⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-26 更新
Portability of Fortran’s `do concurrent’ on GPUs
Authors:Ronald M. Caplan, Miko M. Stulajter, Jon A. Linker, Jeff Larkin, Henry A. Gabb, Shiquan Su, Ivan Rodriguez, Zachary Tschirhart, Nicholas Malaya
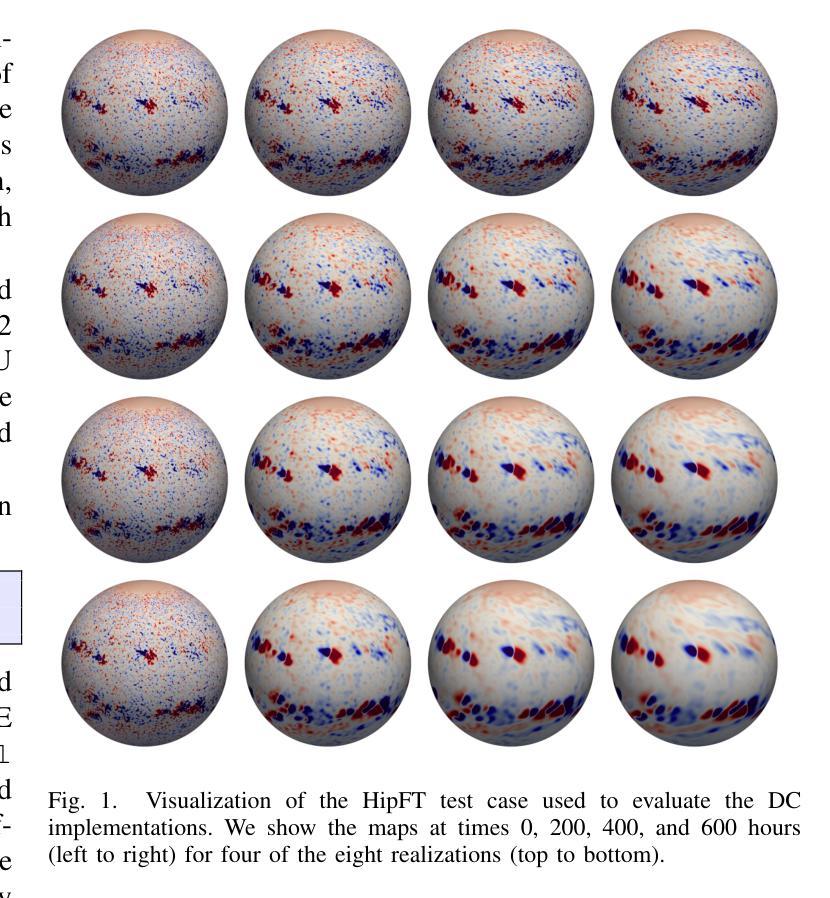
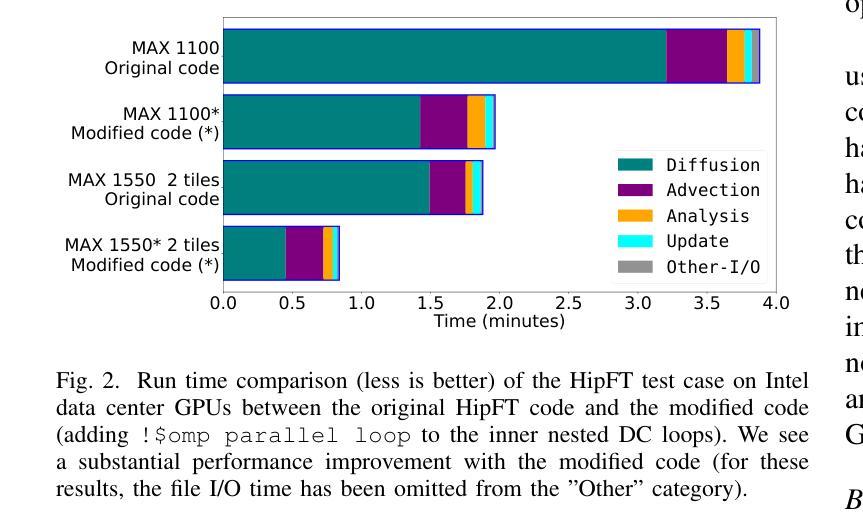
There is a continuing interest in using standard language constructs for accelerated computing in order to avoid (sometimes vendor-specific) external APIs. For Fortran codes, the {\tt do concurrent} (DC) loop has been successfully demonstrated on the NVIDIA platform. However, support for DC on other platforms has taken longer to implement. Recently, Intel has added DC GPU offload support to its compiler, as has HPE for AMD GPUs. In this paper, we explore the current portability of using DC across GPU vendors using the in-production solar surface flux evolution code, HipFT. We discuss implementation and compilation details, including when/where using directive APIs for data movement is needed/desired compared to using a unified memory system. The performance achieved on both data center and consumer platforms is shown.
在利用标准语言构造实现加速计算,避免使用(有时是特定供应商的)外部API方面,一直存在持续的兴趣。对于Fortran代码而言,{\tt do concurrent}(DC)循环已在NVIDIA平台上成功演示。然而,在其他平台上实现DC支持需要更长时间。最近,英特尔在其编译器中增加了对DC GPU卸载的支持,HP也对AMD GPU采取了相同的做法。在这篇论文中,我们探讨了使用DC在GPU供应商之间进行跨平台操作的当前便携性,并使用正在生产的太阳表面通量演化代码HipFT进行说明。我们讨论了实现和编译细节,包括与统一内存系统相比,何时/何地使用指令API进行数据移动是必要或理想的。在数据中心和消费者平台上实现的性能表现均得到了展示。
论文及项目相关链接
PDF 10 pages, 7 figures, To appear in the workshop proceedings of WACCPD24 at SC24
Summary
在NVIDIA平台上,使用标准语言构造进行加速计算以避免外部API(有时是供应商特定的)已成为热门趋势。本文探讨了使用DC循环(do concurrent循环)在GPU供应商间的可移植性,并介绍了HipFT代码的DC实现和编译细节。同时,本文还讨论了使用指令API进行数据移动与统一内存系统的优劣比较。性能在数据中心和消费者平台上均得到展示。
Key Takeaways
- 标准语言构造在加速计算领域越来越受到关注,旨在避免特定的外部API。
- do concurrent (DC) 循环在NVIDIA平台上已被成功验证,但在其他平台上的支持实现较晚。
- Intel和HPE分别为其编译器增加了DC GPU卸载支持,用于AMD GPUs。
- 本文探讨了DC跨GPU供应商的移植性,并使用HipFT代码作为实例。
- 实施和编译细节包括何时/何处使用指令API进行数据移动与使用统一内存系统的比较。
- 在数据中心和消费者平台上展示了其性能表现。
点此查看论文截图