⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-01-02 更新
Distributed Mixture-of-Agents for Edge Inference with Large Language Models
Authors:Purbesh Mitra, Priyanka Kaswan, Sennur Ulukus
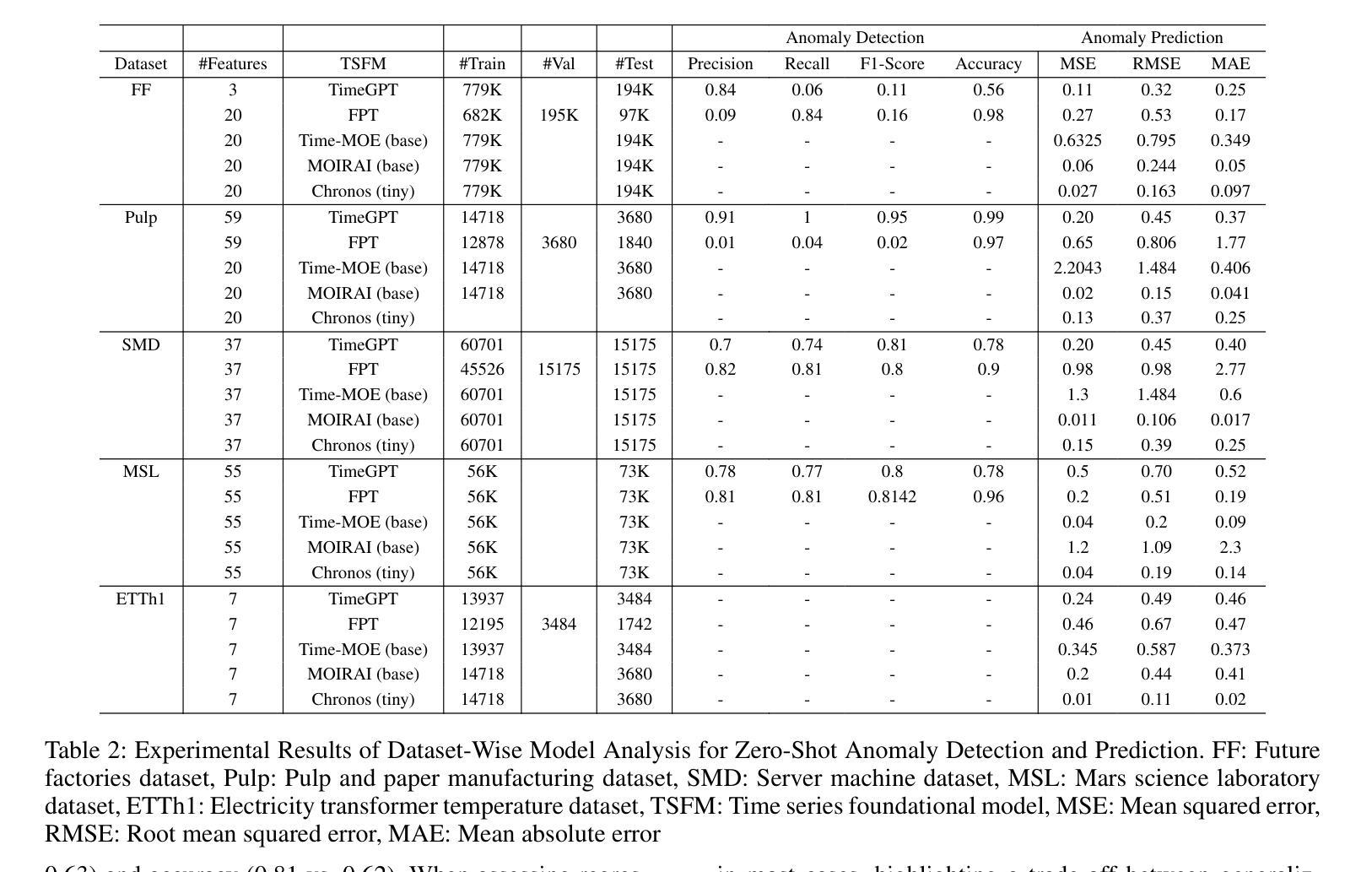
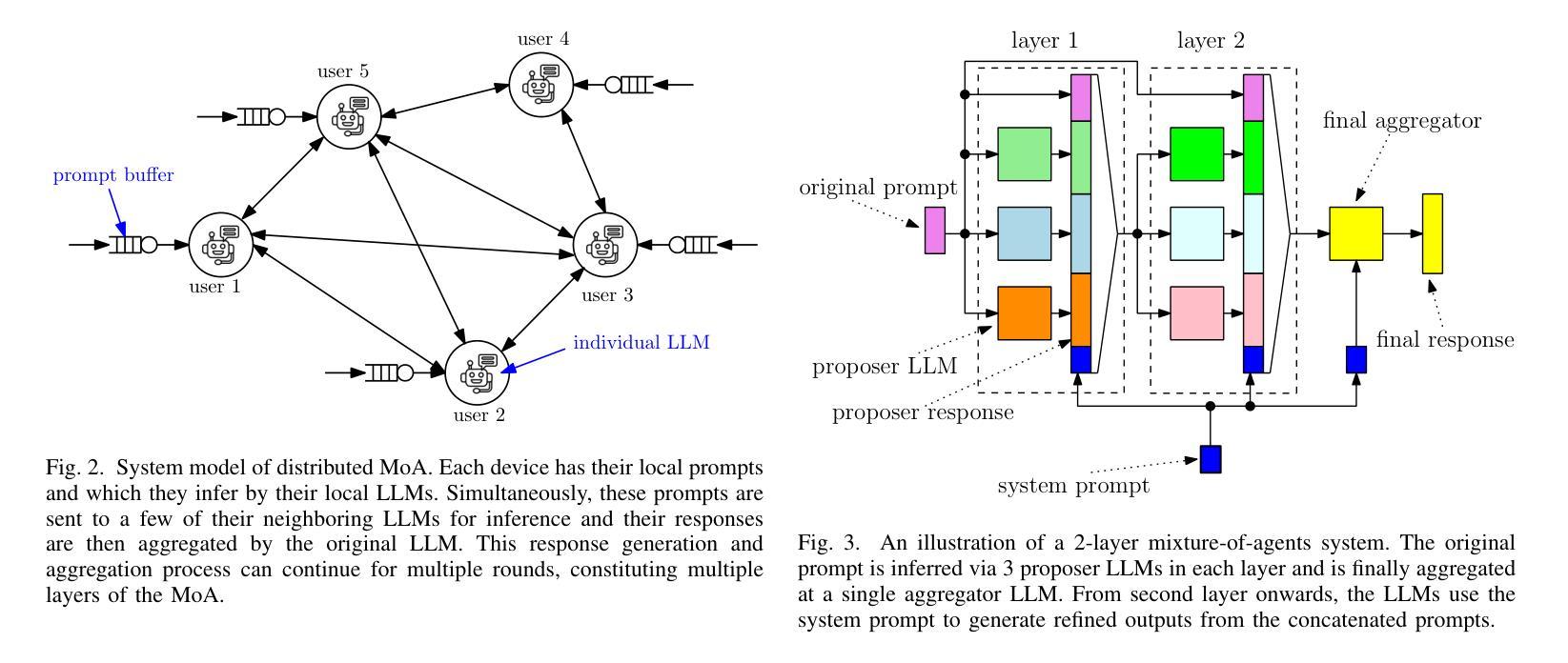
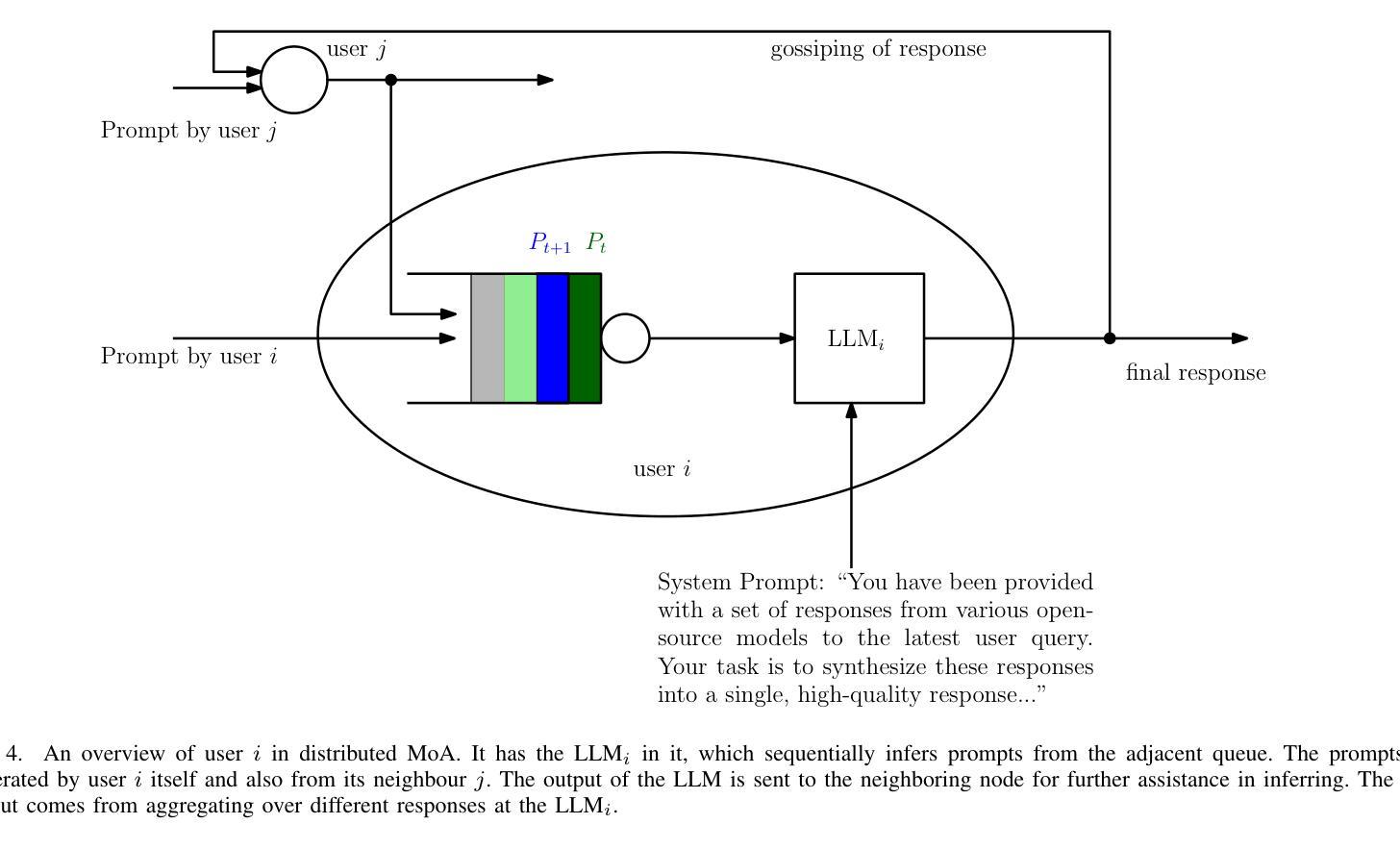
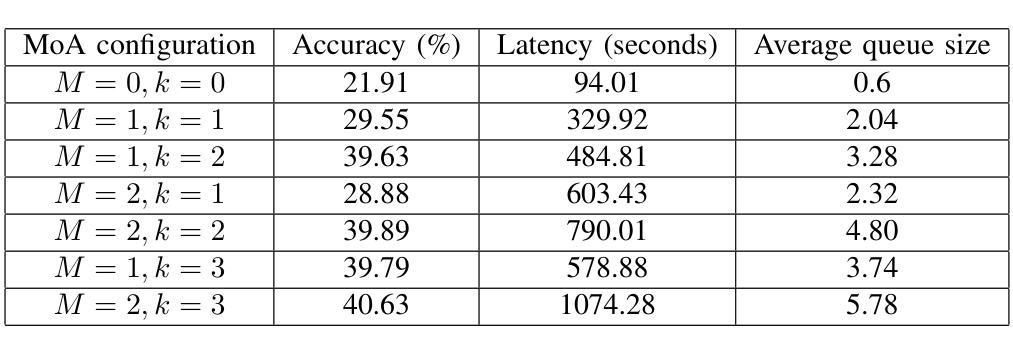
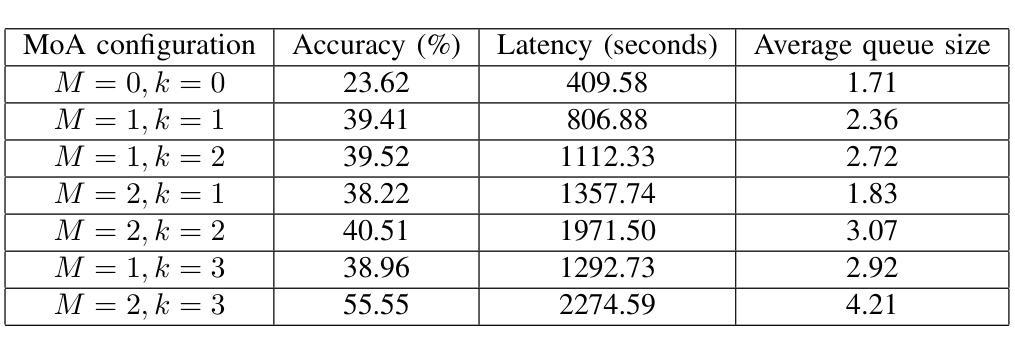
Mixture-of-Agents (MoA) has recently been proposed as a method to enhance performance of large language models (LLMs), enabling multiple individual LLMs to work together for collaborative inference. This collaborative approach results in improved responses to user prompts compared to relying on a single LLM. In this paper, we consider such an MoA architecture in a distributed setting, where LLMs operate on individual edge devices, each uniquely associated with a user and equipped with its own distributed computing power. These devices exchange information using decentralized gossip algorithms, allowing different device nodes to talk without the supervision of a centralized server. In the considered setup, different users have their own LLM models to address user prompts. Additionally, the devices gossip either their own user-specific prompts or augmented prompts to generate more refined answers to certain queries. User prompts are temporarily stored in the device queues when their corresponding LLMs are busy. Given the memory limitations of edge devices, it is crucial to ensure that the average queue sizes in the system remain bounded. In this paper, we address this by theoretically calculating the queuing stability conditions for the device queues under reasonable assumptions, which we validate experimentally as well. Further, we demonstrate through experiments, leveraging open-source LLMs for the implementation of distributed MoA, that certain MoA configurations produce higher-quality responses compared to others, as evaluated on AlpacaEval 2.0 benchmark. The implementation is available at: https://github.com/purbeshmitra/distributed_moa.
Mixture-of-Agents (MoA)作为一种方法被提出,旨在增强大型语言模型(LLM)的性能。它使多个独立的LLM能够协同工作以进行协同推理。这种协同方法相比依赖单个LLM,能产生更好的用户提示响应。在本文中,我们考虑在分布式环境中使用这样的MoA架构,其中LLM在个别边缘设备上运行,每个设备都与用户唯一关联,并拥有自己的分布式计算能力。这些设备使用去中心化的闲聊算法交换信息,允许不同的设备节点在没有中央服务器监督的情况下进行交流。在考虑的系统中,不同用户拥有他们自己的LLM模型来处理用户提示。此外,设备会闲聊它们自己的用户特定提示或增强提示,以生成对某些查询的更精细答案。当用户对应的LLM忙于处理时,用户提示会暂时存储在设备队列中。考虑到边缘设备的内存限制,确保系统中的平均队列大小保持有界至关重要。在本文中,我们通过理论计算设备队列的排队稳定性条件来解决这个问题,这些条件在我们的实验中也得到了验证。此外,我们利用开源LLM实现分布式MoA,并通过实验证明某些MoA配置产生的响应质量更高,这是在AlpacaEval 2.0基准测试上评估的。实现可访问于:https://github.com/purbeshmitra/distributed_moa。
论文及项目相关链接
摘要
近期提出Mixture-of-Agents(MoA)方法提升大型语言模型(LLM)性能,使多个LLM协同工作以进行协同推理。在分布式环境中考虑MoA架构,其中LLM在各自边缘设备上运行,每个设备与用户唯一关联并拥有自己的分布式计算能力。这些设备使用去中心化的闲聊算法交换信息,允许不同设备节点之间无需中心服务器的监督即可通信。在此设置中,用户拥有自己的LLM模型来响应提示。设备会闲聊用户特定的提示或增强提示以生成更精细的答案。用户提示会在相应LLM繁忙时临时存储在设备队列中。鉴于边缘设备的内存限制,确保系统中平均队列大小保持界限至关重要。本文通过理论计算设备队列的稳定条件来解决这一问题,并在实验中进行了验证。此外,我们借助开源LLM实现分布式MoA进行实验,证明某些MoA配置产生的响应质量较高,如在AlpacaEval 2.0基准测试上的表现。相关实现可通过以下链接获取:https://github.com/purbeshmitra/distributed_moa。
关键见解
- MoA方法能够促进多个LLM在分布式环境中协同工作,提高对用户提示的响应质量。
- 边缘设备间的信息交换采用去中心化闲聊算法,实现设备间自主通信,无需中央服务器监督。
- 不同用户拥有各自的LLM模型以处理用户提示,同时设备能够处理排队的用户提示。
- 理论计算设备队列的稳定条件,确保内存有限的边缘设备能维持系统平均队列大小。
- 通过实验验证,某些MoA配置能产生比其他配置更高质量的响应。
- 提供基于开源LLM的分布式MoA实现,并在AlpacaEval 2.0基准测试中表现良好。
点此查看论文截图

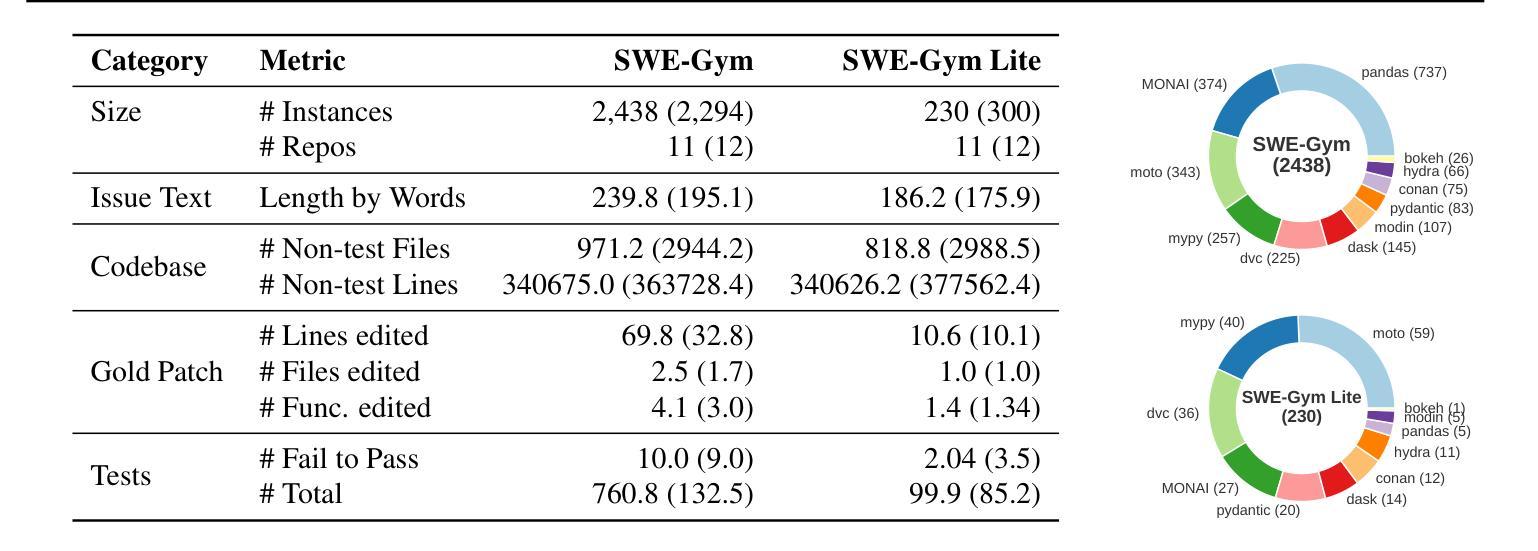
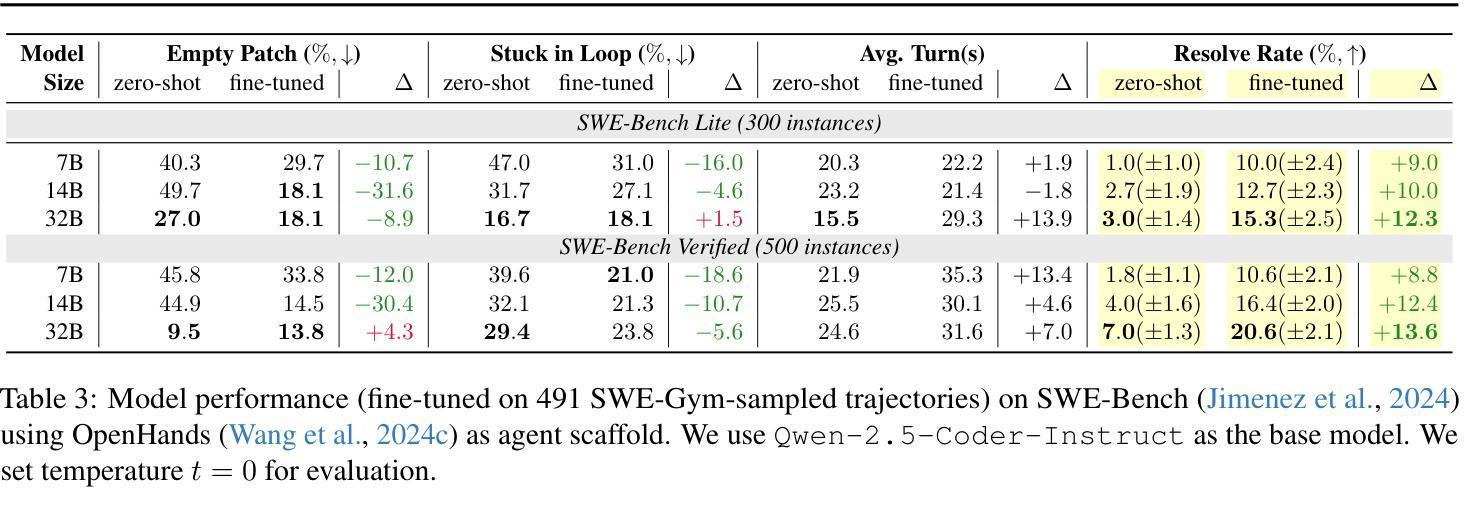
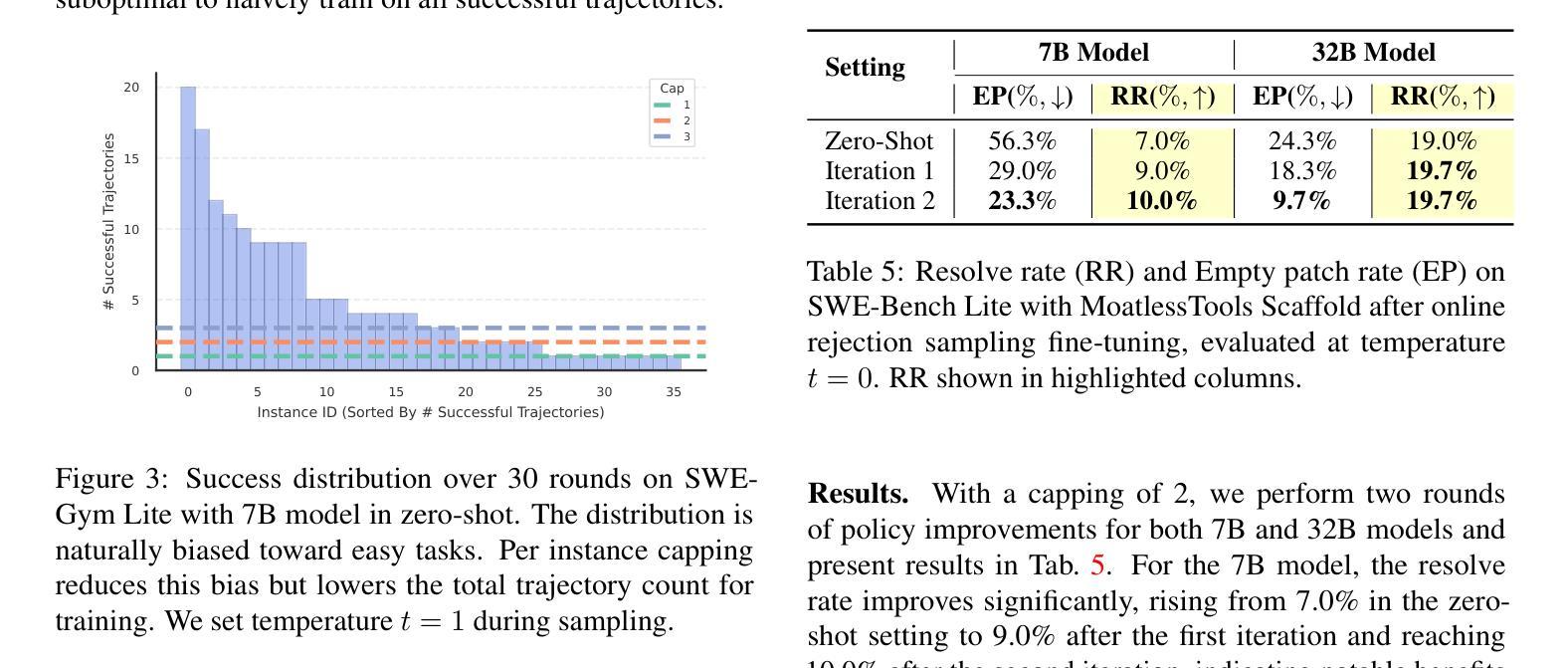
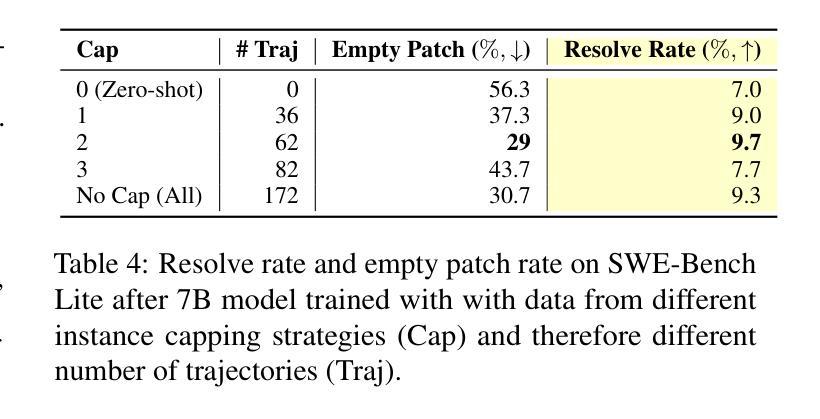
Training Software Engineering Agents and Verifiers with SWE-Gym
Authors:Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, Yizhe Zhang
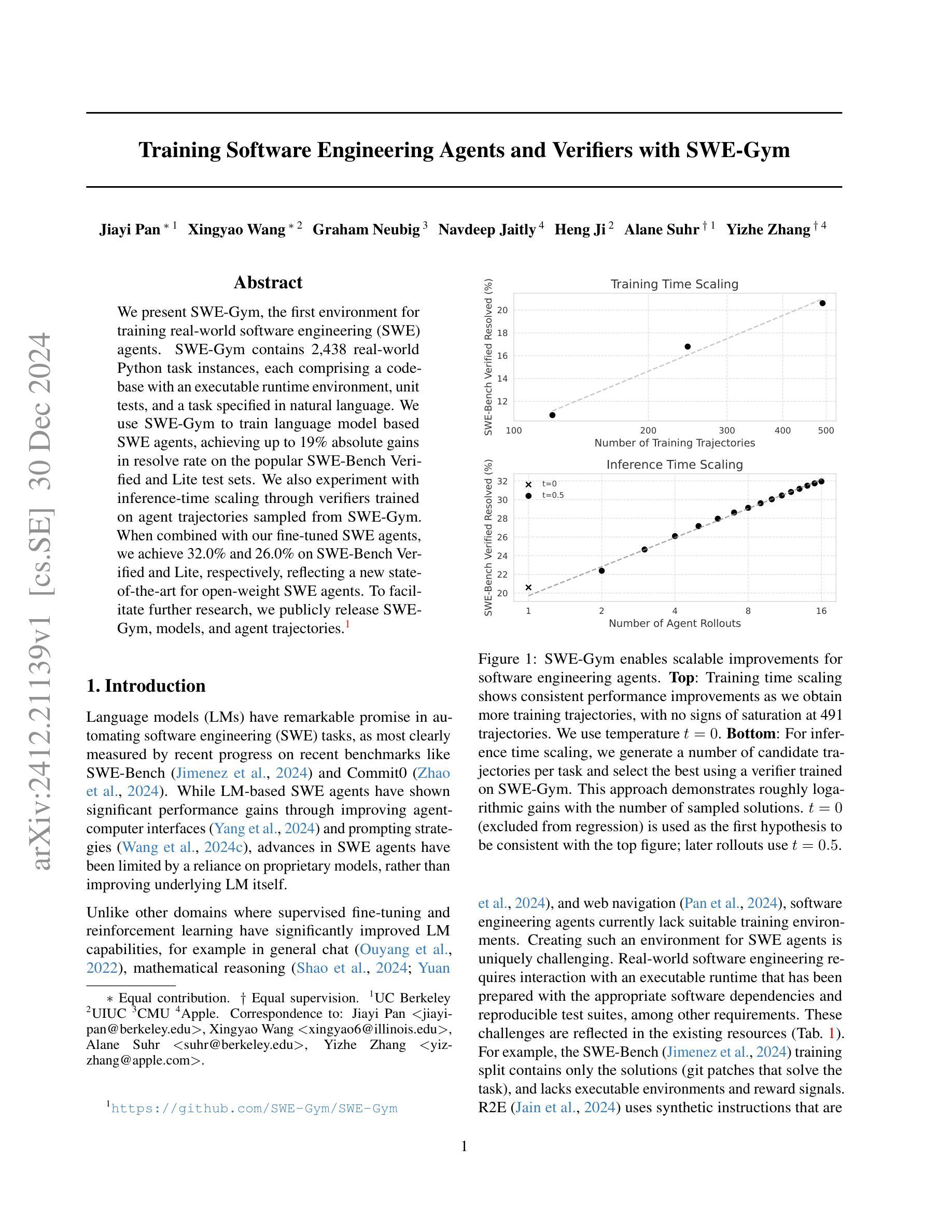
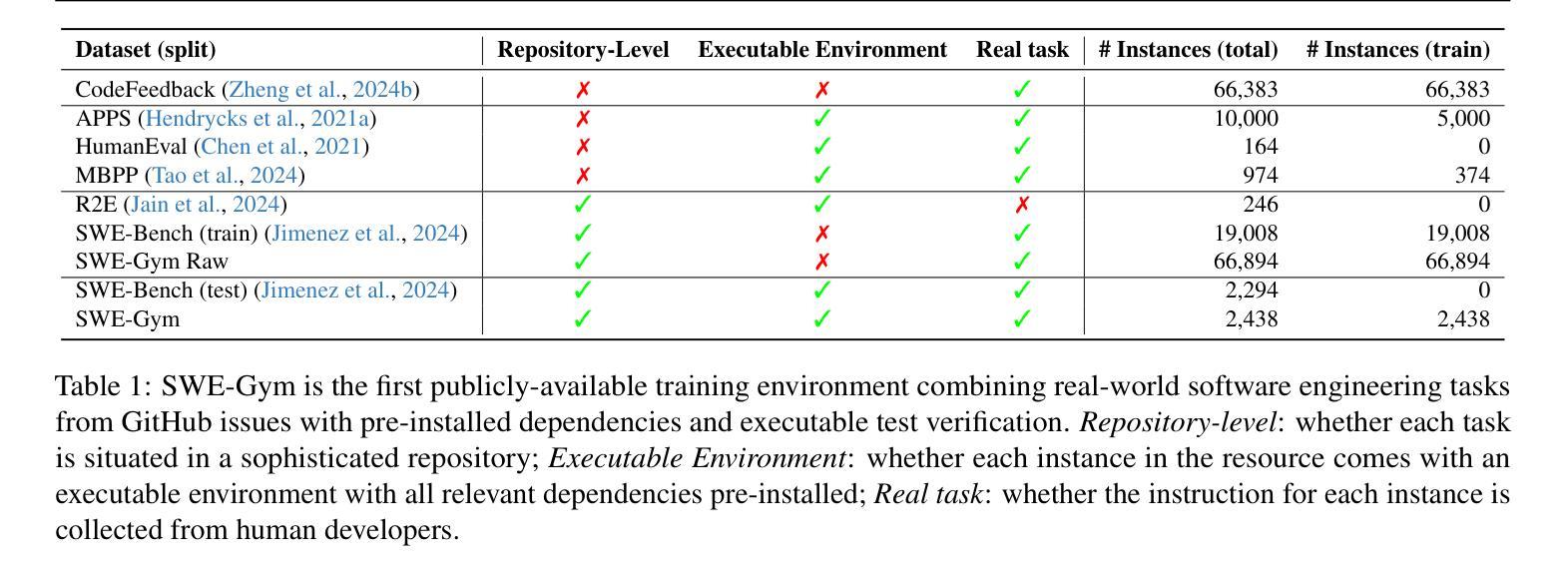
