⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-26 更新
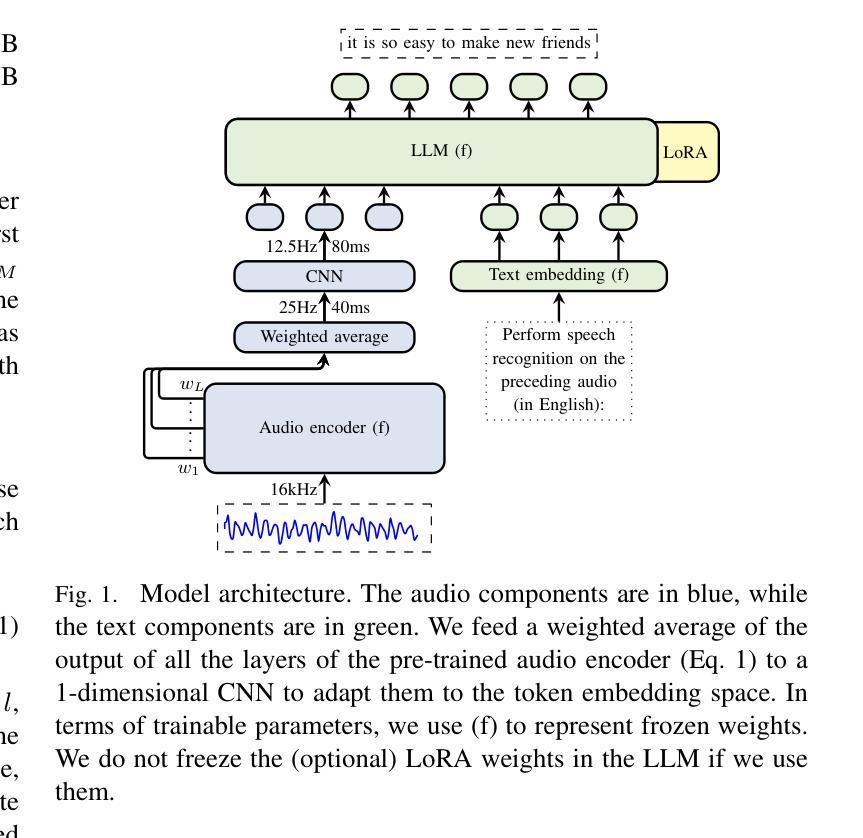
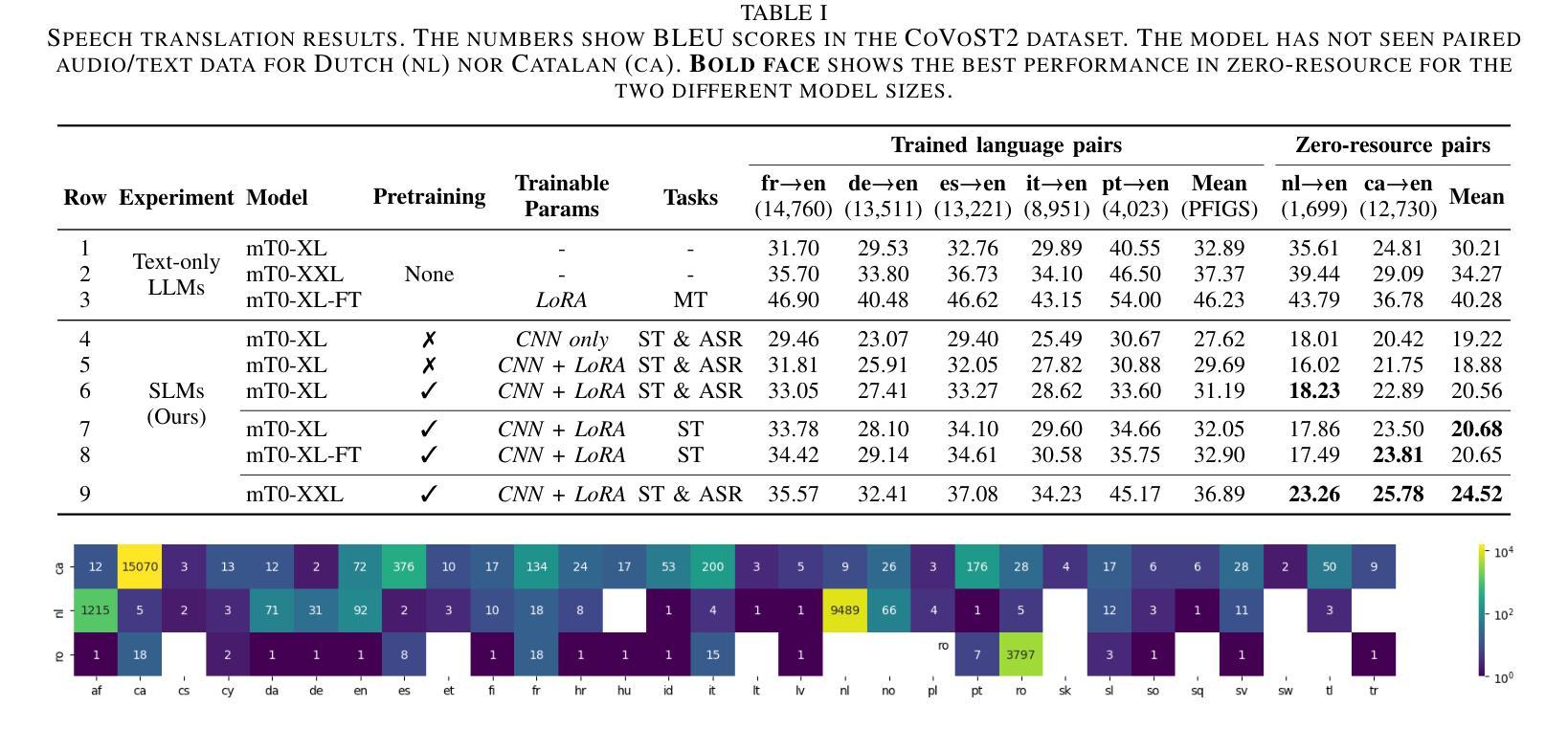
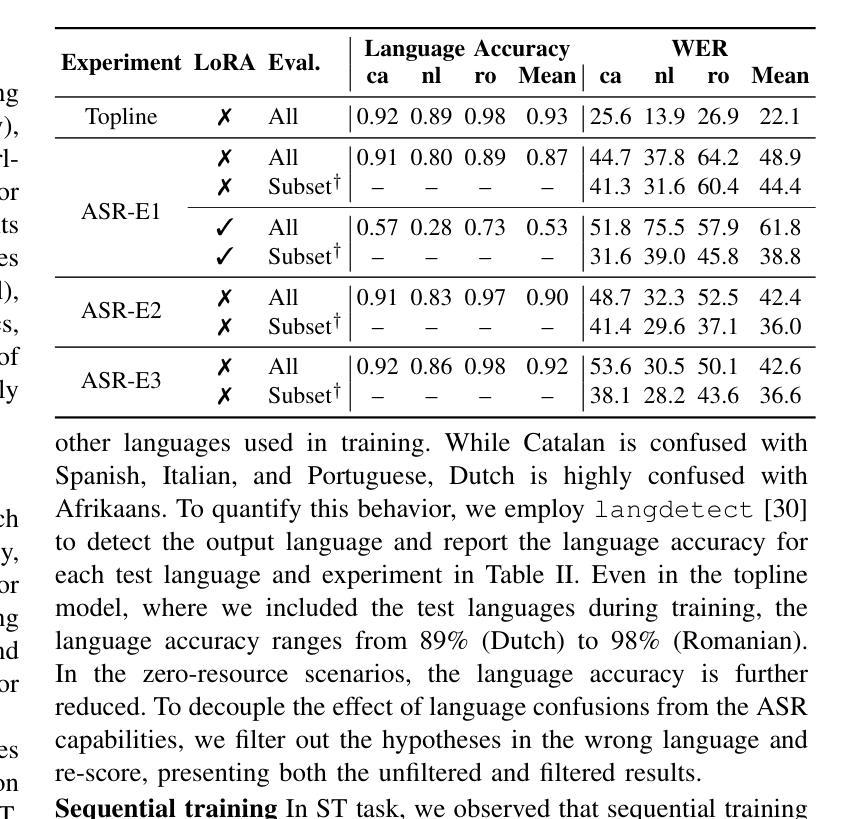
Zero-resource Speech Translation and Recognition with LLMs
Authors:Karel Mundnich, Xing Niu, Prashant Mathur, Srikanth Ronanki, Brady Houston, Veera Raghavendra Elluru, Nilaksh Das, Zejiang Hou, Goeric Huybrechts, Anshu Bhatia, Daniel Garcia-Romero, Kyu J. Han, Katrin Kirchhoff
Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
尽管最近语音处理领域有所进展,但零资源语音翻译(ST)和自动语音识别(ASR)仍是具有挑战性的问题。在这项工作中,我们提出利用多语言大型语言模型(LLM)来执行ST和ASR,针对模型从未接触过的配对语音文本数据的语言。我们通过使用预训练的多语言语音编码器、多语言LLM和一个轻量级适配模块(该模块将音频表示映射到LLM的令牌嵌入空间)来实现这一点。我们在ST和ASR中进行了多次实验,以了解如何最好地训练模型,以及哪些数据在对未见过的语言性能影响方面最为重要。在ST中,我们最好的模型能够在CoVoST2上实现超过23的BLEU分数,用于两种先前未见过的语言;而在ASR中,我们实现高达28.2%的WER。最后,我们表明,我们系统的性能受到LLM输出所需语言文本的能力的限制。
论文及项目相关链接
PDF ICASSP 2025, 5 pages, 2 figures, 2 tables
Summary
本研究探讨了零资源语音翻译(ST)和自动语音识别(ASR)的难题,并提出利用多语言大型语言模型(LLM)在从未接触过配对音频文本数据的语言中进行ST和ASR。通过预训练的多语言语音编码器、多语言LLM和轻量级适应模块,将语音表示映射到LLM的令牌嵌入空间。在ST和ASR方面进行了多次实验,以了解如何最佳地训练模型,以及哪些数据对在未见过的语言中的性能影响最大。在ST中,最佳模型的BLEU得分在CoVoST2上超过23,而在ASR中,我们实现了最高28.2%的WER。最后,表明系统性能受限于LLM输出所需语言文本的能力。
Key Takeaways
- 零资源语音翻译(ST)和自动语音识别(ASR)仍是具有挑战性的问题。
- 研究提出利用多语言大型语言模型(LLM)在未见过的语言中进行ST和ASR。
- 通过预训练的多语言语音编码器、多语言LLM和轻量级适应模块实现语音到文本的转换。
- 在ST和ASR方面进行了多次实验,以优化模型训练并了解数据对性能的影响。
- 在ST方面,最佳模型的BLEU得分在CoVoST2数据集上超过23。
- 在ASR方面,实现了最高28.2%的字错误率(WER)。
点此查看论文截图

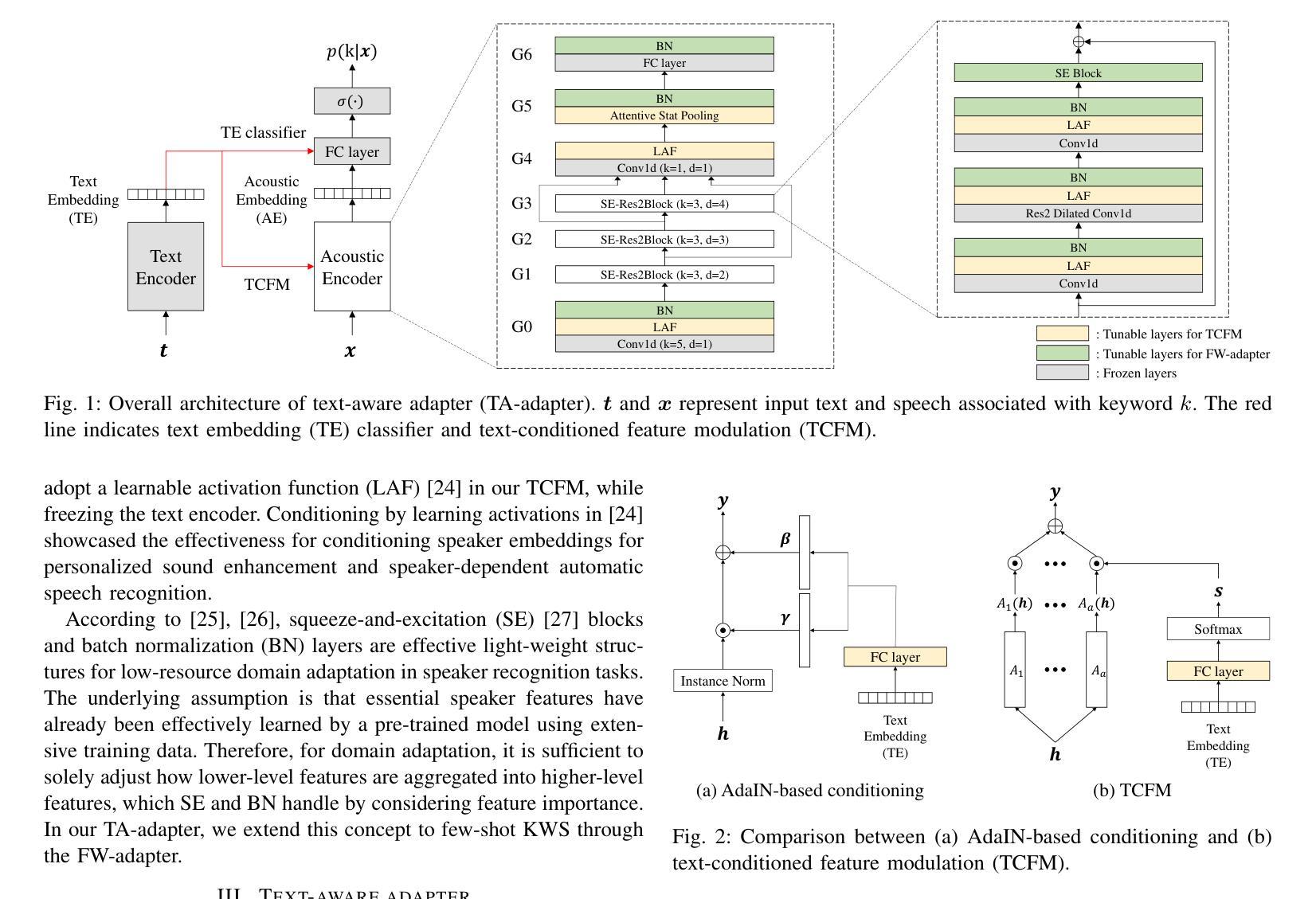
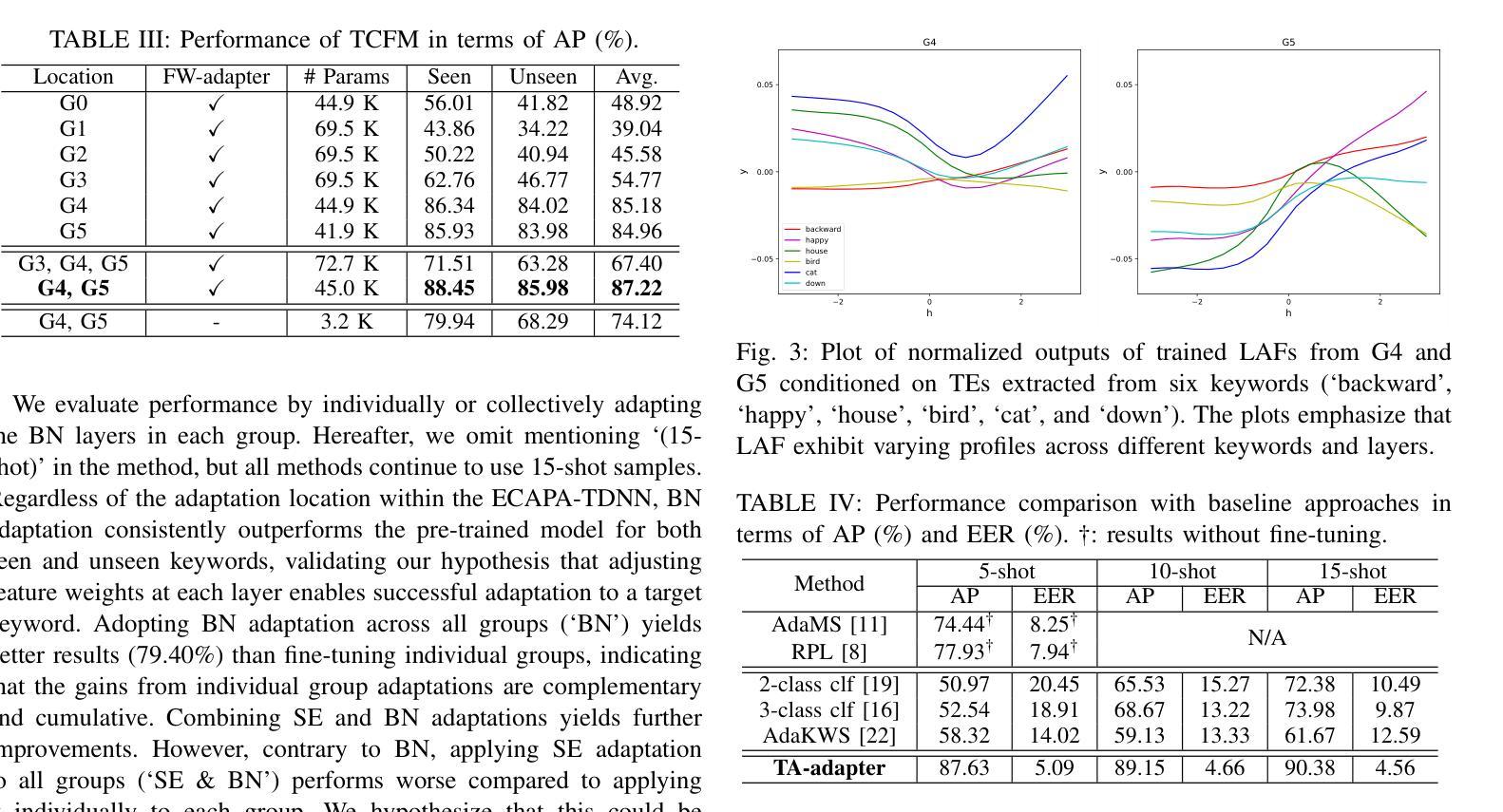
Text-Aware Adapter for Few-Shot Keyword Spotting
Authors:Youngmoon Jung, Jinyoung Lee, Seungjin Lee, Myunghun Jung, Yong-Hyeok Lee, Hoon-Young Cho
Recent advances in flexible keyword spotting (KWS) with text enrollment allow users to personalize keywords without uttering them during enrollment. However, there is still room for improvement in target keyword performance. In this work, we propose a novel few-shot transfer learning method, called text-aware adapter (TA-adapter), designed to enhance a pre-trained flexible KWS model for specific keywords with limited speech samples. To adapt the acoustic encoder, we leverage a jointly pre-trained text encoder to generate a text embedding that acts as a representative vector for the keyword. By fine-tuning only a small portion of the network while keeping the core components’ weights intact, the TA-adapter proves highly efficient for few-shot KWS, enabling a seamless return to the original pre-trained model. In our experiments, the TA-adapter demonstrated significant performance improvements across 35 distinct keywords from the Google Speech Commands V2 dataset, with only a 0.14% increase in the total number of parameters.
近期,文本注册制的灵活关键词识别(KWS)技术取得了进展,允许用户个性化关键词,而无需在注册时发出声音。然而,目标关键词的性能仍有提升空间。在此工作中,我们提出了一种新的少样本迁移学习方法,称为文本感知适配器(TA-adapter),旨在利用有限的语音样本,增强预训练的灵活KWS模型对特定关键词的识别。为了调整声学编码器,我们利用联合预训练的文本编码器生成文本嵌入,作为关键词的代表向量。通过仅微调网络的一部分,同时保持核心组件的权重不变,TA-adapter在少样本KWS中表现出高效率,可以无缝地回归原始预训练模型。在我们的实验中,TA-adapter在Google语音命令V2数据集中的35个不同关键词上显示出显著的性能提升,且总参数仅增加了0.14%。
论文及项目相关链接
PDF 5 pages, 3 figures, Accepted by ICASSP 2025
Summary
本文介绍了一种新型的基于文本感知适配器(TA-adapter)的少量样本迁移学习方法,用于改进预训练的灵活关键词识别模型。通过利用联合预训练的文本编码器生成文本嵌入向量来代表关键词,该方法在微调网络小部分的同时保持核心组件权重不变,实现了高效的少量样本关键词识别。在Google Speech Commands V2数据集上的实验表明,TA-adapter在35个不同关键词上的性能显著提升,总参数仅增加0.14%。
Key Takeaways
- 提出了一种新型的基于文本感知适配器(TA-adapter)的迁移学习方法。
- 方法设计用于改进预训练的灵活关键词识别模型以识别特定关键词。
- 利用联合预训练的文本编码器生成文本嵌入向量来代表关键词。
- 通过微调小部分网络,同时保持核心组件权重不变,实现高效少量的样本关键词识别。
- 实验在Google Speech Commands V2数据集上进行,涉及35个不同关键词。
- TA-adapter显著提高了关键词识别性能。
点此查看论文截图


