⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-26 更新
VisionGRU: A Linear-Complexity RNN Model for Efficient Image Analysis
Authors:Shicheng Yin, Kaixuan Yin, Weixing Chen, Enbo Huang, Yang Liu
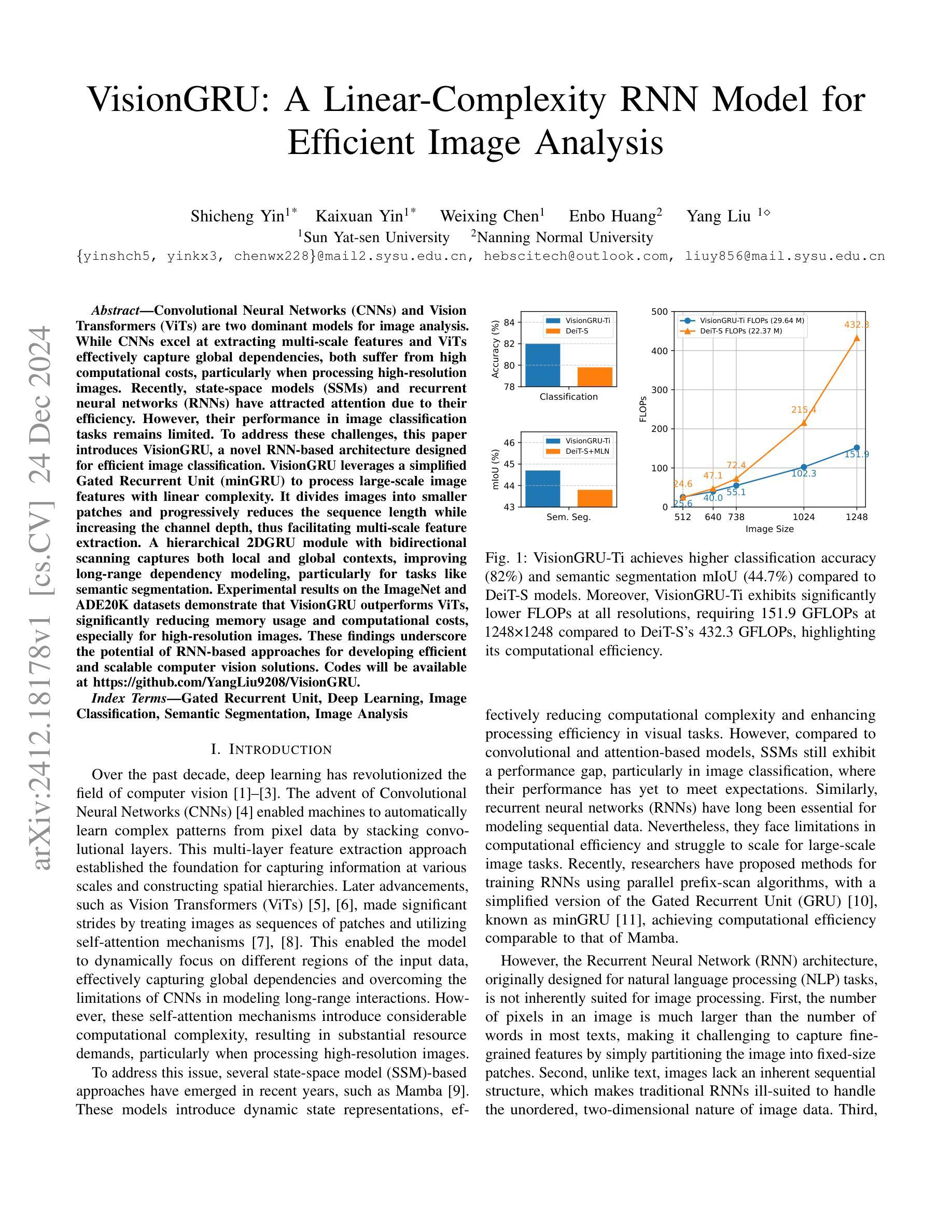
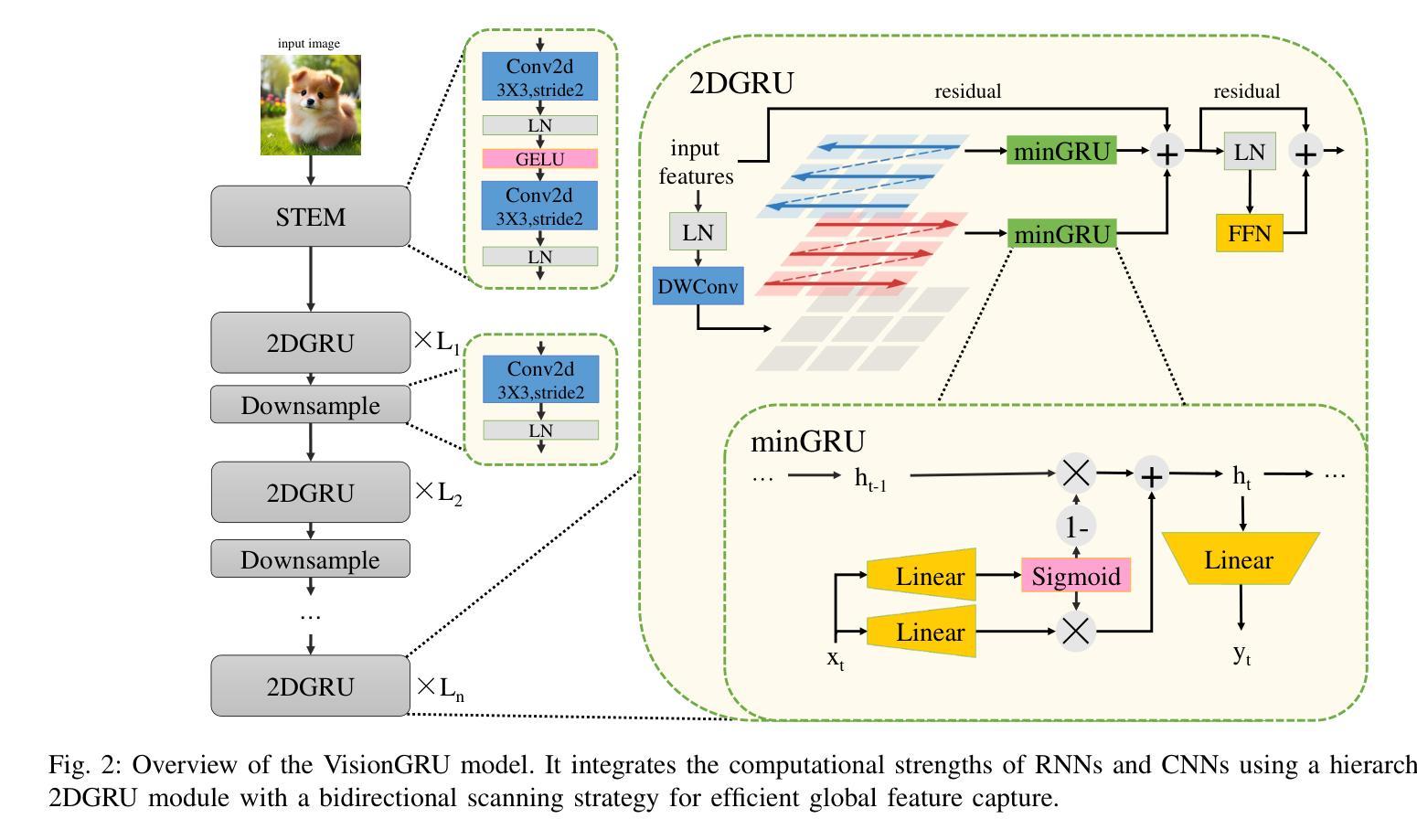
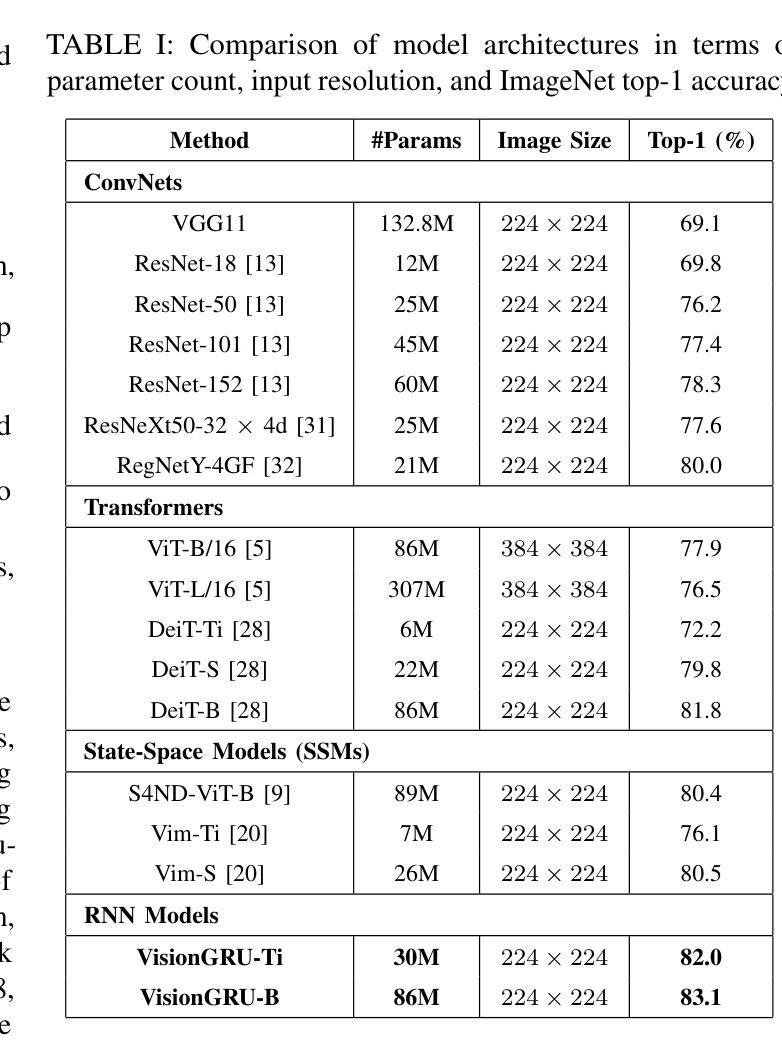
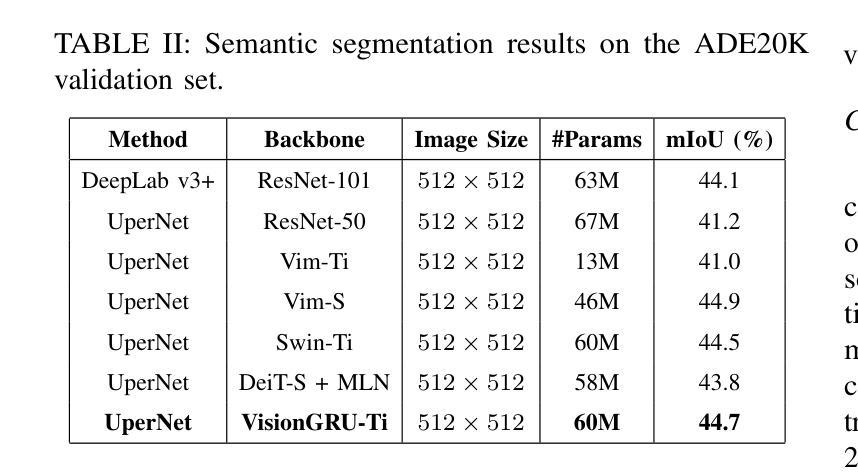
Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) are two dominant models for image analysis. While CNNs excel at extracting multi-scale features and ViTs effectively capture global dependencies, both suffer from high computational costs, particularly when processing high-resolution images. Recently, state-space models (SSMs) and recurrent neural networks (RNNs) have attracted attention due to their efficiency. However, their performance in image classification tasks remains limited. To address these challenges, this paper introduces VisionGRU, a novel RNN-based architecture designed for efficient image classification. VisionGRU leverages a simplified Gated Recurrent Unit (minGRU) to process large-scale image features with linear complexity. It divides images into smaller patches and progressively reduces the sequence length while increasing the channel depth, thus facilitating multi-scale feature extraction. A hierarchical 2DGRU module with bidirectional scanning captures both local and global contexts, improving long-range dependency modeling, particularly for tasks like semantic segmentation. Experimental results on the ImageNet and ADE20K datasets demonstrate that VisionGRU outperforms ViTs, significantly reducing memory usage and computational costs, especially for high-resolution images. These findings underscore the potential of RNN-based approaches for developing efficient and scalable computer vision solutions. Codes will be available at https://github.com/YangLiu9208/VisionGRU.