We present SWE-Gym, the first environment for training real-world software engineering (SWE) agents. SWE-Gym contains 2,438 real-world Python task instances, each comprising a codebase with an executable runtime environment, unit tests, and a task specified in natural language. We use SWE-Gym to train language model based SWE agents , achieving up to 19% absolute gains in resolve rate on the popular SWE-Bench Verified and Lite test sets. We also experiment with inference-time scaling through verifiers trained on agent trajectories sampled from SWE-Gym. When combined with our fine-tuned SWE agents, we achieve 32.0% and 26.0% on SWE-Bench Verified and Lite, respectively, reflecting a new state-of-the-art for open-weight SWE agents. To facilitate further research, we publicly release SWE-Gym, models, and agent trajectories.
我们推出SWE-Gym,这是第一个用于训练现实世界软件工程(SWE)代理的环境。SWE-Gym包含2438个现实世界的Python任务实例,每个实例都包含一个带有可执行运行时环境、单元测试和用自然语言指定的任务的基础代码。我们使用SWE-Gym训练基于语言模型的SWE代理,在流行的SWE-Bench Verified和Lite测试集上实现高达19%的绝对解决率增益。我们还通过实验验证了在SWE-Gym采样的代理轨迹上训练的验证器进行推理时间缩放。结合我们微调过的SWE代理,我们在SWE-Bench Verified和Lite上分别达到了32.0%和26.0%,反映了开放权重SWE代理的最新状态。为了促进进一步研究,我们公开发布SWE-Gym、模型和代理轨迹。
论文及项目相关链接
PDF Code at https://github.com/SWE-Gym/SWE-Gym
Summary:
我们推出了SWE-Gym,这是首个用于训练真实世界软件工程(SWE)代理的环境。SWE-Gym包含2438个真实世界的Python任务实例,每个实例都包含一个可执行运行时环境、单元测试和用自然语言指定的任务。我们使用SWE-Gym训练基于语言模型的SWE代理,在流行的SWE-Bench Verified和Lite测试集上实现了高达19%的绝对解决率增长。此外,我们还尝试通过训练在SWE-Gym中采样的代理轨迹的验证器来进行推理时间缩放。结合我们微调过的SWE代理,我们在SWE-Bench Verified和Lite上分别达到了32.0%和26.0%的表现,反映了开放权重SWE代理的最新状态。为了促进进一步研究,我们公开发布了SWE-Gym、模型和代理轨迹。
Key Takeaways:
- SWE-Gym是首个用于训练真实世界软件工程代理的环境,包含2438个真实世界的Python任务实例。
- 通过使用SWE-Gym训练语言模型,SWE代理在SWE-Bench Verified和Lite测试集上的解决率有了显著提高。
- 推理时间缩放通过训练在SWE-Gym中采样的代理轨迹的验证器实现。
- 结合微调过的SWE代理,在SWE-Bench Verified和Lite上的表现反映了开放权重SWE代理的最新水平。
- SWE-Gym、模型和代理轨迹现已公开,以促进进一步研究。
- SWE-Gym环境为软件工程的自动化和智能化提供了新的可能性,有助于推动软件工程领域的发展。
点此查看论文截图
Exploring and Controlling Diversity in LLM-Agent Conversation
Authors:KuanChao Chu, Yi-Pei Chen, Hideki Nakayama
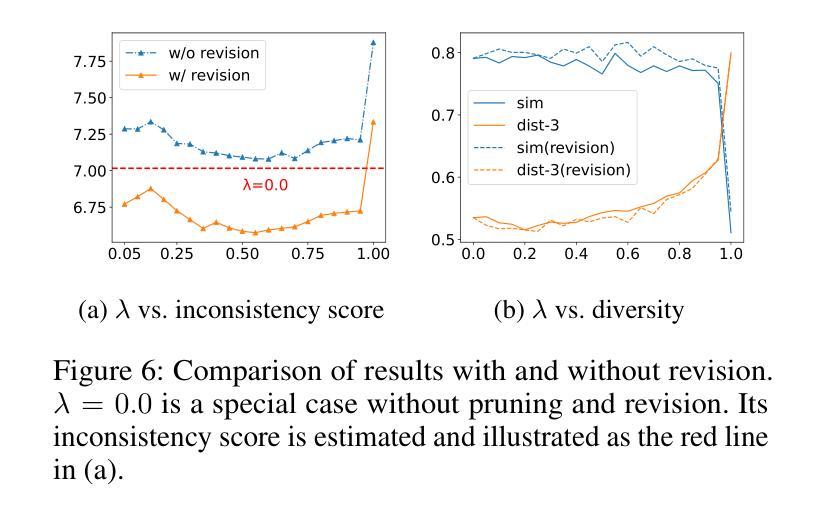
Diversity is a critical aspect of multi-agent communication. In this paper, we focus on controlling and exploring diversity in the context of open-domain multi-agent conversations, particularly for world simulation applications. We propose Adaptive Prompt Pruning (APP), a novel method that dynamically adjusts the content of the utterance generation prompt to control diversity using a single parameter, lambda. Through extensive experiments, we show that APP effectively controls the output diversity across models and datasets, with pruning more information leading to more diverse output. We comprehensively analyze the relationship between prompt content and conversational diversity. Our findings reveal that information from all components of the prompt generally constrains the diversity of the output, with the Memory block exerting the most significant influence. APP is compatible with established techniques like temperature sampling and top-p sampling, providing a versatile tool for diversity management. To address the trade-offs of increased diversity, such as inconsistencies with omitted information, we incorporate a post-generation correction step, which effectively balances diversity enhancement with output consistency. Additionally, we examine how prompt structure, including component order and length, impacts diversity. This study addresses key questions surrounding diversity in multi-agent world simulation, offering insights into its control, influencing factors, and associated trade-offs. Our contributions lay the foundation for systematically engineering diversity in LLM-based multi-agent collaborations, advancing their effectiveness in real-world applications.