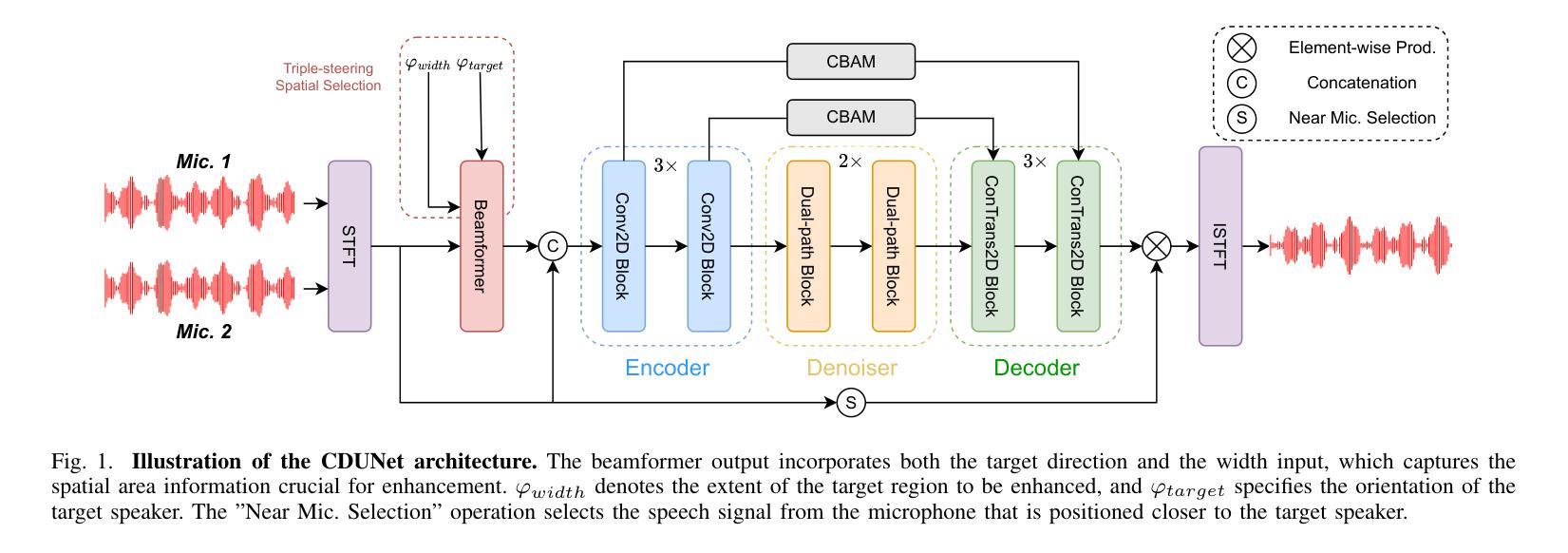
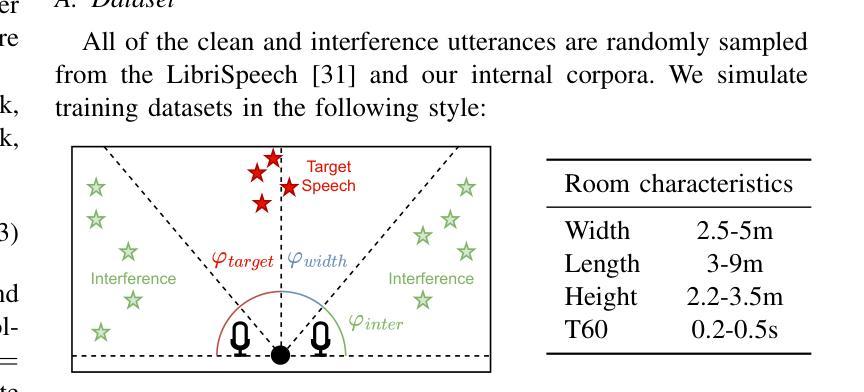
Neural Directed Speech Enhancement with Dual Microphone Array in High Noise Scenario
Authors:Wen Wen, Qiang Zhou, Yu Xi, Haoyu Li, Ziqi Gong, Kai Yu
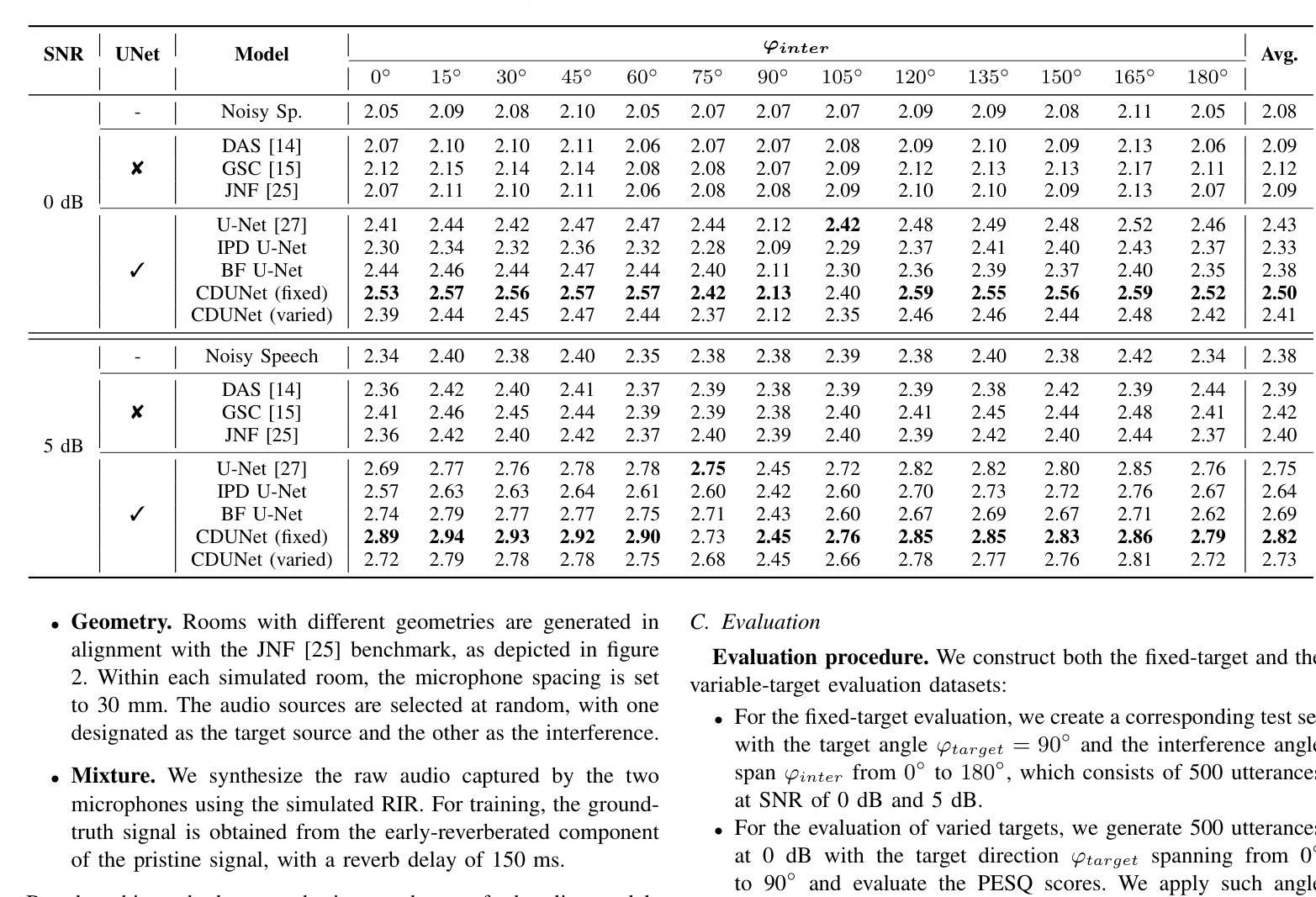
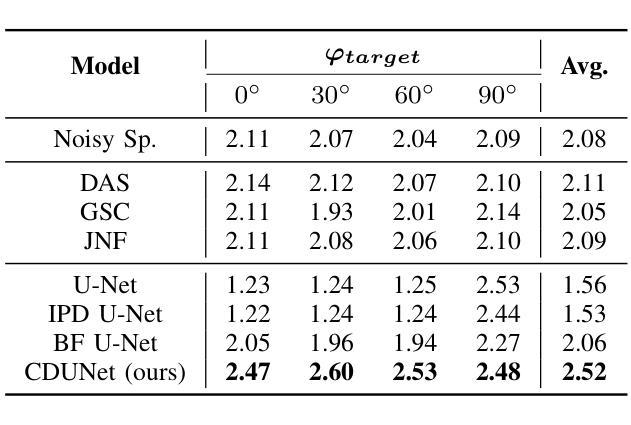
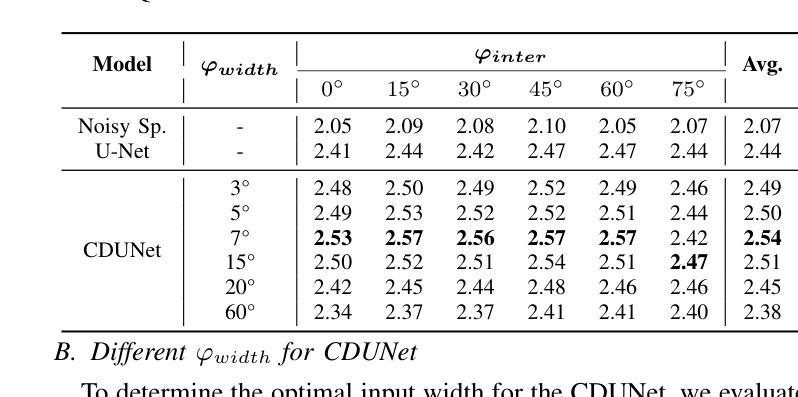
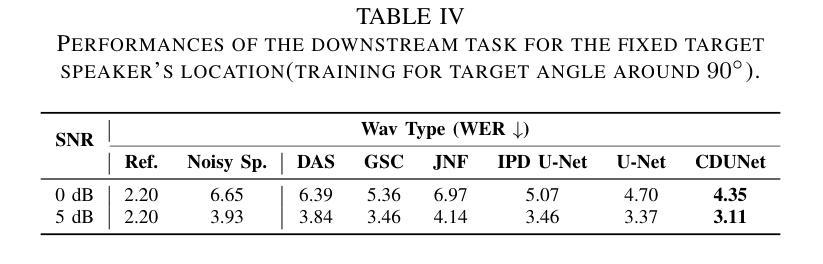
In multi-speaker scenarios, leveraging spatial features is essential for enhancing target speech. While with limited microphone arrays, developing a compact multi-channel speech enhancement system remains challenging, especially in extremely low signal-to-noise ratio (SNR) conditions. To tackle this issue, we propose a triple-steering spatial selection method, a flexible framework that uses three steering vectors to guide enhancement and determine the enhancement range. Specifically, we introduce a causal-directed U-Net (CDUNet) model, which takes raw multi-channel speech and the desired enhancement width as inputs. This enables dynamic adjustment of steering vectors based on the target direction and fine-tuning of the enhancement region according to the angular separation between the target and interference signals. Our model with only a dual microphone array, excels in both speech quality and downstream task performance. It operates in real-time with minimal parameters, making it ideal for low-latency, on-device streaming applications.
在多说话人场景中,利用空间特征增强目标语音至关重要。然而,在有限的麦克风阵列下,开发紧凑的多通道语音增强系统仍然具有挑战性,特别是在极低信噪比(SNR)条件下。为了解决这一问题,我们提出了一种三导向空间选择方法,这是一个灵活的框架,使用三个导向向量来指导增强并确定增强范围。具体来说,我们引入了因果导向U-Net(CDUNet)模型,该模型以原始多通道语音和所需的增强宽度为输入。这可以根据目标方向和干扰信号之间的角度间隔动态调整导向向量,并微调增强区域。我们的模型仅使用双麦克风阵列,在语音质量和下游任务性能方面都表现出色。它以实时方式运行,参数最少,非常适合低延迟的在线流式应用。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
在复杂的多说话人场景中,利用空间特征增强目标语音至关重要。针对有限麦克风阵列在极低信噪比条件下构建紧凑的多通道语音增强系统的挑战,我们提出了一种灵活的三向空间选择方法。该方法使用三个引导向量进行增强并确定增强范围。此外,我们引入了因果导向U-Net模型(CDUNet),能够根据目标方向和角度间隔对干扰信号进行动态调整,从而实现精细化增强。此模型仅用双麦克风阵列就表现出色,适用于实时、低延迟的在线流式应用。
Key Takeaways
- 在多说话人场景中,利用空间特征增强目标语音是必要的。
- 针对有限麦克风阵列和极低信噪比条件,构建多通道语音增强系统具有挑战性。
- 提出了一种灵活的三向空间选择方法,使用三个引导向量进行语音增强。
- 引入了因果导向U-Net(CDUNet)模型,能够根据目标方向和角度间隔动态调整增强效果。
- 该模型在仅有双麦克风阵列的情况下表现出色。
- 模型在语音质量和下游任务性能上均表现优异。
点此查看论文截图

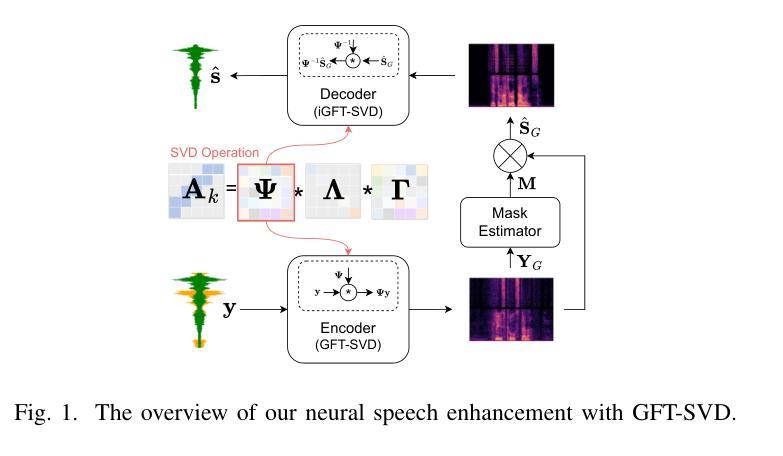
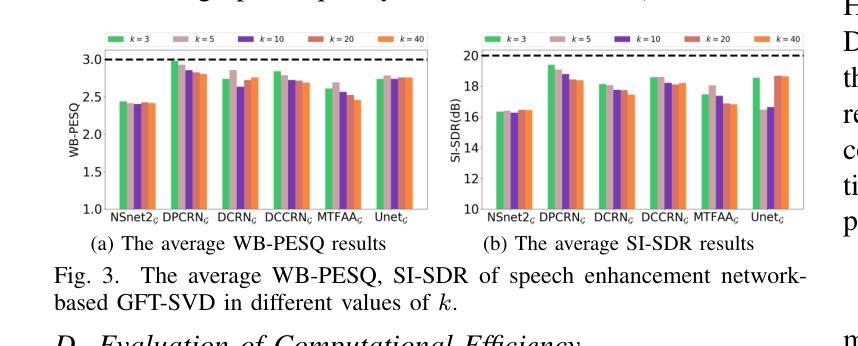
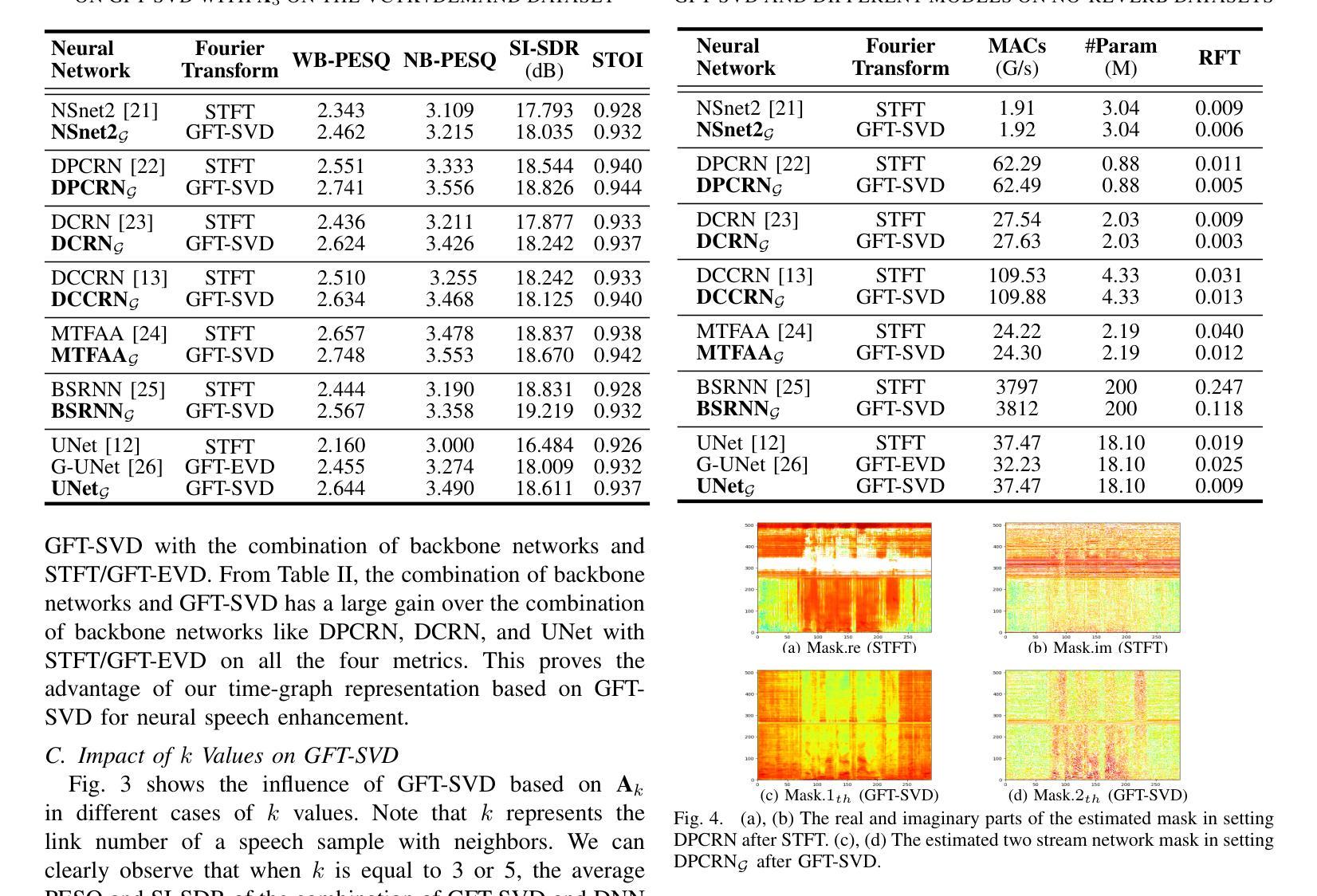
Time-Graph Frequency Representation with Singular Value Decomposition for Neural Speech Enhancement
Authors:Tingting Wang, Tianrui Wang, Meng Ge, Qiquan Zhang, Zirui Ge, Zhen Yang
Time-frequency (T-F) domain methods for monaural speech enhancement have benefited from the success of deep learning. Recently, focus has been put on designing two-stream network models to predict amplitude mask and phase separately, or, coupling the amplitude and phase into Cartesian coordinates and constructing real and imaginary pairs. However, most methods suffer from the alignment modeling of amplitude and phase (real and imaginary pairs) in a two-stream network framework, which inevitably incurs performance restrictions. In this paper, we introduce a graph Fourier transform defined with the singular value decomposition (GFT-SVD), resulting in real-valued time-graph representation for neural speech enhancement. This real-valued representation-based GFT-SVD provides an ability to align the modeling of amplitude and phase, leading to avoiding recovering the target speech phase information. Our findings demonstrate the effects of real-valued time-graph representation based on GFT-SVD for neutral speech enhancement. The extensive speech enhancement experiments establish that the combination of GFT-SVD and DNN outperforms the combination of GFT with the eigenvector decomposition (GFT-EVD) and magnitude estimation UNet, and outperforms the short-time Fourier transform (STFT) and DNN, regarding objective intelligibility and perceptual quality. We release our source code at: https://github.com/Wangfighting0015/GFT\_project.
针对单声道语音增强的时频域方法受益于深度学习取得的成就。最近,人们专注于设计双流传络模型,以便分别预测振幅掩模和相位,或者将振幅和相位耦合到笛卡尔坐标系中,并构建实数和虚数对。然而,大多数方法在双流传络框架中遭受振幅和相位(实数和虚数对)的对齐建模困扰,这不可避免地会导致性能限制。在本文中,我们引入了一种利用奇异值分解定义的图傅里叶变换(GFT-SVD),从而得到用于神经语音增强的实值时间图表示。这种基于实值表示的GFT-SVD提供了对齐振幅和相位建模的能力,避免了恢复目标语音相位信息。我们的研究结果表明,基于GFT-SVD的实值时间图表示对于中性语音增强具有影响。广泛的语音增强实验证实,GFT-SVD与深度神经网络(DNN)的结合优于GFT与特征向量分解(GFT-EVD)的结合以及幅度估计UNet,并且在客观可理解性和感知质量方面优于短时傅里叶变换(STFT)和DNN。我们在以下链接发布了我们的源代码:https://github.com/Wangfighting0015/GFT_project。
论文及项目相关链接
PDF 5 pages, 4 figures, Accepted by ICASSP2025
摘要
利用基于奇异值分解的图傅里叶变换(GFT-SVD)实现真实值时间图表示为神经语音增强提供了一个有效方法。通过对振幅和相位进行实值时间图表示,避免了目标语音相位信息的恢复。实验结果表明,基于实值时间图表示的GFT-SVD对于中性语音增强具有显著效果。在广泛的语音增强实验中,结合GFT-SVD和深度神经网络(DNN)的表现优于结合GFT与特征向量分解(GFT-EVD)以及幅度估计UNet,并且在客观可理解性和感知质量方面优于短时傅里叶变换(STFT)和DNN。
关键见解
- 引入基于奇异值分解的图傅里叶变换(GFT-SVD)实现真实值时间图表示,为神经语音增强提供新方法。
- 实值时间图表示能够实现对振幅和相位的对齐建模,避免恢复目标语音的相位信息。
- GFT-SVD结合DNN的方法在语音增强实验中表现出优越性能。
- GFT-SVD与STFT及DNN等方法相比,在客观可理解性和感知质量方面有更优表现。
- 本文提供的源代码已公开发布在GitHub上。
- 通过实值时间图表示方法提高了神经语音增强的性能。
- 研究展示了实值时间图表示在处理振幅和相位对齐建模问题中的有效性。
点此查看论文截图