卷积神经网络(CNN)和视觉转换器(ViT)是图像分析中的两种主流模型。虽然CNN擅长提取多尺度特征,而ViT能有效捕捉全局依赖性,但两者都存在计算成本高的问题,特别是在处理高分辨率图像时。最近,由于状态空间模型(SSM)和循环神经网络(RNN)的效率,它们引起了人们的关注。然而,它们在图像分类任务中的表现仍然有限。为了解决这些挑战,本文提出了一种基于RNN的新型架构——VisionGRU,用于高效图像分类。VisionGRU利用简化的门控循环单元(minGRU)以线性复杂度处理大规模图像特征。它将图像分割成较小的块,逐步减少序列长度同时增加通道深度,从而便于多尺度特征提取。具有双向扫描的分层2DGRU模块可以捕获局部和全局上下文,改进了长距离依赖建模,特别是对于语义分割等任务。在ImageNet和ADE20K数据集上的实验结果表明,VisionGRU的性能优于ViT,在降低内存使用和计算成本方面有明显优势,尤其适用于高分辨率图像。这些发现强调了基于RNN的方法在开发高效可扩展的计算机视觉解决方案方面的潜力。相关代码将在https://github.com/YangLiu9208/VisionGRU上提供。
论文及项目相关链接
PDF Codes will be available at https://github.com/YangLiu9208/VisionGRU
Summary
本文提出一种基于RNN的新型图像分类架构VisionGRU,利用简化的门控循环单元(minGRU)以线性复杂度处理大规模图像特征。VisionGRU通过将图像分成较小的补丁,渐进地减少序列长度并增加通道深度,实现多尺度特征提取。同时,采用分层2DGRU模块进行双向扫描,捕捉局部和全局上下文,改进了长距离依赖建模,特别是在语义分割等任务上。在ImageNet和ADE20K数据集上的实验结果表明,VisionGRU在降低内存使用和计算成本的同时,优于ViTs,特别是在高分辨率图像上。