多样性是多智能体通信的关键方面。在本文中,我们专注于在开放域多智能体对话的情境中控制和探索多样性,特别是在世界模拟应用方面。我们提出了自适应提示修剪(APP)这一新方法,该方法通过单个参数λ动态调整话语生成提示的内容,以控制多样性。通过广泛的实验,我们证明了APP在模型和数据集之间有效地控制了输出多样性,修剪更多信息会导致输出更加多样化。我们全面分析了提示内容与对话多样性之间的关系。我们的研究发现,提示的所有组成部分的信息通常都限制了输出的多样性,其中记忆块的影响最为显著。APP可以与温度采样、top-p采样等现有技术相结合,提供多样化的工具来进行多样性管理。为了解决增加多样性带来的权衡问题,如省略信息与一致性之间的不一致,我们引入了后生成校正步骤,这有效地平衡了多样性增强与输出一致性。此外,我们还研究了提示结构,包括组件的顺序和长度,对多样性的影响。本研究解决了多智能体世界模拟中多样性的关键问题,为控制、影响因素和相关的权衡提供了见解。我们的贡献为基于LLM的多智能体协作中系统地工程化多样性奠定了基础,提高了其在现实世界应用中的有效性。
论文及项目相关链接
PDF Accepted for the AAAI 2025 Workshop on Advancing LLM-Based Multi-Agent Collaboration
Summary:
本文研究了多智能体通信中的多样性控制问题,特别是在开放领域多智能体对话中的多样性探索。提出了一种名为自适应提示修剪(APP)的新方法,通过动态调整话语生成提示的内容来控制多样性。实验表明,APP能有效控制不同模型和数据的输出多样性,通过删除更多信息来获得更多不同的输出。本文综合分析了提示内容与对话多样性的关系,发现提示的所有组成部分的信息通常都会限制输出的多样性,其中记忆块的影响最为显著。此外,APP可以与现有的技术如温度采样和top-p采样相结合,提供多样化的管理工具。为了解决增加多样性所带来的权衡问题,如省略信息的不一致性,本文引入了后生成校正步骤,有效地平衡了多样性增强与输出一致性。研究还发现提示结构如组件顺序和长度也会影响多样性。本研究解决了多智能体世界模拟中多样性的关键问题,为在大型语言模型基础上系统地工程化多样性提供了见解,提高了其在现实世界应用中的有效性。
Key Takeaways:
- 多智能体通信中的多样性控制是重要研究方向。
- 自适应提示修剪(APP)方法通过动态调整话语生成提示的内容来控制多样性。
- APP方法能有效控制不同模型和数据的输出多样性。
- 提示的所有组成部分都会限制输出的多样性,其中记忆块影响最显著。
- APP可与现有技术结合,提供多样化的管理工具。
- 后生成校正步骤有效平衡了多样性增强与输出一致性。
点此查看论文截图

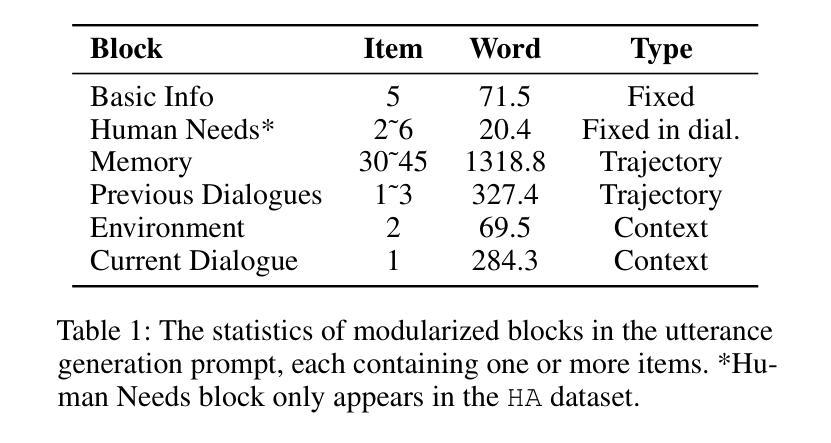

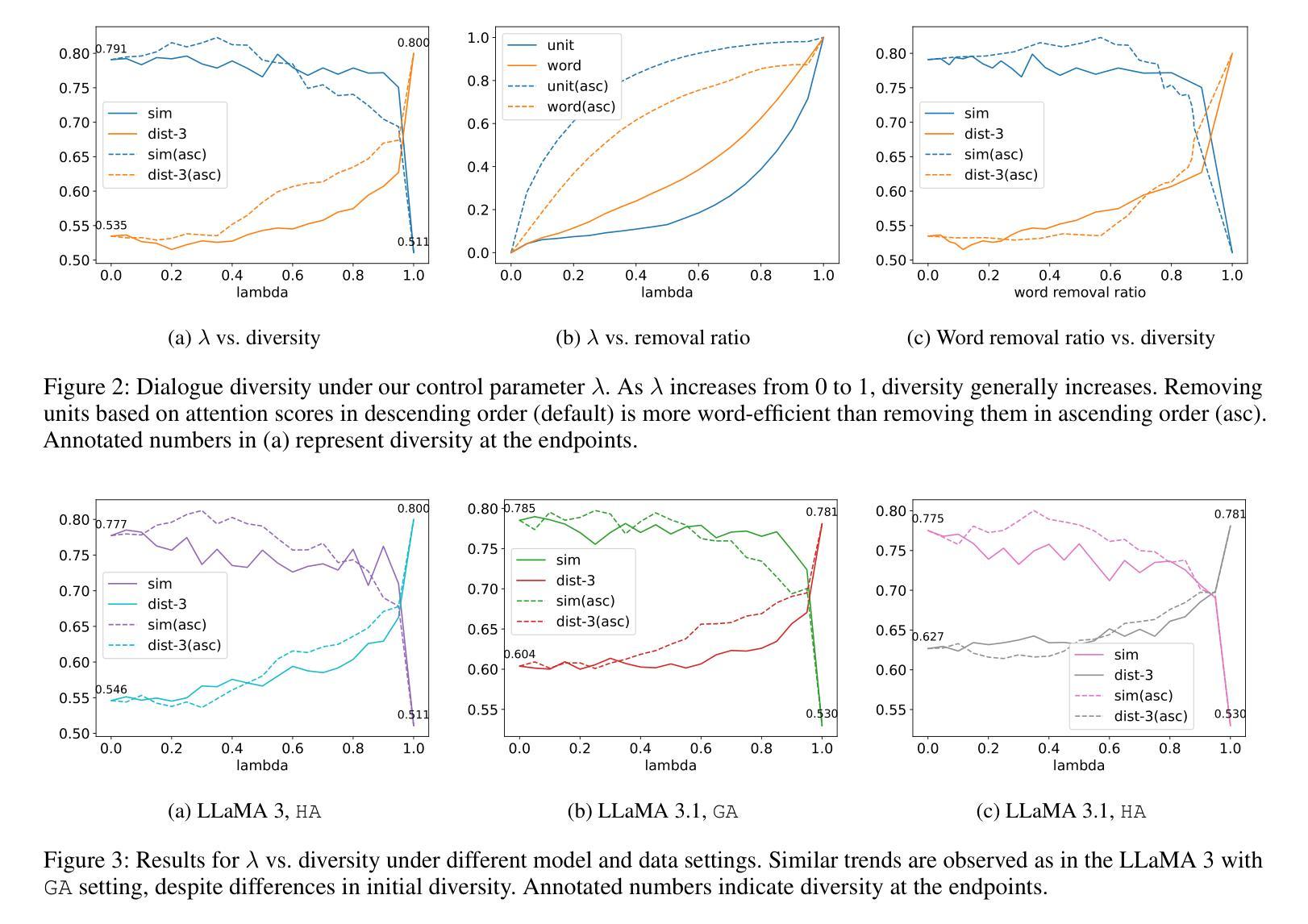
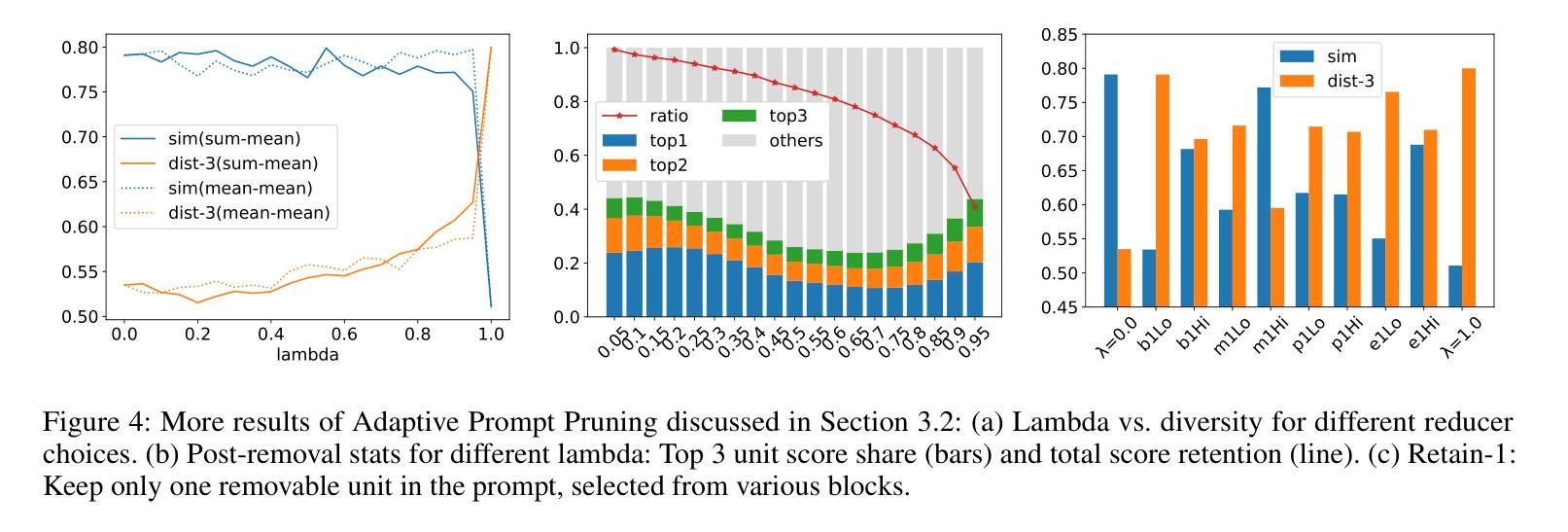
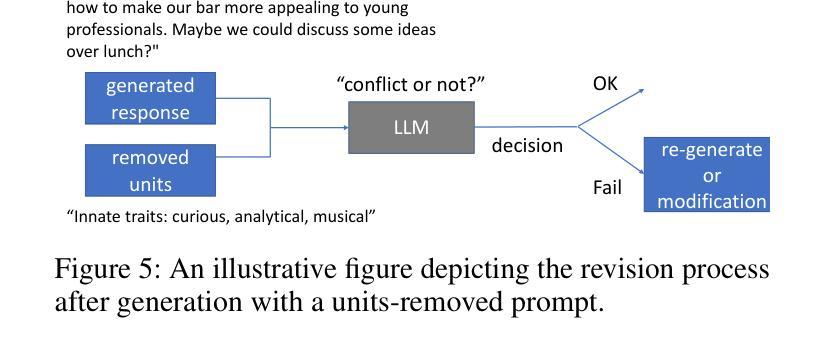
Planning, Living and Judging: A Multi-agent LLM-based Framework for Cyclical Urban Planning
Authors:Hang Ni, Yuzhi Wang, Hao Liu
Urban regeneration presents significant challenges within the context of urbanization, requiring adaptive approaches to tackle evolving needs. Leveraging advancements in large language models (LLMs), we propose Cyclical Urban Planning (CUP), a new paradigm that continuously generates, evaluates, and refines urban plans in a closed-loop. Specifically, our multi-agent LLM-based framework consists of three key components: (1) Planning, where LLM agents generate and refine urban plans based on contextual data; (2) Living, where agents simulate the behaviors and interactions of residents, modeling life in the urban environment; and (3) Judging, which involves evaluating plan effectiveness and providing iterative feedback for improvement. The cyclical process enables a dynamic and responsive planning approach. Experiments on the real-world dataset demonstrate the effectiveness of our framework as a continuous and adaptive planning process.
在城市化背景下,城市再生面临重大挑战,需要适应性的方法来应对不断变化的需求。我们借助大型语言模型(LLM)的进步,提出循环城市规划(CUP)这一新范式,该范式以闭环方式连续生成、评估和优化城市规划。具体来说,我们的基于多智能体的LLM框架包含三个关键部分:(1)规划,其中LLM智能体基于上下文数据生成和细化城市规划;(2)生活,其中智能体模拟居民的行为和互动,模拟城市环境中的生活;(3)判断,涉及评估规划的有效性并提供改进迭代反馈。循环过程使规划方法具有动态性和响应性。在真实数据集上的实验证明了我们框架作为连续自适应规划过程的有效性。
论文及项目相关链接
PDF 4 pages, 2 figures, accepted by The 1st Workshop on AI for Urban Planning (AAAI 2025’s Workshop)
Summary
循环城市计划(CUP)利用大型语言模型(LLMs)应对城市化中的再生挑战,通过持续生成、评估和修正城市计划,形成了一个封闭的循环体系。该框架包括规划、生活和评判三个关键组成部分,旨在动态响应城市需求并改进城市计划。
Key Takeaways
- 城市化背景下的城市再生面临诸多挑战,需要适应性的方法来解决不断变化的需求。
- 提出了一种新的循环城市规划(CUP)范式,利用大型语言模型(LLMs)连续生成、评估和修正城市计划。
- 循环城市计划框架包括三个关键组成部分:规划、生活和评判。
- 规划组件利用LLM代理基于上下文数据生成和细化城市计划。
- 生活组件模拟居民的行为和互动,模拟城市环境中的生活。
- 评判组件评估计划的有效性并提供反馈以进行改进。
点此查看论文截图

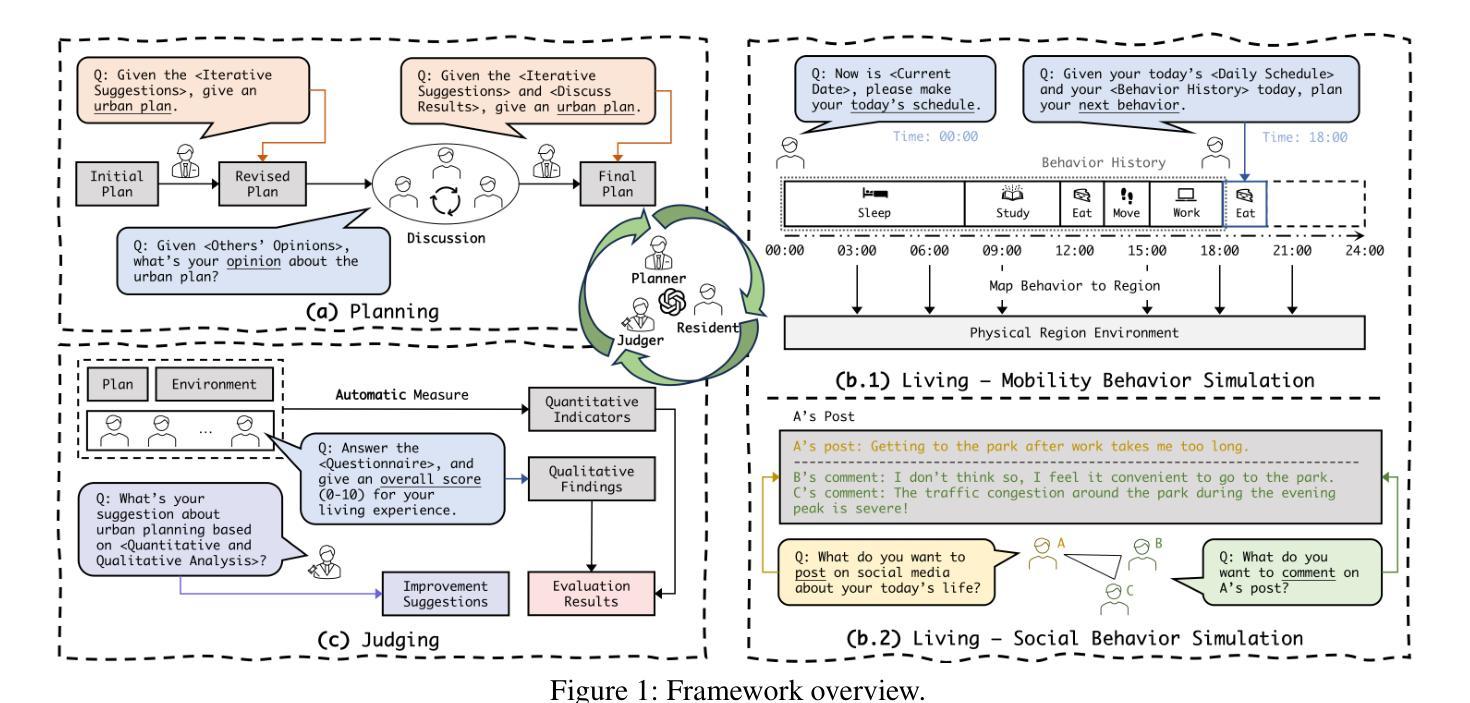
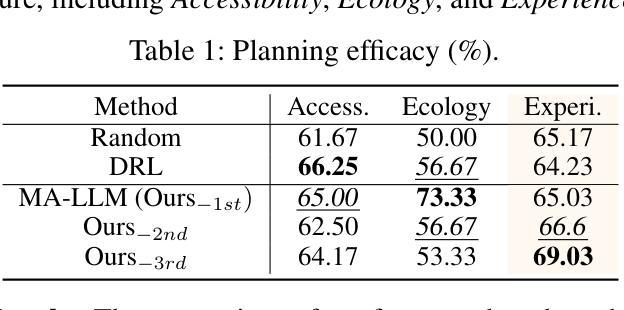
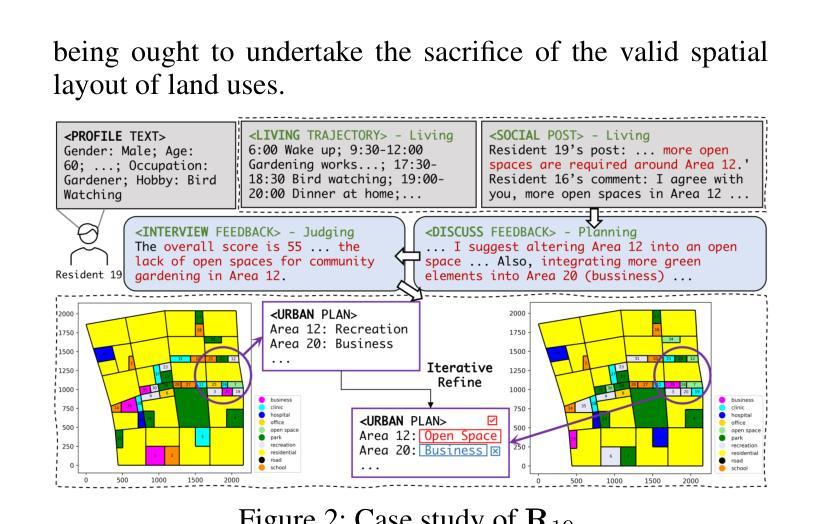
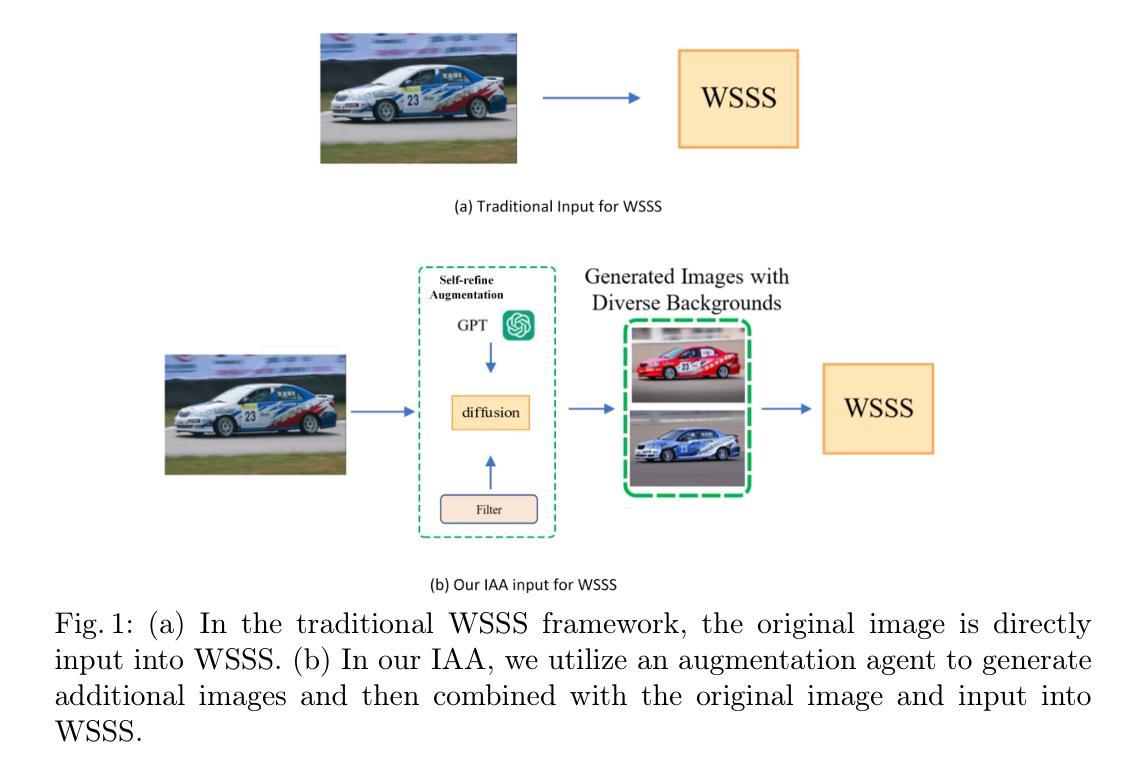
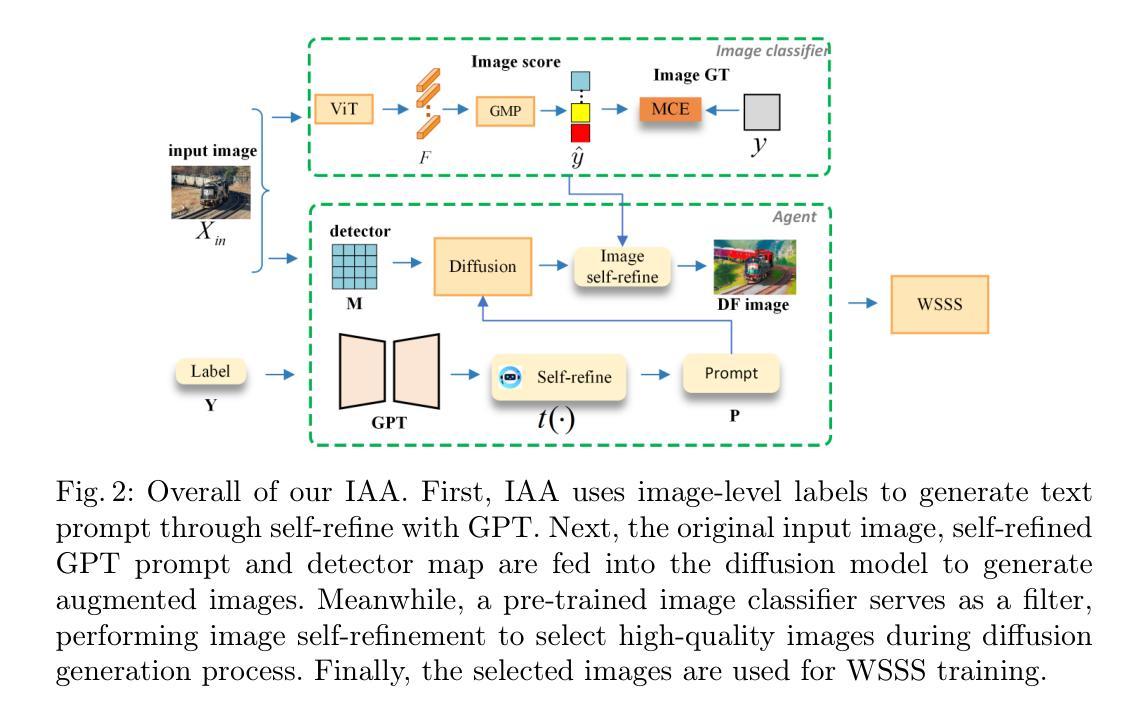
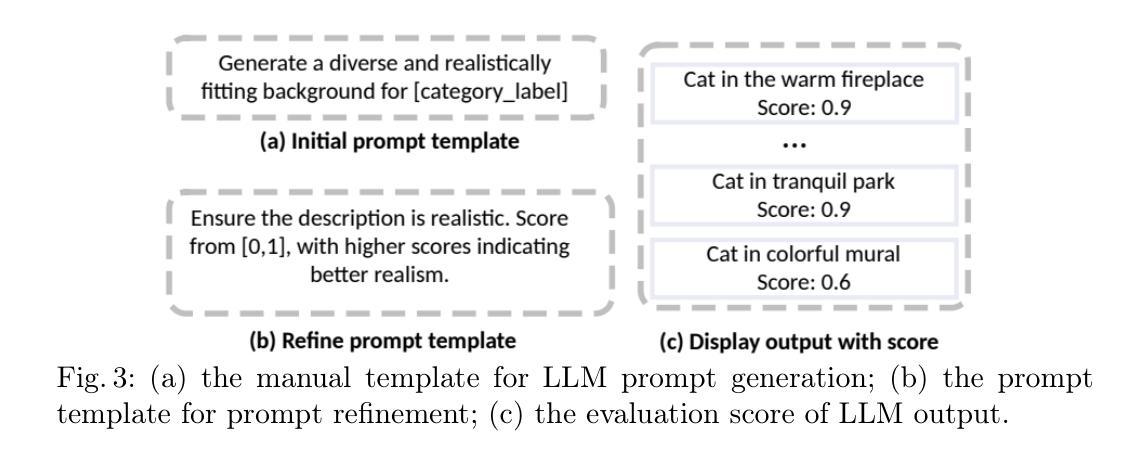
Image Augmentation Agent for Weakly Supervised Semantic Segmentation
Authors:Wangyu Wu, Xianglin Qiu, Siqi Song, Zhenhong Chen, Xiaowei Huang, Fei Ma, Jimin Xiao
Weakly-supervised semantic segmentation (WSSS) has achieved remarkable progress using only image-level labels. However, most existing WSSS methods focus on designing new network structures and loss functions to generate more accurate dense labels, overlooking the limitations imposed by fixed datasets, which can constrain performance improvements. We argue that more diverse trainable images provides WSSS richer information and help model understand more comprehensive semantic pattern. Therefore in this paper, we introduce a novel approach called Image Augmentation Agent (IAA) which shows that it is possible to enhance WSSS from data generation perspective. IAA mainly design an augmentation agent that leverages large language models (LLMs) and diffusion models to automatically generate additional images for WSSS. In practice, to address the instability in prompt generation by LLMs, we develop a prompt self-refinement mechanism. It allow LLMs to re-evaluate the rationality of generated prompts to produce more coherent prompts. Additionally, we insert an online filter into diffusion generation process to dynamically ensure the quality and balance of generated images. Experimental results show that our method significantly surpasses state-of-the-art WSSS approaches on the PASCAL VOC 2012 and MS COCO 2014 datasets.