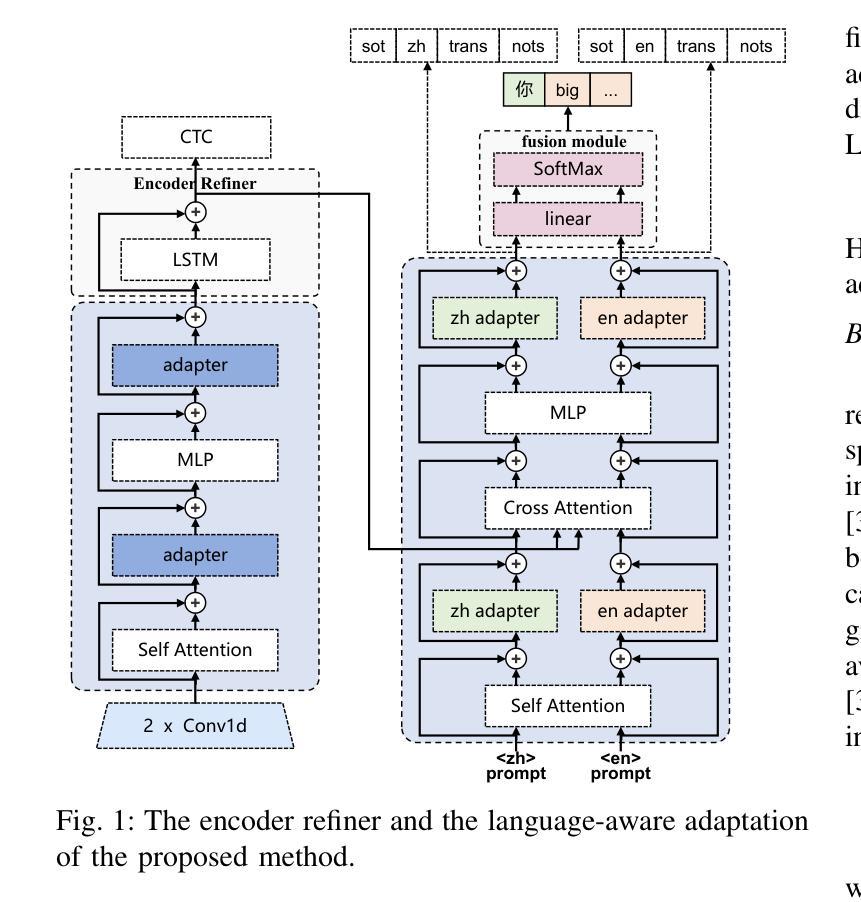
Adapting Whisper for Code-Switching through Encoding Refining and Language-Aware Decoding
Authors:Jiahui Zhao, Hao Shi, Chenrui Cui, Tianrui Wang, Hexin Liu, Zhaoheng Ni, Lingxuan Ye, Longbiao Wang
Code-switching (CS) automatic speech recognition (ASR) faces challenges due to the language confusion resulting from accents, auditory similarity, and seamless language switches. Adaptation on the pre-trained multi-lingual model has shown promising performance for CS-ASR. In this paper, we adapt Whisper, which is a large-scale multilingual pre-trained speech recognition model, to CS from both encoder and decoder parts. First, we propose an encoder refiner to enhance the encoder’s capacity of intra-sentence swithching. Second, we propose using two sets of language-aware adapters with different language prompt embeddings to achieve language-specific decoding information in each decoder layer. Then, a fusion module is added to fuse the language-aware decoding. The experimental results using the SEAME dataset show that, compared with the baseline model, the proposed approach achieves a relative MER reduction of 4.1% and 7.2% on the dev_man and dev_sge test sets, respectively, surpassing state-of-the-art methods. Through experiments, we found that the proposed method significantly improves the performance on non-native language in CS speech, indicating that our approach enables Whisper to better distinguish between the two languages.
代码切换(CS)自动语音识别(ASR)面临着由于口音、听觉相似性和无缝语言切换导致的语言混淆所带来的挑战。预训练的多元语言模型的适配已经显示出对CS-ASR的有前途的性能。在本文中,我们适配了whisper这样一个大规模的多语言预训练语音识别模型,以适应编码器和解码器部分的CS。首先,我们提出了一个编码器精炼器,以提高编码器在句子内切换的能力。其次,我们建议使用两组带有不同语言提示嵌入的语言感知适配器,以实现每个解码器层中的特定语言解码信息。然后,添加一个融合模块来融合语言感知解码。使用SEAME数据集的实验结果表明,与基线模型相比,所提出的方法在dev_man和dev_sge测试集上分别实现了相对MER降低4.1%和7.2%,超过了最先进的方法。通过实验,我们发现该方法在非本地语言的CS语音性能上有了显著提高,这表明我们的方法能使whisper更好地区分两种语言。
论文及项目相关链接
Summary
本文研究了在自动语音识别中,使用预训练的多语言模型进行代码切换的挑战。为了改进性能,对大型预训练语音模型Whisper进行了适应调整,涉及编码器精炼器和解码器部分的改进。通过采用融合模块,实现语言特定的解码信息。实验结果表明,与基线模型相比,所提出的方法在SEAME数据集上的平均错误率有所降低,特别是在非母语代码的切换语音方面表现显著。
Key Takeaways
- 代码切换自动语音识别面临语言混淆的挑战,包括口音、听觉相似性和无缝语言切换。
- 预训练的多语言模型适应于代码切换自动语音识别显示出良好性能。
- 对编码器进行精炼以提高句子内部的切换能力。
- 采用两组语言感知适配器与不同的语言提示嵌入实现每层解码器的语言特定解码信息。
- 添加融合模块以融合语言感知解码。
- 实验结果表明,与基线模型相比,所提出的方法在测试集上的平均错误率有所降低。
点此查看论文截图

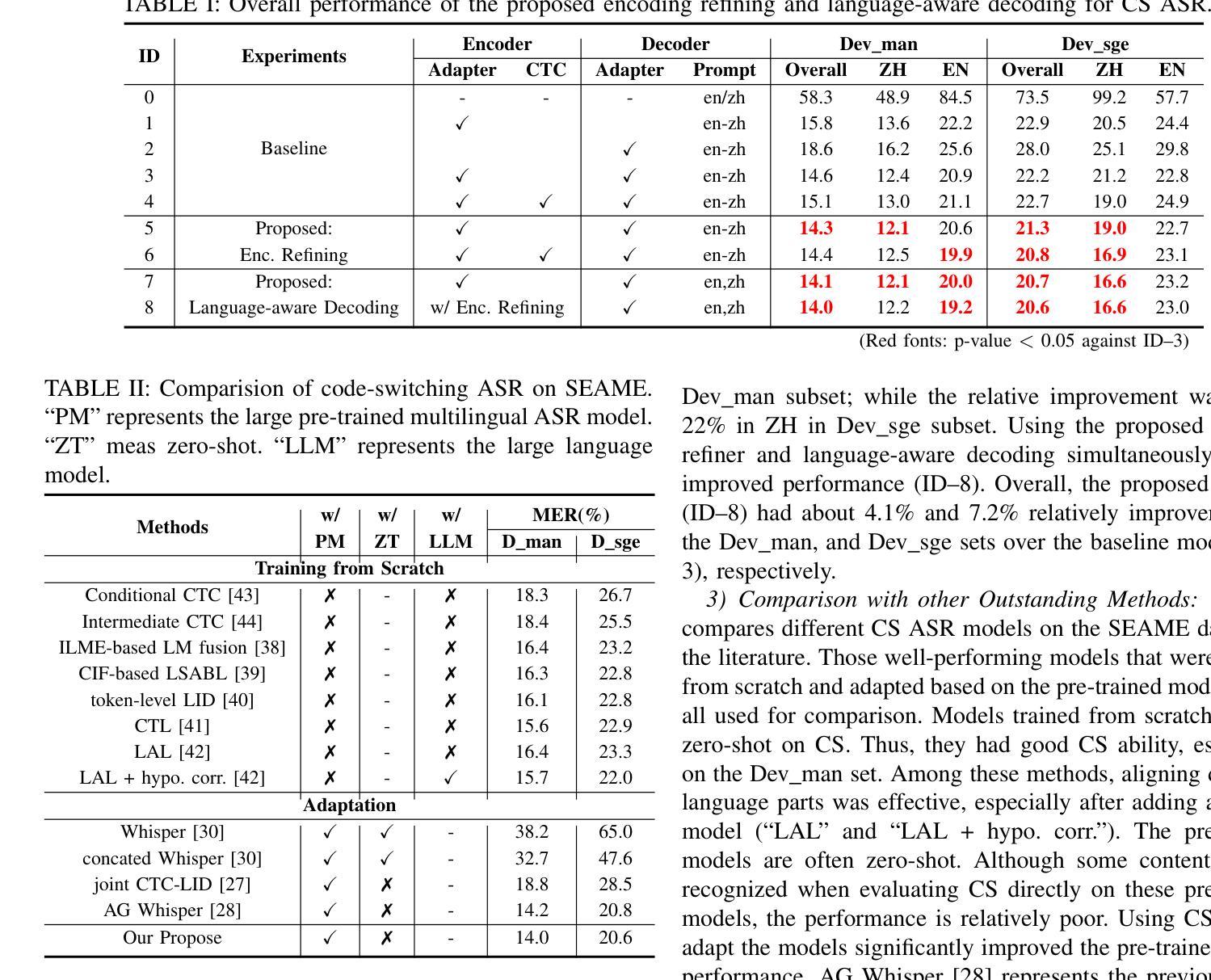
Streaming Keyword Spotting Boosted by Cross-layer Discrimination Consistency
Authors:Yu Xi, Haoyu Li, Xiaoyu Gu, Hao Li, Yidi Jiang, Kai Yu
Connectionist Temporal Classification (CTC), a non-autoregressive training criterion, is widely used in online keyword spotting (KWS). However, existing CTC-based KWS decoding strategies either rely on Automatic Speech Recognition (ASR), which performs suboptimally due to its broad search over the acoustic space without keyword-specific optimization, or on KWS-specific decoding graphs, which are complex to implement and maintain. In this work, we propose a streaming decoding algorithm enhanced by Cross-layer Discrimination Consistency (CDC), tailored for CTC-based KWS. Specifically, we introduce a streamlined yet effective decoding algorithm capable of detecting the start of the keyword at any arbitrary position. Furthermore, we leverage discrimination consistency information across layers to better differentiate between positive and false alarm samples. Our experiments on both clean and noisy Hey Snips datasets show that the proposed streaming decoding strategy outperforms ASR-based and graph-based KWS baselines. The CDC-boosted decoding further improves performance, yielding an average absolute recall improvement of 6.8% and a 46.3% relative reduction in the miss rate compared to the graph-based KWS baseline, with a very low false alarm rate of 0.05 per hour.
连接时序分类(CTC)是一种非自回归训练准则,广泛应用于在线关键词识别(KWS)。然而,现有的基于CTC的KWS解码策略要么依赖于自动语音识别(ASR),由于其在声学空间进行广泛搜索而没有针对关键词进行特定优化,导致性能不佳;要么依赖于特定的KWS解码图,这些图复杂且难以实施和维护。在这项工作中,我们提出了一种通过跨层鉴别一致性(CDC)增强的流式解码算法,适用于基于CTC的KWS。具体来说,我们引入了一种简化但有效的解码算法,能够在任意位置检测关键词的开始。此外,我们利用跨层的鉴别一致性信息来更好地区分正样本和误报样本。我们在干净和嘈杂的Hey Snips数据集上的实验表明,所提出的流式解码策略优于基于ASR和基于图的KWS基线。通过CDC增强的解码进一步提高了性能,与基于图的KWS基线相比,平均绝对召回率提高了6.8%,漏报率相对降低了46.3%,同时每小时误报率非常低,为0.05次。
论文及项目相关链接
PDF Accepted by ICASSP2025
Summary
本文介绍了针对连接时序分类(CTC)的在线关键词识别(KWS)的改进解码算法。该算法通过跨层判别一致性(CDC)增强,引入了一种简化的解码算法,能在任意位置检测关键词的开始。实验表明,与基于自动语音识别(ASR)和基于图的KWS基线相比,该解码策略具有更好的性能。CDC的引入进一步提高了性能,平均绝对召回率提高了6.8%,相对于基于图的KWS基线,误报率降低了46.3%,每小时的误报率仅为每小时0.05次。
Key Takeaways
- 引入连接时序分类(CTC)用于在线关键词识别(KWS)。
- 现有CTC-based KWS解码策略依赖于自动语音识别(ASR)或复杂的KWS解码图,存在性能瓶颈。
- 提出一种改进的解码算法,能在任意位置检测关键词的开始。
- 通过跨层判别一致性(CDC)增强解码算法,提高关键词识别的准确性。
- 实验表明,该解码策略在清洁和嘈杂的Hey Snips数据集上均优于基于ASR和基于图的KWS基线。
- CDC的引入进一步提高了性能,平均绝对召回率提高,误报率降低。
点此查看论文截图