Key Takeaways
- VisionGRU是一种基于RNN的新型图像分类架构,旨在解决CNN和ViT在处理图像时的高计算成本问题。
- VisionGRU利用简化的Gated Recurrent Unit(minGRU)以线性复杂度处理大规模图像特征。
- VisionGRU通过分割图像成较小的补丁,实现多尺度特征提取,同时渐进地减少序列长度并增加通道深度。
- 采用了分层2DGRU模块进行双向扫描,能有效捕捉局部和全局上下文,改进了长距离依赖建模。
- 在ImageNet和ADE20K数据集上的实验结果表明,VisionGRU在图像分类任务上表现出优异的性能,特别是在处理高分辨率图像时。
- VisionGRU相比ViTs,在降低内存使用和计算成本的同时,实现了更好的性能。
点此查看论文截图

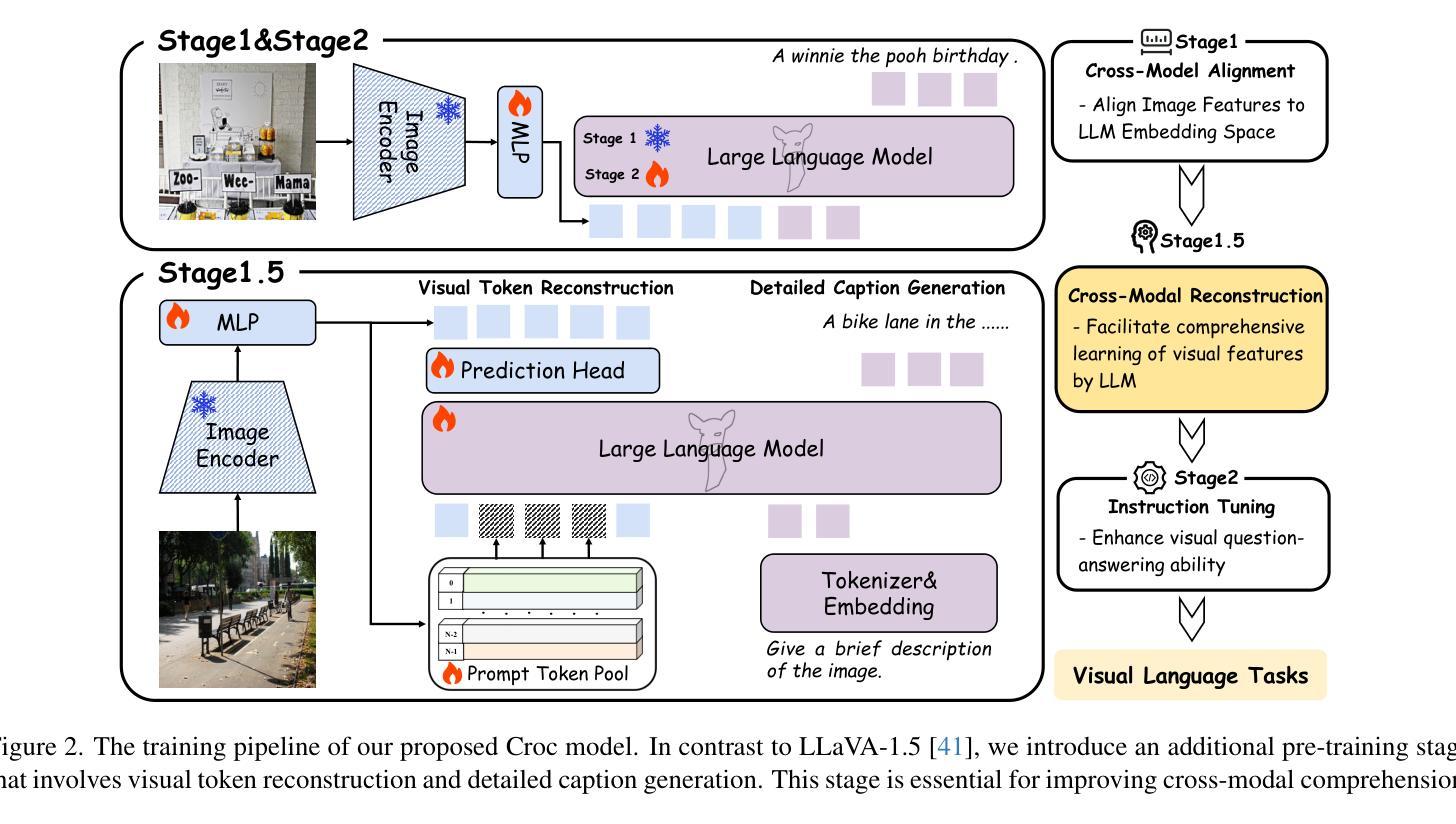
Croc: Pretraining Large Multimodal Models with Cross-Modal Comprehension
Authors:Yin Xie, Kaicheng Yang, Ninghua Yang, Weimo Deng, Xiangzi Dai, Tiancheng Gu, Yumeng Wang, Xiang An, Yongle Zhao, Ziyong Feng, Roy Miles, Ismail Elezi, Jiankang Deng
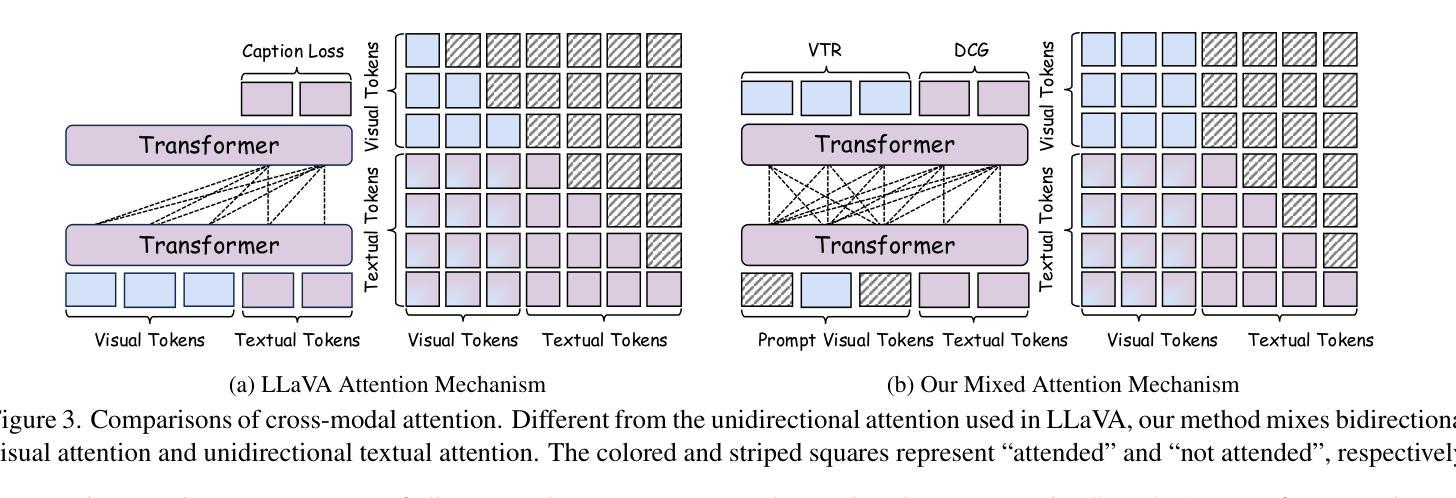
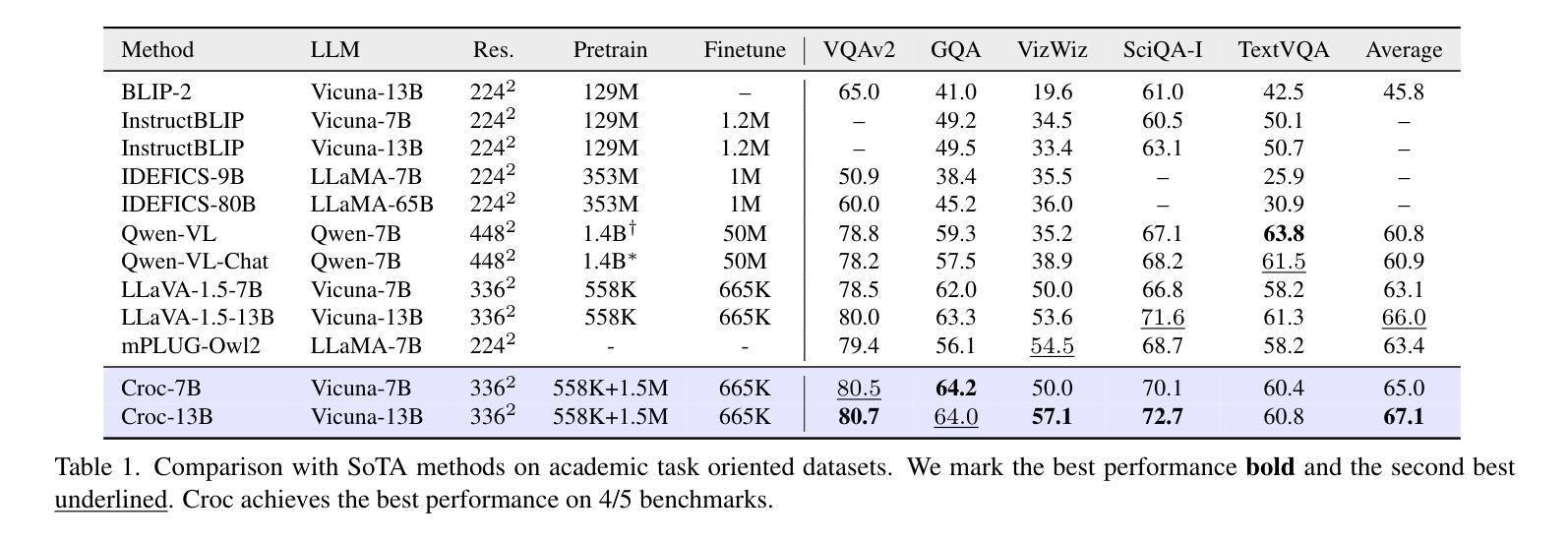
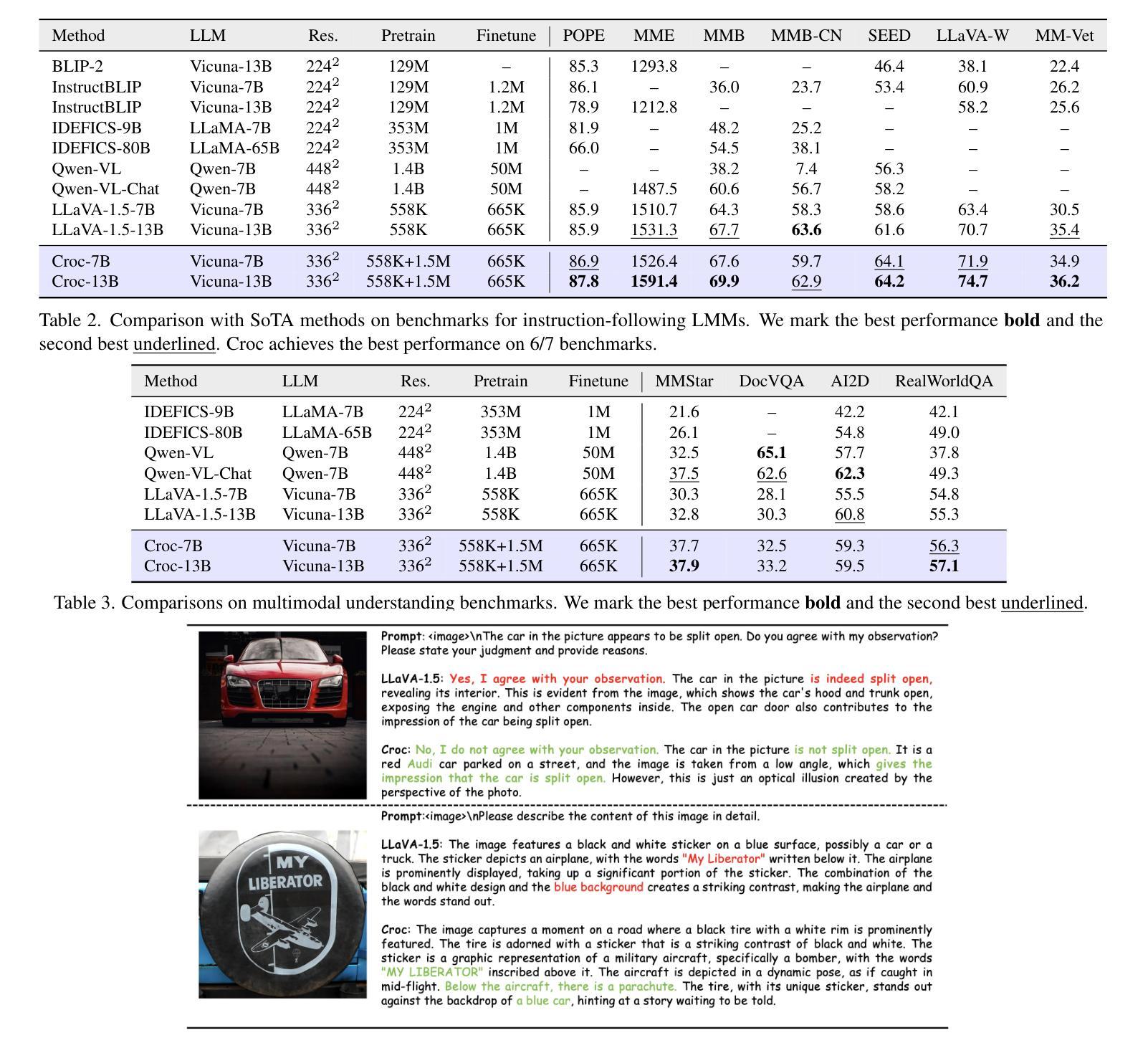