弱监督语义分割(WSSS)仅使用图像级标签取得了显著的进步。然而,大多数现有的WSSS方法主要集中在设计新的网络结构和损失函数来生成更准确的密集标签,而忽视了固定数据集所带来的限制,这些限制可能阻碍性能的提升。我们认为,提供更多可训练图像可以为WSSS提供更丰富的信息,并帮助模型理解更全面的语义模式。因此,在本文中,我们引入了一种新方法,称为图像增强代理(IAA),它表明从数据生成的角度增强WSSS是可能的。IAA主要设计了一个增强代理,利用大型语言模型(LLM)和扩散模型自动为WSSS生成额外的图像。在实践中,为了解决LLM生成提示的不稳定性问题,我们开发了一种提示自我完善机制。它允许LLM重新评估生成的提示的合理性,以产生更连贯的提示。此外,我们在扩散生成过程中插入了一个在线过滤器,以动态确保生成的图像的质量和平衡。实验结果表明,我们的方法在PASCAL VOC 2012和MS COCO 2014数据集上的表现显著超越了最新的WSSS方法。
论文及项目相关链接
Summary
基于图像级标签的弱监督语义分割(WSSS)已经取得了显著进展。然而,现有方法多关注设计新网络结构和损失函数以生成更准确的密集标签,忽视了固定数据集带来的限制。本文提出一种名为图像增强代理(IAA)的新方法,从数据生成角度提升WSSS性能。IAA设计了一个利用大型语言模型(LLMs)和扩散模型自动生成额外图像的增强代理。为解决LLMs在提示生成中的不稳定问题,本文开发了一种提示自我优化机制,使LLMs能够重新评估生成提示的合理性,产生更连贯的提示。此外,还在扩散生成过程中插入在线过滤器,以动态确保生成图像的质量和平衡。实验结果表明,该方法在PASCAL VOC 2012和MS COCO 2014数据集上显著超越了现有WSSS方法。
Key Takeaways
- WSSS已借助图像级标签取得显著进展,但固定数据集的限制影响了性能提升。
- 引入了一种名为图像增强代理(IAA)的新方法,从数据生成角度提升WSSS。
- IAA利用大型语言模型(LLMs)和扩散模型自动生成额外图像。
- 开发了一种提示自我优化机制,解决LLMs在提示生成中的不稳定问题。
- 在扩散生成过程中插入在线过滤器,确保生成图像的质量和平衡。
- 实验结果表明,该方法在PASCAL VOC 2012和MS COCO 2014数据集上表现优异。
点此查看论文截图


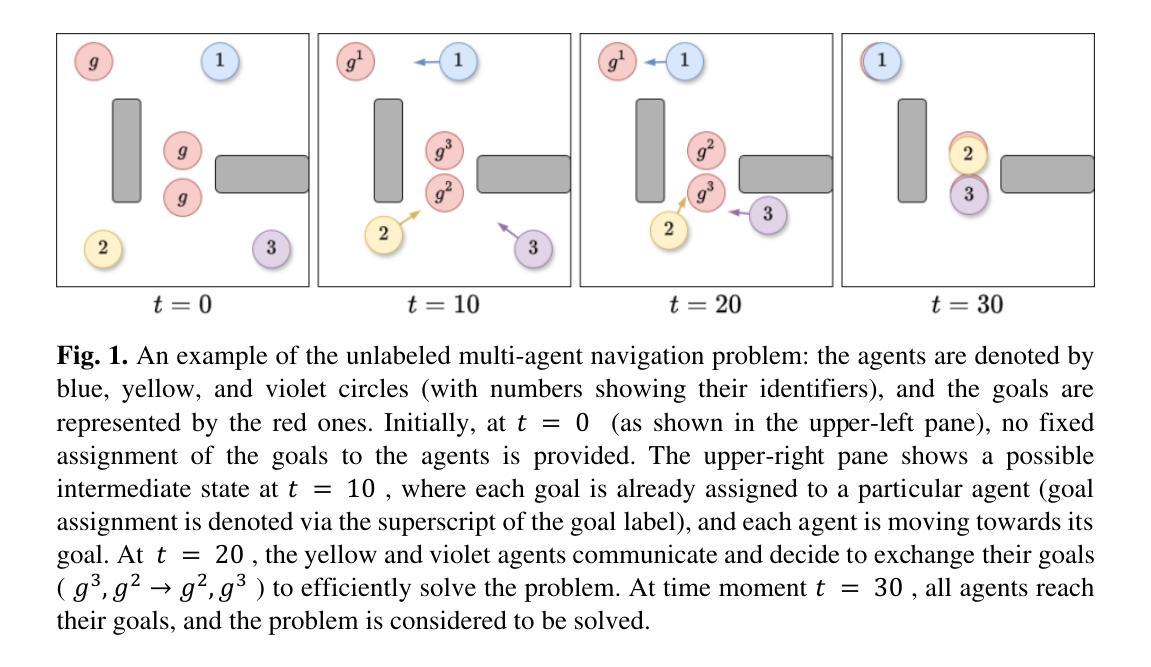
Decentralized Unlabeled Multi-Agent Navigation in Continuous Space
Authors:Stepan Dergachev, Konstantin Yakovlev
In this work, we study the problem where a group of mobile agents needs to reach a set of goal locations, but it does not matter which agent reaches a specific goal. Unlike most of the existing works on this topic that typically assume the existence of the centralized planner (or controller) and limit the agents’ moves to a predefined graph of locations and transitions between them, in this work we focus on the decentralized scenarios, when each agent acts individually relying only on local observations/communications and is free to move in arbitrary direction at any time. Our iterative approach involves agents individually selecting goals, exchanging them, planning paths, and at each time step choose actions that balance between progressing along the paths and avoiding collisions. The proposed method is shown to be complete under specific assumptions on how agents progress towards their current goals, and our empirical evaluation demonstrates its superiority over a baseline decentralized navigation approach in success rate (i.e. is able to solve more problem instances under a given time limit) and a comparison with the centralized TSWAP algorithm reveals its efficiency in minimizing trajectory lengths for mission accomplishment.
在这项工作中,我们研究了一组移动代理需要达到一组目标位置的问题,但哪个代理达到特定目标并不重要。与大多数关于该主题的现有工作不同,这些工作通常假设存在集中规划器(或控制器),并将代理的移动限制在预先定义的位置图和它们之间的转换上,我们的工作重点是在分散场景中,当每个代理只依赖局部观察/通信单独行动,并且可以在任何时间自由地向任意方向移动。我们的迭代方法涉及代理单独选择目标、交换目标、规划路径,并在每个时间步骤中选择行动,在沿路径进步和避免碰撞之间取得平衡。在特定假设下,所提出的方法是完整的,关于代理如何朝着他们的当前目标进步。我们的经验评估表明,它在成功率方面优于基本的分散式导航方法(即能够在给定时间限制内解决更多的问题实例),与集中化的TSWAP算法的比较表明,它在完成使命时最小化轨迹长度方面的效率很高。
论文及项目相关链接
PDF This is a pre-print of the paper accepted to ICR 2024. It contains 16 pages, 5 figures, 1 table
摘要
本研究探讨一组移动代理需要到达一组目标位置的问题,但哪个代理到达特定目标并不重要。不同于大多数现有工作通常假设存在集中规划器(或控制器),并限制代理的移动至预先定义的位置图和位置之间的转换,本研究重点关注分散场景,每个代理仅依靠局部观察/通信独立行动,且任何时候都可自由地向任意方向移动。我们的迭代方法包括代理单独选择目标、交换目标、规划路径,并在每个时间步选择既能沿路径前进又能避免碰撞的行动。所提出的方法在特定假设下被证明是完整的,且我们的经验评估表明,其在成功率上优于基线分散导航方法(即,在给定的时间限制内能够解决更多的问题实例),与集中化的TSWAP算法的比较则显示出其在完成使命时最小化轨迹长度的效率。
关键见解
- 研究的是移动代理群体达到一系列目标位置的问题,重点在分散场景,即每个代理独立行动,可自由地向任意方向移动。
- 提出一种迭代方法,包括代理选择目标、交换目标、规划路径,并平衡沿路径前进和避免碰撞的行动选择。
- 方法的完整性在特定假设下得到验证。
- 相较于基线分散导航方法,所提出的方法在成功率上表现优越。
- 与集中化的TSWAP算法相比,所提出的方法在最小化轨迹长度方面展现出效率。
- 研究处理了哪些代理达到特定目标并不重要的问题,增加了应用场景的实用性。
- 在处理分散移动代理问题时,考虑到了局部观察和通信的重要性。
点此查看论文截图



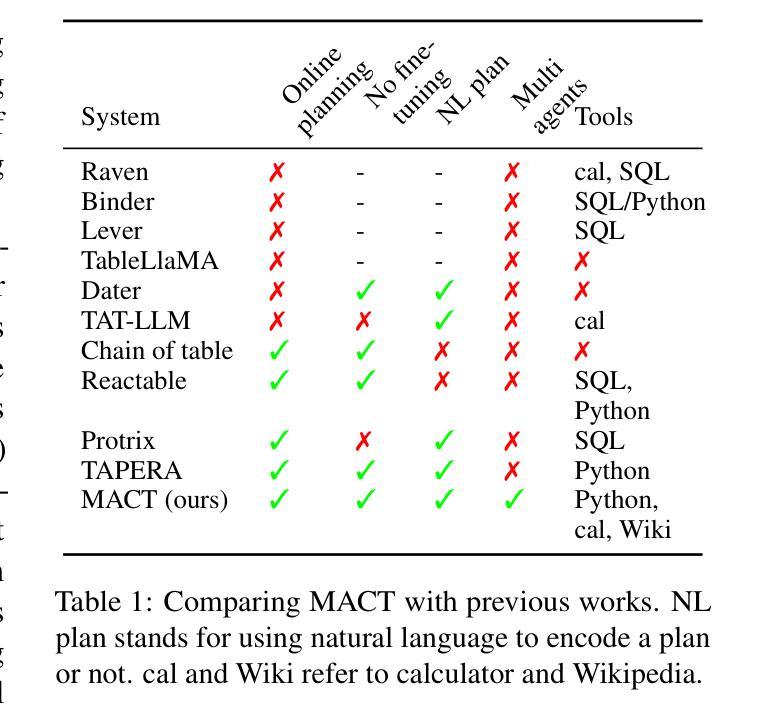
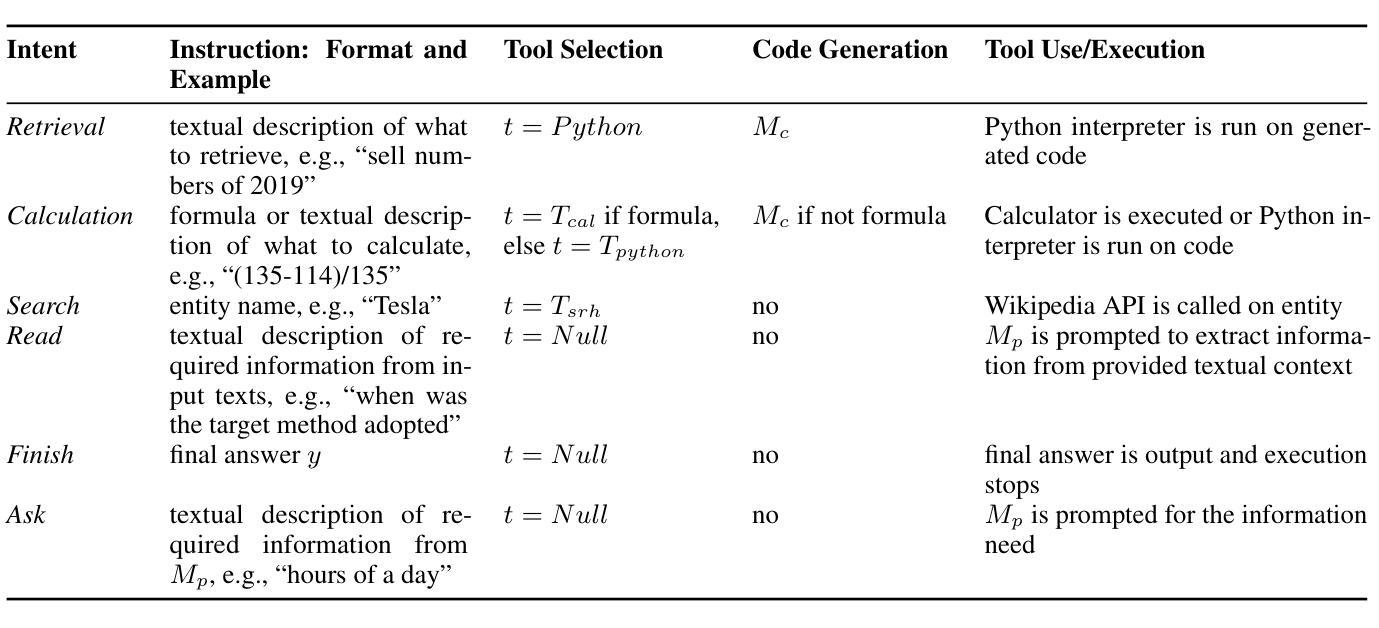
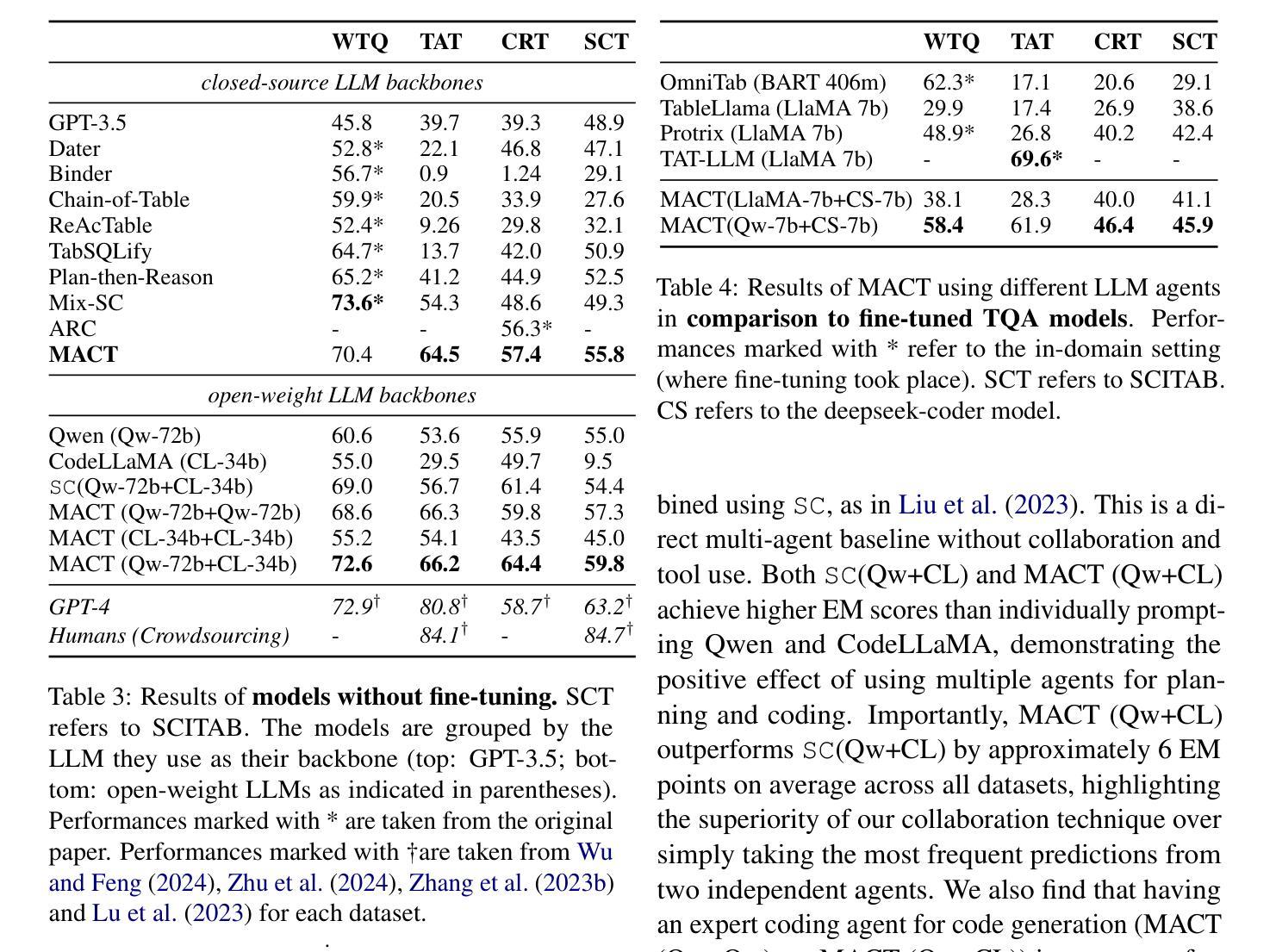
Efficient Multi-Agent Collaboration with Tool Use for Online Planning in Complex Table Question Answering
Authors:Wei Zhou, Mohsen Mesgar, Annemarie Friedrich, Heike Adel
Complex table question answering (TQA) aims to answer questions that require complex reasoning, such as multi-step or multi-category reasoning, over data represented in tabular form. Previous approaches demonstrated notable performance by leveraging either closed-source large language models (LLMs) or fine-tuned open-weight LLMs. However, fine-tuning LLMs requires high-quality training data, which is costly to obtain, and utilizing closed-source LLMs poses accessibility challenges and leads to reproducibility issues. In this paper, we propose Multi-Agent Collaboration with Tool use (MACT), a framework that requires neither closed-source models nor fine-tuning. In MACT, a planning agent and a coding agent that also make use of tools collaborate to answer questions. Our experiments on four TQA benchmarks show that MACT outperforms previous SoTA systems on three out of four benchmarks and that it performs comparably to the larger and more expensive closed-source model GPT-4 on two benchmarks, even when using only open-weight models without any fine-tuning. We conduct extensive analyses to prove the effectiveness of MACT’s multi-agent collaboration in TQA.