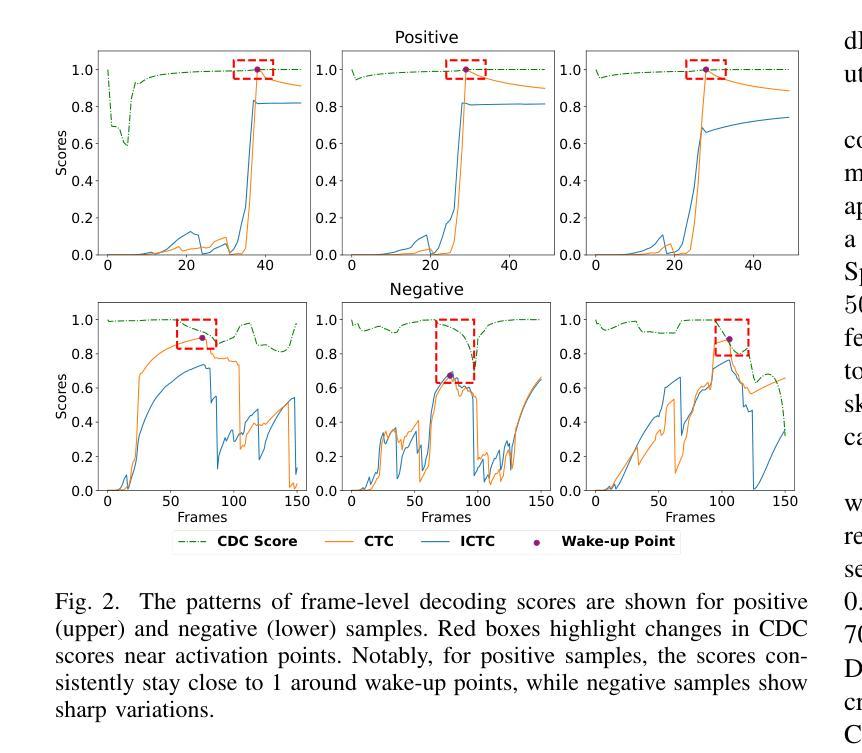
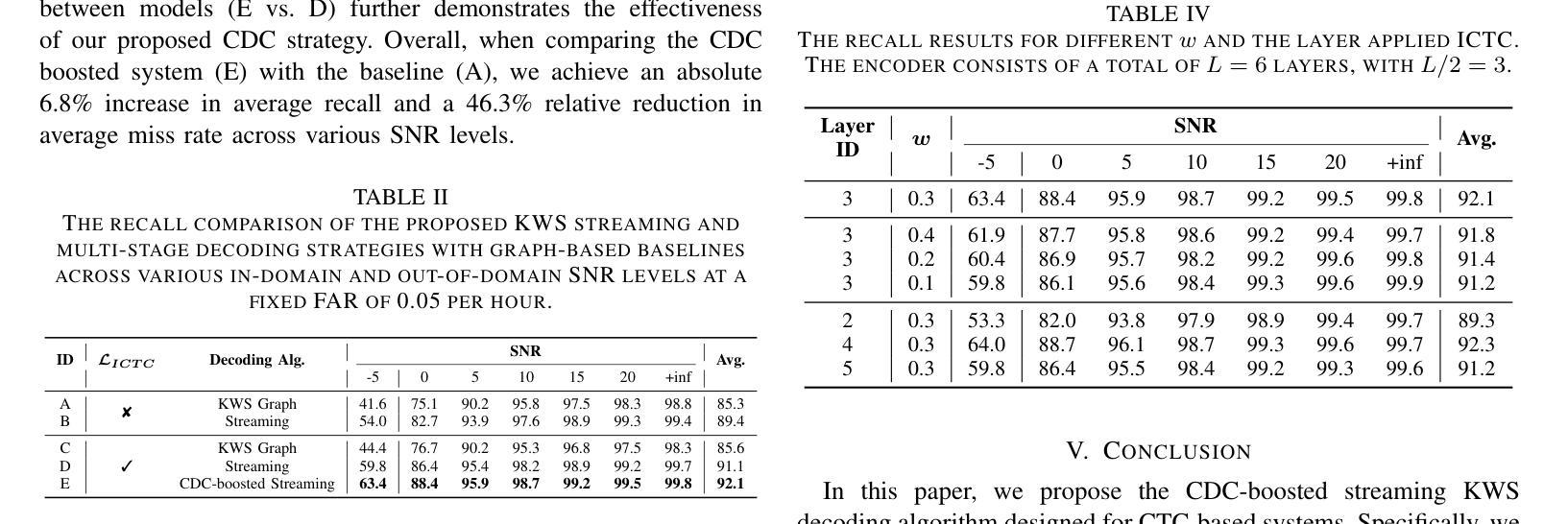
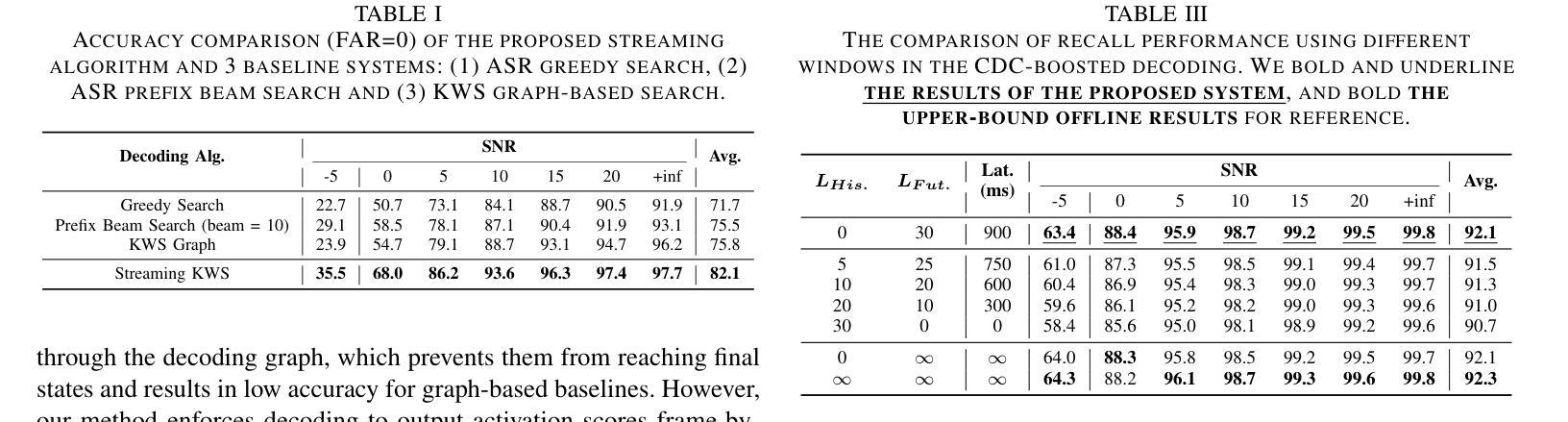
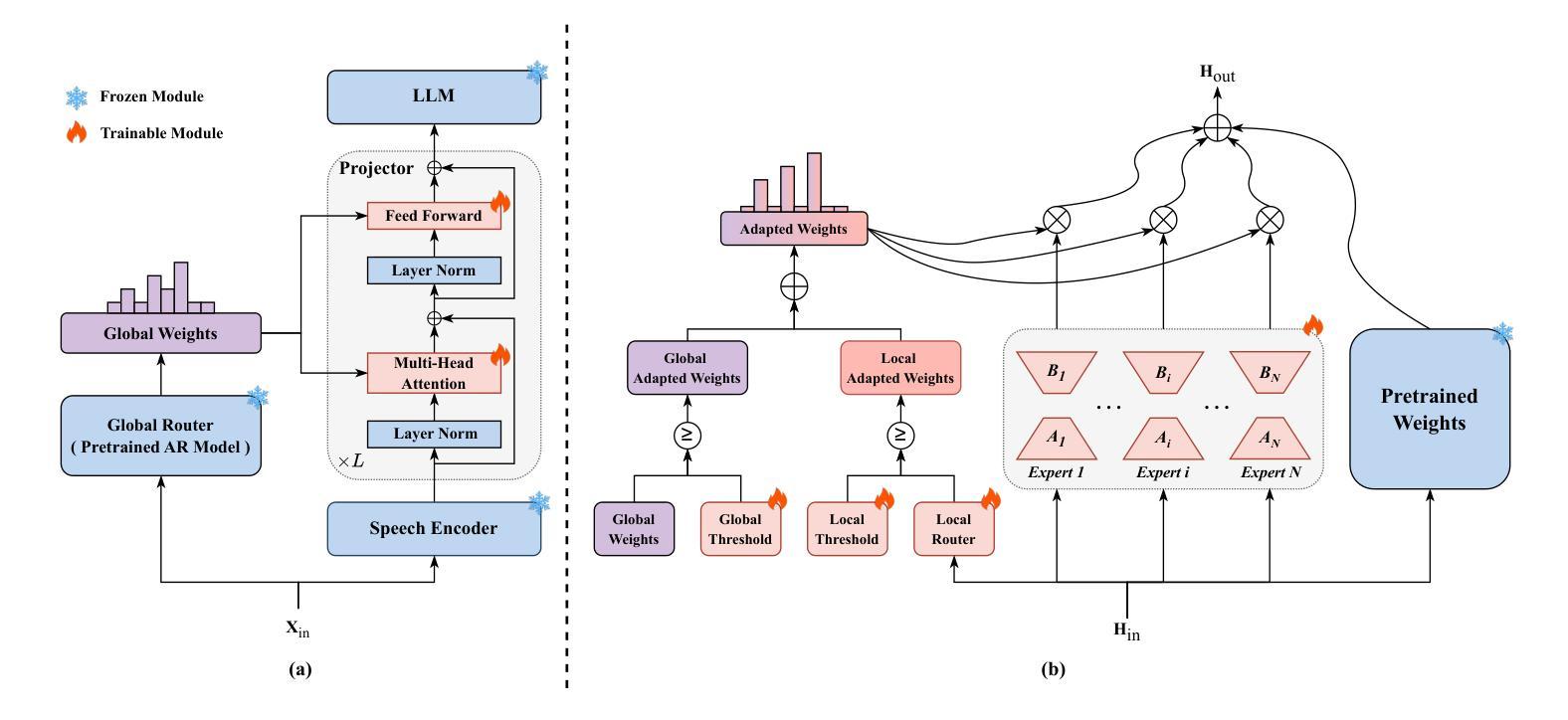
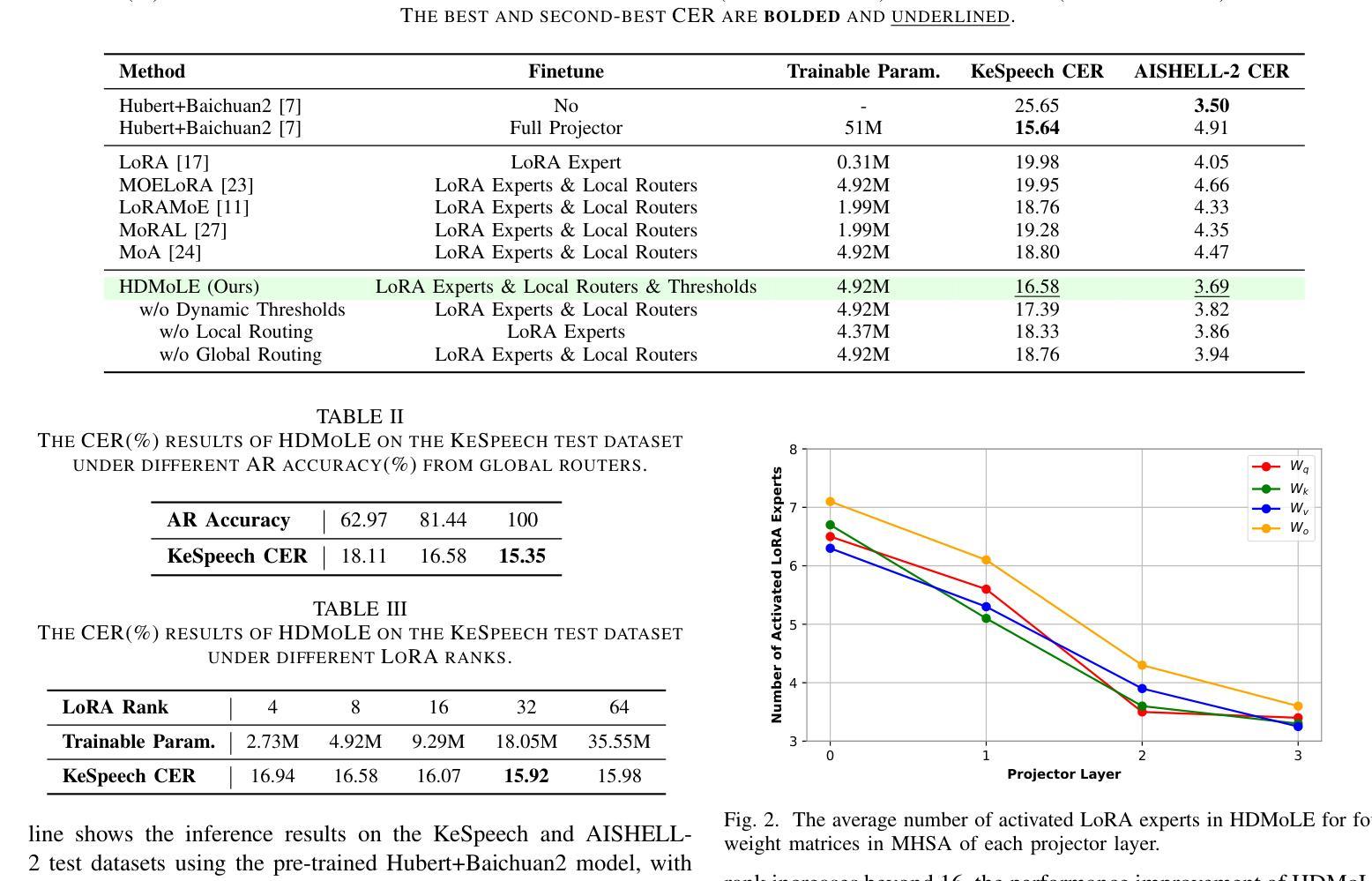
HDMoLE: Mixture of LoRA Experts with Hierarchical Routing and Dynamic Thresholds for Fine-Tuning LLM-based ASR Models
Authors:Bingshen Mu, Kun Wei, Qijie Shao, Yong Xu, Lei Xie
Recent advancements in integrating Large Language Models (LLM) with automatic speech recognition (ASR) have performed remarkably in general domains. While supervised fine-tuning (SFT) of all model parameters is often employed to adapt pre-trained LLM-based ASR models to specific domains, it imposes high computational costs and notably reduces their performance in general domains. In this paper, we propose a novel parameter-efficient multi-domain fine-tuning method for adapting pre-trained LLM-based ASR models to multi-accent domains without catastrophic forgetting named \textit{HDMoLE}, which leverages hierarchical routing and dynamic thresholds based on combining low-rank adaptation (LoRA) with the mixer of experts (MoE) and can be generalized to any linear layer. Hierarchical routing establishes a clear correspondence between LoRA experts and accent domains, improving cross-domain collaboration among the LoRA experts. Unlike the static Top-K strategy for activating LoRA experts, dynamic thresholds can adaptively activate varying numbers of LoRA experts at each MoE layer. Experiments on the multi-accent and standard Mandarin datasets demonstrate the efficacy of HDMoLE. Applying HDMoLE to an LLM-based ASR model projector module achieves similar performance to full fine-tuning in the target multi-accent domains while using only 9.6% of the trainable parameters required for full fine-tuning and minimal degradation in the source general domain.
最近,将大型语言模型(LLM)与自动语音识别(ASR)结合的进展在通用领域取得了显著的效果。虽然通常通过监督微调(SFT)所有模型参数来适应基于预训练LLM的ASR模型到特定领域,但它带来了巨大的计算成本,并且会显著减少其在通用领域中的性能。在本文中,我们提出了一种新的参数高效多领域微调方法,用于适应基于预训练LLM的ASR模型到多口音领域,该方法在多口音领域中无需灾难性遗忘即可进行适应,被称为HDMoLE。它结合了低秩适应(LoRA)与专家混合器(MoE)的优势,并利用层次路由和动态阈值,可以推广到任何线性层。层次路由建立了LoRA专家和口音领域之间的明确对应关系,提高了LoRA专家之间的跨领域协作。与静态Top-K策略激活LoRA专家不同,动态阈值可以自适应地激活MoE层中不同数量的LoRA专家。在多种口音和标准普通话数据集上的实验证明了HDMoLE的有效性。将HDMoLE应用于基于LLM的ASR模型的投影模块,在目标多口音领域取得了与完全微调相似的性能,同时仅使用全微调所需的可训练参数的9.6%,并且在源通用领域的性能几乎没有下降。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
基于预训练的大型语言模型(LLM)的自动语音识别(ASR)技术在通用领域取得了显著进展。然而,对所有模型参数进行有监督微调(SFT)以适应特定领域时,会带来高计算成本并降低其在通用领域的性能。本文提出了一种新型的参数高效多领域微调方法,名为HDMoLE,用于适应多口音领域的预训练LLM-based ASR模型,同时避免灾难性遗忘。该方法结合了低秩适应(LoRA)与专家混合器(MoE),采用层次路由和动态阈值,可以推广到任何线性层。实验表明,HDMoLE在多口音及标准普通话数据集上表现有效。应用于LLM-based ASR模型的投影模块时,HDMoLE在目标多口音领域实现了与全微调相似的性能,同时仅使用全微调所需训练参数的9.6%,并且在源通用领域的性能损失极小。
Key Takeaways
- 大型语言模型(LLM)与自动语音识别(ASR)的集成在通用领域取得了显著进展。
- 监督微调(SFT)虽然能使LLM-based ASR模型适应特定领域,但计算成本高并在通用领域性能降低。
- 提出了一种新型的参数高效多领域微调方法——HDMoLE,适用于多口音领域的预训练LLM-based ASR模型。
- HDMoLE结合了低秩适应(LoRA)与专家混合器(MoE)。
- 层次路由和动态阈值方法被用于HDMoLE,以提高跨领域的协作能力并适应不同数量的LoRA专家。
- 实验表明HDMoLE在多口音及标准普通话数据集上的有效性。
点此查看论文截图

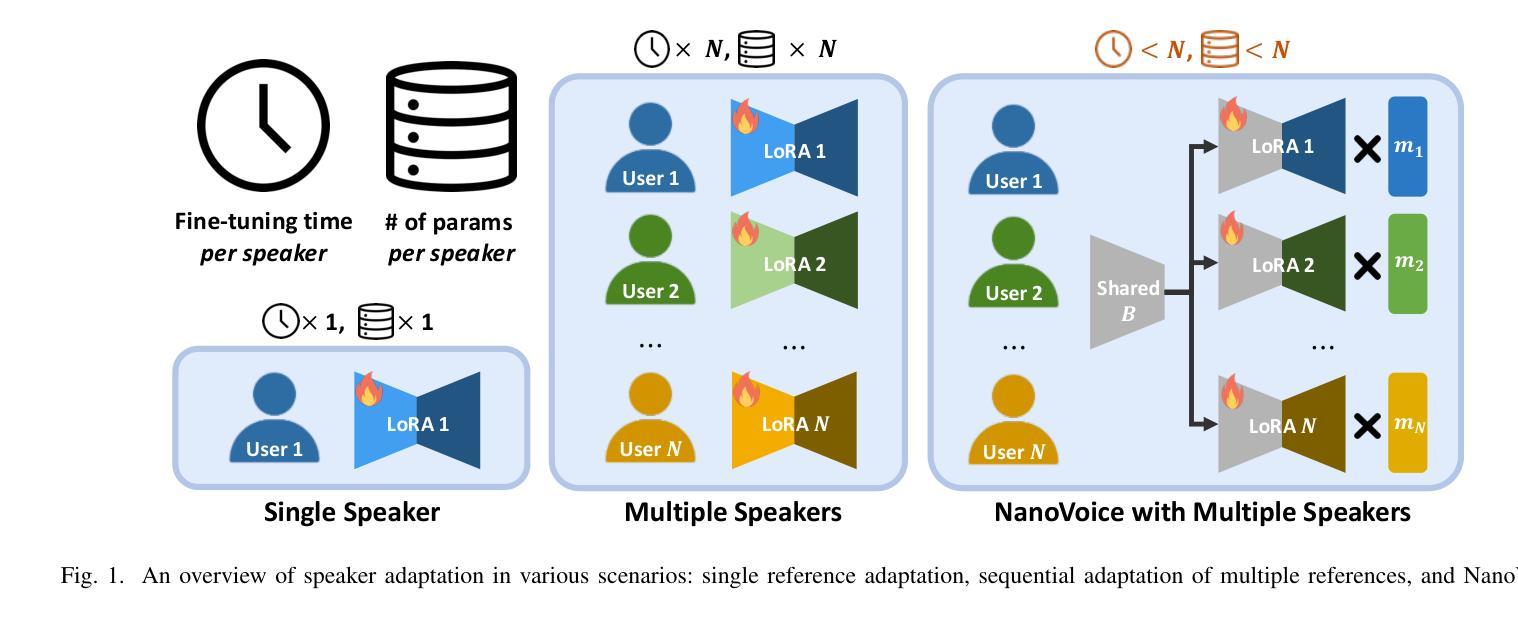
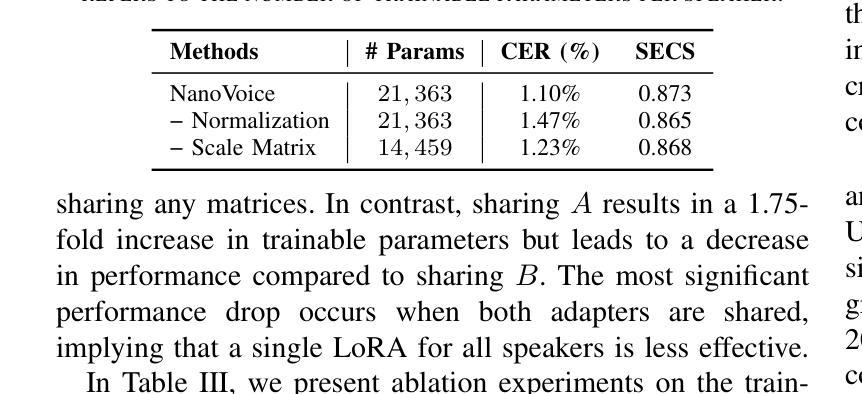
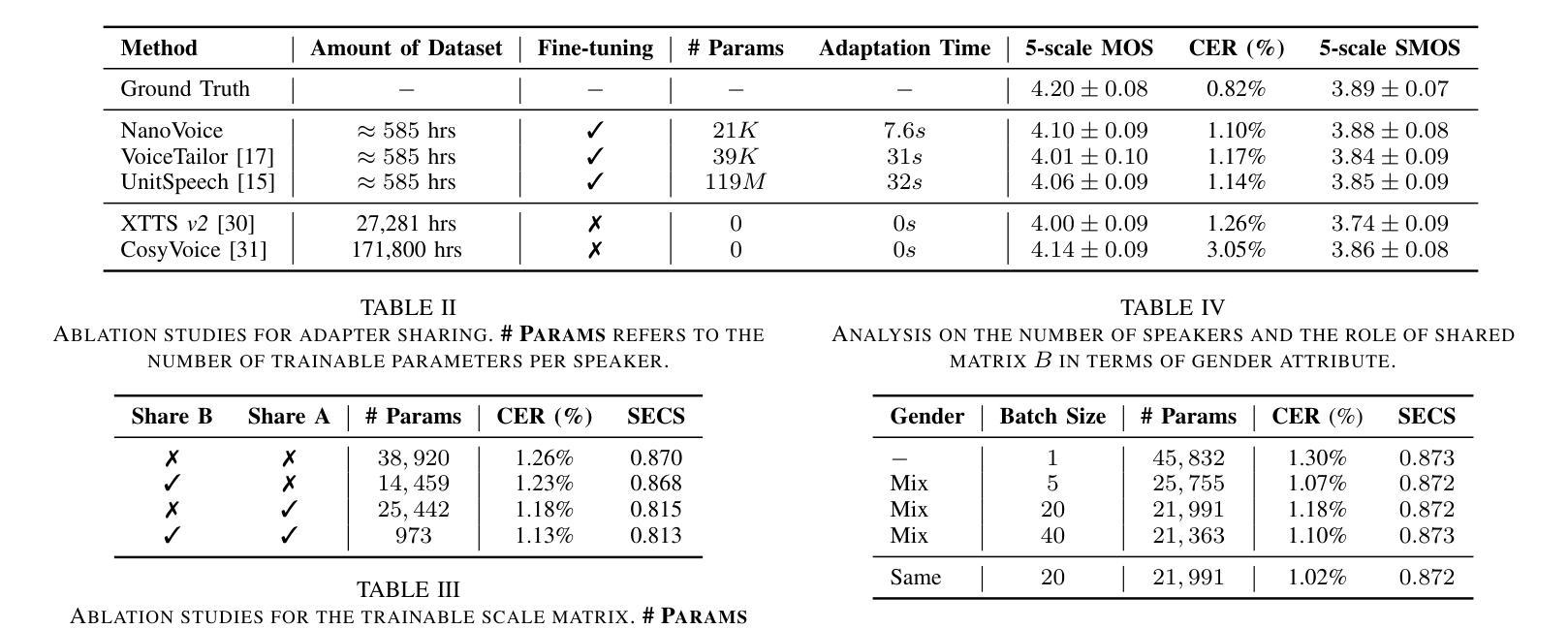
NanoVoice: Efficient Speaker-Adaptive Text-to-Speech for Multiple Speakers
Authors:Nohil Park, Heeseung Kim, Che Hyun Lee, Jooyoung Choi, Jiheum Yeom, Sungroh Yoon
We present NanoVoice, a personalized text-to-speech model that efficiently constructs voice adapters for multiple speakers simultaneously. NanoVoice introduces a batch-wise speaker adaptation technique capable of fine-tuning multiple references in parallel, significantly reducing training time. Beyond building separate adapters for each speaker, we also propose a parameter sharing technique that reduces the number of parameters used for speaker adaptation. By incorporating a novel trainable scale matrix, NanoVoice mitigates potential performance degradation during parameter sharing. NanoVoice achieves performance comparable to the baselines, while training 4 times faster and using 45 percent fewer parameters for speaker adaptation with 40 reference voices. Extensive ablation studies and analysis further validate the efficiency of our model.
我们推出了NanoVoice,这是一款个性化的文本到语音模型,能够高效地为多个发言者同时构建语音适配器。NanoVoice引入了一种批处理说话人适应技术,能够并行微调多个参考数据,从而大大缩短训练时间。除了为每个说话人构建单独的适配器外,我们还提出了一种参数共享技术,以减少用于说话人适应的参数数量。通过引入一个新的可训练比例矩阵,NanoVoice在参数共享时减轻了性能下降的潜在风险。NanoVoice的性能与基线相当,同时训练速度提高了4倍,用于说话人适应的参数减少了45%。广泛的消融实验和分析进一步验证了我们的模型效率。
论文及项目相关链接
PDF IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025, Demo Page: https://nanovoice.github.io/
Summary
NanoVoice是一个个性化的文本到语音模型,能够同时为多个说话者构建语音适配器,并引入了批处理说话者适应技术,能够并行微调多个参考,显著减少训练时间。该模型还提出了一种参数共享技术,减少用于说话者适应的参数数量,并借助新型可训练比例矩阵缓解参数共享期间潜在的性能下降问题。NanoVoice的性能与基线相当,训练速度提高4倍,使用参数进行说话者适应时减少了45%。
Key Takeaways
- NanoVoice是一个文本到语音模型,能同时为多个说话者构建语音适配器。
- 引入批处理说话者适应技术,能并行微调多个参考,显著减少训练时间。
- 提出了参数共享技术,减少用于说话者适应的参数数量。
- 通过新型可训练比例矩阵,缓解参数共享时的性能下降问题。
- NanoVoice的性能与基线相当,训练速度提升4倍,参数使用减少45%。
- 进行了广泛的分析和消融研究,验证了模型的有效性。
点此查看论文截图

