary
基于Transformer的大型语言模型(LLM)利用键值(KV)缓存来加速推理过程,但会消耗大量GPU内存。本文介绍了一种名为HashEvict的算法,该算法使用局部敏感哈希(LSH)来压缩KV缓存。HashEvict通过计算当前查询令牌与缓存令牌键的高斯投影之间的汉明距离,快速定位与查询令牌余弦不相似的令牌。与依赖注意力计算来决定保留令牌的现有压缩策略不同,HashEvict在注意力计算之前做出决策,从而降低了计算成本。此外,HashEvict具有动态性,能够在每一步解码时替换预期产生最低注意力得分的令牌的键和值。实验表明,HashEvict可以将KV缓存压缩30%-70%,同时保持在各种任务上的高性能。
Key Takeaways
- Transformer-based LLMs利用键值缓存加速推理,但消耗大量GPU内存。
- HashEvict算法使用局部敏感哈希(LSH)来压缩KV缓存。
- HashEvict通过计算当前查询令牌与缓存令牌键的汉明距离快速定位相关令牌。
- HashEvict在注意力计算前做出决策,降低计算成本。
- HashEvict具有动态性,能在解码过程中替换预期产生低注意力得分的令牌的键和值。
- HashEvict可以将KV缓存压缩30%-70%。
点此查看论文截图

Can LLMs Obfuscate Code? A Systematic Analysis of Large Language Models into Assembly Code Obfuscation
Authors:Seyedreza Mohseni, Seyedali Mohammadi, Deepa Tilwani, Yash Saxena, Gerald Ndawula, Sriram Vema, Edward Raff, Manas Gaur
Malware authors often employ code obfuscations to make their malware harder to detect. Existing tools for generating obfuscated code often require access to the original source code (e.g., C++ or Java), and adding new obfuscations is a non-trivial, labor-intensive process. In this study, we ask the following question: Can Large Language Models (LLMs) potentially generate a new obfuscated assembly code? If so, this poses a risk to anti-virus engines and potentially increases the flexibility of attackers to create new obfuscation patterns. We answer this in the affirmative by developing the MetamorphASM benchmark comprising MetamorphASM Dataset (MAD) along with three code obfuscation techniques: dead code, register substitution, and control flow change. The MetamorphASM systematically evaluates the ability of LLMs to generate and analyze obfuscated code using MAD, which contains 328,200 obfuscated assembly code samples. We release this dataset and analyze the success rate of various LLMs (e.g., GPT-3.5/4, GPT-4o-mini, Starcoder, CodeGemma, CodeLlama, CodeT5, and LLaMA 3.1) in generating obfuscated assembly code. The evaluation was performed using established information-theoretic metrics and manual human review to ensure correctness and provide the foundation for researchers to study and develop remediations to this risk. The source code can be found at the following GitHub link: https://github.com/mohammadi-ali/MetamorphASM.
恶意软件作者经常使用代码混淆技术来使他们的恶意软件更难被检测。现有的生成混淆代码的工具通常需要访问原始源代码(例如C++或Java),并且添加新的混淆是一项非常繁琐且劳动密集型的流程。在这项研究中,我们提出了以下问题:大型语言模型(LLM)是否能够生成新的混淆汇编代码?如果是这样,这对抗病毒引擎构成风险,并可能提高攻击者创建新混淆模式的灵活性。我们通过开发MetamorphASM基准测试来回答这个问题,该测试包括MetamorphASM数据集(MAD)以及三种代码混淆技术:死代码、寄存器替换和控制流更改。MetamorphASM使用MAD系统地评估LLM生成和分析混淆代码的能力,MAD包含328,200个混淆的汇编代码样本。我们发布了此数据集,并分析了各种LLM(如GPT-3.5/4、GPT-4o-mini、Starcoder、CodeGemma、CodeLlama、CodeT5和LLaMA 3.1)在生成混淆汇编代码方面的成功率。评估是通过建立的信息理论指标和人工审查来完成的,以确保正确性并为研究人员研究和开发对此风险的补救措施提供基础。源代码可在以下GitHub链接中找到:https://github.com/mohammadi-ali/MetamorphASM。
论文及项目相关链接
PDF To appear in AAAI 2025, Main Track
摘要
本研究探讨了大型语言模型(LLM)在生成新的混淆汇编代码方面的潜力。研究构建了MetamorphASM基准测试,包含MetamorphASM数据集(MAD)和三重代码混淆技术:死代码、寄存器替换和控制流变化。通过MAD包含的大量混淆汇编代码样本对LLM进行评估。研究表明,各种LLM(如GPT-3.5/4等)在生成混淆汇编代码方面表现出较高的成功率。这为研究人员提供了研究并制定补救措施的基础。
关键见解
- 大型语言模型(LLM)可用于生成混淆汇编代码,对抗病毒引擎构成风险。
- 研究开发了MetamorphASM基准测试,用于评估LLM生成和分析混淆代码的能力。
- MetamorphASM数据集(MAD)包含大量混淆汇编代码样本,用于评估LLM的性能。
- 不同LLM模型在生成混淆汇编代码方面的成功率有所差异。
- 信息理论指标和人工审核被用于确保评估的正确性。
- 此研究为研究人员提供了深入研究并制定针对该风险的补救措施的机会。
点此查看论文截图