复杂表格问答(TQA)旨在回答需要复杂推理的问题,如多步骤或多类别推理,这些问题涉及以表格形式呈现的数据。之前的方法通过利用封闭的大型语言模型(LLM)或微调开源的大型语言模型来展示显著的性能。然而,微调大型语言模型需要高质量的训练数据,而这些数据的获取成本很高,而利用封闭的大型语言模型则带来了可访问性挑战和可重复性问题的挑战。在本文中,我们提出了不需要封闭模型或微调的多智能体协作工具使用(MACT)框架。在MACT中,一个规划智能体和一个使用工具的编码智能体相互协作来回答问题。我们在四个TQA基准测试上的实验表明,MACT在三个基准测试中超过了以前的最先进的系统,并且在两个基准测试上与更大、更昂贵的封闭模型GPT-4表现相当,即使我们只使用未进行任何微调的开源模型也是如此。我们进行了广泛的分析,以证明MACT在TQA中的多智能体协作的有效性。
论文及项目相关链接
Summary
复杂表格问答(TQA)旨在回答需要复杂推理的问题,如多步骤或多类别推理,涉及表格形式的数据。现有方法通过利用封闭源的大型语言模型(LLMs)或微调开放权重LLMs取得了显著性能。然而,微调LLMs需要高质量的训练数据,成本高昂,使用封闭源LLMs带来访问挑战和可重复性问题。本文提出一种无需封闭源模型和微调的多智能体协作工具使用(MACT)框架。在MACT中,规划智能体和编码智能体利用工具进行协作回答问题。在四个TQA基准测试上的实验表明,MACT在三个基准测试中优于之前的最先进系统,并在两个基准测试上与更大、更昂贵的封闭源模型GPT-4表现相当,即使使用的是未经任何微调的开放权重模型。我们进行了广泛的分析,以证明MACT在TQA中的多智能体协作的有效性。
Key Takeaways
- 复杂表格问答(TQA)旨在解决需要复杂推理的表格数据问题。
- 现有方法主要依赖封闭源的大型语言模型(LLMs)或微调开放权重LLMs,但存在成本高昂和可访问性问题。
- 提出了一种新的框架——多智能体协作工具使用(MACT),无需封闭源模型和微调。
- 在MACT框架中,规划智能体和编码智能体利用工具进行协作以回答问题。
- 在四个TQA基准测试上,MACT在多数测试中表现优于之前的最先进系统。
- MACT与大型、昂贵的封闭源模型GPT-4在部分基准测试上表现相当,即使使用的是未经微调的开放权重模型。
点此查看论文截图

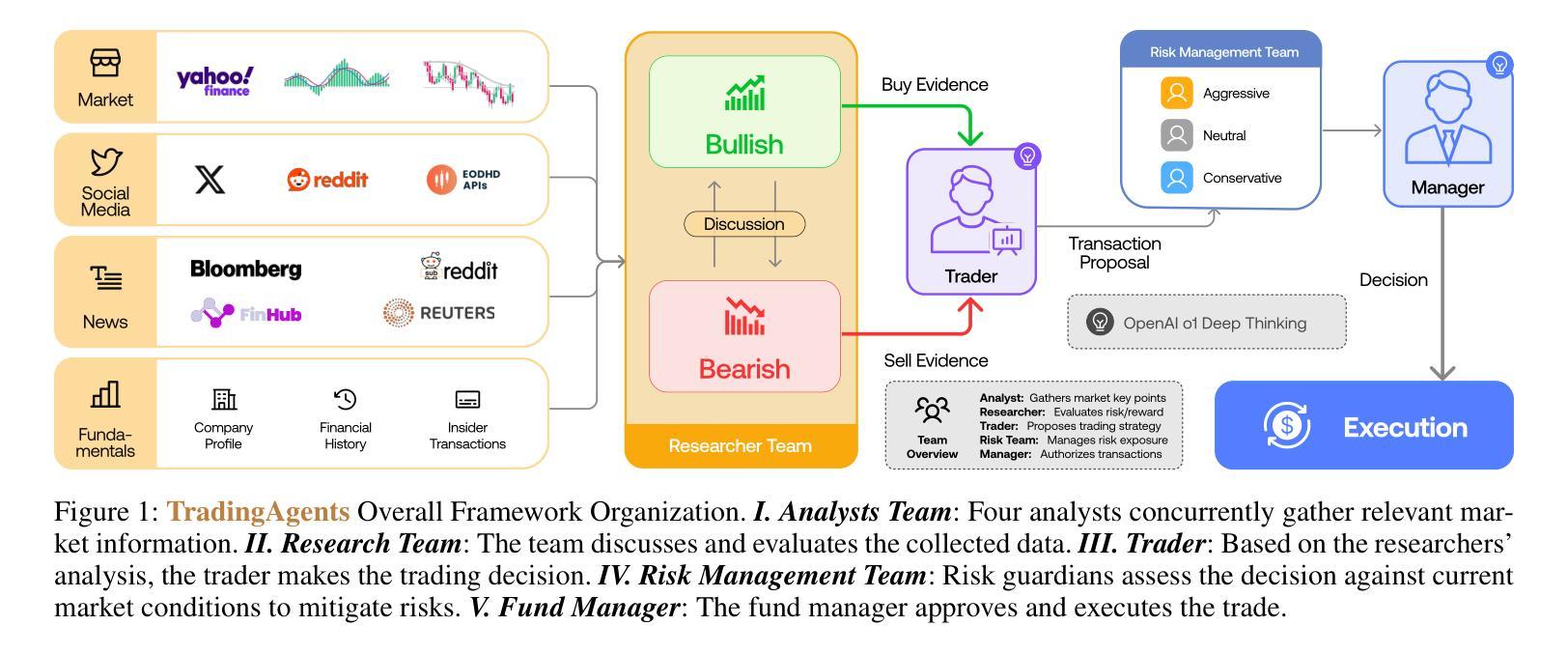
TradingAgents: Multi-Agents LLM Financial Trading Framework
Authors:Yijia Xiao, Edward Sun, Di Luo, Wei Wang
Significant progress has been made in automated problem-solving using societies of agents powered by large language models (LLMs). In finance, efforts have largely focused on single-agent systems handling specific tasks or multi-agent frameworks independently gathering data. However, multi-agent systems’ potential to replicate real-world trading firms’ collaborative dynamics remains underexplored. TradingAgents proposes a novel stock trading framework inspired by trading firms, featuring LLM-powered agents in specialized roles such as fundamental analysts, sentiment analysts, technical analysts, and traders with varied risk profiles. The framework includes Bull and Bear researcher agents assessing market conditions, a risk management team monitoring exposure, and traders synthesizing insights from debates and historical data to make informed decisions. By simulating a dynamic, collaborative trading environment, this framework aims to improve trading performance. Detailed architecture and extensive experiments reveal its superiority over baseline models, with notable improvements in cumulative returns, Sharpe ratio, and maximum drawdown, highlighting the potential of multi-agent LLM frameworks in financial trading.
在利用大型语言模型(LLM)驱动的智能体社会进行自动化问题解决方面,已经取得了重大进展。在金融领域,相关努力主要集中在处理特定任务的单一智能体系统,或独立收集数据的多智能体框架上。然而,多智能体系统在复制现实世界交易公司的协作动态方面的潜力尚未得到充分探索。TradingAgents提出了一个受交易公司启发的股票交易新框架,该框架具有专门角色的LLM驱动的智能体,如基本面分析师、情绪分析师、技术分析师和具有不同风险特征的交易员。该框架包括牛市和熊市研究人员智能体对市场条件进行评估、风险管理团队监控曝光情况、交易员综合辩论和历史数据来做出明智决策。通过模拟动态协作的交易环境,此框架旨在提高交易性能。详细的架构和广泛的实验显示其在基准模型上的优越性,累积收益、夏普比率以及最大回撤方面表现出显著改善,这突显了多智能体LLM框架在金融交易中的潜力。
论文及项目相关链接
PDF Multi-Agent AI in the Real World, AAAI 2025
Summary:基于大型语言模型(LLM)的代理社会在自动化问题解决方面取得了显著进展。在金融领域,尽管单代理系统处理特定任务或多代理框架独立收集数据的工作已得到广泛关注,但多代理系统复制现实世界交易公司协作动力的潜力仍未得到充分探索。TradingAgents提出一个受交易公司启发的股票交易新框架,其中包含由LLM驱动的专门从事各种角色的代理,如基本面分析师、情绪分析师、技术分析师和具有不同风险配置的交易员。该框架模拟动态协作的交易环境,旨在提高交易性能。详细的架构和广泛的实验表明,与基准模型相比,该框架在累计回报、夏普比率和最大回撤方面表现出优越性,突显了多代理LLM框架在金融交易中的潜力。
Key Takeaways:
- 大型语言模型(LLM)驱动的代理社会在自动化问题解决上取得显著进步。
- 金融领域中的多代理系统潜力未被充分探索,特别是在复制交易公司的协作动力方面。
- TradingAgents框架受到真实交易公司的启发,包含多种角色代理,如基本面、情绪和技术分析师以及交易员。
- 该框架模拟动态、协作的交易环境,旨在提高交易性能。
- 详细架构和广泛实验显示该框架在累计回报、夏普比率和最大回撤方面优于基准模型。
- 该框架强调风险管理的重要性,有专门的风险管理团队监控暴露情况。
- 框架中的代理通过辩论和历史数据合成见解以做出决策。
点此查看论文截图




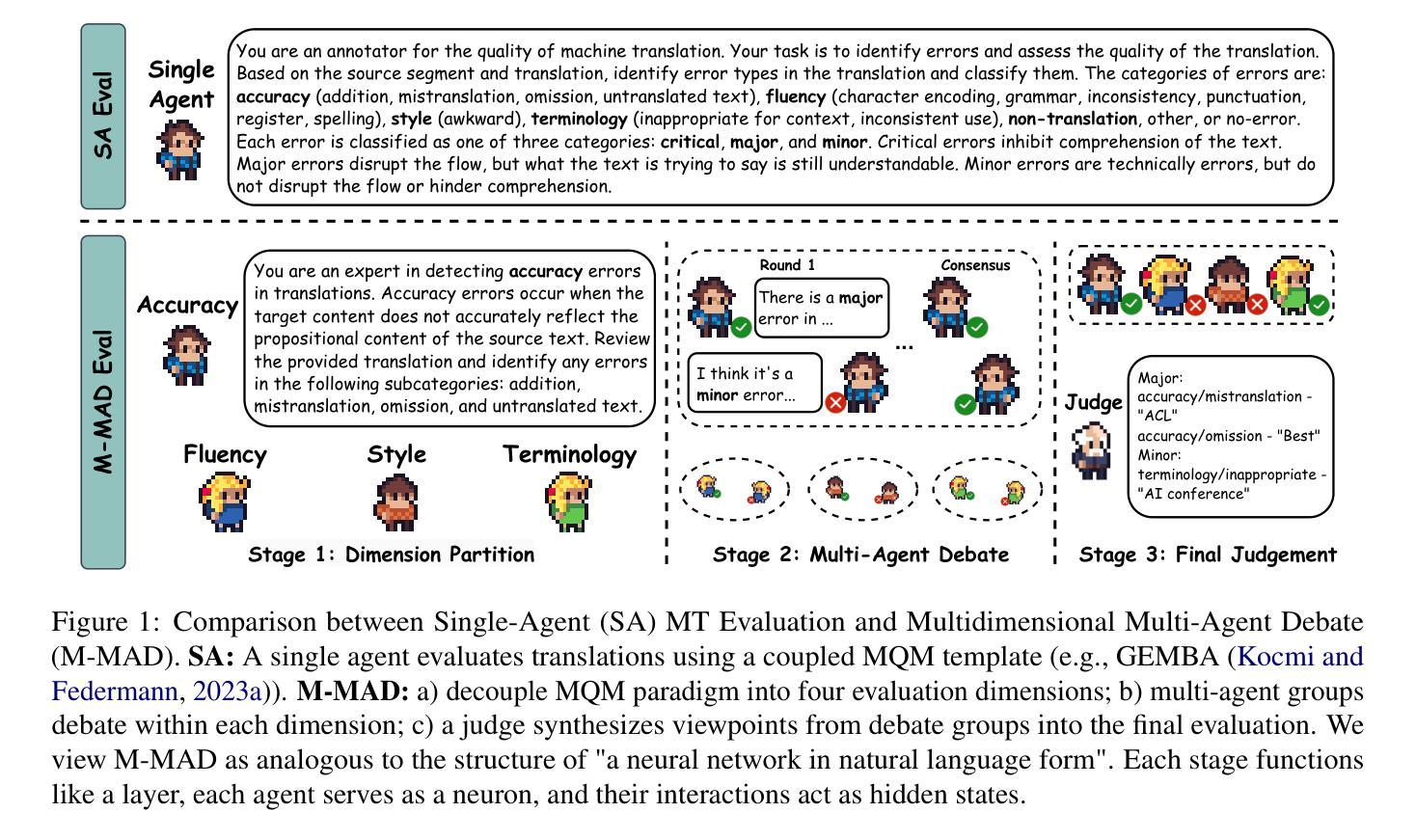
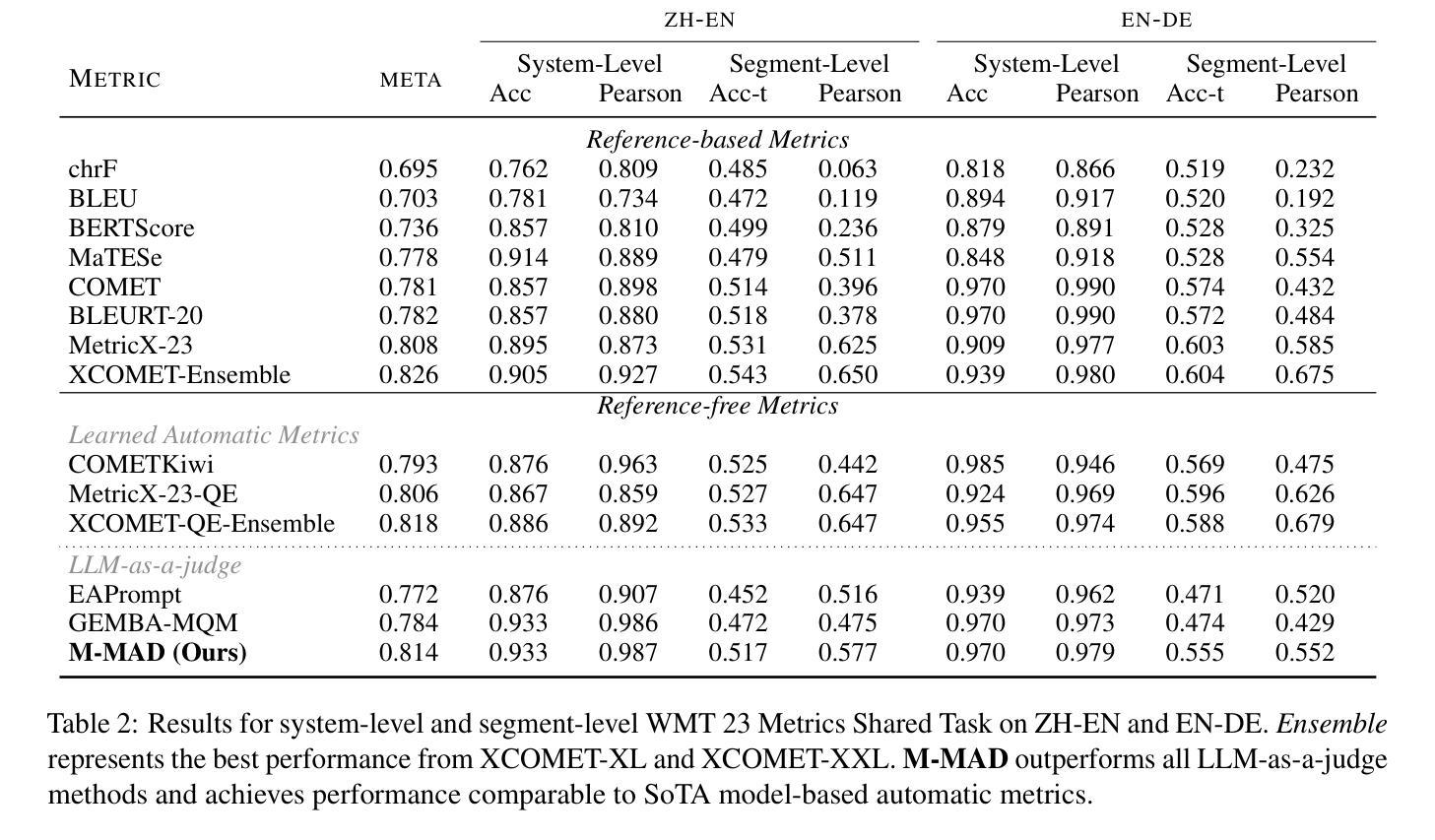
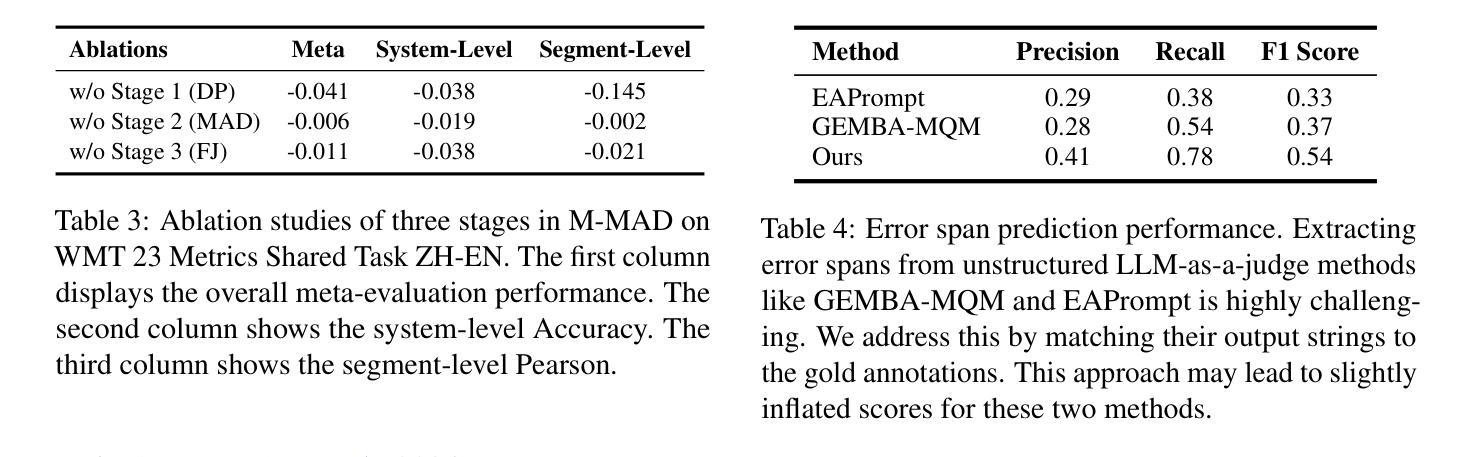
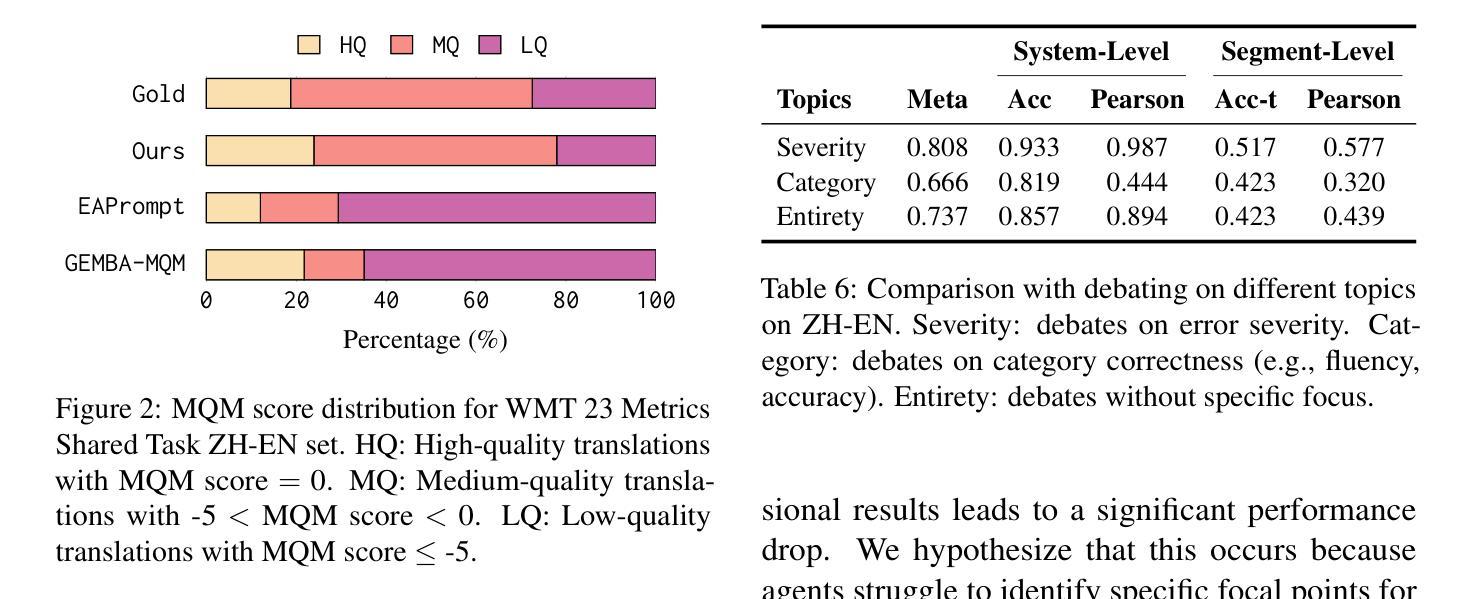
M-MAD: Multidimensional Multi-Agent Debate Framework for Fine-grained Machine Translation Evaluation
Authors:Zhaopeng Feng, Jiayuan Su, Jiamei Zheng, Jiahan Ren, Yan Zhang, Jian Wu, Hongwei Wang, Zuozhu Liu
Recent advancements in large language models (LLMs) have given rise to the LLM-as-a-judge paradigm, showcasing their potential to deliver human-like judgments. However, in the field of machine translation (MT) evaluation, current LLM-as-a-judge methods fall short of learned automatic metrics. In this paper, we propose Multidimensional Multi-Agent Debate (M-MAD), a systematic LLM-based multi-agent framework for advanced LLM-as-a-judge MT evaluation. Our findings demonstrate that M-MAD achieves significant advancements by (1) decoupling heuristic MQM criteria into distinct evaluation dimensions for fine-grained assessments; (2) employing multi-agent debates to harness the collaborative reasoning capabilities of LLMs; (3) synthesizing dimension-specific results into a final evaluation judgment to ensure robust and reliable outcomes. Comprehensive experiments show that M-MAD not only outperforms all existing LLM-as-a-judge methods but also competes with state-of-the-art reference-based automatic metrics, even when powered by a suboptimal model like GPT-4o mini. Detailed ablations and analysis highlight the superiority of our framework design, offering a fresh perspective for LLM-as-a-judge paradigm. Our code and data are publicly available at https://github.com/SU-JIAYUAN/M-MAD.