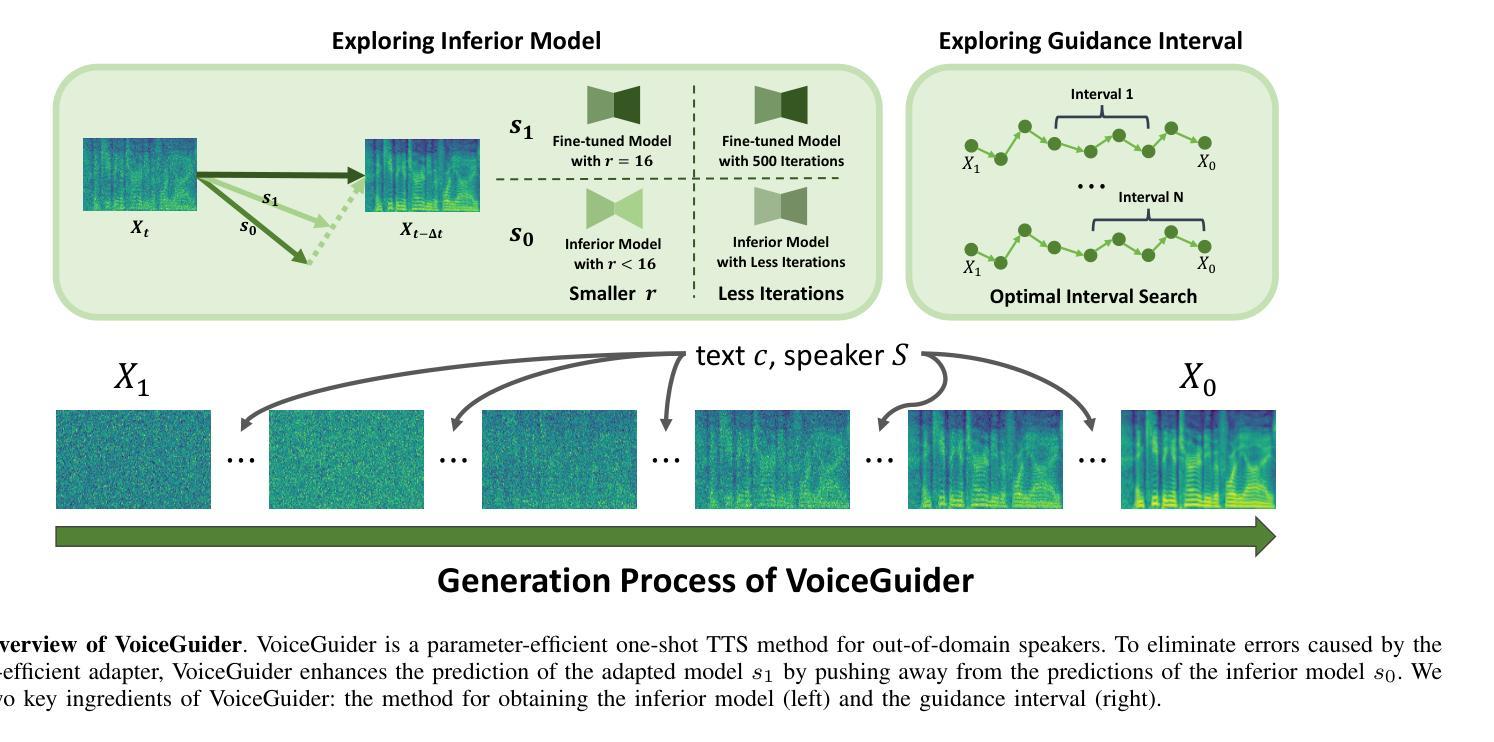
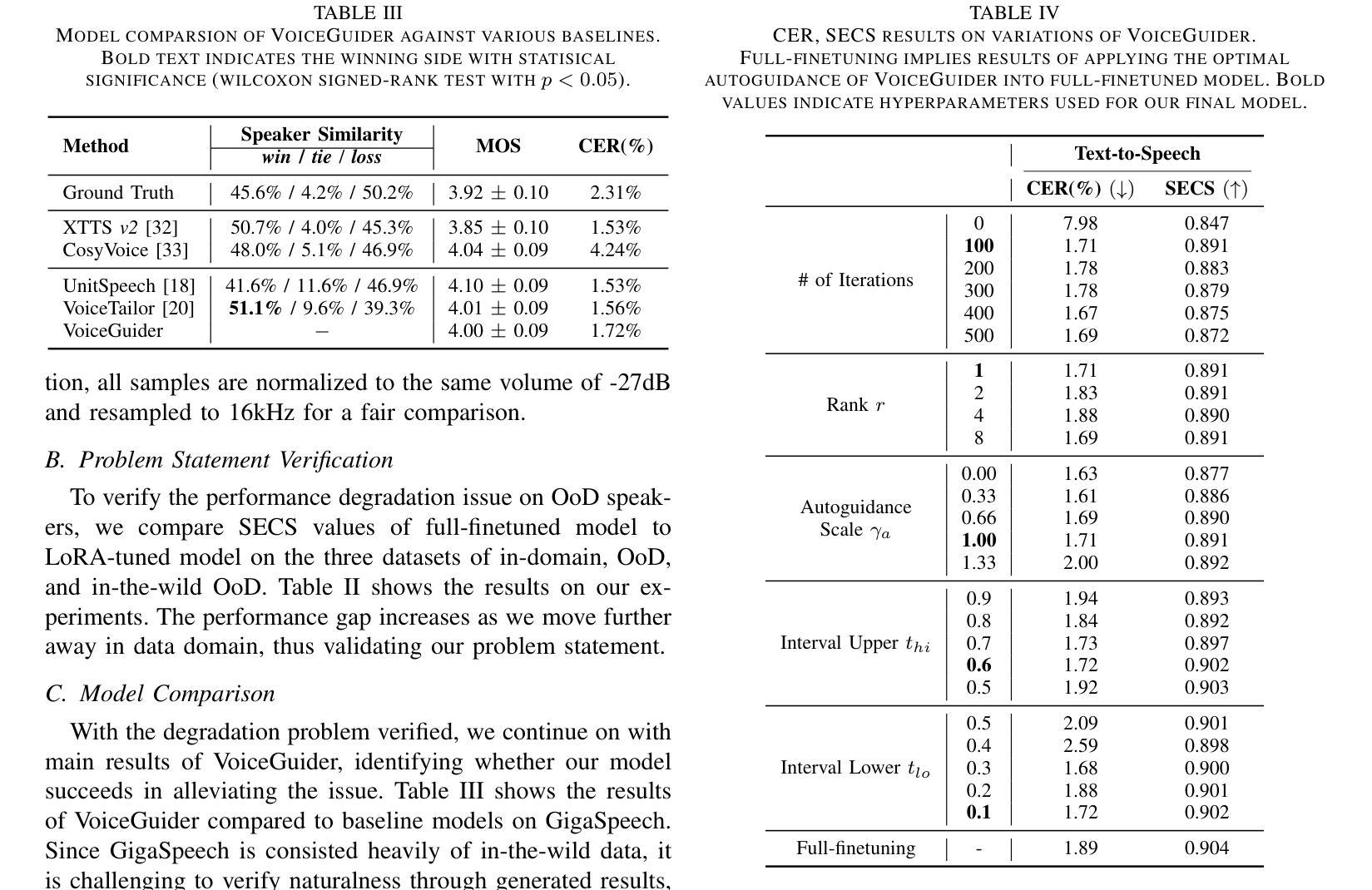
VoiceGuider: Enhancing Out-of-Domain Performance in Parameter-Efficient Speaker-Adaptive Text-to-Speech via Autoguidance
Authors:Jiheum Yeom, Heeseung Kim, Jooyoung Choi, Che Hyun Lee, Nohil Park, Sungroh Yoon
When applying parameter-efficient finetuning via LoRA onto speaker adaptive text-to-speech models, adaptation performance may decline compared to full-finetuned counterparts, especially for out-of-domain speakers. Here, we propose VoiceGuider, a parameter-efficient speaker adaptive text-to-speech system reinforced with autoguidance to enhance the speaker adaptation performance, reducing the gap against full-finetuned models. We carefully explore various ways of strengthening autoguidance, ultimately finding the optimal strategy. VoiceGuider as a result shows robust adaptation performance especially on extreme out-of-domain speech data. We provide audible samples in our demo page.
当通过LoRA进行参数高效的微调来适应说话人的文本到语音模型时,与完全微调过的模型相比,适应性能可能会下降,特别是对于非域内的说话人。针对这一问题,我们提出了VoiceGuider,这是一个通过自动引导增强的参数高效说话人自适应文本到语音系统,以提高说话人适应性能,缩小与完全微调模型之间的差距。我们仔细探索了加强自动引导的各种方法,并最终找到了最佳策略。VoiceGuider在极端非域语音数据上表现出了稳健的适应性能。我们在演示页面上提供了可听的样本。
论文及项目相关链接
PDF IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2025, Demo Page: https://voiceguider.github.io/
Summary
在文本转语音模型中采用LoRA进行参数有效微调时,相比于全微调的模型,其适应性性能可能会下降,特别是对于非域内的发言人更为明显。为解决这一问题,我们提出了VoiceGuider系统,该系统强化了参数有效的语音自适应功能并引入了自动指导机制来增强语音适应性能,缩小了与全微调模型的差距。经过对强化自动指导机制的多种方法的探索,我们找到了最佳策略。VoiceGuider对于极端非域内的语音数据展现出了强大的适应能力。我们将在演示页面中提供可听的样本。
Key Takeaways
- LoRA在应用于语音自适应文本转语音模型时,相较于全微调模型,其适应性性能可能会下降。
- VoiceGuider系统是一种参数有效的语音自适应系统,通过引入自动指导机制强化了性能。
- VoiceGuider系统能有效缩小与全微调模型的性能差距。
- 强化自动指导机制的多种方法被探索,并找到了最佳策略。
- VoiceGuider系统在处理极端非域内的语音数据时表现出强大的适应能力。
- 演示页面中提供了可听的样本以展示VoiceGuider系统的性能。
点此查看论文截图

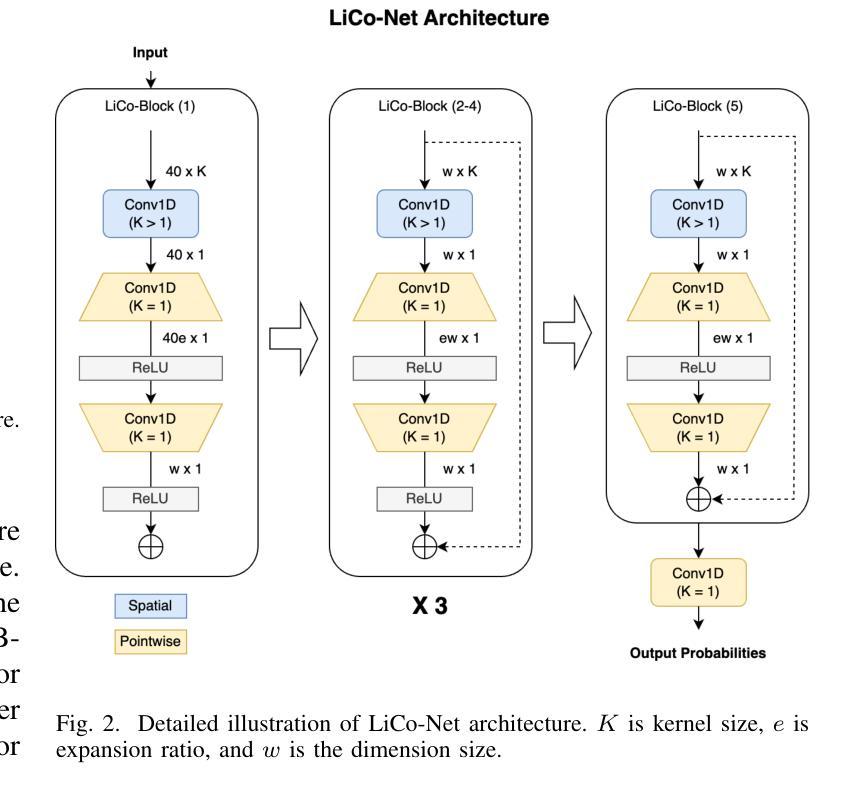
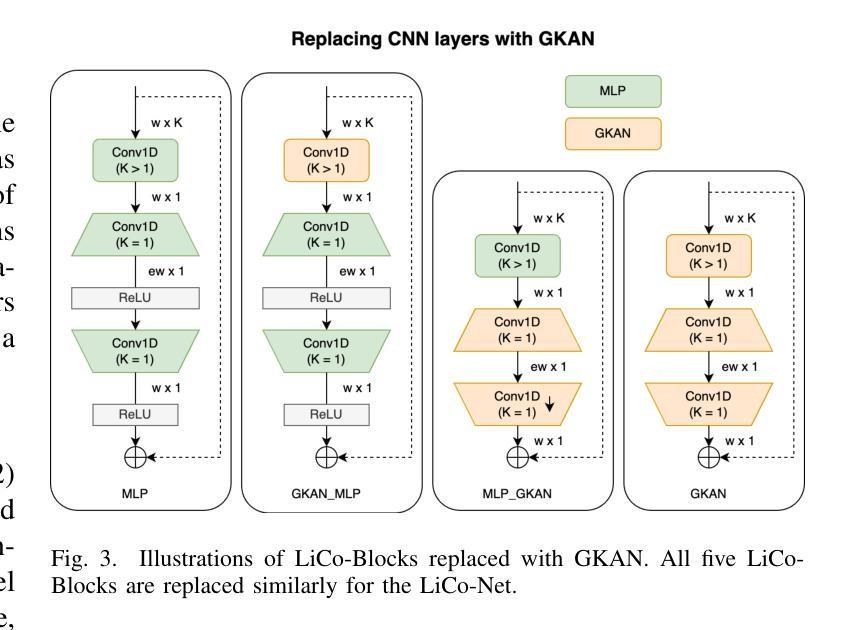
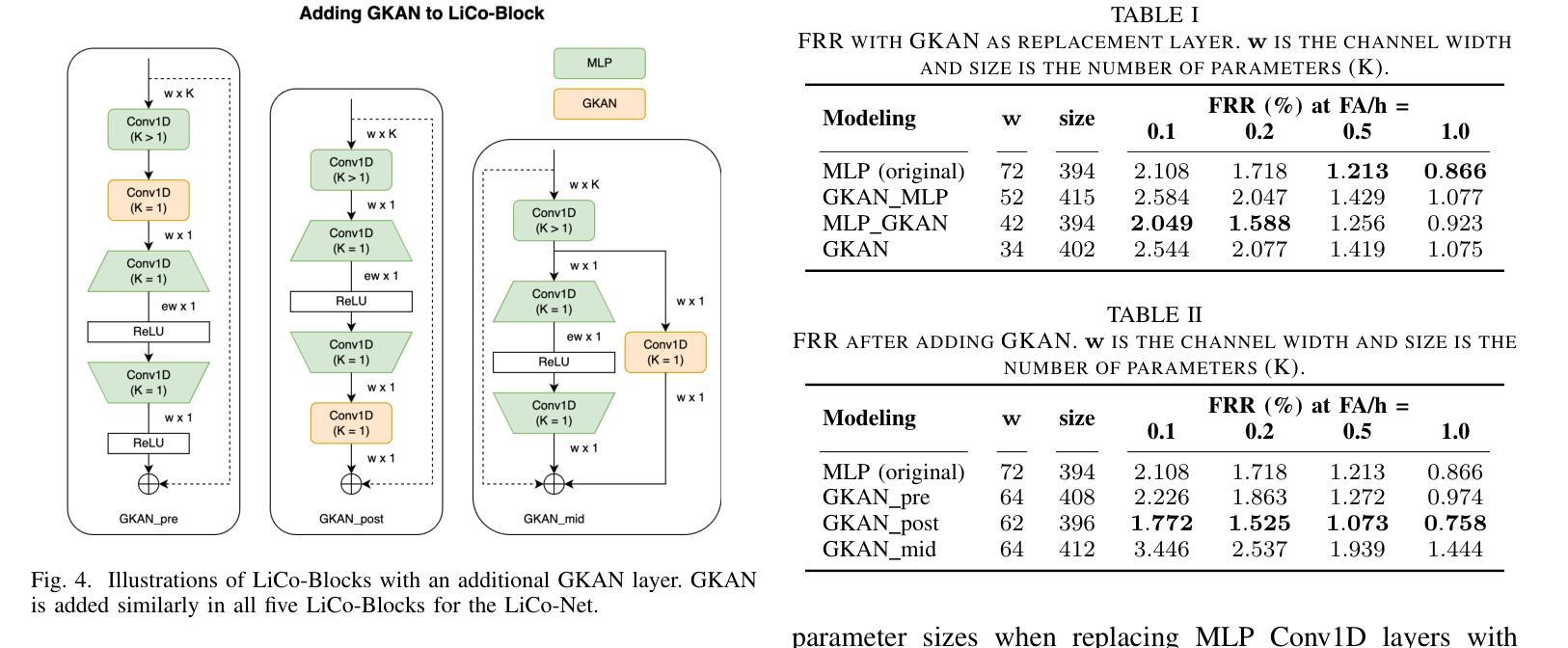
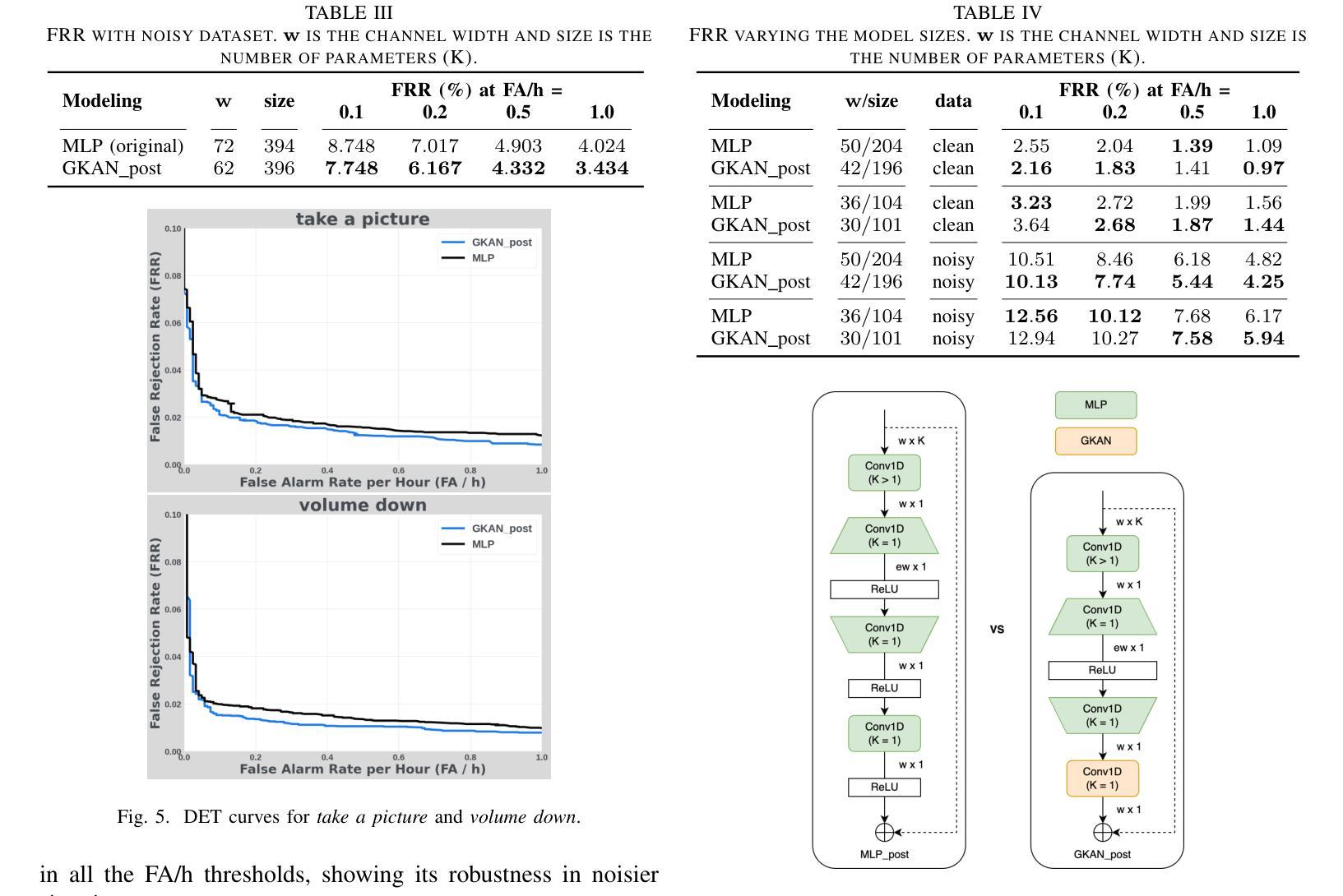
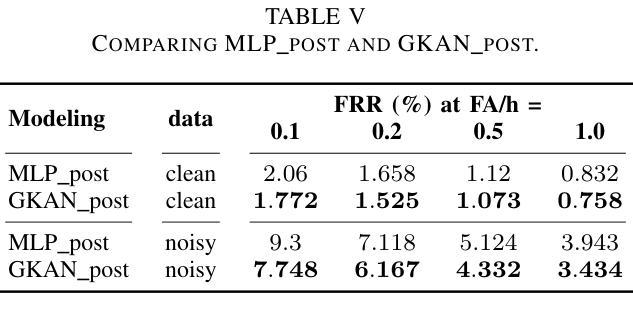
Effective Integration of KAN for Keyword Spotting
Authors:Anfeng Xu, Biqiao Zhang, Shuyu Kong, Yiteng Huang, Zhaojun Yang, Sangeeta Srivastava, Ming Sun
Keyword spotting (KWS) is an important speech processing component for smart devices with voice assistance capability. In this paper, we investigate if Kolmogorov-Arnold Networks (KAN) can be used to enhance the performance of KWS. We explore various approaches to integrate KAN for a model architecture based on 1D Convolutional Neural Networks (CNN). We find that KAN is effective at modeling high-level features in lower-dimensional spaces, resulting in improved KWS performance when integrated appropriately. The findings shed light on understanding KAN for speech processing tasks and on other modalities for future researchers.
关键词识别(KWS)是智能语音助手设备的重要语音处理组件。本文旨在研究Kolmogorov-Arnold网络(KAN)是否能用于提高KWS的性能。我们探索了基于一维卷积神经网络(CNN)的模型架构集成KAN的各种方法。我们发现,在适当集成时,KAN在低维空间中建模高级特征非常有效,从而提高了KWS的性能。这些发现有助于未来研究人员理解KAN在语音处理任务中的应用,并为其他模式提供启示。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary:本文探讨了Kolmogorov-Arnold网络(KAN)在关键词识别(KWS)中的应用,以改进智能设备的语音处理能力。研究发现,KAN能够有效地在低维空间中建立高级特征模型,并可以在适当集成后提高KWS的性能。这一发现有助于未来研究人员理解KAN在语音处理任务及其他领域的应用。
Key Takeaways:
- Kolmogorov-Arnold网络(KAN)被应用于关键词识别(KWS)以提高智能设备的语音处理能力。
- KAN能够有效地在低维空间中建立高级特征模型。
- KAN的适当集成可以提高KWS的性能。
- 本文研究基于1D卷积神经网络(CNN)的模型架构来集成KAN。
- 研究结果有助于未来研究人员理解KAN在语音处理任务中的应用。
- 该研究为其他领域的研究者提供了关于使用KAN的启示。
点此查看论文截图