Recent advances in Large Language Models (LLMs) have catalyzed the development of Large Multimodal Models (LMMs). However, existing research primarily focuses on tuning language and image instructions, ignoring the critical pretraining phase where models learn to process textual and visual modalities jointly. In this paper, we propose a new pretraining paradigm for LMMs to enhance the visual comprehension capabilities of LLMs by introducing a novel cross-modal comprehension stage. Specifically, we design a dynamically learnable prompt token pool and employ the Hungarian algorithm to replace part of the original visual tokens with the most relevant prompt tokens. Then, we conceptualize visual tokens as analogous to a “foreign language” for the LLMs and propose a mixed attention mechanism with bidirectional visual attention and unidirectional textual attention to comprehensively enhance the understanding of visual tokens. Meanwhile, we integrate a detailed caption generation task, leveraging rich descriptions to further facilitate LLMs in understanding visual semantic information. After pretraining on 1.5 million publicly accessible data, we present a new foundation model called Croc. Experimental results demonstrate that Croc achieves new state-of-the-art performance on massive vision-language benchmarks. To support reproducibility and facilitate further research, we release the training code and pre-trained model weights at https://github.com/deepglint/Croc.
最近大型语言模型(LLM)的进展推动了大型多模态模型(LMM)的发展。然而,现有研究主要集中在调整语言和图像指令上,忽略了模型学习处理文本和视觉模态的联合预训练阶段。在本文中,我们提出了针对LMM的新的预训练范式,通过引入新的跨模态理解阶段,增强LMM的视觉理解能力。具体来说,我们设计了一个可动态学习的提示令牌池,并使用匈牙利算法将最相关的提示令牌替换部分原始视觉令牌。