最近大型语言模型(LLM)的进步催生了LLM作为评判员的范式,展示了它们提供类似人类的判断力的潜力。然而,在机器翻译(MT)评估领域,当前的LLM作为评判员的方法还达不到学习到的自动度量标准。在本文中,我们提出了多维度多智能体辩论(M-MAD),这是一个基于LLM的多智能体框架,用于先进的LLM作为评判员的MT评估。我们的研究发现,M-MAD通过以下方式取得了显著进展:(1)将启发式MQM标准解耦为不同的评估维度,进行精细化的评估;(2)利用多智能体辩论来利用LLM的协同推理能力;(3)将特定维度的结果综合成最终的评估判断,以确保稳健和可靠的结果。全面的实验表明,M-MAD不仅优于所有现有的LLM作为评判员的方法,而且与最新的参考基准自动度量标准相竞争,即使在像GPT-4o mini这样的次优模型驱动下也是如此。详细的消融实验和分析突显了我们框架设计的优越性,为LLM作为评判员范式提供了新的视角。我们的代码和数据在https://github.com/SU-JIAYUAN/M-MAD公开可用。
论文及项目相关链接
PDF Work in progress. Code and data are available at https://github.com/SU-JIAYUAN/M-MAD
Summary
近期大型语言模型(LLM)的发展催生了LLM作为评判者的模式,展现出它们提供类似人类判断的能力。然而,在机器翻译(MT)评估领域,当前LLM作为评判者的方法相较于自动评价指标有所不足。本文提出了多维度多智能体辩论(M-MAD)系统,这是一个基于LLM的多智能体框架,用于高级LLM作为评判者的MT评估。研究发现,M-MAD通过将启发式MQM标准解耦为不同的评估维度进行精细评估、利用多智能体辩论发挥LLM的协同推理能力、以及合成特定维度的结果以进行最终评估判断,取得了显著进展。这为LLM作为评判者的模式提供了新的视角。代码和数据已公开。
Key Takeaways
- LLM的发展推动了LLM作为评判者模式的兴起,具有提供类似人类判断的能力。
- 当前LLM作为评判者在机器翻译评估领域与自动评价指标存在差距。
- 提出了一种新的LLM多智能体框架——多维度多智能体辩论(M-MAD)系统,用于高级LLM作为评判者的机器翻译评估。
- M-MAD通过将启发式MQM标准解耦为不同的评估维度来精细评估翻译质量。
- M-MAD利用多智能体辩论发挥LLM的协同推理能力,提高了评估的准确性和可靠性。
- M-MAD的合成方法确保了评估结果的稳健性和可靠性。
点此查看论文截图


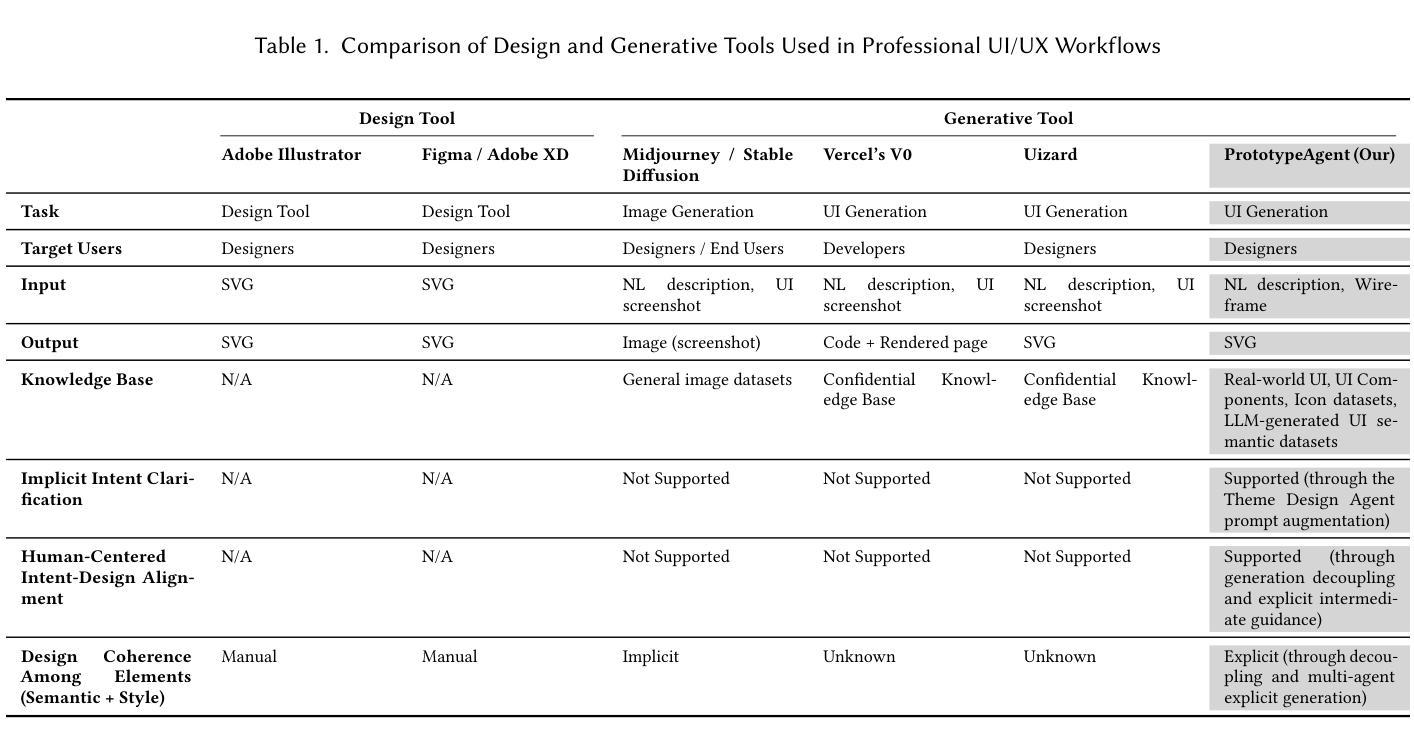
Towards Human-AI Synergy in UI Design: Enhancing Multi-Agent Based UI Generation with Intent Clarification and Alignment
Authors:Mingyue Yuan, Jieshan Chen, Yongquan Hu, Sidong Feng, Mulong Xie, Gelareh Mohammadi, Zhenchang Xing, Aaron Quigley
In automated user interface (UI) design generation, a key challenge is the lack of support for iterative processes, as most systems only focus on end-to-end generation of designs as starting points. This results from (1) limited capabilities to fully interpret user design intent from text or images, and (2) a lack of transparency, which prevents designers from refining intermediate results. To address existing limitations, we introduce PrototypeAgent, a human-centered, multi-agent system for automated UI generation. The core of PrototypeAgent is a theme design agent that clarifies implicit design intent through prompt augmentation, coordinating with specialized sub-agents to generate specific components. Designers interact with the system via an intuitive interface, providing natural language descriptions and layout preferences. During generation, PrototypeAgent enables designers to refine generated intermediate guidance or specific components, ensuring alignment with their intent throughout the generation workflow. Evaluations through experiments and user studies show PrototypeAgent’s effectiveness in producing high-fidelity prototypes that accurately reflect design intent as well as its superiority over baseline models in terms of both quality and diversity.
在自动化用户界面(UI)设计生成领域,一个关键挑战是缺乏迭代过程的支持,因为大多数系统只关注从起点到终点的设计生成。这源于(1)从文本或图像全面解读用户设计意图的能力有限,(2)缺乏透明度,导致设计师无法对中间结果进行精细调整。为了解决现有局限性,我们推出了PrototypeAgent,这是一个以人类为中心的多智能体系统,用于自动化UI生成。PrototypeAgent的核心是主题设计智能体,它通过提示增强来明确隐含的设计意图,并与专业子智能体协调以生成特定组件。设计师通过直观界面与系统交互,提供自然语言描述和布局偏好。在生成过程中,PrototypeAgent允许设计师对生成的中间指导或特定组件进行微调,确保在整个生成工作流程中与他们的意图保持一致。通过实验和用户研究进行的评估表明,PrototypeAgent在生成高保真原型方面非常有效,能够准确反映设计意图,同时在质量和多样性方面优于基准模型。
论文及项目相关链接
PDF 21 pages,9 figures
Summary:
自动化用户界面(UI)设计生成中面临的关键挑战是缺乏迭代过程的支持,大多数系统仅关注设计的端对端生成作为起点。为解决现有局限性,我们推出PrototypeAgent——一种以人为本、多代理的自动化UI生成系统。其核心是主题设计代理,通过提示增强来明确隐含的设计意图,并与专业子代理协调生成特定组件。设计师通过直观界面与系统交互,提供自然语言描述和布局偏好。PrototypeAgent在生成过程中使设计师能够细化生成的中间指导或特定组件,确保整个生成工作流程与他们的意图保持一致。实验和用户研究评估表明,PrototypeAgent在生成高质量、高保真度的原型方面非常有效,能够准确反映设计意图,并且在质量和多样性方面优于基准模型。
Key Takeaways:
- 自动化UI设计生成面临挑战:缺乏迭代过程支持,系统主要关注端对端生成。
- PrototypeAgent是一个以人为本、多代理的自动化UI生成系统,旨在解决现有挑战。
- PrototypeAgent的核心是主题设计代理,能够通过提示增强明确隐含的设计意图。
- PrototypeAgent配备专业子代理,用于生成特定组件。
- 设计师通过直观界面与PrototypeAgent交互,提供自然语言描述和布局偏好。
- PrototypeAgent允许设计师在生成过程中细化中间结果或特定组件,以符合其意图。
点此查看论文截图

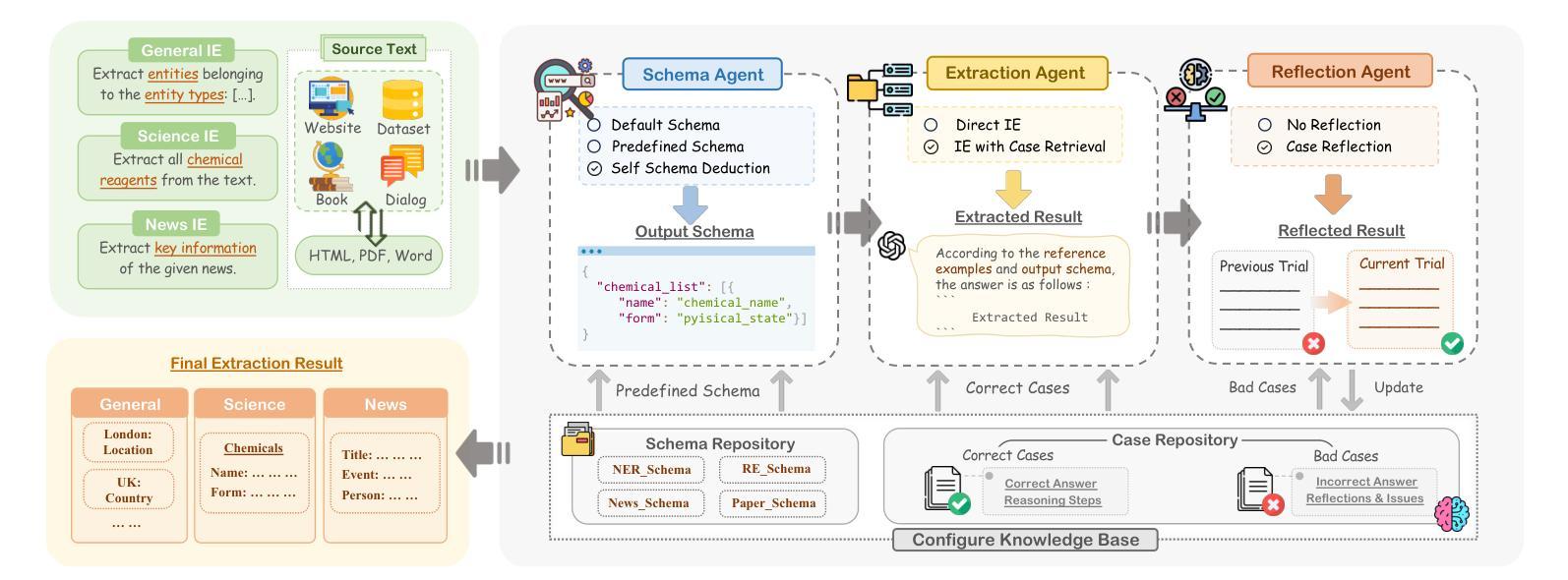
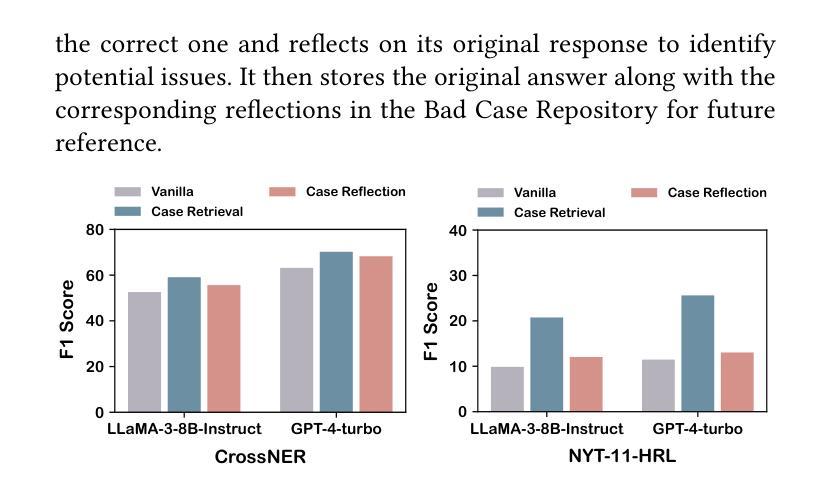
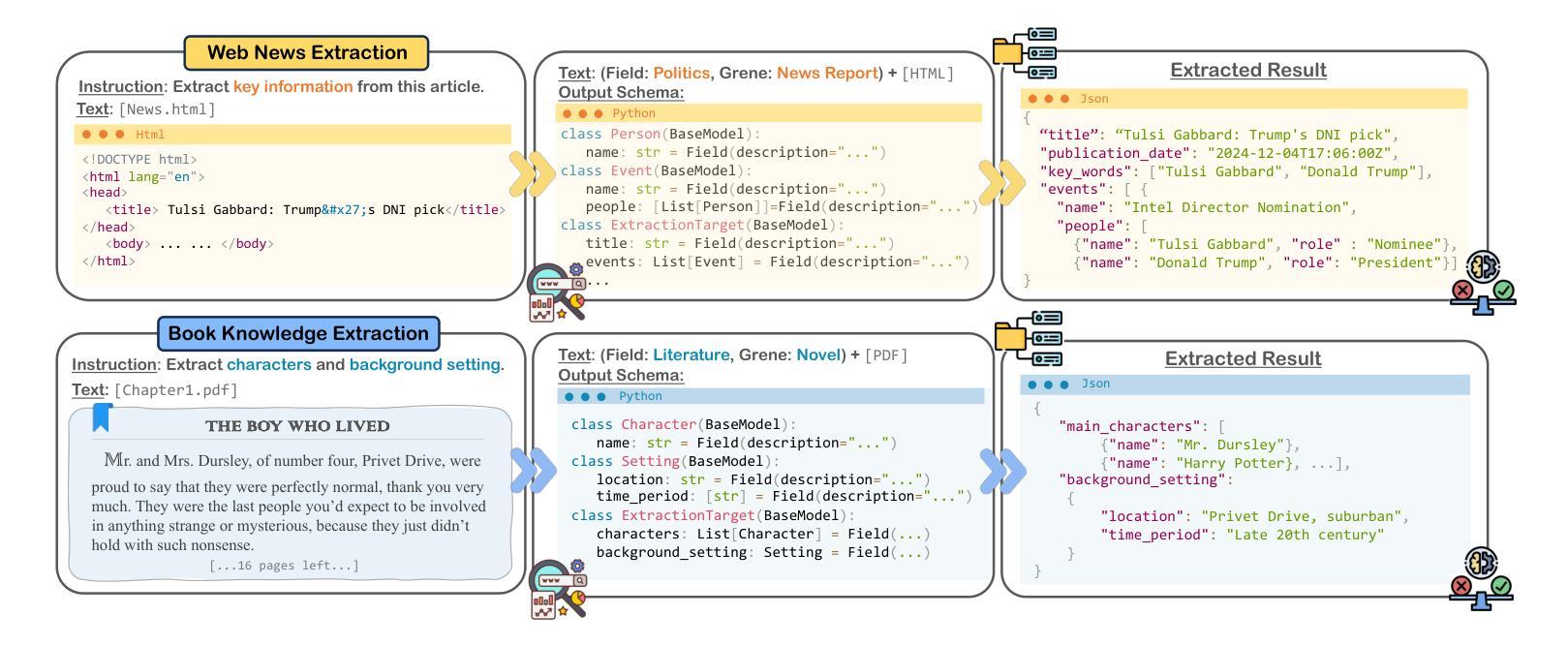
OneKE: A Dockerized Schema-Guided LLM Agent-based Knowledge Extraction System
Authors:Yujie Luo, Xiangyuan Ru, Kangwei Liu, Lin Yuan, Mengshu Sun, Ningyu Zhang, Lei Liang, Zhiqiang Zhang, Jun Zhou, Lanning Wei, Da Zheng, Haofen Wang, Huajun Chen
We introduce OneKE, a dockerized schema-guided knowledge extraction system, which can extract knowledge from the Web and raw PDF Books, and support various domains (science, news, etc.). Specifically, we design OneKE with multiple agents and a configure knowledge base. Different agents perform their respective roles, enabling support for various extraction scenarios. The configure knowledge base facilitates schema configuration, error case debugging and correction, further improving the performance. Empirical evaluations on benchmark datasets demonstrate OneKE’s efficacy, while case studies further elucidate its adaptability to diverse tasks across multiple domains, highlighting its potential for broad applications. We have open-sourced the Code at https://github.com/zjunlp/OneKE and released a Video at http://oneke.openkg.cn/demo.mp4.