Full-text Error Correction for Chinese Speech Recognition with Large Language Model
Authors:Zhiyuan Tang, Dong Wang, Shen Huang, Shidong Shang
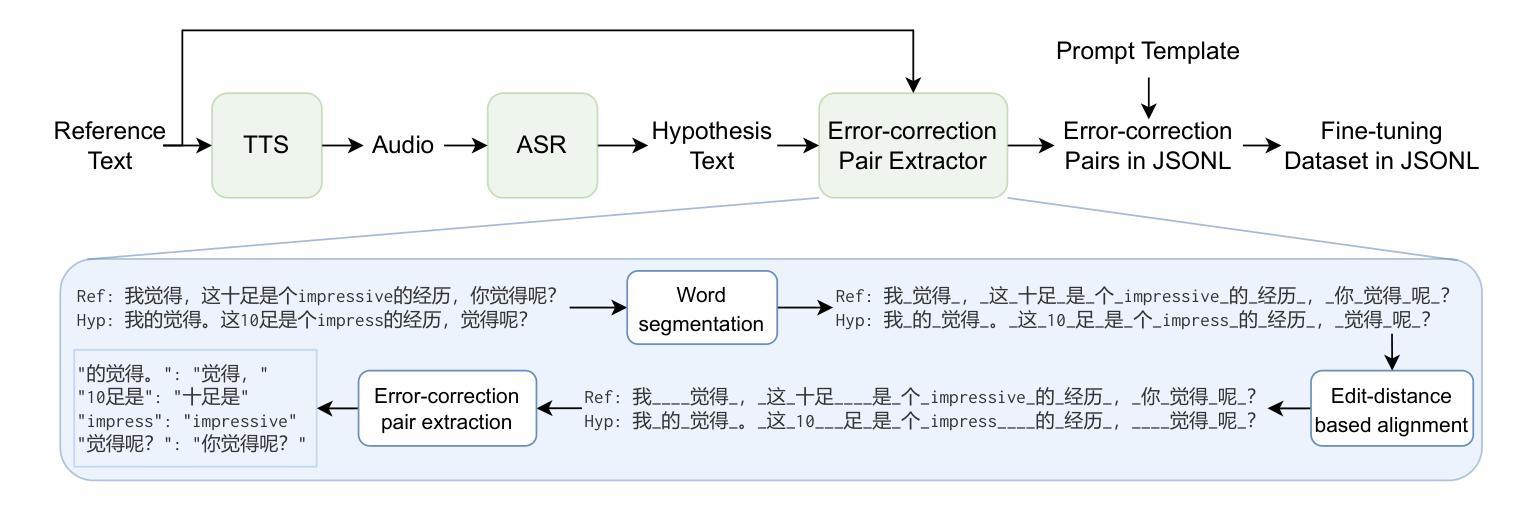
Large Language Models (LLMs) have demonstrated substantial potential for error correction in Automatic Speech Recognition (ASR). However, most research focuses on utterances from short-duration speech recordings, which are the predominant form of speech data for supervised ASR training. This paper investigates the effectiveness of LLMs for error correction in full-text generated by ASR systems from longer speech recordings, such as transcripts from podcasts, news broadcasts, and meetings. First, we develop a Chinese dataset for full-text error correction, named ChFT, utilizing a pipeline that involves text-to-speech synthesis, ASR, and error-correction pair extractor. This dataset enables us to correct errors across contexts, including both full-text and segment, and to address a broader range of error types, such as punctuation restoration and inverse text normalization, thus making the correction process comprehensive. Second, we fine-tune a pre-trained LLM on the constructed dataset using a diverse set of prompts and target formats, and evaluate its performance on full-text error correction. Specifically, we design prompts based on full-text and segment, considering various output formats, such as directly corrected text and JSON-based error-correction pairs. Through various test settings, including homogeneous, up-to-date, and hard test sets, we find that the fine-tuned LLMs perform well in the full-text setting with different prompts, each presenting its own strengths and weaknesses. This establishes a promising baseline for further research. The dataset is available on the website.
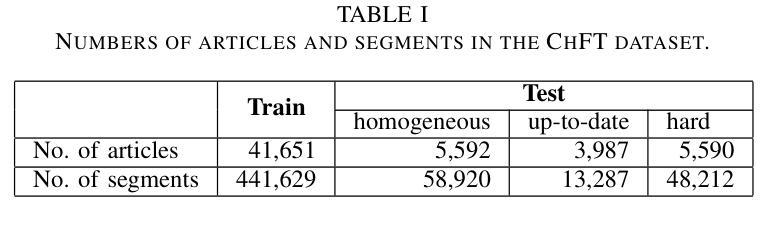
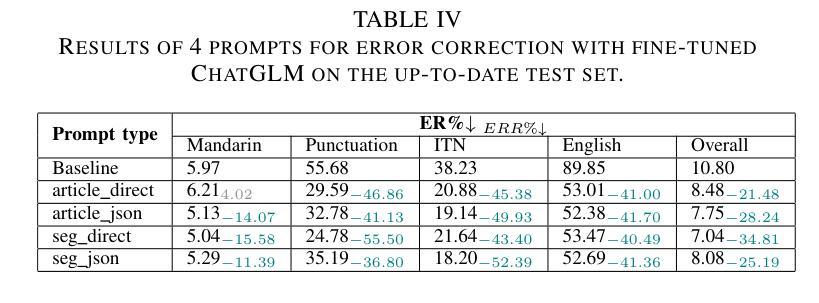
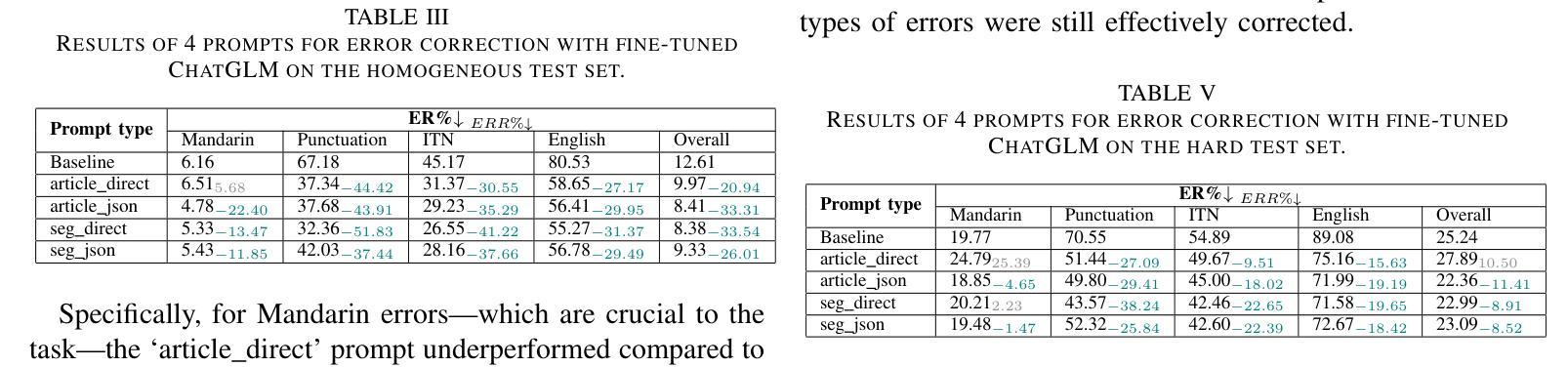
大型语言模型(LLM)在自动语音识别(ASR)的错误纠正方面展现出了巨大的潜力。然而,大多数研究都集中在来自短时段语音记录的片段上,这是有监督ASR训练的主要语音数据形式。本文研究了LLM在由ASR系统从较长语音记录(如播客、新闻广播和会议记录)生成的全文中的错误纠正效果。首先,我们开发了一个用于全文错误纠正的中文数据集,名为ChFT,该数据集采用了包括文本到语音合成、ASR和错误校正配对提取器在内的管道。该数据集使我们能够在不同上下文中纠正错误,包括全文和片段,并处理更广泛的错误类型,如标点恢复和逆向文本规范化,从而使纠正过程更加全面。其次,我们在构建的数据集上对预训练的LLM进行了微调,使用了多种提示和目标格式来评估其在全文错误纠正方面的性能。具体来说,我们基于全文和片段设计了提示,并考虑了各种输出格式,如直接修正的文本和基于JSON的错误校正对。通过包括同质的、最新的和困难的测试集在内的各种测试设置,我们发现经过微调LLM在全文设置中的表现良好,不同的提示各有其优势和劣势。这为进一步的研究奠定了有希望的基准。数据集可在网站上获得。
论文及项目相关链接
PDF ICASSP 2025
摘要
大型语言模型(LLM)在自动语音识别(ASR)的错误校正方面展现出巨大潜力。然而,大多数研究侧重于短期语音录制的发音,这是监督ASR训练的主要形式。本文研究了LLM在由ASR系统从长语音录制中生成的全文错误校正方面的有效性,如Podcast、新闻广播和会议的记录稿。首先,我们开发了一个用于全文错误校正的中文数据集ChFT,该数据集通过文本到语音合成、ASR和错误校正对提取器构成的管道实现。该数据集使我们能够在各种情境下纠正错误,包括全文和段落,并处理更广泛的错误类型,如标点恢复和逆文本规范化,从而使校正过程更加全面。其次,我们在构建的数据集上微调了预训练的LLM,使用各种提示和目标格式对其性能进行了评估。我们设计了基于全文和段落的提示,并考虑了各种输出格式,如直接修正文本和基于JSON的错误校正对。通过各种测试设置,包括同质的、最新的和困难的测试集,我们发现微调后的LLM在全文设置中的表现良好,每种提示都有其自身的优势和劣势。这为未来的研究奠定了有希望的基准。数据集可在网站上获得。
关键见解
- 大型语言模型(LLM)在自动语音识别(ASR)的错误校正方面具有显著潜力。
- 当前研究主要关注短期语音录制的发音,但本文探索了LLM在由长语音录制生成的全文错误校正方面的有效性。
- 引入了一个新的中文全文错误校正数据集ChFT,用于更全面的错误校正,包括上下文中的标点恢复和逆文本规范化等错误类型。
- 通过微调预训练的LLM并在多种测试设置下评估其性能,发现LLM在全文设置中的表现良好,不同提示各有优势与劣势。
- 该研究为未来的研究提供了一个有希望的基准。
- 所构建的数据集ChFT已公开发布,可供研究使用。
点此查看论文截图