然后,我们将视觉令牌概念化为对LLM而言类似于“外语”,并提出一种混合注意力机制,包括双向视觉注意力和单向文本注意力,以全面增强对视觉令牌的理解。同时,我们整合了详细的标题生成任务,利用丰富的描述来进一步帮助LLM理解视觉语义信息。在150万个公开可访问的数据上进行预训练后,我们推出了一款名为Croc的新型基础模型。实验结果表明,Croc在大量的视觉语言基准测试中达到了最新的最先进的性能。为了支持可重复性和促进进一步研究,我们在https://github.com/deepglint/Croc上发布了训练代码和预训练模型权重。
论文及项目相关链接
PDF 14 pages, 12 figures
Summary
大型语言模型(LLM)的进展推动了大型多模态模型(LMM)的发展,但现有研究主要关注语言和图像指令的调整,忽视了模型在预处理阶段共同处理文本和视觉模态的关键能力。本文提出了一种新的LMM预训练范式,通过引入跨模态理解阶段,增强LLM对视觉理解的能力。设计动态可学习的提示令牌池,采用匈牙利算法替换部分原始视觉令牌为最相关的提示令牌。将视觉令牌视为LLM的“外语”,提出混合注意力机制,包括双向视觉注意力和单向文本注意力,以全面增强对视觉令牌的理解。在公开数据上进行150万数据预训练后,推出了名为Croc的基础模型。实验结果表明,Croc在大规模视觉语言基准测试中达到了新的最先进的性能。
Key Takeaways
- 大型语言模型(LLM)的进展推动了大型多模态模型(LMM)的发展。
- 现有研究主要关注语言和图像指令的调整,忽视了预训练阶段的重要性。
- 本文提出了一种新的预训练范式,以增强LLM对视觉理解的能力。
- 通过引入跨模态理解阶段和动态可学习的提示令牌池,提高模型性能。
- 采用匈牙利算法替换部分原始视觉令牌,以增强模型对视觉信息的理解。
- 将视觉令牌视为LLM的“外语”,采用混合注意力机制处理文本和视觉模态。
点此查看论文截图