我们介绍OneKE,这是一个Docker化的schema引导知识提取系统,可以从网页和原始PDF书籍中提取知识,并支持多个领域(如科学、新闻等)。具体来说,我们设计OneKE时采用了多个代理和一个配置知识库。不同的代理执行各自的角色,为各种提取场景提供支持。配置知识库有助于模式配置、错误情况调试和修正,从而进一步提高性能。在基准数据集上的经验评估证明了OneKE的有效性,而案例研究进一步说明了它在多个领域适应不同任务的适应性,凸显了其在广泛应用中的潜力。我们在https://github.com/zjunlp/OneKE上公开了代码,并在http://oneke.openkg.cn/demo.mp4上发布了视频。
论文及项目相关链接
PDF Work in progress
Summary:
我们推出了一款名为OneKE的Docker化、模式引导的知识提取系统,可从网页和PDF书籍中提取知识,并涵盖多个领域(如科学、新闻等)。OneKE采用多代理配置知识库设计,不同代理执行各自任务,支持多种提取场景。配置知识库有助于模式配置、错误调试和修正,提高了系统性能。基准数据集上的实证评估证明了OneKE的有效性,案例研究进一步说明了其在多个领域不同任务的适应性,展现出广泛的应用潜力。我们已在https://github.com/zjunlp/OneKE开源代码,并发布了演示视频http://oneke.openkg.cn/demo.mp4。
Key Takeaways:
- OneKE是一个Docker化的模式引导知识提取系统,可以从网页和PDF书籍中提取知识。
- OneKE支持多种领域,如科学和新闻。
- OneKE采用多代理设计,每个代理执行特定任务,以适应不同的提取场景。
- 配置知识库有助于模式配置、错误调试和修正,提升了系统性能。
- 实证评估证明OneKE在基准数据集上的有效性。
- 案例研究展示了OneKE在多个领域不同任务的适应性。
- OneKE已开源,并提供了演示视频供用户参考。
点此查看论文截图

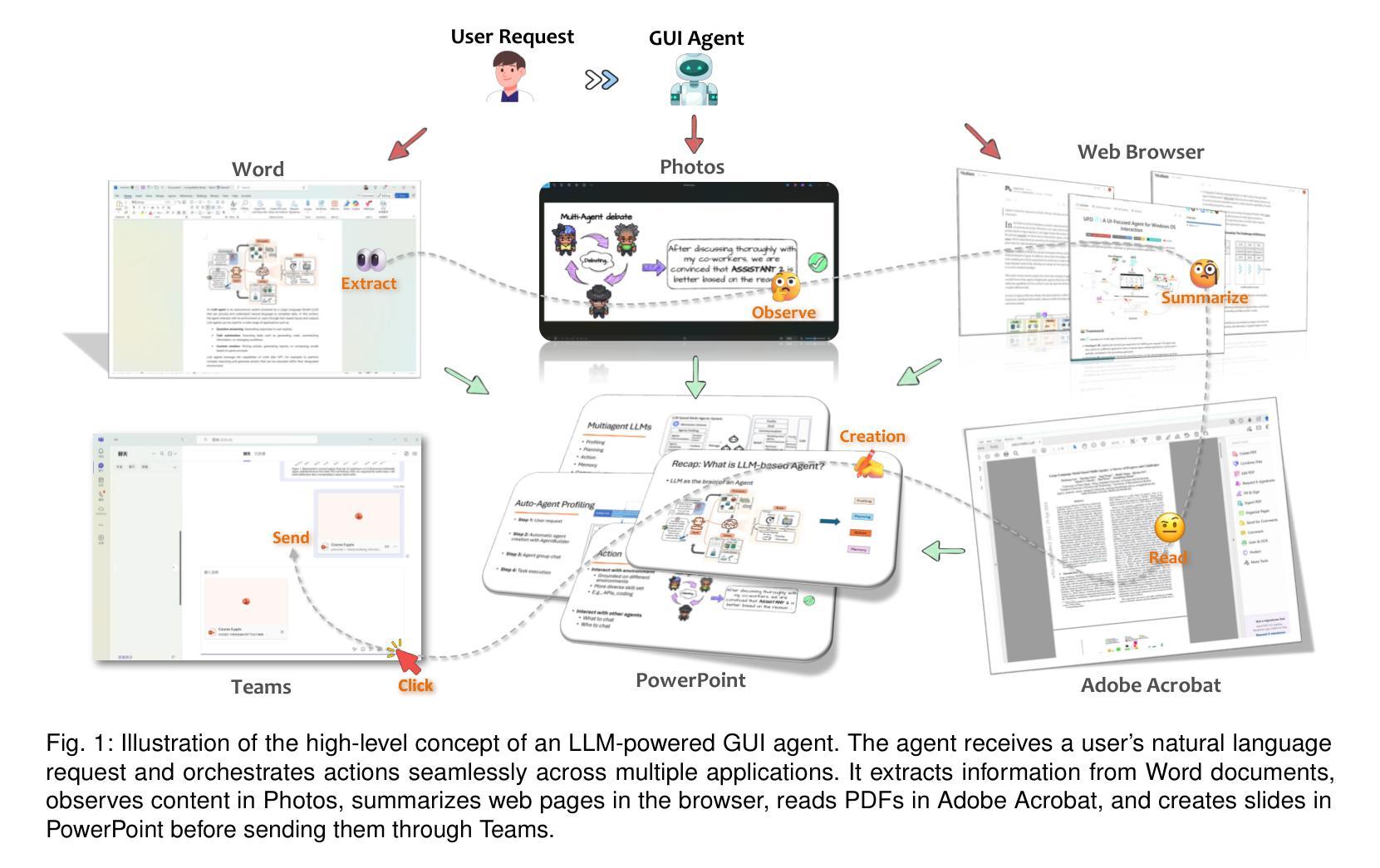
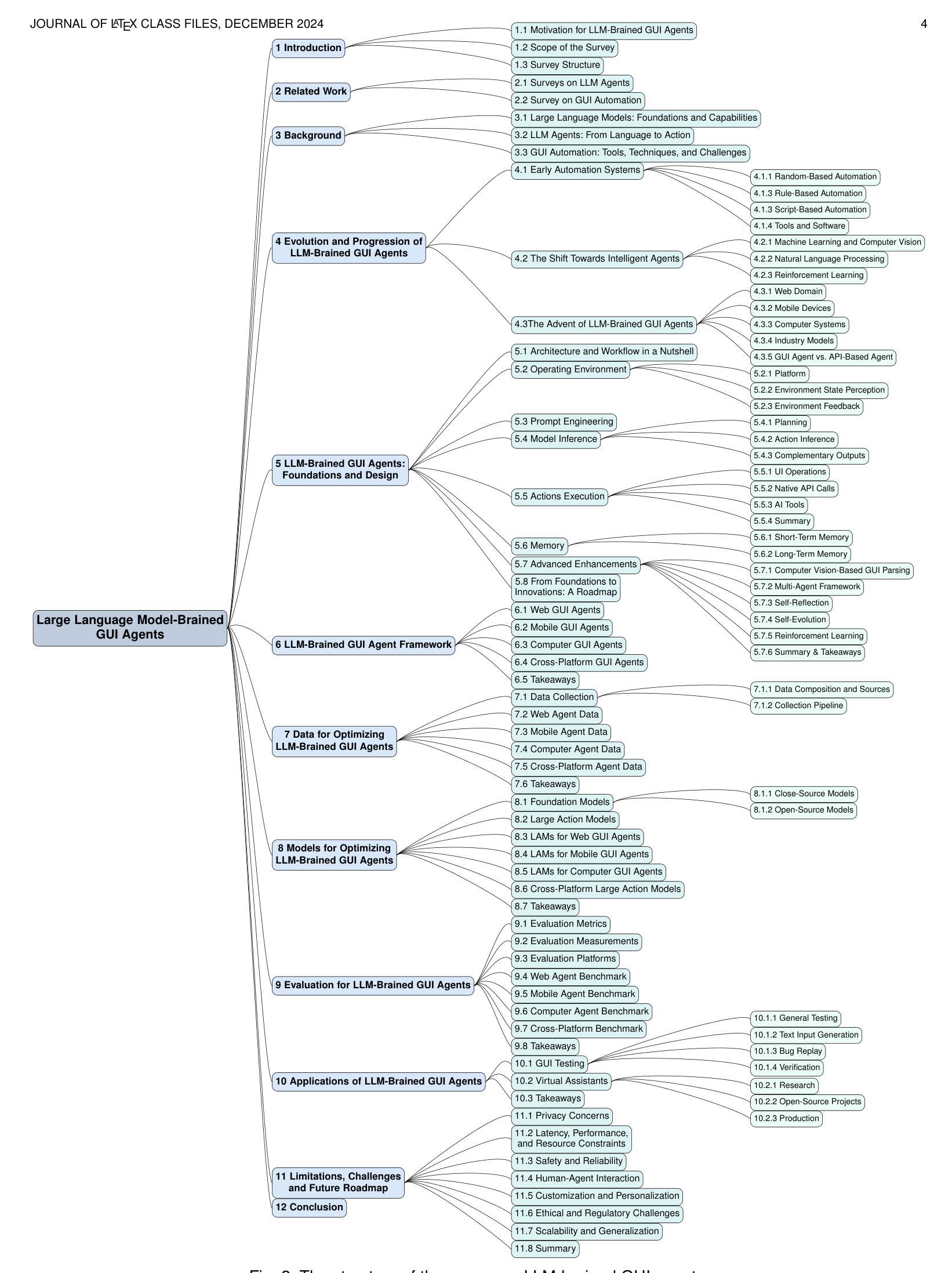
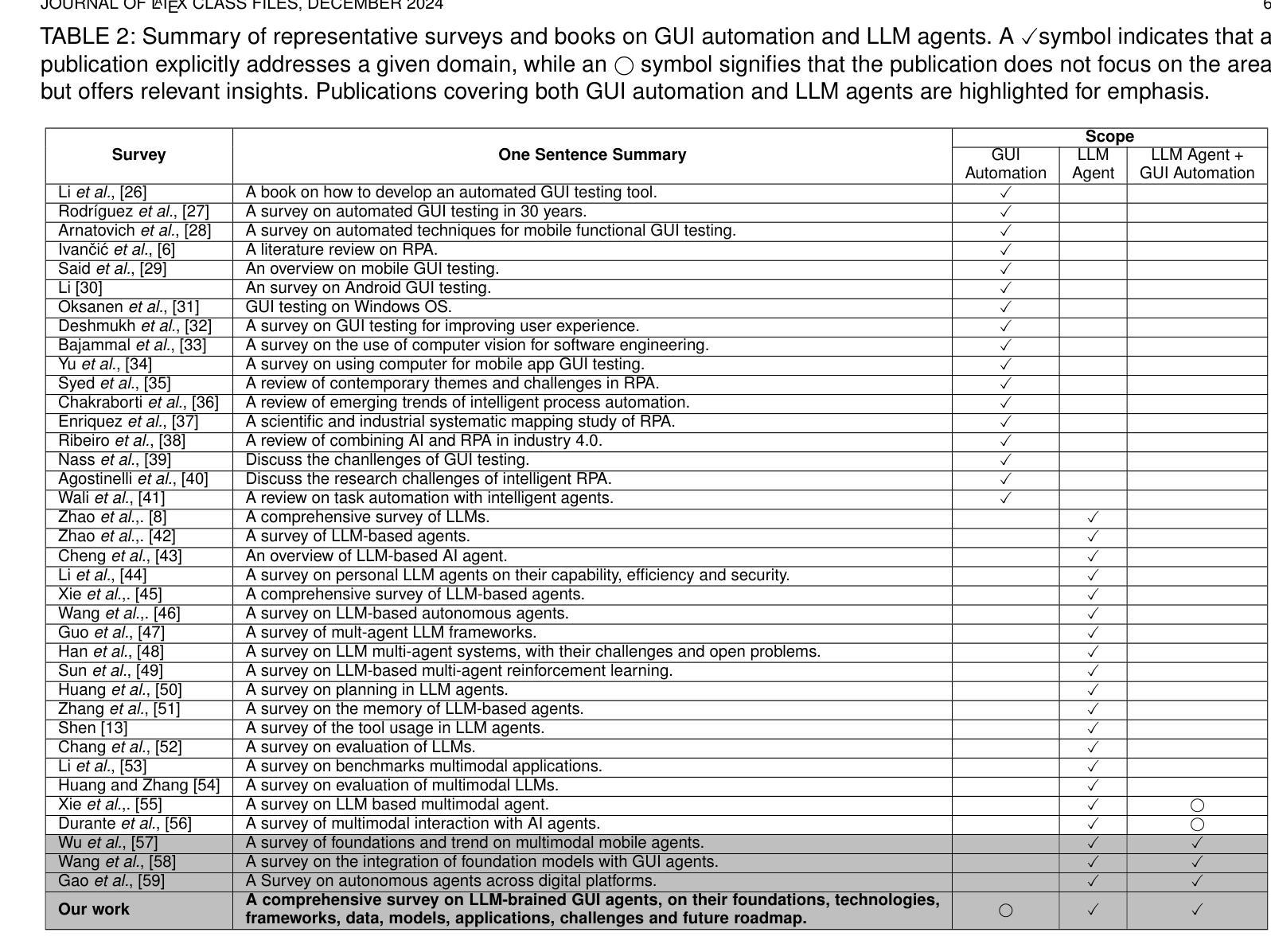
Large Language Model-Brained GUI Agents: A Survey
Authors:Chaoyun Zhang, Shilin He, Jiaxu Qian, Bowen Li, Liqun Li, Si Qin, Yu Kang, Minghua Ma, Guyue Liu, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, Qi Zhang
GUIs have long been central to human-computer interaction, providing an intuitive and visually-driven way to access and interact with digital systems. The advent of LLMs, particularly multimodal models, has ushered in a new era of GUI automation. They have demonstrated exceptional capabilities in natural language understanding, code generation, and visual processing. This has paved the way for a new generation of LLM-brained GUI agents capable of interpreting complex GUI elements and autonomously executing actions based on natural language instructions. These agents represent a paradigm shift, enabling users to perform intricate, multi-step tasks through simple conversational commands. Their applications span across web navigation, mobile app interactions, and desktop automation, offering a transformative user experience that revolutionizes how individuals interact with software. This emerging field is rapidly advancing, with significant progress in both research and industry. To provide a structured understanding of this trend, this paper presents a comprehensive survey of LLM-brained GUI agents, exploring their historical evolution, core components, and advanced techniques. We address research questions such as existing GUI agent frameworks, the collection and utilization of data for training specialized GUI agents, the development of large action models tailored for GUI tasks, and the evaluation metrics and benchmarks necessary to assess their effectiveness. Additionally, we examine emerging applications powered by these agents. Through a detailed analysis, this survey identifies key research gaps and outlines a roadmap for future advancements in the field. By consolidating foundational knowledge and state-of-the-art developments, this work aims to guide both researchers and practitioners in overcoming challenges and unlocking the full potential of LLM-brained GUI agents.
图形用户界面(GUIs)长期以来一直是人机交互的核心,提供了一种直观和视觉驱动的方式来访问和与数字系统交互。大语言模型(LLMs)的出现,特别是多模态模型,已经开启了GUI自动化的新时代。它们在自然语言理解、代码生成和视觉处理方面表现出了卓越的能力。这为新一代基于LLM的GUI代理铺平了道路,这些代理能够解释复杂的GUI元素并基于自然语言指令自主执行操作。这些代理代表了范式转变,使用户能够通过简单的命令执行复杂的多步骤任务。它们的应用范围涵盖网页导航、移动应用交互和桌面自动化,提供变革性的用户体验,彻底改变个人与软件的交互方式。这个新兴领域正在迅速发展,在研究和工业领域都取得了重大进展。为了对这一趋势有一个结构化的理解,本文全面回顾了基于LLM的GUI代理,探索了它们的历史演变、核心组件和先进技术。我们回答了一些研究问题,如现有的GUI代理框架、收集和利用数据来训练专业的GUI代理、为GUI任务开发的大型动作模型、以及评估其有效性的评估指标和基准测试。此外,我们还介绍了这些代理推动的的新兴应用。通过详细分析,本调查确定了关键的研究空白,并为该领域的未来进步制定了路线图。通过整合基础知识和最新发展,本工作旨在指导研究者和实践者克服挑战,充分发挥基于LLM的GUI代理的潜力。
论文及项目相关链接
PDF The collection of papers reviewed in this survey will be hosted and regularly updated on the GitHub repository: https://github.com/vyokky/LLM-Brained-GUI-Agents-Survey Additionally, a searchable webpage is available at https://aka.ms/gui-agent for easier access and exploration
摘要
GUI长期以来一直占据人机交互的中心地位,为访问和与数字系统进行交互提供了一个直观和视觉驱动的方式。大型语言模型(LLM)的出现,特别是多模态模型,已经开启了GUI自动化的新时代。他们在自然语言理解、代码生成和视觉处理方面表现出了惊人的能力。这为新一代基于LLM的GUI代理的发展铺平了道路,这些代理能够解释复杂的GUI元素并根据自然语言指令自主执行操作。这些代理代表了范式转变,使用户能够通过简单的命令执行复杂的多步骤任务。它们的应用程序跨越网页导航、移动应用交互和桌面自动化,为用户提供了一种变革性的体验,彻底改变了个人与软件的交互方式。本文为了提供对这一趋势的结构性理解,全面回顾了基于LLM的GUI代理,探索了它们的历史演变、核心组件和先进技术。我们解答了诸如现有GUI代理框架、收集和利用数据来训练专业GUI代理、为GUI任务开发大型动作模型以及评估其有效性的评估指标和基准测试等研究问题。此外,我们还探讨了这些代理推动的新兴应用。通过详细分析,本综述确定了关键的研究空白并为该领域的未来进步制定了路线图。通过整合基础知识和最新发展,本工作旨在指导研究者和实践者克服挑战并解锁基于LLM的GUI代理的潜力。
关键见解
- 大型语言模型(LLMs)已在GUI自动化领域展现出其潜力,特别是在自然语言理解和视觉处理方面。
- 基于LLM的GUI代理能解释复杂的GUI元素并根据自然语言指令自主执行操作,代表人机交互的范式转变。
- 这些代理的应用范围广泛,包括网页导航、移动应用交互和桌面自动化,提供了更直观和用户友好的交互体验。
- 当前的研究领域包括GUI代理框架、数据收集和利用、大型动作模型的开发以及代理效果的评估指标和基准测试。
- 基于LLM的GUI代理的研究仍处于发展初期,存在许多研究空白,需要进一步的探索和创新。
- 通过整合基础知识和最新发展,该领域的调研工作旨在为研究者和实践者提供指导,以克服挑战并充分发挥基于LLM的GUI代理的潜力。
点此查看论文截图


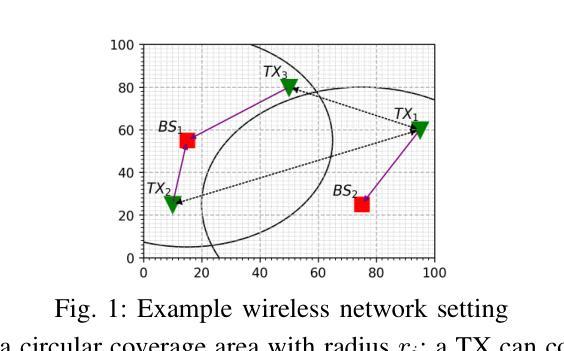
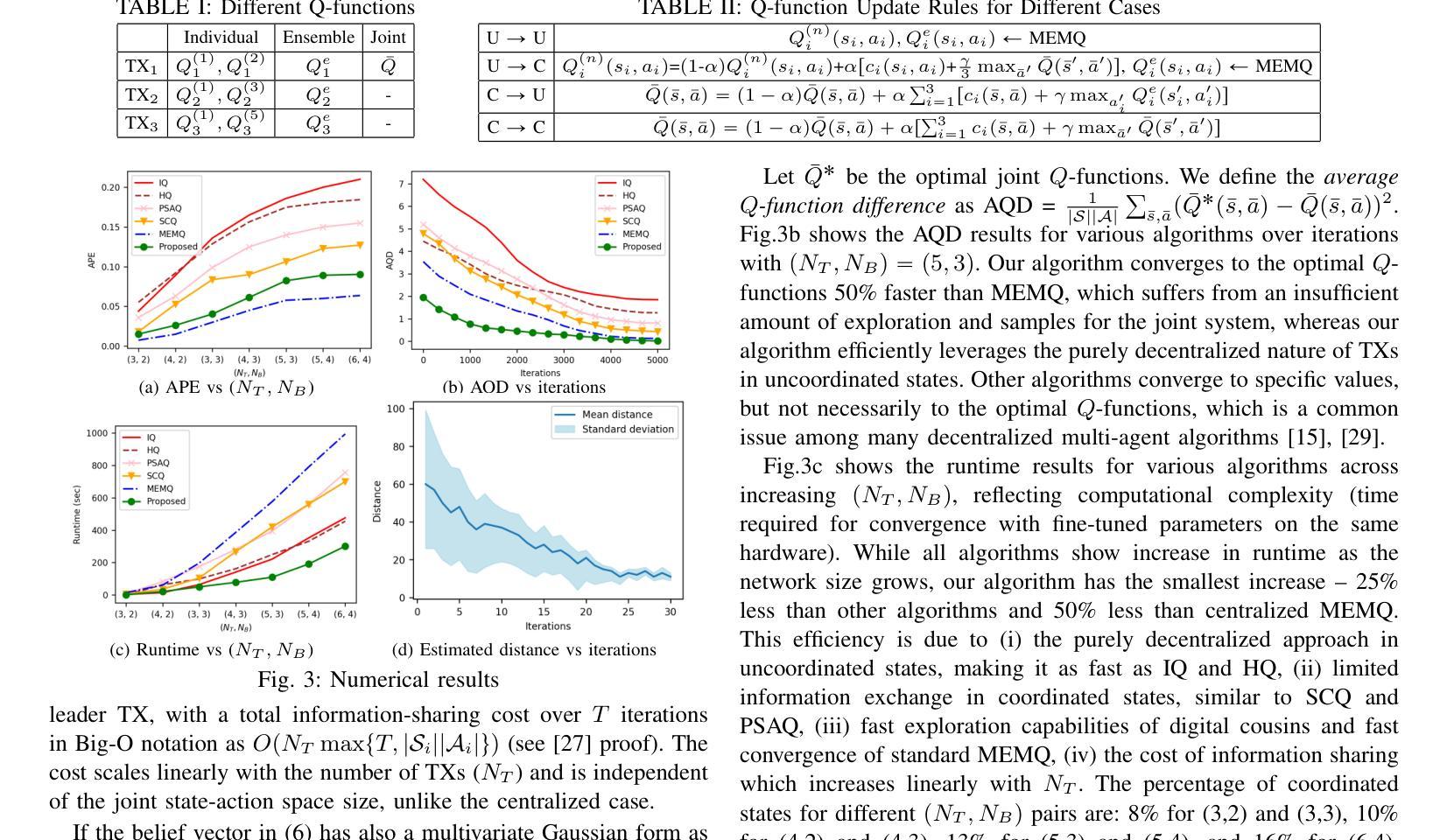
A Multi-Agent Multi-Environment Mixed Q-Learning for Partially Decentralized Wireless Network Optimization
Authors:Talha Bozkus, Urbashi Mitra
Q-learning is a powerful tool for network control and policy optimization in wireless networks, but it struggles with large state spaces. Recent advancements, like multi-environment mixed Q-learning (MEMQ), improves performance and reduces complexity by integrating multiple Q-learning algorithms across multiple related environments so-called digital cousins. However, MEMQ is designed for centralized single-agent networks and is not suitable for decentralized or multi-agent networks. To address this challenge, we propose a novel multi-agent MEMQ algorithm for partially decentralized wireless networks with multiple mobile transmitters (TXs) and base stations (BSs), where TXs do not have access to each other’s states and actions. In uncoordinated states, TXs act independently to minimize their individual costs. In coordinated states, TXs use a Bayesian approach to estimate the joint state based on local observations and share limited information with leader TX to minimize joint cost. The cost of information sharing scales linearly with the number of TXs and is independent of the joint state-action space size. The proposed scheme is 50% faster than centralized MEMQ with only a 20% increase in average policy error (APE) and is 25% faster than several advanced decentralized Q-learning algorithms with 40% less APE. The convergence of the algorithm is also demonstrated.