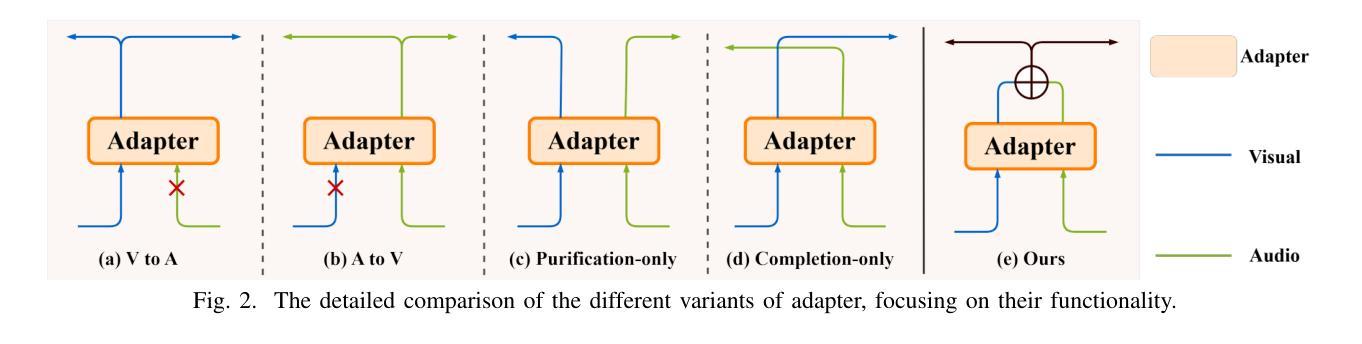
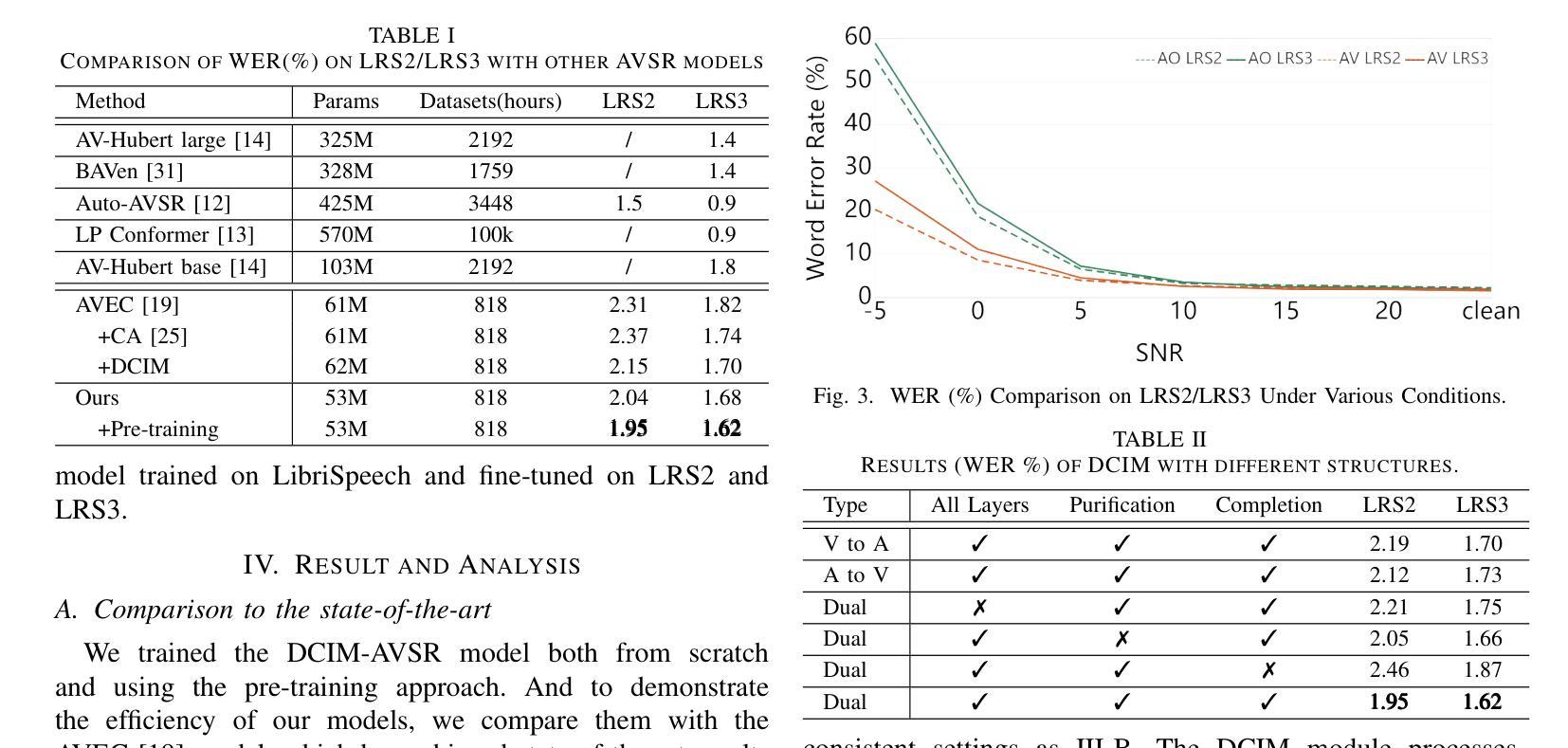
DCIM-AVSR : Efficient Audio-Visual Speech Recognition via Dual Conformer Interaction Module
Authors:Xinyu Wang, Haotian Jiang, Haolin Huang, Yu Fang, Mengjie Xua nd Qian Wang
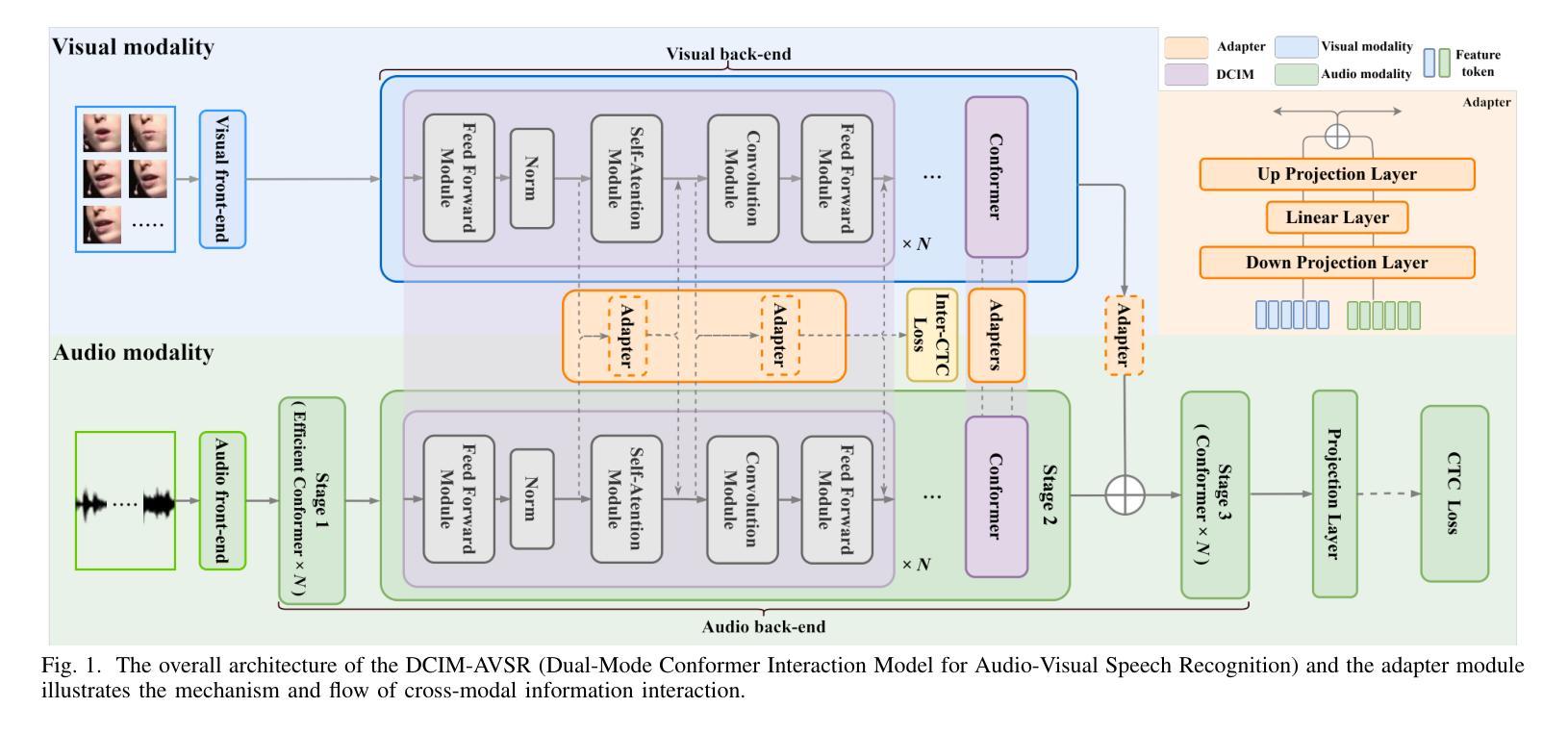
Speech recognition is the technology that enables machines to interpret and process human speech, converting spoken language into text or commands. This technology is essential for applications such as virtual assistants, transcription services, and communication tools. The Audio-Visual Speech Recognition (AVSR) model enhances traditional speech recognition, particularly in noisy environments, by incorporating visual modalities like lip movements and facial expressions. While traditional AVSR models trained on large-scale datasets with numerous parameters can achieve remarkable accuracy, often surpassing human performance, they also come with high training costs and deployment challenges. To address these issues, we introduce an efficient AVSR model that reduces the number of parameters through the integration of a Dual Conformer Interaction Module (DCIM). In addition, we propose a pre-training method that further optimizes model performance by selectively updating parameters, leading to significant improvements in efficiency. Unlike conventional models that require the system to independently learn the hierarchical relationship between audio and visual modalities, our approach incorporates this distinction directly into the model architecture. This design enhances both efficiency and performance, resulting in a more practical and effective solution for AVSR tasks.
语音识别是使机器能够解释和处理人类语音的技术,它将口语转化为文本或命令。对于虚拟助手、转录服务和通信工具等应用程序而言,这项技术至关重要。视听语音识别(AVSR)模型通过融入诸如嘴唇动作和面部表情等视觉模式,增强了传统语音识别,特别是在嘈杂的环境中。虽然经过大规模数据集训练的传统AVSR模型具有许多参数,可以实现惊人的准确性,有时甚至超过人类的表现,但它们也带来了高昂的训练成本和部署挑战。为了解决这些问题,我们引入了一种高效的AVSR模型,通过集成双卷积交互模块(DCIM)减少了参数数量。此外,我们还提出了一种预训练方法,通过选择性更新参数进一步优化模型性能,从而在效率上取得了显着提高。与传统的需要系统独立学习音频和视觉模态之间层次关系的方法不同,我们的方法直接将这种区别纳入模型架构中。这种设计提高了效率和性能,为AVSR任务提供了更实用、更有效的解决方案。
论文及项目相关链接
PDF Accepted to ICASSP 2025
总结
语音识别技术让机器能够解读和处理人类语音,将口语转化为文字或命令。对于虚拟助理、转录服务和通信工具等应用,这项技术至关重要。音频视觉语音识别(AVSR)模型通过在视觉模式(如嘴唇动作和面部表情)的融入,增强了传统语音识别能力,特别是在嘈杂环境中。虽然传统的大型数据集训练AVSR模型有许多参数,可以实现惊人的准确性,有时甚至超越人类表现水平,但它们也带来了高昂的训练成本和部署挑战。为解决这些问题,我们引入了高效的AVSR模型,通过集成双变压器交互模块(DCIM)减少了参数数量。此外,我们还提出了一种选择性更新参数的预训练方法,进一步优化模型性能,在效率上取得了显著改进。不同于传统模型需要系统独立学习音频和视觉模态之间的层次关系,我们的方法直接将这种区别纳入模型架构中。这种设计提高了效率和性能,为AVSR任务提供了更实用、有效的解决方案。
关键见解
- 语音识别技术能将人类语音转化为文字或命令,广泛应用于虚拟助理、转录服务和通信工具等领域。
- 音频视觉语音识别(AVSR)模型在嘈杂环境中表现更优,通过融入视觉模式(如嘴唇动作和面部表情)提升识别能力。
- 传统AVSR模型虽然准确度高,但存在训练成本高和部署挑战。
- 引入高效AVSR模型,通过集成双变压器交互模块(DCIM)减少参数数量,提高效率。
- 提出预训练方法,通过选择性更新参数优化模型性能。
- 与传统模型不同,新方法将音频和视觉模态的区别直接纳入模型架构中,增强了效率和性能。
- 这种设计提供了更实用、有效的解决方案,适用于AVSR任务。
点此查看论文截图

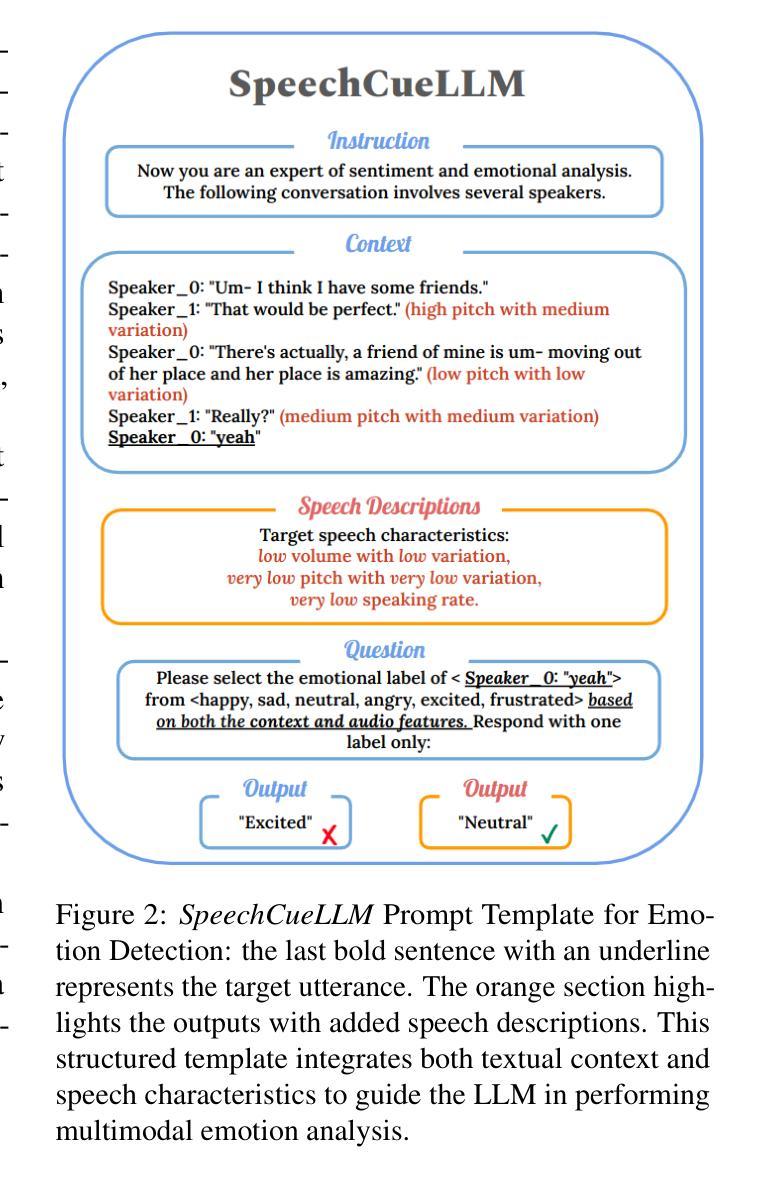
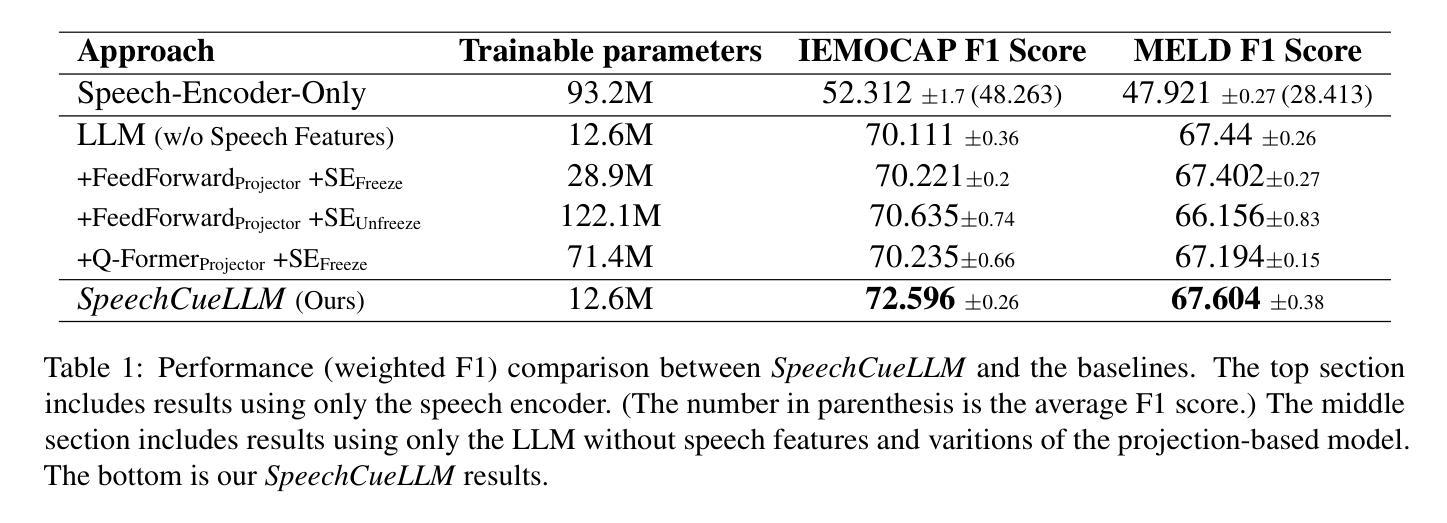
Beyond Silent Letters: Amplifying LLMs in Emotion Recognition with Vocal Nuances
Authors:Zehui Wu, Ziwei Gong, Lin Ai, Pengyuan Shi, Kaan Donbekci, Julia Hirschberg
Emotion recognition in speech is a challenging multimodal task that requires understanding both verbal content and vocal nuances. This paper introduces a novel approach to emotion detection using Large Language Models (LLMs), which have demonstrated exceptional capabilities in natural language understanding. To overcome the inherent limitation of LLMs in processing audio inputs, we propose SpeechCueLLM, a method that translates speech characteristics into natural language descriptions, allowing LLMs to perform multimodal emotion analysis via text prompts without any architectural changes. Our method is minimal yet impactful, outperforming baseline models that require structural modifications. We evaluate SpeechCueLLM on two datasets: IEMOCAP and MELD, showing significant improvements in emotion recognition accuracy, particularly for high-quality audio data. We also explore the effectiveness of various feature representations and fine-tuning strategies for different LLMs. Our experiments demonstrate that incorporating speech descriptions yields a more than 2% increase in the average weighted F1 score on IEMOCAP (from 70.111% to 72.596%).
语音情感识别是一项具有挑战性的多模式任务,需要理解口头内容和语音细微差别。本文介绍了一种使用大型语言模型(LLM)进行情感检测的新方法,LLM在自然语言理解方面表现出了卓越的能力。为了克服LLM在处理音频输入方面的固有局限性,我们提出了SpeechCueLLM方法,将语音特征转化为自然语言描述,允许LLM通过文本提示进行多模式情感分析,而无需进行任何结构更改。我们的方法简单而有效,超越了需要结构修改的基线模型。我们在IEMOCAP和MELD两个数据集上评估了SpeechCueLLM,在情感识别准确率上取得了显著的提升,特别是在高质量音频数据上。我们还探索了针对不同LLM的各种特征表示和微调策略的有效性。我们的实验表明,融入语音描述后,IEMOCAP上的平均加权F1分数提高了2%以上(从70.111%提高到72.596%)。
论文及项目相关链接
Summary
本文提出一种利用大型语言模型(LLMs)进行情绪检测的新方法。针对LLMs处理音频输入时的固有局限性,提出SpeechCueLLM方法,将语音特征转换为自然语言描述,使LLMs能够通过文本提示进行多模式情绪分析,无需进行任何架构更改。该方法在IEMOCAP和MELD两个数据集上进行了评估,显著提高了情绪识别准确率,尤其是对高质量音频数据。实验表明,结合语音描述使IEMOCAP的加权平均F1分数提高了2%以上。
Key Takeaways
- 介绍了一种利用大型语言模型进行情绪识别的新方法。
- 提出SpeechCueLLM方法,将语音特征转换为自然语言描述,以克服LLMs处理音频的局限性。
- 通过文本提示,LLMs可进行多模式情绪分析,无需更改架构。
- 在IEMOCAP和MELD数据集上评估,显示出较高的情绪识别准确率。
- 高质量音频数据的情绪识别效果尤为显著。
- 实验表明,结合语音描述可以提高情绪识别的F1分数。
点此查看论文截图


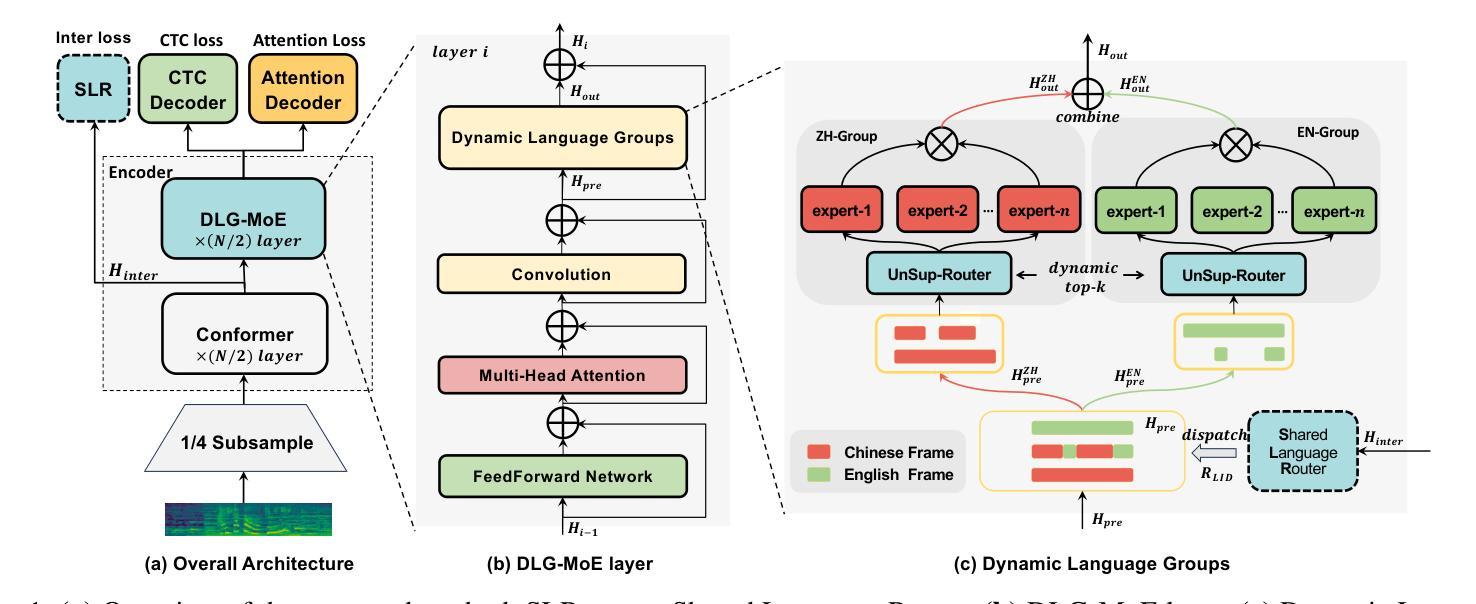
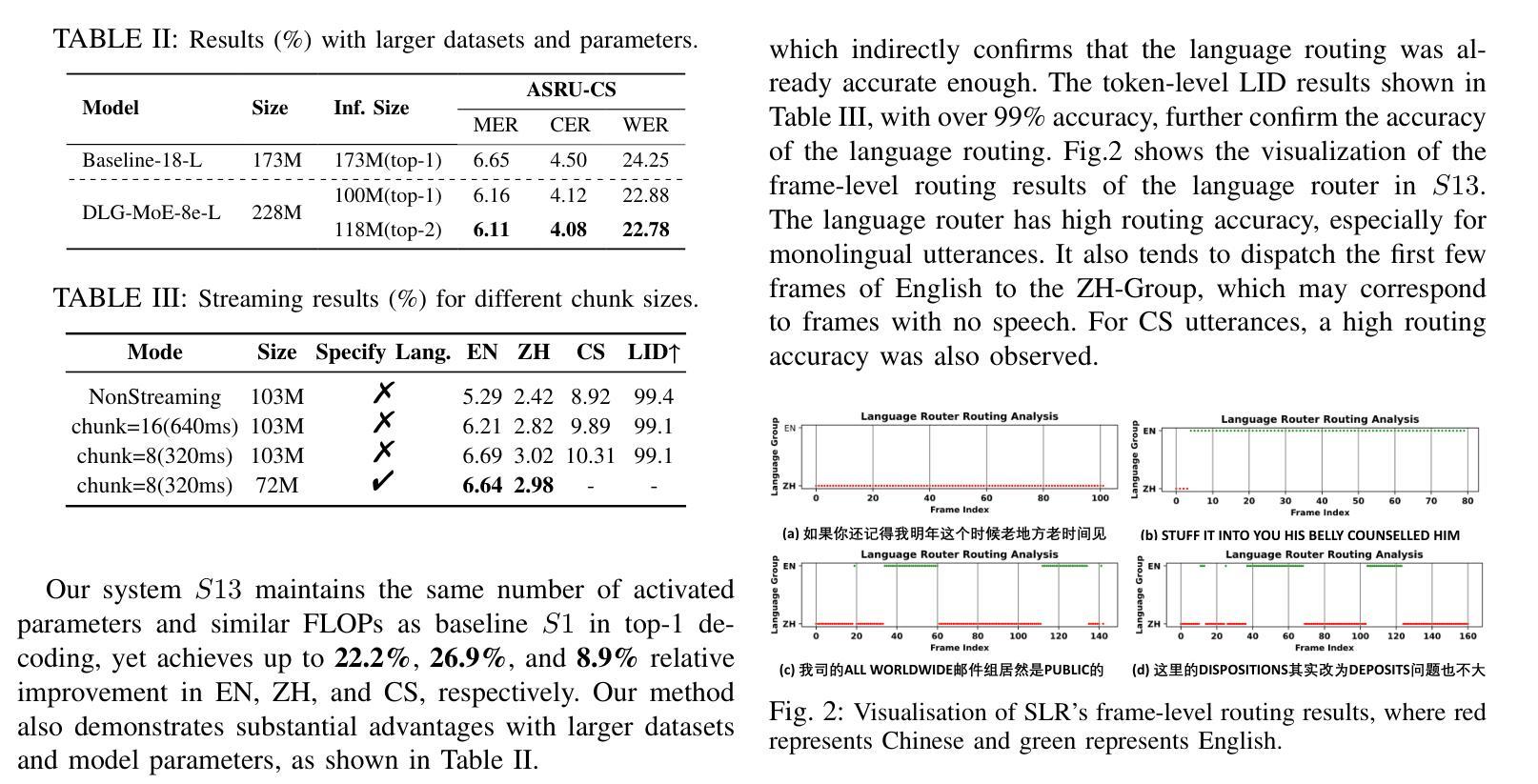
Dynamic Language Group-Based MoE: Enhancing Code-Switching Speech Recognition with Hierarchical Routing
Authors:Hukai Huang, Shenghui Lu, Yahui Shan, He Qu, Fengrun Zhang, Wenhao Guan, Qingyang Hong, Lin Li
The Mixture of Experts (MoE) model is a promising approach for handling code-switching speech recognition (CS-ASR) tasks. However, the existing CS-ASR work on MoE has yet to leverage the advantages of MoE’s parameter scaling ability fully. This work proposes DLG-MoE, a Dynamic Language Group-based MoE, which can effectively handle the CS-ASR task and leverage the advantages of parameter scaling. DLG-MoE operates based on a hierarchical routing mechanism. First, the language router explicitly models the language attribute and dispatches the representations to the corresponding language expert groups. Subsequently, the unsupervised router within each language group implicitly models attributes beyond language and coordinates expert routing and collaboration. DLG-MoE outperforms the existing MoE methods on CS-ASR tasks while demonstrating great flexibility. It supports different top-$k$ inference and streaming capabilities and can also prune the model parameters flexibly to obtain a monolingual sub-model. The code has been released.
专家混合(MoE)模型在处理代码切换语音识别(CS-ASR)任务时展现出巨大的潜力。然而,现有的关于MoE的CS-ASR研究尚未充分利用MoE的参数缩放能力优势。本文提出基于动态语言分组的DLG-MoE,它能够有效地处理CS-ASR任务并充分利用参数缩放的优点。DLG-MoE基于分层路由机制运行。首先,语言路由器显式地建模语言属性并将表示分派到相应的语言专家组。接着,每个语言组内的无监督路由器隐式地建模语言以外的属性,并协调专家路由和协作。在CS-ASR任务上,DLG-MoE的表现优于现有的MoE方法,展现出极大的灵活性。它支持不同的top-k推理和流式传输功能,还可以灵活地修剪模型参数以获得单语子模型。代码已经发布。
论文及项目相关链接
PDF Accepted by ICASSP2025
Summary
基于动态语言分组的MoE模型(DLG-MoE)在代码切换语音识别任务中展现出强大的性能。该模型利用分层路由机制,通过语言路由器明确建模语言属性并调度表示到对应的语言专家组,同时各组内的无监督路由器隐式建模超越语言的属性并协调专家路由与协作。相较于现有MoE方法,DLG-MoE更具灵活性,支持不同的top-k推理和流式处理,并能灵活调整模型参数以获取单语种子模型。代码已发布。
Key Takeaways
- 动态语言分组的MoE模型(DLG-MoE)能有效处理代码切换语音识别(CS-ASR)任务。
- DLG-MoE通过分层路由机制实现语言属性的明确建模和表示调度。
- 语言路由器和无监督路由器协同工作,分别负责语言属性和超越语言的属性建模。
- DLG-MoE相较于现有MoE方法更具灵活性,支持多种推理模式和参数调整。
- DLG-MoE模型可以生成单语种子模型,进一步扩展了其应用场景。
- 该模型的代码已经发布,便于研究和应用。
点此查看论文截图