Q学习是无线网络中网络控制和策略优化的一种强大工具,但在大规模状态空间中表现不佳。最近的进展,如多环境混合Q学习(MEMQ),通过整合多个相关环境中的多个Q学习算法,提高了性能并降低了复杂性,这些环境被称为数字同胞。然而,MEMQ是为集中式单代理网络设计的,并不适合分布式或多代理网络。为了解决这一挑战,我们提出了一种新型的多代理MEMQ算法,适用于部分分散的无线网络,具有多个移动发射机(TX)和基站(BS)。在这种情况下,TX无法相互访问彼此的状态和行动。在不协调的状态下,TX独立行动以最小化其个人成本。在协调状态下,TX使用贝叶斯方法根据局部观察来估计联合状态,并与领导TX共享有限信息以最小化联合成本。信息共享的成本随TX数量的增加而线性增长,与联合状态-行动空间大小无关。所提出的方案比集中式MEMQ快50%,平均策略误差(APE)仅增加20%,并且比几种先进的分布式Q学习算法快25%,同时APE降低了40%。该算法的收敛性也得到了证明。
论文及项目相关链接
PDF Accepted to 2025 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2025)
Summary
新型多智能体MEMQ算法应用于部分分散式无线网络,针对多移动发射器与基站的环境进行设计。在分散状态下,发射器独立运作以降低个别成本;在协同状态下,发射器使用贝叶斯方法估计联合状态并实现信息共享以最小化联合成本。新方案比集中式的MEMQ更快,同时平均策略误差有所增加,但仍优于其他先进的分散式Q-学习算法。算法收敛性得到验证。
Key Takeaways
- Q-学习在网络控制和策略优化中具有强大功能,但在大型状态空间中表现欠佳。
- MEMQ算法通过整合多个相关环境中的Q-学习算法来提升性能并降低复杂性。
- 传统MEMQ设计适用于集中式单智能体网络,不适用于分散式或多智能体网络。
- 提出的新型多智能体MEMQ算法适用于部分分散式无线网络,涉及多个移动发射器和基站。
- 在分散状态下,发射器独立运作以降低个别成本;在协同状态下,通过信息共享最小化联合成本。
- 新方案在执行速度上比集中式MEMQ更快,同时平均策略误差有所上升,但相较于其他先进的分散式Q-学习算法仍有优势。
点此查看论文截图


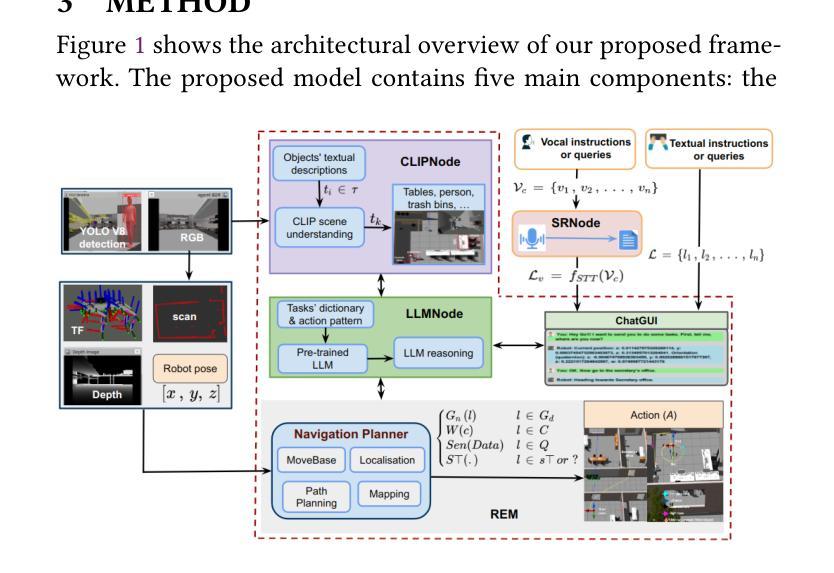
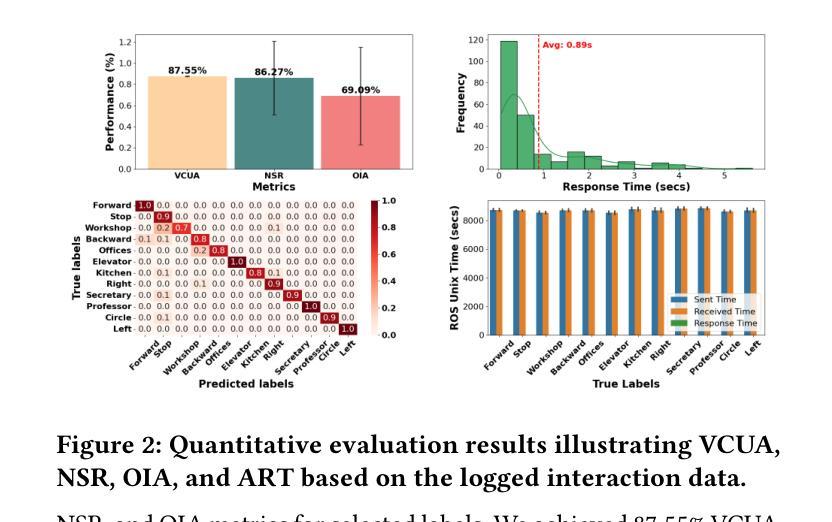
Multimodal Human-Autonomous Agents Interaction Using Pre-Trained Language and Visual Foundation Models
Authors:Linus Nwankwo, Elmar Rueckert
In this paper, we extended the method proposed in [21] to enable humans to interact naturally with autonomous agents through vocal and textual conversations. Our extended method exploits the inherent capabilities of pre-trained large language models (LLMs), multimodal visual language models (VLMs), and speech recognition (SR) models to decode the high-level natural language conversations and semantic understanding of the robot’s task environment, and abstract them to the robot’s actionable commands or queries. We performed a quantitative evaluation of our framework’s natural vocal conversation understanding with participants from different racial backgrounds and English language accents. The participants interacted with the robot using both spoken and textual instructional commands. Based on the logged interaction data, our framework achieved 87.55% vocal commands decoding accuracy, 86.27% commands execution success, and an average latency of 0.89 seconds from receiving the participants’ vocal chat commands to initiating the robot’s actual physical action. The video demonstrations of this paper can be found at https://linusnep.github.io/MTCC-IRoNL/.
在这篇论文中,我们扩展了[21]中提出的方法,使人类能够通过语音和文本对话自然地与自主智能体进行交互。我们的扩展方法利用预训练的大型语言模型(LLM)、多模态视觉语言模型(VLM)和语音识别(SR)模型的固有功能,解码高级自然语言对话和机器人任务环境的语义理解,并将其抽象化为机器人的可执行命令或查询。我们对框架的自然语音对话理解能力进行了定量评估,参与者来自不同的种族背景和英语口音。参与者使用口头和文本指令命令与机器人进行交互。基于记录的交互数据,我们的框架实现了87.55%的语音命令解码准确率、86.27%的命令执行成功率,从接收参与者的语音聊天命令到启动机器人的实际物理动作的平均延迟时间为0.89秒。本论文的视频演示可在https://linusnep.github.io/MTCC-IRoNL/找到。
论文及项目相关链接
Summary
本文扩展了[21]中提出的方法,使人类能够通过语音和文本与自主代理进行自然交互。扩展的方法利用预训练的大型语言模型(LLMs)、多模态视觉语言模型(VLMs)和语音识别(SR)模型的固有功能,解码高级自然语言对话和机器人任务环境的语义理解,并将其抽象为机器人的可操作命令或查询。我们对框架的自然语音对话理解进行了定量评估,参与者来自不同的种族背景和英语口音。参与者通过口语和文本指令与机器人互动。基于记录的互动数据,我们的框架实现了87.55%的语音命令解码准确率、86.27%的命令执行成功率和平均0.89秒的延迟,从接收参与者的语音聊天命令到启动机器人的实际物理动作。
Key Takeaways
- 扩展了原有方法,使人类能通过语音和文本与自主代理自然交互。
- 利用了预训练的大型语言模型、多模态视觉语言模型和语音识别模型的固有功能。
- 框架能够实现高级自然语言对话解码和机器人任务环境的语义理解。
- 框架可将语义理解转化为机器人的可操作命令或查询。
- 框架的自然语音对话理解评估显示,语音命令解码准确率为87.55%,命令执行成功率为86.27%。
- 框架从接收语音命令到启动机器人动作的平均延迟为0.89秒。
点此查看论文截图

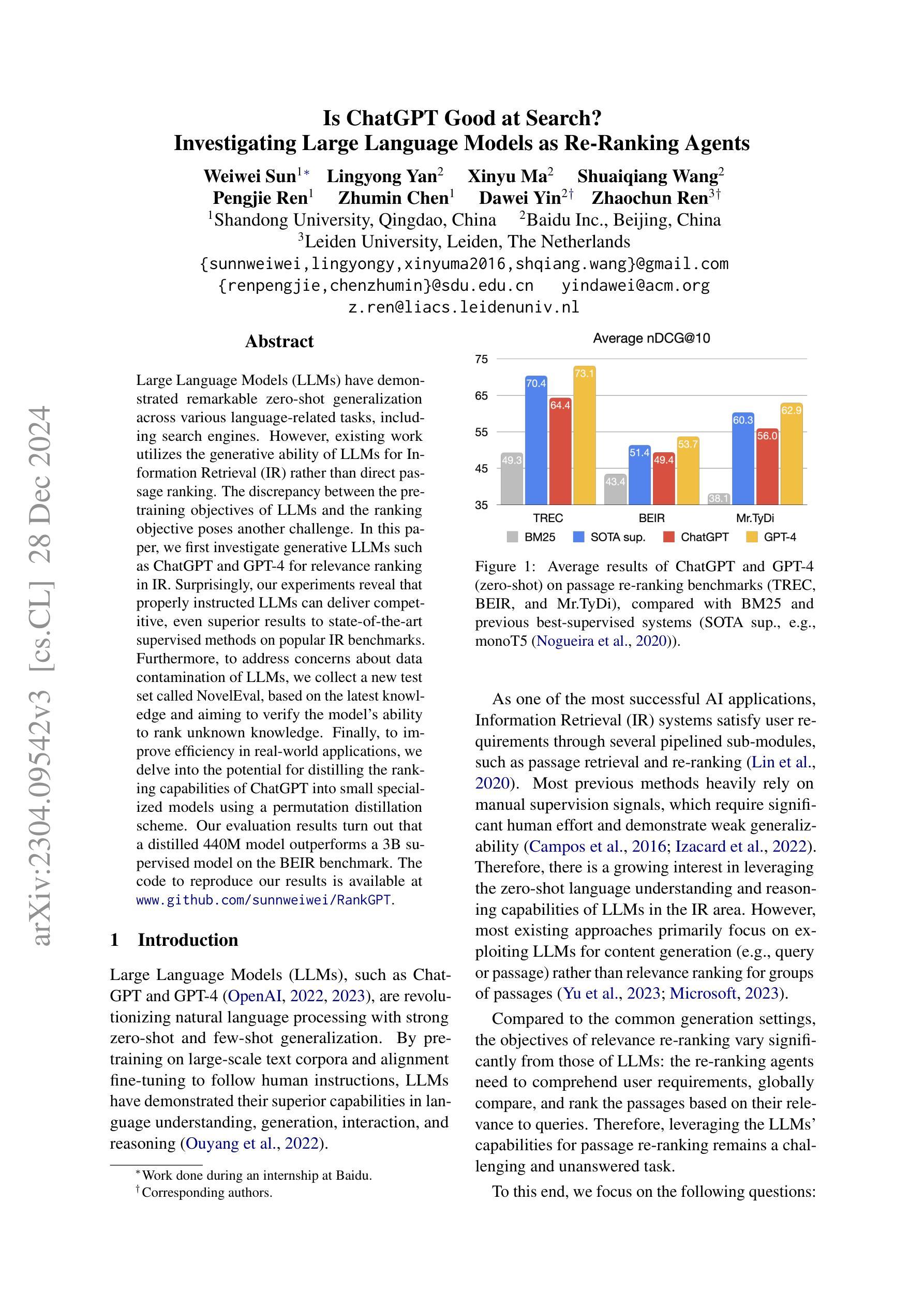
Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
Authors:Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, Zhaochun Ren
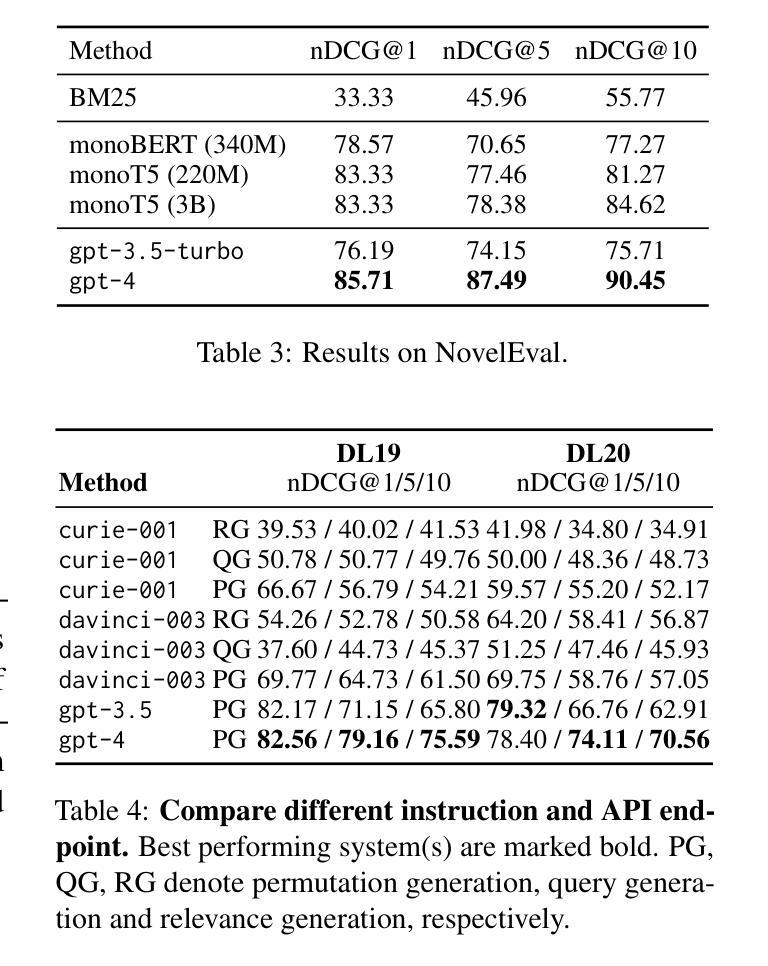
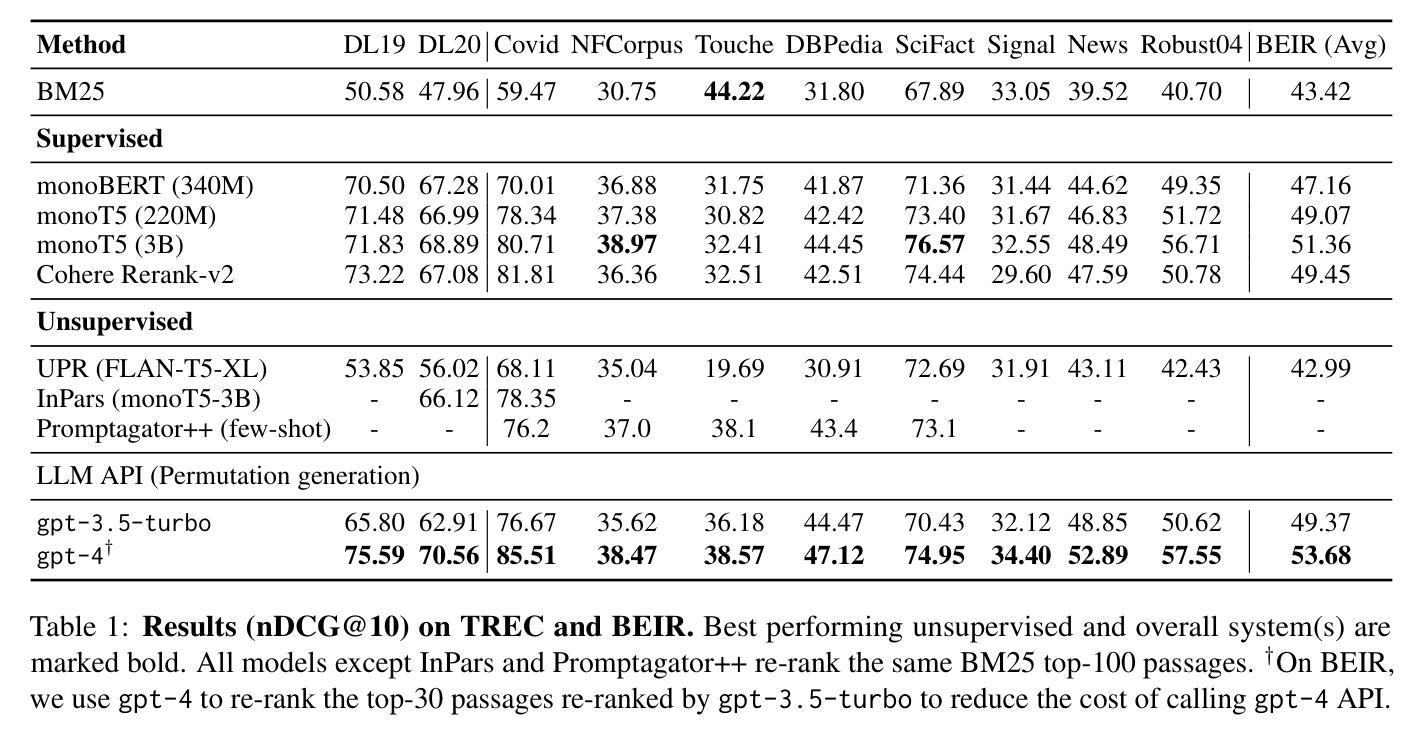
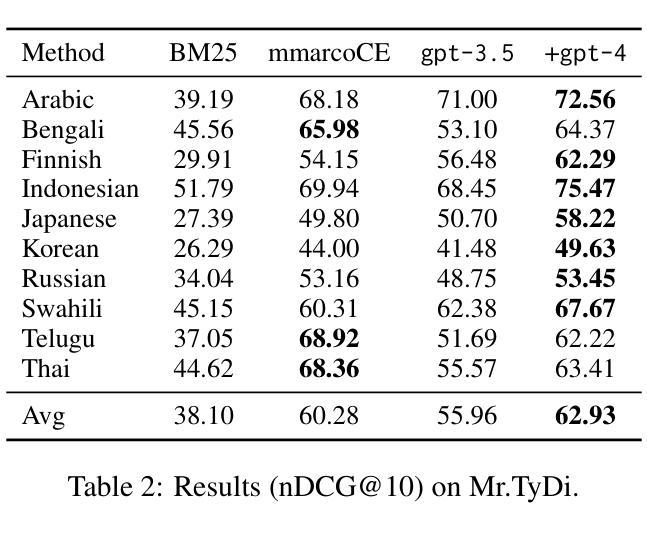
Large Language Models (LLMs) have demonstrated remarkable zero-shot generalization across various language-related tasks, including search engines. However, existing work utilizes the generative ability of LLMs for Information Retrieval (IR) rather than direct passage ranking. The discrepancy between the pre-training objectives of LLMs and the ranking objective poses another challenge. In this paper, we first investigate generative LLMs such as ChatGPT and GPT-4 for relevance ranking in IR. Surprisingly, our experiments reveal that properly instructed LLMs can deliver competitive, even superior results to state-of-the-art supervised methods on popular IR benchmarks. Furthermore, to address concerns about data contamination of LLMs, we collect a new test set called NovelEval, based on the latest knowledge and aiming to verify the model’s ability to rank unknown knowledge. Finally, to improve efficiency in real-world applications, we delve into the potential for distilling the ranking capabilities of ChatGPT into small specialized models using a permutation distillation scheme. Our evaluation results turn out that a distilled 440M model outperforms a 3B supervised model on the BEIR benchmark. The code to reproduce our results is available at www.github.com/sunnweiwei/RankGPT.
大型语言模型(LLMs)在各种语言相关任务中表现出了显著的零样本泛化能力,包括搜索引擎。然而,现有工作利用LLMs的信息检索(IR)生成能力,而非直接进行段落排名。LLMs的预训练目标与排名目标之间的差异构成了另一个挑战。在本文中,我们首先调查了用于信息检索相关性排名的生成式LLMs,如ChatGPT和GPT-4。令人惊讶的是,我们的实验表明,在得到适当指令的情况下,LLMs可以提供有竞争力的结果,甚至在流行的IR基准测试上优于最新的监督方法。此外,为了解决对LLMs数据污染的担忧,我们收集了一个新的测试集,称为NovelEval,它基于最新知识,旨在验证模型对未知知识的排名能力。最后,为了提高在现实世界应用中的效率,我们深入探讨了使用置换蒸馏方案将ChatGPT的排名能力蒸馏到小型专用模型中的潜力。我们的评估结果表明,一个蒸馏后的4.4亿参数模型在BEIR基准测试中表现优于一个30亿参数的监督模型。我们的代码可在www.github.com/sunnweiwei/RankGPT上获取。
论文及项目相关链接
PDF EMNLP 2023
Summary
大型语言模型(LLMs)在多种语言任务中展现了出色的零样本泛化能力,包括搜索引擎。本研究首次探讨了利用ChatGPT和GPT-4等生成式LLM进行信息检索(IR)的相关性排名。实验结果显示,适当指导的LLMs在流行IR基准测试上的表现可与最先进的监督方法相竞争,甚至更优秀。为解决LLMs数据污染问题,研究团队推出新的测试集NovelEval,旨在验证模型对未知知识的排名能力。此外,为提高实际应用的效率,研究还探讨了使用置换蒸馏方案将ChatGPT的排名能力蒸馏到小型专用模型中的潜力。最终实验证实蒸馏后的440M模型在BEIR基准测试上超越了3B监督模型的表现。研究成果可在www.github.com/sunnweiwei/RankGPT复现。
Key Takeaways
- 大型语言模型(LLMs)在不同语言任务中表现出强大的零样本泛化能力。
- LLMs在信息检索(IR)的相关性排名任务中具有潜力。
- 适当指导的LLMs在IR基准测试上的表现优秀,可与最先进的监督方法相竞争。
- 为解决LLMs数据污染问题,推出了新的测试集NovelEval。
- 使用置换蒸馏方案可提高LLMs在实际应用中的效率。
- 蒸馏后的440M模型在BEIR基准测试上的表现优于3B监督模型。
点此查看论文截图