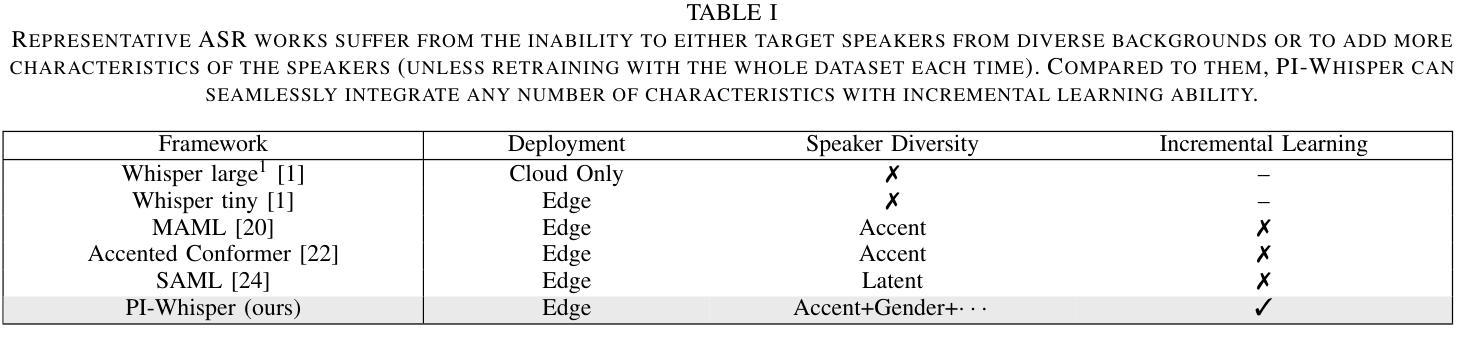
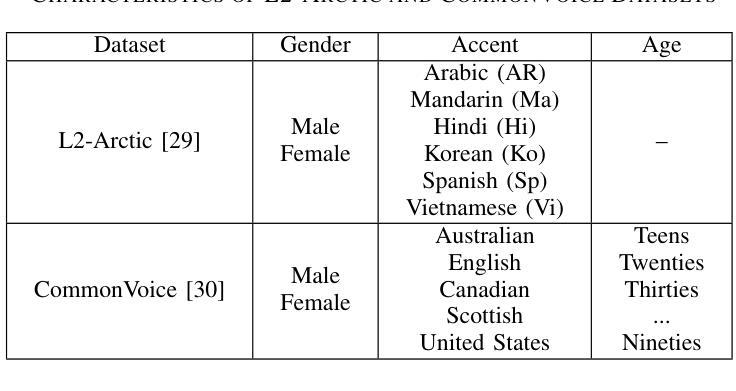
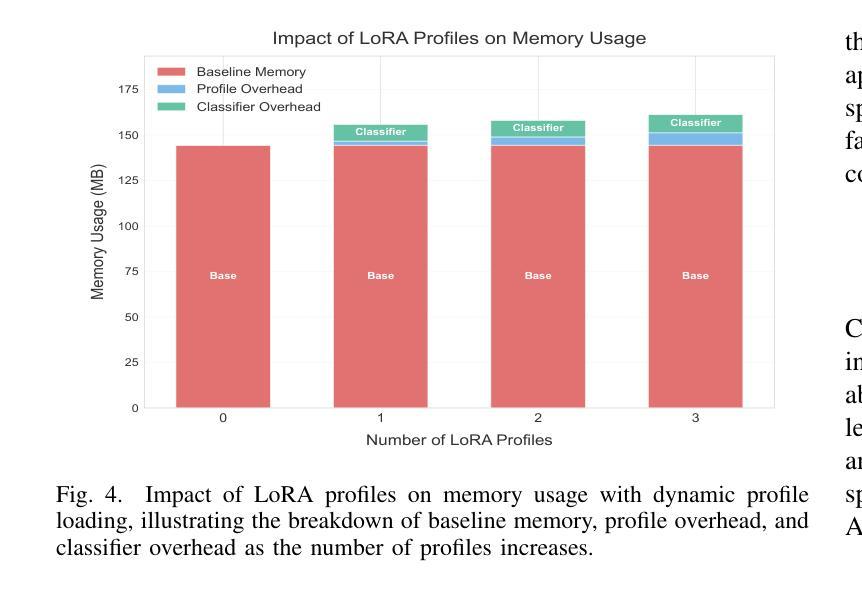
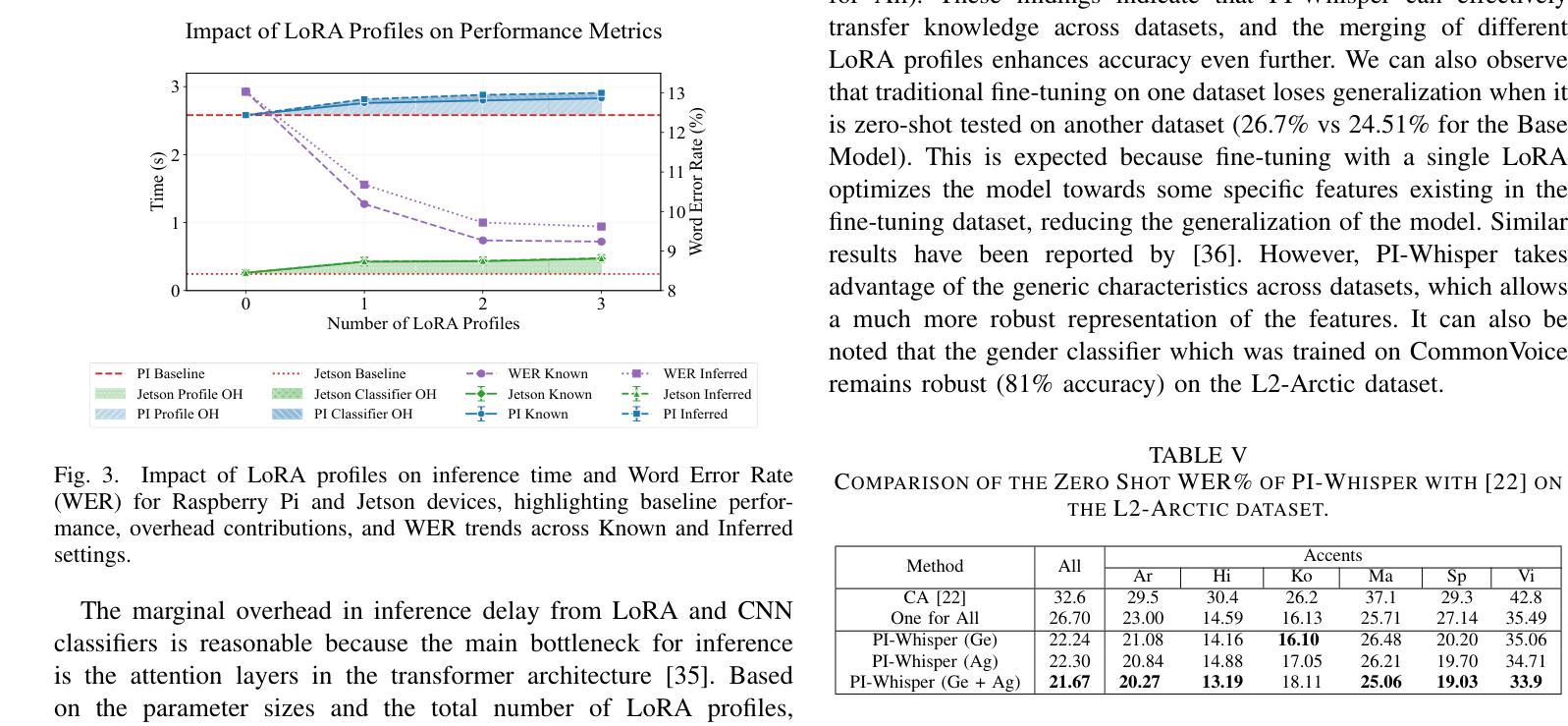
PI-Whisper: Designing an Adaptive and Incremental Automatic Speech Recognition System for Edge Devices
Authors:Amir Nassereldine, Dancheng Liu, Chenhui Xu, Ruiyang Qin, Yiyu Shi, Jinjun Xiong
Edge-based automatic speech recognition (ASR) technologies are increasingly prevalent in the development of intelligent and personalized assistants. However, resource-constrained ASR models face significant challenges in adaptivity, incrementality, and inclusivity when faced with a diverse population. To tackle those challenges, we propose PI-Whisper, a novel ASR system that adaptively enhances recognition capabilities by identifying speakers’ characteristics in real-time. In this work, we show how the design of PI-Whisper allows for incremental adaptation of new characteristics without the need for repetitive retraining, enhances recognition capabilities, and improves equity and fairness across diverse speaker groups. PI-Whisper demonstrates these advantages by achieving state-of-the-art accuracy, reducing the word error rate (WER) by up to 13.7% relative to baselines while scaling linearly to computing resources.
基于边缘的自动语音识别(ASR)技术在智能和个性化助理的开发中越来越普遍。然而,资源有限的ASR模型在面对多样化人群时,在适应性、增量性和包容性方面面临重大挑战。为了解决这些挑战,我们提出了PI-Whisper,这是一种新型ASR系统,通过实时识别说话人的特点,自适应地增强识别能力。在这项工作中,我们展示了PI-Whisper的设计如何允许对新特性进行增量适应,无需重复再训练,增强识别能力,并改善不同说话人群体之间的公平性和公正性。PI-Whisper通过实现最先进的准确性,相对于基准线降低了高达1.7%的单词错误率(WER),并且随着计算资源的增加而线性扩展,从而证明了这些优势。
论文及项目相关链接
PDF in submission
Summary
边缘计算基础上的自动语音识别(ASR)技术在智能个性化助理的开发中越来越普遍。然而,资源有限的ASR模型在适应多样化人群时面临着适应性、增量性和包容性的重大挑战。为解决这些挑战,我们提出了PI-Whisper这一新型ASR系统,它可以通过实时识别说话人的特点来动态提升识别能力。本工作中,我们展示了PI-Whisper的设计可以支持对新特性的增量适应,无需重复训练,提高识别能力,并改善对不同说话群体的公平性和公正性。PI-Whisper的这些优势使其成为业界领先的技术,相对于基线技术,其单词错误率(WER)降低了高达13.7%,并且随着计算资源的增加而线性扩展。
Key Takeaways
- PI-Whisper是一种新型的ASR系统,可实时识别说话人的特点并动态提升识别能力。
- PI-Whisper设计支持对新特性的增量适应,无需重复训练。
- PI-Whisper提高了对不同说话群体的公平性和公正性。
- PI-Whisper实现了业界领先的准确性,单词错误率(WER)相对于基线技术降低了高达13.7%。
- PI-Whisper系统随着计算资源的增加而线性扩展。
- 该系统主要适用于资源有限的ASR模型在面临多样化人群时的挑战。
点此查看论文截图


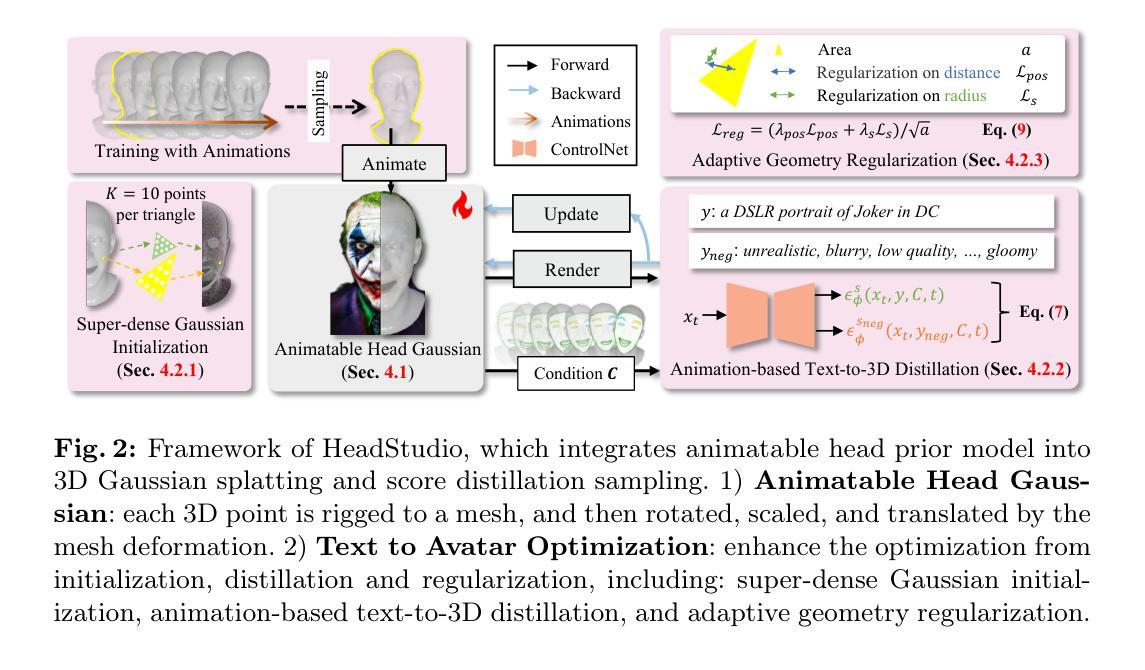
HeadStudio: Text to Animatable Head Avatars with 3D Gaussian Splatting
Authors:Zhenglin Zhou, Fan Ma, Hehe Fan, Zongxin Yang, Yi Yang
Creating digital avatars from textual prompts has long been a desirable yet challenging task. Despite the promising results achieved with 2D diffusion priors, current methods struggle to create high-quality and consistent animated avatars efficiently. Previous animatable head models like FLAME have difficulty in accurately representing detailed texture and geometry. Additionally, high-quality 3D static representations face challenges in semantically driving with dynamic priors. In this paper, we introduce \textbf{HeadStudio}, a novel framework that utilizes 3D Gaussian splatting to generate realistic and animatable avatars from text prompts. Firstly, we associate 3D Gaussians with animatable head prior model, facilitating semantic animation on high-quality 3D representations. To ensure consistent animation, we further enhance the optimization from initialization, distillation, and regularization to jointly learn the shape, texture, and animation. Extensive experiments demonstrate the efficacy of HeadStudio in generating animatable avatars from textual prompts, exhibiting appealing appearances. The avatars are capable of rendering high-quality real-time ($\geq 40$ fps) novel views at a resolution of 1024. Moreover, These avatars can be smoothly driven by real-world speech and video. We hope that HeadStudio can enhance digital avatar creation and gain popularity in the community. Code is at: https://github.com/ZhenglinZhou/HeadStudio.
从文本提示创建数字化身一直是一项令人向往但具有挑战性的任务。尽管利用二维扩散先验取得了有前景的结果,但当前的方法在高效创建高质量且连贯的动画化身方面遇到了困难。像FLAME这样的之前可动画头部模型在准确表示详细纹理和几何结构方面存在困难。此外,高质量的三维静态表示在语义驱动的动态先验方面面临挑战。在本文中,我们介绍了利用三维高斯泼斑技术生成从文本提示出发的真实且可动画的化身的全新框架——HeadStudio。首先,我们将三维高斯分布与可动画头部先验模型关联起来,实现在高质量三维表示上的语义动画。为确保连贯的动画效果,我们从初始化、蒸馏和正则化三个方面进一步优化了形状、纹理和动画的联合学习。大量实验证明了HeadStudio从文本提示生成可动画化身的有效性,展现出吸引人的外观。这些化身能够以高于或等于40帧每秒的速度在1024的分辨率下呈现高质量实时新视角。此外,这些化身可以被现实世界中的语音和视频流畅驱动。我们希望HeadStudio能增强数字化身的创建功能并在社区中广受欢迎。代码地址为:https://github.com/ZhenglinZhou/HeadStudio。
论文及项目相关链接
PDF 26 pages, 18 figures, accepted by ECCV 2024
Summary
本文介绍了一种名为HeadStudio的新型框架,该框架利用3D高斯涂鸦技术,从文本提示生成真实且可动画的头像。HeadStudio通过结合动画头像先验模型与3D高斯分布,实现高质量3D表示上的语义动画。通过优化初始化、蒸馏和正则化过程,联合学习形状、纹理和动画,确保动画的一致性。实验证明,HeadStudio能高效地从文本提示生成可动画的头像,呈现吸引人的外观,并可实时(≥40帧/秒)渲染高质量头像新视角,且头像可被真实语音和视频流畅驱动。
Key Takeaways
- HeadStudio是一种新型框架,可从文本提示生成真实且可动画的头像。
- 利用3D高斯涂鸦技术实现高质量和一致的动画头像生成。
- 结合动画头像先验模型与3D高斯分布,实现语义动画。
- 通过优化初始化、蒸馏和正则化过程,确保动画一致性。
- 能高效生成吸引人的头像,实时渲染高质量新视角。
- 生成的头像能被真实语音和视频流畅驱动。
点此查看论文截图